
upload notebooks
Browse files
Florence-2-Models-Image-Caption/Florence2_Models.ipynb
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"source": [
|
| 6 |
+
"***Florence-2 Models Image Captions : Image-to-Text***\n",
|
| 7 |
+
"\n",
|
| 8 |
+
"*notebook by : [prithivMLmods](https://huggingface.co/prithivMLmods)🤗 x ❤️*"
|
| 9 |
+
],
|
| 10 |
+
"metadata": {
|
| 11 |
+
"id": "0wlBVusvHBDY"
|
| 12 |
+
}
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"cell_type": "markdown",
|
| 16 |
+
"source": [
|
| 17 |
+
"***Installing all necessary packages***"
|
| 18 |
+
],
|
| 19 |
+
"metadata": {
|
| 20 |
+
"id": "v_lhI9uSHcfX"
|
| 21 |
+
}
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"cell_type": "code",
|
| 25 |
+
"execution_count": null,
|
| 26 |
+
"metadata": {
|
| 27 |
+
"id": "d9NXmBEN4-5z"
|
| 28 |
+
},
|
| 29 |
+
"outputs": [],
|
| 30 |
+
"source": [
|
| 31 |
+
"%%capture\n",
|
| 32 |
+
"!pip install transformers==4.48.0 timm\n",
|
| 33 |
+
"!pip install huggingface_hub hf_xet\n",
|
| 34 |
+
"#Hold tight, this will take around 3-5 minutes."
|
| 35 |
+
]
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"cell_type": "markdown",
|
| 39 |
+
"source": [
|
| 40 |
+
"***Run app 💨***"
|
| 41 |
+
],
|
| 42 |
+
"metadata": {
|
| 43 |
+
"id": "exk2jXyoHdwv"
|
| 44 |
+
}
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"cell_type": "code",
|
| 48 |
+
"execution_count": null,
|
| 49 |
+
"metadata": {
|
| 50 |
+
"colab": {
|
| 51 |
+
"background_save": true
|
| 52 |
+
},
|
| 53 |
+
"id": "3Z7bnSM35Sfc"
|
| 54 |
+
},
|
| 55 |
+
"outputs": [],
|
| 56 |
+
"source": [
|
| 57 |
+
"import gradio as gr\n",
|
| 58 |
+
"import subprocess\n",
|
| 59 |
+
"import torch\n",
|
| 60 |
+
"from PIL import Image\n",
|
| 61 |
+
"from transformers import AutoProcessor, AutoModelForCausalLM\n",
|
| 62 |
+
"\n",
|
| 63 |
+
