Spaces:
Sleeping

Sleeping
upload model
Browse files- .gitattributes +5 -0
- .gitignore +12 -0
- configparser.ini +169 -0
- convo_qa_chain.py +387 -0
- data/ABPI Code of Practice for the Pharmaceutical Industry 2021.pdf +0 -0
- data/Attention Is All You Need.pdf +3 -0
- data/Gradient Descent The Ultimate Optimizer.pdf +3 -0
- data/JP Morgan 2022 Environmental Social Governance Report.pdf +3 -0
- data/Language Models are Few-Shot Learners.pdf +3 -0
- data/Language Models are Unsupervised Multitask Learners.pdf +0 -0
- data/United Nations 2022 Annual Report.pdf +3 -0
- docs2db.py +346 -0
- figs/High_Level_Architecture.png +0 -0
- figs/Sliding_Window_Chunking.png +0 -0
- main.py +150 -0
- requirements.txt +13 -1
- toolkit/___init__.py +0 -0
- toolkit/local_llm.py +193 -0
- toolkit/prompts.py +169 -0
- toolkit/retrivers.py +643 -0
- toolkit/together_api_llm.py +72 -0
- toolkit/utils.py +389 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
data/Attention[[:space:]]Is[[:space:]]All[[:space:]]You[[:space:]]Need.pdf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
data/Gradient[[:space:]]Descent[[:space:]]The[[:space:]]Ultimate[[:space:]]Optimizer.pdf filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
data/JP[[:space:]]Morgan[[:space:]]2022[[:space:]]Environmental[[:space:]]Social[[:space:]]Governance[[:space:]]Report.pdf filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
data/Language[[:space:]]Models[[:space:]]are[[:space:]]Few-Shot[[:space:]]Learners.pdf filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
data/United[[:space:]]Nations[[:space:]]2022[[:space:]]Annual[[:space:]]Report.pdf filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
.history
|
| 3 |
+
.vscode
|
| 4 |
+
__pycache__
|
| 5 |
+
Archieve
|
| 6 |
+
database_store
|
| 7 |
+
IncarnaMind.log
|
| 8 |
+
experiments.ipynb
|
| 9 |
+
.pylintrc
|
| 10 |
+
.flake8
|
| 11 |
+
models/
|
| 12 |
+
model/
|
configparser.ini
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[tokens]
|
| 2 |
+
; Enter one/all of your API key here.
|
| 3 |
+
; E.g., OPENAI_API_KEY = sk-xxxxxxx
|
| 4 |
+
OPENAI_API_KEY = sk-proj-2JwvyIn7WoKlkbjPOYVWT3BlbkFJnGAk65YAzvPH6cEVQXmr
|
| 5 |
+
ANTHROPIC_API_KEY = xxxxx
|
| 6 |
+
TOGETHER_API_KEY = xxxxx
|
| 7 |
+
; if you use Meta-Llama models, you may need Huggingface token to access.
|
| 8 |
+
HUGGINGFACE_TOKEN = xxxxx
|
| 9 |
+
VERSION = 1.0.1
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
[directory]
|
| 13 |
+
; Directory for source files.
|
| 14 |
+
DOCS_DIR = ./data
|
| 15 |
+
; Directory to store embeddings and Langchain documents.
|
| 16 |
+
DB_DIR = ./database_store
|
| 17 |
+
LOCAL_MODEL_DIR = ./models
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
; The below parameters are optional to modify:
|
| 21 |
+
; --------------------------------------------
|
| 22 |
+
[parameters]
|
| 23 |
+
; Model name schema: Model Provider|Model Name|Model File. Model File is only valid for GGUF format, set None for other format.
|
| 24 |
+
|
| 25 |
+
; For example:
|
| 26 |
+
; OpenAI|gpt-3.5-turbo|None
|
| 27 |
+
; OpenAI|gpt-4|None
|
| 28 |
+
; Anthropic|claude-2.0|None
|
| 29 |
+
; Together|togethercomputer/llama-2-70b-chat|None
|
| 30 |
+
; HuggingFace|TheBloke/Llama-2-70B-chat-GGUF|llama-2-70b-chat.q4_K_M.gguf
|
| 31 |
+
; HuggingFace|meta-llama/Llama-2-70b-chat-hf|None
|
| 32 |
+
|
| 33 |
+
; The full Together.AI model list can be found in the end of this file; We currently only support quantized gguf and the full huggingface local LLMs.
|
| 34 |
+
MODEL_NAME = OpenAI|gpt-4-1106-preview|None
|
| 35 |
+
; LLM temperature
|
| 36 |
+
TEMPURATURE = 0
|
| 37 |
+
; Maximum tokens for storing chat history.
|
| 38 |
+
MAX_CHAT_HISTORY = 800
|
| 39 |
+
; Maximum tokens for LLM context for retrieved information.
|
| 40 |
+
MAX_LLM_CONTEXT = 1200
|
| 41 |
+
; Maximum tokens for LLM generation.
|
| 42 |
+
MAX_LLM_GENERATION = 1000
|
| 43 |
+
; Supported embeddings: openAIEmbeddings and hkunlpInstructorLarge.
|
| 44 |
+
EMBEDDING_NAME = openAIEmbeddings
|
| 45 |
+
|
| 46 |
+
; This is dependent on your GPU type.
|
| 47 |
+
N_GPU_LAYERS = 100
|
| 48 |
+
; this is depend on your GPU and CPU ram when using open source LLMs.
|
| 49 |
+
N_BATCH = 512
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
; The base (small) chunk size for first stage document retrieval.
|
| 53 |
+
BASE_CHUNK_SIZE = 100
|
| 54 |
+
; Set to 0 for no overlap.
|
| 55 |
+
CHUNK_OVERLAP = 0
|
| 56 |
+
; The final retrieval (medium) chunk size will be BASE_CHUNK_SIZE * CHUNK_SCALE.
|
| 57 |
+
CHUNK_SCALE = 3
|
| 58 |
+
WINDOW_STEPS = 3
|
| 59 |
+
; The # tokens of window chunk will be BASE_CHUNK_SIZE * WINDOW_SCALE.
|
| 60 |
+
WINDOW_SCALE = 18
|
| 61 |
+
|
| 62 |
+
; Ratio of BM25 retriever to Chroma Vectorstore retriever.
|
| 63 |
+
RETRIEVER_WEIGHTS = 0.5, 0.5
|
| 64 |
+
; Number of retrieved chunks will range from FIRST_RETRIEVAL_K to 2*FIRST_RETRIEVAL_K due to the ensemble retriever.
|
| 65 |
+
FIRST_RETRIEVAL_K = 3
|
| 66 |
+
; Number of retrieved chunks will range from SECOND_RETRIEVAL_K to 2*SECOND_RETRIEVAL_K due to the ensemble retriever.
|
| 67 |
+
SECOND_RETRIEVAL_K = 3
|
| 68 |
+
; Number of windows (large chunks) for the third retriever.
|
| 69 |
+
NUM_WINDOWS = 2
|
| 70 |
+
; (The third retrieval gets the final chunks passed to the LLM QA chain. The 'k' value is dynamic (based on MAX_LLM_CONTEXT), depending on the number of rephrased questions and retrieved documents.)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
[logging]
|
| 74 |
+
; If you do not want to enable logging, set enabled to False.
|
| 75 |
+
enabled = True
|
| 76 |
+
level = INFO
|
| 77 |
+
filename = IncarnaMind.log
|
| 78 |
+
format = %(asctime)s [%(levelname)s] %(name)s: %(message)s
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
; Together.AI supported models:
|
| 82 |
+
|
| 83 |
+
; 0 Austism/chronos-hermes-13b
|
| 84 |
+
; 1 EleutherAI/pythia-12b-v0
|
| 85 |
+
; 2 EleutherAI/pythia-1b-v0
|
| 86 |
+
; 3 EleutherAI/pythia-2.8b-v0
|
| 87 |
+
; 4 EleutherAI/pythia-6.9b
|
| 88 |
+
; 5 Gryphe/MythoMax-L2-13b
|
| 89 |
+
; 6 HuggingFaceH4/starchat-alpha
|
| 90 |
+
; 7 NousResearch/Nous-Hermes-13b
|
| 91 |
+
; 8 NousResearch/Nous-Hermes-Llama2-13b
|
| 92 |
+
; 9 NumbersStation/nsql-llama-2-7B
|
| 93 |
+
; 10 OpenAssistant/llama2-70b-oasst-sft-v10
|
| 94 |
+
; 11 OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
|
| 95 |
+
; 12 OpenAssistant/stablelm-7b-sft-v7-epoch-3
|
| 96 |
+
; 13 Phind/Phind-CodeLlama-34B-Python-v1
|
| 97 |
+
; 14 Phind/Phind-CodeLlama-34B-v2
|
| 98 |
+
; 15 SG161222/Realistic_Vision_V3.0_VAE
|
| 99 |
+
; 16 WizardLM/WizardCoder-15B-V1.0
|
| 100 |
+
; 17 WizardLM/WizardCoder-Python-34B-V1.0
|
| 101 |
+
; 18 WizardLM/WizardLM-70B-V1.0
|
| 102 |
+
; 19 bigcode/starcoder
|
| 103 |
+
; 20 databricks/dolly-v2-12b
|
| 104 |
+
; 21 databricks/dolly-v2-3b
|
| 105 |
+
; 22 databricks/dolly-v2-7b
|
| 106 |
+
; 23 defog/sqlcoder
|
| 107 |
+
; 24 garage-bAInd/Platypus2-70B-instruct
|
| 108 |
+
; 25 huggyllama/llama-13b
|
| 109 |
+
; 26 huggyllama/llama-30b
|
| 110 |
+
; 27 huggyllama/llama-65b
|
| 111 |
+
; 28 huggyllama/llama-7b
|
| 112 |
+
; 29 lmsys/fastchat-t5-3b-v1.0
|
| 113 |
+
; 30 lmsys/vicuna-13b-v1.3
|
| 114 |
+
; 31 lmsys/vicuna-13b-v1.5-16k
|
| 115 |
+
; 32 lmsys/vicuna-13b-v1.5
|
| 116 |
+
; 33 lmsys/vicuna-7b-v1.3
|
| 117 |
+
; 34 prompthero/openjourney
|
| 118 |
+
; 35 runwayml/stable-diffusion-v1-5
|
| 119 |
+
; 36 stabilityai/stable-diffusion-2-1
|
| 120 |
+
; 37 stabilityai/stable-diffusion-xl-base-1.0
|
| 121 |
+
; 38 togethercomputer/CodeLlama-13b-Instruct
|
| 122 |
+
; 39 togethercomputer/CodeLlama-13b-Python
|
| 123 |
+
; 40 togethercomputer/CodeLlama-13b
|
| 124 |
+
; 41 togethercomputer/CodeLlama-34b-Instruct
|
| 125 |
+
; 42 togethercomputer/CodeLlama-34b-Python
|
| 126 |
+
; 43 togethercomputer/CodeLlama-34b
|
| 127 |
+
; 44 togethercomputer/CodeLlama-7b-Instruct
|
| 128 |
+
; 45 togethercomputer/CodeLlama-7b-Python
|
| 129 |
+
; 46 togethercomputer/CodeLlama-7b
|
| 130 |
+
; 47 togethercomputer/GPT-JT-6B-v1
|
| 131 |
+
; 48 togethercomputer/GPT-JT-Moderation-6B
|
| 132 |
+
; 49 togethercomputer/GPT-NeoXT-Chat-Base-20B
|
| 133 |
+
; 50 togethercomputer/Koala-13B
|
| 134 |
+
; 51 togethercomputer/LLaMA-2-7B-32K
|
| 135 |
+
; 52 togethercomputer/Llama-2-7B-32K-Instruct
|
| 136 |
+
; 53 togethercomputer/Pythia-Chat-Base-7B-v0.16
|
| 137 |
+
; 54 togethercomputer/Qwen-7B-Chat
|
| 138 |
+
; 55 togethercomputer/Qwen-7B
|
| 139 |
+
; 56 togethercomputer/RedPajama-INCITE-7B-Base
|
| 140 |
+
; 57 togethercomputer/RedPajama-INCITE-7B-Chat
|
| 141 |
+
; 58 togethercomputer/RedPajama-INCITE-7B-Instruct
|
| 142 |
+
; 59 togethercomputer/RedPajama-INCITE-Base-3B-v1
|
| 143 |
+
; 60 togethercomputer/RedPajama-INCITE-Chat-3B-v1
|
| 144 |
+
; 61 togethercomputer/RedPajama-INCITE-Instruct-3B-v1
|
| 145 |
+
; 62 togethercomputer/alpaca-7b
|
| 146 |
+
; 63 togethercomputer/codegen2-16B
|
| 147 |
+
; 64 togethercomputer/codegen2-7B
|
| 148 |
+
; 65 togethercomputer/falcon-40b-instruct
|
| 149 |
+
; 66 togethercomputer/falcon-40b
|
| 150 |
+
; 67 togethercomputer/falcon-7b-instruct
|
| 151 |
+
; 68 togethercomputer/falcon-7b
|
| 152 |
+
; 69 togethercomputer/guanaco-13b
|
| 153 |
+
; 70 togethercomputer/guanaco-33b
|
| 154 |
+
; 71 togethercomputer/guanaco-65b
|
| 155 |
+
; 72 togethercomputer/guanaco-7b
|
| 156 |
+
; 73 togethercomputer/llama-2-13b-chat
|
| 157 |
+
; 74 togethercomputer/llama-2-13b
|
| 158 |
+
; 75 togethercomputer/llama-2-70b-chat
|
| 159 |
+
; 76 togethercomputer/llama-2-70b
|
| 160 |
+
; 77 togethercomputer/llama-2-7b-chat
|
| 161 |
+
; 78 togethercomputer/llama-2-7b
|
| 162 |
+
; 79 togethercomputer/mpt-30b-chat
|
| 163 |
+
; 80 togethercomputer/mpt-30b-instruct
|
| 164 |
+
; 81 togethercomputer/mpt-30b
|
| 165 |
+
; 82 togethercomputer/mpt-7b-chat
|
| 166 |
+
; 83 togethercomputer/mpt-7b
|
| 167 |
+
; 84 togethercomputer/replit-code-v1-3b
|
| 168 |
+
; 85 upstage/SOLAR-0-70b-16bit
|
| 169 |
+
; 86 wavymulder/Analog-Diffusion
|
convo_qa_chain.py
ADDED
|
@@ -0,0 +1,387 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Conversational QA Chain"""
|
| 2 |
+
from __future__ import annotations
|
| 3 |
+
import inspect
|
| 4 |
+
import logging
|
| 5 |
+
from typing import Any, Dict, List, Optional
|
| 6 |
+
from pydantic import Field
|
| 7 |
+
|
| 8 |
+
from langchain.schema import BasePromptTemplate, BaseRetriever, Document
|
| 9 |
+
from langchain.schema.language_model import BaseLanguageModel
|
| 10 |
+
from langchain.chains import LLMChain
|
| 11 |
+
from langchain.chains.question_answering import load_qa_chain
|
| 12 |
+
from langchain.chains.conversational_retrieval.base import (
|
| 13 |
+
BaseConversationalRetrievalChain,
|
| 14 |
+
)
|
| 15 |
+
from langchain.callbacks.manager import (
|
| 16 |
+
AsyncCallbackManagerForChainRun,
|
| 17 |
+
CallbackManagerForChainRun,
|
| 18 |
+
Callbacks,
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
from toolkit.utils import (
|
| 22 |
+
Config,
|
| 23 |
+
_get_chat_history,
|
| 24 |
+
_get_standalone_questions_list,
|
| 25 |
+
)
|
| 26 |
+
from toolkit.retrivers import MyRetriever
|
| 27 |
+
from toolkit.prompts import PromptTemplates
|
| 28 |
+
|
| 29 |
+
configs = Config("configparser.ini")
|
| 30 |
+
logger = logging.getLogger(__name__)
|
| 31 |
+
|
| 32 |
+
prompt_templates = PromptTemplates()
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class ConvoRetrievalChain(BaseConversationalRetrievalChain):
|
| 36 |
+
"""Chain for having a conversation based on retrieved documents.
|
| 37 |
+
|
| 38 |
+
This chain takes in chat history (a list of messages) and new questions,
|
| 39 |
+
and then returns an answer to that question.
|
| 40 |
+
The algorithm for this chain consists of three parts:
|
| 41 |
+
|
| 42 |
+
1. Use the chat history and the new question to create a "standalone question".
|
| 43 |
+
This is done so that this question can be passed into the retrieval step to fetch
|
| 44 |
+
relevant documents. If only the new question was passed in, then relevant context
|
| 45 |
+
may be lacking. If the whole conversation was passed into retrieval, there may
|
| 46 |
+
be unnecessary information there that would distract from retrieval.
|
| 47 |
+
|
| 48 |
+
2. This new question is passed to the retriever and relevant documents are
|
| 49 |
+
returned.
|
| 50 |
+
|
| 51 |
+
3. The retrieved documents are passed to an LLM along with either the new question
|
| 52 |
+
(default behavior) or the original question and chat history to generate a final
|
| 53 |
+
response.
