

add figures of workflow and metrics, add invert transform
Browse files- README.md +13 -26
- configs/evaluate.json +17 -8
- configs/inference.json +11 -8
- configs/metadata.json +2 -1
- configs/train.json +17 -11
- docs/README.md +13 -26
- models/model.pt +2 -2
- models/model.ts +2 -2
README.md
CHANGED
|
@@ -9,9 +9,11 @@ license: apache-2.0
|
|
| 9 |
A pre-trained model for the endoscopic tool segmentation task.
|
| 10 |
|
| 11 |
# Model Overview
|
| 12 |
-
This model is trained using a flexible unet structure with an efficient-
|
| 13 |
The [pytorch model](https://drive.google.com/file/d/14r6WmzaZrgaWLGu0O9vSAzdeIGVFQ3cs/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1i-e5xXHtmvmqitwUP8Q3JqvnmN3mlrEm/view?usp=sharing) are shared in google drive. Details can be found in large_files.yml file. Modify the "bundle_root" parameter specified in configs/train.json and configs/inference.json to reflect where models are downloaded. Expected directory path to place downloaded models is "models/" under "bundle_root".
|
| 14 |
|
|
|
|
|
|
|
| 15 |
## Data
|
| 16 |
Datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
|
| 17 |
|
|
@@ -36,6 +38,16 @@ This model achieves the following IoU score on the test dataset (our own split f
|
|
| 36 |
|
| 37 |
Mean IoU = 0.87
|
| 38 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 39 |
## commands example
|
| 40 |
Execute training:
|
| 41 |
|
|
@@ -61,31 +73,6 @@ Export checkpoint to TorchScript file:
|
|
| 61 |
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
|
| 62 |
```
|
| 63 |
|
| 64 |
-
Export checkpoint to onnx file, which has been tested on pytorch 1.12.0:
|
| 65 |
-
|
| 66 |
-
```
|
| 67 |
-
python scripts/export_to_onnx.py --model models/model.pt --outpath models/model.onnx
|
| 68 |
-
```
|
| 69 |
-
|
| 70 |
-
Export TorchScript file to a torchscript module targeting a TensorRT engine with float16 precision.
|
| 71 |
-
|
| 72 |
-
```
|
| 73 |
-
torchtrtc -p f16 models/model.ts models/model_trt.ts "[(1,3,736,480);(4,3,736,480);(8,3,736,480)]"
|
| 74 |
-
```
|
| 75 |
-
The last parameter is the dynamic input shape in which each parameter means "[(MIN_BATCH, MIN_CHANNEL, MIN_WIDTH, MIN_HEIGHT), (OPT_BATCH, .., ..., OPT_HEIGHT), (MAX_BATCH, .., ..., MAX_HEIGHT)]". Please notice if using docker, the TensorRT CUDA must match the environment CUDA and the Torch-TensorRT c++&python version must be installed. For more examples on how to use the Torch-TensorRT, you can go to this [link](https://pytorch.org/TensorRT/). The [github source code link](https://github.com/pytorch/TensorRT) here shows the detail about how to install it on your own environment.
|
| 76 |
-
|
| 77 |
-
Export TensorRT float16 model from the onnx model:
|
| 78 |
-
|
| 79 |
-
```
|
| 80 |
-
polygraphy surgeon sanitize --fold-constants models/model.onnx -o models/new_model.onnx
|
| 81 |
-
```
|
| 82 |
-
|
| 83 |
-
```
|
| 84 |
-
trtexec --onnx=models/new_model.onnx --saveEngine=models/model.trt --fp16 --minShapes=INPUT__0:1x3x736x480 --optShapes=INPUT__0:4x3x736x480 --maxShapes=INPUT__0:8x3x736x480 --shapes=INPUT__0:4x3x736x480
|
| 85 |
-
```
|
| 86 |
-
This command need TensorRT with correct CUDA installed in the environment. For the detail of installing TensorRT, please refer to [this link](https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html). In addition, there are padding operations in this FlexibleUNet structure that not support by TensorRT. Therefore, when tried to convert the onnx model to a TensorRT engine, an extra polygraphy command is needed to execute.
|
| 87 |
-
|
| 88 |
-
|
| 89 |
# References
|
| 90 |
[1] Tan, M. and Le, Q. V. Efficientnet: Rethinking model scaling for convolutional neural networks. ICML, 2019a. https://arxiv.org/pdf/1905.11946.pdf
|
| 91 |
|
|
|
|
| 9 |
A pre-trained model for the endoscopic tool segmentation task.
