
upload notebooks
Browse files- Behemoth-3B-070225-post0.1/Behemoth_3B_070225_post0_1_ReportLab.ipynb +386 -0
- Megalodon-OCR-Sync-0713-ColabNotebook/Megalodon_OCR_Sync_0713_ReportLab.ipynb +362 -0
- MonkeyOCR-0709/MonkeyOCR-1.2B-0709-ReportLab.ipynb +0 -0
- MonkeyOCR-0709/MonkeyOCR-3B-0709-ReportLab.ipynb +0 -0
- MonkeyOCR-0709/MonkeyOCR-pro-1.2B-ReportLab.ipynb +0 -0
- OCRFlux3B/Multimodal_OCR_ReportLab_OCRFlux_3B.ipynb +0 -0
- Qwen2-VL-OCR-2B-Instruct/Qwen2_VL_OCR_2B_Instruct.ipynb +0 -0
- monkey-OCR/Multimodal_OCR_ReportLab_MonkeyOCR.ipynb +0 -0
- nanonets-OCR/Multimodal_OCR_ReportLab_Nanonets_Cleared.ipynb +0 -0
- typhoon-OCR/Multimodal_OCR_ReportLab_typhoon_ocr_3b.ipynb +0 -0
Behemoth-3B-070225-post0.1/Behemoth_3B_070225_post0_1_ReportLab.ipynb
ADDED
|
@@ -0,0 +1,386 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {
|
| 6 |
+
"id": "uFovmijgUV1Z"
|
| 7 |
+
},
|
| 8 |
+
"source": [
|
| 9 |
+
"***Multimodal Caption ReportLab : Behemoth-3B-070225-post0.1***\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"*notebook by : [prithivMLmods](https://huggingface.co/prithivMLmods)🤗 x ❤️*"
|
| 12 |
+
]
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"cell_type": "markdown",
|
| 16 |
+
"metadata": {
|
| 17 |
+
"id": "RugX4SGZV-8O"
|
| 18 |
+
},
|
| 19 |
+
"source": [
|
| 20 |
+
"***Installing all necessary packages***"
|
| 21 |
+
]
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"cell_type": "code",
|
| 25 |
+
"execution_count": null,
|
| 26 |
+
"metadata": {
|
| 27 |
+
"id": "l-NtFtjSpuJQ"
|
| 28 |
+
},
|
| 29 |
+
"outputs": [],
|
| 30 |
+
"source": [
|
| 31 |
+
"%%capture\n",
|
| 32 |
+
"!pip install gradio transformers transformers-stream-generator qwen-vl-utils\n",
|
| 33 |
+
"!pip install torchvision torch huggingface_hub spaces accelerate ipython\n",
|
| 34 |
+
"!pip install pillow av python-docx requests numpy reportlab fpdf hf_xet\n",
|
| 35 |
+
"#Hold tight, this will take around 3-5 minutes."
|
| 36 |
+
]
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"cell_type": "markdown",
|
| 40 |
+
"metadata": {
|
| 41 |
+
"id": "mvoSnRZcVBu4"
|
| 42 |
+
},
|
| 43 |
+
"source": [
|
| 44 |
+
"***Run app***"
|
| 45 |
+
]
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"cell_type": "code",
|
| 49 |
+
"execution_count": null,
|
| 50 |
+
"metadata": {
|
| 51 |
+
"id": "tElKr2Fkp1bO"
|
| 52 |
+
},
|
| 53 |
+
"outputs": [],
|
| 54 |
+
"source": [
|
| 55 |
+
"# ================================================\n",
|
| 56 |
+
"# Model Configuration\n",
|
| 57 |
+
"# ================================================\n",
|
| 58 |
+
"\n",
|
| 59 |
+
"# Model used in the app:\n",
|
| 60 |
+
"# https://huggingface.co/prithivMLmods/Behemoth-3B-070225-post0.1\n",
|
| 61 |
+
"\n",
|
| 62 |
+
"# Architecture built on:\n",
|
| 63 |
+
"# Qwen2_5_VLForConditionalGeneration [qwen2_5_vl]\n",
|
| 64 |
+
"import gradio as gr\n",
|
| 65 |
+
"import spaces\n",
|
| 66 |
+
"from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor, TextIteratorStreamer\n",
|
| 67 |
+
"from qwen_vl_utils import process_vision_info\n",
|
| 68 |
+
"import torch\n",
|
| 69 |
+
"from PIL import Image\n",
|
| 70 |
+
"import os\n",
|
| 71 |
+
"import uuid\n",
|
| 72 |
+
"import io\n",
|
| 73 |
+
"from threading import Thread\n",
|
| 74 |
+
"from reportlab.lib.pagesizes import A4\n",
|
| 75 |
+
"from reportlab.lib.styles import getSampleStyleSheet\n",
|
| 76 |
+
"from reportlab.lib import colors\n",
|
| 77 |
+
"from reportlab.platypus import SimpleDocTemplate, Image as RLImage, Paragraph, Spacer\n",
|
| 78 |
+
"from reportlab.lib.units import inch\n",
|
| 79 |
+
"from reportlab.pdfbase import pdfmetrics\n",
|
| 80 |
+
