

Added model files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- CODE_OF_CONDUCT.md +9 -0
- LICENSE +21 -0
- README.md +567 -3
- SECURITY.md +41 -0
- SUPPORT.md +25 -0
- added_tokens.json +12 -0
- config.json +221 -0
- configuration_phi4mm.py +235 -0
- figures/audio_understand.png +0 -0
- figures/multi_image.png +0 -0
- figures/speech_qa.png +0 -0
- figures/speech_recog_by_lang.png +0 -0
- figures/speech_recognition.png +0 -0
- figures/speech_summarization.png +0 -0
- figures/speech_translate.png +0 -0
- figures/speech_translate_2.png +0 -0
- figures/vision_radar.png +0 -0
- generation_config.json +11 -0
- merges.txt +0 -0
- model-00001-of-00003.safetensors +3 -0
- model-00002-of-00003.safetensors +3 -0
- model-00003-of-00003.safetensors +3 -0
- model.safetensors.index.json +0 -0
- modeling_phi4mm.py +0 -0
- preprocessor_config.json +14 -0
- processing_phi4mm.py +733 -0
- processor_config.json +6 -0
- sample_finetune_speech.py +478 -0
- sample_finetune_vision.py +556 -0
- sample_inference_phi4mm.py +243 -0
- special_tokens_map.json +24 -0
- speech-lora/adapter_config.json +23 -0
- speech-lora/adapter_model.safetensors +3 -0
- speech-lora/added_tokens.json +12 -0
- speech-lora/special_tokens_map.json +24 -0
- speech-lora/tokenizer.json +3 -0
- speech-lora/tokenizer_config.json +125 -0
- speech-lora/vocab.json +0 -0
- speech_conformer_encoder.py +0 -0
- tokenizer.json +3 -0
- tokenizer_config.json +125 -0
- vision-lora/adapter_config.json +23 -0
- vision-lora/adapter_model.safetensors +3 -0
- vision-lora/added_tokens.json +12 -0
- vision-lora/special_tokens_map.json +24 -0
- vision-lora/tokenizer.json +3 -0
- vision-lora/tokenizer_config.json +125 -0
- vision-lora/vocab.json +0 -0
- vision_siglip_navit.py +1717 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Microsoft Open Source Code of Conduct
|
| 2 |
+
|
| 3 |
+
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
|
| 4 |
+
|
| 5 |
+
Resources:
|
| 6 |
+
|
| 7 |
+
- [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/)
|
| 8 |
+
- [Microsoft Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/)
|
| 9 |
+
- Contact [[email protected]](mailto:[email protected]) with questions or concerns
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Microsoft Corporation.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE
|
README.md
CHANGED
|
@@ -1,3 +1,567 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: mit
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
license_link: https://huggingface.co/microsoft/Phi-4-multimodal-instruct/resolve/main/LICENSE
|
| 4 |
+
language:
|
| 5 |
+
- multilingual
|
| 6 |
+
tags:
|
| 7 |
+
- nlp
|
| 8 |
+
- code
|
| 9 |
+
- audio
|
| 10 |
+
- automatic-speech-recognition
|
| 11 |
+
- speech-summarization
|
| 12 |
+
- speech-translation
|
| 13 |
+
- visual-question-answering
|
| 14 |
+
- phi-4-multimodal
|
| 15 |
+
- phi
|
| 16 |
+
- phi-4-mini
|
| 17 |
+
widget:
|
| 18 |
+
- example_title: Librispeech sample 1
|
| 19 |
+
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
|
| 20 |
+
- example_title: Librispeech sample 2
|
| 21 |
+
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
|
| 22 |
+
- messages:
|
| 23 |
+
- role: user
|
| 24 |
+
content: Can you provide ways to eat combinations of bananas and dragonfruits?
|
| 25 |
+
library_name: transformers
|
| 26 |
+
---
|
| 27 |
+
|
| 28 |
+
## Model Summary
|
| 29 |
+
|
| 30 |
+
Phi-4-multimodal-instruct is a lightweight open multimodal foundation
|
| 31 |
+
model that leverages the language, vision, and speech research
|
| 32 |
+
and datasets used for Phi-3.5 and 4.0 models. The model processes text,
|
| 33 |
+
image, and audio inputs, generating text outputs, and comes with
|
| 34 |
+
128K token context length. The model underwent an enhancement process,
|
| 35 |
+
incorporating both supervised fine-tuning, direct preference
|
| 36 |
+
optimization and RLHF (Reinforcement Learning from Human Feedback)
|
| 37 |
+
to support precise instruction adherence and safety measures.
|
| 38 |
+
The languages that each modal supports are the following:
|
| 39 |
+
- Text: Arabic, Chinese, Czech, Danish, Dutch, English, Finnish,
|
| 40 |
+
French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian,
|
| 41 |
+
Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, Ukrainian
|
| 42 |
+
- Vision: English
|
| 43 |
+
- Audio: English, Chinese, German, French, Italian, Japanese, Spanish, Portuguese
|
| 44 |
+
|
| 45 |
+
🏡 [Phi-4-multimodal Portal]() <br>
|
| 46 |
+
📰 [Phi-4-multimodal Microsoft Blog]() <br>
|
| 47 |
+
📖 [Phi-4-multimodal Technical Report]() <br>
|
| 48 |
+
👩🍳 [Phi-4-multimodal Cookbook]() <br>
|
| 49 |
+
🖥️ [Try It](https://aka.ms/try-phi4mm) <br>
|
| 50 |
+
|
| 51 |
+
**Phi-4**: [[multimodal-instruct](https://huggingface.co/microsoft/Phi-3.5-mini-instruct) | [onnx]()]; [[mini-instruct]]();
|
| 52 |
+
|
| 53 |
+
## Intended Uses
|
| 54 |
+
|
| 55 |
+
### Primary Use Cases
|
| 56 |
+
|
| 57 |
+
The model is intended for broad multilingual and multimodal commercial and research use . The model provides uses for general purpose AI systems and applications which require
|
| 58 |
+
|
| 59 |
+
1) Memory/compute constrained environments
|
| 60 |
+
2) Latency bound scenarios
|
| 61 |
+
3) Strong reasoning (especially math and logic)
|
| 62 |
+
4) Function and tool calling
|
| 63 |
+
5) General image understanding
|
| 64 |
+
6) Optical character recognition
|
| 65 |
+
7) Chart and table understanding
|
| 66 |
+
8) Multiple image comparison
|
| 67 |
+
9) Multi-image or video clip summarization
|
| 68 |
+
10) Speech recognition
|
| 69 |
+
11) Speech translation
|
| 70 |
+
12) Speech QA
|
| 71 |
+
13) Speech summarization
|
| 72 |
+
14) Audio understanding
|
| 73 |
+
|
| 74 |
+
The model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
|
| 75 |
+
|
| 76 |
+
### Use Case Considerations
|
| 77 |
+
|
| 78 |
+
The model is not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models and multimodal models, as well as performance difference across languages, as they select use cases, and evaluate and mitigate for accuracy, safety, and fairness before using within a specific downstream use case, particularly for high-risk scenarios.
|
| 79 |
+
Developers should be aware of and adhere to applicable laws or regulations (including but not limited to privacy, trade compliance laws, etc.) that are relevant to their use case.
|
| 80 |
+
|
| 81 |
+
***Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.***
|
| 82 |
+
|
| 83 |
+
## Release Notes
|
| 84 |
+
|
| 85 |
+
This release of Phi-4-multimodal-instruct is based on valuable user feedback from the Phi-3 series. Previously, users could use a speech recognition model to talk to the Mini and Vision models. To achieve this, users needed to use a pipeline of two models: one model to transcribe the audio to text, and another model for the language or vision tasks. This pipeline means that the core model was not provided the full breadth of input information – e.g. cannot directly observe multiple speakers, background noises, jointly align speech, vision, language information at the same time on the same representation space.
|
| 86 |
+
With Phi-4-multimodal-instruct, a single new open model has been trained across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network. The model employed new architecture, larger vocabulary for efficiency, multilingual, and multimodal support, and better post-training techniques were used for instruction following and function calling, as well as additional data leading to substantial gains on key multimodal capabilities.
|
| 87 |
+
It is anticipated that Phi-4-multimodal-instruct will greatly benefit app developers and various use cases. The enthusiastic support for the Phi-4 series is greatly appreciated. Feedback on Phi-4 is welcomed and crucial to the model's evolution and improvement. Thank you for being part of this journey!
|
| 88 |
+
|
| 89 |
+
## Model Quality
|
| 90 |
+
|
| 91 |
+
To understand the capabilities, Phi-4-multimodal-instruct was compared with a set of models over a variety of benchmarks using an internal benchmark platform (See Appendix A for benchmark methodology). Users can refer to the Phi-4-Mini-Instruct model card for details of language benchmarks. At the high-level overview of the model quality on representative speech and vision benchmarks:
|
| 92 |
+
|
| 93 |
+
### Speech
|
| 94 |
+
|
| 95 |
+
The Phi-4-multimodal-instruct was observed as
|
| 96 |
+
- Having strong automatic speech recognition (ASR) and speech translation (ST) performance, surpassing expert ASR model WhisperV3 and ST models SeamlessM4T-v2-Large.
|
| 97 |
+
- Ranking number 1 on the Huggingface OpenASR leaderboard with word error rate 6.14% in comparison with the current best model 6.5% as of Jan 17, 2025.
|
| 98 |
+
- Being the first open-sourced model that can perform speech summarization, and the performance is close to GPT4o.
|
| 99 |
+
- Having a gap with close models, e.g. Gemini-1.5-Flash and GPT-4o-realtime-preview, on speech QA task. Work is being undertaken to improve this capability in the next iterations.
|
| 100 |
+
|
| 101 |
+
#### Speech Recognition (lower is better)
|
| 102 |
+
|
| 103 |
+
The performance of Phi-4-multimodal-instruct on the aggregated benchmark datasets:
|
| 104 |
+

|
| 105 |
+
|
| 106 |
+
The performance of Phi-4-multimodal-instruct on different languages, averaging the WERs of CommonVoice and FLEURS:
|
| 107 |
+
|
| 108 |
+

|
| 109 |
+
|
| 110 |
+
#### Speech Translation (higher is better)
|
| 111 |
+
|
| 112 |
+
Translating from German, Spanish, French, Italian, Japanese, Portugues, Chinese to English:
|
| 113 |
+
|
| 114 |
+

|
| 115 |
+
|
| 116 |
+
Translating from English to German, Spanish, French, Italian, Japanese, Portugues, Chinese. Noted that WhiperV3 does not support this capability:
|
| 117 |
+
|
| 118 |
+

|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
#### Speech Summarization (higher is better)
|
| 122 |
+
|
| 123 |
+

|
| 124 |
+
|
| 125 |
+
#### Speech QA
|
| 126 |
+
|
| 127 |
+
MT bench scores are scaled by 10x to match the score range of MMMLU:
|
| 128 |
+
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+
#### Audio Uniderstanding
|
| 132 |
+
|
| 133 |
+
AIR bench scores are scaled by 10x to match the score range of MMAU:
|
| 134 |
+
|
| 135 |
+

|
| 136 |
+
|
| 137 |
+
### Vision
|
| 138 |
+
|
| 139 |
+
#### Vision-Speech tasks
|
| 140 |
+
|
| 141 |
+
Phi-4-multimodal-instruct is capable of processing both image and audio together, the following table shows the model quality when the input query for vision content is synthetic speech on chart/table understanding and document reasoning tasks. Compared to other existing state-of-the-art omni models that can enable audio and visual signal as input, Phi-4-multimodal-instruct achieves much stronger performance on multiple benchmarks.
|
| 142 |
+
|
| 143 |
+
| Benchmarks | Phi-4-multimodal-instruct | InternOmni-7B | Gemini-2.0-Flash-Lite-prv-02-05 | Gemini-2.0-Flash | Gemini-1.5-Pro |
|
| 144 |
+
|-----------------------|--------------------------|---------------|--------------------------------|-----------------|----------------|
|
| 145 |
+
| s_AI2D | **68.9** | 53.9 | 62.0 | **69.4** | 67.7 |
|
| 146 |
+
| s_ChartQA | **69.0** | 56.1 | 35.5 | 51.3 | 46.9 |
|
| 147 |
+
| s_DocVQA | **87.3** | 79.9 | 76.0 | 80.3 | 78.2 |
|
| 148 |
+
| s_InfoVQA | **63.7** | 60.3 | 59.4 | 63.6 | **66.1** |
|
| 149 |
+
| **Average** | **72.2** | **62.6** | **58.2** | **66.2** | **64.7** |
|
| 150 |
+
|
| 151 |
+
### Vision tasks
|
| 152 |
+
To understand the vision capabilities, Phi-4-multimodal-instruct was compared with a set of models over a variety of zero-shot benchmarks using an internal benchmark platform. At the high-level overview of the model quality on representative benchmarks:
|
| 153 |
+
|
| 154 |
+
| Dataset | Phi-4-multimodal-ins | Phi-3.5-vision-ins | Qwen 2.5-VL-3B-ins | Intern VL 2.5-4B | Qwen 2.5-VL-7B-ins | Intern VL 2.5-8B | Gemini 2.0-Flash Lite-preview-0205 | Gemini2.0-Flash | Claude-3.5-Sonnet-2024-10-22 | Gpt-4o-2024-11-20 |
|
| 155 |
+
|----------------------------------|---------------------|-------------------|-------------------|-----------------|-------------------|-----------------|--------------------------------|-----------------|----------------------------|------------------|
|
| 156 |
+
| **Popular aggregated benchmark** | | | | | | | | | | |
|
| 157 |
+
| MMMU | **55.1** | 43.0 | 47.0 | 48.3 | 51.8 | 50.6 | 54.1 | **64.7** | 55.8 | 61.7 |
|
| 158 |
+
| MMBench (dev-en) | **86.7** | 81.9 | 84.3 | 86.8 | 87.8 | 88.2 | 85.0 | **90.0** | 86.7 | 89.0 |
|
| 159 |
+
| MMMU-Pro (std/vision) | **38.5** | 21.8 | 29.9 | 32.4 | 36.9 | 34.4 | 45.1 | **54.4** | 54.3 | 53.0 |
|
| 160 |
+
| **Visual science reasoning** | | | | | | | | | | |
|
| 161 |
+
| ScienceQA Visual (img-test) | **97.5** | 91.3 | 79.4 | 96.2 | 87.7 | **97.3** | 85.0 | 88.3 | 81.2 | 88.2 |
|
| 162 |
+
| **Visual math reasoning** | | | | | | | | | | |
|
| 163 |
+
| MathVista (testmini) | **62.4** | 43.9 | 60.8 | 51.2 | **67.8** | 56.7 | 57.6 | 47.2 | 56.9 | 56.1 |
|
| 164 |
+
| InterGPS | **48.6** | 36.3 | 48.3 | 53.7 | 52.7 | 54.1 | 57.9 | **65.4** | 47.1 | 49.1 |
|
| 165 |
+
| **Chart & table reasoning** | | | | | | | | | | |
|
| 166 |
+
| AI2D | **82.3** | 78.1 | 78.4 | 80.0 | 82.6 | 83.0 | 77.6 | 82.1 | 70.6 | **83.8** |
|
| 167 |
+
| ChartQA | **81.4** | 81.8 | 80.0 | 79.1 | **85.0** | 81.0 | 73.0 | 79.0 | 78.4 | 75.1 |
|
| 168 |
+
| DocVQA | **93.2** | 69.3 | 93.9 | 91.6 | **95.7** | 93.0 | 91.2 | 92.1 | 95.2 | 90.9 |
|
| 169 |
+
| InfoVQA | **72.7** | 36.6 | 77.1 | 72.1 | **82.6** | 77.6 | 73.0 | 77.8 | 74.3 | 71.9 |
|
| 170 |
+
| **Document Intelligence** | | | | | | | | | | |
|
| 171 |
+
| TextVQA (val) | **75.6** | 72.0 | 76.8 | 70.9 | **77.7** | 74.8 | 72.9 | 74.4 | 58.6 | 73.1 |
|
| 172 |
+
| OCR Bench | **84.4** | 63.8 | 82.2 | 71.6 | **87.7** | 74.8 | 75.7 | 81.0 | 77.0 | 77.7 |
|
| 173 |
+
| **Object visual presence verification** | | | | | | | | | | |
|
| 174 |
+
| POPE | **85.6** | 86.1 | 87.9 | 89.4 | 87.5 | **89.1** | 87.5 | 88.0 | 82.6 | 86.5 |
|
| 175 |
+
| **Multi-image perception** | | | | | | | | | | |
|
| 176 |
+
| BLINK | **61.3** | 57.0 | 48.1 | 51.2 | 55.3 | 52.5 | 59.3 | **64.0** | 56.9 | 62.4 |
|
| 177 |
+
| Video MME 16 frames | **55.0** | 50.8 | 56.5 | 57.3 | 58.2 | 58.7 | 58.8 | 65.5 | 60.2 | **68.2** |
|
| 178 |
+
| **Average** | **72.0** | **60.9** | **68.7** | **68.8** | **73.1** | **71.1** | **70.2** | **74.3** | **69.1** | **72.4** |
|
| 179 |
+
|
| 180 |
+

|
| 181 |
+
|
| 182 |
+
#### Visual Perception
|
| 183 |
+
|
| 184 |
+
Below are the comparison results on existing multi-image tasks. On average, Phi-4-multimodal-instruct outperforms competitor models of the same size and competitive with much bigger models on multi-frame capabilities.
|
| 185 |
+
BLINK is an aggregated benchmark with 14 visual tasks that humans can solve very quickly but are still hard for current multimodal LLMs.
|
| 186 |
+
|
| 187 |
+
| Dataset | Phi-4-multimodal-instruct | Qwen2.5-VL-3B-Instruct | InternVL 2.5-4B | Qwen2.5-VL-7B-Instruct | InternVL 2.5-8B | Gemini-2.0-Flash-Lite-prv-02-05 | Gemini-2.0-Flash | Claude-3.5-Sonnet-2024-10-22 | Gpt-4o-2024-11-20 |
|
| 188 |
+
|----------------------------|--------------------------|----------------------|-----------------|----------------------|-----------------|--------------------------------|-----------------|----------------------------|------------------|
|
| 189 |
+
| Art Style | **86.3** | 58.1 | 59.8 | 65.0 | 65.0 | 76.9 | 76.9 | 68.4 | 73.5 |
|
| 190 |
+
| Counting | **60.0** | 67.5 | 60.0 | 66.7 | **71.7** | 45.8 | 69.2 | 60.8 | 65.0 |
|
| 191 |
+
| Forensic Detection | **90.2** | 34.8 | 22.0 | 43.9 | 37.9 | 31.8 | 74.2 | 63.6 | 71.2 |
|
| 192 |
+
| Functional Correspondence | **30.0** | 20.0 | 26.9 | 22.3 | 27.7 | 48.5 | **53.1** | 34.6 | 42.3 |
|
| 193 |
+
| IQ Test | **22.7** | 25.3 | 28.7 | 28.7 | 28.7 | 28.0 | **30.7** | 20.7 | 25.3 |
|
| 194 |
+
| Jigsaw | **68.7** | 52.0 | **71.3** | 69.3 | 53.3 | 62.7 | 69.3 | 61.3 | 68.7 |
|
| 195 |
+
| Multi-View Reasoning | **76.7** | 44.4 | 44.4 | 54.1 | 45.1 | 55.6 | 41.4 | 54.9 | 54.1 |
|
| 196 |
+
| Object Localization | **52.5** | 55.7 | 53.3 | 55.7 | 58.2 | 63.9 | **67.2** | 58.2 | 65.6 |
|
| 197 |
+
| Relative Depth | **69.4** | 68.5 | 68.5 | 80.6 | 76.6 | **81.5** | 72.6 | 66.1 | 73.4 |
|
| 198 |
+
| Relative Reflectance | **26.9** | **38.8** | **38.8** | 32.8 | **38.8** | 33.6 | 34.3 | 38.1 | 38.1 |
|
| 199 |
+
| Semantic Correspondence | **52.5** | 32.4 | 33.8 | 28.8 | 24.5 | **56.1** | 55.4 | 43.9 | 47.5 |
|
| 200 |
+
| Spatial Relation | **72.7** | 80.4 | 86.0 | **88.8** | 86.7 | 74.1 | 79.0 | 74.8 | 83.2 |
|
| 201 |
+
| Visual Correspondence | **67.4** | 28.5 | 39.5 | 50.0 | 44.2 | 84.9 | **91.3** | 72.7 | 82.6 |
|
| 202 |
+
| Visual Similarity | **86.7** | 67.4 | 88.1 | 87.4 | 85.2 | **87.4** | 80.7 | 79.3 | 83.0 |
|
| 203 |
+
| **Overall** | **61.6** | **48.1** | **51.2** | **55.3** | **52.5** | **59.3** | **64.0** | **56.9** | **62.4** |
|
| 204 |
+
|
| 205 |
+

|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
## Usage
|
| 209 |
+
|
| 210 |
+
### Requirements
|
| 211 |
+
|
| 212 |
+
Phi-4 family has been integrated in the `4.48.2` version of `transformers`. The current `transformers` version can be verified with: `pip list | grep transformers`.
|
| 213 |
+
|
| 214 |
+
Examples of required packages:
|
| 215 |
+
```
|
| 216 |
+
flash_attn==2.7.4.post1
|
| 217 |
+
torch==2.6.0
|
| 218 |
+
transformers==4.48.2
|
| 219 |
+
accelerate==1.3.0
|
| 220 |
+
soundfile==0.13.1
|
| 221 |
+
pillow==10.3.0
|
| 222 |
+
```
|
| 223 |
+
|
| 224 |
+
Phi-4-multimodal-instruct is also available in [Azure AI Studio]()
|
| 225 |
+
|
| 226 |
+
### Tokenizer
|
| 227 |
+
|
| 228 |
+
Phi-4-multimodal-instruct supports a vocabulary size of up to `200064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-4-multimodal-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
|
| 229 |
+
|
| 230 |
+
### Input Formats
|
| 231 |
+
|
| 232 |
+
Given the nature of the training data, the Phi-4-multimodal-instruct model is best suited for prompts using the chat format as follows:
|
| 233 |
+
|
| 234 |
+
#### Text chat format
|
| 235 |
+
|
| 236 |
+
This format is used for general conversation and instructions:
|
| 237 |
+
|
| 238 |
+
`
|
| 239 |
+
<|system|>You are a helpful assistant.<|end|><|user|>How to explain Internet for a medieval knight?<|end|><|assistant|>
|
| 240 |
+
`
|
| 241 |
+
|
| 242 |
+
#### Tool-enabled function-calling format
|
| 243 |
+
|
| 244 |
+
This format is used when the user wants the model to provide function calls based on
|
| 245 |
+
the given tools. The user should provide the available tools in the system prompt,
|
| 246 |
+
wrapped by <|tool|> and <|/tool|> tokens. The tools should be specified in JSON format,
|
| 247 |
+
using a JSON dump structure. Example:
|
| 248 |
+
|
| 249 |
+
`
|
| 250 |
+
<|system|>You are a helpful assistant with some tools.<|tool|>[{"name": "get_weather_updates", "description": "Fetches weather updates for a given city using the RapidAPI Weather API.", "parameters": {"city": {"description": "The name of the city for which to retrieve weather information.", "type": "str", "default": "London"}}}]<|/tool|><|end|><|user|>What is the weather like in Paris today?<|end|><|assistant|>
|
| 251 |
+
`
|
| 252 |
+
|
| 253 |
+
#### Vision-Language Format
|
| 254 |
+
|
| 255 |
+
This format is used for conversation with image:
|
| 256 |
+
|
| 257 |
+
`
|
| 258 |
+
<|user|><|image_1|>Describe the image in detail.<|end|><|assistant|>
|
| 259 |
+
`
|
| 260 |
+
|
| 261 |
+
For multiple images, the user needs to insert multiple image placeholders in the prompt as below:
|
| 262 |
+
|
| 263 |
+
`
|
| 264 |
+
<|user|><|image_1|><|image_2|><|image_3|>Summarize the content of the images.<|end|><|assistant|>
|
| 265 |
+
`
|
| 266 |
+
|
| 267 |
+
#### Speech-Language Format
|
| 268 |
+
|
| 269 |
+
This format is used for various speech and audio tasks:
|
| 270 |
+
|
| 271 |
+
`
|
| 272 |
+
<|user|><|audio_1|>{task prompt}<|end|><|assistant|>
|
| 273 |
+
`
|
| 274 |
+
|
| 275 |
+
The task prompt can vary for different task.
|
| 276 |
+
Automatic Speech Recognition:
|
| 277 |
+
|
| 278 |
+
`
|
| 279 |
+
<|user|><|audio_1|>Transcribe the audio clip into text.<|end|><|assistant|>
|
| 280 |
+
`
|
| 281 |
+
|
| 282 |
+
Automatic Speech Translation:
|
| 283 |
+
|
| 284 |
+
`
|
| 285 |
+
<|user|><|audio_1|>Translate the audio to {lang}.<|end|><|assistant|>
|
| 286 |
+
`
|
| 287 |
+
|
| 288 |
+
Automatic Speech Translation with chain-of-thoughts:
|
| 289 |
+
|
| 290 |
+
`
|
| 291 |
+
<|user|><|audio_1|>Transcribe the audio to text, and then translate the audio to {lang}. Use <sep> as a separator between the original transcript and the translation.<|end|><|assistant|>
|
| 292 |
+
`
|
| 293 |
+
|
| 294 |
+
Spoken-query Question Answering:
|
| 295 |
+
|
| 296 |
+
`
|
| 297 |
+
<|user|><|audio_1|><|end|><|assistant|>
|
| 298 |
+
`
|
| 299 |
+
|
| 300 |
+
#### Vision-Speech Format
|
| 301 |
+
|
| 302 |
+
This format is used for conversation with image and audio.
|
| 303 |
+
The audio may contain query related to the image:
|
| 304 |
+
|
| 305 |
+
`
|
| 306 |
+
<|user|><|image_1|><|audio_1|><|end|><|assistant|>
|
| 307 |
+
`
|
| 308 |
+
|
| 309 |
+
For multiple images, the user needs to insert multiple image placeholders in the prompt as below:
|
| 310 |
+
|
| 311 |
+
`
|
| 312 |
+
<|user|><|image_1|><|image_2|><|image_3|><|audio_1|><|end|><|assistant|>
|
| 313 |
+
`
|
| 314 |
+
|
| 315 |
+
**Vision**
|
| 316 |
+
- Any common RGB/gray image format (e.g., (".jpg", ".jpeg", ".png", ".ppm", ".bmp", ".pgm", ".tif", ".tiff", ".webp")) can be supported.
|
| 317 |
+
- Resolution depends on the GPU memory size. Higher resolution and more images will produce more tokens, thus using more GPU memory. During training, 64 crops can be supported.
|
| 318 |
+
If it is a square image, the resolution would be around (8*448 by 8*448). For multiple-images, at most 64 frames can be supported, but with more frames as input, the resolution of each frame needs to be reduced to fit in the memory.
|
| 319 |
+
|
| 320 |
+
**Audio**
|
| 321 |
+
- Any audio format that can be loaded by soundfile package should be supported.
|
| 322 |
+
- To keep the satisfactory performance, maximum audio length is suggested to be 40s. For summarization tasks, the maximum audio length is suggested to 30 mins.
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
### Loading the model locally
|
| 326 |
+
|
| 327 |
+
After obtaining the Phi-4-Mini-MM-Instruct model checkpoints, users can use this sample code for inference.
|
| 328 |
+
|
| 329 |
+
```python
|
| 330 |
+
import requests
|
| 331 |
+
import torch
|
| 332 |
+
import os
|
| 333 |
+
from PIL import Image
|
| 334 |
+
import soundfile
|
| 335 |
+
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig,pipeline,AutoTokenizer
|
| 336 |
+
|
| 337 |
+
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
|
| 338 |
+
|
| 339 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 340 |
+
"microsoft/Phi-4-multimodal-instruct",
|
| 341 |
+
device_map="cuda",
|
| 342 |
+
torch_dtype="auto",
|
| 343 |
+
trust_remote_code=True,
|
| 344 |
+
_attn_implementation='flash_attention_2',
|
| 345 |
+
).cuda()
|
| 346 |
+
|
| 347 |
+
generation_config = GenerationConfig.from_pretrained(model_path, 'generation_config.json')
|
| 348 |
+
|
| 349 |
+
user_prompt = '<|user|>'
|
| 350 |
+
assistant_prompt = '<|assistant|>'
|
| 351 |
+
prompt_suffix = '<|end|>'
|
| 352 |
+
|
| 353 |
+
prompt = f'{user_prompt}<|image_1|>What is shown in this image?{prompt_suffix}{assistant_prompt}'
|
| 354 |
+
url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
|
| 355 |
+
print(f'>>> Prompt\n{prompt}')
|
| 356 |
+
image = Image.open(requests.get(url, stream=True).raw)
|
| 357 |
+
inputs = processor(text=prompt, images=image, return_tensors='pt').to('cuda:0')
|
| 358 |
+
generate_ids = model.generate(
|
| 359 |
+
**inputs,
|
| 360 |
+
max_new_tokens=1000,
|
| 361 |
+
generation_config=generation_config,
|
| 362 |
+
)
|
| 363 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 364 |
+
response = processor.batch_decode(
|
| 365 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 366 |
+
)[0]
|
| 367 |
+
print(f'>>> Response\n{response}')
|
| 368 |
+
|
| 369 |
+
|
| 370 |
+
speech_prompt = "Transcribe the audio to text, and then translate the audio to French. Use <sep> as a separator between the original transcript and the translation."
|
| 371 |
+
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
|
| 372 |
+
|
| 373 |
+
print(f'>>> Prompt\n{prompt}')
|
| 374 |
+
audio = soundfile.read('https://voiceage.com/wbsamples/in_mono/Trailer.wav')
|
| 375 |
+
inputs = processor(text=prompt, audios=[audio], return_tensors='pt').to('cuda:0')
|
| 376 |
+
generate_ids = model.generate(
|
| 377 |
+
**inputs,
|
| 378 |
+
max_new_tokens=1000,
|
| 379 |
+
generation_config=generation_config,
|
| 380 |
+
)
|
| 381 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 382 |
+
response = processor.batch_decode(
|
| 383 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 384 |
+
)[0]
|
| 385 |
+
print(f'>>> Response\n{response}')
|
| 386 |
+
```
|
| 387 |
+
|
| 388 |
+
## Responsible AI Considerations
|
| 389 |
+
|
| 390 |
+
Like other language models, the Phi family of models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
|
| 391 |
+
+ Quality of Service: The Phi models are trained primarily on English language content across text, speech, and visual inputs, with some additional multilingual coverage. Performance may vary significantly across different modalities and languages:
|
| 392 |
+
+ Text: Languages other than English will experience reduced performance, with varying levels of degradation across different non-English languages. English language varieties with less representation in the training data may perform worse than standard American English.
|
| 393 |
+
+ Speech: Speech recognition and processing shows similar language-based performance patterns, with optimal performance for standard American English accents and pronunciations. Other English accents, dialects, and non-English languages may experience lower recognition accuracy and response quality. Background noise, audio quality, and speaking speed can further impact performance.
|
| 394 |
+
+ Vision: Visual processing capabilities may be influenced by cultural and geographical biases in the training data. The model may show reduced performance when analyzing images containing text in non-English languages or visual elements more commonly found in non-Western contexts. Image quality, lighting conditions, and composition can also affect processing accuracy.
|
| 395 |
+
+ Multilingual performance and safety gaps: We believe it is important to make language models more widely available across different languages, but the Phi 4 models still exhibit challenges common across multilingual releases. As with any deployment of LLMs, developers will be better positioned to test for performance or safety gaps for their linguistic and cultural context and customize the model with additional fine-tuning and appropriate safeguards.
|
| 396 |
+
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups, cultural contexts, or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
|
| 397 |
+
+ Inappropriate or Offensive Content: These models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the case.
|
| 398 |
+
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
|
| 399 |
+
+ Limited Scope for Code: The majority of Phi 4 training data is based in Python and uses common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, it is strongly recommended that users manually verify all API uses.
|
| 400 |
+
+ Long Conversation: Phi 4 models, like other models, can in some cases generate responses that are repetitive, unhelpful, or inconsistent in very long chat sessions in both English and non-English languages. Developers are encouraged to place appropriate mitigations, like limiting conversation turns to account for the possible conversational drift.
|
| 401 |
+
+ Inference of Sensitive Attributes: The Phi 4 models can sometimes attempt to infer sensitive attributes (such as personality characteristics, country of origin, gender, etc...) from the users’ voices when specifically asked to do so. Phi 4-multimodal-instruct is not designed or intended to be used as a biometric categorization system to categorize individuals based on their biometric data to deduce or infer their race, political opinions, trade union membership, religious or philosophical beliefs, sex life, or sexual orientation. This behavior can be easily and efficiently mitigated at the application level by a system message.
|
| 402 |
+
|
| 403 |
+
Developers should apply responsible AI best practices, including mapping, measuring, and mitigating risks associated with their specific use case and cultural, linguistic context. Phi 4 family of models are general purpose models. As developers plan to deploy these models for specific use cases, they are encouraged to fine-tune the models for their use case and leverage the models as part of broader AI systems with language-specific safeguards in place. Important areas for consideration include:
|
| 404 |
+
|
| 405 |
+
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
|
| 406 |
+
+ High-Risk Scenarios: Developers should assess the suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
|
| 407 |
+
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
|
| 408 |
+
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
|
| 409 |
+
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
|
| 410 |
+
|
| 411 |
+
|
| 412 |
+
## Training
|
| 413 |
+
|
| 414 |
+
### Model
|
| 415 |
+
|
| 416 |
+
+ **Architecture:** Phi-4-multimodal-instruct has 5.6B parameters and is a multimodal transformer model. The model has the pretrained Phi-4-Mini-Instruct as the backbone language model, and the advanced encoders and adapters of vision and speech.<br>
|
| 417 |
+
+ **Inputs:** Text, image, and audio. It is best suited for prompts using the chat format.<br>
|
| 418 |
+
+ **Context length:** 128K tokens<br>
|
| 419 |
+
+ **GPUs:** 512 A100-80G<br>
|
| 420 |
+
+ **Training time:** 28 days<br>
|
| 421 |
+
+ **Training data:** 5T tokens, 2.3M speech hours, and 1.1T image-text tokens<br>
|
| 422 |
+
+ **Outputs:** Generated text in response to the input<br>
|
| 423 |
+
+ **Dates:** Trained between December 2024 and January 2025<br>
|
| 424 |
+
+ **Status:** This is a static model trained on offline datasets with the cutoff date of June 2024 for publicly available data.<br>
|
| 425 |
+
+ **Supported languages:**
|
| 426 |
+
+ Text: Arabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Hebrew, Hungarian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Swedish, Thai, Turkish, Ukrainian<br>
|
| 427 |
+
+ Vision: English<br>
|
| 428 |
+
+ Audio: English, Chinese, German, French, Italian, Japanese, Spanish, Portuguese<br>
|
| 429 |
+
+ **Release date:** February 2025<br>
|
| 430 |
+
|
| 431 |
+
### Training Datasets
|
| 432 |
+
|
| 433 |
+
Phi-4-multimodal-instruct's training data includes a wide variety of sources, totaling 5 trillion text tokens, and is a combination of
|
| 434 |
+
1) publicly available documents filtered for quality, selected high-quality educational data, and code
|
| 435 |
+
2) newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (e.g., science, daily activities, theory of mind, etc.)
|
| 436 |
+
3) high quality human labeled data in chat format
|
| 437 |
+
4) selected high-quality image-text interleave data
|
| 438 |
+
5) synthetic and publicly available image, multi-image, and video data
|
| 439 |
+
6) anonymized in-house speech-text pair data with strong/weak transcriptions
|
| 440 |
+
7) selected high-quality publicly available and anonymized in-house speech data with task-specific supervisions
|
| 441 |
+
8) selected synthetic speech data
|
| 442 |
+
9) synthetic vision-speech data.
|
| 443 |
+
|
| 444 |
+
Focus was placed on the quality of data that could potentially improve the reasoning ability for the model, and the publicly available documents were filtered to contain a preferred level of knowledge. As an example, the result of a game in premier league on a particular day might be good training data for large foundation models, but such information was removed for the Phi-4-multimodal-instruct to leave more model capacity for reasoning for the model's small size. The data collection process involved sourcing information from publicly available documents, with a focus on filtering out undesirable documents and images. To safeguard privacy, image and text data sources were filtered to remove or scrub potentially personal data from the training data.
