Spaces:
Running

Running

Upload 9 files
Browse files- .gitattributes +1 -0
- app.py +85 -0
- testcases/bigtitle.png +0 -0
- testcases/formaterror.png +0 -0
- testcases/greybackground.png +0 -0
- testcases/original.png +0 -0
- testcases/wiki-color.png +3 -0
- testcases/wiki-font.png +0 -0
- testcases/wiki-layout.png +0 -0
- testcases/wiki-original.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
testcases/wiki-color.png filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from transformers import CLIPProcessor, CLIPModel
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
# Load the original CLIP model and processor
|
| 8 |
+
model_original = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
|
| 9 |
+
processor_original = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
| 10 |
+
|
| 11 |
+
# Load the custom variants of the CLIP model
|
| 12 |
+
model_variant_1 = CLIPModel.from_pretrained("biglab/uiclip_jitteredwebsites-2-224-paraphrased")
|
| 13 |
+
model_variant_2 = CLIPModel.from_pretrained("biglab/uiclip_jitteredwebsites-2-224-paraphrased_webpairs")
|
| 14 |
+
model_variant_3 = CLIPModel.from_pretrained("biglab/uiclip_jitteredwebsites-2-224-paraphrased_webpairs_humanpairs")
|
| 15 |
+
|
| 16 |
+
# Define the function to process inputs and run inference with all four models
|