"from reportlab.pdfbase.ttfonts import TTFont\n",
|
| 81 |
+
"import docx\n",
|
| 82 |
+
"from docx.enum.text import WD_ALIGN_PARAGRAPH\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"# Define model options\n",
|
| 85 |
+
"MODEL_OPTIONS = {\n",
|
| 86 |
+
" \"Behemoth-3B-070225-post0.1\": \"prithivMLmods/Behemoth-3B-070225-post0.1\",\n",
|
| 87 |
+
"}\n",
|
| 88 |
+
"\n",
|
| 89 |
+
"# Preload models and processors into CUDA\n",
|
| 90 |
+
"models = {}\n",
|
| 91 |
+
"processors = {}\n",
|
| 92 |
+
"for name, model_id in MODEL_OPTIONS.items():\n",
|
| 93 |
+
" print(f\"Loading {name}🤗. Hold tight, this will take around 4-6 minutes..\")\n",
|
| 94 |
+
" models[name] = Qwen2_5_VLForConditionalGeneration.from_pretrained(\n",
|
| 95 |
+
" model_id,\n",
|
| 96 |
+
" trust_remote_code=True,\n",
|
| 97 |
+
" torch_dtype=torch.float16\n",
|
| 98 |
+
" ).to(\"cuda\").eval()\n",
|
| 99 |
+
" processors[name] = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)\n",
|
| 100 |
+
"\n",
|
| 101 |
+
"image_extensions = Image.registered_extensions()\n",
|
| 102 |
+
"\n",
|
| 103 |
+
"def identify_and_save_blob(blob_path):\n",
|
| 104 |
+
" \"\"\"Identifies if the blob is an image and saves it.\"\"\"\n",
|
| 105 |
+
" try:\n",
|
| 106 |
+
" with open(blob_path, 'rb') as file:\n",
|
| 107 |
+
" blob_content = file.read()\n",
|
| 108 |
+
" try:\n",
|
| 109 |
+
" Image.open(io.BytesIO(blob_content)).verify() # Check if it's a valid image\n",
|
| 110 |
+
" extension = \".png\" # Default to PNG for saving\n",
|
| 111 |
+
" media_type = \"image\"\n",
|
| 112 |
+
" except (IOError, SyntaxError):\n",
|
| 113 |
+
" raise ValueError(\"Unsupported media type. Please upload a valid image.\")\n",
|
| 114 |
+
"\n",
|
| 115 |
+
" filename = f\"temp_{uuid.uuid4()}_media{extension}\"\n",
|
| 116 |
+
" with open(filename, \"wb\") as f:\n",
|
| 117 |
+
" f.write(blob_content)\n",
|
| 118 |
+
"\n",
|
| 119 |
+
" return filename, media_type\n",
|
| 120 |
+
"\n",
|
| 121 |
+
" except FileNotFoundError:\n",
|
| 122 |
+
" raise ValueError(f\"The file {blob_path} was not found.\")\n",
|
| 123 |
+
" except Exception as e:\n",
|
| 124 |
+
" raise ValueError(f\"An error occurred while processing the file: {e}\")\n",
|
| 125 |
+
"\n",
|
| 126 |
+
"@spaces.GPU\n",
|
| 127 |
+
"def qwen_inference(model_name, media_input, text_input=None):\n",
|
| 128 |
+
" \"\"\"Handles inference for the selected model.\"\"\"\n",
|
| 129 |
+
" model = models[model_name]\n",
|
| 130 |
+
" processor = processors[model_name]\n",
|
| 131 |
+
"\n",
|
| 132 |
+
" if isinstance(media_input, str):\n",
|
| 133 |
+
" media_path = media_input\n",
|
| 134 |
+
" if media_path.endswith(tuple([i for i in image_extensions.keys()])):\n",
|
| 135 |
+
" media_type = \"image\"\n",
|
| 136 |
+
" else:\n",
|
| 137 |
+
" try:\n",
|
| 138 |
+
" media_path, media_type = identify_and_save_blob(media_input)\n",
|
| 139 |
+
" except Exception as e:\n",
|
| 140 |
+
" raise ValueError(\"Unsupported media type. Please upload a valid image.\")\n",
|
| 141 |
+
"\n",
|
| 142 |
+
" messages = [\n",
|
| 143 |
+
" {\n",
|
| 144 |
+
" \"role\": \"user\",\n",
|
| 145 |
+
" \"content\": [\n",
|
| 146 |
+
" {\n",
|
| 147 |
+
" \"type\": media_type,\n",
|
| 148 |
+
" media_type: media_path\n",
|
| 149 |
+
" },\n",
|
| 150 |
+
" {\"type\": \"text\", \"text\": text_input},\n",
|
| 151 |
+
" ],\n",
|
| 152 |
+
" }\n",
|
| 153 |
+
" ]\n",
|
| 154 |
+
"\n",
|
| 155 |
+
" text = processor.apply_chat_template(\n",
|
| 156 |
+
" messages, tokenize=False, add_generation_prompt=True\n",
|
| 157 |
+
" )\n",
|
| 158 |
+
" image_inputs, _ = process_vision_info(messages)\n",
|
| 159 |
+
" inputs = processor(\n",
|
| 160 |
+