"#--------- Hold tight — installation takes only 2–3 minutes ---------#\n",
|
| 64 |
+
"# Attempt to install flash-attn\n",
|
| 65 |
+
"try:\n",
|
| 66 |
+
" subprocess.run('pip install flash-attn==1.0.9 --no-build-isolation', env={'FLASH_ATTENTION_SKIP_CUDA_BUILD': \"TRUE\"}, check=True, shell=True)\n",
|
| 67 |
+
"except subprocess.CalledProcessError as e:\n",
|
| 68 |
+
" print(f\"Error installing flash-attn: {e}\")\n",
|
| 69 |
+
" print(\"Continuing without flash-attn.\")\n",
|
| 70 |
+
"#--------- Hold tight — installation takes only 2–3 minutes ---------#\n",
|
| 71 |
+
"\n",
|
| 72 |
+
"# Determine the device to use\n",
|
| 73 |
+
"device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
|
| 74 |
+
"\n",
|
| 75 |
+
"# Load the base model and processor\n",
|
| 76 |
+
"try:\n",
|
| 77 |
+
" vision_language_model_base = AutoModelForCausalLM.from_pretrained('microsoft/Florence-2-base', trust_remote_code=True).to(device).eval()\n",
|
| 78 |
+
" vision_language_processor_base = AutoProcessor.from_pretrained('microsoft/Florence-2-base', trust_remote_code=True)\n",
|
| 79 |
+
"except Exception as e:\n",
|
| 80 |
+
" print(f\"Error loading base model: {e}\")\n",
|
| 81 |
+
" vision_language_model_base = None\n",
|
| 82 |
+
" vision_language_processor_base = None\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"# Load the large model and processor\n",
|
| 85 |
+
"try:\n",
|
| 86 |
+
" vision_language_model_large = AutoModelForCausalLM.from_pretrained('microsoft/Florence-2-large', trust_remote_code=True).to(device).eval()\n",
|
| 87 |
+
" vision_language_processor_large = AutoProcessor.from_pretrained('microsoft/Florence-2-large', trust_remote_code=True)\n",
|
| 88 |
+
"except Exception as e:\n",
|
| 89 |
+
" print(f\"Error loading large model: {e}\")\n",
|
| 90 |
+
" vision_language_model_large = None\n",
|
| 91 |
+
