

Submitted by
 Flourish
Flourish
FlourishGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
Flourish
 Benjamin-eecs
Benjamin-eecs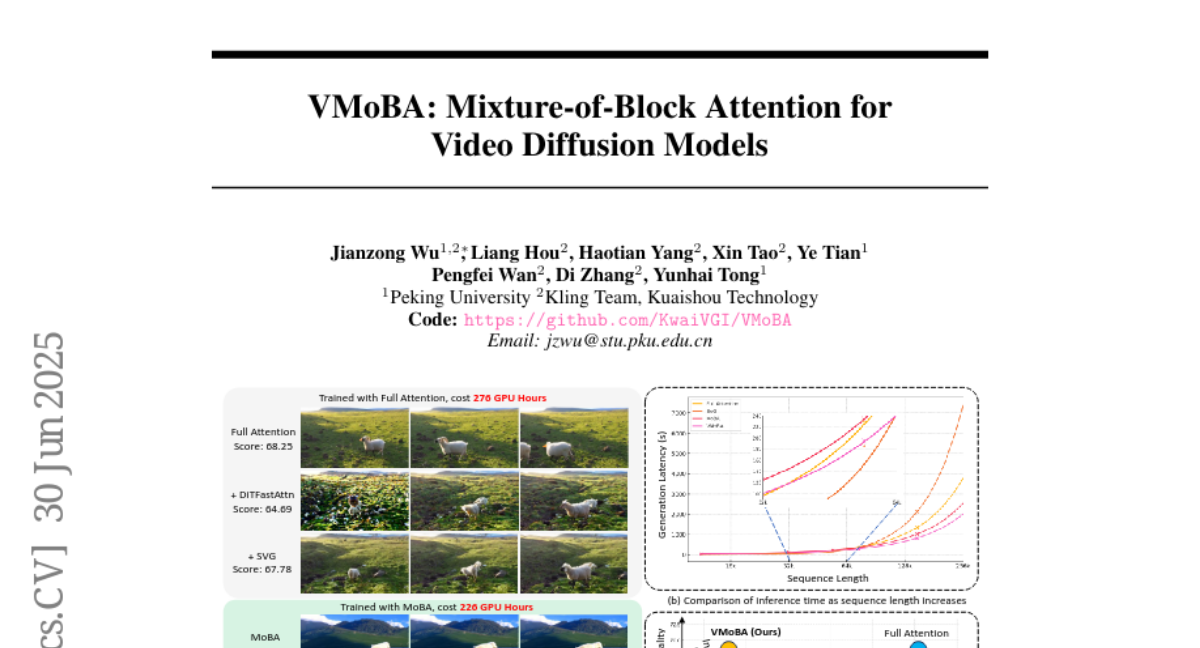
 jianzongwu
jianzongwu
 Meme145
Meme145
 alexgambashidze
alexgambashidze
 Jianyu
Jianyu
 a-yakovenko
a-yakovenko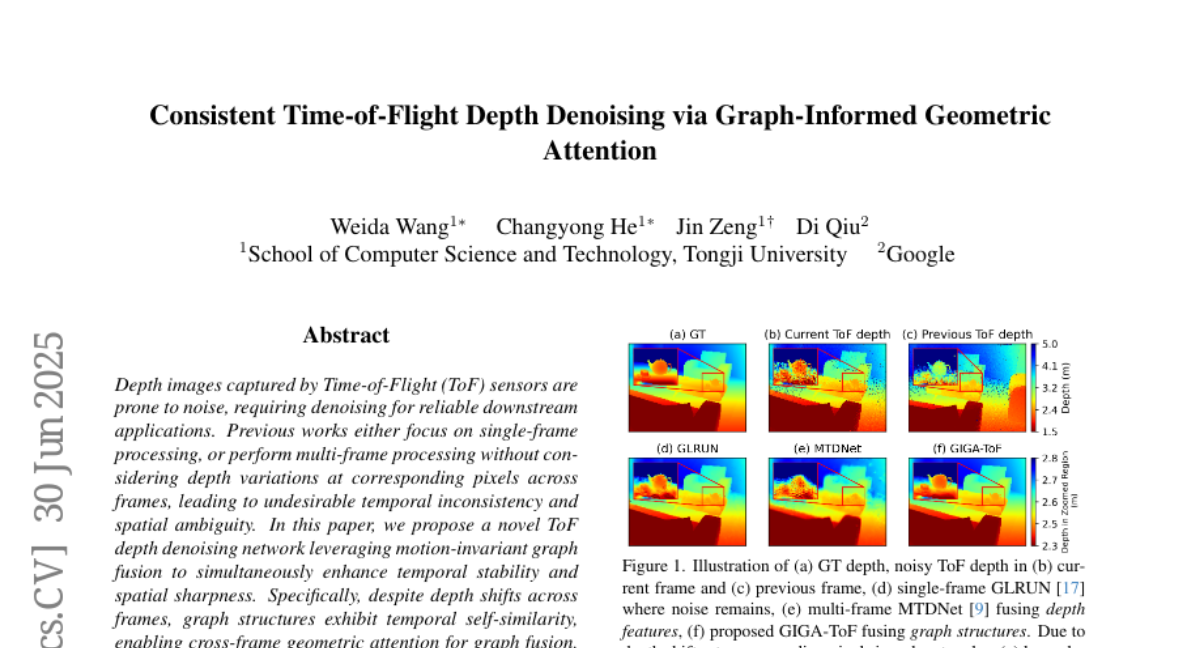
