
Gengzigang
commited on
Commit
·
25bf357
1
Parent(s):
6994a0e
init
Browse files- CLIP.png +0 -0
- README.md +55 -3
- config.json +180 -0
- configuration_evaclip.py +421 -0
- convert_evaclip_pytorch_to_hf.py +193 -0
- modeling_evaclip.py +1510 -0
- pytorch_model.bin +3 -0
- teaser.png +0 -0
CLIP.png
ADDED

|
README.md
CHANGED
|
@@ -1,3 +1,55 @@
|
|
| 1 |
-
---
|
| 2 |
-
license:
|
| 3 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
| 4 |
+
<div align="center">
|
| 5 |
+
|
| 6 |
+
<h2><a href="">LLM2CLIP: Extending the Capability Boundaries of CLIP through Large Language Models</a></h2>
|
| 7 |
+
Weiquan Huang<sup>1*</sup>, Aoqi Wu<sup>1*</sup>, Yifan Yang<sup>2†</sup>, Xufang Luo<sup>2</sup>, Yuqing Yang<sup>2</sup>, Liang Hu<sup>1</sup>, Qi Dai<sup>2</sup>, Xiyang Dai<sup>2</sup>, Dongdong Chen<sup>2</sup>, Chong Luo<sup>2</sup>, Lili Qiu<sup>2</sup>
|
| 8 |
+
|
| 9 |
+
<sup>1</sup>Tongji Universiy, <sup>2</sup>Microsoft Corporation <br><sup>*</sup>Equal contribution <br><sup>†</sup> Corresponding to: [email protected]
|
| 10 |
+
|
| 11 |
+
<p><a rel="nofollow" href="https://github.com/microsoft/LLM2CLIP">[📂 GitHub]</a> <a rel="nofollow" href="https://microsoft.github.io/LLM2CLIP/">[🆕 Blog]</a> <a rel="nofollow" href="">[📜 LLM2CLIP]</a>
|
| 12 |
+
</div>
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
In this paper, we propose LLM2CLIP, a novel approach that embraces the power of LLMs to unlock CLIP’s potential. By fine-tuning the LLM in the caption space with contrastive learning, we extract its textual capabilities into the output embeddings, significantly improving the output layer’s textual discriminability. We then design an efficient training process where the fine-tuned LLM acts as a powerful teacher for CLIP’s visual encoder. Thanks to the LLM’s presence, we can now incorporate longer and more complex captions without being restricted by vanilla CLIP text encoder’s context window and ability limitations. Our experiments demonstrate that this approach brings substantial improvements in cross-modal tasks. Our method directly boosted the performance of the previously SOTA EVA02 model by 16.5% on both long-text and short-text retrieval tasks, transforming a CLIP model trained solely on English data into a state-of-the-art cross-lingual model. Moreover, when integrated into mul- timodal training with models like Llava 1.5, it consistently outperformed CLIP across nearly all benchmarks, demonstrating comprehensive performance improvements.
|
| 16 |
+
|
| 17 |
+
## LLM2CLIP performance
|
| 18 |
+
|
| 19 |
+
<div align="center">
|
| 20 |
+
<img src="teaser.png" alt="summary_tab" width="85%">
|
| 21 |
+
</div>
|
| 22 |
+
**It's important to note that all results presented in the paper are evaluated using PyTorch weights. There may be differences in performance when using Hugging Face (hf) models.**
|
| 23 |
+
|
| 24 |
+
## Model Details
|
| 25 |
+
- **Model Type:** vision foundation model, feature backbone
|
| 26 |
+
- **Pretrain Dataset:** CC3M, CC12M, YFCC15M and Recap-DataComp-1B(30M subset)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
## Usage
|
| 30 |
+
|
| 31 |
+
### Huggingface Version
|
| 32 |
+
```python
|
| 33 |
+
from PIL import Image
|
| 34 |
+
from transformers import AutoModel
|
| 35 |
+
from transformers import CLIPImageProcessor
|
| 36 |
+
import torch
|
| 37 |
+
|
| 38 |
+
image_path = "CLIP.png"
|
| 39 |
+
model_name_or_path = "LLM2CLIP-EVA02-B-16" # or /path/to/local/LLM2CLIP-EVA02-B-16
|
| 40 |
+
image_size = 224
|
| 41 |
+
|
| 42 |
+
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch16")
|
| 43 |
+
model = AutoModel.from_pretrained(
|
| 44 |
+
model_name_or_path,
|
| 45 |
+
torch_dtype=torch.float16,
|
| 46 |
+
trust_remote_code=True).to('cuda').eval()
|
| 47 |
+
|
| 48 |
+
image = Image.open(image_path)
|
| 49 |
+
input_pixels = processor(images=image, return_tensors="pt").pixel_values.to('cuda')
|
| 50 |
+
|
| 51 |
+
with torch.no_grad(), torch.cuda.amp.autocast():
|
| 52 |
+
outputs = model.get_image_features(input_pixels)
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## BibTeX & Citation
|
config.json
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": null,
|
| 3 |
+
"_name_or_path": "LLM2CLIP-EVA02-B-16",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"EvaCLIPModel"
|
| 6 |
+
],
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_evaclip.EvaCLIPConfig",
|
| 9 |
+
"AutoModel": "modeling_evaclip.EvaCLIPModel"
|
| 10 |
+
},
|
| 11 |
+
"initializer_factor": 1.0,
|
| 12 |
+
"logit_scale_init_value": 2.659260036932778,
|
| 13 |
+
"model_type": "clip",
|
| 14 |
+
"projection_dim": 1280,
|
| 15 |
+
"text_config": {
|
| 16 |
+
"_name_or_path": "",
|
| 17 |
+
"add_cross_attention": false,
|
| 18 |
+
"architectures": null,
|
| 19 |
+
"attention_dropout": 0.0,
|
| 20 |
+
"bad_words_ids": null,
|
| 21 |
+
"begin_suppress_tokens": null,
|
| 22 |
+
"bos_token_id": 0,
|
| 23 |
+
"chunk_size_feed_forward": 0,
|
| 24 |
+
"cross_attention_hidden_size": null,
|
| 25 |
+
"decoder_start_token_id": null,
|
| 26 |
+
"diversity_penalty": 0.0,
|
| 27 |
+
"do_sample": false,
|
| 28 |
+
"early_stopping": false,
|
| 29 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 30 |
+
"eos_token_id": 2,
|
| 31 |
+
"exponential_decay_length_penalty": null,
|
| 32 |
+
"finetuning_task": null,
|
| 33 |
+
"forced_bos_token_id": null,
|
| 34 |
+
"forced_eos_token_id": null,
|
| 35 |
+
"hidden_act": "gelu",
|
| 36 |
+
"hidden_size": 512,
|
| 37 |
+
"id2label": {
|
| 38 |
+
"0": "LABEL_0",
|
| 39 |
+
"1": "LABEL_1"
|
| 40 |
+
},
|
| 41 |
+
"initializer_factor": 1.0,
|
| 42 |
+
"initializer_range": 0.02,
|
| 43 |
+
"intermediate_size": 2048,
|
| 44 |
+
"is_decoder": false,
|
| 45 |
+
"is_encoder_decoder": false,
|
| 46 |
+
"k_bias": true,
|
| 47 |
+
"label2id": {
|
| 48 |
+
"LABEL_0": 0,
|
| 49 |
+
"LABEL_1": 1
|
| 50 |
+
},
|
| 51 |
+
"layer_norm_eps": 1e-05,
|
| 52 |
+
"length_penalty": 1.0,
|
| 53 |
+
"max_length": 20,
|
| 54 |
+
"max_position_embeddings": 77,
|
| 55 |
+
"min_length": 0,
|
| 56 |
+
"model_type": "clip_text_model",
|
| 57 |
+
"no_repeat_ngram_size": 0,
|
| 58 |
+
"num_attention_heads": 8,
|
| 59 |
+
"num_beam_groups": 1,
|
| 60 |
+
"num_beams": 1,
|
| 61 |
+
"num_hidden_layers": 12,
|
| 62 |
+
"num_return_sequences": 1,
|
| 63 |
+
"output_attentions": false,
|
| 64 |
+
"output_hidden_states": false,
|
| 65 |
+
"output_scores": false,
|
| 66 |
+
"pad_token_id": 1,
|
| 67 |
+
"post_layernorm": false,
|
| 68 |
+
"prefix": null,
|
| 69 |
+
"problem_type": null,
|
| 70 |
+
"projection_dim": 512,
|
| 71 |
+
"pruned_heads": {},
|
| 72 |
+
"q_bias": true,
|
| 73 |
+
"remove_invalid_values": false,
|
| 74 |
+
"repetition_penalty": 1.0,
|
| 75 |
+
"return_dict": true,
|
| 76 |
+
"return_dict_in_generate": false,
|
| 77 |
+
"sep_token_id": null,
|
| 78 |
+
"suppress_tokens": null,
|
| 79 |
+
"task_specific_params": null,
|
| 80 |
+
"temperature": 1.0,
|
| 81 |
+
"tf_legacy_loss": false,
|
| 82 |
+
"tie_encoder_decoder": false,
|
| 83 |
+
"tie_word_embeddings": true,
|
| 84 |
+
"tokenizer_class": null,
|
| 85 |
+
"top_k": 50,
|
| 86 |
+
"top_p": 1.0,
|
| 87 |
+
"torch_dtype": null,
|
| 88 |
+
"torchscript": false,
|
| 89 |
+
"transformers_version": "4.44.2",
|
| 90 |
+
"typical_p": 1.0,
|
| 91 |
+
"use_bfloat16": false,
|
| 92 |
+
"v_bias": true,
|
| 93 |
+
"vocab_size": 49408
|
| 94 |
+
},
|
| 95 |
+
"torch_dtype": "float32",
|
| 96 |
+
"transformers_version": null,
|
| 97 |
+
"vision_config": {
|
| 98 |
+
"_attn_implementation_autoset": false,
|
| 99 |
+
"_name_or_path": "",
|
| 100 |
+
"add_cross_attention": false,
|
| 101 |
+
"architectures": null,
|
| 102 |
+
"attention_dropout": 0.0,
|
| 103 |
+
"bad_words_ids": null,
|
| 104 |
+
"begin_suppress_tokens": null,
|
| 105 |
+
"bos_token_id": null,
|
| 106 |
+
"chunk_size_feed_forward": 0,
|
| 107 |
+
"cross_attention_hidden_size": null,
|
| 108 |
+
"decoder_start_token_id": null,
|
| 109 |
+
"diversity_penalty": 0.0,
|
| 110 |
+
"do_sample": false,
|
| 111 |
+
"dropout": 0.0,
|
| 112 |
+
"early_stopping": false,
|
| 113 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 114 |
+
"eos_token_id": null,
|
| 115 |
+
"exponential_decay_length_penalty": null,
|
| 116 |
+
"finetuning_task": null,
|
| 117 |
+
"forced_bos_token_id": null,
|
| 118 |
+
"forced_eos_token_id": null,
|
| 119 |
+
"hidden_act": "gelu",
|
| 120 |
+
"hidden_size": 768,
|
| 121 |
+
"id2label": {
|
| 122 |
+
"0": "LABEL_0",
|
| 123 |
+
"1": "LABEL_1"
|
| 124 |
+
},
|
| 125 |
+
"image_size": 224,
|
| 126 |
+
"initializer_factor": 1.0,
|
| 127 |
+
"initializer_range": 0.02,
|
| 128 |
+
"intermediate_size": 2048,
|
| 129 |
+
"is_decoder": false,
|
| 130 |
+
"is_encoder_decoder": false,
|
| 131 |
+
"k_bias": false,
|
| 132 |
+
"label2id": {
|
| 133 |
+
"LABEL_0": 0,
|
| 134 |
+
"LABEL_1": 1
|
| 135 |
+
},
|
| 136 |
+
"layer_norm_eps": 1e-06,
|
| 137 |
+
"length_penalty": 1.0,
|
| 138 |
+
"max_length": 20,
|
| 139 |
+
"min_length": 0,
|
| 140 |
+
"model_type": "clip_vision_model",
|
| 141 |
+
"no_repeat_ngram_size": 0,
|
| 142 |
+
"num_attention_heads": 12,
|
| 143 |
+
"num_beam_groups": 1,
|
| 144 |
+
"num_beams": 1,
|
| 145 |
+
"num_channels": 3,
|
| 146 |
+
"num_hidden_layers": 12,
|
| 147 |
+
"num_return_sequences": 1,
|
| 148 |
+
"output_attentions": false,
|
| 149 |
+
"output_hidden_states": false,
|
| 150 |
+
"output_scores": false,
|
| 151 |
+
"pad_token_id": null,
|
| 152 |
+
"patch_size": 16,
|
| 153 |
+
"post_layernorm": true,
|
| 154 |
+
"prefix": null,
|
| 155 |
+
"problem_type": null,
|
| 156 |
+
"projection_dim": 1280,
|
| 157 |
+
"pruned_heads": {},
|
| 158 |
+
"q_bias": true,
|
| 159 |
+
"remove_invalid_values": false,
|
| 160 |
+
"repetition_penalty": 1.0,
|
| 161 |
+
"return_dict": true,
|
| 162 |
+
"return_dict_in_generate": false,
|
| 163 |
+
"sep_token_id": null,
|
| 164 |
+
"suppress_tokens": null,
|
| 165 |
+
"task_specific_params": null,
|
| 166 |
+
"temperature": 1.0,
|
| 167 |
+
"tf_legacy_loss": false,
|
| 168 |
+
"tie_encoder_decoder": false,
|
| 169 |
+
"tie_word_embeddings": true,
|
| 170 |
+
"tokenizer_class": null,
|
| 171 |
+
"top_k": 50,
|
| 172 |
+
"top_p": 1.0,
|
| 173 |
+
"torch_dtype": null,
|
| 174 |
+
"torchscript": false,
|
| 175 |
+
"transformers_version": "4.44.2",
|
| 176 |
+
"typical_p": 1.0,
|
| 177 |
+
"use_bfloat16": false,
|
| 178 |
+
"v_bias": true
|
| 179 |
+
}
|
| 180 |
+
}
|
configuration_evaclip.py
ADDED
|
@@ -0,0 +1,421 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
""" EvaCLIP model configuration"""
|
| 16 |
+
# Code mainly copied here: https://github.com/huggingface/transformers/blob/main/src/transformers/models/clip/configuration_clip.py
|
| 17 |
+
# and adjusted for evaclip
|
| 18 |
+
|
| 19 |
+
import copy
|
| 20 |
+
import os
|
| 21 |
+
from collections import OrderedDict
|
| 22 |
+
from typing import TYPE_CHECKING, Any, Mapping, Optional, Union
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
if TYPE_CHECKING:
|
| 26 |
+
from transformers.processing_utils import ProcessorMixin
|
| 27 |
+
from transformers.utils import TensorType
|
| 28 |
+
|
| 29 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 30 |
+
from transformers.utils import logging
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
logger = logging.get_logger(__name__)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class EvaCLIPTextConfig(PretrainedConfig):
|
| 37 |
+
r"""
|
| 38 |
+
This is the configuration class to store the configuration of a [`CLIPTextModel`]. It is used to instantiate a CLIP
|
| 39 |
+
text encoder according to the specified arguments, defining the model architecture. Instantiating a configuration
|
| 40 |
+
with the defaults will yield a similar configuration to that of the text encoder of the CLIP
|
| 41 |
+
[openai/clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32) architecture.