| 17 |
+
def clip_predict_comparison(image1, image2, text):
|
| 18 |
+
# Preprocess the image and text inputs using the original processor for all models
|
| 19 |
+
inputs_1 = processor_original(text=[text], images=image1, return_tensors="pt")
|
| 20 |
+
inputs_2 = processor_original(text=[text], images=image2, return_tensors="pt")
|
| 21 |
+
|
| 22 |
+
def compute_similarity_with_softmax(model, inputs_1, inputs_2):
|
| 23 |
+
# Compute similarity for image 1
|
| 24 |
+
with torch.no_grad():
|
| 25 |
+
outputs_image1 = model(**inputs_1)
|
| 26 |
+
similarity_image1 = outputs_image1.logits_per_image.item()
|
| 27 |
+
|
| 28 |
+
# Compute similarity for image 2
|
| 29 |
+
with torch.no_grad():
|
| 30 |
+
outputs_image2 = model(**inputs_2)
|
| 31 |
+
similarity_image2 = outputs_image2.logits_per_image.item()
|
| 32 |
+
|
| 33 |
+
# Apply softmax to normalize the scores between the two images
|
| 34 |
+
similarities = torch.tensor([similarity_image1, similarity_image2])
|
| 35 |
+
normalized_scores = F.softmax(similarities, dim=0)
|
| 36 |
+
|
| 37 |
+
result = f"Image 1: {normalized_scores[0].item():.4f}, Image 2: {normalized_scores[1].item():.4f}"
|
| 38 |
+
|
| 39 |
+
return normalized_scores[0].item(), normalized_scores[1].item(), result
|
| 40 |
+
|
| 41 |
+
# Compute similarities for all four models
|
