
Upload 1162 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +4 -0
- s3prl_s3prl_main/Dockerfile +42 -0
- s3prl_s3prl_main/LICENSE +201 -0
- s3prl_s3prl_main/README.md +357 -0
- s3prl_s3prl_main/__pycache__/hubconf.cpython-310.pyc +0 -0
- s3prl_s3prl_main/__pycache__/hubconf.cpython-39.pyc +0 -0
- s3prl_s3prl_main/ci/format.py +84 -0
- s3prl_s3prl_main/docs/Makefile +20 -0
- s3prl_s3prl_main/docs/README.md +27 -0
- s3prl_s3prl_main/docs/from_scratch_tutorial.md +146 -0
- s3prl_s3prl_main/docs/make.bat +35 -0
- s3prl_s3prl_main/docs/rebuild_docs.sh +9 -0
- s3prl_s3prl_main/docs/source/_static/css/custom.css +3 -0
- s3prl_s3prl_main/docs/source/_static/js/custom.js +7 -0
- s3prl_s3prl_main/docs/source/_templates/custom-module-template.rst +81 -0
- s3prl_s3prl_main/docs/source/conf.py +120 -0
- s3prl_s3prl_main/docs/source/contribute/general.rst +167 -0
- s3prl_s3prl_main/docs/source/contribute/private.rst +104 -0
- s3prl_s3prl_main/docs/source/contribute/public.rst +29 -0
- s3prl_s3prl_main/docs/source/contribute/upstream.rst +100 -0
- s3prl_s3prl_main/docs/source/index.rst +75 -0
- s3prl_s3prl_main/docs/source/tutorial/installation.rst +55 -0
- s3prl_s3prl_main/docs/source/tutorial/problem.rst +122 -0
- s3prl_s3prl_main/docs/source/tutorial/upstream_collection.rst +1457 -0
- s3prl_s3prl_main/docs/util/is_valid.py +21 -0
- s3prl_s3prl_main/example/customize.py +43 -0
- s3prl_s3prl_main/example/run_asr.sh +3 -0
- s3prl_s3prl_main/example/run_sid.sh +4 -0
- s3prl_s3prl_main/example/ssl/pretrain.py +285 -0
- s3prl_s3prl_main/example/superb/train.py +291 -0
- s3prl_s3prl_main/example/superb_asr/inference.py +40 -0
- s3prl_s3prl_main/example/superb_asr/train.py +241 -0
- s3prl_s3prl_main/example/superb_asr/train_with_lightning.py +127 -0
- s3prl_s3prl_main/example/superb_sid/inference.py +40 -0
- s3prl_s3prl_main/example/superb_sid/train.py +235 -0
- s3prl_s3prl_main/example/superb_sid/train_with_lightning.py +127 -0
- s3prl_s3prl_main/example/superb_sv/inference.py +47 -0
- s3prl_s3prl_main/example/superb_sv/train.py +266 -0
- s3prl_s3prl_main/example/superb_sv/train_with_lightning.py +184 -0
- s3prl_s3prl_main/external_tools/install_espnet.sh +20 -0
- s3prl_s3prl_main/file/S3PRL-integration.png +0 -0
- s3prl_s3prl_main/file/S3PRL-interface.png +0 -0
- s3prl_s3prl_main/file/S3PRL-logo.png +0 -0
- s3prl_s3prl_main/file/license.svg +1 -0
- s3prl_s3prl_main/find_content.sh +8 -0
- s3prl_s3prl_main/hubconf.py +4 -0
- s3prl_s3prl_main/pyrightconfig.json +5 -0
- s3prl_s3prl_main/pytest.ini +5 -0
- s3prl_s3prl_main/requirements/all.txt +33 -0
- s3prl_s3prl_main/requirements/dev.txt +11 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
s3prl_s3prl_main/s3prl/downstream/phone_linear/data/converted_aligned_phones.txt filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
s3prl_s3prl_main/s3prl/downstream/voxceleb2_amsoftmax_segment_eval/cache_wav_paths/cache_test_segment.p filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
s3prl_s3prl_main/s3prl/downstream/voxceleb2_amsoftmax_segment_eval/cache_wav_paths/cache_Voxceleb1.p filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
s3prl_s3prl_main/s3prl/downstream/voxceleb2_amsoftmax_segment_eval/cache_wav_paths/cache_Voxceleb2.p filter=lfs diff=lfs merge=lfs -text
|
s3prl_s3prl_main/Dockerfile
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# We need this to use GPUs inside the container
|
| 2 |
+
FROM nvidia/cuda:11.2.2-base
|
| 3 |
+
# Using a multi-stage build simplifies the s3prl installation
|
| 4 |
+
# TODO: Find a slimmer base image that also "just works"
|
| 5 |
+
FROM tiangolo/uvicorn-gunicorn:python3.8
|
| 6 |
+
|
| 7 |
+
RUN apt-get update --fix-missing && apt-get install -y wget \
|
| 8 |
+
libsndfile1 \
|
| 9 |
+
sox \
|
| 10 |
+
git \
|
| 11 |
+
git-lfs
|
| 12 |
+
|
| 13 |
+
RUN python -m pip install --upgrade pip
|
| 14 |
+
RUN python -m pip --no-cache-dir install fairseq@git+https://github.com//pytorch/fairseq.git@f2146bdc7abf293186de9449bfa2272775e39e1d#egg=fairseq
|
| 15 |
+
RUN python -m pip --no-cache-dir install git+https://github.com/s3prl/s3prl.git#egg=s3prl
|
| 16 |
+
|
| 17 |
+
COPY s3prl/ /app/s3prl
|
| 18 |
+
COPY src/ /app/src
|
| 19 |
+
|
| 20 |
+
# Setup filesystem
|
| 21 |
+
RUN mkdir /app/data
|
| 22 |
+
|
| 23 |
+
# Configure Git
|
| 24 |
+
# TODO: Create a dedicated SUPERB account for the project?
|
| 25 |
+
RUN git config --global user.email "[email protected]"
|
| 26 |
+
RUN git config --global user.name "SUPERB Admin"
|
| 27 |
+
|
| 28 |
+
# Default args for fine-tuning
|
| 29 |
+
ENV upstream_model osanseviero/hubert_base
|
| 30 |
+
ENV downstream_task asr
|
| 31 |
+
ENV hub huggingface
|
| 32 |
+
ENV hf_hub_org None
|
| 33 |
+
ENV push_to_hf_hub True
|
| 34 |
+
ENV override None
|
| 35 |
+
|
| 36 |
+
WORKDIR /app/s3prl
|
| 37 |
+
# Each task's config.yaml is used to set all the training parameters, but can be overridden with the `override` argument
|
| 38 |
+
# The results of each training run are stored in /app/s3prl/result/downstream/{downstream_task}
|
| 39 |
+
# and pushed to the Hugging Face Hub with name:
|
| 40 |
+
# Default behaviour - {hf_hub_username}/superb-s3prl-{upstream_model}-{downstream_task}-uuid
|
| 41 |
+
# With hf_hub_org set - {hf_hub_org}/superb-s3prl-{upstream_model}-{downstream_task}-uuid
|
| 42 |
+
CMD python run_downstream.py -n ${downstream_task} -m train -u ${upstream_model} -d ${downstream_task} --hub ${hub} --hf_hub_org ${hf_hub_org} --push_to_hf_hub ${push_to_hf_hub} --override ${override}
|
s3prl_s3prl_main/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "{}"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2022 Andy T. Liu (Ting-Wei Liu) and Shu-wen (Leo) Yang
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
s3prl_s3prl_main/README.md
ADDED
|
@@ -0,0 +1,357 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center">
|
| 2 |
+
<img src="https://raw.githubusercontent.com/s3prl/s3prl/main/file/S3PRL-logo.png" width="900"/>
|
| 3 |
+
<br>
|
| 4 |
+
<br>
|
| 5 |
+
<a href="./LICENSE.txt"><img alt="Apache License 2.0" src="https://raw.githubusercontent.com/s3prl/s3prl/main/file/license.svg" /></a>
|
| 6 |
+
<a href="https://creativecommons.org/licenses/by-nc/4.0/"><img alt="CC_BY_NC License" src="https://img.shields.io/badge/License-CC%20BY--NC%204.0-lightgrey.svg" /></a>
|
| 7 |
+
<a href="https://github.com/s3prl/s3prl/actions/workflows/ci.yml"><img alt="CI" src="https://github.com/s3prl/s3prl/actions/workflows/ci.yml/badge.svg?branch=main&event=push"></a>
|
| 8 |
+
<a href="#development-pattern-for-contributors"><img alt="Codecov" src="https://img.shields.io/badge/contributions-welcome-brightgreen.svg"></a>
|
| 9 |
+
<a href="https://github.com/s3prl/s3prl/issues"><img alt="Bitbucket open issues" src="https://img.shields.io/github/issues/s3prl/s3prl"></a>
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
## Contact
|
| 13 |
+
|
| 14 |
+
We prefer to have discussions directly on Github issue page, so that all the information is transparent to all the contributors and is auto-archived on the Github.
|
| 15 |
+
If you wish to use email, please contact:
|
| 16 |
+
|
| 17 |
+
- [Shu-wen (Leo) Yang](https://leo19941227.github.io/) ([email protected])
|
| 18 |
+
- [Andy T. Liu](https://andi611.github.io/) ([email protected])
|
| 19 |
+
|
| 20 |
+
Please refer to the [legacy citation](https://scholar.google.com/citations?view_op=view_citation&hl=en&user=R1mNI8QAAAAJ&citation_for_view=R1mNI8QAAAAJ:LkGwnXOMwfcC) of S3PRL and the timeline below, which justify our initiative on this project. This information is used to protect us from half-truths. We encourage to cite the individual papers most related to the function you are using to give fair credit to the developer of the function. You can find the names in the [Change Log](#change-log). Finally, we would like to thank our advisor, [Prof. Hung-yi Lee](https://speech.ee.ntu.edu.tw/~hylee/index.php), for his advice. The project would be impossible without his support.
|
| 21 |
+
|
| 22 |
+
If you have any question (e.g., about who came up with / developed which ideas / functions or how the project started), feel free to engage in an open and responsible conversation on the GitHub issue page, and we'll be happy to help!
|
| 23 |
+
|
| 24 |
+
## Contribution (pull request)
|
| 25 |
+
|
| 26 |
+
**Guideline**
|
| 27 |
+
|
| 28 |
+
- Starting in 2024, we will only accept new contributions in the form of new upstream models, so we can save bandwidth for developing new techniques (which will not be in S3PRL.)
|
| 29 |
+
- S3PRL has transitioned into pure maintenance mode, ensuring the long-term maintenance of all existing functions.
|
| 30 |
+
- Reporting bugs or the PR fixing the bugs is always welcome! Thanks!
|
| 31 |
+
|
| 32 |
+
**Tutorials**
|
| 33 |
+
|
| 34 |
+
- [General tutorial](https://s3prl.github.io/s3prl/contribute/general.html)
|
| 35 |
+
- [Tutorial for adding new upstream models](https://s3prl.github.io/s3prl/contribute/upstream.html)
|
| 36 |
+
|
| 37 |
+
## Environment compatibilities [](https://github.com/s3prl/s3prl/actions/workflows/ci.yml)
|
| 38 |
+
|
| 39 |
+
We support the following environments. The test cases are ran with **[tox](./tox.ini)** locally and on **[github action](.github/workflows/ci.yml)**:
|
| 40 |
+
|
| 41 |
+
| Env | versions |
|
| 42 |
+
| --- | --- |
|
| 43 |
+
| os | `ubuntu-18.04`, `ubuntu-20.04` |
|
| 44 |
+
| python | `3.7`, `3.8`, `3.9`, `3.10` |
|
| 45 |
+
| pytorch | `1.8.1`, `1.9.1`, `1.10.2`, `1.11.0`, `1.12.1` , `1.13.1` , `2.0.1` , `2.1.0` |
|
| 46 |
+
|
| 47 |
+
## Star History
|
| 48 |
+
|
| 49 |
+
[](https://star-history.com/#s3prl/s3prl&Date)
|
| 50 |
+
|
| 51 |
+
## Change Log
|
| 52 |
+
|
| 53 |
+
> We only list the major contributors here for conciseness. However, we are deeply grateful for all the contributions. Please see the [Contributors](https://github.com/s3prl/s3prl/graphs/contributors) page for the full list.
|
| 54 |
+
|
| 55 |
+
* *Sep 2024*: Support MS-HuBERT (see [MS-HuBERT](https://arxiv.org/pdf/2406.05661))
|
| 56 |
+
* *Dec 2023*: Support Multi-resolution HuBERT (MR-HuBERT, see [Multiresolution HuBERT](https://arxiv.org/pdf/2310.02720.pdf))
|
| 57 |
+
* *Oct 2023*: Support ESPnet pre-trained upstream models (see [ESPnet HuBERT](https://arxiv.org/abs/2306.06672) and [WavLabLM](https://arxiv.org/abs/2309.15317))
|
| 58 |
+
* *Sep 2022*: In [JSALT 2022](https://jsalt-2022-ssl.github.io/member), We upgrade the codebase to support testing, documentation and a new [S3PRL PyPI package](https://pypi.org/project/s3prl/) for easy installation and usage for upstream models. See our [online doc](https://s3prl.github.io/s3prl/) for more information. The package is now used by many [open-source projects](https://github.com/s3prl/s3prl/network/dependents), including [ESPNet](https://github.com/espnet/espnet/blob/master/espnet2/asr/frontend/s3prl.py). Contributors: [Shu-wen Yang](https://leo19941227.github.io/) ***(NTU)***, [Andy T. Liu](https://andi611.github.io/) ***(NTU)***, [Heng-Jui Chang](https://people.csail.mit.edu/hengjui/) ***(MIT)***, [Haibin Wu](https://hbwu-ntu.github.io/) ***(NTU)*** and [Xuankai Chang](https://www.xuankaic.com/) ***(CMU)***.
|
| 59 |
+
* *Mar 2022*: Introduce [**SUPERB-SG**](https://arxiv.org/abs/2203.06849), see [Speech Translation](./s3prl/downstream/speech_translation) by [Hsiang-Sheng Tsai](https://github.com/bearhsiang) ***(NTU)***, [Out-of-domain ASR](./s3prl/downstream/ctc/) by [Heng-Jui Chang](https://people.csail.mit.edu/hengjui/) ***(NTU)***, [Voice Conversion](./s3prl/downstream/a2o-vc-vcc2020/) by [Wen-Chin Huang](https://unilight.github.io/) ***(Nagoya)***, [Speech Separation](./s3prl/downstream/separation_stft/) and [Speech Enhancement](./s3prl/downstream/enhancement_stft/) by [Zili Huang](https://scholar.google.com/citations?user=iQ-S0fQAAAAJ&hl=en) ***(JHU)*** for more info.
|
| 60 |
+
* *Mar 2022*: Introduce [**SSL for SE/SS**](https://arxiv.org/abs/2203.07960) by [Zili Huang](https://scholar.google.com/citations?user=iQ-S0fQAAAAJ&hl=en) ***(JHU)***. See [SE1](https://github.com/s3prl/s3prl/tree/main/s3prl/downstream/enhancement_stft) and [SS1](https://github.com/s3prl/s3prl/tree/main/s3prl/downstream/separation_stft) folders for more details. Note that the improved performances can be achieved by the later introduced [SE2](https://github.com/s3prl/s3prl/tree/main/s3prl/downstream/enhancement_stft2) and [SS2](https://github.com/s3prl/s3prl/tree/main/s3prl/downstream/separation_stft2). However, for aligning with [SUPERB-SG](https://arxiv.org/abs/2203.06849) benchmarking, please use the version 1.
|
| 61 |
+
* *Nov 2021*: Introduce [**S3PRL-VC**](https://arxiv.org/abs/2110.06280) by [Wen-Chin Huang](https://unilight.github.io/) ***(Nagoya)***, see [Any-to-one](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream/a2o-vc-vcc2020) for more info. We highly recommend to consider the [newly released official repo of S3PRL-VC](https://github.com/unilight/s3prl-vc) which is developed and actively maintained by [Wen-Chin Huang](https://unilight.github.io/). The standalone repo contains much more recepies for the VC experiments. In S3PRL we only include the Any-to-one recipe for reproducing the SUPERB results.
|
| 62 |
+
* *Oct 2021*: Support [**DistilHuBERT**](https://arxiv.org/abs/2110.01900) by [Heng-Jui Chang](https://people.csail.mit.edu/hengjui/) ***(NTU)***, see [docs](./s3prl/upstream/distiller/README.md) for more info.
|
| 63 |
+
* *Sep 2021:* We host a *challenge* in [*AAAI workshop: The 2nd Self-supervised Learning for Audio and Speech Processing*](https://aaai-sas-2022.github.io/)! See [**SUPERB official site**](https://superbbenchmark.org/) for the challenge details and the [**SUPERB documentation**](./s3prl/downstream/docs/superb.md) in this toolkit!
|
| 64 |
+
* *Aug 2021:* [Andy T. Liu](https://andi611.github.io/) ***(NTU)*** and [Shu-wen Yang](https://leo19941227.github.io/) ***(NTU)*** introduces the S3PRL toolkit in [MLSS 2021](https://ai.ntu.edu.tw/%e7%b7%9a%e4%b8%8a%e5%ad%b8%e7%bf%92-2/mlss-2021/), you can also **[watch it on Youtube](https://youtu.be/PkMFnS6cjAc)**!
|
| 65 |
+
* *Aug 2021:* [**TERA**](https://ieeexplore.ieee.org/document/9478264) by [Andy T. Liu](https://andi611.github.io/) ***(NTU)*** is accepted to TASLP!
|
| 66 |
+
* *July 2021:* We are now working on packaging s3prl and reorganizing the file structure in **v0.3**. Please consider using the stable **v0.2.0** for now. We will test and release **v0.3** before August.
|
| 67 |
+
* *June 2021:* Support [**SUPERB:** **S**peech processing **U**niversal **PER**formance **B**enchmark](https://arxiv.org/abs/2105.01051), submitted to Interspeech 2021. Use the tag **superb-interspeech2021** or **v0.2.0**. Contributors: [Shu-wen Yang](https://leo19941227.github.io/) ***(NTU)***, [Pohan Chi](https://scholar.google.com/citations?user=SiyicoEAAAAJ&hl=zh-TW) ***(NTU)***, [Yist Lin](https://scholar.google.com/citations?user=0lrZq9MAAAAJ&hl=en) ***(NTU)***, [Yung-Sung Chuang](https://scholar.google.com/citations?user=3ar1DOwAAAAJ&hl=zh-TW) ***(NTU)***, [Jiatong Shi](https://scholar.google.com/citations?user=FEDNbgkAAAAJ&hl=en) ***(CMU)***, [Xuankai Chang](https://www.xuankaic.com/) ***(CMU)***, [Wei-Cheng Tseng](https://scholar.google.com.tw/citations?user=-d6aNP0AAAAJ&hl=zh-TW) ***(NTU)***, Tzu-Hsien Huang ***(NTU)*** and [Kushal Lakhotia](https://scholar.google.com/citations?user=w9W6zXUAAAAJ&hl=en) ***(Meta)***.
|
| 68 |
+
* *June 2021:* Support extracting multiple hidden states for all the SSL pretrained models by [Shu-wen Yang](https://leo19941227.github.io/) ***(NTU)***.
|
| 69 |
+
* *Jan 2021:* Readme updated with detailed instructions on how to use our latest version!
|
| 70 |
+
* *Dec 2020:* We are migrating to a newer version for a more general, flexible, and scalable code. See the introduction below for more information! The legacy version can be accessed the tag **v0.1.0**.
|
| 71 |
+
* *Oct 2020:* [Shu-wen Yang](https://leo19941227.github.io/) ***(NTU)*** and [Andy T. Liu](https://andi611.github.io/) ***(NTU)*** added varioius classic upstream models, including PASE+, APC, VQ-APC, NPC, wav2vec, vq-wav2vec ...etc.
|
| 72 |
+
* *Oct 2019:* The birth of S3PRL! The repository was created for the [**Mockingjay**](https://arxiv.org/abs/1910.12638) development. [Andy T. Liu](https://andi611.github.io/) ***(NTU)***, [Shu-wen Yang](https://leo19941227.github.io/) ***(NTU)*** and [Pohan Chi](https://scholar.google.com/citations?user=SiyicoEAAAAJ&hl=zh-TW) ***(NTU)*** implemented the pre-training scripts and several simple downstream evaluation tasks. This work was the very start of the S3PRL project which established lots of foundamental modules and coding styles. Feel free to checkout to the old commits to explore our [legacy codebase](https://github.com/s3prl/s3prl/tree/6a53ee92bffeaa75fc2fb56071050bcf71e93785)!
|
| 73 |
+
|
| 74 |
+
****
|
| 75 |
+
|
| 76 |
+
## Introduction and Usages
|
| 77 |
+
|
| 78 |
+
This is an open source toolkit called **s3prl**, which stands for **S**elf-**S**upervised **S**peech **P**re-training and **R**epresentation **L**earning.
|
| 79 |
+
Self-supervised speech pre-trained models are called **upstream** in this toolkit, and are utilized in various **downstream** tasks.
|
| 80 |
+
|
| 81 |
+
The toolkit has **three major usages**:
|
| 82 |
+
|
| 83 |
+
### Pretrain
|
| 84 |
+
|
| 85 |
+
- Pretrain upstream models, including Mockingjay, Audio ALBERT and TERA.
|
| 86 |
+
- Document: [**pretrain/README.md**](./s3prl/pretrain/README.md)
|
| 87 |
+
|
| 88 |
+
### Upstream
|
| 89 |
+
|
| 90 |
+
- Easily load most of the existing upstream models with pretrained weights in a unified I/O interface.
|
| 91 |
+
- Pretrained models are registered through **torch.hub**, which means you can use these models in your own project by one-line plug-and-play without depending on this toolkit's coding style.
|
| 92 |
+
- Document: [**upstream/README.md**](./s3prl/upstream/README.md)
|
| 93 |
+
|
| 94 |
+
### Downstream
|
| 95 |
+
|
| 96 |
+
- Utilize upstream models in lots of downstream tasks
|
| 97 |
+
- Benchmark upstream models with [**SUPERB Benchmark**](./s3prl/downstream/docs/superb.md)
|
| 98 |
+
- Document: [**downstream/README.md**](./s3prl/downstream/README.md)
|
| 99 |
+
|
| 100 |
+
---
|
| 101 |
+
|
| 102 |
+
Here is a high-level illustration of how S3PRL might help you. We support to leverage numerous SSL representations on numerous speech processing tasks in our [GitHub codebase](https://github.com/s3prl/s3prl):
|
| 103 |
+
|
| 104 |
+

|
| 105 |
+
|
| 106 |
+
---
|
| 107 |
+
|
| 108 |
+
We also modularize all the SSL models into a standalone [PyPi package](https://pypi.org/project/s3prl/) so that you can easily install it and use it without depending on our entire codebase. The following shows a simple example and you can find more details in our [documentation](https://s3prl.github.io/s3prl/).
|
| 109 |
+
|
| 110 |
+
1. Install the S3PRL package:
|
| 111 |
+
|
| 112 |
+
```sh
|
| 113 |
+
pip install s3prl
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
2. Use it to extract representations for your own audio:
|
| 117 |
+
|
| 118 |
+
```python
|
| 119 |
+
import torch
|
| 120 |
+
from s3prl.nn import S3PRLUpstream
|
| 121 |
+
|
| 122 |
+
model = S3PRLUpstream("hubert")
|
| 123 |
+
model.eval()
|
| 124 |
+
|
| 125 |
+
with torch.no_grad():
|
| 126 |
+
wavs = torch.randn(2, 16000 * 2)
|
| 127 |
+
wavs_len = torch.LongTensor([16000 * 1, 16000 * 2])
|
| 128 |
+
all_hs, all_hs_len = model(wavs, wavs_len)
|
| 129 |
+
|
| 130 |
+
for hs, hs_len in zip(all_hs, all_hs_len):
|
| 131 |
+
assert isinstance(hs, torch.FloatTensor)
|
| 132 |
+
assert isinstance(hs_len, torch.LongTensor)
|
| 133 |
+
|
| 134 |
+
batch_size, max_seq_len, hidden_size = hs.shape
|
| 135 |
+
assert hs_len.dim() == 1
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
---
|
| 139 |
+
|
| 140 |
+
With this modularization, we have achieved close integration with the general speech processing toolkit [ESPNet](https://github.com/espnet/espnet), enabling the use of SSL models for a broader range of speech processing tasks and corpora to achieve state-of-the-art (SOTA) results (kudos to the [ESPNet Team](https://www.wavlab.org/open_source)):
|
| 141 |
+
|
| 142 |
+

|
| 143 |
+
|
| 144 |
+
You can start the journey of SSL with the following entry points:
|
| 145 |
+
|
| 146 |
+
- S3PRL: [A simple SUPERB downstream task](https://github.com/s3prl/s3prl/blob/main/s3prl/downstream/docs/superb.md#pr-phoneme-recognition)
|
| 147 |
+
- ESPNet: [Levearging S3PRL for ASR](https://github.com/espnet/espnet/tree/master/egs2/librispeech/asr1#self-supervised-learning-features-hubert_large_ll60k-conformer-utt_mvn-with-transformer-lm)
|
| 148 |
+
|
| 149 |
+
---
|
| 150 |
+
|
| 151 |
+
Feel free to use or modify our toolkit in your research. Here is a [list of papers using our toolkit](#used-by). Any question, bug report or improvement suggestion is welcome through [opening up a new issue](https://github.com/s3prl/s3prl/issues).
|
| 152 |
+
|
| 153 |
+
If you find this toolkit helpful to your research, please do consider citing [our papers](#citation), thanks!
|
| 154 |
+
|
| 155 |
+
## Installation
|
| 156 |
+
|
| 157 |
+
1. **Python** >= 3.6
|
| 158 |
+
2. Install **sox** on your OS
|
| 159 |
+
3. Install s3prl: [Read doc](https://s3prl.github.io/s3prl/tutorial/installation.html#) or `pip install -e ".[all]"`
|
| 160 |
+
4. (Optional) Some upstream models require special dependencies. If you encounter error with a specific upstream model, you can look into the `README.md` under each `upstream` folder. E.g., `upstream/pase/README.md`=
|
| 161 |
+
|
| 162 |
+
## Reference Repositories
|
| 163 |
+
|
| 164 |
+
* [Pytorch](https://github.com/pytorch/pytorch), Pytorch.
|
| 165 |
+
* [Audio](https://github.com/pytorch/audio), Pytorch.
|
| 166 |
+
* [Kaldi](https://github.com/kaldi-asr/kaldi), Kaldi-ASR.
|
| 167 |
+
* [Transformers](https://github.com/huggingface/transformers), Hugging Face.
|
| 168 |
+
* [PyTorch-Kaldi](https://github.com/mravanelli/pytorch-kaldi), Mirco Ravanelli.
|
| 169 |
+
* [fairseq](https://github.com/pytorch/fairseq), Facebook AI Research.
|
| 170 |
+
* [CPC](https://github.com/facebookresearch/CPC_audio), Facebook AI Research.
|
| 171 |
+
* [APC](https://github.com/iamyuanchung/Autoregressive-Predictive-Coding), Yu-An Chung.
|
| 172 |
+
* [VQ-APC](https://github.com/s3prl/VQ-APC), Yu-An Chung.
|
| 173 |
+
* [NPC](https://github.com/Alexander-H-Liu/NPC), Alexander-H-Liu.
|
| 174 |
+
* [End-to-end-ASR-Pytorch](https://github.com/Alexander-H-Liu/End-to-end-ASR-Pytorch), Alexander-H-Liu
|
| 175 |
+
* [Mockingjay](https://github.com/andi611/Mockingjay-Speech-Representation), Andy T. Liu.
|
| 176 |
+
* [ESPnet](https://github.com/espnet/espnet), Shinji Watanabe
|
| 177 |
+
* [speech-representations](https://github.com/awslabs/speech-representations), aws lab
|
| 178 |
+
* [PASE](https://github.com/santi-pdp/pase), Santiago Pascual and Mirco Ravanelli
|
| 179 |
+
* [LibriMix](https://github.com/JorisCos/LibriMix), Joris Cosentino and Manuel Pariente
|
| 180 |
+
|
| 181 |
+
## License
|
| 182 |
+
|
| 183 |
+
The majority of S3PRL Toolkit is licensed under the Apache License version 2.0, however all the files authored by Facebook, Inc. (which have explicit copyright statement on the top) are licensed under CC-BY-NC.
|
| 184 |
+
|
| 185 |
+
## Used by
|
| 186 |
+
<details><summary>List of papers that used our toolkit (Feel free to add your own paper by making a pull request)</summary><p>
|
| 187 |
+
|
| 188 |
+
### Self-Supervised Pretraining
|
| 189 |
+
|
| 190 |
+
+ [Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders (Liu et al., 2020)](https://arxiv.org/abs/1910.12638)
|
| 191 |
+
```
|
| 192 |
+
@article{mockingjay,
|
| 193 |
+
title={Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders},
|
| 194 |
+
ISBN={9781509066315},
|
| 195 |
+
url={http://dx.doi.org/10.1109/ICASSP40776.2020.9054458},
|
| 196 |
+
DOI={10.1109/icassp40776.2020.9054458},
|
| 197 |
+
journal={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 198 |
+
publisher={IEEE},
|
| 199 |
+
author={Liu, Andy T. and Yang, Shu-wen and Chi, Po-Han and Hsu, Po-chun and Lee, Hung-yi},
|
| 200 |
+
year={2020},
|
| 201 |
+
month={May}
|
| 202 |
+
}
|
| 203 |
+
```
|
| 204 |
+
+ [TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech (Liu et al., 2020)](https://arxiv.org/abs/2007.06028)
|
| 205 |
+
```
|
| 206 |
+
@misc{tera,
|
| 207 |
+
title={TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech},
|
| 208 |
+
author={Andy T. Liu and Shang-Wen Li and Hung-yi Lee},
|
| 209 |
+
year={2020},
|
| 210 |
+
eprint={2007.06028},
|
| 211 |
+
archivePrefix={arXiv},
|
| 212 |
+
primaryClass={eess.AS}
|
| 213 |
+
}
|
| 214 |
+
```
|
| 215 |
+
+ [Audio ALBERT: A Lite BERT for Self-supervised Learning of Audio Representation (Chi et al., 2020)](https://arxiv.org/abs/2005.08575)
|
| 216 |
+
```
|
| 217 |
+
@inproceedings{audio_albert,
|
| 218 |
+
title={Audio ALBERT: A Lite BERT for Self-supervised Learning of Audio Representation},
|
| 219 |
+
author={Po-Han Chi and Pei-Hung Chung and Tsung-Han Wu and Chun-Cheng Hsieh and Shang-Wen Li and Hung-yi Lee},
|
| 220 |
+
year={2020},
|
| 221 |
+
booktitle={SLT 2020},
|
| 222 |
+
}
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
### Explanability
|
| 226 |
+
|
| 227 |
+
+ [Understanding Self-Attention of Self-Supervised Audio Transformers (Yang et al., 2020)](https://arxiv.org/abs/2006.03265)
|
| 228 |
+
```
|
| 229 |
+
@inproceedings{understanding_sat,
|
| 230 |
+
author={Shu-wen Yang and Andy T. Liu and Hung-yi Lee},
|
| 231 |
+
title={{Understanding Self-Attention of Self-Supervised Audio Transformers}},
|
| 232 |
+
year=2020,
|
| 233 |
+
booktitle={Proc. Interspeech 2020},
|
| 234 |
+
pages={3785--3789},
|
| 235 |
+
doi={10.21437/Interspeech.2020-2231},
|
| 236 |
+
url={http://dx.doi.org/10.21437/Interspeech.2020-2231}
|
| 237 |
+
}
|
| 238 |
+
```
|
| 239 |
+
|
| 240 |
+
### Adversarial Attack
|
| 241 |
+
|
| 242 |
+
+ [Defense for Black-box Attacks on Anti-spoofing Models by Self-Supervised Learning (Wu et al., 2020)](https://arxiv.org/abs/2006.03214), code for computing LNSR: [utility/observe_lnsr.py](https://github.com/s3prl/s3prl/blob/master/utility/observe_lnsr.py)
|
| 243 |
+
```
|
| 244 |
+
@inproceedings{mockingjay_defense,
|
| 245 |
+
author={Haibin Wu and Andy T. Liu and Hung-yi Lee},
|
| 246 |
+
title={{Defense for Black-Box Attacks on Anti-Spoofing Models by Self-Supervised Learning}},
|
| 247 |
+
year=2020,
|
| 248 |
+
booktitle={Proc. Interspeech 2020},
|
| 249 |
+
pages={3780--3784},
|
| 250 |
+
doi={10.21437/Interspeech.2020-2026},
|
| 251 |
+
url={http://dx.doi.org/10.21437/Interspeech.2020-2026}
|
| 252 |
+
}
|
| 253 |
+
```
|
| 254 |
+
|
| 255 |
+
+ [Adversarial Defense for Automatic Speaker Verification by Cascaded Self-Supervised Learning Models (Wu et al., 2021)](https://arxiv.org/abs/2102.07047)
|
| 256 |
+
```
|
| 257 |
+
@misc{asv_ssl,
|
| 258 |
+
title={Adversarial defense for automatic speaker verification by cascaded self-supervised learning models},
|
| 259 |
+
author={Haibin Wu and Xu Li and Andy T. Liu and Zhiyong Wu and Helen Meng and Hung-yi Lee},
|
| 260 |
+
year={2021},
|
| 261 |
+
eprint={2102.07047},
|
| 262 |
+
archivePrefix={arXiv},
|
| 263 |
+
primaryClass={eess.AS}
|
| 264 |
+
```
|
| 265 |
+
|
| 266 |
+
### Voice Conversion
|
| 267 |
+
|
| 268 |
+
+ [S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations (Lin et al., 2021)](https://arxiv.org/abs/2104.02901)
|
| 269 |
+
```
|
| 270 |
+
@misc{s2vc,
|
| 271 |
+
title={S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations},
|
| 272 |
+
author={Jheng-hao Lin and Yist Y. Lin and Chung-Ming Chien and Hung-yi Lee},
|
| 273 |
+
year={2021},
|
| 274 |
+
eprint={2104.02901},
|
| 275 |
+
archivePrefix={arXiv},
|
| 276 |
+
primaryClass={eess.AS}
|
| 277 |
+
}
|
| 278 |
+
```
|
| 279 |
+
|
| 280 |
+
### Benchmark and Evaluation
|
| 281 |
+
|
| 282 |
+
+ [SUPERB: Speech processing Universal PERformance Benchmark (Yang et al., 2021)](https://arxiv.org/abs/2105.01051)
|
| 283 |
+
```
|
| 284 |
+
@misc{superb,
|
| 285 |
+
title={SUPERB: Speech processing Universal PERformance Benchmark},
|
| 286 |
+
author={Shu-wen Yang and Po-Han Chi and Yung-Sung Chuang and Cheng-I Jeff Lai and Kushal Lakhotia and Yist Y. Lin and Andy T. Liu and Jiatong Shi and Xuankai Chang and Guan-Ting Lin and Tzu-Hsien Huang and Wei-Cheng Tseng and Ko-tik Lee and Da-Rong Liu and Zili Huang and Shuyan Dong and Shang-Wen Li and Shinji Watanabe and Abdelrahman Mohamed and Hung-yi Lee},
|
| 287 |
+
year={2021},
|
| 288 |
+
eprint={2105.01051},
|
| 289 |
+
archivePrefix={arXiv},
|
| 290 |
+
primaryClass={cs.CL}
|
| 291 |
+
}
|
| 292 |
+
```
|
| 293 |
+
|
| 294 |
+
+ [Utilizing Self-supervised Representations for MOS Prediction (Tseng et al., 2021)](https://arxiv.org/abs/2104.03017)
|
| 295 |
+
```
|
| 296 |
+
@misc{ssr_mos,
|
| 297 |
+
title={Utilizing Self-supervised Representations for MOS Prediction},
|
| 298 |
+
author={Wei-Cheng Tseng and Chien-yu Huang and Wei-Tsung Kao and Yist Y. Lin and Hung-yi Lee},
|
| 299 |
+
year={2021},
|
| 300 |
+
eprint={2104.03017},
|
| 301 |
+
archivePrefix={arXiv},
|
| 302 |
+
primaryClass={eess.AS}
|
| 303 |
+
}
|
| 304 |
+
```
|
| 305 |
+
}
|
| 306 |
+
|
| 307 |
+
</p></details>
|
| 308 |
+
|
| 309 |
+
## Citation
|
| 310 |
+
|
| 311 |
+
If you find this toolkit useful, please consider citing following papers.