|
| 42 |
+
|
| 43 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 44 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 45 |
+
|
| 46 |
+
Args:
|
| 47 |
+
vocab_size (`int`, *optional*, defaults to 49408):
|
| 48 |
+
Vocabulary size of the CLIP text model. Defines the number of different tokens that can be represented by
|
| 49 |
+
the `inputs_ids` passed when calling [`CLIPModel`].
|
| 50 |
+
hidden_size (`int`, *optional*, defaults to 512):
|
| 51 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 52 |
+
intermediate_size (`int`, *optional*, defaults to 2048):
|
| 53 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 54 |
+
num_hidden_layers (`int`, *optional*, defaults to 12):
|
| 55 |
+
Number of hidden layers in the Transformer encoder.
|
| 56 |
+
num_attention_heads (`int`, *optional*, defaults to 8):
|
| 57 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 58 |
+
max_position_embeddings (`int`, *optional*, defaults to 77):
|
| 59 |
+
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
| 60 |
+
just in case (e.g., 512 or 1024 or 2048).
|
| 61 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
|
| 62 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 63 |
+
`"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
|
| 64 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
|
| 65 |
+
The epsilon used by the layer normalization layers.
|
| 66 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 67 |
+
The dropout ratio for the attention probabilities.
|
| 68 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 69 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 70 |
+
initializer_factor (`float`, *optional*, defaults to 1):
|
| 71 |
+
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
|
| 72 |
+
testing).
|
| 73 |
+
|
| 74 |
+
Example:
|
| 75 |
+
|
| 76 |
+
```python
|
| 77 |
+
>>> from transformers import CLIPTextConfig, CLIPTextModel
|
| 78 |
+
|
| 79 |
+
>>> # Initializing a CLIPTextConfig with openai/clip-vit-base-patch32 style configuration
|
| 80 |
+
>>> configuration = CLIPTextConfig()
|
| 81 |
+
|
| 82 |
+
>>> # Initializing a CLIPTextModel (with random weights) from the openai/clip-vit-base-patch32 style configuration
|
| 83 |
+
>>> model = CLIPTextModel(configuration)
|
| 84 |
+
|
| 85 |
+
>>> # Accessing the model configuration
|
| 86 |
+
>>> configuration = model.config
|
| 87 |
+
```"""
|
| 88 |
+
model_type = "clip_text_model"
|
| 89 |
+
|
| 90 |
+
def __init__(
|
| 91 |
+
self,
|
| 92 |
+
vocab_size=49408,
|
| 93 |
+
hidden_size=512,
|
| 94 |
+
intermediate_size=2048,
|
| 95 |
+
projection_dim=512,
|
| 96 |
+
num_hidden_layers=12,
|
| 97 |
+
num_attention_heads=8,
|
| 98 |
+
max_position_embeddings=77,
|
| 99 |
+
hidden_act="gelu",
|
| 100 |
+
layer_norm_eps=1e-5,
|
| 101 |
+
attention_dropout=0.0,
|
| 102 |
+
initializer_range=0.02,
|
| 103 |
+
initializer_factor=1.0,
|
| 104 |
+
q_bias=True,
|
| 105 |
+
k_bias=True,
|
| 106 |
+
v_bias=True,
|
| 107 |
+
post_layernorm=False,
|
| 108 |
+
pad_token_id=1,
|
| 109 |
+
bos_token_id=0,
|
| 110 |
+
eos_token_id=2,
|
| 111 |
+
**kwargs,
|
| 112 |
+
):
|
| 113 |
+
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
|
| 114 |
+
|
| 115 |
+
self.vocab_size = vocab_size
|
| 116 |
+
self.hidden_size = hidden_size
|
| 117 |
+
self.intermediate_size = intermediate_size
|
| 118 |
+
self.projection_dim = projection_dim
|
| 119 |
+
self.num_hidden_layers = num_hidden_layers
|
| 120 |
+
self.num_attention_heads = num_attention_heads
|
| 121 |
+
self.max_position_embeddings = max_position_embeddings
|
| 122 |
+
self.layer_norm_eps = layer_norm_eps
|
| 123 |
+
self.hidden_act = hidden_act
|
| 124 |
+
self.initializer_range = initializer_range
|
| 125 |
+
self.initializer_factor = initializer_factor
|
| 126 |
+
self.q_bias=q_bias
|
| 127 |
+
self.k_bias=k_bias
|
| 128 |
+
self.v_bias=v_bias
|
| 129 |
+
self.post_layernorm = post_layernorm
|
| 130 |
+
self.attention_dropout = attention_dropout
|
| 131 |
+
|
| 132 |
+
@classmethod
|
| 133 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 134 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 135 |
+
|
| 136 |
+
# get the text config dict if we are loading from CLIPConfig
|
| 137 |
+
if config_dict.get("model_type") == "clip":
|
| 138 |
+
config_dict = config_dict["text_config"]
|
| 139 |
+
|
| 140 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 141 |
+
logger.warning(
|
| 142 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 143 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
class EvaCLIPVisionConfig(PretrainedConfig):
|
| 150 |
+
r"""
|
| 151 |
+
This is the configuration class to store the configuration of a [`CLIPVisionModel`]. It is used to instantiate a
|
| 152 |
+
CLIP vision encoder according to the specified arguments, defining the model architecture. Instantiating a
|
| 153 |
+
configuration with the defaults will yield a similar configuration to that of the vision encoder of the CLIP
|
| 154 |
+
[openai/clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32) architecture.
|
| 155 |
+
|
| 156 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 157 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 158 |
+
|
| 159 |
+
Args:
|
| 160 |
+
hidden_size (`int`, *optional*, defaults to 768):
|
| 161 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 162 |
+
intermediate_size (`int`, *optional*, defaults to 3072):
|
| 163 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 164 |
+
num_hidden_layers (`int`, *optional*, defaults to 12):
|
| 165 |
+
Number of hidden layers in the Transformer encoder.
|
| 166 |
+
num_attention_heads (`int`, *optional*, defaults to 12):
|
| 167 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 168 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 169 |
+
The size (resolution) of each image.
|
| 170 |
+
patch_size (`int`, *optional*, defaults to 32):
|
| 171 |
+
The size (resolution) of each patch.
|
| 172 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
|
| 173 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 174 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
|
| 175 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
|
| 176 |
+
The epsilon used by the layer normalization layers.
|
| 177 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 178 |
+
The dropout ratio for the attention probabilities.
|
| 179 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 180 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 181 |
+
initializer_factor (`float`, *optional*, defaults to 1):
|
| 182 |
+
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
|
| 183 |
+
testing).
|
| 184 |
+
|
| 185 |
+
Example:
|
| 186 |
+
|
| 187 |
+
```python
|
| 188 |
+
>>> from transformers import CLIPVisionConfig, CLIPVisionModel
|
| 189 |
+
|
| 190 |
+
>>> # Initializing a CLIPVisionConfig with openai/clip-vit-base-patch32 style configuration
|
| 191 |
+
>>> configuration = CLIPVisionConfig()
|
| 192 |
+
|
| 193 |
+
>>> # Initializing a CLIPVisionModel (with random weights) from the openai/clip-vit-base-patch32 style configuration
|
| 194 |
+
>>> model = CLIPVisionModel(configuration)
|
| 195 |
+
|
| 196 |
+
>>> # Accessing the model configuration
|
| 197 |
+
>>> configuration = model.config
|
| 198 |
+
```"""
|
| 199 |
+
|
| 200 |
+
model_type = "clip_vision_model"
|
| 201 |
+
|
| 202 |
+
def __init__(
|
| 203 |
+
self,
|
| 204 |
+
hidden_size=768,
|
| 205 |
+
intermediate_size=3072,
|
| 206 |
+
projection_dim=512,
|
| 207 |
+
num_hidden_layers=12,
|
| 208 |
+
num_attention_heads=12,
|
| 209 |
+
num_channels=3,
|
| 210 |
+
image_size=224,
|
| 211 |
+
patch_size=32,
|
| 212 |
+
hidden_act="gelu",
|
| 213 |
+
layer_norm_eps=1e-5,
|
| 214 |
+
attention_dropout=0.0,
|
| 215 |
+
initializer_range=0.02,
|
| 216 |
+
initializer_factor=1.0,
|
| 217 |
+
q_bias=True,
|
| 218 |
+
k_bias=True,
|
| 219 |
+
v_bias=True,
|
| 220 |
+
post_layernorm=False,
|
| 221 |
+
**kwargs,
|
| 222 |
+
):
|
| 223 |
+
super().__init__(**kwargs)
|
| 224 |
+
|
| 225 |
+
self.hidden_size = hidden_size
|
| 226 |
+
self.intermediate_size = intermediate_size
|
| 227 |
+
self.projection_dim = projection_dim
|
| 228 |
+
self.num_hidden_layers = num_hidden_layers
|
| 229 |
+
self.num_attention_heads = num_attention_heads
|
| 230 |
+
self.num_channels = num_channels
|
| 231 |
+
self.patch_size = patch_size
|
| 232 |
+
self.image_size = image_size
|
| 233 |
+
self.initializer_range = initializer_range
|
| 234 |
+
self.initializer_factor = initializer_factor
|
| 235 |
+
self.q_bias=q_bias
|
| 236 |
+
self.k_bias=k_bias
|
| 237 |
+
self.v_bias=v_bias
|
| 238 |
+
self.post_layernorm = post_layernorm
|
| 239 |
+
self.attention_dropout = attention_dropout
|
| 240 |
+
self.layer_norm_eps = layer_norm_eps
|
| 241 |
+
self.hidden_act = hidden_act
|
| 242 |
+
|
| 243 |
+
@classmethod
|
| 244 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 245 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 246 |
+
|
| 247 |
+
# get the vision config dict if we are loading from CLIPConfig
|
| 248 |
+
if config_dict.get("model_type") == "clip":
|
| 249 |
+
config_dict = config_dict["vision_config"]
|
| 250 |
+
|
| 251 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 252 |
+
logger.warning(
|
| 253 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 254 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
class EvaCLIPConfig(PretrainedConfig):
|
| 261 |
+
r"""
|
| 262 |
+
[`CLIPConfig`] is the configuration class to store the configuration of a [`CLIPModel`]. It is used to instantiate
|
| 263 |
+
a CLIP model according to the specified arguments, defining the text model and vision model configs. Instantiating
|
| 264 |
+
a configuration with the defaults will yield a similar configuration to that of the CLIP
|
| 265 |
+
[openai/clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32) architecture.
|
| 266 |
+
|
| 267 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 268 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 269 |
+
|
| 270 |
+
Args:
|
| 271 |
+
text_config (`dict`, *optional*):
|
| 272 |
+
Dictionary of configuration options used to initialize [`CLIPTextConfig`].
|
| 273 |
+
vision_config (`dict`, *optional*):
|
| 274 |
+
Dictionary of configuration options used to initialize [`CLIPVisionConfig`].
|
| 275 |
+
projection_dim (`int`, *optional*, defaults to 512):
|
| 276 |
+
Dimentionality of text and vision projection layers.
|
| 277 |
+
logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
|
| 278 |
+
The inital value of the *logit_scale* paramter. Default is used as per the original CLIP implementation.
|
| 279 |
+
kwargs (*optional*):
|
| 280 |
+
Dictionary of keyword arguments.
|
| 281 |
+
|
| 282 |
+
Example:
|
| 283 |
+
|
| 284 |
+
```python
|
| 285 |
+
>>> from transformers import CLIPConfig, CLIPModel
|
| 286 |
+
|
| 287 |
+
>>> # Initializing a CLIPConfig with openai/clip-vit-base-patch32 style configuration
|
| 288 |
+
>>> configuration = CLIPConfig()
|
| 289 |
+
|
| 290 |
+
>>> # Initializing a CLIPModel (with random weights) from the openai/clip-vit-base-patch32 style configuration
|
| 291 |
+
>>> model = CLIPModel(configuration)
|
| 292 |
+
|
| 293 |
+
>>> # Accessing the model configuration
|
| 294 |
+
>>> configuration = model.config
|
| 295 |
+
|
| 296 |
+
>>> # We can also initialize a CLIPConfig from a CLIPTextConfig and a CLIPVisionConfig
|
| 297 |
+
>>> from transformers import CLIPTextConfig, CLIPVisionConfig
|
| 298 |
+
|
| 299 |
+
>>> # Initializing a CLIPText and CLIPVision configuration
|
| 300 |
+
>>> config_text = CLIPTextConfig()
|
| 301 |
+
>>> config_vision = CLIPVisionConfig()
|
| 302 |
+
|
| 303 |
+
>>> config = CLIPConfig.from_text_vision_configs(config_text, config_vision)
|
| 304 |
+
```"""
|
| 305 |
+
|
| 306 |
+
model_type = "clip"
|
| 307 |
+
is_composition = True
|
| 308 |
+
|
| 309 |
+
def __init__(
|
| 310 |
+
self, text_config=None, vision_config=None, projection_dim=512, logit_scale_init_value=2.6592, **kwargs
|
| 311 |
+
):
|
| 312 |
+
# If `_config_dict` exist, we use them for the backward compatibility.
|
| 313 |
+
# We pop out these 2 attributes before calling `super().__init__` to avoid them being saved (which causes a lot
|
| 314 |
+
# of confusion!).
|
| 315 |
+
text_config_dict = kwargs.pop("text_config_dict", None)
|
| 316 |
+
vision_config_dict = kwargs.pop("vision_config_dict", None)
|
| 317 |
+
|
| 318 |
+
super().__init__(**kwargs)
|
| 319 |
+
|
| 320 |
+
# Instead of simply assigning `[text|vision]_config_dict` to `[text|vision]_config`, we use the values in
|
| 321 |
+
# `[text|vision]_config_dict` to update the values in `[text|vision]_config`. The values should be same in most
|
| 322 |
+
# cases, but we don't want to break anything regarding `_config_dict` that existed before commit `8827e1b2`.
|
| 323 |
+
if text_config_dict is not None:
|
| 324 |
+
if text_config is None:
|
| 325 |
+
text_config = {}
|
| 326 |
+
|
| 327 |
+
# This is the complete result when using `text_config_dict`.
|
| 328 |
+
_text_config_dict = EvaCLIPTextConfig(**text_config_dict).to_dict()
|
| 329 |
+
|
| 330 |
+
# Give a warning if the values exist in both `_text_config_dict` and `text_config` but being different.
|
| 331 |
+
for key, value in _text_config_dict.items():
|
| 332 |
+
if key in text_config and value != text_config[key] and key not in ["transformers_version"]:
|
| 333 |
+
# If specified in `text_config_dict`
|
| 334 |
+
if key in text_config_dict:
|
| 335 |
+
message = (
|
| 336 |
+
f"`{key}` is found in both `text_config_dict` and `text_config` but with different values. "
|
| 337 |
+
f'The value `text_config_dict["{key}"]` will be used instead.'
|
| 338 |
+
)
|
| 339 |
+
# If inferred from default argument values (just to be super careful)
|
| 340 |
+
else:
|
| 341 |
+
message = (
|
| 342 |
+
f"`text_config_dict` is provided which will be used to initialize `CLIPTextConfig`. The "
|
| 343 |
+
f'value `text_config["{key}"]` will be overriden.'
