Spaces:
Paused


Paused
add Image Editor GOT OCR Demo
Browse files- README.md +3 -3
- app.py +158 -193
- globe.py +68 -0
- requirements.txt +13 -6
- res/image/howto_1.png +0 -0
- res/image/howto_2.png +0 -0
- res/image/howto_3.png +0 -0
- res/image/howto_4.png +0 -0
README.md
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
---
|
| 2 |
-
title: Tonic's
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: blue
|
| 5 |
colorTo: red
|
| 6 |
sdk: gradio
|
|
@@ -10,7 +10,7 @@ pinned: true
|
|
| 10 |
license: mit
|
| 11 |
thumbnail: >-
|
| 12 |
https://cdn-uploads.huggingface.co/production/uploads/62a3bb1cd0d8c2c2169f0b88/DlATYnzPl5cLHA_ua48Wl.png
|
| 13 |
-
short_description: '
|
| 14 |
---
|
| 15 |
|
| 16 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Tonic's ImageEditor GOT OCR
|
| 3 |
+
emoji: 📸🫴🏻👁
|
| 4 |
colorFrom: blue
|
| 5 |
colorTo: red
|
| 6 |
sdk: gradio
|
|
|
|
| 10 |
license: mit
|
| 11 |
thumbnail: >-
|
| 12 |
https://cdn-uploads.huggingface.co/production/uploads/62a3bb1cd0d8c2c2169f0b88/DlATYnzPl5cLHA_ua48Wl.png
|
| 13 |
+
short_description: 'Using Gradio Image Editor for GOT-OCR color ocr'
|
| 14 |
---
|
| 15 |
|
| 16 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
CHANGED
|
@@ -1,207 +1,172 @@
|
|
| 1 |
-
import os
|
| 2 |
import gradio as gr
|
| 3 |
-
from vllm import LLM, SamplingParams
|
| 4 |
-
from PIL import Image
|
| 5 |
-
from io import BytesIO
|
| 6 |
-
import base64
|
| 7 |
-
import requests
|
| 8 |
-
from huggingface_hub import login
|
| 9 |
import torch
|
| 10 |
-
import
|
| 11 |
-
|
| 12 |
-
import
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
)
|
| 45 |
-
|
| 46 |
-
def clear_cuda_cache():
|
| 47 |
-
torch.cuda.empty_cache()
|
| 48 |
-
|
| 49 |
-
def encode_image(image: Image.Image, image_format="PNG") -> str:
|
| 50 |
-
im_file = BytesIO()
|
| 51 |
-
image.save(im_file, format=image_format)
|
| 52 |
-
im_bytes = im_file.getvalue()
|
| 53 |
-
im_64 = base64.b64encode(im_bytes).decode("utf-8")
|
| 54 |
-
return im_64
|
| 55 |
-
|
| 56 |
-
def infer(image_url, prompt, temperature, max_tokens, progress=gr.Progress(track_tqdm=True)):
|
| 57 |
-
if llm is None:
|
| 58 |
-
return "Error: LLM initialization failed. Please try again later."
|
| 59 |
|
| 60 |
try:
|
| 61 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
"role": "user",
|
| 70 |
-
"content": [{"type": "text", "text": prompt}, {"type": "image_url", "image_url": {"url": new_image_url}}]
|
| 71 |
-
},
|
| 72 |
-
]
|
| 73 |
-
|
| 74 |
-
outputs = llm.chat(messages, sampling_params=sampling_params)
|
| 75 |
-
clear_cuda_cache()
|
| 76 |
-
return outputs[0].outputs[0].text
|
| 77 |
except Exception as e:
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 87 |
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
def calculate_image_similarity(image1_url, image2_url):
|
| 114 |
-
if llm is None:
|
| 115 |
-
return "Error: LLM initialization failed. Please try again later."