|
| 312 |
+
|
| 313 |
+
- If you use our pre-training scripts, or the downstream tasks considered in *TERA* and *Mockingjay*, please consider citing the following:
|
| 314 |
+
```
|
| 315 |
+
@misc{tera,
|
| 316 |
+
title={TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech},
|
| 317 |
+
author={Andy T. Liu and Shang-Wen Li and Hung-yi Lee},
|
| 318 |
+
year={2020},
|
| 319 |
+
eprint={2007.06028},
|
| 320 |
+
archivePrefix={arXiv},
|
| 321 |
+
primaryClass={eess.AS}
|
| 322 |
+
}
|
| 323 |
+
```
|
| 324 |
+
```
|
| 325 |
+
@article{mockingjay,
|
| 326 |
+
title={Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders},
|
| 327 |
+
ISBN={9781509066315},
|
| 328 |
+
url={http://dx.doi.org/10.1109/ICASSP40776.2020.9054458},
|
| 329 |
+
DOI={10.1109/icassp40776.2020.9054458},
|
| 330 |
+
journal={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 331 |
+
publisher={IEEE},
|
| 332 |
+
author={Liu, Andy T. and Yang, Shu-wen and Chi, Po-Han and Hsu, Po-chun and Lee, Hung-yi},
|
| 333 |
+
year={2020},
|
| 334 |
+
month={May}
|
| 335 |
+
}
|
| 336 |
+
```
|
| 337 |
+
|
| 338 |
+
- If you use our organized upstream interface and features, or the *SUPERB* downstream benchmark, please consider citing the following:
|
| 339 |
+
```
|
| 340 |
+
@article{yang2024large,
|
| 341 |
+
title={A Large-Scale Evaluation of Speech Foundation Models},
|
| 342 |
+
author={Yang, Shu-wen and Chang, Heng-Jui and Huang, Zili and Liu, Andy T and Lai, Cheng-I and Wu, Haibin and Shi, Jiatong and Chang, Xuankai and Tsai, Hsiang-Sheng and Huang, Wen-Chin and others},
|
| 343 |
+
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
|
| 344 |
+
year={2024},
|
| 345 |
+
publisher={IEEE}
|
| 346 |
+
}
|
| 347 |
+
```
|
| 348 |
+
```
|
| 349 |
+
@inproceedings{yang21c_interspeech,
|
| 350 |
+
author={Shu-wen Yang and Po-Han Chi and Yung-Sung Chuang and Cheng-I Jeff Lai and Kushal Lakhotia and Yist Y. Lin and Andy T. Liu and Jiatong Shi and Xuankai Chang and Guan-Ting Lin and Tzu-Hsien Huang and Wei-Cheng Tseng and Ko-tik Lee and Da-Rong Liu and Zili Huang and Shuyan Dong and Shang-Wen Li and Shinji Watanabe and Abdelrahman Mohamed and Hung-yi Lee},
|
| 351 |
+
title={{SUPERB: Speech Processing Universal PERformance Benchmark}},
|
| 352 |
+
year=2021,
|
| 353 |
+
booktitle={Proc. Interspeech 2021},
|
| 354 |
+
pages={1194--1198},
|
| 355 |
+
doi={10.21437/Interspeech.2021-1775}
|
| 356 |
+
}
|
| 357 |
+
```
|
s3prl_s3prl_main/__pycache__/hubconf.cpython-310.pyc
ADDED
|
Binary file (248 Bytes). View file
|
|
|
s3prl_s3prl_main/__pycache__/hubconf.cpython-39.pyc
ADDED
|
Binary file (244 Bytes). View file
|
|
|
s3prl_s3prl_main/ci/format.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
|
| 3 |
+
import argparse
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from subprocess import CalledProcessError, check_output
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def load_valid_paths():
|
| 9 |
+
with open("./valid_paths.txt", "r") as fp:
|
| 10 |
+
paths = [line.strip() for line in fp if line.strip() != ""]
|
| 11 |
+
return paths
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_third_party():
|
| 15 |
+
txt_files = list(Path("./requirements").rglob("*.txt"))
|
| 16 |
+
package_list = []
|
| 17 |
+
for file in txt_files:
|
| 18 |
+
with open(file, "r") as fp:
|
| 19 |
+
for line in fp:
|
| 20 |
+
line = line.strip()
|
| 21 |
+
if line == "":
|
| 22 |
+
continue
|
| 23 |
+
package_list.append(line.split(" ")[0])
|
| 24 |
+
return package_list
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def run_command(command: str):
|
| 28 |
+
try:
|
| 29 |
+
check_output(command.split(" "))
|
| 30 |
+
except CalledProcessError as e:
|
| 31 |
+
print(e.output.decode("utf-8"))
|
| 32 |
+
raise
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def main():
|
| 36 |
+
parser = argparse.ArgumentParser()
|
| 37 |
+
parser.add_argument(
|
| 38 |
+
"files",
|
| 39 |
+
type=str,
|
| 40 |
+
nargs="*",
|
| 41 |
+
default=[],
|
| 42 |
+
help="If no file is given, use the files under ./valid_paths.txt",
|
| 43 |
+
)
|
| 44 |
+
parser.add_argument("--check", action="store_true", help="Only checks the files")
|
| 45 |
+
args = parser.parse_args()
|
| 46 |
+
|
| 47 |
+
if len(args.files) == 0:
|
| 48 |
+
args.files = load_valid_paths()
|
| 49 |
+
|
| 50 |
+
print(f"Formatting files: {args.files}")
|
| 51 |
+
args.files = " ".join(args.files)
|
| 52 |
+
|
| 53 |
+
print("Run flake8")
|
| 54 |
+
# stop the build if there are Python syntax errors or undefined names
|
| 55 |
+
run_command(
|
| 56 |
+
f"flake8 {args.files} --count --select=E9,F63,F7,F82 --show-source --statistics"
|
| 57 |
+
)
|
| 58 |
+
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
|
| 59 |
+
run_command(
|
| 60 |
+
f"flake8 {args.files} --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics"
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
print("Run black")
|
| 64 |
+
if args.check:
|
| 65 |
+
run_command(f"black --check {args.files}")
|
| 66 |
+
else:
|
| 67 |
+
run_command(f"black {args.files}")
|
| 68 |
+
|
| 69 |
+
print("Run isort")
|
| 70 |
+
third_party = get_third_party()
|
| 71 |
+
third_party = ",".join(third_party)
|
| 72 |
+
if args.check:
|
| 73 |
+
run_command(
|
| 74 |
+
f"isort --profile black --thirdparty {third_party} --check {args.files}"
|
| 75 |
+
)
|
| 76 |
+
else:
|
| 77 |
+
run_command(f"isort --profile black --thirdparty {third_party} {args.files}")
|
| 78 |
+
|
| 79 |
+
if args.check:
|
| 80 |
+
print("Successfully passed the format check!")
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
if __name__ == "__main__":
|
| 84 |
+
main()
|
s3prl_s3prl_main/docs/Makefile
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line, and also
|
| 5 |
+
# from the environment for the first two.
|
| 6 |
+
SPHINXOPTS ?=
|
| 7 |
+
SPHINXBUILD ?= sphinx-build
|
| 8 |
+
SOURCEDIR = source
|
| 9 |
+
BUILDDIR = build
|
| 10 |
+
|
| 11 |
+
# Put it first so that "make" without argument is like "make help".
|
| 12 |
+
help:
|
| 13 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 14 |
+
|
| 15 |
+
.PHONY: help Makefile
|
| 16 |
+
|
| 17 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 18 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 19 |
+
%: Makefile
|
| 20 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
s3prl_s3prl_main/docs/README.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Documentation
|
| 2 |
+
|
| 3 |
+
To auto-generate documents for S3PRL, please follow the following steps:
|
| 4 |
+
|
| 5 |
+
1. Activate an python env for the doc-generating tool to import all the modules to realize auto-documentation. There are various ways to achieve this. You can also follow:
|
| 6 |
+
|
| 7 |
+
```sh
|
| 8 |
+
conda create -y -n doc python=3.8
|
| 9 |
+
conda activate doc
|
| 10 |
+
|
| 11 |
+
cd $S3PRL_ROOT
|
| 12 |
+
pip install ".[dev]"
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
2. Auto-generate HTML files for all the packages, modules and their submodules listed in `$S3PRL_ROOT/valid_paths.txt`. The HTML files will appear in `$S3PRL_ROOT/docs/build/html`
|
| 16 |
+
|
| 17 |
+
```sh
|
| 18 |
+
cd $S3PRL_ROOT/docs_src
|
| 19 |
+
./rebuild_docs.sh
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
3. Launch the simple webserver to see the documentation.
|
| 23 |
+
|
| 24 |
+
```sh
|
| 25 |
+
cd $S3PRL_ROOT/docs/build/html
|
| 26 |
+
python3 -m http.server
|
| 27 |
+
```
|
s3prl_s3prl_main/docs/from_scratch_tutorial.md
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# REDAME
|
| 2 |
+
## install sphinx
|
| 3 |
+
```shell
|
| 4 |
+
$ pip install -U sphinx
|
| 5 |
+
```
|
| 6 |
+
|
| 7 |
+
## set up
|
| 8 |
+
at s3prl root directory (s3prl-private/)
|
| 9 |
+
```shell
|
| 10 |
+
$ mkdir docs
|
| 11 |
+
$ cd docs
|
| 12 |
+
$ sphinx-quickstart
|
| 13 |
+
$ cd ..
|
| 14 |
+
$ sphinx-apidoc -d 3 --separate --implicit-namespace -o docs ./s3prl s3prl/downstream s3prl/interface s3prl/preprocess s3prl/pretrain s3prl/problem s3prl/sampler s3prl/submit s3prl/superb s3prl/upstream s3prl/utility s3prl/wrapper s3prl/__init__.py s3prl/hub.py s3prl/optimizers.py s3prl/run_downstream.py s3prl/run_pretrain.py s3prl/run_while.sh s3prl/schedulers.py
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
## install dependencies
|
| 18 |
+
```shell
|
| 19 |
+
$ cd s3prl-private/docs
|
| 20 |
+
$ echo "furo
|
| 21 |
+
torch
|
| 22 |
+
numpy
|
| 23 |
+
pandas
|
| 24 |
+
tqdm
|
| 25 |
+
pytorch_lightning
|
| 26 |
+
matplotlib
|
| 27 |
+
ipdb>=0.13.9
|
| 28 |
+
PyYAML
|
| 29 |
+
transformers
|
| 30 |
+
torchaudio
|
| 31 |
+
gdown
|
| 32 |
+
sklearn
|
| 33 |
+
joblib
|
| 34 |
+
tensorboardX
|
| 35 |
+
librosa
|
| 36 |
+
scipy
|
| 37 |
+
lxml
|
| 38 |
+
h5py
|
| 39 |
+
dtw
|
| 40 |
+
catalyst
|
| 41 |
+
sox
|
| 42 |
+
six
|
| 43 |
+
easydict
|
| 44 |
+
Resemblyzer
|
| 45 |
+
sentencepiece
|
| 46 |
+
pysoundfile
|
| 47 |
+
asteroid
|
| 48 |
+
sacrebleu
|
| 49 |
+
speechbrain
|
| 50 |
+
omegaconf
|
| 51 |
+
editdistance" > requirement.txt
|
| 52 |
+
$ pip install -r requirement.txt
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
add custom.js at s3prl-private/docs/_static/js/
|
| 56 |
+
(just paste the following lines)
|
| 57 |
+
```javascript=
|
| 58 |
+
/*
|
| 59 |
+
change the default sphinx.ext.linkcode's [source] to [Github]
|
| 60 |
+
*/
|
| 61 |
+
document.querySelectorAll(".reference.external .viewcode-link .pre").forEach(item => {
|
| 62 |
+
item.innerHTML = "[Github]"
|
| 63 |
+
item.style.marginRight = "3px"
|
| 64 |
+
})
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
modify s3prl-private/docs/index.rst
|
| 69 |
+
```diff
|
| 70 |
+
# remove these lines
|
| 71 |
+
- .. toctree::
|
| 72 |
+
- :maxdepth: 2
|
| 73 |
+
- :caption: Contents:
|
| 74 |
+
|
| 75 |
+
# replaced with this line
|
| 76 |
+
+ .. include:: s3prl.rst
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
modify s3prl-private/docs/conf.py
|
| 80 |
+
```python
|
| 81 |
+
# add these lines at top
|
| 82 |
+
import inspect
|
| 83 |
+
import os
|
| 84 |
+
import sys
|
| 85 |
+
for x in os.walk('..'):
|
| 86 |
+
sys.path.insert(0, x[0])
|
| 87 |
+
|
| 88 |
+
# add extensions
|
| 89 |
+
extensions = [
|
| 90 |
+
'sphinx.ext.autodoc',
|
| 91 |
+
'sphinx.ext.napoleon',
|
| 92 |
+
'sphinx.ext.viewcode',
|
| 93 |
+
'sphinx.ext.linkcode'
|
| 94 |
+
]
|
| 95 |
+
|
| 96 |
+
html_js_files = [
|
| 97 |
+
'js/custom.js',
|
| 98 |
+
]
|
| 99 |
+
|
| 100 |
+
def linkcode_resolve(domain, info):
|
| 101 |
+
def find_source():
|
| 102 |
+
obj = sys.modules[info['module']]
|
| 103 |
+
if info['fullname'] == 'InitConfig.args': return None
|
| 104 |
+
if info['fullname'] == 'InitConfig.kwargs': return None
|
| 105 |
+
for part in info['fullname'].split('.'):
|
| 106 |
+
obj = getattr(obj, part)
|
| 107 |
+
|
| 108 |
+
if isinstance(obj, property): return None
|
| 109 |
+
|
| 110 |
+
fn = inspect.getsourcefile(obj)
|
| 111 |
+
fn = os.path.relpath(fn, start=os.path.dirname(os.path.abspath(__file__))[:-4])
|
| 112 |
+
|
| 113 |
+
source, lineno = inspect.getsourcelines(obj)
|
| 114 |
+
return fn, lineno, lineno + len(source) - 1
|
| 115 |
+
|
| 116 |
+
if domain != 'py' or not info['module']: return None
|
| 117 |
+
|
| 118 |
+
tag = 'master' if 'dev' in release else ('v' + release) # s3prl github version
|
| 119 |
+
|
| 120 |
+
try:
|
| 121 |
+
filename = '%s#L%d-L%d' % find_source() # specify file page with line number
|
| 122 |
+
except Exception:
|
| 123 |
+
filename = info['module'].replace('.', '/') + '.py' # cannot find corresponding codeblock, use the file page instead
|
| 124 |
+
|
| 125 |
+
return "https://github.com/s3prl/s3prl-private/blob/%s/%s" % (tag, filename)
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
to use the furo theme, add this line in s3prl-private/docs/conf.py (replace the original alabaster theme)
|
| 129 |
+
```python
|
| 130 |
+
html_theme = "furo"
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
## generate html files
|
| 134 |
+
at s3prl-private/docs/
|
| 135 |
+
```shell
|
| 136 |
+
$ make html
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
the html files will be generated at **s3prl-private/docs/_build/html/**
|
| 140 |
+
click on **index.html** to view the doc page on your browser
|
| 141 |
+
|
| 142 |
+
if you want to see how your modified codes looks like, simply do
|
| 143 |
+
```shell
|
| 144 |
+
$ make clean html # this remove the old html files
|
| 145 |
+
$ make html # generate new html files
|
| 146 |
+
```
|
s3prl_s3prl_main/docs/make.bat
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
@ECHO OFF
|
| 2 |
+
|
| 3 |
+
pushd %~dp0
|
| 4 |
+
|
| 5 |
+
REM Command file for Sphinx documentation
|
| 6 |
+
|
| 7 |
+
if "%SPHINXBUILD%" == "" (
|
| 8 |
+
set SPHINXBUILD=sphinx-build
|
| 9 |
+
)
|
| 10 |
+
set SOURCEDIR=source
|
| 11 |
+
set BUILDDIR=build
|
| 12 |
+
|
| 13 |
+
%SPHINXBUILD% >NUL 2>NUL
|
| 14 |
+
if errorlevel 9009 (
|
| 15 |
+
echo.
|
| 16 |
+
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
|
| 17 |
+
echo.installed, then set the SPHINXBUILD environment variable to point
|
| 18 |
+
echo.to the full path of the 'sphinx-build' executable. Alternatively you
|
| 19 |
+
echo.may add the Sphinx directory to PATH.
|
| 20 |
+
echo.
|
| 21 |
+
echo.If you don't have Sphinx installed, grab it from
|
| 22 |
+
echo.https://www.sphinx-doc.org/
|
| 23 |
+
exit /b 1
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
if "%1" == "" goto help
|
| 27 |
+
|
| 28 |
+
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
| 29 |
+
goto end
|
| 30 |
+
|
| 31 |
+
:help
|
| 32 |
+
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
| 33 |
+
|
| 34 |
+
:end
|
| 35 |
+
popd
|
s3prl_s3prl_main/docs/rebuild_docs.sh
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
rm -rf ./source/s3prl.*
|
| 4 |
+
rm -rf ./source/_autosummary
|
| 5 |
+
|
| 6 |
+
make clean html
|
| 7 |
+
|
| 8 |
+
touch build/html/.nojekyll
|
| 9 |
+
|
s3prl_s3prl_main/docs/source/_static/css/custom.css
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.toctree-wrapper.compound .caption-text {
|
| 2 |
+
display: none;
|
| 3 |
+
}
|
s3prl_s3prl_main/docs/source/_static/js/custom.js
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/*
|
| 2 |
+
change the default sphinx.ext.linkcode's [source] to [Github]
|
| 3 |
+
*/
|
| 4 |
+
document.querySelectorAll(".reference.external .viewcode-link .pre").forEach(item => {
|
| 5 |
+
item.innerHTML = "[Github]"
|
| 6 |
+
item.style.marginRight = "3px"
|
| 7 |
+
})
|
s3prl_s3prl_main/docs/source/_templates/custom-module-template.rst
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{{ name | escape | underline}}
|
| 2 |
+
|
| 3 |
+
**({{ fullname }})**
|
| 4 |
+
|
| 5 |
+
.. automodule:: {{ fullname }}
|
| 6 |
+
|
| 7 |
+
{% block modules %}
|
| 8 |
+
{% if modules %}
|
| 9 |
+
|
| 10 |
+
.. autosummary::
|
| 11 |
+
:toctree:
|
| 12 |
+
:template: custom-module-template.rst
|
| 13 |
+
:recursive:
|
| 14 |
+
|
| 15 |
+
{% for item in modules %}
|
| 16 |
+
{{ item }}
|
| 17 |
+
{%- endfor %}
|
| 18 |
+
{% endif %}
|
| 19 |
+
{% endblock %}
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
{% block attributes %}
|
| 23 |
+
{% if attributes %}
|
| 24 |
+
{% for item in attributes %}
|
| 25 |
+
|
| 26 |
+
{{ item }}
|
| 27 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 28 |
+
|
| 29 |
+
.. autoattribute:: {{ item }}
|
| 30 |
+
|
| 31 |
+
{%- endfor %}
|
| 32 |
+
{% endif %}
|
| 33 |
+
{% endblock %}
|
| 34 |
+
|
| 35 |
+
{% block classes %}
|
| 36 |
+
{% if classes %}
|
| 37 |
+
{% for item in classes %}
|
| 38 |
+
|
| 39 |
+
{{ item }}
|
| 40 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 41 |
+
|
| 42 |
+
.. autoclass:: {{ item }}
|
| 43 |
+
:member-order: bysource
|
| 44 |
+
:members:
|
| 45 |
+
:undoc-members:
|
| 46 |
+
:inherited-members: torch.nn.Module,nn.Module,Module
|
| 47 |
+
:show-inheritance:
|
| 48 |
+
|
| 49 |
+
{%- endfor %}
|
| 50 |
+
{% endif %}
|
| 51 |
+
{% endblock %}
|
| 52 |
+
|
| 53 |
+
{% block functions %}
|
| 54 |
+
{% if functions %}
|
| 55 |
+
{% for item in functions %}
|
| 56 |
+
|
| 57 |
+
{{ item }}
|
| 58 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 59 |
+
|
| 60 |
+
.. autofunction:: {{ item }}
|
| 61 |
+
|
| 62 |
+
{%- endfor %}
|
| 63 |
+
{% endif %}
|
| 64 |
+
{% endblock %}
|
| 65 |
+
|
| 66 |
+
{% block exceptions %}
|
| 67 |
+
{% if exceptions %}
|
| 68 |
+
{% for item in exceptions %}
|
| 69 |
+
|
| 70 |
+
{{ item }}
|
| 71 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 72 |
+
|
| 73 |
+
.. autoexception:: {{ item }}
|
| 74 |
+
:members:
|
| 75 |
+
:undoc-members:
|
| 76 |
+
:show-inheritance:
|
| 77 |
+
:member-order: bysource
|
| 78 |
+
|
| 79 |
+
{%- endfor %}
|
| 80 |
+
{% endif %}
|
| 81 |
+
{% endblock %}
|
s3prl_s3prl_main/docs/source/conf.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Configuration file for the Sphinx documentation builder.
|
| 2 |
+
#
|
| 3 |
+
# This file only contains a selection of the most common options. For a full
|
| 4 |
+
# list see the documentation:
|
| 5 |
+
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
| 6 |
+
|
| 7 |
+
# -- Path setup --------------------------------------------------------------
|
| 8 |
+
|
| 9 |
+
# If extensions (or modules to document with autodoc) are in another directory,
|
| 10 |
+
# add these directories to sys.path here. If the directory is relative to the
|
| 11 |
+
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
| 12 |
+
#
|
| 13 |
+
import inspect
|
| 14 |
+
import os
|
| 15 |
+
import sys
|
| 16 |
+
from pathlib import Path
|
| 17 |
+
|
| 18 |
+
# -- Project information -----------------------------------------------------
|
| 19 |
+
|
| 20 |
+
project = "S3PRL"
|
| 21 |
+
copyright = "2022, S3PRL Team"
|
| 22 |
+
author = "S3PRL Team"
|
| 23 |
+
|
| 24 |
+
# The full version, including alpha/beta/rc tags
|
| 25 |
+
with (Path(__file__).parent.parent.parent / "s3prl" / "version.txt").open() as f:
|
| 26 |
+
release = f.read()
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def linkcode_resolve(domain, info):
|
| 30 |
+
def find_source():
|
| 31 |
+
obj = sys.modules[info["module"]]
|
| 32 |
+
for part in info["fullname"].split("."):
|
| 33 |
+
obj = getattr(obj, part)
|
| 34 |
+
|
| 35 |
+
if isinstance(obj, property):
|
| 36 |
+
return None
|
| 37 |
+
|
| 38 |
+
file_parts = Path(inspect.getsourcefile(obj)).parts
|
| 39 |
+
reversed_parts = []
|
| 40 |
+
for part in reversed(file_parts):
|
| 41 |
+
if part == "s3prl":
|
| 42 |
+
reversed_parts.append(part)
|
| 43 |
+
break
|
| 44 |
+
else:
|
| 45 |
+
reversed_parts.append(part)
|
| 46 |
+
fn = "/".join(reversed(reversed_parts))
|
| 47 |
+
|
| 48 |
+
source, lineno = inspect.getsourcelines(obj)
|
| 49 |
+
return fn, lineno, lineno + len(source) - 1
|
| 50 |
+
|
| 51 |
+
if domain != "py" or not info["module"]:
|
| 52 |
+
return None
|
| 53 |
+
|
| 54 |
+
tag = "master" if "dev" in release else ("v" + release) # s3prl github version
|
| 55 |
+
|
| 56 |
+
try:
|
| 57 |
+
filename = "%s#L%d-L%d" % find_source() # specify file page with line number
|
| 58 |
+
except Exception:
|
| 59 |
+
filename = (
|
| 60 |
+
info["module"].replace(".", "/") + ".py"
|
| 61 |
+
) # cannot find corresponding codeblock, use the file page instead
|
| 62 |
+
|
| 63 |
+
return "https://github.com/s3prl/s3prl/blob/%s/%s" % (tag, filename)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
# -- General configuration ---------------------------------------------------
|
| 67 |
+
|
| 68 |
+
# Add any Sphinx extension module names here, as strings. They can be
|
| 69 |
+
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
| 70 |
+
# ones.
|
| 71 |
+
# add extensions
|
| 72 |
+
extensions = [
|
| 73 |
+
"sphinx.ext.autodoc",
|
| 74 |
+
"sphinx.ext.napoleon",
|
| 75 |
+
"sphinx.ext.viewcode",
|
| 76 |
+
"sphinx.ext.linkcode",
|
| 77 |
+
"sphinx.ext.autosummary",
|
| 78 |
+
]
|
| 79 |
+
|
| 80 |
+
autosummary_generate = True
|
| 81 |
+
|
| 82 |
+
html_js_files = [
|
| 83 |
+
"js/custom.js",
|
| 84 |
+
]
|
| 85 |
+
html_css_files = ["css/custom.css"]
|
| 86 |
+
|
| 87 |
+
# Add any paths that contain templates here, relative to this directory.
|
| 88 |
+
templates_path = ["_templates"]
|
| 89 |
+
|
| 90 |
+
# List of patterns, relative to source directory, that match files and
|
| 91 |
+
# directories to ignore when looking for source files.
|
| 92 |
+
# This pattern also affects html_static_path and html_extra_path.
|
| 93 |
+
exclude_patterns = []
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
# -- Options for HTML output -------------------------------------------------
|
| 97 |
+
|
| 98 |
+
# The theme to use for HTML and HTML Help pages. See the documentation for
|
| 99 |
+
# a list of builtin themes.
|
| 100 |
+
#
|
| 101 |
+
html_theme = "furo"
|
| 102 |
+
|
| 103 |
+
# Add any paths that contain custom static files (such as style sheets) here,
|
| 104 |
+
# relative to this directory. They are copied after the builtin static files,
|
| 105 |
+
# so a file named "default.css" will overwrite the builtin "default.css".
|
| 106 |
+
html_static_path = ["_static"]
|
| 107 |
+
|
| 108 |
+
# Uncomment the following if you want to document __call__
|
| 109 |
+
#
|
| 110 |
+
# def skip(app, what, name, obj, would_skip, options):
|
| 111 |
+
# if name == "__call__":
|
| 112 |
+
# return False
|
| 113 |
+
# return would_skip
|
| 114 |
+
#
|
| 115 |
+
# def setup(app):
|
| 116 |
+
# app.connect("autodoc-skip-member", skip)
|
| 117 |
+
|
| 118 |
+
autosummary_imported_members = True
|
| 119 |
+
autosummary_ignore_module_all = False
|
| 120 |
+
autodoc_member_order = "bysource"
|
s3prl_s3prl_main/docs/source/contribute/general.rst
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. _general-contribution-guideline:
|
| 2 |
+
|
| 3 |
+
General Guideline
|
| 4 |
+
==================
|
| 5 |
+
|
| 6 |
+
Thank you for considering contributing to S3PRL, we really appreciate it.
|
| 7 |
+
|
| 8 |
+
However, due to the increasing difficulty of maintenance, please understand that **we might not accept the new feature**.
|
| 9 |
+
|
| 10 |
+
Hence, **before submitting the implemented pull request**,
|
| 11 |
+
please **submit your feature request** to the Github issue page so we can discuss about whether we want it and how to achieve it.
|
| 12 |
+
|
| 13 |
+
.. warning::
|
| 14 |
+
|
| 15 |
+
If we did not go through this discussion, the pull request will not be dealt with and will be directly closed.
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
Discuss
|
| 19 |
+
-----------
|
| 20 |
+
|
| 21 |
+
`Submit your feature request <https://github.com/s3prl/s3prl/issues/new?assignees=&labels=&template=feature_request.md&title=>`_
|
| 22 |
+
on our Github Issue page to propose features and changes.
|
| 23 |
+
|
| 24 |
+
Please wait for our response and do not move on to the following steps before we have a consensus on what is going to be changed.
|
| 25 |
+
|
| 26 |
+
Setup
|
| 27 |
+
-----------
|
| 28 |
+
|
| 29 |
+
Clone the repository to **S3PRL_ROOT** and install the package
|
| 30 |
+
|
| 31 |
+
.. code-block:: bash
|
| 32 |
+
|
| 33 |
+
S3PRL_ROOT="/home/leo/d/s3prl"
|
| 34 |
+
git clone https://github.com/s3prl/s3prl.git ${S3PRL_ROOT}
|
| 35 |
+
cd ${S3PRL_ROOT}
|
| 36 |
+
|
| 37 |
+
pip install -e ".[dev]"
|
| 38 |
+
# This installs the dependencies for the full functionality of S3PRL in the editable mode,
|
| 39 |
+
# including the dependencies for development like testing and building doc
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
Tests
|
| 43 |
+
----------
|
| 44 |
+
|
| 45 |
+
Add unit tests to **${S3PRL_ROOT}/test/** to test your own new modules
|
| 46 |
+
|
| 47 |
+
Verify you pass all the tests
|
| 48 |
+
|
| 49 |
+
.. code-block:: bash
|
| 50 |
+
|
| 51 |
+
cd ${S3PRL_ROOT}
|
| 52 |
+
pytest
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
Documentation
|
| 56 |
+
-------------
|
| 57 |
+
|
| 58 |
+
Make sure you write the documentation on the modules' docstring
|
| 59 |
+
|
| 60 |
+
Build the documentation and make sure it looks correct
|
| 61 |
+
|
| 62 |
+
.. code-block:: bash
|
| 63 |
+
|
| 64 |
+
cd ${S3PRL_ROOT}/docs
|
| 65 |
+
|
| 66 |
+
# build
|
| 67 |
+
./rebuild_docs.sh
|
| 68 |
+
|
| 69 |
+
# launch http server
|
| 70 |
+
python3 -m http.server -d build/html/
|
| 71 |
+
|
| 72 |
+
# You can then use a browser to access the doc webpage on: YOUR_IP_OR_LOCALHOST:8000
|
| 73 |
+
|
| 74 |
+
Coding-style check
|
| 75 |
+
------------------
|
| 76 |
+
|
| 77 |
+
Stage your changes
|
| 78 |
+
|
| 79 |
+
.. code-block:: bash
|
| 80 |
+
|
| 81 |
+
git add "YOUR_CHANGED_OR_ADDED_FILES_ONLY"
|
| 82 |
+
|
| 83 |
+
.. warning::
|
| 84 |
+
|
| 85 |
+
Please do not use **git add .** to add all the files under your repository.
|
| 86 |
+
If there are files not ignored by git (specified in **.gitignore**), like
|
| 87 |
+
temporary experiment result files, they will all be added into git version
|
| 88 |
+
control, which will mess out our repository.
|
| 89 |
+
|
| 90 |
+
.. note::
|
| 91 |
+
|
| 92 |
+
In our **.gitignore**, there are lots of ignored files especially for *.yaml*
|
| 93 |
+
and *.sh* files. If the config files or the shell scripts are important, please
|
| 94 |
+
remember to add them forcely, for example :code::`git add -f asr.yaml`
|
| 95 |
+
|
| 96 |
+
Run **pre-commit** to apply the standardized coding-style on **YOUR_CHANGED_OR_ADDED_FILES_ONLY**
|
| 97 |
+
|
| 98 |
+
.. code-block:: bash
|
| 99 |
+
|
| 100 |
+
pre-commit run
|
| 101 |
+
|
| 102 |
+
If the results show there are files modified by **pre-commit**, you need to re-stage
|
| 103 |
+
these files following the previous step.
