

Upload 11 files
Browse files- notebooks/ch0-intro.ipynb +84 -0
- notebooks/ch1-what-we-will-do.ipynb +73 -0
- notebooks/ch10-sharing-with-gradio.ipynb +168 -0
- notebooks/ch2-the-LLM-advantage.ipynb +45 -0
- notebooks/ch3-getting-started-with-hf.ipynb +63 -0
- notebooks/ch4-installing-jupyterlab.ipynb +142 -0
- notebooks/ch5-prompting-with-python.ipynb +536 -0
- notebooks/ch6-structured-responses.ipynb +719 -0
- notebooks/ch7-bulk-prompts.ipynb +954 -0
- notebooks/ch8-evaluating-prompts.ipynb +655 -0
- notebooks/ch9-improving-prompts.ipynb +669 -0
notebooks/ch0-intro.ipynb
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "bf2cde26",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# First LLM Classifier\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"Learn how journalists use large-language models to organize and analyze massive datasets\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"## What you will learn\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"This class will give you hands-on experience creating a machine-learning model that can read and categorize the text recorded in newsworthy datasets.\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"It will teach you how to:\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"- Submit large-language model prompts with the Python programming language\n",
|
| 19 |
+
"- Write structured prompts that can classify text into predefined categories\n",
|
| 20 |
+
"- Submit dozens of prompts at once as part of an automated routine\n",
|
| 21 |
+
"- Evaluate results using a rigorous, scientific approach\n",
|
| 22 |
+
"- Improve results by training the model with rules and examples\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"By the end, you will understand how LLM classifiers can outperform traditional machine-learning methods with significantly less code. And you will be ready to write a classifier on your own.\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"## Who can take it\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"This course is free. Anyone who has dabbled with code and AI is qualified to work through the materials. A curious mind and good attitude are all that’s required, but a familiarity with Python will certainly come in handy.\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"💬 Need help or want to connect with others? Join the **Journalists on Hugging Face** community by signing up for our Slack group [here](https://forms.gle/JMCULh3jEdgFEsJu5).\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"## Table of contents\n",
|
| 33 |
+
"\n",
|
| 34 |
+
"- [1. What we’ll do](ch1-what-we-will-do.ipynb) \n",
|
| 35 |
+
"- [2. The LLM advantage](ch2-the-LLM-advantage.ipynb) \n",
|
| 36 |
+
"- [3. Getting started with Hugging Face](ch3-getting-started-with-hf.ipynb) \n",
|
| 37 |
+
"- [4. Installing JupyterLab (optional)](ch4-installing-jupyterlab.ipynb) \n",
|
| 38 |
+
"- [5. Prompting with Python](ch5-prompting-with-python.ipynb) \n",
|
| 39 |
+
"- [6. Structured responses](ch6-structured-responses.ipynb) \n",
|
| 40 |
+
"- [7. Bulk prompts](ch7-bulk-prompts.ipynb) \n",
|
| 41 |
+
"- [8. Evaluating prompts](ch8-evaluating-prompts.ipynb) \n",
|
| 42 |
+
"- [9. Improving prompts](ch9-improving-prompts.ipynb) \n",
|
| 43 |
+
"- [10. Sharing your app with Gradio](ch10-sharing-with-gradio.ipynb)\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"## About this class\n",
|
| 46 |
+
"[Ben Welsh](https://palewi.re/who-is-ben-welsh/) and [Derek Willis](https://thescoop.org/about/) prepared this guide for [a training session](https://schedules.ire.org/nicar-2025/index.html#2045) at the National Institute for Computer-Assisted Reporting’s 2025 conference in Minneapolis. \n",
|
| 47 |
+
"The project was adapted to run on Hugging Face by [Florent Daudens](https://www.linkedin.com/in/fdaudens/). \n",
|
| 48 |
+
"\n",
|
| 49 |
+
"Some of the copy was written with the assistance of GitHub’s Copilot, an AI-powered text generator. The materials are available as free and open source.\n",
|
| 50 |
+
"\n",
|
| 51 |
+
"**[1. What we’ll do →](ch1-what-we-will-do.ipynb)**"
|
| 52 |
+
]
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"cell_type": "code",
|
| 56 |
+
"execution_count": null,
|
| 57 |
+
"id": "02477b14-edff-4380-ad41-9954b6c80863",
|
| 58 |
+
"metadata": {},
|
| 59 |
+
"outputs": [],
|
| 60 |
+
"source": []
|
| 61 |
+
}
|
| 62 |
+
],
|
| 63 |
+
"metadata": {
|
| 64 |
+
"kernelspec": {
|
| 65 |
+
"display_name": "Python 3 (ipykernel)",
|
| 66 |
+
"language": "python",
|
| 67 |
+
"name": "python3"
|
| 68 |
+
},
|
| 69 |
+
"language_info": {
|
| 70 |
+
"codemirror_mode": {
|
| 71 |
+
"name": "ipython",
|
| 72 |
+
"version": 3
|
| 73 |
+
},
|
| 74 |
+
"file_extension": ".py",
|
| 75 |
+
"mimetype": "text/x-python",
|
| 76 |
+
"name": "python",
|
| 77 |
+
"nbconvert_exporter": "python",
|
| 78 |
+
"pygments_lexer": "ipython3",
|
| 79 |
+
"version": "3.9.5"
|
| 80 |
+
}
|
| 81 |
+
},
|
| 82 |
+
"nbformat": 4,
|
| 83 |
+
"nbformat_minor": 5
|
| 84 |
+
}
|
notebooks/ch1-what-we-will-do.ipynb
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "9d45b5fc",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# First LLM Classifier\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"## 1. What we’ll do\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"Journalists frequently encounter the mountains of messy data generated by our periphrastic society. This vast and verbose corpus boasts everything from long-hand entries in police reports to the legalese of legislative bills.\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"Understanding and analyzing this data is critical to the job but can be time-consuming and inefficient. Computers can help by automating sorting through blocks of text, extracting key details and flagging unusual patterns.\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"A common goal in this work is to classify text into categories. For example, you might want to sort a collection of emails as “spam” and “not spam” or identify corporate filings that suggest a company is about to go bankrupt.\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"Traditional techniques for classifying text, like keyword searches or regular expressions, can be brittle and error-prone. Machine learning models can be more flexible, but they require large amounts of human training, a high level of computer programming expertise and often yield unimpressive results.\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"Large-language models offer a better deal. We will demonstrate how you can use them to get superior results with less hassle.\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"### 1.1. Our example case\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"To show the power of this approach, we’ll focus on a specific data set: campaign expenditures.\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"Candidates for office must disclose the money they spend on everything from pizza to private jets. Tracking their spending can reveal patterns and lead to important stories.\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"But it’s no easy task. Each election cycle, thousands of candidates log transactions into the public databases where spending is disclosed. That’s so much data that no one can examine it all. To make matters worse, campaigns often use vague or misleading descriptions of their spending, making it difficult to parse and understand.\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"It wasn’t until after his 2022 election to Congress that [journalists discovered](https://www.nytimes.com/2022/12/29/nyregion/george-santos-campaign-finance.html) that Rep. George Santos of New York had spent thousands of campaign dollars on questionable and potentially illegal expenses. While much of his shady spending was publicly disclosed, it was largely overlooked in the run-up to election day.\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"[](https://www.nytimes.com/2022/12/29/nyregion/george-santos-campaign-finance.html)\n",
|
| 33 |
+
"\n",
|
| 34 |
+
"Inspired by this scoop, we will create a classifier that can scan the expenditures logged in campaign finance reports and identify those that may be newsworthy.\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"[](https://californiacivicdata.org/)\n",
|
| 37 |
+
"\n",
|
| 38 |
+
"We will draw data from The Golden State, where the California Civic Data Coalition developed a clean, structured version of the statehouse’s disclosure data.\n",
|
| 39 |
+
"\n",
|
| 40 |
+
"**[2. The LLM advantage →](ch2-the-LLM-advantage.ipynb)**"
|
| 41 |
+
]
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"cell_type": "code",
|
| 45 |
+
"execution_count": null,
|
| 46 |
+
"id": "934bc606-e7a5-4dff-9154-dc5c42bf3fc7",
|
| 47 |
+
"metadata": {},
|
| 48 |
+
"outputs": [],
|
| 49 |
+
"source": []
|
| 50 |
+
}
|
| 51 |
+
],
|
| 52 |
+
"metadata": {
|
| 53 |
+
"kernelspec": {
|
| 54 |
+
"display_name": "Python 3 (ipykernel)",
|
| 55 |
+
"language": "python",
|
| 56 |
+
"name": "python3"
|
| 57 |
+
},
|
| 58 |
+
"language_info": {
|
| 59 |
+
"codemirror_mode": {
|
| 60 |
+
"name": "ipython",
|
| 61 |
+
"version": 3
|
| 62 |
+
},
|
| 63 |
+
"file_extension": ".py",
|
| 64 |
+
"mimetype": "text/x-python",
|
| 65 |
+
"name": "python",
|
| 66 |
+
"nbconvert_exporter": "python",
|
| 67 |
+
"pygments_lexer": "ipython3",
|
| 68 |
+
"version": "3.9.5"
|
| 69 |
+
}
|
| 70 |
+
},
|
| 71 |
+
"nbformat": 4,
|
| 72 |
+
"nbformat_minor": 5
|
| 73 |
+
}
|
notebooks/ch10-sharing-with-gradio.ipynb
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"## 10. Building a Demo with Gradio and Hugging Face Spaces\n",
|
| 8 |
+
"\n",
|
| 9 |
+
"Now that we've built a powerful LLM-based classifier, let's showcase it to the world (or your colleagues) by creating an interactive demo. In this chapter, we'll learn how to:\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"1. Create a user-friendly web interface using Gradio\n",
|
| 12 |
+
"2. Package our demo for deployment\n",
|
| 13 |
+
"3. Deploy it on Hugging Face Spaces for free\n",
|
| 14 |
+
"4. Use the Hugging Face Inference API for model access"
|
| 15 |
+
]
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"cell_type": "markdown",
|
| 19 |
+
"metadata": {},
|
| 20 |
+
"source": [
|
| 21 |
+
"### What we will do is the following:\n",
|
| 22 |
+
"\n",
|
| 23 |
+
"We will essentially start from [the functional notebook](ch9-improving-prompts.ipynb) we created in Chapter 9, and add an interactive component to it.\n",
|
| 24 |
+
"\n",
|
| 25 |
+
"1. **Add Gradio**\n",
|
| 26 |
+
"\n",
|
| 27 |
+
"Gradio is a Python library that allows you to easily create web-based interfaces where users can interact with your model. We will install **Gradio** to set up the interface for our model (it will be included in the requirements file — more on that below).\n",
|
| 28 |
+
"\n",
|
| 29 |
+
" ```python\n",
|
| 30 |
+
" import gradio as gr\n",
|
| 31 |
+
" ```\n",
|
| 32 |
+
"\n",
|
| 33 |
+
"2. **Add an interface function that will call what we already coded**\n",
|
| 34 |
+
"\n",
|
| 35 |
+
"Here we will define the interface function that connects Gradio to the model we built earlier. This function will take input from the user, process it with the classifier, and return the result.\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"```python\n",
|
| 38 |
+
" # -- Gradio interface function --\n",
|
| 39 |
+
" def classify_business_names(input_text):\n",
|
| 40 |
+
" # Parse input text into list of names\n",
|
| 41 |
+
" name_list = [line.strip() for line in input_text.splitlines() if line.strip()]\n",
|
| 42 |
+
" \n",
|
| 43 |
+
" if not name_list:\n",
|
| 44 |
+
" return json.dumps({\"error\": \"No business names provided. Please enter at least one business name.\"})\n",
|
| 45 |
+
" \n",
|
| 46 |
+
" try:\n",
|
| 47 |
+
" result = classify_payees(name_list)\n",
|
| 48 |
+
" return json.dumps(result, indent=2)\n",
|
| 49 |
+
" except Exception as e:\n",
|
| 50 |
+
" return json.dumps({\"error\": f\"Classification failed: {str(e)}\"})\n",
|
| 51 |
+
" ```\n",
|
| 52 |
+
"\n",
|
| 53 |
+
"3. **Launch the Gradio interface**\n",
|
| 54 |
+
" \n",
|
| 55 |
+
" ```python\n",
|
| 56 |
+
" # -- Launch the demo --\n",
|
| 57 |
+
" demo = gr.Interface(\n",
|
| 58 |
+
" fn=classify_business_names,\n",
|
| 59 |
+
" inputs=gr.Textbox(lines=10, placeholder=\"Enter business names, one per line\"),\n",
|
| 60 |
+
" outputs=\"json\",\n",
|
| 61 |
+
" title=\"Business Category Classifier\",\n",
|
| 62 |
+
" description=\"Enter business names and get a classification: Restaurant, Bar, Hotel, or Other.\"\n",
|
| 63 |
+
" )\n",
|
| 64 |
+
"\n",
|
| 65 |
+
" demo.launch(share=True)\n",
|
| 66 |
+
"```"
|
| 67 |
+
]
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"cell_type": "markdown",
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"source": [
|
| 73 |
+
"## 🌍 Publish your demo to Hugging Face Spaces\n",
|
| 74 |
+
"\n",
|
| 75 |
+
"To share your Gradio app with the world, you can deploy it to [Hugging Face Spaces](https://huggingface.co/spaces) in just a few steps.\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"### 1. Prepare your files\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"Make sure your project has:\n",
|
| 80 |
+
"- A `app.py` file containing your Gradio app (e.g. `gr.Interface(...)`)\n",
|
| 81 |
+
"- The `sample.csv` file for the few shots classification\n",
|
| 82 |
+
"- A `requirements.txt` file listing any Python dependencies:\n",
|
| 83 |
+
"```\n",
|
| 84 |
+
"gradio\n",
|
| 85 |
+
"huggingface_hub\n",
|
| 86 |
+
"pandas\n",
|
| 87 |
+
"scikit-learn\n",
|
| 88 |
+
"retry\n",
|
| 89 |
+
"rich\n",
|
| 90 |
+
"```\n",
|
| 91 |
+
"\n",
|
| 92 |
+
"> **Example files are ready to use in the [gradio-app](gradio-app) folder!**\n",
|
| 93 |
+
"\n",
|
| 94 |
+
"### 2. Create a new Space\n",
|
| 95 |
+
"\n",
|
| 96 |
+
"1. Go to [huggingface.co/spaces](https://huggingface.co/spaces)\n",
|
| 97 |
+
"2. Click **\"Create new Space\"**\n",
|
| 98 |
+
"3. Choose:\n",
|
| 99 |
+
" - **SDK**: Gradio\n",
|
| 100 |
+
" - **License**: (choose one, e.g. MIT)\n",
|
| 101 |
+
" - **Visibility**: Public or Private\n",
|
| 102 |
+
"4. Name your Space and click **Create Space**\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"### 3. Upload your files\n",
|
| 105 |
+
"\n",
|
| 106 |
+
"You can:\n",
|
| 107 |
+
"- Use the web interface to upload `app.py`, `sample.csv` and `requirements.txt`, or\n",
|
| 108 |
+
"- Clone the Space repo with Git and push your files:\n",
|
| 109 |
+
"```bash\n",
|
| 110 |
+
"git lfs install\n",
|
| 111 |
+
"git clone https://huggingface.co/spaces/YOUR_USERNAME/YOUR_SPACE_NAME\n",
|
| 112 |
+
"cd YOUR_SPACE_NAME\n",
|
| 113 |
+
"# Add your files here\n",
|
| 114 |
+
"git add .\n",
|
| 115 |
+
"git commit -m \"Initial commit\"\n",
|
| 116 |
+
"git push\n",
|
| 117 |
+
"```\n",
|
| 118 |
+
"### 4. Add your Hugging Face token to Secrets\n",
|
| 119 |
+
"\n",
|
| 120 |
+
"For your Gradio app to interact with Hugging Face’s Inference API (or any other Hugging Face service), you need to securely store your Hugging Face token.\n",
|
| 121 |
+
"\n",
|
| 122 |
+
"1. In your Hugging Face Space:\n",
|
| 123 |
+
" - Navigate to the **Settings** of your Space.\n",
|
| 124 |
+
" - Go to the **Secrets** tab.\n",
|
| 125 |
+
" - Add your token as a new secret with the key `HF_TOKEN`.\n",
|
| 126 |
+
" - **Key**: `HF_TOKEN`\n",
|
| 127 |
+
" - **Value**: Your Hugging Face token, which you can get from [here](https://huggingface.co/settings/tokens).\n",
|
| 128 |
+
"\n",
|
| 129 |
+
"Once added, the token will be accessible in your Space, and you can securely reference it in your code with:\n",
|
| 130 |
+
"\n",
|
| 131 |
+
"```python\n",
|
| 132 |
+
"api_key = os.getenv(\"HF_TOKEN\")\n",
|
| 133 |
+
"client = InferenceClient(token=api_key)\n",
|
| 134 |
+
"```\n",
|
| 135 |
+
"\n",
|
| 136 |
+
"### 5. Done 🎉\n",
|
| 137 |
+
"\n",
|
| 138 |
+
"Your app will build and be available at:\n",
|
| 139 |
+
"```\n",
|
| 140 |
+
"https://huggingface.co/spaces/YOUR_USERNAME/YOUR_SPACE_NAME\n",
|
| 141 |
+
"```\n",
|
| 142 |
+
"\n",
|
| 143 |
+
"Need inspiration? Check out [awesome Spaces](https://huggingface.co/spaces?sort=trending)!\n"
|
| 144 |
+
]
|
| 145 |
+
}
|
| 146 |
+
],
|
| 147 |
+
"metadata": {
|
| 148 |
+
"kernelspec": {
|
| 149 |
+
"display_name": "Python 3 (ipykernel)",
|
| 150 |
+
"language": "python",
|
| 151 |
+
"name": "python3"
|
| 152 |
+
},
|
| 153 |
+
"language_info": {
|
| 154 |
+
"codemirror_mode": {
|
| 155 |
+
"name": "ipython",
|
| 156 |
+
"version": 3
|
| 157 |
+
},
|
| 158 |
+
"file_extension": ".py",
|
| 159 |
+
"mimetype": "text/x-python",
|
| 160 |
+
"name": "python",
|
| 161 |
+
"nbconvert_exporter": "python",
|
| 162 |
+
"pygments_lexer": "ipython3",
|
| 163 |
+
"version": "3.9.5"
|
| 164 |
+
}
|
| 165 |
+
},
|
| 166 |
+
"nbformat": 4,
|
| 167 |
+
"nbformat_minor": 4
|
| 168 |
+
}
|
notebooks/ch2-the-LLM-advantage.ipynb
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "48d73cd4",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"## 2. The LLM advantage\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"A [large-language model](https://en.wikipedia.org/wiki/Large_language_model) is an artificial intelligence system capable of understanding and generating human language due to its extensive training on vast amounts of text. These systems are commonly referred to by the acronym LLM. The most prominent examples include OpenAI’s ChatGPT, Google’s Gemini and Anthropic’s Claude, but there are many others, including several open-source options.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"While they are most famous for their ability to converse with humans as chatbots, LLMs can perform a wide range of language processing tasks, including text classification, summarization and translation.\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"Unlike traditional machine-learning models, LLMs do not require users to provide pre-prepared training data to perform a specific task. Instead, LLMs can be prompted with a broad description of their goals and a few examples of rules they should follow. The LLMs will then generate responses informed by the massive amount of information they contain. That deep knowledge can be especially beneficial when dealing with large and diverse datasets that are difficult for humans to process on their own. This advancement is recognized as a landmark achievement in the development of artificial intelligence.\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"[](https://www.wired.com/story/eight-google-employees-invented-modern-ai-transformers-paper/)\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"LLMs also do not require the user to understand machine-learning concepts, like vectorization or Bayesian statistics, or to write complex code to train and evaluate the model. Instead, users can submit prompts in plain language, which the model will use to generate responses. This makes it easier for journalists to experiment with different approaches and quickly iterate on their work.\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"**[3. Getting started with Hugging Face →](ch3-getting-started-with-hf.ipynb)**"
|
| 21 |
+
]
|
| 22 |
+
}
|
| 23 |
+
],
|
| 24 |
+
"metadata": {
|
| 25 |
+
"kernelspec": {
|
| 26 |
+
"display_name": "Python 3 (ipykernel)",
|
| 27 |
+
"language": "python",
|
| 28 |
+
"name": "python3"
|
| 29 |
+
},
|
| 30 |
+
"language_info": {
|
| 31 |
+
"codemirror_mode": {
|
| 32 |
+
"name": "ipython",
|
| 33 |
+
"version": 3
|
| 34 |
+
},
|
| 35 |
+
"file_extension": ".py",
|
| 36 |
+
"mimetype": "text/x-python",
|
| 37 |
+
"name": "python",
|
| 38 |
+
"nbconvert_exporter": "python",
|
| 39 |
+
"pygments_lexer": "ipython3",
|
| 40 |
+
"version": "3.9.5"
|
| 41 |
+
}
|
| 42 |
+
},
|
| 43 |
+
"nbformat": 4,
|
| 44 |
+
"nbformat_minor": 5
|
| 45 |
+
}
|
notebooks/ch3-getting-started-with-hf.ipynb
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "c2c4bff1",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"## 3. Getting started with Hugging Face\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"In addition to the commercial chatbots that draw the most media attention, there are many other ways to access large-language models — including free and open-source options that you can run directly in the cloud using Hugging Face.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"For this demonstration, we will use [Hugging Face Serverless Inference API](https://huggingface.co/docs/api-inference/en/index), which offers free access to a wide range of powerful language models. It’s fast, beginner-friendly, and widely supported in the AI community. The skills you learn here will transfer easily to other platforms as well.\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"To get started, go to [huggingface.co](https://huggingface.co/). Click on **Sign Up** to create an account or **Log In** at the top right.\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"[](https://huggingface.co/)\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"Once you’re logged in, navigate to your profile dropdown and select **Settings**, then [**Access Tokens**](https://huggingface.co/settings/tokens). Click on **New token**, give it a name (we recommend `first-llm-classifier`), set the role to **Fine-Grained**, select the following options and hit **Generate**.\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"[](https://huggingface.co/)\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"Copy the token that appears — you'll only see it once — and store it somewhere safe. You’ll use it to authenticate your Python scripts when making requests to Hugging Face's APIs.\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"You can now access any public model using the Hugging Face Inference API — no deployment required. For example, visit the [Llama 3.3 70B Instruct model page](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct), click **Deploy**, then go to the **Inference Providers** tab, and select **HF Inference API**. This gives you instant access to the model via a hosted endpoint maintained by Hugging Face.\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"[](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct)\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"This approach is ideal if you want to quickly try out models without spinning up your own infrastructure. Many models are available with generous free-tier access.\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"**[4. Installing JupyterLab →](ch4-installing-jupyterlab.ipynb)**"
|
| 31 |
+
]
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"cell_type": "code",
|
| 35 |
+
"execution_count": null,
|
| 36 |
+
"id": "6f8b3428-2d43-4691-82b4-085341c8a1d2",
|
| 37 |
+
"metadata": {},
|
| 38 |
+
"outputs": [],
|
| 39 |
+
"source": []
|
| 40 |
+
}
|
| 41 |
+
],
|
| 42 |
+
"metadata": {
|
| 43 |
+
"kernelspec": {
|
| 44 |
+
"display_name": "Python 3 (ipykernel)",
|
| 45 |
+
"language": "python",
|
| 46 |
+
"name": "python3"
|
| 47 |
+
},
|
| 48 |
+
"language_info": {
|
| 49 |
+
"codemirror_mode": {
|
| 50 |
+
"name": "ipython",
|
| 51 |
+
"version": 3
|
| 52 |
+
},
|
| 53 |
+
"file_extension": ".py",
|
| 54 |
+
"mimetype": "text/x-python",
|
| 55 |
+
"name": "python",
|
| 56 |
+
"nbconvert_exporter": "python",
|
| 57 |
+
"pygments_lexer": "ipython3",
|
| 58 |
+
"version": "3.9.5"
|
| 59 |
+
}
|
| 60 |
+
},
|
| 61 |
+
"nbformat": 4,
|
| 62 |
+
"nbformat_minor": 5
|
| 63 |
+
}
|
notebooks/ch4-installing-jupyterlab.ipynb
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "26b5a248",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"## 4. Installing JupyterLab\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"> ⚠️ Note: This step is optional. We’ll be running all code directly in JupyterLab on Hugging Face. Follow this step only if you prefer to run the code on your local machine—otherwise, you can skip to the next step.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"This class will show you how to interact with the Hugging Face API using the Python computer programming language.\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"If you want to run it on your computer, you can write Python code in your terminal, in a text file and any number of other places. If you’re a skilled programmer who already has a preferred venue for coding, feel free to use it as you work through this class.\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"If you’re not, the tool we recommend for beginners is [Project Jupyter](http://jupyter.org/), a browser-based interface where you can write, run, remix, and republish code.\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"It is free software that anyone can install and run. It is used by [scientists](http://nbviewer.jupyter.org/github/robertodealmeida/notebooks/blob/master/earth_day_data_challenge/Analyzing%20whale%20tracks.ipynb), [scholars](http://nbviewer.jupyter.org/github/nealcaren/workshop_2014/blob/master/notebooks/5_Times_API.ipynb), [investors](https://github.com/rsvp/fecon235/blob/master/nb/fred-debt-pop.ipynb), and corporations to create and share their research. It is also used by journalists to develop stories and show their work.\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"The easiest way to use it is by installing [JupyterLab Desktop](https://github.com/jupyterlab/jupyterlab-desktop), a self-contained application that provides a ready-to-use Python environment with several popular libraries bundled in. \n",
|
| 21 |
+
"It can be installed on any operating system with a simple point-and-click interface."
