

End of training
Browse files- README.md +1 -1
- all_results.json +7 -7
- eval_results.json +4 -4
- train_results.json +3 -3
- trainer_state.json +62 -62
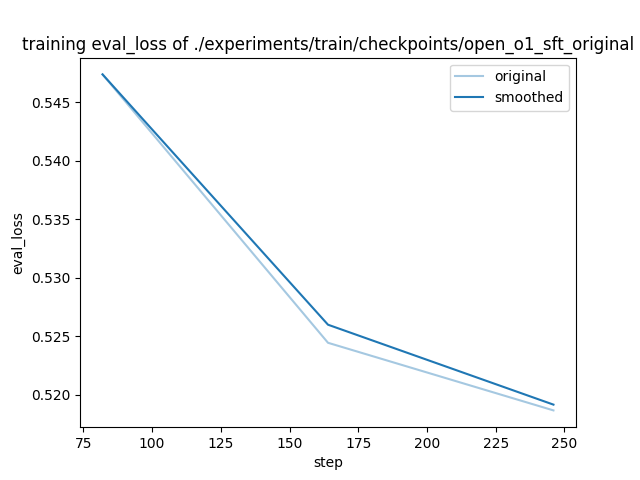
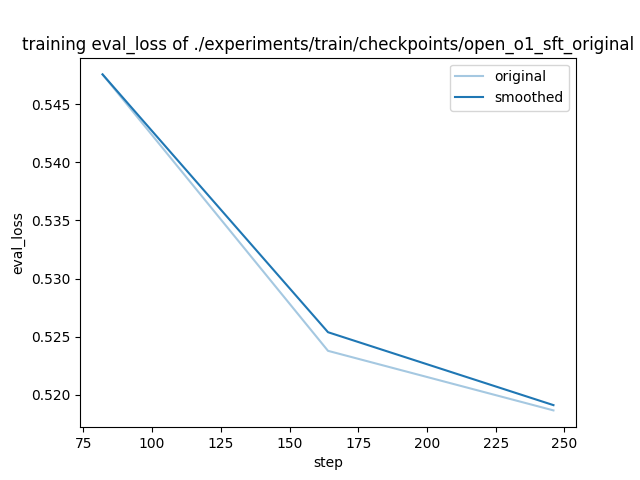
- training_eval_loss.png +0 -0
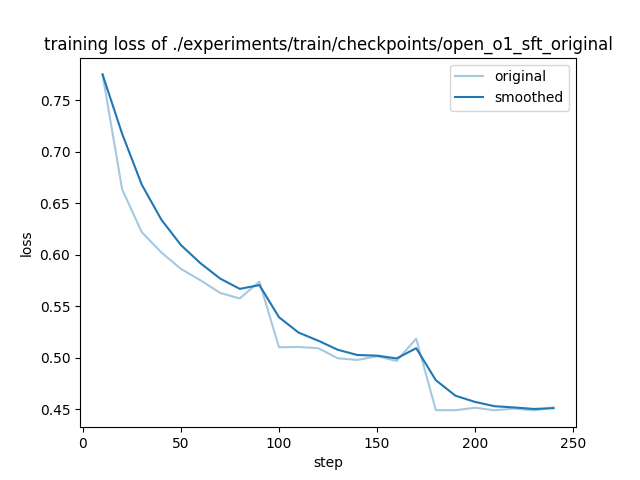
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -16,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 16 |
|
| 17 |
# open-o1-sft-original
|
| 18 |
|
| 19 |
-
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 0.5187
|
| 22 |
|
|
|
|
| 16 |
|
| 17 |
# open-o1-sft-original
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on the mlfoundations-dev/openo1_sft_original dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 0.5187
|
| 22 |
|
all_results.json
CHANGED
|
@@ -1,12 +1,12 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 2.992412746585736,
|
| 3 |
-
"eval_loss": 0.
|
| 4 |
-
"eval_runtime": 31.
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second": 1.
|
| 7 |
"total_flos": 411849782722560.0,
|
| 8 |
-
"train_loss": 0.
|
| 9 |
-
"train_runtime":
|
| 10 |
-
"train_samples_per_second": 19.
|
| 11 |
"train_steps_per_second": 0.038
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 2.992412746585736,
|
| 3 |
+
"eval_loss": 0.5186718702316284,
|
| 4 |
+
"eval_runtime": 31.6385,
|
| 5 |
+
"eval_samples_per_second": 70.136,
|
| 6 |
+
"eval_steps_per_second": 1.106,
|
| 7 |
"total_flos": 411849782722560.0,
|
| 8 |
+
"train_loss": 0.5282489497487138,
|
| 9 |
+
"train_runtime": 6430.2484,
|
| 10 |
+
"train_samples_per_second": 19.666,
|
| 11 |
"train_steps_per_second": 0.038
|
| 12 |
}
|
eval_results.json
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 2.992412746585736,
|
| 3 |
-
"eval_loss": 0.
|
| 4 |
-
"eval_runtime": 31.
|
| 5 |
-
"eval_samples_per_second":
|
| 6 |
-
"eval_steps_per_second": 1.
|
| 7 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 2.992412746585736,
|
| 3 |
+
"eval_loss": 0.5186718702316284,
|
| 4 |
+
"eval_runtime": 31.6385,
|
| 5 |
+
"eval_samples_per_second": 70.136,
|
| 6 |
+
"eval_steps_per_second": 1.106
|
| 7 |
}
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"epoch": 2.992412746585736,
|
| 3 |
"total_flos": 411849782722560.0,
|
| 4 |
-
"train_loss": 0.
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second": 19.
|
| 7 |
"train_steps_per_second": 0.038
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"epoch": 2.992412746585736,
|
| 3 |
"total_flos": 411849782722560.0,
|
| 4 |
+
"train_loss": 0.5282489497487138,
|
| 5 |
+
"train_runtime": 6430.2484,
|
| 6 |
+
"train_samples_per_second": 19.666,
|
| 7 |
"train_steps_per_second": 0.038
|
| 8 |
}
|
trainer_state.json
CHANGED
|
@@ -10,203 +10,203 @@
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.12139605462822459,
|
| 13 |
-
"grad_norm":
|
| 14 |
"learning_rate": 5e-06,
|
| 15 |
-
"loss": 0.
|
| 16 |
"step": 10
|
| 17 |
},
|
| 18 |
{
|
| 19 |
"epoch": 0.24279210925644917,
|
| 20 |
-
"grad_norm":
|
| 21 |
"learning_rate": 5e-06,
|
| 22 |
-
"loss": 0.
|
| 23 |
"step": 20
|
| 24 |
},
|
| 25 |
{
|
| 26 |
"epoch": 0.36418816388467373,
|
| 27 |
-
"grad_norm": 0.
|
| 28 |
"learning_rate": 5e-06,
|
| 29 |
-
"loss": 0.
|
| 30 |
"step": 30
|
| 31 |
},
|
| 32 |
{
|
| 33 |
"epoch": 0.48558421851289835,
|
| 34 |
-
"grad_norm": 0.
|
| 35 |
"learning_rate": 5e-06,
|
| 36 |
-
"loss": 0.
|
| 37 |
"step": 40
|
| 38 |
},
|
| 39 |
{
|
| 40 |
"epoch": 0.6069802731411229,
|
| 41 |
-
"grad_norm": 0.
|
| 42 |
"learning_rate": 5e-06,
|
| 43 |
-
"loss": 0.
|
| 44 |
"step": 50
|
| 45 |
},
|
| 46 |
{
|
| 47 |
"epoch": 0.7283763277693475,
|
| 48 |
-
"grad_norm": 0.
|
| 49 |
"learning_rate": 5e-06,
|
| 50 |
-
"loss": 0.
|
| 51 |
"step": 60
|
| 52 |
},
|
| 53 |
{
|
| 54 |
"epoch": 0.849772382397572,
|
| 55 |
-
"grad_norm": 0.
|
| 56 |
"learning_rate": 5e-06,
|
| 57 |
-
"loss": 0.
