

Updated model card
Browse files
README.md
CHANGED
|
@@ -16,15 +16,13 @@ tags:
|
|
| 16 |
We provide the [.pte file](https://huggingface.co/pytorch/SmolLM3-3B-8da4w/blob/main/smollm3-3b-8da4w.pte) for direct use in ExecuTorch. *(The provided pte file is exported with the default max_seq_length/max_context_length of 2k.)*
|
| 17 |
|
| 18 |
# Running in a mobile app
|
| 19 |
-
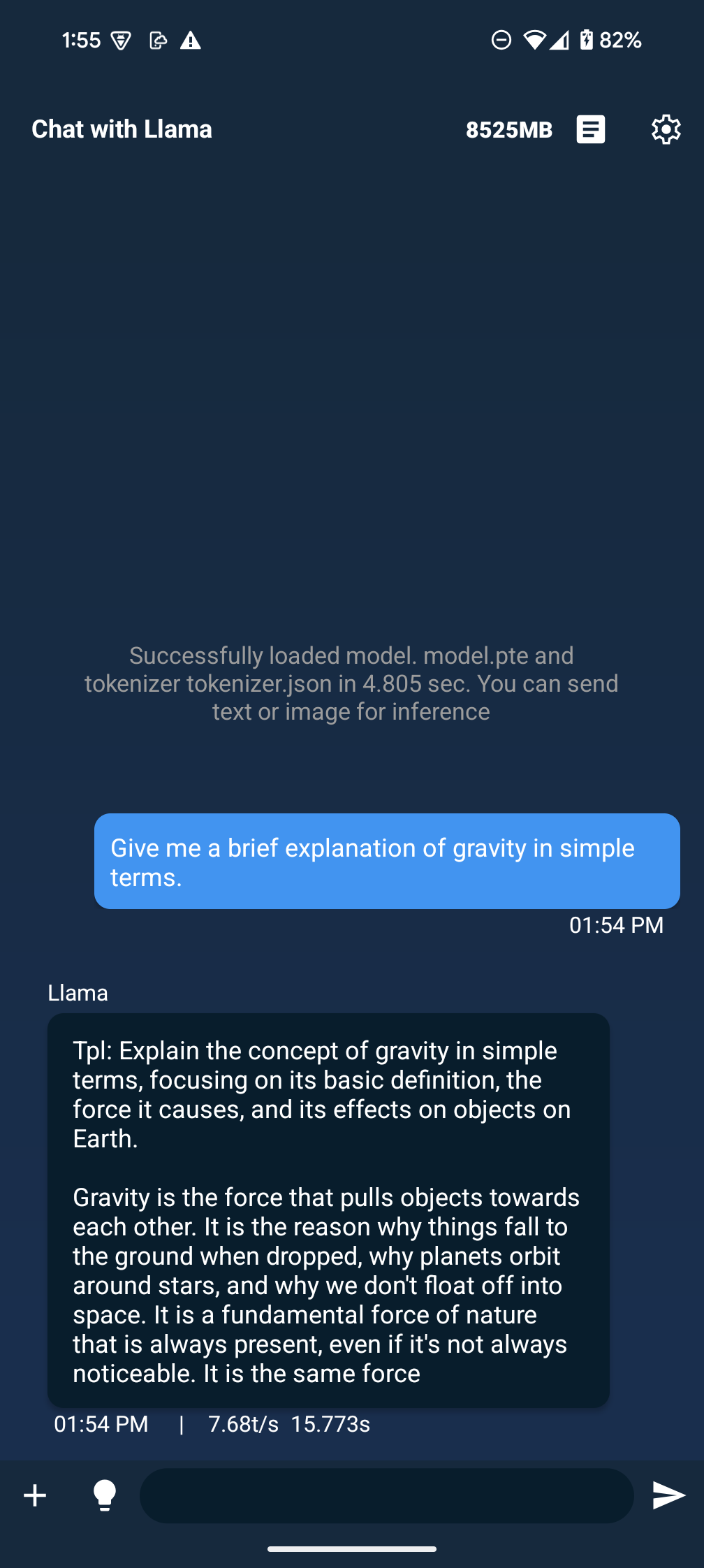
The [.pte file](https://huggingface.co/pytorch/SmolLM3-3B-8da4w/blob/main/smollm3-3b-8da4w.pte) can be run with ExecuTorch on a mobile phone. See the instructions for doing this in [iOS](https://pytorch.org/executorch/main/llm/llama-demo-ios.html) and [Android](https://docs.pytorch.org/executorch/main/llm/llama-demo-android.html).
|
| 20 |
|
| 21 |
-
|
| 22 |
-
|
| 23 |
|
| 24 |
# Running with ExecuTorch’s sample runner
|
| 25 |
You can also run this model using ExecuTorch’s sample runner following [Step 3&4 in this instruction](https://github.com/pytorch/executorch/blob/main/examples/models/llama/README.md#step-3-run-on-your-computer-to-validate).
|
| 26 |
|
| 27 |
-
On Google's Pixel 8 Pro, the model runs at 12.7 tokens/s.
