

initial commit
Browse files- README.md +3 -3
- banner.png +0 -0
- bibliography.bib +108 -0
- index.html +661 -18
- plots/FineWeb.png +0 -0
- plots/Untitled 1.png +0 -0
- plots/Untitled 2.png +0 -0
- plots/Untitled 3.png +0 -0
- plots/Untitled 4.png +0 -0
- plots/Untitled 5.png +0 -0
- plots/Untitled 6.png +0 -0
- plots/Untitled.png +0 -0
- plots/c4_filters.png +0 -0
- plots/cross_ind_unfiltered_comparison.png +0 -0
- plots/dedup_all_dumps_bad.png +0 -0
- plots/dedup_impact_simulation.png +0 -0
- plots/fineweb-recipe.png +0 -0
- plots/fineweb_ablations.png +0 -0
- plots/fineweb_all_filters.png +0 -0
- plots/minhash_parameters_comparison.png +0 -0
- plots/removed_data_cross_dedup.png +0 -0
- plots/score_by_dump.png +0 -0
- plots/wet_comparison.png +0 -0
README.md
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: pink
|
| 5 |
-
colorTo:
|
| 6 |
sdk: static
|
| 7 |
pinned: false
|
| 8 |
---
|
|
|
|
| 1 |
---
|
| 2 |
+
title: "FineWeb: 15T tokens of high quality web data"
|
| 3 |
+
emoji: 🍷
|
| 4 |
colorFrom: pink
|
| 5 |
+
colorTo: red
|
| 6 |
sdk: static
|
| 7 |
pinned: false
|
| 8 |
---
|
banner.png
ADDED

