---
language:
- ace
- acm
- acq
- aeb
- af
- ajp
- ak
- als
- am
- apc
- ar
- ars
- ary
- arz
- as
- ast
- awa
- ayr
- azb
- azj
- ba
- bm
- ban
- be
- bem
- bn
- bho
- bjn
- bo
- bs
- bug
- bg
- ca
- ceb
- cs
- cjk
- ckb
- crh
- cy
- da
- de
- dik
- dyu
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fj
- fi
- fon
- fr
- fur
- fuv
- gaz
- gd
- ga
- gl
- gn
- gu
- ht
- ha
- he
- hi
- hne
- hr
- hu
- hy
- ig
- ilo
- id
- is
- it
- jv
- ja
- kab
- kac
- kam
- kn
- ks
- ka
- kk
- kbp
- kea
- khk
- km
- ki
- rw
- ky
- kmb
- kmr
- knc
- kg
- ko
- lo
- lij
- li
- ln
- lt
- lmo
- ltg
- lb
- lua
- lg
- luo
- lus
- lvs
- mag
- mai
- ml
- mar
- min
- mk
- mt
- mni
- mos
- mi
- my
- nl
- nn
- nb
- npi
- nso
- nus
- ny
- oc
- ory
- pag
- pa
- pap
- pbt
- pes
- plt
- pl
- pt
- prs
- quy
- ro
- rn
- ru
- sg
- sa
- sat
- scn
- shn
- si
- sk
- sl
- sm
- sn
- sd
- so
- st
- es
- sc
- sr
- ss
- su
- sv
- swh
- szl
- ta
- taq
- tt
- te
- tg
- tl
- th
- ti
- tpi
- tn
- ts
- tk
- tum
- tr
- tw
- tzm
- ug
- uk
- umb
- ur
- uzn
- vec
- vi
- war
- wo
- xh
- ydd
- yo
- yue
- zh
- zsm
- zu
language_details: >-
ace_Arab, ace_Latn, acm_Arab, acq_Arab, aeb_Arab, afr_Latn, ajp_Arab,
aka_Latn, amh_Ethi, apc_Arab, arb_Arab, ars_Arab, ary_Arab, arz_Arab,
asm_Beng, ast_Latn, awa_Deva, ayr_Latn, azb_Arab, azj_Latn, bak_Cyrl,
bam_Latn, ban_Latn,bel_Cyrl, bem_Latn, ben_Beng, bho_Deva, bjn_Arab, bjn_Latn,
bod_Tibt, bos_Latn, bug_Latn, bul_Cyrl, cat_Latn, ceb_Latn, ces_Latn,
cjk_Latn, ckb_Arab, crh_Latn, cym_Latn, dan_Latn, deu_Latn, dik_Latn,
dyu_Latn, dzo_Tibt, ell_Grek, eng_Latn, epo_Latn, est_Latn, eus_Latn,
ewe_Latn, fao_Latn, pes_Arab, fij_Latn, fin_Latn, fon_Latn, fra_Latn,
fur_Latn, fuv_Latn, gla_Latn, gle_Latn, glg_Latn, grn_Latn, guj_Gujr,