|
| 10 |
|
| 11 |
# Model Overview
|
| 12 |
+
This model is trained using a flexible unet structure with an efficient-b2 [1] as the backbone and a UNet architecture [2] as the decoder. Datasets use private samples from [Activ Surgical](https://www.activsurgical.com/).
|
| 13 |
The [pytorch model](https://drive.google.com/file/d/14r6WmzaZrgaWLGu0O9vSAzdeIGVFQ3cs/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1i-e5xXHtmvmqitwUP8Q3JqvnmN3mlrEm/view?usp=sharing) are shared in google drive. Details can be found in large_files.yml file. Modify the "bundle_root" parameter specified in configs/train.json and configs/inference.json to reflect where models are downloaded. Expected directory path to place downloaded models is "models/" under "bundle_root".
|
| 14 |
|
| 15 |
+
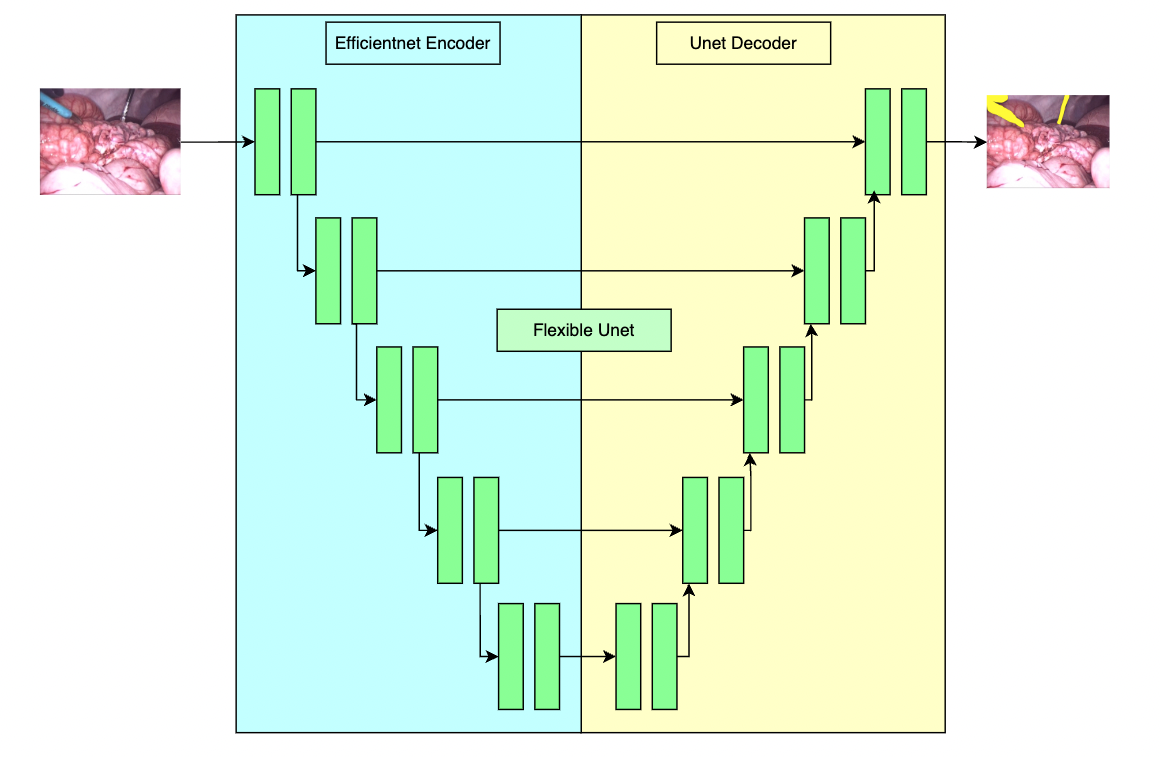
|
| 16 |
+
|
| 17 |
## Data
|
| 18 |
Datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
|
| 19 |
|
|
|
|
| 38 |
|
| 39 |
Mean IoU = 0.87
|
| 40 |
|
| 41 |
+
## Training Performance
|
| 42 |
+
A graph showing the training loss over 100 epochs.