|
bibliography.bib
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
@article{gregor2015draw,
|
| 2 |
+
title={DRAW: A recurrent neural network for image generation},
|
| 3 |
+
author={Gregor, Karol and Danihelka, Ivo and Graves, Alex and Rezende, Danilo Jimenez and Wierstra, Daan},
|
| 4 |
+
journal={arXiv preprint arXiv:1502.04623},
|
| 5 |
+
year={2015},
|
| 6 |
+
url ={https://arxiv.org/pdf/1502.04623.pdf}
|
| 7 |
+
}
|
| 8 |
+
@article{mercier2011humans,
|
| 9 |
+
title={Why do humans reason? Arguments for an argumentative theory},
|
| 10 |
+
author={Mercier, Hugo and Sperber, Dan},
|
| 11 |
+
journal={Behavioral and brain sciences},
|
| 12 |
+
volume={34},
|
| 13 |
+
number={02},
|
| 14 |
+
pages={57--74},
|
| 15 |
+
year={2011},
|
| 16 |
+
publisher={Cambridge Univ Press},
|
| 17 |
+
doi={10.1017/S0140525X10000968}
|
| 18 |
+
}
|
| 19 |
+
|
| 20 |
+
@article{dong2014image,
|
| 21 |
+
title={Image super-resolution using deep convolutional networks},
|
| 22 |
+
author={Dong, Chao and Loy, Chen Change and He, Kaiming and Tang, Xiaoou},
|
| 23 |
+
journal={arXiv preprint arXiv:1501.00092},
|
| 24 |
+
year={2014},
|
| 25 |
+
url={https://arxiv.org/pdf/1501.00092.pdf}
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
@article{dumoulin2016adversarially,
|
| 29 |
+
title={Adversarially Learned Inference},
|
| 30 |
+
author={Dumoulin, Vincent and Belghazi, Ishmael and Poole, Ben and Lamb, Alex and Arjovsky, Martin and Mastropietro, Olivier and Courville, Aaron},
|
| 31 |
+
journal={arXiv preprint arXiv:1606.00704},
|
| 32 |
+
year={2016},
|
| 33 |
+
url={https://arxiv.org/pdf/1606.00704.pdf}
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
@article{dumoulin2016guide,
|
| 37 |
+
title={A guide to convolution arithmetic for deep learning},
|
| 38 |
+
author={Dumoulin, Vincent and Visin, Francesco},
|
| 39 |
+
journal={arXiv preprint arXiv:1603.07285},
|
| 40 |
+
year={2016},
|
| 41 |
+
url={https://arxiv.org/pdf/1603.07285.pdf}
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
@article{gauthier2014conditional,
|
| 45 |
+
title={Conditional generative adversarial nets for convolutional face generation},
|
| 46 |
+
author={Gauthier, Jon},
|
| 47 |
+
journal={Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter semester},
|
| 48 |
+
volume={2014},
|
| 49 |
+
year={2014},
|
| 50 |
+
url={http://www.foldl.me/uploads/papers/tr-cgans.pdf}
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
@article{johnson2016perceptual,
|
| 54 |
+
title={Perceptual losses for real-time style transfer and super-resolution},
|
| 55 |
+
author={Johnson, Justin and Alahi, Alexandre and Fei-Fei, Li},
|
| 56 |
+
journal={arXiv preprint arXiv:1603.08155},
|
| 57 |
+
year={2016},
|
| 58 |
+
url={https://arxiv.org/pdf/1603.08155.pdf}
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
@article{mordvintsev2015inceptionism,
|
| 62 |
+
title={Inceptionism: Going deeper into neural networks},
|
| 63 |
+
author={Mordvintsev, Alexander and Olah, Christopher and Tyka, Mike},
|
| 64 |
+
journal={Google Research Blog},
|
| 65 |
+
year={2015},
|
| 66 |
+
url={https://research.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html}
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
@misc{mordvintsev2016deepdreaming,
|
| 70 |
+
title={DeepDreaming with TensorFlow},
|
| 71 |
+
author={Mordvintsev, Alexander},
|
| 72 |
+
year={2016},
|
| 73 |
+
url={https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/deepdream/deepdream.ipynb},
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
@article{radford2015unsupervised,
|
| 77 |
+
title={Unsupervised representation learning with deep convolutional generative adversarial networks},
|
| 78 |
+
author={Radford, Alec and Metz, Luke and Chintala, Soumith},
|
| 79 |
+
journal={arXiv preprint arXiv:1511.06434},
|
| 80 |
+
year={2015},
|
| 81 |
+
url={https://arxiv.org/pdf/1511.06434.pdf}
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
@inproceedings{salimans2016improved,
|
| 85 |
+
title={Improved techniques for training gans},
|
| 86 |
+
author={Salimans, Tim and Goodfellow, Ian and Zaremba, Wojciech and Cheung, Vicki and Radford, Alec and Chen, Xi},
|
| 87 |
+
booktitle={Advances in Neural Information Processing Systems},
|
| 88 |
+
pages={2226--2234},
|
| 89 |
+
year={2016},
|
| 90 |
+
url={https://arxiv.org/pdf/1606.03498.pdf}
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
@article{shi2016deconvolution,
|
| 94 |
+
title={Is the deconvolution layer the same as a convolutional layer?},
|
| 95 |
+
author={Shi, Wenzhe and Caballero, Jose and Theis, Lucas and Huszar, Ferenc and Aitken, Andrew and Ledig, Christian and Wang, Zehan},
|
| 96 |
+
journal={arXiv preprint arXiv:1609.07009},
|
| 97 |
+
year={2016},
|
| 98 |
+
url={https://arxiv.org/pdf/1609.07009.pdf}
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
@misc{openai2018charter,
|
| 102 |
+
author={OpenAI},
|
| 103 |
+
title={OpenAI Charter},
|
| 104 |
+
type={Blog},
|
| 105 |
+
number={April 9},
|
| 106 |
+
year={2018},
|
| 107 |
+
url={https://blog.openai.com/charter},
|
| 108 |
+
}
|
index.html
CHANGED
|
@@ -1,19 +1,662 @@
|
|
| 1 |
<!doctype html>
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
<!doctype html>
|
| 2 |
+
|
| 3 |
+
<head>
|
| 4 |
+
<script src="https://distill.pub/template.v2.js"></script>
|
| 5 |
+
<meta name="viewport" content="width=device-width, initial-scale=1">
|
| 6 |
+
<meta charset="utf8">
|
| 7 |
+
<title>FineWeb: 15T tokens of high quality web data</title>
|
| 8 |
+
</head>
|
| 9 |
+
|
| 10 |
+
<body>
|
| 11 |
+
<d-front-matter>
|
| 12 |
+
<script id='distill-front-matter' type="text/json">{
|
| 13 |
+
"title": "FineWeb: 15T tokens of high quality web data",
|
| 14 |
+
"description": "This blog covers the FineWeb recipe, why more deduplication is not always better and some interesting findings on the difference in quality of CommonCrawl dumps.",
|
| 15 |
+
"published": "May 28, 2024",
|
| 16 |
+
"authors": [
|
| 17 |
+
{
|
| 18 |
+
"author":"Guilherme Penedo",
|
| 19 |
+
"authorURL":"https://huggingface.co/guipenedo",
|
| 20 |
+
"affiliations": [{"name": "HuggingFace"}]
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"author":"Hynek Kydlíček",
|
| 24 |
+
"authorURL":"https://huggingface.co/hynky"
|
| 25 |
+
},
|
| 26 |
+
{
|
| 27 |
+
"author":"Leandro Werra",
|
| 28 |
+
"authorURL":"https://huggingface.co/lvwerra"
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"author":"Thomas Wolf",
|
| 32 |
+
"authorURL":"https://huggingface.co/thomwolf"
|
| 33 |
+
}
|
| 34 |
+
],
|
| 35 |
+
"katex": {
|
| 36 |
+
"delimiters": [
|
| 37 |
+
{"left": "$$", "right": "$$", "display": false}
|
| 38 |
+
]
|
| 39 |
+
}
|
| 40 |
+
}
|
| 41 |
+
</script>
|
| 42 |
+
</d-front-matter>
|
| 43 |
+
<d-title>
|
| 44 |
+
<figure style="grid-column: page; mix-blend-mode: multiply;">
|
| 45 |
+
<img src="banner.png" alt="FineWeb">
|
| 46 |
+
</figure>
|
| 47 |
+
<!-- <figure style="grid-column: page; margin: 1rem 0;"><img src="banner.png"-->
|
| 48 |
+
<!-- style="width:100%; border: 1px solid rgba(0, 0, 0, 0.2);"/>-->
|
| 49 |
+
<!-- </figure>-->
|
| 50 |
+
</d-title>
|
| 51 |
+
<d-byline></d-byline>
|
| 52 |
+
<d-article>
|
| 53 |
+
<p>We have recently released 🍷FineWeb, our new large scale
|
| 54 |
+
(15T tokens, 44TB disk space) dataset of clean text sourced from the web for LLM pretraining. You can
|
| 55 |
+
download it <a href="https://huggingface.co/datasets/HuggingFaceFW/fineweb">here</a>.</p>
|
| 56 |
+
<p>As 🍷FineWeb has gathered a lot of interest from the
|
| 57 |
+
community, we decided to further explain the steps involved in creating it, our processing decisions and
|
| 58 |
+
some lessons learned along the way. Read on for all the juicy details on large text dataset creation!</p>
|
| 59 |
+
<p><strong>TLDR:</strong> This blog covers the FineWeb
|
| 60 |
+
recipe, why more deduplication is not always better and some interesting findings on the difference in
|
| 61 |
+
quality of CommonCrawl dumps.</p>
|
| 62 |
+
<hr/>
|
| 63 |
+
<h1>Preamble</h1>
|
| 64 |
+
<h2>Sourcing the data</h2>
|
| 65 |
+
<p>A common question we see asked regarding web datasets used
|
| 66 |
+
to train LLMs is “where do they even get all that data?” There are generally two options:</p>
|
| 67 |
+
<ul class="bulleted-list">
|
| 68 |
+
<li style="list-style-type:disc">you either crawl it yourself, like <a
|
| 69 |
+
href="https://platform.openai.com/docs/gptbot">OpenAI</a> or <a
|
| 70 |
+
href="https://darkvisitors.com/agents/claudebot">Anthropic</a> seem to do
|
| 71 |
+
</li>
|
| 72 |
+
</ul>
|
| 73 |
+
<ul class="bulleted-list">
|
| 74 |
+
