
We have recently released 🍷FineWeb, our new large scale (15T tokens, 44TB disk space) dataset of clean text sourced from the web for LLM pretraining. You can download it here.
As 🍷FineWeb has gathered a lot of interest from the community, we decided to further explain the steps involved in creating it, our processing decisions and some lessons learned along the way. Read on for all the juicy details on large text dataset creation!
TLDR: This blog covers the FineWeb recipe, why more deduplication is not always better and some interesting findings on the difference in quality of CommonCrawl dumps.
A common question we see asked regarding web datasets used to train LLMs is “where do they even get all that data?” There are generally two options:
For FineWeb, similarly to what was done for a large number of other public datasets, we used CommonCrawl as a starting point. They have been crawling the web since 2007 (long before LLMs were a thing) and release a new dump usually every 1 or 2 months, which can be freely downloaded.
As an example, their latest crawl (2024-10) contains 3.16 billion web pages, totaling 424.7 TiB of uncompressed content (the size changes from dump to dump). There are 95 dumps since 2013 and 3 dumps from 2008 to 2012, which are in a different (older) format.
Given the sheer size of the data involved, one of the main challenges we had to overcome was having a modular, scalable codebase that would allow us to quickly iterate on our processing decisions and easily try out new ideas, while appropriately parallelizing our workloads and providing clear insights into the data.
For this purpose, we developed datatrove, an open-source data
processing library that allowed us to seamlessly scale our filtering and deduplication setup to thousands of
CPU cores. All of the data processing steps involved in the creation of FineWeb used this library.
This is probably the main question to keep in mind when creating a dataset. A good first lesson is that data that would intuitively be considered high quality by a human may not be necessarily the best data (or at least not all that you need) to train a good model on.
It is still common to train a model on a given corpus (wikipedia, or some other web dataset considered clean) and use it to check the perplexity on the dataset that we were trying to curate. Unfortunately this does not always correlate with performance on downstream tasks, and so another often used approach is to train small models (small because training models is expensive and time consuming, and we want to be able to quickly iterate) on our dataset and evaluate them on a set of evaluation tasks. As we are curating a dataset for pretraining a generalist LLM, it is important to choose a diverse set of tasks and try not to overfit to any one individual benchmark.
Another way to evaluate different datasets would be to train a model on each one and have humans rate and compare the outputs of each one (like on the LMSYS Chatbot Arena). This would arguably provide the most reliable results in terms of representing real model usage, but getting ablation results this way is too expensive and slow.
The approach we ultimately went with was to train small models and evaluate them on a set of benchmark tasks. We believe this is a reasonable proxy for the quality of the data used to train these models.
To be able to compare the impact of a given processing step, we would train 2 models, one where the data included the extra step and another where this step was ablated (cut/removed). These 2 models would have the same number of parameters, architecture, and be trained on an equal number of tokens and with the same hyperparameters — the only difference would be in the training data. We would then evaluate each model on the same set of tasks and compare the average scores.
Our ablation models were trained using nanotron with this config [TODO:
INSERT SIMPLIFIED NANOTRON CONFIG HERE]. The models had 1.82B parameters, used the Llama
architecture with a 2048 sequence length, and a global batch size of ~2 million tokens. For filtering
ablations we mostly trained on ~28B tokens (which is roughly the Chinchilla optimal training size for this
model size).
We evaluated the models using lighteval. We tried selecting
benchmarks that would provide good signal at a relatively small scale (small models trained on only a few
billion tokens). Furthermore, we also used the following criteria when selecting benchmarks:
You can find the full list of tasks and prompts we used here. To have results quickly we capped longer benchmarks at 1000 samples (wall-clock evaluation taking less than 5 min on a single node of 8 GPUs - done in parallel to the training).
In the next subsections we will explain each of the steps
taken to produce the FineWeb dataset. You can find a full reproducible datatrove config here.

CommonCrawl data is available in two main formats: WARC and WET. WARC (Web ARChive format) files contain the raw data from the crawl, including the full page HTML and request metadata. WET (WARC Encapsulated Text) files provide a text only version of those websites.
A large number of datasets take the WET files as their starting point. In our experience the default text extraction (extracting the main text of a webpage from its HTML) used to create these WET files is suboptimal and there are a variety of open-source libraries that provide better text extraction (by, namely, keeping less boilerplate content/navigation menus). We extracted the text content from the WARC files using the trafilatura library. It is important to note, however, that text extraction is one of the most costly steps of our processing, so we believe that using the readily available WET data could be a reasonable trade-off for lower budget teams.