|
| 445 |
+
The decontamination process involved normalizing and tokenizing the dataset, then generating and comparing n-grams between the target dataset and benchmark datasets. Samples with matching n-grams above a threshold were flagged as contaminated and removed from the dataset. A detailed contamination report was generated, summarizing the matched text, matching ratio, and filtered results for further analysis.
|
| 446 |
+
|
| 447 |
+
### Fine-tuning
|
| 448 |
+
|
| 449 |
+
A basic example of supervised fine-tuning (SFT) for [speech](https://huggingface.co/microsoft/Phi-4-multimodal-instruct/resolve/main/sample_finetune_speech.py) and [vision](https://huggingface.co/microsoft/Phi-4-multimodal-instruct/resolve/main/sample_finetune_vision.py) is provided respectively.
|
| 450 |
+
|
| 451 |
+
## Safety
|
| 452 |
+
|
| 453 |
+
The Phi-4 family of models has adopted a robust safety post-training approach. This approach leverages a variety of both open-source and in-house generated datasets. The overall technique employed for safety alignment is a combination of SFT (Supervised Fine-Tuning), DPO (Direct Preference Optimization), and RLHF (Reinforcement Learning from Human Feedback) approaches by utilizing human-labeled and synthetic English-language datasets, including publicly available datasets focusing on helpfulness and harmlessness, as well as various questions and answers targeted to multiple safety categories. For non-English languages, existing datasets were extended via machine translation. Speech Safety datasets were generated by running Text Safety datasets through Azure TTS (Text-To-Speech) Service, for both English and non-English languages. Vision (text & images) Safety datasets were created to cover harm categories identified both in public and internal multi-modal RAI datasets.
|
| 454 |
+
|
| 455 |
+
### Safety Evaluation and Red-Teaming
|
| 456 |
+
|
| 457 |
+
Various evaluation techniques including red teaming, adversarial conversation simulations, and multilingual safety evaluation benchmark datasets were leveraged to evaluate Phi-4 models' propensity to produce undesirable outputs across multiple languages and risk categories. Several approaches were used to compensate for the limitations of one approach alone. Findings across the various evaluation methods indicate that safety post-training that was done as detailed in the [Phi 3 Safety Post-Training paper](https://arxiv.org/abs/2407.13833) had a positive impact across multiple languages and risk categories as observed by refusal rates (refusal to output undesirable outputs) and robustness to jailbreak techniques. Details on prior red team evaluations across Phi models can be found in the [Phi 3 Safety Post-Training paper](https://arxiv.org/abs/2407.13833). For this release, the red teaming effort focused on the newest Audio input modality and on the following safety areas: harmful content, self-injury risks, and exploits. The model was found to be more susceptible to providing undesirable outputs when attacked with context manipulation or persuasive techniques. These findings applied to all languages, with the persuasive techniques mostly affecting French and Italian. This highlights the need for industry-wide investment in the development of high-quality safety evaluation datasets across multiple languages, including low resource languages, and risk areas that account for cultural nuances where those languages are spoken.
|
| 458 |
+
|
| 459 |
+
### Vision Safety Evaluation
|
| 460 |
+
|
| 461 |
+
To assess model safety in scenarios involving both text and images, Microsoft's Azure AI Evaluation SDK was utilized. This tool facilitates the simulation of single-turn conversations with the target model by providing prompt text and images designed to incite harmful responses. The target model's responses are subsequently evaluated by a capable model across multiple harm categories, including violence, sexual content, self-harm, hateful and unfair content, with each response scored based on the severity of the harm identified. The evaluation results were compared with those of Phi-3.5-Vision and open-source models of comparable size. In addition, we ran both an internal and the public RTVLM and VLGuard multi-modal (text & vision) RAI benchmarks, once again comparing scores with Phi-3.5-Vision and open-source models of comparable size. However, the model may be susceptible to language-specific attack prompts and cultural context.
|
| 462 |
+
|
| 463 |
+
### Audio Safety Evaluation
|
| 464 |
+
|
| 465 |
+
In addition to extensive red teaming, the Safety of the model was assessed through three distinct evaluations. First, as performed with Text and Vision inputs, Microsoft's Azure AI Evaluation SDK was leveraged to detect the presence of harmful content in the model's responses to Speech prompts. Second, [Microsoft's Speech Fairness evaluation](https://speech.microsoft.com/portal/responsibleai/assess) was run to verify that Speech-To-Text transcription worked well across a variety of demographics. Third, we proposed and evaluated a mitigation approach via a system message to help prevent the model from inferring sensitive attributes (such as gender, sexual orientation, profession, medical condition, etc...) from the voice of a user.
|
| 466 |
+
|
| 467 |
+
|
| 468 |
+
## Software
|
| 469 |
+
* [PyTorch](https://github.com/pytorch/pytorch)
|
| 470 |
+
* [Transformers](https://github.com/huggingface/transformers)
|
| 471 |
+
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
|
| 472 |
+
* [Accelerate](https://huggingface.co/docs/transformers/main/en/accelerate)
|
| 473 |
+
* [soundfile](https://github.com/bastibe/python-soundfile)
|
| 474 |
+
* [pillow](https://github.com/python-pillow/Pillow)
|
| 475 |
+
|
| 476 |
+
## Hardware
|
| 477 |
+
Note that by default, the Phi-4-multimodal-instruct model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
|
| 478 |
+
* NVIDIA A100
|
| 479 |
+
* NVIDIA A6000
|
| 480 |
+
* NVIDIA H100
|
| 481 |
+
|
| 482 |
+
If you want to run the model on:
|
| 483 |
+
* NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with attn_implementation="eager"
|
| 484 |
+
|
| 485 |
+
## License
|
| 486 |
+
The model is licensed under the [MIT license](./LICENSE).
|
| 487 |
+
|
| 488 |
+
## Trademarks
|
| 489 |
+
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft's Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
|
| 490 |
+
|
| 491 |
+
## Appendix A: Benchmark Methodology
|
| 492 |
+
|
| 493 |
+
We include a brief word on methodology here - and in particular, how we think about optimizing prompts.
|
| 494 |
+
In an ideal world, we would never change any prompts in our benchmarks to ensure it is always an apples-to-apples comparison when comparing different models. Indeed, this is our default approach, and is the case in the vast majority of models we have run to date.
|
| 495 |
+
There are, however, some exceptions to this. In some cases, we see a model that performs worse than expected on a given eval due to a failure to respect the output format. For example:
|
| 496 |
+
|
| 497 |
+
+ A model may refuse to answer questions (for no apparent reason), or in coding tasks models may prefix their response with “Sure, I can help with that. …” which may break the parser. In such cases, we have opted to try different system messages (e.g. “You must always respond to a question” or “Get to the point!”).
|
| 498 |
+
+ Some models, we observed that few shots actually hurt model performance. In this case we did allow running the benchmarks with 0-shots for all cases.
|
| 499 |
+
+ We have tools to convert between chat and completions APIs. When converting a chat prompt to a completion prompt, some models have different keywords e.g. Human vs User. In these cases, we do allow for model-specific mappings for chat to completion prompts.
|
| 500 |
+
|
| 501 |
+
However, we do not:
|
| 502 |
+
|
| 503 |
+
+ Pick different few-shot examples. Few shots will always be the same when comparing different models.
|
| 504 |
+
+ Change prompt format: e.g. if it is an A/B/C/D multiple choice, we do not tweak this to 1/2/3/4 multiple choice.
|
| 505 |
+
|
| 506 |
+
### Vision Benchmark Settings
|
| 507 |
+
|
| 508 |
+
The goal of the benchmark setup is to measure the performance of the LMM when a regular user utilizes these models for a task involving visual input. To this end, we selected 9 popular and publicly available single-frame datasets and 3 multi-frame benchmarks that cover a wide range of challenging topics and tasks (e.g., mathematics, OCR tasks, charts-and-plots understanding, etc.) as well as a set of high-quality models.
|
| 509 |
+
Our benchmarking setup utilizes zero-shot prompts and all the prompt content are the same for every model. We only formatted the prompt content to satisfy the model's prompt API. This ensures that our evaluation is fair across the set of models we tested. Many benchmarks necessitate models to choose their responses from a presented list of options. Therefore, we've included a directive in the prompt's conclusion, guiding all models to pick the option letter that corresponds to the answer they deem correct.
|
| 510 |
+
In terms of the visual input, we use the images from the benchmarks as they come from the original datasets. We converted these images to base-64 using a JPEG encoding for models that require this format (e.g., GPTV, Claude Sonnet 3.5, Gemini 1.5 Pro/Flash). For other models (e.g., Llava Interleave, and InternVL2 4B and 8B), we used their Huggingface interface and passed in PIL images or a JPEG image stored locally. We did not scale or pre-process images in any other way.
|
| 511 |
+
Lastly, we used the same code to extract answers and evaluate them using the same code for every considered model. This ensures that we are fair in assessing the quality of their answers.
|
| 512 |
+
|
| 513 |
+
### Speech Benchmark Settings
|
| 514 |
+
|
| 515 |
+
The objective of this benchmarking setup is to assess the performance of models in speech and audio understanding tasks as utilized by regular users. To accomplish this, we selected several state-of-the-art open-sourced and closed-sourced models and performed evaluations across a variety of public and in-house benchmarks. These benchmarks encompass diverse and challenging topics, including Automatic Speech Recognition (ASR), Automatic Speech Translation (AST), Spoken Query Question Answering (SQQA), Audio Understanding (AU), and Speech Summarization.
|
| 516 |
+
The results are derived from evaluations conducted on identical test data without any further clarifications. All results were obtained without sampling during inference. For an accurate comparison, we employed consistent prompts for models across different tasks, except for certain model APIs (e.g., GPT-4o), which may refuse to respond to specific prompts for some tasks.
|
| 517 |
+
In conclusion, we used uniform code to extract answers and evaluate them for all considered models. This approach ensured fairness by assessing the quality of their responses.
|
| 518 |
+
|
| 519 |
+
### Benchmark datasets
|
| 520 |
+
|
| 521 |
+
The model was evaluated across a breadth of public and internal benchmarks to understand it's capabilities under multiple tasks and conditions. While most evaluations use English, multilingual benchmark was incorporated to cover performance in select languages. More specifically,
|
| 522 |
+
+ Vision:
|
| 523 |
+
+ Popular aggregated benchmark:
|
| 524 |
+
+ MMMU and MMMU-Pro: massive multi-discipline tasks at college-level subject knowledge and deliberate reasoning.
|
| 525 |
+
+ MMBench: large-scale benchmark to evaluate perception and reasoning capabilities.
|
| 526 |
+
+ Visual reasoning:
|
| 527 |
+
+ ScienceQA: multimodal visual question answering on science.
|
| 528 |
+
+ MathVista: visual math reasoning.
|
| 529 |
+
+ InterGPS: Visual 2D geometry reasoning.
|
| 530 |
+
+ Chart reasoning:
|
| 531 |
+
+ ChartQA: visual and logical reasoning on charts.
|
| 532 |
+
+ AI2D: diagram understanding.
|
| 533 |
+
+ Document Intelligence:
|
| 534 |
+
+ TextVQA: read and reason about text in images to answer questions about them.
|
| 535 |
+
+ InfoVQA: read and reason about high-resolution infographics images with arbitrary aspect ratios.
|
| 536 |
+
+ DocVQA: read and reason about document images with dense texts and handwritten texts.
|
| 537 |
+
+ OCRBench: test OCR and QA capability on diverse text related images.
|
| 538 |
+
+ Vision speech multimodal understanding:
|
| 539 |
+
+ s_AI2D: diagram understanding with speech as the question format.
|
| 540 |
+
+ s_ChartQA: visual and logical reasoning on charts with speech as the question format.
|
| 541 |
+
+ s_InfoVQA: read and reason about high-resolution infographics images with speech as the question format.
|
| 542 |
+
+ s_DocVQA: read and reason about document images with dense texts and handwritten texts with speech as the question format.
|
| 543 |
+
+ RAI & Security Benchmarks:
|
| 544 |
+
+ VLGuardExt: VLGuard is a vision-language instruction following public dataset for model safety to address safety on deception
|
| 545 |
+
discrimination, privacy and risky behavior (advice, sexual, violence, political). This was extended to a few internal categories such as child safety and election critical information.
|
| 546 |
+
+ RTVLM: Public benchmark for red-teaming vision-language model on model truthfulness, privacy, safety, and fairness.
|
| 547 |
+
+ GPTV-RAI: In-house benchmark for GPT-4V released from Azure AI, measuring harmfulness (ex. sexual, violent, hate and self-harm), privacy, jailbreak, misinformation.
|
| 548 |
+
|
| 549 |
+
+ Speech:
|
| 550 |
+
+ CommonVoice v15 is an open-source, multilingual speech dataset developed by Mozilla. It includes over 33,000 hours of speech data in 133 languages, contributed and validated by volunteers worldwide.The evaluations were conducted in the eight supported languages.
|
| 551 |
+
+ The OpenASR Leaderboard on Hugging Face is designed for benchmarking and evaluating the robustness of ASR models on English. The datasets in the leaderboard cover diverse speech domains including reading speech, conversations, meetings, and so on.
|
| 552 |
+
+ CoVoST2 is a multilingual speech-to-text translation dataset derived from Mozilla's Common Voice project. It is one of the largest open datasets available for speech translation, providing support for both X-to-English (X→En) and English-to-X (En→X) translation tasks. The directions with supported languages were evaluated on the test sets.
|
| 553 |
+
+ FLEURS is a multilingual speech dataset designed for evaluating speech recognition and speech-to-text translation models across a wide range of languages. The test sets for speech recognition and translation tasks were evaluated with the eight supported languages.
|
| 554 |
+
+ MT Bench (Multi-turn Benchmark) is specifically designed to evaluate the conversational and instruction-following abilities of AI models in multi-turn question-answering (QA) scenarios. To support spoken questions, the text is synthesized into speech.
|
| 555 |
+
+ MMMLU (Multilingual Massive Multitask Language Understanding) is an extensive benchmark designed to evaluate the general knowledge and reasoning capabilities of AI models across a wide array of subjects. To support spoken questions, the text is synthesized into its speech counterpart. The model was evaluated on the eight supported languages for this test set.
|
| 556 |
+
+ AIR-Bench Chat (Audio Instruction and Response Benchmark) is a comprehensive evaluation framework designed to test the capabilities of large audio language models (LALMs). It includes both foundation and chat benchmarks. The chat benchmark is selected for its open-ended question answering for audio capability.
|
| 557 |
+
+ MMAU (Massive Multi-Task Audio Understanding) is a comprehensive dataset designed to evaluate the capabilities of multi-modal models in audio-based understanding and reasoning tasks. The test sets are in the form of multiple-choices QA, covering the categories of music, sound, and speech.
|
| 558 |
+
+ Golden3 is a real-world meeting dataset, containing 108 meeting recordings with corresponding transcripts, averaging 6 minutes each. It is recorded across 30 conference rooms, featuring 4-8 attendees. The dataset is primarily in English, covering a wide range of topics. GPT4 is employed to generate summarization instructions that ask to summarize partial or the entire conversation or control the output style/length/structure.
|
| 559 |
+
+ AMI (Augmented Multi-Party Interaction) is a comprehensive collection of meeting recordings, encompassing approximately 100 hours of data. The test split contains 20 meeting recordings with an average duration of 32 minutes. The model was tested on the close-talking version of audio. GPT4 is employed to generate summarization instructions that ask to summarize partial or the entire conversation or control the output style/length/structure.
|
| 560 |
+
|
| 561 |
+
+ Safety and RAI:
|
| 562 |
+
+ Single-turn trustworthiness evaluation:
|
| 563 |
+
+ DecodingTrust: DecodingTrust is a collection of trustworthiness benchmarks in eight different perspectives
|
| 564 |
+
+ XSTest: XSTest is an exaggerated safety evaluation
|
| 565 |
+
+ Toxigen: Toxigen is adversarial and hate speech detection
|
| 566 |
+
+ Red Team:
|
| 567 |
+
+ Responses to prompts provided by AI Red Team at Microsoft
|
SECURITY.md
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- BEGIN MICROSOFT SECURITY.MD V0.0.9 BLOCK -->
|
| 2 |
+
|
| 3 |
+
## Security
|
| 4 |
+
|
| 5 |
+
Microsoft takes the security of our software products and services seriously, which includes all source code repositories managed through our GitHub organizations, which include [Microsoft](https://github.com/Microsoft), [Azure](https://github.com/Azure), [DotNet](https://github.com/dotnet), [AspNet](https://github.com/aspnet) and [Xamarin](https://github.com/xamarin).
|
| 6 |
+
|
| 7 |
+
If you believe you have found a security vulnerability in any Microsoft-owned repository that meets [Microsoft's definition of a security vulnerability](https://aka.ms/security.md/definition), please report it to us as described below.
|
| 8 |
+
|
| 9 |
+
## Reporting Security Issues
|
| 10 |
+
|
| 11 |
+
**Please do not report security vulnerabilities through public GitHub issues.**
|
| 12 |
+
|
| 13 |
+
Instead, please report them to the Microsoft Security Response Center (MSRC) at [https://msrc.microsoft.com/create-report](https://aka.ms/security.md/msrc/create-report).
|
| 14 |
+
|
| 15 |
+
If you prefer to submit without logging in, send email to [[email protected]](mailto:[email protected]). If possible, encrypt your message with our PGP key; please download it from the [Microsoft Security Response Center PGP Key page](https://aka.ms/security.md/msrc/pgp).
|
| 16 |
+
|
| 17 |
+
You should receive a response within 24 hours. If for some reason you do not, please follow up via email to ensure we received your original message. Additional information can be found at [microsoft.com/msrc](https://www.microsoft.com/msrc).
|
| 18 |
+
|
| 19 |
+
Please include the requested information listed below (as much as you can provide) to help us better understand the nature and scope of the possible issue:
|
| 20 |
+
|
| 21 |
+
* Type of issue (e.g. buffer overflow, SQL injection, cross-site scripting, etc.)
|
| 22 |
+
* Full paths of source file(s) related to the manifestation of the issue
|
| 23 |
+
* The location of the affected source code (tag/branch/commit or direct URL)
|
| 24 |
+
* Any special configuration required to reproduce the issue
|
| 25 |
+
* Step-by-step instructions to reproduce the issue
|
| 26 |
+
* Proof-of-concept or exploit code (if possible)
|
| 27 |
+
* Impact of the issue, including how an attacker might exploit the issue
|
| 28 |
+
|
| 29 |
+
This information will help us triage your report more quickly.
|
| 30 |
+
|
| 31 |
+
If you are reporting for a bug bounty, more complete reports can contribute to a higher bounty award. Please visit our [Microsoft Bug Bounty Program](https://aka.ms/security.md/msrc/bounty) page for more details about our active programs.
|
| 32 |
+
|
| 33 |
+
## Preferred Languages
|
| 34 |
+
|
| 35 |
+
We prefer all communications to be in English.
|
| 36 |
+
|
| 37 |
+
## Policy
|
| 38 |
+
|
| 39 |
+
Microsoft follows the principle of [Coordinated Vulnerability Disclosure](https://aka.ms/security.md/cvd).
|
| 40 |
+
|
| 41 |
+
<!-- END MICROSOFT SECURITY.MD BLOCK -->
|
SUPPORT.md
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TODO: The maintainer of this repo has not yet edited this file
|
| 2 |
+
|
| 3 |
+
**REPO OWNER**: Do you want Customer Service & Support (CSS) support for this product/project?
|
| 4 |
+
|
| 5 |
+
- **No CSS support:** Fill out this template with information about how to file issues and get help.
|
| 6 |
+
- **Yes CSS support:** Fill out an intake form at [aka.ms/onboardsupport](https://aka.ms/onboardsupport). CSS will work with/help you to determine next steps.
|
| 7 |
+
- **Not sure?** Fill out an intake as though the answer were "Yes". CSS will help you decide.
|
| 8 |
+
|
| 9 |
+
*Then remove this first heading from this SUPPORT.MD file before publishing your repo.*
|
| 10 |
+
|
| 11 |
+
# Support
|
| 12 |
+
|
| 13 |
+
## How to file issues and get help
|
| 14 |
+
|
| 15 |
+
This project uses GitHub Issues to track bugs and feature requests. Please search the existing
|
| 16 |
+
issues before filing new issues to avoid duplicates. For new issues, file your bug or
|
| 17 |
+
feature request as a new Issue.
|
| 18 |
+
|
| 19 |
+
For help and questions about using this project, please **REPO MAINTAINER: INSERT INSTRUCTIONS HERE
|
| 20 |
+
FOR HOW TO ENGAGE REPO OWNERS OR COMMUNITY FOR HELP. COULD BE A STACK OVERFLOW TAG OR OTHER
|
| 21 |
+
CHANNEL. WHERE WILL YOU HELP PEOPLE?**.
|
| 22 |
+
|
| 23 |
+
## Microsoft Support Policy
|
| 24 |
+
|
| 25 |
+
Support for this **PROJECT or PRODUCT** is limited to the resources listed above.
|
added_tokens.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|/tool_call|>": 200026,
|
| 3 |
+
"<|/tool|>": 200024,
|
| 4 |
+
"<|assistant|>": 200019,
|
| 5 |
+
"<|end|>": 200020,
|
| 6 |
+
"<|system|>": 200022,
|
| 7 |
+
"<|tag|>": 200028,
|
| 8 |
+
"<|tool_call|>": 200025,
|
| 9 |
+
"<|tool_response|>": 200027,
|
| 10 |
+
"<|tool|>": 200023,
|
| 11 |
+
"<|user|>": 200021
|
| 12 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "Phi-4-multimodal-instruct",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Phi4MMForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_bias": false,
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"audio_processor": {
|
| 9 |
+
"config": {
|
| 10 |
+
"activation": "swish",
|
| 11 |
+
"activation_checkpointing": {
|
| 12 |
+
"interval": 1,
|
| 13 |
+
"module": "transformer",
|
| 14 |
+
"offload": false
|
| 15 |
+
},
|
| 16 |
+
"attention_dim": 1024,
|
| 17 |
+
"attention_heads": 16,
|
| 18 |
+
"batch_norm": false,
|
| 19 |
+
"bias_in_glu": true,
|
| 20 |
+
"causal": true,
|
| 21 |
+
"chunk_size": -1,
|
| 22 |
+
"cnn_layer_norm": true,
|
| 23 |
+
"conv_activation": "swish",
|
| 24 |
+
"conv_glu_type": "swish",
|
| 25 |
+
"depthwise_multiplier": 1,
|
| 26 |
+
"depthwise_seperable_out_channel": 1024,
|
| 27 |
+
"dropout_rate": 0.0,
|
| 28 |
+
"encoder_embedding_config": {
|
| 29 |
+
"input_size": 80
|
| 30 |
+
},
|
| 31 |
+
"ext_pw_kernel_size": 1,
|
| 32 |
+
"ext_pw_out_channel": 1024,
|
| 33 |
+
"input_layer": "nemo_conv",
|
| 34 |
+
"input_size": 80,
|
| 35 |
+
"kernel_size": 3,
|
| 36 |
+
"left_chunk": 18,
|
| 37 |
+
"linear_units": 1536,
|
| 38 |
+
"nemo_conv_settings": {
|
| 39 |
+
"conv_channels": 1024
|
| 40 |
+
},
|
| 41 |
+
"num_blocks": 24,
|
| 42 |
+
"relative_attention_bias_args": {
|
| 43 |
+
"t5_bias_max_distance": 500,
|
| 44 |
+
"type": "t5"
|
| 45 |
+
},
|
| 46 |
+
"time_reduction": 8
|
| 47 |
+
},
|
| 48 |
+
"name": "cascades"
|
| 49 |
+
},
|
| 50 |
+
"auto_map": {
|
| 51 |
+
"AutoConfig": "configuration_phi4mm.Phi4MMConfig",
|
| 52 |
+
"AutoModelForCausalLM": "modeling_phi4mm.Phi4MMForCausalLM",
|
| 53 |
+
"AutoTokenizer": "Xenova/gpt-4o"
|
| 54 |
+
},
|
| 55 |
+
"bos_token_id": 199999,
|
| 56 |
+
"embd_layer": {
|
| 57 |
+
"audio_embd_layer": {
|
| 58 |
+
"compression_rate": 8,
|
| 59 |
+
"downsample_rate": 1,
|
| 60 |
+
"embedding_cls": "audio",
|
| 61 |
+
"enable_gradient_checkpointing": true,
|
| 62 |
+
"projection_cls": "mlp",
|
| 63 |
+
"use_conv_downsample": false,
|
| 64 |
+
"use_qformer": false
|
| 65 |
+
},
|
| 66 |
+
"embedding_cls": "image_audio",
|
| 67 |
+
"image_embd_layer": {
|
| 68 |
+
"crop_size": 448,
|
| 69 |
+
"embedding_cls": "tune_image",
|
| 70 |
+
"enable_gradient_checkpointing": true,
|
| 71 |
+
"hd_transform_order": "sub_glb",
|
| 72 |
+
"image_token_compression_cls": "avg_pool_2d",
|
| 73 |
+
"projection_cls": "mlp",
|
| 74 |
+
"use_hd_transform": true,
|
| 75 |
+
"with_learnable_separator": true
|
| 76 |
+
}
|
| 77 |
+
},
|
| 78 |
+
"embd_pdrop": 0.0,
|
| 79 |
+
"eos_token_id": 199999,
|
| 80 |
+
"full_attn_mod": 1,
|
| 81 |
+
"hidden_act": "silu",
|
| 82 |
+
"hidden_size": 3072,
|
| 83 |
+
"initializer_range": 0.02,
|
| 84 |
+
"intermediate_size": 8192,
|
| 85 |
+
"interpolate_factor": 1,
|
| 86 |
+
"lm_head_bias": false,
|
| 87 |
+
"vision_lora": {
|
| 88 |
+
"dp": 0.0,
|
| 89 |
+
"layer": "layers.*((self_attn\\.(qkv_proj|o_proj))|(mlp\\.(gate_up|down)_proj))",
|
| 90 |
+
"lora_alpha": 512,
|
| 91 |
+
"r": 256
|
| 92 |
+
},
|
| 93 |
+
"speech_lora": {
|
| 94 |
+
"dp": 0.01,
|
| 95 |
+
"layer": "((layers.*self_attn\\.(qkv|o)_proj)|(layers.*mlp\\.(gate_up|down)_proj))",
|
| 96 |
+
"lora_alpha": 640,
|
| 97 |
+
"r": 320
|
| 98 |
+
},
|
| 99 |
+
"max_position_embeddings": 131072,
|
| 100 |
+
"mlp_bias": false,
|
| 101 |
+
"model_type": "phi4mm",
|
| 102 |
+
"num_attention_heads": 24,
|
| 103 |
+
"num_hidden_layers": 32,
|
| 104 |
+
"num_key_value_heads": 8,
|
| 105 |
+
"original_max_position_embeddings": 4096,
|
| 106 |
+
"pad_token_id": 199999,
|
| 107 |
+
"partial_rotary_factor": 0.75,
|
| 108 |
+
"resid_pdrop": 0.0,
|
| 109 |
+
"rms_norm_eps": 1e-05,
|
| 110 |
+
"rope_scaling": {
|
| 111 |
+
"long_factor": [
|
| 112 |
+
1,
|
| 113 |
+
1.118320672,
|
| 114 |
+
1.250641126,
|
| 115 |
+
1.398617824,
|
| 116 |
+
1.564103225,
|
| 117 |
+
1.74916897,
|
| 118 |
+
1.956131817,
|
| 119 |
+
2.187582649,
|
| 120 |
+
2.446418898,
|
| 121 |
+
2.735880826,
|
| 122 |
+
3.059592084,
|
| 123 |
+
3.421605075,
|
| 124 |
+
3.826451687,
|
| 125 |
+
4.279200023,
|
| 126 |
+
4.785517845,
|
| 127 |
+
5.351743533,
|
| 128 |
+
5.984965424,
|
| 129 |
+
6.693110555,
|
| 130 |
+
7.485043894,
|
| 131 |
+
8.370679318,
|
| 132 |
+
9.36110372,
|
| 133 |
+
10.4687158,
|
| 134 |
+
11.70738129,
|
| 135 |
+
13.09260651,
|
| 136 |
+
14.64173252,
|
| 137 |
+
16.37415215,
|
| 138 |
+
18.31155283,
|
| 139 |
+
20.47818807,
|
| 140 |
+
22.90118105,
|
| 141 |
+
25.61086418,
|
| 142 |
+
28.64115884,
|
| 143 |
+
32.03,
|
| 144 |
+
32.1,
|
| 145 |
+
32.13,
|
| 146 |
+
32.23,
|
| 147 |
+
32.6,
|
| 148 |
+
32.61,
|
| 149 |
+
32.64,
|
| 150 |
+
32.66,
|
| 151 |
+
32.7,
|
| 152 |
+
32.71,
|
| 153 |
+
32.93,
|
| 154 |
+
32.97,
|
| 155 |
+
33.28,
|
| 156 |
+
33.49,
|
| 157 |
+
33.5,
|
| 158 |
+
44.16,
|
| 159 |
+
47.77
|
| 160 |
+
],
|
| 161 |
+
"short_factor": [
|
| 162 |
+
1.0,
|
| 163 |
+
1.0,
|
| 164 |
+
1.0,
|
| 165 |
+
1.0,
|
| 166 |
+
1.0,
|
| 167 |
+
1.0,
|
| 168 |
+
1.0,
|
| 169 |
+
1.0,
|
| 170 |
+
1.0,
|
| 171 |
+
1.0,
|
| 172 |
+
1.0,
|
| 173 |
+
1.0,
|
| 174 |
+
1.0,
|
| 175 |
+
1.0,
|
| 176 |
+
1.0,
|
| 177 |
+
1.0,
|
| 178 |
+
1.0,
|
| 179 |
+
1.0,
|
| 180 |
+
1.0,
|
| 181 |
+
1.0,
|
| 182 |
+
1.0,
|
| 183 |
+
1.0,
|
| 184 |
+
1.0,
|
| 185 |
+
1.0,
|
| 186 |
+
1.0,
|
| 187 |
+
1.0,
|
| 188 |
+
1.0,
|
| 189 |
+
1.0,
|
| 190 |
+
1.0,
|
| 191 |
+
1.0,
|
| 192 |
+
1.0,
|
| 193 |
+
1.0,
|
| 194 |
+
1.0,
|
| 195 |
+
1.0,
|
| 196 |
+
1.0,
|
| 197 |
+
1.0,
|
| 198 |
+
1.0,
|
| 199 |
+
1.0,
|
| 200 |
+
1.0,
|
| 201 |
+
1.0,
|
| 202 |
+
1.0,
|
| 203 |
+
1.0,
|
| 204 |
+
1.0,
|
| 205 |
+
1.0,
|
| 206 |
+
1.0,
|
| 207 |
+
1.0,
|
| 208 |
+
1.0,
|
| 209 |
+
1.0
|
| 210 |
+
],
|
| 211 |
+
"type": "longrope"
|
| 212 |
+
},
|
| 213 |
+
"rope_theta": 10000.0,
|
| 214 |
+
"sliding_window": 262144,
|
| 215 |
+
"tie_word_embeddings": true,
|
| 216 |
+
"torch_dtype": "bfloat16",
|
| 217 |
+
"transformers_version": "4.46.1",
|
| 218 |
+
"use_cache": true,
|
| 219 |
+
"vocab_size": 200064,
|
| 220 |
+
"_attn_implementation": "flash_attention_2"
|
| 221 |
+
}
|
configuration_phi4mm.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2024 Microsoft and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
""" Phi-4-MM model configuration"""
|
| 17 |
+
|
| 18 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 19 |
+
from transformers.utils import logging
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
logger = logging.get_logger(__name__)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class Phi4MMConfig(PretrainedConfig):
|
| 26 |
+
r"""
|
| 27 |
+
This is the configuration class to store the configuration of a [`Phi4MMModel`]. It is used to instantiate a Phi-4-MM
|
| 28 |
+
model according to the specified arguments, defining the model architecture.
|
| 29 |
+
|
| 30 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 31 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
vocab_size (`int`, *optional*, defaults to 200064):
|
| 35 |
+
Vocabulary size of the Phi-4-MM model. Defines the number of different tokens that can be represented by the
|
| 36 |
+
`inputs_ids` passed when calling [`Phi4MMModel`].
|
| 37 |
+
hidden_size (`int`, *optional*, defaults to 3072):
|
| 38 |
+
Dimension of the hidden representations.
|
| 39 |
+
intermediate_size (`int`, *optional*, defaults to 8192):
|
| 40 |
+
Dimension of the MLP representations.
|
| 41 |
+
num_hidden_layers (`int`, *optional*, defaults to 32):
|
| 42 |
+
Number of hidden layers in the Transformer decoder.
|
| 43 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 44 |
+
Number of attention heads for each attention layer in the Transformer decoder.
|
| 45 |
+
num_key_value_heads (`int`, *optional*):
|
| 46 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 47 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 48 |
+
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 49 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 50 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 51 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
| 52 |
+
`num_attention_heads`.
|
| 53 |
+
resid_pdrop (`float`, *optional*, defaults to 0.0):
|
| 54 |
+
Dropout probability for mlp outputs.
|
| 55 |
+
embd_pdrop (`int`, *optional*, defaults to 0.0):
|
| 56 |
+
The dropout ratio for the embeddings.
|
| 57 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 58 |
+
The dropout ratio after computing the attention scores.
|
| 59 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 60 |
+
The non-linear activation function (function or string) in the decoder.
|
| 61 |
+
max_position_embeddings (`int`, *optional*, defaults to 4096):
|
| 62 |
+
The maximum sequence length that this model might ever be used with.
|
| 63 |
+
original_max_position_embeddings (`int`, *optional*, defaults to 4096):
|
| 64 |
+
The maximum sequence length that this model was trained with. This is used to determine the size of the
|
| 65 |
+
original RoPE embeddings when using long scaling.
|
| 66 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 67 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 68 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-05):
|
| 69 |
+
The epsilon value used for the RMSNorm.
|
| 70 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 71 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 72 |
+
relevant if `config.is_decoder=True`. Whether to tie weight embeddings or not.
|
| 73 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 74 |
+
Whether to tie weight embeddings
|
| 75 |
+
rope_theta (`float`, *optional*, defaults to 10000.0):
|
| 76 |
+
The base period of the RoPE embeddings.
|
| 77 |
+
rope_scaling (`dict`, *optional*):
|
| 78 |
+
The scaling strategy for the RoPE embeddings. If `None`, no scaling is applied. If a dictionary, it must
|
| 79 |
+
contain the following keys: `type`, `short_factor` and `long_factor`. The `type` must be `longrope` and
|
| 80 |
+
the `short_factor` and `long_factor` must be lists of numbers with the same length as the hidden size
|
| 81 |
+
divided by the number of attention heads divided by 2.
|
| 82 |
+
partial_rotary_factor (`float`, *optional*, defaults to 0.5):
|
| 83 |
+
Percentage of the query and keys which will have rotary embedding.
|
| 84 |
+
bos_token_id (`int`, *optional*, defaults to 199999):
|
| 85 |
+
The id of the "beginning-of-sequence" token.
|
| 86 |
+
eos_token_id (`int`, *optional*, defaults to 199999):
|
| 87 |
+
The id of the "end-of-sequence" token.
|
| 88 |
+
pad_token_id (`int`, *optional*, defaults to 199999):
|
| 89 |
+
The id of the padding token.
|
| 90 |
+
sliding_window (`int`, *optional*):
|
| 91 |
+
Sliding window attention window size. If `None`, no sliding window is applied.