|
| 344 |
+
)
|
| 345 |
+
logger.warning(message)
|
| 346 |
+
|
| 347 |
+
# Update all values in `text_config` with the ones in `_text_config_dict`.
|
| 348 |
+
text_config.update(_text_config_dict)
|
| 349 |
+
|
| 350 |
+
if vision_config_dict is not None:
|
| 351 |
+
if vision_config is None:
|
| 352 |
+
vision_config = {}
|
| 353 |
+
|
| 354 |
+
# This is the complete result when using `vision_config_dict`.
|
| 355 |
+
_vision_config_dict = EvaCLIPVisionConfig(**vision_config_dict).to_dict()
|
| 356 |
+
# convert keys to string instead of integer
|
| 357 |
+
if "id2label" in _vision_config_dict:
|
| 358 |
+
_vision_config_dict["id2label"] = {
|
| 359 |
+
str(key): value for key, value in _vision_config_dict["id2label"].items()
|
| 360 |
+
}
|
| 361 |
+
|
| 362 |
+
# Give a warning if the values exist in both `_vision_config_dict` and `vision_config` but being different.
|
| 363 |
+
for key, value in _vision_config_dict.items():
|
| 364 |
+
if key in vision_config and value != vision_config[key] and key not in ["transformers_version"]:
|
| 365 |
+
# If specified in `vision_config_dict`
|
| 366 |
+
if key in vision_config_dict:
|
| 367 |
+
message = (
|
| 368 |
+
f"`{key}` is found in both `vision_config_dict` and `vision_config` but with different "
|
| 369 |
+
f'values. The value `vision_config_dict["{key}"]` will be used instead.'
|
| 370 |
+
)
|
| 371 |
+
# If inferred from default argument values (just to be super careful)
|
| 372 |
+
else:
|
| 373 |
+
message = (
|
| 374 |
+
f"`vision_config_dict` is provided which will be used to initialize `CLIPVisionConfig`. "
|
| 375 |
+
f'The value `vision_config["{key}"]` will be overriden.'
|
| 376 |
+
)
|
| 377 |
+
logger.warning(message)
|
| 378 |
+
|
| 379 |
+
# Update all values in `vision_config` with the ones in `_vision_config_dict`.
|
| 380 |
+
vision_config.update(_vision_config_dict)
|
| 381 |
+
|
| 382 |
+
if text_config is None:
|
| 383 |
+
text_config = {}
|
| 384 |
+
logger.info("`text_config` is `None`. Initializing the `CLIPTextConfig` with default values.")
|
| 385 |
+
|
| 386 |
+
if vision_config is None:
|
| 387 |
+
vision_config = {}
|
| 388 |
+
logger.info("`vision_config` is `None`. initializing the `CLIPVisionConfig` with default values.")
|
| 389 |
+
|
| 390 |
+
self.text_config = EvaCLIPTextConfig(**text_config)
|
| 391 |
+
self.vision_config = EvaCLIPVisionConfig(**vision_config)
|
| 392 |
+
|
| 393 |
+
self.projection_dim = projection_dim
|
| 394 |
+
self.logit_scale_init_value = logit_scale_init_value
|
| 395 |
+
self.initializer_factor = 1.0
|
| 396 |
+
|
| 397 |
+
@classmethod
|
| 398 |
+
def from_text_vision_configs(cls, text_config: EvaCLIPTextConfig, vision_config: EvaCLIPVisionConfig, **kwargs):
|
| 399 |
+
r"""
|
| 400 |
+
Instantiate a [`CLIPConfig`] (or a derived class) from clip text model configuration and clip vision model
|
| 401 |
+
configuration.
|
| 402 |
+
|
| 403 |
+
Returns:
|
| 404 |
+
[`CLIPConfig`]: An instance of a configuration object
|
| 405 |
+
"""
|
| 406 |
+
|
| 407 |
+
return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
|
| 408 |
+
|
| 409 |
+
def to_dict(self):
|
| 410 |
+
"""
|
| 411 |
+
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
|
| 412 |
+
|
| 413 |
+
Returns:
|
| 414 |
+
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
|
| 415 |
+
"""
|
| 416 |
+
output = copy.deepcopy(self.__dict__)
|
| 417 |
+
output["text_config"] = self.text_config.to_dict()
|
| 418 |
+
output["vision_config"] = self.vision_config.to_dict()
|
| 419 |
+
output["model_type"] = self.__class__.model_type
|
| 420 |
+
return output
|
| 421 |
+
|
convert_evaclip_pytorch_to_hf.py
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
# Part of the code was taken from:
|
| 17 |
+
# https://github.com/huggingface/transformers/blob/main/src/transformers/models/clap/convert_clap_original_pytorch_to_hf.py
|
| 18 |
+
|
| 19 |
+
import argparse
|
| 20 |
+
|
| 21 |
+
import torch
|
| 22 |
+
from PIL import Image
|
| 23 |
+
from transformers import AutoModel, AutoConfig
|
| 24 |
+
from transformers import CLIPImageProcessor, pipeline, CLIPTokenizer
|
| 25 |
+
from configuration_evaclip import EvaCLIPConfig
|
| 26 |
+
from modeling_evaclip import EvaCLIPModel
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
KEYS_TO_MODIFY_MAPPING = {
|
| 30 |
+
"cls_token":"embeddings.class_embedding",
|
| 31 |
+
"pos_embed":"embeddings.position_embedding.weight",
|
| 32 |
+
"patch_embed.proj":"embeddings.patch_embedding",
|
| 33 |
+
".positional_embedding":".embeddings.position_embedding.weight",
|
| 34 |
+
".token_embedding":".embeddings.token_embedding",
|
| 35 |
+
# "text.text_projection":"text_projection.weight",
|
| 36 |
+
"mlp.c_fc":"mlp.fc1",
|
| 37 |
+
"mlp.c_proj":"mlp.fc2",
|
| 38 |
+
"mlp.w1":"mlp.fc1",
|
| 39 |
+
"mlp.w2":"mlp.fc2",
|
| 40 |
+
"mlp.w3":"mlp.fc3",
|
| 41 |
+
".proj.":".out_proj.",
|
| 42 |
+
# "q_bias":"q_proj.bias",
|
| 43 |
+
# "v_bias":"v_proj.bias",
|
| 44 |
+
"out.":"out_proj.",
|
| 45 |
+
"norm1":"layer_norm1",
|
| 46 |
+
"norm2":"layer_norm2",
|
| 47 |
+
"ln_1":"layer_norm1",
|
| 48 |
+
"ln_2":"layer_norm2",
|
| 49 |
+
".attn":".self_attn",
|
| 50 |
+
"norm.":"post_layernorm.",
|
| 51 |
+
"ln_final":"final_layer_norm",
|
| 52 |
+
"visual.blocks":"vision_model.encoder.layers",
|
| 53 |
+
# "text.transformer.resblocks":"text_model.encoder.layers",
|
| 54 |
+
"visual.head":"visual_projection",
|
| 55 |
+
"visual.":"vision_model.",
|
| 56 |
+
# "text.":"text_model.",
|
| 57 |
+
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
def rename_state_dict(state_dict):
|
| 61 |
+
model_state_dict = {}
|
| 62 |
+
|
| 63 |
+
for key, value in state_dict.items():
|
| 64 |
+
# check if any key needs to be modified
|
| 65 |
+
for key_to_modify, new_key in KEYS_TO_MODIFY_MAPPING.items():
|
| 66 |
+
if key_to_modify in key:
|
| 67 |
+
key = key.replace(key_to_modify, new_key)
|
| 68 |
+
if "text_projection" in key:
|
| 69 |
+
model_state_dict[key] = value.T
|
| 70 |
+
elif "attn.qkv" in key:
|
| 71 |
+
# split qkv into query key and value
|
| 72 |
+
mixed_qkv = value
|
| 73 |
+
qkv_dim = mixed_qkv.size(0) // 3
|
| 74 |
+
|
| 75 |
+
query_layer = mixed_qkv[:qkv_dim]
|
| 76 |
+
key_layer = mixed_qkv[qkv_dim : qkv_dim * 2]
|
| 77 |
+
value_layer = mixed_qkv[qkv_dim * 2 :]
|
| 78 |
+
|
| 79 |
+
model_state_dict[key.replace("qkv", "q_proj")] = query_layer
|
| 80 |
+
model_state_dict[key.replace("qkv", "k_proj")] = key_layer
|
| 81 |
+
model_state_dict[key.replace("qkv", "v_proj")] = value_layer
|
| 82 |
+
|
| 83 |
+
elif "attn.in_proj" in key:
|
| 84 |
+
# split qkv into query key and value
|
| 85 |
+
mixed_qkv = value
|
| 86 |
+
qkv_dim = mixed_qkv.size(0) // 3
|
| 87 |
+
|
| 88 |
+
query_layer = mixed_qkv[:qkv_dim]
|
| 89 |
+
key_layer = mixed_qkv[qkv_dim : qkv_dim * 2]
|
| 90 |
+
value_layer = mixed_qkv[qkv_dim * 2 :]
|
| 91 |
+
|
| 92 |
+
model_state_dict[key.replace("in_proj_", "q_proj.")] = query_layer
|
| 93 |
+
model_state_dict[key.replace("in_proj_", "k_proj.")] = key_layer
|
| 94 |
+
model_state_dict[key.replace("in_proj_", "v_proj.")] = value_layer
|
| 95 |
+
|
| 96 |
+
elif "class_embedding" in key:
|
| 97 |
+
model_state_dict[key] = value[0,0,:]
|
| 98 |
+
elif "vision_model.embeddings.position_embedding" in key:
|
| 99 |
+
model_state_dict[key] = value[0,:,:]
|
| 100 |
+
|
| 101 |
+
else:
|
| 102 |
+
model_state_dict[key] = value
|
| 103 |
+
|
| 104 |
+
return model_state_dict
|
| 105 |
+
|
| 106 |
+
# This requires having a clone of https://github.com/baaivision/EVA/tree/master/EVA-CLIP as well as the right conda env
|
| 107 |
+
# Part of the code is copied from https://github.com/baaivision/EVA/blob/master/EVA-CLIP/README.md "Usage" section
|
| 108 |
+
def getevaclip(checkpoint_path, input_pixels, captions):
|
| 109 |
+
from eva_clip import create_model_and_transforms, get_tokenizer
|
| 110 |
+
model_name = "EVA02-CLIP-bigE-14-plus"
|
| 111 |
+
model, _, _ = create_model_and_transforms(model_name, checkpoint_path, force_custom_clip=True)
|
| 112 |
+
tokenizer = get_tokenizer(model_name)
|
| 113 |
+
text = tokenizer(captions)
|
| 114 |
+
|
| 115 |
+
with torch.no_grad():
|
| 116 |
+
text_features = model.encode_text(text)
|
| 117 |
+
image_features = model.encode_image(input_pixels)
|
| 118 |
+
image_features_normed = image_features / image_features.norm(dim=-1, keepdim=True)
|
| 119 |
+
text_features_normed = text_features / text_features.norm(dim=-1, keepdim=True)
|
| 120 |
+
|
| 121 |
+
label_probs = (100.0 * image_features_normed @ text_features_normed.T).softmax(dim=-1)
|
| 122 |
+
|
| 123 |
+
return label_probs
|
| 124 |
+
|
| 125 |
+
def save_model_and_config(pytorch_dump_folder_path, hf_model, transformers_config):
|
| 126 |
+
hf_model.save_pretrained(pytorch_dump_folder_path, safe_serialization=False)
|
| 127 |
+
transformers_config.save_pretrained(pytorch_dump_folder_path)
|
| 128 |
+
|
| 129 |
+
def check_loaded_model(pytorch_dump_folder_path, processor, image):
|
| 130 |
+
# hf_config = AutoConfig.from_pretrained(pytorch_dump_folder_path, trust_remote_code=True)
|
| 131 |
+
# hf_model = AutoModel.from_pretrained(pytorch_dump_folder_path, config=hf_config, trust_remote_code=True)
|
| 132 |
+
hf_model = AutoModel.from_pretrained(pytorch_dump_folder_path, trust_remote_code=True)
|
| 133 |
+
|
| 134 |
+
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch16")
|
| 135 |
+
image_path = 'LLM2CLIP-EVA02-B-16/CLIP.png'
|
| 136 |
+
image = Image.open(image_path)
|
| 137 |
+
input_pixels = processor(images=image, return_tensors="pt").pixel_values
|
| 138 |
+
with torch.no_grad():
|
| 139 |
+
image_features = hf_model.get_image_features(input_pixels)
|
| 140 |
+
print(image_features.shape)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
# detector = pipeline(model=hf_model, task="zero-shot-image-classification", tokenizer = tokenizer, image_processor=processor)
|
| 144 |
+
# detector_probs = detector(image, candidate_labels=captions)
|
| 145 |
+
# print(f"text_probs loaded hf_model using pipeline: {detector_probs}")
|
| 146 |
+
|
| 147 |
+
def convert_evaclip_checkpoint(checkpoint_path, pytorch_dump_folder_path, config_path, image_path, save=False):
|
| 148 |
+
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch16")
|
| 149 |
+
image = Image.open(image_path)
|
| 150 |
+
input_pixels = processor( images=image, return_tensors="pt", padding=True).pixel_values
|
| 151 |
+
|
| 152 |
+
# This requires having a clone of https://github.com/baaivision/EVA/tree/master/EVA-CLIP as well as the right conda env
|
| 153 |
+
# original_evaclip_probs = getevaclip(checkpoint_path, input_pixels, captions)
|
| 154 |
+
# print(f"original_evaclip label probs: {original_evaclip_probs}")
|
| 155 |
+
|
| 156 |
+
transformers_config = EvaCLIPConfig.from_pretrained(config_path)
|
| 157 |
+
hf_model = EvaCLIPModel(transformers_config)
|
| 158 |
+
pt_model_state_dict = torch.load(checkpoint_path)['module']
|
| 159 |
+
state_dict = rename_state_dict(pt_model_state_dict)
|
| 160 |
+
|
| 161 |
+
hf_model.load_state_dict(state_dict, strict=False)
|
| 162 |
+
|
| 163 |
+
with torch.no_grad():
|
| 164 |
+
image_features = hf_model.get_image_features(input_pixels)
|
| 165 |
+
# text_features = hf_model.get_text_features(input_ids)
|
| 166 |
+
image_features /= image_features.norm(dim=-1, keepdim=True)
|
| 167 |
+
# text_features /= text_features.norm(dim=-1, keepdim=True)
|
| 168 |
+
|
| 169 |
+
print(image_features.shape)
|
| 170 |
+
# label_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
|
| 171 |
+
# print(f"hf_model label probs: {label_probs}")
|
| 172 |
+
|
| 173 |
+
if save:
|
| 174 |
+
save_model_and_config(pytorch_dump_folder_path, hf_model, transformers_config)
|
| 175 |
+
|
| 176 |
+
check_loaded_model(pytorch_dump_folder_path, processor, image)
|
| 177 |
+
|
| 178 |
+
# hf_model.push_to_hub("ORGANIZATION_NAME/EVA02_CLIP_E_psz14_plus_s9B")
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
if __name__ == "__main__":
|
| 184 |
+
parser = argparse.ArgumentParser()
|
| 185 |
+
parser.add_argument("--pytorch_dump_folder_path", default="LLM2CLIP-EVA02-B-16" ,type=str, help="Path to the output PyTorch model.")
|
| 186 |
+
parser.add_argument("--checkpoint_path", default="/blob/hwq/data/tune_logs/T_vitB224_512x8_lr1e-5_Rcc12mR_Rcc3m_RIM15v1_RIM15v2_Ryfcc15m_20ep-2024_10_10-23/checkpoints/epoch_20/mp_rank_00_model_states.pt", type=str, help="Path to checkpoint" )
|
| 187 |
+
parser.add_argument("--config_path", default='LLM2CLIP-EVA02-B-16', type=str, help="Path to hf config.json of model to convert")
|
| 188 |
+
parser.add_argument("--image_path", default='LLM2CLIP-EVA02-B-16/CLIP.png', type=str, help="Path to image")
|
| 189 |
+
parser.add_argument("--save", default=False, type=str, help="Path to image")
|
| 190 |
+
|
| 191 |
+
args = parser.parse_args()
|
| 192 |
+
|
| 193 |
+
convert_evaclip_checkpoint(args.checkpoint_path, args.pytorch_dump_folder_path, args.config_path, args.image_path, args.save)
|
modeling_evaclip.py
ADDED
|
@@ -0,0 +1,1510 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2021 The OpenAI Team Authors and The HuggingFace Team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
""" PyTorch EvaCLIP model."""
|
| 16 |
+
# Code mainly taken from https://github.com/huggingface/transformers/blob/main/src/transformers/models/clip/modeling_clip.py#L943
|
| 17 |
+
# and adjusteed for EvaClip
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
from dataclasses import dataclass
|
| 21 |
+
from typing import Any, Optional, Tuple, Union
|
| 22 |
+
|
| 23 |
+
import torch
|
| 24 |
+
import torch.utils.checkpoint
|
| 25 |
+
from torch import nn
|
| 26 |
+
from einops import rearrange, repeat
|
| 27 |
+
|
| 28 |
+
from transformers.activations import ACT2FN
|
| 29 |
+
from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
|
| 30 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 31 |
+
from transformers.utils import (
|
| 32 |
+
ModelOutput,
|
| 33 |
+
add_start_docstrings,
|
| 34 |
+
add_start_docstrings_to_model_forward,
|
| 35 |
+
logging,
|
| 36 |
+
replace_return_docstrings,
|
| 37 |
+
)
|
| 38 |
+
from .configuration_evaclip import EvaCLIPConfig, EvaCLIPTextConfig, EvaCLIPVisionConfig
|
| 39 |
+
|
| 40 |
+
logger = logging.get_logger(__name__)
|
| 41 |
+
|
| 42 |
+
_CHECKPOINT_FOR_DOC = "LLM2CLIP-EVA02-B-16"
|
| 43 |
+
|
| 44 |
+
Eva_CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
| 45 |
+
"LLM2CLIP-EVA02-B-16",
|
| 46 |
+
]
|
| 47 |
+
|
| 48 |
+
# Copied from transformers.models.bart.modeling_bart._expand_mask
|
| 49 |
+
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 50 |
+
"""
|
| 51 |
+
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 52 |
+
"""
|
| 53 |
+
bsz, src_len = mask.size()
|
| 54 |
+
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 55 |
+
|
| 56 |
+
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
| 57 |
+
|
| 58 |
+
inverted_mask = 1.0 - expanded_mask
|
| 59 |
+
|
| 60 |
+
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def broadcat(tensors, dim = -1):
|
| 64 |
+
num_tensors = len(tensors)
|
| 65 |
+
shape_lens = set(list(map(lambda t: len(t.shape), tensors)))
|
| 66 |
+
assert len(shape_lens) == 1, 'tensors must all have the same number of dimensions'
|
| 67 |
+
shape_len = list(shape_lens)[0]
|
| 68 |
+
dim = (dim + shape_len) if dim < 0 else dim
|
| 69 |
+
dims = list(zip(*map(lambda t: list(t.shape), tensors)))
|
| 70 |
+
expandable_dims = [(i, val) for i, val in enumerate(dims) if i != dim]
|
| 71 |
+
assert all([*map(lambda t: len(set(t[1])) <= 2, expandable_dims)]), 'invalid dimensions for broadcastable concatentation'
|
| 72 |
+
max_dims = list(map(lambda t: (t[0], max(t[1])), expandable_dims))
|
| 73 |
+
expanded_dims = list(map(lambda t: (t[0], (t[1],) * num_tensors), max_dims))
|
| 74 |
+
expanded_dims.insert(dim, (dim, dims[dim]))
|
| 75 |
+
expandable_shapes = list(zip(*map(lambda t: t[1], expanded_dims)))
|
| 76 |
+
tensors = list(map(lambda t: t[0].expand(*t[1]), zip(tensors, expandable_shapes)))
|
| 77 |
+
return torch.cat(tensors, dim = dim)
|
| 78 |
+
|
| 79 |
+
class VisionRotaryEmbeddingFast(nn.Module):
|
| 80 |
+
def __init__(
|
| 81 |
+
self,
|
| 82 |
+
dim,
|
| 83 |
+
pt_seq_len,
|
| 84 |
+
ft_seq_len=None,
|
| 85 |
+
custom_freqs = None,
|
| 86 |
+
freqs_for = 'lang',
|
| 87 |
+
theta = 10000,
|
| 88 |
+
max_freq = 10,
|
| 89 |
+
num_freqs = 1,
|
| 90 |
+
patch_dropout = 0.
|
| 91 |
+
):
|
| 92 |
+
super().__init__()
|
| 93 |
+
if custom_freqs:
|
| 94 |
+
freqs = custom_freqs
|
| 95 |
+
elif freqs_for == 'lang':
|
| 96 |
+
freqs = 1. / (theta ** (torch.arange(0, dim, 2)[:(dim // 2)].float() / dim))
|
| 97 |
+
elif freqs_for == 'pixel':
|
| 98 |
+
freqs = torch.linspace(1., max_freq / 2, dim // 2) * pi
|
| 99 |
+
elif freqs_for == 'constant':
|
| 100 |
+
freqs = torch.ones(num_freqs).float()
|
| 101 |
+
else:
|
| 102 |
+
raise ValueError(f'unknown modality {freqs_for}')
|
| 103 |
+
|
| 104 |
+
if ft_seq_len is None: ft_seq_len = pt_seq_len
|
| 105 |
+
t = torch.arange(ft_seq_len) / ft_seq_len * pt_seq_len
|
| 106 |
+
|
| 107 |
+
freqs = torch.einsum('..., f -> ... f', t, freqs)
|
| 108 |
+
freqs = repeat(freqs, '... n -> ... (n r)', r = 2)
|
| 109 |
+
freqs = broadcat((freqs[:, None, :], freqs[None, :, :]), dim = -1)
|
| 110 |
+
|
| 111 |
+
freqs_cos = freqs.cos().view(-1, freqs.shape[-1])
|
| 112 |
+
freqs_sin = freqs.sin().view(-1, freqs.shape[-1])
|
| 113 |
+
|
| 114 |
+
self.patch_dropout = patch_dropout
|
| 115 |
+
|
| 116 |
+
self.register_buffer("freqs_cos", freqs_cos)
|
| 117 |
+
self.register_buffer("freqs_sin", freqs_sin)
|
| 118 |
+
|
| 119 |
+
# logging.info(f'Shape of rope freq: {self.freqs_cos.shape}')
|
| 120 |
+
|
| 121 |
+
def forward(self, t, patch_indices_keep=None):
|
| 122 |
+
if patch_indices_keep is not None:
|
| 123 |
+
batch = t.size()[0]
|
| 124 |
+
batch_indices = torch.arange(batch)
|
| 125 |
+
batch_indices = batch_indices[..., None]
|
| 126 |
+
|
| 127 |
+
freqs_cos = repeat(self.freqs_cos, 'i j -> n i m j', n=t.shape[0], m=t.shape[1])
|
| 128 |
+
freqs_sin = repeat(self.freqs_sin, 'i j -> n i m j', n=t.shape[0], m=t.shape[1])
|
| 129 |
+
|
| 130 |
+
freqs_cos = freqs_cos[batch_indices, patch_indices_keep]
|
| 131 |
+
freqs_cos = rearrange(freqs_cos, 'n i m j -> n m i j')
|
| 132 |
+
freqs_sin = freqs_sin[batch_indices, patch_indices_keep]
|
| 133 |
+
freqs_sin = rearrange(freqs_sin, 'n i m j -> n m i j')
|
| 134 |
+
|
| 135 |
+
return t * freqs_cos + rotate_half(t) * freqs_sin
|
| 136 |
+
|
| 137 |
+
return t * self.freqs_cos + rotate_half(t) * self.freqs_sin
|
| 138 |
+
|
| 139 |
+
# contrastive loss function, adapted from
|
| 140 |
+
# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html
|
| 141 |
+
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
|
| 142 |
+
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
|
| 146 |
+
caption_loss = contrastive_loss(similarity)
|
| 147 |
+
image_loss = contrastive_loss(similarity.t())
|
| 148 |
+
return (caption_loss + image_loss) / 2.0
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
@dataclass
|
| 152 |
+
class EvaCLIPVisionModelOutput(ModelOutput):
|
| 153 |
+
"""
|
| 154 |
+
Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
|
| 155 |
+
|
| 156 |
+
Args:
|
| 157 |
+
image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
|
| 158 |
+
The image embeddings obtained by applying the projection layer to the pooler_output.
|
| 159 |
+
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 160 |
+
Sequence of hidden-states at the output of the last layer of the model.
|
| 161 |
+
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
| 162 |
+
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
| 163 |
+
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
| 164 |
+
|
| 165 |
+
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
| 166 |
+
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
|
| 167 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
|
| 168 |
+
sequence_length)`.
|
| 169 |
+
|
| 170 |
+
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
| 171 |
+
heads.
|
| 172 |
+
"""
|
| 173 |
+
|
| 174 |
+
image_embeds: Optional[torch.FloatTensor] = None
|
| 175 |
+
last_hidden_state: torch.FloatTensor = None
|
| 176 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
| 177 |
+
attentions: Optional[Tuple[torch.FloatTensor]] = None
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
@dataclass
|
| 181 |
+
class EvaCLIPTextModelOutput(ModelOutput):
|
| 182 |
+
"""
|
| 183 |
+
Base class for text model's outputs that also contains a pooling of the last hidden states.
|
| 184 |
+
|
| 185 |
+
Args:
|
| 186 |
+
text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
|
| 187 |
+
The text embeddings obtained by applying the projection layer to the pooler_output.
|
| 188 |
+
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 189 |
+
Sequence of hidden-states at the output of the last layer of the model.
|
| 190 |
+
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
| 191 |
+
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
| 192 |
+
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
| 193 |
+
|
| 194 |
+
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
| 195 |
+
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
|
| 196 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
|
| 197 |
+
sequence_length)`.
|
| 198 |
+
|
| 199 |
+
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
| 200 |
+
heads.
|
| 201 |
+
"""
|
| 202 |
+
|
| 203 |
+
text_embeds: Optional[torch.FloatTensor] = None
|
| 204 |
+
last_hidden_state: torch.FloatTensor = None
|
| 205 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
| 206 |
+
attentions: Optional[Tuple[torch.FloatTensor]] = None
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
@dataclass
|
| 210 |
+
class EvaCLIPOutput(ModelOutput):
|
| 211 |
+
"""
|
| 212 |
+
Args:
|
| 213 |
+
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
|
| 214 |
+
Contrastive loss for image-text similarity.
|
| 215 |
+
logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
|
| 216 |
+
The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
|
| 217 |
+
similarity scores.
|
| 218 |
+
logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
|
| 219 |
+
The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
|
| 220 |
+
similarity scores.
|
| 221 |
+
text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
|
| 222 |
+
The text embeddings obtained by applying the projection layer to the pooled output of [`EvaCLIPTextModel`].
|
| 223 |
+
image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
|
| 224 |
+
The image embeddings obtained by applying the projection layer to the pooled output of [`EvaCLIPVisionModel`].
|
| 225 |
+
text_model_output(`BaseModelOutputWithPooling`):
|
| 226 |
+
The output of the [`EvaCLIPTextModel`].
|
| 227 |
+
vision_model_output(`BaseModelOutputWithPooling`):
|
| 228 |
+
The output of the [`EvaCLIPVisionModel`].
|
| 229 |
+
"""
|
| 230 |
+
|
| 231 |
+
loss: Optional[torch.FloatTensor] = None
|
| 232 |
+
logits_per_image: torch.FloatTensor = None
|
| 233 |
+
logits_per_text: torch.FloatTensor = None
|
| 234 |
+
text_embeds: torch.FloatTensor = None
|
| 235 |
+
image_embeds: torch.FloatTensor = None
|
| 236 |
+
text_model_output: BaseModelOutputWithPooling = None
|
| 237 |
+
vision_model_output: BaseModelOutputWithPooling = None
|
| 238 |
+
|
| 239 |
+
def to_tuple(self) -> Tuple[Any]:
|
| 240 |
+
return tuple(
|
| 241 |
+
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
|
| 242 |
+
for k in self.keys()
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
class EvaCLIPVisionEmbeddings(nn.Module):
|
| 247 |
+
def __init__(self, config: EvaCLIPVisionConfig):
|
| 248 |
+
super().__init__()
|
| 249 |
+
self.config = config
|
| 250 |
+
self.embed_dim = config.hidden_size
|
| 251 |
+
self.image_size = config.image_size
|
| 252 |
+
self.patch_size = config.patch_size
|
| 253 |
+
|
| 254 |
+
self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
|
| 255 |
+
|
| 256 |
+
self.patch_embedding = nn.Conv2d(
|
| 257 |
+
in_channels=config.num_channels,
|
| 258 |
+
out_channels=self.embed_dim,
|
| 259 |
+
kernel_size=self.patch_size,
|
| 260 |
+
stride=self.patch_size,
|
| 261 |
+
bias=True,
|
| 262 |
+
)
|
| 263 |
+
|
| 264 |
+
self.num_patches = (self.image_size // self.patch_size) ** 2
|
| 265 |
+
self.num_positions = self.num_patches + 1
|
| 266 |
+
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
|
| 267 |
+
self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent = False)
|
| 268 |
+
|
| 269 |
+
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
| 270 |
+
batch_size = pixel_values.shape[0]
|
| 271 |
+
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
|
| 272 |
+
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
| 273 |
+
|
| 274 |
+
class_embeds = self.class_embedding.expand(batch_size, 1, -1)
|
| 275 |
+
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
| 276 |
+
embeddings = embeddings + self.position_embedding(self.position_ids)
|
| 277 |
+
return embeddings
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class EvaCLIPTextEmbeddings(nn.Module):
|
| 281 |
+
def __init__(self, config: EvaCLIPTextConfig):
|
| 282 |
+
super().__init__()
|
| 283 |
+
embed_dim = config.hidden_size
|
| 284 |
+
|
| 285 |
+
self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
|
| 286 |
+
self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
|
| 287 |
+
|
| 288 |
+
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
|
| 289 |
+
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False)
|
| 290 |
+
|
| 291 |
+
def forward(
|
| 292 |
+
self,
|
| 293 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 294 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 295 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 296 |
+
) -> torch.Tensor:
|
| 297 |
+
seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
|
| 298 |
+
|
| 299 |
+
if position_ids is None:
|
| 300 |
+
position_ids = self.position_ids[:, :seq_length]
|
| 301 |
+
|
| 302 |
+
if inputs_embeds is None:
|
| 303 |
+
inputs_embeds = self.token_embedding(input_ids)
|
| 304 |
+
|
| 305 |
+
position_embeddings = self.position_embedding(position_ids)
|
| 306 |
+
embeddings = inputs_embeds + position_embeddings
|
| 307 |
+
|
| 308 |
+
return embeddings
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
class EvaCLIPAttention(nn.Module):
|
| 312 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 313 |
+
|
| 314 |
+
def __init__(self, config, rope=None):
|
| 315 |
+
super().__init__()
|
| 316 |
+
self.config = config
|
| 317 |
+
self.rope = rope
|
| 318 |
+
self.embed_dim = config.hidden_size
|
| 319 |
+
self.num_heads = config.num_attention_heads
|
| 320 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 321 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 322 |
+
raise ValueError(
|
| 323 |
+
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
| 324 |
+
f" {self.num_heads})."
