Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -35
- .gitignore +160 -0
- .gradio/certificate.pem +31 -0
- LICENSE +21 -0
- README.md +248 -6
- images/webui_dl_model.png +0 -0
- images/webui_generate.png +0 -0
- images/webui_upload_model.png +0 -0
- notebooks/ultimate_rvc_colab.ipynb +109 -0
- notes/TODO.md +462 -0
- notes/app-doc.md +19 -0
- notes/cli-doc.md +74 -0
- notes/gradio.md +615 -0
- pyproject.toml +225 -0
- src/ultimate_rvc/__init__.py +40 -0
- src/ultimate_rvc/cli/__init__.py +8 -0
- src/ultimate_rvc/cli/generate/song_cover.py +409 -0
- src/ultimate_rvc/cli/main.py +21 -0
- src/ultimate_rvc/common.py +10 -0
- src/ultimate_rvc/core/__init__.py +7 -0
- src/ultimate_rvc/core/common.py +285 -0
- src/ultimate_rvc/core/exceptions.py +297 -0
- src/ultimate_rvc/core/generate/__init__.py +13 -0
- src/ultimate_rvc/core/generate/song_cover.py +1728 -0
- src/ultimate_rvc/core/main.py +48 -0
- src/ultimate_rvc/core/manage/__init__.py +4 -0
- src/ultimate_rvc/core/manage/audio.py +214 -0
- src/ultimate_rvc/core/manage/models.py +424 -0
- src/ultimate_rvc/core/manage/other_settings.py +29 -0
- src/ultimate_rvc/core/manage/public_models.json +646 -0
- src/ultimate_rvc/core/typing_extra.py +294 -0
- src/ultimate_rvc/py.typed +0 -0
- src/ultimate_rvc/stubs/audio_separator/separator/__init__.pyi +100 -0
- src/ultimate_rvc/stubs/gradio/__init__.pyi +245 -0
- src/ultimate_rvc/stubs/gradio/events.pyi +344 -0
- src/ultimate_rvc/stubs/pedalboard_native/io/__init__.pyi +41 -0
- src/ultimate_rvc/stubs/soundfile/__init__.pyi +34 -0
- src/ultimate_rvc/stubs/sox/__init__.pyi +19 -0
- src/ultimate_rvc/stubs/static_ffmpeg/__init__.pyi +1 -0
- src/ultimate_rvc/stubs/static_sox/__init__.pyi +1 -0
- src/ultimate_rvc/stubs/yt_dlp/__init__.pyi +27 -0
- src/ultimate_rvc/typing_extra.py +56 -0
- src/ultimate_rvc/vc/__init__.py +8 -0
- src/ultimate_rvc/vc/configs/32k.json +46 -0
- src/ultimate_rvc/vc/configs/32k_v2.json +46 -0
- src/ultimate_rvc/vc/configs/40k.json +46 -0
- src/ultimate_rvc/vc/configs/48k.json +46 -0
- src/ultimate_rvc/vc/configs/48k_v2.json +46 -0
- src/ultimate_rvc/vc/infer_pack/attentions.py +417 -0
- src/ultimate_rvc/vc/infer_pack/commons.py +166 -0
.gitattributes
CHANGED
|
@@ -1,35 +1,2 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 1 |
+
# Auto detect text files and perform LF normalization
|
| 2 |
+
* text=auto
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.gitignore
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ultimate RVC project
|
| 2 |
+
audio
|
| 3 |
+
models
|
| 4 |
+
temp
|
| 5 |
+
uv
|
| 6 |
+
uv.lock
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
# Byte-compiled / optimized / DLL files
|
| 10 |
+
__pycache__/
|
| 11 |
+
*.py[cod]
|
| 12 |
+
*$py.class
|
| 13 |
+
|
| 14 |
+
# C extensions
|
| 15 |
+
*.so
|
| 16 |
+
|
| 17 |
+
# Distribution / packaging
|
| 18 |
+
.Python
|
| 19 |
+
build/
|
| 20 |
+
develop-eggs/
|
| 21 |
+
dist/
|
| 22 |
+
downloads/
|
| 23 |
+
eggs/
|
| 24 |
+
.eggs/
|
| 25 |
+
lib/
|
| 26 |
+
lib64/
|
| 27 |
+
parts/
|
| 28 |
+
sdist/
|
| 29 |
+
var/
|
| 30 |
+
wheels/
|
| 31 |
+
share/python-wheels/
|
| 32 |
+
*.egg-info/
|
| 33 |
+
.installed.cfg
|
| 34 |
+
*.egg
|
| 35 |
+
MANIFEST
|
| 36 |
+
|
| 37 |
+
# PyInstaller
|
| 38 |
+
# Usually these files are written by a python script from a template
|
| 39 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 40 |
+
*.manifest
|
| 41 |
+
*.spec
|
| 42 |
+
|
| 43 |
+
# Installer logs
|
| 44 |
+
pip-log.txt
|
| 45 |
+
pip-delete-this-directory.txt
|
| 46 |
+
|
| 47 |
+
# Unit test / coverage reports
|
| 48 |
+
htmlcov/
|
| 49 |
+
.tox/
|
| 50 |
+
.nox/
|
| 51 |
+
.coverage
|
| 52 |
+
.coverage.*
|
| 53 |
+
.cache
|
| 54 |
+
nosetests.xml
|
| 55 |
+
coverage.xml
|
| 56 |
+
*.cover
|
| 57 |
+
*.py,cover
|
| 58 |
+
.hypothesis/
|
| 59 |
+
.pytest_cache/
|
| 60 |
+
cover/
|
| 61 |
+
|
| 62 |
+
# Translations
|
| 63 |
+
*.mo
|
| 64 |
+
*.pot
|
| 65 |
+
|
| 66 |
+
# Django stuff:
|
| 67 |
+
*.log
|
| 68 |
+
local_settings.py
|
| 69 |
+
db.sqlite3
|
| 70 |
+
db.sqlite3-journal
|
| 71 |
+
|
| 72 |
+
# Flask stuff:
|
| 73 |
+
instance/
|
| 74 |
+
.webassets-cache
|
| 75 |
+
|
| 76 |
+
# Scrapy stuff:
|
| 77 |
+
.scrapy
|
| 78 |
+
|
| 79 |
+
# Sphinx documentation
|
| 80 |
+
docs/_build/
|
| 81 |
+
|
| 82 |
+
# PyBuilder
|
| 83 |
+
.pybuilder/
|
| 84 |
+
target/
|
| 85 |
+
|
| 86 |
+
# Jupyter Notebook
|
| 87 |
+
.ipynb_checkpoints
|
| 88 |
+
|
| 89 |
+
# IPython
|
| 90 |
+
profile_default/
|
| 91 |
+
ipython_config.py
|
| 92 |
+
|
| 93 |
+
# pyenv
|
| 94 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 95 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 96 |
+
# .python-version
|
| 97 |
+
|
| 98 |
+
# pipenv
|
| 99 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 100 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 101 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 102 |
+
# install all needed dependencies.
|
| 103 |
+
#Pipfile.lock
|
| 104 |
+
|
| 105 |
+
# poetry
|
| 106 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 107 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 108 |
+
# commonly ignored for libraries.
|
| 109 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 110 |
+
#poetry.lock
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintainted in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
.idea/
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 JackismyShephard
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,12 +1,254 @@
|
|
| 1 |
---
|
| 2 |
title: HRVC
|
| 3 |
-
|
| 4 |
-
colorFrom: green
|
| 5 |
-
colorTo: gray
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 5.6.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
title: HRVC
|
| 3 |
+
app_file: src/ultimate_rvc/web/main.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 5.6.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# Ultimate RVC
|
| 8 |
|
| 9 |
+
An extension of [AiCoverGen](https://github.com/SociallyIneptWeeb/AICoverGen), which provides several new features and improvements, enabling users to generate song covers using RVC with ease. Ideal for people who want to incorporate singing functionality into their AI assistant/chatbot/vtuber, or for people who want to hear their favourite characters sing their favourite song.
|
| 10 |
+
|
| 11 |
+
<!-- Showcase: TBA -->
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
Ultimate RVC is under constant development and testing, but you can try it out right now locally or on Google Colab!
|
| 16 |
+
|
| 17 |
+
## New Features
|
| 18 |
+
|
| 19 |
+
* Easy and automated setup using launcher scripts for both windows and Debian-based linux systems
|
| 20 |
+
* Caching system which saves intermediate audio files as needed, thereby reducing inference time as much as possible. For example, if song A has already been converted using model B and now you want to convert song A using model C, then vocal extraction can be skipped and inference time reduced drastically
|
| 21 |
+
* Ability to listen to intermediate audio files in the UI. This is useful for getting an idea of what is happening in each step of the song cover generation pipeline
|
| 22 |
+
* A "multi-step" song cover generation tab: here you can try out each step of the song cover generation pipeline in isolation. For example, if you already have extracted vocals available and only want to convert these using your voice model, then you can do that here. Besides, this tab is useful for experimenting with settings for each step of the song cover generation pipeline
|
| 23 |
+
* An overhaul of the song input component for the song cover generation pipeline. Now cached input songs can be selected from a dropdown, so that you don't have to supply the Youtube link of a song each time you want to convert it.
|
| 24 |
+
* A new "manage models" tab, which collects and revamps all existing functionality for managing voice models, as well as adds some new features, such as the ability to delete existing models
|
| 25 |
+
* A new "manage audio" tab, which allows you to interact with all audio generated by the app. Currently, this tab supports deleting audio files.
|
| 26 |
+
* Lots of visual and performance improvements resulting from updating from Gradio 3 to Gradio 5 and from python 3.9 to python 3.12
|
| 27 |
+
* A redistributable package on PyPI, which allows you to access the Ultimate RVC project without cloning any repositories.
|
| 28 |
+
|
| 29 |
+
## Colab notebook
|
| 30 |
+
|
| 31 |
+
For those without a powerful enough NVIDIA GPU, you may try Ultimate RVC out using Google Colab.
|
| 32 |
+
|
| 33 |
+
[](https://colab.research.google.com/github/JackismyShephard/ultimate-rvc/blob/main/notebooks/ultimate_rvc_colab.ipynb)
|
| 34 |
+
|
| 35 |
+
For those who want to run the Ultimate RVC project locally, follow the setup guide below.
|
| 36 |
+
|
| 37 |
+
## Setup
|
| 38 |
+
|
| 39 |
+
The Ultimate RVC project currently supports Windows and Debian-based Linux distributions, namely Ubuntu 22.04 and Ubuntu 24.04. Support for other platforms is not guaranteed.
|
| 40 |
+
|
| 41 |
+
To setup the project follow the steps below and execute the provided commands in an appropriate terminal. On windows this terminal should be **powershell**, while on Debian-based linux distributions it should be a **bash**-compliant shell.
|
| 42 |
+
|
| 43 |
+
### Install Git
|
| 44 |
+
|
| 45 |
+
Follow the instructions [here](https://git-scm.com/book/en/v2/Getting-Started-Installing-Git) to install Git on your computer.
|
| 46 |
+
|
| 47 |
+
### Set execution policy (Windows only)
|
| 48 |
+
|
| 49 |
+
To execute the subsequent commands on Windows, it is necessary to first grant
|
| 50 |
+
powershell permission to run scripts. This can be done at a user level as follows:
|
| 51 |
+
|
| 52 |
+
```console
|
| 53 |
+
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
### Clone Ultimate RVC repository
|
| 57 |
+
|
| 58 |
+
```console
|
| 59 |
+
git clone https://github.com/JackismyShephard/ultimate-rvc
|
| 60 |
+
cd ultimate-rvc
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
### Install dependencies
|
| 64 |
+
|
| 65 |
+
```console
|
| 66 |
+
./urvc install
|
| 67 |
+
```
|
| 68 |
+
Note that on Linux, this command will install the CUDA 12.4 toolkit system-wide, if it is not already available. In case you have problems, you may need to install the toolkit manually.
|
| 69 |
+
|
| 70 |
+
## Usage
|
| 71 |
+
|
| 72 |
+
### Start the app
|
| 73 |
+
|
| 74 |
+
```console
|
| 75 |
+
./urvc run
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
Once the following output message `Running on local URL: http://127.0.0.1:7860` appears, you can click on the link to open a tab with the web app.
|
| 79 |
+
|
| 80 |
+
### Manage models
|
| 81 |
+
|
| 82 |
+
#### Download models
|
| 83 |
+
|
| 84 |
+

|
| 85 |
+
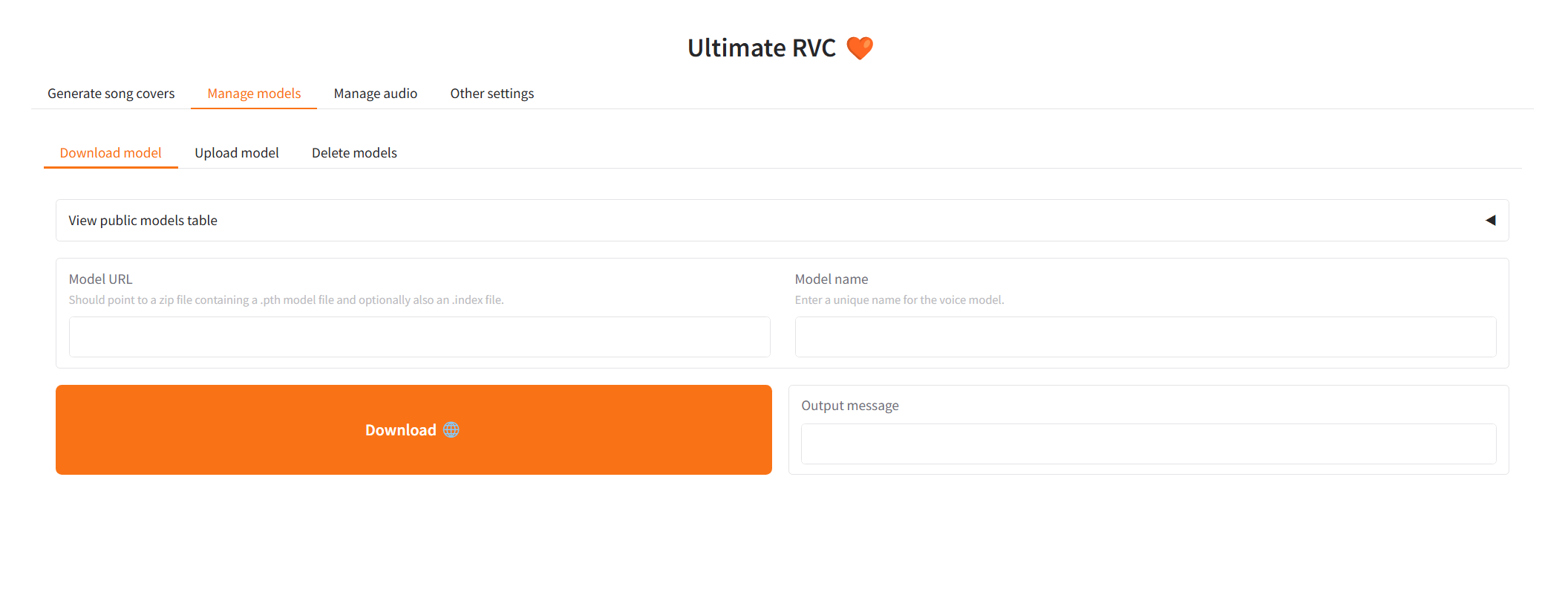
|
| 86 |
+
Navigate to the `Download model` subtab under the `Manage models` tab, and paste the download link to an RVC model and give it a unique name.
|
| 87 |
+
You may search the [AI Hub Discord](https://discord.gg/aihub) where already trained voice models are available for download.
|
| 88 |
+
The downloaded zip file should contain the .pth model file and an optional .index file.
|
| 89 |
+
|
| 90 |
+
Once the 2 input fields are filled in, simply click `Download`! Once the output message says `[NAME] Model successfully downloaded!`, you should be able to use it in the `Generate song covers` tab!
|
| 91 |
+
|
| 92 |
+
#### Upload models
|
| 93 |
+
|
| 94 |
+

|
| 95 |
+
|
| 96 |
+
For people who have trained RVC v2 models locally and would like to use them for AI cover generations.
|
| 97 |
+
Navigate to the `Upload model` subtab under the `Manage models` tab, and follow the instructions.
|
| 98 |
+
Once the output message says `Model with name [NAME] successfully uploaded!`, you should be able to use it in the `Generate song covers` tab!
|
| 99 |
+
|
| 100 |
+
#### Delete RVC models
|
| 101 |
+
|
| 102 |
+
TBA
|
| 103 |
+
|
| 104 |
+
### Generate song covers
|
| 105 |
+
|
| 106 |
+
#### One-click generation
|
| 107 |
+
|
| 108 |
+

|
| 109 |
+
|
| 110 |
+
* From the Voice model dropdown menu, select the voice model to use.
|
| 111 |
+
* In the song input field, copy and paste the link to any song on YouTube, the full path to a local audio file, or select a cached input song.
|
| 112 |
+
* Pitch should be set to either -12, 0, or 12 depending on the original vocals and the RVC AI modal. This ensures the voice is not *out of tune*.
|
| 113 |
+
* Other advanced options for vocal conversion, audio mixing and etc. can be viewed by clicking the appropriate accordion arrow to expand.
|
| 114 |
+
|
| 115 |
+
Once all options are filled in, click `Generate` and the AI generated cover should appear in a less than a few minutes depending on your GPU.
|
| 116 |
+
|
| 117 |
+
#### Multi-step generation
|
| 118 |
+
|
| 119 |
+
TBA
|
| 120 |
+
|
| 121 |
+
## CLI
|
| 122 |
+
|
| 123 |
+
### Manual download of RVC models
|
| 124 |
+
|
| 125 |
+
Unzip (if needed) and transfer the `.pth` and `.index` files to a new folder in the [rvc models](models/rvc) directory. Each folder should only contain one `.pth` and one `.index` file.
|
| 126 |
+
|
| 127 |
+
The directory structure should look something like this:
|
| 128 |
+
|
| 129 |
+
```text
|
| 130 |
+
├── models
|
| 131 |
+
| ├── audio_separator
|
| 132 |
+
| ├── rvc
|
| 133 |
+
│ ├── John
|
| 134 |
+
│ │ ├── JohnV2.pth
|
| 135 |
+
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
|
| 136 |
+
│ ├── May
|
| 137 |
+
│ │ ├── May.pth
|
| 138 |
+
│ │ └── added_IVF2237_Flat_nprobe_1_v2.index
|
| 139 |
+
│ └── hubert_base.pt
|
| 140 |
+
├── notebooks
|
| 141 |
+
├── notes
|
| 142 |
+
└── src
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
### Running the pipeline
|
| 146 |
+
|
| 147 |
+
#### Usage
|
| 148 |
+
|
| 149 |
+
```console
|
| 150 |
+
./urvc cli song-cover run-pipeline [OPTIONS] SOURCE MODEL_NAME
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
##### Arguments
|
| 154 |
+
|
| 155 |
+
* `SOURCE`: A Youtube URL, the path to a local audio file or the path to a song directory. [required]
|
| 156 |
+
* `MODEL_NAME`: The name of the voice model to use for vocal conversion. [required]
|
| 157 |
+
|
| 158 |
+
##### Options
|
| 159 |
+
|
| 160 |
+
* `--n-octaves INTEGER`: The number of octaves to pitch-shift the converted vocals by.Use 1 for male-to-female and -1 for vice-versa. [default: 0]
|
| 161 |
+
* `--n-semitones INTEGER`: The number of semi-tones to pitch-shift the converted vocals, instrumentals, and backup vocals by. Altering this slightly reduces sound quality [default: 0]
|
| 162 |
+
* `--f0-method [rmvpe|mangio-crepe]`: The method to use for pitch detection during vocal conversion. Best option is RMVPE (clarity in vocals), then Mangio-Crepe (smoother vocals). [default: rmvpe]
|
| 163 |
+
* `--index-rate FLOAT RANGE`: A decimal number e.g. 0.5, Controls how much of the accent in the voice model to keep in the converted vocals. Increase to bias the conversion towards the accent of the voice model. [default: 0.5; 0<=x<=1]
|
| 164 |
+
* `--filter-radius INTEGER RANGE`: A number between 0 and 7. If >=3: apply median filtering to the pitch results harvested during vocal conversion. Can help reduce breathiness in the converted vocals. [default: 3; 0<=x<=7]
|
| 165 |
+
* `--rms-mix-rate FLOAT RANGE`: A decimal number e.g. 0.25. Controls how much to mimic the loudness of the input vocals (0) or a fixed loudness (1) during vocal conversion. [default: 0.25; 0<=x<=1]
|
| 166 |
+
* `--protect FLOAT RANGE`: A decimal number e.g. 0.33. Controls protection of voiceless consonants and breath sounds during vocal conversion. Decrease to increase protection at the cost of indexing accuracy. Set to 0.5 to disable. [default: 0.33; 0<=x<=0.5]
|
| 167 |
+
* `--hop-length INTEGER`: Controls how often the CREPE-based pitch detection algorithm checks for pitch changes during vocal conversion. Measured in milliseconds. Lower values lead to longer conversion times and a higher risk of voice cracks, but better pitch accuracy. Recommended value: 128. [default: 128]
|
| 168 |
+
* `--room-size FLOAT RANGE`: The room size of the reverb effect applied to the converted vocals. Increase for longer reverb time. Should be a value between 0 and 1. [default: 0.15; 0<=x<=1]
|
| 169 |
+
* `--wet-level FLOAT RANGE`: The loudness of the converted vocals with reverb effect applied. Should be a value between 0 and 1 [default: 0.2; 0<=x<=1]
|
| 170 |
+
* `--dry-level FLOAT RANGE`: The loudness of the converted vocals wihout reverb effect applied. Should be a value between 0 and 1. [default: 0.8; 0<=x<=1]
|
| 171 |
+
* `--damping FLOAT RANGE`: The absorption of high frequencies in the reverb effect applied to the converted vocals. Should be a value between 0 and 1. [default: 0.7; 0<=x<=1]
|
| 172 |
+
* `--main-gain INTEGER`: The gain to apply to the post-processed vocals. Measured in dB. [default: 0]
|
| 173 |
+
* `--inst-gain INTEGER`: The gain to apply to the pitch-shifted instrumentals. Measured in dB. [default: 0]
|
| 174 |
+
* `--backup-gain INTEGER`: The gain to apply to the pitch-shifted backup vocals. Measured in dB. [default: 0]
|
| 175 |
+
* `--output-sr INTEGER`: The sample rate of the song cover. [default: 44100]
|
| 176 |
+
* `--output-format [mp3|wav|flac|ogg|m4a|aac]`: The audio format of the song cover. [default: mp3]
|
| 177 |
+
* `--output-name TEXT`: The name of the song cover.
|
| 178 |
+
* `--help`: Show this message and exit.
|
| 179 |
+
|
| 180 |
+
## Update to latest version
|
| 181 |
+
|
| 182 |
+
```console
|
| 183 |
+
./urvc update
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
## Development mode
|
| 187 |
+
|
| 188 |
+
When developing new features or debugging, it is recommended to run the app in development mode. This enables hot reloading, which means that the app will automatically reload when changes are made to the code.
|
| 189 |
+
|
| 190 |
+
```console
|
| 191 |
+
./urvc dev
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
## PyPI package
|
| 195 |
+
|
| 196 |
+
The Ultimate RVC project is also available as a [distributable package](https://pypi.org/project/ultimate-rvc/) on [PyPI](https://pypi.org/).
|
| 197 |
+
|
| 198 |
+
### Installation
|
| 199 |
+
|
| 200 |
+
The package can be installed with pip in a **Python 3.12**-based environment. To do so requires first installing PyTorch with Cuda support:
|
| 201 |
+
|
| 202 |
+
```console
|
| 203 |
+
pip install torch==2.5.1+cu124 torchaudio==2.5.1+cu124 --index-url https://download.pytorch.org/whl/cu124
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
Additionally, on Windows the `diffq` package must be installed manually as follows:
|
| 207 |
+
|
| 208 |
+
```console
|
| 209 |
+
pip install https://huggingface.co/JackismyShephard/ultimate-rvc/resolve/main/diffq-0.2.4-cp312-cp312-win_amd64.whl
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
The Ultimate RVC project package can then be installed as follows:
|
| 213 |
+
|
| 214 |
+
```console
|
| 215 |
+
pip install ultimate-rvc
|
| 216 |
+
```
|
| 217 |
+
|
| 218 |
+
### Usage
|
| 219 |
+
|
| 220 |
+
The `ultimate-rvc` package can be used as a python library but is primarily intended to be used as a command line tool. The package exposes two top-level commands:
|
| 221 |
+
|
| 222 |
+
* `urvc` which lets the user generate song covers directly from their terminal
|
| 223 |
+
* `urvc-web` which starts a local instance of the Ultimate RVC web application
|
| 224 |
+
|
| 225 |
+
For more information on either command supply the option `--help`.
|
| 226 |
+
|
| 227 |
+
## Environment Variables
|
| 228 |
+
|
| 229 |
+
The behaviour of the Ultimate RVC project can be customized via a number of environment variables. Currently these environment variables control only logging behaviour. They are as follows:
|
| 230 |
+
|
| 231 |
+
* `URVC_CONSOLE_LOG_LEVEL`: The log level for console logging. If not set, defaults to `ERROR`.
|
| 232 |
+
* `URVC_FILE_LOG_LEVEL`: The log level for file logging. If not set, defaults to `INFO`.
|
| 233 |
+
* `URVC_LOGS_DIR`: The directory in which log files will be stored. If not set, logs will be stored in a `logs` directory in the current working directory.
|
| 234 |
+
* `URVC_NO_LOGGING`: If set to `1`, logging will be disabled.
|
| 235 |
+
|
| 236 |
+
## Terms of Use
|
| 237 |
+
|
| 238 |
+
The use of the converted voice for the following purposes is prohibited.
|
| 239 |
+
|
| 240 |
+
* Criticizing or attacking individuals.
|
| 241 |
+
|
| 242 |
+
* Advocating for or opposing specific political positions, religions, or ideologies.
|
| 243 |
+
|
| 244 |
+
* Publicly displaying strongly stimulating expressions without proper zoning.
|
| 245 |
+
|
| 246 |
+
* Selling of voice models and generated voice clips.
|
| 247 |
+
|
| 248 |
+
* Impersonation of the original owner of the voice with malicious intentions to harm/hurt others.
|
| 249 |
+
|
| 250 |
+
* Fraudulent purposes that lead to identity theft or fraudulent phone calls.
|
| 251 |
+
|
| 252 |
+
## Disclaimer
|
| 253 |
+
|
| 254 |
+
I am not liable for any direct, indirect, consequential, incidental, or special damages arising out of or in any way connected with the use/misuse or inability to use this software.
|
images/webui_dl_model.png
ADDED
|
images/webui_generate.png
ADDED

|
images/webui_upload_model.png
ADDED

|
notebooks/ultimate_rvc_colab.ipynb
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {
|
| 6 |
+
"id": "kmyCzJVyCymN"
|
| 7 |
+
},
|
| 8 |
+
"source": [
|
| 9 |
+
"Colab for [Ultimate RVC](https://github.com/JackismyShephard/ultimate-rvc)\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"This Colab notebook will **help** you if you don’t have a GPU or if your PC isn’t very powerful.\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"Simply click `Runtime` in the top navigation bar and `Run all`. Wait for the output of the final cell to show the public gradio url and click on it.\n"
|
| 14 |
+
]
|
| 15 |
+
},
|
| 16 |
+
{
|
| 17 |
+
"cell_type": "code",
|
| 18 |
+
"execution_count": null,
|
| 19 |
+
"metadata": {},
|
| 20 |
+
"outputs": [],
|
| 21 |
+
"source": [
|
| 22 |
+
"# @title 0: Initialize notebook\n",
|
| 23 |
+
"%pip install ipython-autotime\n",
|
| 24 |
+
"%load_ext autotime\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"import codecs\n",
|
| 27 |
+
"import os\n",
|
| 28 |
+
"\n",
|
| 29 |
+
"from IPython.display import clear_output\n",
|
| 30 |
+
"\n",
|
| 31 |
+
"clear_output()"
|
| 32 |
+
]
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"cell_type": "code",
|
| 36 |
+
"execution_count": null,
|
| 37 |
+
"metadata": {
|
| 38 |
+
"cellView": "form",
|
| 39 |
+
"id": "aaokDv1VzpAX"
|
| 40 |
+
},
|
| 41 |
+
"outputs": [],
|
| 42 |
+
"source": [
|
| 43 |
+
"# @title 1: Clone repository\n",
|
| 44 |
+
"cloneing = codecs.decode(\n",
|
| 45 |
+
" \"uggcf://tvguho.pbz/WnpxvfzlFurcuneq/hygvzngr-eip.tvg\",\n",
|
| 46 |
+
" \"rot_13\",\n",
|
| 47 |
+
")\n",
|
| 48 |
+
"\n",
|
| 49 |
+
"!git clone $cloneing HRVC\n",
|
| 50 |
+
"%cd /content/HRVC\n",
|
| 51 |
+
"clear_output()"
|
| 52 |
+
]
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"cell_type": "code",
|
| 56 |
+
"execution_count": null,
|
| 57 |
+
"metadata": {
|
| 58 |
+
"cellView": "form",
|
| 59 |
+
"id": "lVGNygIa0F_1"
|
| 60 |
+
},
|
| 61 |
+
"outputs": [],
|
| 62 |
+
"source": [
|
| 63 |
+
"# @title 2: Install dependencies\n",
|
| 64 |
+
"\n",
|
| 65 |
+
"light = codecs.decode(\"uggcf://nfgeny.fu/hi/0.5.0/vafgnyy.fu\", \"rot_13\")\n",
|
| 66 |
+
"inits = codecs.decode(\"./fep/hygvzngr_eip/pber/znva.cl\", \"rot_13\")\n",
|
| 67 |
+
"\n",
|
| 68 |
+
"!apt install -y python3-dev unzip\n",
|
| 69 |
+
"!curl -LsSf $light | sh\n",
|
| 70 |
+
"\n",
|
| 71 |
+
"os.environ[\"URVC_CONSOLE_LOG_LEVEL\"] = \"WARNING\"\n",
|
| 72 |
+
"!uv run -q $inits\n",
|
| 73 |
+
"clear_output()"
|
| 74 |
+
]
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"cell_type": "code",
|
| 78 |
+
"execution_count": null,
|
| 79 |
+
"metadata": {
|
| 80 |
+
"cellView": "form",
|
| 81 |
+
"id": "lVGNygIa0F_2"
|
| 82 |
+
},
|
| 83 |
+
"outputs": [],
|
| 84 |
+
"source": [
|
| 85 |
+
"# @title 3: Run Ultimate RVC\n",
|
| 86 |
+
"\n",
|
| 87 |
+
"runpice = codecs.decode(\"./fep/hygvzngr_eip/jro/znva.cl\", \"rot_13\")\n",
|
| 88 |
+
"\n",
|
| 89 |
+
"!uv run $runpice --share"
|
| 90 |
+
]
|
| 91 |
+
}
|
| 92 |
+
],
|
| 93 |
+
"metadata": {
|
| 94 |
+
"accelerator": "GPU",
|
| 95 |
+
"colab": {
|
| 96 |
+
"gpuType": "T4",
|
| 97 |
+
"provenance": []
|
| 98 |
+
},
|
| 99 |
+
"kernelspec": {
|
| 100 |
+
"display_name": "Python 3",
|
| 101 |
+
"name": "python3"
|
| 102 |
+
},
|
| 103 |
+
"language_info": {
|
| 104 |
+
"name": "python"
|
| 105 |
+
}
|
| 106 |
+
},
|
| 107 |
+
"nbformat": 4,
|
| 108 |
+
"nbformat_minor": 0
|
| 109 |
+
}
|
notes/TODO.md
ADDED
|
@@ -0,0 +1,462 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TODO
|
| 2 |
+
|
| 3 |
+
* should rename instances of "models" to "voice models"
|
| 4 |
+
|
| 5 |
+
## Project/task management
|
| 6 |
+
|
| 7 |
+
* Should find tool for project/task management
|
| 8 |
+
* Tool should support:
|
| 9 |
+
* hierarchical tasks
|
| 10 |
+
* custom labels and or priorities on tasks
|
| 11 |
+
* being able to filter tasks based on those labels
|
| 12 |
+
* being able to close and resolve tasks
|
| 13 |
+
* Being able to integrate with vscode
|
| 14 |
+
* Access for multiple people (in a team)
|
| 15 |
+
* Should migrate the content of this file into tool
|
| 16 |
+
* Potential candidates
|
| 17 |
+
* GitHub projects
|
| 18 |
+
* Does not yet support hierarchical tasks so no
|
| 19 |
+
* Trello
|
| 20 |
+
* Does not seem to support hierarchical tasks either
|
| 21 |
+
* Notion
|
| 22 |
+
* Seems to support hierarchical tasks, but is complicated
|
| 23 |
+
* Todoist
|
| 24 |
+
* seems to support both hierarchical tasks, custom labels, filtering on those labels, multiple users and there are unofficial plugins for vscode.
|
| 25 |
+
|
| 26 |
+
## Front end
|
| 27 |
+
|
| 28 |
+
### Modularization
|
| 29 |
+
|
| 30 |
+
* Improve modularization of web code using helper functions defined [here](https://huggingface.co/spaces/WoWoWoWololo/wrapping-layouts/blob/main/app.py)
|
| 31 |
+
* Split front-end modules into further sub-modules.
|
| 32 |
+
* Structure of web folder should be:
|
| 33 |
+
* `web`
|
| 34 |
+
* `manage_models`
|
| 35 |
+
* `__init__.py`
|
| 36 |
+
* `main.py`
|
| 37 |
+
* `manage_audio`
|
| 38 |
+
* `__init__.py`
|
| 39 |
+
* `main.py`
|
| 40 |
+
* `generate_song_covers`
|
| 41 |
+
* `__init__.py`
|
| 42 |
+
* `main.py`
|
| 43 |
+
* `one_click_generation`
|
| 44 |
+
* `__init__.py`
|
| 45 |
+
* `main.py`
|
| 46 |
+
* `accordions`
|
| 47 |
+
* `__init__.py`
|
| 48 |
+
* `options_x.py` ... ?
|
| 49 |
+
* `multi_step_generation`
|
| 50 |
+
* `__init__.py`
|
| 51 |
+
* `main.py`
|
| 52 |
+
* `accordions`
|
| 53 |
+
* `__init__.py`
|
| 54 |
+
* `step_X.py` ...
|
| 55 |
+
* `common.py`
|
| 56 |
+
* For `multi_step_generation/step_X.py`, its potential render function might have to take the set of all "input tracks" in the multi-step generation tab, so these will then have to be defined in `multi_step_generation/main.py`. Other components passed to `multi_step_generation/main.py` might also need to be passed further down to `multi_step_generation/step_X.py`
|
| 57 |
+
* For `one_click_generation/option_X.py`, its potential render function should
|
| 58 |
+
render the accordion for the given options and return the components defined in the accordion? Other components passed to `one_click_generation/main.py` might also need to be passed further down to `one_click_generation/option_X.py`
|
| 59 |
+
* Import components instead of passing them as inputs to render functions (DIFFICULT TO IMPLEMENT)
|
| 60 |
+
* We have had problems before with component ids when components are instantiated outside a Blocks context in a separate module and then import into other modules and rendered in their blocks contexts.
|
| 61 |
+
|
| 62 |
+
### Multi-step generation
|
| 63 |
+
|
| 64 |
+
* If possible merge two consecutive event listeners using `update_cached_songs` in the song retrieval accordion.
|
| 65 |
+
* add description describing how to use each accordion and suggestions for workflows
|
| 66 |
+
|
| 67 |
+
* add option for adding more input tracks to the mix song step
|
| 68 |
+
* new components should be created dynamically based on a textfield with names and a button for creating new component
|
| 69 |
+
* when creating a new component a new transfer button and dropdown should also be created
|
| 70 |
+
* and the transfer choices for all dropdowns should be updated to also include the new input track
|
| 71 |
+
* we need to consider how to want to handle vertical space
|
| 72 |
+
* should be we make a new row once more than 3 tracks are on one row?
|
| 73 |
+
* yes and there should be also created the new slider on a new row
|
| 74 |
+
* right under the first row (which itself is under the row with song dir dropdown)
|
| 75 |
+
|
| 76 |
+
* should also have the possiblity to add more tracks to the pitch shift accordion.
|
| 77 |
+
|
| 78 |
+
* add a confirmation box with warning if trying to transfer output track to input track that is not empty.
|
| 79 |
+
* could also have the possibility to ask the user to transfer to create a new input track and transfer the output track to it.
|
| 80 |
+
* this would just be the same pop up confirmation box as before but in addition to yes and cancel options it will also have a "transfer to new input track" option.
|
| 81 |
+
* we need custom javasctip for this.
|
| 82 |
+
|
| 83 |
+
### Common
|
| 84 |
+
|
| 85 |
+
* fix problem with typing of block.launch()
|
| 86 |
+
* problem stems from doing from gradio import routes
|
| 87 |
+
* so instead should import from gradio.routes directly
|
| 88 |
+
* open a pr with changes
|
| 89 |
+
* save default values for options for song generation in an `SongCoverOptionDefault` enum.
|
| 90 |
+
* then reference this enum across the two tabs
|
| 91 |
+
* and also use `list[SongCoverOptionDefault]` as input to reset settings click event listener in single click generation tab.
|
| 92 |
+
* Persist state of app (currently selected settings etc.) across re-renders
|
| 93 |
+
* This includes:
|
| 94 |
+
* refreshing a browser windows
|
| 95 |
+
* Opening app in new browser window
|
| 96 |
+
* Maybe it should also include when app is started anew?
|
| 97 |
+
* Possible solutions
|
| 98 |
+
* use gr.browserstate to allow state to be preserved acrross page loads.
|
| 99 |
+
* Save any changes to components to a session dictionary and load from it upon refresh
|
| 100 |
+
* See [here](https://github.com/gradio-app/gradio/issues/3106#issuecomment-1694704623)
|
| 101 |
+
* Problem is that this solution might not work with accordions or other types of blocks
|
| 102 |
+
* should use .expand() and .collapse() event listeners on accordions to programmatically reset the state of accordions to what they were before after user has refreshed the page
|
| 103 |
+
* Use localstorage
|
| 104 |
+
* see [here](https://huggingface.co/spaces/YiXinCoding/gradio-chat-history/blob/main/app.py) and [here](https://huggingface.co/spaces/radames/gradio_window_localStorage/blob/main/app.py)
|
| 105 |
+
|
| 106 |
+
* Whenever the state of a component is changed save the new state to a custom JSON file.
|
| 107 |
+
* Then whenever the app is refreshed load the current state of components from the JSON file
|
| 108 |
+
* This solution should probably work for Block types that are not components
|
| 109 |
+
* need to fix the `INFO: Could not find files for the given pattern(s)` on startup of web application on windows (DIFFICULT TO IMPLEMENT)
|
| 110 |
+
* this is an error that gradio needs to fix
|
| 111 |
+
* Remove reset button on slider components (DIFFICULT TO IMPLEMENT)
|
| 112 |
+
* this is a gradio feature that needs to be removed.
|
| 113 |
+
* Fix that gradio removes special symbols from audio paths when loaded into audio components (DIFFICULT TO IMPLEMENT)
|
| 114 |
+
* includes parenthesis, question marks, etc.
|
| 115 |
+
* its a gradio bug so report?
|
| 116 |
+
* Add button for cancelling any currently running jobs (DIFFICULT TO IMPLEMENT)
|
| 117 |
+
* Not supported by Gradio natively
|
| 118 |
+
* Also difficult to implement manually as Gradio seems to be running called backend functions in thread environments
|
| 119 |
+
* dont show error upon missing confirmation (DIFFICULT TO IMPLEMENT)
|
| 120 |
+
* can return `gr.update()`instead of raising an error in relevant event listener function
|
| 121 |
+
* but problem is that subsequent steps will still be executed in this case
|
| 122 |
+
* clearing temporary files with the `delete_cache` parameter only seems to work if all windows are closed before closing the app process (DIFFICULT TO IMPLEMENT)
|
| 123 |
+
* this is a gradio bug so report?
|
| 124 |
+
|
| 125 |
+
## Online hosting optimization
|
| 126 |
+
|
| 127 |
+
* make concurrency_id and concurrency limit on components be dependent on whether gpu is used or not
|
| 128 |
+
* if only cpu then there should be no limit
|
| 129 |
+
* increase value of `default_concurrency_limit` in `Block.queue` so that the same event listener
|
| 130 |
+
* can be called multiple times concurrently
|
| 131 |
+
* use `Block.launch()` with `max_file_size` to prevent too large uploads
|
| 132 |
+
* define as many functions with async as possible to increase responsiveness of app
|
| 133 |
+
* and then use `Block.launch()` with `max_threads`set to an appropriate value representing the number of concurrent threads that can be run on the server (default is 40)
|
| 134 |
+
* Persist state of app (currently selected settings etc.) across re-renders
|
| 135 |
+
* consider setting `max_size` in `Block.queue()` to explicitly limit the number of people that can be in the queue at the same time
|
| 136 |
+
* clearing of temporary files should happen after a user logs in and out
|
| 137 |
+
* and in this case it should only be temporary files for the active user that are cleared
|
| 138 |
+
* Is that even possible to control?
|
| 139 |
+
* enable server side rendering (requires installing node and setting ssr_mode = true in .launch) (DIFFICULT TO IMPLEMENT)
|
| 140 |
+
* Also needs to set GRADIO_NODE_PATH to point to the node executable
|
| 141 |
+
* problem is that on windows there is a ERR_UNSUPPORTED_ESM_URL_SCHEME which needs to be fixed by gradio
|
| 142 |
+
* see here https://github.com/nodejs/node/issues/31710
|
| 143 |
+
* on linux it works but it is not possible to shutdown server using CTRL+ C
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
## Back end
|
| 147 |
+
|
| 148 |
+
### `generate_song_cover.py`
|
| 149 |
+
|
| 150 |
+
* intermediate file prefixes should be made into enums
|
| 151 |
+
* find framework for caching intermediate results rather than relying on your homemade system
|
| 152 |
+
|
| 153 |
+
* Joblib: <https://medium.com/@yuxuzi/unlocking-efficiency-in-machine-learning-projects-with-joblib-a-python-pipeline-powerhouse-feb0ebfdf4df>
|
| 154 |
+
* scikit learn: <https://scikit-learn.org/stable/modules/compose.html#pipeline>
|
| 155 |
+
|
| 156 |
+
* <https://softwarepatternslexicon.com/machine-learning/infrastructure-and-scalability/workflow-management/pipeline-caching/>
|
| 157 |
+
* <https://github.com/bmabey/provenance>
|
| 158 |
+
* <https://docs.sweep.dev/blogs/file-cache>
|
| 159 |
+
|
| 160 |
+
* Support specific audio formats for intermediate audio file?
|
| 161 |
+
* it might require some more code to support custom output format for all pipeline functions.
|
| 162 |
+
|
| 163 |
+
* expand `_get_model_name` so that it can take any audio file in an intermediate audio folder as input (DIFFICULT TO IMPLEMENT)
|
| 164 |
+
* Function should then try to recursively
|
| 165 |
+
* look for a corresponding json metadata file
|
| 166 |
+
* find the model name in that file if it exists
|
| 167 |
+
* otherwise find the path in the input field in the metadata file
|
| 168 |
+
* repeat
|
| 169 |
+
* should also consider whether input audio file belongs to step before audio conversion step
|
| 170 |
+
* use pydantic models to constrain numeric inputs (DIFFICULT TO IMPLEMENT)
|
| 171 |
+
* for inputs to `convert` function for example
|
| 172 |
+
* Use `Annotated[basic type, Field[constraint]]` syntax along with a @validate_call decorator on functions
|
| 173 |
+
* Problem is that pyright does not support `Annotated` so we would have to switch to mypy
|
| 174 |
+
|
| 175 |
+
### `manage_models.py`
|
| 176 |
+
|
| 177 |
+
* use pandas.read_json to load public models table (DIFFICULT TO IMPLEMENT)
|
| 178 |
+
|
| 179 |
+
## CLI
|
| 180 |
+
|
| 181 |
+
### Add remaining CLI interfaces
|
| 182 |
+
|
| 183 |
+
* Interface for `core.manage_models`
|
| 184 |
+
* Interface for `core.manage_audio`
|
| 185 |
+
* Interfaces for individual pipeline functions defined in `core.generate_song_covers`
|
| 186 |
+
|
| 187 |
+
## python package management
|
| 188 |
+
|
| 189 |
+
* need to make project version (in `pyproject.toml`) dynamic so that it is updated automatically when a new release is made
|
| 190 |
+
* once diffq-fixed is used by audio-separator we can remove the url dependency on windows
|
| 191 |
+
* we will still need to wait for uv to make it easy to install package with torch dependency
|
| 192 |
+
* also it is still necessary to install pytorch first as it is not on pypi index
|
| 193 |
+
* figure out way of making ./urvc commands execute faster
|
| 194 |
+
* when ultimate rvc is downloaded as a pypi package the exposed commands are much faster so investigate this
|
| 195 |
+
* update dependencies in pyproject.toml
|
| 196 |
+
* use latest compatible version of all packages
|
| 197 |
+
* remove commented out code, unless strictly necessary
|
| 198 |
+
|
| 199 |
+
## Audio separation
|
| 200 |
+
|
| 201 |
+
* expand back-end function(s) so that they are parametrized by both model type as well as model settings
|
| 202 |
+
* Need to decide whether we only want to support common model settings or also settings that are unique to each model
|
| 203 |
+
* It will probably be the latter, which will then require some extra checks.
|
| 204 |
+
* Need to decide which models supported by `audio_separator` that we want to support
|
| 205 |
+
* Not all of them seem to work
|
| 206 |
+
* Probably MDX models and MDXC models
|
| 207 |
+
* Maybe also VR and demucs?
|
| 208 |
+
* Revisit online guide for optimal models and settings
|
| 209 |
+
* In multi-step generation tab
|
| 210 |
+
* Expand audio-separation accordion so that model can be selected and appropriate settings for that model can then be selected.
|
| 211 |
+
* Model specific settings should expand based on selected model
|
| 212 |
+
* In one-click generation
|
| 213 |
+
* Should have an "vocal extration" option accordion
|
| 214 |
+
* Should be able to choose which audio separation steps to include in pipeline
|
| 215 |
+
* possible steps
|
| 216 |
+
* step 1: separating audio form instrumentals
|
| 217 |
+
* step 2: separating main vocals from background vocals:
|
| 218 |
+
* step 3: de-reverbing vocals
|
| 219 |
+
* Should pick steps from dropdown?
|
| 220 |
+
* For each selected step a new sub-accordion with options for that step will then appear
|
| 221 |
+
* Each accordion should include general settings
|
| 222 |
+
* We should decide whether model specific settings should also be supported
|
| 223 |
+
* We Should also decide whether sub-accordion should setting for choosing a model and if so render specific settings based the chosen model
|
| 224 |
+
* Alternative layout:
|
| 225 |
+
* have option to choose number of separation steps
|
| 226 |
+
* then dynamically render sub accordions for each of the selected number of steps
|
| 227 |
+
* In this case it should be possible to choose models for each accordion
|
| 228 |
+
* this field should be iniitally empty
|
| 229 |
+
* Other setttings should probably have sensible defaults that are the same
|
| 230 |
+
* It might also be a good idea to then have an "examples" pane with recommended combinations of extractions steps
|
| 231 |
+
* When one of these is selected, then the selected number of accordions with the preset settings should be filled out
|
| 232 |
+
* optimize pre-processing
|
| 233 |
+
* check <https://github.com/ArkanDash/Multi-Model-RVC-Inference>
|
| 234 |
+
* Alternatives to `audio-separator` package:
|
| 235 |
+
* [Deezer Spleeter](https://github.com/deezer/spleeter)
|
| 236 |
+
* supports both CLI and python package
|
| 237 |
+
* [Asteroid](https://github.com/asteroid-team/asteroid)
|
| 238 |
+
* [Nuzzle](https://github.com/nussl/nussl)
|
| 239 |
+
|
| 240 |
+
## GitHub
|
| 241 |
+
|
| 242 |
+
### Actions
|
| 243 |
+
|
| 244 |
+
* linting with Ruff
|
| 245 |
+
* typechecking with Pyright
|
| 246 |
+
* running all tests
|
| 247 |
+
* automatic building and publishing of project to pypi
|
| 248 |
+
* includes automatic update of project version number
|
| 249 |
+
* or use pre-commit?
|
| 250 |
+
|
| 251 |
+
### README
|
| 252 |
+
|
| 253 |
+
* Fill out TBA sections in README
|
| 254 |
+
* Add note about not using with VPN?
|
| 255 |
+
* Add different emblems/badges in header
|
| 256 |
+
* like test coverage, build status, etc. (look at other projects for inspiration)
|
| 257 |
+
* spice up text with emojis (look at tiango's projects for inspiration)
|
| 258 |
+
|
| 259 |
+
### Releases
|
| 260 |
+
|
| 261 |
+
* Make regular releases like done for Applio
|
| 262 |
+
* Will be an `.exe` file that when run unzips contents into application folder, where `./urvc run` can then be executed.
