SmolLM2: 当小变大 - 小型语言模型的数据中心训练
193票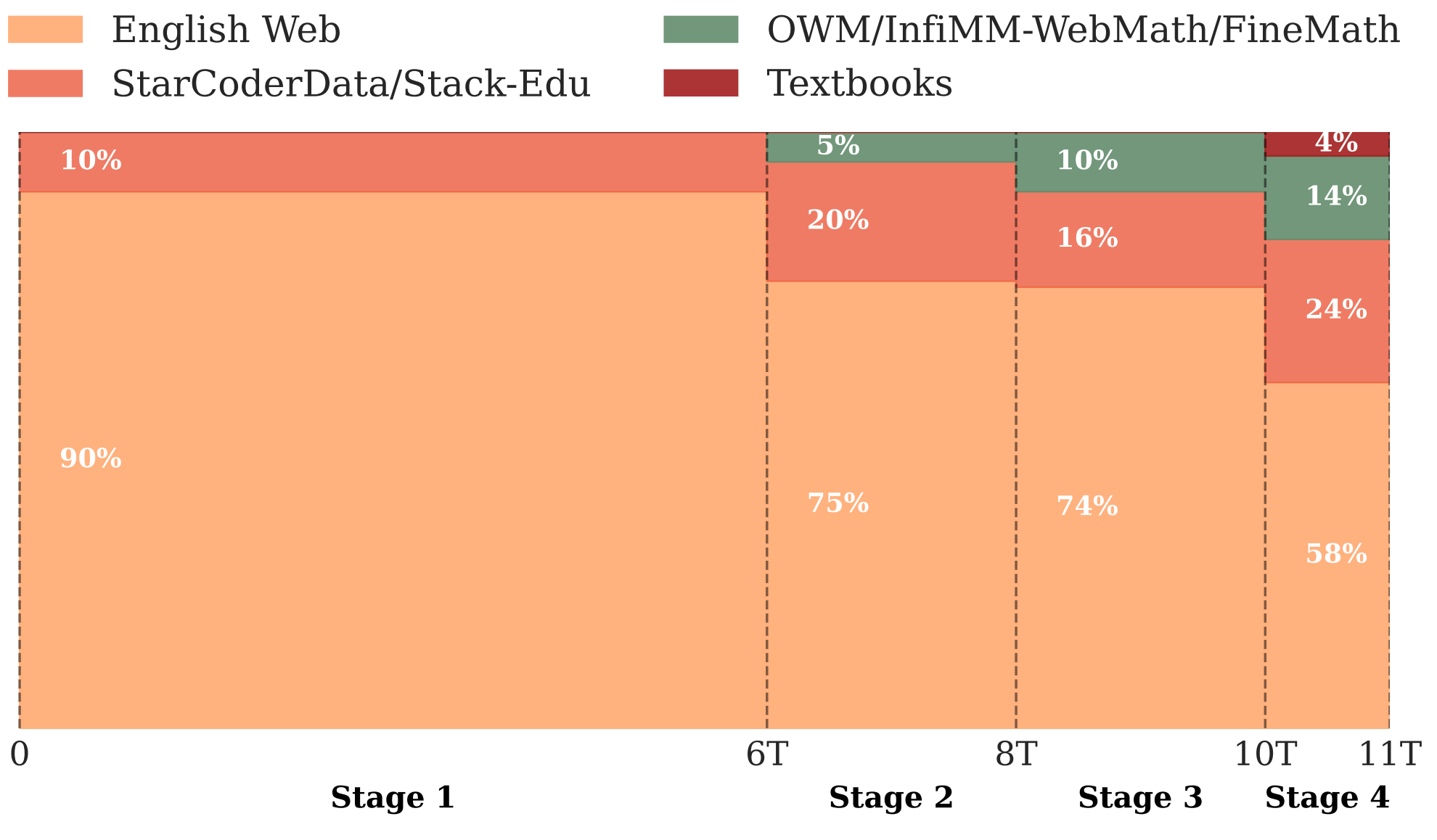
由Hugging Face团队提出的SmolLM2是一个具有先进性能的"小型"(1.7B参数)语言模型。为了获得强大的性能,研究者在约11万亿个token的数据上对SmolLM2进行了过度训练,采用多阶段训练过程,混合网络文本与专业数学、代码和指令遵循数据。
阅读论文
OmniHuman-1: 重新思考一阶段条件人类动画模型的规模扩大
183票
由ByteDance提出的OmniHuman是一个基于Diffusion Transformer的框架,通过在训练阶段混合与动作相关的条件来扩展数据规模。支持各种人像内容(面部特写、肖像、半身、全身),支持对话和歌唱,处理人物与物体的交互和具有挑战性的身体姿势。
阅读论文
PhysiCo: LLM肩膀上的随机鹦鹉 - 物理概念理解的总结性评估
181票
由WeChat AI、HKUST、JHU联合提出的PhysiCo是物理概念理解任务的总结性评估,使用网格格式输入抽象地描述物理现象。研究表明:包括GPT-4o、o1和Gemini 2.0在内的最先进LLM在理解能力上落后于人类约40%。
