
File size: 6,807 Bytes
fe9f8d9 51a4db5 fe9f8d9 a31e2bb 51a4db5 bc42266 51a4db5 bc42266 fe9f8d9 51a4db5 fe9f8d9 a31e2bb fe9f8d9 0707256 fe9f8d9 a31e2bb fe9f8d9 8c8279a fe9f8d9 51a4db5 fe9f8d9 a31e2bb |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- loss:MatryoshkaLoss
- loss:MultipleNegativesRankingLoss
- mteb
base_model: aubmindlab/bert-base-arabertv02
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- pearson_cosine
- spearman_cosine
- pearson_manhattan
- spearman_manhattan
- pearson_euclidean
- spearman_euclidean
- pearson_dot
- spearman_dot
- pearson_max
- spearman_max
model-index:
- name: omarelshehy/Arabic-STS-Matryoshka-V2
results:
- dataset:
config: ar-ar
name: MTEB STS17 (ar-ar)
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: pearson
value: 85.1977
- type: spearman
value: 86.0559
- type: cosine_pearson
value: 85.1977
- type: cosine_spearman
value: 86.0559
- type: manhattan_pearson
value: 83.01950000000001
- type: manhattan_spearman
value: 85.28620000000001
- type: euclidean_pearson
value: 83.1524
- type: euclidean_spearman
value: 85.3787
- type: main_score
value: 86.0559
task:
type: STS
- dataset:
config: en-ar
name: MTEB STS17 (en-ar)
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: pearson
value: 16.234
- type: spearman
value: 13.337499999999999
- type: cosine_pearson
value: 16.234
- type: cosine_spearman
value: 13.337499999999999
- type: manhattan_pearson
value: 11.103200000000001
- type: manhattan_spearman
value: 8.8513
- type: euclidean_pearson
value: 10.7335
- type: euclidean_spearman
value: 7.857
- type: main_score
value: 13.337499999999999
task:
type: STS
- dataset:
config: ar
name: MTEB STS22 (ar)
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: pearson
value: 49.8116
- type: spearman
value: 58.7217
- type: cosine_pearson
value: 49.8116
- type: cosine_spearman
value: 58.7217
- type: manhattan_pearson
value: 55.281499999999994
- type: manhattan_spearman
value: 58.658
- type: euclidean_pearson
value: 54.600300000000004
- type: euclidean_spearman
value: 58.59029999999999
- type: main_score
value: 58.7217
task:
type: STS
---
# SentenceTransformer based on aubmindlab/bert-base-arabertv02
🚀 🚀 This is **Arabic only** [sentence-transformers](https://www.SBERT.net) model finetuned from [aubmindlab/bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for **semantic textual similarity**, **semantic search**, **clustering**, and more.
# Matryoshka Embeddings 🪆
This model supports Matryoshka embeddings, allowing you to truncate embeddings into smaller sizes to optimize performance and memory usage, based on your task requirements. Available truncation sizes include: **768**, **512**, **256**, **128**, and **64**
You can select the appropriate embedding size for your use case, ensuring flexibility in resource management.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [aubmindlab/bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) <!-- at revision 016fb9d6768f522a59c6e0d2d5d5d43a4e1bff60 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("omarelshehy/Arabic-STS-Matryoshka-V2")
# Run inference
sentences = [
'أحب قراءة الكتب في أوقات فراغي.',
'أستمتع بقراءة القصص في المساء قبل النوم.',
'القراءة تعزز معرفتي وتفتح أمامي آفاق جديدة.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
# 📊 Evaluation (Performance vs Embedding size)
I evaluated this model on the MTEB STS17 for arabic for different Embedding sizes 🪆
The results are plotted below:
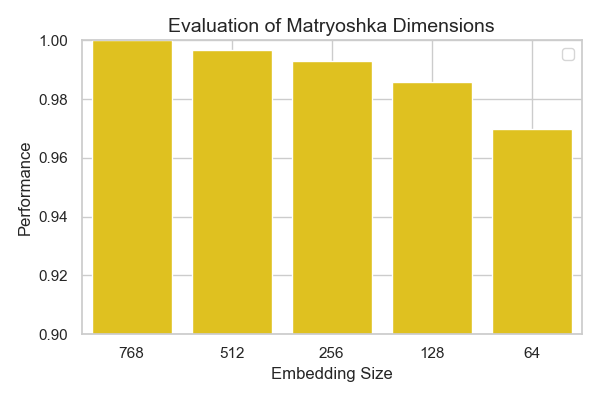
as seen from the plot, only very small degradation of performance happens across smaller matryoshka embedding sizes.
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MatryoshkaLoss
```bibtex
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |