
End of training
Browse files- README.md +5 -5
- all_results.json +9 -9
- egy_training_log.txt +2 -0
- eval_results.json +4 -4
- train_results.json +6 -6
- train_vs_val_loss.png +0 -0
- trainer_state.json +105 -10
README.md
CHANGED
|
@@ -18,11 +18,11 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [riotu-lab/ArabianGPT-01B](https://huggingface.co/riotu-lab/ArabianGPT-01B) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
-
- Loss: 0.
|
| 22 |
-
- Bleu: 0.
|
| 23 |
-
- Rouge1: 0.
|
| 24 |
-
- Rouge2: 0.
|
| 25 |
-
- Rougel: 0.
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
|
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [riotu-lab/ArabianGPT-01B](https://huggingface.co/riotu-lab/ArabianGPT-01B) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.6266
|
| 22 |
+
- Bleu: 0.2679
|
| 23 |
+
- Rouge1: 0.5977
|
| 24 |
+
- Rouge2: 0.3443
|
| 25 |
+
- Rougel: 0.5959
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
all_results.json
CHANGED
|
@@ -1,19 +1,19 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
"eval_bleu": 0.2678870499231116,
|
| 4 |
"eval_loss": 0.6265950798988342,
|
| 5 |
"eval_rouge1": 0.5977012354572853,
|
| 6 |
"eval_rouge2": 0.34430833134800065,
|
| 7 |
"eval_rougeL": 0.5958973349618409,
|
| 8 |
-
"eval_runtime":
|
| 9 |
"eval_samples": 5405,
|
| 10 |
-
"eval_samples_per_second":
|
| 11 |
-
"eval_steps_per_second":
|
| 12 |
"perplexity": 1.8712283369394682,
|
| 13 |
-
"total_flos":
|
| 14 |
-
"train_loss": 0.
|
| 15 |
-
"train_runtime":
|
| 16 |
"train_samples": 21622,
|
| 17 |
-
"train_samples_per_second":
|
| 18 |
-
"train_steps_per_second":
|
| 19 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 15.0,
|
| 3 |
"eval_bleu": 0.2678870499231116,
|
| 4 |
"eval_loss": 0.6265950798988342,
|
| 5 |
"eval_rouge1": 0.5977012354572853,
|
| 6 |
"eval_rouge2": 0.34430833134800065,
|
| 7 |
"eval_rougeL": 0.5958973349618409,
|
| 8 |
+
"eval_runtime": 17.8984,
|
| 9 |
"eval_samples": 5405,
|
| 10 |
+
"eval_samples_per_second": 301.982,
|
| 11 |
+
"eval_steps_per_second": 37.769,
|
| 12 |
"perplexity": 1.8712283369394682,
|
| 13 |
+
"total_flos": 2.118621118464e+16,
|
| 14 |
+
"train_loss": 0.058961041791913305,
|
| 15 |
+
"train_runtime": 1668.9384,
|
| 16 |
"train_samples": 21622,
|
| 17 |
+
"train_samples_per_second": 259.111,
|
| 18 |
+
"train_steps_per_second": 32.392
|
| 19 |
}
|
egy_training_log.txt
CHANGED
|
@@ -614,3 +614,5 @@ INFO:root:Epoch 14.0: Train Loss = 0.1733, Eval Loss = 0.696670651435852
|
|
| 614 |
INFO:absl:Using default tokenizer.
|
| 615 |
INFO:root:Epoch 15.0: Train Loss = 0.1593, Eval Loss = 0.7063180208206177
|
| 616 |
INFO:absl:Using default tokenizer.
|
|
|
|
|
|
|
|
|
| 614 |
INFO:absl:Using default tokenizer.
|
| 615 |
INFO:root:Epoch 15.0: Train Loss = 0.1593, Eval Loss = 0.7063180208206177
|
| 616 |
INFO:absl:Using default tokenizer.
|
| 617 |
+
INFO:__main__:*** Evaluate ***
|
| 618 |
+
INFO:absl:Using default tokenizer.