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
Commit / Push
|
| 107 |
+
-------------
|
| 108 |
+
|
| 109 |
+
Commit and push the changes
|
| 110 |
+
|
| 111 |
+
.. code-block:: bash
|
| 112 |
+
|
| 113 |
+
git commit -m "YOUR_COMMIT_MESSAGE"
|
| 114 |
+
git push origin "YOUR_BRANCH"
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
(Optional) Test against multiple environments
|
| 118 |
+
---------------------------------------------
|
| 119 |
+
|
| 120 |
+
We leverage **tox** to simulate multiple envs, see the `tox configuration <https://github.com/s3prl/s3prl/blob/main/tox.ini>`_ for more information.
|
| 121 |
+
Tox helps automate the pipeline of creating different virtual envs, installing differnet dependencies of S3PRL, running different testing commands.
|
| 122 |
+
Our Github Action CI also relies on tox, hence you can debug the CI error locally with tox.
|
| 123 |
+
|
| 124 |
+
Before using tox, make sure your cli can launch the following python versions. Usually, this can be achieved via `pyenv <https://github.com/pyenv/pyenv>`_
|
| 125 |
+
|
| 126 |
+
- python3.7
|
| 127 |
+
- python3.8
|
| 128 |
+
- python3.9
|
| 129 |
+
- python3.10
|
| 130 |
+
|
| 131 |
+
List all the available environments. An environment means a pre-defined routine of packaging S3PRL, installing S3PRL, installing specific dependencies,
|
| 132 |
+
test specific commands. See `tox configuration <https://github.com/s3prl/s3prl/blob/main/tox.ini>`_ for more information.
|
| 133 |
+
|
| 134 |
+
.. code-block:: bash
|
| 135 |
+
|
| 136 |
+
tox -l
|
| 137 |
+
|
| 138 |
+
Suppose there is an environment named :code:`all_upstream-py38-audio0.12.1`, you can also test against this specific env:
|
| 139 |
+
|
| 140 |
+
.. code-block:: bash
|
| 141 |
+
|
| 142 |
+
tox -e all_upstream-py38-audio0.12.1
|
| 143 |
+
|
| 144 |
+
Test all environments. This simulate the environments you will meet on the Github Action CI
|
| 145 |
+
|
| 146 |
+
.. code-block:: bash
|
| 147 |
+
|
| 148 |
+
tox
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
Send a pull request
|
| 152 |
+
-------------------
|
| 153 |
+
|
| 154 |
+
Verify your codes are in the proper format
|
| 155 |
+
|
| 156 |
+
.. code-block:: bash
|
| 157 |
+
|
| 158 |
+
./ci/format.sh --check
|
| 159 |
+
# If this fails, simply remove --check to do the actual formatting
|
| 160 |
+
|
| 161 |
+
Make sure you add test cases and your change pass the tests
|
| 162 |
+
|
| 163 |
+
.. code-block:: bash
|
| 164 |
+
|
| 165 |
+
pytest
|
| 166 |
+
|
| 167 |
+
Send a pull request on GitHub
|
s3prl_s3prl_main/docs/source/contribute/private.rst
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Internal S3PRL Development
|
| 2 |
+
==========================
|
| 3 |
+
|
| 4 |
+
Write code
|
| 5 |
+
----------
|
| 6 |
+
|
| 7 |
+
1. Make sure you have access to `s3prl/s3prl-private <https://github.com/s3prl/s3prl-private/>`_
|
| 8 |
+
|
| 9 |
+
2. Clone the repository to **S3PRL_ROOT** and install the package
|
| 10 |
+
|
| 11 |
+
.. code-block:: bash
|
| 12 |
+
|
| 13 |
+
git clone s3prl/s3prl-private "S3PRL_ROOT"
|
| 14 |
+
cd "S3PRL_ROOT"
|
| 15 |
+
pip install -e ".[dev]" # This installs the dependencies for the full functionality of S3PRL
|
| 16 |
+
|
| 17 |
+
3. Write code into the packages listed in **S3PRL_ROOT/valid_paths.txt**
|
| 18 |
+
|
| 19 |
+
Unit tests
|
| 20 |
+
----------
|
| 21 |
+
|
| 22 |
+
4. Add unit tests to **S3PRL_ROOT/test/** to test your own new modules
|
| 23 |
+
|
| 24 |
+
5. Verify you pass all the tests
|
| 25 |
+
|
| 26 |
+
.. code-block:: bash
|
| 27 |
+
|
| 28 |
+
cd "S3PRL_ROOT"
|
| 29 |
+
pytest
|
| 30 |
+
|
| 31 |
+
Documentation
|
| 32 |
+
-------------
|
| 33 |
+
|
| 34 |
+
6. Make sure you write the documentation on the modules' docstring
|
| 35 |
+
|
| 36 |
+
7. Build the documentation and make sure it looks correct
|
| 37 |
+
|
| 38 |
+
.. code-block:: bash
|
| 39 |
+
|
| 40 |
+
cd "S3PRL_ROOT"/docs
|
| 41 |
+
|
| 42 |
+
# build
|
| 43 |
+
./rebuild_docs.sh
|
| 44 |
+
|
| 45 |
+
# launch http server
|
| 46 |
+
python3 -m http.server -d build/html/
|
| 47 |
+
|
| 48 |
+
# You can then use a browser to access the doc webpage on: YOUR_IP_OR_LOCALHOST:8000
|
| 49 |
+
|
| 50 |
+
8. OK now your new changes are ready to be commit
|
| 51 |
+
|
| 52 |
+
Coding-style check
|
| 53 |
+
------------------
|
| 54 |
+
|
| 55 |
+
9. Stage your changes
|
| 56 |
+
|
| 57 |
+
.. code-block:: bash
|
| 58 |
+
|
| 59 |
+
git add "YOUR_CHANGED_OR_ADDED_FILES_ONLY"
|
| 60 |
+
|
| 61 |
+
.. warning::
|
| 62 |
+
|
| 63 |
+
Please do not use **git add .** to add all the files under your repository.
|
| 64 |
+
If there are files not ignored by git (specified in **.gitignore**), like
|
| 65 |
+
temporary experiment result files, they will all be added into git version
|
| 66 |
+
control, which will mess out our repository.
|
| 67 |
+
|
| 68 |
+
10. Run **pre-commit** to apply the standardized coding-style on **YOUR_CHANGED_OR_ADDED_FILES_ONLY**
|
| 69 |
+
|
| 70 |
+
.. code-block:: bash
|
| 71 |
+
|
| 72 |
+
pre-commit run
|
| 73 |
+
|
| 74 |
+
If the results show there are files modified by **pre-commit**, you need to re-stage
|
| 75 |
+
these files following step 9.
|
| 76 |
+
|
| 77 |
+
Commit / Push
|
| 78 |
+
-------------
|
| 79 |
+
|
| 80 |
+
12. Commit and push the changes
|
| 81 |
+
|
| 82 |
+
.. code-block:: bash
|
| 83 |
+
|
| 84 |
+
git commit -m "YOUR_COMMIT_MESSAGE"
|
| 85 |
+
git push origin "YOUR_BRANCH"
|
| 86 |
+
|
| 87 |
+
Send a pull request
|
| 88 |
+
-------------------
|
| 89 |
+
|
| 90 |
+
Only do this when you are ready to merge your branch. Since once you send a pull request,
|
| 91 |
+
every newly pushed commit will cause GitHub to run CI, but we have a limited number of
|
| 92 |
+
runnable CI per month, regularized by GitHub. Hence, you should do this only after the
|
| 93 |
+
branch is ready.
|
| 94 |
+
|
| 95 |
+
13. Verify you can pass the CI locally
|
| 96 |
+
|
| 97 |
+
.. code-block:: bash
|
| 98 |
+
|
| 99 |
+
./ci/format.sh --check
|
| 100 |
+
# If this fails, simply remove --check to do the actual formatting
|
| 101 |
+
|
| 102 |
+
pytest
|
| 103 |
+
|
| 104 |
+
14. Send a pull request on GitHub
|
s3prl_s3prl_main/docs/source/contribute/public.rst
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Contribute to S3PRL
|
| 2 |
+
===================
|
| 3 |
+
|
| 4 |
+
Thank you for considering contributing to S3PRL! We really appreciate it!
|
| 5 |
+
|
| 6 |
+
**Please discuss with us on the Github issue page about your "feature request"** before submitting
|
| 7 |
+
the implemented pull request, and we will discuss about the following things:
|
| 8 |
+
|
| 9 |
+
1. Whether we want to add it in S3PRL
|
| 10 |
+
2. If yes, how should we achieve this feature
|
| 11 |
+
3. How can we collaborate on the implementation
|
| 12 |
+
4. Proceed with the actual implementation and the pull request
|
| 13 |
+
|
| 14 |
+
.. warning::
|
| 15 |
+
|
| 16 |
+
If we did not go through this discussion, the pull request will not be dealt with and will be directly closed.
|
| 17 |
+
|
| 18 |
+
.. note::
|
| 19 |
+
|
| 20 |
+
S3PRL has grown too large and become too hard to maintain.
|
| 21 |
+
In principle, we plan to keep only a few essential functionality which is guaranteed to work,
|
| 22 |
+
instead of continually adding lots of tasks, which can be easily added but hard to keep people
|
| 23 |
+
always there to maintain all the functions in the long term.
|
| 24 |
+
Hence, *we welcome all the bug fixes or slight improvement on existing functions,
|
| 25 |
+
while by default we do not accept pull requests containing lots of changes or an entirely new task*,
|
| 26 |
+
unless our core maintainers feel it is maintainable from our side.
|
| 27 |
+
That is, we do not expect outside collaborators to maintain their contribution for a long time,
|
| 28 |
+
which is the usual case in our experience. We wish to keep all the functionality of S3PRL work in the long term,
|
| 29 |
+
and thanks for your kind support and understanding.
|
s3prl_s3prl_main/docs/source/contribute/upstream.rst
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Adding New Upstream
|
| 2 |
+
====================
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
Discuss
|
| 6 |
+
---------
|
| 7 |
+
|
| 8 |
+
Please make sure that you already go through :doc:`./general`.
|
| 9 |
+
Again, please make sure we have consensus on the new feature request.
|
| 10 |
+
The best and the most transparent way is to
|
| 11 |
+
`submit your feature request <https://github.com/s3prl/s3prl/issues/new?assignees=&labels=&template=feature_request.md&title=>`_.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
Copy from the template
|
| 15 |
+
-----------------------
|
| 16 |
+
|
| 17 |
+
To add new upstream, you can start with an `example <https://github.com/s3prl/s3prl/tree/main/s3prl/upstream/example>`_
|
| 18 |
+
Suppose your new upstream called :code:`my_awesome_upstream`, the simplest way to start will be the following:
|
| 19 |
+
|
| 20 |
+
1.
|
| 21 |
+
|
| 22 |
+
.. code-block:: bash
|
| 23 |
+
|
| 24 |
+
cd ${S3PRL_ROOT}
|
| 25 |
+
cp -r s3prl/upstream/example/ s3prl/upstream/my_awesome_upstream
|
| 26 |
+
|
| 27 |
+
2. In :code:`s3prl/upstream/my_awesome_upstream/hubconf.py`, change :code:`customized_upstream` to :code:`my_entry_1`
|
| 28 |
+
3. In :code:`s3prl/hub.py`, add :code:`from s3prl.upstream.my_awesome_upstream.hubconf import *`
|
| 29 |
+
|
| 30 |
+
4.
|
| 31 |
+
|
| 32 |
+
.. code-block:: bash
|
| 33 |
+
|
| 34 |
+
python3 utility/extract_feat.py my_entry_1 sample_hidden_states
|
| 35 |
+
# this script extract hidden states from an upstream entry to the "sample_hidden_states" folder
|
| 36 |
+
|
| 37 |
+
This will extract the hidden states from this :code:`my_entry_1` entry.
|
| 38 |
+
The default content in :code:`s3prl/upstream/example/` always works, so you can simply edit the files
|
| 39 |
+
inside the new :code:`s3prl/upstream/my_awesome_upstream` folder to enable your new upstream.
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
Implement
|
| 43 |
+
----------
|
| 44 |
+
|
| 45 |
+
The folder is in the following structure:
|
| 46 |
+
|
| 47 |
+
.. code-block:: bash
|
| 48 |
+
|
| 49 |
+
my_awesome_upstream
|
| 50 |
+
|
|
| 51 |
+
---- expert.py
|
| 52 |
+
|
|
| 53 |
+
---- hubconf.py
|
| 54 |
+
|
| 55 |
+
In principle, :code:`hubconf.py` serves as the URL registry, where each callable function is an entry specifying
|
| 56 |
+
the source of the checkpoint, while the :code:`expert.py` serves as the wrapper of your model definition to fit
|
| 57 |
+
with our upstream API.
|
| 58 |
+
|
| 59 |
+
During your implementation, please try to remove as many package dependencies as possible, since the upstream
|
| 60 |
+
functionality is our core feature, and should have minimal dependencies to be maintainable.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
Tests
|
| 64 |
+
-------
|
| 65 |
+
|
| 66 |
+
After you implementation, please make sure all your entries can pass `the tests <https://github.com/s3prl/s3prl/blob/8eac602117003e2bb5cdb7a4d0e94cc9975fd4f2/test/test_upstream.py#L194-L250>`_
|
| 67 |
+
The :code:`test_upstream_with_extracted` test case requires you to pre-extract the expected hidden states via:
|
| 68 |
+
|
| 69 |
+
.. code-block:: bash
|
| 70 |
+
|
| 71 |
+
python3 utility/extract_feat.py my_awesome_upstream ./sample_hidden_states
|
| 72 |
+
|
| 73 |
+
That is, the test case expects there will be a :code:`my_awesome_upstream.pt` in the :code:`sample_hidden_states` folder.
|
| 74 |
+
|
| 75 |
+
All the existing sampled hidden states are hosted at a `Huggingface Dataset Repo <https://huggingface.co/datasets/s3prl/sample_hidden_states/tree/main>`_,
|
| 76 |
+
and we expect you to clone (by :code:`git lfs`) this :code:`sample_hidden_states` repo and add the sampled hidden states for your new entries.
|
| 77 |
+
|
| 78 |
+
To make changes to this hidden states repo, please follow the steps `here <https://huggingface.co/datasets/s3prl/sample_hidden_states/discussions>`_
|
| 79 |
+
to create a pull request, so that our core maintainer can sync the hidden states extracted by you.
|
| 80 |
+
|
| 81 |
+
In conclusion, to add new upstream one needs to make two pull requests:
|
| 82 |
+
|
| 83 |
+
- To https://github.com/s3prl/s3prl/pulls
|
| 84 |
+
- To https://huggingface.co/datasets/s3prl/sample_hidden_states/tree/main
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
.. note::
|
| 88 |
+
|
| 89 |
+
In fact, due to the huge time cost, most of the upstreams in S3PRL will not be tested in Github Action CI (or else it will take several hours
|
| 90 |
+
to download all the checkpoints for every PRs). However, our core maintainers will still clone the repository and run tox locally to make sure
|
| 91 |
+
everything works fine, and there is a `tox environment <https://github.com/s3prl/s3prl/blob/8eac602117003e2bb5cdb7a4d0e94cc9975fd4f2/tox.ini#L11>`_
|
| 92 |
+
testing all the upstreams.
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
Documentation
|
| 96 |
+
--------------
|
| 97 |
+
|
| 98 |
+
After all the implementation, make sure your efforts are known by the users by adding documentation of your entries at
|
| 99 |
+
the :doc:`../tutorial/upstream_collection` tutorial page. Also, you can add your name at the bottom of the tutorial
|
| 100 |
+
page if you like.
|
s3prl_s3prl_main/docs/source/index.rst
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. S3PRL documentation master file, created by
|
| 2 |
+
sphinx-quickstart on Sun May 15 15:43:39 2022.
|
| 3 |
+
You can adapt this file completely to your liking, but it should at least
|
| 4 |
+
contain the root `toctree` directive.
|
| 5 |
+
|
| 6 |
+
S3PRL
|
| 7 |
+
=====
|
| 8 |
+
|
| 9 |
+
.. image:: https://raw.githubusercontent.com/s3prl/s3prl/master/file/S3PRL-logo.png
|
| 10 |
+
|
| 11 |
+
**S3PRL** is a toolkit targeting for Self-Supervised Learning for speech processing.
|
| 12 |
+
Its full name is **S**\elf-**S**\upervised **S**\peech **P**\re-training and **R**\epresentation **L**\earning.
|
| 13 |
+
It supports the following three major features:
|
| 14 |
+
|
| 15 |
+
* **Pre-training**
|
| 16 |
+
|
| 17 |
+
* You can train the following models from scratch:
|
| 18 |
+
|
| 19 |
+
* *Mockingjay*, *Audio ALBERT*, *TERA*, *APC*, *VQ-APC*, *NPC*, and *DistilHuBERT*
|
| 20 |
+
|
| 21 |
+
* **Pre-trained models (Upstream) collection**
|
| 22 |
+
|
| 23 |
+
* Easily load most of the existing upstream models with pretrained weights in a unified I/O interface.
|
| 24 |
+
* Pretrained models are registered through torch.hub, which means you can use these models in your own project by one-line plug-and-play without depending on this toolkit's coding style.
|
| 25 |
+
|
| 26 |
+
* **Downstream Evaluation**
|
| 27 |
+
|
| 28 |
+
* Utilize upstream models in lots of downstream tasks
|
| 29 |
+
* The official implementation of the `SUPERB Benchmark <https://superbbenchmark.org/>`_
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
Getting Started
|
| 33 |
+
---------------
|
| 34 |
+
|
| 35 |
+
.. toctree::
|
| 36 |
+
:caption: Getting started
|
| 37 |
+
|
| 38 |
+
./tutorial/installation.rst
|
| 39 |
+
./tutorial/upstream_collection.rst
|
| 40 |
+
./tutorial/problem.rst
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
How to Contribute
|
| 44 |
+
-----------------
|
| 45 |
+
|
| 46 |
+
.. toctree::
|
| 47 |
+
:caption: How to Contribute
|
| 48 |
+
|
| 49 |
+
./contribute/general.rst
|
| 50 |
+
./contribute/upstream.rst
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
API Documentation
|
| 54 |
+
-----------------
|
| 55 |
+
|
| 56 |
+
.. autosummary::
|
| 57 |
+
:caption: API Documentation
|
| 58 |
+
:toctree: _autosummary
|
| 59 |
+
:template: custom-module-template.rst
|
| 60 |
+
:recursive:
|
| 61 |
+
|
| 62 |
+
s3prl.nn
|
| 63 |
+
s3prl.problem
|
| 64 |
+
s3prl.task
|
| 65 |
+
s3prl.dataio
|
| 66 |
+
s3prl.metric
|
| 67 |
+
s3prl.util
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
Indices and tables
|
| 71 |
+
==================
|
| 72 |
+
|
| 73 |
+
* :ref:`genindex`
|
| 74 |
+
* :ref:`modindex`
|
| 75 |
+
* :ref:`search`
|
s3prl_s3prl_main/docs/source/tutorial/installation.rst
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Install S3PRL
|
| 2 |
+
=============
|
| 3 |
+
|
| 4 |
+
Minimal installation
|
| 5 |
+
--------------------
|
| 6 |
+
|
| 7 |
+
This installation only enables the **S3PRL Upstream collection** function to
|
| 8 |
+
keep the minimal dependency. To enable all the functions including downstream benchmarking,
|
| 9 |
+
you need to follow `Full installation`_.
|
| 10 |
+
|
| 11 |
+
.. code-block:: bash
|
| 12 |
+
|
| 13 |
+
pip install s3prl
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
Editable installation
|
| 17 |
+
---------------------
|
| 18 |
+
|
| 19 |
+
Installing a package in the editable mode means when you use a imported class/function,
|
| 20 |
+
the source code of the class/function is right in your cloned repository.
|
| 21 |
+
So, when you modify the code inside it, the newly imported class/function will reflect
|
| 22 |
+
your modification.
|
| 23 |
+
|
| 24 |
+
.. code-block:: bash
|
| 25 |
+
|
| 26 |
+
git clone https://github.com/s3prl/s3prl.git
|
| 27 |
+
cd s3prl
|
| 28 |
+
pip install -e .
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
Full installation
|
| 32 |
+
------------------
|
| 33 |
+
|
| 34 |
+
Install all the dependencies to enable all the S3PRL functions. However, there are **LOTS**
|
| 35 |
+
of dependencies.
|
| 36 |
+
|
| 37 |
+
.. code-block:: bash
|
| 38 |
+
|
| 39 |
+
pip install s3prl[all]
|
| 40 |
+
|
| 41 |
+
# editable
|
| 42 |
+
pip install ".[all]"
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
Development installation
|
| 46 |
+
-------------------------
|
| 47 |
+
|
| 48 |
+
Install dependencies of full installation and extra packages for development,
|
| 49 |
+
including **pytest** for unit-testing and **sphinx** for documentation.
|
| 50 |
+
|
| 51 |
+
Usually, you will use this installation variant only in editable mode
|
| 52 |
+
|
| 53 |
+
.. code-block:: bash
|
| 54 |
+
|
| 55 |
+
pip install ".[dev]"
|
s3prl_s3prl_main/docs/source/tutorial/problem.rst
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Use Problem module to run customizable recipes
|
| 2 |
+
=======================================================
|
| 3 |
+
|
| 4 |
+
The :obj:`s3prl.problem` module provides customizable recipes in pure python (almost).
|
| 5 |
+
See :obj:`s3prl.problem` for all the recipes ready to be ran.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
Usage 1. Import and run on Colab
|
| 9 |
+
--------------------------------
|
| 10 |
+
|
| 11 |
+
All the problem class follows the same usage
|
| 12 |
+
|
| 13 |
+
>>> import torch
|
| 14 |
+
>>> from s3prl.problem import SuperbASR
|
| 15 |
+
...
|
| 16 |
+
>>> problem = SuperbASR()
|
| 17 |
+
>>> config = problem.default_config()
|
| 18 |
+
>>> print(config)
|
| 19 |
+
...
|
| 20 |
+
>>> # See the config for the '???' required fields and fill them
|
| 21 |
+
>>> config["target_dir"] = "result/asr_exp"
|
| 22 |
+
>>> config["prepare_data"]["dataset_root"] = "/corpus/LibriSpeech/"
|
| 23 |
+
...
|
| 24 |
+
>>> problem.run(**config)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
Usage 2. Run & configure from CLI
|
| 28 |
+
-----------------------------------
|
| 29 |
+
|
| 30 |
+
If you want to directly run from command-line, write a python script (:code:`asr.py`) as follow:
|
| 31 |
+
|
| 32 |
+
.. code-block::
|
| 33 |
+
|
| 34 |
+
# This is asr.py
|
| 35 |
+
|
| 36 |
+
from s3prl.problem import SuperbASR
|
| 37 |
+
SuperbASR().main()
|
| 38 |
+
|
| 39 |
+
Then, run the command below:
|
| 40 |
+
|
| 41 |
+
>>> # Note that the main function supports overridding a field in the config by:
|
| 42 |
+
>>> # --{field_name} {value}
|
| 43 |
+
>>> # --{outer_field_name}.{inner_field_name} {value}
|
| 44 |
+
...
|
| 45 |
+
>>> python3 asr.py --target_dir result/asr_exp --prepare_data.dataset_root /corpus/LibriSpeech/
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
Usage 3. Run & configure with the unified :obj:`s3prl-main`
|
| 49 |
+
-----------------------------------------------------------
|
| 50 |
+
|
| 51 |
+
However, this means that for every problem you still need to create a file.
|
| 52 |
+
Hence, we provide an easy helper supporting all the problems in :obj:`s3prl.problem`:
|
| 53 |
+
|
| 54 |
+
>>> python3 -m s3prl.main SuperbASR --target_dir result/asr_exp --prepare_data.dataset_root /corpus/LibriSpeech/
|
| 55 |
+
|
| 56 |
+
or use our CLI entry: :code:`s3prl-main`
|
| 57 |
+
|
| 58 |
+
>>> s3prl-main SuperbASR --target_dir result/asr_exp --prepare_data.dataset_root /corpus/LibriSpeech/
|
| 59 |
+
|
| 60 |
+
Customization
|
| 61 |
+
-------------
|
| 62 |
+
|
| 63 |
+
The core feature of the :obj:`s3prl.problem` module is customization.
|
| 64 |
+
You can easily change the corpus, change the SSL upstream model, change the downstream model,
|
| 65 |
+
optimizer, scheduler... etc, which can all be freely defined by you!
|
| 66 |
+
|
| 67 |
+
We demonstrate how to change the corpus and the downstream model in the following :code:`new_asr.py`:
|
| 68 |
+
|
| 69 |
+
.. code-block:: python
|
| 70 |
+
|
| 71 |
+
# This is new_asr.py
|
| 72 |
+
|
| 73 |
+
import torch
|
| 74 |
+
import pandas as pd
|
| 75 |
+
from s3prl.problem import SuperbASR
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class LowResourceLinearSuperbASR(SuperbASR):
|
| 79 |
+
def prepare_data(
|
| 80 |
+
self, prepare_data: dict, target_dir: str, cache_dir: str, get_path_only=False
|
| 81 |
+
):
|
| 82 |
+
train_path, valid_path, test_paths = super().prepare_data(
|
| 83 |
+
prepare_data, target_dir, cache_dir, get_path_only
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
# Take only the first 100 utterances for training
|
| 87 |
+
df = pd.read_csv(train_path)
|
| 88 |
+
df = df.iloc[:100]
|
| 89 |
+
df.to_csv(train_path, index=False)
|
| 90 |
+
|
| 91 |
+
return train_path, valid_path, test_paths
|
| 92 |
+
|
| 93 |
+
def build_downstream(
|
| 94 |
+
self,
|
| 95 |
+
build_downstream: dict,
|
| 96 |
+
downstream_input_size: int,
|
| 97 |
+
downstream_output_size: int,
|
| 98 |
+
downstream_input_stride: int,
|
| 99 |
+
):
|
| 100 |
+
class Model(torch.nn.Module):
|
| 101 |
+
def __init__(self, input_size, output_size) -> None:
|
| 102 |
+
super().__init__()
|
| 103 |
+
self.linear = torch.nn.Linear(input_size, output_size)
|
| 104 |
+
|
| 105 |
+
def forward(self, x, x_len):
|
| 106 |
+
return self.linear(x), x_len
|
| 107 |
+
|
| 108 |
+
return Model(downstream_input_size, downstream_output_size)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
if __name__ == "__main__":
|
| 112 |
+
LowResourceLinearSuperbASR().main()
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
By subclassing :obj:`SuperbASR`, we create a new problem called :code:`LowResourceLinearSuperbASR` by
|
| 116 |
+
overridding the :code:`prepare_data` and :code:`build_downstream` methods. After this simple modification,
|
| 117 |
+
now the :code:`LowResourceLinearSuperbASR` works exactly the same as :code:`SuperbASR` while with two slight
|
| 118 |
+
setting changes, and then you can follow the first two usages introduced above to launch this new class.
|
| 119 |
+
|
| 120 |
+
For example:
|
| 121 |
+
|
| 122 |
+
>>> python3 new_asr.py --target_dir result/new_asr_exp --prepare_data.dataset_root /corpus/LibriSpeech/
|
s3prl_s3prl_main/docs/source/tutorial/upstream_collection.rst
ADDED
|
@@ -0,0 +1,1457 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
:tocdepth: 2
|
| 2 |
+
|
| 3 |
+
S3PRL Upstream Collection
|
| 4 |
+
=======================================
|
| 5 |
+
|
| 6 |
+
We collect almost all the existing SSL pre-trained models in S3PRL,
|
| 7 |
+
so you can import and use them easily in an unified I/O interface.
|
| 8 |
+
|
| 9 |
+
:obj:`s3prl.nn.upstream.S3PRLUpstream` is an easy interface to retrieve all the self-supervised learning (SSL) pre-trained models
|
| 10 |
+
available in S3PRL. the :code:`name` argument for :obj:`s3prl.nn.upstream.S3PRLUpstream` specifies the checkpoint,
|
| 11 |
+
and then the pre-trained models in this checkpoint will be automatically constructed and
|
| 12 |
+
initialized.
|
| 13 |
+
|
| 14 |
+
Here is an example on how to get a hubert model and its representation using the :code:`name='hubert'`:
|
| 15 |
+
|
| 16 |
+
.. code-block:: python
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
from s3prl.nn import S3PRLUpstream
|
| 20 |
+
|
| 21 |
+
model = S3PRLUpstream("hubert")
|
| 22 |
+
model.eval()
|
| 23 |
+
|
| 24 |
+
with torch.no_grad():
|
| 25 |
+
wavs = torch.randn(2, 16000 * 2)
|
| 26 |
+
wavs_len = torch.LongTensor([16000 * 1, 16000 * 2])
|
| 27 |
+
all_hs, all_hs_len = model(wavs, wavs_len)
|
| 28 |
+
|
| 29 |
+
for hs, hs_len in zip(all_hs, all_hs_len):
|
| 30 |
+
assert isinstance(hs, torch.FloatTensor)
|
| 31 |
+
assert isinstance(hs_len, torch.LongTensor)
|
| 32 |
+
|
| 33 |
+
batch_size, max_seq_len, hidden_size = hs.shape
|
| 34 |
+
assert hs_len.dim() == 1
|
| 35 |
+
|
| 36 |
+
.. tip::
|
| 37 |
+
|
| 38 |
+
For each SSL learning method, like wav2vec 2.0, there are several checkpoint variants, trained by
|
| 39 |
+
different amount of unlabeled data, or different model sizes. Hence there are also various
|
| 40 |
+
:code:`name` to retrieve these different models.
|
| 41 |
+
|
| 42 |
+
Like, the HuBERT method has "hubert" and "hubert_large_ll60k" different names for different
|
| 43 |
+
checkpoint variants.
|
| 44 |
+
|
| 45 |
+
.. tip::
|
| 46 |
+
|
| 47 |
+
Some SSL pre-trained models' entries can be further configured by a :code:`extra_conf` dictionary.
|
| 48 |
+
See :obj:`s3prl.nn.S3PRLUpstream`. You can find the valid :code:`extra_conf` options in each SSL
|
| 49 |
+
model category. If not documented, by default it does not support any :code:`extra_conf`.
|
| 50 |
+
|
| 51 |
+
The following includes the model and checkpoint information for each :code:`name`, including the releasing date,
|
| 52 |
+
paper, citation, model architecture, pre-training data, criterion, and their source code. The format follows:
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
SSL Method
|
| 57 |
+
--------------------------------------------------------
|
| 58 |
+
`Paper full title with arxiv link <https://arxiv.org/>`_
|
| 59 |
+
|
| 60 |
+
.. code-block:: bash
|
| 61 |
+
|
| 62 |
+
@article{citation-block,
|
| 63 |
+
title={Paper Title},
|
| 64 |
+
author={Authors},
|
| 65 |
+
year={2020},
|
| 66 |
+
month={May}
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
The information shared across checkpoint variants.
|
| 70 |
+
|
| 71 |
+
name1
|
| 72 |
+
~~~~~~~~~~~~~~~~~~~
|
| 73 |
+
|
| 74 |
+
The detailed specific information for this checkpoint variant (:code:`name=name1`)
|
| 75 |
+
|
| 76 |
+
name2
|
| 77 |
+
~~~~~~~~~~~~~~~~~~~
|
| 78 |
+
|
| 79 |
+
The detailed specific information for this checkpoint variant (:code:`name=name2`)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
Mockingjay
|
| 84 |
+
--------------------------------------------------------
|
| 85 |
+
`Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders <https://arxiv.org/abs/1910.12638>`_
|
| 86 |
+
|
| 87 |
+
.. code-block:: bash
|
| 88 |
+
|
| 89 |
+
@article{mockingjay,
|
| 90 |
+
title={Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders},
|
| 91 |
+
ISBN={9781509066315},
|
| 92 |
+
url={http://dx.doi.org/10.1109/ICASSP40776.2020.9054458},
|
| 93 |
+
DOI={10.1109/icassp40776.2020.9054458},
|
| 94 |
+
journal={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 95 |
+
publisher={IEEE},
|
| 96 |
+
author={Liu, Andy T. and Yang, Shu-wen and Chi, Po-Han and Hsu, Po-chun and Lee, Hung-yi},
|
| 97 |
+
year={2020},
|
| 98 |
+
month={May}
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
Mockingjay is a BERT on Spectrogram, with 12-layers of transformer encoders in the paper.
