Spaces:
Runtime error

Runtime error
Commit
·
be49b0b
1
Parent(s):
4a5e26f
adding app
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +104 -0
- .pre-commit-config.yaml +7 -0
- LICENSE +674 -0
- README.md +1 -1
- README_yolov6.md +100 -0
- app.py +34 -0
- assets/picture.png +0 -0
- configs/yolov6_tiny.py +53 -0
- configs/yolov6_tiny_finetune.py +53 -0
- configs/yolov6n.py +53 -0
- configs/yolov6n_finetune.py +53 -0
- configs/yolov6s.py +53 -0
- configs/yolov6s_finetune.py +53 -0
- data/coco.yaml +18 -0
- data/images/image1.jpg +0 -0
- data/images/image2.jpg +0 -0
- data/images/image3.jpg +0 -0
- deploy/ONNX/README.md +17 -0
- deploy/ONNX/export_onnx.py +80 -0
- deploy/OpenVINO/README.md +18 -0
- deploy/OpenVINO/export_openvino.py +92 -0
- docs/About_naming_yolov6.md +12 -0
- docs/Test_speed.md +41 -0
- docs/Train_custom_data.md +129 -0
- packages.txt +5 -0
- requirements.txt +15 -0
- tools/eval.py +86 -0
- tools/infer.py +108 -0
- tools/quantization/mnn/README.md +1 -0
- tools/quantization/tensorrt/post_training/Calibrator.py +210 -0
- tools/quantization/tensorrt/post_training/LICENSE +192 -0
- tools/quantization/tensorrt/post_training/README.md +83 -0
- tools/quantization/tensorrt/post_training/onnx_to_tensorrt.py +220 -0
- tools/quantization/tensorrt/post_training/quant.sh +23 -0
- tools/quantization/tensorrt/requirements.txt +7 -0
- tools/quantization/tensorrt/training_aware/QAT_quantizer.py +39 -0
- tools/train.py +87 -0
- yolov6/core/engine.py +262 -0
- yolov6/core/evaler.py +258 -0
- yolov6/core/inferer.py +196 -0
- yolov6/data/data_augment.py +193 -0
- yolov6/data/data_load.py +77 -0
- yolov6/data/datasets.py +533 -0
- yolov6/layers/common.py +269 -0
- yolov6/models/efficientrep.py +102 -0
- yolov6/models/effidehead.py +211 -0
- yolov6/models/loss.py +411 -0
- yolov6/models/reppan.py +108 -0
- yolov6/models/yolo.py +83 -0
- yolov6/solver/build.py +41 -0
.gitignore
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
**/*.pyc
|
| 6 |
+
|
| 7 |
+
# C extensions
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
runs/
|
| 13 |
+
weights/
|
| 14 |
+
develop-eggs/
|
| 15 |
+
dist/
|
| 16 |
+
downloads/
|
| 17 |
+
eggs/
|
| 18 |
+
.eggs/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
*.egg-info/
|
| 24 |
+
.installed.cfg
|
| 25 |
+
*.egg
|
| 26 |
+
MANIFEST
|
| 27 |
+
|
| 28 |
+
# PyInstaller
|
| 29 |
+
# Usually these files are written by a python script from a template
|
| 30 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 31 |
+
*.manifest
|
| 32 |
+
*.spec
|
| 33 |
+
|
| 34 |
+
# Installer logs
|
| 35 |
+
pip-log.txt
|
| 36 |
+
pip-delete-this-directory.txt
|
| 37 |
+
|
| 38 |
+
# Unit test / coverage reports
|
| 39 |
+
htmlcov/
|
| 40 |
+
.tox/
|
| 41 |
+
.coverage
|
| 42 |
+
.coverage.*
|
| 43 |
+
.cache
|
| 44 |
+
nosetests.xml
|
| 45 |
+
coverage.xml
|
| 46 |
+
*.cover
|
| 47 |
+
.hypothesis/
|
| 48 |
+
.pytest_cache/
|
| 49 |
+
|
| 50 |
+
# Translations
|
| 51 |
+
*.mo
|
| 52 |
+
*.pot
|
| 53 |
+
|
| 54 |
+
# Django stuff:
|
| 55 |
+
*.log
|
| 56 |
+
local_settings.py
|
| 57 |
+
db.sqlite3
|
| 58 |
+
|
| 59 |
+
# Flask stuff:
|
| 60 |
+
instance/
|
| 61 |
+
.webassets-cache
|
| 62 |
+
|
| 63 |
+
# Scrapy stuff:
|
| 64 |
+
.scrapy
|
| 65 |
+
|
| 66 |
+
# Sphinx documentation
|
| 67 |
+
docs/_build/
|
| 68 |
+
|
| 69 |
+
# PyBuilder
|
| 70 |
+
target/
|
| 71 |
+
|
| 72 |
+
# Jupyter Notebook
|
| 73 |
+
.ipynb_checkpoints
|
| 74 |
+
|
| 75 |
+
# pyenv
|
| 76 |
+
.python-version
|
| 77 |
+
|
| 78 |
+
# celery beat schedule file
|
| 79 |
+
celerybeat-schedule
|
| 80 |
+
|
| 81 |
+
# SageMath parsed files
|
| 82 |
+
*.sage.py
|
| 83 |
+
|
| 84 |
+
# Environments
|
| 85 |
+
.env
|
| 86 |
+
.venv
|
| 87 |
+
env/
|
| 88 |
+
venv/
|
| 89 |
+
ENV/
|
| 90 |
+
env.bak/
|
| 91 |
+
venv.bak/
|
| 92 |
+
|
| 93 |
+
# Spyder project settings
|
| 94 |
+
.spyderproject
|
| 95 |
+
.spyproject
|
| 96 |
+
|
| 97 |
+
# Rope project settings
|
| 98 |
+
.ropeproject
|
| 99 |
+
|
| 100 |
+
# custom
|
| 101 |
+
.DS_Store
|
| 102 |
+
|
| 103 |
+
# Pytorch
|
| 104 |
+
*.pth
|
.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
repos:
|
| 2 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 3 |
+
rev: v4.3.0
|
| 4 |
+
hooks:
|
| 5 |
+
- id: check-yaml
|
| 6 |
+
- id: end-of-file-fixer
|
| 7 |
+
- id: trailing-whitespace
|
LICENSE
ADDED
|
@@ -0,0 +1,674 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GNU GENERAL PUBLIC LICENSE
|
| 2 |
+
Version 3, 29 June 2007
|
| 3 |
+
|
| 4 |
+
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
| 5 |
+
Everyone is permitted to copy and distribute verbatim copies
|
| 6 |
+
of this license document, but changing it is not allowed.
|
| 7 |
+
|
| 8 |
+
Preamble
|
| 9 |
+
|
| 10 |
+
The GNU General Public License is a free, copyleft license for
|
| 11 |
+
software and other kinds of works.
|
| 12 |
+
|
| 13 |
+
The licenses for most software and other practical works are designed
|
| 14 |
+
to take away your freedom to share and change the works. By contrast,
|
| 15 |
+
the GNU General Public License is intended to guarantee your freedom to
|
| 16 |
+
share and change all versions of a program--to make sure it remains free
|
| 17 |
+
software for all its users. We, the Free Software Foundation, use the
|
| 18 |
+
GNU General Public License for most of our software; it applies also to
|
| 19 |
+
any other work released this way by its authors. You can apply it to
|
| 20 |
+
your programs, too.
|
| 21 |
+
|
| 22 |
+
When we speak of free software, we are referring to freedom, not
|
| 23 |
+
price. Our General Public Licenses are designed to make sure that you
|
| 24 |
+
have the freedom to distribute copies of free software (and charge for
|
| 25 |
+
them if you wish), that you receive source code or can get it if you
|
| 26 |
+
want it, that you can change the software or use pieces of it in new
|
| 27 |
+
free programs, and that you know you can do these things.
|
| 28 |
+
|
| 29 |
+
To protect your rights, we need to prevent others from denying you
|
| 30 |
+
these rights or asking you to surrender the rights. Therefore, you have
|
| 31 |
+
certain responsibilities if you distribute copies of the software, or if
|
| 32 |
+
you modify it: responsibilities to respect the freedom of others.
|
| 33 |
+
|
| 34 |
+
For example, if you distribute copies of such a program, whether
|
| 35 |
+
gratis or for a fee, you must pass on to the recipients the same
|
| 36 |
+
freedoms that you received. You must make sure that they, too, receive
|
| 37 |
+
or can get the source code. And you must show them these terms so they
|
| 38 |
+
know their rights.
|
| 39 |
+
|
| 40 |
+
Developers that use the GNU GPL protect your rights with two steps:
|
| 41 |
+
(1) assert copyright on the software, and (2) offer you this License
|
| 42 |
+
giving you legal permission to copy, distribute and/or modify it.
|
| 43 |
+
|
| 44 |
+
For the developers' and authors' protection, the GPL clearly explains
|
| 45 |
+
that there is no warranty for this free software. For both users' and
|
| 46 |
+
authors' sake, the GPL requires that modified versions be marked as
|
| 47 |
+
changed, so that their problems will not be attributed erroneously to
|
| 48 |
+
authors of previous versions.
|
| 49 |
+
|
| 50 |
+
Some devices are designed to deny users access to install or run
|
| 51 |
+
modified versions of the software inside them, although the manufacturer
|
| 52 |
+
can do so. This is fundamentally incompatible with the aim of
|
| 53 |
+
protecting users' freedom to change the software. The systematic
|
| 54 |
+
pattern of such abuse occurs in the area of products for individuals to
|
| 55 |
+
use, which is precisely where it is most unacceptable. Therefore, we
|
| 56 |
+
have designed this version of the GPL to prohibit the practice for those
|
| 57 |
+
products. If such problems arise substantially in other domains, we
|
| 58 |
+
stand ready to extend this provision to those domains in future versions
|
| 59 |
+
of the GPL, as needed to protect the freedom of users.
|
| 60 |
+
|
| 61 |
+
Finally, every program is threatened constantly by software patents.
|
| 62 |
+
States should not allow patents to restrict development and use of
|
| 63 |
+
software on general-purpose computers, but in those that do, we wish to
|
| 64 |
+
avoid the special danger that patents applied to a free program could
|
| 65 |
+
make it effectively proprietary. To prevent this, the GPL assures that
|
| 66 |
+
patents cannot be used to render the program non-free.
|
| 67 |
+
|
| 68 |
+
The precise terms and conditions for copying, distribution and
|
| 69 |
+
modification follow.
|
| 70 |
+
|
| 71 |
+
TERMS AND CONDITIONS
|
| 72 |
+
|
| 73 |
+
0. Definitions.
|
| 74 |
+
|
| 75 |
+
"This License" refers to version 3 of the GNU General Public License.
|
| 76 |
+
|
| 77 |
+
"Copyright" also means copyright-like laws that apply to other kinds of
|
| 78 |
+
works, such as semiconductor masks.
|
| 79 |
+
|
| 80 |
+
"The Program" refers to any copyrightable work licensed under this
|
| 81 |
+
License. Each licensee is addressed as "you". "Licensees" and
|
| 82 |
+
"recipients" may be individuals or organizations.
|
| 83 |
+
|
| 84 |
+
To "modify" a work means to copy from or adapt all or part of the work
|
| 85 |
+
in a fashion requiring copyright permission, other than the making of an
|
| 86 |
+
exact copy. The resulting work is called a "modified version" of the
|
| 87 |
+
earlier work or a work "based on" the earlier work.
|
| 88 |
+
|
| 89 |
+
A "covered work" means either the unmodified Program or a work based
|
| 90 |
+
on the Program.
|
| 91 |
+
|
| 92 |
+
To "propagate" a work means to do anything with it that, without
|
| 93 |
+
permission, would make you directly or secondarily liable for
|
| 94 |
+
infringement under applicable copyright law, except executing it on a
|
| 95 |
+
computer or modifying a private copy. Propagation includes copying,
|
| 96 |
+
distribution (with or without modification), making available to the
|
| 97 |
+
public, and in some countries other activities as well.
|
| 98 |
+
|
| 99 |
+
To "convey" a work means any kind of propagation that enables other
|
| 100 |
+
parties to make or receive copies. Mere interaction with a user through
|
| 101 |
+
a computer network, with no transfer of a copy, is not conveying.
|
| 102 |
+
|
| 103 |
+
An interactive user interface displays "Appropriate Legal Notices"
|
| 104 |
+
to the extent that it includes a convenient and prominently visible
|
| 105 |
+
feature that (1) displays an appropriate copyright notice, and (2)
|
| 106 |
+
tells the user that there is no warranty for the work (except to the
|
| 107 |
+
extent that warranties are provided), that licensees may convey the
|
| 108 |
+
work under this License, and how to view a copy of this License. If
|
| 109 |
+
the interface presents a list of user commands or options, such as a
|
| 110 |
+
menu, a prominent item in the list meets this criterion.
|
| 111 |
+
|
| 112 |
+
1. Source Code.
|
| 113 |
+
|
| 114 |
+
The "source code" for a work means the preferred form of the work
|
| 115 |
+
for making modifications to it. "Object code" means any non-source
|
| 116 |
+
form of a work.
|
| 117 |
+
|
| 118 |
+
A "Standard Interface" means an interface that either is an official
|
| 119 |
+
standard defined by a recognized standards body, or, in the case of
|
| 120 |
+
interfaces specified for a particular programming language, one that
|
| 121 |
+
is widely used among developers working in that language.
|
| 122 |
+
|
| 123 |
+
The "System Libraries" of an executable work include anything, other
|
| 124 |
+
than the work as a whole, that (a) is included in the normal form of
|
| 125 |
+
packaging a Major Component, but which is not part of that Major
|
| 126 |
+
Component, and (b) serves only to enable use of the work with that
|
| 127 |
+
Major Component, or to implement a Standard Interface for which an
|
| 128 |
+
implementation is available to the public in source code form. A
|
| 129 |
+
"Major Component", in this context, means a major essential component
|
| 130 |
+
(kernel, window system, and so on) of the specific operating system
|
| 131 |
+
(if any) on which the executable work runs, or a compiler used to
|
| 132 |
+
produce the work, or an object code interpreter used to run it.
|
| 133 |
+
|
| 134 |
+
The "Corresponding Source" for a work in object code form means all
|
| 135 |
+
the source code needed to generate, install, and (for an executable
|
| 136 |
+
work) run the object code and to modify the work, including scripts to
|
| 137 |
+
control those activities. However, it does not include the work's
|
| 138 |
+
System Libraries, or general-purpose tools or generally available free
|
| 139 |
+
programs which are used unmodified in performing those activities but
|
| 140 |
+
which are not part of the work. For example, Corresponding Source
|
| 141 |
+
includes interface definition files associated with source files for
|
| 142 |
+
the work, and the source code for shared libraries and dynamically
|
| 143 |
+
linked subprograms that the work is specifically designed to require,
|
| 144 |
+
such as by intimate data communication or control flow between those
|
| 145 |
+
subprograms and other parts of the work.
|
| 146 |
+
|
| 147 |
+
The Corresponding Source need not include anything that users
|
| 148 |
+
can regenerate automatically from other parts of the Corresponding
|
| 149 |
+
Source.
|
| 150 |
+
|
| 151 |
+
The Corresponding Source for a work in source code form is that
|
| 152 |
+
same work.
|
| 153 |
+
|
| 154 |
+
2. Basic Permissions.
|
| 155 |
+
|
| 156 |
+
All rights granted under this License are granted for the term of
|
| 157 |
+
copyright on the Program, and are irrevocable provided the stated
|
| 158 |
+
conditions are met. This License explicitly affirms your unlimited
|
| 159 |
+
permission to run the unmodified Program. The output from running a
|
| 160 |
+
covered work is covered by this License only if the output, given its
|
| 161 |
+
content, constitutes a covered work. This License acknowledges your
|
| 162 |
+
rights of fair use or other equivalent, as provided by copyright law.
|
| 163 |
+
|
| 164 |
+
You may make, run and propagate covered works that you do not
|
| 165 |
+
convey, without conditions so long as your license otherwise remains
|
| 166 |
+
in force. You may convey covered works to others for the sole purpose
|
| 167 |
+
of having them make modifications exclusively for you, or provide you
|
| 168 |
+
with facilities for running those works, provided that you comply with
|
| 169 |
+
the terms of this License in conveying all material for which you do
|
| 170 |
+
not control copyright. Those thus making or running the covered works
|
| 171 |
+
for you must do so exclusively on your behalf, under your direction
|
| 172 |
+
and control, on terms that prohibit them from making any copies of
|
| 173 |
+
your copyrighted material outside their relationship with you.
|
| 174 |
+
|
| 175 |
+
Conveying under any other circumstances is permitted solely under
|
| 176 |
+
the conditions stated below. Sublicensing is not allowed; section 10
|
| 177 |
+
makes it unnecessary.
|
| 178 |
+
|
| 179 |
+
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
| 180 |
+
|
| 181 |
+
No covered work shall be deemed part of an effective technological
|
| 182 |
+
measure under any applicable law fulfilling obligations under article
|
| 183 |
+
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
| 184 |
+
similar laws prohibiting or restricting circumvention of such
|
| 185 |
+
measures.
|
| 186 |
+
|
| 187 |
+
When you convey a covered work, you waive any legal power to forbid
|
| 188 |
+
circumvention of technological measures to the extent such circumvention
|
| 189 |
+
is effected by exercising rights under this License with respect to
|
| 190 |
+
the covered work, and you disclaim any intention to limit operation or
|
| 191 |
+
modification of the work as a means of enforcing, against the work's
|
| 192 |
+
users, your or third parties' legal rights to forbid circumvention of
|
| 193 |
+
technological measures.
|
| 194 |
+
|
| 195 |
+
4. Conveying Verbatim Copies.
|
| 196 |
+
|
| 197 |
+
You may convey verbatim copies of the Program's source code as you
|
| 198 |
+
receive it, in any medium, provided that you conspicuously and
|
| 199 |
+
appropriately publish on each copy an appropriate copyright notice;
|
| 200 |
+
keep intact all notices stating that this License and any
|
| 201 |
+
non-permissive terms added in accord with section 7 apply to the code;
|
| 202 |
+
keep intact all notices of the absence of any warranty; and give all
|
| 203 |
+
recipients a copy of this License along with the Program.
|
| 204 |
+
|
| 205 |
+
You may charge any price or no price for each copy that you convey,
|
| 206 |
+
and you may offer support or warranty protection for a fee.
|
| 207 |
+
|
| 208 |
+
5. Conveying Modified Source Versions.
|
| 209 |
+
|
| 210 |
+
You may convey a work based on the Program, or the modifications to
|
| 211 |
+
produce it from the Program, in the form of source code under the
|
| 212 |
+
terms of section 4, provided that you also meet all of these conditions:
|
| 213 |
+
|
| 214 |
+
a) The work must carry prominent notices stating that you modified
|
| 215 |
+
it, and giving a relevant date.
|
| 216 |
+
|
| 217 |
+
b) The work must carry prominent notices stating that it is
|
| 218 |
+
released under this License and any conditions added under section
|
| 219 |
+
7. This requirement modifies the requirement in section 4 to
|
| 220 |
+
"keep intact all notices".
|
| 221 |
+
|
| 222 |
+
c) You must license the entire work, as a whole, under this
|
| 223 |
+
License to anyone who comes into possession of a copy. This
|
| 224 |
+
License will therefore apply, along with any applicable section 7
|
| 225 |
+
additional terms, to the whole of the work, and all its parts,
|
| 226 |
+
regardless of how they are packaged. This License gives no
|
| 227 |
+
permission to license the work in any other way, but it does not
|
| 228 |
+
invalidate such permission if you have separately received it.
|
| 229 |
+
|
| 230 |
+
d) If the work has interactive user interfaces, each must display
|
| 231 |
+
Appropriate Legal Notices; however, if the Program has interactive
|
| 232 |
+
interfaces that do not display Appropriate Legal Notices, your
|
| 233 |
+
work need not make them do so.
|
| 234 |
+
|
| 235 |
+
A compilation of a covered work with other separate and independent
|
| 236 |
+
works, which are not by their nature extensions of the covered work,
|
| 237 |
+
and which are not combined with it such as to form a larger program,
|
| 238 |
+
in or on a volume of a storage or distribution medium, is called an
|
| 239 |
+
"aggregate" if the compilation and its resulting copyright are not
|
| 240 |
+
used to limit the access or legal rights of the compilation's users
|
| 241 |
+
beyond what the individual works permit. Inclusion of a covered work
|
| 242 |
+
in an aggregate does not cause this License to apply to the other
|
| 243 |
+
parts of the aggregate.
|
| 244 |
+
|
| 245 |
+
6. Conveying Non-Source Forms.
|
| 246 |
+
|
| 247 |
+
You may convey a covered work in object code form under the terms
|
| 248 |
+
of sections 4 and 5, provided that you also convey the
|
| 249 |
+
machine-readable Corresponding Source under the terms of this License,
|
| 250 |
+
in one of these ways:
|
| 251 |
+
|
| 252 |
+
a) Convey the object code in, or embodied in, a physical product
|
| 253 |
+
(including a physical distribution medium), accompanied by the
|
| 254 |
+
Corresponding Source fixed on a durable physical medium
|
| 255 |
+
customarily used for software interchange.
|
| 256 |
+
|
| 257 |
+
b) Convey the object code in, or embodied in, a physical product
|
| 258 |
+
(including a physical distribution medium), accompanied by a
|
| 259 |
+
written offer, valid for at least three years and valid for as
|
| 260 |
+
long as you offer spare parts or customer support for that product
|
| 261 |
+
model, to give anyone who possesses the object code either (1) a
|
| 262 |
+
copy of the Corresponding Source for all the software in the
|
| 263 |
+
product that is covered by this License, on a durable physical
|
| 264 |
+
medium customarily used for software interchange, for a price no
|
| 265 |
+
more than your reasonable cost of physically performing this
|
| 266 |
+
conveying of source, or (2) access to copy the
|
| 267 |
+
Corresponding Source from a network server at no charge.
|
| 268 |
+
|
| 269 |
+
c) Convey individual copies of the object code with a copy of the
|
| 270 |
+
written offer to provide the Corresponding Source. This
|
| 271 |
+
alternative is allowed only occasionally and noncommercially, and
|
| 272 |
+
only if you received the object code with such an offer, in accord
|
| 273 |
+
with subsection 6b.
|
| 274 |
+
|
| 275 |
+
d) Convey the object code by offering access from a designated
|
| 276 |
+
place (gratis or for a charge), and offer equivalent access to the
|
| 277 |
+
Corresponding Source in the same way through the same place at no
|
| 278 |
+
further charge. You need not require recipients to copy the
|
| 279 |
+
Corresponding Source along with the object code. If the place to
|
| 280 |
+
copy the object code is a network server, the Corresponding Source
|
| 281 |
+
may be on a different server (operated by you or a third party)
|
| 282 |
+
that supports equivalent copying facilities, provided you maintain
|
| 283 |
+
clear directions next to the object code saying where to find the
|
| 284 |
+
Corresponding Source. Regardless of what server hosts the
|
| 285 |
+
Corresponding Source, you remain obligated to ensure that it is
|
| 286 |
+
available for as long as needed to satisfy these requirements.
|
| 287 |
+
|
| 288 |
+
e) Convey the object code using peer-to-peer transmission, provided
|
| 289 |
+
you inform other peers where the object code and Corresponding
|
| 290 |
+
Source of the work are being offered to the general public at no
|
| 291 |
+
charge under subsection 6d.
|
| 292 |
+
|
| 293 |
+
A separable portion of the object code, whose source code is excluded
|
| 294 |
+
from the Corresponding Source as a System Library, need not be
|
| 295 |
+
included in conveying the object code work.
|
| 296 |
+
|
| 297 |
+
A "User Product" is either (1) a "consumer product", which means any
|
| 298 |
+
tangible personal property which is normally used for personal, family,
|
| 299 |
+
or household purposes, or (2) anything designed or sold for incorporation
|
| 300 |
+
into a dwelling. In determining whether a product is a consumer product,
|
| 301 |
+
doubtful cases shall be resolved in favor of coverage. For a particular
|
| 302 |
+
product received by a particular user, "normally used" refers to a
|
| 303 |
+
typical or common use of that class of product, regardless of the status
|
| 304 |
+
of the particular user or of the way in which the particular user
|
| 305 |
+
actually uses, or expects or is expected to use, the product. A product
|
| 306 |
+
is a consumer product regardless of whether the product has substantial
|
| 307 |
+
commercial, industrial or non-consumer uses, unless such uses represent
|
| 308 |
+
the only significant mode of use of the product.
|
| 309 |
+
|
| 310 |
+
"Installation Information" for a User Product means any methods,
|
| 311 |
+
procedures, authorization keys, or other information required to install
|
| 312 |
+
and execute modified versions of a covered work in that User Product from
|
| 313 |
+
a modified version of its Corresponding Source. The information must
|
| 314 |
+
suffice to ensure that the continued functioning of the modified object
|
| 315 |
+
code is in no case prevented or interfered with solely because
|
| 316 |
+
modification has been made.
|
| 317 |
+
|
| 318 |
+
If you convey an object code work under this section in, or with, or
|
| 319 |
+
specifically for use in, a User Product, and the conveying occurs as
|
| 320 |
+
part of a transaction in which the right of possession and use of the
|
| 321 |
+
User Product is transferred to the recipient in perpetuity or for a
|
| 322 |
+
fixed term (regardless of how the transaction is characterized), the
|
| 323 |
+
Corresponding Source conveyed under this section must be accompanied
|
| 324 |
+
by the Installation Information. But this requirement does not apply
|
| 325 |
+
if neither you nor any third party retains the ability to install
|
| 326 |
+
modified object code on the User Product (for example, the work has
|
| 327 |
+
been installed in ROM).
|
| 328 |
+
|
| 329 |
+
The requirement to provide Installation Information does not include a
|
| 330 |
+
requirement to continue to provide support service, warranty, or updates
|
| 331 |
+
for a work that has been modified or installed by the recipient, or for
|
| 332 |
+
the User Product in which it has been modified or installed. Access to a
|
| 333 |
+
network may be denied when the modification itself materially and
|
| 334 |
+
adversely affects the operation of the network or violates the rules and
|
| 335 |
+
protocols for communication across the network.
|
| 336 |
+
|
| 337 |
+
Corresponding Source conveyed, and Installation Information provided,
|
| 338 |
+
in accord with this section must be in a format that is publicly
|
| 339 |
+
documented (and with an implementation available to the public in
|
| 340 |
+
source code form), and must require no special password or key for
|
| 341 |
+
unpacking, reading or copying.
|
| 342 |
+
|
| 343 |
+
7. Additional Terms.
|
| 344 |
+
|
| 345 |
+
"Additional permissions" are terms that supplement the terms of this
|
| 346 |
+
License by making exceptions from one or more of its conditions.
|
| 347 |
+
Additional permissions that are applicable to the entire Program shall
|
| 348 |
+
be treated as though they were included in this License, to the extent
|
| 349 |
+
that they are valid under applicable law. If additional permissions
|
| 350 |
+
apply only to part of the Program, that part may be used separately
|
| 351 |
+
under those permissions, but the entire Program remains governed by
|
| 352 |
+
this License without regard to the additional permissions.
|
| 353 |
+
|
| 354 |
+
When you convey a copy of a covered work, you may at your option
|
| 355 |
+
remove any additional permissions from that copy, or from any part of
|
| 356 |
+
it. (Additional permissions may be written to require their own
|
| 357 |
+
removal in certain cases when you modify the work.) You may place
|
| 358 |
+
additional permissions on material, added by you to a covered work,
|
| 359 |
+
for which you have or can give appropriate copyright permission.
|
| 360 |
+
|
| 361 |
+
Notwithstanding any other provision of this License, for material you
|
| 362 |
+
add to a covered work, you may (if authorized by the copyright holders of
|
| 363 |
+
that material) supplement the terms of this License with terms:
|
| 364 |
+
|
| 365 |
+
a) Disclaiming warranty or limiting liability differently from the
|
| 366 |
+
terms of sections 15 and 16 of this License; or
|
| 367 |
+
|
| 368 |
+
b) Requiring preservation of specified reasonable legal notices or
|
| 369 |
+
author attributions in that material or in the Appropriate Legal
|
| 370 |
+
Notices displayed by works containing it; or
|
| 371 |
+
|
| 372 |
+
c) Prohibiting misrepresentation of the origin of that material, or
|
| 373 |
+
requiring that modified versions of such material be marked in
|
| 374 |
+
reasonable ways as different from the original version; or
|
| 375 |
+
|
| 376 |
+
d) Limiting the use for publicity purposes of names of licensors or
|
| 377 |
+
authors of the material; or
|
| 378 |
+
|
| 379 |
+
e) Declining to grant rights under trademark law for use of some
|
| 380 |
+
trade names, trademarks, or service marks; or
|
| 381 |
+
|
| 382 |
+
f) Requiring indemnification of licensors and authors of that
|
| 383 |
+
material by anyone who conveys the material (or modified versions of
|
| 384 |
+
it) with contractual assumptions of liability to the recipient, for
|
| 385 |
+
any liability that these contractual assumptions directly impose on
|
| 386 |
+
those licensors and authors.
|
| 387 |
+
|
| 388 |
+
All other non-permissive additional terms are considered "further
|
| 389 |
+
restrictions" within the meaning of section 10. If the Program as you
|
| 390 |
+
received it, or any part of it, contains a notice stating that it is
|
| 391 |
+
governed by this License along with a term that is a further
|
| 392 |
+
restriction, you may remove that term. If a license document contains
|
| 393 |
+
a further restriction but permits relicensing or conveying under this
|
| 394 |
+
License, you may add to a covered work material governed by the terms
|
| 395 |
+
of that license document, provided that the further restriction does
|
| 396 |
+
not survive such relicensing or conveying.
|
| 397 |
+
|
| 398 |
+
If you add terms to a covered work in accord with this section, you
|
| 399 |
+
must place, in the relevant source files, a statement of the
|
| 400 |
+
additional terms that apply to those files, or a notice indicating
|
| 401 |
+
where to find the applicable terms.
|
| 402 |
+
|
| 403 |
+
Additional terms, permissive or non-permissive, may be stated in the
|
| 404 |
+
form of a separately written license, or stated as exceptions;
|
| 405 |
+
the above requirements apply either way.
|
| 406 |
+
|
| 407 |
+
8. Termination.
|
| 408 |
+
|
| 409 |
+
You may not propagate or modify a covered work except as expressly
|
| 410 |
+
provided under this License. Any attempt otherwise to propagate or
|
| 411 |
+
modify it is void, and will automatically terminate your rights under
|
| 412 |
+
this License (including any patent licenses granted under the third
|
| 413 |
+
paragraph of section 11).
|
| 414 |
+
|
| 415 |
+
However, if you cease all violation of this License, then your
|
| 416 |
+
license from a particular copyright holder is reinstated (a)
|
| 417 |
+
provisionally, unless and until the copyright holder explicitly and
|
| 418 |
+
finally terminates your license, and (b) permanently, if the copyright
|
| 419 |
+
holder fails to notify you of the violation by some reasonable means
|
| 420 |
+
prior to 60 days after the cessation.
|
| 421 |
+
|
| 422 |
+
Moreover, your license from a particular copyright holder is
|
| 423 |
+
reinstated permanently if the copyright holder notifies you of the
|
| 424 |
+
violation by some reasonable means, this is the first time you have
|
| 425 |
+
received notice of violation of this License (for any work) from that
|
| 426 |
+
copyright holder, and you cure the violation prior to 30 days after
|
| 427 |
+
your receipt of the notice.
|
| 428 |
+
|
| 429 |
+
Termination of your rights under this section does not terminate the
|
| 430 |
+
licenses of parties who have received copies or rights from you under
|
| 431 |
+
this License. If your rights have been terminated and not permanently
|
| 432 |
+
reinstated, you do not qualify to receive new licenses for the same
|
| 433 |
+
material under section 10.
|
| 434 |
+
|
| 435 |
+
9. Acceptance Not Required for Having Copies.
|
| 436 |
+
|
| 437 |
+
You are not required to accept this License in order to receive or
|
| 438 |
+
run a copy of the Program. Ancillary propagation of a covered work
|
| 439 |
+
occurring solely as a consequence of using peer-to-peer transmission
|
| 440 |
+
to receive a copy likewise does not require acceptance. However,
|
| 441 |
+
nothing other than this License grants you permission to propagate or
|
| 442 |
+
modify any covered work. These actions infringe copyright if you do
|
| 443 |
+
not accept this License. Therefore, by modifying or propagating a
|
| 444 |
+
covered work, you indicate your acceptance of this License to do so.
|
| 445 |
+
|
| 446 |
+
10. Automatic Licensing of Downstream Recipients.
|
| 447 |
+
|
| 448 |
+
Each time you convey a covered work, the recipient automatically
|
| 449 |
+
receives a license from the original licensors, to run, modify and
|
| 450 |
+
propagate that work, subject to this License. You are not responsible
|
| 451 |
+
for enforcing compliance by third parties with this License.
|
| 452 |
+
|
| 453 |
+
An "entity transaction" is a transaction transferring control of an
|
| 454 |
+
organization, or substantially all assets of one, or subdividing an
|
| 455 |
+
organization, or merging organizations. If propagation of a covered
|
| 456 |
+
work results from an entity transaction, each party to that
|
| 457 |
+
transaction who receives a copy of the work also receives whatever
|
| 458 |
+
licenses to the work the party's predecessor in interest had or could
|
| 459 |
+
give under the previous paragraph, plus a right to possession of the
|
| 460 |
+
Corresponding Source of the work from the predecessor in interest, if
|
| 461 |
+
the predecessor has it or can get it with reasonable efforts.
|
| 462 |
+
|
| 463 |
+
You may not impose any further restrictions on the exercise of the
|
| 464 |
+
rights granted or affirmed under this License. For example, you may
|
| 465 |
+
not impose a license fee, royalty, or other charge for exercise of
|
| 466 |
+
rights granted under this License, and you may not initiate litigation
|
| 467 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
| 468 |
+
any patent claim is infringed by making, using, selling, offering for
|
| 469 |
+
sale, or importing the Program or any portion of it.
|
| 470 |
+
|
| 471 |
+
11. Patents.
|
| 472 |
+
|
| 473 |
+
A "contributor" is a copyright holder who authorizes use under this
|
| 474 |
+
License of the Program or a work on which the Program is based. The
|
| 475 |
+
work thus licensed is called the contributor's "contributor version".
|
| 476 |
+
|
| 477 |
+
A contributor's "essential patent claims" are all patent claims
|
| 478 |
+
owned or controlled by the contributor, whether already acquired or
|
| 479 |
+
hereafter acquired, that would be infringed by some manner, permitted
|
| 480 |
+
by this License, of making, using, or selling its contributor version,
|
| 481 |
+
but do not include claims that would be infringed only as a
|
| 482 |
+
consequence of further modification of the contributor version. For
|
| 483 |
+
purposes of this definition, "control" includes the right to grant
|
| 484 |
+
patent sublicenses in a manner consistent with the requirements of
|
| 485 |
+
this License.
|
| 486 |
+
|
| 487 |
+
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
| 488 |
+
patent license under the contributor's essential patent claims, to
|
| 489 |
+
make, use, sell, offer for sale, import and otherwise run, modify and
|
| 490 |
+
propagate the contents of its contributor version.
|
| 491 |
+
|
| 492 |
+
In the following three paragraphs, a "patent license" is any express
|
| 493 |
+
agreement or commitment, however denominated, not to enforce a patent
|
| 494 |
+
(such as an express permission to practice a patent or covenant not to
|
| 495 |
+
sue for patent infringement). To "grant" such a patent license to a
|
| 496 |
+
party means to make such an agreement or commitment not to enforce a
|
| 497 |
+
patent against the party.
|
| 498 |
+
|
| 499 |
+
If you convey a covered work, knowingly relying on a patent license,
|
| 500 |
+
and the Corresponding Source of the work is not available for anyone
|
| 501 |
+
to copy, free of charge and under the terms of this License, through a
|
| 502 |
+
publicly available network server or other readily accessible means,
|
| 503 |
+
then you must either (1) cause the Corresponding Source to be so
|
| 504 |
+
available, or (2) arrange to deprive yourself of the benefit of the
|
| 505 |
+
patent license for this particular work, or (3) arrange, in a manner
|
| 506 |
+
consistent with the requirements of this License, to extend the patent
|
| 507 |
+
license to downstream recipients. "Knowingly relying" means you have
|
| 508 |
+
actual knowledge that, but for the patent license, your conveying the
|
| 509 |
+
covered work in a country, or your recipient's use of the covered work
|
| 510 |
+
in a country, would infringe one or more identifiable patents in that
|
| 511 |
+
country that you have reason to believe are valid.