|
| 263 |
+
* Could it be possible to have `.exe` file just start webapp when clicked?
|
| 264 |
+
* Could also include pypi package as a release?
|
| 265 |
+
|
| 266 |
+
* use pyinstaller to install app into executable that also includes sox and ffmpeg as dependencies (DLLs)
|
| 267 |
+
|
| 268 |
+
### Other
|
| 269 |
+
|
| 270 |
+
* In the future consider detaching repo from where it is forked from:
|
| 271 |
+
* because it is not possible to make the repo private otherwise
|
| 272 |
+
* see: <https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/detaching-a-fork>
|
| 273 |
+
|
| 274 |
+
## Incorporate upstream changes
|
| 275 |
+
|
| 276 |
+
* Incorporate RVC code from [rvc-cli](https://github.com/blaisewf/rvc-cli) (i.e. changes from Applio)
|
| 277 |
+
* more options for voice conversion and more efficient voice conversion
|
| 278 |
+
* batch conversion sub-tab
|
| 279 |
+
* TTS tab
|
| 280 |
+
* Model training tab
|
| 281 |
+
* support more pre-trained models
|
| 282 |
+
* sub-tab under "manage models" tab
|
| 283 |
+
* support for querying online database with many models that can be downloaded
|
| 284 |
+
* support for audio and model analysis.
|
| 285 |
+
* Voice blending tab
|
| 286 |
+
* Incorporate latest changes from [RVC-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
|
| 287 |
+
|
| 288 |
+
## Vocal Conversion
|
| 289 |
+
|
| 290 |
+
* support arbitrary combination of pitch detection algorithms
|
| 291 |
+
* source: <https://github.com/gitmylo/audio-webui>
|
| 292 |
+
* Investigate using onnx models for inference speedup on cpu
|
| 293 |
+
* Add more pitch detection methods
|
| 294 |
+
* pm
|
| 295 |
+
* harvest
|
| 296 |
+
* dio
|
| 297 |
+
* rvmpe+
|
| 298 |
+
* Implement multi-gpu Inference
|
| 299 |
+
|
| 300 |
+
## TTS conversion
|
| 301 |
+
|
| 302 |
+
* also include original edge voice as output
|
| 303 |
+
* source: <https://github.com/litagin02/rvc-tts-webui>
|
| 304 |
+
|
| 305 |
+
## Model management
|
| 306 |
+
|
| 307 |
+
### Training models
|
| 308 |
+
|
| 309 |
+
* have learning rate for training
|
| 310 |
+
* source: <https://github.com/gitmylo/audio-webui>
|
| 311 |
+
* have a quick training button
|
| 312 |
+
* or have preprocess dataset, extract features and generate index happen by default
|
| 313 |
+
* Support a loss/training graph
|
| 314 |
+
* source: <https://github.com/gitmylo/audio-webui>
|
| 315 |
+
|
| 316 |
+
### Download models
|
| 317 |
+
|
| 318 |
+
* Support batch downloading multiple models
|
| 319 |
+
* requires a tabular request form where both a link column and a name column has to be filled out
|
| 320 |
+
* we can allow selecting multiple items from public models table and then copying them over
|
| 321 |
+
* support quering online database for models matching a given search string like what is done in applio app
|
| 322 |
+
* first n rows of online database should be shown by default in public models table
|
| 323 |
+
* more rows should be retrieved by scrolling down or clicking a button
|
| 324 |
+
* user search string should filter/narrow returned number of rows in public models table
|
| 325 |
+
* When clicking a set of rows they should then be copied over for downloading in the "download" table
|
| 326 |
+
* support a column with preview sample in public models table
|
| 327 |
+
* Only possible if voice snippets are also returned when querying the online database
|
| 328 |
+
* Otherwise we can always support voice snippets for voice models that have already been downloaded
|
| 329 |
+
* run model on sample text ("quick brown fox runs over the lazy") after it is downloaded
|
| 330 |
+
* save the results in a `audio/model_preview` folder
|
| 331 |
+
* Preview can then be loaded into a preview audio component when selecting a model from a dropdown
|
| 332 |
+
* or if we replace the dropdown with a table with two columns we can have the audio track displayed in the second column
|
| 333 |
+
|
| 334 |
+
### Model analysis
|
| 335 |
+
|
| 336 |
+
* we could provide a new tab to analyze an existing model like what is done in applio
|
| 337 |
+
* or this tab could be consolidated with the delete model tab?
|
| 338 |
+
|
| 339 |
+
* we could also provide extra model information after model is downloaded
|
| 340 |
+
* potentialy in dropdown to expand?
|
| 341 |
+
|
| 342 |
+
## Audio management
|
| 343 |
+
|
| 344 |
+
### General
|
| 345 |
+
|
| 346 |
+
* Support audio information tool like in applio?
|
| 347 |
+
* A new tab where you can upload a song to analyze?
|
| 348 |
+
* more elaborate solution:
|
| 349 |
+
* tab where where you
|
| 350 |
+
* can select any song directory
|
| 351 |
+
* select any step in the audio generation pipeline
|
| 352 |
+
* then select any intermediate audio file generated in that step
|
| 353 |
+
* Then have the possibility to
|
| 354 |
+
* Listen to the song
|
| 355 |
+
* see a table with its metadata (based on its associated `.json` file)
|
| 356 |
+
* add timestamp to json files so they can be sorted in table according to creation date
|
| 357 |
+
* And other statistics in a separate component (graph etc.)
|
| 358 |
+
* Could have delete buttons both at the level of song_directory, step, and for each song?
|
| 359 |
+
* Also consider splitting intermediate audio tracks for each step in to subfolder (0,1,2,3...)
|
| 360 |
+
|
| 361 |
+
## Other settings
|
| 362 |
+
|
| 363 |
+
* rework other settings tab
|
| 364 |
+
* this should also contain other settings such as the ability to change the theme of the app
|
| 365 |
+
* there should be a button to apply settings which will reload the app with the new settings
|
| 366 |
+
|
| 367 |
+
## Audio post-processing
|
| 368 |
+
|
| 369 |
+
* Support more effects from the `pedalboard` pakcage.
|
| 370 |
+
* Guitar-style effects: Chorus, Distortion, Phaser, Clipping
|
| 371 |
+
* Loudness and dynamic range effects: Compressor, Gain, Limiter
|
| 372 |
+
* Equalizers and filters: HighpassFilter, LadderFilter, LowpassFilter
|
| 373 |
+
* Spatial effects: Convolution, Delay, Reverb
|
| 374 |
+
* Pitch effects: PitchShift
|
| 375 |
+
* Lossy compression: GSMFullRateCompressor, MP3Compressor
|
| 376 |
+
* Quality reduction: Resample, Bitcrush
|
| 377 |
+
* NoiseGate
|
| 378 |
+
* PeakFilter
|
| 379 |
+
|
| 380 |
+
## Audio Mixing
|
| 381 |
+
|
| 382 |
+
* Add main gain loudness slider?
|
| 383 |
+
* Add option to equalize output audio with respect to input audio
|
| 384 |
+
* i.e. song cover gain (and possibly also more general dynamics) should be the same as those for source song.
|
| 385 |
+
* check to see if pydub has functionality for this
|
| 386 |
+
* otherwise a simple solution would be computing the RMS of the difference between the loudness of the input and output track
|
| 387 |
+
|
| 388 |
+
```python
|
| 389 |
+
rms = np.sqrt(np.mean(np.square(signal)))
|
| 390 |
+
dB = 20*np.log10(rms)
|
| 391 |
+
#add db to output file in mixing function (using pydub)
|
| 392 |
+
```
|
| 393 |
+
|
| 394 |
+
* When this option is selected the option to set main gain of ouput should be disabled?
|
| 395 |
+
|
| 396 |
+
* add more equalization options
|
| 397 |
+
* using `pydub.effects` and `pydub.scipy_effects`?
|
| 398 |
+
|
| 399 |
+
## Custom UI
|
| 400 |
+
|
| 401 |
+
* Experiment with new themes including [Building new ones](https://www.gradio.app/guides/theming-guid)
|
| 402 |
+
* first of all make new theme that is like the default gradio 4 theme in terms of using semi transparent orange as the main color and semi-transparent grey for secondary color. The new gradio 5 theme is good apart from using solid colors so maybe use that as base theme.
|
| 403 |
+
* Support both dark and light theme in app?
|
| 404 |
+
* Add Support for changing theme in app?
|
| 405 |
+
* Use Applio theme as inspiration for default theme?
|
| 406 |
+
* Experiment with using custom CSS
|
| 407 |
+
* Pass `css = {css_string}` to `gr.Blocks` and use `elem_classes` and `elem_id` to have components target the styles define in the CSS string.
|
| 408 |
+
* Experiment with [custom DataFrame styling](https://www.gradio.app/guides/styling-the-gradio-dataframe)
|
| 409 |
+
* Experiment with custom Javascript
|
| 410 |
+
* Look for opportunities for defining new useful custom components
|
| 411 |
+
|
| 412 |
+
## Real-time vocal conversion
|
| 413 |
+
|
| 414 |
+
* Should support being used as OBS plugin
|
| 415 |
+
* Latency is real issue
|
| 416 |
+
* Implementations details:
|
| 417 |
+
* implement back-end in Rust?
|
| 418 |
+
* implement front-end using svelte?
|
| 419 |
+
* implement desktop application using C++ or C#?
|
| 420 |
+
* see <https://github.com/w-okada/voice-changer> and <https://github.com/RVC-Project/obs-rvc> for inspiration
|
| 421 |
+
|
| 422 |
+
## AI assistant mode
|
| 423 |
+
|
| 424 |
+
* similar to vocal conversion streaming but instead of converting your voice on the fly, it should:
|
| 425 |
+
* take your voice,
|
| 426 |
+
* do some language modelling (with an LLM or something)
|
| 427 |
+
* then produce an appropriate verbal response
|
| 428 |
+
* We already have Kyutais [moshi](https://moshi.chat/?queue_id=talktomoshi)
|
| 429 |
+
* Maybe that model can be finetuned to reply with a voice
|
| 430 |
+
* i.e. your favorite singer, actor, best friend, family member.
|
| 431 |
+
|
| 432 |
+
## Ultimate RVC bot for discord
|
| 433 |
+
|
| 434 |
+
* maybe also make a forum on discord?
|
| 435 |
+
|
| 436 |
+
## Make app production ready
|
| 437 |
+
|
| 438 |
+
* have a "report a bug" tab like in applio?
|
| 439 |
+
* should have separate accounts for users when hosting online
|
| 440 |
+
* use `gr.LoginButton` and `gr.LogoutButton`?
|
| 441 |
+
|
| 442 |
+
* deploy using docker
|
| 443 |
+
* See <https://www.gradio.app/guides/deploying-gradio-with-docker>
|
| 444 |
+
* Host on own web-server with Nginx
|
| 445 |
+
* see <https://www.gradio.app/guides/running-gradio-on-your-web-server-with-nginx>
|
| 446 |
+
|
| 447 |
+
* Consider having concurrency limit be dynamic, i.e. instead of always being 1 for jobs using gpu consider having it depend upon what resources are available.
|
| 448 |
+
* We can app set the GPU_CONCURRENCY limit to be os.envrion["GPU_CONCURRENCY_LIMIT] or 1 and then pass GPU_CONCURRENCY as input to places where event listeners are defined
|
| 449 |
+
|
| 450 |
+
## Colab notebook
|
| 451 |
+
|
| 452 |
+
* find way of saving virtual environment with python 3.11 in colab notebook (DIFFICULT TO IMPLEMENT)
|
| 453 |
+
* so that this environment can be loaded directly rather than downloading all dependencies every time app is opened
|
| 454 |
+
|
| 455 |
+
## Testing
|
| 456 |
+
|
| 457 |
+
* Add example audio files to use for testing
|
| 458 |
+
* Should be located in `audio/examples`
|
| 459 |
+
* could have sub-folders `input` and `output`
|
| 460 |
+
* in `output` folder we have `output_audio.ext` files each with a corresponding `input_audio.json` file containing metadata explaining arguments used to generate output
|
| 461 |
+
* We can then test that actual output is close enough to expected output using audio similarity metric.
|
| 462 |
+
* Setup unit testing framework using pytest
|
notes/app-doc.md
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# `main`
|
| 2 |
+
|
| 3 |
+
Run the Ultimate RVC web application.
|
| 4 |
+
|
| 5 |
+
**Usage**:
|
| 6 |
+
|
| 7 |
+
```console
|
| 8 |
+
$ main [OPTIONS]
|
| 9 |
+
```
|
| 10 |
+
|
| 11 |
+
**Options**:
|
| 12 |
+
|
| 13 |
+
* `-s, --share`: Enable sharing
|
| 14 |
+
* `-l, --listen`: Make the web application reachable from your local network.
|
| 15 |
+
* `-h, --listen-host TEXT`: The hostname that the server will use.
|
| 16 |
+
* `-p, --listen-port INTEGER`: The listening port that the server will use.
|
| 17 |
+
* `--install-completion`: Install completion for the current shell.
|
| 18 |
+
* `--show-completion`: Show completion for the current shell, to copy it or customize the installation.
|
| 19 |
+
* `--help`: Show this message and exit.
|
notes/cli-doc.md
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# `urvc-cli`
|
| 2 |
+
|
| 3 |
+
CLI for the Ultimate RVC project
|
| 4 |
+
|
| 5 |
+
**Usage**:
|
| 6 |
+
|
| 7 |
+
```console
|
| 8 |
+
$ urvc-cli [OPTIONS] COMMAND [ARGS]...
|
| 9 |
+
```
|
| 10 |
+
|
| 11 |
+
**Options**:
|
| 12 |
+
|
| 13 |
+
* `--install-completion`: Install completion for the current shell.
|
| 14 |
+
* `--show-completion`: Show completion for the current shell, to copy it or customize the installation.
|
| 15 |
+
* `--help`: Show this message and exit.
|
| 16 |
+
|
| 17 |
+
**Commands**:
|
| 18 |
+
|
| 19 |
+
* `song-cover`: Generate song covers
|
| 20 |
+
|
| 21 |
+
## `urvc-cli song-cover`
|
| 22 |
+
|
| 23 |
+
Generate song covers
|
| 24 |
+
|
| 25 |
+
**Usage**:
|
| 26 |
+
|
| 27 |
+
```console
|
| 28 |
+
$ urvc-cli song-cover [OPTIONS] COMMAND [ARGS]...
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
**Options**:
|
| 32 |
+
|
| 33 |
+
* `--help`: Show this message and exit.
|
| 34 |
+
|
| 35 |
+
**Commands**:
|
| 36 |
+
|
| 37 |
+
* `run-pipeline`: Run the song cover generation pipeline.
|
| 38 |
+
|
| 39 |
+
### `urvc-cli song-cover run-pipeline`
|
| 40 |
+
|
| 41 |
+
Run the song cover generation pipeline.
|
| 42 |
+
|
| 43 |
+
**Usage**:
|
| 44 |
+
|
| 45 |
+
```console
|
| 46 |
+
$ urvc-cli song-cover run-pipeline [OPTIONS] SOURCE MODEL_NAME
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
**Arguments**:
|
| 50 |
+
|
| 51 |
+
* `SOURCE`: A Youtube URL, the path to a local audio file or the path to a song directory. [required]
|
| 52 |
+
* `MODEL_NAME`: The name of the voice model to use for vocal conversion. [required]
|
| 53 |
+
|
| 54 |
+
**Options**:
|
| 55 |
+
|
| 56 |
+
* `--n-octaves INTEGER`: The number of octaves to pitch-shift the converted vocals by.Use 1 for male-to-female and -1 for vice-versa. [default: 0]
|
| 57 |
+
* `--n-semitones INTEGER`: The number of semi-tones to pitch-shift the converted vocals, instrumentals, and backup vocals by. Altering this slightly reduces sound quality [default: 0]
|
| 58 |
+
* `--f0-method [rmvpe|mangio-crepe]`: The method to use for pitch detection during vocal conversion. Best option is RMVPE (clarity in vocals), then Mangio-Crepe (smoother vocals). [default: rmvpe]
|
| 59 |
+
* `--index-rate FLOAT RANGE`: A decimal number e.g. 0.5, Controls how much of the accent in the voice model to keep in the converted vocals. Increase to bias the conversion towards the accent of the voice model. [default: 0.5; 0<=x<=1]
|
| 60 |
+
* `--filter-radius INTEGER RANGE`: A number between 0 and 7. If >=3: apply median filtering to the pitch results harvested during vocal conversion. Can help reduce breathiness in the converted vocals. [default: 3; 0<=x<=7]
|
| 61 |
+
* `--rms-mix-rate FLOAT RANGE`: A decimal number e.g. 0.25. Controls how much to mimic the loudness of the input vocals (0) or a fixed loudness (1) during vocal conversion. [default: 0.25; 0<=x<=1]
|
| 62 |
+
* `--protect FLOAT RANGE`: A decimal number e.g. 0.33. Controls protection of voiceless consonants and breath sounds during vocal conversion. Decrease to increase protection at the cost of indexing accuracy. Set to 0.5 to disable. [default: 0.33; 0<=x<=0.5]
|
| 63 |
+
* `--hop-length INTEGER`: Controls how often the CREPE-based pitch detection algorithm checks for pitch changes during vocal conversion. Measured in milliseconds. Lower values lead to longer conversion times and a higher risk of voice cracks, but better pitch accuracy. Recommended value: 128. [default: 128]
|
| 64 |
+
* `--room-size FLOAT RANGE`: The room size of the reverb effect applied to the converted vocals. Increase for longer reverb time. Should be a value between 0 and 1. [default: 0.15; 0<=x<=1]
|
| 65 |
+
* `--wet-level FLOAT RANGE`: The loudness of the converted vocals with reverb effect applied. Should be a value between 0 and 1 [default: 0.2; 0<=x<=1]
|
| 66 |
+
* `--dry-level FLOAT RANGE`: The loudness of the converted vocals wihout reverb effect applied. Should be a value between 0 and 1. [default: 0.8; 0<=x<=1]
|
| 67 |
+
* `--damping FLOAT RANGE`: The absorption of high frequencies in the reverb effect applied to the converted vocals. Should be a value between 0 and 1. [default: 0.7; 0<=x<=1]
|
| 68 |
+
* `--main-gain INTEGER`: The gain to apply to the post-processed vocals. Measured in dB. [default: 0]
|
| 69 |
+
* `--inst-gain INTEGER`: The gain to apply to the pitch-shifted instrumentals. Measured in dB. [default: 0]
|
| 70 |
+
* `--backup-gain INTEGER`: The gain to apply to the pitch-shifted backup vocals. Measured in dB. [default: 0]
|
| 71 |
+
* `--output-sr INTEGER`: The sample rate of the song cover. [default: 44100]
|
| 72 |
+
* `--output-format [mp3|wav|flac|ogg|m4a|aac]`: The audio format of the song cover. [default: mp3]
|
| 73 |
+
* `--output-name TEXT`: The name of the song cover.
|
| 74 |
+
* `--help`: Show this message and exit.
|
notes/gradio.md
ADDED
|
@@ -0,0 +1,615 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# Gradio notes
|
| 3 |
+
|
| 4 |
+
## Modularizing large gradio codebases
|
| 5 |
+
|
| 6 |
+
See this [tutorial](https://www.gradio.app/guides/wrapping-layouts) and corresponding [code](https://huggingface.co/spaces/WoWoWoWololo/wrapping-layouts/blob/main/app.py).
|
| 7 |
+
|
| 8 |
+
## Event listeners
|
| 9 |
+
|
| 10 |
+
### Attaching event listeners using decorators
|
| 11 |
+
|
| 12 |
+
```python
|
| 13 |
+
@greet_btn.click(inputs=name, outputs=output)
|
| 14 |
+
def greet(name):
|
| 15 |
+
return "Hello " + name + "!"
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
### Function input using dicts
|
| 19 |
+
|
| 20 |
+
```python
|
| 21 |
+
a = gr.Number(label="a")
|
| 22 |
+
b = gr.Number(label="b")
|
| 23 |
+
|
| 24 |
+
def sub(data):
|
| 25 |
+
return data[a] - data[b]
|
| 26 |
+
sub_btn.click(sub, inputs={a, b}, outputs=c)
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
This syntax may be better for functions with many inputs
|
| 30 |
+
|
| 31 |
+
### Function output using dicts
|
| 32 |
+
|
| 33 |
+
```python
|
| 34 |
+
food_box = gr.Number(value=10, label="Food Count")
|
| 35 |
+
status_box = gr.Textbox()
|
| 36 |
+
|
| 37 |
+
def eat(food):
|
| 38 |
+
if food > 0:
|
| 39 |
+
return {food_box: food - 1, status_box: "full"}
|
| 40 |
+
else:
|
| 41 |
+
return {status_box: "hungry"}
|
| 42 |
+
|
| 43 |
+
gr.Button("Eat").click(
|
| 44 |
+
fn=eat,
|
| 45 |
+
inputs=food_box,
|
| 46 |
+
outputs=[food_box, status_box]
|
| 47 |
+
)
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
Allows you to skip updating some output components.
|
| 51 |
+
|
| 52 |
+
### Binding multiple event listeners to one function
|
| 53 |
+
|
| 54 |
+
```python
|
| 55 |
+
name = gr.Textbox(label="Name")
|
| 56 |
+
output = gr.Textbox(label="Output Box")
|
| 57 |
+
greet_btn = gr.Button("Greet")
|
| 58 |
+
trigger = gr.Textbox(label="Trigger Box")
|
| 59 |
+
|
| 60 |
+
def greet(name, evt_data: gr.EventData):
|
| 61 |
+
return "Hello " + name + "!", evt_data.target.__class__.__name__
|
| 62 |
+
|
| 63 |
+
def clear_name(evt_data: gr.EventData):
|
| 64 |
+
return ""
|
| 65 |
+
|
| 66 |
+
gr.on(
|
| 67 |
+
triggers=[name.submit, greet_btn.click],
|
| 68 |
+
fn=greet,
|
| 69 |
+
inputs=name,
|
| 70 |
+
outputs=[output, trigger],
|
| 71 |
+
).then(clear_name, outputs=[name])
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
* Use `gr.on` with optional `triggers` argument. If `triggers` is not set then the given function will be called for all `.change` event listeners in the app.
|
| 75 |
+
* Allows you to DRY a lot of code potentially.
|
| 76 |
+
|
| 77 |
+
### Running events continuously
|
| 78 |
+
|
| 79 |
+
```python
|
| 80 |
+
with gr.Blocks as demo:
|
| 81 |
+
timer = gr.Timer(5)
|
| 82 |
+
textbox = gr.Textbox()
|
| 83 |
+
textbox2 = gr.Textbox()
|
| 84 |
+
timer.tick(set_textbox_fn, textbox, textbox2)
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
Or alternatively the following semantics can be used:
|
| 88 |
+
|
| 89 |
+
```python
|
| 90 |
+
with gr.Blocks as demo:
|
| 91 |
+
timer = gr.Timer(5)
|
| 92 |
+
textbox = gr.Textbox()
|
| 93 |
+
textbox2 = gr.Textbox(set_textbox_fn, inputs=[textbox], every=timer)
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
## Other semantics
|
| 97 |
+
|
| 98 |
+
### Conditional component values
|
| 99 |
+
|
| 100 |
+
```python
|
| 101 |
+
with gr.Blocks() as demo:
|
| 102 |
+
num1 = gr.Number()
|
| 103 |
+
num2 = gr.Number()
|
| 104 |
+
product = gr.Number(lambda a, b: a * b, inputs=[num1, num2])
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
* Value of component must be a function taking two component values and returning a new component value
|
| 108 |
+
* Component must also take a list of inputs indicating which other components should be used to compute its value
|
| 109 |
+
* Components value will always be updated whenever the other components `.change` event listeners are called.
|
| 110 |
+
* Hence this method can be used to DRY code with many `.change` event listeners
|
| 111 |
+
|
| 112 |
+
### Dynamic behavior
|
| 113 |
+
|
| 114 |
+
We can use the `@gr.render` decorator to dynamically define components and event listeners while an app is executing
|
| 115 |
+
|
| 116 |
+
#### Dynamic components
|
| 117 |
+
|
| 118 |
+
```python
|
| 119 |
+
import gradio as gr
|
| 120 |
+
|
| 121 |
+
with gr.Blocks() as demo:
|
| 122 |
+
input_text = gr.Textbox(label="input")
|
| 123 |
+
|
| 124 |
+
@gr.render(inputs=input_text)
|
| 125 |
+
def show_split(text):
|
| 126 |
+
if len(text) == 0:
|
| 127 |
+
gr.Markdown("## No Input Provided")
|
| 128 |
+
else:
|
| 129 |
+
for letter in text:
|
| 130 |
+
gr.Textbox(letter)
|
| 131 |
+
|
| 132 |
+
demo.launch()
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
By default `@gr.render` is called whenever the `.change` event for the given input components are executed or when the app is loaded. This can be overriden by also giving a triggers argument to the decorator:
|
| 136 |
+
|
| 137 |
+
```python
|
| 138 |
+
@gr.render(inputs=input_text, triggers = [input_text.submit])
|
| 139 |
+
...
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
#### Dynamic event listeners
|
| 143 |
+
|
| 144 |
+
```python
|
| 145 |
+
with gr.Blocks() as demo:
|
| 146 |
+
text_count = gr.State(1)
|
| 147 |
+
add_btn = gr.Button("Add Box")
|
| 148 |
+
add_btn.click(lambda x: x + 1, text_count, text_count)
|
| 149 |
+
|
| 150 |
+
@gr.render(inputs=text_count)
|
| 151 |
+
def render_count(count):
|
| 152 |
+
boxes = []
|
| 153 |
+
for i in range(count):
|
| 154 |
+
box = gr.Textbox(key=i, label=f"Box {i}")
|
| 155 |
+
boxes.append(box)
|
| 156 |
+
|
| 157 |
+
def merge(*args):
|
| 158 |
+
return " ".join(args)
|
| 159 |
+
|
| 160 |
+
merge_btn.click(merge, boxes, output)
|
| 161 |
+
|
| 162 |
+
merge_btn = gr.Button("Merge")
|
| 163 |
+
output = gr.Textbox(label="Merged Output")
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
* All event listeners that use components created inside a render function must also be defined inside that render function
|
| 167 |
+
* The event listener can still reference components outside the render function
|
| 168 |
+
* Just as with components, whenever a function re-renders, the event listeners created from the previous render are cleared and the new event listeners from the latest run are attached.
|
| 169 |
+
* setting `key = ...` when instantiating a component ensures that the value of the component is preserved upon rerender
|
| 170 |
+
* This is might also allow us to preserve session state easily across browser refresh?
|
| 171 |
+
|
| 172 |
+
#### A more elaborate example
|
| 173 |
+
|
| 174 |
+
```python
|
| 175 |
+
import gradio as gr
|
| 176 |
+
|
| 177 |
+
with gr.Blocks() as demo:
|
| 178 |
+
|
| 179 |
+
tasks = gr.State([])
|
| 180 |
+
new_task = gr.Textbox(label="Task Name", autofocus=True)
|
| 181 |
+
|
| 182 |
+
def add_task(tasks, new_task_name):
|
| 183 |
+
return tasks + [{"name": new_task_name, "complete": False}], ""
|
| 184 |
+
|
| 185 |
+
new_task.submit(add_task, [tasks, new_task], [tasks, new_task])
|
| 186 |
+
|
| 187 |
+
@gr.render(inputs=tasks)
|
| 188 |
+
def render_todos(task_list):
|
| 189 |
+
complete = [task for task in task_list if task["complete"]]
|
| 190 |
+
incomplete = [task for task in task_list if not task["complete"]]
|
| 191 |
+
gr.Markdown(f"### Incomplete Tasks ({len(incomplete)})")
|
| 192 |
+
for task in incomplete:
|
| 193 |
+
with gr.Row():
|
| 194 |
+
gr.Textbox(task['name'], show_label=False, container=False)
|
| 195 |
+
done_btn = gr.Button("Done", scale=0)
|
| 196 |
+
def mark_done(task=task):
|
| 197 |
+
task["complete"] = True
|
| 198 |
+
return task_list
|
| 199 |
+
done_btn.click(mark_done, None, [tasks])
|
| 200 |
+
|
| 201 |
+
delete_btn = gr.Button("Delete", scale=0, variant="stop")
|
| 202 |
+
def delete(task=task):
|
| 203 |
+
task_list.remove(task)
|
| 204 |
+
return task_list
|
| 205 |
+
delete_btn.click(delete, None, [tasks])
|
| 206 |
+
|
| 207 |
+
gr.Markdown(f"### Complete Tasks ({len(complete)})")
|
| 208 |
+
for task in complete:
|
| 209 |
+
gr.Textbox(task['name'], show_label=False, container=False)
|
| 210 |
+
|
| 211 |
+
demo.launch()
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
* Any event listener that modifies a state variable in a manner that should trigger a re-render must set the state variable as an output. This lets Gradio know to check if the variable has changed behind the scenes.
|
| 215 |
+
* In a `gr.render`, if a variable in a loop is used inside an event listener function, that variable should be "frozen" via setting it to itself as a default argument in the function header. See how we have task=task in both mark_done and delete. This freezes the variable to its "loop-time" value.
|
| 216 |
+
|
| 217 |
+
### Progress bars
|
| 218 |
+
|
| 219 |
+
Instead of doing `gr.progress(percentage, desc= "...")` in core helper functions you can just use tqdm directly in your code by instantiating `gr.progress(track_tqdm = true)` in a web helper function/harness.
|
| 220 |
+
|
| 221 |
+
Alternatively, you can also do `gr.Progress().tqdm(iterable, description, total, unit)` to attach a tqdm iterable to the progress bar
|
| 222 |
+
|
| 223 |
+
Benefits of either approach is:
|
| 224 |
+
|
| 225 |
+
* we do not have to supply a `gr.Progress` object to core functions.
|
| 226 |
+
* Perhaps it will also be possible to get a progress bar that automatically generates several update steps for a given caption, rather than just one step as is the case when using `gr.Progress`
|
| 227 |
+
|
| 228 |
+
### State
|
| 229 |
+
|
| 230 |
+
Any variable created outside a function call is shared by all users of app
|
| 231 |
+
|
| 232 |
+
So when deploying app in future need to use `gr.State()` for all variables declared outside functions?
|
| 233 |
+
|
| 234 |
+
## Notes on Gradio classes
|
| 235 |
+
|
| 236 |
+
* `Blocks.launch()`
|
| 237 |
+
* `prevent_thread_lock` can be used to have an easier way of shutting down app?
|
| 238 |
+
* `show_error`: if `True`can allow us not to have to reraise core exceptions as `gr.Error`?
|
| 239 |
+
* `Tab`
|
| 240 |
+
* event listener triggered when tab is selected could be useful?
|
| 241 |
+
* `File`
|
| 242 |
+
* `file_type`: can use this to limit input types to .pth, .index and .zip when downloading a model
|
| 243 |
+
* `Label`
|
| 244 |
+
* Intended for output of classification models
|
| 245 |
+
* for actual labels in UI maybe use `gr.Markdown`?
|
| 246 |
+
|
| 247 |
+
* `Button`
|
| 248 |
+
* `link`: link to open when button is clicked?
|
| 249 |
+
* `icon`: path to icon to display on button
|
| 250 |
+
|
| 251 |
+
* `Audio`: relevant event listeners:
|
| 252 |
+
* `upload`: when a value is uploaded
|
| 253 |
+
* `input`: when a value is changed
|
| 254 |
+
* `clear`: when a value is cleared
|
| 255 |
+
* `Dropdown`
|
| 256 |
+
* `height`
|
| 257 |
+
* `min_width`
|
| 258 |
+
* `wrap`: if text in cells should wrap
|
| 259 |
+
* `column_widths`: width of each column
|
| 260 |
+
* `datatype`: list of `"str"`, `"number"`, `"bool"`, `"date"`, `"markdown"`
|
| 261 |
+
|
| 262 |
+
## Performance optimization
|
| 263 |
+
|
| 264 |
+
* Can set `max_threads` argument for `Block.launch()`
|
| 265 |
+
if you have any async definitions in your code (`async def`).
|
| 266 |
+
* can set `max_size` argument on `Block.queue()`. This limits how many people can wait in line in the queue. If too many people are in line, new people trying to join will receive an error message. This can be better than default which is just having people wait indefinitely
|
| 267 |
+
* Can increase `default_concurrency_limit` for `Block.queue()`. Default is `1`. Increasing to more might make operations more effective.
|
| 268 |
+
* Rewrite functions so that they take a batched input and set `batched = True` on the event listener calling the function
|
| 269 |
+
|
| 270 |
+
## Environment Variables
|
| 271 |
+
|
| 272 |
+
Gradio supports environment variables which can be used to customize the behavior
|
| 273 |
+
of your app from the command line instead of setting these parameters in `Blocks.launch()`
|
| 274 |
+
|
| 275 |
+
* GRADIO_ANALYTICS_ENABLED
|
| 276 |
+
* GRADIO_SERVER_PORT
|
| 277 |
+
* GRADIO_SERVER_NAME
|
| 278 |
+
* GRADIO_TEMP_DIR
|
| 279 |
+
* GRADIO_SHARE
|
| 280 |
+
* GRADIO_ALLOWED_PATHS
|
| 281 |
+
* GRADIO_BLOCKED_PATHS
|
| 282 |
+
|
| 283 |
+
These could be useful when running gradio apps from a shell script.
|
| 284 |
+
|
| 285 |
+
## Networking
|
| 286 |
+
|
| 287 |
+
### File Access
|
| 288 |
+
|
| 289 |
+
Users can access:
|
| 290 |
+
|
| 291 |
+
* Temporary files created by gradio
|
| 292 |
+
* Files that are allowed via the `allowed_paths` parameter set in `Block.launch()`
|
| 293 |
+
* static files that are set via [gr.set_static_paths](https://www.gradio.app/docs/gradio/set_static_paths)
|
| 294 |
+
* Accepts a list of directories or files names that will not be copied to the cached but served directly from computer.
|
| 295 |
+
* BONUS: This can be used in ULTIMATE RVC for dispensing with the temp gradio directory. Need to consider possible ramifications before implementing this though.
|
| 296 |
+
|
| 297 |
+
Users cannot access:
|
| 298 |
+
|
| 299 |
+
* Files that are blocked via the `blocked_paths` parameter set in `Block.launch()`
|
| 300 |
+
* This parameter takes precedence over the `allowed_paths` parameter and over default allowed paths
|
| 301 |
+
* Any other paths on the host machine
|
| 302 |
+
* This is something to consider when hosting app online
|
| 303 |
+
|
| 304 |
+
#### Limiting file upload size
|
| 305 |
+
|
| 306 |
+
you can use `Block.launch(max_file_size= ...)` to limit max file size in MBs for each user.
|
| 307 |
+
|
| 308 |
+
### Access network request
|
| 309 |
+
|
| 310 |
+
you can access information from a network request directly within a gradio app:
|
| 311 |
+
|
| 312 |
+
```python
|
| 313 |
+
import gradio as gr
|
| 314 |
+
|
| 315 |
+
def echo(text, request: gr.Request):
|
| 316 |
+
if request:
|
| 317 |
+
print("Request headers dictionary:", request.headers)
|
| 318 |
+
print("IP address:", request.client.host)
|
| 319 |
+
print("Query parameters:", dict(request.query_params))
|
| 320 |
+
return text
|
| 321 |
+
|
| 322 |
+
io = gr.Interface(echo, "textbox", "textbox").launch()
|
| 323 |
+
```
|
| 324 |
+
|
| 325 |
+
If the network request is not done via the gradio UI then it will be `None` so always check if it exists
|
| 326 |
+
|
| 327 |
+
### Authentication
|
| 328 |
+
|
| 329 |
+
#### Password protection
|
| 330 |
+
|
| 331 |
+
You can have an authentication page in front of your app by doing:
|
| 332 |
+
|
| 333 |
+
```python
|
| 334 |
+
demo.launch(auth=("admin", "pass1234"))
|
| 335 |
+
```
|
| 336 |
+
|
| 337 |
+
More complex handling can be achieved by giving a function as input:
|
| 338 |
+
|
| 339 |
+
```python
|
| 340 |
+
def same_auth(username, password):
|
| 341 |
+
return username == password
|
| 342 |
+
demo.launch(auth=same_auth)
|
| 343 |
+
```
|
| 344 |
+
|
| 345 |
+
Also support a logout page:
|
| 346 |
+
|
| 347 |
+
```python
|
| 348 |
+
import gradio as gr
|
| 349 |
+
|
| 350 |
+
def update_message(request: gr.Request):
|
| 351 |
+
return f"Welcome, {request.username}"
|
| 352 |
+
|
| 353 |
+
with gr.Blocks() as demo:
|
| 354 |
+
m = gr.Markdown()
|
| 355 |
+
logout_button = gr.Button("Logout", link="/logout")
|
| 356 |
+
demo.load(update_message, None, m)
|
| 357 |
+
|
| 358 |
+
demo.launch(auth=[("Pete", "Pete"), ("Dawood", "Dawood")])
|
| 359 |
+
```
|
| 360 |
+
|
| 361 |
+
NOTE:
|
| 362 |
+
|
| 363 |
+
* For authentication to work properly, third party cookies must be enabled in your browser. This is not the case by default for Safari or for Chrome Incognito Mode.
|
| 364 |
+
* Gradio's built-in authentication provides a straightforward and basic layer of access control but does not offer robust security features for applications that require stringent access controls (e.g. multi-factor authentication, rate limiting, or automatic lockout policies).
|
| 365 |
+
|
| 366 |
+
##### Custom user content
|
| 367 |
+
|
| 368 |
+
Customize content for each user by accessing the network request directly:
|
| 369 |
+
|
| 370 |
+
```python
|
| 371 |
+
import gradio as gr
|
| 372 |
+
|
| 373 |
+
def update_message(request: gr.Request):
|
| 374 |
+
return f"Welcome, {request.username}"
|
| 375 |
+
|
| 376 |
+
with gr.Blocks() as demo:
|
| 377 |
+
m = gr.Markdown()
|
| 378 |
+
demo.load(update_message, None, m)
|
| 379 |
+
|
| 380 |
+
demo.launch(auth=[("Abubakar", "Abubakar"), ("Ali", "Ali")])
|
| 381 |
+
```
|
| 382 |
+
|
| 383 |
+
#### OAuth Authentication
|
| 384 |
+
|
| 385 |
+
See <https://www.gradio.app/guides/sharing-your-app#o-auth-with-external-providers>
|
| 386 |
+
|
| 387 |
+
## Styling
|
| 388 |
+
|
| 389 |
+
### UI Layout
|
| 390 |
+
|
| 391 |
+
#### `gr.Row`
|
| 392 |
+
|
| 393 |
+
* `equal_height = false` will not force component on the same row to have the same height
|
| 394 |
+
* experiment with `variant = 'panel'` or `variant = 'compact'` for different look
|
| 395 |
+
|
| 396 |
+
#### `gr.Column`
|
| 397 |
+
|
| 398 |
+
* experiment with `variant = 'panel'` or `variant = 'compact'` for different look
|
| 399 |
+
|
| 400 |
+
#### `gr.Block`
|
| 401 |
+
|
| 402 |
+
* `fill_height = True` and `fill_width = True` can be used to fill browser window
|
| 403 |
+
|
| 404 |
+
#### `gr.Component`
|
| 405 |
+
|
| 406 |
+
* `scale = 0` can be used to prevent component from expanding to take up space.
|
| 407 |
+
|
| 408 |
+
### DataFrame styling
|
| 409 |
+
|
| 410 |
+
See <https://www.gradio.app/guides/styling-the-gradio-dataframe>
|
| 411 |
+
|
| 412 |
+
### Themes
|
| 413 |
+
|
| 414 |
+
```python
|
| 415 |
+
with gr.Blocks(theme=gr.themes.Glass()):
|
| 416 |
+
...
|
| 417 |
+
```
|
| 418 |
+
|
| 419 |
+
See this [theming guide](https://www.gradio.app/guides/theming-guide) for how to create new custom themes both using the gradio theme builder
|
| 420 |
+
|
| 421 |
+
### Custom CSS
|
| 422 |
+
|
| 423 |
+
Change background color to red:
|
| 424 |
+
|
| 425 |
+
```python
|
| 426 |
+
with gr.Blocks(css=".gradio-container {background-color: red}") as demo:
|
| 427 |
+
...
|
| 428 |
+
```
|
| 429 |
+
|
| 430 |
+
Set background to image file:
|
| 431 |
+
|
| 432 |
+
```python
|
| 433 |
+
with gr.Blocks(css=".gradio-container {background: url('file=clouds.jpg')}") as demo:
|
| 434 |
+
...
|
| 435 |
+
```
|
| 436 |
+
|
| 437 |
+
#### Customize Component style
|
| 438 |
+
|
| 439 |
+
Use `elem_id` and `elem_classes` when instantiating component. This will allow you to select elements more easily with CSS:
|
| 440 |
+
|
| 441 |
+
```python
|
| 442 |
+
css = """
|
| 443 |
+
#warning {background-color: #FFCCCB}
|
| 444 |
+
.feedback textarea {font-size: 24px !important}
|
| 445 |
+
"""
|
| 446 |
+
|
| 447 |
+
with gr.Blocks(css=css) as demo:
|
| 448 |
+
box1 = gr.Textbox(value="Good Job", elem_classes="feedback")
|
| 449 |
+
box2 = gr.Textbox(value="Failure", elem_id="warning", elem_classes="feedback")
|
| 450 |
+
```
|
| 451 |
+
|
| 452 |
+
* `elem_id` adds an HTML element id to the specific component
|
| 453 |
+
* `elem_classes`adds a class or list of classes to the component.
|
| 454 |
+
|
| 455 |
+
## Custom front-end logic
|
| 456 |
+
|
| 457 |
+
### Custom Javascript
|
| 458 |
+
|
| 459 |
+
You can add javascript
|
| 460 |
+
|
| 461 |
+
* as a string or file path when instantiating a block:
|
| 462 |
+
```blocks(js = path or string)```
|
| 463 |
+
* Javascript will be executed when app loads?
|
| 464 |
+
* as a string to an event listener. This javascript code will be executed before the main function attached to the event listner.
|
| 465 |
+
* add javascript code to the head param of the blocks initializer. This will add the code to the head of the HTML document:
|
| 466 |
+
|
| 467 |
+
```python
|
| 468 |
+
head = f"""
|
| 469 |
+
<script async src="https://www.googletagmanager.com/gtag/js?id={google_analytics_tracking_id}"></script>
|
| 470 |
+
<script>
|
| 471 |
+
window.dataLayer = window.dataLayer || [];
|
| 472 |
+
function gtag(){{dataLayer.push(arguments);}}
|
| 473 |
+
gtag('js', new Date());
|
| 474 |
+
gtag('config', '{google_analytics_tracking_id}');
|
| 475 |
+
</script>
|
| 476 |
+
"""
|
| 477 |
+
|
| 478 |
+
with gr.Blocks(head=head) as demo:
|
| 479 |
+
...demo code...
|
| 480 |
+
```
|
| 481 |
+
|
| 482 |
+
### Custom Components
|
| 483 |
+
|
| 484 |
+
See <https://www.gradio.app/guides/custom-components-in-five-minutes>
|
| 485 |
+
|
| 486 |
+
## Connecting to databases
|
| 487 |
+
|
| 488 |
+
Might be useful when we need to retrieve voice models hosted online later.
|
| 489 |
+
|
| 490 |
+
Can import data using a combination of `sqlalchemy.create_engine` and `pandas.read_sql_query`:
|
| 491 |
+
|
| 492 |
+
```python
|
| 493 |
+
from sqlalchemy import create_engine
|
| 494 |
+
import pandas as pd
|
| 495 |
+
|
| 496 |
+
engine = create_engine('sqlite:///your_database.db')
|
| 497 |
+
|
| 498 |
+
with gr.Blocks() as demo:
|
| 499 |
+
origin = gr.Dropdown(["DFW", "DAL", "HOU"], value="DFW", label="Origin")
|
| 500 |
+
|
| 501 |
+
gr.LinePlot(
|
| 502 |
+
lambda origin: pd.read_sql_query(
|
| 503 |
+
f"SELECT time, price from flight_info WHERE origin = {origin};",
|
| 504 |
+
engine
|
| 505 |
+
), inputs=origin, x="time", y="price")
|
| 506 |
+
```
|
| 507 |
+
|
| 508 |
+
## Sharing a Gradio App
|
| 509 |
+
|
| 510 |
+
### Direct sharing
|
| 511 |
+
|
| 512 |
+
* You can do `Blocks.launch(share = True)` to launch app on a public link that expires in 72 hours
|
| 513 |
+
* IT is possible to set up your own Share Server on your own cloud server to overcome this restriction
|
| 514 |
+
* See <https://github.com/huggingface/frp/>
|
| 515 |
+
|
| 516 |
+
### Embedding hosted HF space
|
| 517 |
+
|
| 518 |
+
You can embed a gradio app hosted on huggingface spaces into any other web app.
|
| 519 |
+
|
| 520 |
+
## Gradio app in production
|
| 521 |
+
|
| 522 |
+
Useful information for migrating gradio app to production.
|
| 523 |
+
|
| 524 |
+
### App hosting
|
| 525 |
+
|
| 526 |
+
#### Custom web-server with Nginx
|
| 527 |
+
|
| 528 |
+
see <https://www.gradio.app/guides/running-gradio-on-your-web-server-with-nginx>
|
| 529 |
+
|
| 530 |
+
#### Deploying a gradio app with docker
|
| 531 |
+
|
| 532 |
+
See <https://www.gradio.app/guides/deploying-gradio-with-docker>
|
| 533 |
+
|
| 534 |
+
#### Running serverless apps
|
| 535 |
+
|
| 536 |
+
Web apps hosted completely in your browser (without any server for backend) can be implemented using a combination of Gradio lite + transformers.js.
|
| 537 |
+
|
| 538 |
+
More information:
|
| 539 |
+
|
| 540 |
+
* <https://www.gradio.app/guides/gradio-lite>
|
| 541 |
+
* <https://www.gradio.app/guides/gradio-lite-and-transformers-js>
|
| 542 |
+
|
| 543 |
+
#### Zero-GPU spaces
|
| 544 |
+
|
| 545 |
+
In development.
|
| 546 |
+
|
| 547 |
+
see <https://www.gradio.app/main/docs/python-client/using-zero-gpu-spaces>
|
| 548 |
+
|
| 549 |
+
#### Analytics dashboard
|
| 550 |
+
|
| 551 |
+
Used for monitoring traffic.
|
| 552 |
+
|
| 553 |
+
Analytics can be disabled by setting `analytics_enabled = False` as argument to `gr.Blocks()`
|
| 554 |
+
|
| 555 |
+
### Gradio App as API
|
| 556 |
+
|
| 557 |
+
Each gradio app has a button that redirects you to documentation for a corresponding API. This API can be called via:
|
| 558 |
+
|
| 559 |
+
* Dedicated [Python](https://www.gradio.app/guides/getting-started-with-the-python-client) or [Javascript](https://www.gradio.app/guides/getting-started-with-the-js-client) API clients.
|
| 560 |
+
* [Curl](https://www.gradio.app/guides/querying-gradio-apps-with-curl)
|
| 561 |
+
* Community made [Rust client](https://www.gradio.app/docs/third-party-clients/rust-client).
|
| 562 |
+
|
| 563 |
+
Alternatively, one can
|
| 564 |
+
|
| 565 |
+
* mount gradio app within existing fastapi application
|
| 566 |
+
* do a combination where the python gradio client is used inside fastapi app to query an endpoint from a gradio app.
|
| 567 |
+
|
| 568 |
+
#### Mounting app within FastAPI app
|
| 569 |
+
|
| 570 |
+
```python
|
| 571 |
+
from fastapi import FastAPI
|
| 572 |
+
import gradio as gr
|
| 573 |
+
|
| 574 |
+
CUSTOM_PATH = "/gradio"
|
| 575 |
+
|
| 576 |
+
app = FastAPI()
|
| 577 |
+
|
| 578 |
+
@app.get("/")
|
| 579 |
+
def read_main():
|
| 580 |
+
return {"message": "This is your main app"}
|
| 581 |
+
|
| 582 |
+
io = gr.Interface(lambda x: "Hello, " + x + "!", "textbox", "textbox")
|
| 583 |
+
app = gr.mount_gradio_app(app, io, path=CUSTOM_PATH)
|
| 584 |
+
```
|
| 585 |
+
|
| 586 |
+
* Run this from the terminal as you would normally start a FastAPI app: `uvicorn run:app`
|
| 587 |
+
* and navigate to <http://localhost:8000/gradio> in your browser.
|
| 588 |
+
|
| 589 |
+
#### Using a block context as a function to call
|
| 590 |
+
|
| 591 |
+
```python
|
| 592 |
+
english_translator = gr.load(name="spaces/gradio/english_translator")
|
| 593 |
+
def generate_text(text):
|
| 594 |
+
english_text = english_generator(text)[0]["generated_text"]
|
| 595 |
+
```
|
| 596 |
+
|
| 597 |
+
If the app you are loading defines more than one function, you can specify which function to use with the `fn_index` and `api_name` parameters:
|
| 598 |
+
|
| 599 |
+
```python
|
| 600 |
+
translate_btn.click(translate, inputs=english, outputs=german, api_name="translate-to-german")
|
| 601 |
+
....