|
eval_results.json
CHANGED
|
@@ -1,13 +1,13 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
"eval_bleu": 0.2678870499231116,
|
| 4 |
"eval_loss": 0.6265950798988342,
|
| 5 |
"eval_rouge1": 0.5977012354572853,
|
| 6 |
"eval_rouge2": 0.34430833134800065,
|
| 7 |
"eval_rougeL": 0.5958973349618409,
|
| 8 |
-
"eval_runtime":
|
| 9 |
"eval_samples": 5405,
|
| 10 |
-
"eval_samples_per_second":
|
| 11 |
-
"eval_steps_per_second":
|
| 12 |
"perplexity": 1.8712283369394682
|
| 13 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 15.0,
|
| 3 |
"eval_bleu": 0.2678870499231116,
|
| 4 |
"eval_loss": 0.6265950798988342,
|
| 5 |
"eval_rouge1": 0.5977012354572853,
|
| 6 |
"eval_rouge2": 0.34430833134800065,
|
| 7 |
"eval_rougeL": 0.5958973349618409,
|
| 8 |
+
"eval_runtime": 17.8984,
|
| 9 |
"eval_samples": 5405,
|
| 10 |
+
"eval_samples_per_second": 301.982,
|
| 11 |
+
"eval_steps_per_second": 37.769,
|
| 12 |
"perplexity": 1.8712283369394682
|
| 13 |
}
|
train_results.json
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss": 0.
|
| 5 |
-
"train_runtime":
|
| 6 |
"train_samples": 21622,
|
| 7 |
-
"train_samples_per_second":
|
| 8 |
-
"train_steps_per_second":
|
| 9 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 15.0,
|
| 3 |
+
"total_flos": 2.118621118464e+16,
|
| 4 |
+
"train_loss": 0.058961041791913305,
|
| 5 |
+
"train_runtime": 1668.9384,
|
| 6 |
"train_samples": 21622,
|
| 7 |
+
"train_samples_per_second": 259.111,
|
| 8 |
+
"train_steps_per_second": 32.392
|
| 9 |
}
|
train_vs_val_loss.png
CHANGED

|
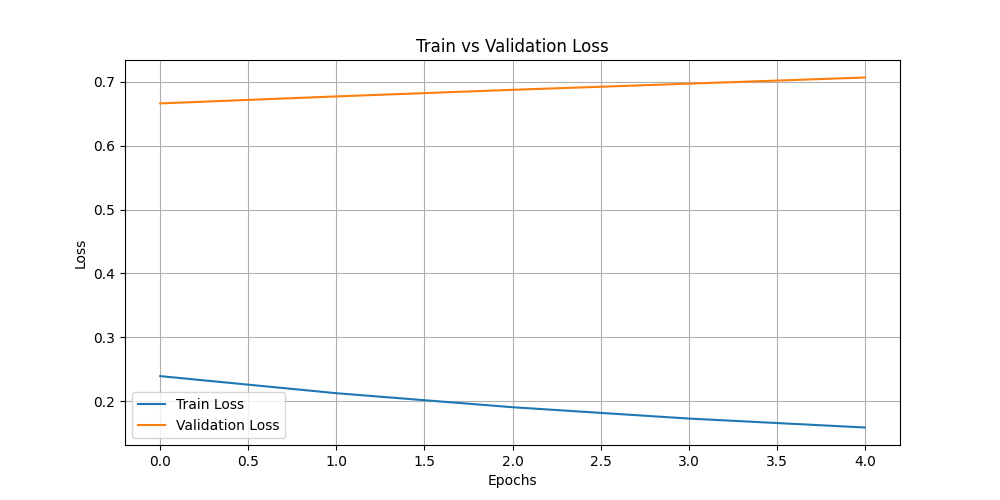
|
trainer_state.json
CHANGED
|
@@ -1,9 +1,9 @@
|
|
| 1 |
{
|
| 2 |
"best_metric": 0.6265950798988342,
|
| 3 |
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/res_nw_dj/checkpoint-13515",
|
| 4 |
-
"epoch":
|
| 5 |
"eval_steps": 500,
|
| 6 |
-
"global_step":
|
| 7 |
"is_hyper_param_search": false,
|
| 8 |
"is_local_process_zero": true,
|
| 9 |
"is_world_process_zero": true,
|
|
@@ -199,13 +199,108 @@
|
|
| 199 |
"step": 27030
|
| 200 |
},
|
| 201 |
{
|
| 202 |
-
"epoch":
|
| 203 |
-
"
|
| 204 |
-
"
|
| 205 |
-
"
|
| 206 |
-
"
|
| 207 |
-
|
| 208 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 209 |
}
|
| 210 |
],
|