|
| 512 |
+
|
| 513 |
+
If, pursuant to or in connection with a single transaction or
|
| 514 |
+
arrangement, you convey, or propagate by procuring conveyance of, a
|
| 515 |
+
covered work, and grant a patent license to some of the parties
|
| 516 |
+
receiving the covered work authorizing them to use, propagate, modify
|
| 517 |
+
or convey a specific copy of the covered work, then the patent license
|
| 518 |
+
you grant is automatically extended to all recipients of the covered
|
| 519 |
+
work and works based on it.
|
| 520 |
+
|
| 521 |
+
A patent license is "discriminatory" if it does not include within
|
| 522 |
+
the scope of its coverage, prohibits the exercise of, or is
|
| 523 |
+
conditioned on the non-exercise of one or more of the rights that are
|
| 524 |
+
specifically granted under this License. You may not convey a covered
|
| 525 |
+
work if you are a party to an arrangement with a third party that is
|
| 526 |
+
in the business of distributing software, under which you make payment
|
| 527 |
+
to the third party based on the extent of your activity of conveying
|
| 528 |
+
the work, and under which the third party grants, to any of the
|
| 529 |
+
parties who would receive the covered work from you, a discriminatory
|
| 530 |
+
patent license (a) in connection with copies of the covered work
|
| 531 |
+
conveyed by you (or copies made from those copies), or (b) primarily
|
| 532 |
+
for and in connection with specific products or compilations that
|
| 533 |
+
contain the covered work, unless you entered into that arrangement,
|
| 534 |
+
or that patent license was granted, prior to 28 March 2007.
|
| 535 |
+
|
| 536 |
+
Nothing in this License shall be construed as excluding or limiting
|
| 537 |
+
any implied license or other defenses to infringement that may
|
| 538 |
+
otherwise be available to you under applicable patent law.
|
| 539 |
+
|
| 540 |
+
12. No Surrender of Others' Freedom.
|
| 541 |
+
|
| 542 |
+
If conditions are imposed on you (whether by court order, agreement or
|
| 543 |
+
otherwise) that contradict the conditions of this License, they do not
|
| 544 |
+
excuse you from the conditions of this License. If you cannot convey a
|
| 545 |
+
covered work so as to satisfy simultaneously your obligations under this
|
| 546 |
+
License and any other pertinent obligations, then as a consequence you may
|
| 547 |
+
not convey it at all. For example, if you agree to terms that obligate you
|
| 548 |
+
to collect a royalty for further conveying from those to whom you convey
|
| 549 |
+
the Program, the only way you could satisfy both those terms and this
|
| 550 |
+
License would be to refrain entirely from conveying the Program.
|
| 551 |
+
|
| 552 |
+
13. Use with the GNU Affero General Public License.
|
| 553 |
+
|
| 554 |
+
Notwithstanding any other provision of this License, you have
|
| 555 |
+
permission to link or combine any covered work with a work licensed
|
| 556 |
+
under version 3 of the GNU Affero General Public License into a single
|
| 557 |
+
combined work, and to convey the resulting work. The terms of this
|
| 558 |
+
License will continue to apply to the part which is the covered work,
|
| 559 |
+
but the special requirements of the GNU Affero General Public License,
|
| 560 |
+
section 13, concerning interaction through a network will apply to the
|
| 561 |
+
combination as such.
|
| 562 |
+
|
| 563 |
+
14. Revised Versions of this License.
|
| 564 |
+
|
| 565 |
+
The Free Software Foundation may publish revised and/or new versions of
|
| 566 |
+
the GNU General Public License from time to time. Such new versions will
|
| 567 |
+
be similar in spirit to the present version, but may differ in detail to
|
| 568 |
+
address new problems or concerns.
|
| 569 |
+
|
| 570 |
+
Each version is given a distinguishing version number. If the
|
| 571 |
+
Program specifies that a certain numbered version of the GNU General
|
| 572 |
+
Public License "or any later version" applies to it, you have the
|
| 573 |
+
option of following the terms and conditions either of that numbered
|
| 574 |
+
version or of any later version published by the Free Software
|
| 575 |
+
Foundation. If the Program does not specify a version number of the
|
| 576 |
+
GNU General Public License, you may choose any version ever published
|
| 577 |
+
by the Free Software Foundation.
|
| 578 |
+
|
| 579 |
+
If the Program specifies that a proxy can decide which future
|
| 580 |
+
versions of the GNU General Public License can be used, that proxy's
|
| 581 |
+
public statement of acceptance of a version permanently authorizes you
|
| 582 |
+
to choose that version for the Program.
|
| 583 |
+
|
| 584 |
+
Later license versions may give you additional or different
|
| 585 |
+
permissions. However, no additional obligations are imposed on any
|
| 586 |
+
author or copyright holder as a result of your choosing to follow a
|
| 587 |
+
later version.
|
| 588 |
+
|
| 589 |
+
15. Disclaimer of Warranty.
|
| 590 |
+
|
| 591 |
+
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
| 592 |
+
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
| 593 |
+
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
| 594 |
+
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
| 595 |
+
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
| 596 |
+
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
| 597 |
+
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
| 598 |
+
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
| 599 |
+
|
| 600 |
+
16. Limitation of Liability.
|
| 601 |
+
|
| 602 |
+
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
| 603 |
+
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
| 604 |
+
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
| 605 |
+
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
| 606 |
+
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
| 607 |
+
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
| 608 |
+
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
| 609 |
+
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
| 610 |
+
SUCH DAMAGES.
|
| 611 |
+
|
| 612 |
+
17. Interpretation of Sections 15 and 16.
|
| 613 |
+
|
| 614 |
+
If the disclaimer of warranty and limitation of liability provided
|
| 615 |
+
above cannot be given local legal effect according to their terms,
|
| 616 |
+
reviewing courts shall apply local law that most closely approximates
|
| 617 |
+
an absolute waiver of all civil liability in connection with the
|
| 618 |
+
Program, unless a warranty or assumption of liability accompanies a
|
| 619 |
+
copy of the Program in return for a fee.
|
| 620 |
+
|
| 621 |
+
END OF TERMS AND CONDITIONS
|
| 622 |
+
|
| 623 |
+
How to Apply These Terms to Your New Programs
|
| 624 |
+
|
| 625 |
+
If you develop a new program, and you want it to be of the greatest
|
| 626 |
+
possible use to the public, the best way to achieve this is to make it
|
| 627 |
+
free software which everyone can redistribute and change under these terms.
|
| 628 |
+
|
| 629 |
+
To do so, attach the following notices to the program. It is safest
|
| 630 |
+
to attach them to the start of each source file to most effectively
|
| 631 |
+
state the exclusion of warranty; and each file should have at least
|
| 632 |
+
the "copyright" line and a pointer to where the full notice is found.
|
| 633 |
+
|
| 634 |
+
<one line to give the program's name and a brief idea of what it does.>
|
| 635 |
+
Copyright (C) <year> <name of author>
|
| 636 |
+
|
| 637 |
+
This program is free software: you can redistribute it and/or modify
|
| 638 |
+
it under the terms of the GNU General Public License as published by
|
| 639 |
+
the Free Software Foundation, either version 3 of the License, or
|
| 640 |
+
(at your option) any later version.
|
| 641 |
+
|
| 642 |
+
This program is distributed in the hope that it will be useful,
|
| 643 |
+
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
| 644 |
+
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
| 645 |
+
GNU General Public License for more details.
|
| 646 |
+
|
| 647 |
+
You should have received a copy of the GNU General Public License
|
| 648 |
+
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
| 649 |
+
|
| 650 |
+
Also add information on how to contact you by electronic and paper mail.
|
| 651 |
+
|
| 652 |
+
If the program does terminal interaction, make it output a short
|
| 653 |
+
notice like this when it starts in an interactive mode:
|
| 654 |
+
|
| 655 |
+
<program> Copyright (C) <year> <name of author>
|
| 656 |
+
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
| 657 |
+
This is free software, and you are welcome to redistribute it
|
| 658 |
+
under certain conditions; type `show c' for details.
|
| 659 |
+
|
| 660 |
+
The hypothetical commands `show w' and `show c' should show the appropriate
|
| 661 |
+
parts of the General Public License. Of course, your program's commands
|
| 662 |
+
might be different; for a GUI interface, you would use an "about box".
|
| 663 |
+
|
| 664 |
+
You should also get your employer (if you work as a programmer) or school,
|
| 665 |
+
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
| 666 |
+
For more information on this, and how to apply and follow the GNU GPL, see
|
| 667 |
+
<https://www.gnu.org/licenses/>.
|
| 668 |
+
|
| 669 |
+
The GNU General Public License does not permit incorporating your program
|
| 670 |
+
into proprietary programs. If your program is a subroutine library, you
|
| 671 |
+
may consider it more useful to permit linking proprietary applications with
|
| 672 |
+
the library. If this is what you want to do, use the GNU Lesser General
|
| 673 |
+
Public License instead of this License. But first, please read
|
| 674 |
+
<https://www.gnu.org/licenses/why-not-lgpl.html>.
|
README.md
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
emoji: 🔥
|
| 4 |
colorFrom: indigo
|
| 5 |
colorTo: pink
|
|
|
|
| 1 |
---
|
| 2 |
+
title: YOLOv6
|
| 3 |
emoji: 🔥
|
| 4 |
colorFrom: indigo
|
| 5 |
colorTo: pink
|
README_yolov6.md
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MT-YOLOv6 [About Naming YOLOv6](./docs/About_naming_yolov6.md)
|
| 2 |
+
|
| 3 |
+
## Introduction
|
| 4 |
+
|
| 5 |
+
YOLOv6 is a single-stage object detection framework dedicated to industrial applications, with hardware-friendly efficient design and high performance.
|
| 6 |
+
|
| 7 |
+
<img src="assets/picture.png" width="800">
|
| 8 |
+
|
| 9 |
+
YOLOv6-nano achieves 35.0 mAP on COCO val2017 dataset with 1242 FPS on T4 using TensorRT FP16 for bs32 inference, and YOLOv6-s achieves 43.1 mAP on COCO val2017 dataset with 520 FPS on T4 using TensorRT FP16 for bs32 inference.
|
| 10 |
+
|
| 11 |
+
YOLOv6 is composed of the following methods:
|
| 12 |
+
|
| 13 |
+
- Hardware-friendly Design for Backbone and Neck
|
| 14 |
+
- Efficient Decoupled Head with SIoU Loss
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
## Coming soon
|
| 18 |
+
|
| 19 |
+
- [ ] YOLOv6 m/l/x model.
|
| 20 |
+
- [ ] Deployment for MNN/TNN/NCNN/CoreML...
|
| 21 |
+
- [ ] Quantization tools
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## Quick Start
|
| 25 |
+
|
| 26 |
+
### Install
|
| 27 |
+
|
| 28 |
+
```shell
|
| 29 |
+
git clone https://github.com/meituan/YOLOv6
|
| 30 |
+
cd YOLOv6
|
| 31 |
+
pip install -r requirements.txt
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
### Inference
|
| 35 |
+
|
| 36 |
+
First, download a pretrained model from the YOLOv6 [release](https://github.com/meituan/YOLOv6/releases/tag/0.1.0)
|
| 37 |
+
|
| 38 |
+
Second, run inference with `tools/infer.py`
|
| 39 |
+
|
| 40 |
+
```shell
|
| 41 |
+
python tools/infer.py --weights yolov6s.pt --source img.jpg / imgdir
|
| 42 |
+
yolov6n.pt
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
### Training
|
| 46 |
+
|
| 47 |
+
Single GPU
|
| 48 |
+
|
| 49 |
+
```shell
|
| 50 |
+
python tools/train.py --batch 32 --conf configs/yolov6s.py --data data/coco.yaml --device 0
|
| 51 |
+
configs/yolov6n.py
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
Multi GPUs (DDP mode recommended)
|
| 55 |
+
|
| 56 |
+
```shell
|
| 57 |
+
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --batch 256 --conf configs/yolov6s.py --data data/coco.yaml --device 0,1,2,3,4,5,6,7
|
| 58 |
+
configs/yolov6n.py
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
- conf: select config file to specify network/optimizer/hyperparameters
|
| 62 |
+
- data: prepare [COCO](http://cocodataset.org) dataset and specify dataset paths in data.yaml
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
### Evaluation
|
| 66 |
+
|
| 67 |
+
Reproduce mAP on COCO val2017 dataset
|
| 68 |
+
|
| 69 |
+
```shell
|
| 70 |
+
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6s.pt --task val
|
| 71 |
+
yolov6n.pt
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
### Deployment
|
| 76 |
+
|
| 77 |
+
* [ONNX](./deploy/ONNX)
|
| 78 |
+
* [OpenVINO](./deploy/OpenVINO)
|
| 79 |
+
|
| 80 |
+
### Tutorials
|
| 81 |
+
|
| 82 |
+
* [Train custom data](./docs/Train_custom_data.md)
|
| 83 |
+
* [Test speed](./docs/Test_speed.md)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
## Benchmark
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
| Model | Size | mAP<sup>val<br/>0.5:0.95 | Speed<sup>V100<br/>fp16 b32 <br/>(ms) | Speed<sup>V100<br/>fp32 b32 <br/>(ms) | Speed<sup>T4<br/>trt fp16 b1 <br/>(fps) | Speed<sup>T4<br/>trt fp16 b32 <br/>(fps) | Params<br/><sup> (M) | Flops<br/><sup> (G) |
|
| 91 |
+
| :-------------- | ----------- | :----------------------- | :------------------------------------ | :------------------------------------ | ---------------------------------------- | ----------------------------------------- | --------------- | -------------- |
|
| 92 |
+
| [**YOLOv6-n**](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6n.pt) | 416<br/>640 | 30.8<br/>35.0 | 0.3<br/>0.5 | 0.4<br/>0.7 | 1100<br/>788 | 2716<br/>1242 | 4.3<br/>4.3 | 4.7<br/>11.1 |
|
| 93 |
+
| [**YOLOv6-tiny**](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6t.pt) | 640 | 41.3 | 0.9 | 1.5 | 425 | 602 | 15.0 | 36.7 |
|
| 94 |
+
| [**YOLOv6-s**](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6s.pt) | 640 | 43.1 | 1.0 | 1.7 | 373 | 520 | 17.2 | 44.2 |
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
- Comparisons of the mAP and speed of different object detectors are tested on [COCO val2017](https://cocodataset.org/#download) dataset.
|
| 98 |
+
- Refer to [Test speed](./docs/Test_speed.md) tutorial to reproduce the speed results of YOLOv6.
|
| 99 |
+
- Params and Flops of YOLOv6 are estimated on deployed model.
|
| 100 |
+
- Speed results of other methods are tested in our environment using official codebase and model if not found from the corresponding official release.
|
app.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import subprocess
|
| 5 |
+
import os
|
| 6 |
+
import PIL
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
import uuid
|
| 9 |
+
|
| 10 |
+
# Images
|
| 11 |
+
torch.hub.download_url_to_file('https://miro.medium.com/max/1400/1*EYFejGUjvjPcc4PZTwoufw.jpeg', '1*EYFejGUjvjPcc4PZTwoufw.jpeg')
|
| 12 |
+
torch.hub.download_url_to_file('https://production-media.paperswithcode.com/tasks/ezgif-frame-001_OZzxdny.jpg', 'ezgif-frame-001_OZzxdny.jpg')
|
| 13 |
+
torch.hub.download_url_to_file('https://favtutor.com/resources/images/uploads/Social_Distancing_Covid_19__1.jpg', 'Social_Distancing_Covid_19__1.jpg')
|
| 14 |
+
torch.hub.download_url_to_file('https://nkcf.org/wp-content/uploads/2017/11/people.jpg', 'people.jpg')
|
| 15 |
+
|
| 16 |
+
def yolo(im):
|
| 17 |
+
file_name = str(uuid.uuid4())
|
| 18 |
+
im.save(f'{file_name}.jpg')
|
| 19 |
+
os.system(f"python tools/infer.py --weights yolov6s.pt --source {str(file_name)}.jpg --project ''")
|
| 20 |
+
img = PIL.Image.open(f"exp/{file_name}.jpg")
|
| 21 |
+
os.remove(f"exp/{file_name}.jpg")
|
| 22 |
+
os.remove(f'{file_name}.jpg')
|
| 23 |
+
return img
|
| 24 |
+
|
| 25 |
+
inputs = gr.inputs.Image(type='pil', label="Original Image")
|
| 26 |
+
outputs = gr.outputs.Image(type="pil", label="Output Image")
|
| 27 |
+
|
| 28 |
+
title = "YOLOv6 - Demo"
|
| 29 |
+
description = "YOLOv6 is a single-stage object detection framework dedicated to industrial applications, with hardware-friendly efficient design and high performance. Here is a quick Gradio Demo for testing YOLOv6s model. More details from <a href='https://github.com/meituan/YOLOv6'>https://github.com/meituan/YOLOv6</a> "
|
| 30 |
+
article = "<p>YOLOv6-nano achieves 35.0 mAP on COCO val2017 dataset with 1242 FPS on T4 using TensorRT FP16 for bs32 inference, and YOLOv6-s achieves 43.1 mAP on COCO val2017 dataset with 520 FPS on T4 using TensorRT FP16 for bs32 inference. More information at <a href='https://github.com/meituan/YOLOv6'>https://github.com/meituan/YOLOv6</a></p>"
|
| 31 |
+
|
| 32 |
+
examples = [['1*EYFejGUjvjPcc4PZTwoufw.jpeg'], ['ezgif-frame-001_OZzxdny.jpg'], ['Social_Distancing_Covid_19__1.jpg'], ['people.jpg']]
|
| 33 |
+
|
| 34 |
+
gr.Interface(yolo, inputs, outputs, title=title, description=description, article=article, examples=examples, analytics_enabled = True, enable_queue=True).launch(inline=False, share=False, debug=False)
|
assets/picture.png
ADDED
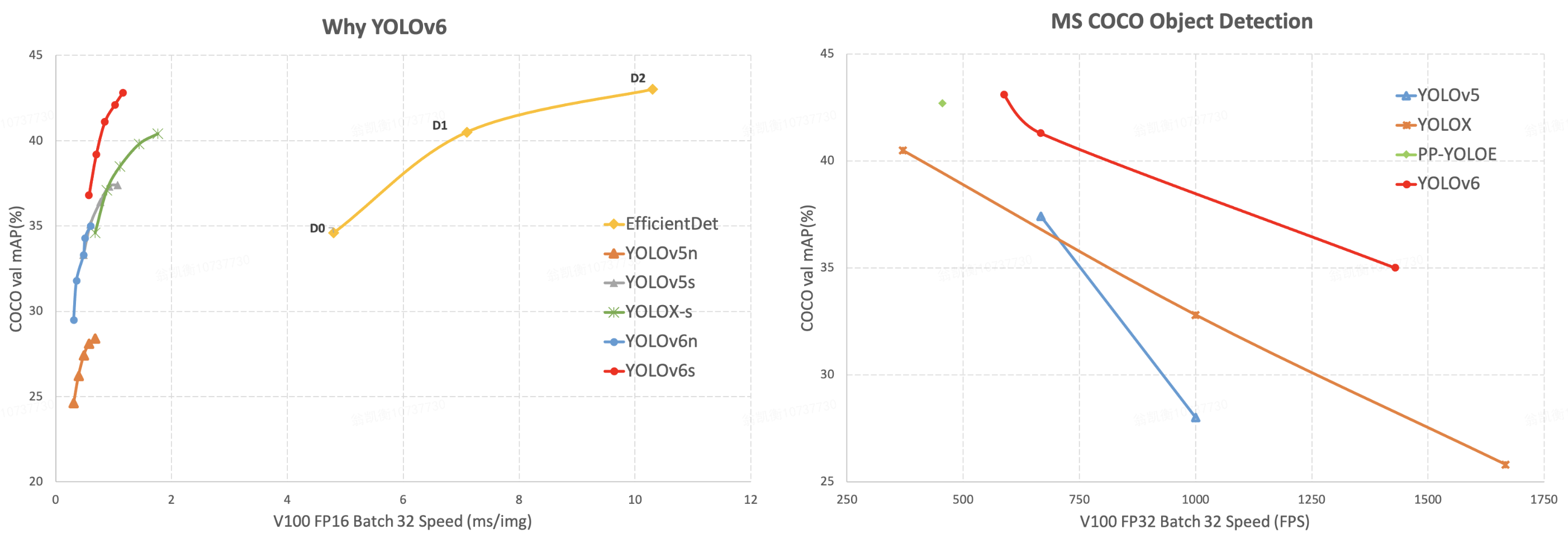
|
configs/yolov6_tiny.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv6t model
|
| 2 |
+
model = dict(
|
| 3 |
+
type='YOLOv6t',
|
| 4 |
+
pretrained=None,
|
| 5 |
+
depth_multiple=0.25,
|
| 6 |
+
width_multiple=0.50,
|
| 7 |
+
backbone=dict(
|
| 8 |
+
type='EfficientRep',
|
| 9 |
+
num_repeats=[1, 6, 12, 18, 6],
|
| 10 |
+
out_channels=[64, 128, 256, 512, 1024],
|
| 11 |
+
),
|
| 12 |
+
neck=dict(
|
| 13 |
+
type='RepPAN',
|
| 14 |
+
num_repeats=[12, 12, 12, 12],
|
| 15 |
+
out_channels=[256, 128, 128, 256, 256, 512],
|
| 16 |
+
),
|
| 17 |
+
head=dict(
|
| 18 |
+
type='EffiDeHead',
|
| 19 |
+
in_channels=[128, 256, 512],
|
| 20 |
+
num_layers=3,
|
| 21 |
+
begin_indices=24,
|
| 22 |
+
anchors=1,
|
| 23 |
+
out_indices=[17, 20, 23],
|
| 24 |
+
strides=[8, 16, 32],
|
| 25 |
+
iou_type='ciou'
|
| 26 |
+
)
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
solver = dict(
|
| 30 |
+
optim='SGD',
|
| 31 |
+
lr_scheduler='Cosine',
|
| 32 |
+
lr0=0.01,
|
| 33 |
+
lrf=0.01,
|
| 34 |
+
momentum=0.937,
|
| 35 |
+
weight_decay=0.0005,
|
| 36 |
+
warmup_epochs=3.0,
|
| 37 |
+
warmup_momentum=0.8,
|
| 38 |
+
warmup_bias_lr=0.1
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
data_aug = dict(
|
| 42 |
+
hsv_h=0.015,
|
| 43 |
+
hsv_s=0.7,
|
| 44 |
+
hsv_v=0.4,
|
| 45 |
+
degrees=0.0,
|
| 46 |
+
translate=0.1,
|
| 47 |
+
scale=0.5,
|
| 48 |
+
shear=0.0,
|
| 49 |
+
flipud=0.0,
|
| 50 |
+
fliplr=0.5,
|
| 51 |
+
mosaic=1.0,
|
| 52 |
+
mixup=0.0,
|
| 53 |
+
)
|
configs/yolov6_tiny_finetune.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv6t model
|
| 2 |
+
model = dict(
|
| 3 |
+
type='YOLOv6t',
|
| 4 |
+
pretrained='./weights/yolov6t.pt',
|
| 5 |
+
depth_multiple=0.25,
|
| 6 |
+
width_multiple=0.50,
|
| 7 |
+
backbone=dict(
|
| 8 |
+
type='EfficientRep',
|
| 9 |
+
num_repeats=[1, 6, 12, 18, 6],
|
| 10 |
+
out_channels=[64, 128, 256, 512, 1024],
|
| 11 |
+
),
|
| 12 |
+
neck=dict(
|
| 13 |
+
type='RepPAN',
|
| 14 |
+
num_repeats=[12, 12, 12, 12],
|
| 15 |
+
out_channels=[256, 128, 128, 256, 256, 512],
|
| 16 |
+
),
|
| 17 |
+
head=dict(
|
| 18 |
+
type='EffiDeHead',
|
| 19 |
+
in_channels=[128, 256, 512],
|
| 20 |
+
num_layers=3,
|
| 21 |
+
begin_indices=24,
|
| 22 |
+
anchors=1,
|
| 23 |
+
out_indices=[17, 20, 23],
|
| 24 |
+
strides=[8, 16, 32],
|
| 25 |
+
iou_type='ciou'
|
| 26 |
+
)
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
solver = dict(
|
| 30 |
+
optim='SGD',
|
| 31 |
+
lr_scheduler='Cosine',
|
| 32 |
+
lr0=0.0032,
|
| 33 |
+
lrf=0.12,
|
| 34 |
+
momentum=0.843,
|
| 35 |
+
weight_decay=0.00036,
|
| 36 |
+
warmup_epochs=2.0,
|
| 37 |
+
warmup_momentum=0.5,
|
| 38 |
+
warmup_bias_lr=0.05
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
data_aug = dict(
|
| 42 |
+
hsv_h=0.0138,
|
| 43 |
+
hsv_s=0.664,
|
| 44 |
+
hsv_v=0.464,
|
| 45 |
+
degrees=0.373,
|
| 46 |
+
translate=0.245,
|
| 47 |
+
scale=0.898,
|
| 48 |
+
shear=0.602,
|
| 49 |
+
flipud=0.00856,
|
| 50 |
+
fliplr=0.5,
|
| 51 |
+
mosaic=1.0,
|
| 52 |
+
mixup=0.243,
|
| 53 |
+
)
|
configs/yolov6n.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv6n model
|
| 2 |
+
model = dict(
|
| 3 |
+
type='YOLOv6n',
|
| 4 |
+
pretrained=None,
|
| 5 |
+
depth_multiple=0.33,
|
| 6 |
+
width_multiple=0.25,
|
| 7 |
+
backbone=dict(
|
| 8 |
+
type='EfficientRep',
|
| 9 |
+
num_repeats=[1, 6, 12, 18, 6],
|
| 10 |
+
out_channels=[64, 128, 256, 512, 1024],
|
| 11 |
+
),
|
| 12 |
+
neck=dict(
|
| 13 |
+
type='RepPAN',
|
| 14 |
+
num_repeats=[12, 12, 12, 12],
|
| 15 |
+
out_channels=[256, 128, 128, 256, 256, 512],
|
| 16 |
+
),
|
| 17 |
+
head=dict(
|
| 18 |
+
type='EffiDeHead',
|
| 19 |
+
in_channels=[128, 256, 512],
|
| 20 |
+
num_layers=3,
|
| 21 |
+
begin_indices=24,
|
| 22 |
+
anchors=1,
|
| 23 |
+
out_indices=[17, 20, 23],
|
| 24 |
+
strides=[8, 16, 32],
|
| 25 |
+
iou_type='ciou'
|
| 26 |
+
)
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
solver = dict(
|
| 30 |
+
optim='SGD',
|
| 31 |
+
lr_scheduler='Cosine',
|
| 32 |
+
lr0=0.01,
|
| 33 |
+
lrf=0.01,
|
| 34 |
+
momentum=0.937,
|
| 35 |
+
weight_decay=0.0005,
|
| 36 |
+
warmup_epochs=3.0,
|
| 37 |
+
warmup_momentum=0.8,
|
| 38 |
+
warmup_bias_lr=0.1
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
data_aug = dict(
|
| 42 |
+
hsv_h=0.015,
|
| 43 |
+
hsv_s=0.7,
|
| 44 |
+
hsv_v=0.4,
|
| 45 |
+
degrees=0.0,
|
| 46 |
+
translate=0.1,
|
| 47 |
+
scale=0.5,
|
| 48 |
+
shear=0.0,
|
| 49 |
+
flipud=0.0,
|
| 50 |
+
fliplr=0.5,
|
| 51 |
+
mosaic=1.0,
|
| 52 |
+
mixup=0.0,
|
| 53 |
+
)
|
configs/yolov6n_finetune.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv6n model
|
| 2 |
+
model = dict(
|
| 3 |
+
type='YOLOv6n',
|
| 4 |
+
pretrained='./weights/yolov6n.pt',
|
| 5 |
+
depth_multiple=0.33,
|
| 6 |
+
width_multiple=0.25,
|
| 7 |
+
backbone=dict(
|
| 8 |
+
type='EfficientRep',
|
| 9 |
+
num_repeats=[1, 6, 12, 18, 6],
|
| 10 |
+
out_channels=[64, 128, 256, 512, 1024],
|
| 11 |
+
),
|
| 12 |
+
neck=dict(
|
| 13 |
+
type='RepPAN',
|
| 14 |
+
num_repeats=[12, 12, 12, 12],
|
| 15 |
+
out_channels=[256, 128, 128, 256, 256, 512],
|
| 16 |
+
),
|
| 17 |
+
head=dict(
|
| 18 |
+
type='EffiDeHead',
|
| 19 |
+
in_channels=[128, 256, 512],
|
| 20 |
+
num_layers=3,
|
| 21 |
+
begin_indices=24,
|
| 22 |
+
anchors=1,
|
| 23 |
+
out_indices=[17, 20, 23],
|
| 24 |
+
strides=[8, 16, 32],
|
| 25 |
+
iou_type='ciou'
|
| 26 |
+
)
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
solver = dict(
|
| 30 |
+
optim='SGD',
|
| 31 |
+
lr_scheduler='Cosine',
|
| 32 |
+
lr0=0.0032,
|
| 33 |
+
lrf=0.12,
|
| 34 |
+
momentum=0.843,
|
| 35 |
+
weight_decay=0.00036,
|
| 36 |
+
warmup_epochs=2.0,
|
| 37 |
+
warmup_momentum=0.5,
|
| 38 |
+
warmup_bias_lr=0.05
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
data_aug = dict(
|
| 42 |
+
hsv_h=0.0138,
|
| 43 |
+
hsv_s=0.664,
|
| 44 |
+
hsv_v=0.464,
|
| 45 |
+
degrees=0.373,
|
| 46 |
+
translate=0.245,
|
| 47 |
+
scale=0.898,
|
| 48 |
+
shear=0.602,
|
| 49 |
+
flipud=0.00856,
|
| 50 |
+
fliplr=0.5,
|
| 51 |
+
mosaic=1.0,
|
| 52 |
+
mixup=0.243
|
| 53 |
+
)
|
configs/yolov6s.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv6s model
|
| 2 |
+
model = dict(
|
| 3 |
+
type='YOLOv6s',
|
| 4 |
+
pretrained=None,
|
| 5 |
+
depth_multiple=0.33,
|
| 6 |
+
width_multiple=0.50,
|
| 7 |
+
backbone=dict(
|
| 8 |
+
type='EfficientRep',
|
| 9 |
+
num_repeats=[1, 6, 12, 18, 6],
|
| 10 |
+
out_channels=[64, 128, 256, 512, 1024],
|
| 11 |
+
),
|
| 12 |
+
neck=dict(
|
| 13 |
+
type='RepPAN',
|
| 14 |
+
num_repeats=[12, 12, 12, 12],
|
| 15 |
+
out_channels=[256, 128, 128, 256, 256, 512],
|
| 16 |
+
),
|
| 17 |
+
head=dict(
|
| 18 |
+
type='EffiDeHead',
|
| 19 |
+
in_channels=[128, 256, 512],
|
| 20 |
+
num_layers=3,
|
| 21 |
+
begin_indices=24,
|
| 22 |
+
anchors=1,
|
| 23 |
+
out_indices=[17, 20, 23],
|
| 24 |
+
strides=[8, 16, 32],
|
| 25 |
+
iou_type='siou'
|
| 26 |
+
)
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
solver = dict(
|
| 30 |
+
optim='SGD',
|
| 31 |
+
lr_scheduler='Cosine',
|
| 32 |
+
lr0=0.01,
|
| 33 |
+
lrf=0.01,
|
| 34 |
+
momentum=0.937,
|
| 35 |
+
weight_decay=0.0005,
|
| 36 |
+
warmup_epochs=3.0,
|
| 37 |
+
warmup_momentum=0.8,
|
| 38 |
+
warmup_bias_lr=0.1
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
data_aug = dict(
|
| 42 |
+
hsv_h=0.015,
|
| 43 |
+
hsv_s=0.7,
|
| 44 |
+
hsv_v=0.4,
|
| 45 |
+
degrees=0.0,
|
| 46 |
+
translate=0.1,
|
| 47 |
+
scale=0.5,
|
| 48 |
+
shear=0.0,
|
| 49 |
+
flipud=0.0,
|
| 50 |
+
fliplr=0.5,
|
| 51 |
+
mosaic=1.0,
|
| 52 |
+
mixup=0.0,
|
| 53 |
+
)
|
configs/yolov6s_finetune.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv6s model
|
| 2 |
+
model = dict(
|
| 3 |
+
type='YOLOv6s',
|
| 4 |
+
pretrained='./weights/yolov6s.pt',
|
| 5 |
+
depth_multiple=0.33,
|
| 6 |
+
width_multiple=0.50,
|
| 7 |
+
backbone=dict(
|
| 8 |
+
type='EfficientRep',
|
| 9 |
+
num_repeats=[1, 6, 12, 18, 6],
|
| 10 |
+
out_channels=[64, 128, 256, 512, 1024],
|
| 11 |
+
),
|
| 12 |
+
neck=dict(
|
| 13 |
+
type='RepPAN',
|
| 14 |
+
num_repeats=[12, 12, 12, 12],
|
| 15 |
+
out_channels=[256, 128, 128, 256, 256, 512],
|
| 16 |
+
),
|
| 17 |
+
head=dict(
|
| 18 |
+
type='EffiDeHead',
|
| 19 |
+
in_channels=[128, 256, 512],
|
| 20 |
+
num_layers=3,
|
| 21 |
+
begin_indices=24,
|
| 22 |
+
anchors=1,
|
| 23 |
+
out_indices=[17, 20, 23],
|
| 24 |
+
strides=[8, 16, 32],
|
| 25 |
+
iou_type='siou'
|
| 26 |
+
)
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
solver = dict(
|
| 30 |
+
optim='SGD',
|
| 31 |
+
lr_scheduler='Cosine',
|
| 32 |
+
lr0=0.0032,
|
| 33 |
+
lrf=0.12,
|
| 34 |
+
momentum=0.843,
|
| 35 |
+
weight_decay=0.00036,
|
| 36 |
+
warmup_epochs=2.0,
|
| 37 |
+
warmup_momentum=0.5,
|
| 38 |
+
warmup_bias_lr=0.05
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
data_aug = dict(
|
| 42 |
+
hsv_h=0.0138,
|
| 43 |
+
hsv_s=0.664,
|
| 44 |
+
hsv_v=0.464,
|
| 45 |
+
degrees=0.373,
|
| 46 |
+
translate=0.245,
|
| 47 |
+
scale=0.898,
|
| 48 |
+
shear=0.602,
|
| 49 |
+
flipud=0.00856,
|
| 50 |
+
fliplr=0.5,
|
| 51 |
+
mosaic=1.0,
|
| 52 |
+
mixup=0.243,
|
| 53 |
+
)
|
data/coco.yaml
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# COCO 2017 dataset http://cocodataset.org
|
| 2 |
+
train: ../coco/images/train2017 # 118287 images
|
| 3 |
+
val: ../coco/images/val2017 # 5000 images
|
| 4 |
+
test: ../coco/images/test2017
|
| 5 |
+
anno_path: ../coco/annotations/instances_val2017.json
|
| 6 |
+
# number of classes
|
| 7 |
+
nc: 80
|
| 8 |
+
|
| 9 |
+
# class names
|
| 10 |
+
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
|
| 11 |
+
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
|
| 12 |
+
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
|
| 13 |
+
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
|
| 14 |
+
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
|
| 15 |
+
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
|
| 16 |
+
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
|
| 17 |
+
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
|
| 18 |
+
'hair drier', 'toothbrush' ]
|
data/images/image1.jpg
ADDED

|
data/images/image2.jpg
ADDED

|
data/images/image3.jpg
ADDED

|
deploy/ONNX/README.md
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Export ONNX Model
|
| 2 |
+
|
| 3 |
+
### Check requirements
|
| 4 |
+
```shell
|
| 5 |
+
pip install onnx>=1.10.0
|
| 6 |
+
```
|
| 7 |
+
|
| 8 |
+
### Export script
|
| 9 |
+
```shell
|
| 10 |
+
python deploy/ONNX/export_onnx.py --weights yolov6s.pt --img 640 --batch 1
|
| 11 |
+
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
### Download
|
| 15 |
+
* [YOLOv6-nano](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6n.onnx)
|
| 16 |
+
* [YOLOv6-tiny](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6t.onnx)
|
| 17 |
+
* [YOLOv6-s](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6s.onnx)
|
deploy/ONNX/export_onnx.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import argparse
|
| 4 |
+
import time
|
| 5 |
+
import sys
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import onnx
|
| 10 |
+
|
| 11 |
+
ROOT = os.getcwd()
|
| 12 |
+
if str(ROOT) not in sys.path:
|
| 13 |
+
sys.path.append(str(ROOT))
|
| 14 |
+
|
| 15 |
+
from yolov6.models.yolo import *
|
| 16 |
+
from yolov6.models.effidehead import Detect
|
| 17 |
+
from yolov6.layers.common import *
|
| 18 |
+
from yolov6.utils.events import LOGGER
|
| 19 |
+
from yolov6.utils.checkpoint import load_checkpoint
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
if __name__ == '__main__':
|
| 23 |
+
parser = argparse.ArgumentParser()
|
| 24 |
+
parser.add_argument('--weights', type=str, default='./yolov6s.pt', help='weights path')
|
| 25 |
+
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
|
| 26 |
+
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
|
| 27 |
+
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
|
| 28 |
+
parser.add_argument('--inplace', action='store_true', help='set Detect() inplace=True')
|
| 29 |
+
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0, 1, 2, 3 or cpu')
|
| 30 |
+
args = parser.parse_args()
|
| 31 |
+
args.img_size *= 2 if len(args.img_size) == 1 else 1 # expand
|
| 32 |
+
print(args)
|
| 33 |
+
t = time.time()
|
| 34 |
+
|
| 35 |
+
# Check device
|
| 36 |
+
cuda = args.device != 'cpu' and torch.cuda.is_available()
|
| 37 |
+
device = torch.device('cuda:0' if cuda else 'cpu')
|
| 38 |
+
assert not (device.type == 'cpu' and args.half), '--half only compatible with GPU export, i.e. use --device 0'
|
| 39 |
+
# Load PyTorch model
|
| 40 |
+
model = load_checkpoint(args.weights, map_location=device, inplace=True, fuse=True) # load FP32 model
|
| 41 |
+
for layer in model.modules():
|
| 42 |
+
if isinstance(layer, RepVGGBlock):
|
| 43 |
+
layer.switch_to_deploy()
|
| 44 |
+
|
| 45 |
+
# Input
|
| 46 |
+
img = torch.zeros(args.batch_size, 3, *args.img_size).to(device) # image size(1,3,320,192) iDetection
|
| 47 |
+
|
| 48 |
+
# Update model
|
| 49 |
+
if args.half:
|
| 50 |
+
img, model = img.half(), model.half() # to FP16
|
| 51 |
+
model.eval()
|
| 52 |
+
for k, m in model.named_modules():
|
| 53 |
+
if isinstance(m, Conv): # assign export-friendly activations
|
| 54 |
+
if isinstance(m.act, nn.SiLU):
|
| 55 |
+
m.act = SiLU()
|
| 56 |
+
elif isinstance(m, Detect):
|
| 57 |
+
m.inplace = args.inplace
|
| 58 |
+
|
| 59 |
+
y = model(img) # dry run
|
| 60 |
+
|
| 61 |
+
# ONNX export
|
| 62 |
+
try:
|
| 63 |
+
LOGGER.info('\nStarting to export ONNX...')