|
| 325 |
+
)
|
| 326 |
+
self.scale = self.head_dim**-0.5
|
| 327 |
+
self.dropout = config.attention_dropout
|
| 328 |
+
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.k_bias)
|
| 329 |
+
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.v_bias)
|
| 330 |
+
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.q_bias)
|
| 331 |
+
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=True)
|
| 332 |
+
subln = True
|
| 333 |
+
self.inner_attn_ln = nn.LayerNorm(self.embed_dim) if subln else nn.Identity()
|
| 334 |
+
|
| 335 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 336 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 337 |
+
|
| 338 |
+
def forward(
|
| 339 |
+
self,
|
| 340 |
+
hidden_states: torch.Tensor,
|
| 341 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 342 |
+
causal_attention_mask: Optional[torch.Tensor] = None,
|
| 343 |
+
output_attentions: Optional[bool] = False,
|
| 344 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 345 |
+
"""Input shape: Batch x Time x Channel"""
|
| 346 |
+
|
| 347 |
+
bsz, tgt_len, embed_dim = hidden_states.size()
|
| 348 |
+
|
| 349 |
+
# get query proj
|
| 350 |
+
query_states = self.q_proj(hidden_states) * self.scale
|
| 351 |
+
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
|
| 352 |
+
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
|
| 353 |
+
|
| 354 |
+
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
|
| 355 |
+
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
|
| 356 |
+
key_states = key_states.view(*proj_shape)
|
| 357 |
+
value_states = value_states.view(*proj_shape)
|
| 358 |
+
|
| 359 |
+
src_len = key_states.size(1)
|
| 360 |
+
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
|
| 361 |
+
|
| 362 |
+
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
|
| 363 |
+
raise ValueError(
|
| 364 |
+
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
|
| 365 |
+
f" {attn_weights.size()}"
|
| 366 |
+
)
|
| 367 |
+
|
| 368 |
+
# apply the causal_attention_mask first
|
| 369 |
+
if causal_attention_mask is not None:
|
| 370 |
+
if causal_attention_mask.size() != (bsz, 1, tgt_len, src_len):
|
| 371 |
+
raise ValueError(
|
| 372 |
+
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
|
| 373 |
+
f" {causal_attention_mask.size()}"
|
| 374 |
+
)
|
| 375 |
+
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + causal_attention_mask
|
| 376 |
+
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
|
| 377 |
+
|
| 378 |
+
if attention_mask is not None:
|
| 379 |
+
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
|
| 380 |
+
raise ValueError(
|
| 381 |
+
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
|
| 382 |
+
)
|
| 383 |
+
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
|
| 384 |
+
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
|
| 385 |
+
|
| 386 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 387 |
+
|
| 388 |
+
if output_attentions:
|
| 389 |
+
# this operation is a bit akward, but it's required to
|
| 390 |
+
# make sure that attn_weights keeps its gradient.
|
| 391 |
+
# In order to do so, attn_weights have to reshaped
|
| 392 |
+
# twice and have to be reused in the following
|
| 393 |
+
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
|
| 394 |
+
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
|
| 395 |
+
else:
|
| 396 |
+
attn_weights_reshaped = None
|
| 397 |
+
|
| 398 |
+
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
|
| 399 |
+
|
| 400 |
+
attn_output = torch.bmm(attn_probs, value_states)
|
| 401 |
+
|
| 402 |
+
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
|
| 403 |
+
raise ValueError(
|
| 404 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
|
| 405 |
+
f" {attn_output.size()}"
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
|
| 409 |
+
attn_output = attn_output.transpose(1, 2)
|
| 410 |
+
attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
|
| 411 |
+
|
| 412 |
+
attn_output = self.inner_attn_ln(attn_output)
|
| 413 |
+
attn_output = self.out_proj(attn_output)
|
| 414 |
+
|
| 415 |
+
return attn_output, attn_weights_reshaped
|
| 416 |
+
|
| 417 |
+
class EvaCLIPTextAttention(nn.Module):
|
| 418 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 419 |
+
|
| 420 |
+
def __init__(self, config):
|
| 421 |
+
super().__init__()
|
| 422 |
+
self.config = config
|
| 423 |
+
self.embed_dim = config.hidden_size
|
| 424 |
+
self.num_heads = config.num_attention_heads
|
| 425 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 426 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 427 |
+
raise ValueError(
|
| 428 |
+
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
| 429 |
+
f" {self.num_heads})."
|
| 430 |
+
)
|
| 431 |
+
self.scale = self.head_dim**-0.5
|
| 432 |
+
self.dropout = config.attention_dropout
|
| 433 |
+
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.k_bias)
|
| 434 |
+
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.v_bias)
|
| 435 |
+
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.q_bias)
|
| 436 |
+
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=True)
|
| 437 |
+
|
| 438 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 439 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 440 |
+
|
| 441 |
+
def forward(
|
| 442 |
+
self,
|
| 443 |
+
hidden_states: torch.Tensor,
|
| 444 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 445 |
+
causal_attention_mask: Optional[torch.Tensor] = None,
|
| 446 |
+
output_attentions: Optional[bool] = False,
|
| 447 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 448 |
+
"""Input shape: Batch x Time x Channel"""
|
| 449 |
+
|
| 450 |
+
bsz, tgt_len, embed_dim = hidden_states.size()
|
| 451 |
+
|
| 452 |
+
# get query proj
|
| 453 |
+
query_states = self.q_proj(hidden_states) * self.scale
|
| 454 |
+
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
|
| 455 |
+
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
|
| 456 |
+
|
| 457 |
+
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
|
| 458 |
+
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
|
| 459 |
+
key_states = key_states.view(*proj_shape)
|
| 460 |
+
value_states = value_states.view(*proj_shape)
|
| 461 |
+
|
| 462 |
+
if self.rope:
|
| 463 |
+
# slightly fast impl
|
| 464 |
+
q_t = query_states[:, :, 1:, :]
|
| 465 |
+
ro_q_t = self.rope(q_t)
|
| 466 |
+
query_states = torch.cat((query_states[:, :, :1, :], ro_q_t), -2).type_as(value_states)
|
| 467 |
+
|
| 468 |
+
k_t = key_states[:, :, 1:, :]
|
| 469 |
+
ro_k_t = self.rope(k_t)
|
| 470 |
+
key_states = torch.cat((key_states[:, :, :1, :], ro_k_t), -2).type_as(value_states)
|
| 471 |
+
|
| 472 |
+
src_len = key_states.size(1)
|
| 473 |
+
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
|
| 474 |
+
|
| 475 |
+
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
|
| 476 |
+
raise ValueError(
|
| 477 |
+
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
|
| 478 |
+
f" {attn_weights.size()}"
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
# apply the causal_attention_mask first
|
| 482 |
+
if causal_attention_mask is not None:
|
| 483 |
+
if causal_attention_mask.size() != (bsz, 1, tgt_len, src_len):
|
| 484 |
+
raise ValueError(
|
| 485 |
+
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
|
| 486 |
+
f" {causal_attention_mask.size()}"
|
| 487 |
+
)
|
| 488 |
+
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + causal_attention_mask
|
| 489 |
+
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
|
| 490 |
+
|
| 491 |
+
if attention_mask is not None:
|
| 492 |
+
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
|
| 493 |
+
raise ValueError(
|
| 494 |
+
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
|
| 495 |
+
)
|
| 496 |
+
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
|
| 497 |
+
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
|
| 498 |
+
|
| 499 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
|
| 500 |
+
|
| 501 |
+
if output_attentions:
|
| 502 |
+
# this operation is a bit akward, but it's required to
|
| 503 |
+
# make sure that attn_weights keeps its gradient.
|
| 504 |
+
# In order to do so, attn_weights have to reshaped
|
| 505 |
+
# twice and have to be reused in the following
|
| 506 |
+
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
|
| 507 |
+
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
|
| 508 |
+
else:
|
| 509 |
+
attn_weights_reshaped = None
|
| 510 |
+
|
| 511 |
+
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
|
| 512 |
+
|
| 513 |
+
attn_output = torch.bmm(attn_probs, value_states)
|
| 514 |
+
|
| 515 |
+
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
|
| 516 |
+
raise ValueError(
|
| 517 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
|
| 518 |
+
f" {attn_output.size()}"
|
| 519 |
+
)
|
| 520 |
+
|
| 521 |
+
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
|
| 522 |
+
attn_output = attn_output.transpose(1, 2)
|
| 523 |
+
attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
|
| 524 |
+
|
| 525 |
+
attn_output = self.out_proj(attn_output)
|
| 526 |
+
|
| 527 |
+
return attn_output, attn_weights_reshaped
|
| 528 |
+
|
| 529 |
+
class SwiGLU(nn.Module):
|
| 530 |
+
def __init__(self, in_features=1024, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.,
|
| 531 |
+
norm_layer=nn.LayerNorm, subln=True):
|
| 532 |
+
super().__init__()
|
| 533 |
+
out_features = out_features or in_features
|
| 534 |
+
hidden_features = hidden_features or in_features
|
| 535 |
+
|
| 536 |
+
self.w1 = nn.Linear(in_features, hidden_features)
|
| 537 |
+
self.w2 = nn.Linear(in_features, hidden_features)
|
| 538 |
+
|
| 539 |
+
self.act = act_layer()
|
| 540 |
+
self.ffn_ln = norm_layer(hidden_features) if subln else nn.Identity()
|
| 541 |
+
self.w3 = nn.Linear(hidden_features, out_features)
|
| 542 |
+
|
| 543 |
+
self.drop = nn.Dropout(drop)
|
| 544 |
+
|
| 545 |
+
def forward(self, x):
|
| 546 |
+
x1 = self.w1(x)
|
| 547 |
+
x2 = self.w2(x)
|
| 548 |
+
hidden = self.act(x1) * x2
|
| 549 |
+
x = self.ffn_ln(hidden)
|
| 550 |
+
x = self.w3(x)
|
| 551 |
+
x = self.dr
|
| 552 |
+
|
| 553 |
+
|
| 554 |
+
# class EvaCLIPMLP(nn.Module):
|
| 555 |
+
# def __init__(self, config):
|
| 556 |
+
# super().__init__()
|
| 557 |
+
# self.config = config
|
| 558 |
+
# self.activation_fn = ACT2FN[config.hidden_act]
|
| 559 |
+
# self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 560 |
+
# self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 561 |
+
# subln = True
|
| 562 |
+
# self.ffn_ln = nn.LayerNorm(config.hidden_size) if subln else nn.Identity()
|
| 563 |
+
|
| 564 |
+
# def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 565 |
+
# hidden_states = self.fc1(hidden_states)
|
| 566 |
+
# hidden_states = self.activation_fn(hidden_states)
|
| 567 |
+
# hidden_states = self.ffn_ln(hidden_states)
|
| 568 |
+
# hidden_states = self.fc2(hidden_states)
|
| 569 |
+
# return hidden_states
|
| 570 |
+
|
| 571 |
+
class EvaCLIPMLP(nn.Module):
|
| 572 |
+
def __init__(self, config):
|
| 573 |
+
super().__init__()
|
| 574 |
+
self.config = config
|
| 575 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 576 |
+
self.fc2 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 577 |
+
|
| 578 |
+
self.act = nn.SiLU()
|
| 579 |
+
subln = True
|
| 580 |
+
self.ffn_ln = nn.LayerNorm(config.intermediate_size) if subln else nn.Identity()
|
| 581 |
+
self.fc3 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 582 |
+
|
| 583 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 584 |
+
x = hidden_states
|
| 585 |
+
x1 = self.fc1(x)
|
| 586 |
+
x2 = self.fc2(x)
|
| 587 |
+
hidden = self.act(x1) * x2
|
| 588 |
+
x = self.ffn_ln(hidden)
|
| 589 |
+
x = self.fc3(x)
|
| 590 |
+
return x
|
| 591 |
+
|
| 592 |
+
|
| 593 |
+
class EvaCLIPEncoderLayer(nn.Module):
|
| 594 |
+
def __init__(self, config: EvaCLIPConfig, rope=None):
|
| 595 |
+
super().__init__()
|
| 596 |
+
self.config = config
|
| 597 |
+
self.rope = rope
|
| 598 |
+
self.embed_dim = config.hidden_size
|
| 599 |
+
self.post_layernorm = config.post_layernorm if config.post_layernorm is not None else False
|
| 600 |
+
self.self_attn = EvaCLIPAttention(config, self.rope)
|
| 601 |
+
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 602 |
+
self.mlp = EvaCLIPMLP(config)
|
| 603 |
+
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 604 |
+
|
| 605 |
+
def forward(
|
| 606 |
+
self,
|
| 607 |
+
hidden_states: torch.Tensor,
|
| 608 |
+
attention_mask: torch.Tensor,
|
| 609 |
+
causal_attention_mask: torch.Tensor,
|
| 610 |
+
output_attentions: Optional[bool] = False,
|
| 611 |
+
) -> Tuple[torch.FloatTensor]:
|
| 612 |
+
"""
|
| 613 |
+
Args:
|
| 614 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 615 |
+
attention_mask (`torch.FloatTensor`): attention mask of size
|
| 616 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 617 |
+
`(config.encoder_attention_heads,)`.
|
| 618 |
+
output_attentions (`bool`, *optional*):
|
| 619 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 620 |
+
returned tensors for more detail.
|
| 621 |
+
"""
|
| 622 |
+
residual = hidden_states
|
| 623 |
+
|
| 624 |
+
if not self.post_layernorm:
|
| 625 |
+
hidden_states = self.layer_norm1(hidden_states)
|
| 626 |
+
hidden_states, attn_weights = self.self_attn(
|
| 627 |
+
hidden_states=hidden_states,
|
| 628 |
+
attention_mask=attention_mask,
|
| 629 |
+
causal_attention_mask=causal_attention_mask,
|
| 630 |
+
output_attentions=output_attentions,
|
| 631 |
+
)
|
| 632 |
+
if self.post_layernorm:
|
| 633 |
+
hidden_states = self.layer_norm1(hidden_states)
|
| 634 |
+
hidden_states = residual + hidden_states
|
| 635 |
+
residual = hidden_states
|
| 636 |
+
if not self.post_layernorm:
|
| 637 |
+
hidden_states = self.layer_norm2(hidden_states)
|
| 638 |
+
hidden_states = self.mlp(hidden_states)
|
| 639 |
+
if self.post_layernorm:
|
| 640 |
+
hidden_states = self.layer_norm2(hidden_states)
|
| 641 |
+
hidden_states = residual + hidden_states
|
| 642 |
+
|
| 643 |
+
outputs = (hidden_states,)
|
| 644 |
+
|
| 645 |
+
if output_attentions:
|
| 646 |
+
outputs += (attn_weights,)
|
| 647 |
+
|
| 648 |
+
return outputs
|
| 649 |
+
|
| 650 |
+
|
| 651 |
+
class EvaCLIPPreTrainedModel(PreTrainedModel):
|
| 652 |
+
"""
|
| 653 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 654 |
+
models.