|
| 92 |
+
|
| 93 |
+
Example:
|
| 94 |
+
|
| 95 |
+
```python
|
| 96 |
+
>>> from transformers import Phi4MMModel, Phi4MMConfig
|
| 97 |
+
|
| 98 |
+
>>> # Initializing a Phi-4-MM style configuration
|
| 99 |
+
>>> configuration = Phi4MMConfig.from_pretrained("TBA")
|
| 100 |
+
|
| 101 |
+
>>> # Initializing a model from the configuration
|
| 102 |
+
>>> model = Phi4MMModel(configuration)
|
| 103 |
+
|
| 104 |
+
>>> # Accessing the model configuration
|
| 105 |
+
>>> configuration = model.config
|
| 106 |
+
```"""
|
| 107 |
+
|
| 108 |
+
model_type = "phi4mm"
|
| 109 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 110 |
+
|
| 111 |
+
def __init__(
|
| 112 |
+
self,
|
| 113 |
+
vocab_size=200064,
|
| 114 |
+
hidden_size=3072,
|
| 115 |
+
intermediate_size=8192,
|
| 116 |
+
num_hidden_layers=32,
|
| 117 |
+
num_attention_heads=32,
|
| 118 |
+
num_key_value_heads=None,
|
| 119 |
+
resid_pdrop=0.0,
|
| 120 |
+
embd_pdrop=0.0,
|
| 121 |
+
attention_dropout=0.0,
|
| 122 |
+
hidden_act="silu",
|
| 123 |
+
max_position_embeddings=4096,
|
| 124 |
+
original_max_position_embeddings=4096,
|
| 125 |
+
initializer_range=0.02,
|
| 126 |
+
rms_norm_eps=1e-5,
|
| 127 |
+
use_cache=True,
|
| 128 |
+
tie_word_embeddings=False,
|
| 129 |
+
rope_theta=10000.0,
|
| 130 |
+
rope_scaling=None,
|
| 131 |
+
partial_rotary_factor=1,
|
| 132 |
+
bos_token_id=199999,
|
| 133 |
+
eos_token_id=199999,
|
| 134 |
+
pad_token_id=199999,
|
| 135 |
+
sliding_window=None,
|
| 136 |
+
embd_layer: str = "default",
|
| 137 |
+
img_processor=None,
|
| 138 |
+
audio_processor=None,
|
| 139 |
+
vision_lora=None,
|
| 140 |
+
speech_lora=None,
|
| 141 |
+
**kwargs,
|
| 142 |
+
):
|
| 143 |
+
self.embd_layer = embd_layer
|
| 144 |
+
self.img_processor = img_processor
|
| 145 |
+
self.audio_processor = audio_processor
|
| 146 |
+
self.vision_lora = vision_lora
|
| 147 |
+
self.speech_lora = speech_lora
|
| 148 |
+
|
| 149 |
+
self.vocab_size = vocab_size
|
| 150 |
+
self.hidden_size = hidden_size
|
| 151 |
+
self.intermediate_size = intermediate_size
|
| 152 |
+
self.num_hidden_layers = num_hidden_layers
|
| 153 |
+
self.num_attention_heads = num_attention_heads
|
| 154 |
+
|
| 155 |
+
if num_key_value_heads is None:
|
| 156 |
+
num_key_value_heads = num_attention_heads
|
| 157 |
+
|
| 158 |
+
self.num_key_value_heads = num_key_value_heads
|
| 159 |
+
self.resid_pdrop = resid_pdrop
|
| 160 |
+
self.embd_pdrop = embd_pdrop
|
| 161 |
+
self.attention_dropout = attention_dropout
|
| 162 |
+
self.hidden_act = hidden_act
|
| 163 |
+
self.max_position_embeddings = max_position_embeddings
|
| 164 |
+
self.original_max_position_embeddings = original_max_position_embeddings
|
| 165 |
+
self.initializer_range = initializer_range
|
| 166 |
+
self.rms_norm_eps = rms_norm_eps
|
| 167 |
+
self.use_cache = use_cache
|
| 168 |
+
self.rope_theta = rope_theta
|
| 169 |
+
self.rope_scaling = rope_scaling
|
| 170 |
+
self.partial_rotary_factor = partial_rotary_factor
|
| 171 |
+
self._rope_scaling_adjustment()
|
| 172 |
+
self._rope_scaling_validation()
|
| 173 |
+
self.sliding_window = sliding_window
|
| 174 |
+
|
| 175 |
+
super().__init__(
|
| 176 |
+
bos_token_id=bos_token_id,
|
| 177 |
+
eos_token_id=eos_token_id,
|
| 178 |
+
pad_token_id=pad_token_id,
|
| 179 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 180 |
+
**kwargs,
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
def _rope_scaling_adjustment(self):
|
| 184 |
+
"""
|
| 185 |
+
Adjust the `type` of the `rope_scaling` configuration for backward compatibility.
|
| 186 |
+
"""
|
| 187 |
+
if self.rope_scaling is None:
|
| 188 |
+
return
|
| 189 |
+
|
| 190 |
+
rope_scaling_type = self.rope_scaling.get("type", None)
|
| 191 |
+
|
| 192 |
+
# For backward compatibility if previous version used "su" or "yarn"
|
| 193 |
+
if rope_scaling_type is not None and rope_scaling_type in ["su", "yarn"]:
|
| 194 |
+
self.rope_scaling["type"] = "longrope"
|
| 195 |
+
|
| 196 |
+
def _rope_scaling_validation(self):
|
| 197 |
+
"""
|
| 198 |
+
Validate the `rope_scaling` configuration.
|
| 199 |
+
"""
|
| 200 |
+
if self.rope_scaling is None:
|
| 201 |
+
return
|
| 202 |
+
|
| 203 |
+
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 3:
|
| 204 |
+
raise ValueError(
|
| 205 |
+
"`rope_scaling` must be a dictionary with three fields, `type`, `short_factor` and `long_factor`, "
|
| 206 |
+
f"got {self.rope_scaling}"
|
| 207 |
+
)
|
| 208 |
+
rope_scaling_type = self.rope_scaling.get("type", None)
|
| 209 |
+
rope_scaling_short_factor = self.rope_scaling.get("short_factor", None)
|
| 210 |
+
rope_scaling_long_factor = self.rope_scaling.get("long_factor", None)
|
| 211 |
+
if rope_scaling_type is None or rope_scaling_type not in ["longrope"]:
|
| 212 |
+
raise ValueError(f"`rope_scaling`'s type field must be one of ['longrope'], got {rope_scaling_type}")
|
| 213 |
+
if not (
|
| 214 |
+
isinstance(rope_scaling_short_factor, list)
|
| 215 |
+
and all(isinstance(x, (int, float)) for x in rope_scaling_short_factor)
|
| 216 |
+
):
|
| 217 |
+
raise ValueError(
|
| 218 |
+
f"`rope_scaling`'s short_factor field must be a list of numbers, got {rope_scaling_short_factor}"
|
| 219 |
+
)
|
| 220 |
+
rotary_ndims = int(self.hidden_size // self.num_attention_heads * self.partial_rotary_factor)
|
| 221 |
+
if not len(rope_scaling_short_factor) == rotary_ndims // 2:
|
| 222 |
+
raise ValueError(
|
| 223 |
+
f"`rope_scaling`'s short_factor field must have length {rotary_ndims // 2}, got {len(rope_scaling_short_factor)}"
|
| 224 |
+
)
|
| 225 |
+
if not (
|
| 226 |
+
isinstance(rope_scaling_long_factor, list)
|
| 227 |
+
and all(isinstance(x, (int, float)) for x in rope_scaling_long_factor)
|
| 228 |
+
):
|
| 229 |
+
raise ValueError(
|
| 230 |
+
f"`rope_scaling`'s long_factor field must be a list of numbers, got {rope_scaling_long_factor}"
|
| 231 |
+
)
|
| 232 |
+
if not len(rope_scaling_long_factor) == rotary_ndims // 2:
|
| 233 |
+
raise ValueError(
|
| 234 |
+
f"`rope_scaling`'s long_factor field must have length {rotary_ndims // 2}, got {len(rope_scaling_long_factor)}"
|
| 235 |
+
)
|
figures/audio_understand.png
ADDED
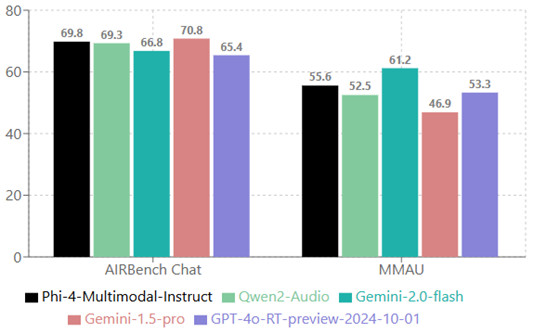
|
figures/multi_image.png
ADDED

|
figures/speech_qa.png
ADDED
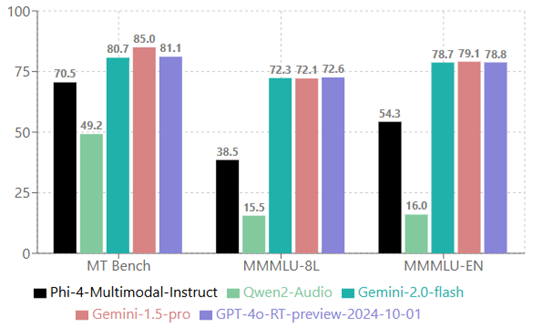
|
figures/speech_recog_by_lang.png
ADDED
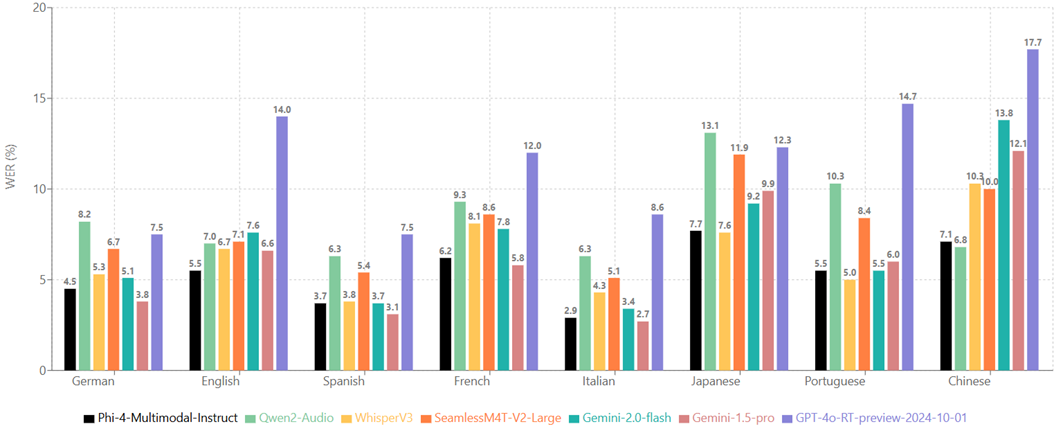
|
figures/speech_recognition.png
ADDED
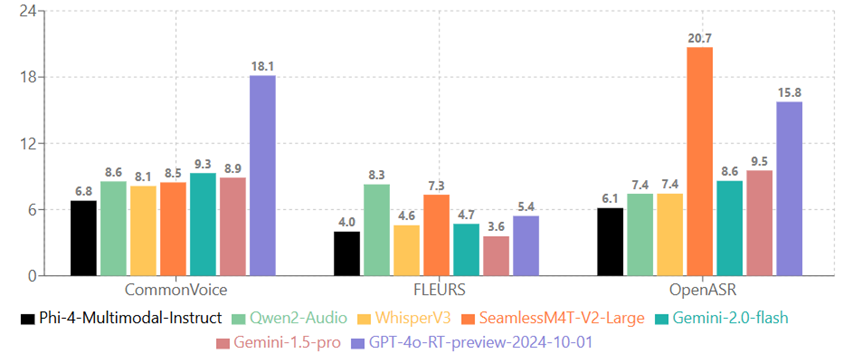
|
figures/speech_summarization.png
ADDED
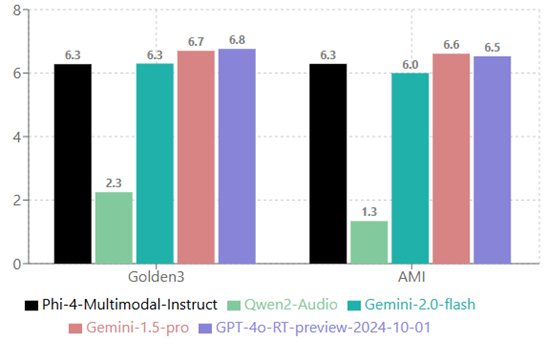
|
figures/speech_translate.png
ADDED
|
|
figures/speech_translate_2.png
ADDED
|
|
figures/vision_radar.png
ADDED

|
generation_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 199999,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
200020,
|
| 6 |
+
199999
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 199999,
|
| 9 |
+
"transformers_version": "4.46.1",
|
| 10 |
+
"use_cache": true
|
| 11 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c46bb03332d82f6a3eaf85bd20af388dd4d4d68b198c2203c965c7381a466094
|
| 3 |
+
size 4997504848
|
model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b3e812c0c8acef4e7f5e34d6c9f77a7640ee4a2b93ea351921365ac62f19918d
|
| 3 |
+
size 4952333128
|
model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7be96b7339303752634b202d3f377bcf312a03046586eca6cea23347ace1e65a
|
| 3 |
+
size 1199389232
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
modeling_phi4mm.py
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_map": {
|
| 3 |
+
"AutoProcessor": "processing_phi4mm.Phi4MMProcessor",
|
| 4 |
+
"AutoImageProcessor": "processing_phi4mm.Phi4MMImageProcessor",
|
| 5 |
+
"AutoFeatureExtractor": "processing_phi4mm.Phi4MMAudioFeatureExtractor"
|
| 6 |
+
},
|
| 7 |
+
"image_processor_type": "Phi4MMImageProcessor",
|
| 8 |
+
"processor_class": "Phi4MMProcessor",
|
| 9 |
+
"feature_extractor_type": "Phi4MMAudioFeatureExtractor",
|
| 10 |
+
"audio_compression_rate": 8,
|
| 11 |
+
"audio_downsample_rate": 1,
|
| 12 |
+
"audio_feat_stride": 1,
|
| 13 |
+
"dynamic_hd": 36
|
| 14 |
+
}
|
processing_phi4mm.py
ADDED
|
@@ -0,0 +1,733 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Microsoft and the HuggingFace Inc. team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
"""
|
| 16 |
+
Processor class for Phi4MM
|
| 17 |
+
"""
|
| 18 |
+
import re
|
| 19 |
+
from typing import List, Optional, Tuple, Union
|
| 20 |
+
import math
|
| 21 |
+
from enum import Enum
|
| 22 |
+
|
| 23 |
+
import numpy as np
|
| 24 |
+
import scipy
|
| 25 |
+
import torch
|
| 26 |
+
import torchvision
|
| 27 |
+
|
| 28 |
+
from transformers import AutoFeatureExtractor, AutoImageProcessor
|
| 29 |
+
from transformers.feature_extraction_sequence_utils import SequenceFeatureExtractor
|
| 30 |
+
from transformers.image_processing_utils import BaseImageProcessor, BatchFeature
|
| 31 |
+
from transformers.image_utils import (
|
| 32 |
+
ImageInput,
|
| 33 |
+
make_list_of_images,
|
| 34 |
+
valid_images,
|
| 35 |
+
)
|
| 36 |
+
from transformers.processing_utils import ProcessorMixin
|
| 37 |
+
from transformers.tokenization_utils_base import PaddingStrategy, TextInput, TruncationStrategy
|
| 38 |
+
from transformers.utils import TensorType, logging
|
| 39 |
+
from torch.nn.utils.rnn import pad_sequence
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
logger = logging.get_logger(__name__)
|
| 43 |
+
|
| 44 |
+
# Special tokens
|
| 45 |
+
_COMPATIBLE_IMAGE_SPECIAL_TOKEN_PATTERN = r'<\|image_\d+\|>' # For backward compatibility
|
| 46 |
+
_COMPATIBLE_AUDIO_SPECIAL_TOKEN_PATTERN = r'<\|audio_\d+\|>' # For backward compatibility
|
| 47 |
+
_IMAGE_SPECIAL_TOKEN = '<|endoftext10|>'
|
| 48 |
+
_AUDIO_SPECIAL_TOKEN = '<|endoftext11|>'
|
| 49 |
+
_IMAGE_SPECIAL_TOKEN_ID = 200010 # '<|endoftext10|>', or we can better name it (in `tokenizer_config.json`)
|
| 50 |
+
_AUDIO_SPECIAL_TOKEN_ID = 200011 # '<|endoftext11|>'
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class InputMode(Enum):
|
| 54 |
+
LANGUAGE = 0
|
| 55 |
+
VISION = 1
|
| 56 |
+
SPEECH = 2
|
| 57 |
+
VISION_SPEECH = 3
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class Phi4MMImageProcessor(BaseImageProcessor):
|
| 61 |
+
r"""
|
| 62 |
+
Constructs a Phi4MM image processor.
|
| 63 |
+
"""
|
| 64 |
+
model_input_names = ["input_image_embeds", "image_sizes", "image_attention_mask"]
|
| 65 |
+
|
| 66 |
+
def __init__(
|
| 67 |
+
self,
|
| 68 |
+
dynamic_hd,
|
| 69 |
+
**kwargs,
|
| 70 |
+
) -> None:
|
| 71 |
+
super().__init__(**kwargs)
|
| 72 |
+
self.dynamic_hd = dynamic_hd
|
| 73 |
+
|
| 74 |
+
def find_closest_aspect_ratio(self, aspect_ratio, target_ratios, width, height, image_size):
|
| 75 |
+
best_ratio_diff = float('inf')
|
| 76 |
+
best_ratio = (1, 1)
|
| 77 |
+
area = width * height
|
| 78 |
+
for ratio in target_ratios:
|
| 79 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 80 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 81 |
+
if ratio_diff < best_ratio_diff:
|
| 82 |
+
best_ratio_diff = ratio_diff
|
| 83 |
+
best_ratio = ratio
|
| 84 |
+
elif ratio_diff == best_ratio_diff:
|
| 85 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 86 |
+
best_ratio = ratio
|
| 87 |
+
return best_ratio
|
| 88 |
+
|
| 89 |
+
def dynamic_preprocess(self, image, min_num=1, max_num=12, image_size=384, mask_size=27, use_thumbnail=True):
|
| 90 |
+
orig_width, orig_height = image.size
|
| 91 |
+
|
| 92 |
+
w_crop_num = math.ceil(orig_width/float(image_size))
|
| 93 |
+
h_crop_num = math.ceil(orig_height/float(image_size))
|
| 94 |
+
if w_crop_num * h_crop_num > max_num:
|
| 95 |
+
|
| 96 |
+
aspect_ratio = orig_width / orig_height
|
| 97 |
+
|
| 98 |
+
# calculate the existing image aspect ratio
|
| 99 |
+
target_ratios = set(
|
| 100 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 101 |
+
i * j <= max_num and i * j >= min_num)
|
| 102 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 103 |
+
|
| 104 |
+
# find the closest aspect ratio to the target
|
| 105 |
+
target_aspect_ratio = self.find_closest_aspect_ratio(
|
| 106 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 107 |
+
|
| 108 |
+
# calculate the target width and height
|
| 109 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 110 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 111 |
+
else:
|
| 112 |
+
target_width = image_size * w_crop_num
|
| 113 |
+
target_height = image_size * h_crop_num
|
| 114 |
+
target_aspect_ratio = (w_crop_num, h_crop_num)
|
| 115 |
+
|
| 116 |
+
# Calculate the ratio
|
| 117 |
+
ratio_width = target_width / orig_width
|
| 118 |
+
ratio_height = target_height / orig_height
|
| 119 |
+
if ratio_width < ratio_height:
|
| 120 |
+
new_size = (target_width, int(orig_height * ratio_width))
|
| 121 |
+
padding_width = 0
|
| 122 |
+
padding_height = target_height - int(orig_height * ratio_width)
|
| 123 |
+
else:
|
| 124 |
+
new_size = (int(orig_width * ratio_height), target_height)
|
| 125 |
+
padding_width = target_width - int(orig_width * ratio_height)
|
| 126 |
+
padding_height = 0
|
| 127 |
+
|
| 128 |
+
attention_mask = torch.ones((int(mask_size*target_aspect_ratio[1]), int(mask_size*target_aspect_ratio[0])))
|
| 129 |
+
if padding_width >= 14:
|
| 130 |
+
attention_mask[:, -math.floor(padding_width/14):] = 0
|
| 131 |
+
if padding_height >= 14:
|
| 132 |
+
attention_mask[-math.floor(padding_height/14):,:] = 0
|
| 133 |
+
assert attention_mask.sum() > 0
|
| 134 |
+
|
| 135 |
+
if min(new_size[1], target_height) < 10 or min(new_size[0], target_width) < 10:
|
| 136 |
+
raise ValueError(f'the aspect ratio is very extreme {new_size}')
|
| 137 |
+
|
| 138 |
+
image = torchvision.transforms.functional.resize(image, [new_size[1], new_size[0]],)
|
| 139 |
+
|
| 140 |
+
resized_img = torchvision.transforms.functional.pad(image, [0, 0, padding_width, padding_height], fill=[255,255,255])
|
| 141 |
+
|
| 142 |
+
return resized_img, attention_mask
|
| 143 |
+
|
| 144 |
+
def pad_to_max_num_crops(self, images, max_crops=5):
|
| 145 |
+
"""
|
| 146 |
+
images: B x 3 x H x W, B<=max_crops
|
| 147 |
+
"""
|
| 148 |
+
B, _, H, W = images.shape
|
| 149 |
+
if B < max_crops:
|
| 150 |
+
pad = torch.zeros(max_crops - B, 3, H, W, dtype=images.dtype, device=images.device)
|
| 151 |
+
images = torch.cat([images, pad], dim=0)
|
| 152 |
+
return images
|
| 153 |
+
|
| 154 |
+
def pad_mask_to_max_num_crops(self, masks, max_crops=5):
|
| 155 |
+
B, H, W = masks.shape
|
| 156 |
+
if B < max_crops:
|
| 157 |
+
pad = torch.ones(max_crops - B, H, W, dtype=masks.dtype, device=masks.device)
|
| 158 |
+
masks = torch.cat([masks, pad], dim=0)
|
| 159 |
+
return masks
|
| 160 |
+
|
| 161 |
+
def preprocess(
|
| 162 |
+
self,
|
| 163 |
+
images: ImageInput,
|
| 164 |
+
return_tensors: Optional[Union[str, TensorType]] = None,
|
| 165 |
+
):
|
| 166 |
+
"""
|
| 167 |
+
Args:
|
| 168 |
+
images (`ImageInput`):
|
| 169 |
+
Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
|
| 170 |
+
passing in images with pixel values between 0 and 1, set `do_rescale=False`.
|
| 171 |
+
return_tensors (`str` or `TensorType`, *optional*):
|
| 172 |
+
The type of tensors to return. Can be one of:
|
| 173 |
+
- Unset: Return a list of `np.ndarray`.
|
| 174 |
+
- `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
|
| 175 |
+
- `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
|
| 176 |
+
- `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
|
| 177 |
+
- `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
|
| 178 |
+
"""
|
| 179 |
+
images = make_list_of_images(images)
|
| 180 |
+
|
| 181 |
+
if not valid_images(images):
|
| 182 |
+
raise ValueError(
|
| 183 |
+
"Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
|
| 184 |
+
"torch.Tensor, tf.Tensor or jax.ndarray."
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
# Basic settings.
|
| 188 |
+
img_processor = torchvision.transforms.Compose([
|
| 189 |
+
torchvision.transforms.ToTensor(),
|
| 190 |
+
torchvision.transforms.Normalize(
|
| 191 |
+
(0.5, 0.5, 0.5),
|
| 192 |
+
(0.5, 0.5, 0.5)
|
| 193 |
+
),
|
| 194 |
+
])
|
| 195 |
+
dyhd_base_resolution = 448
|
| 196 |
+
|
| 197 |
+
# Dynamic HD
|
| 198 |
+
base_resolution = dyhd_base_resolution
|
| 199 |
+
images = [image.convert('RGB') for image in images]
|
| 200 |
+
# cover 384 and 448 resolution
|
| 201 |
+
mask_resolution = base_resolution // 14
|
| 202 |
+
elems, image_attention_masks = [], []
|
| 203 |
+
for im in images:
|
| 204 |
+
elem, attention_mask = self.dynamic_preprocess(im, max_num=self.dynamic_hd, image_size=base_resolution, mask_size=mask_resolution)
|
| 205 |
+
elems.append(elem)
|
| 206 |
+
image_attention_masks.append(attention_mask)
|
| 207 |
+
hd_images = [img_processor(im) for im in elems]
|
| 208 |
+
global_image = [torch.nn.functional.interpolate(im.unsqueeze(0).float(), size=(base_resolution, base_resolution), mode='bicubic',).to(im.dtype) for im in hd_images]
|
| 209 |
+
shapes = [[im.size(1), im.size(2)] for im in hd_images]
|
| 210 |
+
mask_shapes = [[mask.size(0), mask.size(1)] for mask in image_attention_masks]
|
| 211 |
+
global_attention_mask = [torch.ones((1, mask_resolution, mask_resolution)) for _ in hd_images]
|
| 212 |
+
hd_images_reshape = [im.reshape(1, 3,
|
| 213 |
+
h//base_resolution,
|
| 214 |
+
base_resolution,
|
| 215 |
+
w//base_resolution,
|
| 216 |
+
base_resolution
|
| 217 |
+
).permute(0,2,4,1,3,5).reshape(-1, 3, base_resolution, base_resolution).contiguous() for im, (h, w) in zip(hd_images, shapes)]
|
| 218 |
+
attention_masks_reshape = [mask.reshape(1,
|
| 219 |
+
h//mask_resolution,
|
| 220 |
+
mask_resolution,
|
| 221 |
+
w//mask_resolution,
|
| 222 |
+
mask_resolution
|
| 223 |
+
).permute(0,1,3,2,4).reshape(-1, mask_resolution, mask_resolution).contiguous() for mask, (h, w) in zip(image_attention_masks, mask_shapes)]
|
| 224 |
+
downsample_attention_masks = [mask[:,0::2,0::2].reshape(1,
|
| 225 |
+
h//mask_resolution,
|
| 226 |
+
w//mask_resolution,
|
| 227 |
+
mask_resolution//2+mask_resolution%2,
|
| 228 |
+
mask_resolution//2+mask_resolution%2
|
| 229 |
+
).permute(0,1,3,2,4) for mask, (h,w) in zip(attention_masks_reshape, mask_shapes)]
|
| 230 |
+
downsample_attention_masks = [mask.reshape(mask.size(1)*mask.size(2), mask.size(3)*mask.size(4))for mask in downsample_attention_masks]
|
| 231 |
+
num_img_tokens = [256 + 1 + int(mask.sum().item()) + int(mask[:,0].sum().item()) + 16 for mask in downsample_attention_masks]
|
| 232 |
+
|
| 233 |
+
hd_images_reshape = [torch.cat([_global_image] + [_im], dim=0) for _global_image, _im in zip(global_image, hd_images_reshape)]
|
| 234 |
+
hd_masks_reshape = [torch.cat([_global_mask] + [_mask], dim=0) for _global_mask, _mask in zip(global_attention_mask, attention_masks_reshape)]
|
| 235 |
+
max_crops = max([img.size(0) for img in hd_images_reshape])
|
| 236 |
+
image_transformed = [self.pad_to_max_num_crops(im, max_crops) for im in hd_images_reshape]
|
| 237 |
+
image_transformed = torch.stack(image_transformed, dim=0)
|
| 238 |
+
mask_transformed = [self.pad_mask_to_max_num_crops(mask, max_crops) for mask in hd_masks_reshape]
|
| 239 |
+
mask_transformed = torch.stack(mask_transformed, dim=0)
|
| 240 |
+
|
| 241 |
+
returned_input_image_embeds = image_transformed
|
| 242 |
+
returned_image_sizes = torch.tensor(shapes, dtype=torch.long)
|
| 243 |
+
returned_image_attention_mask = mask_transformed
|
| 244 |
+
returned_num_img_tokens = num_img_tokens
|
| 245 |
+
|
| 246 |
+
data = {
|
| 247 |
+
"input_image_embeds": returned_input_image_embeds,
|
| 248 |
+
"image_sizes": returned_image_sizes,
|
| 249 |
+
"image_attention_mask": returned_image_attention_mask,
|
| 250 |
+
"num_img_tokens": returned_num_img_tokens,
|
| 251 |
+
}
|
| 252 |
+
|
| 253 |
+
return BatchFeature(data=data, tensor_type=return_tensors)
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
AudioInput = Tuple[Union[np.ndarray, torch.Tensor], int]
|
| 257 |
+
AudioInputs = List[AudioInput]
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def speechlib_mel(sample_rate, n_fft, n_mels, fmin=None, fmax=None):
|
| 261 |
+
"""Create a Mel filter-bank the same as SpeechLib FbankFC.
|
| 262 |
+
|
| 263 |
+
Args:
|
| 264 |
+
sample_rate (int): Sample rate in Hz. number > 0 [scalar]
|
| 265 |
+
n_fft (int): FFT size. int > 0 [scalar]
|
| 266 |
+
n_mel (int): Mel filter size. int > 0 [scalar]
|
| 267 |
+
fmin (float): lowest frequency (in Hz). If None use 0.0.
|
| 268 |
+
float >= 0 [scalar]
|
| 269 |
+
fmax: highest frequency (in Hz). If None use sample_rate / 2.
|
| 270 |
+
float >= 0 [scalar]
|
| 271 |
+
|
| 272 |
+
Returns
|
| 273 |
+
out (numpy.ndarray): Mel transform matrix
|
| 274 |
+
[shape=(n_mels, 1 + n_fft/2)]
|
| 275 |
+
"""
|
| 276 |
+
|
| 277 |
+
bank_width = int(n_fft // 2 + 1)
|
| 278 |
+
if fmax is None:
|
| 279 |
+
fmax = sample_rate / 2
|
| 280 |
+
if fmin is None:
|
| 281 |
+
fmin = 0
|
| 282 |
+
assert fmin >= 0, "fmin cannot be negtive"
|
| 283 |
+
assert fmin < fmax <= sample_rate / 2, "fmax must be between (fmin, samplerate / 2]"
|
| 284 |
+
|
| 285 |
+
def mel(f):
|
| 286 |
+
return 1127.0 * np.log(1.0 + f / 700.0)
|
| 287 |
+
|
| 288 |
+
def bin2mel(fft_bin):
|
| 289 |
+
return 1127.0 * np.log(1.0 + fft_bin * sample_rate / (n_fft * 700.0))
|
| 290 |
+
|
| 291 |
+
def f2bin(f):
|
| 292 |
+
return int((f * n_fft / sample_rate) + 0.5)
|
| 293 |
+
|
| 294 |
+
# Spec 1: FFT bin range [f2bin(fmin) + 1, f2bin(fmax) - 1]
|
| 295 |
+
klo = f2bin(fmin) + 1
|
| 296 |
+
khi = f2bin(fmax)
|
| 297 |
+
|
| 298 |
+
khi = max(khi, klo)
|
| 299 |
+
|
| 300 |
+
# Spec 2: SpeechLib uses trianges in Mel space
|
| 301 |
+
mlo = mel(fmin)
|
| 302 |
+
mhi = mel(fmax)
|
| 303 |
+
m_centers = np.linspace(mlo, mhi, n_mels + 2)
|
| 304 |
+
ms = (mhi - mlo) / (n_mels + 1)
|
| 305 |
+
|
| 306 |
+
matrix = np.zeros((n_mels, bank_width), dtype=np.float32)
|
| 307 |
+
for m in range(0, n_mels):
|
| 308 |
+
left = m_centers[m]
|
| 309 |
+
center = m_centers[m + 1]
|
| 310 |
+
right = m_centers[m + 2]
|
| 311 |
+
for fft_bin in range(klo, khi):
|
| 312 |
+
mbin = bin2mel(fft_bin)
|
| 313 |
+
if left < mbin < right:
|
| 314 |
+
matrix[m, fft_bin] = 1.0 - abs(center - mbin) / ms
|
| 315 |
+
|
| 316 |
+
return matrix
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class Phi4MMAudioFeatureExtractor(SequenceFeatureExtractor):
|
| 320 |
+
model_input_names = ["input_audio_embeds", "audio_embed_sizes", "audio_attention_mask"]
|
| 321 |
+
|
| 322 |
+
def __init__(self, audio_compression_rate, audio_downsample_rate, audio_feat_stride, **kwargs):
|
| 323 |
+
feature_size = 80
|
| 324 |
+
sampling_rate = 16000
|
| 325 |
+
padding_value = 0.0
|
| 326 |
+
super().__init__(feature_size, sampling_rate, padding_value, **kwargs)
|
| 327 |
+
|
| 328 |
+
self.compression_rate = audio_compression_rate
|
| 329 |
+
self.qformer_compression_rate = audio_downsample_rate
|
| 330 |
+
self.feat_stride = audio_feat_stride
|
| 331 |
+
|
| 332 |
+
self._eightk_method = "fillzero"
|
| 333 |
+
self._mel = speechlib_mel(16000, 512, 80, fmin=None, fmax=7690).T
|
| 334 |
+
|
| 335 |
+
self._hamming400 = np.hamming(400) # for 16k audio
|
| 336 |
+
self._hamming200 = np.hamming(200) # for 8k audio
|
| 337 |
+
|
| 338 |
+
def duration_to_frames(self, duration):
|
| 339 |
+
"""duration in s, estimated frames"""
|
| 340 |
+
frame_rate = 10
|
| 341 |
+
|
| 342 |
+
num_frames = duration * 1000 // frame_rate
|
| 343 |
+
return num_frames
|
| 344 |
+
|
| 345 |
+
def __call__(
|
| 346 |
+
self,
|
| 347 |
+
audios: List[AudioInput],
|
| 348 |
+
return_tensors: Optional[Union[str, TensorType]] = None,
|
| 349 |
+
):
|
| 350 |
+
# Ref: https://github.com/huggingface/transformers/blob/v4.47.0/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py#L161
|
| 351 |
+
returned_input_audio_embeds = []
|
| 352 |
+
returned_audio_embed_sizes = []
|
| 353 |
+
audio_frames_list = []
|
| 354 |
+
|
| 355 |
+
for audio_data, sample_rate in audios:
|
| 356 |
+
audio_embeds = self._extract_features(audio_data, sample_rate)
|
| 357 |
+
audio_frames = len(audio_embeds) * self.feat_stride
|
| 358 |
+
audio_embed_size = self._compute_audio_embed_size(audio_frames)
|
| 359 |
+
|
| 360 |
+
returned_input_audio_embeds.append(torch.tensor(audio_embeds))
|
| 361 |
+
returned_audio_embed_sizes.append(torch.tensor(audio_embed_size).long())
|
| 362 |
+
audio_frames_list.append(audio_frames)
|
| 363 |
+
|
| 364 |
+
returned_input_audio_embeds = pad_sequence(
|
| 365 |
+
returned_input_audio_embeds, batch_first=True
|
| 366 |
+
)
|
| 367 |
+
returned_audio_embed_sizes = torch.stack(returned_audio_embed_sizes, dim=0)
|
| 368 |
+
audio_frames = torch.tensor(audio_frames_list)
|
| 369 |
+
returned_audio_attention_mask = torch.arange(0, audio_frames.max()).unsqueeze(0) < audio_frames.unsqueeze(1) if len(audios) > 1 else None
|
| 370 |
+
|
| 371 |
+
data = {
|
| 372 |
+
"input_audio_embeds": returned_input_audio_embeds,
|
| 373 |
+
"audio_embed_sizes": returned_audio_embed_sizes,
|
| 374 |
+
}
|
| 375 |
+
if returned_audio_attention_mask is not None:
|
| 376 |
+
data["audio_attention_mask"] = returned_audio_attention_mask
|
| 377 |
+
|
| 378 |
+
return BatchFeature(data=data, tensor_type=return_tensors)
|
| 379 |
+
|
| 380 |
+
def _extract_spectrogram(self, wav, fs):
|
| 381 |
+
"""Extract spectrogram features from waveform.
|
| 382 |
+
Args:
|
| 383 |
+
wav (1D array): waveform of the input
|
| 384 |
+
fs (int): sampling rate of the waveform, 16000 or 8000.
|
| 385 |
+
If fs=8000, the waveform will be resampled to 16000Hz.
|
| 386 |
+
Output:
|
| 387 |
+
log_fbank (2D array): a TxD matrix of log Mel filterbank features.
|
| 388 |
+
D=80, and T is the number of frames.
