
Commit
·
7049903
1
Parent(s):
74eaec5
Update README.md
Browse files
README.md
CHANGED
|
@@ -54,16 +54,18 @@ V1原版分支的好处在于,相比于768分支,具有更好的抗杂音抗
|
|
| 54 |
|
| 55 |
# 第五次实验简要记录
|
| 56 |
### 实验目标:
|
| 57 |
-
|
| 58 |
### 实验综述:
|
| 59 |
2023年5月19日,公开用于第五代模型的数据集(取消噪音干涉)
|
| 60 |
数据集来源:番剧1-12集(有小概率混合了其他角色的台词,请见谅,本人也是尽可能筛掉,但不保证没有,几乎不影响使用)、广播剧1-6集
|
| 61 |
主要so-vits模型:采用768分支,在新底模型的基础上,炼制了两个不同版本,一个是21600Step的特殊“加料”版本(Chtholly_V5Sp)(添加了小部分重复推理的高音音频、多语种音频进行套娃式炼制,目的是追求音域适应性),一个是80800Step的通用版本(Chtholly_V5Co)(完全纯净的珂朵莉干声,去除了所有带有可分辨的底噪和电音的数据音频,目的是追求声线相似性)。
|
| 62 |
-
|
| 63 |
|
| 64 |
在某些特殊情况下(如干声中存在海豚音和过高音),使用特殊版本可以获得更好的推理效果。
|
| 65 |
而语音变声和普通的音声推理,使用通用版本即可。
|
|
|
|
| 66 |
<u>聚类模型</u>(标有kmeans的文件):用于提升音色相似度,但是会降低咬字清晰度。一般0.1-0.6之间均可,常用值0.1、0.2,仓库方推荐值0.5。
|
|
|
|
| 67 |
<u>浅扩散模型</u>(以.yaml作为后缀的配置文件和标有model的文件):用于歌声推理,可以一定程度上去除底噪和电音,目前使用52000Step版本下,可用值30-600均有可能。如果是推理TTS出来的纯语音,不建议开启浅扩散模型,因为根本没有底噪,所以开了也没有用处,反而会有小概率推理出来更离谱的鬼音。
|
| 68 |
|
| 69 |
*建议推理参数:(在使用sovits进行TTS音频变声时)打开F0预测;变调[-3,6];F0均值滤波值域[0,0.9]、编码器Crepe;NSF-HIFIGAN增强器高音域适应值域[0,12](影响不如直接变调大)。*
|
|
@@ -76,5 +78,5 @@ V1原版分支的好处在于,相比于768分支,具有更好的抗杂音抗
|
|
| 76 |
|
| 77 |
### 实验结论:
|
| 78 |
- 第四次实验的噪音其实可以通过控制数据集来达到同样效果,故而本次实验删除噪音
|
| 79 |
-
-
|
| 80 |
- 在添加了多语种音频后,模型会更快地失衡。因此,不要训练太多步。