|
| 655 |
+
"""
|
| 656 |
+
|
| 657 |
+
config_class = EvaCLIPConfig
|
| 658 |
+
base_model_prefix = "clip"
|
| 659 |
+
supports_gradient_checkpointing = True
|
| 660 |
+
_keys_to_ignore_on_load_missing = [r"position_ids"]
|
| 661 |
+
|
| 662 |
+
def _init_weights(self, module):
|
| 663 |
+
"""Initialize the weights"""
|
| 664 |
+
factor = self.config.initializer_factor
|
| 665 |
+
if isinstance(module, EvaCLIPTextEmbeddings):
|
| 666 |
+
module.token_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
|
| 667 |
+
module.position_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
|
| 668 |
+
elif isinstance(module, EvaCLIPVisionEmbeddings):
|
| 669 |
+
factor = self.config.initializer_factor
|
| 670 |
+
nn.init.normal_(module.class_embedding, mean=0.0, std=module.embed_dim**-0.5 * factor)
|
| 671 |
+
nn.init.normal_(module.patch_embedding.weight, std=module.config.initializer_range * factor)
|
| 672 |
+
nn.init.normal_(module.position_embedding.weight, std=module.config.initializer_range * factor)
|
| 673 |
+
elif isinstance(module, EvaCLIPAttention):
|
| 674 |
+
factor = self.config.initializer_factor
|
| 675 |
+
in_proj_std = (module.embed_dim**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
|
| 676 |
+
out_proj_std = (module.embed_dim**-0.5) * factor
|
| 677 |
+
nn.init.normal_(module.q_proj.weight, std=in_proj_std)
|
| 678 |
+
nn.init.normal_(module.k_proj.weight, std=in_proj_std)
|
| 679 |
+
nn.init.normal_(module.v_proj.weight, std=in_proj_std)
|
| 680 |
+
nn.init.normal_(module.out_proj.weight, std=out_proj_std)
|
| 681 |
+
elif isinstance(module, EvaCLIPMLP):
|
| 682 |
+
factor = self.config.initializer_factor
|
| 683 |
+
in_proj_std = (
|
| 684 |
+
(module.config.hidden_size**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
|
| 685 |
+
)
|
| 686 |
+
fc_std = (2 * module.config.hidden_size) ** -0.5 * factor
|
| 687 |
+
nn.init.normal_(module.fc1.weight, std=fc_std)
|
| 688 |
+
# nn.init.normal_(module.fc2.weight, std=in_proj_std)
|
| 689 |
+
nn.init.normal_(module.fc2.weight, std=fc_std)
|
| 690 |
+
nn.init.normal_(module.fc3.weight, std=in_proj_std)
|
| 691 |
+
elif isinstance(module, EvaCLIPModel):
|
| 692 |
+
# nn.init.normal_(
|
| 693 |
+
# module.text_projection.weight,
|
| 694 |
+
# std=module.text_embed_dim**-0.5 * self.config.initializer_factor,
|
| 695 |
+
# )
|
| 696 |
+
nn.init.normal_(
|
| 697 |
+
module.visual_projection.weight,
|
| 698 |
+
std=module.vision_embed_dim**-0.5 * self.config.initializer_factor,
|
| 699 |
+
)
|
| 700 |
+
elif isinstance(module, EvaCLIPVisionModelWithProjection):
|
| 701 |
+
nn.init.normal_(
|
| 702 |
+
module.visual_projection.weight,
|
| 703 |
+
std=self.config.hidden_size**-0.5 * self.config.initializer_factor,
|
| 704 |
+
)
|
| 705 |
+
elif isinstance(module, EvaCLIPTextModelWithProjection):
|
| 706 |
+
nn.init.normal_(
|
| 707 |
+
module.text_projection.weight,
|
| 708 |
+
std=self.config.hidden_size**-0.5 * self.config.initializer_factor,
|
| 709 |
+
)
|
| 710 |
+
|
| 711 |
+
if isinstance(module, nn.LayerNorm):
|
| 712 |
+
module.bias.data.zero_()
|
| 713 |
+
module.weight.data.fill_(1.0)
|
| 714 |
+
if isinstance(module, nn.Linear) and module.bias is not None:
|
| 715 |
+
module.bias.data.zero_()
|
| 716 |
+
|
| 717 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 718 |
+
if isinstance(module, EvaCLIPEncoder):
|
| 719 |
+
module.gradient_checkpointing = value
|
| 720 |
+
|
| 721 |
+
|
| 722 |
+
EvaCLIP_START_DOCSTRING = r"""
|
| 723 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 724 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 725 |
+
etc.)
|
| 726 |
+
|
| 727 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 728 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 729 |
+
and behavior.
|
| 730 |
+
|
| 731 |
+
Parameters:
|
| 732 |
+
config ([`CLIPConfig`]): Model configuration class with all the parameters of the model.
|
| 733 |
+
Initializing with a config file does not load the weights associated with the model, only the
|
| 734 |
+
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 735 |
+
"""
|
| 736 |
+
|
| 737 |
+
EvaCLIP_TEXT_INPUTS_DOCSTRING = r"""
|
| 738 |
+
Args:
|
| 739 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 740 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 741 |
+
it.
|
| 742 |
+
|
| 743 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 744 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 745 |
+
|
| 746 |
+
[What are input IDs?](../glossary#input-ids)
|
| 747 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 748 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 749 |
+
|
| 750 |
+
- 1 for tokens that are **not masked**,
|
| 751 |
+
- 0 for tokens that are **masked**.
|
| 752 |
+
|
| 753 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 754 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 755 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 756 |
+
config.max_position_embeddings - 1]`.
|
| 757 |
+
|
| 758 |
+
[What are position IDs?](../glossary#position-ids)
|
| 759 |
+
output_attentions (`bool`, *optional*):
|
| 760 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 761 |
+
tensors for more detail.
|
| 762 |
+
output_hidden_states (`bool`, *optional*):
|
| 763 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 764 |
+
more detail.
|
| 765 |
+
return_dict (`bool`, *optional*):
|
| 766 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 767 |
+
"""
|
| 768 |
+
|
| 769 |
+
EvaCLIP_VISION_INPUTS_DOCSTRING = r"""
|
| 770 |
+
Args:
|
| 771 |
+
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 772 |
+
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
| 773 |
+
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
|
| 774 |
+
output_attentions (`bool`, *optional*):
|
| 775 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 776 |
+
tensors for more detail.
|
| 777 |
+
output_hidden_states (`bool`, *optional*):
|
| 778 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 779 |
+
more detail.
|
| 780 |
+
return_dict (`bool`, *optional*):
|
| 781 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 782 |
+
"""
|
| 783 |
+
|
| 784 |
+
EvaCLIP_INPUTS_DOCSTRING = r"""
|
| 785 |
+
Args:
|
| 786 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 787 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 788 |
+
it.
|
| 789 |
+
|
| 790 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 791 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 792 |
+
|
| 793 |
+
[What are input IDs?](../glossary#input-ids)
|
| 794 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 795 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 796 |
+
|
| 797 |
+
- 1 for tokens that are **not masked**,
|
| 798 |
+
- 0 for tokens that are **masked**.
|
| 799 |
+
|
| 800 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 801 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 802 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 803 |
+
config.max_position_embeddings - 1]`.
|
| 804 |
+
|
| 805 |
+
[What are position IDs?](../glossary#position-ids)
|
| 806 |
+
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 807 |
+
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
| 808 |
+
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
|
| 809 |
+
return_loss (`bool`, *optional*):
|
| 810 |
+
Whether or not to return the contrastive loss.
|
| 811 |
+
output_attentions (`bool`, *optional*):
|
| 812 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 813 |
+
tensors for more detail.
|
| 814 |
+
output_hidden_states (`bool`, *optional*):
|
| 815 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 816 |
+
more detail.
|
| 817 |
+
return_dict (`bool`, *optional*):
|
| 818 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 819 |
+
"""
|
| 820 |
+
|
| 821 |
+
|
| 822 |
+
class EvaCLIPEncoder(nn.Module):
|
| 823 |
+
"""
|
| 824 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 825 |
+
[`CLIPEncoderLayer`].
|
| 826 |
+
|
| 827 |
+
Args:
|
| 828 |
+
config: CLIPConfig
|
| 829 |
+
"""
|
| 830 |
+
|
| 831 |
+
def __init__(self, config: EvaCLIPConfig, rope=False):
|
| 832 |
+
super().__init__()
|
| 833 |
+
self.config = config
|
| 834 |
+
self.layers = nn.ModuleList([EvaCLIPEncoderLayer(config, rope) for _ in range(config.num_hidden_layers)])
|
| 835 |
+
self.gradient_checkpointing = False
|
| 836 |
+
|
| 837 |
+
def forward(
|
| 838 |
+
self,
|
| 839 |
+
inputs_embeds,
|
| 840 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 841 |
+
causal_attention_mask: Optional[torch.Tensor] = None,
|
| 842 |
+
output_attentions: Optional[bool] = None,
|
| 843 |
+
output_hidden_states: Optional[bool] = None,
|
| 844 |
+
return_dict: Optional[bool] = None,
|
| 845 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 846 |
+
r"""
|
| 847 |
+
Args:
|
| 848 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 849 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
|
| 850 |
+
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
|
| 851 |
+
than the model's internal embedding lookup matrix.
|
| 852 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 853 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 854 |
+
|
| 855 |
+
- 1 for tokens that are **not masked**,
|
| 856 |
+
- 0 for tokens that are **masked**.
|
| 857 |
+
|
| 858 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 859 |
+
causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 860 |
+
Causal mask for the text model. Mask values selected in `[0, 1]`:
|
| 861 |
+
|
| 862 |
+
- 1 for tokens that are **not masked**,
|
| 863 |
+
- 0 for tokens that are **masked**.
|
| 864 |
+
|
| 865 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 866 |
+
output_attentions (`bool`, *optional*):
|
| 867 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 868 |
+
returned tensors for more detail.
|
| 869 |
+
output_hidden_states (`bool`, *optional*):
|
| 870 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 871 |
+
for more detail.
|
| 872 |
+
return_dict (`bool`, *optional*):
|
| 873 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 874 |
+
"""
|
| 875 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 876 |
+
output_hidden_states = (
|
| 877 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 878 |
+
)
|
| 879 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 880 |
+
|
| 881 |
+
encoder_states = () if output_hidden_states else None
|
| 882 |
+
all_attentions = () if output_attentions else None
|
| 883 |
+
|
| 884 |
+
hidden_states = inputs_embeds
|
| 885 |
+
for idx, encoder_layer in enumerate(self.layers):
|
| 886 |
+
if output_hidden_states:
|
| 887 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 888 |
+
if self.gradient_checkpointing and self.training:
|
| 889 |
+
|
| 890 |
+
def create_custom_forward(module):
|
| 891 |
+
def custom_forward(*inputs):
|
| 892 |
+
return module(*inputs, output_attentions)
|
| 893 |
+
|
| 894 |
+
return custom_forward
|
| 895 |
+
|
| 896 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 897 |
+
create_custom_forward(encoder_layer),
|
| 898 |
+
hidden_states,
|
| 899 |
+
attention_mask,
|
| 900 |
+
causal_attention_mask,
|
| 901 |
+
)
|
| 902 |
+
else:
|
| 903 |
+
layer_outputs = encoder_layer(
|
| 904 |
+
hidden_states,
|
| 905 |
+
attention_mask,
|
| 906 |
+
causal_attention_mask,
|
| 907 |
+
output_attentions=output_attentions,
|
| 908 |
+
)
|
| 909 |
+
|
| 910 |
+
hidden_states = layer_outputs[0]
|
| 911 |
+
|
| 912 |
+
if output_attentions:
|
| 913 |
+
all_attentions = all_attentions + (layer_outputs[1],)
|
| 914 |
+
|
| 915 |
+
if output_hidden_states:
|
| 916 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 917 |
+
|
| 918 |
+
if not return_dict:
|
| 919 |
+
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
|
| 920 |
+
return BaseModelOutput(
|
| 921 |
+
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
|
| 922 |
+
)
|
| 923 |
+
|
| 924 |
+
|
| 925 |
+
class EvaCLIPTextTransformer(nn.Module):
|
| 926 |
+
def __init__(self, config: EvaCLIPTextConfig):
|
| 927 |
+
super().__init__()
|
| 928 |
+
self.config = config
|
| 929 |
+
embed_dim = config.hidden_size
|
| 930 |
+
self.embeddings = EvaCLIPTextEmbeddings(config)
|
| 931 |
+
self.encoder = EvaCLIPEncoder(config)
|
| 932 |
+
self.final_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
|
| 933 |
+
|
| 934 |
+
@add_start_docstrings_to_model_forward(EvaCLIP_TEXT_INPUTS_DOCSTRING)
|
| 935 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=EvaCLIPTextConfig)
|
| 936 |
+
def forward(
|
| 937 |
+
self,
|
| 938 |
+
input_ids: Optional[torch.Tensor] = None,
|
| 939 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 940 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 941 |
+
output_attentions: Optional[bool] = None,
|
| 942 |
+
output_hidden_states: Optional[bool] = None,
|
| 943 |
+
return_dict: Optional[bool] = None,
|
| 944 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 945 |
+
r"""
|
| 946 |
+
Returns:
|
| 947 |
+
|
| 948 |
+
"""
|
| 949 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 950 |
+
output_hidden_states = (
|
| 951 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 952 |
+
)
|
| 953 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 954 |
+
|
| 955 |
+
if input_ids is None:
|
| 956 |
+
raise ValueError("You have to specify input_ids")
|
| 957 |
+
|
| 958 |
+
input_shape = input_ids.size()