|
| 389 |
+
"""
|
| 390 |
+
if wav.ndim > 1:
|
| 391 |
+
wav = np.squeeze(wav)
|
| 392 |
+
|
| 393 |
+
# by default, we extract the mean if stereo
|
| 394 |
+
if len(wav.shape) == 2:
|
| 395 |
+
wav = wav.mean(1)
|
| 396 |
+
|
| 397 |
+
# Resample to 16000 or 8000 if needed
|
| 398 |
+
if fs > 16000:
|
| 399 |
+
wav = scipy.signal.resample_poly(wav, 1, fs // 16000)
|
| 400 |
+
fs = 16000
|
| 401 |
+
elif 8000 < fs < 16000:
|
| 402 |
+
wav = scipy.signal.resample_poly(wav, 1, fs // 8000)
|
| 403 |
+
fs = 8000
|
| 404 |
+
elif fs < 8000:
|
| 405 |
+
raise RuntimeError(f"Unsupported sample rate {fs}")
|
| 406 |
+
|
| 407 |
+
if fs == 8000:
|
| 408 |
+
if self._eightk_method == "resample":
|
| 409 |
+
# Input audio is 8 kHz. Convert to 16 kHz before feature
|
| 410 |
+
# extraction
|
| 411 |
+
wav = scipy.signal.resample_poly(wav, 2, 1)
|
| 412 |
+
fs = 16000
|
| 413 |
+
# Do nothing here for fillzero method
|
| 414 |
+
elif fs != 16000:
|
| 415 |
+
# Input audio is not a supported sample rate.
|
| 416 |
+
raise RuntimeError(f"Input data using an unsupported sample rate: {fs}")
|
| 417 |
+
|
| 418 |
+
preemphasis = 0.97
|
| 419 |
+
|
| 420 |
+
if fs == 8000:
|
| 421 |
+
n_fft = 256
|
| 422 |
+
win_length = 200
|
| 423 |
+
hop_length = 80
|
| 424 |
+
fft_window = self._hamming200
|
| 425 |
+
elif fs == 16000:
|
| 426 |
+
n_fft = 512
|
| 427 |
+
win_length = 400
|
| 428 |
+
hop_length = 160
|
| 429 |
+
fft_window = self._hamming400
|
| 430 |
+
|
| 431 |
+
# Spec 1: SpeechLib cut remaining sample insufficient for a hop
|
| 432 |
+
n_batch = (wav.shape[0] - win_length) // hop_length + 1
|
| 433 |
+
# Here we don't use stride_tricks since the input array may not satisfy
|
| 434 |
+
# memory layout requirement and we need writeable output
|
| 435 |
+
# Here we only use list of views before copy to desination
|
| 436 |
+
# so it is more efficient than broadcasting
|
| 437 |
+
y_frames = np.array(
|
| 438 |
+
[wav[_stride : _stride + win_length] for _stride in range(0, hop_length * n_batch, hop_length)],
|
| 439 |
+
dtype=np.float32,
|
| 440 |
+
)
|
| 441 |
+
|
| 442 |
+
# Spec 2: SpeechLib applies preemphasis within each batch
|
| 443 |
+
y_frames_prev = np.roll(y_frames, 1, axis=1)
|
| 444 |
+
y_frames_prev[:, 0] = y_frames_prev[:, 1]
|
| 445 |
+
y_frames = (y_frames - preemphasis * y_frames_prev) * 32768
|
| 446 |
+
|
| 447 |
+
S = np.fft.rfft(fft_window * y_frames, n=n_fft, axis=1).astype(np.complex64)
|
| 448 |
+
|
| 449 |
+
if fs == 8000:
|
| 450 |
+
# Need to pad the output to look like 16 kHz data but with zeros in
|
| 451 |
+
# the 4 to 8 kHz bins.
|
| 452 |
+
frames, bins = S.shape
|
| 453 |
+
padarray = np.zeros((frames, bins))
|
| 454 |
+
S = np.concatenate((S[:, 0:-1], padarray), axis=1) # Nyquist bin gets set to zero
|
| 455 |
+
|
| 456 |
+
spec = np.abs(S).astype(np.float32)
|
| 457 |
+
return spec
|
| 458 |
+
|
| 459 |
+
def _extract_features(self, wav, fs):
|
| 460 |
+
"""Extract log filterbank features from waveform.
|
| 461 |
+
Args:
|
| 462 |
+
wav (1D array): waveform of the input
|
| 463 |
+
fs (int): sampling rate of the waveform, 16000 or 8000.
|
| 464 |
+
If fs=8000, the waveform will be resampled to 16000Hz.
|
| 465 |
+
Output:
|
| 466 |
+
log_fbank (2D array): a TxD matrix of log Mel filterbank features.
|
| 467 |
+
D=80, and T is the number of frames.
|
| 468 |
+
"""
|
| 469 |
+
spec = self._extract_spectrogram(wav, fs)
|
| 470 |
+
spec_power = spec**2
|
| 471 |
+
|
| 472 |
+
fbank_power = np.clip(spec_power.dot(self._mel), 1.0, None)
|
| 473 |
+
log_fbank = np.log(fbank_power).astype(np.float32)
|
| 474 |
+
|
| 475 |
+
return log_fbank
|
| 476 |
+
|
| 477 |
+
def _compute_audio_embed_size(self, audio_frames):
|
| 478 |
+
integer = audio_frames // self.compression_rate
|
| 479 |
+
remainder = audio_frames % self.compression_rate
|
| 480 |
+
|
| 481 |
+
result = integer if remainder == 0 else integer + 1
|
| 482 |
+
|
| 483 |
+
integer = result // self.qformer_compression_rate
|
| 484 |
+
remainder = result % self.qformer_compression_rate
|
| 485 |
+
result = integer if remainder == 0 else integer + 1 # qformer compression
|
| 486 |
+
|
| 487 |
+
return result
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
class Phi4MMProcessor(ProcessorMixin):
|
| 491 |
+
r"""
|
| 492 |
+
Constructs a Phi4MM processor which raps an image processor, a audio processor, and a GPT tokenizer into a single processor.
|
| 493 |
+
|
| 494 |
+
[`Phi4MMProcessor`] offers all the functionalities of [`Phi4MMImageProcessor`] and [`GPT2Tokenizer`]. See the
|
| 495 |
+
[`~Phi4MMProcessor.__call__`] and [`~Phi4MMProcessor.decode`] for more information.
|
| 496 |
+
|
| 497 |
+
Args:
|
| 498 |
+
image_processor ([`Phi4MMImageProcessor`], *optional*):
|
| 499 |
+
The image processor is a required input.
|
| 500 |
+
tokenizer ([`GPT2Tokenizer`], *optional*):
|
| 501 |
+
The tokenizer is a required input.
|
| 502 |
+
"""
|
| 503 |
+
|
| 504 |
+
attributes = ["image_processor", "audio_processor", "tokenizer"]
|
| 505 |
+
tokenizer_class = "GPT2TokenizerFast"
|
| 506 |
+
image_processor_class = "AutoImageProcessor" # Phi4MMImageProcessor will be registered later
|
| 507 |
+
audio_processor_class = "AutoFeatureExtractor" # Phi4MMAudioFeatureExtractor will be registered later
|
| 508 |
+
|
| 509 |
+
def __init__(self, image_processor, audio_processor, tokenizer):
|
| 510 |
+
self.image_processor = image_processor
|
| 511 |
+
self.audio_processor = audio_processor
|
| 512 |
+
self.tokenizer = tokenizer
|
| 513 |
+
|
| 514 |
+
def __call__(
|
| 515 |
+
self,
|
| 516 |
+
text: Union[TextInput, List[TextInput]],
|
| 517 |
+
images: Optional[ImageInput] = None,
|
| 518 |
+
audios: Optional[AudioInputs] = None,
|
| 519 |
+
padding: Union[bool, str, PaddingStrategy] = False,
|
| 520 |
+
truncation: Optional[Union[bool, str, TruncationStrategy]] = None,
|
| 521 |
+
max_length=None,
|
| 522 |
+
return_tensors: Optional[Union[str, TensorType]] = TensorType.PYTORCH,
|
| 523 |
+
) -> BatchFeature:
|
| 524 |
+
"""
|
| 525 |
+
Main method to prepare for the model one or several sequences(s) and image(s). This method forards the `text`
|
| 526 |
+
and `kwargs` arguments to GPT2Tokenizer's [`~GPT2Tokenizer.__call__`] if `text` is not `None` to encode
|
| 527 |
+
the text. To prepare the image(s), this method forwards the `images` and `kwrags` arguments to
|
| 528 |
+
Phi4MMImageProcessor's [`~Phi4MMImageProcessor.__call__`] if `images` is not `None`. Please refer to the doctsring
|
| 529 |
+
of the above two methods for more information.
|
| 530 |
+
|
| 531 |
+
Args:
|
| 532 |
+
text (`str`, `List[str]`, `List[List[str]]`):
|
| 533 |
+
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
|
| 534 |
+
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
|
| 535 |
+
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
|
| 536 |
+
images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
|
| 537 |
+
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
|
| 538 |
+
tensor. Both channels-first and channels-last formats are supported.
|
| 539 |
+
padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `False`):
|
| 540 |
+
Select a strategy to pad the returned sequences (according to the model's padding side and padding
|
| 541 |
+
index) among:
|
| 542 |
+
- `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
|
| 543 |
+
sequence if provided).
|
| 544 |
+
- `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
|
| 545 |
+
acceptable input length for the model if that argument is not provided.
|
| 546 |
+
- `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
|
| 547 |
+
lengths).
|
| 548 |
+
max_length (`int`, *optional*):
|
| 549 |
+
Maximum length of the returned list and optionally padding length (see above).
|
| 550 |
+
truncation (`bool`, *optional*):
|
| 551 |
+
Activates truncation to cut input sequences longer than `max_length` to `max_length`.
|
| 552 |
+
return_tensors (`str` or [`~utils.TensorType`], *optional*):
|
| 553 |
+
If set, will return tensors of a particular framework. Acceptable values are:
|
| 554 |
+
|
| 555 |
+
- `'tf'`: Return TensorFlow `tf.constant` objects.
|
| 556 |
+
- `'pt'`: Return PyTorch `torch.Tensor` objects.
|
| 557 |
+
- `'np'`: Return NumPy `np.ndarray` objects.
|
| 558 |
+
- `'jax'`: Return JAX `jnp.ndarray` objects.
|
| 559 |
+
|
| 560 |
+
Returns:
|
| 561 |
+
[`BatchFeature`]: A [`BatchFeature`] with the following fields:
|
| 562 |
+
|
| 563 |
+
- **input_ids** -- List of token ids to be fed to a model.
|
| 564 |
+
- **input_image_embeds** -- Pixel values to be fed to a model.
|
| 565 |
+
- **image_sizes** -- List of tuples specifying the size of each image in `input_image_embeds`.
|
| 566 |
+
- **image_attention_mask** -- List of attention masks for each image in `input_image_embeds`.
|
| 567 |
+
- **input_audio_embeds** -- Audio embeddings to be fed to a model.
|
| 568 |
+
- **audio_embed_sizes** -- List of integers specifying the size of each audio in `input_audio_embeds`.
|
| 569 |
+
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model.
|
| 570 |
+
"""
|
| 571 |
+
image_inputs = self.image_processor(images, return_tensors=return_tensors) if images is not None else {}
|
| 572 |
+
audio_inputs = self.audio_processor(audios, return_tensors=return_tensors) if audios is not None else {}
|
| 573 |
+
inputs = self._convert_images_audios_text_to_inputs(
|
| 574 |
+
image_inputs,
|
| 575 |
+
audio_inputs,
|
| 576 |
+
text,
|
| 577 |
+
padding=padding,
|
| 578 |
+
truncation=truncation,
|
| 579 |
+
max_length=max_length,
|
| 580 |
+
return_tensors=return_tensors,
|
| 581 |
+
)
|
| 582 |
+
|
| 583 |
+
# idenfity the input mode
|
| 584 |
+
if len(image_inputs) > 0 and len(audio_inputs) > 0:
|
| 585 |
+
input_mode = InputMode.VISION_SPEECH
|
| 586 |
+
elif len(image_inputs) > 0:
|
| 587 |
+
input_mode = InputMode.VISION
|
| 588 |
+
elif len(audio_inputs) > 0:
|
| 589 |
+
input_mode = InputMode.SPEECH
|
| 590 |
+
else:
|
| 591 |
+
input_mode = InputMode.LANGUAGE
|
| 592 |
+
inputs["input_mode"] = torch.tensor([input_mode.value], dtype=torch.long)
|
| 593 |
+
|
| 594 |
+
return inputs
|
| 595 |
+
|
| 596 |
+
@property
|
| 597 |
+
def special_image_token_id(self):
|
| 598 |
+
return self.tokenizer.convert_tokens_to_ids(self.special_image_token)
|
| 599 |
+
|
| 600 |
+
def get_special_image_token_id(self):
|
| 601 |
+
return self.tokenizer.convert_tokens_to_ids(self.special_image_token)
|
| 602 |
+
|
| 603 |
+
@property
|
| 604 |
+
def chat_template(self):
|
| 605 |
+
return self.tokenizer.chat_template
|
| 606 |
+
|
| 607 |
+
def _convert_images_audios_text_to_inputs(
|
| 608 |
+
self, images, audios, text, padding=False, truncation=None, max_length=None, return_tensors=None
|
| 609 |
+
):
|
| 610 |
+
# prepare image id to image input ids
|
| 611 |
+
if len(images) > 0:
|
| 612 |
+
input_image_embeds = images["input_image_embeds"]
|
| 613 |
+
image_sizes = images["image_sizes"]
|
| 614 |
+
image_attention_mask = images["image_attention_mask"]
|
| 615 |
+
num_img_tokens = images['num_img_tokens']
|
| 616 |
+
else:
|
| 617 |
+
input_image_embeds = torch.tensor([])
|
| 618 |
+
image_sizes = torch.tensor([])
|
| 619 |
+
image_attention_mask = torch.tensor([])
|
| 620 |
+
num_img_tokens = []
|
| 621 |
+
|
| 622 |
+
# prepare audio id to audio input ids
|
| 623 |
+
if len(audios) > 0:
|
| 624 |
+
input_audio_embeds = audios["input_audio_embeds"]
|
| 625 |
+
audio_embed_sizes = audios["audio_embed_sizes"]
|
| 626 |
+
audio_attention_mask = audios.get("audio_attention_mask", None)
|
| 627 |
+
else:
|
| 628 |
+
input_audio_embeds = torch.tensor([])
|
| 629 |
+
audio_embed_sizes = torch.tensor([])
|
| 630 |
+
audio_attention_mask = None
|
| 631 |
+
|
| 632 |
+
# Replace certain special tokens for compatibility
|
| 633 |
+
# Ref: https://stackoverflow.com/questions/11475885/python-replace-regex
|
| 634 |
+
if isinstance(text, str):
|
| 635 |
+
text = [text]
|
| 636 |
+
assert isinstance(text, list)
|
| 637 |
+
processed_text = [re.sub(_COMPATIBLE_IMAGE_SPECIAL_TOKEN_PATTERN, _IMAGE_SPECIAL_TOKEN, t) for t in text]
|
| 638 |
+
processed_text = [re.sub(_COMPATIBLE_AUDIO_SPECIAL_TOKEN_PATTERN, _AUDIO_SPECIAL_TOKEN, t) for t in processed_text]
|
| 639 |
+
|
| 640 |
+
input_ids_list = [self.tokenizer(t).input_ids for t in processed_text]
|
| 641 |
+
|
| 642 |
+
img_cnt, audio_cnt = 0, 0 # only needed for later assertion
|
| 643 |
+
image_token_count_iter = iter(num_img_tokens)
|
| 644 |
+
audio_embed_size_iter = iter(audio_embed_sizes.tolist())
|
| 645 |
+
new_input_ids_list = []
|
| 646 |
+
for input_ids in input_ids_list:
|
| 647 |
+
i = 0
|
| 648 |
+
while i < len(input_ids):
|
| 649 |
+
token_id = input_ids[i]
|
| 650 |
+
if token_id == _AUDIO_SPECIAL_TOKEN_ID:
|
| 651 |
+
token_count = next(audio_embed_size_iter)
|
| 652 |
+
audio_cnt += 1
|
| 653 |
+
elif token_id == _IMAGE_SPECIAL_TOKEN_ID:
|
| 654 |
+
token_count = next(image_token_count_iter)
|
| 655 |
+
img_cnt += 1
|
| 656 |
+
else:
|
| 657 |
+
i += 1
|
| 658 |
+
continue
|
| 659 |
+
tokens = [token_id] * token_count
|
| 660 |
+
input_ids = input_ids[:i] + tokens + input_ids[i + 1:]
|
| 661 |
+
i += token_count
|
| 662 |
+
input_ids = torch.tensor(input_ids, dtype=torch.long)
|
| 663 |
+
new_input_ids_list.append(input_ids)
|
| 664 |
+
lengths = torch.tensor([len(input_ids) for input_ids in new_input_ids_list])
|
| 665 |
+
max_len = lengths.max()
|
| 666 |
+
input_ids = input_ids.new_full((len(new_input_ids_list), max_len), self.tokenizer.pad_token_id)
|
| 667 |
+
# batched inference requires left padding
|
| 668 |
+
for i in range(len(new_input_ids_list)):
|
| 669 |
+
input_ids[i, max_len - len(new_input_ids_list[i]):] = new_input_ids_list[i]
|
| 670 |
+
|
| 671 |
+
# If the below assertion fails, it might be that input pure-text
|
| 672 |
+
# messages contain image/audio special tokens literally
|
| 673 |
+
# (<|endoftext10|>, <|endoftext11|>).
|
| 674 |
+
assert (
|
| 675 |
+
img_cnt == len(num_img_tokens)
|
| 676 |
+
), (
|
| 677 |
+
f"Number of image tokens in prompt_token_ids ({img_cnt}) "
|
| 678 |
+
f"does not match number of images ({len(num_img_tokens)})"
|
| 679 |
+
)
|
| 680 |
+
assert (
|
| 681 |
+
audio_cnt == len(audio_embed_sizes)
|
| 682 |
+
), (
|
| 683 |
+
f"Number of audio tokens in prompt_token_ids ({audio_cnt}) "
|
| 684 |
+
f"does not match number of audios ({len(audio_embed_sizes)})"
|
| 685 |
+
)
|
| 686 |
+
|
| 687 |
+
# prepare attention mask
|
| 688 |
+
seq_range = torch.arange(max_len - 1, -1, -1)
|
| 689 |
+
attention_mask = seq_range.unsqueeze(0) < lengths.unsqueeze(1)
|
| 690 |
+
|
| 691 |
+
# prepare batch feature
|
| 692 |
+
data = {
|
| 693 |
+
"input_ids": input_ids,
|
| 694 |
+
"input_image_embeds": input_image_embeds,
|
| 695 |
+
"image_sizes": image_sizes,
|
| 696 |
+
"image_attention_mask": image_attention_mask,
|
| 697 |
+
"input_audio_embeds": input_audio_embeds,
|
| 698 |
+
"audio_embed_sizes": audio_embed_sizes,
|
| 699 |
+
"audio_attention_mask": audio_attention_mask,
|
| 700 |
+
"attention_mask": attention_mask,
|
| 701 |
+
}
|
| 702 |
+
|
| 703 |
+
return BatchFeature(
|
| 704 |
+
data=data
|
| 705 |
+
)
|
| 706 |
+
|
| 707 |
+
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.batch_decode with CLIP->Llama
|
| 708 |
+
def batch_decode(self, *args, **kwargs):
|
| 709 |
+
"""
|
| 710 |
+
This method forwards all its arguments to GPT2Tokenizer's [`~PreTrainedTokenizer.batch_decode`]. Please
|
| 711 |
+
refer to the docstring of this method for more information.
|
| 712 |
+
"""
|
| 713 |
+
return self.tokenizer.batch_decode(*args, **kwargs)
|
| 714 |
+
|
| 715 |
+
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.decode with CLIP->Llama
|
| 716 |
+
def decode(self, *args, **kwargs):
|
| 717 |
+
"""
|
| 718 |
+
This method forwards all its arguments to GPT2Tokenizer's [`~PreTrainedTokenizer.decode`]. Please refer to
|
| 719 |
+
the docstring of this method for more information.
|
| 720 |
+
"""
|
| 721 |
+
return self.tokenizer.decode(*args, **kwargs)
|
| 722 |
+
|
| 723 |
+
@property
|
| 724 |
+
# Copied from transformers.models.clip.processing_clip.CLIPProcessor.model_input_names
|
| 725 |
+
def model_input_names(self):
|
| 726 |
+
tokenizer_input_names = self.tokenizer.model_input_names
|
| 727 |
+
image_processor_input_names = self.image_processor.model_input_names
|
| 728 |
+
audio_processor_input_names = self.audio_processor.model_input_names
|
| 729 |
+
return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names + audio_processor_input_names))
|
| 730 |
+
|
| 731 |
+
|
| 732 |
+
AutoImageProcessor.register("Phi4MMImageProcessor", Phi4MMImageProcessor)
|
| 733 |
+
AutoFeatureExtractor.register("Phi4MMAudioFeatureExtractor", Phi4MMAudioFeatureExtractor)
|
processor_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_map": {
|
| 3 |
+
"AutoProcessor": "processing_phi4mm.Phi4MMProcessor"
|
| 4 |
+
},
|
| 5 |
+
"processor_class": "Phi4MMProcessor"
|
| 6 |
+
}
|
sample_finetune_speech.py
ADDED
|
@@ -0,0 +1,478 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
finetune Phi-4-multimodal-instruct on an speech task
|
| 3 |
+
|
| 4 |
+
scipy==1.15.1
|
| 5 |
+
peft==0.13.2
|
| 6 |
+
backoff==2.2.1
|
| 7 |
+
transformers==4.46.1
|
| 8 |
+
accelerate==1.3.0
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import argparse
|
| 12 |
+
import json
|
| 13 |
+
import os
|
| 14 |
+
from pathlib import Path
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
import sacrebleu
|
| 18 |
+
from accelerate import Accelerator
|
| 19 |
+
from accelerate.utils import gather_object
|
| 20 |
+
from datasets import load_dataset
|
| 21 |
+
from torch.utils.data import Dataset
|
| 22 |
+
from tqdm import tqdm
|
| 23 |
+
from transformers import (
|
| 24 |
+
AutoModelForCausalLM,
|
| 25 |
+
AutoProcessor,
|
| 26 |
+
BatchFeature,
|
| 27 |
+
Trainer,
|
| 28 |
+
TrainingArguments,
|
| 29 |
+
StoppingCriteria,
|
| 30 |
+
StoppingCriteriaList,
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
INSTSRUCTION = {
|
| 35 |
+
"en_zh-CN": "Translate the audio to Mandarin.",
|
| 36 |
+
"en_id": "Translate the audio to Indonesian.",
|
| 37 |
+
"en_sl": "Translate the audio to Slovenian.",
|
| 38 |
+
}
|
| 39 |
+
TOKENIZER = {
|
| 40 |
+
"en_zh-CN": "zh",
|
| 41 |
+
"en_ja": "ja-mecab",
|
| 42 |
+
}
|
| 43 |
+
ANSWER_SUFFIX = "<|end|><|endoftext|>"
|
| 44 |
+
_IGNORE_INDEX = -100
|
| 45 |
+
_TRAIN_SIZE = 50000
|
| 46 |
+
_EVAL_SIZE = 200
|
| 47 |
+
|
| 48 |
+
class MultipleTokenBatchStoppingCriteria(StoppingCriteria):
|
| 49 |
+
"""Stopping criteria capable of receiving multiple stop-tokens and handling batched inputs."""
|
| 50 |
+
|
| 51 |
+
def __init__(self, stop_tokens: torch.LongTensor, batch_size: int = 1) -> None:
|
| 52 |
+
"""Initialize the multiple token batch stopping criteria.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
stop_tokens: Stop-tokens.
|
| 56 |
+
batch_size: Batch size.
|
| 57 |
+
|
| 58 |
+
"""
|
| 59 |
+
|
| 60 |
+
self.stop_tokens = stop_tokens
|
| 61 |
+
self.max_stop_tokens = stop_tokens.shape[-1]
|
| 62 |
+
self.stop_tokens_idx = torch.zeros(batch_size, dtype=torch.long, device=stop_tokens.device)
|
| 63 |
+
|
| 64 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 65 |
+
# Only gather the maximum number of inputs compatible with stop tokens
|
| 66 |
+
# and checks whether generated inputs are equal to `stop_tokens`
|
| 67 |
+
generated_inputs = torch.eq(input_ids[:, -self.max_stop_tokens :].unsqueeze(1), self.stop_tokens)
|
| 68 |
+
equal_generated_inputs = torch.all(generated_inputs, dim=2)
|
| 69 |
+
|
| 70 |
+
# Mark the position where a stop token has been produced for each input in the batch,
|
| 71 |
+
# but only if the corresponding entry is not already set
|
| 72 |
+
sequence_idx = torch.any(equal_generated_inputs, dim=1)
|
| 73 |
+
sequence_set_mask = self.stop_tokens_idx == 0
|
| 74 |
+
self.stop_tokens_idx[sequence_idx & sequence_set_mask] = input_ids.shape[-1]
|
| 75 |
+
|
| 76 |
+
return torch.all(self.stop_tokens_idx)
|
| 77 |
+
|
| 78 |
+
class CoVoSTDataset(Dataset):
|
| 79 |
+
def __init__(self, processor, data_dir, split,
|
| 80 |
+
lang="en_zh-CN", rank=0, world_size=1):
|
| 81 |
+
|
| 82 |
+
self.data = load_dataset("facebook/covost2",
|
| 83 |
+
lang,
|
| 84 |
+
data_dir=data_dir,
|
| 85 |
+
split=split,
|
| 86 |
+
trust_remote_code=True
|
| 87 |
+
)
|
| 88 |
+
self.training = "train" in split
|
| 89 |
+
self.processor = processor
|
| 90 |
+
self.instruction = INSTSRUCTION[lang]
|
| 91 |
+
|
| 92 |
+
if world_size > 1:
|
| 93 |
+
self.data = self.data.shard(world_size, rank)
|
| 94 |
+
|
| 95 |
+
def __len__(self):
|
| 96 |
+
return len(self.data)
|
| 97 |
+
|
| 98 |
+
def __getitem__(self, idx):
|
| 99 |
+
"""
|
| 100 |
+
{'client_id': '0013037a1d45cc33460806cc3f8ecee9d536c45639ba4cbbf1564f1c051f53ff3c9f89ef2f1bf04badf55b3a2e7654c086f903681a7b6299616cff6f67598eff',
|
| 101 |
+
'file': '{data_dir}/clips/common_voice_en_699711.mp3',
|
| 102 |
+
'audio': {'path': '{data_dir}/clips/common_voice_en_699711.mp3',
|
| 103 |
+
'array': array([-1.28056854e-09, -1.74622983e-09, -1.16415322e-10, ...,
|
| 104 |
+
3.92560651e-10, 6.62794264e-10, -3.89536581e-09]),
|
| 105 |
+
'sampling_rate': 16000},
|
| 106 |
+
'sentence': '"She\'ll be all right."',
|
| 107 |
+
'translation': '她会没事的。',
|
| 108 |
+
'id': 'common_voice_en_699711'}
|
| 109 |
+
"""
|
| 110 |
+
data = self.data[idx]
|
| 111 |
+
user_message = {
|
| 112 |
+
'role': 'user',
|
| 113 |
+
'content': '<|audio_1|>\n' + self.instruction,
|
| 114 |
+
}
|
| 115 |
+
prompt = self.processor.tokenizer.apply_chat_template(
|
| 116 |
+
[user_message], tokenize=False, add_generation_prompt=True
|
| 117 |
+
)
|
| 118 |
+
inputs = self.processor(text=prompt, audios=[(data["audio"]["array"], data["audio"]["sampling_rate"])], return_tensors='pt')
|
| 119 |
+
|
| 120 |
+
answer = f"{data['translation']}{ANSWER_SUFFIX}"
|
| 121 |
+
answer_ids = self.processor.tokenizer(answer, return_tensors='pt').input_ids
|
| 122 |
+
if self.training:
|
| 123 |
+
input_ids = torch.cat([inputs.input_ids, answer_ids], dim=1)
|
| 124 |
+
labels = torch.full_like(input_ids, _IGNORE_INDEX)
|
| 125 |
+
labels[:, -answer_ids.shape[1] :] = answer_ids
|
| 126 |
+
else:
|
| 127 |
+
input_ids = inputs.input_ids
|
| 128 |
+
labels = answer_ids
|
| 129 |
+
|
| 130 |
+
return {
|
| 131 |
+
'input_ids': input_ids,
|
| 132 |
+
'labels': labels,
|
| 133 |
+
'input_audio_embeds': inputs.input_audio_embeds,
|
| 134 |
+
'audio_embed_sizes': inputs.audio_embed_sizes,
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
def pad_sequence(sequences, padding_side='right', padding_value=0):
|
| 138 |
+
"""
|
| 139 |
+
Pad a list of sequences to the same length.
|
| 140 |
+
sequences: list of tensors in [seq_len, *] shape
|
| 141 |
+
"""
|
| 142 |
+
assert padding_side in ['right', 'left']
|
| 143 |
+
max_size = sequences[0].size()
|
| 144 |
+
trailing_dims = max_size[1:]
|
| 145 |
+
max_len = max(len(seq) for seq in sequences)
|
| 146 |
+
batch_size = len(sequences)
|
| 147 |
+
output = sequences[0].new_full((batch_size, max_len) + trailing_dims, padding_value)
|
| 148 |
+
for i, seq in enumerate(sequences):
|
| 149 |
+
length = seq.size(0)
|
| 150 |
+
if padding_side == 'right':
|
| 151 |
+
output.data[i, :length] = seq
|
| 152 |
+
else:
|
| 153 |
+
output.data[i, -length:] = seq
|
| 154 |
+
return output
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def cat_with_pad(tensors, dim, padding_value=0):
|
| 158 |
+
"""
|
| 159 |
+
cat along dim, while pad to max for all other dims
|
| 160 |
+
"""
|
| 161 |
+
ndim = tensors[0].dim()
|
| 162 |
+
assert all(
|
| 163 |
+
t.dim() == ndim for t in tensors[1:]
|
| 164 |
+
), 'All tensors must have the same number of dimensions'
|
| 165 |
+
|
| 166 |
+
out_size = [max(t.shape[i] for t in tensors) for i in range(ndim)]
|
| 167 |
+
out_size[dim] = sum(t.shape[dim] for t in tensors)
|
| 168 |
+
output = tensors[0].new_full(out_size, padding_value)
|
| 169 |
+
|
| 170 |
+
index = 0
|
| 171 |
+
for t in tensors:
|
| 172 |
+
# Create a slice list where every dimension except dim is full slice
|
| 173 |
+
slices = [slice(0, t.shape[d]) for d in range(ndim)]
|
| 174 |
+
# Update only the concat dimension slice
|
| 175 |
+
slices[dim] = slice(index, index + t.shape[dim])
|
| 176 |
+
|
| 177 |
+
output[slices] = t
|
| 178 |
+
index += t.shape[dim]
|
| 179 |
+
|
| 180 |
+
return output
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def covost_collate_fn(batch):
|
| 184 |
+
input_ids_list = []
|
| 185 |
+
labels_list = []
|
| 186 |
+
input_audio_embeds_list = []
|
| 187 |
+
audio_embed_sizes_list = []
|
| 188 |
+
audio_attention_mask_list = []
|
| 189 |
+
for inputs in batch:
|
| 190 |
+
input_ids_list.append(inputs['input_ids'][0])
|
| 191 |
+
labels_list.append(inputs['labels'][0])
|
| 192 |
+
input_audio_embeds_list.append(inputs['input_audio_embeds'])
|
| 193 |
+
audio_embed_sizes_list.append(inputs['audio_embed_sizes'])
|
| 194 |
+
audio_attention_mask_list.append(
|
| 195 |
+
inputs['input_audio_embeds'].new_full((inputs['input_audio_embeds'].size(1),), True, dtype=torch.bool)
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
try:
|
| 199 |
+
input_ids = pad_sequence(input_ids_list, padding_side='left', padding_value=0)
|
| 200 |
+
labels = pad_sequence(labels_list, padding_side='left', padding_value=0)
|
| 201 |
+
audio_attention_mask = (
|
| 202 |
+
pad_sequence(audio_attention_mask_list, padding_side='right', padding_value=False)
|
| 203 |
+
if len(audio_attention_mask_list) > 1
|
| 204 |
+
else None
|
| 205 |
+
)
|
| 206 |
+
except Exception as e:
|
| 207 |
+
print(e)
|
| 208 |
+
print(input_ids_list)
|
| 209 |
+
print(labels_list)
|
| 210 |
+
raise
|
| 211 |
+
attention_mask = (input_ids != 0).long()
|
| 212 |
+
input_audio_embeds = cat_with_pad(input_audio_embeds_list, dim=0)
|
| 213 |
+
audio_embed_sizes = torch.cat(audio_embed_sizes_list)
|
| 214 |
+
|
| 215 |
+
return BatchFeature(
|
| 216 |
+
{
|
| 217 |
+
'input_ids': input_ids,
|
| 218 |
+
'labels': labels,
|
| 219 |
+
'attention_mask': attention_mask,
|
| 220 |
+
'input_audio_embeds': input_audio_embeds,
|
| 221 |
+
'audio_embed_sizes': audio_embed_sizes,
|
| 222 |
+
'audio_attention_mask': audio_attention_mask,
|
| 223 |
+
'input_mode': 2, # speech mode
|
| 224 |
+
}
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
def create_model(model_name_or_path, use_flash_attention=False):
|
| 230 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 231 |
+
model_name_or_path,
|
| 232 |
+
torch_dtype=torch.bfloat16 if use_flash_attention else torch.float32,
|
| 233 |
+
_attn_implementation='flash_attention_2' if use_flash_attention else 'sdpa',
|
| 234 |
+
trust_remote_code=True,
|
| 235 |
+
).to('cuda')
|
| 236 |
+
|
| 237 |
+
return model
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
@torch.no_grad()
|
| 241 |
+
def evaluate(
|
| 242 |
+
model, processor, eval_dataset, save_path=None, disable_tqdm=False, eval_batch_size=1
|
| 243 |
+
):
|
| 244 |
+
rank = int(os.environ.get('RANK', 0))
|
| 245 |
+
local_rank = int(os.environ.get('LOCAL_RANK', 0))
|
| 246 |
+
|
| 247 |
+
model.eval()
|
| 248 |
+
all_generated_texts = []
|
| 249 |
+
all_labels = []
|
| 250 |
+
|
| 251 |
+
eval_dataloader = torch.utils.data.DataLoader(
|
| 252 |
+
eval_dataset,
|
| 253 |
+
batch_size=eval_batch_size,
|
| 254 |
+
collate_fn=covost_collate_fn,
|
| 255 |
+
shuffle=False,
|
| 256 |
+
drop_last=False,
|
| 257 |
+
num_workers=8,
|
| 258 |
+
prefetch_factor=2,
|
| 259 |
+
pin_memory=True,
|
| 260 |
+
)
|
| 261 |
+
stop_tokens = ["<|end|>", processor.tokenizer.eos_token]
|
| 262 |
+
stop_tokens_ids = processor.tokenizer(stop_tokens, add_special_tokens=False, padding="longest", return_tensors="pt")["input_ids"]
|
| 263 |
+
stop_tokens_ids = stop_tokens_ids.to(f'cuda:{local_rank}')
|
| 264 |
+
|
| 265 |
+
for inputs in tqdm(
|
| 266 |
+
eval_dataloader, disable=(rank != 0) or disable_tqdm, desc='running eval'
|
| 267 |
+
):
|
| 268 |
+
stopping_criteria=StoppingCriteriaList([MultipleTokenBatchStoppingCriteria(stop_tokens_ids, batch_size=inputs.input_ids.size(0))])
|
| 269 |
+
inputs = inputs.to(f'cuda:{local_rank}')
|
| 270 |
+
generated_ids = model.generate(
|
| 271 |
+
**inputs, eos_token_id=processor.tokenizer.eos_token_id, max_new_tokens=64,
|
| 272 |
+
stopping_criteria=stopping_criteria,
|
| 273 |
+
)
|
| 274 |
+
|
| 275 |
+
stop_tokens_idx = stopping_criteria[0].stop_tokens_idx.reshape(inputs.input_ids.size(0), -1)[:, 0]
|
| 276 |
+
|
| 277 |
+
stop_tokens_idx = torch.where(
|
| 278 |
+
stop_tokens_idx > 0,
|
| 279 |
+
stop_tokens_idx - stop_tokens_ids.shape[-1],
|
| 280 |
+
generated_ids.shape[-1],
|
| 281 |
+
)
|
| 282 |
+
generated_text = [
|
| 283 |
+
processor.decode(_pred_ids[inputs["input_ids"].shape[1] : _stop_tokens_idx], skip_special_tokens=True, clean_up_tokenization_spaces=False)
|
| 284 |
+
for _pred_ids, _stop_tokens_idx in zip(generated_ids, stop_tokens_idx)
|
| 285 |
+
]
|
| 286 |
+
all_generated_texts.extend(generated_text)
|
| 287 |
+
labels = [processor.decode(_label_ids[_label_ids != 0]).rstrip(ANSWER_SUFFIX) for _label_ids in inputs["labels"]]
|
| 288 |
+
all_labels.extend(labels)
|
| 289 |
+
|
| 290 |
+
all_generated_texts = gather_object(all_generated_texts)
|
| 291 |
+
all_labels = gather_object(all_labels)
|
| 292 |
+
|
| 293 |
+
if rank == 0:
|
| 294 |
+
assert len(all_generated_texts) == len(all_labels)
|
| 295 |
+
bleu = sacrebleu.corpus_bleu(all_generated_texts, [all_labels])
|
| 296 |
+
print(bleu)
|
| 297 |
+
if save_path:
|
| 298 |
+
with open(save_path, 'w') as f:
|
| 299 |
+
save_dict = {
|
| 300 |
+
'all_generated_texts': all_generated_texts,
|
| 301 |
+
'all_labels': all_labels,
|
| 302 |
+
'score': bleu.score,
|
| 303 |
+
}
|
| 304 |
+
json.dump(save_dict, f)
|
| 305 |
+
|
| 306 |
+
return bleu.score
|
| 307 |
+
return None
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
def main():
|
| 311 |
+
parser = argparse.ArgumentParser()
|
| 312 |
+
parser.add_argument(
|
| 313 |
+
'--model_name_or_path',
|
| 314 |
+
type=str,
|
| 315 |
+
default='microsoft/Phi-4-multimodal-instruct',
|
| 316 |
+
help='Model name or path to load from',
|
| 317 |
+
)
|
| 318 |
+
parser.add_argument(
|
| 319 |
+
"--common_voice_dir",
|
| 320 |
+
type=str,
|
| 321 |
+
default="CommonVoice/EN",
|
| 322 |
+
help="Unzipped Common Voice Audio dataset directory, refer to https://commonvoice.mozilla.org/en/datasets, version 4.0",
|
| 323 |
+
)
|
| 324 |
+
parser.add_argument(
|
| 325 |
+
"--lang",
|
| 326 |
+
type=str,
|
| 327 |
+
default="en_sl",
|
| 328 |
+
help="Language pair for translation.",
|
| 329 |
+
)
|
| 330 |
+
parser.add_argument('--use_flash_attention', action='store_true', help='Use Flash Attention')
|
| 331 |
+
parser.add_argument('--output_dir', type=str, default='./output/', help='Output directory')
|
| 332 |
+
parser.add_argument('--batch_size', type=int, default=128, help='Batch size')
|
| 333 |
+
parser.add_argument(
|
| 334 |
+
'--batch_size_per_gpu',
|
| 335 |
+
type=int,
|
| 336 |
+
default=32,
|
| 337 |
+
help='Batch size per GPU (adjust this to fit in GPU memory)',
|
| 338 |
+
)
|
| 339 |
+
parser.add_argument(
|
| 340 |
+
'--num_train_epochs', type=int, default=1, help='Number of training epochs'
|
| 341 |
+
)
|
| 342 |
+
parser.add_argument('--learning_rate', type=float, default=4.0e-5, help='Learning rate')
|
| 343 |
+
parser.add_argument('--wd', type=float, default=0.01, help='Weight decay')
|
| 344 |
+
parser.add_argument('--no-tqdm', dest='tqdm', action='store_false', help='Disable tqdm')
|
| 345 |
+
args = parser.parse_args()
|
| 346 |
+
|
| 347 |
+
accelerator = Accelerator()
|
| 348 |
+
|
| 349 |
+
with accelerator.local_main_process_first():
|
| 350 |
+
processor = AutoProcessor.from_pretrained(
|
| 351 |
+
args.model_name_or_path,
|
| 352 |
+
trust_remote_code=True,
|
| 353 |
+
)
|
| 354 |
+
model = create_model(
|
| 355 |
+
args.model_name_or_path,
|
| 356 |
+
use_flash_attention=args.use_flash_attention,
|
| 357 |
+
)
|
| 358 |
+
|
| 359 |
+
model.set_lora_adapter('speech')
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
rank = int(os.environ.get('RANK', 0))
|
| 363 |
+
world_size = int(os.environ.get('WORLD_SIZE', 1))
|
| 364 |
+
|
| 365 |
+
eval_dataset = CoVoSTDataset(processor,
|
| 366 |
+
data_dir=args.common_voice_dir,
|
| 367 |
+
split=f'test[:{_EVAL_SIZE}]',
|
| 368 |
+
lang=args.lang,
|
| 369 |
+
rank=rank,
|
| 370 |
+
world_size=world_size)
|
| 371 |
+
|
| 372 |
+
train_dataset = CoVoSTDataset(processor,
|
| 373 |
+
data_dir=args.common_voice_dir,
|
| 374 |
+
split=f'train[:{_TRAIN_SIZE}]',
|
| 375 |
+
lang=args.lang)
|
| 376 |
+
|
| 377 |
+
num_gpus = accelerator.num_processes
|
| 378 |
+
print(f'training on {num_gpus} GPUs')
|
| 379 |
+
assert (
|
| 380 |
+
args.batch_size % (num_gpus * args.batch_size_per_gpu) == 0
|
| 381 |
+
), 'Batch size must be divisible by the number of GPUs'
|
| 382 |
+
gradient_accumulation_steps = args.batch_size // (num_gpus * args.batch_size_per_gpu)
|
| 383 |
+
|
| 384 |
+
if args.use_flash_attention:
|
| 385 |
+
fp16 = False
|
| 386 |
+
bf16 = True
|
| 387 |
+
else:
|
| 388 |
+
fp16 = True
|
| 389 |
+
bf16 = False
|
| 390 |
+
|
| 391 |
+
# hard coded training args
|
| 392 |
+
training_args = TrainingArguments(
|
| 393 |
+
num_train_epochs=args.num_train_epochs,
|
| 394 |
+
per_device_train_batch_size=args.batch_size_per_gpu,
|
| 395 |
+
gradient_checkpointing=True,
|
| 396 |
+
gradient_checkpointing_kwargs={'use_reentrant': False},
|
| 397 |
+
gradient_accumulation_steps=gradient_accumulation_steps,
|
| 398 |
+
optim='adamw_torch',
|
| 399 |
+
adam_beta1=0.9,
|
| 400 |
+
adam_beta2=0.95,
|
| 401 |
+
adam_epsilon=1e-7,
|
| 402 |
+
learning_rate=args.learning_rate,
|
| 403 |
+
weight_decay=args.wd,
|
| 404 |
+
max_grad_norm=1.0,
|
| 405 |
+
lr_scheduler_type='linear',
|
| 406 |
+
warmup_steps=50,
|
| 407 |
+
logging_steps=10,
|
| 408 |
+
output_dir=args.output_dir,
|
| 409 |
+
save_strategy='no',
|
| 410 |
+
save_total_limit=10,
|
| 411 |
+
save_only_model=True,
|
| 412 |
+
bf16=bf16,
|
| 413 |
+
fp16=fp16,
|
| 414 |
+
remove_unused_columns=False,
|
| 415 |
+
report_to='none',
|
| 416 |
+
deepspeed=None,
|
| 417 |
+
disable_tqdm=not args.tqdm,
|
| 418 |
+
dataloader_num_workers=4,
|
| 419 |
+
ddp_find_unused_parameters=True, # for unused SigLIP layers
|
| 420 |
+
)
|
| 421 |
+
|
| 422 |
+
# eval before fine-tuning
|
| 423 |
+
out_path = Path(training_args.output_dir)
|
| 424 |
+
out_path.mkdir(parents=True, exist_ok=True)
|
| 425 |
+
|
| 426 |
+
score = evaluate(
|
| 427 |
+
model,
|
| 428 |
+
processor,
|
| 429 |
+
eval_dataset,
|
| 430 |
+
save_path=out_path / 'eval_before.json',
|
| 431 |
+
disable_tqdm=not args.tqdm,
|
| 432 |
+
eval_batch_size=args.batch_size_per_gpu,
|
| 433 |
+
)
|
| 434 |
+
if accelerator.is_main_process:
|
| 435 |
+
print(f'BLEU Score before finetuning: {score}')
|
| 436 |
+
|
| 437 |
+
trainer = Trainer(
|
| 438 |
+
model=model,
|
| 439 |
+
args=training_args,
|
| 440 |
+
data_collator=covost_collate_fn,
|
| 441 |
+
train_dataset=train_dataset,
|
| 442 |
+
)
|
| 443 |
+
|
| 444 |
+
trainer.train()
|
| 445 |
+
trainer.save_model()
|
| 446 |
+
if accelerator.is_main_process:
|
| 447 |
+
processor.save_pretrained(training_args.output_dir)
|
| 448 |
+
accelerator.wait_for_everyone()
|
| 449 |
+
|
| 450 |
+
# eval after fine-tuning (load saved checkpoint)
|
| 451 |
+
# first try to clear GPU memory
|
| 452 |
+
del model
|
| 453 |
+
del trainer
|
| 454 |
+
__import__('gc').collect()
|
| 455 |
+
torch.cuda.empty_cache()
|
| 456 |
+
|
| 457 |
+
# reload the model for inference
|
| 458 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 459 |
+
training_args.output_dir,
|
| 460 |
+
torch_dtype=torch.bfloat16 if args.use_flash_attention else torch.float32,
|
| 461 |
+
trust_remote_code=True,
|
| 462 |
+
_attn_implementation='flash_attention_2' if args.use_flash_attention else 'sdpa',
|
| 463 |
+
).to('cuda')
|
| 464 |
+
|
| 465 |
+
score = evaluate(
|
| 466 |
+
model,
|
| 467 |
+
processor,
|
| 468 |
+
eval_dataset,
|
| 469 |
+
save_path=out_path / 'eval_after.json',
|
| 470 |
+
disable_tqdm=not args.tqdm,
|
| 471 |
+
eval_batch_size=args.batch_size_per_gpu,
|
| 472 |
+
)
|
| 473 |
+
if accelerator.is_main_process:
|
| 474 |
+
print(f'BLEU Score after finetuning: {score}')
|
| 475 |
+
|
| 476 |
+
|
| 477 |
+
if __name__ == '__main__':
|
| 478 |
+
main()
|
sample_finetune_vision.py
ADDED
|
@@ -0,0 +1,556 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
finetune Phi-4-multimodal-instruct on an image task
|
| 3 |
+
|
| 4 |
+
scipy==1.15.1
|
| 5 |
+
peft==0.13.2
|
| 6 |
+
backoff==2.2.1
|
| 7 |
+
transformers==4.47.0
|
| 8 |
+
accelerate==1.3.0
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import argparse
|
| 12 |
+
import json
|
| 13 |
+
import os
|
| 14 |
+
import tempfile
|
| 15 |
+
import zipfile
|
| 16 |
+
from pathlib import Path
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
from accelerate import Accelerator
|
| 20 |
+
from accelerate.utils import gather_object
|
| 21 |
+
from datasets import load_dataset
|
| 22 |
+
from huggingface_hub import hf_hub_download
|
| 23 |
+
from PIL import Image
|
| 24 |
+
from torch.utils.data import Dataset
|
| 25 |
+
from tqdm import tqdm
|
| 26 |
+
from transformers import (
|
| 27 |
+
AutoModelForCausalLM,
|
| 28 |
+
AutoProcessor,
|
| 29 |
+
BatchFeature,
|
| 30 |
+
Trainer,
|
| 31 |
+
TrainingArguments,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
DEFAULT_INSTSRUCTION = "Answer with the option's letter from the given choices directly."
|
| 35 |
+
_IGNORE_INDEX = -100
|
| 36 |
+
_TRAIN_SIZE = 8000
|
| 37 |
+
_EVAL_SIZE = 500
|
| 38 |
+
_MAX_TRAINING_LENGTH = 8192
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class PmcVqaTrainDataset(Dataset):
|
| 42 |
+
def __init__(self, processor, data_size, instruction=DEFAULT_INSTSRUCTION):
|
| 43 |
+
# Download the file
|
| 44 |
+
file_path = hf_hub_download(
|
| 45 |
+
repo_id='xmcmic/PMC-VQA', # repository name
|
| 46 |
+
filename='images_2.zip', # file to download
|
| 47 |
+
repo_type='dataset', # specify it's a dataset repo
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
# file_path will be the local path where the file was downloaded
|
| 51 |
+
print(f'File downloaded to: {file_path}')
|
| 52 |
+
|
| 53 |
+
# unzip to temp folder
|
| 54 |
+
self.image_folder = Path(tempfile.mkdtemp())
|
| 55 |
+
with zipfile.ZipFile(file_path, 'r') as zip_ref:
|
| 56 |
+
zip_ref.extractall(self.image_folder)
|
| 57 |
+
|
| 58 |
+
data_files = {
|
| 59 |
+
'train': 'https://huggingface.co/datasets/xmcmic/PMC-VQA/resolve/main/train_2.csv',
|
| 60 |
+
}
|
| 61 |
+
split = 'train' if data_size is None else f'train[:{data_size}]'
|
| 62 |
+
self.annotations = load_dataset('xmcmic/PMC-VQA', data_files=data_files, split=split)
|
| 63 |
+
self.processor = processor
|
| 64 |
+
self.instruction = instruction
|
| 65 |
+
|
| 66 |
+
def __len__(self):
|
| 67 |
+
return len(self.annotations)
|
| 68 |
+
|
| 69 |
+
def __getitem__(self, idx):
|
| 70 |
+
"""
|
| 71 |
+
{'index': 35,
|
| 72 |
+
'Figure_path': 'PMC8253797_Fig4_11.jpg',
|
| 73 |
+
'Caption': 'A slightly altered cell . (c-c‴) A highly altered cell as seen from 4 different angles . Note mitochondria/mitochondrial networks (green), Golgi complexes (red), cell nuclei (light blue) and the cell outline (yellow).',
|
| 74 |
+
'Question': ' What color is used to label the Golgi complexes in the image?',
|
| 75 |
+
'Choice A': ' A: Green ',
|
| 76 |
+
'Choice B': ' B: Red ',
|
| 77 |
+
'Choice C': ' C: Light blue ',
|
| 78 |
+
'Choice D': ' D: Yellow',
|
| 79 |
+
'Answer': 'B',
|
| 80 |
+
'split': 'train'}
|
| 81 |
+
"""
|
| 82 |
+
annotation = self.annotations[idx]
|
| 83 |
+
image = Image.open(self.image_folder / 'figures' / annotation['Figure_path'])
|
| 84 |
+
question = annotation['Question']
|
| 85 |
+
choices = [annotation[f'Choice {chr(ord("A") + i)}'] for i in range(4)]
|
| 86 |
+
user_message = {
|
| 87 |
+
'role': 'user',
|
| 88 |
+
'content': '<|image_1|>' + '\n'.join([question] + choices + [self.instruction]),
|
| 89 |
+
}
|
| 90 |
+
prompt = self.processor.tokenizer.apply_chat_template(
|
| 91 |
+
[user_message], tokenize=False, add_generation_prompt=True
|
| 92 |
+
)
|
| 93 |
+
answer = f'{annotation["Answer"]}<|end|><|endoftext|>'
|
| 94 |
+
inputs = self.processor(prompt, images=[image], return_tensors='pt')
|
| 95 |
+
|
| 96 |
+
answer_ids = self.processor.tokenizer(answer, return_tensors='pt').input_ids
|
| 97 |
+
|
| 98 |
+
input_ids = torch.cat([inputs.input_ids, answer_ids], dim=1)
|
| 99 |
+
labels = torch.full_like(input_ids, _IGNORE_INDEX)
|
| 100 |
+
labels[:, -answer_ids.shape[1] :] = answer_ids
|
| 101 |
+
|
| 102 |
+
if input_ids.size(1) > _MAX_TRAINING_LENGTH:
|
| 103 |
+
input_ids = input_ids[:, :_MAX_TRAINING_LENGTH]
|
| 104 |
+
labels = labels[:, :_MAX_TRAINING_LENGTH]
|
| 105 |
+
if torch.all(labels == _IGNORE_INDEX).item():
|
| 106 |
+
# workaround to make sure loss compute won't fail
|
| 107 |
+
labels[:, -1] = self.processor.tokenizer.eos_token_id
|
| 108 |
+
|
| 109 |
+
return {
|
| 110 |
+
'input_ids': input_ids,
|
| 111 |
+
'labels': labels,
|
| 112 |
+
'input_image_embeds': inputs.input_image_embeds,
|
| 113 |
+
'image_attention_mask': inputs.image_attention_mask,
|
| 114 |
+
'image_sizes': inputs.image_sizes,
|
| 115 |
+
}
|
| 116 |
+
|
| 117 |
+
def __del__(self):
|
| 118 |
+
__import__('shutil').rmtree(self.image_folder)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class PmcVqaEvalDataset(Dataset):
|
| 122 |
+
def __init__(
|
| 123 |
+
self, processor, data_size, instruction=DEFAULT_INSTSRUCTION, rank=0, world_size=1
|
| 124 |
+
):
|
| 125 |
+
# Download the file
|
| 126 |
+
file_path = hf_hub_download(
|
| 127 |
+
repo_id='xmcmic/PMC-VQA', # repository name
|
| 128 |
+
filename='images_2.zip', # file to download
|
| 129 |
+
repo_type='dataset', # specify it's a dataset repo
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
# file_path will be the local path where the file was downloaded
|
| 133 |
+
print(f'File downloaded to: {file_path}')
|
| 134 |
+
|
| 135 |
+
# unzip to temp folder
|
| 136 |
+
self.image_folder = Path(tempfile.mkdtemp())
|
| 137 |
+
with zipfile.ZipFile(file_path, 'r') as zip_ref:
|
| 138 |
+
zip_ref.extractall(self.image_folder)
|
| 139 |
+
|
| 140 |
+
data_files = {
|
| 141 |
+
'test': 'https://huggingface.co/datasets/xmcmic/PMC-VQA/resolve/main/test_2.csv',
|
| 142 |
+
}
|
| 143 |
+
split = 'test' if data_size is None else f'test[:{data_size}]'
|
| 144 |
+
self.annotations = load_dataset(
|
| 145 |
+
'xmcmic/PMC-VQA', data_files=data_files, split=split
|
| 146 |
+
).shard(num_shards=world_size, index=rank)
|
| 147 |
+
self.processor = processor
|
| 148 |
+
self.instruction = instruction
|
| 149 |
+
|
| 150 |
+
def __len__(self):
|
| 151 |
+
return len(self.annotations)
|
| 152 |
+
|
| 153 |
+
def __getitem__(self, idx):
|
| 154 |
+
"""
|
| 155 |
+
{'index': 62,
|
| 156 |
+
'Figure_path': 'PMC8253867_Fig2_41.jpg',
|
| 157 |
+
'Caption': 'CT pulmonary angiogram reveals encasement and displacement of the left anterior descending coronary artery ( blue arrows ).',
|
| 158 |
+
'Question': ' What is the name of the artery encased and displaced in the image? ',
|
| 159 |
+
'Choice A': ' A: Right Coronary Artery ',
|
| 160 |
+
'Choice B': ' B: Left Anterior Descending Coronary Artery ',
|
| 161 |
+
'Choice C': ' C: Circumflex Coronary Artery ',
|
| 162 |
+
'Choice D': ' D: Superior Mesenteric Artery ',
|
| 163 |
+
'Answer': 'B',
|
| 164 |
+
'split': 'test'}
|
| 165 |
+
"""
|
| 166 |
+
annotation = self.annotations[idx]
|
| 167 |
+
image = Image.open(self.image_folder / 'figures' / annotation['Figure_path'])
|
| 168 |
+
question = annotation['Question']
|
| 169 |
+
choices = [annotation[f'Choice {chr(ord("A") + i)}'] for i in range(4)]
|
| 170 |
+
user_message = {
|
| 171 |
+
'role': 'user',
|
| 172 |
+
'content': '<|image_1|>' + '\n'.join([question] + choices + [self.instruction]),
|
| 173 |
+
}
|
| 174 |
+
prompt = self.processor.tokenizer.apply_chat_template(
|
| 175 |
+
[user_message], tokenize=False, add_generation_prompt=True
|
| 176 |
+
)
|
| 177 |
+
answer = annotation['Answer']
|
| 178 |
+
inputs = self.processor(prompt, images=[image], return_tensors='pt')
|
| 179 |
+
|
| 180 |
+
unique_id = f'{annotation["index"]:010d}'
|
| 181 |
+
return {
|
| 182 |
+
'id': unique_id,
|
| 183 |
+
'input_ids': inputs.input_ids,
|
| 184 |
+
'input_image_embeds': inputs.input_image_embeds,
|
| 185 |
+
'image_attention_mask': inputs.image_attention_mask,
|
| 186 |
+
'image_sizes': inputs.image_sizes,
|
| 187 |
+
'answer': answer,
|
| 188 |
+
}
|
| 189 |
+
|
| 190 |
+
def __del__(self):
|
| 191 |
+
__import__('shutil').rmtree(self.image_folder)
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def pad_sequence(sequences, padding_side='right', padding_value=0):
|
| 195 |
+
"""
|
| 196 |
+
Pad a list of sequences to the same length.
|
| 197 |
+
sequences: list of tensors in [seq_len, *] shape
|
| 198 |
+
"""
|
| 199 |
+
assert padding_side in ['right', 'left']
|
| 200 |
+
max_size = sequences[0].size()
|
| 201 |
+
trailing_dims = max_size[1:]
|
| 202 |
+
max_len = max(len(seq) for seq in sequences)
|
| 203 |
+
batch_size = len(sequences)
|
| 204 |
+
output = sequences[0].new_full((batch_size, max_len) + trailing_dims, padding_value)
|
| 205 |
+
for i, seq in enumerate(sequences):
|
| 206 |
+
length = seq.size(0)
|
| 207 |
+
if padding_side == 'right':
|
| 208 |
+
output.data[i, :length] = seq
|
| 209 |
+
else:
|
| 210 |
+
output.data[i, -length:] = seq
|
| 211 |
+
return output
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
def cat_with_pad(tensors, dim, padding_value=0):
|
| 215 |
+
"""
|
| 216 |
+
cat along dim, while pad to max for all other dims
|
| 217 |
+
"""
|
| 218 |
+
ndim = tensors[0].dim()
|
| 219 |
+
assert all(
|
| 220 |
+
t.dim() == ndim for t in tensors[1:]
|
| 221 |
+
), 'All tensors must have the same number of dimensions'
|
| 222 |
+
|
| 223 |
+
out_size = [max(t.shape[i] for t in tensors) for i in range(ndim)]
|
| 224 |
+
out_size[dim] = sum(t.shape[dim] for t in tensors)
|
| 225 |
+
output = tensors[0].new_full(out_size, padding_value)
|
| 226 |
+
|
| 227 |
+
index = 0
|
| 228 |
+
for t in tensors:
|
| 229 |
+
# Create a slice list where every dimension except dim is full slice
|
| 230 |
+
slices = [slice(0, t.shape[d]) for d in range(ndim)]
|
| 231 |
+
# Update only the concat dimension slice
|
| 232 |
+
slices[dim] = slice(index, index + t.shape[dim])
|
| 233 |
+
|
| 234 |
+
output[slices] = t
|
| 235 |
+
index += t.shape[dim]
|
| 236 |
+
|
| 237 |
+
return output
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
def pmc_vqa_collate_fn(batch):
|
| 241 |
+
input_ids_list = []
|
| 242 |
+
labels_list = []
|
| 243 |
+
input_image_embeds_list = []
|
| 244 |
+
image_attention_mask_list = []
|
| 245 |
+
image_sizes_list = []
|
| 246 |
+
for inputs in batch:
|
| 247 |
+
input_ids_list.append(inputs['input_ids'][0])
|
| 248 |
+
labels_list.append(inputs['labels'][0])
|
| 249 |
+
input_image_embeds_list.append(inputs['input_image_embeds'])
|
| 250 |
+
image_attention_mask_list.append(inputs['image_attention_mask'])
|
| 251 |
+
image_sizes_list.append(inputs['image_sizes'])
|
| 252 |
+
|
| 253 |
+
input_ids = pad_sequence(input_ids_list, padding_side='right', padding_value=0)
|
| 254 |
+
labels = pad_sequence(labels_list, padding_side='right', padding_value=0)
|
| 255 |
+
attention_mask = (input_ids != 0).long()
|
| 256 |
+
input_image_embeds = cat_with_pad(input_image_embeds_list, dim=0)
|
| 257 |
+
image_attention_mask = cat_with_pad(image_attention_mask_list, dim=0)
|
| 258 |
+
image_sizes = torch.cat(image_sizes_list)
|
| 259 |
+
|
| 260 |
+
return BatchFeature(
|
| 261 |
+
{
|
| 262 |
+
'input_ids': input_ids,
|
| 263 |
+
'labels': labels,
|
| 264 |
+
'attention_mask': attention_mask,
|
| 265 |
+
'input_image_embeds': input_image_embeds,
|
| 266 |
+
'image_attention_mask': image_attention_mask,
|
| 267 |
+
'image_sizes': image_sizes,
|
| 268 |
+
'input_mode': 1, # vision mode
|
| 269 |
+
}
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
def pmc_vqa_eval_collate_fn(batch):
|
| 274 |
+
input_ids_list = []
|
| 275 |
+
input_image_embeds_list = []
|
| 276 |
+
image_attention_mask_list = []
|
| 277 |
+
image_sizes_list = []
|
| 278 |
+
all_unique_ids = []
|
| 279 |
+
all_answers = []
|
| 280 |
+
for inputs in batch:
|
| 281 |
+
input_ids_list.append(inputs['input_ids'][0])
|
| 282 |
+
input_image_embeds_list.append(inputs['input_image_embeds'])
|
| 283 |
+
image_attention_mask_list.append(inputs['image_attention_mask'])
|
| 284 |
+
image_sizes_list.append(inputs['image_sizes'])
|
| 285 |
+
all_unique_ids.append(inputs['id'])
|
| 286 |
+
all_answers.append(inputs['answer'])
|
| 287 |
+
|
| 288 |
+
input_ids = pad_sequence(input_ids_list, padding_side='left', padding_value=0)
|
| 289 |
+
attention_mask = (input_ids != 0).long()
|
| 290 |
+
input_image_embeds = cat_with_pad(input_image_embeds_list, dim=0)
|
| 291 |
+
image_attention_mask = cat_with_pad(image_attention_mask_list, dim=0)
|
| 292 |
+
image_sizes = torch.cat(image_sizes_list)
|
| 293 |
+
|
| 294 |
+
return (
|
| 295 |
+
all_unique_ids,
|
| 296 |
+
all_answers,
|
| 297 |
+
BatchFeature(
|
| 298 |
+
{
|
| 299 |
+
'input_ids': input_ids,
|
| 300 |
+
'attention_mask': attention_mask,
|
| 301 |
+
'input_image_embeds': input_image_embeds,
|
| 302 |
+
'image_attention_mask': image_attention_mask,
|
| 303 |
+
'image_sizes': image_sizes,
|
| 304 |
+
'input_mode': 1, # vision mode
|
| 305 |
+
}
|
| 306 |
+
),
|
| 307 |
+
)
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
def create_model(model_name_or_path, use_flash_attention=False):
|
| 311 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 312 |
+
model_name_or_path,
|
| 313 |
+
torch_dtype=torch.bfloat16 if use_flash_attention else torch.float32,
|
| 314 |
+
_attn_implementation='flash_attention_2' if use_flash_attention else 'sdpa',
|
| 315 |
+
trust_remote_code=True,
|
| 316 |
+
).to('cuda')
|
| 317 |
+
# remove parameters irrelevant to vision tasks
|
| 318 |
+
del model.model.embed_tokens_extend.audio_embed # remove audio encoder
|
| 319 |
+
for layer in model.model.layers:
|
| 320 |
+
# remove audio lora
|
| 321 |
+
del layer.mlp.down_proj.lora_A.speech
|
| 322 |
+
del layer.mlp.down_proj.lora_B.speech
|
| 323 |
+
del layer.mlp.gate_up_proj.lora_A.speech
|
| 324 |
+
del layer.mlp.gate_up_proj.lora_B.speech
|
| 325 |
+
del layer.self_attn.o_proj.lora_A.speech
|
| 326 |
+
del layer.self_attn.o_proj.lora_B.speech
|
| 327 |
+
del layer.self_attn.qkv_proj.lora_A.speech
|
| 328 |
+
del layer.self_attn.qkv_proj.lora_B.speech
|
| 329 |
+
|
| 330 |
+
# TODO remove unused vision layers?
|
| 331 |
+
|
| 332 |
+
return model
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
@torch.no_grad()
|
| 336 |
+
def evaluate(
|
| 337 |
+
model, processor, eval_dataset, save_path=None, disable_tqdm=False, eval_batch_size=1
|
| 338 |
+
):
|
| 339 |
+
rank = int(os.environ.get('RANK', 0))
|
| 340 |
+
local_rank = int(os.environ.get('LOCAL_RANK', 0))
|
| 341 |
+
|
| 342 |
+
model.eval()
|
| 343 |
+
all_answers = []
|
| 344 |
+
all_generated_texts = []
|
| 345 |
+
|
| 346 |
+
eval_dataloader = torch.utils.data.DataLoader(
|
| 347 |
+
eval_dataset,
|
| 348 |
+
batch_size=eval_batch_size,
|
| 349 |
+
collate_fn=pmc_vqa_eval_collate_fn,
|
| 350 |
+
shuffle=False,
|
| 351 |
+
drop_last=False,
|
| 352 |
+
num_workers=4,
|
| 353 |
+
prefetch_factor=2,
|
| 354 |
+
pin_memory=True,
|
| 355 |
+
)
|
| 356 |
+
for ids, answers, inputs in tqdm(
|
| 357 |
+
eval_dataloader, disable=(rank != 0) or disable_tqdm, desc='running eval'
|
| 358 |
+
):
|
| 359 |
+
all_answers.extend({'id': i, 'answer': a.strip().lower()} for i, a in zip(ids, answers))
|
| 360 |
+
|
| 361 |
+
inputs = inputs.to(f'cuda:{local_rank}')
|
| 362 |
+
generated_ids = model.generate(
|
| 363 |
+
**inputs, eos_token_id=processor.tokenizer.eos_token_id, max_new_tokens=64
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
input_len = inputs.input_ids.size(1)
|
| 367 |
+
generated_texts = processor.batch_decode(
|
| 368 |
+
generated_ids[:, input_len:],
|
| 369 |
+
skip_special_tokens=True,
|
| 370 |
+
clean_up_tokenization_spaces=False,
|
| 371 |
+
)
|
| 372 |
+
all_generated_texts.extend(
|
| 373 |
+
{'id': i, 'generated_text': g.strip().lower()} for i, g in zip(ids, generated_texts)
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
# gather outputs from all ranks
|
| 377 |
+
all_answers = gather_object(all_answers)
|
| 378 |
+
all_generated_texts = gather_object(all_generated_texts)
|
| 379 |
+
|
| 380 |
+
if rank == 0:
|
| 381 |
+
assert len(all_answers) == len(all_generated_texts)
|
| 382 |
+
acc = sum(
|
| 383 |
+
a['answer'] == g['generated_text'] for a, g in zip(all_answers, all_generated_texts)
|
| 384 |
+
) / len(all_answers)
|
| 385 |
+
if save_path:
|
| 386 |
+
with open(save_path, 'w') as f:
|
| 387 |
+
save_dict = {
|
| 388 |
+
'answers_unique': all_answers,
|
| 389 |
+
'generated_texts_unique': all_generated_texts,
|
| 390 |
+
'accuracy': acc,
|
| 391 |
+
}
|
| 392 |
+
json.dump(save_dict, f)
|
| 393 |
+
|
| 394 |
+
return acc
|
| 395 |
+
return None
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
def main():
|
| 399 |
+
parser = argparse.ArgumentParser()
|
| 400 |
+
parser.add_argument(
|
| 401 |
+
'--model_name_or_path',
|
| 402 |
+
type=str,
|
| 403 |
+
default='microsoft/Phi-4-multimodal-instruct',
|
| 404 |
+
help='Model name or path to load from',
|
| 405 |
+
)
|
| 406 |
+
parser.add_argument('--use_flash_attention', action='store_true', help='Use Flash Attention')
|
| 407 |
+
parser.add_argument('--output_dir', type=str, default='./output/', help='Output directory')
|
| 408 |
+
parser.add_argument('--batch_size', type=int, default=16, help='Batch size')
|
| 409 |
+
parser.add_argument(
|
| 410 |
+
'--batch_size_per_gpu',
|
| 411 |
+
type=int,
|
| 412 |
+
default=1,
|
| 413 |
+
help='Batch size per GPU (adjust this to fit in GPU memory)',
|
| 414 |
+
)
|
| 415 |
+
parser.add_argument(
|
| 416 |
+
'--dynamic_hd',
|
| 417 |
+
type=int,
|
| 418 |
+
default=36,
|
| 419 |
+
help='Number of maximum image crops',
|
| 420 |
+
)
|
| 421 |
+
parser.add_argument(
|
| 422 |
+
'--num_train_epochs', type=int, default=1, help='Number of training epochs'
|
| 423 |
+
)
|
| 424 |
+
parser.add_argument('--learning_rate', type=float, default=4.0e-5, help='Learning rate')
|
| 425 |
+
parser.add_argument('--wd', type=float, default=0.01, help='Weight decay')
|
| 426 |
+
parser.add_argument('--no_tqdm', dest='tqdm', action='store_false', help='Disable tqdm')
|
| 427 |
+
parser.add_argument('--full_run', action='store_true', help='Run the full training and eval')
|
| 428 |
+
args = parser.parse_args()
|
| 429 |
+
|
| 430 |
+
accelerator = Accelerator()
|
| 431 |
+
|
| 432 |
+
with accelerator.local_main_process_first():
|
| 433 |
+
processor = AutoProcessor.from_pretrained(
|
| 434 |
+
args.model_name_or_path,
|
| 435 |
+
trust_remote_code=True,
|
| 436 |
+
dynamic_hd=args.dynamic_hd,
|
| 437 |
+
)
|
| 438 |
+
model = create_model(
|
| 439 |
+
args.model_name_or_path,
|
| 440 |
+
use_flash_attention=args.use_flash_attention,
|
| 441 |
+
)
|
| 442 |
+
# tune vision encoder and lora
|
| 443 |
+
model.set_lora_adapter('vision')
|
| 444 |
+
for param in model.model.embed_tokens_extend.image_embed.parameters():
|
| 445 |
+
param.requires_grad = True
|
| 446 |
+
|
| 447 |
+
rank = int(os.environ.get('RANK', 0))
|
| 448 |
+
world_size = int(os.environ.get('WORLD_SIZE', 1))
|
| 449 |
+
|
| 450 |
+
train_dataset = PmcVqaTrainDataset(processor, data_size=None if args.full_run else _TRAIN_SIZE)
|
| 451 |
+
eval_dataset = PmcVqaEvalDataset(
|
| 452 |
+
processor,
|
| 453 |
+
data_size=None if args.full_run else _EVAL_SIZE,
|
| 454 |
+
rank=rank,
|
| 455 |
+
world_size=world_size,
|
| 456 |
+
)
|
| 457 |
+
|
| 458 |
+
num_gpus = accelerator.num_processes
|
| 459 |
+
print(f'training on {num_gpus} GPUs')
|
| 460 |
+
assert (
|
| 461 |
+
args.batch_size % (num_gpus * args.batch_size_per_gpu) == 0
|
| 462 |
+
), 'Batch size must be divisible by the number of GPUs'
|
| 463 |
+
gradient_accumulation_steps = args.batch_size // (num_gpus * args.batch_size_per_gpu)
|
| 464 |
+
|
| 465 |
+
if args.use_flash_attention:
|
| 466 |
+
fp16 = False
|
| 467 |
+
bf16 = True
|
| 468 |
+
else:
|
| 469 |
+
fp16 = True
|
| 470 |
+
bf16 = False
|
| 471 |
+
|
| 472 |
+
# hard coded training args
|
| 473 |
+
training_args = TrainingArguments(
|
| 474 |
+
num_train_epochs=args.num_train_epochs,
|
| 475 |
+
per_device_train_batch_size=args.batch_size_per_gpu,
|
| 476 |
+
gradient_checkpointing=True,
|
| 477 |
+
gradient_checkpointing_kwargs={'use_reentrant': False},
|
| 478 |
+
gradient_accumulation_steps=gradient_accumulation_steps,
|
| 479 |
+
optim='adamw_torch',
|
| 480 |
+
adam_beta1=0.9,
|
| 481 |
+
adam_beta2=0.95,
|
| 482 |
+
adam_epsilon=1e-7,
|
| 483 |
+
learning_rate=args.learning_rate,
|
| 484 |
+
weight_decay=args.wd,
|
| 485 |
+
max_grad_norm=1.0,
|
| 486 |
+
lr_scheduler_type='linear',
|
| 487 |
+
warmup_steps=50,
|
| 488 |
+
logging_steps=10,
|
| 489 |
+
output_dir=args.output_dir,
|
| 490 |
+
save_strategy='no',
|
| 491 |
+
save_total_limit=10,
|
| 492 |
+
save_only_model=True,
|
| 493 |
+
bf16=bf16,
|
| 494 |
+
fp16=fp16,
|
| 495 |
+
remove_unused_columns=False,
|
| 496 |
+
report_to='none',
|
| 497 |
+
deepspeed=None,
|
| 498 |
+
disable_tqdm=not args.tqdm,
|
| 499 |
+
dataloader_num_workers=4,
|
| 500 |
+
ddp_find_unused_parameters=True, # for unused SigLIP layers
|
| 501 |
+
)
|
| 502 |
+
|
| 503 |
+
# eval before fine-tuning
|
| 504 |
+
out_path = Path(training_args.output_dir)
|
| 505 |
+
out_path.mkdir(parents=True, exist_ok=True)
|
| 506 |
+
|
| 507 |
+
acc = evaluate(
|
| 508 |
+
model,
|
| 509 |
+
processor,
|
| 510 |
+
eval_dataset,
|
| 511 |
+
save_path=out_path / 'eval_before.json',
|
| 512 |
+
disable_tqdm=not args.tqdm,
|
| 513 |
+
eval_batch_size=args.batch_size_per_gpu,
|
| 514 |
+
)
|
| 515 |
+
if accelerator.is_main_process:
|
| 516 |
+
print(f'Accuracy before finetuning: {acc}')
|
| 517 |
+
|
| 518 |
+
trainer = Trainer(
|
| 519 |
+
model=model,
|
| 520 |
+
args=training_args,
|
| 521 |
+
data_collator=pmc_vqa_collate_fn,
|
| 522 |
+
train_dataset=train_dataset,
|
| 523 |
+
)
|
| 524 |
+
trainer.train()
|
| 525 |
+
trainer.save_model()
|
| 526 |
+
accelerator.wait_for_everyone()
|
| 527 |
+
|
| 528 |
+
# eval after fine-tuning (load saved checkpoint)
|
| 529 |
+
# first try to clear GPU memory
|
| 530 |
+
del model
|
| 531 |
+
del trainer
|
| 532 |
+
__import__('gc').collect()
|
| 533 |
+
torch.cuda.empty_cache()
|
| 534 |
+
|
| 535 |
+
# reload the model for inference
|
| 536 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 537 |
+
training_args.output_dir,
|
| 538 |
+
torch_dtype=torch.bfloat16 if args.use_flash_attention else torch.float32,
|
| 539 |
+
trust_remote_code=True,
|
| 540 |
+
_attn_implementation='flash_attention_2' if args.use_flash_attention else 'sdpa',
|
| 541 |
+
).to('cuda')
|
| 542 |
+
|
| 543 |
+
acc = evaluate(
|
| 544 |
+
model,
|
| 545 |
+
processor,
|
| 546 |
+
eval_dataset,
|
| 547 |
+
save_path=out_path / 'eval_after.json',
|
| 548 |
+
disable_tqdm=not args.tqdm,
|
| 549 |
+
eval_batch_size=args.batch_size_per_gpu,
|
| 550 |
+
)
|
| 551 |
+
if accelerator.is_main_process:
|
| 552 |
+
print(f'Accuracy after finetuning: {acc}')
|
| 553 |
+
|
| 554 |
+
|
| 555 |
+
if __name__ == '__main__':
|
| 556 |
+
main()
|
sample_inference_phi4mm.py
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import requests
|
| 3 |
+
import torch
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import soundfile
|
| 6 |
+
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
|
| 7 |
+
|
| 8 |
+
model_path = './'
|
| 9 |
+
|
| 10 |
+
kwargs = {}
|
| 11 |
+
kwargs['torch_dtype'] = torch.bfloat16
|
| 12 |
+
|
| 13 |
+
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
|
| 14 |
+
print(processor.tokenizer)
|
| 15 |
+
|
| 16 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 17 |
+
model_path,
|
| 18 |
+
trust_remote_code=True,
|
| 19 |
+
torch_dtype='auto',
|
| 20 |
+
_attn_implementation='flash_attention_2',
|
| 21 |
+
).cuda()
|
| 22 |
+
print("model.config._attn_implementation:", model.config._attn_implementation)
|
| 23 |
+
|
| 24 |
+
generation_config = GenerationConfig.from_pretrained(model_path, 'generation_config.json')
|
| 25 |
+
|
| 26 |
+
user_prompt = '<|user|>'
|
| 27 |
+
assistant_prompt = '<|assistant|>'
|
| 28 |
+
prompt_suffix = '<|end|>'
|
| 29 |
+
|
| 30 |
+
#################################################### text-only ####################################################
|
| 31 |
+
prompt = f'{user_prompt}what is the answer for 1+1? Explain it.{prompt_suffix}{assistant_prompt}'
|
| 32 |
+
print(f'>>> Prompt\n{prompt}')
|
| 33 |
+
inputs = processor(prompt, images=None, return_tensors='pt').to('cuda:0')
|
| 34 |
+
|
| 35 |
+
generate_ids = model.generate(
|
| 36 |
+
**inputs,
|
| 37 |
+
max_new_tokens=1000,
|
| 38 |
+
generation_config=generation_config,
|
| 39 |
+
)
|
| 40 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 41 |
+
response = processor.batch_decode(
|
| 42 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 43 |
+
)[0]
|
| 44 |
+
|
| 45 |
+
print(f'>>> Response\n{response}')
|
| 46 |
+
|
| 47 |
+
#################################################### vision (single-turn) ####################################################
|
| 48 |
+
# single-image prompt
|
| 49 |
+
prompt = f'{user_prompt}<|image_1|>What is shown in this image?{prompt_suffix}{assistant_prompt}'
|
| 50 |
+
url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
|
| 51 |
+
print(f'>>> Prompt\n{prompt}')
|
| 52 |
+
image = Image.open(requests.get(url, stream=True).raw)
|
| 53 |
+
inputs = processor(text=prompt, images=image, return_tensors='pt').to('cuda:0')
|
| 54 |
+
generate_ids = model.generate(
|
| 55 |
+
**inputs,
|
| 56 |
+
max_new_tokens=1000,
|
| 57 |
+
generation_config=generation_config,
|
| 58 |
+
)
|
| 59 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 60 |
+
response = processor.batch_decode(
|
| 61 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 62 |
+
)[0]
|
| 63 |
+
print(f'>>> Response\n{response}')
|
| 64 |
+
|
| 65 |
+
#################################################### vision (multi-turn) ####################################################
|
| 66 |
+
# chat template
|
| 67 |
+
chat = [
|
| 68 |
+
{'role': 'user', 'content': f'<|image_1|>What is shown in this image?'},
|
| 69 |
+
{
|
| 70 |
+
'role': 'assistant',
|
| 71 |
+
'content': "The image depicts a street scene with a prominent red stop sign in the foreground. The background showcases a building with traditional Chinese architecture, characterized by its red roof and ornate decorations. There are also several statues of lions, which are common in Chinese culture, positioned in front of the building. The street is lined with various shops and businesses, and there's a car passing by.",
|
| 72 |
+
},
|
| 73 |
+
{'role': 'user', 'content': 'What is so special about this image'},
|
| 74 |
+
]
|
| 75 |
+
url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
|
| 76 |
+
image = Image.open(requests.get(url, stream=True).raw)
|
| 77 |
+
prompt = processor.tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
|
| 78 |
+
# need to remove last <|endoftext|> if it is there, which is used for training, not inference. For training, make sure to add <|endoftext|> in the end.
