Spaces:
Sleeping

Sleeping
Commit
·
4711b94
1
Parent(s):
5102abc
feat(app.py): init commit
Browse files- README.md +29 -0
- app.py +265 -0
- screenshot.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YouTube Video Transcriber
|
| 2 |
+
|
| 3 |
+
A Streamlit app that transcribes YouTube videos using Whisper.
|
| 4 |
+
|
| 5 |
+
## How it works
|
| 6 |
+
|
| 7 |
+
- Downloads audio from YouTube videos.
|
| 8 |
+
- Splits audio into speech segments using Silero VAD.
|
| 9 |
+
- Transcribes segments in batches using OpenAI's Whisper model.
|
| 10 |
+
- Displays transcribed text with timestamps.
|
| 11 |
+
|
| 12 |
+
## Requirements
|
| 13 |
+
|
| 14 |
+
Listed in `requirements.txt`
|
| 15 |
+
|
| 16 |
+
## Usage
|
| 17 |
+
|
| 18 |
+
1. Install dependencies: `pip install -r requirements.txt`
|
| 19 |
+
2. Run the app: `streamlit run app.py`
|
| 20 |
+
3. Enter a YouTube video URL and optional language code.
|
| 21 |
+
4. Click "Transcribe".
|
| 22 |
+
|
| 23 |
+
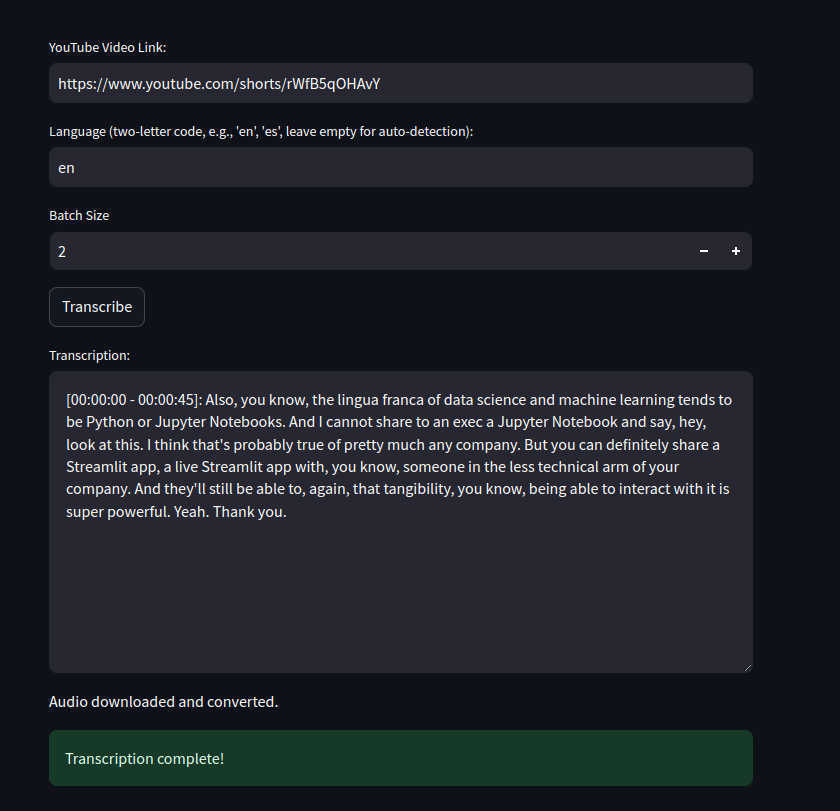
## Screenshot
|
| 24 |
+
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
## License
|
| 28 |
+
|
| 29 |
+
MIT
|
app.py
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import streamlit as st
|
| 3 |
+
import io
|
| 4 |
+
import os
|
| 5 |
+
from transformers import pipeline
|
| 6 |
+
import torch
|
| 7 |
+
import yt_dlp
|
| 8 |
+
from silero_vad import load_silero_vad, get_speech_timestamps
|
| 9 |
+
import numpy as np
|
| 10 |
+
import pydub
|
| 11 |
+
|
| 12 |
+
VAD_SENSITIVITY = 0.1
|
| 13 |
+
|
| 14 |
+
# --- Model Loading and Caching ---
|
| 15 |
+
@st.cache_resource
|
| 16 |
+
def load_transcriber(_device):
|
| 17 |
+
transcriber = pipeline(model="openai/whisper-large-v3-turbo", device=_device)
|
| 18 |
+
return transcriber
|
| 19 |
+
|
| 20 |
+
@st.cache_resource
|
| 21 |
+
def load_vad_model():
|
| 22 |
+
return load_silero_vad()
|
| 23 |
+
|
| 24 |
+
# --- Audio Processing Functions ---
|
| 25 |
+
@st.cache_resource
|
| 26 |
+
def download_and_convert_audio(video_url):
|
| 27 |
+
status_message = st.empty()
|
| 28 |
+
status_message.text("Downloading audio...")