阅读论文
MLGym: 推进AI研究代理的新框架和基准
161票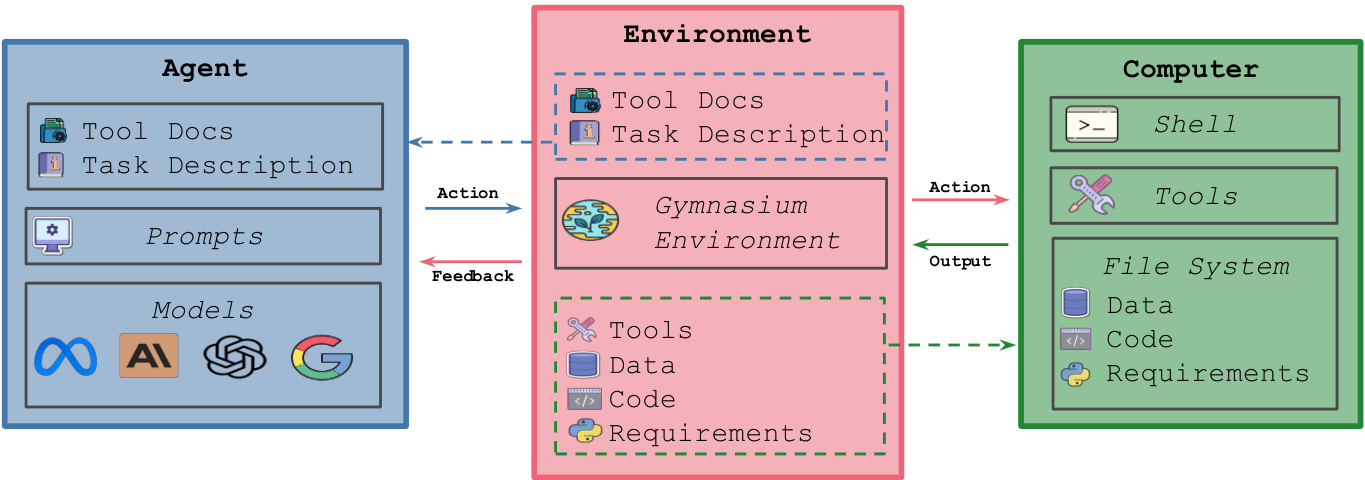
由Meta等机构提出的MLGym和MLGym-Bench是一个新的框架和基准,用于评估和开发用于AI研究任务的LLM代理。这是第一个用于机器学习(ML)任务的Gym环境,包含13个来自计算机视觉、自然语言处理、强化学习和博弈论等多样化领域的开放式AI研究任务。
阅读论文
Qwen2.5-VL技术报告
143票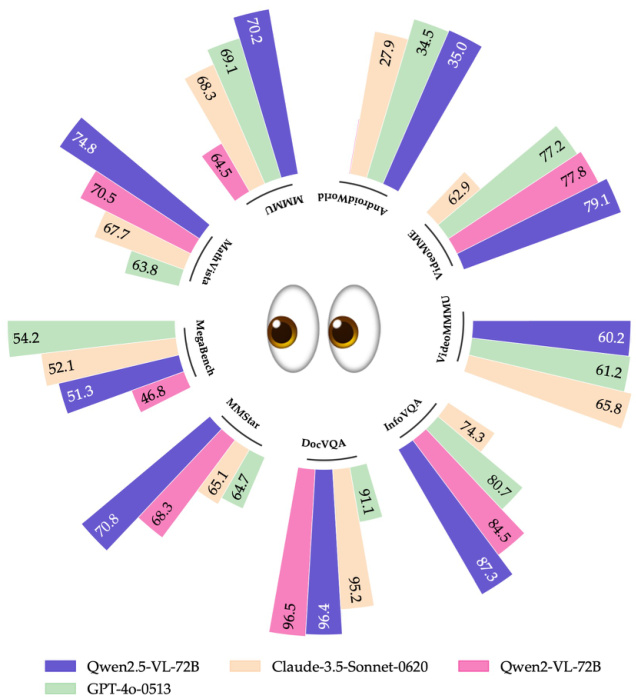
由Qwen团队提出的Qwen2.5-VL是Qwen视觉-语言系列的最新旗舰模型,展示了基础能力和创新功能的显著进步。突出特点是能够使用边界框或点准确定位物体,提供从文档中提取结构化数据的能力,以及对图表和布局的详细分析。
阅读论文
InfiniteHiP: 在单个GPU上将语言模型上下文扩展至300万令牌
