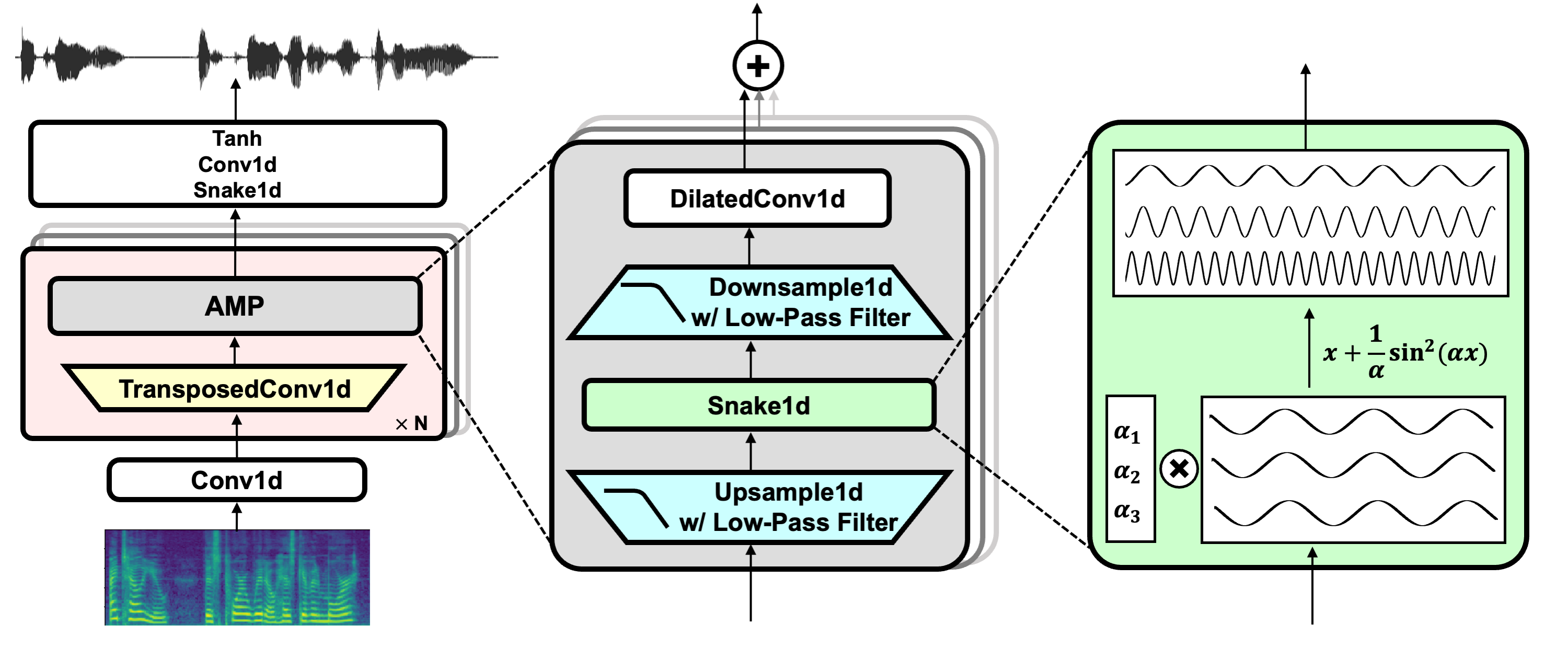
 +
+You can run a local gradio demo using below command:
+
+```python
+pip install -r demo/requirements.txt
+python demo/app.py
+```
+
+## Training
+
+Create symbolic link to the root of the dataset. The codebase uses filelist with the relative path from the dataset. Below are the example commands for LibriTTS dataset:
+
+```shell
+cd filelists/LibriTTS && \
+ln -s /path/to/your/LibriTTS/train-clean-100 train-clean-100 && \
+ln -s /path/to/your/LibriTTS/train-clean-360 train-clean-360 && \
+ln -s /path/to/your/LibriTTS/train-other-500 train-other-500 && \
+ln -s /path/to/your/LibriTTS/dev-clean dev-clean && \
+ln -s /path/to/your/LibriTTS/dev-other dev-other && \
+ln -s /path/to/your/LibriTTS/test-clean test-clean && \
+ln -s /path/to/your/LibriTTS/test-other test-other && \
+cd ../..
+```
+
+Train BigVGAN model. Below is an example command for training BigVGAN-v2 using LibriTTS dataset at 24kHz with a full 100-band mel spectrogram as input:
+
+```shell
+python train.py \
+--config configs/bigvgan_v2_24khz_100band_256x.json \
+--input_wavs_dir filelists/LibriTTS \
+--input_training_file filelists/LibriTTS/train-full.txt \
+--input_validation_file filelists/LibriTTS/val-full.txt \
+--list_input_unseen_wavs_dir filelists/LibriTTS filelists/LibriTTS \
+--list_input_unseen_validation_file filelists/LibriTTS/dev-clean.txt filelists/LibriTTS/dev-other.txt \
+--checkpoint_path exp/bigvgan_v2_24khz_100band_256x
+```
+
+## Synthesis
+
+Synthesize from BigVGAN model. Below is an example command for generating audio from the model.
+It computes mel spectrograms using wav files from `--input_wavs_dir` and saves the generated audio to `--output_dir`.
+
+```shell
+python inference.py \
+--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
+--input_wavs_dir /path/to/your/input_wav \
+--output_dir /path/to/your/output_wav
+```
+
+`inference_e2e.py` supports synthesis directly from the mel spectrogram saved in `.npy` format, with shapes `[1, channel, frame]` or `[channel, frame]`.
+It loads mel spectrograms from `--input_mels_dir` and saves the generated audio to `--output_dir`.
+
+Make sure that the STFT hyperparameters for mel spectrogram are the same as the model, which are defined in `config.json` of the corresponding model.
+
+```shell
+python inference_e2e.py \
+--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
+--input_mels_dir /path/to/your/input_mel \
+--output_dir /path/to/your/output_wav
+```
+
+## Using Custom CUDA Kernel for Synthesis
+
+You can apply the fast CUDA inference kernel by using a parameter `use_cuda_kernel` when instantiating BigVGAN:
+
+```python
+generator = BigVGAN(h, use_cuda_kernel=True)
+```
+
+You can also pass `--use_cuda_kernel` to `inference.py` and `inference_e2e.py` to enable this feature.
+
+When applied for the first time, it builds the kernel using `nvcc` and `ninja`. If the build succeeds, the kernel is saved to `alias_free_activation/cuda/build` and the model automatically loads the kernel. The codebase has been tested using CUDA `12.1`.
+
+Please make sure that both are installed in your system and `nvcc` installed in your system matches the version your PyTorch build is using.
+
+We recommend running `test_cuda_vs_torch_model.py` first to build and check the correctness of the CUDA kernel. See below example command and its output, where it returns `[Success] test CUDA fused vs. plain torch BigVGAN inference`:
+
+```python
+python tests/test_cuda_vs_torch_model.py \
+--checkpoint_file /path/to/your/bigvgan_generator.pt
+```
+
+```shell
+loading plain Pytorch BigVGAN
+...
+loading CUDA kernel BigVGAN with auto-build
+Detected CUDA files, patching ldflags
+Emitting ninja build file /path/to/your/BigVGAN/alias_free_activation/cuda/build/build.ninja..
+Building extension module anti_alias_activation_cuda...
+...
+Loading extension module anti_alias_activation_cuda...
+...
+Loading '/path/to/your/bigvgan_generator.pt'
+...
+[Success] test CUDA fused vs. plain torch BigVGAN inference
+ > mean_difference=0.0007238413265440613
+...
+```
+
+If you see `[Fail] test CUDA fused vs. plain torch BigVGAN inference`, it means that the CUDA kernel inference is incorrect. Please check if `nvcc` installed in your system is compatible with your PyTorch version.
+
+## Pretrained Models
+
+We provide the [pretrained models on Hugging Face Collections](https://huggingface.co/collections/nvidia/bigvgan-66959df3d97fd7d98d97dc9a).
+One can download the checkpoints of the generator weight (named `bigvgan_generator.pt`) and its discriminator/optimizer states (named `bigvgan_discriminator_optimizer.pt`) within the listed model repositories.
+
+| Model Name | Sampling Rate | Mel band | fmax | Upsampling Ratio | Params | Dataset | Steps | Fine-Tuned |
+|:--------------------------------------------------------------------------------------------------------:|:-------------:|:--------:|:-----:|:----------------:|:------:|:--------------------------:|:-----:|:----------:|
+| [bigvgan_v2_44khz_128band_512x](https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_512x) | 44 kHz | 128 | 22050 | 512 | 122M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_44khz_128band_256x](https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_256x) | 44 kHz | 128 | 22050 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_24khz_100band_256x](https://huggingface.co/nvidia/bigvgan_v2_24khz_100band_256x) | 24 kHz | 100 | 12000 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_22khz_80band_256x](https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_256x) | 22 kHz | 80 | 11025 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_22khz_80band_fmax8k_256x](https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_fmax8k_256x) | 22 kHz | 80 | 8000 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_24khz_100band](https://huggingface.co/nvidia/bigvgan_24khz_100band) | 24 kHz | 100 | 12000 | 256 | 112M | LibriTTS | 5M | No |
+| [bigvgan_base_24khz_100band](https://huggingface.co/nvidia/bigvgan_base_24khz_100band) | 24 kHz | 100 | 12000 | 256 | 14M | LibriTTS | 5M | No |
+| [bigvgan_22khz_80band](https://huggingface.co/nvidia/bigvgan_22khz_80band) | 22 kHz | 80 | 8000 | 256 | 112M | LibriTTS + VCTK + LJSpeech | 5M | No |
+| [bigvgan_base_22khz_80band](https://huggingface.co/nvidia/bigvgan_base_22khz_80band) | 22 kHz | 80 | 8000 | 256 | 14M | LibriTTS + VCTK + LJSpeech | 5M | No |
+
+The paper results are based on the original 24kHz BigVGAN models (`bigvgan_24khz_100band` and `bigvgan_base_24khz_100band`) trained on LibriTTS dataset.
+We also provide 22kHz BigVGAN models with band-limited setup (i.e., fmax=8000) for TTS applications.
+Note that the checkpoints use `snakebeta` activation with log scale parameterization, which have the best overall quality.
+
+You can fine-tune the models by:
+
+1. downloading the checkpoints (both the generator weight and its discriminator/optimizer states)
+2. resuming training using your audio dataset by specifying `--checkpoint_path` that includes the checkpoints when launching `train.py`
+
+## Training Details of BigVGAN-v2
+
+Comapred to the original BigVGAN, the pretrained checkpoints of BigVGAN-v2 used `batch_size=32` with a longer `segment_size=65536` and are trained using 8 A100 GPUs.
+
+Note that the BigVGAN-v2 `json` config files in `./configs` use `batch_size=4` as default to fit in a single A100 GPU for training. You can fine-tune the models adjusting `batch_size` depending on your GPUs.
+
+When training BigVGAN-v2 from scratch with small batch size, it can potentially encounter the early divergence problem mentioned in the paper. In such case, we recommend lowering the `clip_grad_norm` value (e.g. `100`) for the early training iterations (e.g. 20000 steps) and increase the value to the default `500`.
+
+## Evaluation Results of BigVGAN-v2
+
+Below are the objective results of the 24kHz model (`bigvgan_v2_24khz_100band_256x`) obtained from the LibriTTS `dev` sets. BigVGAN-v2 shows noticeable improvements of the metrics. The model also exhibits reduced perceptual artifacts, especially for non-speech audio.
+
+| Model | Dataset | Steps | PESQ(↑) | M-STFT(↓) | MCD(↓) | Periodicity(↓) | V/UV F1(↑) |
+|:----------:|:-----------------------:|:-----:|:---------:|:----------:|:----------:|:--------------:|:----------:|
+| BigVGAN | LibriTTS | 1M | 4.027 | 0.7997 | 0.3745 | 0.1018 | 0.9598 |
+| BigVGAN | LibriTTS | 5M | 4.256 | 0.7409 | 0.2988 | 0.0809 | 0.9698 |
+| BigVGAN-v2 | Large-scale Compilation | 3M | 4.359 | 0.7134 | 0.3060 | 0.0621 | 0.9777 |
+| BigVGAN-v2 | Large-scale Compilation | 5M | **4.362** | **0.7026** | **0.2903** | **0.0593** | **0.9793** |
+
+## Speed Benchmark
+
+Below are the speed and VRAM usage benchmark results of BigVGAN from `tests/test_cuda_vs_torch_model.py`, using `bigvgan_v2_24khz_100band_256x` as a reference model.
+
+| GPU | num_mel_frame | use_cuda_kernel | Speed (kHz) | Real-time Factor | VRAM (GB) |
+|:--------------------------:|:-------------:|:---------------:|:-----------:|:----------------:|:---------:|
+| NVIDIA A100 | 256 | False | 1672.1 | 69.7x | 1.3 |
+| | | True | 3916.5 | 163.2x | 1.3 |
+| | 2048 | False | 1899.6 | 79.2x | 1.7 |
+| | | True | 5330.1 | 222.1x | 1.7 |
+| | 16384 | False | 1973.8 | 82.2x | 5.0 |
+| | | True | 5761.7 | 240.1x | 4.4 |
+| NVIDIA GeForce RTX 3080 | 256 | False | 841.1 | 35.0x | 1.3 |
+| | | True | 1598.1 | 66.6x | 1.3 |
+| | 2048 | False | 929.9 | 38.7x | 1.7 |
+| | | True | 1971.3 | 82.1x | 1.6 |
+| | 16384 | False | 943.4 | 39.3x | 5.0 |
+| | | True | 2026.5 | 84.4x | 3.9 |
+| NVIDIA GeForce RTX 2080 Ti | 256 | False | 515.6 | 21.5x | 1.3 |
+| | | True | 811.3 | 33.8x | 1.3 |
+| | 2048 | False | 576.5 | 24.0x | 1.7 |
+| | | True | 1023.0 | 42.6x | 1.5 |
+| | 16384 | False | 589.4 | 24.6x | 5.0 |
+| | | True | 1068.1 | 44.5x | 3.2 |
+
+## Acknowledgements
+
+We thank Vijay Anand Korthikanti and Kevin J. Shih for their generous support in implementing the CUDA kernel for inference.
+
+## References
+
+- [HiFi-GAN](https://github.com/jik876/hifi-gan) (for generator and multi-period discriminator)
+- [Snake](https://github.com/EdwardDixon/snake) (for periodic activation)
+- [Alias-free-torch](https://github.com/junjun3518/alias-free-torch) (for anti-aliasing)
+- [Julius](https://github.com/adefossez/julius) (for low-pass filter)
+- [UnivNet](https://github.com/mindslab-ai/univnet) (for multi-resolution discriminator)
+- [descript-audio-codec](https://github.com/descriptinc/descript-audio-codec) and [vocos](https://github.com/gemelo-ai/vocos) (for multi-band multi-scale STFT discriminator and multi-scale mel spectrogram loss)
+- [Amphion](https://github.com/open-mmlab/Amphion) (for multi-scale sub-band CQT discriminator)
diff --git a/GPT_SoVITS/BigVGAN/activations.py b/GPT_SoVITS/BigVGAN/activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..abe3ad9e25c6ab3d4545c6a8c60e1f85a5a8e98e
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/activations.py
@@ -0,0 +1,122 @@
+# Implementation adapted from https://github.com/EdwardDixon/snake under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import torch
+from torch import nn, sin, pow
+from torch.nn import Parameter
+
+
+class Snake(nn.Module):
+ """
+ Implementation of a sine-based periodic activation function
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter
+ References:
+ - This activation function is from this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snake(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ """
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ """
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha: trainable parameter
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ alpha will be trained along with the rest of your model.
+ """
+ super(Snake, self).__init__()
+ self.in_features = in_features
+
+ # Initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # Log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ else: # Linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+
+ self.alpha.requires_grad = alpha_trainable
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ Snake ∶= x + 1/a * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # Line up with x to [B, C, T]
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ x = x + (1.0 / (alpha + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+
+ return x
+
+
+class SnakeBeta(nn.Module):
+ """
+ A modified Snake function which uses separate parameters for the magnitude of the periodic components
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ References:
+ - This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snakebeta(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ """
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ """
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ beta is initialized to 1 by default, higher values = higher-magnitude.
+ alpha will be trained along with the rest of your model.
+ """
+ super(SnakeBeta, self).__init__()
+ self.in_features = in_features
+
+ # Initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # Log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ self.beta = Parameter(torch.zeros(in_features) * alpha)
+ else: # Linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+ self.beta = Parameter(torch.ones(in_features) * alpha)
+
+ self.alpha.requires_grad = alpha_trainable
+ self.beta.requires_grad = alpha_trainable
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ SnakeBeta ∶= x + 1/b * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # Line up with x to [B, C, T]
+ beta = self.beta.unsqueeze(0).unsqueeze(-1)
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ beta = torch.exp(beta)
+ x = x + (1.0 / (beta + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+
+ return x
diff --git a/GPT_SoVITS/BigVGAN/bigvgan.py b/GPT_SoVITS/BigVGAN/bigvgan.py
new file mode 100644
index 0000000000000000000000000000000000000000..febdf165c354b1fa2932f27e4ef8b7b6da10e2a6
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/bigvgan.py
@@ -0,0 +1,461 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import os
+import json
+from pathlib import Path
+from typing import Optional, Union, Dict
+
+import torch
+import torch.nn as nn
+from torch.nn import Conv1d, ConvTranspose1d
+from torch.nn.utils import weight_norm, remove_weight_norm
+
+from . import activations
+from .utils0 import init_weights, get_padding
+from .alias_free_activation.torch.act import Activation1d as TorchActivation1d
+from .env import AttrDict
+
+from huggingface_hub import PyTorchModelHubMixin, hf_hub_download
+
+
+def load_hparams_from_json(path) -> AttrDict:
+ with open(path) as f:
+ data = f.read()
+ return AttrDict(json.loads(data))
+
+
+class AMPBlock1(torch.nn.Module):
+ """
+ AMPBlock applies Snake / SnakeBeta activation functions with trainable parameters that control periodicity, defined for each layer.
+ AMPBlock1 has additional self.convs2 that contains additional Conv1d layers with a fixed dilation=1 followed by each layer in self.convs1
+
+ Args:
+ h (AttrDict): Hyperparameters.
+ channels (int): Number of convolution channels.
+ kernel_size (int): Size of the convolution kernel. Default is 3.
+ dilation (tuple): Dilation rates for the convolutions. Each dilation layer has two convolutions. Default is (1, 3, 5).
+ activation (str): Activation function type. Should be either 'snake' or 'snakebeta'. Default is None.
