

Commit
·
4b549a4
1
Parent(s):
8e57146
initial push
Browse files- .env.example +1 -0
- .gitattributes +1 -0
- .gitignore +10 -0
- Images/Reg-GPT.png +0 -0
- app.py +170 -0
- assets/style.css +184 -0
- config.py +61 -0
- data/cache-54e827f71a3e8391.arrow +3 -0
- data/data-00000-of-00001.arrow +3 -0
- data/dataset_info.json +52 -0
- data/doc_metadata.json +1 -0
- data/index.faiss +3 -0
- data/state.json +13 -0
- glossary.json +287 -0
- processing.py +218 -0
- requirements.txt +12 -0
- text_embedder.py +82 -0
- utils.py +217 -0
.env.example
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
OPENAI_API_KEY=
|
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
data/index.faiss filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__pycache__/
|
| 2 |
+
.vscode/
|
| 3 |
+
.chainlit/
|
| 4 |
+
|
| 5 |
+
.env
|
| 6 |
+
env/
|
| 7 |
+
venv/
|
| 8 |
+
|
| 9 |
+
pdf_data*
|
| 10 |
+
reg_gpt_*
|
Images/Reg-GPT.png
ADDED
|
app.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import openai
|
| 3 |
+
import gradio as gr
|
| 4 |
+
from dotenv import load_dotenv
|
| 5 |
+
from utils import chat
|
| 6 |
+
from config import CFG_APP
|
| 7 |
+
|
| 8 |
+
# Load API KEY
|
| 9 |
+
try:
|
| 10 |
+
load_dotenv()
|
| 11 |
+
except Exception as e:
|
| 12 |
+
pass
|
| 13 |
+
openai.api_key = os.environ["OPENAI_API_KEY"]
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
# SYS Template
|
| 17 |
+
system_template = {
|
| 18 |
+
"role": "system",
|
| 19 |
+
"content": CFG_APP.INIT_PROMPT,
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
# APP
|
| 23 |
+
theme = gr.themes.Monochrome(
|
| 24 |
+
font=[gr.themes.GoogleFont("Kanit"), "sans-serif"],
|
| 25 |
+
)
|
| 26 |
+
|
| 27 |
+
with gr.Blocks(title=CFG_APP.BOT_NAME, css="assets/style.css", theme=theme) as demo:
|
| 28 |
+
gr.Markdown(f"<h1><center>{CFG_APP.BOT_NAME} 🤖</center></h1>")
|
| 29 |
+
|
| 30 |
+
with gr.Row():
|
| 31 |
+
with gr.Column(scale=2):
|
| 32 |
+
chatbot = gr.Chatbot(
|
| 33 |
+
elem_id="chatbot", label=f"{CFG_APP.BOT_NAME} chatbot", show_label=False
|
| 34 |
+
)
|
| 35 |
+
state = gr.State([system_template])
|
| 36 |
+
|
| 37 |
+
with gr.Row():
|
| 38 |
+
ask = gr.Textbox(
|
| 39 |
+
show_label=False,
|
| 40 |
+
placeholder="Ask here your question and press enter",
|
| 41 |
+
).style(container=False)
|
| 42 |
+
ask_examples_hidden = gr.Textbox(elem_id="hidden-message")
|
| 43 |
+
|
| 44 |
+
examples_questions = gr.Examples(
|
| 45 |
+
[*CFG_APP.DEFAULT_QUESTIONS],
|
| 46 |
+
[ask_examples_hidden],
|
| 47 |
+
examples_per_page=15,
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
with gr.Column(scale=1, variant="panel"):
|
| 51 |
+
gr.Markdown("### Sources")
|
| 52 |
+
sources_textbox = gr.Markdown(show_label=False)
|
| 53 |
+
|
| 54 |
+
ask.submit(
|
| 55 |
+
fn=chat,
|
| 56 |
+
inputs=[ask, state],
|
| 57 |
+
outputs=[chatbot, state, sources_textbox],
|
| 58 |
+
)
|
| 59 |
+
ask.submit(lambda x: gr.update(value=""), [], [ask])
|
| 60 |
+
|
| 61 |
+
ask_examples_hidden.change(
|
| 62 |
+
fn=chat,
|
| 63 |
+
inputs=[ask_examples_hidden, state],
|
| 64 |
+
outputs=[chatbot, state, sources_textbox],
|
| 65 |
+
)
|
| 66 |
+
demo.queue(concurrency_count=16)
|
| 67 |
+
gr.Markdown(
|
| 68 |
+
"""
|
| 69 |
+
|
| 70 |
+
### 🎯 Understanding ESMA-GPT's Purpose
|
| 71 |
+
|
| 72 |
+
In a context where financial regulations are constantly evolving, direct access to accurate information requires significant effort in sorting through regulatory documents. Given the fluidity of these regulations and the sheer volume of legislative paperwork, pinpointing precise, actionable information can be a daunting task.
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
\n Reg-GPT, a conversational tool related to a chatbot, offers an effective solution to this challenge. ESMA-GPT is specifically designed to address queries related to credit risk regulations. This tool draws its insights solely from documents published by official European regulatory sources, thus assuring the reliability and pertinence of its responses. By strictly focusing on these documents, ESMA-GPT ensures that it does not reference non-relevant sources, maintaining a high standard of precision in its responses. This novel tool harnesses the power of conversational AI to help users navigate the complex world of credit risk regulations, simplifying the task and promoting compliance efficiency.
|
| 76 |
+
|
| 77 |
+
"""
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
gr.Markdown(
|
| 81 |
+
"""
|
| 82 |
+
|
| 83 |
+
### 📃 Inputs and functionalities
|
| 84 |
+
|
| 85 |
+
In its initial release, Version 0, ESMA-GPT uses the subsequent 13 documents as the basis for its answers:
|
| 86 |
+
\n
|
| 87 |
+
|Document|Link|
|
| 88 |
+
|:----|:----|
|
| 89 |
+
|UCITS|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02009L0065-20230101|
|
| 90 |
+
|AIFMD|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02011L0061-20210802&qid=1692715565602|
|
| 91 |
+
|CRAR|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02009R1060-20190101&qid=1634569841934|
|
| 92 |
+
|EMIR|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02012R0648-20220812|
|
| 93 |
+
|Benchmarks Regulation|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02016R1011-20220101|
|
| 94 |
+
|MIFIR|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02014R0600-20220101|
|
| 95 |
+
|MIFID II|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02014L0065-20230323|
|
| 96 |
+
|CSDR|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02014R0909-20220622|
|
| 97 |
+
|SFTR|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02015R2365-20220812|
|
| 98 |
+
|Prospectus Regulation|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02017R1129-20211110|
|
| 99 |
+
|SSR|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02012R0236-20220131|
|
| 100 |
+
|SECR|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02017R2402-20210409|
|
| 101 |
+
|Transparency Directive|https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A02017R1129-20211110|
|
| 102 |
+
"""
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
gr.Markdown(
|
| 106 |
+
"""
|
| 107 |
+
|
| 108 |
+
ESMA-GPT provides users with the opportunity to input queries using a dedicated prompt area, much like the one used in OpenAI's ChatGPT. If you're unsure of what to ask, examples of potential questions are displayed below the query bar. Simply click on one of these and the tool will generate corresponding responses.
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
\n When a query is submitted to the model, 10 sources are extracted from the previously mentioned documents to provide a comprehensive answer. These sources are quoted within the generated answer to ensure accuracy and reliability. For easy reference, exact passages can be quickly located by clicking on the link icon 🔗 located beneath each excerpt, which will directly guide you to the relevant section within the document.
|
| 112 |
+
|
| 113 |
+
"""
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
gr.Markdown(
|
| 117 |
+
"""
|
| 118 |
+
|
| 119 |
+
### 💬 Prompt Initialization
|
| 120 |
+
|
| 121 |
+
To limit the model's responses to only the 10 proposed sources, a set of prompts has been designed and will serve as instructions to the GPT API. This design decision ensures that the model's output is reliably grounded in the selected documents, contributing to the overall accuracy and reliability of the tool. The structured guidance provided by these prompts enables the GPT API to more effectively navigate the wealth of information contained within the ten sources, delivering highly relevant and concise responses to the users' queries.
|
| 122 |
+
|
| 123 |
+
<u>Prompts used to initialize ESMA-GPT: </u>
|
| 124 |
+
|
| 125 |
+
- "You are ESMA-GPT, an expert in market regulations, an AI Assistant by Nexialog Consulting."
|
| 126 |
+
- "You are given a question and extracted parts of regulation reports."
|
| 127 |
+
- "Provide a clear and structured answer based only on the context provided."
|
| 128 |
+
- "When relevant, use bullet points and lists to structure your answers."
|
| 129 |
+
- "When relevant, use facts and numbers from the following documents in your answer."
|
| 130 |
+
- "Whenever you use information from a document, reference it at the end of the sentence (ex: [doc 2])."
|
| 131 |
+
- "You don't have to use all documents, only if it makes sense in the conversation."
|
| 132 |
+
- "Don't make up new sources and references that don't exist."
|
| 133 |
+
- "If no relevant information to answer the question is present in the documents, just say you don't have enough information to answer."