|
| 54 |
+
|
| 55 |
+
Example:
|
| 56 |
+
.. code-block:: python
|
| 57 |
+
|
| 58 |
+
from langchain.chains import (
|
| 59 |
+
StuffDocumentsChain, LLMChain, ConversationalRetrievalChain
|
| 60 |
+
)
|
| 61 |
+
from langchain.prompts import PromptTemplate
|
| 62 |
+
from langchain.llms import OpenAI
|
| 63 |
+
|
| 64 |
+
combine_docs_chain = StuffDocumentsChain(...)
|
| 65 |
+
vectorstore = ...
|
| 66 |
+
retriever = vectorstore.as_retriever()
|
| 67 |
+
|
| 68 |
+
# This controls how the standalone question is generated.
|
| 69 |
+
# Should take `chat_history` and `question` as input variables.
|
| 70 |
+
template = (
|
| 71 |
+
"Combine the chat history and follow up question into "
|
| 72 |
+
"a standalone question. Chat History: {chat_history}"
|
| 73 |
+
"Follow up question: {question}"
|
| 74 |
+
)
|
| 75 |
+
prompt = PromptTemplate.from_template(template)
|
| 76 |
+
llm = OpenAI()
|
| 77 |
+
question_generator_chain = LLMChain(llm=llm, prompt=prompt)
|
| 78 |
+
chain = ConversationalRetrievalChain(
|
| 79 |
+
combine_docs_chain=combine_docs_chain,
|
| 80 |
+
retriever=retriever,
|
| 81 |
+
question_generator=question_generator_chain,
|
| 82 |
+
)
|
| 83 |
+
"""
|
| 84 |
+
|
| 85 |
+
retriever: MyRetriever = Field(exclude=True)
|
| 86 |
+
"""Retriever to use to fetch documents."""
|
| 87 |
+
file_names: List = Field(exclude=True)
|
| 88 |
+
"""file_names (List): List of file names used for retrieval."""
|
| 89 |
+
|
| 90 |
+
def _get_docs(
|
| 91 |
+
self,
|
| 92 |
+
question: str,
|
| 93 |
+
inputs: Dict[str, Any],
|
| 94 |
+
num_query: int,
|
| 95 |
+
*,
|
| 96 |
+
run_manager: Optional[CallbackManagerForChainRun] = None,
|
| 97 |
+
) -> List[Document]:
|
| 98 |
+
"""Get docs."""
|
| 99 |
+
try:
|
| 100 |
+
docs = self.retriever.get_relevant_documents(
|
| 101 |
+
question, num_query=num_query, run_manager=run_manager
|
| 102 |
+
)
|
| 103 |
+
return docs
|
| 104 |
+
except (IOError, FileNotFoundError) as error:
|
| 105 |
+
logger.error("An error occurred in _get_docs: %s", error)
|
| 106 |
+
return []
|
| 107 |
+
|
| 108 |
+
def _retrieve(
|
| 109 |
+
self,
|
| 110 |
+
question_list: List[str],
|
| 111 |
+
inputs: Dict[str, Any],
|
| 112 |
+
run_manager: Optional[CallbackManagerForChainRun] = None,
|
| 113 |
+
) -> List[str]:
|
| 114 |
+
num_query = len(question_list)
|
| 115 |
+
accepts_run_manager = (
|
| 116 |
+
"run_manager" in inspect.signature(self._get_docs).parameters
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
total_results = {}
|
| 120 |
+
for question in question_list:
|
| 121 |
+
docs_dict = (
|
| 122 |
+
self._get_docs(
|
| 123 |
+
question, inputs, num_query=num_query, run_manager=run_manager
|
| 124 |
+
)
|
| 125 |
+
if accepts_run_manager
|
| 126 |
+
else self._get_docs(question, inputs, num_query=num_query)
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
for file_name, docs in docs_dict.items():
|
| 130 |
+
if file_name not in total_results:
|
| 131 |
+
total_results[file_name] = docs
|
| 132 |
+
else:
|
| 133 |
+
total_results[file_name].extend(docs)
|
| 134 |
+
|
| 135 |
+
logger.info(
|
| 136 |
+
"-----step_done--------------------------------------------------",
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
snippets = ""
|
| 140 |
+
redundancy = set()
|
| 141 |
+
for file_name, docs in total_results.items():
|
| 142 |
+
sorted_docs = sorted(docs, key=lambda x: x.metadata["medium_chunk_idx"])
|
| 143 |
+
temp = "\n".join(
|
| 144 |
+
doc.page_content
|
| 145 |
+
for doc in sorted_docs
|
| 146 |
+
if doc.metadata["page_content_md5"] not in redundancy
|
| 147 |
+
)
|
| 148 |
+
redundancy.update(doc.metadata["page_content_md5"] for doc in sorted_docs)
|
| 149 |
+
snippets += f"\nContext about {file_name}:\n{{{temp}}}\n"
|
| 150 |
+
|
| 151 |
+
return snippets, docs_dict
|
| 152 |
+
|
| 153 |
+
def _call(
|
| 154 |
+
self,
|
| 155 |
+
inputs: Dict[str, Any],
|
| 156 |
+
run_manager: Optional[CallbackManagerForChainRun] = None,
|
| 157 |
+
) -> Dict[str, Any]:
|
| 158 |
+
_run_manager = run_manager or CallbackManagerForChainRun.get_noop_manager()
|
| 159 |
+
question = inputs["question"]
|
| 160 |
+
get_chat_history = self.get_chat_history or _get_chat_history
|
| 161 |
+
chat_history_str = get_chat_history(inputs["chat_history"])
|
| 162 |
+
|
| 163 |
+
callbacks = _run_manager.get_child()
|
| 164 |
+
new_questions = self.question_generator.run(
|
| 165 |
+
question=question,
|
| 166 |
+
chat_history=chat_history_str,
|
| 167 |
+
database=self.file_names,
|
| 168 |
+
callbacks=callbacks,
|
| 169 |
+
)
|
| 170 |
+
logger.info("new_questions: %s", new_questions)
|
| 171 |
+
new_question_list = _get_standalone_questions_list(new_questions, question)[:3]
|
| 172 |
+
# print("new_question_list:", new_question_list)
|
| 173 |
+
logger.info("user_input: %s", question)
|
| 174 |
+
logger.info("new_question_list: %s", new_question_list)
|
| 175 |
+
|
| 176 |
+
snippets, source_docs = self._retrieve(
|
| 177 |
+
new_question_list, inputs, run_manager=_run_manager
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
docs = [
|
| 181 |
+
Document(
|
| 182 |
+
page_content=snippets,
|
| 183 |
+
metadata={},
|
| 184 |
+
)
|
| 185 |
+
]
|
| 186 |
+
|
| 187 |
+
new_inputs = inputs.copy()
|
| 188 |
+
new_inputs["chat_history"] = chat_history_str
|
| 189 |
+
answer = self.combine_docs_chain.run(
|
| 190 |
+
input_documents=docs,
|
| 191 |
+
database=self.file_names,
|
| 192 |
+
callbacks=_run_manager.get_child(),
|
| 193 |
+
**new_inputs,
|
| 194 |
+
)
|
| 195 |
+
output: Dict[str, Any] = {self.output_key: answer}
|
| 196 |
+
if self.return_source_documents:
|
| 197 |
+
output["source_documents"] = source_docs
|
| 198 |
+
if self.return_generated_question:
|
| 199 |
+
output["generated_question"] = new_questions
|
| 200 |
+
|
| 201 |
+
logger.info("*****response*****: %s", output["answer"])
|
| 202 |
+
logger.info(
|
| 203 |
+
"=====epoch_done============================================================",
|
| 204 |
+
)
|
| 205 |
+
return output
|
| 206 |
+
|
| 207 |
+
async def _aget_docs(
|
| 208 |
+
self,
|
| 209 |
+
question: str,
|
| 210 |
+
inputs: Dict[str, Any],
|
| 211 |
+
num_query: int,
|
| 212 |
+
*,
|
| 213 |
+
run_manager: Optional[AsyncCallbackManagerForChainRun] = None,
|
| 214 |
+
) -> List[Document]:
|
| 215 |
+
"""Get docs."""
|
| 216 |
+
try:
|
| 217 |
+
docs = await self.retriever.aget_relevant_documents(
|
| 218 |
+
question, num_query=num_query, run_manager=run_manager
|
| 219 |
+
)
|
| 220 |
+
return docs
|
| 221 |
+
except (IOError, FileNotFoundError) as error:
|
| 222 |
+
logger.error("An error occurred in _get_docs: %s", error)
|
| 223 |
+
return []
|
| 224 |
+
|
| 225 |
+
async def _aretrieve(
|
| 226 |
+
self,
|
| 227 |
+
question_list: List[str],
|
| 228 |
+
inputs: Dict[str, Any],
|
| 229 |
+
run_manager: Optional[AsyncCallbackManagerForChainRun] = None,
|
| 230 |
+
) -> Dict[str, Any]:
|
| 231 |
+
num_query = len(question_list)
|
| 232 |
+
accepts_run_manager = (
|
| 233 |
+
"run_manager" in inspect.signature(self._get_docs).parameters
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
total_results = {}
|
| 237 |
+
for question in question_list:
|
| 238 |
+
docs_dict = (
|
| 239 |
+
await self._aget_docs(
|
| 240 |
+
question, inputs, num_query=num_query, run_manager=run_manager
|
| 241 |
+
)
|
| 242 |
+
if accepts_run_manager
|
| 243 |
+
else await self._aget_docs(question, inputs, num_query=num_query)
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
for file_name, docs in docs_dict.items():
|
| 247 |
+
if file_name not in total_results:
|
| 248 |
+
total_results[file_name] = docs
|
| 249 |
+
else:
|
| 250 |
+
total_results[file_name].extend(docs)
|
| 251 |
+
|
| 252 |
+
logger.info(
|
| 253 |
+
"-----step_done--------------------------------------------------",
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
snippets = ""
|
| 257 |
+
redundancy = set()
|
| 258 |
+
for file_name, docs in total_results.items():
|
| 259 |
+
sorted_docs = sorted(docs, key=lambda x: x.metadata["medium_chunk_idx"])
|
| 260 |
+
temp = "\n".join(
|
| 261 |
+
doc.page_content
|
| 262 |
+
for doc in sorted_docs
|
| 263 |
+
if doc.metadata["page_content_md5"] not in redundancy
|
| 264 |
+
)
|
| 265 |
+
redundancy.update(doc.metadata["page_content_md5"] for doc in sorted_docs)
|
| 266 |
+
snippets += f"\nContext about {file_name}:\n{{{temp}}}\n"
|
| 267 |
+
|
| 268 |
+
return snippets, docs_dict
|
| 269 |
+
|
| 270 |
+
async def _acall(
|
| 271 |
+
self,
|
| 272 |
+
inputs: Dict[str, Any],
|
| 273 |
+
run_manager: Optional[AsyncCallbackManagerForChainRun] = None,
|
| 274 |
+
) -> Dict[str, Any]:
|
| 275 |
+
_run_manager = run_manager or AsyncCallbackManagerForChainRun.get_noop_manager()
|
| 276 |
+
question = inputs["question"]
|
| 277 |
+
get_chat_history = self.get_chat_history or _get_chat_history
|
| 278 |
+
chat_history_str = get_chat_history(inputs["chat_history"])
|
| 279 |
+
|
| 280 |
+
callbacks = _run_manager.get_child()
|
| 281 |
+
new_questions = await self.question_generator.arun(
|
| 282 |
+
question=question,
|
| 283 |
+
chat_history=chat_history_str,
|
| 284 |
+
database=self.file_names,
|
| 285 |
+
callbacks=callbacks,
|
| 286 |
+
)
|
| 287 |
+
new_question_list = _get_standalone_questions_list(new_questions, question)[:3]
|
| 288 |
+
logger.info("new_questions: %s", new_questions)
|
| 289 |
+
logger.info("new_question_list: %s", new_question_list)
|
| 290 |
+
|
| 291 |
+
snippets, source_docs = await self._aretrieve(
|
| 292 |
+
new_question_list, inputs, run_manager=_run_manager
|
| 293 |
+
)
|
| 294 |
+
|
| 295 |
+
docs = [
|
| 296 |
+
Document(
|
| 297 |
+
page_content=snippets,
|
| 298 |
+
metadata={},
|
| 299 |
+
)
|
| 300 |
+
]
|
| 301 |
+
|
| 302 |
+
new_inputs = inputs.copy()
|
| 303 |
+
new_inputs["chat_history"] = chat_history_str
|
| 304 |
+
answer = await self.combine_docs_chain.arun(
|
| 305 |
+
input_documents=docs,
|
| 306 |
+
database=self.file_names,
|
| 307 |
+
callbacks=_run_manager.get_child(),
|
| 308 |
+
**new_inputs,
|
| 309 |
+
)
|
| 310 |
+
output: Dict[str, Any] = {self.output_key: answer}
|
| 311 |
+
if self.return_source_documents:
|
| 312 |
+
output["source_documents"] = source_docs
|
| 313 |
+
if self.return_generated_question:
|
| 314 |
+
output["generated_question"] = new_questions
|
| 315 |
+
|
| 316 |
+
logger.info("*****response*****: %s", output["answer"])
|
| 317 |
+
logger.info(
|
| 318 |
+
"=====epoch_done============================================================",
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
return output
|
| 322 |
+
|
| 323 |
+
@classmethod
|
| 324 |
+
def from_llm(
|
| 325 |
+
cls,
|
| 326 |
+
llm: BaseLanguageModel,
|
| 327 |
+
retriever: BaseRetriever,
|
| 328 |
+
condense_question_prompt: BasePromptTemplate = prompt_templates.get_refine_qa_template(
|
| 329 |
+
configs.model_name
|
| 330 |
+
),
|
| 331 |
+
chain_type: str = "stuff", # only support stuff chain now
|
| 332 |
+
verbose: bool = False,
|
| 333 |
+
condense_question_llm: Optional[BaseLanguageModel] = None,
|
| 334 |
+
combine_docs_chain_kwargs: Optional[Dict] = None,
|
| 335 |
+
callbacks: Callbacks = None,
|
| 336 |
+
**kwargs: Any,
|
| 337 |
+
) -> BaseConversationalRetrievalChain:
|
| 338 |
+
"""Convenience method to load chain from LLM and retriever.
|
| 339 |
+
|
| 340 |
+
This provides some logic to create the `question_generator` chain
|
| 341 |
+
as well as the combine_docs_chain.
|
| 342 |
+
|
| 343 |
+
Args:
|
| 344 |
+
llm: The default language model to use at every part of this chain
|
| 345 |
+
(eg in both the question generation and the answering)
|
| 346 |
+
retriever: The retriever to use to fetch relevant documents from.
|
| 347 |
+
condense_question_prompt: The prompt to use to condense the chat history
|
| 348 |
+
and new question into standalone question(s).
|
| 349 |
+
chain_type: The chain type to use to create the combine_docs_chain, will
|
| 350 |
+
be sent to `load_qa_chain`.
|
| 351 |
+
verbose: Verbosity flag for logging to stdout.
|
| 352 |
+
condense_question_llm: The language model to use for condensing the chat
|
| 353 |
+
history and new question into standalone question(s). If none is
|
| 354 |
+
provided, will default to `llm`.
|
| 355 |
+
combine_docs_chain_kwargs: Parameters to pass as kwargs to `load_qa_chain`
|
| 356 |
+
when constructing the combine_docs_chain.
|
| 357 |
+
callbacks: Callbacks to pass to all subchains.
|
| 358 |
+
**kwargs: Additional parameters to pass when initializing
|
| 359 |
+
ConversationalRetrievalChain
|
| 360 |
+
"""
|
| 361 |
+
combine_docs_chain_kwargs = combine_docs_chain_kwargs or {
|
| 362 |
+
"prompt": prompt_templates.get_retrieval_qa_template_selector(
|
| 363 |
+
configs.model_name
|
| 364 |
+
).get_prompt(llm)
|
| 365 |
+
}
|
| 366 |
+
doc_chain = load_qa_chain(
|
| 367 |
+
llm,
|
| 368 |
+
chain_type=chain_type,
|
| 369 |
+
verbose=verbose,
|
| 370 |
+
callbacks=callbacks,
|
| 371 |
+
**combine_docs_chain_kwargs,
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
_llm = condense_question_llm or llm
|
| 375 |
+
condense_question_chain = LLMChain(
|
| 376 |
+
llm=_llm,
|
| 377 |
+
prompt=condense_question_prompt,
|
| 378 |
+
verbose=verbose,
|
| 379 |
+
callbacks=callbacks,
|
| 380 |
+
)
|
| 381 |
+
return cls(
|
| 382 |
+
retriever=retriever,
|
| 383 |
+
combine_docs_chain=doc_chain,
|
| 384 |
+
question_generator=condense_question_chain,
|
| 385 |
+
callbacks=callbacks,
|
| 386 |
+
**kwargs,
|
| 387 |
+
)
|
data/ABPI Code of Practice for the Pharmaceutical Industry 2021.pdf
ADDED
|
Binary file (803 kB). View file
|
|
|
data/Attention Is All You Need.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b7d72988fd8107d07f7d278bf0ba6621adb6ed47df74be4014fa4a01f03aff6a
|
| 3 |
+
size 2215244
|
data/Gradient Descent The Ultimate Optimizer.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c76077e02756ef3281ce3b1195d080009cb88e00382a8fc225948db339053296
|
| 3 |
+
size 1923635
|
data/JP Morgan 2022 Environmental Social Governance Report.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:80eab2c81a6c82bde9ccff1a8636fddc8ce1457a13c833d8a7f1e374a4bb439f
|
| 3 |
+
size 7474626
|
data/Language Models are Few-Shot Learners.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:97fd272f1fdfc18677462d0292f5fbf26ca86b4d1b485c2dba03269b643a0e83
|
| 3 |
+
size 6768044
|
data/Language Models are Unsupervised Multitask Learners.pdf
ADDED
|
Binary file (583 kB). View file
|
|
|
data/United Nations 2022 Annual Report.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b4ee2835c06f98e74ab93aa69a0c026577c464fc6bd3942068f14cba5dcad536
|
| 3 |
+
size 36452281
|
docs2db.py
ADDED
|
@@ -0,0 +1,346 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This module save documents to embeddings and langchain Documents.