|
| 58 |
"step": 70
|
| 59 |
},
|
| 60 |
{
|
| 61 |
"epoch": 0.9711684370257967,
|
| 62 |
-
"grad_norm": 0.
|
| 63 |
"learning_rate": 5e-06,
|
| 64 |
-
"loss": 0.
|
| 65 |
"step": 80
|
| 66 |
},
|
| 67 |
{
|
| 68 |
"epoch": 0.9954476479514416,
|
| 69 |
-
"eval_loss": 0.
|
| 70 |
-
"eval_runtime": 31.
|
| 71 |
-
"eval_samples_per_second": 71.
|
| 72 |
"eval_steps_per_second": 1.122,
|
| 73 |
"step": 82
|
| 74 |
},
|
| 75 |
{
|
| 76 |
"epoch": 1.095599393019727,
|
| 77 |
-
"grad_norm": 0.
|
| 78 |
"learning_rate": 5e-06,
|
| 79 |
-
"loss": 0.
|
| 80 |
"step": 90
|
| 81 |
},
|
| 82 |
{
|
| 83 |
"epoch": 1.2169954476479514,
|
| 84 |
-
"grad_norm": 0.
|
| 85 |
"learning_rate": 5e-06,
|
| 86 |
-
"loss": 0.
|
| 87 |
"step": 100
|
| 88 |
},
|
| 89 |
{
|
| 90 |
"epoch": 1.338391502276176,
|
| 91 |
-
"grad_norm": 0.
|
| 92 |
"learning_rate": 5e-06,
|
| 93 |
-
"loss": 0.
|
| 94 |
"step": 110
|
| 95 |
},
|
| 96 |
{
|
| 97 |
"epoch": 1.4597875569044005,
|
| 98 |
-
"grad_norm": 0.
|
| 99 |
"learning_rate": 5e-06,
|
| 100 |
-
"loss": 0.
|
| 101 |
"step": 120
|
| 102 |
},
|
| 103 |
{
|
| 104 |
"epoch": 1.5811836115326252,
|
| 105 |
-
"grad_norm": 0.
|
| 106 |
"learning_rate": 5e-06,
|
| 107 |
-
"loss": 0.
|
| 108 |
"step": 130
|
| 109 |
},
|
| 110 |
{
|
| 111 |
"epoch": 1.7025796661608497,
|
| 112 |
-
"grad_norm": 0.
|
| 113 |
"learning_rate": 5e-06,
|
| 114 |
-
"loss": 0.
|
| 115 |
"step": 140
|
| 116 |
},
|
| 117 |
{
|
| 118 |
"epoch": 1.8239757207890743,
|
| 119 |
-
"grad_norm": 0.
|
| 120 |
"learning_rate": 5e-06,
|
| 121 |
-
"loss": 0.
|
| 122 |
"step": 150
|
| 123 |
},
|
| 124 |
{
|
| 125 |
"epoch": 1.945371775417299,
|
| 126 |
-
"grad_norm": 0.
|
| 127 |
"learning_rate": 5e-06,
|
| 128 |
-
"loss": 0.
|
| 129 |
"step": 160
|
| 130 |
},
|
| 131 |
{
|
| 132 |
"epoch": 1.9939301972685888,
|
| 133 |
-
"eval_loss": 0.
|
| 134 |
-
"eval_runtime": 31.
|
| 135 |
-
"eval_samples_per_second":
|
| 136 |
-
"eval_steps_per_second": 1.
|
| 137 |
"step": 164
|
| 138 |
},
|
| 139 |
{
|
| 140 |
"epoch": 2.069802731411229,
|
| 141 |
-
"grad_norm": 0.
|
| 142 |
"learning_rate": 5e-06,
|
| 143 |
-
"loss": 0.
|
| 144 |
"step": 170
|
| 145 |
},
|
| 146 |
{
|
| 147 |
"epoch": 2.191198786039454,
|
| 148 |
-
"grad_norm":
|
| 149 |
"learning_rate": 5e-06,
|
| 150 |
-
"loss": 0.
