Spaces:
Runtime error

Runtime error
Upload 25 files
Browse files- .gitattributes +1 -0
- README.md +71 -13
- __pycache__/app.cpython-311.pyc +0 -0
- __pycache__/app.cpython-37.pyc +0 -0
- app.py +10 -198
- images/1_gaussian_filter.png +3 -0
- images/inputExample/0.jpg +0 -0
- images/inputExample/1155.jpg +0 -0
- ip_adapter/__init__.py +9 -0
- ip_adapter/__pycache__/__init__.cpython-311.pyc +0 -0
- ip_adapter/__pycache__/__init__.cpython-37.pyc +0 -0
- ip_adapter/__pycache__/attention_processor.cpython-311.pyc +0 -0
- ip_adapter/__pycache__/attention_processor.cpython-37.pyc +0 -0
- ip_adapter/__pycache__/ip_adapter.cpython-311.pyc +0 -0
- ip_adapter/__pycache__/ip_adapter.cpython-37.pyc +0 -0
- ip_adapter/__pycache__/resampler.cpython-311.pyc +0 -0
- ip_adapter/__pycache__/resampler.cpython-37.pyc +0 -0
- ip_adapter/__pycache__/utils.cpython-311.pyc +0 -0
- ip_adapter/__pycache__/utils.cpython-37.pyc +0 -0
- ip_adapter/attention_processor.py +652 -0
- ip_adapter/custom_pipelines.py +394 -0
- ip_adapter/ip_adapter.py +504 -0
- ip_adapter/resampler.py +165 -0
- ip_adapter/test_resampler.py +44 -0
- ip_adapter/utils.py +5 -0
- requirements.txt +10 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/1_gaussian_filter.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,13 +1,71 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
---
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ___***FilterPrompt: Guiding Image Transfer in Diffusion Models***___
|
| 2 |
+
|
| 3 |
+
<a href='https://meaoxixi.github.io/FilterPrompt/'><img src='https://img.shields.io/badge/Project-Page-green'></a>
|
| 4 |
+
<a href='https://arxiv.org/pdf/2404.13263'><img src='https://img.shields.io/badge/Paper-blue'></a>
|
| 5 |
+
<a href='https://arxiv.org/pdf/2404.13263'><img src='https://img.shields.io/badge/Demo-orange'></a>
|
| 6 |
+
|
| 7 |
+
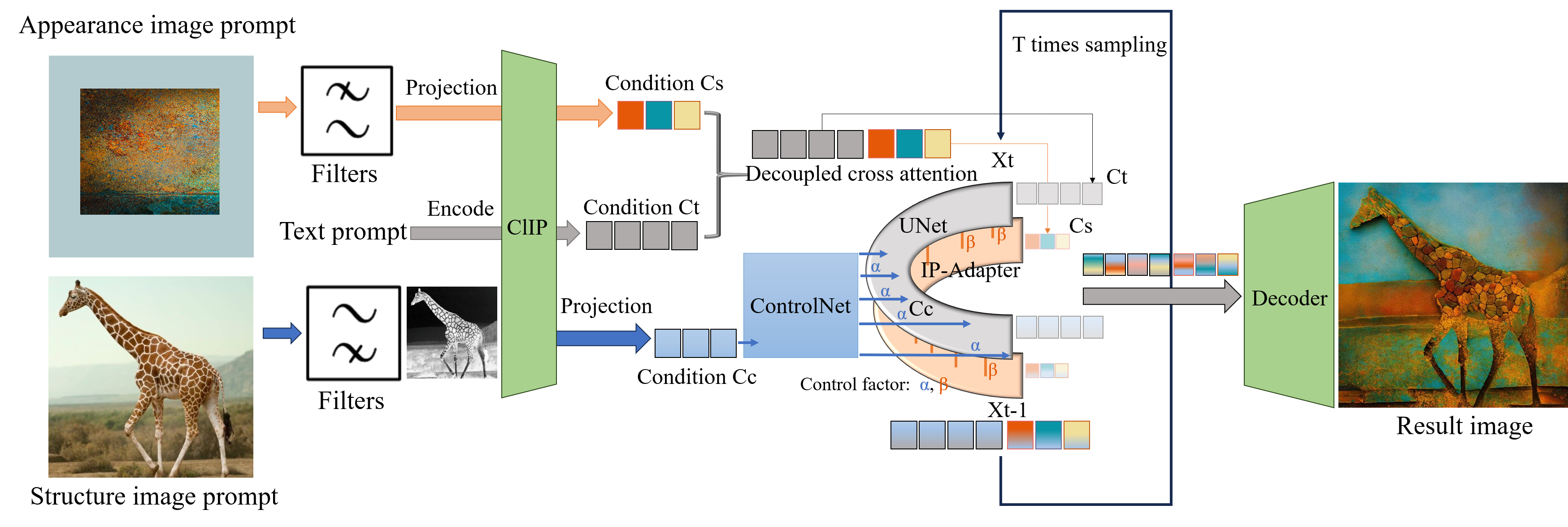
We propose FilterPrompt, an approach to enhance the model control effect. It can be universally applied to any diffusion model, allowing users to adjust the representation of specific image features in accordance with task requirements, thereby facilitating more precise and controllable generation outcomes. In particular, our designed experiments demonstrate that the FilterPrompt optimizes feature correlation, mitigates content conflicts during the generation process, and enhances the model's control capability.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
---
|
| 12 |
+
# Getting Started
|
| 13 |
+
## Prerequisites
|
| 14 |
+
- We recommend running this repository using [Anaconda](https://docs.anaconda.com/anaconda/install/).
|
| 15 |
+
- NVIDIA GPU (Available memory is greater than 20GB)
|
| 16 |
+
- CUDA CuDNN (version ≥ 11.1, we actually use 11.7)
|
| 17 |
+
- Python 3.11.3 (Gradio requires Python 3.8 or higher)
|
| 18 |
+
- PyTorch: [Find the torch version that is suitable for the current cuda](https://pytorch.org/get-started/previous-versions/)
|
| 19 |
+
- 【example】:`pip install torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117`
|
| 20 |
+
|
| 21 |
+
## Installation
|
| 22 |
+
Specifically, inspired by the concept of decoupled cross-attention in [IP-Adapter](https://ip-adapter.github.io/), we apply a similar methodology.
|
| 23 |
+
Please follow the instructions below to complete the environment configuration required for the code:
|
| 24 |
+
- Cloning this repo
|
| 25 |
+
```
|
| 26 |
+
git clone --single-branch --branch main https://github.com/Meaoxixi/FilterPrompt.git
|
| 27 |
+
```
|
| 28 |
+
- Dependencies
|
| 29 |
+
|
| 30 |
+
All dependencies for defining the environment are provided in `requirements.txt`.
|
| 31 |
+
```
|
| 32 |
+
cd FilterPrompt
|
| 33 |
+
conda create --name fp_env python=3.11.3
|
| 34 |
+
conda activate fp_env
|
| 35 |
+
pip install torch==2.0.0+cu117 torchvision==0.15.1+cu117 torchaudio==2.0.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
|
| 36 |
+
pip install -r requirements.txt
|
| 37 |
+
```
|
| 38 |
+
- Download the necessary modules in the relative path `models/` from the following links
|
| 39 |
+
|
| 40 |
+
| Path | Description |
|
| 41 |
+
|:---------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------|
|
| 42 |
+
| `models/` | root path |
|
| 43 |
+
| ├── `ControlNet/` | Place the pre-trained model of [ControlNet](https://huggingface.co/lllyasviel) |
|
| 44 |
+
| ├── `control_v11f1p_sd15_depth ` | [ControlNet_depth](https://huggingface.co/lllyasviel/control_v11f1p_sd15_depth/tree/main) |
|
| 45 |
+
| └── `control_v11p_sd15_softedge` | [ControlNet_softEdge](https://huggingface.co/lllyasviel/control_v11p_sd15_softedge/tree/main) |
|
| 46 |
+
| ├── `IP-Adapter/` | [IP-Adapter](https://huggingface.co/h94/IP-Adapter/tree/main/models) |
|
| 47 |
+
| ├── `image_encoder ` | image_encoder of IP-Adapter |
|
| 48 |
+
| └── `other needed configuration files` | |
|
| 49 |
+
| ├── `sd-vae-ft-mse/` | Place the model of [sd-vae-ft-mse](https://huggingface.co/stabilityai/sd-vae-ft-mse/tree/main) |
|
| 50 |
+
| ├── `stable-diffusion-v1-5/` | Place the model of [stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) |
|
| 51 |
+
| ├── `Realistic_Vision_V4.0_noVAE/` | Place the model of [Realistic_Vision_V4.0_noVAE](https://huggingface.co/SG161222/Realistic_Vision_V4.0_noVAE/tree/main) |
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
## Demo on Gradio
|
| 57 |
+
|
| 58 |
+
After installation and downloading the models, you can use `python app.py` to perform code in gradio. We have designed four task types to facilitate you to experience the application scenarios of FilterPrompt.
|
| 59 |
+
|
| 60 |
+
## Citation
|
| 61 |
+
If you find [FilterPrompt](https://arxiv.org/abs/2404.13263) helpful in your research/applications, please cite using this BibTeX:
|
| 62 |
+
```bibtex
|
| 63 |
+
@misc{wang2024filterprompt,
|
| 64 |
+
title={FilterPrompt: Guiding Image Transfer in Diffusion Models},
|
| 65 |
+
author={Xi Wang and Yichen Peng and Heng Fang and Haoran Xie and Xi Yang and Chuntao Li},
|
| 66 |
+
year={2024},
|
| 67 |
+
eprint={2404.13263},
|
| 68 |
+
archivePrefix={arXiv},
|
| 69 |
+
primaryClass={cs.CV}
|
| 70 |
+
}
|
| 71 |
+
```
|
__pycache__/app.cpython-311.pyc
ADDED
|
Binary file (22 kB). View file
|
|
|
__pycache__/app.cpython-37.pyc
ADDED
|
Binary file (6.39 kB). View file
|
|
|
app.py
CHANGED
|
@@ -2,8 +2,6 @@ import gradio as gr
|
|
| 2 |
import torch
|
| 3 |
from PIL import Image, ImageFilter, ImageOps,ImageEnhance
|
| 4 |
from scipy.ndimage import rank_filter, maximum_filter
|
| 5 |
-
from skimage.filters import gabor
|
| 6 |
-
import skimage.color
|
| 7 |
import numpy as np
|
| 8 |
import pathlib
|
| 9 |
import glob
|
|
@@ -15,8 +13,6 @@ from ip_adapter import IPAdapter
|
|
| 15 |
DESCRIPTION = """# [FilterPrompt](https://arxiv.org/abs/2404.13263): Guiding Imgae Transfer in Diffusion Models
|
| 16 |
<img id="teaser" alt="teaser" src="https://raw.githubusercontent.com/Meaoxixi/FilterPrompt/gh-pages/resources/teaser.png" />
|
| 17 |
"""
|
| 18 |
-
# <img id="overview" alt="overview" src="https://github.com/Meaoxixi/FilterPrompt/blob/gh-pages/resources/teaser.png" />
|
| 19 |
-
# 在你提供的链接中,你需要将 GitHub 页面链接中的 github.com 替换为 raw.githubusercontent.com,并将 blob 分支名称从链接中删除,以便获取原始文件内容。
|
| 20 |
##################################################################################################################
|
| 21 |
# 0. Get Pre-Models' Path Ready
|
| 22 |
##################################################################################################################
|
|
@@ -77,7 +73,6 @@ def image_grid(imgs, rows, cols):
|
|
| 77 |
grid.paste(img, box=(i % cols * w, i // cols * h))
|
| 78 |
return grid
|
| 79 |
#########################################################################
|
| 80 |
-
# 接下来是有关demo有关的函数定义
|
| 81 |
## funcitions for task 1 : style transfer
|
| 82 |
#########################################################################
|
| 83 |
def gaussian_blur(image, blur_radius):
|
|
@@ -120,50 +115,17 @@ def task1_test(photo, blur_radius, sketch):
|
|
| 120 |
#########################################################################
|
| 121 |
## funcitions for task 2 : color transfer
|
| 122 |
#########################################################################
|
| 123 |
-
#
|
| 124 |
-
def desaturate_filter(image):
|
| 125 |
-
image = Image.open(image)
|
| 126 |
-
return ImageOps.grayscale(image)
|
| 127 |
-
|
| 128 |
-
def gabor_filter(image):
|
| 129 |
-
image = Image.open(image)
|
| 130 |
-
image_array = np.array(image.convert('L')) # 转换为灰度图像
|
| 131 |
-
filtered_real, filtered_imag = gabor(image_array, frequency=0.6)
|
| 132 |
-
filtered_image = np.sqrt(filtered_real**2 + filtered_imag**2)
|
| 133 |
-
return Image.fromarray(np.uint8(filtered_image))
|
| 134 |
-
|
| 135 |
-
def rank_filter_func(image):
|
| 136 |
-
image = Image.open(image)
|
| 137 |
-
image_array = np.array(image.convert('L'))
|
| 138 |
-
filtered_image = rank_filter(image_array, rank=5, size=5)
|
| 139 |
-
return Image.fromarray(np.uint8(filtered_image))
|
| 140 |
-
|
| 141 |
-
def max_filter_func(image):
|
| 142 |
-
image = Image.open(image)
|
| 143 |
-
image_array = np.array(image.convert('L'))
|
| 144 |
-
filtered_image = maximum_filter(image_array, size=20)
|
| 145 |
-
return Image.fromarray(np.uint8(filtered_image))
|
| 146 |
-
# 定义处理函数
|
| 147 |
-
def fun2(image,image2, filter_name):
|
| 148 |
-
if filter_name == "Desaturate Filter":
|
| 149 |
-
return desaturate_filter(image),desaturate_filter(image2)
|
| 150 |
-
elif filter_name == "Gabor Filter":
|
| 151 |
-
return gabor_filter(image),gabor_filter(image2)
|
| 152 |
-
elif filter_name == "Rank Filter":
|
| 153 |
-
return rank_filter_func(image),rank_filter_func(image2)
|
| 154 |
-
elif filter_name == "Max Filter":
|
| 155 |
-
return max_filter_func(image),max_filter_func(image2)
|
| 156 |
-
else:
|
| 157 |
-
return image,image2
|
| 158 |
-
|
| 159 |
|
| 160 |
#############################################
|
| 161 |
-
# Demo
|
| 162 |
#############################################
|
| 163 |
-
|
| 164 |
-
#
|
| 165 |
-
|
| 166 |
-
|
|
|
|
|
|
|
| 167 |
gr.Markdown(DESCRIPTION)
|
| 168 |
|
| 169 |
# 1. 第一个任务Style Transfer的界面代码(青铜器拓本转照片)
|
|
@@ -220,161 +182,11 @@ with gr.Blocks(css="style.css") as demo:
|
|
| 220 |
inputs=[photo, gaussianKernel, sketch],
|
| 221 |
outputs=[original_result_task1, result_image_1],
|
| 222 |
)
|
| 223 |
-
|
| 224 |
-
# # 2. 第二个任务增强几何属性保护-Color transfer
|
| 225 |
-
# with gr.Group():
|
| 226 |
-
# ## 2.1 任务描述
|
| 227 |
-
# gr.Markdown(
|
| 228 |
-
# """
|
| 229 |
-
# ## Case 2: Color transferr
|
| 230 |
-
# - In this task, our main goal is to transfer color from imageA to imageB. We can feel the effect of the filter on the protection of geometric properties.
|
| 231 |
-
# - In the standard Controlnet-depth mode, the ideal input is the depth map.
|
| 232 |
-
# - Here, we choose to input the result processed by some filters into the network instead of the original depth map.
|
| 233 |
-
# - You can feel from the use of different filters that "decolorization+inversion+enhancement of contrast" can maximize the retention of detailed geometric information in the original image.
|
| 234 |
-
# """)
|
| 235 |
-
# ## 2.1 输入输出控件布局
|
| 236 |
-
# with gr.Row():
|
| 237 |
-
# with gr.Column():
|
| 238 |
-
# with gr.Row():
|
| 239 |
-
# input_appearImage = gr.Image(label="Input Appearance Image", type="filepath")
|
| 240 |
-
# with gr.Row():
|
| 241 |
-
# filter_dropdown = gr.Dropdown(
|
| 242 |
-
# choices=["Desaturate Filter", "Gabor Filter", "Rank Filter", "Max Filter"],
|
| 243 |
-
# label="Select Filter",
|
| 244 |
-
# value="Desaturate Filter"
|
| 245 |
-
# )
|
| 246 |
-
# with gr.Column():
|
| 247 |
-
# with gr.Row():
|
| 248 |
-
# input_strucImage = gr.Image(label="Input Structure Image", type="filepath")
|
| 249 |
-
# with gr.Row():
|
| 250 |
-
# geometry_button = gr.Button("Preprocess")
|
| 251 |
-
# with gr.Column():
|
| 252 |
-
# with gr.Row():
|
| 253 |
-
# afterFilterImage = gr.Image(label="Appearance image after filter choosed", interactive=False)
|
| 254 |
-
# with gr.Column():
|
| 255 |
-
# result_task2 = gr.Image(label="Generate results")
|
| 256 |
-
# # instyle = gr.State()
|
| 257 |
-
#
|
| 258 |
-
# ## 2.3 示例图展示
|
| 259 |
-
# with gr.Row():
|
| 260 |
-
# gr.Image(value="task/color_transfer.png", label="example Image", type="filepath")
|
| 261 |
-
#
|
| 262 |
-
# # 3. 第3个任务是光照效果的改善
|
| 263 |
-
# with gr.Group():
|
| 264 |
-
# ## 3.1 任务描述
|
| 265 |
-
# gr.Markdown(
|
| 266 |
-
# """
|
| 267 |
-
# ## Case 3: Image-to-Image translation
|
| 268 |
-
# - In this example, our goal is to turn a simple outline drawing/sketch into a detailed and realistic photo.
|
| 269 |
-
# - Here, we provide the original mask generation results, and provide the generation results after superimposing the image on the mask and passing the decolorization filter.
|
| 270 |
-
# - From this, you can feel that the mask obtained by the decolorization operation can retain a certain amount of original lighting information and improve the texture of the generated results.
|
| 271 |
-
# """)
|
| 272 |
-
# ## 3.2 输入输出控件布局
|
| 273 |
-
# with gr.Row():
|
| 274 |
-
# with gr.Column():
|
| 275 |
-
# with gr.Row():
|
| 276 |
-
# input_appearImage = gr.Image(label="Input Appearance Image", type="filepath")
|
| 277 |
-
# with gr.Row():
|
| 278 |
-
# filter_dropdown = gr.Dropdown(
|
| 279 |
-
# choices=["Desaturate Filter", "Gabor Filter", "Rank Filter", "Max Filter"],
|
| 280 |
-
# label="Select Filter",
|
| 281 |
-
# value="Desaturate Filter"
|
| 282 |
-
# )
|
| 283 |
-
# with gr.Column():
|
| 284 |
-
# with gr.Row():
|
| 285 |
-
# input_strucImage = gr.Image(label="Input Structure Image", type="filepath")
|
| 286 |
-
# with gr.Row():
|
| 287 |
-
# geometry_button = gr.Button("Preprocess")
|
| 288 |
-
# with gr.Column():
|
| 289 |
-
# with gr.Row():
|
| 290 |
-
# afterFilterImage = gr.Image(label="Appearance image after filter choosed", interactive=False)
|
| 291 |
-
# with gr.Column():
|
| 292 |
-
# result_task2 = gr.Image(label="Generate results")
|
| 293 |
-
# # instyle = gr.State()
|
| 294 |
-
#
|
| 295 |
-
# ## 3.3 示例图展示
|
| 296 |
-
# with gr.Row():
|
| 297 |
-
# gr.Image(value="task/4_light.jpg", label="example Image", type="filepath")
|
| 298 |
-
#
|
| 299 |
-
# # 4. 第4个任务是materials transfer
|
| 300 |
-
# with gr.Group():
|
| 301 |
-
# ## 4.1 任务描述
|
| 302 |
-
# gr.Markdown(
|
| 303 |
-
# """
|
| 304 |
-
# ## Case 4: Materials Transfer
|
| 305 |
-
# - In this example, our goal is to transfer the material appearance of one object image to another object image. The process involves changing the surface properties of objects in the image so that they appear to be made of another material.
|
| 306 |
-
# - Here, we provide the original generation results and provide a variety of edited filters.
|
| 307 |
-
# - You can specify any filtering operation and intuitively feel the impact of the filtering on the rendering properties in the generated results.
|
| 308 |
-
# - For example, a sharpen filter can sharpen the texture of a stone, a Gaussian blur can smooth the texture of a stone, and a custom filter can change the style of a stone. These all show that filterPrompt is simple and intuitive.
|
| 309 |
-
# """)
|
| 310 |
-
# ## 4.2 输入输出控件布局
|
| 311 |
-
# with gr.Row():
|
| 312 |
-
# with gr.Column():
|
| 313 |
-
# with gr.Row():
|
| 314 |
-
# input_appearImage = gr.Image(label="Input Appearance Image", type="filepath")
|
| 315 |
-
# with gr.Row():
|
| 316 |
-
# filter_dropdown = gr.Dropdown(
|
| 317 |
-
# choices=["Desaturate Filter", "Gabor Filter", "Rank Filter", "Max Filter"],
|
| 318 |
-
# label="Select Filter",
|
| 319 |
-
# value="Desaturate Filter"
|
| 320 |
-
# )
|
| 321 |
-
# with gr.Column():
|
| 322 |
-
# with gr.Row():
|
| 323 |
-
# input_strucImage = gr.Image(label="Input Structure Image", type="filepath")
|
| 324 |
-
# with gr.Row():
|
| 325 |
-
# geometry_button = gr.Button("Preprocess")
|
| 326 |
-
# with gr.Column():
|
| 327 |
-
# with gr.Row():
|
| 328 |
-
# afterFilterImage = gr.Image(label="Appearance image after filter choosed", interactive=False)
|
| 329 |
-
# with gr.Column():
|
| 330 |
-
# result_task2 = gr.Image(label="Generate results")
|
| 331 |
-
# # instyle = gr.State()
|
| 332 |
-
#
|
| 333 |
-
# ## 3.3 示例图展示
|
| 334 |
-
# with gr.Row():
|
| 335 |
-
# gr.Image(value="task/3mateialsTransfer.jpg", label="example Image", type="filepath")
|
| 336 |
-
#
|
| 337 |
-
#
|
| 338 |
-
# geometry_button.click(
|
| 339 |
-
# fn=fun2,
|
| 340 |
-
# inputs=[input_strucImage, input_appearImage, filter_dropdown],
|
| 341 |
-
# outputs=[afterFilterImage, result_task2],
|
| 342 |
-
# )
|
| 343 |
-
# aligned_face.change(
|
| 344 |
-
# fn=model.reconstruct_face,
|
| 345 |
-
# inputs=[aligned_face, encoder_type],
|
| 346 |
-
# outputs=[
|
| 347 |
-
# reconstructed_face,
|
| 348 |
-
# instyle,
|
| 349 |
-
# ],
|
| 350 |
-
# )
|
| 351 |
-
# style_type.change(
|
| 352 |
-
# fn=update_slider,
|
| 353 |
-
# inputs=style_type,
|
| 354 |
-
# outputs=style_index,
|
| 355 |
-
# )
|
| 356 |
-
# style_type.change(
|
| 357 |
-
# fn=update_style_image,
|
| 358 |
-
# inputs=style_type,
|
| 359 |
-
# outputs=style_image,
|
| 360 |
-
# )
|
| 361 |
-
# generate_button.click(
|
| 362 |
-
# fn=model.generate,
|
| 363 |
-
# inputs=[
|
| 364 |
-
# style_type,
|
| 365 |
-
# style_index,
|
| 366 |
-
# structure_weight,
|
| 367 |
-
# color_weight,
|
| 368 |
-
# structure_only,
|
| 369 |
-
# instyle,
|
| 370 |
-
# ],
|
| 371 |
-
# outputs=result,
|
| 372 |
-
#)
|
| 373 |
##################################################################################################################
|
| 374 |
# 2. run Demo on gradio
|
| 375 |
##################################################################################################################
|
| 376 |
|
| 377 |
if __name__ == "__main__":
|
| 378 |
demo.queue(max_size=5).launch()
|
| 379 |
-
|
| 380 |
-
#demo.queue(max_size=5).launch(server_port=12345, share=True)
|
|
|
|
| 2 |
import torch
|
| 3 |
from PIL import Image, ImageFilter, ImageOps,ImageEnhance
|
| 4 |
from scipy.ndimage import rank_filter, maximum_filter
|
|
|
|
|
|
|
| 5 |
import numpy as np
|
| 6 |
import pathlib
|
| 7 |
import glob
|
|
|
|
| 13 |
DESCRIPTION = """# [FilterPrompt](https://arxiv.org/abs/2404.13263): Guiding Imgae Transfer in Diffusion Models
|
| 14 |
<img id="teaser" alt="teaser" src="https://raw.githubusercontent.com/Meaoxixi/FilterPrompt/gh-pages/resources/teaser.png" />
|
| 15 |
"""
|
|
|
|
|
|
|
| 16 |
##################################################################################################################
|
| 17 |
# 0. Get Pre-Models' Path Ready
|
| 18 |
##################################################################################################################
|
|
|
|
| 73 |
grid.paste(img, box=(i % cols * w, i // cols * h))
|
| 74 |
return grid
|
| 75 |
#########################################################################
|
|
|
|
| 76 |
## funcitions for task 1 : style transfer
|
| 77 |
#########################################################################
|
| 78 |
def gaussian_blur(image, blur_radius):
|
|
|
|
| 115 |
#########################################################################
|
| 116 |
## funcitions for task 2 : color transfer
|
| 117 |
#########################################################################
|
| 118 |
+
# todo
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 119 |
|
| 120 |
#############################################
|
| 121 |
+
# Demo
|
| 122 |
#############################################
|
| 123 |
+
theme = gr.themes.Monochrome(primary_hue="blue").set(
|
| 124 |
+
loader_color="#FF0000",
|
| 125 |
+
slider_color="#FF0000",
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
with gr.Blocks(theme=theme) as demo:
|
| 129 |
gr.Markdown(DESCRIPTION)
|
| 130 |
|
| 131 |
# 1. 第一个任务Style Transfer的界面代码(青铜器拓本转照片)
|
|
|
|
| 182 |
inputs=[photo, gaussianKernel, sketch],
|
| 183 |
outputs=[original_result_task1, result_image_1],
|
| 184 |
)
|
| 185 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 186 |
##################################################################################################################
|
| 187 |
# 2. run Demo on gradio
|
| 188 |
##################################################################################################################
|
| 189 |
|
| 190 |
if __name__ == "__main__":
|
| 191 |
demo.queue(max_size=5).launch()
|
| 192 |
+
|
|
|
images/1_gaussian_filter.png
ADDED

|
Git LFS Details
|
images/inputExample/0.jpg
ADDED

|
images/inputExample/1155.jpg
ADDED

|
ip_adapter/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# from .ip_adapter import IPAdapter, IPAdapterPlus, IPAdapterPlusXL, IPAdapterXL, IPAdapterFull
|
| 2 |
+
from .ip_adapter import IPAdapter
|
| 3 |
+
__all__ = [
|
| 4 |
+
"IPAdapter",
|
| 5 |
+
# "IPAdapterPlus",
|
| 6 |
+
# "IPAdapterPlusXL",
|
| 7 |
+
# "IPAdapterXL",
|
| 8 |
+
# "IPAdapterFull",
|
| 9 |
+
]
|
ip_adapter/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (253 Bytes). View file
|
|
|
ip_adapter/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (211 Bytes). View file
|
|
|
ip_adapter/__pycache__/attention_processor.cpython-311.pyc
ADDED
|
Binary file (22.9 kB). View file
|
|
|
ip_adapter/__pycache__/attention_processor.cpython-37.pyc
ADDED
|
Binary file (10.8 kB). View file
|
|
|
ip_adapter/__pycache__/ip_adapter.cpython-311.pyc
ADDED
|
Binary file (22 kB). View file
|
|
|
ip_adapter/__pycache__/ip_adapter.cpython-37.pyc
ADDED
|
Binary file (11 kB). View file
|
|
|
ip_adapter/__pycache__/resampler.cpython-311.pyc
ADDED
|
Binary file (8.54 kB). View file
|
|
|
ip_adapter/__pycache__/resampler.cpython-37.pyc
ADDED
|
Binary file (4.17 kB). View file
|
|
|
ip_adapter/__pycache__/utils.cpython-311.pyc
ADDED
|
Binary file (470 Bytes). View file
|
|
|
ip_adapter/__pycache__/utils.cpython-37.pyc
ADDED
|
Binary file (359 Bytes). View file
|
|
|
ip_adapter/attention_processor.py
ADDED
|
@@ -0,0 +1,652 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from PIL import Image
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class AttnProcessor(nn.Module):
|
| 10 |
+
r"""
|
| 11 |
+
Default processor for performing attention-related computations.
|
| 12 |
+
|
| 13 |
+
用于执行与注意力相关的计算。
|
| 14 |
+
这个类的作用是对注意力相关的计算进行封装,使得代码更易于维护和扩展。
|
| 15 |
+
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
hidden_size=None,
|
| 21 |
+
cross_attention_dim=None,
|
| 22 |
+
):
|
| 23 |
+
super().__init__()
|
| 24 |
+
|
| 25 |
+
# 在__call__方法中,它接受一些输入参数:
|
| 26 |
+
# * attn(注意力机制)
|
| 27 |
+
# hidden_states(隐藏状态)
|
| 28 |
+
# encoder_hidden_states(编码器隐藏状态)
|
| 29 |
+
# attention_mask(注意力掩码)
|
| 30 |
+
# temb(可选的温度参数):通常用于控制注意力分布的集中度。
|
| 31 |
+
# 通过调整temb的数值,可以改变注意力分布的“尖锐程度”,从而影响模型对不同部分的关注程度。
|
| 32 |
+
# 较高的temb值可能会导致更加平均的注意力分布,而较低的temb值则可能导致更加集中的注意力分布。
|
| 33 |
+
# 这种机制可以用来调节模型的行为,使其更加灵活地适应不同的任务和数据特征。
|
| 34 |
+
#
|
| 35 |
+
# 然后它执行一系列操作,包括对隐藏状态进行一些变换,计算注意力分数,应用注意力权重,进行线性投影和丢弃操作,最后返回处理后的隐藏状态。
|
| 36 |
+
#
|
| 37 |
+
def __call__(
|
| 38 |
+
self,
|
| 39 |
+
attn,
|
| 40 |
+
hidden_states,
|
| 41 |
+
encoder_hidden_states=None,
|
| 42 |
+
attention_mask=None,
|
| 43 |
+
temb=None,
|
| 44 |
+
):
|
| 45 |
+
residual = hidden_states
|
| 46 |
+
# 残差连接
|
| 47 |
+
|
| 48 |
+
if attn.spatial_norm is not None:
|
| 49 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 50 |
+
|
| 51 |
+
input_ndim = hidden_states.ndim
|
| 52 |
+
|
| 53 |
+
if input_ndim == 4:
|
| 54 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 55 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 56 |
+
|
| 57 |
+
batch_size, sequence_length, _ = (
|
| 58 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 59 |
+
)
|
| 60 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 61 |
+
|
| 62 |
+
if attn.group_norm is not None:
|
| 63 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 64 |
+
|
| 65 |
+
query = attn.to_q(hidden_states)
|
| 66 |
+
|
| 67 |
+
if encoder_hidden_states is None:
|
| 68 |
+
encoder_hidden_states = hidden_states
|
| 69 |
+
elif attn.norm_cross:
|
| 70 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 71 |
+
|
| 72 |
+
key = attn.to_k(encoder_hidden_states)
|
| 73 |
+
value = attn.to_v(encoder_hidden_states)
|
| 74 |
+
|
| 75 |
+
query = attn.head_to_batch_dim(query)
|
| 76 |
+
key = attn.head_to_batch_dim(key)
|
| 77 |
+
value = attn.head_to_batch_dim(value)
|
| 78 |
+
|
| 79 |
+
# 这段代码首先使用query和key计算注意力分数,同时考虑了可能存在的attention_mask
|
| 80 |
+
# 然后利用这些注意力分数对value进行加权求和,得到了经过注意力机制加权后的hidden_states
|
| 81 |
+
# 最后,通过attn.batch_to_head_dim操作将hidden_states从批处理维度转换回头部维度。
|
| 82 |
+
# 这些操作是多头注意力机制中常见的步骤,用于计算并应用注意力权重。
|
| 83 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 84 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 85 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 86 |
+
|
| 87 |
+
# linear proj
|
| 88 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 89 |
+
# dropout
|
| 90 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 91 |
+
|
| 92 |
+
if input_ndim == 4:
|
| 93 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 94 |
+
|
| 95 |
+
if attn.residual_connection:
|
| 96 |
+
hidden_states = hidden_states + residual
|
| 97 |
+
|
| 98 |
+
# 这个操作可能是为了对输出进行缩放或归一化,以确保输出的数值范围符合模型的需要
|
| 99 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 100 |
+
|
| 101 |
+
return hidden_states
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class IPAttnProcessor(nn.Module):
|
| 105 |
+
r"""
|
| 106 |
+
Attention processor for IP-Adapater.
|
| 107 |
+
Args:
|
| 108 |
+
hidden_size (`int`):
|
| 109 |
+
The hidden size of the attention layer.
|
| 110 |
+
cross_attention_dim (`int`):
|
| 111 |
+
The number of channels in the `encoder_hidden_states`.
|
| 112 |
+
scale (`float`, defaults to 1.0):
|
| 113 |
+
the weight scale of image prompt.
|
| 114 |
+
num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
|
| 115 |
+
The context length of the image features.
|
| 116 |
+
"""
|
| 117 |
+
roundNumber = 0
|
| 118 |
+
|
| 119 |
+
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4, Control_factor=1.0, IP_factor= 1.0):
|
| 120 |
+
super().__init__()
|
| 121 |
+
|
| 122 |
+
self.hidden_size = hidden_size
|
| 123 |
+
self.cross_attention_dim = cross_attention_dim
|
| 124 |
+
#获取到的cross_attention_dim大小为768,这个类调用了16次
|
| 125 |
+
#print(cross_attention_dim)
|
| 126 |
+
self.scale = scale
|
| 127 |
+
self.num_tokens = num_tokens
|
| 128 |
+
self.Control_factor = Control_factor
|
| 129 |
+
self.IP_factor = IP_factor
|
| 130 |
+
#print("IPAttnProcessor中获取得到的Control_factor:{}".format(self.Control_factor))
|
| 131 |
+
|
| 132 |
+
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 133 |
+
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 134 |
+
|
| 135 |
+
def __call__(
|
| 136 |
+
self,
|
| 137 |
+
attn,
|
| 138 |
+
hidden_states,
|
| 139 |
+
encoder_hidden_states=None,
|
| 140 |
+
attention_mask=None,
|
| 141 |
+
temb=None,
|
| 142 |
+
):
|
| 143 |
+
residual = hidden_states
|
| 144 |
+
|
| 145 |
+
if attn.spatial_norm is not None:
|
| 146 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 147 |
+
|
| 148 |
+
input_ndim = hidden_states.ndim
|
| 149 |
+
|
| 150 |
+
if input_ndim == 4:
|
| 151 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 152 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 153 |
+
|
| 154 |
+
batch_size, sequence_length, _ = (
|
| 155 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 156 |
+
)
|
| 157 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 158 |
+
# sequence_length =81
|
| 159 |
+
# batch_size=2
|
| 160 |
+
|
| 161 |
+
if attn.group_norm is not None:
|
| 162 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 163 |
+
|
| 164 |
+
query = attn.to_q(hidden_states)
|
| 165 |
+
# query.shape = [2,6205,320]
|
| 166 |
+
###########################################
|
| 167 |
+
# queryBegin = attn.to_q(hidden_states)
|
| 168 |
+
###########################################
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
# 这段代码首先检查encoder_hidden_states是否为None,如果是空,说明是无条件生成
|
| 172 |
+
if encoder_hidden_states is None:
|
| 173 |
+
encoder_hidden_states = hidden_states
|
| 174 |
+
else:
|
| 175 |
+
# get encoder_hidden_states, ip_hidden_states
|
| 176 |
+
# 如果encoder_hidden_states不为None
|
| 177 |
+
# 则对encoder_hidden_states进行切片操作,将其分为两部分,分别赋值给encoder_hidden_states和ip_hidden_states
|
| 178 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 179 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 180 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 181 |
+
encoder_hidden_states[:, end_pos:, :],
|
| 182 |
+
)
|
| 183 |
+
# 接着,如果attn.norm_cross为True,则对encoder_hidden_states进行规范化处理。
|
| 184 |
+
if attn.norm_cross:
|
| 185 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 186 |
+
|
| 187 |
+
# encoder_hidden_states.shape = [2,77,768]
|
| 188 |
+
# ip_hidden_states.shape = [2,4,768]
|
| 189 |
+
key = attn.to_k(encoder_hidden_states)
|
| 190 |
+
# keyforIPADAPTER = attn.to_q(encoder_hidden_states)
|
| 191 |
+
value = attn.to_v(encoder_hidden_states)
|
| 192 |
+
|
| 193 |
+
query = attn.head_to_batch_dim(query)
|
| 194 |
+
# query.shape = [16,6205,40]
|
| 195 |
+
|
| 196 |
+
key = attn.head_to_batch_dim(key)
|
| 197 |
+
value = attn.head_to_batch_dim(value)
|
| 198 |
+
|
| 199 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 200 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 201 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 202 |
+
# hidden_states.shape = [2,6205,320]
|
| 203 |
+
# print("**************************************************")
|
| 204 |
+
|
| 205 |
+
# queryforip = queryBegin,参数1.5为0就等于原先的IP-Adapter
|
| 206 |
+
#queryforip = 4*attn.to_q(hidden_states)+ 2*queryBegin
|
| 207 |
+
# queryforip = attn.to_q(hidden_states)
|
| 208 |
+
#queryforip = attn.head_to_batch_dim(queryforip)
|
| 209 |
+
# print("hidden_states.shape=queryforip.shape:")
|
| 210 |
+
# print(queryforip.shape)
|
| 211 |
+
# print("**************************************************")
|
| 212 |
+
# for ip-adapter
|
| 213 |
+
ip_key = self.to_k_ip(ip_hidden_states)
|
| 214 |
+
ip_value = self.to_v_ip(ip_hidden_states)
|
| 215 |
+
|
| 216 |
+
ip_key = attn.head_to_batch_dim(ip_key)
|
| 217 |
+
ip_value = attn.head_to_batch_dim(ip_value)
|
| 218 |
+
|
| 219 |
+
# ip_key.shape=[16, 4, 40]
|
| 220 |
+
# query = [16,6025,40]
|
| 221 |
+
# target = [16,6025,4]
|
| 222 |
+
# print("**************************************************")
|
| 223 |
+
# print(query)
|
| 224 |
+
# print("**************************************************")
|
| 225 |
+
# threshold = 5
|
| 226 |
+
# tensor_from_data = torch.tensor(query).to("cuda")
|
| 227 |
+
# binary_mask = torch.where(tensor_from_data > threshold, torch.tensor(0).to("cuda"), torch.tensor(1).to("cuda"))
|
| 228 |
+
# binary_mask = binary_mask.to(torch.float16)
|
| 229 |
+
# print("**************************************************")
|
| 230 |
+
# print(binary_mask)
|
| 231 |
+
# print("**************************************************")
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
# query.shape=[16,6205,40]
|
| 235 |
+
ip_attention_probs = attn.get_attention_scores(query, ip_key, None)
|
| 236 |
+
##########################################
|
| 237 |
+
# attention_probs
|
| 238 |
+
#ip_attention_probs = attn.get_attention_scores(keyforIPADAPTER, ip_key, None)
|
| 239 |
+
##########################################
|
| 240 |
+
|
| 241 |
+
ip_hidden_states = torch.bmm(ip_attention_probs, ip_value)
|
| 242 |
+
##########################################
|
| 243 |
+
# ip_hidden_states = ip_hidden_states*binary_mask +(1-binary_mask)*query
|
| 244 |
+
##########################################
|
| 245 |
+
ip_hidden_states = attn.batch_to_head_dim(ip_hidden_states)
|
| 246 |
+
|
| 247 |
+
# hidden_states.shape=【2,6205,320】s
|
| 248 |
+
# ip_hidden_states.shape=【2,3835,320】
|
| 249 |
+
# hidden_states = hidden_states + self.scale* ip_hidden_states
|
| 250 |
+
#print("Control_factor:{}".format(self.Control_factor))
|
| 251 |
+
#print("IP_factor:{}".format(self.IP_factor))
|
| 252 |
+
hidden_states = self.Control_factor * hidden_states + self.IP_factor * self.scale * ip_hidden_states
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
#hidden_states = 2*hidden_states +0.6*self.scale*ip_hidden_states
|
| 257 |
+
# if self.roundNumber < 12:
|
| 258 |
+
# hidden_states = hidden_states
|
| 259 |
+
# else:
|
| 260 |
+
# hidden_states = 1.2*hidden_states +0.6*self.scale*ip_hidden_states
|
| 261 |
+
# self.roundNumber = self.roundNumber + 1
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
# linear proj
|
| 265 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 266 |
+
# dropout
|
| 267 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 268 |
+
|
| 269 |
+
if input_ndim == 4:
|
| 270 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 271 |
+
|
| 272 |
+
if attn.residual_connection:
|
| 273 |
+
hidden_states = hidden_states + residual
|
| 274 |
+
|
| 275 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 276 |
+
|
| 277 |
+
return hidden_states
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
class AttnProcessor2_0(torch.nn.Module):
|
| 281 |
+
r"""
|
| 282 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 283 |
+
"""
|
| 284 |
+
|
| 285 |
+
def __init__(
|
| 286 |
+
self,
|
| 287 |
+
hidden_size=None,
|
| 288 |
+
cross_attention_dim=None,
|
| 289 |
+
):
|
| 290 |
+
super().__init__()
|
| 291 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 292 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 293 |
+
|
| 294 |
+
def __call__(
|
| 295 |
+
self,
|
| 296 |
+
attn,
|
| 297 |
+
hidden_states,
|
| 298 |
+
encoder_hidden_states=None,
|
| 299 |
+
attention_mask=None,
|
| 300 |
+
temb=None,
|
| 301 |
+
):
|
| 302 |
+
residual = hidden_states
|
| 303 |
+
|
| 304 |
+
if attn.spatial_norm is not None:
|
| 305 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 306 |
+
|
| 307 |
+
input_ndim = hidden_states.ndim
|
| 308 |
+
|
| 309 |
+
if input_ndim == 4:
|
| 310 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 311 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 312 |
+
|
| 313 |
+
batch_size, sequence_length, _ = (
|
| 314 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 315 |
+
)
|
| 316 |
+
|
| 317 |
+
if attention_mask is not None:
|
| 318 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 319 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 320 |
+
# (batch, heads, source_length, target_length)
|
| 321 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 322 |
+
|
| 323 |
+
if attn.group_norm is not None:
|
| 324 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 325 |
+
|
| 326 |
+
query = attn.to_q(hidden_states)
|
| 327 |
+
|
| 328 |
+
if encoder_hidden_states is None:
|
| 329 |
+
encoder_hidden_states = hidden_states
|
| 330 |
+
elif attn.norm_cross:
|
| 331 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 332 |
+
|
| 333 |
+
key = attn.to_k(encoder_hidden_states)
|
| 334 |
+
value = attn.to_v(encoder_hidden_states)
|
| 335 |
+
|
| 336 |
+
inner_dim = key.shape[-1]
|
| 337 |
+
head_dim = inner_dim // attn.heads
|
| 338 |
+
|
| 339 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 340 |
+
|
| 341 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 342 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 343 |
+
|
| 344 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 345 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 346 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 347 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 348 |
+
)
|
| 349 |
+
|
| 350 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 351 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 352 |
+
|
| 353 |
+
# linear proj
|
| 354 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 355 |
+
# dropout
|
| 356 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 357 |
+
|
| 358 |
+
if input_ndim == 4:
|
| 359 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 360 |
+
|
| 361 |
+
if attn.residual_connection:
|
| 362 |
+
hidden_states = hidden_states + residual
|
| 363 |
+
|
| 364 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 365 |
+
|
| 366 |
+
return hidden_states
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
class IPAttnProcessor2_0(torch.nn.Module):
|
| 370 |
+
r"""
|
| 371 |
+
Attention processor for IP-Adapater for PyTorch 2.0.