 wanhaoliu
wanhaoliu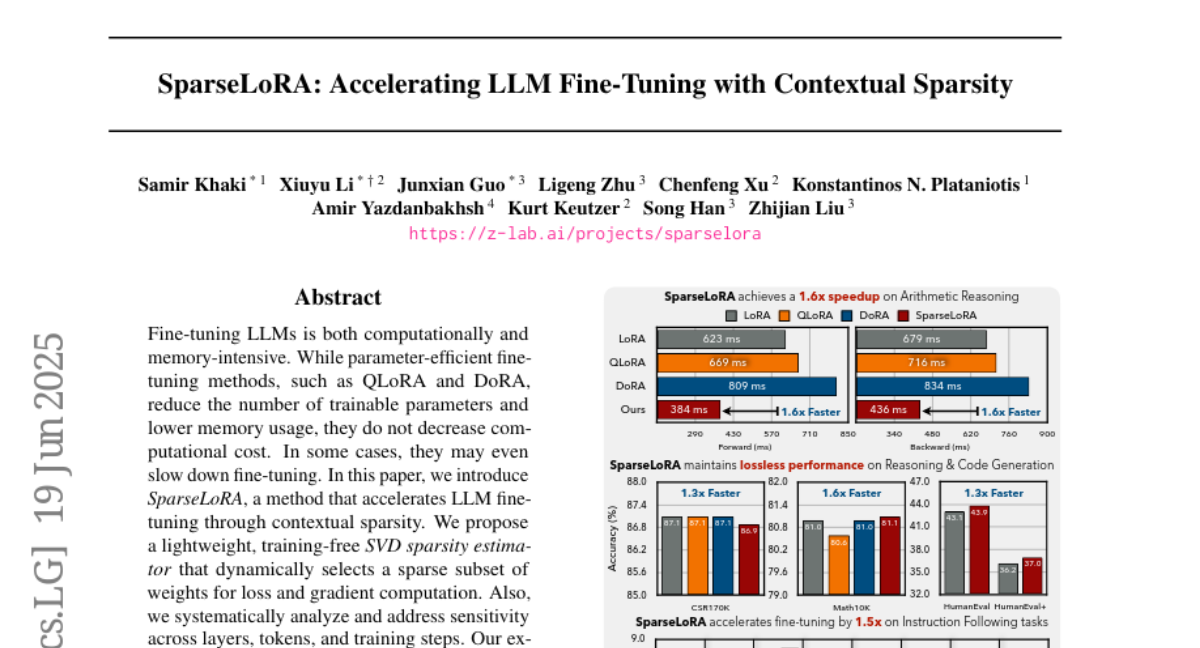
 Skhaki
Skhaki
 Mingyuan1997
Mingyuan1997
 mdmoor
mdmoor
 najoungkim
najoungkim
 JJ-TMT
JJ-TMT
 s-emanuilov
s-emanuilov
 liuhuadai
liuhuadai JJ-TMT
JJ-TMT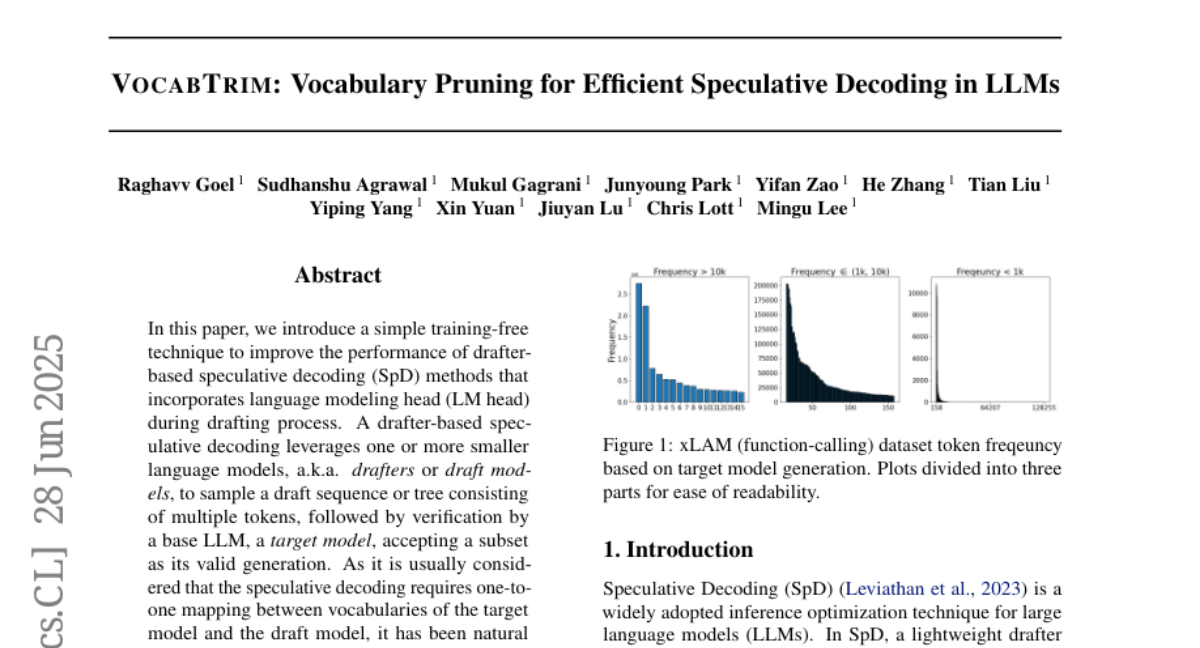
 RaghavvGoel
RaghavvGoel
 jmprcp
jmprcp
 XiaoyunYuan
XiaoyunYuan









