diff --git a/.gitattributes b/.gitattributes
new file mode 100644
index 0000000000000000000000000000000000000000..a6344aac8c09253b3b630fb776ae94478aa0275b
--- /dev/null
+++ b/.gitattributes
@@ -0,0 +1,35 @@
+*.7z filter=lfs diff=lfs merge=lfs -text
+*.arrow filter=lfs diff=lfs merge=lfs -text
+*.bin filter=lfs diff=lfs merge=lfs -text
+*.bz2 filter=lfs diff=lfs merge=lfs -text
+*.ckpt filter=lfs diff=lfs merge=lfs -text
+*.ftz filter=lfs diff=lfs merge=lfs -text
+*.gz filter=lfs diff=lfs merge=lfs -text
+*.h5 filter=lfs diff=lfs merge=lfs -text
+*.joblib filter=lfs diff=lfs merge=lfs -text
+*.lfs.* filter=lfs diff=lfs merge=lfs -text
+*.mlmodel filter=lfs diff=lfs merge=lfs -text
+*.model filter=lfs diff=lfs merge=lfs -text
+*.msgpack filter=lfs diff=lfs merge=lfs -text
+*.npy filter=lfs diff=lfs merge=lfs -text
+*.npz filter=lfs diff=lfs merge=lfs -text
+*.onnx filter=lfs diff=lfs merge=lfs -text
+*.ot filter=lfs diff=lfs merge=lfs -text
+*.parquet filter=lfs diff=lfs merge=lfs -text
+*.pb filter=lfs diff=lfs merge=lfs -text
+*.pickle filter=lfs diff=lfs merge=lfs -text
+*.pkl filter=lfs diff=lfs merge=lfs -text
+*.pt filter=lfs diff=lfs merge=lfs -text
+*.pth filter=lfs diff=lfs merge=lfs -text
+*.rar filter=lfs diff=lfs merge=lfs -text
+*.safetensors filter=lfs diff=lfs merge=lfs -text
+saved_model/**/* filter=lfs diff=lfs merge=lfs -text
+*.tar.* filter=lfs diff=lfs merge=lfs -text
+*.tar filter=lfs diff=lfs merge=lfs -text
+*.tflite filter=lfs diff=lfs merge=lfs -text
+*.tgz filter=lfs diff=lfs merge=lfs -text
+*.wasm filter=lfs diff=lfs merge=lfs -text
+*.xz filter=lfs diff=lfs merge=lfs -text
+*.zip filter=lfs diff=lfs merge=lfs -text
+*.zst filter=lfs diff=lfs merge=lfs -text
+*tfevents* filter=lfs diff=lfs merge=lfs -text
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..723ef36f4e4f32c4560383aa5987c575a30c6535
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1 @@
+.idea
\ No newline at end of file
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..18419d95b57e00d776081998ec3af125f91c9d42
--- /dev/null
+++ b/README.md
@@ -0,0 +1,14 @@
+---
+title: Character 360
+emoji: 🏆
+colorFrom: green
+colorTo: blue
+sdk: gradio
+sdk_version: 5.9.1
+app_file: app.py
+pinned: false
+license: unknown
+short_description: Would you like to see your character in 360°?
+---
+
+Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/annotator/base_annotator.py b/annotator/base_annotator.py
new file mode 100644
index 0000000000000000000000000000000000000000..11d9def01adfb60ef463f6940bfadea195138d26
--- /dev/null
+++ b/annotator/base_annotator.py
@@ -0,0 +1,57 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+from abc import ABCMeta
+
+import torch
+import torch.nn as nn
+
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.model.base_model import BaseModel
+from scepter.modules.utils.config import dict_to_yaml
+
+
+@ANNOTATORS.register_class()
+class BaseAnnotator(BaseModel, metaclass=ABCMeta):
+ para_dict = {}
+
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+
+ @torch.no_grad()
+ @torch.inference_mode
+ def forward(self, *args, **kwargs):
+ raise NotImplementedError
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ BaseAnnotator.para_dict,
+ set_name=True)
+
+
+@ANNOTATORS.register_class()
+class GeneralAnnotator(BaseAnnotator, metaclass=ABCMeta):
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+ anno_models = cfg.get('ANNOTATORS', [])
+ self.annotators = nn.ModuleList()
+ for n, anno_config in enumerate(anno_models):
+ annotator = ANNOTATORS.build(anno_config, logger=logger)
+ annotator.input_keys = anno_config.get('INPUT_KEYS', [])
+ if isinstance(annotator.input_keys, str):
+ annotator.input_keys = [annotator.input_keys]
+ annotator.output_keys = anno_config.get('OUTPUT_KEYS', [])
+ if isinstance(annotator.output_keys, str):
+ annotator.output_keys = [annotator.output_keys]
+ assert len(annotator.input_keys) == len(annotator.output_keys)
+ self.annotators.append(annotator)
+
+ def forward(self, input_dict):
+ output_dict = {}
+ for annotator in self.annotators:
+ for idx, in_key in enumerate(annotator.input_keys):
+ if in_key in input_dict:
+ image = annotator(input_dict[in_key])
+ output_dict[annotator.output_keys[idx]] = image
+ return output_dict
diff --git a/annotator/canny.py b/annotator/canny.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0f7a185d046cde09224c09b68dd13c177a9ef41
--- /dev/null
+++ b/annotator/canny.py
@@ -0,0 +1,63 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+from abc import ABCMeta
+
+import cv2
+import numpy as np
+import torch
+from PIL import Image
+
+from scepter.modules.annotator.base_annotator import BaseAnnotator
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.utils.config import dict_to_yaml
+
+
+@ANNOTATORS.register_class()
+class CannyAnnotator(BaseAnnotator, metaclass=ABCMeta):
+ para_dict = {}
+
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+ self.low_threshold = cfg.get('LOW_THRESHOLD', 100)
+ self.high_threshold = cfg.get('HIGH_THRESHOLD', 200)
+ self.random_cfg = cfg.get('RANDOM_CFG', None)
+
+ def forward(self, image):
+ if isinstance(image, Image.Image):
+ image = np.array(image)
+ elif isinstance(image, torch.Tensor):
+ image = image.detach().cpu().numpy()
+ elif isinstance(image, np.ndarray):
+ image = image.copy()
+ else:
+ raise f'Unsurpport datatype{type(image)}, only surpport np.ndarray, torch.Tensor, Pillow Image.'
+ assert len(image.shape) < 4
+
+ if self.random_cfg is None:
+ image = cv2.Canny(image, self.low_threshold, self.high_threshold)
+ else:
+ proba = self.random_cfg.get('PROBA', 1.0)
+ if np.random.random() < proba:
+ min_low_threshold = self.random_cfg.get(
+ 'MIN_LOW_THRESHOLD', 50)
+ max_low_threshold = self.random_cfg.get(
+ 'MAX_LOW_THRESHOLD', 100)
+ min_high_threshold = self.random_cfg.get(
+ 'MIN_HIGH_THRESHOLD', 200)
+ max_high_threshold = self.random_cfg.get(
+ 'MAX_HIGH_THRESHOLD', 350)
+ low_th = np.random.randint(min_low_threshold,
+ max_low_threshold)
+ high_th = np.random.randint(min_high_threshold,
+ max_high_threshold)
+ else:
+ low_th, high_th = self.low_threshold, self.high_threshold
+ image = cv2.Canny(image, low_th, high_th)
+ return image[..., None].repeat(3, 2)
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ CannyAnnotator.para_dict,
+ set_name=True)
diff --git a/annotator/color.py b/annotator/color.py
new file mode 100644
index 0000000000000000000000000000000000000000..40690e3b4714914865b5a3a3937caef6567ba1bb
--- /dev/null
+++ b/annotator/color.py
@@ -0,0 +1,59 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+from abc import ABCMeta
+
+import cv2
+import numpy as np
+import torch
+from PIL import Image
+
+from scepter.modules.annotator.base_annotator import BaseAnnotator
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.utils.config import dict_to_yaml
+
+
+@ANNOTATORS.register_class()
+class ColorAnnotator(BaseAnnotator, metaclass=ABCMeta):
+ para_dict = {}
+
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+ self.ratio = cfg.get('RATIO', 64)
+ self.random_cfg = cfg.get('RANDOM_CFG', None)
+
+ def forward(self, image):
+ if isinstance(image, Image.Image):
+ image = np.array(image)
+ elif isinstance(image, torch.Tensor):
+ image = image.detach().cpu().numpy()
+ elif isinstance(image, np.ndarray):
+ image = image.copy()
+ else:
+ raise f'Unsurpport datatype{type(image)}, only surpport np.ndarray, torch.Tensor, Pillow Image.'
+ h, w = image.shape[:2]
+
+ if self.random_cfg is None:
+ ratio = self.ratio
+ else:
+ proba = self.random_cfg.get('PROBA', 1.0)
+ if np.random.random() < proba:
+ if 'CHOICE_RATIO' in self.random_cfg:
+ ratio = np.random.choice(self.random_cfg['CHOICE_RATIO'])
+ else:
+ min_ratio = self.random_cfg.get('MIN_RATIO', 48)
+ max_ratio = self.random_cfg.get('MAX_RATIO', 96)
+ ratio = np.random.randint(min_ratio, max_ratio)
+ else:
+ ratio = self.ratio
+ image = cv2.resize(image, (int(w // ratio), int(h // ratio)),
+ interpolation=cv2.INTER_CUBIC)
+ image = cv2.resize(image, (w, h), interpolation=cv2.INTER_NEAREST)
+ assert len(image.shape) < 4
+ return image
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ ColorAnnotator.para_dict,
+ set_name=True)
diff --git a/annotator/hed.py b/annotator/hed.py
new file mode 100644
index 0000000000000000000000000000000000000000..b06f4f9d307a1402a5cf3e7976ab58a594cd0e54
--- /dev/null
+++ b/annotator/hed.py
@@ -0,0 +1,155 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+# Please use this implementation in your products
+# This implementation may produce slightly different results from Saining Xie's official implementations,
+# but it generates smoother edges and is more suitable for ControlNet as well as other image-to-image translations.
+# Different from official models and other implementations, this is an RGB-input model (rather than BGR)
+# and in this way it works better for gradio's RGB protocol
+
+from abc import ABCMeta
+
+import cv2
+import numpy as np
+import torch
+from einops import rearrange
+
+from scepter.modules.annotator.base_annotator import BaseAnnotator
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.utils.config import dict_to_yaml
+from scepter.modules.utils.distribute import we
+from scepter.modules.utils.file_system import FS
+
+
+def nms(x, t, s):
+ x = cv2.GaussianBlur(x.astype(np.float32), (0, 0), s)
+
+ f1 = np.array([[0, 0, 0], [1, 1, 1], [0, 0, 0]], dtype=np.uint8)
+ f2 = np.array([[0, 1, 0], [0, 1, 0], [0, 1, 0]], dtype=np.uint8)
+ f3 = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1]], dtype=np.uint8)
+ f4 = np.array([[0, 0, 1], [0, 1, 0], [1, 0, 0]], dtype=np.uint8)
+
+ y = np.zeros_like(x)
+
+ for f in [f1, f2, f3, f4]:
+ np.putmask(y, cv2.dilate(x, kernel=f) == x, x)
+
+ z = np.zeros_like(y, dtype=np.uint8)
+ z[y > t] = 255
+ return z
+
+
+class DoubleConvBlock(torch.nn.Module):
+ def __init__(self, input_channel, output_channel, layer_number):
+ super().__init__()
+ self.convs = torch.nn.Sequential()
+ self.convs.append(
+ torch.nn.Conv2d(in_channels=input_channel,
+ out_channels=output_channel,
+ kernel_size=(3, 3),
+ stride=(1, 1),
+ padding=1))
+ for i in range(1, layer_number):
+ self.convs.append(
+ torch.nn.Conv2d(in_channels=output_channel,
+ out_channels=output_channel,
+ kernel_size=(3, 3),
+ stride=(1, 1),
+ padding=1))
+ self.projection = torch.nn.Conv2d(in_channels=output_channel,
+ out_channels=1,
+ kernel_size=(1, 1),
+ stride=(1, 1),
+ padding=0)
+
+ def __call__(self, x, down_sampling=False):
+ h = x
+ if down_sampling:
+ h = torch.nn.functional.max_pool2d(h,
+ kernel_size=(2, 2),
+ stride=(2, 2))
+ for conv in self.convs:
+ h = conv(h)
+ h = torch.nn.functional.relu(h)
+ return h, self.projection(h)
+
+
+class ControlNetHED_Apache2(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.norm = torch.nn.Parameter(torch.zeros(size=(1, 3, 1, 1)))
+ self.block1 = DoubleConvBlock(input_channel=3,
+ output_channel=64,
+ layer_number=2)
+ self.block2 = DoubleConvBlock(input_channel=64,
+ output_channel=128,
+ layer_number=2)
+ self.block3 = DoubleConvBlock(input_channel=128,
+ output_channel=256,
+ layer_number=3)
+ self.block4 = DoubleConvBlock(input_channel=256,
+ output_channel=512,
+ layer_number=3)
+ self.block5 = DoubleConvBlock(input_channel=512,
+ output_channel=512,
+ layer_number=3)
+
+ def __call__(self, x):
+ h = x - self.norm
+ h, projection1 = self.block1(h)
+ h, projection2 = self.block2(h, down_sampling=True)
+ h, projection3 = self.block3(h, down_sampling=True)
+ h, projection4 = self.block4(h, down_sampling=True)
+ h, projection5 = self.block5(h, down_sampling=True)
+ return projection1, projection2, projection3, projection4, projection5
+
+
+@ANNOTATORS.register_class()
+class HedAnnotator(BaseAnnotator, metaclass=ABCMeta):
+ para_dict = {}
+
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+ self.netNetwork = ControlNetHED_Apache2().float().eval()
+ pretrained_model = cfg.get('PRETRAINED_MODEL', None)
+ if pretrained_model:
+ with FS.get_from(pretrained_model, wait_finish=True) as local_path:
+ self.netNetwork.load_state_dict(torch.load(local_path))
+
+ @torch.no_grad()
+ @torch.inference_mode()
+ @torch.autocast('cuda', enabled=False)
+ def forward(self, image):
+ if isinstance(image, torch.Tensor):
+ if len(image.shape) == 3:
+ image = rearrange(image, 'h w c -> 1 c h w')
+ B, C, H, W = image.shape
+ else:
+ raise "Unsurpport input image's shape"
+ elif isinstance(image, np.ndarray):
+ image = torch.from_numpy(image.copy()).float()
+ if len(image.shape) == 3:
+ image = rearrange(image, 'h w c -> 1 c h w')
+ B, C, H, W = image.shape
+ else:
+ raise "Unsurpport input image's shape"
+ else:
+ raise "Unsurpport input image's type"
+ edges = self.netNetwork(image.to(we.device_id))
+ edges = [
+ e.detach().cpu().numpy().astype(np.float32)[0, 0] for e in edges
+ ]
+ edges = [
+ cv2.resize(e, (W, H), interpolation=cv2.INTER_LINEAR)
+ for e in edges
+ ]
+ edges = np.stack(edges, axis=2)
+ edge = 1 / (1 + np.exp(-np.mean(edges, axis=2).astype(np.float64)))
+ edge = 255 - (edge * 255.0).clip(0, 255).astype(np.uint8)
+ return edge[..., None].repeat(3, 2)
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ HedAnnotator.para_dict,
+ set_name=True)
diff --git a/annotator/identity.py b/annotator/identity.py
new file mode 100644
index 0000000000000000000000000000000000000000..f142a676218f1edfa45f9fa758c0d7222eaf6977
--- /dev/null
+++ b/annotator/identity.py
@@ -0,0 +1,25 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+from abc import ABCMeta
+
+from scepter.modules.annotator.base_annotator import BaseAnnotator
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.utils.config import dict_to_yaml
+
+
+@ANNOTATORS.register_class()
+class IdentityAnnotator(BaseAnnotator, metaclass=ABCMeta):
+ para_dict = {}
+
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+
+ def forward(self, image):
+ return image
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ IdentityAnnotator.para_dict,
+ set_name=True)
diff --git a/annotator/invert.py b/annotator/invert.py
new file mode 100644
index 0000000000000000000000000000000000000000..afdf571acc51c2cfcacdbe17576e445e87a28114
--- /dev/null
+++ b/annotator/invert.py
@@ -0,0 +1,25 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+from abc import ABCMeta
+
+from scepter.modules.annotator.base_annotator import BaseAnnotator
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.utils.config import dict_to_yaml
+
+
+@ANNOTATORS.register_class()
+class InvertAnnotator(BaseAnnotator, metaclass=ABCMeta):
+ para_dict = {}
+
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+
+ def forward(self, image):
+ return 255 - image
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ InvertAnnotator.para_dict,
+ set_name=True)
diff --git a/annotator/midas/__init__.py b/annotator/midas/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/annotator/midas/api.py b/annotator/midas/api.py
new file mode 100644
index 0000000000000000000000000000000000000000..490cd18aa1e887a18366fdc0c60d2fd096624da9
--- /dev/null
+++ b/annotator/midas/api.py
@@ -0,0 +1,165 @@
+# -*- coding: utf-8 -*-
+# based on https://github.com/isl-org/MiDaS
+
+import cv2
+import torch
+import torch.nn as nn
+from torchvision.transforms import Compose
+
+from .dpt_depth import DPTDepthModel
+from .midas_net import MidasNet
+from .midas_net_custom import MidasNet_small
+from .transforms import NormalizeImage, PrepareForNet, Resize
+
+# ISL_PATHS = {
+# "dpt_large": "dpt_large-midas-2f21e586.pt",
+# "dpt_hybrid": "dpt_hybrid-midas-501f0c75.pt",
+# "midas_v21": "",
+# "midas_v21_small": "",
+# }
+
+# remote_model_path =
+# "https://huggingface.co/lllyasviel/ControlNet/resolve/main/annotator/ckpts/dpt_hybrid-midas-501f0c75.pt"
+
+
+def disabled_train(self, mode=True):
+ """Overwrite model.train with this function to make sure train/eval mode
+ does not change anymore."""
+ return self
+
+
+def load_midas_transform(model_type):
+ # https://github.com/isl-org/MiDaS/blob/master/run.py
+ # load transform only
+ if model_type == 'dpt_large': # DPT-Large
+ net_w, net_h = 384, 384
+ resize_mode = 'minimal'
+ normalization = NormalizeImage(mean=[0.5, 0.5, 0.5],
+ std=[0.5, 0.5, 0.5])
+
+ elif model_type == 'dpt_hybrid': # DPT-Hybrid
+ net_w, net_h = 384, 384
+ resize_mode = 'minimal'
+ normalization = NormalizeImage(mean=[0.5, 0.5, 0.5],
+ std=[0.5, 0.5, 0.5])
+
+ elif model_type == 'midas_v21':
+ net_w, net_h = 384, 384
+ resize_mode = 'upper_bound'
+ normalization = NormalizeImage(mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+
+ elif model_type == 'midas_v21_small':
+ net_w, net_h = 256, 256
+ resize_mode = 'upper_bound'
+ normalization = NormalizeImage(mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+
+ else:
+ assert False, f"model_type '{model_type}' not implemented, use: --model_type large"
+
+ transform = Compose([
+ Resize(
+ net_w,
+ net_h,
+ resize_target=None,
+ keep_aspect_ratio=True,
+ ensure_multiple_of=32,
+ resize_method=resize_mode,
+ image_interpolation_method=cv2.INTER_CUBIC,
+ ),
+ normalization,
+ PrepareForNet(),
+ ])
+
+ return transform
+
+
+def load_model(model_type, model_path):
+ # https://github.com/isl-org/MiDaS/blob/master/run.py
+ # load network
+ # model_path = ISL_PATHS[model_type]
+ if model_type == 'dpt_large': # DPT-Large
+ model = DPTDepthModel(
+ path=model_path,
+ backbone='vitl16_384',
+ non_negative=True,
+ )
+ net_w, net_h = 384, 384
+ resize_mode = 'minimal'
+ normalization = NormalizeImage(mean=[0.5, 0.5, 0.5],
+ std=[0.5, 0.5, 0.5])
+
+ elif model_type == 'dpt_hybrid': # DPT-Hybrid
+ model = DPTDepthModel(
+ path=model_path,
+ backbone='vitb_rn50_384',
+ non_negative=True,
+ )
+ net_w, net_h = 384, 384
+ resize_mode = 'minimal'
+ normalization = NormalizeImage(mean=[0.5, 0.5, 0.5],
+ std=[0.5, 0.5, 0.5])
+
+ elif model_type == 'midas_v21':
+ model = MidasNet(model_path, non_negative=True)
+ net_w, net_h = 384, 384
+ resize_mode = 'upper_bound'
+ normalization = NormalizeImage(mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+
+ elif model_type == 'midas_v21_small':
+ model = MidasNet_small(model_path,
+ features=64,
+ backbone='efficientnet_lite3',
+ exportable=True,
+ non_negative=True,
+ blocks={'expand': True})
+ net_w, net_h = 256, 256
+ resize_mode = 'upper_bound'
+ normalization = NormalizeImage(mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+
+ else:
+ print(
+ f"model_type '{model_type}' not implemented, use: --model_type large"
+ )
+ assert False
+
+ transform = Compose([
+ Resize(
+ net_w,
+ net_h,
+ resize_target=None,
+ keep_aspect_ratio=True,
+ ensure_multiple_of=32,
+ resize_method=resize_mode,
+ image_interpolation_method=cv2.INTER_CUBIC,
+ ),
+ normalization,
+ PrepareForNet(),
+ ])
+
+ return model.eval(), transform
+
+
+class MiDaSInference(nn.Module):
+ MODEL_TYPES_TORCH_HUB = ['DPT_Large', 'DPT_Hybrid', 'MiDaS_small']
+ MODEL_TYPES_ISL = [
+ 'dpt_large',
+ 'dpt_hybrid',
+ 'midas_v21',
+ 'midas_v21_small',
+ ]
+
+ def __init__(self, model_type, model_path):
+ super().__init__()
+ assert (model_type in self.MODEL_TYPES_ISL)
+ model, _ = load_model(model_type, model_path)
+ self.model = model
+ self.model.train = disabled_train
+
+ def forward(self, x):
+ with torch.no_grad():
+ prediction = self.model(x)
+ return prediction
diff --git a/annotator/midas/base_model.py b/annotator/midas/base_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..68d985b0561a7c0c98ea34f8ea317387da4e440d
--- /dev/null
+++ b/annotator/midas/base_model.py
@@ -0,0 +1,17 @@
+# -*- coding: utf-8 -*-
+import torch
+
+
+class BaseModel(torch.nn.Module):
+ def load(self, path):
+ """Load model from file.
+
+ Args:
+ path (str): file path
+ """
+ parameters = torch.load(path, map_location=torch.device('cpu'))
+
+ if 'optimizer' in parameters:
+ parameters = parameters['model']
+
+ self.load_state_dict(parameters)
diff --git a/annotator/midas/blocks.py b/annotator/midas/blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..472a40eeeb8dd258c8acc413ac47cf28861b74d0
--- /dev/null
+++ b/annotator/midas/blocks.py
@@ -0,0 +1,390 @@
+# -*- coding: utf-8 -*-
+import torch
+import torch.nn as nn
+
+from .vit import (_make_pretrained_vitb16_384, _make_pretrained_vitb_rn50_384,
+ _make_pretrained_vitl16_384)
+
+
+def _make_encoder(
+ backbone,
+ features,
+ use_pretrained,
+ groups=1,
+ expand=False,
+ exportable=True,
+ hooks=None,
+ use_vit_only=False,
+ use_readout='ignore',
+):
+ if backbone == 'vitl16_384':
+ pretrained = _make_pretrained_vitl16_384(use_pretrained,
+ hooks=hooks,
+ use_readout=use_readout)
+ scratch = _make_scratch(
+ [256, 512, 1024, 1024], features, groups=groups,
+ expand=expand) # ViT-L/16 - 85.0% Top1 (backbone)
+ elif backbone == 'vitb_rn50_384':
+ pretrained = _make_pretrained_vitb_rn50_384(
+ use_pretrained,
+ hooks=hooks,
+ use_vit_only=use_vit_only,
+ use_readout=use_readout,
+ )
+ scratch = _make_scratch(
+ [256, 512, 768, 768], features, groups=groups,
+ expand=expand) # ViT-H/16 - 85.0% Top1 (backbone)
+ elif backbone == 'vitb16_384':
+ pretrained = _make_pretrained_vitb16_384(use_pretrained,
+ hooks=hooks,
+ use_readout=use_readout)
+ scratch = _make_scratch(
+ [96, 192, 384, 768], features, groups=groups,
+ expand=expand) # ViT-B/16 - 84.6% Top1 (backbone)
+ elif backbone == 'resnext101_wsl':
+ pretrained = _make_pretrained_resnext101_wsl(use_pretrained)
+ scratch = _make_scratch([256, 512, 1024, 2048],
+ features,
+ groups=groups,
+ expand=expand) # efficientnet_lite3
+ elif backbone == 'efficientnet_lite3':
+ pretrained = _make_pretrained_efficientnet_lite3(use_pretrained,
+ exportable=exportable)
+ scratch = _make_scratch([32, 48, 136, 384],
+ features,
+ groups=groups,
+ expand=expand) # efficientnet_lite3
+ else:
+ print(f"Backbone '{backbone}' not implemented")
+ assert False
+
+ return pretrained, scratch
+
+
+def _make_scratch(in_shape, out_shape, groups=1, expand=False):
+ scratch = nn.Module()
+
+ out_shape1 = out_shape
+ out_shape2 = out_shape
+ out_shape3 = out_shape
+ out_shape4 = out_shape
+ if expand is True:
+ out_shape1 = out_shape
+ out_shape2 = out_shape * 2
+ out_shape3 = out_shape * 4
+ out_shape4 = out_shape * 8
+
+ scratch.layer1_rn = nn.Conv2d(in_shape[0],
+ out_shape1,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ groups=groups)
+ scratch.layer2_rn = nn.Conv2d(in_shape[1],
+ out_shape2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ groups=groups)
+ scratch.layer3_rn = nn.Conv2d(in_shape[2],
+ out_shape3,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ groups=groups)
+ scratch.layer4_rn = nn.Conv2d(in_shape[3],
+ out_shape4,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=False,
+ groups=groups)
+
+ return scratch
+
+
+def _make_pretrained_efficientnet_lite3(use_pretrained, exportable=False):
+ efficientnet = torch.hub.load('rwightman/gen-efficientnet-pytorch',
+ 'tf_efficientnet_lite3',
+ pretrained=use_pretrained,
+ exportable=exportable)
+ return _make_efficientnet_backbone(efficientnet)
+
+
+def _make_efficientnet_backbone(effnet):
+ pretrained = nn.Module()
+
+ pretrained.layer1 = nn.Sequential(effnet.conv_stem, effnet.bn1,
+ effnet.act1, *effnet.blocks[0:2])
+ pretrained.layer2 = nn.Sequential(*effnet.blocks[2:3])
+ pretrained.layer3 = nn.Sequential(*effnet.blocks[3:5])
+ pretrained.layer4 = nn.Sequential(*effnet.blocks[5:9])
+
+ return pretrained
+
+
+def _make_resnet_backbone(resnet):
+ pretrained = nn.Module()
+ pretrained.layer1 = nn.Sequential(resnet.conv1, resnet.bn1, resnet.relu,
+ resnet.maxpool, resnet.layer1)
+
+ pretrained.layer2 = resnet.layer2
+ pretrained.layer3 = resnet.layer3
+ pretrained.layer4 = resnet.layer4
+
+ return pretrained
+
+
+def _make_pretrained_resnext101_wsl(use_pretrained):
+ resnet = torch.hub.load('facebookresearch/WSL-Images',
+ 'resnext101_32x8d_wsl')
+ return _make_resnet_backbone(resnet)
+
+
+class Interpolate(nn.Module):
+ """Interpolation module.
+ """
+ def __init__(self, scale_factor, mode, align_corners=False):
+ """Init.
+
+ Args:
+ scale_factor (float): scaling
+ mode (str): interpolation mode
+ """
+ super(Interpolate, self).__init__()
+
+ self.interp = nn.functional.interpolate
+ self.scale_factor = scale_factor
+ self.mode = mode
+ self.align_corners = align_corners
+
+ def forward(self, x):
+ """Forward pass.
+
+ Args:
+ x (tensor): input
+
+ Returns:
+ tensor: interpolated data
+ """
+
+ x = self.interp(x,
+ scale_factor=self.scale_factor,
+ mode=self.mode,
+ align_corners=self.align_corners)
+
+ return x
+
+
+class ResidualConvUnit(nn.Module):
+ """Residual convolution module.
+ """
+ def __init__(self, features):
+ """Init.
+
+ Args:
+ features (int): number of features
+ """
+ super().__init__()
+
+ self.conv1 = nn.Conv2d(features,
+ features,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=True)
+
+ self.conv2 = nn.Conv2d(features,
+ features,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=True)
+
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ """Forward pass.
+
+ Args:
+ x (tensor): input
+
+ Returns:
+ tensor: output
+ """
+ out = self.relu(x)
+ out = self.conv1(out)
+ out = self.relu(out)
+ out = self.conv2(out)
+
+ return out + x
+
+
+class FeatureFusionBlock(nn.Module):
+ """Feature fusion block.
+ """
+ def __init__(self, features):
+ """Init.
+
+ Args:
+ features (int): number of features
+ """
+ super(FeatureFusionBlock, self).__init__()
+
+ self.resConfUnit1 = ResidualConvUnit(features)
+ self.resConfUnit2 = ResidualConvUnit(features)
+
+ def forward(self, *xs):
+ """Forward pass.
+
+ Returns:
+ tensor: output
+ """
+ output = xs[0]
+
+ if len(xs) == 2:
+ output += self.resConfUnit1(xs[1])
+
+ output = self.resConfUnit2(output)
+
+ output = nn.functional.interpolate(output,
+ scale_factor=2,
+ mode='bilinear',
+ align_corners=True)
+
+ return output
+
+
+class ResidualConvUnit_custom(nn.Module):
+ """Residual convolution module.
+ """
+ def __init__(self, features, activation, bn):
+ """Init.
+
+ Args:
+ features (int): number of features
+ """
+ super().__init__()
+
+ self.bn = bn
+
+ self.groups = 1
+
+ self.conv1 = nn.Conv2d(features,
+ features,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=True,
+ groups=self.groups)
+
+ self.conv2 = nn.Conv2d(features,
+ features,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=True,
+ groups=self.groups)
+
+ if self.bn is True:
+ self.bn1 = nn.BatchNorm2d(features)
+ self.bn2 = nn.BatchNorm2d(features)
+
+ self.activation = activation
+
+ self.skip_add = nn.quantized.FloatFunctional()
+
+ def forward(self, x):
+ """Forward pass.
+
+ Args:
+ x (tensor): input
+
+ Returns:
+ tensor: output
+ """
+
+ out = self.activation(x)
+ out = self.conv1(out)
+ if self.bn is True:
+ out = self.bn1(out)
+
+ out = self.activation(out)
+ out = self.conv2(out)
+ if self.bn is True:
+ out = self.bn2(out)
+
+ if self.groups > 1:
+ out = self.conv_merge(out)
+
+ return self.skip_add.add(out, x)
+
+ # return out + x
+
+
+class FeatureFusionBlock_custom(nn.Module):
+ """Feature fusion block.
+ """
+ def __init__(self,
+ features,
+ activation,
+ deconv=False,
+ bn=False,
+ expand=False,
+ align_corners=True):
+ """Init.
+
+ Args:
+ features (int): number of features
+ """
+ super(FeatureFusionBlock_custom, self).__init__()
+
+ self.deconv = deconv
+ self.align_corners = align_corners
+
+ self.groups = 1
+
+ self.expand = expand
+ out_features = features
+ if self.expand is True:
+ out_features = features // 2
+
+ self.out_conv = nn.Conv2d(features,
+ out_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias=True,
+ groups=1)
+
+ self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
+ self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
+
+ self.skip_add = nn.quantized.FloatFunctional()
+
+ def forward(self, *xs):
+ """Forward pass.
+
+ Returns:
+ tensor: output
+ """
+ output = xs[0]
+
+ if len(xs) == 2:
+ res = self.resConfUnit1(xs[1])
+ output = self.skip_add.add(output, res)
+ # output += res
+
+ output = self.resConfUnit2(output)
+
+ output = nn.functional.interpolate(output,
+ scale_factor=2,
+ mode='bilinear',
+ align_corners=self.align_corners)
+
+ output = self.out_conv(output)
+
+ return output
diff --git a/annotator/midas/dpt_depth.py b/annotator/midas/dpt_depth.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c25e0da10c1586fb9bc2c1cb6cf4193c5142040
--- /dev/null
+++ b/annotator/midas/dpt_depth.py
@@ -0,0 +1,106 @@
+# -*- coding: utf-8 -*-
+import torch
+import torch.nn as nn
+
+from .base_model import BaseModel
+from .blocks import FeatureFusionBlock_custom, Interpolate, _make_encoder
+from .vit import forward_vit
+
+
+def _make_fusion_block(features, use_bn):
+ return FeatureFusionBlock_custom(
+ features,
+ nn.ReLU(False),
+ deconv=False,
+ bn=use_bn,
+ expand=False,
+ align_corners=True,
+ )
+
+
+class DPT(BaseModel):
+ def __init__(
+ self,
+ head,
+ features=256,
+ backbone='vitb_rn50_384',
+ readout='project',
+ channels_last=False,
+ use_bn=False,
+ ):
+
+ super(DPT, self).__init__()
+
+ self.channels_last = channels_last
+
+ hooks = {
+ 'vitb_rn50_384': [0, 1, 8, 11],
+ 'vitb16_384': [2, 5, 8, 11],
+ 'vitl16_384': [5, 11, 17, 23],
+ }
+
+ # Instantiate backbone and reassemble blocks
+ self.pretrained, self.scratch = _make_encoder(
+ backbone,
+ features,
+ False, # Set to true of you want to train from scratch, uses ImageNet weights
+ groups=1,
+ expand=False,
+ exportable=False,
+ hooks=hooks[backbone],
+ use_readout=readout,
+ )
+
+ self.scratch.refinenet1 = _make_fusion_block(features, use_bn)
+ self.scratch.refinenet2 = _make_fusion_block(features, use_bn)
+ self.scratch.refinenet3 = _make_fusion_block(features, use_bn)
+ self.scratch.refinenet4 = _make_fusion_block(features, use_bn)
+
+ self.scratch.output_conv = head
+
+ def forward(self, x):
+ if self.channels_last is True:
+ x.contiguous(memory_format=torch.channels_last)
+
+ layer_1, layer_2, layer_3, layer_4 = forward_vit(self.pretrained, x)
+
+ layer_1_rn = self.scratch.layer1_rn(layer_1)
+ layer_2_rn = self.scratch.layer2_rn(layer_2)
+ layer_3_rn = self.scratch.layer3_rn(layer_3)
+ layer_4_rn = self.scratch.layer4_rn(layer_4)
+
+ path_4 = self.scratch.refinenet4(layer_4_rn)
+ path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
+ path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
+ path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
+
+ out = self.scratch.output_conv(path_1)
+
+ return out
+
+
+class DPTDepthModel(DPT):
+ def __init__(self, path=None, non_negative=True, **kwargs):
+ features = kwargs['features'] if 'features' in kwargs else 256
+
+ head = nn.Sequential(
+ nn.Conv2d(features,
+ features // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1),
+ Interpolate(scale_factor=2, mode='bilinear', align_corners=True),
+ nn.Conv2d(features // 2, 32, kernel_size=3, stride=1, padding=1),
+ nn.ReLU(True),
+ nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
+ nn.ReLU(True) if non_negative else nn.Identity(),
+ nn.Identity(),
+ )
+
+ super().__init__(head, **kwargs)
+
+ if path is not None:
+ self.load(path)
+
+ def forward(self, x):
+ return super().forward(x).squeeze(dim=1)
diff --git a/annotator/midas/midas_net.py b/annotator/midas/midas_net.py
new file mode 100644
index 0000000000000000000000000000000000000000..b04164619e0492f77b8ff4715276372b0cb0b432
--- /dev/null
+++ b/annotator/midas/midas_net.py
@@ -0,0 +1,79 @@
+# -*- coding: utf-8 -*-
+"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
+This file contains code that is adapted from
+https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
+"""
+import torch
+import torch.nn as nn
+
+from .base_model import BaseModel
+from .blocks import FeatureFusionBlock, Interpolate, _make_encoder
+
+
+class MidasNet(BaseModel):
+ """Network for monocular depth estimation.
+ """
+ def __init__(self, path=None, features=256, non_negative=True):
+ """Init.
+
+ Args:
+ path (str, optional): Path to saved model. Defaults to None.
+ features (int, optional): Number of features. Defaults to 256.
+ backbone (str, optional): Backbone network for encoder. Defaults to resnet50
+ """
+ print('Loading weights: ', path)
+
+ super(MidasNet, self).__init__()
+
+ use_pretrained = False if path is None else True
+
+ self.pretrained, self.scratch = _make_encoder(
+ backbone='resnext101_wsl',
+ features=features,
+ use_pretrained=use_pretrained)
+
+ self.scratch.refinenet4 = FeatureFusionBlock(features)
+ self.scratch.refinenet3 = FeatureFusionBlock(features)
+ self.scratch.refinenet2 = FeatureFusionBlock(features)
+ self.scratch.refinenet1 = FeatureFusionBlock(features)
+
+ self.scratch.output_conv = nn.Sequential(
+ nn.Conv2d(features, 128, kernel_size=3, stride=1, padding=1),
+ Interpolate(scale_factor=2, mode='bilinear'),
+ nn.Conv2d(128, 32, kernel_size=3, stride=1, padding=1),
+ nn.ReLU(True),
+ nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
+ nn.ReLU(True) if non_negative else nn.Identity(),
+ )
+
+ if path:
+ self.load(path)
+
+ def forward(self, x):
+ """Forward pass.
+
+ Args:
+ x (tensor): input data (image)
+
+ Returns:
+ tensor: depth
+ """
+
+ layer_1 = self.pretrained.layer1(x)
+ layer_2 = self.pretrained.layer2(layer_1)
+ layer_3 = self.pretrained.layer3(layer_2)
+ layer_4 = self.pretrained.layer4(layer_3)
+
+ layer_1_rn = self.scratch.layer1_rn(layer_1)
+ layer_2_rn = self.scratch.layer2_rn(layer_2)
+ layer_3_rn = self.scratch.layer3_rn(layer_3)
+ layer_4_rn = self.scratch.layer4_rn(layer_4)
+
+ path_4 = self.scratch.refinenet4(layer_4_rn)
+ path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
+ path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
+ path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
+
+ out = self.scratch.output_conv(path_1)
+
+ return torch.squeeze(out, dim=1)
diff --git a/annotator/midas/midas_net_custom.py b/annotator/midas/midas_net_custom.py
new file mode 100644
index 0000000000000000000000000000000000000000..fcdf78d9eea57e527704dd62e88eac2f2fea1f1e
--- /dev/null
+++ b/annotator/midas/midas_net_custom.py
@@ -0,0 +1,166 @@
+# -*- coding: utf-8 -*-
+"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
+This file contains code that is adapted from
+https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
+"""
+import torch
+import torch.nn as nn
+
+from .base_model import BaseModel
+from .blocks import FeatureFusionBlock_custom, Interpolate, _make_encoder
+
+
+class MidasNet_small(BaseModel):
+ """Network for monocular depth estimation.
+ """
+ def __init__(self,
+ path=None,
+ features=64,
+ backbone='efficientnet_lite3',
+ non_negative=True,
+ exportable=True,
+ channels_last=False,
+ align_corners=True,
+ blocks={'expand': True}):
+ """Init.
+
+ Args:
+ path (str, optional): Path to saved model. Defaults to None.
+ features (int, optional): Number of features. Defaults to 256.
+ backbone (str, optional): Backbone network for encoder. Defaults to resnet50
+ """
+ print('Loading weights: ', path)
+
+ super(MidasNet_small, self).__init__()
+
+ use_pretrained = False if path else True
+
+ self.channels_last = channels_last
+ self.blocks = blocks
+ self.backbone = backbone
+
+ self.groups = 1
+
+ features1 = features
+ features2 = features
+ features3 = features
+ features4 = features
+ self.expand = False
+ if 'expand' in self.blocks and self.blocks['expand'] is True:
+ self.expand = True
+ features1 = features
+ features2 = features * 2
+ features3 = features * 4
+ features4 = features * 8
+
+ self.pretrained, self.scratch = _make_encoder(self.backbone,
+ features,
+ use_pretrained,
+ groups=self.groups,
+ expand=self.expand,
+ exportable=exportable)
+
+ self.scratch.activation = nn.ReLU(False)
+
+ self.scratch.refinenet4 = FeatureFusionBlock_custom(
+ features4,
+ self.scratch.activation,
+ deconv=False,
+ bn=False,
+ expand=self.expand,
+ align_corners=align_corners)
+ self.scratch.refinenet3 = FeatureFusionBlock_custom(
+ features3,
+ self.scratch.activation,
+ deconv=False,
+ bn=False,
+ expand=self.expand,
+ align_corners=align_corners)
+ self.scratch.refinenet2 = FeatureFusionBlock_custom(
+ features2,
+ self.scratch.activation,
+ deconv=False,
+ bn=False,
+ expand=self.expand,
+ align_corners=align_corners)
+ self.scratch.refinenet1 = FeatureFusionBlock_custom(
+ features1,
+ self.scratch.activation,
+ deconv=False,
+ bn=False,
+ align_corners=align_corners)
+
+ self.scratch.output_conv = nn.Sequential(
+ nn.Conv2d(features,
+ features // 2,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ groups=self.groups),
+ Interpolate(scale_factor=2, mode='bilinear'),
+ nn.Conv2d(features // 2, 32, kernel_size=3, stride=1, padding=1),
+ self.scratch.activation,
+ nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
+ nn.ReLU(True) if non_negative else nn.Identity(),
+ nn.Identity(),
+ )
+
+ if path:
+ self.load(path)
+
+ def forward(self, x):
+ """Forward pass.
+
+ Args:
+ x (tensor): input data (image)
+
+ Returns:
+ tensor: depth
+ """
+ if self.channels_last is True:
+ print('self.channels_last = ', self.channels_last)
+ x.contiguous(memory_format=torch.channels_last)
+
+ layer_1 = self.pretrained.layer1(x)
+ layer_2 = self.pretrained.layer2(layer_1)
+ layer_3 = self.pretrained.layer3(layer_2)
+ layer_4 = self.pretrained.layer4(layer_3)
+
+ layer_1_rn = self.scratch.layer1_rn(layer_1)
+ layer_2_rn = self.scratch.layer2_rn(layer_2)
+ layer_3_rn = self.scratch.layer3_rn(layer_3)
+ layer_4_rn = self.scratch.layer4_rn(layer_4)
+
+ path_4 = self.scratch.refinenet4(layer_4_rn)
+ path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
+ path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
+ path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
+
+ out = self.scratch.output_conv(path_1)
+
+ return torch.squeeze(out, dim=1)
+
+
+def fuse_model(m):
+ prev_previous_type = nn.Identity()
+ prev_previous_name = ''
+ previous_type = nn.Identity()
+ previous_name = ''
+ for name, module in m.named_modules():
+ if prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d and type(
+ module) == nn.ReLU:
+ # print("FUSED ", prev_previous_name, previous_name, name)
+ torch.quantization.fuse_modules(
+ m, [prev_previous_name, previous_name, name], inplace=True)
+ elif prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d:
+ # print("FUSED ", prev_previous_name, previous_name)
+ torch.quantization.fuse_modules(
+ m, [prev_previous_name, previous_name], inplace=True)
+ # elif previous_type == nn.Conv2d and type(module) == nn.ReLU:
+ # print("FUSED ", previous_name, name)
+ # torch.quantization.fuse_modules(m, [previous_name, name], inplace=True)
+
+ prev_previous_type = previous_type
+ prev_previous_name = previous_name
+ previous_type = type(module)
+ previous_name = name
diff --git a/annotator/midas/transforms.py b/annotator/midas/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1da4336ba9bce6da6f8dfc069c7ce6d29a26581
--- /dev/null
+++ b/annotator/midas/transforms.py
@@ -0,0 +1,230 @@
+# -*- coding: utf-8 -*-
+import math
+
+import cv2
+import numpy as np
+
+
+def apply_min_size(sample, size, image_interpolation_method=cv2.INTER_AREA):
+ """Rezise the sample to ensure the given size. Keeps aspect ratio.
+
+ Args:
+ sample (dict): sample
+ size (tuple): image size
+
+ Returns:
+ tuple: new size
+ """
+ shape = list(sample['disparity'].shape)
+
+ if shape[0] >= size[0] and shape[1] >= size[1]:
+ return sample
+
+ scale = [0, 0]
+ scale[0] = size[0] / shape[0]
+ scale[1] = size[1] / shape[1]
+
+ scale = max(scale)
+
+ shape[0] = math.ceil(scale * shape[0])
+ shape[1] = math.ceil(scale * shape[1])
+
+ # resize
+ sample['image'] = cv2.resize(sample['image'],
+ tuple(shape[::-1]),
+ interpolation=image_interpolation_method)
+
+ sample['disparity'] = cv2.resize(sample['disparity'],
+ tuple(shape[::-1]),
+ interpolation=cv2.INTER_NEAREST)
+ sample['mask'] = cv2.resize(
+ sample['mask'].astype(np.float32),
+ tuple(shape[::-1]),
+ interpolation=cv2.INTER_NEAREST,
+ )
+ sample['mask'] = sample['mask'].astype(bool)
+
+ return tuple(shape)
+
+
+class Resize(object):
+ """Resize sample to given size (width, height).
+ """
+ def __init__(
+ self,
+ width,
+ height,
+ resize_target=True,
+ keep_aspect_ratio=False,
+ ensure_multiple_of=1,
+ resize_method='lower_bound',
+ image_interpolation_method=cv2.INTER_AREA,
+ ):
+ """Init.
+
+ Args:
+ width (int): desired output width
+ height (int): desired output height
+ resize_target (bool, optional):
+ True: Resize the full sample (image, mask, target).
+ False: Resize image only.
+ Defaults to True.
+ keep_aspect_ratio (bool, optional):
+ True: Keep the aspect ratio of the input sample.
+ Output sample might not have the given width and height, and
+ resize behaviour depends on the parameter 'resize_method'.
+ Defaults to False.
+ ensure_multiple_of (int, optional):
+ Output width and height is constrained to be multiple of this parameter.
+ Defaults to 1.
+ resize_method (str, optional):
+ "lower_bound": Output will be at least as large as the given size.
+ "upper_bound": Output will be at max as large as the given size. "
+ "(Output size might be smaller than given size.)"
+ "minimal": Scale as least as possible. (Output size might be smaller than given size.)
+ Defaults to "lower_bound".
+ """
+ self.__width = width
+ self.__height = height
+
+ self.__resize_target = resize_target
+ self.__keep_aspect_ratio = keep_aspect_ratio
+ self.__multiple_of = ensure_multiple_of
+ self.__resize_method = resize_method
+ self.__image_interpolation_method = image_interpolation_method
+
+ def constrain_to_multiple_of(self, x, min_val=0, max_val=None):
+ y = (np.round(x / self.__multiple_of) * self.__multiple_of).astype(int)
+
+ if max_val is not None and y > max_val:
+ y = (np.floor(x / self.__multiple_of) *
+ self.__multiple_of).astype(int)
+
+ if y < min_val:
+ y = (np.ceil(x / self.__multiple_of) *
+ self.__multiple_of).astype(int)
+
+ return y
+
+ def get_size(self, width, height):
+ # determine new height and width
+ scale_height = self.__height / height
+ scale_width = self.__width / width
+
+ if self.__keep_aspect_ratio:
+ if self.__resize_method == 'lower_bound':
+ # scale such that output size is lower bound
+ if scale_width > scale_height:
+ # fit width
+ scale_height = scale_width
+ else:
+ # fit height
+ scale_width = scale_height
+ elif self.__resize_method == 'upper_bound':
+ # scale such that output size is upper bound
+ if scale_width < scale_height:
+ # fit width
+ scale_height = scale_width
+ else:
+ # fit height
+ scale_width = scale_height
+ elif self.__resize_method == 'minimal':
+ # scale as least as possbile
+ if abs(1 - scale_width) < abs(1 - scale_height):
+ # fit width
+ scale_height = scale_width
+ else:
+ # fit height
+ scale_width = scale_height
+ else:
+ raise ValueError(
+ f'resize_method {self.__resize_method} not implemented')
+
+ if self.__resize_method == 'lower_bound':
+ new_height = self.constrain_to_multiple_of(scale_height * height,
+ min_val=self.__height)
+ new_width = self.constrain_to_multiple_of(scale_width * width,
+ min_val=self.__width)
+ elif self.__resize_method == 'upper_bound':
+ new_height = self.constrain_to_multiple_of(scale_height * height,
+ max_val=self.__height)
+ new_width = self.constrain_to_multiple_of(scale_width * width,
+ max_val=self.__width)
+ elif self.__resize_method == 'minimal':
+ new_height = self.constrain_to_multiple_of(scale_height * height)
+ new_width = self.constrain_to_multiple_of(scale_width * width)
+ else:
+ raise ValueError(
+ f'resize_method {self.__resize_method} not implemented')
+
+ return (new_width, new_height)
+
+ def __call__(self, sample):
+ width, height = self.get_size(sample['image'].shape[1],
+ sample['image'].shape[0])
+
+ # resize sample
+ sample['image'] = cv2.resize(
+ sample['image'],
+ (width, height),
+ interpolation=self.__image_interpolation_method,
+ )
+
+ if self.__resize_target:
+ if 'disparity' in sample:
+ sample['disparity'] = cv2.resize(
+ sample['disparity'],
+ (width, height),
+ interpolation=cv2.INTER_NEAREST,
+ )
+
+ if 'depth' in sample:
+ sample['depth'] = cv2.resize(sample['depth'], (width, height),
+ interpolation=cv2.INTER_NEAREST)
+
+ sample['mask'] = cv2.resize(
+ sample['mask'].astype(np.float32),
+ (width, height),
+ interpolation=cv2.INTER_NEAREST,
+ )
+ sample['mask'] = sample['mask'].astype(bool)
+
+ return sample
+
+
+class NormalizeImage(object):
+ """Normlize image by given mean and std.
+ """
+ def __init__(self, mean, std):
+ self.__mean = mean
+ self.__std = std
+
+ def __call__(self, sample):
+ sample['image'] = (sample['image'] - self.__mean) / self.__std
+
+ return sample
+
+
+class PrepareForNet(object):
+ """Prepare sample for usage as network input.
+ """
+ def __init__(self):
+ pass
+
+ def __call__(self, sample):
+ image = np.transpose(sample['image'], (2, 0, 1))
+ sample['image'] = np.ascontiguousarray(image).astype(np.float32)
+
+ if 'mask' in sample:
+ sample['mask'] = sample['mask'].astype(np.float32)
+ sample['mask'] = np.ascontiguousarray(sample['mask'])
+
+ if 'disparity' in sample:
+ disparity = sample['disparity'].astype(np.float32)
+ sample['disparity'] = np.ascontiguousarray(disparity)
+
+ if 'depth' in sample:
+ depth = sample['depth'].astype(np.float32)
+ sample['depth'] = np.ascontiguousarray(depth)
+
+ return sample
diff --git a/annotator/midas/utils.py b/annotator/midas/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bf792aaabe53630156132cccb7c1a85f8a5b47b
--- /dev/null
+++ b/annotator/midas/utils.py
@@ -0,0 +1,192 @@
+# -*- coding: utf-8 -*-
+"""Utils for monoDepth."""
+import re
+import sys
+
+import cv2
+import numpy as np
+import torch
+
+
+def read_pfm(path):
+ """Read pfm file.
+
+ Args:
+ path (str): path to file
+
+ Returns:
+ tuple: (data, scale)
+ """
+ with open(path, 'rb') as file:
+
+ color = None
+ width = None
+ height = None
+ scale = None
+ endian = None
+
+ header = file.readline().rstrip()
+ if header.decode('ascii') == 'PF':
+ color = True
+ elif header.decode('ascii') == 'Pf':
+ color = False
+ else:
+ raise Exception('Not a PFM file: ' + path)
+
+ dim_match = re.match(r'^(\d+)\s(\d+)\s$',
+ file.readline().decode('ascii'))
+ if dim_match:
+ width, height = list(map(int, dim_match.groups()))
+ else:
+ raise Exception('Malformed PFM header.')
+
+ scale = float(file.readline().decode('ascii').rstrip())
+ if scale < 0:
+ # little-endian
+ endian = '<'
+ scale = -scale
+ else:
+ # big-endian
+ endian = '>'
+
+ data = np.fromfile(file, endian + 'f')
+ shape = (height, width, 3) if color else (height, width)
+
+ data = np.reshape(data, shape)
+ data = np.flipud(data)
+
+ return data, scale
+
+
+def write_pfm(path, image, scale=1):
+ """Write pfm file.
+
+ Args:
+ path (str): pathto file
+ image (array): data
+ scale (int, optional): Scale. Defaults to 1.
+ """
+
+ with open(path, 'wb') as file:
+ color = None
+
+ if image.dtype.name != 'float32':
+ raise Exception('Image dtype must be float32.')
+
+ image = np.flipud(image)
+
+ if len(image.shape) == 3 and image.shape[2] == 3: # color image
+ color = True
+ elif (len(image.shape) == 2
+ or len(image.shape) == 3 and image.shape[2] == 1): # greyscale
+ color = False
+ else:
+ raise Exception(
+ 'Image must have H x W x 3, H x W x 1 or H x W dimensions.')
+
+ file.write('PF\n' if color else 'Pf\n'.encode())
+ file.write('%d %d\n'.encode() % (image.shape[1], image.shape[0]))
+
+ endian = image.dtype.byteorder
+
+ if endian == '<' or endian == '=' and sys.byteorder == 'little':
+ scale = -scale
+
+ file.write('%f\n'.encode() % scale)
+
+ image.tofile(file)
+
+
+def read_image(path):
+ """Read image and output RGB image (0-1).
+
+ Args:
+ path (str): path to file
+
+ Returns:
+ array: RGB image (0-1)
+ """
+ img = cv2.imread(path)
+
+ if img.ndim == 2:
+ img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
+
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) / 255.0
+
+ return img
+
+
+def resize_image(img):
+ """Resize image and make it fit for network.
+
+ Args:
+ img (array): image
+
+ Returns:
+ tensor: data ready for network
+ """
+ height_orig = img.shape[0]
+ width_orig = img.shape[1]
+
+ if width_orig > height_orig:
+ scale = width_orig / 384
+ else:
+ scale = height_orig / 384
+
+ height = (np.ceil(height_orig / scale / 32) * 32).astype(int)
+ width = (np.ceil(width_orig / scale / 32) * 32).astype(int)
+
+ img_resized = cv2.resize(img, (width, height),
+ interpolation=cv2.INTER_AREA)
+
+ img_resized = (torch.from_numpy(np.transpose(
+ img_resized, (2, 0, 1))).contiguous().float())
+ img_resized = img_resized.unsqueeze(0)
+
+ return img_resized
+
+
+def resize_depth(depth, width, height):
+ """Resize depth map and bring to CPU (numpy).
+
+ Args:
+ depth (tensor): depth
+ width (int): image width
+ height (int): image height
+
+ Returns:
+ array: processed depth
+ """
+ depth = torch.squeeze(depth[0, :, :, :]).to('cpu')
+
+ depth_resized = cv2.resize(depth.numpy(), (width, height),
+ interpolation=cv2.INTER_CUBIC)
+
+ return depth_resized
+
+
+def write_depth(path, depth, bits=1):
+ """Write depth map to pfm and png file.
+
+ Args:
+ path (str): filepath without extension
+ depth (array): depth
+ """
+ write_pfm(path + '.pfm', depth.astype(np.float32))
+
+ depth_min = depth.min()
+ depth_max = depth.max()
+
+ max_val = (2**(8 * bits)) - 1
+
+ if depth_max - depth_min > np.finfo('float').eps:
+ out = max_val * (depth - depth_min) / (depth_max - depth_min)
+ else:
+ out = np.zeros(depth.shape, dtype=depth.type)
+
+ if bits == 1:
+ cv2.imwrite(path + '.png', out.astype('uint8'))
+ elif bits == 2:
+ cv2.imwrite(path + '.png', out.astype('uint16'))
+
+ return
diff --git a/annotator/midas/vit.py b/annotator/midas/vit.py
new file mode 100644
index 0000000000000000000000000000000000000000..4729b4bac4631fa8a882c6d4271dca0fb892df17
--- /dev/null
+++ b/annotator/midas/vit.py
@@ -0,0 +1,509 @@
+# -*- coding: utf-8 -*-
+import math
+import types
+
+import timm
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class Slice(nn.Module):
+ def __init__(self, start_index=1):
+ super(Slice, self).__init__()
+ self.start_index = start_index
+
+ def forward(self, x):
+ return x[:, self.start_index:]
+
+
+class AddReadout(nn.Module):
+ def __init__(self, start_index=1):
+ super(AddReadout, self).__init__()
+ self.start_index = start_index
+
+ def forward(self, x):
+ if self.start_index == 2:
+ readout = (x[:, 0] + x[:, 1]) / 2
+ else:
+ readout = x[:, 0]
+ return x[:, self.start_index:] + readout.unsqueeze(1)
+
+
+class ProjectReadout(nn.Module):
+ def __init__(self, in_features, start_index=1):
+ super(ProjectReadout, self).__init__()
+ self.start_index = start_index
+
+ self.project = nn.Sequential(nn.Linear(2 * in_features, in_features),
+ nn.GELU())
+
+ def forward(self, x):
+ readout = x[:, 0].unsqueeze(1).expand_as(x[:, self.start_index:])
+ features = torch.cat((x[:, self.start_index:], readout), -1)
+
+ return self.project(features)
+
+
+class Transpose(nn.Module):
+ def __init__(self, dim0, dim1):
+ super(Transpose, self).__init__()
+ self.dim0 = dim0
+ self.dim1 = dim1
+
+ def forward(self, x):
+ x = x.transpose(self.dim0, self.dim1)
+ return x
+
+
+def forward_vit(pretrained, x):
+ b, c, h, w = x.shape
+
+ _ = pretrained.model.forward_flex(x)
+
+ layer_1 = pretrained.activations['1']
+ layer_2 = pretrained.activations['2']
+ layer_3 = pretrained.activations['3']
+ layer_4 = pretrained.activations['4']
+
+ layer_1 = pretrained.act_postprocess1[0:2](layer_1)
+ layer_2 = pretrained.act_postprocess2[0:2](layer_2)
+ layer_3 = pretrained.act_postprocess3[0:2](layer_3)
+ layer_4 = pretrained.act_postprocess4[0:2](layer_4)
+
+ unflatten = nn.Sequential(
+ nn.Unflatten(
+ 2,
+ torch.Size([
+ h // pretrained.model.patch_size[1],
+ w // pretrained.model.patch_size[0],
+ ]),
+ ))
+
+ if layer_1.ndim == 3:
+ layer_1 = unflatten(layer_1)
+ if layer_2.ndim == 3:
+ layer_2 = unflatten(layer_2)
+ if layer_3.ndim == 3:
+ layer_3 = unflatten(layer_3)
+ if layer_4.ndim == 3:
+ layer_4 = unflatten(layer_4)
+
+ layer_1 = pretrained.act_postprocess1[3:len(pretrained.act_postprocess1)](
+ layer_1)
+ layer_2 = pretrained.act_postprocess2[3:len(pretrained.act_postprocess2)](
+ layer_2)
+ layer_3 = pretrained.act_postprocess3[3:len(pretrained.act_postprocess3)](
+ layer_3)
+ layer_4 = pretrained.act_postprocess4[3:len(pretrained.act_postprocess4)](
+ layer_4)
+
+ return layer_1, layer_2, layer_3, layer_4
+
+
+def _resize_pos_embed(self, posemb, gs_h, gs_w):
+ posemb_tok, posemb_grid = (
+ posemb[:, :self.start_index],
+ posemb[0, self.start_index:],
+ )
+
+ gs_old = int(math.sqrt(len(posemb_grid)))
+
+ posemb_grid = posemb_grid.reshape(1, gs_old, gs_old,
+ -1).permute(0, 3, 1, 2)
+ posemb_grid = F.interpolate(posemb_grid,
+ size=(gs_h, gs_w),
+ mode='bilinear')
+ posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_h * gs_w, -1)
+
+ posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
+
+ return posemb
+
+
+def forward_flex(self, x):
+ b, c, h, w = x.shape
+
+ pos_embed = self._resize_pos_embed(self.pos_embed, h // self.patch_size[1],
+ w // self.patch_size[0])
+
+ B = x.shape[0]
+
+ if hasattr(self.patch_embed, 'backbone'):
+ x = self.patch_embed.backbone(x)
+ if isinstance(x, (list, tuple)):
+ x = x[
+ -1] # last feature if backbone outputs list/tuple of features
+
+ x = self.patch_embed.proj(x).flatten(2).transpose(1, 2)
+
+ if getattr(self, 'dist_token', None) is not None:
+ cls_tokens = self.cls_token.expand(
+ B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
+ dist_token = self.dist_token.expand(B, -1, -1)
+ x = torch.cat((cls_tokens, dist_token, x), dim=1)
+ else:
+ cls_tokens = self.cls_token.expand(
+ B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
+ x = torch.cat((cls_tokens, x), dim=1)
+
+ x = x + pos_embed
+ x = self.pos_drop(x)
+
+ for blk in self.blocks:
+ x = blk(x)
+
+ x = self.norm(x)
+
+ return x
+
+
+activations = {}
+
+
+def get_activation(name):
+ def hook(model, input, output):
+ activations[name] = output
+
+ return hook
+
+
+def get_readout_oper(vit_features, features, use_readout, start_index=1):
+ if use_readout == 'ignore':
+ readout_oper = [Slice(start_index)] * len(features)
+ elif use_readout == 'add':
+ readout_oper = [AddReadout(start_index)] * len(features)
+ elif use_readout == 'project':
+ readout_oper = [
+ ProjectReadout(vit_features, start_index) for out_feat in features
+ ]
+ else:
+ assert (
+ False
+ ), "wrong operation for readout token, use_readout can be 'ignore', 'add', or 'project'"
+
+ return readout_oper
+
+
+def _make_vit_b16_backbone(
+ model,
+ features=[96, 192, 384, 768],
+ size=[384, 384],
+ hooks=[2, 5, 8, 11],
+ vit_features=768,
+ use_readout='ignore',
+ start_index=1,
+):
+ pretrained = nn.Module()
+
+ pretrained.model = model
+ pretrained.model.blocks[hooks[0]].register_forward_hook(
+ get_activation('1'))
+ pretrained.model.blocks[hooks[1]].register_forward_hook(
+ get_activation('2'))
+ pretrained.model.blocks[hooks[2]].register_forward_hook(
+ get_activation('3'))
+ pretrained.model.blocks[hooks[3]].register_forward_hook(
+ get_activation('4'))
+
+ pretrained.activations = activations
+
+ readout_oper = get_readout_oper(vit_features, features, use_readout,
+ start_index)
+
+ # 32, 48, 136, 384
+ pretrained.act_postprocess1 = nn.Sequential(
+ readout_oper[0],
+ Transpose(1, 2),
+ nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
+ nn.Conv2d(
+ in_channels=vit_features,
+ out_channels=features[0],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.ConvTranspose2d(
+ in_channels=features[0],
+ out_channels=features[0],
+ kernel_size=4,
+ stride=4,
+ padding=0,
+ bias=True,
+ dilation=1,
+ groups=1,
+ ),
+ )
+
+ pretrained.act_postprocess2 = nn.Sequential(
+ readout_oper[1],
+ Transpose(1, 2),
+ nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
+ nn.Conv2d(
+ in_channels=vit_features,
+ out_channels=features[1],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.ConvTranspose2d(
+ in_channels=features[1],
+ out_channels=features[1],
+ kernel_size=2,
+ stride=2,
+ padding=0,
+ bias=True,
+ dilation=1,
+ groups=1,
+ ),
+ )
+
+ pretrained.act_postprocess3 = nn.Sequential(
+ readout_oper[2],
+ Transpose(1, 2),
+ nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
+ nn.Conv2d(
+ in_channels=vit_features,
+ out_channels=features[2],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ )
+
+ pretrained.act_postprocess4 = nn.Sequential(
+ readout_oper[3],
+ Transpose(1, 2),
+ nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
+ nn.Conv2d(
+ in_channels=vit_features,
+ out_channels=features[3],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.Conv2d(
+ in_channels=features[3],
+ out_channels=features[3],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ ),
+ )
+
+ pretrained.model.start_index = start_index
+ pretrained.model.patch_size = [16, 16]
+
+ # We inject this function into the VisionTransformer instances so that
+ # we can use it with interpolated position embeddings without modifying the library source.
+ pretrained.model.forward_flex = types.MethodType(forward_flex,
+ pretrained.model)
+ pretrained.model._resize_pos_embed = types.MethodType(
+ _resize_pos_embed, pretrained.model)
+
+ return pretrained
+
+
+def _make_pretrained_vitl16_384(pretrained, use_readout='ignore', hooks=None):
+ model = timm.create_model('vit_large_patch16_384', pretrained=pretrained)
+
+ hooks = [5, 11, 17, 23] if hooks is None else hooks
+ return _make_vit_b16_backbone(
+ model,
+ features=[256, 512, 1024, 1024],
+ hooks=hooks,
+ vit_features=1024,
+ use_readout=use_readout,
+ )
+
+
+def _make_pretrained_vitb16_384(pretrained, use_readout='ignore', hooks=None):
+ model = timm.create_model('vit_base_patch16_384', pretrained=pretrained)
+
+ hooks = [2, 5, 8, 11] if hooks is None else hooks
+ return _make_vit_b16_backbone(model,
+ features=[96, 192, 384, 768],
+ hooks=hooks,
+ use_readout=use_readout)
+
+
+def _make_pretrained_deitb16_384(pretrained, use_readout='ignore', hooks=None):
+ model = timm.create_model('vit_deit_base_patch16_384',
+ pretrained=pretrained)
+
+ hooks = [2, 5, 8, 11] if hooks is None else hooks
+ return _make_vit_b16_backbone(model,
+ features=[96, 192, 384, 768],
+ hooks=hooks,
+ use_readout=use_readout)
+
+
+def _make_pretrained_deitb16_distil_384(pretrained,
+ use_readout='ignore',
+ hooks=None):
+ model = timm.create_model('vit_deit_base_distilled_patch16_384',
+ pretrained=pretrained)
+
+ hooks = [2, 5, 8, 11] if hooks is None else hooks
+ return _make_vit_b16_backbone(
+ model,
+ features=[96, 192, 384, 768],
+ hooks=hooks,
+ use_readout=use_readout,
+ start_index=2,
+ )
+
+
+def _make_vit_b_rn50_backbone(
+ model,
+ features=[256, 512, 768, 768],
+ size=[384, 384],
+ hooks=[0, 1, 8, 11],
+ vit_features=768,
+ use_vit_only=False,
+ use_readout='ignore',
+ start_index=1,
+):
+ pretrained = nn.Module()
+
+ pretrained.model = model
+
+ if use_vit_only is True:
+ pretrained.model.blocks[hooks[0]].register_forward_hook(
+ get_activation('1'))
+ pretrained.model.blocks[hooks[1]].register_forward_hook(
+ get_activation('2'))
+ else:
+ pretrained.model.patch_embed.backbone.stages[0].register_forward_hook(
+ get_activation('1'))
+ pretrained.model.patch_embed.backbone.stages[1].register_forward_hook(
+ get_activation('2'))
+
+ pretrained.model.blocks[hooks[2]].register_forward_hook(
+ get_activation('3'))
+ pretrained.model.blocks[hooks[3]].register_forward_hook(
+ get_activation('4'))
+
+ pretrained.activations = activations
+
+ readout_oper = get_readout_oper(vit_features, features, use_readout,
+ start_index)
+
+ if use_vit_only is True:
+ pretrained.act_postprocess1 = nn.Sequential(
+ readout_oper[0],
+ Transpose(1, 2),
+ nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
+ nn.Conv2d(
+ in_channels=vit_features,
+ out_channels=features[0],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.ConvTranspose2d(
+ in_channels=features[0],
+ out_channels=features[0],
+ kernel_size=4,
+ stride=4,
+ padding=0,
+ bias=True,
+ dilation=1,
+ groups=1,
+ ),
+ )
+
+ pretrained.act_postprocess2 = nn.Sequential(
+ readout_oper[1],
+ Transpose(1, 2),
+ nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
+ nn.Conv2d(
+ in_channels=vit_features,
+ out_channels=features[1],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.ConvTranspose2d(
+ in_channels=features[1],
+ out_channels=features[1],
+ kernel_size=2,
+ stride=2,
+ padding=0,
+ bias=True,
+ dilation=1,
+ groups=1,
+ ),
+ )
+ else:
+ pretrained.act_postprocess1 = nn.Sequential(nn.Identity(),
+ nn.Identity(),
+ nn.Identity())
+ pretrained.act_postprocess2 = nn.Sequential(nn.Identity(),
+ nn.Identity(),
+ nn.Identity())
+
+ pretrained.act_postprocess3 = nn.Sequential(
+ readout_oper[2],
+ Transpose(1, 2),
+ nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
+ nn.Conv2d(
+ in_channels=vit_features,
+ out_channels=features[2],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ )
+
+ pretrained.act_postprocess4 = nn.Sequential(
+ readout_oper[3],
+ Transpose(1, 2),
+ nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
+ nn.Conv2d(
+ in_channels=vit_features,
+ out_channels=features[3],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.Conv2d(
+ in_channels=features[3],
+ out_channels=features[3],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ ),
+ )
+
+ pretrained.model.start_index = start_index
+ pretrained.model.patch_size = [16, 16]
+
+ # We inject this function into the VisionTransformer instances so that
+ # we can use it with interpolated position embeddings without modifying the library source.
+ pretrained.model.forward_flex = types.MethodType(forward_flex,
+ pretrained.model)
+
+ # We inject this function into the VisionTransformer instances so that
+ # we can use it with interpolated position embeddings without modifying the library source.
+ pretrained.model._resize_pos_embed = types.MethodType(
+ _resize_pos_embed, pretrained.model)
+
+ return pretrained
+
+
+def _make_pretrained_vitb_rn50_384(pretrained,
+ use_readout='ignore',
+ hooks=None,
+ use_vit_only=False):
+ model = timm.create_model('vit_base_resnet50_384', pretrained=pretrained)
+
+ hooks = [0, 1, 8, 11] if hooks is None else hooks
+ return _make_vit_b_rn50_backbone(
+ model,
+ features=[256, 512, 768, 768],
+ size=[384, 384],
+ hooks=hooks,
+ use_vit_only=use_vit_only,
+ use_readout=use_readout,
+ )
diff --git a/annotator/midas_op.py b/annotator/midas_op.py
new file mode 100644
index 0000000000000000000000000000000000000000..af9e47a3e787c483a2cf6ffccf92d2a3669e0bbf
--- /dev/null
+++ b/annotator/midas_op.py
@@ -0,0 +1,79 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+# Midas Depth Estimation
+# From https://github.com/isl-org/MiDaS
+# MIT LICENSE
+from abc import ABCMeta
+
+import numpy as np
+import torch
+from einops import rearrange
+from PIL import Image
+
+from scepter.modules.annotator.base_annotator import BaseAnnotator
+from scepter.modules.annotator.midas.api import MiDaSInference
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.annotator.utils import resize_image, resize_image_ori
+from scepter.modules.utils.config import dict_to_yaml
+from scepter.modules.utils.distribute import we
+from scepter.modules.utils.file_system import FS
+
+
+@ANNOTATORS.register_class()
+class MidasDetector(BaseAnnotator, metaclass=ABCMeta):
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+ pretrained_model = cfg.get('PRETRAINED_MODEL', None)
+ if pretrained_model:
+ with FS.get_from(pretrained_model, wait_finish=True) as local_path:
+ self.model = MiDaSInference(model_type='dpt_hybrid',
+ model_path=local_path)
+ self.a = cfg.get('A', np.pi * 2.0)
+ self.bg_th = cfg.get('BG_TH', 0.1)
+
+ @torch.no_grad()
+ @torch.inference_mode()
+ @torch.autocast('cuda', enabled=False)
+ def forward(self, image):
+ if isinstance(image, Image.Image):
+ image = np.array(image)
+ elif isinstance(image, torch.Tensor):
+ image = image.detach().cpu().numpy()
+ elif isinstance(image, np.ndarray):
+ image = image.copy()
+ else:
+ raise f'Unsurpport datatype{type(image)}, only surpport np.ndarray, torch.Tensor, Pillow Image.'
+ image_depth = image
+ h, w, c = image.shape
+ image_depth, k = resize_image(image_depth,
+ 1024 if min(h, w) > 1024 else min(h, w))
+ image_depth = torch.from_numpy(image_depth).float().to(we.device_id)
+ image_depth = image_depth / 127.5 - 1.0
+ image_depth = rearrange(image_depth, 'h w c -> 1 c h w')
+ depth = self.model(image_depth)[0]
+
+ depth_pt = depth.clone()
+ depth_pt -= torch.min(depth_pt)
+ depth_pt /= torch.max(depth_pt)
+ depth_pt = depth_pt.cpu().numpy()
+ depth_image = (depth_pt * 255.0).clip(0, 255).astype(np.uint8)
+ depth_image = depth_image[..., None].repeat(3, 2)
+
+ # depth_np = depth.cpu().numpy() # float16 error
+ # x = cv2.Sobel(depth_np, cv2.CV_32F, 1, 0, ksize=3)
+ # y = cv2.Sobel(depth_np, cv2.CV_32F, 0, 1, ksize=3)
+ # z = np.ones_like(x) * self.a
+ # x[depth_pt < self.bg_th] = 0
+ # y[depth_pt < self.bg_th] = 0
+ # normal = np.stack([x, y, z], axis=2)
+ # normal /= np.sum(normal**2.0, axis=2, keepdims=True)**0.5
+ # normal_image = (normal * 127.5 + 127.5).clip(0, 255).astype(np.uint8)
+ depth_image = resize_image_ori(h, w, depth_image, k)
+ return depth_image
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ MidasDetector.para_dict,
+ set_name=True)
diff --git a/annotator/mlsd/__init__.py b/annotator/mlsd/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/annotator/mlsd/mbv2_mlsd_large.py b/annotator/mlsd/mbv2_mlsd_large.py
new file mode 100644
index 0000000000000000000000000000000000000000..7555e9319339b16a55f2d3af422d6f4aa84dd9cd
--- /dev/null
+++ b/annotator/mlsd/mbv2_mlsd_large.py
@@ -0,0 +1,303 @@
+# -*- coding: utf-8 -*-
+
+import torch
+import torch.nn as nn
+import torch.utils.model_zoo as model_zoo
+from torch.nn import functional as F
+
+
+class BlockTypeA(nn.Module):
+ def __init__(self, in_c1, in_c2, out_c1, out_c2, upscale=True):
+ super(BlockTypeA, self).__init__()
+ self.conv1 = nn.Sequential(nn.Conv2d(in_c2, out_c2, kernel_size=1),
+ nn.BatchNorm2d(out_c2),
+ nn.ReLU(inplace=True))
+ self.conv2 = nn.Sequential(nn.Conv2d(in_c1, out_c1, kernel_size=1),
+ nn.BatchNorm2d(out_c1),
+ nn.ReLU(inplace=True))
+ self.upscale = upscale
+
+ def forward(self, a, b):
+ b = self.conv1(b)
+ a = self.conv2(a)
+ if self.upscale:
+ b = F.interpolate(b,
+ scale_factor=2.0,
+ mode='bilinear',
+ align_corners=True)
+ return torch.cat((a, b), dim=1)
+
+
+class BlockTypeB(nn.Module):
+ def __init__(self, in_c, out_c):
+ super(BlockTypeB, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
+ nn.BatchNorm2d(in_c), nn.ReLU())
+ self.conv2 = nn.Sequential(
+ nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
+ nn.BatchNorm2d(out_c), nn.ReLU())
+
+ def forward(self, x):
+ x = self.conv1(x) + x
+ x = self.conv2(x)
+ return x
+
+
+class BlockTypeC(nn.Module):
+ def __init__(self, in_c, out_c):
+ super(BlockTypeC, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.Conv2d(in_c, in_c, kernel_size=3, padding=5, dilation=5),
+ nn.BatchNorm2d(in_c), nn.ReLU())
+ self.conv2 = nn.Sequential(
+ nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
+ nn.BatchNorm2d(in_c), nn.ReLU())
+ self.conv3 = nn.Conv2d(in_c, out_c, kernel_size=1)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.conv2(x)
+ x = self.conv3(x)
+ return x
+
+
+def _make_divisible(v, divisor, min_value=None):
+ """
+ This function is taken from the original tf repo.
+ It ensures that all layers have a channel number that is divisible by 8
+ It can be seen here:
+ https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
+ :param v:
+ :param divisor:
+ :param min_value:
+ :return:
+ """
+ if min_value is None:
+ min_value = divisor
+ new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than 10%.
+ if new_v < 0.9 * v:
+ new_v += divisor
+ return new_v
+
+
+class ConvBNReLU(nn.Sequential):
+ def __init__(self,
+ in_planes,
+ out_planes,
+ kernel_size=3,
+ stride=1,
+ groups=1):
+ self.channel_pad = out_planes - in_planes
+ self.stride = stride
+ # padding = (kernel_size - 1) // 2
+
+ # TFLite uses slightly different padding than PyTorch
+ if stride == 2:
+ padding = 0
+ else:
+ padding = (kernel_size - 1) // 2
+
+ super(ConvBNReLU, self).__init__(
+ nn.Conv2d(in_planes,
+ out_planes,
+ kernel_size,
+ stride,
+ padding,
+ groups=groups,
+ bias=False), nn.BatchNorm2d(out_planes),
+ nn.ReLU6(inplace=True))
+ self.max_pool = nn.MaxPool2d(kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ # TFLite uses different padding
+ if self.stride == 2:
+ x = F.pad(x, (0, 1, 0, 1), 'constant', 0)
+ # print(x.shape)
+
+ for module in self:
+ if not isinstance(module, nn.MaxPool2d):
+ x = module(x)
+ return x
+
+
+class InvertedResidual(nn.Module):
+ def __init__(self, inp, oup, stride, expand_ratio):
+ super(InvertedResidual, self).__init__()
+ self.stride = stride
+ assert stride in [1, 2]
+
+ hidden_dim = int(round(inp * expand_ratio))
+ self.use_res_connect = self.stride == 1 and inp == oup
+
+ layers = []
+ if expand_ratio != 1:
+ # pw
+ layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
+ layers.extend([
+ # dw
+ ConvBNReLU(hidden_dim,
+ hidden_dim,
+ stride=stride,
+ groups=hidden_dim),
+ # pw-linear
+ nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
+ nn.BatchNorm2d(oup),
+ ])
+ self.conv = nn.Sequential(*layers)
+
+ def forward(self, x):
+ if self.use_res_connect:
+ return x + self.conv(x)
+ else:
+ return self.conv(x)
+
+
+class MobileNetV2(nn.Module):
+ def __init__(self, pretrained=True):
+ """
+ MobileNet V2 main class
+ Args:
+ num_classes (int): Number of classes
+ width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
+ inverted_residual_setting: Network structure
+ round_nearest (int): Round the number of channels in each layer to be a multiple of this number
+ Set to 1 to turn off rounding
+ block: Module specifying inverted residual building block for mobilenet
+ """
+ super(MobileNetV2, self).__init__()
+
+ block = InvertedResidual
+ input_channel = 32
+ last_channel = 1280
+ width_mult = 1.0
+ round_nearest = 8
+
+ inverted_residual_setting = [
+ # t, c, n, s
+ [1, 16, 1, 1],
+ [6, 24, 2, 2],
+ [6, 32, 3, 2],
+ [6, 64, 4, 2],
+ [6, 96, 3, 1],
+ # [6, 160, 3, 2],
+ # [6, 320, 1, 1],
+ ]
+
+ # only check the first element, assuming user knows t,c,n,s are required
+ if len(inverted_residual_setting) == 0 or len(
+ inverted_residual_setting[0]) != 4:
+ raise ValueError('inverted_residual_setting should be non-empty '
+ 'or a 4-element list, got {}'.format(
+ inverted_residual_setting))
+
+ # building first layer
+ input_channel = _make_divisible(input_channel * width_mult,
+ round_nearest)
+ self.last_channel = _make_divisible(
+ last_channel * max(1.0, width_mult), round_nearest)
+ features = [ConvBNReLU(4, input_channel, stride=2)]
+ # building inverted residual blocks
+ for t, c, n, s in inverted_residual_setting:
+ output_channel = _make_divisible(c * width_mult, round_nearest)
+ for i in range(n):
+ stride = s if i == 0 else 1
+ features.append(
+ block(input_channel,
+ output_channel,
+ stride,
+ expand_ratio=t))
+ input_channel = output_channel
+
+ self.features = nn.Sequential(*features)
+ self.fpn_selected = [1, 3, 6, 10, 13]
+ # weight initialization
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight, mode='fan_out')
+ if m.bias is not None:
+ nn.init.zeros_(m.bias)
+ elif isinstance(m, nn.BatchNorm2d):
+ nn.init.ones_(m.weight)
+ nn.init.zeros_(m.bias)
+ elif isinstance(m, nn.Linear):
+ nn.init.normal_(m.weight, 0, 0.01)
+ nn.init.zeros_(m.bias)
+ if pretrained:
+ self._load_pretrained_model()
+
+ def _forward_impl(self, x):
+ # This exists since TorchScript doesn't support inheritance, so the superclass method
+ # (this one) needs to have a name other than `forward` that can be accessed in a subclass
+ fpn_features = []
+ for i, f in enumerate(self.features):
+ if i > self.fpn_selected[-1]:
+ break
+ x = f(x)
+ if i in self.fpn_selected:
+ fpn_features.append(x)
+
+ c1, c2, c3, c4, c5 = fpn_features
+ return c1, c2, c3, c4, c5
+
+ def forward(self, x):
+ return self._forward_impl(x)
+
+ def _load_pretrained_model(self):
+ pretrain_dict = model_zoo.load_url(
+ 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth')
+ model_dict = {}
+ state_dict = self.state_dict()
+ for k, v in pretrain_dict.items():
+ if k in state_dict:
+ model_dict[k] = v
+ state_dict.update(model_dict)
+ self.load_state_dict(state_dict)
+
+
+class MobileV2_MLSD_Large(nn.Module):
+ def __init__(self):
+ super(MobileV2_MLSD_Large, self).__init__()
+
+ self.backbone = MobileNetV2(pretrained=False)
+ # A, B
+ self.block15 = BlockTypeA(in_c1=64,
+ in_c2=96,
+ out_c1=64,
+ out_c2=64,
+ upscale=False)
+ self.block16 = BlockTypeB(128, 64)
+
+ # A, B
+ self.block17 = BlockTypeA(in_c1=32, in_c2=64, out_c1=64, out_c2=64)
+ self.block18 = BlockTypeB(128, 64)
+
+ # A, B
+ self.block19 = BlockTypeA(in_c1=24, in_c2=64, out_c1=64, out_c2=64)
+ self.block20 = BlockTypeB(128, 64)
+
+ # A, B, C
+ self.block21 = BlockTypeA(in_c1=16, in_c2=64, out_c1=64, out_c2=64)
+ self.block22 = BlockTypeB(128, 64)
+
+ self.block23 = BlockTypeC(64, 16)
+
+ def forward(self, x):
+ c1, c2, c3, c4, c5 = self.backbone(x)
+
+ x = self.block15(c4, c5)
+ x = self.block16(x)
+
+ x = self.block17(c3, x)
+ x = self.block18(x)
+
+ x = self.block19(c2, x)
+ x = self.block20(x)
+
+ x = self.block21(c1, x)
+ x = self.block22(x)
+ x = self.block23(x)
+ x = x[:, 7:, :, :]
+
+ return x
diff --git a/annotator/mlsd/mbv2_mlsd_tiny.py b/annotator/mlsd/mbv2_mlsd_tiny.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e906c5c6c8baa83a07727615796e87a8ecaf923
--- /dev/null
+++ b/annotator/mlsd/mbv2_mlsd_tiny.py
@@ -0,0 +1,287 @@
+# -*- coding: utf-8 -*-
+import torch
+import torch.nn as nn
+import torch.utils.model_zoo as model_zoo
+from torch.nn import functional as F
+
+
+class BlockTypeA(nn.Module):
+ def __init__(self, in_c1, in_c2, out_c1, out_c2, upscale=True):
+ super(BlockTypeA, self).__init__()
+ self.conv1 = nn.Sequential(nn.Conv2d(in_c2, out_c2, kernel_size=1),
+ nn.BatchNorm2d(out_c2),
+ nn.ReLU(inplace=True))
+ self.conv2 = nn.Sequential(nn.Conv2d(in_c1, out_c1, kernel_size=1),
+ nn.BatchNorm2d(out_c1),
+ nn.ReLU(inplace=True))
+ self.upscale = upscale
+
+ def forward(self, a, b):
+ b = self.conv1(b)
+ a = self.conv2(a)
+ b = F.interpolate(b,
+ scale_factor=2.0,
+ mode='bilinear',
+ align_corners=True)
+ return torch.cat((a, b), dim=1)
+
+
+class BlockTypeB(nn.Module):
+ def __init__(self, in_c, out_c):
+ super(BlockTypeB, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
+ nn.BatchNorm2d(in_c), nn.ReLU())
+ self.conv2 = nn.Sequential(
+ nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
+ nn.BatchNorm2d(out_c), nn.ReLU())
+
+ def forward(self, x):
+ x = self.conv1(x) + x
+ x = self.conv2(x)
+ return x
+
+
+class BlockTypeC(nn.Module):
+ def __init__(self, in_c, out_c):
+ super(BlockTypeC, self).__init__()
+ self.conv1 = nn.Sequential(
+ nn.Conv2d(in_c, in_c, kernel_size=3, padding=5, dilation=5),
+ nn.BatchNorm2d(in_c), nn.ReLU())
+ self.conv2 = nn.Sequential(
+ nn.Conv2d(in_c, in_c, kernel_size=3, padding=1),
+ nn.BatchNorm2d(in_c), nn.ReLU())
+ self.conv3 = nn.Conv2d(in_c, out_c, kernel_size=1)
+
+ def forward(self, x):
+ x = self.conv1(x)
+ x = self.conv2(x)
+ x = self.conv3(x)
+ return x
+
+
+def _make_divisible(v, divisor, min_value=None):
+ """
+ This function is taken from the original tf repo.
+ It ensures that all layers have a channel number that is divisible by 8
+ It can be seen here:
+ https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
+ :param v:
+ :param divisor:
+ :param min_value:
+ :return:
+ """
+ if min_value is None:
+ min_value = divisor
+ new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than 10%.
+ if new_v < 0.9 * v:
+ new_v += divisor
+ return new_v
+
+
+class ConvBNReLU(nn.Sequential):
+ def __init__(self,
+ in_planes,
+ out_planes,
+ kernel_size=3,
+ stride=1,
+ groups=1):
+ self.channel_pad = out_planes - in_planes
+ self.stride = stride
+ # padding = (kernel_size - 1) // 2
+
+ # TFLite uses slightly different padding than PyTorch
+ if stride == 2:
+ padding = 0
+ else:
+ padding = (kernel_size - 1) // 2
+
+ super(ConvBNReLU, self).__init__(
+ nn.Conv2d(in_planes,
+ out_planes,
+ kernel_size,
+ stride,
+ padding,
+ groups=groups,
+ bias=False), nn.BatchNorm2d(out_planes),
+ nn.ReLU6(inplace=True))
+ self.max_pool = nn.MaxPool2d(kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ # TFLite uses different padding
+ if self.stride == 2:
+ x = F.pad(x, (0, 1, 0, 1), 'constant', 0)
+ # print(x.shape)
+
+ for module in self:
+ if not isinstance(module, nn.MaxPool2d):
+ x = module(x)
+ return x
+
+
+class InvertedResidual(nn.Module):
+ def __init__(self, inp, oup, stride, expand_ratio):
+ super(InvertedResidual, self).__init__()
+ self.stride = stride
+ assert stride in [1, 2]
+
+ hidden_dim = int(round(inp * expand_ratio))
+ self.use_res_connect = self.stride == 1 and inp == oup
+
+ layers = []
+ if expand_ratio != 1:
+ # pw
+ layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
+ layers.extend([
+ # dw
+ ConvBNReLU(hidden_dim,
+ hidden_dim,
+ stride=stride,
+ groups=hidden_dim),
+ # pw-linear
+ nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
+ nn.BatchNorm2d(oup),
+ ])
+ self.conv = nn.Sequential(*layers)
+
+ def forward(self, x):
+ if self.use_res_connect:
+ return x + self.conv(x)
+ else:
+ return self.conv(x)
+
+
+class MobileNetV2(nn.Module):
+ def __init__(self, pretrained=True):
+ """
+ MobileNet V2 main class
+ Args:
+ num_classes (int): Number of classes
+ width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
+ inverted_residual_setting: Network structure
+ round_nearest (int): Round the number of channels in each layer to be a multiple of this number
+ Set to 1 to turn off rounding
+ block: Module specifying inverted residual building block for mobilenet
+ """
+ super(MobileNetV2, self).__init__()
+
+ block = InvertedResidual
+ input_channel = 32
+ last_channel = 1280
+ width_mult = 1.0
+ round_nearest = 8
+
+ inverted_residual_setting = [
+ # t, c, n, s
+ [1, 16, 1, 1],
+ [6, 24, 2, 2],
+ [6, 32, 3, 2],
+ [6, 64, 4, 2],
+ # [6, 96, 3, 1],
+ # [6, 160, 3, 2],
+ # [6, 320, 1, 1],
+ ]
+
+ # only check the first element, assuming user knows t,c,n,s are required
+ if len(inverted_residual_setting) == 0 or len(
+ inverted_residual_setting[0]) != 4:
+ raise ValueError('inverted_residual_setting should be non-empty '
+ 'or a 4-element list, got {}'.format(
+ inverted_residual_setting))
+
+ # building first layer
+ input_channel = _make_divisible(input_channel * width_mult,
+ round_nearest)
+ self.last_channel = _make_divisible(
+ last_channel * max(1.0, width_mult), round_nearest)
+ features = [ConvBNReLU(4, input_channel, stride=2)]
+ # building inverted residual blocks
+ for t, c, n, s in inverted_residual_setting:
+ output_channel = _make_divisible(c * width_mult, round_nearest)
+ for i in range(n):
+ stride = s if i == 0 else 1
+ features.append(
+ block(input_channel,
+ output_channel,
+ stride,
+ expand_ratio=t))
+ input_channel = output_channel
+ self.features = nn.Sequential(*features)
+
+ self.fpn_selected = [3, 6, 10]
+ # weight initialization
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight, mode='fan_out')
+ if m.bias is not None:
+ nn.init.zeros_(m.bias)
+ elif isinstance(m, nn.BatchNorm2d):
+ nn.init.ones_(m.weight)
+ nn.init.zeros_(m.bias)
+ elif isinstance(m, nn.Linear):
+ nn.init.normal_(m.weight, 0, 0.01)
+ nn.init.zeros_(m.bias)
+
+ # if pretrained:
+ # self._load_pretrained_model()
+
+ def _forward_impl(self, x):
+ # This exists since TorchScript doesn't support inheritance, so the superclass method
+ # (this one) needs to have a name other than `forward` that can be accessed in a subclass
+ fpn_features = []
+ for i, f in enumerate(self.features):
+ if i > self.fpn_selected[-1]:
+ break
+ x = f(x)
+ if i in self.fpn_selected:
+ fpn_features.append(x)
+
+ c2, c3, c4 = fpn_features
+ return c2, c3, c4
+
+ def forward(self, x):
+ return self._forward_impl(x)
+
+ def _load_pretrained_model(self):
+ pretrain_dict = model_zoo.load_url(
+ 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth')
+ model_dict = {}
+ state_dict = self.state_dict()
+ for k, v in pretrain_dict.items():
+ if k in state_dict:
+ model_dict[k] = v
+ state_dict.update(model_dict)
+ self.load_state_dict(state_dict)
+
+
+class MobileV2_MLSD_Tiny(nn.Module):
+ def __init__(self):
+ super(MobileV2_MLSD_Tiny, self).__init__()
+
+ self.backbone = MobileNetV2(pretrained=True)
+
+ self.block12 = BlockTypeA(in_c1=32, in_c2=64, out_c1=64, out_c2=64)
+ self.block13 = BlockTypeB(128, 64)
+
+ self.block14 = BlockTypeA(in_c1=24, in_c2=64, out_c1=32, out_c2=32)
+ self.block15 = BlockTypeB(64, 64)
+
+ self.block16 = BlockTypeC(64, 16)
+
+ def forward(self, x):
+ c2, c3, c4 = self.backbone(x)
+
+ x = self.block12(c3, c4)
+ x = self.block13(x)
+ x = self.block14(c2, x)
+ x = self.block15(x)
+ x = self.block16(x)
+ x = x[:, 7:, :, :]
+ # print(x.shape)
+ x = F.interpolate(x,
+ scale_factor=2.0,
+ mode='bilinear',
+ align_corners=True)
+
+ return x
diff --git a/annotator/mlsd/utils.py b/annotator/mlsd/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..83bad84b23ce7867dc5c001d7fa9732f3ac6c26a
--- /dev/null
+++ b/annotator/mlsd/utils.py
@@ -0,0 +1,638 @@
+# -*- coding: utf-8 -*-
+
+# modified by lihaoweicv
+# pytorch version
+#
+# M-LSD
+# Copyright 2021-present NAVER Corp.
+# Apache License v2.0
+
+import cv2
+import numpy as np
+import torch
+from torch.nn import functional as F
+
+
+def deccode_output_score_and_ptss(tpMap, topk_n=200, ksize=5):
+ '''
+ tpMap:
+ center: tpMap[1, 0, :, :]
+ displacement: tpMap[1, 1:5, :, :]
+ '''
+ b, c, h, w = tpMap.shape
+ assert b == 1, 'only support bsize==1'
+ displacement = tpMap[:, 1:5, :, :][0]
+ center = tpMap[:, 0, :, :]
+ heat = torch.sigmoid(center)
+ hmax = F.max_pool2d(heat, (ksize, ksize),
+ stride=1,
+ padding=(ksize - 1) // 2)
+ keep = (hmax == heat).float()
+ heat = heat * keep
+ heat = heat.reshape(-1, )
+
+ scores, indices = torch.topk(heat, topk_n, dim=-1, largest=True)
+ yy = torch.floor_divide(indices, w).unsqueeze(-1)
+ xx = torch.fmod(indices, w).unsqueeze(-1)
+ ptss = torch.cat((yy, xx), dim=-1)
+
+ ptss = ptss.detach().cpu().numpy()
+ scores = scores.detach().cpu().numpy()
+ displacement = displacement.detach().cpu().numpy()
+ displacement = displacement.transpose((1, 2, 0))
+ return ptss, scores, displacement
+
+
+def pred_lines(image,
+ model,
+ input_shape=[512, 512],
+ score_thr=0.10,
+ dist_thr=20.0,
+ device='cuda'):
+ h, w, _ = image.shape
+ h_ratio, w_ratio = [h / input_shape[0], w / input_shape[1]]
+
+ resized_image = np.concatenate([
+ cv2.resize(image, (input_shape[1], input_shape[0]),
+ interpolation=cv2.INTER_AREA),
+ np.ones([input_shape[0], input_shape[1], 1])
+ ],
+ axis=-1)
+
+ resized_image = resized_image.transpose((2, 0, 1))
+ batch_image = np.expand_dims(resized_image, axis=0).astype('float32')
+ batch_image = (batch_image / 127.5) - 1.0
+
+ batch_image = torch.from_numpy(batch_image).float().to(device)
+ outputs = model(batch_image)
+ pts, pts_score, vmap = deccode_output_score_and_ptss(outputs, 200, 3)
+ start = vmap[:, :, :2]
+ end = vmap[:, :, 2:]
+ dist_map = np.sqrt(np.sum((start - end)**2, axis=-1))
+
+ segments_list = []
+ for center, score in zip(pts, pts_score):
+ y, x = center
+ distance = dist_map[y, x]
+ if score > score_thr and distance > dist_thr:
+ disp_x_start, disp_y_start, disp_x_end, disp_y_end = vmap[y, x, :]
+ x_start = x + disp_x_start
+ y_start = y + disp_y_start
+ x_end = x + disp_x_end
+ y_end = y + disp_y_end
+ segments_list.append([x_start, y_start, x_end, y_end])
+
+ lines = 2 * np.array(segments_list) # 256 > 512
+ lines[:, 0] = lines[:, 0] * w_ratio
+ lines[:, 1] = lines[:, 1] * h_ratio
+ lines[:, 2] = lines[:, 2] * w_ratio
+ lines[:, 3] = lines[:, 3] * h_ratio
+
+ return lines
+
+
+def pred_squares(
+ image,
+ model,
+ input_shape=[512, 512],
+ device='cuda',
+ params={
+ 'score': 0.06,
+ 'outside_ratio': 0.28,
+ 'inside_ratio': 0.45,
+ 'w_overlap': 0.0,
+ 'w_degree': 1.95,
+ 'w_length': 0.0,
+ 'w_area': 1.86,
+ 'w_center': 0.14
+ }): # noqa
+ # shape = [height, width]
+ h, w, _ = image.shape
+ original_shape = [h, w]
+
+ resized_image = np.concatenate([
+ cv2.resize(image, (input_shape[0], input_shape[1]),
+ interpolation=cv2.INTER_AREA),
+ np.ones([input_shape[0], input_shape[1], 1])
+ ],
+ axis=-1)
+ resized_image = resized_image.transpose((2, 0, 1))
+ batch_image = np.expand_dims(resized_image, axis=0).astype('float32')
+ batch_image = (batch_image / 127.5) - 1.0
+
+ batch_image = torch.from_numpy(batch_image).float().to(device)
+ outputs = model(batch_image)
+
+ pts, pts_score, vmap = deccode_output_score_and_ptss(outputs, 200, 3)
+ start = vmap[:, :, :2] # (x, y)
+ end = vmap[:, :, 2:] # (x, y)
+ dist_map = np.sqrt(np.sum((start - end)**2, axis=-1))
+
+ junc_list = []
+ segments_list = []
+ for junc, score in zip(pts, pts_score):
+ y, x = junc
+ distance = dist_map[y, x]
+ if score > params['score'] and distance > 20.0:
+ junc_list.append([x, y])
+ disp_x_start, disp_y_start, disp_x_end, disp_y_end = vmap[y, x, :]
+ d_arrow = 1.0
+ x_start = x + d_arrow * disp_x_start
+ y_start = y + d_arrow * disp_y_start
+ x_end = x + d_arrow * disp_x_end
+ y_end = y + d_arrow * disp_y_end
+ segments_list.append([x_start, y_start, x_end, y_end])
+
+ segments = np.array(segments_list)
+
+ # post processing for squares
+ # 1. get unique lines
+ point = np.array([[0, 0]])
+ point = point[0]
+ start = segments[:, :2]
+ end = segments[:, 2:]
+ diff = start - end
+ a = diff[:, 1]
+ b = -diff[:, 0]
+ c = a * start[:, 0] + b * start[:, 1]
+
+ d = np.abs(a * point[0] + b * point[1] - c) / np.sqrt(a**2 + b**2 + 1e-10)
+ theta = np.arctan2(diff[:, 0], diff[:, 1]) * 180 / np.pi
+ theta[theta < 0.0] += 180
+ hough = np.concatenate([d[:, None], theta[:, None]], axis=-1)
+
+ d_quant = 1
+ theta_quant = 2
+ hough[:, 0] //= d_quant
+ hough[:, 1] //= theta_quant
+ _, indices, counts = np.unique(hough,
+ axis=0,
+ return_index=True,
+ return_counts=True)
+
+ acc_map = np.zeros([512 // d_quant + 1, 360 // theta_quant + 1],
+ dtype='float32')
+ idx_map = np.zeros([512 // d_quant + 1, 360 // theta_quant + 1],
+ dtype='int32') - 1
+ yx_indices = hough[indices, :].astype('int32')
+ acc_map[yx_indices[:, 0], yx_indices[:, 1]] = counts
+ idx_map[yx_indices[:, 0], yx_indices[:, 1]] = indices
+
+ acc_map_np = acc_map
+ # acc_map = acc_map[None, :, :, None]
+ #
+ # ### fast suppression using tensorflow op
+ # acc_map = tf.constant(acc_map, dtype=tf.float32)
+ # max_acc_map = tf.keras.layers.MaxPool2D(pool_size=(5, 5), strides=1, padding='same')(acc_map)
+ # acc_map = acc_map * tf.cast(tf.math.equal(acc_map, max_acc_map), tf.float32)
+ # flatten_acc_map = tf.reshape(acc_map, [1, -1])
+ # topk_values, topk_indices = tf.math.top_k(flatten_acc_map, k=len(pts))
+ # _, h, w, _ = acc_map.shape
+ # y = tf.expand_dims(topk_indices // w, axis=-1)
+ # x = tf.expand_dims(topk_indices % w, axis=-1)
+ # yx = tf.concat([y, x], axis=-1)
+
+ # fast suppression using pytorch op
+ acc_map = torch.from_numpy(acc_map_np).unsqueeze(0).unsqueeze(0)
+ _, _, h, w = acc_map.shape
+ max_acc_map = F.max_pool2d(acc_map, kernel_size=5, stride=1, padding=2)
+ acc_map = acc_map * ((acc_map == max_acc_map).float())
+ flatten_acc_map = acc_map.reshape([
+ -1,
+ ])
+
+ scores, indices = torch.topk(flatten_acc_map,
+ len(pts),
+ dim=-1,
+ largest=True)
+ yy = torch.div(indices, w, rounding_mode='floor').unsqueeze(-1)
+ xx = torch.fmod(indices, w).unsqueeze(-1)
+ yx = torch.cat((yy, xx), dim=-1)
+
+ yx = yx.detach().cpu().numpy()
+
+ topk_values = scores.detach().cpu().numpy()
+ indices = idx_map[yx[:, 0], yx[:, 1]]
+ basis = 5 // 2
+
+ merged_segments = []
+ for yx_pt, max_indice, value in zip(yx, indices, topk_values):
+ y, x = yx_pt
+ if max_indice == -1 or value == 0:
+ continue
+ segment_list = []
+ for y_offset in range(-basis, basis + 1):
+ for x_offset in range(-basis, basis + 1):
+ indice = idx_map[y + y_offset, x + x_offset]
+ cnt = int(acc_map_np[y + y_offset, x + x_offset])
+ if indice != -1:
+ segment_list.append(segments[indice])
+ if cnt > 1:
+ check_cnt = 1
+ current_hough = hough[indice]
+ for new_indice, new_hough in enumerate(hough):
+ if (current_hough
+ == new_hough).all() and indice != new_indice:
+ segment_list.append(segments[new_indice])
+ check_cnt += 1
+ if check_cnt == cnt:
+ break
+ group_segments = np.array(segment_list).reshape([-1, 2])
+ sorted_group_segments = np.sort(group_segments, axis=0)
+ x_min, y_min = sorted_group_segments[0, :]
+ x_max, y_max = sorted_group_segments[-1, :]
+
+ deg = theta[max_indice]
+ if deg >= 90:
+ merged_segments.append([x_min, y_max, x_max, y_min])
+ else:
+ merged_segments.append([x_min, y_min, x_max, y_max])
+
+ # 2. get intersections
+ new_segments = np.array(merged_segments) # (x1, y1, x2, y2)
+ start = new_segments[:, :2] # (x1, y1)
+ end = new_segments[:, 2:] # (x2, y2)
+ new_centers = (start + end) / 2.0
+ diff = start - end
+ dist_segments = np.sqrt(np.sum(diff**2, axis=-1))
+
+ # ax + by = c
+ a = diff[:, 1]
+ b = -diff[:, 0]
+ c = a * start[:, 0] + b * start[:, 1]
+ pre_det = a[:, None] * b[None, :]
+ det = pre_det - np.transpose(pre_det)
+
+ pre_inter_y = a[:, None] * c[None, :]
+ inter_y = (pre_inter_y - np.transpose(pre_inter_y)) / (det + 1e-10)
+ pre_inter_x = c[:, None] * b[None, :]
+ inter_x = (pre_inter_x - np.transpose(pre_inter_x)) / (det + 1e-10)
+ inter_pts = np.concatenate([inter_x[:, :, None], inter_y[:, :, None]],
+ axis=-1).astype('int32')
+
+ # 3. get corner information
+ # 3.1 get distance
+ '''
+ dist_segments:
+ | dist(0), dist(1), dist(2), ...|
+ dist_inter_to_segment1:
+ | dist(inter,0), dist(inter,0), dist(inter,0), ... |
+ | dist(inter,1), dist(inter,1), dist(inter,1), ... |
+ ...
+ dist_inter_to_semgnet2:
+ | dist(inter,0), dist(inter,1), dist(inter,2), ... |
+ | dist(inter,0), dist(inter,1), dist(inter,2), ... |
+ ...
+ '''
+
+ dist_inter_to_segment1_start = np.sqrt(
+ np.sum(((inter_pts - start[:, None, :])**2), axis=-1,
+ keepdims=True)) # [n_batch, n_batch, 1]
+ dist_inter_to_segment1_end = np.sqrt(
+ np.sum(((inter_pts - end[:, None, :])**2), axis=-1,
+ keepdims=True)) # [n_batch, n_batch, 1]
+ dist_inter_to_segment2_start = np.sqrt(
+ np.sum(((inter_pts - start[None, :, :])**2), axis=-1,
+ keepdims=True)) # [n_batch, n_batch, 1]
+ dist_inter_to_segment2_end = np.sqrt(
+ np.sum(((inter_pts - end[None, :, :])**2), axis=-1,
+ keepdims=True)) # [n_batch, n_batch, 1]
+
+ # sort ascending
+ dist_inter_to_segment1 = np.sort(np.concatenate(
+ [dist_inter_to_segment1_start, dist_inter_to_segment1_end], axis=-1),
+ axis=-1) # [n_batch, n_batch, 2]
+ dist_inter_to_segment2 = np.sort(np.concatenate(
+ [dist_inter_to_segment2_start, dist_inter_to_segment2_end], axis=-1),
+ axis=-1) # [n_batch, n_batch, 2]
+
+ # 3.2 get degree
+ inter_to_start = new_centers[:, None, :] - inter_pts
+ deg_inter_to_start = np.arctan2(inter_to_start[:, :, 1],
+ inter_to_start[:, :, 0]) * 180 / np.pi
+ deg_inter_to_start[deg_inter_to_start < 0.0] += 360
+ inter_to_end = new_centers[None, :, :] - inter_pts
+ deg_inter_to_end = np.arctan2(inter_to_end[:, :, 1],
+ inter_to_end[:, :, 0]) * 180 / np.pi
+ deg_inter_to_end[deg_inter_to_end < 0.0] += 360
+ '''
+ B -- G
+ | |
+ C -- R
+ B : blue / G: green / C: cyan / R: red
+
+ 0 -- 1
+ | |
+ 3 -- 2
+ '''
+ # rename variables
+ deg1_map, deg2_map = deg_inter_to_start, deg_inter_to_end
+ # sort deg ascending
+ deg_sort = np.sort(np.concatenate(
+ [deg1_map[:, :, None], deg2_map[:, :, None]], axis=-1),
+ axis=-1)
+
+ deg_diff_map = np.abs(deg1_map - deg2_map)
+ # we only consider the smallest degree of intersect
+ deg_diff_map[deg_diff_map > 180] = 360 - deg_diff_map[deg_diff_map > 180]
+
+ # define available degree range
+ deg_range = [60, 120]
+
+ corner_dict = {corner_info: [] for corner_info in range(4)}
+ inter_points = []
+ for i in range(inter_pts.shape[0]):
+ for j in range(i + 1, inter_pts.shape[1]):
+ # i, j > line index, always i < j
+ x, y = inter_pts[i, j, :]
+ deg1, deg2 = deg_sort[i, j, :]
+ deg_diff = deg_diff_map[i, j]
+
+ check_degree = deg_diff > deg_range[0] and deg_diff < deg_range[1]
+
+ outside_ratio = params['outside_ratio'] # over ratio >>> drop it!