" vision_language_processor_large = None\n",
|
| 92 |
+
"\n",
|
| 93 |
+
"def describe_image(uploaded_image, model_choice):\n",
|
| 94 |
+
" \"\"\"\n",
|
| 95 |
+
" Generates a detailed description of the input image using the selected model.\n",
|
| 96 |
+
"\n",
|
| 97 |
+
" Args:\n",
|
| 98 |
+
" uploaded_image (PIL.Image.Image): The image to describe.\n",
|
| 99 |
+
" model_choice (str): The model to use, either \"Base\" or \"Large\".\n",
|
| 100 |
+
"\n",
|
| 101 |
+
" Returns:\n",
|
| 102 |
+
" str: A detailed textual description of the image or an error message.\n",
|
| 103 |
+
" \"\"\"\n",
|
| 104 |
+
" if uploaded_image is None:\n",
|
| 105 |
+
" return \"Please upload an image.\"\n",
|
| 106 |
+
"\n",
|
| 107 |
+
" if model_choice == \"Florence-2-base\":\n",
|
| 108 |
+
" if vision_language_model_base is None:\n",
|
| 109 |
+
" return \"Base model failed to load.\"\n",
|
| 110 |
+
" model = vision_language_model_base\n",
|
| 111 |
+
" processor = vision_language_processor_base\n",
|
| 112 |
+
" elif model_choice == \"Florence-2-large\":\n",
|
| 113 |
+
" if vision_language_model_large is None:\n",
|
| 114 |
+
" return \"Large model failed to load.\"\n",
|
| 115 |
+
" model = vision_language_model_large\n",
|
| 116 |
+
" processor = vision_language_processor_large\n",
|
| 117 |
+
" else:\n",
|
| 118 |
+
" return \"Invalid model choice.\"\n",
|
| 119 |
+
"\n",
|
| 120 |
+
" if not isinstance(uploaded_image, Image.Image):\n",
|
| 121 |
+
" uploaded_image = Image.fromarray(uploaded_image)\n",
|
| 122 |
+
"\n",
|
| 123 |
+
" inputs = processor(text=\"<MORE_DETAILED_CAPTION>\", images=uploaded_image, return_tensors=\"pt\").to(device)\n",
|
| 124 |
+
" with torch.no_grad():\n",
|
| 125 |
+
" generated_ids = model.generate(\n",
|
| 126 |
+
" input_ids=inputs[\"input_ids\"],\n",
|
| 127 |
+
" pixel_values=inputs[\"pixel_values\"],\n",