|
| 151 |
"step": 180
|
| 152 |
},
|
| 153 |
{
|
| 154 |
"epoch": 2.3125948406676784,
|
| 155 |
-
"grad_norm": 0.
|
| 156 |
"learning_rate": 5e-06,
|
| 157 |
-
"loss": 0.
|
| 158 |
"step": 190
|
| 159 |
},
|
| 160 |
{
|
| 161 |
"epoch": 2.433990895295903,
|
| 162 |
-
"grad_norm": 0.
|
| 163 |
"learning_rate": 5e-06,
|
| 164 |
-
"loss": 0.
|
| 165 |
"step": 200
|
| 166 |
},
|
| 167 |
{
|
| 168 |
"epoch": 2.5553869499241273,
|
| 169 |
-
"grad_norm": 0.
|
| 170 |
"learning_rate": 5e-06,
|
| 171 |
-
"loss": 0.
|
| 172 |
"step": 210
|
| 173 |
},
|
| 174 |
{
|
| 175 |
"epoch": 2.676783004552352,
|
| 176 |
-
"grad_norm": 0.
|
| 177 |
"learning_rate": 5e-06,
|
| 178 |
-
"loss": 0.
|
| 179 |
"step": 220
|
| 180 |
},
|
| 181 |
{
|
| 182 |
"epoch": 2.7981790591805766,
|
| 183 |
-
"grad_norm": 0.
|
| 184 |
"learning_rate": 5e-06,
|
| 185 |
-
"loss": 0.
|
| 186 |
"step": 230
|
| 187 |
},
|
| 188 |
{
|
| 189 |
"epoch": 2.919575113808801,
|
| 190 |
-
"grad_norm": 0.
|
| 191 |
"learning_rate": 5e-06,
|
| 192 |
-
"loss": 0.
|
| 193 |
"step": 240
|
| 194 |
},
|
| 195 |
{
|
| 196 |
"epoch": 2.992412746585736,
|
| 197 |
-
"eval_loss": 0.
|
| 198 |
-
"eval_runtime": 31.
|
| 199 |
-
"eval_samples_per_second": 70.
|
| 200 |
-
"eval_steps_per_second": 1.
|
| 201 |
"step": 246
|
| 202 |
},
|
| 203 |
{
|
| 204 |
"epoch": 2.992412746585736,
|
| 205 |
"step": 246,
|
| 206 |
"total_flos": 411849782722560.0,
|
| 207 |
-
"train_loss": 0.
|
| 208 |
-
"train_runtime":
|
| 209 |
-
"train_samples_per_second": 19.
|
| 210 |
"train_steps_per_second": 0.038
|
| 211 |
}
|
| 212 |
],
|
|
|
|
| 10 |
"log_history": [
|
| 11 |
{
|
| 12 |
"epoch": 0.12139605462822459,
|
| 13 |
+
"grad_norm": 1.9068916730195116,
|
| 14 |
"learning_rate": 5e-06,
|
| 15 |
+
"loss": 0.7721,
|
| 16 |
"step": 10
|
| 17 |
},
|
| 18 |
{
|
| 19 |
"epoch": 0.24279210925644917,
|
| 20 |
+
"grad_norm": 5.44810384092203,
|
| 21 |
"learning_rate": 5e-06,
|
| 22 |
+
"loss": 0.6638,
|
| 23 |
"step": 20
|
| 24 |
},
|
| 25 |
{
|
| 26 |
"epoch": 0.36418816388467373,
|
| 27 |
+
"grad_norm": 0.8162292861303865,
|
| 28 |
"learning_rate": 5e-06,
|
| 29 |
+
"loss": 0.6289,
|
| 30 |
"step": 30
|
| 31 |
},
|
| 32 |
{
|
| 33 |
"epoch": 0.48558421851289835,
|
| 34 |
+
"grad_norm": 0.724722400146013,
|
| 35 |
"learning_rate": 5e-06,
|
| 36 |
+
"loss": 0.6062,
|
| 37 |
"step": 40
|
| 38 |
},
|
| 39 |
{
|
| 40 |
"epoch": 0.6069802731411229,
|
| 41 |
+
"grad_norm": 0.6325755456980601,