|
| 29 |
+
try:
|
| 30 |
+
ydl_opts = {
|
| 31 |
+
'format': 'bestaudio/best',
|
| 32 |
+
'postprocessors': [{
|
| 33 |
+
'key': 'FFmpegExtractAudio',
|
| 34 |
+
'preferredcodec': 'wav',
|
| 35 |
+
'preferredquality': '192',
|
| 36 |
+
}],
|
| 37 |
+
'outtmpl': '%(id)s.%(ext)s',
|
| 38 |
+
}
|
| 39 |
+
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
|
| 40 |
+
info = ydl.extract_info(video_url, download=False)
|
| 41 |
+
video_id = info['id']
|
| 42 |
+
filename = f"{video_id}.wav"
|
| 43 |
+
ydl.download([video_url])
|
| 44 |
+
status_message.text("Audio downloaded and converted.")
|
| 45 |
+
|
| 46 |
+
# Read the file and return its contents
|
| 47 |
+
with open(filename, 'rb') as audio_file:
|
| 48 |
+
audio_bytes = audio_file.read()
|
| 49 |
+
|
| 50 |
+
# Clean up the temporary file
|
| 51 |
+
os.remove(filename)
|
| 52 |
+
|
| 53 |
+
return audio_bytes, 'wav'
|
| 54 |
+
except Exception as e:
|
| 55 |
+
st.error(f"Error during download or conversion: {e}")
|
| 56 |
+
return None, None
|
| 57 |
+
|
| 58 |
+
def aggregate_speech_segments(speech_timestamps, max_duration=30):
|
| 59 |
+
"""Aggregates speech segments into chunks with a maximum duration,
|
| 60 |
+
merging the last segment if it's contained within the second-to-last.
|
| 61 |
+
|
| 62 |
+
Args:
|
| 63 |
+
speech_timestamps: A list of dictionaries, where each dictionary represents
|
| 64 |
+
a speech segment with 'start' and 'end' timestamps
|
| 65 |
+
(in seconds).
|
| 66 |
+
max_duration: The maximum desired duration of each aggregated segment
|
| 67 |
+
(in seconds). Defaults to 30.
|
| 68 |
+
|
| 69 |
+
Returns:
|
| 70 |
+
A list of dictionaries, where each dictionary represents an aggregated
|
| 71 |
+
speech segment with 'start' and 'end' timestamps.
|
| 72 |
+
"""
|
| 73 |
+
|
| 74 |
+
if not speech_timestamps:
|
| 75 |
+
return []
|
| 76 |
+
|
| 77 |
+
aggregated_segments = []
|
| 78 |
+
current_segment_start = speech_timestamps[0]['start']
|
| 79 |
+
current_segment_end = speech_timestamps[0]['end']
|
| 80 |
+
|
| 81 |
+
for segment in speech_timestamps[1:]:
|
| 82 |
+
if segment['start'] - current_segment_start >= max_duration:
|
| 83 |
+
# Start a new segment if the current duration exceeds max_duration
|
| 84 |
+
aggregated_segments.append({'start': current_segment_start, 'end': current_segment_end})
|
| 85 |
+
current_segment_start = segment['start']
|
| 86 |
+
current_segment_end = segment['end']
|
| 87 |
+
else:
|
| 88 |
+
# Extend the current segment
|
| 89 |
+
current_segment_end = segment['end']
|
| 90 |
+
|
| 91 |
+
# Add the last segment, checking for redundancy
|
| 92 |
+
last_segment = {'start': current_segment_start, 'end': current_segment_end}
|
| 93 |
+
if aggregated_segments:
|
| 94 |
+
second_last_segment = aggregated_segments[-1]
|
| 95 |
+
if last_segment['start'] >= second_last_segment['start'] and last_segment['end'] <= second_last_segment['end']:
|
| 96 |
+
# Last segment is fully contained in the second-to-last, so don't add it
|
| 97 |
+
pass
|
| 98 |
+
else:
|
| 99 |
+
aggregated_segments.append(last_segment)
|
| 100 |
+
else:
|
| 101 |
+
# If aggregated_segments is empty, add the last segment
|
| 102 |
+
aggregated_segments.append(last_segment)
|
| 103 |
+
|
| 104 |
+
return aggregated_segments
|
| 105 |
+
|
| 106 |
+
@st.cache_data
|
| 107 |
+
def split_audio_by_vad(audio_data: bytes, ext: str, _vad_model, sensitivity: float, return_seconds: bool = True):
|
| 108 |
+
if not audio_data:
|
| 109 |
+
st.error("No audio data received.")