|
| 79 |
+
if prompt.endswith('<|endoftext|>'):
|
| 80 |
+
prompt = prompt.rstrip('<|endoftext|>')
|
| 81 |
+
|
| 82 |
+
print(f'>>> Prompt\n{prompt}')
|
| 83 |
+
|
| 84 |
+
inputs = processor(prompt, [image], return_tensors='pt').to('cuda:0')
|
| 85 |
+
generate_ids = model.generate(
|
| 86 |
+
**inputs,
|
| 87 |
+
max_new_tokens=1000,
|
| 88 |
+
generation_config=generation_config,
|
| 89 |
+
)
|
| 90 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 91 |
+
response = processor.batch_decode(
|
| 92 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 93 |
+
)[0]
|
| 94 |
+
print(f'>>> Response\n{response}')
|
| 95 |
+
|
| 96 |
+
########################### vision (multi-frame) ################################
|
| 97 |
+
images = []
|
| 98 |
+
placeholder = ''
|
| 99 |
+
for i in range(1, 5):
|
| 100 |
+
url = f'https://image.slidesharecdn.com/azureintroduction-191206101932/75/Introduction-to-Microsoft-Azure-Cloud-{i}-2048.jpg'
|
| 101 |
+
images.append(Image.open(requests.get(url, stream=True).raw))
|
| 102 |
+
placeholder += f'<|image_{i}|>'
|
| 103 |
+
|
| 104 |
+
messages = [
|
| 105 |
+
{'role': 'user', 'content': placeholder + 'Summarize the deck of slides.'},
|
| 106 |
+
]
|
| 107 |
+
|
| 108 |
+
prompt = processor.tokenizer.apply_chat_template(
|
| 109 |
+
messages, tokenize=False, add_generation_prompt=True
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
print(f'>>> Prompt\n{prompt}')
|
| 113 |
+
|
| 114 |
+
inputs = processor(prompt, images, return_tensors='pt').to('cuda:0')
|
| 115 |
+
|
| 116 |
+
generation_args = {
|
| 117 |
+
'max_new_tokens': 1000,
|
| 118 |
+
'temperature': 0.0,
|
| 119 |
+
'do_sample': False,
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
generate_ids = model.generate(
|
| 123 |
+
**inputs, **generation_args, generation_config=generation_config,
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
# remove input tokens
|
| 127 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 128 |
+
response = processor.batch_decode(
|
| 129 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 130 |
+
)[0]
|
| 131 |
+
|
| 132 |
+
print(response)
|
| 133 |
+
|
| 134 |
+
# NOTE: Please prepare the audio file 'examples/what_is_the_traffic_sign_in_the_image.wav'
|
| 135 |
+
# and audio file 'examples/what_is_shown_in_this_image.wav' before running the following code
|
| 136 |
+
# Basically you can record your own voice for the question "What is the traffic sign in the image?" in "examples/what_is_the_traffic_sign_in_the_image.wav".
|
| 137 |
+
# And you can record your own voice for the question "What is shown in this image?" in "examples/what_is_shown_in_this_image.wav".
|
| 138 |
+
|
| 139 |
+
AUDIO_FILE_1 = 'examples/what_is_the_traffic_sign_in_the_image.wav'
|
| 140 |
+
AUDIO_FILE_2 = 'examples/what_is_shown_in_this_image.wav'
|
| 141 |
+
|
| 142 |
+
if not os.path.exists(AUDIO_FILE_1):
|
| 143 |
+
raise FileNotFoundError(f'Please prepare the audio file {AUDIO_FILE_1} before running the following code.')
|
| 144 |
+
########################## vision-speech ################################
|
| 145 |
+
prompt = f'{user_prompt}<|image_1|><|audio_1|>{prompt_suffix}{assistant_prompt}'
|
| 146 |
+
url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
|
| 147 |
+
print(f'>>> Prompt\n{prompt}')
|
| 148 |
+
image = Image.open(requests.get(url, stream=True).raw)
|
| 149 |
+
audio = soundfile.read(AUDIO_FILE_1)
|
| 150 |
+
inputs = processor(text=prompt, images=[image], audios=[audio], return_tensors='pt').to('cuda:0')
|
| 151 |
+
generate_ids = model.generate(
|
| 152 |
+
**inputs,
|
| 153 |
+
max_new_tokens=1000,
|
| 154 |
+
generation_config=generation_config,
|
| 155 |
+
)
|
| 156 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 157 |
+
response = processor.batch_decode(
|
| 158 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 159 |
+
)[0]
|
| 160 |
+
print(f'>>> Response\n{response}')
|
| 161 |
+
|
| 162 |
+
########################## speech only ################################
|
| 163 |
+
speech_prompt = "Based on the attached audio, generate a comprehensive text transcription of the spoken content."
|
| 164 |
+
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
|
| 165 |
+
|
| 166 |
+
print(f'>>> Prompt\n{prompt}')
|
| 167 |
+
audio = soundfile.read(AUDIO_FILE_1)
|
| 168 |
+
inputs = processor(text=prompt, audios=[audio], return_tensors='pt').to('cuda:0')
|
| 169 |
+
generate_ids = model.generate(
|
| 170 |
+
**inputs,
|
| 171 |
+
max_new_tokens=1000,
|
| 172 |
+
generation_config=generation_config,
|
| 173 |
+
)
|
| 174 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 175 |
+
response = processor.batch_decode(
|
| 176 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 177 |
+
)[0]
|
| 178 |
+
print(f'>>> Response\n{response}')
|
| 179 |
+
|
| 180 |
+
if not os.path.exists(AUDIO_FILE_2):
|
| 181 |
+
raise FileNotFoundError(f'Please prepare the audio file {AUDIO_FILE_2} before running the following code.')
|
| 182 |
+
########################### speech only (multi-turn) ################################
|
| 183 |
+
audio_1 = soundfile.read(AUDIO_FILE_2)
|
| 184 |
+
audio_2 = soundfile.read(AUDIO_FILE_1)
|
| 185 |
+
chat = [
|
| 186 |
+
{'role': 'user', 'content': f'<|audio_1|>Based on the attached audio, generate a comprehensive text transcription of the spoken content.'},
|
| 187 |
+
{
|
| 188 |
+
'role': 'assistant',
|
| 189 |
+
'content': "What is shown in this image.",
|
| 190 |
+
},
|
| 191 |
+
{'role': 'user', 'content': f'<|audio_2|>Based on the attached audio, generate a comprehensive text transcription of the spoken content.'},
|
| 192 |
+
]
|
| 193 |
+
prompt = processor.tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
|
| 194 |
+
# need to remove last <|endoftext|> if it is there, which is used for training, not inference. For training, make sure to add <|endoftext|> in the end.
|
| 195 |
+
if prompt.endswith('<|endoftext|>'):
|
| 196 |
+
prompt = prompt.rstrip('<|endoftext|>')
|
| 197 |
+
|
| 198 |
+
print(f'>>> Prompt\n{prompt}')
|
| 199 |
+
|
| 200 |
+
inputs = processor(text=prompt, audios=[audio_1, audio_2], return_tensors='pt').to('cuda:0')
|
| 201 |
+
generate_ids = model.generate(
|
| 202 |
+
**inputs,
|
| 203 |
+
max_new_tokens=1000,
|
| 204 |
+
generation_config=generation_config,
|
| 205 |
+
)
|
| 206 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 207 |
+
response = processor.batch_decode(
|
| 208 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 209 |
+
)[0]
|
| 210 |
+
print(f'>>> Response\n{response}')
|
| 211 |
+
|
| 212 |
+
#################################################### vision-speech (multi-turn) ####################################################
|
| 213 |
+
# chat template
|
| 214 |
+
audio_1 = soundfile.read(AUDIO_FILE_2)
|
| 215 |
+
audio_2 = soundfile.read(AUDIO_FILE_1)
|
| 216 |
+
chat = [
|
| 217 |
+
{'role': 'user', 'content': f'<|image_1|><|audio_1|>'},
|
| 218 |
+
{
|
| 219 |
+
'role': 'assistant',
|
| 220 |
+
'content': "The image depicts a street scene with a prominent red stop sign in the foreground. The background showcases a building with traditional Chinese architecture, characterized by its red roof and ornate decorations. There are also several statues of lions, which are common in Chinese culture, positioned in front of the building. The street is lined with various shops and businesses, and there's a car passing by.",
|
| 221 |
+
},
|
| 222 |
+
{'role': 'user', 'content': f'<|audio_2|>'},
|
| 223 |
+
]
|
| 224 |
+
url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
|
| 225 |
+
image = Image.open(requests.get(url, stream=True).raw)
|
| 226 |
+
prompt = processor.tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
|
| 227 |
+
# need to remove last <|endoftext|> if it is there, which is used for training, not inference. For training, make sure to add <|endoftext|> in the end.
|
| 228 |
+
if prompt.endswith('<|endoftext|>'):
|
| 229 |
+
prompt = prompt.rstrip('<|endoftext|>')
|
| 230 |
+
|
| 231 |
+
print(f'>>> Prompt\n{prompt}')
|
| 232 |
+
|
| 233 |
+
inputs = processor(text=prompt, images=[image], audios=[audio_1, audio_2], return_tensors='pt').to('cuda:0')
|
| 234 |
+
generate_ids = model.generate(
|
| 235 |
+
**inputs,
|
| 236 |
+
max_new_tokens=1000,
|
| 237 |
+
generation_config=generation_config,
|
| 238 |
+
)
|
| 239 |
+
generate_ids = generate_ids[:, inputs['input_ids'].shape[1] :]
|
| 240 |
+
response = processor.batch_decode(
|
| 241 |
+
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 242 |
+
)[0]
|
| 243 |
+
print(f'>>> Response\n{response}')
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|endoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<|endoftext|>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
speech-lora/adapter_config.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_mapping": null,
|
| 3 |
+
"base_model_name_or_path": "TBA",
|
| 4 |
+
"bias": "none",
|
| 5 |
+
"fan_in_fan_out": false,
|
| 6 |
+
"inference_mode": true,
|
| 7 |
+
"init_lora_weights": true,
|
| 8 |
+
"layers_pattern": null,
|
| 9 |
+
"layers_to_transform": null,
|
| 10 |
+
"lora_alpha": 640,
|
| 11 |
+
"lora_dropout": 0.01,
|
| 12 |
+
"modules_to_save": [],
|
| 13 |
+
"peft_type": "LORA",
|
| 14 |
+
"r": 320,
|
| 15 |
+
"revision": null,
|
| 16 |
+
"target_modules": [
|
| 17 |
+
"qkv_proj",
|
| 18 |
+
"o_proj",
|
| 19 |
+
"gate_up_proj",
|
| 20 |
+
"down_proj"
|
| 21 |
+
],
|
| 22 |
+
"task_type": "CAUSAL_LM"
|
| 23 |
+
}
|
speech-lora/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1c2237461a4d1f9292cd128147bd3f0f70326a48d5d79c8e0f7583b26c095b30
|
| 3 |
+
size 922782296
|
speech-lora/added_tokens.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|/tool_call|>": 200026,
|
| 3 |
+
"<|/tool|>": 200024,
|
| 4 |
+
"<|assistant|>": 200019,
|
| 5 |
+
"<|end|>": 200020,
|
| 6 |
+
"<|system|>": 200022,
|
| 7 |
+
"<|tag|>": 200028,
|
| 8 |
+
"<|tool_call|>": 200025,
|
| 9 |
+
"<|tool_response|>": 200027,
|
| 10 |
+
"<|tool|>": 200023,
|
| 11 |
+
"<|user|>": 200021
|
| 12 |
+
}
|
speech-lora/special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|endoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<|endoftext|>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
speech-lora/tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:382cc235b56c725945e149cc25f191da667c836655efd0857b004320e90e91ea
|
| 3 |
+
size 15524095
|
speech-lora/tokenizer_config.json
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"200010": {
|
| 5 |
+
"content": "<|endoftext10|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"200011": {
|
| 13 |
+
"content": "<|endoftext11|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"199999": {
|
| 21 |
+
"content": "<|endoftext|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"200018": {
|
| 29 |
+
"content": "<|endofprompt|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"200019": {
|
| 37 |
+
"content": "<|assistant|>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": true,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"200020": {
|
| 45 |
+
"content": "<|end|>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": true,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"200021": {
|
| 53 |
+
"content": "<|user|>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": true,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"200022": {
|
| 61 |
+
"content": "<|system|>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": true,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"200023": {
|
| 69 |
+
"content": "<|tool|>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": true,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": false
|
| 75 |
+
},
|
| 76 |
+
"200024": {
|
| 77 |
+
"content": "<|/tool|>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": true,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": false
|
| 83 |
+
},
|
| 84 |
+
"200025": {
|
| 85 |
+
"content": "<|tool_call|>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": true,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": false
|
| 91 |
+
},
|
| 92 |
+
"200026": {
|
| 93 |
+
"content": "<|/tool_call|>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": true,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": false
|
| 99 |
+
},
|
| 100 |
+
"200027": {
|
| 101 |
+
"content": "<|tool_response|>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": true,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": false
|
| 107 |
+
},
|
| 108 |
+
"200028": {
|
| 109 |
+
"content": "<|tag|>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": true,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
}
|
| 116 |
+
},
|
| 117 |
+
"bos_token": "<|endoftext|>",
|
| 118 |
+
"chat_template": "{% for message in messages %}{% if message['role'] == 'system' and 'tools' in message and message['tools'] is not none %}{{ '<|' + message['role'] + '|>' + message['content'] + '<|tool|>' + message['tools'] + '<|/tool|>' + '<|end|>' }}{% else %}{{ '<|' + message['role'] + '|>' + message['content'] + '<|end|>' }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ '<|assistant|>' }}{% else %}{{ eos_token }}{% endif %}",
|
| 119 |
+
"clean_up_tokenization_spaces": false,
|
| 120 |
+
"eos_token": "<|endoftext|>",
|
| 121 |
+
"model_max_length": 128000,
|
| 122 |
+
"pad_token": "<|endoftext|>",
|
| 123 |
+
"tokenizer_class": "GPT2TokenizerFast",
|
| 124 |
+
"unk_token": "<|endoftext|>"
|
| 125 |
+
}
|
speech-lora/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
speech_conformer_encoder.py
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4c1b9f641d4f8b7247b8d5007dd3b6a9f6a87cb5123134fe0d326f14d10c0585
|
| 3 |
+
size 15524479
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"200010": {
|
| 5 |
+
"content": "<|endoftext10|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"200011": {
|
| 13 |
+
"content": "<|endoftext11|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"199999": {
|
| 21 |
+
"content": "<|endoftext|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"200018": {
|
| 29 |
+
"content": "<|endofprompt|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"200019": {
|
| 37 |
+
"content": "<|assistant|>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": true,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"200020": {
|
| 45 |
+
"content": "<|end|>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": true,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"200021": {
|
| 53 |
+
"content": "<|user|>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": true,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"200022": {
|
| 61 |
+
"content": "<|system|>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": true,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"200023": {
|
| 69 |
+
"content": "<|tool|>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": true,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": false
|
| 75 |
+
},
|
| 76 |
+
"200024": {
|
| 77 |
+
"content": "<|/tool|>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": true,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": false
|
| 83 |
+
},
|
| 84 |
+
"200025": {
|
| 85 |
+
"content": "<|tool_call|>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": true,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": false
|
| 91 |
+
},
|
| 92 |
+
"200026": {
|
| 93 |
+
"content": "<|/tool_call|>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": true,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": false
|
| 99 |
+
},
|
| 100 |
+
"200027": {
|
| 101 |
+
"content": "<|tool_response|>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": true,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": false
|
| 107 |
+
},
|
| 108 |
+
"200028": {
|
| 109 |
+
"content": "<|tag|>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": true,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
}
|
| 116 |
+
},
|
| 117 |
+
"bos_token": "<|endoftext|>",
|
| 118 |
+
"chat_template": "{% for message in messages %}{% if message['role'] == 'system' and 'tools' in message and message['tools'] is not none %}{{ '<|' + message['role'] + '|>' + message['content'] + '<|tool|>' + message['tools'] + '<|/tool|>' + '<|end|>' }}{% else %}{{ '<|' + message['role'] + '|>' + message['content'] + '<|end|>' }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ '<|assistant|>' }}{% else %}{{ eos_token }}{% endif %}",
|
| 119 |
+
"clean_up_tokenization_spaces": false,
|
| 120 |
+
"eos_token": "<|endoftext|>",
|
| 121 |
+
"model_max_length": 131072,
|
| 122 |
+
"pad_token": "<|endoftext|>",
|
| 123 |
+
"tokenizer_class": "GPT2TokenizerFast",
|
| 124 |
+
"unk_token": "<|endoftext|>"
|
| 125 |
+
}
|
vision-lora/adapter_config.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_mapping": null,
|
| 3 |
+
"base_model_name_or_path": "TBA",
|
| 4 |
+
"bias": "none",
|
| 5 |
+
"fan_in_fan_out": false,
|
| 6 |
+
"inference_mode": true,
|
| 7 |
+
"init_lora_weights": true,
|
| 8 |
+
"layers_pattern": null,
|
| 9 |
+
"layers_to_transform": null,
|
| 10 |
+
"lora_alpha": 512,
|
| 11 |
+
"lora_dropout": 0.0,
|
| 12 |
+
"modules_to_save": [],
|
| 13 |
+
"peft_type": "LORA",
|
| 14 |
+
"r": 256,
|
| 15 |
+
"revision": null,
|
| 16 |
+
"target_modules": [
|
| 17 |
+
"qkv_proj",
|
| 18 |
+
"o_proj",
|
| 19 |
+
"gate_up_proj",
|
| 20 |
+
"down_proj"
|
| 21 |
+
],
|
| 22 |
+
"task_type": "CAUSAL_LM"
|
| 23 |
+
}
|
vision-lora/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1620b16722edf701038bf66e3cd46412c7cc5458e58df89e9f92cedb71fcbde8
|
| 3 |
+
size 738232904
|
vision-lora/added_tokens.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|/tool_call|>": 200026,
|
| 3 |
+
"<|/tool|>": 200024,
|
| 4 |
+
"<|assistant|>": 200019,
|
| 5 |
+
"<|end|>": 200020,
|
| 6 |
+
"<|system|>": 200022,
|
| 7 |
+
"<|tag|>": 200028,
|
| 8 |
+
"<|tool_call|>": 200025,
|
| 9 |
+
"<|tool_response|>": 200027,
|
| 10 |
+
"<|tool|>": 200023,
|
| 11 |
+
"<|user|>": 200021
|
| 12 |
+
}
|
vision-lora/special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|endoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<|endoftext|>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<|endoftext|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
vision-lora/tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:382cc235b56c725945e149cc25f191da667c836655efd0857b004320e90e91ea
|
| 3 |
+
size 15524095
|
vision-lora/tokenizer_config.json
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"200010": {
|
| 5 |
+
"content": "<|endoftext10|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"200011": {
|
| 13 |
+
"content": "<|endoftext11|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"199999": {
|
| 21 |
+
"content": "<|endoftext|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"200018": {
|
| 29 |
+
"content": "<|endofprompt|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"200019": {
|
| 37 |
+
"content": "<|assistant|>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": true,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"200020": {
|
| 45 |
+
"content": "<|end|>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": true,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"200021": {
|
| 53 |
+
"content": "<|user|>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": true,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"200022": {
|
| 61 |
+
"content": "<|system|>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": true,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"200023": {
|
| 69 |
+
"content": "<|tool|>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": true,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": false
|
| 75 |
+
},
|
| 76 |
+
"200024": {
|
| 77 |
+
"content": "<|/tool|>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": true,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": false
|
| 83 |
+
},
|
| 84 |
+
"200025": {
|
| 85 |
+
"content": "<|tool_call|>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": true,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": false
|
| 91 |
+
},
|
| 92 |
+
"200026": {
|
| 93 |
+
"content": "<|/tool_call|>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": true,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": false
|
| 99 |
+
},
|
| 100 |
+
"200027": {
|
| 101 |
+
"content": "<|tool_response|>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": true,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": false
|
| 107 |
+
},
|
| 108 |
+
"200028": {
|
| 109 |
+
"content": "<|tag|>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": true,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
}
|
| 116 |
+
},
|
| 117 |
+
"bos_token": "<|endoftext|>",
|
| 118 |
+
"chat_template": "{% for message in messages %}{% if message['role'] == 'system' and 'tools' in message and message['tools'] is not none %}{{ '<|' + message['role'] + '|>' + message['content'] + '<|tool|>' + message['tools'] + '<|/tool|>' + '<|end|>' }}{% else %}{{ '<|' + message['role'] + '|>' + message['content'] + '<|end|>' }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ '<|assistant|>' }}{% else %}{{ eos_token }}{% endif %}",
|
| 119 |
+
"clean_up_tokenization_spaces": false,
|
| 120 |
+
"eos_token": "<|endoftext|>",
|
| 121 |
+
"model_max_length": 128000,
|
| 122 |
+
"pad_token": "<|endoftext|>",
|
| 123 |
+
"tokenizer_class": "GPT2TokenizerFast",
|
| 124 |
+
"unk_token": "<|endoftext|>"
|
| 125 |
+
}
|
vision-lora/vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
vision_siglip_navit.py
ADDED
|
@@ -0,0 +1,1717 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
""" Siglip model configuration"""
|
| 16 |
+
|
| 17 |
+
import os
|
| 18 |
+
from typing import Union
|
| 19 |
+
|
| 20 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 21 |
+
from transformers.utils import logging
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
logger = logging.get_logger(__name__)
|
| 25 |
+
|
| 26 |
+
SIGLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
| 27 |
+
"google/siglip-base-patch16-224": "https://huggingface.co/google/siglip-base-patch16-224/resolve/main/config.json",
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class SiglipTextConfig(PretrainedConfig):
|
| 32 |
+
r"""
|
| 33 |
+
This is the configuration class to store the configuration of a [`SiglipTextModel`]. It is used to instantiate a
|
| 34 |
+
Siglip text encoder according to the specified arguments, defining the model architecture. Instantiating a
|
| 35 |
+
configuration with the defaults will yield a similar configuration to that of the text encoder of the Siglip
|
| 36 |
+
[google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
|
| 37 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 38 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 39 |
+
Args:
|
| 40 |
+
vocab_size (`int`, *optional*, defaults to 32000):
|
| 41 |
+
Vocabulary size of the Siglip text model. Defines the number of different tokens that can be represented by
|
| 42 |
+
the `inputs_ids` passed when calling [`SiglipModel`].
|
| 43 |
+
hidden_size (`int`, *optional*, defaults to 768):
|
| 44 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 45 |
+
intermediate_size (`int`, *optional*, defaults to 3072):
|
| 46 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 47 |
+
num_hidden_layers (`int`, *optional*, defaults to 12):
|
| 48 |
+
Number of hidden layers in the Transformer encoder.
|
| 49 |
+
num_attention_heads (`int`, *optional*, defaults to 12):
|
| 50 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 51 |
+
max_position_embeddings (`int`, *optional*, defaults to 64):
|
| 52 |
+
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
| 53 |
+
just in case (e.g., 512 or 1024 or 2048).
|
| 54 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
|
| 55 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 56 |
+
`"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
|
| 57 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 58 |
+
The epsilon used by the layer normalization layers.
|
| 59 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 60 |
+
The dropout ratio for the attention probabilities.
|
| 61 |
+
pad_token_id (`int`, *optional*, defaults to 1):
|
| 62 |
+
The id of the padding token in the vocabulary.
|
| 63 |
+
bos_token_id (`int`, *optional*, defaults to 49406):
|
| 64 |
+
The id of the beginning-of-sequence token in the vocabulary.
|
| 65 |
+
eos_token_id (`int`, *optional*, defaults to 49407):
|
| 66 |
+
The id of the end-of-sequence token in the vocabulary.
|
| 67 |
+
Example:
|
| 68 |
+
```python
|
| 69 |
+
>>> from transformers import SiglipTextConfig, SiglipTextModel
|
| 70 |
+
>>> # Initializing a SiglipTextConfig with google/siglip-base-patch16-224 style configuration
|
| 71 |
+
>>> configuration = SiglipTextConfig()
|
| 72 |
+
>>> # Initializing a SiglipTextModel (with random weights) from the google/siglip-base-patch16-224 style configuration
|
| 73 |
+
>>> model = SiglipTextModel(configuration)
|
| 74 |
+
>>> # Accessing the model configuration
|
| 75 |
+
>>> configuration = model.config
|
| 76 |
+
```"""
|
| 77 |
+
|
| 78 |
+
model_type = "siglip_text_model"
|
| 79 |
+
|
| 80 |
+
def __init__(
|
| 81 |
+
self,
|
| 82 |
+
vocab_size=32000,
|
| 83 |
+
hidden_size=768,
|
| 84 |
+
intermediate_size=3072,
|
| 85 |
+
num_hidden_layers=12,
|
| 86 |
+
num_attention_heads=12,
|
| 87 |
+
max_position_embeddings=64,
|
| 88 |
+
hidden_act="gelu_pytorch_tanh",
|
| 89 |
+
layer_norm_eps=1e-6,
|
| 90 |
+
attention_dropout=0.0,
|
| 91 |
+
# This differs from `CLIPTokenizer`'s default and from openai/siglip
|
| 92 |
+
# See https://github.com/huggingface/transformers/pull/24773#issuecomment-1632287538
|
| 93 |
+
pad_token_id=1,
|
| 94 |
+
bos_token_id=49406,
|
| 95 |
+
eos_token_id=49407,
|
| 96 |
+
_flash_attn_2_enabled=True,
|
| 97 |
+
**kwargs,
|
| 98 |
+
):
|
| 99 |
+
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
|
| 100 |
+
|
| 101 |
+
self.vocab_size = vocab_size
|
| 102 |
+
self.hidden_size = hidden_size
|
| 103 |
+
self.intermediate_size = intermediate_size
|
| 104 |
+
self.num_hidden_layers = num_hidden_layers
|
| 105 |
+
self.num_attention_heads = num_attention_heads
|
| 106 |
+
self.max_position_embeddings = max_position_embeddings
|
| 107 |
+
self.layer_norm_eps = layer_norm_eps
|
| 108 |
+
self.hidden_act = hidden_act
|
| 109 |
+
self.attention_dropout = attention_dropout
|
| 110 |
+
self._flash_attn_2_enabled = _flash_attn_2_enabled
|
| 111 |
+
|
| 112 |
+
@classmethod
|
| 113 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 114 |
+
cls._set_token_in_kwargs(kwargs)
|
| 115 |
+
|
| 116 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 117 |
+
|
| 118 |
+
# get the text config dict if we are loading from SiglipConfig
|
| 119 |
+
if config_dict.get("model_type") == "siglip":
|
| 120 |
+
config_dict = config_dict["text_config"]
|
| 121 |
+
|
| 122 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 123 |
+
logger.warning(
|
| 124 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 125 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
class SiglipVisionConfig(PretrainedConfig):
|
| 132 |
+
r"""
|
| 133 |
+
This is the configuration class to store the configuration of a [`SiglipVisionModel`]. It is used to instantiate a
|
| 134 |
+
Siglip vision encoder according to the specified arguments, defining the model architecture. Instantiating a
|
| 135 |
+
configuration with the defaults will yield a similar configuration to that of the vision encoder of the Siglip
|
| 136 |
+
[google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
|
| 137 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 138 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 139 |
+
Args:
|
| 140 |
+
hidden_size (`int`, *optional*, defaults to 768):
|
| 141 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 142 |
+
intermediate_size (`int`, *optional*, defaults to 3072):
|
| 143 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 144 |
+
num_hidden_layers (`int`, *optional*, defaults to 12):
|
| 145 |
+
Number of hidden layers in the Transformer encoder.
|
| 146 |
+
num_attention_heads (`int`, *optional*, defaults to 12):
|
| 147 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 148 |
+
num_channels (`int`, *optional*, defaults to 3):
|
| 149 |
+
Number of channels in the input images.
|
| 150 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 151 |
+
The size (resolution) of each image.
|
| 152 |
+
patch_size (`int`, *optional*, defaults to 16):
|
| 153 |
+
The size (resolution) of each patch.
|
| 154 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
|
| 155 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 156 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
|
| 157 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 158 |
+
The epsilon used by the layer normalization layers.
|
| 159 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 160 |
+
The dropout ratio for the attention probabilities.