| 211 |
"logging_steps": 500,
|
|
@@ -234,7 +329,7 @@
|
|
| 234 |
"attributes": {}
|
| 235 |
}
|
| 236 |
},
|
| 237 |
-
"total_flos":
|
| 238 |
"train_batch_size": 8,
|
| 239 |
"trial_name": null,
|
| 240 |
"trial_params": null
|
|
|
|
| 1 |
{
|
| 2 |
"best_metric": 0.6265950798988342,
|
| 3 |
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/res_nw_dj/checkpoint-13515",
|
| 4 |
+
"epoch": 15.0,
|
| 5 |
"eval_steps": 500,
|
| 6 |
+
"global_step": 40545,
|
| 7 |
"is_hyper_param_search": false,
|
| 8 |
"is_local_process_zero": true,
|
| 9 |
"is_world_process_zero": true,
|
|
|
|
| 199 |
"step": 27030
|
| 200 |
},
|
| 201 |
{
|
| 202 |
+
"epoch": 11.0,
|
| 203 |
+
"grad_norm": 1.3458495140075684,
|
| 204 |
+
"learning_rate": 2.2710044809559374e-05,
|
| 205 |
+
"loss": 0.2129,
|
| 206 |
+
"step": 29733
|
| 207 |
+
},
|
| 208 |
+
{
|
| 209 |
+
"epoch": 11.0,
|
| 210 |
+
"eval_bleu": 0.27843197191410246,
|
| 211 |
+
"eval_loss": 0.6767598390579224,
|
| 212 |
+
"eval_rouge1": 0.6188286228800556,
|
| 213 |
+
"eval_rouge2": 0.3762109244532287,
|
| 214 |
+
"eval_rougeL": 0.617052574223907,
|
| 215 |
+
"eval_runtime": 24.0534,
|
| 216 |
+
"eval_samples_per_second": 224.709,
|
| 217 |
+
"eval_steps_per_second": 28.104,
|
| 218 |
+
"step": 29733
|
| 219 |
+
},
|
| 220 |
+
{
|
| 221 |
+
"epoch": 12.0,
|
| 222 |
+
"grad_norm": 1.636675477027893,
|
| 223 |
+
"learning_rate": 2.018670649738611e-05,
|
| 224 |
+
"loss": 0.191,
|
| 225 |
+
"step": 32436
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"epoch": 12.0,
|
| 229 |
+
"eval_bleu": 0.2780108798800892,
|
| 230 |
+
"eval_loss": 0.6870447993278503,
|
| 231 |
+
"eval_rouge1": 0.6208121821010748,
|
| 232 |
+
"eval_rouge2": 0.37810190638421814,
|
| 233 |
+
"eval_rougeL": 0.6189436880506437,
|
| 234 |
+
"eval_runtime": 42.9158,
|
| 235 |
+
"eval_samples_per_second": 125.944,
|
| 236 |
+
"eval_steps_per_second": 15.752,
|
| 237 |
+
"step": 32436
|
| 238 |
+
},
|
| 239 |
+
{
|
| 240 |
+
"epoch": 13.0,
|
| 241 |
+
"grad_norm": 1.3978990316390991,
|
| 242 |
+
"learning_rate": 1.7663368185212848e-05,
|
| 243 |
+
"loss": 0.1733,
|
| 244 |
+
"step": 35139
|
| 245 |
+
},
|
| 246 |
+
{
|
| 247 |
+
"epoch": 13.0,
|
| 248 |
+
"eval_bleu": 0.2799527424248887,