|
| 64 |
+
export_file = args.weights.replace('.pt', '.onnx') # filename
|
| 65 |
+
torch.onnx.export(model, img, export_file, verbose=False, opset_version=12,
|
| 66 |
+
training=torch.onnx.TrainingMode.EVAL,
|
| 67 |
+
do_constant_folding=True,
|
| 68 |
+
input_names=['image_arrays'],
|
| 69 |
+
output_names=['outputs'],
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
# Checks
|
| 73 |
+
onnx_model = onnx.load(export_file) # load onnx model
|
| 74 |
+
onnx.checker.check_model(onnx_model) # check onnx model
|
| 75 |
+
LOGGER.info(f'ONNX export success, saved as {export_file}')
|
| 76 |
+
except Exception as e:
|
| 77 |
+
LOGGER.info(f'ONNX export failure: {e}')
|
| 78 |
+
|
| 79 |
+
# Finish
|
| 80 |
+
LOGGER.info('\nExport complete (%.2fs)' % (time.time() - t))
|
deploy/OpenVINO/README.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Export OpenVINO Model
|
| 2 |
+
|
| 3 |
+
### Check requirements
|
| 4 |
+
```shell
|
| 5 |
+
pip install --upgrade pip
|
| 6 |
+
pip install openvino-dev
|
| 7 |
+
```
|
| 8 |
+
|
| 9 |
+
### Export script
|
| 10 |
+
```shell
|
| 11 |
+
python deploy/OpenVINO/export_openvino.py --weights yolov6s.pt --img 640 --batch 1
|
| 12 |
+
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
### Download
|
| 16 |
+
* [YOLOv6-nano](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6n_openvino.tar.gz)
|
| 17 |
+
* [YOLOv6-tiny](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6n_openvino.tar.gz)
|
| 18 |
+
* [YOLOv6-s](https://github.com/meituan/YOLOv6/releases/download/0.1.0/yolov6n_openvino.tar.gz)
|
deploy/OpenVINO/export_openvino.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import argparse
|
| 4 |
+
import time
|
| 5 |
+
import sys
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import onnx
|
| 10 |
+
import subprocess
|
| 11 |
+
|
| 12 |
+
ROOT = os.getcwd()
|
| 13 |
+
if str(ROOT) not in sys.path:
|
| 14 |
+
sys.path.append(str(ROOT))
|
| 15 |
+
|
| 16 |
+
from yolov6.models.yolo import *
|
| 17 |
+
from yolov6.models.effidehead import Detect
|
| 18 |
+
from yolov6.layers.common import *
|
| 19 |
+
from yolov6.utils.events import LOGGER
|
| 20 |
+
from yolov6.utils.checkpoint import load_checkpoint
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
if __name__ == '__main__':
|
| 24 |
+
parser = argparse.ArgumentParser()
|
| 25 |
+
parser.add_argument('--weights', type=str, default='./yolov6s.pt', help='weights path')
|
| 26 |
+
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
|
| 27 |
+
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
|
| 28 |
+
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
|
| 29 |
+
parser.add_argument('--inplace', action='store_true', help='set Detect() inplace=True')
|
| 30 |
+
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 31 |
+
args = parser.parse_args()
|
| 32 |
+
args.img_size *= 2 if len(args.img_size) == 1 else 1 # expand
|
| 33 |
+
print(args)
|
| 34 |
+
t = time.time()
|
| 35 |
+
|
| 36 |
+
# Check device
|
| 37 |
+
cuda = args.device != 'cpu' and torch.cuda.is_available()
|
| 38 |
+
device = torch.device('cuda:0' if cuda else 'cpu')
|
| 39 |
+
assert not (device.type == 'cpu' and args.half), '--half only compatible with GPU export, i.e. use --device 0'
|
| 40 |
+
# Load PyTorch model
|
| 41 |
+
model = load_checkpoint(args.weights, map_location=device, inplace=True, fuse=True) # load FP32 model
|
| 42 |
+
for layer in model.modules():
|
| 43 |
+
if isinstance(layer, RepVGGBlock):
|
| 44 |
+
layer.switch_to_deploy()
|
| 45 |
+
|
| 46 |
+
# Input
|
| 47 |
+
img = torch.zeros(args.batch_size, 3, *args.img_size).to(device) # image size(1,3,320,192) iDetection
|
| 48 |
+
|
| 49 |
+
# Update model
|
| 50 |
+
if args.half:
|
| 51 |
+
img, model = img.half(), model.half() # to FP16
|
| 52 |
+
model.eval()
|
| 53 |
+
for k, m in model.named_modules():
|
| 54 |
+
if isinstance(m, Conv): # assign export-friendly activations
|
| 55 |
+
if isinstance(m.act, nn.SiLU):
|
| 56 |
+
m.act = SiLU()
|
| 57 |
+
elif isinstance(m, Detect):
|
| 58 |
+
m.inplace = args.inplace
|
| 59 |
+
|
| 60 |
+
y = model(img) # dry run
|
| 61 |
+
|
| 62 |
+
# ONNX export
|
| 63 |
+
try:
|
| 64 |
+
LOGGER.info('\nStarting to export ONNX...')
|
| 65 |
+
export_file = args.weights.replace('.pt', '.onnx') # filename
|
| 66 |
+
torch.onnx.export(model, img, export_file, verbose=False, opset_version=12,
|
| 67 |
+
training=torch.onnx.TrainingMode.EVAL,
|
| 68 |
+
do_constant_folding=True,
|
| 69 |
+
input_names=['image_arrays'],
|
| 70 |
+
output_names=['outputs'],
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
# Checks
|
| 74 |
+
onnx_model = onnx.load(export_file) # load onnx model
|
| 75 |
+
onnx.checker.check_model(onnx_model) # check onnx model
|
| 76 |
+
LOGGER.info(f'ONNX export success, saved as {export_file}')
|
| 77 |
+
except Exception as e:
|
| 78 |
+
LOGGER.info(f'ONNX export failure: {e}')
|
| 79 |
+
|
| 80 |
+
# OpenVINO export
|
| 81 |
+
try:
|
| 82 |
+
LOGGER.info('\nStarting to export OpenVINO...')
|
| 83 |
+
import_file = args.weights.replace('.pt', '.onnx')
|
| 84 |
+
export_dir = str(import_file).replace('.onnx', '_openvino')
|
| 85 |
+
cmd = f"mo --input_model {import_file} --output_dir {export_dir} --data_type {'FP16' if args.half else 'FP32'}"
|
| 86 |
+
subprocess.check_output(cmd.split())
|
| 87 |
+
LOGGER.info(f'OpenVINO export success, saved as {export_dir}')
|
| 88 |
+
except Exception as e:
|
| 89 |
+
LOGGER.info(f'OpenVINO export failure: {e}')
|
| 90 |
+
|
| 91 |
+
# Finish
|
| 92 |
+
LOGGER.info('\nExport complete (%.2fs)' % (time.time() - t))
|
docs/About_naming_yolov6.md
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# About the naming of YOLOv6
|
| 2 |
+
|
| 3 |
+
### WHY named YOLOv6 ?
|
| 4 |
+
The full name is actually MT-YOLOv6, which is called YOLOv6 for brevity. Our work is majorly inspired by the original idea of the one-stage YOLO detection algorithm and the implementation has leveraged various techniques and tricks of former relevant work . Therefore, we named the project YOLOv6 to pay tribute to the work of YOLO series. Furthermore, we have indeed adopted some novel method and made solid engineering improvements to dedicate the algorithm to industrial applications.
|
| 5 |
+
As for the project, we'll continue to improve and maintain it, contributing more values for industrial applications.
|
| 6 |
+
|
| 7 |
+
P.S. We are contacting the authors of YOLO series about the naming of YOLOv6.
|
| 8 |
+
|
| 9 |
+
Thanks for your attention!
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
docs/Test_speed.md
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Test speed
|
| 2 |
+
|
| 3 |
+
This guidence explains how to reproduce speed results of YOLOv6. For fair comparision, the speed results do not contain the time cost of data pre-processing and NMS post-processing.
|
| 4 |
+
|
| 5 |
+
## 0. Prepare model
|
| 6 |
+
|
| 7 |
+
Download the models you want to test from the latest release.
|
| 8 |
+
|
| 9 |
+
## 1. Prepare testing environment
|
| 10 |
+
|
| 11 |
+
Refer to README, install packages corresponding to CUDA, CUDNN and TensorRT version.
|
| 12 |
+
|
| 13 |
+
Here, we use Torch1.8.0 inference on V100 and TensorRT 7.2 on T4.
|
| 14 |
+
|
| 15 |
+
## 2. Reproduce speed
|
| 16 |
+
|
| 17 |
+
#### 2.1 Torch Inference on V100
|
| 18 |
+
|
| 19 |
+
To get inference speed without TensorRT on V100, you can run the following command:
|
| 20 |
+
|
| 21 |
+
```shell
|
| 22 |
+
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6n.pt --task speed [--half]
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
- Speed results with batchsize = 1 are unstable in multiple runs, thus we do not provide the bs1 speed results.
|
| 26 |
+
|
| 27 |
+
#### 2.2 TensorRT Inference on T4
|
| 28 |
+
|
| 29 |
+
To get inference speed with TensorRT in FP16 mode on T4, you can follow the steps below:
|
| 30 |
+
|
| 31 |
+
First, export pytorch model as onnx format using the following command:
|
| 32 |
+
|
| 33 |
+
```shell
|
| 34 |
+
python deploy/ONNX/export_onnx.py --weights yolov6n.pt --device 0 --batch [1 or 32]
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
Second, generate an inference trt engine and test speed using `trtexec`:
|
| 38 |
+
|
| 39 |
+
```
|
| 40 |
+
trtexec --onnx=yolov6n.onnx --workspace=1024 --avgRuns=1000 --inputIOFormats=fp16:chw --outputIOFormats=fp16:chw
|
| 41 |
+
```
|
docs/Train_custom_data.md
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Train Custom Data
|
| 2 |
+
|
| 3 |
+
This guidence explains how to train your own custom data with YOLOv6 ( take fine-tuning YOLOv6-s model for example).
|
| 4 |
+
|
| 5 |
+
## 0. Before you start
|
| 6 |
+
|
| 7 |
+
Clone this repo and follow README.md to install requirements in a Python3.8 environment.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
## 1. Prepare your own dataset
|
| 11 |
+
|
| 12 |
+
**Step 1** Prepare your own dataset with images. For labeling images, you can use tools like [Labelme](https://github.com/wkentaro/labelme).
|
| 13 |
+
|
| 14 |
+
**Step 2** Generate label files in YOLO format.
|
| 15 |
+
|
| 16 |
+
One image corresponds to one label file, and the label format example is presented as below.
|
| 17 |
+
|
| 18 |
+
```json
|
| 19 |
+
# class_id center_x center_y bbox_width bbox_height
|
| 20 |
+
0 0.300926 0.617063 0.601852 0.765873
|
| 21 |
+
1 0.575 0.319531 0.4 0.551562
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
- Each row represents one object.
|
| 25 |
+
- Class id starts from `0`.
|
| 26 |
+
- Boundingbox coordinates must be in normalized `xywh` format (from 0 - 1). If your boxes are in pixels, divide `center_x` and `bbox_width` by image width, and `center_y` and `bbox_height` by image height.
|
| 27 |
+
|
| 28 |
+
**Step 3** Organize directories.
|
| 29 |
+
|
| 30 |
+
Organize your train and val images and label files according to the example below.
|
| 31 |
+
|
| 32 |
+
```shell
|
| 33 |
+
# image directory
|
| 34 |
+
path/to/data/images/train/im0.jpg
|
| 35 |
+
path/to/data/images/val/im1.jpg
|
| 36 |
+
path/to/data/images/test/im2.jpg
|
| 37 |
+
|
| 38 |
+
# label directory
|
| 39 |
+
path/to/data/labels/train/im0.txt
|
| 40 |
+
path/to/data/labels/val/im1.txt
|
| 41 |
+
path/to/data/labels/test/im2.txt
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
**Step 4** Create `dataset.yaml` in `$YOLOv6_DIR/data`.
|
| 45 |
+
|
| 46 |
+
```yaml
|
| 47 |
+
train: path/to/data/images/train # train images
|
| 48 |
+
val: path/to/data/images/val # val images
|
| 49 |
+
test: path/to/data/images/test # test images (optional)
|
| 50 |
+
|
| 51 |
+
# Classes
|
| 52 |
+
nc: 20 # number of classes
|
| 53 |
+
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
|
| 54 |
+
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
|
| 55 |
+
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## 2. Create a config file
|
| 60 |
+
|
| 61 |
+
We use a config file to specify the network structure and training setting, including optimizer and data augmentation hyperparameters.
|
| 62 |
+
|
| 63 |
+
If you create a new config file, please put it under the configs directory.
|
| 64 |
+
Or just use the provided config file in `$YOLOV6_HOME/configs/*_finetune.py`.
|
| 65 |
+
|
| 66 |
+
```python
|
| 67 |
+
## YOLOv6s Model config file
|
| 68 |
+
model = dict(
|
| 69 |
+
type='YOLOv6s',
|
| 70 |
+
pretrained='./weights/yolov6s.pt', # download pretrain model from YOLOv6 github if use pretrained model
|
| 71 |
+
depth_multiple = 0.33,
|
| 72 |
+
width_multiple = 0.50,
|
| 73 |
+
...
|
| 74 |
+
)
|
| 75 |
+
solver=dict(
|
| 76 |
+
optim='SGD',
|
| 77 |
+
lr_scheduler='Cosine',
|
| 78 |
+
...
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
data_aug = dict(
|
| 82 |
+
hsv_h=0.015,
|
| 83 |
+
hsv_s=0.7,
|
| 84 |
+
hsv_v=0.4,
|
| 85 |
+
...
|
| 86 |
+
)
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
## 3. Train
|
| 92 |
+
|
| 93 |
+
Single GPU
|
| 94 |
+
|
| 95 |
+
```shell
|
| 96 |
+
python tools/train.py --batch 256 --conf configs/yolov6s_finetune.py --data data/data.yaml --device 0
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
Multi GPUs (DDP mode recommended)
|
| 100 |
+
|
| 101 |
+
```shell
|
| 102 |
+
python -m torch.distributed.launch --nproc_per_node 4 tools/train.py --batch 256 --conf configs/yolov6s_finetune.py --data data/data.yaml --device 0,1,2,3
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
## 4. Evaluation
|
| 108 |
+
|
| 109 |
+
```shell
|
| 110 |
+
python tools/eval.py --data data/data.yaml --weights output_dir/name/weights/best_ckpt.pt --device 0
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
## 5. Inference
|
| 116 |
+
|
| 117 |
+
```shell
|
| 118 |
+
python tools/infer.py --weights output_dir/name/weights/best_ckpt.pt --source img.jpg --device 0
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
## 6. Deployment
|
| 124 |
+
|
| 125 |
+
Export as ONNX Format
|
| 126 |
+
|
| 127 |
+
```shell
|
| 128 |
+
python deploy/ONNX/export_onnx.py --weights output_dir/name/weights/best_ckpt.pt --device 0
|
| 129 |
+
```
|
packages.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ffmpeg
|
| 2 |
+
libsm6
|
| 3 |
+
libxext6 -y
|
| 4 |
+
libgl1
|
| 5 |
+
-y libgl1-mesa-glx
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pip install -r requirements.txt
|
| 2 |
+
# python3.8 environment
|
| 3 |
+
|
| 4 |
+
torch>=1.8.0
|
| 5 |
+
torchvision>=0.9.0
|
| 6 |
+
numpy>=1.18.5
|
| 7 |
+
opencv-python>=4.1.2
|
| 8 |
+
PyYAML>=5.3.1
|
| 9 |
+
scipy>=1.4.1
|
| 10 |
+
tqdm>=4.41.0
|
| 11 |
+
addict>=2.4.0
|
| 12 |
+
tensorboard>=2.7.0
|
| 13 |
+
pycocotools>=2.0
|
| 14 |
+
onnx>=1.10.0 # ONNX export
|
| 15 |
+
thop # FLOPs computation
|
tools/eval.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import argparse
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
import torch
|
| 7 |
+
|
| 8 |
+
ROOT = os.getcwd()
|
| 9 |
+
if str(ROOT) not in sys.path:
|
| 10 |
+
sys.path.append(str(ROOT))
|
| 11 |
+
|
| 12 |
+
from yolov6.core.evaler import Evaler
|
| 13 |
+
from yolov6.utils.events import LOGGER
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_args_parser(add_help=True):
|
| 17 |
+
parser = argparse.ArgumentParser(description='YOLOv6 PyTorch Evalating', add_help=add_help)
|
| 18 |
+
parser.add_argument('--data', type=str, default='./data/coco.yaml', help='dataset.yaml path')
|
| 19 |
+
parser.add_argument('--weights', type=str, default='./weights/yolov6s.pt', help='model.pt path(s)')
|
| 20 |
+
parser.add_argument('--batch-size', type=int, default=32, help='batch size')
|
| 21 |
+
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
|
| 22 |
+
parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
|
| 23 |
+
parser.add_argument('--iou-thres', type=float, default=0.65, help='NMS IoU threshold')
|
| 24 |
+
parser.add_argument('--task', default='val', help='val, or speed')
|
| 25 |
+
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 26 |
+
parser.add_argument('--half', default=False, action='store_true', help='whether to use fp16 infer')
|
| 27 |
+
parser.add_argument('--save_dir', type=str, default='runs/val/exp', help='evaluation save dir')
|
| 28 |
+
args = parser.parse_args()
|
| 29 |
+
LOGGER.info(args)
|
| 30 |
+
return args
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
@torch.no_grad()
|
| 34 |
+
def run(data,
|
| 35 |
+
weights=None,
|
| 36 |
+
batch_size=32,
|
| 37 |
+
img_size=640,
|
| 38 |
+
conf_thres=0.001,
|
| 39 |
+
iou_thres=0.65,
|
| 40 |
+
task='val',
|
| 41 |
+
device='',
|
| 42 |
+
half=False,
|
| 43 |
+
model=None,
|
| 44 |
+
dataloader=None,
|
| 45 |
+
save_dir='',
|
| 46 |
+
):
|
| 47 |
+
""" Run the evaluation process
|
| 48 |
+
|
| 49 |
+
This function is the main process of evalutaion, supporting image file and dir containing images.
|
| 50 |
+
It has tasks of 'val', 'train' and 'speed'. Task 'train' processes the evaluation during training phase.
|
| 51 |
+
Task 'val' processes the evaluation purely and return the mAP of model.pt. Task 'speed' precesses the
|
| 52 |
+
evaluation of inference speed of model.pt.
|
| 53 |
+
|
| 54 |
+
"""
|
| 55 |
+
|
| 56 |
+
# task
|
| 57 |
+
Evaler.check_task(task)
|
| 58 |
+
if not os.path.exists(save_dir):
|
| 59 |
+
os.makedirs(save_dir)
|
| 60 |
+
|
| 61 |
+
# reload thres/device/half/data according task
|
| 62 |
+
conf_thres, iou_thres = Evaler.reload_thres(conf_thres, iou_thres, task)
|
| 63 |
+
device = Evaler.reload_device(device, model, task)
|
| 64 |
+
half = device.type != 'cpu' and half
|
| 65 |
+
data = Evaler.reload_dataset(data) if isinstance(data, str) else data
|
| 66 |
+
|
| 67 |
+
# init
|
| 68 |
+
val = Evaler(data, batch_size, img_size, conf_thres, \
|
| 69 |
+
iou_thres, device, half, save_dir)
|
| 70 |
+
model = val.init_model(model, weights, task)
|
| 71 |
+
dataloader = val.init_data(dataloader, task)
|
| 72 |
+
|
| 73 |
+
# eval
|
| 74 |
+
model.eval()
|
| 75 |
+
pred_result = val.predict_model(model, dataloader, task)
|
| 76 |
+
eval_result = val.eval_model(pred_result, model, dataloader, task)
|
| 77 |
+
return eval_result
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def main(args):
|
| 81 |
+
run(**vars(args))
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
if __name__ == "__main__":
|
| 85 |
+
args = get_args_parser()
|
| 86 |
+
main(args)
|
tools/infer.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import argparse
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
import os.path as osp
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
ROOT = os.getcwd()
|
| 11 |
+
if str(ROOT) not in sys.path:
|
| 12 |
+
sys.path.append(str(ROOT))
|
| 13 |
+
|
| 14 |
+
from yolov6.utils.events import LOGGER
|
| 15 |
+
from yolov6.core.inferer import Inferer
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def get_args_parser(add_help=True):
|
| 19 |
+
parser = argparse.ArgumentParser(description='YOLOv6 PyTorch Inference.', add_help=add_help)
|
| 20 |
+
parser.add_argument('--weights', type=str, default='weights/yolov6s.pt', help='model path(s) for inference.')
|
| 21 |
+
parser.add_argument('--source', type=str, default='data/images', help='the source path, e.g. image-file/dir.')
|
| 22 |
+
parser.add_argument('--yaml', type=str, default='data/coco.yaml', help='data yaml file.')
|
| 23 |
+
parser.add_argument('--img-size', type=int, default=640, help='the image-size(h,w) in inference size.')
|
| 24 |
+
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold for inference.')
|
| 25 |
+
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold for inference.')
|
| 26 |
+
parser.add_argument('--max-det', type=int, default=1000, help='maximal inferences per image.')
|
| 27 |
+
parser.add_argument('--device', default='0', help='device to run our model i.e. 0 or 0,1,2,3 or cpu.')
|
| 28 |
+
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt.')
|
| 29 |
+
parser.add_argument('--save-img', action='store_false', help='save visuallized inference results.')
|
| 30 |
+
parser.add_argument('--classes', nargs='+', type=int, help='filter by classes, e.g. --classes 0, or --classes 0 2 3.')
|
| 31 |
+
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS.')
|
| 32 |
+
parser.add_argument('--project', default='runs/inference', help='save inference results to project/name.')
|
| 33 |
+
parser.add_argument('--name', default='exp', help='save inference results to project/name.')
|
| 34 |
+
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels.')
|
| 35 |
+
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences.')
|
| 36 |
+
parser.add_argument('--half', action='store_true', help='whether to use FP16 half-precision inference.')
|
| 37 |
+
|
| 38 |
+
args = parser.parse_args()
|
| 39 |
+
LOGGER.info(args)
|
| 40 |
+
return args
|
| 41 |
+
|
| 42 |
+
@torch.no_grad()
|
| 43 |
+
def run(weights=osp.join(ROOT, 'yolov6s.pt'),
|
| 44 |
+
source=osp.join(ROOT, 'data/images'),
|
| 45 |
+
yaml=None,
|
| 46 |
+
img_size=640,
|
| 47 |
+
conf_thres=0.25,
|
| 48 |
+
iou_thres=0.45,
|
| 49 |
+
max_det=1000,
|
| 50 |
+
device='',
|
| 51 |
+
save_txt=False,
|
| 52 |
+
save_img=True,
|
| 53 |
+
classes=None,
|
| 54 |
+
agnostic_nms=False,
|
| 55 |
+
project=osp.join(ROOT, 'runs/inference'),
|
| 56 |
+
name='exp',
|
| 57 |
+
hide_labels=False,
|
| 58 |
+
hide_conf=False,
|
| 59 |
+
half=False,
|
| 60 |
+
):
|
| 61 |
+
""" Inference process
|
| 62 |
+
|
| 63 |
+
This function is the main process of inference, supporting image files or dirs containing images.
|
| 64 |
+
|
| 65 |
+
Args:
|
| 66 |
+
weights: The path of model.pt, e.g. yolov6s.pt
|
| 67 |
+
source: Source path, supporting image files or dirs containing images.
|
| 68 |
+
yaml: Data yaml file, .
|
| 69 |
+
img_size: Inference image-size, e.g. 640
|
| 70 |
+
conf_thres: Confidence threshold in inference, e.g. 0.25
|
| 71 |
+
iou_thres: NMS IOU threshold in inference, e.g. 0.45
|
| 72 |
+
max_det: Maximal detections per image, e.g. 1000
|
| 73 |
+
device: Cuda device, e.e. 0, or 0,1,2,3 or cpu
|
| 74 |
+
save_txt: Save results to *.txt
|
| 75 |
+
save_img: Save visualized inference results
|
| 76 |
+
classes: Filter by class: --class 0, or --class 0 2 3
|
| 77 |
+
agnostic_nms: Class-agnostic NMS
|
| 78 |
+
project: Save results to project/name
|
| 79 |
+
name: Save results to project/name, e.g. 'exp'
|
| 80 |
+
line_thickness: Bounding box thickness (pixels), e.g. 3
|
| 81 |
+
hide_labels: Hide labels, e.g. False
|
| 82 |
+
hide_conf: Hide confidences
|
| 83 |
+
half: Use FP16 half-precision inference, e.g. False
|
| 84 |
+
"""
|
| 85 |
+
# create save dir
|
| 86 |
+
save_dir = osp.join(project, name)
|
| 87 |
+
if (save_img or save_txt) and not osp.exists(save_dir):
|
| 88 |
+
os.makedirs(save_dir)
|
| 89 |
+
else:
|
| 90 |
+
LOGGER.warning('Save directory already existed')
|
| 91 |
+
if save_txt:
|
| 92 |
+
os.mkdir(osp.join(save_dir, 'labels'))
|
| 93 |
+
|
| 94 |
+
# Inference
|
| 95 |
+
inferer = Inferer(source, weights, device, yaml, img_size, half)
|
| 96 |
+
inferer.infer(conf_thres, iou_thres, classes, agnostic_nms, max_det, save_dir, save_txt, save_img, hide_labels, hide_conf)
|
| 97 |
+
|
| 98 |
+
if save_txt or save_img:
|
| 99 |
+
LOGGER.info(f"Results saved to {save_dir}")
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def main(args):
|
| 103 |
+
run(**vars(args))
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
if __name__ == "__main__":
|
| 107 |
+
args = get_args_parser()
|
| 108 |
+
main(args)
|
tools/quantization/mnn/README.md
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
# Coming soon
|
tools/quantization/tensorrt/post_training/Calibrator.py
ADDED
|
@@ -0,0 +1,210 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#
|
| 2 |
+
# Modified by Meituan
|
| 3 |
+
# 2022.6.24
|
| 4 |
+
#
|
| 5 |
+
|
| 6 |
+
# Copyright 2019 NVIDIA Corporation
|
| 7 |
+
#
|
| 8 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 9 |
+
# you may not use this file except in compliance with the License.
|
| 10 |
+
# You may obtain a copy of the License at
|
| 11 |
+
#
|
| 12 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 13 |
+
#
|
| 14 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 15 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 16 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 17 |
+
# See the License for the specific language governing permissions and
|
| 18 |
+
# limitations under the License.
|
| 19 |
+
|
| 20 |
+
import os
|
| 21 |
+
import sys
|
| 22 |
+
import glob
|
| 23 |
+
import random
|
| 24 |
+
import logging
|
| 25 |
+
import cv2
|
| 26 |
+
|
| 27 |
+
import numpy as np
|
| 28 |
+
from PIL import Image
|
| 29 |
+
import tensorrt as trt
|
| 30 |
+
import pycuda.driver as cuda
|
| 31 |
+
import pycuda.autoinit
|
| 32 |
+
|
| 33 |
+
logging.basicConfig(level=logging.DEBUG,
|
| 34 |
+
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
|
| 35 |
+
datefmt="%Y-%m-%d %H:%M:%S")
|
| 36 |
+
logger = logging.getLogger(__name__)
|
| 37 |
+
|
| 38 |
+
def preprocess_yolov6(image, channels=3, height=224, width=224):
|
| 39 |
+
"""Pre-processing for YOLOv6-based Object Detection Models
|
| 40 |
+
|
| 41 |
+
Parameters
|
| 42 |
+
----------
|
| 43 |
+
image: PIL.Image
|
| 44 |
+
The image resulting from PIL.Image.open(filename) to preprocess
|
| 45 |
+
channels: int
|
| 46 |
+
The number of channels the image has (Usually 1 or 3)
|
| 47 |
+
height: int
|
| 48 |
+
The desired height of the image (usually 640)
|
| 49 |
+
width: int
|
| 50 |
+
The desired width of the image (usually 640)
|
| 51 |
+
|
| 52 |
+
Returns
|
| 53 |
+
-------
|
| 54 |
+
img_data: numpy array
|
| 55 |
+
The preprocessed image data in the form of a numpy array
|
| 56 |
+
|
| 57 |
+
"""
|
| 58 |
+
# Get the image in CHW format
|
| 59 |
+
resized_image = image.resize((width, height), Image.BILINEAR)
|
| 60 |
+
img_data = np.asarray(resized_image).astype(np.float32)
|
| 61 |
+
|
| 62 |
+
if len(img_data.shape) == 2:
|
| 63 |
+
# For images without a channel dimension, we stack
|
| 64 |
+
img_data = np.stack([img_data] * 3)
|
| 65 |
+
logger.debug("Received grayscale image. Reshaped to {:}".format(img_data.shape))
|
| 66 |
+
else:
|
| 67 |
+
img_data = img_data.transpose([2, 0, 1])
|
| 68 |
+
|
| 69 |
+
mean_vec = np.array([0.0, 0.0, 0.0])
|
| 70 |
+
stddev_vec = np.array([1.0, 1.0, 1.0])
|
| 71 |
+
assert img_data.shape[0] == channels
|
| 72 |
+
|
| 73 |
+
for i in range(img_data.shape[0]):
|
| 74 |
+
# Scale each pixel to [0, 1] and normalize per channel.
|
| 75 |
+
img_data[i, :, :] = (img_data[i, :, :] / 255.0 - mean_vec[i]) / stddev_vec[i]
|
| 76 |
+
|
| 77 |
+
return img_data
|
| 78 |
+
|
| 79 |
+
def get_int8_calibrator(calib_cache, calib_data, max_calib_size, calib_batch_size):
|
| 80 |
+
# Use calibration cache if it exists
|
| 81 |
+
if os.path.exists(calib_cache):
|
| 82 |
+
logger.info("Skipping calibration files, using calibration cache: {:}".format(calib_cache))
|
| 83 |
+
calib_files = []
|
| 84 |
+
# Use calibration files from validation dataset if no cache exists
|
| 85 |
+
else:
|
| 86 |
+
if not calib_data:
|
| 87 |
+
raise ValueError("ERROR: Int8 mode requested, but no calibration data provided. Please provide --calibration-data /path/to/calibration/files")
|
| 88 |
+
|
| 89 |
+
calib_files = get_calibration_files(calib_data, max_calib_size)
|
| 90 |
+
|
| 91 |
+
# Choose pre-processing function for INT8 calibration
|
| 92 |
+
preprocess_func = preprocess_yolov6
|
| 93 |
+
|
| 94 |
+
int8_calibrator = ImageCalibrator(calibration_files=calib_files,
|
| 95 |
+
batch_size=calib_batch_size,
|
| 96 |
+
cache_file=calib_cache)
|
| 97 |
+
return int8_calibrator
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def get_calibration_files(calibration_data, max_calibration_size=None, allowed_extensions=(".jpeg", ".jpg", ".png")):
|
| 101 |
+
"""Returns a list of all filenames ending with `allowed_extensions` found in the `calibration_data` directory.
|
| 102 |
+
|
| 103 |
+
Parameters
|
| 104 |
+
----------
|
| 105 |
+
calibration_data: str
|
| 106 |
+
Path to directory containing desired files.
|
| 107 |
+
max_calibration_size: int
|
| 108 |
+
Max number of files to use for calibration. If calibration_data contains more than this number,
|
| 109 |
+
a random sample of size max_calibration_size will be returned instead. If None, all samples will be used.
|
| 110 |
+
|
| 111 |
+
Returns
|
| 112 |
+
-------
|
| 113 |
+
calibration_files: List[str]
|
| 114 |
+
List of filenames contained in the `calibration_data` directory ending with `allowed_extensions`.
|
| 115 |
+
"""
|
| 116 |
+
|
| 117 |
+
logger.info("Collecting calibration files from: {:}".format(calibration_data))
|
| 118 |
+
calibration_files = [path for path in glob.iglob(os.path.join(calibration_data, "**"), recursive=True)
|
| 119 |
+
if os.path.isfile(path) and path.lower().endswith(allowed_extensions)]
|
| 120 |
+
logger.info("Number of Calibration Files found: {:}".format(len(calibration_files)))
|
| 121 |
+
|
| 122 |
+
if len(calibration_files) == 0:
|
| 123 |
+
raise Exception("ERROR: Calibration data path [{:}] contains no files!".format(calibration_data))
|
| 124 |
+
|
| 125 |
+
if max_calibration_size:
|
| 126 |
+
if len(calibration_files) > max_calibration_size:
|
| 127 |
+
logger.warning("Capping number of calibration images to max_calibration_size: {:}".format(max_calibration_size))
|
| 128 |
+
random.seed(42) # Set seed for reproducibility
|
| 129 |
+
calibration_files = random.sample(calibration_files, max_calibration_size)
|
| 130 |
+
|
| 131 |
+
return calibration_files
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
# https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Int8/EntropyCalibrator2.html
|
| 135 |
+
class ImageCalibrator(trt.IInt8EntropyCalibrator2):
|
| 136 |
+
"""INT8 Calibrator Class for Imagenet-based Image Classification Models.
|
| 137 |
+
|
| 138 |
+
Parameters
|
| 139 |
+
----------
|
| 140 |
+
calibration_files: List[str]
|
| 141 |
+
List of image filenames to use for INT8 Calibration
|
| 142 |
+
batch_size: int
|
| 143 |
+
Number of images to pass through in one batch during calibration
|
| 144 |
+
input_shape: Tuple[int]
|
| 145 |
+
Tuple of integers defining the shape of input to the model (Default: (3, 224, 224))
|
| 146 |
+
cache_file: str
|
| 147 |
+
Name of file to read/write calibration cache from/to.
|
| 148 |
+
preprocess_func: function -> numpy.ndarray
|
| 149 |
+
Pre-processing function to run on calibration data. This should match the pre-processing
|
| 150 |
+
done at inference time. In general, this function should return a numpy array of
|
| 151 |
+
shape `input_shape`.