|
| 602 |
+
english_generator(text, api_name="translate-to-german")[0]["generated_text"]
|
| 603 |
+
```
|
| 604 |
+
|
| 605 |
+
#### Automatic API documentation
|
| 606 |
+
|
| 607 |
+
1. Record api calls to generate snippets of calls made in app. Gradio
|
| 608 |
+
|
| 609 |
+
2. Gradio can then reconstruct documentation describing what happened
|
| 610 |
+
|
| 611 |
+
#### LLM agents
|
| 612 |
+
|
| 613 |
+
LLM agents such as those defined using LangChain can call gradio apps and compose the results they produce.
|
| 614 |
+
|
| 615 |
+
More information: <https://www.gradio.app/guides/gradio-and-llm-agents>
|
pyproject.toml
ADDED
|
@@ -0,0 +1,225 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = ["hatchling"]
|
| 3 |
+
build-backend = "hatchling.build"
|
| 4 |
+
|
| 5 |
+
[project]
|
| 6 |
+
name = "ultimate-rvc"
|
| 7 |
+
version = "0.1.24"
|
| 8 |
+
description = "Ultimate RVC"
|
| 9 |
+
readme = "README.md"
|
| 10 |
+
requires-python = "==3.12.*"
|
| 11 |
+
dependencies = [
|
| 12 |
+
# General
|
| 13 |
+
"lib==4.0.0",
|
| 14 |
+
|
| 15 |
+
#Validation
|
| 16 |
+
"pydantic==2.9.2",
|
| 17 |
+
|
| 18 |
+
# CLI
|
| 19 |
+
"typer==0.12.5",
|
| 20 |
+
|
| 21 |
+
# Networking
|
| 22 |
+
"requests==2.32.3",
|
| 23 |
+
"yt_dlp==2024.11.4",
|
| 24 |
+
"nodejs-wheel-binaries==22.11.0",
|
| 25 |
+
# TODO add these later
|
| 26 |
+
# "deemix",
|
| 27 |
+
# "wget",
|
| 28 |
+
# "flask",
|
| 29 |
+
# "beautifulsoup4",
|
| 30 |
+
# "pypresence",
|
| 31 |
+
|
| 32 |
+
# Data science
|
| 33 |
+
"numpy==1.26.4",
|
| 34 |
+
"scipy==1.14.1",
|
| 35 |
+
"matplotlib==3.9.2",
|
| 36 |
+
"tqdm==4.66.6",
|
| 37 |
+
"gradio==5.6.0",
|
| 38 |
+
|
| 39 |
+
# Machine learning
|
| 40 |
+
"torch==2.5.1+cu124",
|
| 41 |
+
"torchaudio==2.5.1+cu124",
|
| 42 |
+
"torchcrepe==0.0.23",
|
| 43 |
+
"fairseq-fixed==0.12.3.1",
|
| 44 |
+
"faiss-cpu==1.9.0",
|
| 45 |
+
# Version of onnxruntime-gpu needs to align with what
|
| 46 |
+
# version audio-separator package uses.
|
| 47 |
+
"onnxruntime-gpu==1.19.2",
|
| 48 |
+
"tensorboardX==2.6.2.2",
|
| 49 |
+
# TODO add these later
|
| 50 |
+
# "tensorboard",
|
| 51 |
+
# "torchfcpe",
|
| 52 |
+
# "local-attention",
|
| 53 |
+
# "libf0",
|
| 54 |
+
# "einops",
|
| 55 |
+
# "numba; sys_platform == 'linux'",
|
| 56 |
+
# "numba==0.57.0; sys_platform == 'darwin' or sys_platform == 'win32'",
|
| 57 |
+
|
| 58 |
+
# Audio
|
| 59 |
+
"static-ffmpeg==2.7",
|
| 60 |
+
"static-sox==1.0.1",
|
| 61 |
+
"typed-ffmpeg==2.1.0",
|
| 62 |
+
"soundfile==0.12.1",
|
| 63 |
+
"librosa==0.10.2",
|
| 64 |
+
"sox==1.5.0",
|
| 65 |
+
"pydub==0.25.1",
|
| 66 |
+
"pydub-stubs==0.25.1.2",
|
| 67 |
+
"pedalboard==0.9.16",
|
| 68 |
+
"audio-separator[gpu]==0.24.1",
|
| 69 |
+
"praat-parselmouth==0.4.5",
|
| 70 |
+
"pyworld-fixed==0.3.8",
|
| 71 |
+
"diffq==0.2.4"
|
| 72 |
+
# TODO add the later
|
| 73 |
+
# "noisereduce",
|
| 74 |
+
# "audio_upscaler==0.1.4",
|
| 75 |
+
# "edge-tts==6.1.9",
|
| 76 |
+
# "ffmpeg-python>=0.2.0",
|
| 77 |
+
# "ffmpy==0.3.1"
|
| 78 |
+
]
|
| 79 |
+
|
| 80 |
+
[project.scripts]
|
| 81 |
+
urvc = "ultimate_rvc.cli.main:app"
|
| 82 |
+
urvc-web = "ultimate_rvc.web.main:app_wrapper"
|
| 83 |
+
|
| 84 |
+
[tool.uv]
|
| 85 |
+
environments = ["sys_platform == 'win32'", "sys_platform == 'linux'"]
|
| 86 |
+
cache-dir = "./uv/cache"
|
| 87 |
+
compile-bytecode = true
|
| 88 |
+
|
| 89 |
+
[tool.uv.sources]
|
| 90 |
+
torch = { index = "torch-cu124"}
|
| 91 |
+
torchaudio = { index = "torch-cu124"}
|
| 92 |
+
diffq = { url = "https://huggingface.co/JackismyShephard/ultimate-rvc/resolve/main/diffq-0.2.4-cp312-cp312-win_amd64.whl", marker = "sys_platform == 'win32'"}
|
| 93 |
+
|
| 94 |
+
[[tool.uv.index]]
|
| 95 |
+
name = "torch-cu124"
|
| 96 |
+
url = "https://download.pytorch.org/whl/cu124"
|
| 97 |
+
explicit = true
|
| 98 |
+
|
| 99 |
+
[tool.pyright]
|
| 100 |
+
stubPath = "src/ultimate_rvc/stubs"
|
| 101 |
+
pythonVersion = "3.12"
|
| 102 |
+
pythonPlatform = "All"
|
| 103 |
+
typeCheckingMode = "strict"
|
| 104 |
+
ignore = ["**/.venv"]
|
| 105 |
+
exclude = ["./uv"]
|
| 106 |
+
|
| 107 |
+
[tool.black]
|
| 108 |
+
target-version = ['py312']
|
| 109 |
+
preview = true
|
| 110 |
+
enable-unstable-feature = ["string_processing"]
|
| 111 |
+
|
| 112 |
+
[tool.ruff]
|
| 113 |
+
target-version = "py312"
|
| 114 |
+
fix = true
|
| 115 |
+
required-version = ">=0.5.7"
|
| 116 |
+
|
| 117 |
+
[tool.ruff.format]
|
| 118 |
+
docstring-code-format = true
|
| 119 |
+
preview = true
|
| 120 |
+
|
| 121 |
+
[tool.ruff.lint]
|
| 122 |
+
select = ["ALL"]
|
| 123 |
+
extend-select = ["I"]
|
| 124 |
+
ignore = [
|
| 125 |
+
# Ignore missing blank before between class name and docstring
|
| 126 |
+
"D203",
|
| 127 |
+
# Do not require a description after summary line in docstring
|
| 128 |
+
"D205",
|
| 129 |
+
# Do not require summary line to be located on first physical line of docstring
|
| 130 |
+
"D212",
|
| 131 |
+
# Do not require docstring section names to end with colon
|
| 132 |
+
"D416",
|
| 133 |
+
# Ignore TODO notes
|
| 134 |
+
"FIX002",
|
| 135 |
+
"TD002",
|
| 136 |
+
"TD003",
|
| 137 |
+
"TD004",
|
| 138 |
+
# Ignore missing copyright notice
|
| 139 |
+
"CPY001",
|
| 140 |
+
# Ignore function signatures with too many arguments
|
| 141 |
+
"PLR0913",
|
| 142 |
+
# ignore function signatures with too many positional arguments
|
| 143 |
+
"PLR0917",
|
| 144 |
+
# Ignore boolean positional argument in function signature
|
| 145 |
+
"FBT002",
|
| 146 |
+
"FBT001",
|
| 147 |
+
]
|
| 148 |
+
unfixable = ["F401"]
|
| 149 |
+
preview = true
|
| 150 |
+
|
| 151 |
+
[tool.ruff.lint.flake8-annotations]
|
| 152 |
+
#ignore-fully-untyped = true
|
| 153 |
+
|
| 154 |
+
[tool.ruff.lint.isort]
|
| 155 |
+
relative-imports-order = "closest-to-furthest"
|
| 156 |
+
section-order = [
|
| 157 |
+
"future",
|
| 158 |
+
"typing",
|
| 159 |
+
"standard-library",
|
| 160 |
+
"third-party",
|
| 161 |
+
"networking",
|
| 162 |
+
"validation",
|
| 163 |
+
"data-science",
|
| 164 |
+
"machine-learning",
|
| 165 |
+
"audio",
|
| 166 |
+
"cli",
|
| 167 |
+
"first-party",
|
| 168 |
+
"ultimate_rvc",
|
| 169 |
+
"local-folder",
|
| 170 |
+
]
|
| 171 |
+
|
| 172 |
+
[tool.ruff.lint.isort.sections]
|
| 173 |
+
"typing" = ["typing", "typing_extensions"]
|
| 174 |
+
"networking" = [
|
| 175 |
+
"requests",
|
| 176 |
+
"yt_dlp",
|
| 177 |
+
"deemix",
|
| 178 |
+
"wget",
|
| 179 |
+
"flask",
|
| 180 |
+
"beautifulsoup4",
|
| 181 |
+
"pypresence",
|
| 182 |
+
]
|
| 183 |
+
"validation" = ["pydantic"]
|
| 184 |
+
"data-science" = [
|
| 185 |
+
"numpy",
|
| 186 |
+
"scipy",
|
| 187 |
+
"matplotlib",
|
| 188 |
+
"tqdm",
|
| 189 |
+
"pandas",
|
| 190 |
+
"gradio"
|
| 191 |
+
]
|
| 192 |
+
"machine-learning" = [
|
| 193 |
+
"torch",
|
| 194 |
+
"torchaudio",
|
| 195 |
+
"torchcrepe",
|
| 196 |
+
"fairseq",
|
| 197 |
+
"faiss",
|
| 198 |
+
"tensorboard",
|
| 199 |
+
"torchfcpe",
|
| 200 |
+
"local_attention",
|
| 201 |
+
"libf0",
|
| 202 |
+
"einops",
|
| 203 |
+
"numba",
|
| 204 |
+
]
|
| 205 |
+
"audio" = [
|
| 206 |
+
"static_ffmpeg",
|
| 207 |
+
"static_sox",
|
| 208 |
+
"ffmpeg",
|
| 209 |
+
"soundfile",
|
| 210 |
+
"librosa",
|
| 211 |
+
"sox",
|
| 212 |
+
"pydub",
|
| 213 |
+
"pedalboard",
|
| 214 |
+
"audio_separator",
|
| 215 |
+
"parselmouth",
|
| 216 |
+
"pyworld",
|
| 217 |
+
"noisereduce",
|
| 218 |
+
"audio_upscaler",
|
| 219 |
+
"edge_tts",
|
| 220 |
+
"ffmpy",
|
| 221 |
+
]
|
| 222 |
+
"cli" = ["typer", "rich"]
|
| 223 |
+
"ultimate_rvc" = ["ultimate_rvc"]
|
| 224 |
+
[tool.ruff.lint.pycodestyle]
|
| 225 |
+
max-doc-length = 72
|
src/ultimate_rvc/__init__.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""The Ultimate RVC project."""
|
| 2 |
+
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
from logging.handlers import RotatingFileHandler
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
|
| 8 |
+
from ultimate_rvc.common import BASE_DIR
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger()
|
| 11 |
+
|
| 12 |
+
URVC_NO_LOGGING = os.getenv("URVC_NO_LOGGING", "0") == "1"
|
| 13 |
+
URVC_LOGS_DIR = Path(os.getenv("URVC_LOGS_DIR") or BASE_DIR / "logs")
|
| 14 |
+
URVC_CONSOLE_LOG_LEVEL = os.getenv("URVC_CONSOLE_LOG_LEVEL", "ERROR")
|
| 15 |
+
URVC_FILE_LOG_LEVEL = os.getenv("URVC_FILE_LOG_LEVEL", "INFO")
|
| 16 |
+
|
| 17 |
+
if URVC_NO_LOGGING:
|
| 18 |
+
logging.basicConfig(handlers=[logging.NullHandler()])
|
| 19 |
+
|
| 20 |
+
else:
|
| 21 |
+
stream_handler = logging.StreamHandler()
|
| 22 |
+
stream_handler.setLevel(URVC_CONSOLE_LOG_LEVEL)
|
| 23 |
+
|
| 24 |
+
URVC_LOGS_DIR.mkdir(exist_ok=True, parents=True)
|
| 25 |
+
file_handler = RotatingFileHandler(
|
| 26 |
+
URVC_LOGS_DIR / "ultimate_rvc.log",
|
| 27 |
+
mode="a",
|
| 28 |
+
maxBytes=1024 * 1024 * 5,
|
| 29 |
+
backupCount=1,
|
| 30 |
+
encoding="utf-8",
|
| 31 |
+
)
|
| 32 |
+
file_handler.setLevel(URVC_FILE_LOG_LEVEL)
|
| 33 |
+
|
| 34 |
+
logging.basicConfig(
|
| 35 |
+
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
| 36 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 37 |
+
style="%",
|
| 38 |
+
level=logging.DEBUG,
|
| 39 |
+
handlers=[stream_handler, file_handler],
|
| 40 |
+
)
|
src/ultimate_rvc/cli/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Package which defines the command-line interface for the Ultimate RVC
|
| 3 |
+
project.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
from ultimate_rvc.core.main import initialize
|
| 7 |
+
|
| 8 |
+
initialize()
|
src/ultimate_rvc/cli/generate/song_cover.py
ADDED
|
@@ -0,0 +1,409 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Module which defines the command-line interface for generating a song
|
| 3 |
+
cover.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
from typing import Annotated
|
| 7 |
+
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
|
| 10 |
+
import typer
|
| 11 |
+
from rich import print as rprint
|
| 12 |
+
from rich.panel import Panel
|
| 13 |
+
from rich.table import Table
|
| 14 |
+
|
| 15 |
+
from ultimate_rvc.core.generate.song_cover import run_pipeline as _run_pipeline
|
| 16 |
+
from ultimate_rvc.core.generate.song_cover import to_wav as _to_wav
|
| 17 |
+
from ultimate_rvc.typing_extra import AudioExt, F0Method
|
| 18 |
+
|
| 19 |
+
app = typer.Typer(
|
| 20 |
+
name="song-cover",
|
| 21 |
+
no_args_is_help=True,
|
| 22 |
+
help="Generate song covers",
|
| 23 |
+
rich_markup_mode="markdown",
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def complete_name(incomplete: str, enumeration: list[str]) -> list[str]:
|
| 28 |
+
"""
|
| 29 |
+
Return a list of names that start with the incomplete string.
|
| 30 |
+
|
| 31 |
+
Parameters
|
| 32 |
+
----------
|
| 33 |
+
incomplete : str
|
| 34 |
+
The incomplete string to complete.
|
| 35 |
+
enumeration : list[str]
|
| 36 |
+
The list of names to complete from.
|
| 37 |
+
|
| 38 |
+
Returns
|
| 39 |
+
-------
|
| 40 |
+
list[str]
|
| 41 |
+
The list of names that start with the incomplete string.
|
| 42 |
+
|
| 43 |
+
"""
|
| 44 |
+
return [name for name in list(enumeration) if name.startswith(incomplete)]
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def complete_audio_ext(incomplete: str) -> list[str]:
|
| 48 |
+
"""
|
| 49 |
+
Return a list of audio extensions that start with the incomplete
|
| 50 |
+
string.
|
| 51 |
+
|
| 52 |
+
Parameters
|
| 53 |
+
----------
|
| 54 |
+
incomplete : str
|
| 55 |
+
The incomplete string to complete.
|
| 56 |
+
|
| 57 |
+
Returns
|
| 58 |
+
-------
|
| 59 |
+
list[str]
|
| 60 |
+
The list of audio extensions that start with the incomplete
|
| 61 |
+
string.
|
| 62 |
+
|
| 63 |
+
"""
|
| 64 |
+
return complete_name(incomplete, list(AudioExt))
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def complete_f0_method(incomplete: str) -> list[str]:
|
| 68 |
+
"""
|
| 69 |
+
Return a list of F0 methods that start with the incomplete string.
|
| 70 |
+
|
| 71 |
+
Parameters
|
| 72 |
+
----------
|
| 73 |
+
incomplete : str
|
| 74 |
+
The incomplete string to complete.
|
| 75 |
+
|
| 76 |
+
Returns
|
| 77 |
+
-------
|
| 78 |
+
list[str]
|
| 79 |
+
The list of F0 methods that start with the incomplete string.
|
| 80 |
+
|
| 81 |
+
"""
|
| 82 |
+
return complete_name(incomplete, list(F0Method))
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
@app.command(no_args_is_help=True)
|
| 86 |
+
def to_wav(
|
| 87 |
+
audio_track: Annotated[
|
| 88 |
+
Path,
|
| 89 |
+
typer.Argument(
|
| 90 |
+
help="The path to the audio track to convert.",
|
| 91 |
+
exists=True,
|
| 92 |
+
file_okay=True,
|
| 93 |
+
dir_okay=False,
|
| 94 |
+
resolve_path=True,
|
| 95 |
+
),
|
| 96 |
+
],
|
| 97 |
+
song_dir: Annotated[
|
| 98 |
+
Path,
|
| 99 |
+
typer.Argument(
|
| 100 |
+
help=(
|
| 101 |
+
"The path to the song directory where the converted audio track will be"
|
| 102 |
+
" saved."
|
| 103 |
+
),
|
| 104 |
+
exists=True,
|
| 105 |
+
file_okay=False,
|
| 106 |
+
dir_okay=True,
|
| 107 |
+
resolve_path=True,
|
| 108 |
+
),
|
| 109 |
+
],
|
| 110 |
+
prefix: Annotated[
|
| 111 |
+
str,
|
| 112 |
+
typer.Argument(
|
| 113 |
+
help="The prefix to use for the name of the converted audio track.",
|
| 114 |
+
),
|
| 115 |
+
],
|
| 116 |
+
accepted_format: Annotated[
|
| 117 |
+
list[AudioExt] | None,
|
| 118 |
+
typer.Option(
|
| 119 |
+
case_sensitive=False,
|
| 120 |
+
autocompletion=complete_audio_ext,
|
| 121 |
+
help=(
|
| 122 |
+
"An audio format to accept for conversion. This option can be used"
|
| 123 |
+
" multiple times to accept multiple formats. If not provided, the"
|
| 124 |
+
" default accepted formats are mp3, ogg, flac, m4a and aac."
|
| 125 |
+
),
|
| 126 |
+
),
|
| 127 |
+
] = None,
|
| 128 |
+
) -> None:
|
| 129 |
+
"""
|
| 130 |
+
Convert a given audio track to wav format if its current format
|
| 131 |
+
is an accepted format. See the --accepted-formats option for more
|
| 132 |
+
information on accepted formats.
|
| 133 |
+
|
| 134 |
+
"""
|
| 135 |
+
rprint()
|
| 136 |
+
wav_path = _to_wav(
|
| 137 |
+
audio_track=audio_track,
|
| 138 |
+
song_dir=song_dir,
|
| 139 |
+
prefix=prefix,
|
| 140 |
+
accepted_formats=set(accepted_format) if accepted_format else None,
|
| 141 |
+
)
|
| 142 |
+
if wav_path == audio_track:
|
| 143 |
+
rprint(
|
| 144 |
+
"[+] Audio track was not converted to WAV format. Presumably, "
|
| 145 |
+
"its format is not in the given list of accepted formats.",
|
| 146 |
+
)
|
| 147 |
+
else:
|
| 148 |
+
rprint("[+] Audio track succesfully converted to WAV format!")
|
| 149 |
+
rprint(Panel(f"[green]{wav_path}", title="WAV Audio Track Path"))
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
@app.command(no_args_is_help=True)
|
| 153 |
+
def run_pipeline(
|
| 154 |
+
source: Annotated[
|
| 155 |
+
str,
|
| 156 |
+
typer.Argument(
|
| 157 |
+
help=(
|
| 158 |
+
"A Youtube URL, the path to a local audio file or the path to a"
|
| 159 |
+
" song directory."
|
| 160 |
+
),
|
| 161 |
+
),
|
| 162 |
+
],
|
| 163 |
+
model_name: Annotated[
|
| 164 |
+
str,
|
| 165 |
+
typer.Argument(help="The name of the voice model to use for vocal conversion."),
|
| 166 |
+
],
|
| 167 |
+
n_octaves: Annotated[
|
| 168 |
+
int,
|
| 169 |
+
typer.Option(
|
| 170 |
+
rich_help_panel="Vocal Conversion Options",
|
| 171 |
+
help=(
|
| 172 |
+
"The number of octaves to pitch-shift the converted vocals by.Use 1 for"
|
| 173 |
+
" male-to-female and -1 for vice-versa."
|
| 174 |
+
),
|
| 175 |
+
),
|
| 176 |
+
] = 0,
|
| 177 |
+
n_semitones: Annotated[
|
| 178 |
+
int,
|
| 179 |
+
typer.Option(
|
| 180 |
+
rich_help_panel="Vocal Conversion Options",
|
| 181 |
+
help=(
|
| 182 |
+
"The number of semi-tones to pitch-shift the converted vocals,"
|
| 183 |
+
" instrumentals, and backup vocals by. Altering this slightly reduces"
|
| 184 |
+
" sound quality"
|
| 185 |
+
),
|
| 186 |
+
),
|
| 187 |
+
] = 0,
|
| 188 |
+
f0_method: Annotated[
|
| 189 |
+
F0Method,
|
| 190 |
+
typer.Option(
|
| 191 |
+
case_sensitive=False,
|
| 192 |
+
autocompletion=complete_f0_method,
|
| 193 |
+
rich_help_panel="Vocal Conversion Options",
|
| 194 |
+
help=(
|
| 195 |
+
"The method to use for pitch detection during vocal conversion. Best"
|
| 196 |
+
" option is RMVPE (clarity in vocals), then Mangio-Crepe (smoother"
|
| 197 |
+
" vocals)."
|
| 198 |
+
),
|
| 199 |
+
),
|
| 200 |
+
] = F0Method.RMVPE,
|
| 201 |
+
index_rate: Annotated[
|
| 202 |
+
float,
|
| 203 |
+
typer.Option(
|
| 204 |
+
min=0,
|
| 205 |
+
max=1,
|
| 206 |
+
rich_help_panel="Vocal Conversion Options",
|
| 207 |
+
help=(
|
| 208 |
+
"A decimal number e.g. 0.5, Controls how much of the accent in the"
|
| 209 |
+
" voice model to keep in the converted vocals. Increase to bias the"
|
| 210 |
+
" conversion towards the accent of the voice model."
|
| 211 |
+
),
|
| 212 |
+
),
|
| 213 |
+
] = 0.5,
|
| 214 |
+
filter_radius: Annotated[
|
| 215 |
+
int,
|
| 216 |
+
typer.Option(
|
| 217 |
+
min=0,
|
| 218 |
+
max=7,
|
| 219 |
+
rich_help_panel="Vocal Conversion Options",
|
| 220 |
+
help=(
|
| 221 |
+
"A number between 0 and 7. If >=3: apply median filtering to the pitch"
|
| 222 |
+
" results harvested during vocal conversion. Can help reduce"
|
| 223 |
+
" breathiness in the converted vocals."
|
| 224 |
+
),
|
| 225 |
+
),
|
| 226 |
+
] = 3,
|
| 227 |
+
rms_mix_rate: Annotated[
|
| 228 |
+
float,
|
| 229 |
+
typer.Option(
|
| 230 |
+
min=0,
|
| 231 |
+
max=1,
|
| 232 |
+
rich_help_panel="Vocal Conversion Options",
|
| 233 |
+
help=(
|
| 234 |
+
"A decimal number e.g. 0.25. Controls how much to mimic the loudness of"
|
| 235 |
+
" the input vocals (0) or a fixed loudness (1) during vocal conversion."
|
| 236 |
+
),
|
| 237 |
+
),
|
| 238 |
+
] = 0.25,
|
| 239 |
+
protect: Annotated[
|
| 240 |
+
float,
|
| 241 |
+
typer.Option(
|
| 242 |
+
min=0,
|
| 243 |
+
max=0.5,
|
| 244 |
+
rich_help_panel="Vocal Conversion Options",
|
| 245 |
+
help=(
|
| 246 |
+
"A decimal number e.g. 0.33. Controls protection of voiceless"
|
| 247 |
+
" consonants and breath sounds during vocal conversion. Decrease to"
|
| 248 |
+
" increase protection at the cost of indexing accuracy. Set to 0.5 to"
|
| 249 |
+
" disable."
|
| 250 |
+
),
|
| 251 |
+
),
|
| 252 |
+
] = 0.33,
|
| 253 |
+
hop_length: Annotated[
|
| 254 |
+
int,
|
| 255 |
+
typer.Option(
|
| 256 |
+
rich_help_panel="Vocal Conversion Options",
|
| 257 |
+
help=(
|
| 258 |
+
"Controls how often the CREPE-based pitch detection algorithm checks"
|
| 259 |
+
" for pitch changes during vocal conversion. Measured in milliseconds."
|
| 260 |
+
" Lower values lead to longer conversion times and a higher risk of"
|
| 261 |
+
" voice cracks, but better pitch accuracy. Recommended value: 128."
|
| 262 |
+
),
|
| 263 |
+
),
|
| 264 |
+
] = 128,
|
| 265 |
+
room_size: Annotated[
|
| 266 |
+
float,
|
| 267 |
+
typer.Option(
|
| 268 |
+
min=0,
|
| 269 |
+
max=1,
|
| 270 |
+
rich_help_panel="Vocal Post-processing Options",
|
| 271 |
+
help=(
|
| 272 |
+
"The room size of the reverb effect applied to the converted vocals."
|
| 273 |
+
" Increase for longer reverb time. Should be a value between 0 and 1."
|
| 274 |
+
),
|
| 275 |
+
),
|
| 276 |
+
] = 0.15,
|
| 277 |
+
wet_level: Annotated[
|
| 278 |
+
float,
|
| 279 |
+
typer.Option(
|
| 280 |
+
min=0,
|
| 281 |
+
max=1,
|
| 282 |
+
rich_help_panel="Vocal Post-processing Options",
|
| 283 |
+
help=(
|
| 284 |
+
"The loudness of the converted vocals with reverb effect applied."
|
| 285 |
+
" Should be a value between 0 and 1"
|
| 286 |
+
),
|
| 287 |
+
),
|
| 288 |
+
] = 0.2,
|
| 289 |
+
dry_level: Annotated[
|
| 290 |
+
float,
|
| 291 |
+
typer.Option(
|
| 292 |
+
min=0,
|
| 293 |
+
max=1,
|
| 294 |
+
rich_help_panel="Vocal Post-processing Options",
|
| 295 |
+
help=(
|
| 296 |
+
"The loudness of the converted vocals wihout reverb effect applied."
|
| 297 |
+
" Should be a value between 0 and 1."
|
| 298 |
+
),
|
| 299 |
+
),
|
| 300 |
+
] = 0.8,
|
| 301 |
+
damping: Annotated[
|
| 302 |
+
float,
|
| 303 |
+
typer.Option(
|
| 304 |
+
min=0,
|
| 305 |
+
max=1,
|
| 306 |
+
rich_help_panel="Vocal Post-processing Options",
|
| 307 |
+
help=(
|
| 308 |
+
"The absorption of high frequencies in the reverb effect applied to the"
|
| 309 |
+
" converted vocals. Should be a value between 0 and 1."
|
| 310 |
+
),
|
| 311 |
+
),
|
| 312 |
+
] = 0.7,
|
| 313 |
+
main_gain: Annotated[
|
| 314 |
+
int,
|
| 315 |
+
typer.Option(
|
| 316 |
+
rich_help_panel="Audio Mixing Options",
|
| 317 |
+
help="The gain to apply to the post-processed vocals. Measured in dB.",
|
| 318 |
+
),
|
| 319 |
+
] = 0,
|
| 320 |
+
inst_gain: Annotated[
|
| 321 |
+
int,
|
| 322 |
+
typer.Option(
|
| 323 |
+
rich_help_panel="Audio Mixing Options",
|
| 324 |
+
help=(
|
| 325 |
+
"The gain to apply to the pitch-shifted instrumentals. Measured in dB."
|
| 326 |
+
),
|
| 327 |
+
),
|
| 328 |
+
] = 0,
|
| 329 |
+
backup_gain: Annotated[
|
| 330 |
+
int,
|
| 331 |
+
typer.Option(
|
| 332 |
+
rich_help_panel="Audio Mixing Options",
|
| 333 |
+
help=(
|
| 334 |
+
"The gain to apply to the pitch-shifted backup vocals. Measured in dB."
|
| 335 |
+
),
|
| 336 |
+
),
|
| 337 |
+
] = 0,
|
| 338 |
+
output_sr: Annotated[
|
| 339 |
+
int,
|
| 340 |
+
typer.Option(
|
| 341 |
+
rich_help_panel="Audio Mixing Options",
|
| 342 |
+
help="The sample rate of the song cover.",
|
| 343 |
+
),
|
| 344 |
+
] = 44100,
|
| 345 |
+
output_format: Annotated[
|
| 346 |
+
AudioExt,
|
| 347 |
+
typer.Option(
|
| 348 |
+
case_sensitive=False,
|
| 349 |
+
autocompletion=complete_audio_ext,
|
| 350 |
+
rich_help_panel="Audio Mixing Options",
|
| 351 |
+
help="The audio format of the song cover.",
|
| 352 |
+
),
|
| 353 |
+
] = AudioExt.MP3,
|
| 354 |
+
output_name: Annotated[
|
| 355 |
+
str | None,
|
| 356 |
+
typer.Option(
|
| 357 |
+
rich_help_panel="Audio Mixing Options",
|
| 358 |
+
help="The name of the song cover.",
|
| 359 |
+
),
|
| 360 |
+
] = None,
|
| 361 |
+
) -> None:
|
| 362 |
+
"""Run the song cover generation pipeline."""
|
| 363 |
+
[song_cover_path, *intermediate_audio_file_paths] = _run_pipeline(
|
| 364 |
+
source=source,
|
| 365 |
+
model_name=model_name,
|
| 366 |
+
n_octaves=n_octaves,
|
| 367 |
+
n_semitones=n_semitones,
|
| 368 |
+
f0_method=f0_method,
|
| 369 |
+
index_rate=index_rate,
|
| 370 |
+
filter_radius=filter_radius,
|
| 371 |
+
rms_mix_rate=rms_mix_rate,
|
| 372 |
+
protect=protect,
|
| 373 |
+
hop_length=hop_length,
|
| 374 |
+
room_size=room_size,
|
| 375 |
+
wet_level=wet_level,
|
| 376 |
+
dry_level=dry_level,
|
| 377 |
+
damping=damping,
|
| 378 |
+
main_gain=main_gain,
|
| 379 |
+
inst_gain=inst_gain,
|
| 380 |
+
backup_gain=backup_gain,
|
| 381 |
+
output_sr=output_sr,
|
| 382 |
+
output_format=output_format,
|
| 383 |
+
output_name=output_name,
|
| 384 |
+
progress_bar=None,
|
| 385 |
+
)
|
| 386 |
+
table = Table()
|
| 387 |
+
table.add_column("Type")
|
| 388 |
+
table.add_column("Path")
|
| 389 |
+
for name, path in zip(
|
| 390 |
+
[
|
| 391 |
+
"Song",
|
| 392 |
+
"Vocals",
|
| 393 |
+
"Instrumentals",
|
| 394 |
+
"Main vocals",
|
| 395 |
+
"Backup vocals",
|
| 396 |
+
"De-reverbed main vocals",
|
| 397 |
+
"Main vocals reverb",
|
| 398 |
+
"Converted vocals",
|
| 399 |
+
"Post-processed vocals",
|
| 400 |
+
"Pitch-shifted instrumentals",
|
| 401 |
+
"Pitch-shifted backup vocals",
|
| 402 |
+
],
|
| 403 |
+
intermediate_audio_file_paths,
|
| 404 |
+
strict=True,
|
| 405 |
+
):
|
| 406 |
+
table.add_row(name, f"[green]{path}")
|
| 407 |
+
rprint("[+] Song cover succesfully generated!")
|
| 408 |
+
rprint(Panel(f"[green]{song_cover_path}", title="Song Cover Path"))
|
| 409 |
+
rprint(Panel(table, title="Intermediate Audio Files"))
|
src/ultimate_rvc/cli/main.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Module which defines the command-line interface for the Ultimate RVC
|
| 3 |
+
project.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import typer
|
| 7 |
+
|
| 8 |
+
from ultimate_rvc.cli.generate.song_cover import app as song_cover_app
|
| 9 |
+
|
| 10 |
+
app = typer.Typer(
|
| 11 |
+
name="urvc-cli",
|
| 12 |
+
no_args_is_help=True,
|
| 13 |
+
help="CLI for the Ultimate RVC project",
|
| 14 |
+
rich_markup_mode="markdown",
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
app.add_typer(song_cover_app)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
if __name__ == "__main__":
|
| 21 |
+
app()
|
src/ultimate_rvc/common.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Common variables used in the Ultimate RVC project."""
|
| 2 |
+
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
BASE_DIR = Path.cwd()
|
| 6 |
+
MODELS_DIR = BASE_DIR / "models"
|
| 7 |
+
RVC_MODELS_DIR = MODELS_DIR / "rvc"
|
| 8 |
+
SEPARATOR_MODELS_DIR = MODELS_DIR / "audio_separator"
|
| 9 |
+
AUDIO_DIR = BASE_DIR / "audio"
|
| 10 |
+
TEMP_DIR = BASE_DIR / "temp"
|
src/ultimate_rvc/core/__init__.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
core package for the Ultimate RVC project.
|
| 3 |
+
|
| 4 |
+
This package contains modules for managing date and settings as well as
|
| 5 |
+
generating audio using RVC based methods.
|
| 6 |
+
|
| 7 |
+
"""
|
src/ultimate_rvc/core/common.py
ADDED
|
@@ -0,0 +1,285 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Common utility functions for the core of the Ultimate RVC project."""
|
| 2 |
+
|
| 3 |
+
import hashlib
|
| 4 |
+
import json
|
| 5 |
+
import shutil
|
| 6 |
+
from collections.abc import Sequence
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
|
| 9 |
+
import requests
|
| 10 |
+
|
| 11 |
+
from pydantic import AnyHttpUrl, TypeAdapter, ValidationError
|
| 12 |
+
|
| 13 |
+
import gradio as gr
|
| 14 |
+
|
| 15 |
+
from rich import print as rprint
|
| 16 |
+
|
| 17 |
+
from ultimate_rvc.common import AUDIO_DIR, RVC_MODELS_DIR
|
| 18 |
+
from ultimate_rvc.core.exceptions import Entity, HttpUrlError, NotFoundError
|
| 19 |
+
from ultimate_rvc.typing_extra import Json, StrPath
|
| 20 |
+
|
| 21 |
+
RVC_DOWNLOAD_URL = "https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/"
|
| 22 |
+
INTERMEDIATE_AUDIO_BASE_DIR = AUDIO_DIR / "intermediate"
|
| 23 |
+
OUTPUT_AUDIO_DIR = AUDIO_DIR / "output"
|
| 24 |
+
FLAG_FILE = RVC_MODELS_DIR / ".initialized"
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def display_progress(
|
| 28 |
+
message: str,
|
| 29 |
+
percentage: float | None = None,
|
| 30 |
+
progress_bar: gr.Progress | None = None,
|
| 31 |
+
) -> None:
|
| 32 |
+
"""
|
| 33 |
+
Display progress message and percentage in console and potentially
|
| 34 |
+
also Gradio progress bar.
|
| 35 |
+
|
| 36 |
+
Parameters
|
| 37 |
+
----------
|
| 38 |
+
message : str
|
| 39 |
+
Message to display.
|
| 40 |
+
percentage : float, optional
|
| 41 |
+
Percentage to display.
|
| 42 |
+
progress_bar : gr.Progress, optional
|
| 43 |
+
The Gradio progress bar to update.
|
| 44 |
+
|
| 45 |
+
"""
|
| 46 |
+
rprint(message)
|
| 47 |
+
if progress_bar is not None:
|
| 48 |
+
progress_bar(percentage, desc=message)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def remove_suffix_after(text: str, occurrence: str) -> str:
|
| 52 |
+
"""
|
| 53 |
+
Remove suffix after the first occurrence of a substring in a string.
|
| 54 |
+
|
| 55 |
+
Parameters
|
| 56 |
+
----------
|
| 57 |
+
text : str
|
| 58 |
+
The string to remove the suffix from.
|
| 59 |
+
occurrence : str
|
| 60 |
+
The substring to remove the suffix after.
|
| 61 |
+
|
| 62 |
+
Returns
|
| 63 |
+
-------
|
| 64 |
+
str
|
| 65 |
+
The string with the suffix removed.
|
| 66 |
+
|
| 67 |
+
"""
|
| 68 |
+
location = text.rfind(occurrence)
|
| 69 |
+
if location == -1:
|
| 70 |
+
return text
|
| 71 |
+
return text[: location + len(occurrence)]
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def copy_files_to_new_dir(files: Sequence[StrPath], directory: StrPath) -> None:
|
| 75 |
+
"""
|
| 76 |
+
Copy files to a new directory.
|
| 77 |
+
|
| 78 |
+
Parameters
|
| 79 |
+
----------
|
| 80 |
+
files : Sequence[StrPath]
|
| 81 |
+
Paths to the files to copy.
|
| 82 |
+
directory : StrPath
|
| 83 |
+
Path to the directory to copy the files to.
|
| 84 |
+
|
| 85 |
+
Raises
|
| 86 |
+
------
|
| 87 |
+
NotFoundError
|
| 88 |
+
If a file does not exist.
|
| 89 |
+
|
| 90 |
+
"""
|
| 91 |
+
dir_path = Path(directory)
|
| 92 |
+
dir_path.mkdir(parents=True)
|
| 93 |
+
for file in files:
|
| 94 |
+
file_path = Path(file)
|
| 95 |
+
if not file_path.exists():
|
| 96 |
+
raise NotFoundError(entity=Entity.FILE, location=file_path)
|
| 97 |
+
shutil.copyfile(file_path, dir_path / file_path.name)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def copy_file_safe(src: StrPath, dest: StrPath) -> Path:
|
| 101 |
+
"""
|
| 102 |
+
Copy a file to a new location, appending a number if a file with the
|
| 103 |
+
same name already exists.
|
| 104 |
+
|
| 105 |
+
Parameters
|
| 106 |
+
----------
|
| 107 |
+
src : strPath
|
| 108 |
+
The source file path.
|
| 109 |
+
dest : strPath
|
| 110 |
+
The candidate destination file path.
|
| 111 |
+
|
| 112 |
+
Returns
|
| 113 |
+
-------
|
| 114 |
+
Path
|
| 115 |
+
The final destination file path.
|
| 116 |
+
|
| 117 |
+
"""
|
| 118 |
+
dest_path = Path(dest)
|
| 119 |
+
src_path = Path(src)
|
| 120 |
+
dest_dir = dest_path.parent
|
| 121 |
+
dest_dir.mkdir(parents=True, exist_ok=True)
|
| 122 |
+
dest_file = dest_path
|
| 123 |
+
counter = 1
|
| 124 |
+
|
| 125 |
+
while dest_file.exists():
|
| 126 |
+
dest_file = dest_dir / f"{dest_path.stem} ({counter}){src_path.suffix}"
|
| 127 |
+
counter += 1
|
| 128 |
+
|
| 129 |
+
shutil.copyfile(src, dest_file)
|
| 130 |
+
return dest_file
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def json_dumps(thing: Json) -> str:
|
| 134 |
+
"""
|
| 135 |
+
Dump a JSON-serializable object to a JSON string.
|
| 136 |
+
|
| 137 |
+
Parameters
|
| 138 |
+
----------
|
| 139 |
+
thing : Json
|
| 140 |
+
The JSON-serializable object to dump.
|
| 141 |
+
|
| 142 |
+
Returns
|
| 143 |
+
-------
|
| 144 |
+
str
|
| 145 |
+
The JSON string representation of the object.
|
| 146 |
+
|
| 147 |
+
"""
|
| 148 |
+
return json.dumps(thing, ensure_ascii=False, indent=4)
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def json_dump(thing: Json, file: StrPath) -> None:
|
| 152 |
+
"""
|
| 153 |
+
Dump a JSON-serializable object to a JSON file.
|
| 154 |
+
|
| 155 |
+
Parameters
|
| 156 |
+
----------
|
| 157 |
+
thing : Json
|
| 158 |
+
The JSON-serializable object to dump.
|
| 159 |
+
file : StrPath
|
| 160 |
+
The path to the JSON file.
|
| 161 |
+
|
| 162 |
+
"""
|
| 163 |
+
with Path(file).open("w", encoding="utf-8") as fp:
|
| 164 |
+
json.dump(thing, fp, ensure_ascii=False, indent=4)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def json_load(file: StrPath, encoding: str = "utf-8") -> Json:
|
| 168 |
+
"""
|
| 169 |
+
Load a JSON-serializable object from a JSON file.
|
| 170 |
+
|
| 171 |
+
Parameters
|
| 172 |
+
----------
|
| 173 |
+
file : StrPath
|
| 174 |
+
The path to the JSON file.
|
| 175 |
+
encoding : str, default='utf-8'
|
| 176 |
+
The encoding of the JSON file.
|
| 177 |
+
|
| 178 |
+
Returns
|
| 179 |
+
-------
|
| 180 |
+
Json
|
| 181 |
+
The JSON-serializable object loaded from the JSON file.
|
| 182 |
+
|
| 183 |
+
"""
|
| 184 |
+
with Path(file).open(encoding=encoding) as fp:
|
| 185 |
+
return json.load(fp)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def get_hash(thing: Json, size: int = 5) -> str:
|
| 189 |
+
"""
|
| 190 |
+
Get the hash of a JSON-serializable object.
|
| 191 |
+
|
| 192 |
+
Parameters
|
| 193 |
+
----------
|
| 194 |
+
thing : Json
|
| 195 |
+
The JSON-serializable object to hash.
|
| 196 |
+
size : int, default=5
|
| 197 |
+
The size of the hash in bytes.
|
| 198 |
+
|
| 199 |
+
Returns
|
| 200 |
+
-------
|
| 201 |
+
str
|
| 202 |
+
The hash of the JSON-serializable object.
|
| 203 |
+
|
| 204 |
+
"""
|
| 205 |
+
return hashlib.blake2b(
|
| 206 |
+
json_dumps(thing).encode("utf-8"),
|
| 207 |
+
digest_size=size,
|
| 208 |
+
).hexdigest()
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
# NOTE consider increasing size to 16 otherwise we might have problems
|
| 212 |
+
# with hash collisions
|
| 213 |
+
def get_file_hash(file: StrPath, size: int = 5) -> str:
|
| 214 |
+
"""
|
| 215 |
+
Get the hash of a file.
|
| 216 |
+
|
| 217 |
+
Parameters
|
| 218 |
+
----------
|
| 219 |
+
file : StrPath
|
| 220 |
+
The path to the file.
|
| 221 |
+
size : int, default=5
|
| 222 |
+
The size of the hash in bytes.
|
| 223 |
+
|
| 224 |
+
Returns
|
| 225 |
+
-------
|
| 226 |
+
str
|
| 227 |
+
The hash of the file.
|
| 228 |
+
|
| 229 |
+
"""
|
| 230 |
+
with Path(file).open("rb") as fp:
|
| 231 |
+
file_hash = hashlib.file_digest(fp, lambda: hashlib.blake2b(digest_size=size))
|
| 232 |
+
return file_hash.hexdigest()
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def validate_url(url: str) -> None:
|
| 236 |
+
"""
|
| 237 |
+
Validate a HTTP-based URL.
|
| 238 |
+
|
| 239 |
+
Parameters
|
| 240 |
+
----------
|
| 241 |
+
url : str
|
| 242 |
+
The URL to validate.
|
| 243 |
+
|
| 244 |
+
Raises
|
| 245 |
+
------
|
| 246 |
+
HttpUrlError
|
| 247 |
+
If the URL is invalid.
|
| 248 |
+
|
| 249 |
+
"""
|
| 250 |
+
try:
|
| 251 |
+
TypeAdapter(AnyHttpUrl).validate_python(url)
|
| 252 |
+
except ValidationError:
|
| 253 |
+
raise HttpUrlError(url) from None
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
def _download_base_model(url: str, name: str, directory: StrPath) -> None:
|
| 257 |
+
"""
|
| 258 |
+
Download a base model and save it to an existing directory.
|
| 259 |
+
|
| 260 |
+
Parameters
|
| 261 |
+
----------
|
| 262 |
+
url : str
|
| 263 |
+
An URL pointing to a location where a base model is hosted.
|
| 264 |
+
name : str
|
| 265 |
+
The name of the base model to download.
|
| 266 |
+
directory : str
|
| 267 |
+
The path to the directory where the base model should be saved.
|
| 268 |
+
|
| 269 |
+
"""
|
| 270 |
+
dir_path = Path(directory)
|
| 271 |
+
with requests.get(f"{url}{name}", timeout=10) as r:
|
| 272 |
+
r.raise_for_status()
|
| 273 |
+
with (dir_path / name).open("wb") as f:
|
| 274 |
+
for chunk in r.iter_content(chunk_size=8192):
|
| 275 |
+
f.write(chunk)
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
def download_base_models() -> None:
|
| 279 |
+
"""Download base models."""
|
| 280 |
+
RVC_MODELS_DIR.mkdir(parents=True, exist_ok=True)
|
| 281 |
+
base_model_names = ["hubert_base.pt", "rmvpe.pt"]
|
| 282 |
+
for base_model_name in base_model_names:
|
| 283 |
+
if not Path(RVC_MODELS_DIR / base_model_name).is_file():
|
| 284 |
+
rprint(f"Downloading {base_model_name}...")
|
| 285 |
+
_download_base_model(RVC_DOWNLOAD_URL, base_model_name, RVC_MODELS_DIR)
|
src/ultimate_rvc/core/exceptions.py
ADDED
|
@@ -0,0 +1,297 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Module which defines custom exception and enumerations used when
|
| 3 |
+
instiating and re-raising those exceptions.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
from enum import StrEnum
|
| 7 |
+
|
| 8 |
+
from ultimate_rvc.typing_extra import StrPath
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class Entity(StrEnum):
|
| 12 |
+
"""Enumeration of entities that can be provided."""
|
| 13 |
+
|
| 14 |
+
DIRECTORY = "directory"
|
| 15 |
+
DIRECTORIES = "directories"
|
| 16 |
+
FILE = "file"
|
| 17 |
+
FILES = "files"
|
| 18 |
+
URL = "URL"
|
| 19 |
+
MODEL_NAME = "model name"
|
| 20 |
+
MODEL_NAMES = "model names"
|
| 21 |
+
MODEL_FILE = "model file"
|
| 22 |
+
SOURCE = "source"
|
| 23 |
+
SONG_DIR = "song directory"
|
| 24 |
+
AUDIO_TRACK = "audio track"
|
| 25 |
+
AUDIO_TRACK_GAIN_PAIRS = "pairs of audio track and gain"
|
| 26 |
+
SONG = "song"
|
| 27 |
+
VOCALS_TRACK = "vocals track"
|
| 28 |
+
INSTRUMENTALS_TRACK = "instrumentals track"
|
| 29 |
+
BACKUP_VOCALS_TRACK = "backup vocals track"
|
| 30 |
+
MAIN_VOCALS_TRACK = "main vocals track"
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class Location(StrEnum):
|
| 34 |
+
"""Enumeration of locations where entities can be found."""
|
| 35 |
+
|
| 36 |
+
INTERMEDIATE_AUDIO_ROOT = "the root of the intermediate audio base directory"
|
| 37 |
+
OUTPUT_AUDIO_ROOT = "the root of the output audio directory"
|
| 38 |
+
EXTRACTED_ZIP_FILE = "extracted zip file"
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class UIMessage(StrEnum):
|
| 42 |
+
"""
|
| 43 |
+
Enumeration of messages that can be displayed in the UI
|
| 44 |
+
in place of core exception messages.
|
| 45 |
+
"""
|
| 46 |
+
|
| 47 |
+
NO_AUDIO_TRACK = "No audio tracks provided."
|
| 48 |
+
NO_SONG_DIR = "No song directory selected."
|
| 49 |
+
NO_SONG_DIRS = (
|
| 50 |
+
"No song directories selected. Please select one or more song directories"
|
| 51 |
+
" containing intermediate audio files to delete."
|
| 52 |
+
)
|
| 53 |
+
NO_OUTPUT_AUDIO_FILES = (
|
| 54 |
+
"No files selected. Please select one or more output audio files to delete."
|
| 55 |
+
)
|
| 56 |
+
NO_UPLOADED_FILES = "No files selected."
|
| 57 |
+
NO_VOICE_MODEL = "No voice model selected."
|
| 58 |
+
NO_VOICE_MODELS = "No voice models selected."
|
| 59 |
+
NO_SOURCE = (
|
| 60 |
+
"No source provided. Please provide a valid Youtube URL, local audio file"
|
| 61 |
+
" or song directory."
