
田贵成
commited on
Commit
·
03d12ba
1
Parent(s):
3bc10dc
init
Browse files- README.md +158 -0
- adapter_config.json +34 -0
- adapter_model.safetensors +3 -0
- added_tokens.json +5 -0
- all_results.json +13 -0
- eval_results.json +8 -0
- merges.txt +0 -0
- special_tokens_map.json +20 -0
- tokenizer.json +0 -0
- tokenizer_config.json +44 -0
- train_results.json +8 -0
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
- training_eval_accuracy.png +0 -0
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
- value_head.safetensors +3 -0
- vocab.json +0 -0
README.md
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: Qwen/Qwen1.5-14B-Chat
|
| 3 |
+
library_name: peft
|
| 4 |
+
license: other
|
| 5 |
+
metrics:
|
| 6 |
+
- accuracy
|
| 7 |
+
tags:
|
| 8 |
+
- llama-factory
|
| 9 |
+
- lora
|
| 10 |
+
- generated_from_trainer
|
| 11 |
+
model-index:
|
| 12 |
+
- name: 20240819-183631_rm_qwen-rm-1e-5
|
| 13 |
+
results: []
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 17 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 18 |
+
|
| 19 |
+
# 20240819-183631_rm_qwen-rm-1e-5
|
| 20 |
+
|
| 21 |
+
This model is a fine-tuned version of [Qwen/Qwen1.5-14B-Chat](https://huggingface.co/Qwen/Qwen1.5-14B-Chat) on the all_reward_cutoff_6000 dataset.
|
| 22 |
+
It achieves the following results on the evaluation set:
|
| 23 |
+
- Loss: 0.6893
|
| 24 |
+
- Accuracy: 0.6641
|
| 25 |
+
|
| 26 |
+
## Model description
|
| 27 |
+
|
| 28 |
+
More information needed
|
| 29 |
+
|
| 30 |
+
## Intended uses & limitations
|
| 31 |
+
|
| 32 |
+
More information needed
|
| 33 |
+
|
| 34 |
+
## Training and evaluation data
|
| 35 |
+
|
| 36 |
+
More information needed
|
| 37 |
+
|
| 38 |
+
## Training procedure
|
| 39 |
+
|
| 40 |
+
### Training hyperparameters
|
| 41 |
+
|
| 42 |
+
The following hyperparameters were used during training:
|
| 43 |
+
- learning_rate: 1e-05
|
| 44 |
+
- train_batch_size: 1
|
| 45 |
+
- eval_batch_size: 1
|
| 46 |
+
- seed: 42
|
| 47 |
+
- gradient_accumulation_steps: 4
|
| 48 |
+
- total_train_batch_size: 4
|
| 49 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 50 |
+
- lr_scheduler_type: cosine
|
| 51 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 52 |
+
- num_epochs: 4.0
|
| 53 |
+
|
| 54 |
+
### Training results
|
| 55 |
+
|
| 56 |
+
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|
| 57 |
+