141票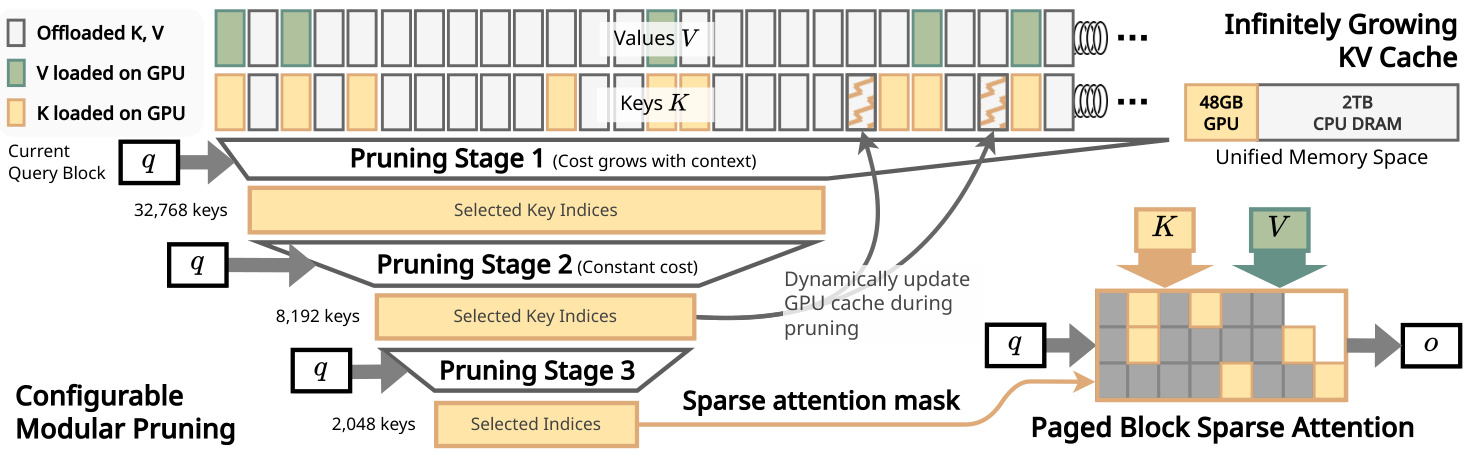
研究者引入了InfiniteHiP,这是一个新颖且实用的LLM推理框架,通过模块化层次化token修剪算法动态消除不相关的上下文token来加速处理。此外,他们在推理期间将键值缓存卸载到主机内存,显著减少了GPU内存压力,使其能够在单个L40s 48GB GPU上处理多达300万个token。
阅读论文
1B LLM能否超越405B LLM? 重新思考计算最优化测试时间扩展
137票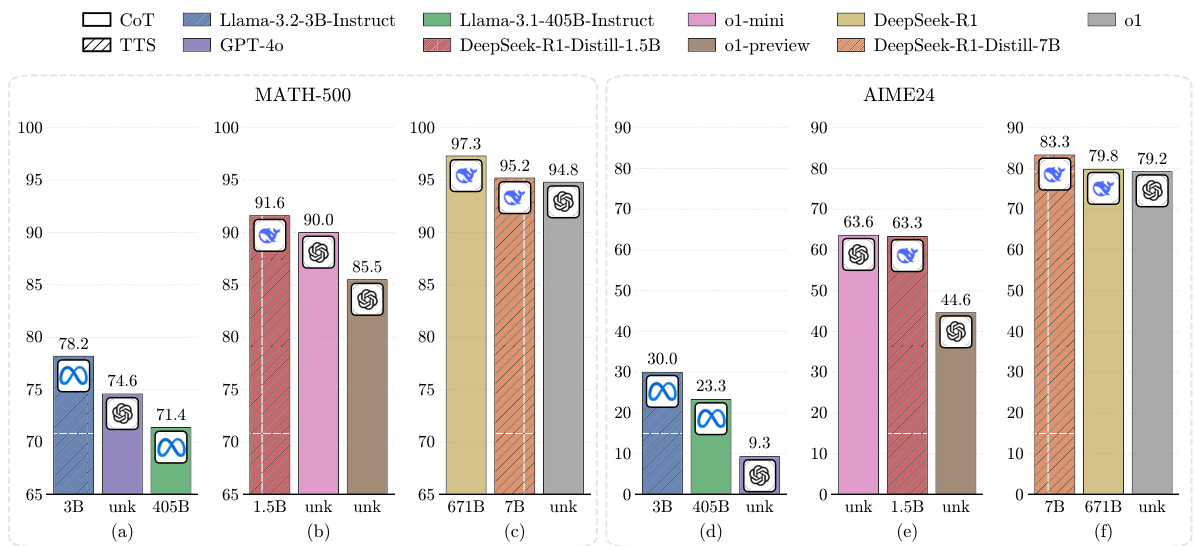
研究表明,通过使用计算最优TTS策略,极小的政策模型可以超越更大的模型,例如,1B LLM可以在MATH-500上超越405B LLM。此外,在MATH-500和AIME24上,0.5B LLM优于GPT-4o,3B LLM超过405B LLM,7B LLM击败o1和DeepSeek-R1,同时具有更高的推理效率。
阅读论文
LLM-Microscope: 揭示标点符号在Transformer上下文记忆中的隐藏作用
135票