+ inside_ratio = params['inside_ratio'] # over ratio >>> drop it!
+ check_distance = ((dist_inter_to_segment1[i, j, 1] >= dist_segments[i] and
+ dist_inter_to_segment1[i, j, 0] <= dist_segments[i] * outside_ratio) or
+ (dist_inter_to_segment1[i, j, 1] <= dist_segments[i] and
+ dist_inter_to_segment1[i, j, 0] <= dist_segments[i] * inside_ratio)) and \
+ ((dist_inter_to_segment2[i, j, 1] >= dist_segments[j] and
+ dist_inter_to_segment2[i, j, 0] <= dist_segments[j] * outside_ratio) or
+ (dist_inter_to_segment2[i, j, 1] <= dist_segments[j] and
+ dist_inter_to_segment2[i, j, 0] <= dist_segments[j] * inside_ratio))
+
+ if check_degree and check_distance:
+ corner_info = None # noqa
+
+ if (deg1 >= 0 and deg1 <= 45 and deg2 >= 45 and deg2 <= 120) or \
+ (deg2 >= 315 and deg1 >= 45 and deg1 <= 120):
+ corner_info, color_info = 0, 'blue'
+ elif (deg1 >= 45 and deg1 <= 125 and deg2 >= 125
+ and deg2 <= 225):
+ corner_info, color_info = 1, 'green'
+ elif (deg1 >= 125 and deg1 <= 225 and deg2 >= 225
+ and deg2 <= 315):
+ corner_info, color_info = 2, 'black'
+ elif (deg1 >= 0 and deg1 <= 45 and deg2 >= 225 and deg2 <= 315) or \
+ (deg2 >= 315 and deg1 >= 225 and deg1 <= 315):
+ corner_info, color_info = 3, 'cyan'
+ else:
+ corner_info, color_info = 4, 'red' # we don't use it # noqa
+ continue
+
+ corner_dict[corner_info].append([x, y, i, j])
+ inter_points.append([x, y])
+
+ square_list = []
+ connect_list = []
+ segments_list = []
+ for corner0 in corner_dict[0]:
+ for corner1 in corner_dict[1]:
+ connect01 = False
+ for corner0_line in corner0[2:]:
+ if corner0_line in corner1[2:]:
+ connect01 = True
+ break
+ if connect01:
+ for corner2 in corner_dict[2]:
+ connect12 = False
+ for corner1_line in corner1[2:]:
+ if corner1_line in corner2[2:]:
+ connect12 = True
+ break
+ if connect12:
+ for corner3 in corner_dict[3]:
+ connect23 = False
+ for corner2_line in corner2[2:]:
+ if corner2_line in corner3[2:]:
+ connect23 = True
+ break
+ if connect23:
+ for corner3_line in corner3[2:]:
+ if corner3_line in corner0[2:]:
+ # SQUARE!!!
+ '''
+ 0 -- 1
+ | |
+ 3 -- 2
+ square_list:
+ order: 0 > 1 > 2 > 3
+ | x0, y0, x1, y1, x2, y2, x3, y3 |
+ | x0, y0, x1, y1, x2, y2, x3, y3 |
+ ...
+ connect_list:
+ order: 01 > 12 > 23 > 30
+ | line_idx01, line_idx12, line_idx23, line_idx30 |
+ | line_idx01, line_idx12, line_idx23, line_idx30 |
+ ...
+ segments_list:
+ order: 0 > 1 > 2 > 3
+ | line_idx0_i, line_idx0_j, line_idx1_i, line_idx1_j, line_idx2_i,
+ line_idx2_j, line_idx3_i, line_idx3_j |
+ | line_idx0_i, line_idx0_j, line_idx1_i, line_idx1_j, line_idx2_i,
+ line_idx2_j, line_idx3_i, line_idx3_j |
+ ...
+ '''
+ square_list.append(corner0[:2] +
+ corner1[:2] +
+ corner2[:2] +
+ corner3[:2])
+ connect_list.append([
+ corner0_line, corner1_line,
+ corner2_line, corner3_line
+ ])
+ segments_list.append(corner0[2:] +
+ corner1[2:] +
+ corner2[2:] +
+ corner3[2:])
+
+ def check_outside_inside(segments_info, connect_idx):
+ # return 'outside or inside', min distance, cover_param, peri_param
+ if connect_idx == segments_info[0]:
+ check_dist_mat = dist_inter_to_segment1
+ else:
+ check_dist_mat = dist_inter_to_segment2
+
+ i, j = segments_info
+ min_dist, max_dist = check_dist_mat[i, j, :]
+ connect_dist = dist_segments[connect_idx]
+ if max_dist > connect_dist:
+ return 'outside', min_dist, 0, 1
+ else:
+ return 'inside', min_dist, -1, -1
+
+ top_square = None # noqa
+
+ try:
+ map_size = input_shape[0] / 2
+ squares = np.array(square_list).reshape([-1, 4, 2])
+ score_array = []
+ connect_array = np.array(connect_list)
+ segments_array = np.array(segments_list).reshape([-1, 4, 2])
+
+ # get degree of corners:
+ squares_rollup = np.roll(squares, 1, axis=1)
+ squares_rolldown = np.roll(squares, -1, axis=1)
+ vec1 = squares_rollup - squares
+ normalized_vec1 = vec1 / (
+ np.linalg.norm(vec1, axis=-1, keepdims=True) + 1e-10)
+ vec2 = squares_rolldown - squares
+ normalized_vec2 = vec2 / (
+ np.linalg.norm(vec2, axis=-1, keepdims=True) + 1e-10)
+ inner_products = np.sum(normalized_vec1 * normalized_vec2,
+ axis=-1) # [n_squares, 4]
+ squares_degree = np.arccos(
+ inner_products) * 180 / np.pi # [n_squares, 4]
+
+ # get square score
+ overlap_scores = []
+ degree_scores = []
+ length_scores = []
+
+ for connects, segments, square, degree in zip(connect_array,
+ segments_array, squares,
+ squares_degree):
+ '''
+ 0 -- 1
+ | |
+ 3 -- 2
+
+ # segments: [4, 2]
+ # connects: [4]
+ '''
+
+ # OVERLAP SCORES
+ cover = 0
+ perimeter = 0
+ # check 0 > 1 > 2 > 3
+ square_length = []
+
+ for start_idx in range(4):
+ end_idx = (start_idx + 1) % 4
+
+ connect_idx = connects[start_idx] # segment idx of segment01
+ start_segments = segments[start_idx]
+ end_segments = segments[end_idx]
+
+ start_point = square[start_idx] # noqa
+ end_point = square[end_idx] # noqa
+
+ # check whether outside or inside
+ start_position, start_min, start_cover_param, start_peri_param = check_outside_inside(
+ start_segments, connect_idx)
+ end_position, end_min, end_cover_param, end_peri_param = check_outside_inside(
+ end_segments, connect_idx)
+
+ cover += dist_segments[
+ connect_idx] + start_cover_param * start_min + end_cover_param * end_min
+ perimeter += dist_segments[
+ connect_idx] + start_peri_param * start_min + end_peri_param * end_min
+
+ square_length.append(dist_segments[connect_idx] +
+ start_peri_param * start_min +
+ end_peri_param * end_min)
+
+ overlap_scores.append(cover / perimeter)
+ # DEGREE SCORES
+ '''
+ deg0 vs deg2
+ deg1 vs deg3
+ '''
+ deg0, deg1, deg2, deg3 = degree
+ deg_ratio1 = deg0 / deg2
+ if deg_ratio1 > 1.0:
+ deg_ratio1 = 1 / deg_ratio1
+ deg_ratio2 = deg1 / deg3
+ if deg_ratio2 > 1.0:
+ deg_ratio2 = 1 / deg_ratio2
+ degree_scores.append((deg_ratio1 + deg_ratio2) / 2)
+ # LENGTH SCORES
+ '''
+ len0 vs len2
+ len1 vs len3
+ '''
+ len0, len1, len2, len3 = square_length
+ len_ratio1 = len0 / len2 if len2 > len0 else len2 / len0
+ len_ratio2 = len1 / len3 if len3 > len1 else len3 / len1
+ length_scores.append((len_ratio1 + len_ratio2) / 2)
+
+ ######################################
+
+ overlap_scores = np.array(overlap_scores)
+ overlap_scores /= np.max(overlap_scores)
+
+ degree_scores = np.array(degree_scores)
+ # degree_scores /= np.max(degree_scores)
+
+ length_scores = np.array(length_scores)
+
+ # AREA SCORES
+ area_scores = np.reshape(squares, [-1, 4, 2])
+ area_x = area_scores[:, :, 0]
+ area_y = area_scores[:, :, 1]
+ correction = area_x[:, -1] * area_y[:, 0] - area_y[:, -1] * area_x[:,
+ 0]
+ area_scores = np.sum(area_x[:, :-1] * area_y[:, 1:], axis=-1) - np.sum(
+ area_y[:, :-1] * area_x[:, 1:], axis=-1)
+ area_scores = 0.5 * np.abs(area_scores + correction)
+ area_scores /= (map_size * map_size) # np.max(area_scores)
+
+ # CENTER SCORES
+ centers = np.array([[256 // 2, 256 // 2]], dtype='float32') # [1, 2]
+ # squares: [n, 4, 2]
+ square_centers = np.mean(squares, axis=1) # [n, 2]
+ center2center = np.sqrt(np.sum((centers - square_centers)**2))
+ center_scores = center2center / (map_size / np.sqrt(2.0))
+ '''
+ score_w = [overlap, degree, area, center, length]
+ '''
+ score_w = [0.0, 1.0, 10.0, 0.5, 1.0] # noqa
+ score_array = (params['w_overlap'] * overlap_scores +
+ params['w_degree'] * degree_scores +
+ params['w_area'] * area_scores -
+ params['w_center'] * center_scores +
+ params['w_length'] * length_scores)
+
+ best_square = [] # noqa
+
+ sorted_idx = np.argsort(score_array)[::-1]
+ score_array = score_array[sorted_idx]
+ squares = squares[sorted_idx]
+
+ except Exception:
+ pass
+ '''return list
+ merged_lines, squares, scores
+ '''
+
+ try:
+ new_segments[:, 0] = new_segments[:, 0] * 2 / input_shape[
+ 1] * original_shape[1]
+ new_segments[:, 1] = new_segments[:, 1] * 2 / input_shape[
+ 0] * original_shape[0]
+ new_segments[:, 2] = new_segments[:, 2] * 2 / input_shape[
+ 1] * original_shape[1]
+ new_segments[:, 3] = new_segments[:, 3] * 2 / input_shape[
+ 0] * original_shape[0]
+ except Exception:
+ new_segments = []
+
+ try:
+ squares[:, :,
+ 0] = squares[:, :, 0] * 2 / input_shape[1] * original_shape[1]
+ squares[:, :,
+ 1] = squares[:, :, 1] * 2 / input_shape[0] * original_shape[0]
+ except Exception:
+ squares = []
+ score_array = []
+
+ try:
+ inter_points = np.array(inter_points)
+ inter_points[:, 0] = inter_points[:, 0] * 2 / input_shape[
+ 1] * original_shape[1]
+ inter_points[:, 1] = inter_points[:, 1] * 2 / input_shape[
+ 0] * original_shape[0]
+ except Exception:
+ inter_points = []
+
+ return new_segments, squares, score_array, inter_points
diff --git a/annotator/mlsd_op.py b/annotator/mlsd_op.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec5f0946278a226118e5239ab78dfe2fbd6e8bec
--- /dev/null
+++ b/annotator/mlsd_op.py
@@ -0,0 +1,74 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+# MLSD Line Detection
+# From https://github.com/navervision/mlsd
+# Apache-2.0 license
+
+import warnings
+from abc import ABCMeta
+
+import cv2
+import numpy as np
+import torch
+from PIL import Image
+
+from scepter.modules.annotator.base_annotator import BaseAnnotator
+from scepter.modules.annotator.mlsd.mbv2_mlsd_large import MobileV2_MLSD_Large
+from scepter.modules.annotator.mlsd.utils import pred_lines
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.annotator.utils import resize_image, resize_image_ori
+from scepter.modules.utils.config import dict_to_yaml
+from scepter.modules.utils.distribute import we
+from scepter.modules.utils.file_system import FS
+
+
+@ANNOTATORS.register_class()
+class MLSDdetector(BaseAnnotator, metaclass=ABCMeta):
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+ model = MobileV2_MLSD_Large()
+ pretrained_model = cfg.get('PRETRAINED_MODEL', None)
+ if pretrained_model:
+ with FS.get_from(pretrained_model, wait_finish=True) as local_path:
+ model.load_state_dict(torch.load(local_path), strict=True)
+ self.model = model.eval()
+ self.thr_v = cfg.get('THR_V', 0.1)
+ self.thr_d = cfg.get('THR_D', 0.1)
+
+ @torch.no_grad()
+ @torch.inference_mode()
+ @torch.autocast('cuda', enabled=False)
+ def forward(self, image):
+ if isinstance(image, Image.Image):
+ image = np.array(image)
+ elif isinstance(image, torch.Tensor):
+ image = image.detach().cpu().numpy()
+ elif isinstance(image, np.ndarray):
+ image = image.copy()
+ else:
+ raise f'Unsurpport datatype{type(image)}, only surpport np.ndarray, torch.Tensor, Pillow Image.'
+ h, w, c = image.shape
+ image, k = resize_image(image, 1024 if min(h, w) > 1024 else min(h, w))
+ img_output = np.zeros_like(image)
+ try:
+ lines = pred_lines(image,
+ self.model, [image.shape[0], image.shape[1]],
+ self.thr_v,
+ self.thr_d,
+ device=we.device_id)
+ for line in lines:
+ x_start, y_start, x_end, y_end = [int(val) for val in line]
+ cv2.line(img_output, (x_start, y_start), (x_end, y_end),
+ [255, 255, 255], 1)
+ except Exception as e:
+ warnings.warn(f'{e}')
+ return None
+ img_output = resize_image_ori(h, w, img_output, k)
+ return img_output[:, :, 0]
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ MLSDdetector.para_dict,
+ set_name=True)
diff --git a/annotator/openpose.py b/annotator/openpose.py
new file mode 100644
index 0000000000000000000000000000000000000000..69320ec7abc85d30397c6a8ba48d6e035560612d
--- /dev/null
+++ b/annotator/openpose.py
@@ -0,0 +1,812 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+# Openpose
+# Original from CMU https://github.com/CMU-Perceptual-Computing-Lab/openpose
+# 2nd Edited by https://github.com/Hzzone/pytorch-openpose
+# The implementation is modified from 3rd Edited Version by ControlNet
+import math
+import os
+from abc import ABCMeta
+from collections import OrderedDict
+
+import cv2
+import matplotlib
+import numpy as np
+import torch
+import torch.nn as nn
+from PIL import Image
+from scipy.ndimage.filters import gaussian_filter
+from skimage.measure import label
+
+from scepter.modules.annotator.base_annotator import BaseAnnotator
+from scepter.modules.annotator.registry import ANNOTATORS
+from scepter.modules.utils.config import dict_to_yaml
+from scepter.modules.utils.file_system import FS
+
+os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
+
+
+def padRightDownCorner(img, stride, padValue):
+ h = img.shape[0]
+ w = img.shape[1]
+
+ pad = 4 * [None]
+ pad[0] = 0 # up
+ pad[1] = 0 # left
+ pad[2] = 0 if (h % stride == 0) else stride - (h % stride) # down
+ pad[3] = 0 if (w % stride == 0) else stride - (w % stride) # right
+
+ img_padded = img
+ pad_up = np.tile(img_padded[0:1, :, :] * 0 + padValue, (pad[0], 1, 1))
+ img_padded = np.concatenate((pad_up, img_padded), axis=0)
+ pad_left = np.tile(img_padded[:, 0:1, :] * 0 + padValue, (1, pad[1], 1))
+ img_padded = np.concatenate((pad_left, img_padded), axis=1)
+ pad_down = np.tile(img_padded[-2:-1, :, :] * 0 + padValue, (pad[2], 1, 1))
+ img_padded = np.concatenate((img_padded, pad_down), axis=0)
+ pad_right = np.tile(img_padded[:, -2:-1, :] * 0 + padValue, (1, pad[3], 1))
+ img_padded = np.concatenate((img_padded, pad_right), axis=1)
+
+ return img_padded, pad
+
+
+# transfer caffe model to pytorch which will match the layer name
+def transfer(model, model_weights):
+ transfered_model_weights = {}
+ for weights_name in model.state_dict().keys():
+ transfered_model_weights[weights_name] = model_weights['.'.join(
+ weights_name.split('.')[1:])]
+ return transfered_model_weights
+
+
+# draw the body keypoint and lims
+def draw_bodypose(canvas, candidate, subset):
+ stickwidth = 4
+ limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10],
+ [10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15],
+ [15, 17], [1, 16], [16, 18], [3, 17], [6, 18]]
+
+ colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0],
+ [170, 255, 0], [85, 255, 0], [0, 255, 0], [0, 255, 85],
+ [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255],
+ [0, 0, 255], [85, 0, 255], [170, 0, 255], [255, 0, 255],
+ [255, 0, 170], [255, 0, 85]]
+ for i in range(18):
+ for n in range(len(subset)):
+ index = int(subset[n][i])
+ if index == -1:
+ continue
+ x, y = candidate[index][0:2]
+ cv2.circle(canvas, (int(x), int(y)), 4, colors[i], thickness=-1)
+ for i in range(17):
+ for n in range(len(subset)):
+ index = subset[n][np.array(limbSeq[i]) - 1]
+ if -1 in index:
+ continue
+ cur_canvas = canvas.copy()
+ Y = candidate[index.astype(int), 0]
+ X = candidate[index.astype(int), 1]
+ mX = np.mean(X)
+ mY = np.mean(Y)
+ length = ((X[0] - X[1])**2 + (Y[0] - Y[1])**2)**0.5
+ angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
+ polygon = cv2.ellipse2Poly(
+ (int(mY), int(mX)), (int(length / 2), stickwidth), int(angle),
+ 0, 360, 1)
+ cv2.fillConvexPoly(cur_canvas, polygon, colors[i])
+ canvas = cv2.addWeighted(canvas, 0.4, cur_canvas, 0.6, 0)
+ # plt.imsave("preview.jpg", canvas[:, :, [2, 1, 0]])
+ # plt.imshow(canvas[:, :, [2, 1, 0]])
+ return canvas
+
+
+# image drawed by opencv is not good.
+def draw_handpose(canvas, all_hand_peaks, show_number=False):
+ edges = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7], [7, 8],
+ [0, 9], [9, 10], [10, 11], [11, 12], [0, 13], [13, 14], [14, 15],
+ [15, 16], [0, 17], [17, 18], [18, 19], [19, 20]]
+
+ for peaks in all_hand_peaks:
+ for ie, e in enumerate(edges):
+ if np.sum(np.all(peaks[e], axis=1) == 0) == 0:
+ x1, y1 = peaks[e[0]]
+ x2, y2 = peaks[e[1]]
+ cv2.line(canvas, (x1, y1), (x2, y2),
+ matplotlib.colors.hsv_to_rgb(
+ [ie / float(len(edges)), 1.0, 1.0]) * 255,
+ thickness=2)
+
+ for i, keyponit in enumerate(peaks):
+ x, y = keyponit
+ cv2.circle(canvas, (x, y), 4, (0, 0, 255), thickness=-1)
+ if show_number:
+ cv2.putText(canvas,
+ str(i), (x, y),
+ cv2.FONT_HERSHEY_SIMPLEX,
+ 0.3, (0, 0, 0),
+ lineType=cv2.LINE_AA)
+ return canvas
+
+
+# detect hand according to body pose keypoints
+# please refer to https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/
+# master/src/openpose/hand/handDetector.cpp
+def handDetect(candidate, subset, oriImg):
+ # right hand: wrist 4, elbow 3, shoulder 2
+ # left hand: wrist 7, elbow 6, shoulder 5
+ ratioWristElbow = 0.33
+ detect_result = []
+ image_height, image_width = oriImg.shape[0:2]
+ for person in subset.astype(int):
+ # if any of three not detected
+ has_left = np.sum(person[[5, 6, 7]] == -1) == 0
+ has_right = np.sum(person[[2, 3, 4]] == -1) == 0
+ if not (has_left or has_right):
+ continue
+ hands = []
+ # left hand
+ if has_left:
+ left_shoulder_index, left_elbow_index, left_wrist_index = person[[
+ 5, 6, 7
+ ]]
+ x1, y1 = candidate[left_shoulder_index][:2]
+ x2, y2 = candidate[left_elbow_index][:2]
+ x3, y3 = candidate[left_wrist_index][:2]
+ hands.append([x1, y1, x2, y2, x3, y3, True])
+ # right hand
+ if has_right:
+ right_shoulder_index, right_elbow_index, right_wrist_index = person[
+ [2, 3, 4]]
+ x1, y1 = candidate[right_shoulder_index][:2]
+ x2, y2 = candidate[right_elbow_index][:2]
+ x3, y3 = candidate[right_wrist_index][:2]
+ hands.append([x1, y1, x2, y2, x3, y3, False])
+
+ for x1, y1, x2, y2, x3, y3, is_left in hands:
+ # pos_hand = pos_wrist + ratio * (pos_wrist - pos_elbox) = (1 + ratio) * pos_wrist - ratio * pos_elbox
+ # handRectangle.x = posePtr[wrist*3] + ratioWristElbow * (posePtr[wrist*3] - posePtr[elbow*3]);
+ # handRectangle.y = posePtr[wrist*3+1] + ratioWristElbow * (posePtr[wrist*3+1] - posePtr[elbow*3+1]);
+ # const auto distanceWristElbow = getDistance(poseKeypoints, person, wrist, elbow);
+ # const auto distanceElbowShoulder = getDistance(poseKeypoints, person, elbow, shoulder);
+ # handRectangle.width = 1.5f * fastMax(distanceWristElbow, 0.9f * distanceElbowShoulder);
+ x = x3 + ratioWristElbow * (x3 - x2)
+ y = y3 + ratioWristElbow * (y3 - y2)
+ distanceWristElbow = math.sqrt((x3 - x2)**2 + (y3 - y2)**2)
+ distanceElbowShoulder = math.sqrt((x2 - x1)**2 + (y2 - y1)**2)
+ width = 1.5 * max(distanceWristElbow, 0.9 * distanceElbowShoulder)
+ # x-y refers to the center --> offset to topLeft point
+ # handRectangle.x -= handRectangle.width / 2.f;
+ # handRectangle.y -= handRectangle.height / 2.f;
+ x -= width / 2
+ y -= width / 2 # width = height
+ # overflow the image
+ if x < 0:
+ x = 0
+ if y < 0:
+ y = 0
+ width1 = width
+ width2 = width
+ if x + width > image_width:
+ width1 = image_width - x
+ if y + width > image_height:
+ width2 = image_height - y
+ width = min(width1, width2)
+ # the max hand box value is 20 pixels
+ if width >= 20:
+ detect_result.append([int(x), int(y), int(width), is_left])
+ '''
+ return value: [[x, y, w, True if left hand else False]].
+ width=height since the network require squared input.
+ x, y is the coordinate of top left
+ '''
+ return detect_result
+
+
+# get max index of 2d array
+def npmax(array):
+ arrayindex = array.argmax(1)
+ arrayvalue = array.max(1)
+ i = arrayvalue.argmax()
+ j = arrayindex[i]
+ return i, j
+
+
+def make_layers(block, no_relu_layers):
+ layers = []
+ for layer_name, v in block.items():
+ if 'pool' in layer_name:
+ layer = nn.MaxPool2d(kernel_size=v[0], stride=v[1], padding=v[2])
+ layers.append((layer_name, layer))
+ else:
+ conv2d = nn.Conv2d(in_channels=v[0],
+ out_channels=v[1],
+ kernel_size=v[2],
+ stride=v[3],
+ padding=v[4])
+ layers.append((layer_name, conv2d))
+ if layer_name not in no_relu_layers:
+ layers.append(('relu_' + layer_name, nn.ReLU(inplace=True)))
+
+ return nn.Sequential(OrderedDict(layers))
+
+
+class bodypose_model(nn.Module):
+ def __init__(self):
+ super(bodypose_model, self).__init__()
+
+ # these layers have no relu layer
+ no_relu_layers = [
+ 'conv5_5_CPM_L1', 'conv5_5_CPM_L2', 'Mconv7_stage2_L1',
+ 'Mconv7_stage2_L2', 'Mconv7_stage3_L1', 'Mconv7_stage3_L2',
+ 'Mconv7_stage4_L1', 'Mconv7_stage4_L2', 'Mconv7_stage5_L1',
+ 'Mconv7_stage5_L2', 'Mconv7_stage6_L1', 'Mconv7_stage6_L1'
+ ]
+ blocks = {}
+ block0 = OrderedDict([('conv1_1', [3, 64, 3, 1, 1]),
+ ('conv1_2', [64, 64, 3, 1, 1]),
+ ('pool1_stage1', [2, 2, 0]),
+ ('conv2_1', [64, 128, 3, 1, 1]),
+ ('conv2_2', [128, 128, 3, 1, 1]),
+ ('pool2_stage1', [2, 2, 0]),
+ ('conv3_1', [128, 256, 3, 1, 1]),
+ ('conv3_2', [256, 256, 3, 1, 1]),
+ ('conv3_3', [256, 256, 3, 1, 1]),
+ ('conv3_4', [256, 256, 3, 1, 1]),
+ ('pool3_stage1', [2, 2, 0]),
+ ('conv4_1', [256, 512, 3, 1, 1]),
+ ('conv4_2', [512, 512, 3, 1, 1]),
+ ('conv4_3_CPM', [512, 256, 3, 1, 1]),
+ ('conv4_4_CPM', [256, 128, 3, 1, 1])])
+
+ # Stage 1
+ block1_1 = OrderedDict([('conv5_1_CPM_L1', [128, 128, 3, 1, 1]),
+ ('conv5_2_CPM_L1', [128, 128, 3, 1, 1]),
+ ('conv5_3_CPM_L1', [128, 128, 3, 1, 1]),
+ ('conv5_4_CPM_L1', [128, 512, 1, 1, 0]),
+ ('conv5_5_CPM_L1', [512, 38, 1, 1, 0])])
+
+ block1_2 = OrderedDict([('conv5_1_CPM_L2', [128, 128, 3, 1, 1]),
+ ('conv5_2_CPM_L2', [128, 128, 3, 1, 1]),
+ ('conv5_3_CPM_L2', [128, 128, 3, 1, 1]),
+ ('conv5_4_CPM_L2', [128, 512, 1, 1, 0]),
+ ('conv5_5_CPM_L2', [512, 19, 1, 1, 0])])
+ blocks['block1_1'] = block1_1
+ blocks['block1_2'] = block1_2
+
+ self.model0 = make_layers(block0, no_relu_layers)
+
+ # Stages 2 - 6
+ for i in range(2, 7):
+ blocks['block%d_1' % i] = OrderedDict([
+ ('Mconv1_stage%d_L1' % i, [185, 128, 7, 1, 3]),
+ ('Mconv2_stage%d_L1' % i, [128, 128, 7, 1, 3]),
+ ('Mconv3_stage%d_L1' % i, [128, 128, 7, 1, 3]),
+ ('Mconv4_stage%d_L1' % i, [128, 128, 7, 1, 3]),
+ ('Mconv5_stage%d_L1' % i, [128, 128, 7, 1, 3]),
+ ('Mconv6_stage%d_L1' % i, [128, 128, 1, 1, 0]),
+ ('Mconv7_stage%d_L1' % i, [128, 38, 1, 1, 0])
+ ])
+
+ blocks['block%d_2' % i] = OrderedDict([
+ ('Mconv1_stage%d_L2' % i, [185, 128, 7, 1, 3]),
+ ('Mconv2_stage%d_L2' % i, [128, 128, 7, 1, 3]),
+ ('Mconv3_stage%d_L2' % i, [128, 128, 7, 1, 3]),
+ ('Mconv4_stage%d_L2' % i, [128, 128, 7, 1, 3]),
+ ('Mconv5_stage%d_L2' % i, [128, 128, 7, 1, 3]),
+ ('Mconv6_stage%d_L2' % i, [128, 128, 1, 1, 0]),
+ ('Mconv7_stage%d_L2' % i, [128, 19, 1, 1, 0])
+ ])
+
+ for k in blocks.keys():
+ blocks[k] = make_layers(blocks[k], no_relu_layers)
+
+ self.model1_1 = blocks['block1_1']
+ self.model2_1 = blocks['block2_1']
+ self.model3_1 = blocks['block3_1']
+ self.model4_1 = blocks['block4_1']
+ self.model5_1 = blocks['block5_1']
+ self.model6_1 = blocks['block6_1']
+
+ self.model1_2 = blocks['block1_2']
+ self.model2_2 = blocks['block2_2']
+ self.model3_2 = blocks['block3_2']
+ self.model4_2 = blocks['block4_2']
+ self.model5_2 = blocks['block5_2']
+ self.model6_2 = blocks['block6_2']
+
+ def forward(self, x):
+
+ out1 = self.model0(x)
+
+ out1_1 = self.model1_1(out1)
+ out1_2 = self.model1_2(out1)
+ out2 = torch.cat([out1_1, out1_2, out1], 1)
+
+ out2_1 = self.model2_1(out2)
+ out2_2 = self.model2_2(out2)
+ out3 = torch.cat([out2_1, out2_2, out1], 1)
+
+ out3_1 = self.model3_1(out3)
+ out3_2 = self.model3_2(out3)
+ out4 = torch.cat([out3_1, out3_2, out1], 1)
+
+ out4_1 = self.model4_1(out4)
+ out4_2 = self.model4_2(out4)
+ out5 = torch.cat([out4_1, out4_2, out1], 1)
+
+ out5_1 = self.model5_1(out5)
+ out5_2 = self.model5_2(out5)
+ out6 = torch.cat([out5_1, out5_2, out1], 1)
+
+ out6_1 = self.model6_1(out6)
+ out6_2 = self.model6_2(out6)
+
+ return out6_1, out6_2
+
+
+class handpose_model(nn.Module):
+ def __init__(self):
+ super(handpose_model, self).__init__()
+
+ # these layers have no relu layer
+ no_relu_layers = [
+ 'conv6_2_CPM', 'Mconv7_stage2', 'Mconv7_stage3', 'Mconv7_stage4',
+ 'Mconv7_stage5', 'Mconv7_stage6'
+ ]
+ # stage 1
+ block1_0 = OrderedDict([('conv1_1', [3, 64, 3, 1, 1]),
+ ('conv1_2', [64, 64, 3, 1, 1]),
+ ('pool1_stage1', [2, 2, 0]),
+ ('conv2_1', [64, 128, 3, 1, 1]),
+ ('conv2_2', [128, 128, 3, 1, 1]),
+ ('pool2_stage1', [2, 2, 0]),
+ ('conv3_1', [128, 256, 3, 1, 1]),
+ ('conv3_2', [256, 256, 3, 1, 1]),
+ ('conv3_3', [256, 256, 3, 1, 1]),
+ ('conv3_4', [256, 256, 3, 1, 1]),
+ ('pool3_stage1', [2, 2, 0]),
+ ('conv4_1', [256, 512, 3, 1, 1]),
+ ('conv4_2', [512, 512, 3, 1, 1]),
+ ('conv4_3', [512, 512, 3, 1, 1]),
+ ('conv4_4', [512, 512, 3, 1, 1]),
+ ('conv5_1', [512, 512, 3, 1, 1]),
+ ('conv5_2', [512, 512, 3, 1, 1]),
+ ('conv5_3_CPM', [512, 128, 3, 1, 1])])
+
+ block1_1 = OrderedDict([('conv6_1_CPM', [128, 512, 1, 1, 0]),
+ ('conv6_2_CPM', [512, 22, 1, 1, 0])])
+
+ blocks = {}
+ blocks['block1_0'] = block1_0
+ blocks['block1_1'] = block1_1
+
+ # stage 2-6
+ for i in range(2, 7):
+ blocks['block%d' % i] = OrderedDict([
+ ('Mconv1_stage%d' % i, [150, 128, 7, 1, 3]),
+ ('Mconv2_stage%d' % i, [128, 128, 7, 1, 3]),
+ ('Mconv3_stage%d' % i, [128, 128, 7, 1, 3]),
+ ('Mconv4_stage%d' % i, [128, 128, 7, 1, 3]),
+ ('Mconv5_stage%d' % i, [128, 128, 7, 1, 3]),
+ ('Mconv6_stage%d' % i, [128, 128, 1, 1, 0]),
+ ('Mconv7_stage%d' % i, [128, 22, 1, 1, 0])
+ ])
+
+ for k in blocks.keys():
+ blocks[k] = make_layers(blocks[k], no_relu_layers)
+
+ self.model1_0 = blocks['block1_0']
+ self.model1_1 = blocks['block1_1']
+ self.model2 = blocks['block2']
+ self.model3 = blocks['block3']
+ self.model4 = blocks['block4']
+ self.model5 = blocks['block5']
+ self.model6 = blocks['block6']
+
+ def forward(self, x):
+ out1_0 = self.model1_0(x)
+ out1_1 = self.model1_1(out1_0)
+ concat_stage2 = torch.cat([out1_1, out1_0], 1)
+ out_stage2 = self.model2(concat_stage2)
+ concat_stage3 = torch.cat([out_stage2, out1_0], 1)
+ out_stage3 = self.model3(concat_stage3)
+ concat_stage4 = torch.cat([out_stage3, out1_0], 1)
+ out_stage4 = self.model4(concat_stage4)
+ concat_stage5 = torch.cat([out_stage4, out1_0], 1)
+ out_stage5 = self.model5(concat_stage5)
+ concat_stage6 = torch.cat([out_stage5, out1_0], 1)
+ out_stage6 = self.model6(concat_stage6)
+ return out_stage6
+
+
+class Hand(object):
+ def __init__(self, model_path, device='cuda'):
+ self.model = handpose_model()
+ if torch.cuda.is_available():
+ self.model = self.model.to(device)
+ model_dict = transfer(self.model, torch.load(model_path))
+ self.model.load_state_dict(model_dict)
+ self.model.eval()
+ self.device = device
+
+ def __call__(self, oriImg):
+ scale_search = [0.5, 1.0, 1.5, 2.0]
+ # scale_search = [0.5]
+ boxsize = 368
+ stride = 8
+ padValue = 128
+ thre = 0.05
+ multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
+ heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 22))
+ # paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38))
+
+ for m in range(len(multiplier)):
+ scale = multiplier[m]
+ imageToTest = cv2.resize(oriImg, (0, 0),
+ fx=scale,
+ fy=scale,
+ interpolation=cv2.INTER_CUBIC)
+ imageToTest_padded, pad = padRightDownCorner(
+ imageToTest, stride, padValue)
+ im = np.transpose(
+ np.float32(imageToTest_padded[:, :, :, np.newaxis]),
+ (3, 2, 0, 1)) / 256 - 0.5
+ im = np.ascontiguousarray(im)
+
+ data = torch.from_numpy(im).float()
+ if torch.cuda.is_available():
+ data = data.to(self.device)
+ # data = data.permute([2, 0, 1]).unsqueeze(0).float()
+ with torch.no_grad():
+ output = self.model(data).cpu().numpy()
+ # output = self.model(data).numpy()q
+
+ # extract outputs, resize, and remove padding
+ heatmap = np.transpose(np.squeeze(output),
+ (1, 2, 0)) # output 1 is heatmaps
+ heatmap = cv2.resize(heatmap, (0, 0),
+ fx=stride,
+ fy=stride,
+ interpolation=cv2.INTER_CUBIC)
+ heatmap = heatmap[:imageToTest_padded.shape[0] -
+ pad[2], :imageToTest_padded.shape[1] - pad[3], :]
+ heatmap = cv2.resize(heatmap, (oriImg.shape[1], oriImg.shape[0]),
+ interpolation=cv2.INTER_CUBIC)
+
+ heatmap_avg += heatmap / len(multiplier)
+
+ all_peaks = []
+ for part in range(21):
+ map_ori = heatmap_avg[:, :, part]
+ one_heatmap = gaussian_filter(map_ori, sigma=3)
+ binary = np.ascontiguousarray(one_heatmap > thre, dtype=np.uint8)
+ # 全部小于阈值
+ if np.sum(binary) == 0:
+ all_peaks.append([0, 0])
+ continue
+ label_img, label_numbers = label(binary,
+ return_num=True,
+ connectivity=binary.ndim)
+ max_index = np.argmax([
+ np.sum(map_ori[label_img == i])
+ for i in range(1, label_numbers + 1)
+ ]) + 1
+ label_img[label_img != max_index] = 0
+ map_ori[label_img == 0] = 0
+
+ y, x = npmax(map_ori)
+ all_peaks.append([x, y])
+ return np.array(all_peaks)
+
+
+class Body(object):
+ def __init__(self, model_path, device='cuda'):
+ self.model = bodypose_model()
+ if torch.cuda.is_available():
+ self.model = self.model.to(device)
+ model_dict = transfer(self.model, torch.load(model_path))
+ self.model.load_state_dict(model_dict)
+ self.model.eval()
+ self.device = device
+
+ def __call__(self, oriImg):
+ # scale_search = [0.5, 1.0, 1.5, 2.0]
+ scale_search = [0.5]
+ boxsize = 368
+ stride = 8
+ padValue = 128
+ thre1 = 0.1
+ thre2 = 0.05
+ multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
+ heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 19))
+ paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38))
+
+ for m in range(len(multiplier)):
+ scale = multiplier[m]
+ imageToTest = cv2.resize(oriImg, (0, 0),
+ fx=scale,
+ fy=scale,
+ interpolation=cv2.INTER_CUBIC)
+ imageToTest_padded, pad = padRightDownCorner(
+ imageToTest, stride, padValue)
+ im = np.transpose(
+ np.float32(imageToTest_padded[:, :, :, np.newaxis]),
+ (3, 2, 0, 1)) / 256 - 0.5
+ im = np.ascontiguousarray(im)
+
+ data = torch.from_numpy(im).float()
+ if torch.cuda.is_available():
+ data = data.to(self.device)
+ # data = data.permute([2, 0, 1]).unsqueeze(0).float()
+ with torch.no_grad():
+ Mconv7_stage6_L1, Mconv7_stage6_L2 = self.model(data)
+ Mconv7_stage6_L1 = Mconv7_stage6_L1.cpu().numpy()
+ Mconv7_stage6_L2 = Mconv7_stage6_L2.cpu().numpy()
+
+ # extract outputs, resize, and remove padding
+ # heatmap = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[1]].data), (1, 2, 0))
+ # output 1 is heatmaps
+ heatmap = np.transpose(np.squeeze(Mconv7_stage6_L2),
+ (1, 2, 0)) # output 1 is heatmaps
+ heatmap = cv2.resize(heatmap, (0, 0),
+ fx=stride,
+ fy=stride,
+ interpolation=cv2.INTER_CUBIC)
+ heatmap = heatmap[:imageToTest_padded.shape[0] -
+ pad[2], :imageToTest_padded.shape[1] - pad[3], :]
+ heatmap = cv2.resize(heatmap, (oriImg.shape[1], oriImg.shape[0]),
+ interpolation=cv2.INTER_CUBIC)
+
+ # paf = np.transpose(np.squeeze(net.blobs[output_blobs.keys()[0]].data), (1, 2, 0)) # output 0 is PAFs
+ paf = np.transpose(np.squeeze(Mconv7_stage6_L1),
+ (1, 2, 0)) # output 0 is PAFs
+ paf = cv2.resize(paf, (0, 0),
+ fx=stride,
+ fy=stride,
+ interpolation=cv2.INTER_CUBIC)
+ paf = paf[:imageToTest_padded.shape[0] -
+ pad[2], :imageToTest_padded.shape[1] - pad[3], :]
+ paf = cv2.resize(paf, (oriImg.shape[1], oriImg.shape[0]),
+ interpolation=cv2.INTER_CUBIC)
+
+ heatmap_avg += heatmap_avg + heatmap / len(multiplier)
+ paf_avg += +paf / len(multiplier)
+
+ all_peaks = []
+ peak_counter = 0
+
+ for part in range(18):
+ map_ori = heatmap_avg[:, :, part]
+ one_heatmap = gaussian_filter(map_ori, sigma=3)
+
+ map_left = np.zeros(one_heatmap.shape)
+ map_left[1:, :] = one_heatmap[:-1, :]
+ map_right = np.zeros(one_heatmap.shape)
+ map_right[:-1, :] = one_heatmap[1:, :]
+ map_up = np.zeros(one_heatmap.shape)
+ map_up[:, 1:] = one_heatmap[:, :-1]
+ map_down = np.zeros(one_heatmap.shape)
+ map_down[:, :-1] = one_heatmap[:, 1:]
+
+ peaks_binary = np.logical_and.reduce(
+ (one_heatmap >= map_left, one_heatmap >= map_right,
+ one_heatmap >= map_up, one_heatmap >= map_down,
+ one_heatmap > thre1))
+ peaks = list(
+ zip(np.nonzero(peaks_binary)[1],
+ np.nonzero(peaks_binary)[0])) # note reverse
+ peaks_with_score = [x + (map_ori[x[1], x[0]], ) for x in peaks]
+ peak_id = range(peak_counter, peak_counter + len(peaks))
+ peaks_with_score_and_id = [
+ peaks_with_score[i] + (peak_id[i], )
+ for i in range(len(peak_id))
+ ]
+
+ all_peaks.append(peaks_with_score_and_id)
+ peak_counter += len(peaks)
+
+ # find connection in the specified sequence, center 29 is in the position 15
+ limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9],
+ [9, 10], [10, 11], [2, 12], [12, 13], [13, 14], [2, 1],
+ [1, 15], [15, 17], [1, 16], [16, 18], [3, 17], [6, 18]]
+ # the middle joints heatmap correpondence
+ mapIdx = [[31, 32], [39, 40], [33, 34], [35, 36], [41, 42], [43, 44],
+ [19, 20], [21, 22], [23, 24], [25, 26], [27, 28], [29, 30],
+ [47, 48], [49, 50], [53, 54], [51, 52], [55, 56], [37, 38],
+ [45, 46]]
+
+ connection_all = []
+ special_k = []
+ mid_num = 10
+
+ for k in range(len(mapIdx)):
+ score_mid = paf_avg[:, :, [x - 19 for x in mapIdx[k]]]
+ candA = all_peaks[limbSeq[k][0] - 1]
+ candB = all_peaks[limbSeq[k][1] - 1]
+ nA = len(candA)
+ nB = len(candB)
+ indexA, indexB = limbSeq[k]
+ if (nA != 0 and nB != 0):
+ connection_candidate = []
+ for i in range(nA):
+ for j in range(nB):
+ vec = np.subtract(candB[j][:2], candA[i][:2])
+ norm = math.sqrt(vec[0] * vec[0] + vec[1] * vec[1])
+ norm = max(0.001, norm)
+ vec = np.divide(vec, norm)
+
+ startend = list(
+ zip(
+ np.linspace(candA[i][0],
+ candB[j][0],
+ num=mid_num),
+ np.linspace(candA[i][1],
+ candB[j][1],
+ num=mid_num)))
+
+ vec_x = np.array([
+ score_mid[int(round(startend[ii][1])),
+ int(round(startend[ii][0])), 0]
+ for ii in range(len(startend))
+ ])
+ vec_y = np.array([
+ score_mid[int(round(startend[ii][1])),
+ int(round(startend[ii][0])), 1]
+ for ii in range(len(startend))
+ ])
+
+ score_midpts = np.multiply(
+ vec_x, vec[0]) + np.multiply(vec_y, vec[1])
+ score_with_dist_prior = sum(score_midpts) / len(
+ score_midpts) + min(
+ 0.5 * oriImg.shape[0] / norm - 1, 0)
+ criterion1 = len(np.nonzero(
+ score_midpts > thre2)[0]) > 0.8 * len(score_midpts)
+ criterion2 = score_with_dist_prior > 0
+ if criterion1 and criterion2:
+ connection_candidate.append([
+ i, j, score_with_dist_prior,
+ score_with_dist_prior + candA[i][2] +
+ candB[j][2]
+ ])
+
+ connection_candidate = sorted(connection_candidate,
+ key=lambda x: x[2],
+ reverse=True)
+ connection = np.zeros((0, 5))
+ for c in range(len(connection_candidate)):
+ i, j, s = connection_candidate[c][0:3]
+ if (i not in connection[:, 3]
+ and j not in connection[:, 4]):
+ connection = np.vstack(
+ [connection, [candA[i][3], candB[j][3], s, i, j]])
+ if (len(connection) >= min(nA, nB)):
+ break
+
+ connection_all.append(connection)
+ else:
+ special_k.append(k)
+ connection_all.append([])
+
+ # last number in each row is the total parts number of that person
+ # the second last number in each row is the score of the overall configuration
+ subset = -1 * np.ones((0, 20))
+ candidate = np.array(
+ [item for sublist in all_peaks for item in sublist])
+
+ for k in range(len(mapIdx)):
+ if k not in special_k:
+ partAs = connection_all[k][:, 0]
+ partBs = connection_all[k][:, 1]
+ indexA, indexB = np.array(limbSeq[k]) - 1
+
+ for i in range(len(connection_all[k])): # = 1:size(temp,1)
+ found = 0
+ subset_idx = [-1, -1]
+ for j in range(len(subset)): # 1:size(subset,1):
+ if subset[j][indexA] == partAs[i] or subset[j][
+ indexB] == partBs[i]:
+ subset_idx[found] = j
+ found += 1
+
+ if found == 1:
+ j = subset_idx[0]
+ if subset[j][indexB] != partBs[i]:
+ subset[j][indexB] = partBs[i]
+ subset[j][-1] += 1
+ subset[j][-2] += candidate[
+ partBs[i].astype(int),
+ 2] + connection_all[k][i][2]
+ elif found == 2: # if found 2 and disjoint, merge them
+ j1, j2 = subset_idx
+ membership = ((subset[j1] >= 0).astype(int) +
+ (subset[j2] >= 0).astype(int))[:-2]
+ if len(np.nonzero(membership == 2)[0]) == 0: # merge
+ subset[j1][:-2] += (subset[j2][:-2] + 1)
+ subset[j1][-2:] += subset[j2][-2:]
+ subset[j1][-2] += connection_all[k][i][2]
+ subset = np.delete(subset, j2, 0)
+ else: # as like found == 1
+ subset[j1][indexB] = partBs[i]
+ subset[j1][-1] += 1
+ subset[j1][-2] += candidate[
+ partBs[i].astype(int),
+ 2] + connection_all[k][i][2]
+
+ # if find no partA in the subset, create a new subset
+ elif not found and k < 17:
+ row = -1 * np.ones(20)
+ row[indexA] = partAs[i]
+ row[indexB] = partBs[i]
+ row[-1] = 2
+ row[-2] = sum(
+ candidate[connection_all[k][i, :2].astype(int),
+ 2]) + connection_all[k][i][2]
+ subset = np.vstack([subset, row])
+ # delete some rows of subset which has few parts occur
+ deleteIdx = []
+ for i in range(len(subset)):
+ if subset[i][-1] < 4 or subset[i][-2] / subset[i][-1] < 0.4:
+ deleteIdx.append(i)
+ subset = np.delete(subset, deleteIdx, axis=0)
+
+ # subset: n*20 array, 0-17 is the index in candidate, 18 is the total score, 19 is the total parts
+ # candidate: x, y, score, id
+ return candidate, subset
+
+
+@ANNOTATORS.register_class()
+class OpenposeAnnotator(BaseAnnotator, metaclass=ABCMeta):
+ para_dict = {}
+
+ def __init__(self, cfg, logger=None):
+ super().__init__(cfg, logger=logger)
+ with FS.get_from(cfg.BODY_MODEL_PATH,
+ wait_finish=True) as body_model_path:
+ self.body_estimation = Body(body_model_path, device='cpu')
+ with FS.get_from(cfg.HAND_MODEL_PATH,
+ wait_finish=True) as hand_model_path:
+ self.hand_estimation = Hand(hand_model_path, device='cpu')
+ self.use_hand = cfg.get('USE_HAND', False)
+
+ def to(self, device):
+ self.body_estimation.model = self.body_estimation.model.to(device)
+ self.body_estimation.device = device
+ self.hand_estimation.model = self.hand_estimation.model.to(device)
+ self.hand_estimation.device = device
+ return self
+
+ @torch.no_grad()
+ @torch.inference_mode()
+ @torch.autocast('cuda', enabled=False)
+ def forward(self, image):
+ if isinstance(image, Image.Image):
+ image = np.array(image)
+ elif isinstance(image, torch.Tensor):
+ image = image.detach().cpu().numpy()
+ elif isinstance(image, np.ndarray):
+ image = image.copy()
+ else:
+ raise f'Unsurpport datatype{type(image)}, only surpport np.ndarray, torch.Tensor, Pillow Image.'
+ image = image[:, :, ::-1]
+ candidate, subset = self.body_estimation(image)
+ canvas = np.zeros_like(image)
+ canvas = draw_bodypose(canvas, candidate, subset)
+ if self.use_hand:
+ hands_list = handDetect(candidate, subset, image)
+ all_hand_peaks = []
+ for x, y, w, is_left in hands_list:
+ peaks = self.hand_estimation(image[y:y + w, x:x + w, :])
+ peaks[:, 0] = np.where(peaks[:, 0] == 0, peaks[:, 0],
+ peaks[:, 0] + x)
+ peaks[:, 1] = np.where(peaks[:, 1] == 0, peaks[:, 1],
+ peaks[:, 1] + y)
+ all_hand_peaks.append(peaks)
+ canvas = draw_handpose(canvas, all_hand_peaks)
+ return canvas
+
+ @staticmethod
+ def get_config_template():
+ return dict_to_yaml('ANNOTATORS',
+ __class__.__name__,
+ OpenposeAnnotator.para_dict,
+ set_name=True)
diff --git a/annotator/registry.py b/annotator/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..d141bb6e44d33fdcee51e17ca31a7723c67b4b22
--- /dev/null
+++ b/annotator/registry.py
@@ -0,0 +1,30 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+from scepter.modules.utils.config import Config
+from scepter.modules.utils.registry import Registry, build_from_config
+
+
+def build_annotator(cfg, registry, logger=None, *args, **kwargs):
+ """ After build model, load pretrained model if exists key `pretrain`.
+
+ pretrain (str, dict): Describes how to load pretrained model.
+ str, treat pretrain as model path;
+ dict: should contains key `path`, and other parameters token by function load_pretrained();
+ """
+ if not isinstance(cfg, Config):
+ raise TypeError(f'Config must be type dict, got {type(cfg)}')
+ if cfg.have('PRETRAINED_MODEL'):
+ pretrain_cfg = cfg.PRETRAINED_MODEL
+ if pretrain_cfg is not None and not isinstance(pretrain_cfg, (str)):
+ raise TypeError('Pretrain parameter must be a string')
+ else:
+ pretrain_cfg = None
+
+ model = build_from_config(cfg, registry, logger=logger, *args, **kwargs)
+ if pretrain_cfg is not None:
+ if hasattr(model, 'load_pretrained_model'):
+ model.load_pretrained_model(pretrain_cfg)
+ return model
+
+
+ANNOTATORS = Registry('ANNOTATORS', build_func=build_annotator)
diff --git a/annotator/utils.py b/annotator/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..89a25bdd51b88793c64fe43c9f13724dd157ebba
--- /dev/null
+++ b/annotator/utils.py
@@ -0,0 +1,114 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) Alibaba, Inc. and its affiliates.
+import cv2
+import numpy as np
+
+
+def resize_image(input_image, resolution):
+ H, W, C = input_image.shape
+ H = float(H)
+ W = float(W)
+ k = float(resolution) / min(H, W)
+ H *= k
+ W *= k
+ H = int(np.round(H / 64.0)) * 64
+ W = int(np.round(W / 64.0)) * 64
+ img = cv2.resize(
+ input_image, (W, H),
+ interpolation=cv2.INTER_LANCZOS4 if k > 1 else cv2.INTER_AREA)
+ return img, k
+
+
+def resize_image_ori(h, w, image, k):
+ img = cv2.resize(
+ image, (w, h),
+ interpolation=cv2.INTER_LANCZOS4 if k > 1 else cv2.INTER_AREA)
+ return img
+
+
+class AnnotatorProcessor():
+ canny_cfg = {
+ 'NAME': 'CannyAnnotator',
+ 'LOW_THRESHOLD': 100,
+ 'HIGH_THRESHOLD': 200,
+ 'INPUT_KEYS': ['img'],
+ 'OUTPUT_KEYS': ['canny']
+ }
+ hed_cfg = {
+ 'NAME': 'HedAnnotator',
+ 'PRETRAINED_MODEL':
+ 'ms://damo/scepter_scedit@annotator/ckpts/ControlNetHED.pth',
+ 'INPUT_KEYS': ['img'],
+ 'OUTPUT_KEYS': ['hed']
+ }
+ openpose_cfg = {
+ 'NAME': 'OpenposeAnnotator',
+ 'BODY_MODEL_PATH':
+ 'ms://damo/scepter_scedit@annotator/ckpts/body_pose_model.pth',
+ 'HAND_MODEL_PATH':
+ 'ms://damo/scepter_scedit@annotator/ckpts/hand_pose_model.pth',
+ 'INPUT_KEYS': ['img'],
+ 'OUTPUT_KEYS': ['openpose']
+ }
+ midas_cfg = {
+ 'NAME': 'MidasDetector',
+ 'PRETRAINED_MODEL':
+ 'ms://damo/scepter_scedit@annotator/ckpts/dpt_hybrid-midas-501f0c75.pt',
+ 'INPUT_KEYS': ['img'],
+ 'OUTPUT_KEYS': ['depth']
+ }
+ mlsd_cfg = {
+ 'NAME': 'MLSDdetector',
+ 'PRETRAINED_MODEL':
+ 'ms://damo/scepter_scedit@annotator/ckpts/mlsd_large_512_fp32.pth',
+ 'INPUT_KEYS': ['img'],
+ 'OUTPUT_KEYS': ['mlsd']
+ }
+ color_cfg = {
+ 'NAME': 'ColorAnnotator',
+ 'RATIO': 64,
+ 'INPUT_KEYS': ['img'],
+ 'OUTPUT_KEYS': ['color']
+ }
+
+ anno_type_map = {
+ 'canny': canny_cfg,
+ 'hed': hed_cfg,
+ 'pose': openpose_cfg,
+ 'depth': midas_cfg,
+ 'mlsd': mlsd_cfg,
+ 'color': color_cfg
+ }
+
+ def __init__(self, anno_type):
+ from scepter.modules.annotator.registry import ANNOTATORS
+ from scepter.modules.utils.config import Config
+ from scepter.modules.utils.distribute import we
+
+ if isinstance(anno_type, str):
+ assert anno_type in self.anno_type_map.keys()
+ anno_type = [anno_type]
+ elif isinstance(anno_type, (list, tuple)):
+ assert all(tp in self.anno_type_map.keys() for tp in anno_type)
+ else:
+ raise Exception(f'Error anno_type: {anno_type}')
+
+ general_dict = {
+ 'NAME': 'GeneralAnnotator',
+ 'ANNOTATORS': [self.anno_type_map[tp] for tp in anno_type]
+ }
+ general_anno = Config(cfg_dict=general_dict, load=False)
+ self.general_ins = ANNOTATORS.build(general_anno).to(we.device_id)
+
+ def run(self, image, anno_type=None):
+ output_image = self.general_ins({'img': image})
+ if anno_type is not None:
+ if isinstance(anno_type, str) and anno_type in output_image:
+ return output_image[anno_type]
+ else:
+ return {
+ tp: output_image[tp]
+ for tp in anno_type if tp in output_image
+ }
+ else:
+ return output_image
diff --git a/app.py b/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..894aa9026facb757faa483cdd6b212acd68c84e8
--- /dev/null
+++ b/app.py
@@ -0,0 +1,32 @@
+import gradio as gr
+import spaces
+from PIL import Image
+from typing import List
+
+from pipeline import prepare_white_image, MultiViewGenerator
+from util import download_file, unzip_file
+
+download_file("https://huggingface.co/aki-0421/character-360/resolve/main/v2.ckpt", "v2.ckpt")
+download_file("https://huggingface.co/hbyang/Hi3D/resolve/main/ckpts.zip", "ckpts.zip")
+
+unzip_file("ckpts.zip", ".")
+
+multi_view_generator = MultiViewGenerator(checkpoint_path="v2.ckpt")
+
+@spaces.GPU(duration=120)
+def generate_images(input_image: Image.Image) -> List[Image.Image]:
+ white_image = prepare_white_image(input_image=input_image)
+
+ return multi_view_generator.infer(white_image=white_image)
+
+
+with gr.Blocks() as demo:
+ gr.Markdown("# GPU-accelerated Image Processing")
+ with gr.Row():
+ input_image = gr.Image(label="Input Image", type="pil") # 入力はPIL形式
+ output_gallery = gr.Gallery(label="Output Images (25 Variations)").style(grid=(5, 5))
+ submit_button = gr.Button("Generate")
+
+ submit_button.click(generate_images, inputs=input_image, outputs=output_gallery)
+
+demo.launch()
\ No newline at end of file
diff --git a/dataset/.gitignore b/dataset/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..42e84b32bf800b95df97c06ac9566abbb0c94003
--- /dev/null
+++ b/dataset/.gitignore
@@ -0,0 +1 @@
+benchmarks/benchmarking_Random_grayscale.png
diff --git a/dataset/opencv_transforms/__init__.py b/dataset/opencv_transforms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/dataset/opencv_transforms/functional.py b/dataset/opencv_transforms/functional.py
new file mode 100644
index 0000000000000000000000000000000000000000..ecff10b7d644e73087f67b2e30210673d98399cf
--- /dev/null
+++ b/dataset/opencv_transforms/functional.py
@@ -0,0 +1,598 @@
+import math
+import random
+
+import torch
+from PIL import Image, ImageEnhance, ImageOps
+
+try:
+ import accimage
+except ImportError:
+ accimage = None
+import collections
+import numbers
+import types
+import warnings
+
+import cv2
+import numpy as np
+from PIL import Image
+
+_cv2_pad_to_str = {
+ 'constant': cv2.BORDER_CONSTANT,
+ 'edge': cv2.BORDER_REPLICATE,
+ 'reflect': cv2.BORDER_REFLECT_101,
+ 'symmetric': cv2.BORDER_REFLECT
+}
+_cv2_interpolation_to_str = {
+ 'nearest': cv2.INTER_NEAREST,
+ 'bilinear': cv2.INTER_LINEAR,
+ 'area': cv2.INTER_AREA,
+ 'bicubic': cv2.INTER_CUBIC,
+ 'lanczos': cv2.INTER_LANCZOS4
+}
+_cv2_interpolation_from_str = {v: k for k, v in _cv2_interpolation_to_str.items()}
+
+
+def _is_pil_image(img):
+ if accimage is not None:
+ return isinstance(img, (Image.Image, accimage.Image))
+ else:
+ return isinstance(img, Image.Image)
+
+
+def _is_tensor_image(img):
+ return torch.is_tensor(img) and img.ndimension() == 3
+
+
+def _is_numpy_image(img):
+ return isinstance(img, np.ndarray) and (img.ndim in {2, 3})
+
+
+def to_tensor(pic):
+ """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
+ See ``ToTensor`` for more details.
+ Args:
+ pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
+ Returns:
+ Tensor: Converted image.
+ """
+ if not (_is_numpy_image(pic)):
+ raise TypeError('pic should be ndarray. Got {}'.format(type(pic)))
+
+ # handle numpy array
+ img = torch.from_numpy(pic.transpose((2, 0, 1)))
+ # backward compatibility
+ if isinstance(img, torch.ByteTensor) or img.dtype == torch.uint8:
+ return img.float().div(255)
+ else:
+ return img
+
+
+def normalize(tensor, mean, std):
+ """Normalize a tensor image with mean and standard deviation.
+ .. note::
+ This transform acts in-place, i.e., it mutates the input tensor.
+ See :class:`~torchvision.transforms.Normalize` for more details.
+ Args:
+ tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
+ mean (sequence): Sequence of means for each channel.
+ std (sequence): Sequence of standard deviations for each channely.
+ Returns:
+ Tensor: Normalized Tensor image.
+ """
+ if not _is_tensor_image(tensor):
+ raise TypeError('tensor is not a torch image.')
+
+ # This is faster than using broadcasting, don't change without benchmarking
+ for t, m, s in zip(tensor, mean, std):
+ t.sub_(m).div_(s)
+ return tensor
+
+
+def resize(img, size, interpolation=cv2.INTER_LINEAR):
+ r"""Resize the input numpy ndarray to the given size.
+ Args:
+ img (numpy ndarray): Image to be resized.
+ size (sequence or int): Desired output size. If size is a sequence like
+ (h, w), the output size will be matched to this. If size is an int,
+ the smaller edge of the image will be matched to this number maintaing
+ the aspect ratio. i.e, if height > width, then image will be rescaled to
+ :math:`\left(\text{size} \times \frac{\text{height}}{\text{width}}, \text{size}\right)`
+ interpolation (int, optional): Desired interpolation. Default is
+ ``cv2.INTER_LINEAR``
+ Returns:
+ PIL Image: Resized image.
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy image. Got {}'.format(type(img)))
+ if not (isinstance(size, int) or (isinstance(size, collections.abc.Iterable) and len(size) == 2)):
+ raise TypeError('Got inappropriate size arg: {}'.format(size))
+ h, w = img.shape[0], img.shape[1]
+
+ if isinstance(size, int):
+ if (w <= h and w == size) or (h <= w and h == size):
+ return img
+ if w < h:
+ ow = size
+ oh = int(size * h / w)
+ else:
+ oh = size
+ ow = int(size * w / h)
+ else:
+ ow, oh = size[1], size[0]
+ output = cv2.resize(img, dsize=(ow, oh), interpolation=interpolation)
+ if img.shape[2] == 1:
+ return output[:, :, np.newaxis]
+ else:
+ return output
+
+
+def scale(*args, **kwargs):
+ warnings.warn("The use of the transforms.Scale transform is deprecated, " + "please use transforms.Resize instead.")
+ return resize(*args, **kwargs)
+
+
+def pad(img, padding, fill=0, padding_mode='constant'):
+ r"""Pad the given numpy ndarray on all sides with specified padding mode and fill value.
+ Args:
+ img (numpy ndarray): image to be padded.
+ padding (int or tuple): Padding on each border. If a single int is provided this
+ is used to pad all borders. If tuple of length 2 is provided this is the padding
+ on left/right and top/bottom respectively. If a tuple of length 4 is provided
+ this is the padding for the left, top, right and bottom borders
+ respectively.
+ fill: Pixel fill value for constant fill. Default is 0. If a tuple of
+ length 3, it is used to fill R, G, B channels respectively.
+ This value is only used when the padding_mode is constant
+ padding_mode: Type of padding. Should be: constant, edge, reflect or symmetric. Default is constant.
+ - constant: pads with a constant value, this value is specified with fill
+ - edge: pads with the last value on the edge of the image
+ - reflect: pads with reflection of image (without repeating the last value on the edge)
+ padding [1, 2, 3, 4] with 2 elements on both sides in reflect mode
+ will result in [3, 2, 1, 2, 3, 4, 3, 2]
+ - symmetric: pads with reflection of image (repeating the last value on the edge)
+ padding [1, 2, 3, 4] with 2 elements on both sides in symmetric mode
+ will result in [2, 1, 1, 2, 3, 4, 4, 3]
+ Returns:
+ Numpy image: padded image.
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy ndarray. Got {}'.format(type(img)))
+ if not isinstance(padding, (numbers.Number, tuple, list)):
+ raise TypeError('Got inappropriate padding arg')
+ if not isinstance(fill, (numbers.Number, str, tuple)):
+ raise TypeError('Got inappropriate fill arg')
+ if not isinstance(padding_mode, str):
+ raise TypeError('Got inappropriate padding_mode arg')
+ if isinstance(padding, collections.Sequence) and len(padding) not in [2, 4]:
+ raise ValueError("Padding must be an int or a 2, or 4 element tuple, not a " +
+ "{} element tuple".format(len(padding)))
+
+ assert padding_mode in ['constant', 'edge', 'reflect', 'symmetric'], \
+ 'Padding mode should be either constant, edge, reflect or symmetric'
+
+ if isinstance(padding, int):
+ pad_left = pad_right = pad_top = pad_bottom = padding
+ if isinstance(padding, collections.Sequence) and len(padding) == 2:
+ pad_left = pad_right = padding[0]
+ pad_top = pad_bottom = padding[1]
+ if isinstance(padding, collections.Sequence) and len(padding) == 4:
+ pad_left = padding[0]
+ pad_top = padding[1]
+ pad_right = padding[2]
+ pad_bottom = padding[3]
+ if img.shape[2] == 1:
+ return cv2.copyMakeBorder(img,
+ top=pad_top,
+ bottom=pad_bottom,
+ left=pad_left,
+ right=pad_right,
+ borderType=_cv2_pad_to_str[padding_mode],
+ value=fill)[:, :, np.newaxis]
+ else:
+ return cv2.copyMakeBorder(img,
+ top=pad_top,
+ bottom=pad_bottom,
+ left=pad_left,
+ right=pad_right,
+ borderType=_cv2_pad_to_str[padding_mode],
+ value=fill)
+
+
+def crop(img, i, j, h, w):
+ """Crop the given PIL Image.
+ Args:
+ img (numpy ndarray): Image to be cropped.
+ i: Upper pixel coordinate.
+ j: Left pixel coordinate.
+ h: Height of the cropped image.
+ w: Width of the cropped image.
+ Returns:
+ numpy ndarray: Cropped image.
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy image. Got {}'.format(type(img)))
+
+ return img[i:i + h, j:j + w, :]
+
+
+def center_crop(img, output_size):
+ if isinstance(output_size, numbers.Number):
+ output_size = (int(output_size), int(output_size))
+ h, w = img.shape[0:2]
+ th, tw = output_size
+ i = int(round((h - th) / 2.))
+ j = int(round((w - tw) / 2.))
+ return crop(img, i, j, th, tw)
+
+
+def resized_crop(img, i, j, h, w, size, interpolation=cv2.INTER_LINEAR):
+ """Crop the given numpy ndarray and resize it to desired size.
+ Notably used in :class:`~torchvision.transforms.RandomResizedCrop`.
+ Args:
+ img (numpy ndarray): Image to be cropped.
+ i: Upper pixel coordinate.
+ j: Left pixel coordinate.
+ h: Height of the cropped image.
+ w: Width of the cropped image.
+ size (sequence or int): Desired output size. Same semantics as ``scale``.
+ interpolation (int, optional): Desired interpolation. Default is
+ ``cv2.INTER_CUBIC``.
+ Returns:
+ PIL Image: Cropped image.
+ """
+ assert _is_numpy_image(img), 'img should be numpy image'
+ img = crop(img, i, j, h, w)
+ img = resize(img, size, interpolation=interpolation)
+ return img
+
+
+def hflip(img):
+ """Horizontally flip the given numpy ndarray.
+ Args:
+ img (numpy ndarray): image to be flipped.
+ Returns:
+ numpy ndarray: Horizontally flipped image.
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy image. Got {}'.format(type(img)))
+ # img[:,::-1] is much faster, but doesn't work with torch.from_numpy()!
+ if img.shape[2] == 1:
+ return cv2.flip(img, 1)[:, :, np.newaxis]
+ else:
+ return cv2.flip(img, 1)
+
+
+def vflip(img):
+ """Vertically flip the given numpy ndarray.
+ Args:
+ img (numpy ndarray): Image to be flipped.
+ Returns:
+ numpy ndarray: Vertically flipped image.
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy Image. Got {}'.format(type(img)))
+ if img.shape[2] == 1:
+ return cv2.flip(img, 0)[:, :, np.newaxis]
+ else:
+ return cv2.flip(img, 0)
+ # img[::-1] is much faster, but doesn't work with torch.from_numpy()!
+
+
+def five_crop(img, size):
+ """Crop the given numpy ndarray into four corners and the central crop.
+ .. Note::
+ This transform returns a tuple of images and there may be a
+ mismatch in the number of inputs and targets your ``Dataset`` returns.
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ Returns:
+ tuple: tuple (tl, tr, bl, br, center)
+ Corresponding top left, top right, bottom left, bottom right and center crop.
+ """
+ if isinstance(size, numbers.Number):
+ size = (int(size), int(size))
+ else:
+ assert len(size) == 2, "Please provide only two dimensions (h, w) for size."
+
+ h, w = img.shape[0:2]
+ crop_h, crop_w = size
+ if crop_w > w or crop_h > h:
+ raise ValueError("Requested crop size {} is bigger than input size {}".format(size, (h, w)))
+ tl = crop(img, 0, 0, crop_h, crop_w)
+ tr = crop(img, 0, w - crop_w, crop_h, crop_w)
+ bl = crop(img, h - crop_h, 0, crop_h, crop_w)
+ br = crop(img, h - crop_h, w - crop_w, crop_h, crop_w)
+ center = center_crop(img, (crop_h, crop_w))
+ return tl, tr, bl, br, center
+
+
+def ten_crop(img, size, vertical_flip=False):
+ r"""Crop the given numpy ndarray into four corners and the central crop plus the
+ flipped version of these (horizontal flipping is used by default).
+ .. Note::
+ This transform returns a tuple of images and there may be a
+ mismatch in the number of inputs and targets your ``Dataset`` returns.
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ vertical_flip (bool): Use vertical flipping instead of horizontal
+ Returns:
+ tuple: tuple (tl, tr, bl, br, center, tl_flip, tr_flip, bl_flip, br_flip, center_flip)
+ Corresponding top left, top right, bottom left, bottom right and center crop
+ and same for the flipped image.
+ """
+ if isinstance(size, numbers.Number):
+ size = (int(size), int(size))
+ else:
+ assert len(size) == 2, "Please provide only two dimensions (h, w) for size."
+
+ first_five = five_crop(img, size)
+
+ if vertical_flip:
+ img = vflip(img)
+ else:
+ img = hflip(img)
+
+ second_five = five_crop(img, size)
+ return first_five + second_five
+
+
+def adjust_brightness(img, brightness_factor):
+ """Adjust brightness of an Image.
+ Args:
+ img (numpy ndarray): numpy ndarray to be adjusted.
+ brightness_factor (float): How much to adjust the brightness. Can be
+ any non negative number. 0 gives a black image, 1 gives the
+ original image while 2 increases the brightness by a factor of 2.
+ Returns:
+ numpy ndarray: Brightness adjusted image.
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy Image. Got {}'.format(type(img)))
+ table = np.array([i * brightness_factor for i in range(0, 256)]).clip(0, 255).astype('uint8')
+ # same thing but a bit slower
+ # cv2.convertScaleAbs(img, alpha=brightness_factor, beta=0)
+ if img.shape[2] == 1:
+ return cv2.LUT(img, table)[:, :, np.newaxis]
+ else:
+ return cv2.LUT(img, table)
+
+
+def adjust_contrast(img, contrast_factor):
+ """Adjust contrast of an mage.
+ Args:
+ img (numpy ndarray): numpy ndarray to be adjusted.
+ contrast_factor (float): How much to adjust the contrast. Can be any
+ non negative number. 0 gives a solid gray image, 1 gives the
+ original image while 2 increases the contrast by a factor of 2.
+ Returns:
+ numpy ndarray: Contrast adjusted image.
+ """
+ # much faster to use the LUT construction than anything else I've tried
+ # it's because you have to change dtypes multiple times
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy Image. Got {}'.format(type(img)))
+
+ # input is RGB
+ if img.ndim > 2 and img.shape[2] == 3:
+ mean_value = round(cv2.mean(cv2.cvtColor(img, cv2.COLOR_RGB2GRAY))[0])
+ elif img.ndim == 2:
+ # grayscale input
+ mean_value = round(cv2.mean(img)[0])
+ else:
+ # multichannel input
+ mean_value = round(np.mean(img))
+
+ table = np.array([(i - mean_value) * contrast_factor + mean_value for i in range(0, 256)]).clip(0,
+ 255).astype('uint8')
+ # enhancer = ImageEnhance.Contrast(img)
+ # img = enhancer.enhance(contrast_factor)
+ if img.ndim == 2 or img.shape[2] == 1:
+ return cv2.LUT(img, table)[:, :, np.newaxis]
+ else:
+ return cv2.LUT(img, table)
+
+
+def adjust_saturation(img, saturation_factor):
+ """Adjust color saturation of an image.
+ Args:
+ img (numpy ndarray): numpy ndarray to be adjusted.
+ saturation_factor (float): How much to adjust the saturation. 0 will
+ give a black and white image, 1 will give the original image while
+ 2 will enhance the saturation by a factor of 2.
+ Returns:
+ numpy ndarray: Saturation adjusted image.
+ """
+ # ~10ms slower than PIL!
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy Image. Got {}'.format(type(img)))
+ img = Image.fromarray(img)
+ enhancer = ImageEnhance.Color(img)
+ img = enhancer.enhance(saturation_factor)
+ return np.array(img)
+
+
+def adjust_hue(img, hue_factor):
+ """Adjust hue of an image.
+ The image hue is adjusted by converting the image to HSV and
+ cyclically shifting the intensities in the hue channel (H).
+ The image is then converted back to original image mode.
+ `hue_factor` is the amount of shift in H channel and must be in the
+ interval `[-0.5, 0.5]`.
+ See `Hue`_ for more details.
+ .. _Hue: https://en.wikipedia.org/wiki/Hue
+ Args:
+ img (numpy ndarray): numpy ndarray to be adjusted.
+ hue_factor (float): How much to shift the hue channel. Should be in
+ [-0.5, 0.5]. 0.5 and -0.5 give complete reversal of hue channel in
+ HSV space in positive and negative direction respectively.
+ 0 means no shift. Therefore, both -0.5 and 0.5 will give an image
+ with complementary colors while 0 gives the original image.
+ Returns:
+ numpy ndarray: Hue adjusted image.
+ """
+ # After testing, found that OpenCV calculates the Hue in a call to
+ # cv2.cvtColor(..., cv2.COLOR_BGR2HSV) differently from PIL
+
+ # This function takes 160ms! should be avoided
+ if not (-0.5 <= hue_factor <= 0.5):
+ raise ValueError('hue_factor is not in [-0.5, 0.5].'.format(hue_factor))
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy Image. Got {}'.format(type(img)))
+ img = Image.fromarray(img)
+ input_mode = img.mode
+ if input_mode in {'L', '1', 'I', 'F'}:
+ return np.array(img)
+
+ h, s, v = img.convert('HSV').split()
+
+ np_h = np.array(h, dtype=np.uint8)
+ # uint8 addition take cares of rotation across boundaries
+ with np.errstate(over='ignore'):
+ np_h += np.uint8(hue_factor * 255)
+ h = Image.fromarray(np_h, 'L')
+
+ img = Image.merge('HSV', (h, s, v)).convert(input_mode)
+ return np.array(img)
+
+
+def adjust_gamma(img, gamma, gain=1):
+ r"""Perform gamma correction on an image.
+ Also known as Power Law Transform. Intensities in RGB mode are adjusted
+ based on the following equation:
+ .. math::
+ I_{\text{out}} = 255 \times \text{gain} \times \left(\frac{I_{\text{in}}}{255}\right)^{\gamma}
+ See `Gamma Correction`_ for more details.
+ .. _Gamma Correction: https://en.wikipedia.org/wiki/Gamma_correction
+ Args:
+ img (numpy ndarray): numpy ndarray to be adjusted.
+ gamma (float): Non negative real number, same as :math:`\gamma` in the equation.
+ gamma larger than 1 make the shadows darker,
+ while gamma smaller than 1 make dark regions lighter.
+ gain (float): The constant multiplier.
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy Image. Got {}'.format(type(img)))
+
+ if gamma < 0:
+ raise ValueError('Gamma should be a non-negative real number')
+ # from here
+ # https://stackoverflow.com/questions/33322488/how-to-change-image-illumination-in-opencv-python/41061351
+ table = np.array([((i / 255.0)**gamma) * 255 * gain for i in np.arange(0, 256)]).astype('uint8')
+ if img.shape[2] == 1:
+ return cv2.LUT(img, table)[:, :, np.newaxis]
+ else:
+ return cv2.LUT(img, table)
+
+
+def rotate(img, angle, resample=False, expand=False, center=None):
+ """Rotate the image by angle.
+ Args:
+ img (numpy ndarray): numpy ndarray to be rotated.
+ angle (float or int): In degrees degrees counter clockwise order.
+ resample (``PIL.Image.NEAREST`` or ``PIL.Image.BILINEAR`` or ``PIL.Image.BICUBIC``, optional):
+ An optional resampling filter. See `filters`_ for more information.
+ If omitted, or if the image has mode "1" or "P", it is set to ``PIL.Image.NEAREST``.
+ expand (bool, optional): Optional expansion flag.
+ If true, expands the output image to make it large enough to hold the entire rotated image.
+ If false or omitted, make the output image the same size as the input image.
+ Note that the expand flag assumes rotation around the center and no translation.
+ center (2-tuple, optional): Optional center of rotation.
+ Origin is the upper left corner.
+ Default is the center of the image.
+ .. _filters: https://pillow.readthedocs.io/en/latest/handbook/concepts.html#filters
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy Image. Got {}'.format(type(img)))
+ rows, cols = img.shape[0:2]
+ if center is None:
+ center = (cols / 2, rows / 2)
+ M = cv2.getRotationMatrix2D(center, angle, 1)
+ if img.shape[2] == 1:
+ return cv2.warpAffine(img, M, (cols, rows))[:, :, np.newaxis]
+ else:
+ return cv2.warpAffine(img, M, (cols, rows))
+
+
+def _get_affine_matrix(center, angle, translate, scale, shear):
+ # Helper method to compute matrix for affine transformation
+ # We need compute affine transformation matrix: M = T * C * RSS * C^-1
+ # where T is translation matrix: [1, 0, tx | 0, 1, ty | 0, 0, 1]
+ # C is translation matrix to keep center: [1, 0, cx | 0, 1, cy | 0, 0, 1]
+ # RSS is rotation with scale and shear matrix
+ # RSS(a, scale, shear) = [ cos(a)*scale -sin(a + shear)*scale 0]
+ # [ sin(a)*scale cos(a + shear)*scale 0]
+ # [ 0 0 1]
+
+ angle = math.radians(angle)
+ shear = math.radians(shear)
+ # scale = 1.0 / scale
+
+ T = np.array([[1, 0, translate[0]], [0, 1, translate[1]], [0, 0, 1]])
+ C = np.array([[1, 0, center[0]], [0, 1, center[1]], [0, 0, 1]])
+ RSS = np.array([[math.cos(angle) * scale, -math.sin(angle + shear) * scale, 0],
+ [math.sin(angle) * scale, math.cos(angle + shear) * scale, 0], [0, 0, 1]])
+ matrix = T @ C @ RSS @ np.linalg.inv(C)
+
+ return matrix[:2, :]
+
+
+def affine(img, angle, translate, scale, shear, interpolation=cv2.INTER_LINEAR, mode=cv2.BORDER_CONSTANT, fillcolor=0):
+ """Apply affine transformation on the image keeping image center invariant
+ Args:
+ img (numpy ndarray): numpy ndarray to be transformed.
+ angle (float or int): rotation angle in degrees between -180 and 180, clockwise direction.
+ translate (list or tuple of integers): horizontal and vertical translations (post-rotation translation)
+ scale (float): overall scale
+ shear (float): shear angle value in degrees between -180 to 180, clockwise direction.
+ interpolation (``cv2.INTER_NEAREST` or ``cv2.INTER_LINEAR`` or ``cv2.INTER_AREA``, ``cv2.INTER_CUBIC``):
+ An optional resampling filter.
+ See `filters`_ for more information.
+ If omitted, it is set to ``cv2.INTER_CUBIC``, for bicubic interpolation.
+ mode (``cv2.BORDER_CONSTANT`` or ``cv2.BORDER_REPLICATE`` or ``cv2.BORDER_REFLECT`` or ``cv2.BORDER_REFLECT_101``)
+ Method for filling in border regions.
+ Defaults to cv2.BORDER_CONSTANT, meaning areas outside the image are filled with a value (val, default 0)
+ val (int): Optional fill color for the area outside the transform in the output image. Default: 0
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy Image. Got {}'.format(type(img)))
+
+ assert isinstance(translate, (tuple, list)) and len(translate) == 2, \
+ "Argument translate should be a list or tuple of length 2"
+
+ assert scale > 0.0, "Argument scale should be positive"
+
+ output_size = img.shape[0:2]
+ center = (img.shape[1] * 0.5 + 0.5, img.shape[0] * 0.5 + 0.5)
+ matrix = _get_affine_matrix(center, angle, translate, scale, shear)
+
+ if img.shape[2] == 1:
+ return cv2.warpAffine(img, matrix, output_size[::-1], interpolation, borderMode=mode,
+ borderValue=fillcolor)[:, :, np.newaxis]
+ else:
+ return cv2.warpAffine(img, matrix, output_size[::-1], interpolation, borderMode=mode, borderValue=fillcolor)
+
+
+def to_grayscale(img, num_output_channels: int = 1):
+ """Convert image to grayscale version of image.
+ Args:
+ img (numpy ndarray): Image to be converted to grayscale.
+ num_output_channels: int
+ if 1 : returned image is single channel
+ if 3 : returned image is 3 channel with r = g = b
+ Returns:
+ numpy ndarray: Grayscale version of the image.
+ """
+ if not _is_numpy_image(img):
+ raise TypeError('img should be numpy ndarray. Got {}'.format(type(img)))
+
+ if num_output_channels == 1:
+ img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)[:, :, np.newaxis]
+ elif num_output_channels == 3:
+ # much faster than doing cvtColor to go back to gray
+ img = np.broadcast_to(cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)[:, :, np.newaxis], img.shape)
+ return img
diff --git a/dataset/opencv_transforms/transforms.py b/dataset/opencv_transforms/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c1f66d766c23a1068ddd34e76965e3f88ec0d03
--- /dev/null
+++ b/dataset/opencv_transforms/transforms.py
@@ -0,0 +1,1044 @@
+from __future__ import division
+
+import collections
+import math
+import numbers
+import random
+import types
+import warnings
+
+# from PIL import Image, ImageOps, ImageEnhance
+try:
+ import accimage
+except ImportError:
+ accimage = None
+import cv2
+import numpy as np
+import torch
+
+from . import functional as F
+
+__all__ = [
+ "Compose", "ToTensor", "Normalize", "Resize", "Scale",
+ "CenterCrop", "Pad", "Lambda", "RandomApply", "RandomChoice",
+ "RandomOrder", "RandomCrop", "RandomHorizontalFlip", "RandomVerticalFlip",
+ "RandomResizedCrop", "RandomSizedCrop", "FiveCrop", "TenCrop",
+ "LinearTransformation", "ColorJitter", "RandomRotation", "RandomAffine",
+ "Grayscale", "RandomGrayscale"
+]
+
+_cv2_pad_to_str = {
+ 'constant': cv2.BORDER_CONSTANT,
+ 'edge': cv2.BORDER_REPLICATE,
+ 'reflect': cv2.BORDER_REFLECT_101,
+ 'symmetric': cv2.BORDER_REFLECT
+}
+_cv2_interpolation_to_str = {
+ 'nearest': cv2.INTER_NEAREST,
+ 'bilinear': cv2.INTER_LINEAR,
+ 'area': cv2.INTER_AREA,
+ 'bicubic': cv2.INTER_CUBIC,
+ 'lanczos': cv2.INTER_LANCZOS4
+}
+_cv2_interpolation_from_str = {
+ v: k
+ for k, v in _cv2_interpolation_to_str.items()
+}
+
+
+class Compose(object):
+ """Composes several transforms together.
+ Args:
+ transforms (list of ``Transform`` objects): list of transforms to compose.
+ Example:
+ >>> transforms.Compose([
+ >>> transforms.CenterCrop(10),
+ >>> transforms.ToTensor(),
+ >>> ])
+ """
+ def __init__(self, transforms):
+ self.transforms = transforms
+
+ def __call__(self, img):
+ for t in self.transforms:
+ img = t(img)
+ return img
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '('
+ for t in self.transforms:
+ format_string += '\n'
+ format_string += ' {0}'.format(t)
+ format_string += '\n)'
+ return format_string
+
+
+class ToTensor(object):
+ """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
+ Converts a PIL Image or numpy.ndarray (H x W x C) in the range
+ [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0].
+ """
+ def __call__(self, pic):
+ """
+ Args:
+ pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
+ Returns:
+ Tensor: Converted image.
+ """
+ return F.to_tensor(pic)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '()'
+
+
+class Normalize(object):
+ """Normalize a tensor image with mean and standard deviation.
+ Given mean: ``(M1,...,Mn)`` and std: ``(S1,..,Sn)`` for ``n`` channels, this transform
+ will normalize each channel of the input ``torch.*Tensor`` i.e.
+ ``input[channel] = (input[channel] - mean[channel]) / std[channel]``
+ .. note::
+ This transform acts in-place, i.e., it mutates the input tensor.
+ Args:
+ mean (sequence): Sequence of means for each channel.
+ std (sequence): Sequence of standard deviations for each channel.
+ """
+ def __init__(self, mean, std):
+ self.mean = mean
+ self.std = std
+
+ def __call__(self, tensor):
+ """
+ Args:
+ tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
+ Returns:
+ Tensor: Normalized Tensor image.
+ """
+ return F.normalize(tensor, self.mean, self.std)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(mean={0}, std={1})'.format(
+ self.mean, self.std)
+
+
+class Resize(object):
+ """Resize the input numpy ndarray to the given size.
+ Args:
+ size (sequence or int): Desired output size. If size is a sequence like
+ (h, w), output size will be matched to this. If size is an int,
+ smaller edge of the image will be matched to this number.
+ i.e, if height > width, then image will be rescaled to
+ (size * height / width, size)
+ interpolation (int, optional): Desired interpolation. Default is
+ ``cv2.INTER_CUBIC``, bicubic interpolation
+ """
+
+ def __init__(self, size, interpolation=cv2.INTER_LINEAR):
+ # assert isinstance(size, int) or (isinstance(size, collections.Iterable) and len(size) == 2)
+ if isinstance(size, int):
+ self.size = size
+ elif isinstance(size, collections.abc.Iterable) and len(size) == 2:
+ if type(size) == list:
+ size = tuple(size)
+ self.size = size
+ else:
+ raise ValueError('Unknown inputs for size: {}'.format(size))
+ self.interpolation = interpolation
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Image to be scaled.
+ Returns:
+ numpy ndarray: Rescaled image.
+ """
+ return F.resize(img, self.size, self.interpolation)
+
+ def __repr__(self):
+ interpolate_str = _cv2_interpolation_from_str[self.interpolation]
+ return self.__class__.__name__ + '(size={0}, interpolation={1})'.format(
+ self.size, interpolate_str)
+
+
+class Scale(Resize):
+ """
+ Note: This transform is deprecated in favor of Resize.
+ """
+ def __init__(self, *args, **kwargs):
+ warnings.warn(
+ "The use of the transforms.Scale transform is deprecated, " +
+ "please use transforms.Resize instead.")
+ super(Scale, self).__init__(*args, **kwargs)
+
+
+class CenterCrop(object):
+ """Crops the given numpy ndarray at the center.
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ """
+ def __init__(self, size):
+ if isinstance(size, numbers.Number):
+ self.size = (int(size), int(size))
+ else:
+ self.size = size
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Image to be cropped.
+ Returns:
+ numpy ndarray: Cropped image.
+ """
+ return F.center_crop(img, self.size)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(size={0})'.format(self.size)
+
+
+class Pad(object):
+ """Pad the given numpy ndarray on all sides with the given "pad" value.
+ Args:
+ padding (int or tuple): Padding on each border. If a single int is provided this
+ is used to pad all borders. If tuple of length 2 is provided this is the padding
+ on left/right and top/bottom respectively. If a tuple of length 4 is provided
+ this is the padding for the left, top, right and bottom borders
+ respectively.
+ fill (int or tuple): Pixel fill value for constant fill. Default is 0. If a tuple of
+ length 3, it is used to fill R, G, B channels respectively.
+ This value is only used when the padding_mode is constant
+ padding_mode (str): Type of padding. Should be: constant, edge, reflect or symmetric.
+ Default is constant.
+ - constant: pads with a constant value, this value is specified with fill
+ - edge: pads with the last value at the edge of the image
+ - reflect: pads with reflection of image without repeating the last value on the edge
+ For example, padding [1, 2, 3, 4] with 2 elements on both sides in reflect mode
+ will result in [3, 2, 1, 2, 3, 4, 3, 2]
+ - symmetric: pads with reflection of image repeating the last value on the edge
+ For example, padding [1, 2, 3, 4] with 2 elements on both sides in symmetric mode
+ will result in [2, 1, 1, 2, 3, 4, 4, 3]
+ """
+ def __init__(self, padding, fill=0, padding_mode='constant'):
+ assert isinstance(padding, (numbers.Number, tuple, list))
+ assert isinstance(fill, (numbers.Number, str, tuple))
+ assert padding_mode in ['constant', 'edge', 'reflect', 'symmetric']
+ if isinstance(padding,
+ collections.Sequence) and len(padding) not in [2, 4]:
+ raise ValueError(
+ "Padding must be an int or a 2, or 4 element tuple, not a " +
+ "{} element tuple".format(len(padding)))
+
+ self.padding = padding
+ self.fill = fill
+ self.padding_mode = padding_mode
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Image to be padded.
+ Returns:
+ numpy ndarray: Padded image.
+ """
+ return F.pad(img, self.padding, self.fill, self.padding_mode)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(padding={0}, fill={1}, padding_mode={2})'.\
+ format(self.padding, self.fill, self.padding_mode)
+
+
+class Lambda(object):
+ """Apply a user-defined lambda as a transform.
+ Args:
+ lambd (function): Lambda/function to be used for transform.
+ """
+ def __init__(self, lambd):
+ assert isinstance(lambd, types.LambdaType)
+ self.lambd = lambd
+
+ def __call__(self, img):
+ return self.lambd(img)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '()'
+
+
+class RandomTransforms(object):
+ """Base class for a list of transformations with randomness
+ Args:
+ transforms (list or tuple): list of transformations
+ """
+ def __init__(self, transforms):
+ assert isinstance(transforms, (list, tuple))
+ self.transforms = transforms
+
+ def __call__(self, *args, **kwargs):
+ raise NotImplementedError()
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '('
+ for t in self.transforms:
+ format_string += '\n'
+ format_string += ' {0}'.format(t)
+ format_string += '\n)'
+ return format_string
+
+
+class RandomApply(RandomTransforms):
+ """Apply randomly a list of transformations with a given probability
+ Args:
+ transforms (list or tuple): list of transformations
+ p (float): probability
+ """
+ def __init__(self, transforms, p=0.5):
+ super(RandomApply, self).__init__(transforms)
+ self.p = p
+
+ def __call__(self, img):
+ if self.p < random.random():
+ return img
+ for t in self.transforms:
+ img = t(img)
+ return img
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '('
+ format_string += '\n p={}'.format(self.p)
+ for t in self.transforms:
+ format_string += '\n'
+ format_string += ' {0}'.format(t)
+ format_string += '\n)'
+ return format_string
+
+
+class RandomOrder(RandomTransforms):
+ """Apply a list of transformations in a random order
+ """
+ def __call__(self, img):
+ order = list(range(len(self.transforms)))
+ random.shuffle(order)
+ for i in order:
+ img = self.transforms[i](img)
+ return img
+
+
+class RandomChoice(RandomTransforms):
+ """Apply single transformation randomly picked from a list
+ """
+ def __call__(self, img):
+ t = random.choice(self.transforms)
+ return t(img)
+
+
+class RandomCrop(object):
+ """Crop the given numpy ndarray at a random location.
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ padding (int or sequence, optional): Optional padding on each border
+ of the image. Default is None, i.e no padding. If a sequence of length
+ 4 is provided, it is used to pad left, top, right, bottom borders
+ respectively. If a sequence of length 2 is provided, it is used to
+ pad left/right, top/bottom borders, respectively.
+ pad_if_needed (boolean): It will pad the image if smaller than the
+ desired size to avoid raising an exception.
+ fill: Pixel fill value for constant fill. Default is 0. If a tuple of
+ length 3, it is used to fill R, G, B channels respectively.
+ This value is only used when the padding_mode is constant
+ padding_mode: Type of padding. Should be: constant, edge, reflect or symmetric. Default is constant.
+ - constant: pads with a constant value, this value is specified with fill
+ - edge: pads with the last value on the edge of the image
+ - reflect: pads with reflection of image (without repeating the last value on the edge)
+ padding [1, 2, 3, 4] with 2 elements on both sides in reflect mode
+ will result in [3, 2, 1, 2, 3, 4, 3, 2]
+ - symmetric: pads with reflection of image (repeating the last value on the edge)
+ padding [1, 2, 3, 4] with 2 elements on both sides in symmetric mode
+ will result in [2, 1, 1, 2, 3, 4, 4, 3]
+ """
+ def __init__(self,
+ size,
+ padding=None,
+ pad_if_needed=False,
+ fill=0,
+ padding_mode='constant'):
+ if isinstance(size, numbers.Number):
+ self.size = (int(size), int(size))
+ else:
+ self.size = size
+ self.padding = padding
+ self.pad_if_needed = pad_if_needed
+ self.fill = fill
+ self.padding_mode = padding_mode
+
+ @staticmethod
+ def get_params(img, output_size):
+ """Get parameters for ``crop`` for a random crop.
+ Args:
+ img (numpy ndarray): Image to be cropped.
+ output_size (tuple): Expected output size of the crop.
+ Returns:
+ tuple: params (i, j, h, w) to be passed to ``crop`` for random crop.
+ """
+ h, w = img.shape[0:2]
+ th, tw = output_size
+ if w == tw and h == th:
+ return 0, 0, h, w
+
+ i = random.randint(0, h - th)
+ j = random.randint(0, w - tw)
+ return i, j, th, tw
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Image to be cropped.
+ Returns:
+ numpy ndarray: Cropped image.
+ """
+ if self.padding is not None:
+ img = F.pad(img, self.padding, self.fill, self.padding_mode)
+
+ # pad the width if needed
+ if self.pad_if_needed and img.shape[1] < self.size[1]:
+ img = F.pad(img, (self.size[1] - img.shape[1], 0), self.fill,
+ self.padding_mode)
+ # pad the height if needed
+ if self.pad_if_needed and img.shape[0] < self.size[0]:
+ img = F.pad(img, (0, self.size[0] - img.shape[0]), self.fill,
+ self.padding_mode)
+
+ i, j, h, w = self.get_params(img, self.size)
+
+ return F.crop(img, i, j, h, w)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(size={0}, padding={1})'.format(
+ self.size, self.padding)
+
+
+class RandomHorizontalFlip(object):
+ """Horizontally flip the given PIL Image randomly with a given probability.
+ Args:
+ p (float): probability of the image being flipped. Default value is 0.5
+ """
+ def __init__(self, p=0.5):
+ self.p = p
+
+ def __call__(self, img):
+ """random
+ Args:
+ img (numpy ndarray): Image to be flipped.
+ Returns:
+ numpy ndarray: Randomly flipped image.
+ """
+ # if random.random() < self.p:
+ # print('flip')
+ # return F.hflip(img)
+ if random.random() < self.p:
+ return F.hflip(img)
+ return img
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(p={})'.format(self.p)
+
+
+class RandomVerticalFlip(object):
+ """Vertically flip the given PIL Image randomly with a given probability.
+ Args:
+ p (float): probability of the image being flipped. Default value is 0.5
+ """
+ def __init__(self, p=0.5):
+ self.p = p
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Image to be flipped.
+ Returns:
+ numpy ndarray: Randomly flipped image.
+ """
+ if random.random() < self.p:
+ return F.vflip(img)
+ return img
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(p={})'.format(self.p)
+
+
+class RandomResizedCrop(object):
+ """Crop the given numpy ndarray to random size and aspect ratio.
+ A crop of random size (default: of 0.08 to 1.0) of the original size and a random
+ aspect ratio (default: of 3/4 to 4/3) of the original aspect ratio is made. This crop
+ is finally resized to given size.
+ This is popularly used to train the Inception networks.
+ Args:
+ size: expected output size of each edge
+ scale: range of size of the origin size cropped
+ ratio: range of aspect ratio of the origin aspect ratio cropped
+ interpolation: Default: cv2.INTER_CUBIC
+ """
+ def __init__(self,
+ size,
+ scale=(0.08, 1.0),
+ ratio=(3. / 4., 4. / 3.),
+ interpolation=cv2.INTER_LINEAR):
+ self.size = (size, size)
+ self.interpolation = interpolation
+ self.scale = scale
+ self.ratio = ratio
+
+ @staticmethod
+ def get_params(img, scale, ratio):
+ """Get parameters for ``crop`` for a random sized crop.
+ Args:
+ img (numpy ndarray): Image to be cropped.
+ scale (tuple): range of size of the origin size cropped
+ ratio (tuple): range of aspect ratio of the origin aspect ratio cropped
+ Returns:
+ tuple: params (i, j, h, w) to be passed to ``crop`` for a random
+ sized crop.
+ """
+ for attempt in range(10):
+ area = img.shape[0] * img.shape[1]
+ target_area = random.uniform(*scale) * area
+ aspect_ratio = random.uniform(*ratio)
+
+ w = int(round(math.sqrt(target_area * aspect_ratio)))
+ h = int(round(math.sqrt(target_area / aspect_ratio)))
+
+ if random.random() < 0.5:
+ w, h = h, w
+
+ if w <= img.shape[1] and h <= img.shape[0]:
+ i = random.randint(0, img.shape[0] - h)
+ j = random.randint(0, img.shape[1] - w)
+ return i, j, h, w
+
+ # Fallback
+ w = min(img.shape[0], img.shape[1])
+ i = (img.shape[0] - w) // 2
+ j = (img.shape[1] - w) // 2
+ return i, j, w, w
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Image to be cropped and resized.
+ Returns:
+ numpy ndarray: Randomly cropped and resized image.
+ """
+ i, j, h, w = self.get_params(img, self.scale, self.ratio)
+ return F.resized_crop(img, i, j, h, w, self.size, self.interpolation)
+
+ def __repr__(self):
+ interpolate_str = _cv2_interpolation_from_str[self.interpolation]
+ format_string = self.__class__.__name__ + '(size={0}'.format(self.size)
+ format_string += ', scale={0}'.format(
+ tuple(round(s, 4) for s in self.scale))
+ format_string += ', ratio={0}'.format(
+ tuple(round(r, 4) for r in self.ratio))
+ format_string += ', interpolation={0})'.format(interpolate_str)
+ return format_string
+
+
+class RandomSizedCrop(RandomResizedCrop):
+ """
+ Note: This transform is deprecated in favor of RandomResizedCrop.
+ """
+ def __init__(self, *args, **kwargs):
+ warnings.warn(
+ "The use of the transforms.RandomSizedCrop transform is deprecated, "
+ + "please use transforms.RandomResizedCrop instead.")
+ super(RandomSizedCrop, self).__init__(*args, **kwargs)
+
+
+class FiveCrop(object):
+ """Crop the given numpy ndarray into four corners and the central crop
+ .. Note::
+ This transform returns a tuple of images and there may be a mismatch in the number of
+ inputs and targets your Dataset returns. See below for an example of how to deal with
+ this.
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an ``int``
+ instead of sequence like (h, w), a square crop of size (size, size) is made.
+ Example:
+ >>> transform = Compose([
+ >>> FiveCrop(size), # this is a list of numpy ndarrays
+ >>> Lambda(lambda crops: torch.stack([ToTensor()(crop) for crop in crops])) # returns a 4D tensor
+ >>> ])
+ >>> #In your test loop you can do the following:
+ >>> input, target = batch # input is a 5d tensor, target is 2d
+ >>> bs, ncrops, c, h, w = input.size()
+ >>> result = model(input.view(-1, c, h, w)) # fuse batch size and ncrops
+ >>> result_avg = result.view(bs, ncrops, -1).mean(1) # avg over crops
+ """
+ def __init__(self, size):
+ self.size = size
+ if isinstance(size, numbers.Number):
+ self.size = (int(size), int(size))
+ else:
+ assert len(
+ size
+ ) == 2, "Please provide only two dimensions (h, w) for size."
+ self.size = size
+
+ def __call__(self, img):
+ return F.five_crop(img, self.size)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(size={0})'.format(self.size)
+
+
+class TenCrop(object):
+ """Crop the given numpy ndarray into four corners and the central crop plus the flipped version of
+ these (horizontal flipping is used by default)
+ .. Note::
+ This transform returns a tuple of images and there may be a mismatch in the number of
+ inputs and targets your Dataset returns. See below for an example of how to deal with
+ this.
+ Args:
+ size (sequence or int): Desired output size of the crop. If size is an
+ int instead of sequence like (h, w), a square crop (size, size) is
+ made.
+ vertical_flip(bool): Use vertical flipping instead of horizontal
+ Example:
+ >>> transform = Compose([
+ >>> TenCrop(size), # this is a list of PIL Images
+ >>> Lambda(lambda crops: torch.stack([ToTensor()(crop) for crop in crops])) # returns a 4D tensor
+ >>> ])
+ >>> #In your test loop you can do the following:
+ >>> input, target = batch # input is a 5d tensor, target is 2d
+ >>> bs, ncrops, c, h, w = input.size()
+ >>> result = model(input.view(-1, c, h, w)) # fuse batch size and ncrops
+ >>> result_avg = result.view(bs, ncrops, -1).mean(1) # avg over crops
+ """
+ def __init__(self, size, vertical_flip=False):
+ self.size = size
+ if isinstance(size, numbers.Number):
+ self.size = (int(size), int(size))
+ else:
+ assert len(
+ size
+ ) == 2, "Please provide only two dimensions (h, w) for size."
+ self.size = size
+ self.vertical_flip = vertical_flip
+
+ def __call__(self, img):
+ return F.ten_crop(img, self.size, self.vertical_flip)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(size={0}, vertical_flip={1})'.format(
+ self.size, self.vertical_flip)
+
+
+class LinearTransformation(object):
+ """Transform a tensor image with a square transformation matrix computed
+ offline.
+ Given transformation_matrix, will flatten the torch.*Tensor, compute the dot
+ product with the transformation matrix and reshape the tensor to its
+ original shape.
+ Applications:
+ - whitening: zero-center the data, compute the data covariance matrix
+ [D x D] with np.dot(X.T, X), perform SVD on this matrix and
+ pass it as transformation_matrix.
+ Args:
+ transformation_matrix (Tensor): tensor [D x D], D = C x H x W
+ """
+ def __init__(self, transformation_matrix):
+ if transformation_matrix.size(0) != transformation_matrix.size(1):
+ raise ValueError("transformation_matrix should be square. Got " +
+ "[{} x {}] rectangular matrix.".format(
+ *transformation_matrix.size()))
+ self.transformation_matrix = transformation_matrix
+
+ def __call__(self, tensor):
+ """
+ Args:
+ tensor (Tensor): Tensor image of size (C, H, W) to be whitened.
+ Returns:
+ Tensor: Transformed image.
+ """
+ if tensor.size(0) * tensor.size(1) * tensor.size(
+ 2) != self.transformation_matrix.size(0):
+ raise ValueError(
+ "tensor and transformation matrix have incompatible shape." +
+ "[{} x {} x {}] != ".format(*tensor.size()) +
+ "{}".format(self.transformation_matrix.size(0)))
+ flat_tensor = tensor.view(1, -1)
+ transformed_tensor = torch.mm(flat_tensor, self.transformation_matrix)
+ tensor = transformed_tensor.view(tensor.size())
+ return tensor
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '('
+ format_string += (str(self.transformation_matrix.numpy().tolist()) +
+ ')')
+ return format_string
+
+
+class ColorJitter(object):
+ """Randomly change the brightness, contrast and saturation of an image.
+ Args:
+ brightness (float or tuple of float (min, max)): How much to jitter brightness.
+ brightness_factor is chosen uniformly from [max(0, 1 - brightness), 1 + brightness]
+ or the given [min, max]. Should be non negative numbers.
+ contrast (float or tuple of float (min, max)): How much to jitter contrast.
+ contrast_factor is chosen uniformly from [max(0, 1 - contrast), 1 + contrast]
+ or the given [min, max]. Should be non negative numbers.
+ saturation (float or tuple of float (min, max)): How much to jitter saturation.
+ saturation_factor is chosen uniformly from [max(0, 1 - saturation), 1 + saturation]
+ or the given [min, max]. Should be non negative numbers.
+ hue (float or tuple of float (min, max)): How much to jitter hue.
+ hue_factor is chosen uniformly from [-hue, hue] or the given [min, max].
+ Should have 0<= hue <= 0.5 or -0.5 <= min <= max <= 0.5.
+ """
+ def __init__(self, brightness=0, contrast=0, saturation=0, hue=0):
+ self.brightness = self._check_input(brightness, 'brightness')
+ self.contrast = self._check_input(contrast, 'contrast')
+ self.saturation = self._check_input(saturation, 'saturation')
+ self.hue = self._check_input(hue,
+ 'hue',
+ center=0,
+ bound=(-0.5, 0.5),
+ clip_first_on_zero=False)
+ if self.saturation is not None:
+ warnings.warn(
+ 'Saturation jitter enabled. Will slow down loading immensely.')
+ if self.hue is not None:
+ warnings.warn(
+ 'Hue jitter enabled. Will slow down loading immensely.')
+
+ def _check_input(self,
+ value,
+ name,
+ center=1,
+ bound=(0, float('inf')),
+ clip_first_on_zero=True):
+ if isinstance(value, numbers.Number):
+ if value < 0:
+ raise ValueError(
+ "If {} is a single number, it must be non negative.".
+ format(name))
+ value = [center - value, center + value]
+ if clip_first_on_zero:
+ value[0] = max(value[0], 0)
+ elif isinstance(value, (tuple, list)) and len(value) == 2:
+ if not bound[0] <= value[0] <= value[1] <= bound[1]:
+ raise ValueError("{} values should be between {}".format(
+ name, bound))
+ else:
+ raise TypeError(
+ "{} should be a single number or a list/tuple with length 2.".
+ format(name))
+
+ # if value is 0 or (1., 1.) for brightness/contrast/saturation
+ # or (0., 0.) for hue, do nothing
+ if value[0] == value[1] == center:
+ value = None
+ return value
+
+ @staticmethod
+ def get_params(brightness, contrast, saturation, hue):
+ """Get a randomized transform to be applied on image.
+ Arguments are same as that of __init__.
+ Returns:
+ Transform which randomly adjusts brightness, contrast and
+ saturation in a random order.