" text=[text],\n",
|
| 161 |
+
" images=image_inputs,\n",
|
| 162 |
+
" padding=True,\n",
|
| 163 |
+
" return_tensors=\"pt\",\n",
|
| 164 |
+
" ).to(\"cuda\")\n",
|
| 165 |
+
"\n",
|
| 166 |
+
" streamer = TextIteratorStreamer(\n",
|
| 167 |
+
" processor.tokenizer, skip_prompt=True, skip_special_tokens=True\n",
|
| 168 |
+
" )\n",
|
| 169 |
+
" generation_kwargs = dict(inputs, streamer=streamer, max_new_tokens=1024)\n",
|
| 170 |
+
"\n",
|
| 171 |
+
" thread = Thread(target=model.generate, kwargs=generation_kwargs)\n",
|
| 172 |
+
" thread.start()\n",
|
| 173 |
+
"\n",
|
| 174 |
+
" buffer = \"\"\n",
|
| 175 |
+
" for new_text in streamer:\n",
|
| 176 |
+
" buffer += new_text\n",
|
| 177 |
+
" # Remove <|im_end|> or similar tokens from the output\n",
|
| 178 |
+
" buffer = buffer.replace(\"<|im_end|>\", \"\")\n",
|
| 179 |
+
" yield buffer\n",
|
| 180 |
+
"\n",
|
| 181 |
+
"def format_plain_text(output_text):\n",
|
| 182 |
+
" \"\"\"Formats the output text as plain text without LaTeX delimiters.\"\"\"\n",
|
| 183 |
+
" # Remove LaTeX delimiters and convert to plain text\n",
|
| 184 |
+
" plain_text = output_text.replace(\"\\\\(\", \"\").replace(\"\\\\)\", \"\").replace(\"\\\\[\", \"\").replace(\"\\\\]\", \"\")\n",
|
| 185 |
+
" return plain_text\n",
|
| 186 |
+
"\n",
|
| 187 |
+
"def generate_document(media_path, output_text, file_format, font_size, line_spacing, alignment, image_size):\n",
|
| 188 |
+
" \"\"\"Generates a document with the input image and plain text output.\"\"\"\n",
|
| 189 |
+
" plain_text = format_plain_text(output_text)\n",
|
| 190 |
+
" if file_format == \"pdf\":\n",
|
| 191 |
+
" return generate_pdf(media_path, plain_text, font_size, line_spacing, alignment, image_size)\n",
|
| 192 |
+
" elif file_format == \"docx\":\n",
|
| 193 |
+
" return generate_docx(media_path, plain_text, font_size, line_spacing, alignment, image_size)\n",
|
| 194 |
+
"\n",
|
| 195 |
+
"def generate_pdf(media_path, plain_text, font_size, line_spacing, alignment, image_size):\n",
|
| 196 |
+
" \"\"\"Generates a PDF document.\"\"\"\n",
|
| 197 |
+
" filename = f\"output_{uuid.uuid4()}.pdf\"\n",
|
| 198 |
+
" doc = SimpleDocTemplate(\n",
|
| 199 |
+
" filename,\n",
|
| 200 |
+
" pagesize=A4,\n",
|
| 201 |
+
" rightMargin=inch,\n",
|
| 202 |
+
" leftMargin=inch,\n",
|
| 203 |
+
" topMargin=inch,\n",
|
| 204 |
+
" bottomMargin=inch\n",
|
| 205 |
+
" )\n",
|
| 206 |
+
" styles = getSampleStyleSheet()\n",
|
| 207 |
+
" styles[\"Normal\"].fontSize = int(font_size)\n",
|
| 208 |
+
" styles[\"Normal\"].leading = int(font_size) * line_spacing\n",
|
| 209 |
+
" styles[\"Normal\"].alignment = {\n",
|
| 210 |
+
" \"Left\": 0,\n",
|
| 211 |
+
" \"Center\": 1,\n",
|
| 212 |
+
" \"Right\": 2,\n",
|
| 213 |
+
" \"Justified\": 4\n",
|
| 214 |
+
" }[alignment]\n",
|
| 215 |
+
"\n",
|
| 216 |
+
" story = []\n",
|
| 217 |
+
"\n",
|
| 218 |
+
" # Add image with size adjustment\n",
|
| 219 |
+
" image_sizes = {\n",
|
| 220 |
+
" \"Small\": (200, 200),\n",
|
| 221 |
+
" \"Medium\": (400, 400),\n",
|
| 222 |
+
" \"Large\": (600, 600)\n",
|
| 223 |
+
" }\n",
|
| 224 |
+
" img = RLImage(media_path, width=image_sizes[image_size][0], height=image_sizes[image_size][1])\n",
|
| 225 |
+
" story.append(img)\n",
|
| 226 |
+
" story.append(Spacer(1, 12))\n",
|
| 227 |
+
"\n",
|
| 228 |
+
" # Add plain text output\n",
|
| 229 |
+
" text = Paragraph(plain_text, styles[\"Normal\"])\n",
|
| 230 |
+
" story.append(text)\n",
|
| 231 |
+
"\n",
|
| 232 |
+
" doc.build(story)\n",
|
| 233 |
+
" return filename\n",
|
| 234 |
+
"\n",
|
| 235 |
+
"def generate_docx(media_path, plain_text, font_size, line_spacing, alignment, image_size):\n",
|
| 236 |
+