|
| 372 |
+
Args:
|
| 373 |
+
hidden_size (`int`):
|
| 374 |
+
The hidden size of the attention layer.
|
| 375 |
+
cross_attention_dim (`int`):
|
| 376 |
+
The number of channels in the `encoder_hidden_states`.
|
| 377 |
+
scale (`float`, defaults to 1.0):
|
| 378 |
+
the weight scale of image prompt.
|
| 379 |
+
num_tokens (`int`, defaults to 4 when do ip_adapter_plus it should be 16):
|
| 380 |
+
The context length of the image features.
|
| 381 |
+
"""
|
| 382 |
+
|
| 383 |
+
def __init__(self, hidden_size, cross_attention_dim=None, scale=1.0, num_tokens=4, Control_factor=1.0, IP_factor= 1.0):
|
| 384 |
+
super().__init__()
|
| 385 |
+
|
| 386 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 387 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 388 |
+
|
| 389 |
+
self.hidden_size = hidden_size
|
| 390 |
+
self.cross_attention_dim = cross_attention_dim
|
| 391 |
+
self.scale = scale
|
| 392 |
+
self.num_tokens = num_tokens
|
| 393 |
+
self.Control_factor = Control_factor
|
| 394 |
+
self.IP_factor = IP_factor
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
self.to_k_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 398 |
+
self.to_v_ip = nn.Linear(cross_attention_dim or hidden_size, hidden_size, bias=False)
|
| 399 |
+
|
| 400 |
+
def __call__(
|
| 401 |
+
self,
|
| 402 |
+
attn,
|
| 403 |
+
hidden_states,
|
| 404 |
+
encoder_hidden_states=None,
|
| 405 |
+
attention_mask=None,
|
| 406 |
+
temb=None,
|
| 407 |
+
):
|
| 408 |
+
residual = hidden_states
|
| 409 |
+
|
| 410 |
+
if attn.spatial_norm is not None:
|
| 411 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 412 |
+
|
| 413 |
+
input_ndim = hidden_states.ndim
|
| 414 |
+
|
| 415 |
+
if input_ndim == 4:
|
| 416 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 417 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 418 |
+
|
| 419 |
+
batch_size, sequence_length, _ = (
|
| 420 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 421 |
+
)
|
| 422 |
+
|
| 423 |
+
if attention_mask is not None:
|
| 424 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 425 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 426 |
+
# (batch, heads, source_length, target_length)
|
| 427 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 428 |
+
|
| 429 |
+
if attn.group_norm is not None:
|
| 430 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 431 |
+
|
| 432 |
+
query = attn.to_q(hidden_states)
|
| 433 |
+
|
| 434 |
+
if encoder_hidden_states is None:
|
| 435 |
+
encoder_hidden_states = hidden_states
|
| 436 |
+
else:
|
| 437 |
+
# get encoder_hidden_states, ip_hidden_states
|
| 438 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 439 |
+
encoder_hidden_states, ip_hidden_states = (
|
| 440 |
+
encoder_hidden_states[:, :end_pos, :],
|
| 441 |
+
encoder_hidden_states[:, end_pos:, :],
|
| 442 |
+
)
|
| 443 |
+
if attn.norm_cross:
|
| 444 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 445 |
+
|
| 446 |
+
key = attn.to_k(encoder_hidden_states)
|
| 447 |
+
value = attn.to_v(encoder_hidden_states)
|
| 448 |
+
|
| 449 |
+
inner_dim = key.shape[-1]
|
| 450 |
+
head_dim = inner_dim // attn.heads
|
| 451 |
+
|
| 452 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 453 |
+
|
| 454 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 455 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 456 |
+
|
| 457 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 458 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 459 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 460 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 461 |
+
)
|
| 462 |
+
|
| 463 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 464 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 465 |
+
|
| 466 |
+
# for ip-adapter
|
| 467 |
+
ip_key = self.to_k_ip(ip_hidden_states)
|
| 468 |
+
ip_value = self.to_v_ip(ip_hidden_states)
|
| 469 |
+
|
| 470 |
+
ip_key = ip_key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 471 |
+
ip_value = ip_value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 472 |
+
|
| 473 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 474 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 475 |
+
ip_hidden_states = F.scaled_dot_product_attention(
|
| 476 |
+
query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False
|
| 477 |
+
)
|
| 478 |
+
|
| 479 |
+
ip_hidden_states = ip_hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 480 |
+
ip_hidden_states = ip_hidden_states.to(query.dtype)
|
| 481 |
+
|
| 482 |
+
#hidden_states = 1.2*hidden_states + self.scale * ip_hidden_states*0.6
|
| 483 |
+
hidden_states = self.Control_factor * hidden_states+ self.IP_factor * self.scale * ip_hidden_states
|
| 484 |
+
|
| 485 |
+
# linear proj
|
| 486 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 487 |
+
# dropout
|
| 488 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 489 |
+
|
| 490 |
+
if input_ndim == 4:
|
| 491 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 492 |
+
|
| 493 |
+
if attn.residual_connection:
|
| 494 |
+
hidden_states = hidden_states + residual
|
| 495 |
+
|
| 496 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 497 |
+
|
| 498 |
+
return hidden_states
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
## for controlnet
|
| 502 |
+
class CNAttnProcessor:
|
| 503 |
+
r"""
|
| 504 |
+
Default processor for performing attention-related computations.
|
| 505 |
+
"""
|
| 506 |
+
|
| 507 |
+
def __init__(self, num_tokens=4):
|
| 508 |
+
self.num_tokens = num_tokens
|
| 509 |
+
|
| 510 |
+
def __call__(self, attn, hidden_states, encoder_hidden_states=None, attention_mask=None, temb=None):
|
| 511 |
+
residual = hidden_states
|
| 512 |
+
|
| 513 |
+
if attn.spatial_norm is not None:
|
| 514 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 515 |
+
|
| 516 |
+
input_ndim = hidden_states.ndim
|
| 517 |
+
|
| 518 |
+
if input_ndim == 4:
|
| 519 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 520 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 521 |
+
|
| 522 |
+
batch_size, sequence_length, _ = (
|
| 523 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 524 |
+
)
|
| 525 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 526 |
+
|
| 527 |
+
if attn.group_norm is not None:
|
| 528 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 529 |
+
|
| 530 |
+
query = attn.to_q(hidden_states)
|
| 531 |
+
|
| 532 |
+
if encoder_hidden_states is None:
|
| 533 |
+
encoder_hidden_states = hidden_states
|
| 534 |
+
else:
|
| 535 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 536 |
+
encoder_hidden_states = encoder_hidden_states[:, :end_pos] # only use text
|
| 537 |
+
if attn.norm_cross:
|
| 538 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 539 |
+
|
| 540 |
+
key = attn.to_k(encoder_hidden_states)
|
| 541 |
+
value = attn.to_v(encoder_hidden_states)
|
| 542 |
+
|
| 543 |
+
query = attn.head_to_batch_dim(query)
|
| 544 |
+
key = attn.head_to_batch_dim(key)
|
| 545 |
+
value = attn.head_to_batch_dim(value)
|
| 546 |
+
|
| 547 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 548 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 549 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 550 |
+
|
| 551 |
+
# linear proj
|
| 552 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 553 |
+
# dropout
|
| 554 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 555 |
+
|
| 556 |
+
if input_ndim == 4:
|
| 557 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 558 |
+
|
| 559 |
+
if attn.residual_connection:
|
| 560 |
+
hidden_states = hidden_states + residual
|
| 561 |
+
|
| 562 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 563 |
+
|
| 564 |
+
return hidden_states
|
| 565 |
+
|
| 566 |
+
|
| 567 |
+
class CNAttnProcessor2_0:
|
| 568 |
+
r"""
|
| 569 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 570 |
+
"""
|
| 571 |
+
|
| 572 |
+
def __init__(self, num_tokens=4):
|
| 573 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 574 |
+
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
| 575 |
+
self.num_tokens = num_tokens
|
| 576 |
+
|
| 577 |
+
def __call__(
|
| 578 |
+
self,
|
| 579 |
+
attn,
|
| 580 |
+
hidden_states,
|
| 581 |
+
encoder_hidden_states=None,
|
| 582 |
+
attention_mask=None,
|
| 583 |
+
temb=None,
|
| 584 |
+
):
|
| 585 |
+
residual = hidden_states
|
| 586 |
+
|
| 587 |
+
if attn.spatial_norm is not None:
|
| 588 |
+
hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 589 |
+
|
| 590 |
+
input_ndim = hidden_states.ndim
|
| 591 |
+
|
| 592 |
+
if input_ndim == 4:
|
| 593 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 594 |
+
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 595 |
+
|
| 596 |
+
batch_size, sequence_length, _ = (
|
| 597 |
+
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
| 598 |
+
)
|
| 599 |
+
|
| 600 |
+
if attention_mask is not None:
|
| 601 |
+
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 602 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 603 |
+
# (batch, heads, source_length, target_length)
|
| 604 |
+
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 605 |
+
|
| 606 |
+
if attn.group_norm is not None:
|
| 607 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 608 |
+
|
| 609 |
+
query = attn.to_q(hidden_states)
|
| 610 |
+
|
| 611 |
+
if encoder_hidden_states is None:
|
| 612 |
+
encoder_hidden_states = hidden_states
|
| 613 |
+
else:
|
| 614 |
+
end_pos = encoder_hidden_states.shape[1] - self.num_tokens
|
| 615 |
+
encoder_hidden_states = encoder_hidden_states[:, :end_pos] # only use text
|
| 616 |
+
if attn.norm_cross:
|
| 617 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 618 |
+
|
| 619 |
+
key = attn.to_k(encoder_hidden_states)
|
| 620 |
+
value = attn.to_v(encoder_hidden_states)
|
| 621 |
+
|
| 622 |
+
inner_dim = key.shape[-1]
|
| 623 |
+
head_dim = inner_dim // attn.heads
|
| 624 |
+
|
| 625 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 626 |
+
|
| 627 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 628 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 629 |
+
|
| 630 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 631 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 632 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 633 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 634 |
+
)
|
| 635 |
+
|
| 636 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
| 637 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 638 |
+
|
| 639 |
+
# linear proj
|
| 640 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 641 |
+
# dropout
|
| 642 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 643 |
+
|
| 644 |
+
if input_ndim == 4:
|
| 645 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
| 646 |
+
|
| 647 |
+
if attn.residual_connection:
|
| 648 |
+
hidden_states = hidden_states + residual
|
| 649 |
+
|
| 650 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 651 |
+
|
| 652 |
+
return hidden_states
|
ip_adapter/custom_pipelines.py
ADDED
|
@@ -0,0 +1,394 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from diffusers import StableDiffusionXLPipeline
|
| 5 |
+
from diffusers.pipelines.stable_diffusion_xl import StableDiffusionXLPipelineOutput
|
| 6 |
+
from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl import rescale_noise_cfg
|
| 7 |
+
|
| 8 |
+
from .utils import is_torch2_available
|
| 9 |
+
|
| 10 |
+
if is_torch2_available():
|
| 11 |
+
from .attention_processor import IPAttnProcessor2_0 as IPAttnProcessor
|
| 12 |
+
else:
|
| 13 |
+
from .attention_processor import IPAttnProcessor
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class StableDiffusionXLCustomPipeline(StableDiffusionXLPipeline):
|
| 17 |
+
def set_scale(self, scale):
|
| 18 |
+
for attn_processor in self.unet.attn_processors.values():
|
| 19 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 20 |
+
attn_processor.scale = scale
|
| 21 |
+
|
| 22 |
+
@torch.no_grad()
|
| 23 |
+
def __call__( # noqa: C901
|
| 24 |
+
self,
|
| 25 |
+
prompt: Optional[Union[str, List[str]]] = None,
|
| 26 |
+
prompt_2: Optional[Union[str, List[str]]] = None,
|
| 27 |
+
height: Optional[int] = None,
|
| 28 |
+
width: Optional[int] = None,
|
| 29 |
+
num_inference_steps: int = 50,
|
| 30 |
+
denoising_end: Optional[float] = None,
|
| 31 |
+
guidance_scale: float = 5.0,
|
| 32 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 33 |
+
negative_prompt_2: Optional[Union[str, List[str]]] = None,
|
| 34 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 35 |
+
eta: float = 0.0,
|
| 36 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 37 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 38 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 39 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 40 |
+
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 41 |
+
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 42 |
+
output_type: Optional[str] = "pil",
|
| 43 |
+
return_dict: bool = True,
|
| 44 |
+
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
| 45 |
+
callback_steps: int = 1,
|
| 46 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 47 |
+
guidance_rescale: float = 0.0,
|
| 48 |
+
original_size: Optional[Tuple[int, int]] = None,
|
| 49 |
+
crops_coords_top_left: Tuple[int, int] = (0, 0),
|
| 50 |
+
target_size: Optional[Tuple[int, int]] = None,
|
| 51 |
+
negative_original_size: Optional[Tuple[int, int]] = None,
|
| 52 |
+
negative_crops_coords_top_left: Tuple[int, int] = (0, 0),
|
| 53 |
+
negative_target_size: Optional[Tuple[int, int]] = None,
|
| 54 |
+
control_guidance_start: float = 0.0,
|
| 55 |
+
control_guidance_end: float = 1.0,
|
| 56 |
+
):
|
| 57 |
+
r"""
|
| 58 |
+
Function invoked when calling the pipeline for generation.