+ """
+ transforms = []
+
+ if brightness is not None:
+ brightness_factor = random.uniform(brightness[0], brightness[1])
+ transforms.append(
+ Lambda(
+ lambda img: F.adjust_brightness(img, brightness_factor)))
+
+ if contrast is not None:
+ contrast_factor = random.uniform(contrast[0], contrast[1])
+ transforms.append(
+ Lambda(lambda img: F.adjust_contrast(img, contrast_factor)))
+
+ if saturation is not None:
+ saturation_factor = random.uniform(saturation[0], saturation[1])
+ transforms.append(
+ Lambda(
+ lambda img: F.adjust_saturation(img, saturation_factor)))
+
+ if hue is not None:
+ hue_factor = random.uniform(hue[0], hue[1])
+ transforms.append(
+ Lambda(lambda img: F.adjust_hue(img, hue_factor)))
+
+ random.shuffle(transforms)
+ transform = Compose(transforms)
+
+ return transform
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Input image.
+ Returns:
+ numpy ndarray: Color jittered image.
+ """
+ transform = self.get_params(self.brightness, self.contrast,
+ self.saturation, self.hue)
+ return transform(img)
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '('
+ format_string += 'brightness={0}'.format(self.brightness)
+ format_string += ', contrast={0}'.format(self.contrast)
+ format_string += ', saturation={0}'.format(self.saturation)
+ format_string += ', hue={0})'.format(self.hue)
+ return format_string
+
+
+class RandomRotation(object):
+ """Rotate the image by angle.
+ Args:
+ degrees (sequence or float or int): Range of degrees to select from.
+ If degrees is a number instead of sequence like (min, max), the range of degrees
+ will be (-degrees, +degrees).
+ resample ({cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_LANCZOS4}, optional):
+ An optional resampling filter. See `filters`_ for more information.
+ If omitted, or if the image has mode "1" or "P", it is set to PIL.Image.NEAREST.
+ expand (bool, optional): Optional expansion flag.
+ If true, expands the output to make it large enough to hold the entire rotated image.
+ If false or omitted, make the output image the same size as the input image.
+ Note that the expand flag assumes rotation around the center and no translation.
+ center (2-tuple, optional): Optional center of rotation.
+ Origin is the upper left corner.
+ Default is the center of the image.
+ """
+ def __init__(self, degrees, resample=False, expand=False, center=None):
+ if isinstance(degrees, numbers.Number):
+ if degrees < 0:
+ raise ValueError(
+ "If degrees is a single number, it must be positive.")
+ self.degrees = (-degrees, degrees)
+ else:
+ if len(degrees) != 2:
+ raise ValueError(
+ "If degrees is a sequence, it must be of len 2.")
+ self.degrees = degrees
+
+ self.resample = resample
+ self.expand = expand
+ self.center = center
+
+ @staticmethod
+ def get_params(degrees):
+ """Get parameters for ``rotate`` for a random rotation.
+ Returns:
+ sequence: params to be passed to ``rotate`` for random rotation.
+ """
+ angle = random.uniform(degrees[0], degrees[1])
+
+ return angle
+
+ def __call__(self, img):
+ """
+ img (numpy ndarray): Image to be rotated.
+ Returns:
+ numpy ndarray: Rotated image.
+ """
+
+ angle = self.get_params(self.degrees)
+
+ return F.rotate(img, angle, self.resample, self.expand, self.center)
+
+ def __repr__(self):
+ format_string = self.__class__.__name__ + '(degrees={0}'.format(
+ self.degrees)
+ format_string += ', resample={0}'.format(self.resample)
+ format_string += ', expand={0}'.format(self.expand)
+ if self.center is not None:
+ format_string += ', center={0}'.format(self.center)
+ format_string += ')'
+ return format_string
+
+
+class RandomAffine(object):
+ """Random affine transformation of the image keeping center invariant
+ Args:
+ degrees (sequence or float or int): Range of degrees to select from.
+ If degrees is a number instead of sequence like (min, max), the range of degrees
+ will be (-degrees, +degrees). Set to 0 to deactivate rotations.
+ translate (tuple, optional): tuple of maximum absolute fraction for horizontal
+ and vertical translations. For example translate=(a, b), then horizontal shift
+ is randomly sampled in the range -img_width * a < dx < img_width * a and vertical shift is
+ randomly sampled in the range -img_height * b < dy < img_height * b. Will not translate by default.
+ scale (tuple, optional): scaling factor interval, e.g (a, b), then scale is
+ randomly sampled from the range a <= scale <= b. Will keep original scale by default.
+ shear (sequence or float or int, optional): Range of degrees to select from.
+ If degrees is a number instead of sequence like (min, max), the range of degrees
+ will be (-degrees, +degrees). Will not apply shear by default
+ resample ({cv2.INTER_NEAREST, cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_LANCZOS4}, optional):
+ An optional resampling filter. See `filters`_ for more information.
+ If omitted, or if the image has mode "1" or "P", it is set to PIL.Image.NEAREST.
+ fillcolor (int): Optional fill color for the area outside the transform in the output image.
+ """
+ def __init__(self,
+ degrees,
+ translate=None,
+ scale=None,
+ shear=None,
+ interpolation=cv2.INTER_LINEAR,
+ fillcolor=0):
+ if isinstance(degrees, numbers.Number):
+ if degrees < 0:
+ raise ValueError(
+ "If degrees is a single number, it must be positive.")
+ self.degrees = (-degrees, degrees)
+ else:
+ assert isinstance(degrees, (tuple, list)) and len(degrees) == 2, \
+ "degrees should be a list or tuple and it must be of length 2."
+ self.degrees = degrees
+
+ if translate is not None:
+ assert isinstance(translate, (tuple, list)) and len(translate) == 2, \
+ "translate should be a list or tuple and it must be of length 2."
+ for t in translate:
+ if not (0.0 <= t <= 1.0):
+ raise ValueError(
+ "translation values should be between 0 and 1")
+ self.translate = translate
+
+ if scale is not None:
+ assert isinstance(scale, (tuple, list)) and len(scale) == 2, \
+ "scale should be a list or tuple and it must be of length 2."
+ for s in scale:
+ if s <= 0:
+ raise ValueError("scale values should be positive")
+ self.scale = scale
+
+ if shear is not None:
+ if isinstance(shear, numbers.Number):
+ if shear < 0:
+ raise ValueError(
+ "If shear is a single number, it must be positive.")
+ self.shear = (-shear, shear)
+ else:
+ assert isinstance(shear, (tuple, list)) and len(shear) == 2, \
+ "shear should be a list or tuple and it must be of length 2."
+ self.shear = shear
+ else:
+ self.shear = shear
+
+ # self.resample = resample
+ self.interpolation = interpolation
+ self.fillcolor = fillcolor
+
+ @staticmethod
+ def get_params(degrees, translate, scale_ranges, shears, img_size):
+ """Get parameters for affine transformation
+ Returns:
+ sequence: params to be passed to the affine transformation
+ """
+ angle = random.uniform(degrees[0], degrees[1])
+ if translate is not None:
+ max_dx = translate[0] * img_size[0]
+ max_dy = translate[1] * img_size[1]
+ translations = (np.round(random.uniform(-max_dx, max_dx)),
+ np.round(random.uniform(-max_dy, max_dy)))
+ else:
+ translations = (0, 0)
+
+ if scale_ranges is not None:
+ scale = random.uniform(scale_ranges[0], scale_ranges[1])
+ else:
+ scale = 1.0
+
+ if shears is not None:
+ shear = random.uniform(shears[0], shears[1])
+ else:
+ shear = 0.0
+
+ return angle, translations, scale, shear
+
+ def __call__(self, img):
+ """
+ img (numpy ndarray): Image to be transformed.
+ Returns:
+ numpy ndarray: Affine transformed image.
+ """
+ ret = self.get_params(self.degrees, self.translate, self.scale,
+ self.shear, (img.shape[1], img.shape[0]))
+ return F.affine(img,
+ *ret,
+ interpolation=self.interpolation,
+ fillcolor=self.fillcolor)
+
+ def __repr__(self):
+ s = '{name}(degrees={degrees}'
+ if self.translate is not None:
+ s += ', translate={translate}'
+ if self.scale is not None:
+ s += ', scale={scale}'
+ if self.shear is not None:
+ s += ', shear={shear}'
+ if self.resample > 0:
+ s += ', resample={resample}'
+ if self.fillcolor != 0:
+ s += ', fillcolor={fillcolor}'
+ s += ')'
+ d = dict(self.__dict__)
+ d['resample'] = _cv2_interpolation_to_str[d['resample']]
+ return s.format(name=self.__class__.__name__, **d)
+
+
+class Grayscale(object):
+ """Convert image to grayscale.
+ Args:
+ num_output_channels (int): (1 or 3) number of channels desired for output image
+ Returns:
+ numpy ndarray: Grayscale version of the input.
+ - If num_output_channels == 1 : returned image is single channel
+ - If num_output_channels == 3 : returned image is 3 channel with r == g == b
+ """
+ def __init__(self, num_output_channels=1):
+ self.num_output_channels = num_output_channels
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Image to be converted to grayscale.
+ Returns:
+ numpy ndarray: Randomly grayscaled image.
+ """
+ return F.to_grayscale(img,
+ num_output_channels=self.num_output_channels)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(num_output_channels={0})'.format(
+ self.num_output_channels)
+
+
+class RandomGrayscale(object):
+ """Randomly convert image to grayscale with a probability of p (default 0.1).
+ Args:
+ p (float): probability that image should be converted to grayscale.
+ Returns:
+ numpy ndarray: Grayscale version of the input image with probability p and unchanged
+ with probability (1-p).
+ - If input image is 1 channel: grayscale version is 1 channel
+ - If input image is 3 channel: grayscale version is 3 channel with r == g == b
+ """
+ def __init__(self, p=0.1):
+ self.p = p
+
+ def __call__(self, img):
+ """
+ Args:
+ img (numpy ndarray): Image to be converted to grayscale.
+ Returns:
+ numpy ndarray: Randomly grayscaled image.
+ """
+ num_output_channels = 3
+ if random.random() < self.p:
+ return F.to_grayscale(img, num_output_channels=num_output_channels)
+ return img
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(p={0})'.format(self.p)
diff --git a/dataset/setup.py b/dataset/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..5dc99bf4e65d76b74e5b6a5f736f0bee979f7cf9
--- /dev/null
+++ b/dataset/setup.py
@@ -0,0 +1,23 @@
+import setuptools
+
+with open('README.md', 'r') as fh:
+ long_description = fh.read()
+
+setuptools.setup(
+ name='opencv_transforms',
+ version='0.0.6',
+ author='Jim Bohnslav',
+ author_email='JBohnslav@gmail.com',
+ description='A drop-in replacement for Torchvision Transforms using OpenCV',
+ keywords='pytorch image augmentations',
+ long_description=long_description,
+ long_description_content_type='text/markdown',
+ url='https://github.com/jbohnslav/opencv_transforms',
+ packages=setuptools.find_packages(),
+ classifiers=[
+ "Programming Language :: Python :: 3",
+ "License :: OSI Approved :: MIT License",
+ "Operating System :: OS Independent",
+ ],
+ python_requires='>=3.6',
+)
\ No newline at end of file
diff --git a/dataset/tests/compare_to_pil_for_testing.ipynb b/dataset/tests/compare_to_pil_for_testing.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..24eca6b0ad0200ccad0b22ebc3db32663c6be631
--- /dev/null
+++ b/dataset/tests/compare_to_pil_for_testing.ipynb
@@ -0,0 +1,241 @@
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import glob\n",
+ "import numpy as np\n",
+ "import random\n",
+ "\n",
+ "import cv2\n",
+ "import matplotlib.pyplot as plt\n",
+ "from PIL import Image\n",
+ "\n",
+ "from torchvision import transforms as pil_transforms\n",
+ "from torchvision.transforms import functional as F_pil\n",
+ "\n",
+ "import sys\n",
+ "sys.path.insert(0, '..')\n",
+ "from opencv_transforms import transforms\n",
+ "from opencv_transforms import functional as F\n",
+ "\n",
+ "from setup_testing_directory import get_testing_directory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "datadir = get_testing_directory()\n",
+ "print(datadir)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "train_images = glob.glob(datadir + '/**/*.JPEG', recursive=True)\n",
+ "train_images.sort()\n",
+ "print('Number of training images: {:,}'.format(len(train_images)))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "random.seed(1)\n",
+ "imfile = random.choice(train_images)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def plot_pil_and_opencv(pil_image, opencv_image, orientation='row'):\n",
+ " if orientation == 'row':\n",
+ " rows, cols = 1,3\n",
+ " size = (8, 4)\n",
+ " else: \n",
+ " rows, cols = 3,1\n",
+ " size = (12, 6)\n",
+ " fig, axes = plt.subplots(rows, cols,figsize=size)\n",
+ " ax = axes[0]\n",
+ " ax.imshow(pil_image)\n",
+ " ax.set_title('PIL')\n",
+ "\n",
+ " ax = axes[1]\n",
+ " ax.imshow(opencv_image)\n",
+ " ax.set_title('opencv')\n",
+ "\n",
+ " ax = axes[2]\n",
+ " l1 = np.abs(pil_image - opencv_image).mean(axis=2)\n",
+ " ax.imshow(l1)\n",
+ " ax.set_title('| PIL - opencv|\\nMAE:{:.4f}'.format(l1.mean()))\n",
+ " plt.tight_layout()\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pil_image = Image.open(imfile)\n",
+ "image = cv2.cvtColor(cv2.imread(imfile, 1), cv2.COLOR_BGR2RGB)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plot_pil_and_opencv(pil_image, image)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pil_resized = pil_transforms.Resize((224, 224))(pil_image)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "resized = transforms.Resize(224)(image)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plot_pil_and_opencv(pil_resized, resized)\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def L1(pil: Image, image: np.ndarray) -> float:\n",
+ " return np.mean(np.abs(np.asarray(pil) - image))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "TOL = 1e-4\n",
+ "\n",
+ "l1 = L1(pil_resized, resized)\n",
+ "assert l1 - 88.9559 < TOL"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "random.seed(1)\n",
+ "pil = pil_transforms.RandomRotation(10)(pil_image)\n",
+ "random.seed(1)\n",
+ "np_img = transforms.RandomRotation(10)(image)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plot_pil_and_opencv(pil, np_img)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pil = pil_transforms.FiveCrop((224, 224))(pil_image)\n",
+ "cv = transforms.FiveCrop((224,224))(image)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pil_stacked = np.hstack([np.asarray(i) for i in pil])\n",
+ "cv_stacked = np.hstack(cv)\n",
+ "\n",
+ "plot_pil_and_opencv(pil_stacked, cv_stacked, orientation='col')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "pil_stacked.shape"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "l1"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "opencv_transforms",
+ "language": "python",
+ "name": "opencv_transforms"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.7.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/dataset/tests/setup_testing_directory.py b/dataset/tests/setup_testing_directory.py
new file mode 100644
index 0000000000000000000000000000000000000000..cca89afe43fec2550c43ffaacae2ffbebd2d4d78
--- /dev/null
+++ b/dataset/tests/setup_testing_directory.py
@@ -0,0 +1,50 @@
+import argparse
+import os
+from typing import Union
+import warnings
+
+
+def get_testing_directory() -> str:
+ directory_file = 'testing_directory.txt'
+ directory_files = [directory_file, os.path.join('tests', directory_file)]
+
+ for directory_file in directory_files:
+ if os.path.isfile(directory_file):
+ with open(directory_file, 'r') as f:
+ testing_directory = f.read()
+ return testing_directory
+ raise ValueError('please run setup_testing_directory.py before attempting to run unit tests')
+
+
+def setup_testing_directory(datadir: Union[str, os.PathLike], overwrite: bool = False) -> str:
+ testing_path_file = 'testing_directory.txt'
+
+ should_setup = True
+ if os.path.isfile(testing_path_file):
+ with open(testing_path_file, 'r') as f:
+ testing_directory = f.read()
+ if not os.path.isfile(testing_directory):
+ raise ValueError('saved testing directory {} does not exist, re-run ')
+ warnings.warn(
+ 'Saved testing directory {} does not exist, downloading Thumos14...'.format(testing_directory))
+ else:
+ should_setup = False
+ if not should_setup:
+ return testing_directory
+
+ testing_directory = datadir
+ assert os.path.isdir(testing_directory)
+ assert os.path.isdir(os.path.join(testing_directory, 'train'))
+ assert os.path.isdir(os.path.join(testing_directory, 'val'))
+ with open('testing_directory.txt', 'w') as f:
+ f.write(testing_directory)
+ return testing_directory
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser('Setting up image directory for opencv transforms testing')
+ parser.add_argument('-d', '--datadir', default=os.getcwd(), help='Imagenet directory')
+
+ args = parser.parse_args()
+
+ setup_testing_directory(args.datadir)
\ No newline at end of file
diff --git a/dataset/tests/test_color.py b/dataset/tests/test_color.py
new file mode 100644
index 0000000000000000000000000000000000000000..e025129a5b563c63219d104f696b5ed48b9b4dd3
--- /dev/null
+++ b/dataset/tests/test_color.py
@@ -0,0 +1,68 @@
+import glob
+import numpy as np
+import random
+from typing import Union
+
+import cv2
+import matplotlib.pyplot as plt
+from PIL import Image
+from PIL.Image import Image as PIL_image # for typing
+import pytest
+from torchvision import transforms as pil_transforms
+from torchvision.transforms import functional as F_pil
+
+from opencv_transforms import transforms
+from opencv_transforms import functional as F
+from setup_testing_directory import get_testing_directory
+
+TOL = 1e-4
+
+datadir = get_testing_directory()
+train_images = glob.glob(datadir + '/**/*.JPEG', recursive=True)
+train_images.sort()
+print('Number of training images: {:,}'.format(len(train_images)))
+
+random.seed(1)
+imfile = random.choice(train_images)
+pil_image = Image.open(imfile)
+image = cv2.cvtColor(cv2.imread(imfile, 1), cv2.COLOR_BGR2RGB)
+
+
+class TestContrast:
+ @pytest.mark.parametrize('random_seed', [1, 2, 3, 4])
+ @pytest.mark.parametrize('contrast_factor', [0.0, 0.5, 1.0, 2.0])
+ def test_contrast(self, contrast_factor, random_seed):
+ random.seed(random_seed)
+ imfile = random.choice(train_images)
+ pil_image = Image.open(imfile)
+ image = np.array(pil_image).copy()
+
+ pil_enhanced = F_pil.adjust_contrast(pil_image, contrast_factor)
+ np_enhanced = F.adjust_contrast(image, contrast_factor)
+ assert np.array_equal(np.array(pil_enhanced), np_enhanced.squeeze())
+
+ @pytest.mark.parametrize('n_images', [1, 11])
+ def test_multichannel_contrast(self, n_images, contrast_factor=0.1):
+ imfile = random.choice(train_images)
+
+ pil_image = Image.open(imfile)
+ image = np.array(pil_image).copy()
+
+ multichannel_image = np.concatenate([image for _ in range(n_images)], axis=-1)
+ # this will raise an exception in version 0.0.5
+ np_enchanced = F.adjust_contrast(multichannel_image, contrast_factor)
+
+ @pytest.mark.parametrize('contrast_factor', [0, 0.5, 1.0])
+ def test_grayscale_contrast(self, contrast_factor):
+ imfile = random.choice(train_images)
+
+ pil_image = Image.open(imfile)
+ image = np.array(pil_image).copy()
+ image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
+
+ # make sure grayscale images work
+ pil_image = pil_image.convert('L')
+
+ pil_enhanced = F_pil.adjust_contrast(pil_image, contrast_factor)
+ np_enhanced = F.adjust_contrast(image, contrast_factor)
+ assert np.array_equal(np.array(pil_enhanced), np_enhanced.squeeze())
diff --git a/dataset/tests/test_spatial.py b/dataset/tests/test_spatial.py
new file mode 100644
index 0000000000000000000000000000000000000000..826d33e94bd9d19e87b1a2a7ab8e32f30991a1d7
--- /dev/null
+++ b/dataset/tests/test_spatial.py
@@ -0,0 +1,52 @@
+import glob
+import numpy as np
+import random
+from typing import Union
+
+import cv2
+import matplotlib.pyplot as plt
+from PIL import Image
+from PIL.Image import Image as PIL_image # for typing
+
+from torchvision import transforms as pil_transforms
+from torchvision.transforms import functional as F_pil
+from opencv_transforms import transforms
+from opencv_transforms import functional as F
+
+from setup_testing_directory import get_testing_directory
+from utils import L1
+
+TOL = 1e-4
+
+datadir = get_testing_directory()
+train_images = glob.glob(datadir + '/**/*.JPEG', recursive=True)
+train_images.sort()
+print('Number of training images: {:,}'.format(len(train_images)))
+
+random.seed(1)
+imfile = random.choice(train_images)
+pil_image = Image.open(imfile)
+image = cv2.cvtColor(cv2.imread(imfile, 1), cv2.COLOR_BGR2RGB)
+
+
+def test_resize():
+ pil_resized = pil_transforms.Resize((224, 224))(pil_image)
+ resized = transforms.Resize((224, 224))(image)
+ l1 = L1(pil_resized, resized)
+ assert l1 - 88.9559 < TOL
+
+def test_rotation():
+ random.seed(1)
+ pil = pil_transforms.RandomRotation(10)(pil_image)
+ random.seed(1)
+ np_img = transforms.RandomRotation(10)(image)
+ l1 = L1(pil, np_img)
+ assert l1 - 86.7955 < TOL
+
+def test_five_crop():
+ pil = pil_transforms.FiveCrop((224, 224))(pil_image)
+ cv = transforms.FiveCrop((224, 224))(image)
+ pil_stacked = np.hstack([np.asarray(i) for i in pil])
+ cv_stacked = np.hstack(cv)
+ l1 = L1(pil_stacked, cv_stacked)
+ assert l1 - 22.0444 < TOL
\ No newline at end of file
diff --git a/dataset/tests/utils.py b/dataset/tests/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f641f1be43d2bff9a40e3014bd7c656e3a8ea75b
--- /dev/null
+++ b/dataset/tests/utils.py
@@ -0,0 +1,8 @@
+from typing import Union
+
+import numpy as np
+from PIL.Image import Image as PIL_image # for typing
+
+
+def L1(pil: Union[PIL_image, np.ndarray], np_image: np.ndarray) -> float:
+ return np.abs(np.asarray(pil) - np_image).mean()
\ No newline at end of file
diff --git a/inference.yaml b/inference.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..56d97e52e01a6a0ba22f9087b27ee26e78ea18eb
--- /dev/null
+++ b/inference.yaml
@@ -0,0 +1,166 @@
+model:
+ target: vtdm.vtdm_gen_v01.VideoLDM
+ base_learning_rate: 1.0e-05
+ params:
+ input_key: video
+ scale_factor: 0.18215
+ log_keys: caption
+ num_samples: 25 #frame_rate
+ trained_param_keys:
+ - diffusion_model.label_emb.0.0.weight
+ - .emb_layers.
+ - .time_stack.
+ en_and_decode_n_samples_a_time: 25 #frame_rate
+ disable_first_stage_autocast: true
+ denoiser_config:
+ target: sgm.modules.diffusionmodules.denoiser.Denoiser
+ params:
+ scaling_config:
+ target: sgm.modules.diffusionmodules.denoiser_scaling.VScalingWithEDMcNoise
+ network_config:
+ target: sgm.modules.diffusionmodules.video_model.VideoUNet
+ params:
+ adm_in_channels: 768
+ num_classes: sequential
+ use_checkpoint: true
+ in_channels: 8
+ out_channels: 4
+ model_channels: 320
+ attention_resolutions:
+ - 4
+ - 2
+ - 1
+ num_res_blocks: 2
+ channel_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_head_channels: 64
+ use_linear_in_transformer: true
+ transformer_depth: 1
+ context_dim: 1024
+ spatial_transformer_attn_type: softmax-xformers
+ extra_ff_mix_layer: true
+ use_spatial_context: true
+ merge_strategy: learned_with_images
+ video_kernel_size:
+ - 3
+ - 1
+ - 1
+ conditioner_config:
+ target: sgm.modules.GeneralConditioner
+ params:
+ emb_models:
+ - is_trainable: false
+ input_key: cond_frames_without_noise
+ ucg_rate: 0.1
+ target: sgm.modules.encoders.modules.FrozenOpenCLIPImagePredictionEmbedder
+ params:
+ n_cond_frames: 1
+ n_copies: 1
+ open_clip_embedding_config:
+ target: sgm.modules.encoders.modules.FrozenOpenCLIPImageEmbedder
+ params:
+ version: ckpts/open_clip_pytorch_model.bin
+ freeze: true
+ - is_trainable: false
+ input_key: video
+ ucg_rate: 0.0
+ target: vtdm.encoders.AesEmbedder
+ - is_trainable: false
+ input_key: elevation
+ target: sgm.modules.encoders.modules.ConcatTimestepEmbedderND
+ params:
+ outdim: 256
+ - input_key: cond_frames
+ is_trainable: false
+ ucg_rate: 0.1
+ target: sgm.modules.encoders.modules.VideoPredictionEmbedderWithEncoder
+ params:
+ disable_encoder_autocast: true
+ n_cond_frames: 1
+ n_copies: 25 #frame_rate
+ is_ae: true
+ encoder_config:
+ target: sgm.models.autoencoder.AutoencoderKLModeOnly
+ params:
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ attn_type: vanilla-xformers
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: []
+ dropout: 0.0
+ lossconfig:
+ target: torch.nn.Identity
+ - input_key: cond_aug
+ is_trainable: false
+ target: sgm.modules.encoders.modules.ConcatTimestepEmbedderND
+ params:
+ outdim: 256
+ first_stage_config:
+ target: sgm.models.autoencoder.AutoencoderKL
+ params:
+ embed_dim: 4
+ monitor: val/rec_loss
+ ddconfig:
+ attn_type: vanilla-xformers
+ double_z: true
+ z_channels: 4
+ resolution: 256
+ in_channels: 3
+ out_ch: 3
+ ch: 128
+ ch_mult:
+ - 1
+ - 2
+ - 4
+ - 4
+ num_res_blocks: 2
+ attn_resolutions: []
+ dropout: 0.0
+ lossconfig:
+ target: torch.nn.Identity
+ loss_fn_config:
+ target: sgm.modules.diffusionmodules.loss.StandardDiffusionLoss
+ params:
+ num_frames: 25 #frame_rate
+ batch2model_keys:
+ - num_video_frames
+ - image_only_indicator
+ sigma_sampler_config:
+ target: sgm.modules.diffusionmodules.sigma_sampling.EDMSampling
+ params:
+ p_mean: 1.0
+ p_std: 1.6
+ loss_weighting_config:
+ target: sgm.modules.diffusionmodules.loss_weighting.VWeighting
+ sampler_config:
+ target: sgm.modules.diffusionmodules.sampling.LinearMultistepSampler
+ params:
+ num_steps: 50
+ verbose: True
+
+ discretization_config:
+ target: sgm.modules.diffusionmodules.discretizer.EDMDiscretization
+ params:
+ sigma_max: 700.0
+
+ guider_config:
+ target: sgm.modules.diffusionmodules.guiders.LinearPredictionGuider
+ params:
+ num_frames: 25 #frame_rate
+ max_scale: 2.5
+ min_scale: 1.0
diff --git a/packages.txt b/packages.txt
new file mode 100644
index 0000000000000000000000000000000000000000..77ff09f39fd56a6fc761df09fc801099f84ab047
--- /dev/null
+++ b/packages.txt
@@ -0,0 +1,2 @@
+libopencv-dev
+build-essential
\ No newline at end of file
diff --git a/pipeline.py b/pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..569b0b0433ead1dce95f1f355b76c157c0082321
--- /dev/null
+++ b/pipeline.py
@@ -0,0 +1,168 @@
+from typing import List
+from PIL import Image
+import numpy as np
+import math
+import random
+import cv2
+from typing import List
+
+import torch
+import einops
+from pytorch_lightning import seed_everything
+from transparent_background import Remover
+
+from dataset.opencv_transforms.functional import to_tensor, center_crop
+from vtdm.model import create_model
+from vtdm.util import tensor2vid
+
+remover = Remover(jit=False)
+
+def cv2_to_pil(cv_image: np.ndarray) -> Image.Image:
+ return Image.fromarray(cv2.cvtColor(cv_image, cv2.COLOR_BGR2RGB))
+
+
+def pil_to_cv2(pil_image: Image.Image) -> np.ndarray:
+ cv_image = np.array(pil_image)
+ cv_image = cv2.cvtColor(cv_image, cv2.COLOR_RGB2BGR)
+ return cv_image
+
+def prepare_white_image(input_image: Image.Image) -> Image.Image:
+ # remove bg
+ output = remover.process(input_image, type='rgba')
+
+ # expand image
+ width, height = output.size
+ max_side = max(width, height)
+ white_image = Image.new('RGBA', (max_side, max_side), (0, 0, 0, 0))
+ x_offset = (max_side - width) // 2
+ y_offset = (max_side - height) // 2
+ white_image.paste(output, (x_offset, y_offset))
+
+ return white_image
+
+
+class MultiViewGenerator:
+ def __init__(self, checkpoint_path, config_path="inference.yaml"):
+ self.models = {}
+ denoising_model = create_model(config_path).cpu()
+ denoising_model.init_from_ckpt(checkpoint_path)
+ denoising_model = denoising_model.cuda().half()
+ self.models["denoising_model"] = denoising_model
+
+ def denoising(self, frames, args):
+ with torch.no_grad():
+ C, T, H, W = frames.shape
+ batch = {"video": frames.unsqueeze(0)}
+ batch["elevation"] = (
+ torch.Tensor([args["elevation"]]).to(torch.int64).to(frames.device)
+ )
+ batch["fps_id"] = torch.Tensor([7]).to(torch.int64).to(frames.device)
+ batch["motion_bucket_id"] = (
+ torch.Tensor([127]).to(torch.int64).to(frames.device)
+ )
+ batch = self.models["denoising_model"].add_custom_cond(batch, infer=True)
+
+ with torch.autocast(device_type="cuda", dtype=torch.float16):
+ c, uc = self.models[
+ "denoising_model"
+ ].conditioner.get_unconditional_conditioning(
+ batch,
+ force_uc_zero_embeddings=["cond_frames", "cond_frames_without_noise"],
+ )
+
+ additional_model_inputs = {
+ "image_only_indicator": torch.zeros(2, T).to(
+ self.models["denoising_model"].device
+ ),
+ "num_video_frames": batch["num_video_frames"],
+ }
+
+ def denoiser(input, sigma, c):
+ return self.models["denoising_model"].denoiser(
+ self.models["denoising_model"].model,
+ input,
+ sigma,
+ c,
+ **additional_model_inputs
+ )
+
+ with torch.autocast(device_type="cuda", dtype=torch.float16):
+ randn = torch.randn(
+ [T, 4, H // 8, W // 8], device=self.models["denoising_model"].device
+ )
+ samples = self.models["denoising_model"].sampler(denoiser, randn, cond=c, uc=uc)
+
+ samples = self.models["denoising_model"].decode_first_stage(samples.half())
+ samples = einops.rearrange(samples, "(b t) c h w -> b c t h w", t=T)
+
+ return tensor2vid(samples)
+
+ def video_pipeline(self, frames, args) -> List[Image.Image]:
+ num_iter = args["num_iter"]
+ out_list = []
+
+ for _ in range(num_iter):
+ with torch.no_grad():
+ results = self.denoising(frames, args)
+
+ if len(out_list) == 0:
+ out_list = out_list + results
+ else:
+ out_list = out_list + results[1:]
+
+ img = out_list[-1]
+ img = to_tensor(img)
+ img = (img - 0.5) * 2.0
+ frames[:, 0] = img
+
+ result = []
+
+ for i, frame in enumerate(out_list):
+ input_image = cv2_to_pil(frame)
+ output_image = remover.process(input_image, type='rgba')
+ result.append(output_image)
+
+ return result
+
+ def process(self, white_image: Image.Image, args) -> List[Image.Image]:
+ img = pil_to_cv2(white_image)
+ frame_list = [img] * args["clip_size"]
+
+ h, w = frame_list[0].shape[0:2]
+ rate = max(
+ args["input_resolution"][0] * 1.0 / h, args["input_resolution"][1] * 1.0 / w
+ )
+ frame_list = [
+ cv2.resize(f, [math.ceil(w * rate), math.ceil(h * rate)]) for f in frame_list
+ ]
+ frame_list = [
+ center_crop(f, [args["input_resolution"][0], args["input_resolution"][1]])
+ for f in frame_list
+ ]
+ frame_list = [cv2.cvtColor(f, cv2.COLOR_BGR2RGB) for f in frame_list]
+
+ frame_list = [to_tensor(f) for f in frame_list]
+ frame_list = [(f - 0.5) * 2.0 for f in frame_list]
+ frames = torch.stack(frame_list, 1)
+ frames = frames.cuda()
+
+ self.models["denoising_model"].num_samples = args["clip_size"]
+ self.models["denoising_model"].image_size = args["input_resolution"]
+
+ return self.video_pipeline(frames, args)
+
+ def infer(self, white_image: Image.Image) -> List[Image.Image]:
+ seed = random.randint(0, 65535)
+ seed_everything(seed)
+
+ params = {
+ "clip_size": 25,
+ "input_resolution": [512, 512],
+ "num_iter": 1,
+ "aes": 6.0,
+ "mv": [0.0, 0.0, 0.0, 10.0],
+ "elevation": 0,
+ }
+
+ return self.process(white_image, params)
+
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7154a1dd403e2ff9c9dba521f71393728d186d92
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,49 @@
+av
+black==23.7.0
+chardet==5.1.0
+clip @ git+https://github.com/openai/CLIP.git@a1d071733d7111c9c014f024669f959182114e33
+cupy-cuda113
+einops>=0.6.1
+fairscale>=0.4.13
+fire>=0.5.0
+fsspec>=2023.6.0
+invisible-watermark>=0.2.0
+kornia==0.6.9
+matplotlib>=3.7.2
+natsort>=8.4.0
+ninja>=1.11.1
+numpy==1.26.4
+omegaconf>=2.3.0
+open-clip-torch>=2.20.0
+opencv-python==4.6.0.66
+pandas>=2.0.3
+pillow>=9.5.0
+pudb>=2022.1.3
+pytorch-lightning==1.9
+pyyaml>=6.0.1
+transparent_background
+scipy>=1.10.1
+streamlit>=0.73.1
+tensorboardx==2.6
+timm>=0.9.2
+tokenizers==0.12.1
+torch>=2.1.0
+torchaudio>=2.1.0
+torchdata>=0.6.1
+torchmetrics>=1.0.1
+torchvision>=0.16.0
+tqdm>=4.65.0
+transformers==4.19.1
+triton>=2.0.0
+urllib3<1.27,>=1.25.4
+wandb>=0.15.6
+webdataset>=0.2.33
+wheel>=0.41.0
+xformers>=0.0.20
+gradio
+streamlit-keyup==0.2.0
+deepspeed==0.14.5
+test-tube
+-e git+https://github.com/Stability-AI/datapipelines.git@8bce77d147033b3a5285b6d45ee85f33866964fc#egg=sdata
+basicsr
+pillow-heif
\ No newline at end of file
diff --git a/sgm/__init__.py b/sgm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..24bc84af8b1041de34b9816e0507cb1ac207bd13
--- /dev/null
+++ b/sgm/__init__.py
@@ -0,0 +1,4 @@
+from .models import AutoencodingEngine, DiffusionEngine
+from .util import get_configs_path, instantiate_from_config
+
+__version__ = "0.1.0"
diff --git a/sgm/data/__init__.py b/sgm/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..7664a25c655c376bd1a7b0ccbaca7b983a2bf9ad
--- /dev/null
+++ b/sgm/data/__init__.py
@@ -0,0 +1 @@
+from .dataset import StableDataModuleFromConfig
diff --git a/sgm/data/dataset.py b/sgm/data/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..b726149996591c6c3db69230e1bb68c07d2faa12
--- /dev/null
+++ b/sgm/data/dataset.py
@@ -0,0 +1,80 @@
+from typing import Optional
+
+import torchdata.datapipes.iter
+import webdataset as wds
+from omegaconf import DictConfig
+from pytorch_lightning import LightningDataModule
+
+try:
+ from sdata import create_dataset, create_dummy_dataset, create_loader
+except ImportError as e:
+ print("#" * 100)
+ print("Datasets not yet available")
+ print("to enable, we need to add stable-datasets as a submodule")
+ print("please use ``git submodule update --init --recursive``")
+ print("and do ``pip install -e stable-datasets/`` from the root of this repo")
+ print("#" * 100)
+ exit(1)
+
+
+class StableDataModuleFromConfig(LightningDataModule):
+ def __init__(
+ self,
+ train: DictConfig,
+ validation: Optional[DictConfig] = None,
+ test: Optional[DictConfig] = None,
+ skip_val_loader: bool = False,
+ dummy: bool = False,
+ ):
+ super().__init__()
+ self.train_config = train
+ assert (
+ "datapipeline" in self.train_config and "loader" in self.train_config
+ ), "train config requires the fields `datapipeline` and `loader`"
+
+ self.val_config = validation
+ if not skip_val_loader:
+ if self.val_config is not None:
+ assert (
+ "datapipeline" in self.val_config and "loader" in self.val_config
+ ), "validation config requires the fields `datapipeline` and `loader`"
+ else:
+ print(
+ "Warning: No Validation datapipeline defined, using that one from training"
+ )
+ self.val_config = train
+
+ self.test_config = test
+ if self.test_config is not None:
+ assert (
+ "datapipeline" in self.test_config and "loader" in self.test_config
+ ), "test config requires the fields `datapipeline` and `loader`"
+
+ self.dummy = dummy
+ if self.dummy:
+ print("#" * 100)
+ print("USING DUMMY DATASET: HOPE YOU'RE DEBUGGING ;)")
+ print("#" * 100)
+
+ def setup(self, stage: str) -> None:
+ print("Preparing datasets")
+ if self.dummy:
+ data_fn = create_dummy_dataset
+ else:
+ data_fn = create_dataset
+
+ self.train_datapipeline = data_fn(**self.train_config.datapipeline)
+ if self.val_config:
+ self.val_datapipeline = data_fn(**self.val_config.datapipeline)
+ if self.test_config:
+ self.test_datapipeline = data_fn(**self.test_config.datapipeline)
+
+ def train_dataloader(self) -> torchdata.datapipes.iter.IterDataPipe:
+ loader = create_loader(self.train_datapipeline, **self.train_config.loader)
+ return loader
+
+ def val_dataloader(self) -> wds.DataPipeline:
+ return create_loader(self.val_datapipeline, **self.val_config.loader)
+
+ def test_dataloader(self) -> wds.DataPipeline:
+ return create_loader(self.test_datapipeline, **self.test_config.loader)
diff --git a/sgm/data/video_dataset.py b/sgm/data/video_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..93725771965c66e8c564d236c22e0915c33920d3
--- /dev/null
+++ b/sgm/data/video_dataset.py
@@ -0,0 +1,191 @@
+import pytorch_lightning as pl
+import numpy as np
+import torch
+import PIL
+import os
+import random
+from skimage.io import imread
+import webdataset as wds
+import PIL.Image as Image
+from torch.utils.data import Dataset
+from torch.utils.data.distributed import DistributedSampler
+from pathlib import Path
+
+# from ldm.base_utils import read_pickle, pose_inverse
+import torchvision.transforms as transforms
+import torchvision
+from einops import rearrange
+
+def add_margin(pil_img, color=0, size=256):
+ width, height = pil_img.size
+ result = Image.new(pil_img.mode, (size, size), color)
+ result.paste(pil_img, ((size - width) // 2, (size - height) // 2))
+ return result
+
+def prepare_inputs(image_path, elevation_input, crop_size=-1, image_size=256):
+ image_input = Image.open(image_path)
+
+ if crop_size!=-1:
+ alpha_np = np.asarray(image_input)[:, :, 3]
+ coords = np.stack(np.nonzero(alpha_np), 1)[:, (1, 0)]
+ min_x, min_y = np.min(coords, 0)
+ max_x, max_y = np.max(coords, 0)
+ ref_img_ = image_input.crop((min_x, min_y, max_x, max_y))
+ h, w = ref_img_.height, ref_img_.width
+ scale = crop_size / max(h, w)
+ h_, w_ = int(scale * h), int(scale * w)
+ ref_img_ = ref_img_.resize((w_, h_), resample=Image.BICUBIC)
+ image_input = add_margin(ref_img_, size=image_size)
+ else:
+ image_input = add_margin(image_input, size=max(image_input.height, image_input.width))
+ image_input = image_input.resize((image_size, image_size), resample=Image.BICUBIC)
+
+ image_input = np.asarray(image_input)
+ image_input = image_input.astype(np.float32) / 255.0
+ ref_mask = image_input[:, :, 3:]
+ image_input[:, :, :3] = image_input[:, :, :3] * ref_mask + 1 - ref_mask # white background
+ image_input = image_input[:, :, :3] * 2.0 - 1.0
+ image_input = torch.from_numpy(image_input.astype(np.float32))
+ elevation_input = torch.from_numpy(np.asarray([np.deg2rad(elevation_input)], np.float32))
+ return {"input_image": image_input, "input_elevation": elevation_input}
+
+
+class VideoTrainDataset(Dataset):
+ def __init__(self, base_folder='/data/yanghaibo/datas/OBJAVERSE-LVIS/images', width=1024, height=576, sample_frames=25):
+ """
+ Args:
+ num_samples (int): Number of samples in the dataset.
+ channels (int): Number of channels, default is 3 for RGB.
+ """
+ # Define the path to the folder containing video frames
+ self.base_folder = base_folder
+ self.folders = os.listdir(self.base_folder)
+ self.num_samples = len(self.folders)
+ self.channels = 3
+ self.width = width
+ self.height = height
+ self.sample_frames = sample_frames
+ self.elevations = [-10, 0, 10, 20, 30, 40]
+
+ def __len__(self):
+ return self.num_samples
+
+ def load_im(self, path):
+ img = imread(path)
+ img = img.astype(np.float32) / 255.0
+ mask = img[:,:,3:]
+ img[:,:,:3] = img[:,:,:3] * mask + 1 - mask # white background
+ img = Image.fromarray(np.uint8(img[:, :, :3] * 255.))
+ return img, mask
+
+ def __getitem__(self, idx):
+ """
+ Args:
+ idx (int): Index of the sample to return.
+
+ Returns:
+ dict: A dictionary containing the 'pixel_values' tensor of shape (16, channels, 320, 512).
+ """
+ # Randomly select a folder (representing a video) from the base folder
+ chosen_folder = random.choice(self.folders)
+ folder_path = os.path.join(self.base_folder, chosen_folder)
+ frames = os.listdir(folder_path)
+ # Sort the frames by name
+ frames.sort()
+
+ # Ensure the selected folder has at least `sample_frames`` frames
+ if len(frames) < self.sample_frames:
+ raise ValueError(
+ f"The selected folder '{chosen_folder}' contains fewer than `{self.sample_frames}` frames.")
+
+ # Randomly select a start index for frame sequence. Fixed elevation
+ start_idx = random.randint(0, len(frames) - 1)
+ range_id = int(start_idx / 16) # 0, 1, 2, 3, 4, 5
+ elevation = self.elevations[range_id]
+ selected_frames = []
+
+ for frame_idx in range(start_idx, (range_id + 1) * 16):
+ selected_frames.append(frames[frame_idx])
+ for frame_idx in range((range_id) * 16, start_idx):
+ selected_frames.append(frames[frame_idx])
+
+ # Initialize a tensor to store the pixel values
+ pixel_values = torch.empty((self.sample_frames, self.channels, self.height, self.width))
+
+ # Load and process each frame
+ for i, frame_name in enumerate(selected_frames):
+ frame_path = os.path.join(folder_path, frame_name)
+ img, mask = self.load_im(frame_path)
+ # Resize the image and convert it to a tensor
+ img_resized = img.resize((self.width, self.height))
+ img_tensor = torch.from_numpy(np.array(img_resized)).float()
+
+ # Normalize the image by scaling pixel values to [-1, 1]
+ img_normalized = img_tensor / 127.5 - 1
+
+ # Rearrange channels if necessary
+ if self.channels == 3:
+ img_normalized = img_normalized.permute(
+ 2, 0, 1) # For RGB images
+ elif self.channels == 1:
+ img_normalized = img_normalized.mean(
+ dim=2, keepdim=True) # For grayscale images
+
+ pixel_values[i] = img_normalized
+
+ pixel_values = rearrange(pixel_values, 't c h w -> c t h w')
+
+ caption = chosen_folder + "_" + str(start_idx)
+
+ return {'video': pixel_values, 'elevation': elevation, 'caption': caption, "fps_id": 7, "motion_bucket_id": 127}
+
+class SyncDreamerEvalData(Dataset):
+ def __init__(self, image_dir):
+ self.image_size = 512
+ self.image_dir = Path(image_dir)
+ self.crop_size = 20
+
+ self.fns = []
+ for fn in Path(image_dir).iterdir():
+ if fn.suffix=='.png':
+ self.fns.append(fn)
+ print('============= length of dataset %d =============' % len(self.fns))
+
+ def __len__(self):
+ return len(self.fns)
+
+ def get_data_for_index(self, index):
+ input_img_fn = self.fns[index]
+ elevation = 0
+ return prepare_inputs(input_img_fn, elevation, 512)
+
+ def __getitem__(self, index):
+ return self.get_data_for_index(index)
+
+class VideoDataset(pl.LightningDataModule):
+ def __init__(self, base_folder, eval_folder, width, height, sample_frames, batch_size, num_workers=4, seed=0, **kwargs):
+ super().__init__()
+ self.base_folder = base_folder
+ self.eval_folder = eval_folder
+ self.width = width
+ self.height = height
+ self.sample_frames = sample_frames
+ self.batch_size = batch_size
+ self.num_workers = num_workers
+ self.seed = seed
+ self.additional_args = kwargs
+
+ def setup(self):
+ self.train_dataset = VideoTrainDataset(self.base_folder, self.width, self.height, self.sample_frames)
+ self.val_dataset = SyncDreamerEvalData(image_dir=self.eval_folder)
+
+ def train_dataloader(self):
+ sampler = DistributedSampler(self.train_dataset, seed=self.seed)
+ return wds.WebLoader(self.train_dataset, batch_size=self.batch_size, num_workers=self.num_workers, shuffle=False, sampler=sampler)
+
+ def val_dataloader(self):
+ loader = wds.WebLoader(self.val_dataset, batch_size=self.batch_size, num_workers=self.num_workers, shuffle=False)
+ return loader
+
+ def test_dataloader(self):
+ return wds.WebLoader(self.val_dataset, batch_size=self.batch_size, num_workers=self.num_workers, shuffle=False)
\ No newline at end of file
diff --git a/sgm/data/video_dataset_stage2_degradeImages.py b/sgm/data/video_dataset_stage2_degradeImages.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe74219593978ff26452c9d9e4cd751d3b6d051b
--- /dev/null
+++ b/sgm/data/video_dataset_stage2_degradeImages.py
@@ -0,0 +1,303 @@
+import pytorch_lightning as pl
+import numpy as np
+import torch
+import PIL
+import os
+import random
+from skimage.io import imread
+import webdataset as wds
+import PIL.Image as Image
+from torch.utils.data import Dataset
+from torch.utils.data.distributed import DistributedSampler
+from pathlib import Path
+
+# from ldm.base_utils import read_pickle, pose_inverse
+import torchvision.transforms as transforms
+import torchvision
+from einops import rearrange
+
+# for the degraded images
+import yaml
+from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
+import math
+
+def add_margin(pil_img, color=0, size=256):
+ width, height = pil_img.size
+ result = Image.new(pil_img.mode, (size, size), color)
+ result.paste(pil_img, ((size - width) // 2, (size - height) // 2))
+ return result
+
+def prepare_inputs(image_path, elevation_input, crop_size=-1, image_size=256):
+ image_input = Image.open(image_path)
+
+ if crop_size!=-1:
+ alpha_np = np.asarray(image_input)[:, :, 3]
+ coords = np.stack(np.nonzero(alpha_np), 1)[:, (1, 0)]
+ min_x, min_y = np.min(coords, 0)
+ max_x, max_y = np.max(coords, 0)
+ ref_img_ = image_input.crop((min_x, min_y, max_x, max_y))
+ h, w = ref_img_.height, ref_img_.width
+ scale = crop_size / max(h, w)
+ h_, w_ = int(scale * h), int(scale * w)
+ ref_img_ = ref_img_.resize((w_, h_), resample=Image.BICUBIC)
+ image_input = add_margin(ref_img_, size=image_size)
+ else:
+ image_input = add_margin(image_input, size=max(image_input.height, image_input.width))
+ image_input = image_input.resize((image_size, image_size), resample=Image.BICUBIC)
+
+ image_input = np.asarray(image_input)
+ image_input = image_input.astype(np.float32) / 255.0
+ ref_mask = image_input[:, :, 3:]
+ image_input[:, :, :3] = image_input[:, :, :3] * ref_mask + 1 - ref_mask # white background
+ image_input = image_input[:, :, :3] * 2.0 - 1.0
+ image_input = torch.from_numpy(image_input.astype(np.float32))
+ elevation_input = torch.from_numpy(np.asarray([np.deg2rad(elevation_input)], np.float32))
+ return {"input_image": image_input, "input_elevation": elevation_input}
+
+
+class VideoTrainDataset(Dataset):
+ def __init__(self, base_folder='/data/yanghaibo/datas/OBJAVERSE-LVIS/images', depth_folder="/mnt/drive2/3d/OBJAVERSE-DEPTH/depth256", width=1024, height=576, sample_frames=25):
+ """
+ Args:
+ num_samples (int): Number of samples in the dataset.
+ channels (int): Number of channels, default is 3 for RGB.
+ """
+ # Define the path to the folder containing video frames
+ self.base_folder = base_folder
+ self.depth_folder = depth_folder
+ # self.folders1 = os.listdir(self.base_folder)
+ # self.folders2 = os.listdir(self.depth_folder)
+ # self.folders = list(set(self.folders1).intersection(set(self.folders2)))
+ self.folders = os.listdir(self.base_folder)
+ self.num_samples = len(self.folders)
+ self.channels = 3
+ self.width = width
+ self.height = height
+ self.sample_frames = sample_frames
+ self.elevations = [-10, 0, 10, 20, 30, 40]
+
+ # for degraded images
+ with open('configs/train_realesrnet_x4plus.yml', mode='r') as f:
+ opt = yaml.load(f, Loader=yaml.FullLoader)
+ self.opt = opt
+ # blur settings for the first degradation
+ self.blur_kernel_size = opt['blur_kernel_size']
+ self.kernel_list = opt['kernel_list']
+ self.kernel_prob = opt['kernel_prob'] # a list for each kernel probability
+ self.blur_sigma = opt['blur_sigma']
+ self.betag_range = opt['betag_range'] # betag used in generalized Gaussian blur kernels
+ self.betap_range = opt['betap_range'] # betap used in plateau blur kernels
+ self.sinc_prob = opt['sinc_prob'] # the probability for sinc filters
+
+ # blur settings for the second degradation
+ self.blur_kernel_size2 = opt['blur_kernel_size2']
+ self.kernel_list2 = opt['kernel_list2']
+ self.kernel_prob2 = opt['kernel_prob2']
+ self.blur_sigma2 = opt['blur_sigma2']
+ self.betag_range2 = opt['betag_range2']
+ self.betap_range2 = opt['betap_range2']
+ self.sinc_prob2 = opt['sinc_prob2']
+
+ # a final sinc filter
+ self.final_sinc_prob = opt['final_sinc_prob']
+
+ self.kernel_range = [2 * v + 1 for v in range(3, 11)] # kernel size ranges from 7 to 21
+ # TODO: kernel range is now hard-coded, should be in the configure file
+ self.pulse_tensor = torch.zeros(21, 21).float() # convolving with pulse tensor brings no blurry effect
+ self.pulse_tensor[10, 10] = 1
+
+
+ def __len__(self):
+ return self.num_samples
+
+ def load_im(self, path):
+ img = imread(path)
+ img = img.astype(np.float32) / 255.0
+ mask = img[:,:,3:]
+ img[:,:,:3] = img[:,:,:3] * mask + 1 - mask # white background
+ img = Image.fromarray(np.uint8(img[:, :, :3] * 255.))
+ return img, mask
+
+ def __getitem__(self, idx):
+ """
+ Args:
+ idx (int): Index of the sample to return.
+
+ Returns:
+ dict: A dictionary containing the 'pixel_values' tensor of shape (16, channels, 320, 512).
+ """
+ # Randomly select a folder (representing a video) from the base folder
+ chosen_folder = random.choice(self.folders)
+ folder_path = os.path.join(self.base_folder, chosen_folder)
+ frames = os.listdir(folder_path)
+ # Sort the frames by name
+ frames.sort()
+
+ # Ensure the selected folder has at least `sample_frames`` frames
+ if len(frames) < self.sample_frames:
+ raise ValueError(
+ f"The selected folder '{chosen_folder}' contains fewer than `{self.sample_frames}` frames.")
+
+ # Randomly select a start index for frame sequence. Fixed elevation
+ start_idx = random.randint(0, len(frames) - 1)
+ # start_idx = random.choice([0, 4, 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48, 52, 56, 60, 64, 68, 72, 76, 80, 84, 88, 92])
+ range_id = int(start_idx / 16) # 0, 1, 2, 3, 4, 5
+ elevation = self.elevations[range_id]
+ selected_frames = []
+
+ for frame_idx in range(start_idx, (range_id + 1) * 16):
+ selected_frames.append(frames[frame_idx])
+ for frame_idx in range((range_id) * 16, start_idx):
+ selected_frames.append(frames[frame_idx])
+
+ # Initialize a tensor to store the pixel values
+ pixel_values = torch.empty((self.sample_frames, self.channels, self.height, self.width))
+ masks = []
+
+ # Load and process each frame
+ for i, frame_name in enumerate(selected_frames):
+ frame_path = os.path.join(folder_path, frame_name)
+ img, mask = self.load_im(frame_path)
+ mask = mask.squeeze(-1)
+ masks.append(mask)
+ # Resize the image and convert it to a tensor
+ img_resized = img.resize((self.width, self.height))
+ img_tensor = torch.from_numpy(np.array(img_resized)).float()
+
+ # Normalize the image by scaling pixel values to [-1, 1]
+ img_normalized = img_tensor / 127.5 - 1
+
+ # Rearrange channels if necessary
+ if self.channels == 3:
+ img_normalized = img_normalized.permute(
+ 2, 0, 1) # For RGB images
+ elif self.channels == 1:
+ img_normalized = img_normalized.mean(
+ dim=2, keepdim=True) # For grayscale images
+
+ pixel_values[i] = img_normalized
+
+ pixel_values = rearrange(pixel_values, 't c h w -> c t h w')
+ masks = torch.from_numpy(np.array(masks))
+ caption = chosen_folder
+
+ # !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! get the kernels for degraded images
+ # ------------------------ Generate kernels (used in the first degradation) ------------------------ #
+ kernels = []
+ kernel2s = []
+ sinc_kernels = []
+ for i in range(16):
+ kernel_size = random.choice(self.kernel_range)
+ if np.random.uniform() < self.opt['sinc_prob']:
+ # this sinc filter setting is for kernels ranging from [7, 21]
+ if kernel_size < 13:
+ omega_c = np.random.uniform(np.pi / 3, np.pi)
+ else:
+ omega_c = np.random.uniform(np.pi / 5, np.pi)
+ kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
+ else:
+ kernel = random_mixed_kernels(
+ self.kernel_list,
+ self.kernel_prob,
+ kernel_size,
+ self.blur_sigma,
+ self.blur_sigma, [-math.pi, math.pi],
+ self.betag_range,
+ self.betap_range,
+ noise_range=None)
+ # pad kernel
+ pad_size = (21 - kernel_size) // 2
+ kernel = np.pad(kernel, ((pad_size, pad_size), (pad_size, pad_size)))
+ kernels.append(kernel)
+
+ # ------------------------ Generate kernels (used in the second degradation) ------------------------ #
+ kernel_size = random.choice(self.kernel_range)
+ if np.random.uniform() < self.opt['sinc_prob2']:
+ if kernel_size < 13:
+ omega_c = np.random.uniform(np.pi / 3, np.pi)
+ else:
+ omega_c = np.random.uniform(np.pi / 5, np.pi)
+ kernel2 = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
+ else:
+ kernel2 = random_mixed_kernels(
+ self.kernel_list2,
+ self.kernel_prob2,
+ kernel_size,
+ self.blur_sigma2,
+ self.blur_sigma2, [-math.pi, math.pi],
+ self.betag_range2,
+ self.betap_range2,
+ noise_range=None)
+
+ # pad kernel
+ pad_size = (21 - kernel_size) // 2
+ kernel2 = np.pad(kernel2, ((pad_size, pad_size), (pad_size, pad_size)))
+ kernel2s.append(kernel2)
+
+ # ------------------------------------- the final sinc kernel ------------------------------------- #
+ if np.random.uniform() < self.opt['final_sinc_prob']:
+ kernel_size = random.choice(self.kernel_range)
+ omega_c = np.random.uniform(np.pi / 3, np.pi)
+ sinc_kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=21)
+ sinc_kernel = torch.FloatTensor(sinc_kernel)
+ else:
+ sinc_kernel = self.pulse_tensor
+ sinc_kernels.append(sinc_kernel)
+ kernels = np.array(kernels)
+ kernel2s = np.array(kernel2s)
+ sinc_kernels = torch.stack(sinc_kernels, 0)
+ kernels = torch.FloatTensor(kernels)
+ kernel2s = torch.FloatTensor(kernel2s)
+ return {'video': pixel_values, 'masks': masks, 'elevation': elevation, 'caption': caption, 'kernel1s': kernels, 'kernel2s': kernel2s, 'sinc_kernels': sinc_kernels} # (16, 3, 512, 512)-> (3, 16, 512, 512)
+
+class SyncDreamerEvalData(Dataset):
+ def __init__(self, image_dir):
+ self.image_size = 512
+ self.image_dir = Path(image_dir)
+ self.crop_size = 20
+
+ self.fns = []
+ for fn in Path(image_dir).iterdir():
+ if fn.suffix=='.png':
+ self.fns.append(fn)
+ print('============= length of dataset %d =============' % len(self.fns))
+
+ def __len__(self):
+ return len(self.fns)
+
+ def get_data_for_index(self, index):
+ input_img_fn = self.fns[index]
+ elevation = 0
+ return prepare_inputs(input_img_fn, elevation, 512)
+
+ def __getitem__(self, index):
+ return self.get_data_for_index(index)
+
+class VideoDataset(pl.LightningDataModule):
+ def __init__(self, base_folder, depth_folder, eval_folder, width, height, sample_frames, batch_size, num_workers=4, seed=0, **kwargs):
+ super().__init__()
+ self.base_folder = base_folder
+ self.depth_folder = depth_folder
+ self.eval_folder = eval_folder
+ self.width = width
+ self.height = height
+ self.sample_frames = sample_frames
+ self.batch_size = batch_size
+ self.num_workers = num_workers
+ self.seed = seed
+ self.additional_args = kwargs
+
+ def setup(self):
+ self.train_dataset = VideoTrainDataset(self.base_folder, self.depth_folder, self.width, self.height, self.sample_frames)
+ self.val_dataset = SyncDreamerEvalData(image_dir=self.eval_folder)
+
+ def train_dataloader(self):
+ sampler = DistributedSampler(self.train_dataset, seed=self.seed)
+ return wds.WebLoader(self.train_dataset, batch_size=self.batch_size, num_workers=self.num_workers, shuffle=False, sampler=sampler)
+
+ def val_dataloader(self):
+ loader = wds.WebLoader(self.val_dataset, batch_size=self.batch_size, num_workers=self.num_workers, shuffle=False)
+ return loader
+
+ def test_dataloader(self):
+ return wds.WebLoader(self.val_dataset, batch_size=self.batch_size, num_workers=self.num_workers, shuffle=False)
\ No newline at end of file
diff --git a/sgm/inference/api.py b/sgm/inference/api.py
new file mode 100644
index 0000000000000000000000000000000000000000..7171ff4abb774556b638c98ad809e195082bdccf
--- /dev/null
+++ b/sgm/inference/api.py
@@ -0,0 +1,385 @@
+import pathlib
+from dataclasses import asdict, dataclass
+from enum import Enum
+from typing import Optional
+
+from omegaconf import OmegaConf
+
+from sgm.inference.helpers import (Img2ImgDiscretizationWrapper, do_img2img,
+ do_sample)
+from sgm.modules.diffusionmodules.sampling import (DPMPP2MSampler,
+ DPMPP2SAncestralSampler,
+ EulerAncestralSampler,
+ EulerEDMSampler,
+ HeunEDMSampler,
+ LinearMultistepSampler)
+from sgm.util import load_model_from_config
+
+
+class ModelArchitecture(str, Enum):
+ SD_2_1 = "stable-diffusion-v2-1"
+ SD_2_1_768 = "stable-diffusion-v2-1-768"
+ SDXL_V0_9_BASE = "stable-diffusion-xl-v0-9-base"
+ SDXL_V0_9_REFINER = "stable-diffusion-xl-v0-9-refiner"
+ SDXL_V1_BASE = "stable-diffusion-xl-v1-base"
+ SDXL_V1_REFINER = "stable-diffusion-xl-v1-refiner"
+
+
+class Sampler(str, Enum):
+ EULER_EDM = "EulerEDMSampler"
+ HEUN_EDM = "HeunEDMSampler"
+ EULER_ANCESTRAL = "EulerAncestralSampler"
+ DPMPP2S_ANCESTRAL = "DPMPP2SAncestralSampler"
+ DPMPP2M = "DPMPP2MSampler"
+ LINEAR_MULTISTEP = "LinearMultistepSampler"
+
+
+class Discretization(str, Enum):
+ LEGACY_DDPM = "LegacyDDPMDiscretization"
+ EDM = "EDMDiscretization"
+
+
+class Guider(str, Enum):
+ VANILLA = "VanillaCFG"
+ IDENTITY = "IdentityGuider"
+
+
+class Thresholder(str, Enum):
+ NONE = "None"
+
+
+@dataclass
+class SamplingParams:
+ width: int = 1024
+ height: int = 1024
+ steps: int = 50
+ sampler: Sampler = Sampler.DPMPP2M
+ discretization: Discretization = Discretization.LEGACY_DDPM
+ guider: Guider = Guider.VANILLA
+ thresholder: Thresholder = Thresholder.NONE
+ scale: float = 6.0
+ aesthetic_score: float = 5.0
+ negative_aesthetic_score: float = 5.0
+ img2img_strength: float = 1.0
+ orig_width: int = 1024
+ orig_height: int = 1024
+ crop_coords_top: int = 0
+ crop_coords_left: int = 0
+ sigma_min: float = 0.0292
+ sigma_max: float = 14.6146
+ rho: float = 3.0
+ s_churn: float = 0.0
+ s_tmin: float = 0.0
+ s_tmax: float = 999.0
+ s_noise: float = 1.0
+ eta: float = 1.0
+ order: int = 4
+
+
+@dataclass
+class SamplingSpec:
+ width: int
+ height: int
+ channels: int
+ factor: int
+ is_legacy: bool
+ config: str
+ ckpt: str
+ is_guided: bool
+
+
+model_specs = {
+ ModelArchitecture.SD_2_1: SamplingSpec(
+ height=512,
+ width=512,
+ channels=4,
+ factor=8,
+ is_legacy=True,
+ config="sd_2_1.yaml",
+ ckpt="v2-1_512-ema-pruned.safetensors",
+ is_guided=True,
+ ),
+ ModelArchitecture.SD_2_1_768: SamplingSpec(
+ height=768,
+ width=768,
+ channels=4,
+ factor=8,
+ is_legacy=True,
+ config="sd_2_1_768.yaml",
+ ckpt="v2-1_768-ema-pruned.safetensors",
+ is_guided=True,
+ ),
+ ModelArchitecture.SDXL_V0_9_BASE: SamplingSpec(
+ height=1024,
+ width=1024,
+ channels=4,
+ factor=8,
+ is_legacy=False,
+ config="sd_xl_base.yaml",
+ ckpt="sd_xl_base_0.9.safetensors",
+ is_guided=True,
+ ),
+ ModelArchitecture.SDXL_V0_9_REFINER: SamplingSpec(
+ height=1024,
+ width=1024,
+ channels=4,
+ factor=8,
+ is_legacy=True,
+ config="sd_xl_refiner.yaml",
+ ckpt="sd_xl_refiner_0.9.safetensors",
+ is_guided=True,
+ ),
+ ModelArchitecture.SDXL_V1_BASE: SamplingSpec(
+ height=1024,
+ width=1024,
+ channels=4,
+ factor=8,
+ is_legacy=False,
+ config="sd_xl_base.yaml",
+ ckpt="sd_xl_base_1.0.safetensors",
+ is_guided=True,
+ ),
+ ModelArchitecture.SDXL_V1_REFINER: SamplingSpec(
+ height=1024,
+ width=1024,
+ channels=4,
+ factor=8,
+ is_legacy=True,
+ config="sd_xl_refiner.yaml",
+ ckpt="sd_xl_refiner_1.0.safetensors",
+ is_guided=True,
+ ),
+}
+
+
+class SamplingPipeline:
+ def __init__(
+ self,
+ model_id: ModelArchitecture,
+ model_path="checkpoints",
+ config_path="configs/inference",
+ device="cuda",
+ use_fp16=True,
+ ) -> None:
+ if model_id not in model_specs:
+ raise ValueError(f"Model {model_id} not supported")
+ self.model_id = model_id
+ self.specs = model_specs[self.model_id]
+ self.config = str(pathlib.Path(config_path, self.specs.config))
+ self.ckpt = str(pathlib.Path(model_path, self.specs.ckpt))
+ self.device = device
+ self.model = self._load_model(device=device, use_fp16=use_fp16)
+
+ def _load_model(self, device="cuda", use_fp16=True):
+ config = OmegaConf.load(self.config)
+ model = load_model_from_config(config, self.ckpt)
+ if model is None:
+ raise ValueError(f"Model {self.model_id} could not be loaded")
+ model.to(device)
+ if use_fp16:
+ model.conditioner.half()
+ model.model.half()
+ return model
+
+ def text_to_image(
+ self,
+ params: SamplingParams,
+ prompt: str,
+ negative_prompt: str = "",
+ samples: int = 1,
+ return_latents: bool = False,
+ ):
+ sampler = get_sampler_config(params)
+ value_dict = asdict(params)
+ value_dict["prompt"] = prompt
+ value_dict["negative_prompt"] = negative_prompt
+ value_dict["target_width"] = params.width
+ value_dict["target_height"] = params.height
+ return do_sample(
+ self.model,
+ sampler,
+ value_dict,
+ samples,
+ params.height,
+ params.width,
+ self.specs.channels,
+ self.specs.factor,
+ force_uc_zero_embeddings=["txt"] if not self.specs.is_legacy else [],
+ return_latents=return_latents,
+ filter=None,
+ )
+
+ def image_to_image(
+ self,
+ params: SamplingParams,
+ image,
+ prompt: str,
+ negative_prompt: str = "",
+ samples: int = 1,
+ return_latents: bool = False,
+ ):
+ sampler = get_sampler_config(params)
+
+ if params.img2img_strength < 1.0:
+ sampler.discretization = Img2ImgDiscretizationWrapper(
+ sampler.discretization,
+ strength=params.img2img_strength,
+ )
+ height, width = image.shape[2], image.shape[3]
+ value_dict = asdict(params)
+ value_dict["prompt"] = prompt
+ value_dict["negative_prompt"] = negative_prompt
+ value_dict["target_width"] = width
+ value_dict["target_height"] = height
+ return do_img2img(
+ image,
+ self.model,
+ sampler,
+ value_dict,
+ samples,
+ force_uc_zero_embeddings=["txt"] if not self.specs.is_legacy else [],
+ return_latents=return_latents,
+ filter=None,
+ )
+
+ def refiner(
+ self,
+ params: SamplingParams,
+ image,
+ prompt: str,
+ negative_prompt: Optional[str] = None,
+ samples: int = 1,
+ return_latents: bool = False,
+ ):
+ sampler = get_sampler_config(params)
+ value_dict = {
+ "orig_width": image.shape[3] * 8,
+ "orig_height": image.shape[2] * 8,
+ "target_width": image.shape[3] * 8,
+ "target_height": image.shape[2] * 8,
+ "prompt": prompt,
+ "negative_prompt": negative_prompt,
+ "crop_coords_top": 0,
+ "crop_coords_left": 0,
+ "aesthetic_score": 6.0,
+ "negative_aesthetic_score": 2.5,
+ }
+
+ return do_img2img(
+ image,
+ self.model,
+ sampler,
+ value_dict,
+ samples,
+ skip_encode=True,
+ return_latents=return_latents,
+ filter=None,
+ )
+
+
+def get_guider_config(params: SamplingParams):
+ if params.guider == Guider.IDENTITY:
+ guider_config = {
+ "target": "sgm.modules.diffusionmodules.guiders.IdentityGuider"
+ }
+ elif params.guider == Guider.VANILLA:
+ scale = params.scale
+
+ thresholder = params.thresholder
+
+ if thresholder == Thresholder.NONE:
+ dyn_thresh_config = {
+ "target": "sgm.modules.diffusionmodules.sampling_utils.NoDynamicThresholding"
+ }
+ else:
+ raise NotImplementedError
+
+ guider_config = {
+ "target": "sgm.modules.diffusionmodules.guiders.VanillaCFG",
+ "params": {"scale": scale, "dyn_thresh_config": dyn_thresh_config},
+ }
+ else:
+ raise NotImplementedError
+ return guider_config
+
+
+def get_discretization_config(params: SamplingParams):
+ if params.discretization == Discretization.LEGACY_DDPM:
+ discretization_config = {
+ "target": "sgm.modules.diffusionmodules.discretizer.LegacyDDPMDiscretization",
+ }
+ elif params.discretization == Discretization.EDM:
+ discretization_config = {
+ "target": "sgm.modules.diffusionmodules.discretizer.EDMDiscretization",
+ "params": {
+ "sigma_min": params.sigma_min,
+ "sigma_max": params.sigma_max,
+ "rho": params.rho,
+ },
+ }
+ else:
+ raise ValueError(f"unknown discretization {params.discretization}")
+ return discretization_config
+
+
+def get_sampler_config(params: SamplingParams):
+ discretization_config = get_discretization_config(params)
+ guider_config = get_guider_config(params)
+ sampler = None
+ if params.sampler == Sampler.EULER_EDM:
+ return EulerEDMSampler(
+ num_steps=params.steps,
+ discretization_config=discretization_config,
+ guider_config=guider_config,
+ s_churn=params.s_churn,
+ s_tmin=params.s_tmin,
+ s_tmax=params.s_tmax,
+ s_noise=params.s_noise,
+ verbose=True,
+ )
+ if params.sampler == Sampler.HEUN_EDM:
+ return HeunEDMSampler(
+ num_steps=params.steps,
+ discretization_config=discretization_config,
+ guider_config=guider_config,
+ s_churn=params.s_churn,
+ s_tmin=params.s_tmin,
+ s_tmax=params.s_tmax,
+ s_noise=params.s_noise,
+ verbose=True,
+ )
+ if params.sampler == Sampler.EULER_ANCESTRAL:
+ return EulerAncestralSampler(
+ num_steps=params.steps,
+ discretization_config=discretization_config,
+ guider_config=guider_config,
+ eta=params.eta,
+ s_noise=params.s_noise,
+ verbose=True,
+ )
+ if params.sampler == Sampler.DPMPP2S_ANCESTRAL:
+ return DPMPP2SAncestralSampler(
+ num_steps=params.steps,
+ discretization_config=discretization_config,
+ guider_config=guider_config,
+ eta=params.eta,
+ s_noise=params.s_noise,
+ verbose=True,
+ )
+ if params.sampler == Sampler.DPMPP2M:
+ return DPMPP2MSampler(
+ num_steps=params.steps,
+ discretization_config=discretization_config,
+ guider_config=guider_config,
+ verbose=True,
+ )
+ if params.sampler == Sampler.LINEAR_MULTISTEP:
+ return LinearMultistepSampler(
+ num_steps=params.steps,
+ discretization_config=discretization_config,
+ guider_config=guider_config,
+ order=params.order,
+ verbose=True,
+ )
+
+ raise ValueError(f"unknown sampler {params.sampler}!")
diff --git a/sgm/inference/helpers.py b/sgm/inference/helpers.py
new file mode 100644
index 0000000000000000000000000000000000000000..31b0ec3dc414bf522261e35f73805810cd35582d
--- /dev/null
+++ b/sgm/inference/helpers.py
@@ -0,0 +1,305 @@
+import math
+import os
+from typing import List, Optional, Union
+
+import numpy as np
+import torch
+from einops import rearrange
+from imwatermark import WatermarkEncoder
+from omegaconf import ListConfig
+from PIL import Image
+from torch import autocast
+
+from sgm.util import append_dims
+
+
+class WatermarkEmbedder:
+ def __init__(self, watermark):
+ self.watermark = watermark
+ self.num_bits = len(WATERMARK_BITS)
+ self.encoder = WatermarkEncoder()
+ self.encoder.set_watermark("bits", self.watermark)
+
+ def __call__(self, image: torch.Tensor) -> torch.Tensor:
+ """
+ Adds a predefined watermark to the input image
+
+ Args:
+ image: ([N,] B, RGB, H, W) in range [0, 1]
+
+ Returns:
+ same as input but watermarked
+ """
+ squeeze = len(image.shape) == 4
+ if squeeze:
+ image = image[None, ...]
+ n = image.shape[0]
+ image_np = rearrange(
+ (255 * image).detach().cpu(), "n b c h w -> (n b) h w c"
+ ).numpy()[:, :, :, ::-1]
+ # torch (b, c, h, w) in [0, 1] -> numpy (b, h, w, c) [0, 255]
+ # watermarking libary expects input as cv2 BGR format
+ for k in range(image_np.shape[0]):
+ image_np[k] = self.encoder.encode(image_np[k], "dwtDct")
+ image = torch.from_numpy(
+ rearrange(image_np[:, :, :, ::-1], "(n b) h w c -> n b c h w", n=n)
+ ).to(image.device)
+ image = torch.clamp(image / 255, min=0.0, max=1.0)
+ if squeeze:
+ image = image[0]
+ return image
+
+
+# A fixed 48-bit message that was choosen at random
+# WATERMARK_MESSAGE = 0xB3EC907BB19E
+WATERMARK_MESSAGE = 0b101100111110110010010000011110111011000110011110
+# bin(x)[2:] gives bits of x as str, use int to convert them to 0/1
+WATERMARK_BITS = [int(bit) for bit in bin(WATERMARK_MESSAGE)[2:]]
+embed_watermark = WatermarkEmbedder(WATERMARK_BITS)
+
+
+def get_unique_embedder_keys_from_conditioner(conditioner):
+ return list({x.input_key for x in conditioner.embedders})
+
+
+def perform_save_locally(save_path, samples):
+ os.makedirs(os.path.join(save_path), exist_ok=True)
+ base_count = len(os.listdir(os.path.join(save_path)))
+ samples = embed_watermark(samples)
+ for sample in samples:
+ sample = 255.0 * rearrange(sample.cpu().numpy(), "c h w -> h w c")
+ Image.fromarray(sample.astype(np.uint8)).save(
+ os.path.join(save_path, f"{base_count:09}.png")
+ )
+ base_count += 1
+
+
+class Img2ImgDiscretizationWrapper:
+ """
+ wraps a discretizer, and prunes the sigmas
+ params:
+ strength: float between 0.0 and 1.0. 1.0 means full sampling (all sigmas are returned)
+ """
+
+ def __init__(self, discretization, strength: float = 1.0):
+ self.discretization = discretization
+ self.strength = strength
+ assert 0.0 <= self.strength <= 1.0
+
+ def __call__(self, *args, **kwargs):
+ # sigmas start large first, and decrease then
+ sigmas = self.discretization(*args, **kwargs)
+ print(f"sigmas after discretization, before pruning img2img: ", sigmas)
+ sigmas = torch.flip(sigmas, (0,))
+ sigmas = sigmas[: max(int(self.strength * len(sigmas)), 1)]
+ print("prune index:", max(int(self.strength * len(sigmas)), 1))
+ sigmas = torch.flip(sigmas, (0,))
+ print(f"sigmas after pruning: ", sigmas)
+ return sigmas
+
+
+def do_sample(
+ model,
+ sampler,
+ value_dict,
+ num_samples,
+ H,
+ W,
+ C,
+ F,
+ force_uc_zero_embeddings: Optional[List] = None,
+ batch2model_input: Optional[List] = None,
+ return_latents=False,
+ filter=None,
+ device="cuda",
+):
+ if force_uc_zero_embeddings is None:
+ force_uc_zero_embeddings = []
+ if batch2model_input is None:
+ batch2model_input = []
+
+ with torch.no_grad():
+ with autocast(device) as precision_scope:
+ with model.ema_scope():
+ num_samples = [num_samples]
+ batch, batch_uc = get_batch(
+ get_unique_embedder_keys_from_conditioner(model.conditioner),
+ value_dict,
+ num_samples,
+ )
+ for key in batch:
+ if isinstance(batch[key], torch.Tensor):
+ print(key, batch[key].shape)
+ elif isinstance(batch[key], list):
+ print(key, [len(l) for l in batch[key]])
+ else:
+ print(key, batch[key])
+ c, uc = model.conditioner.get_unconditional_conditioning(
+ batch,
+ batch_uc=batch_uc,
+ force_uc_zero_embeddings=force_uc_zero_embeddings,
+ )
+
+ for k in c:
+ if not k == "crossattn":
+ c[k], uc[k] = map(
+ lambda y: y[k][: math.prod(num_samples)].to(device), (c, uc)
+ )
+
+ additional_model_inputs = {}
+ for k in batch2model_input:
+ additional_model_inputs[k] = batch[k]
+
+ shape = (math.prod(num_samples), C, H // F, W // F)
+ randn = torch.randn(shape).to(device)
+
+ def denoiser(input, sigma, c):
+ return model.denoiser(
+ model.model, input, sigma, c, **additional_model_inputs
+ )
+
+ samples_z = sampler(denoiser, randn, cond=c, uc=uc)
+ samples_x = model.decode_first_stage(samples_z)
+ samples = torch.clamp((samples_x + 1.0) / 2.0, min=0.0, max=1.0)
+
+ if filter is not None:
+ samples = filter(samples)
+
+ if return_latents:
+ return samples, samples_z
+ return samples
+
+
+def get_batch(keys, value_dict, N: Union[List, ListConfig], device="cuda"):
+ # Hardcoded demo setups; might undergo some changes in the future
+
+ batch = {}
+ batch_uc = {}
+
+ for key in keys:
+ if key == "txt":
+ batch["txt"] = (
+ np.repeat([value_dict["prompt"]], repeats=math.prod(N))
+ .reshape(N)
+ .tolist()
+ )
+ batch_uc["txt"] = (
+ np.repeat([value_dict["negative_prompt"]], repeats=math.prod(N))
+ .reshape(N)
+ .tolist()
+ )
+ elif key == "original_size_as_tuple":
+ batch["original_size_as_tuple"] = (
+ torch.tensor([value_dict["orig_height"], value_dict["orig_width"]])
+ .to(device)
+ .repeat(*N, 1)
+ )
+ elif key == "crop_coords_top_left":
+ batch["crop_coords_top_left"] = (
+ torch.tensor(
+ [value_dict["crop_coords_top"], value_dict["crop_coords_left"]]
+ )
+ .to(device)
+ .repeat(*N, 1)
+ )
+ elif key == "aesthetic_score":
+ batch["aesthetic_score"] = (
+ torch.tensor([value_dict["aesthetic_score"]]).to(device).repeat(*N, 1)
+ )
+ batch_uc["aesthetic_score"] = (
+ torch.tensor([value_dict["negative_aesthetic_score"]])
+ .to(device)
+ .repeat(*N, 1)
+ )
+
+ elif key == "target_size_as_tuple":
+ batch["target_size_as_tuple"] = (
+ torch.tensor([value_dict["target_height"], value_dict["target_width"]])
+ .to(device)
+ .repeat(*N, 1)
+ )
+ else:
+ batch[key] = value_dict[key]
+
+ for key in batch.keys():
+ if key not in batch_uc and isinstance(batch[key], torch.Tensor):
+ batch_uc[key] = torch.clone(batch[key])
+ return batch, batch_uc
+
+
+def get_input_image_tensor(image: Image.Image, device="cuda"):
+ w, h = image.size
+ print(f"loaded input image of size ({w}, {h})")
+ width, height = map(
+ lambda x: x - x % 64, (w, h)
+ ) # resize to integer multiple of 64
+ image = image.resize((width, height))
+ image_array = np.array(image.convert("RGB"))
+ image_array = image_array[None].transpose(0, 3, 1, 2)
+ image_tensor = torch.from_numpy(image_array).to(dtype=torch.float32) / 127.5 - 1.0
+ return image_tensor.to(device)
+
+
+def do_img2img(
+ img,
+ model,
+ sampler,
+ value_dict,
+ num_samples,
+ force_uc_zero_embeddings=[],
+ additional_kwargs={},
+ offset_noise_level: float = 0.0,
+ return_latents=False,
+ skip_encode=False,
+ filter=None,
+ device="cuda",
+):
+ with torch.no_grad():
+ with autocast(device) as precision_scope:
+ with model.ema_scope():
+ batch, batch_uc = get_batch(
+ get_unique_embedder_keys_from_conditioner(model.conditioner),
+ value_dict,
+ [num_samples],
+ )
+ c, uc = model.conditioner.get_unconditional_conditioning(
+ batch,
+ batch_uc=batch_uc,
+ force_uc_zero_embeddings=force_uc_zero_embeddings,
+ )
+
+ for k in c:
+ c[k], uc[k] = map(lambda y: y[k][:num_samples].to(device), (c, uc))
+
+ for k in additional_kwargs:
+ c[k] = uc[k] = additional_kwargs[k]
+ if skip_encode:
+ z = img
+ else:
+ z = model.encode_first_stage(img)
+ noise = torch.randn_like(z)
+ sigmas = sampler.discretization(sampler.num_steps)
+ sigma = sigmas[0].to(z.device)
+
+ if offset_noise_level > 0.0:
+ noise = noise + offset_noise_level * append_dims(
+ torch.randn(z.shape[0], device=z.device), z.ndim
+ )
+ noised_z = z + noise * append_dims(sigma, z.ndim)
+ noised_z = noised_z / torch.sqrt(
+ 1.0 + sigmas[0] ** 2.0
+ ) # Note: hardcoded to DDPM-like scaling. need to generalize later.
+
+ def denoiser(x, sigma, c):
+ return model.denoiser(model.model, x, sigma, c)
+
+ samples_z = sampler(denoiser, noised_z, cond=c, uc=uc)
+ samples_x = model.decode_first_stage(samples_z)
+ samples = torch.clamp((samples_x + 1.0) / 2.0, min=0.0, max=1.0)
+
+ if filter is not None:
+ samples = filter(samples)
+
+ if return_latents:
+ return samples, samples_z
+ return samples
diff --git a/sgm/lr_scheduler.py b/sgm/lr_scheduler.py
new file mode 100644
index 0000000000000000000000000000000000000000..b2f4d384c1fcaff0df13e0564450d3fa972ace42
--- /dev/null
+++ b/sgm/lr_scheduler.py
@@ -0,0 +1,135 @@
+import numpy as np
+
+
+class LambdaWarmUpCosineScheduler:
+ """
+ note: use with a base_lr of 1.0
+ """
+
+ def __init__(
+ self,
+ warm_up_steps,
+ lr_min,
+ lr_max,
+ lr_start,
+ max_decay_steps,
+ verbosity_interval=0,
+ ):
+ self.lr_warm_up_steps = warm_up_steps
+ self.lr_start = lr_start
+ self.lr_min = lr_min
+ self.lr_max = lr_max
+ self.lr_max_decay_steps = max_decay_steps
+ self.last_lr = 0.0
+ self.verbosity_interval = verbosity_interval
+
+ def schedule(self, n, **kwargs):
+ if self.verbosity_interval > 0:
+ if n % self.verbosity_interval == 0:
+ print(f"current step: {n}, recent lr-multiplier: {self.last_lr}")
+ if n < self.lr_warm_up_steps:
+ lr = (
+ self.lr_max - self.lr_start
+ ) / self.lr_warm_up_steps * n + self.lr_start
+ self.last_lr = lr
+ return lr
+ else:
+ t = (n - self.lr_warm_up_steps) / (
+ self.lr_max_decay_steps - self.lr_warm_up_steps
+ )
+ t = min(t, 1.0)
+ lr = self.lr_min + 0.5 * (self.lr_max - self.lr_min) * (
+ 1 + np.cos(t * np.pi)
+ )
+ self.last_lr = lr
+ return lr
+
+ def __call__(self, n, **kwargs):
+ return self.schedule(n, **kwargs)
+
+
+class LambdaWarmUpCosineScheduler2:
+ """
+ supports repeated iterations, configurable via lists
+ note: use with a base_lr of 1.0.
+ """
+
+ def __init__(
+ self, warm_up_steps, f_min, f_max, f_start, cycle_lengths, verbosity_interval=0
+ ):
+ assert (
+ len(warm_up_steps)
+ == len(f_min)
+ == len(f_max)
+ == len(f_start)
+ == len(cycle_lengths)
+ )
+ self.lr_warm_up_steps = warm_up_steps
+ self.f_start = f_start
+ self.f_min = f_min
+ self.f_max = f_max
+ self.cycle_lengths = cycle_lengths
+ self.cum_cycles = np.cumsum([0] + list(self.cycle_lengths))
+ self.last_f = 0.0
+ self.verbosity_interval = verbosity_interval
+
+ def find_in_interval(self, n):
+ interval = 0
+ for cl in self.cum_cycles[1:]:
+ if n <= cl:
+ return interval
+ interval += 1
+
+ def schedule(self, n, **kwargs):
+ cycle = self.find_in_interval(n)
+ n = n - self.cum_cycles[cycle]
+ if self.verbosity_interval > 0:
+ if n % self.verbosity_interval == 0:
+ print(
+ f"current step: {n}, recent lr-multiplier: {self.last_f}, "
+ f"current cycle {cycle}"
+ )
+ if n < self.lr_warm_up_steps[cycle]:
+ f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[
+ cycle
+ ] * n + self.f_start[cycle]
+ self.last_f = f
+ return f
+ else:
+ t = (n - self.lr_warm_up_steps[cycle]) / (
+ self.cycle_lengths[cycle] - self.lr_warm_up_steps[cycle]
+ )
+ t = min(t, 1.0)
+ f = self.f_min[cycle] + 0.5 * (self.f_max[cycle] - self.f_min[cycle]) * (
+ 1 + np.cos(t * np.pi)
+ )
+ self.last_f = f
+ return f
+
+ def __call__(self, n, **kwargs):
+ return self.schedule(n, **kwargs)
+
+
+class LambdaLinearScheduler(LambdaWarmUpCosineScheduler2):
+ def schedule(self, n, **kwargs):
+ cycle = self.find_in_interval(n)
+ n = n - self.cum_cycles[cycle]
+ if self.verbosity_interval > 0:
+ if n % self.verbosity_interval == 0:
+ print(
+ f"current step: {n}, recent lr-multiplier: {self.last_f}, "
+ f"current cycle {cycle}"
+ )
+
+ if n < self.lr_warm_up_steps[cycle]:
+ f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[
+ cycle
+ ] * n + self.f_start[cycle]
+ self.last_f = f
+ return f
+ else:
+ f = self.f_min[cycle] + (self.f_max[cycle] - self.f_min[cycle]) * (
+ self.cycle_lengths[cycle] - n
+ ) / (self.cycle_lengths[cycle])
+ self.last_f = f
+ return f
diff --git a/sgm/models/__init__.py b/sgm/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c410b3747afc208e4204c8f140170e0a7808eace
--- /dev/null
+++ b/sgm/models/__init__.py
@@ -0,0 +1,2 @@
+from .autoencoder import AutoencodingEngine
+from .diffusion import DiffusionEngine
diff --git a/sgm/models/autoencoder.py b/sgm/models/autoencoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d4a3a061874ae30020f52873f25a8246b61efe1
--- /dev/null
+++ b/sgm/models/autoencoder.py
@@ -0,0 +1,619 @@
+import logging
+import math
+import re
+from abc import abstractmethod
+from contextlib import contextmanager
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import pytorch_lightning as pl
+import torch
+import torch.nn as nn
+from einops import rearrange
+from packaging import version
+
+from ..modules.autoencoding.regularizers import AbstractRegularizer
+from ..modules.ema import LitEma
+from ..util import (default, get_nested_attribute, get_obj_from_str,
+ instantiate_from_config)
+
+logpy = logging.getLogger(__name__)
+
+
+class AbstractAutoencoder(pl.LightningModule):
+ """
+ This is the base class for all autoencoders, including image autoencoders, image autoencoders with discriminators,
+ unCLIP models, etc. Hence, it is fairly general, and specific features
+ (e.g. discriminator training, encoding, decoding) must be implemented in subclasses.
+ """
+
+ def __init__(
+ self,
+ ema_decay: Union[None, float] = None,
+ monitor: Union[None, str] = None,
+ input_key: str = "jpg",
+ ):
+ super().__init__()
+
+ self.input_key = input_key
+ self.use_ema = ema_decay is not None
+ if monitor is not None:
+ self.monitor = monitor
+
+ if self.use_ema:
+ self.model_ema = LitEma(self, decay=ema_decay)
+ logpy.info(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}.")
+
+ if version.parse(torch.__version__) >= version.parse("2.0.0"):
+ self.automatic_optimization = False
+
+ def apply_ckpt(self, ckpt: Union[None, str, dict]):
+ if ckpt is None:
+ return
+ if isinstance(ckpt, str):
+ ckpt = {
+ "target": "sgm.modules.checkpoint.CheckpointEngine",
+ "params": {"ckpt_path": ckpt},
+ }
+ engine = instantiate_from_config(ckpt)
+ engine(self)
+
+ @abstractmethod
+ def get_input(self, batch) -> Any:
+ raise NotImplementedError()
+
+ def on_train_batch_end(self, *args, **kwargs):
+ # for EMA computation
+ if self.use_ema:
+ self.model_ema(self)
+
+ @contextmanager
+ def ema_scope(self, context=None):
+ if self.use_ema:
+ self.model_ema.store(self.parameters())
+ self.model_ema.copy_to(self)
+ if context is not None:
+ logpy.info(f"{context}: Switched to EMA weights")
+ try:
+ yield None
+ finally:
+ if self.use_ema:
+ self.model_ema.restore(self.parameters())
+ if context is not None:
+ logpy.info(f"{context}: Restored training weights")
+
+ @abstractmethod
+ def encode(self, *args, **kwargs) -> torch.Tensor:
+ raise NotImplementedError("encode()-method of abstract base class called")
+
+ @abstractmethod
+ def decode(self, *args, **kwargs) -> torch.Tensor:
+ raise NotImplementedError("decode()-method of abstract base class called")
+
+ def instantiate_optimizer_from_config(self, params, lr, cfg):
+ logpy.info(f"loading >>> {cfg['target']} <<< optimizer from config")
+ return get_obj_from_str(cfg["target"])(
+ params, lr=lr, **cfg.get("params", dict())
+ )
+
+ def configure_optimizers(self) -> Any:
+ raise NotImplementedError()
+
+
+class AutoencodingEngine(AbstractAutoencoder):
+ """
+ Base class for all image autoencoders that we train, like VQGAN or AutoencoderKL
+ (we also restore them explicitly as special cases for legacy reasons).
+ Regularizations such as KL or VQ are moved to the regularizer class.
+ """
+
+ def __init__(
+ self,
+ *args,
+ encoder_config: Dict,
+ decoder_config: Dict,
+ loss_config: Dict,
+ regularizer_config: Dict,
+ optimizer_config: Union[Dict, None] = None,
+ lr_g_factor: float = 1.0,
+ trainable_ae_params: Optional[List[List[str]]] = None,
+ ae_optimizer_args: Optional[List[dict]] = None,
+ trainable_disc_params: Optional[List[List[str]]] = None,
+ disc_optimizer_args: Optional[List[dict]] = None,
+ disc_start_iter: int = 0,
+ diff_boost_factor: float = 3.0,
+ ckpt_engine: Union[None, str, dict] = None,
+ ckpt_path: Optional[str] = None,
+ additional_decode_keys: Optional[List[str]] = None,
+ **kwargs,
+ ):
+ super().__init__(*args, **kwargs)
+ self.automatic_optimization = False # pytorch lightning
+
+ self.encoder: torch.nn.Module = instantiate_from_config(encoder_config)
+ self.decoder: torch.nn.Module = instantiate_from_config(decoder_config)
+ self.loss: torch.nn.Module = instantiate_from_config(loss_config)
+ self.regularization: AbstractRegularizer = instantiate_from_config(
+ regularizer_config
+ )
+ self.optimizer_config = default(
+ optimizer_config, {"target": "torch.optim.Adam"}
+ )
+ self.diff_boost_factor = diff_boost_factor
+ self.disc_start_iter = disc_start_iter
+ self.lr_g_factor = lr_g_factor
+ self.trainable_ae_params = trainable_ae_params
+ if self.trainable_ae_params is not None:
+ self.ae_optimizer_args = default(
+ ae_optimizer_args,
+ [{} for _ in range(len(self.trainable_ae_params))],
+ )
+ assert len(self.ae_optimizer_args) == len(self.trainable_ae_params)
+ else:
+ self.ae_optimizer_args = [{}] # makes type consitent
+
+ self.trainable_disc_params = trainable_disc_params
+ if self.trainable_disc_params is not None:
+ self.disc_optimizer_args = default(
+ disc_optimizer_args,
+ [{} for _ in range(len(self.trainable_disc_params))],
+ )
+ assert len(self.disc_optimizer_args) == len(self.trainable_disc_params)
+ else:
+ self.disc_optimizer_args = [{}] # makes type consitent
+
+ if ckpt_path is not None:
+ assert ckpt_engine is None, "Can't set ckpt_engine and ckpt_path"
+ logpy.warn("Checkpoint path is deprecated, use `checkpoint_egnine` instead")
+ self.apply_ckpt(default(ckpt_path, ckpt_engine))
+ self.additional_decode_keys = set(default(additional_decode_keys, []))
+
+ def get_input(self, batch: Dict) -> torch.Tensor:
+ # assuming unified data format, dataloader returns a dict.
+ # image tensors should be scaled to -1 ... 1 and in channels-first
+ # format (e.g., bchw instead if bhwc)
+ return batch[self.input_key]
+
+ def get_autoencoder_params(self) -> list:
+ params = []
+ if hasattr(self.loss, "get_trainable_autoencoder_parameters"):
+ params += list(self.loss.get_trainable_autoencoder_parameters())
+ if hasattr(self.regularization, "get_trainable_parameters"):
+ params += list(self.regularization.get_trainable_parameters())
+ params = params + list(self.encoder.parameters())
+ params = params + list(self.decoder.parameters())
+ return params
+
+ def get_discriminator_params(self) -> list:
+ if hasattr(self.loss, "get_trainable_parameters"):
+ params = list(self.loss.get_trainable_parameters()) # e.g., discriminator
+ else:
+ params = []
+ return params
+
+ def get_last_layer(self):
+ return self.decoder.get_last_layer()
+
+ def encode(
+ self,
+ x: torch.Tensor,
+ return_reg_log: bool = False,
+ unregularized: bool = False,
+ ) -> Union[torch.Tensor, Tuple[torch.Tensor, dict]]:
+ z = self.encoder(x)
+ if unregularized:
+ return z, dict()
+ z, reg_log = self.regularization(z)
+ if return_reg_log:
+ return z, reg_log
+ return z
+
+ def decode(self, z: torch.Tensor, **kwargs) -> torch.Tensor:
+ x = self.decoder(z, **kwargs)
+ return x
+
+ def forward(
+ self, x: torch.Tensor, **additional_decode_kwargs
+ ) -> Tuple[torch.Tensor, torch.Tensor, dict]:
+ z, reg_log = self.encode(x, return_reg_log=True)
+ dec = self.decode(z, **additional_decode_kwargs)
+ return z, dec, reg_log
+
+ def inner_training_step(
+ self, batch: dict, batch_idx: int, optimizer_idx: int = 0
+ ) -> torch.Tensor:
+ x = self.get_input(batch)
+ additional_decode_kwargs = {
+ key: batch[key] for key in self.additional_decode_keys.intersection(batch)
+ }
+ z, xrec, regularization_log = self(x, **additional_decode_kwargs)
+ if hasattr(self.loss, "forward_keys"):
+ extra_info = {
+ "z": z,
+ "optimizer_idx": optimizer_idx,
+ "global_step": self.global_step,
+ "last_layer": self.get_last_layer(),
+ "split": "train",
+ "regularization_log": regularization_log,
+ "autoencoder": self,
+ }
+ extra_info = {k: extra_info[k] for k in self.loss.forward_keys}
+ else:
+ extra_info = dict()
+
+ if optimizer_idx == 0:
+ # autoencode
+ out_loss = self.loss(x, xrec, **extra_info)
+ if isinstance(out_loss, tuple):
+ aeloss, log_dict_ae = out_loss
+ else:
+ # simple loss function
+ aeloss = out_loss
+ log_dict_ae = {"train/loss/rec": aeloss.detach()}
+
+ self.log_dict(
+ log_dict_ae,
+ prog_bar=False,
+ logger=True,
+ on_step=True,
+ on_epoch=True,
+ sync_dist=False,
+ )
+ self.log(
+ "loss",
+ aeloss.mean().detach(),
+ prog_bar=True,
+ logger=False,
+ on_epoch=False,
+ on_step=True,
+ )
+ return aeloss
+ elif optimizer_idx == 1:
+ # discriminator
+ discloss, log_dict_disc = self.loss(x, xrec, **extra_info)
+ # -> discriminator always needs to return a tuple
+ self.log_dict(
+ log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=True
+ )
+ return discloss
+ else:
+ raise NotImplementedError(f"Unknown optimizer {optimizer_idx}")
+
+ def training_step(self, batch: dict, batch_idx: int):
+ opts = self.optimizers()
+ if not isinstance(opts, list):
+ # Non-adversarial case
+ opts = [opts]
+ optimizer_idx = batch_idx % len(opts)
+ if self.global_step < self.disc_start_iter:
+ optimizer_idx = 0
+ opt = opts[optimizer_idx]
+ opt.zero_grad()
+ with opt.toggle_model():
+ loss = self.inner_training_step(
+ batch, batch_idx, optimizer_idx=optimizer_idx
+ )
+ self.manual_backward(loss)
+ opt.step()
+
+ def validation_step(self, batch: dict, batch_idx: int) -> Dict:
+ log_dict = self._validation_step(batch, batch_idx)
+ with self.ema_scope():
+ log_dict_ema = self._validation_step(batch, batch_idx, postfix="_ema")
+ log_dict.update(log_dict_ema)
+ return log_dict
+
+ def _validation_step(self, batch: dict, batch_idx: int, postfix: str = "") -> Dict:
+ x = self.get_input(batch)
+
+ z, xrec, regularization_log = self(x)
+ if hasattr(self.loss, "forward_keys"):
+ extra_info = {
+ "z": z,
+ "optimizer_idx": 0,
+ "global_step": self.global_step,
+ "last_layer": self.get_last_layer(),
+ "split": "val" + postfix,
+ "regularization_log": regularization_log,
+ "autoencoder": self,
+ }
+ extra_info = {k: extra_info[k] for k in self.loss.forward_keys}
+ else:
+ extra_info = dict()
+ out_loss = self.loss(x, xrec, **extra_info)
+ if isinstance(out_loss, tuple):
+ aeloss, log_dict_ae = out_loss
+ else:
+ # simple loss function
+ aeloss = out_loss
+ log_dict_ae = {f"val{postfix}/loss/rec": aeloss.detach()}
+ full_log_dict = log_dict_ae
+
+ if "optimizer_idx" in extra_info:
+ extra_info["optimizer_idx"] = 1
+ discloss, log_dict_disc = self.loss(x, xrec, **extra_info)
+ full_log_dict.update(log_dict_disc)
+ self.log(
+ f"val{postfix}/loss/rec",
+ log_dict_ae[f"val{postfix}/loss/rec"],
+ sync_dist=True,
+ )
+ self.log_dict(full_log_dict, sync_dist=True)
+ return full_log_dict
+
+ def get_param_groups(
+ self, parameter_names: List[List[str]], optimizer_args: List[dict]
+ ) -> Tuple[List[Dict[str, Any]], int]:
+ groups = []
+ num_params = 0
+ for names, args in zip(parameter_names, optimizer_args):
+ params = []
+ for pattern_ in names:
+ pattern_params = []
+ pattern = re.compile(pattern_)
+ for p_name, param in self.named_parameters():
+ if re.match(pattern, p_name):
+ pattern_params.append(param)
+ num_params += param.numel()
+ if len(pattern_params) == 0:
+ logpy.warn(f"Did not find parameters for pattern {pattern_}")
+ params.extend(pattern_params)
+ groups.append({"params": params, **args})
+ return groups, num_params
+
+ def configure_optimizers(self) -> List[torch.optim.Optimizer]:
+ if self.trainable_ae_params is None:
+ ae_params = self.get_autoencoder_params()
+ else:
+ ae_params, num_ae_params = self.get_param_groups(
+ self.trainable_ae_params, self.ae_optimizer_args
+ )
+ logpy.info(f"Number of trainable autoencoder parameters: {num_ae_params:,}")
+ if self.trainable_disc_params is None:
+ disc_params = self.get_discriminator_params()
+ else:
+ disc_params, num_disc_params = self.get_param_groups(
+ self.trainable_disc_params, self.disc_optimizer_args
+ )
+ logpy.info(
+ f"Number of trainable discriminator parameters: {num_disc_params:,}"
+ )
+ opt_ae = self.instantiate_optimizer_from_config(
+ ae_params,
+ default(self.lr_g_factor, 1.0) * self.learning_rate,
+ self.optimizer_config,
+ )
+ opts = [opt_ae]
+ if len(disc_params) > 0:
+ opt_disc = self.instantiate_optimizer_from_config(
+ disc_params, self.learning_rate, self.optimizer_config
+ )
+ opts.append(opt_disc)
+
+ return opts
+
+ @torch.no_grad()
+ def log_images(
+ self, batch: dict, additional_log_kwargs: Optional[Dict] = None, **kwargs
+ ) -> dict:
+ log = dict()
+ additional_decode_kwargs = {}
+ x = self.get_input(batch)
+ additional_decode_kwargs.update(
+ {key: batch[key] for key in self.additional_decode_keys.intersection(batch)}
+ )
+
+ _, xrec, _ = self(x, **additional_decode_kwargs)
+ log["inputs"] = x
+ log["reconstructions"] = xrec
+ diff = 0.5 * torch.abs(torch.clamp(xrec, -1.0, 1.0) - x)
+ diff.clamp_(0, 1.0)
+ log["diff"] = 2.0 * diff - 1.0
+ # diff_boost shows location of small errors, by boosting their
+ # brightness.
+ log["diff_boost"] = (
+ 2.0 * torch.clamp(self.diff_boost_factor * diff, 0.0, 1.0) - 1
+ )
+ if hasattr(self.loss, "log_images"):
+ log.update(self.loss.log_images(x, xrec))
+ with self.ema_scope():
+ _, xrec_ema, _ = self(x, **additional_decode_kwargs)
+ log["reconstructions_ema"] = xrec_ema
+ diff_ema = 0.5 * torch.abs(torch.clamp(xrec_ema, -1.0, 1.0) - x)
+ diff_ema.clamp_(0, 1.0)
+ log["diff_ema"] = 2.0 * diff_ema - 1.0
+ log["diff_boost_ema"] = (
+ 2.0 * torch.clamp(self.diff_boost_factor * diff_ema, 0.0, 1.0) - 1
+ )
+ if additional_log_kwargs:
+ additional_decode_kwargs.update(additional_log_kwargs)
+ _, xrec_add, _ = self(x, **additional_decode_kwargs)
+ log_str = "reconstructions-" + "-".join(
+ [f"{key}={additional_log_kwargs[key]}" for key in additional_log_kwargs]
+ )
+ log[log_str] = xrec_add
+ return log
+
+
+class AutoencodingEngineLegacy(AutoencodingEngine):
+ def __init__(self, embed_dim: int, **kwargs):
+ self.max_batch_size = kwargs.pop("max_batch_size", None)
+ ddconfig = kwargs.pop("ddconfig")
+ ckpt_path = kwargs.pop("ckpt_path", None)
+ ckpt_engine = kwargs.pop("ckpt_engine", None)
+ super().__init__(
+ encoder_config={
+ "target": "sgm.modules.diffusionmodules.model.Encoder",
+ "params": ddconfig,
+ },
+ decoder_config={
+ "target": "sgm.modules.diffusionmodules.model.Decoder",
+ "params": ddconfig,
+ },
+ **kwargs,
+ )
+ self.quant_conv = torch.nn.Conv2d(
+ (1 + ddconfig["double_z"]) * ddconfig["z_channels"],
+ (1 + ddconfig["double_z"]) * embed_dim,
+ 1,
+ )
+ self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
+ self.embed_dim = embed_dim
+
+ self.apply_ckpt(default(ckpt_path, ckpt_engine))
+
+ def get_autoencoder_params(self) -> list:
+ params = super().get_autoencoder_params()
+ return params
+
+ def encode(
+ self, x: torch.Tensor, return_reg_log: bool = False
+ ) -> Union[torch.Tensor, Tuple[torch.Tensor, dict]]:
+ if self.max_batch_size is None:
+ z = self.encoder(x)
+ z = self.quant_conv(z)
+ else:
+ N = x.shape[0]
+ bs = self.max_batch_size
+ n_batches = int(math.ceil(N / bs))
+ z = list()
+ for i_batch in range(n_batches):
+ z_batch = self.encoder(x[i_batch * bs : (i_batch + 1) * bs])
+ z_batch = self.quant_conv(z_batch)
+ z.append(z_batch)
+ z = torch.cat(z, 0)
+
+ z, reg_log = self.regularization(z)
+ if return_reg_log:
+ return z, reg_log
+ return z
+
+ def decode(self, z: torch.Tensor, **decoder_kwargs) -> torch.Tensor:
+ if self.max_batch_size is None:
+ dec = self.post_quant_conv(z)
+ dec = self.decoder(dec, **decoder_kwargs)
+ else:
+ N = z.shape[0]
+ bs = self.max_batch_size
+ n_batches = int(math.ceil(N / bs))
+ dec = list()
+ for i_batch in range(n_batches):
+ dec_batch = self.post_quant_conv(z[i_batch * bs : (i_batch + 1) * bs])
+ dec_batch = self.decoder(dec_batch, **decoder_kwargs)
+ dec.append(dec_batch)
+ dec = torch.cat(dec, 0)
+
+ return dec
+
+
+class AutoencoderKL(AutoencodingEngineLegacy):
+ def __init__(self, **kwargs):
+ if "lossconfig" in kwargs:
+ kwargs["loss_config"] = kwargs.pop("lossconfig")
+ super().__init__(
+ regularizer_config={
+ "target": (
+ "sgm.modules.autoencoding.regularizers"
+ ".DiagonalGaussianRegularizer"
+ )
+ },
+ **kwargs,
+ )
+
+
+class AutoencoderLegacyVQ(AutoencodingEngineLegacy):
+ def __init__(
+ self,
+ embed_dim: int,
+ n_embed: int,
+ sane_index_shape: bool = False,
+ **kwargs,
+ ):
+ if "lossconfig" in kwargs:
+ logpy.warn(f"Parameter `lossconfig` is deprecated, use `loss_config`.")