" \"\"\"Generates a DOCX document.\"\"\"\n",
|
| 237 |
+
" filename = f\"output_{uuid.uuid4()}.docx\"\n",
|
| 238 |
+
" doc = docx.Document()\n",
|
| 239 |
+
"\n",
|
| 240 |
+
" # Add image with size adjustment\n",
|
| 241 |
+
" image_sizes = {\n",
|
| 242 |
+
" \"Small\": docx.shared.Inches(2),\n",
|
| 243 |
+
" \"Medium\": docx.shared.Inches(4),\n",
|
| 244 |
+
" \"Large\": docx.shared.Inches(6)\n",
|
| 245 |
+
" }\n",
|
| 246 |
+
" doc.add_picture(media_path, width=image_sizes[image_size])\n",
|
| 247 |
+
" doc.add_paragraph()\n",
|
| 248 |
+
"\n",
|
| 249 |
+
" # Add plain text output\n",
|
| 250 |
+
" paragraph = doc.add_paragraph()\n",
|
| 251 |
+
" paragraph.paragraph_format.line_spacing = line_spacing\n",
|
| 252 |
+
" paragraph.paragraph_format.alignment = {\n",
|
| 253 |
+
" \"Left\": WD_ALIGN_PARAGRAPH.LEFT,\n",
|
| 254 |
+
" \"Center\": WD_ALIGN_PARAGRAPH.CENTER,\n",
|
| 255 |
+
" \"Right\": WD_ALIGN_PARAGRAPH.RIGHT,\n",
|
| 256 |
+
" \"Justified\": WD_ALIGN_PARAGRAPH.JUSTIFY\n",
|
| 257 |
+
" }[alignment]\n",
|
| 258 |
+
" run = paragraph.add_run(plain_text)\n",
|
| 259 |
+
" run.font.size = docx.shared.Pt(int(font_size))\n",
|
| 260 |
+
"\n",
|
| 261 |
+
" doc.save(filename)\n",
|
| 262 |
+
" return filename\n",
|
| 263 |
+
"\n",
|
| 264 |
+
"# CSS for output styling\n",
|
| 265 |
+
"css = \"\"\"\n",
|
| 266 |
+
" #output {\n",
|
| 267 |
+
" height: 500px;\n",
|
| 268 |
+
" overflow: auto;\n",
|
| 269 |
+
" border: 1px solid #ccc;\n",
|
| 270 |
+
" }\n",
|
| 271 |
+
".submit-btn {\n",
|
| 272 |
+
" background-color: #cf3434 !important;\n",
|
| 273 |
+
" color: white !important;\n",
|
| 274 |
+
"}\n",
|
| 275 |
+
".submit-btn:hover {\n",
|
| 276 |
+
" background-color: #ff2323 !important;\n",
|
| 277 |
+
"}\n",
|
| 278 |
+
".download-btn {\n",
|
| 279 |
+
" background-color: #35a6d6 !important;\n",
|
| 280 |
+
" color: white !important;\n",
|
| 281 |
+
"}\n",
|
| 282 |
+
".download-btn:hover {\n",
|
| 283 |
+
" background-color: #22bcff !important;\n",
|
| 284 |
+
"}\n",
|
| 285 |
+
"\"\"\"\n",
|
| 286 |
+
"\n",
|
| 287 |
+
"# Gradio app setup\n",
|
| 288 |
+
"with gr.Blocks(css=css, theme=\"bethecloud/storj_theme\") as demo:\n",
|
| 289 |
+
" gr.Markdown(\"# **Multimodal-Caption : Behemoth-3B-070225-post0.1**\")\n",
|
| 290 |
+
"\n",
|
| 291 |
+
" with gr.Tab(label=\"Image Input\"):\n",
|
| 292 |
+
"\n",
|
| 293 |
+
" with gr.Row():\n",
|
| 294 |
+
" with gr.Column():\n",
|
| 295 |
+
" model_choice = gr.Dropdown(\n",
|
| 296 |
+
" label=\"Model Selection\",\n",
|
| 297 |
+
" choices=list(MODEL_OPTIONS.keys()),\n",
|
| 298 |
+
" value=\"Behemoth-3B-070225-post0.1\"\n",
|
| 299 |
+
" )\n",
|
| 300 |
+
" input_media = gr.File(\n",
|
| 301 |
+
" label=\"Upload Image\", type=\"filepath\"\n",
|
| 302 |
+
" )\n",
|
| 303 |
+
" text_input = gr.Textbox(label=\"Question\", value=\"OCR the image precisely.\")\n",
|
| 304 |
+
" submit_btn = gr.Button(value=\"Submit\", elem_classes=\"submit-btn\")\n",
|
| 305 |
+
"\n",
|
| 306 |
+
" with gr.Column():\n",
|
| 307 |
+
" output_text = gr.Textbox(label=\"Output Text\", lines=7)\n",
|
| 308 |
+
"\n",
|
| 309 |
+
" with gr.Accordion(\"Plain Text\", open=False):\n",
|
| 310 |
+
" plain_text_output = gr.Textbox(label=\"Standardized Plain Text\", lines=10)\n",
|
| 311 |
+
"\n",
|
| 312 |
+
" submit_btn.click(\n",
|
| 313 |
+
" qwen_inference, [model_choice, input_media, text_input], [output_text]\n",
|
| 314 |
+
" ).then(\n",
|
| 315 |
+
" lambda output_text: format_plain_text(output_text), [output_text], [plain_text_output]\n",
|
| 316 |
+
" )\n",
|
| 317 |
+
"\n",
|
| 318 |
+
" with gr.Accordion(\"Docx/PDF Settings\", open=False):\n",
|
| 319 |
+
" with gr.Row():\n",