To validate this decision, we processed the 2019-18 dump directly using the WET files and with text extracted from WARC files using trafilatura. We applied the same processing to each one (our base filtering+minhash, detailed below) and trained two models. While the resulting dataset is considerably larger for the WET data (around 254BT), it proves to be of much worse quality than the one that used trafilatura to extract text from WARC files (which is around 200BT). Many of these additional tokens on the WET files are unnecessary page boilerplate.

Filtering is an important part of the curation process. It removes part of the data (be it words, lines, or full documents) that would harm performance and is thus deemed to be “lower quality”.
As a basis for our filtering we used part of the setup from RefinedWeb. Namely, we:
After applying this filtering to each of the text
extracted dumps (there are currently 95 dumps) we obtained roughly 36 trillion tokens of data (when
tokenized with the gpt2 tokenizer).
Deduplication is another important step, specially for web datasets. Methods to deduplicate datasets attempt to remove redundant/repeated data. Deduplication is one of the most important steps when creating large web datasets for LLMs.
The web has many aggregators, mirrors, templated pages or just otherwise repeated content spread over different domains and webpages. Often, these duplicated pages can be introduced by the crawler itself, when different links point to the same page.
Removing these duplicates (deduplicating) has been linked to an improvement in model performance and a reduction in memorization of pretraining data, which might allow for better generalization. Additionally, the performance uplift can also be tied to increased training efficiency: by removing duplicated content, for the same number of training tokens, a model will have seen more diverse data.
There are different ways to identify and even define duplicated data. Common approaches rely on hashing techniques to speed up the process, or on building efficient data structures to index the data (like suffix arrays). Methods can also be “fuzzy”, by using some similarity metric to mark documents as duplicates, or “exact” by checking for exact matches between two documents (or lines, paragraphs, or whatever other granularity level being used).
Similarly to RefinedWeb, we decided to apply MinHash, a fuzzy hash based deduplication technique. We chose to compute minhashes on each document’s 5-grams, using 112 hash functions in total, split into 14 buckets of 8 hashes each — targeting documents that are at least 75% similar. Documents with the same 8 minhashes in any bucket are considered a duplicate of each other.
This would mean that for two documents with a similarity (s)
of 0.7, 0.75, 0.8 and 0.85, the probability that they would be identified as duplicates would be 56%, 77%,
92% and 98.8% respectively (1-(1-s^8)^14). See the plot below for a match probability
comparison between our setup with 112 hashes and the one from RefinedWeb, with 9000 hashes, divided into 450
buckets of 20 hashes (that requires a substantially larger amount of compute resources):
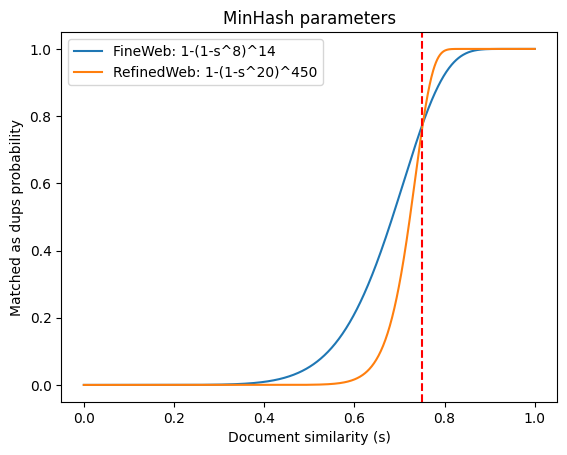
While the high number of hash functions in RefinedWeb allows for a steeper, more well defined cut off, we believe the compute and storage savings are a reasonable trade off.
Our initial approach was to take the entire dataset (all 95 dumps) and deduplicate them as one big dataset using MinHash.
We did this in an iterative manner: starting with the most recent dump (which at the time was 2023-50) and taking the oldest one last, we would deduplicate each dump not only against itself but also by removing any matches with duplicates from the previously processed dumps.
For instance, for the second most recent dump (2023-40 at the time), we deduplicated it against the most recent one in addition to itself. In particular, the oldest dump was deduplicated against all other dumps. As a result, more data was removed in the oldest dumps (last to be deduplicated) than in the most recent ones.
Deduplicating the dataset in this manner resulted in 4 trillion tokens of data, but, quite surprisingly for us, when training on a randomly sampled 350 billion tokens subset, the model showed no improvement over one trained on the non deduplicated data (see orange and green curve below), scoring far below its predecessor RefinedWeb on our aggregate of tasks.