|
| 116 |
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
image2 = Image.open(BytesIO(requests.get(image2_url).content)).convert('RGB')
|
| 120 |
-
image1 = image1.resize((224, 224)) # Resize to match model input size
|
| 121 |
-
image2 = image2.resize((224, 224))
|
| 122 |
-
|
| 123 |
-
image1_tensor = torch.tensor(list(image1.getdata())).view(1, 3, 224, 224).float() / 255.0
|
| 124 |
-
image2_tensor = torch.tensor(list(image2.getdata())).view(1, 3, 224, 224).float() / 255.0
|
| 125 |
-
|
| 126 |
-
with torch.no_grad():
|
| 127 |
-
embedding1 = llm.model.vision_encoder([image1_tensor])
|
| 128 |
-
embedding2 = llm.model.vision_encoder([image2_tensor])
|
| 129 |
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
gr.
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
- Adjust the temperature and max tokens
|
| 155 |
-
- Click "Compare" to get the model's analysis
|
| 156 |
-
3. For Image Similarity:
|
| 157 |
-
- Enter URLs for two images you want to compare
|
| 158 |
-
- Click "Calculate Similarity" to get a similarity score between 0 and 1
|
| 159 |
-
"""
|
| 160 |
-
)
|
| 161 |
-
gr.Markdown(description)
|
| 162 |
-
with gr.Tabs():
|
| 163 |
-
with gr.TabItem("Image-to-Text Generation"):
|
| 164 |
-
with gr.Row():
|
| 165 |
-
image_url = gr.Text(label="Image URL")
|
| 166 |
-
prompt = gr.Text(label="Prompt")
|
| 167 |
-
with gr.Row():
|
| 168 |
-
temperature = gr.Slider(minimum=0.1, maximum=2.0, value=0.7, label="Temperature")
|
| 169 |
-
max_tokens = gr.Number(value=4096, label="Max Tokens")
|
| 170 |
-
generate_button = gr.Button("Generate")
|
| 171 |
-
output = gr.Text(label="Generated Text")
|
| 172 |
-
|
| 173 |
-
generate_button.click(infer, inputs=[image_url, prompt, temperature, max_tokens], outputs=output)
|
| 174 |
-
|
| 175 |
-
with gr.TabItem("Image Comparison"):
|
| 176 |
-
with gr.Row():
|
| 177 |
-
image1_url = gr.Text(label="Image 1 URL")
|
| 178 |
-
image2_url = gr.Text(label="Image 2 URL")
|
| 179 |
-
comparison_prompt = gr.Text(label="Comparison Prompt")
|
| 180 |
with gr.Row():
|
| 181 |
-
|
| 182 |
-
|
| 183 |
-
|
| 184 |
-
|
| 185 |
-
|
| 186 |
-
compare_button.click(compare_images, inputs=[image1_url, image2_url, comparison_prompt, comparison_temperature, comparison_max_tokens], outputs=comparison_output)
|
| 187 |
-
|
| 188 |
-
with gr.TabItem("Image Similarity"):
|
| 189 |
with gr.Row():
|
| 190 |
-
|
| 191 |
-
|
| 192 |
-
|
| 193 |
-
|
| 194 |
-
|
| 195 |
-
|
| 196 |
-
|
| 197 |
-
|
| 198 |
-
|
| 199 |
-
|
| 200 |
-
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
|
| 204 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 205 |
|
| 206 |
if __name__ == "__main__":
|
| 207 |
demo.launch()
|
|
|
|
|
|
|
| 1 |
import gradio as gr