|
| 42 |
"learning_rate": 5e-06,
|
| 43 |
+
"loss": 0.5886,
|
| 44 |
"step": 50
|
| 45 |
},
|
| 46 |
{
|
| 47 |
"epoch": 0.7283763277693475,
|
| 48 |
+
"grad_norm": 0.5102096530669636,
|
| 49 |
"learning_rate": 5e-06,
|
| 50 |
+
"loss": 0.5763,
|
| 51 |
"step": 60
|
| 52 |
},
|
| 53 |
{
|
| 54 |
"epoch": 0.849772382397572,
|
| 55 |
+
"grad_norm": 0.6134528530146113,
|
| 56 |
"learning_rate": 5e-06,
|
| 57 |
+
"loss": 0.5635,
|
| 58 |
"step": 70
|
| 59 |
},
|
| 60 |
{
|
| 61 |
"epoch": 0.9711684370257967,
|
| 62 |
+
"grad_norm": 0.6520975040339092,
|
| 63 |
"learning_rate": 5e-06,
|
| 64 |
+
"loss": 0.5578,
|
| 65 |
"step": 80
|
| 66 |
},
|
| 67 |
{
|
| 68 |
"epoch": 0.9954476479514416,
|
| 69 |
+
"eval_loss": 0.5475569367408752,
|
| 70 |
+
"eval_runtime": 31.1849,
|
| 71 |
+
"eval_samples_per_second": 71.156,
|
| 72 |
"eval_steps_per_second": 1.122,
|
| 73 |
"step": 82
|
| 74 |
},
|
| 75 |
{
|
| 76 |
"epoch": 1.095599393019727,
|
| 77 |
+
"grad_norm": 0.9030012716394636,
|
| 78 |
"learning_rate": 5e-06,
|
| 79 |
+
"loss": 0.5739,
|
| 80 |
"step": 90
|
| 81 |
},
|
| 82 |
{
|
| 83 |
"epoch": 1.2169954476479514,
|
| 84 |
+
"grad_norm": 0.5546978323548724,
|
| 85 |
"learning_rate": 5e-06,
|
| 86 |
+
"loss": 0.5098,
|
| 87 |
"step": 100
|
| 88 |
},
|
| 89 |
{
|
| 90 |
"epoch": 1.338391502276176,
|
| 91 |
+
"grad_norm": 0.7373972665017838,
|
| 92 |
"learning_rate": 5e-06,
|
| 93 |
+
"loss": 0.5099,
|
| 94 |
"step": 110
|
| 95 |
},
|
| 96 |
{
|
| 97 |
"epoch": 1.4597875569044005,
|
| 98 |
+
"grad_norm": 0.8335652060900699,
|
| 99 |
"learning_rate": 5e-06,
|
| 100 |
+
"loss": 0.5086,
|
| 101 |
"step": 120
|
| 102 |
},
|
| 103 |
{
|
| 104 |
"epoch": 1.5811836115326252,
|
| 105 |
+
"grad_norm": 0.9482742766383457,
|
| 106 |
"learning_rate": 5e-06,
|
| 107 |
+
"loss": 0.4988,
|
| 108 |
"step": 130
|
| 109 |
},
|
| 110 |
{
|
| 111 |
"epoch": 1.7025796661608497,
|
| 112 |
+
"grad_norm": 0.7107692585969188,
|
| 113 |
"learning_rate": 5e-06,
|
| 114 |
+
"loss": 0.4973,
|
| 115 |
"step": 140
|
| 116 |
},
|
| 117 |
{
|
| 118 |
"epoch": 1.8239757207890743,
|
| 119 |
+
"grad_norm": 0.6956293579831972,
|
| 120 |
"learning_rate": 5e-06,
|
| 121 |
+
"loss": 0.5006,
|
| 122 |
"step": 150
|
| 123 |
},
|
| 124 |
{
|
| 125 |
"epoch": 1.945371775417299,
|
| 126 |
+
"grad_norm": 0.5537353905530825,
|
| 127 |
"learning_rate": 5e-06,
|
| 128 |
+
"loss": 0.4962,
|
| 129 |
"step": 160
|
| 130 |
},
|
| 131 |
