
Upload app.py
Browse files
app.py
ADDED
|
@@ -0,0 +1,303 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
|
| 3 |
+
from __future__ import annotations
|
| 4 |
+
|
| 5 |
+
import argparse
|
| 6 |
+
import functools
|
| 7 |
+
import os
|
| 8 |
+
import pathlib
|
| 9 |
+
import sys
|
| 10 |
+
from typing import Callable
|
| 11 |
+
|
| 12 |
+
if os.environ.get('SYSTEM') == 'spaces':
|
| 13 |
+
os.system("sed -i '10,17d' DualStyleGAN/model/stylegan/op/fused_act.py")
|
| 14 |
+
os.system("sed -i '10,17d' DualStyleGAN/model/stylegan/op/upfirdn2d.py")
|
| 15 |
+
|
| 16 |
+
sys.path.insert(0, 'DualStyleGAN')
|
| 17 |
+
|
| 18 |
+
import dlib
|
| 19 |
+
import gradio as gr
|
| 20 |
+
import huggingface_hub
|
| 21 |
+
import numpy as np
|
| 22 |
+
import PIL.Image
|
| 23 |
+
import torch
|
| 24 |
+
import torch.nn as nn
|
| 25 |
+
import torchvision.transforms as T
|
| 26 |
+
from model.dualstylegan import DualStyleGAN
|
| 27 |
+
from model.encoder.align_all_parallel import align_face
|
| 28 |
+
from model.encoder.psp import pSp
|
| 29 |
+
|
| 30 |
+
ORIGINAL_REPO_URL = 'https://github.com/williamyang1991/DualStyleGAN'
|
| 31 |
+
TITLE = 'williamyang1991/DualStyleGAN'
|
| 32 |
+
DESCRIPTION = f"""This is a demo for {ORIGINAL_REPO_URL}.
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
You can select style images for each style type from the tables below.
|
| 37 |
+
The style image index should be in the following range:
|
| 38 |
+
(cartoon: 0-316, caricature: 0-198, anime: 0-173, arcane: 0-99, comic: 0-100, pixar: 0-121, slamdunk: 0-119)
|
| 39 |
+
"""
|
| 40 |
+
ARTICLE = """## Style images
|
| 41 |
+
|
| 42 |
+
Note that the style images here for Arcane, comic, Pixar, and Slamdunk are the reconstructed ones, not the original ones due to copyright issues.
|
| 43 |
+
|
| 44 |
+
### Cartoon
|
| 45 |
+

|
| 46 |
+
|
| 47 |
+
### Caricature
|
| 48 |
+

|
| 49 |
+
|
| 50 |
+
### Anime
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
### Arcane
|
| 54 |
+

|
| 55 |
+
|
| 56 |
+
### Comic
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
### Pixar
|
| 60 |
+

|
| 61 |
+
|
| 62 |
+
### Slamdunk
|
| 63 |
+
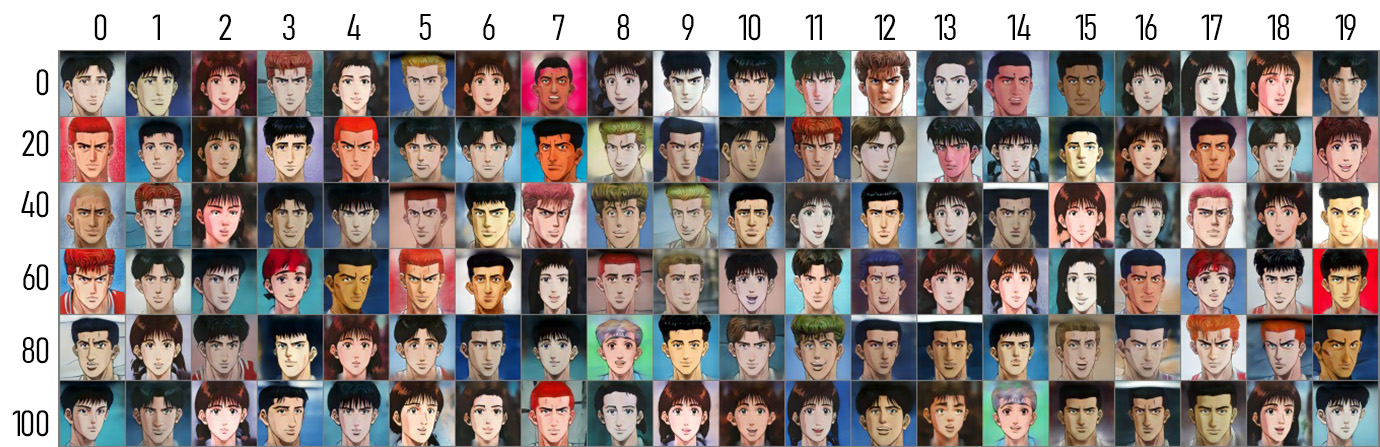
|
| 64 |
+
"""
|
| 65 |
+
|
| 66 |
+
TOKEN = os.environ['TOKEN']
|
| 67 |
+
MODEL_REPO = 'hysts/DualStyleGAN'
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def parse_args() -> argparse.Namespace:
|
| 71 |
+
parser = argparse.ArgumentParser()
|
| 72 |
+
parser.add_argument('--device', type=str, default='cpu')
|
| 73 |
+
parser.add_argument('--theme', type=str)
|
| 74 |
+
parser.add_argument('--live', action='store_true')
|
| 75 |
+
parser.add_argument('--share', action='store_true')
|
| 76 |
+
parser.add_argument('--port', type=int)
|
| 77 |
+
parser.add_argument('--disable-queue',
|
| 78 |
+
dest='enable_queue',
|
| 79 |
+
action='store_false')
|
| 80 |