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class NotProvidedError(ValueError):
|
| 66 |
+
"""Raised when an entity is not provided."""
|
| 67 |
+
|
| 68 |
+
def __init__(self, entity: Entity, ui_msg: UIMessage | None = None) -> None:
|
| 69 |
+
"""
|
| 70 |
+
Initialize a NotProvidedError instance.
|
| 71 |
+
|
| 72 |
+
Exception message will be formatted as:
|
| 73 |
+
|
| 74 |
+
"No `<entity>` provided."
|
| 75 |
+
|
| 76 |
+
Parameters
|
| 77 |
+
----------
|
| 78 |
+
entity : Entity
|
| 79 |
+
The entity that was not provided.
|
| 80 |
+
ui_msg : UIMessage, default=None
|
| 81 |
+
Message which, if provided, is displayed in the UI
|
| 82 |
+
instead of the default exception message.
|
| 83 |
+
|
| 84 |
+
"""
|
| 85 |
+
super().__init__(f"No {entity} provided.")
|
| 86 |
+
self.ui_msg = ui_msg
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class NotFoundError(OSError):
|
| 90 |
+
"""Raised when an entity is not found."""
|
| 91 |
+
|
| 92 |
+
def __init__(
|
| 93 |
+
self,
|
| 94 |
+
entity: Entity,
|
| 95 |
+
location: StrPath | Location,
|
| 96 |
+
is_path: bool = True,
|
| 97 |
+
) -> None:
|
| 98 |
+
"""
|
| 99 |
+
Initialize a NotFoundError instance.
|
| 100 |
+
|
| 101 |
+
Exception message will be formatted as:
|
| 102 |
+
|
| 103 |
+
"`<entity>` not found `(`in `|` as:`)` `<location>`."
|
| 104 |
+
|
| 105 |
+
Parameters
|
| 106 |
+
----------
|
| 107 |
+
entity : Entity
|
| 108 |
+
The entity that was not found.
|
| 109 |
+
location : StrPath | Location
|
| 110 |
+
The location where the entity was not found.
|
| 111 |
+
is_path : bool, default=True
|
| 112 |
+
Whether the location is a path to the entity.
|
| 113 |
+
|
| 114 |
+
"""
|
| 115 |
+
proposition = "at:" if is_path else "in"
|
| 116 |
+
entity_cap = entity.capitalize() if not entity.isupper() else entity
|
| 117 |
+
super().__init__(
|
| 118 |
+
f"{entity_cap} not found {proposition} {location}",
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
class VoiceModelNotFoundError(OSError):
|
| 123 |
+
"""Raised when a voice model is not found."""
|
| 124 |
+
|
| 125 |
+
def __init__(self, name: str) -> None:
|
| 126 |
+
r"""
|
| 127 |
+
Initialize a VoiceModelNotFoundError instance.
|
| 128 |
+
|
| 129 |
+
Exception message will be formatted as:
|
| 130 |
+
|
| 131 |
+
'Voice model with name "`<name>`" not found.'
|
| 132 |
+
|
| 133 |
+
Parameters
|
| 134 |
+
----------
|
| 135 |
+
name : str
|
| 136 |
+
The name of the voice model that was not found.
|
| 137 |
+
|
| 138 |
+
"""
|
| 139 |
+
super().__init__(f'Voice model with name "{name}" not found.')
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
class VoiceModelExistsError(OSError):
|
| 143 |
+
"""Raised when a voice model already exists."""
|
| 144 |
+
|
| 145 |
+
def __init__(self, name: str) -> None:
|
| 146 |
+
r"""
|
| 147 |
+
Initialize a VoiceModelExistsError instance.
|
| 148 |
+
|
| 149 |
+
Exception message will be formatted as:
|
| 150 |
+
|
| 151 |
+
"Voice model with name '`<name>`' already exists. Please provide
|
| 152 |
+
a different name for your voice model."
|
| 153 |
+
|
| 154 |
+
Parameters
|
| 155 |
+
----------
|
| 156 |
+
name : str
|
| 157 |
+
The name of the voice model that already exists.
|
| 158 |
+
|
| 159 |
+
"""
|
| 160 |
+
super().__init__(
|
| 161 |
+
f'Voice model with name "{name}" already exists. Please provide a different'
|
| 162 |
+
" name for your voice model.",
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
class InvalidLocationError(OSError):
|
| 167 |
+
"""Raised when an entity is in a wrong location."""
|
| 168 |
+
|
| 169 |
+
def __init__(self, entity: Entity, location: Location, path: StrPath) -> None:
|
| 170 |
+
r"""
|
| 171 |
+
Initialize an InvalidLocationError instance.
|
| 172 |
+
|
| 173 |
+
Exception message will be formatted as:
|
| 174 |
+
|
| 175 |
+
"`<entity>` should be located in `<location>` but found at:
|
| 176 |
+
`<path>`"
|
| 177 |
+
|
| 178 |
+
Parameters
|
| 179 |
+
----------
|
| 180 |
+
entity : Entity
|
| 181 |
+
The entity that is in a wrong location.
|
| 182 |
+
location : Location
|
| 183 |
+
The correct location for the entity.
|
| 184 |
+
path : StrPath
|
| 185 |
+
The path to the entity.
|
| 186 |
+
|
| 187 |
+
"""
|
| 188 |
+
entity_cap = entity.capitalize() if not entity.isupper() else entity
|
| 189 |
+
super().__init__(
|
| 190 |
+
f"{entity_cap} should be located in {location} but found at: {path}",
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
class HttpUrlError(OSError):
|
| 195 |
+
"""Raised when a HTTP-based URL is invalid."""
|
| 196 |
+
|
| 197 |
+
def __init__(self, url: str) -> None:
|
| 198 |
+
"""
|
| 199 |
+
Initialize a HttpUrlError instance.
|
| 200 |
+
|
| 201 |
+
Exception message will be formatted as:
|
| 202 |
+
|
| 203 |
+
"Invalid HTTP-based URL: `<url>`"
|
| 204 |
+
|
| 205 |
+
Parameters
|
| 206 |
+
----------
|
| 207 |
+
url : str
|
| 208 |
+
The invalid HTTP-based URL.
|
| 209 |
+
|
| 210 |
+
"""
|
| 211 |
+
super().__init__(
|
| 212 |
+
f"Invalid HTTP-based URL: {url}",
|
| 213 |
+
)
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
class YoutubeUrlError(OSError):
|
| 217 |
+
"""
|
| 218 |
+
Raised when an URL does not point to a YouTube video or
|
| 219 |
+
, potentially, a Youtube playlist.
|
| 220 |
+
"""
|
| 221 |
+
|
| 222 |
+
def __init__(self, url: str, playlist: bool) -> None:
|
| 223 |
+
"""
|
| 224 |
+
Initialize a YoutubeURlError instance.
|
| 225 |
+
|
| 226 |
+
Exception message will be formatted as:
|
| 227 |
+
|
| 228 |
+
"URL does not point to a YouTube video `[`or playlist`]`:
|
| 229 |
+
`<url>`"
|
| 230 |
+
|
| 231 |
+
Parameters
|
| 232 |
+
----------
|
| 233 |
+
url : str
|
| 234 |
+
The URL that does not point to a YouTube video or playlist.
|
| 235 |
+
playlist : bool
|
| 236 |
+
Whether the URL might point to a YouTube playlist.
|
| 237 |
+
|
| 238 |
+
"""
|
| 239 |
+
suffix = "or playlist" if playlist else ""
|
| 240 |
+
super().__init__(
|
| 241 |
+
f"Not able to access Youtube video {suffix} at: {url}",
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
class UploadLimitError(ValueError):
|
| 246 |
+
"""Raised when the upload limit for an entity is exceeded."""
|
| 247 |
+
|
| 248 |
+
def __init__(self, entity: Entity, limit: str | float) -> None:
|
| 249 |
+
"""
|
| 250 |
+
Initialize an UploadLimitError instance.
|
| 251 |
+
|
| 252 |
+
Exception message will be formatted as:
|
| 253 |
+
|
| 254 |
+
"At most `<limit>` `<entity>` can be uploaded."
|
| 255 |
+
|
| 256 |
+
Parameters
|
| 257 |
+
----------
|
| 258 |
+
entity : Entity
|
| 259 |
+
The entity for which the upload limit was exceeded.
|
| 260 |
+
limit : str
|
| 261 |
+
The upload limit.
|
| 262 |
+
|
| 263 |
+
"""
|
| 264 |
+
super().__init__(f"At most {limit} {entity} can be uploaded.")
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
class UploadFormatError(ValueError):
|
| 268 |
+
"""
|
| 269 |
+
Raised when one or more uploaded entities have an invalid format
|
| 270 |
+
.
|
| 271 |
+
"""
|
| 272 |
+
|
| 273 |
+
def __init__(self, entity: Entity, formats: list[str], multiple: bool) -> None:
|
| 274 |
+
"""
|
| 275 |
+
Initialize an UploadFileFormatError instance.
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
Exception message will be formatted as:
|
| 279 |
+
|
| 280 |
+
"Only `<entity>` with the following formats can be uploaded
|
| 281 |
+
`(`by themselves | together`)`: `<formats>`."
|
| 282 |
+
|
| 283 |
+
Parameters
|
| 284 |
+
----------
|
| 285 |
+
entity : Entity
|
| 286 |
+
The entity that was uploaded with an invalid format.
|
| 287 |
+
formats : list[str]
|
| 288 |
+
Valid formats.
|
| 289 |
+
multiple : bool
|
| 290 |
+
Whether multiple entities are uploaded.
|
| 291 |
+
|
| 292 |
+
"""
|
| 293 |
+
suffix = "by themselves" if not multiple else "together (at most one of each)"
|
| 294 |
+
super().__init__(
|
| 295 |
+
f"Only {entity} with the following formats can be uploaded {suffix}:"
|
| 296 |
+
f" {', '.join(formats)}.",
|
| 297 |
+
)
|
src/ultimate_rvc/core/generate/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Package which defines modules that facilitate RVC based audio
|
| 3 |
+
generation.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import static_ffmpeg
|
| 7 |
+
import static_sox
|
| 8 |
+
|
| 9 |
+
from ultimate_rvc.core.common import download_base_models
|
| 10 |
+
|
| 11 |
+
download_base_models()
|
| 12 |
+
static_ffmpeg.add_paths()
|
| 13 |
+
static_sox.add_paths()
|
src/ultimate_rvc/core/generate/song_cover.py
ADDED
|
@@ -0,0 +1,1728 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Module which defines functions that faciliatate song cover generation
|
| 3 |
+
using RVC.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
import gc
|
| 7 |
+
import logging
|
| 8 |
+
import operator
|
| 9 |
+
import shutil
|
| 10 |
+
from collections.abc import Sequence
|
| 11 |
+
from contextlib import suppress
|
| 12 |
+
from functools import reduce
|
| 13 |
+
from itertools import starmap
|
| 14 |
+
from pathlib import Path
|
| 15 |
+
from urllib.parse import parse_qs, urlparse
|
| 16 |
+
|
| 17 |
+
import yt_dlp
|
| 18 |
+
|
| 19 |
+
from pydantic import ValidationError
|
| 20 |
+
|
| 21 |
+
import gradio as gr
|
| 22 |
+
|
| 23 |
+
import ffmpeg
|
| 24 |
+
import soundfile as sf
|
| 25 |
+
import sox
|
| 26 |
+
from audio_separator.separator import Separator
|
| 27 |
+
from pedalboard import Compressor, HighpassFilter, Reverb
|
| 28 |
+
from pedalboard._pedalboard import Pedalboard # noqa: PLC2701
|
| 29 |
+
from pedalboard.io import AudioFile
|
| 30 |
+
from pydub import AudioSegment
|
| 31 |
+
from pydub import utils as pydub_utils
|
| 32 |
+
|
| 33 |
+
from ultimate_rvc.common import RVC_MODELS_DIR, SEPARATOR_MODELS_DIR
|
| 34 |
+
from ultimate_rvc.core.common import (
|
| 35 |
+
INTERMEDIATE_AUDIO_BASE_DIR,
|
| 36 |
+
OUTPUT_AUDIO_DIR,
|
| 37 |
+
copy_file_safe,
|
| 38 |
+
display_progress,
|
| 39 |
+
get_file_hash,
|
| 40 |
+
get_hash,
|
| 41 |
+
json_dump,
|
| 42 |
+
json_dumps,
|
| 43 |
+
json_load,
|
| 44 |
+
validate_url,
|
| 45 |
+
)
|
| 46 |
+
from ultimate_rvc.core.exceptions import (
|
| 47 |
+
Entity,
|
| 48 |
+
InvalidLocationError,
|
| 49 |
+
Location,
|
| 50 |
+
NotFoundError,
|
| 51 |
+
NotProvidedError,
|
| 52 |
+
UIMessage,
|
| 53 |
+
VoiceModelNotFoundError,
|
| 54 |
+
YoutubeUrlError,
|
| 55 |
+
)
|
| 56 |
+
from ultimate_rvc.core.typing_extra import (
|
| 57 |
+
AudioExtInternal,
|
| 58 |
+
ConvertedVocalsMetaData,
|
| 59 |
+
EffectedVocalsMetaData,
|
| 60 |
+
FileMetaData,
|
| 61 |
+
MixedSongMetaData,
|
| 62 |
+
PitchShiftMetaData,
|
| 63 |
+
SeparatedAudioMetaData,
|
| 64 |
+
SourceType,
|
| 65 |
+
StagedAudioMetaData,
|
| 66 |
+
WaveifiedAudioMetaData,
|
| 67 |
+
)
|
| 68 |
+
from ultimate_rvc.typing_extra import (
|
| 69 |
+
AudioExt,
|
| 70 |
+
F0Method,
|
| 71 |
+
Json,
|
| 72 |
+
SegmentSize,
|
| 73 |
+
SeparationModel,
|
| 74 |
+
StrPath,
|
| 75 |
+
)
|
| 76 |
+
from ultimate_rvc.vc.rvc import Config, get_vc, load_hubert, rvc_infer
|
| 77 |
+
|
| 78 |
+
logger = logging.getLogger(__name__)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def _get_audio_separator(
|
| 82 |
+
output_dir: StrPath = INTERMEDIATE_AUDIO_BASE_DIR,
|
| 83 |
+
output_format: str = AudioExt.WAV,
|
| 84 |
+
segment_size: int = SegmentSize.SEG_256,
|
| 85 |
+
sample_rate: int = 44100,
|
| 86 |
+
) -> Separator:
|
| 87 |
+
"""
|
| 88 |
+
Get an audio separator.
|
| 89 |
+
|
| 90 |
+
Parameters
|
| 91 |
+
----------
|
| 92 |
+
output_dir : StrPath, default=INTERMEDIATE_AUDIO_BASE_DIR
|
| 93 |
+
The directory to save the separated audio to.
|
| 94 |
+
output_format : str, default=AudioExt.WAV
|
| 95 |
+
The format to save the separated audio in.
|
| 96 |
+
segment_size : int, default=SegmentSize.SEG_256
|
| 97 |
+
The segment size to use for separation.
|
| 98 |
+
sample_rate : int, default=44100
|
| 99 |
+
The sample rate to use for separation.
|
| 100 |
+
|
| 101 |
+
Returns
|
| 102 |
+
-------
|
| 103 |
+
Separator
|
| 104 |
+
An audio separator.
|
| 105 |
+
|
| 106 |
+
"""
|
| 107 |
+
return Separator(
|
| 108 |
+
model_file_dir=SEPARATOR_MODELS_DIR,
|
| 109 |
+
output_dir=output_dir,
|
| 110 |
+
output_format=output_format,
|
| 111 |
+
sample_rate=sample_rate,
|
| 112 |
+
mdx_params={
|
| 113 |
+
"hop_length": 1024,
|
| 114 |
+
"segment_size": segment_size,
|
| 115 |
+
"overlap": 0.001,
|
| 116 |
+
"batch_size": 1,
|
| 117 |
+
"enable_denoise": False,
|
| 118 |
+
},
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def initialize_audio_separator(progress_bar: gr.Progress | None = None) -> None:
|
| 123 |
+
"""
|
| 124 |
+
Initialize the audio separator by downloading the models it uses.
|
| 125 |
+
|
| 126 |
+
Parameters
|
| 127 |
+
----------
|
| 128 |
+
progress_bar : gr.Progress, optional
|
| 129 |
+
Gradio progress bar to update.
|
| 130 |
+
|
| 131 |
+
"""
|
| 132 |
+
audio_separator = _get_audio_separator()
|
| 133 |
+
for i, separator_model in enumerate(SeparationModel):
|
| 134 |
+
if not Path(SEPARATOR_MODELS_DIR / separator_model).is_file():
|
| 135 |
+
display_progress(
|
| 136 |
+
f"Downloading {separator_model}...",
|
| 137 |
+
i / len(SeparationModel),
|
| 138 |
+
progress_bar,
|
| 139 |
+
)
|
| 140 |
+
audio_separator.download_model_files(separator_model)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def _get_input_audio_path(directory: StrPath) -> Path | None:
|
| 144 |
+
"""
|
| 145 |
+
Get the path to the input audio file in the provided directory, if
|
| 146 |
+
it exists.
|
| 147 |
+
|
| 148 |
+
The provided directory must be located in the root of the
|
| 149 |
+
intermediate audio base directory.
|
| 150 |
+
|
| 151 |
+
Parameters
|
| 152 |
+
----------
|
| 153 |
+
directory : StrPath
|
| 154 |
+
The path to a directory.
|
| 155 |
+
|
| 156 |
+
Returns
|
| 157 |
+
-------
|
| 158 |
+
Path | None
|
| 159 |
+
The path to the input audio file in the provided directory, if
|
| 160 |
+
it exists.
|
| 161 |
+
|
| 162 |
+
Raises
|
| 163 |
+
------
|
| 164 |
+
NotFoundError
|
| 165 |
+
If the provided path does not point to an existing directory.
|
| 166 |
+
InvalidLocationError
|
| 167 |
+
If the provided path is not located in the root of the
|
| 168 |
+
intermediate audio base directory"
|
| 169 |
+
|
| 170 |
+
"""
|
| 171 |
+
dir_path = Path(directory)
|
| 172 |
+
|
| 173 |
+
if not dir_path.is_dir():
|
| 174 |
+
raise NotFoundError(entity=Entity.DIRECTORY, location=dir_path)
|
| 175 |
+
|
| 176 |
+
if dir_path.parent != INTERMEDIATE_AUDIO_BASE_DIR:
|
| 177 |
+
raise InvalidLocationError(
|
| 178 |
+
entity=Entity.DIRECTORY,
|
| 179 |
+
location=Location.INTERMEDIATE_AUDIO_ROOT,
|
| 180 |
+
path=dir_path,
|
| 181 |
+
)
|
| 182 |
+
# NOTE directory should never contain more than one element which
|
| 183 |
+
# matches the pattern "00_*"
|
| 184 |
+
return next(dir_path.glob("00_*"), None)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def _get_input_audio_paths() -> list[Path]:
|
| 188 |
+
"""
|
| 189 |
+
Get the paths to all input audio files in the intermediate audio
|
| 190 |
+
base directory.
|
| 191 |
+
|
| 192 |
+
Returns
|
| 193 |
+
-------
|
| 194 |
+
list[Path]
|
| 195 |
+
The paths to all input audio files in the intermediate audio
|
| 196 |
+
base directory.
|
| 197 |
+
|
| 198 |
+
"""
|
| 199 |
+
# NOTE if we later add .json file for input then
|
| 200 |
+
# we need to exclude those here
|
| 201 |
+
return list(INTERMEDIATE_AUDIO_BASE_DIR.glob("*/00_*"))
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def get_named_song_dirs() -> list[tuple[str, str]]:
|
| 205 |
+
"""
|
| 206 |
+
Get the names of all saved songs and the paths to the
|
| 207 |
+
directories where they are stored.
|
| 208 |
+
|
| 209 |
+
Returns
|
| 210 |
+
-------
|
| 211 |
+
list[tuple[str, Path]]
|
| 212 |
+
A list of tuples containing the name of each saved song
|
| 213 |
+
and the path to the directory where it is stored.
|
| 214 |
+
|
| 215 |
+
"""
|
| 216 |
+
return sorted(
|
| 217 |
+
[
|
| 218 |
+
(
|
| 219 |
+
path.stem.removeprefix("00_"),
|
| 220 |
+
str(path.parent),
|
| 221 |
+
)
|
| 222 |
+
for path in _get_input_audio_paths()
|
| 223 |
+
],
|
| 224 |
+
key=operator.itemgetter(0),
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def _get_model_name(
|
| 229 |
+
effected_vocals_track: StrPath | None = None,
|
| 230 |
+
song_dir: StrPath | None = None,
|
| 231 |
+
) -> str:
|
| 232 |
+
"""
|
| 233 |
+
Infer the name of the voice model used for vocal conversion from a
|
| 234 |
+
an effected vocals track in a given song directory.
|
| 235 |
+
|
| 236 |
+
If a voice model name cannot be inferred, "Unknown" is returned.
|
| 237 |
+
|
| 238 |
+
Parameters
|
| 239 |
+
----------
|
| 240 |
+
effected_vocals_track : StrPath, optional
|
| 241 |
+
The path to an effected vocals track.
|
| 242 |
+
song_dir : StrPath, optional
|
| 243 |
+
The path to a song directory.
|
| 244 |
+
|
| 245 |
+
Returns
|
| 246 |
+
-------
|
| 247 |
+
str
|
| 248 |
+
The name of the voice model used for vocal conversion.
|
| 249 |
+
|
| 250 |
+
"""
|
| 251 |
+
model_name = "Unknown"
|
| 252 |
+
if not (effected_vocals_track and song_dir):
|
| 253 |
+
return model_name
|
| 254 |
+
effected_vocals_path = Path(effected_vocals_track)
|
| 255 |
+
song_dir_path = Path(song_dir)
|
| 256 |
+
effected_vocals_json_path = song_dir_path / f"{effected_vocals_path.stem}.json"
|
| 257 |
+
if not effected_vocals_json_path.is_file():
|
| 258 |
+
return model_name
|
| 259 |
+
effected_vocals_dict = json_load(effected_vocals_json_path)
|
| 260 |
+
try:
|
| 261 |
+
effected_vocals_metadata = EffectedVocalsMetaData.model_validate(
|
| 262 |
+
effected_vocals_dict,
|
| 263 |
+
)
|
| 264 |
+
except ValidationError:
|
| 265 |
+
return model_name
|
| 266 |
+
converted_vocals_track_name = effected_vocals_metadata.vocals_track.name
|
| 267 |
+
converted_vocals_json_path = song_dir_path / Path(
|
| 268 |
+
converted_vocals_track_name,
|
| 269 |
+
).with_suffix(
|
| 270 |
+
".json",
|
| 271 |
+
)
|
| 272 |
+
if not converted_vocals_json_path.is_file():
|
| 273 |
+
return model_name
|
| 274 |
+
converted_vocals_dict = json_load(converted_vocals_json_path)
|
| 275 |
+
try:
|
| 276 |
+
converted_vocals_metadata = ConvertedVocalsMetaData.model_validate(
|
| 277 |
+
converted_vocals_dict,
|
| 278 |
+
)
|
| 279 |
+
except ValidationError:
|
| 280 |
+
return model_name
|
| 281 |
+
return converted_vocals_metadata.model_name
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def get_song_cover_name(
|
| 285 |
+
effected_vocals_track: StrPath | None = None,
|
| 286 |
+
song_dir: StrPath | None = None,
|
| 287 |
+
model_name: str | None = None,
|
| 288 |
+
) -> str:
|
| 289 |
+
"""
|
| 290 |
+
Generate a suitable name for a cover of a song based on the name
|
| 291 |
+
of that song and the voice model used for vocal conversion.
|
| 292 |
+
|
| 293 |
+
If the path of an existing song directory is provided, the name
|
| 294 |
+
of the song is inferred from that directory. If a voice model is not
|
| 295 |
+
provided but the path of an existing song directory and the path of
|
| 296 |
+
an effected vocals track in that directory are provided, then the
|
| 297 |
+
voice model is inferred from the effected vocals track.
|
| 298 |
+
|
| 299 |
+
Parameters
|
| 300 |
+
----------
|
| 301 |
+
effected_vocals_track : StrPath, optional
|
| 302 |
+
The path to an effected vocals track.
|
| 303 |
+
song_dir : StrPath, optional
|
| 304 |
+
The path to a song directory.
|
| 305 |
+
model_name : str, optional
|
| 306 |
+
The name of a voice model.
|
| 307 |
+
|
| 308 |
+
Returns
|
| 309 |
+
-------
|
| 310 |
+
str
|
| 311 |
+
The song cover name
|
| 312 |
+
|
| 313 |
+
"""
|
| 314 |
+
song_name = "Unknown"
|
| 315 |
+
if song_dir and (song_path := _get_input_audio_path(song_dir)):
|
| 316 |
+
song_name = song_path.stem.removeprefix("00_")
|
| 317 |
+
model_name = model_name or _get_model_name(effected_vocals_track, song_dir)
|
| 318 |
+
|
| 319 |
+
return f"{song_name} ({model_name} Ver)"
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
def _get_youtube_id(url: str, ignore_playlist: bool = True) -> str:
|
| 323 |
+
"""
|
| 324 |
+
Get the id of a YouTube video or playlist.
|
| 325 |
+
|
| 326 |
+
Parameters
|
| 327 |
+
----------
|
| 328 |
+
url : str
|
| 329 |
+
URL which points to a YouTube video or playlist.
|
| 330 |
+
ignore_playlist : bool, default=True
|
| 331 |
+
Whether to get the id of the first video in a playlist or the
|
| 332 |
+
playlist id itself.
|
| 333 |
+
|
| 334 |
+
Returns
|
| 335 |
+
-------
|
| 336 |
+
str
|
| 337 |
+
The id of a YouTube video or playlist.
|
| 338 |
+
|
| 339 |
+
Raises
|
| 340 |
+
------
|
| 341 |
+
YoutubeUrlError
|
| 342 |
+
If the provided URL does not point to a YouTube video
|
| 343 |
+
or playlist.
|
| 344 |
+
|
| 345 |
+
"""
|
| 346 |
+
yt_id = None
|
| 347 |
+
validate_url(url)
|
| 348 |
+
query = urlparse(url)
|
| 349 |
+
if query.hostname == "youtu.be":
|
| 350 |
+
yt_id = query.query[2:] if query.path[1:] == "watch" else query.path[1:]
|
| 351 |
+
|
| 352 |
+
elif query.hostname in {"www.youtube.com", "youtube.com", "music.youtube.com"}:
|
| 353 |
+
if not ignore_playlist:
|
| 354 |
+
with suppress(KeyError):
|
| 355 |
+
yt_id = parse_qs(query.query)["list"][0]
|
| 356 |
+
elif query.path == "/watch":
|
| 357 |
+
yt_id = parse_qs(query.query)["v"][0]
|
| 358 |
+
elif query.path[:7] == "/watch/":
|
| 359 |
+
yt_id = query.path.split("/")[1]
|
| 360 |
+
elif query.path[:7] == "/embed/" or query.path[:3] == "/v/":
|
| 361 |
+
yt_id = query.path.split("/")[2]
|
| 362 |
+
if yt_id is None:
|
| 363 |
+
raise YoutubeUrlError(url=url, playlist=True)
|
| 364 |
+
|
| 365 |
+
return yt_id
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
def init_song_dir(
|
| 369 |
+
source: str,
|
| 370 |
+
progress_bar: gr.Progress | None = None,
|
| 371 |
+
percentage: float = 0.5,
|
| 372 |
+
) -> tuple[Path, SourceType]:
|
| 373 |
+
"""
|
| 374 |
+
Initialize a directory for a song provided by a given source.
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
The song directory is initialized as follows:
|
| 378 |
+
|
| 379 |
+
* If the source is a YouTube URL, the id of the video which
|
| 380 |
+
that URL points to is extracted. A new song directory with the name
|
| 381 |
+
of that id is then created, if it does not already exist.
|
| 382 |
+
* If the source is a path to a local audio file, the hash of
|
| 383 |
+
that audio file is extracted. A new song directory with the name of
|
| 384 |
+
that hash is then created, if it does not already exist.
|
| 385 |
+
* if the source is a path to an existing song directory, then
|
| 386 |
+
that song directory is used as is.
|
| 387 |
+
|
| 388 |
+
Parameters
|
| 389 |
+
----------
|
| 390 |
+
source : str
|
| 391 |
+
The source providing the song to initialize a directory for.
|
| 392 |
+
progress_bar : gr.Progress, optional
|
| 393 |
+
Gradio progress bar to update.
|
| 394 |
+
percentage : float, default=0.5
|
| 395 |
+
Percentage to display in the progress bar.
|
| 396 |
+
|
| 397 |
+
Returns
|
| 398 |
+
-------
|
| 399 |
+
song_dir : Path
|
| 400 |
+
The path to the initialized song directory.
|
| 401 |
+
source_type : SourceType
|
| 402 |
+
The type of source provided.
|
| 403 |
+
|
| 404 |
+
Raises
|
| 405 |
+
------
|
| 406 |
+
NotProvidedError
|
| 407 |
+
If no source is provided.
|
| 408 |
+
InvalidLocationError
|
| 409 |
+
If a provided path points to a directory that is not located in
|
| 410 |
+
the root of the intermediate audio base directory.
|
| 411 |
+
NotFoundError
|
| 412 |
+
If the provided source is a path to a file that does not exist.
|
| 413 |
+
|
| 414 |
+
"""
|
| 415 |
+
if not source:
|
| 416 |
+
raise NotProvidedError(entity=Entity.SOURCE, ui_msg=UIMessage.NO_SOURCE)
|
| 417 |
+
source_path = Path(source)
|
| 418 |
+
|
| 419 |
+
display_progress("[~] Initializing song directory...", percentage, progress_bar)
|
| 420 |
+
|
| 421 |
+
# if source is a path to an existing song directory
|
| 422 |
+
if source_path.is_dir():
|
| 423 |
+
if source_path.parent != INTERMEDIATE_AUDIO_BASE_DIR:
|
| 424 |
+
raise InvalidLocationError(
|
| 425 |
+
entity=Entity.DIRECTORY,
|
| 426 |
+
location=Location.INTERMEDIATE_AUDIO_ROOT,
|
| 427 |
+
path=source_path,
|
| 428 |
+
)
|
| 429 |
+
display_progress(
|
| 430 |
+
"[~] Using existing song directory...",
|
| 431 |
+
percentage,
|
| 432 |
+
progress_bar,
|
| 433 |
+
)
|
| 434 |
+
source_type = SourceType.SONG_DIR
|
| 435 |
+
return source_path, source_type
|
| 436 |
+
|
| 437 |
+
# if source is a URL
|
| 438 |
+
if urlparse(source).scheme == "https":
|
| 439 |
+
source_type = SourceType.URL
|
| 440 |
+
song_id = _get_youtube_id(source)
|
| 441 |
+
|
| 442 |
+
# if source is a path to a local audio file
|
| 443 |
+
elif source_path.is_file():
|
| 444 |
+
source_type = SourceType.FILE
|
| 445 |
+
song_id = get_file_hash(source_path)
|
| 446 |
+
else:
|
| 447 |
+
raise NotFoundError(entity=Entity.FILE, location=source_path)
|
| 448 |
+
|
| 449 |
+
song_dir_path = INTERMEDIATE_AUDIO_BASE_DIR / song_id
|
| 450 |
+
|
| 451 |
+
song_dir_path.mkdir(parents=True, exist_ok=True)
|
| 452 |
+
|
| 453 |
+
return song_dir_path, source_type
|
| 454 |
+
|
| 455 |
+
|
| 456 |
+
# NOTE consider increasing hash_size to 16. Otherwise
|
| 457 |
+
# we might have problems with hash collisions when using app as CLI
|
| 458 |
+
def get_unique_base_path(
|
| 459 |
+
song_dir: StrPath,
|
| 460 |
+
prefix: str,
|
| 461 |
+
args_dict: Json,
|
| 462 |
+
hash_size: int = 5,
|
| 463 |
+
progress_bar: gr.Progress | None = None,
|
| 464 |
+
percentage: float = 0.5,
|
| 465 |
+
) -> Path:
|
| 466 |
+
"""
|
| 467 |
+
Get a unique base path (a path without any extension) for a file in
|
| 468 |
+
a song directory by hashing the arguments used to generate
|
| 469 |
+
the audio that is stored or will be stored in that file.
|
| 470 |
+
|
| 471 |
+
Parameters
|
| 472 |
+
----------
|
| 473 |
+
song_dir :StrPath
|
| 474 |
+
The path to a song directory.
|
| 475 |
+
prefix : str
|
| 476 |
+
The prefix to use for the base path.
|
| 477 |
+
args_dict : Json
|
| 478 |
+
A JSON-serializable dictionary of named arguments used to
|
| 479 |
+
generate the audio that is stored or will be stored in a file
|
| 480 |
+
in the song directory.
|
| 481 |
+
hash_size : int, default=5
|
| 482 |
+
The size (in bytes) of the hash to use for the base path.
|
| 483 |
+
progress_bar : gr.Progress, optional
|
| 484 |
+
Gradio progress bar to update.
|
| 485 |
+
percentage : float, default=0.5
|
| 486 |
+
Percentage to display in the progress bar.
|
| 487 |
+
|
| 488 |
+
Returns
|
| 489 |
+
-------
|
| 490 |
+
Path
|
| 491 |
+
The unique base path for a file in a song directory.
|
| 492 |
+
|
| 493 |
+
Raises
|
| 494 |
+
------
|
| 495 |
+
NotProvidedError
|
| 496 |
+
If no song directory is provided.
|
| 497 |
+
|
| 498 |
+
"""
|
| 499 |
+
if not song_dir:
|
| 500 |
+
raise NotProvidedError(entity=Entity.SONG_DIR, ui_msg=UIMessage.NO_SONG_DIR)
|
| 501 |
+
song_dir_path = Path(song_dir)
|
| 502 |
+
dict_hash = get_hash(args_dict, size=hash_size)
|
| 503 |
+
while True:
|
| 504 |
+
base_path = song_dir_path / f"{prefix}_{dict_hash}"
|
| 505 |
+
json_path = base_path.with_suffix(".json")
|
| 506 |
+
if json_path.exists():
|
| 507 |
+
file_dict = json_load(json_path)
|
| 508 |
+
if file_dict == args_dict:
|
| 509 |
+
return base_path
|
| 510 |
+
display_progress("[~] Rehashing...", percentage, progress_bar)
|
| 511 |
+
dict_hash = get_hash(dict_hash, size=hash_size)
|
| 512 |
+
else:
|
| 513 |
+
return base_path
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
def _get_youtube_audio(url: str, directory: StrPath) -> Path:
|
| 517 |
+
"""
|
| 518 |
+
Download audio from a YouTube video.
|
| 519 |
+
|
| 520 |
+
Parameters
|
| 521 |
+
----------
|
| 522 |
+
url : str
|
| 523 |
+
URL which points to a YouTube video.
|
| 524 |
+
directory : StrPath
|
| 525 |
+
The directory to save the downloaded audio file to.
|
| 526 |
+
|
| 527 |
+
Returns
|
| 528 |
+
-------
|
| 529 |
+
Path
|
| 530 |
+
The path to the downloaded audio file.
|
| 531 |
+
|
| 532 |
+
Raises
|
| 533 |
+
------
|
| 534 |
+
YoutubeUrlError
|
| 535 |
+
If the provided URL does not point to a YouTube video.
|
| 536 |
+
|
| 537 |
+
"""
|
| 538 |
+
validate_url(url)
|
| 539 |
+
outtmpl = str(Path(directory, "00_%(title)s"))
|
| 540 |
+
ydl_opts = {
|
| 541 |
+
"quiet": True,
|
| 542 |
+
"no_warnings": True,
|
| 543 |
+
"format": "bestaudio",
|
| 544 |
+
"outtmpl": outtmpl,
|
| 545 |
+
"ignoreerrors": True,
|
| 546 |
+
"nocheckcertificate": True,
|
| 547 |
+
"postprocessors": [
|
| 548 |
+
{
|
| 549 |
+
"key": "FFmpegExtractAudio",
|
| 550 |
+
"preferredcodec": "wav",
|
| 551 |
+
"preferredquality": 0,
|
| 552 |
+
},
|
| 553 |
+
],
|
| 554 |
+
}
|
| 555 |
+
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
|
| 556 |
+
result = ydl.extract_info(url, download=True)
|
| 557 |
+
if not result:
|
| 558 |
+
raise YoutubeUrlError(url, playlist=False)
|
| 559 |
+
file = ydl.prepare_filename(result, outtmpl=f"{outtmpl}.wav")
|
| 560 |
+
|
| 561 |
+
return Path(file)
|
| 562 |
+
|
| 563 |
+
|
| 564 |
+
def retrieve_song(
|
| 565 |
+
source: str,
|
| 566 |
+
progress_bar: gr.Progress | None = None,
|
| 567 |
+
percentage: float = 0.5,
|
| 568 |
+
) -> tuple[Path, Path]:
|
| 569 |
+
"""
|
| 570 |
+
Retrieve a song from a source that can either be a YouTube URL, a
|
| 571 |
+
local audio file or a song directory.
|
| 572 |
+
|
| 573 |
+
Parameters
|
| 574 |
+
----------
|
| 575 |
+
source : str
|
| 576 |
+
A Youtube URL, the path to a local audio file or the path to a
|
| 577 |
+
song directory.
|
| 578 |
+
progress_bar : gr.Progress, optional
|
| 579 |
+
Gradio progress bar to update.
|
| 580 |
+
percentage : float, default=0.5
|
| 581 |
+
Percentage to display in the progress bar.
|
| 582 |
+
|
| 583 |
+
Returns
|
| 584 |
+
-------
|
| 585 |
+
song : Path
|
| 586 |
+
The path to the retrieved song.
|
| 587 |
+
song_dir : Path
|
| 588 |
+
The path to the song directory containing the retrieved song.
|
| 589 |
+
|
| 590 |
+
Raises
|
| 591 |
+
------
|
| 592 |
+
NotProvidedError
|
| 593 |
+
If no source is provided.
|
| 594 |
+
|
| 595 |
+
"""
|
| 596 |
+
if not source:
|
| 597 |
+
raise NotProvidedError(entity=Entity.SOURCE, ui_msg=UIMessage.NO_SOURCE)
|
| 598 |
+
|
| 599 |
+
song_dir_path, source_type = init_song_dir(source, progress_bar, percentage)
|
| 600 |
+
song_path = _get_input_audio_path(song_dir_path)
|
| 601 |
+
|
| 602 |
+
if not song_path:
|
| 603 |
+
if source_type == SourceType.URL:
|
| 604 |
+
display_progress("[~] Downloading song...", percentage, progress_bar)
|
| 605 |
+
song_url = source.split("&")[0]
|
| 606 |
+
song_path = _get_youtube_audio(song_url, song_dir_path)
|
| 607 |
+
|
| 608 |
+
else:
|
| 609 |
+
display_progress("[~] Copying song...", percentage, progress_bar)
|
| 610 |
+
source_path = Path(source)
|
| 611 |
+
song_name = f"00_{source_path.name}"
|
| 612 |
+
song_path = song_dir_path / song_name
|
| 613 |
+
shutil.copyfile(source_path, song_path)
|
| 614 |
+
|
| 615 |
+
return song_path, song_dir_path
|
| 616 |
+
|
| 617 |
+
|
| 618 |
+
def _validate_exists(
|
| 619 |
+
identifier: StrPath,
|
| 620 |
+
entity: Entity,
|
| 621 |
+
) -> Path:
|
| 622 |
+
"""
|
| 623 |
+
Validate that the provided identifier is not none and that it
|
| 624 |
+
identifies an existing entity, which can be either a voice model,
|
| 625 |
+
a song directory or an audio track.
|
| 626 |
+
|
| 627 |
+
Parameters
|
| 628 |
+
----------
|
| 629 |
+
identifier : StrPath
|
| 630 |
+
The identifier to validate.
|
| 631 |
+
entity : Entity
|
| 632 |
+
The entity that the identifier should identify.
|
| 633 |
+
|
| 634 |
+
Returns
|
| 635 |
+
-------
|
| 636 |
+
Path
|
| 637 |
+
The path to the identified entity.
|
| 638 |
+
|
| 639 |
+
Raises
|
| 640 |
+
------
|
| 641 |
+
NotProvidedError
|
| 642 |
+
If the identifier is None.
|
| 643 |
+
NotFoundError
|
| 644 |
+
If the identifier does not identify an existing entity.
|
| 645 |
+
VoiceModelNotFoundError
|
| 646 |
+
If the identifier does not identify an existing voice model.
|
| 647 |
+
NotImplementedError
|
| 648 |
+
If the provided entity is not supported.
|
| 649 |
+
|
| 650 |
+
"""
|
| 651 |
+
match entity:
|
| 652 |
+
case Entity.MODEL_NAME:
|
| 653 |
+
if not identifier:
|
| 654 |
+
raise NotProvidedError(entity=entity, ui_msg=UIMessage.NO_VOICE_MODEL)
|
| 655 |
+
path = RVC_MODELS_DIR / identifier
|
| 656 |
+
if not path.is_dir():
|
| 657 |
+
raise VoiceModelNotFoundError(str(identifier))
|
| 658 |
+
case Entity.SONG_DIR:
|
| 659 |
+
if not identifier:
|
| 660 |
+
raise NotProvidedError(entity=entity, ui_msg=UIMessage.NO_SONG_DIR)
|
| 661 |
+
path = Path(identifier)
|
| 662 |
+
if not path.is_dir():
|
| 663 |
+
raise NotFoundError(entity=entity, location=path)
|
| 664 |
+
case (
|
| 665 |
+
Entity.SONG
|
| 666 |
+
| Entity.AUDIO_TRACK
|
| 667 |
+
| Entity.VOCALS_TRACK
|
| 668 |
+
| Entity.INSTRUMENTALS_TRACK
|
| 669 |
+
| Entity.MAIN_VOCALS_TRACK
|
| 670 |
+
| Entity.BACKUP_VOCALS_TRACK
|
| 671 |
+
):
|
| 672 |
+
if not identifier:
|
| 673 |
+
raise NotProvidedError(entity=entity)
|
| 674 |
+
path = Path(identifier)
|
| 675 |
+
if not path.is_file():
|
| 676 |
+
raise NotFoundError(entity=entity, location=path)
|
| 677 |
+
case _:
|
| 678 |
+
error_msg = f"Entity {entity} not supported."
|
| 679 |
+
raise NotImplementedError(error_msg)
|
| 680 |
+
return path
|
| 681 |
+
|
| 682 |
+
|
| 683 |
+
def _validate_all_exist(
|
| 684 |
+
identifier_entity_pairs: Sequence[tuple[StrPath, Entity]],
|
| 685 |
+
) -> list[Path]:
|
| 686 |
+
"""
|
| 687 |
+
Validate that all provided identifiers are not none and that they
|
| 688 |
+
identify existing entities, which can be either voice models, song
|
| 689 |
+
directories or audio tracks.
|
| 690 |
+
|
| 691 |
+
Parameters
|
| 692 |
+
----------
|
| 693 |
+
identifier_entity_pairs : Sequence[tuple[StrPath, Entity]]
|
| 694 |
+
The pairs of identifiers and entities to validate.
|
| 695 |
+
|
| 696 |
+
Returns
|
| 697 |
+
-------
|
| 698 |
+
list[Path]
|
| 699 |
+
The paths to the identified entities.
|
| 700 |
+
|
| 701 |
+
"""
|
| 702 |
+
return list(starmap(_validate_exists, identifier_entity_pairs))
|
| 703 |
+
|
| 704 |
+
|
| 705 |
+
def separate_audio(
|
| 706 |
+
audio_track: StrPath,
|
| 707 |
+
song_dir: StrPath,
|
| 708 |
+
model_name: SeparationModel,
|
| 709 |
+
segment_size: int,
|
| 710 |
+
display_msg: str = "[~] Separating audio...",
|
| 711 |
+
progress_bar: gr.Progress | None = None,
|
| 712 |
+
percentage: float = 0.5,
|
| 713 |
+
) -> tuple[Path, Path]:
|
| 714 |
+
"""
|
| 715 |
+
Separate an audio track into a primary stem and a secondary stem.
|
| 716 |
+
|
| 717 |
+
Parameters
|
| 718 |
+
----------
|
| 719 |
+
audio_track : StrPath
|
| 720 |
+
The path to the audio track to separate.
|
| 721 |
+
song_dir : StrPath
|
| 722 |
+
The path to the song directory where the separated primary stem
|
| 723 |
+
and secondary stem will be saved.
|
| 724 |
+
model_name : str
|
| 725 |
+
The name of the model to use for audio separation.
|
| 726 |
+
segment_size : int
|
| 727 |
+
The segment size to use for audio separation.
|
| 728 |
+
display_msg : str
|
| 729 |
+
The message to display when separating the audio track.
|
| 730 |
+
progress_bar : gr.Progress, optional
|
| 731 |
+
Gradio progress bar to update.
|
| 732 |
+
percentage : float, default=0.5
|
| 733 |
+
Percentage to display in the progress bar.
|
| 734 |
+
|
| 735 |
+
Returns
|
| 736 |
+
-------
|
| 737 |
+
primary_path : Path
|
| 738 |
+
The path to the separated primary stem.
|
| 739 |
+
secondary_path : Path
|
| 740 |
+
The path to the separated secondary stem.
|
| 741 |
+
|
| 742 |
+
"""
|
| 743 |
+
audio_path, song_dir_path = _validate_all_exist(
|
| 744 |
+
[(audio_track, Entity.AUDIO_TRACK), (song_dir, Entity.SONG_DIR)],
|
| 745 |
+
)
|
| 746 |
+
|
| 747 |
+
args_dict = SeparatedAudioMetaData(
|
| 748 |
+
audio_track=FileMetaData(
|
| 749 |
+
name=audio_path.name,
|
| 750 |
+
hash_id=get_file_hash(audio_path),
|
| 751 |
+
),
|
| 752 |
+
model_name=model_name,
|
| 753 |
+
segment_size=segment_size,
|
| 754 |
+
).model_dump()
|
| 755 |
+
|
| 756 |
+
paths = [
|
| 757 |
+
get_unique_base_path(
|
| 758 |
+
song_dir_path,
|
| 759 |
+
prefix,
|
| 760 |
+
args_dict,
|
| 761 |
+
progress_bar=progress_bar,
|
| 762 |
+
percentage=percentage,
|
| 763 |
+
).with_suffix(suffix)
|
| 764 |
+
for prefix in ["11_Stem_Primary", "11_Stem_Secondary"]
|
| 765 |
+
for suffix in [".wav", ".json"]
|
| 766 |
+
]
|
| 767 |
+
|
| 768 |
+
(
|
| 769 |
+
primary_path,
|
| 770 |
+
primary_json_path,
|
| 771 |
+
secondary_path,
|
| 772 |
+
secondary_json_path,
|
| 773 |
+
) = paths
|
| 774 |
+
|
| 775 |
+
if not all(path.exists() for path in paths):
|
| 776 |
+
display_progress(display_msg, percentage, progress_bar)
|
| 777 |
+
audio_separator = _get_audio_separator(
|
| 778 |
+
output_dir=song_dir_path,
|
| 779 |
+
segment_size=segment_size,
|
| 780 |
+
)
|
| 781 |
+
audio_separator.load_model(model_name)
|
| 782 |
+
audio_separator.separate(
|
| 783 |
+
str(audio_path),
|
| 784 |
+
primary_output_name=primary_path.stem,
|
| 785 |
+
secondary_output_name=secondary_path.stem,
|
| 786 |
+
)
|
| 787 |
+
json_dump(args_dict, primary_json_path)
|
| 788 |
+
json_dump(args_dict, secondary_json_path)
|
| 789 |
+
|
| 790 |
+
return primary_path, secondary_path
|
| 791 |
+
|
| 792 |
+
|
| 793 |
+
def _get_rvc_files(model_name: str) -> tuple[Path, Path | None]:
|
| 794 |
+
"""
|
| 795 |
+
Get the RVC model file and potential index file of a voice model.
|
| 796 |
+
|
| 797 |
+
Parameters
|
| 798 |
+
----------
|
| 799 |
+
model_name : str
|
| 800 |
+
The name of the voice model to get the RVC files of.
|
| 801 |
+
|
| 802 |
+
Returns
|
| 803 |
+
-------
|
| 804 |
+
model_file : Path
|
| 805 |
+
The path to the RVC model file.