{
|
| 132 |
"epoch": 1.9939301972685888,
|
| 133 |
+
"eval_loss": 0.5237926244735718,
|
| 134 |
+
"eval_runtime": 31.2236,
|
| 135 |
+
"eval_samples_per_second": 71.068,
|
| 136 |
+
"eval_steps_per_second": 1.121,
|
| 137 |
"step": 164
|
| 138 |
},
|
| 139 |
{
|
| 140 |
"epoch": 2.069802731411229,
|
| 141 |
+
"grad_norm": 0.9676846382246841,
|
| 142 |
"learning_rate": 5e-06,
|
| 143 |
+
"loss": 0.5181,
|
| 144 |
"step": 170
|
| 145 |
},
|
| 146 |
{
|
| 147 |
"epoch": 2.191198786039454,
|
| 148 |
+
"grad_norm": 1.0604432739536909,
|
| 149 |
"learning_rate": 5e-06,
|
| 150 |
+
"loss": 0.4483,
|
| 151 |
"step": 180
|
| 152 |
},
|
| 153 |
{
|
| 154 |
"epoch": 2.3125948406676784,
|
| 155 |
+
"grad_norm": 0.9072874578025836,
|
| 156 |
"learning_rate": 5e-06,
|
| 157 |
+
"loss": 0.4481,
|
| 158 |
"step": 190
|
| 159 |
},
|
| 160 |
{
|
| 161 |
"epoch": 2.433990895295903,
|
| 162 |
+
"grad_norm": 0.93397296136386,
|
| 163 |
"learning_rate": 5e-06,
|
| 164 |
+
"loss": 0.4503,
|
| 165 |
"step": 200
|
| 166 |
},
|
| 167 |
{
|
| 168 |
"epoch": 2.5553869499241273,
|
| 169 |
+
"grad_norm": 0.5608137627707893,
|
| 170 |
"learning_rate": 5e-06,
|
| 171 |
+
"loss": 0.4475,
|
| 172 |
"step": 210
|
| 173 |
},
|
| 174 |
{
|
| 175 |
"epoch": 2.676783004552352,
|
| 176 |
+
"grad_norm": 0.7216376866533744,
|
| 177 |
"learning_rate": 5e-06,
|
| 178 |
+
"loss": 0.4491,
|
| 179 |
"step": 220
|
| 180 |
},
|
| 181 |
{
|
| 182 |
"epoch": 2.7981790591805766,
|
| 183 |
+
"grad_norm": 0.7502162152741092,
|
| 184 |
"learning_rate": 5e-06,
|
| 185 |
+
"loss": 0.4475,
|
| 186 |
"step": 230
|
| 187 |
},
|
| 188 |
{
|
| 189 |
"epoch": 2.919575113808801,
|
| 190 |
+
"grad_norm": 0.6902724753233441,
|
| 191 |
"learning_rate": 5e-06,
|
| 192 |
+
"loss": 0.4505,
|
| 193 |
"step": 240
|
| 194 |
},
|
| 195 |
{
|
| 196 |
"epoch": 2.992412746585736,
|
| 197 |
+
"eval_loss": 0.5186718702316284,
|
| 198 |
+
"eval_runtime": 31.6067,
|
| 199 |
+
"eval_samples_per_second": 70.207,
|
| 200 |
+
"eval_steps_per_second": 1.107,
|
| 201 |
"step": 246
|
| 202 |
},
|
| 203 |
{
|
| 204 |
"epoch": 2.992412746585736,
|
| 205 |
"step": 246,
|
| 206 |
"total_flos": 411849782722560.0,
|
| 207 |
+
"train_loss": 0.5282489497487138,
|
| 208 |
+
"train_runtime": 6430.2484,
|
| 209 |
+
"train_samples_per_second": 19.666,
|
| 210 |
"train_steps_per_second": 0.038
|
| 211 |
}
|
| 212 |
],
|
training_eval_loss.png
CHANGED
|
|
training_loss.png
CHANGED
|

|