<li style="list-style-type:disc">you use a public repository of crawled webpages, like the one maintained by
|
| 75 |
+
the non-profit <a href="https://commoncrawl.org/">CommonCrawl</a></li>
|
| 76 |
+
</ul>
|
| 77 |
+
<p>For FineWeb, similarly to what was done for a large number
|
| 78 |
+
of other public datasets, we used <a href="https://commoncrawl.org/">CommonCrawl</a> as a starting point.
|
| 79 |
+
They have been crawling the web since 2007 (long before LLMs were a thing) and release a new dump usually
|
| 80 |
+
every 1 or 2 months, which can be freely downloaded. </p>
|
| 81 |
+
<p>As an example, their latest crawl (2024-10) contains 3.16
|
| 82 |
+
billion web pages, totaling 424.7 TiB of uncompressed content (the size changes from dump to dump). There
|
| 83 |
+
are 95 dumps since 2013 and 3 dumps from 2008 to 2012, which are in a different (older) format. </p>
|
| 84 |
+
<h2>Processing at scale</h2>
|
| 85 |
+
<p>Given the sheer size of the data involved, one of the main
|
| 86 |
+
challenges we had to overcome was having a modular, scalable codebase that would allow us to quickly iterate
|
| 87 |
+
on our processing decisions and easily try out new ideas, while appropriately parallelizing our workloads
|
| 88 |
+
and providing clear insights into the data. </p>
|
| 89 |
+
<p>For this purpose, we developed <a
|
| 90 |
+
href="https://github.com/huggingface/datatrove"><code>datatrove</code></a>, an open-source data
|
| 91 |
+
processing library that allowed us to seamlessly scale our filtering and deduplication setup to thousands of
|
| 92 |
+
CPU cores. All of the data processing steps involved in the creation of FineWeb used this <a
|
| 93 |
+
href="https://github.com/huggingface/datatrove">library</a>.</p>
|
| 94 |
+
<h2>What is clean, good data?</h2>
|
| 95 |
+
<p>This is probably the main question to keep in mind when
|
| 96 |
+
creating a dataset. A good first lesson is that data that would intuitively be considered high quality by a
|
| 97 |
+
human may not be necessarily the best data (or at least not all that you need) to train a good model on.</p>
|
| 98 |
+
<p>It is still common to train a model on a given corpus
|
| 99 |
+
(wikipedia, or some other web dataset considered clean) and use it to check the perplexity on the dataset
|
| 100 |
+
that we were trying to curate. Unfortunately this does not always correlate with performance on downstream
|
| 101 |
+
tasks, and so another often used approach is to train small models (small because training models is
|
| 102 |
+
expensive and time consuming, and we want to be able to quickly iterate) on our dataset and evaluate them on
|
| 103 |
+
a set of evaluation tasks. As we are curating a dataset for pretraining a generalist LLM, it is important to
|
| 104 |
+
choose a diverse set of tasks and try not to overfit to any one individual benchmark.</p>
|
| 105 |
+
<p>Another way to evaluate different datasets would be to
|
| 106 |
+
train a model on each one and have humans rate and compare the outputs of each one (like on the <a
|
| 107 |
+
href="https://chat.lmsys.org/">LMSYS Chatbot Arena</a>). This would arguably provide the most
|
| 108 |
+
reliable results in terms of representing real model usage, but getting ablation results this way is too
|
| 109 |
+
expensive and slow.</p>
|
| 110 |
+
<p>The approach we ultimately went with was to train small
|
| 111 |
+
models and evaluate them on a set of benchmark tasks. We believe this is a reasonable proxy for the quality
|
| 112 |
+
of the data used to train these models.</p>
|
| 113 |
+
<h3>Ablations and evaluation setup</h3>
|
| 114 |
+
<p>To be able to compare the impact of a given processing
|
| 115 |
+
step, we would train 2 models, one where the data included the extra step and another where this step was
|
| 116 |
+
ablated (cut/removed). These 2 models would have the same number of parameters, architecture, and be trained
|
| 117 |
+
on an equal number of tokens and with the same hyperparameters — the only difference would be in the
|
| 118 |
+
training data. We would then evaluate each model on the same set of tasks and compare the average
|
| 119 |
+
scores.</p>
|
| 120 |
+
<p>Our ablation models were trained using <a
|
| 121 |
+
href="https://github.com/huggingface/nanotron"><code>nanotron</code></a> with this config [<strong>TODO:
|
| 122 |
+
INSERT SIMPLIFIED NANOTRON CONFIG HERE</strong>]. The models had 1.82B parameters, used the Llama
|
| 123 |
+
architecture with a 2048 sequence length, and a global batch size of ~2 million tokens. For filtering
|
| 124 |
+
ablations we mostly trained on ~28B tokens (which is roughly the Chinchilla optimal training size for this
|
| 125 |
+
model size).</p>
|
| 126 |
+
<p>We evaluated the models using <a
|
| 127 |
+
href="https://github.com/huggingface/lighteval/"><code>lighteval</code></a>. We tried selecting
|
| 128 |
+
benchmarks that would provide good signal at a relatively small scale (small models trained on only a few
|
| 129 |
+
billion tokens). Furthermore, we also used the following criteria when selecting benchmarks:</p>
|
| 130 |
+
<ul class="bulleted-list">
|
| 131 |
+
<li style="list-style-type:disc">small variance between runs trained on different samplings of the same
|
| 132 |
+
dataset: we want our runs on a subset of the data to be representative of the whole dataset, and the
|
| 133 |
+
resulting scores to have as little noise as possible
|
| 134 |
+
</li>
|
| 135 |
+
</ul>
|
| 136 |
+
<ul class="bulleted-list">
|
| 137 |
+
<li style="list-style-type:disc">performance increasing monotonically (or close) over a training run:
|
| 138 |
+
ideally, as the number of seen tokens increases, the performance on this benchmark should not decrease
|
| 139 |
+
(should not be too noisy)
|
| 140 |
+
</li>
|
| 141 |
+
</ul>
|
| 142 |
+
<p>You can find the full list of tasks and prompts we used <a
|
| 143 |
+
href="https://huggingface.co/datasets/HuggingFaceFW/fineweb/blob/main/lighteval_tasks.py">here</a>. To
|
| 144 |
+
have results quickly we capped longer benchmarks at 1000 samples (wall-clock evaluation taking less than 5
|
| 145 |
+
min on a single node of 8 GPUs - done in parallel to the training).</p>
|
| 146 |
+
<hr />
|
| 147 |
+
<h1>The FineWeb recipe</h1>
|
| 148 |
+
<p>In the next subsections we will explain each of the steps
|
| 149 |
+
taken to produce the FineWeb dataset. You can find a full reproducible <code>datatrove</code> config <a
|
| 150 |
+
href="https://github.com/huggingface/datatrove/blob/main/examples/fineweb.py">here</a>.</p>
|
| 151 |
+
<style>
|
| 152 |
+
.neighborhood-figure-container {grid-column: screen; width: 100%; margin: auto; margin-top: 30px; margin-bottom: 30px; padding-top: 20px; padding-bottom: 10px; border-bottom: 1px solid #EEE; border-top: 1px solid #EEE;}
|
| 153 |
+
</style>
|
| 154 |
+
<div class="neighborhood-figure-container">
|
| 155 |
+
<figure class="image">
|
| 156 |
+
<img style="width:708px" src="plots/fineweb-recipe.png"/>
|
| 157 |
+
</figure>
|
| 158 |
+
</div>
|
| 159 |
+
<h2>Starting point: text extraction</h2>
|
| 160 |
+
<p>CommonCrawl data is available in two main formats: WARC
|
| 161 |
+
and WET. <strong>WARC </strong>(Web ARChive format) files contain the raw data from the crawl, including the
|
| 162 |
+
full page HTML and request metadata. <strong>WET</strong> (WARC Encapsulated Text) files provide a text only
|
| 163 |
+
version of those websites.</p>
|
| 164 |
+
<p>A large number of datasets take the WET files as their
|
| 165 |
+
starting point. In our experience the default text extraction (extracting the main text of a webpage from
|
| 166 |
+
its HTML) used to create these WET files is suboptimal and there are a variety of open-source libraries that
|
| 167 |
+
provide better text extraction (by, namely, keeping less boilerplate content/navigation menus). We extracted
|
| 168 |
+
the text content from the WARC files using the <a href="https://trafilatura.readthedocs.io/en/latest/">trafilatura</a>
|
| 169 |
+
library. It is important to note, however, that text extraction is one of the most costly steps of our
|
| 170 |
+
processing, so we believe that using the readily available WET data could be a reasonable trade-off for
|
| 171 |
+
lower budget teams.</p>
|
| 172 |
+
<p>To validate this decision, we processed the 2019-18 dump
|
| 173 |
+
directly using the WET files and with text extracted from WARC files using trafilatura. We applied the same
|
| 174 |
+
processing to each one (our base filtering+minhash, detailed below) and trained two models. While the
|
| 175 |
+
resulting dataset is considerably larger for the WET data (around 254BT), it proves to be of much worse
|