|
| 161 |
+
Example:
|
| 162 |
+
```python
|
| 163 |
+
>>> from transformers import SiglipVisionConfig, SiglipVisionModel
|
| 164 |
+
>>> # Initializing a SiglipVisionConfig with google/siglip-base-patch16-224 style configuration
|
| 165 |
+
>>> configuration = SiglipVisionConfig()
|
| 166 |
+
>>> # Initializing a SiglipVisionModel (with random weights) from the google/siglip-base-patch16-224 style configuration
|
| 167 |
+
>>> model = SiglipVisionModel(configuration)
|
| 168 |
+
>>> # Accessing the model configuration
|
| 169 |
+
>>> configuration = model.config
|
| 170 |
+
```"""
|
| 171 |
+
|
| 172 |
+
model_type = "siglip_vision_model"
|
| 173 |
+
|
| 174 |
+
def __init__(
|
| 175 |
+
self,
|
| 176 |
+
hidden_size=768,
|
| 177 |
+
intermediate_size=3072,
|
| 178 |
+
num_hidden_layers=12,
|
| 179 |
+
num_attention_heads=12,
|
| 180 |
+
num_channels=3,
|
| 181 |
+
image_size=224,
|
| 182 |
+
patch_size=16,
|
| 183 |
+
hidden_act="gelu_pytorch_tanh",
|
| 184 |
+
layer_norm_eps=1e-6,
|
| 185 |
+
attention_dropout=0.0,
|
| 186 |
+
_flash_attn_2_enabled=True,
|
| 187 |
+
**kwargs,
|
| 188 |
+
):
|
| 189 |
+
super().__init__(**kwargs)
|
| 190 |
+
|
| 191 |
+
self.hidden_size = hidden_size
|
| 192 |
+
self.intermediate_size = intermediate_size
|
| 193 |
+
self.num_hidden_layers = num_hidden_layers
|
| 194 |
+
self.num_attention_heads = num_attention_heads
|
| 195 |
+
self.num_channels = num_channels
|
| 196 |
+
self.patch_size = patch_size
|
| 197 |
+
self.image_size = image_size
|
| 198 |
+
self.attention_dropout = attention_dropout
|
| 199 |
+
self.layer_norm_eps = layer_norm_eps
|
| 200 |
+
self.hidden_act = hidden_act
|
| 201 |
+
self._flash_attn_2_enabled = _flash_attn_2_enabled
|
| 202 |
+
|
| 203 |
+
@classmethod
|
| 204 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 205 |
+
cls._set_token_in_kwargs(kwargs)
|
| 206 |
+
|
| 207 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 208 |
+
|
| 209 |
+
# get the vision config dict if we are loading from SiglipConfig
|
| 210 |
+
if config_dict.get("model_type") == "siglip":
|
| 211 |
+
config_dict = config_dict["vision_config"]
|
| 212 |
+
|
| 213 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 214 |
+
logger.warning(
|
| 215 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 216 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 217 |
+
)
|
| 218 |
+
|
| 219 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
class SiglipConfig(PretrainedConfig):
|
| 223 |
+
r"""
|
| 224 |
+
[`SiglipConfig`] is the configuration class to store the configuration of a [`SiglipModel`]. It is used to
|
| 225 |
+
instantiate a Siglip model according to the specified arguments, defining the text model and vision model configs.
|
| 226 |
+
Instantiating a configuration with the defaults will yield a similar configuration to that of the Siglip
|
| 227 |
+
[google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
|
| 228 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 229 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 230 |
+
Args:
|
| 231 |
+
text_config (`dict`, *optional*):
|
| 232 |
+
Dictionary of configuration options used to initialize [`SiglipTextConfig`].
|
| 233 |
+
vision_config (`dict`, *optional*):
|
| 234 |
+
Dictionary of configuration options used to initialize [`SiglipVisionConfig`].
|
| 235 |
+
kwargs (*optional*):
|
| 236 |
+
Dictionary of keyword arguments.
|
| 237 |
+
Example:
|
| 238 |
+
```python
|
| 239 |
+
>>> from transformers import SiglipConfig, SiglipModel
|
| 240 |
+
>>> # Initializing a SiglipConfig with google/siglip-base-patch16-224 style configuration
|
| 241 |
+
>>> configuration = SiglipConfig()
|
| 242 |
+
>>> # Initializing a SiglipModel (with random weights) from the google/siglip-base-patch16-224 style configuration
|
| 243 |
+
>>> model = SiglipModel(configuration)
|
| 244 |
+
>>> # Accessing the model configuration
|
| 245 |
+
>>> configuration = model.config
|
| 246 |
+
>>> # We can also initialize a SiglipConfig from a SiglipTextConfig and a SiglipVisionConfig
|
| 247 |
+
>>> from transformers import SiglipTextConfig, SiglipVisionConfig
|
| 248 |
+
>>> # Initializing a SiglipText and SiglipVision configuration
|
| 249 |
+
>>> config_text = SiglipTextConfig()
|
| 250 |
+
>>> config_vision = SiglipVisionConfig()
|
| 251 |
+
>>> config = SiglipConfig.from_text_vision_configs(config_text, config_vision)
|
| 252 |
+
```"""
|
| 253 |
+
|
| 254 |
+
model_type = "siglip"
|
| 255 |
+
|
| 256 |
+
def __init__(self, text_config=None, vision_config=None, **kwargs):
|
| 257 |
+
super().__init__(**kwargs)
|
| 258 |
+
|
| 259 |
+
if text_config is None:
|
| 260 |
+
text_config = {}
|
| 261 |
+
logger.info("`text_config` is `None`. Initializing the `SiglipTextConfig` with default values.")
|
| 262 |
+
|
| 263 |
+
if vision_config is None:
|
| 264 |
+
vision_config = {}
|
| 265 |
+
logger.info("`vision_config` is `None`. initializing the `SiglipVisionConfig` with default values.")
|
| 266 |
+
|
| 267 |
+
self.text_config = SiglipTextConfig(**text_config)
|
| 268 |
+
self.vision_config = SiglipVisionConfig(**vision_config)
|
| 269 |
+
|
| 270 |
+
self.initializer_factor = 1.0
|
| 271 |
+
|
| 272 |
+
@classmethod
|
| 273 |
+
def from_text_vision_configs(cls, text_config: SiglipTextConfig, vision_config: SiglipVisionConfig, **kwargs):
|
| 274 |
+
r"""
|
| 275 |
+
Instantiate a [`SiglipConfig`] (or a derived class) from siglip text model configuration and siglip vision
|
| 276 |
+
model configuration.
|
| 277 |
+
Returns:
|
| 278 |
+
[`SiglipConfig`]: An instance of a configuration object
|
| 279 |
+
"""
|
| 280 |
+
|
| 281 |
+
return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
|
| 282 |
+
|
| 283 |
+
# coding=utf-8
|
| 284 |
+
# Copyright 2024 Google AI and The HuggingFace Team. All rights reserved.
|
| 285 |
+
#
|
| 286 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 287 |
+
# you may not use this file except in compliance with the License.
|
| 288 |
+
# You may obtain a copy of the License at
|
| 289 |
+
#
|
| 290 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 291 |
+
#
|
| 292 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 293 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 294 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 295 |
+
# See the License for the specific language governing permissions and
|
| 296 |
+
# limitations under the License.
|
| 297 |
+
""" PyTorch Siglip model."""
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
import math
|
| 301 |
+
import warnings
|
| 302 |
+
from dataclasses import dataclass
|
| 303 |
+
from typing import Any, Optional, Tuple, Union
|
| 304 |
+
|
| 305 |
+
import numpy as np
|
| 306 |
+
import torch
|
| 307 |
+
import torch.nn.functional as F
|
| 308 |
+
import torch.utils.checkpoint
|
| 309 |
+
from torch import nn
|
| 310 |
+
from torch.nn.init import _calculate_fan_in_and_fan_out
|
| 311 |
+
|
| 312 |
+
from transformers.activations import ACT2FN
|
| 313 |
+
from transformers.modeling_attn_mask_utils import _prepare_4d_attention_mask
|
| 314 |
+
from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
|
| 315 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 316 |
+
from transformers.utils import (
|
| 317 |
+
ModelOutput,
|
| 318 |
+
add_start_docstrings,
|
| 319 |
+
add_start_docstrings_to_model_forward,
|
| 320 |
+
is_flash_attn_2_available,
|
| 321 |
+
logging,
|
| 322 |
+
replace_return_docstrings,
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
logger = logging.get_logger(__name__)
|
| 326 |
+
|
| 327 |
+
_CHECKPOINT_FOR_DOC = "google/siglip-base-patch16-224"
|
| 328 |
+
|
| 329 |
+
SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
| 330 |
+
"google/siglip-base-patch16-224",
|
| 331 |
+
# See all SigLIP models at https://huggingface.co/models?filter=siglip
|
| 332 |
+
]
|
| 333 |
+
|
| 334 |
+
if is_flash_attn_2_available():
|
| 335 |
+
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
| 336 |
+
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
|
| 340 |
+
def _get_unpad_data(attention_mask):
|
| 341 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 342 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 343 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 344 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 345 |
+
return (
|
| 346 |
+
indices,
|
| 347 |
+
cu_seqlens,
|
| 348 |
+
max_seqlen_in_batch,
|
| 349 |
+
)
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
def _trunc_normal_(tensor, mean, std, a, b):
|
| 353 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 354 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 355 |
+
def norm_cdf(x):
|
| 356 |
+
# Computes standard normal cumulative distribution function
|
| 357 |
+
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
|
| 358 |
+
|
| 359 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 360 |
+
warnings.warn(
|
| 361 |
+
"mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 362 |
+
"The distribution of values may be incorrect.",
|
| 363 |
+
stacklevel=2,
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
# Values are generated by using a truncated uniform distribution and
|
| 367 |
+
# then using the inverse CDF for the normal distribution.
|
| 368 |
+
# Get upper and lower cdf values
|
| 369 |
+
l = norm_cdf((a - mean) / std)
|
| 370 |
+
u = norm_cdf((b - mean) / std)
|
| 371 |
+
|
| 372 |
+
# Uniformly fill tensor with values from [l, u], then translate to
|
| 373 |
+
# [2l-1, 2u-1].
|
| 374 |
+
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 375 |
+
|
| 376 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 377 |
+
# standard normal
|
| 378 |
+
if tensor.dtype in [torch.float16, torch.bfloat16]:
|
| 379 |
+
# The `erfinv_` op is not (yet?) defined in float16+cpu, bfloat16+gpu
|
| 380 |
+
og_dtype = tensor.dtype
|
| 381 |
+
tensor = tensor.to(torch.float32)
|
| 382 |
+
tensor.erfinv_()
|
| 383 |
+
tensor = tensor.to(og_dtype)
|
| 384 |
+
else:
|
| 385 |
+
tensor.erfinv_()
|
| 386 |
+
|
| 387 |
+
# Transform to proper mean, std
|
| 388 |
+
tensor.mul_(std * math.sqrt(2.0))
|
| 389 |
+
tensor.add_(mean)
|
| 390 |
+
|
| 391 |
+
# Clamp to ensure it's in the proper range
|
| 392 |
+
if tensor.dtype == torch.float16:
|
| 393 |
+
# The `clamp_` op is not (yet?) defined in float16+cpu
|
| 394 |
+
tensor = tensor.to(torch.float32)
|
| 395 |
+
tensor.clamp_(min=a, max=b)
|
| 396 |
+
tensor = tensor.to(torch.float16)
|
| 397 |
+
else:
|
| 398 |
+
tensor.clamp_(min=a, max=b)
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
def trunc_normal_tf_(
|
| 402 |
+
tensor: torch.Tensor, mean: float = 0.0, std: float = 1.0, a: float = -2.0, b: float = 2.0
|
| 403 |
+
) -> torch.Tensor:
|
| 404 |
+
"""Fills the input Tensor with values drawn from a truncated
|
| 405 |
+
normal distribution. The values are effectively drawn from the
|
| 406 |
+
normal distribution :math:`\\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 407 |
+
with values outside :math:`[a, b]` redrawn until they are within
|
| 408 |
+
the bounds. The method used for generating the random values works
|
| 409 |
+
best when :math:`a \\leq \text{mean} \\leq b`.
|
| 410 |
+
NOTE: this 'tf' variant behaves closer to Tensorflow / JAX impl where the
|
| 411 |
+
bounds [a, b] are applied when sampling the normal distribution with mean=0, std=1.0
|
| 412 |
+
and the result is subsquently scaled and shifted by the mean and std args.
|
| 413 |
+
Args:
|
| 414 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 415 |
+
mean: the mean of the normal distribution
|
| 416 |
+
std: the standard deviation of the normal distribution
|
| 417 |
+
a: the minimum cutoff value
|
| 418 |
+
b: the maximum cutoff value
|
| 419 |
+
"""
|
| 420 |
+
with torch.no_grad():
|
| 421 |
+
_trunc_normal_(tensor, 0, 1.0, a, b)
|
| 422 |
+
tensor.mul_(std).add_(mean)
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="normal"):
|
| 426 |
+
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
|
| 427 |
+
if mode == "fan_in":
|
| 428 |
+
denom = fan_in
|
| 429 |
+
elif mode == "fan_out":
|
| 430 |
+
denom = fan_out
|
| 431 |
+
elif mode == "fan_avg":
|
| 432 |
+
denom = (fan_in + fan_out) / 2
|
| 433 |
+
|
| 434 |
+
variance = scale / denom
|
| 435 |
+
|
| 436 |
+
if distribution == "truncated_normal":
|
| 437 |
+
# constant is stddev of standard normal truncated to (-2, 2)
|
| 438 |
+
trunc_normal_tf_(tensor, std=math.sqrt(variance) / 0.87962566103423978)
|
| 439 |
+
elif distribution == "normal":
|
| 440 |
+
with torch.no_grad():
|
| 441 |
+
tensor.normal_(std=math.sqrt(variance))
|
| 442 |
+
elif distribution == "uniform":
|
| 443 |
+
bound = math.sqrt(3 * variance)
|
| 444 |
+
with torch.no_grad():
|
| 445 |
+
tensor.uniform_(-bound, bound)
|
| 446 |
+
else:
|
| 447 |
+
raise ValueError(f"invalid distribution {distribution}")
|
| 448 |
+
|
| 449 |
+
|
| 450 |
+
def lecun_normal_(tensor):
|
| 451 |
+
variance_scaling_(tensor, mode="fan_in", distribution="truncated_normal")
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
def default_flax_embed_init(tensor):
|
| 455 |
+
variance_scaling_(tensor, mode="fan_in", distribution="normal")
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
@dataclass
|
| 459 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPVisionModelOutput with CLIP->Siglip
|
| 460 |
+
class SiglipVisionModelOutput(ModelOutput):
|
| 461 |
+
"""
|
| 462 |
+
Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
|
| 463 |
+
Args:
|
| 464 |
+
image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
|
| 465 |
+
The image embeddings obtained by applying the projection layer to the pooler_output.
|
| 466 |
+
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 467 |
+
Sequence of hidden-states at the output of the last layer of the model.
|
| 468 |
+
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
| 469 |
+
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
| 470 |
+
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
| 471 |
+
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
| 472 |
+
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
|
| 473 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
|
| 474 |
+
sequence_length)`.
|
| 475 |
+
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
| 476 |
+
heads.
|
| 477 |
+
"""
|
| 478 |
+
|
| 479 |
+
image_embeds: Optional[torch.FloatTensor] = None
|
| 480 |
+
last_hidden_state: torch.FloatTensor = None
|
| 481 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
| 482 |
+
attentions: Optional[Tuple[torch.FloatTensor]] = None
|
| 483 |
+
|
| 484 |
+
|
| 485 |
+
@dataclass
|
| 486 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPTextModelOutput with CLIP->Siglip
|
| 487 |
+
class SiglipTextModelOutput(ModelOutput):
|
| 488 |
+
"""
|
| 489 |
+
Base class for text model's outputs that also contains a pooling of the last hidden states.
|
| 490 |
+
Args:
|
| 491 |
+
text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
|
| 492 |
+
The text embeddings obtained by applying the projection layer to the pooler_output.
|
| 493 |
+
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 494 |
+
Sequence of hidden-states at the output of the last layer of the model.
|
| 495 |
+
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
| 496 |
+
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
| 497 |
+
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
| 498 |
+
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
| 499 |
+
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
|
| 500 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
|
| 501 |
+
sequence_length)`.
|
| 502 |
+
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
| 503 |
+
heads.
|
| 504 |
+
"""
|
| 505 |
+
|
| 506 |
+
text_embeds: Optional[torch.FloatTensor] = None
|
| 507 |
+
last_hidden_state: torch.FloatTensor = None
|
| 508 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
| 509 |
+
attentions: Optional[Tuple[torch.FloatTensor]] = None
|
| 510 |
+
|
| 511 |
+
|
| 512 |
+
@dataclass
|
| 513 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->Siglip
|
| 514 |
+
class SiglipOutput(ModelOutput):
|
| 515 |
+
"""
|
| 516 |
+
Args:
|
| 517 |
+
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
|
| 518 |
+
Contrastive loss for image-text similarity.
|
| 519 |
+
logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
|
| 520 |
+
The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
|
| 521 |
+
similarity scores.
|
| 522 |
+
logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
|
| 523 |
+
The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
|
| 524 |
+
similarity scores.
|
| 525 |
+
text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
|
| 526 |
+
The text embeddings obtained by applying the projection layer to the pooled output of [`SiglipTextModel`].
|
| 527 |
+
image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
|
| 528 |
+
The image embeddings obtained by applying the projection layer to the pooled output of [`SiglipVisionModel`].
|
| 529 |
+
text_model_output(`BaseModelOutputWithPooling`):
|
| 530 |
+
The output of the [`SiglipTextModel`].
|
| 531 |
+
vision_model_output(`BaseModelOutputWithPooling`):
|
| 532 |
+
The output of the [`SiglipVisionModel`].
|
| 533 |
+
"""
|
| 534 |
+
|
| 535 |
+
loss: Optional[torch.FloatTensor] = None
|
| 536 |
+
logits_per_image: torch.FloatTensor = None
|
| 537 |
+
logits_per_text: torch.FloatTensor = None
|
| 538 |
+
text_embeds: torch.FloatTensor = None
|
| 539 |
+
image_embeds: torch.FloatTensor = None
|
| 540 |
+
text_model_output: BaseModelOutputWithPooling = None
|
| 541 |
+
vision_model_output: BaseModelOutputWithPooling = None
|
| 542 |
+
|
| 543 |
+
def to_tuple(self) -> Tuple[Any]:
|
| 544 |
+
return tuple(
|
| 545 |
+
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
|
| 546 |
+
for k in self.keys()
|
| 547 |
+
)
|
| 548 |
+
|
| 549 |
+
|
| 550 |
+
class SiglipVisionEmbeddings(nn.Module):
|
| 551 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 552 |
+
super().__init__()
|
| 553 |
+
self.config = config
|
| 554 |
+
self.embed_dim = config.hidden_size
|
| 555 |
+
self.image_size = config.image_size
|
| 556 |
+
self.patch_size = config.patch_size
|
| 557 |
+
|
| 558 |
+
self.patch_embedding = nn.Conv2d(
|
| 559 |
+
in_channels=config.num_channels,
|
| 560 |
+
out_channels=self.embed_dim,
|
| 561 |
+
kernel_size=self.patch_size,
|
| 562 |
+
stride=self.patch_size,
|
| 563 |
+
padding="valid",
|
| 564 |
+
)
|
| 565 |
+
|
| 566 |
+
self.num_patches_per_side = self.image_size // self.patch_size
|
| 567 |
+
self.num_patches = self.num_patches_per_side**2
|
| 568 |
+
self.num_positions = self.num_patches
|
| 569 |
+
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
|
| 570 |
+
|
| 571 |
+
def forward(self, pixel_values: torch.FloatTensor, patch_attention_mask: torch.BoolTensor) -> torch.Tensor:
|
| 572 |
+
batch_size = pixel_values.size(0)
|
| 573 |
+
|
| 574 |
+
patch_embeds = self.patch_embedding(pixel_values)
|
| 575 |
+
embeddings = patch_embeds.flatten(2).transpose(1, 2)
|
| 576 |
+
|
| 577 |
+
max_im_h, max_im_w = pixel_values.size(2), pixel_values.size(3)
|
| 578 |
+
max_nb_patches_h, max_nb_patches_w = max_im_h // self.patch_size, max_im_w // self.patch_size
|
| 579 |
+
boundaries = torch.arange(1 / self.num_patches_per_side, 1.0, 1 / self.num_patches_per_side)
|
| 580 |
+
position_ids = torch.full(
|
| 581 |
+
size=(
|
| 582 |
+
batch_size,
|
| 583 |
+
max_nb_patches_h * max_nb_patches_w,
|
| 584 |
+
),
|
| 585 |
+
fill_value=0,
|
| 586 |
+
)
|
| 587 |
+
|
| 588 |
+
for batch_idx, p_attn_mask in enumerate(patch_attention_mask):
|
| 589 |
+
nb_patches_h = p_attn_mask[:, 0].sum()
|
| 590 |
+
nb_patches_w = p_attn_mask[0].sum()
|
| 591 |
+
|
| 592 |
+
fractional_coords_h = torch.arange(0, 1 - 1e-6, 1 / nb_patches_h)
|
| 593 |
+
fractional_coords_w = torch.arange(0, 1 - 1e-6, 1 / nb_patches_w)
|
| 594 |
+
|
| 595 |
+
bucket_coords_h = torch.bucketize(fractional_coords_h, boundaries, right=True)
|
| 596 |
+
bucket_coords_w = torch.bucketize(fractional_coords_w, boundaries, right=True)
|
| 597 |
+
|
| 598 |
+
pos_ids = (bucket_coords_h[:, None] * self.num_patches_per_side + bucket_coords_w).flatten()
|
| 599 |
+
position_ids[batch_idx][p_attn_mask.view(-1).cpu()] = pos_ids
|
| 600 |
+
|
| 601 |
+
position_ids = position_ids.to(self.position_embedding.weight.device)
|
| 602 |
+
|
| 603 |
+
embeddings = embeddings + self.position_embedding(position_ids)
|
| 604 |
+
return embeddings
|
| 605 |
+
|
| 606 |
+
|
| 607 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPTextEmbeddings with CLIP->Siglip
|
| 608 |
+
class SiglipTextEmbeddings(nn.Module):
|
| 609 |
+
def __init__(self, config: SiglipTextConfig):
|
| 610 |
+
super().__init__()
|
| 611 |
+
embed_dim = config.hidden_size
|
| 612 |
+
|
| 613 |
+
self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
|
| 614 |
+
self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
|
| 615 |
+
|
| 616 |
+
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
|
| 617 |
+
self.register_buffer(
|
| 618 |
+
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
|
| 619 |
+
)
|
| 620 |
+
|
| 621 |
+
def forward(
|
| 622 |
+
self,
|
| 623 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 624 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 625 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 626 |
+
) -> torch.Tensor:
|
| 627 |
+
seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
|
| 628 |
+
|
| 629 |
+
if position_ids is None:
|
| 630 |
+
position_ids = self.position_ids[:, :seq_length]
|
| 631 |
+
|
| 632 |
+
if inputs_embeds is None:
|
| 633 |
+
inputs_embeds = self.token_embedding(input_ids)
|
| 634 |
+
|
| 635 |
+
position_embeddings = self.position_embedding(position_ids)
|
| 636 |
+
embeddings = inputs_embeds + position_embeddings
|
| 637 |
+
|
| 638 |
+
return embeddings
|
| 639 |
+
|
| 640 |
+
|
| 641 |
+
class SiglipAttention(nn.Module):
|
| 642 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 643 |
+
|
| 644 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPAttention.__init__
|
| 645 |
+
def __init__(self, config):
|
| 646 |
+
super().__init__()
|
| 647 |
+
self.config = config
|
| 648 |
+
self.embed_dim = config.hidden_size
|
| 649 |
+
self.num_heads = config.num_attention_heads
|
| 650 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 651 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 652 |
+
raise ValueError(
|
| 653 |
+
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
| 654 |
+
f" {self.num_heads})."
|
| 655 |
+
)
|
| 656 |
+
self.scale = self.head_dim**-0.5
|
| 657 |
+
self.dropout = config.attention_dropout
|
| 658 |
+
|
| 659 |
+
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 660 |
+
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 661 |
+
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 662 |
+
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 663 |
+
|
| 664 |
+
def forward(
|
| 665 |
+
self,
|
| 666 |
+
hidden_states: torch.Tensor,
|
| 667 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 668 |
+
output_attentions: Optional[bool] = False,
|
| 669 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 670 |
+
"""Input shape: Batch x Time x Channel"""
|
| 671 |
+
|
| 672 |
+
batch_size, q_len, _ = hidden_states.size()
|
| 673 |
+
|
| 674 |
+
query_states = self.q_proj(hidden_states)
|
| 675 |
+
key_states = self.k_proj(hidden_states)
|
| 676 |
+
value_states = self.v_proj(hidden_states)
|
| 677 |
+
|
| 678 |
+
query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 679 |
+
key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 680 |
+
value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 681 |
+
|
| 682 |
+
k_v_seq_len = key_states.shape[-2]
|
| 683 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) * self.scale
|
| 684 |
+
|
| 685 |
+
if attn_weights.size() != (batch_size, self.num_heads, q_len, k_v_seq_len):
|
| 686 |
+
raise ValueError(
|
| 687 |
+
f"Attention weights should be of size {(batch_size, self.num_heads, q_len, k_v_seq_len)}, but is"
|
| 688 |
+
f" {attn_weights.size()}"
|
| 689 |
+
)
|
| 690 |
+
|
| 691 |
+
if attention_mask is not None:
|
| 692 |
+
if attention_mask.size() != (batch_size, 1, q_len, k_v_seq_len):
|
| 693 |
+
raise ValueError(
|
| 694 |
+
f"Attention mask should be of size {(batch_size, 1, q_len, k_v_seq_len)}, but is {attention_mask.size()}"
|
| 695 |
+
)
|
| 696 |
+
attn_weights = attn_weights + attention_mask
|
| 697 |
+
|
| 698 |
+
# upcast attention to fp32
|
| 699 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 700 |
+
attn_weights = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
|
| 701 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 702 |
+
|
| 703 |
+
if attn_output.size() != (batch_size, self.num_heads, q_len, self.head_dim):
|
| 704 |
+
raise ValueError(
|
| 705 |
+
f"`attn_output` should be of size {(batch_size, self.num_heads, q_len, self.head_dim)}, but is"
|
| 706 |
+
f" {attn_output.size()}"
|
| 707 |
+
)
|
| 708 |
+
|
| 709 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 710 |
+
attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim)
|
| 711 |
+
|
| 712 |
+
attn_output = self.out_proj(attn_output)
|
| 713 |
+
|
| 714 |
+
return attn_output, attn_weights
|
| 715 |
+
|
| 716 |
+
|
| 717 |
+
class SiglipFlashAttention2(SiglipAttention):
|
| 718 |
+
"""
|
| 719 |
+
Llama flash attention module. This module inherits from `LlamaAttention` as the weights of the module stays
|
| 720 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 721 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 722 |
+
"""
|
| 723 |
+
|
| 724 |
+
def __init__(self, *args, **kwargs):
|
| 725 |
+
super().__init__(*args, **kwargs)
|
| 726 |
+
self.is_causal = False # Hack to make sure we don't use a causal mask
|
| 727 |
+
|
| 728 |
+
def forward(
|
| 729 |
+
self,
|
| 730 |
+
hidden_states: torch.Tensor,
|
| 731 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 732 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 733 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 734 |
+
output_attentions: bool = False,
|
| 735 |
+
use_cache: bool = False,
|
| 736 |
+
**kwargs,
|
| 737 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 738 |
+
output_attentions = False
|
| 739 |
+
|
| 740 |
+
bsz, q_len, _ = hidden_states.size()
|
| 741 |
+
|
| 742 |
+
query_states = self.q_proj(hidden_states)
|
| 743 |
+
key_states = self.k_proj(hidden_states)
|
| 744 |
+
value_states = self.v_proj(hidden_states)
|
| 745 |
+
|
| 746 |
+
# Flash attention requires the input to have the shape
|
| 747 |
+
# batch_size x seq_length x head_dim x hidden_dim
|
| 748 |
+
# therefore we just need to keep the original shape
|
| 749 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 750 |
+
key_states = key_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 751 |
+
value_states = value_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 752 |
+
|
| 753 |
+
kv_seq_len = key_states.shape[-2]
|
| 754 |
+
if past_key_value is not None:
|
| 755 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 756 |
+
# cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 757 |
+
# query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 758 |
+
|
| 759 |
+
# if past_key_value is not None:
|
| 760 |
+
# cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
|
| 761 |
+
# key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 762 |
+
|
| 763 |
+
# TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
|
| 764 |
+
# to be able to avoid many of these transpose/reshape/view.
|
| 765 |
+
query_states = query_states.transpose(1, 2)
|
| 766 |
+
key_states = key_states.transpose(1, 2)
|
| 767 |
+
value_states = value_states.transpose(1, 2)
|
| 768 |
+
|
| 769 |
+
dropout_rate = self.dropout if self.training else 0.0
|
| 770 |
+
|
| 771 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 772 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 773 |
+
# cast them back in the correct dtype just to be sure everything works as expected.
|
| 774 |
+
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
|
| 775 |
+
# in fp32. (LlamaRMSNorm handles it correctly)
|
| 776 |
+
|
| 777 |
+
input_dtype = query_states.dtype
|
| 778 |
+
if input_dtype == torch.float32:
|
| 779 |
+
if torch.is_autocast_enabled():
|
| 780 |
+
target_dtype = torch.get_autocast_gpu_dtype()
|
| 781 |
+
# Handle the case where the model is quantized
|
| 782 |
+
elif hasattr(self.config, "_pre_quantization_dtype"):
|
| 783 |
+
target_dtype = self.config._pre_quantization_dtype
|
| 784 |
+
else:
|
| 785 |
+
target_dtype = self.q_proj.weight.dtype
|
| 786 |
+
|
| 787 |
+
logger.warning_once(
|
| 788 |
+
"The input hidden states seems to be silently casted in float32, this might be related to the fact"
|
| 789 |
+
" you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
|
| 790 |
+
f" {target_dtype}."
|
| 791 |
+
)
|
| 792 |
+
|
| 793 |
+
query_states = query_states.to(target_dtype)
|
| 794 |
+
key_states = key_states.to(target_dtype)
|
| 795 |
+
value_states = value_states.to(target_dtype)
|
| 796 |
+
|
| 797 |
+
attn_output = self._flash_attention_forward(
|
| 798 |
+
query_states, key_states, value_states, attention_mask, q_len, dropout=dropout_rate
|
| 799 |
+
)
|
| 800 |
+
|
| 801 |
+
attn_output = attn_output.reshape(bsz, q_len, self.embed_dim).contiguous()
|
| 802 |
+
attn_output = self.out_proj(attn_output)
|
| 803 |
+
|
| 804 |
+
if not output_attentions:
|
| 805 |
+
attn_weights = None
|
| 806 |
+
|
| 807 |
+
return attn_output, attn_weights
|
| 808 |
+
|
| 809 |
+
def _flash_attention_forward(
|
| 810 |
+
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
|
| 811 |
+
):
|
| 812 |
+
"""
|
| 813 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 814 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 815 |
+
Args:
|
| 816 |
+
query_states (`torch.Tensor`):
|
| 817 |
+
Input query states to be passed to Flash Attention API
|
| 818 |
+
key_states (`torch.Tensor`):
|
| 819 |
+
Input key states to be passed to Flash Attention API
|
| 820 |
+
value_states (`torch.Tensor`):
|
| 821 |
+
Input value states to be passed to Flash Attention API
|
| 822 |
+
attention_mask (`torch.Tensor`):
|
| 823 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 824 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 825 |
+
dropout (`int`, *optional*):
|
| 826 |
+
Attention dropout
|
| 827 |
+
softmax_scale (`float`, *optional*):
|
| 828 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 829 |
+
"""
|
| 830 |
+
|
| 831 |
+
# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
|
| 832 |
+
causal = self.is_causal and query_length != 1
|
| 833 |
+
|
| 834 |
+
# Contains at least one padding token in the sequence
|
| 835 |
+
if attention_mask is not None:
|
| 836 |
+
batch_size = query_states.shape[0]
|
| 837 |
+
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
|
| 838 |
+
query_states, key_states, value_states, attention_mask, query_length
|
| 839 |
+
)
|
| 840 |
+
|
| 841 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 842 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 843 |
+
|
| 844 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 845 |
+
query_states,
|
| 846 |
+
key_states,
|
| 847 |
+
value_states,
|
| 848 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 849 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 850 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 851 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 852 |
+
dropout_p=dropout,
|
| 853 |
+
softmax_scale=softmax_scale,
|
| 854 |
+
causal=causal,
|
| 855 |
+
)
|
| 856 |
+
|
| 857 |
+
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
|
| 858 |
+
else:
|
| 859 |
+
attn_output = flash_attn_func(
|
| 860 |
+
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
|
| 861 |
+
)
|
| 862 |
+
|
| 863 |
+
return attn_output
|
| 864 |
+
|
| 865 |
+
def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
|
| 866 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
|
| 867 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 868 |
+
|
| 869 |
+
key_layer = index_first_axis(
|
| 870 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 871 |
+
)
|
| 872 |
+
value_layer = index_first_axis(
|
| 873 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 874 |
+
)
|
| 875 |
+
if query_length == kv_seq_len:
|
| 876 |
+
query_layer = index_first_axis(
|
| 877 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
|
| 878 |
+
)
|
| 879 |
+
cu_seqlens_q = cu_seqlens_k
|
| 880 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 881 |
+
indices_q = indices_k
|
| 882 |
+
elif query_length == 1:
|
| 883 |
+
max_seqlen_in_batch_q = 1
|
| 884 |
+
cu_seqlens_q = torch.arange(
|
| 885 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 886 |
+
) # There is a memcpy here, that is very bad.
|
| 887 |
+
indices_q = cu_seqlens_q[:-1]
|
| 888 |
+
query_layer = query_layer.squeeze(1)
|
| 889 |
+
else:
|
| 890 |
+
# The -q_len: slice assumes left padding.
|
| 891 |
+
attention_mask = attention_mask[:, -query_length:]
|
| 892 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
|
| 893 |
+
|
| 894 |
+
return (
|
| 895 |
+
query_layer,
|
| 896 |
+
key_layer,
|
| 897 |
+
value_layer,
|
| 898 |
+
indices_q,
|
| 899 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 900 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 901 |
+
)
|
| 902 |
+
|
| 903 |
+
|
| 904 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->Siglip
|
| 905 |
+
class SiglipMLP(nn.Module):
|
| 906 |
+
def __init__(self, config):
|
| 907 |
+
super().__init__()
|
| 908 |
+
self.config = config
|
| 909 |
+
self.activation_fn = ACT2FN[config.hidden_act]
|
| 910 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 911 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 912 |
+
|
| 913 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 914 |
+
hidden_states = self.fc1(hidden_states)
|
| 915 |
+
hidden_states = self.activation_fn(hidden_states)
|
| 916 |
+
hidden_states = self.fc2(hidden_states)
|
| 917 |
+
return hidden_states
|
| 918 |
+
|
| 919 |
+
|
| 920 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer with CLIP->Siglip
|
| 921 |
+
class SiglipEncoderLayer(nn.Module):
|
| 922 |
+
def __init__(self, config: SiglipConfig):
|
| 923 |
+
super().__init__()
|
| 924 |
+
self.embed_dim = config.hidden_size
|
| 925 |
+
self.self_attn = (
|
| 926 |
+
SiglipAttention(config)
|
| 927 |
+
if not getattr(config, "_flash_attn_2_enabled", False)
|
| 928 |
+
else SiglipFlashAttention2(config)
|
| 929 |
+
)
|
| 930 |
+
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 931 |
+
self.mlp = SiglipMLP(config)
|
| 932 |
+
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 933 |
+
|
| 934 |
+
def forward(
|
| 935 |
+
self,
|
| 936 |
+
hidden_states: torch.Tensor,
|
| 937 |
+
attention_mask: torch.Tensor,
|
| 938 |
+
output_attentions: Optional[bool] = False,
|
| 939 |
+
) -> Tuple[torch.FloatTensor]:
|
| 940 |
+
"""
|
| 941 |
+
Args:
|
| 942 |
+
hidden_states (`torch.FloatTensor`):
|
| 943 |
+
Input to the layer of shape `(batch, seq_len, embed_dim)`.
|
| 944 |
+
attention_mask (`torch.FloatTensor`):
|
| 945 |
+
Attention mask of shape `(batch, 1, q_len, k_v_seq_len)` where padding elements are indicated by very large negative values.
|
| 946 |
+
output_attentions (`bool`, *optional*, defaults to `False`):
|
| 947 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 948 |
+
returned tensors for more detail.
|
| 949 |
+
"""
|
| 950 |
+
residual = hidden_states
|
| 951 |
+
|
| 952 |
+
hidden_states = self.layer_norm1(hidden_states)
|
| 953 |
+
hidden_states, attn_weights = self.self_attn(
|
| 954 |
+
hidden_states=hidden_states,
|
| 955 |
+
attention_mask=attention_mask,
|
| 956 |
+
output_attentions=output_attentions,
|
| 957 |
+
)
|
| 958 |
+
hidden_states = residual + hidden_states
|
| 959 |
+
|
| 960 |
+
residual = hidden_states
|
| 961 |
+
hidden_states = self.layer_norm2(hidden_states)
|
| 962 |
+
hidden_states = self.mlp(hidden_states)
|
| 963 |
+
hidden_states = residual + hidden_states
|
| 964 |
+
|
| 965 |
+
outputs = (hidden_states,)
|
| 966 |
+
|
| 967 |
+
if output_attentions:
|
| 968 |
+
outputs += (attn_weights,)
|
| 969 |
+
|
| 970 |
+
return outputs
|
| 971 |
+
|
| 972 |
+
|
| 973 |
+
class SiglipPreTrainedModel(PreTrainedModel):
|
| 974 |
+
"""
|
| 975 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 976 |
+
models.