|
| 3 |
+
"""
|
| 4 |
+
import os
|
| 5 |
+
import glob
|
| 6 |
+
import pickle
|
| 7 |
+
from typing import List
|
| 8 |
+
from multiprocessing import Pool
|
| 9 |
+
from collections import deque
|
| 10 |
+
import hashlib
|
| 11 |
+
import tiktoken
|
| 12 |
+
|
| 13 |
+
from tqdm import tqdm
|
| 14 |
+
|
| 15 |
+
from langchain.schema import Document
|
| 16 |
+
from langchain.vectorstores import Chroma
|
| 17 |
+
from langchain.text_splitter import (
|
| 18 |
+
RecursiveCharacterTextSplitter,
|
| 19 |
+
)
|
| 20 |
+
from langchain.document_loaders import (
|
| 21 |
+
PyPDFLoader,
|
| 22 |
+
TextLoader,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
from toolkit.utils import Config, choose_embeddings, clean_text
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
# Load the config file
|
| 29 |
+
configs = Config("configparser.ini")
|
| 30 |
+
|
| 31 |
+
os.environ["OPENAI_API_KEY"] = configs.openai_api_key
|
| 32 |
+
os.environ["ANTHROPIC_API_KEY"] = configs.anthropic_api_key
|
| 33 |
+
|
| 34 |
+
embedding_store_path = configs.db_dir
|
| 35 |
+
files_path = glob.glob(configs.docs_dir + "/*")
|
| 36 |
+
|
| 37 |
+
tokenizer_name = tiktoken.encoding_for_model("gpt-3.5-turbo")
|
| 38 |
+
tokenizer = tiktoken.get_encoding(tokenizer_name.name)
|
| 39 |
+
|
| 40 |
+
loaders = {
|
| 41 |
+
"pdf": (PyPDFLoader, {}),
|
| 42 |
+
"txt": (TextLoader, {}),
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def tiktoken_len(text: str):
|
| 47 |
+
"""Calculate the token length of a given text string using TikToken.
|
| 48 |
+
|
| 49 |
+
Args:
|
| 50 |
+
text (str): The text to be tokenized.
|
| 51 |
+
|
| 52 |
+
Returns:
|
| 53 |
+
int: The length of the tokenized text.
|
| 54 |
+
"""
|
| 55 |
+
tokens = tokenizer.encode(text, disallowed_special=())
|
| 56 |
+
|
| 57 |
+
return len(tokens)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def string2md5(text: str):
|
| 61 |
+
"""Convert a string to its MD5 hash.
|
| 62 |
+
|
| 63 |
+
Args:
|
| 64 |
+
text (str): The text to be hashed.
|
| 65 |
+
|
| 66 |
+
Returns:
|
| 67 |
+
str: The MD5 hash of the input string.
|
| 68 |
+
"""
|
| 69 |
+
hash_md5 = hashlib.md5()
|
| 70 |
+
hash_md5.update(text.encode("utf-8"))
|
| 71 |
+
|
| 72 |
+
return hash_md5.hexdigest()
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def load_file(file_path):
|
| 76 |
+
"""Load a file and return its content as a Document object.
|
| 77 |
+
|
| 78 |
+
Args:
|
| 79 |
+
file_path (str): The path to the file.
|
| 80 |
+
|
| 81 |
+
Returns:
|
| 82 |
+
Document: The loaded document.
|
| 83 |
+
"""
|
| 84 |
+
ext = file_path.split(".")[-1]
|
| 85 |
+
|
| 86 |
+
if ext in loaders:
|
| 87 |
+
loader_type, args = loaders[ext]
|
| 88 |
+
loader = loader_type(file_path, **args)
|
| 89 |
+
doc = loader.load()
|
| 90 |
+
|
| 91 |
+
return doc
|
| 92 |
+
|
| 93 |
+
raise ValueError(f"Extension {ext} not supported")
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def docs2vectorstore(docs: List[Document], embedding_name: str, suffix: str = ""):
|
| 97 |
+
"""Convert a list of Documents into a Chroma vector store.
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
docs (Document): The list of Documents.
|
| 101 |
+
suffix (str, optional): Suffix for the embedding. Defaults to "".
|
| 102 |
+
"""
|
| 103 |
+
embedding = choose_embeddings(embedding_name)
|
| 104 |
+
name = f"{embedding_name}_{suffix}"
|
| 105 |
+
# if embedding_store_path is not existing, create it
|
| 106 |
+
if not os.path.exists(embedding_store_path):
|
| 107 |
+
os.makedirs(embedding_store_path)
|
| 108 |
+
Chroma.from_documents(
|
| 109 |
+
docs,
|
| 110 |
+
embedding,
|
| 111 |
+
persist_directory=f"{embedding_store_path}/chroma_{name}",
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def file_names2pickle(file_names: list, save_name: str = ""):
|
| 116 |
+
"""Save the list of file names to a pickle file.
|
| 117 |
+
|
| 118 |
+
Args:
|
| 119 |
+
file_names (list): The list of file names.
|
| 120 |
+
save_name (str, optional): The name for the saved pickle file. Defaults to "".
|
| 121 |
+
"""
|
| 122 |
+
name = f"{save_name}"
|
| 123 |
+
if not os.path.exists(embedding_store_path):
|
| 124 |
+
os.makedirs(embedding_store_path)
|
| 125 |
+
with open(f"{embedding_store_path}/{name}.pkl", "wb") as file:
|
| 126 |
+
pickle.dump(file_names, file)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def docs2pickle(docs: List[Document], suffix: str = ""):
|
| 130 |
+
"""Serializes a list of Document objects to a pickle file.
|
| 131 |
+
|
| 132 |
+
Args:
|
| 133 |
+
docs (Document): List of Document objects.
|
| 134 |
+
suffix (str, optional): Suffix for the pickle file. Defaults to "".
|
| 135 |
+
"""
|
| 136 |
+
for doc in docs:
|
| 137 |
+
doc.page_content = clean_text(doc.page_content)
|
| 138 |
+
name = f"pickle_{suffix}"
|
| 139 |
+
if not os.path.exists(embedding_store_path):
|
| 140 |
+
os.makedirs(embedding_store_path)
|
| 141 |
+
with open(f"{embedding_store_path}/docs_{name}.pkl", "wb") as file:
|
| 142 |
+
pickle.dump(docs, file)
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def split_doc(
|
| 146 |
+
doc: List[Document], chunk_size: int, chunk_overlap: int, chunk_idx_name: str
|
| 147 |
+
):
|
| 148 |
+
"""Splits a document into smaller chunks based on the provided size and overlap.
|
| 149 |
+
|
| 150 |
+
Args:
|
| 151 |
+
doc (Document): Document to be split.
|
| 152 |
+
chunk_size (int): Size of each chunk.
|
| 153 |
+
chunk_overlap (int): Overlap between adjacent chunks.
|
| 154 |
+
chunk_idx_name (str): Metadata key for storing chunk indices.
|
| 155 |
+
|
| 156 |
+
Returns:
|
| 157 |
+
list: List of Document objects representing the chunks.
|
| 158 |
+
"""
|
| 159 |
+
data_splitter = RecursiveCharacterTextSplitter(
|
| 160 |
+
chunk_size=chunk_size,
|
| 161 |
+
chunk_overlap=chunk_overlap,
|
| 162 |
+
length_function=tiktoken_len,
|
| 163 |
+
)
|
| 164 |
+
doc_split = data_splitter.split_documents(doc)
|
| 165 |
+
chunk_idx = 0
|
| 166 |
+
|
| 167 |
+
for d_split in doc_split:
|
| 168 |
+
d_split.metadata[chunk_idx_name] = chunk_idx
|
| 169 |
+
chunk_idx += 1
|
| 170 |
+
|
| 171 |
+
return doc_split
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def process_metadata(doc: List[Document]):
|
| 175 |
+
"""Processes and updates the metadata for a list of Document objects.
|
| 176 |
+
|
| 177 |
+
Args:
|
| 178 |
+
doc (list): List of Document objects.
|
| 179 |
+
"""
|
| 180 |
+
# get file name and remove extension
|
| 181 |
+
file_name_with_extension = os.path.basename(doc[0].metadata["source"])
|
| 182 |
+
file_name, _ = os.path.splitext(file_name_with_extension)
|
| 183 |
+
|
| 184 |
+
for _, item in enumerate(doc):
|
| 185 |
+
for key, value in item.metadata.items():
|
| 186 |
+
if isinstance(value, list):
|
| 187 |
+
item.metadata[key] = str(value)
|
| 188 |
+
item.metadata["page_content"] = item.page_content
|
| 189 |
+
item.metadata["page_content_md5"] = string2md5(item.page_content)
|
| 190 |
+
item.metadata["source_md5"] = string2md5(item.metadata["source"])
|
| 191 |
+
item.page_content = f"{file_name}\n{item.page_content}"
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def add_window(
|
| 195 |
+
doc: Document, window_steps: int, window_size: int, window_idx_name: str
|
| 196 |
+
):
|
| 197 |
+
"""Adds windowing information to the metadata of each document in the list.
|
| 198 |
+
|
| 199 |
+
Args:
|
| 200 |
+
doc (Document): List of Document objects.
|
| 201 |
+
window_steps (int): Step size for windowing.
|
| 202 |
+
window_size (int): Size of each window.
|
| 203 |
+
window_idx_name (str): Metadata key for storing window indices.
|
| 204 |
+
"""
|
| 205 |
+
window_id = 0
|
| 206 |
+
window_deque = deque()
|
| 207 |
+
|
| 208 |
+
for idx, item in enumerate(doc):
|
| 209 |
+
if idx % window_steps == 0 and idx != 0 and idx < len(doc) - window_size:
|
| 210 |
+
window_id += 1
|
| 211 |
+
window_deque.append(window_id)
|
| 212 |
+
|
| 213 |
+
if len(window_deque) > window_size:
|
| 214 |
+
for _ in range(window_steps):
|
| 215 |
+
window_deque.popleft()
|
| 216 |
+
|
| 217 |
+
window = set(window_deque)
|
| 218 |
+
item.metadata[f"{window_idx_name}_lower_bound"] = min(window)
|
| 219 |
+
item.metadata[f"{window_idx_name}_upper_bound"] = max(window)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def merge_metadata(dicts_list: dict):
|
| 223 |
+
"""Merges a list of metadata dictionaries into a single dictionary.
|
| 224 |
+
|
| 225 |
+
Args:
|
| 226 |
+
dicts_list (list): List of metadata dictionaries.
|
| 227 |
+
|
| 228 |
+
Returns:
|
| 229 |
+
dict: Merged metadata dictionary.
|
| 230 |
+
"""
|
| 231 |
+
merged_dict = {}
|
| 232 |
+
bounds_dict = {}
|
| 233 |
+
keys_to_remove = set()
|
| 234 |
+
|
| 235 |
+
for dic in dicts_list:
|
| 236 |
+
for key, value in dic.items():
|
| 237 |
+
if key in merged_dict:
|
| 238 |
+
if value not in merged_dict[key]:
|
| 239 |
+
merged_dict[key].append(value)
|
| 240 |
+
else:
|
| 241 |
+
merged_dict[key] = [value]
|
| 242 |
+
|
| 243 |
+
for key, values in merged_dict.items():
|
| 244 |
+
if len(values) > 1 and all(isinstance(x, (int, float)) for x in values):
|
| 245 |
+
bounds_dict[f"{key}_lower_bound"] = min(values)
|
| 246 |
+
bounds_dict[f"{key}_upper_bound"] = max(values)
|
| 247 |
+
keys_to_remove.add(key)
|
| 248 |
+
|
| 249 |
+
merged_dict.update(bounds_dict)
|
| 250 |
+
|
| 251 |
+
for key in keys_to_remove:
|
| 252 |
+
del merged_dict[key]
|
| 253 |
+
|
| 254 |
+
return {
|
| 255 |
+
k: v[0] if isinstance(v, list) and len(v) == 1 else v
|
| 256 |
+
for k, v in merged_dict.items()
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def merge_chunks(doc: Document, scale_factor: int, chunk_idx_name: str):
|
| 261 |
+
"""Merges adjacent chunks into larger chunks based on a scaling factor.
|
| 262 |
+
|
| 263 |
+
Args:
|
| 264 |
+
doc (Document): List of Document objects.
|
| 265 |
+
scale_factor (int): The number of small chunks to merge into a larger chunk.
|
| 266 |
+
chunk_idx_name (str): Metadata key for storing chunk indices.
|
| 267 |
+
|
| 268 |
+
Returns:
|
| 269 |
+
list: List of Document objects representing the merged chunks.
|
| 270 |
+
"""
|
| 271 |
+
merged_doc = []
|
| 272 |
+
page_content = ""
|
| 273 |
+
metadata_list = []
|
| 274 |
+
chunk_idx = 0
|
| 275 |
+
|
| 276 |
+
for idx, item in enumerate(doc):
|
| 277 |
+
page_content += item.page_content
|
| 278 |
+
metadata_list.append(item.metadata)
|
| 279 |
+
|
| 280 |
+
if (idx + 1) % scale_factor == 0 or idx == len(doc) - 1:
|
| 281 |
+
metadata = merge_metadata(metadata_list)
|
| 282 |
+
metadata[chunk_idx_name] = chunk_idx
|
| 283 |
+
merged_doc.append(
|
| 284 |
+
Document(
|
| 285 |
+
page_content=page_content,
|
| 286 |
+
metadata=metadata,
|
| 287 |
+
)
|
| 288 |
+
)
|
| 289 |
+
chunk_idx += 1
|
| 290 |
+
page_content = ""
|
| 291 |
+
metadata_list = []
|
| 292 |
+
|
| 293 |
+
return merged_doc
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
def process_files():
|
| 297 |
+
"""Main function for processing files. Loads, tokenizes, and saves document data."""