+ """
+
+ def __init__(
+ self,
+ h: AttrDict,
+ channels: int,
+ kernel_size: int = 3,
+ dilation: tuple = (1, 3, 5),
+ activation: str = None,
+ ):
+ super().__init__()
+
+ self.h = h
+
+ self.convs1 = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ stride=1,
+ dilation=d,
+ padding=get_padding(kernel_size, d),
+ )
+ )
+ for d in dilation
+ ]
+ )
+ self.convs1.apply(init_weights)
+
+ self.convs2 = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ stride=1,
+ dilation=1,
+ padding=get_padding(kernel_size, 1),
+ )
+ )
+ for _ in range(len(dilation))
+ ]
+ )
+ self.convs2.apply(init_weights)
+
+ self.num_layers = len(self.convs1) + len(self.convs2) # Total number of conv layers
+
+ # Select which Activation1d, lazy-load cuda version to ensure backward compatibility
+ if self.h.get("use_cuda_kernel", False):
+ from .alias_free_activation.cuda.activation1d import (
+ Activation1d as CudaActivation1d,
+ )
+
+ Activation1d = CudaActivation1d
+ else:
+ Activation1d = TorchActivation1d
+
+ # Activation functions
+ if activation == "snake":
+ self.activations = nn.ModuleList(
+ [
+ Activation1d(activation=activations.Snake(channels, alpha_logscale=h.snake_logscale))
+ for _ in range(self.num_layers)
+ ]
+ )
+ elif activation == "snakebeta":
+ self.activations = nn.ModuleList(
+ [
+ Activation1d(activation=activations.SnakeBeta(channels, alpha_logscale=h.snake_logscale))
+ for _ in range(self.num_layers)
+ ]
+ )
+ else:
+ raise NotImplementedError(
+ "activation incorrectly specified. check the config file and look for 'activation'."
+ )
+
+ def forward(self, x):
+ acts1, acts2 = self.activations[::2], self.activations[1::2]
+ for c1, c2, a1, a2 in zip(self.convs1, self.convs2, acts1, acts2):
+ xt = a1(x)
+ xt = c1(xt)
+ xt = a2(xt)
+ xt = c2(xt)
+ x = xt + x
+
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.convs1:
+ remove_weight_norm(l)
+ for l in self.convs2:
+ remove_weight_norm(l)
+
+
+class AMPBlock2(torch.nn.Module):
+ """
+ AMPBlock applies Snake / SnakeBeta activation functions with trainable parameters that control periodicity, defined for each layer.
+ Unlike AMPBlock1, AMPBlock2 does not contain extra Conv1d layers with fixed dilation=1
+
+ Args:
+ h (AttrDict): Hyperparameters.
+ channels (int): Number of convolution channels.
+ kernel_size (int): Size of the convolution kernel. Default is 3.
+ dilation (tuple): Dilation rates for the convolutions. Each dilation layer has two convolutions. Default is (1, 3, 5).
+ activation (str): Activation function type. Should be either 'snake' or 'snakebeta'. Default is None.
+ """
+
+ def __init__(
+ self,
+ h: AttrDict,
+ channels: int,
+ kernel_size: int = 3,
+ dilation: tuple = (1, 3, 5),
+ activation: str = None,
+ ):
+ super().__init__()
+
+ self.h = h
+
+ self.convs = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ stride=1,
+ dilation=d,
+ padding=get_padding(kernel_size, d),
+ )
+ )
+ for d in dilation
+ ]
+ )
+ self.convs.apply(init_weights)
+
+ self.num_layers = len(self.convs) # Total number of conv layers
+
+ # Select which Activation1d, lazy-load cuda version to ensure backward compatibility
+ if self.h.get("use_cuda_kernel", False):
+ from .alias_free_activation.cuda.activation1d import (
+ Activation1d as CudaActivation1d,
+ )
+
+ Activation1d = CudaActivation1d
+ else:
+ Activation1d = TorchActivation1d
+
+ # Activation functions
+ if activation == "snake":
+ self.activations = nn.ModuleList(
+ [
+ Activation1d(activation=activations.Snake(channels, alpha_logscale=h.snake_logscale))
+ for _ in range(self.num_layers)
+ ]
+ )
+ elif activation == "snakebeta":
+ self.activations = nn.ModuleList(
+ [
+ Activation1d(activation=activations.SnakeBeta(channels, alpha_logscale=h.snake_logscale))
+ for _ in range(self.num_layers)
+ ]
+ )
+ else:
+ raise NotImplementedError(
+ "activation incorrectly specified. check the config file and look for 'activation'."
+ )
+
+ def forward(self, x):
+ for c, a in zip(self.convs, self.activations):
+ xt = a(x)
+ xt = c(xt)
+ x = xt + x
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.convs:
+ remove_weight_norm(l)
+
+
+class BigVGAN(
+ torch.nn.Module,
+ PyTorchModelHubMixin,
+ # library_name="bigvgan",
+ # repo_url="https://github.com/NVIDIA/BigVGAN",
+ # docs_url="https://github.com/NVIDIA/BigVGAN/blob/main/README.md",
+ # pipeline_tag="audio-to-audio",
+ # license="mit",
+ # tags=["neural-vocoder", "audio-generation", "arxiv:2206.04658"],
+):
+ """
+ BigVGAN is a neural vocoder model that applies anti-aliased periodic activation for residual blocks (resblocks).
+ New in BigVGAN-v2: it can optionally use optimized CUDA kernels for AMP (anti-aliased multi-periodicity) blocks.
+
+ Args:
+ h (AttrDict): Hyperparameters.
+ use_cuda_kernel (bool): If set to True, loads optimized CUDA kernels for AMP. This should be used for inference only, as training is not supported with CUDA kernels.
+
+ Note:
+ - The `use_cuda_kernel` parameter should be used for inference only, as training with CUDA kernels is not supported.
+ - Ensure that the activation function is correctly specified in the hyperparameters (h.activation).
+ """
+
+ def __init__(self, h: AttrDict, use_cuda_kernel: bool = False):
+ super().__init__()
+ self.h = h
+ self.h["use_cuda_kernel"] = use_cuda_kernel
+
+ # Select which Activation1d, lazy-load cuda version to ensure backward compatibility
+ if self.h.get("use_cuda_kernel", False):
+ from .alias_free_activation.cuda.activation1d import (
+ Activation1d as CudaActivation1d,
+ )
+
+ Activation1d = CudaActivation1d
+ else:
+ Activation1d = TorchActivation1d
+
+ self.num_kernels = len(h.resblock_kernel_sizes)
+ self.num_upsamples = len(h.upsample_rates)
+
+ # Pre-conv
+ self.conv_pre = weight_norm(Conv1d(h.num_mels, h.upsample_initial_channel, 7, 1, padding=3))
+
+ # Define which AMPBlock to use. BigVGAN uses AMPBlock1 as default
+ if h.resblock == "1":
+ resblock_class = AMPBlock1
+ elif h.resblock == "2":
+ resblock_class = AMPBlock2
+ else:
+ raise ValueError(f"Incorrect resblock class specified in hyperparameters. Got {h.resblock}")
+
+ # Transposed conv-based upsamplers. does not apply anti-aliasing
+ self.ups = nn.ModuleList()
+ for i, (u, k) in enumerate(zip(h.upsample_rates, h.upsample_kernel_sizes)):
+ self.ups.append(
+ nn.ModuleList(
+ [
+ weight_norm(
+ ConvTranspose1d(
+ h.upsample_initial_channel // (2**i),
+ h.upsample_initial_channel // (2 ** (i + 1)),
+ k,
+ u,
+ padding=(k - u) // 2,
+ )
+ )
+ ]
+ )
+ )
+
+ # Residual blocks using anti-aliased multi-periodicity composition modules (AMP)
+ self.resblocks = nn.ModuleList()
+ for i in range(len(self.ups)):
+ ch = h.upsample_initial_channel // (2 ** (i + 1))
+ for j, (k, d) in enumerate(zip(h.resblock_kernel_sizes, h.resblock_dilation_sizes)):
+ self.resblocks.append(resblock_class(h, ch, k, d, activation=h.activation))
+
+ # Post-conv
+ activation_post = (
+ activations.Snake(ch, alpha_logscale=h.snake_logscale)
+ if h.activation == "snake"
+ else (activations.SnakeBeta(ch, alpha_logscale=h.snake_logscale) if h.activation == "snakebeta" else None)
+ )
+ if activation_post is None:
+ raise NotImplementedError(
+ "activation incorrectly specified. check the config file and look for 'activation'."
+ )
+
+ self.activation_post = Activation1d(activation=activation_post)
+
+ # Whether to use bias for the final conv_post. Default to True for backward compatibility
+ self.use_bias_at_final = h.get("use_bias_at_final", True)
+ self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3, bias=self.use_bias_at_final))
+
+ # Weight initialization
+ for i in range(len(self.ups)):
+ self.ups[i].apply(init_weights)
+ self.conv_post.apply(init_weights)
+
+ # Final tanh activation. Defaults to True for backward compatibility
+ self.use_tanh_at_final = h.get("use_tanh_at_final", True)
+
+ def forward(self, x):
+ # Pre-conv
+ x = self.conv_pre(x)
+
+ for i in range(self.num_upsamples):
+ # Upsampling
+ for i_up in range(len(self.ups[i])):
+ x = self.ups[i][i_up](x)
+ # AMP blocks
+ xs = None
+ for j in range(self.num_kernels):
+ if xs is None:
+ xs = self.resblocks[i * self.num_kernels + j](x)
+ else:
+ xs += self.resblocks[i * self.num_kernels + j](x)
+ x = xs / self.num_kernels
+
+ # Post-conv
+ x = self.activation_post(x)
+ x = self.conv_post(x)
+ # Final tanh activation
+ if self.use_tanh_at_final:
+ x = torch.tanh(x)
+ else:
+ x = torch.clamp(x, min=-1.0, max=1.0) # Bound the output to [-1, 1]
+
+ return x
+
+ def remove_weight_norm(self):
+ try:
+ # print("Removing weight norm...")
+ for l in self.ups:
+ for l_i in l:
+ remove_weight_norm(l_i)
+ for l in self.resblocks:
+ l.remove_weight_norm()
+ remove_weight_norm(self.conv_pre)
+ remove_weight_norm(self.conv_post)
+ except ValueError:
+ print("[INFO] Model already removed weight norm. Skipping!")
+ pass
+
+ # Additional methods for huggingface_hub support
+ def _save_pretrained(self, save_directory: Path) -> None:
+ """Save weights and config.json from a Pytorch model to a local directory."""
+
+ model_path = save_directory / "bigvgan_generator.pt"
+ torch.save({"generator": self.state_dict()}, model_path)
+
+ config_path = save_directory / "config.json"
+ with open(config_path, "w") as config_file:
+ json.dump(self.h, config_file, indent=4)
+
+ @classmethod
+ def _from_pretrained(
+ cls,
+ *,
+ model_id: str,
+ revision: str,
+ cache_dir: str,
+ force_download: bool,
+ proxies: Optional[Dict],
+ resume_download: bool,
+ local_files_only: bool,
+ token: Union[str, bool, None],
+ map_location: str = "cpu", # Additional argument
+ strict: bool = False, # Additional argument
+ use_cuda_kernel: bool = False,
+ **model_kwargs,
+ ):
+ """Load Pytorch pretrained weights and return the loaded model."""
+
+ # Download and load hyperparameters (h) used by BigVGAN
+ if os.path.isdir(model_id):
+ # print("Loading config.json from local directory")
+ config_file = os.path.join(model_id, "config.json")
+ else:
+ config_file = hf_hub_download(
+ repo_id=model_id,
+ filename="config.json",
+ revision=revision,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ token=token,
+ local_files_only=local_files_only,
+ )
+ h = load_hparams_from_json(config_file)
+
+ # instantiate BigVGAN using h
+ if use_cuda_kernel:
+ print(
+ "[WARNING] You have specified use_cuda_kernel=True during BigVGAN.from_pretrained(). Only inference is supported (training is not implemented)!"
+ )
+ print(
+ "[WARNING] You need nvcc and ninja installed in your system that matches your PyTorch build is using to build the kernel. If not, the model will fail to initialize or generate incorrect waveform!"
+ )
+ print(
+ "[WARNING] For detail, see the official GitHub repository: https://github.com/NVIDIA/BigVGAN?tab=readme-ov-file#using-custom-cuda-kernel-for-synthesis"
+ )
+ model = cls(h, use_cuda_kernel=use_cuda_kernel)
+
+ # Download and load pretrained generator weight
+ if os.path.isdir(model_id):
+ # print("Loading weights from local directory")
+ model_file = os.path.join(model_id, "bigvgan_generator.pt")
+ else:
+ # print(f"Loading weights from {model_id}")
+ model_file = hf_hub_download(
+ repo_id=model_id,
+ filename="bigvgan_generator.pt",
+ revision=revision,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ token=token,
+ local_files_only=local_files_only,
+ )
+
+ checkpoint_dict = torch.load(model_file, map_location=map_location)
+
+ try:
+ model.load_state_dict(checkpoint_dict["generator"])
+ except RuntimeError:
+ print(
+ "[INFO] the pretrained checkpoint does not contain weight norm. Loading the checkpoint after removing weight norm!"
+ )
+ model.remove_weight_norm()
+ model.load_state_dict(checkpoint_dict["generator"])
+
+ return model
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_22khz_80band.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_22khz_80band.json
new file mode 100644
index 0000000000000000000000000000000000000000..64bca7846edb4e86d7ee22d9ca7a1554cf7f1042
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_22khz_80band.json
@@ -0,0 +1,45 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 32,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "resolutions": [[1024, 120, 600], [2048, 240, 1200], [512, 50, 240]],
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "segment_size": 8192,
+ "num_mels": 80,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 22050,
+
+ "fmin": 0,
+ "fmax": 8000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_24khz_100band.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_24khz_100band.json
new file mode 100644
index 0000000000000000000000000000000000000000..e7f7ff08f6697a4640d8e28c0b3fe7e62d0c3fc7
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_24khz_100band.json
@@ -0,0 +1,45 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 32,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "resolutions": [[1024, 120, 600], [2048, 240, 1200], [512, 50, 240]],
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "segment_size": 8192,
+ "num_mels": 100,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 24000,
+
+ "fmin": 0,
+ "fmax": 12000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_base_22khz_80band.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_base_22khz_80band.json
new file mode 100644
index 0000000000000000000000000000000000000000..fd244848308917f4df7ce49bf6b76530fd04cbc2
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_base_22khz_80band.json
@@ -0,0 +1,45 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 32,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [8,8,2,2],
+ "upsample_kernel_sizes": [16,16,4,4],
+ "upsample_initial_channel": 512,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "resolutions": [[1024, 120, 600], [2048, 240, 1200], [512, 50, 240]],
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "segment_size": 8192,
+ "num_mels": 80,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 22050,
+
+ "fmin": 0,
+ "fmax": 8000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_base_24khz_100band.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_base_24khz_100band.json
new file mode 100644
index 0000000000000000000000000000000000000000..0911508cac4a9346ada8c196bfcc228998da6f42
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_base_24khz_100band.json
@@ -0,0 +1,45 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 32,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [8,8,2,2],
+ "upsample_kernel_sizes": [16,16,4,4],
+ "upsample_initial_channel": 512,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "resolutions": [[1024, 120, 600], [2048, 240, 1200], [512, 50, 240]],
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "segment_size": 8192,
+ "num_mels": 100,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 24000,
+
+ "fmin": 0,
+ "fmax": 12000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_256x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_256x.json
new file mode 100644
index 0000000000000000000000000000000000000000..e96bd5fdd5b99767adba7f13bfcd1f777d5c599a
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_256x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 80,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 22050,
+
+ "fmin": 0,
+ "fmax": null,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_fmax8k_256x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_fmax8k_256x.json
new file mode 100644
index 0000000000000000000000000000000000000000..a3c9699fbe11948f4fd7e3434d2e623a00c802dd
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_fmax8k_256x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 80,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 22050,
+
+ "fmin": 0,
+ "fmax": 8000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_24khz_100band_256x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_24khz_100band_256x.json
new file mode 100644
index 0000000000000000000000000000000000000000..8057ee267c8ed80615362a41892b923a3ccd27e5
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_24khz_100band_256x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 100,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 24000,
+
+ "fmin": 0,
+ "fmax": null,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_256x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_256x.json
new file mode 100644
index 0000000000000000000000000000000000000000..b6999d3028e5d741ec99b16b34f153e763d0cfec
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_256x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 128,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 44100,
+
+ "fmin": 0,
+ "fmax": null,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_512x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_512x.json
new file mode 100644
index 0000000000000000000000000000000000000000..2d7176c910ae0969f208f6d28e3f14abca2dbc7f
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_512x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [8,4,2,2,2,2],
+ "upsample_kernel_sizes": [16,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 128,
+ "num_freq": 2049,
+ "n_fft": 2048,
+ "hop_size": 512,
+ "win_size": 2048,
+
+ "sampling_rate": 44100,
+
+ "fmin": 0,
+ "fmax": null,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/discriminators.py b/GPT_SoVITS/BigVGAN/discriminators.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d44c7983955a1be15a4520f6730de272f799128
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/discriminators.py
@@ -0,0 +1,625 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+
+import torch
+import torch.nn.functional as F
+import torch.nn as nn
+from torch.nn import Conv2d
+from torch.nn.utils import weight_norm, spectral_norm
+from torchaudio.transforms import Spectrogram, Resample
+
+from env import AttrDict
+from utils import get_padding
+import typing
+from typing import List, Tuple
+
+
+class DiscriminatorP(torch.nn.Module):
+ def __init__(
+ self,
+ h: AttrDict,
+ period: List[int],
+ kernel_size: int = 5,
+ stride: int = 3,
+ use_spectral_norm: bool = False,
+ ):
+ super().__init__()
+ self.period = period
+ self.d_mult = h.discriminator_channel_mult
+ norm_f = weight_norm if not use_spectral_norm else spectral_norm
+
+ self.convs = nn.ModuleList(
+ [
+ norm_f(
+ Conv2d(
+ 1,
+ int(32 * self.d_mult),
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(5, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ int(32 * self.d_mult),
+ int(128 * self.d_mult),
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(5, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ int(128 * self.d_mult),
+ int(512 * self.d_mult),
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(5, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ int(512 * self.d_mult),
+ int(1024 * self.d_mult),
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(5, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ int(1024 * self.d_mult),
+ int(1024 * self.d_mult),
+ (kernel_size, 1),
+ 1,
+ padding=(2, 0),
+ )
+ ),
+ ]
+ )
+ self.conv_post = norm_f(Conv2d(int(1024 * self.d_mult), 1, (3, 1), 1, padding=(1, 0)))
+
+ def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ fmap = []
+
+ # 1d to 2d
+ b, c, t = x.shape
+ if t % self.period != 0: # pad first
+ n_pad = self.period - (t % self.period)
+ x = F.pad(x, (0, n_pad), "reflect")
+ t = t + n_pad
+ x = x.view(b, c, t // self.period, self.period)
+
+ for l in self.convs:
+ x = l(x)
+ x = F.leaky_relu(x, 0.1)
+ fmap.append(x)
+ x = self.conv_post(x)
+ fmap.append(x)
+ x = torch.flatten(x, 1, -1)
+
+ return x, fmap
+
+
+class MultiPeriodDiscriminator(torch.nn.Module):
+ def __init__(self, h: AttrDict):
+ super().__init__()
+ self.mpd_reshapes = h.mpd_reshapes
+ print(f"mpd_reshapes: {self.mpd_reshapes}")
+ self.discriminators = nn.ModuleList(
+ [DiscriminatorP(h, rs, use_spectral_norm=h.use_spectral_norm) for rs in self.mpd_reshapes]
+ )
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+ for i, d in enumerate(self.discriminators):
+ y_d_r, fmap_r = d(y)
+ y_d_g, fmap_g = d(y_hat)
+ y_d_rs.append(y_d_r)
+ fmap_rs.append(fmap_r)
+ y_d_gs.append(y_d_g)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+class DiscriminatorR(nn.Module):
+ def __init__(self, cfg: AttrDict, resolution: List[List[int]]):
+ super().__init__()
+
+ self.resolution = resolution
+ assert len(self.resolution) == 3, f"MRD layer requires list with len=3, got {self.resolution}"
+ self.lrelu_slope = 0.1
+
+ norm_f = weight_norm if cfg.use_spectral_norm == False else spectral_norm
+ if hasattr(cfg, "mrd_use_spectral_norm"):
+ print(f"[INFO] overriding MRD use_spectral_norm as {cfg.mrd_use_spectral_norm}")
+ norm_f = weight_norm if cfg.mrd_use_spectral_norm == False else spectral_norm
+ self.d_mult = cfg.discriminator_channel_mult
+ if hasattr(cfg, "mrd_channel_mult"):
+ print(f"[INFO] overriding mrd channel multiplier as {cfg.mrd_channel_mult}")
+ self.d_mult = cfg.mrd_channel_mult
+
+ self.convs = nn.ModuleList(
+ [
+ norm_f(nn.Conv2d(1, int(32 * self.d_mult), (3, 9), padding=(1, 4))),
+ norm_f(
+ nn.Conv2d(
+ int(32 * self.d_mult),
+ int(32 * self.d_mult),
+ (3, 9),
+ stride=(1, 2),
+ padding=(1, 4),
+ )
+ ),
+ norm_f(
+ nn.Conv2d(
+ int(32 * self.d_mult),
+ int(32 * self.d_mult),
+ (3, 9),
+ stride=(1, 2),
+ padding=(1, 4),
+ )
+ ),
+ norm_f(
+ nn.Conv2d(
+ int(32 * self.d_mult),
+ int(32 * self.d_mult),
+ (3, 9),
+ stride=(1, 2),
+ padding=(1, 4),
+ )
+ ),
+ norm_f(
+ nn.Conv2d(
+ int(32 * self.d_mult),
+ int(32 * self.d_mult),
+ (3, 3),
+ padding=(1, 1),
+ )
+ ),
+ ]
+ )
+ self.conv_post = norm_f(nn.Conv2d(int(32 * self.d_mult), 1, (3, 3), padding=(1, 1)))
+
+ def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ fmap = []
+
+ x = self.spectrogram(x)
+ x = x.unsqueeze(1)
+ for l in self.convs:
+ x = l(x)
+ x = F.leaky_relu(x, self.lrelu_slope)
+ fmap.append(x)
+ x = self.conv_post(x)
+ fmap.append(x)
+ x = torch.flatten(x, 1, -1)
+
+ return x, fmap
+
+ def spectrogram(self, x: torch.Tensor) -> torch.Tensor:
+ n_fft, hop_length, win_length = self.resolution
+ x = F.pad(
+ x,
+ (int((n_fft - hop_length) / 2), int((n_fft - hop_length) / 2)),
+ mode="reflect",
+ )
+ x = x.squeeze(1)
+ x = torch.stft(
+ x,
+ n_fft=n_fft,
+ hop_length=hop_length,
+ win_length=win_length,
+ center=False,
+ return_complex=True,
+ )
+ x = torch.view_as_real(x) # [B, F, TT, 2]
+ mag = torch.norm(x, p=2, dim=-1) # [B, F, TT]
+
+ return mag
+
+
+class MultiResolutionDiscriminator(nn.Module):
+ def __init__(self, cfg, debug=False):
+ super().__init__()
+ self.resolutions = cfg.resolutions
+ assert len(self.resolutions) == 3, (
+ f"MRD requires list of list with len=3, each element having a list with len=3. Got {self.resolutions}"
+ )
+ self.discriminators = nn.ModuleList([DiscriminatorR(cfg, resolution) for resolution in self.resolutions])
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+
+ for i, d in enumerate(self.discriminators):
+ y_d_r, fmap_r = d(x=y)
+ y_d_g, fmap_g = d(x=y_hat)
+ y_d_rs.append(y_d_r)
+ fmap_rs.append(fmap_r)
+ y_d_gs.append(y_d_g)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+# Method based on descript-audio-codec: https://github.com/descriptinc/descript-audio-codec
+# Modified code adapted from https://github.com/gemelo-ai/vocos under the MIT license.