|
| 59 |
+
|
| 60 |
+
Args:
|
| 61 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 62 |
+
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
|
| 63 |
+
instead.
|
| 64 |
+
prompt_2 (`str` or `List[str]`, *optional*):
|
| 65 |
+
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
|
| 66 |
+
used in both text-encoders
|
| 67 |
+
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
| 68 |
+
The height in pixels of the generated image. This is set to 1024 by default for the best results.
|
| 69 |
+
Anything below 512 pixels won't work well for
|
| 70 |
+
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
|
| 71 |
+
and checkpoints that are not specifically fine-tuned on low resolutions.
|
| 72 |
+
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
| 73 |
+
The width in pixels of the generated image. This is set to 1024 by default for the best results.
|
| 74 |
+
Anything below 512 pixels won't work well for
|
| 75 |
+
[stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
|
| 76 |
+
and checkpoints that are not specifically fine-tuned on low resolutions.
|
| 77 |
+
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 78 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 79 |
+
expense of slower inference.
|
| 80 |
+
denoising_end (`float`, *optional*):
|
| 81 |
+
When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
|
| 82 |
+
completed before it is intentionally prematurely terminated. As a result, the returned sample will
|
| 83 |
+
still retain a substantial amount of noise as determined by the discrete timesteps selected by the
|
| 84 |
+
scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
|
| 85 |
+
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
|
| 86 |
+
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
|
| 87 |
+
guidance_scale (`float`, *optional*, defaults to 5.0):
|
| 88 |
+
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
| 89 |
+
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
| 90 |
+
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
| 91 |
+
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
| 92 |
+
usually at the expense of lower image quality.
|
| 93 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 94 |
+
The prompt or prompts not to guide the image generation. If not defined, one has to pass
|
| 95 |
+
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
|
| 96 |
+
less than `1`).
|
| 97 |
+
negative_prompt_2 (`str` or `List[str]`, *optional*):
|
| 98 |
+
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
|
| 99 |
+
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
|
| 100 |
+
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 101 |
+
The number of images to generate per prompt.
|
| 102 |
+
eta (`float`, *optional*, defaults to 0.0):
|
| 103 |
+
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
|
| 104 |
+
[`schedulers.DDIMScheduler`], will be ignored for others.
|
| 105 |
+
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
| 106 |
+
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
| 107 |
+
to make generation deterministic.
|
| 108 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 109 |
+
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
| 110 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 111 |
+
tensor will ge generated by sampling using the supplied random `generator`.
|
| 112 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 113 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
|
| 114 |
+
provided, text embeddings will be generated from `prompt` input argument.
|
| 115 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 116 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
| 117 |
+
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
| 118 |
+
argument.
|
| 119 |
+
pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 120 |
+
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
|
| 121 |
+
If not provided, pooled text embeddings will be generated from `prompt` input argument.
|
| 122 |
+
negative_pooled_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 123 |
+
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
| 124 |
+
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
|
| 125 |
+
input argument.
|
| 126 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 127 |
+
The output format of the generate image. Choose between
|
| 128 |
+
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
|
| 129 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 130 |
+
Whether or not to return a [`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] instead
|
| 131 |
+
of a plain tuple.
|
| 132 |
+
callback (`Callable`, *optional*):
|
| 133 |
+
A function that will be called every `callback_steps` steps during inference. The function will be
|
| 134 |
+
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
|
| 135 |
+
callback_steps (`int`, *optional*, defaults to 1):
|
| 136 |
+
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
| 137 |
+
called at every step.
|
| 138 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 139 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 140 |
+
`self.processor` in
|
| 141 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 142 |
+
guidance_rescale (`float`, *optional*, defaults to 0.7):
|
| 143 |
+
Guidance rescale factor proposed by [Common Diffusion Noise Schedules and Sample Steps are
|
| 144 |
+
Flawed](https://arxiv.org/pdf/2305.08891.pdf) `guidance_scale` is defined as `φ` in equation 16. of
|
| 145 |
+
[Common Diffusion Noise Schedules and Sample Steps are Flawed](https://arxiv.org/pdf/2305.08891.pdf).
|
| 146 |
+
Guidance rescale factor should fix overexposure when using zero terminal SNR.
|
| 147 |
+
original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
|
| 148 |
+
If `original_size` is not the same as `target_size` the image will appear to be down- or upsampled.
|
| 149 |
+
`original_size` defaults to `(width, height)` if not specified. Part of SDXL's micro-conditioning as
|
| 150 |
+
explained in section 2.2 of
|
| 151 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
|
| 152 |
+
crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
|
| 153 |
+
`crops_coords_top_left` can be used to generate an image that appears to be "cropped" from the position
|
| 154 |
+
`crops_coords_top_left` downwards. Favorable, well-centered images are usually achieved by setting
|
| 155 |
+
`crops_coords_top_left` to (0, 0). Part of SDXL's micro-conditioning as explained in section 2.2 of
|
| 156 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
|
| 157 |
+
target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
|
| 158 |
+
For most cases, `target_size` should be set to the desired height and width of the generated image. If
|
| 159 |
+
not specified it will default to `(width, height)`. Part of SDXL's micro-conditioning as explained in
|
| 160 |
+
section 2.2 of [https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952).
|
| 161 |
+
negative_original_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
|
| 162 |
+
To negatively condition the generation process based on a specific image resolution. Part of SDXL's
|
| 163 |
+
micro-conditioning as explained in section 2.2 of
|
| 164 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
|
| 165 |
+
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
|
| 166 |
+
negative_crops_coords_top_left (`Tuple[int]`, *optional*, defaults to (0, 0)):
|
| 167 |
+
To negatively condition the generation process based on a specific crop coordinates. Part of SDXL's
|
| 168 |
+
micro-conditioning as explained in section 2.2 of
|
| 169 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
|
| 170 |
+
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
|
| 171 |
+
negative_target_size (`Tuple[int]`, *optional*, defaults to (1024, 1024)):
|
| 172 |
+
To negatively condition the generation process based on a target image resolution. It should be as same
|
| 173 |
+
as the `target_size` for most cases. Part of SDXL's micro-conditioning as explained in section 2.2 of
|
| 174 |
+
[https://huggingface.co/papers/2307.01952](https://huggingface.co/papers/2307.01952). For more
|
| 175 |
+
information, refer to this issue thread: https://github.com/huggingface/diffusers/issues/4208.
|
| 176 |
+
control_guidance_start (`float`, *optional*, defaults to 0.0):
|
| 177 |
+
The percentage of total steps at which the ControlNet starts applying.
|
| 178 |
+
control_guidance_end (`float`, *optional*, defaults to 1.0):
|
| 179 |
+
The percentage of total steps at which the ControlNet stops applying.
|
| 180 |
+
|
| 181 |
+
Examples:
|
| 182 |
+
|
| 183 |
+
Returns:
|
| 184 |
+
[`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] or `tuple`:
|
| 185 |
+
[`~pipelines.stable_diffusion_xl.StableDiffusionXLPipelineOutput`] if `return_dict` is True, otherwise a
|
| 186 |
+
`tuple`. When returning a tuple, the first element is a list with the generated images.
|
| 187 |
+
"""
|
| 188 |
+
# 0. Default height and width to unet
|
| 189 |
+
height = height or self.default_sample_size * self.vae_scale_factor
|
| 190 |
+
width = width or self.default_sample_size * self.vae_scale_factor
|
| 191 |
+
|
| 192 |
+
original_size = original_size or (height, width)
|
| 193 |
+
target_size = target_size or (height, width)
|
| 194 |
+
|
| 195 |
+
# 1. Check inputs. Raise error if not correct
|
| 196 |
+
self.check_inputs(
|
| 197 |
+
prompt,
|
| 198 |
+
prompt_2,
|
| 199 |
+
height,
|
| 200 |
+
width,
|
| 201 |
+
callback_steps,
|
| 202 |
+
negative_prompt,
|
| 203 |
+
negative_prompt_2,
|
| 204 |
+
prompt_embeds,
|
| 205 |
+
negative_prompt_embeds,
|
| 206 |
+
pooled_prompt_embeds,
|
| 207 |
+
negative_pooled_prompt_embeds,
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
# 2. Define call parameters
|
| 211 |
+
if prompt is not None and isinstance(prompt, str):
|
| 212 |
+
batch_size = 1
|
| 213 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 214 |
+
batch_size = len(prompt)
|
| 215 |
+
else:
|
| 216 |
+
batch_size = prompt_embeds.shape[0]
|
| 217 |
+
|
| 218 |
+
device = self._execution_device
|
| 219 |
+
|
| 220 |
+
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 221 |
+
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 222 |
+
# corresponds to doing no classifier free guidance.
|
| 223 |
+
do_classifier_free_guidance = guidance_scale > 1.0
|
| 224 |
+
|
| 225 |
+
# 3. Encode input prompt
|
| 226 |
+
text_encoder_lora_scale = (
|
| 227 |
+
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
| 228 |
+
)
|
| 229 |
+
(
|
| 230 |
+
prompt_embeds,
|
| 231 |
+
negative_prompt_embeds,
|
| 232 |
+
pooled_prompt_embeds,
|
| 233 |
+
negative_pooled_prompt_embeds,
|
| 234 |
+
) = self.encode_prompt(
|
| 235 |
+
prompt=prompt,
|
| 236 |
+
prompt_2=prompt_2,
|
| 237 |
+
device=device,
|
| 238 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 239 |
+
do_classifier_free_guidance=do_classifier_free_guidance,
|
| 240 |
+
negative_prompt=negative_prompt,
|
| 241 |
+
negative_prompt_2=negative_prompt_2,
|
| 242 |
+
prompt_embeds=prompt_embeds,
|
| 243 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 244 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 245 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 246 |
+
lora_scale=text_encoder_lora_scale,
|
| 247 |
+
)
|
| 248 |
+
|
| 249 |
+
# 4. Prepare timesteps
|
| 250 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 251 |
+
|
| 252 |
+
timesteps = self.scheduler.timesteps
|
| 253 |
+
|
| 254 |
+
# 5. Prepare latent variables
|
| 255 |
+
num_channels_latents = self.unet.config.in_channels
|
| 256 |
+
latents = self.prepare_latents(
|
| 257 |
+
batch_size * num_images_per_prompt,
|
| 258 |
+
num_channels_latents,
|
| 259 |
+
height,
|
| 260 |
+
width,
|
| 261 |
+
prompt_embeds.dtype,
|
| 262 |
+
device,
|
| 263 |
+
generator,
|
| 264 |
+
latents,