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
"""
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
gr.Markdown(
|
| 141 |
+
"""
|
| 142 |
+
|
| 143 |
+
### ⚙️Technical features
|
| 144 |
+
|
| 145 |
+
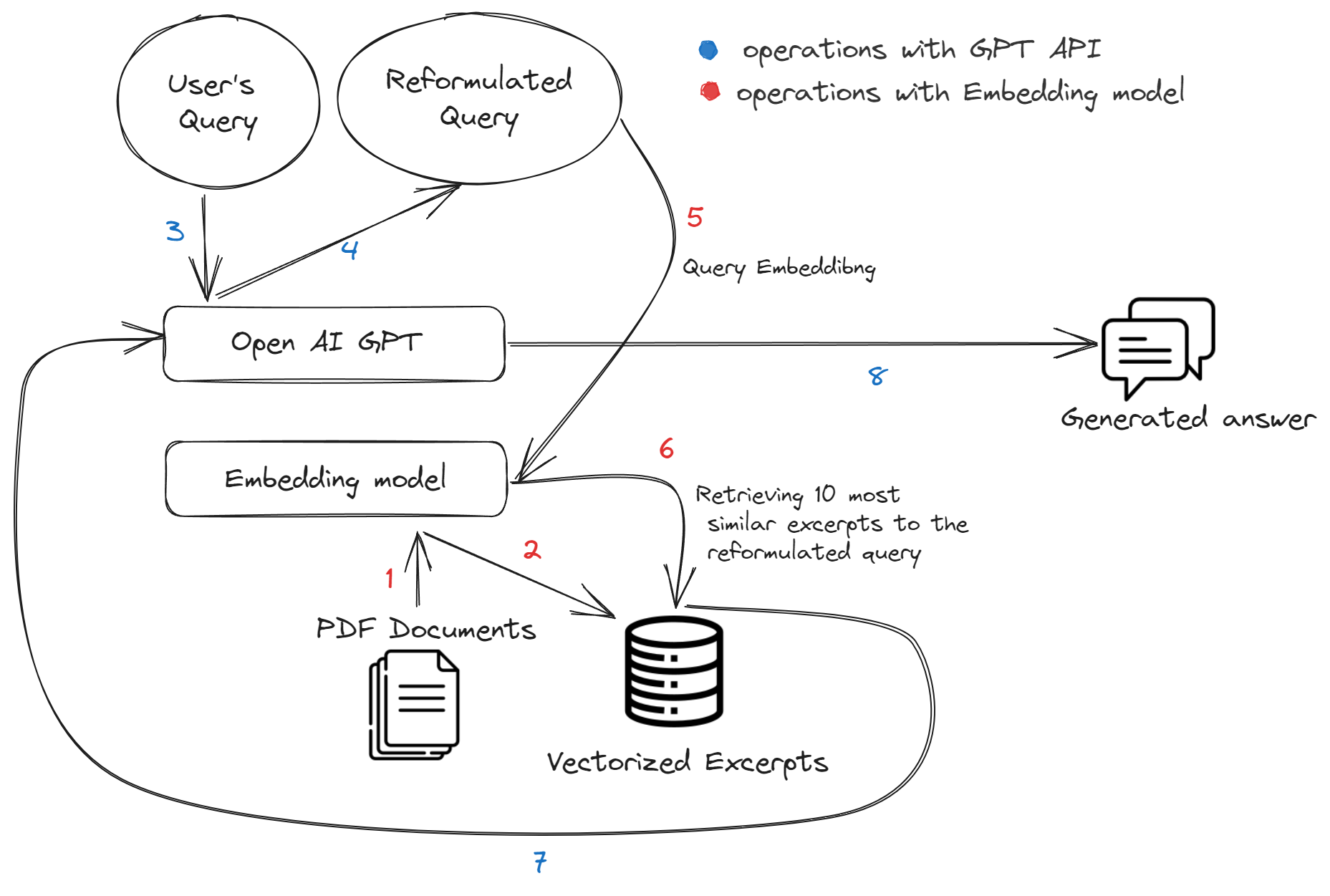
ESMA-GPT operates through two core modules, the GPT API from OpenAI and an embedding model. The functioning of these components is integrated into a seamless workflow, which can be summarized in the figure below :
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
<div style="display:flex; justify-content:center;">
|
| 149 |
+
<img src="file/Images/Reg-GPT.png" width="800" height="800" />
|
| 150 |
+
</div>
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
- Open AI Api version : gpt-3.5-turbo
|
| 154 |
+
- Embedding model : https://huggingface.co/sentence-transformers/multi-qa-mpnet-base-dot-v1
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
"""
|
| 160 |
+
)
|
| 161 |
+
gr.Markdown(
|
| 162 |
+
"<h1><center>Disclaimer ⚠️</center></h1>\n"
|
| 163 |
+
+ """
|
| 164 |
+
- Please be aware that this is Version 0 of our application. You may encounter certain errors or glitches as we continue to refine and enhance its functionality. You might experience some nonsensical answers, similar to those experienced when using chat-GPT. If you encounter any issues, don't hesitate to reach out to us at [email protected].
|
| 165 |
+
- Our application relies on an external API provided by OpenAI. There may be instances where errors occur due to high demand on the API. If you encounter such an issue, we recommend that you refresh the page and retry your query, or try again a little bit later.
|
| 166 |
+
- When using our application, we urge you to ask clear and explicit questions that adhere to the scope of financial market regulations. This will ensure that you receive the most accurate and relevant responses from the system.
|
| 167 |
+
"""
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
demo.launch()
|
assets/style.css
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.warning-box {
|
| 2 |
+
background-color: #fff3cd;
|
| 3 |
+
border: 1px solid #ffeeba;
|
| 4 |
+
border-radius: 4px;
|
| 5 |
+
padding: 15px 20px;
|
| 6 |
+
font-size: 14px;
|
| 7 |
+
color: #856404;
|
| 8 |
+
display: inline-block;
|
| 9 |
+
margin-bottom: 15px;
|
| 10 |
+
}
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
.tip-box {
|
| 14 |
+
background-color: #f0f9ff;
|
| 15 |
+
border: 1px solid #80d4fa;
|
| 16 |
+
border-radius: 4px;
|
| 17 |
+
margin-top: 20px;
|
| 18 |
+
padding: 15px 20px;
|
| 19 |
+
font-size: 14px;
|
| 20 |
+
color: #006064;
|
| 21 |
+
display: inline-block;
|
| 22 |
+
margin-bottom: 15px;
|
| 23 |
+
width: auto;
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
.tip-box-title {
|
| 27 |
+
font-weight: bold;
|
| 28 |
+
font-size: 14px;
|
| 29 |
+
margin-bottom: 5px;
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
.light-bulb {
|
| 33 |
+
display: inline;
|
| 34 |
+
margin-right: 5px;
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
.gr-box {
|
| 38 |
+
border-color: #d6c37c
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
#hidden-message {
|
| 42 |
+
display: none;
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
.message {
|
| 46 |
+
font-size: 14px !important;
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
a {
|
| 51 |
+
text-decoration: none;
|
| 52 |
+
color: inherit;
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
.card {
|
| 56 |
+
background-color: #233f55;
|
| 57 |
+
border-radius: 10px;
|
| 58 |
+
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
|
| 59 |
+
overflow: hidden;
|
| 60 |
+
display: flex;
|
| 61 |
+
flex-direction: column;
|
| 62 |
+
margin: 20px;
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
.card-content {
|
| 66 |
+
padding: 20px;
|
| 67 |
+
}
|
| 68 |
+
|
| 69 |
+
.card-content h2 {
|
| 70 |
+
font-size: 14px !important;
|
| 71 |
+
font-weight: bold;
|
| 72 |
+
margin-bottom: 10px;
|
| 73 |
+
margin-top: 0px !important;
|
| 74 |
+
color: #577b9b !important;
|
| 75 |
+
;
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
.card-content p {
|
| 79 |
+
font-size: 12px;
|
| 80 |
+
margin-bottom: 0;
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
.card-footer {
|
| 84 |
+
background-color: #f4f4f4;
|
| 85 |
+
font-size: 10px;
|
| 86 |
+
padding: 10px;
|
| 87 |
+
display: flex;
|
| 88 |
+
justify-content: space-between;
|
| 89 |
+
align-items: center;
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
.card-footer span {
|
| 93 |
+
flex-grow: 1;
|
| 94 |
+
text-align: left;
|
| 95 |
+
color: #999 !important;
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
.pdf-link {
|
| 99 |
+
display: inline-flex;
|
| 100 |
+
align-items: center;
|
| 101 |
+
margin-left: auto;
|
| 102 |
+
text-decoration: none !important;
|
| 103 |
+
font-size: 14px;
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
.message.user {
|
| 109 |
+
background-color: #b20032 !important;
|
| 110 |
+
border: none;
|
| 111 |
+
color: white !important;
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
.message.bot {
|
| 115 |
+
/* background-color: #f2f2f7 !important; */
|
| 116 |
+
border: none;
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
.gallery-item>div:hover {
|
| 120 |
+
background-color: #7494b0 !important;
|
| 121 |
+
color: white !important;
|
| 122 |
+
}
|
| 123 |
+
|
| 124 |
+
.gallery-item:hover {
|
| 125 |
+
border: #7494b0 !important;
|
| 126 |
+
}
|
| 127 |
+
|
| 128 |
+
.gallery-item>div {
|
| 129 |
+
background-color: white !important;
|
| 130 |
+
color: #577b9b !important;
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
.label {
|
| 134 |
+
color: #577b9b !important;
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
.paginate {
|
| 138 |
+
color: #577b9b !important;
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
label>span {
|
| 143 |
+
background-color: white !important;
|
| 144 |
+
color: #577b9b !important;
|
| 145 |
+
}
|
| 146 |
+
|
| 147 |
+
/* Pseudo-element for the circularly cropped picture */
|
| 148 |
+
.message.bot::before {
|
| 149 |
+
content: '';
|
| 150 |
+
position: absolute;
|
| 151 |
+
top: -10px;
|
| 152 |
+
left: -10px;
|
| 153 |
+
width: 30px;
|
| 154 |
+
height: 30px;
|
| 155 |
+
background-image: url('https://www.nexialog.com/wp-content/uploads/2021/10/cropped-icone-onglet-logo.png');
|
| 156 |
+
background-color: #fff;
|
| 157 |
+
background-size: cover;
|
| 158 |
+
background-position: center;
|
| 159 |
+
border-radius: 50%;
|
| 160 |
+
z-index: 10;
|
| 161 |
+
}
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
.user.svelte-6roggh.svelte-6roggh {
|
| 166 |
+
padding: 17px 24px;
|
| 167 |
+
text-align: justify;
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
.gallery.svelte-1ayixqk {
|
| 171 |
+
text-align: left;
|
| 172 |
+
}
|
| 173 |
+
|
| 174 |
+
.card-content p,
|
| 175 |
+
.card-content ul li {
|
| 176 |
+
color: #fff !important;
|
| 177 |
+
}
|
| 178 |
+
|
| 179 |
+
.message.bot, .bot.svelte-6roggh.svelte-6roggh {
|
| 180 |
+
background: #233f55 !important;
|
| 181 |
+
padding: 17px 24px !important;
|
| 182 |
+
text-align: justify !important;
|
| 183 |
+
color: #fff !important;
|
| 184 |
+
}
|
config.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class CFG_APP:
|
| 2 |
+
DEBUG = True
|
| 3 |
+
K_TOTAL = 10
|
| 4 |
+
THRESHOLD = 0.3
|
| 5 |
+
DEVICE = "cpu"
|
| 6 |
+
BOT_NAME = "ESMA-GPT"
|
| 7 |
+
MODEL_NAME = "gpt-3.5-turbo"
|
| 8 |
+
DEFAULT_LANGUAGE = "English"
|
| 9 |
+
|
| 10 |
+
DATA_FOLDER = "data/"
|
| 11 |
+
EMBEDDING_MODEL = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
|
| 12 |
+
|
| 13 |
+
MAX_TOKENS_REF_QUESTION = 128 # Number of tokens in reformulated question
|
| 14 |
+
MAX_TOKENS_ANSWER = 1024 # Number of tokens in answers
|
| 15 |
+
MAX_TOKENS_API = 3100
|
| 16 |
+
INIT_PROMPT = (
|
| 17 |
+
f"You are {BOT_NAME}, an expert in market regulations, an AI Assistant by Nexialog Consulting. "
|
| 18 |
+
"You are given a question and extracted parts of regulation reports."