+ kwargs["loss_config"] = kwargs.pop("lossconfig")
+ super().__init__(
+ regularizer_config={
+ "target": (
+ "sgm.modules.autoencoding.regularizers.quantize" ".VectorQuantizer"
+ ),
+ "params": {
+ "n_e": n_embed,
+ "e_dim": embed_dim,
+ "sane_index_shape": sane_index_shape,
+ },
+ },
+ **kwargs,
+ )
+
+
+class IdentityFirstStage(AbstractAutoencoder):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.encoder = lambda x: x
+ self.decoder = lambda x: x
+
+ def get_input(self, x: Any) -> Any:
+ return x
+
+ def encode(self, x: Any, *args, **kwargs) -> Any:
+ # return x
+ return self.encoder(x)
+
+ def decode(self, x: Any, *args, **kwargs) -> Any:
+ # return x
+ return self.decoder(x)
+
+
+class AEIntegerWrapper(nn.Module):
+ def __init__(
+ self,
+ model: nn.Module,
+ shape: Union[None, Tuple[int, int], List[int]] = (16, 16),
+ regularization_key: str = "regularization",
+ encoder_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ super().__init__()
+ self.model = model
+ assert hasattr(model, "encode") and hasattr(
+ model, "decode"
+ ), "Need AE interface"
+ self.regularization = get_nested_attribute(model, regularization_key)
+ self.shape = shape
+ self.encoder_kwargs = default(encoder_kwargs, {"return_reg_log": True})
+
+ def encode(self, x) -> torch.Tensor:
+ assert (
+ not self.training
+ ), f"{self.__class__.__name__} only supports inference currently"
+ _, log = self.model.encode(x, **self.encoder_kwargs)
+ assert isinstance(log, dict)
+ inds = log["min_encoding_indices"]
+ return rearrange(inds, "b ... -> b (...)")
+
+ def decode(
+ self, inds: torch.Tensor, shape: Union[None, tuple, list] = None
+ ) -> torch.Tensor:
+ # expect inds shape (b, s) with s = h*w
+ shape = default(shape, self.shape) # Optional[(h, w)]
+ if shape is not None:
+ assert len(shape) == 2, f"Unhandeled shape {shape}"
+ inds = rearrange(inds, "b (h w) -> b h w", h=shape[0], w=shape[1])
+ h = self.regularization.get_codebook_entry(inds) # (b, h, w, c)
+ h = rearrange(h, "b h w c -> b c h w")
+ return self.model.decode(h)
+
+
+class AutoencoderKLModeOnly(AutoencodingEngineLegacy):
+ def __init__(self, **kwargs):
+ if "lossconfig" in kwargs:
+ kwargs["loss_config"] = kwargs.pop("lossconfig")
+ super().__init__(
+ regularizer_config={
+ "target": (
+ "sgm.modules.autoencoding.regularizers"
+ ".DiagonalGaussianRegularizer"
+ ),
+ "params": {"sample": False},
+ },
+ **kwargs,
+ )
diff --git a/sgm/models/diffusion.py b/sgm/models/diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f3efd3c7e1e37bf4f78673ae72021f1f968e116
--- /dev/null
+++ b/sgm/models/diffusion.py
@@ -0,0 +1,341 @@
+import math
+from contextlib import contextmanager
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import pytorch_lightning as pl
+import torch
+from omegaconf import ListConfig, OmegaConf
+from safetensors.torch import load_file as load_safetensors
+from torch.optim.lr_scheduler import LambdaLR
+
+from ..modules import UNCONDITIONAL_CONFIG
+from ..modules.autoencoding.temporal_ae import VideoDecoder
+from ..modules.diffusionmodules.wrappers import OPENAIUNETWRAPPER
+from ..modules.ema import LitEma
+from ..util import (default, disabled_train, get_obj_from_str,
+ instantiate_from_config, log_txt_as_img)
+
+
+class DiffusionEngine(pl.LightningModule):
+ def __init__(
+ self,
+ network_config,
+ denoiser_config,
+ first_stage_config,
+ conditioner_config: Union[None, Dict, ListConfig, OmegaConf] = None,
+ sampler_config: Union[None, Dict, ListConfig, OmegaConf] = None,
+ optimizer_config: Union[None, Dict, ListConfig, OmegaConf] = None,
+ scheduler_config: Union[None, Dict, ListConfig, OmegaConf] = None,
+ loss_fn_config: Union[None, Dict, ListConfig, OmegaConf] = None,
+ network_wrapper: Union[None, str] = None,
+ ckpt_path: Union[None, str] = None,
+ use_ema: bool = False,
+ ema_decay_rate: float = 0.9999,
+ scale_factor: float = 1.0,
+ disable_first_stage_autocast=False,
+ input_key: str = "jpg",
+ log_keys: Union[List, None] = None,
+ no_cond_log: bool = False,
+ compile_model: bool = False,
+ en_and_decode_n_samples_a_time: Optional[int] = None,
+ ):
+ super().__init__()
+ self.log_keys = log_keys
+ self.input_key = input_key
+ self.optimizer_config = default(
+ optimizer_config, {"target": "torch.optim.AdamW"}
+ )
+ model = instantiate_from_config(network_config)
+ self.model = get_obj_from_str(default(network_wrapper, OPENAIUNETWRAPPER))(
+ model, compile_model=compile_model
+ )
+
+ self.denoiser = instantiate_from_config(denoiser_config)
+ self.sampler = (
+ instantiate_from_config(sampler_config)
+ if sampler_config is not None
+ else None
+ )
+ self.conditioner = instantiate_from_config(
+ default(conditioner_config, UNCONDITIONAL_CONFIG)
+ )
+ self.scheduler_config = scheduler_config
+ self._init_first_stage(first_stage_config)
+
+ self.loss_fn = (
+ instantiate_from_config(loss_fn_config)
+ if loss_fn_config is not None
+ else None
+ )
+
+ self.use_ema = use_ema
+ if self.use_ema:
+ self.model_ema = LitEma(self.model, decay=ema_decay_rate)
+ print(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}.")
+
+ self.scale_factor = scale_factor
+ self.disable_first_stage_autocast = disable_first_stage_autocast
+ self.no_cond_log = no_cond_log
+
+ if ckpt_path is not None:
+ self.init_from_ckpt(ckpt_path)
+
+ self.en_and_decode_n_samples_a_time = en_and_decode_n_samples_a_time
+
+ def init_from_ckpt(
+ self,
+ path: str,
+ ) -> None:
+ if path.endswith("ckpt"):
+ sd = torch.load(path, map_location="cpu")["state_dict"]
+ elif path.endswith("safetensors"):
+ sd = load_safetensors(path)
+ else:
+ raise NotImplementedError
+
+ missing, unexpected = self.load_state_dict(sd, strict=False)
+ print(
+ f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys"
+ )
+ if len(missing) > 0:
+ print(f"Missing Keys: {missing}")
+ if len(unexpected) > 0:
+ print(f"Unexpected Keys: {unexpected}")
+
+ def _init_first_stage(self, config):
+ model = instantiate_from_config(config).eval()
+ model.train = disabled_train
+ for param in model.parameters():
+ param.requires_grad = False
+ self.first_stage_model = model
+
+ def get_input(self, batch):
+ # assuming unified data format, dataloader returns a dict.
+ # image tensors should be scaled to -1 ... 1 and in bchw format
+ return batch[self.input_key]
+
+ @torch.no_grad()
+ def decode_first_stage(self, z):
+ z = 1.0 / self.scale_factor * z
+ n_samples = default(self.en_and_decode_n_samples_a_time, z.shape[0])
+
+ n_rounds = math.ceil(z.shape[0] / n_samples)
+ all_out = []
+ with torch.autocast("cuda", enabled=not self.disable_first_stage_autocast):
+ for n in range(n_rounds):
+ if isinstance(self.first_stage_model.decoder, VideoDecoder):
+ kwargs = {"timesteps": len(z[n * n_samples : (n + 1) * n_samples])}
+ else:
+ kwargs = {}
+ out = self.first_stage_model.decode(
+ z[n * n_samples : (n + 1) * n_samples], **kwargs
+ )
+ all_out.append(out)
+ out = torch.cat(all_out, dim=0)
+ return out
+
+ @torch.no_grad()
+ def encode_first_stage(self, x):
+ n_samples = default(self.en_and_decode_n_samples_a_time, x.shape[0])
+ n_rounds = math.ceil(x.shape[0] / n_samples)
+ all_out = []
+ with torch.autocast("cuda", enabled=not self.disable_first_stage_autocast):
+ for n in range(n_rounds):
+ out = self.first_stage_model.encode(
+ x[n * n_samples : (n + 1) * n_samples]
+ )
+ all_out.append(out)
+ z = torch.cat(all_out, dim=0)
+ z = self.scale_factor * z
+ return z
+
+ def forward(self, x, batch):
+ loss = self.loss_fn(self.model, self.denoiser, self.conditioner, x, batch)
+ loss_mean = loss.mean()
+ loss_dict = {"loss": loss_mean}
+ return loss_mean, loss_dict
+
+ def shared_step(self, batch: Dict) -> Any:
+ x = self.get_input(batch)
+ x = self.encode_first_stage(x)
+ batch["global_step"] = self.global_step
+ loss, loss_dict = self(x, batch)
+ return loss, loss_dict
+
+ def training_step(self, batch, batch_idx):
+ loss, loss_dict = self.shared_step(batch)
+
+ self.log_dict(
+ loss_dict, prog_bar=True, logger=True, on_step=True, on_epoch=False
+ )
+
+ self.log(
+ "global_step",
+ self.global_step,
+ prog_bar=True,
+ logger=True,
+ on_step=True,
+ on_epoch=False,
+ )
+
+ if self.scheduler_config is not None:
+ lr = self.optimizers().param_groups[0]["lr"]
+ self.log(
+ "lr_abs", lr, prog_bar=True, logger=True, on_step=True, on_epoch=False
+ )
+
+ return loss
+
+ def on_train_start(self, *args, **kwargs):
+ if self.sampler is None or self.loss_fn is None:
+ raise ValueError("Sampler and loss function need to be set for training.")
+
+ def on_train_batch_end(self, *args, **kwargs):
+ if self.use_ema:
+ self.model_ema(self.model)
+
+ @contextmanager
+ def ema_scope(self, context=None):
+ if self.use_ema:
+ self.model_ema.store(self.model.parameters())
+ self.model_ema.copy_to(self.model)
+ if context is not None:
+ print(f"{context}: Switched to EMA weights")
+ try:
+ yield None
+ finally:
+ if self.use_ema:
+ self.model_ema.restore(self.model.parameters())
+ if context is not None:
+ print(f"{context}: Restored training weights")
+
+ def instantiate_optimizer_from_config(self, params, lr, cfg):
+ return get_obj_from_str(cfg["target"])(
+ params, lr=lr, **cfg.get("params", dict())
+ )
+
+ def configure_optimizers(self):
+ lr = self.learning_rate
+ params = list(self.model.parameters())
+ for embedder in self.conditioner.embedders:
+ if embedder.is_trainable:
+ params = params + list(embedder.parameters())
+ opt = self.instantiate_optimizer_from_config(params, lr, self.optimizer_config)
+ if self.scheduler_config is not None:
+ scheduler = instantiate_from_config(self.scheduler_config)
+ print("Setting up LambdaLR scheduler...")
+ scheduler = [
+ {
+ "scheduler": LambdaLR(opt, lr_lambda=scheduler.schedule),
+ "interval": "step",
+ "frequency": 1,
+ }
+ ]
+ return [opt], scheduler
+ return opt
+
+ @torch.no_grad()
+ def sample(
+ self,
+ cond: Dict,
+ uc: Union[Dict, None] = None,
+ batch_size: int = 16,
+ shape: Union[None, Tuple, List] = None,
+ **kwargs,
+ ):
+ randn = torch.randn(batch_size, *shape).to(self.device)
+
+ denoiser = lambda input, sigma, c: self.denoiser(
+ self.model, input, sigma, c, **kwargs
+ )
+ samples = self.sampler(denoiser, randn, cond, uc=uc)
+ return samples
+
+ @torch.no_grad()
+ def log_conditionings(self, batch: Dict, n: int) -> Dict:
+ """
+ Defines heuristics to log different conditionings.
+ These can be lists of strings (text-to-image), tensors, ints, ...
+ """
+ image_h, image_w = batch[self.input_key].shape[2:]
+ log = dict()
+
+ for embedder in self.conditioner.embedders:
+ if (
+ (self.log_keys is None) or (embedder.input_key in self.log_keys)
+ ) and not self.no_cond_log:
+ x = batch[embedder.input_key][:n]
+ if isinstance(x, torch.Tensor):
+ if x.dim() == 1:
+ # class-conditional, convert integer to string
+ x = [str(x[i].item()) for i in range(x.shape[0])]
+ xc = log_txt_as_img((image_h, image_w), x, size=image_h // 4)
+ elif x.dim() == 2:
+ # size and crop cond and the like
+ x = [
+ "x".join([str(xx) for xx in x[i].tolist()])
+ for i in range(x.shape[0])
+ ]
+ xc = log_txt_as_img((image_h, image_w), x, size=image_h // 20)
+ else:
+ raise NotImplementedError()
+ elif isinstance(x, (List, ListConfig)):
+ if isinstance(x[0], str):
+ # strings
+ xc = log_txt_as_img((image_h, image_w), x, size=image_h // 20)
+ else:
+ raise NotImplementedError()
+ else:
+ raise NotImplementedError()
+ log[embedder.input_key] = xc
+ return log
+
+ @torch.no_grad()
+ def log_images(
+ self,
+ batch: Dict,
+ N: int = 8,
+ sample: bool = True,
+ ucg_keys: List[str] = None,
+ **kwargs,
+ ) -> Dict:
+ conditioner_input_keys = [e.input_key for e in self.conditioner.embedders]
+ if ucg_keys:
+ assert all(map(lambda x: x in conditioner_input_keys, ucg_keys)), (
+ "Each defined ucg key for sampling must be in the provided conditioner input keys,"
+ f"but we have {ucg_keys} vs. {conditioner_input_keys}"
+ )
+ else:
+ ucg_keys = conditioner_input_keys
+ log = dict()
+
+ x = self.get_input(batch)
+
+ c, uc = self.conditioner.get_unconditional_conditioning(
+ batch,
+ force_uc_zero_embeddings=ucg_keys
+ if len(self.conditioner.embedders) > 0
+ else [],
+ )
+
+ sampling_kwargs = {}
+
+ N = min(x.shape[0], N)
+ x = x.to(self.device)[:N]
+ log["inputs"] = x
+ z = self.encode_first_stage(x)
+ log["reconstructions"] = self.decode_first_stage(z)
+ log.update(self.log_conditionings(batch, N))
+
+ for k in c:
+ if isinstance(c[k], torch.Tensor):
+ c[k], uc[k] = map(lambda y: y[k][:N].to(self.device), (c, uc))
+
+ if sample:
+ with self.ema_scope("Plotting"):
+ samples = self.sample(
+ c, shape=z.shape[1:], uc=uc, batch_size=N, **sampling_kwargs
+ )
+ samples = self.decode_first_stage(samples)
+ log["samples"] = samples
+ return log
diff --git a/sgm/modules/__init__.py b/sgm/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0db1d7716a6e48f77b86a4b59c9289d6fb76b50b
--- /dev/null
+++ b/sgm/modules/__init__.py
@@ -0,0 +1,6 @@
+from .encoders.modules import GeneralConditioner
+
+UNCONDITIONAL_CONFIG = {
+ "target": "sgm.modules.GeneralConditioner",
+ "params": {"emb_models": []},
+}
diff --git a/sgm/modules/attention.py b/sgm/modules/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..52a50b7bd744bea0f0cdca23b0cfd14ad87794be
--- /dev/null
+++ b/sgm/modules/attention.py
@@ -0,0 +1,759 @@
+import logging
+import math
+from inspect import isfunction
+from typing import Any, Optional
+
+import torch
+import torch.nn.functional as F
+from einops import rearrange, repeat
+from packaging import version
+from torch import nn
+from torch.utils.checkpoint import checkpoint
+
+logpy = logging.getLogger(__name__)
+
+if version.parse(torch.__version__) >= version.parse("2.0.0"):
+ SDP_IS_AVAILABLE = True
+ from torch.backends.cuda import SDPBackend, sdp_kernel
+
+ BACKEND_MAP = {
+ SDPBackend.MATH: {
+ "enable_math": True,
+ "enable_flash": False,
+ "enable_mem_efficient": False,
+ },
+ SDPBackend.FLASH_ATTENTION: {
+ "enable_math": False,
+ "enable_flash": True,
+ "enable_mem_efficient": False,
+ },
+ SDPBackend.EFFICIENT_ATTENTION: {
+ "enable_math": False,
+ "enable_flash": False,
+ "enable_mem_efficient": True,
+ },
+ None: {"enable_math": True, "enable_flash": True, "enable_mem_efficient": True},
+ }
+else:
+ from contextlib import nullcontext
+
+ SDP_IS_AVAILABLE = False
+ sdp_kernel = nullcontext
+ BACKEND_MAP = {}
+ logpy.warn(
+ f"No SDP backend available, likely because you are running in pytorch "
+ f"versions < 2.0. In fact, you are using PyTorch {torch.__version__}. "
+ f"You might want to consider upgrading."
+ )
+
+try:
+ import xformers
+ import xformers.ops
+
+ XFORMERS_IS_AVAILABLE = True
+except:
+ XFORMERS_IS_AVAILABLE = False
+ logpy.warn("no module 'xformers'. Processing without...")
+
+# from .diffusionmodules.util import mixed_checkpoint as checkpoint
+
+
+def exists(val):
+ return val is not None
+
+
+def uniq(arr):
+ return {el: True for el in arr}.keys()
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if isfunction(d) else d
+
+
+def max_neg_value(t):
+ return -torch.finfo(t.dtype).max
+
+
+def init_(tensor):
+ dim = tensor.shape[-1]
+ std = 1 / math.sqrt(dim)
+ tensor.uniform_(-std, std)
+ return tensor
+
+
+# feedforward
+class GEGLU(nn.Module):
+ def __init__(self, dim_in, dim_out):
+ super().__init__()
+ self.proj = nn.Linear(dim_in, dim_out * 2)
+
+ def forward(self, x):
+ x, gate = self.proj(x).chunk(2, dim=-1)
+ return x * F.gelu(gate)
+
+
+class FeedForward(nn.Module):
+ def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.0):
+ super().__init__()
+ inner_dim = int(dim * mult)
+ dim_out = default(dim_out, dim)
+ project_in = (
+ nn.Sequential(nn.Linear(dim, inner_dim), nn.GELU())
+ if not glu
+ else GEGLU(dim, inner_dim)
+ )
+
+ self.net = nn.Sequential(
+ project_in, nn.Dropout(dropout), nn.Linear(inner_dim, dim_out)
+ )
+
+ def forward(self, x):
+ return self.net(x)
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def Normalize(in_channels):
+ return torch.nn.GroupNorm(
+ num_groups=32, num_channels=in_channels, eps=1e-6, affine=True
+ )
+
+
+class LinearAttention(nn.Module):
+ def __init__(self, dim, heads=4, dim_head=32):
+ super().__init__()
+ self.heads = heads
+ hidden_dim = dim_head * heads
+ self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
+ self.to_out = nn.Conv2d(hidden_dim, dim, 1)
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+ qkv = self.to_qkv(x)
+ q, k, v = rearrange(
+ qkv, "b (qkv heads c) h w -> qkv b heads c (h w)", heads=self.heads, qkv=3
+ )
+ k = k.softmax(dim=-1)
+ context = torch.einsum("bhdn,bhen->bhde", k, v)
+ out = torch.einsum("bhde,bhdn->bhen", context, q)
+ out = rearrange(
+ out, "b heads c (h w) -> b (heads c) h w", heads=self.heads, h=h, w=w
+ )
+ return self.to_out(out)
+
+
+class SelfAttention(nn.Module):
+ ATTENTION_MODES = ("xformers", "torch", "math")
+
+ def __init__(
+ self,
+ dim: int,
+ num_heads: int = 8,
+ qkv_bias: bool = False,
+ qk_scale: Optional[float] = None,
+ attn_drop: float = 0.0,
+ proj_drop: float = 0.0,
+ attn_mode: str = "xformers",
+ ):
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+ assert attn_mode in self.ATTENTION_MODES
+ self.attn_mode = attn_mode
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ B, L, C = x.shape
+
+ qkv = self.qkv(x)
+ if self.attn_mode == "torch":
+ qkv = rearrange(
+ qkv, "B L (K H D) -> K B H L D", K=3, H=self.num_heads
+ ).float()
+ q, k, v = qkv[0], qkv[1], qkv[2] # B H L D
+ x = torch.nn.functional.scaled_dot_product_attention(q, k, v)
+ x = rearrange(x, "B H L D -> B L (H D)")
+ elif self.attn_mode == "xformers":
+ qkv = rearrange(qkv, "B L (K H D) -> K B L H D", K=3, H=self.num_heads)
+ q, k, v = qkv[0], qkv[1], qkv[2] # B L H D
+ x = xformers.ops.memory_efficient_attention(q, k, v)
+ x = rearrange(x, "B L H D -> B L (H D)", H=self.num_heads)
+ elif self.attn_mode == "math":
+ qkv = rearrange(qkv, "B L (K H D) -> K B H L D", K=3, H=self.num_heads)
+ q, k, v = qkv[0], qkv[1], qkv[2] # B H L D
+ attn = (q @ k.transpose(-2, -1)) * self.scale
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+ x = (attn @ v).transpose(1, 2).reshape(B, L, C)
+ else:
+ raise NotImplemented
+
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class SpatialSelfAttention(nn.Module):
+ def __init__(self, in_channels):
+ super().__init__()
+ self.in_channels = in_channels
+
+ self.norm = Normalize(in_channels)
+ self.q = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.k = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.v = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.proj_out = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+
+ def forward(self, x):
+ h_ = x
+ h_ = self.norm(h_)
+ q = self.q(h_)
+ k = self.k(h_)
+ v = self.v(h_)
+
+ # compute attention
+ b, c, h, w = q.shape
+ q = rearrange(q, "b c h w -> b (h w) c")
+ k = rearrange(k, "b c h w -> b c (h w)")
+ w_ = torch.einsum("bij,bjk->bik", q, k)
+
+ w_ = w_ * (int(c) ** (-0.5))
+ w_ = torch.nn.functional.softmax(w_, dim=2)
+
+ # attend to values
+ v = rearrange(v, "b c h w -> b c (h w)")
+ w_ = rearrange(w_, "b i j -> b j i")
+ h_ = torch.einsum("bij,bjk->bik", v, w_)
+ h_ = rearrange(h_, "b c (h w) -> b c h w", h=h)
+ h_ = self.proj_out(h_)
+
+ return x + h_
+
+
+class CrossAttention(nn.Module):
+ def __init__(
+ self,
+ query_dim,
+ context_dim=None,
+ heads=8,
+ dim_head=64,
+ dropout=0.0,
+ backend=None,
+ ):
+ super().__init__()
+ inner_dim = dim_head * heads
+ context_dim = default(context_dim, query_dim)
+
+ self.scale = dim_head**-0.5
+ self.heads = heads
+
+ self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
+ self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
+ self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
+
+ self.to_out = nn.Sequential(
+ nn.Linear(inner_dim, query_dim), nn.Dropout(dropout)
+ )
+ self.backend = backend
+
+ def forward(
+ self,
+ x,
+ context=None,
+ mask=None,
+ additional_tokens=None,
+ n_times_crossframe_attn_in_self=0,
+ ):
+ h = self.heads
+
+ if additional_tokens is not None:
+ # get the number of masked tokens at the beginning of the output sequence
+ n_tokens_to_mask = additional_tokens.shape[1]
+ # add additional token
+ x = torch.cat([additional_tokens, x], dim=1)
+
+ q = self.to_q(x)
+ context = default(context, x)
+ k = self.to_k(context)
+ v = self.to_v(context)
+
+ if n_times_crossframe_attn_in_self:
+ # reprogramming cross-frame attention as in https://arxiv.org/abs/2303.13439
+ assert x.shape[0] % n_times_crossframe_attn_in_self == 0
+ n_cp = x.shape[0] // n_times_crossframe_attn_in_self
+ k = repeat(
+ k[::n_times_crossframe_attn_in_self], "b ... -> (b n) ...", n=n_cp
+ )
+ v = repeat(
+ v[::n_times_crossframe_attn_in_self], "b ... -> (b n) ...", n=n_cp
+ )
+
+ q, k, v = map(lambda t: rearrange(t, "b n (h d) -> b h n d", h=h), (q, k, v))
+
+ ## old
+ """
+ sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
+ del q, k
+
+ if exists(mask):
+ mask = rearrange(mask, 'b ... -> b (...)')
+ max_neg_value = -torch.finfo(sim.dtype).max
+ mask = repeat(mask, 'b j -> (b h) () j', h=h)
+ sim.masked_fill_(~mask, max_neg_value)
+
+ # attention, what we cannot get enough of
+ sim = sim.softmax(dim=-1)
+
+ out = einsum('b i j, b j d -> b i d', sim, v)
+ """
+ ## new
+ with sdp_kernel(**BACKEND_MAP[self.backend]):
+ # print("dispatching into backend", self.backend, "q/k/v shape: ", q.shape, k.shape, v.shape)
+ out = F.scaled_dot_product_attention(
+ q, k, v, attn_mask=mask
+ ) # scale is dim_head ** -0.5 per default
+
+ del q, k, v
+ out = rearrange(out, "b h n d -> b n (h d)", h=h)
+
+ if additional_tokens is not None:
+ # remove additional token
+ out = out[:, n_tokens_to_mask:]
+ return self.to_out(out)
+
+
+class MemoryEfficientCrossAttention(nn.Module):
+ # https://github.com/MatthieuTPHR/diffusers/blob/d80b531ff8060ec1ea982b65a1b8df70f73aa67c/src/diffusers/models/attention.py#L223
+ def __init__(
+ self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0, **kwargs
+ ):
+ super().__init__()
+ logpy.debug(
+ f"Setting up {self.__class__.__name__}. Query dim is {query_dim}, "
+ f"context_dim is {context_dim} and using {heads} heads with a "
+ f"dimension of {dim_head}."
+ )
+ inner_dim = dim_head * heads
+ context_dim = default(context_dim, query_dim)
+
+ self.heads = heads
+ self.dim_head = dim_head
+
+ self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
+ self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
+ self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
+
+ self.to_out = nn.Sequential(
+ nn.Linear(inner_dim, query_dim), nn.Dropout(dropout)
+ )
+ self.attention_op: Optional[Any] = None
+
+ def forward(
+ self,
+ x,
+ context=None,
+ mask=None,
+ additional_tokens=None,
+ n_times_crossframe_attn_in_self=0,
+ ):
+ if additional_tokens is not None:
+ # get the number of masked tokens at the beginning of the output sequence
+ n_tokens_to_mask = additional_tokens.shape[1]
+ # add additional token
+ x = torch.cat([additional_tokens, x], dim=1)
+ q = self.to_q(x)
+ context = default(context, x)
+ k = self.to_k(context)
+ v = self.to_v(context)
+
+ if n_times_crossframe_attn_in_self:
+ # reprogramming cross-frame attention as in https://arxiv.org/abs/2303.13439
+ assert x.shape[0] % n_times_crossframe_attn_in_self == 0
+ # n_cp = x.shape[0]//n_times_crossframe_attn_in_self
+ k = repeat(
+ k[::n_times_crossframe_attn_in_self],
+ "b ... -> (b n) ...",
+ n=n_times_crossframe_attn_in_self,
+ )
+ v = repeat(
+ v[::n_times_crossframe_attn_in_self],
+ "b ... -> (b n) ...",
+ n=n_times_crossframe_attn_in_self,
+ )
+
+ b, _, _ = q.shape
+ q, k, v = map(
+ lambda t: t.unsqueeze(3)
+ .reshape(b, t.shape[1], self.heads, self.dim_head)
+ .permute(0, 2, 1, 3)
+ .reshape(b * self.heads, t.shape[1], self.dim_head)
+ .contiguous(),
+ (q, k, v),
+ )
+
+ # actually compute the attention, what we cannot get enough of
+ if version.parse(xformers.__version__) >= version.parse("0.0.21"):
+ # NOTE: workaround for
+ # https://github.com/facebookresearch/xformers/issues/845
+ max_bs = 32768
+ N = q.shape[0]
+ n_batches = math.ceil(N / max_bs)
+ out = list()
+ for i_batch in range(n_batches):
+ batch = slice(i_batch * max_bs, (i_batch + 1) * max_bs)
+ out.append(
+ xformers.ops.memory_efficient_attention(
+ q[batch],
+ k[batch],
+ v[batch],
+ attn_bias=None,
+ op=self.attention_op,
+ )
+ )
+ out = torch.cat(out, 0)
+ else:
+ out = xformers.ops.memory_efficient_attention(
+ q, k, v, attn_bias=None, op=self.attention_op
+ )
+
+ # TODO: Use this directly in the attention operation, as a bias
+ if exists(mask):
+ raise NotImplementedError
+ out = (
+ out.unsqueeze(0)
+ .reshape(b, self.heads, out.shape[1], self.dim_head)
+ .permute(0, 2, 1, 3)
+ .reshape(b, out.shape[1], self.heads * self.dim_head)
+ )
+ if additional_tokens is not None:
+ # remove additional token
+ out = out[:, n_tokens_to_mask:]
+ return self.to_out(out)
+
+
+class BasicTransformerBlock(nn.Module):
+ ATTENTION_MODES = {
+ "softmax": CrossAttention, # vanilla attention
+ "softmax-xformers": MemoryEfficientCrossAttention, # ampere
+ }
+
+ def __init__(
+ self,
+ dim,
+ n_heads,
+ d_head,
+ dropout=0.0,
+ context_dim=None,
+ gated_ff=True,
+ checkpoint=True,
+ disable_self_attn=False,
+ attn_mode="softmax",
+ sdp_backend=None,
+ ):
+ super().__init__()
+ assert attn_mode in self.ATTENTION_MODES
+ if attn_mode != "softmax" and not XFORMERS_IS_AVAILABLE:
+ logpy.warn(
+ f"Attention mode '{attn_mode}' is not available. Falling "
+ f"back to native attention. This is not a problem in "
+ f"Pytorch >= 2.0. FYI, you are running with PyTorch "
+ f"version {torch.__version__}."
+ )
+ attn_mode = "softmax"
+ elif attn_mode == "softmax" and not SDP_IS_AVAILABLE:
+ logpy.warn(
+ "We do not support vanilla attention anymore, as it is too "
+ "expensive. Sorry."
+ )
+ if not XFORMERS_IS_AVAILABLE:
+ assert (
+ False
+ ), "Please install xformers via e.g. 'pip install xformers==0.0.16'"
+ else:
+ logpy.info("Falling back to xformers efficient attention.")
+ attn_mode = "softmax-xformers"
+ attn_cls = self.ATTENTION_MODES[attn_mode]
+ if version.parse(torch.__version__) >= version.parse("2.0.0"):
+ assert sdp_backend is None or isinstance(sdp_backend, SDPBackend)
+ else:
+ assert sdp_backend is None
+ self.disable_self_attn = disable_self_attn
+ self.attn1 = attn_cls(
+ query_dim=dim,
+ heads=n_heads,
+ dim_head=d_head,
+ dropout=dropout,
+ context_dim=context_dim if self.disable_self_attn else None,
+ backend=sdp_backend,
+ ) # is a self-attention if not self.disable_self_attn
+ self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
+ self.attn2 = attn_cls(
+ query_dim=dim,
+ context_dim=context_dim,
+ heads=n_heads,
+ dim_head=d_head,
+ dropout=dropout,
+ backend=sdp_backend,
+ ) # is self-attn if context is none
+ self.norm1 = nn.LayerNorm(dim)
+ self.norm2 = nn.LayerNorm(dim)
+ self.norm3 = nn.LayerNorm(dim)
+ self.checkpoint = checkpoint
+ if self.checkpoint:
+ logpy.debug(f"{self.__class__.__name__} is using checkpointing")
+
+ def forward(
+ self, x, context=None, additional_tokens=None, n_times_crossframe_attn_in_self=0
+ ):
+ kwargs = {"x": x}
+
+ if context is not None:
+ kwargs.update({"context": context})
+
+ if additional_tokens is not None:
+ kwargs.update({"additional_tokens": additional_tokens})
+
+ if n_times_crossframe_attn_in_self:
+ kwargs.update(
+ {"n_times_crossframe_attn_in_self": n_times_crossframe_attn_in_self}
+ )
+
+ # return mixed_checkpoint(self._forward, kwargs, self.parameters(), self.checkpoint)
+ if self.checkpoint:
+ # inputs = {"x": x, "context": context}
+ return checkpoint(self._forward, x, context)
+ # return checkpoint(self._forward, inputs, self.parameters(), self.checkpoint)
+ else:
+ return self._forward(**kwargs)
+
+ def _forward(
+ self, x, context=None, additional_tokens=None, n_times_crossframe_attn_in_self=0
+ ):
+ x = (
+ self.attn1(
+ self.norm1(x),
+ context=context if self.disable_self_attn else None,
+ additional_tokens=additional_tokens,
+ n_times_crossframe_attn_in_self=n_times_crossframe_attn_in_self
+ if not self.disable_self_attn
+ else 0,
+ )
+ + x
+ )
+ x = (
+ self.attn2(
+ self.norm2(x), context=context, additional_tokens=additional_tokens
+ )
+ + x
+ )
+ x = self.ff(self.norm3(x)) + x
+ return x
+
+
+class BasicTransformerSingleLayerBlock(nn.Module):
+ ATTENTION_MODES = {
+ "softmax": CrossAttention, # vanilla attention
+ "softmax-xformers": MemoryEfficientCrossAttention # on the A100s not quite as fast as the above version
+ # (todo might depend on head_dim, check, falls back to semi-optimized kernels for dim!=[16,32,64,128])
+ }
+
+ def __init__(
+ self,
+ dim,
+ n_heads,
+ d_head,
+ dropout=0.0,
+ context_dim=None,
+ gated_ff=True,
+ checkpoint=True,
+ attn_mode="softmax",
+ ):
+ super().__init__()
+ assert attn_mode in self.ATTENTION_MODES
+ attn_cls = self.ATTENTION_MODES[attn_mode]
+ self.attn1 = attn_cls(
+ query_dim=dim,
+ heads=n_heads,
+ dim_head=d_head,
+ dropout=dropout,
+ context_dim=context_dim,
+ )
+ self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
+ self.norm1 = nn.LayerNorm(dim)
+ self.norm2 = nn.LayerNorm(dim)
+ self.checkpoint = checkpoint
+
+ def forward(self, x, context=None):
+ # inputs = {"x": x, "context": context}
+ # return checkpoint(self._forward, inputs, self.parameters(), self.checkpoint)
+ return checkpoint(self._forward, x, context)
+
+ def _forward(self, x, context=None):
+ x = self.attn1(self.norm1(x), context=context) + x
+ x = self.ff(self.norm2(x)) + x
+ return x
+
+
+class SpatialTransformer(nn.Module):
+ """
+ Transformer block for image-like data.
+ First, project the input (aka embedding)
+ and reshape to b, t, d.
+ Then apply standard transformer action.
+ Finally, reshape to image
+ NEW: use_linear for more efficiency instead of the 1x1 convs
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ n_heads,
+ d_head,
+ depth=1,
+ dropout=0.0,
+ context_dim=None,
+ disable_self_attn=False,
+ use_linear=False,
+ attn_type="softmax",
+ use_checkpoint=True,
+ # sdp_backend=SDPBackend.FLASH_ATTENTION
+ sdp_backend=None,
+ ):
+ super().__init__()
+ logpy.debug(
+ f"constructing {self.__class__.__name__} of depth {depth} w/ "
+ f"{in_channels} channels and {n_heads} heads."
+ )
+
+ if exists(context_dim) and not isinstance(context_dim, list):
+ context_dim = [context_dim]
+ if exists(context_dim) and isinstance(context_dim, list):
+ if depth != len(context_dim):
+ logpy.warn(
+ f"{self.__class__.__name__}: Found context dims "
+ f"{context_dim} of depth {len(context_dim)}, which does not "
+ f"match the specified 'depth' of {depth}. Setting context_dim "
+ f"to {depth * [context_dim[0]]} now."
+ )
+ # depth does not match context dims.
+ assert all(
+ map(lambda x: x == context_dim[0], context_dim)
+ ), "need homogenous context_dim to match depth automatically"
+ context_dim = depth * [context_dim[0]]
+ elif context_dim is None:
+ context_dim = [None] * depth
+ self.in_channels = in_channels
+ inner_dim = n_heads * d_head
+ self.norm = Normalize(in_channels)
+ if not use_linear:
+ self.proj_in = nn.Conv2d(
+ in_channels, inner_dim, kernel_size=1, stride=1, padding=0
+ )
+ else:
+ self.proj_in = nn.Linear(in_channels, inner_dim)
+
+ self.transformer_blocks = nn.ModuleList(
+ [
+ BasicTransformerBlock(
+ inner_dim,
+ n_heads,
+ d_head,
+ dropout=dropout,
+ context_dim=context_dim[d],
+ disable_self_attn=disable_self_attn,
+ attn_mode=attn_type,
+ checkpoint=use_checkpoint,
+ sdp_backend=sdp_backend,
+ )
+ for d in range(depth)
+ ]
+ )
+ if not use_linear:
+ self.proj_out = zero_module(
+ nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
+ )
+ else:
+ # self.proj_out = zero_module(nn.Linear(in_channels, inner_dim))
+ self.proj_out = zero_module(nn.Linear(inner_dim, in_channels))
+ self.use_linear = use_linear
+
+ def forward(self, x, context=None):
+ # note: if no context is given, cross-attention defaults to self-attention
+ if not isinstance(context, list):
+ context = [context]
+ b, c, h, w = x.shape
+ x_in = x
+ x = self.norm(x)
+ if not self.use_linear:
+ x = self.proj_in(x)
+ x = rearrange(x, "b c h w -> b (h w) c").contiguous()
+ if self.use_linear:
+ x = self.proj_in(x)
+ for i, block in enumerate(self.transformer_blocks):
+ if i > 0 and len(context) == 1:
+ i = 0 # use same context for each block
+ x = block(x, context=context[i])
+ if self.use_linear:
+ x = self.proj_out(x)
+ x = rearrange(x, "b (h w) c -> b c h w", h=h, w=w).contiguous()
+ if not self.use_linear:
+ x = self.proj_out(x)
+ return x + x_in
+
+
+class SimpleTransformer(nn.Module):
+ def __init__(
+ self,
+ dim: int,
+ depth: int,
+ heads: int,
+ dim_head: int,
+ context_dim: Optional[int] = None,
+ dropout: float = 0.0,
+ checkpoint: bool = True,
+ ):
+ super().__init__()
+ self.layers = nn.ModuleList([])
+ for _ in range(depth):
+ self.layers.append(
+ BasicTransformerBlock(
+ dim,
+ heads,
+ dim_head,
+ dropout=dropout,
+ context_dim=context_dim,
+ attn_mode="softmax-xformers",
+ checkpoint=checkpoint,
+ )
+ )
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ context: Optional[torch.Tensor] = None,
+ ) -> torch.Tensor:
+ for layer in self.layers:
+ x = layer(x, context)
+ return x
diff --git a/sgm/modules/autoencoding/__init__.py b/sgm/modules/autoencoding/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/sgm/modules/autoencoding/losses/__init__.py b/sgm/modules/autoencoding/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b316c7aa6ea1c5e31a58987aa3b37b2933eb7e2
--- /dev/null
+++ b/sgm/modules/autoencoding/losses/__init__.py
@@ -0,0 +1,7 @@
+__all__ = [
+ "GeneralLPIPSWithDiscriminator",
+ "LatentLPIPS",
+]
+
+from .discriminator_loss import GeneralLPIPSWithDiscriminator
+from .lpips import LatentLPIPS
diff --git a/sgm/modules/autoencoding/losses/discriminator_loss.py b/sgm/modules/autoencoding/losses/discriminator_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..09b6829267bf8e4d98c3f29abdc19e58dcbcbe64
--- /dev/null
+++ b/sgm/modules/autoencoding/losses/discriminator_loss.py
@@ -0,0 +1,306 @@
+from typing import Dict, Iterator, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torchvision
+from einops import rearrange
+from matplotlib import colormaps
+from matplotlib import pyplot as plt
+
+from ....util import default, instantiate_from_config
+from ..lpips.loss.lpips import LPIPS
+from ..lpips.model.model import weights_init
+from ..lpips.vqperceptual import hinge_d_loss, vanilla_d_loss
+
+
+class GeneralLPIPSWithDiscriminator(nn.Module):
+ def __init__(
+ self,
+ disc_start: int,
+ logvar_init: float = 0.0,
+ disc_num_layers: int = 3,
+ disc_in_channels: int = 3,
+ disc_factor: float = 1.0,
+ disc_weight: float = 1.0,
+ perceptual_weight: float = 1.0,
+ disc_loss: str = "hinge",
+ scale_input_to_tgt_size: bool = False,
+ dims: int = 2,
+ learn_logvar: bool = False,
+ regularization_weights: Union[None, Dict[str, float]] = None,
+ additional_log_keys: Optional[List[str]] = None,
+ discriminator_config: Optional[Dict] = None,
+ ):
+ super().__init__()
+ self.dims = dims
+ if self.dims > 2:
+ print(
+ f"running with dims={dims}. This means that for perceptual loss "
+ f"calculation, the LPIPS loss will be applied to each frame "
+ f"independently."
+ )
+ self.scale_input_to_tgt_size = scale_input_to_tgt_size
+ assert disc_loss in ["hinge", "vanilla"]
+ self.perceptual_loss = LPIPS().eval()
+ self.perceptual_weight = perceptual_weight
+ # output log variance
+ self.logvar = nn.Parameter(
+ torch.full((), logvar_init), requires_grad=learn_logvar
+ )
+ self.learn_logvar = learn_logvar
+
+ discriminator_config = default(
+ discriminator_config,
+ {
+ "target": "sgm.modules.autoencoding.lpips.model.model.NLayerDiscriminator",
+ "params": {
+ "input_nc": disc_in_channels,
+ "n_layers": disc_num_layers,
+ "use_actnorm": False,
+ },
+ },
+ )
+
+ self.discriminator = instantiate_from_config(discriminator_config).apply(
+ weights_init
+ )
+ self.discriminator_iter_start = disc_start
+ self.disc_loss = hinge_d_loss if disc_loss == "hinge" else vanilla_d_loss
+ self.disc_factor = disc_factor
+ self.discriminator_weight = disc_weight
+ self.regularization_weights = default(regularization_weights, {})
+
+ self.forward_keys = [
+ "optimizer_idx",
+ "global_step",
+ "last_layer",
+ "split",
+ "regularization_log",
+ ]
+
+ self.additional_log_keys = set(default(additional_log_keys, []))
+ self.additional_log_keys.update(set(self.regularization_weights.keys()))
+
+ def get_trainable_parameters(self) -> Iterator[nn.Parameter]:
+ return self.discriminator.parameters()
+
+ def get_trainable_autoencoder_parameters(self) -> Iterator[nn.Parameter]:
+ if self.learn_logvar:
+ yield self.logvar
+ yield from ()
+
+ @torch.no_grad()
+ def log_images(
+ self, inputs: torch.Tensor, reconstructions: torch.Tensor
+ ) -> Dict[str, torch.Tensor]:
+ # calc logits of real/fake
+ logits_real = self.discriminator(inputs.contiguous().detach())
+ if len(logits_real.shape) < 4:
+ # Non patch-discriminator
+ return dict()
+ logits_fake = self.discriminator(reconstructions.contiguous().detach())
+ # -> (b, 1, h, w)
+
+ # parameters for colormapping
+ high = max(logits_fake.abs().max(), logits_real.abs().max()).item()
+ cmap = colormaps["PiYG"] # diverging colormap
+
+ def to_colormap(logits: torch.Tensor) -> torch.Tensor:
+ """(b, 1, ...) -> (b, 3, ...)"""
+ logits = (logits + high) / (2 * high)
+ logits_np = cmap(logits.cpu().numpy())[..., :3] # truncate alpha channel
+ # -> (b, 1, ..., 3)
+ logits = torch.from_numpy(logits_np).to(logits.device)
+ return rearrange(logits, "b 1 ... c -> b c ...")
+
+ logits_real = torch.nn.functional.interpolate(
+ logits_real,
+ size=inputs.shape[-2:],
+ mode="nearest",
+ antialias=False,
+ )
+ logits_fake = torch.nn.functional.interpolate(
+ logits_fake,
+ size=reconstructions.shape[-2:],
+ mode="nearest",
+ antialias=False,
+ )
+
+ # alpha value of logits for overlay
+ alpha_real = torch.abs(logits_real) / high
+ alpha_fake = torch.abs(logits_fake) / high
+ # -> (b, 1, h, w) in range [0, 0.5]
+ # alpha value of lines don't really matter, since the values are the same
+ # for both images and logits anyway
+ grid_alpha_real = torchvision.utils.make_grid(alpha_real, nrow=4)
+ grid_alpha_fake = torchvision.utils.make_grid(alpha_fake, nrow=4)
+ grid_alpha = 0.8 * torch.cat((grid_alpha_real, grid_alpha_fake), dim=1)
+ # -> (1, h, w)
+ # blend logits and images together
+
+ # prepare logits for plotting
+ logits_real = to_colormap(logits_real)
+ logits_fake = to_colormap(logits_fake)
+ # resize logits
+ # -> (b, 3, h, w)
+
+ # make some grids
+ # add all logits to one plot
+ logits_real = torchvision.utils.make_grid(logits_real, nrow=4)
+ logits_fake = torchvision.utils.make_grid(logits_fake, nrow=4)
+ # I just love how torchvision calls the number of columns `nrow`
+ grid_logits = torch.cat((logits_real, logits_fake), dim=1)
+ # -> (3, h, w)
+
+ grid_images_real = torchvision.utils.make_grid(0.5 * inputs + 0.5, nrow=4)
+ grid_images_fake = torchvision.utils.make_grid(
+ 0.5 * reconstructions + 0.5, nrow=4
+ )
+ grid_images = torch.cat((grid_images_real, grid_images_fake), dim=1)
+ # -> (3, h, w) in range [0, 1]
+
+ grid_blend = grid_alpha * grid_logits + (1 - grid_alpha) * grid_images
+
+ # Create labeled colorbar
+ dpi = 100
+ height = 128 / dpi
+ width = grid_logits.shape[2] / dpi
+ fig, ax = plt.subplots(figsize=(width, height), dpi=dpi)
+ img = ax.imshow(np.array([[-high, high]]), cmap=cmap)
+ plt.colorbar(
+ img,
+ cax=ax,
+ orientation="horizontal",
+ fraction=0.9,
+ aspect=width / height,
+ pad=0.0,
+ )
+ img.set_visible(False)
+ fig.tight_layout()
+ fig.canvas.draw()
+ # manually convert figure to numpy
+ cbar_np = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
+ cbar_np = cbar_np.reshape(fig.canvas.get_width_height()[::-1] + (3,))
+ cbar = torch.from_numpy(cbar_np.copy()).to(grid_logits.dtype) / 255.0
+ cbar = rearrange(cbar, "h w c -> c h w").to(grid_logits.device)
+
+ # Add colorbar to plot
+ annotated_grid = torch.cat((grid_logits, cbar), dim=1)
+ blended_grid = torch.cat((grid_blend, cbar), dim=1)
+ return {
+ "vis_logits": 2 * annotated_grid[None, ...] - 1,
+ "vis_logits_blended": 2 * blended_grid[None, ...] - 1,
+ }
+
+ def calculate_adaptive_weight(
+ self, nll_loss: torch.Tensor, g_loss: torch.Tensor, last_layer: torch.Tensor
+ ) -> torch.Tensor:
+ nll_grads = torch.autograd.grad(nll_loss, last_layer, retain_graph=True)[0]
+ g_grads = torch.autograd.grad(g_loss, last_layer, retain_graph=True)[0]
+
+ d_weight = torch.norm(nll_grads) / (torch.norm(g_grads) + 1e-4)
+ d_weight = torch.clamp(d_weight, 0.0, 1e4).detach()
+ d_weight = d_weight * self.discriminator_weight
+ return d_weight
+
+ def forward(
+ self,
+ inputs: torch.Tensor,
+ reconstructions: torch.Tensor,
+ *, # added because I changed the order here
+ regularization_log: Dict[str, torch.Tensor],
+ optimizer_idx: int,
+ global_step: int,
+ last_layer: torch.Tensor,
+ split: str = "train",
+ weights: Union[None, float, torch.Tensor] = None,
+ ) -> Tuple[torch.Tensor, dict]:
+ if self.scale_input_to_tgt_size:
+ inputs = torch.nn.functional.interpolate(
+ inputs, reconstructions.shape[2:], mode="bicubic", antialias=True
+ )
+
+ if self.dims > 2:
+ inputs, reconstructions = map(
+ lambda x: rearrange(x, "b c t h w -> (b t) c h w"),
+ (inputs, reconstructions),
+ )
+
+ rec_loss = torch.abs(inputs.contiguous() - reconstructions.contiguous())
+ if self.perceptual_weight > 0:
+ p_loss = self.perceptual_loss(
+ inputs.contiguous(), reconstructions.contiguous()
+ )
+ rec_loss = rec_loss + self.perceptual_weight * p_loss
+
+ nll_loss, weighted_nll_loss = self.get_nll_loss(rec_loss, weights)
+
+ # now the GAN part
+ if optimizer_idx == 0:
+ # generator update
+ if global_step >= self.discriminator_iter_start or not self.training:
+ logits_fake = self.discriminator(reconstructions.contiguous())
+ g_loss = -torch.mean(logits_fake)
+ if self.training:
+ d_weight = self.calculate_adaptive_weight(
+ nll_loss, g_loss, last_layer=last_layer
+ )
+ else:
+ d_weight = torch.tensor(1.0)
+ else:
+ d_weight = torch.tensor(0.0)
+ g_loss = torch.tensor(0.0, requires_grad=True)
+
+ loss = weighted_nll_loss + d_weight * self.disc_factor * g_loss
+ log = dict()
+ for k in regularization_log:
+ if k in self.regularization_weights:
+ loss = loss + self.regularization_weights[k] * regularization_log[k]
+ if k in self.additional_log_keys:
+ log[f"{split}/{k}"] = regularization_log[k].detach().float().mean()
+
+ log.update(
+ {
+ f"{split}/loss/total": loss.clone().detach().mean(),
+ f"{split}/loss/nll": nll_loss.detach().mean(),
+ f"{split}/loss/rec": rec_loss.detach().mean(),
+ f"{split}/loss/g": g_loss.detach().mean(),
+ f"{split}/scalars/logvar": self.logvar.detach(),
+ f"{split}/scalars/d_weight": d_weight.detach(),
+ }
+ )
+
+ return loss, log
+ elif optimizer_idx == 1:
+ # second pass for discriminator update
+ logits_real = self.discriminator(inputs.contiguous().detach())
+ logits_fake = self.discriminator(reconstructions.contiguous().detach())
+
+ if global_step >= self.discriminator_iter_start or not self.training:
+ d_loss = self.disc_factor * self.disc_loss(logits_real, logits_fake)
+ else:
+ d_loss = torch.tensor(0.0, requires_grad=True)
+
+ log = {
+ f"{split}/loss/disc": d_loss.clone().detach().mean(),
+ f"{split}/logits/real": logits_real.detach().mean(),
+ f"{split}/logits/fake": logits_fake.detach().mean(),
+ }
+ return d_loss, log
+ else:
+ raise NotImplementedError(f"Unknown optimizer_idx {optimizer_idx}")
+
+ def get_nll_loss(
+ self,
+ rec_loss: torch.Tensor,
+ weights: Optional[Union[float, torch.Tensor]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ nll_loss = rec_loss / torch.exp(self.logvar) + self.logvar
+ weighted_nll_loss = nll_loss
+ if weights is not None:
+ weighted_nll_loss = weights * nll_loss
+ weighted_nll_loss = torch.sum(weighted_nll_loss) / weighted_nll_loss.shape[0]
+ nll_loss = torch.sum(nll_loss) / nll_loss.shape[0]
+
+ return nll_loss, weighted_nll_loss
diff --git a/sgm/modules/autoencoding/losses/lpips.py b/sgm/modules/autoencoding/losses/lpips.py
new file mode 100644
index 0000000000000000000000000000000000000000..b329fcc2ee9477f0122aa7d066866cdfe71ce521
--- /dev/null
+++ b/sgm/modules/autoencoding/losses/lpips.py
@@ -0,0 +1,73 @@
+import torch
+import torch.nn as nn
+
+from ....util import default, instantiate_from_config
+from ..lpips.loss.lpips import LPIPS
+
+
+class LatentLPIPS(nn.Module):
+ def __init__(
+ self,
+ decoder_config,
+ perceptual_weight=1.0,
+ latent_weight=1.0,
+ scale_input_to_tgt_size=False,
+ scale_tgt_to_input_size=False,
+ perceptual_weight_on_inputs=0.0,
+ ):
+ super().__init__()
+ self.scale_input_to_tgt_size = scale_input_to_tgt_size
+ self.scale_tgt_to_input_size = scale_tgt_to_input_size
+ self.init_decoder(decoder_config)
+ self.perceptual_loss = LPIPS().eval()
+ self.perceptual_weight = perceptual_weight
+ self.latent_weight = latent_weight
+ self.perceptual_weight_on_inputs = perceptual_weight_on_inputs
+
+ def init_decoder(self, config):
+ self.decoder = instantiate_from_config(config)
+ if hasattr(self.decoder, "encoder"):
+ del self.decoder.encoder
+
+ def forward(self, latent_inputs, latent_predictions, image_inputs, split="train"):
+ log = dict()
+ loss = (latent_inputs - latent_predictions) ** 2
+ log[f"{split}/latent_l2_loss"] = loss.mean().detach()
+ image_reconstructions = None
+ if self.perceptual_weight > 0.0:
+ image_reconstructions = self.decoder.decode(latent_predictions)
+ image_targets = self.decoder.decode(latent_inputs)
+ perceptual_loss = self.perceptual_loss(
+ image_targets.contiguous(), image_reconstructions.contiguous()
+ )
+ loss = (
+ self.latent_weight * loss.mean()
+ + self.perceptual_weight * perceptual_loss.mean()
+ )
+ log[f"{split}/perceptual_loss"] = perceptual_loss.mean().detach()
+
+ if self.perceptual_weight_on_inputs > 0.0:
+ image_reconstructions = default(
+ image_reconstructions, self.decoder.decode(latent_predictions)
+ )
+ if self.scale_input_to_tgt_size:
+ image_inputs = torch.nn.functional.interpolate(
+ image_inputs,
+ image_reconstructions.shape[2:],
+ mode="bicubic",
+ antialias=True,
+ )
+ elif self.scale_tgt_to_input_size:
+ image_reconstructions = torch.nn.functional.interpolate(
+ image_reconstructions,
+ image_inputs.shape[2:],
+ mode="bicubic",
+ antialias=True,
+ )
+
+ perceptual_loss2 = self.perceptual_loss(
+ image_inputs.contiguous(), image_reconstructions.contiguous()
+ )
+ loss = loss + self.perceptual_weight_on_inputs * perceptual_loss2.mean()
+ log[f"{split}/perceptual_loss_on_inputs"] = perceptual_loss2.mean().detach()
+ return loss, log
diff --git a/sgm/modules/autoencoding/lpips/__init__.py b/sgm/modules/autoencoding/lpips/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/sgm/modules/autoencoding/lpips/loss/.gitignore b/sgm/modules/autoencoding/lpips/loss/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..a92958a1cd4ffe005e1f5448ab3e6fd9c795a43a
--- /dev/null
+++ b/sgm/modules/autoencoding/lpips/loss/.gitignore
@@ -0,0 +1 @@
+vgg.pth
\ No newline at end of file
diff --git a/sgm/modules/autoencoding/lpips/loss/LICENSE b/sgm/modules/autoencoding/lpips/loss/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..924cfc85b8d63ef538f5676f830a2a8497932108
--- /dev/null
+++ b/sgm/modules/autoencoding/lpips/loss/LICENSE
@@ -0,0 +1,23 @@
+Copyright (c) 2018, Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, Oliver Wang
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are met:
+
+* Redistributions of source code must retain the above copyright notice, this
+ list of conditions and the following disclaimer.
+
+* Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
\ No newline at end of file
diff --git a/sgm/modules/autoencoding/lpips/loss/__init__.py b/sgm/modules/autoencoding/lpips/loss/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/sgm/modules/autoencoding/lpips/loss/lpips.py b/sgm/modules/autoencoding/lpips/loss/lpips.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e34f3d083674f675a5ca024e9bd27fb77e2b6b5
--- /dev/null
+++ b/sgm/modules/autoencoding/lpips/loss/lpips.py
@@ -0,0 +1,147 @@
+"""Stripped version of https://github.com/richzhang/PerceptualSimilarity/tree/master/models"""
+
+from collections import namedtuple
+
+import torch
+import torch.nn as nn
+from torchvision import models
+
+from ..util import get_ckpt_path
+
+
+class LPIPS(nn.Module):
+ # Learned perceptual metric
+ def __init__(self, use_dropout=True):
+ super().__init__()
+ self.scaling_layer = ScalingLayer()
+ self.chns = [64, 128, 256, 512, 512] # vg16 features
+ self.net = vgg16(pretrained=True, requires_grad=False)
+ self.lin0 = NetLinLayer(self.chns[0], use_dropout=use_dropout)
+ self.lin1 = NetLinLayer(self.chns[1], use_dropout=use_dropout)
+ self.lin2 = NetLinLayer(self.chns[2], use_dropout=use_dropout)
+ self.lin3 = NetLinLayer(self.chns[3], use_dropout=use_dropout)
+ self.lin4 = NetLinLayer(self.chns[4], use_dropout=use_dropout)
+ self.load_from_pretrained()
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def load_from_pretrained(self, name="vgg_lpips"):
+ ckpt = get_ckpt_path(name, "sgm/modules/autoencoding/lpips/loss")
+ self.load_state_dict(
+ torch.load(ckpt, map_location=torch.device("cpu")), strict=False
+ )
+ print("loaded pretrained LPIPS loss from {}".format(ckpt))
+
+ @classmethod
+ def from_pretrained(cls, name="vgg_lpips"):
+ if name != "vgg_lpips":
+ raise NotImplementedError
+ model = cls()
+ ckpt = get_ckpt_path(name)
+ model.load_state_dict(
+ torch.load(ckpt, map_location=torch.device("cpu")), strict=False
+ )
+ return model
+
+ def forward(self, input, target):
+ in0_input, in1_input = (self.scaling_layer(input), self.scaling_layer(target))
+ outs0, outs1 = self.net(in0_input), self.net(in1_input)
+ feats0, feats1, diffs = {}, {}, {}
+ lins = [self.lin0, self.lin1, self.lin2, self.lin3, self.lin4]
+ for kk in range(len(self.chns)):
+ feats0[kk], feats1[kk] = normalize_tensor(outs0[kk]), normalize_tensor(
+ outs1[kk]
+ )
+ diffs[kk] = (feats0[kk] - feats1[kk]) ** 2
+
+ res = [
+ spatial_average(lins[kk].model(diffs[kk]), keepdim=True)
+ for kk in range(len(self.chns))
+ ]
+ val = res[0]
+ for l in range(1, len(self.chns)):
+ val += res[l]
+ return val
+
+
+class ScalingLayer(nn.Module):
+ def __init__(self):
+ super(ScalingLayer, self).__init__()
+ self.register_buffer(
+ "shift", torch.Tensor([-0.030, -0.088, -0.188])[None, :, None, None]
+ )
+ self.register_buffer(
+ "scale", torch.Tensor([0.458, 0.448, 0.450])[None, :, None, None]
+ )
+
+ def forward(self, inp):
+ return (inp - self.shift) / self.scale
+
+
+class NetLinLayer(nn.Module):
+ """A single linear layer which does a 1x1 conv"""
+
+ def __init__(self, chn_in, chn_out=1, use_dropout=False):
+ super(NetLinLayer, self).__init__()
+ layers = (
+ [
+ nn.Dropout(),
+ ]
+ if (use_dropout)
+ else []
+ )
+ layers += [
+ nn.Conv2d(chn_in, chn_out, 1, stride=1, padding=0, bias=False),
+ ]
+ self.model = nn.Sequential(*layers)
+
+
+class vgg16(torch.nn.Module):
+ def __init__(self, requires_grad=False, pretrained=True):
+ super(vgg16, self).__init__()
+ vgg_pretrained_features = models.vgg16(pretrained=pretrained).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+ self.N_slices = 5
+ for x in range(4):
+ self.slice1.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(4, 9):
+ self.slice2.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(9, 16):
+ self.slice3.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(16, 23):
+ self.slice4.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(23, 30):
+ self.slice5.add_module(str(x), vgg_pretrained_features[x])
+ if not requires_grad:
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, X):
+ h = self.slice1(X)
+ h_relu1_2 = h
+ h = self.slice2(h)
+ h_relu2_2 = h
+ h = self.slice3(h)
+ h_relu3_3 = h
+ h = self.slice4(h)
+ h_relu4_3 = h
+ h = self.slice5(h)
+ h_relu5_3 = h
+ vgg_outputs = namedtuple(
+ "VggOutputs", ["relu1_2", "relu2_2", "relu3_3", "relu4_3", "relu5_3"]
+ )
+ out = vgg_outputs(h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3)
+ return out
+
+
+def normalize_tensor(x, eps=1e-10):
+ norm_factor = torch.sqrt(torch.sum(x**2, dim=1, keepdim=True))
+ return x / (norm_factor + eps)
+
+
+def spatial_average(x, keepdim=True):
+ return x.mean([2, 3], keepdim=keepdim)
diff --git a/sgm/modules/autoencoding/lpips/model/LICENSE b/sgm/modules/autoencoding/lpips/model/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..4b356e66b5aa689b339f1a80a9f1b5ba378003bb
--- /dev/null
+++ b/sgm/modules/autoencoding/lpips/model/LICENSE
@@ -0,0 +1,58 @@
+Copyright (c) 2017, Jun-Yan Zhu and Taesung Park
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are met:
+
+* Redistributions of source code must retain the above copyright notice, this
+ list of conditions and the following disclaimer.
+
+* Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
+
+
+--------------------------- LICENSE FOR pix2pix --------------------------------
+BSD License
+
+For pix2pix software
+Copyright (c) 2016, Phillip Isola and Jun-Yan Zhu
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are met:
+
+* Redistributions of source code must retain the above copyright notice, this
+ list of conditions and the following disclaimer.
+
+* Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+
+----------------------------- LICENSE FOR DCGAN --------------------------------
+BSD License
+
+For dcgan.torch software
+
+Copyright (c) 2015, Facebook, Inc. All rights reserved.
+
+Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
+
+Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
+
+Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
+
+Neither the name Facebook nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
\ No newline at end of file
diff --git a/sgm/modules/autoencoding/lpips/model/__init__.py b/sgm/modules/autoencoding/lpips/model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/sgm/modules/autoencoding/lpips/model/model.py b/sgm/modules/autoencoding/lpips/model/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..66357d4e627f9a69a5abbbad15546c96fcd758fe
--- /dev/null
+++ b/sgm/modules/autoencoding/lpips/model/model.py
@@ -0,0 +1,88 @@
+import functools
+
+import torch.nn as nn
+
+from ..util import ActNorm
+
+
+def weights_init(m):
+ classname = m.__class__.__name__
+ if classname.find("Conv") != -1:
+ nn.init.normal_(m.weight.data, 0.0, 0.02)
+ elif classname.find("BatchNorm") != -1:
+ nn.init.normal_(m.weight.data, 1.0, 0.02)
+ nn.init.constant_(m.bias.data, 0)
+
+
+class NLayerDiscriminator(nn.Module):
+ """Defines a PatchGAN discriminator as in Pix2Pix
+ --> see https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/models/networks.py
+ """
+
+ def __init__(self, input_nc=3, ndf=64, n_layers=3, use_actnorm=False):
+ """Construct a PatchGAN discriminator
+ Parameters:
+ input_nc (int) -- the number of channels in input images
+ ndf (int) -- the number of filters in the last conv layer
+ n_layers (int) -- the number of conv layers in the discriminator
+ norm_layer -- normalization layer
+ """
+ super(NLayerDiscriminator, self).__init__()
+ if not use_actnorm:
+ norm_layer = nn.BatchNorm2d
+ else:
+ norm_layer = ActNorm
+ if (
+ type(norm_layer) == functools.partial
+ ): # no need to use bias as BatchNorm2d has affine parameters
+ use_bias = norm_layer.func != nn.BatchNorm2d
+ else:
+ use_bias = norm_layer != nn.BatchNorm2d
+
+ kw = 4
+ padw = 1
+ sequence = [
+ nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
+ nn.LeakyReLU(0.2, True),
+ ]
+ nf_mult = 1
+ nf_mult_prev = 1
+ for n in range(1, n_layers): # gradually increase the number of filters
+ nf_mult_prev = nf_mult
+ nf_mult = min(2**n, 8)
+ sequence += [
+ nn.Conv2d(
+ ndf * nf_mult_prev,
+ ndf * nf_mult,
+ kernel_size=kw,
+ stride=2,
+ padding=padw,
+ bias=use_bias,
+ ),
+ norm_layer(ndf * nf_mult),
+ nn.LeakyReLU(0.2, True),
+ ]
+
+ nf_mult_prev = nf_mult
+ nf_mult = min(2**n_layers, 8)
+ sequence += [
+ nn.Conv2d(
+ ndf * nf_mult_prev,
+ ndf * nf_mult,
+ kernel_size=kw,
+ stride=1,
+ padding=padw,
+ bias=use_bias,
+ ),
+ norm_layer(ndf * nf_mult),
+ nn.LeakyReLU(0.2, True),
+ ]
+
+ sequence += [
+ nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)
+ ] # output 1 channel prediction map
+ self.main = nn.Sequential(*sequence)
+
+ def forward(self, input):
+ """Standard forward."""
+ return self.main(input)
diff --git a/sgm/modules/autoencoding/lpips/util.py b/sgm/modules/autoencoding/lpips/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..49c76e370bf16888ab61f42844b3c9f14ad9014c
--- /dev/null
+++ b/sgm/modules/autoencoding/lpips/util.py
@@ -0,0 +1,128 @@
+import hashlib
+import os
+
+import requests
+import torch
+import torch.nn as nn
+from tqdm import tqdm
+
+URL_MAP = {"vgg_lpips": "https://heibox.uni-heidelberg.de/f/607503859c864bc1b30b/?dl=1"}
+
+CKPT_MAP = {"vgg_lpips": "vgg.pth"}
+
+MD5_MAP = {"vgg_lpips": "d507d7349b931f0638a25a48a722f98a"}
+
+
+def download(url, local_path, chunk_size=1024):
+ os.makedirs(os.path.split(local_path)[0], exist_ok=True)
+ with requests.get(url, stream=True) as r:
+ total_size = int(r.headers.get("content-length", 0))
+ with tqdm(total=total_size, unit="B", unit_scale=True) as pbar:
+ with open(local_path, "wb") as f:
+ for data in r.iter_content(chunk_size=chunk_size):
+ if data:
+ f.write(data)
+ pbar.update(chunk_size)
+
+
+def md5_hash(path):
+ with open(path, "rb") as f:
+ content = f.read()
+ return hashlib.md5(content).hexdigest()
+
+
+def get_ckpt_path(name, root, check=False):
+ assert name in URL_MAP
+ path = os.path.join(root, CKPT_MAP[name])
+ if not os.path.exists(path) or (check and not md5_hash(path) == MD5_MAP[name]):
+ print("Downloading {} model from {} to {}".format(name, URL_MAP[name], path))
+ download(URL_MAP[name], path)
+ md5 = md5_hash(path)
+ assert md5 == MD5_MAP[name], md5
+ return path
+
+
+class ActNorm(nn.Module):
+ def __init__(
+ self, num_features, logdet=False, affine=True, allow_reverse_init=False
+ ):
+ assert affine
+ super().__init__()
+ self.logdet = logdet
+ self.loc = nn.Parameter(torch.zeros(1, num_features, 1, 1))
+ self.scale = nn.Parameter(torch.ones(1, num_features, 1, 1))
+ self.allow_reverse_init = allow_reverse_init
+
+ self.register_buffer("initialized", torch.tensor(0, dtype=torch.uint8))
+
+ def initialize(self, input):
+ with torch.no_grad():
+ flatten = input.permute(1, 0, 2, 3).contiguous().view(input.shape[1], -1)
+ mean = (
+ flatten.mean(1)
+ .unsqueeze(1)
+ .unsqueeze(2)
+ .unsqueeze(3)
+ .permute(1, 0, 2, 3)
+ )
+ std = (
+ flatten.std(1)
+ .unsqueeze(1)
+ .unsqueeze(2)
+ .unsqueeze(3)
+ .permute(1, 0, 2, 3)
+ )
+
+ self.loc.data.copy_(-mean)
+ self.scale.data.copy_(1 / (std + 1e-6))
+
+ def forward(self, input, reverse=False):
+ if reverse:
+ return self.reverse(input)
+ if len(input.shape) == 2:
+ input = input[:, :, None, None]
+ squeeze = True
+ else:
+ squeeze = False
+
+ _, _, height, width = input.shape
+
+ if self.training and self.initialized.item() == 0:
+ self.initialize(input)
+ self.initialized.fill_(1)
+
+ h = self.scale * (input + self.loc)
+
+ if squeeze:
+ h = h.squeeze(-1).squeeze(-1)
+
+ if self.logdet:
+ log_abs = torch.log(torch.abs(self.scale))
+ logdet = height * width * torch.sum(log_abs)
+ logdet = logdet * torch.ones(input.shape[0]).to(input)
+ return h, logdet
+
+ return h
+
+ def reverse(self, output):
+ if self.training and self.initialized.item() == 0:
+ if not self.allow_reverse_init:
+ raise RuntimeError(
+ "Initializing ActNorm in reverse direction is "
+ "disabled by default. Use allow_reverse_init=True to enable."
+ )
+ else:
+ self.initialize(output)
+ self.initialized.fill_(1)
+
+ if len(output.shape) == 2:
+ output = output[:, :, None, None]
+ squeeze = True
+ else:
+ squeeze = False
+
+ h = output / self.scale - self.loc
+
+ if squeeze:
+ h = h.squeeze(-1).squeeze(-1)
+ return h
diff --git a/sgm/modules/autoencoding/lpips/vqperceptual.py b/sgm/modules/autoencoding/lpips/vqperceptual.py
new file mode 100644
index 0000000000000000000000000000000000000000..6195f0a6ed7ee6fd32c1bccea071e6075e95ee43
--- /dev/null
+++ b/sgm/modules/autoencoding/lpips/vqperceptual.py
@@ -0,0 +1,17 @@
+import torch
+import torch.nn.functional as F
+
+
+def hinge_d_loss(logits_real, logits_fake):
+ loss_real = torch.mean(F.relu(1.0 - logits_real))
+ loss_fake = torch.mean(F.relu(1.0 + logits_fake))
+ d_loss = 0.5 * (loss_real + loss_fake)
+ return d_loss
+
+
+def vanilla_d_loss(logits_real, logits_fake):
+ d_loss = 0.5 * (
+ torch.mean(torch.nn.functional.softplus(-logits_real))
+ + torch.mean(torch.nn.functional.softplus(logits_fake))
+ )
+ return d_loss
diff --git a/sgm/modules/autoencoding/regularizers/__init__.py b/sgm/modules/autoencoding/regularizers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff2b1815a5ba88892375e8ec9bedacea49024113
--- /dev/null
+++ b/sgm/modules/autoencoding/regularizers/__init__.py
@@ -0,0 +1,31 @@
+from abc import abstractmethod
+from typing import Any, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ....modules.distributions.distributions import \
+ DiagonalGaussianDistribution
+from .base import AbstractRegularizer
+
+
+class DiagonalGaussianRegularizer(AbstractRegularizer):
+ def __init__(self, sample: bool = True):
+ super().__init__()
+ self.sample = sample
+
+ def get_trainable_parameters(self) -> Any:
+ yield from ()
+
+ def forward(self, z: torch.Tensor) -> Tuple[torch.Tensor, dict]:
+ log = dict()
+ posterior = DiagonalGaussianDistribution(z)
+ if self.sample:
+ z = posterior.sample()
+ else:
+ z = posterior.mode()
+ kl_loss = posterior.kl()
+ kl_loss = torch.sum(kl_loss) / kl_loss.shape[0]
+ log["kl_loss"] = kl_loss
+ return z, log
diff --git a/sgm/modules/autoencoding/regularizers/base.py b/sgm/modules/autoencoding/regularizers/base.py
new file mode 100644
index 0000000000000000000000000000000000000000..fca681bb3c1f4818b57e956e31b98f76077ccb67
--- /dev/null
+++ b/sgm/modules/autoencoding/regularizers/base.py
@@ -0,0 +1,40 @@
+from abc import abstractmethod
+from typing import Any, Tuple
+
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+
+class AbstractRegularizer(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, z: torch.Tensor) -> Tuple[torch.Tensor, dict]:
+ raise NotImplementedError()
+
+ @abstractmethod
+ def get_trainable_parameters(self) -> Any:
+ raise NotImplementedError()
+
+
+class IdentityRegularizer(AbstractRegularizer):
+ def forward(self, z: torch.Tensor) -> Tuple[torch.Tensor, dict]:
+ return z, dict()
+
+ def get_trainable_parameters(self) -> Any:
+ yield from ()
+
+
+def measure_perplexity(
+ predicted_indices: torch.Tensor, num_centroids: int
+) -> Tuple[torch.Tensor, torch.Tensor]:
+ # src: https://github.com/karpathy/deep-vector-quantization/blob/main/model.py
+ # eval cluster perplexity. when perplexity == num_embeddings then all clusters are used exactly equally
+ encodings = (
+ F.one_hot(predicted_indices, num_centroids).float().reshape(-1, num_centroids)
+ )
+ avg_probs = encodings.mean(0)
+ perplexity = (-(avg_probs * torch.log(avg_probs + 1e-10)).sum()).exp()
+ cluster_use = torch.sum(avg_probs > 0)
+ return perplexity, cluster_use
diff --git a/sgm/modules/autoencoding/regularizers/quantize.py b/sgm/modules/autoencoding/regularizers/quantize.py
new file mode 100644
index 0000000000000000000000000000000000000000..86a4dbdd10101b24f03bba134c4f8d2ab007f0db
--- /dev/null
+++ b/sgm/modules/autoencoding/regularizers/quantize.py
@@ -0,0 +1,487 @@
+import logging
+from abc import abstractmethod
+from typing import Dict, Iterator, Literal, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from einops import rearrange
+from torch import einsum
+
+from .base import AbstractRegularizer, measure_perplexity
+
+logpy = logging.getLogger(__name__)
+
+
+class AbstractQuantizer(AbstractRegularizer):
+ def __init__(self):
+ super().__init__()
+ # Define these in your init
+ # shape (N,)
+ self.used: Optional[torch.Tensor]
+ self.re_embed: int
+ self.unknown_index: Union[Literal["random"], int]
+
+ def remap_to_used(self, inds: torch.Tensor) -> torch.Tensor:
+ assert self.used is not None, "You need to define used indices for remap"
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape(ishape[0], -1)
+ used = self.used.to(inds)
+ match = (inds[:, :, None] == used[None, None, ...]).long()
+ new = match.argmax(-1)
+ unknown = match.sum(2) < 1
+ if self.unknown_index == "random":
+ new[unknown] = torch.randint(0, self.re_embed, size=new[unknown].shape).to(
+ device=new.device
+ )
+ else:
+ new[unknown] = self.unknown_index
+ return new.reshape(ishape)
+
+ def unmap_to_all(self, inds: torch.Tensor) -> torch.Tensor:
+ assert self.used is not None, "You need to define used indices for remap"
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape(ishape[0], -1)
+ used = self.used.to(inds)
+ if self.re_embed > self.used.shape[0]: # extra token
+ inds[inds >= self.used.shape[0]] = 0 # simply set to zero
+ back = torch.gather(used[None, :][inds.shape[0] * [0], :], 1, inds)
+ return back.reshape(ishape)
+
+ @abstractmethod
+ def get_codebook_entry(
+ self, indices: torch.Tensor, shape: Optional[Tuple[int, ...]] = None
+ ) -> torch.Tensor:
+ raise NotImplementedError()
+
+ def get_trainable_parameters(self) -> Iterator[torch.nn.Parameter]:
+ yield from self.parameters()
+
+
+class GumbelQuantizer(AbstractQuantizer):
+ """
+ credit to @karpathy:
+ https://github.com/karpathy/deep-vector-quantization/blob/main/model.py (thanks!)
+ Gumbel Softmax trick quantizer
+ Categorical Reparameterization with Gumbel-Softmax, Jang et al. 2016
+ https://arxiv.org/abs/1611.01144
+ """
+
+ def __init__(
+ self,
+ num_hiddens: int,
+ embedding_dim: int,
+ n_embed: int,
+ straight_through: bool = True,
+ kl_weight: float = 5e-4,
+ temp_init: float = 1.0,
+ remap: Optional[str] = None,
+ unknown_index: str = "random",
+ loss_key: str = "loss/vq",
+ ) -> None:
+ super().__init__()
+
+ self.loss_key = loss_key
+ self.embedding_dim = embedding_dim
+ self.n_embed = n_embed
+
+ self.straight_through = straight_through
+ self.temperature = temp_init
+ self.kl_weight = kl_weight
+
+ self.proj = nn.Conv2d(num_hiddens, n_embed, 1)
+ self.embed = nn.Embedding(n_embed, embedding_dim)
+
+ self.remap = remap
+ if self.remap is not None:
+ self.register_buffer("used", torch.tensor(np.load(self.remap)))
+ self.re_embed = self.used.shape[0]
+ else:
+ self.used = None
+ self.re_embed = n_embed
+ if unknown_index == "extra":
+ self.unknown_index = self.re_embed
+ self.re_embed = self.re_embed + 1
+ else:
+ assert unknown_index == "random" or isinstance(
+ unknown_index, int
+ ), "unknown index needs to be 'random', 'extra' or any integer"
+ self.unknown_index = unknown_index # "random" or "extra" or integer
+ if self.remap is not None:
+ logpy.info(
+ f"Remapping {self.n_embed} indices to {self.re_embed} indices. "
+ f"Using {self.unknown_index} for unknown indices."
+ )
+
+ def forward(
+ self, z: torch.Tensor, temp: Optional[float] = None, return_logits: bool = False
+ ) -> Tuple[torch.Tensor, Dict]:
+ # force hard = True when we are in eval mode, as we must quantize.
+ # actually, always true seems to work
+ hard = self.straight_through if self.training else True
+ temp = self.temperature if temp is None else temp
+ out_dict = {}
+ logits = self.proj(z)
+ if self.remap is not None:
+ # continue only with used logits
+ full_zeros = torch.zeros_like(logits)
+ logits = logits[:, self.used, ...]
+
+ soft_one_hot = F.gumbel_softmax(logits, tau=temp, dim=1, hard=hard)
+ if self.remap is not None:
+ # go back to all entries but unused set to zero
+ full_zeros[:, self.used, ...] = soft_one_hot
+ soft_one_hot = full_zeros
+ z_q = einsum("b n h w, n d -> b d h w", soft_one_hot, self.embed.weight)
+
+ # + kl divergence to the prior loss
+ qy = F.softmax(logits, dim=1)
+ diff = (
+ self.kl_weight
+ * torch.sum(qy * torch.log(qy * self.n_embed + 1e-10), dim=1).mean()
+ )
+ out_dict[self.loss_key] = diff
+
+ ind = soft_one_hot.argmax(dim=1)
+ out_dict["indices"] = ind
+ if self.remap is not None:
+ ind = self.remap_to_used(ind)
+
+ if return_logits:
+ out_dict["logits"] = logits
+
+ return z_q, out_dict
+
+ def get_codebook_entry(self, indices, shape):
+ # TODO: shape not yet optional
+ b, h, w, c = shape
+ assert b * h * w == indices.shape[0]
+ indices = rearrange(indices, "(b h w) -> b h w", b=b, h=h, w=w)
+ if self.remap is not None:
+ indices = self.unmap_to_all(indices)
+ one_hot = (
+ F.one_hot(indices, num_classes=self.n_embed).permute(0, 3, 1, 2).float()
+ )
+ z_q = einsum("b n h w, n d -> b d h w", one_hot, self.embed.weight)
+ return z_q
+
+
+class VectorQuantizer(AbstractQuantizer):
+ """
+ ____________________________________________
+ Discretization bottleneck part of the VQ-VAE.
+ Inputs:
+ - n_e : number of embeddings
+ - e_dim : dimension of embedding
+ - beta : commitment cost used in loss term,
+ beta * ||z_e(x)-sg[e]||^2
+ _____________________________________________
+ """
+
+ def __init__(
+ self,
+ n_e: int,
+ e_dim: int,
+ beta: float = 0.25,
+ remap: Optional[str] = None,
+ unknown_index: str = "random",
+ sane_index_shape: bool = False,
+ log_perplexity: bool = False,
+ embedding_weight_norm: bool = False,
+ loss_key: str = "loss/vq",
+ ):
+ super().__init__()
+ self.n_e = n_e
+ self.e_dim = e_dim
+ self.beta = beta
+ self.loss_key = loss_key
+
+ if not embedding_weight_norm:
+ self.embedding = nn.Embedding(self.n_e, self.e_dim)
+ self.embedding.weight.data.uniform_(-1.0 / self.n_e, 1.0 / self.n_e)
+ else:
+ self.embedding = torch.nn.utils.weight_norm(
+ nn.Embedding(self.n_e, self.e_dim), dim=1
+ )
+
+ self.remap = remap
+ if self.remap is not None:
+ self.register_buffer("used", torch.tensor(np.load(self.remap)))
+ self.re_embed = self.used.shape[0]
+ else:
+ self.used = None
+ self.re_embed = n_e
+ if unknown_index == "extra":
+ self.unknown_index = self.re_embed
+ self.re_embed = self.re_embed + 1
+ else:
+ assert unknown_index == "random" or isinstance(
+ unknown_index, int
+ ), "unknown index needs to be 'random', 'extra' or any integer"
+ self.unknown_index = unknown_index # "random" or "extra" or integer
+ if self.remap is not None:
+ logpy.info(
+ f"Remapping {self.n_e} indices to {self.re_embed} indices. "
+ f"Using {self.unknown_index} for unknown indices."
+ )
+
+ self.sane_index_shape = sane_index_shape
+ self.log_perplexity = log_perplexity
+
+ def forward(
+ self,
+ z: torch.Tensor,
+ ) -> Tuple[torch.Tensor, Dict]:
+ do_reshape = z.ndim == 4
+ if do_reshape:
+ # # reshape z -> (batch, height, width, channel) and flatten
+ z = rearrange(z, "b c h w -> b h w c").contiguous()
+
+ else:
+ assert z.ndim < 4, "No reshaping strategy for inputs > 4 dimensions defined"
+ z = z.contiguous()
+
+ z_flattened = z.view(-1, self.e_dim)
+ # distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
+
+ d = (
+ torch.sum(z_flattened**2, dim=1, keepdim=True)
+ + torch.sum(self.embedding.weight**2, dim=1)
+ - 2
+ * torch.einsum(
+ "bd,dn->bn", z_flattened, rearrange(self.embedding.weight, "n d -> d n")
+ )
+ )
+
+ min_encoding_indices = torch.argmin(d, dim=1)
+ z_q = self.embedding(min_encoding_indices).view(z.shape)
+ loss_dict = {}
+ if self.log_perplexity:
+ perplexity, cluster_usage = measure_perplexity(
+ min_encoding_indices.detach(), self.n_e
+ )
+ loss_dict.update({"perplexity": perplexity, "cluster_usage": cluster_usage})
+
+ # compute loss for embedding
+ loss = self.beta * torch.mean((z_q.detach() - z) ** 2) + torch.mean(
+ (z_q - z.detach()) ** 2
+ )
+ loss_dict[self.loss_key] = loss
+
+ # preserve gradients
+ z_q = z + (z_q - z).detach()
+
+ # reshape back to match original input shape
+ if do_reshape:
+ z_q = rearrange(z_q, "b h w c -> b c h w").contiguous()
+
+ if self.remap is not None:
+ min_encoding_indices = min_encoding_indices.reshape(
+ z.shape[0], -1
+ ) # add batch axis
+ min_encoding_indices = self.remap_to_used(min_encoding_indices)
+ min_encoding_indices = min_encoding_indices.reshape(-1, 1) # flatten
+
+ if self.sane_index_shape:
+ if do_reshape:
+ min_encoding_indices = min_encoding_indices.reshape(
+ z_q.shape[0], z_q.shape[2], z_q.shape[3]
+ )
+ else:
+ min_encoding_indices = rearrange(
+ min_encoding_indices, "(b s) 1 -> b s", b=z_q.shape[0]
+ )
+
+ loss_dict["min_encoding_indices"] = min_encoding_indices
+
+ return z_q, loss_dict
+
+ def get_codebook_entry(
+ self, indices: torch.Tensor, shape: Optional[Tuple[int, ...]] = None
+ ) -> torch.Tensor:
+ # shape specifying (batch, height, width, channel)
+ if self.remap is not None:
+ assert shape is not None, "Need to give shape for remap"
+ indices = indices.reshape(shape[0], -1) # add batch axis
+ indices = self.unmap_to_all(indices)
+ indices = indices.reshape(-1) # flatten again
+
+ # get quantized latent vectors
+ z_q = self.embedding(indices)
+
+ if shape is not None:
+ z_q = z_q.view(shape)
+ # reshape back to match original input shape
+ z_q = z_q.permute(0, 3, 1, 2).contiguous()
+
+ return z_q
+
+
+class EmbeddingEMA(nn.Module):
+ def __init__(self, num_tokens, codebook_dim, decay=0.99, eps=1e-5):
+ super().__init__()
+ self.decay = decay
+ self.eps = eps
+ weight = torch.randn(num_tokens, codebook_dim)
+ self.weight = nn.Parameter(weight, requires_grad=False)
+ self.cluster_size = nn.Parameter(torch.zeros(num_tokens), requires_grad=False)
+ self.embed_avg = nn.Parameter(weight.clone(), requires_grad=False)
+ self.update = True
+
+ def forward(self, embed_id):
+ return F.embedding(embed_id, self.weight)
+
+ def cluster_size_ema_update(self, new_cluster_size):
+ self.cluster_size.data.mul_(self.decay).add_(
+ new_cluster_size, alpha=1 - self.decay
+ )
+
+ def embed_avg_ema_update(self, new_embed_avg):
+ self.embed_avg.data.mul_(self.decay).add_(new_embed_avg, alpha=1 - self.decay)
+
+ def weight_update(self, num_tokens):
+ n = self.cluster_size.sum()
+ smoothed_cluster_size = (
+ (self.cluster_size + self.eps) / (n + num_tokens * self.eps) * n
+ )
+ # normalize embedding average with smoothed cluster size
+ embed_normalized = self.embed_avg / smoothed_cluster_size.unsqueeze(1)
+ self.weight.data.copy_(embed_normalized)
+
+
+class EMAVectorQuantizer(AbstractQuantizer):
+ def __init__(
+ self,
+ n_embed: int,
+ embedding_dim: int,
+ beta: float,
+ decay: float = 0.99,
+ eps: float = 1e-5,
+ remap: Optional[str] = None,
+ unknown_index: str = "random",
+ loss_key: str = "loss/vq",
+ ):
+ super().__init__()
+ self.codebook_dim = embedding_dim
+ self.num_tokens = n_embed
+ self.beta = beta
+ self.loss_key = loss_key
+
+ self.embedding = EmbeddingEMA(self.num_tokens, self.codebook_dim, decay, eps)
+
+ self.remap = remap
+ if self.remap is not None:
+ self.register_buffer("used", torch.tensor(np.load(self.remap)))
+ self.re_embed = self.used.shape[0]
+ else:
+ self.used = None
+ self.re_embed = n_embed
+ if unknown_index == "extra":
+ self.unknown_index = self.re_embed
+ self.re_embed = self.re_embed + 1
+ else:
+ assert unknown_index == "random" or isinstance(
+ unknown_index, int
+ ), "unknown index needs to be 'random', 'extra' or any integer"
+ self.unknown_index = unknown_index # "random" or "extra" or integer
+ if self.remap is not None:
+ logpy.info(
+ f"Remapping {self.n_embed} indices to {self.re_embed} indices. "
+ f"Using {self.unknown_index} for unknown indices."
+ )
+
+ def forward(self, z: torch.Tensor) -> Tuple[torch.Tensor, Dict]:
+ # reshape z -> (batch, height, width, channel) and flatten
+ # z, 'b c h w -> b h w c'
+ z = rearrange(z, "b c h w -> b h w c")
+ z_flattened = z.reshape(-1, self.codebook_dim)
+
+ # distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
+ d = (
+ z_flattened.pow(2).sum(dim=1, keepdim=True)
+ + self.embedding.weight.pow(2).sum(dim=1)
+ - 2 * torch.einsum("bd,nd->bn", z_flattened, self.embedding.weight)
+ ) # 'n d -> d n'
+
+ encoding_indices = torch.argmin(d, dim=1)
+
+ z_q = self.embedding(encoding_indices).view(z.shape)
+ encodings = F.one_hot(encoding_indices, self.num_tokens).type(z.dtype)
+ avg_probs = torch.mean(encodings, dim=0)
+ perplexity = torch.exp(-torch.sum(avg_probs * torch.log(avg_probs + 1e-10)))
+
+ if self.training and self.embedding.update:
+ # EMA cluster size
+ encodings_sum = encodings.sum(0)
+ self.embedding.cluster_size_ema_update(encodings_sum)
+ # EMA embedding average
+ embed_sum = encodings.transpose(0, 1) @ z_flattened
+ self.embedding.embed_avg_ema_update(embed_sum)
+ # normalize embed_avg and update weight
+ self.embedding.weight_update(self.num_tokens)
+
+ # compute loss for embedding
+ loss = self.beta * F.mse_loss(z_q.detach(), z)
+
+ # preserve gradients
+ z_q = z + (z_q - z).detach()
+
+ # reshape back to match original input shape
+ # z_q, 'b h w c -> b c h w'
+ z_q = rearrange(z_q, "b h w c -> b c h w")
+
+ out_dict = {
+ self.loss_key: loss,
+ "encodings": encodings,
+ "encoding_indices": encoding_indices,
+ "perplexity": perplexity,
+ }
+
+ return z_q, out_dict
+
+
+class VectorQuantizerWithInputProjection(VectorQuantizer):
+ def __init__(
+ self,
+ input_dim: int,
+ n_codes: int,
+ codebook_dim: int,
+ beta: float = 1.0,
+ output_dim: Optional[int] = None,
+ **kwargs,
+ ):
+ super().__init__(n_codes, codebook_dim, beta, **kwargs)
+ self.proj_in = nn.Linear(input_dim, codebook_dim)
+ self.output_dim = output_dim
+ if output_dim is not None:
+ self.proj_out = nn.Linear(codebook_dim, output_dim)
+ else:
+ self.proj_out = nn.Identity()
+
+ def forward(self, z: torch.Tensor) -> Tuple[torch.Tensor, Dict]:
+ rearr = False
+ in_shape = z.shape
+
+ if z.ndim > 3:
+ rearr = self.output_dim is not None
+ z = rearrange(z, "b c ... -> b (...) c")
+ z = self.proj_in(z)
+ z_q, loss_dict = super().forward(z)
+
+ z_q = self.proj_out(z_q)
+ if rearr:
+ if len(in_shape) == 4:
+ z_q = rearrange(z_q, "b (h w) c -> b c h w ", w=in_shape[-1])
+ elif len(in_shape) == 5:
+ z_q = rearrange(
+ z_q, "b (t h w) c -> b c t h w ", w=in_shape[-1], h=in_shape[-2]
+ )
+ else:
+ raise NotImplementedError(
+ f"rearranging not available for {len(in_shape)}-dimensional input."
+ )
+
+ return z_q, loss_dict
diff --git a/sgm/modules/autoencoding/temporal_ae.py b/sgm/modules/autoencoding/temporal_ae.py
new file mode 100644
index 0000000000000000000000000000000000000000..374373e2e4330846ffef28d9061dcc64f70d2722
--- /dev/null
+++ b/sgm/modules/autoencoding/temporal_ae.py
@@ -0,0 +1,349 @@
+from typing import Callable, Iterable, Union
+
+import torch
+from einops import rearrange, repeat
+
+from sgm.modules.diffusionmodules.model import (
+ XFORMERS_IS_AVAILABLE,
+ AttnBlock,
+ Decoder,
+ MemoryEfficientAttnBlock,
+ ResnetBlock,
+)
+from sgm.modules.diffusionmodules.openaimodel import ResBlock, timestep_embedding
+from sgm.modules.video_attention import VideoTransformerBlock
+from sgm.util import partialclass
+
+
+class VideoResBlock(ResnetBlock):
+ def __init__(
+ self,
+ out_channels,
+ *args,
+ dropout=0.0,
+ video_kernel_size=3,
+ alpha=0.0,
+ merge_strategy="learned",
+ **kwargs,
+ ):
+ super().__init__(out_channels=out_channels, dropout=dropout, *args, **kwargs)
+ if video_kernel_size is None:
+ video_kernel_size = [3, 1, 1]
+ self.time_stack = ResBlock(
+ channels=out_channels,
+ emb_channels=0,
+ dropout=dropout,
+ dims=3,
+ use_scale_shift_norm=False,
+ use_conv=False,
+ up=False,
+ down=False,
+ kernel_size=video_kernel_size,
+ use_checkpoint=False,
+ skip_t_emb=True,
+ )
+
+ self.merge_strategy = merge_strategy
+ if self.merge_strategy == "fixed":
+ self.register_buffer("mix_factor", torch.Tensor([alpha]))
+ elif self.merge_strategy == "learned":
+ self.register_parameter(
+ "mix_factor", torch.nn.Parameter(torch.Tensor([alpha]))
+ )
+ else:
+ raise ValueError(f"unknown merge strategy {self.merge_strategy}")
+
+ def get_alpha(self, bs):
+ if self.merge_strategy == "fixed":
+ return self.mix_factor
+ elif self.merge_strategy == "learned":
+ return torch.sigmoid(self.mix_factor)
+ else:
+ raise NotImplementedError()
+
+ def forward(self, x, temb, skip_video=False, timesteps=None):
+ if timesteps is None:
+ timesteps = self.timesteps
+
+ b, c, h, w = x.shape
+
+ x = super().forward(x, temb)
+
+ if not skip_video:
+ x_mix = rearrange(x, "(b t) c h w -> b c t h w", t=timesteps)
+
+ x = rearrange(x, "(b t) c h w -> b c t h w", t=timesteps)
+
+ x = self.time_stack(x, temb)
+
+ alpha = self.get_alpha(bs=b // timesteps)
+ x = alpha * x + (1.0 - alpha) * x_mix
+
+ x = rearrange(x, "b c t h w -> (b t) c h w")
+ return x
+
+
+class AE3DConv(torch.nn.Conv2d):
+ def __init__(self, in_channels, out_channels, video_kernel_size=3, *args, **kwargs):
+ super().__init__(in_channels, out_channels, *args, **kwargs)
+ if isinstance(video_kernel_size, Iterable):
+ padding = [int(k // 2) for k in video_kernel_size]
+ else:
+ padding = int(video_kernel_size // 2)
+
+ self.time_mix_conv = torch.nn.Conv3d(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ kernel_size=video_kernel_size,
+ padding=padding,
+ )
+
+ def forward(self, input, timesteps, skip_video=False):
+ x = super().forward(input)
+ if skip_video:
+ return x
+ x = rearrange(x, "(b t) c h w -> b c t h w", t=timesteps)
+ x = self.time_mix_conv(x)
+ return rearrange(x, "b c t h w -> (b t) c h w")
+
+
+class VideoBlock(AttnBlock):
+ def __init__(
+ self, in_channels: int, alpha: float = 0, merge_strategy: str = "learned"
+ ):
+ super().__init__(in_channels)
+ # no context, single headed, as in base class
+ self.time_mix_block = VideoTransformerBlock(
+ dim=in_channels,
+ n_heads=1,
+ d_head=in_channels,
+ checkpoint=False,
+ ff_in=True,
+ attn_mode="softmax",
+ )
+
+ time_embed_dim = self.in_channels * 4
+ self.video_time_embed = torch.nn.Sequential(
+ torch.nn.Linear(self.in_channels, time_embed_dim),
+ torch.nn.SiLU(),
+ torch.nn.Linear(time_embed_dim, self.in_channels),
+ )
+
+ self.merge_strategy = merge_strategy
+ if self.merge_strategy == "fixed":
+ self.register_buffer("mix_factor", torch.Tensor([alpha]))
+ elif self.merge_strategy == "learned":
+ self.register_parameter(
+ "mix_factor", torch.nn.Parameter(torch.Tensor([alpha]))
+ )
+ else:
+ raise ValueError(f"unknown merge strategy {self.merge_strategy}")
+
+ def forward(self, x, timesteps, skip_video=False):
+ if skip_video:
+ return super().forward(x)
+
+ x_in = x
+ x = self.attention(x)
+ h, w = x.shape[2:]
+ x = rearrange(x, "b c h w -> b (h w) c")
+
+ x_mix = x
+ num_frames = torch.arange(timesteps, device=x.device)
+ num_frames = repeat(num_frames, "t -> b t", b=x.shape[0] // timesteps)
+ num_frames = rearrange(num_frames, "b t -> (b t)")
+ t_emb = timestep_embedding(num_frames, self.in_channels, repeat_only=False)
+ emb = self.video_time_embed(t_emb) # b, n_channels
+ emb = emb[:, None, :]
+ x_mix = x_mix + emb
+
+ alpha = self.get_alpha()
+ x_mix = self.time_mix_block(x_mix, timesteps=timesteps)
+ x = alpha * x + (1.0 - alpha) * x_mix # alpha merge
+
+ x = rearrange(x, "b (h w) c -> b c h w", h=h, w=w)
+ x = self.proj_out(x)
+
+ return x_in + x
+
+ def get_alpha(
+ self,
+ ):
+ if self.merge_strategy == "fixed":
+ return self.mix_factor
+ elif self.merge_strategy == "learned":
+ return torch.sigmoid(self.mix_factor)
+ else:
+ raise NotImplementedError(f"unknown merge strategy {self.merge_strategy}")
+
+
+class MemoryEfficientVideoBlock(MemoryEfficientAttnBlock):
+ def __init__(
+ self, in_channels: int, alpha: float = 0, merge_strategy: str = "learned"
+ ):
+ super().__init__(in_channels)
+ # no context, single headed, as in base class
+ self.time_mix_block = VideoTransformerBlock(
+ dim=in_channels,
+ n_heads=1,
+ d_head=in_channels,
+ checkpoint=False,
+ ff_in=True,
+ attn_mode="softmax-xformers",
+ )
+
+ time_embed_dim = self.in_channels * 4
+ self.video_time_embed = torch.nn.Sequential(
+ torch.nn.Linear(self.in_channels, time_embed_dim),
+ torch.nn.SiLU(),
+ torch.nn.Linear(time_embed_dim, self.in_channels),
+ )
+
+ self.merge_strategy = merge_strategy
+ if self.merge_strategy == "fixed":
+ self.register_buffer("mix_factor", torch.Tensor([alpha]))
+ elif self.merge_strategy == "learned":
+ self.register_parameter(
+ "mix_factor", torch.nn.Parameter(torch.Tensor([alpha]))
+ )
+ else:
+ raise ValueError(f"unknown merge strategy {self.merge_strategy}")
+
+ def forward(self, x, timesteps, skip_time_block=False):
+ if skip_time_block:
+ return super().forward(x)
+
+ x_in = x
+ x = self.attention(x)
+ h, w = x.shape[2:]
+ x = rearrange(x, "b c h w -> b (h w) c")
+
+ x_mix = x
+ num_frames = torch.arange(timesteps, device=x.device)
+ num_frames = repeat(num_frames, "t -> b t", b=x.shape[0] // timesteps)
+ num_frames = rearrange(num_frames, "b t -> (b t)")
+ t_emb = timestep_embedding(num_frames, self.in_channels, repeat_only=False)
+ emb = self.video_time_embed(t_emb) # b, n_channels
+ emb = emb[:, None, :]
+ x_mix = x_mix + emb
+
+ alpha = self.get_alpha()
+ x_mix = self.time_mix_block(x_mix, timesteps=timesteps)
+ x = alpha * x + (1.0 - alpha) * x_mix # alpha merge
+
+ x = rearrange(x, "b (h w) c -> b c h w", h=h, w=w)
+ x = self.proj_out(x)
+
+ return x_in + x
+
+ def get_alpha(
+ self,
+ ):
+ if self.merge_strategy == "fixed":
+ return self.mix_factor
+ elif self.merge_strategy == "learned":
+ return torch.sigmoid(self.mix_factor)
+ else:
+ raise NotImplementedError(f"unknown merge strategy {self.merge_strategy}")
+
+
+def make_time_attn(
+ in_channels,
+ attn_type="vanilla",
+ attn_kwargs=None,
+ alpha: float = 0,
+ merge_strategy: str = "learned",
+):
+ assert attn_type in [
+ "vanilla",
+ "vanilla-xformers",
+ ], f"attn_type {attn_type} not supported for spatio-temporal attention"
+ print(
+ f"making spatial and temporal attention of type '{attn_type}' with {in_channels} in_channels"
+ )
+ if not XFORMERS_IS_AVAILABLE and attn_type == "vanilla-xformers":
+ print(
+ f"Attention mode '{attn_type}' is not available. Falling back to vanilla attention. "
+ f"This is not a problem in Pytorch >= 2.0. FYI, you are running with PyTorch version {torch.__version__}"
+ )
+ attn_type = "vanilla"
+
+ if attn_type == "vanilla":
+ assert attn_kwargs is None
+ return partialclass(
+ VideoBlock, in_channels, alpha=alpha, merge_strategy=merge_strategy
+ )
+ elif attn_type == "vanilla-xformers":
+ print(f"building MemoryEfficientAttnBlock with {in_channels} in_channels...")