|
| 43 |
+
|
| 44 |
+
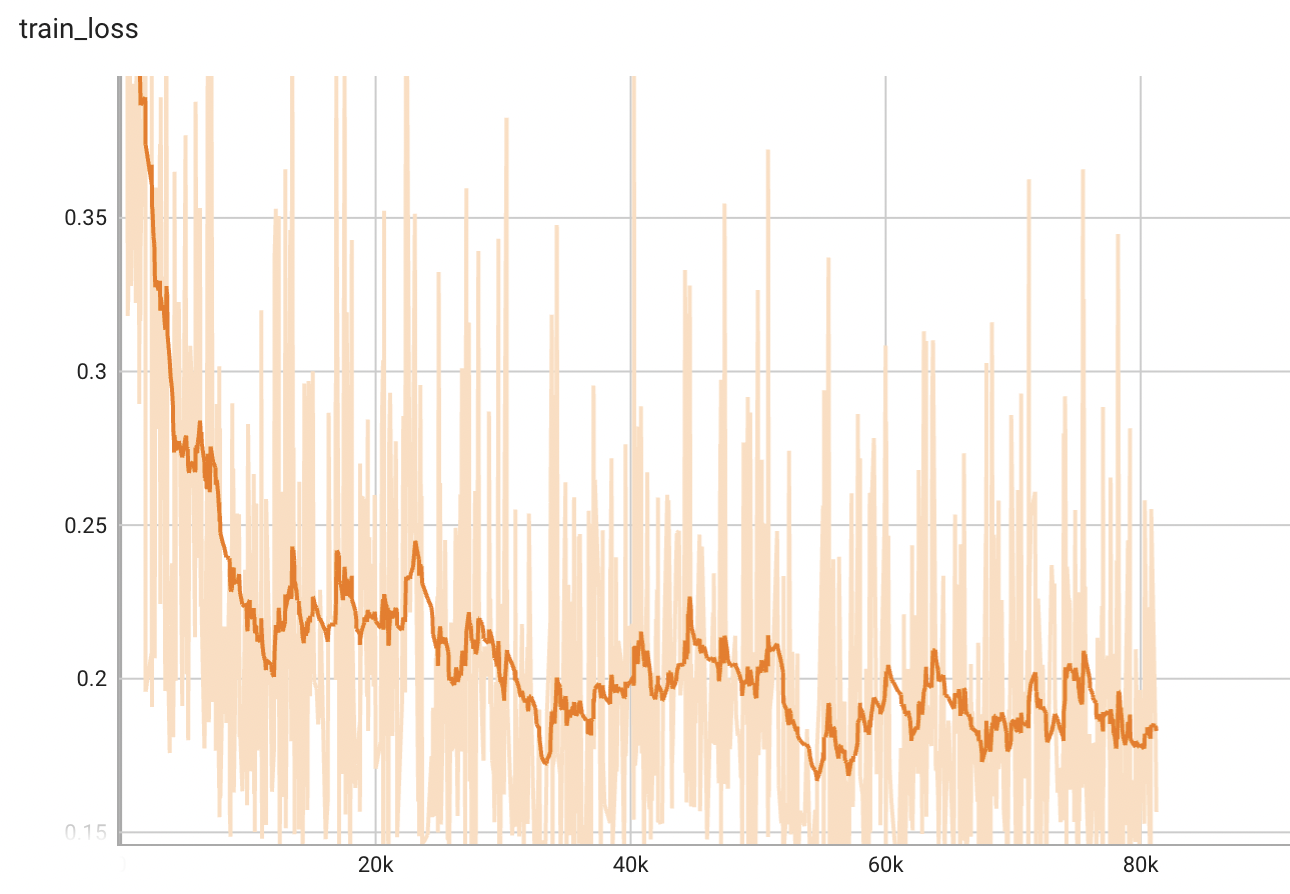 <br>
|
| 45 |
+
|
| 46 |
+
## Validation Performance
|
| 47 |
+
A graph showing the validation mean IoU over 100 epochs.