This was quite puzzling as our intuition regarding web data was that more deduplication would always result in improved performance. We decided to take a closer look at one of the oldest dumps, dump 2013-48:
As an experiment, we tried training two models on 28BT sampled from the following data from 2013-48:
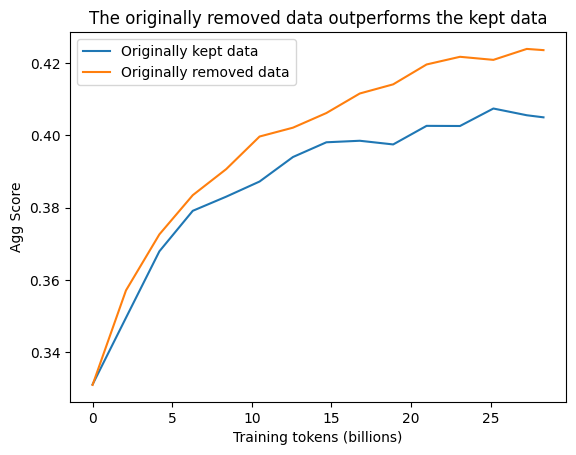
These results show that, for this older dump where we were removing over 90% of the original data, the data that was kept was actually worse than the data removed (considered independently from all the other dumps).
We then tried an alternative approach: we deduplicated each dump with MinHash individually (without considering the other dumps). This resulted in 20 trillion tokens of data.
When training on a random sample from this dataset we see that it now matches RefinedWeb’s performance (blue and red curves below):

We hypothesis that the main improvement gained from deduplication is the removal of very large clusters that are present in every single dump (you will find some examples of these clusters on the RefinedWeb paper, each containing hundreds of thousands of documents) and that further deduplication for low number of deduplications (less than ~100 i.e. the number of dumps) actually harm performance: data that does not find a duplicate match in any other dump might actually be worse quality/more out of distribution (as evidenced by the results on the 2013-48 data).
While you might see some performance improvement when deduplicating a few dumps together, at the scale of all the dumps this upsampling of lower quality data side effect seems to have a great impact.
One possibility to consider is that as filtering quality improves, this effect may not be as prevalent, since the filtering might be able to remove some of this lower quality data. We also experimented with applying different, and often “lighter”, deduplication approaches on top of the individually deduplicated dumps. You can read about them further below.
Given the nature of deduplication, its effect is not always very visible in a smaller slice of the dataset (such as 28B tokens, the size we used for our filtering ablations). Furthermore, one must consider the fact that there are specific effects at play when deduplicating across all CommonCrawl dumps, as some URLs/pages are recrawled from one dump to the next.
To visualize the effect of scaling the number of training tokens on measuring deduplication impact, we considered the following (very extreme and unrealistic regarding the degree of duplication observed) theoretical scenario:
We then simulated uniformly sampling documents from this entire dataset of 20 trillion tokens, to obtain subsets of 1B, 10B, 100B, 350B and 1T tokens. In the image below you can see how often each document would be repeated.

For 1B almost all documents would be unique (#duplicates=1), despite the fact that in the entire dataset each document is repeated 100 times (once per dump). We start seeing some changes at the 100B scale (0.5% of the total dataset), with a large number of documents being repeated twice, and a few even 4-8 times. At the larger scale of 1T (5% of the total dataset), the majority of the documents are repeated up to 8 times, with a some being repeated up to 16 times.
We ran our performance evaluations for the deduplicated data at the 350B scale, which would, under this theoretical scenario, be made up of a significant portion of documents duplicated up to 8 times. This simulation illustrates the inherent difficulties associated with measuring deduplication impact on the training of LLMs, once the biggest document clusters have been removed.