| 176 |
+
quality than the one that used trafilatura to extract text from WARC files (which is around 200BT). Many of
|
| 177 |
+
these additional tokens on the WET files are unnecessary page boilerplate.</p>
|
| 178 |
+
<figure class="image"><a href="plots/wet_comparison.png"><img
|
| 179 |
+
style="width:640px" src="plots/wet_comparison.png"/></a></figure>
|
| 180 |
+
|
| 181 |
+
<h2>Base filtering</h2>
|
| 182 |
+
<p>Filtering is an important part of the curation process. It
|
| 183 |
+
removes part of the data (be it words, lines, or full documents) that would harm performance and is thus
|
| 184 |
+
deemed to be “lower quality”.</p>
|
| 185 |
+
<p>As a basis for our filtering we used part of the setup
|
| 186 |
+
from <a href="https://arxiv.org/abs/2306.01116">RefinedWeb</a>. Namely, we:</p>
|
| 187 |
+
<ul class="bulleted-list">
|
| 188 |
+
<li style="list-style-type:disc">Applied URL filtering using a <a
|
| 189 |
+
href="https://dsi.ut-capitole.fr/blacklists/">blocklist</a> to remove adult content
|
| 190 |
+
</li>
|
| 191 |
+
</ul>
|
| 192 |
+
<ul class="bulleted-list">
|
| 193 |
+
<li style="list-style-type:disc">Applied a <a
|
| 194 |
+
href="https://fasttext.cc/docs/en/language-identification.html">fastText language classifier</a> to
|
| 195 |
+
keep only English text with a score ≥ 0.65
|
| 196 |
+
</li>
|
| 197 |
+
</ul>
|
| 198 |
+
<ul class="bulleted-list">
|
| 199 |
+
<li style="list-style-type:disc">Applied quality and repetition filters from the <a
|
| 200 |
+
href="https://arxiv.org/abs/2112.11446">Gopher</a> paper (using the default thresholds)
|
| 201 |
+
</li>
|
| 202 |
+
</ul>
|
| 203 |
+
<p>After applying this filtering to each of the text
|
| 204 |
+
extracted dumps (there are currently 95 dumps) we obtained roughly 36 trillion tokens of data (when
|
| 205 |
+
tokenized with the <code>gpt2</code> tokenizer).</p>
|
| 206 |
+
<h2>Deduplication</h2>
|
| 207 |
+
<p>Deduplication is another important step, specially for web
|
| 208 |
+
datasets. Methods to deduplicate datasets attempt to remove redundant/repeated data. Deduplication is one of
|
| 209 |
+
the most important steps when creating large web datasets for LLMs.</p>
|
| 210 |
+
<h3>Why deduplicate?</h3>
|
| 211 |
+
<p>The web has many aggregators, mirrors, templated pages or
|
| 212 |
+
just otherwise repeated content spread over different domains and webpages. Often, these duplicated pages
|
| 213 |
+
can be introduced by the crawler itself, when different links point to the same page. </p>
|
| 214 |
+
<p>Removing these duplicates (deduplicating) has been <a
|
| 215 |
+
href="https://arxiv.org/abs/2107.06499">linked to an improvement in model performance</a> and a <a
|
| 216 |
+
href="https://arxiv.org/abs/2202.07646">reduction in memorization of pretraining data</a>, which might
|
| 217 |
+
allow for better generalization. Additionally, the performance uplift can also be tied to increased training
|
| 218 |
+
efficiency: by removing duplicated content, for the same number of training tokens, a model will have seen
|
| 219 |
+
more diverse data.</p>
|
| 220 |
+
<p>There are different ways to identify and even define
|
| 221 |
+
duplicated data. Common approaches rely on hashing techniques to speed up the process, or on building
|
| 222 |
+
efficient data structures to index the data (like suffix arrays). Methods can also be “fuzzy”, by using some
|
| 223 |
+
similarity metric to mark documents as duplicates, or “exact” by checking for exact matches between two
|
| 224 |
+
documents (or lines, paragraphs, or whatever other granularity level being used).</p>
|
| 225 |
+
<h3>Our deduplication parameters</h3>
|
| 226 |
+
<p>Similarly to RefinedWeb, we decided to apply MinHash, a
|
| 227 |
+
fuzzy hash based deduplication technique. We chose to compute minhashes on each document’s 5-grams, using
|
| 228 |
+
112 hash functions in total, split into 14 buckets of 8 hashes each — targeting documents that are at least
|
| 229 |
+
75% similar. Documents with the same 8 minhashes in any bucket are considered a duplicate of each other.</p>
|
| 230 |
+
<p>This would mean that for two documents with a similarity (<code>s</code>)
|
| 231 |
+
of 0.7, 0.75, 0.8 and 0.85, the probability that they would be identified as duplicates would be 56%, 77%,
|
| 232 |
+
92% and 98.8% respectively (<code>1-(1-s^8)^14</code>). See the plot below for a match probability
|
| 233 |
+
comparison between our setup with 112 hashes and the one from RefinedWeb, with 9000 hashes, divided into 450
|
| 234 |
+
buckets of 20 hashes (that requires a substantially larger amount of compute resources):</p>
|
| 235 |
+
<figure class="image"><a
|
| 236 |
+
href="plots/minhash_parameters_comparison.png"><img style="width:567px"
|
| 237 |
+
src="plots/minhash_parameters_comparison.png"/></a>
|
| 238 |
+
</figure>
|
| 239 |
+
<p>While the high number of hash functions in RefinedWeb
|
| 240 |
+
allows for a steeper, more well defined cut off, we believe the compute and storage savings are a reasonable
|
| 241 |
+
trade off.</p>
|
| 242 |
+
<h3>More deduplication is always better, right?</h3>
|
| 243 |
+
<p>Our initial approach was to take the entire dataset (all
|
| 244 |
+
95 dumps) and deduplicate them as one big dataset using MinHash.</p>
|
| 245 |
+
<p>We did this in an iterative manner: starting with the most
|
| 246 |
+
recent dump (which at the time was 2023-50) and taking the oldest one last, we would deduplicate each dump
|
| 247 |
+
not only against itself but also by removing any matches with duplicates from the previously processed
|
| 248 |
+
dumps. </p>
|
| 249 |
+
<p>For instance, for the second most recent dump (2023-40 at
|
| 250 |
+
the time), we deduplicated it against the most recent one in addition to itself. In particular, the oldest
|
| 251 |
+
dump was deduplicated against all other dumps. As a result, more data was removed in the oldest dumps (last
|
| 252 |
+
to be deduplicated) than in the most recent ones.</p>
|
| 253 |
+
<p>Deduplicating the dataset in this manner resulted in 4
|
| 254 |
+
trillion tokens of data, but, quite surprisingly for us, when training on a randomly sampled 350 billion
|
| 255 |
+
tokens subset, the model showed no improvement over one trained on the non deduplicated data (see orange and
|
| 256 |
+
green curve below), scoring far below its predecessor RefinedWeb on our aggregate of tasks.</p>
|
| 257 |
+
<figure class="image"><a href="plots/dedup_all_dumps_bad.png"><img
|
| 258 |
+
style="width:576px" src="plots/dedup_all_dumps_bad.png"/></a></figure>
|
| 259 |
+
<p>This was quite puzzling as our intuition regarding web
|
| 260 |
+
data was that more deduplication would always result in improved performance. We decided to take a closer
|
| 261 |
+
look at one of the oldest dumps, dump 2013-48:</p>
|
| 262 |
+
<ul class="bulleted-list">
|
| 263 |
+
<li style="list-style-type:disc">pre deduplication, this dump had ~490 billion tokens</li>
|
| 264 |
+
</ul>
|
| 265 |
+
<ul class="bulleted-list">
|
| 266 |
+
<li style="list-style-type:disc">after our iterative MinHash, ~31 billion tokens remained (94% of data
|
| 267 |
+
removed)
|
| 268 |
+
</li>
|
| 269 |
+
</ul>
|
| 270 |
+
<p>As an experiment, we tried training two models on 28BT
|
| 271 |
+
sampled from the following data from 2013-48:</p>
|
| 272 |
+
<ul class="bulleted-list">
|
| 273 |
+
<li style="list-style-type:disc">the fully deduplicated remaining ~31 billion tokens (<em>originally kept
|
| 274 |
+
data</em>)
|
| 275 |
+
</li>
|
| 276 |
+
</ul>
|
| 277 |
+
<ul class="bulleted-list">
|
| 278 |
+
<li style="list-style-type:disc">171 billion tokens obtained by individually deduplicating (without
|
| 279 |
+
considering the other dumps) the ~460 billion tokens that had been removed from this dump in the
|
| 280 |
+
iterative dedup process (<em>originally removed data</em>)
|
| 281 |
+
</li>
|
| 282 |
+
</ul>
|
| 283 |
+
<figure class="image"><a
|
| 284 |
+
href="plots/removed_data_cross_dedup.png"><img style="width:576px"
|
| 285 |
+
src="plots/removed_data_cross_dedup.png"/></a></figure>
|
| 286 |
+
<p>These results show that, for this older dump where we were
|
| 287 |
+
removing over 90% of the original data, the data that was kept was actually <em>worse</em> than the data
|
| 288 |
+
removed (considered independently from all the other dumps).</p>
|
| 289 |
+
<h3>Taking a step back: individual dump dedup</h3>
|
| 290 |
+
<p>We then tried an alternative approach: we deduplicated
|
| 291 |
+
each dump with MinHash individually (without considering the other dumps). This resulted in 20 trillion
|
| 292 |
+
tokens of data.</p>
|
| 293 |
+
