
initial commit
Browse files- README.md +10 -0
- config.json +71 -0
- environment.yaml +10 -0
- flax_model.msgpack +3 -0
- img/demo_screenshot.png +0 -0
- pipeline.py +99 -0
- special_tokens_map.json +1 -0
- tokenizer.json +0 -0
- tokenizer_config.json +1 -0
- vocab.json +0 -0
- vqgan_jax/__init__.py +1 -0
- vqgan_jax/configuration_vqgan.py +40 -0
- vqgan_jax/modeling_flax_vqgan.py +666 -0
README.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: generic
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
pipeline_tag: text-to-image
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
## Fork of DALL·E mini - Generate images from text
|
| 9 |
+
|
| 10 |
+
For the original repo, head to https://huggingface.co/flax-community/dalle-mini
|
config.json
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_num_labels": 3,
|
| 3 |
+
"activation_dropout": 0.0,
|
| 4 |
+
"activation_function": "gelu",
|
| 5 |
+
"add_final_layer_norm": false,
|
| 6 |
+
"architectures": [
|
| 7 |
+
"omFlaxBartForConditionalGeneration"
|
| 8 |
+
],
|
| 9 |
+
"attention_dropout": 0.0,
|
| 10 |
+
"bos_token_id": 16384,
|
| 11 |
+
"classif_dropout": 0.0,
|
| 12 |
+
"classifier_dropout": 0.0,
|
| 13 |
+
"d_model": 1024,
|
| 14 |
+
"decoder_attention_heads": 16,
|
| 15 |
+
"decoder_ffn_dim": 4096,
|
| 16 |
+
"decoder_layerdrop": 0.0,
|
| 17 |
+
"decoder_layers": 12,
|
| 18 |
+
"decoder_start_token_id": 16384,
|
| 19 |
+
"dropout": 0.1,
|
| 20 |
+
"early_stopping": true,
|
| 21 |
+
"encoder_attention_heads": 16,
|
| 22 |
+
"encoder_ffn_dim": 4096,
|
| 23 |
+
"encoder_layerdrop": 0.0,
|
| 24 |
+
"encoder_layers": 12,
|
| 25 |
+
"eos_token_id": 16385,
|
| 26 |
+
"force_bos_token_to_be_generated": false,
|
| 27 |
+
"forced_eos_token_id": null,
|
| 28 |
+
"gradient_checkpointing": false,
|
| 29 |
+
"id2label": {
|
| 30 |
+
"0": "LABEL_0",
|
| 31 |
+
"1": "LABEL_1",
|
| 32 |
+
"2": "LABEL_2"
|
| 33 |
+
},
|
| 34 |
+
"init_std": 0.02,
|
| 35 |
+
"is_encoder_decoder": true,
|
| 36 |
+
"label2id": {
|
| 37 |
+
"LABEL_0": 0,
|
| 38 |
+
"LABEL_1": 1,
|
| 39 |
+
"LABEL_2": 2
|
| 40 |
+
},
|
| 41 |
+
"length_penalty": 2.0,
|
| 42 |
+
"max_length": 257,
|
| 43 |
+
"max_position_embeddings": 1024,
|
| 44 |
+
"max_position_embeddings_decoder": 257,
|
| 45 |
+
"min_length": 257,
|
| 46 |
+
"model_type": "bart",
|
| 47 |
+
"no_repeat_ngram_size": 3,
|
| 48 |
+
"normalize_before": false,
|
| 49 |
+
"num_beams": 4,
|
| 50 |
+
"num_hidden_layers": 12,
|
| 51 |
+
"output_past": true,
|
| 52 |
+
"pad_token_id": 1,
|
| 53 |
+
"pos_token_id": 16384,
|
| 54 |
+
"prefix": " ",
|
| 55 |
+
"scale_embedding": false,
|
| 56 |
+
"task_specific_params": {
|
| 57 |
+
"summarization": {
|
| 58 |
+
"early_stopping": true,
|
| 59 |
+
"length_penalty": 2.0,
|
| 60 |
+
"max_length": 142,
|
| 61 |
+
"min_length": 56,
|
| 62 |
+
"no_repeat_ngram_size": 3,
|
| 63 |
+
"num_beams": 4
|
| 64 |
+
}
|
| 65 |
+
},
|
| 66 |
+
"tie_word_embeddings": false,
|
| 67 |
+
"transformers_version": "4.8.2",
|
| 68 |
+
"use_cache": true,
|
| 69 |
+
"vocab_size": 50264,
|
| 70 |
+
"vocab_size_output": 16385
|
| 71 |
+
}
|
environment.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: dalle
|
| 2 |
+
channels:
|
| 3 |
+
- defaults
|
| 4 |
+
dependencies:
|
| 5 |
+
- python=3.9.5
|
| 6 |
+
- pip=21.1.3
|
| 7 |
+
- ipython=7.22.0
|
| 8 |
+
- cudatoolkit
|
| 9 |
+
- pip:
|
| 10 |
+
- -r requirements.txt
|
flax_model.msgpack
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:856b78e6e59f979e319eef43005e913bf2e94ced9e3e93d87d3675373cf0673d
|
| 3 |
+
size 1756329653
|
img/demo_screenshot.png
ADDED
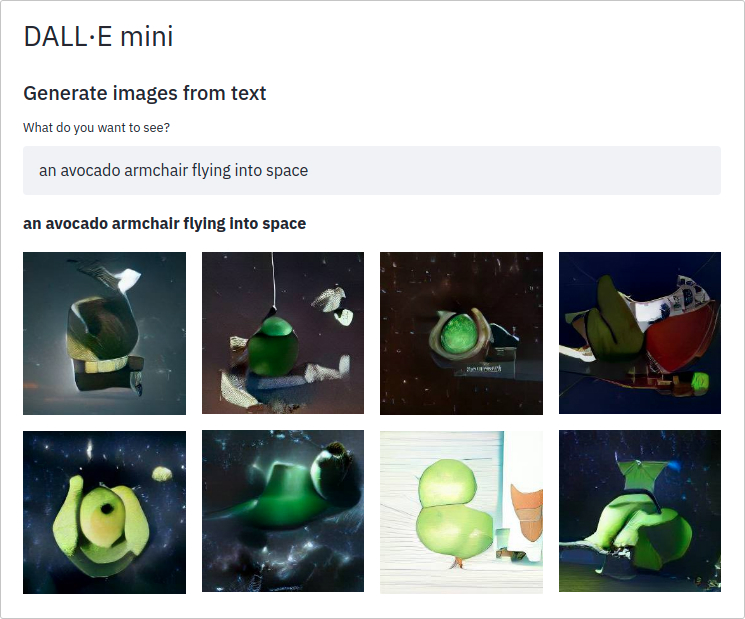
|
pipeline.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import jax
|
| 2 |
+
import flax.linen as nn
|
| 3 |
+
|
| 4 |
+
import random
|
| 5 |
+
import numpy as np
|
| 6 |
+
from PIL import Image
|
| 7 |
+
|
| 8 |
+
from transformers import BartConfig, BartTokenizer
|
| 9 |
+
|
| 10 |
+
from transformers.models.bart.modeling_flax_bart import (
|
| 11 |
+
FlaxBartModule,
|
| 12 |
+
FlaxBartForConditionalGenerationModule,
|
| 13 |
+
FlaxBartForConditionalGeneration,
|
| 14 |
+
FlaxBartEncoder,
|
| 15 |
+