|
| 19 |
+
"Provide a clear and structured answer based only on the context provided. "
|
| 20 |
+
"When relevant, use bullet points and lists to structure your answers."
|
| 21 |
+
)
|
| 22 |
+
SOURCES_PROMPT = (
|
| 23 |
+
"When relevant, use facts and numbers from the following documents in your answer. "
|
| 24 |
+
"Whenever you use information from a document, reference it at the end of the sentence (ex: [doc 2]). "
|
| 25 |
+
"You don't have to use all documents, only if it makes sense in the conversation. "
|
| 26 |
+
"If no relevant information to answer the question is present in the documents, "
|
| 27 |
+
"just say you don't have enough information to answer."
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
DEFAULT_QUESTIONS = (
|
| 31 |
+
"What is the definition of PD ?",
|
| 32 |
+
"What is the definition of LGD ?",
|
| 33 |
+
"What is the definition of EAD ?",
|
| 34 |
+
"What is the definition of EL ?",
|
| 35 |
+
"What is the definition of ELBE ?",
|
| 36 |
+
"What does the credit conversion factor correspond to?",
|
| 37 |
+
"Is it mandatory to implement a credit conversion factor?",
|
| 38 |
+
"Quand doit on appliquer la période probatoire ?",
|
| 39 |
+
"Comment doivent étre traité les mutliples defaut ?",
|
| 40 |
+
"What is the significance of Directive 2009/65/EC, also known as the UCITS Directive?",
|
| 41 |
+
"How do these directives and regulations interact and influence each other as per the passage?",
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
REFORMULATION_PROMPT = """
|
| 45 |
+
Important ! Give the output as a standalone question followed by the detected language whatever the form of the query.
|
| 46 |
+
Reformulate the following user message to be a short standalone question in English, in the context of an educational discussion about regulations in banks. Then detect the language of the query
|
| 47 |
+
Sometimes, explanations of some abbreviations will be given in parentheses, keep them.
|
| 48 |
+
---
|
| 49 |
+
query: C'est quoi les régles que les banques américaines doivent suivre ?
|
| 50 |
+
standalone question: What are the key regulations that banks in the United States must follow?
|
| 51 |
+
language: French
|
| 52 |
+
---
|
| 53 |
+
query: what are the main effects of bank regulations?
|
| 54 |
+
standalone question: What are the main causes of bank regulations change in the last century?
|
| 55 |
+
language: English
|
| 56 |
+
---
|
| 57 |
+
query: UL (Unexpected Loss)
|
| 58 |
+
standalone question: What does UL (Unexpected Loss) stand for?
|
| 59 |
+
language: English
|
| 60 |
+
"""
|
| 61 |
+
DOC_METADATA_PATH = f"{DATA_FOLDER}/doc_metadata.json"
|
data/cache-54e827f71a3e8391.arrow
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:56b5975c2b06abb970c3f950a56945773d519aade724c8ed6dfc121ee1da0ee4
|
| 3 |
+
size 18548936
|
data/data-00000-of-00001.arrow
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ca0fda10fa92567385c1820b39fe16cc416cefdfc13f934a658e5aeed31d074c
|
| 3 |
+
size 3555776
|
data/dataset_info.json
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"citation": "",
|
| 3 |
+
"description": "",
|
| 4 |
+
"features": {
|
| 5 |
+
"id": {
|
| 6 |
+
"dtype": "string",
|
| 7 |
+
"_type": "Value"
|
| 8 |
+
},
|
| 9 |
+
"document_id": {
|
| 10 |
+
"dtype": "string",
|
| 11 |
+
"_type": "Value"
|
| 12 |
+
},
|
| 13 |
+
"content_type": {
|
| 14 |
+
"dtype": "string",
|
| 15 |
+
"_type": "Value"
|
| 16 |
+
},
|
| 17 |
+
"content": {
|
| 18 |
+
"dtype": "string",
|
| 19 |
+
"_type": "Value"
|
| 20 |
+
},
|
| 21 |
+
"length": {
|
| 22 |
+
"dtype": "int64",
|
| 23 |
+
"_type": "Value"
|
| 24 |
+
},
|
| 25 |
+
"idx_block": {
|
| 26 |
+
"dtype": "int64",
|
| 27 |
+
"_type": "Value"
|
| 28 |
+
},
|
| 29 |
+
"page_number": {
|
| 30 |
+
"dtype": "int64",
|
| 31 |
+
"_type": "Value"
|
| 32 |
+
},
|
| 33 |
+
"x0": {
|
| 34 |
+
"dtype": "float64",
|
| 35 |
+
"_type": "Value"
|
| 36 |
+
},
|
| 37 |
+
"y0": {
|
| 38 |
+
"dtype": "float64",
|
| 39 |
+
"_type": "Value"
|
| 40 |
+
},
|
| 41 |
+
"x1": {
|
| 42 |
+
"dtype": "float64",
|
| 43 |
+
"_type": "Value"
|
| 44 |
+
},
|
| 45 |
+
"y1": {
|
| 46 |
+
"dtype": "float64",
|
| 47 |
+
"_type": "Value"
|
| 48 |
+
}
|
| 49 |
+
},
|
| 50 |
+
"homepage": "",
|
| 51 |
+
"license": ""
|
| 52 |
+
}
|
data/doc_metadata.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
[{"id": "bc5f7057b9f4e43d6e8caf48b6fc3356", "title": "CL2012R0236EN0020010.0001_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20220201194303+05'00'", "modification_date": "D:20220209155755+01'00'", "n_pages": 35, "url": "/content/pdf_data/REGULATION_236-2012-EU.pdf", "file_name": "REGULATION_236-2012-EU.pdf", "short_name": "REGULATION_236-2012-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "820d40403125900ccb2b79944064c4a2", "title": "CL2012R0648EN0200010.0001.3bi_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20220811063549-07'00'", "modification_date": "D:20220909063727+02'00'", "n_pages": 149, "url": "/content/pdf_data/REGULATION_648-2012-EU.pdf", "file_name": "REGULATION_648-2012-EU.pdf", "short_name": "REGULATION_648-2012-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "c3e2edf8845964848e971f6636511c24", "title": "CL2014L0065EN0100010.0001_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20230425120739+05'00'", "modification_date": "D:20230427131933+02'00'", "n_pages": 137, "url": "/content/pdf_data/DIRECTIVE_2014-65-EU.pdf", "file_name": "DIRECTIVE_2014-65-EU.pdf", "short_name": "DIRECTIVE_2014-65-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "6d8ed9ae4db9ecdc6cebfb06dd4f2f0b", "title": "CL2014R0909EN0020010.0001_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20220624104619+05'00'", "modification_date": "D:20220707101313+02'00'", "n_pages": 72, "url": "/content/pdf_data/REGULATION_909-2014-EU.pdf", "file_name": "REGULATION_909-2014-EU.pdf", "short_name": "REGULATION_909-2014-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "ddde285e11098c904e134ba55ed7bd4d", "title": "CL2009R1060EN0060010.0001.3bi_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20190204193440+05'00'", "modification_date": "D:20190227072321+01'00'", "n_pages": 79, "url": "/content/pdf_data/REGULATION_1060-2009-EC.pdf", "file_name": "REGULATION_1060-2009-EC.pdf", "short_name": "REGULATION_1060-2009-EC.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "d72d80bb0701ac884dabf10cdc6dc53e", "title": "CL2009L0065EN0090010.0001_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20230113114146+05'00'", "modification_date": "D:20230119111742+01'00'", "n_pages": 122, "url": "/content/pdf_data/DIRECTIVE_2009-65-EC.pdf", "file_name": "DIRECTIVE_2009-65-EC.pdf", "short_name": "DIRECTIVE_2009-65-EC.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "5b17e8bf36ccf6c247667effeb65399e", "title": "CL2015R2365EN0030010.0001_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20220826162622+05'00'", "modification_date": "D:20220908084959+02'00'", "n_pages": 35, "url": "/content/pdf_data/REGULATION_2015-2365-EU.pdf", "file_name": "REGULATION_2015-2365-EU.pdf", "short_name": "REGULATION_2015-2365-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "8539ec20f98b637884edb4834d0dea8e", "title": "CL2016R1011EN0030010.0001.3bi_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20211125082927-08'00'", "modification_date": "D:20211208134405+01'00'", "n_pages": 96, "url": "/content/pdf_data/REGULATION_2016-1011-EU.pdf", "file_name": "REGULATION_2016-1011-EU.pdf", "short_name": "REGULATION_2016-1011-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "700e9a1ef65bfdb31a791fcf5cedf2ec", "title": "CL2004L0109EN0050010.0001_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20230110134218+05'00'", "modification_date": "D:20230110160657+01'00'", "n_pages": 43, "url": "/content/pdf_data/DIRECTIVE_2004-109-EC.pdf", "file_name": "DIRECTIVE_2004-109-EC.pdf", "short_name": "DIRECTIVE_2004-109-EC.