|
| 806 |
+
index_file : Path | None
|
| 807 |
+
The path to the RVC index file, if it exists.
|
| 808 |
+
|
| 809 |
+
Raises
|
| 810 |
+
------
|
| 811 |
+
NotFoundError
|
| 812 |
+
If no model file exists in the voice model directory.
|
| 813 |
+
|
| 814 |
+
|
| 815 |
+
"""
|
| 816 |
+
model_dir_path = _validate_exists(model_name, Entity.MODEL_NAME)
|
| 817 |
+
file_path_map = {
|
| 818 |
+
ext: path
|
| 819 |
+
for path in model_dir_path.iterdir()
|
| 820 |
+
for ext in [".pth", ".index"]
|
| 821 |
+
if ext == path.suffix
|
| 822 |
+
}
|
| 823 |
+
|
| 824 |
+
if ".pth" not in file_path_map:
|
| 825 |
+
raise NotFoundError(
|
| 826 |
+
entity=Entity.MODEL_FILE,
|
| 827 |
+
location=model_dir_path,
|
| 828 |
+
is_path=False,
|
| 829 |
+
)
|
| 830 |
+
|
| 831 |
+
model_file = model_dir_path / file_path_map[".pth"]
|
| 832 |
+
index_file = (
|
| 833 |
+
model_dir_path / file_path_map[".index"] if ".index" in file_path_map else None
|
| 834 |
+
)
|
| 835 |
+
|
| 836 |
+
return model_file, index_file
|
| 837 |
+
|
| 838 |
+
|
| 839 |
+
def _convert(
|
| 840 |
+
voice_track: StrPath,
|
| 841 |
+
output_file: StrPath,
|
| 842 |
+
model_name: str,
|
| 843 |
+
n_semitones: int = 0,
|
| 844 |
+
f0_method: F0Method = F0Method.RMVPE,
|
| 845 |
+
index_rate: float = 0.5,
|
| 846 |
+
filter_radius: int = 3,
|
| 847 |
+
rms_mix_rate: float = 0.25,
|
| 848 |
+
protect: float = 0.33,
|
| 849 |
+
hop_length: int = 128,
|
| 850 |
+
output_sr: int = 44100,
|
| 851 |
+
) -> None:
|
| 852 |
+
"""
|
| 853 |
+
Convert a voice track using a voice model and save the result to a
|
| 854 |
+
an output file.
|
| 855 |
+
|
| 856 |
+
Parameters
|
| 857 |
+
----------
|
| 858 |
+
voice_track : StrPath
|
| 859 |
+
The path to the voice track to convert.
|
| 860 |
+
output_file : StrPath
|
| 861 |
+
The path to the file to save the converted voice track to.
|
| 862 |
+
model_name : str
|
| 863 |
+
The name of the model to use for voice conversion.
|
| 864 |
+
n_semitones : int, default=0
|
| 865 |
+
The number of semitones to pitch-shift the converted voice by.
|
| 866 |
+
f0_method : F0Method, default=F0Method.RMVPE
|
| 867 |
+
The method to use for pitch detection.
|
| 868 |
+
index_rate : float, default=0.5
|
| 869 |
+
The influence of the index file on the voice conversion.
|
| 870 |
+
filter_radius : int, default=3
|
| 871 |
+
The filter radius to use for the voice conversion.
|
| 872 |
+
rms_mix_rate : float, default=0.25
|
| 873 |
+
The blending rate of the volume envelope of the converted voice.
|
| 874 |
+
protect : float, default=0.33
|
| 875 |
+
The protection rate for consonants and breathing sounds.
|
| 876 |
+
hop_length : int, default=128
|
| 877 |
+
The hop length to use for crepe-based pitch detection.
|
| 878 |
+
output_sr : int, default=44100
|
| 879 |
+
The sample rate of the output audio file.
|
| 880 |
+
|
| 881 |
+
"""
|
| 882 |
+
rvc_model_path, rvc_index_path = _get_rvc_files(model_name)
|
| 883 |
+
device = "cuda:0"
|
| 884 |
+
config = Config(device, is_half=True)
|
| 885 |
+
hubert_model = load_hubert(
|
| 886 |
+
device,
|
| 887 |
+
str(RVC_MODELS_DIR / "hubert_base.pt"),
|
| 888 |
+
is_half=config.is_half,
|
| 889 |
+
)
|
| 890 |
+
cpt, version, net_g, tgt_sr, vc = get_vc(
|
| 891 |
+
device,
|
| 892 |
+
config,
|
| 893 |
+
str(rvc_model_path),
|
| 894 |
+
is_half=config.is_half,
|
| 895 |
+
)
|
| 896 |
+
|
| 897 |
+
# convert main vocals
|
| 898 |
+
rvc_infer(
|
| 899 |
+
str(rvc_index_path) if rvc_index_path else "",
|
| 900 |
+
index_rate,
|
| 901 |
+
str(voice_track),
|
| 902 |
+
str(output_file),
|
| 903 |
+
n_semitones,
|
| 904 |
+
f0_method,
|
| 905 |
+
cpt,
|
| 906 |
+
version,
|
| 907 |
+
net_g,
|
| 908 |
+
filter_radius,
|
| 909 |
+
tgt_sr,
|
| 910 |
+
rms_mix_rate,
|
| 911 |
+
protect,
|
| 912 |
+
hop_length,
|
| 913 |
+
vc,
|
| 914 |
+
hubert_model,
|
| 915 |
+
output_sr,
|
| 916 |
+
)
|
| 917 |
+
del hubert_model, cpt
|
| 918 |
+
gc.collect()
|
| 919 |
+
|
| 920 |
+
|
| 921 |
+
def convert(
|
| 922 |
+
vocals_track: StrPath,
|
| 923 |
+
song_dir: StrPath,
|
| 924 |
+
model_name: str,
|
| 925 |
+
n_octaves: int = 0,
|
| 926 |
+
n_semitones: int = 0,
|
| 927 |
+
f0_method: F0Method = F0Method.RMVPE,
|
| 928 |
+
index_rate: float = 0.5,
|
| 929 |
+
filter_radius: int = 3,
|
| 930 |
+
rms_mix_rate: float = 0.25,
|
| 931 |
+
protect: float = 0.33,
|
| 932 |
+
hop_length: int = 128,
|
| 933 |
+
progress_bar: gr.Progress | None = None,
|
| 934 |
+
percentage: float = 0.5,
|
| 935 |
+
) -> Path:
|
| 936 |
+
"""
|
| 937 |
+
Convert a vocals track using a voice model.
|
| 938 |
+
|
| 939 |
+
Parameters
|
| 940 |
+
----------
|
| 941 |
+
vocals_track : StrPath
|
| 942 |
+
The path to the vocals track to convert.
|
| 943 |
+
song_dir : StrPath
|
| 944 |
+
The path to the song directory where the converted vocals track
|
| 945 |
+
will be saved.
|
| 946 |
+
model_name : str
|
| 947 |
+
The name of the model to use for vocal conversion.
|
| 948 |
+
n_octaves : int, default=0
|
| 949 |
+
The number of octaves to pitch-shift the converted vocals by.
|
| 950 |
+
n_semitones : int, default=0
|
| 951 |
+
The number of semitones to pitch-shift the converted vocals by.
|
| 952 |
+
f0_method : F0Method, default=F0Method.RMVPE
|
| 953 |
+
The method to use for pitch detection.
|
| 954 |
+
index_rate : float, default=0.5
|
| 955 |
+
The influence of the index file on the vocal conversion.
|
| 956 |
+
filter_radius : int, default=3
|
| 957 |
+
The filter radius to use for the vocal conversion.
|
| 958 |
+
rms_mix_rate : float, default=0.25
|
| 959 |
+
The blending rate of the volume envelope of the converted
|
| 960 |
+
vocals.
|
| 961 |
+
protect : float, default=0.33
|
| 962 |
+
The protection rate for consonants and breathing sounds.
|
| 963 |
+
hop_length : int, default=128
|
| 964 |
+
The hop length to use for crepe-based pitch detection.
|
| 965 |
+
progress_bar : gr.Progress, optional
|
| 966 |
+
Gradio progress bar to update.
|
| 967 |
+
percentage : float, default=0.5
|
| 968 |
+
Percentage to display in the progress bar.
|
| 969 |
+
|
| 970 |
+
Returns
|
| 971 |
+
-------
|
| 972 |
+
Path
|
| 973 |
+
The path to the converted vocals track.
|
| 974 |
+
|
| 975 |
+
"""
|
| 976 |
+
vocals_path, song_dir_path, _ = _validate_all_exist(
|
| 977 |
+
[
|
| 978 |
+
(vocals_track, Entity.VOCALS_TRACK),
|
| 979 |
+
(song_dir, Entity.SONG_DIR),
|
| 980 |
+
(model_name, Entity.MODEL_NAME),
|
| 981 |
+
],
|
| 982 |
+
)
|
| 983 |
+
|
| 984 |
+
n_semitones = n_octaves * 12 + n_semitones
|
| 985 |
+
|
| 986 |
+
args_dict = ConvertedVocalsMetaData(
|
| 987 |
+
vocals_track=FileMetaData(
|
| 988 |
+
name=vocals_path.name,
|
| 989 |
+
hash_id=get_file_hash(vocals_path),
|
| 990 |
+
),
|
| 991 |
+
model_name=model_name,
|
| 992 |
+
n_semitones=n_semitones,
|
| 993 |
+
f0_method=f0_method,
|
| 994 |
+
index_rate=index_rate,
|
| 995 |
+
filter_radius=filter_radius,
|
| 996 |
+
rms_mix_rate=rms_mix_rate,
|
| 997 |
+
protect=protect,
|
| 998 |
+
hop_length=hop_length,
|
| 999 |
+
).model_dump()
|
| 1000 |
+
|
| 1001 |
+
paths = [
|
| 1002 |
+
get_unique_base_path(
|
| 1003 |
+
song_dir_path,
|
| 1004 |
+
"21_Vocals_Converted",
|
| 1005 |
+
args_dict,
|
| 1006 |
+
progress_bar=progress_bar,
|
| 1007 |
+
percentage=percentage,
|
| 1008 |
+
).with_suffix(suffix)
|
| 1009 |
+
for suffix in [".wav", ".json"]
|
| 1010 |
+
]
|
| 1011 |
+
|
| 1012 |
+
converted_vocals_path, converted_vocals_json_path = paths
|
| 1013 |
+
|
| 1014 |
+
if not all(path.exists() for path in paths):
|
| 1015 |
+
display_progress("[~] Converting vocals using RVC...", percentage, progress_bar)
|
| 1016 |
+
_convert(
|
| 1017 |
+
vocals_path,
|
| 1018 |
+
converted_vocals_path,
|
| 1019 |
+
model_name,
|
| 1020 |
+
n_semitones,
|
| 1021 |
+
f0_method,
|
| 1022 |
+
index_rate,
|
| 1023 |
+
filter_radius,
|
| 1024 |
+
rms_mix_rate,
|
| 1025 |
+
protect,
|
| 1026 |
+
hop_length,
|
| 1027 |
+
output_sr=44100,
|
| 1028 |
+
)
|
| 1029 |
+
json_dump(args_dict, converted_vocals_json_path)
|
| 1030 |
+
return converted_vocals_path
|
| 1031 |
+
|
| 1032 |
+
|
| 1033 |
+
def to_wav(
|
| 1034 |
+
audio_track: StrPath,
|
| 1035 |
+
song_dir: StrPath,
|
| 1036 |
+
prefix: str,
|
| 1037 |
+
accepted_formats: set[AudioExt] | None = None,
|
| 1038 |
+
progress_bar: gr.Progress | None = None,
|
| 1039 |
+
percentage: float = 0.5,
|
| 1040 |
+
) -> Path:
|
| 1041 |
+
"""
|
| 1042 |
+
Convert a given audio track to wav format if its current format is
|
| 1043 |
+
one of the given accepted formats.
|
| 1044 |
+
|
| 1045 |
+
Parameters
|
| 1046 |
+
----------
|
| 1047 |
+
audio_track : StrPath
|
| 1048 |
+
The path to the audio track to convert.
|
| 1049 |
+
song_dir : StrPath
|
| 1050 |
+
The path to the song directory where the converted audio track
|
| 1051 |
+
will be saved.
|
| 1052 |
+
prefix : str
|
| 1053 |
+
The prefix to use for the name of the converted audio track.
|
| 1054 |
+
accepted_formats : set[AudioExt], optional
|
| 1055 |
+
The audio formats to accept for conversion. If None, the
|
| 1056 |
+
accepted formats are mp3, ogg, flac, m4a and aac.
|
| 1057 |
+
progress_bar : gr.Progress, optional
|
| 1058 |
+
Gradio progress bar to update.
|
| 1059 |
+
percentage : float, default=0.5
|
| 1060 |
+
Percentage to display in the progress bar.
|
| 1061 |
+
|
| 1062 |
+
Returns
|
| 1063 |
+
-------
|
| 1064 |
+
Path
|
| 1065 |
+
The path to the audio track in wav format or the original audio
|
| 1066 |
+
track if it is not in one of the accepted formats.
|
| 1067 |
+
|
| 1068 |
+
"""
|
| 1069 |
+
if accepted_formats is None:
|
| 1070 |
+
accepted_formats = set(AudioExt) - {AudioExt.WAV}
|
| 1071 |
+
|
| 1072 |
+
audio_path, song_dir_path = _validate_all_exist(
|
| 1073 |
+
[(audio_track, Entity.AUDIO_TRACK), (song_dir, Entity.SONG_DIR)],
|
| 1074 |
+
)
|
| 1075 |
+
|
| 1076 |
+
wav_path = audio_path
|
| 1077 |
+
|
| 1078 |
+
song_info = pydub_utils.mediainfo(str(audio_path))
|
| 1079 |
+
logger.info("Song Info:\n%s", json_dumps(song_info))
|
| 1080 |
+
if any(
|
| 1081 |
+
accepted_format in song_info["format_name"]
|
| 1082 |
+
if accepted_format == AudioExt.M4A
|
| 1083 |
+
else accepted_format == song_info["format_name"]
|
| 1084 |
+
for accepted_format in accepted_formats
|
| 1085 |
+
):
|
| 1086 |
+
args_dict = WaveifiedAudioMetaData(
|
| 1087 |
+
audio_track=FileMetaData(
|
| 1088 |
+
name=audio_path.name,
|
| 1089 |
+
hash_id=get_file_hash(audio_path),
|
| 1090 |
+
),
|
| 1091 |
+
).model_dump()
|
| 1092 |
+
|
| 1093 |
+
paths = [
|
| 1094 |
+
get_unique_base_path(
|
| 1095 |
+
song_dir_path,
|
| 1096 |
+
prefix,
|
| 1097 |
+
args_dict,
|
| 1098 |
+
progress_bar=progress_bar,
|
| 1099 |
+
percentage=percentage,
|
| 1100 |
+
).with_suffix(suffix)
|
| 1101 |
+
for suffix in [".wav", ".json"]
|
| 1102 |
+
]
|
| 1103 |
+
wav_path, wav_json_path = paths
|
| 1104 |
+
if not all(path.exists() for path in paths):
|
| 1105 |
+
display_progress(
|
| 1106 |
+
"[~] Converting audio track to wav format...",
|
| 1107 |
+
percentage,
|
| 1108 |
+
progress_bar,
|
| 1109 |
+
)
|
| 1110 |
+
|
| 1111 |
+
_, stderr = (
|
| 1112 |
+
ffmpeg.input(audio_path)
|
| 1113 |
+
.output(filename=wav_path, f="wav")
|
| 1114 |
+
.run(
|
| 1115 |
+
overwrite_output=True,
|
| 1116 |
+
quiet=True,
|
| 1117 |
+
)
|
| 1118 |
+
)
|
| 1119 |
+
logger.info("FFmpeg stderr:\n%s", stderr.decode("utf-8"))
|
| 1120 |
+
json_dump(args_dict, wav_json_path)
|
| 1121 |
+
|
| 1122 |
+
return wav_path
|
| 1123 |
+
|
| 1124 |
+
|
| 1125 |
+
def _add_effects(
|
| 1126 |
+
audio_track: StrPath,
|
| 1127 |
+
output_file: StrPath,
|
| 1128 |
+
room_size: float = 0.15,
|
| 1129 |
+
wet_level: float = 0.2,
|
| 1130 |
+
dry_level: float = 0.8,
|
| 1131 |
+
damping: float = 0.7,
|
| 1132 |
+
) -> None:
|
| 1133 |
+
"""
|
| 1134 |
+
Add high-pass filter, compressor and reverb effects to an audio
|
| 1135 |
+
track.
|
| 1136 |
+
|
| 1137 |
+
Parameters
|
| 1138 |
+
----------
|
| 1139 |
+
audio_track : StrPath
|
| 1140 |
+
The path to the audio track to add effects to.
|
| 1141 |
+
output_file : StrPath
|
| 1142 |
+
The path to the file to save the effected audio track to.
|
| 1143 |
+
room_size : float, default=0.15
|
| 1144 |
+
The room size of the reverb effect.
|
| 1145 |
+
wet_level : float, default=0.2
|
| 1146 |
+
The wetness level of the reverb effect.
|
| 1147 |
+
dry_level : float, default=0.8
|
| 1148 |
+
The dryness level of the reverb effect.
|
| 1149 |
+
damping : float, default=0.7
|
| 1150 |
+
The damping of the reverb effect.
|
| 1151 |
+
|
| 1152 |
+
"""
|
| 1153 |
+
board = Pedalboard(
|
| 1154 |
+
[
|
| 1155 |
+
HighpassFilter(),
|
| 1156 |
+
Compressor(ratio=4, threshold_db=-15),
|
| 1157 |
+
Reverb(
|
| 1158 |
+
room_size=room_size,
|
| 1159 |
+
dry_level=dry_level,
|
| 1160 |
+
wet_level=wet_level,
|
| 1161 |
+
damping=damping,
|
| 1162 |
+
),
|
| 1163 |
+
],
|
| 1164 |
+
)
|
| 1165 |
+
|
| 1166 |
+
with (
|
| 1167 |
+
AudioFile(str(audio_track)) as f,
|
| 1168 |
+
AudioFile(str(output_file), "w", f.samplerate, f.num_channels) as o,
|
| 1169 |
+
):
|
| 1170 |
+
# Read one second of audio at a time, until the file is empty:
|
| 1171 |
+
while f.tell() < f.frames:
|
| 1172 |
+
chunk = f.read(int(f.samplerate))
|
| 1173 |
+
effected = board(chunk, f.samplerate, reset=False)
|
| 1174 |
+
o.write(effected)
|
| 1175 |
+
|
| 1176 |
+
|
| 1177 |
+
def postprocess(
|
| 1178 |
+
vocals_track: StrPath,
|
| 1179 |
+
song_dir: StrPath,
|
| 1180 |
+
room_size: float = 0.15,
|
| 1181 |
+
wet_level: float = 0.2,
|
| 1182 |
+
dry_level: float = 0.8,
|
| 1183 |
+
damping: float = 0.7,
|
| 1184 |
+
progress_bar: gr.Progress | None = None,
|
| 1185 |
+
percentage: float = 0.5,
|
| 1186 |
+
) -> Path:
|
| 1187 |
+
"""
|
| 1188 |
+
Apply high-pass filter, compressor and reverb effects to a vocals
|
| 1189 |
+
track.
|
| 1190 |
+
|
| 1191 |
+
Parameters
|
| 1192 |
+
----------
|
| 1193 |
+
vocals_track : StrPath
|
| 1194 |
+
The path to the vocals track to add effects to.
|
| 1195 |
+
song_dir : StrPath
|
| 1196 |
+
The path to the song directory where the effected vocals track
|
| 1197 |
+
will be saved.
|
| 1198 |
+
room_size : float, default=0.15
|
| 1199 |
+
The room size of the reverb effect.
|
| 1200 |
+
wet_level : float, default=0.2
|
| 1201 |
+
The wetness level of the reverb effect.
|
| 1202 |
+
dry_level : float, default=0.8
|
| 1203 |
+
The dryness level of the reverb effect.
|
| 1204 |
+
damping : float, default=0.7
|
| 1205 |
+
The damping of the reverb effect.
|
| 1206 |
+
progress_bar : gr.Progress, optional
|
| 1207 |
+
Gradio progress bar to update.
|
| 1208 |
+
percentage : float, default=0.5
|
| 1209 |
+
Percentage to display in the progress bar.
|
| 1210 |
+
|
| 1211 |
+
Returns
|
| 1212 |
+
-------
|
| 1213 |
+
Path
|
| 1214 |
+
The path to the effected vocals track.
|
| 1215 |
+
|
| 1216 |
+
"""
|
| 1217 |
+
vocals_path, song_dir_path = _validate_all_exist(
|
| 1218 |
+
[(vocals_track, Entity.VOCALS_TRACK), (song_dir, Entity.SONG_DIR)],
|
| 1219 |
+
)
|
| 1220 |
+
|
| 1221 |
+
vocals_path = to_wav(
|
| 1222 |
+
vocals_path,
|
| 1223 |
+
song_dir_path,
|
| 1224 |
+
"30_Input",
|
| 1225 |
+
accepted_formats={AudioExt.M4A, AudioExt.AAC},
|
| 1226 |
+
progress_bar=progress_bar,
|
| 1227 |
+
percentage=percentage,
|
| 1228 |
+
)
|
| 1229 |
+
|
| 1230 |
+
args_dict = EffectedVocalsMetaData(
|
| 1231 |
+
vocals_track=FileMetaData(
|
| 1232 |
+
name=vocals_path.name,
|
| 1233 |
+
hash_id=get_file_hash(vocals_path),
|
| 1234 |
+
),
|
| 1235 |
+
room_size=room_size,
|
| 1236 |
+
wet_level=wet_level,
|
| 1237 |
+
dry_level=dry_level,
|
| 1238 |
+
damping=damping,
|
| 1239 |
+
).model_dump()
|
| 1240 |
+
|
| 1241 |
+
paths = [
|
| 1242 |
+
get_unique_base_path(
|
| 1243 |
+
song_dir_path,
|
| 1244 |
+
"31_Vocals_Effected",
|
| 1245 |
+
args_dict,
|
| 1246 |
+
progress_bar=progress_bar,
|
| 1247 |
+
percentage=percentage,
|
| 1248 |
+
).with_suffix(suffix)
|
| 1249 |
+
for suffix in [".wav", ".json"]
|
| 1250 |
+
]
|
| 1251 |
+
|
| 1252 |
+
effected_vocals_path, effected_vocals_json_path = paths
|
| 1253 |
+
|
| 1254 |
+
if not all(path.exists() for path in paths):
|
| 1255 |
+
display_progress(
|
| 1256 |
+
"[~] Applying audio effects to vocals...",
|
| 1257 |
+
percentage,
|
| 1258 |
+
progress_bar,
|
| 1259 |
+
)
|
| 1260 |
+
_add_effects(
|
| 1261 |
+
vocals_path,
|
| 1262 |
+
effected_vocals_path,
|
| 1263 |
+
room_size,
|
| 1264 |
+
wet_level,
|
| 1265 |
+
dry_level,
|
| 1266 |
+
damping,
|
| 1267 |
+
)
|
| 1268 |
+
json_dump(args_dict, effected_vocals_json_path)
|
| 1269 |
+
return effected_vocals_path
|
| 1270 |
+
|
| 1271 |
+
|
| 1272 |
+
def _pitch_shift(audio_track: StrPath, output_file: StrPath, n_semi_tones: int) -> None:
|
| 1273 |
+
"""
|
| 1274 |
+
Pitch-shift an audio track.
|
| 1275 |
+
|
| 1276 |
+
Parameters
|
| 1277 |
+
----------
|
| 1278 |
+
audio_track : StrPath
|
| 1279 |
+
The path to the audio track to pitch-shift.
|
| 1280 |
+
output_file : StrPath
|
| 1281 |
+
The path to the file to save the pitch-shifted audio track to.
|
| 1282 |
+
n_semi_tones : int
|
| 1283 |
+
The number of semi-tones to pitch-shift the audio track by.
|
| 1284 |
+
|
| 1285 |
+
"""
|
| 1286 |
+
y, sr = sf.read(audio_track)
|
| 1287 |
+
tfm = sox.Transformer()
|
| 1288 |
+
tfm.pitch(n_semi_tones)
|
| 1289 |
+
y_shifted = tfm.build_array(input_array=y, sample_rate_in=sr)
|
| 1290 |
+
sf.write(output_file, y_shifted, sr)
|
| 1291 |
+
|
| 1292 |
+
|
| 1293 |
+
def pitch_shift(
|
| 1294 |
+
audio_track: StrPath,
|
| 1295 |
+
song_dir: StrPath,
|
| 1296 |
+
n_semitones: int,
|
| 1297 |
+
display_msg: str = "[~] Pitch-shifting audio...",
|
| 1298 |
+
progress_bar: gr.Progress | None = None,
|
| 1299 |
+
percentage: float = 0.5,
|
| 1300 |
+
) -> Path:
|
| 1301 |
+
"""
|
| 1302 |
+
Pitch shift an audio track by a given number of semi-tones.
|
| 1303 |
+
|
| 1304 |
+
Parameters
|
| 1305 |
+
----------
|
| 1306 |
+
audio_track : StrPath
|
| 1307 |
+
The path to the audio track to pitch shift.
|
| 1308 |
+
song_dir : StrPath
|
| 1309 |
+
The path to the song directory where the pitch-shifted audio
|
| 1310 |
+
track will be saved.
|
| 1311 |
+
n_semitones : int
|
| 1312 |
+
The number of semi-tones to pitch-shift the audio track by.
|
| 1313 |
+
display_msg : str
|
| 1314 |
+
The message to display when pitch-shifting the audio track.
|
| 1315 |
+
progress_bar : gr.Progress, optional
|
| 1316 |
+
Gradio progress bar to update.
|
| 1317 |
+
percentage : float, default=0.5
|
| 1318 |
+
Percentage to display in the progress bar.
|
| 1319 |
+
|
| 1320 |
+
Returns
|
| 1321 |
+
-------
|
| 1322 |
+
Path
|
| 1323 |
+
The path to the pitch-shifted audio track.
|
| 1324 |
+
|
| 1325 |
+
"""
|
| 1326 |
+
audio_path, song_dir_path = _validate_all_exist(
|
| 1327 |
+
[(audio_track, Entity.AUDIO_TRACK), (song_dir, Entity.SONG_DIR)],
|
| 1328 |
+
)
|
| 1329 |
+
|
| 1330 |
+
audio_path = to_wav(
|
| 1331 |
+
audio_path,
|
| 1332 |
+
song_dir_path,
|
| 1333 |
+
"40_Input",
|
| 1334 |
+
accepted_formats={AudioExt.M4A, AudioExt.AAC},
|
| 1335 |
+
progress_bar=progress_bar,
|
| 1336 |
+
percentage=percentage,
|
| 1337 |
+
)
|
| 1338 |
+
|
| 1339 |
+
shifted_audio_path = audio_path
|
| 1340 |
+
|
| 1341 |
+
if n_semitones != 0:
|
| 1342 |
+
args_dict = PitchShiftMetaData(
|
| 1343 |
+
audio_track=FileMetaData(
|
| 1344 |
+
name=audio_path.name,
|
| 1345 |
+
hash_id=get_file_hash(audio_path),
|
| 1346 |
+
),
|
| 1347 |
+
n_semitones=n_semitones,
|
| 1348 |
+
).model_dump()
|
| 1349 |
+
|
| 1350 |
+
paths = [
|
| 1351 |
+
get_unique_base_path(
|
| 1352 |
+
song_dir_path,
|
| 1353 |
+
"41_Audio_Shifted",
|
| 1354 |
+
args_dict,
|
| 1355 |
+
progress_bar=progress_bar,
|
| 1356 |
+
percentage=percentage,
|
| 1357 |
+
).with_suffix(suffix)
|
| 1358 |
+
for suffix in [".wav", ".json"]
|
| 1359 |
+
]
|
| 1360 |
+
|
| 1361 |
+
shifted_audio_path, shifted_audio_json_path = paths
|
| 1362 |
+
|
| 1363 |
+
if not all(path.exists() for path in paths):
|
| 1364 |
+
display_progress(display_msg, percentage, progress_bar)
|
| 1365 |
+
_pitch_shift(audio_path, shifted_audio_path, n_semitones)
|
| 1366 |
+
json_dump(args_dict, shifted_audio_json_path)
|
| 1367 |
+
|
| 1368 |
+
return shifted_audio_path
|
| 1369 |
+
|
| 1370 |
+
|
| 1371 |
+
def _to_internal(audio_ext: AudioExt) -> AudioExtInternal:
|
| 1372 |
+
"""
|
| 1373 |
+
Map an audio extension to an internally recognized format.
|
| 1374 |
+
|
| 1375 |
+
Parameters
|
| 1376 |
+
----------
|
| 1377 |
+
audio_ext : AudioExt
|
| 1378 |
+
The audio extension to map.
|
| 1379 |
+
|
| 1380 |
+
Returns
|
| 1381 |
+
-------
|
| 1382 |
+
AudioExtInternal
|
| 1383 |
+
The internal audio extension.
|
| 1384 |
+
|
| 1385 |
+
"""
|
| 1386 |
+
match audio_ext:
|
| 1387 |
+
case AudioExt.M4A:
|
| 1388 |
+
return AudioExtInternal.IPOD
|
| 1389 |
+
case AudioExt.AAC:
|
| 1390 |
+
return AudioExtInternal.ADTS
|
| 1391 |
+
case _:
|
| 1392 |
+
return AudioExtInternal(audio_ext)
|
| 1393 |
+
|
| 1394 |
+
|
| 1395 |
+
def _mix_song(
|
| 1396 |
+
audio_track_gain_pairs: Sequence[tuple[StrPath, int]],
|
| 1397 |
+
output_file: StrPath,
|
| 1398 |
+
output_sr: int = 44100,
|
| 1399 |
+
output_format: AudioExt = AudioExt.MP3,
|
| 1400 |
+
) -> None:
|
| 1401 |
+
"""
|
| 1402 |
+
Mix multiple audio tracks to create a song.
|
| 1403 |
+
|
| 1404 |
+
Parameters
|
| 1405 |
+
----------
|
| 1406 |
+
audio_track_gain_pairs : Sequence[tuple[StrPath, int]]
|
| 1407 |
+
A sequence of pairs each containing the path to an audio track
|
| 1408 |
+
and the gain to apply to it.
|
| 1409 |
+
output_file : StrPath
|
| 1410 |
+
The path to the file to save the mixed song to.
|
| 1411 |
+
output_sr : int, default=44100
|
| 1412 |
+
The sample rate of the mixed song.
|
| 1413 |
+
output_format : AudioExt, default=AudioExt.MP3
|
| 1414 |
+
The audio format of the mixed song.
|
| 1415 |
+
|
| 1416 |
+
"""
|
| 1417 |
+
mixed_audio = reduce(
|
| 1418 |
+
lambda a1, a2: a1.overlay(a2),
|
| 1419 |
+
[
|
| 1420 |
+
AudioSegment.from_wav(audio_track) + gain
|
| 1421 |
+
for audio_track, gain in audio_track_gain_pairs
|
| 1422 |
+
],
|
| 1423 |
+
)
|
| 1424 |
+
mixed_audio_resampled = mixed_audio.set_frame_rate(output_sr)
|
| 1425 |
+
mixed_audio_resampled.export(
|
| 1426 |
+
output_file,
|
| 1427 |
+
format=_to_internal(output_format),
|
| 1428 |
+
)
|
| 1429 |
+
|
| 1430 |
+
|
| 1431 |
+
def mix_song(
|
| 1432 |
+
audio_track_gain_pairs: Sequence[tuple[StrPath, int]],
|
| 1433 |
+
song_dir: StrPath,
|
| 1434 |
+
output_sr: int = 44100,
|
| 1435 |
+
output_format: AudioExt = AudioExt.MP3,
|
| 1436 |
+
output_name: str | None = None,
|
| 1437 |
+
display_msg: str = "[~] Mixing audio tracks...",
|
| 1438 |
+
progress_bar: gr.Progress | None = None,
|
| 1439 |
+
percentage: float = 0.5,
|
| 1440 |
+
) -> Path:
|
| 1441 |
+
"""
|
| 1442 |
+
Mix multiple audio tracks to create a song.
|
| 1443 |
+
|
| 1444 |
+
Parameters
|
| 1445 |
+
----------
|
| 1446 |
+
audio_track_gain_pairs : Sequence[tuple[StrPath, int]]
|
| 1447 |
+
A sequence of pairs each containing the path to an audio track
|
| 1448 |
+
and the gain to apply to it.
|
| 1449 |
+
song_dir : StrPath
|
| 1450 |
+
The path to the song directory where the song will be saved.
|
| 1451 |
+
output_sr : int, default=44100
|
| 1452 |
+
The sample rate of the mixed song.
|
| 1453 |
+
output_format : AudioExt, default=AudioExt.MP3
|
| 1454 |
+
The audio format of the mixed song.
|
| 1455 |
+
output_name : str, optional
|
| 1456 |
+
The name of the mixed song.
|
| 1457 |
+
display_msg : str, default="[~] Mixing audio tracks..."
|
| 1458 |
+
The message to display when mixing the audio tracks.
|
| 1459 |
+
progress_bar : gr.Progress, optional
|
| 1460 |
+
Gradio progress bar to update.
|
| 1461 |
+
percentage : float, default=0.5
|
| 1462 |
+
Percentage to display in the progress bar.
|
| 1463 |
+
|
| 1464 |
+
Returns
|
| 1465 |
+
-------
|
| 1466 |
+
Path
|
| 1467 |
+
The path to the song cover.
|
| 1468 |
+
|
| 1469 |
+
Raises
|
| 1470 |
+
------
|
| 1471 |
+
NotProvidedError
|
| 1472 |
+
If no audio tracks are provided.
|
| 1473 |
+
|
| 1474 |
+
"""
|
| 1475 |
+
if not audio_track_gain_pairs:
|
| 1476 |
+
raise NotProvidedError(
|
| 1477 |
+
entity=Entity.AUDIO_TRACK_GAIN_PAIRS,
|
| 1478 |
+
ui_msg=UIMessage.NO_AUDIO_TRACK,
|
| 1479 |
+
)
|
| 1480 |
+
|
| 1481 |
+
audio_path_gain_pairs = [
|
| 1482 |
+
(
|
| 1483 |
+
to_wav(
|
| 1484 |
+
_validate_exists(audio_track, Entity.AUDIO_TRACK),
|
| 1485 |
+
song_dir,
|
| 1486 |
+
"50_Input",
|
| 1487 |
+
progress_bar=progress_bar,
|
| 1488 |
+
percentage=percentage,
|
| 1489 |
+
),
|
| 1490 |
+
gain,
|
| 1491 |
+
)
|
| 1492 |
+
for audio_track, gain in audio_track_gain_pairs
|
| 1493 |
+
]
|
| 1494 |
+
song_dir_path = _validate_exists(song_dir, Entity.SONG_DIR)
|
| 1495 |
+
args_dict = MixedSongMetaData(
|
| 1496 |
+
staged_audio_tracks=[
|
| 1497 |
+
StagedAudioMetaData(
|
| 1498 |
+
audio_track=FileMetaData(
|
| 1499 |
+
name=audio_path.name,
|
| 1500 |
+
hash_id=get_file_hash(audio_path),
|
| 1501 |
+
),
|
| 1502 |
+
gain=gain,
|
| 1503 |
+
)
|
| 1504 |
+
for audio_path, gain in audio_path_gain_pairs
|
| 1505 |
+
],
|
| 1506 |
+
output_sr=output_sr,
|
| 1507 |
+
output_format=output_format,
|
| 1508 |
+
).model_dump()
|
| 1509 |
+
|
| 1510 |
+
paths = [
|
| 1511 |
+
get_unique_base_path(
|
| 1512 |
+
song_dir_path,
|
| 1513 |
+
"51_Mix",
|
| 1514 |
+
args_dict,
|
| 1515 |
+
progress_bar=progress_bar,
|
| 1516 |
+
percentage=percentage,
|
| 1517 |
+
).with_suffix(suffix)
|
| 1518 |
+
for suffix in ["." + output_format, ".json"]
|
| 1519 |
+
]
|
| 1520 |
+
|
| 1521 |
+
mix_path, mix_json_path = paths
|
| 1522 |
+
|
| 1523 |
+
if not all(path.exists() for path in paths):
|
| 1524 |
+
display_progress(display_msg, percentage, progress_bar)
|
| 1525 |
+
|
| 1526 |
+
_mix_song(audio_path_gain_pairs, mix_path, output_sr, output_format)
|
| 1527 |
+
json_dump(args_dict, mix_json_path)
|
| 1528 |
+
output_name = output_name or get_song_cover_name(
|
| 1529 |
+
audio_path_gain_pairs[0][0],
|
| 1530 |
+
song_dir_path,
|
| 1531 |
+
None,
|
| 1532 |
+
)
|
| 1533 |
+
song_path = OUTPUT_AUDIO_DIR / f"{output_name}.{output_format}"
|
| 1534 |
+
return copy_file_safe(mix_path, song_path)
|
| 1535 |
+
|
| 1536 |
+
|
| 1537 |
+
def run_pipeline(
|
| 1538 |
+
source: str,
|
| 1539 |
+
model_name: str,
|
| 1540 |
+
n_octaves: int = 0,
|
| 1541 |
+
n_semitones: int = 0,
|
| 1542 |
+
f0_method: F0Method = F0Method.RMVPE,
|
| 1543 |
+
index_rate: float = 0.5,
|
| 1544 |
+
filter_radius: int = 3,
|
| 1545 |
+
rms_mix_rate: float = 0.25,
|
| 1546 |
+
protect: float = 0.33,
|
| 1547 |
+
hop_length: int = 128,
|
| 1548 |
+
room_size: float = 0.15,
|
| 1549 |
+
wet_level: float = 0.2,
|
| 1550 |
+
dry_level: float = 0.8,
|
| 1551 |
+
damping: float = 0.7,
|
| 1552 |
+
main_gain: int = 0,
|
| 1553 |
+
inst_gain: int = 0,
|
| 1554 |
+
backup_gain: int = 0,
|
| 1555 |
+
output_sr: int = 44100,
|
| 1556 |
+
output_format: AudioExt = AudioExt.MP3,
|
| 1557 |
+
output_name: str | None = None,
|
| 1558 |
+
progress_bar: gr.Progress | None = None,
|
| 1559 |
+
) -> tuple[Path, ...]:
|
| 1560 |
+
"""
|
| 1561 |
+
Run the song cover generation pipeline.
|
| 1562 |
+
|
| 1563 |
+
Parameters
|
| 1564 |
+
----------
|
| 1565 |
+
source : str
|
| 1566 |
+
A Youtube URL, the path to a local audio file or the path to a
|
| 1567 |
+
song directory.
|
| 1568 |
+
model_name : str
|
| 1569 |
+
The name of the voice model to use for vocal conversion.
|
| 1570 |
+
n_octaves : int, default=0
|
| 1571 |
+
The number of octaves to pitch-shift the converted vocals by.
|
| 1572 |
+
n_semitones : int, default=0
|
| 1573 |
+
The number of semi-tones to pitch-shift the converted vocals,
|
| 1574 |
+
instrumentals, and backup vocals by.
|
| 1575 |
+
f0_method : F0Method, default=F0Method.RMVPE
|
| 1576 |
+
The method to use for pitch detection during vocal conversion.
|
| 1577 |
+
index_rate : float, default=0.5
|
| 1578 |
+
The influence of the index file on the vocal conversion.
|
| 1579 |
+
filter_radius : int, default=3
|
| 1580 |
+
The filter radius to use for the vocal conversion.
|
| 1581 |
+
rms_mix_rate : float, default=0.25
|
| 1582 |
+
The blending rate of the volume envelope of the converted
|
| 1583 |
+
vocals.
|
| 1584 |
+
protect : float, default=0.33
|
| 1585 |
+
The protection rate for consonants and breathing sounds during
|
| 1586 |
+
vocal conversion.
|
| 1587 |
+
hop_length : int, default=128
|
| 1588 |
+
The hop length to use for crepe-based pitch detection.
|
| 1589 |
+
room_size : float, default=0.15
|
| 1590 |
+
The room size of the reverb effect to apply to the converted
|
| 1591 |
+
vocals.
|
| 1592 |
+
wet_level : float, default=0.2
|
| 1593 |
+
The wetness level of the reverb effect to apply to the converted
|
| 1594 |
+
vocals.
|
| 1595 |
+
dry_level : float, default=0.8
|
| 1596 |
+
The dryness level of the reverb effect to apply to the converted
|
| 1597 |
+
vocals.
|
| 1598 |
+
damping : float, default=0.7
|
| 1599 |
+
The damping of the reverb effect to apply to the converted
|
| 1600 |
+
vocals.
|
| 1601 |
+
main_gain : int, default=0
|
| 1602 |
+
The gain to apply to the post-processed vocals.
|
| 1603 |
+
inst_gain : int, default=0
|
| 1604 |
+
The gain to apply to the pitch-shifted instrumentals.
|
| 1605 |
+
backup_gain : int, default=0
|
| 1606 |
+
The gain to apply to the pitch-shifted backup vocals.
|
| 1607 |
+
output_sr : int, default=44100
|
| 1608 |
+
The sample rate of the song cover.
|
| 1609 |
+
output_format : AudioExt, default=AudioExt.MP3
|
| 1610 |
+
The audio format of the song cover.
|
| 1611 |
+
output_name : str, optional
|
| 1612 |
+
The name of the song cover.
|
| 1613 |
+
progress_bar : gr.Progress, optional
|
| 1614 |
+
Gradio progress bar to update.
|
| 1615 |
+
|
| 1616 |
+
Returns
|
| 1617 |
+
-------
|
| 1618 |
+
tuple[Path,...]
|
| 1619 |
+
The path to the generated song cover and the paths to any
|
| 1620 |
+
intermediate audio files that were generated.
|
| 1621 |
+
|
| 1622 |
+
"""
|
| 1623 |
+
_validate_exists(model_name, Entity.MODEL_NAME)
|
| 1624 |
+
display_progress("[~] Starting song cover generation pipeline...", 0, progress_bar)
|
| 1625 |
+
song, song_dir = retrieve_song(
|
| 1626 |
+
source,
|
| 1627 |
+
progress_bar=progress_bar,
|
| 1628 |
+
percentage=0 / 9,
|
| 1629 |
+
)
|
| 1630 |
+
vocals_track, instrumentals_track = separate_audio(
|
| 1631 |
+
song,
|
| 1632 |
+
song_dir,
|
| 1633 |
+
SeparationModel.UVR_MDX_NET_VOC_FT,
|
| 1634 |
+
SegmentSize.SEG_512,
|
| 1635 |
+
display_msg="[~] Separating vocals from instrumentals...",
|
| 1636 |
+
progress_bar=progress_bar,
|
| 1637 |
+
percentage=1 / 9,
|
| 1638 |
+
)
|
| 1639 |
+
backup_vocals_track, main_vocals_track = separate_audio(
|
| 1640 |
+
vocals_track,
|
| 1641 |
+
song_dir,
|
| 1642 |
+
SeparationModel.UVR_MDX_NET_KARA_2,
|
| 1643 |
+
SegmentSize.SEG_512,
|
| 1644 |
+
display_msg="[~] Separating main vocals from backup vocals...",
|
| 1645 |
+
progress_bar=progress_bar,
|
| 1646 |
+
percentage=2 / 9,
|
| 1647 |
+
)
|
| 1648 |
+
|
| 1649 |
+
reverb_track, vocals_dereverb_track = separate_audio(
|
| 1650 |
+
main_vocals_track,
|
| 1651 |
+
song_dir,
|
| 1652 |
+
SeparationModel.REVERB_HQ_BY_FOXJOY,
|
| 1653 |
+
SegmentSize.SEG_256,
|
| 1654 |
+
display_msg="[~] De-reverbing vocals...",
|
| 1655 |
+
progress_bar=progress_bar,
|
| 1656 |
+
percentage=3 / 9,
|
| 1657 |
+
)
|
| 1658 |
+
converted_vocals_track = convert(
|
| 1659 |
+
vocals_dereverb_track,
|
| 1660 |
+
song_dir,
|
| 1661 |
+
model_name,
|
| 1662 |
+
n_octaves,
|
| 1663 |
+
n_semitones,
|
| 1664 |
+
f0_method,
|
| 1665 |
+
index_rate,
|
| 1666 |
+
filter_radius,
|
| 1667 |
+
rms_mix_rate,
|
| 1668 |
+
protect,
|
| 1669 |
+
hop_length,
|
| 1670 |
+
progress_bar=progress_bar,
|
| 1671 |
+
percentage=4 / 9,
|
| 1672 |
+
)
|
| 1673 |
+
effected_vocals_track = postprocess(
|
| 1674 |
+
converted_vocals_track,
|
| 1675 |
+
song_dir,
|
| 1676 |
+
room_size,
|
| 1677 |
+
wet_level,
|
| 1678 |
+
dry_level,
|
| 1679 |
+
damping,
|
| 1680 |
+
progress_bar=progress_bar,
|
| 1681 |
+
percentage=5 / 9,
|
| 1682 |
+
)
|
| 1683 |
+
shifted_instrumentals_track = pitch_shift(
|
| 1684 |
+
instrumentals_track,
|
| 1685 |
+
song_dir,
|
| 1686 |
+
n_semitones,
|
| 1687 |
+
display_msg="[~] Pitch-shifting instrumentals...",
|
| 1688 |
+
progress_bar=progress_bar,
|
| 1689 |
+
percentage=6 / 9,
|
| 1690 |
+
)
|
| 1691 |
+
|
| 1692 |
+
shifted_backup_vocals_track = pitch_shift(
|
| 1693 |
+
backup_vocals_track,
|
| 1694 |
+
song_dir,
|
| 1695 |
+
n_semitones,
|
| 1696 |
+
display_msg="[~] Pitch-shifting backup vocals...",
|
| 1697 |
+
progress_bar=progress_bar,
|
| 1698 |
+
percentage=7 / 9,
|
| 1699 |
+
)
|
| 1700 |
+
|
| 1701 |
+
song_cover = mix_song(
|
| 1702 |
+
[
|
| 1703 |
+
(effected_vocals_track, main_gain),
|
| 1704 |
+
(shifted_instrumentals_track, inst_gain),
|
| 1705 |
+
(shifted_backup_vocals_track, backup_gain),
|
| 1706 |
+
],
|
| 1707 |
+
song_dir,
|
| 1708 |
+
output_sr,
|
| 1709 |
+
output_format,
|
| 1710 |
+
output_name,
|
| 1711 |
+
display_msg="[~] Mixing main vocals, instrumentals, and backup vocals...",
|
| 1712 |
+
progress_bar=progress_bar,
|
| 1713 |
+
percentage=8 / 9,
|
| 1714 |
+
)
|
| 1715 |
+
return (
|
| 1716 |
+
song_cover,
|
| 1717 |
+
song,
|
| 1718 |
+
vocals_track,
|
| 1719 |
+
instrumentals_track,
|
| 1720 |
+
main_vocals_track,
|
| 1721 |
+
backup_vocals_track,
|
| 1722 |
+
vocals_dereverb_track,
|
| 1723 |
+
reverb_track,
|
| 1724 |
+
converted_vocals_track,
|
| 1725 |
+
effected_vocals_track,
|
| 1726 |
+
shifted_instrumentals_track,
|
| 1727 |
+
shifted_backup_vocals_track,
|
| 1728 |
+
)
|
src/ultimate_rvc/core/main.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Module which defines functions for initializing the core of the Ultimate
|
| 3 |
+
RVC project.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
|
| 8 |
+
from rich import print as rprint
|
| 9 |
+
|
| 10 |
+
from ultimate_rvc.common import RVC_MODELS_DIR
|
| 11 |
+
from ultimate_rvc.core.common import FLAG_FILE, download_base_models
|
| 12 |
+
from ultimate_rvc.core.generate.song_cover import initialize_audio_separator
|
| 13 |
+
from ultimate_rvc.core.manage.models import download_model
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def download_sample_models() -> None:
|
| 17 |
+
"""Download sample RVC models."""
|
| 18 |
+
named_model_links = [
|
| 19 |
+
(
|
| 20 |
+
"https://huggingface.co/damnedraxx/TaylorSwift/resolve/main/TaylorSwift.zip",
|
| 21 |
+
"Taylor Swift",
|
| 22 |
+
),
|
| 23 |
+
(
|
| 24 |
+
"https://huggingface.co/Vermiculos/balladjames/resolve/main/Ballad%20James.zip?download=true",
|
| 25 |
+
"James Hetfield",
|
| 26 |
+
),
|
| 27 |
+
("https://huggingface.co/ryolez/MMLP/resolve/main/MMLP.zip", "Eminem"),
|
| 28 |
+
]
|
| 29 |
+
for model_url, model_name in named_model_links:
|
| 30 |
+
if not Path(RVC_MODELS_DIR / model_name).is_dir():
|
| 31 |
+
rprint(f"Downloading {model_name}...")
|
| 32 |
+
try:
|
| 33 |
+
download_model(model_url, model_name)
|
| 34 |
+
except Exception as e:
|
| 35 |
+
rprint(f"Failed to download {model_name}: {e}")
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def initialize() -> None:
|
| 39 |
+
"""Initialize the Ultimate RVC project."""