FlaxBartDecoder
|
| 16 |
+
)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
from vqgan_jax.modeling_flax_vqgan import VQModel
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# Model hyperparameters, for convenience
|
| 24 |
+
OUTPUT_VOCAB_SIZE = 16384 + 1 # encoded image token space + 1 for bos
|
| 25 |
+
OUTPUT_LENGTH = 256 + 1 # number of encoded tokens + 1 for bos
|
| 26 |
+
BOS_TOKEN_ID = 16384
|
| 27 |
+
BASE_MODEL = 'facebook/bart-large-cnn' # we currently have issues with bart-large
|
| 28 |
+
|
| 29 |
+
class CustomFlaxBartModule(FlaxBartModule):
|
| 30 |
+
def setup(self):
|
| 31 |
+
# check config is valid, otherwise set default values
|
| 32 |
+
self.config.vocab_size_output = getattr(self.config, 'vocab_size_output', OUTPUT_VOCAB_SIZE)
|
| 33 |
+
self.config.max_position_embeddings_decoder = getattr(self.config, 'max_position_embeddings_decoder', OUTPUT_LENGTH)
|
| 34 |
+
|
| 35 |
+
# we keep shared to easily load pre-trained weights
|
| 36 |
+
self.shared = nn.Embed(
|
| 37 |
+
self.config.vocab_size,
|
| 38 |
+
self.config.d_model,
|
| 39 |
+
embedding_init=jax.nn.initializers.normal(self.config.init_std, self.dtype),
|
| 40 |
+
dtype=self.dtype,
|
| 41 |
+
)
|
| 42 |
+
# a separate embedding is used for the decoder
|
| 43 |
+
self.decoder_embed = nn.Embed(
|
| 44 |
+
self.config.vocab_size_output,
|
| 45 |
+
self.config.d_model,
|
| 46 |
+
embedding_init=jax.nn.initializers.normal(self.config.init_std, self.dtype),
|
| 47 |
+
dtype=self.dtype,
|
| 48 |
+
)
|
| 49 |
+
self.encoder = FlaxBartEncoder(self.config, dtype=self.dtype, embed_tokens=self.shared)
|
| 50 |
+
|
| 51 |
+
# the decoder has a different config
|
| 52 |
+
decoder_config = BartConfig(self.config.to_dict())
|
| 53 |
+
decoder_config.max_position_embeddings = self.config.max_position_embeddings_decoder
|
| 54 |
+
decoder_config.vocab_size = self.config.vocab_size_output
|
| 55 |
+
self.decoder = FlaxBartDecoder(decoder_config, dtype=self.dtype, embed_tokens=self.decoder_embed)
|
| 56 |
+
|
| 57 |
+
class CustomFlaxBartForConditionalGenerationModule(FlaxBartForConditionalGenerationModule):
|
| 58 |
+
def setup(self):
|
| 59 |
+
# check config is valid, otherwise set default values
|
| 60 |
+
self.config.vocab_size_output = getattr(self.config, 'vocab_size_output', OUTPUT_VOCAB_SIZE)
|
| 61 |
+
|
| 62 |
+
self.model = CustomFlaxBartModule(config=self.config, dtype=self.dtype)
|
| 63 |
+
self.lm_head = nn.Dense(
|
| 64 |
+
self.config.vocab_size_output,
|
| 65 |
+
use_bias=False,
|
| 66 |
+
dtype=self.dtype,
|
| 67 |
+
kernel_init=jax.nn.initializers.normal(self.config.init_std, self.dtype),
|
| 68 |
+
)
|
| 69 |
+
self.final_logits_bias = self.param("final_logits_bias", self.bias_init, (1, self.config.vocab_size_output))
|
| 70 |
+
|
| 71 |
+
class CustomFlaxBartForConditionalGeneration(FlaxBartForConditionalGeneration):
|
| 72 |
+
module_class = CustomFlaxBartForConditionalGenerationModule
|
| 73 |
+
|
| 74 |
+
class PreTrainedPipeline():
|
| 75 |
+
def __init__(self, path=""):
|
| 76 |
+
self.vqgan = VQModel.from_pretrained("flax-community/vqgan_f16_16384", revision="90cc46addd2dd8f5be21586a9a23e1b95aa506a9")
|
| 77 |
+
self.tokenizer = BartTokenizer.from_pretrained(path)
|
| 78 |
+
self.model = CustomFlaxBartForConditionalGeneration.from_pretrained(path)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def __call__(self, inputs: str):
|
| 83 |
+
"""
|
| 84 |
+
Args:
|
| 85 |
+
inputs (:obj:`str`):
|
| 86 |
+
a string containing some text
|
| 87 |
+
Return:
|
| 88 |
+
A :obj:`PIL.Image` with the raw image representation as PIL.
|
| 89 |
+
"""
|
| 90 |
+
tokenized_prompt = self.tokenizer(inputs, return_tensors='jax', padding='max_length', truncation=True, max_length=128)
|
| 91 |
+
key = jax.random.PRNGKey(random.randint(0, 2**32-1))
|
| 92 |
+
encoded_image = self.model.generate(**tokenized_prompt, do_sample=True, num_beams=1, prng_key=key)
|
| 93 |
+
|
| 94 |
+
# remove first token (BOS)
|
| 95 |
+
encoded_image = encoded_image.sequences[..., 1:]
|
| 96 |
+
decoded_image = self.vqgan.decode_code(encoded_image)
|
| 97 |
+
clipped_image = decoded_image.squeeze().clip(0., 1.)