<p>When training on a random sample from this dataset we see
|
| 294 |
+
that it now matches RefinedWeb’s performance (blue and red curves below):</p>
|
| 295 |
+
<figure class="image"><a
|
| 296 |
+
href="plots/cross_ind_unfiltered_comparison.png"><img style="width:576px"
|
| 297 |
+
src="plots/cross_ind_unfiltered_comparison.png"/></a>
|
| 298 |
+
</figure>
|
| 299 |
+
<p>We hypothesis that the main improvement gained from
|
| 300 |
+
deduplication is the removal of very large clusters that are present in every single dump (you will find
|
| 301 |
+
some examples of these clusters on the RefinedWeb paper, each containing <em>hundreds of thousands</em> of
|
| 302 |
+
documents) and that further deduplication for low number of deduplications (less than ~100 i.e. the number
|
| 303 |
+
of dumps) actually harm performance: data that does not find a duplicate match in any other dump might
|
| 304 |
+
actually be worse quality/more out of distribution (as evidenced by the results on the 2013-48 data). </p>
|
| 305 |
+
<p>While you might see some performance improvement when
|
| 306 |
+
deduplicating a few dumps together, at the scale of all the dumps this upsampling of lower quality data side
|
| 307 |
+
effect seems to have a great impact.</p>
|
| 308 |
+
<p>One possibility to consider is that as filtering quality
|
| 309 |
+
improves, this effect may not be as prevalent, since the filtering might be able to remove some of this
|
| 310 |
+
lower quality data. We also experimented with applying different, and often “lighter”, deduplication
|
| 311 |
+
approaches on top of the individually deduplicated dumps. You can read about them further below.</p>
|
| 312 |
+
<h3>A note on measuring the effect of deduplication</h3>
|
| 313 |
+
<p>Given the nature of deduplication, its effect is not
|
| 314 |
+
always very visible in a smaller slice of the dataset (such as 28B tokens, the size we used for our
|
| 315 |
+
filtering ablations). Furthermore, one must consider the fact that there are specific effects at play when
|
| 316 |
+
deduplicating across all CommonCrawl dumps, as some URLs/pages are recrawled from one dump to the next.</p>
|
| 317 |
+
<p>To visualize the effect of scaling the number of training
|
| 318 |
+
tokens on measuring deduplication impact, we considered the following (very extreme and unrealistic
|
| 319 |
+
regarding the degree of duplication observed) theoretical scenario:</p>
|
| 320 |
+
<ul class="bulleted-list">
|
| 321 |
+
<li style="list-style-type:disc">there are 100 CommonCrawl dumps (actually roughly true)</li>
|
| 322 |
+
</ul>
|
| 323 |
+
<ul class="bulleted-list">
|
| 324 |
+
<li style="list-style-type:disc">each dump has been perfectly individually deduplicated (every single
|
| 325 |
+
document in it is unique)
|
| 326 |
+
</li>
|
| 327 |
+
</ul>
|
| 328 |
+
<ul class="bulleted-list">
|
| 329 |
+
<li style="list-style-type:disc">each dump is a perfect copy of each other (maximum possible duplication
|
| 330 |
+
across dumps, effectively the worst case scenario)
|
| 331 |
+
</li>
|
| 332 |
+
</ul>
|
| 333 |
+
<ul class="bulleted-list">
|
| 334 |
+
<li style="list-style-type:disc">each dump has 200 billion tokens (for a total of 20 trillion, the resulting
|
| 335 |
+
size of our individual dedup above)
|
| 336 |
+
</li>
|
| 337 |
+
</ul>
|
| 338 |
+
<ul class="bulleted-list">
|
| 339 |
+
<li style="list-style-type:disc">each dump is made up of documents of 1k tokens (200M documents per dump)
|
| 340 |
+
</li>
|
| 341 |
+
</ul>
|
| 342 |
+
<p>We then simulated uniformly sampling documents from this
|
| 343 |
+
entire dataset of 20 trillion tokens, to obtain subsets of 1B, 10B, 100B, 350B and 1T tokens. In the image
|
| 344 |
+
below you can see how often each document would be repeated.</p>
|
| 345 |
+
<figure class="image"><a href="plots/dedup_impact_simulation.png"><img
|
| 346 |
+
style="width:708px" src="plots/dedup_impact_simulation.png"/></a></figure>
|
| 347 |
+
<p>For 1B almost all documents would be unique
|
| 348 |
+
(#duplicates=1), despite the fact that in the entire dataset each document is repeated 100 times (once per
|
| 349 |
+
dump). We start seeing some changes at the 100B scale (0.5% of the total dataset), with a large number of
|
| 350 |
+
documents being repeated twice, and a few even 4-8 times. At the larger scale of 1T (5% of the total
|
| 351 |
+
dataset), the majority of the documents are repeated up to 8 times, with a some being repeated up to 16
|
| 352 |
+
times. </p>
|
| 353 |
+
<p>We ran our performance evaluations for the deduplicated
|
| 354 |
+
data at the 350B scale, which would, under this theoretical scenario, be made up of a significant portion of
|
| 355 |
+
documents duplicated up to 8 times. This simulation illustrates the inherent difficulties associated with
|
| 356 |
+
measuring deduplication impact on the training of LLMs, once the biggest document clusters have been
|
| 357 |
+
removed.</p>
|
| 358 |
+
<h3>Other (failed) approaches</h3>
|
| 359 |
+
<p>We attempted to improve the performance of the
|
| 360 |
+
independently minhash deduped 20T of data by further deduplicating it with the following methods</p>
|
| 361 |
+
<ul class="bulleted-list">
|
| 362 |
+
<li style="list-style-type:disc">URL deduplication, where we only kept one document per normalized
|
| 363 |
+
(lowercased) URL (71.5% of tokens removed, 5.6T left) — <em>FineWeb URL dedup</em></li>
|
| 364 |
+
</ul>
|
| 365 |
+
<ul class="bulleted-list">
|
| 366 |
+
<li style="list-style-type:disc">Line deduplication:
|
| 367 |
+
<ul class="bulleted-list">
|
| 368 |
+
<li style="list-style-type:circle">remove all but 1 occurrence of each duplicated line (77.8% of
|
| 369 |
+
tokens dropped, 4.4T left) — <em>FineWeb line dedup</em></li>
|
| 370 |
+
</ul>
|
| 371 |
+
<ul class="bulleted-list">
|
| 372 |
+
<li style="list-style-type:circle">same as above, but only removing duplicate lines with at least 10
|
| 373 |
+
words and dropping documents with fewer than 3 sentences after deduplication (85% of tokens
|
| 374 |
+
dropped, 2.9T left) — <em>FineWeb line dedup w/ min words</em></li>
|
| 375 |
+
</ul>
|
| 376 |
+
<ul class="bulleted-list">
|
| 377 |
+
<li style="list-style-type:circle">remove all but 1 occurrence of each span of 3 duplicated lines
|
| 378 |
+
with all numbers replaced by 0 (80.9% of tokens removed, 3.7T left) — <em>FineWeb 3-line
|
| 379 |
+
dedup</em></li>
|
| 380 |
+
</ul>
|
| 381 |
+
</li>
|
| 382 |
+
</ul>
|
| 383 |
+
<p>The performance of the models trained on each of these was
|
| 384 |
+
consistently worse (even if to different degrees) than that of the original independently deduplicated
|
| 385 |
+
data:</p>
|
| 386 |
+
<figure class="image"><a href="plots/Untitled.png"><img
|
| 387 |
+
style="width:708px" src="plots/Untitled.png"/></a></figure>
|
| 388 |
+
<h2>Additional filtering</h2>
|
| 389 |
+
<p>By this point we had reached the same performance as
|
| 390 |
+
RefinedWeb, but on our aggregate of tasks, another heavily filtered dataset, <a
|
| 391 |
+
href="https://arxiv.org/abs/1910.10683">the C4 dataset</a>, still showed stronger performance (with
|
| 392 |
+
the caveat that it is a relatively small dataset for current web-scale standards).</p>
|
| 393 |
+
<p>We therefore set out to find new filtering steps that
|
| 394 |
+
would, at first, allow us to match the performance of C4 and eventually surpass it. A natural starting point
|
| 395 |
+
was to look into the processing of C4 itself.</p>
|
| 396 |
+
<h3>C4: A dataset that has stood the test of time</h3>
|
| 397 |
+
<p>The <a href="https://huggingface.co/datasets/c4">C4
|
| 398 |
+
dataset</a> was first released in 2019. It was obtained from the <code>2019-18</code> CommonCrawl dump by
|
| 399 |
+
removing non english data, applying some heuristic filters on both the line and document level,
|
| 400 |
+
deduplicating on the line level and removing documents containing words from a word blocklist.</p>
|
| 401 |
+
<p>Despite its age and limited size (around 175B gpt2
|
| 402 |
+
tokens), models trained on this dataset have strong performance, excelling in particular on the Hellaswag
|
| 403 |
+
benchmark, one of the benchmarks in our “early signal” group with the stronger signal and highest
|
| 404 |
+
signal-over-noise ratio. As such, it has stayed a common sub-set of typical LLM training, for instance in in
|
| 405 |
+
<a href="https://arxiv.org/abs/2302.13971">the relatively recent Llama1 model</a>. We experimented applying
|
| 406 |
+
each of the different filters used in C4 to a baseline of the independently deduped FineWeb 2019-18 dump
|
| 407 |
+
(plot smoothed with a 3 checkpoints sliding window):</p>
