
Commit
•
b147f61
1
Parent(s):
ac4a7f6
Upload 5 files
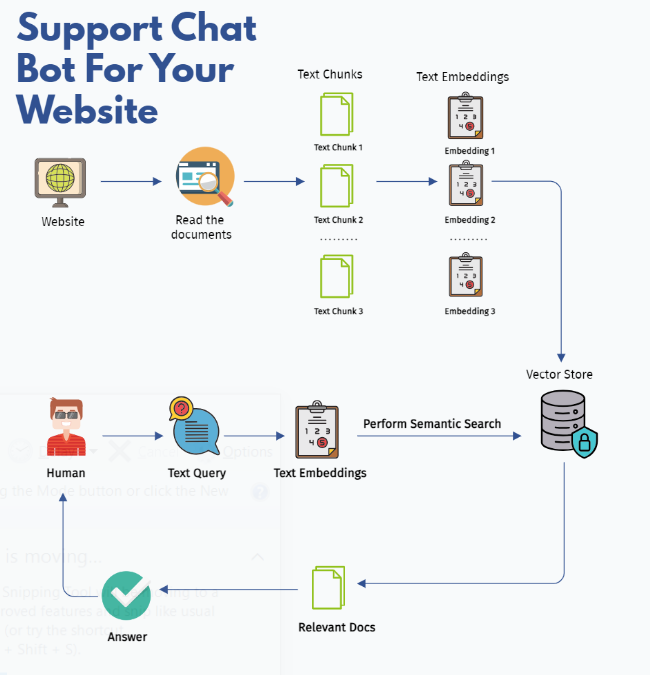
Browse files- Support Chat Bot For Website.PNG +0 -0
- app.py +96 -0
- constants.py +3 -0
- requirements.txt +0 -0
- utils.py +76 -0
Support Chat Bot For Website.PNG
ADDED
|
app.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from utils import *
|
| 3 |
+
import constants
|
| 4 |
+
|
| 5 |
+
# Creating Session State Variable
|
| 6 |
+
if 'HuggingFace_API_Key' not in st.session_state:
|
| 7 |
+
st.session_state['HuggingFace_API_Key'] =''
|
| 8 |
+
if 'Pinecone_API_Key' not in st.session_state:
|
| 9 |
+
st.session_state['Pinecone_API_Key'] =''
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
#
|
| 13 |
+
st.title('🤖 AI Assistance For Website')
|
| 14 |
+
|
| 15 |
+
#********SIDE BAR Funtionality started*******
|
| 16 |
+
|
| 17 |
+
# Sidebar to capture the API keys
|
| 18 |
+
st.sidebar.title("😎🗝️")
|
| 19 |
+
st.session_state['HuggingFace_API_Key']= st.sidebar.text_input("What's your HuggingFace API key?",type="password")
|
| 20 |
+
st.session_state['Pinecone_API_Key']= st.sidebar.text_input("What's your Pinecone API key?",type="password")
|
| 21 |
+
|
| 22 |
+
#Recent changes by langchain team, expects ""PINECONE_API_KEY" environment variable for Pinecone usage! So we are creating it here
|
| 23 |
+
import os
|
| 24 |
+
os.environ["PINECONE_API_KEY"] = st.session_state['Pinecone_API_Key']
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
load_button = st.sidebar.button("Load data to Pinecone", key="load_button")
|
| 28 |
+
|
| 29 |
+
#If the bove button is clicked, pushing the data to Pinecone...
|
| 30 |
+
if load_button:
|
| 31 |
+
#Proceed only if API keys are provided
|
| 32 |
+
if st.session_state['HuggingFace_API_Key'] !="" and st.session_state['Pinecone_API_Key']!="" :
|
| 33 |
+
|
| 34 |
+
#Fetch data from site
|
| 35 |
+
site_data=get_website_data(constants.WEBSITE_URL)
|
| 36 |
+
st.write("Data pull done...")
|
| 37 |
+
|
| 38 |
+
#Split data into chunks
|
| 39 |
+
chunks_data=split_data(site_data)
|
| 40 |
+
st.write("Spliting data done...")
|
| 41 |
+
|
| 42 |
+
#Creating embeddings instance
|
| 43 |
+
embeddings=create_embeddings()
|
| 44 |
+
st.write("Embeddings instance creation done...")
|
| 45 |
+
|
| 46 |
+
#Push data to Pinecone
|
| 47 |
+
|
| 48 |
+
push_to_pinecone(st.session_state['Pinecone_API_Key'],constants.PINECONE_ENVIRONMENT,constants.PINECONE_INDEX,embeddings,chunks_data)
|
| 49 |
+
st.write("Pushing data to Pinecone done...")
|
| 50 |
+
|
| 51 |
+
st.sidebar.success("Data pushed to Pinecone successfully!")
|
| 52 |
+
else:
|
| 53 |
+
st.sidebar.error("Ooopssss!!! Please provide API keys.....")
|
| 54 |
+
|
| 55 |
+
#********SIDE BAR Funtionality ended*******
|
| 56 |
+
|
| 57 |
+
#Captures User Inputs
|
| 58 |
+
prompt = st.text_input('How can I help you my friend ❓',key="prompt") # The box for the text prompt
|
| 59 |
+
document_count = st.slider('No.Of links to return 🔗 - (0 LOW || 5 HIGH)', 0, 5, 2,step=1)
|
| 60 |
+
|
| 61 |
+
submit = st.button("Search")
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
if submit:
|
| 65 |
+
#Proceed only if API keys are provided
|
| 66 |
+
if st.session_state['HuggingFace_API_Key'] !="" and st.session_state['Pinecone_API_Key']!="" :
|
| 67 |
+
|
| 68 |
+
#Creating embeddings instance
|
| 69 |
+
embeddings=create_embeddings()
|
| 70 |
+
st.write("Embeddings instance creation done...")