|
| 152 |
+
"""
|
| 153 |
+
|
| 154 |
+
def __init__(self, calibration_files=[], batch_size=32, input_shape=(3, 224, 224),
|
| 155 |
+
cache_file="calibration.cache", use_cv2=False):
|
| 156 |
+
super().__init__()
|
| 157 |
+
self.input_shape = input_shape
|
| 158 |
+
self.cache_file = cache_file
|
| 159 |
+
self.batch_size = batch_size
|
| 160 |
+
self.batch = np.zeros((self.batch_size, *self.input_shape), dtype=np.float32)
|
| 161 |
+
self.device_input = cuda.mem_alloc(self.batch.nbytes)
|
| 162 |
+
|
| 163 |
+
self.files = calibration_files
|
| 164 |
+
self.use_cv2 = use_cv2
|
| 165 |
+
# Pad the list so it is a multiple of batch_size
|
| 166 |
+
if len(self.files) % self.batch_size != 0:
|
| 167 |
+
logger.info("Padding # calibration files to be a multiple of batch_size {:}".format(self.batch_size))
|
| 168 |
+
self.files += calibration_files[(len(calibration_files) % self.batch_size):self.batch_size]
|
| 169 |
+
|
| 170 |
+
self.batches = self.load_batches()
|
| 171 |
+
self.preprocess_func = preprocess_yolov6
|
| 172 |
+
|
| 173 |
+
def load_batches(self):
|
| 174 |
+
# Populates a persistent self.batch buffer with images.
|
| 175 |
+
for index in range(0, len(self.files), self.batch_size):
|
| 176 |
+
for offset in range(self.batch_size):
|
| 177 |
+
if self.use_cv2:
|
| 178 |
+
image = cv2.imread(self.files[index + offset])
|
| 179 |
+
else:
|
| 180 |
+
image = Image.open(self.files[index + offset])
|
| 181 |
+
self.batch[offset] = self.preprocess_func(image, *self.input_shape)
|
| 182 |
+
logger.info("Calibration images pre-processed: {:}/{:}".format(index+self.batch_size, len(self.files)))
|
| 183 |
+
yield self.batch
|
| 184 |
+
|
| 185 |
+
def get_batch_size(self):
|
| 186 |
+
return self.batch_size
|
| 187 |
+
|
| 188 |
+
def get_batch(self, names):
|
| 189 |
+
try:
|
| 190 |
+
# Assume self.batches is a generator that provides batch data.
|
| 191 |
+
batch = next(self.batches)
|
| 192 |
+
# Assume that self.device_input is a device buffer allocated by the constructor.
|
| 193 |
+
cuda.memcpy_htod(self.device_input, batch)
|
| 194 |
+
return [int(self.device_input)]
|
| 195 |
+
except StopIteration:
|
| 196 |
+
# When we're out of batches, we return either [] or None.
|
| 197 |
+
# This signals to TensorRT that there is no calibration data remaining.
|
| 198 |
+
return None
|
| 199 |
+
|
| 200 |
+
def read_calibration_cache(self):
|
| 201 |
+
# If there is a cache, use it instead of calibrating again. Otherwise, implicitly return None.
|
| 202 |
+
if os.path.exists(self.cache_file):
|
| 203 |
+
with open(self.cache_file, "rb") as f:
|
| 204 |
+
logger.info("Using calibration cache to save time: {:}".format(self.cache_file))
|
| 205 |
+
return f.read()
|
| 206 |
+
|
| 207 |
+
def write_calibration_cache(self, cache):
|
| 208 |
+
with open(self.cache_file, "wb") as f:
|
| 209 |
+
logger.info("Caching calibration data for future use: {:}".format(self.cache_file))
|
| 210 |
+
f.write(cache)
|
tools/quantization/tensorrt/post_training/LICENSE
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Apache License
|
| 3 |
+
Version 2.0, January 2004
|
| 4 |
+
http://www.apache.org/licenses/
|
| 5 |
+
|
| 6 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 7 |
+
|
| 8 |
+
1. Definitions.
|
| 9 |
+
|
| 10 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 11 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 12 |
+
|
| 13 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 14 |
+
the copyright owner that is granting the License.
|
| 15 |
+
|
| 16 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 17 |
+
other entities that control, are controlled by, or are under common
|
| 18 |
+
control with that entity. For the purposes of this definition,
|
| 19 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 20 |
+
direction or management of such entity, whether by contract or
|
| 21 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 22 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 23 |
+
|
| 24 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 25 |
+
exercising permissions granted by this License.
|
| 26 |
+
|
| 27 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 28 |
+
including but not limited to software source code, documentation
|
| 29 |
+
source, and configuration files.
|
| 30 |
+
|
| 31 |
+
"Object" form shall mean any form resulting from mechanical
|
| 32 |
+
transformation or translation of a Source form, including but
|
| 33 |
+
not limited to compiled object code, generated documentation,
|
| 34 |
+
and conversions to other media types.
|
| 35 |
+
|
| 36 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 37 |
+
Object form, made available under the License, as indicated by a
|
| 38 |
+
copyright notice that is included in or attached to the work
|
| 39 |
+
(an example is provided in the Appendix below).
|
| 40 |
+
|
| 41 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 42 |
+
form, that is based on (or derived from) the Work and for which the
|
| 43 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 44 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 45 |
+
of this License, Derivative Works shall not include works that remain
|
| 46 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 47 |
+
the Work and Derivative Works thereof.
|
| 48 |
+
|
| 49 |
+
"Contribution" shall mean any work of authorship, including
|
| 50 |
+
the original version of the Work and any modifications or additions
|
| 51 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 52 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 53 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 54 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 55 |
+
means any form of electronic, verbal, or written communication sent
|
| 56 |
+
to the Licensor or its representatives, including but not limited to
|
| 57 |
+
communication on electronic mailing lists, source code control systems,
|
| 58 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 59 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 60 |
+
excluding communication that is conspicuously marked or otherwise
|
| 61 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 62 |
+
|
| 63 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 64 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 65 |
+
subsequently incorporated within the Work.
|
| 66 |
+
|
| 67 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 68 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 69 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 70 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 71 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 72 |
+
Work and such Derivative Works in Source or Object form.
|
| 73 |
+
|
| 74 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 75 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 76 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 77 |
+
(except as stated in this section) patent license to make, have made,
|
| 78 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 79 |
+
where such license applies only to those patent claims licensable
|
| 80 |
+
by such Contributor that are necessarily infringed by their
|
| 81 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 82 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 83 |
+
institute patent litigation against any entity (including a
|
| 84 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 85 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 86 |
+
or contributory patent infringement, then any patent licenses
|
| 87 |
+
granted to You under this License for that Work shall terminate
|
| 88 |
+
as of the date such litigation is filed.
|
| 89 |
+
|
| 90 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 91 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 92 |
+
modifications, and in Source or Object form, provided that You
|
| 93 |
+
meet the following conditions:
|
| 94 |
+
|
| 95 |
+
(a) You must give any other recipients of the Work or
|
| 96 |
+
Derivative Works a copy of this License; and
|
| 97 |
+
|
| 98 |
+
(b) You must cause any modified files to carry prominent notices
|
| 99 |
+
stating that You changed the files; and
|
| 100 |
+
|
| 101 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 102 |
+
that You distribute, all copyright, patent, trademark, and
|
| 103 |
+
attribution notices from the Source form of the Work,
|
| 104 |
+
excluding those notices that do not pertain to any part of
|
| 105 |
+
the Derivative Works; and
|
| 106 |
+
|
| 107 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 108 |
+
distribution, then any Derivative Works that You distribute must
|
| 109 |
+
include a readable copy of the attribution notices contained
|
| 110 |
+
within such NOTICE file, excluding those notices that do not
|
| 111 |
+
pertain to any part of the Derivative Works, in at least one
|
| 112 |
+
of the following places: within a NOTICE text file distributed
|
| 113 |
+
as part of the Derivative Works; within the Source form or
|
| 114 |
+
documentation, if provided along with the Derivative Works; or,
|
| 115 |
+
within a display generated by the Derivative Works, if and
|
| 116 |
+
wherever such third-party notices normally appear. The contents
|
| 117 |
+
of the NOTICE file are for informational purposes only and
|
| 118 |
+
do not modify the License. You may add Your own attribution
|
| 119 |
+
notices within Derivative Works that You distribute, alongside
|
| 120 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 121 |
+
that such additional attribution notices cannot be construed
|
| 122 |
+
as modifying the License.
|
| 123 |
+
|
| 124 |
+
You may add Your own copyright statement to Your modifications and
|
| 125 |
+
may provide additional or different license terms and conditions
|
| 126 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 127 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 128 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 129 |
+
the conditions stated in this License.
|
| 130 |
+
|
| 131 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 132 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 133 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 134 |
+
this License, without any additional terms or conditions.
|
| 135 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 136 |
+
the terms of any separate license agreement you may have executed
|
| 137 |
+
with Licensor regarding such Contributions.
|
| 138 |
+
|
| 139 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 140 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 141 |
+
except as required for reasonable and customary use in describing the
|
| 142 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 143 |
+
|
| 144 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 145 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 146 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 147 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 148 |
+
implied, including, without limitation, any warranties or conditions
|
| 149 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 150 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 151 |
+
appropriateness of using or redistributing the Work and assume any
|
| 152 |
+
risks associated with Your exercise of permissions under this License.
|
| 153 |
+
|
| 154 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 155 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 156 |
+
unless required by applicable law (such as deliberate and grossly
|
| 157 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 158 |
+
liable to You for damages, including any direct, indirect, special,
|
| 159 |
+
incidental, or consequential damages of any character arising as a
|
| 160 |
+
result of this License or out of the use or inability to use the
|
| 161 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 162 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 163 |
+
other commercial damages or losses), even if such Contributor
|
| 164 |
+
has been advised of the possibility of such damages.
|
| 165 |
+
|
| 166 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 167 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 168 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 169 |
+
or other liability obligations and/or rights consistent with this
|
| 170 |
+
License. However, in accepting such obligations, You may act only
|
| 171 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 172 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 173 |
+
defend, and hold each Contributor harmless for any liability
|
| 174 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 175 |
+
of your accepting any such warranty or additional liability.
|
| 176 |
+
|
| 177 |
+
END OF TERMS AND CONDITIONS
|
| 178 |
+
|
| 179 |
+
Copyright 2020 NVIDIA Corporation
|
| 180 |
+
|
| 181 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 182 |
+
you may not use this file except in compliance with the License.
|
| 183 |
+
You may obtain a copy of the License at
|
| 184 |
+
|
| 185 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 186 |
+
|
| 187 |
+
Unless required by applicable law or agreed to in writing, software
|
| 188 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 189 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 190 |
+
See the License for the specific language governing permissions and
|
| 191 |
+
limitations under the License.
|
| 192 |
+
|
tools/quantization/tensorrt/post_training/README.md
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ONNX -> TensorRT INT8
|
| 2 |
+
These scripts were last tested using the
|
| 3 |
+
[NGC TensorRT Container Version 20.06-py3](https://ngc.nvidia.com/catalog/containers/nvidia:tensorrt).
|
| 4 |
+
You can see the corresponding framework versions for this container [here](https://docs.nvidia.com/deeplearning/sdk/tensorrt-container-release-notes/rel_20.06.html#rel_20.06).
|
| 5 |
+
|
| 6 |
+
## Quickstart
|
| 7 |
+
|
| 8 |
+
> **NOTE**: This INT8 example is only valid for **fixed-shape** ONNX models at the moment.
|
| 9 |
+
>
|
| 10 |
+
INT8 Calibration on **dynamic-shape** models is now supported, however this example has not been updated
|
| 11 |
+
to reflect that yet. For more details on INT8 Calibration for **dynamic-shape** models, please
|
| 12 |
+
see the [documentation](https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#int8-calib-dynamic-shapes).
|
| 13 |
+
|
| 14 |
+
### 1. Convert ONNX model to TensorRT INT8
|
| 15 |
+
|
| 16 |
+
See `./onnx_to_tensorrt.py -h` for full list of command line arguments.
|
| 17 |
+
|
| 18 |
+
```bash
|
| 19 |
+
./onnx_to_tensorrt.py --explicit-batch \
|
| 20 |
+
--onnx resnet50/model.onnx \
|
| 21 |
+
--fp16 \
|
| 22 |
+
--int8 \
|
| 23 |
+
--calibration-cache="caches/yolov6.cache" \
|
| 24 |
+
-o resnet50.int8.engine
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
See the [INT8 Calibration](#int8-calibration) section below for details on calibration
|
| 28 |
+
using your own model or different data, where you don't have an existing calibration cache
|
| 29 |
+
or want to create a new one.
|
| 30 |
+
|
| 31 |
+
## INT8 Calibration
|
| 32 |
+
|
| 33 |
+
See [ImagenetCalibrator.py](ImagenetCalibrator.py) for a reference implementation
|
| 34 |
+
of TensorRT's [IInt8EntropyCalibrator2](https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Int8/EntropyCalibrator2.html).
|
| 35 |
+
|
| 36 |
+
This class can be tweaked to work for other kinds of models, inputs, etc.
|
| 37 |
+
|
| 38 |
+
In the [Quickstart](#quickstart) section above, we made use of a pre-existing cache,
|
| 39 |
+
[caches/yolov6.cache](caches/yolov6.cache), to save time for the sake of an example.
|
| 40 |
+
|
| 41 |
+
However, to calibrate using different data or a different model, you can do so with the `--calibration-data` argument.
|
| 42 |
+
|
| 43 |
+
* This requires that you've mounted a dataset, such as Imagenet, to use for calibration.
|
| 44 |
+
* Add something like `-v /imagenet:/imagenet` to your Docker command in Step (1)
|
| 45 |
+
to mount a dataset found locally at `/imagenet`.
|
| 46 |
+
* You can specify your own `preprocess_func` by defining it inside of `ImageCalibrator.py`
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
# Path to dataset to use for calibration.
|
| 50 |
+
# **Not necessary if you already have a calibration cache from a previous run.
|
| 51 |
+
CALIBRATION_DATA="/imagenet"
|
| 52 |
+
|
| 53 |
+
# Truncate calibration images to a random sample of this amount if more are found.
|
| 54 |
+
# **Not necessary if you already have a calibration cache from a previous run.
|
| 55 |
+
MAX_CALIBRATION_SIZE=512
|
| 56 |
+
|
| 57 |
+
# Calibration cache to be used instead of calibration data if it already exists,
|
| 58 |
+
# or the cache will be created from the calibration data if it doesn't exist.
|
| 59 |
+
CACHE_FILENAME="caches/yolov6.cache"
|
| 60 |
+
|
| 61 |
+
# Path to ONNX model
|
| 62 |
+
ONNX_MODEL="model/yolov6.onnx"
|
| 63 |
+
|
| 64 |
+
# Path to write TensorRT engine to
|
| 65 |
+
OUTPUT="yolov6.int8.engine"
|
| 66 |
+
|
| 67 |
+
# Creates an int8 engine from your ONNX model, creating ${CACHE_FILENAME} based
|
| 68 |
+
# on your ${CALIBRATION_DATA}, unless ${CACHE_FILENAME} already exists, then
|
| 69 |
+
# it will use simply use that instead.
|
| 70 |
+
python3 onnx_to_tensorrt.py --fp16 --int8 -v \
|
| 71 |
+
--max_calibration_size=${MAX_CALIBRATION_SIZE} \
|
| 72 |
+
--calibration-data=${CALIBRATION_DATA} \
|
| 73 |
+
--calibration-cache=${CACHE_FILENAME} \
|
| 74 |
+
--preprocess_func=${PREPROCESS_FUNC} \
|
| 75 |
+
--explicit-batch \
|
| 76 |
+
--onnx ${ONNX_MODEL} -o ${OUTPUT}
|
| 77 |
+
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
### Pre-processing
|
| 81 |
+
|
| 82 |
+
In order to calibrate your model correctly, you should `pre-process` your data the same way
|
| 83 |
+
that you would during inference.
|
tools/quantization/tensorrt/post_training/onnx_to_tensorrt.py
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
|
| 3 |
+
#
|
| 4 |
+
# Modified by Meituan
|
| 5 |
+
# 2022.6.24
|
| 6 |
+
#
|
| 7 |
+
|
| 8 |
+
# Copyright 2019 NVIDIA Corporation
|
| 9 |
+
#
|
| 10 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 11 |
+
# you may not use this file except in compliance with the License.
|
| 12 |
+
# You may obtain a copy of the License at
|
| 13 |
+
#
|
| 14 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 15 |
+
#
|
| 16 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 17 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 18 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 19 |
+
# See the License for the specific language governing permissions and
|
| 20 |
+
# limitations under the License.
|
| 21 |
+
|
| 22 |
+
import os
|
| 23 |
+
import sys
|
| 24 |
+
import glob
|
| 25 |
+
import math
|
| 26 |
+
import logging
|
| 27 |
+
import argparse
|
| 28 |
+
|
| 29 |
+
import tensorrt as trt
|
| 30 |
+
#sys.path.remove('/opt/ros/kinetic/lib/python2.7/dist-packages')
|
| 31 |
+
|
| 32 |
+
TRT_LOGGER = trt.Logger()
|
| 33 |
+
logging.basicConfig(level=logging.DEBUG,
|
| 34 |
+
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
|
| 35 |
+
datefmt="%Y-%m-%d %H:%M:%S")
|
| 36 |
+
logger = logging.getLogger(__name__)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def add_profiles(config, inputs, opt_profiles):
|
| 40 |
+
logger.debug("=== Optimization Profiles ===")
|
| 41 |
+
for i, profile in enumerate(opt_profiles):
|
| 42 |
+
for inp in inputs:
|
| 43 |
+
_min, _opt, _max = profile.get_shape(inp.name)
|
| 44 |
+
logger.debug("{} - OptProfile {} - Min {} Opt {} Max {}".format(inp.name, i, _min, _opt, _max))
|
| 45 |
+
config.add_optimization_profile(profile)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def mark_outputs(network):
|
| 49 |
+
# Mark last layer's outputs if not already marked
|
| 50 |
+
# NOTE: This may not be correct in all cases
|
| 51 |
+
last_layer = network.get_layer(network.num_layers-1)
|
| 52 |
+
if not last_layer.num_outputs:
|
| 53 |
+
logger.error("Last layer contains no outputs.")
|
| 54 |
+
return
|
| 55 |
+
|
| 56 |
+
for i in range(last_layer.num_outputs):
|
| 57 |
+
network.mark_output(last_layer.get_output(i))
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def check_network(network):
|
| 61 |
+
if not network.num_outputs:
|
| 62 |
+
logger.warning("No output nodes found, marking last layer's outputs as network outputs. Correct this if wrong.")
|
| 63 |
+
mark_outputs(network)
|
| 64 |
+
|
| 65 |
+
inputs = [network.get_input(i) for i in range(network.num_inputs)]
|
| 66 |
+
outputs = [network.get_output(i) for i in range(network.num_outputs)]
|
| 67 |
+
max_len = max([len(inp.name) for inp in inputs] + [len(out.name) for out in outputs])
|
| 68 |
+
|
| 69 |
+
logger.debug("=== Network Description ===")
|
| 70 |
+
for i, inp in enumerate(inputs):
|
| 71 |
+
logger.debug("Input {0} | Name: {1:{2}} | Shape: {3}".format(i, inp.name, max_len, inp.shape))
|
| 72 |
+
for i, out in enumerate(outputs):
|
| 73 |
+
logger.debug("Output {0} | Name: {1:{2}} | Shape: {3}".format(i, out.name, max_len, out.shape))
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def get_batch_sizes(max_batch_size):
|
| 77 |
+
# Returns powers of 2, up to and including max_batch_size
|
| 78 |
+
max_exponent = math.log2(max_batch_size)
|
| 79 |
+
for i in range(int(max_exponent)+1):
|
| 80 |
+
batch_size = 2**i
|
| 81 |
+
yield batch_size
|
| 82 |
+
|
| 83 |
+
if max_batch_size != batch_size:
|
| 84 |
+
yield max_batch_size
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
# TODO: This only covers dynamic shape for batch size, not dynamic shape for other dimensions
|
| 88 |
+
def create_optimization_profiles(builder, inputs, batch_sizes=[1,8,16,32,64]):
|
| 89 |
+
# Check if all inputs are fixed explicit batch to create a single profile and avoid duplicates
|
| 90 |
+
if all([inp.shape[0] > -1 for inp in inputs]):
|
| 91 |
+
profile = builder.create_optimization_profile()
|
| 92 |
+
for inp in inputs:
|
| 93 |
+
fbs, shape = inp.shape[0], inp.shape[1:]
|
| 94 |
+
profile.set_shape(inp.name, min=(fbs, *shape), opt=(fbs, *shape), max=(fbs, *shape))
|
| 95 |
+
return [profile]
|
| 96 |
+
|
| 97 |
+
# Otherwise for mixed fixed+dynamic explicit batch inputs, create several profiles
|
| 98 |
+
profiles = {}
|
| 99 |
+
for bs in batch_sizes:
|
| 100 |
+
if not profiles.get(bs):
|
| 101 |
+
profiles[bs] = builder.create_optimization_profile()
|
| 102 |
+
|
| 103 |
+
for inp in inputs:
|
| 104 |
+
shape = inp.shape[1:]
|
| 105 |
+
# Check if fixed explicit batch
|
| 106 |
+
if inp.shape[0] > -1:
|
| 107 |
+
bs = inp.shape[0]
|
| 108 |
+
|
| 109 |
+
profiles[bs].set_shape(inp.name, min=(bs, *shape), opt=(bs, *shape), max=(bs, *shape))
|
| 110 |
+
|
| 111 |
+
return list(profiles.values())
|
| 112 |
+
|
| 113 |
+
def main():
|
| 114 |
+
parser = argparse.ArgumentParser(description="Creates a TensorRT engine from the provided ONNX file.\n")
|
| 115 |
+
parser.add_argument("--onnx", required=True, help="The ONNX model file to convert to TensorRT")
|
| 116 |
+
parser.add_argument("-o", "--output", type=str, default="model.engine", help="The path at which to write the engine")
|
| 117 |
+
parser.add_argument("-b", "--max-batch-size", type=int, help="The max batch size for the TensorRT engine input")
|
| 118 |
+
parser.add_argument("-v", "--verbosity", action="count", help="Verbosity for logging. (None) for ERROR, (-v) for INFO/WARNING/ERROR, (-vv) for VERBOSE.")
|
| 119 |
+
parser.add_argument("--explicit-batch", action='store_true', help="Set trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH.")
|
| 120 |
+
parser.add_argument("--explicit-precision", action='store_true', help="Set trt.NetworkDefinitionCreationFlag.EXPLICIT_PRECISION.")
|
| 121 |
+
parser.add_argument("--gpu-fallback", action='store_true', help="Set trt.BuilderFlag.GPU_FALLBACK.")
|
| 122 |
+
parser.add_argument("--refittable", action='store_true', help="Set trt.BuilderFlag.REFIT.")
|
| 123 |
+
parser.add_argument("--debug", action='store_true', help="Set trt.BuilderFlag.DEBUG.")
|
| 124 |
+
parser.add_argument("--strict-types", action='store_true', help="Set trt.BuilderFlag.STRICT_TYPES.")
|
| 125 |
+
parser.add_argument("--fp16", action="store_true", help="Attempt to use FP16 kernels when possible.")
|
| 126 |
+
parser.add_argument("--int8", action="store_true", help="Attempt to use INT8 kernels when possible. This should generally be used in addition to the --fp16 flag. \
|
| 127 |
+
ONLY SUPPORTS RESNET-LIKE MODELS SUCH AS RESNET50/VGG16/INCEPTION/etc.")
|
| 128 |
+
parser.add_argument("--calibration-cache", help="(INT8 ONLY) The path to read/write from calibration cache.", default="calibration.cache")
|
| 129 |
+
parser.add_argument("--calibration-data", help="(INT8 ONLY) The directory containing {*.jpg, *.jpeg, *.png} files to use for calibration. (ex: Imagenet Validation Set)", default=None)
|
| 130 |
+
parser.add_argument("--calibration-batch-size", help="(INT8 ONLY) The batch size to use during calibration.", type=int, default=128)
|
| 131 |
+
parser.add_argument("--max-calibration-size", help="(INT8 ONLY) The max number of data to calibrate on from --calibration-data.", type=int, default=2048)
|
| 132 |
+
parser.add_argument("-s", "--simple", action="store_true", help="Use SimpleCalibrator with random data instead of ImagenetCalibrator for INT8 calibration.")
|
| 133 |
+
args, _ = parser.parse_known_args()
|
| 134 |
+
|
| 135 |
+
print(args)
|
| 136 |
+
|
| 137 |
+
# Adjust logging verbosity
|
| 138 |
+
if args.verbosity is None:
|
| 139 |
+
TRT_LOGGER.min_severity = trt.Logger.Severity.ERROR
|
| 140 |
+
# -v
|
| 141 |
+
elif args.verbosity == 1:
|
| 142 |
+
TRT_LOGGER.min_severity = trt.Logger.Severity.INFO
|
| 143 |
+
# -vv
|
| 144 |
+
else:
|
| 145 |
+
TRT_LOGGER.min_severity = trt.Logger.Severity.VERBOSE
|
| 146 |
+
logger.info("TRT_LOGGER Verbosity: {:}".format(TRT_LOGGER.min_severity))
|
| 147 |
+
|
| 148 |
+
# Network flags
|
| 149 |
+
network_flags = 0
|
| 150 |
+
if args.explicit_batch:
|
| 151 |
+
network_flags |= 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
|
| 152 |
+
if args.explicit_precision:
|
| 153 |
+
network_flags |= 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_PRECISION)
|
| 154 |
+
|
| 155 |
+
builder_flag_map = {
|
| 156 |
+
'gpu_fallback': trt.BuilderFlag.GPU_FALLBACK,
|
| 157 |
+
'refittable': trt.BuilderFlag.REFIT,
|
| 158 |
+
'debug': trt.BuilderFlag.DEBUG,
|
| 159 |
+
'strict_types': trt.BuilderFlag.STRICT_TYPES,
|
| 160 |
+
'fp16': trt.BuilderFlag.FP16,
|
| 161 |
+
'int8': trt.BuilderFlag.INT8,
|
| 162 |
+
}
|
| 163 |
+
|
| 164 |
+
# Building engine
|
| 165 |
+
with trt.Builder(TRT_LOGGER) as builder, \
|
| 166 |
+
builder.create_network(network_flags) as network, \
|
| 167 |
+
builder.create_builder_config() as config, \
|
| 168 |
+
trt.OnnxParser(network, TRT_LOGGER) as parser:
|
| 169 |
+
|
| 170 |
+
config.max_workspace_size = 2**30 # 1GiB
|
| 171 |
+
|
| 172 |
+
# Set Builder Config Flags
|
| 173 |
+
for flag in builder_flag_map:
|
| 174 |
+
if getattr(args, flag):
|
| 175 |
+
logger.info("Setting {}".format(builder_flag_map[flag]))
|
| 176 |
+
config.set_flag(builder_flag_map[flag])
|
| 177 |
+
|
| 178 |
+
# Fill network atrributes with information by parsing model
|
| 179 |
+
with open(args.onnx, "rb") as f:
|
| 180 |
+
if not parser.parse(f.read()):
|
| 181 |
+
print('ERROR: Failed to parse the ONNX file: {}'.format(args.onnx))
|
| 182 |
+
for error in range(parser.num_errors):
|
| 183 |
+
print(parser.get_error(error))
|
| 184 |
+
sys.exit(1)
|
| 185 |
+
|
| 186 |
+
# Display network info and check certain properties
|
| 187 |
+
check_network(network)
|
| 188 |
+
|
| 189 |
+
if args.explicit_batch:
|
| 190 |
+
# Add optimization profiles
|
| 191 |
+
batch_sizes = [1, 8, 16, 32, 64]
|
| 192 |
+
inputs = [network.get_input(i) for i in range(network.num_inputs)]
|
| 193 |
+
opt_profiles = create_optimization_profiles(builder, inputs, batch_sizes)
|
| 194 |
+
add_profiles(config, inputs, opt_profiles)
|
| 195 |
+
# Implicit Batch Network
|
| 196 |
+
else:
|
| 197 |
+
builder.max_batch_size = args.max_batch_size
|
| 198 |
+
opt_profiles = []
|
| 199 |
+
|
| 200 |
+
# Precision flags
|
| 201 |
+
if args.fp16 and not builder.platform_has_fast_fp16:
|
| 202 |
+
logger.warning("FP16 not supported on this platform.")
|
| 203 |
+
|
| 204 |
+
if args.int8 and not builder.platform_has_fast_int8:
|
| 205 |
+
logger.warning("INT8 not supported on this platform.")
|
| 206 |
+
|
| 207 |
+
if args.int8:
|
| 208 |
+
from Calibrator import ImageCalibrator, get_int8_calibrator # local module
|
| 209 |
+
config.int8_calibrator = get_int8_calibrator(args.calibration_cache,
|
| 210 |
+
args.calibration_data,
|
| 211 |
+
args.max_calibration_size,
|
| 212 |
+
args.calibration_batch_size)
|
| 213 |
+
|
| 214 |
+
logger.info("Building Engine...")
|
| 215 |
+
with builder.build_engine(network, config) as engine, open(args.output, "wb") as f:
|
| 216 |
+
logger.info("Serializing engine to file: {:}".format(args.output))
|
| 217 |
+
f.write(engine.serialize())
|
| 218 |
+
|
| 219 |
+
if __name__ == "__main__":
|
| 220 |
+
main()
|
tools/quantization/tensorrt/post_training/quant.sh
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Path to ONNX model
|
| 2 |
+
# ex: ../yolov6.onnx
|
| 3 |
+
ONNX_MODEL=$1
|
| 4 |
+
|
| 5 |
+
# Path to dataset to use for calibration.
|
| 6 |
+
# **Not necessary if you already have a calibration cache from a previous run.
|
| 7 |
+
CALIBRATION_DATA=$2
|
| 8 |
+
|
| 9 |
+
# Path to Cache file to Serving
|
| 10 |
+
# ex: ./caches/demo.cache
|
| 11 |
+
CACHE_FILENAME=$3
|
| 12 |
+
|
| 13 |
+
# Path to write TensorRT engine to
|
| 14 |
+
OUTPUT=$4
|
| 15 |
+
|
| 16 |
+
# Creates an int8 engine from your ONNX model, creating ${CACHE_FILENAME} based
|
| 17 |
+
# on your ${CALIBRATION_DATA}, unless ${CACHE_FILENAME} already exists, then
|
| 18 |
+
# it will use simply use that instead.
|
| 19 |
+
python3 onnx_to_tensorrt.py --fp16 --int8 -v \
|
| 20 |
+
--calibration-data=${CALIBRATION_DATA} \
|
| 21 |
+
--calibration-cache=${CACHE_FILENAME} \
|
| 22 |
+
--explicit-batch \
|
| 23 |
+
--onnx ${ONNX_MODEL} -o ${OUTPUT}
|
tools/quantization/tensorrt/requirements.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pip install -r requirements.txt
|
| 2 |
+
# python3.8 environment
|
| 3 |
+
|
| 4 |
+
tensorrt # TensorRT 8.0+
|
| 5 |
+
pycuda==2020.1 # CUDA 11.0
|
| 6 |
+
nvidia-pyindex
|
| 7 |
+
pytorch-quantization
|
tools/quantization/tensorrt/training_aware/QAT_quantizer.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#
|
| 2 |
+
# QAT_quantizer.py
|
| 3 |
+
# YOLOv6
|
| 4 |
+
#
|
| 5 |
+
# Created by Meituan on 2022/06/24.
|
| 6 |
+
# Copyright © 2022
|
| 7 |
+
#
|
| 8 |
+
|
| 9 |
+
from absl import logging
|
| 10 |
+
from pytorch_quantization import nn as quant_nn
|
| 11 |
+
from pytorch_quantization import quant_modules
|
| 12 |
+
|
| 13 |
+
# Call this function before defining the model
|
| 14 |
+
def tensorrt_official_qat():
|
| 15 |
+
# Quantization Aware Training is based on Straight Through Estimator (STE) derivative approximation.
|
| 16 |
+
# It is some time known as “quantization aware training”.
|
| 17 |
+
|
| 18 |
+
# PyTorch-Quantization is a toolkit for training and evaluating PyTorch models with simulated quantization.
|
| 19 |
+
# Quantization can be added to the model automatically, or manually, allowing the model to be tuned for accuracy and performance.