|
| 22 |
+
]
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"cell_type": "code",
|
| 26 |
+
"execution_count": 2,
|
| 27 |
+
"id": "c97c32a7-0497-4231-a628-647afdaac68b",
|
| 28 |
+
"metadata": {},
|
| 29 |
+
"outputs": [
|
| 30 |
+
{
|
| 31 |
+
"data": {
|
| 32 |
+
"text/html": [
|
| 33 |
+
"\n",
|
| 34 |
+
"<div style=\"position: relative; padding-bottom: 56.25%; height: 0; overflow: hidden; max-width: 100%;\">\n",
|
| 35 |
+
" <iframe \n",
|
| 36 |
+
" src=\"https://www.youtube.com/embed/578B63wZ7rI\" \n",
|
| 37 |
+
" style=\"position: absolute; top: 0; left: 0; width: 100%; height: 100%;\" \n",
|
| 38 |
+
" frameborder=\"0\" \n",
|
| 39 |
+
" allowfullscreen>\n",
|
| 40 |
+
" </iframe>\n",
|
| 41 |
+
"</div>\n"
|
| 42 |
+
],
|
| 43 |
+
"text/plain": [
|
| 44 |
+
"<IPython.core.display.HTML object>"
|
| 45 |
+
]
|
| 46 |
+
},
|
| 47 |
+
"execution_count": 2,
|
| 48 |
+
"metadata": {},
|
| 49 |
+
"output_type": "execute_result"
|
| 50 |
+
}
|
| 51 |
+
],
|
| 52 |
+
"source": [
|
| 53 |
+
"from IPython.display import HTML\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"HTML(\"\"\"\n",
|
| 56 |
+
"<div style=\"position: relative; padding-bottom: 56.25%; height: 0; overflow: hidden; max-width: 100%;\">\n",
|
| 57 |
+
" <iframe \n",
|
| 58 |
+
" src=\"https://www.youtube.com/embed/578B63wZ7rI\" \n",
|
| 59 |
+
" style=\"position: absolute; top: 0; left: 0; width: 100%; height: 100%;\" \n",
|
| 60 |
+
" frameborder=\"0\" \n",
|
| 61 |
+
" allowfullscreen>\n",
|
| 62 |
+
" </iframe>\n",
|
| 63 |
+
"</div>\n",
|
| 64 |
+
"\"\"\")"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "markdown",
|
| 69 |
+
"id": "d5decd99-55a2-4a56-b88f-1930a6245203",
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"source": [
|
| 72 |
+
"The first step is to visit [JupyterLab Desktop’s homepage on GitHub](https://github.com/jupyterlab/jupyterlab-desktop) in your web browser. \n",
|
| 73 |
+
"\n",
|
| 74 |
+
"\n",
|
| 75 |
+
"\n",
|
| 76 |
+
"Scroll down to the documentation below the code until you reach the [Installation](https://github.com/jupyterlab/jupyterlab-desktop) section. \n",
|
| 77 |
+
"\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"\n",
|
| 80 |
+
"Then pick the link appropriate for your operating system. The installation file is large, so the download might take a while.\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"Find the file in your downloads directory and double-click it to begin the installation process. \n",
|
| 83 |
+
"\n",
|
| 84 |
+
"Follow the instructions presented by the pop-up windows, sticking to the default options.\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"> ⚠️ **Warning** \n",
|
| 87 |
+
"> Your computer’s operating system might flag the JupyterLab Desktop installer as an unverified or insecure application. Don’t worry. The tool has been vetted by Project Jupyter’s core developers and it’s safe to use. \n",
|
| 88 |
+
"> If your system is blocking you from installing the tool, you’ll likely need to work around its barriers. For instance, on macOS, this might require [visiting your system’s security settings](https://www.wikihow.com/Install-Software-from-Unsigned-Developers-on-a-Mac) to allow the installation.\n",
|
| 89 |
+
"\n",
|
| 90 |
+
"Once JupyterLab Desktop is installed, you can accept the installation wizard’s offer to immediately open the program, or you can search for “Jupyter Lab” in your operating system’s application finder.\n",
|
| 91 |
+
"\n",
|
| 92 |
+
"That will open up a new window that looks something like this:\n",
|
| 93 |
+
"\n",
|
| 94 |
+
"\n",
|
| 95 |
+
"\n",
|
| 96 |
+
"> ⚠️ **Warning** \n",
|
| 97 |
+
"> If you see a warning bar at the bottom of the screen that says you need to install Python, click the link provided to make that happen.\n",
|
| 98 |
+
"\n",
|
| 99 |
+
"Click the “New notebook…” button to open the Python interface.\n",
|
| 100 |
+
"\n",
|
| 101 |
+
"\n",
|
| 102 |
+
"\n",
|
| 103 |
+
"Welcome to your first Jupyter notebook. Now you’re ready to move on to writing code.\n",
|
| 104 |
+
"\n",
|
| 105 |
+
"> 💡 **Note** \n",
|
| 106 |
+
"> If you’re struggling to make Jupyter work and need help with the basics, \n",
|
| 107 |
+
"> we recommend you check out [“First Python Notebook”](https://palewi.re/docs/first-python-notebook/), where you can get up to speed.\n",
|
| 108 |
+
"\n",
|
| 109 |
+
"**[5. Prompting with Python →](ch5-prompting-with-python.ipynb)**"
|
| 110 |
+
]
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"cell_type": "code",
|
| 114 |
+
"execution_count": null,
|
| 115 |
+
"id": "cca91757-438f-4a5f-b3d5-2bdd774278de",
|
| 116 |
+
"metadata": {},
|
| 117 |
+
"outputs": [],
|
| 118 |
+
"source": []
|
| 119 |
+
}
|
| 120 |
+
],
|
| 121 |
+
"metadata": {
|
| 122 |
+
"kernelspec": {
|
| 123 |
+
"display_name": "Python 3 (ipykernel)",
|
| 124 |
+
"language": "python",
|
| 125 |
+
"name": "python3"
|
| 126 |
+
},
|
| 127 |
+
"language_info": {
|
| 128 |
+
"codemirror_mode": {
|
| 129 |
+
"name": "ipython",
|
| 130 |
+
"version": 3
|
| 131 |
+
},
|
| 132 |
+
"file_extension": ".py",
|
| 133 |
+
"mimetype": "text/x-python",
|
| 134 |
+
"name": "python",
|
| 135 |
+
"nbconvert_exporter": "python",
|
| 136 |
+
"pygments_lexer": "ipython3",
|
| 137 |
+
"version": "3.9.5"
|
| 138 |
+
}
|
| 139 |
+
},
|
| 140 |
+
"nbformat": 4,
|
| 141 |
+
"nbformat_minor": 5
|
| 142 |
+
}
|
notebooks/ch5-prompting-with-python.ipynb
ADDED
|
@@ -0,0 +1,536 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "84dd193e",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"## 5. Prompting with Python"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"cell_type": "markdown",
|
| 13 |
+
"id": "862b8218",
|
| 14 |
+
"metadata": {},
|
| 15 |
+
"source": [
|
| 16 |
+
"First, we’ll install the libraries we need. The `huggingface_hub` package is the official client for Hugging Face’s API. The `rich` and `ipywidgets` packages are helper libraries that will improve how your outputs look in Jupyter notebooks."
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "markdown",
|
| 21 |
+
"id": "c09f0b15",
|
| 22 |
+
"metadata": {},
|
| 23 |
+
"source": [
|
| 24 |
+
"A common way to install packages from inside your JupyterLab Desktop notebook is to use the `%pip command`. Hit the play button in the top toolbar after selecting the cell below."
|
| 25 |
+
]
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"cell_type": "code",
|
| 29 |
+
"execution_count": null,
|
| 30 |
+
"id": "e728c5fe",
|
| 31 |
+
"metadata": {
|
| 32 |
+
"scrolled": true
|
| 33 |
+
},
|
| 34 |
+
"outputs": [],
|
| 35 |
+
"source": [
|
| 36 |
+
"%pip install rich ipywidgets huggingface_hub"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "markdown",
|
| 41 |
+
"id": "79f96b1a",
|
| 42 |
+
"metadata": {},
|
| 43 |
+
"source": [
|
| 44 |
+
"If the `%pip command` doesn’t work on your computer, try substituting the `!pip command` instead. Or you can install the packages from the command line on your computer and restart your notebook."
|
| 45 |
+
]
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"cell_type": "markdown",
|
| 49 |
+
"id": "75f1366a",
|
| 50 |
+
"metadata": {},
|
| 51 |
+
"source": [
|
| 52 |
+
"Now let's import them in the cell that appears below the installation output. Hit play again."
|
| 53 |
+
]
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"cell_type": "code",
|
| 57 |
+
"execution_count": 2,
|
| 58 |
+
"id": "8013a72c-670e-48ab-8619-99a337fd5392",
|
| 59 |
+
"metadata": {},
|
| 60 |
+
"outputs": [],
|
| 61 |
+
"source": [
|
| 62 |
+
"import os\n",
|
| 63 |
+
"from rich import print\n",
|
| 64 |
+
"from huggingface_hub import InferenceClient"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "markdown",
|
| 69 |
+
"id": "fdd7b199",
|
| 70 |
+
"metadata": {},
|
| 71 |
+
"source": [
|
| 72 |
+
"With `api_key = os.getenv(\"HF_TOKEN\")`, we're calling the free Hugging Face Inference API, using an authentication token stored in the \"Secrets\" of this Space. If you'd like to duplicate this Space, you'll need to create a token with your account [here](https://huggingface.co/settings/tokens).\n",
|
| 73 |
+
"\n",
|
| 74 |
+
"You should continue adding new cells as you need throughout the rest of the class."
|
| 75 |
+
]
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"cell_type": "code",
|
| 79 |
+
"execution_count": 3,
|
| 80 |
+
"id": "a5ec5ea4-5bd1-4ba7-b4cb-3f0a98505f29",
|
| 81 |
+
"metadata": {},
|
| 82 |
+
"outputs": [],
|
| 83 |
+
"source": [
|
| 84 |
+
"api_key = os.getenv(\"HF_TOKEN\")"
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"cell_type": "markdown",
|
| 89 |
+
"id": "b9e81187",
|
| 90 |
+
"metadata": {},
|
| 91 |
+
"source": [
|
| 92 |
+
"Let’s make our first prompt. To do that, we submit a dictionary to Hugging Face’s `chat.completions.create` method. The dictionary has a `messages` key that contains a list of dictionaries. Each dictionary in the list represents a message in the conversation. When the role is \"user\" it is roughly the same as asking a question to a chatbot."
|
| 93 |
+
]
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"cell_type": "markdown",
|
| 97 |
+
"id": "e83c5390",
|
| 98 |
+
"metadata": {},
|
| 99 |
+
"source": [
|
| 100 |
+
"We also need to pick a model from among the choices Hugging Face gives us. We’re picking Llama 3.3, the latest from Meta."
|
| 101 |
+
]
|
| 102 |
+
},
|
| 103 |
+
{
|
| 104 |
+
"cell_type": "code",
|
| 105 |
+
"execution_count": 4,
|
| 106 |
+
"id": "54a5befd-0c64-4039-9b26-14733c9f007e",
|
| 107 |
+
"metadata": {},
|
| 108 |
+
"outputs": [],
|
| 109 |
+
"source": [
|
| 110 |
+
"client = InferenceClient(\n",
|
| 111 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 112 |
+
" token=api_key,\n",
|
| 113 |
+
")"
|
| 114 |
+
]
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"cell_type": "code",
|
| 118 |
+
"execution_count": 5,
|
| 119 |
+
"id": "38abe6e0",
|
| 120 |
+
"metadata": {},
|
| 121 |
+
"outputs": [],
|
| 122 |
+
"source": [
|
| 123 |
+
"response = client.chat.completions.create(\n",
|
| 124 |
+
" messages=[\n",
|
| 125 |
+
" {\n",
|
| 126 |
+
" \"role\": \"user\",\n",
|
| 127 |
+
" \"content\": \"Explain the importance of data journalism in a concise sentence\"\n",
|
| 128 |
+
" }\n",
|
| 129 |
+
" ],\n",
|
| 130 |
+
")"
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"cell_type": "markdown",
|
| 135 |
+
"id": "3156058c",
|
| 136 |
+
"metadata": {},
|
| 137 |
+
"source": [
|
| 138 |
+
"Our client saves the response as a variable. Print that Python object to see what it contains."
|
| 139 |
+
]
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"cell_type": "code",
|
| 143 |
+
"execution_count": 6,
|
| 144 |
+
"id": "49bf29f5",
|
| 145 |
+
"metadata": {},
|
| 146 |
+
"outputs": [
|
| 147 |
+
{
|
| 148 |
+
"data": {
|
| 149 |
+
"text/html": [
|
| 150 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"><span style=\"color: #800080; text-decoration-color: #800080; font-weight: bold\">ChatCompletionOutput</span><span style=\"font-weight: bold\">(</span><span style=\"color: #808000; text-decoration-color: #808000\">choices</span>=<span style=\"font-weight: bold\">[</span><span style=\"color: #800080; text-decoration-color: #800080; font-weight: bold\">ChatCompletionOutputComplete</span><span style=\"font-weight: bold\">(</span><span style=\"color: #808000; text-decoration-color: #808000\">finish_reason</span>=<span style=\"color: #008000; text-decoration-color: #008000\">'stop'</span>, <span style=\"color: #808000; text-decoration-color: #808000\">index</span>=<span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0</span>, \n",
|
| 151 |
+
"<span style=\"color: #808000; text-decoration-color: #808000\">message</span>=<span style=\"color: #800080; text-decoration-color: #800080; font-weight: bold\">ChatCompletionOutputMessage</span><span style=\"font-weight: bold\">(</span><span style=\"color: #808000; text-decoration-color: #808000\">role</span>=<span style=\"color: #008000; text-decoration-color: #008000\">'assistant'</span>, <span style=\"color: #808000; text-decoration-color: #808000\">content</span>=<span style=\"color: #008000; text-decoration-color: #008000\">'Data journalism plays a crucial role in holding </span>\n",
|
| 152 |
+
"<span style=\"color: #008000; text-decoration-color: #008000\">institutions accountable and informing the public by analyzing and interpreting complex data to uncover trends, </span>\n",
|
| 153 |
+
"<span style=\"color: #008000; text-decoration-color: #008000\">patterns, and insights that can lead to more informed decision-making and a deeper understanding of social </span>\n",
|
| 154 |
+
"<span style=\"color: #008000; text-decoration-color: #008000\">issues.'</span>, <span style=\"color: #808000; text-decoration-color: #808000\">tool_calls</span>=<span style=\"color: #800080; text-decoration-color: #800080; font-style: italic\">None</span><span style=\"font-weight: bold\">)</span>, <span style=\"color: #808000; text-decoration-color: #808000\">logprobs</span>=<span style=\"color: #800080; text-decoration-color: #800080; font-style: italic\">None</span><span style=\"font-weight: bold\">)]</span>, <span style=\"color: #808000; text-decoration-color: #808000\">created</span>=<span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1742869712</span>, <span style=\"color: #808000; text-decoration-color: #808000\">id</span>=<span style=\"color: #008000; text-decoration-color: #008000\">''</span>, <span style=\"color: #808000; text-decoration-color: #808000\">model</span>=<span style=\"color: #008000; text-decoration-color: #008000\">'meta-llama/Llama-3.3-70B-Instruct'</span>, \n",
|
| 155 |
+
"<span style=\"color: #808000; text-decoration-color: #808000\">system_fingerprint</span>=<span style=\"color: #008000; text-decoration-color: #008000\">'3.0.1-sha-bb9095a'</span>, <span style=\"color: #808000; text-decoration-color: #808000\">usage</span>=<span style=\"color: #800080; text-decoration-color: #800080; font-weight: bold\">ChatCompletionOutputUsage</span><span style=\"font-weight: bold\">(</span><span style=\"color: #808000; text-decoration-color: #808000\">completion_tokens</span>=<span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">45</span>, <span style=\"color: #808000; text-decoration-color: #808000\">prompt_tokens</span>=<span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">46</span>, \n",
|
| 156 |
+
"<span style=\"color: #808000; text-decoration-color: #808000\">total_tokens</span>=<span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">91</span><span style=\"font-weight: bold\">)</span>, <span style=\"color: #808000; text-decoration-color: #808000\">object</span>=<span style=\"color: #008000; text-decoration-color: #008000\">'chat.completion'</span><span style=\"font-weight: bold\">)</span>\n",
|
| 157 |
+
"</pre>\n"
|
| 158 |
+
],
|
| 159 |
+
"text/plain": [
|
| 160 |
+
"\u001b[1;35mChatCompletionOutput\u001b[0m\u001b[1m(\u001b[0m\u001b[33mchoices\u001b[0m=\u001b[1m[\u001b[0m\u001b[1;35mChatCompletionOutputComplete\u001b[0m\u001b[1m(\u001b[0m\u001b[33mfinish_reason\u001b[0m=\u001b[32m'stop'\u001b[0m, \u001b[33mindex\u001b[0m=\u001b[1;36m0\u001b[0m, \n",
|
| 161 |
+
"\u001b[33mmessage\u001b[0m=\u001b[1;35mChatCompletionOutputMessage\u001b[0m\u001b[1m(\u001b[0m\u001b[33mrole\u001b[0m=\u001b[32m'assistant'\u001b[0m, \u001b[33mcontent\u001b[0m=\u001b[32m'Data journalism plays a crucial role in holding \u001b[0m\n",
|
| 162 |
+
"\u001b[32minstitutions accountable and informing the public by analyzing and interpreting complex data to uncover trends, \u001b[0m\n",
|
| 163 |
+
"\u001b[32mpatterns, and insights that can lead to more informed decision-making and a deeper understanding of social \u001b[0m\n",
|
| 164 |
+
"\u001b[32missues.'\u001b[0m, \u001b[33mtool_calls\u001b[0m=\u001b[3;35mNone\u001b[0m\u001b[1m)\u001b[0m, \u001b[33mlogprobs\u001b[0m=\u001b[3;35mNone\u001b[0m\u001b[1m)\u001b[0m\u001b[1m]\u001b[0m, \u001b[33mcreated\u001b[0m=\u001b[1;36m1742869712\u001b[0m, \u001b[33mid\u001b[0m=\u001b[32m''\u001b[0m, \u001b[33mmodel\u001b[0m=\u001b[32m'meta-llama/Llama-3.3-70B-Instruct'\u001b[0m, \n",
|
| 165 |
+
"\u001b[33msystem_fingerprint\u001b[0m=\u001b[32m'3.0.1-sha-bb9095a'\u001b[0m, \u001b[33musage\u001b[0m=\u001b[1;35mChatCompletionOutputUsage\u001b[0m\u001b[1m(\u001b[0m\u001b[33mcompletion_tokens\u001b[0m=\u001b[1;36m45\u001b[0m, \u001b[33mprompt_tokens\u001b[0m=\u001b[1;36m46\u001b[0m, \n",
|
| 166 |
+
"\u001b[33mtotal_tokens\u001b[0m=\u001b[1;36m91\u001b[0m\u001b[1m)\u001b[0m, \u001b[33mobject\u001b[0m=\u001b[32m'chat.completion'\u001b[0m\u001b[1m)\u001b[0m\n"
|
| 167 |
+
]
|
| 168 |
+
},
|
| 169 |
+
"metadata": {},
|
| 170 |
+
"output_type": "display_data"
|
| 171 |
+
}
|
| 172 |
+
],
|
| 173 |
+
"source": [
|
| 174 |
+
"print(response)"
|
| 175 |
+
]
|
| 176 |
+
},
|
| 177 |
+
{
|
| 178 |
+
"cell_type": "markdown",
|
| 179 |
+
"id": "d9f86d8e",
|
| 180 |
+
"metadata": {},
|
| 181 |
+
"source": [
|
| 182 |
+
"You should see something like:"
|
| 183 |
+
]
|
| 184 |
+
},
|
| 185 |
+
{
|
| 186 |
+
"cell_type": "markdown",
|
| 187 |
+
"id": "cdf08e93-a6cc-4245-9fa3-2cc456208bcf",
|
| 188 |
+
"metadata": {},
|
| 189 |
+
"source": [
|
| 190 |
+
"```\n",
|
| 191 |
+
"ChatCompletionOutput(\n",
|
| 192 |
+
" choices=[\n",
|
| 193 |
+
" ChatCompletionOutputComplete(\n",
|
| 194 |
+
" finish_reason='stop',\n",
|
| 195 |
+
" index=0,\n",
|
| 196 |
+
" message=ChatCompletionOutputMessage(\n",
|
| 197 |
+
" role='assistant',\n",
|
| 198 |
+
" content='Data journalism plays a crucial role in holding those in power accountable by using data analysis and visualization to uncover insights, trends, and patterns that inform and engage the public on important issues.',\n",
|
| 199 |
+
" tool_calls=None\n",
|
| 200 |
+
" ),\n",
|
| 201 |
+
" logprobs=None\n",
|
| 202 |
+
" )\n",
|
| 203 |
+
" ],\n",
|
| 204 |
+
" created=1742592105,\n",
|
| 205 |
+
" id='',\n",
|
| 206 |
+
" model='meta-llama/Llama-3.3-70B-Instruct',\n",
|
| 207 |
+
" system_fingerprint='3.2.1-native',\n",
|
| 208 |
+
" usage=ChatCompletionOutputUsage(\n",
|
| 209 |
+
" completion_tokens=37,\n",
|
| 210 |
+
" prompt_tokens=46,\n",
|
| 211 |
+
" total_tokens=83\n",
|
| 212 |
+
" ),\n",
|
| 213 |
+
" object='chat.completion'\n",
|
| 214 |
+
")\n",
|
| 215 |
+
"```"
|
| 216 |
+
]
|
| 217 |
+
},
|
| 218 |
+
{
|
| 219 |
+
"cell_type": "markdown",
|
| 220 |
+
"id": "ff414bab",
|
| 221 |
+
"metadata": {},
|
| 222 |
+
"source": [
|
| 223 |
+
"There’s a lot here, but the `message` has the actual response from the LLM. Let’s just print the content from that message. Note that your response probably varies from this guide. That’s because LLMs mostly are probablistic prediction machines. Every response can be a little different."
|
| 224 |
+
]
|
| 225 |
+
},
|
| 226 |
+
{
|
| 227 |
+
"cell_type": "code",
|
| 228 |
+
"execution_count": 7,
|
| 229 |
+
"id": "0f291693",
|
| 230 |
+
"metadata": {},
|
| 231 |
+
"outputs": [
|
| 232 |
+
{
|
| 233 |
+
"data": {
|
| 234 |
+
"text/html": [
|
| 235 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">Data journalism plays a crucial role in holding institutions accountable and informing the public by analyzing and \n",
|
| 236 |
+
"interpreting complex data to uncover trends, patterns, and insights that can lead to more informed decision-making \n",
|
| 237 |
+
"and a deeper understanding of social issues.\n",
|
| 238 |
+
"</pre>\n"
|
| 239 |
+
],
|
| 240 |
+
"text/plain": [
|
| 241 |
+
"Data journalism plays a crucial role in holding institutions accountable and informing the public by analyzing and \n",
|
| 242 |
+
"interpreting complex data to uncover trends, patterns, and insights that can lead to more informed decision-making \n",
|
| 243 |
+
"and a deeper understanding of social issues.\n"
|
| 244 |
+
]
|
| 245 |
+
},
|
| 246 |
+
"metadata": {},
|
| 247 |
+
"output_type": "display_data"
|
| 248 |
+
}
|
| 249 |
+
],
|
| 250 |
+
"source": [
|
| 251 |
+
"print(response.choices[0].message.content)"
|
| 252 |
+
]
|
| 253 |
+
},
|
| 254 |
+
{
|
| 255 |
+
"cell_type": "markdown",
|
| 256 |
+
"id": "0c1e292a",
|
| 257 |
+
"metadata": {},
|
| 258 |
+
"source": [
|
| 259 |
+
"Let’s pick a different model from amongthe choices that Hugging Face offers. One we could try is Gemma2, an open model from Google. Rather than add a new cell, lets revise the code we already have and rerun it."
|
| 260 |
+
]
|
| 261 |
+
},
|
| 262 |
+
{
|
| 263 |
+
"cell_type": "code",
|
| 264 |
+
"execution_count": 8,
|
| 265 |
+
"id": "9fb3f9b8",
|
| 266 |
+
"metadata": {},
|
| 267 |
+
"outputs": [],
|
| 268 |
+
"source": [
|
| 269 |
+
"response = client.chat.completions.create(\n",
|
| 270 |
+
" messages=[\n",
|
| 271 |
+
" {\n",
|
| 272 |
+
" \"role\": \"user\",\n",
|
| 273 |
+
" \"content\": \"Explain the importance of data journalism in a concise sentence\",\n",
|
| 274 |
+
" }\n",
|
| 275 |
+
" ],\n",
|
| 276 |
+
" model=\"google/gemma-2-9b-it\", # NEW\n",
|
| 277 |
+
")"
|
| 278 |
+
]
|
| 279 |
+
},
|
| 280 |
+
{
|
| 281 |
+
"cell_type": "markdown",
|
| 282 |
+
"id": "aa6662ed",
|
| 283 |
+
"metadata": {},
|
| 284 |
+
"source": [
|
| 285 |
+
"Again, your response might vary from what’s here. Let’s find out."
|
| 286 |
+
]
|
| 287 |
+
},
|
| 288 |
+
{
|
| 289 |
+
"cell_type": "code",
|
| 290 |
+
"execution_count": 9,
|
| 291 |
+
"id": "0f036c66",
|
| 292 |
+
"metadata": {},
|
| 293 |
+
"outputs": [
|
| 294 |
+
{
|
| 295 |
+
"data": {
|
| 296 |
+
"text/html": [
|
| 297 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">Data journalism plays a crucial role in holding those in power accountable by uncovering hidden trends, patterns, \n",
|
| 298 |
+
"and insights through the analysis and visualization of data, enabling informed decision-making and promoting \n",
|
| 299 |
+
"transparency.\n",
|
| 300 |
+
"</pre>\n"
|
| 301 |
+
],
|
| 302 |
+
"text/plain": [
|
| 303 |
+
"Data journalism plays a crucial role in holding those in power accountable by uncovering hidden trends, patterns, \n",
|
| 304 |
+
"and insights through the analysis and visualization of data, enabling informed decision-making and promoting \n",
|
| 305 |
+
"transparency.\n"
|
| 306 |
+
]
|
| 307 |
+
},
|
| 308 |
+
"metadata": {},
|
| 309 |
+
"output_type": "display_data"
|
| 310 |
+
}
|
| 311 |
+
],
|
| 312 |
+
"source": [
|
| 313 |
+
"print(response.choices[0].message.content)"
|
| 314 |
+
]
|
| 315 |
+
},
|
| 316 |
+
{
|
| 317 |
+
"cell_type": "markdown",
|
| 318 |
+
"id": "12802cac",
|
| 319 |
+
"metadata": {},
|
| 320 |
+
"source": [
|
| 321 |
+
"---\n",
|
| 322 |
+
"### Sidenote:\n",
|
| 323 |
+
"Hugging Face’s Python library is very similar to the ones offered by OpenAI, Anthropic and other LLM providers. If you prefer to use those tools, the techniques you learn here should be easily transferable."
|
| 324 |
+
]
|
| 325 |
+
},
|
| 326 |
+
{
|
| 327 |
+
"cell_type": "markdown",
|
| 328 |
+
"id": "e7668bd3",
|
| 329 |
+
"metadata": {},
|
| 330 |
+
"source": [
|
| 331 |
+
"For instance, here’s how you’d make this same call with Anthropic’s Python library:"
|
| 332 |
+
]
|
| 333 |
+
},
|
| 334 |
+
{
|
| 335 |
+
"cell_type": "code",
|
| 336 |
+
"execution_count": null,
|
| 337 |
+
"id": "11e567e3",
|
| 338 |
+
"metadata": {},
|
| 339 |
+
"outputs": [],
|
| 340 |
+
"source": [
|
| 341 |
+
"from anthropic import Anthropic\n",
|
| 342 |
+
"\n",
|
| 343 |
+
"client = Anthropic(api_key=api_key)\n",
|
| 344 |
+
"\n",
|
| 345 |
+
"response = client.messages.create(\n",
|
| 346 |
+
" messages=[\n",
|
| 347 |
+
" {\"role\": \"user\", \"content\": \"Explain the importance of data journalism in a concise sentence\"},\n",
|
| 348 |
+
" ],\n",
|
| 349 |
+
" model=\"claude-3-5-sonnet-20240620\",\n",
|
| 350 |
+
")\n",
|
| 351 |
+
"\n",
|
| 352 |
+
"print(response.content[0].text)"
|
| 353 |
+
]
|
| 354 |
+
},
|
| 355 |
+
{
|
| 356 |
+
"cell_type": "markdown",
|
| 357 |
+
"id": "182e8e6b",
|
| 358 |
+
"metadata": {},
|
| 359 |
+
"source": [
|
| 360 |
+
"---\n",
|
| 361 |
+
"A well-structured prompt helps the LLM provide more accurate and useful responses."
|
| 362 |
+
]
|
| 363 |
+
},
|
| 364 |
+
{
|
| 365 |
+
"cell_type": "markdown",
|
| 366 |
+
"id": "da211bea",
|
| 367 |
+
"metadata": {},
|
| 368 |
+
"source": [
|
| 369 |
+
"One common technique for improving results is to open with a “system” prompt to establish the model’s tone and role. Let’s switch back to Llama 3.3 and provide a `system` message that provides a specific motivation for the LLM’s responses."
|
| 370 |
+
]
|
| 371 |
+
},
|
| 372 |
+
{
|
| 373 |
+
"cell_type": "code",
|
| 374 |
+
"execution_count": 11,
|
| 375 |
+
"id": "a5660ed5",
|
| 376 |
+
"metadata": {},
|
| 377 |
+
"outputs": [],
|
| 378 |
+
"source": [
|
| 379 |
+
"response = client.chat.completions.create(\n",
|
| 380 |
+
" messages=[\n",
|
| 381 |
+
" ### <-- NEW\n",
|
| 382 |
+
" {\n",
|
| 383 |
+
" \"role\": \"system\",\n",
|
| 384 |
+
" \"content\": \"you are an enthusiastic nerd who believes data journalism is the future.\"\n",
|
| 385 |
+
" },\n",
|
| 386 |
+
" ### -->\n",
|
| 387 |
+
" {\n",
|
| 388 |
+
" \"role\": \"user\",\n",
|
| 389 |
+
" \"content\": \"Explain the importance of data journalism in a concise sentence\",\n",
|
| 390 |
+
" }\n",
|
| 391 |
+
" ],\n",
|
| 392 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\", # NEW\n",
|
| 393 |
+
")"
|
| 394 |
+
]
|
| 395 |
+
},
|
| 396 |
+
{
|
| 397 |
+
"cell_type": "markdown",
|
| 398 |
+
"id": "598dd139",
|
| 399 |
+
"metadata": {},
|
| 400 |
+
"source": [
|
| 401 |
+
"Check out the results."