|
| 48 |
+
|
| 49 |
+
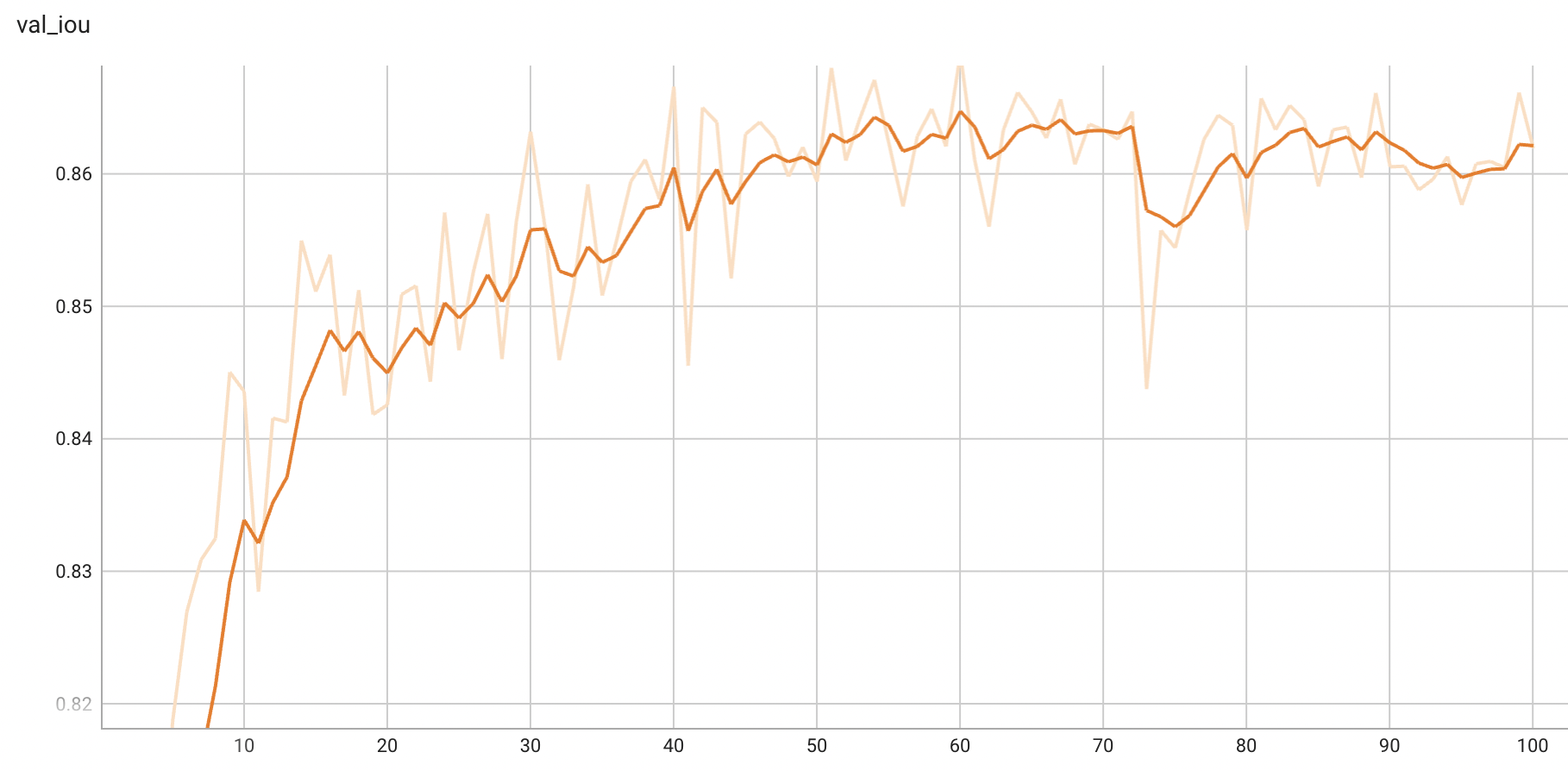 <br>
|
| 50 |
+
|
| 51 |
## commands example
|
| 52 |
Execute training:
|
| 53 |
|
|
|
|
| 73 |
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
|
| 74 |
```
|
| 75 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 76 |
# References
|
| 77 |
[1] Tan, M. and Le, Q. V. Efficientnet: Rethinking model scaling for convolutional neural networks. ICML, 2019a. https://arxiv.org/pdf/1905.11946.pdf
|
| 78 |
|
configs/evaluate.json
CHANGED
|
@@ -2,6 +2,21 @@
|
|
| 2 |
"validate#postprocessing": {
|
| 3 |
"_target_": "Compose",
|
| 4 |
"transforms": [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
{
|
| 6 |
"_target_": "AsDiscreted",
|
| 7 |
"keys": [
|
|
@@ -14,20 +29,14 @@
|
|
| 14 |
],
|
| 15 |
"to_onehot": 2
|
| 16 |
},
|
| 17 |
-
{
|
| 18 |
-
"_target_": "Lambdad",
|
| 19 |
-
"keys": [
|
| 20 |
-
"pred"
|
| 21 |
-
],
|
| 22 |
-
"func": "$lambda x : x[1:]"
|
| 23 |
-
},
|
| 24 |
{
|
| 25 |
"_target_": "SaveImaged",
|
|
|
|
| 26 |
"keys": "pred",
|
| 27 |
"meta_keys": "pred_meta_dict",
|
| 28 |
"output_dir": "@output_dir",
|
| 29 |
"output_ext": ".png",
|
| 30 |
-
"
|
| 31 |
"squeeze_end_dims": true
|
| 32 |
}
|
| 33 |
]
|
|
|
|
| 2 |
"validate#postprocessing": {
|
| 3 |
"_target_": "Compose",
|
| 4 |
"transforms": [
|
| 5 |
+
{
|
| 6 |
+
"_target_": "Invertd",
|
| 7 |
+
"keys": [
|
| 8 |
+
"pred",
|
| 9 |
+
"label"
|
| 10 |
+
],
|
| 11 |
+
"transform": "@validate#preprocessing",
|
| 12 |
+
"orig_keys": "image",
|
| 13 |
+
"meta_key_postfix": "meta_dict",
|
| 14 |
+
"nearest_interp": [
|
| 15 |
+
false,
|
| 16 |
+
true
|
| 17 |
+
],
|
| 18 |
+
"to_tensor": true
|
| 19 |
+
},
|
| 20 |
{
|
| 21 |
"_target_": "AsDiscreted",
|
| 22 |
"keys": [
|
|
|
|
| 29 |
],
|
| 30 |
"to_onehot": 2
|
| 31 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
{
|
| 33 |
"_target_": "SaveImaged",
|
| 34 |
+
"_disabled_": true,
|
| 35 |
"keys": "pred",
|
| 36 |