+
parser.add_argument('--allow-flagging', type=str, default='never')
|
| 81 |
+
parser.add_argument('--allow-screenshot', action='store_true')
|
| 82 |
+
return parser.parse_args()
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def load_encoder(device: torch.device) -> nn.Module:
|
| 86 |
+
ckpt_path = huggingface_hub.hf_hub_download(MODEL_REPO,
|
| 87 |
+
'models/encoder.pt',
|
| 88 |
+
use_auth_token=TOKEN)
|
| 89 |
+
ckpt = torch.load(ckpt_path, map_location='cpu')
|
| 90 |
+
opts = ckpt['opts']
|
| 91 |
+
opts['device'] = device.type
|
| 92 |
+
opts['checkpoint_path'] = ckpt_path
|
| 93 |
+
opts = argparse.Namespace(**opts)
|
| 94 |
+
model = pSp(opts)
|
| 95 |
+
model.to(device)
|
| 96 |
+
model.eval()
|
| 97 |
+
return model
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def load_generator(style_type: str, device: torch.device) -> nn.Module:
|
| 101 |
+
model = DualStyleGAN(1024, 512, 8, 2, res_index=6)
|
| 102 |
+
ckpt_path = huggingface_hub.hf_hub_download(
|
| 103 |
+
MODEL_REPO, f'models/{style_type}/generator.pt', use_auth_token=TOKEN)
|
| 104 |
+
ckpt = torch.load(ckpt_path, map_location='cpu')
|
| 105 |
+
model.load_state_dict(ckpt['g_ema'])
|
| 106 |
+
model.to(device)
|
| 107 |
+
model.eval()
|
| 108 |
+
return model
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def load_exstylecode(style_type: str) -> dict[str, np.ndarray]:
|
| 112 |
+
if style_type in ['cartoon', 'caricature', 'anime']:
|
| 113 |
+
filename = 'refined_exstyle_code.npy'
|
| 114 |
+
else:
|
| 115 |
+
filename = 'exstyle_code.npy'
|
| 116 |
+
path = huggingface_hub.hf_hub_download(MODEL_REPO,
|
| 117 |
+
f'models/{style_type}/{filename}',
|
| 118 |
+
use_auth_token=TOKEN)
|
| 119 |
+
exstyles = np.load(path, allow_pickle=True).item()
|
| 120 |
+
return exstyles
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def create_transform() -> Callable:
|
| 124 |
+
transform = T.Compose([
|
| 125 |
+
T.Resize(256),
|
| 126 |
+
T.CenterCrop(256),
|
| 127 |
+
T.ToTensor(),
|
| 128 |
+
T.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
|
| 129 |
+
])
|
| 130 |
+
return transform
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def create_dlib_landmark_model():
|
| 134 |
+
path = huggingface_hub.hf_hub_download(
|
| 135 |
+
'hysts/dlib_face_landmark_model',
|
| 136 |
+
'shape_predictor_68_face_landmarks.dat',
|
| 137 |
+
use_auth_token=TOKEN)
|
| 138 |
+
return dlib.shape_predictor(path)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def denormalize(tensor: torch.Tensor) -> torch.Tensor:
|
| 142 |
+
return torch.clamp((tensor + 1) / 2 * 255, 0, 255).to(torch.uint8)
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def postprocess(tensor: torch.Tensor) -> PIL.Image.Image:
|
| 146 |
+
tensor = denormalize(tensor)
|
| 147 |
+
image = tensor.cpu().numpy().transpose(1, 2, 0)
|
| 148 |
+