|
| 402 |
+
]
|
| 403 |
+
},
|
| 404 |
+
{
|
| 405 |
+
"cell_type": "code",
|
| 406 |
+
"execution_count": 12,
|
| 407 |
+
"id": "a5c74d22",
|
| 408 |
+
"metadata": {},
|
| 409 |
+
"outputs": [
|
| 410 |
+
{
|
| 411 |
+
"data": {
|
| 412 |
+
"text/html": [
|
| 413 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">Data journalism is revolutionizing the way we consume news by using statistical analysis and visualizations to \n",
|
| 414 |
+
"uncover hidden truths, provide fact-based evidence, and hold those in power accountable, thereby fostering a more \n",
|
| 415 |
+
"informed and engaged citizenry!\n",
|
| 416 |
+
"</pre>\n"
|
| 417 |
+
],
|
| 418 |
+
"text/plain": [
|
| 419 |
+
"Data journalism is revolutionizing the way we consume news by using statistical analysis and visualizations to \n",
|
| 420 |
+
"uncover hidden truths, provide fact-based evidence, and hold those in power accountable, thereby fostering a more \n",
|
| 421 |
+
"informed and engaged citizenry!\n"
|
| 422 |
+
]
|
| 423 |
+
},
|
| 424 |
+
"metadata": {},
|
| 425 |
+
"output_type": "display_data"
|
| 426 |
+
}
|
| 427 |
+
],
|
| 428 |
+
"source": [
|
| 429 |
+
"print(response.choices[0].message.content)"
|
| 430 |
+
]
|
| 431 |
+
},
|
| 432 |
+
{
|
| 433 |
+
"cell_type": "markdown",
|
| 434 |
+
"id": "304bbabc",
|
| 435 |
+
"metadata": {},
|
| 436 |
+
"source": [
|
| 437 |
+
"Want to see how tone affects the response? Change the system prompt to something old-school."
|
| 438 |
+
]
|
| 439 |
+
},
|
| 440 |
+
{
|
| 441 |
+
"cell_type": "code",
|
| 442 |
+
"execution_count": 13,
|
| 443 |
+
"id": "3123cd0b",
|
| 444 |
+
"metadata": {},
|
| 445 |
+
"outputs": [],
|
| 446 |
+
"source": [
|
| 447 |
+
"response = client.chat.completions.create(\n",
|
| 448 |
+
" messages=[\n",
|
| 449 |
+
" {\n",
|
| 450 |
+
" \"role\": \"system\",\n",
|
| 451 |
+
" \"content\": \"you are a crusty, ill-tempered editor who hates math and thinks data journalism is a waste of time and resources.\" # NEW\n",
|
| 452 |
+
" },\n",
|
| 453 |
+
" {\n",
|
| 454 |
+
" \"role\": \"user\",\n",
|
| 455 |
+
" \"content\": \"Explain the importance of data journalism in a concise sentence\",\n",
|
| 456 |
+
" }\n",
|
| 457 |
+
" ],\n",
|
| 458 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 459 |
+
")"
|
| 460 |
+
]
|
| 461 |
+
},
|
| 462 |
+
{
|
| 463 |
+
"cell_type": "markdown",
|
| 464 |
+
"id": "b90dd487",
|
| 465 |
+
"metadata": {},
|
| 466 |
+
"source": [
|
| 467 |
+
"Then re-run the code and summon J. Jonah Jameson."
|
| 468 |
+
]
|
| 469 |
+
},
|
| 470 |
+
{
|
| 471 |
+
"cell_type": "code",
|
| 472 |
+
"execution_count": 14,
|
| 473 |
+
"id": "3defdc9c",
|
| 474 |
+
"metadata": {},
|
| 475 |
+
"outputs": [
|
| 476 |
+
{
|
| 477 |
+
"data": {
|
| 478 |
+
"text/html": [
|
| 479 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">If I must, data journalism is supposedly important because it allows reporters to use numbers and statistics to \n",
|
| 480 |
+
"fact-check claims, identify trends, and hold those in power accountable, but frankly, I've seen better storytelling\n",
|
| 481 |
+
"in a spreadsheet.\n",
|
| 482 |
+
"</pre>\n"
|
| 483 |
+
],
|
| 484 |
+
"text/plain": [
|
| 485 |
+
"If I must, data journalism is supposedly important because it allows reporters to use numbers and statistics to \n",
|
| 486 |
+
"fact-check claims, identify trends, and hold those in power accountable, but frankly, I've seen better storytelling\n",
|
| 487 |
+
"in a spreadsheet.\n"
|
| 488 |
+
]
|
| 489 |
+
},
|
| 490 |
+
"metadata": {},
|
| 491 |
+
"output_type": "display_data"
|
| 492 |
+
}
|
| 493 |
+
],
|
| 494 |
+
"source": [
|
| 495 |
+
"print(response.choices[0].message.content)"
|
| 496 |
+
]
|
| 497 |
+
},
|
| 498 |
+
{
|
| 499 |
+
"cell_type": "markdown",
|
| 500 |
+
"id": "957517fa-e69b-42bb-88b5-3a71b680972f",
|
| 501 |
+
"metadata": {},
|
| 502 |
+
"source": [
|
| 503 |
+
"**[6. Structured responses →](ch6-structured-responses.ipynb)**"
|
| 504 |
+
]
|
| 505 |
+
},
|
| 506 |
+
{
|
| 507 |
+
"cell_type": "code",
|
| 508 |
+
"execution_count": null,
|
| 509 |
+
"id": "0e45220f-a77c-4463-8211-96dd79b09840",
|
| 510 |
+
"metadata": {},
|
| 511 |
+
"outputs": [],
|
| 512 |
+
"source": []
|
| 513 |
+
}
|
| 514 |
+
],
|
| 515 |
+
"metadata": {
|
| 516 |
+
"kernelspec": {
|
| 517 |
+
"display_name": "Python 3 (ipykernel)",
|
| 518 |
+
"language": "python",
|
| 519 |
+
"name": "python3"
|
| 520 |
+
},
|
| 521 |
+
"language_info": {
|
| 522 |
+
"codemirror_mode": {
|
| 523 |
+
"name": "ipython",
|
| 524 |
+
"version": 3
|
| 525 |
+
},
|
| 526 |
+
"file_extension": ".py",
|
| 527 |
+
"mimetype": "text/x-python",
|
| 528 |
+
"name": "python",
|
| 529 |
+
"nbconvert_exporter": "python",
|
| 530 |
+
"pygments_lexer": "ipython3",
|
| 531 |
+
"version": "3.9.5"
|
| 532 |
+
}
|
| 533 |
+
},
|
| 534 |
+
"nbformat": 4,
|
| 535 |
+
"nbformat_minor": 5
|
| 536 |
+
}
|
notebooks/ch6-structured-responses.ipynb
ADDED
|
@@ -0,0 +1,719 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"## 6. Structured Responses\n",
|
| 8 |
+
"\n",
|
| 9 |
+
"Here's a public service announcement. There's no law that says you have to ask LLMs for essays, poems or relationship advice.\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"Yes, they're great at drumming up long blocks of text. An LLM can spit out a long answer to almost any question. It's how they've been tuned and marketed by companies selling chatbots and more conversational forms of search.\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"But they're also great at answering simple questions, a skill that has been overlooked in much of the hoopla that followed the introduction of ChatGPT.\n",
|
| 14 |
+
"\n",
|
| 15 |
+
"Here's a example that simply prompts the LLM to answer a straightforward question."
|
| 16 |
+
]
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"cell_type": "code",
|
| 20 |
+
"execution_count": 38,
|
| 21 |
+
"metadata": {},
|
| 22 |
+
"outputs": [],
|
| 23 |
+
"source": [
|
| 24 |
+
"import os\n",
|
| 25 |
+
"from rich import print\n",
|
| 26 |
+
"\n",
|
| 27 |
+
"# Reuse the Hugging Face client setup from the previous chapter\n",
|
| 28 |
+
"from huggingface_hub import InferenceClient\n",
|
| 29 |
+
"api_key = os.getenv(\"HF_TOKEN\")\n",
|
| 30 |
+
"client = InferenceClient(\n",
|
| 31 |
+
" token=api_key,\n",
|
| 32 |
+
")"
|
| 33 |
+
]
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"cell_type": "code",
|
| 37 |
+
"execution_count": 39,
|
| 38 |
+
"metadata": {},
|
| 39 |
+
"outputs": [],
|
| 40 |
+
"source": [
|
| 41 |
+
"prompt = \"\"\"\n",
|
| 42 |
+
"You are an AI model trained to classify text.\n",
|
| 43 |
+
"\n",
|
| 44 |
+
"I will provide the name of a professional sports team.\n",
|
| 45 |
+
"\n",
|
| 46 |
+
"You will reply with the sports league in which they compete.\n",
|
| 47 |
+
"\"\"\""
|
| 48 |
+
]
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
"cell_type": "markdown",
|
| 52 |
+
"metadata": {},
|
| 53 |
+
"source": [
|
| 54 |
+
"Lace that into our request."
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"cell_type": "code",
|
| 59 |
+
"execution_count": 40,
|
| 60 |
+
"metadata": {},
|
| 61 |
+
"outputs": [],
|
| 62 |
+
"source": [
|
| 63 |
+
"response = client.chat.completions.create(\n",
|
| 64 |
+
" messages=[\n",
|
| 65 |
+
" {\n",
|
| 66 |
+
" \"role\": \"system\",\n",
|
| 67 |
+
" \"content\": prompt # NEW\n",
|
| 68 |
+
" },\n",
|
| 69 |
+
" ],\n",
|
| 70 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 71 |
+
")"
|
| 72 |
+
]
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"cell_type": "markdown",
|
| 76 |
+
"metadata": {},
|
| 77 |
+
"source": [
|
| 78 |
+
"And now add a user message that provides the name of a professional sports team."
|
| 79 |
+
]
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"cell_type": "code",
|
| 83 |
+
"execution_count": 41,
|
| 84 |
+
"metadata": {},
|
| 85 |
+
"outputs": [],
|
| 86 |
+
"source": [
|
| 87 |
+
"response = client.chat.completions.create(\n",
|
| 88 |
+
" messages=[\n",
|
| 89 |
+
" {\n",
|
| 90 |
+
" \"role\": \"system\",\n",
|
| 91 |
+
" \"content\": prompt\n",
|
| 92 |
+
" },\n",
|
| 93 |
+
" ### <-- NEW \n",
|
| 94 |
+
" {\n",
|
| 95 |
+
" \"role\": \"user\",\n",
|
| 96 |
+
" \"content\": \"Minnesota Twins\",\n",
|
| 97 |
+
" }\n",
|
| 98 |
+
" ### -->\n",
|
| 99 |
+
" ],\n",
|
| 100 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 101 |
+
")"
|
| 102 |
+
]
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"cell_type": "markdown",
|
| 106 |
+
"metadata": {},
|
| 107 |
+
"source": [
|
| 108 |
+
"Check the response."
|
| 109 |
+
]
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"cell_type": "code",
|
| 113 |
+
"execution_count": 42,
|
| 114 |
+
"metadata": {},
|
| 115 |
+
"outputs": [
|
| 116 |
+
{
|
| 117 |
+
"data": {
|
| 118 |
+
"text/html": [
|
| 119 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">Major League Baseball <span style=\"font-weight: bold\">(</span>MLB<span style=\"font-weight: bold\">)</span>\n",
|
| 120 |
+
"</pre>\n"
|
| 121 |
+
],
|
| 122 |
+
"text/plain": [
|
| 123 |
+
"Major League Baseball \u001b[1m(\u001b[0mMLB\u001b[1m)\u001b[0m\n"
|
| 124 |
+
]
|
| 125 |
+
},
|
| 126 |
+
"metadata": {},
|
| 127 |
+
"output_type": "display_data"
|
| 128 |
+
}
|
| 129 |
+
],
|
| 130 |
+
"source": [
|
| 131 |
+
"print(response.choices[0].message.content)"
|
| 132 |
+
]
|
| 133 |
+
},
|
| 134 |
+
{
|
| 135 |
+
"cell_type": "markdown",
|
| 136 |
+
"metadata": {},
|
| 137 |
+
"source": [
|
| 138 |
+
"And we'll bet you get the right answer.\n",
|
| 139 |
+
"\n",
|
| 140 |
+
"```\n",
|
| 141 |
+
"Major League Baseball (MLB)\n",
|
| 142 |
+
"```\n",
|
| 143 |
+
"\n",
|
| 144 |
+
"Try another one."
|
| 145 |
+
]
|
| 146 |
+
},
|
| 147 |
+
{
|
| 148 |
+
"cell_type": "code",
|
| 149 |
+
"execution_count": 43,
|
| 150 |
+
"metadata": {},
|
| 151 |
+
"outputs": [],
|
| 152 |
+
"source": [
|
| 153 |
+
"response = client.chat.completions.create(\n",
|
| 154 |
+
" messages=[\n",
|
| 155 |
+
" {\n",
|
| 156 |
+
" \"role\": \"system\",\n",
|
| 157 |
+
" \"content\": prompt\n",
|
| 158 |
+
" },\n",
|
| 159 |
+
" {\n",
|
| 160 |
+
" \"role\": \"user\",\n",
|
| 161 |
+
" \"content\": \"Minnesota Vikings\", # NEW\n",
|
| 162 |
+
" }\n",
|
| 163 |
+
" ],\n",
|
| 164 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 165 |
+
")"
|
| 166 |
+
]
|
| 167 |
+
},
|
| 168 |
+
{
|
| 169 |
+
"cell_type": "code",
|
| 170 |
+
"execution_count": 44,
|
| 171 |
+
"metadata": {},
|
| 172 |
+
"outputs": [
|
| 173 |
+
{
|
| 174 |
+
"data": {
|
| 175 |
+
"text/html": [
|
| 176 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">National Football League <span style=\"font-weight: bold\">(</span>NFL<span style=\"font-weight: bold\">)</span>\n",
|
| 177 |
+
"</pre>\n"
|
| 178 |
+
],
|
| 179 |
+
"text/plain": [
|
| 180 |
+
"National Football League \u001b[1m(\u001b[0mNFL\u001b[1m)\u001b[0m\n"
|
| 181 |
+
]
|
| 182 |
+
},
|
| 183 |
+
"metadata": {},
|
| 184 |
+
"output_type": "display_data"
|
| 185 |
+
}
|
| 186 |
+
],
|
| 187 |
+
"source": [
|
| 188 |
+
"print(response.choices[0].message.content)"
|
| 189 |
+
]
|
| 190 |
+
},
|
| 191 |
+
{
|
| 192 |
+
"cell_type": "markdown",
|
| 193 |
+
"metadata": {},
|
| 194 |
+
"source": [
|
| 195 |
+
"See what we mean?\n",
|
| 196 |
+
"\n",
|
| 197 |
+
"```\n",
|
| 198 |
+
"National Football League (NFL)\n",
|
| 199 |
+
"```\n",
|
| 200 |
+
"\n",
|
| 201 |
+
"This approach can be use to classify large datasets, adding a new column of data that categories text in a way that makes it easier to analyze.\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"Let's try it by making a function that will classify whatever team you provide."
|
| 204 |
+
]
|
| 205 |
+
},
|
| 206 |
+
{
|
| 207 |
+
"cell_type": "code",
|
| 208 |
+
"execution_count": 45,
|
| 209 |
+
"metadata": {},
|
| 210 |
+
"outputs": [],
|
| 211 |
+
"source": [
|
| 212 |
+
"def classify_team(name):\n",
|
| 213 |
+
" prompt = \"\"\"\n",
|
| 214 |
+
"You are an AI model trained to classify text.\n",
|
| 215 |
+
"\n",
|
| 216 |
+
"I will provide the name of a professional sports team.\n",
|
| 217 |
+
"\n",
|
| 218 |
+
"You will reply with the sports league in which they compete.\n",
|
| 219 |
+
"\"\"\"\n",
|
| 220 |
+
"\n",
|
| 221 |
+
" response = client.chat.completions.create(\n",
|
| 222 |
+
" messages=[\n",
|
| 223 |
+
" {\n",
|
| 224 |
+
" \"role\": \"system\",\n",
|
| 225 |
+
" \"content\": prompt,\n",
|
| 226 |
+
" },\n",
|
| 227 |
+
" {\n",
|
| 228 |
+
" \"role\": \"user\",\n",
|
| 229 |
+
" \"content\": name,\n",
|
| 230 |
+
" }\n",
|
| 231 |
+
" ],\n",
|
| 232 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 233 |
+
" )\n",
|
| 234 |
+
"\n",
|
| 235 |
+
" return response.choices[0].message.content"
|
| 236 |
+
]
|
| 237 |
+
},
|
| 238 |
+
{
|
| 239 |
+
"cell_type": "markdown",
|
| 240 |
+
"metadata": {},
|
| 241 |
+
"source": [
|
| 242 |
+
"A list of teams."
|
| 243 |
+
]
|
| 244 |
+
},
|
| 245 |
+
{
|
| 246 |
+
"cell_type": "code",
|
| 247 |
+
"execution_count": 46,
|
| 248 |
+
"metadata": {},
|
| 249 |
+
"outputs": [],
|
| 250 |
+
"source": [
|
| 251 |
+
"team_list = [\"Minnesota Twins\", \"Minnesota Vikings\", \"Minnesota Timberwolves\"]"
|
| 252 |
+
]
|
| 253 |
+
},
|
| 254 |
+
{
|
| 255 |
+
"cell_type": "markdown",
|
| 256 |
+
"metadata": {},
|
| 257 |
+
"source": [
|
| 258 |
+
"Now, loop through the list and ask the LLM to code them one by one."
|
| 259 |
+
]
|
| 260 |
+
},
|
| 261 |
+
{
|
| 262 |
+
"cell_type": "code",
|
| 263 |
+
"execution_count": 47,
|
| 264 |
+
"metadata": {},
|
| 265 |
+
"outputs": [
|
| 266 |
+
{
|
| 267 |
+
"data": {
|
| 268 |
+
"text/html": [
|
| 269 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"><span style=\"font-weight: bold\">[</span><span style=\"color: #008000; text-decoration-color: #008000\">'Minnesota Twins'</span>, <span style=\"color: #008000; text-decoration-color: #008000\">'Major League Baseball (MLB)'</span><span style=\"font-weight: bold\">]</span>\n",
|
| 270 |
+
"</pre>\n"
|
| 271 |
+
],
|
| 272 |
+
"text/plain": [
|
| 273 |
+
"\u001b[1m[\u001b[0m\u001b[32m'Minnesota Twins'\u001b[0m, \u001b[32m'Major League Baseball \u001b[0m\u001b[32m(\u001b[0m\u001b[32mMLB\u001b[0m\u001b[32m)\u001b[0m\u001b[32m'\u001b[0m\u001b[1m]\u001b[0m\n"
|
| 274 |
+
]
|
| 275 |
+
},
|
| 276 |
+
"metadata": {},
|
| 277 |
+
"output_type": "display_data"
|
| 278 |
+
},
|
| 279 |
+
{
|
| 280 |
+
"data": {
|
| 281 |
+
"text/html": [
|
| 282 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"><span style=\"font-weight: bold\">[</span><span style=\"color: #008000; text-decoration-color: #008000\">'Minnesota Vikings'</span>, <span style=\"color: #008000; text-decoration-color: #008000\">'National Football League (NFL)'</span><span style=\"font-weight: bold\">]</span>\n",
|
| 283 |
+
"</pre>\n"
|
| 284 |
+
],
|
| 285 |
+
"text/plain": [
|
| 286 |
+
"\u001b[1m[\u001b[0m\u001b[32m'Minnesota Vikings'\u001b[0m, \u001b[32m'National Football League \u001b[0m\u001b[32m(\u001b[0m\u001b[32mNFL\u001b[0m\u001b[32m)\u001b[0m\u001b[32m'\u001b[0m\u001b[1m]\u001b[0m\n"
|
| 287 |
+
]
|
| 288 |
+
},
|
| 289 |
+
"metadata": {},
|
| 290 |
+
"output_type": "display_data"
|
| 291 |
+
},
|
| 292 |
+
{
|
| 293 |
+
"data": {
|
| 294 |
+
"text/html": [
|
| 295 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"><span style=\"font-weight: bold\">[</span><span style=\"color: #008000; text-decoration-color: #008000\">'Minnesota Timberwolves'</span>, <span style=\"color: #008000; text-decoration-color: #008000\">'National Basketball Association (NBA)'</span><span style=\"font-weight: bold\">]</span>\n",
|
| 296 |
+
"</pre>\n"
|
| 297 |
+
],
|
| 298 |
+
"text/plain": [
|
| 299 |
+
"\u001b[1m[\u001b[0m\u001b[32m'Minnesota Timberwolves'\u001b[0m, \u001b[32m'National Basketball Association \u001b[0m\u001b[32m(\u001b[0m\u001b[32mNBA\u001b[0m\u001b[32m)\u001b[0m\u001b[32m'\u001b[0m\u001b[1m]\u001b[0m\n"
|
| 300 |
+
]
|
| 301 |
+
},
|
| 302 |
+
"metadata": {},
|
| 303 |
+
"output_type": "display_data"
|
| 304 |
+
}
|
| 305 |
+
],
|
| 306 |
+
"source": [
|
| 307 |
+
"for team in team_list:\n",
|
| 308 |
+
" league = classify_team(team)\n",
|
| 309 |
+
" print([team, league])"
|
| 310 |
+
]
|
| 311 |
+
},
|
| 312 |
+
{
|
| 313 |
+
"cell_type": "markdown",
|
| 314 |
+
"metadata": {},
|
| 315 |
+
"source": [
|
| 316 |
+
"Due its probabilistic nature, the LLM can sometimes return slight variations on the same answer. You can prevent this by adding a validation system that will only accept responses from a pre-defined list."
|
| 317 |
+
]
|
| 318 |
+
},
|
| 319 |
+
{
|
| 320 |
+
"cell_type": "code",
|
| 321 |
+
"execution_count": 57,
|
| 322 |
+
"metadata": {},
|
| 323 |
+
"outputs": [],
|
| 324 |
+
"source": [
|
| 325 |
+
"def classify_team(name):\n",
|
| 326 |
+
" prompt = \"\"\"\n",
|
| 327 |
+
"You are an AI model trained to classify text.\n",
|
| 328 |
+
"\n",
|
| 329 |
+
"I will provide the name of a professional sports team.\n",
|
| 330 |
+
"\n",
|
| 331 |
+
"You will reply with the sports league in which they compete.\n",
|
| 332 |
+
"\n",
|
| 333 |
+
"Your responses must come from the following list:\n",
|
| 334 |
+
"- Major League Baseball (MLB)\n",
|
| 335 |
+
"- National Football League (NFL)\n",
|
| 336 |
+
"- National Basketball Association (NBA)\n",
|
| 337 |
+
"\"\"\"\n",
|
| 338 |
+
"\n",
|
| 339 |
+
" response = client.chat.completions.create(\n",
|
| 340 |
+
" messages=[\n",
|
| 341 |
+
" {\n",
|
| 342 |
+
" \"role\": \"system\",\n",
|
| 343 |
+
" \"content\": prompt,\n",
|
| 344 |
+
" },\n",
|
| 345 |
+
" {\n",
|
| 346 |
+
" \"role\": \"user\",\n",
|
| 347 |
+
" \"content\": name,\n",
|
| 348 |
+
" }\n",
|
| 349 |
+
" ],\n",
|
| 350 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 351 |
+
" )\n",
|
| 352 |
+
"\n",
|
| 353 |
+
" answer = response.choices[0].message.content\n",
|
| 354 |
+
" ### <-- NEW\n",
|
| 355 |
+
" acceptable_answers = [\n",
|
| 356 |
+
" \"Major League Baseball (MLB)\",\n",
|
| 357 |
+
" \"National Football League (NFL)\",\n",
|
| 358 |
+
" \"National Basketball Association (NBA)\",\n",
|
| 359 |
+
" ]\n",
|
| 360 |
+
" if answer not in acceptable_answers:\n",
|
| 361 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 362 |
+
" ### -->\n",
|
| 363 |
+
" return answer"
|
| 364 |
+
]
|
| 365 |
+
},
|
| 366 |
+
{
|
| 367 |
+
"cell_type": "markdown",
|
| 368 |
+
"metadata": {},
|
| 369 |
+
"source": [
|
| 370 |
+
"Now, ask it for a team that's not in one of those leagues. You should get an error."
|
| 371 |
+
]
|
| 372 |
+
},
|
| 373 |
+
{
|
| 374 |
+
"cell_type": "code",
|
| 375 |
+
"execution_count": 51,
|
| 376 |
+
"metadata": {},
|
| 377 |
+
"outputs": [
|
| 378 |
+
{
|
| 379 |
+
"ename": "ValueError",
|
| 380 |
+
"evalue": "National Hockey League (NHL) \n\nNote: The provided team doesn't fit into the specified leagues (MLB, NFL, NBA), as the Minnesota Wild is a part of the National Hockey League. not in list of acceptable answers",
|
| 381 |
+
"output_type": "error",
|
| 382 |
+
"traceback": [
|
| 383 |
+
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
|
| 384 |
+
"\u001b[0;31mValueError\u001b[0m Traceback (most recent call last)",
|
| 385 |
+
"Cell \u001b[0;32mIn[51], line 1\u001b[0m\n\u001b[0;32m----> 1\u001b[0m \u001b[43mclassify_team\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[38;5;124;43mMinnesota Wild\u001b[39;49m\u001b[38;5;124;43m\"\u001b[39;49m\u001b[43m)\u001b[49m\n",
|
| 386 |
+
"Cell \u001b[0;32mIn[50], line 37\u001b[0m, in \u001b[0;36mclassify_team\u001b[0;34m(name)\u001b[0m\n\u001b[1;32m 31\u001b[0m acceptable_answers \u001b[38;5;241m=\u001b[39m [\n\u001b[1;32m 32\u001b[0m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mMajor League Baseball (MLB)\u001b[39m\u001b[38;5;124m\"\u001b[39m,\n\u001b[1;32m 33\u001b[0m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mNational Football League (NFL)\u001b[39m\u001b[38;5;124m\"\u001b[39m,\n\u001b[1;32m 34\u001b[0m \u001b[38;5;124m\"\u001b[39m\u001b[38;5;124mNational Basketball Association (NBA)\u001b[39m\u001b[38;5;124m\"\u001b[39m,\n\u001b[1;32m 35\u001b[0m ]\n\u001b[1;32m 36\u001b[0m \u001b[38;5;28;01mif\u001b[39;00m answer \u001b[38;5;129;01mnot\u001b[39;00m \u001b[38;5;129;01min\u001b[39;00m acceptable_answers:\n\u001b[0;32m---> 37\u001b[0m \u001b[38;5;28;01mraise\u001b[39;00m \u001b[38;5;167;01mValueError\u001b[39;00m(\u001b[38;5;124mf\u001b[39m\u001b[38;5;124m\"\u001b[39m\u001b[38;5;132;01m{\u001b[39;00manswer\u001b[38;5;132;01m}\u001b[39;00m\u001b[38;5;124m not in list of acceptable answers\u001b[39m\u001b[38;5;124m\"\u001b[39m)\n\u001b[1;32m 39\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m answer\n",
|
| 387 |
+
"\u001b[0;31mValueError\u001b[0m: National Hockey League (NHL) \n\nNote: The provided team doesn't fit into the specified leagues (MLB, NFL, NBA), as the Minnesota Wild is a part of the National Hockey League. not in list of acceptable answers"
|
| 388 |
+
]
|
| 389 |
+
}
|
| 390 |
+
],
|
| 391 |
+
"source": [
|
| 392 |
+
"classify_team(\"Minnesota Wild\")"
|
| 393 |
+
]
|
| 394 |
+
},
|
| 395 |
+
{
|
| 396 |
+
"cell_type": "code",
|
| 397 |
+
"execution_count": 52,
|
| 398 |
+
"metadata": {},
|
| 399 |
+
"outputs": [],
|
| 400 |
+
"source": [
|
| 401 |
+
"def classify_team(name):\n",
|
| 402 |
+
" # Last sentence is the prompt is new\n",
|
| 403 |
+
" prompt = \"\"\"\n",
|
| 404 |
+
"You are an AI model trained to classify text.\n",
|
| 405 |
+
"\n",
|
| 406 |
+
"I will provide the name of a professional sports team.\n",
|
| 407 |
+
"\n",
|
| 408 |
+
"You will reply with the sports league in which they compete.\n",
|
| 409 |
+
"\n",
|
| 410 |
+
"Your responses must come from the following list:\n",
|
| 411 |
+
"- Major League Baseball (MLB)\n",
|
| 412 |
+
"- National Football League (NFL)\n",
|
| 413 |
+
"- National Basketball Association (NBA)\n",
|
| 414 |
+
"\n",
|
| 415 |
+
"If the team's league is not on the list, you should label them as \"Other\".\n",
|
| 416 |
+
"\"\"\"\n",
|
| 417 |
+
" response = client.chat.completions.create(\n",
|
| 418 |
+
" messages=[\n",
|
| 419 |
+
" {\n",
|
| 420 |
+
" \"role\": \"system\",\n",
|
| 421 |
+
" \"content\": prompt,\n",
|
| 422 |
+
" },\n",
|
| 423 |
+
" {\n",
|
| 424 |
+
" \"role\": \"user\",\n",
|
| 425 |
+
" \"content\": name,\n",
|
| 426 |
+
" }\n",
|
| 427 |
+
" ],\n",
|
| 428 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 429 |
+
" )\n",
|
| 430 |
+
"\n",
|
| 431 |
+
" answer = response.choices[0].message.content\n",
|
| 432 |
+
"\n",
|
| 433 |
+
" acceptable_answers = [\n",
|
| 434 |
+
" \"Major League Baseball (MLB)\",\n",
|
| 435 |
+
" \"National Football League (NFL)\",\n",
|
| 436 |
+
" \"National Basketball Association (NBA)\",\n",
|
| 437 |
+
" \"Other\", # NEW\n",
|
| 438 |
+
" ]\n",
|
| 439 |
+
" if answer not in acceptable_answers:\n",
|
| 440 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 441 |
+
"\n",
|
| 442 |
+
" return answer"
|
| 443 |
+
]
|
| 444 |
+
},
|
| 445 |
+
{
|
| 446 |
+
"cell_type": "markdown",
|
| 447 |
+
"metadata": {},
|
| 448 |
+
"source": [
|
| 449 |
+
"Now try the Minnesota Wild again."