|
| 71 |
+
|
| 72 |
+
#Pull index data from Pinecone
|
| 73 |
+
index=pull_from_pinecone(st.session_state['Pinecone_API_Key'],constants.PINECONE_ENVIRONMENT,constants.PINECONE_INDEX,embeddings)
|
| 74 |
+
st.write("Pinecone index retrieval done...")
|
| 75 |
+
|
| 76 |
+
#Fetch relavant documents from Pinecone index
|
| 77 |
+
relavant_docs=get_similar_docs(index,prompt,document_count)
|
| 78 |
+
st.write(relavant_docs)
|
| 79 |
+
|
| 80 |
+
#Displaying search results
|
| 81 |
+
st.success("Please find the search results :")
|
| 82 |
+
#Displaying search results
|
| 83 |
+
st.write("search results list....")
|
| 84 |
+
for document in relavant_docs:
|
| 85 |
+
|
| 86 |
+
st.write("👉**Result : "+ str(relavant_docs.index(document)+1)+"**")
|
| 87 |
+
st.write("**Info**: "+document.page_content)
|
| 88 |
+
st.write("**Link**: "+ document.metadata['source'])
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
else:
|
| 93 |
+
st.sidebar.error("Ooopssss!!! Please provide API keys.....")
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
|
constants.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
WEBSITE_URL="https://jobs.excelcult.com/wp-sitemap-posts-post-1.xml"
|
| 2 |
+
PINECONE_ENVIRONMENT="gcp-starter"
|
| 3 |
+
PINECONE_INDEX="chatbot"
|
requirements.txt
ADDED
|
Binary file (252 Bytes). View file
|
|
|
utils.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 2 |
+
#The below import has been replaced by the later one
|
| 3 |
+
#from langchain.vectorstores import Pinecone
|
| 4 |
+
from langchain_community.vectorstores import Pinecone
|
| 5 |
+
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
|
| 6 |
+
#Pinecone as made some changes recently and we have to import it in the below way from now on :)
|
| 7 |
+
from pinecone import Pinecone as PineconeClient
|
| 8 |
+
import asyncio
|
| 9 |
+
from langchain.document_loaders.sitemap import SitemapLoader
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
#Function to fetch data from website
|
| 13 |
+
#https://python.langchain.com/docs/modules/data_connection/document_loaders/integrations/sitemap
|
| 14 |
+
def get_website_data(sitemap_url):
|
| 15 |
+
|
| 16 |
+
loop = asyncio.new_event_loop()
|
| 17 |
+
asyncio.set_event_loop(loop)
|
| 18 |
+
loader = SitemapLoader(
|
| 19 |
+
sitemap_url
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
docs = loader.load()
|
| 23 |
+
|
| 24 |
+
return docs
|
| 25 |
+
|
| 26 |
+
#Function to split data into smaller chunks
|
| 27 |
+
def split_data(docs):
|
| 28 |
+
|
| 29 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 30 |
+
chunk_size = 1000,
|
| 31 |
+
chunk_overlap = 200,
|
| 32 |
+
length_function = len,
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
docs_chunks = text_splitter.split_documents(docs)
|
| 36 |
+
return docs_chunks
|
| 37 |
+
|
| 38 |
+
#Function to create embeddings instance
|
| 39 |
+
def create_embeddings():
|
| 40 |
+
|
| 41 |
+
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
|
| 42 |
+
return embeddings
|
| 43 |
+
|
| 44 |
+
#Function to push data to Pinecone
|
| 45 |
+
def push_to_pinecone(pinecone_apikey,pinecone_environment,pinecone_index_name,embeddings,docs):
|
| 46 |
+
|
| 47 |
+
PineconeClient(
|
| 48 |
+
api_key=pinecone_apikey,
|
| 49 |
+
environment=pinecone_environment
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
index_name = pinecone_index_name
|
| 53 |
+
#PineconeStore is an alias name of Pinecone class, please look at the imports section at the top :)
|
| 54 |
+
index = Pinecone.from_documents(docs, embeddings, index_name=index_name)
|
| 55 |
+
return index
|
| 56 |
+
|
| 57 |
+
#Function to pull index data from Pinecone
|
| 58 |
+
def pull_from_pinecone(pinecone_apikey,pinecone_environment,pinecone_index_name,embeddings):
|
| 59 |
+
|
| 60 |
+
PineconeClient(
|
| 61 |
+
api_key=pinecone_apikey,
|
| 62 |
+
environment=pinecone_environment
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
index_name = pinecone_index_name
|
| 66 |
+
#PineconeStore is an alias name of Pinecone class, please look at the imports section at the top :)
|
| 67 |
+
index = Pinecone.from_existing_index(index_name, embeddings)
|
| 68 |
+
return index
|
| 69 |
+
|
| 70 |
+
#This function will help us in fetching the top relevent documents from our vector store - Pinecone Index
|
| 71 |
+
def get_similar_docs(index,query,k=2):
|
| 72 |
+
|
| 73 |
+
similar_docs = index.similarity_search(query, k=k)
|
| 74 |
+
return similar_docs
|
| 75 |
+
|
| 76 |
+
|