|
| 128 |
+
" max_new_tokens=1024,\n",
|
| 129 |
+
" early_stopping=False,\n",
|
| 130 |
+
" do_sample=False,\n",
|
| 131 |
+
" num_beams=3,\n",
|
| 132 |
+
" )\n",
|
| 133 |
+
" generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]\n",
|
| 134 |
+
" processed_description = processor.post_process_generation(\n",
|
| 135 |
+
" generated_text,\n",
|
| 136 |
+
" task=\"<MORE_DETAILED_CAPTION>\",\n",
|
| 137 |
+
" image_size=(uploaded_image.width, uploaded_image.height)\n",
|
| 138 |
+
" )\n",
|
| 139 |
+
" image_description = processed_description[\"<MORE_DETAILED_CAPTION>\"]\n",
|
| 140 |
+
" print(\"\\nImage description generated!:\", image_description)\n",
|
| 141 |
+
" return image_description\n",
|
| 142 |
+
"\n",
|
| 143 |
+
"# Description for the interface\n",
|
| 144 |
+
"description = \"> Select the model to use for generating the image description. 'Base' is smaller and faster, while 'Large' is more accurate but slower.\"\n",
|
| 145 |
+
"if device == \"cpu\":\n",
|
| 146 |
+
" description += \" Note: Running on CPU, which may be slow for large models.\"\n",
|
| 147 |
+
"\n",
|
| 148 |
+
"css = \"\"\"\n",
|
| 149 |
+
".submit-btn {\n",
|
| 150 |
+
" background-color: #4682B4 !important;\n",
|
| 151 |
+
" color: white !important;\n",
|
| 152 |
+
"}\n",
|
| 153 |
+
".submit-btn:hover {\n",
|
| 154 |
+
" background-color: #87CEEB !important;\n",
|
| 155 |
+
"}\n",
|
| 156 |
+
"\"\"\"\n",
|
| 157 |
+
"\n",
|
| 158 |
+
"# Create the Gradio interface with Blocks\n",
|
| 159 |
+
"with gr.Blocks(theme=\"bethecloud/storj_theme\", css=css) as demo:\n",
|
| 160 |
+
" gr.Markdown(\"# **[Florence-2 Models Image Captions](https://huggingface.co/collections/prithivMLmods/multimodal-implementations-67c9982ea04b39f0608badb0)**\")\n",
|
| 161 |
+
" gr.Markdown(description)\n",
|
| 162 |
+