+# LICENSE is in incl_licenses directory.
+class DiscriminatorB(nn.Module):
+ def __init__(
+ self,
+ window_length: int,
+ channels: int = 32,
+ hop_factor: float = 0.25,
+ bands: Tuple[Tuple[float, float], ...] = (
+ (0.0, 0.1),
+ (0.1, 0.25),
+ (0.25, 0.5),
+ (0.5, 0.75),
+ (0.75, 1.0),
+ ),
+ ):
+ super().__init__()
+ self.window_length = window_length
+ self.hop_factor = hop_factor
+ self.spec_fn = Spectrogram(
+ n_fft=window_length,
+ hop_length=int(window_length * hop_factor),
+ win_length=window_length,
+ power=None,
+ )
+ n_fft = window_length // 2 + 1
+ bands = [(int(b[0] * n_fft), int(b[1] * n_fft)) for b in bands]
+ self.bands = bands
+ convs = lambda: nn.ModuleList(
+ [
+ weight_norm(nn.Conv2d(2, channels, (3, 9), (1, 1), padding=(1, 4))),
+ weight_norm(nn.Conv2d(channels, channels, (3, 9), (1, 2), padding=(1, 4))),
+ weight_norm(nn.Conv2d(channels, channels, (3, 9), (1, 2), padding=(1, 4))),
+ weight_norm(nn.Conv2d(channels, channels, (3, 9), (1, 2), padding=(1, 4))),
+ weight_norm(nn.Conv2d(channels, channels, (3, 3), (1, 1), padding=(1, 1))),
+ ]
+ )
+ self.band_convs = nn.ModuleList([convs() for _ in range(len(self.bands))])
+
+ self.conv_post = weight_norm(nn.Conv2d(channels, 1, (3, 3), (1, 1), padding=(1, 1)))
+
+ def spectrogram(self, x: torch.Tensor) -> List[torch.Tensor]:
+ # Remove DC offset
+ x = x - x.mean(dim=-1, keepdims=True)
+ # Peak normalize the volume of input audio
+ x = 0.8 * x / (x.abs().max(dim=-1, keepdim=True)[0] + 1e-9)
+ x = self.spec_fn(x)
+ x = torch.view_as_real(x)
+ x = x.permute(0, 3, 2, 1) # [B, F, T, C] -> [B, C, T, F]
+ # Split into bands
+ x_bands = [x[..., b[0] : b[1]] for b in self.bands]
+ return x_bands
+
+ def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ x_bands = self.spectrogram(x.squeeze(1))
+ fmap = []
+ x = []
+
+ for band, stack in zip(x_bands, self.band_convs):
+ for i, layer in enumerate(stack):
+ band = layer(band)
+ band = torch.nn.functional.leaky_relu(band, 0.1)
+ if i > 0:
+ fmap.append(band)
+ x.append(band)
+
+ x = torch.cat(x, dim=-1)
+ x = self.conv_post(x)
+ fmap.append(x)
+
+ return x, fmap
+
+
+# Method based on descript-audio-codec: https://github.com/descriptinc/descript-audio-codec
+# Modified code adapted from https://github.com/gemelo-ai/vocos under the MIT license.
+# LICENSE is in incl_licenses directory.
+class MultiBandDiscriminator(nn.Module):
+ def __init__(
+ self,
+ h,
+ ):
+ """
+ Multi-band multi-scale STFT discriminator, with the architecture based on https://github.com/descriptinc/descript-audio-codec.
+ and the modified code adapted from https://github.com/gemelo-ai/vocos.
+ """
+ super().__init__()
+ # fft_sizes (list[int]): Tuple of window lengths for FFT. Defaults to [2048, 1024, 512] if not set in h.
+ self.fft_sizes = h.get("mbd_fft_sizes", [2048, 1024, 512])
+ self.discriminators = nn.ModuleList([DiscriminatorB(window_length=w) for w in self.fft_sizes])
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+
+ for d in self.discriminators:
+ y_d_r, fmap_r = d(x=y)
+ y_d_g, fmap_g = d(x=y_hat)
+ y_d_rs.append(y_d_r)
+ fmap_rs.append(fmap_r)
+ y_d_gs.append(y_d_g)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+# Adapted from https://github.com/open-mmlab/Amphion/blob/main/models/vocoders/gan/discriminator/mssbcqtd.py under the MIT license.
+# LICENSE is in incl_licenses directory.
+class DiscriminatorCQT(nn.Module):
+ def __init__(self, cfg: AttrDict, hop_length: int, n_octaves: int, bins_per_octave: int):
+ super().__init__()
+ self.cfg = cfg
+
+ self.filters = cfg["cqtd_filters"]
+ self.max_filters = cfg["cqtd_max_filters"]
+ self.filters_scale = cfg["cqtd_filters_scale"]
+ self.kernel_size = (3, 9)
+ self.dilations = cfg["cqtd_dilations"]
+ self.stride = (1, 2)
+
+ self.in_channels = cfg["cqtd_in_channels"]
+ self.out_channels = cfg["cqtd_out_channels"]
+ self.fs = cfg["sampling_rate"]
+ self.hop_length = hop_length
+ self.n_octaves = n_octaves
+ self.bins_per_octave = bins_per_octave
+
+ # Lazy-load
+ from nnAudio import features
+
+ self.cqt_transform = features.cqt.CQT2010v2(
+ sr=self.fs * 2,
+ hop_length=self.hop_length,
+ n_bins=self.bins_per_octave * self.n_octaves,
+ bins_per_octave=self.bins_per_octave,
+ output_format="Complex",
+ pad_mode="constant",
+ )
+
+ self.conv_pres = nn.ModuleList()
+ for _ in range(self.n_octaves):
+ self.conv_pres.append(
+ nn.Conv2d(
+ self.in_channels * 2,
+ self.in_channels * 2,
+ kernel_size=self.kernel_size,
+ padding=self.get_2d_padding(self.kernel_size),
+ )
+ )
+
+ self.convs = nn.ModuleList()
+
+ self.convs.append(
+ nn.Conv2d(
+ self.in_channels * 2,
+ self.filters,
+ kernel_size=self.kernel_size,
+ padding=self.get_2d_padding(self.kernel_size),
+ )
+ )
+
+ in_chs = min(self.filters_scale * self.filters, self.max_filters)
+ for i, dilation in enumerate(self.dilations):
+ out_chs = min((self.filters_scale ** (i + 1)) * self.filters, self.max_filters)
+ self.convs.append(
+ weight_norm(
+ nn.Conv2d(
+ in_chs,
+ out_chs,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ dilation=(dilation, 1),
+ padding=self.get_2d_padding(self.kernel_size, (dilation, 1)),
+ )
+ )
+ )
+ in_chs = out_chs
+ out_chs = min(
+ (self.filters_scale ** (len(self.dilations) + 1)) * self.filters,
+ self.max_filters,
+ )
+ self.convs.append(
+ weight_norm(
+ nn.Conv2d(
+ in_chs,
+ out_chs,
+ kernel_size=(self.kernel_size[0], self.kernel_size[0]),
+ padding=self.get_2d_padding((self.kernel_size[0], self.kernel_size[0])),
+ )
+ )
+ )
+
+ self.conv_post = weight_norm(
+ nn.Conv2d(
+ out_chs,
+ self.out_channels,
+ kernel_size=(self.kernel_size[0], self.kernel_size[0]),
+ padding=self.get_2d_padding((self.kernel_size[0], self.kernel_size[0])),
+ )
+ )
+
+ self.activation = torch.nn.LeakyReLU(negative_slope=0.1)
+ self.resample = Resample(orig_freq=self.fs, new_freq=self.fs * 2)
+
+ self.cqtd_normalize_volume = self.cfg.get("cqtd_normalize_volume", False)
+ if self.cqtd_normalize_volume:
+ print(
+ "[INFO] cqtd_normalize_volume set to True. Will apply DC offset removal & peak volume normalization in CQTD!"
+ )
+
+ def get_2d_padding(
+ self,
+ kernel_size: typing.Tuple[int, int],
+ dilation: typing.Tuple[int, int] = (1, 1),
+ ):
+ return (
+ ((kernel_size[0] - 1) * dilation[0]) // 2,
+ ((kernel_size[1] - 1) * dilation[1]) // 2,
+ )
+
+ def forward(self, x: torch.tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ fmap = []
+
+ if self.cqtd_normalize_volume:
+ # Remove DC offset
+ x = x - x.mean(dim=-1, keepdims=True)
+ # Peak normalize the volume of input audio
+ x = 0.8 * x / (x.abs().max(dim=-1, keepdim=True)[0] + 1e-9)
+
+ x = self.resample(x)
+
+ z = self.cqt_transform(x)
+
+ z_amplitude = z[:, :, :, 0].unsqueeze(1)
+ z_phase = z[:, :, :, 1].unsqueeze(1)
+
+ z = torch.cat([z_amplitude, z_phase], dim=1)
+ z = torch.permute(z, (0, 1, 3, 2)) # [B, C, W, T] -> [B, C, T, W]
+
+ latent_z = []
+ for i in range(self.n_octaves):
+ latent_z.append(
+ self.conv_pres[i](
+ z[
+ :,
+ :,
+ :,
+ i * self.bins_per_octave : (i + 1) * self.bins_per_octave,
+ ]
+ )
+ )
+ latent_z = torch.cat(latent_z, dim=-1)
+
+ for i, l in enumerate(self.convs):
+ latent_z = l(latent_z)
+
+ latent_z = self.activation(latent_z)
+ fmap.append(latent_z)
+
+ latent_z = self.conv_post(latent_z)
+
+ return latent_z, fmap
+
+
+class MultiScaleSubbandCQTDiscriminator(nn.Module):
+ def __init__(self, cfg: AttrDict):
+ super().__init__()
+
+ self.cfg = cfg
+ # Using get with defaults
+ self.cfg["cqtd_filters"] = self.cfg.get("cqtd_filters", 32)
+ self.cfg["cqtd_max_filters"] = self.cfg.get("cqtd_max_filters", 1024)
+ self.cfg["cqtd_filters_scale"] = self.cfg.get("cqtd_filters_scale", 1)
+ self.cfg["cqtd_dilations"] = self.cfg.get("cqtd_dilations", [1, 2, 4])
+ self.cfg["cqtd_in_channels"] = self.cfg.get("cqtd_in_channels", 1)
+ self.cfg["cqtd_out_channels"] = self.cfg.get("cqtd_out_channels", 1)
+ # Multi-scale params to loop over
+ self.cfg["cqtd_hop_lengths"] = self.cfg.get("cqtd_hop_lengths", [512, 256, 256])
+ self.cfg["cqtd_n_octaves"] = self.cfg.get("cqtd_n_octaves", [9, 9, 9])
+ self.cfg["cqtd_bins_per_octaves"] = self.cfg.get("cqtd_bins_per_octaves", [24, 36, 48])
+
+ self.discriminators = nn.ModuleList(
+ [
+ DiscriminatorCQT(
+ self.cfg,
+ hop_length=self.cfg["cqtd_hop_lengths"][i],
+ n_octaves=self.cfg["cqtd_n_octaves"][i],
+ bins_per_octave=self.cfg["cqtd_bins_per_octaves"][i],
+ )
+ for i in range(len(self.cfg["cqtd_hop_lengths"]))
+ ]
+ )
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+
+ for disc in self.discriminators:
+ y_d_r, fmap_r = disc(y)
+ y_d_g, fmap_g = disc(y_hat)
+ y_d_rs.append(y_d_r)
+ fmap_rs.append(fmap_r)
+ y_d_gs.append(y_d_g)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+class CombinedDiscriminator(nn.Module):
+ """
+ Wrapper of chaining multiple discrimiantor architectures.
+ Example: combine mbd and cqtd as a single class
+ """
+
+ def __init__(self, list_discriminator: List[nn.Module]):
+ super().__init__()
+ self.discrimiantor = nn.ModuleList(list_discriminator)
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+
+ for disc in self.discrimiantor:
+ y_d_r, y_d_g, fmap_r, fmap_g = disc(y, y_hat)
+ y_d_rs.extend(y_d_r)
+ fmap_rs.extend(fmap_r)
+ y_d_gs.extend(y_d_g)
+ fmap_gs.extend(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
diff --git a/GPT_SoVITS/BigVGAN/env.py b/GPT_SoVITS/BigVGAN/env.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf8ac6cea644c78d115dd3902b902993f366ee61
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/env.py
@@ -0,0 +1,18 @@
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import os
+import shutil
+
+
+class AttrDict(dict):
+ def __init__(self, *args, **kwargs):
+ super(AttrDict, self).__init__(*args, **kwargs)
+ self.__dict__ = self
+
+
+def build_env(config, config_name, path):
+ t_path = os.path.join(path, config_name)
+ if config != t_path:
+ os.makedirs(path, exist_ok=True)
+ shutil.copyfile(config, os.path.join(path, config_name))
diff --git a/GPT_SoVITS/BigVGAN/inference.py b/GPT_SoVITS/BigVGAN/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f892a3c807a7020eff7fea35179b0f6e5f991c9
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/inference.py
@@ -0,0 +1,85 @@
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+from __future__ import absolute_import, division, print_function, unicode_literals
+
+import os
+import argparse
+import json
+import torch
+import librosa
+from utils import load_checkpoint
+from meldataset import get_mel_spectrogram
+from scipy.io.wavfile import write
+from env import AttrDict
+from meldataset import MAX_WAV_VALUE
+from bigvgan import BigVGAN as Generator
+
+h = None
+device = None
+torch.backends.cudnn.benchmark = False
+
+
+def inference(a, h):
+ generator = Generator(h, use_cuda_kernel=a.use_cuda_kernel).to(device)
+
+ state_dict_g = load_checkpoint(a.checkpoint_file, device)
+ generator.load_state_dict(state_dict_g["generator"])
+
+ filelist = os.listdir(a.input_wavs_dir)
+
+ os.makedirs(a.output_dir, exist_ok=True)
+
+ generator.eval()
+ generator.remove_weight_norm()
+ with torch.no_grad():
+ for i, filname in enumerate(filelist):
+ # Load the ground truth audio and resample if necessary
+ wav, sr = librosa.load(os.path.join(a.input_wavs_dir, filname), sr=h.sampling_rate, mono=True)
+ wav = torch.FloatTensor(wav).to(device)
+ # Compute mel spectrogram from the ground truth audio
+ x = get_mel_spectrogram(wav.unsqueeze(0), generator.h)
+
+ y_g_hat = generator(x)
+
+ audio = y_g_hat.squeeze()
+ audio = audio * MAX_WAV_VALUE
+ audio = audio.cpu().numpy().astype("int16")
+
+ output_file = os.path.join(a.output_dir, os.path.splitext(filname)[0] + "_generated.wav")
+ write(output_file, h.sampling_rate, audio)
+ print(output_file)
+
+
+def main():
+ print("Initializing Inference Process..")
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--input_wavs_dir", default="test_files")
+ parser.add_argument("--output_dir", default="generated_files")
+ parser.add_argument("--checkpoint_file", required=True)
+ parser.add_argument("--use_cuda_kernel", action="store_true", default=False)
+
+ a = parser.parse_args()
+
+ config_file = os.path.join(os.path.split(a.checkpoint_file)[0], "config.json")
+ with open(config_file) as f:
+ data = f.read()
+
+ global h
+ json_config = json.loads(data)
+ h = AttrDict(json_config)
+
+ torch.manual_seed(h.seed)
+ global device
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed(h.seed)
+ device = torch.device("cuda")
+ else:
+ device = torch.device("cpu")
+
+ inference(a, h)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/GPT_SoVITS/BigVGAN/inference_e2e.py b/GPT_SoVITS/BigVGAN/inference_e2e.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c0df77435e91935beaca365dd5fd38d76098a4a
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/inference_e2e.py
@@ -0,0 +1,100 @@
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+from __future__ import absolute_import, division, print_function, unicode_literals
+
+import glob
+import os
+import numpy as np
+import argparse
+import json
+import torch
+from scipy.io.wavfile import write
+from env import AttrDict
+from meldataset import MAX_WAV_VALUE
+from bigvgan import BigVGAN as Generator
+
+h = None
+device = None
+torch.backends.cudnn.benchmark = False
+
+
+def load_checkpoint(filepath, device):
+ assert os.path.isfile(filepath)
+ print(f"Loading '{filepath}'")
+ checkpoint_dict = torch.load(filepath, map_location=device)
+ print("Complete.")