|
| 298 |
+
with Pool() as pool:
|
| 299 |
+
chunks_small = []
|
| 300 |
+
chunks_medium = []
|
| 301 |
+
file_names = []
|
| 302 |
+
|
| 303 |
+
with tqdm(total=len(files_path), desc="Processing files", ncols=80) as pbar:
|
| 304 |
+
for doc in pool.imap_unordered(load_file, files_path):
|
| 305 |
+
file_name_with_extension = os.path.basename(doc[0].metadata["source"])
|
| 306 |
+
# file_name, _ = os.path.splitext(file_name_with_extension)
|
| 307 |
+
|
| 308 |
+
chunk_split_small = split_doc(
|
| 309 |
+
doc=doc,
|
| 310 |
+
chunk_size=configs.base_chunk_size,
|
| 311 |
+
chunk_overlap=configs.chunk_overlap,
|
| 312 |
+
chunk_idx_name="small_chunk_idx",
|
| 313 |
+
)
|
| 314 |
+
add_window(
|
| 315 |
+
doc=chunk_split_small,
|
| 316 |
+
window_steps=configs.window_steps,
|
| 317 |
+
window_size=configs.window_scale,
|
| 318 |
+
window_idx_name="large_chunks_idx",
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
chunk_split_medium = merge_chunks(
|
| 322 |
+
doc=chunk_split_small,
|
| 323 |
+
scale_factor=configs.chunk_scale,
|
| 324 |
+
chunk_idx_name="medium_chunk_idx",
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
process_metadata(chunk_split_small)
|
| 328 |
+
process_metadata(chunk_split_medium)
|
| 329 |
+
|
| 330 |
+
file_names.append(file_name_with_extension)
|
| 331 |
+
chunks_small.extend(chunk_split_small)
|
| 332 |
+
chunks_medium.extend(chunk_split_medium)
|
| 333 |
+
|
| 334 |
+
pbar.update()
|
| 335 |
+
|
| 336 |
+
file_names2pickle(file_names, save_name="file_names")
|
| 337 |
+
|
| 338 |
+
docs2vectorstore(chunks_small, configs.embedding_name, suffix="chunks_small")
|
| 339 |
+
docs2vectorstore(chunks_medium, configs.embedding_name, suffix="chunks_medium")
|
| 340 |
+
|
| 341 |
+
docs2pickle(chunks_small, suffix="chunks_small")
|
| 342 |
+
docs2pickle(chunks_medium, suffix="chunks_medium")
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
if __name__ == "__main__":
|
| 346 |
+
process_files()
|
figs/High_Level_Architecture.png
ADDED
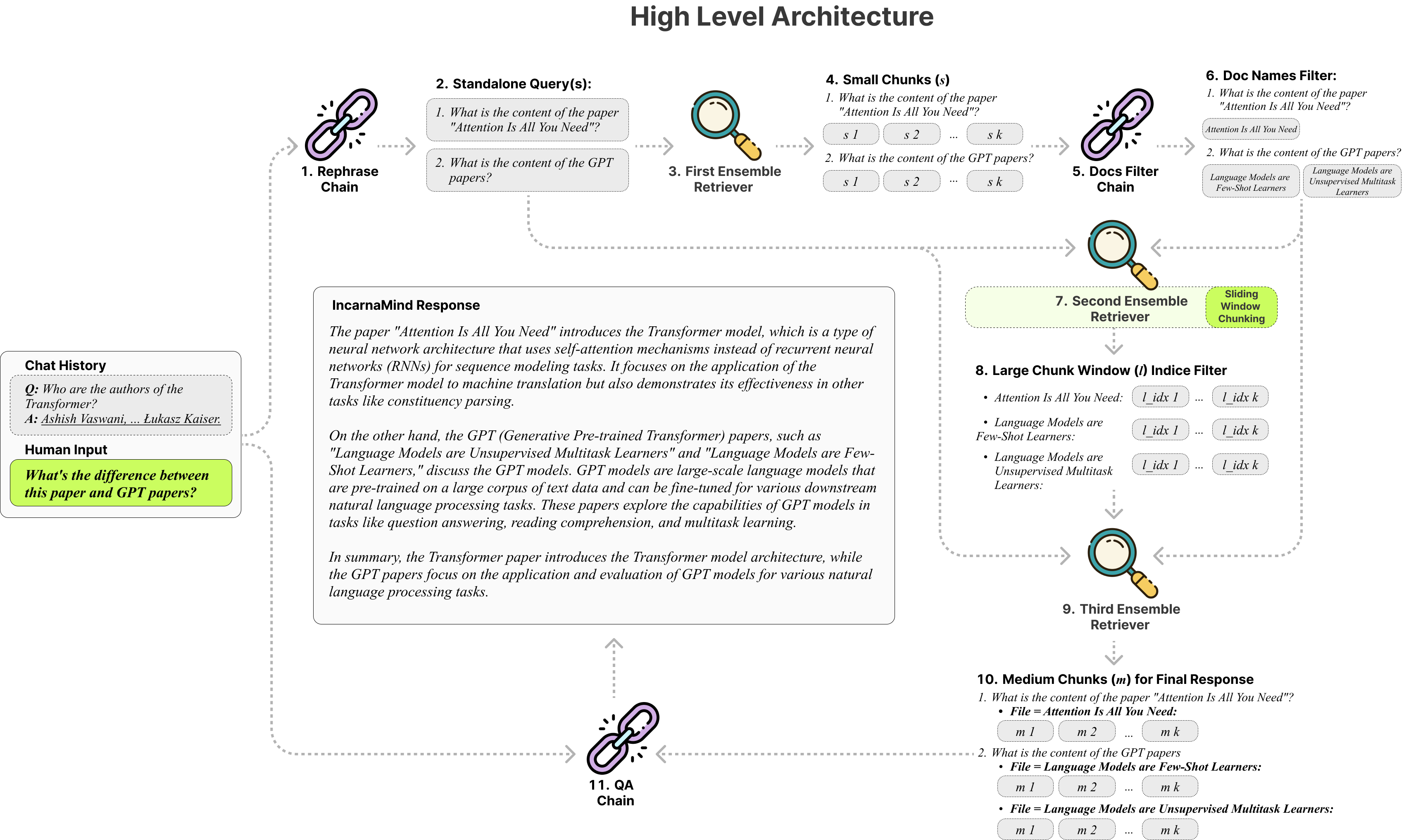
|
figs/Sliding_Window_Chunking.png
ADDED

|
main.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Conversational QA Chain"""
|
| 2 |
+
from __future__ import annotations
|
| 3 |
+
import os
|
| 4 |
+
import re
|
| 5 |
+
import time
|
| 6 |
+
import logging
|
| 7 |
+
|
| 8 |
+
from langchain.chat_models import ChatOpenAI, ChatAnthropic
|
| 9 |
+
from langchain.memory import ConversationTokenBufferMemory
|
| 10 |
+
from convo_qa_chain import ConvoRetrievalChain
|
| 11 |
+
|
| 12 |
+
from toolkit.together_api_llm import TogetherLLM
|
| 13 |
+
from toolkit.retrivers import MyRetriever
|
| 14 |
+
from toolkit.local_llm import load_local_llm
|
| 15 |
+
from toolkit.utils import (
|
| 16 |
+
Config,
|
| 17 |
+
choose_embeddings,
|
| 18 |
+
load_embedding,
|
| 19 |
+
load_pickle,
|
| 20 |
+
check_device,
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
# Load the config file
|
| 25 |
+
configs = Config("configparser.ini")
|
| 26 |
+
logger = logging.getLogger(__name__)
|
| 27 |
+
|
| 28 |
+
os.environ["OPENAI_API_KEY"] = configs.openai_api_key
|
| 29 |
+
os.environ["ANTHROPIC_API_KEY"] = configs.anthropic_api_key
|
| 30 |
+
|
| 31 |
+
embedding = choose_embeddings(configs.embedding_name)
|
| 32 |
+
db_store_path = configs.db_dir
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# get models
|
| 36 |
+
def get_llm(llm_name: str, temperature: float, max_tokens: int):
|
| 37 |
+
"""Get the LLM model from the model name."""
|
| 38 |
+
|
| 39 |
+
if not os.path.exists(configs.local_model_dir):
|
| 40 |
+
os.makedirs(configs.local_model_dir)
|
| 41 |
+
|
| 42 |
+
splits = llm_name.split("|") # [provider, model_name, model_file]
|
| 43 |
+
|
| 44 |
+
if "openai" in splits[0].lower():
|
| 45 |
+
llm_model = ChatOpenAI(
|
| 46 |
+
model=splits[1],
|
| 47 |
+
temperature=temperature,
|
| 48 |
+
max_tokens=max_tokens,
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
elif "anthropic" in splits[0].lower():
|
| 52 |
+
llm_model = ChatAnthropic(
|
| 53 |
+
model=splits[1],
|
| 54 |
+
temperature=temperature,
|
| 55 |
+
max_tokens_to_sample=max_tokens,
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
elif "together" in splits[0].lower():
|
| 59 |
+
llm_model = TogetherLLM(
|
| 60 |
+
model=splits[1],
|
| 61 |
+
temperature=temperature,
|
| 62 |
+
max_tokens=max_tokens,
|
| 63 |
+
)
|
| 64 |
+
elif "huggingface" in splits[0].lower():
|
| 65 |
+
llm_model = load_local_llm(
|
| 66 |
+
model_id=splits[1],
|
| 67 |
+
model_basename=splits[-1],
|
| 68 |
+
temperature=temperature,
|
| 69 |
+
max_tokens=max_tokens,
|
| 70 |
+
device_type=check_device(),
|
| 71 |
+
)
|
| 72 |
+
else:
|
| 73 |
+
raise ValueError("Invalid Model Name")
|
| 74 |
+
|
| 75 |
+
return llm_model
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
llm = get_llm(configs.model_name, configs.temperature, configs.max_llm_generation)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
# load retrieval database
|
| 82 |
+
db_embedding_chunks_small = load_embedding(
|
| 83 |
+
store_name=configs.embedding_name,
|
| 84 |
+
embedding=embedding,
|
| 85 |
+
suffix="chunks_small",
|
| 86 |
+
path=db_store_path,
|
| 87 |
+
)
|
| 88 |
+
db_embedding_chunks_medium = load_embedding(
|
| 89 |
+
store_name=configs.embedding_name,
|
| 90 |
+
embedding=embedding,
|
| 91 |
+
suffix="chunks_medium",
|
| 92 |
+
path=db_store_path,
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
db_docs_chunks_small = load_pickle(
|
| 96 |
+
prefix="docs_pickle", suffix="chunks_small", path=db_store_path
|
| 97 |
+
)
|
| 98 |
+
db_docs_chunks_medium = load_pickle(
|
| 99 |
+
prefix="docs_pickle", suffix="chunks_medium", path=db_store_path
|
| 100 |
+
)
|
| 101 |
+
file_names = load_pickle(prefix="file", suffix="names", path=db_store_path)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
# Initialize the retriever
|
| 105 |
+
my_retriever = MyRetriever(
|
| 106 |
+
llm=llm,
|
| 107 |
+
embedding_chunks_small=db_embedding_chunks_small,
|
| 108 |
+
embedding_chunks_medium=db_embedding_chunks_medium,
|
| 109 |
+
docs_chunks_small=db_docs_chunks_small,
|
| 110 |
+
docs_chunks_medium=db_docs_chunks_medium,
|
| 111 |
+
first_retrieval_k=configs.first_retrieval_k,
|
| 112 |
+
second_retrieval_k=configs.second_retrieval_k,
|
| 113 |
+
num_windows=configs.num_windows,
|
| 114 |
+
retriever_weights=configs.retriever_weights,
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
# Initialize the memory
|
| 119 |
+
memory = ConversationTokenBufferMemory(
|
| 120 |
+
llm=llm,
|
| 121 |
+
memory_key="chat_history",
|
| 122 |
+
input_key="question",
|
| 123 |
+
output_key="answer",
|
| 124 |
+
return_messages=True,
|
| 125 |
+
max_token_limit=configs.max_chat_history,
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
# Initialize the QA chain
|
| 130 |
+
qa = ConvoRetrievalChain.from_llm(
|
| 131 |
+
llm,
|
| 132 |
+
my_retriever,
|
| 133 |
+
file_names=file_names,
|
| 134 |
+
memory=memory,
|
| 135 |
+
return_source_documents=False,
|
| 136 |
+
return_generated_question=False,
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
if __name__ == "__main__":
|
| 141 |
+
while True:
|
| 142 |
+
user_input = input("Human: ")
|
| 143 |
+
start_time = time.time()
|
| 144 |
+
user_input_ = re.sub(r"^Human: ", "", user_input)
|
| 145 |
+
print("*" * 6)
|
| 146 |
+
resp = qa({"question": user_input_})
|
| 147 |
+
print()
|
| 148 |
+
print(f"AI:{resp['answer']}")
|
| 149 |
+
print(f"Time used: {time.time() - start_time}")
|
| 150 |
+
print("-" * 60)
|
requirements.txt
CHANGED
|
@@ -1 +1,13 @@
|
|
| 1 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
chromadb==0.4.13
|
| 2 |
+
InstructorEmbedding==1.0.1
|
| 3 |
+
langchain==0.0.308
|
| 4 |
+
openai==0.28.1
|
| 5 |
+
pypdf==3.16.2
|
| 6 |
+
rank-bm25==0.2.2
|
| 7 |
+
sentence-transformers==2.2.2
|
| 8 |
+
tiktoken==0.5.1
|
| 9 |
+
torch==2.0.1
|
| 10 |
+
torchaudio==2.0.2
|
| 11 |
+
torchvision==0.15.2
|
| 12 |
+
together==0.2.4
|
| 13 |
+
tqdm==4.66.1
|
toolkit/___init__.py
ADDED
|
File without changes
|
toolkit/local_llm.py
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""The below code is borrowed from: https://github.com/PromtEngineer/localGPT
|
| 2 |
+
The reason to use gguf/ggml models: https://huggingface.co/TheBloke/wizardLM-7B-GGML/discussions/3"""
|
| 3 |
+
import logging
|
| 4 |
+
import torch
|
| 5 |
+
from huggingface_hub import hf_hub_download
|
| 6 |
+
from huggingface_hub import login
|
| 7 |
+
from langchain.llms import LlamaCpp, HuggingFacePipeline
|
| 8 |
+
from transformers import (
|
| 9 |
+
AutoModelForCausalLM,
|
| 10 |
+
AutoTokenizer,
|
| 11 |
+
LlamaForCausalLM,
|
| 12 |
+
LlamaTokenizer,
|
| 13 |
+
GenerationConfig,
|
| 14 |
+
pipeline,
|
| 15 |
+
)
|
| 16 |
+
from toolkit.utils import Config
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
configs = Config("configparser.ini")
|
| 20 |
+
logger = logging.getLogger(__name__)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def load_gguf_hf_model(
|
| 24 |
+
model_id: str,
|
| 25 |
+
model_basename: str,
|
| 26 |
+
max_tokens: int,
|
| 27 |
+
temperature: float,
|
| 28 |
+
device_type: str,
|
| 29 |
+
):
|
| 30 |
+
"""
|
| 31 |
+
Load a GGUF/GGML quantized model using LlamaCpp.
|
| 32 |
+
|
| 33 |
+
This function attempts to load a GGUF/GGML quantized model using the LlamaCpp library.
|
| 34 |
+
If the model is of type GGML, and newer version of LLAMA-CPP is used which does not support GGML,
|
| 35 |
+
it logs a message indicating that LLAMA-CPP has dropped support for GGML.
|
| 36 |
+
|
| 37 |
+
Parameters:
|
| 38 |
+
- model_id (str): The identifier for the model on HuggingFace Hub.
|
| 39 |
+
- model_basename (str): The base name of the model file.
|
| 40 |
+
- max_tokens (int): The maximum number of tokens to generate in the completion.
|
| 41 |
+
- temperature (float): The temperature of LLM.
|
| 42 |
+
- device_type (str): The type of device where the model will run, e.g., 'mps', 'cuda', etc.
|
| 43 |
+
|
| 44 |
+
Returns:
|
| 45 |
+
- LlamaCpp: An instance of the LlamaCpp model if successful, otherwise None.
|
| 46 |
+
|
| 47 |
+
Notes:
|
| 48 |
+
- The function uses the `hf_hub_download` function to download the model from the HuggingFace Hub.
|
| 49 |
+
- The number of GPU layers is set based on the device type.
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
try:
|
| 53 |
+
logger.info("Using Llamacpp for GGUF/GGML quantized models")
|
| 54 |
+
model_path = hf_hub_download(
|
| 55 |
+
repo_id=model_id,
|
| 56 |
+
filename=model_basename,
|
| 57 |
+
resume_download=True,
|
| 58 |
+
cache_dir=configs.local_model_dir,
|
| 59 |
+
)
|
| 60 |
+
kwargs = {
|
| 61 |
+
"model_path": model_path,
|
| 62 |
+
"n_ctx": configs.max_llm_context,
|
| 63 |
+
"max_tokens": max_tokens,
|
| 64 |
+
"temperature": temperature,
|
| 65 |
+
"n_batch": configs.n_batch, # set this based on your GPU & CPU RAM
|
| 66 |
+
"verbose": False,
|
| 67 |
+
}
|
| 68 |
+
if device_type.lower() == "mps":
|
| 69 |
+
kwargs["n_gpu_layers"] = 1
|
| 70 |
+
if device_type.lower() == "cuda":
|
| 71 |
+
kwargs["n_gpu_layers"] = configs.n_gpu_layers # set this based on your GPU
|
| 72 |
+
|
| 73 |
+
return LlamaCpp(**kwargs)
|
| 74 |
+
except:
|
| 75 |
+
if "ggml" in model_basename:
|
| 76 |
+
logger.info(
|
| 77 |
+
"If you were using GGML model, LLAMA-CPP Dropped Support, Use GGUF Instead"
|
| 78 |
+
)
|
| 79 |
+
return None
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def load_full_hf_model(model_id: str, model_basename: str, device_type: str):
|
| 83 |
+
"""
|
| 84 |
+
Load a full model using either LlamaTokenizer or AutoModelForCausalLM.
|
| 85 |
+
|
| 86 |
+
This function loads a full model based on the specified device type.
|
| 87 |
+
If the device type is 'mps' or 'cpu', it uses LlamaTokenizer and LlamaForCausalLM.
|
| 88 |
+
Otherwise, it uses AutoModelForCausalLM.
|
| 89 |
+
|
| 90 |
+
Parameters:
|
| 91 |
+
- model_id (str): The identifier for the model on HuggingFace Hub.
|
| 92 |
+
- model_basename (str): The base name of the model file.
|
| 93 |
+
- device_type (str): The type of device where the model will run.
|
| 94 |
+
|
| 95 |
+
Returns:
|
| 96 |
+
- model (Union[LlamaForCausalLM, AutoModelForCausalLM]): The loaded model.
|
| 97 |
+
- tokenizer (Union[LlamaTokenizer, AutoTokenizer]): The tokenizer associated with the model.
|
| 98 |
+
|
| 99 |
+
Notes:
|
| 100 |
+
- The function uses the `from_pretrained` method to load both the model and the tokenizer.
|
| 101 |
+
- Additional settings are provided for NVIDIA GPUs, such as loading in 4-bit and setting the compute dtype.