"meta_keys": "pred_meta_dict",
|
| 37 |
"output_dir": "@output_dir",
|
| 38 |
"output_ext": ".png",
|
| 39 |
+
"resample": false,
|
| 40 |
"squeeze_end_dims": true
|
| 41 |
}
|
| 42 |
]
|
configs/inference.json
CHANGED
|
@@ -12,9 +12,9 @@
|
|
| 12 |
"_target_": "FlexibleUNet",
|
| 13 |
"in_channels": 3,
|
| 14 |
"out_channels": 2,
|
| 15 |
-
"backbone": "efficientnet-
|
| 16 |
"spatial_dims": 2,
|
| 17 |
-
"pretrained":
|
| 18 |
"is_pad": false
|
| 19 |
},
|
| 20 |
"network": "$@network_def.to(@device)",
|
|
@@ -27,12 +27,6 @@
|
|
| 27 |
"image"
|
| 28 |
]
|
| 29 |
},
|
| 30 |
-
{
|
| 31 |
-
"_target_": "ToTensord",
|
| 32 |
-
"keys": [
|
| 33 |
-
"image"
|
| 34 |
-
]
|
| 35 |
-
},
|
| 36 |
{
|
| 37 |
"_target_": "AsChannelFirstd",
|
| 38 |
"keys": [
|
|
@@ -78,6 +72,15 @@
|
|
| 78 |
"postprocessing": {
|
| 79 |
"_target_": "Compose",
|
| 80 |
"transforms": [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 81 |
{
|
| 82 |
"_target_": "AsDiscreted",
|
| 83 |
"argmax": true,
|
|
|
|
| 12 |
"_target_": "FlexibleUNet",
|
| 13 |
"in_channels": 3,
|
| 14 |
"out_channels": 2,
|
| 15 |
+
"backbone": "efficientnet-b2",
|
| 16 |
"spatial_dims": 2,
|
| 17 |
+
"pretrained": false,
|
| 18 |
"is_pad": false
|
| 19 |
},
|
| 20 |
"network": "$@network_def.to(@device)",
|
|
|
|
| 27 |
"image"
|
| 28 |
]
|
| 29 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 30 |
{
|
| 31 |
"_target_": "AsChannelFirstd",
|
| 32 |
"keys": [
|
|
|
|
| 72 |
"postprocessing": {
|
| 73 |
"_target_": "Compose",
|
| 74 |
"transforms": [
|
| 75 |
+
{
|
| 76 |
+
"_target_": "Invertd",
|
| 77 |
+
"keys": "pred",
|
| 78 |
+
"transform": "@preprocessing",
|
| 79 |
+
"orig_keys": "image",
|
| 80 |
+
"meta_key_postfix": "meta_dict",
|
| 81 |
+
"nearest_interp": false,
|
| 82 |
+
"to_tensor": true
|
| 83 |
+
},
|
| 84 |
{
|
| 85 |
"_target_": "AsDiscreted",
|
| 86 |
"argmax": true,
|
configs/metadata.json
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
-
"version": "0.3.