+ return checkpoint_dict
+
+
+def scan_checkpoint(cp_dir, prefix):
+ pattern = os.path.join(cp_dir, prefix + "*")
+ cp_list = glob.glob(pattern)
+ if len(cp_list) == 0:
+ return ""
+ return sorted(cp_list)[-1]
+
+
+def inference(a, h):
+ generator = Generator(h, use_cuda_kernel=a.use_cuda_kernel).to(device)
+
+ state_dict_g = load_checkpoint(a.checkpoint_file, device)
+ generator.load_state_dict(state_dict_g["generator"])
+
+ filelist = os.listdir(a.input_mels_dir)
+
+ os.makedirs(a.output_dir, exist_ok=True)
+
+ generator.eval()
+ generator.remove_weight_norm()
+ with torch.no_grad():
+ for i, filname in enumerate(filelist):
+ # Load the mel spectrogram in .npy format
+ x = np.load(os.path.join(a.input_mels_dir, filname))
+ x = torch.FloatTensor(x).to(device)
+ if len(x.shape) == 2:
+ x = x.unsqueeze(0)
+
+ y_g_hat = generator(x)
+
+ audio = y_g_hat.squeeze()
+ audio = audio * MAX_WAV_VALUE
+ audio = audio.cpu().numpy().astype("int16")
+
+ output_file = os.path.join(a.output_dir, os.path.splitext(filname)[0] + "_generated_e2e.wav")
+ write(output_file, h.sampling_rate, audio)
+ print(output_file)
+
+
+def main():
+ print("Initializing Inference Process..")
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--input_mels_dir", default="test_mel_files")
+ parser.add_argument("--output_dir", default="generated_files_from_mel")
+ parser.add_argument("--checkpoint_file", required=True)
+ parser.add_argument("--use_cuda_kernel", action="store_true", default=False)
+
+ a = parser.parse_args()
+
+ config_file = os.path.join(os.path.split(a.checkpoint_file)[0], "config.json")
+ with open(config_file) as f:
+ data = f.read()
+
+ global h
+ json_config = json.loads(data)
+ h = AttrDict(json_config)
+
+ torch.manual_seed(h.seed)
+ global device
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed(h.seed)
+ device = torch.device("cuda")
+ else:
+ device = torch.device("cpu")
+
+ inference(a, h)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/GPT_SoVITS/BigVGAN/loss.py b/GPT_SoVITS/BigVGAN/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..c295a144ff7bcfc0d91d9d4676bedfa7015cdb79
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/loss.py
@@ -0,0 +1,238 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+
+import torch
+import torch.nn as nn
+from librosa.filters import mel as librosa_mel_fn
+from scipy import signal
+
+import typing
+from typing import List, Tuple
+from collections import namedtuple
+import math
+import functools
+
+
+# Adapted from https://github.com/descriptinc/descript-audio-codec/blob/main/dac/nn/loss.py under the MIT license.
+# LICENSE is in incl_licenses directory.
+class MultiScaleMelSpectrogramLoss(nn.Module):
+ """Compute distance between mel spectrograms. Can be used
+ in a multi-scale way.
+
+ Parameters
+ ----------
+ n_mels : List[int]
+ Number of mels per STFT, by default [5, 10, 20, 40, 80, 160, 320],
+ window_lengths : List[int], optional
+ Length of each window of each STFT, by default [32, 64, 128, 256, 512, 1024, 2048]
+ loss_fn : typing.Callable, optional
+ How to compare each loss, by default nn.L1Loss()
+ clamp_eps : float, optional
+ Clamp on the log magnitude, below, by default 1e-5
+ mag_weight : float, optional
+ Weight of raw magnitude portion of loss, by default 0.0 (no ampliciation on mag part)
+ log_weight : float, optional
+ Weight of log magnitude portion of loss, by default 1.0
+ pow : float, optional
+ Power to raise magnitude to before taking log, by default 1.0
+ weight : float, optional
+ Weight of this loss, by default 1.0
+ match_stride : bool, optional
+ Whether to match the stride of convolutional layers, by default False
+
+ Implementation copied from: https://github.com/descriptinc/lyrebird-audiotools/blob/961786aa1a9d628cca0c0486e5885a457fe70c1a/audiotools/metrics/spectral.py
+ Additional code copied and modified from https://github.com/descriptinc/audiotools/blob/master/audiotools/core/audio_signal.py
+ """
+
+ def __init__(
+ self,
+ sampling_rate: int,
+ n_mels: List[int] = [5, 10, 20, 40, 80, 160, 320],
+ window_lengths: List[int] = [32, 64, 128, 256, 512, 1024, 2048],
+ loss_fn: typing.Callable = nn.L1Loss(),
+ clamp_eps: float = 1e-5,
+ mag_weight: float = 0.0,
+ log_weight: float = 1.0,
+ pow: float = 1.0,
+ weight: float = 1.0,
+ match_stride: bool = False,
+ mel_fmin: List[float] = [0, 0, 0, 0, 0, 0, 0],
+ mel_fmax: List[float] = [None, None, None, None, None, None, None],
+ window_type: str = "hann",
+ ):
+ super().__init__()
+ self.sampling_rate = sampling_rate
+
+ STFTParams = namedtuple(
+ "STFTParams",
+ ["window_length", "hop_length", "window_type", "match_stride"],
+ )
+
+ self.stft_params = [
+ STFTParams(
+ window_length=w,
+ hop_length=w // 4,
+ match_stride=match_stride,
+ window_type=window_type,
+ )
+ for w in window_lengths
+ ]
+ self.n_mels = n_mels
+ self.loss_fn = loss_fn
+ self.clamp_eps = clamp_eps
+ self.log_weight = log_weight
+ self.mag_weight = mag_weight
+ self.weight = weight
+ self.mel_fmin = mel_fmin
+ self.mel_fmax = mel_fmax
+ self.pow = pow
+
+ @staticmethod
+ @functools.lru_cache(None)
+ def get_window(
+ window_type,
+ window_length,
+ ):
+ return signal.get_window(window_type, window_length)
+
+ @staticmethod
+ @functools.lru_cache(None)
+ def get_mel_filters(sr, n_fft, n_mels, fmin, fmax):
+ return librosa_mel_fn(sr=sr, n_fft=n_fft, n_mels=n_mels, fmin=fmin, fmax=fmax)
+
+ def mel_spectrogram(
+ self,
+ wav,
+ n_mels,
+ fmin,
+ fmax,
+ window_length,
+ hop_length,
+ match_stride,
+ window_type,
+ ):
+ """
+ Mirrors AudioSignal.mel_spectrogram used by BigVGAN-v2 training from:
+ https://github.com/descriptinc/audiotools/blob/master/audiotools/core/audio_signal.py
+ """
+ B, C, T = wav.shape
+
+ if match_stride:
+ assert hop_length == window_length // 4, "For match_stride, hop must equal n_fft // 4"
+ right_pad = math.ceil(T / hop_length) * hop_length - T
+ pad = (window_length - hop_length) // 2
+ else:
+ right_pad = 0
+ pad = 0
+
+ wav = torch.nn.functional.pad(wav, (pad, pad + right_pad), mode="reflect")
+
+ window = self.get_window(window_type, window_length)
+ window = torch.from_numpy(window).to(wav.device).float()
+
+ stft = torch.stft(
+ wav.reshape(-1, T),
+ n_fft=window_length,
+ hop_length=hop_length,
+ window=window,
+ return_complex=True,
+ center=True,
+ )
+ _, nf, nt = stft.shape
+ stft = stft.reshape(B, C, nf, nt)
+ if match_stride:
+ """
+ Drop first two and last two frames, which are added, because of padding. Now num_frames * hop_length = num_samples.
+ """
+ stft = stft[..., 2:-2]
+ magnitude = torch.abs(stft)
+
+ nf = magnitude.shape[2]
+ mel_basis = self.get_mel_filters(self.sampling_rate, 2 * (nf - 1), n_mels, fmin, fmax)
+ mel_basis = torch.from_numpy(mel_basis).to(wav.device)
+ mel_spectrogram = magnitude.transpose(2, -1) @ mel_basis.T
+ mel_spectrogram = mel_spectrogram.transpose(-1, 2)
+
+ return mel_spectrogram
+
+ def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
+ """Computes mel loss between an estimate and a reference
+ signal.
+
+ Parameters
+ ----------
+ x : torch.Tensor
+ Estimate signal
+ y : torch.Tensor
+ Reference signal
+
+ Returns
+ -------
+ torch.Tensor
+ Mel loss.
+ """
+
+ loss = 0.0
+ for n_mels, fmin, fmax, s in zip(self.n_mels, self.mel_fmin, self.mel_fmax, self.stft_params):
+ kwargs = {
+ "n_mels": n_mels,
+ "fmin": fmin,
+ "fmax": fmax,
+ "window_length": s.window_length,
+ "hop_length": s.hop_length,
+ "match_stride": s.match_stride,
+ "window_type": s.window_type,
+ }
+
+ x_mels = self.mel_spectrogram(x, **kwargs)
+ y_mels = self.mel_spectrogram(y, **kwargs)
+ x_logmels = torch.log(x_mels.clamp(min=self.clamp_eps).pow(self.pow)) / torch.log(torch.tensor(10.0))
+ y_logmels = torch.log(y_mels.clamp(min=self.clamp_eps).pow(self.pow)) / torch.log(torch.tensor(10.0))
+
+ loss += self.log_weight * self.loss_fn(x_logmels, y_logmels)
+ loss += self.mag_weight * self.loss_fn(x_logmels, y_logmels)
+
+ return loss
+
+
+# Loss functions
+def feature_loss(fmap_r: List[List[torch.Tensor]], fmap_g: List[List[torch.Tensor]]) -> torch.Tensor:
+ loss = 0
+ for dr, dg in zip(fmap_r, fmap_g):
+ for rl, gl in zip(dr, dg):
+ loss += torch.mean(torch.abs(rl - gl))
+
+ return loss * 2 # This equates to lambda=2.0 for the feature matching loss
+
+
+def discriminator_loss(
+ disc_real_outputs: List[torch.Tensor], disc_generated_outputs: List[torch.Tensor]
+) -> Tuple[torch.Tensor, List[torch.Tensor], List[torch.Tensor]]:
+ loss = 0
+ r_losses = []
+ g_losses = []
+ for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
+ r_loss = torch.mean((1 - dr) ** 2)
+ g_loss = torch.mean(dg**2)
+ loss += r_loss + g_loss
+ r_losses.append(r_loss.item())
+ g_losses.append(g_loss.item())
+
+ return loss, r_losses, g_losses
+
+
+def generator_loss(
+ disc_outputs: List[torch.Tensor],
+) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ loss = 0
+ gen_losses = []
+ for dg in disc_outputs:
+ l = torch.mean((1 - dg) ** 2)
+ gen_losses.append(l)
+ loss += l
+
+ return loss, gen_losses
diff --git a/GPT_SoVITS/BigVGAN/meldataset.py b/GPT_SoVITS/BigVGAN/meldataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc12c9874cfb9958d6f4842cc067ffda66a390eb
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/meldataset.py
@@ -0,0 +1,370 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import math
+import os
+import random
+import torch
+import torch.utils.data
+import numpy as np
+import librosa
+from librosa.filters import mel as librosa_mel_fn
+import pathlib
+from tqdm import tqdm
+from typing import List, Tuple, Optional
+from .env import AttrDict
+
+MAX_WAV_VALUE = 32767.0 # NOTE: 32768.0 -1 to prevent int16 overflow (results in popping sound in corner cases)
+
+
+def dynamic_range_compression(x, C=1, clip_val=1e-5):
+ return np.log(np.clip(x, a_min=clip_val, a_max=None) * C)
+
+
+def dynamic_range_decompression(x, C=1):
+ return np.exp(x) / C
+
+
+def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
+ return torch.log(torch.clamp(x, min=clip_val) * C)
+
+
+def dynamic_range_decompression_torch(x, C=1):
+ return torch.exp(x) / C
+
+
+def spectral_normalize_torch(magnitudes):
+ return dynamic_range_compression_torch(magnitudes)
+
+
+def spectral_de_normalize_torch(magnitudes):
+ return dynamic_range_decompression_torch(magnitudes)
+
+
+mel_basis_cache = {}
+hann_window_cache = {}
+
+
+def mel_spectrogram(
+ y: torch.Tensor,
+ n_fft: int,
+ num_mels: int,
+ sampling_rate: int,
+ hop_size: int,
+ win_size: int,
+ fmin: int,
+ fmax: int = None,
+ center: bool = False,
+) -> torch.Tensor:
+ """
+ Calculate the mel spectrogram of an input signal.
+ This function uses slaney norm for the librosa mel filterbank (using librosa.filters.mel) and uses Hann window for STFT (using torch.stft).
+
+ Args:
+ y (torch.Tensor): Input signal.
+ n_fft (int): FFT size.
+ num_mels (int): Number of mel bins.
+ sampling_rate (int): Sampling rate of the input signal.
+ hop_size (int): Hop size for STFT.
+ win_size (int): Window size for STFT.
+ fmin (int): Minimum frequency for mel filterbank.
+ fmax (int): Maximum frequency for mel filterbank. If None, defaults to half the sampling rate (fmax = sr / 2.0) inside librosa_mel_fn
+ center (bool): Whether to pad the input to center the frames. Default is False.
+
+ Returns:
+ torch.Tensor: Mel spectrogram.
+ """
+ if torch.min(y) < -1.0:
+ print(f"[WARNING] Min value of input waveform signal is {torch.min(y)}")
+ if torch.max(y) > 1.0:
+ print(f"[WARNING] Max value of input waveform signal is {torch.max(y)}")
+
+ device = y.device
+ key = f"{n_fft}_{num_mels}_{sampling_rate}_{hop_size}_{win_size}_{fmin}_{fmax}_{device}"
+
+ if key not in mel_basis_cache:
+ mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax)
+ mel_basis_cache[key] = torch.from_numpy(mel).float().to(device)
+ hann_window_cache[key] = torch.hann_window(win_size).to(device)
+
+ mel_basis = mel_basis_cache[key]
+ hann_window = hann_window_cache[key]
+
+ padding = (n_fft - hop_size) // 2
+ y = torch.nn.functional.pad(y.unsqueeze(1), (padding, padding), mode="reflect").squeeze(1)
+
+ spec = torch.stft(
+ y,
+ n_fft,
+ hop_length=hop_size,
+ win_length=win_size,
+ window=hann_window,
+ center=center,
+ pad_mode="reflect",
+ normalized=False,
+ onesided=True,
+ return_complex=True,
+ )
+ spec = torch.sqrt(torch.view_as_real(spec).pow(2).sum(-1) + 1e-9)
+
+ mel_spec = torch.matmul(mel_basis, spec)
+ mel_spec = spectral_normalize_torch(mel_spec)
+
+ return mel_spec
+
+
+def get_mel_spectrogram(wav, h):
+ """
+ Generate mel spectrogram from a waveform using given hyperparameters.
+
+ Args:
+ wav (torch.Tensor): Input waveform.
+ h: Hyperparameters object with attributes n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax.
+
+ Returns:
+ torch.Tensor: Mel spectrogram.
+ """
+ return mel_spectrogram(
+ wav,
+ h.n_fft,
+ h.num_mels,
+ h.sampling_rate,
+ h.hop_size,
+ h.win_size,
+ h.fmin,
+ h.fmax,
+ )
+
+
+def get_dataset_filelist(a):
+ training_files = []
+ validation_files = []
+ list_unseen_validation_files = []
+
+ with open(a.input_training_file, "r", encoding="utf-8") as fi:
+ training_files = [
+ os.path.join(a.input_wavs_dir, x.split("|")[0] + ".wav") for x in fi.read().split("\n") if len(x) > 0
+ ]
+ print(f"first training file: {training_files[0]}")
+
+ with open(a.input_validation_file, "r", encoding="utf-8") as fi:
+ validation_files = [
+ os.path.join(a.input_wavs_dir, x.split("|")[0] + ".wav") for x in fi.read().split("\n") if len(x) > 0
+ ]
+ print(f"first validation file: {validation_files[0]}")
+
+ for i in range(len(a.list_input_unseen_validation_file)):
+ with open(a.list_input_unseen_validation_file[i], "r", encoding="utf-8") as fi:
+ unseen_validation_files = [
+ os.path.join(a.list_input_unseen_wavs_dir[i], x.split("|")[0] + ".wav")
+ for x in fi.read().split("\n")
+ if len(x) > 0
+ ]
+ print(f"first unseen {i}th validation fileset: {unseen_validation_files[0]}")
+ list_unseen_validation_files.append(unseen_validation_files)
+
+ return training_files, validation_files, list_unseen_validation_files
+
+
+class MelDataset(torch.utils.data.Dataset):
+ def __init__(
+ self,
+ training_files: List[str],
+ hparams: AttrDict,
+ segment_size: int,
+ n_fft: int,
+ num_mels: int,
+ hop_size: int,
+ win_size: int,
+ sampling_rate: int,
+ fmin: int,
+ fmax: Optional[int],
+ split: bool = True,
+ shuffle: bool = True,
+ device: str = None,
+ fmax_loss: Optional[int] = None,
+ fine_tuning: bool = False,
+ base_mels_path: str = None,
+ is_seen: bool = True,
+ ):
+ self.audio_files = training_files
+ random.seed(1234)
+ if shuffle:
+ random.shuffle(self.audio_files)
+ self.hparams = hparams
+ self.is_seen = is_seen
+ if self.is_seen:
+ self.name = pathlib.Path(self.audio_files[0]).parts[0]
+ else:
+ self.name = "-".join(pathlib.Path(self.audio_files[0]).parts[:2]).strip("/")
+
+ self.segment_size = segment_size
+ self.sampling_rate = sampling_rate
+ self.split = split
+ self.n_fft = n_fft
+ self.num_mels = num_mels
+ self.hop_size = hop_size
+ self.win_size = win_size
+ self.fmin = fmin
+ self.fmax = fmax
+ self.fmax_loss = fmax_loss
+ self.device = device
+ self.fine_tuning = fine_tuning
+ self.base_mels_path = base_mels_path
+
+ print("[INFO] checking dataset integrity...")