|
| 20 |
+
# Quantization is compatible with NVIDIAs high performance integer kernels which leverage integer Tensor Cores.
|
| 21 |
+
# The quantized model can be exported to ONNX and imported by TensorRT 8.0 and later.
|
| 22 |
+
# https://github.com/NVIDIA/TensorRT/blob/main/tools/pytorch-quantization/examples/finetune_quant_resnet50.ipynb
|
| 23 |
+
|
| 24 |
+
# The example to export the
|
| 25 |
+
# model.eval()
|
| 26 |
+
# quant_nn.TensorQuantizer.use_fb_fake_quant = True # We have to shift to pytorch's fake quant ops before exporting the model to ONNX
|
| 27 |
+
# opset_version = 13
|
| 28 |
+
|
| 29 |
+
# Export ONNX for multiple batch sizes
|
| 30 |
+
# print("Creating ONNX file: " + onnx_filename)
|
| 31 |
+
# dummy_input = torch.randn(batch_onnx, 3, 224, 224, device='cuda') #TODO: switch input dims by model
|
| 32 |
+
# torch.onnx.export(model, dummy_input, onnx_filename, verbose=False, opset_version=opset_version, enable_onnx_checker=False, do_constant_folding=True)
|
| 33 |
+
try:
|
| 34 |
+
quant_modules.initialize()
|
| 35 |
+
except NameError:
|
| 36 |
+
logging.info("initialzation error for quant_modules")
|
| 37 |
+
|
| 38 |
+
# def QAT_quantizer():
|
| 39 |
+
# coming soon
|
tools/train.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import argparse
|
| 4 |
+
import os
|
| 5 |
+
import os.path as osp
|
| 6 |
+
import torch
|
| 7 |
+
import torch.distributed as dist
|
| 8 |
+
import sys
|
| 9 |
+
|
| 10 |
+
ROOT = os.getcwd()
|
| 11 |
+
if str(ROOT) not in sys.path:
|
| 12 |
+
sys.path.append(str(ROOT))
|
| 13 |
+
|
| 14 |
+
from yolov6.core.engine import Trainer
|
| 15 |
+
from yolov6.utils.config import Config
|
| 16 |
+
from yolov6.utils.events import LOGGER, save_yaml
|
| 17 |
+
from yolov6.utils.envs import get_envs, select_device, set_random_seed
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_args_parser(add_help=True):
|
| 21 |
+
parser = argparse.ArgumentParser(description='YOLOv6 PyTorch Training', add_help=add_help)
|
| 22 |
+
parser.add_argument('--data-path', default='./data/coco.yaml', type=str, help='dataset path')
|
| 23 |
+
parser.add_argument('--conf-file', default='./configs/yolov6s.py', type=str, help='experiment description file')
|
| 24 |
+
parser.add_argument('--img-size', type=int, default=640, help='train, val image size (pixels)')
|
| 25 |
+
parser.add_argument('--batch-size', default=32, type=int, help='total batch size for all GPUs')
|
| 26 |
+
parser.add_argument('--epochs', default=400, type=int, help='number of total epochs to run')
|
| 27 |
+
parser.add_argument('--workers', default=8, type=int, help='number of data loading workers (default: 8)')
|
| 28 |
+
parser.add_argument('--device', default='0', type=str, help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 29 |
+
parser.add_argument('--noval', action='store_true', help='only evaluate in final epoch')
|
| 30 |
+
parser.add_argument('--check-images', action='store_true', help='check images when initializing datasets')
|
| 31 |
+
parser.add_argument('--check-labels', action='store_true', help='check label files when initializing datasets')
|
| 32 |
+
parser.add_argument('--output-dir', default='./runs/train', type=str, help='path to save outputs')
|
| 33 |
+
parser.add_argument('--name', default='exp', type=str, help='experiment name, save to output_dir/name')
|
| 34 |
+
parser.add_argument('--dist_url', type=str, default="tcp://127.0.0.1:8888")
|
| 35 |
+
parser.add_argument('--gpu_count', type=int, default=0)
|
| 36 |
+
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
|
| 37 |
+
|
| 38 |
+
return parser
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def check_and_init(args):
|
| 42 |
+
'''check config files and device, and initialize '''
|
| 43 |
+
|
| 44 |
+
# check files
|
| 45 |
+
args.save_dir = osp.join(args.output_dir, args.name)
|
| 46 |
+
os.makedirs(args.save_dir, exist_ok=True)
|
| 47 |
+
cfg = Config.fromfile(args.conf_file)
|
| 48 |
+
|
| 49 |
+
# check device
|
| 50 |
+
device = select_device(args.device)
|
| 51 |
+
|
| 52 |
+
# set random seed
|
| 53 |
+
set_random_seed(1+args.rank, deterministic=(args.rank == -1))
|
| 54 |
+
|
| 55 |
+
# save args
|
| 56 |
+
save_yaml(vars(args), osp.join(args.save_dir, 'args.yaml'))
|
| 57 |
+
|
| 58 |
+
return cfg, device
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def main(args):
|
| 62 |
+
'''main function of training'''
|
| 63 |
+
# Setup
|
| 64 |
+
args.rank, args.local_rank, args.world_size = get_envs()
|
| 65 |
+
LOGGER.info(f'training args are: {args}\n')
|
| 66 |
+
cfg, device = check_and_init(args)
|
| 67 |
+
|
| 68 |
+
if args.local_rank != -1: # if DDP mode
|
| 69 |
+
torch.cuda.set_device(args.local_rank)
|
| 70 |
+
device = torch.device('cuda', args.local_rank)
|
| 71 |
+
LOGGER.info('Initializing process group... ')
|
| 72 |
+
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo", \
|
| 73 |
+
init_method=args.dist_url, rank=args.local_rank, world_size=args.world_size)
|
| 74 |
+
|
| 75 |
+
# Start
|
| 76 |
+
trainer = Trainer(args, cfg, device)
|
| 77 |
+
trainer.train()
|
| 78 |
+
|
| 79 |
+
# End
|
| 80 |
+
if args.world_size > 1 and args.rank == 0:
|
| 81 |
+
LOGGER.info('Destroying process group... ')
|
| 82 |
+
dist.destroy_process_group()
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
if __name__ == '__main__':
|
| 86 |
+
args = get_args_parser().parse_args()
|
| 87 |
+
main(args)
|
yolov6/core/engine.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
from copy import deepcopy
|
| 6 |
+
import os.path as osp
|
| 7 |
+
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
from torch.cuda import amp
|
| 13 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 14 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 15 |
+
|
| 16 |
+
import tools.eval as eval
|
| 17 |
+
from yolov6.data.data_load import create_dataloader
|
| 18 |
+
from yolov6.models.yolo import build_model
|
| 19 |
+
from yolov6.models.loss import ComputeLoss
|
| 20 |
+
from yolov6.utils.events import LOGGER, NCOLS, load_yaml, write_tblog
|
| 21 |
+
from yolov6.utils.ema import ModelEMA, de_parallel
|
| 22 |
+
from yolov6.utils.checkpoint import load_state_dict, save_checkpoint, strip_optimizer
|
| 23 |
+
from yolov6.solver.build import build_optimizer, build_lr_scheduler
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class Trainer:
|
| 27 |
+
def __init__(self, args, cfg, device):
|
| 28 |
+
self.args = args
|
| 29 |
+
self.cfg = cfg
|
| 30 |
+
self.device = device
|
| 31 |
+
|
| 32 |
+
self.rank = args.rank
|
| 33 |
+
self.local_rank = args.local_rank
|
| 34 |
+
self.world_size = args.world_size
|
| 35 |
+
self.main_process = self.rank in [-1, 0]
|
| 36 |
+
self.save_dir = args.save_dir
|
| 37 |
+
# get data loader
|
| 38 |
+
self.data_dict = load_yaml(args.data_path)
|
| 39 |
+
self.num_classes = self.data_dict['nc']
|
| 40 |
+
self.train_loader, self.val_loader = self.get_data_loader(args, cfg, self.data_dict)
|
| 41 |
+
# get model and optimizer
|
| 42 |
+
model = self.get_model(args, cfg, self.num_classes, device)
|
| 43 |
+
self.optimizer = self.get_optimizer(args, cfg, model)
|
| 44 |
+
self.scheduler, self.lf = self.get_lr_scheduler(args, cfg, self.optimizer)
|
| 45 |
+
self.ema = ModelEMA(model) if self.main_process else None
|
| 46 |
+
self.model = self.parallel_model(args, model, device)
|
| 47 |
+
self.model.nc, self.model.names = self.data_dict['nc'], self.data_dict['names']
|
| 48 |
+
# tensorboard
|
| 49 |
+
self.tblogger = SummaryWriter(self.save_dir) if self.main_process else None
|
| 50 |
+
|
| 51 |
+
self.start_epoch = 0
|
| 52 |
+
self.max_epoch = args.epochs
|
| 53 |
+
self.max_stepnum = len(self.train_loader)
|
| 54 |
+
self.batch_size = args.batch_size
|
| 55 |
+
self.img_size = args.img_size
|
| 56 |
+
|
| 57 |
+
# Training Process
|
| 58 |
+
def train(self):
|
| 59 |
+
try:
|
| 60 |
+
self.train_before_loop()
|
| 61 |
+
for self.epoch in range(self.start_epoch, self.max_epoch):
|
| 62 |
+
self.train_in_loop()
|
| 63 |
+
|
| 64 |
+
except Exception as _:
|
| 65 |
+
LOGGER.error('ERROR in training loop or eval/save model.')
|
| 66 |
+
raise
|
| 67 |
+
finally:
|
| 68 |
+
self.train_after_loop()
|
| 69 |
+
|
| 70 |
+
# Training loop for each epoch
|
| 71 |
+
def train_in_loop(self):
|
| 72 |
+
try:
|
| 73 |
+
self.prepare_for_steps()
|
| 74 |
+
for self.step, self.batch_data in self.pbar:
|
| 75 |
+
self.train_in_steps()
|
| 76 |
+
self.print_details()
|
| 77 |
+
except Exception as _:
|
| 78 |
+
LOGGER.error('ERROR in training steps.')
|
| 79 |
+
raise
|
| 80 |
+
try:
|
| 81 |
+
self.eval_and_save()
|
| 82 |
+
except Exception as _:
|
| 83 |
+
LOGGER.error('ERROR in evaluate and save model.')
|
| 84 |
+
raise
|
| 85 |
+
|
| 86 |
+
# Training loop for batchdata
|
| 87 |
+
def train_in_steps(self):
|
| 88 |
+
images, targets = self.prepro_data(self.batch_data, self.device)
|
| 89 |
+
# forward
|
| 90 |
+
with amp.autocast(enabled=self.device != 'cpu'):
|
| 91 |
+
preds = self.model(images)
|
| 92 |
+
total_loss, loss_items = self.compute_loss(preds, targets)
|
| 93 |
+
if self.rank != -1:
|
| 94 |
+
total_loss *= self.world_size
|
| 95 |
+
# backward
|
| 96 |
+
self.scaler.scale(total_loss).backward()
|
| 97 |
+
self.loss_items = loss_items
|
| 98 |
+
self.update_optimizer()
|
| 99 |
+
|
| 100 |
+
def eval_and_save(self):
|
| 101 |
+
epoch_sub = self.max_epoch - self.epoch
|
| 102 |
+
val_period = 20 if epoch_sub > 100 else 1 # to fasten training time, evaluate in every 20 epochs for the early stage.
|
| 103 |
+
is_val_epoch = (not self.args.noval or (epoch_sub == 1)) and (self.epoch % val_period == 0)
|
| 104 |
+
if self.main_process:
|
| 105 |
+
self.ema.update_attr(self.model, include=['nc', 'names', 'stride']) # update attributes for ema model
|
| 106 |
+
if is_val_epoch:
|
| 107 |
+
self.eval_model()
|
| 108 |
+
self.ap = self.evaluate_results[0] * 0.1 + self.evaluate_results[1] * 0.9
|
| 109 |
+
self.best_ap = max(self.ap, self.best_ap)
|
| 110 |
+
# save ckpt
|
| 111 |
+
ckpt = {
|
| 112 |
+
'model': deepcopy(de_parallel(self.model)).half(),
|
| 113 |
+
'ema': deepcopy(self.ema.ema).half(),
|
| 114 |
+
'updates': self.ema.updates,
|
| 115 |
+
'optimizer': self.optimizer.state_dict(),
|
| 116 |
+
'epoch': self.epoch,
|
| 117 |
+
}
|
| 118 |
+
|
| 119 |
+
save_ckpt_dir = osp.join(self.save_dir, 'weights')
|
| 120 |
+
save_checkpoint(ckpt, (is_val_epoch) and (self.ap == self.best_ap), save_ckpt_dir, model_name='last_ckpt')
|
| 121 |
+
del ckpt
|
| 122 |
+
# log for tensorboard
|
| 123 |
+
write_tblog(self.tblogger, self.epoch, self.evaluate_results, self.mean_loss)
|
| 124 |
+
|
| 125 |
+
def eval_model(self):
|
| 126 |
+
results = eval.run(self.data_dict,
|
| 127 |
+
batch_size=self.batch_size // self.world_size * 2,
|
| 128 |
+
img_size=self.img_size,
|
| 129 |
+
model=self.ema.ema,
|
| 130 |
+
dataloader=self.val_loader,
|
| 131 |
+
save_dir=self.save_dir,
|
| 132 |
+
task='train')
|
| 133 |
+
|
| 134 |
+
LOGGER.info(f"Epoch: {self.epoch} | [email protected]: {results[0]} | [email protected]:0.95: {results[1]}")
|
| 135 |
+
self.evaluate_results = results[:2]
|
| 136 |
+
|
| 137 |
+
def train_before_loop(self):
|
| 138 |
+
LOGGER.info('Training start...')
|
| 139 |
+
self.start_time = time.time()
|
| 140 |
+
self.warmup_stepnum = max(round(self.cfg.solver.warmup_epochs * self.max_stepnum), 1000)
|
| 141 |
+
self.scheduler.last_epoch = self.start_epoch - 1
|
| 142 |
+
self.last_opt_step = -1
|
| 143 |
+
self.scaler = amp.GradScaler(enabled=self.device != 'cpu')
|
| 144 |
+
|
| 145 |
+
self.best_ap, self.ap = 0.0, 0.0
|
| 146 |
+
self.evaluate_results = (0, 0) # AP50, AP50_95
|
| 147 |
+
self.compute_loss = ComputeLoss(iou_type=self.cfg.model.head.iou_type)
|
| 148 |
+
|
| 149 |
+
def prepare_for_steps(self):
|
| 150 |
+
if self.epoch > self.start_epoch:
|
| 151 |
+
self.scheduler.step()
|
| 152 |
+
self.model.train()
|
| 153 |
+
if self.rank != -1:
|
| 154 |
+
self.train_loader.sampler.set_epoch(self.epoch)
|
| 155 |
+
self.mean_loss = torch.zeros(4, device=self.device)
|
| 156 |
+
self.optimizer.zero_grad()
|
| 157 |
+
|
| 158 |
+
LOGGER.info(('\n' + '%10s' * 5) % ('Epoch', 'iou_loss', 'l1_loss', 'obj_loss', 'cls_loss'))
|
| 159 |
+
self.pbar = enumerate(self.train_loader)
|
| 160 |
+
if self.main_process:
|
| 161 |
+
self.pbar = tqdm(self.pbar, total=self.max_stepnum, ncols=NCOLS, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}')
|
| 162 |
+
|
| 163 |
+
# Print loss after each steps
|
| 164 |
+
def print_details(self):
|
| 165 |
+
if self.main_process:
|
| 166 |
+
self.mean_loss = (self.mean_loss * self.step + self.loss_items) / (self.step + 1)
|
| 167 |
+
self.pbar.set_description(('%10s' + '%10.4g' * 4) % (f'{self.epoch}/{self.max_epoch - 1}', \
|
| 168 |
+
*(self.mean_loss)))
|
| 169 |
+
|
| 170 |
+
# Empty cache if training finished
|
| 171 |
+
def train_after_loop(self):
|
| 172 |
+
if self.main_process:
|
| 173 |
+
LOGGER.info(f'\nTraining completed in {(time.time() - self.start_time) / 3600:.3f} hours.')
|
| 174 |
+
save_ckpt_dir = osp.join(self.save_dir, 'weights')
|
| 175 |
+
strip_optimizer(save_ckpt_dir) # strip optimizers for saved pt model
|
| 176 |
+
if self.device != 'cpu':
|
| 177 |
+
torch.cuda.empty_cache()
|
| 178 |
+
|
| 179 |
+
def update_optimizer(self):
|
| 180 |
+
curr_step = self.step + self.max_stepnum * self.epoch
|
| 181 |
+
self.accumulate = max(1, round(64 / self.batch_size))
|
| 182 |
+
if curr_step <= self.warmup_stepnum:
|
| 183 |
+
self.accumulate = max(1, np.interp(curr_step, [0, self.warmup_stepnum], [1, 64 / self.batch_size]).round())
|
| 184 |
+
for k, param in enumerate(self.optimizer.param_groups):
|
| 185 |
+
warmup_bias_lr = self.cfg.solver.warmup_bias_lr if k == 2 else 0.0
|
| 186 |
+
param['lr'] = np.interp(curr_step, [0, self.warmup_stepnum], [warmup_bias_lr, param['initial_lr'] * self.lf(self.epoch)])
|
| 187 |
+
if 'momentum' in param:
|
| 188 |
+
param['momentum'] = np.interp(curr_step, [0, self.warmup_stepnum], [self.cfg.solver.warmup_momentum, self.cfg.solver.momentum])
|
| 189 |
+
if curr_step - self.last_opt_step >= self.accumulate:
|
| 190 |
+
self.scaler.step(self.optimizer)
|
| 191 |
+
self.scaler.update()
|
| 192 |
+
self.optimizer.zero_grad()
|
| 193 |
+
if self.ema:
|
| 194 |
+
self.ema.update(self.model)
|
| 195 |
+
self.last_opt_step = curr_step
|
| 196 |
+
|
| 197 |
+
@staticmethod
|
| 198 |
+
def get_data_loader(args, cfg, data_dict):
|
| 199 |
+
train_path, val_path = data_dict['train'], data_dict['val']
|
| 200 |
+
# check data
|
| 201 |
+
nc = int(data_dict['nc'])
|
| 202 |
+
class_names = data_dict['names']
|
| 203 |
+
assert len(class_names) == nc, f'the length of class names does not match the number of classes defined'
|
| 204 |
+
grid_size = max(int(max(cfg.model.head.strides)), 32)
|
| 205 |
+
# create train dataloader
|
| 206 |
+
train_loader = create_dataloader(train_path, args.img_size, args.batch_size // args.world_size, grid_size,
|
| 207 |
+
hyp=dict(cfg.data_aug), augment=True, rect=False, rank=args.local_rank,
|
| 208 |
+
workers=args.workers, shuffle=True, check_images=args.check_images,
|
| 209 |
+
check_labels=args.check_labels, class_names=class_names, task='train')[0]
|
| 210 |
+
# create val dataloader
|
| 211 |
+
val_loader = None
|
| 212 |
+
if args.rank in [-1, 0]:
|
| 213 |
+
val_loader = create_dataloader(val_path, args.img_size, args.batch_size // args.world_size * 2, grid_size,
|
| 214 |
+
hyp=dict(cfg.data_aug), rect=True, rank=-1, pad=0.5,
|
| 215 |
+
workers=args.workers, check_images=args.check_images,
|
| 216 |
+
check_labels=args.check_labels, class_names=class_names, task='val')[0]
|
| 217 |
+
|
| 218 |
+
return train_loader, val_loader
|
| 219 |
+
|
| 220 |
+
@staticmethod
|
| 221 |
+
def prepro_data(batch_data, device):
|
| 222 |
+
images = batch_data[0].to(device, non_blocking=True).float() / 255
|
| 223 |
+
targets = batch_data[1].to(device)
|
| 224 |
+
return images, targets
|
| 225 |
+
|
| 226 |
+
@staticmethod
|
| 227 |
+
def get_model(args, cfg, nc, device):
|
| 228 |
+
model = build_model(cfg, nc, device)
|
| 229 |
+
weights = cfg.model.pretrained
|
| 230 |
+
if weights: # finetune if pretrained model is set
|
| 231 |
+
LOGGER.info(f'Loading state_dict from {weights} for fine-tuning...')
|
| 232 |
+
model = load_state_dict(weights, model, map_location=device)
|
| 233 |
+
LOGGER.info('Model: {}'.format(model))
|
| 234 |
+
return model
|
| 235 |
+
|
| 236 |
+
@staticmethod
|
| 237 |
+
def parallel_model(args, model, device):
|
| 238 |
+
# If DP mode
|
| 239 |
+
dp_mode = device.type != 'cpu' and args.rank == -1
|
| 240 |
+
if dp_mode and torch.cuda.device_count() > 1:
|
| 241 |
+
LOGGER.warning('WARNING: DP not recommended, use DDP instead.\n')
|
| 242 |
+
model = torch.nn.DataParallel(model)
|
| 243 |
+
|
| 244 |
+
# If DDP mode
|
| 245 |
+
ddp_mode = device.type != 'cpu' and args.rank != -1
|
| 246 |
+
if ddp_mode:
|
| 247 |
+
model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank)
|
| 248 |
+
|
| 249 |
+
return model
|
| 250 |
+
|
| 251 |
+
@staticmethod
|
| 252 |
+
def get_optimizer(args, cfg, model):
|
| 253 |
+
accumulate = max(1, round(64 / args.batch_size))
|
| 254 |
+
cfg.solver.weight_decay *= args.batch_size * accumulate / 64
|
| 255 |
+
optimizer = build_optimizer(cfg, model)
|
| 256 |
+
return optimizer
|
| 257 |
+
|
| 258 |
+
@staticmethod
|
| 259 |
+
def get_lr_scheduler(args, cfg, optimizer):
|
| 260 |
+
epochs = args.epochs
|
| 261 |
+
lr_scheduler, lf = build_lr_scheduler(cfg, optimizer, epochs)
|
| 262 |
+
return lr_scheduler, lf
|
yolov6/core/evaler.py
ADDED
|
@@ -0,0 +1,258 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import os
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
import numpy as np
|
| 6 |
+
import json
|
| 7 |
+
import torch
|
| 8 |
+
import yaml
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
|
| 11 |
+
from pycocotools.coco import COCO
|
| 12 |
+
from pycocotools.cocoeval import COCOeval
|
| 13 |
+
|
| 14 |
+
from yolov6.data.data_load import create_dataloader
|
| 15 |
+
from yolov6.utils.events import LOGGER, NCOLS
|
| 16 |
+
from yolov6.utils.nms import non_max_suppression
|
| 17 |
+
from yolov6.utils.checkpoint import load_checkpoint
|
| 18 |
+
from yolov6.utils.torch_utils import time_sync, get_model_info
|
| 19 |
+
|
| 20 |
+
'''
|
| 21 |
+
|
| 22 |
+
python tools/eval.py --task 'train'/'val'/'speed'
|
| 23 |
+
|
| 24 |
+
'''
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class Evaler:
|
| 28 |
+
def __init__(self,
|
| 29 |
+
data,
|
| 30 |
+
batch_size=32,
|
| 31 |
+
img_size=640,
|
| 32 |
+
conf_thres=0.001,
|
| 33 |
+
iou_thres=0.65,
|
| 34 |
+
device='',
|
| 35 |
+
half=True,
|
| 36 |
+
save_dir=''):
|
| 37 |
+
self.data = data
|
| 38 |
+
self.batch_size = batch_size
|
| 39 |
+
self.img_size = img_size
|
| 40 |
+
self.conf_thres = conf_thres
|
| 41 |
+
self.iou_thres = iou_thres
|
| 42 |
+
self.device = device
|
| 43 |
+
self.half = half
|
| 44 |
+
self.save_dir = save_dir
|
| 45 |
+
|
| 46 |
+
def init_model(self, model, weights, task):
|
| 47 |
+
if task != 'train':
|
| 48 |
+
model = load_checkpoint(weights, map_location=self.device)
|
| 49 |
+
self.stride = int(model.stride.max())
|
| 50 |
+
if self.device.type != 'cpu':
|
| 51 |
+
model(torch.zeros(1, 3, self.img_size, self.img_size).to(self.device).type_as(next(model.parameters())))
|
| 52 |
+
# switch to deploy
|
| 53 |
+
from yolov6.layers.common import RepVGGBlock
|
| 54 |
+
for layer in model.modules():
|
| 55 |
+
if isinstance(layer, RepVGGBlock):
|
| 56 |
+
layer.switch_to_deploy()
|
| 57 |
+
LOGGER.info("Switch model to deploy modality.")
|
| 58 |
+
LOGGER.info("Model Summary: {}".format(get_model_info(model, self.img_size)))
|
| 59 |
+
model.half() if self.half else model.float()
|
| 60 |
+
return model
|
| 61 |
+
|
| 62 |
+
def init_data(self, dataloader, task):
|
| 63 |
+
'''Initialize dataloader.
|
| 64 |
+
Returns a dataloader for task val or speed.
|
| 65 |
+
'''
|
| 66 |
+
self.is_coco = isinstance(self.data.get('val'), str) and 'coco' in self.data['val'] # COCO dataset
|
| 67 |
+
self.ids = self.coco80_to_coco91_class() if self.is_coco else list(range(1000))
|
| 68 |
+
if task != 'train':
|
| 69 |
+
pad = 0.0 if task == 'speed' else 0.5
|
| 70 |
+
dataloader = create_dataloader(self.data[task if task in ('train', 'val', 'test') else 'val'],
|
| 71 |
+
self.img_size, self.batch_size, self.stride, pad=pad, rect=True,
|
| 72 |
+
class_names=self.data['names'], task=task)[0]
|
| 73 |
+
return dataloader
|
| 74 |
+
|
| 75 |
+
def predict_model(self, model, dataloader, task):
|
| 76 |
+
'''Model prediction
|
| 77 |
+
Predicts the whole dataset and gets the prediced results and inference time.
|
| 78 |
+
'''
|
| 79 |
+
self.speed_result = torch.zeros(4, device=self.device)
|
| 80 |
+
pred_results = []
|
| 81 |
+
pbar = tqdm(dataloader, desc="Inferencing model in val datasets.", ncols=NCOLS)
|
| 82 |
+
for imgs, targets, paths, shapes in pbar:
|
| 83 |
+
# pre-process
|
| 84 |
+
t1 = time_sync()
|
| 85 |
+
imgs = imgs.to(self.device, non_blocking=True)
|
| 86 |
+
imgs = imgs.half() if self.half else imgs.float()
|
| 87 |
+
imgs /= 255
|
| 88 |
+
self.speed_result[1] += time_sync() - t1 # pre-process time
|
| 89 |
+
|
| 90 |
+
# Inference
|
| 91 |
+
t2 = time_sync()
|
| 92 |
+
outputs = model(imgs)
|
| 93 |
+
self.speed_result[2] += time_sync() - t2 # inference time
|
| 94 |
+
|
| 95 |
+
# post-process
|
| 96 |
+
t3 = time_sync()
|
| 97 |
+
outputs = non_max_suppression(outputs, self.conf_thres, self.iou_thres, multi_label=True)
|
| 98 |
+
self.speed_result[3] += time_sync() - t3 # post-process time
|
| 99 |
+
self.speed_result[0] += len(outputs)
|
| 100 |
+
|
| 101 |
+
# save result
|
| 102 |
+
pred_results.extend(self.convert_to_coco_format(outputs, imgs, paths, shapes, self.ids))
|
| 103 |
+
return pred_results
|
| 104 |
+
|
| 105 |
+
def eval_model(self, pred_results, model, dataloader, task):
|
| 106 |
+
'''Evaluate models
|
| 107 |
+
For task speed, this function only evaluates the speed of model and outputs inference time.
|
| 108 |
+
For task val, this function evalutates the speed and mAP by pycocotools, and returns
|
| 109 |
+
inference time and mAP value.
|
| 110 |
+
'''
|
| 111 |
+
LOGGER.info(f'\nEvaluating speed.')
|
| 112 |
+
self.eval_speed(task)
|
| 113 |
+
|
| 114 |
+
LOGGER.info(f'\nEvaluating mAP by pycocotools.')
|
| 115 |
+
if task != 'speed' and len(pred_results):
|
| 116 |
+
if 'anno_path' in self.data:
|
| 117 |
+
anno_json = self.data['anno_path']
|
| 118 |
+
else:
|
| 119 |
+
# generated coco format labels in dataset initialization
|
| 120 |
+
dataset_root = os.path.dirname(os.path.dirname(self.data['val']))
|
| 121 |
+
base_name = os.path.basename(self.data['val'])
|
| 122 |
+
anno_json = os.path.join(dataset_root, 'annotations', f'instances_{base_name}.json')
|
| 123 |
+
pred_json = os.path.join(self.save_dir, "predictions.json")
|
| 124 |
+
LOGGER.info(f'Saving {pred_json}...')
|
| 125 |
+
with open(pred_json, 'w') as f:
|
| 126 |
+
json.dump(pred_results, f)
|
| 127 |
+
|
| 128 |
+
anno = COCO(anno_json)
|
| 129 |
+
pred = anno.loadRes(pred_json)
|
| 130 |
+
cocoEval = COCOeval(anno, pred, 'bbox')
|
| 131 |
+
if self.is_coco:
|
| 132 |
+
imgIds = [int(os.path.basename(x).split(".")[0])
|
| 133 |
+
for x in dataloader.dataset.img_paths]
|
| 134 |
+
cocoEval.params.imgIds = imgIds
|
| 135 |
+
cocoEval.evaluate()
|
| 136 |
+
cocoEval.accumulate()
|
| 137 |
+
cocoEval.summarize()
|
| 138 |
+
map, map50 = cocoEval.stats[:2] # update results ([email protected]:0.95, [email protected])
|
| 139 |
+
# Return results
|
| 140 |
+
model.float() # for training
|
| 141 |
+
if task != 'train':
|
| 142 |
+
LOGGER.info(f"Results saved to {self.save_dir}")
|
| 143 |
+
return (map50, map)
|
| 144 |
+
return (0.0, 0.0)
|
| 145 |
+
|
| 146 |
+
def eval_speed(self, task):
|
| 147 |
+
'''Evaluate model inference speed.'''
|
| 148 |
+
if task != 'train':
|
| 149 |
+
n_samples = self.speed_result[0].item()
|
| 150 |
+
pre_time, inf_time, nms_time = 1000 * self.speed_result[1:].cpu().numpy() / n_samples
|
| 151 |
+
for n, v in zip(["pre-process", "inference", "NMS"],[pre_time, inf_time, nms_time]):
|
| 152 |
+
LOGGER.info("Average {} time: {:.2f} ms".format(n, v))
|
| 153 |
+
|
| 154 |
+
def box_convert(self, x):
|
| 155 |
+
# Convert boxes with shape [n, 4] from [x1, y1, x2, y2] to [x, y, w, h] where x1y1=top-left, x2y2=bottom-right
|
| 156 |
+
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
| 157 |
+
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
|
| 158 |
+
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
|
| 159 |
+
y[:, 2] = x[:, 2] - x[:, 0] # width
|
| 160 |
+
y[:, 3] = x[:, 3] - x[:, 1] # height
|
| 161 |
+
return y
|
| 162 |
+
|
| 163 |
+
def scale_coords(self, img1_shape, coords, img0_shape, ratio_pad=None):
|
| 164 |
+
# Rescale coords (xyxy) from img1_shape to img0_shape
|
| 165 |
+
if ratio_pad is None: # calculate from img0_shape
|
| 166 |
+
gain = min(img1_shape[0] / img0_shape[0], img1_shape[1] / img0_shape[1]) # gain = old / new
|
| 167 |
+
pad = (img1_shape[1] - img0_shape[1] * gain) / 2, (img1_shape[0] - img0_shape[0] * gain) / 2 # wh padding
|
| 168 |
+
else:
|
| 169 |
+
gain = ratio_pad[0][0]
|
| 170 |
+
pad = ratio_pad[1]
|
| 171 |
+
|
| 172 |
+
coords[:, [0, 2]] -= pad[0] # x padding
|
| 173 |
+
coords[:, [1, 3]] -= pad[1] # y padding
|
| 174 |
+
coords[:, :4] /= gain
|
| 175 |
+
if isinstance(coords, torch.Tensor): # faster individually
|
| 176 |
+
coords[:, 0].clamp_(0, img0_shape[1]) # x1
|
| 177 |
+
coords[:, 1].clamp_(0, img0_shape[0]) # y1
|
| 178 |
+
coords[:, 2].clamp_(0, img0_shape[1]) # x2
|
| 179 |
+
coords[:, 3].clamp_(0, img0_shape[0]) # y2
|
| 180 |
+
else: # np.array (faster grouped)
|
| 181 |
+
coords[:, [0, 2]] = coords[:, [0, 2]].clip(0, img0_shape[1]) # x1, x2
|
| 182 |
+
coords[:, [1, 3]] = coords[:, [1, 3]].clip(0, img0_shape[0]) # y1, y2
|
| 183 |
+
return coords
|
| 184 |
+
|
| 185 |
+
def convert_to_coco_format(self, outputs, imgs, paths, shapes, ids):
|
| 186 |
+
pred_results = []
|
| 187 |
+
for i, pred in enumerate(outputs):
|
| 188 |
+
if len(pred) == 0:
|
| 189 |
+
continue
|
| 190 |
+
path, shape = Path(paths[i]), shapes[i][0]
|
| 191 |
+
self.scale_coords(imgs[i].shape[1:], pred[:, :4], shape, shapes[i][1])
|
| 192 |
+
image_id = int(path.stem) if path.stem.isnumeric() else path.stem
|
| 193 |
+
bboxes = self.box_convert(pred[:, 0:4])
|
| 194 |
+
bboxes[:, :2] -= bboxes[:, 2:] / 2
|
| 195 |
+
cls = pred[:, 5]
|
| 196 |
+
scores = pred[:, 4]
|
| 197 |
+
for ind in range(pred.shape[0]):
|
| 198 |
+
category_id = ids[int(cls[ind])]
|
| 199 |
+
bbox = [round(x, 3) for x in bboxes[ind].tolist()]
|
| 200 |
+
score = round(scores[ind].item(), 5)
|
| 201 |
+
pred_data = {
|
| 202 |
+
"image_id": image_id,
|
| 203 |
+
"category_id": category_id,
|
| 204 |
+
"bbox": bbox,
|
| 205 |
+
"score": score
|
| 206 |
+
}
|
| 207 |
+
pred_results.append(pred_data)
|
| 208 |
+
return pred_results
|
| 209 |
+
|
| 210 |
+
@staticmethod
|
| 211 |
+
def check_task(task):
|
| 212 |
+
if task not in ['train','val','speed']:
|
| 213 |
+
raise Exception("task argument error: only support 'train' / 'val' / 'speed' task.")
|
| 214 |
+
|
| 215 |
+
@staticmethod
|
| 216 |
+
def reload_thres(conf_thres, iou_thres, task):
|
| 217 |
+
'''Sets conf and iou threshold for task val/speed'''
|
| 218 |
+
if task != 'train':
|
| 219 |
+
if task == 'val':
|
| 220 |
+
conf_thres = 0.001
|
| 221 |
+
if task == 'speed':
|
| 222 |
+
conf_thres = 0.25
|
| 223 |
+
iou_thres = 0.45
|
| 224 |
+
return conf_thres, iou_thres
|
| 225 |
+
|
| 226 |
+
@staticmethod
|
| 227 |
+
def reload_device(device, model, task):
|
| 228 |
+
# device = 'cpu' or '0' or '0,1,2,3'
|
| 229 |
+
if task == 'train':
|
| 230 |
+
device = next(model.parameters()).device
|
| 231 |
+
else:
|
| 232 |
+
if device == 'cpu':
|
| 233 |
+
os.environ['CUDA_VISIBLE_DEVICES'] = '-1'
|
| 234 |
+
elif device:
|
| 235 |
+
os.environ['CUDA_VISIBLE_DEVICES'] = device
|
| 236 |
+
assert torch.cuda.is_available()
|
| 237 |
+
cuda = device != 'cpu' and torch.cuda.is_available()
|
| 238 |
+
device = torch.device('cuda:0' if cuda else 'cpu')
|
| 239 |
+
return device
|
| 240 |
+
|
| 241 |
+
@staticmethod
|
| 242 |
+
def reload_dataset(data):
|
| 243 |
+
with open(data, errors='ignore') as yaml_file:
|
| 244 |
+
data = yaml.safe_load(yaml_file)
|
| 245 |
+
val = data.get('val')
|
| 246 |
+
if not os.path.exists(val):
|
| 247 |
+
raise Exception('Dataset not found.')
|
| 248 |
+
return data
|
| 249 |
+
|
| 250 |
+
@staticmethod
|
| 251 |
+
def coco80_to_coco91_class(): # converts 80-index (val2014) to 91-index (paper)
|
| 252 |
+
# https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
|
| 253 |
+
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20,
|
| 254 |
+
21, 22, 23, 24, 25, 27, 28, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
|
| 255 |
+
41, 42, 43, 44, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58,
|
| 256 |
+
59, 60, 61, 62, 63, 64, 65, 67, 70, 72, 73, 74, 75, 76, 77, 78, 79,
|
| 257 |
+
80, 81, 82, 84, 85, 86, 87, 88, 89, 90]
|
| 258 |
+
return x
|
yolov6/core/inferer.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import os
|
| 4 |
+
import os.path as osp
|
| 5 |
+
import math
|
| 6 |
+
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
import cv2
|
| 11 |
+
import torch
|
| 12 |
+
from PIL import ImageFont
|
| 13 |
+
|
| 14 |
+
from yolov6.utils.events import LOGGER, load_yaml
|
| 15 |
+
|
| 16 |
+
from yolov6.layers.common import DetectBackend
|
| 17 |
+
from yolov6.data.data_augment import letterbox
|
| 18 |
+
from yolov6.utils.nms import non_max_suppression
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Inferer:
|
| 22 |
+
def __init__(self, source, weights, device, yaml, img_size, half):
|
| 23 |
+
import glob
|
| 24 |
+
from yolov6.data.datasets import IMG_FORMATS
|
| 25 |
+
|
| 26 |
+
self.__dict__.update(locals())
|
| 27 |
+
|
| 28 |
+
# Init model
|
| 29 |
+
self.device = device
|
| 30 |
+
self.img_size = img_size
|
| 31 |
+
cuda = self.device != 'cpu' and torch.cuda.is_available()
|
| 32 |
+
self.device = torch.device('cuda:0' if cuda else 'cpu')
|
| 33 |
+
self.model = DetectBackend(weights, device=self.device)
|
| 34 |
+
self.stride = self.model.stride
|
| 35 |
+
self.class_names = load_yaml(yaml)['names']
|
| 36 |
+
self.img_size = self.check_img_size(self.img_size, s=self.stride) # check image size
|
| 37 |
+
|
| 38 |
+
# Half precision
|
| 39 |
+
if half & (self.device.type != 'cpu'):
|
| 40 |
+
self.model.model.half()
|
| 41 |
+
else:
|
| 42 |
+
self.model.model.float()
|
| 43 |
+
half = False
|
| 44 |
+
|
| 45 |
+
if self.device.type != 'cpu':
|
| 46 |
+
self.model(torch.zeros(1, 3, *self.img_size).to(self.device).type_as(next(self.model.model.parameters()))) # warmup
|
| 47 |
+
|
| 48 |
+
# Load data
|
| 49 |
+
if os.path.isdir(source):
|
| 50 |
+
img_paths = sorted(glob.glob(os.path.join(source, '*.*'))) # dir
|
| 51 |
+
elif os.path.isfile(source):
|
| 52 |
+
img_paths = [source] # files
|
| 53 |
+
else:
|
| 54 |
+
raise Exception(f'Invalid path: {source}')
|
| 55 |
+
self.img_paths = [img_path for img_path in img_paths if img_path.split('.')[-1].lower() in IMG_FORMATS]
|
| 56 |
+
|
| 57 |
+
def infer(self, conf_thres, iou_thres, classes, agnostic_nms, max_det, save_dir, save_txt, save_img, hide_labels, hide_conf):
|
| 58 |
+
''' Model Inference and results visualization '''
|
| 59 |
+
|
| 60 |
+
for img_path in tqdm(self.img_paths):
|
| 61 |
+
img, img_src = self.precess_image(img_path, self.img_size, self.stride, self.half)
|
| 62 |
+
img = img.to(self.device)
|
| 63 |
+
if len(img.shape) == 3:
|
| 64 |
+
img = img[None]
|
| 65 |
+
# expand for batch dim
|
| 66 |
+
pred_results = self.model(img)
|
| 67 |
+
det = non_max_suppression(pred_results, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)[0]
|
| 68 |
+
|
| 69 |
+
save_path = osp.join(save_dir, osp.basename(img_path)) # im.jpg
|
| 70 |
+
txt_path = osp.join(save_dir, 'labels', osp.basename(img_path).split('.')[0])
|
| 71 |
+
|
| 72 |
+
gn = torch.tensor(img_src.shape)[[1, 0, 1, 0]] # normalization gain whwh
|
| 73 |
+
img_ori = img_src
|
| 74 |
+
|
| 75 |
+
# check image and font
|
| 76 |
+
assert img_ori.data.contiguous, 'Image needs to be contiguous. Please apply to input images with np.ascontiguousarray(im).'