|
| 450 |
+
]
|
| 451 |
+
},
|
| 452 |
+
{
|
| 453 |
+
"cell_type": "code",
|
| 454 |
+
"execution_count": 53,
|
| 455 |
+
"metadata": {},
|
| 456 |
+
"outputs": [
|
| 457 |
+
{
|
| 458 |
+
"data": {
|
| 459 |
+
"text/plain": [
|
| 460 |
+
"'Other'"
|
| 461 |
+
]
|
| 462 |
+
},
|
| 463 |
+
"execution_count": 53,
|
| 464 |
+
"metadata": {},
|
| 465 |
+
"output_type": "execute_result"
|
| 466 |
+
}
|
| 467 |
+
],
|
| 468 |
+
"source": [
|
| 469 |
+
"classify_team(\"Minnesota Wild\")"
|
| 470 |
+
]
|
| 471 |
+
},
|
| 472 |
+
{
|
| 473 |
+
"cell_type": "markdown",
|
| 474 |
+
"metadata": {},
|
| 475 |
+
"source": [
|
| 476 |
+
"And you'll get the answer you expect.\n",
|
| 477 |
+
"\n",
|
| 478 |
+
"```\n",
|
| 479 |
+
"'Other'\n",
|
| 480 |
+
"```\n",
|
| 481 |
+
"\n",
|
| 482 |
+
"Most LLMs are pre-programmed to be creative and generate a range of responses to same prompt. For structured responses like this, we don't want that. We want consistency. So it's a good idea to ask the LLM to be more straightforward by reducing a creativity setting known as `temperature` to zero."
|
| 483 |
+
]
|
| 484 |
+
},
|
| 485 |
+
{
|
| 486 |
+
"cell_type": "code",
|
| 487 |
+
"execution_count": 54,
|
| 488 |
+
"metadata": {},
|
| 489 |
+
"outputs": [],
|
| 490 |
+
"source": [
|
| 491 |
+
"def classify_team(name):\n",
|
| 492 |
+
" prompt = \"\"\"\n",
|
| 493 |
+
"You are an AI model trained to classify text.\n",
|
| 494 |
+
"\n",
|
| 495 |
+
"I will provide the name of a professional sports team.\n",
|
| 496 |
+
"\n",
|
| 497 |
+
"You will reply with the sports league in which they compete.\n",
|
| 498 |
+
"\n",
|
| 499 |
+
"Your responses must come from the following list:\n",
|
| 500 |
+
"- Major League Baseball (MLB)\n",
|
| 501 |
+
"- National Football League (NFL)\n",
|
| 502 |
+
"- National Basketball Association (NBA)\n",
|
| 503 |
+
"\n",
|
| 504 |
+
"If the team's league is not on the list, you should label them as \"Other\".\n",
|
| 505 |
+
"\"\"\"\n",
|
| 506 |
+
"\n",
|
| 507 |
+
" response = client.chat.completions.create(\n",
|
| 508 |
+
" messages=[\n",
|
| 509 |
+
" {\n",
|
| 510 |
+
" \"role\": \"system\",\n",
|
| 511 |
+
" \"content\": prompt,\n",
|
| 512 |
+
" },\n",
|
| 513 |
+
" {\n",
|
| 514 |
+
" \"role\": \"user\",\n",
|
| 515 |
+
" \"content\": name,\n",
|
| 516 |
+
" }\n",
|
| 517 |
+
" ],\n",
|
| 518 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 519 |
+
" temperature=0, # NEW\n",
|
| 520 |
+
" )\n",
|
| 521 |
+
"\n",
|
| 522 |
+
" answer = response.choices[0].message.content\n",
|
| 523 |
+
"\n",
|
| 524 |
+
" acceptable_answers = [\n",
|
| 525 |
+
" \"Major League Baseball (MLB)\",\n",
|
| 526 |
+
" \"National Football League (NFL)\",\n",
|
| 527 |
+
" \"National Basketball Association (NBA)\",\n",
|
| 528 |
+
" \"Other\",\n",
|
| 529 |
+
" ]\n",
|
| 530 |
+
" if answer not in acceptable_answers:\n",
|
| 531 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 532 |
+
"\n",
|
| 533 |
+
" return answer"
|
| 534 |
+
]
|
| 535 |
+
},
|
| 536 |
+
{
|
| 537 |
+
"cell_type": "markdown",
|
| 538 |
+
"metadata": {},
|
| 539 |
+
"source": [
|
| 540 |
+
"You can also increase reliability by priming the LLM with examples of the type of response you want. This technique is called [\"few shot prompting\"](https://www.ibm.com/think/topics/few-shot-prompting). In this style of prompting, which can feel like a strange form of roleplaying, you provide both the \"user\" input as well as the \"assistant\" response you want the LLM to mimic.\n",
|
| 541 |
+
"\n",
|
| 542 |
+
"Here's how it's done:"
|
| 543 |
+
]
|
| 544 |
+
},
|
| 545 |
+
{
|
| 546 |
+
"cell_type": "code",
|
| 547 |
+
"execution_count": 56,
|
| 548 |
+
"metadata": {},
|
| 549 |
+
"outputs": [],
|
| 550 |
+
"source": [
|
| 551 |
+
"def classify_team(name):\n",
|
| 552 |
+
" prompt = \"\"\"\n",
|
| 553 |
+
"You are an AI model trained to classify text.\n",
|
| 554 |
+
"\n",
|
| 555 |
+
"I will provide the name of a professional sports team.\n",
|
| 556 |
+
"\n",
|
| 557 |
+
"You will reply with the sports league in which they compete.\n",
|
| 558 |
+
"\n",
|
| 559 |
+
"Your responses must come from the following list:\n",
|
| 560 |
+
"- Major League Baseball (MLB)\n",
|
| 561 |
+
"- National Football League (NFL)\n",
|
| 562 |
+
"- National Basketball Association (NBA)\n",
|
| 563 |
+
"\n",
|
| 564 |
+
"If the team's league is not on the list, you should label them as \"Other\".\n",
|
| 565 |
+
"\"\"\"\n",
|
| 566 |
+
"\n",
|
| 567 |
+
" response = client.chat.completions.create(\n",
|
| 568 |
+
" messages=[\n",
|
| 569 |
+
" {\n",
|
| 570 |
+
" \"role\": \"system\",\n",
|
| 571 |
+
" \"content\": prompt,\n",
|
| 572 |
+
" },\n",
|
| 573 |
+
" ### <-- NEW \n",
|
| 574 |
+
" {\n",
|
| 575 |
+
" \"role\": \"user\",\n",
|
| 576 |
+
" \"content\": \"Los Angeles Rams\",\n",
|
| 577 |
+
" },\n",
|
| 578 |
+
" {\n",
|
| 579 |
+
" \"role\": \"assistant\",\n",
|
| 580 |
+
" \"content\": \"National Football League (NFL)\",\n",
|
| 581 |
+
" },\n",
|
| 582 |
+
" {\n",
|
| 583 |
+
" \"role\": \"user\",\n",
|
| 584 |
+
" \"content\": \"Los Angeles Dodgers\",\n",
|
| 585 |
+
" },\n",
|
| 586 |
+
" {\n",
|
| 587 |
+
" \"role\": \"assistant\",\n",
|
| 588 |
+
" \"content\": \" Major League Baseball (MLB)\",\n",
|
| 589 |
+
" },\n",
|
| 590 |
+
" {\n",
|
| 591 |
+
" \"role\": \"user\",\n",
|
| 592 |
+
" \"content\": \"Los Angeles Lakers\",\n",
|
| 593 |
+
" },\n",
|
| 594 |
+
" {\n",
|
| 595 |
+
" \"role\": \"assistant\",\n",
|
| 596 |
+
" \"content\": \"National Basketball Association (NBA)\",\n",
|
| 597 |
+
" },\n",
|
| 598 |
+
" {\n",
|
| 599 |
+
" \"role\": \"user\",\n",
|
| 600 |
+
" \"content\": \"Los Angeles Kings\",\n",
|
| 601 |
+
" },\n",
|
| 602 |
+
" {\n",
|
| 603 |
+
" \"role\": \"assistant\",\n",
|
| 604 |
+
" \"content\": \"Other\",\n",
|
| 605 |
+
" },\n",
|
| 606 |
+
" ### -->\n",
|
| 607 |
+
" {\n",
|
| 608 |
+
" \"role\": \"user\",\n",
|
| 609 |
+
" \"content\": name,\n",
|
| 610 |
+
" }\n",
|
| 611 |
+
" ],\n",
|
| 612 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 613 |
+
" temperature=0,\n",
|
| 614 |
+
" )\n",
|
| 615 |
+
"\n",
|
| 616 |
+
" answer = response.choices[0].message.content\n",
|
| 617 |
+
"\n",
|
| 618 |
+
" acceptable_answers = [\n",
|
| 619 |
+
" \"Major League Baseball (MLB)\",\n",
|
| 620 |
+
" \"National Football League (NFL)\",\n",
|
| 621 |
+
" \"National Basketball Association (NBA)\",\n",
|
| 622 |
+
" \"Other\",\n",
|
| 623 |
+
" ]\n",
|
| 624 |
+
" if answer not in acceptable_answers:\n",
|
| 625 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 626 |
+
"\n",
|
| 627 |
+
" return answer"
|
| 628 |
+
]
|
| 629 |
+
},
|
| 630 |
+
{
|
| 631 |
+
"cell_type": "markdown",
|
| 632 |
+
"metadata": {},
|
| 633 |
+
"source": [
|
| 634 |
+
"You can also ask the function to automatically retry if it doesn't get a valid response. This will give the LLM a second chance to get it right in cases where it gets too creative.\n",
|
| 635 |
+
"\n",
|
| 636 |
+
"To do that, we'll return installation step and in the `retry` package."
|
| 637 |
+
]
|
| 638 |
+
},
|
| 639 |
+
{
|
| 640 |
+
"cell_type": "code",
|
| 641 |
+
"execution_count": null,
|
| 642 |
+
"metadata": {
|
| 643 |
+
"scrolled": true
|
| 644 |
+
},
|
| 645 |
+
"outputs": [],
|
| 646 |
+
"source": [
|
| 647 |
+
"%pip install rich ipywidgets retry"
|
| 648 |
+
]
|
| 649 |
+
},
|
| 650 |
+
{
|
| 651 |
+
"cell_type": "markdown",
|
| 652 |
+
"metadata": {},
|
| 653 |
+
"source": [
|
| 654 |
+
"Now import the `retry` package."
|
| 655 |
+
]
|
| 656 |
+
},
|
| 657 |
+
{
|
| 658 |
+
"cell_type": "code",
|
| 659 |
+
"execution_count": 31,
|
| 660 |
+
"metadata": {},
|
| 661 |
+
"outputs": [],
|
| 662 |
+
"source": [
|
| 663 |
+
"from rich import print\n",
|
| 664 |
+
"import requests\n",
|
| 665 |
+
"from huggingface_hub import InferenceClient\n",
|
| 666 |
+
"from retry import retry # NEW"
|
| 667 |
+
]
|
| 668 |
+
},
|
| 669 |
+
{
|
| 670 |
+
"cell_type": "markdown",
|
| 671 |
+
"metadata": {},
|
| 672 |
+
"source": [
|
| 673 |
+
"And add the `retry` decorator to the function that will catch the `ValueError` exception and try again, as many times as you specify."
|
| 674 |
+
]
|
| 675 |
+
},
|
| 676 |
+
{
|
| 677 |
+
"cell_type": "code",
|
| 678 |
+
"execution_count": 59,
|
| 679 |
+
"metadata": {},
|
| 680 |
+
"outputs": [],
|
| 681 |
+
"source": [
|
| 682 |
+
"@retry(ValueError, tries=2, delay=2) # NEW\n",
|
| 683 |
+
"def classify_team(name):\n",
|
| 684 |
+
" prompt = \"\"\"\n",
|
| 685 |
+
"You are an AI model trained to classify text.\n",
|
| 686 |
+
"...\n",
|
| 687 |
+
"\"\"\""
|
| 688 |
+
]
|
| 689 |
+
},
|
| 690 |
+
{
|
| 691 |
+
"cell_type": "markdown",
|
| 692 |
+
"metadata": {},
|
| 693 |
+
"source": [
|
| 694 |
+
"**[7. Bulk prompts →](ch7-bulk-prompts.ipynb)**"
|
| 695 |
+
]
|
| 696 |
+
}
|
| 697 |
+
],
|
| 698 |
+
"metadata": {
|
| 699 |
+
"kernelspec": {
|
| 700 |
+
"display_name": "Python 3 (ipykernel)",
|
| 701 |
+
"language": "python",
|
| 702 |
+
"name": "python3"
|
| 703 |
+
},
|
| 704 |
+
"language_info": {
|
| 705 |
+
"codemirror_mode": {
|
| 706 |
+
"name": "ipython",
|
| 707 |
+
"version": 3
|
| 708 |
+
},
|
| 709 |
+
"file_extension": ".py",
|
| 710 |
+
"mimetype": "text/x-python",
|
| 711 |
+
"name": "python",
|
| 712 |
+
"nbconvert_exporter": "python",
|
| 713 |
+
"pygments_lexer": "ipython3",
|
| 714 |
+
"version": "3.9.5"
|
| 715 |
+
}
|
| 716 |
+
},
|
| 717 |
+
"nbformat": 4,
|
| 718 |
+
"nbformat_minor": 4
|
| 719 |
+
}
|
notebooks/ch7-bulk-prompts.ipynb
ADDED
|
@@ -0,0 +1,954 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"id": "3eb9d2c1",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"## 7. Bulk prompts"
|
| 9 |
+
]
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"cell_type": "markdown",
|
| 13 |
+
"id": "960b1cbf",
|
| 14 |
+
"metadata": {},
|
| 15 |
+
"source": [
|
| 16 |
+
"Our reusable prompting function is pretty cool. But requesting answers one by one across a big dataset could take forever. And with the Hugging Face free API, we’re likely to hit rate limits or timeouts if we send too many requests too quickly.\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"One solution is to submit your requests in batches and then ask the LLM to return its responses in bulk.\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"A common way to do that is to prompt the LLM to return its responses in JSON, a JavaScript data format that is easy to work with in Python.\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"To try that, we start by adding the built-in json library to our imports."
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"cell_type": "code",
|
| 27 |
+
"execution_count": 49,
|
| 28 |
+
"id": "ec94fe49",
|
| 29 |
+
"metadata": {},
|
| 30 |
+
"outputs": [],
|
| 31 |
+
"source": [
|
| 32 |
+
"import json # NEW\n",
|
| 33 |
+
"from rich import print\n",
|
| 34 |
+
"import requests\n",
|
| 35 |
+
"from retry import retry\n",
|
| 36 |
+
"import os\n",
|
| 37 |
+
"\n",
|
| 38 |
+
"api_key = os.getenv(\"HF_TOKEN\")\n",
|
| 39 |
+
"client = InferenceClient(\n",
|
| 40 |
+
" token=api_key,\n",
|
| 41 |
+
")"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "markdown",
|
| 46 |
+
"id": "eac8a34e",
|
| 47 |
+
"metadata": {},
|
| 48 |
+
"source": [
|
| 49 |
+
"Next, we make a series of changes to our function to adapt it to work with a batch of inputs. Get ready. It’s a lot.\n",
|
| 50 |
+
"- We tweak the name of the function.\n",
|
| 51 |
+
"- We change our input argument to a list.\n",
|
| 52 |
+
"- We expand our prompt to explain that we will provide a list of team names.\n",
|
| 53 |
+
"- We ask the LLM to classify them individually, returning its answers in a JSON list.\n",
|
| 54 |
+
"- We insist on getting one answer for each input.\n",
|
| 55 |
+
"- We tweak our few-shot training to reflect this new approach.\n",
|
| 56 |
+
"- We submit our input as a single string with new lines separating each team name.\n",
|
| 57 |
+
"- We convert the LLM’s response from a string to a list using the `json.loads` function.\n",
|
| 58 |
+
"- We check that the LLM’s answers are in our list of acceptable answers with a loop through the list.\n",
|
| 59 |
+
"- We merge the team names and the LLM’s answers into a dictionary returned by the function."
|
| 60 |
+
]
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"cell_type": "code",
|
| 64 |
+
"execution_count": 26,
|
| 65 |
+
"id": "70477229",
|
| 66 |
+
"metadata": {},
|
| 67 |
+
"outputs": [],
|
| 68 |
+
"source": [
|
| 69 |
+
"@retry(ValueError, tries=2, delay=2)\n",
|
| 70 |
+
"def classify_teams(name_list): # NEW\n",
|
| 71 |
+
" prompt = \"\"\"\n",
|
| 72 |
+
"You are an AI model trained to classify text.\n",
|
| 73 |
+
"\n",
|
| 74 |
+
"I will provide list of professional sports team names separated by new lines\n",
|
| 75 |
+
"\n",
|
| 76 |
+
"You will reply with the sports league in which they compete.\n",
|
| 77 |
+
"\n",
|
| 78 |
+
"Your responses must come from the following list:\n",
|
| 79 |
+
"- Major League Baseball (MLB)\n",
|
| 80 |
+
"- National Football League (NFL)\n",
|
| 81 |
+
"- National Basketball Association (NBA)\n",
|
| 82 |
+
"\n",
|
| 83 |
+
"If the team's league is not on the list, you should label them as \"Other\".\n",
|
| 84 |
+
"\n",
|
| 85 |
+
"Your answers should be returned as a flat JSON list.\n",
|
| 86 |
+
"\n",
|
| 87 |
+
"It is very important that the length of JSON list you return is exactly the same as the number of names you receive.\n",
|
| 88 |
+
"\n",
|
| 89 |
+
"If I were to submit:\n",
|
| 90 |
+
"\n",
|
| 91 |
+
"\"Los Angeles Rams\\nLos Angeles Dodgers\\nLos Angeles Lakers\\nLos Angeles Kings\"\n",
|
| 92 |
+
"\n",
|
| 93 |
+
"You should return the following:\n",
|
| 94 |
+
"\n",
|
| 95 |
+
"[\"National Football League (NFL)\", \"Major League Baseball (MLB)\", \"National Basketball Association (NBA)\", \"Other\"]\n",
|
| 96 |
+
"\"\"\"\n",
|
| 97 |
+
"\n",
|
| 98 |
+
" response = client.chat.completions.create(\n",
|
| 99 |
+
" messages=[\n",
|
| 100 |
+
" {\n",
|
| 101 |
+
" \"role\": \"system\",\n",
|
| 102 |
+
" \"content\": prompt,\n",
|
| 103 |
+
" },\n",
|
| 104 |
+
" ### <-- NEW \n",
|
| 105 |
+
" {\n",
|
| 106 |
+
" \"role\": \"user\",\n",
|
| 107 |
+
" \"content\": \"Chicago Bears\\nChicago Cubs\\nChicago Bulls\\nChicago Blackhawks\",\n",
|
| 108 |
+
" },\n",
|
| 109 |
+
" {\n",
|
| 110 |
+
" \"role\": \"assistant\",\n",
|
| 111 |
+
" \"content\": '[\"National Football League (NFL)\", \"Major League Baseball (MLB)\", \"National Basketball Association (NBA)\", \"Other\"]',\n",
|
| 112 |
+
" },\n",
|
| 113 |
+
" {\n",
|
| 114 |
+
" \"role\": \"user\",\n",
|
| 115 |
+
" \"content\": \"\\n\".join(name_list),\n",
|
| 116 |
+
" }\n",
|
| 117 |
+
" ### --> \n",
|
| 118 |
+
" ],\n",
|
| 119 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 120 |
+
" temperature=0,\n",
|
| 121 |
+
" )\n",
|
| 122 |
+
"\n",
|
| 123 |
+
" answer_str = response.choices[0].message.content # NEW\n",
|
| 124 |
+
" answer_list = json.loads(answer_str) # NEW\n",
|
| 125 |
+
"\n",
|
| 126 |
+
" acceptable_answers = [\n",
|
| 127 |
+
" \"Major League Baseball (MLB)\",\n",
|
| 128 |
+
" \"National Football League (NFL)\",\n",
|
| 129 |
+
" \"National Basketball Association (NBA)\",\n",
|
| 130 |
+
" \"Other\",\n",
|
| 131 |
+
" ]\n",
|
| 132 |
+
" ### <-- NEW\n",
|
| 133 |
+
" for answer in answer_list:\n",
|
| 134 |
+
" if answer not in acceptable_answers:\n",
|
| 135 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 136 |
+
" return dict(zip(name_list, answer_list))\n",
|
| 137 |
+
" ### -->"
|
| 138 |
+
]
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"cell_type": "markdown",
|
| 142 |
+
"id": "4a0909ed",
|
| 143 |
+
"metadata": {},
|
| 144 |
+
"source": [
|
| 145 |
+
"Try that with our team list. And you’ll see that it works with only a single API call. The same technique will work for a batch of any size."
|
| 146 |
+
]
|
| 147 |
+
},
|
| 148 |
+
{
|
| 149 |
+
"cell_type": "code",
|
| 150 |
+
"execution_count": 28,
|
| 151 |
+
"id": "2bb71639",
|
| 152 |
+
"metadata": {},
|
| 153 |
+
"outputs": [
|
| 154 |
+
{
|
| 155 |
+
"data": {
|
| 156 |
+
"text/plain": [
|
| 157 |
+
"{'Minnesota Twins': 'Major League Baseball (MLB)',\n",
|
| 158 |
+
" 'Minnesota Vikings': 'National Football League (NFL)',\n",
|
| 159 |
+
" 'Minnesota Timberwolves': 'National Basketball Association (NBA)'}"
|
| 160 |
+
]
|
| 161 |
+
},
|
| 162 |
+
"execution_count": 28,
|
| 163 |
+
"metadata": {},
|
| 164 |
+
"output_type": "execute_result"
|
| 165 |
+
}
|
| 166 |
+
],
|
| 167 |
+
"source": [
|
| 168 |
+
"team_list = [\"Minnesota Twins\", \"Minnesota Vikings\", \"Minnesota Timberwolves\"]\n",
|
| 169 |
+
"classify_teams(team_list)"
|
| 170 |
+
]
|
| 171 |
+
},
|
| 172 |
+
{
|
| 173 |
+
"cell_type": "markdown",
|
| 174 |
+
"id": "b6815a5c",
|
| 175 |
+
"metadata": {},
|
| 176 |
+
"source": [
|
| 177 |
+
"Though, as you batches get bigger, one common problem is that the number of outputs from the LLM can fail to match the number of inputs you provide. This problem may lessen as LLMs improve, but for now it’s a good idea to limit to batches to a few dozen inputs and to verify that you’re getting the right number back."
|
| 178 |
+
]
|
| 179 |
+
},
|
| 180 |
+
{
|
| 181 |
+
"cell_type": "code",
|
| 182 |
+
"execution_count": 29,
|
| 183 |
+
"id": "8295afc9",
|
| 184 |
+
"metadata": {},
|
| 185 |
+
"outputs": [],
|
| 186 |
+
"source": [
|
| 187 |
+
"@retry(ValueError, tries=2, delay=2)\n",
|
| 188 |
+
"def classify_teams(name_list):\n",
|
| 189 |
+
" prompt = \"\"\"\n",
|
| 190 |
+
"You are an AI model trained to classify text.\n",
|
| 191 |
+
"\n",
|
| 192 |
+
"I will provide list of professional sports team names separated by new lines\n",
|
| 193 |
+
"\n",
|
| 194 |
+
"You will reply with the sports league in which they compete.\n",
|
| 195 |
+
"\n",
|
| 196 |
+
"Your responses must come from the following list:\n",
|
| 197 |
+
"- Major League Baseball (MLB)\n",
|
| 198 |
+
"- National Football League (NFL)\n",
|
| 199 |
+
"- National Basketball Association (NBA)\n",
|
| 200 |
+
"\n",
|
| 201 |
+
"If the team's league is not on the list, you should label them as \"Other\".\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"Your answers should be returned as a flat JSON list.\n",
|
| 204 |
+
"\n",
|
| 205 |
+
"It is very important that the length of JSON list you return is exactly the same as the number of names you receive.\n",
|
| 206 |
+
"\n",
|
| 207 |
+
"If I were to submit:\n",
|
| 208 |
+
"\n",
|
| 209 |
+
"\"Los Angeles Rams\\nLos Angeles Dodgers\\nLos Angeles Lakers\\nLos Angeles Kings\"\n",
|
| 210 |
+
"\n",
|
| 211 |
+
"You should return the following:\n",
|
| 212 |
+
"\n",
|
| 213 |
+
"[\"National Football League (NFL)\", \"Major League Baseball (MLB)\", \"National Basketball Association (NBA)\", \"Other\"]\n",
|
| 214 |
+
"\"\"\"\n",
|
| 215 |
+
"\n",
|
| 216 |
+
" response = client.chat.completions.create(\n",
|
| 217 |
+
" messages=[\n",
|
| 218 |
+
" {\n",
|
| 219 |
+
" \"role\": \"system\",\n",
|
| 220 |
+
" \"content\": prompt,\n",
|
| 221 |
+
" },\n",
|
| 222 |
+
" {\n",
|
| 223 |
+
" \"role\": \"user\",\n",
|
| 224 |
+
" \"content\": \"Chicago Bears,Chicago Cubs,Chicago Bulls,Chicago Blackhawks\",\n",
|
| 225 |
+
" },\n",
|
| 226 |
+
" {\n",
|
| 227 |
+
" \"role\": \"assistant\",\n",
|
| 228 |
+
" \"content\": '[\"National Football League (NFL)\", \"Major League Baseball (MLB)\", \"National Basketball Association (NBA)\", \"Other\"]',\n",
|
| 229 |
+
" },\n",
|
| 230 |
+
" {\n",
|
| 231 |
+
" \"role\": \"user\",\n",
|
| 232 |
+
" \"content\": \"\\n\".join(name_list),\n",
|
| 233 |
+
" }\n",
|
| 234 |
+
" ],\n",
|
| 235 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 236 |
+
" temperature=0,\n",
|
| 237 |
+
" )\n",
|
| 238 |
+
"\n",
|
| 239 |
+
" answer_str = response.choices[0].message.content\n",
|
| 240 |
+
" answer_list = json.loads(answer_str)\n",
|
| 241 |
+
"\n",
|
| 242 |
+
" acceptable_answers = [\n",
|
| 243 |
+
" \"Major League Baseball (MLB)\",\n",
|
| 244 |
+
" \"National Football League (NFL)\",\n",
|
| 245 |
+
" \"National Basketball Association (NBA)\",\n",
|
| 246 |
+
" \"Other\",\n",
|
| 247 |
+
" ]\n",
|
| 248 |
+
" for answer in answer_list:\n",
|
| 249 |
+
" if answer not in acceptable_answers:\n",
|
| 250 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 251 |
+
"\n",
|
| 252 |
+
" ### <-- NEW\n",
|
| 253 |
+
" try:\n",
|
| 254 |
+
" assert len(name_list) == len(answer_list)\n",
|
| 255 |
+
" except AssertionError:\n",
|
| 256 |
+
" raise ValueError(f\"Number of outputs ({len(name_list)}) does not equal the number of inputs ({len(answer_list)})\")\n",
|
| 257 |
+
" ### -->\n",
|
| 258 |
+
" return dict(zip(name_list, answer_list))"
|
| 259 |
+
]
|
| 260 |
+
},
|
| 261 |
+
{
|
| 262 |
+
"cell_type": "markdown",
|
| 263 |
+
"id": "587604c0",
|
| 264 |
+
"metadata": {},
|
| 265 |
+
"source": [
|
| 266 |
+
"Okay. Naming sports teams is a cute trick, but what about something hard? And whatever happened to that George Santos idea?\n",
|
| 267 |
+
"\n",
|
| 268 |
+
"We’ll tackle that by pulling in our example dataset using `pandas`, a popular data manipulation library in Python.\n",
|
| 269 |
+
"\n",
|
| 270 |
+
"First, we need to install it. Back to our installation cell."