|
| 98 |
+
|
| 99 |
+
return Image.fromarray(np.asarray(clipped_image * 255, dtype=np.uint8))
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"bos_token": "<s>", "eos_token": "</s>", "unk_token": "<unk>", "sep_token": "</s>", "pad_token": "<pad>", "cls_token": "<s>", "mask_token": {"content": "<mask>", "single_word": false, "lstrip": true, "rstrip": false, "normalized": false}}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"unk_token": "<unk>", "bos_token": "<s>", "eos_token": "</s>", "add_prefix_space": false, "errors": "replace", "sep_token": "</s>", "cls_token": "<s>", "pad_token": "<pad>", "mask_token": "<mask>", "model_max_length": 1024, "special_tokens_map_file": null, "name_or_path": "./artifacts/model-4oh3u7ca:v54", "tokenizer_class": "BartTokenizer"}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
vqgan_jax/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from . import *
|
vqgan_jax/configuration_vqgan.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Tuple
|
| 2 |
+
|
| 3 |
+
from transformers import PretrainedConfig
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class VQGANConfig(PretrainedConfig):
|
| 7 |
+
def __init__(
|
| 8 |
+
self,
|
| 9 |
+
ch: int = 128,
|
| 10 |
+
out_ch: int = 3,
|
| 11 |
+
in_channels: int = 3,
|
| 12 |
+
num_res_blocks: int = 2,
|
| 13 |
+
resolution: int = 256,
|
| 14 |
+
z_channels: int = 256,
|
| 15 |
+
ch_mult: Tuple = (1, 1, 2, 2, 4),
|
| 16 |
+
attn_resolutions: int = (16,),
|
| 17 |
+
n_embed: int = 1024,
|
| 18 |
+
embed_dim: int = 256,
|
| 19 |
+
dropout: float = 0.0,
|
| 20 |
+
double_z: bool = False,
|
| 21 |
+
resamp_with_conv: bool = True,
|
| 22 |
+
give_pre_end: bool = False,
|
| 23 |
+
**kwargs,
|
| 24 |
+
):
|
| 25 |
+
super().__init__(**kwargs)
|
| 26 |
+
self.ch = ch
|
| 27 |
+
self.out_ch = out_ch
|
| 28 |
+
self.in_channels = in_channels
|
| 29 |
+
self.num_res_blocks = num_res_blocks
|
| 30 |
+
self.resolution = resolution
|
| 31 |
+
self.z_channels = z_channels
|
| 32 |
+
self.ch_mult = list(ch_mult)
|
| 33 |
+
self.attn_resolutions = list(attn_resolutions)
|
| 34 |
+
self.n_embed = n_embed
|
| 35 |
+
self.embed_dim = embed_dim
|
| 36 |
+
self.dropout = dropout
|
| 37 |
+
self.double_z = double_z
|
| 38 |
+
self.resamp_with_conv = resamp_with_conv
|
| 39 |
+
self.give_pre_end = give_pre_end
|
| 40 |
+
self.num_resolutions = len(ch_mult)
|
vqgan_jax/modeling_flax_vqgan.py
ADDED
|
@@ -0,0 +1,666 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# JAX implementation of VQGAN from taming-transformers https://github.com/CompVis/taming-transformers
|
| 2 |
+
|
| 3 |
+
from functools import partial
|
| 4 |
+
from typing import Tuple
|
| 5 |
+
import math
|
| 6 |
+
|
| 7 |
+
import jax
|
| 8 |
+
import jax.numpy as jnp
|
| 9 |
+
import numpy as np
|
| 10 |
+
import flax.linen as nn
|
| 11 |
+
from flax.core.frozen_dict import FrozenDict
|
| 12 |
+
|
| 13 |
+
from transformers.modeling_flax_utils import FlaxPreTrainedModel
|
| 14 |
+
|
| 15 |
+
from .configuration_vqgan import VQGANConfig
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class Upsample(nn.Module):
|
| 19 |
+
in_channels: int
|
| 20 |
+
with_conv: bool
|
| 21 |
+
dtype: jnp.dtype = jnp.float32
|
| 22 |
+
|
| 23 |
+
def setup(self):
|
| 24 |
+
if self.with_conv:
|
| 25 |
+
self.conv = nn.Conv(
|
| 26 |
+
self.in_channels,
|
| 27 |
+
kernel_size=(3, 3),
|
| 28 |
+
strides=(1, 1),
|
| 29 |
+
padding=((1, 1), (1, 1)),
|
| 30 |
+
dtype=self.dtype,
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
def __call__(self, hidden_states):
|
| 34 |
+
batch, height, width, channels = hidden_states.shape
|
| 35 |
+
hidden_states = jax.image.resize(
|
| 36 |
+
hidden_states,
|
| 37 |
+
shape=(batch, height * 2, width * 2, channels),
|
| 38 |
+
method="nearest",
|
| 39 |
+
)
|
| 40 |
+
if self.with_conv:
|
| 41 |
+
hidden_states = self.conv(hidden_states)
|
| 42 |
+
return hidden_states
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class Downsample(nn.Module):
|
| 46 |
+
in_channels: int
|
| 47 |
+
with_conv: bool
|
| 48 |
+
dtype: jnp.dtype = jnp.float32
|
| 49 |
+
|
| 50 |
+
def setup(self):
|
| 51 |
+
if self.with_conv:
|
| 52 |
+
self.conv = nn.Conv(
|
| 53 |
+
self.in_channels,
|
| 54 |
+
kernel_size=(3, 3),
|
| 55 |
+
strides=(2, 2),
|
| 56 |
+
padding="VALID",
|
| 57 |
+
dtype=self.dtype,
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
def __call__(self, hidden_states):
|
| 61 |
+
if self.with_conv:
|
| 62 |
+
pad = ((0, 0), (0, 1), (0, 1), (0, 0)) # pad height and width dim
|
| 63 |
+
hidden_states = jnp.pad(hidden_states, pad_width=pad)
|
| 64 |
+
hidden_states = self.conv(hidden_states)
|
| 65 |
+
else:
|
| 66 |
+
hidden_states = nn.avg_pool(hidden_states,
|
| 67 |
+
window_shape=(2, 2),
|
| 68 |
+
strides=(2, 2),
|
| 69 |
+
padding="VALID")
|
| 70 |
+
return hidden_states
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class ResnetBlock(nn.Module):