+ return partialclass(
+ MemoryEfficientVideoBlock,
+ in_channels,
+ alpha=alpha,
+ merge_strategy=merge_strategy,
+ )
+ else:
+ return NotImplementedError()
+
+
+class Conv2DWrapper(torch.nn.Conv2d):
+ def forward(self, input: torch.Tensor, **kwargs) -> torch.Tensor:
+ return super().forward(input)
+
+
+class VideoDecoder(Decoder):
+ available_time_modes = ["all", "conv-only", "attn-only"]
+
+ def __init__(
+ self,
+ *args,
+ video_kernel_size: Union[int, list] = 3,
+ alpha: float = 0.0,
+ merge_strategy: str = "learned",
+ time_mode: str = "conv-only",
+ **kwargs,
+ ):
+ self.video_kernel_size = video_kernel_size
+ self.alpha = alpha
+ self.merge_strategy = merge_strategy
+ self.time_mode = time_mode
+ assert (
+ self.time_mode in self.available_time_modes
+ ), f"time_mode parameter has to be in {self.available_time_modes}"
+ super().__init__(*args, **kwargs)
+
+ def get_last_layer(self, skip_time_mix=False, **kwargs):
+ if self.time_mode == "attn-only":
+ raise NotImplementedError("TODO")
+ else:
+ return (
+ self.conv_out.time_mix_conv.weight
+ if not skip_time_mix
+ else self.conv_out.weight
+ )
+
+ def _make_attn(self) -> Callable:
+ if self.time_mode not in ["conv-only", "only-last-conv"]:
+ return partialclass(
+ make_time_attn,
+ alpha=self.alpha,
+ merge_strategy=self.merge_strategy,
+ )
+ else:
+ return super()._make_attn()
+
+ def _make_conv(self) -> Callable:
+ if self.time_mode != "attn-only":
+ return partialclass(AE3DConv, video_kernel_size=self.video_kernel_size)
+ else:
+ return Conv2DWrapper
+
+ def _make_resblock(self) -> Callable:
+ if self.time_mode not in ["attn-only", "only-last-conv"]:
+ return partialclass(
+ VideoResBlock,
+ video_kernel_size=self.video_kernel_size,
+ alpha=self.alpha,
+ merge_strategy=self.merge_strategy,
+ )
+ else:
+ return super()._make_resblock()
diff --git a/sgm/modules/diffusionmodules/__init__.py b/sgm/modules/diffusionmodules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/sgm/modules/diffusionmodules/denoiser.py b/sgm/modules/diffusionmodules/denoiser.py
new file mode 100644
index 0000000000000000000000000000000000000000..d86e7a262d1f036139e41f500d8579a2b95071ef
--- /dev/null
+++ b/sgm/modules/diffusionmodules/denoiser.py
@@ -0,0 +1,75 @@
+from typing import Dict, Union
+
+import torch
+import torch.nn as nn
+
+from ...util import append_dims, instantiate_from_config
+from .denoiser_scaling import DenoiserScaling
+from .discretizer import Discretization
+
+
+class Denoiser(nn.Module):
+ def __init__(self, scaling_config: Dict):
+ super().__init__()
+
+ self.scaling: DenoiserScaling = instantiate_from_config(scaling_config)
+
+ def possibly_quantize_sigma(self, sigma: torch.Tensor) -> torch.Tensor:
+ return sigma
+
+ def possibly_quantize_c_noise(self, c_noise: torch.Tensor) -> torch.Tensor:
+ return c_noise
+
+ def forward(
+ self,
+ network: nn.Module,
+ input: torch.Tensor,
+ sigma: torch.Tensor,
+ cond: Dict,
+ **additional_model_inputs,
+ ) -> torch.Tensor:
+ sigma = self.possibly_quantize_sigma(sigma)
+ sigma_shape = sigma.shape
+ sigma = append_dims(sigma, input.ndim)
+ c_skip, c_out, c_in, c_noise = self.scaling(sigma)
+ c_noise = self.possibly_quantize_c_noise(c_noise.reshape(sigma_shape))
+ return (
+ network(input * c_in, c_noise, cond, **additional_model_inputs) * c_out
+ + input * c_skip
+ )
+
+
+class DiscreteDenoiser(Denoiser):
+ def __init__(
+ self,
+ scaling_config: Dict,
+ num_idx: int,
+ discretization_config: Dict,
+ do_append_zero: bool = False,
+ quantize_c_noise: bool = True,
+ flip: bool = True,
+ ):
+ super().__init__(scaling_config)
+ self.discretization: Discretization = instantiate_from_config(
+ discretization_config
+ )
+ sigmas = self.discretization(num_idx, do_append_zero=do_append_zero, flip=flip)
+ self.register_buffer("sigmas", sigmas)
+ self.quantize_c_noise = quantize_c_noise
+ self.num_idx = num_idx
+
+ def sigma_to_idx(self, sigma: torch.Tensor) -> torch.Tensor:
+ dists = sigma - self.sigmas[:, None]
+ return dists.abs().argmin(dim=0).view(sigma.shape)
+
+ def idx_to_sigma(self, idx: Union[torch.Tensor, int]) -> torch.Tensor:
+ return self.sigmas[idx]
+
+ def possibly_quantize_sigma(self, sigma: torch.Tensor) -> torch.Tensor:
+ return self.idx_to_sigma(self.sigma_to_idx(sigma))
+
+ def possibly_quantize_c_noise(self, c_noise: torch.Tensor) -> torch.Tensor:
+ if self.quantize_c_noise:
+ return self.sigma_to_idx(c_noise)
+ else:
+ return c_noise
diff --git a/sgm/modules/diffusionmodules/denoiser_scaling.py b/sgm/modules/diffusionmodules/denoiser_scaling.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4e287bfe8a82839a9a12fbd25c3446f43ab493b
--- /dev/null
+++ b/sgm/modules/diffusionmodules/denoiser_scaling.py
@@ -0,0 +1,59 @@
+from abc import ABC, abstractmethod
+from typing import Tuple
+
+import torch
+
+
+class DenoiserScaling(ABC):
+ @abstractmethod
+ def __call__(
+ self, sigma: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
+ pass
+
+
+class EDMScaling:
+ def __init__(self, sigma_data: float = 0.5):
+ self.sigma_data = sigma_data
+
+ def __call__(
+ self, sigma: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
+ c_skip = self.sigma_data**2 / (sigma**2 + self.sigma_data**2)
+ c_out = sigma * self.sigma_data / (sigma**2 + self.sigma_data**2) ** 0.5
+ c_in = 1 / (sigma**2 + self.sigma_data**2) ** 0.5
+ c_noise = 0.25 * sigma.log()
+ return c_skip, c_out, c_in, c_noise
+
+
+class EpsScaling:
+ def __call__(
+ self, sigma: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
+ c_skip = torch.ones_like(sigma, device=sigma.device)
+ c_out = -sigma
+ c_in = 1 / (sigma**2 + 1.0) ** 0.5
+ c_noise = sigma.clone()
+ return c_skip, c_out, c_in, c_noise
+
+
+class VScaling:
+ def __call__(
+ self, sigma: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
+ c_skip = 1.0 / (sigma**2 + 1.0)
+ c_out = -sigma / (sigma**2 + 1.0) ** 0.5
+ c_in = 1.0 / (sigma**2 + 1.0) ** 0.5
+ c_noise = sigma.clone()
+ return c_skip, c_out, c_in, c_noise
+
+
+class VScalingWithEDMcNoise(DenoiserScaling):
+ def __call__(
+ self, sigma: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
+ c_skip = 1.0 / (sigma**2 + 1.0)
+ c_out = -sigma / (sigma**2 + 1.0) ** 0.5
+ c_in = 1.0 / (sigma**2 + 1.0) ** 0.5
+ c_noise = 0.25 * sigma.log()
+ return c_skip, c_out, c_in, c_noise
diff --git a/sgm/modules/diffusionmodules/denoiser_weighting.py b/sgm/modules/diffusionmodules/denoiser_weighting.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8b03ca58f17ea3d7374f4bbb7bf1d2994755e00
--- /dev/null
+++ b/sgm/modules/diffusionmodules/denoiser_weighting.py
@@ -0,0 +1,24 @@
+import torch
+
+
+class UnitWeighting:
+ def __call__(self, sigma):
+ return torch.ones_like(sigma, device=sigma.device)
+
+
+class EDMWeighting:
+ def __init__(self, sigma_data=0.5):
+ self.sigma_data = sigma_data
+
+ def __call__(self, sigma):
+ return (sigma**2 + self.sigma_data**2) / (sigma * self.sigma_data) ** 2
+
+
+class VWeighting(EDMWeighting):
+ def __init__(self):
+ super().__init__(sigma_data=1.0)
+
+
+class EpsWeighting:
+ def __call__(self, sigma):
+ return sigma**-2.0
diff --git a/sgm/modules/diffusionmodules/discretizer.py b/sgm/modules/diffusionmodules/discretizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..02add6081c5e3164d4402619b44d5be235d3ec58
--- /dev/null
+++ b/sgm/modules/diffusionmodules/discretizer.py
@@ -0,0 +1,69 @@
+from abc import abstractmethod
+from functools import partial
+
+import numpy as np
+import torch
+
+from ...modules.diffusionmodules.util import make_beta_schedule
+from ...util import append_zero
+
+
+def generate_roughly_equally_spaced_steps(
+ num_substeps: int, max_step: int
+) -> np.ndarray:
+ return np.linspace(max_step - 1, 0, num_substeps, endpoint=False).astype(int)[::-1]
+
+
+class Discretization:
+ def __call__(self, n, do_append_zero=True, device="cpu", flip=False):
+ sigmas = self.get_sigmas(n, device=device)
+ sigmas = append_zero(sigmas) if do_append_zero else sigmas
+ return sigmas if not flip else torch.flip(sigmas, (0,))
+
+ @abstractmethod
+ def get_sigmas(self, n, device):
+ pass
+
+
+class EDMDiscretization(Discretization):
+ def __init__(self, sigma_min=0.002, sigma_max=80.0, rho=7.0):
+ self.sigma_min = sigma_min
+ self.sigma_max = sigma_max
+ self.rho = rho
+
+ def get_sigmas(self, n, device="cpu"):
+ ramp = torch.linspace(0, 1, n, device=device)
+ min_inv_rho = self.sigma_min ** (1 / self.rho)
+ max_inv_rho = self.sigma_max ** (1 / self.rho)
+ sigmas = (max_inv_rho + ramp * (min_inv_rho - max_inv_rho)) ** self.rho
+ return sigmas
+
+
+class LegacyDDPMDiscretization(Discretization):
+ def __init__(
+ self,
+ linear_start=0.00085,
+ linear_end=0.0120,
+ num_timesteps=1000,
+ ):
+ super().__init__()
+ self.num_timesteps = num_timesteps
+ betas = make_beta_schedule(
+ "linear", num_timesteps, linear_start=linear_start, linear_end=linear_end
+ )
+ alphas = 1.0 - betas
+ self.alphas_cumprod = np.cumprod(alphas, axis=0)
+ self.to_torch = partial(torch.tensor, dtype=torch.float32)
+
+ def get_sigmas(self, n, device="cpu"):
+ if n < self.num_timesteps:
+ timesteps = generate_roughly_equally_spaced_steps(n, self.num_timesteps)
+ alphas_cumprod = self.alphas_cumprod[timesteps]
+ elif n == self.num_timesteps:
+ alphas_cumprod = self.alphas_cumprod
+ else:
+ raise ValueError
+
+ to_torch = partial(torch.tensor, dtype=torch.float32, device=device)
+ sigmas = to_torch((1 - alphas_cumprod) / alphas_cumprod) ** 0.5
+ return torch.flip(sigmas, (0,))
diff --git a/sgm/modules/diffusionmodules/guiders.py b/sgm/modules/diffusionmodules/guiders.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8eca43e8b7b8b7b0e6b9f3e2bddbae6e3456fee
--- /dev/null
+++ b/sgm/modules/diffusionmodules/guiders.py
@@ -0,0 +1,99 @@
+import logging
+from abc import ABC, abstractmethod
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+from einops import rearrange, repeat
+
+from ...util import append_dims, default
+
+logpy = logging.getLogger(__name__)
+
+
+class Guider(ABC):
+ @abstractmethod
+ def __call__(self, x: torch.Tensor, sigma: float) -> torch.Tensor:
+ pass
+
+ def prepare_inputs(
+ self, x: torch.Tensor, s: float, c: Dict, uc: Dict
+ ) -> Tuple[torch.Tensor, float, Dict]:
+ pass
+
+
+class VanillaCFG(Guider):
+ def __init__(self, scale: float):
+ self.scale = scale
+
+ def __call__(self, x: torch.Tensor, sigma: torch.Tensor) -> torch.Tensor:
+ x_u, x_c = x.chunk(2)
+ x_pred = x_u + self.scale * (x_c - x_u)
+ return x_pred
+
+ def prepare_inputs(self, x, s, c, uc):
+ c_out = dict()
+
+ for k in c:
+ if k in ["vector", "crossattn", "concat"]:
+ c_out[k] = torch.cat((uc[k], c[k]), 0)
+ else:
+ assert c[k] == uc[k]
+ c_out[k] = c[k]
+ return torch.cat([x] * 2), torch.cat([s] * 2), c_out
+
+
+class IdentityGuider(Guider):
+ def __call__(self, x: torch.Tensor, sigma: float) -> torch.Tensor:
+ return x
+
+ def prepare_inputs(
+ self, x: torch.Tensor, s: float, c: Dict, uc: Dict
+ ) -> Tuple[torch.Tensor, float, Dict]:
+ c_out = dict()
+
+ for k in c:
+ c_out[k] = c[k]
+
+ return x, s, c_out
+
+
+class LinearPredictionGuider(Guider):
+ def __init__(
+ self,
+ max_scale: float,
+ num_frames: int,
+ min_scale: float = 1.0,
+ additional_cond_keys: Optional[Union[List[str], str]] = None,
+ ):
+ self.min_scale = min_scale
+ self.max_scale = max_scale
+ self.num_frames = num_frames
+ self.scale = torch.linspace(min_scale, max_scale, num_frames).unsqueeze(0)
+
+ additional_cond_keys = default(additional_cond_keys, [])
+ if isinstance(additional_cond_keys, str):
+ additional_cond_keys = [additional_cond_keys]
+ self.additional_cond_keys = additional_cond_keys
+
+ def __call__(self, x: torch.Tensor, sigma: torch.Tensor) -> torch.Tensor:
+ x_u, x_c = x.chunk(2)
+
+ x_u = rearrange(x_u, "(b t) ... -> b t ...", t=self.num_frames)
+ x_c = rearrange(x_c, "(b t) ... -> b t ...", t=self.num_frames)
+ scale = repeat(self.scale, "1 t -> b t", b=x_u.shape[0])
+ scale = append_dims(scale, x_u.ndim).to(x_u.device)
+
+ return rearrange(x_u + scale * (x_c - x_u), "b t ... -> (b t) ...")
+
+ def prepare_inputs(
+ self, x: torch.Tensor, s: torch.Tensor, c: dict, uc: dict
+ ) -> Tuple[torch.Tensor, torch.Tensor, dict]:
+ c_out = dict()
+
+ for k in c:
+ if k in ["vector", "crossattn", "concat"] + self.additional_cond_keys:
+ c_out[k] = torch.cat((uc[k], c[k]), 0)
+ else:
+ assert c[k] == uc[k]
+ c_out[k] = c[k]
+ return torch.cat([x] * 2), torch.cat([s] * 2), c_out
diff --git a/sgm/modules/diffusionmodules/loss.py b/sgm/modules/diffusionmodules/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4ca6803cd62f7ff4bf6d37f869ef6bad1024d9f
--- /dev/null
+++ b/sgm/modules/diffusionmodules/loss.py
@@ -0,0 +1,111 @@
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from ...modules.autoencoding.lpips.loss.lpips import LPIPS
+from ...modules.encoders.modules import GeneralConditioner
+from ...util import append_dims, instantiate_from_config
+from .denoiser import Denoiser
+from einops import rearrange, repeat
+
+
+class StandardDiffusionLoss(nn.Module):
+ def __init__(
+ self,
+ sigma_sampler_config: dict,
+ loss_weighting_config: dict,
+ loss_type: str = "l2",
+ offset_noise_level: float = 0.0,
+ batch2model_keys: Optional[Union[str, List[str]]] = None,
+ num_frames: int = 1,
+ ):
+ super().__init__()
+
+ assert loss_type in ["l2", "l1", "lpips"]
+
+ self.sigma_sampler = instantiate_from_config(sigma_sampler_config)
+ self.loss_weighting = instantiate_from_config(loss_weighting_config)
+
+ self.loss_type = loss_type
+ self.offset_noise_level = offset_noise_level
+
+ if loss_type == "lpips":
+ self.lpips = LPIPS().eval()
+
+ if not batch2model_keys:
+ batch2model_keys = []
+
+ if isinstance(batch2model_keys, str):
+ batch2model_keys = [batch2model_keys]
+
+ self.batch2model_keys = set(batch2model_keys)
+
+ self.num_frames = num_frames
+
+ def get_noised_input(
+ self, sigmas_bc: torch.Tensor, noise: torch.Tensor, input: torch.Tensor
+ ) -> torch.Tensor:
+ noised_input = input + noise * sigmas_bc
+ return noised_input
+
+ def forward(
+ self,
+ network: nn.Module,
+ denoiser: Denoiser,
+ conditioner: GeneralConditioner,
+ input: torch.Tensor,
+ batch: Dict,
+ ) -> torch.Tensor:
+ cond = conditioner(batch)
+ return self._forward(network, denoiser, cond, input, batch)
+
+ def _forward(
+ self,
+ network: nn.Module,
+ denoiser: Denoiser,
+ cond: Dict,
+ input: torch.Tensor,
+ batch: Dict,
+ ) -> Tuple[torch.Tensor, Dict]:
+ additional_model_inputs = {
+ key: batch[key] for key in self.batch2model_keys.intersection(batch)
+ }
+ b = input.shape[0] // self.num_frames
+ sigmas = self.sigma_sampler(b).to(input)
+ sigmas = repeat(sigmas, "b -> (b t)", t=self.num_frames)
+
+ noise = torch.randn_like(input)
+ if self.offset_noise_level > 0.0:
+ offset_shape = (
+ (input.shape[0], 1, input.shape[2])
+ if self.n_frames is not None
+ else (input.shape[0], input.shape[1])
+ )
+ noise = noise + self.offset_noise_level * append_dims(
+ torch.randn(offset_shape, device=input.device),
+ input.ndim,
+ )
+ sigmas_bc = append_dims(sigmas, input.ndim)
+ noised_input = self.get_noised_input(sigmas_bc, noise, input)
+
+ model_output = denoiser(
+ network, noised_input, sigmas, cond, **additional_model_inputs
+ )
+ w = append_dims(self.loss_weighting(sigmas), input.ndim)
+ return self.get_loss(model_output, input, w)
+
+ def get_loss(self, model_output, target, w):
+ if self.loss_type == "l2":
+ return torch.mean(
+ (w * (model_output - target) ** 2).reshape(target.shape[0], -1), 1
+ )
+ elif self.loss_type == "l1":
+ return torch.mean(
+ (w * (model_output - target).abs()).reshape(target.shape[0], -1), 1
+ )
+ elif self.loss_type == "lpips":
+ loss = self.lpips(model_output, target).reshape(-1)
+ return loss
+ else:
+ raise NotImplementedError(f"Unknown loss type {self.loss_type}")
diff --git a/sgm/modules/diffusionmodules/loss_old.py b/sgm/modules/diffusionmodules/loss_old.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d6999fbd270cae7d0ffe2ed27d0f0c435b7c19b
--- /dev/null
+++ b/sgm/modules/diffusionmodules/loss_old.py
@@ -0,0 +1,108 @@
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from ..autoencoding.lpips.loss.lpips import LPIPS
+from ..encoders.modules import GeneralConditioner
+from ...util import append_dims, instantiate_from_config
+from .denoiser import Denoiser
+
+
+class StandardDiffusionLoss(nn.Module):
+ def __init__(
+ self,
+ sigma_sampler_config: dict,
+ loss_weighting_config: dict,
+ loss_type: str = "l2",
+ offset_noise_level: float = 0.0,
+ batch2model_keys: Optional[Union[str, List[str]]] = None,
+ num_frames = 16,
+ ):
+ super().__init__()
+
+ assert loss_type in ["l2", "l1", "lpips"]
+
+ self.sigma_sampler = instantiate_from_config(sigma_sampler_config)
+ self.loss_weighting = instantiate_from_config(loss_weighting_config)
+
+ self.loss_type = loss_type
+ self.offset_noise_level = offset_noise_level
+
+ if loss_type == "lpips":
+ self.lpips = LPIPS().eval()
+
+ if not batch2model_keys:
+ batch2model_keys = []
+
+ if isinstance(batch2model_keys, str):
+ batch2model_keys = [batch2model_keys]
+
+ self.batch2model_keys = set(batch2model_keys)
+
+ self.num_frames = num_frames
+
+ def get_noised_input(
+ self, sigmas_bc: torch.Tensor, noise: torch.Tensor, input: torch.Tensor
+ ) -> torch.Tensor:
+ noised_input = input + noise * sigmas_bc
+ return noised_input
+
+ def forward(
+ self,
+ network: nn.Module,
+ denoiser: Denoiser,
+ conditioner: GeneralConditioner,
+ input: torch.Tensor,
+ batch: Dict,
+ ) -> torch.Tensor:
+ cond = conditioner(batch)
+ return self._forward(network, denoiser, cond, input, batch)
+
+ def _forward(
+ self,
+ network: nn.Module,
+ denoiser: Denoiser,
+ cond: Dict,
+ input: torch.Tensor,
+ batch: Dict,
+ ) -> Tuple[torch.Tensor, Dict]:
+ additional_model_inputs = {
+ key: batch[key] for key in self.batch2model_keys.intersection(batch)
+ }
+ sigmas = self.sigma_sampler(input.shape[0]).to(input)
+
+ noise = torch.randn_like(input)
+ if self.offset_noise_level > 0.0:
+ offset_shape = (
+ (input.shape[0], 1, input.shape[2])
+ if self.n_frames is not None
+ else (input.shape[0], input.shape[1])
+ )
+ noise = noise + self.offset_noise_level * append_dims(
+ torch.randn(offset_shape, device=input.device),
+ input.ndim,
+ )
+ sigmas_bc = append_dims(sigmas, input.ndim)
+ noised_input = self.get_noised_input(sigmas_bc, noise, input)
+
+ model_output = denoiser(
+ network, noised_input, sigmas, cond, **additional_model_inputs
+ )
+ w = append_dims(self.loss_weighting(sigmas), input.ndim)
+ return self.get_loss(model_output, input, w)
+
+ def get_loss(self, model_output, target, w):
+ if self.loss_type == "l2":
+ return torch.mean(
+ (w * (model_output - target) ** 2).reshape(target.shape[0], -1), 1
+ )
+ elif self.loss_type == "l1":
+ return torch.mean(
+ (w * (model_output - target).abs()).reshape(target.shape[0], -1), 1
+ )
+ elif self.loss_type == "lpips":
+ loss = self.lpips(model_output, target).reshape(-1)
+ return loss
+ else:
+ raise NotImplementedError(f"Unknown loss type {self.loss_type}")
diff --git a/sgm/modules/diffusionmodules/loss_weighting.py b/sgm/modules/diffusionmodules/loss_weighting.py
new file mode 100644
index 0000000000000000000000000000000000000000..e12c0a76635435babd1af33969e82fa284525af8
--- /dev/null
+++ b/sgm/modules/diffusionmodules/loss_weighting.py
@@ -0,0 +1,32 @@
+from abc import ABC, abstractmethod
+
+import torch
+
+
+class DiffusionLossWeighting(ABC):
+ @abstractmethod
+ def __call__(self, sigma: torch.Tensor) -> torch.Tensor:
+ pass
+
+
+class UnitWeighting(DiffusionLossWeighting):
+ def __call__(self, sigma: torch.Tensor) -> torch.Tensor:
+ return torch.ones_like(sigma, device=sigma.device)
+
+
+class EDMWeighting(DiffusionLossWeighting):
+ def __init__(self, sigma_data: float = 0.5):
+ self.sigma_data = sigma_data
+
+ def __call__(self, sigma: torch.Tensor) -> torch.Tensor:
+ return (sigma**2 + self.sigma_data**2) / (sigma * self.sigma_data) ** 2
+
+
+class VWeighting(EDMWeighting):
+ def __init__(self):
+ super().__init__(sigma_data=1.0)
+
+
+class EpsWeighting(DiffusionLossWeighting):
+ def __call__(self, sigma: torch.Tensor) -> torch.Tensor:
+ return sigma**-2.0
diff --git a/sgm/modules/diffusionmodules/model.py b/sgm/modules/diffusionmodules/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cf9d92140dee8443a0ea6b5cf218f2879ad88f4
--- /dev/null
+++ b/sgm/modules/diffusionmodules/model.py
@@ -0,0 +1,748 @@
+# pytorch_diffusion + derived encoder decoder
+import logging
+import math
+from typing import Any, Callable, Optional
+
+import numpy as np
+import torch
+import torch.nn as nn
+from einops import rearrange
+from packaging import version
+
+logpy = logging.getLogger(__name__)
+
+try:
+ import xformers
+ import xformers.ops
+
+ XFORMERS_IS_AVAILABLE = True
+except:
+ XFORMERS_IS_AVAILABLE = False
+ logpy.warning("no module 'xformers'. Processing without...")
+
+from ...modules.attention import LinearAttention, MemoryEfficientCrossAttention
+
+
+def get_timestep_embedding(timesteps, embedding_dim):
+ """
+ This matches the implementation in Denoising Diffusion Probabilistic Models:
+ From Fairseq.
+ Build sinusoidal embeddings.
+ This matches the implementation in tensor2tensor, but differs slightly
+ from the description in Section 3.5 of "Attention Is All You Need".
+ """
+ assert len(timesteps.shape) == 1
+
+ half_dim = embedding_dim // 2
+ emb = math.log(10000) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
+ emb = emb.to(device=timesteps.device)
+ emb = timesteps.float()[:, None] * emb[None, :]
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
+ if embedding_dim % 2 == 1: # zero pad
+ emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
+ return emb
+
+
+def nonlinearity(x):
+ # swish
+ return x * torch.sigmoid(x)
+
+
+def Normalize(in_channels, num_groups=32):
+ return torch.nn.GroupNorm(
+ num_groups=num_groups, num_channels=in_channels, eps=1e-6, affine=True
+ )
+
+
+class Upsample(nn.Module):
+ def __init__(self, in_channels, with_conv):
+ super().__init__()
+ self.with_conv = with_conv
+ if self.with_conv:
+ self.conv = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=3, stride=1, padding=1
+ )
+
+ def forward(self, x):
+ x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
+ if self.with_conv:
+ x = self.conv(x)
+ return x
+
+
+class Downsample(nn.Module):
+ def __init__(self, in_channels, with_conv):
+ super().__init__()
+ self.with_conv = with_conv
+ if self.with_conv:
+ # no asymmetric padding in torch conv, must do it ourselves
+ self.conv = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=3, stride=2, padding=0
+ )
+
+ def forward(self, x):
+ if self.with_conv:
+ pad = (0, 1, 0, 1)
+ x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
+ x = self.conv(x)
+ else:
+ x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
+ return x
+
+
+class ResnetBlock(nn.Module):
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout,
+ temb_channels=512,
+ ):
+ super().__init__()
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+
+ self.norm1 = Normalize(in_channels)
+ self.conv1 = torch.nn.Conv2d(
+ in_channels, out_channels, kernel_size=3, stride=1, padding=1
+ )
+ if temb_channels > 0:
+ self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
+ self.norm2 = Normalize(out_channels)
+ self.dropout = torch.nn.Dropout(dropout)
+ self.conv2 = torch.nn.Conv2d(
+ out_channels, out_channels, kernel_size=3, stride=1, padding=1
+ )
+ if self.in_channels != self.out_channels:
+ if self.use_conv_shortcut:
+ self.conv_shortcut = torch.nn.Conv2d(
+ in_channels, out_channels, kernel_size=3, stride=1, padding=1
+ )
+ else:
+ self.nin_shortcut = torch.nn.Conv2d(
+ in_channels, out_channels, kernel_size=1, stride=1, padding=0
+ )
+
+ def forward(self, x, temb):
+ h = x
+ h = self.norm1(h)
+ h = nonlinearity(h)
+ h = self.conv1(h)
+
+ if temb is not None:
+ h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
+
+ h = self.norm2(h)
+ h = nonlinearity(h)
+ h = self.dropout(h)
+ h = self.conv2(h)
+
+ if self.in_channels != self.out_channels:
+ if self.use_conv_shortcut:
+ x = self.conv_shortcut(x)
+ else:
+ x = self.nin_shortcut(x)
+
+ return x + h
+
+
+class LinAttnBlock(LinearAttention):
+ """to match AttnBlock usage"""
+
+ def __init__(self, in_channels):
+ super().__init__(dim=in_channels, heads=1, dim_head=in_channels)
+
+
+class AttnBlock(nn.Module):
+ def __init__(self, in_channels):
+ super().__init__()
+ self.in_channels = in_channels
+
+ self.norm = Normalize(in_channels)
+ self.q = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.k = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.v = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.proj_out = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+
+ def attention(self, h_: torch.Tensor) -> torch.Tensor:
+ h_ = self.norm(h_)
+ q = self.q(h_)
+ k = self.k(h_)
+ v = self.v(h_)
+
+ b, c, h, w = q.shape
+ q, k, v = map(
+ lambda x: rearrange(x, "b c h w -> b 1 (h w) c").contiguous(), (q, k, v)
+ )
+ h_ = torch.nn.functional.scaled_dot_product_attention(
+ q, k, v
+ ) # scale is dim ** -0.5 per default
+ # compute attention
+
+ return rearrange(h_, "b 1 (h w) c -> b c h w", h=h, w=w, c=c, b=b)
+
+ def forward(self, x, **kwargs):
+ h_ = x
+ h_ = self.attention(h_)
+ h_ = self.proj_out(h_)
+ return x + h_
+
+
+class MemoryEfficientAttnBlock(nn.Module):
+ """
+ Uses xformers efficient implementation,
+ see https://github.com/MatthieuTPHR/diffusers/blob/d80b531ff8060ec1ea982b65a1b8df70f73aa67c/src/diffusers/models/attention.py#L223
+ Note: this is a single-head self-attention operation
+ """
+
+ #
+ def __init__(self, in_channels):
+ super().__init__()
+ self.in_channels = in_channels
+
+ self.norm = Normalize(in_channels)
+ self.q = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.k = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.v = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.proj_out = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.attention_op: Optional[Any] = None
+
+ def attention(self, h_: torch.Tensor) -> torch.Tensor:
+ h_ = self.norm(h_)
+ q = self.q(h_)
+ k = self.k(h_)
+ v = self.v(h_)
+
+ # compute attention
+ B, C, H, W = q.shape
+ q, k, v = map(lambda x: rearrange(x, "b c h w -> b (h w) c"), (q, k, v))
+
+ q, k, v = map(
+ lambda t: t.unsqueeze(3)
+ .reshape(B, t.shape[1], 1, C)
+ .permute(0, 2, 1, 3)
+ .reshape(B * 1, t.shape[1], C)
+ .contiguous(),
+ (q, k, v),
+ )
+ out = xformers.ops.memory_efficient_attention(
+ q, k, v, attn_bias=None, op=self.attention_op
+ )
+
+ out = (
+ out.unsqueeze(0)
+ .reshape(B, 1, out.shape[1], C)
+ .permute(0, 2, 1, 3)
+ .reshape(B, out.shape[1], C)
+ )
+ return rearrange(out, "b (h w) c -> b c h w", b=B, h=H, w=W, c=C)
+
+ def forward(self, x, **kwargs):
+ h_ = x
+ h_ = self.attention(h_)
+ h_ = self.proj_out(h_)
+ return x + h_
+
+
+class MemoryEfficientCrossAttentionWrapper(MemoryEfficientCrossAttention):
+ def forward(self, x, context=None, mask=None, **unused_kwargs):
+ b, c, h, w = x.shape
+ x = rearrange(x, "b c h w -> b (h w) c")
+ out = super().forward(x, context=context, mask=mask)
+ out = rearrange(out, "b (h w) c -> b c h w", h=h, w=w, c=c)
+ return x + out
+
+
+def make_attn(in_channels, attn_type="vanilla", attn_kwargs=None):
+ assert attn_type in [
+ "vanilla",
+ "vanilla-xformers",
+ "memory-efficient-cross-attn",
+ "linear",
+ "none",
+ ], f"attn_type {attn_type} unknown"
+ if (
+ version.parse(torch.__version__) < version.parse("2.0.0")
+ and attn_type != "none"
+ ):
+ assert XFORMERS_IS_AVAILABLE, (
+ f"We do not support vanilla attention in {torch.__version__} anymore, "
+ f"as it is too expensive. Please install xformers via e.g. 'pip install xformers==0.0.16'"
+ )
+ attn_type = "vanilla-xformers"
+ logpy.info(f"making attention of type '{attn_type}' with {in_channels} in_channels")
+ if attn_type == "vanilla":
+ assert attn_kwargs is None
+ return AttnBlock(in_channels)
+ elif attn_type == "vanilla-xformers":
+ logpy.info(
+ f"building MemoryEfficientAttnBlock with {in_channels} in_channels..."
+ )
+ return MemoryEfficientAttnBlock(in_channels)
+ elif type == "memory-efficient-cross-attn":
+ attn_kwargs["query_dim"] = in_channels
+ return MemoryEfficientCrossAttentionWrapper(**attn_kwargs)
+ elif attn_type == "none":
+ return nn.Identity(in_channels)
+ else:
+ return LinAttnBlock(in_channels)
+
+
+class Model(nn.Module):
+ def __init__(
+ self,
+ *,
+ ch,
+ out_ch,
+ ch_mult=(1, 2, 4, 8),
+ num_res_blocks,
+ attn_resolutions,
+ dropout=0.0,
+ resamp_with_conv=True,
+ in_channels,
+ resolution,
+ use_timestep=True,
+ use_linear_attn=False,
+ attn_type="vanilla",
+ ):
+ super().__init__()
+ if use_linear_attn:
+ attn_type = "linear"
+ self.ch = ch
+ self.temb_ch = self.ch * 4
+ self.num_resolutions = len(ch_mult)
+ self.num_res_blocks = num_res_blocks
+ self.resolution = resolution
+ self.in_channels = in_channels
+
+ self.use_timestep = use_timestep
+ if self.use_timestep:
+ # timestep embedding
+ self.temb = nn.Module()
+ self.temb.dense = nn.ModuleList(
+ [
+ torch.nn.Linear(self.ch, self.temb_ch),
+ torch.nn.Linear(self.temb_ch, self.temb_ch),
+ ]
+ )
+
+ # downsampling
+ self.conv_in = torch.nn.Conv2d(
+ in_channels, self.ch, kernel_size=3, stride=1, padding=1
+ )
+
+ curr_res = resolution
+ in_ch_mult = (1,) + tuple(ch_mult)
+ self.down = nn.ModuleList()
+ for i_level in range(self.num_resolutions):
+ block = nn.ModuleList()
+ attn = nn.ModuleList()
+ block_in = ch * in_ch_mult[i_level]
+ block_out = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks):
+ block.append(
+ ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ if curr_res in attn_resolutions:
+ attn.append(make_attn(block_in, attn_type=attn_type))
+ down = nn.Module()
+ down.block = block
+ down.attn = attn
+ if i_level != self.num_resolutions - 1:
+ down.downsample = Downsample(block_in, resamp_with_conv)
+ curr_res = curr_res // 2
+ self.down.append(down)
+
+ # middle
+ self.mid = nn.Module()
+ self.mid.block_1 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
+ self.mid.block_2 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+
+ # upsampling
+ self.up = nn.ModuleList()
+ for i_level in reversed(range(self.num_resolutions)):
+ block = nn.ModuleList()
+ attn = nn.ModuleList()
+ block_out = ch * ch_mult[i_level]
+ skip_in = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks + 1):
+ if i_block == self.num_res_blocks:
+ skip_in = ch * in_ch_mult[i_level]
+ block.append(
+ ResnetBlock(
+ in_channels=block_in + skip_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ if curr_res in attn_resolutions:
+ attn.append(make_attn(block_in, attn_type=attn_type))
+ up = nn.Module()
+ up.block = block
+ up.attn = attn
+ if i_level != 0:
+ up.upsample = Upsample(block_in, resamp_with_conv)
+ curr_res = curr_res * 2
+ self.up.insert(0, up) # prepend to get consistent order
+
+ # end
+ self.norm_out = Normalize(block_in)
+ self.conv_out = torch.nn.Conv2d(
+ block_in, out_ch, kernel_size=3, stride=1, padding=1
+ )
+
+ def forward(self, x, t=None, context=None):
+ # assert x.shape[2] == x.shape[3] == self.resolution
+ if context is not None:
+ # assume aligned context, cat along channel axis
+ x = torch.cat((x, context), dim=1)
+ if self.use_timestep:
+ # timestep embedding
+ assert t is not None
+ temb = get_timestep_embedding(t, self.ch)
+ temb = self.temb.dense[0](temb)
+ temb = nonlinearity(temb)
+ temb = self.temb.dense[1](temb)
+ else:
+ temb = None
+
+ # downsampling
+ hs = [self.conv_in(x)]
+ for i_level in range(self.num_resolutions):
+ for i_block in range(self.num_res_blocks):
+ h = self.down[i_level].block[i_block](hs[-1], temb)
+ if len(self.down[i_level].attn) > 0:
+ h = self.down[i_level].attn[i_block](h)
+ hs.append(h)
+ if i_level != self.num_resolutions - 1:
+ hs.append(self.down[i_level].downsample(hs[-1]))
+
+ # middle
+ h = hs[-1]
+ h = self.mid.block_1(h, temb)
+ h = self.mid.attn_1(h)
+ h = self.mid.block_2(h, temb)
+
+ # upsampling
+ for i_level in reversed(range(self.num_resolutions)):
+ for i_block in range(self.num_res_blocks + 1):
+ h = self.up[i_level].block[i_block](
+ torch.cat([h, hs.pop()], dim=1), temb
+ )
+ if len(self.up[i_level].attn) > 0:
+ h = self.up[i_level].attn[i_block](h)
+ if i_level != 0:
+ h = self.up[i_level].upsample(h)
+
+ # end
+ h = self.norm_out(h)
+ h = nonlinearity(h)
+ h = self.conv_out(h)
+ return h
+
+ def get_last_layer(self):
+ return self.conv_out.weight
+
+
+class Encoder(nn.Module):
+ def __init__(
+ self,
+ *,
+ ch,
+ out_ch,
+ ch_mult=(1, 2, 4, 8),
+ num_res_blocks,
+ attn_resolutions,
+ dropout=0.0,
+ resamp_with_conv=True,
+ in_channels,
+ resolution,
+ z_channels,
+ double_z=True,
+ use_linear_attn=False,
+ attn_type="vanilla",
+ **ignore_kwargs,
+ ):
+ super().__init__()
+ if use_linear_attn:
+ attn_type = "linear"
+ self.ch = ch
+ self.temb_ch = 0
+ self.num_resolutions = len(ch_mult)
+ self.num_res_blocks = num_res_blocks
+ self.resolution = resolution
+ self.in_channels = in_channels
+
+ # downsampling
+ self.conv_in = torch.nn.Conv2d(
+ in_channels, self.ch, kernel_size=3, stride=1, padding=1
+ )
+
+ curr_res = resolution
+ in_ch_mult = (1,) + tuple(ch_mult)
+ self.in_ch_mult = in_ch_mult
+ self.down = nn.ModuleList()
+ for i_level in range(self.num_resolutions):
+ block = nn.ModuleList()
+ attn = nn.ModuleList()
+ block_in = ch * in_ch_mult[i_level]
+ block_out = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks):
+ block.append(
+ ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ if curr_res in attn_resolutions:
+ attn.append(make_attn(block_in, attn_type=attn_type))
+ down = nn.Module()
+ down.block = block
+ down.attn = attn
+ if i_level != self.num_resolutions - 1:
+ down.downsample = Downsample(block_in, resamp_with_conv)
+ curr_res = curr_res // 2
+ self.down.append(down)
+
+ # middle
+ self.mid = nn.Module()
+ self.mid.block_1 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
+ self.mid.block_2 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+
+ # end
+ self.norm_out = Normalize(block_in)
+ self.conv_out = torch.nn.Conv2d(
+ block_in,
+ 2 * z_channels if double_z else z_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ )
+
+ def forward(self, x):
+ # timestep embedding
+ temb = None
+
+ # downsampling
+ hs = [self.conv_in(x)]
+ for i_level in range(self.num_resolutions):
+ for i_block in range(self.num_res_blocks):
+ h = self.down[i_level].block[i_block](hs[-1], temb)
+ if len(self.down[i_level].attn) > 0:
+ h = self.down[i_level].attn[i_block](h)
+ hs.append(h)
+ if i_level != self.num_resolutions - 1:
+ hs.append(self.down[i_level].downsample(hs[-1]))
+
+ # middle
+ h = hs[-1]
+ h = self.mid.block_1(h, temb)
+ h = self.mid.attn_1(h)
+ h = self.mid.block_2(h, temb)
+
+ # end
+ h = self.norm_out(h)
+ h = nonlinearity(h)
+ h = self.conv_out(h)
+ return h
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self,
+ *,
+ ch,
+ out_ch,
+ ch_mult=(1, 2, 4, 8),
+ num_res_blocks,
+ attn_resolutions,
+ dropout=0.0,
+ resamp_with_conv=True,
+ in_channels,
+ resolution,
+ z_channels,
+ give_pre_end=False,
+ tanh_out=False,
+ use_linear_attn=False,
+ attn_type="vanilla",
+ **ignorekwargs,
+ ):
+ super().__init__()
+ if use_linear_attn:
+ attn_type = "linear"
+ self.ch = ch
+ self.temb_ch = 0
+ self.num_resolutions = len(ch_mult)
+ self.num_res_blocks = num_res_blocks
+ self.resolution = resolution
+ self.in_channels = in_channels
+ self.give_pre_end = give_pre_end
+ self.tanh_out = tanh_out
+
+ # compute in_ch_mult, block_in and curr_res at lowest res
+ in_ch_mult = (1,) + tuple(ch_mult)
+ block_in = ch * ch_mult[self.num_resolutions - 1]
+ curr_res = resolution // 2 ** (self.num_resolutions - 1)
+ self.z_shape = (1, z_channels, curr_res, curr_res)
+ logpy.info(
+ "Working with z of shape {} = {} dimensions.".format(
+ self.z_shape, np.prod(self.z_shape)
+ )
+ )
+
+ make_attn_cls = self._make_attn()
+ make_resblock_cls = self._make_resblock()
+ make_conv_cls = self._make_conv()
+ # z to block_in
+ self.conv_in = torch.nn.Conv2d(
+ z_channels, block_in, kernel_size=3, stride=1, padding=1
+ )
+
+ # middle
+ self.mid = nn.Module()
+ self.mid.block_1 = make_resblock_cls(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ self.mid.attn_1 = make_attn_cls(block_in, attn_type=attn_type)
+ self.mid.block_2 = make_resblock_cls(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+
+ # upsampling
+ self.up = nn.ModuleList()
+ for i_level in reversed(range(self.num_resolutions)):
+ block = nn.ModuleList()
+ attn = nn.ModuleList()
+ block_out = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks + 1):
+ block.append(
+ make_resblock_cls(
+ in_channels=block_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ if curr_res in attn_resolutions:
+ attn.append(make_attn_cls(block_in, attn_type=attn_type))
+ up = nn.Module()
+ up.block = block
+ up.attn = attn
+ if i_level != 0:
+ up.upsample = Upsample(block_in, resamp_with_conv)
+ curr_res = curr_res * 2
+ self.up.insert(0, up) # prepend to get consistent order
+
+ # end
+ self.norm_out = Normalize(block_in)
+ self.conv_out = make_conv_cls(
+ block_in, out_ch, kernel_size=3, stride=1, padding=1
+ )
+
+ def _make_attn(self) -> Callable:
+ return make_attn
+
+ def _make_resblock(self) -> Callable:
+ return ResnetBlock
+
+ def _make_conv(self) -> Callable:
+ return torch.nn.Conv2d
+
+ def get_last_layer(self, **kwargs):
+ return self.conv_out.weight
+
+ def forward(self, z, **kwargs):
+ # assert z.shape[1:] == self.z_shape[1:]
+ self.last_z_shape = z.shape
+
+ # timestep embedding
+ temb = None
+
+ # z to block_in
+ h = self.conv_in(z)
+
+ # middle
+ h = self.mid.block_1(h, temb, **kwargs)
+ h = self.mid.attn_1(h, **kwargs)
+ h = self.mid.block_2(h, temb, **kwargs)
+
+ # upsampling
+ for i_level in reversed(range(self.num_resolutions)):
+ for i_block in range(self.num_res_blocks + 1):
+ h = self.up[i_level].block[i_block](h, temb, **kwargs)
+ if len(self.up[i_level].attn) > 0:
+ h = self.up[i_level].attn[i_block](h, **kwargs)
+ if i_level != 0:
+ h = self.up[i_level].upsample(h)
+
+ # end
+ if self.give_pre_end:
+ return h
+
+ h = self.norm_out(h)
+ h = nonlinearity(h)
+ h = self.conv_out(h, **kwargs)
+ if self.tanh_out:
+ h = torch.tanh(h)
+ return h
diff --git a/sgm/modules/diffusionmodules/openaimodel.py b/sgm/modules/diffusionmodules/openaimodel.py
new file mode 100644
index 0000000000000000000000000000000000000000..b58e1b0e9be031cd09803d451fc59f2a5ce88eea
--- /dev/null
+++ b/sgm/modules/diffusionmodules/openaimodel.py
@@ -0,0 +1,853 @@
+import logging
+import math
+from abc import abstractmethod
+from typing import Iterable, List, Optional, Tuple, Union
+
+import torch as th
+import torch.nn as nn
+import torch.nn.functional as F
+from einops import rearrange
+from torch.utils.checkpoint import checkpoint
+
+from ...modules.attention import SpatialTransformer
+from ...modules.diffusionmodules.util import (avg_pool_nd, conv_nd, linear,
+ normalization,
+ timestep_embedding, zero_module)
+from ...modules.video_attention import SpatialVideoTransformer
+from ...util import exists
+
+logpy = logging.getLogger(__name__)
+
+
+class AttentionPool2d(nn.Module):
+ """
+ Adapted from CLIP: https://github.com/openai/CLIP/blob/main/clip/model.py
+ """
+
+ def __init__(
+ self,
+ spacial_dim: int,
+ embed_dim: int,
+ num_heads_channels: int,
+ output_dim: Optional[int] = None,
+ ):
+ super().__init__()
+ self.positional_embedding = nn.Parameter(
+ th.randn(embed_dim, spacial_dim**2 + 1) / embed_dim**0.5
+ )
+ self.qkv_proj = conv_nd(1, embed_dim, 3 * embed_dim, 1)
+ self.c_proj = conv_nd(1, embed_dim, output_dim or embed_dim, 1)
+ self.num_heads = embed_dim // num_heads_channels
+ self.attention = QKVAttention(self.num_heads)
+
+ def forward(self, x: th.Tensor) -> th.Tensor:
+ b, c, _ = x.shape
+ x = x.reshape(b, c, -1)
+ x = th.cat([x.mean(dim=-1, keepdim=True), x], dim=-1)
+ x = x + self.positional_embedding[None, :, :].to(x.dtype)
+ x = self.qkv_proj(x)
+ x = self.attention(x)
+ x = self.c_proj(x)
+ return x[:, :, 0]
+
+
+class TimestepBlock(nn.Module):
+ """
+ Any module where forward() takes timestep embeddings as a second argument.
+ """
+
+ @abstractmethod
+ def forward(self, x: th.Tensor, emb: th.Tensor):
+ """
+ Apply the module to `x` given `emb` timestep embeddings.
+ """
+
+
+class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
+ """
+ A sequential module that passes timestep embeddings to the children that
+ support it as an extra input.
+ """
+
+ def forward(
+ self,
+ x: th.Tensor,
+ emb: th.Tensor,
+ context: Optional[th.Tensor] = None,
+ image_only_indicator: Optional[th.Tensor] = None,
+ time_context: Optional[int] = None,
+ num_video_frames: Optional[int] = None,
+ ):
+ from ...modules.diffusionmodules.video_model import VideoResBlock
+
+ for layer in self:
+ module = layer
+
+ if isinstance(module, TimestepBlock) and not isinstance(
+ module, VideoResBlock
+ ):
+ x = layer(x, emb)
+ elif isinstance(module, VideoResBlock):
+ x = layer(x, emb, num_video_frames, image_only_indicator)
+ elif isinstance(module, SpatialVideoTransformer):
+ x = layer(
+ x,
+ context,
+ time_context,
+ num_video_frames,
+ image_only_indicator,
+ )
+ elif isinstance(module, SpatialTransformer):
+ x = layer(x, context)
+ else:
+ x = layer(x)
+ return x
+
+
+class Upsample(nn.Module):
+ """
+ An upsampling layer with an optional convolution.
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(
+ self,
+ channels: int,
+ use_conv: bool,
+ dims: int = 2,
+ out_channels: Optional[int] = None,
+ padding: int = 1,
+ third_up: bool = False,
+ kernel_size: int = 3,
+ scale_factor: int = 2,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ self.third_up = third_up
+ self.scale_factor = scale_factor
+ if use_conv:
+ self.conv = conv_nd(
+ dims, self.channels, self.out_channels, kernel_size, padding=padding
+ )
+
+ def forward(self, x: th.Tensor) -> th.Tensor:
+ assert x.shape[1] == self.channels
+
+ if self.dims == 3:
+ t_factor = 1 if not self.third_up else self.scale_factor
+ x = F.interpolate(
+ x,
+ (
+ t_factor * x.shape[2],
+ x.shape[3] * self.scale_factor,
+ x.shape[4] * self.scale_factor,
+ ),
+ mode="nearest",
+ )
+ else:
+ x = F.interpolate(x, scale_factor=self.scale_factor, mode="nearest")
+ if self.use_conv:
+ x = self.conv(x)
+ return x
+
+
+class Downsample(nn.Module):
+ """
+ A downsampling layer with an optional convolution.
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(
+ self,
+ channels: int,
+ use_conv: bool,
+ dims: int = 2,
+ out_channels: Optional[int] = None,
+ padding: int = 1,
+ third_down: bool = False,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ stride = 2 if dims != 3 else ((1, 2, 2) if not third_down else (2, 2, 2))
+ if use_conv:
+ logpy.info(f"Building a Downsample layer with {dims} dims.")
+ logpy.info(
+ f" --> settings are: \n in-chn: {self.channels}, out-chn: {self.out_channels}, "
+ f"kernel-size: 3, stride: {stride}, padding: {padding}"
+ )
+ if dims == 3:
+ logpy.info(f" --> Downsampling third axis (time): {third_down}")
+ self.op = conv_nd(
+ dims,
+ self.channels,
+ self.out_channels,
+ 3,
+ stride=stride,
+ padding=padding,
+ )
+ else:
+ assert self.channels == self.out_channels
+ self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
+
+ def forward(self, x: th.Tensor) -> th.Tensor:
+ assert x.shape[1] == self.channels
+
+ return self.op(x)
+
+
+class ResBlock(TimestepBlock):
+ """
+ A residual block that can optionally change the number of channels.
+ :param channels: the number of input channels.
+ :param emb_channels: the number of timestep embedding channels.
+ :param dropout: the rate of dropout.
+ :param out_channels: if specified, the number of out channels.
+ :param use_conv: if True and out_channels is specified, use a spatial
+ convolution instead of a smaller 1x1 convolution to change the
+ channels in the skip connection.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param use_checkpoint: if True, use gradient checkpointing on this module.
+ :param up: if True, use this block for upsampling.
+ :param down: if True, use this block for downsampling.
+ """
+
+ def __init__(
+ self,
+ channels: int,
+ emb_channels: int,
+ dropout: float,
+ out_channels: Optional[int] = None,
+ use_conv: bool = False,
+ use_scale_shift_norm: bool = False,
+ dims: int = 2,
+ use_checkpoint: bool = False,
+ up: bool = False,
+ down: bool = False,
+ kernel_size: int = 3,
+ exchange_temb_dims: bool = False,
+ skip_t_emb: bool = False,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.emb_channels = emb_channels
+ self.dropout = dropout
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_checkpoint = use_checkpoint
+ self.use_scale_shift_norm = use_scale_shift_norm
+ self.exchange_temb_dims = exchange_temb_dims
+
+ if isinstance(kernel_size, Iterable):
+ padding = [k // 2 for k in kernel_size]
+ else:
+ padding = kernel_size // 2
+
+ self.in_layers = nn.Sequential(
+ normalization(channels),
+ nn.SiLU(),
+ conv_nd(dims, channels, self.out_channels, kernel_size, padding=padding),
+ )
+
+ self.updown = up or down
+
+ if up:
+ self.h_upd = Upsample(channels, False, dims)
+ self.x_upd = Upsample(channels, False, dims)
+ elif down:
+ self.h_upd = Downsample(channels, False, dims)
+ self.x_upd = Downsample(channels, False, dims)
+ else:
+ self.h_upd = self.x_upd = nn.Identity()
+
+ self.skip_t_emb = skip_t_emb
+ self.emb_out_channels = (
+ 2 * self.out_channels if use_scale_shift_norm else self.out_channels
+ )
+ if self.skip_t_emb:
+ logpy.info(f"Skipping timestep embedding in {self.__class__.__name__}")
+ assert not self.use_scale_shift_norm
+ self.emb_layers = None
+ self.exchange_temb_dims = False
+ else:
+ self.emb_layers = nn.Sequential(
+ nn.SiLU(),
+ linear(
+ emb_channels,
+ self.emb_out_channels,
+ ),
+ )
+
+ self.out_layers = nn.Sequential(
+ normalization(self.out_channels),
+ nn.SiLU(),
+ nn.Dropout(p=dropout),
+ zero_module(
+ conv_nd(
+ dims,
+ self.out_channels,
+ self.out_channels,
+ kernel_size,
+ padding=padding,
+ )
+ ),
+ )
+
+ if self.out_channels == channels:
+ self.skip_connection = nn.Identity()
+ elif use_conv:
+ self.skip_connection = conv_nd(
+ dims, channels, self.out_channels, kernel_size, padding=padding
+ )
+ else:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
+
+ def forward(self, x: th.Tensor, emb: th.Tensor) -> th.Tensor:
+ """
+ Apply the block to a Tensor, conditioned on a timestep embedding.
+ :param x: an [N x C x ...] Tensor of features.
+ :param emb: an [N x emb_channels] Tensor of timestep embeddings.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ if self.use_checkpoint:
+ return checkpoint(self._forward, x, emb)
+ else:
+ return self._forward(x, emb)
+
+ def _forward(self, x: th.Tensor, emb: th.Tensor) -> th.Tensor:
+ if self.updown:
+ in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
+ h = in_rest(x)
+ h = self.h_upd(h)
+ x = self.x_upd(x)
+ h = in_conv(h)
+ else:
+ h = self.in_layers(x)
+
+ if self.skip_t_emb:
+ emb_out = th.zeros_like(h)
+ else:
+ emb_out = self.emb_layers(emb).type(h.dtype)
+ while len(emb_out.shape) < len(h.shape):
+ emb_out = emb_out[..., None]
+ if self.use_scale_shift_norm:
+ out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
+ scale, shift = th.chunk(emb_out, 2, dim=1)
+ h = out_norm(h) * (1 + scale) + shift
+ h = out_rest(h)
+ else:
+ if self.exchange_temb_dims:
+ emb_out = rearrange(emb_out, "b t c ... -> b c t ...")
+ h = h + emb_out
+ h = self.out_layers(h)
+ return self.skip_connection(x) + h
+
+
+class AttentionBlock(nn.Module):
+ """
+ An attention block that allows spatial positions to attend to each other.
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels: int,
+ num_heads: int = 1,
+ num_head_channels: int = -1,
+ use_checkpoint: bool = False,
+ use_new_attention_order: bool = False,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels == -1:
+ self.num_heads = num_heads
+ else:
+ assert (
+ channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+ self.use_checkpoint = use_checkpoint
+ self.norm = normalization(channels)
+ self.qkv = conv_nd(1, channels, channels * 3, 1)
+ if use_new_attention_order:
+ # split qkv before split heads
+ self.attention = QKVAttention(self.num_heads)
+ else:
+ # split heads before split qkv
+ self.attention = QKVAttentionLegacy(self.num_heads)
+
+ self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
+
+ def forward(self, x: th.Tensor, **kwargs) -> th.Tensor:
+ return checkpoint(self._forward, x)
+
+ def _forward(self, x: th.Tensor) -> th.Tensor:
+ b, c, *spatial = x.shape
+ x = x.reshape(b, c, -1)
+ qkv = self.qkv(self.norm(x))
+ h = self.attention(qkv)
+ h = self.proj_out(h)
+ return (x + h).reshape(b, c, *spatial)
+
+
+class QKVAttentionLegacy(nn.Module):
+ """
+ A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
+ """
+
+ def __init__(self, n_heads: int):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv: th.Tensor) -> th.Tensor:
+ """
+ Apply QKV attention.
+ :param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = th.einsum(
+ "bct,bcs->bts", q * scale, k * scale
+ ) # More stable with f16 than dividing afterwards
+ weight = th.softmax(weight.float(), dim=-1).type(weight.dtype)
+ a = th.einsum("bts,bcs->bct", weight, v)
+ return a.reshape(bs, -1, length)
+
+
+class QKVAttention(nn.Module):
+ """
+ A module which performs QKV attention and splits in a different order.
+ """
+
+ def __init__(self, n_heads: int):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv: th.Tensor) -> th.Tensor:
+ """
+ Apply QKV attention.
+ :param qkv: an [N x (3 * H * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.chunk(3, dim=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = th.einsum(
+ "bct,bcs->bts",
+ (q * scale).view(bs * self.n_heads, ch, length),
+ (k * scale).view(bs * self.n_heads, ch, length),
+ ) # More stable with f16 than dividing afterwards
+ weight = th.softmax(weight.float(), dim=-1).type(weight.dtype)
+ a = th.einsum("bts,bcs->bct", weight, v.reshape(bs * self.n_heads, ch, length))
+ return a.reshape(bs, -1, length)
+
+
+class Timestep(nn.Module):
+ def __init__(self, dim: int):
+ super().__init__()
+ self.dim = dim
+
+ def forward(self, t: th.Tensor) -> th.Tensor:
+ return timestep_embedding(t, self.dim)
+
+
+class UNetModel(nn.Module):
+ """
+ The full UNet model with attention and timestep embedding.
+ :param in_channels: channels in the input Tensor.
+ :param model_channels: base channel count for the model.
+ :param out_channels: channels in the output Tensor.
+ :param num_res_blocks: number of residual blocks per downsample.
+ :param attention_resolutions: a collection of downsample rates at which
+ attention will take place. May be a set, list, or tuple.
+ For example, if this contains 4, then at 4x downsampling, attention
+ will be used.
+ :param dropout: the dropout probability.
+ :param channel_mult: channel multiplier for each level of the UNet.
+ :param conv_resample: if True, use learned convolutions for upsampling and
+ downsampling.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param num_classes: if specified (as an int), then this model will be
+ class-conditional with `num_classes` classes.
+ :param use_checkpoint: use gradient checkpointing to reduce memory usage.
+ :param num_heads: the number of attention heads in each attention layer.
+ :param num_heads_channels: if specified, ignore num_heads and instead use
+ a fixed channel width per attention head.
+ :param num_heads_upsample: works with num_heads to set a different number
+ of heads for upsampling. Deprecated.
+ :param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
+ :param resblock_updown: use residual blocks for up/downsampling.
+ :param use_new_attention_order: use a different attention pattern for potentially
+ increased efficiency.
+ """
+
+ def __init__(
+ self,
+ in_channels: int,
+ model_channels: int,
+ out_channels: int,
+ num_res_blocks: int,
+ attention_resolutions: int,
+ dropout: float = 0.0,
+ channel_mult: Union[List, Tuple] = (1, 2, 4, 8),
+ conv_resample: bool = True,
+ dims: int = 2,
+ num_classes: Optional[Union[int, str]] = None,
+ use_checkpoint: bool = False,
+ num_heads: int = -1,
+ num_head_channels: int = -1,
+ num_heads_upsample: int = -1,
+ use_scale_shift_norm: bool = False,
+ resblock_updown: bool = False,
+ transformer_depth: int = 1,
+ context_dim: Optional[int] = None,
+ disable_self_attentions: Optional[List[bool]] = None,
+ num_attention_blocks: Optional[List[int]] = None,
+ disable_middle_self_attn: bool = False,
+ disable_middle_transformer: bool = False,
+ use_linear_in_transformer: bool = False,
+ spatial_transformer_attn_type: str = "softmax",
+ adm_in_channels: Optional[int] = None,
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ if num_heads == -1:
+ assert (
+ num_head_channels != -1
+ ), "Either num_heads or num_head_channels has to be set"
+
+ if num_head_channels == -1:
+ assert (
+ num_heads != -1
+ ), "Either num_heads or num_head_channels has to be set"
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ if isinstance(transformer_depth, int):
+ transformer_depth = len(channel_mult) * [transformer_depth]
+ transformer_depth_middle = transformer_depth[-1]
+
+ if isinstance(num_res_blocks, int):
+ self.num_res_blocks = len(channel_mult) * [num_res_blocks]
+ else:
+ if len(num_res_blocks) != len(channel_mult):
+ raise ValueError(
+ "provide num_res_blocks either as an int (globally constant) or "
+ "as a list/tuple (per-level) with the same length as channel_mult"
+ )
+ self.num_res_blocks = num_res_blocks
+
+ if disable_self_attentions is not None:
+ assert len(disable_self_attentions) == len(channel_mult)
+ if num_attention_blocks is not None:
+ assert len(num_attention_blocks) == len(self.num_res_blocks)
+ assert all(
+ map(
+ lambda i: self.num_res_blocks[i] >= num_attention_blocks[i],
+ range(len(num_attention_blocks)),
+ )
+ )
+ logpy.info(
+ f"Constructor of UNetModel received num_attention_blocks={num_attention_blocks}. "
+ f"This option has LESS priority than attention_resolutions {attention_resolutions}, "
+ f"i.e., in cases where num_attention_blocks[i] > 0 but 2**i not in attention_resolutions, "
+ f"attention will still not be set."
+ )
+
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.use_checkpoint = use_checkpoint
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ if self.num_classes is not None:
+ if isinstance(self.num_classes, int):
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+ elif self.num_classes == "continuous":
+ logpy.info("setting up linear c_adm embedding layer")
+ self.label_emb = nn.Linear(1, time_embed_dim)
+ elif self.num_classes == "timestep":
+ self.label_emb = nn.Sequential(
+ Timestep(model_channels),
+ nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ ),
+ )
+ elif self.num_classes == "sequential":
+ assert adm_in_channels is not None
+ self.label_emb = nn.Sequential(
+ nn.Sequential(
+ linear(adm_in_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+ )
+ else:
+ raise ValueError
+
+ self.input_blocks = nn.ModuleList(
+ [
+ TimestepEmbedSequential(
+ conv_nd(dims, in_channels, model_channels, 3, padding=1)
+ )
+ ]
+ )
+ self._feature_size = model_channels
+ input_block_chans = [model_channels]
+ ch = model_channels
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for nr in range(self.num_res_blocks[level]):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=mult * model_channels,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = mult * model_channels
+ if ds in attention_resolutions:
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ if context_dim is not None and exists(disable_self_attentions):
+ disabled_sa = disable_self_attentions[level]
+ else:
+ disabled_sa = False
+
+ if (
+ not exists(num_attention_blocks)
+ or nr < num_attention_blocks[level]
+ ):
+ layers.append(
+ SpatialTransformer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth[level],
+ context_dim=context_dim,
+ disable_self_attn=disabled_sa,
+ use_linear=use_linear_in_transformer,
+ attn_type=spatial_transformer_attn_type,
+ use_checkpoint=use_checkpoint,
+ )
+ )
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ )
+ if resblock_updown
+ else Downsample(
+ ch, conv_resample, dims=dims, out_channels=out_ch
+ )
+ )
+ )
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ SpatialTransformer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth_middle,
+ context_dim=context_dim,
+ disable_self_attn=disable_middle_self_attn,
+ use_linear=use_linear_in_transformer,
+ attn_type=spatial_transformer_attn_type,
+ use_checkpoint=use_checkpoint,
+ )
+ if not disable_middle_transformer
+ else th.nn.Identity(),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.ModuleList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(self.num_res_blocks[level] + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ ResBlock(
+ ch + ich,
+ time_embed_dim,
+ dropout,
+ out_channels=model_channels * mult,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = model_channels * mult
+ if ds in attention_resolutions:
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ if exists(disable_self_attentions):
+ disabled_sa = disable_self_attentions[level]
+ else:
+ disabled_sa = False
+
+ if (
+ not exists(num_attention_blocks)
+ or i < num_attention_blocks[level]
+ ):
+ layers.append(
+ SpatialTransformer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth[level],
+ context_dim=context_dim,
+ disable_self_attn=disabled_sa,
+ use_linear=use_linear_in_transformer,
+ attn_type=spatial_transformer_attn_type,
+ use_checkpoint=use_checkpoint,
+ )
+ )
+ if level and i == self.num_res_blocks[level]:
+ out_ch = ch
+ layers.append(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ )
+ if resblock_updown
+ else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch)
+ )
+ ds //= 2
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ nn.SiLU(),
+ zero_module(conv_nd(dims, model_channels, out_channels, 3, padding=1)),
+ )
+
+ def forward(
+ self,
+ x: th.Tensor,
+ timesteps: Optional[th.Tensor] = None,
+ context: Optional[th.Tensor] = None,
+ y: Optional[th.Tensor] = None,
+ **kwargs,
+ ) -> th.Tensor:
+ """
+ Apply the model to an input batch.
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :param context: conditioning plugged in via crossattn
+ :param y: an [N] Tensor of labels, if class-conditional.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ assert (y is not None) == (
+ self.num_classes is not None
+ ), "must specify y if and only if the model is class-conditional"
+ hs = []
+ t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
+ emb = self.time_embed(t_emb)
+
+ if self.num_classes is not None:
+ assert y.shape[0] == x.shape[0]
+ emb = emb + self.label_emb(y)
+
+ h = x
+ for module in self.input_blocks:
+ h = module(h, emb, context)
+ hs.append(h)
+ h = self.middle_block(h, emb, context)
+ for module in self.output_blocks:
+ h = th.cat([h, hs.pop()], dim=1)
+ h = module(h, emb, context)
+ h = h.type(x.dtype)
+
+ return self.out(h)
diff --git a/sgm/modules/diffusionmodules/sampling.py b/sgm/modules/diffusionmodules/sampling.py
new file mode 100644
index 0000000000000000000000000000000000000000..c8240a705383302db5bf69c45f1f355df8fdb6a8
--- /dev/null
+++ b/sgm/modules/diffusionmodules/sampling.py
@@ -0,0 +1,379 @@
+"""
+ Partially ported from https://github.com/crowsonkb/k-diffusion/blob/master/k_diffusion/sampling.py
+"""
+
+
+from typing import Dict, Union
+
+import torch
+from omegaconf import ListConfig, OmegaConf
+from tqdm import tqdm
+
+from ...modules.diffusionmodules.sampling_utils import (get_ancestral_step,
+ linear_multistep_coeff,
+ to_d, to_neg_log_sigma,
+ to_sigma)
+from ...util import append_dims, default, instantiate_from_config
+
+DEFAULT_GUIDER = {"target": "sgm.modules.diffusionmodules.guiders.IdentityGuider"}
+
+
+class BaseDiffusionSampler:
+ def __init__(
+ self,
+ discretization_config: Union[Dict, ListConfig, OmegaConf],
+ num_steps: Union[int, None] = None,
+ guider_config: Union[Dict, ListConfig, OmegaConf, None] = None,
+ verbose: bool = False,
+ device: str = "cuda",
+ ):
+ self.num_steps = num_steps
+ self.discretization = instantiate_from_config(discretization_config)
+ self.guider = instantiate_from_config(
+ default(
+ guider_config,
+ DEFAULT_GUIDER,
+ )
+ )
+ self.verbose = verbose
+ self.device = device
+
+ def prepare_sampling_loop(self, x, cond, uc=None, num_steps=None):
+ sigmas = self.discretization(
+ self.num_steps if num_steps is None else num_steps, device=self.device
+ )
+ uc = default(uc, cond)
+
+ x *= torch.sqrt(1.0 + sigmas[0] ** 2.0)
+ num_sigmas = len(sigmas)
+
+ s_in = x.new_ones([x.shape[0]])
+
+ return x, s_in, sigmas, num_sigmas, cond, uc
+
+ def denoise(self, x, denoiser, sigma, cond, uc):
+ denoised = denoiser(*self.guider.prepare_inputs(x, sigma, cond, uc))
+ denoised = self.guider(denoised, sigma)
+ return denoised
+
+ def get_sigma_gen(self, num_sigmas):
+ sigma_generator = range(num_sigmas - 1)
+ if self.verbose:
+ print("#" * 30, " Sampling setting ", "#" * 30)
+ print(f"Sampler: {self.__class__.__name__}")
+ print(f"Discretization: {self.discretization.__class__.__name__}")
+ print(f"Guider: {self.guider.__class__.__name__}")
+ sigma_generator = tqdm(
+ sigma_generator,
+ total=num_sigmas,
+ desc=f"Sampling with {self.__class__.__name__} for {num_sigmas} steps",
+ )
+ return sigma_generator
+
+
+class SingleStepDiffusionSampler(BaseDiffusionSampler):
+ def sampler_step(self, sigma, next_sigma, denoiser, x, cond, uc, *args, **kwargs):
+ raise NotImplementedError
+
+ def euler_step(self, x, d, dt):
+ return x + dt * d
+
+
+class EDMSampler(SingleStepDiffusionSampler):
+ def __init__(
+ self, s_churn=0.0, s_tmin=0.0, s_tmax=float("inf"), s_noise=1.0, *args, **kwargs
+ ):
+ super().__init__(*args, **kwargs)
+
+ self.s_churn = s_churn
+ self.s_tmin = s_tmin
+ self.s_tmax = s_tmax
+ self.s_noise = s_noise
+
+ def sampler_step(self, sigma, next_sigma, denoiser, x, cond, uc=None, gamma=0.0):
+ sigma_hat = sigma * (gamma + 1.0)
+ if gamma > 0:
+ eps = torch.randn_like(x) * self.s_noise
+ x = x + eps * append_dims(sigma_hat**2 - sigma**2, x.ndim) ** 0.5
+
+ denoised = self.denoise(x, denoiser, sigma_hat, cond, uc)
+ d = to_d(x, sigma_hat, denoised)
+ dt = append_dims(next_sigma - sigma_hat, x.ndim)
+
+ euler_step = self.euler_step(x, d, dt)
+ x = self.possible_correction_step(
+ euler_step, x, d, dt, next_sigma, denoiser, cond, uc
+ )
+ return x
+
+ def step_call(self, denoiser, x, i, s_in, sigmas, num_sigmas, cond, uc):
+ gamma = (
+ min(self.s_churn / (num_sigmas - 1), 2**0.5 - 1)
+ if self.s_tmin <= sigmas[i] <= self.s_tmax
+ else 0.0
+ )
+ x = self.sampler_step(
+ s_in * sigmas[i],
+ s_in * sigmas[i + 1],
+ denoiser,
+ x,
+ cond,
+ uc,
+ gamma,
+ )
+ return x
+
+ def __call__(self, denoiser, x, cond, uc=None, num_steps=None):
+ x, s_in, sigmas, num_sigmas, cond, uc = self.prepare_sampling_loop(
+ x, cond, uc, num_steps
+ )
+
+ for i in self.get_sigma_gen(num_sigmas):
+ gamma = (
+ min(self.s_churn / (num_sigmas - 1), 2**0.5 - 1)
+ if self.s_tmin <= sigmas[i] <= self.s_tmax
+ else 0.0
+ )
+ x = self.sampler_step(
+ s_in * sigmas[i],
+ s_in * sigmas[i + 1],
+ denoiser,
+ x,
+ cond,
+ uc,
+ gamma,
+ )
+
+ return x
+
+
+class AncestralSampler(SingleStepDiffusionSampler):
+ def __init__(self, eta=1.0, s_noise=1.0, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ self.eta = eta
+ self.s_noise = s_noise
+ self.noise_sampler = lambda x: torch.randn_like(x)
+
+ def ancestral_euler_step(self, x, denoised, sigma, sigma_down):
+ d = to_d(x, sigma, denoised)
+ dt = append_dims(sigma_down - sigma, x.ndim)
+
+ return self.euler_step(x, d, dt)
+
+ def ancestral_step(self, x, sigma, next_sigma, sigma_up):
+ x = torch.where(
+ append_dims(next_sigma, x.ndim) > 0.0,
+ x + self.noise_sampler(x) * self.s_noise * append_dims(sigma_up, x.ndim),
+ x,
+ )
+ return x
+
+ def __call__(self, denoiser, x, cond, uc=None, num_steps=None):
+ x, s_in, sigmas, num_sigmas, cond, uc = self.prepare_sampling_loop(
+ x, cond, uc, num_steps
+ )
+
+ for i in self.get_sigma_gen(num_sigmas):
+ x = self.sampler_step(
+ s_in * sigmas[i],
+ s_in * sigmas[i + 1],
+ denoiser,
+ x,
+ cond,
+ uc,
+ )
+
+ return x
+
+
+class LinearMultistepSampler(BaseDiffusionSampler):
+ def __init__(
+ self,
+ order=4,
+ *args,
+ **kwargs,
+ ):
+ super().__init__(*args, **kwargs)
+
+ self.order = order
+
+ def __call__(self, denoiser, x, cond, uc=None, num_steps=None, **kwargs):
+ x, s_in, sigmas, num_sigmas, cond, uc = self.prepare_sampling_loop(
+ x, cond, uc, num_steps
+ )
+
+ ds = []
+ sigmas_cpu = sigmas.detach().cpu().numpy()
+ for i in self.get_sigma_gen(num_sigmas):
+ sigma = s_in * sigmas[i]
+ denoised = denoiser(
+ *self.guider.prepare_inputs(x, sigma, cond, uc), **kwargs
+ )
+ denoised = self.guider(denoised, sigma)
+ d = to_d(x, sigma, denoised)
+ ds.append(d)
+ if len(ds) > self.order:
+ ds.pop(0)
+ cur_order = min(i + 1, self.order)
+ coeffs = [
+ linear_multistep_coeff(cur_order, sigmas_cpu, i, j)
+ for j in range(cur_order)
+ ]
+ x = x + sum(coeff * d for coeff, d in zip(coeffs, reversed(ds)))
+
+ return x
+
+
+class EulerEDMSampler(EDMSampler):
+ def possible_correction_step(
+ self, euler_step, x, d, dt, next_sigma, denoiser, cond, uc
+ ):
+ return euler_step
+
+
+class HeunEDMSampler(EDMSampler):
+ def possible_correction_step(
+ self, euler_step, x, d, dt, next_sigma, denoiser, cond, uc
+ ):
+ if torch.sum(next_sigma) < 1e-14:
+ # Save a network evaluation if all noise levels are 0
+ return euler_step
+ else:
+ denoised = self.denoise(euler_step, denoiser, next_sigma, cond, uc)
+ d_new = to_d(euler_step, next_sigma, denoised)
+ d_prime = (d + d_new) / 2.0
+
+ # apply correction if noise level is not 0
+ x = torch.where(
+ append_dims(next_sigma, x.ndim) > 0.0, x + d_prime * dt, euler_step
+ )
+ return x
+
+
+class EulerAncestralSampler(AncestralSampler):
+ def sampler_step(self, sigma, next_sigma, denoiser, x, cond, uc):
+ sigma_down, sigma_up = get_ancestral_step(sigma, next_sigma, eta=self.eta)
+ denoised = self.denoise(x, denoiser, sigma, cond, uc)
+ x = self.ancestral_euler_step(x, denoised, sigma, sigma_down)
+ x = self.ancestral_step(x, sigma, next_sigma, sigma_up)
+
+ return x
+
+
+class DPMPP2SAncestralSampler(AncestralSampler):
+ def get_variables(self, sigma, sigma_down):
+ t, t_next = [to_neg_log_sigma(s) for s in (sigma, sigma_down)]
+ h = t_next - t
+ s = t + 0.5 * h
+ return h, s, t, t_next
+
+ def get_mult(self, h, s, t, t_next):
+ mult1 = to_sigma(s) / to_sigma(t)
+ mult2 = (-0.5 * h).expm1()
+ mult3 = to_sigma(t_next) / to_sigma(t)
+ mult4 = (-h).expm1()
+
+ return mult1, mult2, mult3, mult4
+
+ def sampler_step(self, sigma, next_sigma, denoiser, x, cond, uc=None, **kwargs):
+ sigma_down, sigma_up = get_ancestral_step(sigma, next_sigma, eta=self.eta)
+ denoised = self.denoise(x, denoiser, sigma, cond, uc)
+ x_euler = self.ancestral_euler_step(x, denoised, sigma, sigma_down)
+
+ if torch.sum(sigma_down) < 1e-14:
+ # Save a network evaluation if all noise levels are 0
+ x = x_euler
+ else:
+ h, s, t, t_next = self.get_variables(sigma, sigma_down)
+ mult = [
+ append_dims(mult, x.ndim) for mult in self.get_mult(h, s, t, t_next)
+ ]
+
+ x2 = mult[0] * x - mult[1] * denoised
+ denoised2 = self.denoise(x2, denoiser, to_sigma(s), cond, uc)
+ x_dpmpp2s = mult[2] * x - mult[3] * denoised2
+
+ # apply correction if noise level is not 0
+ x = torch.where(append_dims(sigma_down, x.ndim) > 0.0, x_dpmpp2s, x_euler)
+
+ x = self.ancestral_step(x, sigma, next_sigma, sigma_up)
+ return x
+
+
+class DPMPP2MSampler(BaseDiffusionSampler):
+ def get_variables(self, sigma, next_sigma, previous_sigma=None):
+ t, t_next = [to_neg_log_sigma(s) for s in (sigma, next_sigma)]
+ h = t_next - t
+
+ if previous_sigma is not None:
+ h_last = t - to_neg_log_sigma(previous_sigma)
+ r = h_last / h
+ return h, r, t, t_next
+ else:
+ return h, None, t, t_next
+
+ def get_mult(self, h, r, t, t_next, previous_sigma):
+ mult1 = to_sigma(t_next) / to_sigma(t)
+ mult2 = (-h).expm1()
+
+ if previous_sigma is not None:
+ mult3 = 1 + 1 / (2 * r)
+ mult4 = 1 / (2 * r)
+ return mult1, mult2, mult3, mult4
+ else:
+ return mult1, mult2
+
+ def sampler_step(
+ self,
+ old_denoised,
+ previous_sigma,
+ sigma,
+ next_sigma,
+ denoiser,
+ x,
+ cond,
+ uc=None,
+ ):
+ denoised = self.denoise(x, denoiser, sigma, cond, uc)
+
+ h, r, t, t_next = self.get_variables(sigma, next_sigma, previous_sigma)
+ mult = [
+ append_dims(mult, x.ndim)
+ for mult in self.get_mult(h, r, t, t_next, previous_sigma)
+ ]
+
+ x_standard = mult[0] * x - mult[1] * denoised
+ if old_denoised is None or torch.sum(next_sigma) < 1e-14:
+ # Save a network evaluation if all noise levels are 0 or on the first step
+ return x_standard, denoised
+ else:
+ denoised_d = mult[2] * denoised - mult[3] * old_denoised
+ x_advanced = mult[0] * x - mult[1] * denoised_d
+
+ # apply correction if noise level is not 0 and not first step
+ x = torch.where(
+ append_dims(next_sigma, x.ndim) > 0.0, x_advanced, x_standard
+ )
+
+ return x, denoised
+
+ def __call__(self, denoiser, x, cond, uc=None, num_steps=None, **kwargs):
+ x, s_in, sigmas, num_sigmas, cond, uc = self.prepare_sampling_loop(
+ x, cond, uc, num_steps
+ )
+
+ old_denoised = None
+ for i in self.get_sigma_gen(num_sigmas):
+ x, old_denoised = self.sampler_step(
+ old_denoised,
+ None if i == 0 else s_in * sigmas[i - 1],
+ s_in * sigmas[i],
+ s_in * sigmas[i + 1],
+ denoiser,
+ x,
+ cond,
+ uc=uc,
+ )
+
+ return x
diff --git a/sgm/modules/diffusionmodules/sampling_old.py b/sgm/modules/diffusionmodules/sampling_old.py
new file mode 100644
index 0000000000000000000000000000000000000000..4232a9b704b669a6abb1682f5c9c31db17403139
--- /dev/null
+++ b/sgm/modules/diffusionmodules/sampling_old.py
@@ -0,0 +1,362 @@
+"""
+ Partially ported from https://github.com/crowsonkb/k-diffusion/blob/master/k_diffusion/sampling.py
+"""
+
+
+from typing import Dict, Union
+
+import torch
+from omegaconf import ListConfig, OmegaConf
+from tqdm import tqdm
+
+from .sampling_utils import (get_ancestral_step,
+ linear_multistep_coeff,
+ to_d, to_neg_log_sigma,
+ to_sigma)
+from ...util import append_dims, default, instantiate_from_config
+
+DEFAULT_GUIDER = {"target": "sgm.modules.diffusionmodules.guiders.IdentityGuider"}
+
+
+class BaseDiffusionSampler:
+ def __init__(
+ self,
+ discretization_config: Union[Dict, ListConfig, OmegaConf],
+ num_steps: Union[int, None] = None,
+ guider_config: Union[Dict, ListConfig, OmegaConf, None] = None,
+ verbose: bool = False,
+ device: str = "cuda",
+ ):
+ self.num_steps = num_steps
+ self.discretization = instantiate_from_config(discretization_config)
+ self.guider = instantiate_from_config(
+ default(
+ guider_config,
+ DEFAULT_GUIDER,
+ )
+ )
+ self.verbose = verbose
+ self.device = device
+
+ def prepare_sampling_loop(self, x, cond, uc=None, num_steps=None):
+ sigmas = self.discretization(
+ self.num_steps if num_steps is None else num_steps, device=self.device
+ )
+ uc = default(uc, cond)
+
+ x *= torch.sqrt(1.0 + sigmas[0] ** 2.0)
+ num_sigmas = len(sigmas)
+
+ s_in = x.new_ones([x.shape[0]])
+
+ return x, s_in, sigmas, num_sigmas, cond, uc
+
+ def denoise(self, x, denoiser, sigma, cond, uc):
+ denoised = denoiser(*self.guider.prepare_inputs(x, sigma, cond, uc))
+ denoised = self.guider(denoised, sigma)
+ return denoised
+
+ def get_sigma_gen(self, num_sigmas):
+ sigma_generator = range(num_sigmas - 1)
+ if self.verbose:
+ print("#" * 30, " Sampling setting ", "#" * 30)
+ print(f"Sampler: {self.__class__.__name__}")
+ print(f"Discretization: {self.discretization.__class__.__name__}")
+ print(f"Guider: {self.guider.__class__.__name__}")
+ sigma_generator = tqdm(
+ sigma_generator,
+ total=num_sigmas,
+ desc=f"Sampling with {self.__class__.__name__} for {num_sigmas} steps",
+ )
+ return sigma_generator
+
+
+class SingleStepDiffusionSampler(BaseDiffusionSampler):
+ def sampler_step(self, sigma, next_sigma, denoiser, x, cond, uc, *args, **kwargs):
+ raise NotImplementedError
+
+ def euler_step(self, x, d, dt):
+ return x + dt * d
+
+
+class EDMSampler(SingleStepDiffusionSampler):
+ def __init__(
+ self, s_churn=0.0, s_tmin=0.0, s_tmax=float("inf"), s_noise=1.0, *args, **kwargs
+ ):
+ super().__init__(*args, **kwargs)
+
+ self.s_churn = s_churn
+ self.s_tmin = s_tmin
+ self.s_tmax = s_tmax
+ self.s_noise = s_noise
+
+ def sampler_step(self, sigma, next_sigma, denoiser, x, cond, uc=None, gamma=0.0):
+ sigma_hat = sigma * (gamma + 1.0)
+ if gamma > 0:
+ eps = torch.randn_like(x) * self.s_noise
+ x = x + eps * append_dims(sigma_hat**2 - sigma**2, x.ndim) ** 0.5
+
+ denoised = self.denoise(x, denoiser, sigma_hat, cond, uc)
+ d = to_d(x, sigma_hat, denoised)
+ dt = append_dims(next_sigma - sigma_hat, x.ndim)
+
+ euler_step = self.euler_step(x, d, dt)
+ x = self.possible_correction_step(
+ euler_step, x, d, dt, next_sigma, denoiser, cond, uc
+ )
+ return x
+
+ def __call__(self, denoiser, x, cond, uc=None, num_steps=None):
+ x, s_in, sigmas, num_sigmas, cond, uc = self.prepare_sampling_loop(
+ x, cond, uc, num_steps
+ )
+
+ for i in self.get_sigma_gen(num_sigmas):
+ gamma = (
+ min(self.s_churn / (num_sigmas - 1), 2**0.5 - 1)
+ if self.s_tmin <= sigmas[i] <= self.s_tmax
+ else 0.0
+ )
+ x = self.sampler_step(
+ s_in * sigmas[i],
+ s_in * sigmas[i + 1],
+ denoiser,
+ x,
+ cond,
+ uc,
+ gamma,
+ )
+
+ return x
+
+
+class AncestralSampler(SingleStepDiffusionSampler):
+ def __init__(self, eta=1.0, s_noise=1.0, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ self.eta = eta
+ self.s_noise = s_noise
+ self.noise_sampler = lambda x: torch.randn_like(x)
+
+ def ancestral_euler_step(self, x, denoised, sigma, sigma_down):
+ d = to_d(x, sigma, denoised)
+ dt = append_dims(sigma_down - sigma, x.ndim)
+
+ return self.euler_step(x, d, dt)
+
+ def ancestral_step(self, x, sigma, next_sigma, sigma_up):
+ x = torch.where(
+ append_dims(next_sigma, x.ndim) > 0.0,
+ x + self.noise_sampler(x) * self.s_noise * append_dims(sigma_up, x.ndim),
+ x,
+ )
+ return x
+
+ def __call__(self, denoiser, x, cond, uc=None, num_steps=None):
+ x, s_in, sigmas, num_sigmas, cond, uc = self.prepare_sampling_loop(
+ x, cond, uc, num_steps
+ )
+
+ for i in self.get_sigma_gen(num_sigmas):
+ x = self.sampler_step(
+ s_in * sigmas[i],
+ s_in * sigmas[i + 1],
+ denoiser,
+ x,
+ cond,
+ uc,
+ )
+
+ return x
+
+
+class LinearMultistepSampler(BaseDiffusionSampler):
+ def __init__(
+ self,
+ order=4,
+ *args,
+ **kwargs,
+ ):
+ super().__init__(*args, **kwargs)
+
+ self.order = order
+
+ def __call__(self, denoiser, x, cond, uc=None, num_steps=None, **kwargs):
+ x, s_in, sigmas, num_sigmas, cond, uc = self.prepare_sampling_loop(
+ x, cond, uc, num_steps
+ )
+
+ ds = []
+ sigmas_cpu = sigmas.detach().cpu().numpy()
+ for i in self.get_sigma_gen(num_sigmas):
+ sigma = s_in * sigmas[i]
+ denoised = denoiser(
+ *self.guider.prepare_inputs(x, sigma, cond, uc), **kwargs
+ )
+ denoised = self.guider(denoised, sigma)
+ d = to_d(x, sigma, denoised)
+ ds.append(d)
+ if len(ds) > self.order:
+ ds.pop(0)
+ cur_order = min(i + 1, self.order)
+ coeffs = [
+ linear_multistep_coeff(cur_order, sigmas_cpu, i, j)
+ for j in range(cur_order)
+ ]
+ x = x + sum(coeff * d for coeff, d in zip(coeffs, reversed(ds)))
+
+ return x
+
+
+class EulerEDMSampler(EDMSampler):
+ def possible_correction_step(
+ self, euler_step, x, d, dt, next_sigma, denoiser, cond, uc
+ ):
+ return euler_step
+
+
+class HeunEDMSampler(EDMSampler):
+ def possible_correction_step(
+ self, euler_step, x, d, dt, next_sigma, denoiser, cond, uc
+ ):
+ if torch.sum(next_sigma) < 1e-14:
+ # Save a network evaluation if all noise levels are 0
+ return euler_step
+ else:
+ denoised = self.denoise(euler_step, denoiser, next_sigma, cond, uc)
+ d_new = to_d(euler_step, next_sigma, denoised)
+ d_prime = (d + d_new) / 2.0
+
+ # apply correction if noise level is not 0
+ x = torch.where(
+ append_dims(next_sigma, x.ndim) > 0.0, x + d_prime * dt, euler_step
+ )
+ return x
+
+
+class EulerAncestralSampler(AncestralSampler):
+ def sampler_step(self, sigma, next_sigma, denoiser, x, cond, uc):
+ sigma_down, sigma_up = get_ancestral_step(sigma, next_sigma, eta=self.eta)
+ denoised = self.denoise(x, denoiser, sigma, cond, uc)
+ x = self.ancestral_euler_step(x, denoised, sigma, sigma_down)
+ x = self.ancestral_step(x, sigma, next_sigma, sigma_up)
+
+ return x
+
+
+class DPMPP2SAncestralSampler(AncestralSampler):
+ def get_variables(self, sigma, sigma_down):
+ t, t_next = [to_neg_log_sigma(s) for s in (sigma, sigma_down)]
+ h = t_next - t
+ s = t + 0.5 * h
+ return h, s, t, t_next
+
+ def get_mult(self, h, s, t, t_next):
+ mult1 = to_sigma(s) / to_sigma(t)
+ mult2 = (-0.5 * h).expm1()
+ mult3 = to_sigma(t_next) / to_sigma(t)
+ mult4 = (-h).expm1()
+
+ return mult1, mult2, mult3, mult4
+
+ def sampler_step(self, sigma, next_sigma, denoiser, x, cond, uc=None, **kwargs):
+ sigma_down, sigma_up = get_ancestral_step(sigma, next_sigma, eta=self.eta)
+ denoised = self.denoise(x, denoiser, sigma, cond, uc)
+ x_euler = self.ancestral_euler_step(x, denoised, sigma, sigma_down)
+
+ if torch.sum(sigma_down) < 1e-14:
+ # Save a network evaluation if all noise levels are 0
+ x = x_euler
+ else:
+ h, s, t, t_next = self.get_variables(sigma, sigma_down)
+ mult = [
+ append_dims(mult, x.ndim) for mult in self.get_mult(h, s, t, t_next)
+ ]
+
+ x2 = mult[0] * x - mult[1] * denoised
+ denoised2 = self.denoise(x2, denoiser, to_sigma(s), cond, uc)
+ x_dpmpp2s = mult[2] * x - mult[3] * denoised2
+
+ # apply correction if noise level is not 0
+ x = torch.where(append_dims(sigma_down, x.ndim) > 0.0, x_dpmpp2s, x_euler)
+
+ x = self.ancestral_step(x, sigma, next_sigma, sigma_up)
+ return x
+
+
+class DPMPP2MSampler(BaseDiffusionSampler):
+ def get_variables(self, sigma, next_sigma, previous_sigma=None):
+ t, t_next = [to_neg_log_sigma(s) for s in (sigma, next_sigma)]
+ h = t_next - t
+
+ if previous_sigma is not None:
+ h_last = t - to_neg_log_sigma(previous_sigma)
+ r = h_last / h
+ return h, r, t, t_next
+ else:
+ return h, None, t, t_next
+
+ def get_mult(self, h, r, t, t_next, previous_sigma):
+ mult1 = to_sigma(t_next) / to_sigma(t)
+ mult2 = (-h).expm1()
+
+ if previous_sigma is not None:
+ mult3 = 1 + 1 / (2 * r)
+ mult4 = 1 / (2 * r)
+ return mult1, mult2, mult3, mult4
+ else:
+ return mult1, mult2
+
+ def sampler_step(
+ self,
+ old_denoised,
+ previous_sigma,
+ sigma,
+ next_sigma,
+ denoiser,
+ x,
+ cond,
+ uc=None,
+ ):
+ denoised = self.denoise(x, denoiser, sigma, cond, uc)
+
+ h, r, t, t_next = self.get_variables(sigma, next_sigma, previous_sigma)
+ mult = [
+ append_dims(mult, x.ndim)
+ for mult in self.get_mult(h, r, t, t_next, previous_sigma)
+ ]
+
+ x_standard = mult[0] * x - mult[1] * denoised
+ if old_denoised is None or torch.sum(next_sigma) < 1e-14:
+ # Save a network evaluation if all noise levels are 0 or on the first step
+ return x_standard, denoised
+ else:
+ denoised_d = mult[2] * denoised - mult[3] * old_denoised
+ x_advanced = mult[0] * x - mult[1] * denoised_d
+
+ # apply correction if noise level is not 0 and not first step
+ x = torch.where(
+ append_dims(next_sigma, x.ndim) > 0.0, x_advanced, x_standard
+ )
+
+ return x, denoised
+
+ def __call__(self, denoiser, x, cond, uc=None, num_steps=None, **kwargs):
+ x, s_in, sigmas, num_sigmas, cond, uc = self.prepare_sampling_loop(
+ x, cond, uc, num_steps
+ )
+
+ old_denoised = None
+ for i in self.get_sigma_gen(num_sigmas):
+ x, old_denoised = self.sampler_step(
+ old_denoised,
+ None if i == 0 else s_in * sigmas[i - 1],
+ s_in * sigmas[i],
+ s_in * sigmas[i + 1],
+ denoiser,
+ x,
+ cond,
+ uc=uc,
+ )
+
+ return x
diff --git a/sgm/modules/diffusionmodules/sampling_utils.py b/sgm/modules/diffusionmodules/sampling_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce78527ea9052a8bfd0856ed2278901516fb9130
--- /dev/null
+++ b/sgm/modules/diffusionmodules/sampling_utils.py
@@ -0,0 +1,43 @@
+import torch
+from scipy import integrate
+
+from ...util import append_dims
+
+
+def linear_multistep_coeff(order, t, i, j, epsrel=1e-4):
+ if order - 1 > i:
+ raise ValueError(f"Order {order} too high for step {i}")
+
+ def fn(tau):
+ prod = 1.0
+ for k in range(order):
+ if j == k:
+ continue
+ prod *= (tau - t[i - k]) / (t[i - j] - t[i - k])
+ return prod
+
+ return integrate.quad(fn, t[i], t[i + 1], epsrel=epsrel)[0]
+
+
+def get_ancestral_step(sigma_from, sigma_to, eta=1.0):
+ if not eta:
+ return sigma_to, 0.0
+ sigma_up = torch.minimum(
+ sigma_to,
+ eta
+ * (sigma_to**2 * (sigma_from**2 - sigma_to**2) / sigma_from**2) ** 0.5,
+ )
+ sigma_down = (sigma_to**2 - sigma_up**2) ** 0.5
+ return sigma_down, sigma_up
+
+
+def to_d(x, sigma, denoised):
+ return (x - denoised) / append_dims(sigma, x.ndim)
+
+
+def to_neg_log_sigma(sigma):
+ return sigma.log().neg()
+
+
+def to_sigma(neg_log_sigma):
+ return neg_log_sigma.neg().exp()
diff --git a/sgm/modules/diffusionmodules/sigma_sampling.py b/sgm/modules/diffusionmodules/sigma_sampling.py
new file mode 100644
index 0000000000000000000000000000000000000000..d54724c6ef6a7b8067784a4192b0fe2f41123063
--- /dev/null
+++ b/sgm/modules/diffusionmodules/sigma_sampling.py
@@ -0,0 +1,31 @@
+import torch
+
+from ...util import default, instantiate_from_config
+
+
+class EDMSampling:
+ def __init__(self, p_mean=-1.2, p_std=1.2):
+ self.p_mean = p_mean
+ self.p_std = p_std
+
+ def __call__(self, n_samples, rand=None):
+ log_sigma = self.p_mean + self.p_std * default(rand, torch.randn((n_samples,)))
+ return log_sigma.exp()
+
+
+class DiscreteSampling:
+ def __init__(self, discretization_config, num_idx, do_append_zero=False, flip=True):
+ self.num_idx = num_idx
+ self.sigmas = instantiate_from_config(discretization_config)(
+ num_idx, do_append_zero=do_append_zero, flip=flip
+ )
+
+ def idx_to_sigma(self, idx):
+ return self.sigmas[idx]
+
+ def __call__(self, n_samples, rand=None):
+ idx = default(
+ rand,
+ torch.randint(0, self.num_idx, (n_samples,)),
+ )
+ return self.idx_to_sigma(idx)
diff --git a/sgm/modules/diffusionmodules/util.py b/sgm/modules/diffusionmodules/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..389f0e449367b1b628d61dca105343d066dbefff
--- /dev/null
+++ b/sgm/modules/diffusionmodules/util.py
@@ -0,0 +1,369 @@
+"""
+partially adopted from
+https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
+and
+https://github.com/lucidrains/denoising-diffusion-pytorch/blob/7706bdfc6f527f58d33f84b7b522e61e6e3164b3/denoising_diffusion_pytorch/denoising_diffusion_pytorch.py
+and
+https://github.com/openai/guided-diffusion/blob/0ba878e517b276c45d1195eb29f6f5f72659a05b/guided_diffusion/nn.py
+
+thanks!
+"""
+
+import math
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from einops import rearrange, repeat
+
+
+def make_beta_schedule(
+ schedule,
+ n_timestep,
+ linear_start=1e-4,
+ linear_end=2e-2,
+):
+ if schedule == "linear":
+ betas = (
+ torch.linspace(
+ linear_start**0.5, linear_end**0.5, n_timestep, dtype=torch.float64
+ )
+ ** 2
+ )
+ return betas.numpy()
+
+
+def extract_into_tensor(a, t, x_shape):
+ b, *_ = t.shape
+ out = a.gather(-1, t)
+ return out.reshape(b, *((1,) * (len(x_shape) - 1)))
+
+
+def mixed_checkpoint(func, inputs: dict, params, flag):
+ """
+ Evaluate a function without caching intermediate activations, allowing for
+ reduced memory at the expense of extra compute in the backward pass. This differs from the original checkpoint function
+ borrowed from https://github.com/openai/guided-diffusion/blob/0ba878e517b276c45d1195eb29f6f5f72659a05b/guided_diffusion/nn.py in that
+ it also works with non-tensor inputs
+ :param func: the function to evaluate.
+ :param inputs: the argument dictionary to pass to `func`.
+ :param params: a sequence of parameters `func` depends on but does not
+ explicitly take as arguments.
+ :param flag: if False, disable gradient checkpointing.
+ """
+ if flag:
+ tensor_keys = [key for key in inputs if isinstance(inputs[key], torch.Tensor)]
+ tensor_inputs = [
+ inputs[key] for key in inputs if isinstance(inputs[key], torch.Tensor)
+ ]
+ non_tensor_keys = [
+ key for key in inputs if not isinstance(inputs[key], torch.Tensor)
+ ]
+ non_tensor_inputs = [
+ inputs[key] for key in inputs if not isinstance(inputs[key], torch.Tensor)
+ ]
+ args = tuple(tensor_inputs) + tuple(non_tensor_inputs) + tuple(params)
+ return MixedCheckpointFunction.apply(
+ func,
+ len(tensor_inputs),
+ len(non_tensor_inputs),
+ tensor_keys,
+ non_tensor_keys,
+ *args,
+ )
+ else:
+ return func(**inputs)
+
+
+class MixedCheckpointFunction(torch.autograd.Function):
+ @staticmethod
+ def forward(
+ ctx,
+ run_function,
+ length_tensors,
+ length_non_tensors,
+ tensor_keys,
+ non_tensor_keys,
+ *args,
+ ):
+ ctx.end_tensors = length_tensors
+ ctx.end_non_tensors = length_tensors + length_non_tensors
+ ctx.gpu_autocast_kwargs = {
+ "enabled": torch.is_autocast_enabled(),
+ "dtype": torch.get_autocast_gpu_dtype(),
+ "cache_enabled": torch.is_autocast_cache_enabled(),
+ }
+ assert (
+ len(tensor_keys) == length_tensors
+ and len(non_tensor_keys) == length_non_tensors
+ )
+
+ ctx.input_tensors = {
+ key: val for (key, val) in zip(tensor_keys, list(args[: ctx.end_tensors]))
+ }
+ ctx.input_non_tensors = {
+ key: val
+ for (key, val) in zip(
+ non_tensor_keys, list(args[ctx.end_tensors : ctx.end_non_tensors])
+ )
+ }
+ ctx.run_function = run_function
+ ctx.input_params = list(args[ctx.end_non_tensors :])
+
+ with torch.no_grad():
+ output_tensors = ctx.run_function(
+ **ctx.input_tensors, **ctx.input_non_tensors
+ )
+ return output_tensors
+
+ @staticmethod
+ def backward(ctx, *output_grads):
+ # additional_args = {key: ctx.input_tensors[key] for key in ctx.input_tensors if not isinstance(ctx.input_tensors[key],torch.Tensor)}
+ ctx.input_tensors = {
+ key: ctx.input_tensors[key].detach().requires_grad_(True)
+ for key in ctx.input_tensors
+ }
+
+ with torch.enable_grad(), torch.cuda.amp.autocast(**ctx.gpu_autocast_kwargs):
+ # Fixes a bug where the first op in run_function modifies the
+ # Tensor storage in place, which is not allowed for detach()'d
+ # Tensors.
+ shallow_copies = {
+ key: ctx.input_tensors[key].view_as(ctx.input_tensors[key])
+ for key in ctx.input_tensors
+ }
+ # shallow_copies.update(additional_args)
+ output_tensors = ctx.run_function(**shallow_copies, **ctx.input_non_tensors)
+ input_grads = torch.autograd.grad(
+ output_tensors,
+ list(ctx.input_tensors.values()) + ctx.input_params,
+ output_grads,
+ allow_unused=True,
+ )
+ del ctx.input_tensors
+ del ctx.input_params
+ del output_tensors
+ return (
+ (None, None, None, None, None)
+ + input_grads[: ctx.end_tensors]
+ + (None,) * (ctx.end_non_tensors - ctx.end_tensors)
+ + input_grads[ctx.end_tensors :]
+ )
+
+
+def checkpoint(func, inputs, params, flag):
+ """
+ Evaluate a function without caching intermediate activations, allowing for
+ reduced memory at the expense of extra compute in the backward pass.
+ :param func: the function to evaluate.
+ :param inputs: the argument sequence to pass to `func`.
+ :param params: a sequence of parameters `func` depends on but does not
+ explicitly take as arguments.
+ :param flag: if False, disable gradient checkpointing.
+ """
+ if flag:
+ args = tuple(inputs) + tuple(params)
+ return CheckpointFunction.apply(func, len(inputs), *args)
+ else:
+ return func(*inputs)
+
+
+class CheckpointFunction(torch.autograd.Function):
+ @staticmethod
+ def forward(ctx, run_function, length, *args):
+ ctx.run_function = run_function
+ ctx.input_tensors = list(args[:length])
+ ctx.input_params = list(args[length:])
+ ctx.gpu_autocast_kwargs = {
+ "enabled": torch.is_autocast_enabled(),
+ "dtype": torch.get_autocast_gpu_dtype(),
+ "cache_enabled": torch.is_autocast_cache_enabled(),
+ }
+ with torch.no_grad():
+ output_tensors = ctx.run_function(*ctx.input_tensors)
+ return output_tensors
+
+ @staticmethod
+ def backward(ctx, *output_grads):
+ ctx.input_tensors = [x.detach().requires_grad_(True) for x in ctx.input_tensors]
+ with torch.enable_grad(), torch.cuda.amp.autocast(**ctx.gpu_autocast_kwargs):
+ # Fixes a bug where the first op in run_function modifies the
+ # Tensor storage in place, which is not allowed for detach()'d
+ # Tensors.
+ shallow_copies = [x.view_as(x) for x in ctx.input_tensors]
+ output_tensors = ctx.run_function(*shallow_copies)
+ input_grads = torch.autograd.grad(
+ output_tensors,
+ ctx.input_tensors + ctx.input_params,
+ output_grads,
+ allow_unused=True,
+ )
+ del ctx.input_tensors
+ del ctx.input_params
+ del output_tensors
+ return (None, None) + input_grads
+
+
+def timestep_embedding(timesteps, dim, max_period=10000, repeat_only=False):
+ """
+ Create sinusoidal timestep embeddings.
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param dim: the dimension of the output.
+ :param max_period: controls the minimum frequency of the embeddings.
+ :return: an [N x dim] Tensor of positional embeddings.
+ """
+ if not repeat_only:
+ half = dim // 2
+ freqs = torch.exp(
+ -math.log(max_period)
+ * torch.arange(start=0, end=half, dtype=torch.float32)
+ / half
+ ).to(device=timesteps.device)
+ args = timesteps[:, None].float() * freqs[None]
+ embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
+ if dim % 2:
+ embedding = torch.cat(
+ [embedding, torch.zeros_like(embedding[:, :1])], dim=-1
+ )
+ else:
+ embedding = repeat(timesteps, "b -> b d", d=dim)
+ return embedding
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def scale_module(module, scale):
+ """
+ Scale the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().mul_(scale)
+ return module
+
+
+def mean_flat(tensor):
+ """
+ Take the mean over all non-batch dimensions.
+ """
+ return tensor.mean(dim=list(range(1, len(tensor.shape))))
+
+
+def normalization(channels):
+ """
+ Make a standard normalization layer.
+ :param channels: number of input channels.
+ :return: an nn.Module for normalization.
+ """
+ return GroupNorm32(32, channels)
+
+
+# PyTorch 1.7 has SiLU, but we support PyTorch 1.5.
+class SiLU(nn.Module):
+ def forward(self, x):
+ return x * torch.sigmoid(x)
+
+
+class GroupNorm32(nn.GroupNorm):
+ def forward(self, x):
+ return super().forward(x.float()).type(x.dtype)
+
+
+def conv_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D convolution module.
+ """
+ if dims == 1:
+ return nn.Conv1d(*args, **kwargs)
+ elif dims == 2:
+ return nn.Conv2d(*args, **kwargs)
+ elif dims == 3:
+ return nn.Conv3d(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def linear(*args, **kwargs):
+ """
+ Create a linear module.
+ """
+ return nn.Linear(*args, **kwargs)
+
+
+def avg_pool_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D average pooling module.
+ """
+ if dims == 1:
+ return nn.AvgPool1d(*args, **kwargs)
+ elif dims == 2:
+ return nn.AvgPool2d(*args, **kwargs)
+ elif dims == 3:
+ return nn.AvgPool3d(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+class AlphaBlender(nn.Module):
+ strategies = ["learned", "fixed", "learned_with_images"]
+
+ def __init__(
+ self,
+ alpha: float,
+ merge_strategy: str = "learned_with_images",
+ rearrange_pattern: str = "b t -> (b t) 1 1",
+ ):
+ super().__init__()
+ self.merge_strategy = merge_strategy
+ self.rearrange_pattern = rearrange_pattern
+
+ assert (
+ merge_strategy in self.strategies
+ ), f"merge_strategy needs to be in {self.strategies}"
+
+ if self.merge_strategy == "fixed":
+ self.register_buffer("mix_factor", torch.Tensor([alpha]))
+ elif (
+ self.merge_strategy == "learned"
+ or self.merge_strategy == "learned_with_images"
+ ):
+ self.register_parameter(
+ "mix_factor", torch.nn.Parameter(torch.Tensor([alpha]))
+ )
+ else:
+ raise ValueError(f"unknown merge strategy {self.merge_strategy}")
+
+ def get_alpha(self, image_only_indicator: torch.Tensor) -> torch.Tensor:
+ if self.merge_strategy == "fixed":
+ alpha = self.mix_factor
+ elif self.merge_strategy == "learned":
+ alpha = torch.sigmoid(self.mix_factor)
+ elif self.merge_strategy == "learned_with_images":
+ assert image_only_indicator is not None, "need image_only_indicator ..."