|
| 271 |
+
]
|
| 272 |
+
},
|
| 273 |
+
{
|
| 274 |
+
"cell_type": "code",
|
| 275 |
+
"execution_count": null,
|
| 276 |
+
"id": "9ff5e26c",
|
| 277 |
+
"metadata": {
|
| 278 |
+
"scrolled": true
|
| 279 |
+
},
|
| 280 |
+
"outputs": [],
|
| 281 |
+
"source": [
|
| 282 |
+
"%pip install huggingface_hub rich ipywidgets retry pandas"
|
| 283 |
+
]
|
| 284 |
+
},
|
| 285 |
+
{
|
| 286 |
+
"cell_type": "markdown",
|
| 287 |
+
"id": "295346d4",
|
| 288 |
+
"metadata": {},
|
| 289 |
+
"source": [
|
| 290 |
+
"Then import it."
|
| 291 |
+
]
|
| 292 |
+
},
|
| 293 |
+
{
|
| 294 |
+
"cell_type": "code",
|
| 295 |
+
"execution_count": 32,
|
| 296 |
+
"id": "c6d289d7",
|
| 297 |
+
"metadata": {},
|
| 298 |
+
"outputs": [],
|
| 299 |
+
"source": [
|
| 300 |
+
"import json\n",
|
| 301 |
+
"from rich import print\n",
|
| 302 |
+
"import requests\n",
|
| 303 |
+
"from retry import retry\n",
|
| 304 |
+
"import pandas as pd # NEW"
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"cell_type": "markdown",
|
| 309 |
+
"id": "1ee5cf9f",
|
| 310 |
+
"metadata": {},
|
| 311 |
+
"source": [
|
| 312 |
+
"Now we’re ready to load the California expenditures data prepared for the class. It contains the distinct list of all vendors listed as payees in itemized receipts attached to disclosure filings."
|
| 313 |
+
]
|
| 314 |
+
},
|
| 315 |
+
{
|
| 316 |
+
"cell_type": "code",
|
| 317 |
+
"execution_count": 33,
|
| 318 |
+
"id": "3ae2b2fc",
|
| 319 |
+
"metadata": {},
|
| 320 |
+
"outputs": [],
|
| 321 |
+
"source": [
|
| 322 |
+
"df = pd.read_csv(\"https://raw.githubusercontent.com/palewire/first-llm-classifier/refs/heads/main/_notebooks/Form460ScheduleESubItem.csv\")"
|
| 323 |
+
]
|
| 324 |
+
},
|
| 325 |
+
{
|
| 326 |
+
"cell_type": "markdown",
|
| 327 |
+
"id": "bca7002b",
|
| 328 |
+
"metadata": {},
|
| 329 |
+
"source": [
|
| 330 |
+
"Have a look at a random sample to get a taste of what’s in there."
|
| 331 |
+
]
|
| 332 |
+
},
|
| 333 |
+
{
|
| 334 |
+
"cell_type": "code",
|
| 335 |
+
"execution_count": 34,
|
| 336 |
+
"id": "0aa44f42",
|
| 337 |
+
"metadata": {},
|
| 338 |
+
"outputs": [
|
| 339 |
+
{
|
| 340 |
+
"data": {
|
| 341 |
+
"text/html": [
|
| 342 |
+
"<div>\n",
|
| 343 |
+
"<style scoped>\n",
|
| 344 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 345 |
+
" vertical-align: middle;\n",
|
| 346 |
+
" }\n",
|
| 347 |
+
"\n",
|
| 348 |
+
" .dataframe tbody tr th {\n",
|
| 349 |
+
" vertical-align: top;\n",
|
| 350 |
+
" }\n",
|
| 351 |
+
"\n",
|
| 352 |
+
" .dataframe thead th {\n",
|
| 353 |
+
" text-align: right;\n",
|
| 354 |
+
" }\n",
|
| 355 |
+
"</style>\n",
|
| 356 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 357 |
+
" <thead>\n",
|
| 358 |
+
" <tr style=\"text-align: right;\">\n",
|
| 359 |
+
" <th></th>\n",
|
| 360 |
+
" <th>payee</th>\n",
|
| 361 |
+
" </tr>\n",
|
| 362 |
+
" </thead>\n",
|
| 363 |
+
" <tbody>\n",
|
| 364 |
+
" <tr>\n",
|
| 365 |
+
" <th>5822</th>\n",
|
| 366 |
+
" <td>GRAND HYATT SAN FRANCISCO</td>\n",
|
| 367 |
+
" </tr>\n",
|
| 368 |
+
" <tr>\n",
|
| 369 |
+
" <th>8765</th>\n",
|
| 370 |
+
" <td>LIZ FIGUEROA FOR LT. GOVERNOR</td>\n",
|
| 371 |
+
" </tr>\n",
|
| 372 |
+
" <tr>\n",
|
| 373 |
+
" <th>2027</th>\n",
|
| 374 |
+
" <td>CA STATE UNIVERSITY NORTHRIDGE YOUNG DEMOCRATS</td>\n",
|
| 375 |
+
" </tr>\n",
|
| 376 |
+
" <tr>\n",
|
| 377 |
+
" <th>1371</th>\n",
|
| 378 |
+
" <td>BEN FRANKLIN CRAFTS</td>\n",
|
| 379 |
+
" </tr>\n",
|
| 380 |
+
" <tr>\n",
|
| 381 |
+
" <th>9033</th>\n",
|
| 382 |
+
" <td>LYNWOOD FOR BETTER HEALTHCARE, SPONSORED BY SE...</td>\n",
|
| 383 |
+
" </tr>\n",
|
| 384 |
+
" <tr>\n",
|
| 385 |
+
" <th>11720</th>\n",
|
| 386 |
+
" <td>QUINTESSA</td>\n",
|
| 387 |
+
" </tr>\n",
|
| 388 |
+
" <tr>\n",
|
| 389 |
+
" <th>7983</th>\n",
|
| 390 |
+
" <td>KOST FM</td>\n",
|
| 391 |
+
" </tr>\n",
|
| 392 |
+
" <tr>\n",
|
| 393 |
+
" <th>4324</th>\n",
|
| 394 |
+
" <td>DUNKIN DONUTS</td>\n",
|
| 395 |
+
" </tr>\n",
|
| 396 |
+
" <tr>\n",
|
| 397 |
+
" <th>2434</th>\n",
|
| 398 |
+
" <td>CARDENAS MARKETS, INC.</td>\n",
|
| 399 |
+
" </tr>\n",
|
| 400 |
+
" <tr>\n",
|
| 401 |
+
" <th>5738</th>\n",
|
| 402 |
+
" <td>GOLDEN PALACE</td>\n",
|
| 403 |
+
" </tr>\n",
|
| 404 |
+
" </tbody>\n",
|
| 405 |
+
"</table>\n",
|
| 406 |
+
"</div>"
|
| 407 |
+
],
|
| 408 |
+
"text/plain": [
|
| 409 |
+
" payee\n",
|
| 410 |
+
"5822 GRAND HYATT SAN FRANCISCO\n",
|
| 411 |
+
"8765 LIZ FIGUEROA FOR LT. GOVERNOR\n",
|
| 412 |
+
"2027 CA STATE UNIVERSITY NORTHRIDGE YOUNG DEMOCRATS\n",
|
| 413 |
+
"1371 BEN FRANKLIN CRAFTS\n",
|
| 414 |
+
"9033 LYNWOOD FOR BETTER HEALTHCARE, SPONSORED BY SE...\n",
|
| 415 |
+
"11720 QUINTESSA\n",
|
| 416 |
+
"7983 KOST FM\n",
|
| 417 |
+
"4324 DUNKIN DONUTS\n",
|
| 418 |
+
"2434 CARDENAS MARKETS, INC.\n",
|
| 419 |
+
"5738 GOLDEN PALACE"
|
| 420 |
+
]
|
| 421 |
+
},
|
| 422 |
+
"execution_count": 34,
|
| 423 |
+
"metadata": {},
|
| 424 |
+
"output_type": "execute_result"
|
| 425 |
+
}
|
| 426 |
+
],
|
| 427 |
+
"source": [
|
| 428 |
+
"df.sample(10)"
|
| 429 |
+
]
|
| 430 |
+
},
|
| 431 |
+
{
|
| 432 |
+
"cell_type": "markdown",
|
| 433 |
+
"id": "9fe1e695",
|
| 434 |
+
"metadata": {},
|
| 435 |
+
"source": [
|
| 436 |
+
"Now let’s adapt what we have to fit. Instead of asking for a sports league back, we will ask the LLM to classify each payee as a restaurant, bar, hotel or other establishment."
|
| 437 |
+
]
|
| 438 |
+
},
|
| 439 |
+
{
|
| 440 |
+
"cell_type": "code",
|
| 441 |
+
"execution_count": 35,
|
| 442 |
+
"id": "970c5161",
|
| 443 |
+
"metadata": {},
|
| 444 |
+
"outputs": [],
|
| 445 |
+
"source": [
|
| 446 |
+
"@retry(ValueError, tries=2, delay=2)\n",
|
| 447 |
+
"### <-- NEW\n",
|
| 448 |
+
"def classify_payees(name_list):\n",
|
| 449 |
+
" prompt = \"\"\"You are an AI model trained to categorize businesses based on their names.\n",
|
| 450 |
+
"\n",
|
| 451 |
+
"You will be given a list of business names, each separated by a new line.\n",
|
| 452 |
+
"\n",
|
| 453 |
+
"Your task is to analyze each name and classify it into one of the following categories: Restaurant, Bar, Hotel, or Other.\n",
|
| 454 |
+
"\n",
|
| 455 |
+
"It is extremely critical that there is a corresponding category output for each business name provided as an input.\n",
|
| 456 |
+
"\n",
|
| 457 |
+
"If a business does not clearly fall into Restaurant, Bar, or Hotel categories, you should classify it as \"Other\".\n",
|
| 458 |
+
"\n",
|
| 459 |
+
"Even if the type of business is not immediately clear from the name, it is essential that you provide your best guess based on the information available to you. If you can't make a good guess, classify it as Other.\n",
|
| 460 |
+
"\n",
|
| 461 |
+
"For example, if given the following input:\n",
|
| 462 |
+
"\n",
|
| 463 |
+
"\"Intercontinental Hotel\\nPizza Hut\\nCheers\\nWelsh's Family Restaurant\\nKTLA\\nDirect Mailing\"\n",
|
| 464 |
+
"\n",
|
| 465 |
+
"Your output should be a JSON list in the following format:\n",
|
| 466 |
+
"\n",
|
| 467 |
+
"[\"Hotel\", \"Restaurant\", \"Bar\", \"Restaurant\", \"Other\", \"Other\"]\n",
|
| 468 |
+
"\n",
|
| 469 |
+
"This means that you have classified \"Intercontinental Hotel\" as a Hotel, \"Pizza Hut\" as a Restaurant, \"Cheers\" as a Bar, \"Welsh's Family Restaurant\" as a Restaurant, and both \"KTLA\" and \"Direct Mailing\" as Other.\n",
|
| 470 |
+
"\n",
|
| 471 |
+
"Ensure that the number of classifications in your output matches the number of business names in the input. It is very important that the length of JSON list you return is exactly the same as the number of business names youyou receive.\n",
|
| 472 |
+
"\"\"\"\n",
|
| 473 |
+
"### -->\n",
|
| 474 |
+
" response = client.chat.completions.create(\n",
|
| 475 |
+
" messages=[\n",
|
| 476 |
+
" {\n",
|
| 477 |
+
" \"role\": \"system\",\n",
|
| 478 |
+
" \"content\": prompt,\n",
|
| 479 |
+
" },\n",
|
| 480 |
+
" ### <-- NEW\n",
|
| 481 |
+
" {\n",
|
| 482 |
+
" \"role\": \"user\",\n",
|
| 483 |
+
" \"content\": \"Intercontinental Hotel\\nPizza Hut\\nCheers\\nWelsh's Family Restaurant\\nKTLA\\nDirect Mailing\",\n",
|
| 484 |
+
" },\n",
|
| 485 |
+
" {\n",
|
| 486 |
+
" \"role\": \"assistant\",\n",
|
| 487 |
+
" \"content\": '[\"Hotel\", \"Restaurant\", \"Bar\", \"Restaurant\", \"Other\", \"Other\"]',\n",
|
| 488 |
+
" },\n",
|
| 489 |
+
" {\n",
|
| 490 |
+
" \"role\": \"user\",\n",
|
| 491 |
+
" \"content\": \"Subway Sandwiches\\nRuth Chris Steakhouse\\nPolitical Consulting Co\\nThe Lamb's Club\",\n",
|
| 492 |
+
" },\n",
|
| 493 |
+
" {\n",
|
| 494 |
+
" \"role\": \"assistant\",\n",
|
| 495 |
+
" \"content\": '[\"Restaurant\", \"Restaurant\", \"Other\", \"Bar\"]',\n",
|
| 496 |
+
" },\n",
|
| 497 |
+
" ### -->\n",
|
| 498 |
+
" {\n",
|
| 499 |
+
" \"role\": \"user\",\n",
|
| 500 |
+
" \"content\": \"\\n\".join(name_list),\n",
|
| 501 |
+
" }\n",
|
| 502 |
+
" ],\n",
|
| 503 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 504 |
+
" temperature=0,\n",
|
| 505 |
+
" )\n",
|
| 506 |
+
"\n",
|
| 507 |
+
" answer_str = response.choices[0].message.content\n",
|
| 508 |
+
" answer_list = json.loads(answer_str)\n",
|
| 509 |
+
"\n",
|
| 510 |
+
" ### <-- NEW \n",
|
| 511 |
+
" acceptable_answers = [\n",
|
| 512 |
+
" \"Restaurant\",\n",
|
| 513 |
+
" \"Bar\",\n",
|
| 514 |
+
" \"Hotel\",\n",
|
| 515 |
+
" \"Other\",\n",
|
| 516 |
+
" ] \n",
|
| 517 |
+
" ### -->\n",
|
| 518 |
+
" \n",
|
| 519 |
+
" for answer in answer_list:\n",
|
| 520 |
+
" if answer not in acceptable_answers:\n",
|
| 521 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 522 |
+
"\n",
|
| 523 |
+
" try:\n",
|
| 524 |
+
" assert len(name_list) == len(answer_list)\n",
|
| 525 |
+
" except AssertionError:\n",
|
| 526 |
+
" raise ValueError(f\"Number of outputs ({len(name_list)}) does not equal the number of inputs ({len(answer_list)})\")\n",
|
| 527 |
+
"\n",
|
| 528 |
+
" return dict(zip(name_list, answer_list))"
|
| 529 |
+
]
|
| 530 |
+
},
|
| 531 |
+
{
|
| 532 |
+
"cell_type": "markdown",
|
| 533 |
+
"id": "bf9b69a0",
|
| 534 |
+
"metadata": {},
|
| 535 |
+
"source": [
|
| 536 |
+
"Now pull out a random sample of payees as a list."
|
| 537 |
+
]
|
| 538 |
+
},
|
| 539 |
+
{
|
| 540 |
+
"cell_type": "code",
|
| 541 |
+
"execution_count": 36,
|
| 542 |
+
"id": "fe74a8ed",
|
| 543 |
+
"metadata": {},
|
| 544 |
+
"outputs": [],
|
| 545 |
+
"source": [
|
| 546 |
+
"sample_list = list(df.sample(10).payee)"
|
| 547 |
+
]
|
| 548 |
+
},
|
| 549 |
+
{
|
| 550 |
+
"cell_type": "markdown",
|
| 551 |
+
"id": "688192ae",
|
| 552 |
+
"metadata": {},
|
| 553 |
+
"source": [
|
| 554 |
+
"And see how it does."
|
| 555 |
+
]
|
| 556 |
+
},
|
| 557 |
+
{
|
| 558 |
+
"cell_type": "code",
|
| 559 |
+
"execution_count": 38,
|
| 560 |
+
"id": "a84d364a",
|
| 561 |
+
"metadata": {},
|
| 562 |
+
"outputs": [
|
| 563 |
+
{
|
| 564 |
+
"data": {
|
| 565 |
+
"text/plain": [
|
| 566 |
+
"{'CALIFORNIA NOW ORGANIZATION': 'Other',\n",
|
| 567 |
+
" 'ALOHA SIGNS': 'Other',\n",
|
| 568 |
+
" \"SABELLA'S ITALIAN MARKET\": 'Restaurant',\n",
|
| 569 |
+
" 'ELIZABETH ESPARZA': 'Other',\n",
|
| 570 |
+
" 'DATA-SCRIBE': 'Other',\n",
|
| 571 |
+
" \"LISA HEMENWAY'S BISTRO\": 'Restaurant',\n",
|
| 572 |
+
" 'NEW EDGE MULTIMEDIA': 'Other',\n",
|
| 573 |
+
" 'FUSILLI': 'Restaurant',\n",
|
| 574 |
+
" 'FRIENDS OF DR IRENE PINKARD FOR CITY COUNCIL': 'Other',\n",
|
| 575 |
+
" 'ZEN SUSHI SACRAMENTO': 'Restaurant'}"
|
| 576 |
+
]
|
| 577 |
+
},
|
| 578 |
+
"execution_count": 38,
|
| 579 |
+
"metadata": {},
|
| 580 |
+
"output_type": "execute_result"
|
| 581 |
+
}
|
| 582 |
+
],
|
| 583 |
+
"source": [
|
| 584 |
+
"classify_payees(sample_list)"
|
| 585 |
+
]
|
| 586 |
+
},
|
| 587 |
+
{
|
| 588 |
+
"cell_type": "markdown",
|
| 589 |
+
"id": "197856d9",
|
| 590 |
+
"metadata": {},
|
| 591 |
+
"source": [
|
| 592 |
+
"That’s nice for a sample. But how do you loop through the entire dataset and code them.\n",
|
| 593 |
+
"\n",
|
| 594 |
+
"One way to start is to write a function that will split up a list into batches of a certain size."
|
| 595 |
+
]
|
| 596 |
+
},
|
| 597 |
+
{
|
| 598 |
+
"cell_type": "code",
|
| 599 |
+
"execution_count": 39,
|
| 600 |
+
"id": "b784940f",
|
| 601 |
+
"metadata": {},
|
| 602 |
+
"outputs": [],
|
| 603 |
+
"source": [
|
| 604 |
+
"def get_batch_list(li, n=10):\n",
|
| 605 |
+
" \"\"\"Split the provided list into batches of size `n`.\"\"\"\n",
|
| 606 |
+
" batch_list = []\n",
|
| 607 |
+
" for i in range(0, len(li), n):\n",
|
| 608 |
+
" batch_list.append(li[i : i + n])\n",
|
| 609 |
+
" return batch_list"
|
| 610 |
+
]
|
| 611 |
+
},
|
| 612 |
+
{
|
| 613 |
+
"cell_type": "markdown",
|
| 614 |
+
"id": "9e35948e",
|
| 615 |
+
"metadata": {},
|
| 616 |
+
"source": [
|
| 617 |
+
"Before we loop through our payees, let’s add a couple libraries that will let us avoid hammering HF and keep tabs on our progress."
|
| 618 |
+
]
|
| 619 |
+
},
|
| 620 |
+
{
|
| 621 |
+
"cell_type": "code",
|
| 622 |
+
"execution_count": 40,
|
| 623 |
+
"id": "f1593a7d",
|
| 624 |
+
"metadata": {},
|
| 625 |
+
"outputs": [],
|
| 626 |
+
"source": [
|
| 627 |
+
"import time # NEW\n",
|
| 628 |
+
"import json\n",
|
| 629 |
+
"from rich import print\n",
|
| 630 |
+
"from rich.progress import track # NEW\n",
|
| 631 |
+
"import requests\n",
|
| 632 |
+
"from retry import retry\n",
|
| 633 |
+
"import pandas as pd"
|
| 634 |
+
]
|
| 635 |
+
},
|
| 636 |
+
{
|
| 637 |
+
"cell_type": "markdown",
|
| 638 |
+
"id": "da68c37f",
|
| 639 |
+
"metadata": {},
|
| 640 |
+
"source": [
|
| 641 |
+
"That batching trick can then be fit into a new function that will accept a big list of payees and classify them batch by batch."
|
| 642 |
+
]
|
| 643 |
+
},
|
| 644 |
+
{
|
| 645 |
+
"cell_type": "code",
|
| 646 |
+
"execution_count": 41,
|
| 647 |
+
"id": "6e6965f9",
|
| 648 |
+
"metadata": {},
|
| 649 |
+
"outputs": [],
|
| 650 |
+
"source": [
|
| 651 |
+
"def classify_batches(name_list, batch_size=10, wait=2):\n",
|
| 652 |
+
" \"\"\"Split the provided list of names into batches and classify with our LLM them one by one.\"\"\"\n",
|
| 653 |
+
" # Create a place to store the results\n",
|
| 654 |
+
" all_results = {}\n",
|
| 655 |
+
"\n",
|
| 656 |
+
" # Batch up the list\n",
|
| 657 |
+
" batch_list = get_batch_list(name_list, n=batch_size)\n",
|
| 658 |
+
"\n",
|
| 659 |
+
" # Loop through the list in batches\n",
|
| 660 |
+
" for batch in track(batch_list):\n",
|
| 661 |
+
" # Classify it with the LLM\n",
|
| 662 |
+
" batch_results = classify_payees(batch)\n",
|
| 663 |
+
"\n",
|
| 664 |
+
" # Add what we get back to the results\n",
|
| 665 |
+
" all_results.update(batch_results)\n",
|
| 666 |
+
"\n",
|
| 667 |
+
" # Tap the brakes to avoid overloading groq's API\n",
|
| 668 |
+
" time.sleep(wait)\n",
|
| 669 |
+
"\n",
|
| 670 |
+
" # Return the results\n",
|
| 671 |
+
" return all_results"
|
| 672 |
+
]
|
| 673 |
+
},
|
| 674 |
+
{
|
| 675 |
+
"cell_type": "markdown",
|
| 676 |
+
"id": "222a3846",
|
| 677 |
+
"metadata": {},
|
| 678 |
+
"source": [
|
| 679 |
+
"Now, let’s take out a bigger sample."
|
| 680 |
+
]
|
| 681 |
+
},
|
| 682 |
+
{
|
| 683 |
+
"cell_type": "code",
|
| 684 |
+
"execution_count": 42,
|
| 685 |
+
"id": "39778766",
|
| 686 |
+
"metadata": {},
|
| 687 |
+
"outputs": [],
|
| 688 |
+
"source": [
|
| 689 |
+
"bigger_sample = list(df.sample(100).payee)"
|
| 690 |
+
]
|
| 691 |
+
},
|
| 692 |
+
{
|
| 693 |
+
"cell_type": "markdown",
|
| 694 |
+
"id": "722de39a",
|
| 695 |
+
"metadata": {},
|
| 696 |
+
"source": [
|
| 697 |
+
"And let it rip."
|
| 698 |
+
]
|
| 699 |
+
},
|
| 700 |
+
{
|
| 701 |
+
"cell_type": "code",
|
| 702 |
+
"execution_count": null,
|
| 703 |
+
"id": "7f676e52",
|
| 704 |
+
"metadata": {
|
| 705 |
+
"scrolled": true
|
| 706 |
+
},
|
| 707 |
+
"outputs": [],
|
| 708 |
+
"source": [
|
| 709 |
+
"classify_batches(bigger_sample)"
|
| 710 |
+
]
|
| 711 |
+
},
|
| 712 |
+
{
|
| 713 |
+
"cell_type": "markdown",
|
| 714 |
+
"id": "fc2c1f94",
|
| 715 |
+
"metadata": {},
|
| 716 |
+
"source": [
|
| 717 |
+
"Printing out to the console is interesting, but eventually you’ll want to be able to work with the results in a more structured way. So let’s convert the results into a `pandas` DataFrame by modifying our function."
|
| 718 |
+
]
|
| 719 |
+
},
|
| 720 |
+
{
|
| 721 |
+
"cell_type": "code",
|
| 722 |
+
"execution_count": 44,
|
| 723 |
+
"id": "c41b736f",
|
| 724 |
+
"metadata": {},
|
| 725 |
+
"outputs": [],
|
| 726 |
+
"source": [
|
| 727 |
+
"def classify_batches(name_list, batch_size=10, wait=2):\n",
|
| 728 |
+
" # Store the results\n",
|
| 729 |
+
" all_results = {}\n",
|
| 730 |
+
"\n",
|
| 731 |
+
" # Batch up the list\n",
|
| 732 |
+
" batch_list = get_batch_list(name_list, n=batch_size)\n",
|
| 733 |
+
"\n",
|
| 734 |
+
" # Loop through the list in batches\n",
|
| 735 |
+
" for batch in track(batch_list):\n",
|
| 736 |
+
" # Classify it\n",
|
| 737 |
+
" batch_results = classify_payees(batch)\n",
|
| 738 |
+
"\n",
|
| 739 |
+
" # Add it to the results\n",
|
| 740 |
+
" all_results.update(batch_results)\n",
|
| 741 |
+
"\n",
|
| 742 |
+
" # Tap the brakes\n",
|
| 743 |
+
" time.sleep(wait)\n",
|
| 744 |
+
"\n",
|
| 745 |
+
" # Return the results (NEW)\n",
|
| 746 |
+
" return pd.DataFrame(\n",
|
| 747 |
+
" all_results.items(),\n",
|
| 748 |
+
" columns=[\"payee\", \"category\"]\n",
|
| 749 |
+
" )"
|
| 750 |
+
]
|
| 751 |
+
},
|
| 752 |
+
{
|
| 753 |
+
"cell_type": "markdown",
|
| 754 |
+
"id": "353adf11",
|
| 755 |
+
"metadata": {},
|
| 756 |
+
"source": [
|
| 757 |
+
"Results can now be stored as a DataFrame."