|
| 110 |
+
return []
|
| 111 |
+
|
| 112 |
+
try:
|
| 113 |
+
audio = pydub.AudioSegment.from_file(io.BytesIO(audio_data), format=ext)
|
| 114 |
+
|
| 115 |
+
# VAD parameters
|
| 116 |
+
rate = audio.frame_rate
|
| 117 |
+
window_size_samples = int(512 + (1536 - 512) * (1 - sensitivity))
|
| 118 |
+
speech_threshold = 0.5 + (0.95 - 0.5) * sensitivity
|
| 119 |
+
|
| 120 |
+
# Convert audio to numpy array for VAD
|
| 121 |
+
samples = np.array(audio.get_array_of_samples())
|
| 122 |
+
|
| 123 |
+
# Get speech timestamps
|
| 124 |
+
speech_timestamps = get_speech_timestamps(
|
| 125 |
+
samples,
|
| 126 |
+
_vad_model,
|
| 127 |
+
sampling_rate=rate,
|
| 128 |
+
return_seconds=return_seconds,
|
| 129 |
+
window_size_samples=window_size_samples,
|
| 130 |
+
threshold=speech_threshold,
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
if not speech_timestamps:
|
| 134 |
+
st.warning("No speech segments detected.")
|
| 135 |
+
return []
|
| 136 |
+
|
| 137 |
+
# rectify timestamps
|
| 138 |
+
speech_timestamps[0]["start"] = 0.
|
| 139 |
+
speech_timestamps[-1]['end'] = audio.duration_seconds
|
| 140 |
+
for i, chunk in enumerate(speech_timestamps[1:], start=1):
|
| 141 |
+
chunk["start"] = speech_timestamps[i-1]['end']
|
| 142 |
+
|
| 143 |
+
# Aggregate segments into ~30 second chunks
|
| 144 |
+
aggregated_segments = aggregate_speech_segments(speech_timestamps, max_duration=30)
|
| 145 |
+
|
| 146 |
+
if not aggregated_segments:
|
| 147 |
+
return []
|
| 148 |
+
|
| 149 |
+
# Create audio chunks based on timestamps
|
| 150 |
+
chunks = []
|
| 151 |
+
for segment in aggregated_segments:
|
| 152 |
+
start_ms = int(segment['start'] * 1000)
|
| 153 |
+
end_ms = int(segment['end'] * 1000)
|
| 154 |
+
chunk = audio[start_ms:end_ms]
|
| 155 |
+
|
| 156 |
+
# Export chunk to bytes
|
| 157 |
+
chunk_io = io.BytesIO()
|
| 158 |
+
chunk.export(chunk_io, format=ext)
|
| 159 |
+
chunk_data = chunk_io.getvalue() # Get bytes directly
|
| 160 |
+
|
| 161 |
+
chunks.append({
|
| 162 |
+
'data': chunk_data,
|
| 163 |
+
'start': segment['start'],
|
| 164 |
+
'end': segment['end']
|
| 165 |
+
})
|
| 166 |
+
chunk_io.close() # Close the BytesIO object after getting the value
|
| 167 |
+
|
| 168 |
+
return chunks
|
| 169 |
+
except Exception as e:
|
| 170 |
+
st.error(f"Error processing audio in split_audio_by_vad: {str(e)}")
|
| 171 |
+
return []
|
| 172 |
+
finally:
|
| 173 |
+
# Explicitly release pydub resources to prevent memory issues
|
| 174 |
+
if 'audio' in locals():
|
| 175 |
+
del audio
|
| 176 |
+
if 'samples' in locals():
|
| 177 |
+
del samples
|
| 178 |
+
|
| 179 |
+
@st.cache_data
|
| 180 |
+
def transcribe_batch(batch, _transcriber, language=None):
|
| 181 |
+
transcriptions = []
|
| 182 |
+
for i, chunk_data in enumerate(batch):
|
| 183 |
+
try:
|
| 184 |
+
generate_kwargs = {
|
| 185 |
+
"task": "transcribe",
|
| 186 |
+
"return_timestamps": True
|
| 187 |
+
}
|
| 188 |
+
if language:
|
| 189 |
+
generate_kwargs["language"] = language
|
| 190 |
+
|
| 191 |
+
transcription = _transcriber(
|
| 192 |
+
chunk_data['data'],
|
| 193 |
+
generate_kwargs=generate_kwargs
|
| 194 |
+
)
|
| 195 |
+
transcriptions.append({
|
| 196 |
+
'text': transcription["text"],
|
| 197 |
+