|
| 4 |
"changelog": {
|
|
|
|
| 5 |
"0.3.0": "update dataset processing",
|
| 6 |
"0.2.1": "update to use monai 1.0.1",
|
| 7 |
"0.2.0": "update license files",
|
|
|
|
| 1 |
{
|
| 2 |
"schema": "https://github.com/Project-MONAI/MONAI-extra-test-data/releases/download/0.8.1/meta_schema_20220324.json",
|
| 3 |
+
"version": "0.3.1",
|
| 4 |
"changelog": {
|
| 5 |
+
"0.3.1": "add figures of workflow and metrics, add invert transform",
|
| 6 |
"0.3.0": "update dataset processing",
|
| 7 |
"0.2.1": "update to use monai 1.0.1",
|
| 8 |
"0.2.0": "update license files",
|
configs/train.json
CHANGED
|
@@ -11,7 +11,7 @@
|
|
| 11 |
"dataset_dir": "/workspace/data/endoscopic_tool_dataset",
|
| 12 |
"images": "$list(sorted(glob.glob(os.path.join(@dataset_dir,'train', '*', '*[!seg].jpg'))))",
|
| 13 |
"labels": "$[x.replace('.jpg', '_seg.jpg') for x in @images]",
|
| 14 |
-
"val_images": "$list(sorted(glob.glob(os.path.join(@dataset_dir,'
|
| 15 |
"val_labels": "$[x.replace('.jpg', '_seg.jpg') for x in @val_images]",
|
| 16 |
"val_interval": 1,
|
| 17 |
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
|
@@ -19,8 +19,9 @@
|
|
| 19 |
"_target_": "FlexibleUNet",
|
| 20 |
"in_channels": 3,
|
| 21 |
"out_channels": 2,
|
| 22 |
-
"backbone": "efficientnet-
|
| 23 |
"spatial_dims": 2,
|
|
|
|
| 24 |
"pretrained": true,
|
| 25 |
"is_pad": false
|
| 26 |
},
|
|
@@ -29,13 +30,20 @@
|
|
| 29 |
"_target_": "DiceLoss",
|
| 30 |
"include_background": false,
|
| 31 |
"to_onehot_y": true,
|
| 32 |
-
"softmax": true
|
|
|
|
| 33 |
},
|
| 34 |
"optimizer": {
|
| 35 |
"_target_": "torch.optim.Adam",
|
| 36 |
"params": "[email protected]()",
|
| 37 |
"lr": 0.0001
|
| 38 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 39 |
"train": {
|
| 40 |
"deterministic_transforms": [
|
| 41 |
{
|
|
@@ -45,13 +53,6 @@
|
|
| 45 |
"label"
|
| 46 |
]
|
| 47 |
},
|
| 48 |
-
{
|
| 49 |
-
"_target_": "ToTensord",
|
| 50 |
-
"keys": [
|
| 51 |
-
"image",
|
| 52 |
-
"label"
|
| 53 |
-
]
|
| 54 |
-
},
|
| 55 |
{
|
| 56 |
"_target_": "AsChannelFirstd",
|
| 57 |
"keys": "image"
|
|
@@ -150,6 +151,11 @@
|
|
| 150 |
"log_dir": "@output_dir",
|
| 151 |
"tag_name": "train_loss",
|
| 152 |
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 153 |
}
|
| 154 |
],
|
| 155 |
"key_metric": {
|
|
@@ -182,7 +188,7 @@
|
|
| 182 |
},
|
| 183 |
"trainer": {
|
| 184 |
"_target_": "SupervisedTrainer",
|
| 185 |
-
"max_epochs":
|
| 186 |
"device": "@device",
|
| 187 |
"train_data_loader": "@train#dataloader",
|
| 188 |
"network": "@network",
|
|
|
|
| 11 |
"dataset_dir": "/workspace/data/endoscopic_tool_dataset",
|
| 12 |
"images": "$list(sorted(glob.glob(os.path.join(@dataset_dir,'train', '*', '*[!seg].jpg'))))",
|
| 13 |
"labels": "$[x.replace('.jpg', '_seg.jpg') for x in @images]",
|
| 14 |
+
"val_images": "$list(sorted(glob.glob(os.path.join(@dataset_dir,'val', '*', '*[!seg].jpg'))))",
|
| 15 |
"val_labels": "$[x.replace('.jpg', '_seg.jpg') for x in @val_images]",
|
| 16 |
"val_interval": 1,
|
| 17 |
"device": "$torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')",
|
|
|
|
| 19 |
"_target_": "FlexibleUNet",
|
| 20 |
"in_channels": 3,