We attempted to improve the performance of the independently minhash deduped 20T of data by further deduplicating it with the following methods
The performance of the models trained on each of these was consistently worse (even if to different degrees) than that of the original independently deduplicated data:
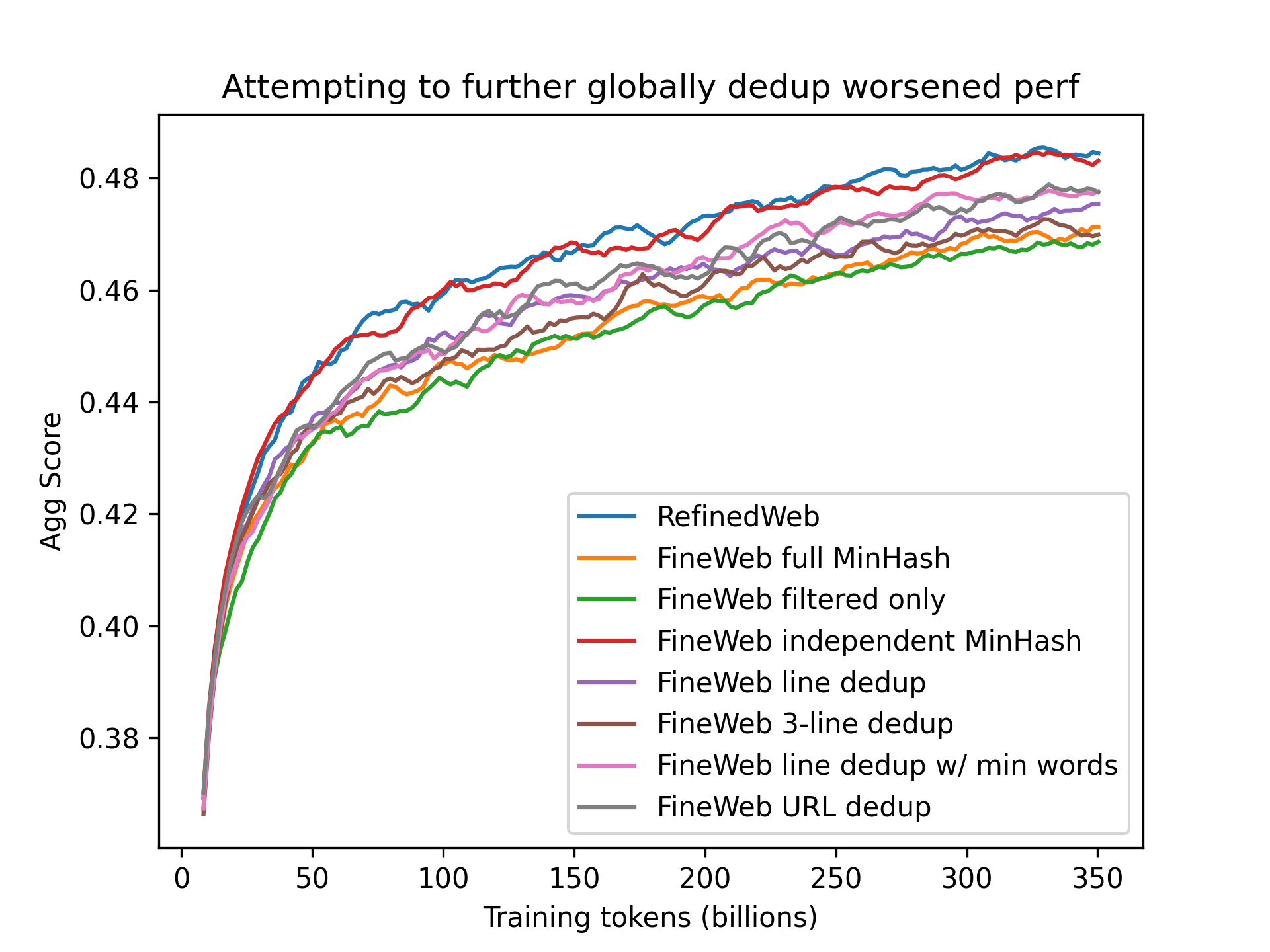
By this point we had reached the same performance as RefinedWeb, but on our aggregate of tasks, another heavily filtered dataset, the C4 dataset, still showed stronger performance (with the caveat that it is a relatively small dataset for current web-scale standards).
We therefore set out to find new filtering steps that would, at first, allow us to match the performance of C4 and eventually surpass it. A natural starting point was to look into the processing of C4 itself.
The C4
dataset was first released in 2019. It was obtained from the 2019-18 CommonCrawl dump by
removing non english data, applying some heuristic filters on both the line and document level,
deduplicating on the line level and removing documents containing words from a word blocklist.
Despite its age and limited size (around 175B gpt2 tokens), models trained on this dataset have strong performance, excelling in particular on the Hellaswag benchmark, one of the benchmarks in our “early signal” group with the stronger signal and highest signal-over-noise ratio. As such, it has stayed a common sub-set of typical LLM training, for instance in in the relatively recent Llama1 model. We experimented applying each of the different filters used in C4 to a baseline of the independently deduped FineWeb 2019-18 dump (plot smoothed with a 3 checkpoints sliding window):

{) allows us to match C4’s HellaSwag performance (purple versus
pink curves).