+ for i in tqdm(range(len(self.audio_files))):
+ assert os.path.exists(self.audio_files[i]), f"{self.audio_files[i]} not found"
+
+ def __getitem__(self, index: int) -> Tuple[torch.Tensor, torch.Tensor, str, torch.Tensor]:
+ try:
+ filename = self.audio_files[index]
+
+ # Use librosa.load that ensures loading waveform into mono with [-1, 1] float values
+ # Audio is ndarray with shape [T_time]. Disable auto-resampling here to minimize overhead
+ # The on-the-fly resampling during training will be done only for the obtained random chunk
+ audio, source_sampling_rate = librosa.load(filename, sr=None, mono=True)
+
+ # Main logic that uses
+
+You can run a local gradio demo using below command:
+
+```python
+pip install -r demo/requirements.txt
+python demo/app.py
+```
+
+## Training
+
+Create symbolic link to the root of the dataset. The codebase uses filelist with the relative path from the dataset. Below are the example commands for LibriTTS dataset:
+
+```shell
+cd filelists/LibriTTS && \
+ln -s /path/to/your/LibriTTS/train-clean-100 train-clean-100 && \
+ln -s /path/to/your/LibriTTS/train-clean-360 train-clean-360 && \
+ln -s /path/to/your/LibriTTS/train-other-500 train-other-500 && \
+ln -s /path/to/your/LibriTTS/dev-clean dev-clean && \
+ln -s /path/to/your/LibriTTS/dev-other dev-other && \
+ln -s /path/to/your/LibriTTS/test-clean test-clean && \
+ln -s /path/to/your/LibriTTS/test-other test-other && \
+cd ../..
+```
+
+Train BigVGAN model. Below is an example command for training BigVGAN-v2 using LibriTTS dataset at 24kHz with a full 100-band mel spectrogram as input:
+
+```shell
+python train.py \
+--config configs/bigvgan_v2_24khz_100band_256x.json \
+--input_wavs_dir filelists/LibriTTS \
+--input_training_file filelists/LibriTTS/train-full.txt \
+--input_validation_file filelists/LibriTTS/val-full.txt \
+--list_input_unseen_wavs_dir filelists/LibriTTS filelists/LibriTTS \
+--list_input_unseen_validation_file filelists/LibriTTS/dev-clean.txt filelists/LibriTTS/dev-other.txt \
+--checkpoint_path exp/bigvgan_v2_24khz_100band_256x
+```
+
+## Synthesis
+
+Synthesize from BigVGAN model. Below is an example command for generating audio from the model.
+It computes mel spectrograms using wav files from `--input_wavs_dir` and saves the generated audio to `--output_dir`.
+
+```shell
+python inference.py \
+--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
+--input_wavs_dir /path/to/your/input_wav \
+--output_dir /path/to/your/output_wav
+```
+
+`inference_e2e.py` supports synthesis directly from the mel spectrogram saved in `.npy` format, with shapes `[1, channel, frame]` or `[channel, frame]`.
+It loads mel spectrograms from `--input_mels_dir` and saves the generated audio to `--output_dir`.
+
+Make sure that the STFT hyperparameters for mel spectrogram are the same as the model, which are defined in `config.json` of the corresponding model.
+
+```shell
+python inference_e2e.py \
+--checkpoint_file /path/to/your/bigvgan_v2_24khz_100band_256x/bigvgan_generator.pt \
+--input_mels_dir /path/to/your/input_mel \
+--output_dir /path/to/your/output_wav
+```
+
+## Using Custom CUDA Kernel for Synthesis
+
+You can apply the fast CUDA inference kernel by using a parameter `use_cuda_kernel` when instantiating BigVGAN:
+
+```python
+generator = BigVGAN(h, use_cuda_kernel=True)
+```
+
+You can also pass `--use_cuda_kernel` to `inference.py` and `inference_e2e.py` to enable this feature.
+
+When applied for the first time, it builds the kernel using `nvcc` and `ninja`. If the build succeeds, the kernel is saved to `alias_free_activation/cuda/build` and the model automatically loads the kernel. The codebase has been tested using CUDA `12.1`.
+
+Please make sure that both are installed in your system and `nvcc` installed in your system matches the version your PyTorch build is using.
+
+We recommend running `test_cuda_vs_torch_model.py` first to build and check the correctness of the CUDA kernel. See below example command and its output, where it returns `[Success] test CUDA fused vs. plain torch BigVGAN inference`:
+
+```python
+python tests/test_cuda_vs_torch_model.py \
+--checkpoint_file /path/to/your/bigvgan_generator.pt
+```
+
+```shell
+loading plain Pytorch BigVGAN
+...
+loading CUDA kernel BigVGAN with auto-build
+Detected CUDA files, patching ldflags
+Emitting ninja build file /path/to/your/BigVGAN/alias_free_activation/cuda/build/build.ninja..
+Building extension module anti_alias_activation_cuda...
+...
+Loading extension module anti_alias_activation_cuda...
+...
+Loading '/path/to/your/bigvgan_generator.pt'
+...
+[Success] test CUDA fused vs. plain torch BigVGAN inference
+ > mean_difference=0.0007238413265440613
+...
+```
+
+If you see `[Fail] test CUDA fused vs. plain torch BigVGAN inference`, it means that the CUDA kernel inference is incorrect. Please check if `nvcc` installed in your system is compatible with your PyTorch version.
+
+## Pretrained Models
+
+We provide the [pretrained models on Hugging Face Collections](https://huggingface.co/collections/nvidia/bigvgan-66959df3d97fd7d98d97dc9a).
+One can download the checkpoints of the generator weight (named `bigvgan_generator.pt`) and its discriminator/optimizer states (named `bigvgan_discriminator_optimizer.pt`) within the listed model repositories.
+
+| Model Name | Sampling Rate | Mel band | fmax | Upsampling Ratio | Params | Dataset | Steps | Fine-Tuned |
+|:--------------------------------------------------------------------------------------------------------:|:-------------:|:--------:|:-----:|:----------------:|:------:|:--------------------------:|:-----:|:----------:|
+| [bigvgan_v2_44khz_128band_512x](https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_512x) | 44 kHz | 128 | 22050 | 512 | 122M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_44khz_128band_256x](https://huggingface.co/nvidia/bigvgan_v2_44khz_128band_256x) | 44 kHz | 128 | 22050 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_24khz_100band_256x](https://huggingface.co/nvidia/bigvgan_v2_24khz_100band_256x) | 24 kHz | 100 | 12000 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_22khz_80band_256x](https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_256x) | 22 kHz | 80 | 11025 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_v2_22khz_80band_fmax8k_256x](https://huggingface.co/nvidia/bigvgan_v2_22khz_80band_fmax8k_256x) | 22 kHz | 80 | 8000 | 256 | 112M | Large-scale Compilation | 5M | No |
+| [bigvgan_24khz_100band](https://huggingface.co/nvidia/bigvgan_24khz_100band) | 24 kHz | 100 | 12000 | 256 | 112M | LibriTTS | 5M | No |
+| [bigvgan_base_24khz_100band](https://huggingface.co/nvidia/bigvgan_base_24khz_100band) | 24 kHz | 100 | 12000 | 256 | 14M | LibriTTS | 5M | No |
+| [bigvgan_22khz_80band](https://huggingface.co/nvidia/bigvgan_22khz_80band) | 22 kHz | 80 | 8000 | 256 | 112M | LibriTTS + VCTK + LJSpeech | 5M | No |
+| [bigvgan_base_22khz_80band](https://huggingface.co/nvidia/bigvgan_base_22khz_80band) | 22 kHz | 80 | 8000 | 256 | 14M | LibriTTS + VCTK + LJSpeech | 5M | No |
+
+The paper results are based on the original 24kHz BigVGAN models (`bigvgan_24khz_100band` and `bigvgan_base_24khz_100band`) trained on LibriTTS dataset.
+We also provide 22kHz BigVGAN models with band-limited setup (i.e., fmax=8000) for TTS applications.
+Note that the checkpoints use `snakebeta` activation with log scale parameterization, which have the best overall quality.
+
+You can fine-tune the models by:
+
+1. downloading the checkpoints (both the generator weight and its discriminator/optimizer states)
+2. resuming training using your audio dataset by specifying `--checkpoint_path` that includes the checkpoints when launching `train.py`
+
+## Training Details of BigVGAN-v2
+
+Comapred to the original BigVGAN, the pretrained checkpoints of BigVGAN-v2 used `batch_size=32` with a longer `segment_size=65536` and are trained using 8 A100 GPUs.
+
+Note that the BigVGAN-v2 `json` config files in `./configs` use `batch_size=4` as default to fit in a single A100 GPU for training. You can fine-tune the models adjusting `batch_size` depending on your GPUs.
+
+When training BigVGAN-v2 from scratch with small batch size, it can potentially encounter the early divergence problem mentioned in the paper. In such case, we recommend lowering the `clip_grad_norm` value (e.g. `100`) for the early training iterations (e.g. 20000 steps) and increase the value to the default `500`.
+
+## Evaluation Results of BigVGAN-v2
+
+Below are the objective results of the 24kHz model (`bigvgan_v2_24khz_100band_256x`) obtained from the LibriTTS `dev` sets. BigVGAN-v2 shows noticeable improvements of the metrics. The model also exhibits reduced perceptual artifacts, especially for non-speech audio.
+
+| Model | Dataset | Steps | PESQ(↑) | M-STFT(↓) | MCD(↓) | Periodicity(↓) | V/UV F1(↑) |
+|:----------:|:-----------------------:|:-----:|:---------:|:----------:|:----------:|:--------------:|:----------:|
+| BigVGAN | LibriTTS | 1M | 4.027 | 0.7997 | 0.3745 | 0.1018 | 0.9598 |
+| BigVGAN | LibriTTS | 5M | 4.256 | 0.7409 | 0.2988 | 0.0809 | 0.9698 |
+| BigVGAN-v2 | Large-scale Compilation | 3M | 4.359 | 0.7134 | 0.3060 | 0.0621 | 0.9777 |
+| BigVGAN-v2 | Large-scale Compilation | 5M | **4.362** | **0.7026** | **0.2903** | **0.0593** | **0.9793** |
+
+## Speed Benchmark
+
+Below are the speed and VRAM usage benchmark results of BigVGAN from `tests/test_cuda_vs_torch_model.py`, using `bigvgan_v2_24khz_100band_256x` as a reference model.
+
+| GPU | num_mel_frame | use_cuda_kernel | Speed (kHz) | Real-time Factor | VRAM (GB) |
+|:--------------------------:|:-------------:|:---------------:|:-----------:|:----------------:|:---------:|
+| NVIDIA A100 | 256 | False | 1672.1 | 69.7x | 1.3 |
+| | | True | 3916.5 | 163.2x | 1.3 |
+| | 2048 | False | 1899.6 | 79.2x | 1.7 |
+| | | True | 5330.1 | 222.1x | 1.7 |
+| | 16384 | False | 1973.8 | 82.2x | 5.0 |
+| | | True | 5761.7 | 240.1x | 4.4 |
+| NVIDIA GeForce RTX 3080 | 256 | False | 841.1 | 35.0x | 1.3 |
+| | | True | 1598.1 | 66.6x | 1.3 |
+| | 2048 | False | 929.9 | 38.7x | 1.7 |
+| | | True | 1971.3 | 82.1x | 1.6 |
+| | 16384 | False | 943.4 | 39.3x | 5.0 |
+| | | True | 2026.5 | 84.4x | 3.9 |
+| NVIDIA GeForce RTX 2080 Ti | 256 | False | 515.6 | 21.5x | 1.3 |
+| | | True | 811.3 | 33.8x | 1.3 |
+| | 2048 | False | 576.5 | 24.0x | 1.7 |
+| | | True | 1023.0 | 42.6x | 1.5 |
+| | 16384 | False | 589.4 | 24.6x | 5.0 |
+| | | True | 1068.1 | 44.5x | 3.2 |
+
+## Acknowledgements
+
+We thank Vijay Anand Korthikanti and Kevin J. Shih for their generous support in implementing the CUDA kernel for inference.
+
+## References
+
+- [HiFi-GAN](https://github.com/jik876/hifi-gan) (for generator and multi-period discriminator)
+- [Snake](https://github.com/EdwardDixon/snake) (for periodic activation)
+- [Alias-free-torch](https://github.com/junjun3518/alias-free-torch) (for anti-aliasing)
+- [Julius](https://github.com/adefossez/julius) (for low-pass filter)
+- [UnivNet](https://github.com/mindslab-ai/univnet) (for multi-resolution discriminator)
+- [descript-audio-codec](https://github.com/descriptinc/descript-audio-codec) and [vocos](https://github.com/gemelo-ai/vocos) (for multi-band multi-scale STFT discriminator and multi-scale mel spectrogram loss)
+- [Amphion](https://github.com/open-mmlab/Amphion) (for multi-scale sub-band CQT discriminator)
diff --git a/GPT_SoVITS/BigVGAN/activations.py b/GPT_SoVITS/BigVGAN/activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..abe3ad9e25c6ab3d4545c6a8c60e1f85a5a8e98e
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/activations.py
@@ -0,0 +1,122 @@
+# Implementation adapted from https://github.com/EdwardDixon/snake under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import torch
+from torch import nn, sin, pow
+from torch.nn import Parameter
+
+
+class Snake(nn.Module):
+ """
+ Implementation of a sine-based periodic activation function
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter
+ References:
+ - This activation function is from this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snake(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ """
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ """
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha: trainable parameter
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ alpha will be trained along with the rest of your model.
+ """
+ super(Snake, self).__init__()
+ self.in_features = in_features
+
+ # Initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # Log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ else: # Linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+
+ self.alpha.requires_grad = alpha_trainable
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ Snake ∶= x + 1/a * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # Line up with x to [B, C, T]
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ x = x + (1.0 / (alpha + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+
+ return x
+
+
+class SnakeBeta(nn.Module):
+ """
+ A modified Snake function which uses separate parameters for the magnitude of the periodic components
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ References:
+ - This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snakebeta(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ """
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ """
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ beta is initialized to 1 by default, higher values = higher-magnitude.
+ alpha will be trained along with the rest of your model.
+ """
+ super(SnakeBeta, self).__init__()
+ self.in_features = in_features
+
+ # Initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # Log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ self.beta = Parameter(torch.zeros(in_features) * alpha)
+ else: # Linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+ self.beta = Parameter(torch.ones(in_features) * alpha)
+
+ self.alpha.requires_grad = alpha_trainable
+ self.beta.requires_grad = alpha_trainable
+
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ """
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ SnakeBeta ∶= x + 1/b * sin^2 (xa)
+ """
+ alpha = self.alpha.unsqueeze(0).unsqueeze(-1) # Line up with x to [B, C, T]
+ beta = self.beta.unsqueeze(0).unsqueeze(-1)
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ beta = torch.exp(beta)
+ x = x + (1.0 / (beta + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+
+ return x
diff --git a/GPT_SoVITS/BigVGAN/bigvgan.py b/GPT_SoVITS/BigVGAN/bigvgan.py
new file mode 100644
index 0000000000000000000000000000000000000000..febdf165c354b1fa2932f27e4ef8b7b6da10e2a6
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/bigvgan.py
@@ -0,0 +1,461 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import os
+import json
+from pathlib import Path
+from typing import Optional, Union, Dict
+
+import torch
+import torch.nn as nn
+from torch.nn import Conv1d, ConvTranspose1d
+from torch.nn.utils import weight_norm, remove_weight_norm
+
+from . import activations
+from .utils0 import init_weights, get_padding
+from .alias_free_activation.torch.act import Activation1d as TorchActivation1d
+from .env import AttrDict
+
+from huggingface_hub import PyTorchModelHubMixin, hf_hub_download
+
+
+def load_hparams_from_json(path) -> AttrDict:
+ with open(path) as f:
+ data = f.read()
+ return AttrDict(json.loads(data))
+
+
+class AMPBlock1(torch.nn.Module):
+ """
+ AMPBlock applies Snake / SnakeBeta activation functions with trainable parameters that control periodicity, defined for each layer.
+ AMPBlock1 has additional self.convs2 that contains additional Conv1d layers with a fixed dilation=1 followed by each layer in self.convs1
+
+ Args:
+ h (AttrDict): Hyperparameters.
+ channels (int): Number of convolution channels.
+ kernel_size (int): Size of the convolution kernel. Default is 3.
+ dilation (tuple): Dilation rates for the convolutions. Each dilation layer has two convolutions. Default is (1, 3, 5).
+ activation (str): Activation function type. Should be either 'snake' or 'snakebeta'. Default is None.
+ """
+
+ def __init__(
+ self,
+ h: AttrDict,
+ channels: int,
+ kernel_size: int = 3,
+ dilation: tuple = (1, 3, 5),
+ activation: str = None,
+ ):
+ super().__init__()
+
+ self.h = h
+
+ self.convs1 = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ stride=1,
+ dilation=d,
+ padding=get_padding(kernel_size, d),
+ )
+ )
+ for d in dilation
+ ]
+ )
+ self.convs1.apply(init_weights)
+
+ self.convs2 = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ stride=1,
+ dilation=1,
+ padding=get_padding(kernel_size, 1),
+ )
+ )
+ for _ in range(len(dilation))
+ ]
+ )
+ self.convs2.apply(init_weights)
+
+ self.num_layers = len(self.convs1) + len(self.convs2) # Total number of conv layers
+
+ # Select which Activation1d, lazy-load cuda version to ensure backward compatibility
+ if self.h.get("use_cuda_kernel", False):
+ from .alias_free_activation.cuda.activation1d import (
+ Activation1d as CudaActivation1d,
+ )
+
+ Activation1d = CudaActivation1d
+ else:
+ Activation1d = TorchActivation1d
+
+ # Activation functions
+ if activation == "snake":
+ self.activations = nn.ModuleList(
+ [
+ Activation1d(activation=activations.Snake(channels, alpha_logscale=h.snake_logscale))
+ for _ in range(self.num_layers)
+ ]
+ )
+ elif activation == "snakebeta":
+ self.activations = nn.ModuleList(
+ [
+ Activation1d(activation=activations.SnakeBeta(channels, alpha_logscale=h.snake_logscale))
+ for _ in range(self.num_layers)
+ ]
+ )
+ else:
+ raise NotImplementedError(
+ "activation incorrectly specified. check the config file and look for 'activation'."
+ )
+
+ def forward(self, x):
+ acts1, acts2 = self.activations[::2], self.activations[1::2]
+ for c1, c2, a1, a2 in zip(self.convs1, self.convs2, acts1, acts2):
+ xt = a1(x)
+ xt = c1(xt)
+ xt = a2(xt)
+ xt = c2(xt)
+ x = xt + x
+
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.convs1:
+ remove_weight_norm(l)
+ for l in self.convs2:
+ remove_weight_norm(l)
+
+
+class AMPBlock2(torch.nn.Module):
+ """
+ AMPBlock applies Snake / SnakeBeta activation functions with trainable parameters that control periodicity, defined for each layer.
+ Unlike AMPBlock1, AMPBlock2 does not contain extra Conv1d layers with fixed dilation=1
+
+ Args:
+ h (AttrDict): Hyperparameters.
+ channels (int): Number of convolution channels.
+ kernel_size (int): Size of the convolution kernel. Default is 3.
+ dilation (tuple): Dilation rates for the convolutions. Each dilation layer has two convolutions. Default is (1, 3, 5).
+ activation (str): Activation function type. Should be either 'snake' or 'snakebeta'. Default is None.