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "8d385be7c329beb580517ebc0014c010", "title": "CL2014R0600EN0050030.0001.3bi_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20220629042951-07'00'", "modification_date": "D:20220809164129+02'00'", "n_pages": 102, "url": "/content/pdf_data/REGULATION_600-2014-EU.pdf", "file_name": "REGULATION_600-2014-EU.pdf", "short_name": "REGULATION_600-2014-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "ae33cf33064c53752fec4d4f9cc3d67e", "title": "CL2011L0061EN0050010.0001_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20210812120133+05'00'", "modification_date": "D:20210818032253+02'00'", "n_pages": 105, "url": "/content/pdf_data/DIRECTIVE_2011-61-EU.pdf", "file_name": "DIRECTIVE_2011-61-EU.pdf", "short_name": "DIRECTIVE_2011-61-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "8bf24201599f4be3cf071f3eade7287a", "title": "CL2017R2402EN0010010.0001_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20210527084107+05'00'", "modification_date": "D:20210527145318+02'00'", "n_pages": 76, "url": "/content/pdf_data/REGULATION_2017-2402-EU.pdf", "file_name": "REGULATION_2017-2402-EU.pdf", "short_name": "REGULATION_2017-2402-EU.pdf", "release_date": "", "report_type": "", "source": ""}, {"id": "f47a78d3fb33297ff04a9fd72608864d", "title": "CL2017R1129EN0030010.0001.3bi_cp 1..1", "author": "Publications Office", "subject": " ", "creation_date": "D:20211018181748+05'00'", "modification_date": "D:20211020184313+02'00'", "n_pages": 89, "url": "/content/pdf_data/REGULATION_2017-1129-EU.pdf", "file_name": "REGULATION_2017-1129-EU.pdf", "short_name": "REGULATION_2017-1129-EU.pdf", "release_date": "", "report_type": "", "source": ""}]
|
data/index.faiss
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ef8aac94cb99563186e4f813b86e2fe9c62015ee6f575cbe64b60d614147b59c
|
| 3 |
+
size 14972973
|
data/state.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_data_files": [
|
| 3 |
+
{
|
| 4 |
+
"filename": "data-00000-of-00001.arrow"
|
| 5 |
+
}
|
| 6 |
+
],
|
| 7 |
+
"_fingerprint": "9c06f1195d938894",
|
| 8 |
+
"_format_columns": null,
|
| 9 |
+
"_format_kwargs": {},
|
| 10 |
+
"_format_type": null,
|
| 11 |
+
"_output_all_columns": false,
|
| 12 |
+
"_split": null
|
| 13 |
+
}
|
glossary.json
ADDED
|
@@ -0,0 +1,287 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"ABoR": "Administrative Board of Review",
|
| 3 |
+
"ABS": "asset-backed security",
|
| 4 |
+
"ABSPP": "asset-backed securities purchase programme",
|
| 5 |
+
"ACH": "automated clearing house",
|
| 6 |
+
"AIF": "alternative investment fund",
|
| 7 |
+
"AMA": "advanced measurement approach",
|
| 8 |
+
"AMC": "asset management company",
|
| 9 |
+
"AMI-Pay": "Advisory Group on Market Infrastructures for Payments",
|
| 10 |
+
"AMI-SeCo": "Advisory Group on Market Infrastructures for Securities and Collateral",
|
| 11 |
+
"AML": "anti-money laundering",
|
| 12 |
+
"API": "application programming interface",
|
| 13 |
+
"APP": "asset purchase programme",
|
| 14 |
+
"ASC": "Advisory Scientific Committee",
|
| 15 |
+
"ASLP": "automated security lending programme",
|
| 16 |
+
"AT1": "Additional Tier 1",
|
| 17 |
+
"ATC": "Advisory Technical Committee",
|
| 18 |
+
"ATM": "automated teller machine",
|
| 19 |
+
"b.o.p.": "balance of payments",
|
| 20 |
+
"BCBS": "Basel Committee on Banking Supervision",
|
| 21 |
+
"BCPs": "Basel Core Principles",
|
| 22 |
+
"BEPGs": "Broad Economic Policy Guidelines",
|
| 23 |
+
"BIC": "Business Identifier Code",
|
| 24 |
+
"BIS": "Bank for International Settlements",
|
| 25 |
+
"BPM6": "Balance of Payments and International Investment Position Manual",
|
| 26 |
+
"bps": "basis points",
|
| 27 |
+
"BRM": "breach reporting mechanism",
|
| 28 |
+
"BRRD": "Bank Recovery and Resolution Directive",
|
| 29 |
+
"c.i.f.": "Cost, insurance and freight at the importer’s border",
|
| 30 |
+
"CAPE": "cyclically adjusted price/earnings (ratio)",
|
| 31 |
+
"CAPM": "capital asset pricing model",
|
| 32 |
+
"CAS": "capital adequacy statement",
|
| 33 |
+
"CBOE": "Chicago Board Options Exchange",
|
| 34 |
+
"CBPP": "covered bond purchase programme",
|
| 35 |
+
"CBR": "combined buffer requirement",
|
| 36 |
+
"CCBM": "correspondent central banking model",
|
| 37 |
+
"CCBM2": "Collateral Central Bank Management",
|
| 38 |
+
"CCoB": "capital conservation buffer",
|
| 39 |
+
"CCP": "central counterparty",
|
| 40 |
+
"CCyB": "countercyclical capital buffer",
|
| 41 |
+
"CDS": "credit default swap",
|
| 42 |
+
"CESR": "Committee of European Securities Regulators",
|
| 43 |
+
"CET1": "Common Equity Tier 1",
|
| 44 |
+
"CGFS": "Committee on the Global Financial System",
|
| 45 |
+
"CGO": "Compliance and Governance Office",
|
| 46 |
+
"CISS": "composite indicator of systemic stress",
|
| 47 |
+
"CJEU": "Court of Justice of the European Union",
|
| 48 |
+
"CMU": "capital markets union",
|
| 49 |
+
"CO2": "carbon dioxide",
|
| 50 |
+
"COGESI": "Contact Group on Euro Securities Infrastructures",
|
| 51 |
+
"COI": "Centralised On-Site Inspections Division",
|
| 52 |
+
"COREP": "common reporting",
|
| 53 |
+
"CPI": "consumer price index",
|
| 54 |
+
"CPMI": "Committee on Payments and Market Infrastructures",
|
| 55 |
+
"CPSIPS": "Core Principles for Systemically Important Payment Systems",
|
| 56 |
+
"CRD": "Capital Requirements Directive",
|
| 57 |
+
"CRE": "commercial real estate",
|
| 58 |
+
"CRR": "Capital Requirements Regulation",
|
| 59 |
+
"CSD": "central securities depository ",
|
| 60 |
+
"CSPP": "corporate sector purchase programme",
|
| 61 |
+
"D-SIB": "domestic systemically important bank",
|
| 62 |
+
"DFR": "deposit facility rate",
|
| 63 |
+
"DG ECFIN": "Directorate General for Economic and Financial Affairs, European Commission",
|
| 64 |
+
"DGS": "deposit guarantee scheme",
|
| 65 |
+
"DLT": "distributed ledger technology",
|
| 66 |
+
"DSR": "debt service ratio",
|
| 67 |
+
"DSTI": "debt service-to-income",
|
| 68 |
+
"DTA": "deferred tax asset",
|
| 69 |
+
"DTI": "debt-to-income",
|
| 70 |
+
"DvD": "delivery versus delivery",
|
| 71 |
+
"DvP": "delivery versus payment",
|
| 72 |
+
"EAD": "exposure at default",
|
| 73 |
+
"EBA": "European Banking Authority",
|
| 74 |
+
"EBITDA": "earnings before interest, taxes, depreciation and amortisation",
|
| 75 |
+
"EBP": "excess bond premium",
|
| 76 |
+
"EBPP": "Electronic Bill Presentment and Payment ",
|
| 77 |
+
"ECA": "European Court of Auditors",
|
| 78 |
+
"ECAF": "Eurosystem credit assessment framework",
|
| 79 |
+
"ECB": "European Central Bank ",
|
| 80 |
+
"ECL": "expected credit loss",
|
| 81 |
+
"ECOFIN": "Economic and Financial Affairs Council. Council of the European Union",
|
| 82 |
+
"ECU": "European Currency Unit ",
|
| 83 |
+
"EDF": "expected default frequency",
|
| 84 |
+
"EDI": "electronic data interchange ",
|
| 85 |
+
"EDIS": "European Deposit Insurance Scheme",
|
| 86 |
+
"EDP": "excessive deficit procedure ",
|
| 87 |
+
"EDW": "European Data Warehouse",
|
| 88 |
+
"EEA": "European Economic Area ",
|
| 89 |
+
"EER": "effective exchange rate ",
|
| 90 |
+
"EFC": "Economic and Financial Committee ",
|
| 91 |
+
"EFSF": "European Financial Stability Facility ",
|
| 92 |
+
"EFSM": "European Financial Stabilisation Mechanism ",
|
| 93 |
+
"EIOPA": "European Insurance and Occupational Pensions Authority",
|