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 268 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 269 |
+
|
| 270 |
+
# 7. Prepare added time ids & embeddings
|
| 271 |
+
add_text_embeds = pooled_prompt_embeds
|
| 272 |
+
if self.text_encoder_2 is None:
|
| 273 |
+
text_encoder_projection_dim = int(pooled_prompt_embeds.shape[-1])
|
| 274 |
+
else:
|
| 275 |
+
text_encoder_projection_dim = self.text_encoder_2.config.projection_dim
|
| 276 |
+
|
| 277 |
+
add_time_ids = self._get_add_time_ids(
|
| 278 |
+
original_size,
|
| 279 |
+
crops_coords_top_left,
|
| 280 |
+
target_size,
|
| 281 |
+
dtype=prompt_embeds.dtype,
|
| 282 |
+
text_encoder_projection_dim=text_encoder_projection_dim,
|
| 283 |
+
)
|
| 284 |
+
if negative_original_size is not None and negative_target_size is not None:
|
| 285 |
+
negative_add_time_ids = self._get_add_time_ids(
|
| 286 |
+
negative_original_size,
|
| 287 |
+
negative_crops_coords_top_left,
|
| 288 |
+
negative_target_size,
|
| 289 |
+
dtype=prompt_embeds.dtype,
|
| 290 |
+
text_encoder_projection_dim=text_encoder_projection_dim,
|
| 291 |
+
)
|
| 292 |
+
else:
|
| 293 |
+
negative_add_time_ids = add_time_ids
|
| 294 |
+
|
| 295 |
+
if do_classifier_free_guidance:
|
| 296 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 297 |
+
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
|
| 298 |
+
add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
|
| 299 |
+
|
| 300 |
+
prompt_embeds = prompt_embeds.to(device)
|
| 301 |
+
add_text_embeds = add_text_embeds.to(device)
|
| 302 |
+
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
|
| 303 |
+
|
| 304 |
+
# 8. Denoising loop
|
| 305 |
+
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
|
| 306 |
+
|
| 307 |
+
# 7.1 Apply denoising_end
|
| 308 |
+
if denoising_end is not None and isinstance(denoising_end, float) and denoising_end > 0 and denoising_end < 1:
|
| 309 |
+
discrete_timestep_cutoff = int(
|
| 310 |
+
round(
|
| 311 |
+
self.scheduler.config.num_train_timesteps
|
| 312 |
+
- (denoising_end * self.scheduler.config.num_train_timesteps)
|
| 313 |
+
)
|
| 314 |
+
)
|
| 315 |
+
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
|
| 316 |
+
timesteps = timesteps[:num_inference_steps]
|
| 317 |
+
|
| 318 |
+
# get init conditioning scale
|
| 319 |
+
for attn_processor in self.unet.attn_processors.values():
|
| 320 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 321 |
+
conditioning_scale = attn_processor.scale
|
| 322 |
+
break
|
| 323 |
+
|
| 324 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 325 |
+
for i, t in enumerate(timesteps):
|
| 326 |
+
if (i / len(timesteps) < control_guidance_start) or ((i + 1) / len(timesteps) > control_guidance_end):
|
| 327 |
+
self.set_scale(0.0)
|
| 328 |
+
else:
|
| 329 |
+
self.set_scale(conditioning_scale)
|
| 330 |
+
|
| 331 |
+
# expand the latents if we are doing classifier free guidance
|
| 332 |
+
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
| 333 |
+
|
| 334 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 335 |
+
|
| 336 |
+
# predict the noise residual
|
| 337 |
+
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
|
| 338 |
+
noise_pred = self.unet(
|
| 339 |
+
latent_model_input,
|
| 340 |
+
t,
|
| 341 |
+
encoder_hidden_states=prompt_embeds,
|
| 342 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 343 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 344 |
+
return_dict=False,
|
| 345 |
+
)[0]
|
| 346 |
+
|
| 347 |
+
# perform guidance
|
| 348 |
+
if do_classifier_free_guidance:
|
| 349 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 350 |
+
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 351 |
+
|
| 352 |
+
if do_classifier_free_guidance and guidance_rescale > 0.0:
|
| 353 |
+
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
|
| 354 |
+
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
|
| 355 |
+
|
| 356 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 357 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 358 |
+
|
| 359 |
+
# call the callback, if provided
|
| 360 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 361 |
+
progress_bar.update()
|
| 362 |
+
if callback is not None and i % callback_steps == 0:
|
| 363 |
+
callback(i, t, latents)
|
| 364 |
+
|
| 365 |
+
if not output_type == "latent":
|
| 366 |
+
# make sure the VAE is in float32 mode, as it overflows in float16
|
| 367 |
+
needs_upcasting = self.vae.dtype == torch.float16 and self.vae.config.force_upcast
|
| 368 |
+
|
| 369 |
+
if needs_upcasting:
|
| 370 |
+
self.upcast_vae()
|
| 371 |
+
latents = latents.to(next(iter(self.vae.post_quant_conv.parameters())).dtype)
|
| 372 |
+
|
| 373 |
+
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
|
| 374 |
+
|
| 375 |
+
# cast back to fp16 if needed
|
| 376 |
+
if needs_upcasting:
|
| 377 |
+
self.vae.to(dtype=torch.float16)
|
| 378 |
+
else:
|
| 379 |
+
image = latents
|
| 380 |
+
|
| 381 |
+
if output_type != "latent":
|
| 382 |
+
# apply watermark if available
|
| 383 |
+
if self.watermark is not None:
|
| 384 |
+
image = self.watermark.apply_watermark(image)
|
| 385 |
+
|
| 386 |
+
image = self.image_processor.postprocess(image, output_type=output_type)
|
| 387 |
+
|
| 388 |
+
# Offload all models
|
| 389 |
+
self.maybe_free_model_hooks()
|
| 390 |
+
|
| 391 |
+
if not return_dict:
|
| 392 |
+
return (image,)
|
| 393 |
+
|
| 394 |
+
return StableDiffusionXLPipelineOutput(images=image)
|
ip_adapter/ip_adapter.py
ADDED
|
@@ -0,0 +1,504 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
import torch
|
| 4 |
+
from diffusers import StableDiffusionPipeline
|
| 5 |
+
# from diffusers.pipelines.controlnet import MultiControlNetModel
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from diffusers.pipelines.controlnet import MultiControlNetModel
|
| 8 |
+
from safetensors import safe_open
|
| 9 |
+
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
|
| 10 |
+
from .utils import is_torch2_available
|
| 11 |
+
|
| 12 |
+
if is_torch2_available():
|
| 13 |
+
from .attention_processor import (
|
| 14 |
+
AttnProcessor2_0 as AttnProcessor,
|
| 15 |
+
)
|
| 16 |
+
from .attention_processor import (
|
| 17 |
+
CNAttnProcessor2_0 as CNAttnProcessor,
|
| 18 |
+
)
|
| 19 |
+
from .attention_processor import (
|
| 20 |
+
IPAttnProcessor2_0 as IPAttnProcessor,
|
| 21 |
+
)
|
| 22 |
+
else:
|
| 23 |
+
from .attention_processor import AttnProcessor, CNAttnProcessor, IPAttnProcessor
|
| 24 |
+
from .resampler import Resampler
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class ImageProjModel(torch.nn.Module):
|
| 28 |
+
"""Projection Model"""
|
| 29 |
+
|
| 30 |
+
def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024, clip_extra_context_tokens=4):
|
| 31 |
+
super().__init__()
|
| 32 |
+
|
| 33 |
+
# cross_attention_dim = 768
|
| 34 |
+
# clip_extra_context_tokens = 4
|
| 35 |
+
# clip_embeddings_dim = 1024
|
| 36 |
+
self.cross_attention_dim = cross_attention_dim
|
| 37 |
+
self.clip_extra_context_tokens = clip_extra_context_tokens
|
| 38 |
+
# 创建了一个线性层self.proj,将clip_embeddings_dim作为输入维度,将self.clip_extra_context_tokens * cross_attention_dim作为输出维度。
|
| 39 |
+
self.proj = torch.nn.Linear(clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim)
|
| 40 |
+
# self.proj_1 = torch.nn.Linear(clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim)
|
| 41 |
+
#
|
| 42 |
+
# # 访问线性层的权重参数
|
| 43 |
+
# weights = self.proj.weight
|
| 44 |
+
# print("proj_weights")
|
| 45 |
+
# print(weights)
|
| 46 |
+
# # 访问线性层的权重参数
|
| 47 |
+
# weights_1 = self.proj_1.weight
|
| 48 |
+
# print("proj_1_weights")
|
| 49 |
+
# print(weights_1)
|
| 50 |
+
#
|
| 51 |
+
# # 访问线性层的偏置参数
|
| 52 |
+
# bias = self.proj.bias
|
| 53 |
+
# print("proj_bias")
|
| 54 |
+
# print(bias)
|
| 55 |
+
# # 访问线性层的偏置参数
|
| 56 |
+
# bias_1 = self.proj_1.bias
|
| 57 |
+
# print("proj_1_bias")
|
| 58 |
+
# print(bias_1)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# 接着,它创建了一个LayerNorm层self.norm,将cross_attention_dim作为输入维度
|
| 62 |
+
# LayerNorm层能对每个通道进行归一化处理,确保每个通道均值方差一致,使得每个通道的特征分布相对一致,帮助模型学习特征
|
| 63 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 64 |
+
|
| 65 |
+
def forward(self, image_embeds):
|
| 66 |
+
# 在前向传播函数中,它接受image_embeds作为输入,然后将其赋值给embeds。
|
| 67 |
+
embeds = image_embeds
|
| 68 |
+
# embeds.shape = [1,1024]
|
| 69 |
+
# self.proj(embeds).shape = [1,3072]
|
| 70 |
+
# 接着,它使用self.proj对embeds进行线性变换,并将结果reshape
|
| 71 |
+
clip_extra_context_tokens = self.proj(embeds).reshape(
|
| 72 |
+
-1, self.clip_extra_context_tokens, self.cross_attention_dim
|
| 73 |
+
)
|
| 74 |
+
# clip_extra_context_tokens.shape = [1,4,768]
|
| 75 |
+
# 然后,它将结果传入self.norm进行LayerNorm操作,并返回处理后的结果clip_extra_context_tokens。
|
| 76 |
+
clip_extra_context_tokens = self.norm(clip_extra_context_tokens)
|
| 77 |
+
# clip_extra_context_tokens.shape = [1,4,768]
|
| 78 |
+
return clip_extra_context_tokens
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
# self.proj = torch.nn.Sequential
|
| 82 |
+
class MLPProjModel(torch.nn.Module):
|
| 83 |
+
"""SD model with image prompt"""
|
| 84 |
+
def __init__(self, cross_attention_dim=1024, clip_embeddings_dim=1024):
|
| 85 |
+
super().__init__()
|
| 86 |
+
|
| 87 |
+
self.proj = torch.nn.Sequential(
|
| 88 |
+
torch.nn.Linear(clip_embeddings_dim, clip_embeddings_dim),
|
| 89 |
+
torch.nn.GELU(),
|
| 90 |
+
torch.nn.Linear(clip_embeddings_dim, cross_attention_dim),
|
| 91 |
+
torch.nn.LayerNorm(cross_attention_dim)
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
def forward(self, image_embeds):
|
| 95 |
+
clip_extra_context_tokens = self.proj(image_embeds)
|
| 96 |
+
return clip_extra_context_tokens
|
| 97 |
+
|
| 98 |
+
# image_proj_model = MLPProjModel
|
| 99 |
+
class IPAdapter:
|
| 100 |
+
def __init__(self, sd_pipe, image_encoder_path, ip_ckpt, device, num_tokens=4, Control_factor = 1.0, IP_factor= 1.0):
|
| 101 |
+
self.device = device
|
| 102 |
+
self.image_encoder_path = image_encoder_path
|
| 103 |
+
self.ip_ckpt = ip_ckpt
|
| 104 |
+
self.num_tokens = num_tokens
|
| 105 |
+
self.Control_factor = Control_factor
|
| 106 |
+
self.IP_factor = IP_factor
|
| 107 |
+
|
| 108 |
+
self.pipe = sd_pipe.to(self.device)
|
| 109 |
+
self.set_ip_adapter()
|
| 110 |
+
|
| 111 |
+
# load image encoder
|
| 112 |
+
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(self.image_encoder_path).to(
|
| 113 |
+
self.device, dtype=torch.float16
|
| 114 |
+
)
|
| 115 |
+
self.clip_image_processor = CLIPImageProcessor()
|
| 116 |
+
# image proj model
|
| 117 |
+
self.image_proj_model = self.init_proj()
|
| 118 |
+
|
| 119 |
+
self.load_ip_adapter()
|
| 120 |
+
|
| 121 |
+
def init_proj(self):
|
| 122 |
+
image_proj_model = ImageProjModel(
|
| 123 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 124 |
+
clip_embeddings_dim=self.image_encoder.config.projection_dim,
|
| 125 |
+
clip_extra_context_tokens=self.num_tokens,
|
| 126 |
+
).to(self.device, dtype=torch.float16)
|
| 127 |
+
return image_proj_model
|
| 128 |
+
|
| 129 |
+
def set_ip_adapter(self):
|
| 130 |
+
# 首先,它获取了self.pipe.unet中的unet,
|
| 131 |
+
unet = self.pipe.unet
|
| 132 |
+
# 并初始化了一个空的字典attn_procs
|
| 133 |
+
attn_procs = {}
|
| 134 |
+
# 然后,它遍历unet.attn_processors中的每个键名name
|
| 135 |
+
for name in unet.attn_processors.keys():
|
| 136 |
+
# 在循环中,它根据name的不同情况设置cross_attention_dim和hidden_size
|
| 137 |
+
# 如果name以"attn1.processor"结尾,那么cross_attention_dim被设置为None;否则,它被设置为unet.config.cross_attention_dim。
|
| 138 |
+
cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
|
| 139 |
+
# 接着,根据name的前缀不同,设置了hidden_size的值
|
| 140 |
+
if name.startswith("mid_block"):
|
| 141 |
+
hidden_size = unet.config.block_out_channels[-1]
|
| 142 |
+
elif name.startswith("up_blocks"):
|
| 143 |
+
block_id = int(name[len("up_blocks.")])
|
| 144 |
+
hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
|
| 145 |
+
elif name.startswith("down_blocks"):
|
| 146 |
+
block_id = int(name[len("down_blocks.")])