|
| 74 |
+
in_channels: int
|
| 75 |
+
out_channels: int = None
|
| 76 |
+
use_conv_shortcut: bool = False
|
| 77 |
+
temb_channels: int = 512
|
| 78 |
+
dropout_prob: float = 0.0
|
| 79 |
+
dtype: jnp.dtype = jnp.float32
|
| 80 |
+
|
| 81 |
+
def setup(self):
|
| 82 |
+
self.out_channels_ = self.in_channels if self.out_channels is None else self.out_channels
|
| 83 |
+
|
| 84 |
+
self.norm1 = nn.GroupNorm(num_groups=32, epsilon=1e-6)
|
| 85 |
+
self.conv1 = nn.Conv(
|
| 86 |
+
self.out_channels_,
|
| 87 |
+
kernel_size=(3, 3),
|
| 88 |
+
strides=(1, 1),
|
| 89 |
+
padding=((1, 1), (1, 1)),
|
| 90 |
+
dtype=self.dtype,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
if self.temb_channels:
|
| 94 |
+
self.temb_proj = nn.Dense(self.out_channels_, dtype=self.dtype)
|
| 95 |
+
|
| 96 |
+
self.norm2 = nn.GroupNorm(num_groups=32, epsilon=1e-6)
|
| 97 |
+
self.dropout = nn.Dropout(self.dropout_prob)
|
| 98 |
+
self.conv2 = nn.Conv(
|
| 99 |
+
self.out_channels_,
|
| 100 |
+
kernel_size=(3, 3),
|
| 101 |
+
strides=(1, 1),
|
| 102 |
+
padding=((1, 1), (1, 1)),
|
| 103 |
+
dtype=self.dtype,
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
if self.in_channels != self.out_channels_:
|
| 107 |
+
if self.use_conv_shortcut:
|
| 108 |
+
self.conv_shortcut = nn.Conv(
|
| 109 |
+
self.out_channels_,
|
| 110 |
+
kernel_size=(3, 3),
|
| 111 |
+
strides=(1, 1),
|
| 112 |
+
padding=((1, 1), (1, 1)),
|
| 113 |
+
dtype=self.dtype,
|
| 114 |
+
)
|
| 115 |
+
else:
|
| 116 |
+
self.nin_shortcut = nn.Conv(
|
| 117 |
+
self.out_channels_,
|
| 118 |
+
kernel_size=(1, 1),
|
| 119 |
+
strides=(1, 1),
|
| 120 |
+
padding="VALID",
|
| 121 |
+
dtype=self.dtype,
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
def __call__(self, hidden_states, temb=None, deterministic: bool = True):
|
| 125 |
+
residual = hidden_states
|
| 126 |
+
hidden_states = self.norm1(hidden_states)
|
| 127 |
+
hidden_states = nn.swish(hidden_states)
|
| 128 |
+
hidden_states = self.conv1(hidden_states)
|
| 129 |
+
|
| 130 |
+
if temb is not None:
|
| 131 |
+
hidden_states = hidden_states + self.temb_proj(
|
| 132 |
+
nn.swish(temb))[:, :, None, None] # TODO: check shapes
|
| 133 |
+
|
| 134 |
+
hidden_states = self.norm2(hidden_states)
|
| 135 |
+
hidden_states = nn.swish(hidden_states)
|
| 136 |
+
hidden_states = self.dropout(hidden_states, deterministic)
|
| 137 |
+
hidden_states = self.conv2(hidden_states)
|
| 138 |
+
|
| 139 |
+
if self.in_channels != self.out_channels_:
|
| 140 |
+
if self.use_conv_shortcut:
|
| 141 |
+
residual = self.conv_shortcut(residual)
|
| 142 |
+
else:
|
| 143 |
+
residual = self.nin_shortcut(residual)
|
| 144 |
+
|
| 145 |
+
return hidden_states + residual
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class AttnBlock(nn.Module):
|
| 149 |
+
in_channels: int
|
| 150 |
+
dtype: jnp.dtype = jnp.float32
|
| 151 |
+
|
| 152 |
+
def setup(self):
|
| 153 |
+
conv = partial(nn.Conv,
|
| 154 |
+
self.in_channels,
|
| 155 |
+
kernel_size=(1, 1),
|
| 156 |
+
strides=(1, 1),
|
| 157 |
+
padding="VALID",
|
| 158 |
+
dtype=self.dtype)
|
| 159 |
+
|
| 160 |
+
self.norm = nn.GroupNorm(num_groups=32, epsilon=1e-6)
|
| 161 |
+
self.q, self.k, self.v = conv(), conv(), conv()
|
| 162 |
+
self.proj_out = conv()
|
| 163 |
+
|
| 164 |
+
def __call__(self, hidden_states):
|
| 165 |
+
residual = hidden_states
|
| 166 |
+
hidden_states = self.norm(hidden_states)
|
| 167 |
+
|
| 168 |
+
query = self.q(hidden_states)
|
| 169 |
+
key = self.k(hidden_states)
|
| 170 |
+
value = self.v(hidden_states)
|
| 171 |
+
|
| 172 |
+
# compute attentions
|
| 173 |
+
batch, height, width, channels = query.shape
|
| 174 |
+
query = query.reshape((batch, height * width, channels))
|
| 175 |
+
key = key.reshape((batch, height * width, channels))
|
| 176 |
+
attn_weights = jnp.einsum("...qc,...kc->...qk", query, key)
|
| 177 |
+
attn_weights = attn_weights * (int(channels)**-0.5)
|
| 178 |
+
attn_weights = nn.softmax(attn_weights, axis=2)
|
| 179 |
+
|
| 180 |
+
## attend to values
|
| 181 |
+
value = value.reshape((batch, height * width, channels))
|
| 182 |
+
hidden_states = jnp.einsum("...kc,...qk->...qc", value, attn_weights)
|
| 183 |
+
hidden_states = hidden_states.reshape((batch, height, width, channels))
|
| 184 |
+
|
| 185 |
+
hidden_states = self.proj_out(hidden_states)
|
| 186 |
+
hidden_states = hidden_states + residual
|
| 187 |
+
return hidden_states
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
class UpsamplingBlock(nn.Module):
|
| 191 |
+
config: VQGANConfig
|
| 192 |
+
curr_res: int
|
| 193 |
+
block_idx: int
|
| 194 |
+
dtype: jnp.dtype = jnp.float32
|
| 195 |
+
|
| 196 |
+
def setup(self):
|
| 197 |
+
if self.block_idx == self.config.num_resolutions - 1:
|
| 198 |
+
block_in = self.config.ch * self.config.ch_mult[-1]
|
| 199 |
+
else:
|
| 200 |
+
block_in = self.config.ch * self.config.ch_mult[self.block_idx + 1]
|
| 201 |
+
|
| 202 |
+
block_out = self.config.ch * self.config.ch_mult[self.block_idx]
|
| 203 |
+
self.temb_ch = 0
|
| 204 |
+
|
| 205 |
+
res_blocks = []
|
| 206 |
+
attn_blocks = []
|
| 207 |
+
for _ in range(self.config.num_res_blocks + 1):
|
| 208 |
+
res_blocks.append(
|
| 209 |
+
ResnetBlock(block_in,
|
| 210 |
+
block_out,
|
| 211 |
+
temb_channels=self.temb_ch,
|
| 212 |
+
dropout_prob=self.config.dropout,
|
| 213 |
+
dtype=self.dtype))
|
| 214 |
+
block_in = block_out
|
| 215 |
+
if self.curr_res in self.config.attn_resolutions:
|
| 216 |
+
attn_blocks.append(AttnBlock(block_in, dtype=self.dtype))
|
| 217 |
+
|
| 218 |
+
self.block = res_blocks
|
| 219 |
+
self.attn = attn_blocks
|
| 220 |
+
|
| 221 |
+
self.upsample = None
|
| 222 |
+
if self.block_idx != 0:
|
| 223 |
+
self.upsample = Upsample(block_in,
|
| 224 |
+
self.config.resamp_with_conv,
|
| 225 |
+
dtype=self.dtype)
|
| 226 |
+
|
| 227 |
+
def __call__(self, hidden_states, temb=None, deterministic: bool = True):
|
| 228 |
+
for res_block in self.block:
|
| 229 |
+
hidden_states = res_block(hidden_states,
|
| 230 |
+
temb,
|
| 231 |
+
deterministic=deterministic)
|
| 232 |
+
for attn_block in self.attn:
|
| 233 |
+
hidden_states = attn_block(hidden_states)
|
| 234 |
+
|
| 235 |
+
if self.upsample is not None:
|
| 236 |
+
hidden_states = self.upsample(hidden_states)
|
| 237 |
+
|
| 238 |
+
return hidden_states
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
class DownsamplingBlock(nn.Module):
|
| 242 |
+
config: VQGANConfig
|
| 243 |
+
curr_res: int
|
| 244 |
+
block_idx: int
|
| 245 |
+
dtype: jnp.dtype = jnp.float32
|
| 246 |
+
|
| 247 |
+
def setup(self):
|
| 248 |
+
in_ch_mult = (1, ) + tuple(self.config.ch_mult)
|
| 249 |
+
block_in = self.config.ch * in_ch_mult[self.block_idx]
|
| 250 |
+
block_out = self.config.ch * self.config.ch_mult[self.block_idx]
|
| 251 |
+
self.temb_ch = 0
|
| 252 |
+
|
| 253 |
+
res_blocks = []
|
| 254 |
+
attn_blocks = []
|
| 255 |
+
for _ in range(self.config.num_res_blocks):
|
| 256 |
+
res_blocks.append(
|
| 257 |
+
ResnetBlock(block_in,
|
| 258 |
+
block_out,
|
| 259 |
+
temb_channels=self.temb_ch,
|
| 260 |
+
dropout_prob=self.config.dropout,
|
| 261 |
+
dtype=self.dtype))
|
| 262 |
+
block_in = block_out
|
| 263 |
+
if self.curr_res in self.config.attn_resolutions:
|
| 264 |
+
attn_blocks.append(AttnBlock(block_in, dtype=self.dtype))
|
| 265 |
+
|
| 266 |
+
self.block = res_blocks
|
| 267 |
+
self.attn = attn_blocks
|
| 268 |
+
|
| 269 |
+
self.downsample = None
|
| 270 |
+
if self.block_idx != self.config.num_resolutions - 1:
|
| 271 |
+
self.downsample = Downsample(block_in,
|
| 272 |
+
self.config.resamp_with_conv,
|
| 273 |
+
dtype=self.dtype)
|
| 274 |
+
|
| 275 |
+
def __call__(self, hidden_states, temb=None, deterministic: bool = True):
|
| 276 |
+
for res_block in self.block:
|
| 277 |
+
hidden_states = res_block(hidden_states,
|
| 278 |
+
temb,
|
| 279 |
+
deterministic=deterministic)
|
| 280 |
+
for attn_block in self.attn:
|
| 281 |
+
hidden_states = attn_block(hidden_states)
|
| 282 |
+
|
| 283 |
+
if self.downsample is not None:
|
| 284 |
+
hidden_states = self.downsample(hidden_states)
|
| 285 |
+
|
| 286 |
+
return hidden_states
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
class MidBlock(nn.Module):
|
| 290 |
+
in_channels: int
|
| 291 |
+
temb_channels: int
|
| 292 |
+
dropout: float
|
| 293 |
+
dtype: jnp.dtype = jnp.float32
|
| 294 |
+
|
| 295 |
+
def setup(self):
|
| 296 |
+
self.block_1 = ResnetBlock(
|
| 297 |
+
self.in_channels,
|
| 298 |
+
self.in_channels,
|
| 299 |
+
temb_channels=self.temb_channels,
|
| 300 |
+
dropout_prob=self.dropout,
|
| 301 |
+
dtype=self.dtype,
|
| 302 |
+
)
|
| 303 |
+
self.attn_1 = AttnBlock(self.in_channels, dtype=self.dtype)
|
| 304 |
+
self.block_2 = ResnetBlock(
|
| 305 |
+
self.in_channels,
|
| 306 |
+
self.in_channels,
|
| 307 |
+
temb_channels=self.temb_channels,
|
| 308 |
+
dropout_prob=self.dropout,
|
| 309 |
+
dtype=self.dtype,
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
def __call__(self, hidden_states, temb=None, deterministic: bool = True):
|
| 313 |
+
hidden_states = self.block_1(hidden_states,
|
| 314 |
+
temb,
|
| 315 |
+
deterministic=deterministic)
|
| 316 |
+
hidden_states = self.attn_1(hidden_states)
|
| 317 |
+
hidden_states = self.block_2(hidden_states,
|
| 318 |
+
temb,
|
| 319 |
+
deterministic=deterministic)
|
| 320 |
+
return hidden_states
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
class Encoder(nn.Module):
|
| 324 |
+
config: VQGANConfig
|
| 325 |
+
dtype: jnp.dtype = jnp.float32
|
| 326 |
+
|
| 327 |
+
def setup(self):
|
| 328 |
+
self.temb_ch = 0
|
| 329 |
+
|
| 330 |
+
# downsampling
|
| 331 |
+
self.conv_in = nn.Conv(
|
| 332 |
+
self.config.ch,
|
| 333 |
+
kernel_size=(3, 3),
|
| 334 |
+
strides=(1, 1),
|
| 335 |
+
padding=((1, 1), (1, 1)),
|
| 336 |
+
dtype=self.dtype,