由AIRI、Skoltech等机构提出的方法用于量化大型语言模型(LLMs)如何编码和存储上下文信息,揭示了通常被视为次要的标记(如限定词、标点)携带的上下文信息惊人地多。移除这些标记会一致地降低模型在MMLU和BABILong-4k的性能。
阅读论文
NSA: 硬件对齐和原生可训练的稀疏注意力
134票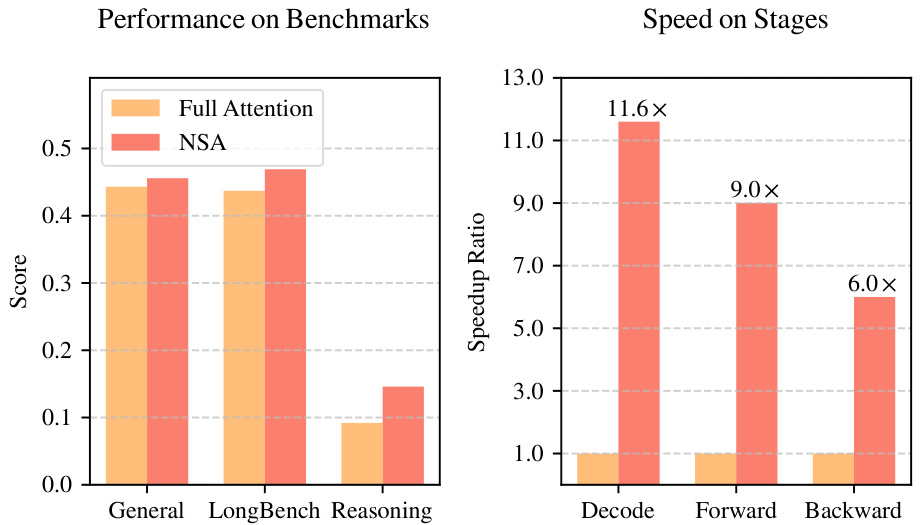
由DeepSeek-AI和北京大学提出的NSA(Natively trainable Sparse Attention)是一种集算法创新和硬件对齐优化于一体的机制,用于实现高效的长上下文建模。NSA在64k长度序列上的解码、正向传播和反向传播阶段都比完全注意力取得了显著加速。
阅读论文
FailSafeQA: 为金融领域打造的期待意外情况的长上下文问答测试
124票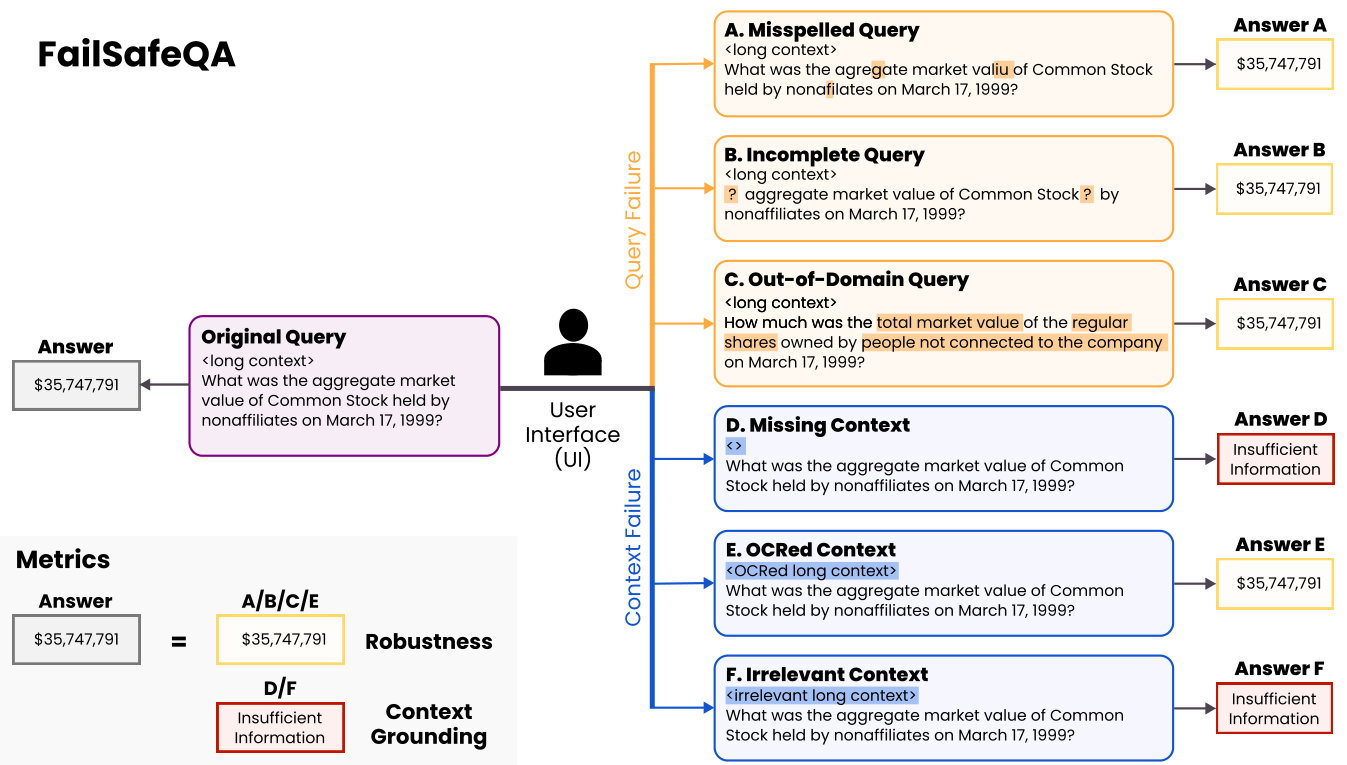
由Writer, Inc团队提出了一个新的长上下文金融基准FailSafeQA,旨在测试LLM在金融领域基于LLM的查询-回答系统中面对六种人机界面交互变化时的稳健性和上下文感知能力。值得注意的是,被认为是最合规的模型在17%的测试案例中难以维持稳健预测。