We decided to apply all C4 filters mentioned above except the terminal punctuation one. We validated these results with a longer run, which you will find in a plot in the next section.
To come up with new possible filtering rules, we collected a very large list of statistics (statistical metrics) — over 50 — from different reference datasets (C4, RefinedWeb, etc) and from a select list of our processed dumps, on both the independently minhashed version and the result from the (worse quality) full dedup. This allowed us to compare the different datasets at a macro level, by looking at the distribution of these metrics for each one.
The collected statistics ranged from common document-level
metrics (e.g. number of lines, avg. line/word length, etc) to inter-document repetition metrics (gopher
inspired). Perhaps not too surprisingly given our findings for deduplication, we found significant
disparities in most of the metrics for the two deduplication methods. For instance, the line-char-duplicates
metric (nb. of characters in duplicated lines / nb. characters), roughly doubled from the independent dedup
(0.0053 for 2015-22 and 0.0058 for 2013-48), to the full dedup (0.011 for 2015-22 and 0.01 for 2013-48),
indicating that the latter had higher inter-document repetition.
Working under the assumption that these differences were caused by lower quality data on the full dedup version, we inspected histograms and manually defined thresholds for the metrics where these differences were starker. This process yielded 17 candidate threshold-filter pairs. In the image below, you can see 3 of these histograms.

To assess the effectiveness of these newly created filters, we conducted 28B tokens ablation runs on the 2019-18 crawl. Out of all those runs, we identified three filters (the ones based on the histograms above) that demonstrated the most significant improvements on the aggregate score:

The final FineWeb dataset comprises 15T tokens and includes the following previously mentioned steps, in order, each providing a performance boost on our group of benchmark tasks:

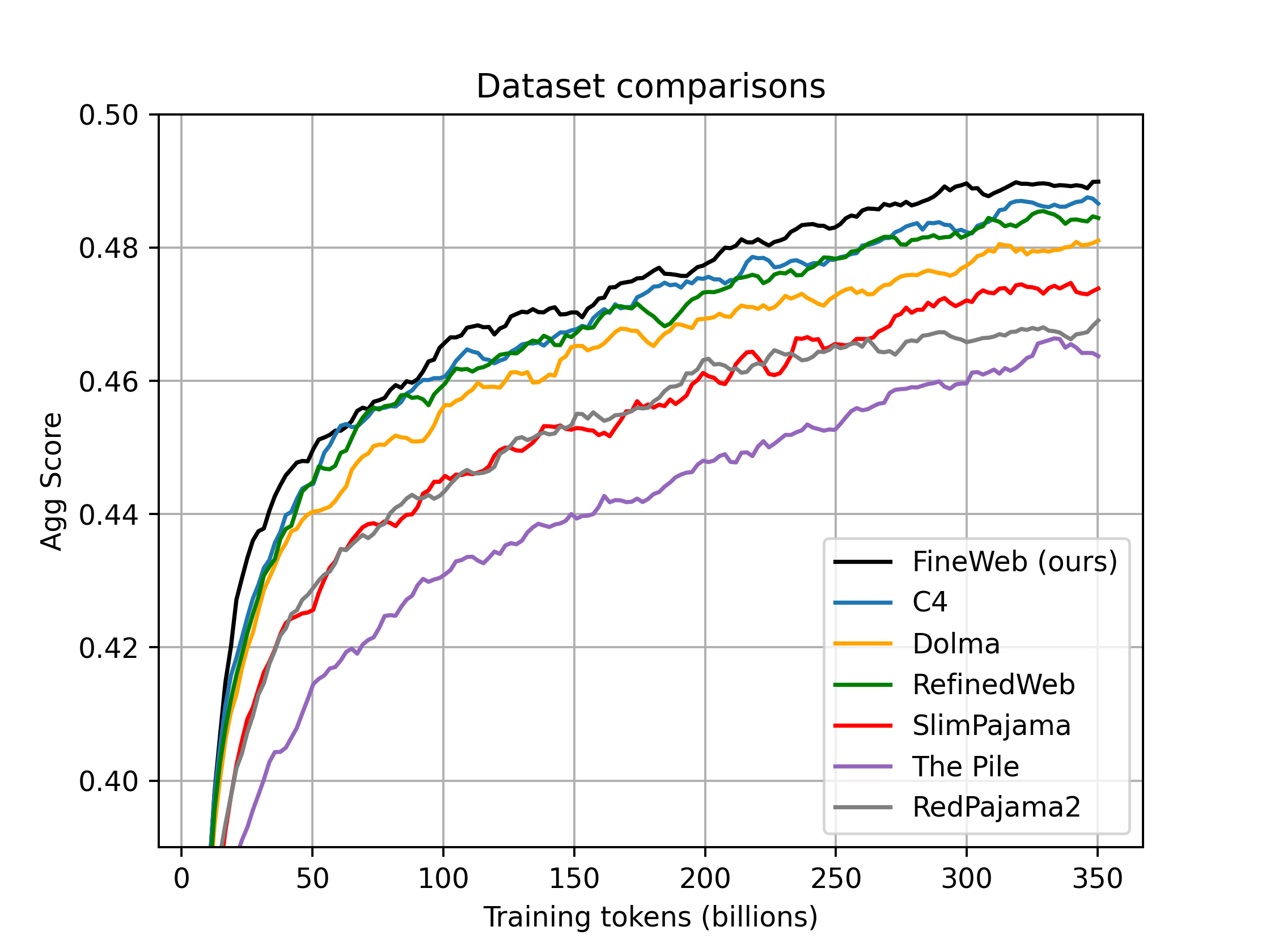
We compared 🍷 FineWeb with the following datasets:
You will find these models on this collection. We have uploaded checkpoints at every 1000 training steps. You will also find our full evaluation results here.