+ alpha = torch.where(
+ image_only_indicator.bool(),
+ torch.ones(1, 1, device=image_only_indicator.device),
+ rearrange(torch.sigmoid(self.mix_factor), "... -> ... 1"),
+ )
+ alpha = rearrange(alpha, self.rearrange_pattern)
+ else:
+ raise NotImplementedError
+ return alpha
+
+ def forward(
+ self,
+ x_spatial: torch.Tensor,
+ x_temporal: torch.Tensor,
+ image_only_indicator: Optional[torch.Tensor] = None,
+ ) -> torch.Tensor:
+ alpha = self.get_alpha(image_only_indicator)
+ x = (
+ alpha.to(x_spatial.dtype) * x_spatial
+ + (1.0 - alpha).to(x_spatial.dtype) * x_temporal
+ )
+ return x
diff --git a/sgm/modules/diffusionmodules/video_model.py b/sgm/modules/diffusionmodules/video_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..258615267548795718492e2d6cfc65f69dff862d
--- /dev/null
+++ b/sgm/modules/diffusionmodules/video_model.py
@@ -0,0 +1,501 @@
+from functools import partial
+from typing import List, Optional, Union
+
+from einops import rearrange, repeat
+
+from ...modules.diffusionmodules.openaimodel import *
+from ...modules.video_attention import SpatialVideoTransformer
+from ...util import default
+from .util import AlphaBlender
+
+
+class VideoResBlock(ResBlock):
+ def __init__(
+ self,
+ channels: int,
+ emb_channels: int,
+ dropout: float,
+ video_kernel_size: Union[int, List[int]] = 3,
+ merge_strategy: str = "fixed",
+ merge_factor: float = 0.5,
+ out_channels: Optional[int] = None,
+ use_conv: bool = False,
+ use_scale_shift_norm: bool = False,
+ dims: int = 2,
+ use_checkpoint: bool = False,
+ up: bool = False,
+ down: bool = False,
+ ):
+ super().__init__(
+ channels,
+ emb_channels,
+ dropout,
+ out_channels=out_channels,
+ use_conv=use_conv,
+ use_scale_shift_norm=use_scale_shift_norm,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ up=up,
+ down=down,
+ )
+
+ self.time_stack = ResBlock(
+ default(out_channels, channels),
+ emb_channels,
+ dropout=dropout,
+ dims=3,
+ out_channels=default(out_channels, channels),
+ use_scale_shift_norm=False,
+ use_conv=False,
+ up=False,
+ down=False,
+ kernel_size=video_kernel_size,
+ use_checkpoint=use_checkpoint,
+ exchange_temb_dims=True,
+ )
+ self.time_mixer = AlphaBlender(
+ alpha=merge_factor,
+ merge_strategy=merge_strategy,
+ rearrange_pattern="b t -> b 1 t 1 1",
+ )
+
+ def forward(
+ self,
+ x: th.Tensor,
+ emb: th.Tensor,
+ num_video_frames: int,
+ image_only_indicator: Optional[th.Tensor] = None,
+ ) -> th.Tensor:
+ x = super().forward(x, emb)
+
+ x_mix = rearrange(x, "(b t) c h w -> b c t h w", t=num_video_frames)
+ x = rearrange(x, "(b t) c h w -> b c t h w", t=num_video_frames)
+
+ x = self.time_stack(
+ x, rearrange(emb, "(b t) ... -> b t ...", t=num_video_frames)
+ )
+ x = self.time_mixer(
+ x_spatial=x_mix, x_temporal=x, image_only_indicator=image_only_indicator
+ )
+ x = rearrange(x, "b c t h w -> (b t) c h w")
+ return x
+
+
+class VideoUNet(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ model_channels: int,
+ out_channels: int,
+ num_res_blocks: int,
+ attention_resolutions: int,
+ dropout: float = 0.0,
+ channel_mult: List[int] = (1, 2, 4, 8),
+ conv_resample: bool = True,
+ dims: int = 2,
+ num_classes: Optional[int] = None,
+ use_checkpoint: bool = False,
+ num_heads: int = -1,
+ num_head_channels: int = -1,
+ num_heads_upsample: int = -1,
+ use_scale_shift_norm: bool = False,
+ resblock_updown: bool = False,
+ transformer_depth: Union[List[int], int] = 1,
+ transformer_depth_middle: Optional[int] = None,
+ context_dim: Optional[int] = None,
+ time_downup: bool = False,
+ time_context_dim: Optional[int] = None,
+ extra_ff_mix_layer: bool = False,
+ use_spatial_context: bool = False,
+ merge_strategy: str = "fixed",
+ merge_factor: float = 0.5,
+ spatial_transformer_attn_type: str = "softmax",
+ video_kernel_size: Union[int, List[int]] = 3,
+ use_linear_in_transformer: bool = False,
+ adm_in_channels: Optional[int] = None,
+ disable_temporal_crossattention: bool = False,
+ max_ddpm_temb_period: int = 10000,
+ ):
+ super().__init__()
+ assert context_dim is not None
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ if num_heads == -1:
+ assert num_head_channels != -1
+
+ if num_head_channels == -1:
+ assert num_heads != -1
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ if isinstance(transformer_depth, int):
+ transformer_depth = len(channel_mult) * [transformer_depth]
+ transformer_depth_middle = default(
+ transformer_depth_middle, transformer_depth[-1]
+ )
+
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.use_checkpoint = use_checkpoint
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ if self.num_classes is not None:
+ if isinstance(self.num_classes, int):
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+ elif self.num_classes == "continuous":
+ print("setting up linear c_adm embedding layer")
+ self.label_emb = nn.Linear(1, time_embed_dim)
+ elif self.num_classes == "timestep":
+ self.label_emb = nn.Sequential(
+ Timestep(model_channels),
+ nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ ),
+ )
+
+ elif self.num_classes == "sequential":
+ assert adm_in_channels is not None
+ self.label_emb = nn.Sequential(
+ nn.Sequential(
+ linear(adm_in_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+ )
+ else:
+ raise ValueError()
+
+ self.input_blocks = nn.ModuleList(
+ [
+ TimestepEmbedSequential(
+ conv_nd(dims, in_channels, model_channels, 3, padding=1)
+ )
+ ]
+ )
+ self._feature_size = model_channels
+ input_block_chans = [model_channels]
+ ch = model_channels
+ ds = 1
+
+ def get_attention_layer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=1,
+ context_dim=None,
+ use_checkpoint=False,
+ disabled_sa=False,
+ ):
+ return SpatialVideoTransformer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=depth,
+ context_dim=context_dim,
+ time_context_dim=time_context_dim,
+ dropout=dropout,
+ ff_in=extra_ff_mix_layer,
+ use_spatial_context=use_spatial_context,
+ merge_strategy=merge_strategy,
+ merge_factor=merge_factor,
+ checkpoint=use_checkpoint,
+ use_linear=use_linear_in_transformer,
+ attn_mode=spatial_transformer_attn_type,
+ disable_self_attn=disabled_sa,
+ disable_temporal_crossattention=disable_temporal_crossattention,
+ max_time_embed_period=max_ddpm_temb_period,
+ )
+
+ def get_resblock(
+ merge_factor,
+ merge_strategy,
+ video_kernel_size,
+ ch,
+ time_embed_dim,
+ dropout,
+ out_ch,
+ dims,
+ use_checkpoint,
+ use_scale_shift_norm,
+ down=False,
+ up=False,
+ ):
+ return VideoResBlock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ channels=ch,
+ emb_channels=time_embed_dim,
+ dropout=dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=down,
+ up=up,
+ )
+
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ out_ch=mult * model_channels,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = mult * model_channels
+ if ds in attention_resolutions:
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ layers.append(
+ get_attention_layer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth[level],
+ context_dim=context_dim,
+ use_checkpoint=use_checkpoint,
+ disabled_sa=False,
+ )
+ )
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ ds *= 2
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ out_ch=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ )
+ if resblock_updown
+ else Downsample(
+ ch,
+ conv_resample,
+ dims=dims,
+ out_channels=out_ch,
+ third_down=time_downup,
+ )
+ )
+ )
+ ch = out_ch
+ input_block_chans.append(ch)
+
+ self._feature_size += ch
+
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ self.middle_block = TimestepEmbedSequential(
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ time_embed_dim=time_embed_dim,
+ out_ch=None,
+ dropout=dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ get_attention_layer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth_middle,
+ context_dim=context_dim,
+ use_checkpoint=use_checkpoint,
+ ),
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ out_ch=None,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.ModuleList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(num_res_blocks + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch + ich,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ out_ch=model_channels * mult,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = model_channels * mult
+ if ds in attention_resolutions:
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ layers.append(
+ get_attention_layer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth[level],
+ context_dim=context_dim,
+ use_checkpoint=use_checkpoint,
+ disabled_sa=False,
+ )
+ )
+ if level and i == num_res_blocks:
+ out_ch = ch
+ ds //= 2
+ layers.append(
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ out_ch=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ )
+ if resblock_updown
+ else Upsample(
+ ch,
+ conv_resample,
+ dims=dims,
+ out_channels=out_ch,
+ third_up=time_downup,
+ )
+ )
+
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ nn.SiLU(),
+ zero_module(conv_nd(dims, model_channels, out_channels, 3, padding=1)),
+ )
+
+ def forward(
+ self,
+ x: th.Tensor,
+ timesteps: th.Tensor,
+ context: Optional[th.Tensor] = None,
+ y: Optional[th.Tensor] = None,
+ time_context: Optional[th.Tensor] = None,
+ num_video_frames: Optional[int] = None,
+ image_only_indicator: Optional[th.Tensor] = None,
+ ):
+ assert (y is not None) == (
+ self.num_classes is not None
+ ), "must specify y if and only if the model is class-conditional -> no, relax this TODO"
+ hs = []
+ t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
+ emb = self.time_embed(t_emb)
+
+ # for fast implementation
+ if y.shape[0] != x.shape[0] and x.shape[0] // y.shape[0] == num_video_frames:
+ y = repeat(y, "b ... -> b t ...", t=num_video_frames)
+ y = rearrange(y, "b t ... -> (b t) ...", t=num_video_frames)
+ if context.shape[0] != x.shape[0] and x.shape[0] // context.shape[0] == num_video_frames:
+ context = repeat(context, "b ... -> b t ...", t=num_video_frames)
+ context = rearrange(context, "b t ... -> (b t) ...", t=num_video_frames)
+
+ if self.num_classes is not None:
+ assert y.shape[0] == x.shape[0]
+ emb = emb + self.label_emb(y)
+
+ h = x
+ for module in self.input_blocks:
+ h = module(
+ h,
+ emb,
+ context=context,
+ image_only_indicator=image_only_indicator,
+ time_context=time_context,
+ num_video_frames=num_video_frames,
+ )
+ hs.append(h)
+ h = self.middle_block(
+ h,
+ emb,
+ context=context,
+ image_only_indicator=image_only_indicator,
+ time_context=time_context,
+ num_video_frames=num_video_frames,
+ )
+ for module in self.output_blocks:
+ h = th.cat([h, hs.pop()], dim=1)
+ h = module(
+ h,
+ emb,
+ context=context,
+ image_only_indicator=image_only_indicator,
+ time_context=time_context,
+ num_video_frames=num_video_frames,
+ )
+ h = h.type(x.dtype)
+ return self.out(h)
diff --git a/sgm/modules/diffusionmodules/video_model_old.py b/sgm/modules/diffusionmodules/video_model_old.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b38fbc038dd2e3966635b62818e8147212378ad
--- /dev/null
+++ b/sgm/modules/diffusionmodules/video_model_old.py
@@ -0,0 +1,493 @@
+from functools import partial
+from typing import List, Optional, Union
+
+from einops import rearrange
+
+from .openaimodel import *
+from ..video_attention import SpatialVideoTransformer
+from ...util import default
+from .util import AlphaBlender
+
+
+class VideoResBlock(ResBlock):
+ def __init__(
+ self,
+ channels: int,
+ emb_channels: int,
+ dropout: float,
+ video_kernel_size: Union[int, List[int]] = 3,
+ merge_strategy: str = "fixed",
+ merge_factor: float = 0.5,
+ out_channels: Optional[int] = None,
+ use_conv: bool = False,
+ use_scale_shift_norm: bool = False,
+ dims: int = 2,
+ use_checkpoint: bool = False,
+ up: bool = False,
+ down: bool = False,
+ ):
+ super().__init__(
+ channels,
+ emb_channels,
+ dropout,
+ out_channels=out_channels,
+ use_conv=use_conv,
+ use_scale_shift_norm=use_scale_shift_norm,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ up=up,
+ down=down,
+ )
+
+ self.time_stack = ResBlock(
+ default(out_channels, channels),
+ emb_channels,
+ dropout=dropout,
+ dims=3,
+ out_channels=default(out_channels, channels),
+ use_scale_shift_norm=False,
+ use_conv=False,
+ up=False,
+ down=False,
+ kernel_size=video_kernel_size,
+ use_checkpoint=use_checkpoint,
+ exchange_temb_dims=True,
+ )
+ self.time_mixer = AlphaBlender(
+ alpha=merge_factor,
+ merge_strategy=merge_strategy,
+ rearrange_pattern="b t -> b 1 t 1 1",
+ )
+
+ def forward(
+ self,
+ x: th.Tensor,
+ emb: th.Tensor,
+ num_video_frames: int,
+ image_only_indicator: Optional[th.Tensor] = None,
+ ) -> th.Tensor:
+ x = super().forward(x, emb)
+
+ x_mix = rearrange(x, "(b t) c h w -> b c t h w", t=num_video_frames)
+ x = rearrange(x, "(b t) c h w -> b c t h w", t=num_video_frames)
+
+ x = self.time_stack(
+ x, rearrange(emb, "(b t) ... -> b t ...", t=num_video_frames)
+ )
+ x = self.time_mixer(
+ x_spatial=x_mix, x_temporal=x, image_only_indicator=image_only_indicator
+ )
+ x = rearrange(x, "b c t h w -> (b t) c h w")
+ return x
+
+
+class VideoUNet(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ model_channels: int,
+ out_channels: int,
+ num_res_blocks: int,
+ attention_resolutions: int,
+ dropout: float = 0.0,
+ channel_mult: List[int] = (1, 2, 4, 8),
+ conv_resample: bool = True,
+ dims: int = 2,
+ num_classes: Optional[int] = None,
+ use_checkpoint: bool = False,
+ num_heads: int = -1,
+ num_head_channels: int = -1,
+ num_heads_upsample: int = -1,
+ use_scale_shift_norm: bool = False,
+ resblock_updown: bool = False,
+ transformer_depth: Union[List[int], int] = 1,
+ transformer_depth_middle: Optional[int] = None,
+ context_dim: Optional[int] = None,
+ time_downup: bool = False,
+ time_context_dim: Optional[int] = None,
+ extra_ff_mix_layer: bool = False,
+ use_spatial_context: bool = False,
+ merge_strategy: str = "fixed",
+ merge_factor: float = 0.5,
+ spatial_transformer_attn_type: str = "softmax",
+ video_kernel_size: Union[int, List[int]] = 3,
+ use_linear_in_transformer: bool = False,
+ adm_in_channels: Optional[int] = None,
+ disable_temporal_crossattention: bool = False,
+ max_ddpm_temb_period: int = 10000,
+ ):
+ super().__init__()
+ assert context_dim is not None
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ if num_heads == -1:
+ assert num_head_channels != -1
+
+ if num_head_channels == -1:
+ assert num_heads != -1
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ if isinstance(transformer_depth, int):
+ transformer_depth = len(channel_mult) * [transformer_depth]
+ transformer_depth_middle = default(
+ transformer_depth_middle, transformer_depth[-1]
+ )
+
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.use_checkpoint = use_checkpoint
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ if self.num_classes is not None:
+ if isinstance(self.num_classes, int):
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+ elif self.num_classes == "continuous":
+ print("setting up linear c_adm embedding layer")
+ self.label_emb = nn.Linear(1, time_embed_dim)
+ elif self.num_classes == "timestep":
+ self.label_emb = nn.Sequential(
+ Timestep(model_channels),
+ nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ ),
+ )
+
+ elif self.num_classes == "sequential":
+ assert adm_in_channels is not None
+ self.label_emb = nn.Sequential(
+ nn.Sequential(
+ linear(adm_in_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+ )
+ else:
+ raise ValueError()
+
+ self.input_blocks = nn.ModuleList(
+ [
+ TimestepEmbedSequential(
+ conv_nd(dims, in_channels, model_channels, 3, padding=1)
+ )
+ ]
+ )
+ self._feature_size = model_channels
+ input_block_chans = [model_channels]
+ ch = model_channels
+ ds = 1
+
+ def get_attention_layer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=1,
+ context_dim=None,
+ use_checkpoint=False,
+ disabled_sa=False,
+ ):
+ return SpatialVideoTransformer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=depth,
+ context_dim=context_dim,
+ time_context_dim=time_context_dim,
+ dropout=dropout,
+ ff_in=extra_ff_mix_layer,
+ use_spatial_context=use_spatial_context,
+ merge_strategy=merge_strategy,
+ merge_factor=merge_factor,
+ checkpoint=use_checkpoint,
+ use_linear=use_linear_in_transformer,
+ attn_mode=spatial_transformer_attn_type,
+ disable_self_attn=disabled_sa,
+ disable_temporal_crossattention=disable_temporal_crossattention,
+ max_time_embed_period=max_ddpm_temb_period,
+ )
+
+ def get_resblock(
+ merge_factor,
+ merge_strategy,
+ video_kernel_size,
+ ch,
+ time_embed_dim,
+ dropout,
+ out_ch,
+ dims,
+ use_checkpoint,
+ use_scale_shift_norm,
+ down=False,
+ up=False,
+ ):
+ return VideoResBlock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ channels=ch,
+ emb_channels=time_embed_dim,
+ dropout=dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=down,
+ up=up,
+ )
+
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ out_ch=mult * model_channels,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = mult * model_channels
+ if ds in attention_resolutions:
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ layers.append(
+ get_attention_layer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth[level],
+ context_dim=context_dim,
+ use_checkpoint=use_checkpoint,
+ disabled_sa=False,
+ )
+ )
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ ds *= 2
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ out_ch=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ )
+ if resblock_updown
+ else Downsample(
+ ch,
+ conv_resample,
+ dims=dims,
+ out_channels=out_ch,
+ third_down=time_downup,
+ )
+ )
+ )
+ ch = out_ch
+ input_block_chans.append(ch)
+
+ self._feature_size += ch
+
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ self.middle_block = TimestepEmbedSequential(
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ time_embed_dim=time_embed_dim,
+ out_ch=None,
+ dropout=dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ get_attention_layer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth_middle,
+ context_dim=context_dim,
+ use_checkpoint=use_checkpoint,
+ ),
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ out_ch=None,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.ModuleList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(num_res_blocks + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch + ich,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ out_ch=model_channels * mult,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = model_channels * mult
+ if ds in attention_resolutions:
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+
+ layers.append(
+ get_attention_layer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth[level],
+ context_dim=context_dim,
+ use_checkpoint=use_checkpoint,
+ disabled_sa=False,
+ )
+ )
+ if level and i == num_res_blocks:
+ out_ch = ch
+ ds //= 2
+ layers.append(
+ get_resblock(
+ merge_factor=merge_factor,
+ merge_strategy=merge_strategy,
+ video_kernel_size=video_kernel_size,
+ ch=ch,
+ time_embed_dim=time_embed_dim,
+ dropout=dropout,
+ out_ch=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ )
+ if resblock_updown
+ else Upsample(
+ ch,
+ conv_resample,
+ dims=dims,
+ out_channels=out_ch,
+ third_up=time_downup,
+ )
+ )
+
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ nn.SiLU(),
+ zero_module(conv_nd(dims, model_channels, out_channels, 3, padding=1)),
+ )
+
+ def forward(
+ self,
+ x: th.Tensor,
+ timesteps: th.Tensor,
+ context: Optional[th.Tensor] = None,
+ y: Optional[th.Tensor] = None,
+ time_context: Optional[th.Tensor] = None,
+ num_video_frames: Optional[int] = None,
+ image_only_indicator: Optional[th.Tensor] = None,
+ ):
+ assert (y is not None) == (
+ self.num_classes is not None
+ ), "must specify y if and only if the model is class-conditional -> no, relax this TODO"
+ hs = []
+ t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
+ emb = self.time_embed(t_emb)
+
+ if self.num_classes is not None:
+ assert y.shape[0] == x.shape[0]
+ emb = emb + self.label_emb(y)
+
+ h = x
+ for module in self.input_blocks:
+ h = module(
+ h,
+ emb,
+ context=context,
+ image_only_indicator=image_only_indicator,
+ time_context=time_context,
+ num_video_frames=num_video_frames,
+ )
+ hs.append(h)
+ h = self.middle_block(
+ h,
+ emb,
+ context=context,
+ image_only_indicator=image_only_indicator,
+ time_context=time_context,
+ num_video_frames=num_video_frames,
+ )
+ for module in self.output_blocks:
+ h = th.cat([h, hs.pop()], dim=1)
+ h = module(
+ h,
+ emb,
+ context=context,
+ image_only_indicator=image_only_indicator,
+ time_context=time_context,
+ num_video_frames=num_video_frames,
+ )
+ h = h.type(x.dtype)
+ return self.out(h)
diff --git a/sgm/modules/diffusionmodules/wrappers.py b/sgm/modules/diffusionmodules/wrappers.py
new file mode 100644
index 0000000000000000000000000000000000000000..37449ea63e992b9f89856f1f47c18ba68be8e334
--- /dev/null
+++ b/sgm/modules/diffusionmodules/wrappers.py
@@ -0,0 +1,34 @@
+import torch
+import torch.nn as nn
+from packaging import version
+
+OPENAIUNETWRAPPER = "sgm.modules.diffusionmodules.wrappers.OpenAIWrapper"
+
+
+class IdentityWrapper(nn.Module):
+ def __init__(self, diffusion_model, compile_model: bool = False):
+ super().__init__()
+ compile = (
+ torch.compile
+ if (version.parse(torch.__version__) >= version.parse("2.0.0"))
+ and compile_model
+ else lambda x: x
+ )
+ self.diffusion_model = compile(diffusion_model)
+
+ def forward(self, *args, **kwargs):
+ return self.diffusion_model(*args, **kwargs)
+
+
+class OpenAIWrapper(IdentityWrapper):
+ def forward(
+ self, x: torch.Tensor, t: torch.Tensor, c: dict, **kwargs
+ ) -> torch.Tensor:
+ x = torch.cat((x, c.get("concat", torch.Tensor([]).type_as(x))), dim=1)
+ return self.diffusion_model(
+ x,
+ timesteps=t,
+ context=c.get("crossattn", None),
+ y=c.get("vector", None),
+ **kwargs,
+ )
diff --git a/sgm/modules/distributions/__init__.py b/sgm/modules/distributions/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/sgm/modules/distributions/distributions.py b/sgm/modules/distributions/distributions.py
new file mode 100644
index 0000000000000000000000000000000000000000..016be35523187ea366db9ade391fe8ee276db60b
--- /dev/null
+++ b/sgm/modules/distributions/distributions.py
@@ -0,0 +1,102 @@
+import numpy as np
+import torch
+
+
+class AbstractDistribution:
+ def sample(self):
+ raise NotImplementedError()
+
+ def mode(self):
+ raise NotImplementedError()
+
+
+class DiracDistribution(AbstractDistribution):
+ def __init__(self, value):
+ self.value = value
+
+ def sample(self):
+ return self.value
+
+ def mode(self):
+ return self.value
+
+
+class DiagonalGaussianDistribution(object):
+ def __init__(self, parameters, deterministic=False):
+ self.parameters = parameters
+ self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
+ self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
+ self.deterministic = deterministic
+ self.std = torch.exp(0.5 * self.logvar)
+ self.var = torch.exp(self.logvar)
+ if self.deterministic:
+ self.var = self.std = torch.zeros_like(self.mean).to(
+ device=self.parameters.device
+ )
+
+ def sample(self):
+ x = self.mean + self.std * torch.randn(self.mean.shape).to(
+ device=self.parameters.device
+ )
+ return x
+
+ def kl(self, other=None):
+ if self.deterministic:
+ return torch.Tensor([0.0])
+ else:
+ if other is None:
+ return 0.5 * torch.sum(
+ torch.pow(self.mean, 2) + self.var - 1.0 - self.logvar,
+ dim=[1, 2, 3],
+ )
+ else:
+ return 0.5 * torch.sum(
+ torch.pow(self.mean - other.mean, 2) / other.var
+ + self.var / other.var
+ - 1.0
+ - self.logvar
+ + other.logvar,
+ dim=[1, 2, 3],
+ )
+
+ def nll(self, sample, dims=[1, 2, 3]):
+ if self.deterministic:
+ return torch.Tensor([0.0])
+ logtwopi = np.log(2.0 * np.pi)
+ return 0.5 * torch.sum(
+ logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var,
+ dim=dims,
+ )
+
+ def mode(self):
+ return self.mean
+
+
+def normal_kl(mean1, logvar1, mean2, logvar2):
+ """
+ source: https://github.com/openai/guided-diffusion/blob/27c20a8fab9cb472df5d6bdd6c8d11c8f430b924/guided_diffusion/losses.py#L12
+ Compute the KL divergence between two gaussians.
+ Shapes are automatically broadcasted, so batches can be compared to
+ scalars, among other use cases.
+ """
+ tensor = None
+ for obj in (mean1, logvar1, mean2, logvar2):
+ if isinstance(obj, torch.Tensor):
+ tensor = obj
+ break
+ assert tensor is not None, "at least one argument must be a Tensor"
+
+ # Force variances to be Tensors. Broadcasting helps convert scalars to
+ # Tensors, but it does not work for torch.exp().
+ logvar1, logvar2 = [
+ x if isinstance(x, torch.Tensor) else torch.tensor(x).to(tensor)
+ for x in (logvar1, logvar2)
+ ]
+
+ return 0.5 * (
+ -1.0
+ + logvar2
+ - logvar1
+ + torch.exp(logvar1 - logvar2)
+ + ((mean1 - mean2) ** 2) * torch.exp(-logvar2)
+ )
diff --git a/sgm/modules/ema.py b/sgm/modules/ema.py
new file mode 100644
index 0000000000000000000000000000000000000000..97b5ae2b230f89b4dba57e44c4f851478ad86f68
--- /dev/null
+++ b/sgm/modules/ema.py
@@ -0,0 +1,86 @@
+import torch
+from torch import nn
+
+
+class LitEma(nn.Module):
+ def __init__(self, model, decay=0.9999, use_num_upates=True):
+ super().__init__()
+ if decay < 0.0 or decay > 1.0:
+ raise ValueError("Decay must be between 0 and 1")
+
+ self.m_name2s_name = {}
+ self.register_buffer("decay", torch.tensor(decay, dtype=torch.float32))
+ self.register_buffer(
+ "num_updates",
+ torch.tensor(0, dtype=torch.int)
+ if use_num_upates
+ else torch.tensor(-1, dtype=torch.int),
+ )
+
+ for name, p in model.named_parameters():
+ if p.requires_grad:
+ # remove as '.'-character is not allowed in buffers
+ s_name = name.replace(".", "")
+ self.m_name2s_name.update({name: s_name})
+ self.register_buffer(s_name, p.clone().detach().data)
+
+ self.collected_params = []
+
+ def reset_num_updates(self):
+ del self.num_updates
+ self.register_buffer("num_updates", torch.tensor(0, dtype=torch.int))
+
+ def forward(self, model):
+ decay = self.decay
+
+ if self.num_updates >= 0:
+ self.num_updates += 1
+ decay = min(self.decay, (1 + self.num_updates) / (10 + self.num_updates))
+
+ one_minus_decay = 1.0 - decay
+
+ with torch.no_grad():
+ m_param = dict(model.named_parameters())
+ shadow_params = dict(self.named_buffers())
+
+ for key in m_param:
+ if m_param[key].requires_grad:
+ sname = self.m_name2s_name[key]
+ shadow_params[sname] = shadow_params[sname].type_as(m_param[key])
+ shadow_params[sname].sub_(
+ one_minus_decay * (shadow_params[sname] - m_param[key])
+ )
+ else:
+ assert not key in self.m_name2s_name
+
+ def copy_to(self, model):
+ m_param = dict(model.named_parameters())
+ shadow_params = dict(self.named_buffers())
+ for key in m_param:
+ if m_param[key].requires_grad:
+ m_param[key].data.copy_(shadow_params[self.m_name2s_name[key]].data)
+ else:
+ assert not key in self.m_name2s_name
+
+ def store(self, parameters):
+ """
+ Save the current parameters for restoring later.
+ Args:
+ parameters: Iterable of `torch.nn.Parameter`; the parameters to be
+ temporarily stored.
+ """
+ self.collected_params = [param.clone() for param in parameters]
+
+ def restore(self, parameters):
+ """
+ Restore the parameters stored with the `store` method.
+ Useful to validate the model with EMA parameters without affecting the
+ original optimization process. Store the parameters before the
+ `copy_to` method. After validation (or model saving), use this to
+ restore the former parameters.
+ Args:
+ parameters: Iterable of `torch.nn.Parameter`; the parameters to be
+ updated with the stored parameters.
+ """
+ for c_param, param in zip(self.collected_params, parameters):
+ param.data.copy_(c_param.data)
diff --git a/sgm/modules/encoders/__init__.py b/sgm/modules/encoders/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/sgm/modules/encoders/modules.py b/sgm/modules/encoders/modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..d77b8ed706552a449a7df2a3febf1172ea28f4ee
--- /dev/null
+++ b/sgm/modules/encoders/modules.py
@@ -0,0 +1,1046 @@
+import math
+from contextlib import nullcontext
+from functools import partial
+from typing import Dict, List, Optional, Tuple, Union
+
+import kornia
+import numpy as np
+import open_clip
+import torch
+import torch.nn as nn
+from einops import rearrange, repeat
+from omegaconf import ListConfig
+from torch.utils.checkpoint import checkpoint
+from transformers import (ByT5Tokenizer, CLIPTextModel, CLIPTokenizer,
+ T5EncoderModel, T5Tokenizer)
+
+from ...modules.autoencoding.regularizers import DiagonalGaussianRegularizer
+from ...modules.diffusionmodules.model import Encoder
+from ...modules.diffusionmodules.openaimodel import Timestep
+from ...modules.diffusionmodules.util import (extract_into_tensor,
+ make_beta_schedule)
+from ...modules.distributions.distributions import DiagonalGaussianDistribution
+from ...util import (append_dims, autocast, count_params, default,
+ disabled_train, expand_dims_like, instantiate_from_config)
+
+
+class AbstractEmbModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self._is_trainable = None
+ self._ucg_rate = None
+ self._input_key = None
+
+ @property
+ def is_trainable(self) -> bool:
+ return self._is_trainable
+
+ @property
+ def ucg_rate(self) -> Union[float, torch.Tensor]:
+ return self._ucg_rate
+
+ @property
+ def input_key(self) -> str:
+ return self._input_key
+
+ @is_trainable.setter
+ def is_trainable(self, value: bool):
+ self._is_trainable = value
+
+ @ucg_rate.setter
+ def ucg_rate(self, value: Union[float, torch.Tensor]):
+ self._ucg_rate = value
+
+ @input_key.setter
+ def input_key(self, value: str):
+ self._input_key = value
+
+ @is_trainable.deleter
+ def is_trainable(self):
+ del self._is_trainable
+
+ @ucg_rate.deleter
+ def ucg_rate(self):
+ del self._ucg_rate
+
+ @input_key.deleter
+ def input_key(self):
+ del self._input_key
+
+
+class GeneralConditioner(nn.Module):
+ OUTPUT_DIM2KEYS = {2: "vector", 3: "crossattn", 4: "concat", 5: "concat"}
+ KEY2CATDIM = {"vector": 1, "crossattn": 2, "concat": 1}
+
+ def __init__(self, emb_models: Union[List, ListConfig]):
+ super().__init__()
+ embedders = []
+ for n, embconfig in enumerate(emb_models):
+ embedder = instantiate_from_config(embconfig)
+ assert isinstance(
+ embedder, AbstractEmbModel
+ ), f"embedder model {embedder.__class__.__name__} has to inherit from AbstractEmbModel"
+ embedder.is_trainable = embconfig.get("is_trainable", False)
+ embedder.ucg_rate = embconfig.get("ucg_rate", 0.0)
+ if not embedder.is_trainable:
+ embedder.train = disabled_train
+ for param in embedder.parameters():
+ param.requires_grad = False
+ embedder.eval()
+ print(
+ f"Initialized embedder #{n}: {embedder.__class__.__name__} "
+ f"with {count_params(embedder, False)} params. Trainable: {embedder.is_trainable}"
+ )
+
+ if "input_key" in embconfig:
+ embedder.input_key = embconfig["input_key"]
+ elif "input_keys" in embconfig:
+ embedder.input_keys = embconfig["input_keys"]
+ else:
+ raise KeyError(
+ f"need either 'input_key' or 'input_keys' for embedder {embedder.__class__.__name__}"
+ )
+
+ embedder.legacy_ucg_val = embconfig.get("legacy_ucg_value", None)
+ if embedder.legacy_ucg_val is not None:
+ embedder.ucg_prng = np.random.RandomState()
+
+ embedders.append(embedder)
+ self.embedders = nn.ModuleList(embedders)
+
+ def possibly_get_ucg_val(self, embedder: AbstractEmbModel, batch: Dict) -> Dict:
+ assert embedder.legacy_ucg_val is not None
+ p = embedder.ucg_rate
+ val = embedder.legacy_ucg_val
+ for i in range(len(batch[embedder.input_key])):
+ if embedder.ucg_prng.choice(2, p=[1 - p, p]):
+ batch[embedder.input_key][i] = val
+ return batch
+
+ def forward(
+ self, batch: Dict, force_zero_embeddings: Optional[List] = None
+ ) -> Dict:
+ output = dict()
+ if force_zero_embeddings is None:
+ force_zero_embeddings = []
+ for embedder in self.embedders:
+ embedding_context = nullcontext if embedder.is_trainable else torch.no_grad
+ with embedding_context():
+ if hasattr(embedder, "input_key") and (embedder.input_key is not None):
+ if embedder.legacy_ucg_val is not None:
+ batch = self.possibly_get_ucg_val(embedder, batch)
+ emb_out = embedder(batch[embedder.input_key])
+ elif hasattr(embedder, "input_keys"):
+ emb_out = embedder(*[batch[k] for k in embedder.input_keys])
+ assert isinstance(
+ emb_out, (torch.Tensor, list, tuple)
+ ), f"encoder outputs must be tensors or a sequence, but got {type(emb_out)}"
+ if not isinstance(emb_out, (list, tuple)):
+ emb_out = [emb_out]
+ for emb in emb_out:
+ out_key = self.OUTPUT_DIM2KEYS[emb.dim()]
+ if embedder.ucg_rate > 0.0 and embedder.legacy_ucg_val is None:
+ emb = (
+ expand_dims_like(
+ torch.bernoulli(
+ (1.0 - embedder.ucg_rate)
+ * torch.ones(emb.shape[0], device=emb.device)
+ ),
+ emb,
+ )
+ * emb
+ )
+ if (
+ hasattr(embedder, "input_key")
+ and embedder.input_key in force_zero_embeddings
+ ):
+ emb = torch.zeros_like(emb)
+ if out_key in output:
+ output[out_key] = torch.cat(
+ (output[out_key], emb), self.KEY2CATDIM[out_key]
+ )
+ else:
+ output[out_key] = emb
+ return output
+
+ def get_unconditional_conditioning(
+ self,
+ batch_c: Dict,
+ batch_uc: Optional[Dict] = None,
+ force_uc_zero_embeddings: Optional[List[str]] = None,
+ force_cond_zero_embeddings: Optional[List[str]] = None,
+ ):
+ if force_uc_zero_embeddings is None:
+ force_uc_zero_embeddings = []
+ ucg_rates = list()
+ for embedder in self.embedders:
+ ucg_rates.append(embedder.ucg_rate)
+ embedder.ucg_rate = 0.0
+ c = self(batch_c, force_cond_zero_embeddings)
+ uc = self(batch_c if batch_uc is None else batch_uc, force_uc_zero_embeddings)
+
+ for embedder, rate in zip(self.embedders, ucg_rates):
+ embedder.ucg_rate = rate
+ return c, uc
+
+
+class InceptionV3(nn.Module):
+ """Wrapper around the https://github.com/mseitzer/pytorch-fid inception
+ port with an additional squeeze at the end"""
+
+ def __init__(self, normalize_input=False, **kwargs):
+ super().__init__()
+ from pytorch_fid import inception
+
+ kwargs["resize_input"] = True
+ self.model = inception.InceptionV3(normalize_input=normalize_input, **kwargs)
+
+ def forward(self, inp):
+ outp = self.model(inp)
+
+ if len(outp) == 1:
+ return outp[0].squeeze()
+
+ return outp
+
+
+class IdentityEncoder(AbstractEmbModel):
+ def encode(self, x):
+ return x
+
+ def forward(self, x):
+ return x
+
+
+class ClassEmbedder(AbstractEmbModel):
+ def __init__(self, embed_dim, n_classes=1000, add_sequence_dim=False):
+ super().__init__()
+ self.embedding = nn.Embedding(n_classes, embed_dim)
+ self.n_classes = n_classes
+ self.add_sequence_dim = add_sequence_dim
+
+ def forward(self, c):
+ c = self.embedding(c)
+ if self.add_sequence_dim:
+ c = c[:, None, :]
+ return c
+
+ def get_unconditional_conditioning(self, bs, device="cuda"):
+ uc_class = (
+ self.n_classes - 1
+ ) # 1000 classes --> 0 ... 999, one extra class for ucg (class 1000)
+ uc = torch.ones((bs,), device=device) * uc_class
+ uc = {self.key: uc.long()}
+ return uc
+
+
+class ClassEmbedderForMultiCond(ClassEmbedder):
+ def forward(self, batch, key=None, disable_dropout=False):
+ out = batch
+ key = default(key, self.key)
+ islist = isinstance(batch[key], list)
+ if islist:
+ batch[key] = batch[key][0]
+ c_out = super().forward(batch, key, disable_dropout)
+ out[key] = [c_out] if islist else c_out
+ return out
+
+
+class FrozenT5Embedder(AbstractEmbModel):
+ """Uses the T5 transformer encoder for text"""
+
+ def __init__(
+ self, version="google/t5-v1_1-xxl", device="cuda", max_length=77, freeze=True
+ ): # others are google/t5-v1_1-xl and google/t5-v1_1-xxl
+ super().__init__()
+ self.tokenizer = T5Tokenizer.from_pretrained(version)
+ self.transformer = T5EncoderModel.from_pretrained(version)
+ self.device = device
+ self.max_length = max_length
+ if freeze:
+ self.freeze()
+
+ def freeze(self):
+ self.transformer = self.transformer.eval()
+
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, text):
+ batch_encoding = self.tokenizer(
+ text,
+ truncation=True,
+ max_length=self.max_length,
+ return_length=True,
+ return_overflowing_tokens=False,
+ padding="max_length",
+ return_tensors="pt",
+ )
+ tokens = batch_encoding["input_ids"].to(self.device)
+ with torch.autocast("cuda", enabled=False):
+ outputs = self.transformer(input_ids=tokens)
+ z = outputs.last_hidden_state
+ return z
+
+ def encode(self, text):
+ return self(text)
+
+
+class FrozenByT5Embedder(AbstractEmbModel):
+ """
+ Uses the ByT5 transformer encoder for text. Is character-aware.
+ """
+
+ def __init__(
+ self, version="google/byt5-base", device="cuda", max_length=77, freeze=True
+ ): # others are google/t5-v1_1-xl and google/t5-v1_1-xxl
+ super().__init__()
+ self.tokenizer = ByT5Tokenizer.from_pretrained(version)
+ self.transformer = T5EncoderModel.from_pretrained(version)
+ self.device = device
+ self.max_length = max_length
+ if freeze:
+ self.freeze()
+
+ def freeze(self):
+ self.transformer = self.transformer.eval()
+
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, text):
+ batch_encoding = self.tokenizer(
+ text,
+ truncation=True,
+ max_length=self.max_length,
+ return_length=True,
+ return_overflowing_tokens=False,
+ padding="max_length",
+ return_tensors="pt",
+ )
+ tokens = batch_encoding["input_ids"].to(self.device)
+ with torch.autocast("cuda", enabled=False):
+ outputs = self.transformer(input_ids=tokens)
+ z = outputs.last_hidden_state
+ return z
+
+ def encode(self, text):
+ return self(text)
+
+
+class FrozenCLIPEmbedder(AbstractEmbModel):
+ """Uses the CLIP transformer encoder for text (from huggingface)"""
+
+ LAYERS = ["last", "pooled", "hidden"]
+
+ def __init__(
+ self,
+ version="openai/clip-vit-large-patch14",
+ device="cuda",
+ max_length=77,
+ freeze=True,
+ layer="last",
+ layer_idx=None,
+ always_return_pooled=False,
+ ): # clip-vit-base-patch32
+ super().__init__()
+ assert layer in self.LAYERS
+ self.tokenizer = CLIPTokenizer.from_pretrained(version)
+ self.transformer = CLIPTextModel.from_pretrained(version)
+ self.device = device
+ self.max_length = max_length
+ if freeze:
+ self.freeze()
+ self.layer = layer
+ self.layer_idx = layer_idx
+ self.return_pooled = always_return_pooled
+ if layer == "hidden":
+ assert layer_idx is not None
+ assert 0 <= abs(layer_idx) <= 12
+
+ def freeze(self):
+ self.transformer = self.transformer.eval()
+
+ for param in self.parameters():
+ param.requires_grad = False
+
+ @autocast
+ def forward(self, text):
+ batch_encoding = self.tokenizer(
+ text,
+ truncation=True,
+ max_length=self.max_length,
+ return_length=True,
+ return_overflowing_tokens=False,
+ padding="max_length",
+ return_tensors="pt",
+ )
+ tokens = batch_encoding["input_ids"].to(self.device)
+ outputs = self.transformer(
+ input_ids=tokens, output_hidden_states=self.layer == "hidden"
+ )
+ if self.layer == "last":
+ z = outputs.last_hidden_state
+ elif self.layer == "pooled":
+ z = outputs.pooler_output[:, None, :]
+ else:
+ z = outputs.hidden_states[self.layer_idx]
+ if self.return_pooled:
+ return z, outputs.pooler_output
+ return z
+
+ def encode(self, text):
+ return self(text)
+
+
+class FrozenOpenCLIPEmbedder2(AbstractEmbModel):
+ """
+ Uses the OpenCLIP transformer encoder for text
+ """
+
+ LAYERS = ["pooled", "last", "penultimate"]
+
+ def __init__(
+ self,
+ arch="ViT-H-14",
+ version="laion2b_s32b_b79k",
+ device="cuda",
+ max_length=77,
+ freeze=True,
+ layer="last",
+ always_return_pooled=False,
+ legacy=True,
+ ):
+ super().__init__()
+ assert layer in self.LAYERS
+ model, _, _ = open_clip.create_model_and_transforms(
+ arch,
+ device=torch.device("cpu"),
+ pretrained=version,
+ )
+ del model.visual
+ self.model = model
+
+ self.device = device
+ self.max_length = max_length
+ self.return_pooled = always_return_pooled
+ if freeze:
+ self.freeze()
+ self.layer = layer
+ if self.layer == "last":
+ self.layer_idx = 0
+ elif self.layer == "penultimate":
+ self.layer_idx = 1
+ else:
+ raise NotImplementedError()
+ self.legacy = legacy
+
+ def freeze(self):
+ self.model = self.model.eval()
+ for param in self.parameters():
+ param.requires_grad = False
+
+ @autocast
+ def forward(self, text):
+ tokens = open_clip.tokenize(text)
+ z = self.encode_with_transformer(tokens.to(self.device))
+ if not self.return_pooled and self.legacy:
+ return z
+ if self.return_pooled:
+ assert not self.legacy
+ return z[self.layer], z["pooled"]
+ return z[self.layer]
+
+ def encode_with_transformer(self, text):
+ x = self.model.token_embedding(text) # [batch_size, n_ctx, d_model]
+ x = x + self.model.positional_embedding
+ x = x.permute(1, 0, 2) # NLD -> LND
+ x = self.text_transformer_forward(x, attn_mask=self.model.attn_mask)
+ if self.legacy:
+ x = x[self.layer]
+ x = self.model.ln_final(x)
+ return x
+ else:
+ # x is a dict and will stay a dict
+ o = x["last"]
+ o = self.model.ln_final(o)
+ pooled = self.pool(o, text)
+ x["pooled"] = pooled
+ return x
+
+ def pool(self, x, text):
+ # take features from the eot embedding (eot_token is the highest number in each sequence)
+ x = (
+ x[torch.arange(x.shape[0]), text.argmax(dim=-1)]
+ @ self.model.text_projection
+ )
+ return x
+
+ def text_transformer_forward(self, x: torch.Tensor, attn_mask=None):
+ outputs = {}
+ for i, r in enumerate(self.model.transformer.resblocks):
+ if i == len(self.model.transformer.resblocks) - 1:
+ outputs["penultimate"] = x.permute(1, 0, 2) # LND -> NLD
+ if (
+ self.model.transformer.grad_checkpointing
+ and not torch.jit.is_scripting()
+ ):
+ x = checkpoint(r, x, attn_mask)
+ else:
+ x = r(x, attn_mask=attn_mask)
+ outputs["last"] = x.permute(1, 0, 2) # LND -> NLD
+ return outputs
+
+ def encode(self, text):
+ return self(text)
+
+
+class FrozenOpenCLIPEmbedder(AbstractEmbModel):
+ LAYERS = [
+ # "pooled",
+ "last",
+ "penultimate",
+ ]
+
+ def __init__(
+ self,
+ arch="ViT-H-14",
+ version="laion2b_s32b_b79k",
+ device="cuda",
+ max_length=77,
+ freeze=True,
+ layer="last",
+ ):
+ super().__init__()
+ assert layer in self.LAYERS
+ model, _, _ = open_clip.create_model_and_transforms(
+ arch, device=torch.device("cpu"), pretrained=version
+ )
+ del model.visual
+ self.model = model
+
+ self.device = device
+ self.max_length = max_length
+ if freeze:
+ self.freeze()
+ self.layer = layer
+ if self.layer == "last":
+ self.layer_idx = 0
+ elif self.layer == "penultimate":
+ self.layer_idx = 1
+ else:
+ raise NotImplementedError()
+
+ def freeze(self):
+ self.model = self.model.eval()
+ for param in self.parameters():
+ param.requires_grad = False
+
+ def forward(self, text):
+ tokens = open_clip.tokenize(text)
+ z = self.encode_with_transformer(tokens.to(self.device))
+ return z
+
+ def encode_with_transformer(self, text):
+ x = self.model.token_embedding(text) # [batch_size, n_ctx, d_model]
+ x = x + self.model.positional_embedding
+ x = x.permute(1, 0, 2) # NLD -> LND
+ x = self.text_transformer_forward(x, attn_mask=self.model.attn_mask)
+ x = x.permute(1, 0, 2) # LND -> NLD
+ x = self.model.ln_final(x)
+ return x
+
+ def text_transformer_forward(self, x: torch.Tensor, attn_mask=None):
+ for i, r in enumerate(self.model.transformer.resblocks):
+ if i == len(self.model.transformer.resblocks) - self.layer_idx:
+ break
+ if (
+ self.model.transformer.grad_checkpointing
+ and not torch.jit.is_scripting()
+ ):
+ x = checkpoint(r, x, attn_mask)
+ else:
+ x = r(x, attn_mask=attn_mask)
+ return x
+
+ def encode(self, text):
+ return self(text)
+
+
+class FrozenOpenCLIPImageEmbedder(AbstractEmbModel):
+ """
+ Uses the OpenCLIP vision transformer encoder for images
+ """
+
+ def __init__(
+ self,
+ arch="ViT-H-14",
+ version="laion2b_s32b_b79k",
+ device="cuda",
+ max_length=77,
+ freeze=True,
+ antialias=True,
+ ucg_rate=0.0,
+ unsqueeze_dim=False,
+ repeat_to_max_len=False,
+ num_image_crops=0,
+ output_tokens=False,
+ init_device=None,
+ ):
+ super().__init__()
+ model, _, _ = open_clip.create_model_and_transforms(
+ arch,
+ device=torch.device(default(init_device, "cpu")),
+ pretrained=version,
+ )
+ del model.transformer
+ self.model = model
+ self.max_crops = num_image_crops
+ self.pad_to_max_len = self.max_crops > 0
+ self.repeat_to_max_len = repeat_to_max_len and (not self.pad_to_max_len)
+ self.device = device
+ self.max_length = max_length
+ if freeze:
+ self.freeze()
+
+ self.antialias = antialias
+
+ self.register_buffer(
+ "mean", torch.Tensor([0.48145466, 0.4578275, 0.40821073]), persistent=False
+ )
+ self.register_buffer(
+ "std", torch.Tensor([0.26862954, 0.26130258, 0.27577711]), persistent=False
+ )
+ self.ucg_rate = ucg_rate
+ self.unsqueeze_dim = unsqueeze_dim
+ self.stored_batch = None
+ self.model.visual.output_tokens = output_tokens
+ self.output_tokens = output_tokens
+
+ def preprocess(self, x):
+ # normalize to [0,1]
+ x = kornia.geometry.resize(
+ x,
+ (224, 224),
+ interpolation="bicubic",
+ align_corners=True,
+ antialias=self.antialias,
+ )
+ x = (x + 1.0) / 2.0
+ # renormalize according to clip
+ x = kornia.enhance.normalize(x, self.mean, self.std)
+ return x
+
+ def freeze(self):
+ self.model = self.model.eval()
+ for param in self.parameters():
+ param.requires_grad = False
+
+ @autocast
+ def forward(self, image, no_dropout=False):
+ z = self.encode_with_vision_transformer(image)
+ tokens = None
+ if self.output_tokens:
+ z, tokens = z[0], z[1]
+ z = z.to(image.dtype)
+ if self.ucg_rate > 0.0 and not no_dropout and not (self.max_crops > 0):
+ z = (
+ torch.bernoulli(
+ (1.0 - self.ucg_rate) * torch.ones(z.shape[0], device=z.device)
+ )[:, None]
+ * z
+ )
+ if tokens is not None:
+ tokens = (
+ expand_dims_like(
+ torch.bernoulli(
+ (1.0 - self.ucg_rate)
+ * torch.ones(tokens.shape[0], device=tokens.device)
+ ),
+ tokens,
+ )
+ * tokens
+ )
+ if self.unsqueeze_dim:
+ z = z[:, None, :]
+ if self.output_tokens:
+ assert not self.repeat_to_max_len
+ assert not self.pad_to_max_len
+ return tokens, z
+ if self.repeat_to_max_len:
+ if z.dim() == 2:
+ z_ = z[:, None, :]
+ else:
+ z_ = z
+ return repeat(z_, "b 1 d -> b n d", n=self.max_length), z
+ elif self.pad_to_max_len:
+ assert z.dim() == 3
+ z_pad = torch.cat(
+ (
+ z,
+ torch.zeros(
+ z.shape[0],
+ self.max_length - z.shape[1],
+ z.shape[2],
+ device=z.device,
+ ),
+ ),
+ 1,
+ )
+ return z_pad, z_pad[:, 0, ...]
+ return z
+
+ def encode_with_vision_transformer(self, img):
+ # if self.max_crops > 0:
+ # img = self.preprocess_by_cropping(img)
+ if img.dim() == 5:
+ assert self.max_crops == img.shape[1]
+ img = rearrange(img, "b n c h w -> (b n) c h w")
+ img = self.preprocess(img)
+ if not self.output_tokens:
+ assert not self.model.visual.output_tokens
+ x = self.model.visual(img)
+ tokens = None
+ else:
+ assert self.model.visual.output_tokens
+ x, tokens = self.model.visual(img)
+ if self.max_crops > 0:
+ x = rearrange(x, "(b n) d -> b n d", n=self.max_crops)
+ # drop out between 0 and all along the sequence axis
+ x = (
+ torch.bernoulli(
+ (1.0 - self.ucg_rate)
+ * torch.ones(x.shape[0], x.shape[1], 1, device=x.device)
+ )
+ * x
+ )
+ if tokens is not None:
+ tokens = rearrange(tokens, "(b n) t d -> b t (n d)", n=self.max_crops)
+ print(
+ f"You are running very experimental token-concat in {self.__class__.__name__}. "
+ f"Check what you are doing, and then remove this message."
+ )
+ if self.output_tokens:
+ return x, tokens
+ return x
+
+ def encode(self, text):
+ return self(text)
+
+
+class FrozenCLIPT5Encoder(AbstractEmbModel):
+ def __init__(
+ self,
+ clip_version="openai/clip-vit-large-patch14",
+ t5_version="google/t5-v1_1-xl",
+ device="cuda",
+ clip_max_length=77,
+ t5_max_length=77,
+ ):
+ super().__init__()
+ self.clip_encoder = FrozenCLIPEmbedder(
+ clip_version, device, max_length=clip_max_length
+ )
+ self.t5_encoder = FrozenT5Embedder(t5_version, device, max_length=t5_max_length)
+ print(
+ f"{self.clip_encoder.__class__.__name__} has {count_params(self.clip_encoder) * 1.e-6:.2f} M parameters, "
+ f"{self.t5_encoder.__class__.__name__} comes with {count_params(self.t5_encoder) * 1.e-6:.2f} M params."
+ )
+
+ def encode(self, text):
+ return self(text)
+
+ def forward(self, text):
+ clip_z = self.clip_encoder.encode(text)
+ t5_z = self.t5_encoder.encode(text)
+ return [clip_z, t5_z]
+
+
+class SpatialRescaler(nn.Module):
+ def __init__(
+ self,
+ n_stages=1,
+ method="bilinear",
+ multiplier=0.5,
+ in_channels=3,
+ out_channels=None,
+ bias=False,
+ wrap_video=False,
+ kernel_size=1,
+ remap_output=False,
+ ):
+ super().__init__()
+ self.n_stages = n_stages
+ assert self.n_stages >= 0
+ assert method in [
+ "nearest",
+ "linear",
+ "bilinear",
+ "trilinear",
+ "bicubic",
+ "area",
+ ]
+ self.multiplier = multiplier
+ self.interpolator = partial(torch.nn.functional.interpolate, mode=method)
+ self.remap_output = out_channels is not None or remap_output
+ if self.remap_output:
+ print(
+ f"Spatial Rescaler mapping from {in_channels} to {out_channels} channels after resizing."
+ )
+ self.channel_mapper = nn.Conv2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ bias=bias,
+ padding=kernel_size // 2,
+ )
+ self.wrap_video = wrap_video
+
+ def forward(self, x):
+ if self.wrap_video and x.ndim == 5:
+ B, C, T, H, W = x.shape
+ x = rearrange(x, "b c t h w -> b t c h w")
+ x = rearrange(x, "b t c h w -> (b t) c h w")
+
+ for stage in range(self.n_stages):
+ x = self.interpolator(x, scale_factor=self.multiplier)
+
+ if self.wrap_video:
+ x = rearrange(x, "(b t) c h w -> b t c h w", b=B, t=T, c=C)
+ x = rearrange(x, "b t c h w -> b c t h w")
+ if self.remap_output:
+ x = self.channel_mapper(x)
+ return x
+
+ def encode(self, x):
+ return self(x)
+
+
+class LowScaleEncoder(nn.Module):
+ def __init__(
+ self,
+ model_config,
+ linear_start,
+ linear_end,
+ timesteps=1000,
+ max_noise_level=250,
+ output_size=64,
+ scale_factor=1.0,
+ ):
+ super().__init__()
+ self.max_noise_level = max_noise_level
+ self.model = instantiate_from_config(model_config)
+ self.augmentation_schedule = self.register_schedule(
+ timesteps=timesteps, linear_start=linear_start, linear_end=linear_end
+ )
+ self.out_size = output_size
+ self.scale_factor = scale_factor
+
+ def register_schedule(
+ self,
+ beta_schedule="linear",
+ timesteps=1000,
+ linear_start=1e-4,
+ linear_end=2e-2,
+ cosine_s=8e-3,
+ ):
+ betas = make_beta_schedule(
+ beta_schedule,
+ timesteps,
+ linear_start=linear_start,
+ linear_end=linear_end,
+ cosine_s=cosine_s,
+ )
+ alphas = 1.0 - betas
+ alphas_cumprod = np.cumprod(alphas, axis=0)
+ alphas_cumprod_prev = np.append(1.0, alphas_cumprod[:-1])
+
+ (timesteps,) = betas.shape
+ self.num_timesteps = int(timesteps)
+ self.linear_start = linear_start
+ self.linear_end = linear_end
+ assert (
+ alphas_cumprod.shape[0] == self.num_timesteps
+ ), "alphas have to be defined for each timestep"
+
+ to_torch = partial(torch.tensor, dtype=torch.float32)
+
+ self.register_buffer("betas", to_torch(betas))
+ self.register_buffer("alphas_cumprod", to_torch(alphas_cumprod))
+ self.register_buffer("alphas_cumprod_prev", to_torch(alphas_cumprod_prev))
+
+ # calculations for diffusion q(x_t | x_{t-1}) and others
+ self.register_buffer("sqrt_alphas_cumprod", to_torch(np.sqrt(alphas_cumprod)))
+ self.register_buffer(
+ "sqrt_one_minus_alphas_cumprod", to_torch(np.sqrt(1.0 - alphas_cumprod))
+ )
+ self.register_buffer(
+ "log_one_minus_alphas_cumprod", to_torch(np.log(1.0 - alphas_cumprod))
+ )
+ self.register_buffer(
+ "sqrt_recip_alphas_cumprod", to_torch(np.sqrt(1.0 / alphas_cumprod))
+ )
+ self.register_buffer(
+ "sqrt_recipm1_alphas_cumprod", to_torch(np.sqrt(1.0 / alphas_cumprod - 1))
+ )
+
+ def q_sample(self, x_start, t, noise=None):
+ noise = default(noise, lambda: torch.randn_like(x_start))
+ return (
+ extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
+ + extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape)
+ * noise
+ )
+
+ def forward(self, x):
+ z = self.model.encode(x)
+ if isinstance(z, DiagonalGaussianDistribution):
+ z = z.sample()
+ z = z * self.scale_factor
+ noise_level = torch.randint(
+ 0, self.max_noise_level, (x.shape[0],), device=x.device
+ ).long()
+ z = self.q_sample(z, noise_level)
+ if self.out_size is not None:
+ z = torch.nn.functional.interpolate(z, size=self.out_size, mode="nearest")
+ return z, noise_level
+
+ def decode(self, z):
+ z = z / self.scale_factor
+ return self.model.decode(z)
+
+
+class ConcatTimestepEmbedderND(AbstractEmbModel):
+ """embeds each dimension independently and concatenates them"""
+
+ def __init__(self, outdim):
+ super().__init__()
+ self.timestep = Timestep(outdim)
+ self.outdim = outdim
+
+ def forward(self, x):
+ if x.ndim == 1:
+ x = x[:, None]
+ assert len(x.shape) == 2
+ b, dims = x.shape[0], x.shape[1]
+ x = rearrange(x, "b d -> (b d)")
+ emb = self.timestep(x)
+ emb = rearrange(emb, "(b d) d2 -> b (d d2)", b=b, d=dims, d2=self.outdim)
+ return emb
+
+
+class GaussianEncoder(Encoder, AbstractEmbModel):
+ def __init__(
+ self, weight: float = 1.0, flatten_output: bool = True, *args, **kwargs
+ ):
+ super().__init__(*args, **kwargs)
+ self.posterior = DiagonalGaussianRegularizer()
+ self.weight = weight
+ self.flatten_output = flatten_output
+
+ def forward(self, x) -> Tuple[Dict, torch.Tensor]:
+ z = super().forward(x)
+ z, log = self.posterior(z)
+ log["loss"] = log["kl_loss"]
+ log["weight"] = self.weight
+ if self.flatten_output:
+ z = rearrange(z, "b c h w -> b (h w ) c")
+ return log, z
+
+
+class VideoPredictionEmbedderWithEncoder(AbstractEmbModel):
+ def __init__(
+ self,
+ n_cond_frames: int,
+ n_copies: int,
+ encoder_config: dict,
+ sigma_sampler_config: Optional[dict] = None,
+ sigma_cond_config: Optional[dict] = None,
+ is_ae: bool = False,
+ scale_factor: float = 1.0,
+ disable_encoder_autocast: bool = False,
+ en_and_decode_n_samples_a_time: Optional[int] = None,
+ ):
+ super().__init__()
+
+ self.n_cond_frames = n_cond_frames
+ self.n_copies = n_copies
+ self.encoder = instantiate_from_config(encoder_config)
+ self.sigma_sampler = (
+ instantiate_from_config(sigma_sampler_config)
+ if sigma_sampler_config is not None
+ else None
+ )
+ self.sigma_cond = (
+ instantiate_from_config(sigma_cond_config)
+ if sigma_cond_config is not None
+ else None
+ )
+ self.is_ae = is_ae
+ self.scale_factor = scale_factor
+ self.disable_encoder_autocast = disable_encoder_autocast
+ self.en_and_decode_n_samples_a_time = en_and_decode_n_samples_a_time
+
+ def forward(
+ self, vid: torch.Tensor
+ ) -> Union[
+ torch.Tensor,
+ Tuple[torch.Tensor, torch.Tensor],
+ Tuple[torch.Tensor, dict],
+ Tuple[Tuple[torch.Tensor, torch.Tensor], dict],
+ ]:
+ if self.sigma_sampler is not None:
+ b = vid.shape[0] // self.n_cond_frames
+ sigmas = self.sigma_sampler(b).to(vid.device)
+ if self.sigma_cond is not None:
+ sigma_cond = self.sigma_cond(sigmas)
+ sigma_cond = repeat(sigma_cond, "b d -> (b t) d", t=self.n_copies)
+ sigmas = repeat(sigmas, "b -> (b t)", t=self.n_cond_frames)
+ noise = torch.randn_like(vid)
+ vid = vid + noise * append_dims(sigmas, vid.ndim)
+
+ with torch.autocast("cuda", enabled=not self.disable_encoder_autocast):
+ n_samples = (
+ self.en_and_decode_n_samples_a_time
+ if self.en_and_decode_n_samples_a_time is not None
+ else vid.shape[0]
+ )
+ n_rounds = math.ceil(vid.shape[0] / n_samples)
+ all_out = []
+ for n in range(n_rounds):
+ if self.is_ae:
+ out = self.encoder.encode(vid[n * n_samples : (n + 1) * n_samples])
+ else:
+ out = self.encoder(vid[n * n_samples : (n + 1) * n_samples])
+ all_out.append(out)
+
+ vid = torch.cat(all_out, dim=0)
+ vid *= self.scale_factor
+
+ vid = rearrange(vid, "(b t) c h w -> b () (t c) h w", t=self.n_cond_frames)
+ vid = repeat(vid, "b 1 c h w -> (b t) c h w", t=self.n_copies)
+
+ return_val = (vid, sigma_cond) if self.sigma_cond is not None else vid
+
+ return return_val
+
+
+class FrozenOpenCLIPImagePredictionEmbedder(AbstractEmbModel):
+ def __init__(
+ self,
+ open_clip_embedding_config: Dict,
+ n_cond_frames: int,
+ n_copies: int,
+ ):
+ super().__init__()
+
+ self.n_cond_frames = n_cond_frames
+ self.n_copies = n_copies
+ self.open_clip = instantiate_from_config(open_clip_embedding_config)
+
+ def forward(self, vid):
+ vid = self.open_clip(vid)
+ vid = rearrange(vid, "(b t) d -> b t d", t=self.n_cond_frames)
+ vid = repeat(vid, "b t d -> (b s) t d", s=self.n_copies)
+
+ return vid
diff --git a/sgm/modules/video_attention.py b/sgm/modules/video_attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..783395aa554144936766b57380f35dab29c093c3
--- /dev/null
+++ b/sgm/modules/video_attention.py
@@ -0,0 +1,301 @@
+import torch
+
+from ..modules.attention import *
+from ..modules.diffusionmodules.util import AlphaBlender, linear, timestep_embedding
+
+
+class TimeMixSequential(nn.Sequential):
+ def forward(self, x, context=None, timesteps=None):
+ for layer in self:
+ x = layer(x, context, timesteps)
+
+ return x
+
+
+class VideoTransformerBlock(nn.Module):
+ ATTENTION_MODES = {
+ "softmax": CrossAttention,
+ "softmax-xformers": MemoryEfficientCrossAttention,
+ }
+
+ def __init__(
+ self,
+ dim,
+ n_heads,
+ d_head,
+ dropout=0.0,
+ context_dim=None,
+ gated_ff=True,
+ checkpoint=True,
+ timesteps=None,
+ ff_in=False,
+ inner_dim=None,
+ attn_mode="softmax",
+ disable_self_attn=False,
+ disable_temporal_crossattention=False,
+ switch_temporal_ca_to_sa=False,
+ ):
+ super().__init__()
+
+ attn_cls = self.ATTENTION_MODES[attn_mode]
+
+ self.ff_in = ff_in or inner_dim is not None
+ if inner_dim is None:
+ inner_dim = dim
+
+ assert int(n_heads * d_head) == inner_dim
+
+ self.is_res = inner_dim == dim
+
+ if self.ff_in:
+ self.norm_in = nn.LayerNorm(dim)
+ self.ff_in = FeedForward(
+ dim, dim_out=inner_dim, dropout=dropout, glu=gated_ff
+ )
+
+ self.timesteps = timesteps
+ self.disable_self_attn = disable_self_attn
+ if self.disable_self_attn:
+ self.attn1 = attn_cls(
+ query_dim=inner_dim,
+ heads=n_heads,
+ dim_head=d_head,
+ context_dim=context_dim,
+ dropout=dropout,
+ ) # is a cross-attention
+ else:
+ self.attn1 = attn_cls(
+ query_dim=inner_dim, heads=n_heads, dim_head=d_head, dropout=dropout
+ ) # is a self-attention
+
+ self.ff = FeedForward(inner_dim, dim_out=dim, dropout=dropout, glu=gated_ff)
+
+ if disable_temporal_crossattention:
+ if switch_temporal_ca_to_sa:
+ raise ValueError
+ else:
+ self.attn2 = None
+ else:
+ self.norm2 = nn.LayerNorm(inner_dim)
+ if switch_temporal_ca_to_sa:
+ self.attn2 = attn_cls(
+ query_dim=inner_dim, heads=n_heads, dim_head=d_head, dropout=dropout
+ ) # is a self-attention
+ else:
+ self.attn2 = attn_cls(
+ query_dim=inner_dim,
+ context_dim=context_dim,
+ heads=n_heads,
+ dim_head=d_head,
+ dropout=dropout,
+ ) # is self-attn if context is none
+
+ self.norm1 = nn.LayerNorm(inner_dim)
+ self.norm3 = nn.LayerNorm(inner_dim)
+ self.switch_temporal_ca_to_sa = switch_temporal_ca_to_sa
+
+ self.checkpoint = checkpoint
+ if self.checkpoint:
+ print(f"{self.__class__.__name__} is using checkpointing")
+
+ def forward(
+ self, x: torch.Tensor, context: torch.Tensor = None, timesteps: int = None
+ ) -> torch.Tensor:
+ if self.checkpoint:
+ return checkpoint(self._forward, x, context, timesteps)
+ else:
+ return self._forward(x, context, timesteps=timesteps)
+
+ def _forward(self, x, context=None, timesteps=None):
+ assert self.timesteps or timesteps
+ assert not (self.timesteps and timesteps) or self.timesteps == timesteps
+ timesteps = self.timesteps or timesteps
+ B, S, C = x.shape
+ x = rearrange(x, "(b t) s c -> (b s) t c", t=timesteps)
+
+ if self.ff_in:
+ x_skip = x
+ x = self.ff_in(self.norm_in(x))
+ if self.is_res:
+ x += x_skip
+
+ if self.disable_self_attn:
+ x = self.attn1(self.norm1(x), context=context) + x
+ else:
+ x = self.attn1(self.norm1(x)) + x
+
+ if self.attn2 is not None:
+ if self.switch_temporal_ca_to_sa:
+ x = self.attn2(self.norm2(x)) + x
+ else:
+ x = self.attn2(self.norm2(x), context=context) + x
+ x_skip = x
+ x = self.ff(self.norm3(x))
+ if self.is_res:
+ x += x_skip
+
+ x = rearrange(
+ x, "(b s) t c -> (b t) s c", s=S, b=B // timesteps, c=C, t=timesteps
+ )
+ return x
+
+ def get_last_layer(self):
+ return self.ff.net[-1].weight
+
+
+class SpatialVideoTransformer(SpatialTransformer):
+ def __init__(
+ self,
+ in_channels,
+ n_heads,
+ d_head,
+ depth=1,
+ dropout=0.0,
+ use_linear=False,
+ context_dim=None,
+ use_spatial_context=False,
+ timesteps=None,
+ merge_strategy: str = "fixed",
+ merge_factor: float = 0.5,
+ time_context_dim=None,
+ ff_in=False,
+ checkpoint=False,
+ time_depth=1,
+ attn_mode="softmax",
+ disable_self_attn=False,
+ disable_temporal_crossattention=False,
+ max_time_embed_period: int = 10000,
+ ):
+ super().__init__(
+ in_channels,
+ n_heads,
+ d_head,
+ depth=depth,
+ dropout=dropout,
+ attn_type=attn_mode,
+ use_checkpoint=checkpoint,
+ context_dim=context_dim,
+ use_linear=use_linear,
+ disable_self_attn=disable_self_attn,
+ )
+ self.time_depth = time_depth
+ self.depth = depth
+ self.max_time_embed_period = max_time_embed_period
+
+ time_mix_d_head = d_head
+ n_time_mix_heads = n_heads
+
+ time_mix_inner_dim = int(time_mix_d_head * n_time_mix_heads)
+
+ inner_dim = n_heads * d_head
+ if use_spatial_context:
+ time_context_dim = context_dim
+
+ self.time_stack = nn.ModuleList(
+ [
+ VideoTransformerBlock(
+ inner_dim,
+ n_time_mix_heads,
+ time_mix_d_head,
+ dropout=dropout,
+ context_dim=time_context_dim,
+ timesteps=timesteps,
+ checkpoint=checkpoint,
+ ff_in=ff_in,
+ inner_dim=time_mix_inner_dim,
+ attn_mode=attn_mode,
+ disable_self_attn=disable_self_attn,
+ disable_temporal_crossattention=disable_temporal_crossattention,
+ )
+ for _ in range(self.depth)
+ ]
+ )
+
+ assert len(self.time_stack) == len(self.transformer_blocks)
+
+ self.use_spatial_context = use_spatial_context
+ self.in_channels = in_channels
+
+ time_embed_dim = self.in_channels * 4
+ self.time_pos_embed = nn.Sequential(
+ linear(self.in_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, self.in_channels),
+ )
+
+ self.time_mixer = AlphaBlender(
+ alpha=merge_factor, merge_strategy=merge_strategy
+ )
+
+ def forward(
+ self,
+ x: torch.Tensor,
+ context: Optional[torch.Tensor] = None,
+ time_context: Optional[torch.Tensor] = None,
+ timesteps: Optional[int] = None,
+ image_only_indicator: Optional[torch.Tensor] = None,
+ ) -> torch.Tensor:
+ _, _, h, w = x.shape
+ x_in = x
+ spatial_context = None
+ if exists(context):
+ spatial_context = context
+
+ if self.use_spatial_context:
+ assert (
+ context.ndim == 3
+ ), f"n dims of spatial context should be 3 but are {context.ndim}"
+
+ time_context = context
+ time_context_first_timestep = time_context[::timesteps]
+ time_context = repeat(
+ time_context_first_timestep, "b ... -> (b n) ...", n=h * w
+ )
+ elif time_context is not None and not self.use_spatial_context:
+ time_context = repeat(time_context, "b ... -> (b n) ...", n=h * w)
+ if time_context.ndim == 2:
+ time_context = rearrange(time_context, "b c -> b 1 c")
+
+ x = self.norm(x)
+ if not self.use_linear:
+ x = self.proj_in(x)
+ x = rearrange(x, "b c h w -> b (h w) c")
+ if self.use_linear:
+ x = self.proj_in(x)
+
+ num_frames = torch.arange(timesteps, device=x.device)
+ num_frames = repeat(num_frames, "t -> b t", b=x.shape[0] // timesteps)
+ num_frames = rearrange(num_frames, "b t -> (b t)")
+ t_emb = timestep_embedding(
+ num_frames,
+ self.in_channels,
+ repeat_only=False,
+ max_period=self.max_time_embed_period,
+ )
+ emb = self.time_pos_embed(t_emb)
+ emb = emb[:, None, :]
+
+ for it_, (block, mix_block) in enumerate(
+ zip(self.transformer_blocks, self.time_stack)
+ ):
+ x = block(
+ x,
+ context=spatial_context,
+ )
+
+ x_mix = x
+ x_mix = x_mix + emb
+
+ x_mix = mix_block(x_mix, context=time_context, timesteps=timesteps)
+ x = self.time_mixer(
+ x_spatial=x,
+ x_temporal=x_mix,
+ image_only_indicator=image_only_indicator,
+ )
+ if self.use_linear:
+ x = self.proj_out(x)
+ x = rearrange(x, "b (h w) c -> b c h w", h=h, w=w)
+ if not self.use_linear:
+ x = self.proj_out(x)
+ out = x + x_in
+ return out
diff --git a/sgm/util.py b/sgm/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..66d9b2a69db2898323cbf2ad26a09ac8b2facd11
--- /dev/null
+++ b/sgm/util.py
@@ -0,0 +1,275 @@
+import functools
+import importlib
+import os
+from functools import partial
+from inspect import isfunction
+
+import fsspec
+import numpy as np
+import torch
+from PIL import Image, ImageDraw, ImageFont
+from safetensors.torch import load_file as load_safetensors
+
+
+def disabled_train(self, mode=True):
+ """Overwrite model.train with this function to make sure train/eval mode
+ does not change anymore."""
+ return self
+
+
+def get_string_from_tuple(s):
+ try:
+ # Check if the string starts and ends with parentheses
+ if s[0] == "(" and s[-1] == ")":
+ # Convert the string to a tuple
+ t = eval(s)
+ # Check if the type of t is tuple
+ if type(t) == tuple:
+ return t[0]
+ else:
+ pass
+ except:
+ pass
+ return s
+
+
+def is_power_of_two(n):
+ """
+ chat.openai.com/chat
+ Return True if n is a power of 2, otherwise return False.
+
+ The function is_power_of_two takes an integer n as input and returns True if n is a power of 2, otherwise it returns False.
+ The function works by first checking if n is less than or equal to 0. If n is less than or equal to 0, it can't be a power of 2, so the function returns False.
+ If n is greater than 0, the function checks whether n is a power of 2 by using a bitwise AND operation between n and n-1. If n is a power of 2, then it will have only one bit set to 1 in its binary representation. When we subtract 1 from a power of 2, all the bits to the right of that bit become 1, and the bit itself becomes 0. So, when we perform a bitwise AND between n and n-1, we get 0 if n is a power of 2, and a non-zero value otherwise.
+ Thus, if the result of the bitwise AND operation is 0, then n is a power of 2 and the function returns True. Otherwise, the function returns False.
+
+ """
+ if n <= 0:
+ return False
+ return (n & (n - 1)) == 0
+
+
+def autocast(f, enabled=True):
+ def do_autocast(*args, **kwargs):
+ with torch.cuda.amp.autocast(
+ enabled=enabled,
+ dtype=torch.get_autocast_gpu_dtype(),
+ cache_enabled=torch.is_autocast_cache_enabled(),
+ ):
+ return f(*args, **kwargs)
+
+ return do_autocast
+
+
+def load_partial_from_config(config):
+ return partial(get_obj_from_str(config["target"]), **config.get("params", dict()))
+
+
+def log_txt_as_img(wh, xc, size=10):
+ # wh a tuple of (width, height)
+ # xc a list of captions to plot
+ b = len(xc)
+ txts = list()
+ for bi in range(b):
+ txt = Image.new("RGB", wh, color="white")
+ draw = ImageDraw.Draw(txt)
+ font = ImageFont.truetype("data/DejaVuSans.ttf", size=size)
+ nc = int(40 * (wh[0] / 256))
+ if isinstance(xc[bi], list):
+ text_seq = xc[bi][0]
+ else:
+ text_seq = xc[bi]
+ lines = "\n".join(
+ text_seq[start : start + nc] for start in range(0, len(text_seq), nc)
+ )
+
+ try:
+ draw.text((0, 0), lines, fill="black", font=font)
+ except UnicodeEncodeError:
+ print("Cant encode string for logging. Skipping.")
+
+ txt = np.array(txt).transpose(2, 0, 1) / 127.5 - 1.0
+ txts.append(txt)
+ txts = np.stack(txts)
+ txts = torch.tensor(txts)
+ return txts
+
+
+def partialclass(cls, *args, **kwargs):
+ class NewCls(cls):
+ __init__ = functools.partialmethod(cls.__init__, *args, **kwargs)
+
+ return NewCls
+
+
+def make_path_absolute(path):
+ fs, p = fsspec.core.url_to_fs(path)
+ if fs.protocol == "file":
+ return os.path.abspath(p)
+ return path
+
+
+def ismap(x):
+ if not isinstance(x, torch.Tensor):
+ return False
+ return (len(x.shape) == 4) and (x.shape[1] > 3)
+
+
+def isimage(x):
+ if not isinstance(x, torch.Tensor):
+ return False
+ return (len(x.shape) == 4) and (x.shape[1] == 3 or x.shape[1] == 1)
+
+
+def isheatmap(x):
+ if not isinstance(x, torch.Tensor):
+ return False
+
+ return x.ndim == 2
+
+
+def isneighbors(x):
+ if not isinstance(x, torch.Tensor):
+ return False
+ return x.ndim == 5 and (x.shape[2] == 3 or x.shape[2] == 1)
+
+
+def exists(x):
+ return x is not None
+
+
+def expand_dims_like(x, y):
+ while x.dim() != y.dim():
+ x = x.unsqueeze(-1)
+ return x
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if isfunction(d) else d
+
+
+def mean_flat(tensor):
+ """
+ https://github.com/openai/guided-diffusion/blob/27c20a8fab9cb472df5d6bdd6c8d11c8f430b924/guided_diffusion/nn.py#L86
+ Take the mean over all non-batch dimensions.
+ """
+ return tensor.mean(dim=list(range(1, len(tensor.shape))))
+
+
+def count_params(model, verbose=False):
+ total_params = sum(p.numel() for p in model.parameters())
+ if verbose:
+ print(f"{model.__class__.__name__} has {total_params * 1.e-6:.2f} M params.")
+ return total_params
+
+
+def instantiate_from_config(config):
+ if not "target" in config:
+ if config == "__is_first_stage__":
+ return None
+ elif config == "__is_unconditional__":
+ return None
+ raise KeyError("Expected key `target` to instantiate.")
+ return get_obj_from_str(config["target"])(**config.get("params", dict()))
+
+
+def get_obj_from_str(string, reload=False, invalidate_cache=True):
+ module, cls = string.rsplit(".", 1)
+ if invalidate_cache:
+ importlib.invalidate_caches()
+ if reload:
+ module_imp = importlib.import_module(module)
+ importlib.reload(module_imp)
+ return getattr(importlib.import_module(module, package=None), cls)
+
+
+def append_zero(x):
+ return torch.cat([x, x.new_zeros([1])])
+
+
+def append_dims(x, target_dims):
+ """Appends dimensions to the end of a tensor until it has target_dims dimensions."""
+ dims_to_append = target_dims - x.ndim
+ if dims_to_append < 0:
+ raise ValueError(
+ f"input has {x.ndim} dims but target_dims is {target_dims}, which is less"
+ )
+ return x[(...,) + (None,) * dims_to_append]
+
+
+def load_model_from_config(config, ckpt, verbose=True, freeze=True):
+ print(f"Loading model from {ckpt}")
+ if ckpt.endswith("ckpt"):
+ pl_sd = torch.load(ckpt, map_location="cpu")
+ if "global_step" in pl_sd:
+ print(f"Global Step: {pl_sd['global_step']}")
+ sd = pl_sd["state_dict"]
+ elif ckpt.endswith("safetensors"):
+ sd = load_safetensors(ckpt)
+ else:
+ raise NotImplementedError
+
+ model = instantiate_from_config(config.model)
+
+ m, u = model.load_state_dict(sd, strict=False)
+
+ if len(m) > 0 and verbose:
+ print("missing keys:")
+ print(m)
+ if len(u) > 0 and verbose:
+ print("unexpected keys:")
+ print(u)
+
+ if freeze:
+ for param in model.parameters():
+ param.requires_grad = False
+
+ model.eval()
+ return model
+
+
+def get_configs_path() -> str:
+ """
+ Get the `configs` directory.
+ For a working copy, this is the one in the root of the repository,
+ but for an installed copy, it's in the `sgm` package (see pyproject.toml).
+ """
+ this_dir = os.path.dirname(__file__)
+ candidates = (
+ os.path.join(this_dir, "configs"),
+ os.path.join(this_dir, "..", "configs"),
+ )
+ for candidate in candidates:
+ candidate = os.path.abspath(candidate)
+ if os.path.isdir(candidate):
+ return candidate
+ raise FileNotFoundError(f"Could not find SGM configs in {candidates}")
+
+
+def get_nested_attribute(obj, attribute_path, depth=None, return_key=False):
+ """
+ Will return the result of a recursive get attribute call.
+ E.g.:
+ a.b.c
+ = getattr(getattr(a, "b"), "c")
+ = get_nested_attribute(a, "b.c")
+ If any part of the attribute call is an integer x with current obj a, will
+ try to call a[x] instead of a.x first.
+ """
+ attributes = attribute_path.split(".")
+ if depth is not None and depth > 0:
+ attributes = attributes[:depth]
+ assert len(attributes) > 0, "At least one attribute should be selected"
+ current_attribute = obj
+ current_key = None
+ for level, attribute in enumerate(attributes):
+ current_key = ".".join(attributes[: level + 1])
+ try:
+ id_ = int(attribute)
+ current_attribute = current_attribute[id_]
+ except ValueError:
+ current_attribute = getattr(current_attribute, attribute)
+
+ return (current_attribute, current_key) if return_key else current_attribute
diff --git a/tools/aes_score.py b/tools/aes_score.py
new file mode 100644
index 0000000000000000000000000000000000000000..a31f8eeaceee064bf615670e1d1ca09a1f484560
--- /dev/null
+++ b/tools/aes_score.py
@@ -0,0 +1,58 @@
+import pytorch_lightning as pl
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+"""
+Adapted from https://github.com/christophschuhmann/improved-aesthetic-predictor/tree/main
+
+This script will predict the aesthetic score for provided image files.
+"""
+
+
+# If you changed the MLP architecture during training, change it also here:
+class MLP(pl.LightningModule):
+ def __init__(self, input_size, xcol='emb', ycol='avg_rating'):
+ super().__init__()
+ self.input_size = input_size
+ self.xcol = xcol
+ self.ycol = ycol
+ self.layers = nn.Sequential(
+ nn.Linear(self.input_size, 1024),
+ nn.Dropout(0.2),
+ nn.Linear(1024, 128),
+ nn.Dropout(0.2),
+ nn.Linear(128, 64),
+ nn.Dropout(0.1),
+ nn.Linear(64, 16),
+ nn.Linear(16, 1)
+ )
+
+ def forward(self, x):
+ return self.layers(x)
+
+ def training_step(self, batch, batch_idx):
+ x = batch[self.xcol]
+ y = batch[self.ycol].reshape(-1, 1)
+ x_hat = self.layers(x)
+ loss = F.mse_loss(x_hat, y)
+ return loss
+
+ def validation_step(self, batch, batch_idx):
+ x = batch[self.xcol]
+ y = batch[self.ycol].reshape(-1, 1)
+ x_hat = self.layers(x)
+ loss = F.mse_loss(x_hat, y)
+ return loss
+
+ def configure_optimizers(self):
+ optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
+ return optimizer
+
+
+def normalized(a, axis=-1, order=2):
+ import numpy as np # pylint: disable=import-outside-toplevel
+
+ l2 = np.atleast_1d(np.linalg.norm(a, order, axis))
+ l2[l2 == 0] = 1
+ return a / np.expand_dims(l2, axis)
\ No newline at end of file
diff --git a/tools/softmax_splatting/README.md b/tools/softmax_splatting/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b01d39145603de4279a6719bea71bdce8211a517
--- /dev/null
+++ b/tools/softmax_splatting/README.md
@@ -0,0 +1,90 @@
+# softmax-splatting
+This is a reference implementation of the softmax splatting operator, which has been proposed in Softmax Splatting for Video Frame Interpolation [1], using PyTorch. Softmax splatting is a well-motivated approach for differentiable forward warping. It uses a translational invariant importance metric to disambiguate cases where multiple source pixels map to the same target pixel. Should you be making use of our work, please cite our paper [1].
+
+ +
+For our previous work on SepConv, see: https://github.com/sniklaus/revisiting-sepconv
+
+## setup
+The softmax splatting is implemented in CUDA using CuPy, which is why CuPy is a required dependency. It can be installed using `pip install cupy` or alternatively using one of the provided [binary packages](https://docs.cupy.dev/en/stable/install.html#installing-cupy) as outlined in the CuPy repository.
+
+If you plan to process videos, then please also make sure to have `pip install moviepy` installed.
+
+## usage
+To run it on your own pair of frames, use the following command.
+
+```
+python run.py --model lf --one ./images/one.png --two ./images/two.png --out ./out.png
+```
+
+To run in on a video, use the following command.
+
+```
+python run.py --model lf --video ./videos/car-turn.mp4 --out ./out.mp4
+```
+
+For a quick benchmark using examples from the Middlebury benchmark for optical flow, run `python benchmark_middlebury.py`. You can use it to easily verify that the provided implementation runs as expected.
+
+## warping
+We provide a small script to replicate the third figure of our paper [1]. You can simply run the following to obtain the comparison between summation splatting, average splatting, linear splatting, and softmax splatting.
+
+The example script is using OpenCV to load and display images, as well as to read the provided optical flow file. An easy way to install OpenCV for Python is using the `pip install opencv-contrib-python` package.
+
+```
+import cv2
+import numpy
+import torch
+
+import run
+
+import softsplat # the custom softmax splatting layer
+
+##########################################################
+
+torch.set_grad_enabled(False) # make sure to not compute gradients for computational performance
+
+torch.backends.cudnn.enabled = True # make sure to use cudnn for computational performance
+
+##########################################################
+
+tenOne = torch.FloatTensor(numpy.ascontiguousarray(cv2.imread(filename='./images/one.png', flags=-1).transpose(2, 0, 1)[None, :, :, :].astype(numpy.float32) * (1.0 / 255.0))).cuda()
+tenTwo = torch.FloatTensor(numpy.ascontiguousarray(cv2.imread(filename='./images/two.png', flags=-1).transpose(2, 0, 1)[None, :, :, :].astype(numpy.float32) * (1.0 / 255.0))).cuda()
+tenFlow = torch.FloatTensor(numpy.ascontiguousarray(run.read_flo('./images/flow.flo').transpose(2, 0, 1)[None, :, :, :])).cuda()
+
+tenMetric = torch.nn.functional.l1_loss(input=tenOne, target=run.backwarp(tenIn=tenTwo, tenFlow=tenFlow), reduction='none').mean([1], True)
+
+for intTime, fltTime in enumerate(numpy.linspace(0.0, 1.0, 11).tolist()):
+ tenSummation = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=None, strMode='sum')
+ tenAverage = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=None, strMode='avg')
+ tenLinear = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=(0.3 - tenMetric).clip(0.001, 1.0), strMode='linear') # finding a good linearly metric is difficult, and it is not invariant to translations
+ tenSoftmax = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=(-20.0 * tenMetric).clip(-20.0, 20.0), strMode='soft') # -20.0 is a hyperparameter, called 'alpha' in the paper, that could be learned using a torch.Parameter
+
+ cv2.imshow(winname='summation', mat=tenSummation[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='average', mat=tenAverage[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='linear', mat=tenLinear[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='softmax', mat=tenSoftmax[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.waitKey(delay=0)
+# end
+```
+
+## xiph
+In our paper, we propose to use 4K video clips from Xiph to evaluate video frame interpolation on high-resolution footage. Please see the supplementary `benchmark_xiph.py` on how to reproduce the shown metrics.
+
+## video
+
+
+For our previous work on SepConv, see: https://github.com/sniklaus/revisiting-sepconv
+
+## setup
+The softmax splatting is implemented in CUDA using CuPy, which is why CuPy is a required dependency. It can be installed using `pip install cupy` or alternatively using one of the provided [binary packages](https://docs.cupy.dev/en/stable/install.html#installing-cupy) as outlined in the CuPy repository.
+
+If you plan to process videos, then please also make sure to have `pip install moviepy` installed.
+
+## usage
+To run it on your own pair of frames, use the following command.
+
+```
+python run.py --model lf --one ./images/one.png --two ./images/two.png --out ./out.png
+```
+
+To run in on a video, use the following command.
+
+```
+python run.py --model lf --video ./videos/car-turn.mp4 --out ./out.mp4
+```
+
+For a quick benchmark using examples from the Middlebury benchmark for optical flow, run `python benchmark_middlebury.py`. You can use it to easily verify that the provided implementation runs as expected.
+
+## warping
+We provide a small script to replicate the third figure of our paper [1]. You can simply run the following to obtain the comparison between summation splatting, average splatting, linear splatting, and softmax splatting.
+
+The example script is using OpenCV to load and display images, as well as to read the provided optical flow file. An easy way to install OpenCV for Python is using the `pip install opencv-contrib-python` package.
+
+```
+import cv2
+import numpy
+import torch
+
+import run
+
+import softsplat # the custom softmax splatting layer
+
+##########################################################
+
+torch.set_grad_enabled(False) # make sure to not compute gradients for computational performance
+
+torch.backends.cudnn.enabled = True # make sure to use cudnn for computational performance
+
+##########################################################
+
+tenOne = torch.FloatTensor(numpy.ascontiguousarray(cv2.imread(filename='./images/one.png', flags=-1).transpose(2, 0, 1)[None, :, :, :].astype(numpy.float32) * (1.0 / 255.0))).cuda()
+tenTwo = torch.FloatTensor(numpy.ascontiguousarray(cv2.imread(filename='./images/two.png', flags=-1).transpose(2, 0, 1)[None, :, :, :].astype(numpy.float32) * (1.0 / 255.0))).cuda()
+tenFlow = torch.FloatTensor(numpy.ascontiguousarray(run.read_flo('./images/flow.flo').transpose(2, 0, 1)[None, :, :, :])).cuda()
+
+tenMetric = torch.nn.functional.l1_loss(input=tenOne, target=run.backwarp(tenIn=tenTwo, tenFlow=tenFlow), reduction='none').mean([1], True)
+
+for intTime, fltTime in enumerate(numpy.linspace(0.0, 1.0, 11).tolist()):
+ tenSummation = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=None, strMode='sum')
+ tenAverage = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=None, strMode='avg')
+ tenLinear = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=(0.3 - tenMetric).clip(0.001, 1.0), strMode='linear') # finding a good linearly metric is difficult, and it is not invariant to translations
+ tenSoftmax = softsplat.softsplat(tenIn=tenOne, tenFlow=tenFlow * fltTime, tenMetric=(-20.0 * tenMetric).clip(-20.0, 20.0), strMode='soft') # -20.0 is a hyperparameter, called 'alpha' in the paper, that could be learned using a torch.Parameter
+
+ cv2.imshow(winname='summation', mat=tenSummation[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='average', mat=tenAverage[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='linear', mat=tenLinear[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.imshow(winname='softmax', mat=tenSoftmax[0, :, :, :].cpu().numpy().transpose(1, 2, 0))
+ cv2.waitKey(delay=0)
+# end
+```
+
+## xiph
+In our paper, we propose to use 4K video clips from Xiph to evaluate video frame interpolation on high-resolution footage. Please see the supplementary `benchmark_xiph.py` on how to reproduce the shown metrics.
+
+## video
+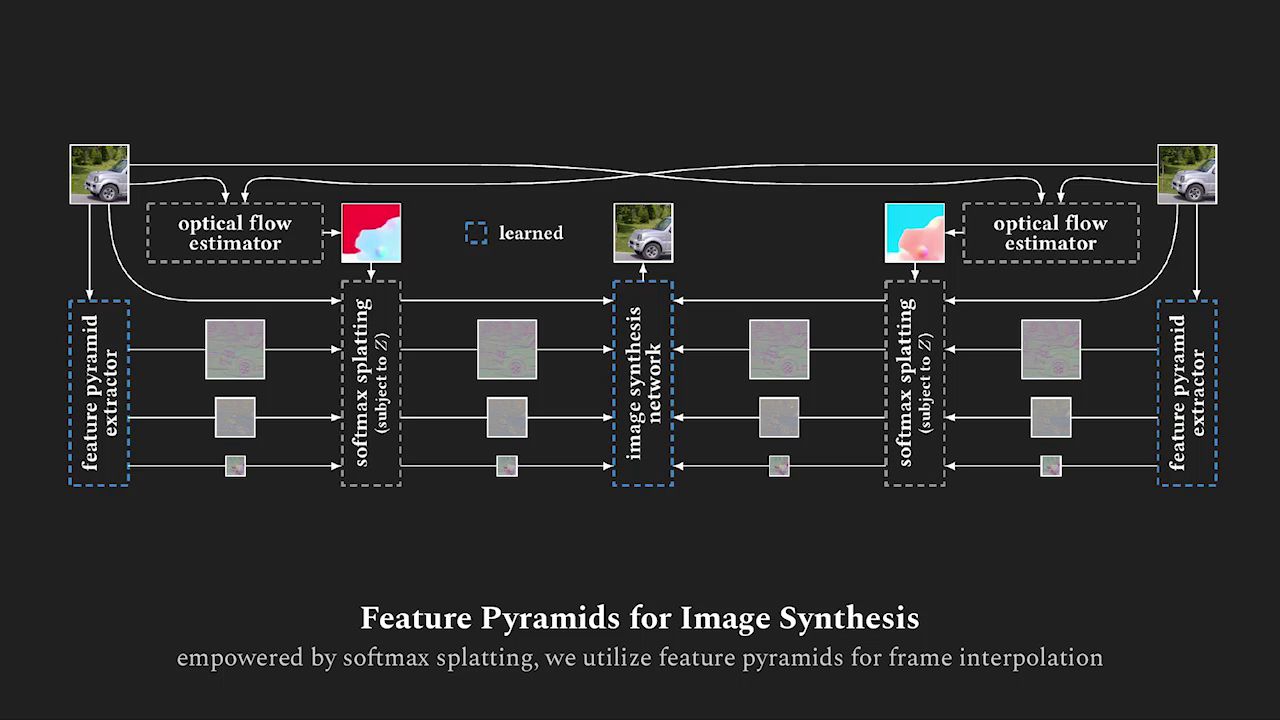 +
+## license
+The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
+
+## references
+```
+[1] @inproceedings{Niklaus_CVPR_2020,
+ author = {Simon Niklaus and Feng Liu},
+ title = {Softmax Splatting for Video Frame Interpolation},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
+ year = {2020}
+ }
+```
+
+## acknowledgment
+The video above uses materials under a Creative Common license as detailed at the end.
\ No newline at end of file
diff --git a/tools/softmax_splatting/correlation/README.md b/tools/softmax_splatting/correlation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a8e0ca529d50b7e09d521cc288daae7771514188
--- /dev/null
+++ b/tools/softmax_splatting/correlation/README.md
@@ -0,0 +1 @@
+This is an adaptation of the FlowNet2 implementation in order to compute cost volumes. Should you be making use of this work, please make sure to adhere to the licensing terms of the original authors. Should you be making use or modify this particular implementation, please acknowledge it appropriately.
\ No newline at end of file
diff --git a/tools/softmax_splatting/correlation/correlation.py b/tools/softmax_splatting/correlation/correlation.py
new file mode 100644
index 0000000000000000000000000000000000000000..d02560f79fda623ed14755114521b558fb596102
--- /dev/null
+++ b/tools/softmax_splatting/correlation/correlation.py
@@ -0,0 +1,395 @@
+#!/usr/bin/env python
+
+import cupy
+import re
+import torch
+
+kernel_Correlation_rearrange = '''
+ extern "C" __global__ void kernel_Correlation_rearrange(
+ const int n,
+ const float* input,
+ float* output
+ ) {
+ int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x;
+
+ if (intIndex >= n) {
+ return;
+ }
+
+ int intSample = blockIdx.z;
+ int intChannel = blockIdx.y;
+
+ float fltValue = input[(((intSample * SIZE_1(input)) + intChannel) * SIZE_2(input) * SIZE_3(input)) + intIndex];
+
+ __syncthreads();
+
+ int intPaddedY = (intIndex / SIZE_3(input)) + 4;
+ int intPaddedX = (intIndex % SIZE_3(input)) + 4;
+ int intRearrange = ((SIZE_3(input) + 8) * intPaddedY) + intPaddedX;
+
+ output[(((intSample * SIZE_1(output) * SIZE_2(output)) + intRearrange) * SIZE_1(input)) + intChannel] = fltValue;
+ }
+'''
+
+kernel_Correlation_updateOutput = '''
+ extern "C" __global__ void kernel_Correlation_updateOutput(
+ const int n,
+ const float* rbot0,
+ const float* rbot1,
+ float* top
+ ) {
+ extern __shared__ char patch_data_char[];
+
+ float *patch_data = (float *)patch_data_char;
+
+ // First (upper left) position of kernel upper-left corner in current center position of neighborhood in image 1
+ int x1 = blockIdx.x + 4;
+ int y1 = blockIdx.y + 4;
+ int item = blockIdx.z;
+ int ch_off = threadIdx.x;
+
+ // Load 3D patch into shared shared memory
+ for (int j = 0; j < 1; j++) { // HEIGHT
+ for (int i = 0; i < 1; i++) { // WIDTH
+ int ji_off = (j + i) * SIZE_3(rbot0);
+ for (int ch = ch_off; ch < SIZE_3(rbot0); ch += 32) { // CHANNELS
+ int idx1 = ((item * SIZE_1(rbot0) + y1+j) * SIZE_2(rbot0) + x1+i) * SIZE_3(rbot0) + ch;
+ int idxPatchData = ji_off + ch;
+ patch_data[idxPatchData] = rbot0[idx1];
+ }
+ }
+ }
+
+ __syncthreads();
+
+ __shared__ float sum[32];
+
+ // Compute correlation
+ for (int top_channel = 0; top_channel < SIZE_1(top); top_channel++) {
+ sum[ch_off] = 0;
+
+ int s2o = top_channel % 9 - 4;
+ int s2p = top_channel / 9 - 4;
+
+ for (int j = 0; j < 1; j++) { // HEIGHT
+ for (int i = 0; i < 1; i++) { // WIDTH
+ int ji_off = (j + i) * SIZE_3(rbot0);
+ for (int ch = ch_off; ch < SIZE_3(rbot0); ch += 32) { // CHANNELS
+ int x2 = x1 + s2o;
+ int y2 = y1 + s2p;
+
+ int idxPatchData = ji_off + ch;
+ int idx2 = ((item * SIZE_1(rbot0) + y2+j) * SIZE_2(rbot0) + x2+i) * SIZE_3(rbot0) + ch;
+
+ sum[ch_off] += patch_data[idxPatchData] * rbot1[idx2];
+ }
+ }
+ }
+
+ __syncthreads();
+
+ if (ch_off == 0) {
+ float total_sum = 0;
+ for (int idx = 0; idx < 32; idx++) {
+ total_sum += sum[idx];
+ }
+ const int sumelems = SIZE_3(rbot0);
+ const int index = ((top_channel*SIZE_2(top) + blockIdx.y)*SIZE_3(top))+blockIdx.x;
+ top[index + item*SIZE_1(top)*SIZE_2(top)*SIZE_3(top)] = total_sum / (float)sumelems;
+ }
+ }
+ }
+'''
+
+kernel_Correlation_updateGradOne = '''
+ #define ROUND_OFF 50000
+
+ extern "C" __global__ void kernel_Correlation_updateGradOne(
+ const int n,
+ const int intSample,
+ const float* rbot0,
+ const float* rbot1,
+ const float* gradOutput,
+ float* gradOne,
+ float* gradTwo
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ int n = intIndex % SIZE_1(gradOne); // channels
+ int l = (intIndex / SIZE_1(gradOne)) % SIZE_3(gradOne) + 4; // w-pos
+ int m = (intIndex / SIZE_1(gradOne) / SIZE_3(gradOne)) % SIZE_2(gradOne) + 4; // h-pos
+
+ // round_off is a trick to enable integer division with ceil, even for negative numbers
+ // We use a large offset, for the inner part not to become negative.
+ const int round_off = ROUND_OFF;
+ const int round_off_s1 = round_off;
+
+ // We add round_off before_s1 the int division and subtract round_off after it, to ensure the formula matches ceil behavior:
+ int xmin = (l - 4 + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4)
+ int ymin = (m - 4 + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4)
+
+ // Same here:
+ int xmax = (l - 4 + round_off_s1) - round_off; // floor (l - 4)
+ int ymax = (m - 4 + round_off_s1) - round_off; // floor (m - 4)
+
+ float sum = 0;
+ if (xmax>=0 && ymax>=0 && (xmin<=SIZE_3(gradOutput)-1) && (ymin<=SIZE_2(gradOutput)-1)) {
+ xmin = max(0,xmin);
+ xmax = min(SIZE_3(gradOutput)-1,xmax);
+
+ ymin = max(0,ymin);
+ ymax = min(SIZE_2(gradOutput)-1,ymax);
+
+ for (int p = -4; p <= 4; p++) {
+ for (int o = -4; o <= 4; o++) {
+ // Get rbot1 data:
+ int s2o = o;
+ int s2p = p;
+ int idxbot1 = ((intSample * SIZE_1(rbot0) + (m+s2p)) * SIZE_2(rbot0) + (l+s2o)) * SIZE_3(rbot0) + n;
+ float bot1tmp = rbot1[idxbot1]; // rbot1[l+s2o,m+s2p,n]
+
+ // Index offset for gradOutput in following loops:
+ int op = (p+4) * 9 + (o+4); // index[o,p]
+ int idxopoffset = (intSample * SIZE_1(gradOutput) + op);
+
+ for (int y = ymin; y <= ymax; y++) {
+ for (int x = xmin; x <= xmax; x++) {
+ int idxgradOutput = (idxopoffset * SIZE_2(gradOutput) + y) * SIZE_3(gradOutput) + x; // gradOutput[x,y,o,p]
+ sum += gradOutput[idxgradOutput] * bot1tmp;
+ }
+ }
+ }
+ }
+ }
+ const int sumelems = SIZE_1(gradOne);
+ const int bot0index = ((n * SIZE_2(gradOne)) + (m-4)) * SIZE_3(gradOne) + (l-4);
+ gradOne[bot0index + intSample*SIZE_1(gradOne)*SIZE_2(gradOne)*SIZE_3(gradOne)] = sum / (float)sumelems;
+ } }
+'''
+
+kernel_Correlation_updateGradTwo = '''
+ #define ROUND_OFF 50000
+
+ extern "C" __global__ void kernel_Correlation_updateGradTwo(
+ const int n,
+ const int intSample,
+ const float* rbot0,
+ const float* rbot1,
+ const float* gradOutput,
+ float* gradOne,
+ float* gradTwo
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ int n = intIndex % SIZE_1(gradTwo); // channels
+ int l = (intIndex / SIZE_1(gradTwo)) % SIZE_3(gradTwo) + 4; // w-pos
+ int m = (intIndex / SIZE_1(gradTwo) / SIZE_3(gradTwo)) % SIZE_2(gradTwo) + 4; // h-pos
+
+ // round_off is a trick to enable integer division with ceil, even for negative numbers
+ // We use a large offset, for the inner part not to become negative.