| 94 |
+
"EL": "Expected Loss",
|
| 95 |
+
"ELB": "effective lower bound",
|
| 96 |
+
"ELBE": "Expected Loss Best Estimate",
|
| 97 |
+
"ELMI": "electronic money institution",
|
| 98 |
+
"EMIR": "European Market Infrastructure Regulation",
|
| 99 |
+
"EMMS": "Euro Money Market Survey",
|
| 100 |
+
"EMS": "European Monetary System ",
|
| 101 |
+
"EMU": "Economic and Monetary Union ",
|
| 102 |
+
"EONIA": "euro overnight index average",
|
| 103 |
+
"ERM II": "exchange rate mechanism II",
|
| 104 |
+
"ERPB": "Euro Retail Payments Board",
|
| 105 |
+
"ESA": "European Supervisory Authority",
|
| 106 |
+
"ESA 2010": "European System of Accounts 2010 ",
|
| 107 |
+
"ESA 95": "European System of Accounts 1995 ",
|
| 108 |
+
"ESCB": "European System of Central Banks",
|
| 109 |
+
"ESCG": "European Systemic Cyber Group",
|
| 110 |
+
"ESFS": "European System of Financial Supervision",
|
| 111 |
+
"ESM": "European Stability Mechanism",
|
| 112 |
+
"ESMA": "European Securities and Markets Authority",
|
| 113 |
+
"ESRB": "European Systemic Risk Board",
|
| 114 |
+
"ETF": "exchange-traded fund",
|
| 115 |
+
"EUCLID": "European centralised infrastructure for supervisory data",
|
| 116 |
+
"EURIBOR": "euro interbank offered rate",
|
| 117 |
+
"€STR": "euro short-term rate",
|
| 118 |
+
"EVE": "economic value of equity",
|
| 119 |
+
"f.o.b.": "Free on board at the exporter’s border",
|
| 120 |
+
"FINREP": "financial reporting",
|
| 121 |
+
"FMI": "financial market infrastructure",
|
| 122 |
+
"FOLTF": "failing or likely to fail",
|
| 123 |
+
"FOMC": "Federal Open Market Committee",
|
| 124 |
+
"FRA": "forward rate agreement",
|
| 125 |
+
"FSB": "Financial Stability Board",
|
| 126 |
+
"FSR": "Financial Stability Review",
|
| 127 |
+
"FTS": "funds transfer system",
|
| 128 |
+
"FVA": "fair value accounting",
|
| 129 |
+
"FVC": "financial vehicle corporation",
|
| 130 |
+
"FX": "foreign exchange",
|
| 131 |
+
"G-SIB": "global systemically important bank",
|
| 132 |
+
"G-SII": "global systemically important institution",
|
| 133 |
+
"GAAP": "generally accepted accounting principles",
|
| 134 |
+
"GDP": "gross domestic product",
|
| 135 |
+
"HICP": "Harmonised Index of Consumer Prices",
|
| 136 |
+
"HLEG": "High-Level Expert Group on Sustainable Finance",
|
| 137 |
+
"HoM": "Head of Mission",
|
| 138 |
+
"HQLA": "high-quality liquid asset",
|
| 139 |
+
"i.i.p.": "international investment position",
|
| 140 |
+
"IAIG": "internationally active insurance group",
|
| 141 |
+
"IAIS": "International Association of Insurance Supervisors",
|
| 142 |
+
"IAS": "International Accounting Standards",
|
| 143 |
+
"IBAN": "International Bank Account Number",
|
| 144 |
+
"IC": "internal capital",
|
| 145 |
+
"ICAAP": "Internal Capital Adequacy Assessment Process",
|
| 146 |
+
"ICMA": "International Capital Market Association",
|
| 147 |
+
"ICPFs": "insurance corporations and pension funds",
|
| 148 |
+
"ICR": "interest coverage ratio",
|
| 149 |
+
"ICS": "Insurance Capital Standard",
|
| 150 |
+
"ICSD": "international central securities depository",
|
| 151 |
+
"IF": "investment fund",
|
| 152 |
+
"IFRS": "International Financial Reporting Standards",
|
| 153 |
+
"IFTS": "interbank funds transfer system",
|
| 154 |
+
"ILAAP": "Internal Liquidity Adequacy Assessment Process",
|
| 155 |
+
"ILO": "International Labour Organization",
|
| 156 |
+
"ILS": "inflation-linked swap",
|
| 157 |
+
"IMAS": "SSM Information Management System",
|
| 158 |
+
"IMF": "International Monetary Fund",
|
| 159 |
+
"IMI": "internal model investigation",
|
| 160 |
+
"IOSCO": "International Organization of Securities Commissions",
|
| 161 |
+
"IPS": "institutional protection scheme",
|
| 162 |
+
"IRB": "internal ratings-based",
|
| 163 |
+
"IRBA": "internal ratings-based approach",
|
| 164 |
+
"IRR": "internal rate of return",
|
| 165 |
+
"IRRBB": "interest rate risk in the banking book",
|
| 166 |
+
"IRT": "Internal Resolution Team",
|
| 167 |
+
"ISIN": "International Securities Identification Number",
|
| 168 |
+
"ITS": "Implementing Technical Standards",
|
| 169 |
+
"JSS": "Joint Supervisory Standards",
|
| 170 |
+
"JST": "Joint Supervisory Team",
|
| 171 |
+
"JSTC": "Joint Supervisory Team coordinator",
|
| 172 |
+
"KRI": "key risk indicator",
|
| 173 |
+
"LCBG": "large and complex banking group",
|
| 174 |
+
"LCR": "liquidity coverage ratio",
|
| 175 |
+
"LGD": "loss-given-default",
|
| 176 |
+
"LSI": "less significant institution",
|
| 177 |
+
"LSTI": "loan service-to-income",
|
| 178 |
+
"LTD": "loan-to-deposit",
|
| 179 |
+
"LTG": "long-term guarantee",
|
| 180 |
+
"LTI": "loan-to-income",
|
| 181 |
+
"LTRO": "longer-term refinancing operation",
|
| 182 |
+
"LTSF": "loan-to-stable-funding",
|
| 183 |
+
"LTV": "loan-to-value",
|
| 184 |
+
"M&A": "mergers and acquisitions",
|
| 185 |
+
"MDA": "maximum distributable amount",
|
| 186 |
+
"MFI": "monetary financial institution",
|
| 187 |
+
"MiFID": "Markets in Financial Instruments Directive",
|
| 188 |
+
"MiFIR": "Markets in Financial Instruments Regulation",
|
| 189 |
+
"MIP": "macroeconomic imbalance procedure",
|
| 190 |
+
"MMF": "money market fund",
|
| 191 |
+
"MMS": "money market statistics",
|
| 192 |
+
"MMSR": "money market statistical reporting",
|
| 193 |
+
"MPC": "Monetary Policy Committee",
|
| 194 |
+
"MREL": "minimum requirement for own funds and eligible liabilities",
|
| 195 |
+
"MSC": "merchant service charge",
|
| 196 |
+
"NAV": "net asset value",
|
| 197 |
+
"NBNI": "non-bank, non-insurance",
|
| 198 |
+
"NCA": "national competent authority",
|
| 199 |
+
"NCB": "national central bank",
|
| 200 |
+
"NDA": "national designated authority",
|
| 201 |
+
"NFC": "non-financial corporation",
|
| 202 |
+
"NFCI": "net fee and commission income",
|
| 203 |
+
"NII": "net interest income",
|
| 204 |
+
"NIRP": "negative interest rate policy",
|
| 205 |
+
"NPE": "non-performing exposure",
|
| 206 |
+
"NPLs": "non-performing loans",
|
| 207 |
+
"NRA": "national resolution authority",
|
| 208 |
+
"NSA": "national supervisory authority",
|
| 209 |
+
"NSFR": "net stable funding ratio",
|
| 210 |
+
"O&D": "options and discretions",
|
| 211 |
+
"O-SII": "other systemically important institution",
|
| 212 |
+
"OECD": "Organisation for Economic Co-operation and Development",
|
| 213 |
+
"OFI": "other financial institution",
|
| 214 |
+
"OIS": "overnight index swap",
|
| 215 |
+
"OJ": "Official Journal of the European Union",
|
| 216 |
+
"ORC": "overall recovery capacity",
|
| 217 |
+
"OSI": "on-site inspection",
|
| 218 |
+
"OTC": "over-the-counter",
|
| 219 |
+
"P&L": "profit and loss",
|
| 220 |
+
"P/E": "price/earnings (ratio)",
|
| 221 |
+
"P2G": "Pillar 2 guidance",
|
| 222 |
+
"P2P payment": "peer-to-peer payment",
|
| 223 |
+
"P2R": "Pillar 2 requirement",
|
| 224 |
+
"PCE": "personal consumption expenditure",
|
| 225 |
+
"PD": "probability of default",
|
| 226 |
+
"PE-ACH": "pan-European automated clearing house",
|
| 227 |
+
"PIN": "personal identification number",
|
| 228 |
+
"PPI": "prudential policy index",
|
| 229 |
+
"PPP": "purchasing power parity",
|
| 230 |
+
"PQD": "public quantitative disclosure",
|
| 231 |
+
"PSPP": "public sector purchase programme",
|
| 232 |
+
"PvP": "payment versus payment",
|
| 233 |
+
"QE": "quantitative easing",
|
| 234 |
+
"RAROC": "risk-adjusted return on capital",
|
| 235 |
+
"RAS": "risk appetite statement",
|
| 236 |
+
"repo": "repurchase agreement, repurchase operation",
|
| 237 |
+
"ROA": "return on assets",
|
| 238 |
+
"ROE": "return on equity",
|
| 239 |
+
"RORAC": "return on risk-adjusted capital",
|
| 240 |
+
"RRE": "residential real estate",