阅读论文
通过潜在推理扩展测试时间计算:递归深度方法
117票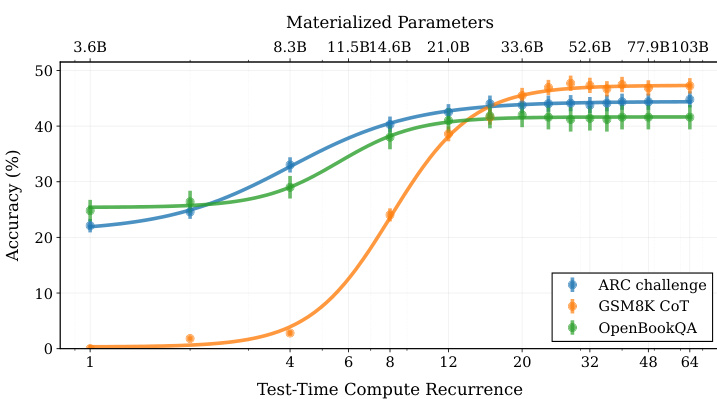
研究者研究了一种新颖的语言模型架构,能够通过在潜在空间中隐式推理来扩展测试时间计算。该模型通过迭代递归块工作,从而在测试时展开到任意深度。研究者证明了所得模型可以改进其在推理基准上的性能,达到相当于500亿参数的计算负载。
阅读论文
SigLIP 2: 具有改进语义理解、定位和密集特征的多语言视觉语言编码器
115票
由Google DeepMind提出的SigLIP 2是一个新的多语言视觉语言编码器系列。通过扩展原始图像-文本训练目标与多种技术,SigLIP 2模型在所有模型规模上的核心能力超过了其前作,包括零样本分类、图像-文本检索,以及为VLM提取视觉表示的迁移性能。
阅读论文
直接对齐算法之间的差异是模糊的
111票
研究首先表明直接对齐算法(DAA)中的单阶段方法表现不如两阶段方法。为解决这个问题,研究者将显式SFT阶段引入单阶段ORPO和ASFT中,并引入了β参数来控制偏好优化的强度。分析表明,关键因素是方法是使用成对还是逐点目标,而不是特定的隐式奖励或损失函数。