|
| 320 |
+
" with gr.Column():\n",
|
| 321 |
+
" line_spacing = gr.Dropdown(\n",
|
| 322 |
+
" choices=[0.5, 1.0, 1.15, 1.5, 2.0, 2.5, 3.0],\n",
|
| 323 |
+
" value=1.5,\n",
|
| 324 |
+
" label=\"Line Spacing\"\n",
|
| 325 |
+
" )\n",
|
| 326 |
+
" font_size = gr.Dropdown(\n",
|
| 327 |
+
" choices=[\"8\", \"10\", \"12\", \"14\", \"16\", \"18\", \"20\", \"22\", \"24\"],\n",
|
| 328 |
+
" value=\"16\",\n",
|
| 329 |
+
" label=\"Font Size\"\n",
|
| 330 |
+
" )\n",
|
| 331 |
+
" alignment = gr.Dropdown(\n",
|
| 332 |
+
" choices=[\"Left\", \"Center\", \"Right\", \"Justified\"],\n",
|
| 333 |
+
" value=\"Justified\",\n",
|
| 334 |
+
" label=\"Text Alignment\"\n",
|
| 335 |
+
" )\n",
|
| 336 |
+
" image_size = gr.Dropdown(\n",
|
| 337 |
+
" choices=[\"Small\", \"Medium\", \"Large\"],\n",
|
| 338 |
+
" value=\"Medium\",\n",
|
| 339 |
+
" label=\"Image Size\"\n",
|
| 340 |
+
" )\n",
|
| 341 |
+
" file_format = gr.Radio([\"pdf\", \"docx\"], label=\"File Format\", value=\"pdf\")\n",
|
| 342 |
+
"\n",
|
| 343 |
+
" get_document_btn = gr.Button(value=\"Get Document\", elem_classes=\"download-btn\")\n",
|
| 344 |
+
"\n",
|
| 345 |
+
" get_document_btn.click(\n",
|
| 346 |
+
" generate_document, [input_media, output_text, file_format, font_size, line_spacing, alignment, image_size], gr.File(label=\"Download Document\")\n",
|
| 347 |
+
" )\n",
|
| 348 |
+
"\n",
|
| 349 |
+
"demo.launch(debug=True)"
|
| 350 |
+
]
|
| 351 |
+
},
|
| 352 |
+
{
|
| 353 |
+
"cell_type": "markdown",
|
| 354 |
+
"source": [
|
| 355 |
+
"## **Demo Inference**\n",
|
| 356 |
+
"\n",
|
| 357 |
+
"\n",
|
| 358 |
+
"| Preview |\n",
|
| 359 |
+
"|:--:|\n",
|
| 360 |
+
"| 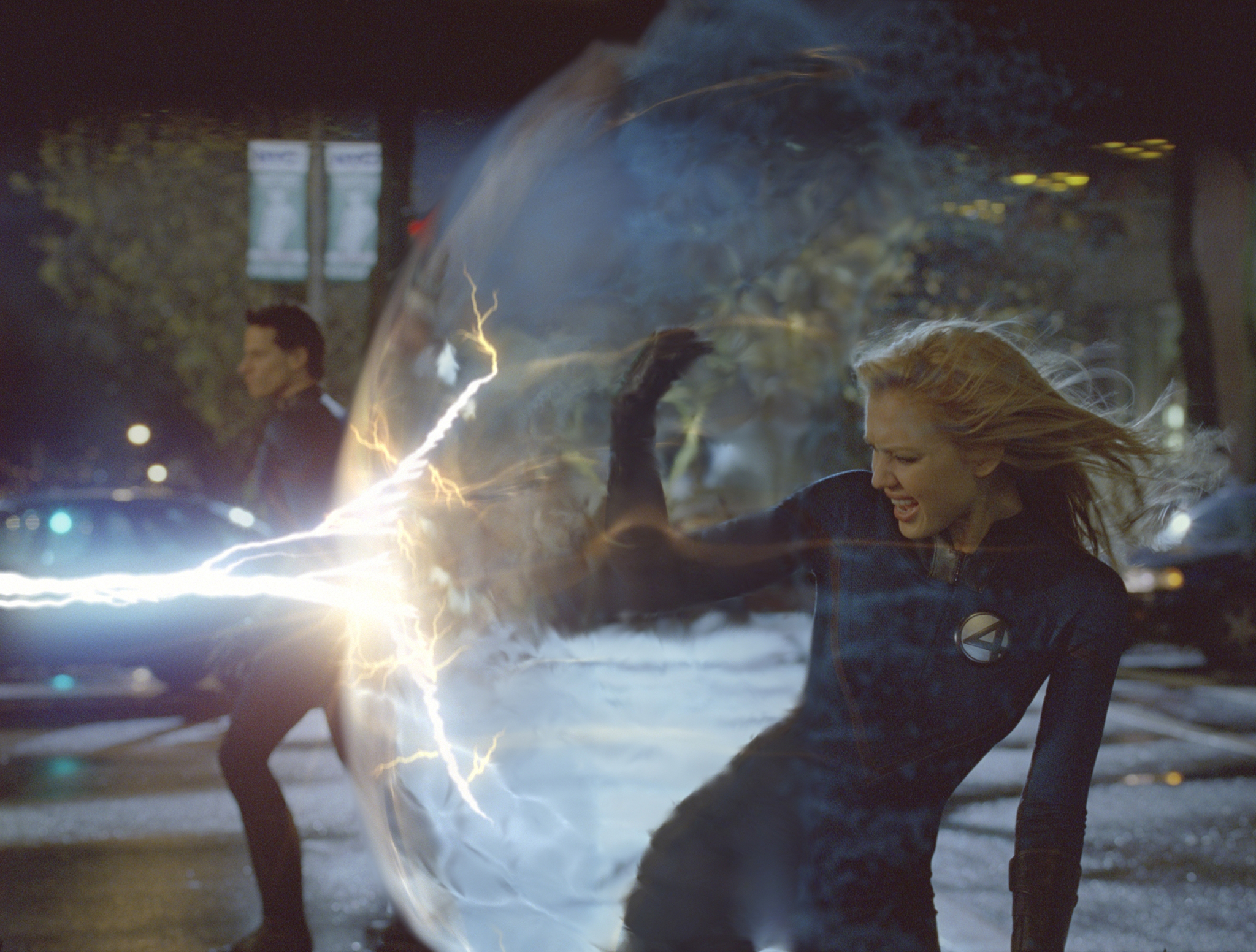 |\n",
|
| 361 |
+
"| *Movie Still / Poster* |\n",
|
| 362 |
+
"| 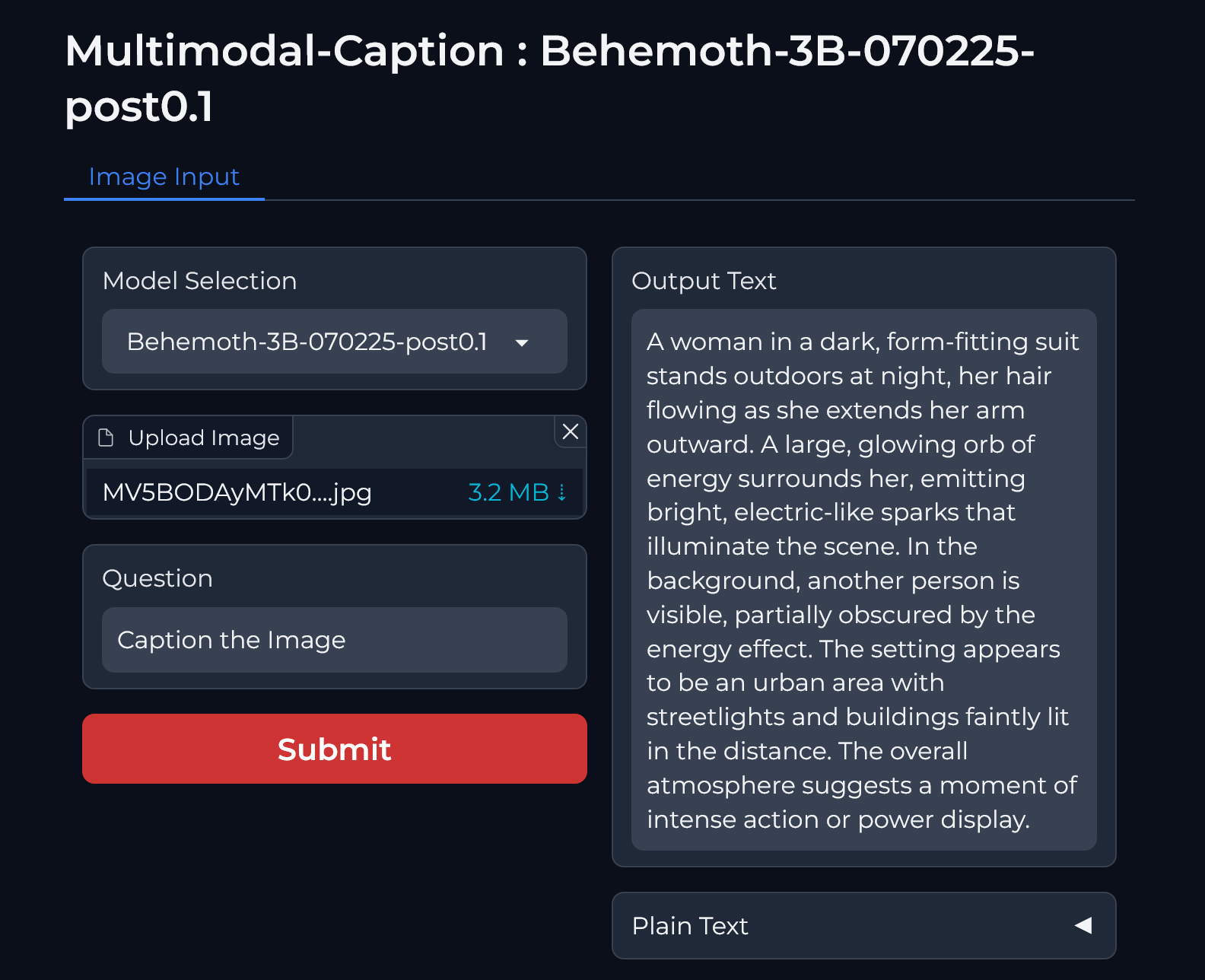 |\n",
|
| 363 |
+
"| *Gradio UI Screenshot* |\n"
|
| 364 |
+
],
|
| 365 |
+
"metadata": {
|
| 366 |
+
"id": "ynyjulRaDl3m"
|
| 367 |
+
}
|
| 368 |
+
}
|
| 369 |
+
],
|
| 370 |
+
"metadata": {
|
| 371 |
+
"accelerator": "GPU",
|
| 372 |
+
"colab": {
|
| 373 |
+
"gpuType": "T4",
|
| 374 |
+
"provenance": []
|
| 375 |
+
},
|
| 376 |
+
"kernelspec": {
|
| 377 |
+
"display_name": "Python 3",
|
| 378 |
+
"name": "python3"
|
| 379 |
+
},
|
| 380 |
+
"language_info": {
|
| 381 |
+
"name": "python"
|
| 382 |
+
}
|
| 383 |
+
},
|
| 384 |
+
"nbformat": 4,
|
| 385 |
+
"nbformat_minor": 0
|
| 386 |
+
}
|
Megalodon-OCR-Sync-0713-ColabNotebook/Megalodon_OCR_Sync_0713_ReportLab.ipynb
ADDED
|
@@ -0,0 +1,362 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {
|
| 6 |
+
"id": "uFovmijgUV1Z"
|
| 7 |
+
},
|
| 8 |
+
"source": [
|
| 9 |
+
"***Multimodal OCR ReportLab : Megalodon-OCR-Sync-0713***\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"*notebook by : [prithivMLmods](https://huggingface.co/prithivMLmods)🤗 x ❤️*"
|
| 12 |
+
]
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"cell_type": "markdown",
|
| 16 |
+
"metadata": {
|
| 17 |
+
"id": "RugX4SGZV-8O"
|
| 18 |
+
},
|
| 19 |
+
"source": [
|
| 20 |
+
"***Installing all necessary packages***"
|
| 21 |
+
]
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"cell_type": "code",
|
| 25 |
+
"execution_count": null,
|
| 26 |
+
"metadata": {
|
| 27 |
+
"id": "l-NtFtjSpuJQ"
|
| 28 |
+
},
|
| 29 |
+
"outputs": [],
|
| 30 |
+
"source": [
|
| 31 |
+
"%%capture\n",
|
| 32 |
+
"!pip install gradio transformers transformers-stream-generator qwen-vl-utils\n",
|
| 33 |
+
"!pip install torchvision torch huggingface_hub spaces accelerate ipython\n",
|
| 34 |
+
"!pip install pillow av python-docx requests numpy reportlab fpdf hf_xet\n",
|
| 35 |
+
"#Hold tight, this will take around 3-5 minutes."