+ const int round_off = ROUND_OFF;
+ const int round_off_s1 = round_off;
+
+ float sum = 0;
+ for (int p = -4; p <= 4; p++) {
+ for (int o = -4; o <= 4; o++) {
+ int s2o = o;
+ int s2p = p;
+
+ //Get X,Y ranges and clamp
+ // We add round_off before_s1 the int division and subtract round_off after it, to ensure the formula matches ceil behavior:
+ int xmin = (l - 4 - s2o + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4 - s2o)
+ int ymin = (m - 4 - s2p + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4 - s2o)
+
+ // Same here:
+ int xmax = (l - 4 - s2o + round_off_s1) - round_off; // floor (l - 4 - s2o)
+ int ymax = (m - 4 - s2p + round_off_s1) - round_off; // floor (m - 4 - s2p)
+
+ if (xmax>=0 && ymax>=0 && (xmin<=SIZE_3(gradOutput)-1) && (ymin<=SIZE_2(gradOutput)-1)) {
+ xmin = max(0,xmin);
+ xmax = min(SIZE_3(gradOutput)-1,xmax);
+
+ ymin = max(0,ymin);
+ ymax = min(SIZE_2(gradOutput)-1,ymax);
+
+ // Get rbot0 data:
+ int idxbot0 = ((intSample * SIZE_1(rbot0) + (m-s2p)) * SIZE_2(rbot0) + (l-s2o)) * SIZE_3(rbot0) + n;
+ float bot0tmp = rbot0[idxbot0]; // rbot1[l+s2o,m+s2p,n]
+
+ // Index offset for gradOutput in following loops:
+ int op = (p+4) * 9 + (o+4); // index[o,p]
+ int idxopoffset = (intSample * SIZE_1(gradOutput) + op);
+
+ for (int y = ymin; y <= ymax; y++) {
+ for (int x = xmin; x <= xmax; x++) {
+ int idxgradOutput = (idxopoffset * SIZE_2(gradOutput) + y) * SIZE_3(gradOutput) + x; // gradOutput[x,y,o,p]
+ sum += gradOutput[idxgradOutput] * bot0tmp;
+ }
+ }
+ }
+ }
+ }
+ const int sumelems = SIZE_1(gradTwo);
+ const int bot1index = ((n * SIZE_2(gradTwo)) + (m-4)) * SIZE_3(gradTwo) + (l-4);
+ gradTwo[bot1index + intSample*SIZE_1(gradTwo)*SIZE_2(gradTwo)*SIZE_3(gradTwo)] = sum / (float)sumelems;
+ } }
+'''
+
+def cupy_kernel(strFunction, objVariables):
+ strKernel = globals()[strFunction]
+
+ while True:
+ objMatch = re.search('(SIZE_)([0-4])(\()([^\)]*)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArg = int(objMatch.group(2))
+
+ strTensor = objMatch.group(4)
+ intSizes = objVariables[strTensor].size()
+
+ strKernel = strKernel.replace(objMatch.group(), str(intSizes[intArg] if torch.is_tensor(intSizes[intArg]) == False else intSizes[intArg].item()))
+
+ while True:
+ objMatch = re.search('(VALUE_)([0-4])(\()([^\)]+)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = objMatch.group(4).split(',')
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+ strIndex = [ '((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')' for intArg in range(intArgs) ]
+
+ strKernel = strKernel.replace(objMatch.group(0), strTensor + '[' + str.join('+', strIndex) + ']')
+ # end
+
+ return strKernel
+# end
+
+@cupy.memoize(for_each_device=True)
+def cupy_launch(strFunction, strKernel):
+ return cupy.cuda.compile_with_cache(strKernel).get_function(strFunction)
+# end
+
+class _FunctionCorrelation(torch.autograd.Function):
+ @staticmethod
+ def forward(self, one, two):
+ rbot0 = one.new_zeros([ one.shape[0], one.shape[2] + 8, one.shape[3] + 8, one.shape[1] ])
+ rbot1 = one.new_zeros([ one.shape[0], one.shape[2] + 8, one.shape[3] + 8, one.shape[1] ])
+
+ one = one.contiguous(); assert(one.is_cuda == True)
+ two = two.contiguous(); assert(two.is_cuda == True)
+
+ output = one.new_zeros([ one.shape[0], 81, one.shape[2], one.shape[3] ])
+
+ if one.is_cuda == True:
+ n = one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_rearrange', cupy_kernel('kernel_Correlation_rearrange', {
+ 'input': one,
+ 'output': rbot0
+ }))(
+ grid=tuple([ int((n + 25 - 1) / 25), one.shape[1], one.shape[0] ]), #frame_rate
+ block=tuple([ 25, 1, 1 ]), #frame_rate
+ args=[ cupy.int32(n), one.data_ptr(), rbot0.data_ptr() ]
+ )
+
+ n = two.shape[2] * two.shape[3]
+ cupy_launch('kernel_Correlation_rearrange', cupy_kernel('kernel_Correlation_rearrange', {
+ 'input': two,
+ 'output': rbot1
+ }))(
+ grid=tuple([ int((n + 25 - 1) / 25), two.shape[1], two.shape[0] ]), #frame_rate
+ block=tuple([ 25, 1, 1 ]), #frame_rate
+ args=[ cupy.int32(n), two.data_ptr(), rbot1.data_ptr() ]
+ )
+
+ n = output.shape[1] * output.shape[2] * output.shape[3]
+ cupy_launch('kernel_Correlation_updateOutput', cupy_kernel('kernel_Correlation_updateOutput', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'top': output
+ }))(
+ grid=tuple([ output.shape[3], output.shape[2], output.shape[0] ]),
+ block=tuple([ 32, 1, 1 ]),
+ shared_mem=one.shape[1] * 4,
+ args=[ cupy.int32(n), rbot0.data_ptr(), rbot1.data_ptr(), output.data_ptr() ]
+ )
+
+ elif one.is_cuda == False:
+ raise NotImplementedError()
+
+ # end
+
+ self.save_for_backward(one, two, rbot0, rbot1)
+
+ return output
+ # end
+
+ @staticmethod
+ def backward(self, gradOutput):
+ one, two, rbot0, rbot1 = self.saved_tensors
+
+ gradOutput = gradOutput.contiguous(); assert(gradOutput.is_cuda == True)
+
+ gradOne = one.new_zeros([ one.shape[0], one.shape[1], one.shape[2], one.shape[3] ]) if self.needs_input_grad[0] == True else None
+ gradTwo = one.new_zeros([ one.shape[0], one.shape[1], one.shape[2], one.shape[3] ]) if self.needs_input_grad[1] == True else None
+
+ if one.is_cuda == True:
+ if gradOne is not None:
+ for intSample in range(one.shape[0]):
+ n = one.shape[1] * one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_updateGradOne', cupy_kernel('kernel_Correlation_updateGradOne', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'gradOutput': gradOutput,
+ 'gradOne': gradOne,
+ 'gradTwo': None
+ }))(
+ grid=tuple([ int((n + 512 - 1) / 512), 1, 1 ]),
+ block=tuple([ 512, 1, 1 ]),
+ args=[ cupy.int32(n), intSample, rbot0.data_ptr(), rbot1.data_ptr(), gradOutput.data_ptr(), gradOne.data_ptr(), None ]
+ )
+ # end
+ # end
+
+ if gradTwo is not None:
+ for intSample in range(one.shape[0]):
+ n = one.shape[1] * one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_updateGradTwo', cupy_kernel('kernel_Correlation_updateGradTwo', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'gradOutput': gradOutput,
+ 'gradOne': None,
+ 'gradTwo': gradTwo
+ }))(
+ grid=tuple([ int((n + 512 - 1) / 512), 1, 1 ]),
+ block=tuple([ 512, 1, 1 ]),
+ args=[ cupy.int32(n), intSample, rbot0.data_ptr(), rbot1.data_ptr(), gradOutput.data_ptr(), None, gradTwo.data_ptr() ]
+ )
+ # end
+ # end
+
+ elif one.is_cuda == False:
+ raise NotImplementedError()
+
+ # end
+
+ return gradOne, gradTwo
+ # end
+# end
+
+def FunctionCorrelation(tenOne, tenTwo):
+ return _FunctionCorrelation.apply(tenOne, tenTwo)
+# end
+
+class ModuleCorrelation(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ # end
+
+ def forward(self, tenOne, tenTwo):
+ return _FunctionCorrelation.apply(tenOne, tenTwo)
+ # end
+# end
diff --git a/tools/softmax_splatting/run.py b/tools/softmax_splatting/run.py
new file mode 100644
index 0000000000000000000000000000000000000000..22313f889dabafb31c675f199029713332751952
--- /dev/null
+++ b/tools/softmax_splatting/run.py
@@ -0,0 +1,871 @@
+#!/usr/bin/env python
+
+import getopt
+import math
+import sys
+import typing
+
+import numpy
+import PIL
+import PIL.Image
+import torch
+
+from . import softsplat # the custom softmax splatting layer
+
+try:
+ from .correlation import correlation # the custom cost volume layer
+except:
+ sys.path.insert(0, './correlation'); import correlation # you should consider upgrading python
+# end
+
+##########################################################
+
+torch.set_grad_enabled(False) # make sure to not compute gradients for computational performance
+
+torch.backends.cudnn.enabled = True # make sure to use cudnn for computational performance
+
+##########################################################
+
+arguments_strModel = 'lf'
+arguments_strOne = './images/one.png'
+arguments_strTwo = './images/two.png'
+arguments_strVideo = './videos/car-turn.mp4'
+arguments_strOut = './out.png'
+arguments_strVideo2 = ''
+
+for strOption, strArgument in getopt.getopt(sys.argv[1:], '', [strParameter[2:] + '=' for strParameter in sys.argv[1::2]])[0]:
+ if strOption == '--model' and strArgument != '': arguments_strModel = strArgument # which model to use
+ if strOption == '--one' and strArgument != '': arguments_strOne = strArgument # path to the first frame
+ if strOption == '--two' and strArgument != '': arguments_strTwo = strArgument # path to the second frame
+ if strOption == '--video' and strArgument != '': arguments_strVideo = strArgument # path to a video
+ if strOption == '--video2' and strArgument != '': arguments_strVideo2 = strArgument # path to a video
+ if strOption == '--out' and strArgument != '': arguments_strOut = strArgument # path to where the output should be stored
+# end
+
+##########################################################
+
+def read_flo(strFile):
+ with open(strFile, 'rb') as objFile:
+ strFlow = objFile.read()
+ # end
+
+ assert(numpy.frombuffer(buffer=strFlow, dtype=numpy.float32, count=1, offset=0) == 202021.25)
+
+ intWidth = numpy.frombuffer(buffer=strFlow, dtype=numpy.int32, count=1, offset=4)[0]
+ intHeight = numpy.frombuffer(buffer=strFlow, dtype=numpy.int32, count=1, offset=8)[0]
+
+ return numpy.frombuffer(buffer=strFlow, dtype=numpy.float32, count=intHeight * intWidth * 2, offset=12).reshape(intHeight, intWidth, 2)
+# end
+
+##########################################################
+
+backwarp_tenGrid = {}
+
+def backwarp(tenIn, tenFlow):
+ if str(tenFlow.shape) not in backwarp_tenGrid:
+ tenHor = torch.linspace(start=-1.0, end=1.0, steps=tenFlow.shape[3], dtype=tenFlow.dtype, device=tenFlow.device).view(1, 1, 1, -1).repeat(1, 1, tenFlow.shape[2], 1)
+ tenVer = torch.linspace(start=-1.0, end=1.0, steps=tenFlow.shape[2], dtype=tenFlow.dtype, device=tenFlow.device).view(1, 1, -1, 1).repeat(1, 1, 1, tenFlow.shape[3])
+
+ backwarp_tenGrid[str(tenFlow.shape)] = torch.cat([tenHor, tenVer], 1).cuda()
+ # end
+
+ tenFlow = torch.cat([tenFlow[:, 0:1, :, :] / ((tenIn.shape[3] - 1.0) / 2.0), tenFlow[:, 1:2, :, :] / ((tenIn.shape[2] - 1.0) / 2.0)], 1)
+
+ return torch.nn.functional.grid_sample(input=tenIn, grid=(backwarp_tenGrid[str(tenFlow.shape)] + tenFlow).permute(0, 2, 3, 1), mode='bilinear', padding_mode='zeros', align_corners=True)
+# end
+
+##########################################################
+
+class Flow(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ class Extractor(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netFirst = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netSecond = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netThird = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netFourth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=64, out_channels=96, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netFifth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=96, out_channels=128, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netSixth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+ # end
+
+ def forward(self, tenInput):
+ tenFirst = self.netFirst(tenInput)
+ tenSecond = self.netSecond(tenFirst)
+ tenThird = self.netThird(tenSecond)
+ tenFourth = self.netFourth(tenThird)
+ tenFifth = self.netFifth(tenFourth)
+ tenSixth = self.netSixth(tenFifth)
+
+ return [tenFirst, tenSecond, tenThird, tenFourth, tenFifth, tenSixth]
+ # end
+ # end
+
+ class Decoder(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=intChannels, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=96, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=96, out_channels=64, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=64, out_channels=32, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=32, out_channels=2, kernel_size=3, stride=1, padding=1)
+ )
+ # end
+
+ def forward(self, tenOne, tenTwo, objPrevious):
+ intWidth = tenOne.shape[3] and tenTwo.shape[3]
+ intHeight = tenOne.shape[2] and tenTwo.shape[2]
+
+ tenMain = None
+
+ if objPrevious is None:
+ tenVolume = correlation.FunctionCorrelation(tenOne=tenOne, tenTwo=tenTwo)
+
+ tenMain = torch.cat([tenOne, tenVolume], 1)
+
+ elif objPrevious is not None:
+ tenForward = torch.nn.functional.interpolate(input=objPrevious['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) / float(objPrevious['tenForward'].shape[3]) * float(intWidth)
+
+ tenVolume = correlation.FunctionCorrelation(tenOne=tenOne, tenTwo=backwarp(tenTwo, tenForward))
+
+ tenMain = torch.cat([tenOne, tenVolume, tenForward], 1)
+
+ # end
+
+ return {
+ 'tenForward': self.netMain(tenMain)
+ }
+ # end
+ # end
+
+ self.netExtractor = Extractor()
+
+ self.netFirst = Decoder(16 + 81 + 2)
+ self.netSecond = Decoder(32 + 81 + 2)
+ self.netThird = Decoder(64 + 81 + 2)
+ self.netFourth = Decoder(96 + 81 + 2)
+ self.netFifth = Decoder(128 + 81 + 2)
+ self.netSixth = Decoder(192 + 81)
+ # end
+
+ def forward(self, tenOne, tenTwo):
+ intWidth = tenOne.shape[3] and tenTwo.shape[3]
+ intHeight = tenOne.shape[2] and tenTwo.shape[2]
+
+ tenOne = self.netExtractor(tenOne)
+ tenTwo = self.netExtractor(tenTwo)
+
+ objForward = None
+ objBackward = None
+
+ objForward = self.netSixth(tenOne[-1], tenTwo[-1], objForward)
+ objBackward = self.netSixth(tenTwo[-1], tenOne[-1], objBackward)
+
+ objForward = self.netFifth(tenOne[-2], tenTwo[-2], objForward)
+ objBackward = self.netFifth(tenTwo[-2], tenOne[-2], objBackward)
+
+ objForward = self.netFourth(tenOne[-3], tenTwo[-3], objForward)
+ objBackward = self.netFourth(tenTwo[-3], tenOne[-3], objBackward)
+
+ objForward = self.netThird(tenOne[-4], tenTwo[-4], objForward)
+ objBackward = self.netThird(tenTwo[-4], tenOne[-4], objBackward)
+
+ objForward = self.netSecond(tenOne[-5], tenTwo[-5], objForward)
+ objBackward = self.netSecond(tenTwo[-5], tenOne[-5], objBackward)
+
+ objForward = self.netFirst(tenOne[-6], tenTwo[-6], objForward)
+ objBackward = self.netFirst(tenTwo[-6], tenOne[-6], objBackward)
+
+ return {
+ 'tenForward': torch.nn.functional.interpolate(input=objForward['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) * (float(intWidth) / float(objForward['tenForward'].shape[3])),
+ 'tenBackward': torch.nn.functional.interpolate(input=objBackward['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) * (float(intWidth) / float(objBackward['tenForward'].shape[3]))
+ }
+ # end
+# end
+
+##########################################################
+
+class Synthesis(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ class Basic(torch.nn.Module):
+ def __init__(self, strType, intChannels, boolSkip):
+ super().__init__()
+
+ if strType == 'relu-conv-relu-conv':
+ self.netMain = torch.nn.Sequential(
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+
+ elif strType == 'conv-relu-conv':
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+
+ # end
+
+ self.boolSkip = boolSkip
+
+ if boolSkip == True:
+ if intChannels[0] == intChannels[2]:
+ self.netShortcut = None
+
+ elif intChannels[0] != intChannels[2]:
+ self.netShortcut = torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[2], kernel_size=1, stride=1, padding=0, bias=False)
+
+ # end
+ # end
+ # end
+
+ def forward(self, tenInput):
+ if self.boolSkip == False:
+ return self.netMain(tenInput)
+ # end
+
+ if self.netShortcut is None:
+ return self.netMain(tenInput) + tenInput
+
+ elif self.netShortcut is not None:
+ return self.netMain(tenInput) + self.netShortcut(tenInput)
+
+ # end
+ # end
+ # end
+
+ class Downsample(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ # end
+
+ def forward(self, tenInput):
+ return self.netMain(tenInput)
+ # end
+ # end
+
+ class Upsample(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ # end
+
+ def forward(self, tenInput):
+ return self.netMain(tenInput)
+ # end
+ # end
+
+ class Encode(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netOne = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=32, init=0.25),
+ torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=32, init=0.25)
+ )
+
+ self.netTwo = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=64, init=0.25),
+ torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=64, init=0.25)
+ )
+
+ self.netThr = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=64, out_channels=96, kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=96, init=0.25),
+ torch.nn.Conv2d(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=96, init=0.25)
+ )
+ # end
+
+ def forward(self, tenInput):
+ tenOutput = []
+
+ tenOutput.append(self.netOne(tenInput))
+ tenOutput.append(self.netTwo(tenOutput[-1]))
+ tenOutput.append(self.netThr(tenOutput[-1]))
+
+ return [torch.cat([tenInput, tenOutput[0]], 1)] + tenOutput[1:]
+ # end
+ # end
+
+ class Softmetric(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netInput = torch.nn.Conv2d(in_channels=3, out_channels=12, kernel_size=3, stride=1, padding=1, bias=False)
+ self.netError = torch.nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, stride=1, padding=1, bias=False)
+
+ for intRow, intFeatures in [(0, 16), (1, 32), (2, 64), (3, 96)]:
+ self.add_module(str(intRow) + 'x0' + ' - ' + str(intRow) + 'x1', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ # end
+
+ for intCol in [0]:
+ self.add_module('0x' + str(intCol) + ' - ' + '1x' + str(intCol), Downsample([16, 32, 32]))
+ self.add_module('1x' + str(intCol) + ' - ' + '2x' + str(intCol), Downsample([32, 64, 64]))
+ self.add_module('2x' + str(intCol) + ' - ' + '3x' + str(intCol), Downsample([64, 96, 96]))
+ # end
+
+ for intCol in [1]:
+ self.add_module('3x' + str(intCol) + ' - ' + '2x' + str(intCol), Upsample([96, 64, 64]))
+ self.add_module('2x' + str(intCol) + ' - ' + '1x' + str(intCol), Upsample([64, 32, 32]))
+ self.add_module('1x' + str(intCol) + ' - ' + '0x' + str(intCol), Upsample([32, 16, 16]))
+ # end
+
+ self.netOutput = Basic('conv-relu-conv', [16, 16, 1], True)
+ # end
+
+ def forward(self, tenEncone, tenEnctwo, tenFlow):
+ tenColumn = [None, None, None, None]
+
+ tenColumn[0] = torch.cat([self.netInput(tenEncone[0][:, 0:3, :, :]), self.netError(torch.nn.functional.l1_loss(input=tenEncone[0], target=backwarp(tenEnctwo[0], tenFlow), reduction='none').mean([1], True))], 1)
+ tenColumn[1] = self._modules['0x0 - 1x0'](tenColumn[0])
+ tenColumn[2] = self._modules['1x0 - 2x0'](tenColumn[1])
+ tenColumn[3] = self._modules['2x0 - 3x0'](tenColumn[2])
+
+ intColumn = 1
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ return self.netOutput(tenColumn[0])
+ # end
+ # end
+
+ class Warp(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netOne = Basic('conv-relu-conv', [3 + 3 + 32 + 32 + 1 + 1, 32, 32], True)
+ self.netTwo = Basic('conv-relu-conv', [0 + 0 + 64 + 64 + 1 + 1, 64, 64], True)
+ self.netThr = Basic('conv-relu-conv', [0 + 0 + 96 + 96 + 1 + 1, 96, 96], True)
+ # end
+
+ def forward(self, tenEncone, tenEnctwo, tenMetricone, tenMetrictwo, tenForward, tenBackward):
+ tenOutput = []
+
+ for intLevel in range(3):
+ if intLevel != 0:
+ tenMetricone = torch.nn.functional.interpolate(input=tenMetricone, size=(tenEncone[intLevel].shape[2], tenEncone[intLevel].shape[3]), mode='bilinear', align_corners=False)
+ tenMetrictwo = torch.nn.functional.interpolate(input=tenMetrictwo, size=(tenEnctwo[intLevel].shape[2], tenEnctwo[intLevel].shape[3]), mode='bilinear', align_corners=False)
+
+ tenForward = torch.nn.functional.interpolate(input=tenForward, size=(tenEncone[intLevel].shape[2], tenEncone[intLevel].shape[3]), mode='bilinear', align_corners=False) * (float(tenEncone[intLevel].shape[3]) / float(tenForward.shape[3]))
+ tenBackward = torch.nn.functional.interpolate(input=tenBackward, size=(tenEnctwo[intLevel].shape[2], tenEnctwo[intLevel].shape[3]), mode='bilinear', align_corners=False) * (float(tenEnctwo[intLevel].shape[3]) / float(tenBackward.shape[3]))
+ # end
+
+ tenOutput.append([self.netOne, self.netTwo, self.netThr][intLevel](torch.cat([
+ softsplat.softsplat(tenIn=torch.cat([tenEncone[intLevel], tenMetricone], 1), tenFlow=tenForward, tenMetric=tenMetricone.neg().clip(-20.0, 20.0), strMode='soft'),
+ softsplat.softsplat(tenIn=torch.cat([tenEnctwo[intLevel], tenMetrictwo], 1), tenFlow=tenBackward, tenMetric=tenMetrictwo.neg().clip(-20.0, 20.0), strMode='soft')
+ ], 1)))
+ # end
+
+ return tenOutput
+ # end
+ # end
+
+ self.netEncode = Encode()
+
+ self.netSoftmetric = Softmetric()
+
+ self.netWarp = Warp()
+
+ for intRow, intFeatures in [(0, 32), (1, 64), (2, 96)]:
+ self.add_module(str(intRow) + 'x0' + ' - ' + str(intRow) + 'x1', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x1' + ' - ' + str(intRow) + 'x2', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x2' + ' - ' + str(intRow) + 'x3', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x3' + ' - ' + str(intRow) + 'x4', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x4' + ' - ' + str(intRow) + 'x5', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ # end
+
+ for intCol in [0, 1, 2]:
+ self.add_module('0x' + str(intCol) + ' - ' + '1x' + str(intCol), Downsample([32, 64, 64]))
+ self.add_module('1x' + str(intCol) + ' - ' + '2x' + str(intCol), Downsample([64, 96, 96]))
+ # end
+
+ for intCol in [3, 4, 5]:
+ self.add_module('2x' + str(intCol) + ' - ' + '1x' + str(intCol), Upsample([96, 64, 64]))
+ self.add_module('1x' + str(intCol) + ' - ' + '0x' + str(intCol), Upsample([64, 32, 32]))
+ # end
+
+ self.netOutput = Basic('conv-relu-conv', [32, 32, 3], True)
+ # end
+
+ def forward(self, tenOne, tenTwo, tenForward, tenBackward, fltTime):
+ tenEncone = self.netEncode(tenOne)
+ tenEnctwo = self.netEncode(tenTwo)
+
+ tenMetricone = self.netSoftmetric(tenEncone, tenEnctwo, tenForward) * 2.0 * fltTime
+ tenMetrictwo = self.netSoftmetric(tenEnctwo, tenEncone, tenBackward) * 2.0 * (1.0 - fltTime)
+
+ tenForward = tenForward * fltTime
+ tenBackward = tenBackward * (1.0 - fltTime)
+
+ tenWarp = self.netWarp(tenEncone, tenEnctwo, tenMetricone, tenMetrictwo, tenForward, tenBackward)
+
+ tenColumn = [None, None, None]
+
+ tenColumn[0] = tenWarp[0]
+ tenColumn[1] = tenWarp[1] + self._modules['0x0 - 1x0'](tenColumn[0])
+ tenColumn[2] = tenWarp[2] + self._modules['1x0 - 2x0'](tenColumn[1])
+
+ intColumn = 1
+ for intRow in range(len(tenColumn)):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != 0:
+ tenColumn[intRow] = tenColumn[intRow] + self._modules[str(intRow - 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow - 1])
+ # end
+ # end
+
+ intColumn = 2
+ for intRow in range(len(tenColumn)):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != 0:
+ tenColumn[intRow] = tenColumn[intRow] + self._modules[str(intRow - 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow - 1])
+ # end
+ # end
+
+ intColumn = 3
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ intColumn = 4
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ intColumn = 5
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ return self.netOutput(tenColumn[0])
+ # end
+# end
+
+##########################################################
+
+class Network(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netFlow = Flow()
+
+ self.netSynthesis = Synthesis()
+
+ self.load_state_dict({strKey.replace('module', 'net'): tenWeight for strKey, tenWeight in torch.hub.load_state_dict_from_url(url='http://content.sniklaus.com/softsplat/network-' + arguments_strModel + '.pytorch', file_name='softsplat-' + arguments_strModel).items()})
+ # end
+
+ def forward(self, tenOne, tenTwo, fltTimes):
+ with torch.set_grad_enabled(False):
+ tenStats = [tenOne, tenTwo]
+ tenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in tenStats]) / len(tenStats)
+ tenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (tenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in tenStats]) / len(tenStats)).sqrt()
+ tenOne = ((tenOne - tenMean) / (tenStd + 0.0000001)).detach()
+ tenTwo = ((tenTwo - tenMean) / (tenStd + 0.0000001)).detach()
+ # end
+
+ objFlow = self.netFlow(tenOne, tenTwo)
+
+ tenImages = [self.netSynthesis(tenOne, tenTwo, objFlow['tenForward'], objFlow['tenBackward'], fltTime) for fltTime in fltTimes]
+
+ return [(tenImage * tenStd) + tenMean for tenImage in tenImages]
+ # end
+# end
+
+netNetwork = None
+
+##########################################################
+
+def estimate(tenOne, tenTwo, fltTimes):
+ global netNetwork
+
+ if netNetwork is None:
+ netNetwork = Network().cuda().eval()
+ # end
+
+ assert(tenOne.shape[1] == tenTwo.shape[1])
+ assert(tenOne.shape[2] == tenTwo.shape[2])
+
+ intWidth = tenOne.shape[2]
+ intHeight = tenOne.shape[1]
+
+ tenPreprocessedOne = tenOne.cuda().view(1, 3, intHeight, intWidth)
+ tenPreprocessedTwo = tenTwo.cuda().view(1, 3, intHeight, intWidth)
+
+ intPadr = (2 - (intWidth % 2)) % 2
+ intPadb = (2 - (intHeight % 2)) % 2
+
+ tenPreprocessedOne = torch.nn.functional.pad(input=tenPreprocessedOne, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenPreprocessedTwo = torch.nn.functional.pad(input=tenPreprocessedTwo, pad=[0, intPadr, 0, intPadb], mode='replicate')
+
+ return [tenImage[0, :, :intHeight, :intWidth].cpu() for tenImage in netNetwork(tenPreprocessedOne, tenPreprocessedTwo, fltTimes)]
+# end
+##########################################################
+import logging
+
+logger = logging.getLogger(__name__)
+
+raft = None
+
+class Raft:
+ def __init__(self):
+ from torchvision.models.optical_flow import (Raft_Large_Weights,
+ raft_large)
+
+ weights = Raft_Large_Weights.DEFAULT
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ model = raft_large(weights=weights, progress=False).to(self.device)
+ self.model = model.eval()
+
+ def __call__(self,img1,img2):
+ with torch.no_grad():
+ img1 = img1.to(self.device)
+ img2 = img2.to(self.device)
+ i1 = torch.vstack([img1,img2])
+ i2 = torch.vstack([img2,img1])
+ list_of_flows = self.model(i1, i2)
+
+ predicted_flows = list_of_flows[-1]
+ return { 'tenForward' : predicted_flows[0].unsqueeze(dim=0) , 'tenBackward' : predicted_flows[1].unsqueeze(dim=0) }
+
+img_count = 0
+def debug_save_img(img, comment, inc=False):
+ return
+ global img_count
+ from torchvision.utils import save_image
+
+ save_image(img, f"debug0/{img_count:04d}_{comment}.png")
+
+ if inc:
+ img_count += 1
+
+
+class Network2(torch.nn.Module):
+ def __init__(self, model_file_path):
+ super().__init__()
+
+ self.netFlow = Flow()
+
+ self.netSynthesis = Synthesis()
+
+ d = torch.load(model_file_path)
+
+ d = {strKey.replace('module', 'net'): tenWeight for strKey, tenWeight in d.items()}
+
+ self.load_state_dict(d)
+ # end
+
+ def forward(self, tenOne, tenTwo, guideFrameList):
+ global raft
+
+ do_composite = True
+ use_raft = True
+
+ if use_raft:
+ if raft is None:
+ raft = Raft()
+
+
+ with torch.set_grad_enabled(False):
+ tenStats = [tenOne, tenTwo]
+ tenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in tenStats]) / len(tenStats)
+ tenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (tenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in tenStats]) / len(tenStats)).sqrt()
+ tenOne = ((tenOne - tenMean) / (tenStd + 0.0000001)).detach()
+ tenTwo = ((tenTwo - tenMean) / (tenStd + 0.0000001)).detach()
+
+ gtenStats = guideFrameList
+ gtenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in gtenStats]) / len(gtenStats)
+ gtenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (gtenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in gtenStats]) / len(gtenStats)).sqrt()
+ guideFrameList = [((g - gtenMean) / (gtenStd + 0.0000001)).detach() for g in guideFrameList]
+
+ # end
+
+ tenImages =[]
+ l = len(guideFrameList)
+ i = 1
+ g1 = guideFrameList.pop(0)
+
+ if use_raft:
+ styleFlow = raft(tenOne, tenTwo)
+ else:
+ styleFlow = self.netFlow(tenOne, tenTwo)
+
+ def composite1(fA, fB, nA, nB):
+ # 1,2,768,512
+ A = fA[:,0,:,:]
+ B = fA[:,1,:,:]
+ Z = nA
+
+ UA = A / Z
+ UB = B / Z
+
+ A2 = fB[:,0,:,:]
+ B2 = fB[:,1,:,:]
+ Z2 = nB
+ fB[:,0,:,:] = Z2 * UA
+ fB[:,1,:,:] = Z2 * UB
+ return fB
+
+ def mask_dilate(ten, kernel_size=3):
+ ten = ten.to(torch.float32)
+ k=torch.ones(1, 1, kernel_size, kernel_size, dtype=torch.float32).cuda()
+ ten = torch.nn.functional.conv2d(ten, k, padding=(kernel_size//2, kernel_size// 2))
+ result = torch.clamp(ten, 0, 1)
+ return result.to(torch.bool)
+
+ def composite2(fA, fB, nA, nB):
+ Z = nA
+ Z2 = nB
+
+ mean2 = torch.mean(Z2)
+ max2 = torch.max(Z2)
+ mask2 = (Z2 > (mean2+max2)/2)
+ debug_save_img(mask2.to(torch.float), "mask2_0")
+ mask2 = mask_dilate(mask2, 9)
+ debug_save_img(mask2.to(torch.float), "mask2_1")
+ mask2 = ~mask2
+
+ debug_save_img(mask2.to(torch.float), "mask2")
+
+ mean1 = torch.mean(Z)
+ max1 = torch.max(Z)
+ mask1 = (Z > (mean1+max1)/2)
+
+ debug_save_img(mask1.to(torch.float), "mask1")
+
+ mask = mask1 & mask2
+ mask = mask.squeeze()
+
+ debug_save_img(mask.to(torch.float), "cmask", True)
+
+ fB[:,:,mask] = fA[:,:,mask]
+
+ return fB
+
+
+ def composite(fA, fB):
+ A = fA[:,0,:,:]
+ B = fA[:,1,:,:]
+ Z = (A*A + B*B)**0.5
+ A2 = fB[:,0,:,:]
+ B2 = fB[:,1,:,:]
+ Z2 = (A2*A2 + B2*B2)**0.5
+
+ fB = composite1(fA, fB, Z, Z2)
+ fB = composite2(fA, fB, Z, Z2)
+ return fB
+
+ for g2 in guideFrameList:
+ if use_raft:
+ objFlow = raft(g1, g2)
+ else:
+ objFlow = self.netFlow(g1, g2)
+
+
+ objFlow['tenForward'] = objFlow['tenForward'] * (l/i)
+ objFlow['tenBackward'] = objFlow['tenBackward'] * (l/i)
+
+ if do_composite:
+ objFlow['tenForward'] = composite(objFlow['tenForward'], styleFlow['tenForward'])
+ objFlow['tenBackward'] = composite(objFlow['tenBackward'], styleFlow['tenBackward'])
+
+ img = self.netSynthesis(tenOne, tenTwo, objFlow['tenForward'], objFlow['tenBackward'], i/l)
+ tenImages.append(img)
+ i += 1
+
+ return [(tenImage * tenStd) + tenMean for tenImage in tenImages]
+
+
+# end
+
+netNetwork = None
+
+##########################################################
+
+def estimate2(img1: PIL.Image, img2:PIL.Image, guideFrames, model_file_path):
+ global netNetwork
+
+ if netNetwork is None:
+ netNetwork = Network2(model_file_path).cuda().eval()
+ # end
+
+ def forTensor(im):
+ return torch.FloatTensor(numpy.ascontiguousarray(numpy.array(im)[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ tenOne = forTensor(img1)
+ tenTwo = forTensor(img2)
+
+ tenGuideFrames=[]
+ for g in guideFrames:
+ tenGuideFrames.append(forTensor(g))
+
+ assert(tenOne.shape[1] == tenTwo.shape[1])
+ assert(tenOne.shape[2] == tenTwo.shape[2])
+
+ intWidth = tenOne.shape[2]
+ intHeight = tenOne.shape[1]
+
+ tenPreprocessedOne = tenOne.cuda().view(1, 3, intHeight, intWidth)
+ tenPreprocessedTwo = tenTwo.cuda().view(1, 3, intHeight, intWidth)
+ tenGuideFrames = [ ten.cuda().view(1, 3, intHeight, intWidth) for ten in tenGuideFrames]
+
+ intPadr = (2 - (intWidth % 2)) % 2
+ intPadb = (2 - (intHeight % 2)) % 2
+
+ tenPreprocessedOne = torch.nn.functional.pad(input=tenPreprocessedOne, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenPreprocessedTwo = torch.nn.functional.pad(input=tenPreprocessedTwo, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenGuideFrames = [ torch.nn.functional.pad(input=ten, pad=[0, intPadr, 0, intPadb], mode='replicate') for ten in tenGuideFrames]
+
+ result = [tenImage[0, :, :intHeight, :intWidth].cpu() for tenImage in netNetwork(tenPreprocessedOne, tenPreprocessedTwo, tenGuideFrames)]
+ result = [ PIL.Image.fromarray((r.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8)) for r in result]
+
+ return result
+# end
+
+##########################################################
+'''
+if __name__ == '__main__':
+ if arguments_strOut.split('.')[-1] in ['bmp', 'jpg', 'jpeg', 'png']:
+ tenOne = torch.FloatTensor(numpy.ascontiguousarray(numpy.array(PIL.Image.open(arguments_strOne))[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+ tenTwo = torch.FloatTensor(numpy.ascontiguousarray(numpy.array(PIL.Image.open(arguments_strTwo))[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ tenOutput = estimate(tenOne, tenTwo, [0.5])[0]
+
+ PIL.Image.fromarray((tenOutput.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8)).save(arguments_strOut)
+
+ elif arguments_strOut.split('.')[-1] in ['avi', 'mp4', 'webm', 'wmv']:
+ import moviepy
+ import moviepy.editor
+ import moviepy.video.io.ffmpeg_writer
+
+ objVideoreader = moviepy.editor.VideoFileClip(filename=arguments_strVideo)
+ objVideoreader2 = moviepy.editor.VideoFileClip(filename=arguments_strVideo2)
+
+ from moviepy.video.fx.resize import resize
+ objVideoreader2 = resize(objVideoreader2, (objVideoreader.w, objVideoreader.h))
+
+ intWidth = objVideoreader.w
+ intHeight = objVideoreader.h
+
+ tenFrames = [None, None, None, None]
+
+ with moviepy.video.io.ffmpeg_writer.FFMPEG_VideoWriter(filename=arguments_strOut, size=(intWidth, intHeight), fps=objVideoreader.fps) as objVideowriter:
+ for npyFrame in objVideoreader.iter_frames():
+ tenFrames[3] = torch.FloatTensor(numpy.ascontiguousarray(npyFrame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ if tenFrames[0] is not None:
+ tenFrames[1:3] = estimate(tenFrames[0], tenFrames[3], [0.333, 0.666])
+
+ objVideowriter.write_frame((tenFrames[0].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ objVideowriter.write_frame((tenFrames[1].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ objVideowriter.write_frame((tenFrames[2].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+# objVideowriter.write_frame((tenFrames[3].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ # end
+
+ tenFrames[0] = torch.FloatTensor(numpy.ascontiguousarray(npyFrame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+ # end
+ # end
+
+ # end
+# end
+'''
\ No newline at end of file
diff --git a/tools/softmax_splatting/softsplat.py b/tools/softmax_splatting/softsplat.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc50de3e400e92908a2bae60e6f1d3309383eeff
--- /dev/null
+++ b/tools/softmax_splatting/softsplat.py
@@ -0,0 +1,529 @@
+#!/usr/bin/env python
+
+import collections
+import cupy
+import os
+import re
+import torch
+import typing
+
+
+##########################################################
+
+
+objCudacache = {}
+
+
+def cuda_int32(intIn:int):
+ return cupy.int32(intIn)
+# end
+
+
+def cuda_float32(fltIn:float):
+ return cupy.float32(fltIn)
+# end
+
+
+def cuda_kernel(strFunction:str, strKernel:str, objVariables:typing.Dict):
+ if 'device' not in objCudacache:
+ objCudacache['device'] = torch.cuda.get_device_name()
+ # end
+
+ strKey = strFunction
+
+ for strVariable in objVariables:
+ objValue = objVariables[strVariable]
+
+ strKey += strVariable
+
+ if objValue is None:
+ continue
+
+ elif type(objValue) == int:
+ strKey += str(objValue)
+
+ elif type(objValue) == float:
+ strKey += str(objValue)
+
+ elif type(objValue) == bool:
+ strKey += str(objValue)
+
+ elif type(objValue) == str:
+ strKey += objValue
+
+ elif type(objValue) == torch.Tensor:
+ strKey += str(objValue.dtype)
+ strKey += str(objValue.shape)
+ strKey += str(objValue.stride())
+
+ elif True:
+ print(strVariable, type(objValue))
+ assert(False)
+
+ # end
+ # end
+
+ strKey += objCudacache['device']
+
+ if strKey not in objCudacache:
+ for strVariable in objVariables:
+ objValue = objVariables[strVariable]
+
+ if objValue is None:
+ continue
+
+ elif type(objValue) == int:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == float:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == bool:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == str:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', objValue)
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.uint8:
+ strKernel = strKernel.replace('{{type}}', 'unsigned char')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float16:
+ strKernel = strKernel.replace('{{type}}', 'half')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float32:
+ strKernel = strKernel.replace('{{type}}', 'float')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float64:
+ strKernel = strKernel.replace('{{type}}', 'double')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.int32:
+ strKernel = strKernel.replace('{{type}}', 'int')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.int64:
+ strKernel = strKernel.replace('{{type}}', 'long')
+
+ elif type(objValue) == torch.Tensor:
+ print(strVariable, objValue.dtype)
+ assert(False)
+
+ elif True:
+ print(strVariable, type(objValue))
+ assert(False)
+
+ # end
+ # end
+
+ while True:
+ objMatch = re.search('(SIZE_)([0-4])(\()([^\)]*)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArg = int(objMatch.group(2))
+
+ strTensor = objMatch.group(4)
+ intSizes = objVariables[strTensor].size()
+
+ strKernel = strKernel.replace(objMatch.group(), str(intSizes[intArg] if torch.is_tensor(intSizes[intArg]) == False else intSizes[intArg].item()))
+ # end
+
+ while True:
+ objMatch = re.search('(OFFSET_)([0-4])(\()', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intStart = objMatch.span()[1]
+ intStop = objMatch.span()[1]
+ intParentheses = 1
+
+ while True:
+ intParentheses += 1 if strKernel[intStop] == '(' else 0
+ intParentheses -= 1 if strKernel[intStop] == ')' else 0
+
+ if intParentheses == 0:
+ break
+ # end
+
+ intStop += 1
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = strKernel[intStart:intStop].split(',')
+
+ assert(intArgs == len(strArgs) - 1)
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+
+ strIndex = []
+
+ for intArg in range(intArgs):
+ strIndex.append('((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')')
+ # end
+
+ strKernel = strKernel.replace('OFFSET_' + str(intArgs) + '(' + strKernel[intStart:intStop] + ')', '(' + str.join('+', strIndex) + ')')
+ # end
+
+ while True:
+ objMatch = re.search('(VALUE_)([0-4])(\()', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intStart = objMatch.span()[1]
+ intStop = objMatch.span()[1]
+ intParentheses = 1
+
+ while True:
+ intParentheses += 1 if strKernel[intStop] == '(' else 0
+ intParentheses -= 1 if strKernel[intStop] == ')' else 0
+
+ if intParentheses == 0:
+ break
+ # end
+
+ intStop += 1
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = strKernel[intStart:intStop].split(',')
+
+ assert(intArgs == len(strArgs) - 1)
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+
+ strIndex = []
+
+ for intArg in range(intArgs):
+ strIndex.append('((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')')
+ # end
+
+ strKernel = strKernel.replace('VALUE_' + str(intArgs) + '(' + strKernel[intStart:intStop] + ')', strTensor + '[' + str.join('+', strIndex) + ']')
+ # end
+
+ objCudacache[strKey] = {
+ 'strFunction': strFunction,
+ 'strKernel': strKernel
+ }
+ # end
+
+ return strKey
+# end
+
+
+@cupy.memoize(for_each_device=True)
+def cuda_launch(strKey:str):
+ if 'CUDA_HOME' not in os.environ:
+ os.environ['CUDA_HOME'] = cupy.cuda.get_cuda_path()
+ # end
+
+ return cupy.cuda.compile_with_cache(objCudacache[strKey]['strKernel'], tuple(['-I ' + os.environ['CUDA_HOME'], '-I ' + os.environ['CUDA_HOME'] + '/include'])).get_function(objCudacache[strKey]['strFunction'])
+# end
+
+
+##########################################################
+
+
+def softsplat(tenIn:torch.Tensor, tenFlow:torch.Tensor, tenMetric:torch.Tensor, strMode:str):
+ assert(strMode.split('-')[0] in ['sum', 'avg', 'linear', 'soft'])
+
+ if strMode == 'sum': assert(tenMetric is None)
+ if strMode == 'avg': assert(tenMetric is None)
+ if strMode.split('-')[0] == 'linear': assert(tenMetric is not None)
+ if strMode.split('-')[0] == 'soft': assert(tenMetric is not None)
+
+ if strMode == 'avg':
+ tenIn = torch.cat([tenIn, tenIn.new_ones([tenIn.shape[0], 1, tenIn.shape[2], tenIn.shape[3]])], 1)
+
+ elif strMode.split('-')[0] == 'linear':
+ tenIn = torch.cat([tenIn * tenMetric, tenMetric], 1)
+
+ elif strMode.split('-')[0] == 'soft':
+ tenIn = torch.cat([tenIn * tenMetric.exp(), tenMetric.exp()], 1)
+
+ # end
+
+ tenOut = softsplat_func.apply(tenIn, tenFlow)
+
+ if strMode.split('-')[0] in ['avg', 'linear', 'soft']:
+ tenNormalize = tenOut[:, -1:, :, :]
+
+ if len(strMode.split('-')) == 1:
+ tenNormalize = tenNormalize + 0.0000001
+
+ elif strMode.split('-')[1] == 'addeps':
+ tenNormalize = tenNormalize + 0.0000001
+
+ elif strMode.split('-')[1] == 'zeroeps':
+ tenNormalize[tenNormalize == 0.0] = 1.0
+
+ elif strMode.split('-')[1] == 'clipeps':
+ tenNormalize = tenNormalize.clip(0.0000001, None)
+
+ # end
+
+ tenOut = tenOut[:, :-1, :, :] / tenNormalize
+ # end
+
+ return tenOut
+# end
+
+
+class softsplat_func(torch.autograd.Function):
+ @staticmethod
+ @torch.amp.custom_fwd(cast_inputs=torch.float32, device_type='cuda')
+ def forward(self, tenIn, tenFlow):
+ tenOut = tenIn.new_zeros([tenIn.shape[0], tenIn.shape[1], tenIn.shape[2], tenIn.shape[3]])
+
+ if tenIn.is_cuda == True:
+ cuda_launch(cuda_kernel('softsplat_out', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_out(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ {{type}}* __restrict__ tenOut
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenOut) / SIZE_2(tenOut) / SIZE_1(tenOut) ) % SIZE_0(tenOut);
+ const int intC = ( intIndex / SIZE_3(tenOut) / SIZE_2(tenOut) ) % SIZE_1(tenOut);
+ const int intY = ( intIndex / SIZE_3(tenOut) ) % SIZE_2(tenOut);
+ const int intX = ( intIndex ) % SIZE_3(tenOut);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ {{type}} fltIn = VALUE_4(tenIn, intN, intC, intY, intX);
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (intSoutheastY) - fltY);
+ {{type}} fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (intSouthwestY) - fltY);
+ {{type}} fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (fltY - ({{type}}) (intNortheastY));
+ {{type}} fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (fltY - ({{type}}) (intNorthwestY));
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOut)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intNorthwestY, intNorthwestX)], fltIn * fltNorthwest);
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOut)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intNortheastY, intNortheastX)], fltIn * fltNortheast);
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOut)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intSouthwestY, intSouthwestX)], fltIn * fltSouthwest);
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOut)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intSoutheastY, intSoutheastX)], fltIn * fltSoutheast);
+ }
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOut': tenOut
+ }))(
+ grid=tuple([int((tenOut.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenOut.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOut.data_ptr()],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+
+ elif tenIn.is_cuda != True:
+ assert(False)
+
+ # end
+
+ self.save_for_backward(tenIn, tenFlow)
+
+ return tenOut
+ # end
+
+ @staticmethod
+ @torch.cuda.amp.custom_bwd
+ def backward(self, tenOutgrad):
+ tenIn, tenFlow = self.saved_tensors
+
+ tenOutgrad = tenOutgrad.contiguous(); assert(tenOutgrad.is_cuda == True)
+
+ tenIngrad = tenIn.new_zeros([tenIn.shape[0], tenIn.shape[1], tenIn.shape[2], tenIn.shape[3]]) if self.needs_input_grad[0] == True else None
+ tenFlowgrad = tenFlow.new_zeros([tenFlow.shape[0], tenFlow.shape[1], tenFlow.shape[2], tenFlow.shape[3]]) if self.needs_input_grad[1] == True else None
+
+ if tenIngrad is not None:
+ cuda_launch(cuda_kernel('softsplat_ingrad', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_ingrad(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ const {{type}}* __restrict__ tenOutgrad,
+ {{type}}* __restrict__ tenIngrad,
+ {{type}}* __restrict__ tenFlowgrad
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenIngrad) / SIZE_2(tenIngrad) / SIZE_1(tenIngrad) ) % SIZE_0(tenIngrad);
+ const int intC = ( intIndex / SIZE_3(tenIngrad) / SIZE_2(tenIngrad) ) % SIZE_1(tenIngrad);
+ const int intY = ( intIndex / SIZE_3(tenIngrad) ) % SIZE_2(tenIngrad);
+ const int intX = ( intIndex ) % SIZE_3(tenIngrad);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltIngrad = 0.0f;
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (intSoutheastY) - fltY);
+ {{type}} fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (intSouthwestY) - fltY);
+ {{type}} fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (fltY - ({{type}}) (intNortheastY));
+ {{type}} fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (fltY - ({{type}}) (intNorthwestY));
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOutgrad)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intNorthwestY, intNorthwestX) * fltNorthwest;
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOutgrad)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intNortheastY, intNortheastX) * fltNortheast;
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOutgrad)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intSouthwestY, intSouthwestX) * fltSouthwest;
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOutgrad)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intSoutheastY, intSoutheastX) * fltSoutheast;
+ }
+
+ tenIngrad[intIndex] = fltIngrad;
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOutgrad': tenOutgrad,
+ 'tenIngrad': tenIngrad,
+ 'tenFlowgrad': tenFlowgrad
+ }))(
+ grid=tuple([int((tenIngrad.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenIngrad.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOutgrad.data_ptr(), tenIngrad.data_ptr(), None],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+ # end
+
+ if tenFlowgrad is not None:
+ cuda_launch(cuda_kernel('softsplat_flowgrad', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_flowgrad(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ const {{type}}* __restrict__ tenOutgrad,
+ {{type}}* __restrict__ tenIngrad,
+ {{type}}* __restrict__ tenFlowgrad
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenFlowgrad) / SIZE_2(tenFlowgrad) / SIZE_1(tenFlowgrad) ) % SIZE_0(tenFlowgrad);
+ const int intC = ( intIndex / SIZE_3(tenFlowgrad) / SIZE_2(tenFlowgrad) ) % SIZE_1(tenFlowgrad);
+ const int intY = ( intIndex / SIZE_3(tenFlowgrad) ) % SIZE_2(tenFlowgrad);
+ const int intX = ( intIndex ) % SIZE_3(tenFlowgrad);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltFlowgrad = 0.0f;
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = 0.0f;
+ {{type}} fltNortheast = 0.0f;
+ {{type}} fltSouthwest = 0.0f;
+ {{type}} fltSoutheast = 0.0f;
+
+ if (intC == 0) {
+ fltNorthwest = (({{type}}) (-1.0f)) * (({{type}}) (intSoutheastY) - fltY);
+ fltNortheast = (({{type}}) (+1.0f)) * (({{type}}) (intSouthwestY) - fltY);
+ fltSouthwest = (({{type}}) (-1.0f)) * (fltY - ({{type}}) (intNortheastY));
+ fltSoutheast = (({{type}}) (+1.0f)) * (fltY - ({{type}}) (intNorthwestY));
+
+ } else if (intC == 1) {
+ fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (-1.0f));
+ fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (-1.0f));
+ fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (({{type}}) (+1.0f));
+ fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (({{type}}) (+1.0f));
+
+ }
+
+ for (int intChannel = 0; intChannel < SIZE_1(tenOutgrad); intChannel += 1) {
+ {{type}} fltIn = VALUE_4(tenIn, intN, intChannel, intY, intX);
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOutgrad)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intNorthwestY, intNorthwestX) * fltIn * fltNorthwest;
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOutgrad)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intNortheastY, intNortheastX) * fltIn * fltNortheast;
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOutgrad)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intSouthwestY, intSouthwestX) * fltIn * fltSouthwest;
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOutgrad)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intSoutheastY, intSoutheastX) * fltIn * fltSoutheast;
+ }
+ }
+
+ tenFlowgrad[intIndex] = fltFlowgrad;
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOutgrad': tenOutgrad,
+ 'tenIngrad': tenIngrad,
+ 'tenFlowgrad': tenFlowgrad
+ }))(
+ grid=tuple([int((tenFlowgrad.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenFlowgrad.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOutgrad.data_ptr(), None, tenFlowgrad.data_ptr()],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+ # end
+
+ return tenIngrad, tenFlowgrad
+ # end
+# end
diff --git a/util.py b/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..be2796bafffdc1b061aaca654b2fb1b7770dea16
--- /dev/null
+++ b/util.py
@@ -0,0 +1,12 @@
+import requests
+import zipfile
+
+def download_file(url, save_path):
+ response = requests.get(url)
+
+ with open(save_path, 'wb') as f:
+ f.write(response.content)
+
+def unzip_file(zip_path, extract_to):
+ with zipfile.ZipFile(zip_path, 'r') as zip_ref:
+ zip_ref.extractall(extract_to)
\ No newline at end of file
diff --git a/vtdm/callbacks.py b/vtdm/callbacks.py
new file mode 100644
index 0000000000000000000000000000000000000000..b96c935056eda83697f4016bc66fef95af7c8dfa
--- /dev/null
+++ b/vtdm/callbacks.py
@@ -0,0 +1,277 @@
+import argparse, os, sys, datetime, glob, importlib, csv
+import numpy as np
+import time
+import torch
+import torchvision
+import pytorch_lightning as pl
+
+from omegaconf import OmegaConf
+from PIL import Image
+from torchvision.utils import make_grid
+from einops import rearrange
+from logging import Logger
+from typing import Callable, Optional
+
+from pytorch_lightning.callbacks import Callback
+from pytorch_lightning.utilities import rank_zero_only
+from pytorch_lightning.utilities import rank_zero_info
+
+from vtdm.util import tensor2vid, export_to_video
+
+
+class SetupCallback(Callback):
+ def __init__(self, resume, now, logdir, ckptdir, cfgdir, config, lightning_config):
+ super().__init__()
+ self.resume = resume
+ self.now = now
+ self.logdir = logdir
+ self.ckptdir = ckptdir
+ self.cfgdir = cfgdir
+ self.config = config
+ self.lightning_config = lightning_config
+
+ def on_keyboard_interrupt(self, trainer, pl_module):
+ if trainer.global_rank == 0:
+ print("Summoning checkpoint.")
+ ckpt_path = os.path.join(self.ckptdir, "last.ckpt")
+ trainer.save_checkpoint(ckpt_path)
+
+ def on_pretrain_routine_start(self, trainer, pl_module):
+ #def on_fit_start(self, trainer, pl_module):
+ if trainer.global_rank == 0:
+ # Create logdirs and save configs
+ os.makedirs(self.logdir, exist_ok=True)
+ os.makedirs(self.ckptdir, exist_ok=True)
+ os.makedirs(self.cfgdir, exist_ok=True)
+
+ if "callbacks" in self.lightning_config:
+ if 'metrics_over_trainsteps_checkpoint' in self.lightning_config['callbacks']:
+ os.makedirs(os.path.join(self.ckptdir, 'trainstep_checkpoints'), exist_ok=True)
+ print("Project config")
+ print(OmegaConf.to_yaml(self.config))
+ OmegaConf.save(self.config, os.path.join(self.cfgdir, "{}-project.yaml".format(self.now)))
+
+ print("Lightning config")
+ print(OmegaConf.to_yaml(self.lightning_config))
+ OmegaConf.save(OmegaConf.create({"lightning": self.lightning_config}), os.path.join(self.cfgdir, "{}-lightning.yaml".format(self.now)))
+
+ else:
+ # ModelCheckpoint callback created log directory --- remove it
+ if not self.resume and os.path.exists(self.logdir):
+ dst, name = os.path.split(self.logdir)
+ dst = os.path.join(dst, "child_runs", name)
+ os.makedirs(os.path.split(dst)[0], exist_ok=True)
+ # try:
+ # os.rename(self.logdir, dst)
+ # except FileNotFoundError:
+ # pass
+
+
+class ImageLogger(Callback):
+ def __init__(self, batch_frequency=2000, max_images=4, clamp=True, increase_log_steps=True,
+ rescale=True, disabled=False, log_on_batch_idx=False, log_first_step=False,
+ log_images_kwargs=None):
+ super().__init__()
+ self.rescale = rescale
+ self.batch_freq = batch_frequency
+ self.max_images = max_images
+ if not increase_log_steps:
+ self.log_steps = [self.batch_freq]
+ self.clamp = clamp
+ self.disabled = disabled
+ self.log_on_batch_idx = log_on_batch_idx
+ self.log_images_kwargs = log_images_kwargs if log_images_kwargs else {}
+ self.log_first_step = log_first_step
+
+ @rank_zero_only
+ def log_local(self, save_dir, split, images, global_step, current_epoch, batch_idx):
+ root = os.path.join(save_dir, "image_log", split)
+ for k in images:
+ filename = "{}_gs-{:06}_e-{:06}_b-{:06}".format(k, global_step, current_epoch, batch_idx)
+ path = os.path.join(root, filename)
+ os.makedirs(os.path.split(path)[0], exist_ok=True)
+
+ if 'video' in k: # log to video
+ export_to_video(images[k], path + '.mp4', save_to_gif=False, use_cv2=False, fps=6)
+ else:
+ grid = torchvision.utils.make_grid(images[k], nrow=4)
+ if self.rescale:
+ grid = (grid + 1.0) / 2.0 # -1,1 -> 0,1; c,h,w
+ grid = grid.transpose(0, 1).transpose(1, 2).squeeze(-1)
+ grid = grid.numpy()
+ grid = (grid * 255).astype(np.uint8)
+ Image.fromarray(grid).save(path + '.png')
+
+ def log_img(self, pl_module, batch, batch_idx, split="train"):
+ check_idx = batch_idx # if self.log_on_batch_idx else pl_module.global_step
+ if (self.check_frequency(check_idx) and # batch_idx % self.batch_freq == 0
+ hasattr(pl_module, "log_images") and
+ callable(pl_module.log_images) and
+ self.max_images > 0):
+ logger = type(pl_module.logger)
+
+ is_train = pl_module.training
+ if is_train:
+ pl_module.eval()
+
+ with torch.no_grad():
+ images = pl_module.log_images(batch, split=split, **self.log_images_kwargs)
+
+ for k in images:
+ if 'video' in k: # log to video
+ images[k] = tensor2vid(images[k])
+ else:
+ images[k] = images[k].to(dtype=torch.float32)
+ N = min(images[k].shape[0], self.max_images)
+ images[k] = images[k][:N]
+ if isinstance(images[k], torch.Tensor):
+ images[k] = images[k].detach().cpu()
+ if self.clamp:
+ images[k] = torch.clamp(images[k], -1., 1.)
+
+ self.log_local(pl_module.logger.save_dir, split, images,
+ pl_module.global_step, pl_module.current_epoch, batch_idx)
+
+ if is_train:
+ pl_module.train()
+
+ def check_frequency(self, check_idx):
+ return check_idx % self.batch_freq == 0
+
+ def on_train_batch_end(self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx):
+ if not self.disabled:
+ self.log_img(pl_module, batch, batch_idx, split="train")
+
+
+class CUDACallback(Callback):
+ # see https://github.com/SeanNaren/minGPT/blob/master/mingpt/callback.py
+ def on_train_epoch_start(self, trainer, pl_module):
+ # Reset the memory use counter
+ torch.cuda.reset_peak_memory_stats(trainer.root_gpu)
+ torch.cuda.synchronize(trainer.root_gpu)
+ self.start_time = time.time()
+
+ def on_train_epoch_end(self, trainer, pl_module):
+ torch.cuda.synchronize(trainer.root_gpu)
+ max_memory = torch.cuda.max_memory_allocated(trainer.root_gpu) / 2 ** 20
+ epoch_time = time.time() - self.start_time
+
+ try:
+ max_memory = trainer.training_type_plugin.reduce(max_memory)
+ epoch_time = trainer.training_type_plugin.reduce(epoch_time)
+
+ rank_zero_info(f"Average Epoch time: {epoch_time:.2f} seconds")
+ rank_zero_info(f"Average Peak memory {max_memory:.2f} MiB")
+ except AttributeError:
+ pass
+
+
+class TextProgressBar(pl.callbacks.ProgressBarBase):
+
+ """A custom ProgressBar to log the training progress."""
+
+ def __init__(self, logger: Logger, refresh_rate: int = 50) -> None:
+ super().__init__()
+ self._logger = logger
+ self._refresh_rate = refresh_rate
+ self._enabled = True
+
+ # a time flag to indicate the beginning of an epoch
+ self._time = 0
+
+ @property
+ def refresh_rate(self) -> int:
+ return self._refresh_rate
+
+ @property
+ def is_enabled(self) -> bool:
+ return self._enabled
+
+ @property
+ def is_disabled(self) -> bool:
+ return not self.is_enabled
+
+ def disable(self) -> None:
+ # No need to disable the ProgressBar on processes with LOCAL_RANK != 1, because the
+ # StreamHandler of logging is disabled on these processes.
+ self._enabled = True
+
+ def enable(self) -> None:
+ self._enabled = True
+
+ @staticmethod
+ def _serialize_metrics(progressbar_log_dict: dict, filter_fn: Optional[Callable[[str], bool]] = None) -> str:
+ if filter_fn:
+ progressbar_log_dict = {k: v for k, v in progressbar_log_dict.items() if filter_fn(k)}
+ msg = ''
+ for metric, value in progressbar_log_dict.items():
+ if type(value) is str:
+ msg += f'{metric}: {value:.5f} '
+ elif 'acc' in metric:
+ msg += f'{metric}: {value:.3%} '
+ else:
+ msg += f'{metric}: {value:f} '
+ return msg
+
+ def on_train_start(self, trainer, pl_module):
+ super().on_train_start(trainer, pl_module)
+
+ def on_train_epoch_start(self, trainer, pl_module):
+ super().on_train_epoch_start(trainer, pl_module)
+ self._logger.info(f'Epoch: {trainer.current_epoch}, batch_num: {self.total_train_batches}')
+ self._time = time.time()
+
+ def on_train_batch_end(self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx):
+ # super().on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx, dataloader_idx)
+ super().on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
+ current = self.train_batch_idx
+ if self._should_update(current, self.total_train_batches):
+ batch_time = (time.time() - self._time) / self.train_batch_idx
+ msg = f'[Epoch {trainer.current_epoch}] [Batch {self.train_batch_idx}/{self.total_train_batches} {batch_time:.2f} s/batch] => '
+ if current != self.total_train_batches:
+ filter_fn = lambda x: not x.startswith('val') and not x.startswith('test') and not x.startswith('global') and not x.endswith('_epoch')
+ else:
+ filter_fn = lambda x: not x.startswith('val') and not x.startswith('test') and not x.startswith('global')
+ msg += self._serialize_metrics(trainer.progress_bar_metrics, filter_fn=filter_fn)
+ self._logger.info(msg)
+
+ def on_train_end(self, trainer, pl_module):
+ super().on_train_end(trainer, pl_module)
+ self._logger.info(f'Training finished.')
+
+ def on_validation_start(self, trainer, pl_module):
+ super().on_validation_start(trainer, pl_module)
+ self._logger.info('Validation Begins. Epoch: {}, val batch num: {}'.format(trainer.current_epoch, self.total_val_batches))
+
+ def on_validation_batch_end(self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx):
+ super().on_validation_batch_end(trainer, pl_module, outputs, batch, batch_idx, dataloader_idx)
+ current = self.val_batch_idx
+ if self._should_update(current, self.total_val_batches):
+ batch_time = (time.time() - self._time) / self.val_batch_idx
+ msg = f'[Epoch {trainer.current_epoch}] [Val Batch {self.val_batch_idx}/{self.total_val_batches} {batch_time:.2f} s/batch] => '
+ if current != self.total_val_batches:
+ filter_fn = lambda x: x.startswith('val') and not x.endswith('_epoch')
+ else:
+ filter_fn = lambda x: x.startswith('val')
+ msg += self._serialize_metrics(trainer.progress_bar_metrics, filter_fn=filter_fn)
+ self._logger.info(msg)
+
+ def on_validation_end(self, trainer, pl_module):
+ super().on_validation_end(trainer, pl_module)
+ msg = f'[Epoch {trainer.current_epoch}] [Validation finished] => '
+ msg += self._serialize_metrics(trainer.progress_bar_metrics, filter_fn=lambda x: x.startswith('val') and x.endswith('_epoch'))
+ self._logger.info(msg)
+
+ def get_metrics(self, trainer, pl_module):
+ items = super().get_metrics(trainer, pl_module)
+ # don't show the version number
+ items.pop("v_num", None)
+ return items
+
+ def _should_update(self, current: int, total: int) -> bool:
+ return self.is_enabled and (current % self.refresh_rate == 0 or current == total)
+
+ def print(self, *args, sep: str = " ", **kwargs):
+ s = sep.join(map(str, args))
+ self._logger.info(f"[Progress Print] {s}")
+
diff --git a/vtdm/degraded_images.py b/vtdm/degraded_images.py
new file mode 100644
index 0000000000000000000000000000000000000000..457ad77afd26844302890b1f848a8a538f9b9670
--- /dev/null
+++ b/vtdm/degraded_images.py
@@ -0,0 +1,189 @@
+import os
+# os.environ["CUDA_VISIBLE_DEVICES"] = "4"
+import re
+import cv2
+import einops
+import numpy as np
+import torch
+import random
+import math
+from PIL import Image, ImageDraw, ImageFont
+import shutil
+import glob
+from tqdm import tqdm
+import subprocess as sp
+import argparse
+
+import imageio
+import sys
+import json
+import datetime
+import string
+from dataset.opencv_transforms.functional import to_tensor, center_crop
+
+from pytorch_lightning import seed_everything
+from sgm.util import append_dims
+from sgm.util import autocast, instantiate_from_config
+from vtdm.model import create_model, load_state_dict
+from vtdm.util import tensor2vid, export_to_video
+
+from einops import rearrange
+
+import yaml
+import numpy as np
+import random
+import torch
+from basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
+from basicsr.data.transforms import paired_random_crop
+from basicsr.models.sr_model import SRModel
+from basicsr.utils import DiffJPEG, USMSharp
+from basicsr.utils.img_process_util import filter2D
+from basicsr.utils.registry import MODEL_REGISTRY
+from torch.nn import functional as F
+import torch.nn as nn
+
+class DegradedImages(torch.nn.Module):
+ def __init__(self, freeze=True):
+ super().__init__()
+
+ with open('configs/train_realesrnet_x4plus.yml', mode='r') as f:
+ opt = yaml.load(f, Loader=yaml.FullLoader)
+ self.opt = opt
+
+ @autocast
+ @torch.no_grad()
+ def forward(self, images, videos, masks, kernel1s, kernel2s, sinc_kernels):
+ '''
+ images: (2, 3, 1024, 1024) [-1, 1]
+ videos: (2, 3, 16, 1024, 1024) [-1, 1]
+ masks: (2, 16, 1024, 1024)
+ kernel1s, kernel2s, sinc_kernels: (2, 16, 21, 21)
+ '''
+ self.jpeger = DiffJPEG(differentiable=False).cuda()
+ B, C, H, W = images.shape
+ ori_h, ori_w = videos.size()[3:5]
+ videos = videos / 2.0 + 0.5
+ videos = rearrange(videos, 'b c t h w -> b t c h w') #(2, 16, 3, 1024, 1024)
+
+ all_lqs = []
+
+ for i in range(B):
+ kernel1 = kernel1s[i]
+ kernel2 = kernel2s[i]
+ sinc_kernel = sinc_kernels[i]
+
+ gt = videos[i] # (16, 3, 1024, 1024)
+ mask = masks[i] # (16, 1024, 1024)
+
+ # ----------------------- The first degradation process ----------------------- #
+ # blur
+ out = filter2D(gt, kernel1)
+ # random resize
+ updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
+ if updown_type == 'up':
+ scale = np.random.uniform(1, self.opt['resize_range'][1])
+ elif updown_type == 'down':
+ scale = np.random.uniform(self.opt['resize_range'][0], 1)
+ else:
+ scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, scale_factor=scale, mode=mode)
+ # add noise
+ gray_noise_prob = self.opt['gray_noise_prob']
+ if np.random.uniform() < self.opt['gaussian_noise_prob']:
+ out = random_add_gaussian_noise_pt(
+ out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
+ else:
+ out = random_add_poisson_noise_pt(
+ out,
+ scale_range=self.opt['poisson_scale_range'],
+ gray_prob=gray_noise_prob,
+ clip=True,
+ rounds=False)
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
+ out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
+ out = self.jpeger(out, quality=jpeg_p)
+
+ # ----------------------- The second degradation process ----------------------- #
+ # blur
+ if np.random.uniform() < self.opt['second_blur_prob']:
+ out = filter2D(out, kernel2)
+ # random resize
+ updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
+ if updown_type == 'up':
+ scale = np.random.uniform(1, self.opt['resize_range2'][1])
+ elif updown_type == 'down':
+ scale = np.random.uniform(self.opt['resize_range2'][0], 1)
+ else:
+ scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(
+ out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
+ # add noise
+ gray_noise_prob = self.opt['gray_noise_prob2']
+ if np.random.uniform() < self.opt['gaussian_noise_prob2']:
+ out = random_add_gaussian_noise_pt(
+ out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
+ else:
+ out = random_add_poisson_noise_pt(
+ out,
+ scale_range=self.opt['poisson_scale_range2'],
+ gray_prob=gray_noise_prob,
+ clip=True,
+ rounds=False)
+
+ # JPEG compression + the final sinc filter
+ # We also need to resize images to desired sizes. We group [resize back + sinc filter] together
+ # as one operation.
+ # We consider two orders:
+ # 1. [resize back + sinc filter] + JPEG compression
+ # 2. JPEG compression + [resize back + sinc filter]
+ # Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
+ if np.random.uniform() < 0.5:
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
+ out = filter2D(out, sinc_kernel)
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
+ out = torch.clamp(out, 0, 1)
+ out = self.jpeger(out, quality=jpeg_p)
+ else:
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
+ out = torch.clamp(out, 0, 1)
+ out = self.jpeger(out, quality=jpeg_p)
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
+ out = filter2D(out, sinc_kernel)
+
+ # clamp and round
+ lqs = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ lqs = F.interpolate(lqs, size=(ori_h, ori_w), mode=mode) # 16,3,1024,1024
+
+ lqs = rearrange(lqs, 't c h w -> t h w c') # 16, 1024, 1024, 3
+ for j in range(16):
+ lqs[j][mask[j]==0] = 1.0
+ all_lqs.append(lqs)
+
+ # import cv2
+ # gt1 = gt[0]
+ # lq1 = lqs[0]
+ # gt1 = rearrange(gt1, 'c h w -> h w c')
+
+ # gt1 = (gt1.cpu().numpy() * 255.).astype('uint8')
+ # lq1 = (lq1.cpu().numpy() * 255.).astype('uint8')
+ # cv2.imwrite(f'gt{i}.png', gt1)
+ # cv2.imwrite(f'lq{i}.png', lq1)
+
+
+ all_lqs = [(f - 0.5) * 2.0 for f in all_lqs]
+ all_lqs = torch.stack(all_lqs, 0) # 2, 16, 1024, 1024, 3
+ all_lqs = rearrange(all_lqs, 'b t h w c -> b t c h w')
+ for i in range(B):
+ all_lqs[i][0] = images[i]
+ all_lqs = rearrange(all_lqs, 'b t c h w -> (b t) c h w')
+ return all_lqs
\ No newline at end of file
diff --git a/vtdm/encoders.py b/vtdm/encoders.py
new file mode 100644
index 0000000000000000000000000000000000000000..50309442dd55d11e51736fdfa60d7008a979e38a
--- /dev/null
+++ b/vtdm/encoders.py
@@ -0,0 +1,91 @@
+import torch
+from annotator.midas.api import MiDaSInference
+from einops import rearrange, repeat
+from sgm.modules.encoders.modules import AbstractEmbModel
+from tools.aes_score import MLP, normalized
+import clip
+from sgm.modules.diffusionmodules.util import timestep_embedding
+from sgm.util import autocast, instantiate_from_config
+from torchvision.models.optical_flow import raft_large
+from typing import Any, Dict, List, Tuple, Union
+from tools.softmax_splatting.softsplat import softsplat
+from vtdm.model import create_model, load_state_dict
+
+
+class DepthEmbedder(AbstractEmbModel):
+ def __init__(self, freeze=True, use_3d=False, shuffle_size=3, scale_factor=2.6666, sample_frames=25):
+ super().__init__()
+ self.model = MiDaSInference(model_type="dpt_hybrid", model_path="ckpts/dpt_hybrid_384.pt").cuda()
+ self.use_3d = use_3d
+ self.shuffle_size = shuffle_size
+ self.scale_factor = scale_factor
+ if freeze:
+ self.freeze()
+
+ def freeze(self):
+ self.model = self.model.eval()
+ for param in self.parameters():
+ param.requires_grad = False
+
+ @autocast
+ @torch.no_grad()
+ def forward(self, x):
+ if len(x.shape) == 4: # (16, 3, 512, 512)
+ x = rearrange(x, '(b t) c h w -> b c t h w', t=25)
+ B, C, T, H, W = x.shape # (1, 3, 16, 1024, 1024)
+
+ sH = int(H / self.scale_factor / 32) * 32
+ sW = int(W / self.scale_factor / 32) * 32
+
+ y = rearrange(x, 'b c t h w -> (b t) c h w')
+ y = torch.nn.functional.interpolate(y, [sH, sW], mode='bilinear')
+ # y = torch.nn.functional.interpolate(y, [576, 1024], mode='bilinear')
+
+ y = self.model(y)
+ y = rearrange(y, 'b h w -> b 1 h w')
+ y = torch.nn.functional.interpolate(y, [H // 8 * self.shuffle_size, W // 8 * self.shuffle_size], mode='bilinear')
+ for i in range(y.shape[0]):
+ y[i] -= torch.min(y[i])
+ y[i] /= max(torch.max(y[i]).item(), 1e-6)
+ y = rearrange(y, 'b c (h h0) (w w0) -> b (c h0 w0) h w', h0=self.shuffle_size, w0=self.shuffle_size)
+ if self.use_3d:
+ y = rearrange(y, '(b t) c h w -> b c t h w', t=T)
+ return y
+
+
+class AesEmbedder(AbstractEmbModel):
+ def __init__(self, freeze=True):
+ super().__init__()
+ aesthetic_model, _ = clip.load("ckpts/ViT-L-14.pt")
+ del aesthetic_model.transformer
+ self.aesthetic_model = aesthetic_model
+ self.aesthetic_mlp = MLP(768)
+ self.aesthetic_mlp.load_state_dict(torch.load("ckpts/metric_models/sac+logos+ava1-l14-linearMSE.pth"))
+
+ if freeze:
+ self.freeze()
+
+ def freeze(self):
+ self.aesthetic_model = self.aesthetic_model.eval()
+ self.aesthetic_mlp = self.aesthetic_mlp.eval()
+ for param in self.parameters():
+ param.requires_grad = False
+
+ @autocast
+ @torch.no_grad()
+ def forward(self, x):
+ B, C, T, H, W = x.shape
+
+ y = x[:, :, T//2]
+ y = torch.nn.functional.interpolate(y, [224, 384], mode='bilinear')
+ y = y[:, :, :, 80:304]
+ y = (y + 1) * 0.5
+ y[:, 0] = (y[:, 0] - 0.48145466) / 0.26862954
+ y[:, 1] = (y[:, 1] - 0.4578275) / 0.26130258
+ y[:, 2] = (y[:, 2] - 0.40821073) / 0.27577711
+
+ image_features = self.aesthetic_model.encode_image(y)
+ im_emb_arr = normalized(image_features.cpu().detach().numpy())
+ aesthetic = self.aesthetic_mlp(torch.from_numpy(im_emb_arr).to('cuda').type(torch.cuda.FloatTensor))
+
+ return torch.cat([aesthetic, timestep_embedding(aesthetic[:, 0] * 100, 255)], 1)
\ No newline at end of file
diff --git a/vtdm/hack.py b/vtdm/hack.py
new file mode 100644
index 0000000000000000000000000000000000000000..b677ac2b9bc006160b5fe6c7e818745b0f25d34e
--- /dev/null
+++ b/vtdm/hack.py
@@ -0,0 +1,111 @@
+import torch
+import einops
+
+import sgm.modules.encoders.modules
+import sgm.modules.attention
+
+from transformers import logging
+from sgm.modules.attention import default
+
+
+def disable_verbosity():
+ logging.set_verbosity_error()
+ print('logging improved.')
+ return
+
+
+def enable_sliced_attention():
+ ldm.modules.attention.CrossAttention.forward = _hacked_sliced_attentin_forward
+ print('Enabled sliced_attention.')
+ return
+
+
+def hack_everything(clip_skip=0):
+ disable_verbosity()
+ ldm.modules.encoders.modules.FrozenCLIPEmbedder.forward = _hacked_clip_forward
+ ldm.modules.encoders.modules.FrozenCLIPEmbedder.clip_skip = clip_skip
+ print('Enabled clip hacks.')
+ return
+
+
+# Written by Lvmin
+def _hacked_clip_forward(self, text):
+ PAD = self.tokenizer.pad_token_id
+ EOS = self.tokenizer.eos_token_id
+ BOS = self.tokenizer.bos_token_id
+
+ def tokenize(t):
+ return self.tokenizer(t, truncation=False, add_special_tokens=False)["input_ids"]
+
+ def transformer_encode(t):
+ if self.clip_skip > 1:
+ rt = self.transformer(input_ids=t, output_hidden_states=True)
+ return self.transformer.text_model.final_layer_norm(rt.hidden_states[-self.clip_skip])
+ else:
+ return self.transformer(input_ids=t, output_hidden_states=False).last_hidden_state
+
+ def split(x):
+ return x[75 * 0: 75 * 1], x[75 * 1: 75 * 2], x[75 * 2: 75 * 3]
+
+ def pad(x, p, i):
+ return x[:i] if len(x) >= i else x + [p] * (i - len(x))
+
+ raw_tokens_list = tokenize(text)
+ tokens_list = []
+
+ for raw_tokens in raw_tokens_list:
+ raw_tokens_123 = split(raw_tokens)
+ raw_tokens_123 = [[BOS] + raw_tokens_i + [EOS] for raw_tokens_i in raw_tokens_123]
+ raw_tokens_123 = [pad(raw_tokens_i, PAD, 77) for raw_tokens_i in raw_tokens_123]
+ tokens_list.append(raw_tokens_123)
+
+ tokens_list = torch.IntTensor(tokens_list).to(self.device)
+
+ feed = einops.rearrange(tokens_list, 'b f i -> (b f) i')
+ y = transformer_encode(feed)
+ z = einops.rearrange(y, '(b f) i c -> b (f i) c', f=3)
+
+ return z
+
+
+# Stolen from https://github.com/basujindal/stable-diffusion/blob/main/optimizedSD/splitAttention.py
+def _hacked_sliced_attentin_forward(self, x, context=None, mask=None):
+ h = self.heads
+
+ q = self.to_q(x)
+ context = default(context, x)
+ k = self.to_k(context)
+ v = self.to_v(context)
+ del context, x
+
+ q, k, v = map(lambda t: einops.rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
+
+ limit = k.shape[0]
+ att_step = 1
+ q_chunks = list(torch.tensor_split(q, limit // att_step, dim=0))
+ k_chunks = list(torch.tensor_split(k, limit // att_step, dim=0))
+ v_chunks = list(torch.tensor_split(v, limit // att_step, dim=0))
+
+ q_chunks.reverse()
+ k_chunks.reverse()
+ v_chunks.reverse()
+ sim = torch.zeros(q.shape[0], q.shape[1], v.shape[2], device=q.device)
+ del k, q, v
+ for i in range(0, limit, att_step):
+ q_buffer = q_chunks.pop()
+ k_buffer = k_chunks.pop()
+ v_buffer = v_chunks.pop()
+ sim_buffer = torch.einsum('b i d, b j d -> b i j', q_buffer, k_buffer) * self.scale
+
+ del k_buffer, q_buffer
+ # attention, what we cannot get enough of, by chunks
+
+ sim_buffer = sim_buffer.softmax(dim=-1)
+
+ sim_buffer = torch.einsum('b i j, b j d -> b i d', sim_buffer, v_buffer)
+ del v_buffer
+ sim[i:i + att_step, :, :] = sim_buffer
+
+ del sim_buffer
+ sim = einops.rearrange(sim, '(b h) n d -> b n (h d)', h=h)
+ return self.to_out(sim)
diff --git a/vtdm/logger.py b/vtdm/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..74eddd725c73339c4c8e9361fe0f8d2687bfbb3a
--- /dev/null
+++ b/vtdm/logger.py
@@ -0,0 +1,83 @@
+import functools
+import logging
+import os
+import sys
+from termcolor import colored
+
+
+class _ColorfulFormatter(logging.Formatter):
+ def __init__(self, *args, **kwargs):
+ self._root_name = kwargs.pop("root_name") + "."
+ self._abbrev_name = kwargs.pop("abbrev_name", "")
+ if len(self._abbrev_name):
+ self._abbrev_name = self._abbrev_name + "."
+ super(_ColorfulFormatter, self).__init__(*args, **kwargs)
+
+ def formatMessage(self, record):
+ record.name = record.name.replace(self._root_name, self._abbrev_name)
+ log = super(_ColorfulFormatter, self).formatMessage(record)
+ if record.levelno == logging.WARNING:
+ prefix = colored("WARNING", "red", attrs=["blink"])
+ elif record.levelno == logging.ERROR or record.levelno == logging.CRITICAL:
+ prefix = colored("ERROR", "red", attrs=["blink", "underline"])
+ else:
+ return log
+ return prefix + " " + log
+
+
+# so that calling setup_logger multiple times won't add many handlers
+@functools.lru_cache()
+def setup_logger(
+ output=None, distributed_rank=0, *, color=True, name="video-diffusion", abbrev_name=None
+):
+ logger = logging.getLogger(name)
+ logger.setLevel(logging.DEBUG)
+ logger.propagate = False
+
+ if abbrev_name is None:
+ abbrev_name = name
+
+ plain_formatter = logging.Formatter(
+ "[%(asctime)s] %(name)s %(levelname)s: %(message)s", datefmt="%m/%d %H:%M:%S"
+ )
+ # stdout logging: master only
+ if distributed_rank == 0:
+ ch = logging.StreamHandler(stream=sys.stdout)
+ ch.setLevel(logging.DEBUG)
+ if color:
+ formatter = _ColorfulFormatter(
+ colored("[%(asctime)s %(name)s]: ", "green") + "%(message)s",
+ datefmt="%m/%d %H:%M:%S",
+ root_name=name,
+ abbrev_name=str(abbrev_name),
+ )
+ else:
+ formatter = plain_formatter
+ ch.setFormatter(formatter)
+ logger.addHandler(ch)
+
+ # file logging: all workers
+ if output is not None:
+ if output.endswith(".txt") or output.endswith(".log"):
+ filename = output
+ else:
+ filename = os.path.join(output, "log.txt")
+
+ #if distributed_rank > 0:
+ # filename = filename + ".rank{}".format(distributed_rank)
+ #os.makedirs(os.path.dirname(filename), exist_ok=True)
+
+ fh = logging.StreamHandler(_cached_log_stream(filename))
+ fh.setLevel(logging.DEBUG)
+ fh.setFormatter(plain_formatter)
+ logger.addHandler(fh)
+
+ return logger
+
+
+# cache the opened file object, so that different calls to `setup_logger`
+# with the same file name can safely write to the same file.
+@functools.lru_cache(maxsize=None)
+def _cached_log_stream(filename):
+ return open(filename, "a")
+
diff --git a/vtdm/model.py b/vtdm/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..90c9e8faf10ba714d72e3d4cebeff3679838dda5
--- /dev/null
+++ b/vtdm/model.py
@@ -0,0 +1,28 @@
+import os
+import torch
+
+from omegaconf import OmegaConf
+from sgm.util import instantiate_from_config
+
+
+def get_state_dict(d):
+ return d.get('state_dict', d)
+
+
+def load_state_dict(ckpt_path, location='cpu'):
+ _, extension = os.path.splitext(ckpt_path)
+ if extension.lower() == ".safetensors":
+ import safetensors.torch
+ state_dict = safetensors.torch.load_file(ckpt_path, device=location)
+ else:
+ state_dict = get_state_dict(torch.load(ckpt_path, map_location=torch.device(location)))
+ state_dict = get_state_dict(state_dict)
+ print(f'Loaded state_dict from [{ckpt_path}]')
+ return state_dict
+
+
+def create_model(config_path):
+ config = OmegaConf.load(config_path)
+ model = instantiate_from_config(config.model).cpu()
+ print(f'Loaded model config from [{config_path}]')
+ return model
diff --git a/vtdm/util.py b/vtdm/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..1dd4df5ead20decf46a207d7f7a5524454e3aceb
--- /dev/null
+++ b/vtdm/util.py
@@ -0,0 +1,50 @@
+import torch
+import cv2
+import numpy as np
+import imageio
+import torchvision
+import math
+
+from einops import rearrange
+from typing import List
+
+from PIL import Image, ImageDraw, ImageFont
+
+def tensor2vid(video: torch.Tensor, mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) -> List[np.ndarray]:
+ mean = torch.tensor(mean, device=video.device).reshape(1, -1, 1, 1, 1) # ncfhw
+ std = torch.tensor(std, device=video.device).reshape(1, -1, 1, 1, 1) # ncfhw
+ video = video.mul_(std).add_(mean) # unnormalize back to [0,1]
+ video.clamp_(0, 1)
+ images = rearrange(video, 'i c f h w -> (i f) h w c')
+ images = images.unbind(dim=0)
+ images = [(image.cpu().numpy() * 255).astype('uint8') for image in images] # f h w c
+ return images
+
+
+def export_to_video(video_frames: List[np.ndarray], output_video_path: str = None, save_to_gif=False, use_cv2=True, fps=8) -> str:
+ h, w, c = video_frames[0].shape
+ if save_to_gif:
+ image_lst = []
+ if output_video_path.endswith('mp4'):
+ output_video_path = output_video_path[:-3] + 'gif'
+ for i in range(len(video_frames)):
+ image_lst.append(video_frames[i])
+ imageio.mimsave(output_video_path, image_lst, fps=fps)
+ return output_video_path
+ else:
+ if use_cv2:
+ fourcc = cv2.VideoWriter_fourcc(*"mp4v")
+ video_writer = cv2.VideoWriter(output_video_path, fourcc, fps=fps, frameSize=(w, h))
+ for i in range(len(video_frames)):
+ img = cv2.cvtColor(video_frames[i], cv2.COLOR_RGB2BGR)
+ video_writer.write(img)
+ video_writer.release()
+ else:
+ duration = math.ceil(len(video_frames) / fps)
+ append_num = duration * fps - len(video_frames)
+ for k in range(append_num): video_frames.append(video_frames[-1])
+ video_stack = np.stack(video_frames, axis=0)
+ video_tensor = torch.from_numpy(video_stack)
+ # torchvision.io.write_video(output_video_path, video_tensor, fps=fps, options={"crf": "17"})
+ torchvision.io.write_video(output_video_path, video_tensor, fps=fps, options={"crf": "17"})
+ return output_video_path
\ No newline at end of file
diff --git a/vtdm/vtdm_gen_stage2_degradeImage.py b/vtdm/vtdm_gen_stage2_degradeImage.py
new file mode 100644
index 0000000000000000000000000000000000000000..dd7269e23f34dd70951cf4b15dd42f6dc01fbf96
--- /dev/null
+++ b/vtdm/vtdm_gen_stage2_degradeImage.py
@@ -0,0 +1,213 @@
+import einops
+import torch
+import torch as th
+import torch.nn as nn
+import os
+from typing import Any, Dict, List, Tuple, Union
+
+from sgm.modules.diffusionmodules.util import (
+ conv_nd,
+ linear,
+ zero_module,
+ timestep_embedding,
+)
+
+from einops import rearrange, repeat
+from torchvision.utils import make_grid
+from sgm.modules.attention import SpatialTransformer
+from sgm.modules.diffusionmodules.openaimodel import UNetModel, TimestepEmbedSequential, Downsample, ResBlock, AttentionBlock
+from sgm.models.diffusion import DiffusionEngine
+from sgm.util import log_txt_as_img, exists, instantiate_from_config
+from safetensors.torch import load_file as load_safetensors
+from .model import load_state_dict
+from .degraded_images import DegradedImages
+
+class VideoLDM(DiffusionEngine):
+ def __init__(self, num_samples, trained_param_keys=[''], *args, **kwargs):
+ self.trained_param_keys = trained_param_keys
+ super().__init__(*args, **kwargs)
+ self.num_samples = num_samples
+
+ # self.warp_model = FirstFrameFlowWarper(freeze=True)
+ self.warp_model = DegradedImages(freeze=True)
+ # self.warp_model = FirstFrameFlowWarper(freeze=True)
+
+ def init_from_ckpt(
+ self,
+ path: str,
+ ) -> None:
+ if path.endswith("ckpt"):
+ sd = torch.load(path, map_location="cpu")
+ if "state_dict" in sd:
+ sd = sd["state_dict"]
+ elif path.endswith("pt"):
+ sd_raw = torch.load(path, map_location="cpu")
+ sd = {}
+ for k in sd_raw['module']:
+ sd[k[len('module.'):]] = sd_raw['module'][k]
+ elif path.endswith("safetensors"):
+ sd = load_safetensors(path)
+ else:
+ raise NotImplementedError
+
+ missing, unexpected = self.load_state_dict(sd, strict=False)
+ print(
+ f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys"
+ )
+ if len(missing) > 0:
+ print(f"Missing Keys: {missing}")
+ if len(unexpected) > 0:
+ print(f"Unexpected Keys: {unexpected}")
+
+ @torch.no_grad()
+ def add_custom_cond(self, batch, infer=False):
+ batch['num_video_frames'] = self.num_samples
+
+ image = batch['video'][:, :, 0] # (1, 3, 16, 1024, 1024)
+ batch['cond_frames_without_noise'] = image.half()
+
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ if not infer:
+ video_warp = self.warp_model(image, batch['video'], batch['masks'], batch['kernel1s'], batch['kernel2s'], batch['sinc_kernels']) # (16, 3, 512, 512)
+ else:
+ video_warp = rearrange(batch['video'], 'b c t h w -> (b t) c h w')
+
+ N = batch['video'].shape[0]
+ if not infer:
+ cond_aug = ((-3.0) + (0.5) * torch.randn((N,))).exp().cuda().half()
+ else:
+ cond_aug = torch.full((N, ), 0.02).cuda().half()
+ batch['cond_aug'] = cond_aug
+ batch['cond_frames'] = (video_warp + rearrange(repeat(cond_aug, "b -> (b t)", t=self.num_samples), 'b -> b 1 1 1') * torch.randn_like(video_warp)).half()
+
+ # for dataset without indicator
+ if not 'image_only_indicator' in batch:
+ batch['image_only_indicator'] = torch.zeros((N, self.num_samples)).cuda().half()
+ return batch
+
+ def shared_step(self, batch: Dict) -> Any:
+ frames = self.get_input(batch) # b c t h w
+ batch = self.add_custom_cond(batch)
+
+ frames_reshape = rearrange(frames, 'b c t h w -> (b t) c h w')
+ x = self.encode_first_stage(frames_reshape)
+
+ batch["global_step"] = self.global_step
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ loss, loss_dict = self(x, batch)
+ return loss, loss_dict
+
+ @torch.no_grad()
+ def log_images(
+ self,
+ batch: Dict,
+ N: int = 8,
+ sample: bool = True,
+ ucg_keys: List[str] = None,
+ **kwargs,
+ ) -> Dict:
+ conditioner_input_keys = [e.input_key for e in self.conditioner.embedders]
+ if ucg_keys:
+ assert all(map(lambda x: x in conditioner_input_keys, ucg_keys)), (
+ "Each defined ucg key for sampling must be in the provided conditioner input keys,"
+ f"but we have {ucg_keys} vs. {conditioner_input_keys}"
+ )
+ else:
+ ucg_keys = conditioner_input_keys
+ log = dict()
+
+ frames = self.get_input(batch)
+ batch = self.add_custom_cond(batch, infer=False)
+ N = min(frames.shape[0], N)
+ frames = frames[:N]
+ x = rearrange(frames, 'b c t h w -> (b t) c h w')
+
+ c, uc = self.conditioner.get_unconditional_conditioning(
+ batch,
+ force_uc_zero_embeddings=ucg_keys
+ if len(self.conditioner.embedders) > 0
+ else [],
+ )
+
+ sampling_kwargs = {}
+
+ aes = c['vector'][:, -256-256]
+ caption = batch['caption'][:N]
+ for idx in range(N):
+ sub_str = str(aes[idx].item())
+ caption[idx] = sub_str + '\n' + caption[idx]
+
+ x = x.to(self.device)
+
+ z = self.encode_first_stage(x.half())
+ x_rec = self.decode_first_stage(z.half())
+ log["reconstructions-video"] = rearrange(x_rec, '(b t) c h w -> b c t h w', t=self.num_samples)
+ log["conditioning"] = log_txt_as_img((512, 512), caption, size=16)
+ x_d = c['concat'][:, :9] # (16, 9, 64, 64) (0-1)
+ x_d = rearrange(x_d, 'b (c h0 w0) h w -> b c (h h0) (w w0)', h0=3, w0=3)
+ log["depth-video"] = rearrange(x_d.repeat([1, 3, 1, 1]) * 2.0 - 1.0, '(b t) c h w -> b c t h w', t=self.num_samples)
+
+ x_cond = self.decode_first_stage(c['concat'][:, 9:].half() * self.scale_factor)
+ log["cond-video"] = rearrange(x_cond, '(b t) c h w -> b c t h w', t=self.num_samples)
+
+ for k in c:
+ if isinstance(c[k], torch.Tensor):
+ if k == 'concat':
+ c[k], uc[k] = map(lambda y: y[k][:N * self.num_samples].to(self.device), (c, uc))
+ else:
+ c[k], uc[k] = map(lambda y: y[k][:N].to(self.device), (c, uc))
+
+ additional_model_inputs = {}
+ additional_model_inputs["image_only_indicator"] = torch.zeros(
+ N * 2, self.num_samples
+ ).to(self.device)
+ additional_model_inputs["num_video_frames"] = batch["num_video_frames"]
+ def denoiser(input, sigma, c):
+ return self.denoiser(
+ self.model, input, sigma, c, **additional_model_inputs
+ )
+
+ if sample:
+ with self.ema_scope("Plotting"):
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ randn = torch.randn(z.shape, device=self.device)
+ samples = self.sampler(denoiser, randn, cond=c, uc=uc)
+ samples = self.decode_first_stage(samples.half())
+ log["samples-video"] = rearrange(samples, '(b t) c h w -> b c t h w', t=self.num_samples)
+ return log
+
+ def configure_optimizers(self):
+ lr = self.learning_rate
+ if 'all' in self.trained_param_keys:
+ params = list(self.model.parameters())
+ else:
+ names = []
+ params = []
+ for name, param in self.model.named_parameters():
+ flag = False
+ for k in self.trained_param_keys:
+ if k in name:
+ names += [name]
+ params += [param]
+ flag = True
+ if flag:
+ break
+ print(names)
+
+ for embedder in self.conditioner.embedders:
+ if embedder.is_trainable:
+ params = params + list(embedder.parameters())
+
+ opt = self.instantiate_optimizer_from_config(params, lr, self.optimizer_config)
+ if self.scheduler_config is not None:
+ scheduler = instantiate_from_config(self.scheduler_config)
+ print("Setting up LambdaLR scheduler...")
+ scheduler = [
+ {
+ "scheduler": LambdaLR(opt, lr_lambda=scheduler.schedule),
+ "interval": "step",
+ "frequency": 1,
+ }
+ ]
+ return [opt], scheduler
+ return opt
diff --git a/vtdm/vtdm_gen_v01.py b/vtdm/vtdm_gen_v01.py
new file mode 100644
index 0000000000000000000000000000000000000000..8df31aee493138ddbe25bd9b9a171d355c60638b
--- /dev/null
+++ b/vtdm/vtdm_gen_v01.py
@@ -0,0 +1,201 @@
+import einops
+import torch
+import torch as th
+import torch.nn as nn
+import os
+from typing import Any, Dict, List, Tuple, Union
+
+from sgm.modules.diffusionmodules.util import (
+ conv_nd,
+ linear,
+ zero_module,
+ timestep_embedding,
+)
+
+from einops import rearrange, repeat
+from torchvision.utils import make_grid
+from sgm.modules.attention import SpatialTransformer
+from sgm.modules.diffusionmodules.openaimodel import UNetModel, TimestepEmbedSequential, Downsample, ResBlock, AttentionBlock
+from sgm.models.diffusion import DiffusionEngine
+from sgm.util import log_txt_as_img, exists, instantiate_from_config
+from safetensors.torch import load_file as load_safetensors
+from .model import load_state_dict
+
+class VideoLDM(DiffusionEngine):
+ def __init__(self, num_samples, trained_param_keys=[''], *args, **kwargs):
+ self.trained_param_keys = trained_param_keys
+ super().__init__(*args, **kwargs)
+ self.num_samples = num_samples
+
+ def init_from_ckpt(
+ self,
+ path: str,
+ ) -> None:
+ if path.endswith("ckpt"):
+ sd = torch.load(path, map_location="cpu")
+ if "state_dict" in sd:
+ sd = sd["state_dict"]
+ elif path.endswith("pt"):
+ sd_raw = torch.load(path, map_location="cpu")
+ sd = {}
+ for k in sd_raw['module']:
+ sd[k[len('module.'):]] = sd_raw['module'][k]
+ elif path.endswith("safetensors"):
+ sd = load_safetensors(path)
+ else:
+ raise NotImplementedError
+
+ # missing, unexpected = self.load_state_dict(sd, strict=True)
+ missing, unexpected = self.load_state_dict(sd, strict=False)
+ print(
+ f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys"
+ )
+ if len(missing) > 0:
+ print(f"Missing Keys: {missing}")
+ if len(unexpected) > 0:
+ print(f"Unexpected Keys: {unexpected}")
+
+ @torch.no_grad()
+ def add_custom_cond(self, batch, infer=False):
+ batch['num_video_frames'] = self.num_samples
+
+ image = batch['video'][:, :, 0]
+ batch['cond_frames_without_noise'] = image.half()
+
+ N = batch['video'].shape[0]
+ if not infer:
+ cond_aug = ((-3.0) + (0.5) * torch.randn((N,))).exp().cuda().half()
+ else:
+ cond_aug = torch.full((N, ), 0.02).cuda().half()
+ batch['cond_aug'] = cond_aug
+ batch['cond_frames'] = (image + rearrange(cond_aug, 'b -> b 1 1 1') * torch.randn_like(image)).half()
+
+ # for dataset without indicator
+ if not 'image_only_indicator' in batch:
+ batch['image_only_indicator'] = torch.zeros((N, self.num_samples)).cuda().half()
+ return batch
+
+ def shared_step(self, batch: Dict) -> Any:
+ frames = self.get_input(batch) # b c t h w
+ batch = self.add_custom_cond(batch)
+
+ frames_reshape = rearrange(frames, 'b c t h w -> (b t) c h w')
+ x = self.encode_first_stage(frames_reshape)
+
+ batch["global_step"] = self.global_step
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ loss, loss_dict = self(x, batch)
+ return loss, loss_dict
+
+ @torch.no_grad()
+ def log_images(
+ self,
+ batch: Dict,
+ N: int = 8,
+ sample: bool = True,
+ ucg_keys: List[str] = None,
+ **kwargs,
+ ) -> Dict:
+ conditioner_input_keys = [e.input_key for e in self.conditioner.embedders]
+ if ucg_keys:
+ assert all(map(lambda x: x in conditioner_input_keys, ucg_keys)), (
+ "Each defined ucg key for sampling must be in the provided conditioner input keys,"
+ f"but we have {ucg_keys} vs. {conditioner_input_keys}"
+ )
+ else:
+ ucg_keys = conditioner_input_keys
+ log = dict()
+
+ frames = self.get_input(batch)
+ batch = self.add_custom_cond(batch, infer=True)
+ N = min(frames.shape[0], N)
+ frames = frames[:N]
+ x = rearrange(frames, 'b c t h w -> (b t) c h w')
+
+ c, uc = self.conditioner.get_unconditional_conditioning(
+ batch,
+ force_uc_zero_embeddings=ucg_keys
+ if len(self.conditioner.embedders) > 0
+ else [],
+ )
+
+ sampling_kwargs = {}
+
+ aes = c['vector'][:, -256-256-256]
+ cm1 = c['vector'][:, -256-256]
+ cm2 = c['vector'][:, -256-192]
+ cm3 = c['vector'][:, -256-128]
+ cm4 = c['vector'][:, -256-64]
+ caption = batch['caption'][:N]
+ for idx in range(N):
+ sub_str = str(aes[idx].item()) + '\n' + str(cm1[idx].item()) + '\n' + str(cm2[idx].item()) + '\n' + str(cm3[idx].item()) + '\n' + str(cm4[idx].item())
+ caption[idx] = sub_str + '\n' + caption[idx]
+
+ x = x.to(self.device)
+
+ z = self.encode_first_stage(x.half())
+ x_rec = self.decode_first_stage(z.half())
+ log["reconstructions-video"] = rearrange(x_rec, '(b t) c h w -> b c t h w', t=self.num_samples)
+ log["conditioning"] = log_txt_as_img((512, 512), caption, size=16)
+
+ for k in c:
+ if isinstance(c[k], torch.Tensor):
+ if k == 'concat':
+ c[k], uc[k] = map(lambda y: y[k][:N * self.num_samples].to(self.device), (c, uc))
+ else:
+ c[k], uc[k] = map(lambda y: y[k][:N].to(self.device), (c, uc))
+
+ additional_model_inputs = {}
+ additional_model_inputs["image_only_indicator"] = torch.zeros(
+ N * 2, self.num_samples
+ ).to(self.device)
+ additional_model_inputs["num_video_frames"] = batch["num_video_frames"]
+ def denoiser(input, sigma, c):
+ return self.denoiser(
+ self.model, input, sigma, c, **additional_model_inputs
+ )
+
+ if sample:
+ with self.ema_scope("Plotting"):
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ randn = torch.randn(z.shape, device=self.device)
+ samples = self.sampler(denoiser, randn, cond=c, uc=uc)
+ samples = self.decode_first_stage(samples.half())
+ log["samples-video"] = rearrange(samples, '(b t) c h w -> b c t h w', t=self.num_samples)
+ return log
+
+ def configure_optimizers(self):
+ lr = self.learning_rate
+ if 'all' in self.trained_param_keys:
+ params = list(self.model.parameters())
+ else:
+ names = []
+ params = []
+ for name, param in self.model.named_parameters():
+ flag = False
+ for k in self.trained_param_keys:
+ if k in name:
+ names += [name]
+ params += [param]
+ flag = True
+ if flag:
+ break
+ print(names)
+
+ for embedder in self.conditioner.embedders:
+ if embedder.is_trainable:
+ params = params + list(embedder.parameters())
+
+ opt = self.instantiate_optimizer_from_config(params, lr, self.optimizer_config)
+ if self.scheduler_config is not None:
+ scheduler = instantiate_from_config(self.scheduler_config)
+ print("Setting up LambdaLR scheduler...")
+ scheduler = [
+ {
+ "scheduler": LambdaLR(opt, lr_lambda=scheduler.schedule),
+ "interval": "step",
+ "frequency": 1,
+ }
+ ]
+ return [opt], scheduler
+ return opt
+
+## license
+The provided implementation is strictly for academic purposes only. Should you be interested in using our technology for any commercial use, please feel free to contact us.
+
+## references
+```
+[1] @inproceedings{Niklaus_CVPR_2020,
+ author = {Simon Niklaus and Feng Liu},
+ title = {Softmax Splatting for Video Frame Interpolation},
+ booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
+ year = {2020}
+ }
+```
+
+## acknowledgment
+The video above uses materials under a Creative Common license as detailed at the end.
\ No newline at end of file
diff --git a/tools/softmax_splatting/correlation/README.md b/tools/softmax_splatting/correlation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a8e0ca529d50b7e09d521cc288daae7771514188
--- /dev/null
+++ b/tools/softmax_splatting/correlation/README.md
@@ -0,0 +1 @@
+This is an adaptation of the FlowNet2 implementation in order to compute cost volumes. Should you be making use of this work, please make sure to adhere to the licensing terms of the original authors. Should you be making use or modify this particular implementation, please acknowledge it appropriately.
\ No newline at end of file
diff --git a/tools/softmax_splatting/correlation/correlation.py b/tools/softmax_splatting/correlation/correlation.py
new file mode 100644
index 0000000000000000000000000000000000000000..d02560f79fda623ed14755114521b558fb596102
--- /dev/null
+++ b/tools/softmax_splatting/correlation/correlation.py
@@ -0,0 +1,395 @@
+#!/usr/bin/env python
+
+import cupy
+import re
+import torch
+
+kernel_Correlation_rearrange = '''
+ extern "C" __global__ void kernel_Correlation_rearrange(
+ const int n,
+ const float* input,
+ float* output
+ ) {
+ int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x;
+
+ if (intIndex >= n) {
+ return;
+ }
+
+ int intSample = blockIdx.z;
+ int intChannel = blockIdx.y;
+
+ float fltValue = input[(((intSample * SIZE_1(input)) + intChannel) * SIZE_2(input) * SIZE_3(input)) + intIndex];
+
+ __syncthreads();
+
+ int intPaddedY = (intIndex / SIZE_3(input)) + 4;
+ int intPaddedX = (intIndex % SIZE_3(input)) + 4;
+ int intRearrange = ((SIZE_3(input) + 8) * intPaddedY) + intPaddedX;
+
+ output[(((intSample * SIZE_1(output) * SIZE_2(output)) + intRearrange) * SIZE_1(input)) + intChannel] = fltValue;
+ }
+'''
+
+kernel_Correlation_updateOutput = '''
+ extern "C" __global__ void kernel_Correlation_updateOutput(
+ const int n,
+ const float* rbot0,
+ const float* rbot1,
+ float* top
+ ) {
+ extern __shared__ char patch_data_char[];
+
+ float *patch_data = (float *)patch_data_char;
+
+ // First (upper left) position of kernel upper-left corner in current center position of neighborhood in image 1
+ int x1 = blockIdx.x + 4;
+ int y1 = blockIdx.y + 4;
+ int item = blockIdx.z;
+ int ch_off = threadIdx.x;
+
+ // Load 3D patch into shared shared memory
+ for (int j = 0; j < 1; j++) { // HEIGHT
+ for (int i = 0; i < 1; i++) { // WIDTH
+ int ji_off = (j + i) * SIZE_3(rbot0);
+ for (int ch = ch_off; ch < SIZE_3(rbot0); ch += 32) { // CHANNELS
+ int idx1 = ((item * SIZE_1(rbot0) + y1+j) * SIZE_2(rbot0) + x1+i) * SIZE_3(rbot0) + ch;
+ int idxPatchData = ji_off + ch;
+ patch_data[idxPatchData] = rbot0[idx1];
+ }
+ }
+ }
+
+ __syncthreads();
+
+ __shared__ float sum[32];
+
+ // Compute correlation
+ for (int top_channel = 0; top_channel < SIZE_1(top); top_channel++) {
+ sum[ch_off] = 0;
+
+ int s2o = top_channel % 9 - 4;
+ int s2p = top_channel / 9 - 4;
+
+ for (int j = 0; j < 1; j++) { // HEIGHT
+ for (int i = 0; i < 1; i++) { // WIDTH
+ int ji_off = (j + i) * SIZE_3(rbot0);
+ for (int ch = ch_off; ch < SIZE_3(rbot0); ch += 32) { // CHANNELS
+ int x2 = x1 + s2o;
+ int y2 = y1 + s2p;
+
+ int idxPatchData = ji_off + ch;
+ int idx2 = ((item * SIZE_1(rbot0) + y2+j) * SIZE_2(rbot0) + x2+i) * SIZE_3(rbot0) + ch;
+
+ sum[ch_off] += patch_data[idxPatchData] * rbot1[idx2];
+ }
+ }
+ }
+
+ __syncthreads();
+
+ if (ch_off == 0) {
+ float total_sum = 0;
+ for (int idx = 0; idx < 32; idx++) {
+ total_sum += sum[idx];
+ }
+ const int sumelems = SIZE_3(rbot0);
+ const int index = ((top_channel*SIZE_2(top) + blockIdx.y)*SIZE_3(top))+blockIdx.x;
+ top[index + item*SIZE_1(top)*SIZE_2(top)*SIZE_3(top)] = total_sum / (float)sumelems;
+ }
+ }
+ }
+'''
+
+kernel_Correlation_updateGradOne = '''
+ #define ROUND_OFF 50000
+
+ extern "C" __global__ void kernel_Correlation_updateGradOne(
+ const int n,
+ const int intSample,
+ const float* rbot0,
+ const float* rbot1,
+ const float* gradOutput,
+ float* gradOne,
+ float* gradTwo
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ int n = intIndex % SIZE_1(gradOne); // channels
+ int l = (intIndex / SIZE_1(gradOne)) % SIZE_3(gradOne) + 4; // w-pos
+ int m = (intIndex / SIZE_1(gradOne) / SIZE_3(gradOne)) % SIZE_2(gradOne) + 4; // h-pos
+
+ // round_off is a trick to enable integer division with ceil, even for negative numbers
+ // We use a large offset, for the inner part not to become negative.
+ const int round_off = ROUND_OFF;
+ const int round_off_s1 = round_off;
+
+ // We add round_off before_s1 the int division and subtract round_off after it, to ensure the formula matches ceil behavior:
+ int xmin = (l - 4 + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4)
+ int ymin = (m - 4 + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4)
+
+ // Same here:
+ int xmax = (l - 4 + round_off_s1) - round_off; // floor (l - 4)
+ int ymax = (m - 4 + round_off_s1) - round_off; // floor (m - 4)
+
+ float sum = 0;
+ if (xmax>=0 && ymax>=0 && (xmin<=SIZE_3(gradOutput)-1) && (ymin<=SIZE_2(gradOutput)-1)) {
+ xmin = max(0,xmin);
+ xmax = min(SIZE_3(gradOutput)-1,xmax);
+
+ ymin = max(0,ymin);
+ ymax = min(SIZE_2(gradOutput)-1,ymax);
+
+ for (int p = -4; p <= 4; p++) {
+ for (int o = -4; o <= 4; o++) {
+ // Get rbot1 data:
+ int s2o = o;
+ int s2p = p;
+ int idxbot1 = ((intSample * SIZE_1(rbot0) + (m+s2p)) * SIZE_2(rbot0) + (l+s2o)) * SIZE_3(rbot0) + n;
+ float bot1tmp = rbot1[idxbot1]; // rbot1[l+s2o,m+s2p,n]
+
+ // Index offset for gradOutput in following loops:
+ int op = (p+4) * 9 + (o+4); // index[o,p]
+ int idxopoffset = (intSample * SIZE_1(gradOutput) + op);
+
+ for (int y = ymin; y <= ymax; y++) {
+ for (int x = xmin; x <= xmax; x++) {
+ int idxgradOutput = (idxopoffset * SIZE_2(gradOutput) + y) * SIZE_3(gradOutput) + x; // gradOutput[x,y,o,p]
+ sum += gradOutput[idxgradOutput] * bot1tmp;
+ }
+ }
+ }
+ }
+ }
+ const int sumelems = SIZE_1(gradOne);
+ const int bot0index = ((n * SIZE_2(gradOne)) + (m-4)) * SIZE_3(gradOne) + (l-4);
+ gradOne[bot0index + intSample*SIZE_1(gradOne)*SIZE_2(gradOne)*SIZE_3(gradOne)] = sum / (float)sumelems;
+ } }
+'''
+
+kernel_Correlation_updateGradTwo = '''
+ #define ROUND_OFF 50000
+
+ extern "C" __global__ void kernel_Correlation_updateGradTwo(
+ const int n,
+ const int intSample,
+ const float* rbot0,
+ const float* rbot1,
+ const float* gradOutput,
+ float* gradOne,
+ float* gradTwo
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ int n = intIndex % SIZE_1(gradTwo); // channels
+ int l = (intIndex / SIZE_1(gradTwo)) % SIZE_3(gradTwo) + 4; // w-pos
+ int m = (intIndex / SIZE_1(gradTwo) / SIZE_3(gradTwo)) % SIZE_2(gradTwo) + 4; // h-pos
+
+ // round_off is a trick to enable integer division with ceil, even for negative numbers
+ // We use a large offset, for the inner part not to become negative.