+ """
+
+ def __init__(
+ self,
+ h: AttrDict,
+ channels: int,
+ kernel_size: int = 3,
+ dilation: tuple = (1, 3, 5),
+ activation: str = None,
+ ):
+ super().__init__()
+
+ self.h = h
+
+ self.convs = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ stride=1,
+ dilation=d,
+ padding=get_padding(kernel_size, d),
+ )
+ )
+ for d in dilation
+ ]
+ )
+ self.convs.apply(init_weights)
+
+ self.num_layers = len(self.convs) # Total number of conv layers
+
+ # Select which Activation1d, lazy-load cuda version to ensure backward compatibility
+ if self.h.get("use_cuda_kernel", False):
+ from .alias_free_activation.cuda.activation1d import (
+ Activation1d as CudaActivation1d,
+ )
+
+ Activation1d = CudaActivation1d
+ else:
+ Activation1d = TorchActivation1d
+
+ # Activation functions
+ if activation == "snake":
+ self.activations = nn.ModuleList(
+ [
+ Activation1d(activation=activations.Snake(channels, alpha_logscale=h.snake_logscale))
+ for _ in range(self.num_layers)
+ ]
+ )
+ elif activation == "snakebeta":
+ self.activations = nn.ModuleList(
+ [
+ Activation1d(activation=activations.SnakeBeta(channels, alpha_logscale=h.snake_logscale))
+ for _ in range(self.num_layers)
+ ]
+ )
+ else:
+ raise NotImplementedError(
+ "activation incorrectly specified. check the config file and look for 'activation'."
+ )
+
+ def forward(self, x):
+ for c, a in zip(self.convs, self.activations):
+ xt = a(x)
+ xt = c(xt)
+ x = xt + x
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.convs:
+ remove_weight_norm(l)
+
+
+class BigVGAN(
+ torch.nn.Module,
+ PyTorchModelHubMixin,
+ # library_name="bigvgan",
+ # repo_url="https://github.com/NVIDIA/BigVGAN",
+ # docs_url="https://github.com/NVIDIA/BigVGAN/blob/main/README.md",
+ # pipeline_tag="audio-to-audio",
+ # license="mit",
+ # tags=["neural-vocoder", "audio-generation", "arxiv:2206.04658"],
+):
+ """
+ BigVGAN is a neural vocoder model that applies anti-aliased periodic activation for residual blocks (resblocks).
+ New in BigVGAN-v2: it can optionally use optimized CUDA kernels for AMP (anti-aliased multi-periodicity) blocks.
+
+ Args:
+ h (AttrDict): Hyperparameters.
+ use_cuda_kernel (bool): If set to True, loads optimized CUDA kernels for AMP. This should be used for inference only, as training is not supported with CUDA kernels.
+
+ Note:
+ - The `use_cuda_kernel` parameter should be used for inference only, as training with CUDA kernels is not supported.
+ - Ensure that the activation function is correctly specified in the hyperparameters (h.activation).
+ """
+
+ def __init__(self, h: AttrDict, use_cuda_kernel: bool = False):
+ super().__init__()
+ self.h = h
+ self.h["use_cuda_kernel"] = use_cuda_kernel
+
+ # Select which Activation1d, lazy-load cuda version to ensure backward compatibility
+ if self.h.get("use_cuda_kernel", False):
+ from .alias_free_activation.cuda.activation1d import (
+ Activation1d as CudaActivation1d,
+ )
+
+ Activation1d = CudaActivation1d
+ else:
+ Activation1d = TorchActivation1d
+
+ self.num_kernels = len(h.resblock_kernel_sizes)
+ self.num_upsamples = len(h.upsample_rates)
+
+ # Pre-conv
+ self.conv_pre = weight_norm(Conv1d(h.num_mels, h.upsample_initial_channel, 7, 1, padding=3))
+
+ # Define which AMPBlock to use. BigVGAN uses AMPBlock1 as default
+ if h.resblock == "1":
+ resblock_class = AMPBlock1
+ elif h.resblock == "2":
+ resblock_class = AMPBlock2
+ else:
+ raise ValueError(f"Incorrect resblock class specified in hyperparameters. Got {h.resblock}")
+
+ # Transposed conv-based upsamplers. does not apply anti-aliasing
+ self.ups = nn.ModuleList()
+ for i, (u, k) in enumerate(zip(h.upsample_rates, h.upsample_kernel_sizes)):
+ self.ups.append(
+ nn.ModuleList(
+ [
+ weight_norm(
+ ConvTranspose1d(
+ h.upsample_initial_channel // (2**i),
+ h.upsample_initial_channel // (2 ** (i + 1)),
+ k,
+ u,
+ padding=(k - u) // 2,
+ )
+ )
+ ]
+ )
+ )
+
+ # Residual blocks using anti-aliased multi-periodicity composition modules (AMP)
+ self.resblocks = nn.ModuleList()
+ for i in range(len(self.ups)):
+ ch = h.upsample_initial_channel // (2 ** (i + 1))
+ for j, (k, d) in enumerate(zip(h.resblock_kernel_sizes, h.resblock_dilation_sizes)):
+ self.resblocks.append(resblock_class(h, ch, k, d, activation=h.activation))
+
+ # Post-conv
+ activation_post = (
+ activations.Snake(ch, alpha_logscale=h.snake_logscale)
+ if h.activation == "snake"
+ else (activations.SnakeBeta(ch, alpha_logscale=h.snake_logscale) if h.activation == "snakebeta" else None)
+ )
+ if activation_post is None:
+ raise NotImplementedError(
+ "activation incorrectly specified. check the config file and look for 'activation'."
+ )
+
+ self.activation_post = Activation1d(activation=activation_post)
+
+ # Whether to use bias for the final conv_post. Default to True for backward compatibility
+ self.use_bias_at_final = h.get("use_bias_at_final", True)
+ self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3, bias=self.use_bias_at_final))
+
+ # Weight initialization
+ for i in range(len(self.ups)):
+ self.ups[i].apply(init_weights)
+ self.conv_post.apply(init_weights)
+
+ # Final tanh activation. Defaults to True for backward compatibility
+ self.use_tanh_at_final = h.get("use_tanh_at_final", True)
+
+ def forward(self, x):
+ # Pre-conv
+ x = self.conv_pre(x)
+
+ for i in range(self.num_upsamples):
+ # Upsampling
+ for i_up in range(len(self.ups[i])):
+ x = self.ups[i][i_up](x)
+ # AMP blocks
+ xs = None
+ for j in range(self.num_kernels):
+ if xs is None:
+ xs = self.resblocks[i * self.num_kernels + j](x)
+ else:
+ xs += self.resblocks[i * self.num_kernels + j](x)
+ x = xs / self.num_kernels
+
+ # Post-conv
+ x = self.activation_post(x)
+ x = self.conv_post(x)
+ # Final tanh activation
+ if self.use_tanh_at_final:
+ x = torch.tanh(x)
+ else:
+ x = torch.clamp(x, min=-1.0, max=1.0) # Bound the output to [-1, 1]
+
+ return x
+
+ def remove_weight_norm(self):
+ try:
+ # print("Removing weight norm...")
+ for l in self.ups:
+ for l_i in l:
+ remove_weight_norm(l_i)
+ for l in self.resblocks:
+ l.remove_weight_norm()
+ remove_weight_norm(self.conv_pre)
+ remove_weight_norm(self.conv_post)
+ except ValueError:
+ print("[INFO] Model already removed weight norm. Skipping!")
+ pass
+
+ # Additional methods for huggingface_hub support
+ def _save_pretrained(self, save_directory: Path) -> None:
+ """Save weights and config.json from a Pytorch model to a local directory."""
+
+ model_path = save_directory / "bigvgan_generator.pt"
+ torch.save({"generator": self.state_dict()}, model_path)
+
+ config_path = save_directory / "config.json"
+ with open(config_path, "w") as config_file:
+ json.dump(self.h, config_file, indent=4)
+
+ @classmethod
+ def _from_pretrained(
+ cls,
+ *,
+ model_id: str,
+ revision: str,
+ cache_dir: str,
+ force_download: bool,
+ proxies: Optional[Dict],
+ resume_download: bool,
+ local_files_only: bool,
+ token: Union[str, bool, None],
+ map_location: str = "cpu", # Additional argument
+ strict: bool = False, # Additional argument
+ use_cuda_kernel: bool = False,
+ **model_kwargs,
+ ):
+ """Load Pytorch pretrained weights and return the loaded model."""
+
+ # Download and load hyperparameters (h) used by BigVGAN
+ if os.path.isdir(model_id):
+ # print("Loading config.json from local directory")
+ config_file = os.path.join(model_id, "config.json")
+ else:
+ config_file = hf_hub_download(
+ repo_id=model_id,
+ filename="config.json",
+ revision=revision,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ token=token,
+ local_files_only=local_files_only,
+ )
+ h = load_hparams_from_json(config_file)
+
+ # instantiate BigVGAN using h
+ if use_cuda_kernel:
+ print(
+ "[WARNING] You have specified use_cuda_kernel=True during BigVGAN.from_pretrained(). Only inference is supported (training is not implemented)!"
+ )
+ print(
+ "[WARNING] You need nvcc and ninja installed in your system that matches your PyTorch build is using to build the kernel. If not, the model will fail to initialize or generate incorrect waveform!"
+ )
+ print(
+ "[WARNING] For detail, see the official GitHub repository: https://github.com/NVIDIA/BigVGAN?tab=readme-ov-file#using-custom-cuda-kernel-for-synthesis"
+ )
+ model = cls(h, use_cuda_kernel=use_cuda_kernel)
+
+ # Download and load pretrained generator weight
+ if os.path.isdir(model_id):
+ # print("Loading weights from local directory")
+ model_file = os.path.join(model_id, "bigvgan_generator.pt")
+ else:
+ # print(f"Loading weights from {model_id}")
+ model_file = hf_hub_download(
+ repo_id=model_id,
+ filename="bigvgan_generator.pt",
+ revision=revision,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ token=token,
+ local_files_only=local_files_only,
+ )
+
+ checkpoint_dict = torch.load(model_file, map_location=map_location)
+
+ try:
+ model.load_state_dict(checkpoint_dict["generator"])
+ except RuntimeError:
+ print(
+ "[INFO] the pretrained checkpoint does not contain weight norm. Loading the checkpoint after removing weight norm!"
+ )
+ model.remove_weight_norm()
+ model.load_state_dict(checkpoint_dict["generator"])
+
+ return model
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_22khz_80band.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_22khz_80band.json
new file mode 100644
index 0000000000000000000000000000000000000000..64bca7846edb4e86d7ee22d9ca7a1554cf7f1042
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_22khz_80band.json
@@ -0,0 +1,45 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 32,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "resolutions": [[1024, 120, 600], [2048, 240, 1200], [512, 50, 240]],
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "segment_size": 8192,
+ "num_mels": 80,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 22050,
+
+ "fmin": 0,
+ "fmax": 8000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_24khz_100band.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_24khz_100band.json
new file mode 100644
index 0000000000000000000000000000000000000000..e7f7ff08f6697a4640d8e28c0b3fe7e62d0c3fc7
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_24khz_100band.json
@@ -0,0 +1,45 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 32,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "resolutions": [[1024, 120, 600], [2048, 240, 1200], [512, 50, 240]],
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "segment_size": 8192,
+ "num_mels": 100,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 24000,
+
+ "fmin": 0,
+ "fmax": 12000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_base_22khz_80band.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_base_22khz_80band.json
new file mode 100644
index 0000000000000000000000000000000000000000..fd244848308917f4df7ce49bf6b76530fd04cbc2
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_base_22khz_80band.json
@@ -0,0 +1,45 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 32,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [8,8,2,2],
+ "upsample_kernel_sizes": [16,16,4,4],
+ "upsample_initial_channel": 512,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "resolutions": [[1024, 120, 600], [2048, 240, 1200], [512, 50, 240]],
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "segment_size": 8192,
+ "num_mels": 80,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 22050,
+
+ "fmin": 0,
+ "fmax": 8000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_base_24khz_100band.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_base_24khz_100band.json
new file mode 100644
index 0000000000000000000000000000000000000000..0911508cac4a9346ada8c196bfcc228998da6f42
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_base_24khz_100band.json
@@ -0,0 +1,45 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 32,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [8,8,2,2],
+ "upsample_kernel_sizes": [16,16,4,4],
+ "upsample_initial_channel": 512,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "resolutions": [[1024, 120, 600], [2048, 240, 1200], [512, 50, 240]],
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "segment_size": 8192,
+ "num_mels": 100,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 24000,
+
+ "fmin": 0,
+ "fmax": 12000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_256x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_256x.json
new file mode 100644
index 0000000000000000000000000000000000000000..e96bd5fdd5b99767adba7f13bfcd1f777d5c599a
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_256x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 80,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 22050,
+
+ "fmin": 0,
+ "fmax": null,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_fmax8k_256x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_fmax8k_256x.json
new file mode 100644
index 0000000000000000000000000000000000000000..a3c9699fbe11948f4fd7e3434d2e623a00c802dd
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_22khz_80band_fmax8k_256x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 80,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 22050,
+
+ "fmin": 0,
+ "fmax": 8000,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_24khz_100band_256x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_24khz_100band_256x.json
new file mode 100644
index 0000000000000000000000000000000000000000..8057ee267c8ed80615362a41892b923a3ccd27e5
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_24khz_100band_256x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 100,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 24000,
+
+ "fmin": 0,
+ "fmax": null,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_256x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_256x.json
new file mode 100644
index 0000000000000000000000000000000000000000..b6999d3028e5d741ec99b16b34f153e763d0cfec
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_256x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [4,4,2,2,2,2],
+ "upsample_kernel_sizes": [8,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 128,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 256,
+ "win_size": 1024,
+
+ "sampling_rate": 44100,
+
+ "fmin": 0,
+ "fmax": null,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_512x.json b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_512x.json
new file mode 100644
index 0000000000000000000000000000000000000000..2d7176c910ae0969f208f6d28e3f14abca2dbc7f
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/configs/bigvgan_v2_44khz_128band_512x.json
@@ -0,0 +1,61 @@
+{
+ "resblock": "1",
+ "num_gpus": 0,
+ "batch_size": 4,
+ "learning_rate": 0.0001,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.9999996,
+ "seed": 1234,
+
+ "upsample_rates": [8,4,2,2,2,2],
+ "upsample_kernel_sizes": [16,8,4,4,4,4],
+ "upsample_initial_channel": 1536,
+ "resblock_kernel_sizes": [3,7,11],
+ "resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
+
+ "use_tanh_at_final": false,
+ "use_bias_at_final": false,
+
+ "activation": "snakebeta",
+ "snake_logscale": true,
+
+ "use_cqtd_instead_of_mrd": true,
+ "cqtd_filters": 128,
+ "cqtd_max_filters": 1024,
+ "cqtd_filters_scale": 1,
+ "cqtd_dilations": [1, 2, 4],
+ "cqtd_hop_lengths": [512, 256, 256],
+ "cqtd_n_octaves": [9, 9, 9],
+ "cqtd_bins_per_octaves": [24, 36, 48],
+
+ "mpd_reshapes": [2, 3, 5, 7, 11],
+ "use_spectral_norm": false,
+ "discriminator_channel_mult": 1,
+
+ "use_multiscale_melloss": true,
+ "lambda_melloss": 15,
+
+ "clip_grad_norm": 500,
+
+ "segment_size": 65536,
+ "num_mels": 128,
+ "num_freq": 2049,
+ "n_fft": 2048,
+ "hop_size": 512,
+ "win_size": 2048,
+
+ "sampling_rate": 44100,
+
+ "fmin": 0,
+ "fmax": null,
+ "fmax_for_loss": null,
+
+ "num_workers": 4,
+
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1
+ }
+}
diff --git a/GPT_SoVITS/BigVGAN/discriminators.py b/GPT_SoVITS/BigVGAN/discriminators.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d44c7983955a1be15a4520f6730de272f799128
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/discriminators.py
@@ -0,0 +1,625 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+
+import torch
+import torch.nn.functional as F
+import torch.nn as nn
+from torch.nn import Conv2d
+from torch.nn.utils import weight_norm, spectral_norm
+from torchaudio.transforms import Spectrogram, Resample
+
+from env import AttrDict
+from utils import get_padding
+import typing
+from typing import List, Tuple
+
+
+class DiscriminatorP(torch.nn.Module):
+ def __init__(
+ self,
+ h: AttrDict,
+ period: List[int],
+ kernel_size: int = 5,
+ stride: int = 3,
+ use_spectral_norm: bool = False,
+ ):
+ super().__init__()
+ self.period = period
+ self.d_mult = h.discriminator_channel_mult
+ norm_f = weight_norm if not use_spectral_norm else spectral_norm
+
+ self.convs = nn.ModuleList(
+ [
+ norm_f(
+ Conv2d(
+ 1,
+ int(32 * self.d_mult),
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(5, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ int(32 * self.d_mult),
+ int(128 * self.d_mult),
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(5, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ int(128 * self.d_mult),
+ int(512 * self.d_mult),
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(5, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ int(512 * self.d_mult),
+ int(1024 * self.d_mult),
+ (kernel_size, 1),
+ (stride, 1),
+ padding=(get_padding(5, 1), 0),
+ )
+ ),
+ norm_f(
+ Conv2d(
+ int(1024 * self.d_mult),
+ int(1024 * self.d_mult),
+ (kernel_size, 1),
+ 1,
+ padding=(2, 0),
+ )
+ ),
+ ]
+ )
+ self.conv_post = norm_f(Conv2d(int(1024 * self.d_mult), 1, (3, 1), 1, padding=(1, 0)))
+
+ def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ fmap = []
+
+ # 1d to 2d
+ b, c, t = x.shape
+ if t % self.period != 0: # pad first
+ n_pad = self.period - (t % self.period)
+ x = F.pad(x, (0, n_pad), "reflect")
+ t = t + n_pad
+ x = x.view(b, c, t // self.period, self.period)
+
+ for l in self.convs:
+ x = l(x)
+ x = F.leaky_relu(x, 0.1)
+ fmap.append(x)
+ x = self.conv_post(x)
+ fmap.append(x)
+ x = torch.flatten(x, 1, -1)
+
+ return x, fmap
+
+
+class MultiPeriodDiscriminator(torch.nn.Module):
+ def __init__(self, h: AttrDict):
+ super().__init__()
+ self.mpd_reshapes = h.mpd_reshapes
+ print(f"mpd_reshapes: {self.mpd_reshapes}")
+ self.discriminators = nn.ModuleList(
+ [DiscriminatorP(h, rs, use_spectral_norm=h.use_spectral_norm) for rs in self.mpd_reshapes]
+ )
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+ for i, d in enumerate(self.discriminators):
+ y_d_r, fmap_r = d(y)
+ y_d_g, fmap_g = d(y_hat)
+ y_d_rs.append(y_d_r)
+ fmap_rs.append(fmap_r)
+ y_d_gs.append(y_d_g)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+class DiscriminatorR(nn.Module):
+ def __init__(self, cfg: AttrDict, resolution: List[List[int]]):
+ super().__init__()
+
+ self.resolution = resolution
+ assert len(self.resolution) == 3, f"MRD layer requires list with len=3, got {self.resolution}"
+ self.lrelu_slope = 0.1
+
+ norm_f = weight_norm if cfg.use_spectral_norm == False else spectral_norm
+ if hasattr(cfg, "mrd_use_spectral_norm"):
+ print(f"[INFO] overriding MRD use_spectral_norm as {cfg.mrd_use_spectral_norm}")
+ norm_f = weight_norm if cfg.mrd_use_spectral_norm == False else spectral_norm
+ self.d_mult = cfg.discriminator_channel_mult
+ if hasattr(cfg, "mrd_channel_mult"):
+ print(f"[INFO] overriding mrd channel multiplier as {cfg.mrd_channel_mult}")
+ self.d_mult = cfg.mrd_channel_mult
+
+ self.convs = nn.ModuleList(
+ [
+ norm_f(nn.Conv2d(1, int(32 * self.d_mult), (3, 9), padding=(1, 4))),
+ norm_f(
+ nn.Conv2d(
+ int(32 * self.d_mult),
+ int(32 * self.d_mult),
+ (3, 9),
+ stride=(1, 2),
+ padding=(1, 4),
+ )
+ ),
+ norm_f(
+ nn.Conv2d(
+ int(32 * self.d_mult),
+ int(32 * self.d_mult),
+ (3, 9),
+ stride=(1, 2),
+ padding=(1, 4),
+ )
+ ),
+ norm_f(
+ nn.Conv2d(
+ int(32 * self.d_mult),
+ int(32 * self.d_mult),
+ (3, 9),
+ stride=(1, 2),
+ padding=(1, 4),
+ )
+ ),
+ norm_f(
+ nn.Conv2d(
+ int(32 * self.d_mult),
+ int(32 * self.d_mult),
+ (3, 3),
+ padding=(1, 1),
+ )
+ ),
+ ]
+ )
+ self.conv_post = norm_f(nn.Conv2d(int(32 * self.d_mult), 1, (3, 3), padding=(1, 1)))
+
+ def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ fmap = []
+
+ x = self.spectrogram(x)
+ x = x.unsqueeze(1)
+ for l in self.convs:
+ x = l(x)
+ x = F.leaky_relu(x, self.lrelu_slope)
+ fmap.append(x)
+ x = self.conv_post(x)
+ fmap.append(x)
+ x = torch.flatten(x, 1, -1)
+
+ return x, fmap
+
+ def spectrogram(self, x: torch.Tensor) -> torch.Tensor:
+ n_fft, hop_length, win_length = self.resolution
+ x = F.pad(
+ x,
+ (int((n_fft - hop_length) / 2), int((n_fft - hop_length) / 2)),
+ mode="reflect",
+ )
+ x = x.squeeze(1)
+ x = torch.stft(
+ x,
+ n_fft=n_fft,
+ hop_length=hop_length,
+ win_length=win_length,
+ center=False,
+ return_complex=True,
+ )
+ x = torch.view_as_real(x) # [B, F, TT, 2]
+ mag = torch.norm(x, p=2, dim=-1) # [B, F, TT]
+
+ return mag
+
+
+class MultiResolutionDiscriminator(nn.Module):
+ def __init__(self, cfg, debug=False):
+ super().__init__()
+ self.resolutions = cfg.resolutions
+ assert len(self.resolutions) == 3, (
+ f"MRD requires list of list with len=3, each element having a list with len=3. Got {self.resolutions}"
+ )
+ self.discriminators = nn.ModuleList([DiscriminatorR(cfg, resolution) for resolution in self.resolutions])
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+
+ for i, d in enumerate(self.discriminators):
+ y_d_r, fmap_r = d(x=y)
+ y_d_g, fmap_g = d(x=y_hat)
+ y_d_rs.append(y_d_r)
+ fmap_rs.append(fmap_r)
+ y_d_gs.append(y_d_g)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+# Method based on descript-audio-codec: https://github.com/descriptinc/descript-audio-codec
+# Modified code adapted from https://github.com/gemelo-ai/vocos under the MIT license.