|
| 36 |
+
]
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"cell_type": "markdown",
|
| 40 |
+
"metadata": {
|
| 41 |
+
"id": "mvoSnRZcVBu4"
|
| 42 |
+
},
|
| 43 |
+
"source": [
|
| 44 |
+
"***Run app***"
|
| 45 |
+
]
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"cell_type": "code",
|
| 49 |
+
"execution_count": null,
|
| 50 |
+
"metadata": {
|
| 51 |
+
"id": "tElKr2Fkp1bO"
|
| 52 |
+
},
|
| 53 |
+
"outputs": [],
|
| 54 |
+
"source": [
|
| 55 |
+
"#Model used in the app: https://huggingface.co/prithivMLmods/Megalodon-OCR-Sync-0713\n",
|
| 56 |
+
"#Architecture built on: Qwen2_5_VLForConditionalGeneration [qwen2_5_vl]\n",
|
| 57 |
+
"import gradio as gr\n",
|
| 58 |
+
"import spaces\n",
|
| 59 |
+
"from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor, TextIteratorStreamer\n",
|
| 60 |
+
"from qwen_vl_utils import process_vision_info\n",
|
| 61 |
+
"import torch\n",
|
| 62 |
+
"from PIL import Image\n",
|
| 63 |
+
"import os\n",
|
| 64 |
+
"import uuid\n",
|
| 65 |
+
"import io\n",
|
| 66 |
+
"from threading import Thread\n",
|
| 67 |
+
"from reportlab.lib.pagesizes import A4\n",
|
| 68 |
+
"from reportlab.lib.styles import getSampleStyleSheet\n",
|
| 69 |
+
"from reportlab.lib import colors\n",
|
| 70 |
+
"from reportlab.platypus import SimpleDocTemplate, Image as RLImage, Paragraph, Spacer\n",
|
| 71 |
+
"from reportlab.lib.units import inch\n",
|
| 72 |
+
"from reportlab.pdfbase import pdfmetrics\n",
|
| 73 |
+
"from reportlab.pdfbase.ttfonts import TTFont\n",
|
| 74 |
+
"import docx\n",
|
| 75 |
+
"from docx.enum.text import WD_ALIGN_PARAGRAPH\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"# Define model options\n",
|
| 78 |
+
"MODEL_OPTIONS = {\n",
|
| 79 |
+
" \"Megalodon-OCR-Sync-0713\": \"prithivMLmods/Megalodon-OCR-Sync-0713\",\n",
|
| 80 |
+
"}\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"# Preload models and processors into CUDA\n",
|
| 83 |
+
"models = {}\n",
|
| 84 |
+
"processors = {}\n",
|
| 85 |
+
"for name, model_id in MODEL_OPTIONS.items():\n",
|
| 86 |
+
" print(f\"Loading {name}🤗. Hold tight, this will take around 4-6 minutes..\")\n",
|
| 87 |
+
" models[name] = Qwen2_5_VLForConditionalGeneration.from_pretrained(\n",
|
| 88 |
+
" model_id,\n",
|
| 89 |
+
" trust_remote_code=True,\n",
|
| 90 |
+
" torch_dtype=torch.float16\n",
|
| 91 |
+
" ).to(\"cuda\").eval()\n",
|
| 92 |
+
" processors[name] = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)\n",
|
| 93 |
+
"\n",
|
| 94 |
+
"image_extensions = Image.registered_extensions()\n",
|
| 95 |
+
"\n",
|
| 96 |
+
"def identify_and_save_blob(blob_path):\n",
|
| 97 |
+
" \"\"\"Identifies if the blob is an image and saves it.\"\"\"\n",
|
| 98 |
+
" try:\n",
|
| 99 |
+
" with open(blob_path, 'rb') as file:\n",
|
| 100 |
+
" blob_content = file.read()\n",
|
| 101 |
+
" try:\n",
|
| 102 |
+
" Image.open(io.BytesIO(blob_content)).verify() # Check if it's a valid image\n",
|
| 103 |
+
" extension = \".png\" # Default to PNG for saving\n",
|
| 104 |
+
" media_type = \"image\"\n",
|
| 105 |
+
" except (IOError, SyntaxError):\n",
|
| 106 |
+
" raise ValueError(\"Unsupported media type. Please upload a valid image.\")\n",
|
| 107 |
+
"\n",
|
| 108 |
+
" filename = f\"temp_{uuid.uuid4()}_media{extension}\"\n",
|
| 109 |
+
" with open(filename, \"wb\") as f:\n",
|
| 110 |
+
" f.write(blob_content)\n",
|
| 111 |
+
"\n",
|
| 112 |
+
" return filename, media_type\n",
|
| 113 |
+
"\n",
|
| 114 |
+
" except FileNotFoundError:\n",
|
| 115 |
+
" raise ValueError(f\"The file {blob_path} was not found.\")\n",
|
| 116 |
+
" except Exception as e:\n",
|
| 117 |
+
" raise ValueError(f\"An error occurred while processing the file: {e}\")\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"@spaces.GPU\n",
|
| 120 |
+
"def qwen_inference(model_name, media_input, text_input=None):\n",
|
| 121 |
+
" \"\"\"Handles inference for the selected model.\"\"\"\n",
|
| 122 |
+
" model = models[model_name]\n",
|
| 123 |
+
" processor = processors[model_name]\n",
|
| 124 |
+
"\n",
|
| 125 |
+
" if isinstance(media_input, str):\n",
|
| 126 |
+
" media_path = media_input\n",
|
| 127 |
+
" if media_path.endswith(tuple([i for i in image_extensions.keys()])):\n",
|
| 128 |
+
" media_type = \"image\"\n",
|
| 129 |
+
" else:\n",
|
| 130 |
+
" try:\n",
|
| 131 |
+
" media_path, media_type = identify_and_save_blob(media_input)\n",
|
| 132 |
+
" except Exception as e:\n",
|
| 133 |
+
" raise ValueError(\"Unsupported media type. Please upload a valid image.\")\n",
|
| 134 |
+
"\n",
|
| 135 |
+
" messages = [\n",
|
| 136 |
+
" {\n",
|
| 137 |
+
" \"role\": \"user\",\n",
|
| 138 |
+
" \"content\": [\n",
|
| 139 |
+
" {\n",
|
| 140 |
+
" \"type\": media_type,\n",
|
| 141 |
+
" media_type: media_path\n",
|
| 142 |
+
" },\n",
|
| 143 |
+
" {\"type\": \"text\", \"text\": text_input},\n",
|
| 144 |
+
" ],\n",
|
| 145 |
+
" }\n",
|
| 146 |
+
" ]\n",
|
| 147 |
+
"\n",
|
| 148 |
+
" text = processor.apply_chat_template(\n",
|
| 149 |
+
" messages, tokenize=False, add_generation_prompt=True\n",
|
| 150 |
+
" )\n",
|
| 151 |
+