|
| 147 |
+
hidden_size = unet.config.block_out_channels[block_id]
|
| 148 |
+
# 接下来,根据cross_attention_dim的值,为每个name创建了一个对应的AttnProcessor或IPAttnProcessor,并将其加入attn_procs字典中最后
|
| 149 |
+
if cross_attention_dim is None:
|
| 150 |
+
#print("initialization:attn_procs[name] = AttnProcessor()")
|
| 151 |
+
attn_procs[name] = AttnProcessor()
|
| 152 |
+
else:
|
| 153 |
+
#print("initialization:attn_procs[name] = IPAttnProcessor()")
|
| 154 |
+
attn_procs[name] = IPAttnProcessor(
|
| 155 |
+
hidden_size= hidden_size,
|
| 156 |
+
cross_attention_dim=cross_attention_dim,
|
| 157 |
+
scale=1.0,
|
| 158 |
+
num_tokens=self.num_tokens,
|
| 159 |
+
Control_factor=self.Control_factor,
|
| 160 |
+
IP_factor=self.IP_factor,
|
| 161 |
+
).to(self.device, dtype=torch.float16)
|
| 162 |
+
# 调用unet.set_attn_processor(attn_procs)来设置unet的注意力处理器
|
| 163 |
+
# 同时调用self.pipe.controlnet.set_attn_processor(CNAttnProcessor(num_tokens=self.num_tokens))来设置self.pipe.controlnet的注意力处理器。
|
| 164 |
+
unet.set_attn_processor(attn_procs)
|
| 165 |
+
#self.pipe.controlnet.set_attn_processor(CNAttnProcessor(num_tokens=self.num_tokens))
|
| 166 |
+
if hasattr(self.pipe, "controlnet"):
|
| 167 |
+
if isinstance(self.pipe.controlnet, MultiControlNetModel):
|
| 168 |
+
for controlnet in self.pipe.controlnet.nets:
|
| 169 |
+
controlnet.set_attn_processor(CNAttnProcessor(num_tokens=self.num_tokens))
|
| 170 |
+
else:
|
| 171 |
+
self.pipe.controlnet.set_attn_processor(CNAttnProcessor(num_tokens=self.num_tokens))
|
| 172 |
+
|
| 173 |
+
def load_ip_adapter(self):
|
| 174 |
+
# 该方法用于加载IP适配器的状态。然后,它使用safe_open函数打开self.ip_ckpt文件,并遍历文件中的键名。
|
| 175 |
+
# 首先,它检查self.ip_ckpt的文件扩展名是否为".safetensors"。
|
| 176 |
+
if os.path.splitext(self.ip_ckpt)[-1] == ".safetensors":
|
| 177 |
+
# 如果是,它创建了一个空的state_dict字典,包含"image_proj"和"ip_adapter"两个键。
|
| 178 |
+
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
| 179 |
+
# 对于以"image_proj."开头的键名,它将对应的张量存入state_dict["image_proj"]中;对于以"ip_adapter."开头的键名,它将对应的张量存入state_dict["ip_adapter"]中。
|
| 180 |
+
with safe_open(self.ip_ckpt, framework="pt", device="cpu") as f:
|
| 181 |
+
for key in f.keys():
|
| 182 |
+
if key.startswith("image_proj."):
|
| 183 |
+
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
| 184 |
+
elif key.startswith("ip_adapter."):
|
| 185 |
+
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
| 186 |
+
else:
|
| 187 |
+
# 如果self.ip_ckpt的文件扩展名不是".safetensors",那么它直接使用torch.load函数加载self.ip_ckpt文件的状态,并将其存入state_dict中。
|
| 188 |
+
state_dict = torch.load(self.ip_ckpt, map_location="cpu")
|
| 189 |
+
# 这段代码中的两行分别用于加载预训练模型的参数。
|
| 190 |
+
# 第一行使用load_state_dict方法将state_dict中的"image_proj"部分加载到self.image_proj_model中
|
| 191 |
+
# 而第二行则尝试将state_dict中的"ip_adapter"部分加载到ip_layers中。
|
| 192 |
+
# 需要注意的是,ip_layers是一个ModuleList,它包含了多个attn_processors,因此在尝试加载"ip_adapter"部分时,需要确保state_dict中的键能够与ip_layers中的各个子模块对应上。
|
| 193 |
+
self.image_proj_model.load_state_dict(state_dict["image_proj"])
|
| 194 |
+
ip_layers = torch.nn.ModuleList(self.pipe.unet.attn_processors.values())
|
| 195 |
+
ip_layers.load_state_dict(state_dict["ip_adapter"])
|
| 196 |
+
|
| 197 |
+
@torch.inference_mode()
|
| 198 |
+
def get_image_embeds(self, pil_image=None, clip_image_embeds=None):
|
| 199 |
+
if pil_image is not None:
|
| 200 |
+
if isinstance(pil_image, Image.Image):
|
| 201 |
+
pil_image = [pil_image]
|
| 202 |
+
clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
| 203 |
+
clip_image_embeds = self.image_encoder(clip_image.to(self.device, dtype=torch.float16)).image_embeds
|
| 204 |
+
|
| 205 |
+
# clip_imageBroken = self.clip_image_processor(images=image_broken, return_tensors="pt").pixel_values
|
| 206 |
+
# clip_imageBroken_embeds = self.image_encoder(clip_imageBroken.to(self.device, dtype=torch.float16)).image_embeds
|
| 207 |
+
# clip_image_embeds.shape: torch.Size([1, 1024])
|
| 208 |
+
# style_vector = clip_image_embeds-clip_imageBroken_embeds
|
| 209 |
+
else:
|
| 210 |
+
clip_image_embeds = clip_image_embeds.to(self.device, dtype=torch.float16)
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
# image_prompt_embeds = self.image_proj_model(style_vector)
|
| 214 |
+
image_prompt_embeds = self.image_proj_model(clip_image_embeds)
|
| 215 |
+
uncond_image_prompt_embeds = self.image_proj_model(torch.zeros_like(clip_image_embeds))
|
| 216 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 217 |
+
|
| 218 |
+
def set_scale(self, scale):
|
| 219 |
+
for attn_processor in self.pipe.unet.attn_processors.values():
|
| 220 |
+
if isinstance(attn_processor, IPAttnProcessor):
|
| 221 |
+
attn_processor.scale = scale
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def generate(
|
| 225 |
+
self,
|
| 226 |
+
pil_image=None,
|
| 227 |
+
image_broken=None,
|
| 228 |
+
clip_image_embeds=None,
|
| 229 |
+
prompt=None,
|
| 230 |
+
negative_prompt=None,
|
| 231 |
+
scale=1.0,
|
| 232 |
+
num_samples=4,
|
| 233 |
+
seed=None,
|
| 234 |
+
guidance_scale=7.5,
|
| 235 |
+
num_inference_steps=50,
|
| 236 |
+
**kwargs,
|
| 237 |
+
):
|
| 238 |
+
self.set_scale(scale)
|
| 239 |
+
|
| 240 |
+
# 这段代码是一个生成方法,用于生成图像。首先,它根据传入的参数设置了一些默认值,然后调用了self.set_scale方法来设置缩放比例。
|
| 241 |
+
# 接着,根据传入的pil_image和clip_image_embeds参数,确定num_prompts的值。
|
| 242 |
+
if pil_image is not None:
|
| 243 |
+
num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
|
| 244 |
+
else:
|
| 245 |
+
num_prompts = clip_image_embeds.size(0)
|
| 246 |
+
|
| 247 |
+
# 然后,它对prompt和negative_prompt进行了处理,确保它们是列表类型。
|
| 248 |
+
if prompt is None:
|
| 249 |
+
prompt = "best quality, high quality"
|
| 250 |
+
if negative_prompt is None:
|
| 251 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 252 |
+
|
| 253 |
+
if not isinstance(prompt, List):
|
| 254 |
+
prompt = [prompt] * num_prompts
|
| 255 |
+
if not isinstance(negative_prompt, List):
|
| 256 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 257 |
+
|
| 258 |
+
# 接着,它调用self.get_image_embeds方法获取图像提示的嵌入表示,并对这些表示进行了扩展,以便用于生成多个样本。
|
| 259 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(
|
| 260 |
+
pil_image=pil_image, clip_image_embeds=clip_image_embeds
|
| 261 |
+
)
|
| 262 |
+
# image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(
|
| 263 |
+
# pil_image=pil_image, image_broken=image_broken, clip_image_embeds=clip_image_embeds
|
| 264 |
+
# )
|
| 265 |
+
# 上面这行代码包含两个事,首先是使用clip的图像编码器将图像编码为[1,1024]的向量,然后调用IPAdapter自己的投影网络#89将图像encoder结果投影到[1,4,768]的特征序列上
|
| 266 |
+
# 这行代码的作用是将uncond_image_prompt_embeds的形状从(bs_embed, seq_len, -1)变换为(bs_embed * num_samples, seq_len, -1)。
|
| 267 |
+
# 这样做的效果是将uncond_image_prompt_embeds中的每个样本都重复num_samples次,以便在后续的处理中能够同时处理多个样本。
|
| 268 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 269 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 270 |
+
# image_prompt_embeds.shape:torch.Size([1, 4, 768]
|
| 271 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 272 |
+
# image_prompt_embeds.shape:torch.Size([1, 4, 768]
|
| 273 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 274 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
# 在获取了图像提示的embedding表示后,它使用torch.inference_mode()进入推断模式,然后调用self.pipe.encode_prompt方法获取提示的嵌入表示
|
| 278 |
+
with torch.inference_mode():
|
| 279 |
+
prompt_embeds_, negative_prompt_embeds_ = self.pipe.encode_prompt(
|
| 280 |
+
prompt,
|
| 281 |
+
device=self.device,
|
| 282 |
+
num_images_per_prompt=num_samples,
|
| 283 |
+
do_classifier_free_guidance=True,
|
| 284 |
+
negative_prompt=negative_prompt,
|
| 285 |
+
)
|
| 286 |
+
# prompt_embeds_.shape:torch.Size([1, 77, 768]
|
| 287 |
+
# 接着,它将获取的提示嵌入表示与图像提示的嵌入表示进行拼接,得到最终的提示嵌入表示和负面提示嵌入表示。
|
| 288 |
+
prompt_embeds = torch.cat([prompt_embeds_, image_prompt_embeds], dim=1)
|
| 289 |
+
# prompt_embeds.shape:[1, 81, 768]
|
| 290 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds_, uncond_image_prompt_embeds], dim=1)
|
| 291 |
+
|
| 292 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 293 |
+
# 最后,它使用self.pipe方法,传入提示嵌入表示、负面提示嵌入表示以及其他参数,来生成图像。生成的图像存储在images中,并最终返回。
|
| 294 |
+
images = self.pipe(
|
| 295 |
+
prompt_embeds=prompt_embeds,
|
| 296 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 297 |
+
guidance_scale=guidance_scale,
|
| 298 |
+
num_inference_steps=num_inference_steps,
|
| 299 |
+
generator=generator,
|
| 300 |
+
**kwargs,
|
| 301 |
+
).images
|
| 302 |
+
|
| 303 |
+
return images
|
| 304 |
+
|
| 305 |
+
# image_proj_model = MLPProjModel
|
| 306 |
+
class IPAdapterXL(IPAdapter):
|
| 307 |
+
"""SDXL"""
|
| 308 |
+
|
| 309 |
+
def generate(
|
| 310 |
+
self,
|
| 311 |
+
pil_image,
|
| 312 |
+
prompt=None,
|
| 313 |
+
negative_prompt=None,
|
| 314 |
+
scale=1.0,
|
| 315 |
+
num_samples=4,
|
| 316 |
+
seed=None,
|
| 317 |
+
num_inference_steps=50,
|
| 318 |
+
**kwargs,
|
| 319 |
+
):
|
| 320 |
+
self.set_scale(scale)
|
| 321 |
+
|
| 322 |
+
num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
|
| 323 |
+
|
| 324 |
+
if prompt is None:
|
| 325 |
+
prompt = "best quality, high quality"
|
| 326 |
+
#prompt = "cartoon style"
|
| 327 |
+
if negative_prompt is None:
|
| 328 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 329 |
+
|
| 330 |
+
if not isinstance(prompt, List):
|
| 331 |
+
prompt = [prompt] * num_prompts
|
| 332 |
+
if not isinstance(negative_prompt, List):
|
| 333 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 334 |
+
|
| 335 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image)
|
| 336 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 337 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 338 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 339 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 340 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 341 |
+
|
| 342 |
+
with torch.inference_mode():
|
| 343 |
+
(
|
| 344 |
+
prompt_embeds,
|
| 345 |
+
negative_prompt_embeds,
|
| 346 |
+
pooled_prompt_embeds,
|
| 347 |
+
negative_pooled_prompt_embeds,
|
| 348 |
+
) = self.pipe.encode_prompt(
|
| 349 |
+
prompt,
|
| 350 |
+
num_images_per_prompt=num_samples,
|
| 351 |
+
do_classifier_free_guidance=True,
|
| 352 |
+
negative_prompt=negative_prompt,
|
| 353 |
+
)
|
| 354 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 355 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 356 |
+
|
| 357 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 358 |
+
images = self.pipe(
|
| 359 |
+
prompt_embeds=prompt_embeds,
|
| 360 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 361 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 362 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 363 |
+
num_inference_steps=num_inference_steps,
|
| 364 |
+
generator=generator,
|
| 365 |
+
**kwargs,
|
| 366 |
+
).images
|
| 367 |
+
|
| 368 |
+
return images
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
# image_proj_model = Resampler
|
| 372 |
+
class IPAdapterPlus(IPAdapter):
|
| 373 |
+
"""IP-Adapter with fine-grained features"""
|
| 374 |
+
|
| 375 |
+
def init_proj(self):
|
| 376 |
+
image_proj_model = Resampler(
|
| 377 |
+
dim=self.pipe.unet.config.cross_attention_dim,
|
| 378 |
+
depth=4,
|
| 379 |
+
dim_head=64,
|
| 380 |
+
heads=12,
|
| 381 |
+
num_queries=self.num_tokens,
|
| 382 |
+
embedding_dim=self.image_encoder.config.hidden_size,
|
| 383 |
+
output_dim=self.pipe.unet.config.cross_attention_dim,
|
| 384 |
+
ff_mult=4,
|
| 385 |
+
).to(self.device, dtype=torch.float16)
|
| 386 |
+
return image_proj_model
|
| 387 |
+
|
| 388 |
+
@torch.inference_mode()
|
| 389 |
+
def get_image_embeds(self, pil_image=None, clip_image_embeds=None):
|
| 390 |
+
if isinstance(pil_image, Image.Image):
|
| 391 |
+
pil_image = [pil_image]
|
| 392 |
+
clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
| 393 |
+
clip_image = clip_image.to(self.device, dtype=torch.float16)
|
| 394 |
+
clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
| 395 |
+
image_prompt_embeds = self.image_proj_model(clip_image_embeds)
|
| 396 |
+
uncond_clip_image_embeds = self.image_encoder(
|
| 397 |
+
torch.zeros_like(clip_image), output_hidden_states=True
|
| 398 |
+
).hidden_states[-2]
|
| 399 |
+
uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
|
| 400 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 401 |
+
|
| 402 |
+
|
| 403 |
+
# image_proj_model = MLPProjModel
|
| 404 |
+
class IPAdapterFull(IPAdapterPlus):
|
| 405 |
+
"""IP-Adapter with full features"""
|
| 406 |
+
|
| 407 |
+
def init_proj(self):
|
| 408 |
+
image_proj_model = MLPProjModel(
|
| 409 |
+
cross_attention_dim=self.pipe.unet.config.cross_attention_dim,
|
| 410 |
+
clip_embeddings_dim=self.image_encoder.config.hidden_size,
|
| 411 |
+
).to(self.device, dtype=torch.float16)
|
| 412 |
+
return image_proj_model
|
| 413 |
+
|
| 414 |
+
# image_proj_model = Resampler(
|
| 415 |
+
class IPAdapterPlusXL(IPAdapter):
|
| 416 |
+
"""SDXL"""
|
| 417 |
+
|
| 418 |
+
def init_proj(self):
|
| 419 |
+
image_proj_model = Resampler(