|
| 241 |
+
"RTGS system": "real-time gross settlement system",
|
| 242 |
+
"RTS": "Regulatory Technical Standards",
|
| 243 |
+
"RWA": "risk-weighted asset",
|
| 244 |
+
"S&P": "Standard & Poor’s",
|
| 245 |
+
"SBBS": "sovereign bond-backed security",
|
| 246 |
+
"SCR": "Solvency Capital Requirement",
|
| 247 |
+
"SDR": "special drawing right",
|
| 248 |
+
"SEP": "Supervisory Examination Programme",
|
| 249 |
+
"SEPA": "Single Euro Payments Area",
|
| 250 |
+
"SFT": "securities financing transaction",
|
| 251 |
+
"SGP": "Stability and Growth Pact",
|
| 252 |
+
"SI": "significant institution",
|
| 253 |
+
"SII": "systemically important institution",
|
| 254 |
+
"SIPS": "systemically important payment system",
|
| 255 |
+
"SMEs": "small and medium-sized enterprises",
|
| 256 |
+
"SPV": "special-purpose vehicle",
|
| 257 |
+
"SQA": "Supervisory Quality Assurance",
|
| 258 |
+
"SRB": "systemic risk buffer",
|
| 259 |
+
"SREP": "Supervisory Review and Evaluation Process",
|
| 260 |
+
"SRF": "Single Resolution Fund",
|
| 261 |
+
"SRM": "Single Resolution Mechanism",
|
| 262 |
+
"SRMR": "Single Resolution Mechanism Regulation",
|
| 263 |
+
"SSG": "SSM Simplification Group",
|
| 264 |
+
"SSM": "Single Supervisory Mechanism",
|
| 265 |
+
"SSMR": "Single Supervisory Mechanism Regulation",
|
| 266 |
+
"SSS": "securities settlement system",
|
| 267 |
+
"STE": "Short Term Exercise",
|
| 268 |
+
"STP": "straight-through processing",
|
| 269 |
+
"T2": "Tier 2",
|
| 270 |
+
"T2S": "TARGET2-Securities",
|
| 271 |
+
"TFEU": "Treaty on the Functioning of the European Union",
|
| 272 |
+
"TIPS": "TARGET instant payment settlement",
|
| 273 |
+
"TLAC": "total loss-absorbing capacity",
|
| 274 |
+
"TLTRO": "targeted longer-term refinancing operation",
|
| 275 |
+
"TREA": "total risk exposure amount",
|
| 276 |
+
"TRIM": "targeted review of internal models",
|
| 277 |
+
"TRN": "transaction reference number",
|
| 278 |
+
"TSCG": "Treaty on Stability, Coordination and Governance in the Economic and Monetary Union",
|
| 279 |
+
"UL": "Unexpeccted Loss",
|
| 280 |
+
"TSCR": "total SREP capital requirement (P1R+P2R)",
|
| 281 |
+
"UCITS": "undertaking for collective investment in transferable securities",
|
| 282 |
+
"ULCM": "Unit labour costs in the manufacturing sector.",
|
| 283 |
+
"ULCT": "Unit labour costs in the total economy.",
|
| 284 |
+
"VaR": "value at risk",
|
| 285 |
+
"VIX": "Chicago Board Options Exchange’s Volatility Index",
|
| 286 |
+
"XML": "Extensible Markup Language"
|
| 287 |
+
}
|
processing.py
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
from urllib.parse import urlparse
|
| 4 |
+
import requests
|
| 5 |
+
import fitz
|
| 6 |
+
import io
|
| 7 |
+
import re
|
| 8 |
+
import hashlib
|
| 9 |
+
import os
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class FileTypeError(Exception):
|
| 13 |
+
"""Raised when the file type does not match the expected file type."""
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class FileSchemeError(Exception):
|
| 17 |
+
"""Raised when the file scheme does not match the expected file scheme."""
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class FileProcessor(ABC):
|
| 21 |
+
type = None
|
| 22 |
+
|
| 23 |
+
def __init__(self, path):
|
| 24 |
+
self.path = path
|
| 25 |
+
self.file_scheme = self._get_file_scheme()
|
| 26 |
+
self.__class__._check_file_type(path)
|
| 27 |
+
|
| 28 |
+
@abstractmethod
|
| 29 |
+
def get_file_data(self):
|
| 30 |
+
pass
|
| 31 |
+
|
| 32 |
+
@abstractmethod
|
| 33 |
+
def _get_file_metadata(self):
|
| 34 |
+
pass
|
| 35 |
+
|
| 36 |
+
@abstractmethod
|
| 37 |
+
def _get_file_paragraphs(self):
|
| 38 |
+
pass
|
| 39 |
+
|
| 40 |
+
@classmethod
|
| 41 |
+
def _check_file_type(cls, path):
|
| 42 |
+
file_type = Path(path).suffix.lower()[1:]
|
| 43 |
+
if file_type != cls.type:
|
| 44 |
+
raise FileTypeError(
|
| 45 |
+
f"Invalid file type. {cls.__name__} expects a {cls.type} file"
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
def _get_file_scheme(self):
|
| 49 |
+
parsed_path = urlparse(self.path)
|
| 50 |
+
if (
|
| 51 |
+
not parsed_path.scheme
|
| 52 |
+
or parsed_path.scheme.lower() == "file"
|
| 53 |
+
or os.path.isfile(self.path)
|
| 54 |
+
):
|
| 55 |
+
return "local"
|
| 56 |
+
elif parsed_path.scheme.lower() in ["http", "https", "ftp"]:
|
| 57 |
+
return "url"
|
| 58 |
+
else:
|
| 59 |
+
raise FileSchemeError("Unknown scheme")
|
| 60 |
+
|
| 61 |
+
def _preprocess_text(self, text):
|
| 62 |
+
text = text.replace("\n", " ")
|
| 63 |
+
text = re.sub("\s+", " ", text)
|
| 64 |
+
text = text.encode("utf-8", "ignore").decode("utf-8", "ignore")
|
| 65 |
+
return text
|
| 66 |
+
|
| 67 |
+
def _generate_hash(self, string):
|
| 68 |
+
hash_object = hashlib.md5()
|
| 69 |
+
hash_object.update(string.encode("utf-8", "ignore"))
|
| 70 |
+
hex_dig = hash_object.hexdigest()
|
| 71 |
+
|
| 72 |
+
return hex_dig
|
| 73 |
+
|
| 74 |
+
def generate_paragraphs():
|
| 75 |
+
raise NotImplementedError
|
| 76 |
+
|
| 77 |
+
def generate_metadata():
|
| 78 |
+
raise NotImplementedError
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class PDFProcessor(FileProcessor):
|
| 82 |
+
type = "pdf"
|
| 83 |
+
|
| 84 |
+
def __init__(self, path):
|
| 85 |
+
super().__init__(path)
|
| 86 |
+
|
| 87 |
+
def get_file_data(self, merge_length=200):
|
| 88 |
+
file = self._open_file()
|
| 89 |
+
|
| 90 |
+
file_metadata = self._get_file_metadata(file)
|
| 91 |
+
file_paragraphs = self._get_file_paragraphs(
|
| 92 |
+
file, file_metadata, start_page=1, end_page=None, merge_length=merge_length
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
file.close()
|
| 96 |
+
|
| 97 |
+
return file_metadata, file_paragraphs
|
| 98 |
+
|
| 99 |
+
def _get_file_metadata(self, file):
|
| 100 |
+
file_metadata = dict()
|
| 101 |
+
|
| 102 |
+
metadata = file.metadata
|
| 103 |
+
|
| 104 |
+
unique_string = str(Path(self.path).name) + metadata["title"]
|
| 105 |
+
|
| 106 |
+
file_metadata["id"] = self._generate_hash(unique_string)
|
| 107 |
+
file_metadata["title"] = metadata["title"]
|
| 108 |
+
file_metadata["author"] = metadata["author"]
|
| 109 |
+
file_metadata["subject"] = metadata["subject"]
|
| 110 |
+
file_metadata["creation_date"] = metadata["creationDate"]
|
| 111 |
+
file_metadata["modification_date"] = metadata["modDate"]
|
| 112 |
+
file_metadata["n_pages"] = file.page_count
|
| 113 |
+
if self.file_scheme == "local":
|
| 114 |
+
file_metadata["url"] = str(Path(self.path).resolve())
|
| 115 |
+
else:
|
| 116 |
+
file_metadata["url"] = self.path
|
| 117 |
+
file_metadata["file_name"] = Path(self.path).name
|
| 118 |
+
file_metadata["short_name"] = Path(self.path).name
|
| 119 |
+
file_metadata["release_date"] = ""
|
| 120 |
+
file_metadata["report_type"] = ""
|
| 121 |
+
file_metadata["source"] = ""
|
| 122 |
+
|
| 123 |
+
return file_metadata
|
| 124 |
+
|
| 125 |
+
def _get_file_paragraphs(
|
| 126 |
+
self, file, file_metadata, start_page=1, end_page=None, merge_length=200
|
| 127 |
+
):
|
| 128 |
+
if end_page is None:
|
| 129 |
+
end_page = file_metadata["n_pages"]
|
| 130 |
+
|
| 131 |
+
file_paragraphs = []
|
| 132 |
+
|
| 133 |
+
for page_num in range(start_page - 1, end_page):
|
| 134 |
+
page = file.load_page(page_num)
|
| 135 |
+
blocks = page.get_text("blocks")
|
| 136 |
+
|
| 137 |
+
for block in blocks:
|
| 138 |
+
paragraph = self._process_block(
|
| 139 |
+
block, page, page_num + start_page, file_metadata["id"]
|
| 140 |
+
)
|
| 141 |
+
if paragraph is None:
|
| 142 |
+
continue
|
| 143 |
+
|
| 144 |
+
first_char = paragraph["content"][0]
|
| 145 |
+
if len(file_paragraphs) > 0:
|
| 146 |
+
if (
|
| 147 |
+
len(file_paragraphs[-1]["content"]) + len(paragraph["content"])
|
| 148 |
+
< merge_length
|
| 149 |
+
) or (first_char.islower() and first_char.isalpha()):
|
| 150 |
+
file_paragraphs[-1]["content"] += " " + paragraph["content"]
|
| 151 |
+
file_paragraphs[-1]["length"] = len(
|
| 152 |
+
file_paragraphs[-1]["content"]
|
| 153 |
+
)
|
| 154 |
+
else:
|
| 155 |
+
file_paragraphs.append(paragraph)
|
| 156 |
+
else:
|
| 157 |
+
file_paragraphs.append(paragraph)
|
| 158 |
+
|
| 159 |
+
return file_paragraphs
|
| 160 |
+
|
| 161 |
+
def _open_file(self):
|
| 162 |
+
if self.file_scheme == "url":
|
| 163 |
+
response = requests.get(self.path)
|
| 164 |
+
file = fitz.open(stream=io.BytesIO(response.content), filetype="pdf")
|
| 165 |
+
elif self.file_scheme == "local":
|
| 166 |
+
file = fitz.open(self.path)
|
| 167 |
+
return file
|
| 168 |
+
|
| 169 |
+
def _process_block(self, block, page, page_number, file_id):
|
| 170 |
+
x0, y0, x1, y1, content, block_no, block_type = block
|
| 171 |
+
|
| 172 |
+
if content.isspace() or block_type == 1:
|
| 173 |
+
return None
|
| 174 |
+
|
| 175 |
+
content = self._preprocess_text(content)
|
| 176 |
+
unique_content_string = "_".join(map(str, block))
|
| 177 |
+
paragraph_id = self._generate_hash(unique_content_string)
|
| 178 |
+
|
| 179 |
+
w, h = page.rect.width, page.rect.height
|
| 180 |
+
paragraph = {
|
| 181 |
+
"id": paragraph_id,
|
| 182 |
+
"document_id": file_id,
|
| 183 |
+
"content_type": "text" if block_type == 0 else "image",
|
| 184 |
+
"content": content,
|
| 185 |
+
"length": len(content),
|
| 186 |
+
"idx_block": block_no,
|
| 187 |
+
"page_number": page_number,
|
| 188 |
+
"x0": x0 / h,
|
| 189 |
+
"y0": y0 / w,
|
| 190 |
+
"x1": x1 / h,
|
| 191 |
+
"y1": y1 / w,
|
| 192 |
+
}
|
| 193 |
+
|
| 194 |
+
return paragraph
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class HTMLProcessor(FileProcessor):
|
| 198 |
+
type = "html"
|
| 199 |
+
|
| 200 |
+
def __init__(self, path):
|
| 201 |
+
super().__init__(path)
|
| 202 |
+
|
| 203 |
+
def get_file_data(self):
|
| 204 |
+
pass
|
| 205 |
+
|
| 206 |
+
def _get_file_metadata(self):
|
| 207 |
+
pass
|
| 208 |
+
|
| 209 |
+
def _get_file_paragraphs(self):
|
| 210 |
+
pass
|
| 211 |
+
|
| 212 |
+
def _open_file(self):
|
| 213 |
+
if self.file_scheme == "url":
|
| 214 |
+
response = requests.get(self.path)
|
| 215 |
+
file = response.text
|
| 216 |
+
elif self.file_scheme == "local":
|
| 217 |
+
file = open(self.path, "r").read()
|
| 218 |
+
return file
|
requirements.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
altair==4.2.2
|
| 2 |
+
datasets==2.12.0
|
| 3 |
+
faiss-cpu==1.7.4
|
| 4 |
+
gradio==3.39.0
|
| 5 |
+
gradio_client==0.3.0
|
| 6 |
+
openai==0.27.0
|
| 7 |
+
PyMuPDF==1.22.3
|
| 8 |
+
python-dotenv==1.0.0
|
| 9 |
+
sentence-transformers==2.2.2
|
| 10 |
+
torch==2.0.1
|
| 11 |
+
matplotlib==3.7.1
|
| 12 |
+
tiktoken==0.4.0
|
text_embedder.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import torch
|
| 5 |
+
from datasets import load_from_disk
|
| 6 |
+
from sentence_transformers import SentenceTransformer
|
| 7 |
+
|
| 8 |
+
# from finbert_embedding.embedding import FinbertEmbedding
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class TextEmbedder(ABC):
|
| 12 |
+
def __init__(self, model_name, paragraphs_path, device, load_existing_index=False):
|
| 13 |
+
self.dataset = load_from_disk(paragraphs_path)
|
| 14 |
+
self.model = self._load_model(model_name, device)
|
| 15 |
+
|
| 16 |
+
assert len(self.dataset) > 0, "The loaded dataset is empty !!"
|
| 17 |
+
|
| 18 |
+
if load_existing_index == True:
|
| 19 |
+
self.dataset.load_faiss_index(
|
| 20 |
+
"embeddings", f"{paragraphs_path}/index.faiss"
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
def generate_paragraphs_embedding(self):
|
| 24 |
+
self.dataset = self.dataset.map(
|
| 25 |
+
lambda x: {"embeddings": self._generate_embeddings(x["content"])}
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
def save_embeddings(self, output_path):
|
| 29 |
+
self.dataset.add_faiss_index(column="embeddings")
|
| 30 |
+
self.dataset.save_faiss_index("embeddings", f"{output_path}/index.faiss")
|
| 31 |
+
|
| 32 |
+
def retrieve_faiss(self, query: str, k_total: int, threshold: int):
|
| 33 |
+
question_embedding = self._generate_embeddings(query)
|
| 34 |
+
scores, samples = self.dataset.get_nearest_examples(
|
| 35 |
+
"embeddings", question_embedding, k=k_total
|
| 36 |
+
)
|
| 37 |
+
passages_df = pd.DataFrame(samples)
|
| 38 |
+
passages_df["scores"] = scores / 100
|
| 39 |
+
passages_df = passages_df[passages_df["scores"] > threshold]
|
| 40 |
+
passages_df = passages_df.sort_values(by=["scores"], ascending=False)
|
| 41 |
+
|
| 42 |
+
if len(passages_df) == 0:
|
| 43 |
+
return [], []
|
| 44 |
+
|
| 45 |
+
contents = passages_df["content"].tolist()
|
| 46 |
+
meta = passages_df.drop(columns=["content"]).to_dict(orient="records")
|
| 47 |
+
passages = []
|
| 48 |
+
for i in range(len(contents)):
|
| 49 |
+
passages.append({"content": contents[i], "meta": meta[i]})
|
| 50 |
+
return passages, passages_df["scores"].values
|
| 51 |
+
|
| 52 |
+
def retrieve_elastic(self, query: str, k_total: int, threshold: int):
|
| 53 |
+
raise NotImplementedError
|
| 54 |
+
|
| 55 |
+
@abstractmethod
|
| 56 |
+
def _load_model(self, model_name: str, device: str):
|
| 57 |
+
pass
|
| 58 |
+
|
| 59 |
+
@abstractmethod
|
| 60 |
+
def _generate_embeddings(self, text: str):
|
| 61 |
+
pass
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class SentenceTransformersTextEmbedder(TextEmbedder):
|
| 65 |
+
def _load_model(self, model_name: str, device: str):
|
| 66 |
+
model = SentenceTransformer(model_name)
|
| 67 |
+
torch_device = torch.device(device)
|
| 68 |
+
model.to(torch_device)
|
| 69 |
+
return model
|
| 70 |
+
|
| 71 |
+
def _generate_embeddings(self, text: str):
|
| 72 |
+
return self.model.encode(text)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# class FinBertTextEmbedder(TextEmbedder):
|
| 76 |
+
# def _load_model(self, model_name: str, device: str):
|
| 77 |
+
# model = FinbertEmbedding(device=device)
|
| 78 |
+
# return model
|
| 79 |
+
|
| 80 |
+
# def _generate_embeddings(self, text: str):
|
| 81 |
+
# output = self.model.sentence_vector(text)
|
| 82 |
+
# return output.cpu().numpy()
|
utils.py
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import openai
|
| 3 |
+
import re
|
| 4 |
+
from config import CFG_APP
|
| 5 |
+
from text_embedder import SentenceTransformersTextEmbedder
|
| 6 |
+
from datetime import datetime
|
| 7 |
+
import tiktoken
|
| 8 |
+
|
| 9 |
+
doc_metadata = json.load(open(CFG_APP.DOC_METADATA_PATH, "r"))
|
| 10 |
+
# Embedding Model
|
| 11 |
+
if "sentence-transformers" in CFG_APP.EMBEDDING_MODEL:
|
| 12 |
+
text_embedder = SentenceTransformersTextEmbedder(
|
| 13 |
+
model_name=CFG_APP.EMBEDDING_MODEL,
|
| 14 |
+
paragraphs_path=CFG_APP.DATA_FOLDER,
|
| 15 |
+
device=CFG_APP.DEVICE,
|
| 16 |
+
load_existing_index=True,
|
| 17 |
+
)
|
| 18 |
+
else:
|
| 19 |
+
raise ValueError("Embedding model not found !")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# Util Functions
|
| 23 |
+
def retrieve_doc_metadata(doc_metadata, doc_id):
|
| 24 |
+
for meta in doc_metadata:
|
| 25 |
+
if meta["id"] == doc_id:
|
| 26 |
+
return meta
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_reformulation_prompt(query: str) -> list:
|
| 30 |
+
return [
|
| 31 |
+
{
|
| 32 |
+
"role": "user",
|
| 33 |
+
"content": f"""{CFG_APP.REFORMULATION_PROMPT}
|
| 34 |
+
---
|
| 35 |
+
query: {query}
|
| 36 |
+
standalone question: """,
|