|
| 21 |
"out_channels": 2,
|
| 22 |
+
"backbone": "efficientnet-b2",
|
| 23 |
"spatial_dims": 2,
|
| 24 |
+
"dropout": 0.5,
|
| 25 |
"pretrained": true,
|
| 26 |
"is_pad": false
|
| 27 |
},
|
|
|
|
| 30 |
"_target_": "DiceLoss",
|
| 31 |
"include_background": false,
|
| 32 |
"to_onehot_y": true,
|
| 33 |
+
"softmax": true,
|
| 34 |
+
"jaccard": true
|
| 35 |
},
|
| 36 |
"optimizer": {
|
| 37 |
"_target_": "torch.optim.Adam",
|
| 38 |
"params": "[email protected]()",
|
| 39 |
"lr": 0.0001
|
| 40 |
},
|
| 41 |
+
"lr_scheduler": {
|
| 42 |
+
"_target_": "torch.optim.lr_scheduler.CosineAnnealingWarmRestarts",
|
| 43 |
+
"optimizer": "@optimizer",
|
| 44 |
+
"T_0": 100,
|
| 45 |
+
"T_mult": 1
|
| 46 |
+
},
|
| 47 |
"train": {
|
| 48 |
"deterministic_transforms": [
|
| 49 |
{
|
|
|
|
| 53 |
"label"
|
| 54 |
]
|
| 55 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 56 |
{
|
| 57 |
"_target_": "AsChannelFirstd",
|
| 58 |
"keys": "image"
|
|
|
|
| 151 |
"log_dir": "@output_dir",
|
| 152 |
"tag_name": "train_loss",
|
| 153 |
"output_transform": "$monai.handlers.from_engine(['loss'], first=True)"
|
| 154 |
+
},
|
| 155 |
+
{
|
| 156 |
+
"_target_": "LrScheduleHandler",
|
| 157 |
+
"lr_scheduler": "@lr_scheduler",
|
| 158 |
+
"print_lr": true
|
| 159 |
}
|
| 160 |
],
|
| 161 |
"key_metric": {
|
|
|
|
| 188 |
},
|
| 189 |
"trainer": {
|
| 190 |
"_target_": "SupervisedTrainer",
|
| 191 |
+
"max_epochs": 100,
|
| 192 |
"device": "@device",
|
| 193 |
"train_data_loader": "@train#dataloader",
|
| 194 |
"network": "@network",
|
docs/README.md
CHANGED
|
@@ -2,9 +2,11 @@
|
|
| 2 |
A pre-trained model for the endoscopic tool segmentation task.
|
| 3 |
|
| 4 |
# Model Overview
|
| 5 |
-
This model is trained using a flexible unet structure with an efficient-
|
| 6 |
The [pytorch model](https://drive.google.com/file/d/14r6WmzaZrgaWLGu0O9vSAzdeIGVFQ3cs/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1i-e5xXHtmvmqitwUP8Q3JqvnmN3mlrEm/view?usp=sharing) are shared in google drive. Details can be found in large_files.yml file. Modify the "bundle_root" parameter specified in configs/train.json and configs/inference.json to reflect where models are downloaded. Expected directory path to place downloaded models is "models/" under "bundle_root".
|
| 7 |
|
|
|
|
|
|
|
| 8 |
## Data
|
| 9 |
Datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
|
| 10 |
|
|
@@ -29,6 +31,16 @@ This model achieves the following IoU score on the test dataset (our own split f
|
|
| 29 |
|
| 30 |
Mean IoU = 0.87
|
| 31 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
## commands example
|
| 33 |
Execute training:
|
| 34 |
|
|
@@ -54,31 +66,6 @@ Export checkpoint to TorchScript file:
|
|
| 54 |
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
|
| 55 |
```
|
| 56 |
|
| 57 |
-
Export checkpoint to onnx file, which has been tested on pytorch 1.12.0:
|
| 58 |
-
|
| 59 |
-
```
|
| 60 |
-
python scripts/export_to_onnx.py --model models/model.pt --outpath models/model.onnx
|
| 61 |
-
```
|
| 62 |
-
|
| 63 |
-
Export TorchScript file to a torchscript module targeting a TensorRT engine with float16 precision.