|
| 102 |
+
"""
|
| 103 |
+
if "meta-llama" in model_id.lower():
|
| 104 |
+
login(token=configs.huggingface_token)
|
| 105 |
+
|
| 106 |
+
if device_type.lower() in ["mps", "cpu"]:
|
| 107 |
+
logger.info("Using LlamaTokenizer")
|
| 108 |
+
tokenizer = LlamaTokenizer.from_pretrained(
|
| 109 |
+
model_id,
|
| 110 |
+
cache_dir=configs.local_model_dir,
|
| 111 |
+
)
|
| 112 |
+
model = LlamaForCausalLM.from_pretrained(
|
| 113 |
+
model_id,
|
| 114 |
+
cache_dir=configs.local_model_dir,
|
| 115 |
+
)
|
| 116 |
+
else:
|
| 117 |
+
logger.info("Using AutoModelForCausalLM for full models")
|
| 118 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 119 |
+
model_id, cache_dir=configs.local_model_dir
|
| 120 |
+
)
|
| 121 |
+
logger.info("Tokenizer loaded")
|
| 122 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 123 |
+
model_id,
|
| 124 |
+
device_map="auto",
|
| 125 |
+
torch_dtype=torch.float16,
|
| 126 |
+
low_cpu_mem_usage=True,
|
| 127 |
+
cache_dir=configs.local_model_dir,
|
| 128 |
+
# trust_remote_code=True, # set these if you are using NVIDIA GPU
|
| 129 |
+
# load_in_4bit=True,
|
| 130 |
+
# bnb_4bit_quant_type="nf4",
|
| 131 |
+
# bnb_4bit_compute_dtype=torch.float16,
|
| 132 |
+
# max_memory={0: "15GB"} # Uncomment this line with you encounter CUDA out of memory errors
|
| 133 |
+
)
|
| 134 |
+
model.tie_weights()
|
| 135 |
+
return model, tokenizer
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def load_local_llm(
|
| 139 |
+
model_id: str,
|
| 140 |
+
model_basename: str,
|
| 141 |
+
temperature: float,
|
| 142 |
+
max_tokens: int,
|
| 143 |
+
device_type: str,
|
| 144 |
+
):
|
| 145 |
+
"""
|
| 146 |
+
Select a model for text generation using the HuggingFace library.
|
| 147 |
+
If you are running this for the first time, it will download a model for you.
|
| 148 |
+
subsequent runs will use the model from the disk.
|
| 149 |
+
|
| 150 |
+
Args:
|
| 151 |
+
device_type (str): Type of device to use, e.g., "cuda" for GPU or "cpu" for CPU.
|
| 152 |
+
model_id (str): Identifier of the model to load from HuggingFace's model hub.
|
| 153 |
+
model_basename (str, optional): Basename of the model if using quantized models.
|
| 154 |
+
Defaults to None.
|
| 155 |
+
|
| 156 |
+
Returns:
|
| 157 |
+
HuggingFacePipeline: A pipeline object for text generation using the loaded model.
|
| 158 |
+
|
| 159 |
+
Raises:
|
| 160 |
+
ValueError: If an unsupported model or device type is provided.
|
| 161 |
+
"""
|
| 162 |
+
logger.info(f"Loading Model: {model_id}, on: {device_type}")
|
| 163 |
+
logger.info("This action can take a few minutes!")
|
| 164 |
+
|
| 165 |
+
if model_basename.lower() != "none":
|
| 166 |
+
if ".gguf" in model_basename.lower():
|
| 167 |
+
llm = load_gguf_hf_model(
|
| 168 |
+
model_id, model_basename, max_tokens, temperature, device_type
|
| 169 |
+
)
|
| 170 |
+
return llm
|
| 171 |
+
|
| 172 |
+
model, tokenizer = load_full_hf_model(model_id, None, device_type)
|
| 173 |
+
# Load configuration from the model to avoid warnings
|
| 174 |
+
generation_config = GenerationConfig.from_pretrained(model_id)
|
| 175 |
+
# see here for details:
|
| 176 |
+
# https://huggingface.co/docs/transformers/
|
| 177 |
+
# main_classes/text_generation#transformers.GenerationConfig.from_pretrained.returns
|
| 178 |
+
|
| 179 |
+
# Create a pipeline for text generation
|
| 180 |
+
pipe = pipeline(
|
| 181 |
+
"text-generation",
|
| 182 |
+
model=model,
|
| 183 |
+
tokenizer=tokenizer,
|
| 184 |
+
max_length=max_tokens,
|
| 185 |
+
temperature=temperature,
|
| 186 |
+
# top_p=0.95,
|
| 187 |
+
repetition_penalty=1.15,
|
| 188 |
+
generation_config=generation_config,
|
| 189 |
+
)
|
| 190 |
+
local_llm = HuggingFacePipeline(pipeline=pipe)
|
| 191 |
+
logger.info("Local LLM Loaded")
|
| 192 |
+
|
| 193 |
+
return local_llm
|
toolkit/prompts.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.prompts import PromptTemplate
|
| 2 |
+
from langchain.prompts.chat import (
|
| 3 |
+
ChatPromptTemplate,
|
| 4 |
+
HumanMessagePromptTemplate,
|
| 5 |
+
SystemMessagePromptTemplate,
|
| 6 |
+
)
|
| 7 |
+
from langchain.chains.prompt_selector import ConditionalPromptSelector, is_chat_model
|
| 8 |
+
|
| 9 |
+
# ================================================================================
|
| 10 |
+
|
| 11 |
+
REFINE_QA_TEMPLATE = """Break down or rephrase the follow up input into fewer than 3 heterogeneous one-hop queries to be the input of a retrieval tool, if the follow up inout is multi-hop, multi-step, complex or comparative queries and relevant to Chat History and Document Names. Otherwise keep the follow up input as it is.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
The output format should strictly follow the following, and each query can only conatain 1 document name:
|
| 15 |
+
```
|
| 16 |
+
1. One-hop standalone query
|
| 17 |
+
...
|
| 18 |
+
3. One-hop standalone query
|
| 19 |
+
...
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
Document Names in the database:
|
| 24 |
+
```
|
| 25 |
+
{database}
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
Chat History:
|
| 30 |
+
```
|
| 31 |
+
{chat_history}
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
Begin:
|
| 36 |
+
|
| 37 |
+
Follow Up Input: {question}
|
| 38 |
+
|
| 39 |
+
One-hop standalone queries(s):
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# ================================================================================
|
| 44 |
+
|
| 45 |
+
DOCS_SELECTION_TEMPLATE = """Below are some verified sources and a human input. If you think any of them are relevant to the human input, then list all possible context numbers.
|
| 46 |
+
|
| 47 |
+
```
|
| 48 |
+
{snippets}
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
The output format must be like the following, nothing else. If not, you will output []:
|
| 52 |
+
[0, ..., n]
|
| 53 |
+
|
| 54 |
+
Human Input: {query}
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
# ================================================================================
|
| 59 |
+
|
| 60 |
+
RETRIEVAL_QA_SYS = """You are a helpful assistant designed by IncarnaMind.
|
| 61 |
+
If you think the below below information are relevant to the human input, please respond to the human based on the relevant retrieved sources; otherwise, respond in your own words only about the human input."""
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
RETRIEVAL_QA_TEMPLATE = """
|
| 65 |
+
File Names in the database:
|
| 66 |
+
```
|
| 67 |
+
{database}
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
Chat History:
|
| 72 |
+
```
|
| 73 |
+
{chat_history}
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
Verified Sources:
|
| 78 |
+
```
|
| 79 |
+
{context}
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
User: {question}
|
| 84 |
+
"""
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
RETRIEVAL_QA_CHAT_TEMPLATE = """
|
| 88 |
+
File Names in the database:
|
| 89 |
+
```
|
| 90 |
+
{database}
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
Chat History:
|
| 95 |
+
```
|
| 96 |
+
{chat_history}
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
Verified Sources:
|
| 101 |
+
```
|
| 102 |
+
{context}
|
| 103 |
+
```
|
| 104 |
+
"""
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class PromptTemplates:
|
| 108 |
+
"""_summary_"""
|
| 109 |
+
|
| 110 |
+
def __init__(self):
|
| 111 |
+
self.refine_qa_prompt = REFINE_QA_TEMPLATE
|
| 112 |
+
self.docs_selection_prompt = DOCS_SELECTION_TEMPLATE
|
| 113 |
+
self.retrieval_qa_sys = RETRIEVAL_QA_SYS
|
| 114 |
+
self.retrieval_qa_prompt = RETRIEVAL_QA_TEMPLATE
|
| 115 |
+
self.retrieval_qa_chat_prompt = RETRIEVAL_QA_CHAT_TEMPLATE
|
| 116 |
+
|
| 117 |
+
def get_refine_qa_template(self, llm: str):
|
| 118 |
+
"""get the refine qa prompt template"""
|
| 119 |
+
if "llama" in llm.lower():
|
| 120 |
+
temp = f"[INST] {self.refine_qa_prompt} [/INST]"
|
| 121 |
+
else:
|
| 122 |
+
temp = self.refine_qa_prompt
|
| 123 |
+
|
| 124 |
+
return PromptTemplate(
|
| 125 |
+
input_variables=["database", "chat_history", "question"],
|
| 126 |
+
template=temp,
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
def get_docs_selection_template(self, llm: str):
|
| 130 |
+
"""get the docs selection prompt template"""
|
| 131 |
+
if "llama" in llm.lower():
|
| 132 |
+
temp = f"[INST] {self.docs_selection_prompt} [/INST]"
|
| 133 |
+
else:
|
| 134 |
+
temp = self.docs_selection_prompt
|
| 135 |
+
|
| 136 |
+
return PromptTemplate(
|
| 137 |
+
input_variables=["snippets", "query"],
|
| 138 |
+
template=temp,
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
def get_retrieval_qa_template_selector(self, llm: str):
|
| 142 |
+
"""get the retrieval qa prompt template"""
|
| 143 |
+
if "llama" in llm.lower():
|
| 144 |
+
temp = f"[INST] <<SYS>>\n{self.retrieval_qa_sys}\n<</SYS>>\n\n{self.retrieval_qa_prompt} [/INST]"
|
| 145 |
+
messages = [
|
| 146 |
+
SystemMessagePromptTemplate.from_template(
|
| 147 |
+
f"[INST] <<SYS>>\n{self.retrieval_qa_sys}\n<</SYS>>\n\n{self.retrieval_qa_chat_prompt} [/INST]"
|
| 148 |
+
),
|
| 149 |
+
HumanMessagePromptTemplate.from_template("{question}"),
|
| 150 |
+
]
|
| 151 |
+
else:
|
| 152 |
+
temp = f"{self.retrieval_qa_sys}\n{self.retrieval_qa_prompt}"
|
| 153 |
+
messages = [
|
| 154 |
+
SystemMessagePromptTemplate.from_template(
|
| 155 |
+
f"{self.retrieval_qa_sys}\n{self.retrieval_qa_chat_prompt}"
|
| 156 |
+
),
|
| 157 |
+
HumanMessagePromptTemplate.from_template("{question}"),
|
| 158 |
+
]
|
| 159 |
+
|
| 160 |
+
prompt_temp = PromptTemplate(
|
| 161 |
+
template=temp,
|
| 162 |
+
input_variables=["database", "chat_history", "context", "question"],
|
| 163 |
+
)
|
| 164 |
+
prompt_temp_chat = ChatPromptTemplate.from_messages(messages)
|
| 165 |
+
|
| 166 |
+
return ConditionalPromptSelector(
|
| 167 |
+
default_prompt=prompt_temp,
|
| 168 |
+
conditionals=[(is_chat_model, prompt_temp_chat)],
|
| 169 |
+
)
|
toolkit/retrivers.py
ADDED
|
@@ -0,0 +1,643 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This module provides custom implementation of a document retriever, designed for multi-stage retrieval.
|
| 3 |
+
The system uses ensemble methods combining BM25 and Chroma Embeddings to retrieve relevant documents for a given query.
|
| 4 |
+
It also utilizes various optimizations like rank fusion and weighted reciprocal rank by Langchain.
|
| 5 |
+
|
| 6 |
+
Classes:
|
| 7 |
+
--------
|
| 8 |
+
- MyEnsembleRetriever: Custom retriever for BM25 and Chroma Embeddings.
|
| 9 |
+
- MyRetriever: Handles multi-stage retrieval.
|
| 10 |
+
|
| 11 |
+
"""
|
| 12 |
+
import re
|
| 13 |
+
import ast
|
| 14 |
+
import copy
|
| 15 |
+
import math
|
| 16 |
+
import logging
|
| 17 |
+
from typing import Dict, List, Optional
|
| 18 |
+
from langchain.chains import LLMChain
|
| 19 |
+
from langchain.schema import BaseRetriever, Document
|
| 20 |
+
from langchain.retrievers import BM25Retriever, EnsembleRetriever
|
| 21 |
+
from langchain.callbacks.manager import (
|
| 22 |
+
AsyncCallbackManagerForRetrieverRun,
|
| 23 |
+
CallbackManagerForRetrieverRun,
|
| 24 |
+
AsyncCallbackManagerForChainRun,
|
| 25 |
+
CallbackManagerForChainRun,
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
from toolkit.utils import Config, clean_text, DocIndexer, IndexerOperator
|
| 29 |
+
from toolkit.prompts import PromptTemplates
|
| 30 |
+
|
| 31 |
+
prompt_templates = PromptTemplates()
|
| 32 |
+
|
| 33 |
+
configs = Config("configparser.ini")
|
| 34 |
+
logger = logging.getLogger(__name__)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class MyEnsembleRetriever(EnsembleRetriever):
|
| 38 |
+
"""
|
| 39 |
+
Custom retriever for BM24 and Chroma Embeddings
|
| 40 |
+
"""
|
| 41 |
+
|
| 42 |
+
retrievers: Dict[str, BaseRetriever]
|
| 43 |
+
|
| 44 |
+
def rank_fusion(
|
| 45 |
+
self, query: str, run_manager: CallbackManagerForRetrieverRun
|
| 46 |
+
) -> List[Document]:
|
| 47 |
+
"""
|
| 48 |
+
Retrieve the results of the retrievers and use rank_fusion_func to get
|
| 49 |
+
the final result.
|
| 50 |
+
|
| 51 |
+
Args:
|
| 52 |
+
query: The query to search for.
|
| 53 |
+
|
| 54 |
+
Returns:
|
| 55 |
+
A list of reranked documents.
|
| 56 |
+
"""
|
| 57 |
+
# Get the results of all retrievers.
|
| 58 |
+
retriever_docs = []
|
| 59 |
+
for key, retriever in self.retrievers.items():
|
| 60 |
+
if key == "bm25":
|
| 61 |
+
res = retriever.get_relevant_documents(
|
| 62 |
+
clean_text(query),
|
| 63 |
+
callbacks=run_manager.get_child(tag=f"retriever_{key}"),
|
| 64 |
+
)
|
| 65 |
+
retriever_docs.append(res)
|
| 66 |
+
else:
|
| 67 |
+
res = retriever.get_relevant_documents(
|
| 68 |
+
query, callbacks=run_manager.get_child(tag=f"retriever_{key}")
|
| 69 |
+
)
|
| 70 |
+
retriever_docs.append(res)
|
| 71 |
+
|
| 72 |
+
# apply rank fusion
|
| 73 |
+
fused_documents = self.weighted_reciprocal_rank(retriever_docs)
|
| 74 |
+
|
| 75 |
+
return fused_documents
|
| 76 |
+
|
| 77 |
+
async def arank_fusion(
|
| 78 |
+
self, query: str, run_manager: AsyncCallbackManagerForRetrieverRun
|
| 79 |
+
) -> List[Document]:
|
| 80 |
+
"""
|
| 81 |
+
Asynchronously retrieve the results of the retrievers
|
| 82 |
+
and use rank_fusion_func to get the final result.
|
| 83 |
+
|
| 84 |
+
Args:
|
| 85 |
+
query: The query to search for.
|
| 86 |
+
|
| 87 |
+
Returns:
|
| 88 |
+
A list of reranked documents.
|
| 89 |
+
"""
|
| 90 |
+
|
| 91 |
+
# Get the results of all retrievers.
|
| 92 |
+
retriever_docs = []
|
| 93 |
+
for key, retriever in self.retrievers.items():
|
| 94 |
+
if key == "bm25":
|
| 95 |
+
res = retriever.get_relevant_documents(
|
| 96 |
+
clean_text(query),
|
| 97 |
+
callbacks=run_manager.get_child(tag=f"retriever_{key}"),
|
| 98 |
+
)
|
| 99 |
+
retriever_docs.append(res)
|
| 100 |
+
# print("retriever_docs 1:", res)
|
| 101 |
+
else:
|
| 102 |
+
res = await retriever.aget_relevant_documents(
|
| 103 |
+
query, callbacks=run_manager.get_child(tag=f"retriever_{key}")
|
| 104 |
+
)
|
| 105 |
+
retriever_docs.append(res)
|
| 106 |
+
|
| 107 |
+
# apply rank fusion
|
| 108 |
+
fused_documents = self.weighted_reciprocal_rank(retriever_docs)
|
| 109 |
+
|
| 110 |
+
return fused_documents
|
| 111 |
+
|
| 112 |
+
def weighted_reciprocal_rank(
|
| 113 |
+
self, doc_lists: List[List[Document]]
|
| 114 |
+
) -> List[Document]:
|
| 115 |
+
"""
|
| 116 |
+
Perform weighted Reciprocal Rank Fusion on multiple rank lists.
|
| 117 |
+
You can find more details about RRF here:
|
| 118 |
+
https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf
|
| 119 |
+
|
| 120 |
+
Args:
|
| 121 |
+
doc_lists: A list of rank lists, where each rank list contains unique items.
|
| 122 |
+
|
| 123 |
+
Returns:
|
| 124 |
+
list: The final aggregated list of items sorted by their weighted RRF
|
| 125 |
+
scores in descending order.
|
| 126 |
+
"""
|
| 127 |
+
if len(doc_lists) != len(self.weights):
|
| 128 |
+
raise ValueError(
|
| 129 |
+
"Number of rank lists must be equal to the number of weights."