|
|
|
|
| 54 |
|
| 55 |
# 第五次实验简要记录
|
| 56 |
### 实验目标:
|
| 57 |
+
60%情况下,在入门级发烧HiFi设备下无法识别出与人类声音的区别
|
| 58 |
### 实验综述:
|
| 59 |
2023年5月19日,公开用于第五代模型的数据集(取消噪音干涉)
|
| 60 |
数据集来源:番剧1-12集(有小概率混合了其他角色的台词,请见谅,本人也是尽可能筛掉,但不保证没有,几乎不影响使用)、广播剧1-6集
|
| 61 |
主要so-vits模型:采用768分支,在新底模型的基础上,炼制了两个不同版本,一个是21600Step的特殊“加料”版本(Chtholly_V5Sp)(添加了小部分重复推理的高音音频、多语种音频进行套娃式炼制,目的是追求音域适应性),一个是80800Step的通用版本(Chtholly_V5Co)(完全纯净的珂朵莉干声,去除了所有带有可分辨的底噪和电音的数据音频,目的是追求声线相似性)。
|
| 62 |
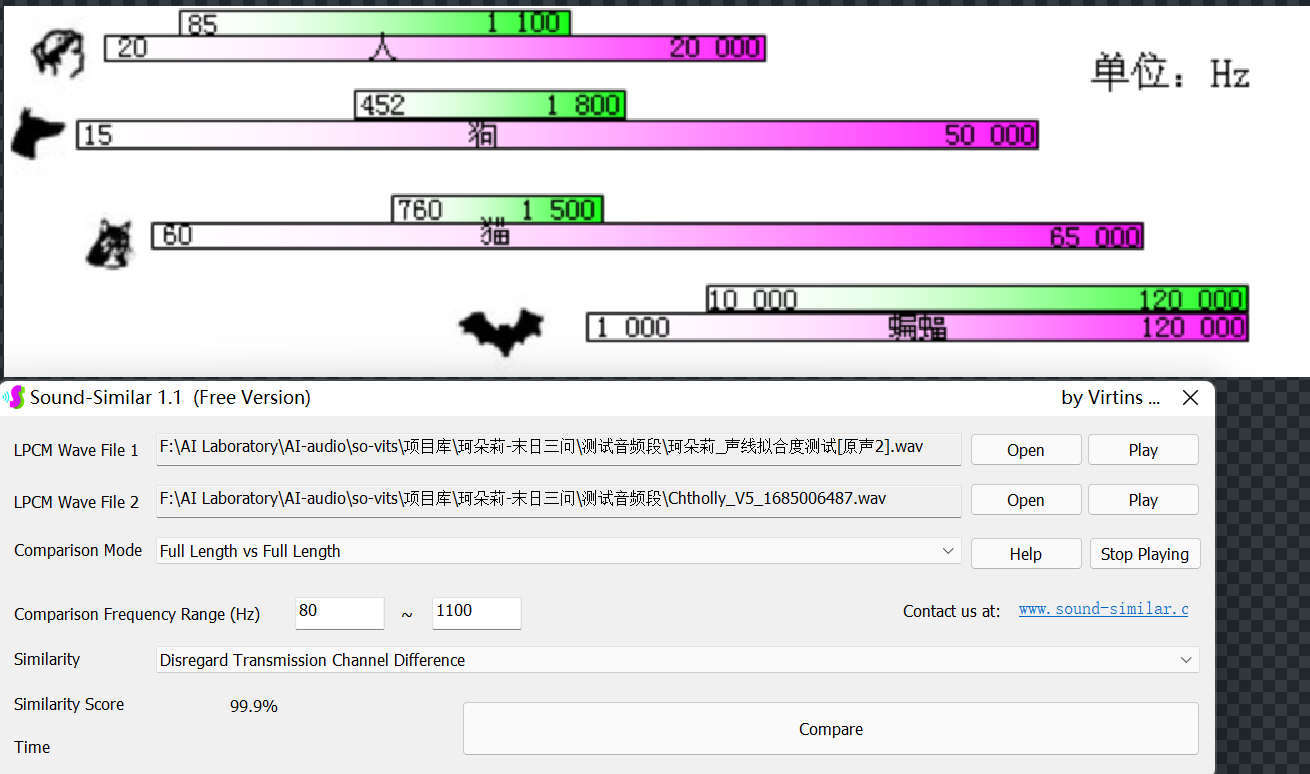
+
使用通用版第五代模型推理的音频已在Sound Similar Free中,测试达到99.9%声纹相似度。
|
| 63 |

|
| 64 |
在某些特殊情况下(如干声中存在海豚音和过高音),使用特殊版本可以获得更好的推理效果。
|
| 65 |
而语音变声和普通的音声推理,使用通用版本即可。
|
| 66 |
+
|
| 67 |
<u>聚类模型</u>(标有kmeans的文件):用于提升音色相似度,但是会降低咬字清晰度。一般0.1-0.6之间均可,常用值0.1、0.2,仓库方推荐值0.5。
|
| 68 |
+
|
| 69 |
<u>浅扩散模型</u>(以.yaml作为后缀的配置文件和标有model的文件):用于歌声推理,可以一定程度上去除底噪和电音,目前使用52000Step版本下,可用值30-600均有可能。如果是推理TTS出来的纯语音,不建议开启浅扩散模型,因为根本没有底噪,所以开了也没有用处,反而会有小概率推理出来更离谱的鬼音。
|
| 70 |
|
| 71 |
*建议推理参数:(在使用sovits进行TTS音频变声时)打开F0预测;变调[-3,6];F0均值滤波值域[0,0.9]、编码器Crepe;NSF-HIFIGAN增强器高音域适应值域[0,12](影响不如直接变调大)。*
|
|
|
|
| 78 |
|
| 79 |
### 实验结论:
|
| 80 |
- 第四次实验的噪音其实可以通过控制数据集来达到同样效果,故而本次实验删除噪音
|
| 81 |
+
- 60%情况下,在入门级发烧HiFi设备下无法识别出与人类声音的区别(请调制好参数)
|
| 82 |
- 在添加了多语种音频后,模型会更快地失衡。因此,不要训练太多步。
|