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
import torch
|
| 3 |
+
from transformers import AutoModel, AutoTokenizer, AutoConfig
|
| 4 |
+
import os
|
| 5 |
+
import base64
|
| 6 |
+
import io
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import numpy as np
|
| 9 |
+
import uuid
|
| 10 |
+
import cv2
|
| 11 |
+
import re
|
| 12 |
+
from globe import title, description, modelinfor, joinus, howto
|
| 13 |
+
|
| 14 |
+
model_name = 'ucaslcl/GOT-OCR2_0'
|
| 15 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 16 |
+
config = AutoConfig.from_pretrained(model_name, trust_remote_code=True)
|
| 17 |
+
model = AutoModel.from_pretrained(model_name, trust_remote_code=True, low_cpu_mem_usage=True, device_map='cuda', use_safetensors=True, pad_token_id=tokenizer.eos_token_id)
|
| 18 |
+
model = model.eval().cuda()
|
| 19 |
+
model.config.pad_token_id = tokenizer.eos_token_id
|
| 20 |
+
|
| 21 |
+
UPLOAD_FOLDER = "./uploads"
|
| 22 |
+
RESULTS_FOLDER = "./results"
|
| 23 |
+
|
| 24 |
+
for folder in [UPLOAD_FOLDER, RESULTS_FOLDER]:
|
| 25 |
+
if not os.path.exists(folder):
|
| 26 |
+
os.makedirs(folder)
|
| 27 |
+
|
| 28 |
+
def image_to_base64(image):
|
| 29 |
+
buffered = io.BytesIO()
|
| 30 |
+
image.save(buffered, format="PNG")
|
| 31 |
+
return base64.b64encode(buffered.getvalue()).decode()
|
| 32 |
+
|
| 33 |
+
def process_image(image, ocr_type, ocr_box=None, ocr_color=None):
|
| 34 |
+
unique_id = str(uuid.uuid4())
|
| 35 |
+
image_path = os.path.join(UPLOAD_FOLDER, f"{unique_id}.png")
|
| 36 |
+
result_path = os.path.join(RESULTS_FOLDER, f"{unique_id}.html")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
|
| 38 |
try:
|
| 39 |
+
if isinstance(image, dict):
|
| 40 |
+
composite_image = image.get("composite")
|
| 41 |
+
if composite_image is not None:
|
| 42 |
+
if isinstance(composite_image, np.ndarray):
|
| 43 |
+
cv2.imwrite(image_path, cv2.cvtColor(composite_image, cv2.COLOR_RGB2BGR))
|
| 44 |
+
elif isinstance(composite_image, Image.Image):
|
| 45 |
+
composite_image.save(image_path)
|
| 46 |
+
else:
|
| 47 |
+
return "Error: Unsupported image format from ImageEditor", None
|
| 48 |
+
else:
|
| 49 |
+
return "Error: No composite image found in ImageEditor output", None
|
| 50 |
+
else:
|
| 51 |
+
return "Error: Unsupported image format", None
|
| 52 |
+
|
| 53 |
+
if ocr_color:
|
| 54 |
+
res = model.chat(tokenizer, image_path, ocr_type=ocr_type, ocr_color=ocr_color, render=True, save_render_file=result_path)
|
| 55 |
+
else:
|
| 56 |
+
res = model.chat(tokenizer, image_path, ocr_type=ocr_type, ocr_box=ocr_box, render=True, save_render_file=result_path)
|
| 57 |
|
| 58 |
+
if os.path.exists(result_path):
|
| 59 |
+
with open(result_path, 'r') as f:
|
| 60 |
+
html_content = f.read()
|
| 61 |
+