return PIL.Image.fromarray(image)
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
@torch.inference_mode()
|
| 152 |
+
def run(
|
| 153 |
+
image,
|
| 154 |
+
style_type: str,
|
| 155 |
+
style_id: float,
|
| 156 |
+
structure_weight: float,
|
| 157 |
+
color_weight: float,
|
| 158 |
+
dlib_landmark_model,
|
| 159 |
+
encoder: nn.Module,
|
| 160 |
+
generator_dict: dict[str, nn.Module],
|
| 161 |
+
exstyle_dict: dict[str, dict[str, np.ndarray]],
|
| 162 |
+
transform: Callable,
|
| 163 |
+
device: torch.device,
|
| 164 |
+
) -> tuple[PIL.Image.Image, PIL.Image.Image, PIL.Image.Image, PIL.Image.Image,
|
| 165 |
+
PIL.Image.Image]:
|
| 166 |
+
generator = generator_dict[style_type]
|
| 167 |
+
exstyles = exstyle_dict[style_type]
|
| 168 |
+
|
| 169 |
+
style_id = int(style_id)
|
| 170 |
+
style_id = min(max(0, style_id), len(exstyles) - 1)
|
| 171 |
+
|
| 172 |
+
stylename = list(exstyles.keys())[style_id]
|
| 173 |
+
|
| 174 |
+
image = align_face(filepath=image.name, predictor=dlib_landmark_model)
|
| 175 |
+
input_data = transform(image).unsqueeze(0).to(device)
|
| 176 |
+
|
| 177 |
+
img_rec, instyle = encoder(input_data,
|
| 178 |
+
randomize_noise=False,
|
| 179 |
+
return_latents=True,
|
| 180 |
+
z_plus_latent=True,
|
| 181 |
+
return_z_plus_latent=True,
|
| 182 |
+
resize=False)
|
| 183 |
+
img_rec = torch.clamp(img_rec.detach(), -1, 1)
|
| 184 |
+
|
| 185 |
+
latent = torch.tensor(exstyles[stylename]).repeat(2, 1, 1).to(device)
|
| 186 |
+
# latent[0] for both color and structrue transfer and latent[1] for only structrue transfer
|
| 187 |
+
latent[1, 7:18] = instyle[0, 7:18]
|
| 188 |
+
exstyle = generator.generator.style(
|
| 189 |
+
latent.reshape(latent.shape[0] * latent.shape[1],
|
| 190 |
+
latent.shape[2])).reshape(latent.shape)
|
| 191 |
+
|
| 192 |
+
img_gen, _ = generator([instyle.repeat(2, 1, 1)],
|
| 193 |
+
exstyle,
|
| 194 |
+
z_plus_latent=True,
|
| 195 |
+
truncation=0.7,
|
| 196 |
+
truncation_latent=0,
|
| 197 |
+
use_res=True,
|
| 198 |
+
interp_weights=[structure_weight] * 7 +
|
| 199 |
+
[color_weight] * 11)
|
| 200 |
+
img_gen = torch.clamp(img_gen.detach(), -1, 1)
|
| 201 |
+
# deactivate color-related layers by setting w_c = 0
|
| 202 |
+
img_gen2, _ = generator([instyle],
|
| 203 |
+
exstyle[0:1],
|
| 204 |
+
z_plus_latent=True,
|
| 205 |
+
truncation=0.7,
|
| 206 |
+
truncation_latent=0,
|
| 207 |
+
use_res=True,
|
| 208 |
+
interp_weights=[structure_weight] * 7 + [0] * 11)
|
| 209 |
+
img_gen2 = torch.clamp(img_gen2.detach(), -1, 1)
|
| 210 |
+
|
| 211 |
+
img_rec = postprocess(img_rec[0])
|
| 212 |
+
img_gen0 = postprocess(img_gen[0])
|
| 213 |
+
img_gen1 = postprocess(img_gen[1])
|
| 214 |
+
img_gen2 = postprocess(img_gen2[0])
|
| 215 |
+
|
| 216 |
+
return image, img_rec, img_gen0, img_gen1, img_gen2
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
def main():