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
mockingjay
|
| 105 |
+
~~~~~~~~~~~~~~~~
|
| 106 |
+
|
| 107 |
+
This is alias for `mockingjay_origin`_
|
| 108 |
+
|
| 109 |
+
mockingjay_origin
|
| 110 |
+
~~~~~~~~~~~~~~~~~~~~~~~~
|
| 111 |
+
|
| 112 |
+
This is alias for `mockingjay_logMelLinearLarge_T_AdamW_b32_500k_360hr_drop1`_
|
| 113 |
+
|
| 114 |
+
mockingjay_100hr
|
| 115 |
+
~~~~~~~~~~~~~~~~
|
| 116 |
+
|
| 117 |
+
This is alias for `mockingjay_logMelBase_T_AdamW_b32_200k_100hr`_
|
| 118 |
+
|
| 119 |
+
mockingjay_960hr
|
| 120 |
+
~~~~~~~~~~~~~~~~
|
| 121 |
+
|
| 122 |
+
This is alias for `mockingjay_logMelBase_T_AdamW_b32_1m_960hr_drop1`_
|
| 123 |
+
|
| 124 |
+
mockingjay_logMelBase_T_AdamW_b32_200k_100hr
|
| 125 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 126 |
+
|
| 127 |
+
- Feature: 80-dim log Mel
|
| 128 |
+
- Alteration: time
|
| 129 |
+
- Optimizer: AdamW
|
| 130 |
+
- Batch size: 32
|
| 131 |
+
- Total steps: 200k
|
| 132 |
+
- Unlabled Speech: LibriSpeech 100hr
|
| 133 |
+
|
| 134 |
+
mockingjay_logMelLinearLarge_T_AdamW_b32_500k_360hr_drop1
|
| 135 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 136 |
+
|
| 137 |
+
- Feature: 80-dim log Mel (input) / 201-dim Linear (target)
|
| 138 |
+
- Alteration: time
|
| 139 |
+
- Optimizer: AdamW
|
| 140 |
+
- Batch size: 32
|
| 141 |
+
- Total steps: 500k
|
| 142 |
+
- Unlabled Speech: LibriSpeech 360hr
|
| 143 |
+
|
| 144 |
+
mockingjay_logMelBase_T_AdamW_b32_1m_960hr
|
| 145 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 146 |
+
|
| 147 |
+
- Feature: 80-dim log Mel
|
| 148 |
+
- Alteration: time
|
| 149 |
+
- Optimizer: AdamW
|
| 150 |
+
- Batch size: 32
|
| 151 |
+
- Total steps: 1M
|
| 152 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 153 |
+
|
| 154 |
+
mockingjay_logMelBase_T_AdamW_b32_1m_960hr_drop1
|
| 155 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 156 |
+
|
| 157 |
+
- Feature: 80-dim log Mel
|
| 158 |
+
- Alteration: time
|
| 159 |
+
- Optimizer: AdamW
|
| 160 |
+
- Batch size: 32
|
| 161 |
+
- Total steps: 1M
|
| 162 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 163 |
+
- Differences: Dropout of 0.1 (instead of 0.3)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
mockingjay_logMelBase_T_AdamW_b32_1m_960hr_seq3k
|
| 167 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 168 |
+
|
| 169 |
+
- Feature: 80-dim log Mel
|
| 170 |
+
- Alteration: time
|
| 171 |
+
- Optimizer: AdamW
|
| 172 |
+
- Batch size: 32
|
| 173 |
+
- Total steps: 1M
|
| 174 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 175 |
+
- Differences: sequence length of 3k (instead of 1.5k)
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
TERA
|
| 180 |
+
--------------------------------------------------------
|
| 181 |
+
`TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech <https://arxiv.org/abs/2007.06028>`_
|
| 182 |
+
|
| 183 |
+
.. code-block:: bash
|
| 184 |
+
|
| 185 |
+
@misc{tera,
|
| 186 |
+
title={TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech},
|
| 187 |
+
author={Andy T. Liu and Shang-Wen Li and Hung-yi Lee},
|
| 188 |
+
year={2020},
|
| 189 |
+
eprint={2007.06028},
|
| 190 |
+
archivePrefix={arXiv},
|
| 191 |
+
primaryClass={eess.AS}
|
| 192 |
+
}
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
tera
|
| 196 |
+
~~~~~~~~~~~~~~~~
|
| 197 |
+
|
| 198 |
+
This is alias for `tera_960hr`_
|
| 199 |
+
|
| 200 |
+
tera_100hr
|
| 201 |
+
~~~~~~~~~~~~~~~~~~
|
| 202 |
+
|
| 203 |
+
This is alias for `tera_logMelBase_T_F_M_AdamW_b32_200k_100hr`_
|
| 204 |
+
|
| 205 |
+
tera_960hr
|
| 206 |
+
~~~~~~~~~~~~~~~~~~~
|
| 207 |
+
|
| 208 |
+
This is alias for `tera_logMelBase_T_F_M_AdamW_b32_1m_960hr_drop1`_
|
| 209 |
+
|
| 210 |
+
tera_logMelBase_T_F_AdamW_b32_200k_100hr
|
| 211 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 212 |
+
|
| 213 |
+
- Feature: 80-dim log Mel
|
| 214 |
+
- Alteration: time + freq
|
| 215 |
+
- Optimizer: AdamW
|
| 216 |
+
- Batch size: 32
|
| 217 |
+
- Total steps: 200k
|
| 218 |
+
- Unlabled Speech: LibriSpeech 100hr
|
| 219 |
+
|
| 220 |
+
tera_logMelBase_T_F_M_AdamW_b32_200k_100hr
|
| 221 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 222 |
+
|
| 223 |
+
- Feature: 80-dim log Mel
|
| 224 |
+
- Alteration: time + freq + mag
|
| 225 |
+
- Optimizer: AdamW
|
| 226 |
+
- Batch size: 32
|
| 227 |
+
- Total steps: 200k
|
| 228 |
+
- Unlabled Speech: LibriSpeech 100hr
|
| 229 |
+
|
| 230 |
+
tera_logMelBase_T_F_AdamW_b32_1m_960hr
|
| 231 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 232 |
+
|
| 233 |
+
- Feature: 80-dim log Mel
|
| 234 |
+
- Alteration: time + freq
|
| 235 |
+
- Optimizer: AdamW
|
| 236 |
+
- Batch size: 32
|
| 237 |
+
- Total steps: 1M
|
| 238 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 239 |
+
|
| 240 |
+
tera_logMelBase_T_F_AdamW_b32_1m_960hr_drop1
|
| 241 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 242 |
+
|
| 243 |
+
- Feature: 80-dim log Mel
|
| 244 |
+
- Alteration: time + freq
|
| 245 |
+
- Optimizer: AdamW
|
| 246 |
+
- Batch size: 32
|
| 247 |
+
- Total steps: 1M
|
| 248 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 249 |
+
- Differences: Dropout of 0.1 (instead of 0.3)
|
| 250 |
+
|
| 251 |
+
tera_logMelBase_T_F_AdamW_b32_1m_960hr_seq3k
|
| 252 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 253 |
+
|
| 254 |
+
- Feature: 80-dim log Mel
|
| 255 |
+
- Alteration: time + freq
|
| 256 |
+
- Optimizer: AdamW
|
| 257 |
+
- Batch size: 32
|
| 258 |
+
- Total steps: 1M
|
| 259 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 260 |
+
- Differences: sequence length of 3k (instead of 1.5k)
|
| 261 |
+
|
| 262 |
+
tera_logMelBase_T_F_M_AdamW_b32_1m_960hr_drop1
|
| 263 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 264 |
+
|
| 265 |
+
- Feature: 80-dim log Mel
|
| 266 |
+
- Alteration: time + freq + mag
|
| 267 |
+
- Optimizer: AdamW
|
| 268 |
+
- Batch size: 32
|
| 269 |
+
- Total steps: 1M
|
| 270 |
+
- Unlabled Speech: 960hr
|
| 271 |
+
- Differences: Dropout of 0.1 (instead of 0.3)
|
| 272 |
+
|
| 273 |
+
tera_fbankBase_T_F_AdamW_b32_200k_100hr
|
| 274 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 275 |
+
|
| 276 |
+
- Feature: 240-dim fbank
|
| 277 |
+
- Alteration: time + freq
|
| 278 |
+
- Optimizer: AdamW
|
| 279 |
+
- Batch size: 32
|
| 280 |
+
- Total steps: 200k
|
| 281 |
+
- Unlabled Speech: LibriSpeech 100hr
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
Audio ALBERT
|
| 286 |
+
--------------------------------------------------------
|
| 287 |
+
`Audio ALBERT: A Lite BERT for Self-supervised Learning of Audio Representation <https://arxiv.org/abs/2007.06028>`_
|
| 288 |
+
|
| 289 |
+
.. code-block:: bash
|
| 290 |
+
|
| 291 |
+
@inproceedings{chi2021audio,
|
| 292 |
+
title={Audio albert: A lite bert for self-supervised learning of audio representation},
|
| 293 |
+
author={Chi, Po-Han and Chung, Pei-Hung and Wu, Tsung-Han and Hsieh, Chun-Cheng and Chen, Yen-Hao and Li, Shang-Wen and Lee, Hung-yi},
|
| 294 |
+
booktitle={2021 IEEE Spoken Language Technology Workshop (SLT)},
|
| 295 |
+
pages={344--350},
|
| 296 |
+
year={2021},
|
| 297 |
+
organization={IEEE}
|
| 298 |
+
}
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
audio_albert
|
| 302 |
+
~~~~~~~~~~~~~~~~
|
| 303 |
+
|
| 304 |
+
This is alias of `audio_albert_960hr`_
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
audio_albert_960hr
|
| 308 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 309 |
+
|
| 310 |
+
This is alias of `audio_albert_logMelBase_T_share_AdamW_b32_1m_960hr_drop1`_
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
audio_albert_logMelBase_T_share_AdamW_b32_1m_960hr_drop1
|
| 314 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 315 |
+
|
| 316 |
+
- Feature: 80-dim log Mel
|
| 317 |
+
- Alteration: time
|
| 318 |
+
- Optimizer: AdamW
|
| 319 |
+
- Batch size: 32
|
| 320 |
+
- Total steps: 1M
|
| 321 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
APC
|
| 326 |
+
--------------------------------------------------------
|
| 327 |
+
`An Unsupervised Autoregressive Model for Speech Representation Learning <https://arxiv.org/abs/1904.03240>`_
|
| 328 |
+
|
| 329 |
+
.. code-block:: bash
|
| 330 |
+
|
| 331 |
+
@inproceedings{chung2019unsupervised,
|
| 332 |
+
title = {An unsupervised autoregressive model for speech representation learning},
|
| 333 |
+
author = {Chung, Yu-An and Hsu, Wei-Ning and Tang, Hao and Glass, James},
|
| 334 |
+
booktitle = {Interspeech},
|
| 335 |
+
year = {2019}
|
| 336 |
+
}
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
apc
|
| 340 |
+
~~~~~~~~~~~~~~~~
|
| 341 |
+
|
| 342 |
+
This is alias of `apc_360hr`_
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
apc_360hr
|
| 346 |
+
~~~~~~~~~~~~~~~~~~
|
| 347 |
+
|
| 348 |
+
- Unlabled Speech: LibriSpeech 360hr
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
apc_960hr
|
| 352 |
+
~~~~~~~~~~~~~~~~~~
|
| 353 |
+
|
| 354 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
VQ-APC
|
| 359 |
+
--------------------------------------------------------
|
| 360 |
+
`Vector-Quantized Autoregressive Predictive Coding <https://arxiv.org/abs/2005.08392>`_
|
| 361 |
+
|
| 362 |
+
.. code-block:: bash
|
| 363 |
+
|
| 364 |
+
@inproceedings{chung2020vqapc,
|
| 365 |
+
title = {Vector-quantized autoregressive predictive coding},
|
| 366 |
+
autohor = {Chung, Yu-An and Tang, Hao and Glass, James},
|
| 367 |
+
booktitle = {Interspeech},
|
| 368 |
+
year = {2020}
|
| 369 |
+
}
|
| 370 |
+
|
| 371 |
+
vq_apc
|
| 372 |
+
~~~~~~~~~~~~~~~~
|
| 373 |
+
|
| 374 |
+
This is alias of `vq_apc_360hr`_
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
vq_apc_360hr
|
| 378 |
+
~~~~~~~~~~~~~~~~
|
| 379 |
+
|
| 380 |
+
- Unlabled Speech: LibriSpeech 360hr
|
| 381 |
+
|
| 382 |
+
|
| 383 |
+
vq_apc_960hr
|
| 384 |
+
~~~~~~~~~~~~~~~~~
|
| 385 |
+
|
| 386 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 387 |
+
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
NPC
|
| 391 |
+
--------------------------------------------------------
|
| 392 |
+
`Non-Autoregressive Predictive Coding for Learning Speech Representations from Local Dependencies <https://arxiv.org/abs/2011.00406>`_
|
| 393 |
+
|
| 394 |
+
.. code-block:: bash
|
| 395 |
+
|
| 396 |
+
@article{liu2020nonautoregressive,
|
| 397 |
+
title = {Non-Autoregressive Predictive Coding for Learning Speech Representations from Local Dependencies},
|
| 398 |
+
author = {Liu, Alexander and Chung, Yu-An and Glass, James},
|
| 399 |
+
journal = {arXiv preprint arXiv:2011.00406},
|
| 400 |
+
year = {2020}
|
| 401 |
+
}
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
npc
|
| 405 |
+
~~~~~~~~~~~~~~~~
|
| 406 |
+
|
| 407 |
+
This is alias of `npc_360hr`_
|
| 408 |
+
|
| 409 |
+
|
| 410 |
+
npc_360hr
|
| 411 |
+
~~~~~~~~~~~~~~~~~~
|
| 412 |
+
|
| 413 |
+
- Unlabled Speech: LibriSpeech 360hr
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
npc_960hr
|
| 417 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 418 |
+
|
| 419 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
PASE+
|
| 424 |
+
--------------------------------------------------------
|
| 425 |
+
`Multi-task self-supervised learning for Robust Speech Recognition <https://arxiv.org/abs/2001.09239>`_
|
| 426 |
+
|
| 427 |
+
.. code-block:: bash
|
| 428 |
+
|
| 429 |
+
@inproceedings{ravanelli2020multi,
|
| 430 |
+
title={Multi-task self-supervised learning for robust speech recognition},
|
| 431 |
+
author={Ravanelli, Mirco and Zhong, Jianyuan and Pascual, Santiago and Swietojanski, Pawel and Monteiro, Joao and Trmal, Jan and Bengio, Yoshua},
|
| 432 |
+
booktitle={ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 433 |
+
pages={6989--6993},
|
| 434 |
+
year={2020},
|
| 435 |
+
organization={IEEE}
|
| 436 |
+
}
|
| 437 |
+
|
| 438 |
+
.. hint::
|
| 439 |
+
|
| 440 |
+
To use PASE models, there are many extra dependencies required to install.
|
| 441 |
+
Please follow the below installation instruction:
|
| 442 |
+
|
| 443 |
+
.. code-block:: bash
|
| 444 |
+
|
| 445 |
+
pip install -r https://raw.githubusercontent.com/s3prl/s3prl/master/s3prl/upstream/pase/requirements.txt
|
| 446 |
+
|
| 447 |
+
|
| 448 |
+
pase_plus
|
| 449 |
+
~~~~~~~~~~~~~~~~
|
| 450 |
+
|
| 451 |
+
- Unlabled Speech: LibriSpeech 50hr
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
Modified CPC
|
| 456 |
+
--------------------------------------------------------
|
| 457 |
+
`Unsupervised pretraining transfers well across languages <https://arxiv.org/abs/2002.02848>`_
|
| 458 |
+
|
| 459 |
+
.. code-block:: bash
|
| 460 |
+
|
| 461 |
+
@inproceedings{riviere2020unsupervised,
|
| 462 |
+
title={Unsupervised pretraining transfers well across languages},
|
| 463 |
+
author={Riviere, Morgane and Joulin, Armand and Mazar{\'e}, Pierre-Emmanuel and Dupoux, Emmanuel},
|
| 464 |
+
booktitle={ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 465 |
+
pages={7414--7418},
|
| 466 |
+
year={2020},
|
| 467 |
+
organization={IEEE}
|
| 468 |
+
}
|
| 469 |
+
|
| 470 |
+
.. note::
|
| 471 |
+
|
| 472 |
+
This is a slightly improved version on the original CPC by DeepMind. To cite the DeepMind version:
|
| 473 |
+
|
| 474 |
+
.. code-block:: bash
|
| 475 |
+
|
| 476 |
+
@article{oord2018representation,
|
| 477 |
+
title={Representation learning with contrastive predictive coding},
|
| 478 |
+
author={Oord, Aaron van den and Li, Yazhe and Vinyals, Oriol},
|
| 479 |
+
journal={arXiv preprint arXiv:1807.03748},
|
| 480 |
+
year={2018}
|
| 481 |
+
}
|
| 482 |
+
|
| 483 |
+
|
| 484 |
+
modified_cpc
|
| 485 |
+
~~~~~~~~~~~~~~~~
|
| 486 |
+
|
| 487 |
+
- Unlabled Speech: LibriLight 60k hours
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
|
| 491 |
+
DeCoAR
|
| 492 |
+
--------------------------------------------------------
|
| 493 |
+
`Deep contextualized acoustic representations for semi-supervised speech recognition <https://arxiv.org/abs/1912.01679>`_
|
| 494 |
+
|
| 495 |
+
.. code-block:: bash
|
| 496 |
+
|
| 497 |
+
@inproceedings{ling2020deep,
|
| 498 |
+
title={Deep contextualized acoustic representations for semi-supervised speech recognition},
|
| 499 |
+
author={Ling, Shaoshi and Liu, Yuzong and Salazar, Julian and Kirchhoff, Katrin},
|
| 500 |
+
booktitle={ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 501 |
+
pages={6429--6433},
|
| 502 |
+
year={2020},
|
| 503 |
+
organization={IEEE}
|
| 504 |
+
}
|
| 505 |
+
|
| 506 |
+
|
| 507 |
+
decoar_layers
|
| 508 |
+
~~~~~~~~~~~~~~~~
|
| 509 |
+
|
| 510 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
DeCoAR 2.0
|
| 514 |
+
--------------------------------------------------------
|
| 515 |
+
`DeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization <https://arxiv.org/abs/2012.06659>`_
|
| 516 |
+
|
| 517 |
+
.. code-block:: bash
|
| 518 |
+
|
| 519 |
+
@misc{ling2020decoar,
|
| 520 |
+
title={DeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization},
|
| 521 |
+
author={Shaoshi Ling and Yuzong Liu},
|
| 522 |
+
year={2020},
|
| 523 |
+
eprint={2012.06659},
|
| 524 |
+
archivePrefix={arXiv},
|
| 525 |
+
primaryClass={eess.AS}
|
| 526 |
+
}
|
| 527 |
+
|
| 528 |
+
|
| 529 |
+
decoar2
|
| 530 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 531 |
+
|
| 532 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 533 |
+
|
| 534 |
+
|
| 535 |
+
|
| 536 |
+
wav2vec
|
| 537 |
+
--------------------------------------------------
|
| 538 |
+
`wav2vec: Unsupervised Pre-Training for Speech Recognition <https://arxiv.org/abs/1904.05862>`_
|
| 539 |
+
|
| 540 |
+
.. code-block:: bash
|
| 541 |
+
|
| 542 |
+
@article{schneider2019wav2vec,
|
| 543 |
+
title={wav2vec: Unsupervised Pre-Training for Speech Recognition},
|
| 544 |
+
author={Schneider, Steffen and Baevski, Alexei and Collobert, Ronan and Auli, Michael},
|
| 545 |
+
journal={Proc. Interspeech 2019},
|
| 546 |
+
pages={3465--3469},
|
| 547 |
+
year={2019}
|
| 548 |
+
}
|
| 549 |
+
|
| 550 |
+
|
| 551 |
+
wav2vec
|
| 552 |
+
~~~~~~~~~~~
|
| 553 |
+
|
| 554 |
+
This is alias of `wav2vec_large`_
|
| 555 |
+
|
| 556 |
+
|
| 557 |
+
wav2vec_large
|
| 558 |
+
~~~~~~~~~~~~~~~
|
| 559 |
+
|
| 560 |
+
This is the official wav2vec model from fairseq.
|
| 561 |
+
|
| 562 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 563 |
+
|
| 564 |
+
|
| 565 |
+
vq-wav2vec
|
| 566 |
+
--------------------------------------------------
|
| 567 |
+
`vq-wav2vec: Self-supervised learning of discrete speech representations <https://arxiv.org/abs/1910.05453>`_
|
| 568 |
+
|
| 569 |
+
.. code-block:: bash
|
| 570 |
+
|
| 571 |
+
@inproceedings{baevski2019vq,
|
| 572 |
+
title={vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations},
|
| 573 |
+
author={Baevski, Alexei and Schneider, Steffen and Auli, Michael},
|
| 574 |
+
booktitle={International Conference on Learning Representations},
|
| 575 |
+
year={2019}
|
| 576 |
+
}
|
| 577 |
+
|
| 578 |
+
.. note::
|
| 579 |
+
|
| 580 |
+
We only take the Conv encoders' hidden_states for vq-wav2vec in this SSL method category.
|
| 581 |
+
If you wish to consider the BERT model after ths Conv encoders, please refer to `Discrete BERT`_.
|
| 582 |
+
|
| 583 |
+
vq_wav2vec
|
| 584 |
+
~~~~~~~~~~~
|
| 585 |
+
|
| 586 |
+
This is alias of `vq_wav2vec_gumbel`_
|
| 587 |
+
|
| 588 |
+
|
| 589 |
+
vq_wav2vec_gumbel
|
| 590 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 591 |
+
|
| 592 |
+
This is the official vq-wav2vec model from fairseq.
|
| 593 |
+
This model uses gumbel-softmax as the quantization technique
|
| 594 |
+
|
| 595 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 596 |
+
|
| 597 |
+
|
| 598 |
+
vq_wav2vec_kmeans
|
| 599 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 600 |
+
|
| 601 |
+
This is the official vq-wav2vec model from fairseq.
|
| 602 |
+
This model uses K-means as the quantization technique
|
| 603 |
+
|
| 604 |
+
|
| 605 |
+
Discrete BERT
|
| 606 |
+
--------------------------------------------------
|
| 607 |
+
`vq-wav2vec: Self-supervised learning of discrete speech representations <https://arxiv.org/abs/1910.05453>`_
|
| 608 |
+
|
| 609 |
+
.. code-block:: bash
|
| 610 |
+
|
| 611 |
+
@inproceedings{baevski2019vq,
|
| 612 |
+
title={vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations},
|
| 613 |
+
author={Baevski, Alexei and Schneider, Steffen and Auli, Michael},
|
| 614 |
+
booktitle={International Conference on Learning Representations},
|
| 615 |
+
year={2019}
|
| 616 |
+
}
|
| 617 |
+
|
| 618 |
+
This method takes the Conv feature encoder's output, quantize it into token ids, and feed the
|
| 619 |
+
tokens into a NLP BERT (Specifically, RoBERTa). The output hidden_states are all the hidden hidden_states
|
| 620 |
+
of the NLP BERT (excluding the hidden_states in `vq-wav2vec`_)
|
| 621 |
+
|
| 622 |
+
|
| 623 |
+
discretebert
|
| 624 |
+
~~~~~~~~~~~~~~~~
|
| 625 |
+
|
| 626 |
+
Alias of `vq_wav2vec_kmeans_roberta`_
|
| 627 |
+
|
| 628 |
+
|
| 629 |
+
vq_wav2vec_kmeans_roberta
|
| 630 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 631 |
+
|
| 632 |
+
This model uses `vq_wav2vec_kmeans`_ as the frontend waveform tokenizer. After the waveform is tokenized
|
| 633 |
+
into a sequence of token ids, tokens are then fed into a RoBERTa model.
|
| 634 |
+
|
| 635 |
+
|
| 636 |
+
|
| 637 |
+
wav2vec 2.0
|
| 638 |
+
--------------------------------------------------
|
| 639 |
+
`wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations <https://arxiv.org/abs/2006.11477>`_
|
| 640 |
+
|
| 641 |
+
.. code-block:: bash
|
| 642 |
+
|
| 643 |
+
@article{baevski2020wav2vec,
|
| 644 |
+
title={wav2vec 2.0: A framework for self-supervised learning of speech representations},
|
| 645 |
+
author={Baevski, Alexei and Zhou, Yuhao and Mohamed, Abdelrahman and Auli, Michael},
|
| 646 |
+
journal={Advances in Neural Information Processing Systems},
|
| 647 |
+
volume={33},
|
| 648 |
+
pages={12449--12460},
|
| 649 |
+
year={2020}
|
| 650 |
+
}
|
| 651 |
+
|
| 652 |
+
All the entries below support the following :code:`extra_conf`:
|
| 653 |
+
|
| 654 |
+
==================== ====================
|
| 655 |
+
column description
|
| 656 |
+
==================== ====================
|
| 657 |
+
feature_selection (str) -
|
| 658 |
+
if :code:`fairseq_layers` or :code:`fairseq_layers_before_residual`,
|
| 659 |
+
extract the representation following official fairseq API.
|
| 660 |
+
for :code:`fairseq_layers`, it is the output of each transformer
|
| 661 |
+
encoder layer; for :code:`fairseq_layers_before_residual`, it is
|
| 662 |
+
the output of the feedforward layer (before adding with the
|
| 663 |
+
main residual) of each transformer encoder layer. by default
|
| 664 |
+
this option is None, which follows the default place to extract
|
| 665 |
+
in S3PRL.
|
| 666 |
+
==================== ====================
|
| 667 |
+
|
| 668 |
+
|
| 669 |
+
wav2vec2_custom
|
| 670 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 671 |
+
|
| 672 |
+
This entry expects you to provide the source of the checkpoint: :code:`path_or_url`, which should be
|
| 673 |
+
the local path or a url of the checkpoint converted by :code:`s3prl/upstream/wav2vec2/convert.py` (
|
| 674 |
+
from a regular fairseq checkpoint.)
|
| 675 |
+
|
| 676 |
+
This entry also supports the following additional :code:`extra_conf`.
|
| 677 |
+
|
| 678 |
+
==================== ====================
|
| 679 |
+
column description
|
| 680 |
+
==================== ====================
|
| 681 |
+
fairseq (bool) -
|
| 682 |
+
If True, perform the on-the-fly checkpoint conversion, so that
|
| 683 |
+
you can directly give the fairseq checkpoint to the :code:`path_or_url`
|
| 684 |
+
argument, either a fairseq URL or a fairseq checkpoint local path.
|
| 685 |
+
==================== ====================
|
| 686 |
+
|
| 687 |
+
|
| 688 |
+
hf_wav2vec2_custom
|
| 689 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 690 |
+
|
| 691 |
+
This entry expects you to provide the source of the checkpoint: :code:`path_or_url`, which should be
|
| 692 |
+
in the HuggingFace format, like :code:`facebook/wav2vec2-large-960h`
|
| 693 |
+
|
| 694 |
+
|
| 695 |
+
wav2vec2
|
| 696 |
+
~~~~~~~~~~~~~~~~
|
| 697 |
+
|
| 698 |
+
This is the alias of `wav2vec2_base_960`_
|
| 699 |
+
|
| 700 |
+
|
| 701 |
+
wav2vec2_base_960
|
| 702 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 703 |
+
This is the official wav2vec 2.0 model in fairseq
|
| 704 |
+
|
| 705 |
+
- Architecture: 12-layer Transformer encoders
|
| 706 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 707 |
+
|
| 708 |
+
|
| 709 |
+
wav2vec2_large_960
|
| 710 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 711 |
+
|
| 712 |
+
- Architecture: 24-layer Transformer encoders
|
| 713 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 714 |
+
|
| 715 |
+
|
| 716 |
+
wav2vec2_large_ll60k
|
| 717 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 718 |
+
|
| 719 |
+
- Architecture: 24-layer Transformer encoders
|
| 720 |
+
- Unlabled Speech: LibriLight LL60k hours
|
| 721 |
+
|
| 722 |
+
|
| 723 |
+
wav2vec2_large_lv60_cv_swbd_fsh
|
| 724 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 725 |
+
|
| 726 |
+
The Large model trained on Libri-Light 60k hours + CommonVoice + Switchboard + Fisher
|
| 727 |
+
|
| 728 |
+
- Architecture: 24-layer Transformer encoders
|
| 729 |
+
- Unlabeled Speech: Libri-Light 60k hours + CommonVoice + Switchboard + Fisher
|
| 730 |
+
|
| 731 |
+
|
| 732 |
+
wav2vec2_conformer_relpos
|
| 733 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 734 |
+
|
| 735 |
+
The results can be found in the Table 4 of `fairseq S2T: Fast Speech-to-Text Modeling with fairseq <https://arxiv.org/abs/2010.05171>`_.
|
| 736 |
+
|
| 737 |
+
- Architecture: 24-layer Conformer encoders with relative positional encoding
|
| 738 |
+
- Unlabeled Speech: LibriLight LL60k hours
|
| 739 |
+
|
| 740 |
+
|
| 741 |
+
wav2vec2_conformer_rope
|
| 742 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 743 |
+
|
| 744 |
+
The results can be found in the Table 4 of `fairseq S2T: Fast Speech-to-Text Modeling with fairseq <https://arxiv.org/abs/2010.05171>`_.
|
| 745 |
+
|
| 746 |
+
- Architecture: 24-layer Conformer encoders with ROPE positional encoding
|
| 747 |
+
- Unlabeled Speech: LibriLight LL60k hours
|
| 748 |
+
|
| 749 |
+
|
| 750 |
+
wav2vec2_base_s2st_es_voxpopuli
|
| 751 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 752 |
+
|
| 753 |
+
- The wav2vec2 model from `Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation <https://arxiv.org/abs/2204.02967>`_,
|
| 754 |
+
- released in Fairseq with the link: `https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/s2st_finetuning/w2v2/es/transformer_B.pt <https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/s2st_finetuning/w2v2/es/transformer_B.pt>`_
|
| 755 |
+
|
| 756 |
+
|
| 757 |
+
wav2vec2_base_s2st_en_librilight
|
| 758 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 759 |
+
|
| 760 |
+
- The wav2vec2 model from `Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation <https://arxiv.org/abs/2204.02967>`_,
|
| 761 |
+
- released in Fairseq with the link: `https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/s2st_finetuning/w2v2/en/transformer_B.pt <https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/s2st_finetuning/w2v2/en/transformer_B.pt>`_
|
| 762 |
+
|
| 763 |
+
|
| 764 |
+
wav2vec2_conformer_large_s2st_es_voxpopuli
|
| 765 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 766 |
+
|
| 767 |
+
- The wav2vec2 model from `Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation <https://arxiv.org/abs/2204.02967>`_,
|
| 768 |
+
- released in Fairseq with the link: `https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/s2st_finetuning/w2v2/es/conformer_L.pt <https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/s2st_finetuning/w2v2/es/conformer_L.pt>`_
|
| 769 |
+
|
| 770 |
+
|
| 771 |
+
wav2vec2_conformer_large_s2st_en_librilight
|
| 772 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 773 |
+
|
| 774 |
+
- The wav2vec2 model from `Enhanced Direct Speech-to-Speech Translation Using Self-supervised Pre-training and Data Augmentation <https://arxiv.org/abs/2204.02967>`_,
|
| 775 |
+
- released in Fairseq with the link: `https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/s2st_finetuning/w2v2/en/conformer_L.pt <https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/s2st_finetuning/w2v2/en/conformer_L.pt>`_
|
| 776 |
+
|
| 777 |
+
|
| 778 |
+
xlsr_53
|
| 779 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 780 |
+
|
| 781 |
+
The wav2vec 2.0 model trained on multilingual presented in `Unsupervised Cross-lingual Representation Learning for Speech Recognition <https://arxiv.org/abs/2006.13979>`_
|
| 782 |
+
|
| 783 |
+
.. code-block:: bash
|
| 784 |
+
|
| 785 |
+
@article{conneau2020unsupervised,
|
| 786 |
+
title={Unsupervised cross-lingual representation learning for speech recognition},
|
| 787 |
+
author={Conneau, Alexis and Baevski, Alexei and Collobert, Ronan and Mohamed, Abdelrahman and Auli, Michael},
|
| 788 |
+
journal={arXiv preprint arXiv:2006.13979},
|
| 789 |
+
year={2020}
|
| 790 |
+
}
|
| 791 |
+
|
| 792 |
+
|
| 793 |
+
XLS-R
|
| 794 |
+
--------------------------------------------------
|
| 795 |
+
`XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale <https://arxiv.org/abs/2111.09296>`_
|
| 796 |
+
|
| 797 |
+
.. code-block:: bash
|
| 798 |
+
|
| 799 |
+
@article{babu2021xls,
|
| 800 |
+
title={XLS-R: Self-supervised cross-lingual speech representation learning at scale},
|
| 801 |
+
author={Babu, Arun and Wang, Changhan and Tjandra, Andros and Lakhotia, Kushal and Xu, Qiantong and Goyal, Naman and Singh, Kritika and von Platen, Patrick and Saraf, Yatharth and Pino, Juan and others},
|
| 802 |
+
journal={arXiv preprint arXiv:2111.09296},
|
| 803 |
+
year={2021}
|
| 804 |
+
}
|
| 805 |
+
|
| 806 |
+
|
| 807 |
+
xls_r_300m
|
| 808 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 809 |
+
|
| 810 |
+
- Unlabled Speech: 128 languages, 436K hours
|
| 811 |
+
|
| 812 |
+
|
| 813 |
+
xls_r_1b
|
| 814 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 815 |
+
|
| 816 |
+
- Unlabled Speech: 128 languages, 436K hours
|
| 817 |
+
|
| 818 |
+
|
| 819 |
+
xls_r_2b
|
| 820 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 821 |
+
|
| 822 |
+
- Unlabled Speech: 128 languages, 436K hours
|
| 823 |
+
|
| 824 |
+
|
| 825 |
+
HuBERT
|
| 826 |
+
--------------------------------------------------
|
| 827 |
+
`HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units <https://arxiv.org/abs/2106.07447>`_
|
| 828 |
+
|
| 829 |
+
.. code-block:: bash
|
| 830 |
+
|
| 831 |
+
@article{hsu2021hubert,
|
| 832 |
+
title={Hubert: Self-supervised speech representation learning by masked prediction of hidden units},
|
| 833 |
+
author={Hsu, Wei-Ning and Bolte, Benjamin and Tsai, Yao-Hung Hubert and Lakhotia, Kushal and Salakhutdinov, Ruslan and Mohamed, Abdelrahman},
|
| 834 |
+
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
|
| 835 |
+
volume={29},
|
| 836 |
+
pages={3451--3460},
|
| 837 |
+
year={2021},
|
| 838 |
+
publisher={IEEE}
|
| 839 |
+
}
|
| 840 |
+
|
| 841 |
+
|
| 842 |
+
hubert_custom
|
| 843 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 844 |
+
|
| 845 |
+
This entry expects you to provide the source of the checkpoint: :code:`path_or_url`, which should be
|
| 846 |
+
the local path or a url of the checkpoint converted by :code:`s3prl/upstream/hubert/convert.py` (
|
| 847 |
+
from a regular fairseq checkpoint.)
|
| 848 |
+
|
| 849 |
+
This entry also supports the following additional :code:`extra_conf`.
|
| 850 |
+
|
| 851 |
+
==================== ====================
|
| 852 |
+
column description
|
| 853 |
+
==================== ====================
|
| 854 |
+
fairseq (bool) -
|
| 855 |
+
If True, perform the on-the-fly checkpoint conversion, so that
|
| 856 |
+
you can directly give the fairseq checkpoint to the :code:`path_or_url`
|
| 857 |
+
argument, either a fairseq URL or a fairseq checkpoint local path.