return res, html_content
|
| 62 |
+
else:
|
| 63 |
+
return res, None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 64 |
except Exception as e:
|
| 65 |
+
return f"Error: {str(e)}", None
|
| 66 |
+
finally:
|
| 67 |
+
if os.path.exists(image_path):
|
| 68 |
+
os.remove(image_path)
|
| 69 |
+
|
| 70 |
+
def parse_latex_output(res):
|
| 71 |
+
lines = re.split(r'(\$\$.*?\$\$)', res, flags=re.DOTALL)
|
| 72 |
+
parsed_lines = []
|
| 73 |
+
in_latex = False
|
| 74 |
+
latex_buffer = []
|
| 75 |
+
|
| 76 |
+
for line in lines:
|
| 77 |
+
if line == '\n':
|
| 78 |
+
if in_latex:
|
| 79 |
+
latex_buffer.append(line)
|
| 80 |
+
else:
|
| 81 |
+
parsed_lines.append(line)
|
| 82 |
+
continue
|
| 83 |
+
|
| 84 |
+
line = line.strip()
|
| 85 |
|
| 86 |
+
latex_patterns = [r'\{', r'\}', r'\[', r'\]', r'\\', r'\$', r'_', r'^', r'"']
|
| 87 |
+
contains_latex = any(re.search(pattern, line) for pattern in latex_patterns)
|
| 88 |
+
|
| 89 |
+
if contains_latex:
|
| 90 |
+
if not in_latex:
|
| 91 |
+
in_latex = True
|
| 92 |
+
latex_buffer = ['$$']
|
| 93 |
+
latex_buffer.append(line)
|
| 94 |
+
else:
|
| 95 |
+
if in_latex:
|
| 96 |
+
latex_buffer.append('$$')
|
| 97 |
+
parsed_lines.extend(latex_buffer)
|
| 98 |
+
in_latex = False
|
| 99 |
+
latex_buffer = []
|
| 100 |
+
parsed_lines.append(line)
|
| 101 |
+
|
| 102 |
+
if in_latex:
|
| 103 |
+
latex_buffer.append('$$')
|
| 104 |
+
parsed_lines.extend(latex_buffer)
|
| 105 |
+
|
| 106 |
+
return '$$\\$$\n'.join(parsed_lines)
|
| 107 |
+
|
| 108 |
+
def ocr_demo(image, ocr_type, ocr_color):
|
| 109 |
+
res, html_content = process_image(image, ocr_type, ocr_color=ocr_color)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 110 |
|
| 111 |
+
if isinstance(res, str) and res.startswith("Error:"):
|
| 112 |
+
return res, None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 113 |
|
| 114 |
+
res = res.replace("\\title", "\\title ")
|
| 115 |
+
formatted_res = parse_latex_output(res)
|
| 116 |
+
|
| 117 |
+
if html_content:
|
| 118 |
+
encoded_html = base64.b64encode(html_content.encode('utf-8')).decode('utf-8')
|
| 119 |
+
iframe_src = f"data:text/html;base64,{encoded_html}"
|
| 120 |
+
iframe = f'<iframe src="{iframe_src}" width="100%" height="600px"></iframe>'
|
| 121 |
+
download_link = f'<a href="data:text/html;base64,{encoded_html}" download="result_{uuid.uuid4()}.html">Download Full Result</a>'
|
| 122 |
+
return formatted_res, f"{iframe}<br>{download_link}"
|
| 123 |
+
return formatted_res, None
|
| 124 |
+
|
| 125 |
+
with gr.Blocks(theme=gr.themes.Base()) as demo:
|
| 126 |
+
with gr.Row():
|
| 127 |
+
gr.Markdown(title)
|
| 128 |
+
with gr.Row():
|
| 129 |
+
with gr.Column(scale=1):
|
| 130 |
+
with gr.Group():
|
| 131 |
+
gr.Markdown(description)