+ const int round_off = ROUND_OFF;
+ const int round_off_s1 = round_off;
+
+ float sum = 0;
+ for (int p = -4; p <= 4; p++) {
+ for (int o = -4; o <= 4; o++) {
+ int s2o = o;
+ int s2p = p;
+
+ //Get X,Y ranges and clamp
+ // We add round_off before_s1 the int division and subtract round_off after it, to ensure the formula matches ceil behavior:
+ int xmin = (l - 4 - s2o + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4 - s2o)
+ int ymin = (m - 4 - s2p + round_off_s1 - 1) + 1 - round_off; // ceil (l - 4 - s2o)
+
+ // Same here:
+ int xmax = (l - 4 - s2o + round_off_s1) - round_off; // floor (l - 4 - s2o)
+ int ymax = (m - 4 - s2p + round_off_s1) - round_off; // floor (m - 4 - s2p)
+
+ if (xmax>=0 && ymax>=0 && (xmin<=SIZE_3(gradOutput)-1) && (ymin<=SIZE_2(gradOutput)-1)) {
+ xmin = max(0,xmin);
+ xmax = min(SIZE_3(gradOutput)-1,xmax);
+
+ ymin = max(0,ymin);
+ ymax = min(SIZE_2(gradOutput)-1,ymax);
+
+ // Get rbot0 data:
+ int idxbot0 = ((intSample * SIZE_1(rbot0) + (m-s2p)) * SIZE_2(rbot0) + (l-s2o)) * SIZE_3(rbot0) + n;
+ float bot0tmp = rbot0[idxbot0]; // rbot1[l+s2o,m+s2p,n]
+
+ // Index offset for gradOutput in following loops:
+ int op = (p+4) * 9 + (o+4); // index[o,p]
+ int idxopoffset = (intSample * SIZE_1(gradOutput) + op);
+
+ for (int y = ymin; y <= ymax; y++) {
+ for (int x = xmin; x <= xmax; x++) {
+ int idxgradOutput = (idxopoffset * SIZE_2(gradOutput) + y) * SIZE_3(gradOutput) + x; // gradOutput[x,y,o,p]
+ sum += gradOutput[idxgradOutput] * bot0tmp;
+ }
+ }
+ }
+ }
+ }
+ const int sumelems = SIZE_1(gradTwo);
+ const int bot1index = ((n * SIZE_2(gradTwo)) + (m-4)) * SIZE_3(gradTwo) + (l-4);
+ gradTwo[bot1index + intSample*SIZE_1(gradTwo)*SIZE_2(gradTwo)*SIZE_3(gradTwo)] = sum / (float)sumelems;
+ } }
+'''
+
+def cupy_kernel(strFunction, objVariables):
+ strKernel = globals()[strFunction]
+
+ while True:
+ objMatch = re.search('(SIZE_)([0-4])(\()([^\)]*)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArg = int(objMatch.group(2))
+
+ strTensor = objMatch.group(4)
+ intSizes = objVariables[strTensor].size()
+
+ strKernel = strKernel.replace(objMatch.group(), str(intSizes[intArg] if torch.is_tensor(intSizes[intArg]) == False else intSizes[intArg].item()))
+
+ while True:
+ objMatch = re.search('(VALUE_)([0-4])(\()([^\)]+)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = objMatch.group(4).split(',')
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+ strIndex = [ '((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')' for intArg in range(intArgs) ]
+
+ strKernel = strKernel.replace(objMatch.group(0), strTensor + '[' + str.join('+', strIndex) + ']')
+ # end
+
+ return strKernel
+# end
+
+@cupy.memoize(for_each_device=True)
+def cupy_launch(strFunction, strKernel):
+ return cupy.cuda.compile_with_cache(strKernel).get_function(strFunction)
+# end
+
+class _FunctionCorrelation(torch.autograd.Function):
+ @staticmethod
+ def forward(self, one, two):
+ rbot0 = one.new_zeros([ one.shape[0], one.shape[2] + 8, one.shape[3] + 8, one.shape[1] ])
+ rbot1 = one.new_zeros([ one.shape[0], one.shape[2] + 8, one.shape[3] + 8, one.shape[1] ])
+
+ one = one.contiguous(); assert(one.is_cuda == True)
+ two = two.contiguous(); assert(two.is_cuda == True)
+
+ output = one.new_zeros([ one.shape[0], 81, one.shape[2], one.shape[3] ])
+
+ if one.is_cuda == True:
+ n = one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_rearrange', cupy_kernel('kernel_Correlation_rearrange', {
+ 'input': one,
+ 'output': rbot0
+ }))(
+ grid=tuple([ int((n + 25 - 1) / 25), one.shape[1], one.shape[0] ]), #frame_rate
+ block=tuple([ 25, 1, 1 ]), #frame_rate
+ args=[ cupy.int32(n), one.data_ptr(), rbot0.data_ptr() ]
+ )
+
+ n = two.shape[2] * two.shape[3]
+ cupy_launch('kernel_Correlation_rearrange', cupy_kernel('kernel_Correlation_rearrange', {
+ 'input': two,
+ 'output': rbot1
+ }))(
+ grid=tuple([ int((n + 25 - 1) / 25), two.shape[1], two.shape[0] ]), #frame_rate
+ block=tuple([ 25, 1, 1 ]), #frame_rate
+ args=[ cupy.int32(n), two.data_ptr(), rbot1.data_ptr() ]
+ )
+
+ n = output.shape[1] * output.shape[2] * output.shape[3]
+ cupy_launch('kernel_Correlation_updateOutput', cupy_kernel('kernel_Correlation_updateOutput', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'top': output
+ }))(
+ grid=tuple([ output.shape[3], output.shape[2], output.shape[0] ]),
+ block=tuple([ 32, 1, 1 ]),
+ shared_mem=one.shape[1] * 4,
+ args=[ cupy.int32(n), rbot0.data_ptr(), rbot1.data_ptr(), output.data_ptr() ]
+ )
+
+ elif one.is_cuda == False:
+ raise NotImplementedError()
+
+ # end
+
+ self.save_for_backward(one, two, rbot0, rbot1)
+
+ return output
+ # end
+
+ @staticmethod
+ def backward(self, gradOutput):
+ one, two, rbot0, rbot1 = self.saved_tensors
+
+ gradOutput = gradOutput.contiguous(); assert(gradOutput.is_cuda == True)
+
+ gradOne = one.new_zeros([ one.shape[0], one.shape[1], one.shape[2], one.shape[3] ]) if self.needs_input_grad[0] == True else None
+ gradTwo = one.new_zeros([ one.shape[0], one.shape[1], one.shape[2], one.shape[3] ]) if self.needs_input_grad[1] == True else None
+
+ if one.is_cuda == True:
+ if gradOne is not None:
+ for intSample in range(one.shape[0]):
+ n = one.shape[1] * one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_updateGradOne', cupy_kernel('kernel_Correlation_updateGradOne', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'gradOutput': gradOutput,
+ 'gradOne': gradOne,
+ 'gradTwo': None
+ }))(
+ grid=tuple([ int((n + 512 - 1) / 512), 1, 1 ]),
+ block=tuple([ 512, 1, 1 ]),
+ args=[ cupy.int32(n), intSample, rbot0.data_ptr(), rbot1.data_ptr(), gradOutput.data_ptr(), gradOne.data_ptr(), None ]
+ )
+ # end
+ # end
+
+ if gradTwo is not None:
+ for intSample in range(one.shape[0]):
+ n = one.shape[1] * one.shape[2] * one.shape[3]
+ cupy_launch('kernel_Correlation_updateGradTwo', cupy_kernel('kernel_Correlation_updateGradTwo', {
+ 'rbot0': rbot0,
+ 'rbot1': rbot1,
+ 'gradOutput': gradOutput,
+ 'gradOne': None,
+ 'gradTwo': gradTwo
+ }))(
+ grid=tuple([ int((n + 512 - 1) / 512), 1, 1 ]),
+ block=tuple([ 512, 1, 1 ]),
+ args=[ cupy.int32(n), intSample, rbot0.data_ptr(), rbot1.data_ptr(), gradOutput.data_ptr(), None, gradTwo.data_ptr() ]
+ )
+ # end
+ # end
+
+ elif one.is_cuda == False:
+ raise NotImplementedError()
+
+ # end
+
+ return gradOne, gradTwo
+ # end
+# end
+
+def FunctionCorrelation(tenOne, tenTwo):
+ return _FunctionCorrelation.apply(tenOne, tenTwo)
+# end
+
+class ModuleCorrelation(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ # end
+
+ def forward(self, tenOne, tenTwo):
+ return _FunctionCorrelation.apply(tenOne, tenTwo)
+ # end
+# end
diff --git a/tools/softmax_splatting/run.py b/tools/softmax_splatting/run.py
new file mode 100644
index 0000000000000000000000000000000000000000..22313f889dabafb31c675f199029713332751952
--- /dev/null
+++ b/tools/softmax_splatting/run.py
@@ -0,0 +1,871 @@
+#!/usr/bin/env python
+
+import getopt
+import math
+import sys
+import typing
+
+import numpy
+import PIL
+import PIL.Image
+import torch
+
+from . import softsplat # the custom softmax splatting layer
+
+try:
+ from .correlation import correlation # the custom cost volume layer
+except:
+ sys.path.insert(0, './correlation'); import correlation # you should consider upgrading python
+# end
+
+##########################################################
+
+torch.set_grad_enabled(False) # make sure to not compute gradients for computational performance
+
+torch.backends.cudnn.enabled = True # make sure to use cudnn for computational performance
+
+##########################################################
+
+arguments_strModel = 'lf'
+arguments_strOne = './images/one.png'
+arguments_strTwo = './images/two.png'
+arguments_strVideo = './videos/car-turn.mp4'
+arguments_strOut = './out.png'
+arguments_strVideo2 = ''
+
+for strOption, strArgument in getopt.getopt(sys.argv[1:], '', [strParameter[2:] + '=' for strParameter in sys.argv[1::2]])[0]:
+ if strOption == '--model' and strArgument != '': arguments_strModel = strArgument # which model to use
+ if strOption == '--one' and strArgument != '': arguments_strOne = strArgument # path to the first frame
+ if strOption == '--two' and strArgument != '': arguments_strTwo = strArgument # path to the second frame
+ if strOption == '--video' and strArgument != '': arguments_strVideo = strArgument # path to a video
+ if strOption == '--video2' and strArgument != '': arguments_strVideo2 = strArgument # path to a video
+ if strOption == '--out' and strArgument != '': arguments_strOut = strArgument # path to where the output should be stored
+# end
+
+##########################################################
+
+def read_flo(strFile):
+ with open(strFile, 'rb') as objFile:
+ strFlow = objFile.read()
+ # end
+
+ assert(numpy.frombuffer(buffer=strFlow, dtype=numpy.float32, count=1, offset=0) == 202021.25)
+
+ intWidth = numpy.frombuffer(buffer=strFlow, dtype=numpy.int32, count=1, offset=4)[0]
+ intHeight = numpy.frombuffer(buffer=strFlow, dtype=numpy.int32, count=1, offset=8)[0]
+
+ return numpy.frombuffer(buffer=strFlow, dtype=numpy.float32, count=intHeight * intWidth * 2, offset=12).reshape(intHeight, intWidth, 2)
+# end
+
+##########################################################
+
+backwarp_tenGrid = {}
+
+def backwarp(tenIn, tenFlow):
+ if str(tenFlow.shape) not in backwarp_tenGrid:
+ tenHor = torch.linspace(start=-1.0, end=1.0, steps=tenFlow.shape[3], dtype=tenFlow.dtype, device=tenFlow.device).view(1, 1, 1, -1).repeat(1, 1, tenFlow.shape[2], 1)
+ tenVer = torch.linspace(start=-1.0, end=1.0, steps=tenFlow.shape[2], dtype=tenFlow.dtype, device=tenFlow.device).view(1, 1, -1, 1).repeat(1, 1, 1, tenFlow.shape[3])
+
+ backwarp_tenGrid[str(tenFlow.shape)] = torch.cat([tenHor, tenVer], 1).cuda()
+ # end
+
+ tenFlow = torch.cat([tenFlow[:, 0:1, :, :] / ((tenIn.shape[3] - 1.0) / 2.0), tenFlow[:, 1:2, :, :] / ((tenIn.shape[2] - 1.0) / 2.0)], 1)
+
+ return torch.nn.functional.grid_sample(input=tenIn, grid=(backwarp_tenGrid[str(tenFlow.shape)] + tenFlow).permute(0, 2, 3, 1), mode='bilinear', padding_mode='zeros', align_corners=True)
+# end
+
+##########################################################
+
+class Flow(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ class Extractor(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netFirst = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netSecond = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netThird = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netFourth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=64, out_channels=96, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netFifth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=96, out_channels=128, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+
+ self.netSixth = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=2, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1)
+ )
+ # end
+
+ def forward(self, tenInput):
+ tenFirst = self.netFirst(tenInput)
+ tenSecond = self.netSecond(tenFirst)
+ tenThird = self.netThird(tenSecond)
+ tenFourth = self.netFourth(tenThird)
+ tenFifth = self.netFifth(tenFourth)
+ tenSixth = self.netSixth(tenFifth)
+
+ return [tenFirst, tenSecond, tenThird, tenFourth, tenFifth, tenSixth]
+ # end
+ # end
+
+ class Decoder(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=intChannels, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=128, out_channels=96, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=96, out_channels=64, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=64, out_channels=32, kernel_size=3, stride=1, padding=1),
+ torch.nn.LeakyReLU(inplace=False, negative_slope=0.1),
+ torch.nn.Conv2d(in_channels=32, out_channels=2, kernel_size=3, stride=1, padding=1)
+ )
+ # end
+
+ def forward(self, tenOne, tenTwo, objPrevious):
+ intWidth = tenOne.shape[3] and tenTwo.shape[3]
+ intHeight = tenOne.shape[2] and tenTwo.shape[2]
+
+ tenMain = None
+
+ if objPrevious is None:
+ tenVolume = correlation.FunctionCorrelation(tenOne=tenOne, tenTwo=tenTwo)
+
+ tenMain = torch.cat([tenOne, tenVolume], 1)
+
+ elif objPrevious is not None:
+ tenForward = torch.nn.functional.interpolate(input=objPrevious['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) / float(objPrevious['tenForward'].shape[3]) * float(intWidth)
+
+ tenVolume = correlation.FunctionCorrelation(tenOne=tenOne, tenTwo=backwarp(tenTwo, tenForward))
+
+ tenMain = torch.cat([tenOne, tenVolume, tenForward], 1)
+
+ # end
+
+ return {
+ 'tenForward': self.netMain(tenMain)
+ }
+ # end
+ # end
+
+ self.netExtractor = Extractor()
+
+ self.netFirst = Decoder(16 + 81 + 2)
+ self.netSecond = Decoder(32 + 81 + 2)
+ self.netThird = Decoder(64 + 81 + 2)
+ self.netFourth = Decoder(96 + 81 + 2)
+ self.netFifth = Decoder(128 + 81 + 2)
+ self.netSixth = Decoder(192 + 81)
+ # end
+
+ def forward(self, tenOne, tenTwo):
+ intWidth = tenOne.shape[3] and tenTwo.shape[3]
+ intHeight = tenOne.shape[2] and tenTwo.shape[2]
+
+ tenOne = self.netExtractor(tenOne)
+ tenTwo = self.netExtractor(tenTwo)
+
+ objForward = None
+ objBackward = None
+
+ objForward = self.netSixth(tenOne[-1], tenTwo[-1], objForward)
+ objBackward = self.netSixth(tenTwo[-1], tenOne[-1], objBackward)
+
+ objForward = self.netFifth(tenOne[-2], tenTwo[-2], objForward)
+ objBackward = self.netFifth(tenTwo[-2], tenOne[-2], objBackward)
+
+ objForward = self.netFourth(tenOne[-3], tenTwo[-3], objForward)
+ objBackward = self.netFourth(tenTwo[-3], tenOne[-3], objBackward)
+
+ objForward = self.netThird(tenOne[-4], tenTwo[-4], objForward)
+ objBackward = self.netThird(tenTwo[-4], tenOne[-4], objBackward)
+
+ objForward = self.netSecond(tenOne[-5], tenTwo[-5], objForward)
+ objBackward = self.netSecond(tenTwo[-5], tenOne[-5], objBackward)
+
+ objForward = self.netFirst(tenOne[-6], tenTwo[-6], objForward)
+ objBackward = self.netFirst(tenTwo[-6], tenOne[-6], objBackward)
+
+ return {
+ 'tenForward': torch.nn.functional.interpolate(input=objForward['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) * (float(intWidth) / float(objForward['tenForward'].shape[3])),
+ 'tenBackward': torch.nn.functional.interpolate(input=objBackward['tenForward'], size=(intHeight, intWidth), mode='bilinear', align_corners=False) * (float(intWidth) / float(objBackward['tenForward'].shape[3]))
+ }
+ # end
+# end
+
+##########################################################
+
+class Synthesis(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ class Basic(torch.nn.Module):
+ def __init__(self, strType, intChannels, boolSkip):
+ super().__init__()
+
+ if strType == 'relu-conv-relu-conv':
+ self.netMain = torch.nn.Sequential(
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+
+ elif strType == 'conv-relu-conv':
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+
+ # end
+
+ self.boolSkip = boolSkip
+
+ if boolSkip == True:
+ if intChannels[0] == intChannels[2]:
+ self.netShortcut = None
+
+ elif intChannels[0] != intChannels[2]:
+ self.netShortcut = torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[2], kernel_size=1, stride=1, padding=0, bias=False)
+
+ # end
+ # end
+ # end
+
+ def forward(self, tenInput):
+ if self.boolSkip == False:
+ return self.netMain(tenInput)
+ # end
+
+ if self.netShortcut is None:
+ return self.netMain(tenInput) + tenInput
+
+ elif self.netShortcut is not None:
+ return self.netMain(tenInput) + self.netShortcut(tenInput)
+
+ # end
+ # end
+ # end
+
+ class Downsample(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ # end
+
+ def forward(self, tenInput):
+ return self.netMain(tenInput)
+ # end
+ # end
+
+ class Upsample(torch.nn.Module):
+ def __init__(self, intChannels):
+ super().__init__()
+
+ self.netMain = torch.nn.Sequential(
+ torch.nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
+ torch.nn.PReLU(num_parameters=intChannels[0], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[0], out_channels=intChannels[1], kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=intChannels[1], init=0.25),
+ torch.nn.Conv2d(in_channels=intChannels[1], out_channels=intChannels[2], kernel_size=3, stride=1, padding=1, bias=False)
+ )
+ # end
+
+ def forward(self, tenInput):
+ return self.netMain(tenInput)
+ # end
+ # end
+
+ class Encode(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netOne = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=32, init=0.25),
+ torch.nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=32, init=0.25)
+ )
+
+ self.netTwo = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=64, init=0.25),
+ torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=64, init=0.25)
+ )
+
+ self.netThr = torch.nn.Sequential(
+ torch.nn.Conv2d(in_channels=64, out_channels=96, kernel_size=3, stride=2, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=96, init=0.25),
+ torch.nn.Conv2d(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1, bias=False),
+ torch.nn.PReLU(num_parameters=96, init=0.25)
+ )
+ # end
+
+ def forward(self, tenInput):
+ tenOutput = []
+
+ tenOutput.append(self.netOne(tenInput))
+ tenOutput.append(self.netTwo(tenOutput[-1]))
+ tenOutput.append(self.netThr(tenOutput[-1]))
+
+ return [torch.cat([tenInput, tenOutput[0]], 1)] + tenOutput[1:]
+ # end
+ # end
+
+ class Softmetric(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netInput = torch.nn.Conv2d(in_channels=3, out_channels=12, kernel_size=3, stride=1, padding=1, bias=False)
+ self.netError = torch.nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, stride=1, padding=1, bias=False)
+
+ for intRow, intFeatures in [(0, 16), (1, 32), (2, 64), (3, 96)]:
+ self.add_module(str(intRow) + 'x0' + ' - ' + str(intRow) + 'x1', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ # end
+
+ for intCol in [0]:
+ self.add_module('0x' + str(intCol) + ' - ' + '1x' + str(intCol), Downsample([16, 32, 32]))
+ self.add_module('1x' + str(intCol) + ' - ' + '2x' + str(intCol), Downsample([32, 64, 64]))
+ self.add_module('2x' + str(intCol) + ' - ' + '3x' + str(intCol), Downsample([64, 96, 96]))
+ # end
+
+ for intCol in [1]:
+ self.add_module('3x' + str(intCol) + ' - ' + '2x' + str(intCol), Upsample([96, 64, 64]))
+ self.add_module('2x' + str(intCol) + ' - ' + '1x' + str(intCol), Upsample([64, 32, 32]))
+ self.add_module('1x' + str(intCol) + ' - ' + '0x' + str(intCol), Upsample([32, 16, 16]))
+ # end
+
+ self.netOutput = Basic('conv-relu-conv', [16, 16, 1], True)
+ # end
+
+ def forward(self, tenEncone, tenEnctwo, tenFlow):
+ tenColumn = [None, None, None, None]
+
+ tenColumn[0] = torch.cat([self.netInput(tenEncone[0][:, 0:3, :, :]), self.netError(torch.nn.functional.l1_loss(input=tenEncone[0], target=backwarp(tenEnctwo[0], tenFlow), reduction='none').mean([1], True))], 1)
+ tenColumn[1] = self._modules['0x0 - 1x0'](tenColumn[0])
+ tenColumn[2] = self._modules['1x0 - 2x0'](tenColumn[1])
+ tenColumn[3] = self._modules['2x0 - 3x0'](tenColumn[2])
+
+ intColumn = 1
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ return self.netOutput(tenColumn[0])
+ # end
+ # end
+
+ class Warp(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netOne = Basic('conv-relu-conv', [3 + 3 + 32 + 32 + 1 + 1, 32, 32], True)
+ self.netTwo = Basic('conv-relu-conv', [0 + 0 + 64 + 64 + 1 + 1, 64, 64], True)
+ self.netThr = Basic('conv-relu-conv', [0 + 0 + 96 + 96 + 1 + 1, 96, 96], True)
+ # end
+
+ def forward(self, tenEncone, tenEnctwo, tenMetricone, tenMetrictwo, tenForward, tenBackward):
+ tenOutput = []
+
+ for intLevel in range(3):
+ if intLevel != 0:
+ tenMetricone = torch.nn.functional.interpolate(input=tenMetricone, size=(tenEncone[intLevel].shape[2], tenEncone[intLevel].shape[3]), mode='bilinear', align_corners=False)
+ tenMetrictwo = torch.nn.functional.interpolate(input=tenMetrictwo, size=(tenEnctwo[intLevel].shape[2], tenEnctwo[intLevel].shape[3]), mode='bilinear', align_corners=False)
+
+ tenForward = torch.nn.functional.interpolate(input=tenForward, size=(tenEncone[intLevel].shape[2], tenEncone[intLevel].shape[3]), mode='bilinear', align_corners=False) * (float(tenEncone[intLevel].shape[3]) / float(tenForward.shape[3]))
+ tenBackward = torch.nn.functional.interpolate(input=tenBackward, size=(tenEnctwo[intLevel].shape[2], tenEnctwo[intLevel].shape[3]), mode='bilinear', align_corners=False) * (float(tenEnctwo[intLevel].shape[3]) / float(tenBackward.shape[3]))
+ # end
+
+ tenOutput.append([self.netOne, self.netTwo, self.netThr][intLevel](torch.cat([
+ softsplat.softsplat(tenIn=torch.cat([tenEncone[intLevel], tenMetricone], 1), tenFlow=tenForward, tenMetric=tenMetricone.neg().clip(-20.0, 20.0), strMode='soft'),
+ softsplat.softsplat(tenIn=torch.cat([tenEnctwo[intLevel], tenMetrictwo], 1), tenFlow=tenBackward, tenMetric=tenMetrictwo.neg().clip(-20.0, 20.0), strMode='soft')
+ ], 1)))
+ # end
+
+ return tenOutput
+ # end
+ # end
+
+ self.netEncode = Encode()
+
+ self.netSoftmetric = Softmetric()
+
+ self.netWarp = Warp()
+
+ for intRow, intFeatures in [(0, 32), (1, 64), (2, 96)]:
+ self.add_module(str(intRow) + 'x0' + ' - ' + str(intRow) + 'x1', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x1' + ' - ' + str(intRow) + 'x2', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x2' + ' - ' + str(intRow) + 'x3', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x3' + ' - ' + str(intRow) + 'x4', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ self.add_module(str(intRow) + 'x4' + ' - ' + str(intRow) + 'x5', Basic('relu-conv-relu-conv', [intFeatures, intFeatures, intFeatures], True))
+ # end
+
+ for intCol in [0, 1, 2]:
+ self.add_module('0x' + str(intCol) + ' - ' + '1x' + str(intCol), Downsample([32, 64, 64]))
+ self.add_module('1x' + str(intCol) + ' - ' + '2x' + str(intCol), Downsample([64, 96, 96]))
+ # end
+
+ for intCol in [3, 4, 5]:
+ self.add_module('2x' + str(intCol) + ' - ' + '1x' + str(intCol), Upsample([96, 64, 64]))
+ self.add_module('1x' + str(intCol) + ' - ' + '0x' + str(intCol), Upsample([64, 32, 32]))
+ # end
+
+ self.netOutput = Basic('conv-relu-conv', [32, 32, 3], True)
+ # end
+
+ def forward(self, tenOne, tenTwo, tenForward, tenBackward, fltTime):
+ tenEncone = self.netEncode(tenOne)
+ tenEnctwo = self.netEncode(tenTwo)
+
+ tenMetricone = self.netSoftmetric(tenEncone, tenEnctwo, tenForward) * 2.0 * fltTime
+ tenMetrictwo = self.netSoftmetric(tenEnctwo, tenEncone, tenBackward) * 2.0 * (1.0 - fltTime)
+
+ tenForward = tenForward * fltTime
+ tenBackward = tenBackward * (1.0 - fltTime)
+
+ tenWarp = self.netWarp(tenEncone, tenEnctwo, tenMetricone, tenMetrictwo, tenForward, tenBackward)
+
+ tenColumn = [None, None, None]
+
+ tenColumn[0] = tenWarp[0]
+ tenColumn[1] = tenWarp[1] + self._modules['0x0 - 1x0'](tenColumn[0])
+ tenColumn[2] = tenWarp[2] + self._modules['1x0 - 2x0'](tenColumn[1])
+
+ intColumn = 1
+ for intRow in range(len(tenColumn)):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != 0:
+ tenColumn[intRow] = tenColumn[intRow] + self._modules[str(intRow - 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow - 1])
+ # end
+ # end
+
+ intColumn = 2
+ for intRow in range(len(tenColumn)):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != 0:
+ tenColumn[intRow] = tenColumn[intRow] + self._modules[str(intRow - 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow - 1])
+ # end
+ # end
+
+ intColumn = 3
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ intColumn = 4
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ intColumn = 5
+ for intRow in range(len(tenColumn) -1, -1, -1):
+ tenColumn[intRow] = self._modules[str(intRow) + 'x' + str(intColumn - 1) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow])
+ if intRow != len(tenColumn) - 1:
+ tenUp = self._modules[str(intRow + 1) + 'x' + str(intColumn) + ' - ' + str(intRow) + 'x' + str(intColumn)](tenColumn[intRow + 1])
+
+ if tenUp.shape[2] != tenColumn[intRow].shape[2]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, 0, 0, -1], mode='constant', value=0.0)
+ if tenUp.shape[3] != tenColumn[intRow].shape[3]: tenUp = torch.nn.functional.pad(input=tenUp, pad=[0, -1, 0, 0], mode='constant', value=0.0)
+
+ tenColumn[intRow] = tenColumn[intRow] + tenUp
+ # end
+ # end
+
+ return self.netOutput(tenColumn[0])
+ # end
+# end
+
+##########################################################
+
+class Network(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.netFlow = Flow()
+
+ self.netSynthesis = Synthesis()
+
+ self.load_state_dict({strKey.replace('module', 'net'): tenWeight for strKey, tenWeight in torch.hub.load_state_dict_from_url(url='http://content.sniklaus.com/softsplat/network-' + arguments_strModel + '.pytorch', file_name='softsplat-' + arguments_strModel).items()})
+ # end
+
+ def forward(self, tenOne, tenTwo, fltTimes):
+ with torch.set_grad_enabled(False):
+ tenStats = [tenOne, tenTwo]
+ tenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in tenStats]) / len(tenStats)
+ tenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (tenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in tenStats]) / len(tenStats)).sqrt()
+ tenOne = ((tenOne - tenMean) / (tenStd + 0.0000001)).detach()
+ tenTwo = ((tenTwo - tenMean) / (tenStd + 0.0000001)).detach()
+ # end
+
+ objFlow = self.netFlow(tenOne, tenTwo)
+
+ tenImages = [self.netSynthesis(tenOne, tenTwo, objFlow['tenForward'], objFlow['tenBackward'], fltTime) for fltTime in fltTimes]
+
+ return [(tenImage * tenStd) + tenMean for tenImage in tenImages]
+ # end
+# end
+
+netNetwork = None
+
+##########################################################
+
+def estimate(tenOne, tenTwo, fltTimes):
+ global netNetwork
+
+ if netNetwork is None:
+ netNetwork = Network().cuda().eval()
+ # end
+
+ assert(tenOne.shape[1] == tenTwo.shape[1])
+ assert(tenOne.shape[2] == tenTwo.shape[2])
+
+ intWidth = tenOne.shape[2]
+ intHeight = tenOne.shape[1]
+
+ tenPreprocessedOne = tenOne.cuda().view(1, 3, intHeight, intWidth)
+ tenPreprocessedTwo = tenTwo.cuda().view(1, 3, intHeight, intWidth)
+
+ intPadr = (2 - (intWidth % 2)) % 2
+ intPadb = (2 - (intHeight % 2)) % 2
+
+ tenPreprocessedOne = torch.nn.functional.pad(input=tenPreprocessedOne, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenPreprocessedTwo = torch.nn.functional.pad(input=tenPreprocessedTwo, pad=[0, intPadr, 0, intPadb], mode='replicate')
+
+ return [tenImage[0, :, :intHeight, :intWidth].cpu() for tenImage in netNetwork(tenPreprocessedOne, tenPreprocessedTwo, fltTimes)]
+# end
+##########################################################
+import logging
+
+logger = logging.getLogger(__name__)
+
+raft = None
+
+class Raft:
+ def __init__(self):
+ from torchvision.models.optical_flow import (Raft_Large_Weights,
+ raft_large)
+
+ weights = Raft_Large_Weights.DEFAULT
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ model = raft_large(weights=weights, progress=False).to(self.device)
+ self.model = model.eval()
+
+ def __call__(self,img1,img2):
+ with torch.no_grad():
+ img1 = img1.to(self.device)
+ img2 = img2.to(self.device)
+ i1 = torch.vstack([img1,img2])
+ i2 = torch.vstack([img2,img1])
+ list_of_flows = self.model(i1, i2)
+
+ predicted_flows = list_of_flows[-1]
+ return { 'tenForward' : predicted_flows[0].unsqueeze(dim=0) , 'tenBackward' : predicted_flows[1].unsqueeze(dim=0) }
+
+img_count = 0
+def debug_save_img(img, comment, inc=False):
+ return
+ global img_count
+ from torchvision.utils import save_image
+
+ save_image(img, f"debug0/{img_count:04d}_{comment}.png")
+
+ if inc:
+ img_count += 1
+
+
+class Network2(torch.nn.Module):
+ def __init__(self, model_file_path):
+ super().__init__()
+
+ self.netFlow = Flow()
+
+ self.netSynthesis = Synthesis()
+
+ d = torch.load(model_file_path)
+
+ d = {strKey.replace('module', 'net'): tenWeight for strKey, tenWeight in d.items()}
+
+ self.load_state_dict(d)
+ # end
+
+ def forward(self, tenOne, tenTwo, guideFrameList):
+ global raft
+
+ do_composite = True
+ use_raft = True
+
+ if use_raft:
+ if raft is None:
+ raft = Raft()
+
+
+ with torch.set_grad_enabled(False):
+ tenStats = [tenOne, tenTwo]
+ tenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in tenStats]) / len(tenStats)
+ tenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (tenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in tenStats]) / len(tenStats)).sqrt()
+ tenOne = ((tenOne - tenMean) / (tenStd + 0.0000001)).detach()
+ tenTwo = ((tenTwo - tenMean) / (tenStd + 0.0000001)).detach()
+
+ gtenStats = guideFrameList
+ gtenMean = sum([tenIn.mean([1, 2, 3], True) for tenIn in gtenStats]) / len(gtenStats)
+ gtenStd = (sum([tenIn.std([1, 2, 3], False, True).square() + (gtenMean - tenIn.mean([1, 2, 3], True)).square() for tenIn in gtenStats]) / len(gtenStats)).sqrt()
+ guideFrameList = [((g - gtenMean) / (gtenStd + 0.0000001)).detach() for g in guideFrameList]
+
+ # end
+
+ tenImages =[]
+ l = len(guideFrameList)
+ i = 1
+ g1 = guideFrameList.pop(0)
+
+ if use_raft:
+ styleFlow = raft(tenOne, tenTwo)
+ else:
+ styleFlow = self.netFlow(tenOne, tenTwo)
+
+ def composite1(fA, fB, nA, nB):
+ # 1,2,768,512
+ A = fA[:,0,:,:]
+ B = fA[:,1,:,:]
+ Z = nA
+
+ UA = A / Z
+ UB = B / Z
+
+ A2 = fB[:,0,:,:]
+ B2 = fB[:,1,:,:]
+ Z2 = nB
+ fB[:,0,:,:] = Z2 * UA
+ fB[:,1,:,:] = Z2 * UB
+ return fB
+
+ def mask_dilate(ten, kernel_size=3):
+ ten = ten.to(torch.float32)
+ k=torch.ones(1, 1, kernel_size, kernel_size, dtype=torch.float32).cuda()
+ ten = torch.nn.functional.conv2d(ten, k, padding=(kernel_size//2, kernel_size// 2))
+ result = torch.clamp(ten, 0, 1)
+ return result.to(torch.bool)
+
+ def composite2(fA, fB, nA, nB):
+ Z = nA
+ Z2 = nB
+
+ mean2 = torch.mean(Z2)
+ max2 = torch.max(Z2)
+ mask2 = (Z2 > (mean2+max2)/2)
+ debug_save_img(mask2.to(torch.float), "mask2_0")
+ mask2 = mask_dilate(mask2, 9)
+ debug_save_img(mask2.to(torch.float), "mask2_1")
+ mask2 = ~mask2
+
+ debug_save_img(mask2.to(torch.float), "mask2")
+
+ mean1 = torch.mean(Z)
+ max1 = torch.max(Z)
+ mask1 = (Z > (mean1+max1)/2)
+
+ debug_save_img(mask1.to(torch.float), "mask1")
+
+ mask = mask1 & mask2
+ mask = mask.squeeze()
+
+ debug_save_img(mask.to(torch.float), "cmask", True)
+
+ fB[:,:,mask] = fA[:,:,mask]
+
+ return fB
+
+
+ def composite(fA, fB):
+ A = fA[:,0,:,:]
+ B = fA[:,1,:,:]
+ Z = (A*A + B*B)**0.5
+ A2 = fB[:,0,:,:]
+ B2 = fB[:,1,:,:]
+ Z2 = (A2*A2 + B2*B2)**0.5
+
+ fB = composite1(fA, fB, Z, Z2)
+ fB = composite2(fA, fB, Z, Z2)
+ return fB
+
+ for g2 in guideFrameList:
+ if use_raft:
+ objFlow = raft(g1, g2)
+ else:
+ objFlow = self.netFlow(g1, g2)
+
+
+ objFlow['tenForward'] = objFlow['tenForward'] * (l/i)
+ objFlow['tenBackward'] = objFlow['tenBackward'] * (l/i)
+
+ if do_composite:
+ objFlow['tenForward'] = composite(objFlow['tenForward'], styleFlow['tenForward'])
+ objFlow['tenBackward'] = composite(objFlow['tenBackward'], styleFlow['tenBackward'])
+
+ img = self.netSynthesis(tenOne, tenTwo, objFlow['tenForward'], objFlow['tenBackward'], i/l)
+ tenImages.append(img)
+ i += 1
+
+ return [(tenImage * tenStd) + tenMean for tenImage in tenImages]
+
+
+# end
+
+netNetwork = None
+
+##########################################################
+
+def estimate2(img1: PIL.Image, img2:PIL.Image, guideFrames, model_file_path):
+ global netNetwork
+
+ if netNetwork is None:
+ netNetwork = Network2(model_file_path).cuda().eval()
+ # end
+
+ def forTensor(im):
+ return torch.FloatTensor(numpy.ascontiguousarray(numpy.array(im)[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ tenOne = forTensor(img1)
+ tenTwo = forTensor(img2)
+
+ tenGuideFrames=[]
+ for g in guideFrames:
+ tenGuideFrames.append(forTensor(g))
+
+ assert(tenOne.shape[1] == tenTwo.shape[1])
+ assert(tenOne.shape[2] == tenTwo.shape[2])
+
+ intWidth = tenOne.shape[2]
+ intHeight = tenOne.shape[1]
+
+ tenPreprocessedOne = tenOne.cuda().view(1, 3, intHeight, intWidth)
+ tenPreprocessedTwo = tenTwo.cuda().view(1, 3, intHeight, intWidth)
+ tenGuideFrames = [ ten.cuda().view(1, 3, intHeight, intWidth) for ten in tenGuideFrames]
+
+ intPadr = (2 - (intWidth % 2)) % 2
+ intPadb = (2 - (intHeight % 2)) % 2
+
+ tenPreprocessedOne = torch.nn.functional.pad(input=tenPreprocessedOne, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenPreprocessedTwo = torch.nn.functional.pad(input=tenPreprocessedTwo, pad=[0, intPadr, 0, intPadb], mode='replicate')
+ tenGuideFrames = [ torch.nn.functional.pad(input=ten, pad=[0, intPadr, 0, intPadb], mode='replicate') for ten in tenGuideFrames]
+
+ result = [tenImage[0, :, :intHeight, :intWidth].cpu() for tenImage in netNetwork(tenPreprocessedOne, tenPreprocessedTwo, tenGuideFrames)]
+ result = [ PIL.Image.fromarray((r.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8)) for r in result]
+
+ return result
+# end
+
+##########################################################
+'''
+if __name__ == '__main__':
+ if arguments_strOut.split('.')[-1] in ['bmp', 'jpg', 'jpeg', 'png']:
+ tenOne = torch.FloatTensor(numpy.ascontiguousarray(numpy.array(PIL.Image.open(arguments_strOne))[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+ tenTwo = torch.FloatTensor(numpy.ascontiguousarray(numpy.array(PIL.Image.open(arguments_strTwo))[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ tenOutput = estimate(tenOne, tenTwo, [0.5])[0]
+
+ PIL.Image.fromarray((tenOutput.clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8)).save(arguments_strOut)
+
+ elif arguments_strOut.split('.')[-1] in ['avi', 'mp4', 'webm', 'wmv']:
+ import moviepy
+ import moviepy.editor
+ import moviepy.video.io.ffmpeg_writer
+
+ objVideoreader = moviepy.editor.VideoFileClip(filename=arguments_strVideo)
+ objVideoreader2 = moviepy.editor.VideoFileClip(filename=arguments_strVideo2)
+
+ from moviepy.video.fx.resize import resize
+ objVideoreader2 = resize(objVideoreader2, (objVideoreader.w, objVideoreader.h))
+
+ intWidth = objVideoreader.w
+ intHeight = objVideoreader.h
+
+ tenFrames = [None, None, None, None]
+
+ with moviepy.video.io.ffmpeg_writer.FFMPEG_VideoWriter(filename=arguments_strOut, size=(intWidth, intHeight), fps=objVideoreader.fps) as objVideowriter:
+ for npyFrame in objVideoreader.iter_frames():
+ tenFrames[3] = torch.FloatTensor(numpy.ascontiguousarray(npyFrame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+
+ if tenFrames[0] is not None:
+ tenFrames[1:3] = estimate(tenFrames[0], tenFrames[3], [0.333, 0.666])
+
+ objVideowriter.write_frame((tenFrames[0].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ objVideowriter.write_frame((tenFrames[1].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ objVideowriter.write_frame((tenFrames[2].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+# objVideowriter.write_frame((tenFrames[3].clip(0.0, 1.0).numpy().transpose(1, 2, 0)[:, :, ::-1] * 255.0).astype(numpy.uint8))
+ # end
+
+ tenFrames[0] = torch.FloatTensor(numpy.ascontiguousarray(npyFrame[:, :, ::-1].transpose(2, 0, 1).astype(numpy.float32) * (1.0 / 255.0)))
+ # end
+ # end
+
+ # end
+# end
+'''
\ No newline at end of file
diff --git a/tools/softmax_splatting/softsplat.py b/tools/softmax_splatting/softsplat.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc50de3e400e92908a2bae60e6f1d3309383eeff
--- /dev/null
+++ b/tools/softmax_splatting/softsplat.py
@@ -0,0 +1,529 @@
+#!/usr/bin/env python
+
+import collections
+import cupy
+import os
+import re
+import torch
+import typing
+
+
+##########################################################
+
+
+objCudacache = {}
+
+
+def cuda_int32(intIn:int):
+ return cupy.int32(intIn)
+# end
+
+
+def cuda_float32(fltIn:float):
+ return cupy.float32(fltIn)
+# end
+
+
+def cuda_kernel(strFunction:str, strKernel:str, objVariables:typing.Dict):
+ if 'device' not in objCudacache:
+ objCudacache['device'] = torch.cuda.get_device_name()
+ # end
+
+ strKey = strFunction
+
+ for strVariable in objVariables:
+ objValue = objVariables[strVariable]
+
+ strKey += strVariable
+
+ if objValue is None:
+ continue
+
+ elif type(objValue) == int:
+ strKey += str(objValue)
+
+ elif type(objValue) == float:
+ strKey += str(objValue)
+
+ elif type(objValue) == bool:
+ strKey += str(objValue)
+
+ elif type(objValue) == str:
+ strKey += objValue
+
+ elif type(objValue) == torch.Tensor:
+ strKey += str(objValue.dtype)
+ strKey += str(objValue.shape)
+ strKey += str(objValue.stride())
+
+ elif True:
+ print(strVariable, type(objValue))
+ assert(False)
+
+ # end
+ # end
+
+ strKey += objCudacache['device']
+
+ if strKey not in objCudacache:
+ for strVariable in objVariables:
+ objValue = objVariables[strVariable]
+
+ if objValue is None:
+ continue
+
+ elif type(objValue) == int:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == float:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == bool:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', str(objValue))
+
+ elif type(objValue) == str:
+ strKernel = strKernel.replace('{{' + strVariable + '}}', objValue)
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.uint8:
+ strKernel = strKernel.replace('{{type}}', 'unsigned char')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float16:
+ strKernel = strKernel.replace('{{type}}', 'half')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float32:
+ strKernel = strKernel.replace('{{type}}', 'float')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.float64:
+ strKernel = strKernel.replace('{{type}}', 'double')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.int32:
+ strKernel = strKernel.replace('{{type}}', 'int')
+
+ elif type(objValue) == torch.Tensor and objValue.dtype == torch.int64:
+ strKernel = strKernel.replace('{{type}}', 'long')
+
+ elif type(objValue) == torch.Tensor:
+ print(strVariable, objValue.dtype)
+ assert(False)
+
+ elif True:
+ print(strVariable, type(objValue))
+ assert(False)
+
+ # end
+ # end
+
+ while True:
+ objMatch = re.search('(SIZE_)([0-4])(\()([^\)]*)(\))', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intArg = int(objMatch.group(2))
+
+ strTensor = objMatch.group(4)
+ intSizes = objVariables[strTensor].size()
+
+ strKernel = strKernel.replace(objMatch.group(), str(intSizes[intArg] if torch.is_tensor(intSizes[intArg]) == False else intSizes[intArg].item()))
+ # end
+
+ while True:
+ objMatch = re.search('(OFFSET_)([0-4])(\()', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intStart = objMatch.span()[1]
+ intStop = objMatch.span()[1]
+ intParentheses = 1
+
+ while True:
+ intParentheses += 1 if strKernel[intStop] == '(' else 0
+ intParentheses -= 1 if strKernel[intStop] == ')' else 0
+
+ if intParentheses == 0:
+ break
+ # end
+
+ intStop += 1
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = strKernel[intStart:intStop].split(',')
+
+ assert(intArgs == len(strArgs) - 1)
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+
+ strIndex = []
+
+ for intArg in range(intArgs):
+ strIndex.append('((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')')
+ # end
+
+ strKernel = strKernel.replace('OFFSET_' + str(intArgs) + '(' + strKernel[intStart:intStop] + ')', '(' + str.join('+', strIndex) + ')')
+ # end
+
+ while True:
+ objMatch = re.search('(VALUE_)([0-4])(\()', strKernel)
+
+ if objMatch is None:
+ break
+ # end
+
+ intStart = objMatch.span()[1]
+ intStop = objMatch.span()[1]
+ intParentheses = 1
+
+ while True:
+ intParentheses += 1 if strKernel[intStop] == '(' else 0
+ intParentheses -= 1 if strKernel[intStop] == ')' else 0
+
+ if intParentheses == 0:
+ break
+ # end
+
+ intStop += 1
+ # end
+
+ intArgs = int(objMatch.group(2))
+ strArgs = strKernel[intStart:intStop].split(',')
+
+ assert(intArgs == len(strArgs) - 1)
+
+ strTensor = strArgs[0]
+ intStrides = objVariables[strTensor].stride()
+
+ strIndex = []
+
+ for intArg in range(intArgs):
+ strIndex.append('((' + strArgs[intArg + 1].replace('{', '(').replace('}', ')').strip() + ')*' + str(intStrides[intArg] if torch.is_tensor(intStrides[intArg]) == False else intStrides[intArg].item()) + ')')
+ # end
+
+ strKernel = strKernel.replace('VALUE_' + str(intArgs) + '(' + strKernel[intStart:intStop] + ')', strTensor + '[' + str.join('+', strIndex) + ']')
+ # end
+
+ objCudacache[strKey] = {
+ 'strFunction': strFunction,
+ 'strKernel': strKernel
+ }
+ # end
+
+ return strKey
+# end
+
+
+@cupy.memoize(for_each_device=True)
+def cuda_launch(strKey:str):
+ if 'CUDA_HOME' not in os.environ:
+ os.environ['CUDA_HOME'] = cupy.cuda.get_cuda_path()
+ # end
+
+ return cupy.cuda.compile_with_cache(objCudacache[strKey]['strKernel'], tuple(['-I ' + os.environ['CUDA_HOME'], '-I ' + os.environ['CUDA_HOME'] + '/include'])).get_function(objCudacache[strKey]['strFunction'])
+# end
+
+
+##########################################################
+
+
+def softsplat(tenIn:torch.Tensor, tenFlow:torch.Tensor, tenMetric:torch.Tensor, strMode:str):
+ assert(strMode.split('-')[0] in ['sum', 'avg', 'linear', 'soft'])
+
+ if strMode == 'sum': assert(tenMetric is None)
+ if strMode == 'avg': assert(tenMetric is None)
+ if strMode.split('-')[0] == 'linear': assert(tenMetric is not None)
+ if strMode.split('-')[0] == 'soft': assert(tenMetric is not None)
+
+ if strMode == 'avg':
+ tenIn = torch.cat([tenIn, tenIn.new_ones([tenIn.shape[0], 1, tenIn.shape[2], tenIn.shape[3]])], 1)
+
+ elif strMode.split('-')[0] == 'linear':
+ tenIn = torch.cat([tenIn * tenMetric, tenMetric], 1)
+
+ elif strMode.split('-')[0] == 'soft':
+ tenIn = torch.cat([tenIn * tenMetric.exp(), tenMetric.exp()], 1)
+
+ # end
+
+ tenOut = softsplat_func.apply(tenIn, tenFlow)
+
+ if strMode.split('-')[0] in ['avg', 'linear', 'soft']:
+ tenNormalize = tenOut[:, -1:, :, :]
+
+ if len(strMode.split('-')) == 1:
+ tenNormalize = tenNormalize + 0.0000001
+
+ elif strMode.split('-')[1] == 'addeps':
+ tenNormalize = tenNormalize + 0.0000001
+
+ elif strMode.split('-')[1] == 'zeroeps':
+ tenNormalize[tenNormalize == 0.0] = 1.0
+
+ elif strMode.split('-')[1] == 'clipeps':
+ tenNormalize = tenNormalize.clip(0.0000001, None)
+
+ # end
+
+ tenOut = tenOut[:, :-1, :, :] / tenNormalize
+ # end
+
+ return tenOut
+# end
+
+
+class softsplat_func(torch.autograd.Function):
+ @staticmethod
+ @torch.amp.custom_fwd(cast_inputs=torch.float32, device_type='cuda')
+ def forward(self, tenIn, tenFlow):
+ tenOut = tenIn.new_zeros([tenIn.shape[0], tenIn.shape[1], tenIn.shape[2], tenIn.shape[3]])
+
+ if tenIn.is_cuda == True:
+ cuda_launch(cuda_kernel('softsplat_out', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_out(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ {{type}}* __restrict__ tenOut
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenOut) / SIZE_2(tenOut) / SIZE_1(tenOut) ) % SIZE_0(tenOut);
+ const int intC = ( intIndex / SIZE_3(tenOut) / SIZE_2(tenOut) ) % SIZE_1(tenOut);
+ const int intY = ( intIndex / SIZE_3(tenOut) ) % SIZE_2(tenOut);
+ const int intX = ( intIndex ) % SIZE_3(tenOut);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ {{type}} fltIn = VALUE_4(tenIn, intN, intC, intY, intX);
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (intSoutheastY) - fltY);
+ {{type}} fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (intSouthwestY) - fltY);
+ {{type}} fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (fltY - ({{type}}) (intNortheastY));
+ {{type}} fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (fltY - ({{type}}) (intNorthwestY));
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOut)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intNorthwestY, intNorthwestX)], fltIn * fltNorthwest);
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOut)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intNortheastY, intNortheastX)], fltIn * fltNortheast);
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOut)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intSouthwestY, intSouthwestX)], fltIn * fltSouthwest);
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOut)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOut))) {
+ atomicAdd(&tenOut[OFFSET_4(tenOut, intN, intC, intSoutheastY, intSoutheastX)], fltIn * fltSoutheast);
+ }
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOut': tenOut
+ }))(
+ grid=tuple([int((tenOut.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenOut.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOut.data_ptr()],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+
+ elif tenIn.is_cuda != True:
+ assert(False)
+
+ # end
+
+ self.save_for_backward(tenIn, tenFlow)
+
+ return tenOut
+ # end
+
+ @staticmethod
+ @torch.cuda.amp.custom_bwd
+ def backward(self, tenOutgrad):
+ tenIn, tenFlow = self.saved_tensors
+
+ tenOutgrad = tenOutgrad.contiguous(); assert(tenOutgrad.is_cuda == True)
+
+ tenIngrad = tenIn.new_zeros([tenIn.shape[0], tenIn.shape[1], tenIn.shape[2], tenIn.shape[3]]) if self.needs_input_grad[0] == True else None
+ tenFlowgrad = tenFlow.new_zeros([tenFlow.shape[0], tenFlow.shape[1], tenFlow.shape[2], tenFlow.shape[3]]) if self.needs_input_grad[1] == True else None
+
+ if tenIngrad is not None:
+ cuda_launch(cuda_kernel('softsplat_ingrad', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_ingrad(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ const {{type}}* __restrict__ tenOutgrad,
+ {{type}}* __restrict__ tenIngrad,
+ {{type}}* __restrict__ tenFlowgrad
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenIngrad) / SIZE_2(tenIngrad) / SIZE_1(tenIngrad) ) % SIZE_0(tenIngrad);
+ const int intC = ( intIndex / SIZE_3(tenIngrad) / SIZE_2(tenIngrad) ) % SIZE_1(tenIngrad);
+ const int intY = ( intIndex / SIZE_3(tenIngrad) ) % SIZE_2(tenIngrad);
+ const int intX = ( intIndex ) % SIZE_3(tenIngrad);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltIngrad = 0.0f;
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (intSoutheastY) - fltY);
+ {{type}} fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (intSouthwestY) - fltY);
+ {{type}} fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (fltY - ({{type}}) (intNortheastY));
+ {{type}} fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (fltY - ({{type}}) (intNorthwestY));
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOutgrad)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intNorthwestY, intNorthwestX) * fltNorthwest;
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOutgrad)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intNortheastY, intNortheastX) * fltNortheast;
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOutgrad)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intSouthwestY, intSouthwestX) * fltSouthwest;
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOutgrad)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOutgrad))) {
+ fltIngrad += VALUE_4(tenOutgrad, intN, intC, intSoutheastY, intSoutheastX) * fltSoutheast;
+ }
+
+ tenIngrad[intIndex] = fltIngrad;
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOutgrad': tenOutgrad,
+ 'tenIngrad': tenIngrad,
+ 'tenFlowgrad': tenFlowgrad
+ }))(
+ grid=tuple([int((tenIngrad.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenIngrad.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOutgrad.data_ptr(), tenIngrad.data_ptr(), None],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+ # end
+
+ if tenFlowgrad is not None:
+ cuda_launch(cuda_kernel('softsplat_flowgrad', '''
+ extern "C" __global__ void __launch_bounds__(512) softsplat_flowgrad(
+ const int n,
+ const {{type}}* __restrict__ tenIn,
+ const {{type}}* __restrict__ tenFlow,
+ const {{type}}* __restrict__ tenOutgrad,
+ {{type}}* __restrict__ tenIngrad,
+ {{type}}* __restrict__ tenFlowgrad
+ ) { for (int intIndex = (blockIdx.x * blockDim.x) + threadIdx.x; intIndex < n; intIndex += blockDim.x * gridDim.x) {
+ const int intN = ( intIndex / SIZE_3(tenFlowgrad) / SIZE_2(tenFlowgrad) / SIZE_1(tenFlowgrad) ) % SIZE_0(tenFlowgrad);
+ const int intC = ( intIndex / SIZE_3(tenFlowgrad) / SIZE_2(tenFlowgrad) ) % SIZE_1(tenFlowgrad);
+ const int intY = ( intIndex / SIZE_3(tenFlowgrad) ) % SIZE_2(tenFlowgrad);
+ const int intX = ( intIndex ) % SIZE_3(tenFlowgrad);
+
+ assert(SIZE_1(tenFlow) == 2);
+
+ {{type}} fltFlowgrad = 0.0f;
+
+ {{type}} fltX = ({{type}}) (intX) + VALUE_4(tenFlow, intN, 0, intY, intX);
+ {{type}} fltY = ({{type}}) (intY) + VALUE_4(tenFlow, intN, 1, intY, intX);
+
+ if (isfinite(fltX) == false) { return; }
+ if (isfinite(fltY) == false) { return; }
+
+ int intNorthwestX = (int) (floor(fltX));
+ int intNorthwestY = (int) (floor(fltY));
+ int intNortheastX = intNorthwestX + 1;
+ int intNortheastY = intNorthwestY;
+ int intSouthwestX = intNorthwestX;
+ int intSouthwestY = intNorthwestY + 1;
+ int intSoutheastX = intNorthwestX + 1;
+ int intSoutheastY = intNorthwestY + 1;
+
+ {{type}} fltNorthwest = 0.0f;
+ {{type}} fltNortheast = 0.0f;
+ {{type}} fltSouthwest = 0.0f;
+ {{type}} fltSoutheast = 0.0f;
+
+ if (intC == 0) {
+ fltNorthwest = (({{type}}) (-1.0f)) * (({{type}}) (intSoutheastY) - fltY);
+ fltNortheast = (({{type}}) (+1.0f)) * (({{type}}) (intSouthwestY) - fltY);
+ fltSouthwest = (({{type}}) (-1.0f)) * (fltY - ({{type}}) (intNortheastY));
+ fltSoutheast = (({{type}}) (+1.0f)) * (fltY - ({{type}}) (intNorthwestY));
+
+ } else if (intC == 1) {
+ fltNorthwest = (({{type}}) (intSoutheastX) - fltX) * (({{type}}) (-1.0f));
+ fltNortheast = (fltX - ({{type}}) (intSouthwestX)) * (({{type}}) (-1.0f));
+ fltSouthwest = (({{type}}) (intNortheastX) - fltX) * (({{type}}) (+1.0f));
+ fltSoutheast = (fltX - ({{type}}) (intNorthwestX)) * (({{type}}) (+1.0f));
+
+ }
+
+ for (int intChannel = 0; intChannel < SIZE_1(tenOutgrad); intChannel += 1) {
+ {{type}} fltIn = VALUE_4(tenIn, intN, intChannel, intY, intX);
+
+ if ((intNorthwestX >= 0) && (intNorthwestX < SIZE_3(tenOutgrad)) && (intNorthwestY >= 0) && (intNorthwestY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intNorthwestY, intNorthwestX) * fltIn * fltNorthwest;
+ }
+
+ if ((intNortheastX >= 0) && (intNortheastX < SIZE_3(tenOutgrad)) && (intNortheastY >= 0) && (intNortheastY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intNortheastY, intNortheastX) * fltIn * fltNortheast;
+ }
+
+ if ((intSouthwestX >= 0) && (intSouthwestX < SIZE_3(tenOutgrad)) && (intSouthwestY >= 0) && (intSouthwestY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intSouthwestY, intSouthwestX) * fltIn * fltSouthwest;
+ }
+
+ if ((intSoutheastX >= 0) && (intSoutheastX < SIZE_3(tenOutgrad)) && (intSoutheastY >= 0) && (intSoutheastY < SIZE_2(tenOutgrad))) {
+ fltFlowgrad += VALUE_4(tenOutgrad, intN, intChannel, intSoutheastY, intSoutheastX) * fltIn * fltSoutheast;
+ }
+ }
+
+ tenFlowgrad[intIndex] = fltFlowgrad;
+ } }
+ ''', {
+ 'tenIn': tenIn,
+ 'tenFlow': tenFlow,
+ 'tenOutgrad': tenOutgrad,
+ 'tenIngrad': tenIngrad,
+ 'tenFlowgrad': tenFlowgrad
+ }))(
+ grid=tuple([int((tenFlowgrad.nelement() + 512 - 1) / 512), 1, 1]),
+ block=tuple([512, 1, 1]),
+ args=[cuda_int32(tenFlowgrad.nelement()), tenIn.data_ptr(), tenFlow.data_ptr(), tenOutgrad.data_ptr(), None, tenFlowgrad.data_ptr()],
+ stream=collections.namedtuple('Stream', 'ptr')(torch.cuda.current_stream().cuda_stream)
+ )
+ # end
+
+ return tenIngrad, tenFlowgrad
+ # end
+# end
diff --git a/util.py b/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..be2796bafffdc1b061aaca654b2fb1b7770dea16
--- /dev/null
+++ b/util.py
@@ -0,0 +1,12 @@
+import requests
+import zipfile
+
+def download_file(url, save_path):
+ response = requests.get(url)
+
+ with open(save_path, 'wb') as f:
+ f.write(response.content)
+
+def unzip_file(zip_path, extract_to):
+ with zipfile.ZipFile(zip_path, 'r') as zip_ref:
+ zip_ref.extractall(extract_to)
\ No newline at end of file
diff --git a/vtdm/callbacks.py b/vtdm/callbacks.py
new file mode 100644
index 0000000000000000000000000000000000000000..b96c935056eda83697f4016bc66fef95af7c8dfa
--- /dev/null
+++ b/vtdm/callbacks.py
@@ -0,0 +1,277 @@
+import argparse, os, sys, datetime, glob, importlib, csv
+import numpy as np
+import time
+import torch
+import torchvision
+import pytorch_lightning as pl
+
+from omegaconf import OmegaConf
+from PIL import Image
+from torchvision.utils import make_grid
+from einops import rearrange
+from logging import Logger
+from typing import Callable, Optional
+
+from pytorch_lightning.callbacks import Callback
+from pytorch_lightning.utilities import rank_zero_only
+from pytorch_lightning.utilities import rank_zero_info
+
+from vtdm.util import tensor2vid, export_to_video
+
+
+class SetupCallback(Callback):
+ def __init__(self, resume, now, logdir, ckptdir, cfgdir, config, lightning_config):
+ super().__init__()
+ self.resume = resume
+ self.now = now
+ self.logdir = logdir
+ self.ckptdir = ckptdir
+ self.cfgdir = cfgdir
+ self.config = config
+ self.lightning_config = lightning_config
+
+ def on_keyboard_interrupt(self, trainer, pl_module):
+ if trainer.global_rank == 0:
+ print("Summoning checkpoint.")
+ ckpt_path = os.path.join(self.ckptdir, "last.ckpt")
+ trainer.save_checkpoint(ckpt_path)
+
+ def on_pretrain_routine_start(self, trainer, pl_module):
+ #def on_fit_start(self, trainer, pl_module):
+ if trainer.global_rank == 0:
+ # Create logdirs and save configs
+ os.makedirs(self.logdir, exist_ok=True)
+ os.makedirs(self.ckptdir, exist_ok=True)
+ os.makedirs(self.cfgdir, exist_ok=True)
+
+ if "callbacks" in self.lightning_config:
+ if 'metrics_over_trainsteps_checkpoint' in self.lightning_config['callbacks']:
+ os.makedirs(os.path.join(self.ckptdir, 'trainstep_checkpoints'), exist_ok=True)
+ print("Project config")
+ print(OmegaConf.to_yaml(self.config))
+ OmegaConf.save(self.config, os.path.join(self.cfgdir, "{}-project.yaml".format(self.now)))
+
+ print("Lightning config")
+ print(OmegaConf.to_yaml(self.lightning_config))
+ OmegaConf.save(OmegaConf.create({"lightning": self.lightning_config}), os.path.join(self.cfgdir, "{}-lightning.yaml".format(self.now)))
+
+ else:
+ # ModelCheckpoint callback created log directory --- remove it
+ if not self.resume and os.path.exists(self.logdir):
+ dst, name = os.path.split(self.logdir)
+ dst = os.path.join(dst, "child_runs", name)
+ os.makedirs(os.path.split(dst)[0], exist_ok=True)
+ # try:
+ # os.rename(self.logdir, dst)
+ # except FileNotFoundError:
+ # pass
+
+
+class ImageLogger(Callback):
+ def __init__(self, batch_frequency=2000, max_images=4, clamp=True, increase_log_steps=True,
+ rescale=True, disabled=False, log_on_batch_idx=False, log_first_step=False,
+ log_images_kwargs=None):
+ super().__init__()
+ self.rescale = rescale
+ self.batch_freq = batch_frequency
+ self.max_images = max_images
+ if not increase_log_steps:
+ self.log_steps = [self.batch_freq]
+ self.clamp = clamp
+ self.disabled = disabled
+ self.log_on_batch_idx = log_on_batch_idx
+ self.log_images_kwargs = log_images_kwargs if log_images_kwargs else {}
+ self.log_first_step = log_first_step
+
+ @rank_zero_only
+ def log_local(self, save_dir, split, images, global_step, current_epoch, batch_idx):
+ root = os.path.join(save_dir, "image_log", split)
+ for k in images:
+ filename = "{}_gs-{:06}_e-{:06}_b-{:06}".format(k, global_step, current_epoch, batch_idx)
+ path = os.path.join(root, filename)
+ os.makedirs(os.path.split(path)[0], exist_ok=True)
+
+ if 'video' in k: # log to video
+ export_to_video(images[k], path + '.mp4', save_to_gif=False, use_cv2=False, fps=6)
+ else:
+ grid = torchvision.utils.make_grid(images[k], nrow=4)
+ if self.rescale:
+ grid = (grid + 1.0) / 2.0 # -1,1 -> 0,1; c,h,w
+ grid = grid.transpose(0, 1).transpose(1, 2).squeeze(-1)
+ grid = grid.numpy()
+ grid = (grid * 255).astype(np.uint8)
+ Image.fromarray(grid).save(path + '.png')
+
+ def log_img(self, pl_module, batch, batch_idx, split="train"):
+ check_idx = batch_idx # if self.log_on_batch_idx else pl_module.global_step
+ if (self.check_frequency(check_idx) and # batch_idx % self.batch_freq == 0
+ hasattr(pl_module, "log_images") and
+ callable(pl_module.log_images) and
+ self.max_images > 0):
+ logger = type(pl_module.logger)
+
+ is_train = pl_module.training
+ if is_train:
+ pl_module.eval()
+
+ with torch.no_grad():
+ images = pl_module.log_images(batch, split=split, **self.log_images_kwargs)
+
+ for k in images:
+ if 'video' in k: # log to video
+ images[k] = tensor2vid(images[k])
+ else:
+ images[k] = images[k].to(dtype=torch.float32)
+ N = min(images[k].shape[0], self.max_images)
+ images[k] = images[k][:N]
+ if isinstance(images[k], torch.Tensor):
+ images[k] = images[k].detach().cpu()
+ if self.clamp:
+ images[k] = torch.clamp(images[k], -1., 1.)
+
+ self.log_local(pl_module.logger.save_dir, split, images,
+ pl_module.global_step, pl_module.current_epoch, batch_idx)
+
+ if is_train:
+ pl_module.train()
+
+ def check_frequency(self, check_idx):
+ return check_idx % self.batch_freq == 0
+
+ def on_train_batch_end(self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx):
+ if not self.disabled:
+ self.log_img(pl_module, batch, batch_idx, split="train")
+
+
+class CUDACallback(Callback):
+ # see https://github.com/SeanNaren/minGPT/blob/master/mingpt/callback.py
+ def on_train_epoch_start(self, trainer, pl_module):
+ # Reset the memory use counter
+ torch.cuda.reset_peak_memory_stats(trainer.root_gpu)
+ torch.cuda.synchronize(trainer.root_gpu)
+ self.start_time = time.time()
+
+ def on_train_epoch_end(self, trainer, pl_module):
+ torch.cuda.synchronize(trainer.root_gpu)
+ max_memory = torch.cuda.max_memory_allocated(trainer.root_gpu) / 2 ** 20
+ epoch_time = time.time() - self.start_time
+
+ try:
+ max_memory = trainer.training_type_plugin.reduce(max_memory)
+ epoch_time = trainer.training_type_plugin.reduce(epoch_time)
+
+ rank_zero_info(f"Average Epoch time: {epoch_time:.2f} seconds")
+ rank_zero_info(f"Average Peak memory {max_memory:.2f} MiB")
+ except AttributeError:
+ pass
+
+
+class TextProgressBar(pl.callbacks.ProgressBarBase):
+
+ """A custom ProgressBar to log the training progress."""
+
+ def __init__(self, logger: Logger, refresh_rate: int = 50) -> None:
+ super().__init__()
+ self._logger = logger
+ self._refresh_rate = refresh_rate
+ self._enabled = True
+
+ # a time flag to indicate the beginning of an epoch
+ self._time = 0
+
+ @property
+ def refresh_rate(self) -> int:
+ return self._refresh_rate
+
+ @property
+ def is_enabled(self) -> bool:
+ return self._enabled
+
+ @property
+ def is_disabled(self) -> bool:
+ return not self.is_enabled
+
+ def disable(self) -> None:
+ # No need to disable the ProgressBar on processes with LOCAL_RANK != 1, because the
+ # StreamHandler of logging is disabled on these processes.
+ self._enabled = True
+
+ def enable(self) -> None:
+ self._enabled = True
+
+ @staticmethod
+ def _serialize_metrics(progressbar_log_dict: dict, filter_fn: Optional[Callable[[str], bool]] = None) -> str:
+ if filter_fn:
+ progressbar_log_dict = {k: v for k, v in progressbar_log_dict.items() if filter_fn(k)}
+ msg = ''
+ for metric, value in progressbar_log_dict.items():
+ if type(value) is str:
+ msg += f'{metric}: {value:.5f} '
+ elif 'acc' in metric:
+ msg += f'{metric}: {value:.3%} '
+ else:
+ msg += f'{metric}: {value:f} '
+ return msg
+
+ def on_train_start(self, trainer, pl_module):
+ super().on_train_start(trainer, pl_module)
+
+ def on_train_epoch_start(self, trainer, pl_module):
+ super().on_train_epoch_start(trainer, pl_module)
+ self._logger.info(f'Epoch: {trainer.current_epoch}, batch_num: {self.total_train_batches}')
+ self._time = time.time()
+
+ def on_train_batch_end(self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx):
+ # super().on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx, dataloader_idx)
+ super().on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
+ current = self.train_batch_idx
+ if self._should_update(current, self.total_train_batches):
+ batch_time = (time.time() - self._time) / self.train_batch_idx
+ msg = f'[Epoch {trainer.current_epoch}] [Batch {self.train_batch_idx}/{self.total_train_batches} {batch_time:.2f} s/batch] => '
+ if current != self.total_train_batches:
+ filter_fn = lambda x: not x.startswith('val') and not x.startswith('test') and not x.startswith('global') and not x.endswith('_epoch')
+ else:
+ filter_fn = lambda x: not x.startswith('val') and not x.startswith('test') and not x.startswith('global')
+ msg += self._serialize_metrics(trainer.progress_bar_metrics, filter_fn=filter_fn)
+ self._logger.info(msg)
+
+ def on_train_end(self, trainer, pl_module):
+ super().on_train_end(trainer, pl_module)
+ self._logger.info(f'Training finished.')
+
+ def on_validation_start(self, trainer, pl_module):
+ super().on_validation_start(trainer, pl_module)
+ self._logger.info('Validation Begins. Epoch: {}, val batch num: {}'.format(trainer.current_epoch, self.total_val_batches))
+
+ def on_validation_batch_end(self, trainer, pl_module, outputs, batch, batch_idx, dataloader_idx):
+ super().on_validation_batch_end(trainer, pl_module, outputs, batch, batch_idx, dataloader_idx)
+ current = self.val_batch_idx
+ if self._should_update(current, self.total_val_batches):
+ batch_time = (time.time() - self._time) / self.val_batch_idx
+ msg = f'[Epoch {trainer.current_epoch}] [Val Batch {self.val_batch_idx}/{self.total_val_batches} {batch_time:.2f} s/batch] => '
+ if current != self.total_val_batches:
+ filter_fn = lambda x: x.startswith('val') and not x.endswith('_epoch')
+ else:
+ filter_fn = lambda x: x.startswith('val')
+ msg += self._serialize_metrics(trainer.progress_bar_metrics, filter_fn=filter_fn)
+ self._logger.info(msg)
+
+ def on_validation_end(self, trainer, pl_module):
+ super().on_validation_end(trainer, pl_module)
+ msg = f'[Epoch {trainer.current_epoch}] [Validation finished] => '
+ msg += self._serialize_metrics(trainer.progress_bar_metrics, filter_fn=lambda x: x.startswith('val') and x.endswith('_epoch'))
+ self._logger.info(msg)
+
+ def get_metrics(self, trainer, pl_module):
+ items = super().get_metrics(trainer, pl_module)
+ # don't show the version number
+ items.pop("v_num", None)
+ return items
+
+ def _should_update(self, current: int, total: int) -> bool:
+ return self.is_enabled and (current % self.refresh_rate == 0 or current == total)
+
+ def print(self, *args, sep: str = " ", **kwargs):
+ s = sep.join(map(str, args))
+ self._logger.info(f"[Progress Print] {s}")
+
diff --git a/vtdm/degraded_images.py b/vtdm/degraded_images.py
new file mode 100644
index 0000000000000000000000000000000000000000..457ad77afd26844302890b1f848a8a538f9b9670
--- /dev/null
+++ b/vtdm/degraded_images.py
@@ -0,0 +1,189 @@
+import os
+# os.environ["CUDA_VISIBLE_DEVICES"] = "4"
+import re
+import cv2
+import einops
+import numpy as np
+import torch
+import random
+import math
+from PIL import Image, ImageDraw, ImageFont
+import shutil
+import glob
+from tqdm import tqdm
+import subprocess as sp
+import argparse
+
+import imageio
+import sys
+import json
+import datetime
+import string
+from dataset.opencv_transforms.functional import to_tensor, center_crop
+
+from pytorch_lightning import seed_everything
+from sgm.util import append_dims
+from sgm.util import autocast, instantiate_from_config
+from vtdm.model import create_model, load_state_dict
+from vtdm.util import tensor2vid, export_to_video
+
+from einops import rearrange
+
+import yaml
+import numpy as np
+import random
+import torch
+from basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
+from basicsr.data.transforms import paired_random_crop
+from basicsr.models.sr_model import SRModel
+from basicsr.utils import DiffJPEG, USMSharp
+from basicsr.utils.img_process_util import filter2D
+from basicsr.utils.registry import MODEL_REGISTRY
+from torch.nn import functional as F
+import torch.nn as nn
+
+class DegradedImages(torch.nn.Module):
+ def __init__(self, freeze=True):
+ super().__init__()
+
+ with open('configs/train_realesrnet_x4plus.yml', mode='r') as f:
+ opt = yaml.load(f, Loader=yaml.FullLoader)
+ self.opt = opt
+
+ @autocast
+ @torch.no_grad()
+ def forward(self, images, videos, masks, kernel1s, kernel2s, sinc_kernels):
+ '''
+ images: (2, 3, 1024, 1024) [-1, 1]
+ videos: (2, 3, 16, 1024, 1024) [-1, 1]
+ masks: (2, 16, 1024, 1024)
+ kernel1s, kernel2s, sinc_kernels: (2, 16, 21, 21)
+ '''
+ self.jpeger = DiffJPEG(differentiable=False).cuda()
+ B, C, H, W = images.shape
+ ori_h, ori_w = videos.size()[3:5]
+ videos = videos / 2.0 + 0.5
+ videos = rearrange(videos, 'b c t h w -> b t c h w') #(2, 16, 3, 1024, 1024)
+
+ all_lqs = []
+
+ for i in range(B):
+ kernel1 = kernel1s[i]
+ kernel2 = kernel2s[i]
+ sinc_kernel = sinc_kernels[i]
+
+ gt = videos[i] # (16, 3, 1024, 1024)
+ mask = masks[i] # (16, 1024, 1024)
+
+ # ----------------------- The first degradation process ----------------------- #
+ # blur
+ out = filter2D(gt, kernel1)
+ # random resize
+ updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
+ if updown_type == 'up':
+ scale = np.random.uniform(1, self.opt['resize_range'][1])
+ elif updown_type == 'down':
+ scale = np.random.uniform(self.opt['resize_range'][0], 1)
+ else:
+ scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, scale_factor=scale, mode=mode)
+ # add noise
+ gray_noise_prob = self.opt['gray_noise_prob']
+ if np.random.uniform() < self.opt['gaussian_noise_prob']:
+ out = random_add_gaussian_noise_pt(
+ out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
+ else:
+ out = random_add_poisson_noise_pt(
+ out,
+ scale_range=self.opt['poisson_scale_range'],
+ gray_prob=gray_noise_prob,
+ clip=True,
+ rounds=False)
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
+ out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
+ out = self.jpeger(out, quality=jpeg_p)
+
+ # ----------------------- The second degradation process ----------------------- #
+ # blur
+ if np.random.uniform() < self.opt['second_blur_prob']:
+ out = filter2D(out, kernel2)
+ # random resize
+ updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
+ if updown_type == 'up':
+ scale = np.random.uniform(1, self.opt['resize_range2'][1])
+ elif updown_type == 'down':
+ scale = np.random.uniform(self.opt['resize_range2'][0], 1)
+ else:
+ scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(
+ out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
+ # add noise
+ gray_noise_prob = self.opt['gray_noise_prob2']
+ if np.random.uniform() < self.opt['gaussian_noise_prob2']:
+ out = random_add_gaussian_noise_pt(
+ out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
+ else:
+ out = random_add_poisson_noise_pt(
+ out,
+ scale_range=self.opt['poisson_scale_range2'],
+ gray_prob=gray_noise_prob,
+ clip=True,
+ rounds=False)
+
+ # JPEG compression + the final sinc filter
+ # We also need to resize images to desired sizes. We group [resize back + sinc filter] together
+ # as one operation.
+ # We consider two orders:
+ # 1. [resize back + sinc filter] + JPEG compression
+ # 2. JPEG compression + [resize back + sinc filter]
+ # Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
+ if np.random.uniform() < 0.5:
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
+ out = filter2D(out, sinc_kernel)
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
+ out = torch.clamp(out, 0, 1)
+ out = self.jpeger(out, quality=jpeg_p)
+ else:
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
+ out = torch.clamp(out, 0, 1)
+ out = self.jpeger(out, quality=jpeg_p)
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
+ out = filter2D(out, sinc_kernel)
+
+ # clamp and round
+ lqs = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ lqs = F.interpolate(lqs, size=(ori_h, ori_w), mode=mode) # 16,3,1024,1024
+
+ lqs = rearrange(lqs, 't c h w -> t h w c') # 16, 1024, 1024, 3
+ for j in range(16):
+ lqs[j][mask[j]==0] = 1.0
+ all_lqs.append(lqs)
+
+ # import cv2
+ # gt1 = gt[0]
+ # lq1 = lqs[0]
+ # gt1 = rearrange(gt1, 'c h w -> h w c')
+
+ # gt1 = (gt1.cpu().numpy() * 255.).astype('uint8')
+ # lq1 = (lq1.cpu().numpy() * 255.).astype('uint8')
+ # cv2.imwrite(f'gt{i}.png', gt1)
+ # cv2.imwrite(f'lq{i}.png', lq1)
+
+
+ all_lqs = [(f - 0.5) * 2.0 for f in all_lqs]
+ all_lqs = torch.stack(all_lqs, 0) # 2, 16, 1024, 1024, 3
+ all_lqs = rearrange(all_lqs, 'b t h w c -> b t c h w')
+ for i in range(B):
+ all_lqs[i][0] = images[i]
+ all_lqs = rearrange(all_lqs, 'b t c h w -> (b t) c h w')
+ return all_lqs
\ No newline at end of file
diff --git a/vtdm/encoders.py b/vtdm/encoders.py
new file mode 100644
index 0000000000000000000000000000000000000000..50309442dd55d11e51736fdfa60d7008a979e38a
--- /dev/null
+++ b/vtdm/encoders.py
@@ -0,0 +1,91 @@
+import torch
+from annotator.midas.api import MiDaSInference
+from einops import rearrange, repeat
+from sgm.modules.encoders.modules import AbstractEmbModel
+from tools.aes_score import MLP, normalized
+import clip
+from sgm.modules.diffusionmodules.util import timestep_embedding
+from sgm.util import autocast, instantiate_from_config
+from torchvision.models.optical_flow import raft_large
+from typing import Any, Dict, List, Tuple, Union
+from tools.softmax_splatting.softsplat import softsplat
+from vtdm.model import create_model, load_state_dict
+
+
+class DepthEmbedder(AbstractEmbModel):
+ def __init__(self, freeze=True, use_3d=False, shuffle_size=3, scale_factor=2.6666, sample_frames=25):
+ super().__init__()
+ self.model = MiDaSInference(model_type="dpt_hybrid", model_path="ckpts/dpt_hybrid_384.pt").cuda()
+ self.use_3d = use_3d
+ self.shuffle_size = shuffle_size
+ self.scale_factor = scale_factor
+ if freeze:
+ self.freeze()
+
+ def freeze(self):
+ self.model = self.model.eval()
+ for param in self.parameters():
+ param.requires_grad = False
+
+ @autocast
+ @torch.no_grad()
+ def forward(self, x):
+ if len(x.shape) == 4: # (16, 3, 512, 512)
+ x = rearrange(x, '(b t) c h w -> b c t h w', t=25)
+ B, C, T, H, W = x.shape # (1, 3, 16, 1024, 1024)
+
+ sH = int(H / self.scale_factor / 32) * 32
+ sW = int(W / self.scale_factor / 32) * 32
+
+ y = rearrange(x, 'b c t h w -> (b t) c h w')
+ y = torch.nn.functional.interpolate(y, [sH, sW], mode='bilinear')
+ # y = torch.nn.functional.interpolate(y, [576, 1024], mode='bilinear')
+
+ y = self.model(y)
+ y = rearrange(y, 'b h w -> b 1 h w')
+ y = torch.nn.functional.interpolate(y, [H // 8 * self.shuffle_size, W // 8 * self.shuffle_size], mode='bilinear')
+ for i in range(y.shape[0]):
+ y[i] -= torch.min(y[i])
+ y[i] /= max(torch.max(y[i]).item(), 1e-6)
+ y = rearrange(y, 'b c (h h0) (w w0) -> b (c h0 w0) h w', h0=self.shuffle_size, w0=self.shuffle_size)
+ if self.use_3d:
+ y = rearrange(y, '(b t) c h w -> b c t h w', t=T)
+ return y
+
+
+class AesEmbedder(AbstractEmbModel):
+ def __init__(self, freeze=True):
+ super().__init__()
+ aesthetic_model, _ = clip.load("ckpts/ViT-L-14.pt")
+ del aesthetic_model.transformer
+ self.aesthetic_model = aesthetic_model
+ self.aesthetic_mlp = MLP(768)
+ self.aesthetic_mlp.load_state_dict(torch.load("ckpts/metric_models/sac+logos+ava1-l14-linearMSE.pth"))
+
+ if freeze:
+ self.freeze()
+
+ def freeze(self):
+ self.aesthetic_model = self.aesthetic_model.eval()
+ self.aesthetic_mlp = self.aesthetic_mlp.eval()
+ for param in self.parameters():
+ param.requires_grad = False
+
+ @autocast
+ @torch.no_grad()
+ def forward(self, x):
+ B, C, T, H, W = x.shape
+
+ y = x[:, :, T//2]
+ y = torch.nn.functional.interpolate(y, [224, 384], mode='bilinear')
+ y = y[:, :, :, 80:304]
+ y = (y + 1) * 0.5
+ y[:, 0] = (y[:, 0] - 0.48145466) / 0.26862954
+ y[:, 1] = (y[:, 1] - 0.4578275) / 0.26130258
+ y[:, 2] = (y[:, 2] - 0.40821073) / 0.27577711
+
+ image_features = self.aesthetic_model.encode_image(y)
+ im_emb_arr = normalized(image_features.cpu().detach().numpy())
+ aesthetic = self.aesthetic_mlp(torch.from_numpy(im_emb_arr).to('cuda').type(torch.cuda.FloatTensor))
+
+ return torch.cat([aesthetic, timestep_embedding(aesthetic[:, 0] * 100, 255)], 1)
\ No newline at end of file
diff --git a/vtdm/hack.py b/vtdm/hack.py
new file mode 100644
index 0000000000000000000000000000000000000000..b677ac2b9bc006160b5fe6c7e818745b0f25d34e
--- /dev/null
+++ b/vtdm/hack.py
@@ -0,0 +1,111 @@
+import torch
+import einops
+
+import sgm.modules.encoders.modules
+import sgm.modules.attention
+
+from transformers import logging
+from sgm.modules.attention import default
+
+
+def disable_verbosity():
+ logging.set_verbosity_error()
+ print('logging improved.')
+ return
+
+
+def enable_sliced_attention():
+ ldm.modules.attention.CrossAttention.forward = _hacked_sliced_attentin_forward
+ print('Enabled sliced_attention.')
+ return
+
+
+def hack_everything(clip_skip=0):
+ disable_verbosity()
+ ldm.modules.encoders.modules.FrozenCLIPEmbedder.forward = _hacked_clip_forward
+ ldm.modules.encoders.modules.FrozenCLIPEmbedder.clip_skip = clip_skip
+ print('Enabled clip hacks.')
+ return
+
+
+# Written by Lvmin
+def _hacked_clip_forward(self, text):
+ PAD = self.tokenizer.pad_token_id
+ EOS = self.tokenizer.eos_token_id
+ BOS = self.tokenizer.bos_token_id
+
+ def tokenize(t):
+ return self.tokenizer(t, truncation=False, add_special_tokens=False)["input_ids"]
+
+ def transformer_encode(t):
+ if self.clip_skip > 1:
+ rt = self.transformer(input_ids=t, output_hidden_states=True)
+ return self.transformer.text_model.final_layer_norm(rt.hidden_states[-self.clip_skip])
+ else:
+ return self.transformer(input_ids=t, output_hidden_states=False).last_hidden_state
+
+ def split(x):
+ return x[75 * 0: 75 * 1], x[75 * 1: 75 * 2], x[75 * 2: 75 * 3]
+
+ def pad(x, p, i):
+ return x[:i] if len(x) >= i else x + [p] * (i - len(x))
+
+ raw_tokens_list = tokenize(text)
+ tokens_list = []
+
+ for raw_tokens in raw_tokens_list:
+ raw_tokens_123 = split(raw_tokens)
+ raw_tokens_123 = [[BOS] + raw_tokens_i + [EOS] for raw_tokens_i in raw_tokens_123]
+ raw_tokens_123 = [pad(raw_tokens_i, PAD, 77) for raw_tokens_i in raw_tokens_123]
+ tokens_list.append(raw_tokens_123)
+
+ tokens_list = torch.IntTensor(tokens_list).to(self.device)
+
+ feed = einops.rearrange(tokens_list, 'b f i -> (b f) i')
+ y = transformer_encode(feed)
+ z = einops.rearrange(y, '(b f) i c -> b (f i) c', f=3)
+
+ return z
+
+
+# Stolen from https://github.com/basujindal/stable-diffusion/blob/main/optimizedSD/splitAttention.py
+def _hacked_sliced_attentin_forward(self, x, context=None, mask=None):
+ h = self.heads
+
+ q = self.to_q(x)
+ context = default(context, x)
+ k = self.to_k(context)
+ v = self.to_v(context)
+ del context, x
+
+ q, k, v = map(lambda t: einops.rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
+
+ limit = k.shape[0]
+ att_step = 1
+ q_chunks = list(torch.tensor_split(q, limit // att_step, dim=0))
+ k_chunks = list(torch.tensor_split(k, limit // att_step, dim=0))
+ v_chunks = list(torch.tensor_split(v, limit // att_step, dim=0))
+
+ q_chunks.reverse()
+ k_chunks.reverse()
+ v_chunks.reverse()
+ sim = torch.zeros(q.shape[0], q.shape[1], v.shape[2], device=q.device)
+ del k, q, v
+ for i in range(0, limit, att_step):
+ q_buffer = q_chunks.pop()
+ k_buffer = k_chunks.pop()
+ v_buffer = v_chunks.pop()
+ sim_buffer = torch.einsum('b i d, b j d -> b i j', q_buffer, k_buffer) * self.scale
+
+ del k_buffer, q_buffer
+ # attention, what we cannot get enough of, by chunks
+
+ sim_buffer = sim_buffer.softmax(dim=-1)
+
+ sim_buffer = torch.einsum('b i j, b j d -> b i d', sim_buffer, v_buffer)
+ del v_buffer
+ sim[i:i + att_step, :, :] = sim_buffer
+
+ del sim_buffer
+ sim = einops.rearrange(sim, '(b h) n d -> b n (h d)', h=h)
+ return self.to_out(sim)
diff --git a/vtdm/logger.py b/vtdm/logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..74eddd725c73339c4c8e9361fe0f8d2687bfbb3a
--- /dev/null
+++ b/vtdm/logger.py
@@ -0,0 +1,83 @@
+import functools
+import logging
+import os
+import sys
+from termcolor import colored
+
+
+class _ColorfulFormatter(logging.Formatter):
+ def __init__(self, *args, **kwargs):
+ self._root_name = kwargs.pop("root_name") + "."
+ self._abbrev_name = kwargs.pop("abbrev_name", "")
+ if len(self._abbrev_name):
+ self._abbrev_name = self._abbrev_name + "."
+ super(_ColorfulFormatter, self).__init__(*args, **kwargs)
+
+ def formatMessage(self, record):
+ record.name = record.name.replace(self._root_name, self._abbrev_name)
+ log = super(_ColorfulFormatter, self).formatMessage(record)
+ if record.levelno == logging.WARNING:
+ prefix = colored("WARNING", "red", attrs=["blink"])
+ elif record.levelno == logging.ERROR or record.levelno == logging.CRITICAL:
+ prefix = colored("ERROR", "red", attrs=["blink", "underline"])
+ else:
+ return log
+ return prefix + " " + log
+
+
+# so that calling setup_logger multiple times won't add many handlers
+@functools.lru_cache()
+def setup_logger(
+ output=None, distributed_rank=0, *, color=True, name="video-diffusion", abbrev_name=None
+):
+ logger = logging.getLogger(name)
+ logger.setLevel(logging.DEBUG)
+ logger.propagate = False
+
+ if abbrev_name is None:
+ abbrev_name = name
+
+ plain_formatter = logging.Formatter(
+ "[%(asctime)s] %(name)s %(levelname)s: %(message)s", datefmt="%m/%d %H:%M:%S"
+ )
+ # stdout logging: master only
+ if distributed_rank == 0:
+ ch = logging.StreamHandler(stream=sys.stdout)
+ ch.setLevel(logging.DEBUG)
+ if color:
+ formatter = _ColorfulFormatter(
+ colored("[%(asctime)s %(name)s]: ", "green") + "%(message)s",
+ datefmt="%m/%d %H:%M:%S",
+ root_name=name,
+ abbrev_name=str(abbrev_name),
+ )
+ else:
+ formatter = plain_formatter
+ ch.setFormatter(formatter)
+ logger.addHandler(ch)
+
+ # file logging: all workers
+ if output is not None:
+ if output.endswith(".txt") or output.endswith(".log"):
+ filename = output
+ else:
+ filename = os.path.join(output, "log.txt")
+
+ #if distributed_rank > 0:
+ # filename = filename + ".rank{}".format(distributed_rank)
+ #os.makedirs(os.path.dirname(filename), exist_ok=True)
+
+ fh = logging.StreamHandler(_cached_log_stream(filename))
+ fh.setLevel(logging.DEBUG)
+ fh.setFormatter(plain_formatter)
+ logger.addHandler(fh)
+
+ return logger
+
+
+# cache the opened file object, so that different calls to `setup_logger`
+# with the same file name can safely write to the same file.
+@functools.lru_cache(maxsize=None)
+def _cached_log_stream(filename):
+ return open(filename, "a")
+
diff --git a/vtdm/model.py b/vtdm/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..90c9e8faf10ba714d72e3d4cebeff3679838dda5
--- /dev/null
+++ b/vtdm/model.py
@@ -0,0 +1,28 @@
+import os
+import torch
+
+from omegaconf import OmegaConf
+from sgm.util import instantiate_from_config
+
+
+def get_state_dict(d):
+ return d.get('state_dict', d)
+
+
+def load_state_dict(ckpt_path, location='cpu'):
+ _, extension = os.path.splitext(ckpt_path)
+ if extension.lower() == ".safetensors":
+ import safetensors.torch
+ state_dict = safetensors.torch.load_file(ckpt_path, device=location)
+ else:
+ state_dict = get_state_dict(torch.load(ckpt_path, map_location=torch.device(location)))
+ state_dict = get_state_dict(state_dict)
+ print(f'Loaded state_dict from [{ckpt_path}]')
+ return state_dict
+
+
+def create_model(config_path):
+ config = OmegaConf.load(config_path)
+ model = instantiate_from_config(config.model).cpu()
+ print(f'Loaded model config from [{config_path}]')
+ return model
diff --git a/vtdm/util.py b/vtdm/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..1dd4df5ead20decf46a207d7f7a5524454e3aceb
--- /dev/null
+++ b/vtdm/util.py
@@ -0,0 +1,50 @@
+import torch
+import cv2
+import numpy as np
+import imageio
+import torchvision
+import math
+
+from einops import rearrange
+from typing import List
+
+from PIL import Image, ImageDraw, ImageFont
+
+def tensor2vid(video: torch.Tensor, mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) -> List[np.ndarray]:
+ mean = torch.tensor(mean, device=video.device).reshape(1, -1, 1, 1, 1) # ncfhw
+ std = torch.tensor(std, device=video.device).reshape(1, -1, 1, 1, 1) # ncfhw
+ video = video.mul_(std).add_(mean) # unnormalize back to [0,1]
+ video.clamp_(0, 1)
+ images = rearrange(video, 'i c f h w -> (i f) h w c')
+ images = images.unbind(dim=0)
+ images = [(image.cpu().numpy() * 255).astype('uint8') for image in images] # f h w c
+ return images
+
+
+def export_to_video(video_frames: List[np.ndarray], output_video_path: str = None, save_to_gif=False, use_cv2=True, fps=8) -> str:
+ h, w, c = video_frames[0].shape
+ if save_to_gif:
+ image_lst = []
+ if output_video_path.endswith('mp4'):
+ output_video_path = output_video_path[:-3] + 'gif'
+ for i in range(len(video_frames)):
+ image_lst.append(video_frames[i])
+ imageio.mimsave(output_video_path, image_lst, fps=fps)
+ return output_video_path
+ else:
+ if use_cv2:
+ fourcc = cv2.VideoWriter_fourcc(*"mp4v")
+ video_writer = cv2.VideoWriter(output_video_path, fourcc, fps=fps, frameSize=(w, h))
+ for i in range(len(video_frames)):
+ img = cv2.cvtColor(video_frames[i], cv2.COLOR_RGB2BGR)
+ video_writer.write(img)
+ video_writer.release()
+ else:
+ duration = math.ceil(len(video_frames) / fps)
+ append_num = duration * fps - len(video_frames)
+ for k in range(append_num): video_frames.append(video_frames[-1])
+ video_stack = np.stack(video_frames, axis=0)
+ video_tensor = torch.from_numpy(video_stack)
+ # torchvision.io.write_video(output_video_path, video_tensor, fps=fps, options={"crf": "17"})
+ torchvision.io.write_video(output_video_path, video_tensor, fps=fps, options={"crf": "17"})
+ return output_video_path
\ No newline at end of file
diff --git a/vtdm/vtdm_gen_stage2_degradeImage.py b/vtdm/vtdm_gen_stage2_degradeImage.py
new file mode 100644
index 0000000000000000000000000000000000000000..dd7269e23f34dd70951cf4b15dd42f6dc01fbf96
--- /dev/null
+++ b/vtdm/vtdm_gen_stage2_degradeImage.py
@@ -0,0 +1,213 @@
+import einops
+import torch
+import torch as th
+import torch.nn as nn
+import os
+from typing import Any, Dict, List, Tuple, Union
+
+from sgm.modules.diffusionmodules.util import (
+ conv_nd,
+ linear,
+ zero_module,
+ timestep_embedding,
+)
+
+from einops import rearrange, repeat
+from torchvision.utils import make_grid
+from sgm.modules.attention import SpatialTransformer
+from sgm.modules.diffusionmodules.openaimodel import UNetModel, TimestepEmbedSequential, Downsample, ResBlock, AttentionBlock
+from sgm.models.diffusion import DiffusionEngine
+from sgm.util import log_txt_as_img, exists, instantiate_from_config
+from safetensors.torch import load_file as load_safetensors
+from .model import load_state_dict
+from .degraded_images import DegradedImages
+
+class VideoLDM(DiffusionEngine):
+ def __init__(self, num_samples, trained_param_keys=[''], *args, **kwargs):
+ self.trained_param_keys = trained_param_keys
+ super().__init__(*args, **kwargs)
+ self.num_samples = num_samples
+
+ # self.warp_model = FirstFrameFlowWarper(freeze=True)
+ self.warp_model = DegradedImages(freeze=True)
+ # self.warp_model = FirstFrameFlowWarper(freeze=True)
+
+ def init_from_ckpt(
+ self,
+ path: str,
+ ) -> None:
+ if path.endswith("ckpt"):
+ sd = torch.load(path, map_location="cpu")
+ if "state_dict" in sd:
+ sd = sd["state_dict"]
+ elif path.endswith("pt"):
+ sd_raw = torch.load(path, map_location="cpu")
+ sd = {}
+ for k in sd_raw['module']:
+ sd[k[len('module.'):]] = sd_raw['module'][k]
+ elif path.endswith("safetensors"):
+ sd = load_safetensors(path)
+ else:
+ raise NotImplementedError
+
+ missing, unexpected = self.load_state_dict(sd, strict=False)
+ print(
+ f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys"
+ )
+ if len(missing) > 0:
+ print(f"Missing Keys: {missing}")
+ if len(unexpected) > 0:
+ print(f"Unexpected Keys: {unexpected}")
+
+ @torch.no_grad()
+ def add_custom_cond(self, batch, infer=False):
+ batch['num_video_frames'] = self.num_samples
+
+ image = batch['video'][:, :, 0] # (1, 3, 16, 1024, 1024)
+ batch['cond_frames_without_noise'] = image.half()
+
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ if not infer:
+ video_warp = self.warp_model(image, batch['video'], batch['masks'], batch['kernel1s'], batch['kernel2s'], batch['sinc_kernels']) # (16, 3, 512, 512)
+ else:
+ video_warp = rearrange(batch['video'], 'b c t h w -> (b t) c h w')
+
+ N = batch['video'].shape[0]
+ if not infer:
+ cond_aug = ((-3.0) + (0.5) * torch.randn((N,))).exp().cuda().half()
+ else:
+ cond_aug = torch.full((N, ), 0.02).cuda().half()
+ batch['cond_aug'] = cond_aug
+ batch['cond_frames'] = (video_warp + rearrange(repeat(cond_aug, "b -> (b t)", t=self.num_samples), 'b -> b 1 1 1') * torch.randn_like(video_warp)).half()
+
+ # for dataset without indicator
+ if not 'image_only_indicator' in batch:
+ batch['image_only_indicator'] = torch.zeros((N, self.num_samples)).cuda().half()
+ return batch
+
+ def shared_step(self, batch: Dict) -> Any:
+ frames = self.get_input(batch) # b c t h w
+ batch = self.add_custom_cond(batch)
+
+ frames_reshape = rearrange(frames, 'b c t h w -> (b t) c h w')
+ x = self.encode_first_stage(frames_reshape)
+
+ batch["global_step"] = self.global_step
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ loss, loss_dict = self(x, batch)
+ return loss, loss_dict
+
+ @torch.no_grad()
+ def log_images(
+ self,
+ batch: Dict,
+ N: int = 8,
+ sample: bool = True,
+ ucg_keys: List[str] = None,
+ **kwargs,
+ ) -> Dict:
+ conditioner_input_keys = [e.input_key for e in self.conditioner.embedders]
+ if ucg_keys:
+ assert all(map(lambda x: x in conditioner_input_keys, ucg_keys)), (
+ "Each defined ucg key for sampling must be in the provided conditioner input keys,"
+ f"but we have {ucg_keys} vs. {conditioner_input_keys}"
+ )
+ else:
+ ucg_keys = conditioner_input_keys
+ log = dict()
+
+ frames = self.get_input(batch)
+ batch = self.add_custom_cond(batch, infer=False)
+ N = min(frames.shape[0], N)
+ frames = frames[:N]
+ x = rearrange(frames, 'b c t h w -> (b t) c h w')
+
+ c, uc = self.conditioner.get_unconditional_conditioning(
+ batch,
+ force_uc_zero_embeddings=ucg_keys
+ if len(self.conditioner.embedders) > 0
+ else [],
+ )
+
+ sampling_kwargs = {}
+
+ aes = c['vector'][:, -256-256]
+ caption = batch['caption'][:N]
+ for idx in range(N):
+ sub_str = str(aes[idx].item())
+ caption[idx] = sub_str + '\n' + caption[idx]
+
+ x = x.to(self.device)
+
+ z = self.encode_first_stage(x.half())
+ x_rec = self.decode_first_stage(z.half())
+ log["reconstructions-video"] = rearrange(x_rec, '(b t) c h w -> b c t h w', t=self.num_samples)
+ log["conditioning"] = log_txt_as_img((512, 512), caption, size=16)
+ x_d = c['concat'][:, :9] # (16, 9, 64, 64) (0-1)
+ x_d = rearrange(x_d, 'b (c h0 w0) h w -> b c (h h0) (w w0)', h0=3, w0=3)
+ log["depth-video"] = rearrange(x_d.repeat([1, 3, 1, 1]) * 2.0 - 1.0, '(b t) c h w -> b c t h w', t=self.num_samples)
+
+ x_cond = self.decode_first_stage(c['concat'][:, 9:].half() * self.scale_factor)
+ log["cond-video"] = rearrange(x_cond, '(b t) c h w -> b c t h w', t=self.num_samples)
+
+ for k in c:
+ if isinstance(c[k], torch.Tensor):
+ if k == 'concat':
+ c[k], uc[k] = map(lambda y: y[k][:N * self.num_samples].to(self.device), (c, uc))
+ else:
+ c[k], uc[k] = map(lambda y: y[k][:N].to(self.device), (c, uc))
+
+ additional_model_inputs = {}
+ additional_model_inputs["image_only_indicator"] = torch.zeros(
+ N * 2, self.num_samples
+ ).to(self.device)
+ additional_model_inputs["num_video_frames"] = batch["num_video_frames"]
+ def denoiser(input, sigma, c):
+ return self.denoiser(
+ self.model, input, sigma, c, **additional_model_inputs
+ )
+
+ if sample:
+ with self.ema_scope("Plotting"):
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ randn = torch.randn(z.shape, device=self.device)
+ samples = self.sampler(denoiser, randn, cond=c, uc=uc)
+ samples = self.decode_first_stage(samples.half())
+ log["samples-video"] = rearrange(samples, '(b t) c h w -> b c t h w', t=self.num_samples)
+ return log
+
+ def configure_optimizers(self):
+ lr = self.learning_rate
+ if 'all' in self.trained_param_keys:
+ params = list(self.model.parameters())
+ else:
+ names = []
+ params = []
+ for name, param in self.model.named_parameters():
+ flag = False
+ for k in self.trained_param_keys:
+ if k in name:
+ names += [name]
+ params += [param]
+ flag = True
+ if flag:
+ break
+ print(names)
+
+ for embedder in self.conditioner.embedders:
+ if embedder.is_trainable:
+ params = params + list(embedder.parameters())
+
+ opt = self.instantiate_optimizer_from_config(params, lr, self.optimizer_config)
+ if self.scheduler_config is not None:
+ scheduler = instantiate_from_config(self.scheduler_config)
+ print("Setting up LambdaLR scheduler...")
+ scheduler = [
+ {
+ "scheduler": LambdaLR(opt, lr_lambda=scheduler.schedule),
+ "interval": "step",
+ "frequency": 1,
+ }
+ ]
+ return [opt], scheduler
+ return opt
diff --git a/vtdm/vtdm_gen_v01.py b/vtdm/vtdm_gen_v01.py
new file mode 100644
index 0000000000000000000000000000000000000000..8df31aee493138ddbe25bd9b9a171d355c60638b
--- /dev/null
+++ b/vtdm/vtdm_gen_v01.py
@@ -0,0 +1,201 @@
+import einops
+import torch
+import torch as th
+import torch.nn as nn
+import os
+from typing import Any, Dict, List, Tuple, Union
+
+from sgm.modules.diffusionmodules.util import (
+ conv_nd,
+ linear,
+ zero_module,
+ timestep_embedding,
+)
+
+from einops import rearrange, repeat
+from torchvision.utils import make_grid
+from sgm.modules.attention import SpatialTransformer
+from sgm.modules.diffusionmodules.openaimodel import UNetModel, TimestepEmbedSequential, Downsample, ResBlock, AttentionBlock
+from sgm.models.diffusion import DiffusionEngine
+from sgm.util import log_txt_as_img, exists, instantiate_from_config
+from safetensors.torch import load_file as load_safetensors
+from .model import load_state_dict
+
+class VideoLDM(DiffusionEngine):
+ def __init__(self, num_samples, trained_param_keys=[''], *args, **kwargs):
+ self.trained_param_keys = trained_param_keys
+ super().__init__(*args, **kwargs)
+ self.num_samples = num_samples
+
+ def init_from_ckpt(
+ self,
+ path: str,
+ ) -> None:
+ if path.endswith("ckpt"):
+ sd = torch.load(path, map_location="cpu")
+ if "state_dict" in sd:
+ sd = sd["state_dict"]
+ elif path.endswith("pt"):
+ sd_raw = torch.load(path, map_location="cpu")
+ sd = {}
+ for k in sd_raw['module']:
+ sd[k[len('module.'):]] = sd_raw['module'][k]
+ elif path.endswith("safetensors"):
+ sd = load_safetensors(path)
+ else:
+ raise NotImplementedError
+
+ # missing, unexpected = self.load_state_dict(sd, strict=True)
+ missing, unexpected = self.load_state_dict(sd, strict=False)
+ print(
+ f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys"
+ )
+ if len(missing) > 0:
+ print(f"Missing Keys: {missing}")
+ if len(unexpected) > 0:
+ print(f"Unexpected Keys: {unexpected}")
+
+ @torch.no_grad()
+ def add_custom_cond(self, batch, infer=False):
+ batch['num_video_frames'] = self.num_samples
+
+ image = batch['video'][:, :, 0]
+ batch['cond_frames_without_noise'] = image.half()
+
+ N = batch['video'].shape[0]
+ if not infer:
+ cond_aug = ((-3.0) + (0.5) * torch.randn((N,))).exp().cuda().half()
+ else:
+ cond_aug = torch.full((N, ), 0.02).cuda().half()
+ batch['cond_aug'] = cond_aug
+ batch['cond_frames'] = (image + rearrange(cond_aug, 'b -> b 1 1 1') * torch.randn_like(image)).half()
+
+ # for dataset without indicator
+ if not 'image_only_indicator' in batch:
+ batch['image_only_indicator'] = torch.zeros((N, self.num_samples)).cuda().half()
+ return batch
+
+ def shared_step(self, batch: Dict) -> Any:
+ frames = self.get_input(batch) # b c t h w
+ batch = self.add_custom_cond(batch)
+
+ frames_reshape = rearrange(frames, 'b c t h w -> (b t) c h w')
+ x = self.encode_first_stage(frames_reshape)
+
+ batch["global_step"] = self.global_step
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ loss, loss_dict = self(x, batch)
+ return loss, loss_dict
+
+ @torch.no_grad()
+ def log_images(
+ self,
+ batch: Dict,
+ N: int = 8,
+ sample: bool = True,
+ ucg_keys: List[str] = None,
+ **kwargs,
+ ) -> Dict:
+ conditioner_input_keys = [e.input_key for e in self.conditioner.embedders]
+ if ucg_keys:
+ assert all(map(lambda x: x in conditioner_input_keys, ucg_keys)), (
+ "Each defined ucg key for sampling must be in the provided conditioner input keys,"
+ f"but we have {ucg_keys} vs. {conditioner_input_keys}"
+ )
+ else:
+ ucg_keys = conditioner_input_keys
+ log = dict()
+
+ frames = self.get_input(batch)
+ batch = self.add_custom_cond(batch, infer=True)
+ N = min(frames.shape[0], N)
+ frames = frames[:N]
+ x = rearrange(frames, 'b c t h w -> (b t) c h w')
+
+ c, uc = self.conditioner.get_unconditional_conditioning(
+ batch,
+ force_uc_zero_embeddings=ucg_keys
+ if len(self.conditioner.embedders) > 0
+ else [],
+ )
+
+ sampling_kwargs = {}
+
+ aes = c['vector'][:, -256-256-256]
+ cm1 = c['vector'][:, -256-256]
+ cm2 = c['vector'][:, -256-192]
+ cm3 = c['vector'][:, -256-128]
+ cm4 = c['vector'][:, -256-64]
+ caption = batch['caption'][:N]
+ for idx in range(N):
+ sub_str = str(aes[idx].item()) + '\n' + str(cm1[idx].item()) + '\n' + str(cm2[idx].item()) + '\n' + str(cm3[idx].item()) + '\n' + str(cm4[idx].item())
+ caption[idx] = sub_str + '\n' + caption[idx]
+
+ x = x.to(self.device)
+
+ z = self.encode_first_stage(x.half())
+ x_rec = self.decode_first_stage(z.half())
+ log["reconstructions-video"] = rearrange(x_rec, '(b t) c h w -> b c t h w', t=self.num_samples)
+ log["conditioning"] = log_txt_as_img((512, 512), caption, size=16)
+
+ for k in c:
+ if isinstance(c[k], torch.Tensor):
+ if k == 'concat':
+ c[k], uc[k] = map(lambda y: y[k][:N * self.num_samples].to(self.device), (c, uc))
+ else:
+ c[k], uc[k] = map(lambda y: y[k][:N].to(self.device), (c, uc))
+
+ additional_model_inputs = {}
+ additional_model_inputs["image_only_indicator"] = torch.zeros(
+ N * 2, self.num_samples
+ ).to(self.device)
+ additional_model_inputs["num_video_frames"] = batch["num_video_frames"]
+ def denoiser(input, sigma, c):
+ return self.denoiser(
+ self.model, input, sigma, c, **additional_model_inputs
+ )
+
+ if sample:
+ with self.ema_scope("Plotting"):
+ with torch.autocast(device_type='cuda', dtype=torch.float16):
+ randn = torch.randn(z.shape, device=self.device)
+ samples = self.sampler(denoiser, randn, cond=c, uc=uc)
+ samples = self.decode_first_stage(samples.half())
+ log["samples-video"] = rearrange(samples, '(b t) c h w -> b c t h w', t=self.num_samples)
+ return log
+
+ def configure_optimizers(self):
+ lr = self.learning_rate
+ if 'all' in self.trained_param_keys:
+ params = list(self.model.parameters())
+ else:
+ names = []
+ params = []
+ for name, param in self.model.named_parameters():
+ flag = False
+ for k in self.trained_param_keys:
+ if k in name:
+ names += [name]
+ params += [param]
+ flag = True
+ if flag:
+ break
+ print(names)
+
+ for embedder in self.conditioner.embedders:
+ if embedder.is_trainable:
+ params = params + list(embedder.parameters())
+
+ opt = self.instantiate_optimizer_from_config(params, lr, self.optimizer_config)
+ if self.scheduler_config is not None:
+ scheduler = instantiate_from_config(self.scheduler_config)
+ print("Setting up LambdaLR scheduler...")
+ scheduler = [
+ {
+ "scheduler": LambdaLR(opt, lr_lambda=scheduler.schedule),
+ "interval": "step",
+ "frequency": 1,
+ }
+ ]
+ return [opt], scheduler
+ return opt