|
| 858 |
+
==================== ====================
|
| 859 |
+
|
| 860 |
+
|
| 861 |
+
hf_hubert_custom
|
| 862 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 863 |
+
|
| 864 |
+
This entry expects you to provide the source of the checkpoint: :code:`path_or_url`, which should be
|
| 865 |
+
in the HuggingFace format, like :code:`facebook/hubert-large-ll60k`
|
| 866 |
+
|
| 867 |
+
|
| 868 |
+
hubert
|
| 869 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 870 |
+
|
| 871 |
+
This is alias of `hubert_base`_
|
| 872 |
+
|
| 873 |
+
|
| 874 |
+
hubert_base
|
| 875 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 876 |
+
|
| 877 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 878 |
+
|
| 879 |
+
|
| 880 |
+
hubert_large_ll60k
|
| 881 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 882 |
+
|
| 883 |
+
- Unlabled Speech: LibriLight ll60k hours
|
| 884 |
+
|
| 885 |
+
|
| 886 |
+
mhubert_base_vp_en_es_fr_it3
|
| 887 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 888 |
+
|
| 889 |
+
- The multilingual model from `Textless Speech-to-Speech Translation on Real Data <https://arxiv.org/abs/2112.08352>`_
|
| 890 |
+
|
| 891 |
+
|
| 892 |
+
ESPnetHuBERT
|
| 893 |
+
----------------------
|
| 894 |
+
`Reducing Barriers to Self-Supervised Learning: HuBERT Pre-training with Academic Compute <https://arxiv.org/abs/2306.06672>`_
|
| 895 |
+
|
| 896 |
+
.. code-block:: bash
|
| 897 |
+
|
| 898 |
+
@inproceedings{chen23l_interspeech,
|
| 899 |
+
author={William Chen and Xuankai Chang and Yifan Peng and Zhaoheng Ni and Soumi Maiti and Shinji Watanabe},
|
| 900 |
+
title={{Reducing Barriers to Self-Supervised Learning: HuBERT Pre-training with Academic Compute}},
|
| 901 |
+
year=2023,
|
| 902 |
+
booktitle={Proc. INTERSPEECH 2023},
|
| 903 |
+
pages={4404--4408},
|
| 904 |
+
doi={10.21437/Interspeech.2023-1176}
|
| 905 |
+
}
|
| 906 |
+
|
| 907 |
+
|
| 908 |
+
espnet_hubert_custom
|
| 909 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 910 |
+
|
| 911 |
+
This entry expects you to provide the source of the checkpoint: :code:`ckpt`, which should be
|
| 912 |
+
the local path of the checkpoint pretrained from ESPnet (e.g., latest.pth).
|
| 913 |
+
|
| 914 |
+
|
| 915 |
+
espnet_hubert_base_iter0
|
| 916 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 917 |
+
|
| 918 |
+
- Unlabeled Speech: LibriSpeech 960hr (first iteration of HuBERT pre-training)
|
| 919 |
+
|
| 920 |
+
|
| 921 |
+
espnet_hubert_base_iter1
|
| 922 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 923 |
+
|
| 924 |
+
- Unlabeled Speech: LibriSpeech 960hr (second iteration of HuBERT pre-training)
|
| 925 |
+
|
| 926 |
+
|
| 927 |
+
espnet_hubert_large_gs_ll60k
|
| 928 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 929 |
+
|
| 930 |
+
- Unlabeled Speech: LibriLight ll60k hours
|
| 931 |
+
- Labeled Speech: GigaSpeech 10k hours (to get units)
|
| 932 |
+
|
| 933 |
+
|
| 934 |
+
WavLabLM
|
| 935 |
+
----------------------
|
| 936 |
+
`Joint Prediction and Denoising for Large-scale Multilingual Self-supervised Learning <https://arxiv.org/abs/2309.15317>`_
|
| 937 |
+
|
| 938 |
+
.. code-block:: bash
|
| 939 |
+
|
| 940 |
+
@inproceedings{chen23joint,
|
| 941 |
+
author={William Chen and Jiatong Shi and Brian Yan and Dan Berrebbi and Wangyou Zhang and Yifan Peng and Xuankai Chang and Soumi Maiti and Shinji Watanabe},
|
| 942 |
+
title={Joint Prediction and Denoising for Large-scale Multilingual Self-supervised Learning},
|
| 943 |
+
year=2023,
|
| 944 |
+
booktitle={IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)},
|
| 945 |
+
}
|
| 946 |
+
|
| 947 |
+
|
| 948 |
+
cvhubert
|
| 949 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 950 |
+
|
| 951 |
+
- Unlabeled Speech: Commonvoice V11 Multilingual Data (13.6k hours)
|
| 952 |
+
- only 20ms resolution version is provided. `check huggingface for other resolutions <https://huggingface.co/espnet/espnet_cvhubert/tree/main>`_
|
| 953 |
+
|
| 954 |
+
|
| 955 |
+
wavlablm_ek_40k
|
| 956 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 957 |
+
|
| 958 |
+
- Unlabeled Speech: Openli110 (Combination of Commonvoice, Voxpopuli, MLS, Googlei18n, around 39k hours)
|
| 959 |
+
- Initialed from hubert_large_ll60k and continue train with English based k-means from librispeech
|
| 960 |
+
|
| 961 |
+
|
| 962 |
+
wavlablm_mk_40k
|
| 963 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 964 |
+
|
| 965 |
+
- Unlabeled Speech: Openli110 (Combination of Commonvoice, Voxpopuli, MLS, Googlei18n, around 39k hours)
|
| 966 |
+
- Trained from scratch and use a multilingual k-means from the training data
|
| 967 |
+
|
| 968 |
+
|
| 969 |
+
wavlablm_ms_40k
|
| 970 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 971 |
+
|
| 972 |
+
- Unlabeled Speech: Openli110 (Combination of Commonvoice, Voxpopuli, MLS, Googlei18n, around 39k hours)
|
| 973 |
+
- Trained from scratch and use a multilingual k-means from the training data with a multi-stage training
|
| 974 |
+
|
| 975 |
+
|
| 976 |
+
Multiresolution HuBERT (MR-HuBERT)
|
| 977 |
+
----------------------
|
| 978 |
+
`Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction <https://openreview.net/pdf?id=kUuKFW7DIF>`_
|
| 979 |
+
|
| 980 |
+
.. code-block:: bash
|
| 981 |
+
|
| 982 |
+
@inproceedings{anonymous2023multiresolution,
|
| 983 |
+
title={Multi-resolution Hu{BERT}: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction},
|
| 984 |
+
author={Anonymous},
|
| 985 |
+
booktitle={Submitted to The Twelfth International Conference on Learning Representations},
|
| 986 |
+
year={2023},
|
| 987 |
+
url={https://openreview.net/forum?id=kUuKFW7DIF},
|
| 988 |
+
note={under review}
|
| 989 |
+
}
|
| 990 |
+
|
| 991 |
+
|
| 992 |
+
multires_hubert_custom
|
| 993 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 994 |
+
|
| 995 |
+
This entry expects you to provide the source of the checkpoint: :code:`ckpt`, which should be
|
| 996 |
+
the local path or a url of the checkpoint converted by :code:`s3prl/upstream/multires_hubert/convert.py` (
|
| 997 |
+
from a regular fairseq checkpoint.)
|
| 998 |
+
For more available checkpoints, please check `Fairseq official release <https://github.com/facebookresearch/fairseq/blob/main/examples/mr_hubert/README.md>`_
|
| 999 |
+
Related converted checkpoints are also at `S3PRL HuggingFace Repo <https://huggingface.co/s3prl/mr_hubert>`_
|
| 1000 |
+
|
| 1001 |
+
|
| 1002 |
+
multires_hubert_base
|
| 1003 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 1004 |
+
|
| 1005 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 1006 |
+
- K-means extracted from `hubert_base`_
|
| 1007 |
+
|
| 1008 |
+
|
| 1009 |
+
multires_hubert_large
|
| 1010 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 1011 |
+
|
| 1012 |
+
- Unlabeled Speech: LibriLight 60khr
|
| 1013 |
+
- K-means extracted from `hubert_base`_
|
| 1014 |
+
|
| 1015 |
+
|
| 1016 |
+
multires_hubert_multilingual_base
|
| 1017 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 1018 |
+
|
| 1019 |
+
- Unlabeled Speech: Voxpopuli 100khr
|
| 1020 |
+
- K-means extracted from `hubert_base`_
|
| 1021 |
+
|
| 1022 |
+
|
| 1023 |
+
multires_hubert_multilingual_large400k
|
| 1024 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 1025 |
+
|
| 1026 |
+
- Unlabeled Speech: Voxpopuli 100khr
|
| 1027 |
+
- K-means extracted from `hubert_base`_
|
| 1028 |
+
- Training steps 400k
|
| 1029 |
+
|
| 1030 |
+
|
| 1031 |
+
multires_hubert_multilingual_large600k
|
| 1032 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 1033 |
+
|
| 1034 |
+
- Unlabeled Speech: Voxpopuli 100khr
|
| 1035 |
+
- K-means extracted from `hubert_base`_
|
| 1036 |
+
- Training steps 600k
|
| 1037 |
+
|
| 1038 |
+
|
| 1039 |
+
DistilHuBERT
|
| 1040 |
+
----------------------
|
| 1041 |
+
`DistilHuBERT: Speech Representation Learning by Layer-wise Distillation of Hidden-unit BERT <https://arxiv.org/abs/2110.01900>`_
|
| 1042 |
+
|
| 1043 |
+
.. code-block:: bash
|
| 1044 |
+
|
| 1045 |
+
@inproceedings{chang2022distilhubert,
|
| 1046 |
+
title={DistilHuBERT: Speech representation learning by layer-wise distillation of hidden-unit BERT},
|
| 1047 |
+
author={Chang, Heng-Jui and Yang, Shu-wen and Lee, Hung-yi},
|
| 1048 |
+
booktitle={ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 1049 |
+
pages={7087--7091},
|
| 1050 |
+
year={2022},
|
| 1051 |
+
organization={IEEE}
|
| 1052 |
+
}
|
| 1053 |
+
|
| 1054 |
+
|
| 1055 |
+
distilhubert
|
| 1056 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 1057 |
+
|
| 1058 |
+
Alias of `distilhubert_base`_
|
| 1059 |
+
|
| 1060 |
+
|
| 1061 |
+
distilhubert_base
|
| 1062 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 1063 |
+
|
| 1064 |
+
- Teacher: `hubert_base`_
|
| 1065 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 1066 |
+
|
| 1067 |
+
|
| 1068 |
+
HuBERT-MGR
|
| 1069 |
+
--------------------------------------------------
|
| 1070 |
+
`Improving Distortion Robustness of Self-supervised Speech Processing Tasks with Domain Adaptation <https://arxiv.org/abs/2203.16104>`_
|
| 1071 |
+
|
| 1072 |
+
.. code-block:: bash
|
| 1073 |
+
|
| 1074 |
+
@article{huang2022improving,
|
| 1075 |
+
title={Improving Distortion Robustness of Self-supervised Speech Processing Tasks with Domain Adaptation},
|
| 1076 |
+
author={Huang, Kuan Po and Fu, Yu-Kuan and Zhang, Yu and Lee, Hung-yi},
|
| 1077 |
+
journal={arXiv preprint arXiv:2203.16104},
|
| 1078 |
+
year={2022}
|
| 1079 |
+
}
|
| 1080 |
+
|
| 1081 |
+
|
| 1082 |
+
hubert_base_robust_mgr
|
| 1083 |
+
~~~~~~~~~~~~~~~~~~~~~~~
|
| 1084 |
+
|
| 1085 |
+
- Unlabled Speech: LibriSpeech 960hr
|
| 1086 |
+
- Augmentation: MUSAN, gaussian, reverberation
|
| 1087 |
+
|
| 1088 |
+
|
| 1089 |
+
Unispeech-SAT
|
| 1090 |
+
--------------------------------------------------
|
| 1091 |
+
`Unispeech-sat: Universal speech representation learning with speaker aware pre-training <https://arxiv.org/abs/2110.05752>`_
|
| 1092 |
+
|
| 1093 |
+
.. code-block:: bash
|
| 1094 |
+
|
| 1095 |
+
@inproceedings{chen2022unispeech,
|
| 1096 |
+
title={Unispeech-sat: Universal speech representation learning with speaker aware pre-training},
|
| 1097 |
+
author={Chen, Sanyuan and Wu, Yu and Wang, Chengyi and Chen, Zhengyang and Chen, Zhuo and Liu, Shujie and Wu, Jian and Qian, Yao and Wei, Furu and Li, Jinyu and others},
|
| 1098 |
+
booktitle={ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 1099 |
+
pages={6152--6156},
|
| 1100 |
+
year={2022},
|
| 1101 |
+
organization={IEEE}
|
| 1102 |
+
}
|
| 1103 |
+
|
| 1104 |
+
|
| 1105 |
+
unispeech_sat
|
| 1106 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 1107 |
+
|
| 1108 |
+
Alias of `unispeech_sat_base`_
|
| 1109 |
+
|
| 1110 |
+
|
| 1111 |
+
unispeech_sat_base
|
| 1112 |
+
~~~~~~~~~~~~~~~~~~~~~~
|
| 1113 |
+
|
| 1114 |
+
- Model Architecture: 12 layers Transformer blocks
|
| 1115 |
+
- Unlabled Speech: LibriSpeech 960 hours
|
| 1116 |
+
|
| 1117 |
+
|
| 1118 |
+
unispeech_sat_base_plus
|
| 1119 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 1120 |
+
|
| 1121 |
+
- Model Architecture: 12 layers Transformer blocks
|
| 1122 |
+
- Unlabled Speech: LibriLight 60k hours + Gigaspeech 10k hours + VoxPopuli 24k hours = 94k hours
|
| 1123 |
+
|
| 1124 |
+
|
| 1125 |
+
unispeech_sat_large
|
| 1126 |
+
~~~~~~~~~~~~~~~~~~~~~~~~
|
| 1127 |
+
|
| 1128 |
+
- Model Architecture: 24 layers Transformer blocks
|
| 1129 |
+
- Unlabled Speech: LibriLight 60k hours + Gigaspeech 10k hours + VoxPopuli 24k hours = 94k hours
|
| 1130 |
+
|
| 1131 |
+
|
| 1132 |
+
|
| 1133 |
+
WavLM
|
| 1134 |
+
--------------------------------------------------
|
| 1135 |
+
`WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing <https://arxiv.org/abs/2110.13900>`_
|
| 1136 |
+
|
| 1137 |
+
.. code-block:: bash
|
| 1138 |
+
|
| 1139 |
+
@article{Chen2021WavLM,
|
| 1140 |
+
title = {WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing},
|
| 1141 |
+
author = {Sanyuan Chen and Chengyi Wang and Zhengyang Chen and Yu Wu and Shujie Liu and Zhuo Chen and Jinyu Li and Naoyuki Kanda and Takuya Yoshioka and Xiong Xiao and Jian Wu and Long Zhou and Shuo Ren and Yanmin Qian and Yao Qian and Jian Wu and Michael Zeng and Furu Wei},
|
| 1142 |
+
eprint={2110.13900},
|
| 1143 |
+
archivePrefix={arXiv},
|
| 1144 |
+
primaryClass={cs.CL},
|
| 1145 |
+
year={2021}
|
| 1146 |
+
}
|
| 1147 |
+
|
| 1148 |
+
|
| 1149 |
+
wavlm
|
| 1150 |
+
~~~~~~~~~~~~~~~~~
|
| 1151 |
+
|
| 1152 |
+
Alias of `wavlm_base_plus`_
|
| 1153 |
+
|
| 1154 |
+
|
| 1155 |
+
wavlm_base
|
| 1156 |
+
~~~~~~~~~~~~~~~~
|
| 1157 |
+
|
| 1158 |
+
- Model Architecture: 12 layers Transformer blocks
|
| 1159 |
+
- Unlabled Speech: LibriSpeech 960 hours
|
| 1160 |
+
|
| 1161 |
+
|
| 1162 |
+
wavlm_base_plus
|
| 1163 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 1164 |
+
|
| 1165 |
+
- Model Architecture: 12 layers Transformer blocks
|
| 1166 |
+
- Unlabled Speech: LibriLight 60k hours + Gigaspeech 10k hours + VoxPopuli 24k hours = 94k hours
|
| 1167 |
+
|
| 1168 |
+
|
| 1169 |
+
wavlm_large
|
| 1170 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 1171 |
+
|
| 1172 |
+
- Model Architecture: 24 layers Transformer blocks
|
| 1173 |
+
- Unlabled Speech: LibriLight 60k hours + Gigaspeech 10k hours + VoxPopuli 24k hours = 94k hours
|
| 1174 |
+
|
| 1175 |
+
|
| 1176 |
+
data2vec
|
| 1177 |
+
--------------------------------------------------
|
| 1178 |
+
`data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language <https://arxiv.org/abs/2202.03555>`_
|
| 1179 |
+
|
| 1180 |
+
.. code-block:: bash
|
| 1181 |
+
|
| 1182 |
+
@article{baevski2022data2vec,
|
| 1183 |
+
title={Data2vec: A general framework for self-supervised learning in speech, vision and language},
|
| 1184 |
+
author={Baevski, Alexei and Hsu, Wei-Ning and Xu, Qiantong and Babu, Arun and Gu, Jiatao and Auli, Michael},
|
| 1185 |
+
journal={arXiv preprint arXiv:2202.03555},
|
| 1186 |
+
year={2022}
|
| 1187 |
+
}
|
| 1188 |
+
|
| 1189 |
+
|
| 1190 |
+
data2vec
|
| 1191 |
+
~~~~~~~~~~~~~~~~~
|
| 1192 |
+
|
| 1193 |
+
Alias of `data2vec_base_960`_
|
| 1194 |
+
|
| 1195 |
+
|
| 1196 |
+
data2vec_base_960
|
| 1197 |
+
~~~~~~~~~~~~~~~~~~
|
| 1198 |
+
|
| 1199 |
+
- Model Architecture: 12 layers Transformer blocks
|
| 1200 |
+
- Unlabled Speech: LibriSpeech 960 hours
|
| 1201 |
+
|
| 1202 |
+
|
| 1203 |
+
data2vec_large_ll60k
|
| 1204 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 1205 |
+
|
| 1206 |
+
- Model Architecture: 24 layers Transformer blocks
|
| 1207 |
+
- Unlabled Speech: LibriLight 60k hours
|
| 1208 |
+
|
| 1209 |
+
|
| 1210 |
+
AST
|
| 1211 |
+
--------------------------------------------------
|
| 1212 |
+
`AST: Audio Spectrogram Transformer <https://arxiv.org/abs/2104.01778>`_
|
| 1213 |
+
|
| 1214 |
+
.. code-block:: bash
|
| 1215 |
+
|
| 1216 |
+
@article{gong2021ast,
|
| 1217 |
+
title={Ast: Audio spectrogram transformer},
|
| 1218 |
+
author={Gong, Yuan and Chung, Yu-An and Glass, James},
|
| 1219 |
+
journal={arXiv preprint arXiv:2104.01778},
|
| 1220 |
+
year={2021}
|
| 1221 |
+
}
|
| 1222 |
+
|
| 1223 |
+
|
| 1224 |
+
All the entries below support the following :code:`extra_conf`:
|
| 1225 |
+
|
| 1226 |
+
==================== ====================
|
| 1227 |
+
column description
|
| 1228 |
+
==================== ====================
|
| 1229 |
+
window_secs (float) -
|
| 1230 |
+
The segment waveform length to feed into the
|
| 1231 |
+
AST model. If the input waveform is longer than this
|
| 1232 |
+
length, do sliding windowing on the waveform and concat
|
| 1233 |
+
the results along the time axis.
|
| 1234 |
+
stride_secs (float) -
|
| 1235 |
+
When doing sliding window on the waveform (see
|
| 1236 |
+
above), the stride seconds between windows.
|
| 1237 |
+
==================== ====================
|
| 1238 |
+
|
| 1239 |
+
|
| 1240 |
+
ast
|
| 1241 |
+
~~~~~~~~~~~~~~~~~~
|
| 1242 |
+
|
| 1243 |
+
- Labeled Data: AudioSet
|
| 1244 |
+
|
| 1245 |
+
|
| 1246 |
+
SSAST
|
| 1247 |
+
--------------------------------------------------
|
| 1248 |
+
`SSAST: Self-Supervised Audio Spectrogram Transformer <https://arxiv.org/abs/2110.09784>`_
|
| 1249 |
+
|
| 1250 |
+
.. code-block:: bash
|
| 1251 |
+
|
| 1252 |
+
@inproceedings{gong2022ssast,
|
| 1253 |
+
title={Ssast: Self-supervised audio spectrogram transformer},
|
| 1254 |
+
author={Gong, Yuan and Lai, Cheng-I and Chung, Yu-An and Glass, James},
|
| 1255 |
+
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
|
| 1256 |
+
volume={36},
|
| 1257 |
+
number={10},
|
| 1258 |
+
pages={10699--10709},
|
| 1259 |
+
year={2022}
|
| 1260 |
+
}
|
| 1261 |
+
|
| 1262 |
+
|
| 1263 |
+
All the entries below support the following :code:`extra_conf`:
|
| 1264 |
+
|
| 1265 |
+
==================== ====================
|
| 1266 |
+
column description
|
| 1267 |
+
==================== ====================
|
| 1268 |
+
window_secs (float) -
|
| 1269 |
+
The segment waveform length to feed into the
|
| 1270 |
+
AST model. If the input waveform is longer than this
|
| 1271 |
+
length, do sliding windowing on the waveform and concat
|
| 1272 |
+
the results along the time axis.
|
| 1273 |
+
==================== ====================
|
| 1274 |
+
|
| 1275 |
+
|
| 1276 |
+
ssast_frame_base
|
| 1277 |
+
~~~~~~~~~~~~~~~~~~
|
| 1278 |
+
|
| 1279 |
+
- Unlabled Data: LibriSpeech & AudioSet
|
| 1280 |
+
- fbank patch size: 128 (freq) * 2 (time)
|
| 1281 |
+
|
| 1282 |
+
ssast_patch_base
|
| 1283 |
+
~~~~~~~~~~~~~~~~~~~
|
| 1284 |
+
|
| 1285 |
+
- Unlabled Data: LibriSpeech & AudioSet
|
| 1286 |
+
- fbank patch size: 16 (freq) * 16 (time)
|
| 1287 |
+
|
| 1288 |
+
|
| 1289 |
+
MAE-AST
|
| 1290 |
+
--------------------------------------------------
|
| 1291 |
+
`MAE-AST: Masked Autoencoding Audio Spectrogram Transformer <https://arxiv.org/abs/2203.16691>`_
|
| 1292 |
+
|
| 1293 |
+
.. code-block:: bash
|
| 1294 |
+
|
| 1295 |
+
@article{baade2022mae,
|
| 1296 |
+
title={MAE-AST: Masked Autoencoding Audio Spectrogram Transformer},
|
| 1297 |
+
author={Baade, Alan and Peng, Puyuan and Harwath, David},
|
| 1298 |
+
journal={arXiv preprint arXiv:2203.16691},
|
| 1299 |
+
year={2022}
|
| 1300 |
+
}
|
| 1301 |
+
|
| 1302 |
+
|
| 1303 |
+
mae_ast_frame
|
| 1304 |
+
~~~~~~~~~~~~~~~~~~
|
| 1305 |
+
|
| 1306 |
+
- Unlabled Data: LibriSpeech & AudioSet
|
| 1307 |
+
- fbank patch size: 128 (freq) * 2 (time)
|
| 1308 |
+
|
| 1309 |
+
|
| 1310 |
+
mae_ast_patch
|
| 1311 |
+
~~~~~~~~~~~~~~~~~~
|
| 1312 |
+
|
| 1313 |
+
- Unlabled Data: LibriSpeech & AudioSet
|
| 1314 |
+
- fbank patch size: 16 (freq) * 16 (time)
|
| 1315 |
+
|
| 1316 |
+
|
| 1317 |
+
Byol-A
|
| 1318 |
+
--------------------------------------------------
|
| 1319 |
+
`BYOL for Audio: Self-Supervised Learning for General-Purpose Audio Representation <https://arxiv.org/abs/2103.06695>`_
|
| 1320 |
+
|
| 1321 |
+
.. code-block:: bash
|
| 1322 |
+
|
| 1323 |
+
@inproceedings{niizumi2021byol,
|
| 1324 |
+
title={BYOL for audio: Self-supervised learning for general-purpose audio representation},
|
| 1325 |
+
author={Niizumi, Daisuke and Takeuchi, Daiki and Ohishi, Yasunori and Harada, Noboru and Kashino, Kunio},
|
| 1326 |
+
booktitle={2021 International Joint Conference on Neural Networks (IJCNN)},
|
| 1327 |
+
pages={1--8},
|
| 1328 |
+
year={2021},
|
| 1329 |
+
organization={IEEE}
|
| 1330 |
+
}
|
| 1331 |
+
|
| 1332 |
+
|
| 1333 |
+
All the entries below support the following :code:`extra_conf`:
|
| 1334 |
+
|
| 1335 |
+
==================== ====================
|
| 1336 |
+
column description
|
| 1337 |
+
==================== ====================
|
| 1338 |
+
window_secs (float) -
|
| 1339 |
+
The segment waveform length to feed into the
|
| 1340 |
+
AST model. If the input waveform is longer than this
|
| 1341 |
+
length, do sliding windowing on the waveform and concat
|
| 1342 |
+
the results along the time axis.
|
| 1343 |
+
stride_secs (float) -
|
| 1344 |
+
When doing sliding window on the waveform (see
|
| 1345 |
+
above), the stride seconds between windows.
|
| 1346 |
+
==================== ====================
|
| 1347 |
+
|
| 1348 |
+
|
| 1349 |
+
byol_a_2048
|
| 1350 |
+
~~~~~~~~~~~~~~~~~~
|
| 1351 |
+
|
| 1352 |
+
- Unlabled Data: AudioSet
|
| 1353 |
+
|
| 1354 |
+
|
| 1355 |
+
byol_a_1024
|
| 1356 |
+
~~~~~~~~~~~~~~~~~~
|
| 1357 |
+
|
| 1358 |
+
- Unlabled Data: AudioSet
|
| 1359 |
+
|
| 1360 |
+
|
| 1361 |
+
byol_a_512
|
| 1362 |
+
~~~~~~~~~~~~~~~~~~
|
| 1363 |
+
|
| 1364 |
+
- Unlabled Data: AudioSet
|
| 1365 |
+
|
| 1366 |
+
|
| 1367 |
+
Byol-S
|
| 1368 |
+
--------------------------------------------------
|
| 1369 |
+
`BYOL-S: Learning Self-supervised Speech Representations by Bootstrapping <https://arxiv.org/abs/2206.12038>`_
|
| 1370 |
+
|
| 1371 |
+
.. code-block:: bash
|
| 1372 |
+
|
| 1373 |
+
@article{elbanna2022byol,
|
| 1374 |
+
title={Byol-s: Learning self-supervised speech representations by bootstrapping},
|
| 1375 |
+
author={Elbanna, Gasser and Scheidwasser-Clow, Neil and Kegler, Mikolaj and Beckmann, Pierre and Hajal, Karl El and Cernak, Milos},
|
| 1376 |
+
journal={arXiv preprint arXiv:2206.12038},
|
| 1377 |
+
year={2022}
|
| 1378 |
+
}
|
| 1379 |
+
|
| 1380 |
+
|
| 1381 |
+
byol_s_default
|
| 1382 |
+
~~~~~~~~~~~~~~~~~~
|
| 1383 |
+
|
| 1384 |
+
- Unlabled Data: AudioSet (Speech subset)
|
| 1385 |
+
|
| 1386 |
+
|
| 1387 |
+
byol_s_cvt
|
| 1388 |
+
~~~~~~~~~~~~~~~~~~
|
| 1389 |
+
|
| 1390 |
+
- Unlabled Data: AudioSet (Speech subset)
|
| 1391 |
+
|
| 1392 |
+
|
| 1393 |
+
byol_s_resnetish34
|
| 1394 |
+
~~~~~~~~~~~~~~~~~~
|
| 1395 |
+
|
| 1396 |
+
- Unlabled Data: AudioSet (Speech subset)
|
| 1397 |
+
|
| 1398 |
+
|
| 1399 |
+
VGGish
|
| 1400 |
+
--------------------------------------------------
|
| 1401 |
+
`CNN Architectures for Large-Scale Audio Classification <https://arxiv.org/abs/1609.09430>`_
|
| 1402 |
+
|
| 1403 |
+
.. code-block:: bash
|
| 1404 |
+
|
| 1405 |
+
@inproceedings{hershey2017cnn,
|
| 1406 |
+
title={CNN architectures for large-scale audio classification},
|
| 1407 |
+
author={Hershey, Shawn and Chaudhuri, Sourish and Ellis, Daniel PW and Gemmeke, Jort F and Jansen, Aren and Moore, R Channing and Plakal, Manoj and Platt, Devin and Saurous, Rif A and Seybold, Bryan and others},
|
| 1408 |
+
booktitle={2017 ieee international conference on acoustics, speech and signal processing (icassp)},
|
| 1409 |
+
pages={131--135},
|
| 1410 |
+
year={2017},
|
| 1411 |
+
organization={IEEE}
|
| 1412 |
+
}
|
| 1413 |
+
|
| 1414 |
+
|
| 1415 |
+
vggish
|
| 1416 |
+
~~~~~~~~~~~~~~~~~~
|
| 1417 |
+
|
| 1418 |
+
- Labaled Data: AudioSet
|
| 1419 |
+
|
| 1420 |
+
|
| 1421 |
+
PaSST
|
| 1422 |
+
--------------------------------------------------
|
| 1423 |
+
`Efficient Training of Audio Transformers with Patchout <https://arxiv.org/abs/2110.05069>`_
|
| 1424 |
+
|
| 1425 |
+
.. code-block:: bash
|
| 1426 |
+
|
| 1427 |
+
@article{koutini2021efficient,
|
| 1428 |
+
title={Efficient training of audio transformers with patchout},
|
| 1429 |
+
author={Koutini, Khaled and Schl{\"u}ter, Jan and Eghbal-zadeh, Hamid and Widmer, Gerhard},
|
| 1430 |
+
journal={arXiv preprint arXiv:2110.05069},
|
| 1431 |
+
year={2021}
|
| 1432 |
+
}
|
| 1433 |
+
|
| 1434 |
+
All the entries below support the following :code:`extra_conf`:
|
| 1435 |
+
|
| 1436 |
+
==================== ====================
|
| 1437 |
+
column description
|
| 1438 |
+
==================== ====================
|
| 1439 |
+
window_secs (float) -
|
| 1440 |
+
The segment waveform length to feed into the
|
| 1441 |
+
model. If the input waveform is longer than this
|
| 1442 |
+
length, do sliding windowing on the waveform and concat
|
| 1443 |
+
the results along the time axis.
|
| 1444 |
+
stride_secs (float) -
|
| 1445 |
+
When doing sliding window on the waveform (see
|
| 1446 |
+
above), the stride seconds between windows.
|
| 1447 |
+
==================== ====================
|
| 1448 |
+
|
| 1449 |
+
passt_base
|
| 1450 |
+
~~~~~~~~~~~~~~~~~~
|
| 1451 |
+
|
| 1452 |
+
- Labaled Data: AudioSet
|
| 1453 |
+
|
| 1454 |
+
|
| 1455 |
+
Authors:
|
| 1456 |
+
|
| 1457 |
+
- Leo 2022
|
s3prl_s3prl_main/docs/util/is_valid.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import argparse
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
if __name__ == "__main__":
|
| 6 |
+
parser = argparse.ArgumentParser()
|
| 7 |
+
parser.add_argument("module_root")
|
| 8 |
+
parser.add_argument("valid_paths")
|
| 9 |
+
args = parser.parse_args()
|
| 10 |
+
|
| 11 |
+
with open(args.valid_paths) as file:
|
| 12 |
+
valid_paths = [line.strip() for line in file.readlines()]
|
| 13 |
+
|
| 14 |
+
ignored_paths = []
|
| 15 |
+
module_root_name = Path(args.module_root).stem
|
| 16 |
+
for item in os.listdir(args.module_root):
|
| 17 |
+
pattern = f"{module_root_name}/{item}"
|
| 18 |
+
if pattern not in valid_paths:
|
| 19 |
+
ignored_paths.append(pattern)
|
| 20 |
+
|
| 21 |
+
print(" ".join(ignored_paths))
|
s3prl_s3prl_main/example/customize.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from s3prl.problem import SuperbASR
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class LowResourceLinearSuperbASR(SuperbASR):
|
| 8 |
+
def prepare_data(
|
| 9 |
+
self, prepare_data: dict, target_dir: str, cache_dir: str, get_path_only=False
|
| 10 |
+
):
|
| 11 |
+
train_path, valid_path, test_paths = super().prepare_data(
|
| 12 |
+
prepare_data, target_dir, cache_dir, get_path_only
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
# Take only the first 100 utterances for training
|
| 16 |
+
df = pd.read_csv(train_path)
|
| 17 |
+
df = df.iloc[:100]
|
| 18 |
+
df.to_csv(train_path, index=False)
|
| 19 |
+
|
| 20 |
+
return train_path, valid_path, test_paths
|
| 21 |
+
|
| 22 |
+
def build_downstream(
|
| 23 |
+
self,
|
| 24 |
+
build_downstream: dict,
|
| 25 |
+
downstream_input_size: int,
|
| 26 |
+
downstream_output_size: int,
|
| 27 |
+
downstream_input_stride: int,
|
| 28 |
+
):
|
| 29 |
+
import torch
|
| 30 |
+
|
| 31 |
+
class Model(torch.nn.Module):
|
| 32 |
+
def __init__(self, input_size, output_size) -> None:
|
| 33 |
+
super().__init__()
|
| 34 |
+
self.linear = torch.nn.Linear(input_size, output_size)
|
| 35 |
+
|
| 36 |
+
def forward(self, x, x_len):
|
| 37 |
+
return self.linear(x), x_len
|
| 38 |
+
|
| 39 |
+
return Model(downstream_input_size, downstream_output_size)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
if __name__ == "__main__":
|
| 43 |
+
LowResourceLinearSuperbASR().main()
|
s3prl_s3prl_main/example/run_asr.sh
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
python3 s3prl/main.py SuperbASR --target_dir result/asr --prepare_data.dataset_root /home/leo/d/datasets/LibriSpeech/ --build_upstream.name apc
|
s3prl_s3prl_main/example/run_sid.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
python3 s3prl/main.py SuperbSID --target_dir result/tmp/ic --prepare_data.dataset_root /home/leo/d/datasets/VoxCeleb1/ --build_upstream.name apc
|
| 4 |
+
|
s3prl_s3prl_main/example/ssl/pretrain.py
ADDED
|
@@ -0,0 +1,285 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import math
|
| 4 |
+
import os
|
| 5 |
+
from copy import deepcopy
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from torch.utils.data import DataLoader
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
|
| 12 |
+
from s3prl import Container, Logs, Object, Output
|
| 13 |
+
from s3prl.dataset.base import AugmentedDynamicItemDataset, DataLoader
|
| 14 |
+
from s3prl.sampler import DistributedBatchSamplerWrapper
|
| 15 |
+
from s3prl.util.configuration import parse_override, qualname_to_cls
|
| 16 |
+
from s3prl.util.seed import fix_random_seeds
|
| 17 |
+
|
| 18 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 19 |
+
logger = logging.getLogger(__name__)
|
| 20 |
+
|
| 21 |
+
DRYRUN_CONFIG = dict(
|
| 22 |
+
Trainer=dict(
|
| 23 |
+
total_steps=200000,
|
| 24 |
+
log_step=5000,
|
| 25 |
+
valid_step=5000,
|
| 26 |
+
save_step=5000,
|
| 27 |
+
eval_batch=8,
|
| 28 |
+
),
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def parse_args():
|
| 33 |
+
parser = argparse.ArgumentParser()
|
| 34 |
+
parser.add_argument(
|
| 35 |
+
"problem", help="The problem module. E.g. `s3prl.problem.ssl.tera.Tera`"
|
| 36 |
+
)
|
| 37 |
+
parser.add_argument("dataset_root", help="The dataset root for pretrain.")