|
| 408 |
+
<figure class="image"><a href="plots/c4_filters.png"><img
|
| 409 |
+
style="width:708px" src="plots/c4_filters.png"/></a></figure>
|
| 410 |
+
<ul class="bulleted-list">
|
| 411 |
+
<li style="list-style-type:disc">applying “All filters” (drop lines not ending on punctuation marks,
|
| 412 |
+
mentioning javascript and cookie notices + drop documents outside length thresholds, containing “lorem
|
| 413 |
+
ipsum” or a curly bracket, <code>{</code>) allows us to match C4’s HellaSwag performance (purple versus
|
| 414 |
+
pink curves).
|
| 415 |
+
</li>
|
| 416 |
+
</ul>
|
| 417 |
+
<ul class="bulleted-list">
|
| 418 |
+
<li style="list-style-type:disc">The curly bracket filter, and the word lengths filter only give a small
|
| 419 |
+
boost, removing 2.8% and 4.3% of tokens, respectively
|
| 420 |
+
</li>
|
| 421 |
+
</ul>
|
| 422 |
+
<ul class="bulleted-list">
|
| 423 |
+
<li style="list-style-type:disc">The terminal punctuation filter, by itself, gives the biggest individual
|
| 424 |
+
boost, but removes <em>around 30%</em> of all tokens (!)
|
| 425 |
+
</li>
|
| 426 |
+
</ul>
|
| 427 |
+
<ul class="bulleted-list">
|
| 428 |
+
<li style="list-style-type:disc">The lorem_ipsum, javascript and policy rules each remove <0.5% of
|
| 429 |
+
training tokens, so we did not train on them individually
|
| 430 |
+
</li>
|
| 431 |
+
</ul>
|
| 432 |
+
<ul class="bulleted-list">
|
| 433 |
+
<li style="list-style-type:disc">All filters except the very destructive terminal_punct perform better than
|
| 434 |
+
terminal_punct by itself, while removing less in total (~7%)
|
| 435 |
+
</li>
|
| 436 |
+
</ul>
|
| 437 |
+
<p>We decided to apply all C4 filters mentioned above except
|
| 438 |
+
the terminal punctuation one. We validated these results with a longer run, which you will find in a plot in
|
| 439 |
+
the next section.</p>
|
| 440 |
+
<h3>A statistical approach to develop heuristic filters</h3>
|
| 441 |
+
<p>To come up with new possible filtering rules, we collected
|
| 442 |
+
a very large list of statistics (statistical metrics) — over <strong>50</strong> �� from different reference
|
| 443 |
+
datasets (C4, RefinedWeb, etc) and from a select list of our processed dumps, on both the independently
|
| 444 |
+
minhashed version and the result from the (worse quality) full dedup. This allowed us to compare the
|
| 445 |
+
different datasets at a macro level, by looking at the distribution of these metrics for each one.</p>
|
| 446 |
+
<p>The collected statistics ranged from common document-level
|
| 447 |
+
metrics (e.g. number of lines, avg. line/word length, etc) to inter-document repetition metrics (gopher
|
| 448 |
+
inspired). Perhaps not too surprisingly given our findings for deduplication, we found significant
|
| 449 |
+
disparities in most of the metrics for the two deduplication methods. For instance, the <code>line-char-duplicates</code>
|
| 450 |
+
metric (nb. of characters in duplicated lines / nb. characters), roughly doubled from the independent dedup
|
| 451 |
+
(0.0053 for 2015-22 and 0.0058 for 2013-48), to the full dedup (0.011 for 2015-22 and 0.01 for 2013-48),
|
| 452 |
+
indicating that the latter had higher inter-document repetition.</p>
|
| 453 |
+
<p>Working under the assumption that these differences were
|
| 454 |
+
caused by lower quality data on the full dedup version, we inspected histograms and manually defined
|
| 455 |
+
thresholds for the metrics where these differences were starker. This process yielded 17 candidate
|
| 456 |
+
threshold-filter pairs. In the image below, you can see 3 of these histograms.</p>
|
| 457 |
+
<figure class="image"><a href="plots/Untitled%201.png"><img
|
| 458 |
+
style="width:790px" src="plots/Untitled%201.png"/></a></figure>
|
| 459 |
+
|
| 460 |
+
<p>To assess the effectiveness of these newly created
|
| 461 |
+
filters, we conducted <strong>28B tokens </strong>ablation runs on the <strong>2019-18 crawl</strong>. Out
|
| 462 |
+
of all those runs, we identified three filters (the ones based on the histograms above) that demonstrated
|
| 463 |
+
the most significant improvements on the aggregate score:</p>
|
| 464 |
+
<ul class="bulleted-list">
|
| 465 |
+
<li style="list-style-type:disc">Remove documents where the fraction of lines ending with punctuation ≤ 0.12
|
| 466 |
+
(10.14% of tokens removed) — vs the 30% from the original C4 terminal punct filter
|
| 467 |
+
</li>
|
| 468 |
+
</ul>
|
| 469 |
+
<ul class="bulleted-list">
|
| 470 |
+
<li style="list-style-type:disc">Remove documents where the fraction of characters in duplicated lines ≥ 0.1
|
| 471 |
+
(12.47% of tokens removed) — the original Gopher threshold for this ratio is ≥ 0.2
|
| 472 |
+
</li>
|
| 473 |
+
</ul>
|
| 474 |
+
<ul class="bulleted-list">
|
| 475 |
+
<li style="list-style-type:disc">Remove documents where the fraction of lines shorter than 30 characters ≥
|
| 476 |
+
0.67 (3.73% of tokens removed)
|
| 477 |
+
</li>
|
| 478 |
+
</ul>
|
| 479 |
+
<ul class="bulleted-list">
|
| 480 |
+
<li style="list-style-type:disc">When applying the 3 together, ~22% of tokens were removed</li>
|
| 481 |
+
</ul>
|
| 482 |
+
<figure class="image"><a href="plots/Untitled%202.png"><img
|
| 483 |
+
style="width:708px" src="plots/Untitled%202.png"/></a></figure>
|
| 484 |
+
<hr />
|
| 485 |
+
<h1>The final dataset</h1>
|
| 486 |
+
<p>The final FineWeb dataset comprises 15T tokens and
|
| 487 |
+
includes the following previously mentioned steps, in order, each providing a performance boost on our group
|
| 488 |
+
of benchmark tasks:</p>
|
| 489 |
+
<ul class="bulleted-list">
|
| 490 |
+
<li style="list-style-type:disc">base filtering</li>
|
| 491 |
+
</ul>
|
| 492 |
+
<ul class="bulleted-list">
|
| 493 |
+
<li style="list-style-type:disc">independent MinHash deduplication per dump</li>
|
| 494 |
+
</ul>
|
| 495 |
+
<ul class="bulleted-list">
|
| 496 |
+
<li style="list-style-type:disc">a selection of C4 filters</li>
|
| 497 |
+
</ul>
|
| 498 |
+
<ul class="bulleted-list">
|
| 499 |
+
<li style="list-style-type:disc">our custom filters (mentioned in the previous section)</li>
|
| 500 |
+
</ul>
|
| 501 |
+
<figure class="image"><a href="plots/fineweb_all_filters.png"><img
|
| 502 |
+
style="width:708px" src="plots/fineweb_all_filters.png"/></a></figure>
|
| 503 |
+
<p>We compared 🍷 FineWeb with the following datasets:</p>
|
| 504 |
+
<ul class="bulleted-list">
|
| 505 |
+
<li style="list-style-type:disc"><a
|
| 506 |
+
href="https://huggingface.co/datasets/tiiuae/falcon-refinedweb">RefinedWeb</a>
|
| 507 |
+
</li>
|
| 508 |
+
</ul>
|
| 509 |
+
<ul class="bulleted-list">
|
| 510 |
+
<li style="list-style-type:disc"><a href="https://huggingface.co/datasets/allenai/c4">C4</a></li>
|
| 511 |
+
</ul>
|
| 512 |
+
<ul class="bulleted-list">
|
| 513 |
+
<li style="list-style-type:disc"><a href="https://huggingface.co/datasets/allenai/dolma">Dolma v1.6</a> (the
|
| 514 |
+
CommonCrawl part)
|
| 515 |
+
</li>
|
| 516 |
+
</ul>
|
| 517 |
+
<ul class="bulleted-list">
|
| 518 |
+
<li style="list-style-type:disc"><a href="https://huggingface.co/datasets/EleutherAI/pile">The Pile</a></li>
|
| 519 |
+
</ul>
|
| 520 |
+
<ul class="bulleted-list">
|
| 521 |
+
<li style="list-style-type:disc"><a
|
| 522 |
+
href="https://huggingface.co/datasets/cerebras/SlimPajama-627B">SlimPajama</a>
|
| 523 |
+
</li>
|
| 524 |
+
</ul>
|
| 525 |
+
<ul class="bulleted-list">
|
| 526 |
+
<li style="list-style-type:disc"><a
|
| 527 |
+
href="https://huggingface.co/datasets/togethercomputer/RedPajama-Data-V2">RedPajama2</a>
|
| 528 |
+
(deduplicated)
|
| 529 |
+
</li>
|
| 530 |
+
</ul>
|
| 531 |
+
<p>You will find these models on <a
|
| 532 |
+
href="https://huggingface.co/collections/HuggingFaceFW/ablation-models-662457b0d213e8c14fe47f32">this
|
| 533 |
+
collection</a>. We have uploaded checkpoints at every 1000 training steps. You will also find our full <a
|
| 534 |
+
href="https://huggingface.co/datasets/HuggingFaceFW/fineweb/blob/main/eval_results.csv">evaluation
|
| 535 |
+
results here</a>.</p>
|
| 536 |
+
<figure class="image"><a href="plots/fineweb_ablations.png"><img
|
| 537 |
+
style="width:708px" src="plots/fineweb_ablations.png"/></a></figure>
|
| 538 |
+
<p>Some histogram comparisons of C4, Dolma, RefinedWeb and
|
| 539 |
+
FineWeb:</p>
|
| 540 |
+
<figure class="image"><a href="plots/Untitled%203.png"><img
|
| 541 |
+
style="width:4587px" src="plots/Untitled%203.png"/></a></figure>
|
| 542 |
+
<hr />
|
| 543 |
+
<h1>Just like fine wine, not all crawls are created
|
| 544 |
+
equal</h1>
|
| 545 |
+
<p>During our ablation runs, we observed that certain crawls