|
| 28 |
|
| 29 |
# Export Recipe
|
| 30 |
You can re-create the `.pte` file from eager source using this export recipe.
|
|
|
|
| 16 |
We provide the [.pte file](https://huggingface.co/pytorch/SmolLM3-3B-8da4w/blob/main/smollm3-3b-8da4w.pte) for direct use in ExecuTorch. *(The provided pte file is exported with the default max_seq_length/max_context_length of 2k.)*
|
| 17 |
|
| 18 |
# Running in a mobile app
|
| 19 |
+
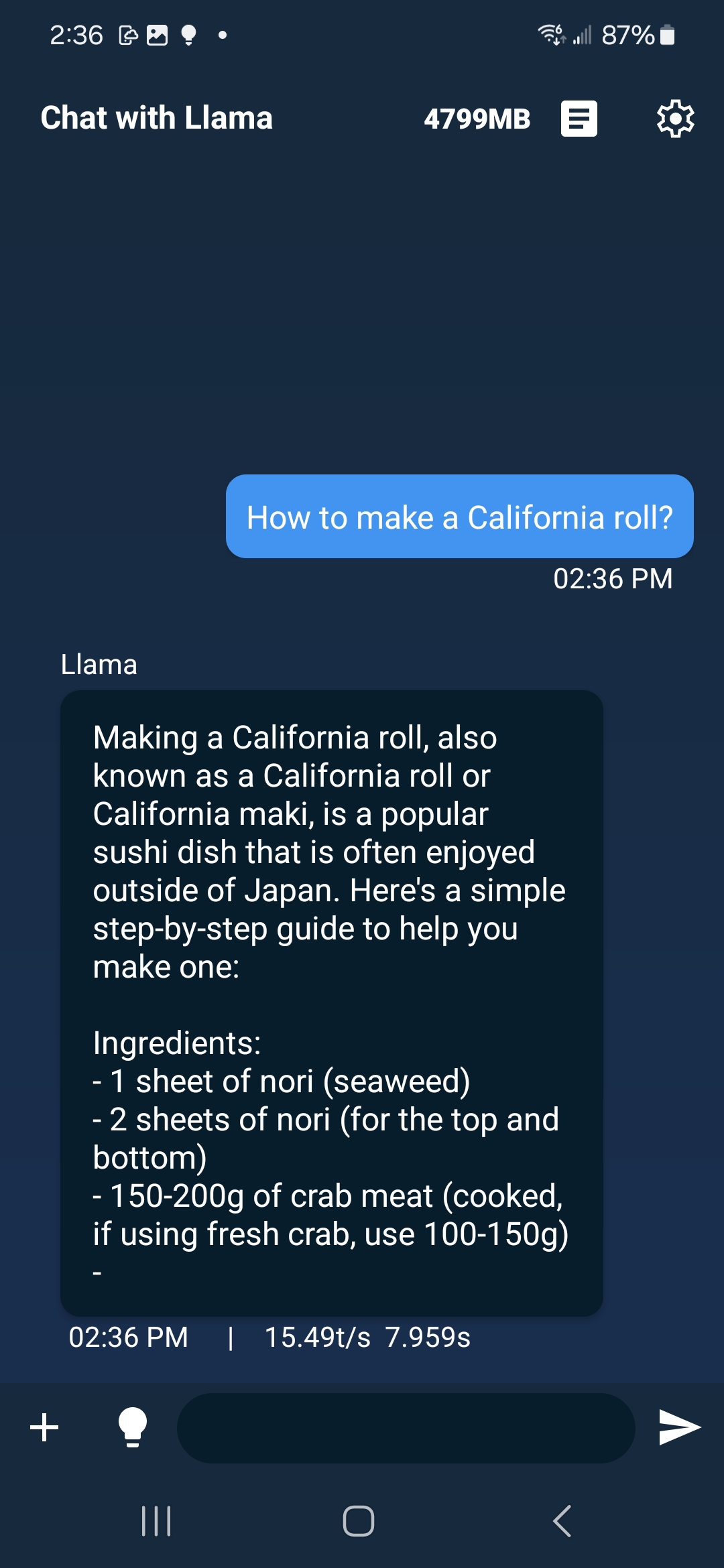
The [.pte file](https://huggingface.co/pytorch/SmolLM3-3B-8da4w/blob/main/smollm3-3b-8da4w.pte) can be run with ExecuTorch on a mobile phone. See the instructions for doing this in [iOS](https://pytorch.org/executorch/main/llm/llama-demo-ios.html) and [Android](https://docs.pytorch.org/executorch/main/llm/llama-demo-android.html). On Galagy S22, the model runs at 15.5 tokens/s.
|
| 20 |
|
| 21 |
+
|
|
|
|
| 22 |
|
| 23 |
# Running with ExecuTorch’s sample runner
|
| 24 |
You can also run this model using ExecuTorch’s sample runner following [Step 3&4 in this instruction](https://github.com/pytorch/executorch/blob/main/examples/models/llama/README.md#step-3-run-on-your-computer-to-validate).
|
| 25 |
|
|
|
|
| 26 |
|
| 27 |
# Export Recipe
|
| 28 |
You can re-create the `.pte` file from eager source using this export recipe.
|