'start': chunk_data['start'],
|
| 198 |
+
'end': chunk_data['end']}
|
| 199 |
+
)
|
| 200 |
+
except Exception as e:
|
| 201 |
+
st.error(f"Error transcribing chunk {i}: {str(e)}")
|
| 202 |
+
return []
|
| 203 |
+
return transcriptions
|
| 204 |
+
|
| 205 |
+
# --- Streamlit App ---
|
| 206 |
+
def setup_ui():
|
| 207 |
+
st.title("YouTube Video Transcriber")
|
| 208 |
+
video_url = st.text_input("YouTube Video Link:")
|
| 209 |
+
language = st.text_input("Language (two-letter code, e.g., 'en', 'es', leave empty for auto-detection):", max_chars=2)
|
| 210 |
+
batch_size = st.number_input("Batch Size", min_value=1, max_value=10, value=2) # Batch size selection
|
| 211 |
+
transcribe_button = st.button("Transcribe")
|
| 212 |
+
return video_url, language,batch_size, transcribe_button
|
| 213 |
+
|
| 214 |
+
@st.cache_resource
|
| 215 |
+
def initialize_models():
|
| 216 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 217 |
+
transcriber = load_transcriber(device)
|
| 218 |
+
vad_model = load_vad_model()
|
| 219 |
+
return transcriber, vad_model
|
| 220 |
+
|
| 221 |
+
def process_transcription(video_url, vad_sensitivity, batch_size, transcriber, vad_model, language=None):
|
| 222 |
+
transcription_output = st.empty()
|
| 223 |
+
audio_data, ext = download_and_convert_audio(video_url)
|
| 224 |
+
if not audio_data:
|
| 225 |
+
return
|
| 226 |
+
|
| 227 |
+
chunks = split_audio_by_vad(audio_data, ext, vad_model, vad_sensitivity)
|
| 228 |
+
if not chunks:
|
| 229 |
+
return
|
| 230 |
+
|
| 231 |
+
total_chunks = len(chunks)
|
| 232 |
+
transcriptions = []
|
| 233 |
+
for i in range(0, total_chunks, batch_size):
|
| 234 |
+
batch = chunks[i:i + batch_size]
|
| 235 |
+
batch_transcriptions = transcribe_batch(batch, transcriber, language)
|
| 236 |
+
transcriptions.extend(batch_transcriptions)
|
| 237 |
+
display_transcription(transcriptions, transcription_output)
|
| 238 |
+
|
| 239 |
+
st.success("Transcription complete!")
|
| 240 |
+
|
| 241 |
+
def display_transcription(transcriptions, output_area):
|
| 242 |
+
full_transcription = ""
|
| 243 |
+
for chunk in transcriptions:
|
| 244 |
+
start_time = format_seconds(chunk['start'])
|
| 245 |
+
end_time = format_seconds(chunk['end'])
|
| 246 |
+
full_transcription += f"[{start_time} - {end_time}]: {chunk['text'].strip()}\n\n"
|
| 247 |
+
output_area.text_area("Transcription:", value=full_transcription, height=300, key=random.random())
|
| 248 |
+
|
| 249 |
+
def format_seconds(seconds):
|
| 250 |
+
"""Formats seconds into HH:MM:SS string."""
|
| 251 |
+
minutes, seconds = divmod(seconds, 60)
|
| 252 |
+
hours, minutes = divmod(minutes, 60)
|
| 253 |
+
return f"{int(hours):02}:{int(minutes):02}:{int(seconds):02}"
|
| 254 |
+
|
| 255 |
+
def main():
|
| 256 |
+
transcriber, vad_model = initialize_models()
|
| 257 |
+
video_url, language, batch_size, transcribe_button = setup_ui()
|
| 258 |
+
if transcribe_button:
|
| 259 |
+
if not video_url:
|
| 260 |
+
st.error("Please enter a YouTube video link.")
|
| 261 |
+
return
|
| 262 |
+
process_transcription(video_url, VAD_SENSITIVITY, batch_size, transcriber, vad_model, language)
|
| 263 |
+
|
| 264 |
+
if __name__ == "__main__":
|
| 265 |
+
main()
|
screenshot.png
ADDED
|