|
| 77 |
+
self.font_check()
|
| 78 |
+
|
| 79 |
+
if len(det):
|
| 80 |
+
det[:, :4] = self.rescale(img.shape[2:], det[:, :4], img_src.shape).round()
|
| 81 |
+
|
| 82 |
+
for *xyxy, conf, cls in reversed(det):
|
| 83 |
+
if save_txt: # Write to file
|
| 84 |
+
xywh = (self.box_convert(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
|
| 85 |
+
line = (cls, *xywh, conf)
|
| 86 |
+
with open(txt_path + '.txt', 'a') as f:
|
| 87 |
+
f.write(('%g ' * len(line)).rstrip() % line + '\n')
|
| 88 |
+
|
| 89 |
+
if save_img:
|
| 90 |
+
class_num = int(cls) # integer class
|
| 91 |
+
label = None if hide_labels else (self.class_names[class_num] if hide_conf else f'{self.class_names[class_num]} {conf:.2f}')
|
| 92 |
+
|
| 93 |
+
self.plot_box_and_label(img_ori, max(round(sum(img_ori.shape) / 2 * 0.003), 2), xyxy, label, color=self.generate_colors(class_num, True))
|
| 94 |
+
|
| 95 |
+
img_src = np.asarray(img_ori)
|
| 96 |
+
|
| 97 |
+
# Save results (image with detections)
|
| 98 |
+
if save_img:
|
| 99 |
+
cv2.imwrite(save_path, img_src)
|
| 100 |
+
|
| 101 |
+
@staticmethod
|
| 102 |
+
def precess_image(path, img_size, stride, half):
|
| 103 |
+
'''Process image before image inference.'''
|
| 104 |
+
try:
|
| 105 |
+
img_src = cv2.imread(path)
|
| 106 |
+
assert img_src is not None, f'Invalid image: {path}'
|
| 107 |
+
except Exception as e:
|
| 108 |
+
LOGGER.Warning(e)
|
| 109 |
+
image = letterbox(img_src, img_size, stride=stride)[0]
|
| 110 |
+
|
| 111 |
+
# Convert
|
| 112 |
+
image = image.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
|
| 113 |
+
image = torch.from_numpy(np.ascontiguousarray(image))
|
| 114 |
+
image = image.half() if half else image.float() # uint8 to fp16/32
|
| 115 |
+
image /= 255 # 0 - 255 to 0.0 - 1.0
|
| 116 |
+
|
| 117 |
+
return image, img_src
|
| 118 |
+
|
| 119 |
+
@staticmethod
|
| 120 |
+
def rescale(ori_shape, boxes, target_shape):
|
| 121 |
+
'''Rescale the output to the original image shape'''
|
| 122 |
+
ratio = min(ori_shape[0] / target_shape[0], ori_shape[1] / target_shape[1])
|
| 123 |
+
padding = (ori_shape[1] - target_shape[1] * ratio) / 2, (ori_shape[0] - target_shape[0] * ratio) / 2
|
| 124 |
+
|
| 125 |
+
boxes[:, [0, 2]] -= padding[0]
|
| 126 |
+
boxes[:, [1, 3]] -= padding[1]
|
| 127 |
+
boxes[:, :4] /= ratio
|
| 128 |
+
|
| 129 |
+
boxes[:, 0].clamp_(0, target_shape[1]) # x1
|
| 130 |
+
boxes[:, 1].clamp_(0, target_shape[0]) # y1
|
| 131 |
+
boxes[:, 2].clamp_(0, target_shape[1]) # x2
|
| 132 |
+
boxes[:, 3].clamp_(0, target_shape[0]) # y2
|
| 133 |
+
|
| 134 |
+
return boxes
|
| 135 |
+
|
| 136 |
+
def check_img_size(self, img_size, s=32, floor=0):
|
| 137 |
+
"""Make sure image size is a multiple of stride s in each dimension, and return a new shape list of image."""
|
| 138 |
+
if isinstance(img_size, int): # integer i.e. img_size=640
|
| 139 |
+
new_size = max(self.make_divisible(img_size, int(s)), floor)
|
| 140 |
+
elif isinstance(img_size, list): # list i.e. img_size=[640, 480]
|
| 141 |
+
new_size = [max(self.make_divisible(x, int(s)), floor) for x in img_size]
|
| 142 |
+
else:
|
| 143 |
+
raise Exception(f"Unsupported type of img_size: {type(img_size)}")
|
| 144 |
+
|
| 145 |
+
if new_size != img_size:
|
| 146 |
+
print(f'WARNING: --img-size {img_size} must be multiple of max stride {s}, updating to {new_size}')
|
| 147 |
+
return new_size if isinstance(img_size,list) else [new_size]*2
|
| 148 |
+
|
| 149 |
+
def make_divisible(self, x, divisor):
|
| 150 |
+
# Upward revision the value x to make it evenly divisible by the divisor.
|
| 151 |
+
return math.ceil(x / divisor) * divisor
|
| 152 |
+
|
| 153 |
+
@staticmethod
|
| 154 |
+
def plot_box_and_label(image, lw, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
|
| 155 |
+
# Add one xyxy box to image with label
|
| 156 |
+
p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
|
| 157 |
+
cv2.rectangle(image, p1, p2, color, thickness=lw, lineType=cv2.LINE_AA)
|
| 158 |
+
if label:
|
| 159 |
+
tf = max(lw - 1, 1) # font thickness
|
| 160 |
+
w, h = cv2.getTextSize(label, 0, fontScale=lw / 3, thickness=tf)[0] # text width, height
|
| 161 |
+
outside = p1[1] - h - 3 >= 0 # label fits outside box
|
| 162 |
+
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
|
| 163 |
+
cv2.rectangle(image, p1, p2, color, -1, cv2.LINE_AA) # filled
|
| 164 |
+
cv2.putText(image, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2), 0, lw / 3, txt_color,
|
| 165 |
+
thickness=tf, lineType=cv2.LINE_AA)
|
| 166 |
+
|
| 167 |
+
@staticmethod
|
| 168 |
+
def font_check(font='./yolov6/utils/Arial.ttf', size=10):
|
| 169 |
+
# Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
|
| 170 |
+
assert osp.exists(font), f'font path not exists: {font}'
|
| 171 |
+
try:
|
| 172 |
+
return ImageFont.truetype(str(font) if font.exists() else font.name, size)
|
| 173 |
+
except Exception as e: # download if missing
|
| 174 |
+
return ImageFont.truetype(str(font), size)
|
| 175 |
+
|
| 176 |
+
@staticmethod
|
| 177 |
+
def box_convert(x):
|
| 178 |
+
# Convert boxes with shape [n, 4] from [x1, y1, x2, y2] to [x, y, w, h] where x1y1=top-left, x2y2=bottom-right
|
| 179 |
+
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
|
| 180 |
+
y[:, 0] = (x[:, 0] + x[:, 2]) / 2 # x center
|
| 181 |
+
y[:, 1] = (x[:, 1] + x[:, 3]) / 2 # y center
|
| 182 |
+
y[:, 2] = x[:, 2] - x[:, 0] # width
|
| 183 |
+
y[:, 3] = x[:, 3] - x[:, 1] # height
|
| 184 |
+
return y
|
| 185 |
+
|
| 186 |
+
@staticmethod
|
| 187 |
+
def generate_colors(i, bgr=False):
|
| 188 |
+
hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
|
| 189 |
+
'2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
|
| 190 |
+
palette = []
|
| 191 |
+
for iter in hex:
|
| 192 |
+
h = '#' + iter
|
| 193 |
+
palette.append(tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4)))
|
| 194 |
+
num = len(palette)
|
| 195 |
+
color = palette[int(i) % num]
|
| 196 |
+
return (color[2], color[1], color[0]) if bgr else color
|
yolov6/data/data_augment.py
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
# This code is based on
|
| 4 |
+
# https://github.com/ultralytics/yolov5/blob/master/utils/dataloaders.py
|
| 5 |
+
|
| 6 |
+
import math
|
| 7 |
+
import random
|
| 8 |
+
|
| 9 |
+
import cv2
|
| 10 |
+
import numpy as np
|
| 11 |
+
|
| 12 |
+
def augment_hsv(im, hgain=0.5, sgain=0.5, vgain=0.5):
|
| 13 |
+
# HSV color-space augmentation
|
| 14 |
+
if hgain or sgain or vgain:
|
| 15 |
+
r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains
|
| 16 |
+
hue, sat, val = cv2.split(cv2.cvtColor(im, cv2.COLOR_BGR2HSV))
|
| 17 |
+
dtype = im.dtype # uint8
|
| 18 |
+
|
| 19 |
+
x = np.arange(0, 256, dtype=r.dtype)
|
| 20 |
+
lut_hue = ((x * r[0]) % 180).astype(dtype)
|
| 21 |
+
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
|
| 22 |
+
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
|
| 23 |
+
|
| 24 |
+
im_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
|
| 25 |
+
cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR, dst=im) # no return needed
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleup=True, stride=32):
|
| 30 |
+
# Resize and pad image while meeting stride-multiple constraints
|
| 31 |
+
shape = im.shape[:2] # current shape [height, width]
|
| 32 |
+
if isinstance(new_shape, int):
|
| 33 |
+
new_shape = (new_shape, new_shape)
|
| 34 |
+
|
| 35 |
+
# Scale ratio (new / old)
|
| 36 |
+
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
|
| 37 |
+
if not scaleup: # only scale down, do not scale up (for better val mAP)
|
| 38 |
+
r = min(r, 1.0)
|
| 39 |
+
|
| 40 |
+
# Compute padding
|
| 41 |
+
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
|
| 42 |
+
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
|
| 43 |
+
|
| 44 |
+
if auto: # minimum rectangle
|
| 45 |
+
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
|
| 46 |
+
|
| 47 |
+
dw /= 2 # divide padding into 2 sides
|
| 48 |
+
dh /= 2
|
| 49 |
+
|
| 50 |
+
if shape[::-1] != new_unpad: # resize
|
| 51 |
+
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
|
| 52 |
+
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
|
| 53 |
+
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
|
| 54 |
+
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
|
| 55 |
+
return im, r, (dw, dh)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def mixup(im, labels, im2, labels2):
|
| 59 |
+
# Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
|
| 60 |
+
r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
|
| 61 |
+
im = (im * r + im2 * (1 - r)).astype(np.uint8)
|
| 62 |
+
labels = np.concatenate((labels, labels2), 0)
|
| 63 |
+
return im, labels
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
|
| 67 |
+
# Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
|
| 68 |
+
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
|
| 69 |
+
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
|
| 70 |
+
ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
|
| 71 |
+
return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def random_affine(img, labels=(), degrees=10, translate=.1, scale=.1, shear=10,
|
| 75 |
+
new_shape=(640,640)):
|
| 76 |
+
|
| 77 |
+
n = len(labels)
|
| 78 |
+
height,width = new_shape
|
| 79 |
+
|
| 80 |
+
M,s = get_transform_matrix(img.shape[:2],(height,width),degrees,scale,shear,translate)
|
| 81 |
+
if (M != np.eye(3)).any(): # image changed
|
| 82 |
+
img = cv2.warpAffine(img, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
|
| 83 |
+
|
| 84 |
+
# Transform label coordinates
|
| 85 |
+
if n:
|
| 86 |
+
new = np.zeros((n, 4))
|
| 87 |
+
|
| 88 |
+
xy = np.ones((n * 4, 3))
|
| 89 |
+
xy[:, :2] = labels[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
|
| 90 |
+
xy = xy @ M.T # transform
|
| 91 |
+
xy = xy[:, :2].reshape(n, 8) # perspective rescale or affine
|
| 92 |
+
|
| 93 |
+
# create new boxes
|
| 94 |
+
x = xy[:, [0, 2, 4, 6]]
|
| 95 |
+
y = xy[:, [1, 3, 5, 7]]
|
| 96 |
+
new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
|
| 97 |
+
|
| 98 |
+
# clip
|
| 99 |
+
new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
|
| 100 |
+
new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
|
| 101 |
+
|
| 102 |
+
# filter candidates
|
| 103 |
+
i = box_candidates(box1=labels[:, 1:5].T * s, box2=new.T, area_thr=0.1)
|
| 104 |
+
labels = labels[i]
|
| 105 |
+
labels[:, 1:5] = new[i]
|
| 106 |
+
|
| 107 |
+
return img, labels
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def get_transform_matrix(img_shape,new_shape,degrees,scale,shear,translate):
|
| 111 |
+
new_height,new_width = new_shape
|
| 112 |
+
# Center
|
| 113 |
+
C = np.eye(3)
|
| 114 |
+
C[0, 2] = -img_shape[1] / 2 # x translation (pixels)
|
| 115 |
+
C[1, 2] = -img_shape[0] / 2 # y translation (pixels)
|
| 116 |
+
|
| 117 |
+
# Rotation and Scale
|
| 118 |
+
R = np.eye(3)
|
| 119 |
+
a = random.uniform(-degrees, degrees)
|
| 120 |
+
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
|
| 121 |
+
s = random.uniform(1 - scale, 1 + scale)
|
| 122 |
+
# s = 2 ** random.uniform(-scale, scale)
|
| 123 |
+
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
|
| 124 |
+
|
| 125 |
+
# Shear
|
| 126 |
+
S = np.eye(3)
|
| 127 |
+
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
|
| 128 |
+
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
|
| 129 |
+
|
| 130 |
+
# Translation
|
| 131 |
+
T = np.eye(3)
|
| 132 |
+
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * new_width # x translation (pixels)
|
| 133 |
+
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * new_height # y transla ion (pixels)
|
| 134 |
+
|
| 135 |
+
# Combined rotation matrix
|
| 136 |
+
M = T @ S @ R @ C # order of operations (right to left) is IMPORTANT
|
| 137 |
+
return M,s
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
def mosaic_augmentation(img_size, imgs, hs, ws, labels, hyp):
|
| 141 |
+
|
| 142 |
+
assert len(imgs)==4, "Mosaic augmentaion of current version only supports 4 images."
|
| 143 |
+
|
| 144 |
+
labels4 = []
|
| 145 |
+
s = img_size
|
| 146 |
+
yc, xc = (int(random.uniform(s//2, 3*s//2)) for _ in range(2)) # mosaic center x, y
|
| 147 |
+
for i in range(len(imgs)):
|
| 148 |
+
# Load image
|
| 149 |
+
img, h, w = imgs[i],hs[i],ws[i]
|
| 150 |
+
# place img in img4
|
| 151 |
+
if i == 0: # top left
|
| 152 |
+
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
|
| 153 |
+
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
|
| 154 |
+
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
|
| 155 |
+
elif i == 1: # top right
|
| 156 |
+
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
|
| 157 |
+
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
|
| 158 |
+
elif i == 2: # bottom left
|
| 159 |
+
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
|
| 160 |
+
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
|
| 161 |
+
elif i == 3: # bottom right
|
| 162 |
+
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
|
| 163 |
+
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
|
| 164 |
+
|
| 165 |
+
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
|
| 166 |
+
padw = x1a - x1b
|
| 167 |
+
padh = y1a - y1b
|
| 168 |
+
|
| 169 |
+
# Labels
|
| 170 |
+
labels_per_img= labels[i].copy()
|
| 171 |
+
if labels_per_img.size:
|
| 172 |
+
boxes = np.copy(labels_per_img[:,1:])
|
| 173 |
+
boxes[:, 0] = w * (labels_per_img[:, 1] - labels_per_img[:, 3] / 2) + padw # top left x
|
| 174 |
+
boxes[:, 1] = h * (labels_per_img[:, 2] - labels_per_img[:, 4] / 2) + padh # top left y
|
| 175 |
+
boxes[:, 2] = w * (labels_per_img[:, 1] + labels_per_img[:, 3] / 2) + padw # bottom right x
|
| 176 |
+
boxes[:, 3] = h * (labels_per_img[:, 2] + labels_per_img[:, 4] / 2) + padh # bottom right y
|
| 177 |
+
labels_per_img[:,1:] = boxes
|
| 178 |
+
|
| 179 |
+
labels4.append(labels_per_img)
|
| 180 |
+
|
| 181 |
+
# Concat/clip labels
|
| 182 |
+
labels4 = np.concatenate(labels4, 0)
|
| 183 |
+
for x in (labels4[:, 1:]):
|
| 184 |
+
np.clip(x, 0, 2 * s, out=x)
|
| 185 |
+
|
| 186 |
+
# Augment
|
| 187 |
+
img4, labels4 = random_affine(img4, labels4,
|
| 188 |
+
degrees=hyp['degrees'],
|
| 189 |
+
translate=hyp['translate'],
|
| 190 |
+
scale=hyp['scale'],
|
| 191 |
+
shear=hyp['shear'])
|
| 192 |
+
|
| 193 |
+
return img4, labels4
|
yolov6/data/data_load.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
# This code is based on
|
| 4 |
+
# https://github.com/ultralytics/yolov5/blob/master/utils/dataloaders.py
|
| 5 |
+
|
| 6 |
+
import os
|
| 7 |
+
from torch.utils.data import dataloader, distributed
|
| 8 |
+
|
| 9 |
+
from .datasets import TrainValDataset
|
| 10 |
+
from yolov6.utils.events import LOGGER
|
| 11 |
+
from yolov6.utils.torch_utils import torch_distributed_zero_first
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def create_dataloader(path, img_size, batch_size, stride, hyp=None, augment=False, check_images=False, check_labels=False, pad=0.0, rect=False, rank=-1, workers=8, shuffle=False,class_names=None, task='Train'):
|
| 15 |
+
'''Create general dataloader.
|
| 16 |
+
|
| 17 |
+
Returns dataloader and dataset
|
| 18 |
+
'''
|
| 19 |
+
if rect and shuffle:
|
| 20 |
+
LOGGER.warning('WARNING: --rect is incompatible with DataLoader shuffle, setting shuffle=False')
|
| 21 |
+
shuffle = False
|
| 22 |
+
with torch_distributed_zero_first(rank):
|
| 23 |
+
dataset = TrainValDataset(path, img_size, batch_size,
|
| 24 |
+
augment=augment,
|
| 25 |
+
hyp=hyp,
|
| 26 |
+
rect=rect,
|
| 27 |
+
check_images=check_images,
|
| 28 |
+
stride=int(stride),
|
| 29 |
+
pad=pad,
|
| 30 |
+
rank=rank,
|
| 31 |
+
class_names=class_names,
|
| 32 |
+
task=task)
|
| 33 |
+
|
| 34 |
+
batch_size = min(batch_size, len(dataset))
|
| 35 |
+
workers = min([os.cpu_count() // int(os.getenv('WORLD_SIZE', 1)), batch_size if batch_size > 1 else 0, workers]) # number of workers
|
| 36 |
+
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
|
| 37 |
+
return TrainValDataLoader(dataset,
|
| 38 |
+
batch_size=batch_size,
|
| 39 |
+
shuffle=shuffle and sampler is None,
|
| 40 |
+
num_workers=workers,
|
| 41 |
+
sampler=sampler,
|
| 42 |
+
pin_memory=True,
|
| 43 |
+
collate_fn=TrainValDataset.collate_fn), dataset
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class TrainValDataLoader(dataloader.DataLoader):
|
| 47 |
+
""" Dataloader that reuses workers
|
| 48 |
+
|
| 49 |
+
Uses same syntax as vanilla DataLoader
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(self, *args, **kwargs):
|
| 53 |
+
super().__init__(*args, **kwargs)
|
| 54 |
+
object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
|
| 55 |
+
self.iterator = super().__iter__()
|
| 56 |
+
|
| 57 |
+
def __len__(self):
|
| 58 |
+
return len(self.batch_sampler.sampler)
|
| 59 |
+
|
| 60 |
+
def __iter__(self):
|
| 61 |
+
for i in range(len(self)):
|
| 62 |
+
yield next(self.iterator)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class _RepeatSampler:
|
| 66 |
+
""" Sampler that repeats forever
|
| 67 |
+
|
| 68 |
+
Args:
|
| 69 |
+
sampler (Sampler)
|
| 70 |
+
"""
|
| 71 |
+
|
| 72 |
+
def __init__(self, sampler):
|
| 73 |
+
self.sampler = sampler
|
| 74 |
+
|
| 75 |
+
def __iter__(self):
|
| 76 |
+
while True:
|
| 77 |
+
yield from iter(self.sampler)
|
yolov6/data/datasets.py
ADDED
|
@@ -0,0 +1,533 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
|
| 4 |
+
import glob
|
| 5 |
+
import os
|
| 6 |
+
import os.path as osp
|
| 7 |
+
import random
|
| 8 |
+
import json
|
| 9 |
+
import time
|
| 10 |
+
|
| 11 |
+
from multiprocessing.pool import Pool
|
| 12 |
+
|
| 13 |
+
import cv2
|
| 14 |
+
import numpy as np
|
| 15 |
+
import torch
|
| 16 |
+
from PIL import ExifTags, Image, ImageOps
|
| 17 |
+
from torch.utils.data import Dataset
|
| 18 |
+
from tqdm import tqdm
|
| 19 |
+
from pathlib import Path
|
| 20 |
+
|
| 21 |
+
from .data_augment import (
|
| 22 |
+
augment_hsv,
|
| 23 |
+
letterbox,
|
| 24 |
+
mixup,
|
| 25 |
+
random_affine,
|
| 26 |
+
mosaic_augmentation,
|
| 27 |
+
)
|
| 28 |
+
from yolov6.utils.events import LOGGER
|
| 29 |
+
|
| 30 |
+
# Parameters
|
| 31 |
+
IMG_FORMATS = ["bmp", "jpg", "jpeg", "png", "tif", "tiff", "dng", "webp", "mpo"]
|
| 32 |
+
# Get orientation exif tag
|
| 33 |
+
for k, v in ExifTags.TAGS.items():
|
| 34 |
+
if v == "Orientation":
|
| 35 |
+
ORIENTATION = k
|
| 36 |
+
break
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class TrainValDataset(Dataset):
|
| 40 |
+
# YOLOv6 train_loader/val_loader, loads images and labels for training and validation
|
| 41 |
+
def __init__(
|
| 42 |
+
self,
|
| 43 |
+
img_dir,
|
| 44 |
+
img_size=640,
|
| 45 |
+
batch_size=16,
|
| 46 |
+
augment=False,
|
| 47 |
+
hyp=None,
|
| 48 |
+
rect=False,
|
| 49 |
+
check_images=False,
|
| 50 |
+
check_labels=False,
|
| 51 |
+
stride=32,
|
| 52 |
+
pad=0.0,
|
| 53 |
+
rank=-1,
|
| 54 |
+
class_names=None,
|
| 55 |
+
task="train",
|
| 56 |
+
):
|
| 57 |
+
assert task.lower() in ("train", "val", "speed"), f"Not supported task: {task}"
|
| 58 |
+
t1 = time.time()
|
| 59 |
+
self.__dict__.update(locals())
|
| 60 |
+
self.main_process = self.rank in (-1, 0)
|
| 61 |
+
self.task = self.task.capitalize()
|
| 62 |
+
self.img_paths, self.labels = self.get_imgs_labels(self.img_dir)
|
| 63 |
+
if self.rect:
|
| 64 |
+
shapes = [self.img_info[p]["shape"] for p in self.img_paths]
|
| 65 |
+
self.shapes = np.array(shapes, dtype=np.float64)
|
| 66 |
+
self.batch_indices = np.floor(
|
| 67 |
+
np.arange(len(shapes)) / self.batch_size
|
| 68 |
+
).astype(
|
| 69 |
+
np.int
|
| 70 |
+
) # batch indices of each image
|
| 71 |
+
self.sort_files_shapes()
|
| 72 |
+
t2 = time.time()
|
| 73 |
+
if self.main_process:
|
| 74 |
+
LOGGER.info(f"%.1fs for dataset initialization." % (t2 - t1))
|
| 75 |
+
|
| 76 |
+
def __len__(self):
|
| 77 |
+
"""Get the length of dataset"""
|
| 78 |
+
return len(self.img_paths)
|
| 79 |
+
|
| 80 |
+
def __getitem__(self, index):
|
| 81 |
+
"""Fetching a data sample for a given key.
|
| 82 |
+
This function applies mosaic and mixup augments during training.
|
| 83 |
+
During validation, letterbox augment is applied.
|
| 84 |
+
"""
|
| 85 |
+
# Mosaic Augmentation
|
| 86 |
+
if self.augment and random.random() < self.hyp["mosaic"]:
|
| 87 |
+
img, labels = self.get_mosaic(index)
|
| 88 |
+
shapes = None
|
| 89 |
+
|
| 90 |
+
# MixUp augmentation
|
| 91 |
+
if random.random() < self.hyp["mixup"]:
|
| 92 |
+
img_other, labels_other = self.get_mosaic(
|
| 93 |
+
random.randint(0, len(self.img_paths) - 1)
|
| 94 |
+
)
|
| 95 |
+
img, labels = mixup(img, labels, img_other, labels_other)
|
| 96 |
+
|
| 97 |
+
else:
|
| 98 |
+
# Load image
|
| 99 |
+
img, (h0, w0), (h, w) = self.load_image(index)
|
| 100 |
+
|
| 101 |
+
# Letterbox
|
| 102 |
+
shape = (
|
| 103 |
+
self.batch_shapes[self.batch_indices[index]]
|
| 104 |
+
if self.rect
|
| 105 |
+
else self.img_size
|
| 106 |
+
) # final letterboxed shape
|
| 107 |
+
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
|
| 108 |
+
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
|
| 109 |
+
|
| 110 |
+
labels = self.labels[index].copy()
|
| 111 |
+
if labels.size:
|
| 112 |
+
w *= ratio
|
| 113 |
+
h *= ratio
|
| 114 |
+
# new boxes
|
| 115 |
+
boxes = np.copy(labels[:, 1:])
|
| 116 |
+
boxes[:, 0] = (
|
| 117 |
+
w * (labels[:, 1] - labels[:, 3] / 2) + pad[0]
|
| 118 |
+
) # top left x
|
| 119 |
+
boxes[:, 1] = (
|
| 120 |
+
h * (labels[:, 2] - labels[:, 4] / 2) + pad[1]
|
| 121 |
+
) # top left y
|
| 122 |
+
boxes[:, 2] = (
|
| 123 |
+
w * (labels[:, 1] + labels[:, 3] / 2) + pad[0]
|
| 124 |
+
) # bottom right x
|
| 125 |
+
boxes[:, 3] = (
|
| 126 |
+
h * (labels[:, 2] + labels[:, 4] / 2) + pad[1]
|
| 127 |
+
) # bottom right y
|
| 128 |
+
labels[:, 1:] = boxes
|
| 129 |
+
|
| 130 |
+
if self.augment:
|
| 131 |
+
img, labels = random_affine(
|
| 132 |
+
img,
|
| 133 |
+
labels,
|
| 134 |
+
degrees=self.hyp["degrees"],
|
| 135 |
+
translate=self.hyp["translate"],
|
| 136 |
+
scale=self.hyp["scale"],
|
| 137 |
+
shear=self.hyp["shear"],
|
| 138 |
+
new_shape=(self.img_size, self.img_size),
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
if len(labels):
|
| 142 |
+
h, w = img.shape[:2]
|
| 143 |
+
|
| 144 |
+
labels[:, [1, 3]] = labels[:, [1, 3]].clip(0, w - 1e-3) # x1, x2
|
| 145 |
+
labels[:, [2, 4]] = labels[:, [2, 4]].clip(0, h - 1e-3) # y1, y2
|
| 146 |
+
|
| 147 |
+
boxes = np.copy(labels[:, 1:])
|
| 148 |
+
boxes[:, 0] = ((labels[:, 1] + labels[:, 3]) / 2) / w # x center
|
| 149 |
+
boxes[:, 1] = ((labels[:, 2] + labels[:, 4]) / 2) / h # y center
|
| 150 |
+
boxes[:, 2] = (labels[:, 3] - labels[:, 1]) / w # width
|
| 151 |
+
boxes[:, 3] = (labels[:, 4] - labels[:, 2]) / h # height
|
| 152 |
+
labels[:, 1:] = boxes
|
| 153 |
+
|
| 154 |
+
if self.augment:
|
| 155 |
+
img, labels = self.general_augment(img, labels)
|
| 156 |
+
|
| 157 |
+
labels_out = torch.zeros((len(labels), 6))
|
| 158 |
+
if len(labels):
|
| 159 |
+
labels_out[:, 1:] = torch.from_numpy(labels)
|
| 160 |
+
|
| 161 |
+
# Convert
|
| 162 |
+
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
|
| 163 |
+
img = np.ascontiguousarray(img)
|
| 164 |
+
|
| 165 |
+
return torch.from_numpy(img), labels_out, self.img_paths[index], shapes
|
| 166 |
+
|
| 167 |
+
def load_image(self, index):
|
| 168 |
+
"""Load image.
|
| 169 |
+
This function loads image by cv2, resize original image to target shape(img_size) with keeping ratio.
|
| 170 |
+
|
| 171 |
+
Returns:
|
| 172 |
+
Image, original shape of image, resized image shape
|
| 173 |
+
"""
|
| 174 |
+
path = self.img_paths[index]
|
| 175 |
+
im = cv2.imread(path)
|
| 176 |
+
assert im is not None, f"Image Not Found {path}, workdir: {os.getcwd()}"
|
| 177 |
+
|
| 178 |
+
h0, w0 = im.shape[:2] # origin shape
|
| 179 |
+
r = self.img_size / max(h0, w0)
|
| 180 |
+
if r != 1:
|
| 181 |
+
im = cv2.resize(
|
| 182 |
+
im,
|
| 183 |
+
(int(w0 * r), int(h0 * r)),
|
| 184 |
+
interpolation=cv2.INTER_AREA
|
| 185 |
+
if r < 1 and not self.augment
|
| 186 |
+
else cv2.INTER_LINEAR,
|
| 187 |
+
)
|
| 188 |
+
return im, (h0, w0), im.shape[:2]
|
| 189 |
+
|
| 190 |
+
@staticmethod
|
| 191 |
+
def collate_fn(batch):
|
| 192 |
+
"""Merges a list of samples to form a mini-batch of Tensor(s)"""
|
| 193 |
+
img, label, path, shapes = zip(*batch)
|
| 194 |
+
for i, l in enumerate(label):
|
| 195 |
+
l[:, 0] = i # add target image index for build_targets()
|
| 196 |
+
return torch.stack(img, 0), torch.cat(label, 0), path, shapes
|
| 197 |
+
|
| 198 |
+
def get_imgs_labels(self, img_dir):
|
| 199 |
+
|
| 200 |
+
assert osp.exists(img_dir), f"{img_dir} is an invalid directory path!"
|
| 201 |
+
valid_img_record = osp.join(
|
| 202 |
+
osp.dirname(img_dir), "." + osp.basename(img_dir) + ".json"
|
| 203 |
+
)
|
| 204 |
+
img_info = {}
|
| 205 |
+
NUM_THREADS = min(8, os.cpu_count())
|
| 206 |
+
# check images
|
| 207 |
+
if (
|
| 208 |
+
self.check_images or not osp.exists(valid_img_record)
|
| 209 |
+
) and self.main_process:
|
| 210 |
+
img_paths = glob.glob(osp.join(img_dir, "*"), recursive=True)
|
| 211 |
+
img_paths = sorted(
|
| 212 |
+
p for p in img_paths if p.split(".")[-1].lower() in IMG_FORMATS
|
| 213 |
+
)
|
| 214 |
+
assert img_paths, f"No images found in {img_dir}."
|
| 215 |
+
|
| 216 |
+
nc, msgs = 0, [] # number corrupt, messages
|
| 217 |
+
LOGGER.info(
|
| 218 |
+
f"{self.task}: Checking formats of images with {NUM_THREADS} process(es): "
|
| 219 |
+
)
|
| 220 |
+
with Pool(NUM_THREADS) as pool:
|
| 221 |
+
pbar = tqdm(
|
| 222 |
+
pool.imap(TrainValDataset.check_image, img_paths),
|
| 223 |
+
total=len(img_paths),
|
| 224 |
+
)
|
| 225 |
+
for img_path, shape_per_img, nc_per_img, msg in pbar:
|
| 226 |
+
if nc_per_img == 0: # not corrupted
|
| 227 |
+
img_info[img_path] = {"shape": shape_per_img}
|
| 228 |
+
nc += nc_per_img
|
| 229 |
+
if msg:
|
| 230 |
+
msgs.append(msg)
|
| 231 |
+
pbar.desc = f"{nc} image(s) corrupted"
|
| 232 |
+
pbar.close()
|
| 233 |
+
if msgs:
|
| 234 |
+
LOGGER.info("\n".join(msgs))
|
| 235 |
+
|
| 236 |
+
# save valid image paths.
|
| 237 |
+
with open(valid_img_record, "w") as f:
|
| 238 |
+
json.dump(img_info, f)
|
| 239 |
+
|
| 240 |
+
# check and load anns
|
| 241 |
+
label_dir = osp.join(
|
| 242 |
+
osp.dirname(osp.dirname(img_dir)), "labels", osp.basename(img_dir)
|
| 243 |
+
)
|
| 244 |
+
assert osp.exists(label_dir), f"{label_dir} is an invalid directory path!"
|
| 245 |
+
if not img_info:
|
| 246 |
+
with open(valid_img_record, "r") as f:
|
| 247 |
+
img_info = json.load(f)
|
| 248 |
+
assert (
|
| 249 |
+
img_info
|
| 250 |
+
), "No information in record files, please add option --check_images."
|
| 251 |
+
img_paths = list(img_info.keys())
|
| 252 |
+
label_paths = [
|
| 253 |
+
osp.join(label_dir, osp.basename(p).split(".")[0] + ".txt")
|
| 254 |
+
for p in img_paths
|
| 255 |
+
]
|
| 256 |
+
if (
|
| 257 |
+
self.check_labels or "labels" not in img_info[img_paths[0]]
|
| 258 |
+
): # key 'labels' not saved in img_info
|
| 259 |
+
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number corrupt, messages
|
| 260 |
+
LOGGER.info(
|
| 261 |
+
f"{self.task}: Checking formats of labels with {NUM_THREADS} process(es): "
|
| 262 |
+
)
|
| 263 |
+
with Pool(NUM_THREADS) as pool:
|
| 264 |
+
pbar = pool.imap(
|
| 265 |
+
TrainValDataset.check_label_files, zip(img_paths, label_paths)
|
| 266 |
+
)
|
| 267 |
+
pbar = tqdm(pbar, total=len(label_paths)) if self.main_process else pbar
|
| 268 |
+
for (
|
| 269 |
+
img_path,
|
| 270 |
+
labels_per_file,
|
| 271 |
+
nc_per_file,
|
| 272 |
+
nm_per_file,
|
| 273 |
+
nf_per_file,
|
| 274 |
+
ne_per_file,
|
| 275 |
+
msg,
|
| 276 |
+
) in pbar:
|
| 277 |
+
if img_path:
|
| 278 |
+
img_info[img_path]["labels"] = labels_per_file
|
| 279 |
+
else:
|
| 280 |
+
img_info.pop(img_path)
|
| 281 |
+
nc += nc_per_file
|
| 282 |
+
nm += nm_per_file
|
| 283 |
+
nf += nf_per_file
|
| 284 |
+
ne += ne_per_file
|
| 285 |
+
if msg:
|
| 286 |
+
msgs.append(msg)
|
| 287 |
+
if self.main_process:
|
| 288 |
+
pbar.desc = f"{nf} label(s) found, {nm} label(s) missing, {ne} label(s) empty, {nc} invalid label files"
|
| 289 |
+
if self.main_process:
|
| 290 |
+
pbar.close()
|
| 291 |
+
with open(valid_img_record, "w") as f:
|
| 292 |
+
json.dump(img_info, f)
|
| 293 |
+
if msgs:
|
| 294 |
+
LOGGER.info("\n".join(msgs))
|
| 295 |
+
if nf == 0:
|
| 296 |
+
LOGGER.warning(
|
| 297 |
+
f"WARNING: No labels found in {osp.dirname(self.img_paths[0])}. "
|
| 298 |
+
)
|
| 299 |
+
else:
|
| 300 |
+
with open(valid_img_record) as f:
|
| 301 |
+
img_info = json.load(f)
|
| 302 |
+
if self.task.lower() == "val":
|
| 303 |
+
assert (
|
| 304 |
+
self.class_names
|
| 305 |
+
), "Class names is required when converting labels to coco format for evaluating."