Some histogram comparisons of C4, Dolma, RefinedWeb and FineWeb:

During our ablation runs, we observed that certain crawls outperformed others by a significant margin. To investigate this phenomenon, we conducted 27B token runs for each dump (we used the version with base filtering + ind dedup), with 2 trainings per dump, where each used a different data subset. We trained 190 such models, totaling over 60k H100 GPU-hours. We subsequently took the last 3 checkpoints for both seeds and plotted the average of these 6 data points per dump.
The plot below clearly shows that some dumps perform far worse than others. Each year has a different color, and the number of crawls per year also changes.

We identified 5 main relevant time intervals:
One possibility to improve performance when training models on < 15T would be to train on FineWeb while excluding the worst quality CommonCrawl dumps.
We conducted further analysis to investigate the factors causing these differences from dump to dump. In particular, we considered 3 potential causes:
We go over each one in the following sections.
For each crawl from 2021-10 onwards, we gathered a list of the 60k most frequent FQDNs (fully qualified domain name). We then calculated the Jaccard similarity between consecutive crawls. A high value means that a crawl/dump has many of the same FQDNs as the dump immediately preceding it, while a small value means that a considerable number of top 60k FQDNs were downsampled or removed, or that alternatively new FQDNs were added to the top 60k.
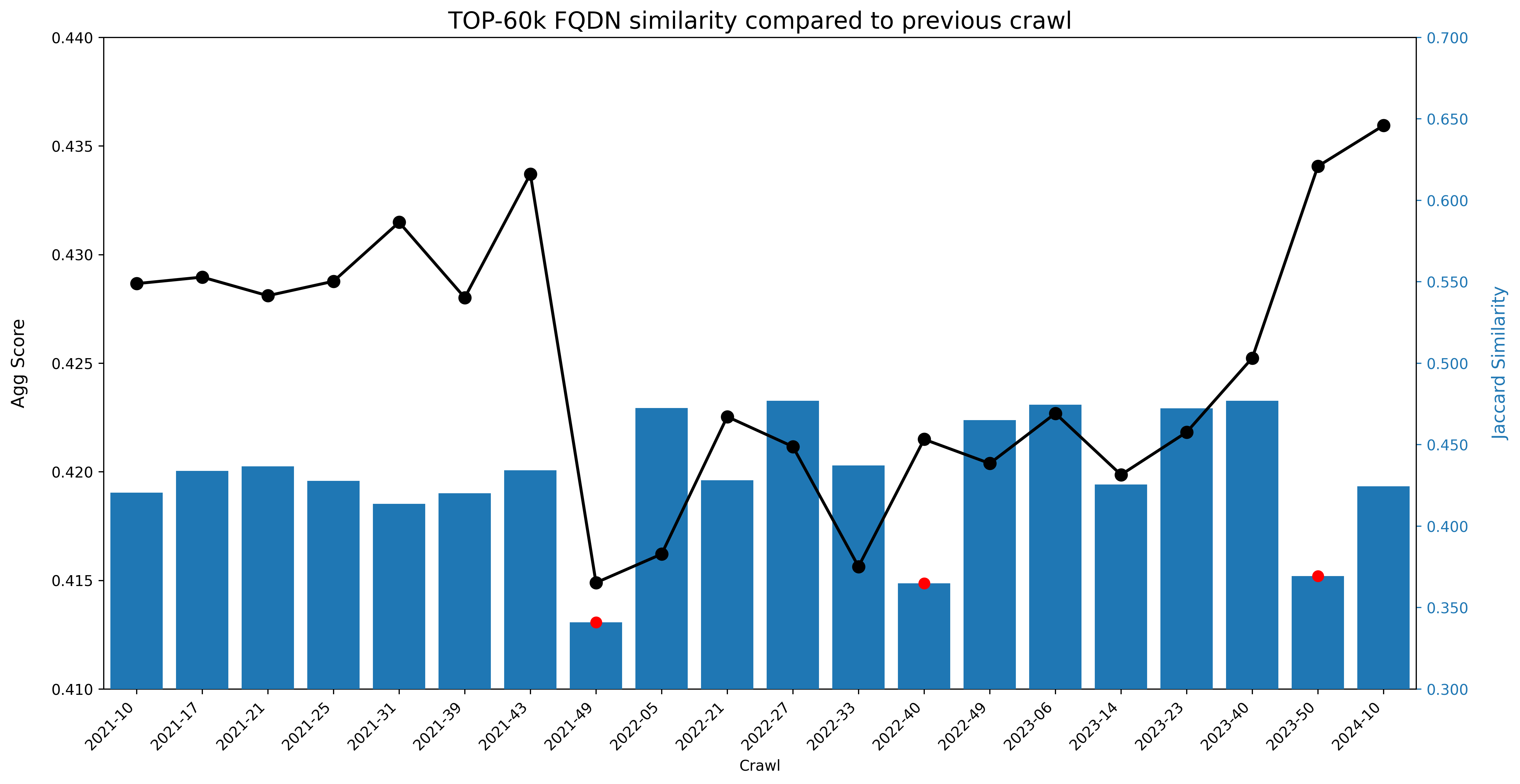
The data indicates three significant changes: 2021-43/2021-49, 2022-33/2022-40, and 2023-40/2023-50.
The explanation for the changes between 2022-33/2022-40 and 2023-40/2023-50 is straightforward: CommonCrawl accidentally did not index several popular suffixes, such as .co.uk, as documented on this erratum. This particular change does not seem particularly correlated on the overall dump quality.
As to the shift from 2021-43 to 2021-49, which coincides with a sharp performance drop, roughly half (~30k) of the former’s top 60k FQDNs are not present in the latter’s list of top 60k FQDNs, and the dump size itself also decreased (19% reduction in WARC size, and a 28% token reduction after deduplication).