阅读论文
s1: 简单的测试时间扩展
106票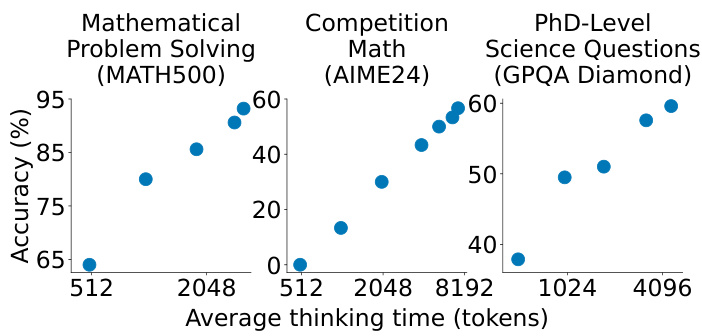
研究者寻求实现测试时间扩展和强大推理性能的最简单方法。他们精心策划了一个名为s1K的小型数据集,包含1,000个配对问题和推理痕迹。使用预算强制来控制测试时间计算,使模型能够复查其答案,经常修复不正确的推理步骤。他们的模型s1在竞赛数学问题上超过了o1-preview高达27%。
阅读论文
SuperGPQA: 跨285个研究生学科扩展LLM评估
91票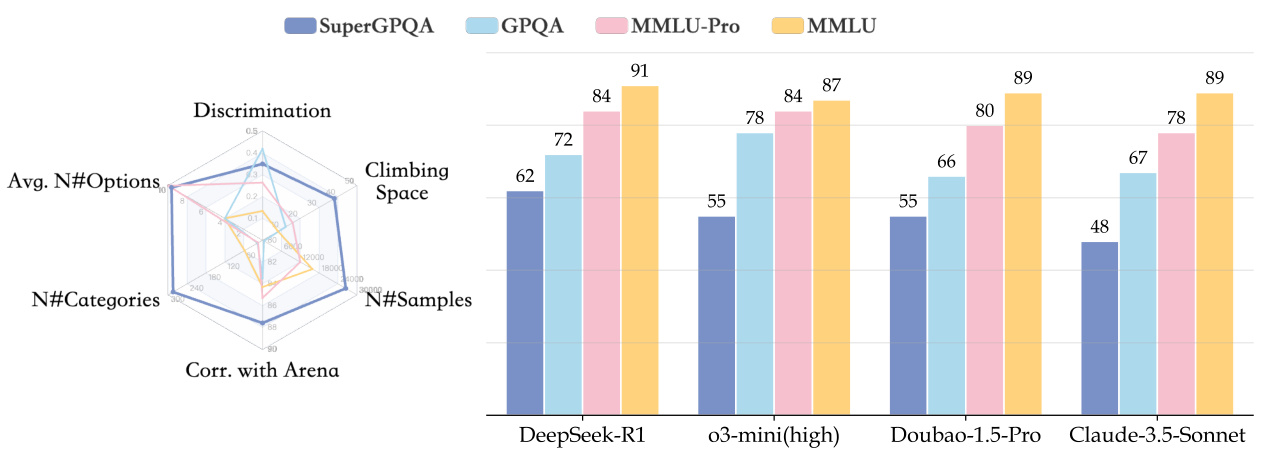
由ByteDance提出的SuperGPQA是一个全面的基准,评估LLM在285个研究生水平学科中的知识和推理能力。该基准采用了人类-LLM协作过滤机制,通过基于LLM响应和专家反馈的迭代细化,消除琐碎或模糊的问题。注重推理的模型DeepSeek-R1在SuperGPQA上达到了61.82%的最高准确率。