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
# replace the page_content with the original uncleaned page_content
|
| 133 |
+
doc_lists_ = copy.copy(doc_lists)
|
| 134 |
+
for doc_list in doc_lists_:
|
| 135 |
+
for doc in doc_list:
|
| 136 |
+
doc.page_content = doc.metadata["page_content"]
|
| 137 |
+
# doc.metadata["page_content"] = None
|
| 138 |
+
|
| 139 |
+
# Create a union of all unique documents in the input doc_lists
|
| 140 |
+
all_documents = set()
|
| 141 |
+
for doc_list in doc_lists_:
|
| 142 |
+
for doc in doc_list:
|
| 143 |
+
all_documents.add(doc.page_content)
|
| 144 |
+
|
| 145 |
+
# Initialize the RRF score dictionary for each document
|
| 146 |
+
rrf_score_dic = {doc: 0.0 for doc in all_documents}
|
| 147 |
+
|
| 148 |
+
# Calculate RRF scores for each document
|
| 149 |
+
for doc_list, weight in zip(doc_lists_, self.weights):
|
| 150 |
+
for rank, doc in enumerate(doc_list, start=1):
|
| 151 |
+
rrf_score = weight * (1 / (rank + self.c))
|
| 152 |
+
rrf_score_dic[doc.page_content] += rrf_score
|
| 153 |
+
|
| 154 |
+
# Sort documents by their RRF scores in descending order
|
| 155 |
+
sorted_documents = sorted(
|
| 156 |
+
rrf_score_dic.keys(), key=lambda x: rrf_score_dic[x], reverse=True
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
# Map the sorted page_content back to the original document objects
|
| 160 |
+
page_content_to_doc_map = {
|
| 161 |
+
doc.page_content: doc for doc_list in doc_lists_ for doc in doc_list
|
| 162 |
+
}
|
| 163 |
+
sorted_docs = [
|
| 164 |
+
page_content_to_doc_map[page_content] for page_content in sorted_documents
|
| 165 |
+
]
|
| 166 |
+
|
| 167 |
+
return sorted_docs
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class MyRetriever:
|
| 171 |
+
"""
|
| 172 |
+
Retriever class to handle multi-stage retrieval.
|
| 173 |
+
"""
|
| 174 |
+
|
| 175 |
+
def __init__(
|
| 176 |
+
self,
|
| 177 |
+
llm,
|
| 178 |
+
embedding_chunks_small: List[Document],
|
| 179 |
+
embedding_chunks_medium: List[Document],
|
| 180 |
+
docs_chunks_small: DocIndexer,
|
| 181 |
+
docs_chunks_medium: DocIndexer,
|
| 182 |
+
first_retrieval_k: int,
|
| 183 |
+
second_retrieval_k: int,
|
| 184 |
+
num_windows: int,
|
| 185 |
+
retriever_weights: List[float],
|
| 186 |
+
):
|
| 187 |
+
"""
|
| 188 |
+
Initialize the MyRetriever class.
|
| 189 |
+
|
| 190 |
+
Args:
|
| 191 |
+
llm: Language model for retrieval.
|
| 192 |
+
embedding_chunks_small (List[Document]): List of small embedding chunks.
|
| 193 |
+
embedding_chunks_medium (List[Document]): List of medium embedding chunks.
|
| 194 |
+
docs_chunks_small (DocIndexer): Document indexer for small chunks.
|
| 195 |
+
docs_chunks_medium (DocIndexer): Document indexer for medium chunks.
|
| 196 |
+
first_retrieval_k (int): Number of top documents to retrieve in first retrieval.
|
| 197 |
+
second_retrieval_k (int): Number of top documents to retrieve in second retrieval.
|
| 198 |
+
num_windows (int): Number of overlapping windows to consider.
|
| 199 |
+
retriever_weights (List[float]): Weights for ensemble retrieval.
|
| 200 |
+
"""
|
| 201 |
+
self.llm = llm
|
| 202 |
+
self.embedding_chunks_small = embedding_chunks_small
|
| 203 |
+
self.embedding_chunks_medium = embedding_chunks_medium
|
| 204 |
+
self.docs_index_small = DocIndexer(docs_chunks_small)
|
| 205 |
+
self.docs_index_medium = DocIndexer(docs_chunks_medium)
|
| 206 |
+
|
| 207 |
+
self.first_retrieval_k = first_retrieval_k
|
| 208 |
+
self.second_retrieval_k = second_retrieval_k
|
| 209 |
+
self.num_windows = num_windows
|
| 210 |
+
self.retriever_weights = retriever_weights
|
| 211 |
+
|
| 212 |
+
def get_retriever(
|
| 213 |
+
self,
|
| 214 |
+
docs_chunks,
|
| 215 |
+
emb_chunks,
|
| 216 |
+
emb_filter=None,
|
| 217 |
+
k=2,
|
| 218 |
+
weights=(0.5, 0.5),
|
| 219 |
+
):
|
| 220 |
+
"""
|
| 221 |
+
Initialize and return a retriever instance with specified parameters.
|
| 222 |
+
|
| 223 |
+
Args:
|
| 224 |
+
docs_chunks: The document chunks for the BM25 retriever.
|
| 225 |
+
emb_chunks: The document chunks for the Embedding retriever.
|
| 226 |
+
emb_filter: A filter for embedding retriever.
|
| 227 |
+
k (int): The number of top documents to return.
|
| 228 |
+
weights (list): Weights for ensemble retrieval.
|
| 229 |
+
|
| 230 |
+
Returns:
|
| 231 |
+
MyEnsembleRetriever: An instance of MyEnsembleRetriever.
|
| 232 |
+
"""
|
| 233 |
+
bm25_retriever = BM25Retriever.from_documents(docs_chunks)
|
| 234 |
+
bm25_retriever.k = k
|
| 235 |
+
|
| 236 |
+
emb_retriever = emb_chunks.as_retriever(
|
| 237 |
+
search_kwargs={
|
| 238 |
+
"filter": emb_filter,
|
| 239 |
+
"k": k,
|
| 240 |
+
"search_type": "mmr",
|
| 241 |
+
}
|
| 242 |
+
)
|
| 243 |
+
return MyEnsembleRetriever(
|
| 244 |
+
retrievers={"bm25": bm25_retriever, "chroma": emb_retriever},
|
| 245 |
+
weights=weights,
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
def find_overlaps(self, doc: List[Document]):
|
| 249 |
+
"""
|
| 250 |
+
Find overlapping intervals of windows.
|
| 251 |
+
|
| 252 |
+
Args:
|
| 253 |
+
doc (Document): A document object to find overlaps in.
|
| 254 |
+
|
| 255 |
+
Returns:
|
| 256 |
+
list: A list of overlapping intervals.
|
| 257 |
+
"""
|
| 258 |
+
intervals = []
|
| 259 |
+
for item in doc:
|
| 260 |
+
intervals.append(
|
| 261 |
+
(
|
| 262 |
+
item.metadata["large_chunks_idx_lower_bound"],
|
| 263 |
+
item.metadata["large_chunks_idx_upper_bound"],
|
| 264 |
+
)
|
| 265 |
+
)
|
| 266 |
+
remaining_intervals, grouped_intervals, centroids = intervals.copy(), [], []
|
| 267 |
+
|
| 268 |
+
while remaining_intervals:
|
| 269 |
+
curr_interval = remaining_intervals.pop(0)
|
| 270 |
+
curr_group = [curr_interval]
|
| 271 |
+
subset_interval = None
|
| 272 |
+
|
| 273 |
+
for start, end in remaining_intervals.copy():
|
| 274 |
+
for s, e in curr_group:
|
| 275 |
+
overlap = set(range(s, e + 1)) & set(range(start, end + 1))
|
| 276 |
+
if overlap:
|
| 277 |
+
curr_group.append((start, end))
|
| 278 |
+
remaining_intervals.remove((start, end))
|
| 279 |
+
if set(range(start, end + 1)).issubset(set(range(s, e + 1))):
|
| 280 |
+
subset_interval = (start, end)
|
| 281 |
+
break
|
| 282 |
+
|
| 283 |
+
if subset_interval:
|
| 284 |
+
centroid = [math.ceil((subset_interval[0] + subset_interval[1]) / 2)]
|
| 285 |
+
elif len(curr_group) > 2:
|
| 286 |
+
first_overlap = max(
|
| 287 |
+
set(range(curr_group[0][0], curr_group[0][1] + 1))
|
| 288 |
+
& set(range(curr_group[1][0], curr_group[1][1] + 1))
|
| 289 |
+
)
|
| 290 |
+
last_overlap_set = set(
|
| 291 |
+
range(curr_group[-1][0], curr_group[-1][1] + 1)
|
| 292 |
+
) & set(range(curr_group[-2][0], curr_group[-2][1] + 1))
|
| 293 |
+
|
| 294 |
+
if not last_overlap_set:
|
| 295 |
+
last_overlap = first_overlap # Fallback if no overlap
|
| 296 |
+
else:
|
| 297 |
+
last_overlap = min(last_overlap_set)
|
| 298 |
+
|
| 299 |
+
step = 1 if first_overlap <= last_overlap else -1
|
| 300 |
+
centroid = list(range(first_overlap, last_overlap + step, step))
|
| 301 |
+
else:
|
| 302 |
+
centroid = [
|
| 303 |
+
round(
|
| 304 |
+
sum([math.ceil((s + e) / 2) for s, e in curr_group])
|
| 305 |
+
/ len(curr_group)
|
| 306 |
+
)
|
| 307 |
+
]
|
| 308 |
+
|
| 309 |
+
grouped_intervals.append(
|
| 310 |
+
curr_group if len(curr_group) > 1 else curr_group[0]
|
| 311 |
+
)
|
| 312 |
+
centroids.extend(centroid)
|
| 313 |
+
|
| 314 |
+
return centroids
|
| 315 |
+
|
| 316 |
+
def get_filter(self, top_k: int, file_md5: str, doc: List[Document]):
|
| 317 |
+
"""
|
| 318 |
+
Create a filter for retrievers based on overlapping intervals.
|
| 319 |
+
|
| 320 |
+
Args:
|
| 321 |
+
top_k (int): Number of top intervals to consider.
|
| 322 |
+
file_md5 (str): MD5 hash of the file to filter.
|
| 323 |
+
doc (List[Document]): List of document objects.
|
| 324 |
+
|
| 325 |
+
Returns:
|
| 326 |
+
tuple: A tuple of containing dictionary filters for DocIndexer and Chroma retrievers.
|
| 327 |
+
"""
|
| 328 |
+
overlaps = self.find_overlaps(doc)
|
| 329 |
+
if len(overlaps) < 1:
|
| 330 |
+
raise ValueError("No overlapping intervals found.")
|
| 331 |
+
|
| 332 |
+
overlaps_k = overlaps[:top_k]
|
| 333 |
+
logger.info("windows_at_2nd_retrieval: %s", overlaps_k)
|
| 334 |
+
search_dict_docindexer = {"OR": []}
|
| 335 |
+
search_dict_chroma = {"$or": []}
|
| 336 |
+
|
| 337 |
+
for chunk_idx in overlaps_k:
|
| 338 |
+
search_dict_docindexer["OR"].append(
|
| 339 |
+
{
|
| 340 |
+
"large_chunks_idx_lower_bound": (
|
| 341 |
+
IndexerOperator.LTE,
|
| 342 |
+
chunk_idx,
|
| 343 |
+
),
|
| 344 |
+
"large_chunks_idx_upper_bound": (
|
| 345 |
+
IndexerOperator.GTE,
|
| 346 |
+
chunk_idx,
|
| 347 |
+
),
|
| 348 |
+
"source_md5": (IndexerOperator.EQ, file_md5),
|
| 349 |
+
}
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
if len(overlaps_k) == 1:
|
| 353 |
+
search_dict_chroma = {
|
| 354 |
+
"$and": [
|
| 355 |
+
{"large_chunks_idx_lower_bound": {"$lte": overlaps_k[0]}},
|
| 356 |
+
{"large_chunks_idx_upper_bound": {"$gte": overlaps_k[0]}},
|
| 357 |
+
{"source_md5": {"$eq": file_md5}},
|
| 358 |
+
]
|
| 359 |
+
}
|
| 360 |
+
else:
|
| 361 |
+
search_dict_chroma["$or"].append(
|
| 362 |
+
{
|
| 363 |
+
"$and": [
|
| 364 |
+
{"large_chunks_idx_lower_bound": {"$lte": chunk_idx}},
|
| 365 |
+
{"large_chunks_idx_upper_bound": {"$gte": chunk_idx}},
|
| 366 |
+
{"source_md5": {"$eq": file_md5}},
|
| 367 |
+
]
|
| 368 |
+
}
|
| 369 |
+
)
|
| 370 |
+
|
| 371 |
+
return search_dict_docindexer, search_dict_chroma
|
| 372 |
+
|
| 373 |
+
def get_relevant_doc_ids(self, docs: List[Document], query: str):
|
| 374 |
+
"""
|
| 375 |
+
Get relevant document IDs given a query using an LLM.
|
| 376 |
+
|
| 377 |
+
Args:
|
| 378 |
+
docs (List[Document]): List of document objects to find relevant IDs in.
|
| 379 |
+
query (str): The query string.
|
| 380 |
+
|
| 381 |
+
Returns:
|
| 382 |
+
list: A list of relevant document IDs.
|
| 383 |
+
"""
|
| 384 |
+
snippets = "\n\n\n".join(
|
| 385 |
+
[
|
| 386 |
+
f"Context {idx}:\n{{{doc.page_content}}}. {{source: {doc.metadata['source']}}}"
|
| 387 |
+
for idx, doc in enumerate(docs)
|
| 388 |
+
]
|
| 389 |
+
)
|
| 390 |
+
id_chain = LLMChain(
|
| 391 |
+
llm=self.llm,
|
| 392 |
+
prompt=prompt_templates.get_docs_selection_template(configs.model_name),
|
| 393 |
+
output_key="IDs",
|
| 394 |
+
)
|
| 395 |
+
ids = id_chain.run({"query": query, "snippets": snippets})
|
| 396 |
+
logger.info("relevant doc ids: %s", ids)
|
| 397 |
+
pattern = r"\[\s*\d+\s*(?:,\s*\d+\s*)*\]"
|
| 398 |
+
match = re.search(pattern, ids)
|
| 399 |
+
if match:
|
| 400 |
+
return ast.literal_eval(match.group(0))
|
| 401 |
+
else:
|
| 402 |
+
return []
|
| 403 |
+
|
| 404 |
+
def get_relevant_documents(
|
| 405 |
+
self,
|
| 406 |
+
query: str,
|
| 407 |
+
num_query: int,
|
| 408 |
+
*,
|
| 409 |
+
run_manager: Optional[CallbackManagerForChainRun] = None,
|
| 410 |
+
) -> List[Document]:
|
| 411 |
+
"""
|
| 412 |
+
Perform multi-stage retrieval to get relevant documents.
|
| 413 |
+
|
| 414 |
+
Args:
|
| 415 |
+
query (str): The query string.
|
| 416 |
+
num_query (int): Number of queries.
|
| 417 |
+
run_manager (Optional[CallbackManagerForChainRun], optional): Callback manager for chain run.
|
| 418 |
+
|
| 419 |
+
Returns:
|
| 420 |
+
List[Document]: A list of relevant documents.