We were unable to find a clear reason for this drastic change, but upon reaching out to CommonCrawl, we were informed that these differences likely stem from a major update in adult content and malicious site blocking. It is therefore possible that the new updated adult site filter could have also removed a high number of high quality domains resulting in poor performance of the crawl. [TODO: change this framing a bit, it seems to suggest adult content is high quality for LLMs]
Secondly, we wondered if part of the changes in performance on recent dumps could be attributed to the presence of a larger quantity of synthetic data (data generated by LLMs). Such a change would not be surprising due to the recent increase in popularity of LLMs, notably of ChatGPT.
Since, to the best of our knowledge, there is no fool
proof method to detect synthetic data, we opted to use a proxy metric: we measured the frequency of the
following words: delve, as a large language model, it's important to note, rich tapestry,
intertwined, certainly!, dive into, which are words commonly used by ChatGPT.
It is important to note that not all samples containing one of these phrases were necessarily generated by ChatGPT (and also that many ChatGPT generated samples do not contain any of these phrases), but assuming that the amount of synthetic data were to not change across dumps, one would expect these frequencies to remain approximately constant over time.
The results are shown in the following graph:

While the frequency remained approximately constant until 2023-14 (ChatGPT was released at the end of 2022), not only do we find a steep increase of our proxy metric in recent crawls, as the proxy metric also correlates well with the agg score, with a pearson correlation of 0.590. It is therefore possible that synthetic data has positively impacted performance in our selected tasks for these most recent dumps (with all limitations in interpretation from a single correlation measurement without intervention of randomization or any causality tools being used here). In particular, it could explain why the 2023-50 and 2024-10 dumps have such a strong performance.
