
Update README.md
Browse files
README.md
CHANGED
|
@@ -3,4 +3,37 @@ license: apache-2.0
|
|
| 3 |
language:
|
| 4 |
- zh
|
| 5 |
- en
|
| 6 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
language:
|
| 4 |
- zh
|
| 5 |
- en
|
| 6 |
+
---
|
| 7 |
+
## 中文Mistral简介
|
| 8 |
+
Chinese-Mistral由清华大学地学系地球空间信息科学实验室开发。
|
| 9 |
+
该模型基于Mistral发布的Mistral-7B-v0.1训练得到。首先进行中文词表扩充,然后采用实验室提出的PREPARED训练框架(under review)在中英双语语料上进行增量预训练。
|
| 10 |
+
## 训练语料及清洗
|
| 11 |
+
语料采样于WuDao、WanJuan、Dolma等高质量开源数据集。我们仔细检查了这些数据集,发现可以进一步提高数据质量。我们采用KenLM计算文档的PPL、启发式算法、定义过滤规则等方法进一步清洗语料,最终保留了90%的语料。
|
| 12 |
+
## 词表扩充
|
| 13 |
+
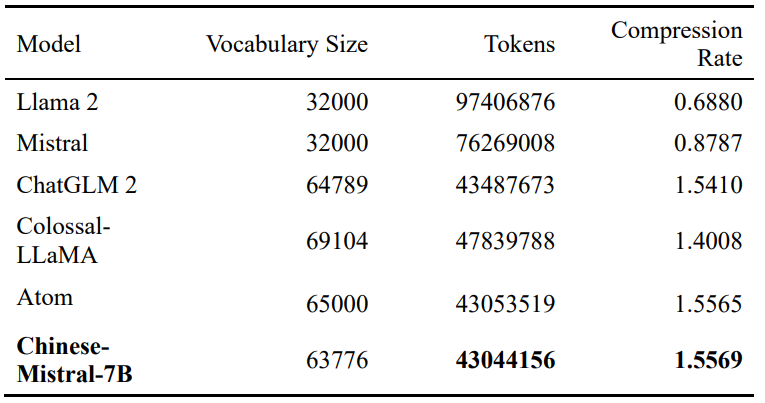
采用BPE算法(Sentencepiece实现)扩充中文词表,将mistral的词表由32000扩充至63776。我们随机从WuDao中抽取了多个文档,这些文档包括67,013,857个单词。多个模型的词表性能对比如下表。
|
| 14 |
+
结果显示,Chinese-Mistral的编码效率最高。
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
## 中文与英文通用能力比较
|
| 18 |
+
采用C-Eval(用于评测中文能力)、C-MMLU(用于评测中文能力)、MMLU(用于评测英文能力)的测试集进行评测。
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
与openbuddy社区开源的中文mistral在统一的实验环境中进行对比,显示Chinese-Mistral中英文能力均优于Openbuddy-mistral-7b-v13-base。
|
| 22 |
+
|
| 23 |
+

|
| 24 |
+
## 模型推理
|
| 25 |
+
```python
|
| 26 |
+
import torch
|
| 27 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 28 |
+
|
| 29 |
+
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
|
| 30 |
+
|
| 31 |
+
model_path = "itpossible/Chinese-Mistral-7B-v0.1"
|
| 32 |
+
tokenizer = AutoTokenizer.from_pretrained(model_path)
|
| 33 |
+
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map=device)
|
| 34 |
+
|
| 35 |
+
text = "在一场大雨后,我"
|
| 36 |
+
inputs = tokenizer(text, return_tensors="pt").to(device)
|
| 37 |
+
|
| 38 |
+
outputs = model.generate(**inputs, max_new_tokens=20)
|
| 39 |
+
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|