|
| 420 |
+
dim=1280,
|
| 421 |
+
depth=4,
|
| 422 |
+
dim_head=64,
|
| 423 |
+
heads=20,
|
| 424 |
+
num_queries=self.num_tokens,
|
| 425 |
+
embedding_dim=self.image_encoder.config.hidden_size,
|
| 426 |
+
output_dim=self.pipe.unet.config.cross_attention_dim,
|
| 427 |
+
ff_mult=4,
|
| 428 |
+
).to(self.device, dtype=torch.float16)
|
| 429 |
+
return image_proj_model
|
| 430 |
+
|
| 431 |
+
@torch.inference_mode()
|
| 432 |
+
def get_image_embeds(self, pil_image):
|
| 433 |
+
if isinstance(pil_image, Image.Image):
|
| 434 |
+
pil_image = [pil_image]
|
| 435 |
+
clip_image = self.clip_image_processor(images=pil_image, return_tensors="pt").pixel_values
|
| 436 |
+
clip_image = clip_image.to(self.device, dtype=torch.float16)
|
| 437 |
+
clip_image_embeds = self.image_encoder(clip_image, output_hidden_states=True).hidden_states[-2]
|
| 438 |
+
image_prompt_embeds = self.image_proj_model(clip_image_embeds)
|
| 439 |
+
uncond_clip_image_embeds = self.image_encoder(
|
| 440 |
+
torch.zeros_like(clip_image), output_hidden_states=True
|
| 441 |
+
).hidden_states[-2]
|
| 442 |
+
uncond_image_prompt_embeds = self.image_proj_model(uncond_clip_image_embeds)
|
| 443 |
+
return image_prompt_embeds, uncond_image_prompt_embeds
|
| 444 |
+
|
| 445 |
+
def generate(
|
| 446 |
+
self,
|
| 447 |
+
pil_image,
|
| 448 |
+
prompt=None,
|
| 449 |
+
negative_prompt=None,
|
| 450 |
+
scale=1.0,
|
| 451 |
+
|
| 452 |
+
num_samples=4,
|
| 453 |
+
seed=None,
|
| 454 |
+
num_inference_steps=50,
|
| 455 |
+
**kwargs,
|
| 456 |
+
):
|
| 457 |
+
self.set_scale(scale)
|
| 458 |
+
|
| 459 |
+
num_prompts = 1 if isinstance(pil_image, Image.Image) else len(pil_image)
|
| 460 |
+
|
| 461 |
+
if prompt is None:
|
| 462 |
+
prompt = "best quality, high quality,blur"
|
| 463 |
+
if negative_prompt is None:
|
| 464 |
+
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
|
| 465 |
+
|
| 466 |
+
if not isinstance(prompt, List):
|
| 467 |
+
prompt = [prompt] * num_prompts
|
| 468 |
+
if not isinstance(negative_prompt, List):
|
| 469 |
+
negative_prompt = [negative_prompt] * num_prompts
|
| 470 |
+
|
| 471 |
+
image_prompt_embeds, uncond_image_prompt_embeds = self.get_image_embeds(pil_image)
|
| 472 |
+
bs_embed, seq_len, _ = image_prompt_embeds.shape
|
| 473 |
+
image_prompt_embeds = image_prompt_embeds.repeat(1, num_samples, 1)
|
| 474 |
+
image_prompt_embeds = image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 475 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.repeat(1, num_samples, 1)
|
| 476 |
+
uncond_image_prompt_embeds = uncond_image_prompt_embeds.view(bs_embed * num_samples, seq_len, -1)
|
| 477 |
+
|
| 478 |
+
with torch.inference_mode():
|
| 479 |
+
(
|
| 480 |
+
prompt_embeds,
|
| 481 |
+
negative_prompt_embeds,
|
| 482 |
+
pooled_prompt_embeds,
|
| 483 |
+
negative_pooled_prompt_embeds,
|
| 484 |
+
) = self.pipe.encode_prompt(
|
| 485 |
+
prompt,
|
| 486 |
+
num_images_per_prompt=num_samples,
|
| 487 |
+
do_classifier_free_guidance=True,
|
| 488 |
+
negative_prompt=negative_prompt,
|
| 489 |
+
)
|
| 490 |
+
prompt_embeds = torch.cat([prompt_embeds, image_prompt_embeds], dim=1)
|
| 491 |
+
negative_prompt_embeds = torch.cat([negative_prompt_embeds, uncond_image_prompt_embeds], dim=1)
|
| 492 |
+
|
| 493 |
+
generator = torch.Generator(self.device).manual_seed(seed) if seed is not None else None
|
| 494 |
+
images = self.pipe(
|
| 495 |
+
prompt_embeds=prompt_embeds,
|
| 496 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 497 |
+
pooled_prompt_embeds=pooled_prompt_embeds,
|
| 498 |
+
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
| 499 |
+
num_inference_steps=num_inference_steps,
|
| 500 |
+
generator=generator,
|
| 501 |
+
**kwargs,
|
| 502 |
+
).images
|
| 503 |
+
|
| 504 |
+
return images
|
ip_adapter/resampler.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/mlfoundations/open_flamingo/blob/main/open_flamingo/src/helpers.py
|
| 2 |
+
# and https://github.com/lucidrains/imagen-pytorch/blob/main/imagen_pytorch/imagen_pytorch.py
|
| 3 |
+
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
from einops.layers.torch import Rearrange
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
# FFN
|
| 13 |
+
def FeedForward(dim, mult=4):
|
| 14 |
+
inner_dim = int(dim * mult)
|
| 15 |
+
return nn.Sequential(
|
| 16 |
+
nn.LayerNorm(dim),
|
| 17 |
+
nn.Linear(dim, inner_dim, bias=False),
|
| 18 |
+
nn.GELU(),
|
| 19 |
+
nn.Linear(inner_dim, dim, bias=False),
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def reshape_tensor(x, heads):
|
| 24 |
+
bs, length, width = x.shape
|
| 25 |
+
# (bs, length, width) --> (bs, length, n_heads, dim_per_head)
|
| 26 |
+
x = x.view(bs, length, heads, -1)
|
| 27 |
+
# (bs, length, n_heads, dim_per_head) --> (bs, n_heads, length, dim_per_head)
|
| 28 |
+
x = x.transpose(1, 2)
|
| 29 |
+
# (bs, n_heads, length, dim_per_head) --> (bs*n_heads, length, dim_per_head)
|
| 30 |
+
x = x.reshape(bs, heads, length, -1)
|
| 31 |
+
return x
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class PerceiverAttention(nn.Module):
|
| 35 |
+
def __init__(self, *, dim, dim_head=64, heads=8):
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.scale = dim_head**-0.5
|
| 38 |
+
self.dim_head = dim_head
|
| 39 |
+
self.heads = heads
|
| 40 |
+
inner_dim = dim_head * heads
|
| 41 |
+
|
| 42 |
+
self.norm1 = nn.LayerNorm(dim)
|
| 43 |
+
self.norm2 = nn.LayerNorm(dim)
|
| 44 |
+
|
| 45 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 46 |
+
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
|
| 47 |
+
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
| 48 |
+
|
| 49 |
+
def forward(self, x, latents):
|
| 50 |
+
"""
|
| 51 |
+
Args:
|
| 52 |
+
x (torch.Tensor): image features
|
| 53 |
+
shape (b, n1, D)
|
| 54 |
+
latent (torch.Tensor): latent features
|
| 55 |
+
shape (b, n2, D)
|
| 56 |
+
"""
|
| 57 |
+
x = self.norm1(x)
|
| 58 |
+
latents = self.norm2(latents)
|
| 59 |
+
|
| 60 |
+
b, l, _ = latents.shape
|
| 61 |
+
|
| 62 |
+
q = self.to_q(latents)
|
| 63 |
+
kv_input = torch.cat((x, latents), dim=-2)
|
| 64 |
+
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
|
| 65 |
+
|
| 66 |
+
q = reshape_tensor(q, self.heads)
|
| 67 |
+
k = reshape_tensor(k, self.heads)
|
| 68 |
+
v = reshape_tensor(v, self.heads)
|
| 69 |
+
|
| 70 |
+
# attention
|
| 71 |
+
scale = 1 / math.sqrt(math.sqrt(self.dim_head))
|
| 72 |
+
weight = (q * scale) @ (k * scale).transpose(-2, -1) # More stable with f16 than dividing afterwards
|
| 73 |
+
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
| 74 |
+
out = weight @ v
|
| 75 |
+
|
| 76 |
+
out = out.permute(0, 2, 1, 3).reshape(b, l, -1)
|
| 77 |
+
|
| 78 |
+
return self.to_out(out)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class Resampler(nn.Module):
|
| 82 |
+
def __init__(
|
| 83 |
+
self,
|
| 84 |
+
dim=1024,
|
| 85 |
+
depth=8,
|
| 86 |
+
dim_head=64,
|
| 87 |
+
heads=16,
|
| 88 |
+
num_queries=8,
|
| 89 |
+
embedding_dim=768,
|
| 90 |
+
output_dim=1024,
|
| 91 |
+
ff_mult=4,
|
| 92 |
+
max_seq_len: int = 257, # CLIP tokens + CLS token
|
| 93 |
+
apply_pos_emb: bool = False,
|
| 94 |
+
num_latents_mean_pooled: int = 0, # number of latents derived from mean pooled representation of the sequence
|
| 95 |
+
):
|
| 96 |
+
super().__init__()
|
| 97 |
+
self.pos_emb = nn.Embedding(max_seq_len, embedding_dim) if apply_pos_emb else None
|
| 98 |
+
|
| 99 |
+
# 这行代码创建了一个可学习的参数self.latents,它是一个大小为1 x num_queries x dim的张量,张量中的值是从标准正态分布中随机抽取的,并且除以dim的平方根。这种初始化方法通常用于确保参数的初始值不会过大,有助于训练的稳定性。
|
| 100 |
+
self.latents = nn.Parameter(torch.randn(1, num_queries, dim) / dim**0.5)
|
| 101 |
+
|
| 102 |
+
# 这些代码定义了神经网络模型中的几个关键层:
|
| 103 |
+
# self.proj_in是一个线性变换层,它将输入的embedding_dim维度的特征映射到dim维度的特征。
|
| 104 |
+
# self.proj_out是另一个线性变换层,它将dim维度的特征映射到output_dim维度的特征。
|
| 105 |
+
# self.norm_out是一个LayerNorm层,用于对output_dim维度的特征进行层归一化。
|
| 106 |
+
self.proj_in = nn.Linear(embedding_dim, dim)
|
| 107 |
+
self.proj_out = nn.Linear(dim, output_dim)
|
| 108 |
+
self.norm_out = nn.LayerNorm(output_dim)
|
| 109 |
+
|
| 110 |
+
# 这段代码定义了一个处理层self.to_latents_from_mean_pooled_seq。
|
| 111 |
+
# 这个处理层是一个nn.Sequential,包含了一个LayerNorm层、一个线性变换层和一个形状变换层Rearrange。这些层被串联在一起,用于将输入的均值池化序列转换为latents。这个处理层只有在num_latents_mean_pooled大于0时才会被创建,否则被设为None。
|
| 112 |
+
self.to_latents_from_mean_pooled_seq = (
|
| 113 |
+
nn.Sequential(
|
| 114 |
+
nn.LayerNorm(dim),
|
| 115 |
+
nn.Linear(dim, dim * num_latents_mean_pooled),
|
| 116 |
+
Rearrange("b (n d) -> b n d", n=num_latents_mean_pooled),
|
| 117 |
+
)
|
| 118 |
+
if num_latents_mean_pooled > 0
|
| 119 |
+
else None
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
# 这段代码创建了一个神经网络模型的层结构self.layers。它使用了nn.ModuleList来存储多个层,其中每个层由PerceiverAttention和FeedForward两个子层组成。在一个循环中,根据给定的深度depth,将这些层添加到self.layers中。这种模块化的层结构可以方便地定义和管理复杂的神经网络模型。
|
| 123 |
+
self.layers = nn.ModuleList([])
|
| 124 |
+
for _ in range(depth):
|
| 125 |
+
self.layers.append(
|
| 126 |
+
nn.ModuleList(
|
| 127 |
+
[
|
| 128 |
+
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
| 129 |
+
FeedForward(dim=dim, mult=ff_mult),
|
| 130 |
+
]
|
| 131 |
+
)
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
def forward(self, x):
|
| 135 |
+
if self.pos_emb is not None:
|
| 136 |
+
n, device = x.shape[1], x.device
|
| 137 |
+
pos_emb = self.pos_emb(torch.arange(n, device=device))
|
| 138 |
+
x = x + pos_emb
|
| 139 |
+
|
| 140 |
+
latents = self.latents.repeat(x.size(0), 1, 1)
|
| 141 |
+
|
| 142 |
+
x = self.proj_in(x)
|
| 143 |
+
|
| 144 |
+
if self.to_latents_from_mean_pooled_seq:
|
| 145 |
+
meanpooled_seq = masked_mean(x, dim=1, mask=torch.ones(x.shape[:2], device=x.device, dtype=torch.bool))
|
| 146 |
+
meanpooled_latents = self.to_latents_from_mean_pooled_seq(meanpooled_seq)
|
| 147 |
+
latents = torch.cat((meanpooled_latents, latents), dim=-2)
|
| 148 |
+
|
| 149 |
+
for attn, ff in self.layers:
|
| 150 |
+
latents = attn(x, latents) + latents
|
| 151 |
+
latents = ff(latents) + latents
|
| 152 |
+
|
| 153 |
+
latents = self.proj_out(latents)
|
| 154 |
+
return self.norm_out(latents)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def masked_mean(t, *, dim, mask=None):
|
| 158 |
+
if mask is None:
|
| 159 |
+
return t.mean(dim=dim)
|
| 160 |
+
|
| 161 |
+
denom = mask.sum(dim=dim, keepdim=True)
|
| 162 |
+
mask = rearrange(mask, "b n -> b n 1")
|
| 163 |
+
masked_t = t.masked_fill(~mask, 0.0)
|
| 164 |
+
|
| 165 |
+
return masked_t.sum(dim=dim) / denom.clamp(min=1e-5)
|
ip_adapter/test_resampler.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from resampler import Resampler
|
| 3 |
+
from transformers import CLIPVisionModel
|
| 4 |
+
|
| 5 |
+
BATCH_SIZE = 2
|
| 6 |
+
OUTPUT_DIM = 1280
|
| 7 |
+
NUM_QUERIES = 8
|
| 8 |
+
NUM_LATENTS_MEAN_POOLED = 4 # 0 for no mean pooling (previous behavior)
|
| 9 |
+
APPLY_POS_EMB = True # False for no positional embeddings (previous behavior)
|
| 10 |
+
IMAGE_ENCODER_NAME_OR_PATH = "laion/CLIP-ViT-H-14-laion2B-s32B-b79K"
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def main():
|
| 14 |
+
image_encoder = CLIPVisionModel.from_pretrained(IMAGE_ENCODER_NAME_OR_PATH)
|
| 15 |
+
embedding_dim = image_encoder.config.hidden_size
|
| 16 |
+
print(f"image_encoder hidden size: ", embedding_dim)
|
| 17 |
+
|
| 18 |
+
image_proj_model = Resampler(
|
| 19 |
+
dim=1024,
|
| 20 |
+
depth=2,
|
| 21 |
+
dim_head=64,
|
| 22 |
+
heads=16,
|
| 23 |
+
num_queries=NUM_QUERIES,
|
| 24 |
+
embedding_dim=embedding_dim,
|
| 25 |
+
output_dim=OUTPUT_DIM,
|
| 26 |
+
ff_mult=2,
|
| 27 |
+
max_seq_len=257,
|
| 28 |
+
apply_pos_emb=APPLY_POS_EMB,
|
| 29 |
+
num_latents_mean_pooled=NUM_LATENTS_MEAN_POOLED,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
dummy_images = torch.randn(BATCH_SIZE, 3, 224, 224)
|
| 33 |
+
with torch.no_grad():
|
| 34 |
+
image_embeds = image_encoder(dummy_images, output_hidden_states=True).hidden_states[-2]
|
| 35 |
+
print("image_embds shape: ", image_embeds.shape)
|
| 36 |
+
|
| 37 |
+
with torch.no_grad():
|
| 38 |
+
ip_tokens = image_proj_model(image_embeds)
|
| 39 |
+
print("ip_tokens shape:", ip_tokens.shape)
|
| 40 |
+
assert ip_tokens.shape == (BATCH_SIZE, NUM_QUERIES + NUM_LATENTS_MEAN_POOLED, OUTPUT_DIM)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
if __name__ == "__main__":
|
| 44 |
+
main()
|
ip_adapter/utils.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn.functional as F
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def is_torch2_available():
|
| 5 |
+
return hasattr(F, "scaled_dot_product_attention")
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate==0.21.0
|
| 2 |
+
diffusers==0.28.2
|
| 3 |
+
einops==0.8.0
|
| 4 |
+
gradio==4.36.1
|
| 5 |
+
numpy==1.24.4
|
| 6 |
+
opencv-python==4.9.0.80
|
| 7 |
+
Pillow==9.4.0
|
| 8 |
+
safetensors==0.4.3
|
| 9 |
+
scipy==1.10.1
|
| 10 |
+
transformers==4.28.1
|