|:-------------:|:------:|:----:|:---------------:|:--------:|
|
| 58 |
+
| 1.075 | 0.0431 | 50 | 1.0182 | 0.4932 |
|
| 59 |
+
| 1.0505 | 0.0863 | 100 | 0.9944 | 0.5010 |
|
| 60 |
+
| 0.9387 | 0.1294 | 150 | 0.9101 | 0.5049 |
|
| 61 |
+
| 0.92 | 0.1726 | 200 | 0.9020 | 0.5049 |
|
| 62 |
+
| 0.9531 | 0.2157 | 250 | 0.8868 | 0.5223 |
|
| 63 |
+
| 0.849 | 0.2589 | 300 | 0.8567 | 0.5340 |
|
| 64 |
+
| 0.8897 | 0.3020 | 350 | 0.8523 | 0.5262 |
|
| 65 |
+
| 0.8512 | 0.3452 | 400 | 0.8105 | 0.5262 |
|
| 66 |
+
| 0.7854 | 0.3883 | 450 | 0.7994 | 0.5107 |
|
| 67 |
+
| 0.8147 | 0.4315 | 500 | 0.7859 | 0.5398 |
|
| 68 |
+
| 0.8075 | 0.4746 | 550 | 0.7566 | 0.5553 |
|
| 69 |
+
| 0.8282 | 0.5178 | 600 | 0.7454 | 0.5146 |
|
| 70 |
+
| 0.7524 | 0.5609 | 650 | 0.7317 | 0.4990 |
|
| 71 |
+
| 0.7338 | 0.6041 | 700 | 0.7267 | 0.5340 |
|
| 72 |
+
| 0.7909 | 0.6472 | 750 | 0.7111 | 0.5612 |
|
| 73 |
+
| 0.7783 | 0.6904 | 800 | 0.7211 | 0.5301 |
|
| 74 |
+
| 0.7895 | 0.7335 | 850 | 0.7070 | 0.5592 |
|
| 75 |
+
| 0.6881 | 0.7767 | 900 | 0.7710 | 0.5379 |
|
| 76 |
+
| 0.7137 | 0.8198 | 950 | 0.6908 | 0.5806 |
|
| 77 |
+
| 0.6924 | 0.8630 | 1000 | 0.6857 | 0.6 |
|
| 78 |
+
| 0.7275 | 0.9061 | 1050 | 0.6835 | 0.5767 |
|
| 79 |
+
| 0.67 | 0.9493 | 1100 | 0.6888 | 0.5709 |
|
| 80 |
+
| 0.6787 | 0.9924 | 1150 | 0.6860 | 0.5961 |
|
| 81 |
+
| 0.7012 | 1.0356 | 1200 | 0.6847 | 0.5709 |
|
| 82 |
+
| 0.6765 | 1.0787 | 1250 | 0.6961 | 0.5786 |
|
| 83 |
+
| 0.7052 | 1.1219 | 1300 | 0.6881 | 0.6058 |
|
| 84 |
+
| 0.6804 | 1.1650 | 1350 | 0.6778 | 0.6097 |
|
| 85 |
+
| 0.6644 | 1.2082 | 1400 | 0.6810 | 0.6194 |
|
| 86 |
+
| 0.6566 | 1.2513 | 1450 | 0.6820 | 0.6136 |
|
| 87 |
+
| 0.7024 | 1.2945 | 1500 | 0.6745 | 0.6117 |
|
| 88 |
+
| 0.7241 | 1.3376 | 1550 | 0.6698 | 0.6136 |
|
| 89 |
+
| 0.7378 | 1.3808 | 1600 | 0.6734 | 0.6058 |
|
| 90 |
+
| 0.6584 | 1.4239 | 1650 | 0.6994 | 0.6 |
|
| 91 |
+
| 0.6724 | 1.4671 | 1700 | 0.6715 | 0.6097 |
|
| 92 |
+
| 0.6774 | 1.5102 | 1750 | 0.6700 | 0.6136 |
|
| 93 |
+
| 0.6653 | 1.5534 | 1800 | 0.6696 | 0.6097 |
|
| 94 |
+
| 0.6641 | 1.5965 | 1850 | 0.6733 | 0.5981 |
|
| 95 |
+
| 0.7241 | 1.6397 | 1900 | 0.6653 | 0.5961 |
|
| 96 |
+
| 0.6496 | 1.6828 | 1950 | 0.6761 | 0.6117 |
|
| 97 |
+
| 0.662 | 1.7260 | 2000 | 0.6729 | 0.6039 |
|
| 98 |
+
| 0.7049 | 1.7691 | 2050 | 0.6758 | 0.6136 |
|
| 99 |
+
| 0.6483 | 1.8123 | 2100 | 0.6742 | 0.6136 |