|
| 546 |
+
outperformed others by a significant margin. To investigate this phenomenon, we conducted 27B token runs for
|
| 547 |
+
each dump (we used the version with base filtering + ind dedup), with 2 trainings per dump, where each used
|
| 548 |
+
a different data subset. We trained 190 such models, totaling over 60k H100 GPU-hours. We subsequently took
|
| 549 |
+
the last 3 checkpoints for both seeds and plotted the average of these 6 data points per dump. </p>
|
| 550 |
+
<p>The plot below clearly shows that some dumps perform far
|
| 551 |
+
worse than others. Each year has a different color, and the number of crawls per year also changes.</p>
|
| 552 |
+
<figure class="image"><a href="plots/score_by_dump.png"><img
|
| 553 |
+
style="width:708px" src="plots/score_by_dump.png"/></a></figure>
|
| 554 |
+
<p>We identified 5 main relevant time intervals:</p>
|
| 555 |
+
<ul class="bulleted-list">
|
| 556 |
+
<li style="list-style-type:disc">2013 to 2016: relatively stable, average quality</li>
|
| 557 |
+
</ul>
|
| 558 |
+
<ul class="bulleted-list">
|
| 559 |
+
<li style="list-style-type:disc">2017 to 2018: high quality, with a drop by the end of 2018</li>
|
| 560 |
+
</ul>
|
| 561 |
+
<ul class="bulleted-list">
|
| 562 |
+
<li style="list-style-type:disc">2019 to 2021: high quality, steadily increase</li>
|
| 563 |
+
</ul>
|
| 564 |
+
<ul class="bulleted-list">
|
| 565 |
+
<li style="list-style-type:disc">2021-49 and 2022: very large drop in performance, followed by worse quality
|
| 566 |
+
dumps
|
| 567 |
+
</li>
|
| 568 |
+
</ul>
|
| 569 |
+
<ul class="bulleted-list">
|
| 570 |
+
<li style="list-style-type:disc">2023 and 2024-10: almost exponential improvement. In particular, 2023-50
|
| 571 |
+
and 2024-10 are by far the best dumps
|
| 572 |
+
</li>
|
| 573 |
+
</ul>
|
| 574 |
+
<p>One possibility to improve performance when training
|
| 575 |
+
models on < 15T would be to train on FineWeb while excluding the worst quality CommonCrawl dumps.</p>
|
| 576 |
+
<p>We conducted further analysis to investigate the factors
|
| 577 |
+
causing these differences from dump to dump. In particular, we considered 3 potential causes: </p>
|
| 578 |
+
<ul class="bulleted-list">
|
| 579 |
+
<li style="list-style-type:disc">large sudden changes in the list of crawled URLs;</li>
|
| 580 |
+
</ul>
|
| 581 |
+
<ul class="bulleted-list">
|
| 582 |
+
<li style="list-style-type:disc">synthetic (LLM generated) data;</li>
|
| 583 |
+
</ul>
|
| 584 |
+
<ul class="bulleted-list">
|
| 585 |
+
<li style="list-style-type:disc">benchmark contamination;</li>
|
| 586 |
+
</ul>
|
| 587 |
+
<p>We go over each one in the following sections.</p>
|
| 588 |
+
<h3>Changes in the most frequent URLs [HAVE TO RECHECK]</h3>
|
| 589 |
+
<p>For each crawl from 2021-10 onwards, we gathered a list of
|
| 590 |
+
the 60k most frequent <strong>FQDNs</strong> (fully qualified domain name). We then calculated the <a
|
| 591 |
+
href="https://en.wikipedia.org/wiki/Jaccard_index">Jaccard similarity</a> between consecutive
|
| 592 |
+
crawls. A high value means that a crawl/dump has many of the same FQDNs as the dump immediately preceding
|
| 593 |
+
it, while a small value means that a considerable number of top 60k FQDNs were downsampled or removed, or
|
| 594 |
+
that alternatively new FQDNs were added to the top 60k.</p>
|
| 595 |
+
<figure class="image"><a href="plots/Untitled%204.png"><img
|
| 596 |
+
style="width:5026px" src="plots/Untitled%204.png"/></a></figure>
|
| 597 |
+
<p>The data indicates three significant changes:
|
| 598 |
+
2021-43/2021-49, 2022-33/2022-40, and 2023-40/2023-50.</p>
|
| 599 |
+
<p>The explanation for the changes between 2022-33/2022-40
|
| 600 |
+
and 2023-40/2023-50 is straightforward: CommonCrawl accidentally did not index several popular suffixes,
|
| 601 |
+
such as .co.uk, as documented on <a href="https://commoncrawl.org/errata/co-uk-cctld-not-included">this
|
| 602 |
+
erratum</a>. This particular change does not seem particularly correlated on the overall dump quality.
|
| 603 |
+
</p>
|
| 604 |
+
<p>As to the shift from 2021-43 to 2021-49, which coincides
|
| 605 |
+
with a sharp performance drop, roughly half (~30k) of the former’s top 60k FQDNs are not present in the
|
| 606 |
+
latter’s list of top 60k FQDNs, and the dump size itself also decreased (19% reduction in WARC size, and a
|
| 607 |
+
28% token reduction after deduplication). </p>
|
| 608 |
+
<p>We were unable to find a clear reason for this drastic
|
| 609 |
+
change, but upon reaching out to CommonCrawl, we were informed that these differences likely stem from a
|
| 610 |
+
major update in adult content and malicious site blocking. It is therefore possible that the new updated
|
| 611 |
+
adult site filter could have also removed a high number of high quality domains resulting in poor
|
| 612 |
+
performance of the crawl. <strong>[TODO: change this framing a bit, it seems to suggest adult content is
|
| 613 |
+
high quality for LLMs]</strong></p>
|
| 614 |
+
<h3>Synthetic data contamination [HAVE TO RECHECK]</h3>
|
| 615 |
+
<p>Secondly, we wondered if part of the changes in
|
| 616 |
+
performance on recent dumps could be attributed to the presence of a larger quantity of synthetic data (data
|
| 617 |
+
generated by LLMs). Such a change would not be surprising due to the recent increase in popularity of LLMs,
|
| 618 |
+
notably of ChatGPT.</p>
|
| 619 |
+
<p>Since, to the best of our knowledge, there is no fool
|
| 620 |
+
proof method to detect synthetic data, we opted to use a proxy metric: we measured the frequency of the
|
| 621 |
+
following words: <code>delve, as a large language model, it's important to note, rich tapestry,
|
| 622 |
+
intertwined, certainly!, dive into</code>, which are words commonly used by ChatGPT.</p>
|
| 623 |
+
<p>It is important to note that not all samples containing
|
| 624 |
+
one of these phrases were necessarily generated by ChatGPT (and also that many ChatGPT generated samples do
|
| 625 |
+
not contain any of these phrases), but assuming that the amount of synthetic data were to not change across
|
| 626 |
+
dumps, one would expect these frequencies to remain approximately constant over time.</p>
|
| 627 |
+
<p>The results are shown in the following graph:</p>
|
| 628 |
+
<figure class="image"><a href="plots/Untitled%205.png"><img
|
| 629 |
+
style="width:4156px" src="plots/Untitled%205.png"/></a></figure>
|
| 630 |
+
<p>While the frequency remained approximately constant until
|
| 631 |
+
2023-14 (ChatGPT was released at the end of 2022), not only do we find a steep increase of our proxy metric
|
| 632 |
+
in recent crawls, as the proxy metric also correlates well with the agg score, with a pearson correlation of
|
| 633 |
+
<strong>0.590</strong>. It is therefore possible that synthetic data has positively impacted performance in
|
| 634 |
+
our selected tasks for these most recent dumps (with all limitations in interpretation from a single
|
| 635 |
+
correlation measurement without intervention of randomization or any causality tools being used here). In
|
| 636 |
+
particular, it could explain why the 2023-50 and 2024-10 dumps have such a strong performance. </p>
|
| 637 |
+
<h3>Benchmarks contamination [HAVE TO RECHECK]</h3>
|
| 638 |
+
<p>Also, most of our used benchmarks were introduced around
|
| 639 |
+
<strong>2019</strong>. It’s thus possible that the 2019-XX 2021-43 performance increase might be caused by
|
| 640 |
+
higher benchmark contamination in those crawls. Similarly, the recent increase in LLM popularity and
|
| 641 |
+
evaluations, might have increased the contamination in recent benchmarks, explaining the score improvements
|
| 642 |
+
of the two most recent crawls. <strong>[NOTE: the plot does not seem to support this at all]</strong></p>
|
| 643 |
+
|
| 644 |
+
<figure class="image"><a href="plots/Untitled%206.png"><img
|
| 645 |
+
style="width:708px" src="plots/Untitled%206.png"/></a></figure>
|
| 646 |
+
<hr />
|
| 647 |
+
<h1>Next steps</h1>
|
| 648 |
+
<p>We want to continue improving FineWeb and will also
|
| 649 |
+
release a technical report with more details soon.</p>
|
| 650 |
+
<p>Adapting the FineWeb recipe [wip]</p>
|
| 651 |
+
</d-article>
|
| 652 |
+
|
| 653 |
+
<d-appendix>
|
| 654 |
+
|
| 655 |
+
<h3>Contributions</h3>
|
| 656 |
+
<p>Some text describing who did what.</p>
|
| 657 |
+
<h3>Reviewers</h3>
|
| 658 |
+
<p>Some text with links describing who reviewed the article.</p>
|
| 659 |
+
|
| 660 |
+
<d-bibliography src="bibliography.bib"></d-bibliography>
|
| 661 |
+
</d-appendix>
|
| 662 |
+
</body>
|
plots/FineWeb.png
ADDED