" image_inputs, _ = process_vision_info(messages)\n",
|
| 152 |
+
" inputs = processor(\n",
|
| 153 |
+
" text=[text],\n",
|
| 154 |
+
" images=image_inputs,\n",
|
| 155 |
+
" padding=True,\n",
|
| 156 |
+
" return_tensors=\"pt\",\n",
|
| 157 |
+
" ).to(\"cuda\")\n",
|
| 158 |
+
"\n",
|
| 159 |
+
" streamer = TextIteratorStreamer(\n",
|
| 160 |
+
" processor.tokenizer, skip_prompt=True, skip_special_tokens=True\n",
|
| 161 |
+
" )\n",
|
| 162 |
+
" generation_kwargs = dict(inputs, streamer=streamer, max_new_tokens=1024)\n",
|
| 163 |
+
"\n",
|
| 164 |
+
" thread = Thread(target=model.generate, kwargs=generation_kwargs)\n",
|
| 165 |
+
" thread.start()\n",
|
| 166 |
+
"\n",
|
| 167 |
+
" buffer = \"\"\n",
|
| 168 |
+
" for new_text in streamer:\n",
|
| 169 |
+
" buffer += new_text\n",
|
| 170 |
+
" # Remove <|im_end|> or similar tokens from the output\n",
|
| 171 |
+
" buffer = buffer.replace(\"<|im_end|>\", \"\")\n",
|
| 172 |
+
" yield buffer\n",
|
| 173 |
+
"\n",
|
| 174 |
+
"def format_plain_text(output_text):\n",
|
| 175 |
+
" \"\"\"Formats the output text as plain text without LaTeX delimiters.\"\"\"\n",
|
| 176 |
+
" # Remove LaTeX delimiters and convert to plain text\n",
|
| 177 |
+
" plain_text = output_text.replace(\"\\\\(\", \"\").replace(\"\\\\)\", \"\").replace(\"\\\\[\", \"\").replace(\"\\\\]\", \"\")\n",
|
| 178 |
+
" return plain_text\n",
|
| 179 |
+
"\n",
|
| 180 |
+
"def generate_document(media_path, output_text, file_format, font_size, line_spacing, alignment, image_size):\n",
|
| 181 |
+
" \"\"\"Generates a document with the input image and plain text output.\"\"\"\n",
|
| 182 |
+
" plain_text = format_plain_text(output_text)\n",
|
| 183 |
+
" if file_format == \"pdf\":\n",
|
| 184 |
+
" return generate_pdf(media_path, plain_text, font_size, line_spacing, alignment, image_size)\n",
|
| 185 |
+
" elif file_format == \"docx\":\n",
|
| 186 |
+
" return generate_docx(media_path, plain_text, font_size, line_spacing, alignment, image_size)\n",
|
| 187 |
+
"\n",
|
| 188 |
+
"def generate_pdf(media_path, plain_text, font_size, line_spacing, alignment, image_size):\n",
|
| 189 |
+
" \"\"\"Generates a PDF document.\"\"\"\n",
|
| 190 |
+
" filename = f\"output_{uuid.uuid4()}.pdf\"\n",
|
| 191 |
+
" doc = SimpleDocTemplate(\n",
|
| 192 |
+
" filename,\n",
|
| 193 |
+
" pagesize=A4,\n",
|
| 194 |
+
" rightMargin=inch,\n",
|
| 195 |
+
" leftMargin=inch,\n",
|
| 196 |
+
" topMargin=inch,\n",
|
| 197 |
+
" bottomMargin=inch\n",
|
| 198 |
+
" )\n",
|
| 199 |
+
" styles = getSampleStyleSheet()\n",
|
| 200 |
+
" styles[\"Normal\"].fontSize = int(font_size)\n",
|
| 201 |
+
" styles[\"Normal\"].leading = int(font_size) * line_spacing\n",
|
| 202 |
+
" styles[\"Normal\"].alignment = {\n",
|
| 203 |
+
" \"Left\": 0,\n",
|
| 204 |
+
" \"Center\": 1,\n",
|
| 205 |
+
" \"Right\": 2,\n",
|
| 206 |
+
" \"Justified\": 4\n",
|
| 207 |
+
" }[alignment]\n",
|
| 208 |
+
"\n",
|
| 209 |
+
" story = []\n",
|
| 210 |
+
"\n",
|
| 211 |
+
" # Add image with size adjustment\n",
|
| 212 |
+
" image_sizes = {\n",
|
| 213 |
+
" \"Small\": (200, 200),\n",
|
| 214 |
+
" \"Medium\": (400, 400),\n",
|
| 215 |
+
" \"Large\": (600, 600)\n",
|
| 216 |
+
" }\n",
|
| 217 |
+
" img = RLImage(media_path, width=image_sizes[image_size][0], height=image_sizes[image_size][1])\n",
|
| 218 |
+
" story.append(img)\n",
|
| 219 |
+
" story.append(Spacer(1, 12))\n",
|
| 220 |
+
"\n",
|
| 221 |
+
" # Add plain text output\n",
|
| 222 |
+
" text = Paragraph(plain_text, styles[\"Normal\"])\n",
|
| 223 |
+
" story.append(text)\n",
|
| 224 |
+
"\n",
|
| 225 |
+
" doc.build(story)\n",
|
| 226 |
+
" return filename\n",
|
| 227 |
+
"\n",
|
| 228 |
+
"def generate_docx(media_path, plain_text, font_size, line_spacing, alignment, image_size):\n",
|
| 229 |
+
" \"\"\"Generates a DOCX document.\"\"\"\n",
|
| 230 |
+
" filename = f\"output_{uuid.uuid4()}.docx\"\n",
|
| 231 |
+
" doc = docx.Document()\n",
|
| 232 |
+
"\n",
|
| 233 |
+
" # Add image with size adjustment\n",
|
| 234 |
+
" image_sizes = {\n",
|
| 235 |
+
" \"Small\": docx.shared.Inches(2),\n",
|
| 236 |
+
" \"Medium\": docx.shared.Inches(4),\n",
|
| 237 |
+
" \"Large\": docx.shared.Inches(6)\n",
|
| 238 |
+
" }\n",
|
| 239 |
+
" doc.add_picture(media_path, width=image_sizes[image_size])\n",
|
| 240 |
+
" doc.add_paragraph()\n",
|
| 241 |
+
"\n",
|
| 242 |
+
" # Add plain text output\n",
|
| 243 |
+
" paragraph = doc.add_paragraph()\n",
|
| 244 |
+
" paragraph.paragraph_format.line_spacing = line_spacing\n",
|
| 245 |
+
" paragraph.paragraph_format.alignment = {\n",
|
| 246 |
+
" \"Left\": WD_ALIGN_PARAGRAPH.LEFT,\n",
|
| 247 |
+
" \"Center\": WD_ALIGN_PARAGRAPH.CENTER,\n",
|
| 248 |
+
" \"Right\": WD_ALIGN_PARAGRAPH.RIGHT,\n",
|
| 249 |
+
" \"Justified\": WD_ALIGN_PARAGRAPH.JUSTIFY\n",
|
| 250 |
+
" }[alignment]\n",
|
| 251 |
+
" run = paragraph.add_run(plain_text)\n",
|
| 252 |
+
" run.font.size = docx.shared.Pt(int(font_size))\n",
|
| 253 |
+
"\n",
|
| 254 |
+
" doc.save(filename)\n",
|
| 255 |
+
" return filename\n",
|
| 256 |
+
"\n",
|
| 257 |
+
"# CSS for output styling\n",
