Introduction
Large Language Models (LLMs) are increasingly being integrated into services such as ChatGPT to provide responses to user queries. To mitigate potential harm and prevent misuse, there have been concerted efforts to align the LLMs with human values and legal compliance by incorporating various techniques, such as Reinforcement Learning from Human Feedback (RLHF), into the training of the LLMs. However, recent research has exposed that even aligned LLMs are susceptible to adversarial manipulations known as Jailbreak Attacks. To address this challenge, this paper proposes a method called Token Highlighter to inspect and mitigate the potential jailbreak threats in the user query. Token Highlighter introduced a concept called Affirmation Loss to measure the LLM's willingness to answer the user query. It then uses the gradient of Affirmation Loss for each token in the user query to locate the jailbreak-critical tokens. Further, Token Highlighter exploits our proposed Soft Removal technique to mitigate the jailbreak effects of critical tokens via shrinking their token embeddings. Experimental results on two aligned LLMs (LLaMA-2 and Vicuna-V1.5) demonstrate that the proposed method can effectively defend against a variety of Jailbreak Attacks while maintaining competent performance on benign questions of the AlpacaEval benchmark. In addition, Token Highlighter is a cost-effective and interpretable defense because it only needs to query the protected LLM once to compute the Affirmation Loss and can highlight the critical tokens upon refusal.
What is Jailbreak?
Aligned Large Language Models (LLMs) have been shown to exhibit vulnerabilities to jailbreak attacks, which exploit token-level or prompt-level manipulations to bypass and circumvent the safety guardrails embedded within these models. A notable example is that a jailbroken LLM would be tricked into giving tutorials on how to cause harm to others. Jailbreak techniques often employ sophisticated strategies, including but not limited to role-playing , instruction disguising , leading language , and the normalization of illicit action, as illustrated in the examples below.

Token Highlighter: Principle and Interpretability
High-level speaking, successful jailbreaks share a common principle that they are trying to make the LLMs willing to affirm the user request which will be rejected at the beginning. Drawing upon this inspiration, our proposed defense aims to find the tokens that are most critical in forcing the LLM to generate such affirmative responses, decrease their importance in the generation, and thereby resolve the potential jailbreak risks brought by these tokens. To identify these tokens, we propose a new concept called the Affirmation Loss. We then use the loss's gradient norm with respoect to each token in the user input prompt to find the jailbreak-critical tokens. We select those tokens with the larger gradient norm and then apply soft removal on them to mitigate the potential jailbreak risks. Below we introduce how we define these concepts mathematically.
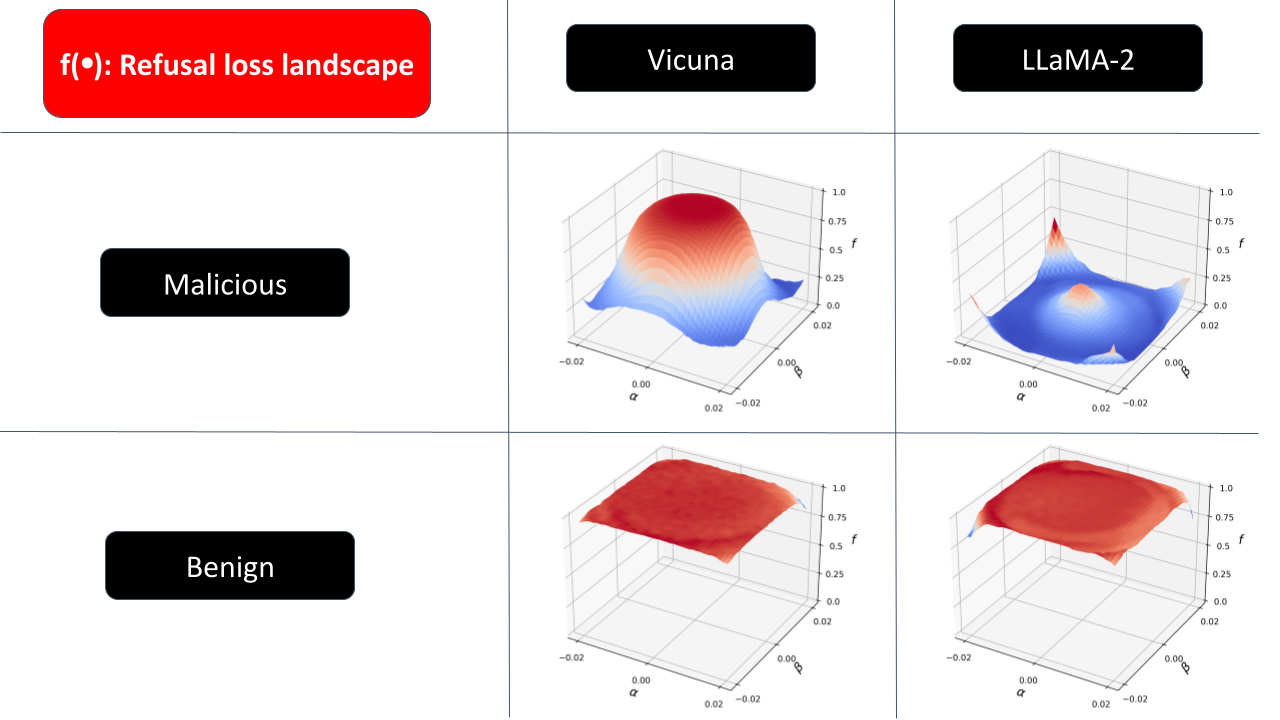
Performance evaluation against practical Jailbreaks
With the exploration of the Refusal Loss landscape, we propose Gradient Cuff, a two-step jailbreak detection method based on checking the refusal loss and its gradient norm. Our detection procedure is shown below:

Gradient Cuff can be summarized into two phases:
(Phase 1) Sampling-based Rejection: In the first step, we reject the user query by checking whether the Refusal Loss value is below 0.5. If true, then user query is rejected, otherwise, the user query is pushed into phase 2.