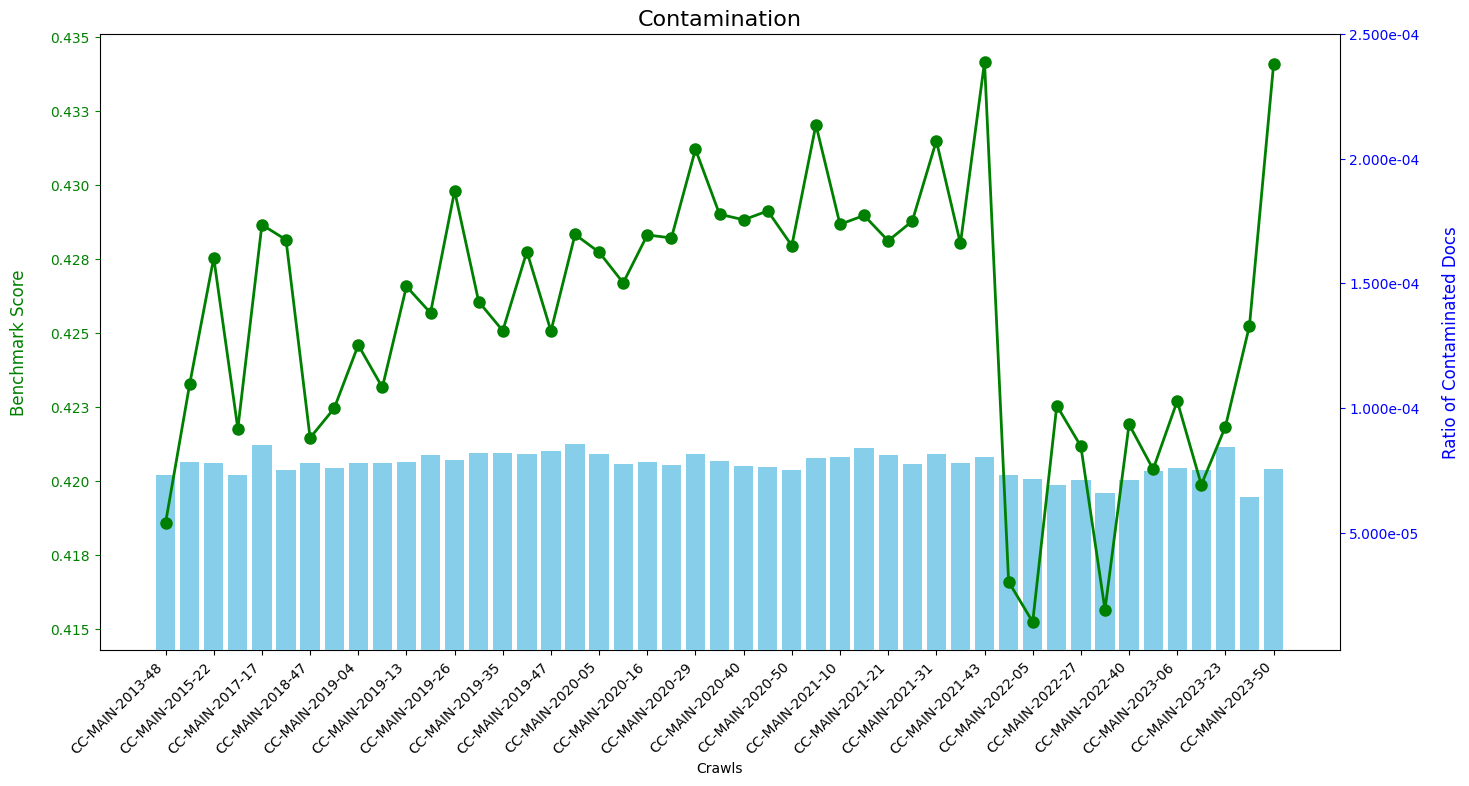
Also, most of our used benchmarks were introduced around 2019. It’s thus possible that the 2019-XX 2021-43 performance increase might be caused by higher benchmark contamination in those crawls. Similarly, the recent increase in LLM popularity and evaluations, might have increased the contamination in recent benchmarks, explaining the score improvements of the two most recent crawls. [NOTE: the plot does not seem to support this at all]
We want to continue improving FineWeb and will also release a technical report with more details soon.
Adapting the FineWeb recipe [wip]
Some text describing who did what.
Some text with links describing who reviewed the article.