hat_Latn, hau_Latn, heb_Hebr, hin_Deva, hne_Deva, hrv_Latn, hun_Latn,
hye_Armn, ibo_Latn, ilo_Latn, ind_Latn, isl_Latn, ita_Latn, jav_Latn,
jpn_Jpan, kab_Latn, kac_Latn, kam_Latn, kan_Knda, kas_Arab, kas_Deva,
kat_Geor, knc_Arab, knc_Latn, kaz_Cyrl, kbp_Latn, kea_Latn, khm_Khmr,
kik_Latn, kin_Latn, kir_Cyrl, kmb_Latn, kon_Latn, kor_Hang, kmr_Latn,
lao_Laoo, lvs_Latn, lij_Latn, lim_Latn, lin_Latn, lit_Latn, lmo_Latn,
ltg_Latn, ltz_Latn, lua_Latn, lug_Latn, luo_Latn, lus_Latn, mag_Deva,
mai_Deva, mal_Mlym, mar_Deva, min_Latn, mkd_Cyrl, plt_Latn, mlt_Latn,
mni_Beng, khk_Cyrl, mos_Latn, mri_Latn, zsm_Latn, mya_Mymr, nld_Latn,
nno_Latn, nob_Latn, npi_Deva, nso_Latn, nus_Latn, nya_Latn, oci_Latn,
gaz_Latn, ory_Orya, pag_Latn, pan_Guru, pap_Latn, pol_Latn, por_Latn,
prs_Arab, pbt_Arab, quy_Latn, ron_Latn, run_Latn, rus_Cyrl, sag_Latn,
san_Deva, sat_Beng, scn_Latn, shn_Mymr, sin_Sinh, slk_Latn, slv_Latn,
smo_Latn, sna_Latn, snd_Arab, som_Latn, sot_Latn, spa_Latn, als_Latn,
srd_Latn, srp_Cyrl, ssw_Latn, sun_Latn, swe_Latn, swh_Latn, szl_Latn,
tam_Taml, tat_Cyrl, tel_Telu, tgk_Cyrl, tgl_Latn, tha_Thai, tir_Ethi,
taq_Latn, taq_Tfng, tpi_Latn, tsn_Latn, tso_Latn, tuk_Latn, tum_Latn,
tur_Latn, twi_Latn, tzm_Tfng, uig_Arab, ukr_Cyrl, umb_Latn, urd_Arab,
uzn_Latn, vec_Latn, vie_Latn, war_Latn, wol_Latn, xho_Latn, ydd_Hebr,
yor_Latn, yue_Hant, zho_Hans, zho_Hant, zul_Latn
license: mit
metrics:
- bleu
datasets:
- mozilla-foundation/common_voice_8_0
pipeline_tag: automatic-speech-recognition
tags:
- zeroswot
- speech translation
- zero-shot
- end-to-end
- nllb
- wav2vec2
---
# ZeroSwot ✨🤖✨
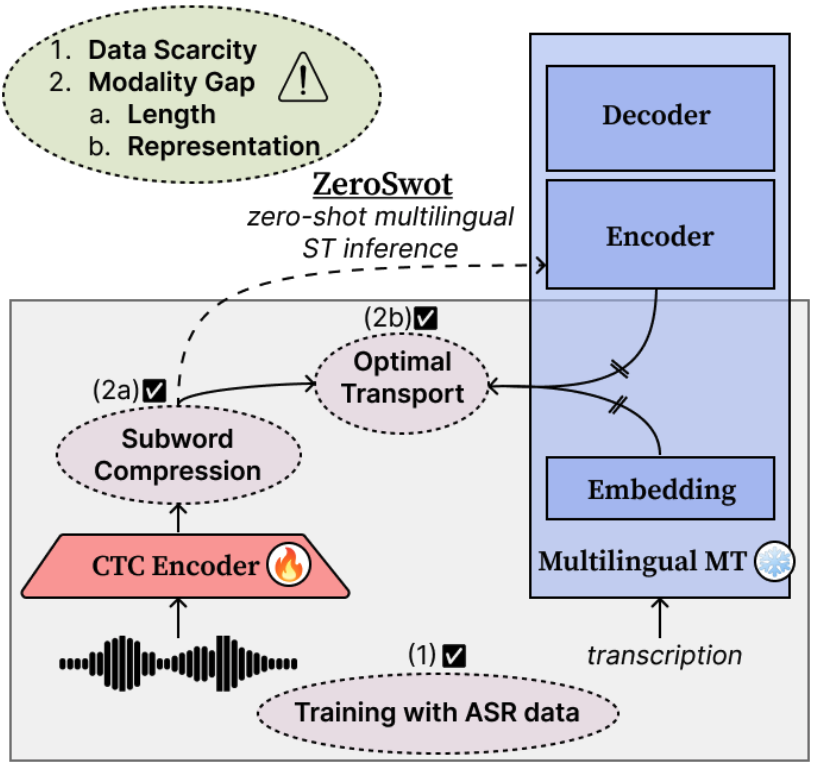
ZeroSwot is a state-of-the-art zero-shot end-to-end Speech Translation system.