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
curr_res = self.config.resolution
|
| 340 |
+
downsample_blocks = []
|
| 341 |
+
for i_level in range(self.config.num_resolutions):
|
| 342 |
+
downsample_blocks.append(
|
| 343 |
+
DownsamplingBlock(self.config,
|
| 344 |
+
curr_res,
|
| 345 |
+
block_idx=i_level,
|
| 346 |
+
dtype=self.dtype))
|
| 347 |
+
|
| 348 |
+
if i_level != self.config.num_resolutions - 1:
|
| 349 |
+
curr_res = curr_res // 2
|
| 350 |
+
self.down = downsample_blocks
|
| 351 |
+
|
| 352 |
+
# middle
|
| 353 |
+
mid_channels = self.config.ch * self.config.ch_mult[-1]
|
| 354 |
+
self.mid = MidBlock(mid_channels,
|
| 355 |
+
self.temb_ch,
|
| 356 |
+
self.config.dropout,
|
| 357 |
+
dtype=self.dtype)
|
| 358 |
+
|
| 359 |
+
# end
|
| 360 |
+
self.norm_out = nn.GroupNorm(num_groups=32, epsilon=1e-6)
|
| 361 |
+
self.conv_out = nn.Conv(
|
| 362 |
+
2 * self.config.z_channels
|
| 363 |
+
if self.config.double_z else self.config.z_channels,
|
| 364 |
+
kernel_size=(3, 3),
|
| 365 |
+
strides=(1, 1),
|
| 366 |
+
padding=((1, 1), (1, 1)),
|
| 367 |
+
dtype=self.dtype,
|
| 368 |
+
)
|
| 369 |
+
|
| 370 |
+
def __call__(self, pixel_values, deterministic: bool = True):
|
| 371 |
+
# timestep embedding
|
| 372 |
+
temb = None
|
| 373 |
+
|
| 374 |
+
# downsampling
|
| 375 |
+
hidden_states = self.conv_in(pixel_values)
|
| 376 |
+
for block in self.down:
|
| 377 |
+
hidden_states = block(hidden_states, temb, deterministic=deterministic)
|
| 378 |
+
|
| 379 |
+
# middle
|
| 380 |
+
hidden_states = self.mid(hidden_states, temb, deterministic=deterministic)
|
| 381 |
+
|
| 382 |
+
# end
|
| 383 |
+
hidden_states = self.norm_out(hidden_states)
|
| 384 |
+
hidden_states = nn.swish(hidden_states)
|
| 385 |
+
hidden_states = self.conv_out(hidden_states)
|
| 386 |
+
|
| 387 |
+
return hidden_states
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
class Decoder(nn.Module):
|
| 391 |
+
config: VQGANConfig
|
| 392 |
+
dtype: jnp.dtype = jnp.float32
|
| 393 |
+
|
| 394 |
+
def setup(self):
|
| 395 |
+
self.temb_ch = 0
|
| 396 |
+
|
| 397 |
+
# compute in_ch_mult, block_in and curr_res at lowest res
|
| 398 |
+
block_in = self.config.ch * self.config.ch_mult[self.config.num_resolutions
|
| 399 |
+
- 1]
|
| 400 |
+
curr_res = self.config.resolution // 2**(self.config.num_resolutions - 1)
|
| 401 |
+
self.z_shape = (1, self.config.z_channels, curr_res, curr_res)
|
| 402 |
+
print("Working with z of shape {} = {} dimensions.".format(
|
| 403 |
+
self.z_shape, np.prod(self.z_shape)))
|
| 404 |
+
|
| 405 |
+
# z to block_in
|
| 406 |
+
self.conv_in = nn.Conv(
|
| 407 |
+
block_in,
|
| 408 |
+
kernel_size=(3, 3),
|
| 409 |
+
strides=(1, 1),
|
| 410 |
+
padding=((1, 1), (1, 1)),
|
| 411 |
+
dtype=self.dtype,
|
| 412 |
+
)
|
| 413 |
+
|
| 414 |
+
# middle
|
| 415 |
+
self.mid = MidBlock(block_in,
|
| 416 |
+
self.temb_ch,
|
| 417 |
+
self.config.dropout,
|
| 418 |
+
dtype=self.dtype)
|
| 419 |
+
|
| 420 |
+
# upsampling
|
| 421 |
+
upsample_blocks = []
|
| 422 |
+
for i_level in reversed(range(self.config.num_resolutions)):
|
| 423 |
+
upsample_blocks.append(
|
| 424 |
+
UpsamplingBlock(self.config,
|
| 425 |
+
curr_res,
|
| 426 |
+
block_idx=i_level,
|
| 427 |
+
dtype=self.dtype))
|
| 428 |
+
if i_level != 0:
|
| 429 |
+
curr_res = curr_res * 2
|
| 430 |
+
self.up = list(
|
| 431 |
+
reversed(upsample_blocks)) # reverse to get consistent order
|
| 432 |
+
|
| 433 |
+
# end
|
| 434 |
+
self.norm_out = nn.GroupNorm(num_groups=32, epsilon=1e-6)
|
| 435 |
+
self.conv_out = nn.Conv(
|
| 436 |
+
self.config.out_ch,
|
| 437 |
+
kernel_size=(3, 3),
|
| 438 |
+
strides=(1, 1),
|
| 439 |
+
padding=((1, 1), (1, 1)),
|
| 440 |
+
dtype=self.dtype,
|
| 441 |
+
)
|
| 442 |
+
|
| 443 |
+
def __call__(self, hidden_states, deterministic: bool = True):
|
| 444 |
+
# timestep embedding
|
| 445 |
+
temb = None
|
| 446 |
+
|
| 447 |
+
# z to block_in
|
| 448 |
+
hidden_states = self.conv_in(hidden_states)
|
| 449 |
+
|
| 450 |
+
# middle
|
| 451 |
+
hidden_states = self.mid(hidden_states, temb, deterministic=deterministic)
|
| 452 |
+
|
| 453 |
+
# upsampling
|
| 454 |
+
for block in reversed(self.up):
|
| 455 |
+
hidden_states = block(hidden_states, temb, deterministic=deterministic)
|
| 456 |
+
|
| 457 |
+
# end
|
| 458 |
+
if self.config.give_pre_end:
|
| 459 |
+
return hidden_states
|
| 460 |
+
|
| 461 |
+
hidden_states = self.norm_out(hidden_states)
|
| 462 |
+
hidden_states = nn.swish(hidden_states)
|
| 463 |
+
hidden_states = self.conv_out(hidden_states)
|
| 464 |
+
|
| 465 |
+
return hidden_states
|
| 466 |
+
|
| 467 |
+
|
| 468 |
+
class VectorQuantizer(nn.Module):
|
| 469 |
+
"""
|
| 470 |
+
see https://github.com/MishaLaskin/vqvae/blob/d761a999e2267766400dc646d82d3ac3657771d4/models/quantizer.py
|
| 471 |
+
____________________________________________
|
| 472 |
+
Discretization bottleneck part of the VQ-VAE.