|
| 100 |
+
| 0.678 | 1.8554 | 2150 | 0.6696 | 0.6311 |
|
| 101 |
+
| 0.678 | 1.8986 | 2200 | 0.6690 | 0.6233 |
|
| 102 |
+
| 0.6953 | 1.9417 | 2250 | 0.6624 | 0.6252 |
|
| 103 |
+
| 0.6969 | 1.9849 | 2300 | 0.6725 | 0.6369 |
|
| 104 |
+
| 0.6492 | 2.0280 | 2350 | 0.6568 | 0.6485 |
|
| 105 |
+
| 0.6572 | 2.0712 | 2400 | 0.6698 | 0.6447 |
|
| 106 |
+
| 0.6204 | 2.1143 | 2450 | 0.6550 | 0.6544 |
|
| 107 |
+
| 0.6479 | 2.1575 | 2500 | 0.6610 | 0.6447 |
|
| 108 |
+
| 0.6954 | 2.2006 | 2550 | 0.6637 | 0.6680 |
|
| 109 |
+
| 0.5668 | 2.2438 | 2600 | 0.6660 | 0.6583 |
|
| 110 |
+
| 0.6185 | 2.2869 | 2650 | 0.6793 | 0.6680 |
|
| 111 |
+
| 0.5314 | 2.3301 | 2700 | 0.6752 | 0.6718 |
|
| 112 |
+
| 0.6406 | 2.3732 | 2750 | 0.6681 | 0.6563 |
|
| 113 |
+
| 0.7011 | 2.4164 | 2800 | 0.6722 | 0.6680 |
|
| 114 |
+
| 0.6195 | 2.4595 | 2850 | 0.6644 | 0.6757 |
|
| 115 |
+
| 0.6675 | 2.5027 | 2900 | 0.6530 | 0.6602 |
|
| 116 |
+
| 0.5796 | 2.5458 | 2950 | 0.6489 | 0.6602 |
|
| 117 |
+
| 0.6148 | 2.5890 | 3000 | 0.6675 | 0.6680 |
|
| 118 |
+
| 0.6293 | 2.6321 | 3050 | 0.6685 | 0.6369 |
|
| 119 |
+
| 0.6095 | 2.6753 | 3100 | 0.6718 | 0.6621 |
|
| 120 |
+
| 0.5422 | 2.7184 | 3150 | 0.6905 | 0.6485 |
|
| 121 |
+
| 0.6089 | 2.7616 | 3200 | 0.6814 | 0.6544 |
|
| 122 |
+
| 0.6238 | 2.8047 | 3250 | 0.6739 | 0.6466 |
|
| 123 |
+
| 0.7386 | 2.8479 | 3300 | 0.6622 | 0.6485 |
|
| 124 |
+
| 0.6166 | 2.8910 | 3350 | 0.6567 | 0.6544 |
|
| 125 |
+
| 0.5866 | 2.9342 | 3400 | 0.6616 | 0.6505 |
|
| 126 |
+
| 0.6348 | 2.9773 | 3450 | 0.6634 | 0.6563 |
|
| 127 |
+
| 0.5907 | 3.0205 | 3500 | 0.6642 | 0.6583 |
|
| 128 |
+
| 0.4985 | 3.0636 | 3550 | 0.6904 | 0.6544 |
|
| 129 |
+
| 0.53 | 3.1068 | 3600 | 0.6926 | 0.6466 |
|
| 130 |
+
| 0.5728 | 3.1499 | 3650 | 0.6939 | 0.6544 |
|
| 131 |
+
| 0.5011 | 3.1931 | 3700 | 0.6916 | 0.6602 |
|
| 132 |
+
| 0.4987 | 3.2362 | 3750 | 0.6906 | 0.6544 |
|
| 133 |
+
| 0.5909 | 3.2794 | 3800 | 0.6882 | 0.6583 |
|
| 134 |
+
| 0.5194 | 3.3225 | 3850 | 0.6874 | 0.6524 |
|
| 135 |
+
| 0.5925 | 3.3657 | 3900 | 0.6854 | 0.6602 |
|
| 136 |
+
| 0.4709 | 3.4088 | 3950 | 0.6879 | 0.6621 |
|
| 137 |
+
| 0.5317 | 3.4520 | 4000 | 0.6886 | 0.6602 |
|
| 138 |
+
| 0.5821 | 3.4951 | 4050 | 0.6889 | 0.6660 |
|
| 139 |
+
| 0.5887 | 3.5383 | 4100 | 0.6891 | 0.6641 |
|
| 140 |
+
| 0.5362 | 3.5814 | 4150 | 0.6879 | 0.6641 |
|
| 141 |
+