|
plots/Untitled 1.png
ADDED

|
plots/Untitled 2.png
ADDED
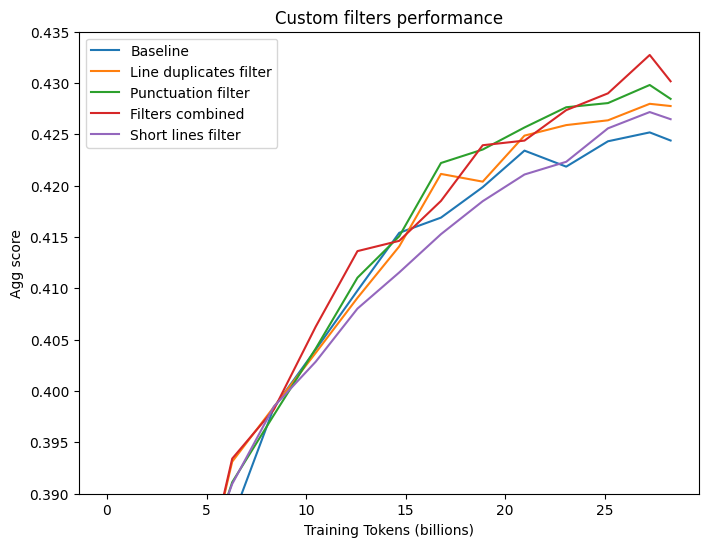
|
plots/Untitled 3.png
ADDED
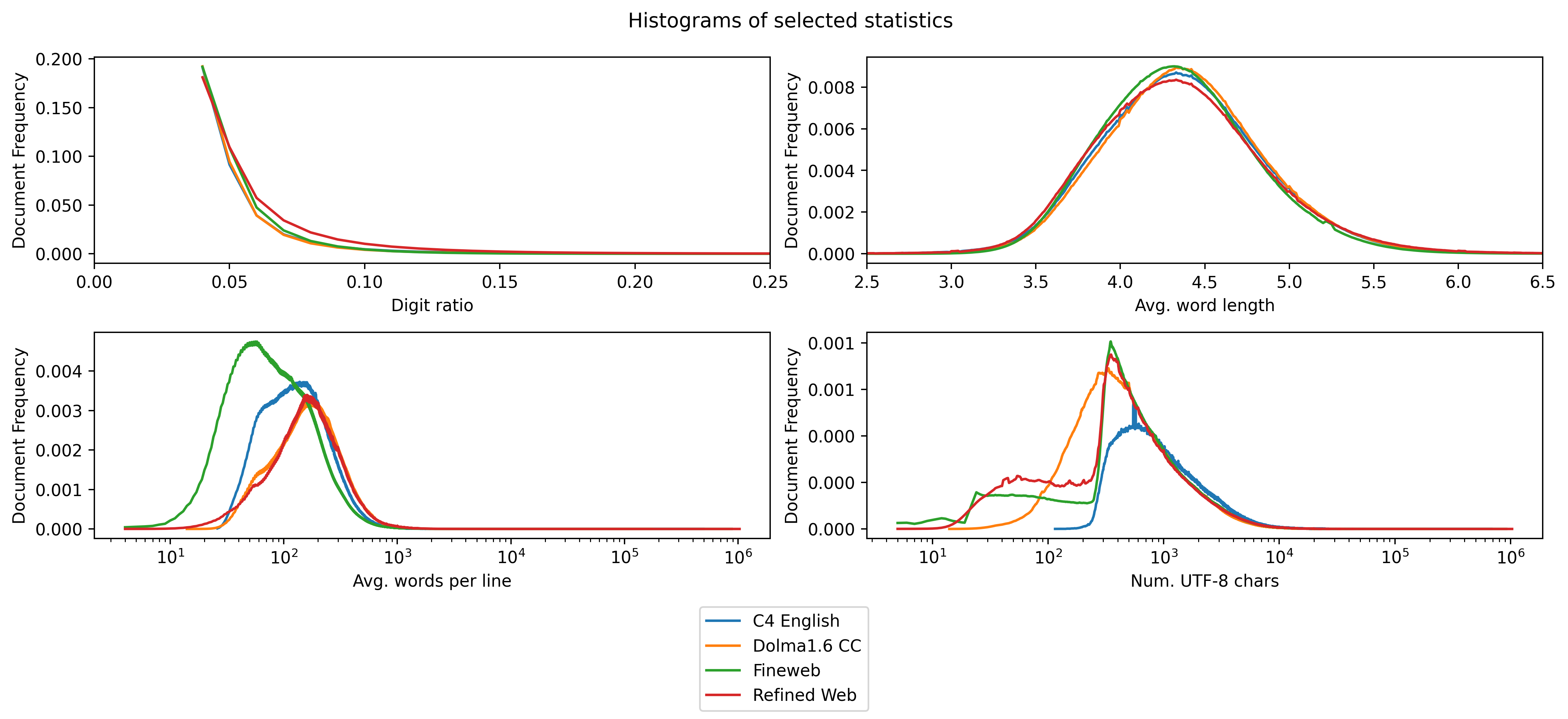
|
plots/Untitled 4.png
ADDED
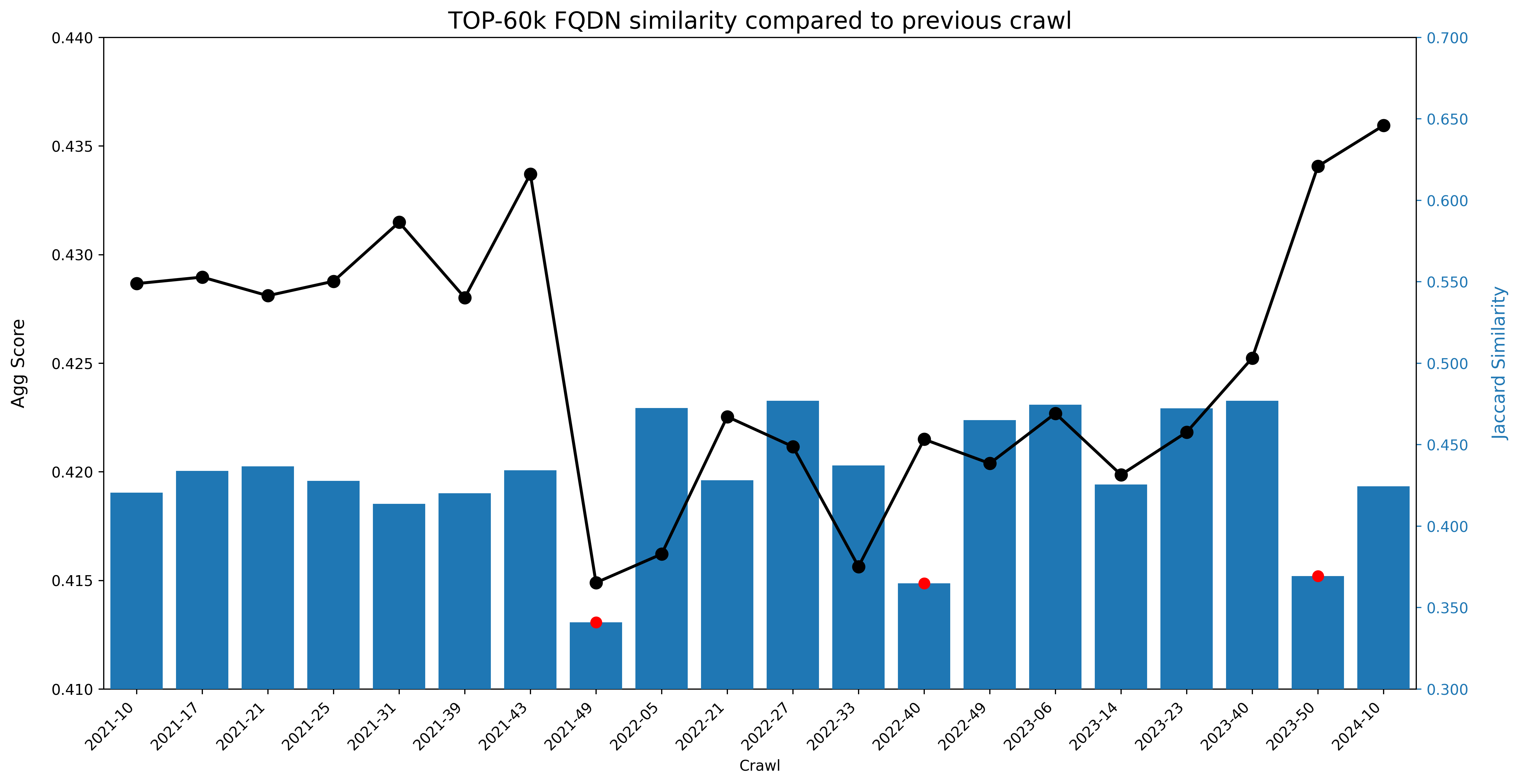
|
plots/Untitled 5.png
ADDED

|
plots/Untitled 6.png
ADDED

|
plots/Untitled.png
ADDED

|
plots/c4_filters.png
ADDED

|
plots/cross_ind_unfiltered_comparison.png
ADDED

|
plots/dedup_all_dumps_bad.png
ADDED
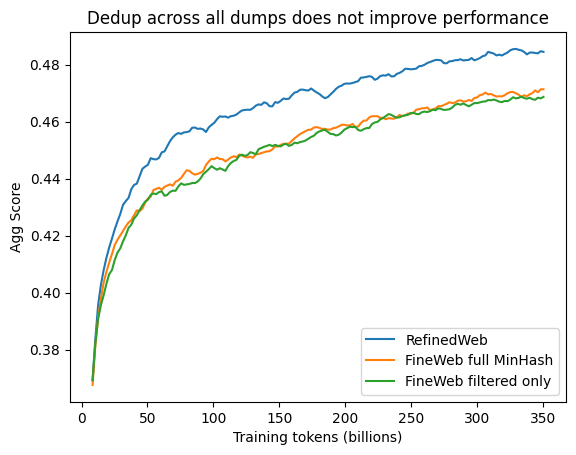
|
plots/dedup_impact_simulation.png
ADDED

|
plots/fineweb-recipe.png
ADDED
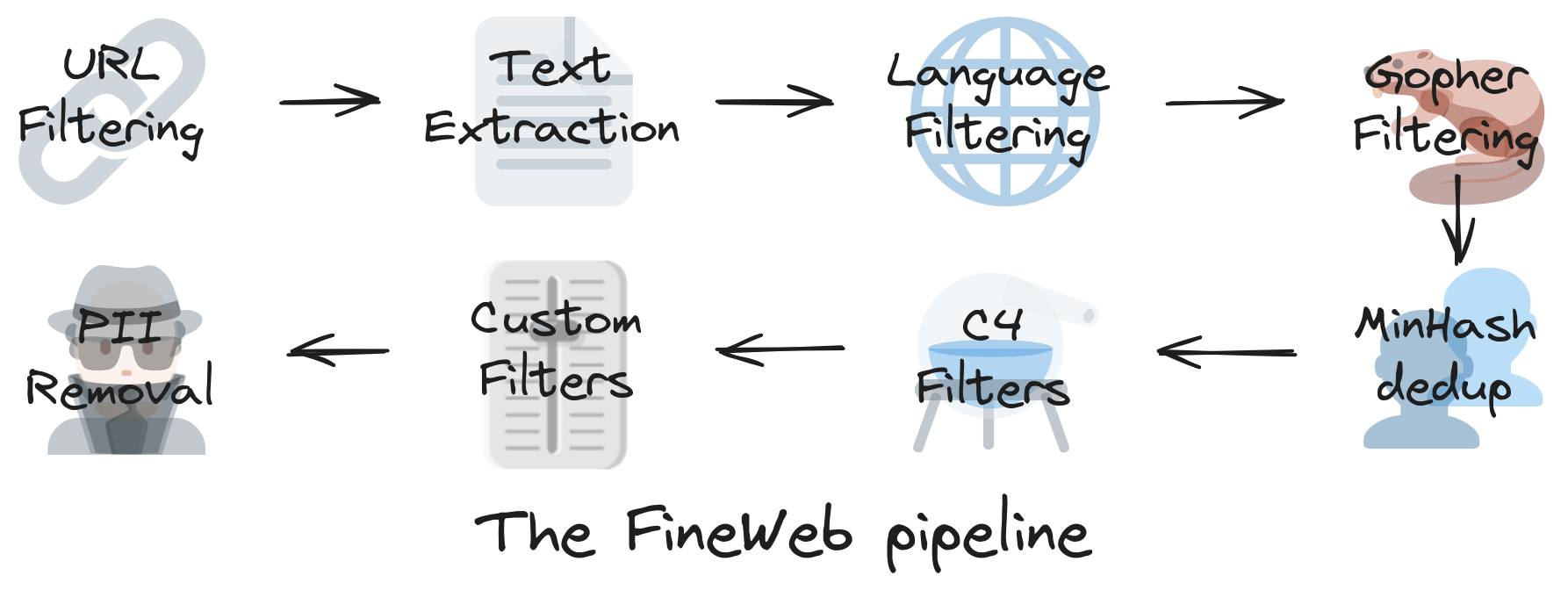
|
plots/fineweb_ablations.png
ADDED

|
plots/fineweb_all_filters.png
ADDED

|
plots/minhash_parameters_comparison.png
ADDED

|
plots/removed_data_cross_dedup.png
ADDED

|
plots/score_by_dump.png
ADDED
|
plots/wet_comparison.png
ADDED

|