|
| 132 |
+
with gr.Column(scale=1):
|
| 133 |
+
with gr.Group():
|
| 134 |
+
gr.Markdown(modelinfor)
|
| 135 |
+
gr.Markdown(joinus)
|
| 136 |
+
with gr.Row():
|
| 137 |
+
with gr.Accordion("How to use 🫴🏻👁GOT OCR", open=True):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 138 |
with gr.Row():
|
| 139 |
+
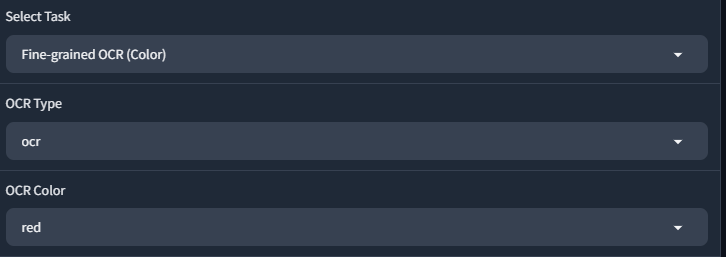
gr.Image("res/image/howto_1.png", label="Select the Following Parameters")
|
| 140 |
+
gr.Image("res/image/howto_2.png", label="Click on Paintbrush in the Image Editor")
|
| 141 |
+
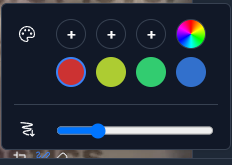
gr.Image("res/image/howto_3.png", label="Select your Brush Color (Red)")
|
| 142 |
+
gr.Image("res/image/howto_4.png", label="Make a Box Around The Text")
|
|
|
|
|
|
|
|
|
|
|
|
|
| 143 |
with gr.Row():
|
| 144 |
+
with gr.Group():
|
| 145 |
+
gr.Markdown(howto)
|
| 146 |
+
with gr.Row():
|
| 147 |
+
with gr.Column(scale=1):
|
| 148 |
+
image_editor = gr.ImageEditor(label="Image Editor", type="pil")
|
| 149 |
+
ocr_type_dropdown = gr.Dropdown(
|
| 150 |
+
choices=["ocr", "format"],
|
| 151 |
+
label="OCR Type",
|
| 152 |
+
value="ocr"
|
| 153 |
+
)
|
| 154 |
+
ocr_color_dropdown = gr.Dropdown(
|
| 155 |
+
choices=["red", "green", "blue"],
|
| 156 |
+
label="OCR Color",
|
| 157 |
+
value="red"
|
| 158 |
+
)
|
| 159 |
+
submit_button = gr.Button("Process")
|
| 160 |
+
|
| 161 |
+
with gr.Column(scale=1):
|
| 162 |
+
output_markdown = gr.Markdown(label="OCR Result")
|
| 163 |
+
output_html = gr.HTML(label="Rendered Result")
|
| 164 |
+
|
| 165 |
+
submit_button.click(
|
| 166 |
+
ocr_demo,
|
| 167 |
+
inputs=[image_editor, ocr_type_dropdown, ocr_color_dropdown],
|
| 168 |
+
outputs=[output_markdown, output_html]
|
| 169 |
+
)
|
| 170 |
|
| 171 |
if __name__ == "__main__":
|
| 172 |
demo.launch()
|
globe.py
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
title = """# 🙋🏻♂️Welcome to Tonic's ImageEditor📸🫴🏻👁GOT-OCR Demo
|
| 3 |
+
---
|
| 4 |
+
"""
|
| 5 |
+
|
| 6 |
+
description = """
|
| 7 |
+
The **🫴🏻👁GOT-OCR model** is a cutting-edge OCR system with **580M parameters**, designed to process a wide range of "characters." Equipped with a **high-compression encoder** and a **long-context decoder**, it excels in both scene and document-style images. The model supports **multi-page** and **dynamic resolution OCR**, enhancing its versatility.
|
| 8 |
+
|
| 9 |
+
### Key Features
|
| 10 |
+
|
| 11 |
+
- **Plain Text OCR**: Extracts text from images.
|
| 12 |
+
- **Formatted Text OCR**: Retains the original formatting, including tables and formulas.
|
| 13 |
+
- **Fine-grained OCR**: Offers box-based and color-based OCR for precision in specific regions.
|
| 14 |
+
- **Multi-crop OCR**: Handles multiple cropped sections within an image.