|
| 959 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 960 |
+
|
| 961 |
+
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
|
| 962 |
+
|
| 963 |
+
bsz, seq_len = input_shape
|
| 964 |
+
# CLIP's text model uses causal mask, prepare it here.
|
| 965 |
+
# https://github.com/openai/CLIP/blob/cfcffb90e69f37bf2ff1e988237a0fbe41f33c04/clip/model.py#L324
|
| 966 |
+
causal_attention_mask = self._build_causal_attention_mask(bsz, seq_len, hidden_states.dtype).to(
|
| 967 |
+
hidden_states.device
|
| 968 |
+
)
|
| 969 |
+
# expand attention_mask
|
| 970 |
+
if attention_mask is not None:
|
| 971 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 972 |
+
attention_mask = _expand_mask(attention_mask, hidden_states.dtype)
|
| 973 |
+
|
| 974 |
+
encoder_outputs = self.encoder(
|
| 975 |
+
inputs_embeds=hidden_states,
|
| 976 |
+
attention_mask=attention_mask,
|
| 977 |
+
causal_attention_mask=causal_attention_mask,
|
| 978 |
+
output_attentions=output_attentions,
|
| 979 |
+
output_hidden_states=output_hidden_states,
|
| 980 |
+
return_dict=return_dict,
|
| 981 |
+
)
|
| 982 |
+
|
| 983 |
+
last_hidden_state = encoder_outputs[0]
|
| 984 |
+
last_hidden_state = self.final_layer_norm(last_hidden_state)
|
| 985 |
+
|
| 986 |
+
# text_embeds.shape = [batch_size, sequence_length, transformer.width]
|
| 987 |
+
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
| 988 |
+
# casting to torch.int for onnx compatibility: argmax doesn't support int64 inputs with opset 14
|
| 989 |
+
pooled_output = last_hidden_state[
|
| 990 |
+
torch.arange(last_hidden_state.shape[0], device=last_hidden_state.device),
|
| 991 |
+
input_ids.to(dtype=torch.int, device=last_hidden_state.device).argmax(dim=-1),
|
| 992 |
+
]
|
| 993 |
+
|
| 994 |
+
if not return_dict:
|
| 995 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 996 |
+
|
| 997 |
+
return BaseModelOutputWithPooling(
|
| 998 |
+
last_hidden_state=last_hidden_state,
|
| 999 |
+
pooler_output=pooled_output,
|
| 1000 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 1001 |
+
attentions=encoder_outputs.attentions,
|
| 1002 |
+
)
|
| 1003 |
+
|
| 1004 |
+
def _build_causal_attention_mask(self, bsz, seq_len, dtype):
|
| 1005 |
+
# lazily create causal attention mask, with full attention between the vision tokens
|
| 1006 |
+
# pytorch uses additive attention mask; fill with -inf
|
| 1007 |
+
mask = torch.empty(bsz, seq_len, seq_len, dtype=dtype)
|
| 1008 |
+
mask.fill_(torch.tensor(torch.finfo(dtype).min))
|
| 1009 |
+
mask.triu_(1) # zero out the lower diagonal
|
| 1010 |
+
mask = mask.unsqueeze(1) # expand mask
|
| 1011 |
+
return mask
|
| 1012 |
+
|
| 1013 |
+
|
| 1014 |
+
@add_start_docstrings(
|
| 1015 |
+
"""The text model from EvaCLIP without any head or projection on top.""",
|
| 1016 |
+
EvaCLIP_START_DOCSTRING,
|
| 1017 |
+
)
|
| 1018 |
+
class EvaCLIPTextModel(EvaCLIPPreTrainedModel):
|
| 1019 |
+
config_class = EvaCLIPTextConfig
|
| 1020 |
+
|
| 1021 |
+
_no_split_modules = ["EvaCLIPEncoderLayer"]
|
| 1022 |
+
|
| 1023 |
+
def __init__(self, config: EvaCLIPTextConfig):
|
| 1024 |
+
super().__init__(config)
|
| 1025 |
+
self.text_model = EvaCLIPTextTransformer(config)
|
| 1026 |
+
# Initialize weights and apply final processing
|
| 1027 |
+
self.post_init()
|
| 1028 |
+
|
| 1029 |
+
def get_input_embeddings(self) -> nn.Module:
|
| 1030 |
+
return self.text_model.embeddings.token_embedding
|
| 1031 |
+
|
| 1032 |
+
def set_input_embeddings(self, value):
|
| 1033 |
+
self.text_model.embeddings.token_embedding = value
|
| 1034 |
+
|
| 1035 |
+
@add_start_docstrings_to_model_forward(EvaCLIP_TEXT_INPUTS_DOCSTRING)
|
| 1036 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=EvaCLIPTextConfig)
|
| 1037 |
+
def forward(
|
| 1038 |
+
self,
|
| 1039 |
+
input_ids: Optional[torch.Tensor] = None,
|
| 1040 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1041 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 1042 |
+
output_attentions: Optional[bool] = None,
|
| 1043 |
+
output_hidden_states: Optional[bool] = None,
|
| 1044 |
+
return_dict: Optional[bool] = None,
|
| 1045 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 1046 |
+
r"""
|
| 1047 |
+
Returns:
|
| 1048 |
+
|
| 1049 |
+
Examples:
|
| 1050 |
+
|
| 1051 |
+
```python
|
| 1052 |
+
>>> from transformers import AutoTokenizer, CLIPTextModel
|
| 1053 |
+
|
| 1054 |
+
>>> model = CLIPTextModel.from_pretrained("openai/clip-vit-base-patch32")
|
| 1055 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-base-patch32")
|
| 1056 |
+
|
| 1057 |
+
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
|
| 1058 |
+
|
| 1059 |
+
>>> outputs = model(**inputs)
|
| 1060 |
+
>>> last_hidden_state = outputs.last_hidden_state
|
| 1061 |
+
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
|
| 1062 |
+
```"""
|
| 1063 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1064 |
+
|
| 1065 |
+
return self.text_model(
|
| 1066 |
+
input_ids=input_ids,
|
| 1067 |
+
attention_mask=attention_mask,
|
| 1068 |
+
position_ids=position_ids,
|
| 1069 |
+
output_attentions=output_attentions,
|
| 1070 |
+
output_hidden_states=output_hidden_states,
|
| 1071 |
+
return_dict=return_dict,
|
| 1072 |
+
)
|
| 1073 |
+
|
| 1074 |
+
|
| 1075 |
+
class EvaCLIPVisionTransformer(nn.Module):
|
| 1076 |
+
def __init__(self, config: EvaCLIPVisionConfig):
|
| 1077 |
+
super().__init__()
|
| 1078 |
+
self.config = config
|
| 1079 |
+
embed_dim = config.hidden_size
|
| 1080 |
+
|
| 1081 |
+
rope = True
|
| 1082 |
+
pt_hw_seq_len=16
|
| 1083 |
+
intp_freq=True
|
| 1084 |
+
if rope:
|
| 1085 |
+
half_head_dim = config.hidden_size // config.num_attention_heads // 2
|
| 1086 |
+
hw_seq_len = config.image_size // config.patch_size
|
| 1087 |
+
self.rope = VisionRotaryEmbeddingFast(
|
| 1088 |
+
dim=half_head_dim,
|
| 1089 |
+
pt_seq_len=pt_hw_seq_len,
|
| 1090 |
+
ft_seq_len=hw_seq_len if intp_freq else None,
|
| 1091 |
+
# patch_dropout=patch_dropout
|
| 1092 |
+
)
|
| 1093 |
+
else:
|
| 1094 |
+
self.rope = None
|
| 1095 |
+
|
| 1096 |
+
self.embeddings = EvaCLIPVisionEmbeddings(config)
|
| 1097 |
+
self.encoder = EvaCLIPEncoder(config, self.rope)
|
| 1098 |
+
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
|
| 1099 |
+
|
| 1100 |
+
@add_start_docstrings_to_model_forward(EvaCLIP_VISION_INPUTS_DOCSTRING)
|
| 1101 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=EvaCLIPVisionConfig)
|
| 1102 |
+
def forward(
|
| 1103 |
+
self,
|
| 1104 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 1105 |
+
output_attentions: Optional[bool] = None,
|
| 1106 |
+
output_hidden_states: Optional[bool] = None,
|
| 1107 |
+
return_dict: Optional[bool] = None,
|
| 1108 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 1109 |
+
r"""
|
| 1110 |
+
Returns:
|
| 1111 |
+
|
| 1112 |
+
"""
|
| 1113 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1114 |
+
output_hidden_states = (
|
| 1115 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1116 |
+
)
|
| 1117 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1118 |
+
|
| 1119 |
+
if pixel_values is None:
|
| 1120 |
+
raise ValueError("You have to specify pixel_values")
|
| 1121 |
+
|
| 1122 |
+
hidden_states = self.embeddings(pixel_values)
|
| 1123 |
+
|
| 1124 |
+
encoder_outputs = self.encoder(
|
| 1125 |
+
inputs_embeds=hidden_states,
|
| 1126 |
+
output_attentions=output_attentions,
|
| 1127 |
+
output_hidden_states=output_hidden_states,
|
| 1128 |
+
return_dict=return_dict,
|
| 1129 |
+
)
|
| 1130 |
+
|
| 1131 |
+
last_hidden_state = encoder_outputs[0]
|
| 1132 |
+
pooled_output = last_hidden_state[:, 0, :]
|
| 1133 |
+
pooled_output = self.post_layernorm(pooled_output)
|
| 1134 |
+
|
| 1135 |
+
if not return_dict:
|
| 1136 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 1137 |
+
|
| 1138 |
+
return BaseModelOutputWithPooling(
|
| 1139 |
+
last_hidden_state=last_hidden_state,
|
| 1140 |
+
pooler_output=pooled_output,
|
| 1141 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 1142 |
+
attentions=encoder_outputs.attentions,
|
| 1143 |
+
)
|
| 1144 |
+
|
| 1145 |
+
|
| 1146 |
+
@add_start_docstrings(
|
| 1147 |
+
"""The vision model from EvaCLIP without any head or projection on top.""",
|
| 1148 |
+
EvaCLIP_START_DOCSTRING,
|
| 1149 |
+
)
|
| 1150 |
+
class EvaCLIPVisionModel(EvaCLIPPreTrainedModel):
|
| 1151 |
+
config_class = EvaCLIPVisionConfig
|
| 1152 |
+
main_input_name = "pixel_values"
|
| 1153 |
+
|
| 1154 |
+
def __init__(self, config: EvaCLIPVisionConfig):
|
| 1155 |
+
super().__init__(config)
|
| 1156 |
+
self.vision_model = EvaCLIPVisionTransformer(config)
|
| 1157 |
+
# Initialize weights and apply final processing
|
| 1158 |
+
self.post_init()
|
| 1159 |
+
|
| 1160 |
+
def get_input_embeddings(self) -> nn.Module:
|
| 1161 |
+
return self.vision_model.embeddings.patch_embedding
|
| 1162 |
+
|
| 1163 |
+
@add_start_docstrings_to_model_forward(EvaCLIP_VISION_INPUTS_DOCSTRING)
|
| 1164 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=EvaCLIPVisionConfig)
|
| 1165 |
+
def forward(
|
| 1166 |
+
self,
|
| 1167 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 1168 |
+
output_attentions: Optional[bool] = None,
|
| 1169 |
+
output_hidden_states: Optional[bool] = None,
|
| 1170 |
+
return_dict: Optional[bool] = None,
|
| 1171 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 1172 |
+
r"""
|
| 1173 |
+
Returns:
|
| 1174 |
+
|
| 1175 |
+
Examples:
|
| 1176 |
+
|
| 1177 |
+
```python
|
| 1178 |
+
>>> from PIL import Image
|
| 1179 |
+
>>> import requests
|
| 1180 |
+
>>> from transformers import AutoProcessor, CLIPVisionModel
|
| 1181 |
+
|
| 1182 |
+
>>> model = CLIPVisionModel.from_pretrained("openai/clip-vit-base-patch32")
|
| 1183 |
+
>>> processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
| 1184 |
+
|
| 1185 |
+
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 1186 |
+
>>> image = Image.open(requests.get(url, stream=True).raw)
|
| 1187 |
+
|
| 1188 |
+
>>> inputs = processor(images=image, return_tensors="pt")
|
| 1189 |
+
|
| 1190 |
+
>>> outputs = model(**inputs)
|
| 1191 |
+
>>> last_hidden_state = outputs.last_hidden_state
|
| 1192 |
+
>>> pooled_output = outputs.pooler_output # pooled CLS states
|
| 1193 |
+
```"""
|
| 1194 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1195 |
+
|
| 1196 |
+
return self.vision_model(
|
| 1197 |
+
pixel_values=pixel_values,
|
| 1198 |
+
output_attentions=output_attentions,
|
| 1199 |
+
output_hidden_states=output_hidden_states,
|
| 1200 |
+
return_dict=return_dict,
|
| 1201 |
+
)
|
| 1202 |
+
|
| 1203 |
+
|
| 1204 |
+
@add_start_docstrings(EvaCLIP_START_DOCSTRING)
|
| 1205 |
+
class EvaCLIPModel(EvaCLIPPreTrainedModel):
|
| 1206 |
+
config_class = EvaCLIPConfig
|
| 1207 |
+
|
| 1208 |
+
def __init__(self, config: EvaCLIPConfig):
|
| 1209 |
+
super().__init__(config)
|
| 1210 |
+
|
| 1211 |
+
# if not (type(config.text_config).__name__ == "EvaCLIPTextConfig"):
|
| 1212 |
+
# raise ValueError(
|
| 1213 |
+
# "config.text_config is expected to be of type EvaCLIPTextConfig but is of type"
|
| 1214 |
+
# f" {type(config.text_config)}."
|
| 1215 |
+
# )
|
| 1216 |
+
|
| 1217 |
+
if not (type(config.vision_config).__name__ == "EvaCLIPVisionConfig"):
|
| 1218 |
+
raise ValueError(
|
| 1219 |
+
"config.vision_config is expected to be of type EvaCLIPVisionConfig but is of type"
|
| 1220 |
+
f" {type(config.vision_config)}."
|
| 1221 |
+
)
|
| 1222 |
+
|
| 1223 |
+
text_config = config.text_config
|
| 1224 |
+
vision_config = config.vision_config
|
| 1225 |
+
|
| 1226 |
+
self.projection_dim = config.projection_dim
|
| 1227 |
+
self.text_embed_dim = text_config.hidden_size
|
| 1228 |
+
self.vision_embed_dim = vision_config.hidden_size
|
| 1229 |
+
|
| 1230 |
+
# self.text_model = EvaCLIPTextTransformer(text_config)
|
| 1231 |
+
self.vision_model = EvaCLIPVisionTransformer(vision_config)
|
| 1232 |
+
|
| 1233 |
+
self.visual_projection = nn.Linear(self.vision_embed_dim, self.projection_dim, bias=True)
|
| 1234 |
+
# self.text_projection = nn.Linear(self.text_embed_dim, self.projection_dim, bias=False)
|
| 1235 |
+
# self.logit_scale = nn.Parameter(torch.ones([]) * self.config.logit_scale_init_value)
|
| 1236 |
+
|
| 1237 |
+
# Initialize weights and apply final processing
|
| 1238 |
+
self.post_init()
|
| 1239 |
+
|
| 1240 |
+
@add_start_docstrings_to_model_forward(EvaCLIP_VISION_INPUTS_DOCSTRING)
|
| 1241 |
+
def get_image_features(
|
| 1242 |
+
self,
|
| 1243 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 1244 |
+
output_attentions: Optional[bool] = None,
|
| 1245 |
+
output_hidden_states: Optional[bool] = None,
|
| 1246 |
+
return_dict: Optional[bool] = None,
|
| 1247 |
+
) -> torch.FloatTensor:
|
| 1248 |
+
r"""
|
| 1249 |
+
Returns:
|
| 1250 |
+
image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
|
| 1251 |
+
applying the projection layer to the pooled output of [`EvaCLIPVisionModel`].