|
| 220 |
+
gr.close_all()
|
| 221 |
+
|
| 222 |
+
args = parse_args()
|
| 223 |
+
device = torch.device(args.device)
|
| 224 |
+
|
| 225 |
+
style_types = [
|
| 226 |
+
'cartoon',
|
| 227 |
+
'caricature',
|
| 228 |
+
'anime',
|
| 229 |
+
'arcane',
|
| 230 |
+
'comic',
|
| 231 |
+
'pixar',
|
| 232 |
+
'slamdunk',
|
| 233 |
+
]
|
| 234 |
+
generator_dict = {
|
| 235 |
+
style_type: load_generator(style_type, device)
|
| 236 |
+
for style_type in style_types
|
| 237 |
+
}
|
| 238 |
+
exstyle_dict = {
|
| 239 |
+
style_type: load_exstylecode(style_type)
|
| 240 |
+
for style_type in style_types
|
| 241 |
+
}
|
| 242 |
+
|
| 243 |
+
dlib_landmark_model = create_dlib_landmark_model()
|
| 244 |
+
encoder = load_encoder(device)
|
| 245 |
+
transform = create_transform()
|
| 246 |
+
|
| 247 |
+
func = functools.partial(run,
|
| 248 |
+
dlib_landmark_model=dlib_landmark_model,
|
| 249 |
+
encoder=encoder,
|
| 250 |
+
generator_dict=generator_dict,
|
| 251 |
+
exstyle_dict=exstyle_dict,
|
| 252 |
+
transform=transform,
|
| 253 |
+
device=device)
|
| 254 |
+
func = functools.update_wrapper(func, run)
|
| 255 |
+
|
| 256 |
+
image_paths = sorted(pathlib.Path('images').glob('*.jpg'))
|
| 257 |
+
examples = [[path.as_posix(), 'cartoon', 26, 0.6, 1.0]
|
| 258 |
+
for path in image_paths]
|
| 259 |
+
|
| 260 |
+
gr.Interface(
|
| 261 |
+
func,
|
| 262 |
+
[
|
| 263 |
+
gr.inputs.Image(type='file', label='Input Image'),
|
| 264 |
+
gr.inputs.Radio(
|
| 265 |
+
style_types,
|
| 266 |
+
type='value',
|
| 267 |
+
default='cartoon',
|
| 268 |
+
label='Style Type',
|
| 269 |
+
),
|
| 270 |
+
gr.inputs.Number(default=26, label='Style Image Index'),
|
| 271 |
+
gr.inputs.Slider(
|
| 272 |
+
0, 1, step=0.1, default=0.6, label='Structure Weight'),
|
| 273 |
+
gr.inputs.Slider(0, 1, step=0.1, default=1.0,
|
| 274 |
+
label='Color Weight'),
|
| 275 |
+
],
|
| 276 |
+
[
|
| 277 |
+
gr.outputs.Image(type='pil', label='Aligned Face'),
|
| 278 |
+
gr.outputs.Image(type='pil', label='Reconstructed'),
|
| 279 |
+
gr.outputs.Image(type='pil',
|
| 280 |
+
label='Result 1 (Color and structure transfer)'),
|
| 281 |
+
gr.outputs.Image(type='pil',
|
| 282 |
+
label='Result 2 (Structure transfer only)'),
|
| 283 |
+
gr.outputs.Image(
|
| 284 |
+
type='pil',
|
| 285 |
+
label='Result 3 (Color-related layers deactivated)'),
|
| 286 |
+
],
|
| 287 |
+
examples=examples,
|
| 288 |
+
theme=args.theme,
|
| 289 |
+
title=TITLE,
|
| 290 |
+
description=DESCRIPTION,
|
| 291 |
+
article=ARTICLE,
|
| 292 |
+
allow_screenshot=args.allow_screenshot,
|
| 293 |
+
allow_flagging=args.allow_flagging,
|
| 294 |
+
live=args.live,
|
| 295 |
+
).launch(
|
| 296 |
+
enable_queue=args.enable_queue,
|
| 297 |
+
server_port=args.port,
|
| 298 |
+
share=args.share,
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
if __name__ == '__main__':
|
| 303 |
+
main()
|