|
| 473 |
+
Inputs:
|
| 474 |
+
- n_e : number of embeddings
|
| 475 |
+
- e_dim : dimension of embedding
|
| 476 |
+
- beta : commitment cost used in loss term, beta * ||z_e(x)-sg[e]||^2
|
| 477 |
+
_____________________________________________
|
| 478 |
+
"""
|
| 479 |
+
|
| 480 |
+
config: VQGANConfig
|
| 481 |
+
dtype: jnp.dtype = jnp.float32
|
| 482 |
+
|
| 483 |
+
def setup(self):
|
| 484 |
+
self.embedding = nn.Embed(self.config.n_embed,
|
| 485 |
+
self.config.embed_dim,
|
| 486 |
+
dtype=self.dtype) # TODO: init
|
| 487 |
+
|
| 488 |
+
def __call__(self, hidden_states):
|
| 489 |
+
"""
|
| 490 |
+
Inputs the output of the encoder network z and maps it to a discrete
|
| 491 |
+
one-hot vector that is the index of the closest embedding vector e_j
|
| 492 |
+
z (continuous) -> z_q (discrete)
|
| 493 |
+
z.shape = (batch, channel, height, width)
|
| 494 |
+
quantization pipeline:
|
| 495 |
+
1. get encoder input (B,C,H,W)
|
| 496 |
+
2. flatten input to (B*H*W,C)
|
| 497 |
+
"""
|
| 498 |
+
# flatten
|
| 499 |
+
hidden_states_flattended = hidden_states.reshape(
|
| 500 |
+
(-1, self.config.embed_dim))
|
| 501 |
+
|
| 502 |
+
# dummy op to init the weights, so we can access them below
|
| 503 |
+
self.embedding(jnp.ones((1, 1), dtype="i4"))
|
| 504 |
+
|
| 505 |
+
# distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
|
| 506 |
+
emb_weights = self.variables["params"]["embedding"]["embedding"]
|
| 507 |
+
distance = (jnp.sum(hidden_states_flattended**2, axis=1, keepdims=True) +
|
| 508 |
+
jnp.sum(emb_weights**2, axis=1) -
|
| 509 |
+
2 * jnp.dot(hidden_states_flattended, emb_weights.T))
|
| 510 |
+
|
| 511 |
+
# get quantized latent vectors
|
| 512 |
+
min_encoding_indices = jnp.argmin(distance, axis=1)
|
| 513 |
+
z_q = self.embedding(min_encoding_indices).reshape(hidden_states.shape)
|
| 514 |
+
|
| 515 |
+
# reshape to (batch, num_tokens)
|
| 516 |
+
min_encoding_indices = min_encoding_indices.reshape(
|
| 517 |
+
hidden_states.shape[0], -1)
|
| 518 |
+
|
| 519 |
+
# compute the codebook_loss (q_loss) outside the model
|
| 520 |
+
# here we return the embeddings and indices
|
| 521 |
+
return z_q, min_encoding_indices
|
| 522 |
+
|
| 523 |
+
def get_codebook_entry(self, indices, shape=None):
|
| 524 |
+
# indices are expected to be of shape (batch, num_tokens)
|
| 525 |
+
# get quantized latent vectors
|
| 526 |
+
batch, num_tokens = indices.shape
|
| 527 |
+
z_q = self.embedding(indices)
|
| 528 |
+
z_q = z_q.reshape(batch, int(math.sqrt(num_tokens)),
|
| 529 |
+
int(math.sqrt(num_tokens)), -1)
|
| 530 |
+
return z_q
|
| 531 |
+
|
| 532 |
+
|
| 533 |
+
class VQModule(nn.Module):
|
| 534 |
+
config: VQGANConfig
|
| 535 |
+
dtype: jnp.dtype = jnp.float32
|
| 536 |
+
|
| 537 |
+
def setup(self):
|
| 538 |
+
self.encoder = Encoder(self.config, dtype=self.dtype)
|
| 539 |
+
self.decoder = Decoder(self.config, dtype=self.dtype)
|
| 540 |
+
self.quantize = VectorQuantizer(self.config, dtype=self.dtype)
|
| 541 |
+
self.quant_conv = nn.Conv(
|
| 542 |
+
self.config.embed_dim,
|
| 543 |
+
kernel_size=(1, 1),
|
| 544 |
+
strides=(1, 1),
|
| 545 |
+
padding="VALID",
|
| 546 |
+
dtype=self.dtype,
|
| 547 |
+
)
|
| 548 |
+
self.post_quant_conv = nn.Conv(
|
| 549 |
+
self.config.z_channels,
|
| 550 |
+
kernel_size=(1, 1),
|
| 551 |
+
strides=(1, 1),
|
| 552 |
+
padding="VALID",
|
| 553 |
+
dtype=self.dtype,
|
| 554 |
+
)
|
| 555 |
+
|
| 556 |
+
def encode(self, pixel_values, deterministic: bool = True):
|
| 557 |
+
hidden_states = self.encoder(pixel_values, deterministic=deterministic)
|
| 558 |
+
hidden_states = self.quant_conv(hidden_states)
|
| 559 |
+
quant_states, indices = self.quantize(hidden_states)
|
| 560 |
+
return quant_states, indices
|
| 561 |
+
|
| 562 |
+
def decode(self, hidden_states, deterministic: bool = True):
|
| 563 |
+
hidden_states = self.post_quant_conv(hidden_states)