" with gr.Row():\n",
|
| 163 |
+
" # Left column: Input image and Generate button\n",
|
| 164 |
+
" with gr.Column():\n",
|
| 165 |
+
" image_input = gr.Image(label=\"Upload Image\", type=\"pil\")\n",
|
| 166 |
+
" generate_btn = gr.Button(\"Generate Caption\", elem_classes=\"submit-btn\")\n",
|
| 167 |
+
" # Right column: Model choice, output, and examples\n",
|
| 168 |
+
" with gr.Column():\n",
|
| 169 |
+
" model_choice = gr.Radio([\"Florence-2-base\", \"Florence-2-large\"], label=\"Model Choice\", value=\"Florence-2-base\")\n",
|
| 170 |
+
" with gr.Row():\n",
|
| 171 |
+
" output = gr.Textbox(label=\"Generated Caption\", lines=4, show_copy_button=True)\n",
|
| 172 |
+
" # Connect the button to the function\n",
|
| 173 |
+
" generate_btn.click(fn=describe_image, inputs=[image_input, model_choice], outputs=output)\n",
|
| 174 |
+
"\n",
|
| 175 |
+
"# Launch the interface\n",
|
| 176 |
+
"demo.launch(debug=True)"
|
| 177 |
+
]
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"cell_type": "markdown",
|
| 181 |
+
"source": [
|
| 182 |
+
"## **Demo Inference Screenshots**\n",
|
| 183 |
+
"\n",
|
| 184 |
+
"| 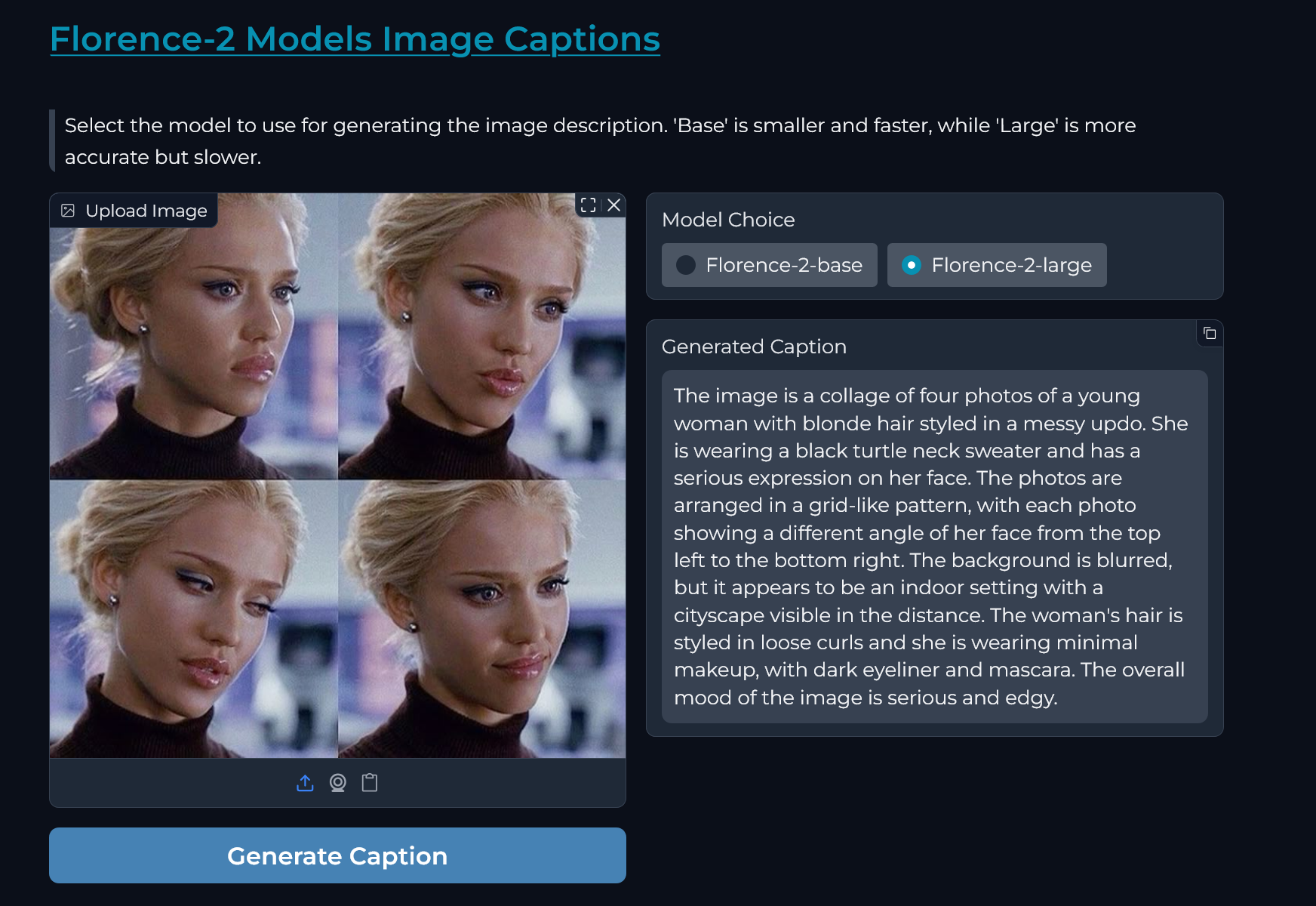 | 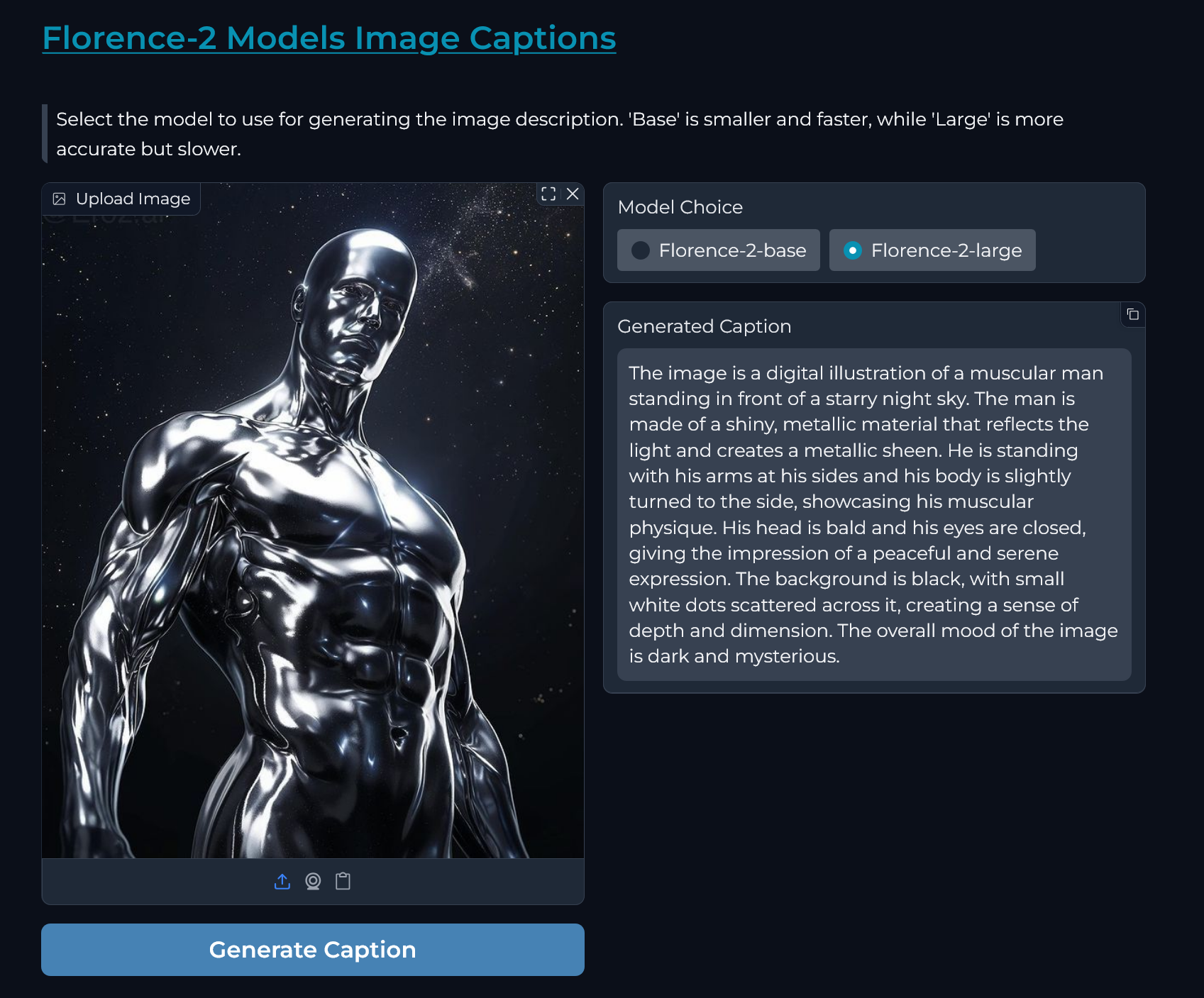 |\n",
|
| 185 |
+
"|:---------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------:|\n"
|
| 186 |
+
],
|
| 187 |
+
"metadata": {
|
| 188 |
+
"id": "NFKGwtueGfcW"
|
| 189 |
+
}
|
| 190 |
+
}
|
| 191 |
+
],
|
| 192 |
+
"metadata": {
|
| 193 |
+
"accelerator": "GPU",
|
| 194 |
+
"colab": {
|
| 195 |
+
"gpuType": "T4",
|
| 196 |
+
"provenance": []
|
| 197 |
+
},
|
| 198 |
+
"kernelspec": {
|
| 199 |
+
"display_name": "Python 3",
|
| 200 |
+
"name": "python3"
|
| 201 |
+
},
|
| 202 |
+
"language_info": {
|
| 203 |
+
"name": "python"
|
| 204 |
+
}
|
| 205 |
+
},
|
| 206 |
+
"nbformat": 4,
|
| 207 |
+
"nbformat_minor": 0
|
| 208 |
+
}
|