+# LICENSE is in incl_licenses directory.
+class DiscriminatorB(nn.Module):
+ def __init__(
+ self,
+ window_length: int,
+ channels: int = 32,
+ hop_factor: float = 0.25,
+ bands: Tuple[Tuple[float, float], ...] = (
+ (0.0, 0.1),
+ (0.1, 0.25),
+ (0.25, 0.5),
+ (0.5, 0.75),
+ (0.75, 1.0),
+ ),
+ ):
+ super().__init__()
+ self.window_length = window_length
+ self.hop_factor = hop_factor
+ self.spec_fn = Spectrogram(
+ n_fft=window_length,
+ hop_length=int(window_length * hop_factor),
+ win_length=window_length,
+ power=None,
+ )
+ n_fft = window_length // 2 + 1
+ bands = [(int(b[0] * n_fft), int(b[1] * n_fft)) for b in bands]
+ self.bands = bands
+ convs = lambda: nn.ModuleList(
+ [
+ weight_norm(nn.Conv2d(2, channels, (3, 9), (1, 1), padding=(1, 4))),
+ weight_norm(nn.Conv2d(channels, channels, (3, 9), (1, 2), padding=(1, 4))),
+ weight_norm(nn.Conv2d(channels, channels, (3, 9), (1, 2), padding=(1, 4))),
+ weight_norm(nn.Conv2d(channels, channels, (3, 9), (1, 2), padding=(1, 4))),
+ weight_norm(nn.Conv2d(channels, channels, (3, 3), (1, 1), padding=(1, 1))),
+ ]
+ )
+ self.band_convs = nn.ModuleList([convs() for _ in range(len(self.bands))])
+
+ self.conv_post = weight_norm(nn.Conv2d(channels, 1, (3, 3), (1, 1), padding=(1, 1)))
+
+ def spectrogram(self, x: torch.Tensor) -> List[torch.Tensor]:
+ # Remove DC offset
+ x = x - x.mean(dim=-1, keepdims=True)
+ # Peak normalize the volume of input audio
+ x = 0.8 * x / (x.abs().max(dim=-1, keepdim=True)[0] + 1e-9)
+ x = self.spec_fn(x)
+ x = torch.view_as_real(x)
+ x = x.permute(0, 3, 2, 1) # [B, F, T, C] -> [B, C, T, F]
+ # Split into bands
+ x_bands = [x[..., b[0] : b[1]] for b in self.bands]
+ return x_bands
+
+ def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ x_bands = self.spectrogram(x.squeeze(1))
+ fmap = []
+ x = []
+
+ for band, stack in zip(x_bands, self.band_convs):
+ for i, layer in enumerate(stack):
+ band = layer(band)
+ band = torch.nn.functional.leaky_relu(band, 0.1)
+ if i > 0:
+ fmap.append(band)
+ x.append(band)
+
+ x = torch.cat(x, dim=-1)
+ x = self.conv_post(x)
+ fmap.append(x)
+
+ return x, fmap
+
+
+# Method based on descript-audio-codec: https://github.com/descriptinc/descript-audio-codec
+# Modified code adapted from https://github.com/gemelo-ai/vocos under the MIT license.
+# LICENSE is in incl_licenses directory.
+class MultiBandDiscriminator(nn.Module):
+ def __init__(
+ self,
+ h,
+ ):
+ """
+ Multi-band multi-scale STFT discriminator, with the architecture based on https://github.com/descriptinc/descript-audio-codec.
+ and the modified code adapted from https://github.com/gemelo-ai/vocos.
+ """
+ super().__init__()
+ # fft_sizes (list[int]): Tuple of window lengths for FFT. Defaults to [2048, 1024, 512] if not set in h.
+ self.fft_sizes = h.get("mbd_fft_sizes", [2048, 1024, 512])
+ self.discriminators = nn.ModuleList([DiscriminatorB(window_length=w) for w in self.fft_sizes])
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+
+ for d in self.discriminators:
+ y_d_r, fmap_r = d(x=y)
+ y_d_g, fmap_g = d(x=y_hat)
+ y_d_rs.append(y_d_r)
+ fmap_rs.append(fmap_r)
+ y_d_gs.append(y_d_g)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+# Adapted from https://github.com/open-mmlab/Amphion/blob/main/models/vocoders/gan/discriminator/mssbcqtd.py under the MIT license.
+# LICENSE is in incl_licenses directory.
+class DiscriminatorCQT(nn.Module):
+ def __init__(self, cfg: AttrDict, hop_length: int, n_octaves: int, bins_per_octave: int):
+ super().__init__()
+ self.cfg = cfg
+
+ self.filters = cfg["cqtd_filters"]
+ self.max_filters = cfg["cqtd_max_filters"]
+ self.filters_scale = cfg["cqtd_filters_scale"]
+ self.kernel_size = (3, 9)
+ self.dilations = cfg["cqtd_dilations"]
+ self.stride = (1, 2)
+
+ self.in_channels = cfg["cqtd_in_channels"]
+ self.out_channels = cfg["cqtd_out_channels"]
+ self.fs = cfg["sampling_rate"]
+ self.hop_length = hop_length
+ self.n_octaves = n_octaves
+ self.bins_per_octave = bins_per_octave
+
+ # Lazy-load
+ from nnAudio import features
+
+ self.cqt_transform = features.cqt.CQT2010v2(
+ sr=self.fs * 2,
+ hop_length=self.hop_length,
+ n_bins=self.bins_per_octave * self.n_octaves,
+ bins_per_octave=self.bins_per_octave,
+ output_format="Complex",
+ pad_mode="constant",
+ )
+
+ self.conv_pres = nn.ModuleList()
+ for _ in range(self.n_octaves):
+ self.conv_pres.append(
+ nn.Conv2d(
+ self.in_channels * 2,
+ self.in_channels * 2,
+ kernel_size=self.kernel_size,
+ padding=self.get_2d_padding(self.kernel_size),
+ )
+ )
+
+ self.convs = nn.ModuleList()
+
+ self.convs.append(
+ nn.Conv2d(
+ self.in_channels * 2,
+ self.filters,
+ kernel_size=self.kernel_size,
+ padding=self.get_2d_padding(self.kernel_size),
+ )
+ )
+
+ in_chs = min(self.filters_scale * self.filters, self.max_filters)
+ for i, dilation in enumerate(self.dilations):
+ out_chs = min((self.filters_scale ** (i + 1)) * self.filters, self.max_filters)
+ self.convs.append(
+ weight_norm(
+ nn.Conv2d(
+ in_chs,
+ out_chs,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ dilation=(dilation, 1),
+ padding=self.get_2d_padding(self.kernel_size, (dilation, 1)),
+ )
+ )
+ )
+ in_chs = out_chs
+ out_chs = min(
+ (self.filters_scale ** (len(self.dilations) + 1)) * self.filters,
+ self.max_filters,
+ )
+ self.convs.append(
+ weight_norm(
+ nn.Conv2d(
+ in_chs,
+ out_chs,
+ kernel_size=(self.kernel_size[0], self.kernel_size[0]),
+ padding=self.get_2d_padding((self.kernel_size[0], self.kernel_size[0])),
+ )
+ )
+ )
+
+ self.conv_post = weight_norm(
+ nn.Conv2d(
+ out_chs,
+ self.out_channels,
+ kernel_size=(self.kernel_size[0], self.kernel_size[0]),
+ padding=self.get_2d_padding((self.kernel_size[0], self.kernel_size[0])),
+ )
+ )
+
+ self.activation = torch.nn.LeakyReLU(negative_slope=0.1)
+ self.resample = Resample(orig_freq=self.fs, new_freq=self.fs * 2)
+
+ self.cqtd_normalize_volume = self.cfg.get("cqtd_normalize_volume", False)
+ if self.cqtd_normalize_volume:
+ print(
+ "[INFO] cqtd_normalize_volume set to True. Will apply DC offset removal & peak volume normalization in CQTD!"
+ )
+
+ def get_2d_padding(
+ self,
+ kernel_size: typing.Tuple[int, int],
+ dilation: typing.Tuple[int, int] = (1, 1),
+ ):
+ return (
+ ((kernel_size[0] - 1) * dilation[0]) // 2,
+ ((kernel_size[1] - 1) * dilation[1]) // 2,
+ )
+
+ def forward(self, x: torch.tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ fmap = []
+
+ if self.cqtd_normalize_volume:
+ # Remove DC offset
+ x = x - x.mean(dim=-1, keepdims=True)
+ # Peak normalize the volume of input audio
+ x = 0.8 * x / (x.abs().max(dim=-1, keepdim=True)[0] + 1e-9)
+
+ x = self.resample(x)
+
+ z = self.cqt_transform(x)
+
+ z_amplitude = z[:, :, :, 0].unsqueeze(1)
+ z_phase = z[:, :, :, 1].unsqueeze(1)
+
+ z = torch.cat([z_amplitude, z_phase], dim=1)
+ z = torch.permute(z, (0, 1, 3, 2)) # [B, C, W, T] -> [B, C, T, W]
+
+ latent_z = []
+ for i in range(self.n_octaves):
+ latent_z.append(
+ self.conv_pres[i](
+ z[
+ :,
+ :,
+ :,
+ i * self.bins_per_octave : (i + 1) * self.bins_per_octave,
+ ]
+ )
+ )
+ latent_z = torch.cat(latent_z, dim=-1)
+
+ for i, l in enumerate(self.convs):
+ latent_z = l(latent_z)
+
+ latent_z = self.activation(latent_z)
+ fmap.append(latent_z)
+
+ latent_z = self.conv_post(latent_z)
+
+ return latent_z, fmap
+
+
+class MultiScaleSubbandCQTDiscriminator(nn.Module):
+ def __init__(self, cfg: AttrDict):
+ super().__init__()
+
+ self.cfg = cfg
+ # Using get with defaults
+ self.cfg["cqtd_filters"] = self.cfg.get("cqtd_filters", 32)
+ self.cfg["cqtd_max_filters"] = self.cfg.get("cqtd_max_filters", 1024)
+ self.cfg["cqtd_filters_scale"] = self.cfg.get("cqtd_filters_scale", 1)
+ self.cfg["cqtd_dilations"] = self.cfg.get("cqtd_dilations", [1, 2, 4])
+ self.cfg["cqtd_in_channels"] = self.cfg.get("cqtd_in_channels", 1)
+ self.cfg["cqtd_out_channels"] = self.cfg.get("cqtd_out_channels", 1)
+ # Multi-scale params to loop over
+ self.cfg["cqtd_hop_lengths"] = self.cfg.get("cqtd_hop_lengths", [512, 256, 256])
+ self.cfg["cqtd_n_octaves"] = self.cfg.get("cqtd_n_octaves", [9, 9, 9])
+ self.cfg["cqtd_bins_per_octaves"] = self.cfg.get("cqtd_bins_per_octaves", [24, 36, 48])
+
+ self.discriminators = nn.ModuleList(
+ [
+ DiscriminatorCQT(
+ self.cfg,
+ hop_length=self.cfg["cqtd_hop_lengths"][i],
+ n_octaves=self.cfg["cqtd_n_octaves"][i],
+ bins_per_octave=self.cfg["cqtd_bins_per_octaves"][i],
+ )
+ for i in range(len(self.cfg["cqtd_hop_lengths"]))
+ ]
+ )
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+
+ for disc in self.discriminators:
+ y_d_r, fmap_r = disc(y)
+ y_d_g, fmap_g = disc(y_hat)
+ y_d_rs.append(y_d_r)
+ fmap_rs.append(fmap_r)
+ y_d_gs.append(y_d_g)
+ fmap_gs.append(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
+
+
+class CombinedDiscriminator(nn.Module):
+ """
+ Wrapper of chaining multiple discrimiantor architectures.
+ Example: combine mbd and cqtd as a single class
+ """
+
+ def __init__(self, list_discriminator: List[nn.Module]):
+ super().__init__()
+ self.discrimiantor = nn.ModuleList(list_discriminator)
+
+ def forward(
+ self, y: torch.Tensor, y_hat: torch.Tensor
+ ) -> Tuple[
+ List[torch.Tensor],
+ List[torch.Tensor],
+ List[List[torch.Tensor]],
+ List[List[torch.Tensor]],
+ ]:
+ y_d_rs = []
+ y_d_gs = []
+ fmap_rs = []
+ fmap_gs = []
+
+ for disc in self.discrimiantor:
+ y_d_r, y_d_g, fmap_r, fmap_g = disc(y, y_hat)
+ y_d_rs.extend(y_d_r)
+ fmap_rs.extend(fmap_r)
+ y_d_gs.extend(y_d_g)
+ fmap_gs.extend(fmap_g)
+
+ return y_d_rs, y_d_gs, fmap_rs, fmap_gs
diff --git a/GPT_SoVITS/BigVGAN/env.py b/GPT_SoVITS/BigVGAN/env.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf8ac6cea644c78d115dd3902b902993f366ee61
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/env.py
@@ -0,0 +1,18 @@
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import os
+import shutil
+
+
+class AttrDict(dict):
+ def __init__(self, *args, **kwargs):
+ super(AttrDict, self).__init__(*args, **kwargs)
+ self.__dict__ = self
+
+
+def build_env(config, config_name, path):
+ t_path = os.path.join(path, config_name)
+ if config != t_path:
+ os.makedirs(path, exist_ok=True)
+ shutil.copyfile(config, os.path.join(path, config_name))
diff --git a/GPT_SoVITS/BigVGAN/inference.py b/GPT_SoVITS/BigVGAN/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f892a3c807a7020eff7fea35179b0f6e5f991c9
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/inference.py
@@ -0,0 +1,85 @@
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+from __future__ import absolute_import, division, print_function, unicode_literals
+
+import os
+import argparse
+import json
+import torch
+import librosa
+from utils import load_checkpoint
+from meldataset import get_mel_spectrogram
+from scipy.io.wavfile import write
+from env import AttrDict
+from meldataset import MAX_WAV_VALUE
+from bigvgan import BigVGAN as Generator
+
+h = None
+device = None
+torch.backends.cudnn.benchmark = False
+
+
+def inference(a, h):
+ generator = Generator(h, use_cuda_kernel=a.use_cuda_kernel).to(device)
+
+ state_dict_g = load_checkpoint(a.checkpoint_file, device)
+ generator.load_state_dict(state_dict_g["generator"])
+
+ filelist = os.listdir(a.input_wavs_dir)
+
+ os.makedirs(a.output_dir, exist_ok=True)
+
+ generator.eval()
+ generator.remove_weight_norm()
+ with torch.no_grad():
+ for i, filname in enumerate(filelist):
+ # Load the ground truth audio and resample if necessary
+ wav, sr = librosa.load(os.path.join(a.input_wavs_dir, filname), sr=h.sampling_rate, mono=True)
+ wav = torch.FloatTensor(wav).to(device)
+ # Compute mel spectrogram from the ground truth audio
+ x = get_mel_spectrogram(wav.unsqueeze(0), generator.h)
+
+ y_g_hat = generator(x)
+
+ audio = y_g_hat.squeeze()
+ audio = audio * MAX_WAV_VALUE
+ audio = audio.cpu().numpy().astype("int16")
+
+ output_file = os.path.join(a.output_dir, os.path.splitext(filname)[0] + "_generated.wav")
+ write(output_file, h.sampling_rate, audio)
+ print(output_file)
+
+
+def main():
+ print("Initializing Inference Process..")
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--input_wavs_dir", default="test_files")
+ parser.add_argument("--output_dir", default="generated_files")
+ parser.add_argument("--checkpoint_file", required=True)
+ parser.add_argument("--use_cuda_kernel", action="store_true", default=False)
+
+ a = parser.parse_args()
+
+ config_file = os.path.join(os.path.split(a.checkpoint_file)[0], "config.json")
+ with open(config_file) as f:
+ data = f.read()
+
+ global h
+ json_config = json.loads(data)
+ h = AttrDict(json_config)
+
+ torch.manual_seed(h.seed)
+ global device
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed(h.seed)
+ device = torch.device("cuda")
+ else:
+ device = torch.device("cpu")
+
+ inference(a, h)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/GPT_SoVITS/BigVGAN/inference_e2e.py b/GPT_SoVITS/BigVGAN/inference_e2e.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c0df77435e91935beaca365dd5fd38d76098a4a
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/inference_e2e.py
@@ -0,0 +1,100 @@
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+from __future__ import absolute_import, division, print_function, unicode_literals
+
+import glob
+import os
+import numpy as np
+import argparse
+import json
+import torch
+from scipy.io.wavfile import write
+from env import AttrDict
+from meldataset import MAX_WAV_VALUE
+from bigvgan import BigVGAN as Generator
+
+h = None
+device = None
+torch.backends.cudnn.benchmark = False
+
+
+def load_checkpoint(filepath, device):
+ assert os.path.isfile(filepath)
+ print(f"Loading '{filepath}'")
+ checkpoint_dict = torch.load(filepath, map_location=device)
+ print("Complete.")