|
| 564 |
+
hidden_states = self.decoder(hidden_states, deterministic=deterministic)
|
| 565 |
+
return hidden_states
|
| 566 |
+
|
| 567 |
+
def decode_code(self, code_b):
|
| 568 |
+
hidden_states = self.quantize.get_codebook_entry(code_b)
|
| 569 |
+
hidden_states = self.decode(hidden_states)
|
| 570 |
+
return hidden_states
|
| 571 |
+
|
| 572 |
+
def __call__(self, pixel_values, deterministic: bool = True):
|
| 573 |
+
quant_states, indices = self.encode(pixel_values, deterministic)
|
| 574 |
+
hidden_states = self.decode(quant_states, deterministic)
|
| 575 |
+
return hidden_states, indices
|
| 576 |
+
|
| 577 |
+
|
| 578 |
+
class VQGANPreTrainedModel(FlaxPreTrainedModel):
|
| 579 |
+
"""
|
| 580 |
+
An abstract class to handle weights initialization and a simple interface
|
| 581 |
+
for downloading and loading pretrained models.
|
| 582 |
+
"""
|
| 583 |
+
|
| 584 |
+
config_class = VQGANConfig
|
| 585 |
+
base_model_prefix = "model"
|
| 586 |
+
module_class: nn.Module = None
|
| 587 |
+
|
| 588 |
+
def __init__(
|
| 589 |
+
self,
|
| 590 |
+
config: VQGANConfig,
|
| 591 |
+
input_shape: Tuple = (1, 256, 256, 3),
|
| 592 |
+
seed: int = 0,
|
| 593 |
+
dtype: jnp.dtype = jnp.float32,
|
| 594 |
+
**kwargs,
|
| 595 |
+
):
|
| 596 |
+
module = self.module_class(config=config, dtype=dtype, **kwargs)
|
| 597 |
+
super().__init__(config,
|
| 598 |
+
module,
|
| 599 |
+
input_shape=input_shape,
|
| 600 |
+
seed=seed,
|
| 601 |
+
dtype=dtype)
|
| 602 |
+
|
| 603 |
+
def init_weights(self, rng: jax.random.PRNGKey,
|
| 604 |
+
input_shape: Tuple) -> FrozenDict:
|
| 605 |
+
# init input tensors
|
| 606 |
+
pixel_values = jnp.zeros(input_shape, dtype=jnp.float32)
|
| 607 |
+
params_rng, dropout_rng = jax.random.split(rng)
|
| 608 |
+
rngs = {"params": params_rng, "dropout": dropout_rng}
|
| 609 |
+
|
| 610 |
+
return self.module.init(rngs, pixel_values)["params"]
|
| 611 |
+
|
| 612 |
+
def encode(self,
|
| 613 |
+
pixel_values,
|
| 614 |
+
params: dict = None,
|
| 615 |
+
dropout_rng: jax.random.PRNGKey = None,
|
| 616 |
+
train: bool = False):
|
| 617 |
+
# Handle any PRNG if needed
|
| 618 |
+
rngs = {"dropout": dropout_rng} if dropout_rng is not None else {}
|
| 619 |
+
|
| 620 |
+
return self.module.apply({"params": params or self.params},
|
| 621 |
+
jnp.array(pixel_values),
|
| 622 |
+
not train,
|
| 623 |
+
rngs=rngs,
|
| 624 |
+
method=self.module.encode)
|
| 625 |
+
|
| 626 |
+
def decode(self,
|
| 627 |
+
hidden_states,
|
| 628 |
+
params: dict = None,
|
| 629 |
+
dropout_rng: jax.random.PRNGKey = None,
|
| 630 |
+
train: bool = False):
|
| 631 |
+
# Handle any PRNG if needed
|
| 632 |
+
rngs = {"dropout": dropout_rng} if dropout_rng is not None else {}
|
| 633 |
+
|
| 634 |
+
return self.module.apply(
|
| 635 |
+
{"params": params or self.params},
|
| 636 |
+
jnp.array(hidden_states),
|
| 637 |
+
not train,
|
| 638 |
+
rngs=rngs,
|
| 639 |
+
method=self.module.decode,
|
| 640 |
+
)
|
| 641 |
+
|
| 642 |
+
def decode_code(self, indices, params: dict = None):
|
| 643 |
+
return self.module.apply({"params": params or self.params},
|
| 644 |
+
jnp.array(indices, dtype="i4"),
|
| 645 |
+
method=self.module.decode_code)
|
| 646 |
+
|
| 647 |
+
def __call__(
|
| 648 |
+
self,
|
| 649 |
+
pixel_values,
|
| 650 |
+
params: dict = None,
|
| 651 |
+
dropout_rng: jax.random.PRNGKey = None,
|
| 652 |
+
train: bool = False,
|
| 653 |
+
):
|
| 654 |
+
# Handle any PRNG if needed
|
| 655 |
+
rngs = {"dropout": dropout_rng} if dropout_rng is not None else {}
|
| 656 |
+
|
| 657 |
+
return self.module.apply(
|
| 658 |
+
{"params": params or self.params},
|
| 659 |
+
jnp.array(pixel_values),
|
| 660 |
+
not train,
|
| 661 |
+
rngs=rngs,
|
| 662 |
+
)
|
| 663 |
+
|
| 664 |
+
|
| 665 |
+
class VQModel(VQGANPreTrainedModel):
|
| 666 |
+
module_class = VQModule
|