|
| 306 |
+
save_dir = osp.join(osp.dirname(osp.dirname(img_dir)), "annotations")
|
| 307 |
+
if not osp.exists(save_dir):
|
| 308 |
+
os.mkdir(save_dir)
|
| 309 |
+
save_path = osp.join(
|
| 310 |
+
save_dir, "instances_" + osp.basename(img_dir) + ".json"
|
| 311 |
+
)
|
| 312 |
+
if not osp.exists(save_path):
|
| 313 |
+
TrainValDataset.generate_coco_format_labels(
|
| 314 |
+
img_info, self.class_names, save_path
|
| 315 |
+
)
|
| 316 |
+
|
| 317 |
+
img_paths, labels = list(
|
| 318 |
+
zip(
|
| 319 |
+
*[
|
| 320 |
+
(
|
| 321 |
+
img_path,
|
| 322 |
+
np.array(info["labels"], dtype=np.float32)
|
| 323 |
+
if info["labels"]
|
| 324 |
+
else np.zeros((0, 5), dtype=np.float32),
|
| 325 |
+
)
|
| 326 |
+
for img_path, info in img_info.items()
|
| 327 |
+
]
|
| 328 |
+
)
|
| 329 |
+
)
|
| 330 |
+
self.img_info = img_info
|
| 331 |
+
LOGGER.info(
|
| 332 |
+
f"{self.task}: Final numbers of valid images: {len(img_paths)}/ labels: {len(labels)}. "
|
| 333 |
+
)
|
| 334 |
+
return img_paths, labels
|
| 335 |
+
|
| 336 |
+
def get_mosaic(self, index):
|
| 337 |
+
"""Gets images and labels after mosaic augments"""
|
| 338 |
+
indices = [index] + random.choices(
|
| 339 |
+
range(0, len(self.img_paths)), k=3
|
| 340 |
+
) # 3 additional image indices
|
| 341 |
+
random.shuffle(indices)
|
| 342 |
+
imgs, hs, ws, labels = [], [], [], []
|
| 343 |
+
for index in indices:
|
| 344 |
+
img, _, (h, w) = self.load_image(index)
|
| 345 |
+
labels_per_img = self.labels[index]
|
| 346 |
+
imgs.append(img)
|
| 347 |
+
hs.append(h)
|
| 348 |
+
ws.append(w)
|
| 349 |
+
labels.append(labels_per_img)
|
| 350 |
+
img, labels = mosaic_augmentation(self.img_size, imgs, hs, ws, labels, self.hyp)
|
| 351 |
+
return img, labels
|
| 352 |
+
|
| 353 |
+
def general_augment(self, img, labels):
|
| 354 |
+
"""Gets images and labels after general augment
|
| 355 |
+
This function applies hsv, random ud-flip and random lr-flips augments.
|
| 356 |
+
"""
|
| 357 |
+
nl = len(labels)
|
| 358 |
+
|
| 359 |
+
# HSV color-space
|
| 360 |
+
augment_hsv(
|
| 361 |
+
img,
|
| 362 |
+
hgain=self.hyp["hsv_h"],
|
| 363 |
+
sgain=self.hyp["hsv_s"],
|
| 364 |
+
vgain=self.hyp["hsv_v"],
|
| 365 |
+
)
|
| 366 |
+
|
| 367 |
+
# Flip up-down
|
| 368 |
+
if random.random() < self.hyp["flipud"]:
|
| 369 |
+
img = np.flipud(img)
|
| 370 |
+
if nl:
|
| 371 |
+
labels[:, 2] = 1 - labels[:, 2]
|
| 372 |
+
|
| 373 |
+
# Flip left-right
|
| 374 |
+
if random.random() < self.hyp["fliplr"]:
|
| 375 |
+
img = np.fliplr(img)
|
| 376 |
+
if nl:
|
| 377 |
+
labels[:, 1] = 1 - labels[:, 1]
|
| 378 |
+
|
| 379 |
+
return img, labels
|
| 380 |
+
|
| 381 |
+
def sort_files_shapes(self):
|
| 382 |
+
# Sort by aspect ratio
|
| 383 |
+
batch_num = self.batch_indices[-1] + 1
|
| 384 |
+
s = self.shapes # wh
|
| 385 |
+
ar = s[:, 1] / s[:, 0] # aspect ratio
|
| 386 |
+
irect = ar.argsort()
|
| 387 |
+
self.img_paths = [self.img_paths[i] for i in irect]
|
| 388 |
+
self.labels = [self.labels[i] for i in irect]
|
| 389 |
+
self.shapes = s[irect] # wh
|
| 390 |
+
ar = ar[irect]
|
| 391 |
+
|
| 392 |
+
# Set training image shapes
|
| 393 |
+
shapes = [[1, 1]] * batch_num
|
| 394 |
+
for i in range(batch_num):
|
| 395 |
+
ari = ar[self.batch_indices == i]
|
| 396 |
+
mini, maxi = ari.min(), ari.max()
|
| 397 |
+
if maxi < 1:
|
| 398 |
+
shapes[i] = [maxi, 1]
|
| 399 |
+
elif mini > 1:
|
| 400 |
+
shapes[i] = [1, 1 / mini]
|
| 401 |
+
self.batch_shapes = (
|
| 402 |
+
np.ceil(np.array(shapes) * self.img_size / self.stride + self.pad).astype(
|
| 403 |
+
np.int
|
| 404 |
+
)
|
| 405 |
+
* self.stride
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
@staticmethod
|
| 409 |
+
def check_image(im_file):
|
| 410 |
+
# verify an image.
|
| 411 |
+
nc, msg = 0, ""
|
| 412 |
+
try:
|
| 413 |
+
im = Image.open(im_file)
|
| 414 |
+
im.verify() # PIL verify
|
| 415 |
+
shape = im.size # (width, height)
|
| 416 |
+
im_exif = im._getexif()
|
| 417 |
+
if im_exif and ORIENTATION in im_exif:
|
| 418 |
+
rotation = im_exif[ORIENTATION]
|
| 419 |
+
if rotation in (6, 8):
|
| 420 |
+
shape = (shape[1], shape[0])
|
| 421 |
+
|
| 422 |
+
assert (shape[0] > 9) & (shape[1] > 9), f"image size {shape} <10 pixels"
|
| 423 |
+
assert im.format.lower() in IMG_FORMATS, f"invalid image format {im.format}"
|
| 424 |
+
if im.format.lower() in ("jpg", "jpeg"):
|
| 425 |
+
with open(im_file, "rb") as f:
|
| 426 |
+
f.seek(-2, 2)
|
| 427 |
+
if f.read() != b"\xff\xd9": # corrupt JPEG
|
| 428 |
+
ImageOps.exif_transpose(Image.open(im_file)).save(
|
| 429 |
+
im_file, "JPEG", subsampling=0, quality=100
|
| 430 |
+
)
|
| 431 |
+
msg += f"WARNING: {im_file}: corrupt JPEG restored and saved"
|
| 432 |
+
return im_file, shape, nc, msg
|
| 433 |
+
except Exception as e:
|
| 434 |
+
nc = 1
|
| 435 |
+
msg = f"WARNING: {im_file}: ignoring corrupt image: {e}"
|
| 436 |
+
return im_file, None, nc, msg
|
| 437 |
+
|
| 438 |
+
@staticmethod
|
| 439 |
+
def check_label_files(args):
|
| 440 |
+
img_path, lb_path = args
|
| 441 |
+
nm, nf, ne, nc, msg = 0, 0, 0, 0, "" # number (missing, found, empty, message
|
| 442 |
+
try:
|
| 443 |
+
if osp.exists(lb_path):
|
| 444 |
+
nf = 1 # label found
|
| 445 |
+
with open(lb_path, "r") as f:
|
| 446 |
+
labels = [
|
| 447 |
+
x.split() for x in f.read().strip().splitlines() if len(x)
|
| 448 |
+
]
|
| 449 |
+
labels = np.array(labels, dtype=np.float32)
|
| 450 |
+
if len(labels):
|
| 451 |
+
assert all(
|
| 452 |
+
len(l) == 5 for l in labels
|
| 453 |
+
), f"{lb_path}: wrong label format."
|
| 454 |
+
assert (
|
| 455 |
+
labels >= 0
|
| 456 |
+
).all(), f"{lb_path}: Label values error: all values in label file must > 0"
|
| 457 |
+
assert (
|
| 458 |
+
labels[:, 1:] <= 1
|
| 459 |
+
).all(), f"{lb_path}: Label values error: all coordinates must be normalized"
|
| 460 |
+
|
| 461 |
+
_, indices = np.unique(labels, axis=0, return_index=True)
|
| 462 |
+
if len(indices) < len(labels): # duplicate row check
|
| 463 |
+
labels = labels[indices] # remove duplicates
|
| 464 |
+
msg += f"WARNING: {lb_path}: {len(labels) - len(indices)} duplicate labels removed"
|
| 465 |
+
labels = labels.tolist()
|
| 466 |
+
else:
|
| 467 |
+
ne = 1 # label empty
|
| 468 |
+
labels = []
|
| 469 |
+
else:
|
| 470 |
+
nm = 1 # label missing
|
| 471 |
+
labels = []
|
| 472 |
+
|
| 473 |
+
return img_path, labels, nc, nm, nf, ne, msg
|
| 474 |
+
except Exception as e:
|
| 475 |
+
nc = 1
|
| 476 |
+
msg = f"WARNING: {lb_path}: ignoring invalid labels: {e}"
|
| 477 |
+
return None, None, nc, nm, nf, ne, msg
|
| 478 |
+
|
| 479 |
+
@staticmethod
|
| 480 |
+
def generate_coco_format_labels(img_info, class_names, save_path):
|
| 481 |
+
# for evaluation with pycocotools
|
| 482 |
+
dataset = {"categories": [], "annotations": [], "images": []}
|
| 483 |
+
for i, class_name in enumerate(class_names):
|
| 484 |
+
dataset["categories"].append(
|
| 485 |
+
{"id": i, "name": class_name, "supercategory": ""}
|
| 486 |
+
)
|
| 487 |
+
|
| 488 |
+
ann_id = 0
|
| 489 |
+
LOGGER.info(f"Convert to COCO format")
|
| 490 |
+
for i, (img_path, info) in enumerate(tqdm(img_info.items())):
|
| 491 |
+
labels = info["labels"] if info["labels"] else []
|
| 492 |
+
path = Path(img_path)
|
| 493 |
+
img_id = int(path.stem) if path.stem.isnumeric() else path.stem
|
| 494 |
+
img_w, img_h = info["shape"]
|
| 495 |
+
dataset["images"].append(
|
| 496 |
+
{
|
| 497 |
+
"file_name": os.path.basename(img_path),
|
| 498 |
+
"id": img_id,
|
| 499 |
+
"width": img_w,
|
| 500 |
+
"height": img_h,
|
| 501 |
+
}
|
| 502 |
+
)
|
| 503 |
+
if labels:
|
| 504 |
+
for label in labels:
|
| 505 |
+
c, x, y, w, h = label[:5]
|
| 506 |
+
# convert x,y,w,h to x1,y1,x2,y2
|
| 507 |
+
x1 = (x - w / 2) * img_w
|
| 508 |
+
y1 = (y - h / 2) * img_h
|
| 509 |
+
x2 = (x + w / 2) * img_w
|
| 510 |
+
y2 = (y + h / 2) * img_h
|
| 511 |
+
# cls_id starts from 0
|
| 512 |
+
cls_id = int(c)
|
| 513 |
+
w = max(0, x2 - x1)
|
| 514 |
+
h = max(0, y2 - y1)
|
| 515 |
+
dataset["annotations"].append(
|
| 516 |
+
{
|
| 517 |
+
"area": h * w,
|
| 518 |
+
"bbox": [x1, y1, w, h],
|
| 519 |
+
"category_id": cls_id,
|
| 520 |
+
"id": ann_id,
|
| 521 |
+
"image_id": img_id,
|
| 522 |
+
"iscrowd": 0,
|
| 523 |
+
# mask
|
| 524 |
+
"segmentation": [],
|
| 525 |
+
}
|
| 526 |
+
)
|
| 527 |
+
ann_id += 1
|
| 528 |
+
|
| 529 |
+
with open(save_path, "w") as f:
|
| 530 |
+
json.dump(dataset, f)
|
| 531 |
+
LOGGER.info(
|
| 532 |
+
f"Convert to COCO format finished. Resutls saved in {save_path}"
|
| 533 |
+
)
|
yolov6/layers/common.py
ADDED
|
@@ -0,0 +1,269 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
|
| 4 |
+
import warnings
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class SiLU(nn.Module):
|
| 13 |
+
'''Activation of SiLU'''
|
| 14 |
+
@staticmethod
|
| 15 |
+
def forward(x):
|
| 16 |
+
return x * torch.sigmoid(x)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class Conv(nn.Module):
|
| 20 |
+
'''Normal Conv with SiLU activation'''
|
| 21 |
+
def __init__(self, in_channels, out_channels, kernel_size, stride, groups=1, bias=False):
|
| 22 |
+
super().__init__()
|
| 23 |
+
padding = kernel_size // 2
|
| 24 |
+
self.conv = nn.Conv2d(
|
| 25 |
+
in_channels,
|
| 26 |
+
out_channels,
|
| 27 |
+
kernel_size=kernel_size,
|
| 28 |
+
stride=stride,
|
| 29 |
+
padding=padding,
|
| 30 |
+
groups=groups,
|
| 31 |
+
bias=bias,
|
| 32 |
+
)
|
| 33 |
+
self.bn = nn.BatchNorm2d(out_channels)
|
| 34 |
+
self.act = nn.SiLU()
|
| 35 |
+
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
return self.act(self.bn(self.conv(x)))
|
| 38 |
+
|
| 39 |
+
def forward_fuse(self, x):
|
| 40 |
+
return self.act(self.conv(x))
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class SimConv(nn.Module):
|
| 44 |
+
'''Normal Conv with ReLU activation'''
|
| 45 |
+
def __init__(self, in_channels, out_channels, kernel_size, stride, groups=1, bias=False):
|
| 46 |
+
super().__init__()
|
| 47 |
+
padding = kernel_size // 2
|
| 48 |
+
self.conv = nn.Conv2d(
|
| 49 |
+
in_channels,
|
| 50 |
+
out_channels,
|
| 51 |
+
kernel_size=kernel_size,
|
| 52 |
+
stride=stride,
|
| 53 |
+
padding=padding,
|
| 54 |
+
groups=groups,
|
| 55 |
+
bias=bias,
|
| 56 |
+
)
|
| 57 |
+
self.bn = nn.BatchNorm2d(out_channels)
|
| 58 |
+
self.act = nn.ReLU()
|
| 59 |
+
|
| 60 |
+
def forward(self, x):
|
| 61 |
+
return self.act(self.bn(self.conv(x)))
|
| 62 |
+
|
| 63 |
+
def forward_fuse(self, x):
|
| 64 |
+
return self.act(self.conv(x))
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class SimSPPF(nn.Module):
|
| 68 |
+
'''Simplified SPPF with ReLU activation'''
|
| 69 |
+
def __init__(self, in_channels, out_channels, kernel_size=5):
|
| 70 |
+
super().__init__()
|
| 71 |
+
c_ = in_channels // 2 # hidden channels
|
| 72 |
+
self.cv1 = SimConv(in_channels, c_, 1, 1)
|
| 73 |
+
self.cv2 = SimConv(c_ * 4, out_channels, 1, 1)
|
| 74 |
+
self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size // 2)
|
| 75 |
+
|
| 76 |
+
def forward(self, x):
|
| 77 |
+
x = self.cv1(x)
|
| 78 |
+
with warnings.catch_warnings():
|
| 79 |
+
warnings.simplefilter('ignore')
|
| 80 |
+
y1 = self.m(x)
|
| 81 |
+
y2 = self.m(y1)
|
| 82 |
+
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class Transpose(nn.Module):
|
| 86 |
+
'''Normal Transpose, default for upsampling'''
|
| 87 |
+
def __init__(self, in_channels, out_channels, kernel_size=2, stride=2):
|
| 88 |
+
super().__init__()
|
| 89 |
+
self.upsample_transpose = torch.nn.ConvTranspose2d(
|
| 90 |
+
in_channels=in_channels,
|
| 91 |
+
out_channels=out_channels,
|
| 92 |
+
kernel_size=kernel_size,
|
| 93 |
+
stride=stride,
|
| 94 |
+
bias=True
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
def forward(self, x):
|
| 98 |
+
return self.upsample_transpose(x)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class Concat(nn.Module):
|
| 102 |
+
def __init__(self, dimension=1):
|
| 103 |
+
super().__init__()
|
| 104 |
+
self.d = dimension
|
| 105 |
+
|
| 106 |
+
def forward(self, x):
|
| 107 |
+
return torch.cat(x, self.d)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
|
| 111 |
+
'''Basic cell for rep-style block, including conv and bn'''
|
| 112 |
+
result = nn.Sequential()
|
| 113 |
+
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
|
| 114 |
+
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False))
|
| 115 |
+
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
|
| 116 |
+
return result
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
class RepBlock(nn.Module):
|
| 120 |
+
'''
|
| 121 |
+
RepBlock is a stage block with rep-style basic block
|
| 122 |
+
'''
|
| 123 |
+
def __init__(self, in_channels, out_channels, n=1):
|
| 124 |
+
super().__init__()
|
| 125 |
+
self.conv1 = RepVGGBlock(in_channels, out_channels)
|
| 126 |
+
self.block = nn.Sequential(*(RepVGGBlock(out_channels, out_channels) for _ in range(n - 1))) if n > 1 else None
|
| 127 |
+
|
| 128 |
+
def forward(self, x):
|
| 129 |
+
x = self.conv1(x)
|
| 130 |
+
if self.block is not None:
|
| 131 |
+
x = self.block(x)
|
| 132 |
+
return x
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class RepVGGBlock(nn.Module):
|
| 136 |
+
'''RepVGGBlock is a basic rep-style block, including training and deploy status
|
| 137 |
+
This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
|
| 138 |
+
'''
|
| 139 |
+
def __init__(self, in_channels, out_channels, kernel_size=3,
|
| 140 |
+
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):
|
| 141 |
+
super(RepVGGBlock, self).__init__()
|
| 142 |
+
""" Intialization of the class.
|
| 143 |
+
Args:
|
| 144 |
+
in_channels (int): Number of channels in the input image
|
| 145 |
+
out_channels (int): Number of channels produced by the convolution
|
| 146 |
+
kernel_size (int or tuple): Size of the convolving kernel
|
| 147 |
+
stride (int or tuple, optional): Stride of the convolution. Default: 1
|
| 148 |
+
padding (int or tuple, optional): Zero-padding added to both sides of
|
| 149 |
+
the input. Default: 1
|
| 150 |
+
dilation (int or tuple, optional): Spacing between kernel elements. Default: 1
|
| 151 |
+
groups (int, optional): Number of blocked connections from input
|
| 152 |
+
channels to output channels. Default: 1
|
| 153 |
+
padding_mode (string, optional): Default: 'zeros'
|
| 154 |
+
deploy: Whether to be deploy status or training status. Default: False
|
| 155 |
+
use_se: Whether to use se. Default: False
|
| 156 |
+
"""
|
| 157 |
+
self.deploy = deploy
|
| 158 |
+
self.groups = groups
|
| 159 |
+
self.in_channels = in_channels
|
| 160 |
+
self.out_channels = out_channels
|
| 161 |
+
|
| 162 |
+
assert kernel_size == 3
|
| 163 |
+
assert padding == 1
|
| 164 |
+
|
| 165 |
+
padding_11 = padding - kernel_size // 2
|
| 166 |
+
|
| 167 |
+
self.nonlinearity = nn.ReLU()
|
| 168 |
+
|
| 169 |
+
if use_se:
|
| 170 |
+
raise NotImplementedError("se block not supported yet")
|
| 171 |
+
else:
|
| 172 |
+
self.se = nn.Identity()
|
| 173 |
+
|
| 174 |
+
if deploy:
|
| 175 |
+
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
|
| 176 |
+
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
|
| 177 |
+
|
| 178 |
+
else:
|
| 179 |
+
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None
|
| 180 |
+
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)
|
| 181 |
+
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)
|
| 182 |
+
|
| 183 |
+
def forward(self, inputs):
|
| 184 |
+
'''Forward process'''
|
| 185 |
+
if hasattr(self, 'rbr_reparam'):
|
| 186 |
+
return self.nonlinearity(self.se(self.rbr_reparam(inputs)))
|
| 187 |
+
|
| 188 |
+
if self.rbr_identity is None:
|
| 189 |
+
id_out = 0
|
| 190 |
+
else:
|
| 191 |
+
id_out = self.rbr_identity(inputs)
|
| 192 |
+
|
| 193 |
+
return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))
|
| 194 |
+
|
| 195 |
+
def get_equivalent_kernel_bias(self):
|
| 196 |
+
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
|
| 197 |
+
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
|
| 198 |
+
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
|
| 199 |
+
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
|
| 200 |
+
|
| 201 |
+
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
|
| 202 |
+
if kernel1x1 is None:
|
| 203 |
+
return 0
|
| 204 |
+
else:
|
| 205 |
+
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
|
| 206 |
+
|
| 207 |
+
def _fuse_bn_tensor(self, branch):
|
| 208 |
+
if branch is None:
|
| 209 |
+
return 0, 0
|
| 210 |
+
if isinstance(branch, nn.Sequential):
|
| 211 |
+
kernel = branch.conv.weight
|
| 212 |
+
running_mean = branch.bn.running_mean
|
| 213 |
+
running_var = branch.bn.running_var
|
| 214 |
+
gamma = branch.bn.weight
|
| 215 |
+
beta = branch.bn.bias
|
| 216 |
+
eps = branch.bn.eps
|
| 217 |
+
else:
|
| 218 |
+
assert isinstance(branch, nn.BatchNorm2d)
|
| 219 |
+
if not hasattr(self, 'id_tensor'):
|
| 220 |
+
input_dim = self.in_channels // self.groups
|
| 221 |
+
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
|
| 222 |
+
for i in range(self.in_channels):
|
| 223 |
+
kernel_value[i, i % input_dim, 1, 1] = 1
|
| 224 |
+
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
|
| 225 |
+
kernel = self.id_tensor
|
| 226 |
+
running_mean = branch.running_mean
|
| 227 |
+
running_var = branch.running_var
|
| 228 |
+
gamma = branch.weight
|
| 229 |
+
beta = branch.bias
|
| 230 |
+
eps = branch.eps
|
| 231 |
+
std = (running_var + eps).sqrt()
|
| 232 |
+
t = (gamma / std).reshape(-1, 1, 1, 1)
|
| 233 |
+
return kernel * t, beta - running_mean * gamma / std
|
| 234 |
+
|
| 235 |
+
def switch_to_deploy(self):
|
| 236 |
+
if hasattr(self, 'rbr_reparam'):
|
| 237 |
+
return
|
| 238 |
+
kernel, bias = self.get_equivalent_kernel_bias()
|
| 239 |
+
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,
|
| 240 |
+
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
|
| 241 |
+
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)
|
| 242 |
+
self.rbr_reparam.weight.data = kernel
|
| 243 |
+
self.rbr_reparam.bias.data = bias
|
| 244 |
+
for para in self.parameters():
|
| 245 |
+
para.detach_()
|
| 246 |
+
self.__delattr__('rbr_dense')
|
| 247 |
+
self.__delattr__('rbr_1x1')
|
| 248 |
+
if hasattr(self, 'rbr_identity'):
|
| 249 |
+
self.__delattr__('rbr_identity')
|
| 250 |
+
if hasattr(self, 'id_tensor'):
|
| 251 |
+
self.__delattr__('id_tensor')
|
| 252 |
+
self.deploy = True
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
class DetectBackend(nn.Module):
|
| 256 |
+
def __init__(self, weights='yolov6s.pt', device=None, dnn=True):
|
| 257 |
+
|
| 258 |
+
super().__init__()
|
| 259 |
+
assert isinstance(weights, str) and Path(weights).suffix == '.pt', f'{Path(weights).suffix} format is not supported.'
|
| 260 |
+
from yolov6.utils.checkpoint import load_checkpoint
|
| 261 |
+
model = load_checkpoint(weights, map_location=device)
|
| 262 |
+
stride = int(model.stride.max())
|
| 263 |
+
self.__dict__.update(locals()) # assign all variables to self
|
| 264 |
+
|
| 265 |
+
def forward(self, im, val=False):
|
| 266 |
+
y = self.model(im)
|
| 267 |
+
if isinstance(y, np.ndarray):
|
| 268 |
+
y = torch.tensor(y, device=self.device)
|
| 269 |
+
return y
|
yolov6/models/efficientrep.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
from yolov6.layers.common import RepVGGBlock, RepBlock, SimSPPF
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class EfficientRep(nn.Module):
|
| 6 |
+
'''EfficientRep Backbone
|
| 7 |
+
EfficientRep is handcrafted by hardware-aware neural network design.
|
| 8 |
+
With rep-style struct, EfficientRep is friendly to high-computation hardware(e.g. GPU).
|
| 9 |
+
'''
|
| 10 |
+
|
| 11 |
+
def __init__(
|
| 12 |
+
self,
|
| 13 |
+
in_channels=3,
|
| 14 |
+
channels_list=None,
|
| 15 |
+
num_repeats=None,
|
| 16 |
+
):
|
| 17 |
+
super().__init__()
|
| 18 |
+
|
| 19 |
+
assert channels_list is not None
|
| 20 |
+
assert num_repeats is not None
|
| 21 |
+
|
| 22 |
+
self.stem = RepVGGBlock(
|
| 23 |
+
in_channels=in_channels,
|
| 24 |
+
out_channels=channels_list[0],
|
| 25 |
+
kernel_size=3,
|
| 26 |
+
stride=2
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
self.ERBlock_2 = nn.Sequential(
|
| 30 |
+
RepVGGBlock(
|
| 31 |
+
in_channels=channels_list[0],
|
| 32 |
+
out_channels=channels_list[1],
|
| 33 |
+
kernel_size=3,
|
| 34 |
+
stride=2
|
| 35 |
+
),
|
| 36 |
+
RepBlock(
|
| 37 |
+
in_channels=channels_list[1],
|
| 38 |
+
out_channels=channels_list[1],
|
| 39 |
+
n=num_repeats[1]
|
| 40 |
+
)
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
self.ERBlock_3 = nn.Sequential(
|
| 44 |
+
RepVGGBlock(
|
| 45 |
+
in_channels=channels_list[1],
|
| 46 |
+
out_channels=channels_list[2],
|
| 47 |
+
kernel_size=3,
|
| 48 |
+
stride=2
|
| 49 |
+
),
|
| 50 |
+
RepBlock(
|
| 51 |
+
in_channels=channels_list[2],
|
| 52 |
+
out_channels=channels_list[2],
|
| 53 |
+
n=num_repeats[2]
|
| 54 |
+
)
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
self.ERBlock_4 = nn.Sequential(
|
| 58 |
+
RepVGGBlock(
|
| 59 |
+
in_channels=channels_list[2],
|
| 60 |
+
out_channels=channels_list[3],
|
| 61 |
+
kernel_size=3,
|
| 62 |
+
stride=2
|
| 63 |
+
),
|
| 64 |
+
RepBlock(
|
| 65 |
+
in_channels=channels_list[3],
|
| 66 |
+
out_channels=channels_list[3],
|
| 67 |
+
n=num_repeats[3]
|
| 68 |
+
)
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
self.ERBlock_5 = nn.Sequential(
|
| 72 |
+
RepVGGBlock(
|
| 73 |
+
in_channels=channels_list[3],
|
| 74 |
+
out_channels=channels_list[4],
|
| 75 |
+
kernel_size=3,
|
| 76 |
+
stride=2,
|
| 77 |
+
),
|
| 78 |
+
RepBlock(
|
| 79 |
+
in_channels=channels_list[4],
|
| 80 |
+
out_channels=channels_list[4],
|
| 81 |
+
n=num_repeats[4]
|
| 82 |
+
),
|
| 83 |
+
SimSPPF(
|
| 84 |
+
in_channels=channels_list[4],
|
| 85 |
+
out_channels=channels_list[4],
|
| 86 |
+
kernel_size=5
|
| 87 |
+
)
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
def forward(self, x):
|
| 91 |
+
|
| 92 |
+
outputs = []
|
| 93 |
+
x = self.stem(x)
|
| 94 |
+
x = self.ERBlock_2(x)
|
| 95 |
+
x = self.ERBlock_3(x)
|
| 96 |
+
outputs.append(x)
|
| 97 |
+
x = self.ERBlock_4(x)
|
| 98 |
+
outputs.append(x)
|
| 99 |
+
x = self.ERBlock_5(x)
|
| 100 |
+
outputs.append(x)
|
| 101 |
+
|
| 102 |
+
return tuple(outputs)
|
yolov6/models/effidehead.py
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import math
|
| 4 |
+
from yolov6.layers.common import *
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class Detect(nn.Module):
|
| 8 |
+
'''Efficient Decoupled Head
|
| 9 |
+
With hardware-aware degisn, the decoupled head is optimized with
|
| 10 |
+
hybridchannels methods.
|
| 11 |
+
'''
|
| 12 |
+
def __init__(self, num_classes=80, anchors=1, num_layers=3, inplace=True, head_layers=None): # detection layer
|
| 13 |
+
super().__init__()
|
| 14 |
+
assert head_layers is not None
|
| 15 |
+
self.nc = num_classes # number of classes
|
| 16 |
+
self.no = num_classes + 5 # number of outputs per anchor
|
| 17 |
+
self.nl = num_layers # number of detection layers
|
| 18 |
+
if isinstance(anchors, (list, tuple)):
|
| 19 |
+
self.na = len(anchors[0]) // 2
|
| 20 |
+
else:
|
| 21 |
+
self.na = anchors
|
| 22 |
+
self.anchors = anchors
|
| 23 |
+
self.grid = [torch.zeros(1)] * num_layers
|
| 24 |
+
self.prior_prob = 1e-2
|
| 25 |
+
self.inplace = inplace
|
| 26 |
+
stride = [8, 16, 32] # strides computed during build
|
| 27 |
+
self.stride = torch.tensor(stride)
|
| 28 |
+
|
| 29 |
+
# Init decouple head
|
| 30 |
+
self.cls_convs = nn.ModuleList()
|
| 31 |
+
self.reg_convs = nn.ModuleList()
|
| 32 |
+
self.cls_preds = nn.ModuleList()
|
| 33 |
+
self.reg_preds = nn.ModuleList()
|
| 34 |
+
self.obj_preds = nn.ModuleList()
|
| 35 |
+
self.stems = nn.ModuleList()
|
| 36 |
+
|
| 37 |
+
# Efficient decoupled head layers
|
| 38 |
+
for i in range(num_layers):
|
| 39 |
+
idx = i*6
|
| 40 |
+
self.stems.append(head_layers[idx])
|
| 41 |
+
self.cls_convs.append(head_layers[idx+1])
|
| 42 |
+
self.reg_convs.append(head_layers[idx+2])
|
| 43 |
+
self.cls_preds.append(head_layers[idx+3])
|
| 44 |
+
self.reg_preds.append(head_layers[idx+4])
|
| 45 |
+
self.obj_preds.append(head_layers[idx+5])
|
| 46 |
+
|
| 47 |
+
def initialize_biases(self):
|
| 48 |
+
for conv in self.cls_preds:
|
| 49 |
+
b = conv.bias.view(self.na, -1)
|
| 50 |
+
b.data.fill_(-math.log((1 - self.prior_prob) / self.prior_prob))
|
| 51 |
+
conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
|
| 52 |
+
for conv in self.obj_preds:
|
| 53 |
+
b = conv.bias.view(self.na, -1)
|
| 54 |
+
b.data.fill_(-math.log((1 - self.prior_prob) / self.prior_prob))
|
| 55 |
+
conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
|
| 56 |
+
|
| 57 |
+
def forward(self, x):
|
| 58 |
+
z = []
|
| 59 |
+
for i in range(self.nl):
|
| 60 |
+
x[i] = self.stems[i](x[i])
|
| 61 |
+
cls_x = x[i]
|
| 62 |
+
reg_x = x[i]
|
| 63 |
+
cls_feat = self.cls_convs[i](cls_x)
|
| 64 |
+
cls_output = self.cls_preds[i](cls_feat)
|
| 65 |
+
reg_feat = self.reg_convs[i](reg_x)
|
| 66 |
+
reg_output = self.reg_preds[i](reg_feat)
|
| 67 |
+
obj_output = self.obj_preds[i](reg_feat)
|
| 68 |
+
if self.training:
|
| 69 |
+
x[i] = torch.cat([reg_output, obj_output, cls_output], 1)
|
| 70 |
+
bs, _, ny, nx = x[i].shape
|
| 71 |
+
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
|
| 72 |
+
else:
|
| 73 |
+
y = torch.cat([reg_output, obj_output.sigmoid(), cls_output.sigmoid()], 1)
|
| 74 |
+
bs, _, ny, nx = y.shape
|
| 75 |
+
y = y.view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
|
| 76 |
+
if self.grid[i].shape[2:4] != y.shape[2:4]:
|
| 77 |
+
d = self.stride.device
|
| 78 |
+
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
|
| 79 |
+
self.grid[i] = torch.stack((xv, yv), 2).view(1, self.na, ny, nx, 2).float()
|
| 80 |
+
if self.inplace:
|
| 81 |
+
y[..., 0:2] = (y[..., 0:2] + self.grid[i]) * self.stride[i] # xy
|
| 82 |
+
y[..., 2:4] = torch.exp(y[..., 2:4]) * self.stride[i] # wh
|
| 83 |
+
else:
|
| 84 |
+
xy = (y[..., 0:2] + self.grid[i]) * self.stride[i] # xy
|
| 85 |
+
wh = torch.exp(y[..., 2:4]) * self.stride[i] # wh
|
| 86 |
+
y = torch.cat((xy, wh, y[..., 4:]), -1)
|
| 87 |
+
z.append(y.view(bs, -1, self.no))
|
| 88 |
+
return x if self.training else torch.cat(z, 1)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def build_effidehead_layer(channels_list, num_anchors, num_classes):
|
| 92 |
+
head_layers = nn.Sequential(
|
| 93 |
+
# stem0
|
| 94 |
+
Conv(
|
| 95 |
+
in_channels=channels_list[6],
|
| 96 |
+
out_channels=channels_list[6],
|
| 97 |
+
kernel_size=1,
|
| 98 |
+
stride=1
|
| 99 |
+
),
|
| 100 |
+
# cls_conv0
|
| 101 |
+
Conv(
|
| 102 |
+
in_channels=channels_list[6],
|
| 103 |
+
out_channels=channels_list[6],
|
| 104 |
+
kernel_size=3,
|
| 105 |
+
stride=1
|
| 106 |
+
),
|
| 107 |
+
# reg_conv0
|
| 108 |
+
Conv(
|
| 109 |
+
in_channels=channels_list[6],
|
| 110 |
+
out_channels=channels_list[6],
|
| 111 |
+
kernel_size=3,
|
| 112 |
+
stride=1
|
| 113 |
+
),
|
| 114 |
+
# cls_pred0
|
| 115 |
+
nn.Conv2d(
|
| 116 |
+
in_channels=channels_list[6],
|
| 117 |
+
out_channels=num_classes * num_anchors,
|
| 118 |
+
kernel_size=1
|
| 119 |
+
),
|
| 120 |
+
# reg_pred0
|
| 121 |
+
nn.Conv2d(
|
| 122 |
+
in_channels=channels_list[6],
|
| 123 |
+
out_channels=4 * num_anchors,
|
| 124 |
+
kernel_size=1
|
| 125 |
+
),
|
| 126 |
+
# obj_pred0
|
| 127 |
+
nn.Conv2d(
|
| 128 |
+
in_channels=channels_list[6],
|
| 129 |
+
out_channels=1 * num_anchors,
|
| 130 |
+
kernel_size=1
|
| 131 |
+
),
|
| 132 |
+
# stem1
|
| 133 |
+
Conv(
|
| 134 |
+
in_channels=channels_list[8],
|
| 135 |
+
out_channels=channels_list[8],
|
| 136 |
+
kernel_size=1,
|
| 137 |
+
stride=1
|
| 138 |
+
),
|
| 139 |
+
# cls_conv1
|
| 140 |
+
Conv(
|
| 141 |
+
in_channels=channels_list[8],
|
| 142 |
+
out_channels=channels_list[8],
|
| 143 |
+
kernel_size=3,
|
| 144 |
+
stride=1
|
| 145 |
+
),
|
| 146 |
+
# reg_conv1
|
| 147 |
+
Conv(
|
| 148 |
+
in_channels=channels_list[8],
|
| 149 |
+
out_channels=channels_list[8],
|
| 150 |
+
kernel_size=3,
|
| 151 |
+
stride=1
|
| 152 |
+
),
|
| 153 |
+
# cls_pred1
|
| 154 |
+
nn.Conv2d(
|
| 155 |
+
in_channels=channels_list[8],
|
| 156 |
+
out_channels=num_classes * num_anchors,
|
| 157 |
+
kernel_size=1
|
| 158 |
+
),
|
| 159 |
+
# reg_pred1
|
| 160 |
+
nn.Conv2d(
|
| 161 |
+
in_channels=channels_list[8],
|
| 162 |
+
out_channels=4 * num_anchors,
|
| 163 |
+
kernel_size=1
|
| 164 |
+
),
|
| 165 |
+
# obj_pred1
|
| 166 |
+
nn.Conv2d(
|
| 167 |
+
in_channels=channels_list[8],
|
| 168 |
+
out_channels=1 * num_anchors,
|
| 169 |
+
kernel_size=1
|
| 170 |
+
),
|
| 171 |
+
# stem2
|
| 172 |
+
Conv(
|
| 173 |
+
in_channels=channels_list[10],
|
| 174 |
+
out_channels=channels_list[10],
|
| 175 |
+
kernel_size=1,
|
| 176 |
+
stride=1
|
| 177 |
+
),
|
| 178 |
+
# cls_conv2
|
| 179 |
+
Conv(
|
| 180 |
+
in_channels=channels_list[10],
|
| 181 |
+
out_channels=channels_list[10],
|
| 182 |
+
kernel_size=3,
|
| 183 |
+
stride=1
|
| 184 |
+
),
|
| 185 |
+
# reg_conv2
|
| 186 |
+
Conv(
|
| 187 |
+
in_channels=channels_list[10],
|
| 188 |
+
out_channels=channels_list[10],
|
| 189 |
+
kernel_size=3,
|
| 190 |
+
stride=1
|
| 191 |
+
),
|
| 192 |
+
# cls_pred2
|
| 193 |
+
nn.Conv2d(
|
| 194 |
+
in_channels=channels_list[10],
|
| 195 |
+
out_channels=num_classes * num_anchors,
|
| 196 |
+
kernel_size=1
|
| 197 |
+
),
|
| 198 |
+
# reg_pred2
|
| 199 |
+
nn.Conv2d(
|
| 200 |
+
in_channels=channels_list[10],
|
| 201 |
+
out_channels=4 * num_anchors,
|
| 202 |
+
kernel_size=1
|
| 203 |
+
),
|
| 204 |
+
# obj_pred2
|
| 205 |
+
nn.Conv2d(
|
| 206 |
+
in_channels=channels_list[10],
|
| 207 |
+
out_channels=1 * num_anchors,
|
| 208 |
+
kernel_size=1
|
| 209 |
+
)
|
| 210 |
+
)
|
| 211 |
+
return head_layers
|
yolov6/models/loss.py
ADDED
|
@@ -0,0 +1,411 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
|
| 4 |
+
# The code is based on
|
| 5 |
+
# https://github.com/Megvii-BaseDetection/YOLOX/blob/main/yolox/models/yolo_head.py
|
| 6 |
+
# Copyright (c) Megvii, Inc. and its affiliates.
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn as nn
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from yolov6.utils.figure_iou import IOUloss, pairwise_bbox_iou
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class ComputeLoss:
|
| 16 |
+
'''Loss computation func.