|
| 15 |
+
|
| 16 |
+
## Supported Content Types
|
| 17 |
+
|
| 18 |
+
- Plain text
|
| 19 |
+
- Math/molecular formulas
|
| 20 |
+
- Tables and charts
|
| 21 |
+
- Sheet music
|
| 22 |
+
- Geometric shapes
|
| 23 |
+
|
| 24 |
+
"""
|
| 25 |
+
joinus = """
|
| 26 |
+
## Join us :
|
| 27 |
+
|
| 28 |
+
🌟TeamTonic🌟 is always making cool demos! Join our active builder's 🛠️community 👻 [](https://discord.gg/qdfnvSPcqP) On 🤗Huggingface:[MultiTransformer](https://huggingface.co/MultiTransformer) On 🌐Github: [Tonic-AI](https://github.com/tonic-ai) & contribute to🌟 [Build Tonic](https://git.tonic-ai.com/contribute)🤗Big thanks to Yuvi Sharma and all the folks at huggingface for the community grant 🤗
|
| 29 |
+
"""
|
| 30 |
+
modelinfor = """
|
| 31 |
+
## How to Use
|
| 32 |
+
|
| 33 |
+
1. Select a task from the dropdown menu.
|
| 34 |
+
2. Upload an image.
|
| 35 |
+
3. Use Paintbrush to draw a circle around the text you want to OCR.
|
| 36 |
+
4. Click **Process** to view the results.
|
| 37 |
+
|
| 38 |
+
## Model Information
|
| 39 |
+
|
| 40 |
+
- **Model Name**: GOT-OCR 2.0
|
| 41 |
+
- **Hugging Face Repository**: [ucaslcl/GOT-OCR2_0](https://huggingface.co/ucaslcl/GOT-OCR2_0)
|
| 42 |
+
- **Environment**: CUDA 11.8 + PyTorch 2.0.1
|
| 43 |
+
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
tasks = [
|
| 47 |
+
"Plain Text OCR",
|
| 48 |
+
"Format Text OCR",
|
| 49 |
+
"Fine-grained OCR (Box)",
|
| 50 |
+
"Fine-grained OCR (Color)",
|
| 51 |
+
"Multi-crop OCR",
|
| 52 |
+
"Render Formatted OCR"
|
| 53 |
+
]
|
| 54 |
+
|
| 55 |
+
ocr_types = ["ocr", "format"]
|
| 56 |
+
ocr_colors = ["red", "green", "blue"]
|
| 57 |
+
|
| 58 |
+
howto = """
|
| 59 |
+
## To use Fine-grained OCR (Color):
|
| 60 |
+
1. Click on 'Fine-grained OCR (Color)' in the task dropdown.
|
| 61 |
+
2. Set 'OCR Type' to 'ocr'.
|
| 62 |
+
3. This will display the image editor.
|
| 63 |
+
4. Upload an image to the editor.
|
| 64 |
+
5. Use the drawing tools to draw a circle around the text you want to OCR.
|
| 65 |
+
6. Select the color that matches your circle in the 'OCR Color' dropdown.
|
| 66 |
+
7. Click 'Process Edited Image' to run the OCR on the selected area.
|
| 67 |
+
"""
|
| 68 |
+
|
requirements.txt
CHANGED
|
@@ -1,7 +1,14 @@
|
|
| 1 |
-
torch
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
loadimg
|
| 7 |
-
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==2.0.1
|
| 2 |
+
torchvision==0.15.2
|
| 3 |
+
transformers==4.37.2
|
| 4 |
+
megfile==3.1.2
|
| 5 |
+
tiktoken
|
| 6 |
+
verovio
|
| 7 |
+
opencv-python
|
| 8 |
+
cairosvg
|
| 9 |
+
accelerate
|
| 10 |
+
numpy==1.26.4
|
| 11 |
loadimg
|
| 12 |
+
pillow
|
| 13 |
+
markdown
|
| 14 |
+
shutils
|
res/image/howto_1.png
ADDED
|
res/image/howto_2.png
ADDED

|
res/image/howto_3.png
ADDED
|
res/image/howto_4.png
ADDED

|