|
| 64 |
-
|
| 65 |
-
```
|
| 66 |
-
torchtrtc -p f16 models/model.ts models/model_trt.ts "[(1,3,736,480);(4,3,736,480);(8,3,736,480)]"
|
| 67 |
-
```
|
| 68 |
-
The last parameter is the dynamic input shape in which each parameter means "[(MIN_BATCH, MIN_CHANNEL, MIN_WIDTH, MIN_HEIGHT), (OPT_BATCH, .., ..., OPT_HEIGHT), (MAX_BATCH, .., ..., MAX_HEIGHT)]". Please notice if using docker, the TensorRT CUDA must match the environment CUDA and the Torch-TensorRT c++&python version must be installed. For more examples on how to use the Torch-TensorRT, you can go to this [link](https://pytorch.org/TensorRT/). The [github source code link](https://github.com/pytorch/TensorRT) here shows the detail about how to install it on your own environment.
|
| 69 |
-
|
| 70 |
-
Export TensorRT float16 model from the onnx model:
|
| 71 |
-
|
| 72 |
-
```
|
| 73 |
-
polygraphy surgeon sanitize --fold-constants models/model.onnx -o models/new_model.onnx
|
| 74 |
-
```
|
| 75 |
-
|
| 76 |
-
```
|
| 77 |
-
trtexec --onnx=models/new_model.onnx --saveEngine=models/model.trt --fp16 --minShapes=INPUT__0:1x3x736x480 --optShapes=INPUT__0:4x3x736x480 --maxShapes=INPUT__0:8x3x736x480 --shapes=INPUT__0:4x3x736x480
|
| 78 |
-
```
|
| 79 |
-
This command need TensorRT with correct CUDA installed in the environment. For the detail of installing TensorRT, please refer to [this link](https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html). In addition, there are padding operations in this FlexibleUNet structure that not support by TensorRT. Therefore, when tried to convert the onnx model to a TensorRT engine, an extra polygraphy command is needed to execute.
|
| 80 |
-
|
| 81 |
-
|
| 82 |
# References
|
| 83 |
[1] Tan, M. and Le, Q. V. Efficientnet: Rethinking model scaling for convolutional neural networks. ICML, 2019a. https://arxiv.org/pdf/1905.11946.pdf
|
| 84 |
|
|
|
|
| 2 |
A pre-trained model for the endoscopic tool segmentation task.
|
| 3 |
|
| 4 |
# Model Overview
|
| 5 |
+
This model is trained using a flexible unet structure with an efficient-b2 [1] as the backbone and a UNet architecture [2] as the decoder. Datasets use private samples from [Activ Surgical](https://www.activsurgical.com/).
|
| 6 |
The [pytorch model](https://drive.google.com/file/d/14r6WmzaZrgaWLGu0O9vSAzdeIGVFQ3cs/view?usp=sharing) and [torchscript model](https://drive.google.com/file/d/1i-e5xXHtmvmqitwUP8Q3JqvnmN3mlrEm/view?usp=sharing) are shared in google drive. Details can be found in large_files.yml file. Modify the "bundle_root" parameter specified in configs/train.json and configs/inference.json to reflect where models are downloaded. Expected directory path to place downloaded models is "models/" under "bundle_root".
|
| 7 |
|
| 8 |
+

|
| 9 |
+
|
| 10 |
## Data
|
| 11 |
Datasets used in this work were provided by [Activ Surgical](https://www.activsurgical.com/).
|
| 12 |
|
|
|
|
| 31 |
|
| 32 |
Mean IoU = 0.87
|
| 33 |
|
| 34 |
+
## Training Performance
|
| 35 |
+
A graph showing the training loss over 100 epochs.
|
| 36 |
+
|
| 37 |
+
 <br>
|
| 38 |
+
|
| 39 |
+
## Validation Performance
|
| 40 |
+
A graph showing the validation mean IoU over 100 epochs.
|
| 41 |
+
|
| 42 |
+
 <br>
|
| 43 |
+
|
| 44 |
## commands example
|
| 45 |
Execute training:
|
| 46 |
|
|
|
|
| 66 |
python -m monai.bundle ckpt_export network_def --filepath models/model.ts --ckpt_file models/model.pt --meta_file configs/metadata.json --config_file configs/inference.json
|
| 67 |
```
|
| 68 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 69 |
# References
|
| 70 |
[1] Tan, M. and Le, Q. V. Efficientnet: Rethinking model scaling for convolutional neural networks. ICML, 2019a. https://arxiv.org/pdf/1905.11946.pdf
|
| 71 |
|
models/model.pt
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:844e9e97c6c9e7ebab1dab660c42ceb923c085ab895cf74f989a3cd9c5a0b028
|
| 3 |
+
size 46262677
|
models/model.ts
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9fa9f747ea2cc8ddffd4839af0c8d8f1b62c63c1013a8d80af8baf412bb3e5f9
|
| 3 |
+
size 46493609
|