阅读论文
Goku: 基于流的视频生成基础模型
88票
由香港大学和ByteDance提出的Goku是一个最先进的联合图像和视频生成模型系列,利用矫正流Transformer实现行业领先的性能。Goku在定性和定量评估中表现出卓越的性能,在文本到图像生成方面在GenEval上达到0.76,在DPG-Bench上达到83.65,在文本到视频任务的VBench上达到84.85。
阅读论文
SynthDetoxM: 现代LLM是少样本平行解毒数据标注器
85票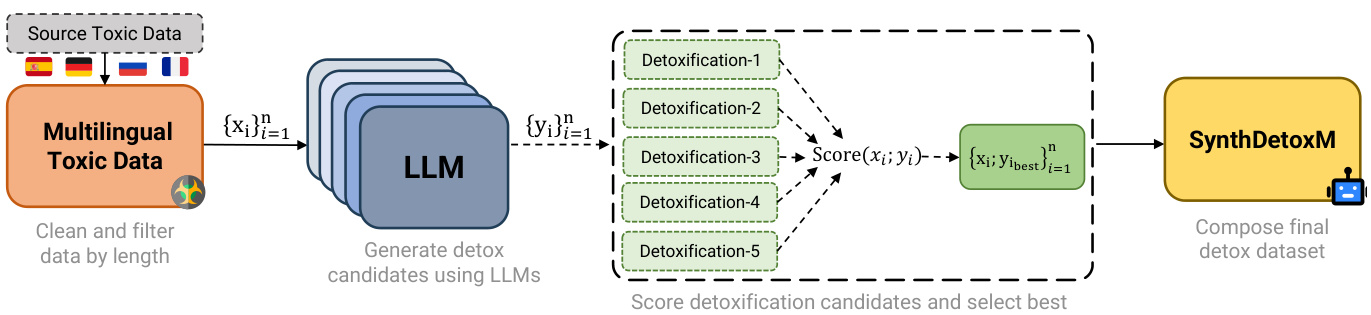
由AIRI、Skoltech等机构提出的SynthDetoxM是一个手动收集和合成生成的多语言平行文本解毒数据集,包括德语、法语、西班牙语和俄语的16,000对高质量解毒句对。实验表明,在生成的合成数据集上训练的模型比在人类标注的MultiParaDetox数据集上训练的模型表现更好。
阅读论文
SurveyX: 通过大型语言模型实现学术调查自动化
83票