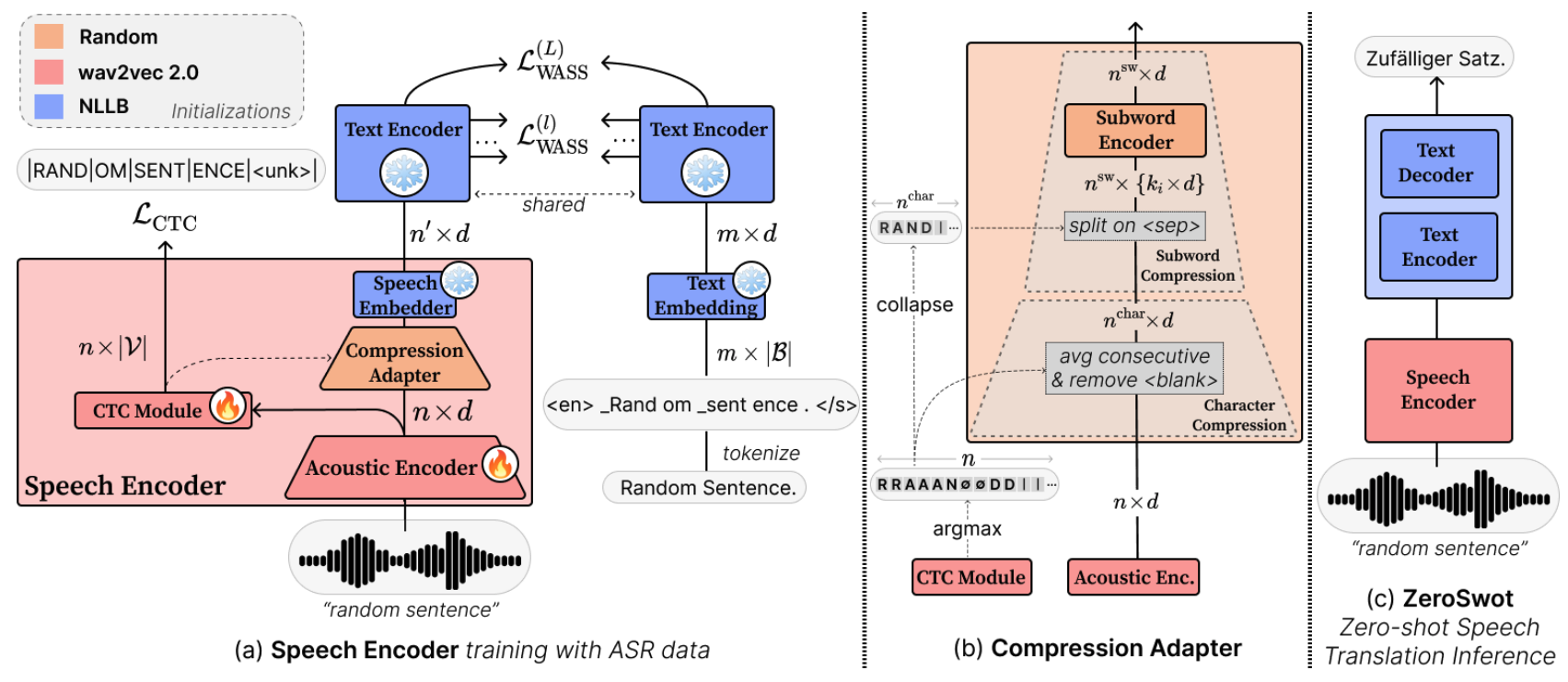
The model is created by adapting a wav2vec2.0-based encoder to the embedding space of NLLB, using a novel subword compression module and Optimal Transport, while only utilizing ASR data. It thus enables **Zero-shot E2E Speech Translation to all the 200 languages supported by NLLB**.
For more details please refer to our [paper](https://arxiv.org/abs/2402.10422) and the [original repo](https://github.com/mt-upc/ZeroSwot) build on fairseq.