|
| 40 |
+
download_base_models()
|
| 41 |
+
if not FLAG_FILE.is_file():
|
| 42 |
+
download_sample_models()
|
| 43 |
+
FLAG_FILE.touch()
|
| 44 |
+
initialize_audio_separator()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
if __name__ == "__main__":
|
| 48 |
+
initialize()
|
src/ultimate_rvc/core/manage/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Package which defines modules that facilitate managing settings and
|
| 3 |
+
data.
|
| 4 |
+
"""
|
src/ultimate_rvc/core/manage/audio.py
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Module which defines functions to manage audio files."""
|
| 2 |
+
|
| 3 |
+
import operator
|
| 4 |
+
import shutil
|
| 5 |
+
from collections.abc import Sequence
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
|
| 10 |
+
from ultimate_rvc.core.common import (
|
| 11 |
+
INTERMEDIATE_AUDIO_BASE_DIR,
|
| 12 |
+
OUTPUT_AUDIO_DIR,
|
| 13 |
+
display_progress,
|
| 14 |
+
)
|
| 15 |
+
from ultimate_rvc.core.exceptions import (
|
| 16 |
+
Entity,
|
| 17 |
+
InvalidLocationError,
|
| 18 |
+
Location,
|
| 19 |
+
NotFoundError,
|
| 20 |
+
NotProvidedError,
|
| 21 |
+
UIMessage,
|
| 22 |
+
)
|
| 23 |
+
from ultimate_rvc.typing_extra import StrPath
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def get_saved_output_audio() -> list[tuple[str, str]]:
|
| 27 |
+
"""
|
| 28 |
+
Get the name and path of all output audio files.
|
| 29 |
+
|
| 30 |
+
Returns
|
| 31 |
+
-------
|
| 32 |
+
list[tuple[str, Path]]
|
| 33 |
+
A list of tuples containing the name and path of each output
|
| 34 |
+
audio file.
|
| 35 |
+
|
| 36 |
+
"""
|
| 37 |
+
if OUTPUT_AUDIO_DIR.is_dir():
|
| 38 |
+
named_output_files = [
|
| 39 |
+
(file_path.name, str(file_path)) for file_path in OUTPUT_AUDIO_DIR.iterdir()
|
| 40 |
+
]
|
| 41 |
+
return sorted(named_output_files, key=operator.itemgetter(0))
|
| 42 |
+
return []
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def delete_intermediate_audio(
|
| 46 |
+
directories: Sequence[StrPath],
|
| 47 |
+
progress_bar: gr.Progress | None = None,
|
| 48 |
+
percentage: float = 0.5,
|
| 49 |
+
) -> None:
|
| 50 |
+
"""
|
| 51 |
+
Delete provided directories containing intermediate audio files.
|
| 52 |
+
|
| 53 |
+
The provided directories must be located in the root of the
|
| 54 |
+
intermediate audio base directory.
|
| 55 |
+
|
| 56 |
+
Parameters
|
| 57 |
+
----------
|
| 58 |
+
directories : Sequence[StrPath]
|
| 59 |
+
Paths to directories containing intermediate audio files to
|
| 60 |
+
delete.
|
| 61 |
+
progress_bar : gr.Progress, optional
|
| 62 |
+
Gradio progress bar to update.
|
| 63 |
+
percentage : float, default=0.5
|
| 64 |
+
Percentage to display in the progress bar.
|
| 65 |
+
|
| 66 |
+
Raises
|
| 67 |
+
------
|
| 68 |
+
NotProvidedError
|
| 69 |
+
If no paths are provided.
|
| 70 |
+
NotFoundError
|
| 71 |
+
if a provided path does not point to an existing directory.
|
| 72 |
+
InvalidLocationError
|
| 73 |
+
If a provided path does not point to a location in the root of
|
| 74 |
+
the intermediate audio base directory.
|
| 75 |
+
|
| 76 |
+
"""
|
| 77 |
+
if not directories:
|
| 78 |
+
raise NotProvidedError(entity=Entity.DIRECTORIES, ui_msg=UIMessage.NO_SONG_DIRS)
|
| 79 |
+
display_progress(
|
| 80 |
+
"[~] Deleting directories ...",
|
| 81 |
+
percentage,
|
| 82 |
+
progress_bar,
|
| 83 |
+
)
|
| 84 |
+
for directory in directories:
|
| 85 |
+
dir_path = Path(directory)
|
| 86 |
+
if not dir_path.is_dir():
|
| 87 |
+
raise NotFoundError(entity=Entity.DIRECTORY, location=dir_path)
|
| 88 |
+
if dir_path.parent != INTERMEDIATE_AUDIO_BASE_DIR:
|
| 89 |
+
raise InvalidLocationError(
|
| 90 |
+
entity=Entity.DIRECTORY,
|
| 91 |
+
location=Location.INTERMEDIATE_AUDIO_ROOT,
|
| 92 |
+
path=dir_path,
|
| 93 |
+
)
|
| 94 |
+
shutil.rmtree(dir_path)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def delete_all_intermediate_audio(
|
| 98 |
+
progress_bar: gr.Progress | None = None,
|
| 99 |
+
percentage: float = 0.5,
|
| 100 |
+
) -> None:
|
| 101 |
+
"""
|
| 102 |
+
Delete all intermediate audio files.
|
| 103 |
+
|
| 104 |
+
Parameters
|
| 105 |
+
----------
|
| 106 |
+
progress_bar : gr.Progress, optional
|
| 107 |
+
Gradio progress bar to update.
|
| 108 |
+
percentage : float, default=0.5
|
| 109 |
+
Percentage to display in the progress bar.
|
| 110 |
+
|
| 111 |
+
"""
|
| 112 |
+
display_progress(
|
| 113 |
+
"[~] Deleting all intermediate audio files...",
|
| 114 |
+
percentage,
|
| 115 |
+
progress_bar,
|
| 116 |
+
)
|
| 117 |
+
if INTERMEDIATE_AUDIO_BASE_DIR.is_dir():
|
| 118 |
+
shutil.rmtree(INTERMEDIATE_AUDIO_BASE_DIR)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def delete_output_audio(
|
| 122 |
+
files: Sequence[StrPath],
|
| 123 |
+
progress_bar: gr.Progress | None = None,
|
| 124 |
+
percentage: float = 0.5,
|
| 125 |
+
) -> None:
|
| 126 |
+
"""
|
| 127 |
+
Delete provided output audio files.
|
| 128 |
+
|
| 129 |
+
The provided files must be located in the root of the output audio
|
| 130 |
+
directory.
|
| 131 |
+
|
| 132 |
+
Parameters
|
| 133 |
+
----------
|
| 134 |
+
files : Sequence[StrPath]
|
| 135 |
+
Paths to the output audio files to delete.
|
| 136 |
+
progress_bar : gr.Progress, optional
|
| 137 |
+
Gradio progress bar to update.
|
| 138 |
+
percentage : float, default=0.5
|
| 139 |
+
Percentage to display in the progress bar.
|
| 140 |
+
|
| 141 |
+
Raises
|
| 142 |
+
------
|
| 143 |
+
NotProvidedError
|
| 144 |
+
If no paths are provided.
|
| 145 |
+
NotFoundError
|
| 146 |
+
If a provided path does not point to an existing file.
|
| 147 |
+
InvalidLocationError
|
| 148 |
+
If a provided path does not point to a location in the root of
|
| 149 |
+
the output audio directory.
|
| 150 |
+
|
| 151 |
+
"""
|
| 152 |
+
if not files:
|
| 153 |
+
raise NotProvidedError(
|
| 154 |
+
entity=Entity.FILES,
|
| 155 |
+
ui_msg=UIMessage.NO_OUTPUT_AUDIO_FILES,
|
| 156 |
+
)
|
| 157 |
+
display_progress(
|
| 158 |
+
"[~] Deleting output audio files...",
|
| 159 |
+
percentage,
|
| 160 |
+
progress_bar,
|
| 161 |
+
)
|
| 162 |
+
for file in files:
|
| 163 |
+
file_path = Path(file)
|
| 164 |
+
if not file_path.is_file():
|
| 165 |
+
raise NotFoundError(entity=Entity.FILE, location=file_path)
|
| 166 |
+
if file_path.parent != OUTPUT_AUDIO_DIR:
|
| 167 |
+
raise InvalidLocationError(
|
| 168 |
+
entity=Entity.FILE,
|
| 169 |
+
location=Location.OUTPUT_AUDIO_ROOT,
|
| 170 |
+
path=file_path,
|
| 171 |
+
)
|
| 172 |
+
file_path.unlink()
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def delete_all_output_audio(
|
| 176 |
+
progress_bar: gr.Progress | None = None,
|
| 177 |
+
percentage: float = 0.5,
|
| 178 |
+
) -> None:
|
| 179 |
+
"""
|
| 180 |
+
Delete all output audio files.
|
| 181 |
+
|
| 182 |
+
Parameters
|
| 183 |
+
----------
|
| 184 |
+
progress_bar : gr.Progress, optional
|
| 185 |
+
Gradio progress bar to update.
|
| 186 |
+
percentage : float, default=0.5
|
| 187 |
+
Percentage to display in the progress bar.
|
| 188 |
+
|
| 189 |
+
"""
|
| 190 |
+
display_progress("[~] Deleting all output audio files...", percentage, progress_bar)
|
| 191 |
+
if OUTPUT_AUDIO_DIR.is_dir():
|
| 192 |
+
shutil.rmtree(OUTPUT_AUDIO_DIR)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def delete_all_audio(
|
| 196 |
+
progress_bar: gr.Progress | None = None,
|
| 197 |
+
percentage: float = 0.5,
|
| 198 |
+
) -> None:
|
| 199 |
+
"""
|
| 200 |
+
Delete all audio files.
|
| 201 |
+
|
| 202 |
+
Parameters
|
| 203 |
+
----------
|
| 204 |
+
progress_bar : gr.Progress, optional
|
| 205 |
+
Gradio progress bar to update.
|
| 206 |
+
percentage : float, default=0.5
|
| 207 |
+
Percentage to display in the progress bar.
|
| 208 |
+
|
| 209 |
+
"""
|
| 210 |
+
display_progress("[~] Deleting all audio files...", percentage, progress_bar)
|
| 211 |
+
if INTERMEDIATE_AUDIO_BASE_DIR.is_dir():
|
| 212 |
+
shutil.rmtree(INTERMEDIATE_AUDIO_BASE_DIR)
|
| 213 |
+
if OUTPUT_AUDIO_DIR.is_dir():
|
| 214 |
+
shutil.rmtree(OUTPUT_AUDIO_DIR)
|
src/ultimate_rvc/core/manage/models.py
ADDED
|
@@ -0,0 +1,424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Module which defines functions to manage voice models."""
|
| 2 |
+
|
| 3 |
+
import re
|
| 4 |
+
import shutil
|
| 5 |
+
import urllib.request
|
| 6 |
+
import zipfile
|
| 7 |
+
from _collections_abc import Sequence
|
| 8 |
+
from pathlib import Path
|
| 9 |
+
|
| 10 |
+
import gradio as gr
|
| 11 |
+
|
| 12 |
+
from ultimate_rvc.common import RVC_MODELS_DIR
|
| 13 |
+
from ultimate_rvc.core.common import (
|
| 14 |
+
FLAG_FILE,
|
| 15 |
+
copy_files_to_new_dir,
|
| 16 |
+
display_progress,
|
| 17 |
+
json_load,
|
| 18 |
+
validate_url,
|
| 19 |
+
)
|
| 20 |
+
from ultimate_rvc.core.exceptions import (
|
| 21 |
+
Entity,
|
| 22 |
+
Location,
|
| 23 |
+
NotFoundError,
|
| 24 |
+
NotProvidedError,
|
| 25 |
+
UIMessage,
|
| 26 |
+
UploadFormatError,
|
| 27 |
+
UploadLimitError,
|
| 28 |
+
VoiceModelExistsError,
|
| 29 |
+
VoiceModelNotFoundError,
|
| 30 |
+
)
|
| 31 |
+
from ultimate_rvc.core.typing_extra import (
|
| 32 |
+
ModelMetaData,
|
| 33 |
+
ModelMetaDataList,
|
| 34 |
+
ModelMetaDataPredicate,
|
| 35 |
+
ModelMetaDataTable,
|
| 36 |
+
ModelTagName,
|
| 37 |
+
)
|
| 38 |
+
from ultimate_rvc.typing_extra import StrPath
|
| 39 |
+
|
| 40 |
+
PUBLIC_MODELS_JSON = json_load(Path(__file__).parent / "public_models.json")
|
| 41 |
+
PUBLIC_MODELS_TABLE = ModelMetaDataTable.model_validate(PUBLIC_MODELS_JSON)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_saved_model_names() -> list[str]:
|
| 45 |
+
"""
|
| 46 |
+
Get the names of all saved voice models.
|
| 47 |
+
|
| 48 |
+
Returns
|
| 49 |
+
-------
|
| 50 |
+
list[str]
|
| 51 |
+
A list of names of all saved voice models.
|
| 52 |
+
|
| 53 |
+
"""
|
| 54 |
+
model_paths = RVC_MODELS_DIR.iterdir()
|
| 55 |
+
names_to_remove = ["hubert_base.pt", "rmvpe.pt", FLAG_FILE.name]
|
| 56 |
+
return sorted([
|
| 57 |
+
model_path.name
|
| 58 |
+
for model_path in model_paths
|
| 59 |
+
if model_path.name not in names_to_remove
|
| 60 |
+
])
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def load_public_models_table(
|
| 64 |
+
predicates: Sequence[ModelMetaDataPredicate],
|
| 65 |
+
) -> ModelMetaDataList:
|
| 66 |
+
"""
|
| 67 |
+
Load table containing metadata of public voice models, optionally
|
| 68 |
+
filtered by a set of predicates.
|
| 69 |
+
|
| 70 |
+
Parameters
|
| 71 |
+
----------
|
| 72 |
+
predicates : Sequence[ModelMetaDataPredicate]
|
| 73 |
+
Predicates to filter the metadata table by.
|
| 74 |
+
|
| 75 |
+
Returns
|
| 76 |
+
-------
|
| 77 |
+
ModelMetaDataList
|
| 78 |
+
List containing metadata for each public voice model that
|
| 79 |
+
satisfies the given predicates.
|
| 80 |
+
|
| 81 |
+
"""
|
| 82 |
+
return [
|
| 83 |
+
[
|
| 84 |
+
model.name,
|
| 85 |
+
model.description,
|
| 86 |
+
model.tags,
|
| 87 |
+
model.credit,
|
| 88 |
+
model.added,
|
| 89 |
+
model.url,
|
| 90 |
+
]
|
| 91 |
+
for model in PUBLIC_MODELS_TABLE.models
|
| 92 |
+
if all(predicate(model) for predicate in predicates)
|
| 93 |
+
]
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def get_public_model_tags() -> list[ModelTagName]:
|
| 97 |
+
"""
|
| 98 |
+
get the names of all valid public voice model tags.
|
| 99 |
+
|
| 100 |
+
Returns
|
| 101 |
+
-------
|
| 102 |
+
list[str]
|
| 103 |
+
A list of names of all valid public voice model tags.
|
| 104 |
+
|
| 105 |
+
"""
|
| 106 |
+
return [tag.name for tag in PUBLIC_MODELS_TABLE.tags]
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def filter_public_models_table(
|
| 110 |
+
tags: Sequence[str],
|
| 111 |
+
query: str,
|
| 112 |
+
) -> ModelMetaDataList:
|
| 113 |
+
"""
|
| 114 |
+
Filter table containing metadata of public voice models by tags and
|
| 115 |
+
a search query.
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
The search query is matched against the name, description, tags,
|
| 119 |
+
credit,and added date of each entry in the metadata table. Case
|
| 120 |
+
insensitive search is performed. If the search query is empty, the
|
| 121 |
+
metadata table is filtered only bythe given tags.
|
| 122 |
+
|
| 123 |
+
Parameters
|
| 124 |
+
----------
|
| 125 |
+
tags : Sequence[str]
|
| 126 |
+
Tags to filter the metadata table by.
|
| 127 |
+
query : str
|
| 128 |
+
Search query to filter the metadata table by.
|
| 129 |
+
|
| 130 |
+
Returns
|
| 131 |
+
-------
|
| 132 |
+
ModelMetaDataList
|
| 133 |
+
List containing metadata for each public voice model that
|
| 134 |
+
match the given tags and search query.
|
| 135 |
+
|
| 136 |
+
"""
|
| 137 |
+
|
| 138 |
+
def _tags_predicate(model: ModelMetaData) -> bool:
|
| 139 |
+
return all(tag in model.tags for tag in tags)
|
| 140 |
+
|
| 141 |
+
def _query_predicate(model: ModelMetaData) -> bool:
|
| 142 |
+
return (
|
| 143 |
+
query.lower()
|
| 144 |
+
in (
|
| 145 |
+
f"{model.name} {model.description} {' '.join(model.tags)} "
|
| 146 |
+
f"{model.credit} {model.added}"
|
| 147 |
+
).lower()
|
| 148 |
+
if query
|
| 149 |
+
else True
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
filter_fns = [_tags_predicate, _query_predicate]
|
| 153 |
+
|
| 154 |
+
return load_public_models_table(filter_fns)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def _extract_model(
|
| 158 |
+
zip_file: StrPath,
|
| 159 |
+
extraction_dir: StrPath,
|
| 160 |
+
remove_incomplete: bool = True,
|
| 161 |
+
remove_zip: bool = False,
|
| 162 |
+
) -> None:
|
| 163 |
+
"""
|
| 164 |
+
Extract a zipped voice model to a directory.
|
| 165 |
+
|
| 166 |
+
Parameters
|
| 167 |
+
----------
|
| 168 |
+
zip_file : StrPath
|
| 169 |
+
The path to a zip file containing the voice model to extract.
|
| 170 |
+
extraction_dir : StrPath
|
| 171 |
+
The path to the directory to extract the voice model to.
|
| 172 |
+
|
| 173 |
+
remove_incomplete : bool, default=True
|
| 174 |
+
Whether to remove the extraction directory if the extraction
|
| 175 |
+
process fails.
|
| 176 |
+
remove_zip : bool, default=False
|
| 177 |
+
Whether to remove the zip file once the extraction process is
|
| 178 |
+
complete.
|
| 179 |
+
|
| 180 |
+
Raises
|
| 181 |
+
------
|
| 182 |
+
NotFoundError
|
| 183 |
+
If no model file is found in the extracted zip file.
|
| 184 |
+
|
| 185 |
+
"""
|
| 186 |
+
extraction_path = Path(extraction_dir)
|
| 187 |
+
zip_path = Path(zip_file)
|
| 188 |
+
extraction_completed = False
|
| 189 |
+
try:
|
| 190 |
+
extraction_path.mkdir(parents=True)
|
| 191 |
+
with zipfile.ZipFile(zip_path, "r") as zip_ref:
|
| 192 |
+
zip_ref.extractall(extraction_path)
|
| 193 |
+
file_path_map = {
|
| 194 |
+
ext: Path(root, name)
|
| 195 |
+
for root, _, files in extraction_path.walk()
|
| 196 |
+
for name in files
|
| 197 |
+
for ext in [".index", ".pth"]
|
| 198 |
+
if Path(name).suffix == ext
|
| 199 |
+
and Path(root, name).stat().st_size
|
| 200 |
+
> 1024 * (100 if ext == ".index" else 1024 * 40)
|
| 201 |
+
}
|
| 202 |
+
if ".pth" not in file_path_map:
|
| 203 |
+
raise NotFoundError(
|
| 204 |
+
entity=Entity.MODEL_FILE,
|
| 205 |
+
location=Location.EXTRACTED_ZIP_FILE,
|
| 206 |
+
is_path=False,
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
# move model and index file to root of the extraction directory
|
| 210 |
+
for file_path in file_path_map.values():
|
| 211 |
+
file_path.rename(extraction_path / file_path.name)
|
| 212 |
+
|
| 213 |
+
# remove any sub-directories within the extraction directory
|
| 214 |
+
for path in extraction_path.iterdir():
|
| 215 |
+
if path.is_dir():
|
| 216 |
+
shutil.rmtree(path)
|
| 217 |
+
extraction_completed = True
|
| 218 |
+
finally:
|
| 219 |
+
if not extraction_completed and remove_incomplete and extraction_path.is_dir():
|
| 220 |
+
shutil.rmtree(extraction_path)
|
| 221 |
+
if remove_zip and zip_path.exists():
|
| 222 |
+
zip_path.unlink()
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
def download_model(
|
| 226 |
+
url: str,
|
| 227 |
+
name: str,
|
| 228 |
+
progress_bar: gr.Progress | None = None,
|
| 229 |
+
percentages: tuple[float, float] = (0.0, 0.5),
|
| 230 |
+
) -> None:
|
| 231 |
+
"""
|
| 232 |
+
Download a zipped voice model.
|
| 233 |
+
|
| 234 |
+
Parameters
|
| 235 |
+
----------
|
| 236 |
+
url : str
|
| 237 |
+
An URL pointing to a location where the zipped voice model can
|
| 238 |
+
be downloaded from.
|
| 239 |
+
name : str
|
| 240 |
+
The name to give to the downloaded voice model.
|
| 241 |
+
progress_bar : gr.Progress, optional
|
| 242 |
+
Gradio progress bar to update.
|
| 243 |
+
percentages : tuple[float, float], default=(0.0, 0.5)
|
| 244 |
+
Percentages to display in the progress bar.
|
| 245 |
+
|
| 246 |
+
Raises
|
| 247 |
+
------
|
| 248 |
+
NotProvidedError
|
| 249 |
+
If no URL or name is provided.
|
| 250 |
+
VoiceModelExistsError
|
| 251 |
+
If a voice model with the provided name already exists.
|
| 252 |
+
|
| 253 |
+
"""
|
| 254 |
+
if not url:
|
| 255 |
+
raise NotProvidedError(entity=Entity.URL)
|
| 256 |
+
if not name:
|
| 257 |
+
raise NotProvidedError(entity=Entity.MODEL_NAME)
|
| 258 |
+
extraction_path = RVC_MODELS_DIR / name
|
| 259 |
+
if extraction_path.exists():
|
| 260 |
+
raise VoiceModelExistsError(name)
|
| 261 |
+
|
| 262 |
+
validate_url(url)
|
| 263 |
+
zip_name = url.split("/")[-1].split("?")[0]
|
| 264 |
+
|
| 265 |
+
# NOTE in case huggingface link is a direct link rather
|
| 266 |
+
# than a resolve link then convert it to a resolve link
|
| 267 |
+
url = re.sub(
|
| 268 |
+
r"https://huggingface.co/([^/]+)/([^/]+)/blob/(.*)",
|
| 269 |
+
r"https://huggingface.co/\1/\2/resolve/\3",
|
| 270 |
+
url,
|
| 271 |
+
)
|
| 272 |
+
if "pixeldrain.com" in url:
|
| 273 |
+
url = f"https://pixeldrain.com/api/file/{zip_name}"
|
| 274 |
+
|
| 275 |
+
display_progress(
|
| 276 |
+
"[~] Downloading voice model ...",
|
| 277 |
+
percentages[0],
|
| 278 |
+
progress_bar,
|
| 279 |
+
)
|
| 280 |
+
urllib.request.urlretrieve(url, zip_name) # noqa: S310
|
| 281 |
+
|
| 282 |
+
display_progress("[~] Extracting zip file...", percentages[1], progress_bar)
|
| 283 |
+
_extract_model(zip_name, extraction_path, remove_zip=True)
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
def upload_model(
|
| 287 |
+
files: Sequence[StrPath],
|
| 288 |
+
name: str,
|
| 289 |
+
progress_bar: gr.Progress | None = None,
|
| 290 |
+
percentage: float = 0.5,
|
| 291 |
+
) -> None:
|
| 292 |
+
"""
|
| 293 |
+
Upload a voice model from either a zip file or a .pth file and an
|
| 294 |
+
optional index file.
|
| 295 |
+
|
| 296 |
+
Parameters
|
| 297 |
+
----------
|
| 298 |
+
files : Sequence[StrPath]
|
| 299 |
+
Paths to the files to upload.
|
| 300 |
+
name : str
|
| 301 |
+
The name to give to the uploaded voice model.
|
| 302 |
+
progress_bar : gr.Progress, optional
|
| 303 |
+
Gradio progress bar to update.
|
| 304 |
+
percentage : float, default=0.5
|
| 305 |
+
Percentage to display in the progress bar.
|
| 306 |
+
|
| 307 |
+
Raises
|
| 308 |
+
------
|
| 309 |
+
NotProvidedError
|
| 310 |
+
If no file paths or name are provided.
|
| 311 |
+
VoiceModelExistsError
|
| 312 |
+
If a voice model with the provided name already
|
| 313 |
+
exists.
|
| 314 |
+
UploadFormatError
|
| 315 |
+
If a single uploaded file is not a .pth file or a .zip file.
|
| 316 |
+
If two uploaded files are not a .pth file and an .index file.
|
| 317 |
+
UploadLimitError
|
| 318 |
+
If more than two file paths are provided.
|
| 319 |
+
|
| 320 |
+
"""
|
| 321 |
+
if not files:
|
| 322 |
+
raise NotProvidedError(entity=Entity.FILES, ui_msg=UIMessage.NO_UPLOADED_FILES)
|
| 323 |
+
if not name:
|
| 324 |
+
raise NotProvidedError(entity=Entity.MODEL_NAME)
|
| 325 |
+
model_dir_path = RVC_MODELS_DIR / name
|
| 326 |
+
if model_dir_path.exists():
|
| 327 |
+
raise VoiceModelExistsError(name)
|
| 328 |
+
sorted_file_paths = sorted([Path(f) for f in files], key=lambda f: f.suffix)
|
| 329 |
+
match sorted_file_paths:
|
| 330 |
+
case [file_path]:
|
| 331 |
+
if file_path.suffix == ".pth":
|
| 332 |
+
display_progress("[~] Copying .pth file ...", percentage, progress_bar)
|
| 333 |
+
copy_files_to_new_dir([file_path], model_dir_path)
|
| 334 |
+
# NOTE a .pth file is actually itself a zip file
|
| 335 |
+
elif zipfile.is_zipfile(file_path):
|
| 336 |
+
display_progress("[~] Extracting zip file...", percentage, progress_bar)
|
| 337 |
+
_extract_model(file_path, model_dir_path)
|
| 338 |
+
else:
|
| 339 |
+
raise UploadFormatError(
|
| 340 |
+
entity=Entity.FILES,
|
| 341 |
+
formats=[".pth", ".zip"],
|
| 342 |
+
multiple=False,
|
| 343 |
+
)
|
| 344 |
+
case [index_path, pth_path]:
|
| 345 |
+
if index_path.suffix == ".index" and pth_path.suffix == ".pth":
|
| 346 |
+
display_progress(
|
| 347 |
+
"[~] Copying .pth file and index file ...",
|
| 348 |
+
percentage,
|
| 349 |
+
progress_bar,
|
| 350 |
+
)
|
| 351 |
+
copy_files_to_new_dir([index_path, pth_path], model_dir_path)
|
| 352 |
+
else:
|
| 353 |
+
raise UploadFormatError(
|
| 354 |
+
entity=Entity.FILES,
|
| 355 |
+
formats=[".pth", ".index"],
|
| 356 |
+
multiple=True,
|
| 357 |
+
)
|
| 358 |
+
case _:
|
| 359 |
+
raise UploadLimitError(entity=Entity.FILES, limit="two")
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
def delete_models(
|
| 363 |
+
names: Sequence[str],
|
| 364 |
+
progress_bar: gr.Progress | None = None,
|
| 365 |
+
percentage: float = 0.5,
|
| 366 |
+
) -> None:
|
| 367 |
+
"""
|
| 368 |
+
Delete one or more voice models.
|
| 369 |
+
|
| 370 |
+
Parameters
|
| 371 |
+
----------
|
| 372 |
+
names : Sequence[str]
|
| 373 |
+
Names of the voice models to delete.
|
| 374 |
+
progress_bar : gr.Progress, optional
|
| 375 |
+
Gradio progress bar to update.
|
| 376 |
+
percentage : float, default=0.5
|
| 377 |
+
Percentage to display in the progress bar.
|
| 378 |
+
|
| 379 |
+
Raises
|
| 380 |
+
------
|
| 381 |
+
NotProvidedError
|
| 382 |
+
If no names are provided.
|
| 383 |
+
VoiceModelNotFoundError
|
| 384 |
+
If a voice model with a provided name does not exist.
|
| 385 |
+
|
| 386 |
+
"""
|
| 387 |
+
if not names:
|
| 388 |
+
raise NotProvidedError(
|
| 389 |
+
entity=Entity.MODEL_NAMES,
|
| 390 |
+
ui_msg=UIMessage.NO_VOICE_MODELS,
|
| 391 |
+
)
|
| 392 |
+
display_progress(
|
| 393 |
+
"[~] Deleting voice models ...",
|
| 394 |
+
percentage,
|
| 395 |
+
progress_bar,
|
| 396 |
+
)
|
| 397 |
+
for name in names:
|
| 398 |
+
model_dir_path = RVC_MODELS_DIR / name
|
| 399 |
+
if not model_dir_path.is_dir():
|
| 400 |
+
raise VoiceModelNotFoundError(name)
|
| 401 |
+
shutil.rmtree(model_dir_path)
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
def delete_all_models(
|
| 405 |
+
progress_bar: gr.Progress | None = None,
|
| 406 |
+
percentage: float = 0.5,
|
| 407 |
+
) -> None:
|
| 408 |
+
"""
|
| 409 |
+
Delete all voice models.
|
| 410 |
+
|
| 411 |
+
Parameters
|
| 412 |
+
----------
|
| 413 |
+
progress_bar : gr.Progress, optional
|
| 414 |
+
Gradio progress bar to update.
|
| 415 |
+
percentage : float, default=0.5
|
| 416 |
+
Percentage to display in the progress bar.
|
| 417 |
+
|
| 418 |
+
"""
|
| 419 |
+
all_model_names = get_saved_model_names()
|
| 420 |
+
display_progress("[~] Deleting all voice models ...", percentage, progress_bar)
|
| 421 |
+
for model_name in all_model_names:
|
| 422 |
+
model_dir_path = RVC_MODELS_DIR / model_name
|
| 423 |
+
if model_dir_path.is_dir():
|
| 424 |
+
shutil.rmtree(model_dir_path)
|
src/ultimate_rvc/core/manage/other_settings.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Module which defines functions used for managing various settings."""
|
| 2 |
+
|
| 3 |
+
import shutil
|
| 4 |
+
|
| 5 |
+
import gradio as gr
|
| 6 |
+
|
| 7 |
+
from ultimate_rvc.common import TEMP_DIR
|
| 8 |
+
from ultimate_rvc.core.common import display_progress
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def delete_temp_files(
|
| 12 |
+
progress_bar: gr.Progress | None = None,
|
| 13 |
+
percentage: float = 0.5,
|
| 14 |
+
) -> None:
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
Delete all temporary files.
|
| 18 |
+
|
| 19 |
+
Parameters
|
| 20 |
+
----------
|
| 21 |
+
progress_bar : gr.Progress, optional
|
| 22 |
+
Progress bar to update.
|
| 23 |
+
percentage : float, optional
|
| 24 |
+
The percentage to display in the progress bar.
|
| 25 |
+
|
| 26 |
+
"""
|
| 27 |
+
display_progress("[~] Deleting all temporary files...", percentage, progress_bar)
|
| 28 |
+
if TEMP_DIR.is_dir():
|
| 29 |
+
shutil.rmtree(TEMP_DIR)
|
src/ultimate_rvc/core/manage/public_models.json
ADDED
|
@@ -0,0 +1,646 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"tags": [
|
| 3 |
+
{
|
| 4 |
+
"name": "English",
|
| 5 |
+
"description": "Character speaks English"
|
| 6 |
+
},
|
| 7 |
+
{
|
| 8 |
+
"name": "Japanese",
|
| 9 |
+
"description": "Character speaks Japanese"
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"name": "Other Language",
|
| 13 |
+
"description": "The character speaks Other Language"
|
| 14 |
+
},
|
| 15 |
+
{
|
| 16 |
+
"name": "Anime",
|
| 17 |
+
"description": "Character from anime"
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"name": "Vtuber",
|
| 21 |
+
"description": "Character is a vtuber"
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"name": "Real person",
|
| 25 |
+
"description": "A person who exists in the real world"
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"name": "Game character",
|
| 29 |
+
"description": "A character from the game"
|
| 30 |
+
}
|
| 31 |
+
],
|
| 32 |
+
"models": [
|
| 33 |
+
{
|
| 34 |
+
"name": "Emilia",
|
| 35 |
+
"url": "https://huggingface.co/RinkaEmina/RVC_Sharing/resolve/main/Emilia%20V2%2048000.zip",
|
| 36 |
+
"description": "Emilia from Re:Zero",
|
| 37 |
+
"added": "2023-07-31",
|
| 38 |
+
"credit": "rinka4759",
|
| 39 |
+
"tags": [
|
| 40 |
+
"Anime"
|
| 41 |
+
]
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"name": "Klee",
|
| 45 |
+
"url": "https://huggingface.co/qweshkka/Klee/resolve/main/Klee.zip",
|
| 46 |
+
"description": "Klee from Genshin Impact",
|
| 47 |
+
"added": "2023-07-31",
|
| 48 |
+
"credit": "qweshsmashjuicefruity",
|
| 49 |
+
"tags": [
|
| 50 |
+
"Game character",
|
| 51 |
+
"Japanese"
|
| 52 |
+
]
|
| 53 |
+
},
|
| 54 |
+
{
|
| 55 |
+
"name": "Yelan",
|
| 56 |
+
"url": "https://huggingface.co/iroaK/RVC2_Yelan_GenshinImpact/resolve/main/YelanJP.zip",
|
| 57 |
+
"description": "Yelan from Genshin Impact",
|
| 58 |
+
"added": "2023-07-31",
|
| 59 |
+
"credit": "iroak",
|
| 60 |
+
"tags": [
|
| 61 |
+
"Game character",
|
| 62 |
+
"Japanese"
|
| 63 |
+
]
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"name": "Yae Miko",
|
| 67 |
+
"url": "https://huggingface.co/iroaK/RVC2_YaeMiko_GenshinImpact/resolve/main/Yae_MikoJP.zip",
|
| 68 |
+
"description": "Yae Miko from Genshin Impact",
|
| 69 |
+
"added": "2023-07-31",
|
| 70 |
+
"credit": "iroak",
|
| 71 |
+
"tags": [
|
| 72 |
+
"Game character",
|
| 73 |
+
"Japanese"
|
| 74 |
+
]
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"name": "Lisa",
|
| 78 |
+
"url": "https://huggingface.co/qweshkka/Lisa2ver/resolve/main/Lisa.zip",
|
| 79 |
+
"description": "Lisa from Genshin Impact",
|
| 80 |
+
"added": "2023-07-31",
|
| 81 |
+
"credit": "qweshsmashjuicefruity",
|
| 82 |
+
"tags": [
|
| 83 |
+
"Game character",
|
| 84 |
+
"English"
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"name": "Kazuha",
|
| 89 |
+
"url": "https://huggingface.co/iroaK/RVC2_Kazuha_GenshinImpact/resolve/main/Kazuha.zip",
|
| 90 |
+
"description": "Kaedehara Kazuha from Genshin Impact",
|
| 91 |
+
"added": "2023-07-31",
|
| 92 |
+
"credit": "iroak",
|
| 93 |
+
"tags": [
|
| 94 |
+
"Game character",
|
| 95 |
+
"Japanese"
|
| 96 |
+
]
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"name": "Barbara",
|
| 100 |
+
"url": "https://huggingface.co/iroaK/RVC2_Barbara_GenshinImpact/resolve/main/BarbaraJP.zip",
|
| 101 |
+
"description": "Barbara from Genshin Impact",
|
| 102 |
+
"added": "2023-07-31",
|
| 103 |
+
"credit": "iroak",
|
| 104 |
+
"tags": [
|
| 105 |
+
"Game character",
|
| 106 |
+
"Japanese"
|
| 107 |
+
]
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"name": "Tom Holland",
|
| 111 |
+
"url": "https://huggingface.co/TJKAI/TomHolland/resolve/main/TomHolland.zip",
|
| 112 |
+
"description": "Tom Holland (Spider-Man)",
|
| 113 |
+
"added": "2023-08-03",
|
| 114 |
+
"credit": "tjkcreative",
|
| 115 |
+
"tags": [
|
| 116 |
+
"Real person",
|
| 117 |
+
"English"
|
| 118 |
+
]
|
| 119 |
+
},
|
| 120 |
+
{
|
| 121 |
+
"name": "Kamisato Ayaka",
|
| 122 |
+
"url": "https://huggingface.co/benitheworld/ayaka-cn/resolve/main/ayaka-cn.zip",
|
| 123 |
+
"description": "Kamisato Ayaka from Genshin Impact - CN voice actor",
|
| 124 |
+
"added": "2023-08-03",
|
| 125 |
+
"credit": "kannysoap",
|
| 126 |
+
"tags": [
|
| 127 |
+
"Game character",
|
| 128 |
+
"Other Language"
|
| 129 |
+
]
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"name": "Amai Odayaka",
|
| 133 |
+
"url": "https://huggingface.co/NoIdea4Username/NoIdeaRVCCollection/resolve/main/Amai-Odayaka.zip",
|
| 134 |
+
"description": "Amai Odayaka from Yandere Simulator",
|
| 135 |
+
"added": "2023-08-03",
|
| 136 |
+
"credit": "minecraftian47",
|
| 137 |
+
"tags": [
|
| 138 |
+
"Anime",
|
| 139 |
+
"English"
|
| 140 |
+
]
|
| 141 |
+
},
|
| 142 |
+
{
|
| 143 |
+
"name": "Compa - Hyperdimension Neptunia",
|
| 144 |
+
"url": "https://huggingface.co/zeerowiibu/WiibuRVCCollection/resolve/main/Compa%20(Choujigen%20Game%20Neptunia)%20(JPN)%20(RVC%20v2)%20(150%20Epochs).zip",
|
| 145 |
+
"description": "Compa from Choujigen Game Neptune (aka Hyperdimension Neptunia)",
|
| 146 |
+
"added": "2023-08-03",
|
| 147 |
+
"credit": "zeerowiibu",
|
| 148 |
+
"tags": [
|
| 149 |
+
"Anime",
|
| 150 |
+
"Japanese"
|
| 151 |
+
]
|
| 152 |
+
},
|
| 153 |
+
{
|
| 154 |
+
"name": "Fu Xuan",
|
| 155 |
+
"url": "https://huggingface.co/Juneuarie/FuXuan/resolve/main/FuXuan.zip",
|
| 156 |
+
"description": "Fu Xuan from Honkai Star Rail (HSR)",
|
| 157 |
+
"added": "2023-08-03",
|
| 158 |
+
"credit": "__june",
|
| 159 |
+
"tags": [
|
| 160 |
+
"Game character",
|
| 161 |
+
"English"
|
| 162 |
+
]
|
| 163 |
+
},
|
| 164 |
+
{
|
| 165 |
+
"name": "Xinyan",
|
| 166 |
+
"url": "https://huggingface.co/AnimeSessions/rvc_voice_models/resolve/main/XinyanRVC.zip",
|
| 167 |
+
"description": "Xinyan from Genshin Impact",
|
| 168 |
+
"added": "2023-08-03",
|
| 169 |
+
"credit": "shyelijah",
|
| 170 |
+
"tags": [
|
| 171 |
+
"Game character",
|
| 172 |
+
"English"
|
| 173 |
+
]
|
| 174 |
+
},
|
| 175 |
+
{
|
| 176 |
+
"name": "Enterprise",
|
| 177 |
+
"url": "https://huggingface.co/NoIdea4Username/NoIdeaRVCCollection/resolve/main/Enterprise-JP.zip",
|
| 178 |
+
"description": "Enterprise from Azur Lane",
|
| 179 |
+
"added": "2023-08-03",
|
| 180 |
+
"credit": "minecraftian47",
|
| 181 |
+
"tags": [
|
| 182 |
+
"Anime",
|
| 183 |
+
"Japanese"
|
| 184 |
+
]
|
| 185 |
+
},
|
| 186 |
+
{
|
| 187 |
+
"name": "Kurt Cobain",
|
| 188 |
+
"url": "https://huggingface.co/Florstie/Kurt_Cobain_byFlorst/resolve/main/Kurt_Florst.zip",
|
| 189 |
+
"description": "singer Kurt Cobain",
|
| 190 |
+
"added": "2023-08-03",
|
| 191 |
+
"credit": "florst",
|
| 192 |
+
"tags": [
|
| 193 |
+
"Real person",
|
| 194 |
+
"English"
|
| 195 |
+
]
|
| 196 |
+
},
|
| 197 |
+
{
|
| 198 |
+
"name": "Ironmouse",
|
| 199 |
+
"url": "https://huggingface.co/Tempo-Hawk/IronmouseV2/resolve/main/IronmouseV2.zip",
|
| 200 |
+
"description": "Ironmouse",
|
| 201 |
+
"added": "2023-08-03",
|
| 202 |
+
"credit": "ladyimpa",
|
| 203 |
+
"tags": [
|
| 204 |
+
"Vtuber",
|
| 205 |
+
"English"
|
| 206 |
+
]
|
| 207 |
+
},
|
| 208 |
+
{
|
| 209 |
+
"name": "Bratishkinoff",
|
| 210 |
+
"url": "https://huggingface.co/JHmashups/Bratishkinoff/resolve/main/bratishkin.zip",
|
| 211 |
+
"description": "Bratishkinoff (Bratishkin | Братишкин) - russian steamer ",
|
| 212 |
+
"added": "2023-08-03",
|
| 213 |
+
"credit": ".caddii",
|
| 214 |
+
"tags": [
|
| 215 |
+
"Real person",
|
| 216 |
+
"Other Language"
|
| 217 |
+
]
|
| 218 |
+
},
|
| 219 |
+
{
|
| 220 |
+
"name": "Yagami Light",
|
| 221 |
+
"url": "https://huggingface.co/geekdom-tr/Yagami-Light/resolve/main/Yagami-Light.zip",
|
| 222 |
+
"description": "Yagami Light (Miyano Mamoru) from death note",
|
| 223 |
+
"added": "2023-08-03",
|
| 224 |
+
"credit": "takka / takka#7700",
|
| 225 |
+
"tags": [
|
| 226 |
+
"Anime",
|
| 227 |
+
"Japanese"
|
| 228 |
+
]
|
| 229 |
+
},
|
| 230 |
+
{
|
| 231 |
+
"name": "Itashi",
|
| 232 |
+
"url": "https://huggingface.co/4uGGun/4uGGunRVC/resolve/main/itashi.zip",
|
| 233 |
+
"description": "Itashi (Russian fandubber AniLibria) ",
|
| 234 |
+
"added": "2023-08-03",
|
| 235 |
+
"credit": "BelochkaOff",
|
| 236 |
+
"tags": [
|
| 237 |
+
"Anime",
|
| 238 |
+
"Other Language",
|
| 239 |
+
"Real person"
|
| 240 |
+
]
|
| 241 |
+
},
|
| 242 |
+
{
|
| 243 |
+
"name": "Michiru Kagemori",
|
| 244 |
+
"url": "https://huggingface.co/WolfMK/MichiruKagemori/resolve/main/MichiruKagemori_RVC_V2.zip",
|
| 245 |
+
"description": "Michiru Kagemori from Brand New Animal (300 Epochs)",
|
| 246 |
+
"added": "2023-08-03",
|
| 247 |
+
"credit": "wolfmk",
|
| 248 |
+
"tags": [
|
| 249 |
+
"Anime",
|
| 250 |
+
"English"
|
| 251 |
+
]
|
| 252 |
+
},
|
| 253 |
+
{
|
| 254 |
+
"name": "Kaeya",
|
| 255 |
+
"url": "https://huggingface.co/nlordqting4444/nlordqtingRVC/resolve/main/Kaeya.zip",
|
| 256 |
+
"description": "Kaeya (VA: Kohsuke Toriumi) from Genshin Impact (300 Epochs)",
|
| 257 |
+
"added": "2023-08-03",
|
| 258 |
+
"credit": "nlordqting4444",
|
| 259 |
+
"tags": [
|
| 260 |
+
"Game character",
|
| 261 |
+
"Japanese"
|
| 262 |
+
]
|
| 263 |
+
},
|
| 264 |
+
{
|
| 265 |
+
"name": "Mona Megistus",
|
| 266 |
+
"url": "https://huggingface.co/AnimeSessions/rvc_voice_models/resolve/main/MonaRVC.zip",
|
| 267 |
+
"description": "Mona Megistus (VA: Felecia Angelle) from Genshin Impact (250 Epochs)",
|
| 268 |
+
"added": "2023-08-03",
|
| 269 |
+
"credit": "shyelijah",
|
| 270 |
+
"tags": [
|
| 271 |
+
"Game character",
|
| 272 |
+
"English"
|
| 273 |
+
]
|
| 274 |
+
},
|
| 275 |
+
{
|
| 276 |
+
"name": "Klee",
|
| 277 |
+
"url": "https://huggingface.co/hardbop/AI_MODEL_THINGY/resolve/main/kleeeng_rvc.zip",
|
| 278 |
+
"description": "Klee from Genshin Impact (400 Epochs)",
|
| 279 |
+
"added": "2023-08-03",
|
| 280 |
+
"credit": "hardbop",
|
| 281 |
+
"tags": [
|
| 282 |
+
"Game character",
|
| 283 |
+
"English"
|
| 284 |
+
]
|
| 285 |
+
},
|
| 286 |
+
{
|
| 287 |
+
"name": "Sakurakoji Kinako",
|
| 288 |
+
"url": "https://huggingface.co/Gorodogi/RVC2MangioCrepe/resolve/main/kinakobetatwo700.zip",
|
| 289 |
+
"description": "Sakurakoji Kinako (Suzuhara Nozomi) from Love Live! Superstar!! (700 Epoch)",
|
| 290 |
+
"added": "2023-08-03",
|
| 291 |
+
"credit": "ck1089",
|
| 292 |
+
"tags": [
|
| 293 |
+
"Anime",
|
| 294 |
+
"Japanese"
|
| 295 |
+
]
|
| 296 |
+
},
|
| 297 |
+
{
|
| 298 |
+
"name": "Minamo Kurosawa",
|
| 299 |
+
"url": "https://huggingface.co/timothy10583/RVC/resolve/main/minamo-kurosawa.zip",
|
| 300 |
+
"description": "Minamo (Nyamo) Kurosawa (Azumanga Daioh US DUB) (300 Epochs)",
|
| 301 |
+
"added": "2023-08-03",
|
| 302 |
+
"credit": "timothy10583",
|
| 303 |
+
"tags": [
|
| 304 |
+
"Anime"
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"name": "Neco Arc",
|
| 309 |
+
"url": "https://huggingface.co/Ozzy-Helix/Neko_Arc_Neko_Aruku.RVCv2/resolve/main/Neko_Arc-V3-E600.zip",
|
| 310 |
+
"description": "Neco Arc (Neco-Aruku) (Epochs 600)",
|
| 311 |
+
"added": "2023-08-03",
|
| 312 |
+
"credit": "ozzy_helix_",