| 0.4971 | 3.6246 | 4200 | 0.6888 | 0.6641 |
|
| 142 |
+
| 0.5009 | 3.6677 | 4250 | 0.6899 | 0.6641 |
|
| 143 |
+
| 0.5813 | 3.7109 | 4300 | 0.6887 | 0.6621 |
|
| 144 |
+
| 0.6147 | 3.7540 | 4350 | 0.6891 | 0.6641 |
|
| 145 |
+
| 0.6033 | 3.7972 | 4400 | 0.6891 | 0.6641 |
|
| 146 |
+
| 0.565 | 3.8403 | 4450 | 0.6891 | 0.6660 |
|
| 147 |
+
| 0.5044 | 3.8835 | 4500 | 0.6893 | 0.6641 |
|
| 148 |
+
| 0.613 | 3.9266 | 4550 | 0.6894 | 0.6660 |
|
| 149 |
+
| 0.4614 | 3.9698 | 4600 | 0.6896 | 0.6641 |
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
### Framework versions
|
| 153 |
+
|
| 154 |
+
- PEFT 0.11.1
|
| 155 |
+
- Transformers 4.43.4
|
| 156 |
+
- Pytorch 2.2.2+cu121
|
| 157 |
+
- Datasets 2.18.0
|
| 158 |
+
- Tokenizers 0.19.1
|
adapter_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "Qwen/Qwen1.5-14B-Chat",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layer_replication": null,
|
| 10 |
+
"layers_pattern": null,
|
| 11 |
+
"layers_to_transform": null,
|
| 12 |
+
"loftq_config": {},
|
| 13 |
+
"lora_alpha": 16,
|
| 14 |
+
"lora_dropout": 0.0,
|
| 15 |
+
"megatron_config": null,
|
| 16 |
+
"megatron_core": "megatron.core",
|
| 17 |
+
"modules_to_save": null,
|
| 18 |
+
"peft_type": "LORA",
|
| 19 |
+
"r": 8,
|
| 20 |
+
"rank_pattern": {},
|
| 21 |
+
"revision": null,
|
| 22 |
+
"target_modules": [
|
| 23 |
+
"up_proj",
|
| 24 |
+
"q_proj",
|
| 25 |
+
"o_proj",
|
| 26 |
+
"gate_proj",
|
| 27 |
+
"v_proj",
|
| 28 |
+
"k_proj",
|
| 29 |
+
"down_proj"
|
| 30 |
+
],
|
| 31 |
+
"task_type": "CAUSAL_LM",
|
| 32 |
+
"use_dora": false,
|
| 33 |
+
"use_rslora": false
|
| 34 |
+
}
|
adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:644d9df2baa902d7309573e8b02b4bb0ea91a273749961d88dc0da24c5b2998c
|
| 3 |
+
size 124756544
|
added_tokens.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|endoftext|>": 151643,
|
| 3 |
+
"<|im_end|>": 151645,
|
| 4 |
+
"<|im_start|>": 151644
|
| 5 |
+
}
|
all_results.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 3.997411003236246,
|
| 3 |
+
"eval_accuracy": 0.6640776699029126,
|
| 4 |
+
"eval_loss": 0.6892674565315247,
|
| 5 |
+
"eval_runtime": 320.8936,
|
| 6 |
+
"eval_samples_per_second": 1.605,
|
| 7 |
+
"eval_steps_per_second": 1.605,
|
| 8 |
+
"total_flos": 0.0,
|
| 9 |
+
"train_loss": 0.6694142627746947,
|
| 10 |
+
"train_runtime": 66014.9203,
|
| 11 |
+
"train_samples_per_second": 0.281,