|
| 249 |
+
"eval_loss": 0.696670651435852,
|
| 250 |
+
"eval_rouge1": 0.6213835516562576,
|
| 251 |
+
"eval_rouge2": 0.3799254363900967,
|
| 252 |
+
"eval_rougeL": 0.6195026516671875,
|
| 253 |
+
"eval_runtime": 17.6056,
|
| 254 |
+
"eval_samples_per_second": 307.005,
|
| 255 |
+
"eval_steps_per_second": 38.397,
|
| 256 |
+
"step": 35139
|
| 257 |
+
},
|
| 258 |
+
{
|
| 259 |
+
"epoch": 14.0,
|
| 260 |
+
"grad_norm": 1.386664628982544,
|
| 261 |
+
"learning_rate": 1.5140029873039583e-05,
|
| 262 |
+
"loss": 0.1593,
|
| 263 |
+
"step": 37842
|
| 264 |
+
},
|
| 265 |
+
{
|
| 266 |
+
"epoch": 14.0,
|
| 267 |
+
"eval_bleu": 0.2790160057234741,
|
| 268 |
+
"eval_loss": 0.7063180208206177,
|
| 269 |
+
"eval_rouge1": 0.6214879203521921,
|
| 270 |
+
"eval_rouge2": 0.379862056883408,
|
| 271 |
+
"eval_rougeL": 0.6194802915698101,
|
| 272 |
+
"eval_runtime": 17.8263,
|
| 273 |
+
"eval_samples_per_second": 303.204,
|
| 274 |
+
"eval_steps_per_second": 37.921,
|
| 275 |
+
"step": 37842
|
| 276 |
+
},
|
| 277 |
+
{
|
| 278 |
+
"epoch": 15.0,
|
| 279 |
+
"grad_norm": 1.5141432285308838,
|
| 280 |
+
"learning_rate": 1.261669156086632e-05,
|
| 281 |
+
"loss": 0.1478,
|
| 282 |
+
"step": 40545
|
| 283 |
+
},
|
| 284 |
+
{
|
| 285 |
+
"epoch": 15.0,
|
| 286 |
+
"eval_bleu": 0.2808668290315019,
|
| 287 |
+
"eval_loss": 0.7138631939888,
|
| 288 |
+
"eval_rouge1": 0.6216459883291815,
|
| 289 |
+
"eval_rouge2": 0.3804311054098596,
|
| 290 |
+
"eval_rougeL": 0.6196983257570402,
|
| 291 |
+
"eval_runtime": 17.6502,
|
| 292 |
+
"eval_samples_per_second": 306.229,
|
| 293 |
+
"eval_steps_per_second": 38.3,
|
| 294 |
+
"step": 40545
|
| 295 |
+
},
|
| 296 |
+
{
|
| 297 |
+
"epoch": 15.0,
|
| 298 |
+
"step": 40545,
|
| 299 |
+
"total_flos": 2.118621118464e+16,
|
| 300 |
+
"train_loss": 0.058961041791913305,
|
| 301 |
+
"train_runtime": 1668.9384,
|
| 302 |
+
"train_samples_per_second": 259.111,
|
| 303 |
+
"train_steps_per_second": 32.392
|
| 304 |
}
|
| 305 |
],
|
| 306 |
"logging_steps": 500,
|
|
|
|
| 329 |
"attributes": {}
|
| 330 |
}
|
| 331 |
},
|
| 332 |
+
"total_flos": 2.118621118464e+16,
|
| 333 |
"train_batch_size": 8,
|
| 334 |
"trial_name": null,
|
| 335 |
"trial_params": null
|