|
| 758 |
+
]
|
| 759 |
+
},
|
| 760 |
+
{
|
| 761 |
+
"cell_type": "code",
|
| 762 |
+
"execution_count": 45,
|
| 763 |
+
"id": "51aa0550",
|
| 764 |
+
"metadata": {},
|
| 765 |
+
"outputs": [
|
| 766 |
+
{
|
| 767 |
+
"data": {
|
| 768 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 769 |
+
"model_id": "a4b561bb64554c70a7bfd309c43b60da",
|
| 770 |
+
"version_major": 2,
|
| 771 |
+
"version_minor": 0
|
| 772 |
+
},
|
| 773 |
+
"text/plain": [
|
| 774 |
+
"Output()"
|
| 775 |
+
]
|
| 776 |
+
},
|
| 777 |
+
"metadata": {},
|
| 778 |
+
"output_type": "display_data"
|
| 779 |
+
},
|
| 780 |
+
{
|
| 781 |
+
"data": {
|
| 782 |
+
"text/html": [
|
| 783 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"></pre>\n"
|
| 784 |
+
],
|
| 785 |
+
"text/plain": []
|
| 786 |
+
},
|
| 787 |
+
"metadata": {},
|
| 788 |
+
"output_type": "display_data"
|
| 789 |
+
}
|
| 790 |
+
],
|
| 791 |
+
"source": [
|
| 792 |
+
"results_df = classify_batches(bigger_sample)"
|
| 793 |
+
]
|
| 794 |
+
},
|
| 795 |
+
{
|
| 796 |
+
"cell_type": "markdown",
|
| 797 |
+
"id": "96bd75bc",
|
| 798 |
+
"metadata": {},
|
| 799 |
+
"source": [
|
| 800 |
+
"And inspected using the standard `pandas` tools. Let's take a peek at the first records:"
|
| 801 |
+
]
|
| 802 |
+
},
|
| 803 |
+
{
|
| 804 |
+
"cell_type": "code",
|
| 805 |
+
"execution_count": 46,
|
| 806 |
+
"id": "514971f9",
|
| 807 |
+
"metadata": {},
|
| 808 |
+
"outputs": [
|
| 809 |
+
{
|
| 810 |
+
"data": {
|
| 811 |
+
"text/html": [
|
| 812 |
+
"<div>\n",
|
| 813 |
+
"<style scoped>\n",
|
| 814 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 815 |
+
" vertical-align: middle;\n",
|
| 816 |
+
" }\n",
|
| 817 |
+
"\n",
|
| 818 |
+
" .dataframe tbody tr th {\n",
|
| 819 |
+
" vertical-align: top;\n",
|
| 820 |
+
" }\n",
|
| 821 |
+
"\n",
|
| 822 |
+
" .dataframe thead th {\n",
|
| 823 |
+
" text-align: right;\n",
|
| 824 |
+
" }\n",
|
| 825 |
+
"</style>\n",
|
| 826 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 827 |
+
" <thead>\n",
|
| 828 |
+
" <tr style=\"text-align: right;\">\n",
|
| 829 |
+
" <th></th>\n",
|
| 830 |
+
" <th>payee</th>\n",
|
| 831 |
+
" <th>category</th>\n",
|
| 832 |
+
" </tr>\n",
|
| 833 |
+
" </thead>\n",
|
| 834 |
+
" <tbody>\n",
|
| 835 |
+
" <tr>\n",
|
| 836 |
+
" <th>0</th>\n",
|
| 837 |
+
" <td>TAXIPASS</td>\n",
|
| 838 |
+
" <td>Other</td>\n",
|
| 839 |
+
" </tr>\n",
|
| 840 |
+
" <tr>\n",
|
| 841 |
+
" <th>1</th>\n",
|
| 842 |
+
" <td>THE JEFFERSON HOTEL</td>\n",
|
| 843 |
+
" <td>Hotel</td>\n",
|
| 844 |
+
" </tr>\n",
|
| 845 |
+
" <tr>\n",
|
| 846 |
+
" <th>2</th>\n",
|
| 847 |
+
" <td>NORMS RESTAURANT</td>\n",
|
| 848 |
+
" <td>Restaurant</td>\n",
|
| 849 |
+
" </tr>\n",
|
| 850 |
+
" <tr>\n",
|
| 851 |
+
" <th>3</th>\n",
|
| 852 |
+
" <td>JENNY OROPEZA FOR STATE SENATE</td>\n",
|
| 853 |
+
" <td>Other</td>\n",
|
| 854 |
+
" </tr>\n",
|
| 855 |
+
" <tr>\n",
|
| 856 |
+
" <th>4</th>\n",
|
| 857 |
+
" <td>BIG MAMA'S & PAPA'S PIZZERIA</td>\n",
|
| 858 |
+
" <td>Restaurant</td>\n",
|
| 859 |
+
" </tr>\n",
|
| 860 |
+
" </tbody>\n",
|
| 861 |
+
"</table>\n",
|
| 862 |
+
"</div>"
|
| 863 |
+
],
|
| 864 |
+
"text/plain": [
|
| 865 |
+
" payee category\n",
|
| 866 |
+
"0 TAXIPASS Other\n",
|
| 867 |
+
"1 THE JEFFERSON HOTEL Hotel\n",
|
| 868 |
+
"2 NORMS RESTAURANT Restaurant\n",
|
| 869 |
+
"3 JENNY OROPEZA FOR STATE SENATE Other\n",
|
| 870 |
+
"4 BIG MAMA'S & PAPA'S PIZZERIA Restaurant"
|
| 871 |
+
]
|
| 872 |
+
},
|
| 873 |
+
"execution_count": 46,
|
| 874 |
+
"metadata": {},
|
| 875 |
+
"output_type": "execute_result"
|
| 876 |
+
}
|
| 877 |
+
],
|
| 878 |
+
"source": [
|
| 879 |
+
"results_df.head()"
|
| 880 |
+
]
|
| 881 |
+
},
|
| 882 |
+
{
|
| 883 |
+
"cell_type": "markdown",
|
| 884 |
+
"id": "fef7be4e",
|
| 885 |
+
"metadata": {},
|
| 886 |
+
"source": [
|
| 887 |
+
"Or a sum of all the categories."
|
| 888 |
+
]
|
| 889 |
+
},
|
| 890 |
+
{
|
| 891 |
+
"cell_type": "code",
|
| 892 |
+
"execution_count": 47,
|
| 893 |
+
"id": "6911dc37",
|
| 894 |
+
"metadata": {},
|
| 895 |
+
"outputs": [
|
| 896 |
+
{
|
| 897 |
+
"data": {
|
| 898 |
+
"text/plain": [
|
| 899 |
+
"category\n",
|
| 900 |
+
"Other 67\n",
|
| 901 |
+
"Restaurant 20\n",
|
| 902 |
+
"Hotel 12\n",
|
| 903 |
+
"Bar 1\n",
|
| 904 |
+
"Name: count, dtype: int64"
|
| 905 |
+
]
|
| 906 |
+
},
|
| 907 |
+
"execution_count": 47,
|
| 908 |
+
"metadata": {},
|
| 909 |
+
"output_type": "execute_result"
|
| 910 |
+
}
|
| 911 |
+
],
|
| 912 |
+
"source": [
|
| 913 |
+
"results_df.category.value_counts()"
|
| 914 |
+
]
|
| 915 |
+
},
|
| 916 |
+
{
|
| 917 |
+
"cell_type": "markdown",
|
| 918 |
+
"id": "a8705a48-49e6-4ec8-8f3f-126bcf011f0f",
|
| 919 |
+
"metadata": {},
|
| 920 |
+
"source": [
|
| 921 |
+
"**[8. Evaluating prompts →](ch8-evaluating-prompts.ipynb)**"
|
| 922 |
+
]
|
| 923 |
+
},
|
| 924 |
+
{
|
| 925 |
+
"cell_type": "code",
|
| 926 |
+
"execution_count": null,
|
| 927 |
+
"id": "d96f1b46-7e66-4e5a-8d17-84a75b70404e",
|
| 928 |
+
"metadata": {},
|
| 929 |
+
"outputs": [],
|
| 930 |
+
"source": []
|
| 931 |
+
}
|
| 932 |
+
],
|
| 933 |
+
"metadata": {
|
| 934 |
+
"kernelspec": {
|
| 935 |
+
"display_name": "Python 3 (ipykernel)",
|
| 936 |
+
"language": "python",
|
| 937 |
+
"name": "python3"
|
| 938 |
+
},
|
| 939 |
+
"language_info": {
|
| 940 |
+
"codemirror_mode": {
|
| 941 |
+
"name": "ipython",
|
| 942 |
+
"version": 3
|
| 943 |
+
},
|
| 944 |
+
"file_extension": ".py",
|
| 945 |
+
"mimetype": "text/x-python",
|
| 946 |
+
"name": "python",
|
| 947 |
+
"nbconvert_exporter": "python",
|
| 948 |
+
"pygments_lexer": "ipython3",
|
| 949 |
+
"version": "3.9.5"
|
| 950 |
+
}
|
| 951 |
+
},
|
| 952 |
+
"nbformat": 4,
|
| 953 |
+
"nbformat_minor": 5
|
| 954 |
+
}
|
notebooks/ch8-evaluating-prompts.ipynb
ADDED
|
@@ -0,0 +1,655 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"## 8. Evaluating Prompts\n",
|
| 8 |
+
"\n",
|
| 9 |
+
"Before the advent of large-language models, machine-learning systems were trained using a technique called [supervised learning](https://en.wikipedia.org/wiki/Supervised_learning). This approach required users to provide carefully prepared training data that showed the computer what was expected.\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"For instance, if you were developing a model to distinguish spam emails from legitimate ones, you would need to provide the model with a set of spam emails and another set of legitimate emails. The model would then use that data to learn the relationships between the inputs and outputs, which it could then apply to new emails.\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"In addition to training the model, the curated input would be used to evaluate the model's performance. This process typically involved splitting the supervised data into two sets: one for training and one for testing. The model could then be evaluated using a separate set of supervised data to ensure it could generalize beyond the examples it had been fed during training.\n",
|
| 14 |
+
"\n",
|
| 15 |
+
"Large-language models operate differently. They are trained on vast amounts of text and can generate responses based on the relationships they derive from various machine-learning approaches. The result is that they can be used to perform a wide range of tasks without requiring supervised data to be prepared beforehand.\n",
|
| 16 |
+
"\n",
|
| 17 |
+
"This is a significant advantage. However, it also raises questions about evaluating an LLM prompt. If we don't have a supervised sample to test its results, how do we know if it's doing a good job? How can we improve its performance if we can't see where it gets things wrong?\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"In the final chapters, we will show how traditional supervision can still play a vital role in evaluating and improving an LLM prompt."
|
| 20 |
+
]
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"cell_type": "code",
|
| 24 |
+
"execution_count": 84,
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"source": [
|
| 28 |
+
"import time # NEW\n",
|
| 29 |
+
"import json\n",
|
| 30 |
+
"from rich import print\n",
|
| 31 |
+
"from rich.progress import track # NEW\n",
|
| 32 |
+
"import requests\n",
|
| 33 |
+
"from retry import retry\n",
|
| 34 |
+
"import pandas as pd\n",
|
| 35 |
+
"from huggingface_hub import InferenceClient\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"api_key = os.getenv(\"HF_TOKEN\")\n",
|
| 38 |
+
"client = InferenceClient(\n",
|
| 39 |
+
" token=api_key,\n",
|
| 40 |
+
")\n",
|
| 41 |
+
"df = pd.read_csv(\"https://raw.githubusercontent.com/palewire/first-llm-classifier/refs/heads/main/_notebooks/Form460ScheduleESubItem.csv\")"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "markdown",
|
| 46 |
+
"metadata": {},
|
| 47 |
+
"source": [
|
| 48 |
+
"Start by outputting a random sample from the dataset to a file of comma-separated values. It will serve as our supervised sample. In general, the larger the sample the better the evaluation. But at a certain point the returns diminish. For this exercise, we will use a sample of 250 records."
|
| 49 |
+
]
|
| 50 |
+
},
|
| 51 |
+
{
|
| 52 |
+
"cell_type": "code",
|
| 53 |
+
"execution_count": 85,
|
| 54 |
+
"metadata": {},
|
| 55 |
+
"outputs": [],
|
| 56 |
+
"source": [
|
| 57 |
+
"df.sample(250).to_csv(\"./sample.csv\", index=False)"
|
| 58 |
+
]
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"cell_type": "markdown",
|
| 62 |
+
"metadata": {},
|
| 63 |
+
"source": [
|
| 64 |
+
"You can open the file in a spreadsheet program like Excel or Google Sheets. For each payee in the sample, you would provide the correct category in a companion column. This gradually becomes the supervised sample.\n",
|
| 65 |
+
"\n",
|
| 66 |
+
"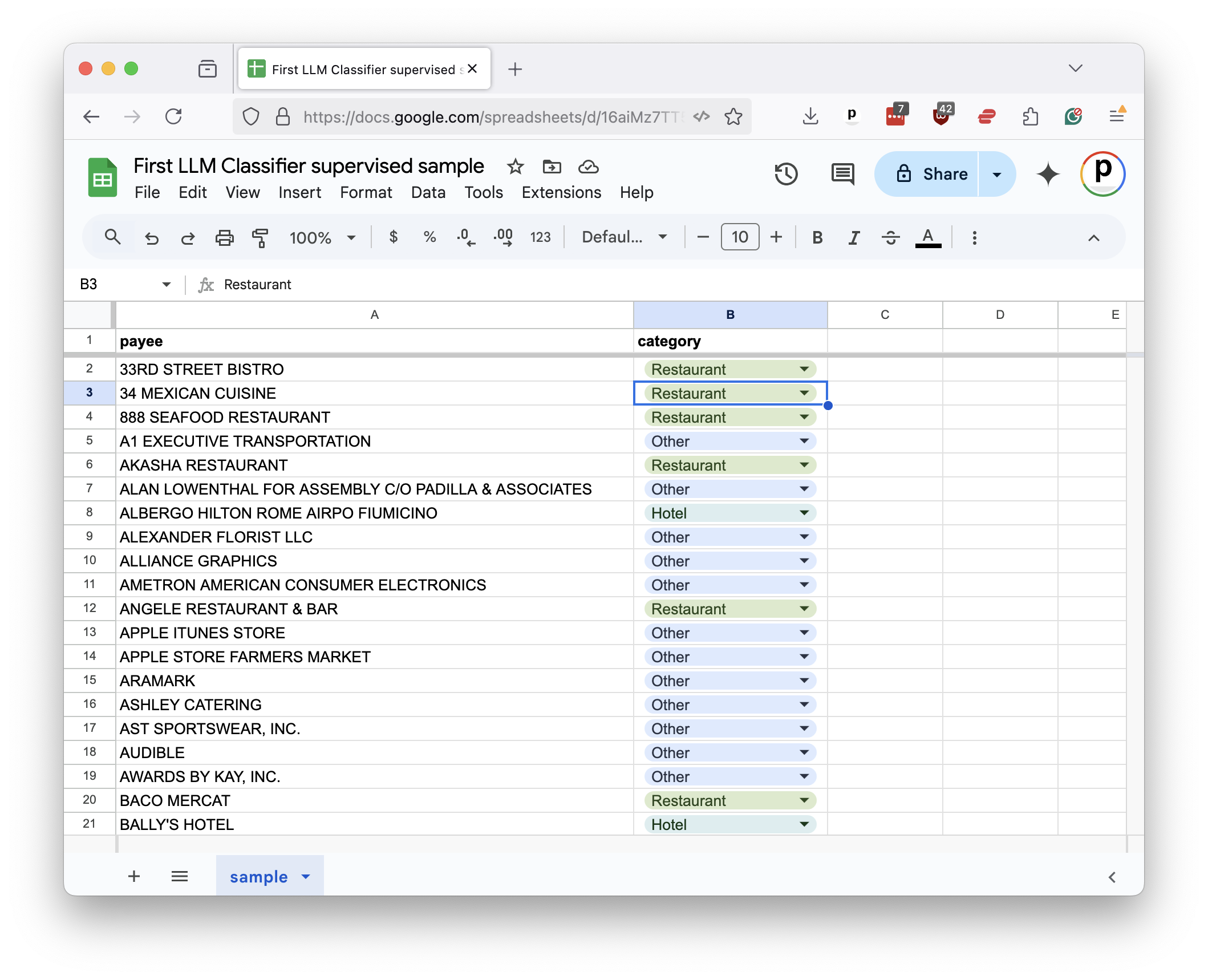\n",
|
| 67 |
+
"\n",
|
| 68 |
+
"To speed the class along, we've already prepared a sample for you in [the class repository](https://github.com/palewire/first-llm-classifier). Our next step is to read it back into a DataFrame."
|
| 69 |
+
]
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"cell_type": "code",
|
| 73 |
+
"execution_count": 86,
|
| 74 |
+
"metadata": {},
|
| 75 |
+
"outputs": [],
|
| 76 |
+
"source": [
|
| 77 |
+
"sample_df = pd.read_csv(\"sample_classified.csv\")"
|
| 78 |
+
]
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"cell_type": "markdown",
|
| 82 |
+
"metadata": {},
|
| 83 |
+
"source": [
|
| 84 |
+
"We'll install the Python packages `scikit-learn`, `matplotlib`, and `seaborn`. Prior to LLMs, these libraries were the go-to tools for training and evaluating machine-learning models. We'll primarily be using them for testing.\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"Return to the Jupyter notebook and install the packages alongside our other dependencies."
|
| 87 |
+
]
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"cell_type": "code",
|
| 91 |
+
"execution_count": null,
|
| 92 |
+
"metadata": {
|
| 93 |
+
"scrolled": true
|
| 94 |
+
},
|
| 95 |
+
"outputs": [],
|
| 96 |
+
"source": [
|
| 97 |
+
"%pip install huggingface_hub rich ipywidgets retry pandas scikit-learn matplotlib seaborn"
|
| 98 |
+
]
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"cell_type": "markdown",
|
| 102 |
+
"metadata": {},
|
| 103 |
+
"source": [
|
| 104 |
+
"Add the `test_train_split` function from `scikit-learn` to the import statement."
|
| 105 |
+
]
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
"cell_type": "code",
|
| 109 |
+
"execution_count": 88,
|
| 110 |
+
"metadata": {},
|
| 111 |
+
"outputs": [],
|
| 112 |
+
"source": [
|
| 113 |
+
"import json\n",
|
| 114 |
+
"from rich import print\n",
|
| 115 |
+
"import requests\n",
|
| 116 |
+
"from retry import retry\n",
|
| 117 |
+
"import pandas as pd\n",
|
| 118 |
+
"from sklearn.model_selection import train_test_split #NEW "
|
| 119 |
+
]
|
| 120 |
+
},
|
| 121 |
+
{
|
| 122 |
+
"cell_type": "markdown",
|
| 123 |
+
"metadata": {},
|
| 124 |
+
"source": [
|
| 125 |
+
"This tool is used to split a supervised sample into separate sets for training and testing.\n",
|
| 126 |
+
"\n",
|
| 127 |
+
"The first input is the DataFrame column containing our supervised payees. The second input is the DataFrame column containing the correct categories.\n",
|
| 128 |
+
"\n",
|
| 129 |
+
"The `test_size` parameter determines the proportion of the sample that will be used for testing. The `random_state` parameter ensures that the split is reproducible by setting a seed for the random number generator that draws the samples."
|
| 130 |
+
]
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"cell_type": "code",
|
| 134 |
+
"execution_count": 89,
|
| 135 |
+
"metadata": {
|
| 136 |
+
"scrolled": true
|
| 137 |
+
},
|
| 138 |
+
"outputs": [],
|
| 139 |
+
"source": [
|
| 140 |
+
"training_input, test_input, training_output, test_output = train_test_split(\n",
|
| 141 |
+
" sample_df[['payee']],\n",
|
| 142 |
+
" sample_df['category'],\n",
|
| 143 |
+
" test_size=0.33,\n",
|
| 144 |
+
" random_state=42, # Remember Jackie Robinson. Remember Douglas Adams.\n",
|
| 145 |
+
")"
|
| 146 |
+
]
|
| 147 |
+
},
|
| 148 |
+
{
|
| 149 |
+
"cell_type": "markdown",
|
| 150 |
+
"metadata": {},
|
| 151 |
+
"source": [
|
| 152 |
+
"In a traditional training setup, the next step would be to train a machine-learning model in `sklearn` using the `training_input` and `training_output` sets. The model would then be evaluated using the `test_input` and `test_output` sets.\n",
|
| 153 |
+
"\n",
|
| 154 |
+
"With the LLM we skip ahead to the testing phase. We pass the `test_input` set to our LLM prompt and compare the results to the right answers found in `test_output` set.\n",
|
| 155 |
+
"\n",
|
| 156 |
+
"All that requires is that we pass the `payee` column from our `test_input` DataFrame to the function we created in the previous chapters."
|
| 157 |
+
]
|
| 158 |
+
},
|
| 159 |
+
{
|
| 160 |
+
"cell_type": "code",
|
| 161 |
+
"execution_count": 90,
|
| 162 |
+
"metadata": {},
|
| 163 |
+
"outputs": [
|
| 164 |
+
{
|
| 165 |
+
"data": {
|
| 166 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 167 |
+
"model_id": "2549c6db6c4a428a959aa78c686afce1",
|
| 168 |
+
"version_major": 2,
|
| 169 |
+
"version_minor": 0
|
| 170 |
+
},
|
| 171 |
+
"text/plain": [
|
| 172 |
+
"Output()"
|
| 173 |
+
]
|
| 174 |
+
},
|
| 175 |
+
"metadata": {},
|
| 176 |
+
"output_type": "display_data"
|
| 177 |
+
},
|
| 178 |
+
{
|
| 179 |
+
"data": {
|
| 180 |
+
"text/html": [
|
| 181 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"></pre>\n"
|
| 182 |
+
],
|
| 183 |
+
"text/plain": []
|
| 184 |
+
},
|
| 185 |
+
"metadata": {},
|
| 186 |
+
"output_type": "display_data"
|
| 187 |
+
}
|
| 188 |
+
],
|
| 189 |
+
"source": [
|
| 190 |
+
"###REPEAT FROM PREVIOUS NOTEBOOK\n",
|
| 191 |
+
"@retry(ValueError, tries=2, delay=2)\n",
|
| 192 |
+
"def classify_payees(name_list):\n",
|
| 193 |
+
" prompt = \"\"\"You are an AI model trained to categorize businesses based on their names.\n",
|
| 194 |
+
"\n",
|
| 195 |
+
"You will be given a list of business names, each separated by a new line.\n",
|
| 196 |
+
"\n",
|
| 197 |
+
"Your task is to analyze each name and classify it into one of the following categories: Restaurant, Bar, Hotel, or Other.\n",
|
| 198 |
+
"\n",
|
| 199 |
+
"It is extremely critical that there is a corresponding category output for each business name provided as an input.\n",
|
| 200 |
+
"\n",
|
| 201 |
+
"If a business does not clearly fall into Restaurant, Bar, or Hotel categories, you should classify it as \"Other\".\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"Even if the type of business is not immediately clear from the name, it is essential that you provide your best guess based on the information available to you. If you can't make a good guess, classify it as Other.\n",
|
| 204 |
+
"\n",
|
| 205 |
+
"For example, if given the following input:\n",
|
| 206 |
+
"\n",
|
| 207 |
+
"\"Intercontinental Hotel\\nPizza Hut\\nCheers\\nWelsh's Family Restaurant\\nKTLA\\nDirect Mailing\"\n",
|
| 208 |
+
"\n",
|
| 209 |
+
"Your output should be a JSON list in the following format:\n",
|
| 210 |
+
"\n",
|
| 211 |
+
"[\"Hotel\", \"Restaurant\", \"Bar\", \"Restaurant\", \"Other\", \"Other\"]\n",
|
| 212 |
+
"\n",
|
| 213 |
+
"This means that you have classified \"Intercontinental Hotel\" as a Hotel, \"Pizza Hut\" as a Restaurant, \"Cheers\" as a Bar, \"Welsh's Family Restaurant\" as a Restaurant, and both \"KTLA\" and \"Direct Mailing\" as Other.\n",
|
| 214 |
+
"\n",
|
| 215 |
+
"Ensure that the number of classifications in your output matches the number of business names in the input. It is very important that the length of JSON list you return is exactly the same as the number of business names you receive.\n",
|
| 216 |
+
"\"\"\"\n",
|
| 217 |
+
" response = client.chat.completions.create(\n",
|
| 218 |
+
" messages=[\n",
|
| 219 |
+
" {\n",
|
| 220 |
+
" \"role\": \"system\",\n",
|
| 221 |
+
" \"content\": prompt,\n",
|
| 222 |
+
" },\n",
|
| 223 |
+
" {\n",
|
| 224 |
+
" \"role\": \"user\",\n",
|
| 225 |
+
" \"content\": \"Intercontinental Hotel\\nPizza Hut\\nCheers\\nWelsh's Family Restaurant\\nKTLA\\nDirect Mailing\",\n",
|
| 226 |
+
" },\n",
|
| 227 |
+
" {\n",
|
| 228 |
+
" \"role\": \"assistant\",\n",
|
| 229 |
+
" \"content\": '[\"Hotel\", \"Restaurant\", \"Bar\", \"Restaurant\", \"Other\", \"Other\"]',\n",
|
| 230 |
+
" },\n",
|
| 231 |
+
" {\n",
|
| 232 |
+
" \"role\": \"user\",\n",
|
| 233 |
+
" \"content\": \"Subway Sandwiches\\nRuth Chris Steakhouse\\nPolitical Consulting Co\\nThe Lamb's Club\",\n",
|
| 234 |
+
" },\n",
|
| 235 |
+
" {\n",
|
| 236 |
+
" \"role\": \"assistant\",\n",
|
| 237 |
+
" \"content\": '[\"Restaurant\", \"Restaurant\", \"Other\", \"Bar\"]',\n",
|
| 238 |
+
" },\n",
|
| 239 |
+
" {\n",
|
| 240 |
+
" \"role\": \"user\",\n",
|
| 241 |
+
" \"content\": \"\\n\".join(name_list),\n",
|
| 242 |
+
" }\n",
|
| 243 |
+
" ],\n",
|
| 244 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 245 |
+
" temperature=0,\n",
|
| 246 |
+
" )\n",
|
| 247 |
+
"\n",
|
| 248 |
+
" answer_str = response.choices[0].message.content\n",
|
| 249 |
+
" answer_list = json.loads(answer_str)\n",
|
| 250 |
+
"\n",
|
| 251 |
+
" acceptable_answers = [\n",
|
| 252 |
+
" \"Restaurant\",\n",
|
| 253 |
+
" \"Bar\",\n",
|
| 254 |
+
" \"Hotel\",\n",
|
| 255 |
+
" \"Other\",\n",
|
| 256 |
+
" ]\n",
|
| 257 |
+
" for answer in answer_list:\n",
|
| 258 |
+
" if answer not in acceptable_answers:\n",
|
| 259 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 260 |
+
"\n",
|
| 261 |
+
" try:\n",
|
| 262 |
+
" assert len(name_list) == len(answer_list)\n",
|
| 263 |
+
" except AssertionError:\n",
|
| 264 |
+
" raise ValueError(f\"Number of outputs ({len(name_list)}) does not equal the number of inputs ({len(answer_list)})\")\n",
|
| 265 |
+
"\n",
|
| 266 |
+
" return dict(zip(name_list, answer_list))\n",
|
| 267 |
+
"\n",
|
| 268 |
+
"def get_batch_list(li, n=10):\n",
|
| 269 |
+
" \"\"\"Split the provided list into batches of size `n`.\"\"\"\n",
|
| 270 |
+
" batch_list = []\n",
|
| 271 |
+
" for i in range(0, len(li), n):\n",
|
| 272 |
+
" batch_list.append(li[i : i + n])\n",
|
| 273 |
+
" return batch_list\n",
|
| 274 |
+
" \n",
|
| 275 |
+
"def classify_batches(name_list, batch_size=11, wait=2):\n",
|
| 276 |
+
" \"\"\"Split the provided list of names into batches and classify with our LLM them one by one.\"\"\"\n",
|
| 277 |
+
" # Create a place to store the results\n",
|
| 278 |
+
" all_results = {}\n",
|
| 279 |
+
"\n",
|
| 280 |
+
" # Batch up the list\n",
|
| 281 |
+
" batch_list = get_batch_list(name_list, n=batch_size)\n",
|
| 282 |
+
"\n",
|
| 283 |
+
" # Loop through the list in batches\n",
|
| 284 |
+
" for batch in track(batch_list):\n",
|
| 285 |
+
" # Classify it with the LLM\n",
|
| 286 |
+
" batch_results = classify_payees(batch)\n",
|
| 287 |
+
"\n",
|
| 288 |
+
" # Add what we get back to the results\n",
|
| 289 |
+
" all_results.update(batch_results)\n",
|
| 290 |
+
"\n",
|
| 291 |
+
" # Tap the brakes to avoid overloading HF's API\n",
|
| 292 |
+
" time.sleep(wait)\n",
|
| 293 |
+
"\n",
|
| 294 |
+
" # Return the results\n",
|
| 295 |
+
" return all_results\n",
|
| 296 |
+
" \n",
|
| 297 |
+
"llm_dict = classify_batches(list(test_input.payee))"
|
| 298 |
+
]
|
| 299 |
+
},
|
| 300 |
+
{
|
| 301 |
+
"cell_type": "markdown",
|
| 302 |
+
"metadata": {},
|
| 303 |
+
"source": [
|
| 304 |
+
"Next, we import the `classification_report` and `confusion_matrix` functions from `sklearn`, which are used to evaluate a model's performance. We'll also pull in `seaborn` and `matplotlib` to visualize the results."