|
| 421 |
+
"""
|
| 422 |
+
# ! First retrieval
|
| 423 |
+
first_retriever = self.get_retriever(
|
| 424 |
+
docs_chunks=self.docs_index_small.documents,
|
| 425 |
+
emb_chunks=self.embedding_chunks_small,
|
| 426 |
+
emb_filter=None,
|
| 427 |
+
k=self.first_retrieval_k,
|
| 428 |
+
weights=self.retriever_weights,
|
| 429 |
+
)
|
| 430 |
+
first = first_retriever.get_relevant_documents(
|
| 431 |
+
query, callbacks=run_manager.get_child()
|
| 432 |
+
)
|
| 433 |
+
for doc in first:
|
| 434 |
+
logger.info("----1st retrieval----: %s", doc)
|
| 435 |
+
ids_clean = self.get_relevant_doc_ids(first, query)
|
| 436 |
+
# ids_clean = [0, 1, 2]
|
| 437 |
+
logger.info("relevant cleaned doc ids: %s", ids_clean)
|
| 438 |
+
qa_chunks = {} # key is file name, value is a list of relevant documents
|
| 439 |
+
# res_chunks = []
|
| 440 |
+
if ids_clean and isinstance(ids_clean, list):
|
| 441 |
+
source_md5_dict = {}
|
| 442 |
+
for ids_c in ids_clean:
|
| 443 |
+
if ids_c < len(first):
|
| 444 |
+
if ids_c not in source_md5_dict:
|
| 445 |
+
source_md5_dict[first[ids_c].metadata["source_md5"]] = [
|
| 446 |
+
first[ids_c]
|
| 447 |
+
]
|
| 448 |
+
# else:
|
| 449 |
+
# source_md5_dict[first[ids_c].metadata["source_md5"]].append(
|
| 450 |
+
# ids_clean[ids_c]
|
| 451 |
+
# )
|
| 452 |
+
if len(source_md5_dict) == 0:
|
| 453 |
+
source_md5_dict[first[0].metadata["source_md5"]] = [first[0]]
|
| 454 |
+
num_docs = len(source_md5_dict.keys())
|
| 455 |
+
third_num_k = max(
|
| 456 |
+
1,
|
| 457 |
+
(
|
| 458 |
+
int(
|
| 459 |
+
(
|
| 460 |
+
configs.max_llm_context
|
| 461 |
+
/ (configs.base_chunk_size * configs.chunk_scale)
|
| 462 |
+
)
|
| 463 |
+
// (num_docs * num_query)
|
| 464 |
+
)
|
| 465 |
+
),
|
| 466 |
+
)
|
| 467 |
+
|
| 468 |
+
for source_md5, docs in source_md5_dict.items():
|
| 469 |
+
logger.info(
|
| 470 |
+
"selected_docs_at_1st_retrieval: %s", docs[0].metadata["source"]
|
| 471 |
+
)
|
| 472 |
+
second_docs_chunks = self.docs_index_small.retrieve_metadata(
|
| 473 |
+
{
|
| 474 |
+
"source_md5": (IndexerOperator.EQ, source_md5),
|
| 475 |
+
}
|
| 476 |
+
)
|
| 477 |
+
second_retriever = self.get_retriever(
|
| 478 |
+
docs_chunks=second_docs_chunks,
|
| 479 |
+
emb_chunks=self.embedding_chunks_small,
|
| 480 |
+
emb_filter={"source_md5": source_md5},
|
| 481 |
+
k=self.second_retrieval_k,
|
| 482 |
+
weights=self.retriever_weights,
|
| 483 |
+
)
|
| 484 |
+
# ! Second retrieval
|
| 485 |
+
second = second_retriever.get_relevant_documents(
|
| 486 |
+
query, callbacks=run_manager.get_child()
|
| 487 |
+
)
|
| 488 |
+
for doc in second:
|
| 489 |
+
logger.info("----2nd retrieval----: %s", doc)
|
| 490 |
+
docs.extend(second)
|
| 491 |
+
docindexer_filter, chroma_filter = self.get_filter(
|
| 492 |
+
self.num_windows, source_md5, docs
|
| 493 |
+
)
|
| 494 |
+
third_docs_chunks = self.docs_index_medium.retrieve_metadata(
|
| 495 |
+
docindexer_filter
|
| 496 |
+
)
|
| 497 |
+
third_retriever = self.get_retriever(
|
| 498 |
+
docs_chunks=third_docs_chunks,
|
| 499 |
+
emb_chunks=self.embedding_chunks_medium,
|
| 500 |
+
emb_filter=chroma_filter,
|
| 501 |
+
k=third_num_k,
|
| 502 |
+
weights=self.retriever_weights,
|
| 503 |
+
)
|
| 504 |
+
# ! Third retrieval
|
| 505 |
+
third_temp = third_retriever.get_relevant_documents(
|
| 506 |
+
query, callbacks=run_manager.get_child()
|
| 507 |
+
)
|
| 508 |
+
third = third_temp[:third_num_k]
|
| 509 |
+
# chunks = sorted(third, key=lambda x: x.metadata["medium_chunk_idx"])
|
| 510 |
+
for doc in third:
|
| 511 |
+
logger.info(
|
| 512 |
+
"----3rd retrieval----page_content: %s", [doc.page_content]
|
| 513 |
+
)
|
| 514 |
+
mtdata = doc.metadata
|
| 515 |
+
mtdata["page_content"] = None
|
| 516 |
+
logger.info("----3rd retrieval----metadata: %s", mtdata)
|
| 517 |
+
file_name = third[0].metadata["source"].split("/")[-1]
|
| 518 |
+
if file_name not in qa_chunks:
|
| 519 |
+
qa_chunks[file_name] = third
|
| 520 |
+
else:
|
| 521 |
+
qa_chunks[file_name].extend(third)
|
| 522 |
+
|
| 523 |
+
return qa_chunks
|
| 524 |
+
|
| 525 |
+
async def aget_relevant_documents(
|
| 526 |
+
self,
|
| 527 |
+
query: str,
|
| 528 |
+
num_query: int,
|
| 529 |
+
*,
|
| 530 |
+
run_manager: AsyncCallbackManagerForChainRun,
|
| 531 |
+
) -> List[Document]:
|
| 532 |
+
"""
|
| 533 |
+
Asynchronous version of get_relevant_documents method.
|
| 534 |
+
|
| 535 |
+
Args:
|
| 536 |
+
query (str): The query string.
|
| 537 |
+
num_query (int): Number of queries.
|
| 538 |
+
run_manager (AsyncCallbackManagerForChainRun): Callback manager for asynchronous chain run.
|
| 539 |
+
|
| 540 |
+
Returns:
|
| 541 |
+
List[Document]: A list of relevant documents.
|
| 542 |
+
"""
|
| 543 |
+
# ! First retrieval
|
| 544 |
+
first_retriever = self.get_retriever(
|
| 545 |
+
docs_chunks=self.docs_index_small.documents,
|
| 546 |
+
emb_chunks=self.embedding_chunks_small,
|
| 547 |
+
emb_filter=None,
|
| 548 |
+
k=self.first_retrieval_k,
|
| 549 |
+
weights=self.retriever_weights,
|
| 550 |
+
)
|
| 551 |
+
first = await first_retriever.aget_relevant_documents(
|
| 552 |
+
query, callbacks=run_manager.get_child()
|
| 553 |
+
)
|
| 554 |
+
for doc in first:
|
| 555 |
+
logger.info("----1st retrieval----: %s", doc)
|
| 556 |
+
ids_clean = self.get_relevant_doc_ids(first, query)
|
| 557 |
+
logger.info("relevant doc ids: %s", ids_clean)
|
| 558 |
+
qa_chunks = {} # key is file name, value is a list of relevant documents
|
| 559 |
+
# res_chunks = []
|
| 560 |
+
if ids_clean and isinstance(ids_clean, list):
|
| 561 |
+
source_md5_dict = {}
|
| 562 |
+
for ids_c in ids_clean:
|
| 563 |
+
if ids_c < len(first):
|
| 564 |
+
if ids_c not in source_md5_dict:
|
| 565 |
+
source_md5_dict[first[ids_c].metadata["source_md5"]] = [
|
| 566 |
+
first[ids_c]
|
| 567 |
+
]
|
| 568 |
+
# else:
|
| 569 |
+
# source_md5_dict[first[ids_c].metadata["source_md5"]].append(
|
| 570 |
+
# ids_clean[ids_c]
|
| 571 |
+
# )
|
| 572 |
+
if len(source_md5_dict) == 0:
|
| 573 |
+
source_md5_dict[first[0].metadata["source_md5"]] = [first[0]]
|
| 574 |
+
num_docs = len(source_md5_dict.keys())
|
| 575 |
+
third_num_k = max(
|
| 576 |
+
1,
|
| 577 |
+
(
|
| 578 |
+
int(
|
| 579 |
+
(
|
| 580 |
+
configs.max_llm_context
|
| 581 |
+
/ (configs.base_chunk_size * configs.chunk_scale)
|
| 582 |
+
)
|
| 583 |
+
// (num_docs * num_query)
|
| 584 |
+
)
|
| 585 |
+
),
|
| 586 |
+
)
|
| 587 |
+
|
| 588 |
+
for source_md5, docs in source_md5_dict.items():
|
| 589 |
+
logger.info(
|
| 590 |
+
"selected_docs_at_1st_retrieval: %s", docs[0].metadata["source"]
|
| 591 |
+
)
|
| 592 |
+
second_docs_chunks = self.docs_index_small.retrieve_metadata(
|
| 593 |
+
{
|
| 594 |
+
"source_md5": (IndexerOperator.EQ, source_md5),
|
| 595 |
+
}
|
| 596 |
+
)
|
| 597 |
+
second_retriever = self.get_retriever(
|
| 598 |
+
docs_chunks=second_docs_chunks,
|
| 599 |
+
emb_chunks=self.embedding_chunks_small,
|
| 600 |
+
emb_filter={"source_md5": source_md5},
|
| 601 |
+
k=self.second_retrieval_k,
|
| 602 |
+
weights=self.retriever_weights,
|
| 603 |
+
)
|
| 604 |
+
# ! Second retrieval
|
| 605 |
+
second = await second_retriever.aget_relevant_documents(
|
| 606 |
+
query, callbacks=run_manager.get_child()
|
| 607 |
+
)
|
| 608 |
+
for doc in second:
|
| 609 |
+
logger.info("----2nd retrieval----: %s", doc)
|
| 610 |
+
docs.extend(second)
|
| 611 |
+
docindexer_filter, chroma_filter = self.get_filter(
|
| 612 |
+
self.num_windows, source_md5, docs
|
| 613 |
+
)
|
| 614 |
+
third_docs_chunks = self.docs_index_medium.retrieve_metadata(
|
| 615 |
+
docindexer_filter
|
| 616 |
+
)
|
| 617 |
+
third_retriever = self.get_retriever(
|
| 618 |
+
docs_chunks=third_docs_chunks,
|
| 619 |
+
emb_chunks=self.embedding_chunks_medium,
|
| 620 |
+
emb_filter=chroma_filter,
|
| 621 |
+
k=third_num_k,
|
| 622 |
+
weights=self.retriever_weights,
|
| 623 |
+
)
|
| 624 |
+
# ! Third retrieval
|
| 625 |
+
third_temp = await third_retriever.aget_relevant_documents(
|
| 626 |
+
query, callbacks=run_manager.get_child()
|
| 627 |
+
)
|
| 628 |
+
third = third_temp[:third_num_k]
|
| 629 |
+
# chunks = sorted(third, key=lambda x: x.metadata["medium_chunk_idx"])
|
| 630 |
+
for doc in third:
|
| 631 |
+
logger.info(
|
| 632 |
+
"----3rd retrieval----page_content: %s", [doc.page_content]
|
| 633 |
+
)
|
| 634 |
+
mtdata = doc.metadata
|
| 635 |
+
mtdata["page_content"] = None
|
| 636 |
+
logger.info("----3rd retrieval----metadata: %s", mtdata)
|
| 637 |
+
file_name = third[0].metadata["source"].split("/")[-1]
|
| 638 |
+
if file_name not in qa_chunks:
|
| 639 |
+
qa_chunks[file_name] = third
|
| 640 |
+
else:
|
| 641 |
+
qa_chunks[file_name].extend(third)
|
| 642 |
+
|
| 643 |
+
return qa_chunks
|
toolkit/together_api_llm.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""The code borrowed from https://colab.research.google.com/drive/1RW2yTxh5b9w7F3IrK00Iz51FTO5W01Rx?usp=sharing#scrollTo=RgbLVmf-o4j7"""
|
| 2 |
+
import os
|
| 3 |
+
from typing import Any, Dict
|
| 4 |
+
import together
|
| 5 |
+
from pydantic import Extra, root_validator
|
| 6 |
+
|
| 7 |
+
from langchain.llms.base import LLM
|
| 8 |
+
from langchain.utils import get_from_dict_or_env
|
| 9 |
+
from toolkit.utils import Config
|
| 10 |
+
|
| 11 |
+
configs = Config("configparser.ini")
|
| 12 |
+
os.environ["TOGETHER_API_KEY"] = configs.together_api_key
|
| 13 |
+
|
| 14 |
+
# together.api_key = configs.together_api_key
|
| 15 |
+
# models = together.Models.list()
|
| 16 |
+
# for idx, model in enumerate(models):
|
| 17 |
+
# print(idx, model["name"])
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class TogetherLLM(LLM):
|
| 21 |
+
"""Together large language models."""
|
| 22 |
+
|
| 23 |
+
model: str = "togethercomputer/llama-2-70b-chat"
|
| 24 |
+
"""model endpoint to use"""
|
| 25 |
+
|
| 26 |
+
together_api_key: str = os.environ["TOGETHER_API_KEY"]
|
| 27 |
+
"""Together API key"""
|
| 28 |
+
|
| 29 |
+
temperature: float = 0
|
| 30 |
+
"""What sampling temperature to use."""
|
| 31 |
+
|
| 32 |
+
max_tokens: int = 512
|
| 33 |
+
"""The maximum number of tokens to generate in the completion."""
|
| 34 |
+
|
| 35 |
+
class Config:
|
| 36 |
+
extra = "forbid"
|
| 37 |
+
|
| 38 |
+
# @root_validator()
|
| 39 |
+
# def validate_environment(cls, values: Dict) -> Dict:
|
| 40 |
+
# """Validate that the API key is set."""
|
| 41 |
+
# api_key = get_from_dict_or_env(values, "together_api_key", "TOGETHER_API_KEY")
|
| 42 |
+
# values["together_api_key"] = api_key
|
| 43 |
+
# return values
|
| 44 |
+
|
| 45 |
+
@property
|
| 46 |
+
def _llm_type(self) -> str:
|
| 47 |
+
"""Return type of LLM."""
|
| 48 |
+
return "together"
|
| 49 |
+
|
| 50 |
+
def _call(
|
| 51 |
+
self,
|
| 52 |
+
prompt: str,
|
| 53 |
+
**kwargs: Any,
|
| 54 |
+
) -> str:
|
| 55 |
+
"""Call to Together endpoint."""
|
| 56 |
+
together.api_key = self.together_api_key
|
| 57 |
+
output = together.Complete.create(
|
| 58 |
+
prompt,
|
| 59 |
+
model=self.model,
|
| 60 |
+
max_tokens=self.max_tokens,
|
| 61 |
+
temperature=self.temperature,
|
| 62 |
+
)
|
| 63 |
+
text = output["output"]["choices"][0]["text"]
|
| 64 |
+
return text
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
# if __name__ == "__main__":
|
| 68 |
+
# test_llm = TogetherLLM(
|
| 69 |
+
# model="togethercomputer/llama-2-70b-chat", temperature=0, max_tokens=1000
|
| 70 |
+
# )
|
| 71 |
+
|
| 72 |
+
# print(test_llm("What are the olympics? "))
|
toolkit/utils.py
ADDED
|
@@ -0,0 +1,389 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
The widgets defines utility functions for loading data, text cleaning,
|
| 3 |
+
and indexing documents, as well as classes for handling document queries
|
| 4 |
+
and formatting chat history.
|
| 5 |
+
"""
|
| 6 |
+
import re
|
| 7 |
+
import pickle
|
| 8 |
+
import string
|
| 9 |
+
import logging
|
| 10 |
+
import configparser
|
| 11 |
+
from enum import Enum
|
| 12 |
+
from typing import List, Tuple, Union
|
| 13 |
+
import nltk
|
| 14 |
+
from nltk.stem import WordNetLemmatizer
|
| 15 |
+
from nltk.tokenize import word_tokenize
|
| 16 |
+
from nltk.corpus import stopwords
|
| 17 |
+
import torch
|
| 18 |
+
import tiktoken
|
| 19 |
+
from langchain.vectorstores import Chroma
|
| 20 |
+
|
| 21 |
+
from langchain.schema import Document, BaseMessage
|
| 22 |
+
from langchain.embeddings import HuggingFaceEmbeddings, HuggingFaceInstructEmbeddings
|
| 23 |
+
from langchain.embeddings.openai import OpenAIEmbeddings
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
tokenizer_name = tiktoken.encoding_for_model("gpt-3.5-turbo")
|
| 27 |
+
tokenizer = tiktoken.get_encoding(tokenizer_name.name)
|
| 28 |
+
|
| 29 |
+
# if nltk stopwords, punkt and wordnet are not downloaded, download it
|
| 30 |
+
try:
|
| 31 |
+
nltk.data.find("corpora/stopwords")
|
| 32 |
+
except LookupError:
|
| 33 |
+
nltk.download("stopwords")
|
| 34 |
+
try:
|
| 35 |
+
nltk.data.find("tokenizers/punkt")
|
| 36 |
+
except LookupError:
|
| 37 |
+
nltk.download("punkt")
|
| 38 |
+
try:
|
| 39 |
+
nltk.data.find("corpora/wordnet")
|
| 40 |
+
except LookupError:
|
| 41 |
+
nltk.download("wordnet")
|
| 42 |
+
|
| 43 |
+
ChatTurnType = Union[Tuple[str, str], BaseMessage]
|
| 44 |
+
_ROLE_MAP = {"human": "Human: ", "ai": "Assistant: "}
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class Config:
|
| 48 |
+
"""Initializes configs."""