|
| 313 |
+
"tags": [
|
| 314 |
+
"Anime"
|
| 315 |
+
]
|
| 316 |
+
},
|
| 317 |
+
{
|
| 318 |
+
"name": "Makima",
|
| 319 |
+
"url": "https://huggingface.co/andolei/makimaen/resolve/main/makima-en-dub.zip",
|
| 320 |
+
"description": "Makima from Chainsaw Man (300 Epochs)",
|
| 321 |
+
"added": "2023-08-03",
|
| 322 |
+
"credit": "andpproximately",
|
| 323 |
+
"tags": [
|
| 324 |
+
"Anime",
|
| 325 |
+
"English"
|
| 326 |
+
]
|
| 327 |
+
},
|
| 328 |
+
{
|
| 329 |
+
"name": "PomPom",
|
| 330 |
+
"url": "https://huggingface.co/benitheworld/pom-pom/resolve/main/pom-pom.zip",
|
| 331 |
+
"description": "PomPom from Honkai Star Rail (HSR) (200 Epochs)",
|
| 332 |
+
"added": "2023-08-03",
|
| 333 |
+
"credit": "kannysoap",
|
| 334 |
+
"tags": [
|
| 335 |
+
"Game character",
|
| 336 |
+
"English"
|
| 337 |
+
]
|
| 338 |
+
},
|
| 339 |
+
{
|
| 340 |
+
"name": "Asuka Langley Soryu",
|
| 341 |
+
"url": "https://huggingface.co/Piegirl/asukaadv/resolve/main/asuka.zip",
|
| 342 |
+
"description": "Asuka Langley Soryu/Tiffany Grant from Neon Genesis Evangelion (400 Epochs)",
|
| 343 |
+
"added": "2023-08-03",
|
| 344 |
+
"credit": "piegirl",
|
| 345 |
+
"tags": [
|
| 346 |
+
"Anime",
|
| 347 |
+
"English"
|
| 348 |
+
]
|
| 349 |
+
},
|
| 350 |
+
{
|
| 351 |
+
"name": "Ochaco Uraraka",
|
| 352 |
+
"url": "https://huggingface.co/legitdark/JP-Uraraka-By-Dan/resolve/main/JP-Uraraka-By-Dan.zip",
|
| 353 |
+
"description": "Ochaco Uraraka from Boku no Hero Academia (320 Epochs)",
|
| 354 |
+
"added": "2023-08-03",
|
| 355 |
+
"credit": "danthevegetable",
|
| 356 |
+
"tags": [
|
| 357 |
+
"Anime",
|
| 358 |
+
"Japanese"
|
| 359 |
+
]
|
| 360 |
+
},
|
| 361 |
+
{
|
| 362 |
+
"name": "Sunaokami Shiroko",
|
| 363 |
+
"url": "https://huggingface.co/LordDavis778/BlueArchivevoicemodels/resolve/main/SunaokamiShiroko.zip",
|
| 364 |
+
"description": "Sunaokami Shiroko from Blue Archive (500 Epochs)",
|
| 365 |
+
"added": "2023-08-03",
|
| 366 |
+
"credit": "lorddavis778",
|
| 367 |
+
"tags": [
|
| 368 |
+
"Anime"
|
| 369 |
+
]
|
| 370 |
+
},
|
| 371 |
+
{
|
| 372 |
+
"name": "Dainsleif",
|
| 373 |
+
"url": "https://huggingface.co/Nasleyy/NasleyRVC/resolve/main/Voices/Dainsleif/Dainsleif.zip",
|
| 374 |
+
"description": "Dainsleif from Genshin Impact (335 Epochs)",
|
| 375 |
+
"added": "2023-08-03",
|
| 376 |
+
"credit": "nasley",
|
| 377 |
+
"tags": [
|
| 378 |
+
"Game character",
|
| 379 |
+
"English"
|
| 380 |
+
]
|
| 381 |
+
},
|
| 382 |
+
{
|
| 383 |
+
"name": "Mae Asmr",
|
| 384 |
+
"url": "https://huggingface.co/ctian/VRC/resolve/main/MaeASMR.zip",
|
| 385 |
+
"description": "Mae Asmr - harvest mommy voice (YOUTUBE) (300 Epochs)",
|
| 386 |
+
"added": "2023-08-03",
|
| 387 |
+
"credit": "ctian_04",
|
| 388 |
+
"tags": [
|
| 389 |
+
"English",
|
| 390 |
+
"Real person",
|
| 391 |
+
"Vtuber"
|
| 392 |
+
]
|
| 393 |
+
},
|
| 394 |
+
{
|
| 395 |
+
"name": "Hana Shirosaki ",
|
| 396 |
+
"url": "https://huggingface.co/Pawlik17/HanaWataten/resolve/main/HanaWATATEN.zip",
|
| 397 |
+
"description": "Hana Shirosaki / 白 咲 花 From Watashi ni Tenshi ga Maiorita! (570 Epochs)",
|
| 398 |
+
"added": "2023-08-03",
|
| 399 |
+
"credit": "tamalik",
|
| 400 |
+
"tags": [
|
| 401 |
+
"Anime",
|
| 402 |
+
"Japanese"
|
| 403 |
+
]
|
| 404 |
+
},
|
| 405 |
+
{
|
| 406 |
+
"name": "Kaguya Shinomiya ",
|
| 407 |
+
"url": "https://huggingface.co/1ski/1skiRVCModels/resolve/main/kaguyav5.zip",
|
| 408 |
+
"description": "Kaguya Shinomiya from Kaguya-Sama Love is war (200 Epochs)",
|
| 409 |
+
"added": "2023-08-03",
|
| 410 |
+
"credit": "1ski",
|
| 411 |
+
"tags": [
|
| 412 |
+
"Anime",
|
| 413 |
+
"Japanese"
|
| 414 |
+
]
|
| 415 |
+
},
|
| 416 |
+
{
|
| 417 |
+
"name": "Nai Shiro",
|
| 418 |
+
"url": "https://huggingface.co/kuushiro/Shiro-RVC-No-Game-No-Life/resolve/main/shiro-jp-360-epochs.zip",
|
| 419 |
+
"description": "Nai Shiro (Ai Kayano) from No Game No Life (360 Epochs)",
|
| 420 |
+
"added": "2023-08-03",
|
| 421 |
+
"credit": "kxouyou",
|
| 422 |
+
"tags": [
|
| 423 |
+
"Anime",
|
| 424 |
+
"Japanese"
|
| 425 |
+
]
|
| 426 |
+
},
|
| 427 |
+
{
|
| 428 |
+
"name": "Yuigahama Yui",
|
| 429 |
+
"url": "https://huggingface.co/Zerokano/Yuigahama_Yui-RVCv2/resolve/main/Yuigahama_Yui.zip",
|
| 430 |
+
"description": "Yuigahama Yui from Yahari Ore no Seishun Love Comedy wa Machigatteiru (250 Epochs)",
|
| 431 |
+
"added": "2023-08-03",
|
| 432 |
+
"credit": "zerokano",
|
| 433 |
+
"tags": [
|
| 434 |
+
"Anime",
|
| 435 |
+
"Japanese"
|
| 436 |
+
]
|
| 437 |
+
},
|
| 438 |
+
{
|
| 439 |
+
"name": "Fuwawa Abyssgard",
|
| 440 |
+
"url": "https://huggingface.co/megaaziib/my-rvc-models-collection/resolve/main/fuwawa.zip",
|
| 441 |
+
"description": "Fuwawa Abyssgard (FUWAMOCO) from Hololive gen 3 (250 Epochs)",
|
| 442 |
+
"added": "2023-08-03",
|
| 443 |
+
"credit": "megaaziib",
|
| 444 |
+
"tags": [
|
| 445 |
+
"Vtuber",
|
| 446 |
+
"English"
|
| 447 |
+
]
|
| 448 |
+
},
|
| 449 |
+
{
|
| 450 |
+
"name": "Kana Arima",
|
| 451 |
+
"url": "https://huggingface.co/ddoumakunn/arimakanna/resolve/main/arimakanna.zip",
|
| 452 |
+
"description": "Kana Arima from Oshi no Ko (250 Epochs)",
|
| 453 |
+
"added": "2023-08-03",
|
| 454 |
+
"credit": "ddoumakunn",
|
| 455 |
+
"tags": [
|
| 456 |
+
"Anime",
|
| 457 |
+
"Japanese"
|
| 458 |
+
]
|
| 459 |
+
},
|
| 460 |
+
{
|
| 461 |
+
"name": "Raiden Shogun",
|
| 462 |
+
"url": "https://huggingface.co/Nasleyy/NasleyRVC/resolve/main/Voices/RaidenShogun/RaidenShogun.zip",
|
| 463 |
+
"description": "Raiden Shogun from Genshin Impact (310 Epochs)",
|
| 464 |
+
"added": "2023-08-03",
|
| 465 |
+
"credit": "nasley",
|
| 466 |
+
"tags": [
|
| 467 |
+
"Game character",
|
| 468 |
+
"English"
|
| 469 |
+
]
|
| 470 |
+
},
|
| 471 |
+
{
|
| 472 |
+
"name": "Alhaitham",
|
| 473 |
+
"url": "https://huggingface.co/Nasleyy/NasleyRVC/resolve/main/Voices/Alhaitham/Alhaitham.zip",
|
| 474 |
+
"description": "Alhaitham from Genshin Impact (320 Epochs)",
|
| 475 |
+
"added": "2023-08-03",
|
| 476 |
+
"credit": "nasley",
|
| 477 |
+
"tags": [
|
| 478 |
+
"Game character",
|
| 479 |
+
"English"
|
| 480 |
+
]
|
| 481 |
+
},
|
| 482 |
+
{
|
| 483 |
+
"name": "Izuku Midoriya",
|
| 484 |
+
"url": "https://huggingface.co/BigGuy635/MHA/resolve/main/DekuJP.zip",
|
| 485 |
+
"description": "Izuku Midoriya from Boku no Hero Academia (100 Epochs)",
|
| 486 |
+
"added": "2023-08-03",
|
| 487 |
+
"credit": "khjjnoffical",
|
| 488 |
+
"tags": [
|
| 489 |
+
"Anime",
|
| 490 |
+
"Japanese"
|
| 491 |
+
]
|
| 492 |
+
},
|
| 493 |
+
{
|
| 494 |
+
"name": "Kurumi Shiratori",
|
| 495 |
+
"url": "https://huggingface.co/HarunaKasuga/YoshikoTsushima/resolve/main/KurumiShiratori.zip",
|
| 496 |
+
"description": "Kurumi Shiratori (VA: Ruka Fukagawa) from D4DJ (500 Epochs)",
|
| 497 |
+
"added": "2023-08-03",
|
| 498 |
+
"credit": "seakrait",
|
| 499 |
+
"tags": [
|
| 500 |
+
"Anime",
|
| 501 |
+
"Japanese"
|
| 502 |
+
]
|
| 503 |
+
},
|
| 504 |
+
{
|
| 505 |
+
"name": "Veibae",
|
| 506 |
+
"url": "https://huggingface.co/datasets/Papaquans/Veibae/resolve/main/veibae_e165_s125565.zip",
|
| 507 |
+
"description": "Veibae (165 Epochs)",
|
| 508 |
+
"added": "2023-08-03",
|
| 509 |
+
"credit": "recairo",
|
| 510 |
+
"tags": [
|
| 511 |
+
"Vtuber",
|
| 512 |
+
"English"
|
| 513 |
+
]
|
| 514 |
+
},
|
| 515 |
+
{
|
| 516 |
+
"name": "Black Panther",
|
| 517 |
+
"url": "https://huggingface.co/TJKAI/BlackPannther/resolve/main/BlackPanther.zip",
|
| 518 |
+
"description": "Black Panther (Chadwick Boseman) (300 Epochs)",
|
| 519 |
+
"added": "2023-08-03",
|
| 520 |
+
"credit": "tjkcreative",
|
| 521 |
+
"tags": [
|
| 522 |
+
"Real person",
|
| 523 |
+
"English"
|
| 524 |
+
]
|
| 525 |
+
},
|
| 526 |
+
{
|
| 527 |
+
"name": "Gawr Gura",
|
| 528 |
+
"url": "https://pixeldrain.com/u/3tJmABXA",
|
| 529 |
+
"description": "Gawr Gura from Hololive EN",
|
| 530 |
+
"added": "2023-08-05",
|
| 531 |
+
"credit": "dacoolkid44 & hijack",
|
| 532 |
+
"tags": [
|
| 533 |
+
"Vtuber"
|
| 534 |
+
]
|
| 535 |
+
},
|
| 536 |
+
{
|
| 537 |
+
"name": "Houshou Marine",
|
| 538 |
+
"url": "https://pixeldrain.com/u/L1YLfZyU",
|
| 539 |
+
"description": "Houshou Marine from Hololive JP",
|
| 540 |
+
"added": "2023-08-05",
|
| 541 |
+
"credit": "dacoolkid44 & hijack",
|
| 542 |
+
"tags": [
|
| 543 |
+
"Vtuber",
|
| 544 |
+
"Japanese"
|
| 545 |
+
]
|
| 546 |
+
},
|
| 547 |
+
{
|
| 548 |
+
"name": "Hoshimachi Suisei",
|
| 549 |
+
"url": "https://pixeldrain.com/u/YP89C21u",
|
| 550 |
+
"description": "Hoshimachi Suisei from Hololive JP",
|
| 551 |
+
"added": "2023-08-05",
|
| 552 |
+
"credit": "dacoolkid44 & hijack & Maki Ligon",
|
| 553 |
+
"tags": [
|
| 554 |
+
"Vtuber",
|
| 555 |
+
"Japanese"
|
| 556 |
+
]
|
| 557 |
+
},
|
| 558 |
+
{
|
| 559 |
+
"name": "Laplus Darkness",
|
| 560 |
+
"url": "https://pixeldrain.com/u/zmuxv5Bf",
|
| 561 |
+
"description": "Laplus Darkness from Hololive JP",
|
| 562 |
+
"added": "2023-08-05",
|
| 563 |
+
"credit": "dacoolkid44 & hijack",
|
| 564 |
+
"tags": [
|
| 565 |
+
"Vtuber",
|
| 566 |
+
"Japanese"
|
| 567 |
+
]
|
| 568 |
+
},
|
| 569 |
+
{
|
| 570 |
+
"name": "AZKi",
|
| 571 |
+
"url": "https://huggingface.co/Kit-Lemonfoot/kitlemonfoot_rvc_models/resolve/main/AZKi%20(Hybrid).zip",
|
| 572 |
+
"description": "AZKi from Hololive JP",
|
| 573 |
+
"added": "2023-08-05",
|
| 574 |
+
"credit": "Kit Lemonfoot / NSHFB",
|
| 575 |
+
"tags": [
|
| 576 |
+
"Vtuber",
|
| 577 |
+
"Japanese"
|
| 578 |
+
]
|
| 579 |
+
},
|
| 580 |
+
{
|
| 581 |
+
"name": "Ado",
|
| 582 |
+
"url": "https://huggingface.co/pjesek/AdoRVCv2/resolve/main/AdoRVCv2.zip",
|
| 583 |
+
"description": "Talented JP artist (500 epochs using every song from her first album)",
|
| 584 |
+
"added": "2023-08-05",
|
| 585 |
+
"credit": "pjesek",
|
| 586 |
+
"tags": [
|
| 587 |
+
"Real person",
|
| 588 |
+
"Japanese"
|
| 589 |
+
]
|
| 590 |
+
},
|
| 591 |
+
{
|
| 592 |
+
"name": "LiSA",
|
| 593 |
+
"url": "https://huggingface.co/phant0m4r/LiSA/resolve/main/LiSA.zip",
|
| 594 |
+
"description": "Talented JP artist (400 epochs)",
|
| 595 |
+
"added": "2023-08-05",
|
| 596 |
+
"credit": "Phant0m",
|
| 597 |
+
"tags": [
|
| 598 |
+
"Real person",
|
| 599 |
+
"Japanese"
|
| 600 |
+
]
|
| 601 |
+
},
|
| 602 |
+
{
|
| 603 |
+
"name": "Kokomi",
|
| 604 |
+
"url": "https://huggingface.co/benitheworld/kokomi-kr/resolve/main/kokomi-kr.zip",
|
| 605 |
+
"description": "Kokomi from Genshin Impact KR (300 Epochs)",
|
| 606 |
+
"added": "2023-08-09",
|
| 607 |
+
"credit": "kannysoap",
|
| 608 |
+
"tags": [
|
| 609 |
+
"Game character",
|
| 610 |
+
"Other Language"
|
| 611 |
+
]
|
| 612 |
+
},
|
| 613 |
+
{
|
| 614 |
+
"name": "Ivanzolo",
|
| 615 |
+
"url": "https://huggingface.co/fenikkusugosuto/IvanZolo2004/resolve/main/ivanZolo.zip",
|
| 616 |
+
"description": "Ivanzolo2004 russian streamer | Иван Золо 2004",
|
| 617 |
+
"added": "2023-08-09",
|
| 618 |
+
"credit": "prezervativ_naruto2009",
|
| 619 |
+
"tags": [
|
| 620 |
+
"Other Language",
|
| 621 |
+
"Real person"
|
| 622 |
+
]
|
| 623 |
+
},
|
| 624 |
+
{
|
| 625 |
+
"name": "Nilou",
|
| 626 |
+
"url": "https://huggingface.co/benitheworld/nilou-kr/resolve/main/nilou-kr.zip",
|
| 627 |
+
"description": "Nilou from Genshin Impact KR (300 Epochs)",
|
| 628 |
+
"added": "2023-08-09",
|
| 629 |
+
"credit": "kannysoap",
|
| 630 |
+
"tags": [
|
| 631 |
+
"Game character",
|
| 632 |
+
"Other Language"
|
| 633 |
+
]
|
| 634 |
+
},
|
| 635 |
+
{
|
| 636 |
+
"name": "Dr. Doofenshmirtz",
|
| 637 |
+
"url": "https://huggingface.co/Argax/doofenshmirtz-RUS/resolve/main/doofenshmirtz.zip",
|
| 638 |
+
"description": "RUS Dr. Doofenshmirtz from Phineas and Ferb (300 epochs)",
|
| 639 |
+
"added": "2023-08-09",
|
| 640 |
+
"credit": "argaxus",
|
| 641 |
+
"tags": [
|
| 642 |
+
"Other Language"
|
| 643 |
+
]
|
| 644 |
+
}
|
| 645 |
+
]
|
| 646 |
+
}
|
src/ultimate_rvc/core/typing_extra.py
ADDED
|
@@ -0,0 +1,294 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Module which defines extra types for the core of the Ultimate RVC
|
| 3 |
+
project.
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
from collections.abc import Callable
|
| 7 |
+
from enum import StrEnum, auto
|
| 8 |
+
|
| 9 |
+
from pydantic import BaseModel, ConfigDict
|
| 10 |
+
|
| 11 |
+
from ultimate_rvc.typing_extra import AudioExt, F0Method
|
| 12 |
+
|
| 13 |
+
# Voice model management
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class ModelTagName(StrEnum):
|
| 17 |
+
"""Names of valid voice model tags."""
|
| 18 |
+
|
| 19 |
+
ENGLISH = "English"
|
| 20 |
+
JAPANESE = "Japanese"
|
| 21 |
+
OTHER_LANGUAGE = "Other Language"
|
| 22 |
+
ANIME = "Anime"
|
| 23 |
+
VTUBER = "Vtuber"
|
| 24 |
+
REAL_PERSON = "Real person"
|
| 25 |
+
GAME_CHARACTER = "Game character"
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class ModelTagMetaData(BaseModel):
|
| 29 |
+
"""
|
| 30 |
+
Metadata for a voice model tag.
|
| 31 |
+
|
| 32 |
+
Attributes
|
| 33 |
+
----------
|
| 34 |
+
name : ModelTagName
|
| 35 |
+
The name of the tag.
|
| 36 |
+
description : str
|
| 37 |
+
The description of the tag.
|
| 38 |
+
|
| 39 |
+
"""
|
| 40 |
+
|
| 41 |
+
name: ModelTagName
|
| 42 |
+
description: str
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class ModelMetaData(BaseModel):
|
| 46 |
+
"""
|
| 47 |
+
Metadata for a voice model.
|
| 48 |
+
|
| 49 |
+
Attributes
|
| 50 |
+
----------
|
| 51 |
+
name : str
|
| 52 |
+
The name of the voice model.
|
| 53 |
+
description : str
|
| 54 |
+
A description of the voice model.
|
| 55 |
+
tags : list[ModelTagName]
|
| 56 |
+
The tags associated with the voice model.
|
| 57 |
+
credit : str
|
| 58 |
+
Who created the voice model.
|
| 59 |
+
added : str
|
| 60 |
+
The date the voice model was created.
|
| 61 |
+
url : str
|
| 62 |
+
An URL pointing to a location where the voice model can be
|
| 63 |
+
downloaded.
|
| 64 |
+
|
| 65 |
+
"""
|
| 66 |
+
|
| 67 |
+
name: str
|
| 68 |
+
description: str
|
| 69 |
+
tags: list[ModelTagName]
|
| 70 |
+
credit: str
|
| 71 |
+
added: str
|
| 72 |
+
url: str
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class ModelMetaDataTable(BaseModel):
|
| 76 |
+
"""
|
| 77 |
+
Table with metadata for a set of voice models.
|
| 78 |
+
|
| 79 |
+
Attributes
|
| 80 |
+
----------
|
| 81 |
+
tags : list[ModelTagMetaData]
|
| 82 |
+
Metadata for the tags associated with the given set of voice
|
| 83 |
+
models.
|
| 84 |
+
models : list[ModelMetaData]
|
| 85 |
+
Metadata for the given set of voice models.
|
| 86 |
+
|
| 87 |
+
"""
|
| 88 |
+
|
| 89 |
+
tags: list[ModelTagMetaData]
|
| 90 |
+
models: list[ModelMetaData]
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
ModelMetaDataPredicate = Callable[[ModelMetaData], bool]
|
| 94 |
+
|
| 95 |
+
ModelMetaDataList = list[list[str | list[ModelTagName]]]
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
# Song cover generation
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class SourceType(StrEnum):
|
| 102 |
+
"""The type of source providing the song to generate a cover of."""
|
| 103 |
+
|
| 104 |
+
URL = auto()
|
| 105 |
+
FILE = auto()
|
| 106 |
+
SONG_DIR = auto()
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class AudioExtInternal(StrEnum):
|
| 110 |
+
"""Audio file formats for internal use."""
|
| 111 |
+
|
| 112 |
+
MP3 = "mp3"
|
| 113 |
+
WAV = "wav"
|
| 114 |
+
FLAC = "flac"
|
| 115 |
+
OGG = "ogg"
|
| 116 |
+
IPOD = "ipod"
|
| 117 |
+
ADTS = "adts"
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
class FileMetaData(BaseModel):
|
| 121 |
+
"""
|
| 122 |
+
Metadata for a file.
|
| 123 |
+
|
| 124 |
+
Attributes
|
| 125 |
+
----------
|
| 126 |
+
name : str
|
| 127 |
+
The name of the file.
|
| 128 |
+
hash_id : str
|
| 129 |
+
The hash ID of the file.
|
| 130 |
+
|
| 131 |
+
"""
|
| 132 |
+
|
| 133 |
+
name: str
|
| 134 |
+
hash_id: str
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class WaveifiedAudioMetaData(BaseModel):
|
| 138 |
+
"""
|
| 139 |
+
Metadata for a waveified audio track.
|
| 140 |
+
|
| 141 |
+
Attributes
|
| 142 |
+
----------
|
| 143 |
+
audio_track : FileMetaData
|
| 144 |
+
Metadata for the audio track that was waveified.
|
| 145 |
+
|
| 146 |
+
"""
|
| 147 |
+
|
| 148 |
+
audio_track: FileMetaData
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
class SeparatedAudioMetaData(BaseModel):
|
| 152 |
+
"""
|
| 153 |
+
Metadata for a separated audio track.
|
| 154 |
+
|
| 155 |
+
Attributes
|
| 156 |
+
----------
|
| 157 |
+
audio_track : FileMetaData
|
| 158 |
+
Metadata for the audio track that was separated.
|
| 159 |
+
model_name : str
|
| 160 |
+
The name of the model used for separation.
|
| 161 |
+
segment_size : int
|
| 162 |
+
The segment size used for separation.
|
| 163 |
+
|
| 164 |
+
"""
|
| 165 |
+
|
| 166 |
+
audio_track: FileMetaData
|
| 167 |
+
model_name: str
|
| 168 |
+
segment_size: int
|
| 169 |
+
|
| 170 |
+
model_config = ConfigDict(protected_namespaces=())
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class ConvertedVocalsMetaData(BaseModel):
|
| 174 |
+
"""
|
| 175 |
+
Metadata for an RVC converted vocals track.
|
| 176 |
+
|
| 177 |
+
Attributes
|
| 178 |
+
----------
|
| 179 |
+
vocals_track : FileMetaData
|
| 180 |
+
Metadata for the vocals track that was converted.
|
| 181 |
+
model_name : str
|
| 182 |
+
The name of the model used for vocal conversion.
|
| 183 |
+
n_semitones : int
|
| 184 |
+
The number of semitones the converted vocals were pitch-shifted
|
| 185 |
+
by.
|
| 186 |
+
f0_method : F0Method
|
| 187 |
+
The method used for pitch detection.
|
| 188 |
+
index_rate : float
|
| 189 |
+
The influence of the index file on the vocal conversion.
|
| 190 |
+
filter_radius : int
|
| 191 |
+
The filter radius used for the vocal conversion.
|
| 192 |
+
rms_mix_rate : float
|
| 193 |
+
The blending of the volume envelope of the converted vocals.
|
| 194 |
+
protect : float
|
| 195 |
+
The protection rate used for consonants and breathing sounds.
|
| 196 |
+
hop_length : int
|
| 197 |
+
The hop length used for crepe-based pitch detection.
|
| 198 |
+
|
| 199 |
+
"""
|
| 200 |
+
|
| 201 |
+
vocals_track: FileMetaData
|
| 202 |
+
model_name: str
|
| 203 |
+
n_semitones: int
|
| 204 |
+
f0_method: F0Method
|
| 205 |
+
index_rate: float
|
| 206 |
+
filter_radius: int
|
| 207 |
+
rms_mix_rate: float
|
| 208 |
+
protect: float
|
| 209 |
+
hop_length: int
|
| 210 |
+
|
| 211 |
+
model_config = ConfigDict(protected_namespaces=())
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
class EffectedVocalsMetaData(BaseModel):
|
| 215 |
+
"""
|
| 216 |
+
Metadata for an effected vocals track.
|
| 217 |
+
|
| 218 |
+
Attributes
|
| 219 |
+
----------
|
| 220 |
+
vocals_track : FileMetaData
|
| 221 |
+
Metadata for the vocals track that effects were applied to.
|
| 222 |
+
room_size : float
|
| 223 |
+
The room size of the reverb effect applied to the vocals track.
|
| 224 |
+
wet_level : float
|
| 225 |
+
The wetness level of the reverb effect applied to the vocals
|
| 226 |
+
track.
|
| 227 |
+
dry_level : float
|
| 228 |
+
The dryness level of the reverb effect. applied to the vocals
|
| 229 |
+
track.
|
| 230 |
+
damping : float
|
| 231 |
+
The damping of the reverb effect applied to the vocals track.
|
| 232 |
+
|
| 233 |
+
"""
|
| 234 |
+
|
| 235 |
+
vocals_track: FileMetaData
|
| 236 |
+
room_size: float
|
| 237 |
+
wet_level: float
|
| 238 |
+
dry_level: float
|
| 239 |
+
damping: float
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
class PitchShiftMetaData(BaseModel):
|
| 243 |
+
"""
|
| 244 |
+
Metadata for a pitch-shifted audio track.
|
| 245 |
+
|
| 246 |
+
Attributes
|
| 247 |
+
----------
|
| 248 |
+
audio_track : FileMetaData
|
| 249 |
+
Metadata for the audio track that was pitch-shifted.
|
| 250 |
+
n_semitones : int
|
| 251 |
+
The number of semitones the audio track was pitch-shifted by.
|
| 252 |
+
|
| 253 |
+
"""
|
| 254 |
+
|
| 255 |
+
audio_track: FileMetaData
|
| 256 |
+
n_semitones: int
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
class StagedAudioMetaData(BaseModel):
|
| 260 |
+
"""
|
| 261 |
+
Metadata for a staged audio track.
|
| 262 |
+
|
| 263 |
+
Attributes
|
| 264 |
+
----------
|
| 265 |
+
audio_track : FileMetaData
|
| 266 |
+
Metadata for the audio track that was staged.
|
| 267 |
+
gain : float
|
| 268 |
+
The gain applied to the audio track.
|
| 269 |
+
|
| 270 |
+
"""
|
| 271 |
+
|
| 272 |
+
audio_track: FileMetaData
|
| 273 |
+
gain: float
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
class MixedSongMetaData(BaseModel):
|
| 277 |
+
"""
|
| 278 |
+
Metadata for a mixed song.
|
| 279 |
+
|
| 280 |
+
Attributes
|
| 281 |
+
----------
|
| 282 |
+
staged_audio_tracks : list[StagedAudioMetaData]
|
| 283 |
+
Metadata for the staged audio tracks that were mixed.
|
| 284 |
+
|
| 285 |
+
output_sr : int
|
| 286 |
+
The sample rate of the mixed song.
|
| 287 |
+
output_format : AudioExt
|
| 288 |
+
The audio file format of the mixed song.
|
| 289 |
+
|
| 290 |
+
"""
|
| 291 |
+
|
| 292 |
+
staged_audio_tracks: list[StagedAudioMetaData]
|
| 293 |
+
output_sr: int
|
| 294 |
+
output_format: AudioExt
|
src/ultimate_rvc/py.typed
ADDED
|
File without changes
|
src/ultimate_rvc/stubs/audio_separator/separator/__init__.pyi
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import TypedDict
|
| 2 |
+
|
| 3 |
+
import logging
|
| 4 |
+
|
| 5 |
+
from ultimate_rvc.typing_extra import StrPath
|
| 6 |
+
|
| 7 |
+
class MDXParams(TypedDict):
|
| 8 |
+
hop_length: int
|
| 9 |
+
segment_size: int
|
| 10 |
+
overlap: float
|
| 11 |
+
batch_size: int
|
| 12 |
+
enable_denoise: bool
|
| 13 |
+
|
| 14 |
+
class VRParams(TypedDict):
|
| 15 |
+
batch_size: int
|
| 16 |
+
window_size: int
|
| 17 |
+
aggression: int
|
| 18 |
+
enable_tta: bool
|
| 19 |
+
enable_post_process: bool
|
| 20 |
+
post_process_threshold: float
|
| 21 |
+
high_end_process: bool
|
| 22 |
+
|
| 23 |
+
class DemucsParams(TypedDict):
|
| 24 |
+
segment_size: str
|
| 25 |
+
shifts: int
|
| 26 |
+
overlap: float
|
| 27 |
+
segments_enabled: bool
|
| 28 |
+
|
| 29 |
+
class MDXCParams(TypedDict):
|
| 30 |
+
segment_size: int
|
| 31 |
+
override_model_segment_size: bool
|
| 32 |
+
batch_size: int
|
| 33 |
+
overlap: int
|
| 34 |
+
pitch_shift: int
|
| 35 |
+
|
| 36 |
+
class ArchSpecificParams(TypedDict):
|
| 37 |
+
MDX: MDXParams
|
| 38 |
+
VR: VRParams
|
| 39 |
+
Demucs: DemucsParams
|
| 40 |
+
MDXC: MDXCParams
|
| 41 |
+
|
| 42 |
+
class Separator:
|
| 43 |
+
arch_specific_params: ArchSpecificParams
|
| 44 |
+
def __init__(
|
| 45 |
+
self,
|
| 46 |
+
log_level: int = ...,
|
| 47 |
+
log_formatter: logging.Formatter | None = None,
|
| 48 |
+
model_file_dir: StrPath = "/tmp/audio-separator-models/", # noqa: S108
|
| 49 |
+
output_dir: StrPath | None = None,
|
| 50 |
+
output_format: str = "WAV",
|
| 51 |
+
output_bitrate: str | None = None,
|
| 52 |
+
normalization_threshold: float = 0.9,
|
| 53 |
+
amplification_threshold: float = 0.6,
|
| 54 |
+
output_single_stem: str | None = None,
|
| 55 |
+
invert_using_spec: bool = False,
|
| 56 |
+
sample_rate: int = 44100,
|
| 57 |
+
mdx_params: MDXParams = {
|
| 58 |
+
"hop_length": 1024,
|
| 59 |
+
"segment_size": 256,
|
| 60 |
+
"overlap": 0.25,
|
| 61 |
+
"batch_size": 1,
|
| 62 |
+
"enable_denoise": False,
|
| 63 |
+
},
|
| 64 |
+
vr_params: VRParams = {
|
| 65 |
+
"batch_size": 1,
|
| 66 |
+
"window_size": 512,
|
| 67 |
+
"aggression": 5,
|
| 68 |
+
"enable_tta": False,
|
| 69 |
+
"enable_post_process": False,
|
| 70 |
+
"post_process_threshold": 0.2,
|
| 71 |
+
"high_end_process": False,
|
| 72 |
+
},
|
| 73 |
+
demucs_params: DemucsParams = {
|
| 74 |
+
"segment_size": "Default",
|
| 75 |
+
"shifts": 2,
|
| 76 |
+
"overlap": 0.25,
|
| 77 |
+
"segments_enabled": True,
|
| 78 |
+
},
|
| 79 |
+
mdxc_params: MDXCParams = {
|
| 80 |
+
"segment_size": 256,
|
| 81 |
+
"override_model_segment_size": False,
|
| 82 |
+
"batch_size": 1,
|
| 83 |
+
"overlap": 8,
|
| 84 |
+
"pitch_shift": 0,
|
| 85 |
+
},
|
| 86 |
+
) -> None: ...
|
| 87 |
+
def download_model_files(
|
| 88 |
+
self,
|
| 89 |
+
model_filename: str,
|
| 90 |
+
) -> tuple[str, str, str, str, str | None]: ...
|
| 91 |
+
def load_model(
|
| 92 |
+
self,
|
| 93 |
+
model_filename: str = "model_mel_band_roformer_ep_3005_sdr_11.4360.ckpt",
|
| 94 |
+
) -> None: ...
|
| 95 |
+
def separate(
|
| 96 |
+
self,
|
| 97 |
+
audio_file_path: str,
|
| 98 |
+
primary_output_name: str | None = None,
|
| 99 |
+
secondary_output_name: str | None = None,
|
| 100 |
+
) -> list[str]: ...
|
src/ultimate_rvc/stubs/gradio/__init__.pyi
ADDED
|
@@ -0,0 +1,245 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
from gradio import (
|
| 4 |
+
_simple_templates,
|
| 5 |
+
components,
|
| 6 |
+
image_utils,
|
| 7 |
+
layouts,
|
| 8 |
+
processing_utils,
|
| 9 |
+
templates,
|
| 10 |
+
themes,
|
| 11 |
+
)
|
| 12 |
+
from gradio.blocks import Blocks
|
| 13 |
+
from gradio.chat_interface import ChatInterface
|
| 14 |
+
from gradio.components import (
|
| 15 |
+
HTML,
|
| 16 |
+
JSON,
|
| 17 |
+
AnnotatedImage,
|
| 18 |
+
Annotatedimage,
|
| 19 |
+
Audio,
|
| 20 |
+
BarPlot,
|
| 21 |
+
BrowserState,
|
| 22 |
+
Button,
|
| 23 |
+
Chatbot,
|
| 24 |
+
ChatMessage,
|
| 25 |
+
Checkbox,
|
| 26 |
+
CheckboxGroup,
|
| 27 |
+
Checkboxgroup,
|
| 28 |
+
ClearButton,
|
| 29 |
+
Code,
|
| 30 |
+
ColorPicker,
|
| 31 |
+
DataFrame,
|
| 32 |
+
Dataframe,
|
| 33 |
+
Dataset,
|
| 34 |
+
DateTime,
|
| 35 |
+
DownloadButton,
|
| 36 |
+
Dropdown,
|
| 37 |
+
DuplicateButton,
|
| 38 |
+
File,
|
| 39 |
+
FileExplorer,
|
| 40 |
+
Gallery,
|
| 41 |
+
Highlight,
|
| 42 |
+
HighlightedText,
|
| 43 |
+
Highlightedtext,
|
| 44 |
+
Image,
|
| 45 |
+
ImageEditor,
|
| 46 |
+
Json,
|
| 47 |
+
Label,
|
| 48 |
+
LinePlot,
|
| 49 |
+
LoginButton,
|
| 50 |
+
Markdown,
|
| 51 |
+
MessageDict,
|
| 52 |
+
Model3D,
|
| 53 |
+
MultimodalTextbox,
|
| 54 |
+
Number,
|
| 55 |
+
ParamViewer,
|
| 56 |
+
Plot,
|
| 57 |
+
Radio,
|
| 58 |
+
ScatterPlot,
|
| 59 |
+
Slider,
|
| 60 |
+
State,
|
| 61 |
+
Text,
|
| 62 |
+
Textbox,
|
| 63 |
+
Timer,
|
| 64 |
+
UploadButton,
|
| 65 |
+
Video,
|
| 66 |
+
component,
|
| 67 |
+
)
|
| 68 |
+
from gradio.components.audio import WaveformOptions
|
| 69 |
+
from gradio.components.image_editor import Brush, Eraser
|
| 70 |
+
from gradio.data_classes import FileData
|
| 71 |
+
from gradio.events import (
|
| 72 |
+
DeletedFileData,
|
| 73 |
+
DownloadData,
|
| 74 |
+
EventData,
|
| 75 |
+
KeyUpData,
|
| 76 |
+
LikeData,
|
| 77 |
+
RetryData,
|
| 78 |
+
SelectData,
|
| 79 |
+
UndoData,
|
| 80 |
+
on,
|
| 81 |
+
)
|
| 82 |
+
from gradio.exceptions import Error
|
| 83 |
+
from gradio.external import load
|
| 84 |
+
from gradio.flagging import (
|
| 85 |
+
CSVLogger,
|
| 86 |
+
FlaggingCallback,
|
| 87 |
+
SimpleCSVLogger,
|
| 88 |
+
)
|
| 89 |
+
from gradio.helpers import (
|
| 90 |
+
Info,
|
| 91 |
+
Progress,
|
| 92 |
+
Warning,
|
| 93 |
+
skip,
|
| 94 |
+
update,
|
| 95 |
+
)
|
| 96 |
+
from gradio.helpers import create_examples as Examples # noqa: N812
|
| 97 |
+
from gradio.interface import Interface, TabbedInterface, close_all
|
| 98 |
+
from gradio.layouts import Accordion, Column, Group, Row, Tab, TabItem, Tabs
|
| 99 |
+
from gradio.oauth import OAuthProfile, OAuthToken
|
| 100 |
+
from gradio.renderable import render
|
| 101 |
+
from gradio.routes import Request, mount_gradio_app
|
| 102 |
+
from gradio.templates import (
|
| 103 |
+
Files,
|
| 104 |
+
ImageMask,
|
| 105 |
+
List,
|
| 106 |
+
Matrix,
|
| 107 |
+
Mic,
|
| 108 |
+
Microphone,
|
| 109 |
+
Numpy,
|
| 110 |
+
Paint,
|
| 111 |
+
PlayableVideo,
|
| 112 |
+
Sketchpad,
|
| 113 |
+
TextArea,
|
| 114 |
+
)
|
| 115 |
+
from gradio.themes import Base as Theme
|
| 116 |
+
from gradio.utils import NO_RELOAD, FileSize, get_package_version, set_static_paths
|
| 117 |
+
from gradio.wasm_utils import IS_WASM
|
| 118 |
+
|
| 119 |
+
if not IS_WASM: # noqa: PYI002
|
| 120 |
+
from gradio.cli import deploy
|
| 121 |
+
from gradio.ipython_ext import load_ipython_extension
|
| 122 |
+
|
| 123 |
+
__version__ = ...
|
| 124 |
+
__all__ = [
|
| 125 |
+
"HTML",
|
| 126 |
+
"IS_WASM",
|
| 127 |
+
"JSON",
|
| 128 |
+
"NO_RELOAD",
|
| 129 |
+
"Accordion",
|
| 130 |
+
"AnnotatedImage",
|
| 131 |
+
"Annotatedimage",
|
| 132 |
+
"Audio",
|
| 133 |
+
"BarPlot",
|
| 134 |
+
"Blocks",
|
| 135 |
+
"BrowserState",
|
| 136 |
+
"Brush",
|
| 137 |
+
"Button",
|
| 138 |
+
"CSVLogger",
|
| 139 |
+
"ChatInterface",
|
| 140 |
+
"ChatMessage",
|
| 141 |
+
"Chatbot",
|
| 142 |
+
"Checkbox",
|
| 143 |
+
"CheckboxGroup",
|
| 144 |
+
"Checkboxgroup",
|
| 145 |
+
"ClearButton",
|
| 146 |
+
"Code",
|
| 147 |
+
"ColorPicker",
|
| 148 |
+
"Column",
|
| 149 |
+
"DataFrame",
|
| 150 |
+
"Dataframe",
|
| 151 |
+
"Dataset",
|
| 152 |
+
"DateTime",
|
| 153 |
+
"DeletedFileData",
|
| 154 |
+
"DownloadButton",
|
| 155 |
+
"DownloadData",
|
| 156 |
+
"Dropdown",
|
| 157 |
+
"DuplicateButton",
|
| 158 |
+
"Eraser",
|
| 159 |
+
"Error",
|
| 160 |
+
"EventData",
|
| 161 |
+
"Examples",
|
| 162 |
+
"File",
|
| 163 |
+
"FileData",
|
| 164 |
+
"FileExplorer",
|
| 165 |
+
"FileSize",
|
| 166 |
+
"Files",
|
| 167 |
+
"FlaggingCallback",
|
| 168 |
+
"Gallery",
|
| 169 |
+
"Group",
|
| 170 |
+
"Highlight",
|
| 171 |
+
"HighlightedText",
|
| 172 |
+
"Highlightedtext",
|
| 173 |
+
"Image",
|
| 174 |
+
"ImageEditor",
|
| 175 |
+
"ImageMask",
|
| 176 |
+
"Info",
|
| 177 |
+
"Interface",
|
| 178 |
+
"Json",
|
| 179 |
+
"KeyUpData",
|
| 180 |
+
"Label",
|
| 181 |
+
"LikeData",
|
| 182 |
+
"LinePlot",
|
| 183 |
+
"List",
|
| 184 |
+
"LoginButton",
|
| 185 |
+
"Markdown",
|
| 186 |
+
"Matrix",
|
| 187 |
+
"MessageDict",
|
| 188 |
+
"Mic",
|
| 189 |
+
"Microphone",
|
| 190 |
+
"Model3D",
|
| 191 |
+
"MultimodalTextbox",
|
| 192 |
+
"Number",
|
| 193 |
+
"Numpy",
|
| 194 |
+
"OAuthProfile",
|
| 195 |
+
"OAuthToken",
|
| 196 |
+
"Paint",
|
| 197 |
+
"ParamViewer",
|
| 198 |
+
"PlayableVideo",
|
| 199 |
+
"Plot",
|
| 200 |
+
"Progress",
|
| 201 |
+
"Radio",
|
| 202 |
+
"Request",
|
| 203 |
+
"RetryData",
|
| 204 |
+
"Row",
|
| 205 |
+
"ScatterPlot",
|
| 206 |
+
"SelectData",
|
| 207 |
+
"SimpleCSVLogger",
|
| 208 |
+
"Sketchpad",
|
| 209 |
+
"Slider",
|
| 210 |
+
"State",
|
| 211 |
+
"Tab",
|
| 212 |
+
"TabItem",
|
| 213 |
+
"TabbedInterface",
|
| 214 |
+
"Tabs",
|
| 215 |
+
"Text",
|
| 216 |
+
"TextArea",
|
| 217 |
+
"Textbox",
|
| 218 |
+
"Theme",
|
| 219 |
+
"Timer",
|
| 220 |
+
"UndoData",
|
| 221 |
+
"UploadButton",
|
| 222 |
+
"Video",
|
| 223 |
+
"Warning",
|
| 224 |
+
"WaveformOptions",
|
| 225 |
+
"_simple_templates",
|
| 226 |
+
"close_all",
|
| 227 |
+
"component",
|
| 228 |
+
"components",
|
| 229 |
+
"deploy",
|
| 230 |
+
"get_package_version",
|
| 231 |
+
"image_utils",
|
| 232 |
+
"json",
|
| 233 |
+
"layouts",
|
| 234 |
+
"load",
|
| 235 |
+
"load_ipython_extension",
|
| 236 |
+
"mount_gradio_app",
|
| 237 |
+
"on",
|
| 238 |
+
"processing_utils",
|
| 239 |
+
"render",
|
| 240 |
+
"set_static_paths",
|
| 241 |
+
"skip",
|
| 242 |
+
"templates",
|
| 243 |
+
"themes",
|
| 244 |
+
"update",
|
| 245 |
+
]
|
src/ultimate_rvc/stubs/gradio/events.pyi
ADDED
|
@@ -0,0 +1,344 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Literal, NotRequired, Protocol, Self, TypedDict
|
| 2 |
+
|
| 3 |
+
import dataclasses
|
| 4 |
+
from collections import UserString
|
| 5 |
+
from collections.abc import Callable, Sequence
|
| 6 |
+
from collections.abc import Set as AbstractSet
|
| 7 |
+
|
| 8 |
+
from _typeshed import SupportsKeysAndGetItem
|
| 9 |
+
|
| 10 |
+
from gradio.blocks import Block, BlockContext, Component
|
| 11 |
+
from gradio.components import Timer
|
| 12 |
+
from gradio.data_classes import FileData, FileDataDict
|
| 13 |
+
|
| 14 |
+
type Dependency = _Dependency[Any, Any, Any]
|
| 15 |
+
type EventListenerCallable = _EventListenerCallable[Any, Any, Any]
|
| 16 |
+
type EventListener = _EventListener[Any, Any, Any]
|
| 17 |
+
|
| 18 |
+
class _EventListenerCallable[T, V, **P](Protocol):
|
| 19 |
+
def __call__(
|
| 20 |
+
self,
|
| 21 |
+
fn: Callable[P, T] | Literal["decorator"] | None = "decorator",
|
| 22 |
+
inputs: (
|
| 23 |
+
Component
|
| 24 |
+
| BlockContext
|
| 25 |
+
| Sequence[Component | BlockContext]
|
| 26 |
+
| AbstractSet[Component | BlockContext]
|
| 27 |
+
| None
|
| 28 |
+
) = None,
|
| 29 |
+
outputs: (
|
| 30 |
+
Component
|
| 31 |
+
| BlockContext
|
| 32 |
+
| Sequence[Component | BlockContext]
|
| 33 |
+
| AbstractSet[Component | BlockContext]
|
| 34 |
+
| None
|
| 35 |
+
) = None,
|
| 36 |
+
api_name: str | Literal[False] | None = None,
|
| 37 |
+
scroll_to_output: bool = False,
|
| 38 |
+
show_progress: Literal["full", "minimal", "hidden"] = "full",
|
| 39 |
+
queue: bool = True,
|
| 40 |
+
batch: bool = False,
|
| 41 |
+
max_batch_size: int = 4,
|
| 42 |
+
preprocess: bool = True,
|
| 43 |
+
postprocess: bool = True,
|
| 44 |
+
cancels: Dependency | list[Dependency] | None = None,
|
| 45 |
+
trigger_mode: Literal["once", "multiple", "always_last"] | None = None,
|
| 46 |
+
js: str | None = None,
|
| 47 |
+
concurrency_limit: int | Literal["default"] | None = "default",
|
| 48 |
+
concurrency_id: str | None = None,
|
| 49 |
+
show_api: bool = True,
|
| 50 |
+
stream_every: float = 0.5,
|
| 51 |
+
like_user_message: bool = False,
|
| 52 |
+
) -> _Dependency[T, V, P]: ...
|
| 53 |
+
|
| 54 |
+
class _EventListenerCallableFull[T, V, **P](Protocol):
|
| 55 |
+
def __call__(
|
| 56 |
+
self,
|
| 57 |
+
block: Block | None,
|
| 58 |
+
fn: Callable[P, T] | Literal["decorator"] | None = "decorator",
|
| 59 |
+
inputs: (
|
| 60 |
+
Component
|
| 61 |
+
| BlockContext
|
| 62 |
+
| Sequence[Component | BlockContext]
|
| 63 |
+
| AbstractSet[Component | BlockContext]
|
| 64 |
+
| None
|
| 65 |
+
) = None,
|
| 66 |
+
outputs: (
|
| 67 |
+
Component
|
| 68 |
+
| BlockContext
|
| 69 |
+
| Sequence[Component | BlockContext]
|
| 70 |
+
| AbstractSet[Component | BlockContext]
|
| 71 |
+
| None
|
| 72 |
+
) = None,
|
| 73 |
+
api_name: str | Literal[False] | None = None,
|
| 74 |
+
scroll_to_output: bool = False,
|
| 75 |
+
show_progress: Literal["full", "minimal", "hidden"] = "full",
|
| 76 |
+
queue: bool = True,
|
| 77 |
+
batch: bool = False,
|
| 78 |
+
max_batch_size: int = 4,
|
| 79 |
+
preprocess: bool = True,
|
| 80 |
+
postprocess: bool = True,
|
| 81 |
+
cancels: Dependency | list[Dependency] | None = None,
|
| 82 |
+
trigger_mode: Literal["once", "multiple", "always_last"] | None = None,
|
| 83 |
+
js: str | None = None,
|
| 84 |
+
concurrency_limit: int | Literal["default"] | None = "default",
|
| 85 |
+
concurrency_id: str | None = None,
|
| 86 |
+
show_api: bool = True,
|
| 87 |
+
time_limit: int | None = None,
|
| 88 |
+
stream_every: float = 0.5,
|
| 89 |
+
like_user_message: bool = False,
|
| 90 |
+
) -> _Dependency[T, V, P]: ...
|
| 91 |
+
|
| 92 |
+
def set_cancel_events(
|
| 93 |
+
triggers: Sequence[EventListenerMethod],
|
| 94 |
+
cancels: Dependency | list[Dependency] | None,
|
| 95 |
+
) -> None: ...
|
| 96 |
+
|
| 97 |
+
class _Dependency[T, V, **P](dict[str, V]):
|
| 98 |
+
fn: Callable[P, T]
|
| 99 |
+
associated_timer: Timer | None
|
| 100 |
+
then: EventListenerCallable
|
| 101 |
+
success: EventListenerCallable
|
| 102 |
+
|
| 103 |
+
def __init__(
|
| 104 |
+
self,
|
| 105 |
+
trigger: Block | None,
|
| 106 |
+
key_vals: SupportsKeysAndGetItem[str, V],
|
| 107 |
+
dep_index: int | None,
|
| 108 |
+
fn: Callable[P, T],
|
| 109 |
+
associated_timer: Timer | None = None,
|
| 110 |
+
) -> None: ...
|
| 111 |
+
def __call__(self, *args: P.args, **kwargs: P.kwargs) -> T: ...