## Architecture
The compression module is a light-weight transformer that takes as input the hidden state of wav2vec2.0 and the corresponding CTC predictions, and compresses them to subword-like embeddings similar to those expected from NLLB and aligns them using Optimal Transport. For inference we simply pass the output of the speech encoder to NLLB encoder.
## Version
This version of ZeroSwot is trained with ASR data from CommonVoice, and adapted [wav2vec2.0-large](https://huggingface.co/facebook/wav2vec2-large-960h-lv60-self) to the [nllb-200-distilled-600M](https://huggingface.co/facebook/nllb-200-distilled-600M) model.
## Usage
The model is tested with python 3.9.16 and Transformer v4.41.2. Install also torchaudio and sentencepiece for processing.
```bash
pip install transformers torchaudio sentencepiece
```
```python
from transformers import Wav2Vec2Processor, NllbTokenizer, AutoModel, AutoModelForSeq2SeqLM
import torchaudio
def load_and_resample_audio(audio_path, target_sr=16000):
audio, orig_freq = torchaudio.load(audio_path)
if orig_freq != target_sr:
audio = torchaudio.functional.resample(audio, orig_freq=orig_freq, new_freq=target_sr)
audio = audio.squeeze(0).numpy()
return audio
# Load processors and tokenizers
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
# Load ZeroSwot Encoder
commit_hash = "eafabee295ea1c8b45483d1fd26bd747d9a7d937"
zeroswot_encoder = AutoModel.from_pretrained(
"johntsi/ZeroSwot-Medium_asr-cv_en-to-200", trust_remote_code=True, revision=commit_hash,
)
zeroswot_encoder.eval()
zeroswot_encoder.to("cuda")
# Load NLLB Model
nllb_model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M")
nllb_model.eval()
nllb_model.to("cuda")
# Load audio file
audio = load_and_resample_audio(path_to_audio_file) # you can use "resources/sample.wav" for testing
input_values = processor(audio, sampling_rate=16000, return_tensors="pt").to("cuda")
# translation to German
compressed_embeds, attention_mask = zeroswot_encoder(**input_values)
predicted_ids = nllb_model.generate(
inputs_embeds=compressed_embeds,
attention_mask=attention_mask,
forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"],
num_beams=5,
)
translation = tokenizer.decode(predicted_ids[0], skip_special_tokens=True)
print(translation)
```
## Results
BLEU scores on CoVoST-2 test compared to supervised SOTA models [XLS-R-1B](https://huggingface.co/facebook/wav2vec2-xls-r-1b) and [SeamlessM4T-Medium](https://huggingface.co/facebook/seamless-m4t-medium). You can refer to Table 5 of the Results section in the paper for more details.
| Models | ZS | Size (B) | Ar | Ca | Cy | De | Et | Fa | Id | Ja | Lv | Mn | Sl | Sv | Ta | Tr | Zh | Average |
|:--------------:|:----:|:----------:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:-------:|
| XLS-R-1B | ✗ | 1.0 | 19.2 | 32.1 | **31.8** | 26.2 | 22.4 | 21.3 | 30.3 | 39.9 | 22.0 | 14.9 | 25.4 | 32.3 | 18.1 | 17.1 | 36.7 | 26.0 |
| SeamlessM4T-M | ✗ | 1.2 | 20.8 | 37.3 | 29.9 | **31.4** | 23.3 | 17.2 | 34.8 | 37.5 | 19.5 | 12.9 | 29.0 | 37.3 | 18.9 | **19.8** | 30.0 | 26.6 |
| ZeroSwot-M_asr-cv | ✓ | 0.35/0.95 | **24.4** | **38.7** | 28.8 | 31.2 | **26.2** | **26.0** | **36.0** | **46.0** | **24.8** | **19.0** | **31.6** | **37.8** | **24.4** | 18.6 | **39.0** | **30.2** |
## Citation
If you find ZeroSwot useful for your research, please cite our paper :)
```
@misc{tsiamas2024pushing,
title={{Pushing the Limits of Zero-shot End-to-End Speech Translation}},
author={Ioannis Tsiamas and Gerard I. Gállego and José A. R. Fonollosa and Marta R. Costa-jussà},
year={2024},
eprint={2402.10422},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```