|
| 1252 |
+
|
| 1253 |
+
Examples:
|
| 1254 |
+
|
| 1255 |
+
```python
|
| 1256 |
+
>>> from PIL import Image
|
| 1257 |
+
>>> import requests
|
| 1258 |
+
>>> from transformers import AutoProcessor, CLIPModel
|
| 1259 |
+
|
| 1260 |
+
>>> model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
|
| 1261 |
+
>>> processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
| 1262 |
+
|
| 1263 |
+
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 1264 |
+
>>> image = Image.open(requests.get(url, stream=True).raw)
|
| 1265 |
+
|
| 1266 |
+
>>> inputs = processor(images=image, return_tensors="pt")
|
| 1267 |
+
|
| 1268 |
+
>>> image_features = model.get_image_features(**inputs)
|
| 1269 |
+
```"""
|
| 1270 |
+
# Use EvaCLIP model's config for some fields (if specified) instead of those of vision & text components.
|
| 1271 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1272 |
+
output_hidden_states = (
|
| 1273 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1274 |
+
)
|
| 1275 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1276 |
+
|
| 1277 |
+
vision_outputs = self.vision_model(
|
| 1278 |
+
pixel_values=pixel_values,
|
| 1279 |
+
output_attentions=output_attentions,
|
| 1280 |
+
output_hidden_states=output_hidden_states,
|
| 1281 |
+
return_dict=return_dict,
|
| 1282 |
+
)
|
| 1283 |
+
|
| 1284 |
+
pooled_output = vision_outputs[1] # pooled_output
|
| 1285 |
+
image_features = self.visual_projection(pooled_output)
|
| 1286 |
+
|
| 1287 |
+
return image_features
|
| 1288 |
+
|
| 1289 |
+
@add_start_docstrings_to_model_forward(EvaCLIP_INPUTS_DOCSTRING)
|
| 1290 |
+
@replace_return_docstrings(output_type=EvaCLIPOutput, config_class=EvaCLIPConfig)
|
| 1291 |
+
def forward(
|
| 1292 |
+
self,
|
| 1293 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 1294 |
+
output_attentions: Optional[bool] = None,
|
| 1295 |
+
output_hidden_states: Optional[bool] = None,
|
| 1296 |
+
return_dict: Optional[bool] = None,
|
| 1297 |
+
) -> Union[Tuple, EvaCLIPOutput]:
|
| 1298 |
+
r"""
|
| 1299 |
+
Returns:
|
| 1300 |
+
|
| 1301 |
+
Examples:
|
| 1302 |
+
|
| 1303 |
+
```python
|
| 1304 |
+
>>> from PIL import Image
|
| 1305 |
+
>>> import requests
|
| 1306 |
+
>>> from transformers import AutoProcessor, CLIPModel
|
| 1307 |
+
|
| 1308 |
+
>>> model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
|
| 1309 |
+
>>> processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
| 1310 |
+
|
| 1311 |
+
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 1312 |
+
>>> image = Image.open(requests.get(url, stream=True).raw)
|
| 1313 |
+
|
| 1314 |
+
>>> inputs = processor(
|
| 1315 |
+
... images=image, return_tensors="pt"
|
| 1316 |
+
... )
|
| 1317 |
+
|
| 1318 |
+
>>> outputs = model(**inputs)
|
| 1319 |
+
>>> image_embeds = outputs.image_embeds # this is the image embedding
|
| 1320 |
+
```"""
|
| 1321 |
+
# Use CLIP model's config for some fields (if specified) instead of those of vision & text components.
|
| 1322 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1323 |
+
output_hidden_states = (
|
| 1324 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1325 |
+
)
|
| 1326 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1327 |
+
|
| 1328 |
+
vision_outputs = self.vision_model(
|
| 1329 |
+
pixel_values=pixel_values,
|
| 1330 |
+
output_attentions=output_attentions,
|
| 1331 |
+
output_hidden_states=output_hidden_states,
|
| 1332 |
+
return_dict=return_dict,
|
| 1333 |
+
)
|
| 1334 |
+
|
| 1335 |
+
image_embeds = vision_outputs[1]
|
| 1336 |
+
image_embeds = self.visual_projection(image_embeds)
|
| 1337 |
+
|
| 1338 |
+
# normalized features
|
| 1339 |
+
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
|
| 1340 |
+
if not return_dict:
|
| 1341 |
+
output = (image_embeds, vision_outputs)
|
| 1342 |
+
return output
|
| 1343 |
+
|
| 1344 |
+
return EvaCLIPOutput(
|
| 1345 |
+
loss=None,
|
| 1346 |
+
logits_per_image=None,
|
| 1347 |
+
logits_per_text=None,
|
| 1348 |
+
text_embeds=None,
|
| 1349 |
+
image_embeds=image_embeds,
|
| 1350 |
+
text_model_output=None,
|
| 1351 |
+
vision_model_output=vision_outputs,
|
| 1352 |
+
)
|
| 1353 |
+
|
| 1354 |
+
@add_start_docstrings(
|
| 1355 |
+
"""
|
| 1356 |
+
EvaCLIP Text Model with a projection layer on top (a linear layer on top of the pooled output).
|
| 1357 |
+
""",
|
| 1358 |
+
EvaCLIP_START_DOCSTRING,
|
| 1359 |
+
)
|
| 1360 |
+
class EvaCLIPTextModelWithProjection(EvaCLIPPreTrainedModel):
|
| 1361 |
+
config_class = EvaCLIPTextConfig
|
| 1362 |
+
|
| 1363 |
+
_no_split_modules = ["EvaCLIPEncoderLayer"]
|
| 1364 |
+
|
| 1365 |
+
def __init__(self, config: EvaCLIPTextConfig):
|
| 1366 |
+
super().__init__(config)
|
| 1367 |
+
|
| 1368 |
+
self.text_model = EvaCLIPTextTransformer(config)
|
| 1369 |
+
|
| 1370 |
+
self.text_projection = nn.Linear(config.hidden_size, config.projection_dim, bias=False)
|
| 1371 |
+
|
| 1372 |
+
# Initialize weights and apply final processing
|
| 1373 |
+
self.posxt_init()
|
| 1374 |
+
|
| 1375 |
+
def get_input_embeddings(self) -> nn.Module:
|
| 1376 |
+
return self.text_model.embeddings.token_embedding
|
| 1377 |
+
|
| 1378 |
+
def set_input_embeddings(self, value):
|
| 1379 |
+
self.text_model.embeddings.token_embedding = value
|
| 1380 |
+
|
| 1381 |
+
@add_start_docstrings_to_model_forward(EvaCLIP_TEXT_INPUTS_DOCSTRING)
|
| 1382 |
+
@replace_return_docstrings(output_type=EvaCLIPTextModelOutput, config_class=EvaCLIPTextConfig)
|
| 1383 |
+
def forward(
|
| 1384 |
+
self,
|
| 1385 |
+
input_ids: Optional[torch.Tensor] = None,
|
| 1386 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1387 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 1388 |
+
output_attentions: Optional[bool] = None,
|
| 1389 |
+
output_hidden_states: Optional[bool] = None,
|
| 1390 |
+
return_dict: Optional[bool] = None,
|
| 1391 |
+
) -> Union[Tuple, EvaCLIPTextModelOutput]:
|
| 1392 |
+
r"""
|
| 1393 |
+
Returns:
|
| 1394 |
+
|
| 1395 |
+
Examples:
|
| 1396 |
+
|
| 1397 |
+
```python
|
| 1398 |
+
>>> from transformers import AutoTokenizer, CLIPTextModelWithProjection
|
| 1399 |
+
|
| 1400 |
+
>>> model = CLIPTextModelWithProjection.from_pretrained("openai/clip-vit-base-patch32")
|
| 1401 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-base-patch32")
|
| 1402 |
+
|
| 1403 |
+
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
|
| 1404 |
+
|
| 1405 |
+
>>> outputs = model(**inputs)
|
| 1406 |
+
>>> text_embeds = outputs.text_embeds
|
| 1407 |
+
```"""
|
| 1408 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1409 |
+
|
| 1410 |
+
text_outputs = self.text_model(
|
| 1411 |
+
input_ids=input_ids,
|
| 1412 |
+
attention_mask=attention_mask,
|
| 1413 |
+
position_ids=position_ids,
|
| 1414 |
+
output_attentions=output_attentions,
|
| 1415 |
+
output_hidden_states=output_hidden_states,
|
| 1416 |
+
return_dict=return_dict,
|
| 1417 |
+
)
|
| 1418 |
+
|
| 1419 |
+
pooled_output = text_outputs[1]
|
| 1420 |
+
|
| 1421 |
+
text_embeds = self.text_projection(pooled_output)
|
| 1422 |
+
|
| 1423 |
+
if not return_dict:
|
| 1424 |
+
outputs = (text_embeds, text_outputs[0]) + text_outputs[2:]
|
| 1425 |
+
return tuple(output for output in outputs if output is not None)
|
| 1426 |
+
|
| 1427 |
+
return EvaCLIPTextModelOutput(
|
| 1428 |
+
text_embeds=text_embeds,
|
| 1429 |
+
last_hidden_state=text_outputs.last_hidden_state,
|
| 1430 |
+
hidden_states=text_outputs.hidden_states,
|
| 1431 |
+
attentions=text_outputs.attentions,
|
| 1432 |
+
)
|
| 1433 |
+
|
| 1434 |
+
|
| 1435 |
+
@add_start_docstrings(
|
| 1436 |
+
"""
|
| 1437 |
+
EvaCLIP Vision Model with a projection layer on top (a linear layer on top of the pooled output).
|
| 1438 |
+
""",
|
| 1439 |
+
EvaCLIP_START_DOCSTRING,
|
| 1440 |
+
)
|
| 1441 |
+
class EvaCLIPVisionModelWithProjection(EvaCLIPPreTrainedModel):
|
| 1442 |
+
config_class = EvaCLIPVisionConfig
|
| 1443 |
+
main_input_name = "pixel_values"
|
| 1444 |
+
|
| 1445 |
+
def __init__(self, config: EvaCLIPVisionConfig):
|
| 1446 |
+
super().__init__(config)
|
| 1447 |
+
|
| 1448 |
+
self.vision_model = EvaCLIPVisionTransformer(config)
|
| 1449 |
+
|
| 1450 |
+
self.visual_projection = nn.Linear(config.hidden_size, config.projection_dim, bias=False)
|
| 1451 |
+
|
| 1452 |
+
# Initialize weights and apply final processing
|
| 1453 |
+
self.post_init()
|
| 1454 |
+
|
| 1455 |
+
def get_input_embeddings(self) -> nn.Module:
|
| 1456 |
+
return self.vision_model.embeddings.patch_embedding
|
| 1457 |
+
|
| 1458 |
+
@add_start_docstrings_to_model_forward(EvaCLIP_VISION_INPUTS_DOCSTRING)
|
| 1459 |
+
@replace_return_docstrings(output_type=EvaCLIPVisionModelOutput, config_class=EvaCLIPVisionConfig)
|
| 1460 |
+
def forward(
|
| 1461 |
+
self,
|
| 1462 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 1463 |
+
output_attentions: Optional[bool] = None,
|
| 1464 |
+
output_hidden_states: Optional[bool] = None,
|
| 1465 |
+
return_dict: Optional[bool] = None,
|
| 1466 |
+
) -> Union[Tuple, EvaCLIPVisionModelOutput]:
|
| 1467 |
+
r"""
|
| 1468 |
+
Returns:
|
| 1469 |
+
|
| 1470 |
+
Examples:
|
| 1471 |
+
|
| 1472 |
+
```python
|
| 1473 |
+
>>> from PIL import Image
|
| 1474 |
+
>>> import requests
|
| 1475 |
+
>>> from transformers import AutoProcessor, CLIPVisionModelWithProjection
|
| 1476 |
+
|
| 1477 |
+
>>> model = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-base-patch32")
|
| 1478 |
+
>>> processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
| 1479 |
+
|
| 1480 |
+
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 1481 |
+
>>> image = Image.open(requests.get(url, stream=True).raw)
|
| 1482 |
+
|
| 1483 |
+
>>> inputs = processor(images=image, return_tensors="pt")
|
| 1484 |
+
|
| 1485 |
+
>>> outputs = model(**inputs)
|
| 1486 |
+
>>> image_embeds = outputs.image_embeds
|
| 1487 |
+
```"""
|
| 1488 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1489 |
+
|
| 1490 |
+
vision_outputs = self.vision_model(
|
| 1491 |
+
pixel_values=pixel_values,
|
| 1492 |
+
output_attentions=output_attentions,
|
| 1493 |
+
output_hidden_states=output_hidden_states,
|
| 1494 |
+
return_dict=return_dict,
|
| 1495 |
+
)
|
| 1496 |
+
|
| 1497 |
+
pooled_output = vision_outputs[1] # pooled_output
|
| 1498 |
+
|
| 1499 |
+
image_embeds = self.visual_projection(pooled_output)
|
| 1500 |
+
|
| 1501 |
+
if not return_dict:
|
| 1502 |
+
outputs = (image_embeds, vision_outputs[0]) + vision_outputs[2:]
|
| 1503 |
+
return tuple(output for output in outputs if output is not None)
|
| 1504 |
+
|
| 1505 |
+
return EvaCLIPVisionModelOutput(
|
| 1506 |
+
image_embeds=image_embeds,
|
| 1507 |
+
last_hidden_state=vision_outputs.last_hidden_state,
|
| 1508 |
+
hidden_states=vision_outputs.hidden_states,
|
| 1509 |
+
attentions=vision_outputs.attentions,
|
| 1510 |
+
)
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5238174a3999150581237824e183b8fd46f201f0c20c7d8f9e7eaacd21e9ebfe
|
| 3 |
+
size 347607650
|
teaser.png
ADDED
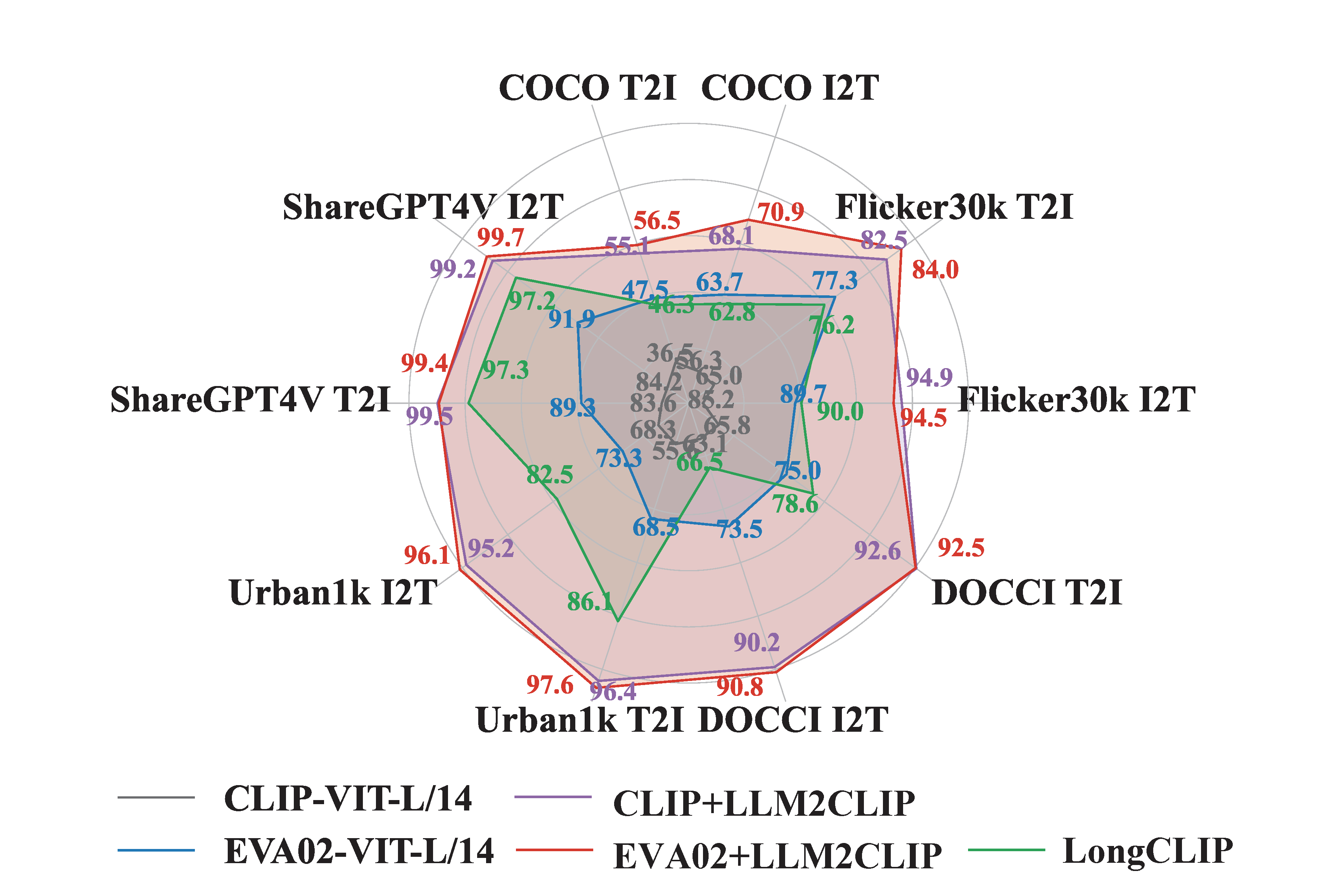
|