|
| 17 |
+
This func contains SimOTA and siou loss.
|
| 18 |
+
'''
|
| 19 |
+
def __init__(self,
|
| 20 |
+
reg_weight=5.0,
|
| 21 |
+
iou_weight=3.0,
|
| 22 |
+
cls_weight=1.0,
|
| 23 |
+
center_radius=2.5,
|
| 24 |
+
eps=1e-7,
|
| 25 |
+
in_channels=[256, 512, 1024],
|
| 26 |
+
strides=[8, 16, 32],
|
| 27 |
+
n_anchors=1,
|
| 28 |
+
iou_type='ciou'
|
| 29 |
+
):
|
| 30 |
+
|
| 31 |
+
self.reg_weight = reg_weight
|
| 32 |
+
self.iou_weight = iou_weight
|
| 33 |
+
self.cls_weight = cls_weight
|
| 34 |
+
|
| 35 |
+
self.center_radius = center_radius
|
| 36 |
+
self.eps = eps
|
| 37 |
+
self.n_anchors = n_anchors
|
| 38 |
+
self.strides = strides
|
| 39 |
+
self.grids = [torch.zeros(1)] * len(in_channels)
|
| 40 |
+
|
| 41 |
+
# Define criteria
|
| 42 |
+
self.l1_loss = nn.L1Loss(reduction="none")
|
| 43 |
+
self.bcewithlog_loss = nn.BCEWithLogitsLoss(reduction="none")
|
| 44 |
+
self.iou_loss = IOUloss(iou_type=iou_type, reduction="none")
|
| 45 |
+
|
| 46 |
+
def __call__(
|
| 47 |
+
self,
|
| 48 |
+
outputs,
|
| 49 |
+
targets
|
| 50 |
+
):
|
| 51 |
+
dtype = outputs[0].type()
|
| 52 |
+
device = targets.device
|
| 53 |
+
loss_cls, loss_obj, loss_iou, loss_l1 = torch.zeros(1, device=device), torch.zeros(1, device=device), \
|
| 54 |
+
torch.zeros(1, device=device), torch.zeros(1, device=device)
|
| 55 |
+
num_classes = outputs[0].shape[-1] - 5
|
| 56 |
+
|
| 57 |
+
outputs, outputs_origin, gt_bboxes_scale, xy_shifts, expanded_strides = self.get_outputs_and_grids(
|
| 58 |
+
outputs, self.strides, dtype, device)
|
| 59 |
+
|
| 60 |
+
total_num_anchors = outputs.shape[1]
|
| 61 |
+
bbox_preds = outputs[:, :, :4] # [batch, n_anchors_all, 4]
|
| 62 |
+
bbox_preds_org = outputs_origin[:, :, :4] # [batch, n_anchors_all, 4]
|
| 63 |
+
obj_preds = outputs[:, :, 4].unsqueeze(-1) # [batch, n_anchors_all, 1]
|
| 64 |
+
cls_preds = outputs[:, :, 5:] # [batch, n_anchors_all, n_cls]
|
| 65 |
+
|
| 66 |
+
# targets
|
| 67 |
+
batch_size = bbox_preds.shape[0]
|
| 68 |
+
targets_list = np.zeros((batch_size, 1, 5)).tolist()
|
| 69 |
+
for i, item in enumerate(targets.cpu().numpy().tolist()):
|
| 70 |
+
targets_list[int(item[0])].append(item[1:])
|
| 71 |
+
max_len = max((len(l) for l in targets_list))
|
| 72 |
+
|
| 73 |
+
targets = torch.from_numpy(np.array(list(map(lambda l:l + [[-1,0,0,0,0]]*(max_len - len(l)), targets_list)))[:,1:,:]).to(targets.device)
|
| 74 |
+
num_targets_list = (targets.sum(dim=2) > 0).sum(dim=1) # number of objects
|
| 75 |
+
|
| 76 |
+
num_fg, num_gts = 0, 0
|
| 77 |
+
cls_targets, reg_targets, l1_targets, obj_targets, fg_masks = [], [], [], [], []
|
| 78 |
+
|
| 79 |
+
for batch_idx in range(batch_size):
|
| 80 |
+
num_gt = int(num_targets_list[batch_idx])
|
| 81 |
+
num_gts += num_gt
|
| 82 |
+
if num_gt == 0:
|
| 83 |
+
cls_target = outputs.new_zeros((0, num_classes))
|
| 84 |
+
reg_target = outputs.new_zeros((0, 4))
|
| 85 |
+
l1_target = outputs.new_zeros((0, 4))
|
| 86 |
+
obj_target = outputs.new_zeros((total_num_anchors, 1))
|
| 87 |
+
fg_mask = outputs.new_zeros(total_num_anchors).bool()
|
| 88 |
+
else:
|
| 89 |
+
|
| 90 |
+
gt_bboxes_per_image = targets[batch_idx, :num_gt, 1:5].mul_(gt_bboxes_scale)
|
| 91 |
+
gt_classes = targets[batch_idx, :num_gt, 0]
|
| 92 |
+
bboxes_preds_per_image = bbox_preds[batch_idx]
|
| 93 |
+
cls_preds_per_image = cls_preds[batch_idx]
|
| 94 |
+
obj_preds_per_image = obj_preds[batch_idx]
|
| 95 |
+
|
| 96 |
+
try:
|
| 97 |
+
(
|
| 98 |
+
gt_matched_classes,
|
| 99 |
+
fg_mask,
|
| 100 |
+
pred_ious_this_matching,
|
| 101 |
+
matched_gt_inds,
|
| 102 |
+
num_fg_img,
|
| 103 |
+
) = self.get_assignments(
|
| 104 |
+
batch_idx,
|
| 105 |
+
num_gt,
|
| 106 |
+
total_num_anchors,
|
| 107 |
+
gt_bboxes_per_image,
|
| 108 |
+
gt_classes,
|
| 109 |
+
bboxes_preds_per_image,
|
| 110 |
+
cls_preds_per_image,
|
| 111 |
+
obj_preds_per_image,
|
| 112 |
+
expanded_strides,
|
| 113 |
+
xy_shifts,
|
| 114 |
+
num_classes
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
except RuntimeError:
|
| 118 |
+
print(
|
| 119 |
+
"OOM RuntimeError is raised due to the huge memory cost during label assignment. \
|
| 120 |
+
CPU mode is applied in this batch. If you want to avoid this issue, \
|
| 121 |
+
try to reduce the batch size or image size."
|
| 122 |
+
)
|
| 123 |
+
torch.cuda.empty_cache()
|
| 124 |
+
print("------------CPU Mode for This Batch-------------")
|
| 125 |
+
|
| 126 |
+
_gt_bboxes_per_image = gt_bboxes_per_image.cpu().float()
|
| 127 |
+
_gt_classes = gt_classes.cpu().float()
|
| 128 |
+
_bboxes_preds_per_image = bboxes_preds_per_image.cpu().float()
|
| 129 |
+
_cls_preds_per_image = cls_preds_per_image.cpu().float()
|
| 130 |
+
_obj_preds_per_image = obj_preds_per_image.cpu().float()
|
| 131 |
+
|
| 132 |
+
_expanded_strides = expanded_strides.cpu().float()
|
| 133 |
+
_xy_shifts = xy_shifts.cpu()
|
| 134 |
+
|
| 135 |
+
(
|
| 136 |
+
gt_matched_classes,
|
| 137 |
+
fg_mask,
|
| 138 |
+
pred_ious_this_matching,
|
| 139 |
+
matched_gt_inds,
|
| 140 |
+
num_fg_img,
|
| 141 |
+
) = self.get_assignments(
|
| 142 |
+
batch_idx,
|
| 143 |
+
num_gt,
|
| 144 |
+
total_num_anchors,
|
| 145 |
+
_gt_bboxes_per_image,
|
| 146 |
+
_gt_classes,
|
| 147 |
+
_bboxes_preds_per_image,
|
| 148 |
+
_cls_preds_per_image,
|
| 149 |
+
_obj_preds_per_image,
|
| 150 |
+
_expanded_strides,
|
| 151 |
+
_xy_shifts,
|
| 152 |
+
num_classes
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
gt_matched_classes = gt_matched_classes.cuda()
|
| 156 |
+
fg_mask = fg_mask.cuda()
|
| 157 |
+
pred_ious_this_matching = pred_ious_this_matching.cuda()
|
| 158 |
+
matched_gt_inds = matched_gt_inds.cuda()
|
| 159 |
+
|
| 160 |
+
torch.cuda.empty_cache()
|
| 161 |
+
num_fg += num_fg_img
|
| 162 |
+
if num_fg_img > 0:
|
| 163 |
+
cls_target = F.one_hot(
|
| 164 |
+
gt_matched_classes.to(torch.int64), num_classes
|
| 165 |
+
) * pred_ious_this_matching.unsqueeze(-1)
|
| 166 |
+
obj_target = fg_mask.unsqueeze(-1)
|
| 167 |
+
reg_target = gt_bboxes_per_image[matched_gt_inds]
|
| 168 |
+
|
| 169 |
+
l1_target = self.get_l1_target(
|
| 170 |
+
outputs.new_zeros((num_fg_img, 4)),
|
| 171 |
+
gt_bboxes_per_image[matched_gt_inds],
|
| 172 |
+
expanded_strides[0][fg_mask],
|
| 173 |
+
xy_shifts=xy_shifts[0][fg_mask],
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
cls_targets.append(cls_target)
|
| 177 |
+
reg_targets.append(reg_target)
|
| 178 |
+
obj_targets.append(obj_target)
|
| 179 |
+
l1_targets.append(l1_target)
|
| 180 |
+
fg_masks.append(fg_mask)
|
| 181 |
+
|
| 182 |
+
cls_targets = torch.cat(cls_targets, 0)
|
| 183 |
+
reg_targets = torch.cat(reg_targets, 0)
|
| 184 |
+
obj_targets = torch.cat(obj_targets, 0)
|
| 185 |
+
l1_targets = torch.cat(l1_targets, 0)
|
| 186 |
+
fg_masks = torch.cat(fg_masks, 0)
|
| 187 |
+
|
| 188 |
+
num_fg = max(num_fg, 1)
|
| 189 |
+
# loss
|
| 190 |
+
loss_iou += (self.iou_loss(bbox_preds.view(-1, 4)[fg_masks].T, reg_targets)).sum() / num_fg
|
| 191 |
+
loss_l1 += (self.l1_loss(bbox_preds_org.view(-1, 4)[fg_masks], l1_targets)).sum() / num_fg
|
| 192 |
+
|
| 193 |
+
loss_obj += (self.bcewithlog_loss(obj_preds.view(-1, 1), obj_targets*1.0)).sum() / num_fg
|
| 194 |
+
loss_cls += (self.bcewithlog_loss(cls_preds.view(-1, num_classes)[fg_masks], cls_targets)).sum() / num_fg
|
| 195 |
+
|
| 196 |
+
total_losses = self.reg_weight * loss_iou + loss_l1 + loss_obj + loss_cls
|
| 197 |
+
return total_losses, torch.cat((self.reg_weight * loss_iou, loss_l1, loss_obj, loss_cls)).detach()
|
| 198 |
+
|
| 199 |
+
def decode_output(self, output, k, stride, dtype, device):
|
| 200 |
+
grid = self.grids[k].to(device)
|
| 201 |
+
batch_size = output.shape[0]
|
| 202 |
+
hsize, wsize = output.shape[2:4]
|
| 203 |
+
if grid.shape[2:4] != output.shape[2:4]:
|
| 204 |
+
yv, xv = torch.meshgrid([torch.arange(hsize), torch.arange(wsize)])
|
| 205 |
+
grid = torch.stack((xv, yv), 2).view(1, 1, hsize, wsize, 2).type(dtype).to(device)
|
| 206 |
+
self.grids[k] = grid
|
| 207 |
+
|
| 208 |
+
output = output.reshape(batch_size, self.n_anchors * hsize * wsize, -1)
|
| 209 |
+
output_origin = output.clone()
|
| 210 |
+
grid = grid.view(1, -1, 2)
|
| 211 |
+
|
| 212 |
+
output[..., :2] = (output[..., :2] + grid) * stride
|
| 213 |
+
output[..., 2:4] = torch.exp(output[..., 2:4]) * stride
|
| 214 |
+
|
| 215 |
+
return output, output_origin, grid, hsize, wsize
|
| 216 |
+
|
| 217 |
+
def get_outputs_and_grids(self, outputs, strides, dtype, device):
|
| 218 |
+
xy_shifts = []
|
| 219 |
+
expanded_strides = []
|
| 220 |
+
outputs_new = []
|
| 221 |
+
outputs_origin = []
|
| 222 |
+
|
| 223 |
+
for k, output in enumerate(outputs):
|
| 224 |
+
output, output_origin, grid, feat_h, feat_w = self.decode_output(
|
| 225 |
+
output, k, strides[k], dtype, device)
|
| 226 |
+
|
| 227 |
+
xy_shift = grid
|
| 228 |
+
expanded_stride = torch.full((1, grid.shape[1], 1), strides[k], dtype=grid.dtype, device=grid.device)
|
| 229 |
+
|
| 230 |
+
xy_shifts.append(xy_shift)
|
| 231 |
+
expanded_strides.append(expanded_stride)
|
| 232 |
+
outputs_new.append(output)
|
| 233 |
+
outputs_origin.append(output_origin)
|
| 234 |
+
|
| 235 |
+
xy_shifts = torch.cat(xy_shifts, 1) # [1, n_anchors_all, 2]
|
| 236 |
+
expanded_strides = torch.cat(expanded_strides, 1) # [1, n_anchors_all, 1]
|
| 237 |
+
outputs_origin = torch.cat(outputs_origin, 1)
|
| 238 |
+
outputs = torch.cat(outputs_new, 1)
|
| 239 |
+
|
| 240 |
+
feat_h *= strides[-1]
|
| 241 |
+
feat_w *= strides[-1]
|
| 242 |
+
gt_bboxes_scale = torch.Tensor([[feat_w, feat_h, feat_w, feat_h]]).type_as(outputs)
|
| 243 |
+
|
| 244 |
+
return outputs, outputs_origin, gt_bboxes_scale, xy_shifts, expanded_strides
|
| 245 |
+
|
| 246 |
+
def get_l1_target(self, l1_target, gt, stride, xy_shifts, eps=1e-8):
|
| 247 |
+
|
| 248 |
+
l1_target[:, 0:2] = gt[:, 0:2] / stride - xy_shifts
|
| 249 |
+
l1_target[:, 2:4] = torch.log(gt[:, 2:4] / stride + eps)
|
| 250 |
+
return l1_target
|
| 251 |
+
|
| 252 |
+
@torch.no_grad()
|
| 253 |
+
def get_assignments(
|
| 254 |
+
self,
|
| 255 |
+
batch_idx,
|
| 256 |
+
num_gt,
|
| 257 |
+
total_num_anchors,
|
| 258 |
+
gt_bboxes_per_image,
|
| 259 |
+
gt_classes,
|
| 260 |
+
bboxes_preds_per_image,
|
| 261 |
+
cls_preds_per_image,
|
| 262 |
+
obj_preds_per_image,
|
| 263 |
+
expanded_strides,
|
| 264 |
+
xy_shifts,
|
| 265 |
+
num_classes
|
| 266 |
+
):
|
| 267 |
+
|
| 268 |
+
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(
|
| 269 |
+
gt_bboxes_per_image,
|
| 270 |
+
expanded_strides,
|
| 271 |
+
xy_shifts,
|
| 272 |
+
total_num_anchors,
|
| 273 |
+
num_gt,
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask]
|
| 277 |
+
cls_preds_ = cls_preds_per_image[fg_mask]
|
| 278 |
+
obj_preds_ = obj_preds_per_image[fg_mask]
|
| 279 |
+
num_in_boxes_anchor = bboxes_preds_per_image.shape[0]
|
| 280 |
+
|
| 281 |
+
# cost
|
| 282 |
+
pair_wise_ious = pairwise_bbox_iou(gt_bboxes_per_image, bboxes_preds_per_image, box_format='xywh')
|
| 283 |
+
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
|
| 284 |
+
|
| 285 |
+
gt_cls_per_image = (
|
| 286 |
+
F.one_hot(gt_classes.to(torch.int64), num_classes)
|
| 287 |
+
.float()
|
| 288 |
+
.unsqueeze(1)
|
| 289 |
+
.repeat(1, num_in_boxes_anchor, 1)
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
with torch.cuda.amp.autocast(enabled=False):
|
| 293 |
+
cls_preds_ = (
|
| 294 |
+
cls_preds_.float().sigmoid_().unsqueeze(0).repeat(num_gt, 1, 1)
|
| 295 |
+
* obj_preds_.float().sigmoid_().unsqueeze(0).repeat(num_gt, 1, 1)
|
| 296 |
+
)
|
| 297 |
+
pair_wise_cls_loss = F.binary_cross_entropy(
|
| 298 |
+
cls_preds_.sqrt_(), gt_cls_per_image, reduction="none"
|
| 299 |
+
).sum(-1)
|
| 300 |
+
del cls_preds_, obj_preds_
|
| 301 |
+
|
| 302 |
+
cost = (
|
| 303 |
+
self.cls_weight * pair_wise_cls_loss
|
| 304 |
+
+ self.iou_weight * pair_wise_ious_loss
|
| 305 |
+
+ 100000.0 * (~is_in_boxes_and_center)
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
(
|
| 309 |
+
num_fg,
|
| 310 |
+
gt_matched_classes,
|
| 311 |
+
pred_ious_this_matching,
|
| 312 |
+
matched_gt_inds,
|
| 313 |
+
) = self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)
|
| 314 |
+
|
| 315 |
+
del pair_wise_cls_loss, cost, pair_wise_ious, pair_wise_ious_loss
|
| 316 |
+
|
| 317 |
+
return (
|
| 318 |
+
gt_matched_classes,
|
| 319 |
+
fg_mask,
|
| 320 |
+
pred_ious_this_matching,
|
| 321 |
+
matched_gt_inds,
|
| 322 |
+
num_fg,
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
def get_in_boxes_info(
|
| 326 |
+
self,
|
| 327 |
+
gt_bboxes_per_image,
|
| 328 |
+
expanded_strides,
|
| 329 |
+
xy_shifts,
|
| 330 |
+
total_num_anchors,
|
| 331 |
+
num_gt,
|
| 332 |
+
):
|
| 333 |
+
expanded_strides_per_image = expanded_strides[0]
|
| 334 |
+
xy_shifts_per_image = xy_shifts[0] * expanded_strides_per_image
|
| 335 |
+
xy_centers_per_image = (
|
| 336 |
+
(xy_shifts_per_image + 0.5 * expanded_strides_per_image)
|
| 337 |
+
.unsqueeze(0)
|
| 338 |
+
.repeat(num_gt, 1, 1)
|
| 339 |
+
) # [n_anchor, 2] -> [n_gt, n_anchor, 2]
|
| 340 |
+
|
| 341 |
+
gt_bboxes_per_image_lt = (
|
| 342 |
+
(gt_bboxes_per_image[:, 0:2] - 0.5 * gt_bboxes_per_image[:, 2:4])
|
| 343 |
+
.unsqueeze(1)
|
| 344 |
+
.repeat(1, total_num_anchors, 1)
|
| 345 |
+
)
|
| 346 |
+
gt_bboxes_per_image_rb = (
|
| 347 |
+
(gt_bboxes_per_image[:, 0:2] + 0.5 * gt_bboxes_per_image[:, 2:4])
|
| 348 |
+
.unsqueeze(1)
|
| 349 |
+
.repeat(1, total_num_anchors, 1)
|
| 350 |
+
) # [n_gt, 2] -> [n_gt, n_anchor, 2]
|
| 351 |
+
|
| 352 |
+
b_lt = xy_centers_per_image - gt_bboxes_per_image_lt
|
| 353 |
+
b_rb = gt_bboxes_per_image_rb - xy_centers_per_image
|
| 354 |
+
bbox_deltas = torch.cat([b_lt, b_rb], 2)
|
| 355 |
+
|
| 356 |
+
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0
|
| 357 |
+
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0
|
| 358 |
+
|
| 359 |
+
# in fixed center
|
| 360 |
+
gt_bboxes_per_image_lt = (gt_bboxes_per_image[:, 0:2]).unsqueeze(1).repeat(
|
| 361 |
+
1, total_num_anchors, 1
|
| 362 |
+
) - self.center_radius * expanded_strides_per_image.unsqueeze(0)
|
| 363 |
+
gt_bboxes_per_image_rb = (gt_bboxes_per_image[:, 0:2]).unsqueeze(1).repeat(
|
| 364 |
+
1, total_num_anchors, 1
|
| 365 |
+
) + self.center_radius * expanded_strides_per_image.unsqueeze(0)
|
| 366 |
+
|
| 367 |
+
c_lt = xy_centers_per_image - gt_bboxes_per_image_lt
|
| 368 |
+
c_rb = gt_bboxes_per_image_rb - xy_centers_per_image
|
| 369 |
+
center_deltas = torch.cat([c_lt, c_rb], 2)
|
| 370 |
+
is_in_centers = center_deltas.min(dim=-1).values > 0.0
|
| 371 |
+
is_in_centers_all = is_in_centers.sum(dim=0) > 0
|
| 372 |
+
|
| 373 |
+
# in boxes and in centers
|
| 374 |
+
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all
|
| 375 |
+
|
| 376 |
+
is_in_boxes_and_center = (
|
| 377 |
+
is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor]
|
| 378 |
+
)
|
| 379 |
+
return is_in_boxes_anchor, is_in_boxes_and_center
|
| 380 |
+
|
| 381 |
+
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
|
| 382 |
+
matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
|
| 383 |
+
ious_in_boxes_matrix = pair_wise_ious
|
| 384 |
+
n_candidate_k = min(10, ious_in_boxes_matrix.size(1))
|
| 385 |
+
topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=1)
|
| 386 |
+
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)
|
| 387 |
+
dynamic_ks = dynamic_ks.tolist()
|
| 388 |
+
|
| 389 |
+
for gt_idx in range(num_gt):
|
| 390 |
+
_, pos_idx = torch.topk(
|
| 391 |
+
cost[gt_idx], k=dynamic_ks[gt_idx], largest=False
|
| 392 |
+
)
|
| 393 |
+
matching_matrix[gt_idx][pos_idx] = 1
|
| 394 |
+
del topk_ious, dynamic_ks, pos_idx
|
| 395 |
+
|
| 396 |
+
anchor_matching_gt = matching_matrix.sum(0)
|
| 397 |
+
if (anchor_matching_gt > 1).sum() > 0:
|
| 398 |
+
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
|
| 399 |
+
matching_matrix[:, anchor_matching_gt > 1] *= 0
|
| 400 |
+
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1
|
| 401 |
+
fg_mask_inboxes = matching_matrix.sum(0) > 0
|
| 402 |
+
num_fg = fg_mask_inboxes.sum().item()
|
| 403 |
+
fg_mask[fg_mask.clone()] = fg_mask_inboxes
|
| 404 |
+
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
|
| 405 |
+
gt_matched_classes = gt_classes[matched_gt_inds]
|
| 406 |
+
|
| 407 |
+
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[
|
| 408 |
+
fg_mask_inboxes
|
| 409 |
+
]
|
| 410 |
+
|
| 411 |
+
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
|
yolov6/models/reppan.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
from yolov6.layers.common import RepBlock, SimConv, Transpose
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class RepPANNeck(nn.Module):
|
| 7 |
+
"""RepPANNeck Module
|
| 8 |
+
EfficientRep is the default backbone of this model.
|
| 9 |
+
RepPANNeck has the balance of feature fusion ability and hardware efficiency.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
def __init__(
|
| 13 |
+
self,
|
| 14 |
+
channels_list=None,
|
| 15 |
+
num_repeats=None
|
| 16 |
+
):
|
| 17 |
+
super().__init__()
|
| 18 |
+
|
| 19 |
+
assert channels_list is not None
|
| 20 |
+
assert num_repeats is not None
|
| 21 |
+
|
| 22 |
+
self.Rep_p4 = RepBlock(
|
| 23 |
+
in_channels=channels_list[3] + channels_list[5],
|
| 24 |
+
out_channels=channels_list[5],
|
| 25 |
+
n=num_repeats[5],
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
self.Rep_p3 = RepBlock(
|
| 29 |
+
in_channels=channels_list[2] + channels_list[6],
|
| 30 |
+
out_channels=channels_list[6],
|
| 31 |
+
n=num_repeats[6]
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
self.Rep_n3 = RepBlock(
|
| 35 |
+
in_channels=channels_list[6] + channels_list[7],
|
| 36 |
+
out_channels=channels_list[8],
|
| 37 |
+
n=num_repeats[7],
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
self.Rep_n4 = RepBlock(
|
| 41 |
+
in_channels=channels_list[5] + channels_list[9],
|
| 42 |
+
out_channels=channels_list[10],
|
| 43 |
+
n=num_repeats[8]
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
self.reduce_layer0 = SimConv(
|
| 47 |
+
in_channels=channels_list[4],
|
| 48 |
+
out_channels=channels_list[5],
|
| 49 |
+
kernel_size=1,
|
| 50 |
+
stride=1
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
self.upsample0 = Transpose(
|
| 54 |
+
in_channels=channels_list[5],
|
| 55 |
+
out_channels=channels_list[5],
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
self.reduce_layer1 = SimConv(
|
| 59 |
+
in_channels=channels_list[5],
|
| 60 |
+
out_channels=channels_list[6],
|
| 61 |
+
kernel_size=1,
|
| 62 |
+
stride=1
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
self.upsample1 = Transpose(
|
| 66 |
+
in_channels=channels_list[6],
|
| 67 |
+
out_channels=channels_list[6]
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
self.downsample2 = SimConv(
|
| 71 |
+
in_channels=channels_list[6],
|
| 72 |
+
out_channels=channels_list[7],
|
| 73 |
+
kernel_size=3,
|
| 74 |
+
stride=2
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
self.downsample1 = SimConv(
|
| 78 |
+
in_channels=channels_list[8],
|
| 79 |
+
out_channels=channels_list[9],
|
| 80 |
+
kernel_size=3,
|
| 81 |
+
stride=2
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
def forward(self, input):
|
| 85 |
+
|
| 86 |
+
(x2, x1, x0) = input
|
| 87 |
+
|
| 88 |
+
fpn_out0 = self.reduce_layer0(x0)
|
| 89 |
+
upsample_feat0 = self.upsample0(fpn_out0)
|
| 90 |
+
f_concat_layer0 = torch.cat([upsample_feat0, x1], 1)
|
| 91 |
+
f_out0 = self.Rep_p4(f_concat_layer0)
|
| 92 |
+
|
| 93 |
+
fpn_out1 = self.reduce_layer1(f_out0)
|
| 94 |
+
upsample_feat1 = self.upsample1(fpn_out1)
|
| 95 |
+
f_concat_layer1 = torch.cat([upsample_feat1, x2], 1)
|
| 96 |
+
pan_out2 = self.Rep_p3(f_concat_layer1)
|
| 97 |
+
|
| 98 |
+
down_feat1 = self.downsample2(pan_out2)
|
| 99 |
+
p_concat_layer1 = torch.cat([down_feat1, fpn_out1], 1)
|
| 100 |
+
pan_out1 = self.Rep_n3(p_concat_layer1)
|
| 101 |
+
|
| 102 |
+
down_feat0 = self.downsample1(pan_out1)
|
| 103 |
+
p_concat_layer2 = torch.cat([down_feat0, fpn_out0], 1)
|
| 104 |
+
pan_out0 = self.Rep_n4(p_concat_layer2)
|
| 105 |
+
|
| 106 |
+
outputs = [pan_out2, pan_out1, pan_out0]
|
| 107 |
+
|
| 108 |
+
return outputs
|
yolov6/models/yolo.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import math
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from yolov6.layers.common import *
|
| 6 |
+
from yolov6.utils.torch_utils import initialize_weights
|
| 7 |
+
from yolov6.models.efficientrep import EfficientRep
|
| 8 |
+
from yolov6.models.reppan import RepPANNeck
|
| 9 |
+
from yolov6.models.effidehead import Detect, build_effidehead_layer
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class Model(nn.Module):
|
| 13 |
+
'''YOLOv6 model with backbone, neck and head.
|
| 14 |
+
The default parts are EfficientRep Backbone, Rep-PAN and
|
| 15 |
+
Efficient Decoupled Head.
|
| 16 |
+
'''
|
| 17 |
+
def __init__(self, config, channels=3, num_classes=None, anchors=None): # model, input channels, number of classes
|
| 18 |
+
super().__init__()
|
| 19 |
+
# Build network
|
| 20 |
+
num_layers = config.model.head.num_layers
|
| 21 |
+
self.backbone, self.neck, self.detect = build_network(config, channels, num_classes, anchors, num_layers)
|
| 22 |
+
|
| 23 |
+
# Init Detect head
|
| 24 |
+
begin_indices = config.model.head.begin_indices
|
| 25 |
+
out_indices_head = config.model.head.out_indices
|
| 26 |
+
self.stride = self.detect.stride
|
| 27 |
+
self.detect.i = begin_indices
|
| 28 |
+
self.detect.f = out_indices_head
|
| 29 |
+
self.detect.initialize_biases()
|
| 30 |
+
|
| 31 |
+
# Init weights
|
| 32 |
+
initialize_weights(self)
|
| 33 |
+
|
| 34 |
+
def forward(self, x):
|
| 35 |
+
x = self.backbone(x)
|
| 36 |
+
x = self.neck(x)
|
| 37 |
+
x = self.detect(x)
|
| 38 |
+
return x
|
| 39 |
+
|
| 40 |
+
def _apply(self, fn):
|
| 41 |
+
self = super()._apply(fn)
|
| 42 |
+
self.detect.stride = fn(self.detect.stride)
|
| 43 |
+
self.detect.grid = list(map(fn, self.detect.grid))
|
| 44 |
+
return self
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def make_divisible(x, divisor):
|
| 48 |
+
# Upward revision the value x to make it evenly divisible by the divisor.
|
| 49 |
+
return math.ceil(x / divisor) * divisor
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def build_network(config, channels, num_classes, anchors, num_layers):
|
| 53 |
+
depth_mul = config.model.depth_multiple
|
| 54 |
+
width_mul = config.model.width_multiple
|
| 55 |
+
num_repeat_backbone = config.model.backbone.num_repeats
|
| 56 |
+
channels_list_backbone = config.model.backbone.out_channels
|
| 57 |
+
num_repeat_neck = config.model.neck.num_repeats
|
| 58 |
+
channels_list_neck = config.model.neck.out_channels
|
| 59 |
+
num_anchors = config.model.head.anchors
|
| 60 |
+
num_repeat = [(max(round(i * depth_mul), 1) if i > 1 else i) for i in (num_repeat_backbone + num_repeat_neck)]
|
| 61 |
+
channels_list = [make_divisible(i * width_mul, 8) for i in (channels_list_backbone + channels_list_neck)]
|
| 62 |
+
|
| 63 |
+
backbone = EfficientRep(
|
| 64 |
+
in_channels=channels,
|
| 65 |
+
channels_list=channels_list,
|
| 66 |
+
num_repeats=num_repeat
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
neck = RepPANNeck(
|
| 70 |
+
channels_list=channels_list,
|
| 71 |
+
num_repeats=num_repeat
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
head_layers = build_effidehead_layer(channels_list, num_anchors, num_classes)
|
| 75 |
+
|
| 76 |
+
head = Detect(num_classes, anchors, num_layers, head_layers=head_layers)
|
| 77 |
+
|
| 78 |
+
return backbone, neck, head
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def build_model(cfg, num_classes, device):
|
| 82 |
+
model = Model(cfg, channels=3, num_classes=num_classes, anchors=cfg.model.head.anchors).to(device)
|
| 83 |
+
return model
|
yolov6/solver/build.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# -*- coding:utf-8 -*-
|
| 3 |
+
import os
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
|
| 9 |
+
def build_optimizer(cfg, model):
|
| 10 |
+
""" Build optimizer from cfg file."""
|
| 11 |
+
g_bnw, g_w, g_b = [], [], []
|
| 12 |
+
for v in model.modules():
|
| 13 |
+
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):
|
| 14 |
+
g_b.append(v.bias)
|
| 15 |
+
if isinstance(v, nn.BatchNorm2d):
|
| 16 |
+
g_bnw.append(v.weight)
|
| 17 |
+
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
|
| 18 |
+
g_w.append(v.weight)
|
| 19 |
+
|
| 20 |
+
assert cfg.solver.optim == 'SGD' or 'Adam', 'ERROR: unknown optimizer, use SGD defaulted'
|
| 21 |
+
if cfg.solver.optim == 'SGD':
|
| 22 |
+
optimizer = torch.optim.SGD(g_bnw, lr=cfg.solver.lr0, momentum=cfg.solver.momentum, nesterov=True)
|
| 23 |
+
elif cfg.solver.optim == 'Adam':
|
| 24 |
+
optimizer = torch.optim.Adam(g_bnw, lr=cfg.solver.lr0, betas=(cfg.solver.momentum, 0.999))
|
| 25 |
+
|
| 26 |
+
optimizer.add_param_group({'params': g_w, 'weight_decay': cfg.solver.weight_decay})
|
| 27 |
+
optimizer.add_param_group({'params': g_b})
|
| 28 |
+
|
| 29 |
+
del g_bnw, g_w, g_b
|
| 30 |
+
return optimizer
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def build_lr_scheduler(cfg, optimizer, epochs):
|
| 34 |
+
"""Build learning rate scheduler from cfg file."""
|
| 35 |
+
if cfg.solver.lr_scheduler == 'Cosine':
|
| 36 |
+
lf = lambda x: ((1 - math.cos(x * math.pi / epochs)) / 2) * (cfg.solver.lrf - 1) + 1
|
| 37 |
+
else:
|
| 38 |
+
LOGGER.error('unknown lr scheduler, use Cosine defaulted')
|
| 39 |
+
|
| 40 |
+
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
|
| 41 |
+
return scheduler, lf
|