|
| 112 |
+
|
| 113 |
+
class EventData[T]:
|
| 114 |
+
target: Block | None
|
| 115 |
+
_data: T
|
| 116 |
+
|
| 117 |
+
def __init__(self, target: Block | None, _data: T) -> None: ...
|
| 118 |
+
|
| 119 |
+
class _SelectData(TypedDict):
|
| 120 |
+
index: int | tuple[int, int]
|
| 121 |
+
value: Any
|
| 122 |
+
row_value: NotRequired[list[Any]]
|
| 123 |
+
col_value: NotRequired[list[Any]]
|
| 124 |
+
selected: NotRequired[bool]
|
| 125 |
+
|
| 126 |
+
class SelectData(EventData[_SelectData]):
|
| 127 |
+
index: int | tuple[int, int]
|
| 128 |
+
value: Any
|
| 129 |
+
row_value: list[Any] | None
|
| 130 |
+
col_value: list[Any] | None
|
| 131 |
+
selected: bool
|
| 132 |
+
|
| 133 |
+
def __init__(self, target: Block | None, data: _SelectData) -> None: ...
|
| 134 |
+
|
| 135 |
+
class _KeyUpData(TypedDict):
|
| 136 |
+
key: str
|
| 137 |
+
input_value: str
|
| 138 |
+
|
| 139 |
+
class KeyUpData(EventData[_KeyUpData]):
|
| 140 |
+
key: str
|
| 141 |
+
input_value: str
|
| 142 |
+
|
| 143 |
+
def __init__(self, target: Block | None, data: _KeyUpData) -> None: ...
|
| 144 |
+
|
| 145 |
+
class DeletedFileData(EventData[FileDataDict]):
|
| 146 |
+
file: FileData
|
| 147 |
+
|
| 148 |
+
def __init__(self, target: Block | None, data: FileDataDict) -> None: ...
|
| 149 |
+
|
| 150 |
+
class _LikeData(TypedDict):
|
| 151 |
+
index: int | tuple[int, int]
|
| 152 |
+
value: Any
|
| 153 |
+
liked: NotRequired[bool]
|
| 154 |
+
|
| 155 |
+
class LikeData(EventData[_LikeData]):
|
| 156 |
+
index: int | tuple[int, int]
|
| 157 |
+
value: Any
|
| 158 |
+
liked: bool
|
| 159 |
+
|
| 160 |
+
def __init__(self, target: Block | None, data: _LikeData) -> None: ...
|
| 161 |
+
|
| 162 |
+
class _RetryData(TypedDict):
|
| 163 |
+
index: int | tuple[int, int]
|
| 164 |
+
value: Any
|
| 165 |
+
|
| 166 |
+
class RetryData(EventData[_RetryData]):
|
| 167 |
+
index: int | tuple[int, int]
|
| 168 |
+
value: Any
|
| 169 |
+
|
| 170 |
+
def __init__(self, target: Block | None, data: _RetryData) -> None: ...
|
| 171 |
+
|
| 172 |
+
class _UndoData(TypedDict):
|
| 173 |
+
index: int | tuple[int, int]
|
| 174 |
+
value: Any
|
| 175 |
+
|
| 176 |
+
class UndoData(EventData[_UndoData]):
|
| 177 |
+
index: int | tuple[int, int]
|
| 178 |
+
value: Any
|
| 179 |
+
|
| 180 |
+
def __init__(self, target: Block | None, data: _UndoData) -> None: ...
|
| 181 |
+
|
| 182 |
+
class DownloadData(EventData[FileDataDict]):
|
| 183 |
+
file: FileData
|
| 184 |
+
|
| 185 |
+
def __init__(self, target: Block | None, data: FileDataDict) -> None: ...
|
| 186 |
+
|
| 187 |
+
@dataclasses.dataclass
|
| 188 |
+
class EventListenerMethod:
|
| 189 |
+
block: Block | None
|
| 190 |
+
event_name: str
|
| 191 |
+
|
| 192 |
+
class _EventListener[T, V, **P](UserString):
|
| 193 |
+
__slots__ = (
|
| 194 |
+
"callback",
|
| 195 |
+
"config_data",
|
| 196 |
+
"connection",
|
| 197 |
+
"doc",
|
| 198 |
+
"event_name",
|
| 199 |
+
"event_specific_args",
|
| 200 |
+
"has_trigger",
|
| 201 |
+
"listener",
|
| 202 |
+
"show_progress",
|
| 203 |
+
"trigger_after",
|
| 204 |
+
"trigger_only_on_success",
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
event_name: str
|
| 208 |
+
has_trigger: bool
|
| 209 |
+
config_data: Callable[..., dict[str, T]]
|
| 210 |
+
show_progress: Literal["full", "minimal", "hidden"]
|
| 211 |
+
callback: Callable[[Block], None] | None
|
| 212 |
+
trigger_after: int | None
|
| 213 |
+
trigger_only_on_success: bool
|
| 214 |
+
doc: str
|
| 215 |
+
connection: Literal["sse", "stream"]
|
| 216 |
+
event_specific_args: list[dict[str, str]]
|
| 217 |
+
listener: _EventListenerCallableFull[T, V, P]
|
| 218 |
+
|
| 219 |
+
def __new__(
|
| 220 |
+
cls,
|
| 221 |
+
event_name: str,
|
| 222 |
+
has_trigger: bool = True,
|
| 223 |
+
config_data: Callable[..., dict[str, T]] = dict, # noqa: PYI011
|
| 224 |
+
show_progress: Literal["full", "minimal", "hidden"] = "full",
|
| 225 |
+
callback: Callable[[Block], None] | None = None,
|
| 226 |
+
trigger_after: int | None = None,
|
| 227 |
+
trigger_only_on_success: bool = False,
|
| 228 |
+
doc: str = "",
|
| 229 |
+
connection: Literal["sse", "stream"] = "sse",
|
| 230 |
+
event_specific_args: list[dict[str, str]] | None = None,
|
| 231 |
+
) -> Self: ...
|
| 232 |
+
def __init__(
|
| 233 |
+
self,
|
| 234 |
+
event_name: str,
|
| 235 |
+
has_trigger: bool = True,
|
| 236 |
+
config_data: Callable[..., dict[str, T]] = dict, # noqa: PYI011
|
| 237 |
+
show_progress: Literal["full", "minimal", "hidden"] = "full",
|
| 238 |
+
callback: Callable[[Block], None] | None = None,
|
| 239 |
+
trigger_after: int | None = None,
|
| 240 |
+
trigger_only_on_success: bool = False,
|
| 241 |
+
doc: str = "",
|
| 242 |
+
connection: Literal["sse", "stream"] = "sse",
|
| 243 |
+
event_specific_args: list[dict[str, str]] | None = None,
|
| 244 |
+
) -> None: ...
|
| 245 |
+
def set_doc(self, component: str) -> None: ...
|
| 246 |
+
def copy(self) -> _EventListener[T, V, P]: ...
|
| 247 |
+
@staticmethod
|
| 248 |
+
def _setup(
|
| 249 |
+
_event_name: str,
|
| 250 |
+
_has_trigger: bool,
|
| 251 |
+
_show_progress: Literal["full", "minimal", "hidden"],
|
| 252 |
+
_callback: Callable[[Block], None] | None,
|
| 253 |
+
_trigger_after: int | None,
|
| 254 |
+
_trigger_only_on_success: bool,
|
| 255 |
+
_event_specific_args: list[dict[str, str]],
|
| 256 |
+
_connection: Literal["sse", "stream"] = "sse",
|
| 257 |
+
) -> _EventListenerCallableFull[T, V, P]: ...
|
| 258 |
+
|
| 259 |
+
def on[T, **P](
|
| 260 |
+
triggers: Sequence[EventListenerCallable] | EventListenerCallable | None = None,
|
| 261 |
+
fn: Callable[P, T] | Literal["decorator"] | None = "decorator",
|
| 262 |
+
inputs: (
|
| 263 |
+
Component
|
| 264 |
+
| BlockContext
|
| 265 |
+
| Sequence[Component | BlockContext]
|
| 266 |
+
| AbstractSet[Component | BlockContext]
|
| 267 |
+
| None
|
| 268 |
+
) = None,
|
| 269 |
+
outputs: (
|
| 270 |
+
Component
|
| 271 |
+
| BlockContext
|
| 272 |
+
| Sequence[Component | BlockContext]
|
| 273 |
+
| AbstractSet[Component | BlockContext]
|
| 274 |
+
| None
|
| 275 |
+
) = None,
|
| 276 |
+
*,
|
| 277 |
+
api_name: str | Literal[False] | None = None,
|
| 278 |
+
scroll_to_output: bool = False,
|
| 279 |
+
show_progress: Literal["full", "minimal", "hidden"] = "full",
|
| 280 |
+
queue: bool = True,
|
| 281 |
+
batch: bool = False,
|
| 282 |
+
max_batch_size: int = 4,
|
| 283 |
+
preprocess: bool = True,
|
| 284 |
+
postprocess: bool = True,
|
| 285 |
+
cancels: Dependency | list[Dependency] | None = None,
|
| 286 |
+
trigger_mode: Literal["once", "multiple", "always_last"] | None = None,
|
| 287 |
+
js: str | None = None,
|
| 288 |
+
concurrency_limit: int | Literal["default"] | None = "default",
|
| 289 |
+
concurrency_id: str | None = None,
|
| 290 |
+
show_api: bool = True,
|
| 291 |
+
time_limit: int | None = None,
|
| 292 |
+
stream_every: float = 0.5,
|
| 293 |
+
) -> _Dependency[T, Any, P]: ...
|
| 294 |
+
|
| 295 |
+
class Events:
|
| 296 |
+
change: EventListener
|
| 297 |
+
input: EventListener
|
| 298 |
+
click: EventListener
|
| 299 |
+
double_click: EventListener
|
| 300 |
+
submit: EventListener
|
| 301 |
+
edit: EventListener
|
| 302 |
+
clear: EventListener
|
| 303 |
+
play: EventListener
|
| 304 |
+
pause: EventListener
|
| 305 |
+
stop: EventListener
|
| 306 |
+
end: EventListener
|
| 307 |
+
start_recording: EventListener
|
| 308 |
+
pause_recording: EventListener
|
| 309 |
+
stop_recording: EventListener
|
| 310 |
+
focus: EventListener
|
| 311 |
+
blur: EventListener
|
| 312 |
+
upload: EventListener
|
| 313 |
+
release: EventListener
|
| 314 |
+
select: EventListener
|
| 315 |
+
stream: EventListener
|
| 316 |
+
like: EventListener
|
| 317 |
+
example_select: EventListener
|
| 318 |
+
load: EventListener
|
| 319 |
+
key_up: EventListener
|
| 320 |
+
apply: EventListener
|
| 321 |
+
delete: EventListener
|
| 322 |
+
tick: EventListener
|
| 323 |
+
undo: EventListener
|
| 324 |
+
retry: EventListener
|
| 325 |
+
expand: EventListener
|
| 326 |
+
collapse: EventListener
|
| 327 |
+
download: EventListener
|
| 328 |
+
|
| 329 |
+
__all__ = [
|
| 330 |
+
"DeletedFileData",
|
| 331 |
+
"Dependency",
|
| 332 |
+
"DownloadData",
|
| 333 |
+
"EventData",
|
| 334 |
+
"EventListener",
|
| 335 |
+
"EventListenerMethod",
|
| 336 |
+
"Events",
|
| 337 |
+
"KeyUpData",
|
| 338 |
+
"LikeData",
|
| 339 |
+
"RetryData",
|
| 340 |
+
"SelectData",
|
| 341 |
+
"UndoData",
|
| 342 |
+
"on",
|
| 343 |
+
"set_cancel_events",
|
| 344 |
+
]
|
src/ultimate_rvc/stubs/pedalboard_native/io/__init__.pyi
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Literal, Self, overload
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
from numpy.typing import NDArray
|
| 5 |
+
|
| 6 |
+
class AudioFile:
|
| 7 |
+
@classmethod
|
| 8 |
+
@overload
|
| 9 |
+
def __new__(
|
| 10 |
+
cls: object,
|
| 11 |
+
filename: str,
|
| 12 |
+
mode: Literal["r"] = "r",
|
| 13 |
+
) -> ReadableAudioFile: ...
|
| 14 |
+
@classmethod
|
| 15 |
+
@overload
|
| 16 |
+
def __new__(
|
| 17 |
+
cls: object,
|
| 18 |
+
filename: str,
|
| 19 |
+
mode: Literal["w"],
|
| 20 |
+
samplerate: float | None = None,
|
| 21 |
+
num_channels: int = 1,
|
| 22 |
+
bit_depth: int = 16,
|
| 23 |
+
quality: str | float | None = None,
|
| 24 |
+
) -> WriteableAudioFile: ...
|
| 25 |
+
|
| 26 |
+
class ReadableAudioFile(AudioFile):
|
| 27 |
+
def __enter__(self) -> Self: ...
|
| 28 |
+
def __exit__(self, arg0: object, arg1: object, arg2: object) -> None: ...
|
| 29 |
+
def read(self, num_frames: float = 0) -> NDArray[np.float32]: ...
|
| 30 |
+
def tell(self) -> int: ...
|
| 31 |
+
@property
|
| 32 |
+
def frames(self) -> int: ...
|
| 33 |
+
@property
|
| 34 |
+
def num_channels(self) -> int: ...
|
| 35 |
+
@property
|
| 36 |
+
def samplerate(self) -> float | int: ...
|
| 37 |
+
|
| 38 |
+
class WriteableAudioFile(AudioFile):
|
| 39 |
+
def __enter__(self) -> Self: ...
|
| 40 |
+
def __exit__(self, arg0: object, arg1: object, arg2: object) -> None: ...
|
| 41 |
+
def write(self, samples: NDArray[...]) -> None: ...
|
src/ultimate_rvc/stubs/soundfile/__init__.pyi
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Literal
|
| 2 |
+
|
| 3 |
+
from os import PathLike
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
from numpy.typing import NDArray
|
| 7 |
+
|
| 8 |
+
type DEFAULT_NDARRAY = NDArray[np.float64 | np.float32 | np.int32 | np.int16]
|
| 9 |
+
|
| 10 |
+
def read(
|
| 11 |
+
file: int | str | PathLike[str] | PathLike[bytes],
|
| 12 |
+
frames: int = -1,
|
| 13 |
+
start: int = 0,
|
| 14 |
+
stop: int | None = None,
|
| 15 |
+
dtype: Literal["float64", "float32", "int32", "int16"] = "float64",
|
| 16 |
+
always_2d: bool = False,
|
| 17 |
+
fill_value: float | None = None,
|
| 18 |
+
out: DEFAULT_NDARRAY | None = None,
|
| 19 |
+
samplerate: int | None = None,
|
| 20 |
+
channels: int | None = None,
|
| 21 |
+
format: str | None = None, # noqa: A002
|
| 22 |
+
subtype: str | None = None,
|
| 23 |
+
endian: Literal["FILE", "LITTLE", "BIG", "CPU"] | None = None,
|
| 24 |
+
closefd: bool | None = True,
|
| 25 |
+
) -> tuple[DEFAULT_NDARRAY, int]: ...
|
| 26 |
+
def write(
|
| 27 |
+
file: int | str | PathLike[str] | PathLike[bytes],
|
| 28 |
+
data: DEFAULT_NDARRAY,
|
| 29 |
+
samplerate: int,
|
| 30 |
+
subtype: str | None = None,
|
| 31 |
+
endian: Literal["FILE", "LITTLE", "BIG", "CPU"] | None = None,
|
| 32 |
+
format: str | None = None, # noqa: A002
|
| 33 |
+
closefd: bool | None = True,
|
| 34 |
+
) -> None: ...
|
src/ultimate_rvc/stubs/sox/__init__.pyi
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Self
|
| 2 |
+
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
|
| 5 |
+
from numpy.typing import NDArray
|
| 6 |
+
|
| 7 |
+
class Transformer:
|
| 8 |
+
def pitch(
|
| 9 |
+
self,
|
| 10 |
+
n_semitones: float,
|
| 11 |
+
quick: bool = False,
|
| 12 |
+
) -> Self: ...
|
| 13 |
+
def build_array(
|
| 14 |
+
self,
|
| 15 |
+
input_filepath: str | Path | None = None,
|
| 16 |
+
input_array: NDArray[...] | None = None,
|
| 17 |
+
sample_rate_in: float | None = None,
|
| 18 |
+
extra_args: list[str] | None = None,
|
| 19 |
+
) -> NDArray[...]: ...
|
src/ultimate_rvc/stubs/static_ffmpeg/__init__.pyi
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
def add_paths(weak: bool = False) -> bool: ...
|
src/ultimate_rvc/stubs/static_sox/__init__.pyi
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
def add_paths(weak: bool = False) -> bool: ...
|
src/ultimate_rvc/stubs/yt_dlp/__init__.pyi
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Self
|
| 2 |
+
|
| 3 |
+
class YoutubeDL:
|
| 4 |
+
def __init__(
|
| 5 |
+
self,
|
| 6 |
+
params: dict[str, Any] | None = None,
|
| 7 |
+
auto_init: bool = True,
|
| 8 |
+
) -> None: ...
|
| 9 |
+
def extract_info(
|
| 10 |
+
self,
|
| 11 |
+
url: str,
|
| 12 |
+
download: bool = True,
|
| 13 |
+
ie_key: str | None = None,
|
| 14 |
+
extra_info: dict[str, Any] | None = None,
|
| 15 |
+
process: bool = True,
|
| 16 |
+
force_generic_extractor: bool = False,
|
| 17 |
+
) -> dict[str, Any]: ...
|
| 18 |
+
def prepare_filename(
|
| 19 |
+
self,
|
| 20 |
+
info_dict: dict[str, Any],
|
| 21 |
+
dir_type: str = "",
|
| 22 |
+
*,
|
| 23 |
+
outtmpl: str | None = None,
|
| 24 |
+
warn: bool = False,
|
| 25 |
+
) -> str: ...
|
| 26 |
+
def __enter__(self) -> Self: ...
|
| 27 |
+
def __exit__(self, *args: object) -> None: ...
|
src/ultimate_rvc/typing_extra.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Extra typing for the Ultimate RVC project."""
|
| 2 |
+
|
| 3 |
+
from collections.abc import Mapping, Sequence
|
| 4 |
+
from enum import IntEnum, StrEnum
|
| 5 |
+
from os import PathLike
|
| 6 |
+
|
| 7 |
+
type StrPath = str | PathLike[str]
|
| 8 |
+
|
| 9 |
+
type Json = Mapping[str, Json] | Sequence[Json] | str | int | float | bool | None
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class SeparationModel(StrEnum):
|
| 13 |
+
"""The model to use for audio separation."""
|
| 14 |
+
|
| 15 |
+
UVR_MDX_NET_VOC_FT = "UVR-MDX-NET-Voc_FT.onnx"
|
| 16 |
+
UVR_MDX_NET_KARA_2 = "UVR_MDXNET_KARA_2.onnx"
|
| 17 |
+
REVERB_HQ_BY_FOXJOY = "Reverb_HQ_By_FoxJoy.onnx"
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class SegmentSize(IntEnum):
|
| 21 |
+
"""The segment size to use for audio separation."""
|
| 22 |
+
|
| 23 |
+
SEG_64 = 64
|
| 24 |
+
SEG_128 = 128
|
| 25 |
+
SEG_256 = 256
|
| 26 |
+
SEG_512 = 512
|
| 27 |
+
SEG_1024 = 1024
|
| 28 |
+
SEG_2048 = 2048
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class F0Method(StrEnum):
|
| 32 |
+
"""The method to use for pitch detection."""
|
| 33 |
+
|
| 34 |
+
RMVPE = "rmvpe"
|
| 35 |
+
MANGIO_CREPE = "mangio-crepe"
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class SampleRate(IntEnum):
|
| 39 |
+
"""The sample rate of an audio file."""
|
| 40 |
+
|
| 41 |
+
HZ_16000 = 16000
|
| 42 |
+
HZ_44100 = 44100
|
| 43 |
+
HZ_48000 = 48000
|
| 44 |
+
HZ_96000 = 96000
|
| 45 |
+
HZ_192000 = 192000
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class AudioExt(StrEnum):
|
| 49 |
+
"""Audio file formats."""
|
| 50 |
+
|
| 51 |
+
MP3 = "mp3"
|
| 52 |
+
WAV = "wav"
|
| 53 |
+
FLAC = "flac"
|
| 54 |
+
OGG = "ogg"
|
| 55 |
+
M4A = "m4a"
|
| 56 |
+
AAC = "aac"
|
src/ultimate_rvc/vc/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Voice conversion package for the Ultimate RVC project.
|
| 3 |
+
|
| 4 |
+
This package contains modules exposing functionality that enable voice
|
| 5 |
+
conversion using RVC. The implementation code is primarily built on
|
| 6 |
+
PyTorch to achieve high-performant processing using GPU acceleration.
|
| 7 |
+
|
| 8 |
+
"""
|
src/ultimate_rvc/vc/configs/32k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": false,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 32000,
|
| 21 |
+
"filter_length": 1024,
|
| 22 |
+
"hop_length": 320,
|
| 23 |
+
"win_length": 1024,
|
| 24 |
+
"n_mel_channels": 80,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,4,2,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/ultimate_rvc/vc/configs/32k_v2.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 32000,
|
| 21 |
+
"filter_length": 1024,
|
| 22 |
+
"hop_length": 320,
|
| 23 |
+
"win_length": 1024,
|
| 24 |
+
"n_mel_channels": 80,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,8,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [20,16,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/ultimate_rvc/vc/configs/40k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": false,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 12800,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 40000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 400,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 125,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,10,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/ultimate_rvc/vc/configs/48k.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": false,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 11520,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 48000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 480,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 128,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [10,6,2,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [16,16,4,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/ultimate_rvc/vc/configs/48k_v2.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train": {
|
| 3 |
+
"log_interval": 200,
|
| 4 |
+
"seed": 1234,
|
| 5 |
+
"epochs": 20000,
|
| 6 |
+
"learning_rate": 1e-4,
|
| 7 |
+
"betas": [0.8, 0.99],
|
| 8 |
+
"eps": 1e-9,
|
| 9 |
+
"batch_size": 4,
|
| 10 |
+
"fp16_run": true,
|
| 11 |
+
"lr_decay": 0.999875,
|
| 12 |
+
"segment_size": 17280,
|
| 13 |
+
"init_lr_ratio": 1,
|
| 14 |
+
"warmup_epochs": 0,
|
| 15 |
+
"c_mel": 45,
|
| 16 |
+
"c_kl": 1.0
|
| 17 |
+
},
|
| 18 |
+
"data": {
|
| 19 |
+
"max_wav_value": 32768.0,
|
| 20 |
+
"sampling_rate": 48000,
|
| 21 |
+
"filter_length": 2048,
|
| 22 |
+
"hop_length": 480,
|
| 23 |
+
"win_length": 2048,
|
| 24 |
+
"n_mel_channels": 128,
|
| 25 |
+
"mel_fmin": 0.0,
|
| 26 |
+
"mel_fmax": null
|
| 27 |
+
},
|
| 28 |
+
"model": {
|
| 29 |
+
"inter_channels": 192,
|
| 30 |
+
"hidden_channels": 192,
|
| 31 |
+
"filter_channels": 768,
|
| 32 |
+
"n_heads": 2,
|
| 33 |
+
"n_layers": 6,
|
| 34 |
+
"kernel_size": 3,
|
| 35 |
+
"p_dropout": 0,
|
| 36 |
+
"resblock": "1",
|
| 37 |
+
"resblock_kernel_sizes": [3,7,11],
|
| 38 |
+
"resblock_dilation_sizes": [[1,3,5], [1,3,5], [1,3,5]],
|
| 39 |
+
"upsample_rates": [12,10,2,2],
|
| 40 |
+
"upsample_initial_channel": 512,
|
| 41 |
+
"upsample_kernel_sizes": [24,20,4,4],
|
| 42 |
+
"use_spectral_norm": false,
|
| 43 |
+
"gin_channels": 256,
|
| 44 |
+
"spk_embed_dim": 109
|
| 45 |
+
}
|
| 46 |
+
}
|
src/ultimate_rvc/vc/infer_pack/attentions.py
ADDED
|
@@ -0,0 +1,417 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
from ultimate_rvc.vc.infer_pack import commons
|
| 9 |
+
from ultimate_rvc.vc.infer_pack import modules
|
| 10 |
+
from ultimate_rvc.vc.infer_pack.modules import LayerNorm
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Encoder(nn.Module):
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
hidden_channels,
|
| 17 |
+
filter_channels,
|
| 18 |
+
n_heads,
|
| 19 |
+
n_layers,
|
| 20 |
+
kernel_size=1,
|
| 21 |
+
p_dropout=0.0,
|
| 22 |
+
window_size=10,
|
| 23 |
+
**kwargs
|
| 24 |
+
):
|
| 25 |
+
super().__init__()
|
| 26 |
+
self.hidden_channels = hidden_channels
|
| 27 |
+
self.filter_channels = filter_channels
|
| 28 |
+
self.n_heads = n_heads
|
| 29 |
+
self.n_layers = n_layers
|
| 30 |
+
self.kernel_size = kernel_size
|
| 31 |
+
self.p_dropout = p_dropout
|
| 32 |
+
self.window_size = window_size
|
| 33 |
+
|
| 34 |
+
self.drop = nn.Dropout(p_dropout)
|
| 35 |
+
self.attn_layers = nn.ModuleList()
|
| 36 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 37 |
+
self.ffn_layers = nn.ModuleList()
|
| 38 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 39 |
+
for i in range(self.n_layers):
|
| 40 |
+
self.attn_layers.append(
|
| 41 |
+
MultiHeadAttention(
|
| 42 |
+
hidden_channels,
|
| 43 |
+
hidden_channels,
|
| 44 |
+
n_heads,
|
| 45 |
+
p_dropout=p_dropout,
|
| 46 |
+
window_size=window_size,
|
| 47 |
+
)
|
| 48 |
+
)
|
| 49 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 50 |
+
self.ffn_layers.append(
|
| 51 |
+
FFN(
|
| 52 |
+
hidden_channels,
|
| 53 |
+
hidden_channels,
|
| 54 |
+
filter_channels,
|
| 55 |
+
kernel_size,
|
| 56 |
+
p_dropout=p_dropout,
|
| 57 |
+
)
|
| 58 |
+
)
|
| 59 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 60 |
+
|
| 61 |
+
def forward(self, x, x_mask):
|
| 62 |
+
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 63 |
+
x = x * x_mask
|
| 64 |
+
for i in range(self.n_layers):
|
| 65 |
+
y = self.attn_layers[i](x, x, attn_mask)
|
| 66 |
+
y = self.drop(y)
|
| 67 |
+
x = self.norm_layers_1[i](x + y)
|
| 68 |
+
|
| 69 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 70 |
+
y = self.drop(y)
|
| 71 |
+
x = self.norm_layers_2[i](x + y)
|
| 72 |
+
x = x * x_mask
|
| 73 |
+
return x
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class Decoder(nn.Module):
|
| 77 |
+
def __init__(
|
| 78 |
+
self,
|
| 79 |
+
hidden_channels,
|
| 80 |
+
filter_channels,
|
| 81 |
+
n_heads,
|
| 82 |
+
n_layers,
|
| 83 |
+
kernel_size=1,
|
| 84 |
+
p_dropout=0.0,
|
| 85 |
+
proximal_bias=False,
|
| 86 |
+
proximal_init=True,
|
| 87 |
+
**kwargs
|
| 88 |
+
):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.hidden_channels = hidden_channels
|
| 91 |
+
self.filter_channels = filter_channels
|
| 92 |
+
self.n_heads = n_heads
|
| 93 |
+
self.n_layers = n_layers
|
| 94 |
+
self.kernel_size = kernel_size
|
| 95 |
+
self.p_dropout = p_dropout
|
| 96 |
+
self.proximal_bias = proximal_bias
|
| 97 |
+
self.proximal_init = proximal_init
|
| 98 |
+
|
| 99 |
+
self.drop = nn.Dropout(p_dropout)
|
| 100 |
+
self.self_attn_layers = nn.ModuleList()
|
| 101 |
+
self.norm_layers_0 = nn.ModuleList()
|
| 102 |
+
self.encdec_attn_layers = nn.ModuleList()
|
| 103 |
+
self.norm_layers_1 = nn.ModuleList()
|
| 104 |
+
self.ffn_layers = nn.ModuleList()
|
| 105 |
+
self.norm_layers_2 = nn.ModuleList()
|
| 106 |
+
for i in range(self.n_layers):
|
| 107 |
+
self.self_attn_layers.append(
|
| 108 |
+
MultiHeadAttention(
|
| 109 |
+
hidden_channels,
|
| 110 |
+
hidden_channels,
|
| 111 |
+
n_heads,
|
| 112 |
+
p_dropout=p_dropout,
|
| 113 |
+
proximal_bias=proximal_bias,
|
| 114 |
+
proximal_init=proximal_init,
|
| 115 |
+
)
|
| 116 |
+
)
|
| 117 |
+
self.norm_layers_0.append(LayerNorm(hidden_channels))
|
| 118 |
+
self.encdec_attn_layers.append(
|
| 119 |
+
MultiHeadAttention(
|
| 120 |
+
hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
|
| 121 |
+
)
|
| 122 |
+
)
|
| 123 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 124 |
+
self.ffn_layers.append(
|
| 125 |
+
FFN(
|
| 126 |
+
hidden_channels,
|
| 127 |
+
hidden_channels,
|
| 128 |
+
filter_channels,
|
| 129 |
+
kernel_size,
|
| 130 |
+
p_dropout=p_dropout,
|
| 131 |
+
causal=True,
|
| 132 |
+
)
|
| 133 |
+
)
|
| 134 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 135 |
+
|
| 136 |
+
def forward(self, x, x_mask, h, h_mask):
|
| 137 |
+
"""
|
| 138 |
+
x: decoder input
|
| 139 |
+
h: encoder output
|
| 140 |
+
"""
|
| 141 |
+
self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
|
| 142 |
+
device=x.device, dtype=x.dtype
|
| 143 |
+
)
|
| 144 |
+
encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 145 |
+
x = x * x_mask
|
| 146 |
+
for i in range(self.n_layers):
|
| 147 |
+
y = self.self_attn_layers[i](x, x, self_attn_mask)
|
| 148 |
+
y = self.drop(y)
|
| 149 |
+
x = self.norm_layers_0[i](x + y)
|
| 150 |
+
|
| 151 |
+
y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
|
| 152 |
+
y = self.drop(y)
|
| 153 |
+
x = self.norm_layers_1[i](x + y)
|
| 154 |
+
|
| 155 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 156 |
+
y = self.drop(y)
|
| 157 |
+
x = self.norm_layers_2[i](x + y)
|
| 158 |
+
x = x * x_mask
|
| 159 |
+
return x
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class MultiHeadAttention(nn.Module):
|
| 163 |
+
def __init__(
|
| 164 |
+
self,
|
| 165 |
+
channels,
|
| 166 |
+
out_channels,
|
| 167 |
+
n_heads,
|
| 168 |
+
p_dropout=0.0,
|
| 169 |
+
window_size=None,
|
| 170 |
+
heads_share=True,
|
| 171 |
+
block_length=None,
|
| 172 |
+
proximal_bias=False,
|
| 173 |
+
proximal_init=False,
|
| 174 |
+
):
|
| 175 |
+
super().__init__()
|
| 176 |
+
assert channels % n_heads == 0
|
| 177 |
+
|
| 178 |
+
self.channels = channels
|
| 179 |
+
self.out_channels = out_channels
|
| 180 |
+
self.n_heads = n_heads
|
| 181 |
+
self.p_dropout = p_dropout
|
| 182 |
+
self.window_size = window_size
|
| 183 |
+
self.heads_share = heads_share
|
| 184 |
+
self.block_length = block_length
|
| 185 |
+
self.proximal_bias = proximal_bias
|
| 186 |
+
self.proximal_init = proximal_init
|
| 187 |
+
self.attn = None
|
| 188 |
+
|
| 189 |
+
self.k_channels = channels // n_heads
|
| 190 |
+
self.conv_q = nn.Conv1d(channels, channels, 1)
|
| 191 |
+
self.conv_k = nn.Conv1d(channels, channels, 1)
|
| 192 |
+
self.conv_v = nn.Conv1d(channels, channels, 1)
|
| 193 |
+
self.conv_o = nn.Conv1d(channels, out_channels, 1)
|
| 194 |
+
self.drop = nn.Dropout(p_dropout)
|
| 195 |
+
|
| 196 |
+
if window_size is not None:
|
| 197 |
+
n_heads_rel = 1 if heads_share else n_heads
|
| 198 |
+
rel_stddev = self.k_channels**-0.5
|
| 199 |
+
self.emb_rel_k = nn.Parameter(
|
| 200 |
+
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
|
| 201 |
+
* rel_stddev
|
| 202 |
+
)
|
| 203 |
+
self.emb_rel_v = nn.Parameter(
|
| 204 |
+
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
|
| 205 |
+
* rel_stddev
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
nn.init.xavier_uniform_(self.conv_q.weight)
|
| 209 |
+
nn.init.xavier_uniform_(self.conv_k.weight)
|
| 210 |
+
nn.init.xavier_uniform_(self.conv_v.weight)
|
| 211 |
+
if proximal_init:
|
| 212 |
+
with torch.no_grad():
|
| 213 |
+
self.conv_k.weight.copy_(self.conv_q.weight)
|
| 214 |
+
self.conv_k.bias.copy_(self.conv_q.bias)
|
| 215 |
+
|
| 216 |
+
def forward(self, x, c, attn_mask=None):
|
| 217 |
+
q = self.conv_q(x)
|
| 218 |
+
k = self.conv_k(c)
|
| 219 |
+
v = self.conv_v(c)
|
| 220 |
+
|
| 221 |
+
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
| 222 |
+
|
| 223 |
+
x = self.conv_o(x)
|
| 224 |
+
return x
|
| 225 |
+
|
| 226 |
+
def attention(self, query, key, value, mask=None):
|
| 227 |
+
# reshape [b, d, t] -> [b, n_h, t, d_k]
|
| 228 |
+
b, d, t_s, t_t = (*key.size(), query.size(2))
|
| 229 |
+
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
| 230 |
+
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 231 |
+
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 232 |
+
|
| 233 |
+
scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
|
| 234 |
+
if self.window_size is not None:
|
| 235 |
+
assert (
|
| 236 |
+
t_s == t_t
|
| 237 |
+
), "Relative attention is only available for self-attention."
|
| 238 |
+
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
| 239 |
+
rel_logits = self._matmul_with_relative_keys(
|
| 240 |
+
query / math.sqrt(self.k_channels), key_relative_embeddings
|
| 241 |
+
)
|
| 242 |
+
scores_local = self._relative_position_to_absolute_position(rel_logits)
|
| 243 |
+
scores = scores + scores_local
|
| 244 |
+
if self.proximal_bias:
|
| 245 |
+
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
| 246 |
+
scores = scores + self._attention_bias_proximal(t_s).to(
|
| 247 |
+
device=scores.device, dtype=scores.dtype
|
| 248 |
+
)
|
| 249 |
+
if mask is not None:
|
| 250 |
+
scores = scores.masked_fill(mask == 0, -1e4)
|
| 251 |
+
if self.block_length is not None:
|
| 252 |
+
assert (
|
| 253 |
+
t_s == t_t
|
| 254 |
+
), "Local attention is only available for self-attention."
|
| 255 |
+
block_mask = (
|
| 256 |
+
torch.ones_like(scores)
|
| 257 |
+
.triu(-self.block_length)
|
| 258 |
+
.tril(self.block_length)
|
| 259 |
+
)
|
| 260 |
+
scores = scores.masked_fill(block_mask == 0, -1e4)
|
| 261 |
+
p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
|
| 262 |
+
p_attn = self.drop(p_attn)
|
| 263 |
+
output = torch.matmul(p_attn, value)
|
| 264 |
+
if self.window_size is not None:
|
| 265 |
+
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
| 266 |
+
value_relative_embeddings = self._get_relative_embeddings(
|
| 267 |
+
self.emb_rel_v, t_s
|
| 268 |
+
)
|
| 269 |
+
output = output + self._matmul_with_relative_values(
|
| 270 |
+
relative_weights, value_relative_embeddings
|
| 271 |
+
)
|
| 272 |
+
output = (
|
| 273 |
+
output.transpose(2, 3).contiguous().view(b, d, t_t)
|
| 274 |
+
) # [b, n_h, t_t, d_k] -> [b, d, t_t]
|
| 275 |
+
return output, p_attn
|
| 276 |
+
|
| 277 |
+
def _matmul_with_relative_values(self, x, y):
|
| 278 |
+
"""
|
| 279 |
+
x: [b, h, l, m]
|
| 280 |
+
y: [h or 1, m, d]
|
| 281 |
+
ret: [b, h, l, d]
|
| 282 |
+
"""
|
| 283 |
+
ret = torch.matmul(x, y.unsqueeze(0))
|
| 284 |
+
return ret
|
| 285 |
+
|
| 286 |
+
def _matmul_with_relative_keys(self, x, y):
|
| 287 |
+
"""
|
| 288 |
+
x: [b, h, l, d]
|
| 289 |
+
y: [h or 1, m, d]
|
| 290 |
+
ret: [b, h, l, m]
|
| 291 |
+
"""
|
| 292 |
+
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
| 293 |
+
return ret
|
| 294 |
+
|
| 295 |
+
def _get_relative_embeddings(self, relative_embeddings, length):
|
| 296 |
+
max_relative_position = 2 * self.window_size + 1
|
| 297 |
+
# Pad first before slice to avoid using cond ops.
|
| 298 |
+
pad_length = max(length - (self.window_size + 1), 0)
|
| 299 |
+
slice_start_position = max((self.window_size + 1) - length, 0)
|
| 300 |
+
slice_end_position = slice_start_position + 2 * length - 1
|
| 301 |
+
if pad_length > 0:
|
| 302 |
+
padded_relative_embeddings = F.pad(
|
| 303 |
+
relative_embeddings,
|
| 304 |
+
commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
|
| 305 |
+
)
|
| 306 |
+
else:
|
| 307 |
+
padded_relative_embeddings = relative_embeddings
|
| 308 |
+
used_relative_embeddings = padded_relative_embeddings[
|
| 309 |
+
:, slice_start_position:slice_end_position
|
| 310 |
+
]
|
| 311 |
+
return used_relative_embeddings
|
| 312 |
+
|
| 313 |
+
def _relative_position_to_absolute_position(self, x):
|
| 314 |
+
"""
|
| 315 |
+
x: [b, h, l, 2*l-1]
|
| 316 |
+
ret: [b, h, l, l]
|
| 317 |
+
"""
|
| 318 |
+
batch, heads, length, _ = x.size()
|
| 319 |
+
# Concat columns of pad to shift from relative to absolute indexing.
|
| 320 |
+
x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
|
| 321 |
+
|
| 322 |
+
# Concat extra elements so to add up to shape (len+1, 2*len-1).
|
| 323 |
+
x_flat = x.view([batch, heads, length * 2 * length])
|
| 324 |
+
x_flat = F.pad(
|
| 325 |
+
x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]])
|
| 326 |
+
)
|
| 327 |
+
|
| 328 |
+
# Reshape and slice out the padded elements.
|
| 329 |
+
x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
|
| 330 |
+
:, :, :length, length - 1 :
|
| 331 |
+
]
|
| 332 |
+
return x_final
|
| 333 |
+
|
| 334 |
+
def _absolute_position_to_relative_position(self, x):
|
| 335 |
+
"""
|
| 336 |
+
x: [b, h, l, l]
|
| 337 |
+
ret: [b, h, l, 2*l-1]
|
| 338 |
+
"""
|
| 339 |
+
batch, heads, length, _ = x.size()
|
| 340 |
+
# padd along column
|
| 341 |
+
x = F.pad(
|
| 342 |
+
x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]])
|
| 343 |
+
)
|
| 344 |
+
x_flat = x.view([batch, heads, length**2 + length * (length - 1)])
|
| 345 |
+
# add 0's in the beginning that will skew the elements after reshape
|
| 346 |
+
x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
| 347 |
+
x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
|
| 348 |
+
return x_final
|
| 349 |
+
|
| 350 |
+
def _attention_bias_proximal(self, length):
|
| 351 |
+
"""Bias for self-attention to encourage attention to close positions.
|
| 352 |
+
Args:
|
| 353 |
+
length: an integer scalar.
|
| 354 |
+
Returns:
|
| 355 |
+
a Tensor with shape [1, 1, length, length]
|
| 356 |
+
"""
|
| 357 |
+
r = torch.arange(length, dtype=torch.float32)
|
| 358 |
+
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
| 359 |
+
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
class FFN(nn.Module):
|
| 363 |
+
def __init__(
|
| 364 |
+
self,
|
| 365 |
+
in_channels,
|
| 366 |
+
out_channels,
|
| 367 |
+
filter_channels,
|
| 368 |
+
kernel_size,
|
| 369 |
+
p_dropout=0.0,
|
| 370 |
+
activation=None,
|
| 371 |
+
causal=False,
|
| 372 |
+
):
|
| 373 |
+
super().__init__()
|
| 374 |
+
self.in_channels = in_channels
|
| 375 |
+
self.out_channels = out_channels
|
| 376 |
+
self.filter_channels = filter_channels
|
| 377 |
+
self.kernel_size = kernel_size
|
| 378 |
+
self.p_dropout = p_dropout
|
| 379 |
+
self.activation = activation
|
| 380 |
+
self.causal = causal
|
| 381 |
+
|
| 382 |
+
if causal:
|
| 383 |
+
self.padding = self._causal_padding
|
| 384 |
+
else:
|
| 385 |
+
self.padding = self._same_padding
|
| 386 |
+
|
| 387 |
+
self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
|
| 388 |
+
self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
|
| 389 |
+
self.drop = nn.Dropout(p_dropout)
|
| 390 |
+
|
| 391 |
+
def forward(self, x, x_mask):
|
| 392 |
+
x = self.conv_1(self.padding(x * x_mask))
|
| 393 |
+
if self.activation == "gelu":
|
| 394 |
+
x = x * torch.sigmoid(1.702 * x)
|
| 395 |
+
else:
|
| 396 |
+
x = torch.relu(x)
|
| 397 |
+
x = self.drop(x)
|
| 398 |
+
x = self.conv_2(self.padding(x * x_mask))
|
| 399 |
+
return x * x_mask
|
| 400 |
+
|
| 401 |
+
def _causal_padding(self, x):
|
| 402 |
+
if self.kernel_size == 1:
|
| 403 |
+
return x
|
| 404 |
+
pad_l = self.kernel_size - 1
|
| 405 |
+
pad_r = 0
|
| 406 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 407 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 408 |
+
return x
|
| 409 |
+
|
| 410 |
+
def _same_padding(self, x):
|
| 411 |
+
if self.kernel_size == 1:
|
| 412 |
+
return x
|
| 413 |
+
pad_l = (self.kernel_size - 1) // 2
|
| 414 |
+
pad_r = self.kernel_size // 2
|
| 415 |
+
padding = [[0, 0], [0, 0], [pad_l, pad_r]]
|
| 416 |
+
x = F.pad(x, commons.convert_pad_shape(padding))
|
| 417 |
+
return x
|
src/ultimate_rvc/vc/infer_pack/commons.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 9 |
+
classname = m.__class__.__name__
|
| 10 |
+
if classname.find("Conv") != -1:
|
| 11 |
+
m.weight.data.normal_(mean, std)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def get_padding(kernel_size, dilation=1):
|
| 15 |
+
return int((kernel_size * dilation - dilation) / 2)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def convert_pad_shape(pad_shape):
|
| 19 |
+
l = pad_shape[::-1]
|
| 20 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 21 |
+
return pad_shape
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def kl_divergence(m_p, logs_p, m_q, logs_q):
|
| 25 |
+
"""KL(P||Q)"""
|
| 26 |
+
kl = (logs_q - logs_p) - 0.5
|
| 27 |
+
kl += (
|
| 28 |
+
0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
|
| 29 |
+
)
|
| 30 |
+
return kl
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def rand_gumbel(shape):
|
| 34 |
+
"""Sample from the Gumbel distribution, protect from overflows."""
|
| 35 |
+
uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
|
| 36 |
+
return -torch.log(-torch.log(uniform_samples))
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def rand_gumbel_like(x):
|
| 40 |
+
g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
|
| 41 |
+
return g
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def slice_segments(x, ids_str, segment_size=4):
|
| 45 |
+
ret = torch.zeros_like(x[:, :, :segment_size])
|
| 46 |
+
for i in range(x.size(0)):
|
| 47 |
+
idx_str = ids_str[i]
|
| 48 |
+
idx_end = idx_str + segment_size
|
| 49 |
+
ret[i] = x[i, :, idx_str:idx_end]
|
| 50 |
+
return ret
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def slice_segments2(x, ids_str, segment_size=4):
|
| 54 |
+
ret = torch.zeros_like(x[:, :segment_size])
|
| 55 |
+
for i in range(x.size(0)):
|
| 56 |
+
idx_str = ids_str[i]
|
| 57 |
+
idx_end = idx_str + segment_size
|
| 58 |
+
ret[i] = x[i, idx_str:idx_end]
|
| 59 |
+
return ret
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def rand_slice_segments(x, x_lengths=None, segment_size=4):
|
| 63 |
+
b, d, t = x.size()
|
| 64 |
+
if x_lengths is None:
|
| 65 |
+
x_lengths = t
|
| 66 |
+
ids_str_max = x_lengths - segment_size + 1
|
| 67 |
+
ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
|
| 68 |
+
ret = slice_segments(x, ids_str, segment_size)
|
| 69 |
+
return ret, ids_str
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
|
| 73 |
+
position = torch.arange(length, dtype=torch.float)
|
| 74 |
+
num_timescales = channels // 2
|
| 75 |
+
log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
|
| 76 |
+
num_timescales - 1
|
| 77 |
+
)
|
| 78 |
+
inv_timescales = min_timescale * torch.exp(
|
| 79 |
+
torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
|
| 80 |
+
)
|
| 81 |
+
scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
|
| 82 |
+
signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
|
| 83 |
+
signal = F.pad(signal, [0, 0, 0, channels % 2])
|
| 84 |
+
signal = signal.view(1, channels, length)
|
| 85 |
+
return signal
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
|
| 89 |
+
b, channels, length = x.size()
|
| 90 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 91 |
+
return x + signal.to(dtype=x.dtype, device=x.device)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
|
| 95 |
+
b, channels, length = x.size()
|
| 96 |
+
signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
|
| 97 |
+
return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def subsequent_mask(length):
|
| 101 |
+
mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
|
| 102 |
+
return mask
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
@torch.jit.script
|
| 106 |
+
def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
|
| 107 |
+
n_channels_int = n_channels[0]
|
| 108 |
+
in_act = input_a + input_b
|
| 109 |
+
t_act = torch.tanh(in_act[:, :n_channels_int, :])
|
| 110 |
+
s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
|
| 111 |
+
acts = t_act * s_act
|
| 112 |
+
return acts
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def convert_pad_shape(pad_shape):
|
| 116 |
+
l = pad_shape[::-1]
|
| 117 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 118 |
+
return pad_shape
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def shift_1d(x):
|
| 122 |
+
x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
|
| 123 |
+
return x
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def sequence_mask(length, max_length=None):
|
| 127 |
+
if max_length is None:
|
| 128 |
+
max_length = length.max()
|
| 129 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 130 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def generate_path(duration, mask):
|
| 134 |
+
"""
|
| 135 |
+
duration: [b, 1, t_x]
|
| 136 |
+
mask: [b, 1, t_y, t_x]
|
| 137 |
+
"""
|
| 138 |
+
device = duration.device
|
| 139 |
+
|
| 140 |
+
b, _, t_y, t_x = mask.shape
|
| 141 |
+
cum_duration = torch.cumsum(duration, -1)
|
| 142 |
+
|
| 143 |
+
cum_duration_flat = cum_duration.view(b * t_x)
|
| 144 |
+
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
| 145 |
+
path = path.view(b, t_x, t_y)
|
| 146 |
+
path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
|
| 147 |
+
path = path.unsqueeze(1).transpose(2, 3) * mask
|
| 148 |
+
return path
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def clip_grad_value_(parameters, clip_value, norm_type=2):
|
| 152 |
+
if isinstance(parameters, torch.Tensor):
|
| 153 |
+
parameters = [parameters]
|
| 154 |
+
parameters = list(filter(lambda p: p.grad is not None, parameters))
|
| 155 |
+
norm_type = float(norm_type)
|
| 156 |
+
if clip_value is not None:
|
| 157 |
+
clip_value = float(clip_value)
|
| 158 |
+
|
| 159 |
+
total_norm = 0
|
| 160 |
+
for p in parameters:
|
| 161 |
+
param_norm = p.grad.data.norm(norm_type)
|
| 162 |
+
total_norm += param_norm.item() ** norm_type
|
| 163 |
+
if clip_value is not None:
|
| 164 |
+
p.grad.data.clamp_(min=-clip_value, max=clip_value)
|
| 165 |
+
total_norm = total_norm ** (1.0 / norm_type)
|
| 166 |
+
return total_norm
|