由中国人民大学等机构提出的SurveyX是一个高效且有组织的自动调查生成系统,将调查撰写过程分解为准备阶段和生成阶段。通过创新地引入在线参考检索、AttributeTree预处理方法和重新润色过程,SurveyX在内容质量和引用质量方面显著优于现有系统。
阅读论文
大型语言扩散模型
80票
研究者通过引入LLaDA挑战了自回归模型(ARMs)是LLM基石的观念。LLaDA是一个从头训练的扩散模型,采用前向数据掩码过程和由vanilla Transformer参数化的反向过程来建模分布。LLaDA 8B在上下文学习方面与LLaMA3 8B等强大的LLM相比具有竞争力,并解决了逆转诅咒问题。
阅读论文
Soundwave: 在LLM中语音-文本对齐的少即是多
76票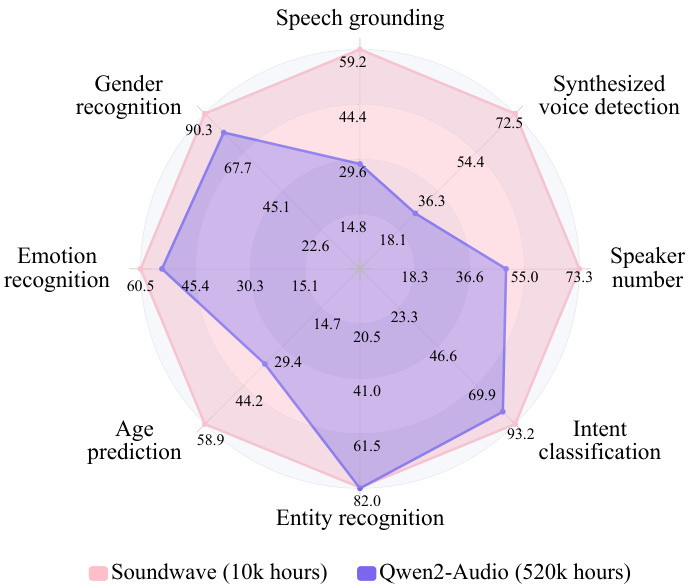
由香港中文大学(深圳)提出的Soundwave关注语音和文本之间的两个基本问题:表示空间差距和序列长度不一致。Soundwave利用一种高效的训练策略和新颖的架构来解决这些问题。结果表明,Soundwave在语音翻译和AIR-Bench语音任务上的表现优于先进的Qwen2-Audio,仅使用了五十分之一的训练数据。
阅读论文