|
| 38 |
+
parser.add_argument("save_to", help="The directory to save checkpoint")
|
| 39 |
+
parser.add_argument("--n_jobs", type=int, default=8)
|
| 40 |
+
parser.add_argument(
|
| 41 |
+
"--override",
|
| 42 |
+
default=None,
|
| 43 |
+
help=(
|
| 44 |
+
"Override the default_config of the problem module. "
|
| 45 |
+
"E.g. --override ValidSampler.batch_size=4,,TestSampler.batch_size=4"
|
| 46 |
+
),
|
| 47 |
+
)
|
| 48 |
+
parser.add_argument("--resume", action="store_true")
|
| 49 |
+
parser.add_argument("--dryrun", action="store_true")
|
| 50 |
+
parser.add_argument("--seed", type=int, default=1337)
|
| 51 |
+
args = parser.parse_args()
|
| 52 |
+
|
| 53 |
+
fix_random_seeds(args.seed)
|
| 54 |
+
problem = qualname_to_cls(args.problem)
|
| 55 |
+
config = Container(deepcopy(problem.default_config))
|
| 56 |
+
|
| 57 |
+
for key, value in vars(args).items():
|
| 58 |
+
if key not in ["override"]:
|
| 59 |
+
config[key] = value
|
| 60 |
+
|
| 61 |
+
if args.dryrun:
|
| 62 |
+
config.override(DRYRUN_CONFIG)
|
| 63 |
+
|
| 64 |
+
if isinstance(args.override, str) and len(args.override) > 0:
|
| 65 |
+
override_dict = parse_override(args.override)
|
| 66 |
+
config.override(override_dict)
|
| 67 |
+
|
| 68 |
+
return problem, config
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def main():
|
| 72 |
+
logging.basicConfig(level=logging.INFO)
|
| 73 |
+
|
| 74 |
+
problem, config = parse_args()
|
| 75 |
+
save_to = Path(config.save_to)
|
| 76 |
+
save_to.mkdir(exist_ok=True, parents=True)
|
| 77 |
+
|
| 78 |
+
# configure any upstream
|
| 79 |
+
body = problem.Body(**config.Body)
|
| 80 |
+
head = problem.Head(**config.Head)
|
| 81 |
+
loss = problem.Loss(**config.Loss)
|
| 82 |
+
stats = Container()
|
| 83 |
+
|
| 84 |
+
logger.info("Preparing corpus")
|
| 85 |
+
corpus = problem.Corpus(config.dataset_root, **config.Corpus)
|
| 86 |
+
train_data, valid_data, test_data, corpus_stats = corpus().split(3)
|
| 87 |
+
stats.add(corpus_stats)
|
| 88 |
+
|
| 89 |
+
logger.info("Preparing train data")
|
| 90 |
+
train_dataset = AugmentedDynamicItemDataset(train_data, tools=stats)
|
| 91 |
+
train_dataset = problem.TrainData(**config.TrainData)(train_dataset)
|
| 92 |
+
assert train_dataset.get_tool("feat_dim") == problem.input_size
|
| 93 |
+
train_sampler = DistributedBatchSamplerWrapper(
|
| 94 |
+
problem.TrainSampler(train_dataset, **config.TrainSampler),
|
| 95 |
+
num_replicas=1,
|
| 96 |
+
rank=0,
|
| 97 |
+
)
|
| 98 |
+
train_dataloader = DataLoader(
|
| 99 |
+
train_dataset,
|
| 100 |
+
train_sampler,
|
| 101 |
+
num_workers=config.n_jobs,
|
| 102 |
+
)
|
| 103 |
+
stats.add(train_dataset.all_tools())
|
| 104 |
+
|
| 105 |
+
logger.info("Preparing valid data")
|
| 106 |
+
valid_dataset = AugmentedDynamicItemDataset(valid_data, tools=stats)
|
| 107 |
+
valid_dataset = problem.ValidData(**config.ValidData)(valid_dataset)
|
| 108 |
+
valid_sampler = DistributedBatchSamplerWrapper(
|
| 109 |
+
problem.ValidSampler(valid_dataset, **config.ValidSampler),
|
| 110 |
+
num_replicas=1,
|
| 111 |
+
rank=0,
|
| 112 |
+
)
|
| 113 |
+
valid_dataloader = DataLoader(
|
| 114 |
+
valid_dataset,
|
| 115 |
+
valid_sampler,
|
| 116 |
+
num_workers=12,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
logger.info("Preparing test data")
|
| 120 |
+
test_dataset = AugmentedDynamicItemDataset(test_data, tools=stats)
|
| 121 |
+
test_dataset = problem.TestData(**config.TestData)(test_dataset)
|
| 122 |
+
test_sampler = DistributedBatchSamplerWrapper(
|
| 123 |
+
problem.ValidSampler(test_dataset, **config.TestSampler),
|
| 124 |
+
num_replicas=1,
|
| 125 |
+
rank=0,
|
| 126 |
+
)
|
| 127 |
+
test_dataloader = DataLoader(
|
| 128 |
+
test_dataset,
|
| 129 |
+
test_sampler,
|
| 130 |
+
num_workers=12,
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
sorted_ckpt_dirs = sorted(
|
| 134 |
+
[
|
| 135 |
+
file
|
| 136 |
+
for file in save_to.iterdir()
|
| 137 |
+
if file.is_dir() and str(file).endswith(".ckpts")
|
| 138 |
+
],
|
| 139 |
+
key=os.path.getmtime,
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
if config.resume and len(sorted_ckpt_dirs) > 0:
|
| 143 |
+
logger.info("Last checkpoint found. Load model and optimizer from checkpoint")
|
| 144 |
+
task = Object.load_checkpoint(sorted_ckpt_dirs[1] / "task.ckpt").to(device)
|
| 145 |
+
else:
|
| 146 |
+
logger.info("Create a new model")
|
| 147 |
+
task = problem.Task(body, head, loss, **stats)
|
| 148 |
+
task = task.to(device)
|
| 149 |
+
|
| 150 |
+
# ALL THE FOLLOWING CODES ARE FOR TRAINER
|
| 151 |
+
# WHICH CAN BE LARGELY SIMPLIFIED WHEN USING OTHER TRAINER PACKAGES
|
| 152 |
+
|
| 153 |
+
opt_cls_qualname, opt_cfgs = config.Optimizer.split(1)
|
| 154 |
+
optimizer = qualname_to_cls(opt_cls_qualname)(task.parameters(), **opt_cfgs)
|
| 155 |
+
if config.resume and len(sorted_ckpt_dirs) > 0:
|
| 156 |
+
optimizer.load_state_dict(torch.load(sorted_ckpt_dirs[-1] / "optimizer.ckpt"))
|
| 157 |
+
|
| 158 |
+
if config.Trainer.use_valid:
|
| 159 |
+
if config.resume and len(sorted_ckpt_dirs) > 0:
|
| 160 |
+
valid_best_score = torch.load(
|
| 161 |
+
sorted_ckpt_dirs[-1] / "valid_best_score.ckpt"
|
| 162 |
+
)[config.Trainer.valid_metric]
|
| 163 |
+
else:
|
| 164 |
+
valid_best_score = -100000 if config.Trainer.valid_higher_better else 100000
|
| 165 |
+
|
| 166 |
+
def save_checkpoint(name):
|
| 167 |
+
ckpt_dir: Path = save_to / f"{name}.ckpts"
|
| 168 |
+
ckpt_dir.mkdir(parents=True, exist_ok=True)
|
| 169 |
+
logger.info(f"Save checkpoint to: {ckpt_dir}")
|
| 170 |
+
|
| 171 |
+
if hasattr(problem, "save_checkpoint"):
|
| 172 |
+
logger.info(f"Save upstream checkpoint to: {ckpt_dir}")
|
| 173 |
+
problem.save_checkpoint(config, body, head, ckpt_dir / "upstream.ckpt")
|
| 174 |
+
task.save_checkpoint(ckpt_dir / "task.ckpt")
|
| 175 |
+
torch.save(optimizer.state_dict(), ckpt_dir / "optimizer.ckpt")
|
| 176 |
+
torch.save(
|
| 177 |
+
{config.Trainer.valid_metric: valid_best_score},
|
| 178 |
+
ckpt_dir / "valid_best_score.ckpt",
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
pbar = tqdm(total=config.Trainer.total_steps, desc="Total")
|
| 182 |
+
train_completed = False
|
| 183 |
+
accum_grad_steps = 0
|
| 184 |
+
while not train_completed:
|
| 185 |
+
batch_results = []
|
| 186 |
+
for batch in tqdm(train_dataloader, desc="Train", total=len(train_dataloader)):
|
| 187 |
+
pbar.update(1)
|
| 188 |
+
global_step = pbar.n
|
| 189 |
+
|
| 190 |
+
assert isinstance(batch, Output)
|
| 191 |
+
batch = batch.to(device)
|
| 192 |
+
|
| 193 |
+
task.train()
|
| 194 |
+
result = task.train_step(**batch)
|
| 195 |
+
assert isinstance(result, Output)
|
| 196 |
+
|
| 197 |
+
result.loss /= config.Trainer.gradient_accumulate_steps
|
| 198 |
+
result.loss.backward()
|
| 199 |
+
|
| 200 |
+
grad_norm = torch.nn.utils.clip_grad_norm_(
|
| 201 |
+
task.parameters(), max_norm=config.Trainer.gradient_clipping
|
| 202 |
+
)
|
| 203 |
+
|
| 204 |
+
if math.isnan(grad_norm):
|
| 205 |
+
logger.warning(f"Grad norm is NaN at step {global_step}")
|
| 206 |
+
optimizer.zero_grad()
|
| 207 |
+
accum_grad_steps = 0
|
| 208 |
+
else:
|
| 209 |
+
accum_grad_steps += 1
|
| 210 |
+
if accum_grad_steps == config.Trainer.gradient_accumulate_steps:
|
| 211 |
+
optimizer.step()
|
| 212 |
+
optimizer.zero_grad()
|
| 213 |
+
accum_grad_steps = 0
|
| 214 |
+
batch_results.append(result.cacheable())
|
| 215 |
+
|
| 216 |
+
if global_step % config.Trainer.log_step == 0:
|
| 217 |
+
logs: Logs = task.train_reduction(batch_results).logs
|
| 218 |
+
logger.info(f"[Train] step {global_step}")
|
| 219 |
+
for name, value in logs.Scalar.items():
|
| 220 |
+
if name == "loss":
|
| 221 |
+
value *= config.Trainer.gradient_accumulate_steps
|
| 222 |
+
logger.info(f"{name}: {value}")
|
| 223 |
+
batch_results = []
|
| 224 |
+
|
| 225 |
+
if global_step % config.Trainer.valid_step == 0:
|
| 226 |
+
with torch.no_grad():
|
| 227 |
+
if config.Trainer.use_valid:
|
| 228 |
+
valid_results = []
|
| 229 |
+
for batch_idx, batch in enumerate(
|
| 230 |
+
tqdm(
|
| 231 |
+
valid_dataloader,
|
| 232 |
+
desc="Valid",
|
| 233 |
+
total=len(valid_dataloader),
|
| 234 |
+
)
|
| 235 |
+
):
|
| 236 |
+
if batch_idx == config.Trainer.get("eval_batch", -1):
|
| 237 |
+
break
|
| 238 |
+
batch = batch.to(device)
|
| 239 |
+
task.eval()
|
| 240 |
+
result = task.valid_step(**batch)
|
| 241 |
+
valid_results.append(result.cacheable())
|
| 242 |
+
|
| 243 |
+
logs: Logs = task.valid_reduction(valid_results).slice(1)
|
| 244 |
+
logger.info(f"[Valid] step {global_step}")
|
| 245 |
+
for name, value in logs.Scalar.items():
|
| 246 |
+
logger.info(f"{name}: {value}")
|
| 247 |
+
if name == config.Trainer.valid_metric:
|
| 248 |
+
cond1 = config.Trainer.valid_higher_better and (
|
| 249 |
+
value > valid_best_score
|
| 250 |
+
)
|
| 251 |
+
cond2 = (not config.Trainer.valid_higher_better) and (
|
| 252 |
+
value < valid_best_score
|
| 253 |
+
)
|
| 254 |
+
if cond1 or cond2:
|
| 255 |
+
valid_best_score = value
|
| 256 |
+
save_checkpoint("valid_best")
|
| 257 |
+
|
| 258 |
+
if (
|
| 259 |
+
global_step % config.Trainer.save_step == 0
|
| 260 |
+
or global_step == config.Trainer.total_steps
|
| 261 |
+
):
|
| 262 |
+
save_checkpoint(f"global_step_{global_step}")
|
| 263 |
+
|
| 264 |
+
if global_step == config.Trainer.total_steps:
|
| 265 |
+
train_completed = True
|
| 266 |
+
break
|
| 267 |
+
|
| 268 |
+
test_results = []
|
| 269 |
+
for batch_idx, batch in enumerate(
|
| 270 |
+
tqdm(test_dataloader, desc="Test", total=len(test_dataloader))
|
| 271 |
+
):
|
| 272 |
+
if batch_idx == config.Trainer.get("eval_batch", -1):
|
| 273 |
+
break
|
| 274 |
+
batch = batch.to(device)
|
| 275 |
+
result = task.test_step(**batch)
|
| 276 |
+
test_results.append(result.cacheable())
|
| 277 |
+
|
| 278 |
+
logs: Logs = task.test_reduction(test_results).slice(1)
|
| 279 |
+
logger.info(f"[Test] step {global_step}")
|
| 280 |
+
for name, value in logs.Scalar.items():
|
| 281 |
+
logger.info(f"{name}: {value}")
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
if __name__ == "__main__":
|
| 285 |
+
main()
|
s3prl_s3prl_main/example/superb/train.py
ADDED
|
@@ -0,0 +1,291 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import math
|
| 4 |
+
import os
|
| 5 |
+
from copy import deepcopy
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
|
| 11 |
+
from s3prl import Container, Logs, Object, Output
|
| 12 |
+
from s3prl.dataset.base import AugmentedDynamicItemDataset, DataLoader
|
| 13 |
+
from s3prl.nn import S3PRLUpstream, UpstreamDownstreamModel
|
| 14 |
+
from s3prl.sampler import DistributedBatchSamplerWrapper
|
| 15 |
+
from s3prl.util.configuration import parse_override, qualname_to_cls
|
| 16 |
+
from s3prl.util.seed import fix_random_seeds
|
| 17 |
+
|
| 18 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 19 |
+
logger = logging.getLogger(__name__)
|
| 20 |
+
|
| 21 |
+
DRYRUN_CONFIG = dict(
|
| 22 |
+
Trainer=dict(
|
| 23 |
+
total_steps=10,
|
| 24 |
+
log_step=2,
|
| 25 |
+
valid_step=5,
|
| 26 |
+
save_step=5,
|
| 27 |
+
eval_batch=5,
|
| 28 |
+
),
|
| 29 |
+
)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def parse_args():
|
| 33 |
+
parser = argparse.ArgumentParser()
|
| 34 |
+
parser.add_argument("upstream", help="The upstream name. E.g. wav2vec2")
|
| 35 |
+
parser.add_argument(
|
| 36 |
+
"problem",
|
| 37 |
+
help="The problem module. E.g. s3prl.problem.SuperbSID",
|
| 38 |
+
)
|
| 39 |
+
parser.add_argument(
|
| 40 |
+
"dataset_root",
|
| 41 |
+
help="The dataset root of your problem.",
|
| 42 |
+
)
|
| 43 |
+
parser.add_argument("save_to", help="The directory to save checkpoint")
|
| 44 |
+
parser.add_argument("--feature_selection", default="hidden_states")
|
| 45 |
+
parser.add_argument("--n_jobs", type=int, default=6)
|
| 46 |
+
parser.add_argument(
|
| 47 |
+
"--override",
|
| 48 |
+
default=None,
|
| 49 |
+
help=(
|
| 50 |
+
"Override the default_config of the problem module. "
|
| 51 |
+
"E.g. --override ValidSampler.batch_size=4,,TestSampler.batch_size=4"
|
| 52 |
+
),
|
| 53 |
+
)
|
| 54 |
+
parser.add_argument("--resume", action="store_true")
|
| 55 |
+
parser.add_argument("--dryrun", action="store_true")
|
| 56 |
+
parser.add_argument("--seed", type=int, default=1337)
|
| 57 |
+
args = parser.parse_args()
|
| 58 |
+
|
| 59 |
+
fix_random_seeds(args.seed)
|
| 60 |
+
problem = qualname_to_cls(args.problem)
|
| 61 |
+
config = Container(deepcopy(problem.default_config))
|
| 62 |
+
|
| 63 |
+
for key, value in vars(args).items():
|
| 64 |
+
if key not in ["override"]:
|
| 65 |
+
config[key] = value
|
| 66 |
+
|
| 67 |
+
if args.dryrun:
|
| 68 |
+
config.override(DRYRUN_CONFIG)
|
| 69 |
+
|
| 70 |
+
if isinstance(args.override, str) and len(args.override) > 0:
|
| 71 |
+
override_dict = parse_override(args.override)
|
| 72 |
+
config.override(override_dict)
|
| 73 |
+
|
| 74 |
+
return problem, config
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def main():
|
| 78 |
+
logging.basicConfig(level=logging.INFO)
|
| 79 |
+
|
| 80 |
+
problem, config = parse_args()
|
| 81 |
+
save_to = Path(config.save_to)
|
| 82 |
+
save_to.mkdir(exist_ok=True, parents=True)
|
| 83 |
+
|
| 84 |
+
# configure any upstream
|
| 85 |
+
upstream = S3PRLUpstream(config.upstream, config.feature_selection)
|
| 86 |
+
stats = Container(upstream_rate=upstream.downsample_rate)
|
| 87 |
+
|
| 88 |
+
logger.info("Preparing corpus")
|
| 89 |
+
corpus = problem.Corpus(config.dataset_root, **config.Corpus)
|
| 90 |
+
train_data, valid_data, test_data, corpus_stats = corpus().split(3)
|
| 91 |
+
stats.add(corpus_stats)
|
| 92 |
+
|
| 93 |
+
logger.info("Preparing train data")
|
| 94 |
+
train_dataset = AugmentedDynamicItemDataset(train_data, tools=stats)
|
| 95 |
+
train_dataset = problem.TrainData(**config.TrainData)(train_dataset)
|
| 96 |
+
train_sampler = DistributedBatchSamplerWrapper(
|
| 97 |
+
problem.TrainSampler(train_dataset, **config.TrainSampler),
|
| 98 |
+
num_replicas=1,
|
| 99 |
+
rank=0,
|
| 100 |
+
)
|
| 101 |
+
train_dataloader = DataLoader(
|
| 102 |
+
train_dataset,
|
| 103 |
+
train_sampler,
|
| 104 |
+
num_workers=config.n_jobs,
|
| 105 |
+
)
|
| 106 |
+
stats.add(train_dataset.all_tools())
|
| 107 |
+
|
| 108 |
+
logger.info("Preparing valid data")
|
| 109 |
+
valid_dataset = AugmentedDynamicItemDataset(valid_data, tools=stats)
|
| 110 |
+
valid_dataset = problem.ValidData(**config.ValidData)(valid_dataset)
|
| 111 |
+
valid_sampler = DistributedBatchSamplerWrapper(
|
| 112 |
+
problem.ValidSampler(valid_dataset, **config.ValidSampler),
|
| 113 |
+
num_replicas=1,
|
| 114 |
+
rank=0,
|
| 115 |
+
)
|
| 116 |
+
valid_dataloader = DataLoader(
|
| 117 |
+
valid_dataset,
|
| 118 |
+
valid_sampler,
|
| 119 |
+
num_workers=12,
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
logger.info("Preparing test data")
|
| 123 |
+
test_dataset = AugmentedDynamicItemDataset(test_data, tools=stats)
|
| 124 |
+
test_dataset = problem.TestData(**config.TestData)(test_dataset)
|
| 125 |
+
test_sampler = DistributedBatchSamplerWrapper(
|
| 126 |
+
problem.ValidSampler(test_dataset, **config.TestSampler),
|
| 127 |
+
num_replicas=1,
|
| 128 |
+
rank=0,
|
| 129 |
+
)
|
| 130 |
+
test_dataloader = DataLoader(
|
| 131 |
+
test_dataset,
|
| 132 |
+
test_sampler,
|
| 133 |
+
num_workers=12,
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
sorted_ckpt_dirs = sorted(
|
| 137 |
+
[
|
| 138 |
+
file
|
| 139 |
+
for file in save_to.iterdir()
|
| 140 |
+
if file.is_dir() and str(file).endswith(".ckpts")
|
| 141 |
+
],
|
| 142 |
+
key=os.path.getmtime,
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
if config.resume and len(sorted_ckpt_dirs) > 0:
|
| 146 |
+
logger.info("Last checkpoint found. Load model and optimizer from checkpoint")
|
| 147 |
+
task = Object.load_checkpoint(sorted_ckpt_dirs[1] / "task.ckpt").to(device)
|
| 148 |
+
else:
|
| 149 |
+
logger.info("Create a new model")
|
| 150 |
+
downstream = problem.Downstream(
|
| 151 |
+
upstream.output_size,
|
| 152 |
+
**stats,
|
| 153 |
+
)
|
| 154 |
+
model = UpstreamDownstreamModel(upstream, downstream)
|
| 155 |
+
# task = problem.Task(model, **{**stats, **config.Task})
|
| 156 |
+
task = problem.Task(model, **stats, **config.Task)
|
| 157 |
+
task = task.to(device)
|
| 158 |
+
|
| 159 |
+
# ALL THE FOLLOWING CODES ARE FOR TRAINER
|
| 160 |
+
# WHICH CAN BE LARGELY SIMPLIFIED WHEN USING OTHER TRAINER PACKAGES
|
| 161 |
+
|
| 162 |
+
opt_cls_qualname, opt_cfgs = config.Optimizer.split(1)
|
| 163 |
+
optimizer = qualname_to_cls(opt_cls_qualname)(task.parameters(), **opt_cfgs)
|
| 164 |
+
if config.resume and len(sorted_ckpt_dirs) > 0:
|
| 165 |
+
optimizer.load_state_dict(torch.load(sorted_ckpt_dirs[-1] / "optimizer.ckpt"))
|
| 166 |
+
|
| 167 |
+
if config.Trainer.use_valid:
|
| 168 |
+
if config.resume and len(sorted_ckpt_dirs) > 0:
|
| 169 |
+
valid_best_score = torch.load(
|
| 170 |
+
sorted_ckpt_dirs[-1] / "valid_best_score.ckpt"
|
| 171 |
+
)[config.Trainer.valid_metric]
|
| 172 |
+
else:
|
| 173 |
+
valid_best_score = -100000 if config.Trainer.valid_higher_better else 100000
|
| 174 |
+
|
| 175 |
+
def save_checkpoint(name):
|
| 176 |
+
ckpt_dir: Path = save_to / f"{name}.ckpts"
|
| 177 |
+
ckpt_dir.mkdir(parents=True, exist_ok=True)
|
| 178 |
+
logger.info(f"Save checkpoint to: {ckpt_dir}")
|
| 179 |
+
|
| 180 |
+
task.save_checkpoint(ckpt_dir / "task.ckpt")
|
| 181 |
+
torch.save(optimizer.state_dict(), ckpt_dir / "optimizer.ckpt")
|
| 182 |
+
torch.save(
|
| 183 |
+
{config.Trainer.valid_metric: valid_best_score},
|
| 184 |
+
ckpt_dir / "valid_best_score.ckpt",
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
pbar = tqdm(total=config.Trainer.total_steps, desc="Total")
|
| 188 |
+
train_completed = False
|
| 189 |
+
accum_grad_steps = 0
|
| 190 |
+
while not train_completed:
|
| 191 |
+
batch_results = []
|
| 192 |
+
for batch in tqdm(train_dataloader, desc="Train", total=len(train_dataloader)):
|
| 193 |
+
pbar.update(1)
|
| 194 |
+
global_step = pbar.n
|
| 195 |
+
|
| 196 |
+
assert isinstance(batch, Output)
|
| 197 |
+
batch = batch.to(device)
|
| 198 |
+
|
| 199 |
+
task.train()
|
| 200 |
+
result = task.train_step(**batch)
|
| 201 |
+
assert isinstance(result, Output)
|
| 202 |
+
|
| 203 |
+
result.loss /= config.Trainer.gradient_accumulate_steps
|
| 204 |
+
result.loss.backward()
|
| 205 |
+
|
| 206 |
+
grad_norm = torch.nn.utils.clip_grad_norm_(
|
| 207 |
+
task.parameters(), max_norm=config.Trainer.gradient_clipping
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
if math.isnan(grad_norm):
|
| 211 |
+
logger.warning(f"Grad norm is NaN at step {global_step}")
|
| 212 |
+
optimizer.zero_grad()
|
| 213 |
+
accum_grad_steps = 0
|
| 214 |
+
else:
|
| 215 |
+
accum_grad_steps += 1
|
| 216 |
+
if accum_grad_steps == config.Trainer.gradient_accumulate_steps:
|
| 217 |
+
optimizer.step()
|
| 218 |
+
optimizer.zero_grad()
|
| 219 |
+
accum_grad_steps = 0
|
| 220 |
+
batch_results.append(result.cacheable())
|
| 221 |
+
|
| 222 |
+
if global_step % config.Trainer.log_step == 0:
|
| 223 |
+
logs: Logs = task.train_reduction(batch_results).logs
|
| 224 |
+
logger.info(f"[Train] step {global_step}")
|
| 225 |
+
for name, value in logs.Scalar.items():
|
| 226 |
+
if name == "loss":
|
| 227 |
+
value *= config.Trainer.gradient_accumulate_steps
|
| 228 |
+
logger.info(f"{name}: {value}")
|
| 229 |
+
batch_results = []
|
| 230 |
+
|
| 231 |
+
if global_step % config.Trainer.valid_step == 0:
|
| 232 |
+
with torch.no_grad():
|
| 233 |
+
if config.Trainer.use_valid:
|
| 234 |
+
valid_results = []
|
| 235 |
+
for batch_idx, batch in enumerate(
|
| 236 |
+
tqdm(
|
| 237 |
+
valid_dataloader,
|
| 238 |
+
desc="Valid",
|
| 239 |
+
total=len(valid_dataloader),
|
| 240 |
+
)
|
| 241 |
+
):
|
| 242 |
+
if batch_idx == config.Trainer.get("eval_batch", -1):
|
| 243 |
+
break
|
| 244 |
+
batch = batch.to(device)
|
| 245 |
+
task.eval()
|
| 246 |
+
result = task.valid_step(**batch)
|
| 247 |
+
valid_results.append(result.cacheable())
|
| 248 |
+
|
| 249 |
+
logs: Logs = task.valid_reduction(valid_results).slice(1)
|
| 250 |
+
logger.info(f"[Valid] step {global_step}")
|
| 251 |
+
for name, value in logs.Scalar.items():
|
| 252 |
+
logger.info(f"{name}: {value}")
|
| 253 |
+
if name == config.Trainer.valid_metric:
|
| 254 |
+
cond1 = config.Trainer.valid_higher_better and (
|
| 255 |
+
value > valid_best_score
|
| 256 |
+
)
|
| 257 |
+
cond2 = (not config.Trainer.valid_higher_better) and (
|
| 258 |
+
value < valid_best_score
|
| 259 |
+
)
|
| 260 |
+
if cond1 or cond2:
|
| 261 |
+
valid_best_score = value
|
| 262 |
+
save_checkpoint("valid_best")
|
| 263 |
+
|
| 264 |
+
if (
|
| 265 |
+
global_step % config.Trainer.save_step == 0
|
| 266 |
+
or global_step == config.Trainer.total_steps
|
| 267 |
+
):
|
| 268 |
+
save_checkpoint(f"global_step_{global_step}")
|
| 269 |
+
|
| 270 |
+
if global_step == config.Trainer.total_steps:
|
| 271 |
+
train_completed = True
|
| 272 |
+
break
|
| 273 |
+
|
| 274 |
+
test_results = []
|
| 275 |
+
for batch_idx, batch in enumerate(
|
| 276 |
+
tqdm(test_dataloader, desc="Test", total=len(test_dataloader))
|
| 277 |
+
):
|
| 278 |
+
if batch_idx == config.Trainer.get("eval_batch", -1):
|
| 279 |
+
break
|
| 280 |
+
batch = batch.to(device)
|
| 281 |
+
result = task.test_step(**batch)
|
| 282 |
+
test_results.append(result.cacheable())
|
| 283 |
+
|
| 284 |
+
logs: Logs = task.test_reduction(test_results).slice(1)
|
| 285 |
+
logger.info(f"[Test] step {global_step}")
|
| 286 |
+
for name, value in logs.Scalar.items():
|
| 287 |
+
logger.info(f"{name}: {value}")
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
if __name__ == "__main__":
|
| 291 |
+
main()
|
s3prl_s3prl_main/example/superb_asr/inference.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from s3prl import Dataset, Output, Task
|
| 7 |
+
from s3prl.base.object import Object
|
| 8 |
+
|
| 9 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def parse_args():
|
| 13 |
+
parser = argparse.ArgumentParser()
|
| 14 |
+
parser.add_argument(
|
| 15 |
+
"load_from", help="The directory containing all the checkpoints"
|
| 16 |
+
)
|
| 17 |
+
args = parser.parse_args()
|
| 18 |
+
return args
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def main():
|
| 22 |
+
args = parse_args()
|
| 23 |
+
load_from = Path(args.load_from)
|
| 24 |
+
|
| 25 |
+
task: Task = Object.load_checkpoint(load_from / "task.ckpt").to(device)
|
| 26 |
+
task.eval()
|
| 27 |
+
|
| 28 |
+
test_dataset: Dataset = Object.load_checkpoint(load_from / "test_dataset.ckpt")
|
| 29 |
+
test_dataloader = test_dataset.to_dataloader(batch_size=1, num_workers=6)
|
| 30 |
+
|
| 31 |
+
with torch.no_grad():
|
| 32 |
+
for batch in test_dataloader:
|
| 33 |
+
batch: Output = batch.to(device)
|
| 34 |
+
result = task(**batch.subset("x", "x_len", as_type="dict"))
|
| 35 |
+
for name, prediction in zip(batch.name, result.prediction):
|
| 36 |
+
print(name, prediction)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
if __name__ == "__main__":
|
| 40 |
+
main()
|
s3prl_s3prl_main/example/superb_asr/train.py
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import math
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.optim as optim
|
| 8 |
+
from torch.utils.data import DataLoader
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
|
| 11 |
+
from s3prl import Logs, Object, Output
|
| 12 |
+
from s3prl.nn import S3PRLUpstream, UpstreamDownstreamModel
|
| 13 |
+
from s3prl.sampler import DistributedBatchSamplerWrapper
|
| 14 |
+
from s3prl.superb import asr as problem
|
| 15 |
+
|
| 16 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def parse_args():
|
| 21 |
+
parser = argparse.ArgumentParser()
|
| 22 |
+
parser.add_argument("librispeech", help="The root directory of LibriSpeech")
|
| 23 |
+
parser.add_argument("save_to", help="The directory to save checkpoint")
|
| 24 |
+
parser.add_argument("--total_steps", type=int, default=200000)
|
| 25 |
+
parser.add_argument("--log_step", type=int, default=100)
|
| 26 |
+
parser.add_argument("--eval_step", type=int, default=5000)
|
| 27 |
+
parser.add_argument("--save_step", type=int, default=100)
|
| 28 |
+
args = parser.parse_args()
|
| 29 |
+
return args
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def main():
|
| 33 |
+
logging.basicConfig()
|
| 34 |
+
logger.setLevel(logging.INFO)
|
| 35 |
+
|
| 36 |
+
args = parse_args()
|
| 37 |
+
librispeech = Path(args.librispeech)
|
| 38 |
+
assert librispeech.is_dir()
|
| 39 |
+
save_to = Path(args.save_to)
|
| 40 |
+
save_to.mkdir(exist_ok=True, parents=True)
|
| 41 |
+
|
| 42 |
+
logger.info("Preparing preprocessor")
|
| 43 |
+
preprocessor = problem.Preprocessor(
|
| 44 |
+
librispeech, splits=["train-clean-100", "dev-clean", "test-clean"]
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
logger.info("Preparing train dataloader")
|
| 48 |
+
train_dataset = problem.TrainDataset(**preprocessor.train_data())
|
| 49 |
+
train_sampler = problem.TrainSampler(
|
| 50 |
+
train_dataset, max_timestamp=16000 * 1000, shuffle=True
|
| 51 |
+
)
|
| 52 |
+
train_sampler = DistributedBatchSamplerWrapper(
|
| 53 |
+
train_sampler, num_replicas=1, rank=0
|
| 54 |
+
)
|
| 55 |
+
train_dataloader = DataLoader(
|
| 56 |
+
train_dataset,
|
| 57 |
+
batch_sampler=train_sampler,
|
| 58 |
+
num_workers=4,
|
| 59 |
+
collate_fn=train_dataset.collate_fn,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
logger.info("Preparing valid dataloader")
|
| 63 |
+
valid_dataset = problem.ValidDataset(
|
| 64 |
+
**preprocessor.valid_data(),
|
| 65 |
+
**train_dataset.statistics(),
|
| 66 |
+
)
|
| 67 |
+
valid_dataset.save_checkpoint(save_to / "valid_dataset.ckpt")
|
| 68 |
+
valid_sampler = problem.ValidSampler(valid_dataset, 8)
|
| 69 |
+
valid_sampler = DistributedBatchSamplerWrapper(
|
| 70 |
+
valid_sampler, num_replicas=1, rank=0
|
| 71 |
+
)
|
| 72 |
+
valid_dataloader = DataLoader(
|
| 73 |
+
valid_dataset,
|
| 74 |
+
batch_sampler=valid_sampler,
|
| 75 |
+
num_workers=4,
|
| 76 |
+
collate_fn=valid_dataset.collate_fn,
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
logger.info("Preparing test dataloader")
|
| 80 |
+
test_dataset = problem.TestDataset(
|
| 81 |
+
**preprocessor.test_data(),
|
| 82 |
+
**train_dataset.statistics(),
|
| 83 |
+
)
|
| 84 |
+
test_dataset.save_checkpoint(save_to / "test_dataset.ckpt")
|
| 85 |
+
test_sampler = problem.TestSampler(test_dataset, 8)
|
| 86 |
+
test_sampler = DistributedBatchSamplerWrapper(test_sampler, num_replicas=1, rank=0)
|
| 87 |
+
test_dataloader = DataLoader(
|
| 88 |
+
test_dataset,
|
| 89 |
+
batch_sampler=test_sampler,
|
| 90 |
+
num_workers=4,
|
| 91 |
+
collate_fn=test_dataset.collate_fn,
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
latest_task = save_to / "task.ckpt"
|
| 95 |
+
if latest_task.is_file():
|
| 96 |
+
logger.info("Last checkpoint found. Load model and optimizer from checkpoint")