|
| 977 |
+
"""
|
| 978 |
+
|
| 979 |
+
config_class = SiglipConfig
|
| 980 |
+
base_model_prefix = "siglip"
|
| 981 |
+
supports_gradient_checkpointing = True
|
| 982 |
+
|
| 983 |
+
def _init_weights(self, module):
|
| 984 |
+
"""Initialize the weights"""
|
| 985 |
+
|
| 986 |
+
if isinstance(module, SiglipVisionEmbeddings):
|
| 987 |
+
width = (
|
| 988 |
+
self.config.vision_config.hidden_size
|
| 989 |
+
if isinstance(self.config, SiglipConfig)
|
| 990 |
+
else self.config.hidden_size
|
| 991 |
+
)
|
| 992 |
+
nn.init.normal_(module.position_embedding.weight, std=1 / np.sqrt(width))
|
| 993 |
+
elif isinstance(module, nn.Embedding):
|
| 994 |
+
default_flax_embed_init(module.weight)
|
| 995 |
+
elif isinstance(module, SiglipAttention):
|
| 996 |
+
nn.init.normal_(module.q_proj.weight)
|
| 997 |
+
nn.init.normal_(module.k_proj.weight)
|
| 998 |
+
nn.init.normal_(module.v_proj.weight)
|
| 999 |
+
nn.init.normal_(module.out_proj.weight)
|
| 1000 |
+
nn.init.zeros_(module.q_proj.bias)
|
| 1001 |
+
nn.init.zeros_(module.k_proj.bias)
|
| 1002 |
+
nn.init.zeros_(module.v_proj.bias)
|
| 1003 |
+
nn.init.zeros_(module.out_proj.bias)
|
| 1004 |
+
elif isinstance(module, SiglipMLP):
|
| 1005 |
+
nn.init.normal_(module.fc1.weight)
|
| 1006 |
+
nn.init.normal_(module.fc2.weight)
|
| 1007 |
+
nn.init.normal_(module.fc1.bias, std=1e-6)
|
| 1008 |
+
nn.init.normal_(module.fc2.bias, std=1e-6)
|
| 1009 |
+
elif isinstance(module, SiglipMultiheadAttentionPoolingHead):
|
| 1010 |
+
nn.init.normal_(module.probe.data)
|
| 1011 |
+
nn.init.normal_(module.attention.in_proj_weight.data)
|
| 1012 |
+
nn.init.zeros_(module.attention.in_proj_bias.data)
|
| 1013 |
+
elif isinstance(module, SiglipModel):
|
| 1014 |
+
logit_scale_init = torch.tensor(0.0)
|
| 1015 |
+
module.logit_scale.data.fill_(logit_scale_init)
|
| 1016 |
+
module.logit_bias.data.zero_()
|
| 1017 |
+
elif isinstance(module, (nn.Linear, nn.Conv2d)):
|
| 1018 |
+
lecun_normal_(module.weight)
|
| 1019 |
+
if module.bias is not None:
|
| 1020 |
+
nn.init.zeros_(module.bias)
|
| 1021 |
+
elif isinstance(module, nn.LayerNorm):
|
| 1022 |
+
module.bias.data.zero_()
|
| 1023 |
+
module.weight.data.fill_(1.0)
|
| 1024 |
+
|
| 1025 |
+
|
| 1026 |
+
SIGLIP_START_DOCSTRING = r"""
|
| 1027 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 1028 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 1029 |
+
etc.)
|
| 1030 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 1031 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 1032 |
+
and behavior.
|
| 1033 |
+
Parameters:
|
| 1034 |
+
config ([`SiglipConfig`]): Model configuration class with all the parameters of the model.
|
| 1035 |
+
Initializing with a config file does not load the weights associated with the model, only the
|
| 1036 |
+
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 1037 |
+
"""
|
| 1038 |
+
|
| 1039 |
+
SIGLIP_TEXT_INPUTS_DOCSTRING = r"""
|
| 1040 |
+
Args:
|
| 1041 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 1042 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 1043 |
+
it.
|
| 1044 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 1045 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 1046 |
+
[What are input IDs?](../glossary#input-ids)
|
| 1047 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1048 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 1049 |
+
- 1 for tokens that are **not masked**,
|
| 1050 |
+
- 0 for tokens that are **masked**.
|
| 1051 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 1052 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1053 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 1054 |
+
config.max_position_embeddings - 1]`.
|
| 1055 |
+
[What are position IDs?](../glossary#position-ids)
|
| 1056 |
+
output_attentions (`bool`, *optional*):
|
| 1057 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 1058 |
+
tensors for more detail.
|
| 1059 |
+
output_hidden_states (`bool`, *optional*):
|
| 1060 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 1061 |
+
more detail.
|
| 1062 |
+
return_dict (`bool`, *optional*):
|
| 1063 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 1064 |
+
"""
|
| 1065 |
+
|
| 1066 |
+
SIGLIP_VISION_INPUTS_DOCSTRING = r"""
|
| 1067 |
+
Args:
|
| 1068 |
+
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 1069 |
+
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
| 1070 |
+
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
|
| 1071 |
+
output_attentions (`bool`, *optional*):
|
| 1072 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 1073 |
+
tensors for more detail.
|
| 1074 |
+
output_hidden_states (`bool`, *optional*):
|
| 1075 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 1076 |
+
more detail.
|
| 1077 |
+
return_dict (`bool`, *optional*):
|
| 1078 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 1079 |
+
"""
|
| 1080 |
+
|
| 1081 |
+
SIGLIP_INPUTS_DOCSTRING = r"""
|
| 1082 |
+
Args:
|
| 1083 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 1084 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 1085 |
+
it.
|
| 1086 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 1087 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 1088 |
+
[What are input IDs?](../glossary#input-ids)
|
| 1089 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1090 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 1091 |
+
- 1 for tokens that are **not masked**,
|
| 1092 |
+
- 0 for tokens that are **masked**.
|
| 1093 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 1094 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1095 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 1096 |
+
config.max_position_embeddings - 1]`.
|
| 1097 |
+
[What are position IDs?](../glossary#position-ids)
|
| 1098 |
+
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 1099 |
+
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
| 1100 |
+
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
|
| 1101 |
+
return_loss (`bool`, *optional*):
|
| 1102 |
+
Whether or not to return the contrastive loss.
|
| 1103 |
+
output_attentions (`bool`, *optional*):
|
| 1104 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 1105 |
+
tensors for more detail.
|
| 1106 |
+
output_hidden_states (`bool`, *optional*):
|
| 1107 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 1108 |
+
more detail.
|
| 1109 |
+
return_dict (`bool`, *optional*):
|
| 1110 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 1111 |
+
"""
|
| 1112 |
+
|
| 1113 |
+
|
| 1114 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPEncoder with CLIP->Siglip
|
| 1115 |
+
class SiglipEncoder(nn.Module):
|
| 1116 |
+
"""
|
| 1117 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 1118 |
+
[`SiglipEncoderLayer`].
|
| 1119 |
+
Args:
|
| 1120 |
+
config: SiglipConfig
|
| 1121 |
+
"""
|
| 1122 |
+
|
| 1123 |
+
def __init__(self, config: SiglipConfig):
|
| 1124 |
+
super().__init__()
|
| 1125 |
+
self.config = config
|
| 1126 |
+
self.layers = nn.ModuleList([SiglipEncoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 1127 |
+
self.gradient_checkpointing = False
|
| 1128 |
+
|
| 1129 |
+
# Ignore copy
|
| 1130 |
+
def forward(
|
| 1131 |
+
self,
|
| 1132 |
+
inputs_embeds,
|
| 1133 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1134 |
+
output_attentions: Optional[bool] = None,
|
| 1135 |
+
output_hidden_states: Optional[bool] = None,
|
| 1136 |
+
return_dict: Optional[bool] = None,
|
| 1137 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 1138 |
+
r"""
|
| 1139 |
+
Args:
|
| 1140 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 1141 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
|
| 1142 |
+
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
|
| 1143 |
+
than the model's internal embedding lookup matrix.
|
| 1144 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1145 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 1146 |
+
- 1 for tokens that are **not masked**,
|
| 1147 |
+
- 0 for tokens that are **masked**.
|
| 1148 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 1149 |
+
output_attentions (`bool`, *optional*):
|
| 1150 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 1151 |
+
returned tensors for more detail.
|
| 1152 |
+
output_hidden_states (`bool`, *optional*):
|
| 1153 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 1154 |
+
for more detail.
|
| 1155 |
+
return_dict (`bool`, *optional*):
|
| 1156 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 1157 |
+
"""
|
| 1158 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1159 |
+
output_hidden_states = (
|
| 1160 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1161 |
+
)
|
| 1162 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1163 |
+
|
| 1164 |
+
encoder_states = () if output_hidden_states else None
|
| 1165 |
+
all_attentions = () if output_attentions else None
|
| 1166 |
+
|
| 1167 |
+
hidden_states = inputs_embeds
|
| 1168 |
+
for encoder_layer in self.layers:
|
| 1169 |
+
if output_hidden_states:
|
| 1170 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 1171 |
+
if self.gradient_checkpointing and self.training:
|
| 1172 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 1173 |
+
encoder_layer.__call__,
|
| 1174 |
+
hidden_states,
|
| 1175 |
+
attention_mask,
|
| 1176 |
+
output_attentions,
|
| 1177 |
+
)
|
| 1178 |
+
else:
|
| 1179 |
+
layer_outputs = encoder_layer(
|
| 1180 |
+
hidden_states,
|
| 1181 |
+
attention_mask,
|
| 1182 |
+
output_attentions=output_attentions,
|
| 1183 |
+
)
|
| 1184 |
+
|
| 1185 |
+
hidden_states = layer_outputs[0]
|
| 1186 |
+
|
| 1187 |
+
if output_attentions:
|
| 1188 |
+
all_attentions = all_attentions + (layer_outputs[1],)
|
| 1189 |
+
|
| 1190 |
+
if output_hidden_states:
|
| 1191 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 1192 |
+
|
| 1193 |
+
if not return_dict:
|
| 1194 |
+
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
|
| 1195 |
+
return BaseModelOutput(
|
| 1196 |
+
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
|
| 1197 |
+
)
|
| 1198 |
+
|
| 1199 |
+
|
| 1200 |
+
class SiglipTextTransformer(nn.Module):
|
| 1201 |
+
def __init__(self, config: SiglipTextConfig):
|
| 1202 |
+
super().__init__()
|
| 1203 |
+
self.config = config
|
| 1204 |
+
embed_dim = config.hidden_size
|
| 1205 |
+
self.embeddings = SiglipTextEmbeddings(config)
|
| 1206 |
+
self.encoder = SiglipEncoder(config)
|
| 1207 |
+
self.final_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
|
| 1208 |
+
|
| 1209 |
+
self.head = nn.Linear(embed_dim, embed_dim)
|
| 1210 |
+
|
| 1211 |
+
@add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
|
| 1212 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipTextConfig)
|
| 1213 |
+
def forward(
|
| 1214 |
+
self,
|
| 1215 |
+
input_ids: Optional[torch.Tensor] = None,
|
| 1216 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1217 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 1218 |
+
output_attentions: Optional[bool] = None,
|
| 1219 |
+
output_hidden_states: Optional[bool] = None,
|
| 1220 |
+
return_dict: Optional[bool] = None,
|
| 1221 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 1222 |
+
r"""
|
| 1223 |
+
Returns:
|
| 1224 |
+
"""
|
| 1225 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1226 |
+
output_hidden_states = (
|
| 1227 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1228 |
+
)
|
| 1229 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1230 |
+
|
| 1231 |
+
if input_ids is None:
|
| 1232 |
+
raise ValueError("You have to specify input_ids")
|
| 1233 |
+
|
| 1234 |
+
input_shape = input_ids.size()
|
| 1235 |
+
input_ids = input_ids.view(-1, input_shape[-1])
|
| 1236 |
+
|
| 1237 |
+
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
|
| 1238 |
+
|
| 1239 |
+
# note: SigLIP's text model does not use a causal mask, unlike the original CLIP model.
|
| 1240 |
+
# expand attention_mask
|
| 1241 |
+
if attention_mask is not None:
|
| 1242 |
+
# [batch_size, seq_len] -> [batch_size, 1, tgt_seq_len, src_seq_len]
|
| 1243 |
+
attention_mask = _prepare_4d_attention_mask(attention_mask, hidden_states.dtype)
|
| 1244 |
+
|
| 1245 |
+
encoder_outputs = self.encoder(
|
| 1246 |
+
inputs_embeds=hidden_states,
|
| 1247 |
+
attention_mask=attention_mask,
|
| 1248 |
+
output_attentions=output_attentions,
|
| 1249 |
+
output_hidden_states=output_hidden_states,
|
| 1250 |
+
return_dict=return_dict,
|
| 1251 |
+
)
|
| 1252 |
+
|
| 1253 |
+
last_hidden_state = encoder_outputs[0]
|
| 1254 |
+
last_hidden_state = self.final_layer_norm(last_hidden_state)
|
| 1255 |
+
|
| 1256 |
+
# Assuming "sticky" EOS tokenization, last token is always EOS.
|
| 1257 |
+
pooled_output = last_hidden_state[:, -1, :]
|
| 1258 |
+
pooled_output = self.head(pooled_output)
|
| 1259 |
+
|
| 1260 |
+
if not return_dict:
|
| 1261 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 1262 |
+
|
| 1263 |
+
return BaseModelOutputWithPooling(
|
| 1264 |
+
last_hidden_state=last_hidden_state,
|
| 1265 |
+
pooler_output=pooled_output,
|
| 1266 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 1267 |
+
attentions=encoder_outputs.attentions,
|
| 1268 |
+
)
|
| 1269 |
+
|
| 1270 |
+
|
| 1271 |
+
@add_start_docstrings(
|
| 1272 |
+
"""The text model from SigLIP without any head or projection on top.""",
|
| 1273 |
+
SIGLIP_START_DOCSTRING,
|
| 1274 |
+
)
|
| 1275 |
+
class SiglipTextModel(SiglipPreTrainedModel):
|
| 1276 |
+
config_class = SiglipTextConfig
|
| 1277 |
+
|
| 1278 |
+
_no_split_modules = ["SiglipTextEmbeddings", "SiglipEncoderLayer"]
|
| 1279 |
+
|
| 1280 |
+
def __init__(self, config: SiglipTextConfig):
|
| 1281 |
+
super().__init__(config)
|
| 1282 |
+
self.text_model = SiglipTextTransformer(config)
|
| 1283 |
+
# Initialize weights and apply final processing
|
| 1284 |
+
self.post_init()
|
| 1285 |
+
|
| 1286 |
+
def get_input_embeddings(self) -> nn.Module:
|
| 1287 |
+
return self.text_model.embeddings.token_embedding
|
| 1288 |
+
|
| 1289 |
+
def set_input_embeddings(self, value):
|
| 1290 |
+
self.text_model.embeddings.token_embedding = value
|
| 1291 |
+
|
| 1292 |
+
@add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
|
| 1293 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipTextConfig)
|
| 1294 |
+
def forward(
|
| 1295 |
+
self,
|
| 1296 |
+
input_ids: Optional[torch.Tensor] = None,
|
| 1297 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1298 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 1299 |
+
output_attentions: Optional[bool] = None,
|
| 1300 |
+
output_hidden_states: Optional[bool] = None,
|
| 1301 |
+
return_dict: Optional[bool] = None,
|
| 1302 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 1303 |
+
r"""
|
| 1304 |
+
Returns:
|
| 1305 |
+
Examples:
|
| 1306 |
+
```python
|
| 1307 |
+
>>> from transformers import AutoTokenizer, SiglipTextModel
|
| 1308 |
+
>>> model = SiglipTextModel.from_pretrained("google/siglip-base-patch16-224")
|
| 1309 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
|
| 1310 |
+
>>> # important: make sure to set padding="max_length" as that's how the model was trained
|
| 1311 |
+
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
|
| 1312 |
+
>>> outputs = model(**inputs)
|
| 1313 |
+
>>> last_hidden_state = outputs.last_hidden_state
|
| 1314 |
+
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
|
| 1315 |
+
```"""
|
| 1316 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1317 |
+
|
| 1318 |
+
return self.text_model(
|
| 1319 |
+
input_ids=input_ids,
|
| 1320 |
+
attention_mask=attention_mask,
|
| 1321 |
+
position_ids=position_ids,
|
| 1322 |
+
output_attentions=output_attentions,
|
| 1323 |
+
output_hidden_states=output_hidden_states,
|
| 1324 |
+
return_dict=return_dict,
|
| 1325 |
+
)
|
| 1326 |
+
|
| 1327 |
+
|
| 1328 |
+
class SiglipVisionTransformer(nn.Module):
|
| 1329 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 1330 |
+
super().__init__()
|
| 1331 |
+
self.config = config
|
| 1332 |
+
embed_dim = config.hidden_size
|
| 1333 |
+
|
| 1334 |
+
self.embeddings = SiglipVisionEmbeddings(config)
|
| 1335 |
+
self.encoder = SiglipEncoder(config)
|
| 1336 |
+
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
|
| 1337 |
+
self.head = SiglipMultiheadAttentionPoolingHead(config)
|
| 1338 |
+
|
| 1339 |
+
@add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
|
| 1340 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
|
| 1341 |
+
def forward(
|
| 1342 |
+
self,
|
| 1343 |
+
pixel_values,
|
| 1344 |
+
patch_attention_mask: Optional[torch.BoolTensor] = None,
|
| 1345 |
+
output_attentions: Optional[bool] = None,
|
| 1346 |
+
output_hidden_states: Optional[bool] = None,
|
| 1347 |
+
return_dict: Optional[bool] = None,
|
| 1348 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 1349 |
+
r"""
|
| 1350 |
+
Returns:
|
| 1351 |
+
"""
|
| 1352 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1353 |
+
output_hidden_states = (
|
| 1354 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1355 |
+
)
|
| 1356 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1357 |
+
|
| 1358 |
+
batch_size = pixel_values.size(0)
|
| 1359 |
+
if patch_attention_mask is None:
|
| 1360 |
+
patch_attention_mask = torch.ones(
|
| 1361 |
+
size=(
|
| 1362 |
+
batch_size,
|
| 1363 |
+
pixel_values.size(2) // self.config.patch_size,
|
| 1364 |
+
pixel_values.size(3) // self.config.patch_size,
|
| 1365 |
+
),
|
| 1366 |
+
dtype=torch.bool,
|
| 1367 |
+
device=pixel_values.device,
|
| 1368 |
+
)
|
| 1369 |
+
|
| 1370 |
+
hidden_states = self.embeddings(pixel_values=pixel_values, patch_attention_mask=patch_attention_mask)
|
| 1371 |
+
|
| 1372 |
+
patch_attention_mask = patch_attention_mask.view(batch_size, -1)
|
| 1373 |
+
# The call to `_upad_input` in `_flash_attention_forward` is expensive
|
| 1374 |
+
# So when the `patch_attention_mask` is full of 1s (i.e. attending to the whole sequence),
|
| 1375 |
+
# avoiding passing the attention_mask, which is equivalent to attending to the full sequence
|
| 1376 |
+
if not torch.any(~patch_attention_mask):
|
| 1377 |
+
attention_mask=None
|
| 1378 |
+
else:
|
| 1379 |
+
attention_mask = (
|
| 1380 |
+
_prepare_4d_attention_mask(patch_attention_mask, hidden_states.dtype)
|
| 1381 |
+
if not self.config._flash_attn_2_enabled
|
| 1382 |
+
else patch_attention_mask
|
| 1383 |
+
)
|
| 1384 |
+
|
| 1385 |
+
encoder_outputs = self.encoder(
|
| 1386 |
+
inputs_embeds=hidden_states,
|
| 1387 |
+
attention_mask=attention_mask,
|
| 1388 |
+
output_attentions=output_attentions,
|
| 1389 |
+
output_hidden_states=output_hidden_states,
|
| 1390 |
+
return_dict=return_dict,
|
| 1391 |
+
)
|
| 1392 |
+
|
| 1393 |
+
last_hidden_state = encoder_outputs[0]
|
| 1394 |
+
last_hidden_state = self.post_layernorm(last_hidden_state)
|
| 1395 |
+
|
| 1396 |
+
pooled_output = self.head(
|
| 1397 |
+
hidden_state=last_hidden_state,
|
| 1398 |
+
attention_mask=patch_attention_mask,
|
| 1399 |
+
)
|
| 1400 |
+
|
| 1401 |
+
if not return_dict:
|
| 1402 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 1403 |
+
|
| 1404 |
+
return BaseModelOutputWithPooling(
|
| 1405 |
+
last_hidden_state=last_hidden_state,
|
| 1406 |
+
pooler_output=pooled_output,
|
| 1407 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 1408 |
+
attentions=encoder_outputs.attentions,
|
| 1409 |
+
)
|
| 1410 |
+
|
| 1411 |
+
|
| 1412 |
+
class SiglipMultiheadAttentionPoolingHead(nn.Module):
|
| 1413 |
+
"""Multihead Attention Pooling."""
|
| 1414 |
+
|
| 1415 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 1416 |
+
super().__init__()
|
| 1417 |
+
|
| 1418 |
+
self.probe = nn.Parameter(torch.randn(1, 1, config.hidden_size))
|
| 1419 |
+
self.attention = torch.nn.MultiheadAttention(config.hidden_size, config.num_attention_heads, batch_first=True)
|
| 1420 |
+
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
|
| 1421 |
+
self.mlp = SiglipMLP(config)
|
| 1422 |
+
|
| 1423 |
+
def forward(self, hidden_state, attention_mask):
|
| 1424 |
+
batch_size = hidden_state.shape[0]
|
| 1425 |
+
probe = self.probe.repeat(batch_size, 1, 1)
|
| 1426 |
+
|
| 1427 |
+
hidden_state = self.attention(
|
| 1428 |
+
query=probe, key=hidden_state, value=hidden_state, key_padding_mask=~attention_mask
|
| 1429 |
+
)[0]
|
| 1430 |
+
|
| 1431 |
+
residual = hidden_state
|
| 1432 |
+
hidden_state = self.layernorm(hidden_state)
|
| 1433 |
+
hidden_state = residual + self.mlp(hidden_state)
|
| 1434 |
+
|
| 1435 |
+
return hidden_state[:, 0]
|
| 1436 |
+
|
| 1437 |
+
|
| 1438 |
+
@add_start_docstrings(
|
| 1439 |
+
"""The vision model from SigLIP without any head or projection on top.""",
|
| 1440 |
+
SIGLIP_START_DOCSTRING,
|
| 1441 |
+
)
|
| 1442 |
+
class SiglipVisionModel(SiglipPreTrainedModel):
|
| 1443 |
+
config_class = SiglipVisionConfig
|
| 1444 |
+
main_input_name = "pixel_values"
|
| 1445 |
+
|
| 1446 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 1447 |
+
super().__init__(config)
|
| 1448 |
+
|
| 1449 |
+
self.vision_model = SiglipVisionTransformer(config)
|
| 1450 |
+
|
| 1451 |
+
# Initialize weights and apply final processing
|
| 1452 |
+
self.post_init()
|
| 1453 |
+
|
| 1454 |
+
def get_input_embeddings(self) -> nn.Module:
|
| 1455 |
+
return self.vision_model.embeddings.patch_embedding
|
| 1456 |
+
|
| 1457 |
+
@add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
|
| 1458 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
|
| 1459 |
+
def forward(
|
| 1460 |
+
self,
|
| 1461 |
+
pixel_values,
|
| 1462 |
+
patch_attention_mask: Optional[torch.BoolTensor] = None,
|
| 1463 |
+
output_attentions: Optional[bool] = None,
|
| 1464 |
+
output_hidden_states: Optional[bool] = None,
|
| 1465 |
+
return_dict: Optional[bool] = None,
|
| 1466 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 1467 |
+
r"""
|
| 1468 |
+
Returns:
|
| 1469 |
+
Examples:
|
| 1470 |
+
```python
|
| 1471 |
+
>>> from PIL import Image
|
| 1472 |
+
>>> import requests
|
| 1473 |
+
>>> from transformers import AutoProcessor, SiglipVisionModel
|
| 1474 |
+
>>> model = SiglipVisionModel.from_pretrained("google/siglip-base-patch16-224")
|
| 1475 |
+
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
|
| 1476 |
+
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 1477 |
+
>>> image = Image.open(requests.get(url, stream=True).raw)
|
| 1478 |
+
>>> inputs = processor(images=image, return_tensors="pt")
|
| 1479 |
+
>>> outputs = model(**inputs)
|
| 1480 |
+
>>> last_hidden_state = outputs.last_hidden_state
|
| 1481 |
+
>>> pooled_output = outputs.pooler_output # pooled features
|
| 1482 |
+
```"""
|
| 1483 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1484 |
+
|
| 1485 |
+
return self.vision_model(
|
| 1486 |
+
pixel_values=pixel_values,
|
| 1487 |
+
patch_attention_mask=patch_attention_mask,
|
| 1488 |
+
output_attentions=output_attentions,
|
| 1489 |
+
output_hidden_states=output_hidden_states,
|
| 1490 |
+
return_dict=return_dict,
|
| 1491 |
+
)
|
| 1492 |
+
|
| 1493 |
+
|
| 1494 |
+
@add_start_docstrings(SIGLIP_START_DOCSTRING)
|
| 1495 |
+
class SiglipModel(SiglipPreTrainedModel):
|
| 1496 |
+
config_class = SiglipConfig
|
| 1497 |
+
|
| 1498 |
+
def __init__(self, config: SiglipConfig):
|
| 1499 |
+
super().__init__(config)
|
| 1500 |
+
|
| 1501 |
+
if not isinstance(config.text_config, SiglipTextConfig):
|
| 1502 |
+
raise ValueError(
|
| 1503 |
+
"config.text_config is expected to be of type SiglipTextConfig but is of type"
|
| 1504 |
+
f" {type(config.text_config)}."
|
| 1505 |
+
)
|
| 1506 |
+
|
| 1507 |
+
if not isinstance(config.vision_config, SiglipVisionConfig):
|
| 1508 |
+
raise ValueError(
|
| 1509 |
+
"config.vision_config is expected to be of type SiglipVisionConfig but is of type"
|
| 1510 |
+
f" {type(config.vision_config)}."
|
| 1511 |
+
)
|
| 1512 |
+
|
| 1513 |
+
text_config = config.text_config
|
| 1514 |
+
vision_config = config.vision_config
|
| 1515 |
+
|
| 1516 |
+
self.text_model = SiglipTextTransformer(text_config)
|
| 1517 |
+
self.vision_model = SiglipVisionTransformer(vision_config)
|
| 1518 |
+
|
| 1519 |
+
self.logit_scale = nn.Parameter(torch.randn(1))
|
| 1520 |
+
self.logit_bias = nn.Parameter(torch.randn(1))
|
| 1521 |
+
|
| 1522 |
+
# Initialize weights and apply final processing
|
| 1523 |
+
self.post_init()
|
| 1524 |
+
|
| 1525 |
+
@add_start_docstrings_to_model_forward(SIGLIP_TEXT_INPUTS_DOCSTRING)
|
| 1526 |
+
def get_text_features(
|
| 1527 |
+
self,
|
| 1528 |
+
input_ids: Optional[torch.Tensor] = None,
|
| 1529 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1530 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 1531 |
+
output_attentions: Optional[bool] = None,
|
| 1532 |
+
output_hidden_states: Optional[bool] = None,
|
| 1533 |
+
return_dict: Optional[bool] = None,
|
| 1534 |
+
) -> torch.FloatTensor:
|
| 1535 |
+
r"""
|
| 1536 |
+
Returns:
|
| 1537 |
+
text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
|
| 1538 |
+
applying the projection layer to the pooled output of [`SiglipTextModel`].
|
| 1539 |
+
Examples:
|
| 1540 |
+
```python
|
| 1541 |
+
>>> from transformers import AutoTokenizer, AutoModel
|
| 1542 |
+
>>> import torch
|
| 1543 |
+
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
|
| 1544 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
|
| 1545 |
+
>>> # important: make sure to set padding="max_length" as that's how the model was trained
|
| 1546 |
+
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
|
| 1547 |
+
>>> with torch.no_grad():
|
| 1548 |
+
... text_features = model.get_text_features(**inputs)
|
| 1549 |
+
```"""
|
| 1550 |
+
# Use SigLIP model's config for some fields (if specified) instead of those of vision & text components.
|
| 1551 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1552 |
+
output_hidden_states = (
|
| 1553 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1554 |
+
)
|
| 1555 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1556 |
+
|
| 1557 |
+
text_outputs = self.text_model(
|
| 1558 |
+
input_ids=input_ids,
|
| 1559 |
+
attention_mask=attention_mask,
|
| 1560 |
+
position_ids=position_ids,
|
| 1561 |
+
output_attentions=output_attentions,
|
| 1562 |
+
output_hidden_states=output_hidden_states,
|
| 1563 |
+
return_dict=return_dict,
|
| 1564 |
+
)
|
| 1565 |
+
|
| 1566 |
+
pooled_output = text_outputs[1]
|
| 1567 |
+
|
| 1568 |
+
return pooled_output
|
| 1569 |
+
|
| 1570 |
+
@add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
|
| 1571 |
+
def get_image_features(
|
| 1572 |
+
self,
|
| 1573 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 1574 |
+
output_attentions: Optional[bool] = None,
|
| 1575 |
+
output_hidden_states: Optional[bool] = None,
|
| 1576 |
+
return_dict: Optional[bool] = None,
|
| 1577 |
+
) -> torch.FloatTensor:
|
| 1578 |
+
r"""
|
| 1579 |
+
Returns:
|
| 1580 |
+
image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
|
| 1581 |
+
applying the projection layer to the pooled output of [`SiglipVisionModel`].
|
| 1582 |
+
Examples:
|
| 1583 |
+
```python
|
| 1584 |
+
>>> from PIL import Image
|
| 1585 |
+
>>> import requests
|
| 1586 |
+
>>> from transformers import AutoProcessor, AutoModel
|
| 1587 |
+
>>> import torch
|
| 1588 |
+
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
|
| 1589 |
+
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
|
| 1590 |
+
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 1591 |
+
>>> image = Image.open(requests.get(url, stream=True).raw)
|
| 1592 |
+
>>> inputs = processor(images=image, return_tensors="pt")
|
| 1593 |
+
>>> with torch.no_grad():
|
| 1594 |
+
... image_features = model.get_image_features(**inputs)
|
| 1595 |
+
```"""
|
| 1596 |
+
# Use SiglipModel's config for some fields (if specified) instead of those of vision & text components.
|
| 1597 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1598 |
+
output_hidden_states = (
|
| 1599 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1600 |
+
)
|
| 1601 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1602 |
+
|
| 1603 |
+
vision_outputs = self.vision_model(
|
| 1604 |
+
pixel_values=pixel_values,
|
| 1605 |
+
output_attentions=output_attentions,
|
| 1606 |
+
output_hidden_states=output_hidden_states,
|
| 1607 |
+
return_dict=return_dict,
|
| 1608 |
+
)
|
| 1609 |
+
|
| 1610 |
+
pooled_output = vision_outputs[1]
|
| 1611 |
+
|
| 1612 |
+
return pooled_output
|
| 1613 |
+
|
| 1614 |
+
@add_start_docstrings_to_model_forward(SIGLIP_INPUTS_DOCSTRING)
|
| 1615 |
+
@replace_return_docstrings(output_type=SiglipOutput, config_class=SiglipConfig)
|
| 1616 |
+
def forward(
|
| 1617 |
+
self,
|
| 1618 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1619 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 1620 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1621 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1622 |
+
return_loss: Optional[bool] = None,
|
| 1623 |
+
output_attentions: Optional[bool] = None,
|
| 1624 |
+
output_hidden_states: Optional[bool] = None,
|
| 1625 |
+
return_dict: Optional[bool] = None,
|
| 1626 |
+
) -> Union[Tuple, SiglipOutput]:
|
| 1627 |
+
r"""
|
| 1628 |
+
Returns:
|
| 1629 |
+
Examples:
|
| 1630 |
+
```python
|
| 1631 |
+
>>> from PIL import Image
|
| 1632 |
+
>>> import requests
|
| 1633 |
+
>>> from transformers import AutoProcessor, AutoModel
|
| 1634 |
+
>>> import torch
|
| 1635 |
+
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
|
| 1636 |
+
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
|
| 1637 |
+
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 1638 |
+
>>> image = Image.open(requests.get(url, stream=True).raw)
|
| 1639 |
+
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
|
| 1640 |
+
>>> # important: we pass `padding=max_length` since the model was trained with this
|
| 1641 |
+
>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
|
| 1642 |
+
>>> with torch.no_grad():
|
| 1643 |
+
... outputs = model(**inputs)
|
| 1644 |
+
>>> logits_per_image = outputs.logits_per_image
|
| 1645 |
+
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
|
| 1646 |
+
>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
|
| 1647 |
+
31.9% that image 0 is 'a photo of 2 cats'
|
| 1648 |
+
```"""
|
| 1649 |
+
# Use SigLIP model's config for some fields (if specified) instead of those of vision & text components.
|
| 1650 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1651 |
+
output_hidden_states = (
|
| 1652 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1653 |
+
)
|
| 1654 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1655 |
+
|
| 1656 |
+
vision_outputs = self.vision_model(
|
| 1657 |
+
pixel_values=pixel_values,
|
| 1658 |
+
output_attentions=output_attentions,
|
| 1659 |
+
output_hidden_states=output_hidden_states,
|
| 1660 |
+
return_dict=return_dict,
|
| 1661 |
+
)
|
| 1662 |
+
|
| 1663 |
+
text_outputs = self.text_model(
|
| 1664 |
+
input_ids=input_ids,
|
| 1665 |
+
attention_mask=attention_mask,
|
| 1666 |
+
position_ids=position_ids,
|
| 1667 |
+
output_attentions=output_attentions,
|
| 1668 |
+
output_hidden_states=output_hidden_states,
|
| 1669 |
+
return_dict=return_dict,
|
| 1670 |
+
)
|
| 1671 |
+
|
| 1672 |
+
image_embeds = vision_outputs[1]
|
| 1673 |
+
text_embeds = text_outputs[1]
|
| 1674 |
+
|
| 1675 |
+
# normalized features
|
| 1676 |
+
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
|
| 1677 |
+
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
|
| 1678 |
+
|
| 1679 |
+
# cosine similarity as logits
|
| 1680 |
+
logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * self.logit_scale.exp() + self.logit_bias
|
| 1681 |
+
logits_per_image = logits_per_text.t()
|
| 1682 |
+
|
| 1683 |
+
loss = None
|
| 1684 |
+
if return_loss:
|
| 1685 |
+
raise NotImplementedError("SigLIP loss to be implemented")
|
| 1686 |
+
|
| 1687 |
+
if not return_dict:
|
| 1688 |
+
output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
|
| 1689 |
+
return ((loss,) + output) if loss is not None else output
|
| 1690 |
+
|
| 1691 |
+
return SiglipOutput(
|
| 1692 |
+
loss=loss,
|
| 1693 |
+
logits_per_image=logits_per_image,
|
| 1694 |
+
logits_per_text=logits_per_text,
|
| 1695 |
+
text_embeds=text_embeds,
|
| 1696 |
+
image_embeds=image_embeds,
|
| 1697 |
+
text_model_output=text_outputs,
|
| 1698 |
+
vision_model_output=vision_outputs,
|
| 1699 |
+
)
|
| 1700 |
+
|
| 1701 |
+
|
| 1702 |
+
def get_siglip_vision_model(_flash_attn_2_enabled=True, **kwargs):
|
| 1703 |
+
siglip_vision_config = {
|
| 1704 |
+
"hidden_size": 1152,
|
| 1705 |
+
"image_size": 448,
|
| 1706 |
+
"intermediate_size": 4304,
|
| 1707 |
+
"model_type": "siglip_vision_model",
|
| 1708 |
+
"num_attention_heads": 16,
|
| 1709 |
+
"num_hidden_layers": 27,
|
| 1710 |
+
"patch_size": 14,
|
| 1711 |
+
}
|
| 1712 |
+
|
| 1713 |
+
model_config = SiglipVisionConfig(**siglip_vision_config, _flash_attn_2_enabled=_flash_attn_2_enabled, **kwargs)
|
| 1714 |
+
|
| 1715 |
+
vision_model = SiglipVisionModel(model_config).vision_model
|
| 1716 |
+
|
| 1717 |
+
return vision_model
|