|
| 258 |
+
"css = \"\"\"\n",
|
| 259 |
+
" #output {\n",
|
| 260 |
+
" height: 500px;\n",
|
| 261 |
+
" overflow: auto;\n",
|
| 262 |
+
" border: 1px solid #ccc;\n",
|
| 263 |
+
" }\n",
|
| 264 |
+
".submit-btn {\n",
|
| 265 |
+
" background-color: #cf3434 !important;\n",
|
| 266 |
+
" color: white !important;\n",
|
| 267 |
+
"}\n",
|
| 268 |
+
".submit-btn:hover {\n",
|
| 269 |
+
" background-color: #ff2323 !important;\n",
|
| 270 |
+
"}\n",
|
| 271 |
+
".download-btn {\n",
|
| 272 |
+
" background-color: #35a6d6 !important;\n",
|
| 273 |
+
" color: white !important;\n",
|
| 274 |
+
"}\n",
|
| 275 |
+
".download-btn:hover {\n",
|
| 276 |
+
" background-color: #22bcff !important;\n",
|
| 277 |
+
"}\n",
|
| 278 |
+
"\"\"\"\n",
|
| 279 |
+
"\n",
|
| 280 |
+
"# Gradio app setup\n",
|
| 281 |
+
"with gr.Blocks(css=css, theme=\"bethecloud/storj_theme\") as demo:\n",
|
| 282 |
+
" gr.Markdown(\"# **Multimodal-OCR : Megalodon-OCR-Sync-0713**\")\n",
|
| 283 |
+
"\n",
|
| 284 |
+
" with gr.Tab(label=\"Image Input\"):\n",
|
| 285 |
+
"\n",
|
| 286 |
+
" with gr.Row():\n",
|
| 287 |
+
" with gr.Column():\n",
|
| 288 |
+
" model_choice = gr.Dropdown(\n",
|
| 289 |
+
" label=\"Model Selection\",\n",
|
| 290 |
+
" choices=list(MODEL_OPTIONS.keys()),\n",
|
| 291 |
+
" value=\"Megalodon-OCR-Sync-0713\"\n",
|
| 292 |
+
" )\n",
|
| 293 |
+
" input_media = gr.File(\n",
|
| 294 |
+
" label=\"Upload Image\", type=\"filepath\"\n",
|
| 295 |
+
" )\n",
|
| 296 |
+
" text_input = gr.Textbox(label=\"Question\", value=\"OCR the image precisely.\")\n",
|
| 297 |
+
" submit_btn = gr.Button(value=\"Submit\", elem_classes=\"submit-btn\")\n",
|
| 298 |
+
"\n",
|
| 299 |
+
" with gr.Column():\n",
|
| 300 |
+
" output_text = gr.Textbox(label=\"Output Text\", lines=7)\n",
|
| 301 |
+
"\n",
|
| 302 |
+
" with gr.Accordion(\"Plain Text\", open=False):\n",
|
| 303 |
+
" plain_text_output = gr.Textbox(label=\"Standardized Plain Text\", lines=10)\n",
|
| 304 |
+
"\n",
|
| 305 |
+
" submit_btn.click(\n",
|
| 306 |
+
" qwen_inference, [model_choice, input_media, text_input], [output_text]\n",
|
| 307 |
+
" ).then(\n",
|
| 308 |
+
" lambda output_text: format_plain_text(output_text), [output_text], [plain_text_output]\n",
|
| 309 |
+
" )\n",
|
| 310 |
+
"\n",
|
| 311 |
+
" with gr.Accordion(\"Docx/PDF Settings\", open=False):\n",
|
| 312 |
+
" with gr.Row():\n",
|
| 313 |
+
" with gr.Column():\n",
|
| 314 |
+
" line_spacing = gr.Dropdown(\n",
|
| 315 |
+
" choices=[0.5, 1.0, 1.15, 1.5, 2.0, 2.5, 3.0],\n",
|
| 316 |
+
" value=1.5,\n",
|
| 317 |
+
" label=\"Line Spacing\"\n",
|
| 318 |
+
" )\n",
|
| 319 |
+
" font_size = gr.Dropdown(\n",
|
| 320 |
+
" choices=[\"8\", \"10\", \"12\", \"14\", \"16\", \"18\", \"20\", \"22\", \"24\"],\n",
|
| 321 |
+
" value=\"16\",\n",
|
| 322 |
+
" label=\"Font Size\"\n",
|
| 323 |
+
" )\n",
|
| 324 |
+
" alignment = gr.Dropdown(\n",
|
| 325 |
+
" choices=[\"Left\", \"Center\", \"Right\", \"Justified\"],\n",
|
| 326 |
+
" value=\"Justified\",\n",
|
| 327 |
+
" label=\"Text Alignment\"\n",
|
| 328 |
+
" )\n",
|
| 329 |
+
" image_size = gr.Dropdown(\n",
|
| 330 |
+
" choices=[\"Small\", \"Medium\", \"Large\"],\n",
|
| 331 |
+
" value=\"Medium\",\n",
|
| 332 |
+
" label=\"Image Size\"\n",
|
| 333 |
+
" )\n",
|
| 334 |
+
" file_format = gr.Radio([\"pdf\", \"docx\"], label=\"File Format\", value=\"pdf\")\n",
|
| 335 |
+
"\n",
|
| 336 |
+
" get_document_btn = gr.Button(value=\"Get Document\", elem_classes=\"download-btn\")\n",
|
| 337 |
+
"\n",
|
| 338 |
+
" get_document_btn.click(\n",
|
| 339 |
+
" generate_document, [input_media, output_text, file_format, font_size, line_spacing, alignment, image_size], gr.File(label=\"Download Document\")\n",
|
| 340 |
+
" )\n",
|
| 341 |
+
"\n",
|
| 342 |
+
"demo.launch(debug=True)"
|
| 343 |
+
]
|
| 344 |
+
}
|
| 345 |
+
],
|
| 346 |
+
"metadata": {
|
| 347 |
+
"accelerator": "GPU",
|
| 348 |
+
"colab": {
|
| 349 |
+
"gpuType": "T4",
|
| 350 |
+
"provenance": []
|
| 351 |
+
},
|
| 352 |
+
"kernelspec": {
|
| 353 |
+
"display_name": "Python 3",
|
| 354 |
+
"name": "python3"
|
| 355 |
+
},
|
| 356 |
+
"language_info": {
|
| 357 |
+
"name": "python"
|
| 358 |
+
}
|
| 359 |
+
},
|
| 360 |
+
"nbformat": 4,
|
| 361 |
+
"nbformat_minor": 0
|
| 362 |
+
}
|
MonkeyOCR-0709/MonkeyOCR-1.2B-0709-ReportLab.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MonkeyOCR-0709/MonkeyOCR-3B-0709-ReportLab.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
MonkeyOCR-0709/MonkeyOCR-pro-1.2B-ReportLab.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
OCRFlux3B/Multimodal_OCR_ReportLab_OCRFlux_3B.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Qwen2-VL-OCR-2B-Instruct/Qwen2_VL_OCR_2B_Instruct.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
monkey-OCR/Multimodal_OCR_ReportLab_MonkeyOCR.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
nanonets-OCR/Multimodal_OCR_ReportLab_Nanonets_Cleared.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
typhoon-OCR/Multimodal_OCR_ReportLab_typhoon_ocr_3b.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|