|
| 12 |
+
"train_steps_per_second": 0.07
|
| 13 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 3.997411003236246,
|
| 3 |
+
"eval_accuracy": 0.6640776699029126,
|
| 4 |
+
"eval_loss": 0.6892674565315247,
|
| 5 |
+
"eval_runtime": 320.8936,
|
| 6 |
+
"eval_samples_per_second": 1.605,
|
| 7 |
+
"eval_steps_per_second": 1.605
|
| 8 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>"
|
| 5 |
+
],
|
| 6 |
+
"eos_token": {
|
| 7 |
+
"content": "<|im_end|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false
|
| 12 |
+
},
|
| 13 |
+
"pad_token": {
|
| 14 |
+
"content": "<|endoftext|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false
|
| 19 |
+
}
|
| 20 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
}
|
| 28 |
+
},
|
| 29 |
+
"additional_special_tokens": [
|
| 30 |
+
"<|im_start|>",
|
| 31 |
+
"<|im_end|>"
|
| 32 |
+
],
|
| 33 |
+
"bos_token": null,
|
| 34 |
+
"chat_template": "{% set system_message = 'You are a helpful assistant.' %}{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ '<|im_start|>system\n' + system_message + '<|im_end|>\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|im_start|>user\n' + content + '<|im_end|>\n<|im_start|>assistant\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\n' }}{% endif %}{% endfor %}",
|
| 35 |
+
"clean_up_tokenization_spaces": false,
|
| 36 |
+
"eos_token": "<|im_end|>",
|
| 37 |
+
"errors": "replace",
|
| 38 |
+
"model_max_length": 32768,
|
| 39 |
+
"pad_token": "<|endoftext|>",
|
| 40 |
+
"padding_side": "right",
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 43 |
+
"unk_token": null
|
| 44 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 3.997411003236246,
|
| 3 |
+
"total_flos": 0.0,
|
| 4 |
+
"train_loss": 0.6694142627746947,
|
| 5 |
+
"train_runtime": 66014.9203,
|
| 6 |
+
"train_samples_per_second": 0.281,
|
| 7 |
+
"train_steps_per_second": 0.07
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6c27aae13966f8d29cf532f061e2cc40c91aade7e1806f67541fa8f4d331e219
|
| 3 |
+
size 5432
|
training_eval_accuracy.png
ADDED

|
training_eval_loss.png
ADDED

|
training_loss.png
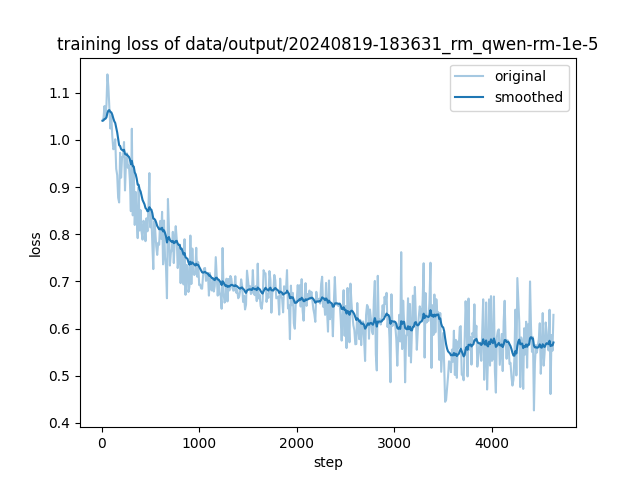
ADDED
|
value_head.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c5b94b8226272a90516bb5a06e5501672ffd0c038f8ca4a3f31dfbcbc9d3fa2a
|
| 3 |
+
size 20684
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|