|
| 97 |
+
|
| 98 |
+
# Object.load_checkpoint() from a checkpoint path and
|
| 99 |
+
# Object.from_checkpoint() from a loaded checkpoint dictionary
|
| 100 |
+
# are like AutoModel in Huggingface which you only need to
|
| 101 |
+
# provide the checkpoint for restoring the module.
|
| 102 |
+
#
|
| 103 |
+
# Note that source code definition should be importable, since this
|
| 104 |
+
# auto loading mechanism is just automating the model re-initialization
|
| 105 |
+
# steps instead of scriptify (torch.jit) all the source code in the
|
| 106 |
+
# checkpoint
|
| 107 |
+
|
| 108 |
+
task = Object.load_checkpoint(latest_task).to(device)
|
| 109 |
+
|
| 110 |
+
else:
|
| 111 |
+
logger.info("No last checkpoint found. Create new model")
|
| 112 |
+
|
| 113 |
+
# Model creation block which can be fully customized
|
| 114 |
+
upstream = S3PRLUpstream("apc")
|
| 115 |
+
downstream = problem.DownstreamModel(
|
| 116 |
+
upstream.output_size,
|
| 117 |
+
preprocessor.statistics().output_size,
|
| 118 |
+
hidden_size=[512],
|
| 119 |
+
dropout=[0.2],
|
| 120 |
+
)
|
| 121 |
+
model = UpstreamDownstreamModel(upstream, downstream)
|
| 122 |
+
|
| 123 |
+
# After customize your own model, simply put it into task object
|
| 124 |
+
task = problem.Task(model, preprocessor.statistics().label_loader)
|
| 125 |
+
task = task.to(device)
|
| 126 |
+
|
| 127 |
+
# We do not handle optimizer/scheduler in any special way in S3PRL, since
|
| 128 |
+
# there are lots of dedicated package for this. Hence, we also do not handle
|
| 129 |
+
# the checkpointing for optimizer/scheduler. Depends on what training pipeline
|
| 130 |
+
# the user prefer, either Lightning or SpeechBrain, these frameworks will
|
| 131 |
+
# provide different solutions on how to save these objects. By not handling
|
| 132 |
+
# these objects in S3PRL we are making S3PRL more flexible and agnostic to training pipeline
|
| 133 |
+
# The following optimizer codeblock aims to align with the standard usage
|
| 134 |
+
# of PyTorch which is the standard way to save it.
|
| 135 |
+
|
| 136 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 137 |
+
latest_optimizer = save_to / "optimizer.ckpt"
|
| 138 |
+
if latest_optimizer.is_file():
|
| 139 |
+
optimizer.load_state_dict(torch.load(save_to / "optimizer.ckpt"))
|
| 140 |
+
else:
|
| 141 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 142 |
+
|
| 143 |
+
# The following code block demonstrate how to train with your own training loop
|
| 144 |
+
# This entire block can be easily replaced with Lightning/SpeechBrain Trainer as
|
| 145 |
+
#
|
| 146 |
+
# Trainer(task)
|
| 147 |
+
# Trainer.fit(train_dataloader, valid_dataloader, test_dataloader)
|
| 148 |
+
#
|
| 149 |
+
# As you can see, there is a huge similarity among train/valid/test loops below,
|
| 150 |
+
# so it is a natural step to share these logics with a generic Trainer class
|
| 151 |
+
# as done in Lightning/SpeechBrain
|
| 152 |
+
|
| 153 |
+
pbar = tqdm(total=args.total_steps, desc="Total")
|
| 154 |
+
while True:
|
| 155 |
+
batch_results = []
|
| 156 |
+
for batch in tqdm(train_dataloader, desc="Train", total=len(train_dataloader)):
|
| 157 |
+
pbar.update(1)
|
| 158 |
+
global_step = pbar.n
|
| 159 |
+
|
| 160 |
+
assert isinstance(batch, Output)
|
| 161 |
+
optimizer.zero_grad()
|
| 162 |
+
|
| 163 |
+
# An Output object can more all its direct
|
| 164 |
+
# attributes/values to the device
|
| 165 |
+
batch = batch.to(device)
|
| 166 |
+
|
| 167 |
+
# An Output object is an OrderedDict so we
|
| 168 |
+
# can use dict decomposition here
|
| 169 |
+
task.train()
|
| 170 |
+
result = task.train_step(**batch)
|
| 171 |
+
assert isinstance(result, Output)
|
| 172 |
+
|
| 173 |
+
# The output of train step must contain
|
| 174 |
+
# at least a loss key
|
| 175 |
+
result.loss.backward()
|
| 176 |
+
|
| 177 |
+
# gradient clipping
|
| 178 |
+
grad_norm = torch.nn.utils.clip_grad_norm_(task.parameters(), max_norm=1.0)
|
| 179 |
+
|
| 180 |
+
if math.isnan(grad_norm):
|
| 181 |
+
logger.warning(f"Grad norm is NaN at step {global_step}")
|
| 182 |
+
else:
|
| 183 |
+
optimizer.step()
|
| 184 |
+
|
| 185 |
+
# Detach from GPU, remove large logging (to Tensorboard or local files)
|
| 186 |
+
# objects like logits and leave only small data like loss scalars / prediction
|
| 187 |
+
# strings, so that these objects can be safely cached in a list in the MEM,
|
| 188 |
+
# and become useful for calculating metrics later
|
| 189 |
+
# The Output class can do these with self.cacheable()
|
| 190 |
+
cacheable_result = result.cacheable()
|
| 191 |
+
|
| 192 |
+
# Cache these small data for later metric calculation
|
| 193 |
+
batch_results.append(cacheable_result)
|
| 194 |
+
|
| 195 |
+
if (global_step + 1) % args.log_step == 0:
|
| 196 |
+
logs: Logs = task.train_reduction(batch_results).logs
|
| 197 |
+
logger.info(f"[Train] step {global_step}")
|
| 198 |
+
for log in logs.values():
|
| 199 |
+
logger.info(f"{log.name}: {log.data}")
|
| 200 |
+
batch_results = []
|
| 201 |
+
|
| 202 |
+
if (global_step + 1) % args.eval_step == 0:
|
| 203 |
+
with torch.no_grad():
|
| 204 |
+
task.eval()
|
| 205 |
+
|
| 206 |
+
# valid
|
| 207 |
+
valid_results = []
|
| 208 |
+
for batch in tqdm(
|
| 209 |
+
valid_dataloader, desc="Valid", total=len(valid_dataloader)
|
| 210 |
+
):
|
| 211 |
+
batch = batch.to(device)
|
| 212 |
+
result = task.valid_step(**batch)
|
| 213 |
+
cacheable_result = result.cacheable()
|
| 214 |
+
valid_results.append(cacheable_result)
|
| 215 |
+
|
| 216 |
+
logs: Logs = task.valid_reduction(valid_results).logs
|
| 217 |
+
logger.info(f"[Valid] step {global_step}")
|
| 218 |
+
for log in logs.values():
|
| 219 |
+
logger.info(f"{log.name}: {log.data}")
|
| 220 |
+
|
| 221 |
+
if (global_step + 1) % args.save_step == 0:
|
| 222 |
+
task.save_checkpoint(save_to / "task.ckpt")
|
| 223 |
+
torch.save(optimizer.state_dict(), save_to / "optimizer.ckpt")
|
| 224 |
+
|
| 225 |
+
with torch.no_grad():
|
| 226 |
+
# test
|
| 227 |
+
test_results = []
|
| 228 |
+
for batch in tqdm(test_dataloader, desc="Test", total=len(test_dataloader)):
|
| 229 |
+
batch = batch.to(device)
|
| 230 |
+
result = task.test_step(**batch)
|
| 231 |
+
cacheable_result = result.cacheable()
|
| 232 |
+
test_results.append(cacheable_result)
|
| 233 |
+
|
| 234 |
+
logs: Logs = task.test_reduction(test_results).logs
|
| 235 |
+
logger.info(f"[Test] step results")
|
| 236 |
+
for log in logs.values():
|
| 237 |
+
logger.info(f"{log.name}: {log.data}")
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
if __name__ == "__main__":
|
| 241 |
+
main()
|
s3prl_s3prl_main/example/superb_asr/train_with_lightning.py
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.optim as optim
|
| 7 |
+
from pytorch_lightning import Trainer
|
| 8 |
+
from pytorch_lightning.callbacks import ModelCheckpoint
|
| 9 |
+
|
| 10 |
+
from s3prl.nn import S3PRLUpstream, UpstreamDownstreamModel
|
| 11 |
+
from s3prl.superb import asr as problem
|
| 12 |
+
from s3prl.wrapper import LightningModuleSimpleWrapper
|
| 13 |
+
|
| 14 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def parse_args():
|
| 19 |
+
parser = argparse.ArgumentParser()
|
| 20 |
+
parser.add_argument("librispeech", help="The root directory of LibriSpeech")
|
| 21 |
+
parser.add_argument("save_to", help="The directory to save checkpoint")
|
| 22 |
+
parser.add_argument("--total_steps", type=int, default=200000)
|
| 23 |
+
parser.add_argument("--log_step", type=int, default=100)
|
| 24 |
+
parser.add_argument("--eval_step", type=int, default=5000)
|
| 25 |
+
parser.add_argument("--save_step", type=int, default=100)
|
| 26 |
+
parser.add_argument(
|
| 27 |
+
"--not_resume",
|
| 28 |
+
action="store_true",
|
| 29 |
+
help="Don't resume from the last checkpoint",
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
# for debugging
|
| 33 |
+
parser.add_argument("--limit_train_batches", type=int)
|
| 34 |
+
parser.add_argument("--limit_val_batches", type=int)
|
| 35 |
+
parser.add_argument("--fast_dev_run", action="store_true")
|
| 36 |
+
args = parser.parse_args()
|
| 37 |
+
return args
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def main():
|
| 41 |
+
logging.basicConfig(level=logging.INFO)
|
| 42 |
+
|
| 43 |
+
args = parse_args()
|
| 44 |
+
librispeech = Path(args.librispeech)
|
| 45 |
+
save_to = Path(args.save_to)
|
| 46 |
+
save_to.mkdir(exist_ok=True, parents=True)
|
| 47 |
+
|
| 48 |
+
logger.info("Preparing preprocessor")
|
| 49 |
+
preprocessor = problem.Preprocessor(librispeech)
|
| 50 |
+
|
| 51 |
+
logger.info("Preparing train dataloader")
|
| 52 |
+
train_dataset = problem.TrainDataset(**preprocessor.train_data())
|
| 53 |
+
train_dataloader = train_dataset.to_dataloader(
|
| 54 |
+
batch_size=8,
|
| 55 |
+
num_workers=6,
|
| 56 |
+
shuffle=True,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
logger.info("Preparing valid dataloader")
|
| 60 |
+
valid_dataset = problem.ValidDataset(
|
| 61 |
+
**preprocessor.valid_data(),
|
| 62 |
+
**train_dataset.statistics(),
|
| 63 |
+
)
|
| 64 |
+
valid_dataloader = valid_dataset.to_dataloader(batch_size=8, num_workers=6)
|
| 65 |
+
|
| 66 |
+
logger.info("Preparing test dataloader")
|
| 67 |
+
test_dataset = problem.TestDataset(
|
| 68 |
+
**preprocessor.test_data(),
|
| 69 |
+
**train_dataset.statistics(),
|
| 70 |
+
)
|
| 71 |
+
test_dataloader = test_dataset.to_dataloader(batch_size=8, num_workers=6)
|
| 72 |
+
|
| 73 |
+
valid_dataset.save_checkpoint(save_to / "valid_dataset.ckpt")
|
| 74 |
+
test_dataset.save_checkpoint(save_to / "test_dataset.ckpt")
|
| 75 |
+
|
| 76 |
+
upstream = S3PRLUpstream("apc")
|
| 77 |
+
downstream = problem.DownstreamModel(
|
| 78 |
+
upstream.output_size, preprocessor.statistics().output_size
|
| 79 |
+
)
|
| 80 |
+
model = UpstreamDownstreamModel(upstream, downstream)
|
| 81 |
+
task = problem.Task(model, preprocessor.statistics().label_loader)
|
| 82 |
+
|
| 83 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 84 |
+
lightning_task = LightningModuleSimpleWrapper(task, optimizer)
|
| 85 |
+
|
| 86 |
+
# The above is the usage of our library
|
| 87 |
+
|
| 88 |
+
# The below is pytorch-lightning specific usage, which can be very simple
|
| 89 |
+
# or very sophisticated, depending on how much you want to customized your
|
| 90 |
+
# training loop
|
| 91 |
+
|
| 92 |
+
checkpoint_callback = ModelCheckpoint(
|
| 93 |
+
dirpath=str(save_to),
|
| 94 |
+
filename="superb-asr-{step:02d}-{valid_0_wer:.2f}",
|
| 95 |
+
monitor="valid_0_wer", # since might have multiple valid dataloaders
|
| 96 |
+
save_last=True,
|
| 97 |
+
save_top_k=3, # top 3 best ckpt on valid
|
| 98 |
+
mode="min", # lower, better
|
| 99 |
+
every_n_train_steps=args.save_step,
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
trainer = Trainer(
|
| 103 |
+
callbacks=[checkpoint_callback],
|
| 104 |
+
accelerator="gpu",
|
| 105 |
+
gpus=1,
|
| 106 |
+
max_steps=args.total_steps,
|
| 107 |
+
log_every_n_steps=args.log_step,
|
| 108 |
+
val_check_interval=args.eval_step,
|
| 109 |
+
limit_val_batches=args.limit_val_batches or 1.0,
|
| 110 |
+
limit_train_batches=args.limit_train_batches or 1.0,
|
| 111 |
+
fast_dev_run=args.fast_dev_run,
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
last_ckpt = save_to / "last.ckpt"
|
| 115 |
+
if args.not_resume or not last_ckpt.is_file():
|
| 116 |
+
last_ckpt = None
|
| 117 |
+
|
| 118 |
+
trainer.fit(
|
| 119 |
+
lightning_task,
|
| 120 |
+
train_dataloader,
|
| 121 |
+
val_dataloaders=[valid_dataloader, test_dataloader],
|
| 122 |
+
ckpt_path=last_ckpt,
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
if __name__ == "__main__":
|
| 127 |
+
main()
|
s3prl_s3prl_main/example/superb_sid/inference.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from s3prl import Dataset, Output, Task
|
| 7 |
+
from s3prl.base.object import Object
|
| 8 |
+
|
| 9 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def parse_args():
|
| 13 |
+
parser = argparse.ArgumentParser()
|
| 14 |
+
parser.add_argument(
|
| 15 |
+
"load_from", help="The directory containing all the checkpoints"
|
| 16 |
+
)
|
| 17 |
+
args = parser.parse_args()
|
| 18 |
+
return args
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def main():
|
| 22 |
+
args = parse_args()
|
| 23 |
+
load_from = Path(args.load_from)
|
| 24 |
+
|
| 25 |
+
task: Task = Object.load_checkpoint(load_from / "task.ckpt").to(device)
|
| 26 |
+
task.eval()
|
| 27 |
+
|
| 28 |
+
test_dataset: Dataset = Object.load_checkpoint(load_from / "test_dataset.ckpt")
|
| 29 |
+
test_dataloader = test_dataset.to_dataloader(batch_size=1, num_workers=6)
|
| 30 |
+
|
| 31 |
+
with torch.no_grad():
|
| 32 |
+
for batch in test_dataloader:
|
| 33 |
+
batch: Output = batch.to(device)
|
| 34 |
+
result = task(**batch.subset("x", "x_len", as_type="dict"))
|
| 35 |
+
for name, prediction in zip(batch.name, result.prediction):
|
| 36 |
+
print(name, prediction)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
if __name__ == "__main__":
|
| 40 |
+
main()
|
s3prl_s3prl_main/example/superb_sid/train.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import math
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.optim as optim
|
| 8 |
+
from torch.utils.data import DataLoader
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
|
| 11 |
+
from s3prl import Logs, Object, Output
|
| 12 |
+
from s3prl.nn import S3PRLUpstream, UpstreamDownstreamModel
|
| 13 |
+
from s3prl.sampler import DistributedBatchSamplerWrapper
|
| 14 |
+
from s3prl.superb import sid as problem
|
| 15 |
+
|
| 16 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def parse_args():
|
| 21 |
+
parser = argparse.ArgumentParser()
|
| 22 |
+
parser.add_argument("voxceleb1", help="The root directory of VoxCeleb1")
|
| 23 |
+
parser.add_argument("save_to", help="The directory to save checkpoint")
|
| 24 |
+
parser.add_argument("--total_steps", type=int, default=200000)
|
| 25 |
+
parser.add_argument("--log_step", type=int, default=100)
|
| 26 |
+
parser.add_argument("--eval_step", type=int, default=5000)
|
| 27 |
+
parser.add_argument("--save_step", type=int, default=100)
|
| 28 |
+
parser.add_argument("--resume", action="store_true")
|
| 29 |
+
args = parser.parse_args()
|
| 30 |
+
return args
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def main():
|
| 34 |
+
logging.basicConfig()
|
| 35 |
+
logger.setLevel(logging.INFO)
|
| 36 |
+
|
| 37 |
+
args = parse_args()
|
| 38 |
+
voxceleb1 = Path(args.voxceleb1)
|
| 39 |
+
assert voxceleb1.is_dir()
|
| 40 |
+
save_to = Path(args.save_to)
|
| 41 |
+
save_to.mkdir(exist_ok=True, parents=True)
|
| 42 |
+
|
| 43 |
+
logger.info("Preparing preprocessor")
|
| 44 |
+
preprocessor = problem.Preprocessor(voxceleb1)
|
| 45 |
+
|
| 46 |
+
logger.info("Preparing train dataloader")
|
| 47 |
+
train_dataset = problem.TrainDataset(**preprocessor.train_data())
|
| 48 |
+
train_sampler = problem.TrainSampler(
|
| 49 |
+
train_dataset, max_timestamp=16000 * 200, shuffle=True
|
| 50 |
+
)
|
| 51 |
+
train_sampler = DistributedBatchSamplerWrapper(
|
| 52 |
+
train_sampler, num_replicas=1, rank=0
|
| 53 |
+
)
|
| 54 |
+
train_dataloader = DataLoader(
|
| 55 |
+
train_dataset,
|
| 56 |
+
batch_sampler=train_sampler,
|
| 57 |
+
num_workers=12,
|
| 58 |
+
collate_fn=train_dataset.collate_fn,
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
logger.info("Preparing valid dataloader")
|
| 62 |
+
valid_dataset = problem.ValidDataset(
|
| 63 |
+
**preprocessor.valid_data(),
|
| 64 |
+
**train_dataset.statistics(),
|
| 65 |
+
)
|
| 66 |
+
valid_dataset.save_checkpoint(save_to / "valid_dataset.ckpt")
|
| 67 |
+
valid_sampler = problem.ValidSampler(valid_dataset, 8)
|
| 68 |
+
valid_sampler = DistributedBatchSamplerWrapper(
|
| 69 |
+
valid_sampler, num_replicas=1, rank=0
|
| 70 |
+
)
|
| 71 |
+
valid_dataloader = DataLoader(
|
| 72 |
+
valid_dataset,
|
| 73 |
+
batch_sampler=valid_sampler,
|
| 74 |
+
num_workers=12,
|
| 75 |
+
collate_fn=valid_dataset.collate_fn,
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
logger.info("Preparing test dataloader")
|
| 79 |
+
test_dataset = problem.TestDataset(
|
| 80 |
+
**preprocessor.test_data(),
|
| 81 |
+
**train_dataset.statistics(),
|
| 82 |
+
)
|
| 83 |
+
test_dataset.save_checkpoint(save_to / "test_dataset.ckpt")
|
| 84 |
+
test_sampler = problem.TestSampler(test_dataset, 8)
|
| 85 |
+
test_sampler = DistributedBatchSamplerWrapper(test_sampler, num_replicas=1, rank=0)
|
| 86 |
+
test_dataloader = DataLoader(
|
| 87 |
+
test_dataset, batch_size=8, num_workers=12, collate_fn=test_dataset.collate_fn
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
latest_task = save_to / "task.ckpt"
|
| 91 |
+
if args.resume and latest_task.is_file():
|
| 92 |
+
logger.info("Last checkpoint found. Load model and optimizer from checkpoint")
|
| 93 |
+
|
| 94 |
+
# Object.load_checkpoint() from a checkpoint path and
|
| 95 |
+
# Object.from_checkpoint() from a loaded checkpoint dictionary
|
| 96 |
+
# are like AutoModel in Huggingface which you only need to
|
| 97 |
+
# provide the checkpoint for restoring the module.
|
| 98 |
+
#
|
| 99 |
+
# Note that source code definition should be importable, since this
|
| 100 |
+
# auto loading mechanism is just automating the model re-initialization
|
| 101 |
+
# steps instead of scriptify (torch.jit) all the source code in the
|
| 102 |
+
# checkpoint
|
| 103 |
+
|
| 104 |
+
task = Object.load_checkpoint(latest_task).to(device)
|
| 105 |
+
|
| 106 |
+
else:
|
| 107 |
+
logger.info("No last checkpoint found. Create new model")
|
| 108 |
+
|
| 109 |
+
# Model creation block which can be fully customized
|
| 110 |
+
upstream = S3PRLUpstream("wav2vec2")
|
| 111 |
+
downstream = problem.DownstreamModel(
|
| 112 |
+
upstream.output_size, len(preprocessor.statistics().category)
|
| 113 |
+
)
|
| 114 |
+
model = UpstreamDownstreamModel(upstream, downstream)
|
| 115 |
+
|
| 116 |
+
# After customize your own model, simply put it into task object
|
| 117 |
+
task = problem.Task(model, preprocessor.statistics().category)
|
| 118 |
+
task = task.to(device)
|
| 119 |
+
|
| 120 |
+
# We do not handle optimizer/scheduler in any special way in S3PRL, since
|
| 121 |
+
# there are lots of dedicated package for this. Hence, we also do not handle
|
| 122 |
+
# the checkpointing for optimizer/scheduler. Depends on what training pipeline
|
| 123 |
+
# the user prefer, either Lightning or SpeechBrain, these frameworks will
|
| 124 |
+
# provide different solutions on how to save these objects. By not handling
|
| 125 |
+
# these objects in S3PRL we are making S3PRL more flexible and agnostic to training pipeline
|
| 126 |
+
# The following optimizer codeblock aims to align with the standard usage
|
| 127 |
+
# of PyTorch which is the standard way to save it.
|
| 128 |
+
|
| 129 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 130 |
+
latest_optimizer = save_to / "optimizer.ckpt"
|
| 131 |
+
if args.resume and latest_optimizer.is_file():
|
| 132 |
+
optimizer.load_state_dict(torch.load(save_to / "optimizer.ckpt"))
|
| 133 |
+
else:
|
| 134 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 135 |
+
|
| 136 |
+
# The following code block demonstrate how to train with your own training loop
|
| 137 |
+
# This entire block can be easily replaced with Lightning/SpeechBrain Trainer as
|
| 138 |
+
#
|
| 139 |
+
# Trainer(task)
|
| 140 |
+
# Trainer.fit(train_dataloader, valid_dataloader, test_dataloader)
|
| 141 |
+
#
|
| 142 |
+
# As you can see, there is a huge similarity among train/valid/test loops below,
|
| 143 |
+
# so it is a natural step to share these logics with a generic Trainer class
|
| 144 |
+
# as done in Lightning/SpeechBrain
|
| 145 |
+
|
| 146 |
+
pbar = tqdm(total=args.total_steps, desc="Total")
|
| 147 |
+
while True:
|
| 148 |
+
batch_results = []
|
| 149 |
+
for batch in tqdm(train_dataloader, desc="Train", total=len(train_dataloader)):
|
| 150 |
+
pbar.update(1)
|
| 151 |
+
global_step = pbar.n
|
| 152 |
+
|
| 153 |
+
assert isinstance(batch, Output)
|
| 154 |
+
optimizer.zero_grad()
|
| 155 |
+
|
| 156 |
+
# An Output object can more all its direct
|
| 157 |
+
# attributes/values to the device
|
| 158 |
+
batch = batch.to(device)
|
| 159 |
+
|
| 160 |
+
# An Output object is an OrderedDict so we
|
| 161 |
+
# can use dict decomposition here
|
| 162 |
+
task.train()
|
| 163 |
+
result = task.train_step(**batch)
|
| 164 |
+
assert isinstance(result, Output)
|
| 165 |
+
|
| 166 |
+
# The output of train step must contain
|
| 167 |
+
# at least a loss key
|
| 168 |
+
result.loss.backward()
|
| 169 |
+
|
| 170 |
+
# gradient clipping
|
| 171 |
+
grad_norm = torch.nn.utils.clip_grad_norm_(task.parameters(), max_norm=1.0)
|
| 172 |
+
|
| 173 |
+
if math.isnan(grad_norm):
|
| 174 |
+
logger.warning(f"Grad norm is NaN at step {global_step}")
|
| 175 |
+
else:
|
| 176 |
+
optimizer.step()
|
| 177 |
+
|
| 178 |
+
# Detach from GPU, remove large logging (to Tensorboard or local files)
|
| 179 |
+
# objects like logits and leave only small data like loss scalars / prediction
|
| 180 |
+
# strings, so that these objects can be safely cached in a list in the MEM,
|
| 181 |
+
# and become useful for calculating metrics later
|
| 182 |
+
# The Output class can do these with self.cacheable()
|
| 183 |
+
cacheable_result = result.cacheable()
|
| 184 |
+
|
| 185 |
+
# Cache these small data for later metric calculation
|
| 186 |
+
batch_results.append(cacheable_result)
|
| 187 |
+
|
| 188 |
+
if (global_step + 1) % args.log_step == 0:
|
| 189 |
+
logs: Logs = task.train_reduction(batch_results).logs
|
| 190 |
+
logger.info(f"[Train] step {global_step}")
|
| 191 |
+
for log in logs.values():
|
| 192 |
+
logger.info(f"{log.name}: {log.data}")
|
| 193 |
+
batch_results = []
|
| 194 |
+
|
| 195 |
+
if (global_step + 1) % args.eval_step == 0:
|
| 196 |
+
with torch.no_grad():
|
| 197 |
+
task.eval()
|
| 198 |
+
|
| 199 |
+
# valid
|
| 200 |
+
valid_results = []
|
| 201 |
+
for batch in tqdm(
|
| 202 |
+
valid_dataloader, desc="Valid", total=len(valid_dataloader)
|
| 203 |
+
):
|
| 204 |
+
batch = batch.to(device)
|
| 205 |
+
result = task.valid_step(**batch)
|
| 206 |
+
cacheable_result = result.cacheable()
|
| 207 |
+
valid_results.append(cacheable_result)
|
| 208 |
+
|
| 209 |
+
logs: Logs = task.valid_reduction(valid_results).logs
|
| 210 |
+
logger.info(f"[Valid] step {global_step}")
|
| 211 |
+
for log in logs.values():
|
| 212 |
+
logger.info(f"{log.name}: {log.data}")
|
| 213 |
+
|
| 214 |
+
# test
|
| 215 |
+
test_results = []
|
| 216 |
+
for batch in tqdm(
|
| 217 |
+
test_dataloader, desc="Test", total=len(test_dataloader)
|
| 218 |
+
):
|
| 219 |
+
batch = batch.to(device)
|
| 220 |
+
result = task.test_step(**batch)
|
| 221 |
+
cacheable_result = result.cacheable()
|
| 222 |
+
test_results.append(cacheable_result)
|
| 223 |
+
|
| 224 |
+
logs: Logs = task.test_reduction(test_results).logs
|
| 225 |
+
logger.info(f"[Test] step {global_step}")
|
| 226 |
+
for log in logs.values():
|
| 227 |
+
logger.info(f"{log.name}: {log.data}")
|
| 228 |
+
|
| 229 |
+
if (global_step + 1) % args.save_step == 0:
|
| 230 |
+
task.save_checkpoint(save_to / "task.ckpt")
|
| 231 |
+
torch.save(optimizer.state_dict(), save_to / "optimizer.ckpt")
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
if __name__ == "__main__":
|
| 235 |
+
main()
|
s3prl_s3prl_main/example/superb_sid/train_with_lightning.py
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.optim as optim
|
| 7 |
+
from pytorch_lightning import Trainer
|
| 8 |
+
from pytorch_lightning.callbacks import ModelCheckpoint
|
| 9 |
+
|
| 10 |
+
from s3prl.nn import S3PRLUpstream, UpstreamDownstreamModel
|
| 11 |
+
from s3prl.superb import sid as problem
|
| 12 |
+
from s3prl.wrapper import LightningModuleSimpleWrapper
|
| 13 |
+
|
| 14 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def parse_args():
|
| 19 |
+
parser = argparse.ArgumentParser()
|
| 20 |
+
parser.add_argument("voxceleb1", help="The root directory of VoxCeleb1")
|
| 21 |
+
parser.add_argument("save_to", help="The directory to save checkpoint")
|
| 22 |
+
parser.add_argument("--total_steps", type=int, default=200000)
|
| 23 |
+
parser.add_argument("--log_step", type=int, default=100)
|
| 24 |
+
parser.add_argument("--eval_step", type=int, default=5000)
|
| 25 |
+
parser.add_argument("--save_step", type=int, default=100)
|
| 26 |
+
parser.add_argument(
|
| 27 |
+
"--not_resume",
|
| 28 |
+
action="store_true",
|
| 29 |
+
help="Don't resume from the last checkpoint",
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
# for debugging
|
| 33 |
+
parser.add_argument("--limit_train_batches", type=int)
|
| 34 |
+
parser.add_argument("--limit_val_batches", type=int)
|
| 35 |
+
parser.add_argument("--fast_dev_run", action="store_true")
|
| 36 |
+
args = parser.parse_args()
|
| 37 |
+
return args
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def main():
|
| 41 |
+
logging.basicConfig(level=logging.INFO)
|
| 42 |
+
|
| 43 |
+
args = parse_args()
|
| 44 |
+
voxceleb1 = Path(args.voxceleb1)
|
| 45 |
+
save_to = Path(args.save_to)
|
| 46 |
+
save_to.mkdir(exist_ok=True, parents=True)
|
| 47 |
+
|
| 48 |
+
logger.info("Preparing preprocessor")
|
| 49 |
+
preprocessor = problem.Preprocessor(voxceleb1)
|
| 50 |
+
|
| 51 |
+
logger.info("Preparing train dataloader")
|
| 52 |
+
train_dataset = problem.TrainDataset(**preprocessor.train_data())
|
| 53 |
+
train_dataloader = train_dataset.to_dataloader(
|
| 54 |
+
batch_size=8,
|
| 55 |
+
num_workers=6,
|
| 56 |
+
shuffle=True,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
logger.info("Preparing valid dataloader")
|
| 60 |
+
valid_dataset = problem.ValidDataset(
|
| 61 |
+
**preprocessor.valid_data(),
|
| 62 |
+
**train_dataset.statistics(),
|
| 63 |
+
)
|
| 64 |
+
valid_dataloader = valid_dataset.to_dataloader(batch_size=8, num_workers=6)
|
| 65 |
+
|
| 66 |
+
logger.info("Preparing test dataloader")
|
| 67 |
+
test_dataset = problem.TestDataset(
|
| 68 |
+
**preprocessor.test_data(),
|
| 69 |
+
**train_dataset.statistics(),
|
| 70 |
+
)
|
| 71 |
+
test_dataloader = test_dataset.to_dataloader(batch_size=8, num_workers=6)
|
| 72 |
+
|
| 73 |
+
valid_dataset.save_checkpoint(save_to / "valid_dataset.ckpt")
|
| 74 |
+
test_dataset.save_checkpoint(save_to / "test_dataset.ckpt")
|
| 75 |
+
|
| 76 |
+
upstream = S3PRLUpstream("apc")
|
| 77 |
+
downstream = problem.DownstreamModel(
|
| 78 |
+
upstream.output_size, len(preprocessor.statistics().category)
|
| 79 |
+
)
|
| 80 |
+
model = UpstreamDownstreamModel(upstream, downstream)
|
| 81 |
+
task = problem.Task(model, preprocessor.statistics().category)
|
| 82 |
+
|
| 83 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 84 |
+
lightning_task = LightningModuleSimpleWrapper(task, optimizer)
|
| 85 |
+
|
| 86 |
+
# The above is the usage of our library
|
| 87 |
+
|
| 88 |
+
# The below is pytorch-lightning specific usage, which can be very simple
|
| 89 |
+
# or very sophisticated, depending on how much you want to customized your
|
| 90 |
+
# training loop
|
| 91 |
+
|
| 92 |
+
checkpoint_callback = ModelCheckpoint(
|
| 93 |
+
dirpath=str(save_to),
|
| 94 |
+
filename="superb-sid-{step:02d}-{valid_0_accuracy:.2f}",
|
| 95 |
+
monitor="valid_0_accuracy", # since might have multiple valid dataloaders
|
| 96 |
+
save_last=True,
|
| 97 |
+
save_top_k=3, # top 3 best ckpt on valid
|
| 98 |
+
mode="max", # higher, better
|
| 99 |
+
every_n_train_steps=args.save_step,
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
trainer = Trainer(
|
| 103 |
+
callbacks=[checkpoint_callback],
|
| 104 |
+
accelerator="gpu",
|
| 105 |
+
gpus=1,
|
| 106 |
+
max_steps=args.total_steps,
|
| 107 |
+
log_every_n_steps=args.log_step,
|
| 108 |
+
val_check_interval=args.eval_step,
|
| 109 |
+
limit_val_batches=args.limit_val_batches or 1.0,
|
| 110 |
+
limit_train_batches=args.limit_train_batches or 1.0,
|
| 111 |
+
fast_dev_run=args.fast_dev_run,
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
last_ckpt = save_to / "last.ckpt"
|
| 115 |
+
if args.not_resume or not last_ckpt.is_file():
|
| 116 |
+
last_ckpt = None
|
| 117 |
+
|
| 118 |
+
trainer.fit(
|
| 119 |
+
lightning_task,
|
| 120 |
+
train_dataloader,
|
| 121 |
+
val_dataloaders=[valid_dataloader, test_dataloader],
|
| 122 |
+
ckpt_path=last_ckpt,
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
if __name__ == "__main__":
|
| 127 |
+
main()
|
s3prl_s3prl_main/example/superb_sv/inference.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch.utils.data import DataLoader
|
| 6 |
+
|
| 7 |
+
from s3prl import Output
|
| 8 |
+
from s3prl.base.object import Object
|
| 9 |
+
from s3prl.dataset import Dataset
|
| 10 |
+
from s3prl.task import Task
|
| 11 |
+
|
| 12 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def parse_args():
|
| 16 |
+
parser = argparse.ArgumentParser()
|
| 17 |
+
parser.add_argument(
|
| 18 |
+
"--load_from",
|
| 19 |
+
type=str,
|
| 20 |
+
default="result/sv",
|
| 21 |
+
help="The directory containing all the checkpoints",
|
| 22 |
+
)
|
| 23 |
+
args = parser.parse_args()
|
| 24 |
+
return args
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def main():
|
| 28 |
+
args = parse_args()
|
| 29 |
+
load_from = Path(args.load_from)
|
| 30 |
+
|
| 31 |
+
task: Task = Object.load_checkpoint(load_from / "task.ckpt").to(device)
|
| 32 |
+
task.eval()
|
| 33 |
+
|
| 34 |
+
test_dataset: Dataset = Object.load_checkpoint(load_from / "test_dataset.ckpt")
|
| 35 |
+
test_dataloader = DataLoader(
|
| 36 |
+
test_dataset, batch_size=1, num_workers=6, collate_fn=test_dataset.collate_fn
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
with torch.no_grad():
|
| 40 |
+
for batch in test_dataloader:
|
| 41 |
+
batch: Output = batch.to(device)
|
| 42 |
+
result = task(**batch.subset("x", "x_len", as_type="dict"))
|
| 43 |
+
print(result.hidden_states.shape)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
if __name__ == "__main__":
|
| 47 |
+
main()
|
s3prl_s3prl_main/example/superb_sv/train.py
ADDED
|
@@ -0,0 +1,266 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import math
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.optim as optim
|
| 8 |
+
from torch.utils.data import DataLoader
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
|
| 11 |
+
from s3prl import Logs, Object, Output
|
| 12 |
+
from s3prl.nn import S3PRLUpstream, UpstreamDownstreamModel
|
| 13 |
+
from s3prl.sampler import DistributedBatchSamplerWrapper
|
| 14 |
+
from s3prl.superb import sv as problem
|
| 15 |
+
|
| 16 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def parse_args():
|
| 21 |
+
parser = argparse.ArgumentParser()
|
| 22 |
+
parser.add_argument(
|
| 23 |
+
"--voxceleb1",
|
| 24 |
+
type=str,
|
| 25 |
+
default="/work/jason410/PublicData/Voxceleb1",
|
| 26 |
+
help="The root directory of VoxCeleb1",
|
| 27 |
+
)
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
"--save_to",
|
| 30 |
+
type=str,
|
| 31 |
+
default="result/sv",
|
| 32 |
+
help="The directory to save checkpoint",
|
| 33 |
+
)
|
| 34 |
+
parser.add_argument("--total_steps", type=int, default=200000)
|
| 35 |
+
parser.add_argument("--log_step", type=int, default=100)
|
| 36 |
+
parser.add_argument("--eval_step", type=int, default=200)
|
| 37 |
+
parser.add_argument("--save_step", type=int, default=100)
|
| 38 |
+
|
| 39 |
+
parser.add_argument("--backbone", type=str, default="XVector")
|
| 40 |
+
parser.add_argument("--pooling_type", type=str, default="TAP")
|
| 41 |
+
parser.add_argument("--loss_type", type=str, default="softmax")
|
| 42 |
+
parser.add_argument("--spk_embd_dim", type=int, default=1500)
|
| 43 |
+
args = parser.parse_args()
|
| 44 |
+
return args
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def main():
|
| 48 |
+
logging.basicConfig()
|
| 49 |
+
logger.setLevel(logging.INFO)
|
| 50 |
+
|
| 51 |
+
args = parse_args()
|
| 52 |
+
voxceleb1 = Path(args.voxceleb1)
|
| 53 |
+
assert voxceleb1.is_dir()
|
| 54 |
+
save_to = Path(args.save_to)
|
| 55 |
+
save_to.mkdir(exist_ok=True, parents=True)
|
| 56 |
+
|
| 57 |
+
logger.info("Preparing preprocessor")
|
| 58 |
+
preprocessor = problem.Preprocessor(voxceleb1)
|
| 59 |
+
|
| 60 |
+
logger.info("Preparing train dataloader")
|
| 61 |
+
train_dataset = problem.TrainDataset(**preprocessor.train_data())
|
| 62 |
+
train_sampler = problem.TrainSampler(
|
| 63 |
+
train_dataset, max_timestamp=16000 * 1000, shuffle=True
|
| 64 |
+
)
|
| 65 |
+
train_sampler = DistributedBatchSamplerWrapper(
|
| 66 |
+
train_sampler, num_replicas=1, rank=0
|
| 67 |
+
)
|
| 68 |
+
train_dataloader = DataLoader(
|
| 69 |
+
train_dataset,
|
| 70 |
+
batch_sampler=train_sampler,
|
| 71 |
+
num_workers=6,
|
| 72 |
+
collate_fn=train_dataset.collate_fn,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
logger.info("Preparing valid dataloader")
|
| 76 |
+
valid_dataset = problem.ValidDataset(
|
| 77 |
+
**preprocessor.valid_data(),
|
| 78 |
+
**train_dataset.statistics(),
|
| 79 |
+
)
|
| 80 |
+
valid_dataset.save_checkpoint(save_to / "valid_dataset.ckpt")
|
| 81 |
+
# valid_dataset_reload = Object.load_checkpoint(save_to / "valid_dataset.ckpt")
|
| 82 |
+
valid_sampler = problem.TrainSampler(
|
| 83 |
+
valid_dataset, max_timestamp=16000 * 1000, shuffle=True
|
| 84 |
+
)
|
| 85 |
+
valid_sampler = DistributedBatchSamplerWrapper(
|
| 86 |
+
valid_sampler, num_replicas=1, rank=0
|
| 87 |
+
)
|
| 88 |
+
valid_dataloader = DataLoader(
|
| 89 |
+
valid_dataset,
|
| 90 |
+
batch_sampler=valid_sampler,
|
| 91 |
+
num_workers=6,
|
| 92 |
+
collate_fn=valid_dataset.collate_fn,
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
logger.info("Preparing test dataloader")
|
| 96 |
+
test_dataset = problem.TestDataset(
|
| 97 |
+
**preprocessor.test_data(),
|
| 98 |
+
**train_dataset.statistics(),
|
| 99 |
+
)
|
| 100 |
+
test_dataset.save_checkpoint(save_to / "test_dataset.ckpt")
|
| 101 |
+
test_sampler = problem.TestSampler(test_dataset, 8)
|
| 102 |
+
test_sampler = DistributedBatchSamplerWrapper(test_sampler, num_replicas=1, rank=0)
|
| 103 |
+
test_dataloader = DataLoader(
|
| 104 |
+
test_dataset, batch_size=1, num_workers=6, collate_fn=test_dataset.collate_fn
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
latest_task = save_to / "task.ckpt"
|
| 108 |
+
if latest_task.is_file():
|
| 109 |
+
logger.info("Last checkpoint found. Load model and optimizer from checkpoint")