|
| 49 |
+
|
| 50 |
+
def __init__(self, config_file):
|
| 51 |
+
self.config = configparser.ConfigParser(interpolation=None)
|
| 52 |
+
self.config.read(config_file)
|
| 53 |
+
|
| 54 |
+
# Tokens
|
| 55 |
+
self.openai_api_key = self.config.get("tokens", "OPENAI_API_KEY")
|
| 56 |
+
self.anthropic_api_key = self.config.get("tokens", "ANTHROPIC_API_KEY")
|
| 57 |
+
self.together_api_key = self.config.get("tokens", "TOGETHER_API_KEY")
|
| 58 |
+
self.huggingface_token = self.config.get("tokens", "HUGGINGFACE_TOKEN")
|
| 59 |
+
self.version = self.config.get("tokens", "VERSION")
|
| 60 |
+
|
| 61 |
+
# Directory
|
| 62 |
+
self.docs_dir = self.config.get("directory", "DOCS_DIR")
|
| 63 |
+
self.db_dir = self.config.get("directory", "db_DIR")
|
| 64 |
+
self.local_model_dir = self.config.get("directory", "LOCAL_MODEL_DIR")
|
| 65 |
+
|
| 66 |
+
# Parameters
|
| 67 |
+
self.model_name = self.config.get("parameters", "MODEL_NAME")
|
| 68 |
+
self.temperature = self.config.getfloat("parameters", "TEMPURATURE")
|
| 69 |
+
self.max_chat_history = self.config.getint("parameters", "MAX_CHAT_HISTORY")
|
| 70 |
+
self.max_llm_context = self.config.getint("parameters", "MAX_LLM_CONTEXT")
|
| 71 |
+
self.max_llm_generation = self.config.getint("parameters", "MAX_LLM_GENERATION")
|
| 72 |
+
self.embedding_name = self.config.get("parameters", "EMBEDDING_NAME")
|
| 73 |
+
|
| 74 |
+
self.n_gpu_layers = self.config.getint("parameters", "N_GPU_LAYERS")
|
| 75 |
+
self.n_batch = self.config.getint("parameters", "N_BATCH")
|
| 76 |
+
|
| 77 |
+
self.base_chunk_size = self.config.getint("parameters", "BASE_CHUNK_SIZE")
|
| 78 |
+
self.chunk_overlap = self.config.getint("parameters", "CHUNK_OVERLAP")
|
| 79 |
+
self.chunk_scale = self.config.getint("parameters", "CHUNK_SCALE")
|
| 80 |
+
self.window_steps = self.config.getint("parameters", "WINDOW_STEPS")
|
| 81 |
+
self.window_scale = self.config.getint("parameters", "WINDOW_SCALE")
|
| 82 |
+
|
| 83 |
+
self.retriever_weights = [
|
| 84 |
+
float(x.strip())
|
| 85 |
+
for x in self.config.get("parameters", "RETRIEVER_WEIGHTS").split(",")
|
| 86 |
+
]
|
| 87 |
+
self.first_retrieval_k = self.config.getint("parameters", "FIRST_RETRIEVAL_K")
|
| 88 |
+
self.second_retrieval_k = self.config.getint("parameters", "SECOND_RETRIEVAL_K")
|
| 89 |
+
self.num_windows = self.config.getint("parameters", "NUM_WINDOWS")
|
| 90 |
+
|
| 91 |
+
# Logging
|
| 92 |
+
self.logging_enabled = self.config.getboolean("logging", "enabled")
|
| 93 |
+
self.logging_level = self.config.get("logging", "level")
|
| 94 |
+
self.logging_filename = self.config.get("logging", "filename")
|
| 95 |
+
self.logging_format = self.config.get("logging", "format")
|
| 96 |
+
|
| 97 |
+
self.configure_logging()
|
| 98 |
+
|
| 99 |
+
def configure_logging(self):
|
| 100 |
+
"""
|
| 101 |
+
Configure the logger for each .py files.
|
| 102 |
+
"""
|
| 103 |
+
|
| 104 |
+
if not self.logging_enabled:
|
| 105 |
+
logging.disable(logging.CRITICAL + 1)
|
| 106 |
+
return
|
| 107 |
+
|
| 108 |
+
log_level = self.config.get("logging", "level")
|
| 109 |
+
log_filename = self.config.get("logging", "filename")
|
| 110 |
+
log_format = self.config.get("logging", "format")
|
| 111 |
+
|
| 112 |
+
logging.basicConfig(level=log_level, filename=log_filename, format=log_format)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def configure_logger():
|
| 116 |
+
"""
|
| 117 |
+
Configure the logger for each .py files.
|
| 118 |
+
"""
|
| 119 |
+
config = configparser.ConfigParser(interpolation=None)
|
| 120 |
+
config.read("configparser.ini")
|
| 121 |
+
|
| 122 |
+
enabled = config.getboolean("logging", "enabled")
|
| 123 |
+
|
| 124 |
+
if not enabled:
|
| 125 |
+
logging.disable(logging.CRITICAL + 1)
|
| 126 |
+
return
|
| 127 |
+
|
| 128 |
+
log_level = config.get("logging", "level")
|
| 129 |
+
log_filename = config.get("logging", "filename")
|
| 130 |
+
log_format = config.get("logging", "format")
|
| 131 |
+
|
| 132 |
+
logging.basicConfig(level=log_level, filename=log_filename, format=log_format)
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def tiktoken_len(text):
|
| 136 |
+
"""token length function"""
|
| 137 |
+
tokens = tokenizer.encode(text, disallowed_special=())
|
| 138 |
+
return len(tokens)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def check_device():
|
| 142 |
+
"""Check if cuda or MPS is available, else fallback to CPU"""
|
| 143 |
+
if torch.cuda.is_available():
|
| 144 |
+
device = "cuda"
|
| 145 |
+
elif torch.backends.mps.is_available():
|
| 146 |
+
device = "mps"
|
| 147 |
+
else:
|
| 148 |
+
device = "cpu"
|
| 149 |
+
return device
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def choose_embeddings(embedding_name):
|
| 153 |
+
"""Choose embeddings for a given model's name"""
|
| 154 |
+
try:
|
| 155 |
+
if embedding_name == "openAIEmbeddings":
|
| 156 |
+
return OpenAIEmbeddings()
|
| 157 |
+
elif embedding_name == "hkunlpInstructorLarge":
|
| 158 |
+
device = check_device()
|
| 159 |
+
return HuggingFaceInstructEmbeddings(
|
| 160 |
+
model_name="hkunlp/instructor-large", model_kwargs={"device": device}
|
| 161 |
+
)
|
| 162 |
+
else:
|
| 163 |
+
device = check_device()
|
| 164 |
+
return HuggingFaceEmbeddings(model_name=embedding_name, device=device)
|
| 165 |
+
except Exception as error:
|
| 166 |
+
raise ValueError(f"Embedding {embedding_name} not supported") from error
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def load_embedding(store_name, embedding, suffix, path):
|
| 170 |
+
"""Load chroma embeddings"""
|
| 171 |
+
vector_store = Chroma(
|
| 172 |
+
persist_directory=f"{path}/chroma_{store_name}_{suffix}",
|
| 173 |
+
embedding_function=embedding,
|
| 174 |
+
)
|
| 175 |
+
return vector_store
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
def load_pickle(prefix, suffix, path):
|
| 179 |
+
"""Load langchain documents from a pickle file.
|
| 180 |
+
|
| 181 |
+
Args:
|
| 182 |
+
store_name (str): The name of the store where data is saved.
|
| 183 |
+
suffix (str): Suffix to append to the store name.
|
| 184 |
+
path (str): The path where the pickle file is stored.
|
| 185 |
+
|
| 186 |
+
Returns:
|
| 187 |
+
Document: documents from the pickle file
|
| 188 |
+
"""
|
| 189 |
+
with open(f"{path}/{prefix}_{suffix}.pkl", "rb") as file:
|
| 190 |
+
return pickle.load(file)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def clean_text(text):
|
| 194 |
+
"""
|
| 195 |
+
Converts text to lowercase, removes punctuation, stopwords, and lemmatizes it
|
| 196 |
+
for BM25 retriever.
|
| 197 |
+
|
| 198 |
+
Parameters:
|
| 199 |
+
text (str): The text to be cleaned.
|
| 200 |
+
|
| 201 |
+
Returns:
|
| 202 |
+
str: The cleaned and lemmatized text.
|
| 203 |
+
"""
|
| 204 |
+
# remove [SEP] in the text
|
| 205 |
+
text = text.replace("[SEP]", "")
|
| 206 |
+
# Tokenization
|
| 207 |
+
tokens = word_tokenize(text)
|
| 208 |
+
# Lowercasing
|
| 209 |
+
tokens = [w.lower() for w in tokens]
|
| 210 |
+
# Remove punctuation
|
| 211 |
+
table = str.maketrans("", "", string.punctuation)
|
| 212 |
+
stripped = [w.translate(table) for w in tokens]
|
| 213 |
+
# Keep tokens that are alphabetic, numeric, or contain both.
|
| 214 |
+
words = [
|
| 215 |
+
word
|
| 216 |
+
for word in stripped
|
| 217 |
+
if word.isalpha()
|
| 218 |
+
or word.isdigit()
|
| 219 |
+
or (re.search("\d", word) and re.search("[a-zA-Z]", word))
|
| 220 |
+
]
|
| 221 |
+
# Remove stopwords
|
| 222 |
+
stop_words = set(stopwords.words("english"))
|
| 223 |
+
words = [w for w in words if w not in stop_words]
|
| 224 |
+
# Lemmatization (or you could use stemming instead)
|
| 225 |
+
lemmatizer = WordNetLemmatizer()
|
| 226 |
+
lemmatized = [lemmatizer.lemmatize(w) for w in words]
|
| 227 |
+
# Convert list of words to a string
|
| 228 |
+
lemmatized_ = " ".join(lemmatized)
|
| 229 |
+
|
| 230 |
+
return lemmatized_
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
class IndexerOperator(Enum):
|
| 234 |
+
"""
|
| 235 |
+
Enumeration for different query operators used in indexing.
|
| 236 |
+
"""
|
| 237 |
+
|
| 238 |
+
EQ = "=="
|
| 239 |
+
GT = ">"
|
| 240 |
+
GTE = ">="
|
| 241 |
+
LT = "<"
|
| 242 |
+
LTE = "<="
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
class DocIndexer:
|
| 246 |
+
"""
|
| 247 |
+
A class to handle indexing and searching of documents.
|
| 248 |
+
|
| 249 |
+
Attributes:
|
| 250 |
+
documents (List[Document]): List of documents to be indexed.
|
| 251 |
+
"""
|
| 252 |
+
|
| 253 |
+
def __init__(self, documents):
|
| 254 |
+
self.documents = documents
|
| 255 |
+
self.index = self.build_index(documents)
|
| 256 |
+
|
| 257 |
+
def build_index(self, documents):
|
| 258 |
+
"""
|
| 259 |
+
Build an index for the given list of documents.
|
| 260 |
+
|
| 261 |
+
Parameters:
|
| 262 |
+
documents (List[Document]): The list of documents to be indexed.
|
| 263 |
+
|
| 264 |
+
Returns:
|
| 265 |
+
dict: The built index.
|
| 266 |
+
"""
|
| 267 |
+
index = {}
|
| 268 |
+
for doc in documents:
|
| 269 |
+
for key, value in doc.metadata.items():
|
| 270 |
+
if key not in index:
|
| 271 |
+
index[key] = {}
|
| 272 |
+
if value not in index[key]:
|
| 273 |
+
index[key][value] = []
|
| 274 |
+
index[key][value].append(doc)
|
| 275 |
+
return index
|
| 276 |
+
|
| 277 |
+
def retrieve_metadata(self, search_dict):
|
| 278 |
+
"""
|
| 279 |
+
Retrieve documents based on the search criteria provided in search_dict.
|
| 280 |
+
|
| 281 |
+
Parameters:
|
| 282 |
+
search_dict (dict): Dictionary specifying the search criteria.
|
| 283 |
+
It can contain "AND" or "OR" operators for
|
| 284 |
+
complex queries.
|
| 285 |
+
|
| 286 |
+
Returns:
|
| 287 |
+
List[Document]: List of documents that match the search criteria.
|
| 288 |
+
"""
|
| 289 |
+
if "AND" in search_dict:
|
| 290 |
+
return self._handle_and(search_dict["AND"])
|
| 291 |
+
elif "OR" in search_dict:
|
| 292 |
+
return self._handle_or(search_dict["OR"])
|
| 293 |
+
else:
|
| 294 |
+
return self._handle_single(search_dict)
|
| 295 |
+
|
| 296 |
+
def _handle_and(self, search_dicts):
|
| 297 |
+
results = [self.retrieve_metadata(sd) for sd in search_dicts]
|
| 298 |
+
if results:
|
| 299 |
+
intersection = set.intersection(
|
| 300 |
+
*[set(map(self._hash_doc, r)) for r in results]
|
| 301 |
+
)
|
| 302 |
+
return [self._unhash_doc(h) for h in intersection]
|
| 303 |
+
else:
|
| 304 |
+
return []
|
| 305 |
+
|
| 306 |
+
def _handle_or(self, search_dicts):
|
| 307 |
+
results = [self.retrieve_metadata(sd) for sd in search_dicts]
|
| 308 |
+
union = set.union(*[set(map(self._hash_doc, r)) for r in results])
|
| 309 |
+
return [self._unhash_doc(h) for h in union]
|
| 310 |
+
|
| 311 |
+
def _handle_single(self, search_dict):
|
| 312 |
+
unions = []
|
| 313 |
+
for key, query in search_dict.items():
|
| 314 |
+
operator, value = query
|
| 315 |
+
union = set()
|
| 316 |
+
if operator == IndexerOperator.EQ:
|
| 317 |
+
if key in self.index and value in self.index[key]:
|
| 318 |
+
union.update(map(self._hash_doc, self.index[key][value]))
|
| 319 |
+
else:
|
| 320 |
+
if key in self.index:
|
| 321 |
+
for k, v in self.index[key].items():
|
| 322 |
+
if (
|
| 323 |
+
(operator == IndexerOperator.GT and k > value)
|
| 324 |
+
or (operator == IndexerOperator.GTE and k >= value)
|
| 325 |
+
or (operator == IndexerOperator.LT and k < value)
|
| 326 |
+
or (operator == IndexerOperator.LTE and k <= value)
|
| 327 |
+
):
|
| 328 |
+
union.update(map(self._hash_doc, v))
|
| 329 |
+
if union:
|
| 330 |
+
unions.append(union)
|
| 331 |
+
|
| 332 |
+
if unions:
|
| 333 |
+
intersection = set.intersection(*unions)
|
| 334 |
+
return [self._unhash_doc(h) for h in intersection]
|
| 335 |
+
else:
|
| 336 |
+
return []
|
| 337 |
+
|
| 338 |
+
def _hash_doc(self, doc):
|
| 339 |
+
return (doc.page_content, frozenset(doc.metadata.items()))
|
| 340 |
+
|
| 341 |
+
def _unhash_doc(self, hashed_doc):
|
| 342 |
+
page_content, metadata = hashed_doc
|
| 343 |
+
return Document(page_content=page_content, metadata=dict(metadata))
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+
def _get_chat_history(chat_history: List[ChatTurnType]) -> str:
|
| 347 |
+
buffer = ""
|
| 348 |
+
for dialogue_turn in chat_history:
|
| 349 |
+
if isinstance(dialogue_turn, BaseMessage):
|
| 350 |
+
role_prefix = _ROLE_MAP.get(dialogue_turn.type, f"{dialogue_turn.type}: ")
|
| 351 |
+
buffer += f"\n{role_prefix}{dialogue_turn.content}"
|
| 352 |
+
elif isinstance(dialogue_turn, tuple):
|
| 353 |
+
human = "Human: " + dialogue_turn[0]
|
| 354 |
+
ai = "Assistant: " + dialogue_turn[1]
|
| 355 |
+
buffer += "\n" + "\n".join([human, ai])
|
| 356 |
+
else:
|
| 357 |
+
raise ValueError(
|
| 358 |
+
f"Unsupported chat history format: {type(dialogue_turn)}."
|
| 359 |
+
f" Full chat history: {chat_history} "
|
| 360 |
+
)
|
| 361 |
+
return buffer
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
def _get_standalone_questions_list(
|
| 365 |
+
standalone_questions_str: str, original_question: str
|
| 366 |
+
) -> List[str]:
|
| 367 |
+
pattern = r"\d+\.\s(.*?)(?=\n\d+\.|\n|$)"
|
| 368 |
+
|
| 369 |
+
matches = [
|
| 370 |
+
match.group(1) for match in re.finditer(pattern, standalone_questions_str)
|
| 371 |
+
]
|
| 372 |
+
if matches:
|
| 373 |
+
return matches
|
| 374 |
+
|
| 375 |
+
match = re.search(
|
| 376 |
+
r"(?i)standalone[^\n]*:[^\n](.*)", standalone_questions_str, re.DOTALL
|
| 377 |
+
)
|
| 378 |
+
sentence_source = match.group(1).strip() if match else standalone_questions_str
|
| 379 |
+
sentences = sentence_source.split("\n")
|
| 380 |
+
|
| 381 |
+
return [
|
| 382 |
+
re.sub(
|
| 383 |
+
r"^\((\d+)\)\.? ?|^\d+\.? ?\)?|^(\d+)\) ?|^(\d+)\) ?|^[Qq]uery \d+: ?|^[Qq]uery: ?",
|
| 384 |
+
"",
|
| 385 |
+
sentence.strip(),
|
| 386 |
+
)
|
| 387 |
+
for sentence in sentences
|
| 388 |
+
if sentence.strip()
|
| 389 |
+
]
|