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"cell_type": "code",
|
| 309 |
+
"execution_count": 91,
|
| 310 |
+
"metadata": {},
|
| 311 |
+
"outputs": [],
|
| 312 |
+
"source": [
|
| 313 |
+
"import json\n",
|
| 314 |
+
"from rich import print\n",
|
| 315 |
+
"import requests\n",
|
| 316 |
+
"from retry import retry\n",
|
| 317 |
+
"import pandas as pd\n",
|
| 318 |
+
"import seaborn as sns # NEW\n",
|
| 319 |
+
"import matplotlib.pyplot as plt # NEW \n",
|
| 320 |
+
"from sklearn.model_selection import train_test_split\n",
|
| 321 |
+
"from sklearn.metrics import confusion_matrix, classification_report # NEW"
|
| 322 |
+
]
|
| 323 |
+
},
|
| 324 |
+
{
|
| 325 |
+
"cell_type": "markdown",
|
| 326 |
+
"metadata": {},
|
| 327 |
+
"source": [
|
| 328 |
+
"The `classification_report` function generats a report card on a model's performance. You provide it with the correct answers in the `test_output` set and the model's predictions in your prompt's DataFrame. In this case, our LLM's predictions are stored in the `llm_df` DataFrame's `category` column."
|
| 329 |
+
]
|
| 330 |
+
},
|
| 331 |
+
{
|
| 332 |
+
"cell_type": "code",
|
| 333 |
+
"execution_count": 92,
|
| 334 |
+
"metadata": {},
|
| 335 |
+
"outputs": [],
|
| 336 |
+
"source": [
|
| 337 |
+
"llm_df = pd.DataFrame.from_dict(llm_dict, orient=\"index\", columns=[\"category\"])"
|
| 338 |
+
]
|
| 339 |
+
},
|
| 340 |
+
{
|
| 341 |
+
"cell_type": "code",
|
| 342 |
+
"execution_count": 93,
|
| 343 |
+
"metadata": {},
|
| 344 |
+
"outputs": [
|
| 345 |
+
{
|
| 346 |
+
"data": {
|
| 347 |
+
"text/html": [
|
| 348 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"> precision recall f1-score support\n",
|
| 349 |
+
"\n",
|
| 350 |
+
" Bar <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">2</span>\n",
|
| 351 |
+
" Hotel <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">9</span>\n",
|
| 352 |
+
" Other <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.98</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.99</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">57</span>\n",
|
| 353 |
+
" Restaurant <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.94</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.97</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">15</span>\n",
|
| 354 |
+
"\n",
|
| 355 |
+
" accuracy <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.99</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">83</span>\n",
|
| 356 |
+
" macro avg <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.98</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">1.00</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.99</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">83</span>\n",
|
| 357 |
+
"weighted avg <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.99</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.99</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">0.99</span> <span style=\"color: #008080; text-decoration-color: #008080; font-weight: bold\">83</span>\n",
|
| 358 |
+
"\n",
|
| 359 |
+
"</pre>\n"
|
| 360 |
+
],
|
| 361 |
+
"text/plain": [
|
| 362 |
+
" precision recall f1-score support\n",
|
| 363 |
+
"\n",
|
| 364 |
+
" Bar \u001b[1;36m1.00\u001b[0m \u001b[1;36m1.00\u001b[0m \u001b[1;36m1.00\u001b[0m \u001b[1;36m2\u001b[0m\n",
|
| 365 |
+
" Hotel \u001b[1;36m1.00\u001b[0m \u001b[1;36m1.00\u001b[0m \u001b[1;36m1.00\u001b[0m \u001b[1;36m9\u001b[0m\n",
|
| 366 |
+
" Other \u001b[1;36m1.00\u001b[0m \u001b[1;36m0.98\u001b[0m \u001b[1;36m0.99\u001b[0m \u001b[1;36m57\u001b[0m\n",
|
| 367 |
+
" Restaurant \u001b[1;36m0.94\u001b[0m \u001b[1;36m1.00\u001b[0m \u001b[1;36m0.97\u001b[0m \u001b[1;36m15\u001b[0m\n",
|
| 368 |
+
"\n",
|
| 369 |
+
" accuracy \u001b[1;36m0.99\u001b[0m \u001b[1;36m83\u001b[0m\n",
|
| 370 |
+
" macro avg \u001b[1;36m0.98\u001b[0m \u001b[1;36m1.00\u001b[0m \u001b[1;36m0.99\u001b[0m \u001b[1;36m83\u001b[0m\n",
|
| 371 |
+
"weighted avg \u001b[1;36m0.99\u001b[0m \u001b[1;36m0.99\u001b[0m \u001b[1;36m0.99\u001b[0m \u001b[1;36m83\u001b[0m\n",
|
| 372 |
+
"\n"
|
| 373 |
+
]
|
| 374 |
+
},
|
| 375 |
+
"metadata": {},
|
| 376 |
+
"output_type": "display_data"
|
| 377 |
+
}
|
| 378 |
+
],
|
| 379 |
+
"source": [
|
| 380 |
+
"print(classification_report(test_output, llm_df.category))"
|
| 381 |
+
]
|
| 382 |
+
},
|
| 383 |
+
{
|
| 384 |
+
"cell_type": "markdown",
|
| 385 |
+
"metadata": {},
|
| 386 |
+
"source": [
|
| 387 |
+
"That will output a report that looks something like this:\n",
|
| 388 |
+
"\n",
|
| 389 |
+
"```\n",
|
| 390 |
+
" precision recall f1-score support\n",
|
| 391 |
+
"\n",
|
| 392 |
+
" Bar 1.00 1.00 1.00 2\n",
|
| 393 |
+
" Hotel 0.89 0.80 0.84 10\n",
|
| 394 |
+
" Other 0.96 0.96 0.96 57\n",
|
| 395 |
+
" Restaurant 0.87 0.93 0.90 14\n",
|
| 396 |
+
"\n",
|
| 397 |
+
" accuracy 0.94 83\n",
|
| 398 |
+
" macro avg 0.93 0.92 0.93 83\n",
|
| 399 |
+
"weighted avg 0.94 0.94 0.94 83\n",
|
| 400 |
+
"```\n",
|
| 401 |
+
"\n",
|
| 402 |
+
"At first, the report can be a bit overwhelming. What are all these technical terms?\n",
|
| 403 |
+
"\n",
|
| 404 |
+
"Precision measures what statistics nerds call \"positive predictive value.\" It's how often the model made the correct decision when it applied a category. For instance, in the \"Bar\" category, the LLM correctly predicted both of the bars in our supervised sample. That's a precision of 1.00. An analogy here is a baseball player's contact rate. Precision is a measure of how often the model connects with the ball when it swings its bat.\n",
|
| 405 |
+
"\n",
|
| 406 |
+
"Recall measures how many of the supervised instances were identified by the model. In this case, it shows that the LLM correctly spotted 80% of the hotels in our manual sample.\n",
|
| 407 |
+
"\n",
|
| 408 |
+
"The f1-score is a combination of precision and recall. It's a way to measure a model's overall performance by balancing the two.\n",
|
| 409 |
+
"\n",
|
| 410 |
+
"The support column shows how many instances of each category were in the supervised sample.\n",
|
| 411 |
+
"\n",
|
| 412 |
+
"The averages at the bottom combine the results for all categories. The macro row is a simple average all the scores in that column. The weighted row is a weighted average based on the number of instances in each category.\n",
|
| 413 |
+
"\n",
|
| 414 |
+
"In the example result provided above, we can see that the LLM was guessing correctly more than 90% of the time no matter how you slice it."
|
| 415 |
+
]
|
| 416 |
+
},
|
| 417 |
+
{
|
| 418 |
+
"cell_type": "markdown",
|
| 419 |
+
"metadata": {},
|
| 420 |
+
"source": [
|
| 421 |
+
"Another technique for evaluating classifiers is to visualize the results using a chart known as a confusion matrix. This chart shows how often the model correctly predicted each category and where it got things wrong.\n",
|
| 422 |
+
"\n",
|
| 423 |
+
"Drawing one up requires the `confusion_matrix` function from `sklearn` and an embarassing tangle of code from `seaborn` and `matplotlib` libraries. Most of it is boilerplate, but you need to punch your test variables, as well as the proper labels for the categories, in a few picky places."
|
| 424 |
+
]
|
| 425 |
+
},
|
| 426 |
+
{
|
| 427 |
+
"cell_type": "code",
|
| 428 |
+
"execution_count": null,
|
| 429 |
+
"metadata": {},
|
| 430 |
+
"outputs": [],
|
| 431 |
+
"source": [
|
| 432 |
+
"conf_mat = confusion_matrix(\n",
|
| 433 |
+
" test_output, # labels\n",
|
| 434 |
+
" llm_df.category, # labels\n",
|
| 435 |
+
" labels=llm_df.category.unique() # labels\n",
|
| 436 |
+
")\n",
|
| 437 |
+
"fig, ax = plt.subplots(figsize=(5,5))\n",
|
| 438 |
+
"sns.heatmap(\n",
|
| 439 |
+
" conf_mat,\n",
|
| 440 |
+
" annot=True,\n",
|
| 441 |
+
" fmt='d',\n",
|
| 442 |
+
" xticklabels=llm_df.category.unique(), # labels\n",
|
| 443 |
+
" yticklabels=llm_df.category.unique() # labels\n",
|
| 444 |
+
")\n",
|
| 445 |
+
"plt.ylabel('Actual')\n",
|
| 446 |
+
"plt.xlabel('Predicted')"
|
| 447 |
+
]
|
| 448 |
+
},
|
| 449 |
+
{
|
| 450 |
+
"cell_type": "markdown",
|
| 451 |
+
"metadata": {},
|
| 452 |
+
"source": [
|
| 453 |
+
"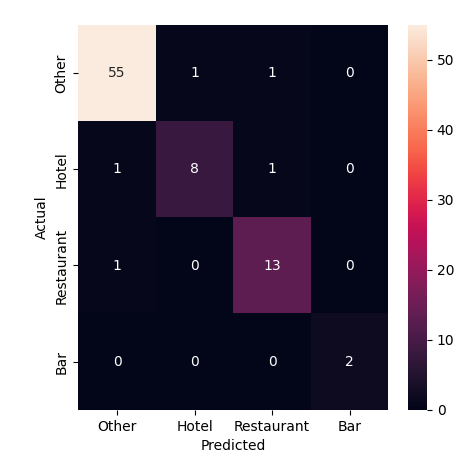\n",
|
| 454 |
+
"\n",
|
| 455 |
+
"The diagonal line of cells running from the upper left to the lower right shows where the model correctly predicted the category. The off-diagonal cells show where it got things wrong. The color of the cells indicates how often the model made that prediction. For instance, we can see that one miscategorized hotel in the sample was predicted to be a restaurant and the second was predicted to be \"Other.\"\n",
|
| 456 |
+
"\n",
|
| 457 |
+
"Due to the inherent randomness in the LLM's predictions, it's a good idea to test your sample and run these reports multiple times to get a sense of the model's performance."
|
| 458 |
+
]
|
| 459 |
+
},
|
| 460 |
+
{
|
| 461 |
+
"cell_type": "markdown",
|
| 462 |
+
"metadata": {},
|
| 463 |
+
"source": [
|
| 464 |
+
"Before we look at how you might improve the LLM's performance, let's take a moment to compare the results of this evaluation against the old school approach where the supervised sample is used to train a machine-learning model that doesn't have access to the ocean of knowledge poured into an LLM.\n",
|
| 465 |
+
"\n",
|
| 466 |
+
"This will require importing a mess of `sklearn` functions and classes. We'll use `TfidfVectorizer` to convert the payee text into a numerical representation that can be used by a `LinearSVC` classifier. We'll then use a `Pipeline` to chain the two together. If you have no idea what any of that means, don't worry. Now that we have LLMs in this world, you might never need to know."
|
| 467 |
+
]
|
| 468 |
+
},
|
| 469 |
+
{
|
| 470 |
+
"cell_type": "code",
|
| 471 |
+
"execution_count": null,
|
| 472 |
+
"metadata": {},
|
| 473 |
+
"outputs": [],
|
| 474 |
+
"source": [
|
| 475 |
+
"import json\n",
|
| 476 |
+
"from rich import print\n",
|
| 477 |
+
"import requests\n",
|
| 478 |
+
"from retry import retry\n",
|
| 479 |
+
"import pandas as pd\n",
|
| 480 |
+
"import seaborn as sns\n",
|
| 481 |
+
"import matplotlib.pyplot as plt\n",
|
| 482 |
+
"from sklearn.model_selection import train_test_split\n",
|
| 483 |
+
"from sklearn.metrics import confusion_matrix, classification_report\n",
|
| 484 |
+
"from sklearn.svm import LinearSVC # NEW\n",
|
| 485 |
+
"from sklearn.pipeline import Pipeline # NEW\n",
|
| 486 |
+
"from sklearn.compose import ColumnTransformer # NEW\n",
|
| 487 |
+
"from sklearn.feature_extraction.text import TfidfVectorizer # NEW"
|
| 488 |
+
]
|
| 489 |
+
},
|
| 490 |
+
{
|
| 491 |
+
"cell_type": "markdown",
|
| 492 |
+
"metadata": {},
|
| 493 |
+
"source": [
|
| 494 |
+
"Here's a simple example of how you might train and evaluate a traditional machine-learning model using the supervised sample.\n",
|
| 495 |
+
"\n",
|
| 496 |
+
"First you setup all the machinery."
|
| 497 |
+
]
|
| 498 |
+
},
|
| 499 |
+
{
|
| 500 |
+
"cell_type": "code",
|
| 501 |
+
"execution_count": null,
|
| 502 |
+
"metadata": {},
|
| 503 |
+
"outputs": [],
|
| 504 |
+
"source": [
|
| 505 |
+
"vectorizer = TfidfVectorizer(\n",
|
| 506 |
+
" sublinear_tf=True,\n",
|
| 507 |
+
" min_df=5,\n",
|
| 508 |
+
" norm='l2',\n",
|
| 509 |
+
" encoding='latin-1',\n",
|
| 510 |
+
" ngram_range=(1, 3),\n",
|
| 511 |
+
")\n",
|
| 512 |
+
"preprocessor = ColumnTransformer(\n",
|
| 513 |
+
" transformers=[\n",
|
| 514 |
+
" ('payee', vectorizer, 'payee')\n",
|
| 515 |
+
" ],\n",
|
| 516 |
+
" sparse_threshold=0,\n",
|
| 517 |
+
" remainder='drop'\n",
|
| 518 |
+
")\n",
|
| 519 |
+
"pipeline = Pipeline([\n",
|
| 520 |
+
" ('preprocessor', preprocessor),\n",
|
| 521 |
+
" ('classifier', LinearSVC(dual=\"auto\"))\n",
|
| 522 |
+
"])"
|
| 523 |
+
]
|
| 524 |
+
},
|
| 525 |
+
{
|
| 526 |
+
"cell_type": "markdown",
|
| 527 |
+
"metadata": {},
|
| 528 |
+
"source": [
|
| 529 |
+
"Then you train the model using those training sets we split out at the start."
|
| 530 |
+
]
|
| 531 |
+
},
|
| 532 |
+
{
|
| 533 |
+
"cell_type": "code",
|
| 534 |
+
"execution_count": null,
|
| 535 |
+
"metadata": {},
|
| 536 |
+
"outputs": [],
|
| 537 |
+
"source": [
|
| 538 |
+
"model = pipeline.fit(training_input, training_output)"
|
| 539 |
+
]
|
| 540 |
+
},
|
| 541 |
+
{
|
| 542 |
+
"cell_type": "markdown",
|
| 543 |
+
"metadata": {},
|
| 544 |
+
"source": [
|
| 545 |
+
"And you ask the model to use its training to predict the right answers for the test set."
|
| 546 |
+
]
|
| 547 |
+
},
|
| 548 |
+
{
|
| 549 |
+
"cell_type": "code",
|
| 550 |
+
"execution_count": null,
|
| 551 |
+
"metadata": {},
|
| 552 |
+
"outputs": [],
|
| 553 |
+
"source": [
|
| 554 |
+
"predictions = model.predict(test_input)"
|
| 555 |
+
]
|
| 556 |
+
},
|
| 557 |
+
{
|
| 558 |
+
"cell_type": "markdown",
|
| 559 |
+
"metadata": {},
|
| 560 |
+
"source": [
|
| 561 |
+
"Now, you can run the same evaluation code as before to see how the traditional model performed."
|
| 562 |
+
]
|
| 563 |
+
},
|
| 564 |
+
{
|
| 565 |
+
"cell_type": "code",
|
| 566 |
+
"execution_count": null,
|
| 567 |
+
"metadata": {},
|
| 568 |
+
"outputs": [],
|
| 569 |
+
"source": [
|
| 570 |
+
"print(classification_report(test_output, predictions))"
|
| 571 |
+
]
|
| 572 |
+
},
|
| 573 |
+
{
|
| 574 |
+
"cell_type": "markdown",
|
| 575 |
+
"metadata": {},
|
| 576 |
+
"source": [
|
| 577 |
+
"```\n",
|
| 578 |
+
" precision recall f1-score support\n",
|
| 579 |
+
"\n",
|
| 580 |
+
" Bar 0.00 0.00 0.00 2\n",
|
| 581 |
+
" Hotel 1.00 0.27 0.43 10\n",
|
| 582 |
+
" Other 0.75 1.00 0.85 57\n",
|
| 583 |
+
" Restaurant 0.80 0.29 0.42 14\n",
|
| 584 |
+
"\n",
|
| 585 |
+
" accuracy 0.76 83\n",
|
| 586 |
+
" macro avg 0.64 0.39 0.43 83\n",
|
| 587 |
+
"weighted avg 0.77 0.76 0.70 83\n",
|
| 588 |
+
"```"
|
| 589 |
+
]
|
| 590 |
+
},
|
| 591 |
+
{
|
| 592 |
+
"cell_type": "code",
|
| 593 |
+
"execution_count": null,
|
| 594 |
+
"metadata": {},
|
| 595 |
+
"outputs": [],
|
| 596 |
+
"source": [
|
| 597 |
+
"conf_mat = confusion_matrix(test_output, llm_df.category, labels=llm_df.category.unique())\n",
|
| 598 |
+
"fig, ax = plt.subplots(figsize=(5,5))\n",
|
| 599 |
+
"sns.heatmap(\n",
|
| 600 |
+
" conf_mat,\n",
|
| 601 |
+
" annot=True,\n",
|
| 602 |
+
" fmt='d',\n",
|
| 603 |
+
" xticklabels=llm_df.category.unique(),\n",
|
| 604 |
+
" yticklabels=llm_df.category.unique()\n",
|
| 605 |
+
")\n",
|
| 606 |
+
"plt.ylabel('Actual')\n",
|
| 607 |
+
"plt.xlabel('Predicted')"
|
| 608 |
+
]
|
| 609 |
+
},
|
| 610 |
+
{
|
| 611 |
+
"cell_type": "markdown",
|
| 612 |
+
"metadata": {},
|
| 613 |
+
"source": [
|
| 614 |
+
"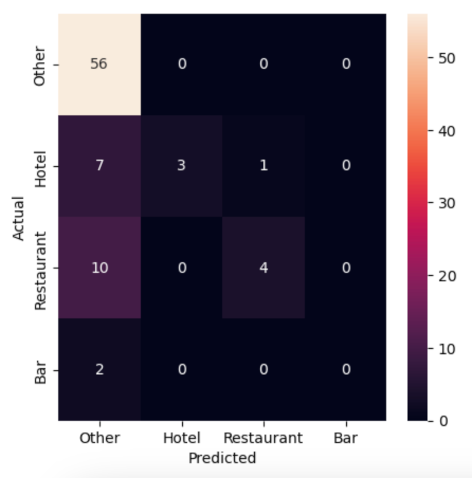\n",
|
| 615 |
+
"\n",
|
| 616 |
+
"Not great. The traditional model is guessing correctly about 75% of the time, but it's missing most cases of our \"Bar\", \"Hotel\" and \"Restaurant\" categories as almost everything is getting filed as \"Other.\" The LLM, on the other hand, is guessing correctly more than 90% of the time and flagging many of the rare categories that we're seeking to find in the haystack of data."
|
| 617 |
+
]
|
| 618 |
+
},
|
| 619 |
+
{
|
| 620 |
+
"cell_type": "markdown",
|
| 621 |
+
"metadata": {},
|
| 622 |
+
"source": [
|
| 623 |
+
"**[9. Improving prompts →](ch9-improving-prompts.ipynb)**"
|
| 624 |
+
]
|
| 625 |
+
},
|
| 626 |
+
{
|
| 627 |
+
"cell_type": "code",
|
| 628 |
+
"execution_count": null,
|
| 629 |
+
"metadata": {},
|
| 630 |
+
"outputs": [],
|
| 631 |
+
"source": []
|
| 632 |
+
}
|
| 633 |
+
],
|
| 634 |
+
"metadata": {
|
| 635 |
+
"kernelspec": {
|
| 636 |
+
"display_name": "Python 3 (ipykernel)",
|
| 637 |
+
"language": "python",
|
| 638 |
+
"name": "python3"
|
| 639 |
+
},
|
| 640 |
+
"language_info": {
|
| 641 |
+
"codemirror_mode": {
|
| 642 |
+
"name": "ipython",
|
| 643 |
+
"version": 3
|
| 644 |
+
},
|
| 645 |
+
"file_extension": ".py",
|
| 646 |
+
"mimetype": "text/x-python",
|
| 647 |
+
"name": "python",
|
| 648 |
+
"nbconvert_exporter": "python",
|
| 649 |
+
"pygments_lexer": "ipython3",
|
| 650 |
+
"version": "3.9.5"
|
| 651 |
+
}
|
| 652 |
+
},
|
| 653 |
+
"nbformat": 4,
|
| 654 |
+
"nbformat_minor": 4
|
| 655 |
+
}
|
notebooks/ch9-improving-prompts.ipynb
ADDED
|
@@ -0,0 +1,669 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"## 9. Improving Prompts\n",
|
| 8 |
+
"\n",
|
| 9 |
+
"With our LLM prompt showing such strong results, you might be content to leave it as it is. But there are always ways to improve, and you might come across a circumstance where the model's performance is less than ideal.\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"Earlier in the lesson, we showed how you can feed the LLM examples of inputs and output prior to your request as part of a \"few shot\" prompt. An added benefit of coding a supervised sample for testing is that you can also use the training slice of the set to prime the LLM with this technique. If you've already done the work of labeling your data, you might as well use it to improve your model as well.\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"Converting the training set you held to the side into a few-shot prompt is a simple matter of formatting it to fit your LLM's expected input. Here's how you might do it in our case."
|
| 14 |
+
]
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"cell_type": "code",
|
| 18 |
+
"execution_count": 1,
|
| 19 |
+
"metadata": {},
|
| 20 |
+
"outputs": [],
|
| 21 |
+
"source": [
|
| 22 |
+
"import json\n",
|
| 23 |
+
"import time\n",
|
| 24 |
+
"import os\n",
|
| 25 |
+
"from retry import retry\n",
|
| 26 |
+
"from rich.progress import track\n",
|
| 27 |
+
"from huggingface_hub import InferenceClient\n",
|
| 28 |
+
"from sklearn.model_selection import train_test_split\n",
|
| 29 |
+
"from sklearn.metrics import confusion_matrix, classification_report\n",
|
| 30 |
+
"import pandas as pd\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"api_key = os.getenv(\"HF_TOKEN\")\n",
|
| 33 |
+
"client = InferenceClient(\n",
|
| 34 |
+
" token=api_key,\n",
|
| 35 |
+
")\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"sample_df = pd.read_csv(\"sample.csv\")"
|
| 38 |
+
]
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"cell_type": "markdown",
|
| 42 |
+
"metadata": {},
|
| 43 |
+
"source": [
|
| 44 |
+
"Calling our previous `get_batch_list` function again:"
|
| 45 |
+
]
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"cell_type": "code",
|
| 49 |
+
"execution_count": 2,
|
| 50 |
+
"metadata": {},
|
| 51 |
+
"outputs": [],
|
| 52 |
+
"source": [
|
| 53 |
+
"def get_batch_list(li, n=10):\n",
|
| 54 |
+
" \"\"\"Split the provided list into batches of size `n`.\"\"\"\n",
|
| 55 |
+
" batch_list = []\n",
|
| 56 |
+
" for i in range(0, len(li), n):\n",
|
| 57 |
+
" batch_list.append(li[i : i + n])\n",
|
| 58 |
+
" return batch_list\n",
|
| 59 |
+
"\n",
|
| 60 |
+
"training_input, test_input, training_output, test_output = train_test_split(\n",
|
| 61 |
+
" sample_df[['payee']],\n",
|
| 62 |
+
" sample_df['category'],\n",
|
| 63 |
+
" test_size=0.33,\n",
|
| 64 |
+
" random_state=42\n",
|
| 65 |
+
")"
|
| 66 |
+
]
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"cell_type": "code",
|
| 70 |
+
"execution_count": 3,
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"outputs": [],
|
| 73 |
+
"source": [
|
| 74 |
+
"def get_fewshots(training_input, training_output, batch_size=10):\n",
|
| 75 |
+
" \"\"\"Convert the training input and output from sklearn's train_test_split into a few-shot prompt\"\"\"\n",
|
| 76 |
+
" # Batch up the training input into groups of `batch_size`\n",
|
| 77 |
+
" input_batches = get_batch_list(list(training_input.payee), n=batch_size)\n",
|
| 78 |
+
"\n",
|
| 79 |
+
" # Do the same for the output\n",
|
| 80 |
+
" output_batches = get_batch_list(list(training_output), n=batch_size)\n",
|
| 81 |
+
"\n",
|
| 82 |
+
" # Create a list to hold the formatted few-shot examples\n",
|
| 83 |
+
" fewshot_list = []\n",
|
| 84 |
+
"\n",
|
| 85 |
+
" # Loop through the batches\n",
|
| 86 |
+
" for i, input_list in enumerate(input_batches):\n",
|
| 87 |
+
" fewshot_list.extend([\n",
|
| 88 |
+
" # Create a \"user\" message for the LLM formatted the same was a our prompt with newlines\n",
|
| 89 |
+
" {\n",
|
| 90 |
+
" \"role\": \"user\",\n",
|
| 91 |
+
" \"content\": \"\\n\".join(input_list),\n",
|
| 92 |
+
" },\n",
|
| 93 |
+
" # Create the expected \"assistant\" response as the JSON formatted output we expect\n",
|
| 94 |
+
" {\n",
|
| 95 |
+
" \"role\": \"assistant\",\n",
|
| 96 |
+
" \"content\": json.dumps(output_batches[i])\n",
|
| 97 |
+
" }\n",
|
| 98 |
+
" ])\n",
|
| 99 |
+
"\n",
|
| 100 |
+
" # Return the list of few-shot examples, one for each batch\n",
|
| 101 |
+
" return fewshot_list"
|
| 102 |
+
]
|
| 103 |
+
},
|
| 104 |
+
{
|
| 105 |
+
"cell_type": "markdown",
|
| 106 |
+
"metadata": {},
|
| 107 |
+
"source": [
|
| 108 |
+
"Pass in your training data."
|
| 109 |
+
]
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"cell_type": "code",
|
| 113 |
+
"execution_count": 4,
|
| 114 |
+
"metadata": {},
|
| 115 |
+
"outputs": [],
|
| 116 |
+
"source": [
|
| 117 |
+
"fewshot_list = get_fewshots(training_input, training_output)"
|
| 118 |
+
]
|
| 119 |
+
},
|
| 120 |
+
{
|
| 121 |
+
"cell_type": "markdown",
|
| 122 |
+
"metadata": {},
|
| 123 |
+
"source": [
|
| 124 |
+
"Take a peek at the first pair to see if it's what we expect."