|
| 110 |
+
|
| 111 |
+
# Object.load_checkpoint() from a checkpoint path and
|
| 112 |
+
# Object.from_checkpoint() from a loaded checkpoint dictionary
|
| 113 |
+
# are like AutoModel in Huggingface which you only need to
|
| 114 |
+
# provide the checkpoint for restoring the module.
|
| 115 |
+
#
|
| 116 |
+
# Note that source code definition should be importable, since this
|
| 117 |
+
# auto loading mechanism is just automating the model re-initialization
|
| 118 |
+
# steps instead of scriptify (torch.jit) all the source code in the
|
| 119 |
+
# checkpoint
|
| 120 |
+
|
| 121 |
+
task = Object.load_checkpoint(latest_task).to(device)
|
| 122 |
+
|
| 123 |
+
else:
|
| 124 |
+
logger.info("No last checkpoint found. Create new model")
|
| 125 |
+
|
| 126 |
+
# Model creation block which can be fully customized
|
| 127 |
+
upstream = S3PRLUpstream("apc")
|
| 128 |
+
# Have to specify the backbone, pooling_type
|
| 129 |
+
downstream = problem.speaker_embedding_extractor(
|
| 130 |
+
backbone=args.backbone,
|
| 131 |
+
pooling_type=args.pooling_type,
|
| 132 |
+
input_size=upstream.output_size,
|
| 133 |
+
output_size=args.spk_embd_dim,
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
model = UpstreamDownstreamModel(upstream, downstream)
|
| 137 |
+
|
| 138 |
+
# Have to specify the loss_type
|
| 139 |
+
task = problem.Task(
|
| 140 |
+
model=model,
|
| 141 |
+
categories=preprocessor.statistics().category,
|
| 142 |
+
loss_type=args.loss_type,
|
| 143 |
+
trials=test_dataset.statistics().label,
|
| 144 |
+
)
|
| 145 |
+
task = task.to(device)
|
| 146 |
+
|
| 147 |
+
# We do not handle optimizer/scheduler in any special way in S3PRL, since
|
| 148 |
+
# there are lots of dedicated package for this. Hence, we also do not handle
|
| 149 |
+
# the checkpointing for optimizer/scheduler. Depends on what training pipeline
|
| 150 |
+
# the user prefer, either Lightning or SpeechBrain, these frameworks will
|
| 151 |
+
# provide different solutions on how to save these objects. By not handling
|
| 152 |
+
# these objects in S3PRL we are making S3PRL more flexible and agnostic to training pipeline
|
| 153 |
+
# The following optimizer codeblock aims to align with the standard usage
|
| 154 |
+
# of PyTorch which is the standard way to save it.
|
| 155 |
+
|
| 156 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 157 |
+
latest_optimizer = save_to / "optimizer.ckpt"
|
| 158 |
+
|
| 159 |
+
if latest_optimizer.is_file():
|
| 160 |
+
optimizer.load_state_dict(torch.load(save_to / "optimizer.ckpt"))
|
| 161 |
+
else:
|
| 162 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 163 |
+
|
| 164 |
+
# The following code block demonstrate how to train with your own training loop
|
| 165 |
+
# This entire block can be easily replaced with Lightning/SpeechBrain Trainer as
|
| 166 |
+
#
|
| 167 |
+
# Trainer(task)
|
| 168 |
+
# Trainer.fit(train_dataloader, valid_dataloader, test_dataloader)
|
| 169 |
+
#
|
| 170 |
+
# As you can see, there is a huge similarity among train/valid/test loops below,
|
| 171 |
+
# so it is a natural step to share these logics with a generic Trainer class
|
| 172 |
+
# as done in Lightning/SpeechBrain
|
| 173 |
+
|
| 174 |
+
pbar = tqdm(total=args.total_steps, desc="Total")
|
| 175 |
+
while True:
|
| 176 |
+
batch_results = []
|
| 177 |
+
for batch in tqdm(train_dataloader, desc="Train", total=len(train_dataloader)):
|
| 178 |
+
pbar.update(1)
|
| 179 |
+
global_step = pbar.n
|
| 180 |
+
|
| 181 |
+
assert isinstance(batch, Output)
|
| 182 |
+
optimizer.zero_grad()
|
| 183 |
+
|
| 184 |
+
# An Output object can more all its direct
|
| 185 |
+
# attributes/values to the device
|
| 186 |
+
batch = batch.to(device)
|
| 187 |
+
|
| 188 |
+
# An Output object is an OrderedDict so we
|
| 189 |
+
# can use dict decomposition here
|
| 190 |
+
task.train()
|
| 191 |
+
result = task.train_step(**batch)
|
| 192 |
+
assert isinstance(result, Output)
|
| 193 |
+
|
| 194 |
+
# The output of train step must contain
|
| 195 |
+
# at least a loss key
|
| 196 |
+
result.loss.backward()
|
| 197 |
+
|
| 198 |
+
# gradient clipping
|
| 199 |
+
grad_norm = torch.nn.utils.clip_grad_norm_(task.parameters(), max_norm=1.0)
|
| 200 |
+
|
| 201 |
+
if math.isnan(grad_norm):
|
| 202 |
+
logger.warning(f"Grad norm is NaN at step {global_step}")
|
| 203 |
+
else:
|
| 204 |
+
optimizer.step()
|
| 205 |
+
|
| 206 |
+
# Detach from GPU, remove large logging (to Tensorboard or local files)
|
| 207 |
+
# objects like logits and leave only small data like loss scalars / prediction
|
| 208 |
+
# strings, so that these objects can be safely cached in a list in the MEM,
|
| 209 |
+
# and become useful for calculating metrics later
|
| 210 |
+
# The Output class can do these with self.cacheable()
|
| 211 |
+
cacheable_result = result.cacheable()
|
| 212 |
+
|
| 213 |
+
# Cache these small data for later metric calculation
|
| 214 |
+
batch_results.append(cacheable_result)
|
| 215 |
+
|
| 216 |
+
if (global_step + 1) % args.log_step == 0:
|
| 217 |
+
logs: Logs = task.train_reduction(batch_results).logs
|
| 218 |
+
logger.info(f"[Train] step {global_step}")
|
| 219 |
+
for log in logs.values():
|
| 220 |
+
logger.info(f"{log.name}: {log.data}")
|
| 221 |
+
batch_results = []
|
| 222 |
+
|
| 223 |
+
if (global_step + 1) % args.eval_step == 0:
|
| 224 |
+
with torch.no_grad():
|
| 225 |
+
task.eval()
|
| 226 |
+
|
| 227 |
+
# valid
|
| 228 |
+
valid_results = []
|
| 229 |
+
for batch in tqdm(
|
| 230 |
+
valid_dataloader, desc="Valid", total=len(valid_dataloader)
|
| 231 |
+
):
|
| 232 |
+
batch = batch.to(device)
|
| 233 |
+
result = task.valid_step(**batch)
|
| 234 |
+
cacheable_result = result.cacheable()
|
| 235 |
+
valid_results.append(cacheable_result)
|
| 236 |
+
|
| 237 |
+
logs: Logs = task.valid_reduction(valid_results).logs
|
| 238 |
+
logger.info(f"[Valid] step {global_step}")
|
| 239 |
+
for log in logs.values():
|
| 240 |
+
logger.info(f"{log.name}: {log.data}")
|
| 241 |
+
|
| 242 |
+
# test
|
| 243 |
+
test_results = []
|
| 244 |
+
for batch in tqdm(
|
| 245 |
+
test_dataloader, desc="Test", total=len(test_dataloader)
|
| 246 |
+
):
|
| 247 |
+
batch = batch.to(device)
|
| 248 |
+
result = task.test_step(**batch)
|
| 249 |
+
test_results.append(result)
|
| 250 |
+
# for key, value in zip(result.name, result.output):
|
| 251 |
+
# test_results[key] = value
|
| 252 |
+
|
| 253 |
+
logs: Logs = task.test_reduction(
|
| 254 |
+
batch_results=test_results,
|
| 255 |
+
).logs
|
| 256 |
+
logger.info(f"[Test] step {global_step}")
|
| 257 |
+
for log in logs.values():
|
| 258 |
+
logger.info(f"{log.name}: {log.data}")
|
| 259 |
+
|
| 260 |
+
if (global_step + 1) % args.save_step == 0:
|
| 261 |
+
task.save_checkpoint(save_to / "task.ckpt")
|
| 262 |
+
torch.save(optimizer.state_dict(), save_to / "optimizer.ckpt")
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
if __name__ == "__main__":
|
| 266 |
+
main()
|
s3prl_s3prl_main/example/superb_sv/train_with_lightning.py
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.optim as optim
|
| 7 |
+
from pytorch_lightning import Trainer
|
| 8 |
+
from pytorch_lightning.callbacks import ModelCheckpoint
|
| 9 |
+
from torch.utils.data import DataLoader
|
| 10 |
+
|
| 11 |
+
from s3prl.nn import S3PRLUpstream, UpstreamDownstreamModel
|
| 12 |
+
from s3prl.sampler import DistributedBatchSamplerWrapper
|
| 13 |
+
from s3prl.superb import sv as problem
|
| 14 |
+
from s3prl.wrapper import LightningModuleSimpleWrapper
|
| 15 |
+
|
| 16 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def parse_args():
|
| 21 |
+
parser = argparse.ArgumentParser()
|
| 22 |
+
parser.add_argument(
|
| 23 |
+
"--voxceleb1",
|
| 24 |
+
type=str,
|
| 25 |
+
default="/work/jason410/PublicData/Voxceleb1",
|
| 26 |
+
help="The root directory of VoxCeleb1",
|
| 27 |
+
)
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
"--save_to",
|
| 30 |
+
type=str,
|
| 31 |
+
default="lightning_result/sv",
|
| 32 |
+
help="The directory to save checkpoint",
|
| 33 |
+
)
|
| 34 |
+
parser.add_argument("--total_steps", type=int, default=200000)
|
| 35 |
+
parser.add_argument("--log_step", type=int, default=100)
|
| 36 |
+
parser.add_argument("--eval_step", type=int, default=1000)
|
| 37 |
+
parser.add_argument("--save_step", type=int, default=100)
|
| 38 |
+
parser.add_argument(
|
| 39 |
+
"--not_resume",
|
| 40 |
+
action="store_true",
|
| 41 |
+
help="Don't resume from the last checkpoint",
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
# for debugging
|
| 45 |
+
parser.add_argument("--limit_train_batches", type=int)
|
| 46 |
+
parser.add_argument("--limit_val_batches", type=int)
|
| 47 |
+
parser.add_argument("--fast_dev_run", action="store_true")
|
| 48 |
+
|
| 49 |
+
parser.add_argument("--backbone", type=str, default="XVector")
|
| 50 |
+
parser.add_argument("--pooling_type", type=str, default="TAP")
|
| 51 |
+
parser.add_argument("--loss_type", type=str, default="softmax")
|
| 52 |
+
parser.add_argument("--spk_embd_dim", type=int, default=1500)
|
| 53 |
+
args = parser.parse_args()
|
| 54 |
+
return args
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def main():
|
| 58 |
+
logging.basicConfig()
|
| 59 |
+
logger.setLevel(logging.INFO)
|
| 60 |
+
|
| 61 |
+
args = parse_args()
|
| 62 |
+
voxceleb1 = Path(args.voxceleb1)
|
| 63 |
+
assert voxceleb1.is_dir()
|
| 64 |
+
save_to = Path(args.save_to)
|
| 65 |
+
save_to.mkdir(exist_ok=True, parents=True)
|
| 66 |
+
|
| 67 |
+
logger.info("Preparing preprocessor")
|
| 68 |
+
preprocessor = problem.Preprocessor(voxceleb1)
|
| 69 |
+
|
| 70 |
+
logger.info("Preparing train dataloader")
|
| 71 |
+
train_dataset = problem.TrainDataset(**preprocessor.train_data())
|
| 72 |
+
train_sampler = problem.TrainSampler(
|
| 73 |
+
train_dataset, max_timestamp=16000 * 1000, shuffle=True
|
| 74 |
+
)
|
| 75 |
+
train_sampler = DistributedBatchSamplerWrapper(
|
| 76 |
+
train_sampler, num_replicas=1, rank=0
|
| 77 |
+
)
|
| 78 |
+
train_dataloader = DataLoader(
|
| 79 |
+
train_dataset,
|
| 80 |
+
batch_sampler=train_sampler,
|
| 81 |
+
num_workers=6,
|
| 82 |
+
collate_fn=train_dataset.collate_fn,
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
logger.info("Preparing valid dataloader")
|
| 86 |
+
valid_dataset = problem.ValidDataset(
|
| 87 |
+
**preprocessor.valid_data(),
|
| 88 |
+
**train_dataset.statistics(),
|
| 89 |
+
)
|
| 90 |
+
valid_dataset.save_checkpoint(save_to / "valid_dataset.ckpt")
|
| 91 |
+
# valid_dataset_reload = Object.load_checkpoint(save_to / "valid_dataset.ckpt")
|
| 92 |
+
valid_sampler = problem.TrainSampler(
|
| 93 |
+
valid_dataset, max_timestamp=16000 * 1000, shuffle=True
|
| 94 |
+
)
|
| 95 |
+
valid_sampler = DistributedBatchSamplerWrapper(
|
| 96 |
+
valid_sampler, num_replicas=1, rank=0
|
| 97 |
+
)
|
| 98 |
+
valid_dataloader = DataLoader(
|
| 99 |
+
valid_dataset,
|
| 100 |
+
batch_sampler=valid_sampler,
|
| 101 |
+
num_workers=6,
|
| 102 |
+
collate_fn=valid_dataset.collate_fn,
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
logger.info("Preparing test dataloader")
|
| 106 |
+
test_dataset = problem.TestDataset(
|
| 107 |
+
**preprocessor.test_data(),
|
| 108 |
+
**train_dataset.statistics(),
|
| 109 |
+
)
|
| 110 |
+
test_dataset.save_checkpoint(save_to / "test_dataset.ckpt")
|
| 111 |
+
test_sampler = problem.TestSampler(test_dataset, 8)
|
| 112 |
+
test_sampler = DistributedBatchSamplerWrapper(test_sampler, num_replicas=1, rank=0)
|
| 113 |
+
test_dataloader = DataLoader(
|
| 114 |
+
test_dataset, batch_size=1, num_workers=6, collate_fn=test_dataset.collate_fn
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
upstream = S3PRLUpstream("apc")
|
| 118 |
+
# Have to specify the backbone, pooling_type, spk_embd_dim
|
| 119 |
+
downstream = problem.speaker_embedding_extractor(
|
| 120 |
+
backbone=args.backbone,
|
| 121 |
+
pooling_type=args.pooling_type,
|
| 122 |
+
input_size=upstream.output_size,
|
| 123 |
+
output_size=args.spk_embd_dim,
|
| 124 |
+
)
|
| 125 |
+
model = UpstreamDownstreamModel(upstream, downstream)
|
| 126 |
+
# Have to specify the loss_type
|
| 127 |
+
task = problem.Task(
|
| 128 |
+
model=model,
|
| 129 |
+
categories=preprocessor.statistics().category,
|
| 130 |
+
loss_type=args.loss_type,
|
| 131 |
+
trials=test_dataset.statistics().label,
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
optimizer = optim.Adam(task.parameters(), lr=1e-3)
|
| 135 |
+
lightning_task = LightningModuleSimpleWrapper(task, optimizer)
|
| 136 |
+
|
| 137 |
+
# The above is the usage of our library
|
| 138 |
+
|
| 139 |
+
# The below is pytorch-lightning specific usage, which can be very simple
|
| 140 |
+
# or very sophisticated, depending on how much you want to customized your
|
| 141 |
+
# training loop
|
| 142 |
+
|
| 143 |
+
checkpoint_callback = ModelCheckpoint(
|
| 144 |
+
dirpath=str(save_to),
|
| 145 |
+
filename="superb-sv-{step:02d}-{valid_0_accuracy:.2f}",
|
| 146 |
+
monitor="valid_0_accuracy", # since might have multiple valid dataloaders
|
| 147 |
+
save_last=True,
|
| 148 |
+
save_top_k=3, # top 3 best ckpt on valid
|
| 149 |
+
mode="max", # higher, better
|
| 150 |
+
every_n_train_steps=args.save_step,
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
trainer = Trainer(
|
| 154 |
+
callbacks=[checkpoint_callback],
|
| 155 |
+
accelerator="gpu",
|
| 156 |
+
gpus=1,
|
| 157 |
+
max_steps=args.total_steps,
|
| 158 |
+
log_every_n_steps=args.log_step,
|
| 159 |
+
val_check_interval=args.eval_step,
|
| 160 |
+
limit_val_batches=args.limit_val_batches or 1.0,
|
| 161 |
+
limit_train_batches=args.limit_train_batches or 1.0,
|
| 162 |
+
fast_dev_run=args.fast_dev_run,
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
last_ckpt = save_to / "last.ckpt"
|
| 166 |
+
if args.not_resume or not last_ckpt.is_file():
|
| 167 |
+
last_ckpt = None
|
| 168 |
+
|
| 169 |
+
trainer.fit(
|
| 170 |
+
lightning_task,
|
| 171 |
+
train_dataloader,
|
| 172 |
+
val_dataloaders=valid_dataloader,
|
| 173 |
+
ckpt_path=last_ckpt,
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
trainer.test(
|
| 177 |
+
lightning_task,
|
| 178 |
+
dataloaders=test_dataloader,
|
| 179 |
+
ckpt_path=last_ckpt,
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
if __name__ == "__main__":
|
| 184 |
+
main()
|
s3prl_s3prl_main/external_tools/install_espnet.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
set -euo pipefail
|
| 3 |
+
|
| 4 |
+
if [ $# != 0 ]; then
|
| 5 |
+
echo "Usage: $0"
|
| 6 |
+
exit 1;
|
| 7 |
+
fi
|
| 8 |
+
|
| 9 |
+
if [ ! -e espnet.done ]; then
|
| 10 |
+
if ! python3 -c "import espnet2" &> /dev/null; then
|
| 11 |
+
pip install "espnet>=202308"
|
| 12 |
+
else
|
| 13 |
+
echo echo "espnet is already installed"
|
| 14 |
+
fi
|
| 15 |
+
touch espnet.done
|
| 16 |
+
else
|
| 17 |
+
echo "espnet is already installed"
|
| 18 |
+
fi
|
| 19 |
+
|
| 20 |
+
|
s3prl_s3prl_main/file/S3PRL-integration.png
ADDED
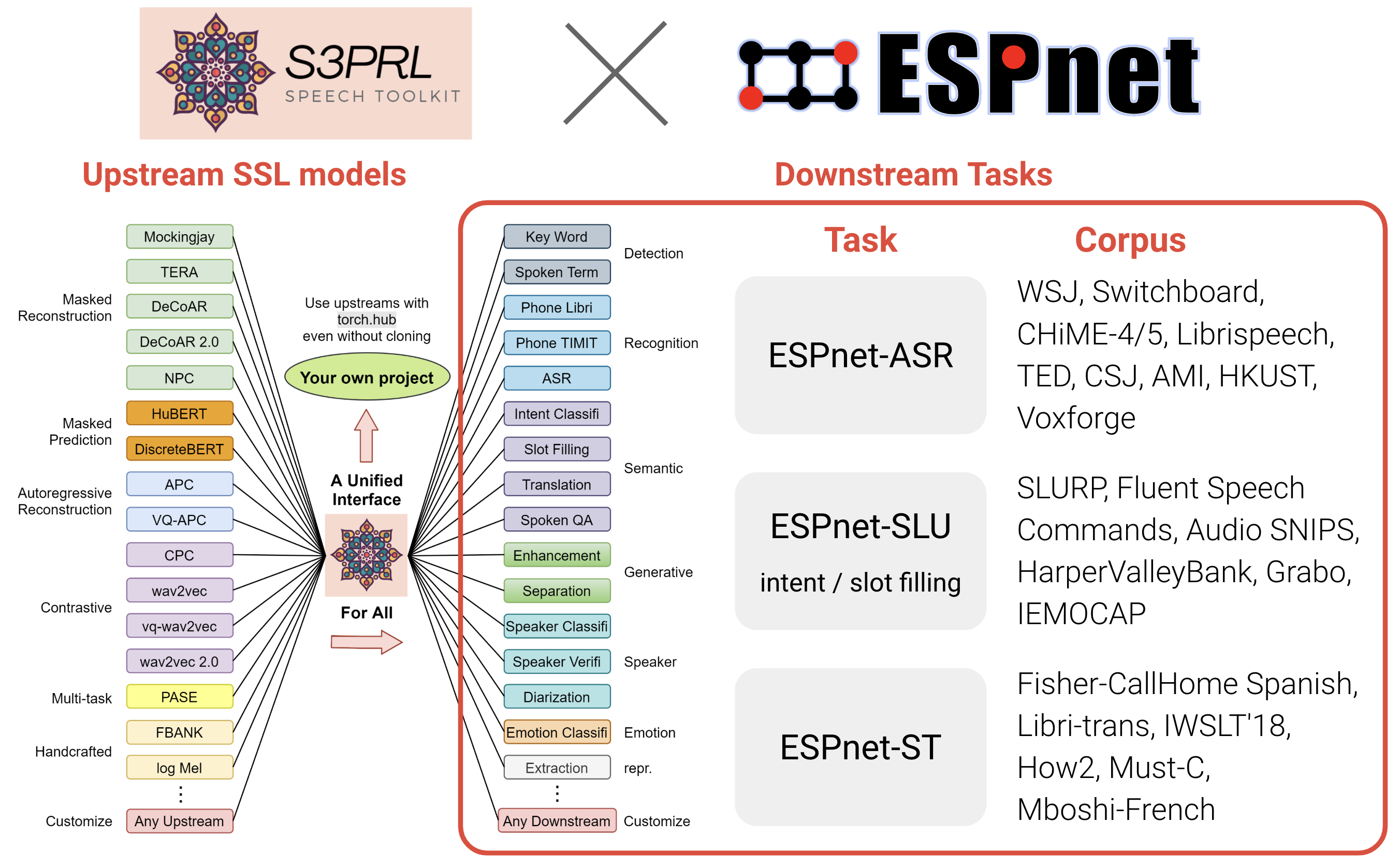
|
s3prl_s3prl_main/file/S3PRL-interface.png
ADDED

|
s3prl_s3prl_main/file/S3PRL-logo.png
ADDED
|
|
s3prl_s3prl_main/file/license.svg
ADDED

|
s3prl_s3prl_main/find_content.sh
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
if [ -z $1 ]; then
|
| 4 |
+
echo "Usage: $0 <pattern>"
|
| 5 |
+
exit 1
|
| 6 |
+
fi
|
| 7 |
+
|
| 8 |
+
ag $1 $(cat valid_paths.txt)
|
s3prl_s3prl_main/hubconf.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from s3prl import hub
|
| 2 |
+
|
| 3 |
+
for _option in hub.options():
|
| 4 |
+
globals()[_option] = getattr(hub, _option)
|
s3prl_s3prl_main/pyrightconfig.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"exclude": [
|
| 3 |
+
"**/result/**",
|
| 4 |
+
],
|
| 5 |
+
}
|
s3prl_s3prl_main/pytest.ini
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[pytest]
|
| 2 |
+
minversion = 6.0
|
| 3 |
+
addopts = -ra -q --log-cli-level INFO
|
| 4 |
+
testpaths =
|
| 5 |
+
test
|
s3prl_s3prl_main/requirements/all.txt
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
joblib >=0.12.4
|
| 2 |
+
librosa >=0.7.2
|
| 3 |
+
scipy >=1.5.4
|
| 4 |
+
scikit-learn >=0.23.2
|
| 5 |
+
pandas>=1.1.5
|
| 6 |
+
matplotlib >=3.3.4
|
| 7 |
+
Pillow >=6.2.2
|
| 8 |
+
numba >=0.48
|
| 9 |
+
cython >=0.29.21
|
| 10 |
+
packaging >=20.9
|
| 11 |
+
transformers >=4.10.0,<5.0
|
| 12 |
+
dtw-python ==1.3.0
|
| 13 |
+
asteroid ==0.4.4
|
| 14 |
+
sacrebleu >=2.0.0
|
| 15 |
+
h5py
|
| 16 |
+
sox
|
| 17 |
+
tabulate
|
| 18 |
+
intervaltree
|
| 19 |
+
lxml
|
| 20 |
+
soundfile
|
| 21 |
+
pysndfx
|
| 22 |
+
nltk
|
| 23 |
+
normalise
|
| 24 |
+
editdistance
|
| 25 |
+
easydict
|
| 26 |
+
catalyst
|
| 27 |
+
sentencepiece
|
| 28 |
+
huggingface_hub >=0.2.1
|
| 29 |
+
mutagen
|
| 30 |
+
pydantic
|
| 31 |
+
sed_eval
|
| 32 |
+
more_itertools
|
| 33 |
+
tensorboard
|
s3prl_s3prl_main/requirements/dev.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python-dotenv
|
| 2 |
+
pytest
|
| 3 |
+
pytest-xdist
|
| 4 |
+
tox
|
| 5 |
+
pre-commit
|
| 6 |
+
flake8 ==3.9.2
|
| 7 |
+
black ==22.3.0
|
| 8 |
+
isort ==5.10.1
|
| 9 |
+
sphinx ==5.1.1 # follow https://github.com/sphinx-doc/sphinx/issues/6316
|
| 10 |
+
furo
|
| 11 |
+
importlib_metadata <5.0 # required by flake8
|