+ return checkpoint_dict
+
+
+def scan_checkpoint(cp_dir, prefix):
+ pattern = os.path.join(cp_dir, prefix + "*")
+ cp_list = glob.glob(pattern)
+ if len(cp_list) == 0:
+ return ""
+ return sorted(cp_list)[-1]
+
+
+def inference(a, h):
+ generator = Generator(h, use_cuda_kernel=a.use_cuda_kernel).to(device)
+
+ state_dict_g = load_checkpoint(a.checkpoint_file, device)
+ generator.load_state_dict(state_dict_g["generator"])
+
+ filelist = os.listdir(a.input_mels_dir)
+
+ os.makedirs(a.output_dir, exist_ok=True)
+
+ generator.eval()
+ generator.remove_weight_norm()
+ with torch.no_grad():
+ for i, filname in enumerate(filelist):
+ # Load the mel spectrogram in .npy format
+ x = np.load(os.path.join(a.input_mels_dir, filname))
+ x = torch.FloatTensor(x).to(device)
+ if len(x.shape) == 2:
+ x = x.unsqueeze(0)
+
+ y_g_hat = generator(x)
+
+ audio = y_g_hat.squeeze()
+ audio = audio * MAX_WAV_VALUE
+ audio = audio.cpu().numpy().astype("int16")
+
+ output_file = os.path.join(a.output_dir, os.path.splitext(filname)[0] + "_generated_e2e.wav")
+ write(output_file, h.sampling_rate, audio)
+ print(output_file)
+
+
+def main():
+ print("Initializing Inference Process..")
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--input_mels_dir", default="test_mel_files")
+ parser.add_argument("--output_dir", default="generated_files_from_mel")
+ parser.add_argument("--checkpoint_file", required=True)
+ parser.add_argument("--use_cuda_kernel", action="store_true", default=False)
+
+ a = parser.parse_args()
+
+ config_file = os.path.join(os.path.split(a.checkpoint_file)[0], "config.json")
+ with open(config_file) as f:
+ data = f.read()
+
+ global h
+ json_config = json.loads(data)
+ h = AttrDict(json_config)
+
+ torch.manual_seed(h.seed)
+ global device
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed(h.seed)
+ device = torch.device("cuda")
+ else:
+ device = torch.device("cpu")
+
+ inference(a, h)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/GPT_SoVITS/BigVGAN/loss.py b/GPT_SoVITS/BigVGAN/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..c295a144ff7bcfc0d91d9d4676bedfa7015cdb79
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/loss.py
@@ -0,0 +1,238 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+
+import torch
+import torch.nn as nn
+from librosa.filters import mel as librosa_mel_fn
+from scipy import signal
+
+import typing
+from typing import List, Tuple
+from collections import namedtuple
+import math
+import functools
+
+
+# Adapted from https://github.com/descriptinc/descript-audio-codec/blob/main/dac/nn/loss.py under the MIT license.
+# LICENSE is in incl_licenses directory.
+class MultiScaleMelSpectrogramLoss(nn.Module):
+ """Compute distance between mel spectrograms. Can be used
+ in a multi-scale way.
+
+ Parameters
+ ----------
+ n_mels : List[int]
+ Number of mels per STFT, by default [5, 10, 20, 40, 80, 160, 320],
+ window_lengths : List[int], optional
+ Length of each window of each STFT, by default [32, 64, 128, 256, 512, 1024, 2048]
+ loss_fn : typing.Callable, optional
+ How to compare each loss, by default nn.L1Loss()
+ clamp_eps : float, optional
+ Clamp on the log magnitude, below, by default 1e-5
+ mag_weight : float, optional
+ Weight of raw magnitude portion of loss, by default 0.0 (no ampliciation on mag part)
+ log_weight : float, optional
+ Weight of log magnitude portion of loss, by default 1.0
+ pow : float, optional
+ Power to raise magnitude to before taking log, by default 1.0
+ weight : float, optional
+ Weight of this loss, by default 1.0
+ match_stride : bool, optional
+ Whether to match the stride of convolutional layers, by default False
+
+ Implementation copied from: https://github.com/descriptinc/lyrebird-audiotools/blob/961786aa1a9d628cca0c0486e5885a457fe70c1a/audiotools/metrics/spectral.py
+ Additional code copied and modified from https://github.com/descriptinc/audiotools/blob/master/audiotools/core/audio_signal.py
+ """
+
+ def __init__(
+ self,
+ sampling_rate: int,
+ n_mels: List[int] = [5, 10, 20, 40, 80, 160, 320],
+ window_lengths: List[int] = [32, 64, 128, 256, 512, 1024, 2048],
+ loss_fn: typing.Callable = nn.L1Loss(),
+ clamp_eps: float = 1e-5,
+ mag_weight: float = 0.0,
+ log_weight: float = 1.0,
+ pow: float = 1.0,
+ weight: float = 1.0,
+ match_stride: bool = False,
+ mel_fmin: List[float] = [0, 0, 0, 0, 0, 0, 0],
+ mel_fmax: List[float] = [None, None, None, None, None, None, None],
+ window_type: str = "hann",
+ ):
+ super().__init__()
+ self.sampling_rate = sampling_rate
+
+ STFTParams = namedtuple(
+ "STFTParams",
+ ["window_length", "hop_length", "window_type", "match_stride"],
+ )
+
+ self.stft_params = [
+ STFTParams(
+ window_length=w,
+ hop_length=w // 4,
+ match_stride=match_stride,
+ window_type=window_type,
+ )
+ for w in window_lengths
+ ]
+ self.n_mels = n_mels
+ self.loss_fn = loss_fn
+ self.clamp_eps = clamp_eps
+ self.log_weight = log_weight
+ self.mag_weight = mag_weight
+ self.weight = weight
+ self.mel_fmin = mel_fmin
+ self.mel_fmax = mel_fmax
+ self.pow = pow
+
+ @staticmethod
+ @functools.lru_cache(None)
+ def get_window(
+ window_type,
+ window_length,
+ ):
+ return signal.get_window(window_type, window_length)
+
+ @staticmethod
+ @functools.lru_cache(None)
+ def get_mel_filters(sr, n_fft, n_mels, fmin, fmax):
+ return librosa_mel_fn(sr=sr, n_fft=n_fft, n_mels=n_mels, fmin=fmin, fmax=fmax)
+
+ def mel_spectrogram(
+ self,
+ wav,
+ n_mels,
+ fmin,
+ fmax,
+ window_length,
+ hop_length,
+ match_stride,
+ window_type,
+ ):
+ """
+ Mirrors AudioSignal.mel_spectrogram used by BigVGAN-v2 training from:
+ https://github.com/descriptinc/audiotools/blob/master/audiotools/core/audio_signal.py
+ """
+ B, C, T = wav.shape
+
+ if match_stride:
+ assert hop_length == window_length // 4, "For match_stride, hop must equal n_fft // 4"
+ right_pad = math.ceil(T / hop_length) * hop_length - T
+ pad = (window_length - hop_length) // 2
+ else:
+ right_pad = 0
+ pad = 0
+
+ wav = torch.nn.functional.pad(wav, (pad, pad + right_pad), mode="reflect")
+
+ window = self.get_window(window_type, window_length)
+ window = torch.from_numpy(window).to(wav.device).float()
+
+ stft = torch.stft(
+ wav.reshape(-1, T),
+ n_fft=window_length,
+ hop_length=hop_length,
+ window=window,
+ return_complex=True,
+ center=True,
+ )
+ _, nf, nt = stft.shape
+ stft = stft.reshape(B, C, nf, nt)
+ if match_stride:
+ """
+ Drop first two and last two frames, which are added, because of padding. Now num_frames * hop_length = num_samples.
+ """
+ stft = stft[..., 2:-2]
+ magnitude = torch.abs(stft)
+
+ nf = magnitude.shape[2]
+ mel_basis = self.get_mel_filters(self.sampling_rate, 2 * (nf - 1), n_mels, fmin, fmax)
+ mel_basis = torch.from_numpy(mel_basis).to(wav.device)
+ mel_spectrogram = magnitude.transpose(2, -1) @ mel_basis.T
+ mel_spectrogram = mel_spectrogram.transpose(-1, 2)
+
+ return mel_spectrogram
+
+ def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
+ """Computes mel loss between an estimate and a reference
+ signal.
+
+ Parameters
+ ----------
+ x : torch.Tensor
+ Estimate signal
+ y : torch.Tensor
+ Reference signal
+
+ Returns
+ -------
+ torch.Tensor
+ Mel loss.
+ """
+
+ loss = 0.0
+ for n_mels, fmin, fmax, s in zip(self.n_mels, self.mel_fmin, self.mel_fmax, self.stft_params):
+ kwargs = {
+ "n_mels": n_mels,
+ "fmin": fmin,
+ "fmax": fmax,
+ "window_length": s.window_length,
+ "hop_length": s.hop_length,
+ "match_stride": s.match_stride,
+ "window_type": s.window_type,
+ }
+
+ x_mels = self.mel_spectrogram(x, **kwargs)
+ y_mels = self.mel_spectrogram(y, **kwargs)
+ x_logmels = torch.log(x_mels.clamp(min=self.clamp_eps).pow(self.pow)) / torch.log(torch.tensor(10.0))
+ y_logmels = torch.log(y_mels.clamp(min=self.clamp_eps).pow(self.pow)) / torch.log(torch.tensor(10.0))
+
+ loss += self.log_weight * self.loss_fn(x_logmels, y_logmels)
+ loss += self.mag_weight * self.loss_fn(x_logmels, y_logmels)
+
+ return loss
+
+
+# Loss functions
+def feature_loss(fmap_r: List[List[torch.Tensor]], fmap_g: List[List[torch.Tensor]]) -> torch.Tensor:
+ loss = 0
+ for dr, dg in zip(fmap_r, fmap_g):
+ for rl, gl in zip(dr, dg):
+ loss += torch.mean(torch.abs(rl - gl))
+
+ return loss * 2 # This equates to lambda=2.0 for the feature matching loss
+
+
+def discriminator_loss(
+ disc_real_outputs: List[torch.Tensor], disc_generated_outputs: List[torch.Tensor]
+) -> Tuple[torch.Tensor, List[torch.Tensor], List[torch.Tensor]]:
+ loss = 0
+ r_losses = []
+ g_losses = []
+ for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
+ r_loss = torch.mean((1 - dr) ** 2)
+ g_loss = torch.mean(dg**2)
+ loss += r_loss + g_loss
+ r_losses.append(r_loss.item())
+ g_losses.append(g_loss.item())
+
+ return loss, r_losses, g_losses
+
+
+def generator_loss(
+ disc_outputs: List[torch.Tensor],
+) -> Tuple[torch.Tensor, List[torch.Tensor]]:
+ loss = 0
+ gen_losses = []
+ for dg in disc_outputs:
+ l = torch.mean((1 - dg) ** 2)
+ gen_losses.append(l)
+ loss += l
+
+ return loss, gen_losses
diff --git a/GPT_SoVITS/BigVGAN/meldataset.py b/GPT_SoVITS/BigVGAN/meldataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc12c9874cfb9958d6f4842cc067ffda66a390eb
--- /dev/null
+++ b/GPT_SoVITS/BigVGAN/meldataset.py
@@ -0,0 +1,370 @@
+# Copyright (c) 2024 NVIDIA CORPORATION.
+# Licensed under the MIT license.
+
+# Adapted from https://github.com/jik876/hifi-gan under the MIT license.
+# LICENSE is in incl_licenses directory.
+
+import math
+import os
+import random
+import torch
+import torch.utils.data
+import numpy as np
+import librosa
+from librosa.filters import mel as librosa_mel_fn
+import pathlib
+from tqdm import tqdm
+from typing import List, Tuple, Optional
+from .env import AttrDict
+
+MAX_WAV_VALUE = 32767.0 # NOTE: 32768.0 -1 to prevent int16 overflow (results in popping sound in corner cases)
+
+
+def dynamic_range_compression(x, C=1, clip_val=1e-5):
+ return np.log(np.clip(x, a_min=clip_val, a_max=None) * C)
+
+
+def dynamic_range_decompression(x, C=1):
+ return np.exp(x) / C
+
+
+def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
+ return torch.log(torch.clamp(x, min=clip_val) * C)
+
+
+def dynamic_range_decompression_torch(x, C=1):
+ return torch.exp(x) / C
+
+
+def spectral_normalize_torch(magnitudes):
+ return dynamic_range_compression_torch(magnitudes)
+
+
+def spectral_de_normalize_torch(magnitudes):
+ return dynamic_range_decompression_torch(magnitudes)
+
+
+mel_basis_cache = {}
+hann_window_cache = {}
+
+
+def mel_spectrogram(
+ y: torch.Tensor,
+ n_fft: int,
+ num_mels: int,
+ sampling_rate: int,
+ hop_size: int,
+ win_size: int,
+ fmin: int,
+ fmax: int = None,
+ center: bool = False,
+) -> torch.Tensor:
+ """
+ Calculate the mel spectrogram of an input signal.
+ This function uses slaney norm for the librosa mel filterbank (using librosa.filters.mel) and uses Hann window for STFT (using torch.stft).
+
+ Args:
+ y (torch.Tensor): Input signal.
+ n_fft (int): FFT size.
+ num_mels (int): Number of mel bins.
+ sampling_rate (int): Sampling rate of the input signal.
+ hop_size (int): Hop size for STFT.
+ win_size (int): Window size for STFT.
+ fmin (int): Minimum frequency for mel filterbank.
+ fmax (int): Maximum frequency for mel filterbank. If None, defaults to half the sampling rate (fmax = sr / 2.0) inside librosa_mel_fn
+ center (bool): Whether to pad the input to center the frames. Default is False.
+
+ Returns:
+ torch.Tensor: Mel spectrogram.
+ """
+ if torch.min(y) < -1.0:
+ print(f"[WARNING] Min value of input waveform signal is {torch.min(y)}")
+ if torch.max(y) > 1.0:
+ print(f"[WARNING] Max value of input waveform signal is {torch.max(y)}")
+
+ device = y.device
+ key = f"{n_fft}_{num_mels}_{sampling_rate}_{hop_size}_{win_size}_{fmin}_{fmax}_{device}"
+
+ if key not in mel_basis_cache:
+ mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax)
+ mel_basis_cache[key] = torch.from_numpy(mel).float().to(device)
+ hann_window_cache[key] = torch.hann_window(win_size).to(device)
+
+ mel_basis = mel_basis_cache[key]
+ hann_window = hann_window_cache[key]
+
+ padding = (n_fft - hop_size) // 2
+ y = torch.nn.functional.pad(y.unsqueeze(1), (padding, padding), mode="reflect").squeeze(1)
+
+ spec = torch.stft(
+ y,
+ n_fft,
+ hop_length=hop_size,
+ win_length=win_size,
+ window=hann_window,
+ center=center,
+ pad_mode="reflect",
+ normalized=False,
+ onesided=True,
+ return_complex=True,
+ )
+ spec = torch.sqrt(torch.view_as_real(spec).pow(2).sum(-1) + 1e-9)
+
+ mel_spec = torch.matmul(mel_basis, spec)
+ mel_spec = spectral_normalize_torch(mel_spec)
+
+ return mel_spec
+
+
+def get_mel_spectrogram(wav, h):
+ """
+ Generate mel spectrogram from a waveform using given hyperparameters.
+
+ Args:
+ wav (torch.Tensor): Input waveform.
+ h: Hyperparameters object with attributes n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax.
+
+ Returns:
+ torch.Tensor: Mel spectrogram.
+ """
+ return mel_spectrogram(
+ wav,
+ h.n_fft,
+ h.num_mels,
+ h.sampling_rate,
+ h.hop_size,
+ h.win_size,
+ h.fmin,
+ h.fmax,
+ )
+
+
+def get_dataset_filelist(a):
+ training_files = []
+ validation_files = []
+ list_unseen_validation_files = []
+
+ with open(a.input_training_file, "r", encoding="utf-8") as fi:
+ training_files = [
+ os.path.join(a.input_wavs_dir, x.split("|")[0] + ".wav") for x in fi.read().split("\n") if len(x) > 0
+ ]
+ print(f"first training file: {training_files[0]}")
+
+ with open(a.input_validation_file, "r", encoding="utf-8") as fi:
+ validation_files = [
+ os.path.join(a.input_wavs_dir, x.split("|")[0] + ".wav") for x in fi.read().split("\n") if len(x) > 0
+ ]
+ print(f"first validation file: {validation_files[0]}")
+
+ for i in range(len(a.list_input_unseen_validation_file)):
+ with open(a.list_input_unseen_validation_file[i], "r", encoding="utf-8") as fi:
+ unseen_validation_files = [
+ os.path.join(a.list_input_unseen_wavs_dir[i], x.split("|")[0] + ".wav")
+ for x in fi.read().split("\n")
+ if len(x) > 0
+ ]
+ print(f"first unseen {i}th validation fileset: {unseen_validation_files[0]}")
+ list_unseen_validation_files.append(unseen_validation_files)
+
+ return training_files, validation_files, list_unseen_validation_files
+
+
+class MelDataset(torch.utils.data.Dataset):
+ def __init__(
+ self,
+ training_files: List[str],
+ hparams: AttrDict,
+ segment_size: int,
+ n_fft: int,
+ num_mels: int,
+ hop_size: int,
+ win_size: int,
+ sampling_rate: int,
+ fmin: int,
+ fmax: Optional[int],
+ split: bool = True,
+ shuffle: bool = True,
+ device: str = None,
+ fmax_loss: Optional[int] = None,
+ fine_tuning: bool = False,
+ base_mels_path: str = None,
+ is_seen: bool = True,
+ ):
+ self.audio_files = training_files
+ random.seed(1234)
+ if shuffle:
+ random.shuffle(self.audio_files)
+ self.hparams = hparams
+ self.is_seen = is_seen
+ if self.is_seen:
+ self.name = pathlib.Path(self.audio_files[0]).parts[0]
+ else:
+ self.name = "-".join(pathlib.Path(self.audio_files[0]).parts[:2]).strip("/")
+
+ self.segment_size = segment_size
+ self.sampling_rate = sampling_rate
+ self.split = split
+ self.n_fft = n_fft
+ self.num_mels = num_mels
+ self.hop_size = hop_size
+ self.win_size = win_size
+ self.fmin = fmin
+ self.fmax = fmax
+ self.fmax_loss = fmax_loss
+ self.device = device
+ self.fine_tuning = fine_tuning
+ self.base_mels_path = base_mels_path
+
+ print("[INFO] checking dataset integrity...")
+ for i in tqdm(range(len(self.audio_files))):
+ assert os.path.exists(self.audio_files[i]), f"{self.audio_files[i]} not found"
+
+ def __getitem__(self, index: int) -> Tuple[torch.Tensor, torch.Tensor, str, torch.Tensor]:
+ try:
+ filename = self.audio_files[index]
+
+ # Use librosa.load that ensures loading waveform into mono with [-1, 1] float values
+ # Audio is ndarray with shape [T_time]. Disable auto-resampling here to minimize overhead
+ # The on-the-fly resampling during training will be done only for the obtained random chunk
+ audio, source_sampling_rate = librosa.load(filename, sr=None, mono=True)
+
+ # Main logic that uses