|
| 125 |
+
]
|
| 126 |
+
},
|
| 127 |
+
{
|
| 128 |
+
"cell_type": "code",
|
| 129 |
+
"execution_count": 5,
|
| 130 |
+
"metadata": {},
|
| 131 |
+
"outputs": [
|
| 132 |
+
{
|
| 133 |
+
"data": {
|
| 134 |
+
"text/plain": [
|
| 135 |
+
"[{'role': 'user',\n",
|
| 136 |
+
" 'content': 'UFW OF AMERICA - AFL-CIO\\nRE-ELECT FIONA MA\\nELLA DINNING ROOM\\nMICHAEL EMERY PHOTOGRAPHY\\nLAKELAND VILLAGE\\nTHE IVY RESTAURANT\\nMOORLACH FOR SENATE 2016\\nBROWN PALACE HOTEL\\nAPPLE STORE FARMERS MARKET\\nCABLETIME TV'},\n",
|
| 137 |
+
" {'role': 'assistant',\n",
|
| 138 |
+
" 'content': '[\"Other\", \"Other\", \"Other\", \"Other\", \"Other\", \"Restaurant\", \"Other\", \"Hotel\", \"Other\", \"Other\"]'}]"
|
| 139 |
+
]
|
| 140 |
+
},
|
| 141 |
+
"execution_count": 5,
|
| 142 |
+
"metadata": {},
|
| 143 |
+
"output_type": "execute_result"
|
| 144 |
+
}
|
| 145 |
+
],
|
| 146 |
+
"source": [
|
| 147 |
+
"fewshot_list[:2]"
|
| 148 |
+
]
|
| 149 |
+
},
|
| 150 |
+
{
|
| 151 |
+
"cell_type": "markdown",
|
| 152 |
+
"metadata": {},
|
| 153 |
+
"source": [
|
| 154 |
+
"Now, we can add those examples to our prompt's `messages`."
|
| 155 |
+
]
|
| 156 |
+
},
|
| 157 |
+
{
|
| 158 |
+
"cell_type": "code",
|
| 159 |
+
"execution_count": 6,
|
| 160 |
+
"metadata": {},
|
| 161 |
+
"outputs": [],
|
| 162 |
+
"source": [
|
| 163 |
+
"@retry(ValueError, tries=2, delay=2)\n",
|
| 164 |
+
"def classify_payees(name_list):\n",
|
| 165 |
+
" prompt = \"\"\"You are an AI model trained to categorize businesses based on their names.\n",
|
| 166 |
+
"\n",
|
| 167 |
+
"You will be given a list of business names, each separated by a new line.\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"Your task is to analyze each name and classify it into one of the following categories: Restaurant, Bar, Hotel, or Other.\n",
|
| 170 |
+
"\n",
|
| 171 |
+
"It is extremely critical that there is a corresponding category output for each business name provided as an input.\n",
|
| 172 |
+
"\n",
|
| 173 |
+
"If a business does not clearly fall into Restaurant, Bar, or Hotel categories, you should classify it as \"Other\".\n",
|
| 174 |
+
"\n",
|
| 175 |
+
"Even if the type of business is not immediately clear from the name, it is essential that you provide your best guess based on the information available to you. If you can't make a good guess, classify it as Other.\n",
|
| 176 |
+
"\n",
|
| 177 |
+
"For example, if given the following input:\n",
|
| 178 |
+
"\n",
|
| 179 |
+
"\"Intercontinental Hotel\\nPizza Hut\\nCheers\\nWelsh's Family Restaurant\\nKTLA\\nDirect Mailing\"\n",
|
| 180 |
+
"\n",
|
| 181 |
+
"Your output should be a JSON list in the following format:\n",
|
| 182 |
+
"\n",
|
| 183 |
+
"[\"Hotel\", \"Restaurant\", \"Bar\", \"Restaurant\", \"Other\", \"Other\"]\n",
|
| 184 |
+
"\n",
|
| 185 |
+
"This means that you have classified \"Intercontinental Hotel\" as a Hotel, \"Pizza Hut\" as a Restaurant, \"Cheers\" as a Bar, \"Welsh's Family Restaurant\" as a Restaurant, and both \"KTLA\" and \"Direct Mailing\" as Other.\n",
|
| 186 |
+
"\n",
|
| 187 |
+
"Ensure that the number of classifications in your output matches the number of business names in the input. It is very important that the length of JSON list you return is exactly the same as the number of business names you receive.\n",
|
| 188 |
+
"\"\"\"\n",
|
| 189 |
+
" response = client.chat.completions.create(\n",
|
| 190 |
+
" messages=[\n",
|
| 191 |
+
" ### <-- NEW \n",
|
| 192 |
+
" {\n",
|
| 193 |
+
" \"role\": \"system\",\n",
|
| 194 |
+
" \"content\": prompt,\n",
|
| 195 |
+
" },\n",
|
| 196 |
+
" *fewshot_list,\n",
|
| 197 |
+
" {\n",
|
| 198 |
+
" \"role\": \"user\",\n",
|
| 199 |
+
" \"content\": \"\\n\".join(name_list),\n",
|
| 200 |
+
" }\n",
|
| 201 |
+
" ### -->\n",
|
| 202 |
+
" ],\n",
|
| 203 |
+
" model=\"meta-llama/Llama-3.3-70B-Instruct\",\n",
|
| 204 |
+
" temperature=0,\n",
|
| 205 |
+
" )\n",
|
| 206 |
+
"\n",
|
| 207 |
+
" answer_str = response.choices[0].message.content\n",
|
| 208 |
+
" answer_list = json.loads(answer_str)\n",
|
| 209 |
+
"\n",
|
| 210 |
+
" acceptable_answers = [\n",
|
| 211 |
+
" \"Restaurant\",\n",
|
| 212 |
+
" \"Bar\",\n",
|
| 213 |
+
" \"Hotel\",\n",
|
| 214 |
+
" \"Other\",\n",
|
| 215 |
+
" ]\n",
|
| 216 |
+
" for answer in answer_list:\n",
|
| 217 |
+
" if answer not in acceptable_answers:\n",
|
| 218 |
+
" raise ValueError(f\"{answer} not in list of acceptable answers\")\n",
|
| 219 |
+
"\n",
|
| 220 |
+
" try:\n",
|
| 221 |
+
" assert len(name_list) == len(answer_list)\n",
|
| 222 |
+
" except:\n",
|
| 223 |
+
" raise ValueError(f\"Number of outputs ({len(name_list)}) does not equal the number of inputs ({len(answer_list)})\")\n",
|
| 224 |
+
"\n",
|
| 225 |
+
" return dict(zip(name_list, answer_list))"
|
| 226 |
+
]
|
| 227 |
+
},
|
| 228 |
+
{
|
| 229 |
+
"cell_type": "markdown",
|
| 230 |
+
"metadata": {},
|
| 231 |
+
"source": [
|
| 232 |
+
"Calling our previous `classify_batches`function again:"
|
| 233 |
+
]
|
| 234 |
+
},
|
| 235 |
+
{
|
| 236 |
+
"cell_type": "code",
|
| 237 |
+
"execution_count": 7,
|
| 238 |
+
"metadata": {},
|
| 239 |
+
"outputs": [],
|
| 240 |
+
"source": [
|
| 241 |
+
"def classify_batches(name_list, batch_size=10, wait=2):\n",
|
| 242 |
+
" # Store the results\n",
|
| 243 |
+
" all_results = {}\n",
|
| 244 |
+
"\n",
|
| 245 |
+
" # Batch up the list\n",
|
| 246 |
+
" batch_list = get_batch_list(name_list, n=batch_size)\n",
|
| 247 |
+
"\n",
|
| 248 |
+
" # Loop through the list in batches\n",
|
| 249 |
+
" for batch in track(batch_list):\n",
|
| 250 |
+
" # Classify it\n",
|
| 251 |
+
" batch_results = classify_payees(batch)\n",
|
| 252 |
+
"\n",
|
| 253 |
+
" # Add it to the results\n",
|
| 254 |
+
" all_results.update(batch_results)\n",
|
| 255 |
+
"\n",
|
| 256 |
+
" # Tap the brakes\n",
|
| 257 |
+
" time.sleep(wait)\n",
|
| 258 |
+
"\n",
|
| 259 |
+
" # Return the results\n",
|
| 260 |
+
" return pd.DataFrame(\n",
|
| 261 |
+
" all_results.items(),\n",
|
| 262 |
+
" columns=[\"payee\", \"category\"]\n",
|
| 263 |
+
" )"
|
| 264 |
+
]
|
| 265 |
+
},
|
| 266 |
+
{
|
| 267 |
+
"cell_type": "markdown",
|
| 268 |
+
"metadata": {},
|
| 269 |
+
"source": [
|
| 270 |
+
"And all you need to do is run it again."
|
| 271 |
+
]
|
| 272 |
+
},
|
| 273 |
+
{
|
| 274 |
+
"cell_type": "code",
|
| 275 |
+
"execution_count": 8,
|
| 276 |
+
"metadata": {},
|
| 277 |
+
"outputs": [
|
| 278 |
+
{
|
| 279 |
+
"data": {
|
| 280 |
+
"application/vnd.jupyter.widget-view+json": {
|
| 281 |
+
"model_id": "39e9e883ab8042049e00c2ae87a089c1",
|
| 282 |
+
"version_major": 2,
|
| 283 |
+
"version_minor": 0
|
| 284 |
+
},
|
| 285 |
+
"text/plain": [
|
| 286 |
+
"Output()"
|
| 287 |
+
]
|
| 288 |
+
},
|
| 289 |
+
"metadata": {},
|
| 290 |
+
"output_type": "display_data"
|
| 291 |
+
},
|
| 292 |
+
{
|
| 293 |
+
"data": {
|
| 294 |
+
"text/html": [
|
| 295 |
+
"<pre style=\"white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\"></pre>\n"
|
| 296 |
+
],
|
| 297 |
+
"text/plain": []
|
| 298 |
+
},
|
| 299 |
+
"metadata": {},
|
| 300 |
+
"output_type": "display_data"
|
| 301 |
+
}
|
| 302 |
+
],
|
| 303 |
+
"source": [
|
| 304 |
+
"llm_df = classify_batches(list(test_input.payee))"
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"cell_type": "markdown",
|
| 309 |
+
"metadata": {},
|
| 310 |
+
"source": [
|
| 311 |
+
"And see if your results are any better"
|
| 312 |
+
]
|
| 313 |
+
},
|
| 314 |
+
{
|
| 315 |
+
"cell_type": "code",
|
| 316 |
+
"execution_count": 9,
|
| 317 |
+
"metadata": {},
|
| 318 |
+
"outputs": [
|
| 319 |
+
{
|
| 320 |
+
"name": "stdout",
|
| 321 |
+
"output_type": "stream",
|
| 322 |
+
"text": [
|
| 323 |
+
" precision recall f1-score support\n",
|
| 324 |
+
"\n",
|
| 325 |
+
" Bar 1.00 1.00 1.00 2\n",
|
| 326 |
+
" Hotel 1.00 1.00 1.00 9\n",
|
| 327 |
+
" Other 1.00 0.98 0.99 57\n",
|
| 328 |
+
" Restaurant 0.94 1.00 0.97 15\n",
|
| 329 |
+
"\n",
|
| 330 |
+
" accuracy 0.99 83\n",
|
| 331 |
+
" macro avg 0.98 1.00 0.99 83\n",
|
| 332 |
+
"weighted avg 0.99 0.99 0.99 83\n",
|
| 333 |
+
"\n"
|
| 334 |
+
]
|
| 335 |
+
}
|
| 336 |
+
],
|
| 337 |
+
"source": [
|
| 338 |
+
"print(classification_report(\n",
|
| 339 |
+
" test_output,\n",
|
| 340 |
+
" llm_df.category,\n",
|
| 341 |
+
"))"
|
| 342 |
+
]
|
| 343 |
+
},
|
| 344 |
+
{
|
| 345 |
+
"cell_type": "markdown",
|
| 346 |
+
"metadata": {},
|
| 347 |
+
"source": [
|
| 348 |
+
"Another common tactic is to examine the misclassifications and tweak your prompt to address any patterns they reveal.\n",
|
| 349 |
+
"\n",
|
| 350 |
+
"One simple way to do this is to merge the LLM's predictions with the human-labeled data and filter for discrepancies."
|
| 351 |
+
]
|
| 352 |
+
},
|
| 353 |
+
{
|
| 354 |
+
"cell_type": "code",
|
| 355 |
+
"execution_count": 10,
|
| 356 |
+
"metadata": {},
|
| 357 |
+
"outputs": [],
|
| 358 |
+
"source": [
|
| 359 |
+
"comparison_df = llm_df.merge(\n",
|
| 360 |
+
" sample_df,\n",
|
| 361 |
+
" on=\"payee\",\n",
|
| 362 |
+
" how=\"inner\",\n",
|
| 363 |
+
" suffixes=[\"_llm\", \"_human\"]\n",
|
| 364 |
+
")"
|
| 365 |
+
]
|
| 366 |
+
},
|
| 367 |
+
{
|
| 368 |
+
"cell_type": "markdown",
|
| 369 |
+
"metadata": {},
|
| 370 |
+
"source": [
|
| 371 |
+
"And filter to cases where the LLM and human labels don't match."
|
| 372 |
+
]
|
| 373 |
+
},
|
| 374 |
+
{
|
| 375 |
+
"cell_type": "code",
|
| 376 |
+
"execution_count": 11,
|
| 377 |
+
"metadata": {},
|
| 378 |
+
"outputs": [
|
| 379 |
+
{
|
| 380 |
+
"data": {
|
| 381 |
+
"text/html": [
|
| 382 |
+
"<div>\n",
|
| 383 |
+
"<style scoped>\n",
|
| 384 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 385 |
+
" vertical-align: middle;\n",
|
| 386 |
+
" }\n",
|
| 387 |
+
"\n",
|
| 388 |
+
" .dataframe tbody tr th {\n",
|
| 389 |
+
" vertical-align: top;\n",
|
| 390 |
+
" }\n",
|
| 391 |
+
"\n",
|
| 392 |
+
" .dataframe thead th {\n",
|
| 393 |
+
" text-align: right;\n",
|
| 394 |
+
" }\n",
|
| 395 |
+
"</style>\n",
|
| 396 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 397 |
+
" <thead>\n",
|
| 398 |
+
" <tr style=\"text-align: right;\">\n",
|
| 399 |
+
" <th></th>\n",
|
| 400 |
+
" <th>payee</th>\n",
|
| 401 |
+
" <th>category_llm</th>\n",
|
| 402 |
+
" <th>category_human</th>\n",
|
| 403 |
+
" </tr>\n",
|
| 404 |
+
" </thead>\n",
|
| 405 |
+
" <tbody>\n",
|
| 406 |
+
" <tr>\n",
|
| 407 |
+
" <th>16</th>\n",
|
| 408 |
+
" <td>SOTTOVOCE MADERO</td>\n",
|
| 409 |
+
" <td>Restaurant</td>\n",
|
| 410 |
+
" <td>Other</td>\n",
|
| 411 |
+
" </tr>\n",
|
| 412 |
+
" </tbody>\n",
|
| 413 |
+
"</table>\n",
|
| 414 |
+
"</div>"
|
| 415 |
+
],
|
| 416 |
+
"text/plain": [
|
| 417 |
+
" payee category_llm category_human\n",
|
| 418 |
+
"16 SOTTOVOCE MADERO Restaurant Other"
|
| 419 |
+
]
|
| 420 |
+
},
|
| 421 |
+
"execution_count": 11,
|
| 422 |
+
"metadata": {},
|
| 423 |
+
"output_type": "execute_result"
|
| 424 |
+
}
|
| 425 |
+
],
|
| 426 |
+
"source": [
|
| 427 |
+
"comparison_df[comparison_df.category_llm != comparison_df.category_human]"
|
| 428 |
+
]
|
| 429 |
+
},
|
| 430 |
+
{
|
| 431 |
+
"cell_type": "markdown",
|
| 432 |
+
"metadata": {},
|
| 433 |
+
"source": [
|
| 434 |
+
"Looking at the misclassifications, you might notice that the LLM is struggling with a particular type of business name. You can then adjust your prompt to address that specific issue."
|
| 435 |
+
]
|
| 436 |
+
},
|
| 437 |
+
{
|
| 438 |
+
"cell_type": "code",
|
| 439 |
+
"execution_count": 12,
|
| 440 |
+
"metadata": {},
|
| 441 |
+
"outputs": [
|
| 442 |
+
{
|
| 443 |
+
"data": {
|
| 444 |
+
"text/html": [
|
| 445 |
+
"<div>\n",
|
| 446 |
+
"<style scoped>\n",
|
| 447 |
+
" .dataframe tbody tr th:only-of-type {\n",
|
| 448 |
+
" vertical-align: middle;\n",
|
| 449 |
+
" }\n",
|
| 450 |
+
"\n",
|
| 451 |
+
" .dataframe tbody tr th {\n",
|
| 452 |
+
" vertical-align: top;\n",
|
| 453 |
+
" }\n",
|
| 454 |
+
"\n",
|
| 455 |
+
" .dataframe thead th {\n",
|
| 456 |
+
" text-align: right;\n",
|
| 457 |
+
" }\n",
|
| 458 |
+
"</style>\n",
|
| 459 |
+
"<table border=\"1\" class=\"dataframe\">\n",
|
| 460 |
+
" <thead>\n",
|
| 461 |
+
" <tr style=\"text-align: right;\">\n",
|
| 462 |
+
" <th></th>\n",
|
| 463 |
+
" <th>payee</th>\n",
|
| 464 |
+
" <th>category_llm</th>\n",
|
| 465 |
+
" <th>category_human</th>\n",
|
| 466 |
+
" </tr>\n",
|
| 467 |
+
" </thead>\n",
|
| 468 |
+
" <tbody>\n",
|
| 469 |
+
" <tr>\n",
|
| 470 |
+
" <th>0</th>\n",
|
| 471 |
+
" <td>MIDTOWN FRAMING</td>\n",
|
| 472 |
+
" <td>Other</td>\n",
|
| 473 |
+
" <td>Other</td>\n",
|
| 474 |
+
" </tr>\n",
|
| 475 |
+
" <tr>\n",
|
| 476 |
+
" <th>1</th>\n",
|
| 477 |
+
" <td>ALBERGO HILTON ROME AIRPO FIUMICINO</td>\n",
|
| 478 |
+
" <td>Hotel</td>\n",
|
| 479 |
+
" <td>Hotel</td>\n",
|
| 480 |
+
" </tr>\n",
|
| 481 |
+
" <tr>\n",
|
| 482 |
+
" <th>2</th>\n",
|
| 483 |
+
" <td>ISTOCK PHOTOS</td>\n",
|
| 484 |
+
" <td>Other</td>\n",
|
| 485 |
+
" <td>Other</td>\n",
|
| 486 |
+
" </tr>\n",
|
| 487 |
+
" <tr>\n",
|
| 488 |
+
" <th>3</th>\n",
|
| 489 |
+
" <td>DORIAN B. GARCIA</td>\n",
|
| 490 |
+
" <td>Other</td>\n",
|
| 491 |
+
" <td>Other</td>\n",
|
| 492 |
+
" </tr>\n",
|
| 493 |
+
" <tr>\n",
|
| 494 |
+
" <th>4</th>\n",
|
| 495 |
+
" <td>KEELER ADVERTISING</td>\n",
|
| 496 |
+
" <td>Other</td>\n",
|
| 497 |
+
" <td>Other</td>\n",
|
| 498 |
+
" </tr>\n",
|
| 499 |
+
" </tbody>\n",
|
| 500 |
+
"</table>\n",
|
| 501 |
+
"</div>"
|
| 502 |
+
],
|
| 503 |
+
"text/plain": [
|
| 504 |
+
" payee category_llm category_human\n",
|
| 505 |
+
"0 MIDTOWN FRAMING Other Other\n",
|
| 506 |
+
"1 ALBERGO HILTON ROME AIRPO FIUMICINO Hotel Hotel\n",
|
| 507 |
+
"2 ISTOCK PHOTOS Other Other\n",
|
| 508 |
+
"3 DORIAN B. GARCIA Other Other\n",
|
| 509 |
+
"4 KEELER ADVERTISING Other Other"
|
| 510 |
+
]
|
| 511 |
+
},
|
| 512 |
+
"execution_count": 12,
|
| 513 |
+
"metadata": {},
|
| 514 |
+
"output_type": "execute_result"
|
| 515 |
+
}
|
| 516 |
+
],
|
| 517 |
+
"source": [
|
| 518 |
+
"comparison_df.head()"
|
| 519 |
+
]
|
| 520 |
+
},
|
| 521 |
+
{
|
| 522 |
+
"cell_type": "markdown",
|
| 523 |
+
"metadata": {},
|
| 524 |
+
"source": [
|
| 525 |
+
"In this case, I observed that the LLM was struggling with businesses that had both the word bar and the word restaurant in their name. A simple fix would be to add a new line to your prompt that instructs the LLM what to do in that case:\n",
|
| 526 |
+
"\n",
|
| 527 |
+
"`If a business name contains both the word \"Restaurant\" and the word \"Bar\", you should classify it as a Restaurant.`"
|
| 528 |
+
]
|
| 529 |
+
},
|
| 530 |
+
{
|
| 531 |
+
"cell_type": "code",
|
| 532 |
+
"execution_count": 13,
|
| 533 |
+
"metadata": {},
|
| 534 |
+
"outputs": [],
|
| 535 |
+
"source": [
|
| 536 |
+
"prompt = \"\"\"You are an AI model trained to categorize businesses based on their names.\n",
|
| 537 |
+
"\n",
|
| 538 |
+
"You will be given a list of business names, each separated by a new line.\n",
|
| 539 |
+
"\n",
|
| 540 |
+
"Your task is to analyze each name and classify it into one of the following categories: Restaurant, Bar, Hotel, or Other.\n",
|
| 541 |
+
"\n",
|
| 542 |
+
"It is extremely critical that there is a corresponding category output for each business name provided as an input.\n",
|
| 543 |
+
"\n",
|
| 544 |
+
"If a business does not clearly fall into Restaurant, Bar, or Hotel categories, you should classify it as \"Other\".\n",
|
| 545 |
+
"\n",
|
| 546 |
+
"Even if the type of business is not immediately clear from the name, it is essential that you provide your best guess based on the information available to you. If you can't make a good guess, classify it as Other.\n",
|
| 547 |
+
"\n",
|
| 548 |
+
"For example, if given the following input:\n",
|
| 549 |
+
"\n",
|
| 550 |
+
"\"Intercontinental Hotel\\nPizza Hut\\nCheers\\nWelsh's Family Restaurant\\nKTLA\\nDirect Mailing\"\n",
|
| 551 |
+
"\n",
|
| 552 |
+
"Your output should be a JSON list in the following format:\n",
|
| 553 |
+
"\n",
|
| 554 |
+
"[\"Hotel\", \"Restaurant\", \"Bar\", \"Restaurant\", \"Other\", \"Other\"]\n",
|
| 555 |
+
"\n",
|
| 556 |
+
"This means that you have classified \"Intercontinental Hotel\" as a Hotel, \"Pizza Hut\" as a Restaurant, \"Cheers\" as a Bar, \"Welsh's Family Restaurant\" as a Restaurant, and both \"KTLA\" and \"Direct Mailing\" as Other.\n",
|
| 557 |
+
"\n",
|
| 558 |
+
"If a business name contains both the word \"Restaurant\" and the word \"Bar\", you should classify it as a Restaurant.\n",
|
| 559 |
+
"\n",
|
| 560 |
+
"Ensure that the number of classifications in your output matches the number of business names in the input. It is very important that the length of JSON list you return is exactly the same as the number of business names you receive.\n",
|
| 561 |
+
"\"\"\""
|
| 562 |
+
]
|
| 563 |
+
},
|
| 564 |
+
{
|
| 565 |
+
"cell_type": "markdown",
|
| 566 |
+
"metadata": {},
|
| 567 |
+
"source": [
|
| 568 |
+
"Repeating this disciplined, scientific process of prompt refinement, testing and review can, after a few careful cycles, gradually improve your prompt to return even better results."
|
| 569 |
+
]
|
| 570 |
+
},
|
| 571 |
+
{
|
| 572 |
+
"cell_type": "code",
|
| 573 |
+
"execution_count": null,
|
| 574 |
+
"metadata": {
|
| 575 |
+
"scrolled": true
|
| 576 |
+
},
|
| 577 |
+
"outputs": [],
|
| 578 |
+
"source": [
|
| 579 |
+
"%pip install gradio jupyter-server-proxy"
|
| 580 |
+
]
|
| 581 |
+
},
|
| 582 |
+
{
|
| 583 |
+
"cell_type": "code",
|
| 584 |
+
"execution_count": 20,
|
| 585 |
+
"metadata": {},
|
| 586 |
+
"outputs": [
|
| 587 |
+
{
|
| 588 |
+
"data": {
|
| 589 |
+
"text/html": [
|
| 590 |
+
"<div><iframe src=\"http://localhost:7873/\" width=\"100%\" height=\"500\" allow=\"autoplay; camera; microphone; clipboard-read; clipboard-write;\" frameborder=\"0\" allowfullscreen></iframe></div>"
|
| 591 |
+
],
|
| 592 |
+
"text/plain": [
|
| 593 |
+
"<IPython.core.display.HTML object>"
|
| 594 |
+
]
|
| 595 |
+
},
|
| 596 |
+
"metadata": {},
|
| 597 |
+
"output_type": "display_data"
|
| 598 |
+
},
|
| 599 |
+
{
|
| 600 |
+
"data": {
|
| 601 |
+
"text/plain": []
|
| 602 |
+
},
|
| 603 |
+
"execution_count": 20,
|
| 604 |
+
"metadata": {},
|
| 605 |
+
"output_type": "execute_result"
|
| 606 |
+
}
|
| 607 |
+
],
|
| 608 |
+
"source": [
|
| 609 |
+
"import gradio as gr\n",
|
| 610 |
+
"import json\n",
|
| 611 |
+
"\n",
|
| 612 |
+
"# -- Gradio interface function --\n",
|
| 613 |
+
"def classify_business_names(input_text):\n",
|
| 614 |
+
" name_list = [line.strip() for line in input_text.splitlines() if line.strip()]\n",
|
| 615 |
+
" try:\n",
|
| 616 |
+
" result = classify_payees(name_list)\n",
|
| 617 |
+
" return json.dumps(result, indent=2)\n",
|
| 618 |
+
" except Exception as e:\n",
|
| 619 |
+
" return f\"Error: {e}\"\n",
|
| 620 |
+
"\n",
|
| 621 |
+
"# -- Launch the demo --\n",
|
| 622 |
+
"demo = gr.Interface(\n",
|
| 623 |
+
" fn=classify_business_names,\n",
|
| 624 |
+
" inputs=gr.Textbox(lines=10, placeholder=\"Enter business names, one per line\"),\n",
|
| 625 |
+
" outputs=\"json\",\n",
|
| 626 |
+
" title=\"Business Category Classifier\",\n",
|
| 627 |
+
" description=\"Enter business names and get a classification: Restaurant, Bar, Hotel, or Other.\"\n",
|
| 628 |
+
")\n",
|
| 629 |
+
"\n",
|
| 630 |
+
"demo.launch(server_name=\"0.0.0.0\", server_port=7873, root_path=\"/proxy/7873/\", quiet=True)"
|
| 631 |
+
]
|
| 632 |
+
},
|
| 633 |
+
{
|
| 634 |
+
"cell_type": "markdown",
|
| 635 |
+
"metadata": {},
|
| 636 |
+
"source": [
|
| 637 |
+
"**[10. Sharing your classifier →](ch10-sharing-with-gradio.ipynb)**"
|
| 638 |
+
]
|
| 639 |
+
},
|
| 640 |
+
{
|
| 641 |
+
"cell_type": "code",
|
| 642 |
+
"execution_count": null,
|
| 643 |
+
"metadata": {},
|
| 644 |
+
"outputs": [],
|
| 645 |
+
"source": []
|
| 646 |
+
}
|
| 647 |
+
],
|
| 648 |
+
"metadata": {
|
| 649 |
+
"kernelspec": {
|
| 650 |
+
"display_name": "Python 3 (ipykernel)",
|
| 651 |
+
"language": "python",
|
| 652 |
+
"name": "python3"
|
| 653 |
+
},
|
| 654 |
+
"language_info": {
|
| 655 |
+
"codemirror_mode": {
|
| 656 |
+
"name": "ipython",
|
| 657 |
+
"version": 3
|
| 658 |
+
},
|
| 659 |
+
"file_extension": ".py",
|
| 660 |
+
"mimetype": "text/x-python",
|
| 661 |
+
"name": "python",
|
| 662 |
+
"nbconvert_exporter": "python",
|
| 663 |
+
"pygments_lexer": "ipython3",
|
| 664 |
+
"version": "3.9.5"
|
| 665 |
+
}
|
| 666 |
+
},
|
| 667 |
+
"nbformat": 4,
|
| 668 |
+
"nbformat_minor": 4
|
| 669 |
+
}
|