(Phase 2) Gradient Norm Rejection: In the second step, we regard the user query as having jailbreak attempts if the norm of the estimated gradient is larger than a configurable threshold t.
We provide more details about the running flow of Gradient Cuff in the paper.
Demonstration
We evaluated Gradient Cuff as well as 4 baselines (Perplexity Filter, SmoothLLM, Erase-and-Check, and Self-Reminder) against 6 different jailbreak attacks (GCG, AutoDAN, PAIR, TAP, Base64, and LRL) and benign user queries on 2 LLMs (LLaMA-2-7B-Chat and Vicuna-7B-V1.5). We below demonstrate the average refusal rate across these 6 malicious user query datasets as the Average Malicious Refusal Rate and the refusal rate on benign user queries as the Benign Refusal Rate. The defending performance against different jailbreak types is shown in the provided bar chart.
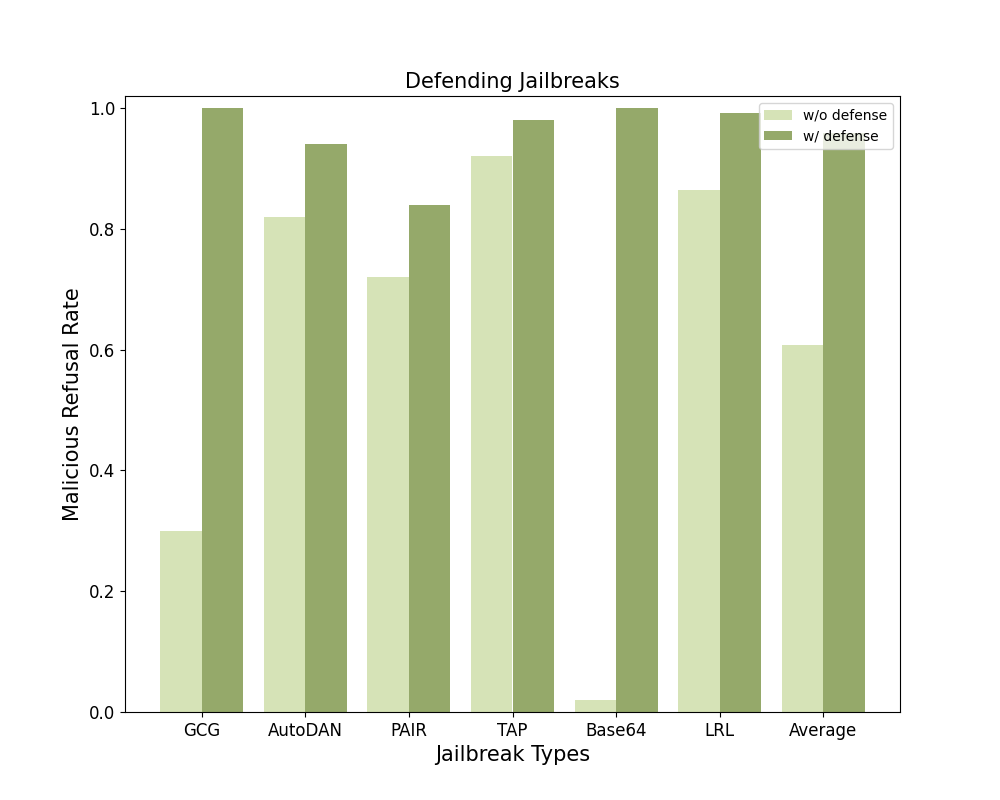
Higher malicious refusal rate and lower benign refusal rate mean a better defense. Overall, Gradient Cuff is the most performant compared with those baselines. We also evaluated Gradient Cuff against adaptive attacks in the paper.
Inquiries on LLM with Gradient Cuff defense
Please contact Xiaomeng Hu and Pin-Yu Chen
Citations
If you find Gradient Cuff helpful and useful for your research, please cite our main paper as follows:
@article{DBLP:journals/corr/abs-2412-18171,
author = {Xiaomeng Hu and
Pin{-}Yu Chen and
Tsung{-}Yi Ho},
title = {Token Highlighter: Inspecting and Mitigating Jailbreak Prompts for
Large Language Models},
journal = {CoRR},
volume = {abs/2412.18171},
year = {2024},
url = {https://doi.org/10.48550/arXiv.2412.18171},
doi = {10.48550/ARXIV.2412.18171},
eprinttype = {arXiv},
eprint = {2412.18171},
timestamp = {Sat, 25 Jan 2025 12:51:16 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2412-18171.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}