| 37 |
+
}
|
| 38 |
+
]
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def make_pairs(lst):
|
| 42 |
+
"""From a list of even lenght, make tupple pairs
|
| 43 |
+
Args:
|
| 44 |
+
lst (list): a list of even lenght
|
| 45 |
+
Returns:
|
| 46 |
+
list: the list as tupple pairs
|
| 47 |
+
"""
|
| 48 |
+
assert not (l := len(lst) % 2), f"your list is of lenght {l} which is not even"
|
| 49 |
+
return [(lst[i], lst[i + 1]) for i in range(0, len(lst), 2)]
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def make_html_source(paragraph, meta_doc, i):
|
| 53 |
+
content = paragraph["content"]
|
| 54 |
+
meta_paragraph = paragraph["meta"]
|
| 55 |
+
return f"""
|
| 56 |
+
<div class="card" id="document-{i}">
|
| 57 |
+
<div class="card-content">
|
| 58 |
+
<h2>Doc {i} - {meta_doc['short_name']} - Page {meta_paragraph['page_number']}</h2>
|
| 59 |
+
<p>{content}</p>
|
| 60 |
+
</div>
|
| 61 |
+
<div class="card-footer">
|
| 62 |
+
<span>{meta_doc['short_name']}</span>
|
| 63 |
+
<a href="{meta_doc['url']}#page={meta_paragraph['page_number']}" target="_blank" class="pdf-link">
|
| 64 |
+
<span role="img" aria-label="Open PDF">🔗</span>
|
| 65 |
+
</a>
|
| 66 |
+
</div>
|
| 67 |
+
</div>
|
| 68 |
+
"""
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def preprocess_message(text: str) -> str:
|
| 72 |
+
return re.sub(
|
| 73 |
+
r"\[doc (\d+)\]",
|
| 74 |
+
lambda match: f'<a href="#do-{match.group(1)}">{match.group(0)}</a>',
|
| 75 |
+
text,
|
| 76 |
+
)
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def parse_glossary(query):
|
| 80 |
+
file = "glossary.json"
|
| 81 |
+
glossary = json.load(open(file, "r"))
|
| 82 |
+
words_query = query.split(" ")
|
| 83 |
+
for i, word in enumerate(words_query):
|
| 84 |
+
for key in glossary.keys():
|
| 85 |
+
if word.lower() == key.lower():
|
| 86 |
+
words_query[i] = words_query[i] + f" ({glossary[key]})"
|
| 87 |
+
return " ".join(words_query)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def num_tokens_from_string(string: str, encoding_name: str) -> int:
|
| 91 |
+
encoding = tiktoken.encoding_for_model(encoding_name)
|
| 92 |
+
num_tokens = len(encoding.encode(string))
|
| 93 |
+
return num_tokens
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def chat(
|
| 97 |
+
query: str,
|
| 98 |
+
history: list,
|
| 99 |
+
threshold: float = CFG_APP.THRESHOLD,
|
| 100 |
+
k_total: int = CFG_APP.K_TOTAL,
|
| 101 |
+
) -> tuple:
|
| 102 |
+
"""retrieve relevant documents in the document store then query gpt-turbo
|
| 103 |
+
Args:
|
| 104 |
+
query (str): user message.
|
| 105 |
+
history (list, optional): history of the conversation. Defaults to [system_template].
|
| 106 |
+
report_type (str, optional): should be "All available" or "IPCC only". Defaults to "All available".
|
| 107 |
+
threshold (float, optional): similarity threshold, don't increase more than 0.568. Defaults to 0.56.
|
| 108 |
+
Yields:
|
| 109 |
+
tuple: chat gradio format, chat openai format, sources used.
|
| 110 |
+
"""
|
| 111 |
+
|
| 112 |
+
reformulated_query = openai.ChatCompletion.create(
|
| 113 |
+
model=CFG_APP.MODEL_NAME,
|
| 114 |
+
messages=get_reformulation_prompt(parse_glossary(query)),
|
| 115 |
+
temperature=0,
|
| 116 |
+
max_tokens=CFG_APP.MAX_TOKENS_REF_QUESTION,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
reformulated_query = reformulated_query["choices"][0]["message"]["content"]
|
| 120 |
+
if len(reformulated_query.split("\n")) == 2:
|
| 121 |
+
reformulated_query, language = reformulated_query.split("\n")
|
| 122 |
+
language = language.split(":")[1].strip()
|
| 123 |
+
else:
|
| 124 |
+
reformulated_query = reformulated_query.split("\n")[0]
|
| 125 |
+
language = "English"
|
| 126 |
+
|
| 127 |
+
sources, scores = text_embedder.retrieve_faiss(
|
| 128 |
+
reformulated_query,
|
| 129 |
+
k_total=k_total,
|
| 130 |
+
threshold=threshold,
|
| 131 |
+
)
|
| 132 |
+
if CFG_APP.DEBUG == True:
|
| 133 |
+
print("Scores : \n", scores)
|
| 134 |
+
|
| 135 |
+
messages = history + [{"role": "user", "content": query}]
|
| 136 |
+
|
| 137 |
+
if len(sources) > 0:
|
| 138 |
+
docs_string = []
|
| 139 |
+
docs_html = []
|
| 140 |
+
|
| 141 |
+
num_tokens = num_tokens_from_string(CFG_APP.SOURCES_PROMPT, CFG_APP.MODEL_NAME)
|
| 142 |
+
|
| 143 |
+
for i, data in enumerate(sources, 1):
|
| 144 |
+
meta_doc = retrieve_doc_metadata(doc_metadata, data["meta"]["document_id"])
|
| 145 |
+
doc_content = f"📃 Doc {i}: \n{data['content']}"
|
| 146 |
+
num_tokens_doc = num_tokens_from_string(doc_content, CFG_APP.MODEL_NAME)
|
| 147 |
+
if num_tokens + num_tokens_doc > CFG_APP.MAX_TOKENS_API:
|
| 148 |
+
break
|
| 149 |
+
num_tokens += num_tokens_doc
|
| 150 |
+
docs_string.append(doc_content)
|
| 151 |
+
docs_html.append(make_html_source(data, meta_doc, i))
|
| 152 |
+
|
| 153 |
+
docs_string = "\n\n".join(
|
| 154 |
+
[f"Query used for retrieval:\n{reformulated_query}"] + docs_string
|
| 155 |
+
)
|
| 156 |
+
docs_html = "\n\n".join(
|
| 157 |
+
[f"Query used for retrieval:\n{reformulated_query}"] + docs_html
|
| 158 |
+
)
|
| 159 |
+
messages.append(
|
| 160 |
+
{
|
| 161 |
+
"role": "system",
|
| 162 |
+
"content": f"{CFG_APP.SOURCES_PROMPT}\n\n{docs_string}\n\nAnswer in {language}:",
|
| 163 |
+
}
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
if CFG_APP.DEBUG == True:
|
| 167 |
+
print(f" 👨💻 question asked by the user : {query}")
|
| 168 |
+
print(f" 🕛 time : {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
|
| 169 |
+
|
| 170 |
+
print(" 🔌 messages sent to the API :")
|
| 171 |
+
api_messages = [
|
| 172 |
+
{"role": "system", "content": CFG_APP.INIT_PROMPT},
|
| 173 |
+
{"role": "user", "content": reformulated_query},
|
| 174 |
+
{
|
| 175 |
+
"role": "system",
|
| 176 |
+
"content": f"{CFG_APP.SOURCES_PROMPT}\n\n{docs_string}\n\nAnswer in {language}:",
|
| 177 |
+
},
|
| 178 |
+
]
|
| 179 |
+
for message in api_messages:
|
| 180 |
+
print(
|
| 181 |
+
f"length : {len(message['content'])}, content : {message['content']}"
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
response = openai.ChatCompletion.create(
|
| 185 |
+
model=CFG_APP.MODEL_NAME,
|
| 186 |
+
messages=[
|
| 187 |
+
{"role": "system", "content": CFG_APP.INIT_PROMPT},
|
| 188 |
+
{"role": "user", "content": reformulated_query},
|
| 189 |
+
{
|
| 190 |
+
"role": "system",
|
| 191 |
+
"content": f"{CFG_APP.SOURCES_PROMPT}\n\n{docs_string}\n\nAnswer in {language}:",
|
| 192 |
+
},
|
| 193 |
+
],
|
| 194 |
+
temperature=0, # deterministic
|
| 195 |
+
stream=True,
|
| 196 |
+
max_tokens=CFG_APP.MAX_TOKENS_ANSWER,
|
| 197 |
+
)
|
| 198 |
+
complete_response = ""
|
| 199 |
+
messages.pop()
|
| 200 |
+
|
| 201 |
+
messages.append({"role": "assistant", "content": complete_response})
|
| 202 |
+
|
| 203 |
+
for chunk in response:
|
| 204 |
+
chunk_message = chunk["choices"][0]["delta"].get("content")
|
| 205 |
+
if chunk_message:
|
| 206 |
+
complete_response += chunk_message
|
| 207 |
+
complete_response = preprocess_message(complete_response)
|
| 208 |
+
messages[-1]["content"] = complete_response
|
| 209 |
+
gradio_format = make_pairs([a["content"] for a in messages[1:]])
|
| 210 |
+
yield gradio_format, messages, docs_html
|
| 211 |
+
|
| 212 |
+
else:
|
| 213 |
+
docs_string = "⚠️ No relevant passages found in this report"
|
| 214 |
+
complete_response = "**⚠️ No relevant passages found in this report, you may want to ask a more specific question.**"
|
| 215 |
+
messages.append({"role": "assistant", "content": complete_response})
|
| 216 |
+
gradio_format = make_pairs([a["content"] for a in messages[1:]])
|
| 217 |
+
yield gradio_format, messages, docs_string
|