| 42 |
+
similarity_original_1, similarity_original_2, result_original = compute_similarity_with_softmax(model_original, inputs_1, inputs_2)
|
| 43 |
+
similarity_variant_1_1, similarity_variant_1_2, result_variant_1 = compute_similarity_with_softmax(model_variant_1, inputs_1, inputs_2)
|
| 44 |
+
similarity_variant_2_1, similarity_variant_2_2, result_variant_2 = compute_similarity_with_softmax(model_variant_2, inputs_1, inputs_2)
|
| 45 |
+
similarity_variant_3_1, similarity_variant_3_2, result_variant_3 = compute_similarity_with_softmax(model_variant_3, inputs_1, inputs_2)
|
| 46 |
+
|
| 47 |
+
# Return the normalized similarity scores from all models along with the comparison result
|
| 48 |
+
return (
|
| 49 |
+
f"Original CLIP: {result_original}",
|
| 50 |
+
f"UIClip: {result_variant_1}",
|
| 51 |
+
f"UIClip + Webpairs: {result_variant_2}",
|
| 52 |
+
f"UIClip + Webpairs + Humanpairs: {result_variant_3}"
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
# Example inputs (paths to image files and corresponding text descriptions)
|
| 56 |
+
examples = [
|
| 57 |
+
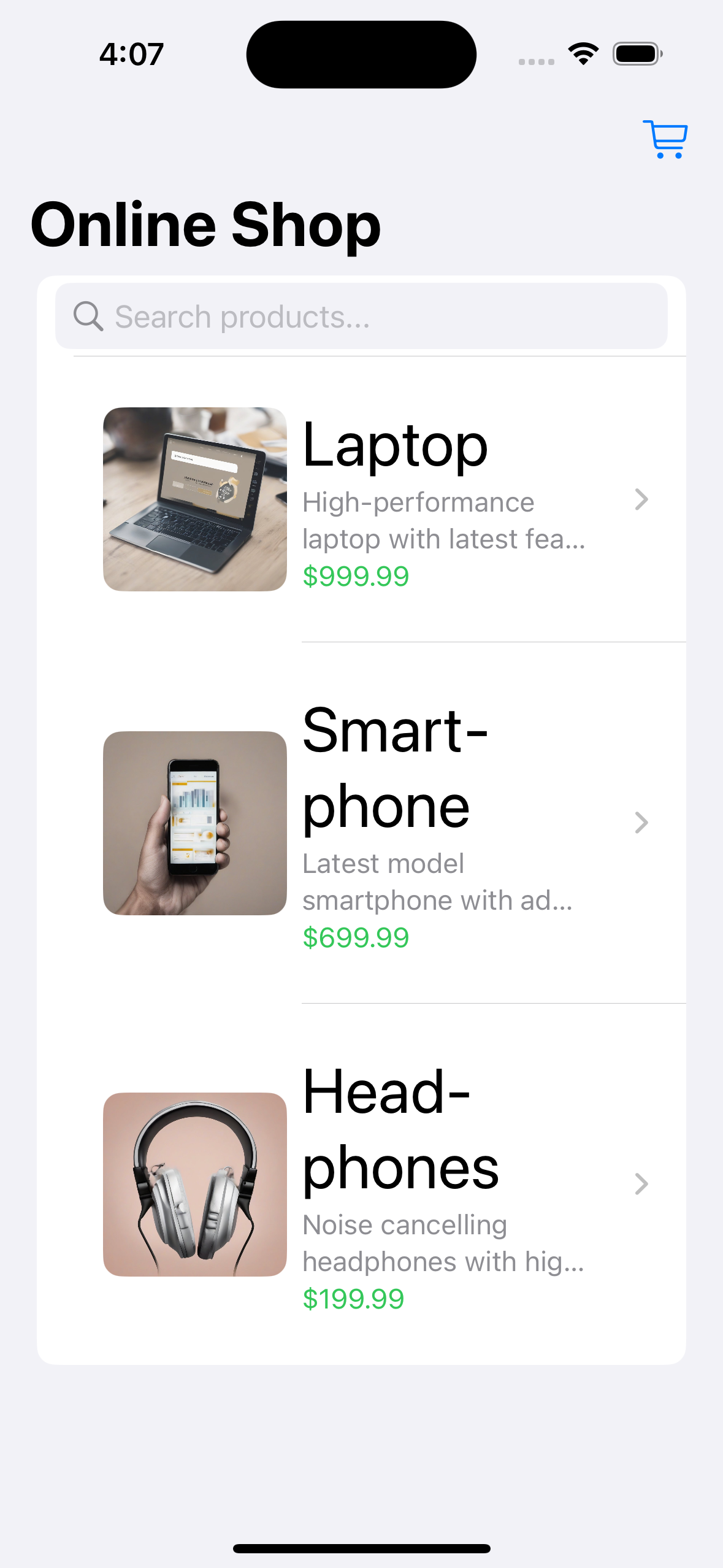
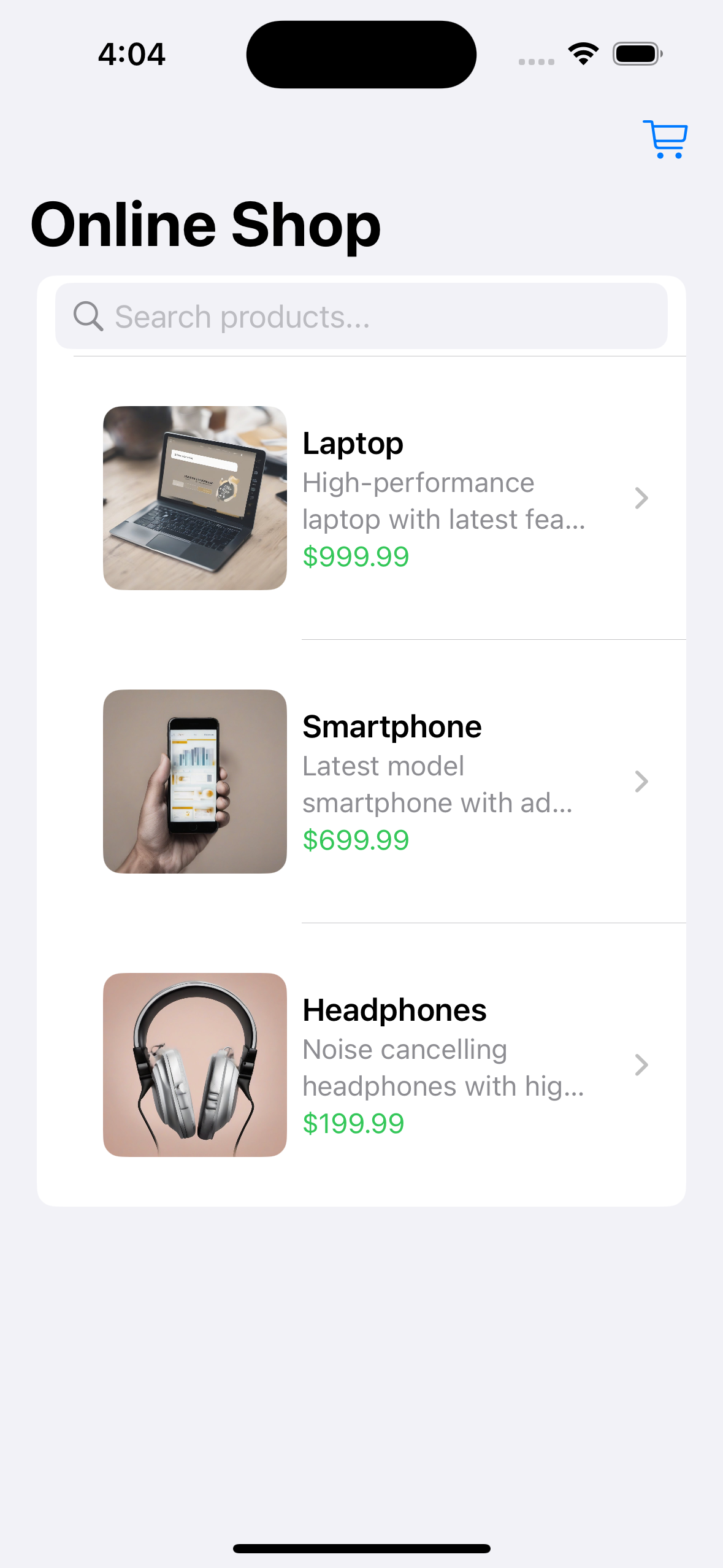
["testcases/original.png", "testcases/bigtitle.png", "ui screenshot. well-designed. e-commerce shopping app"],
|
| 58 |
+
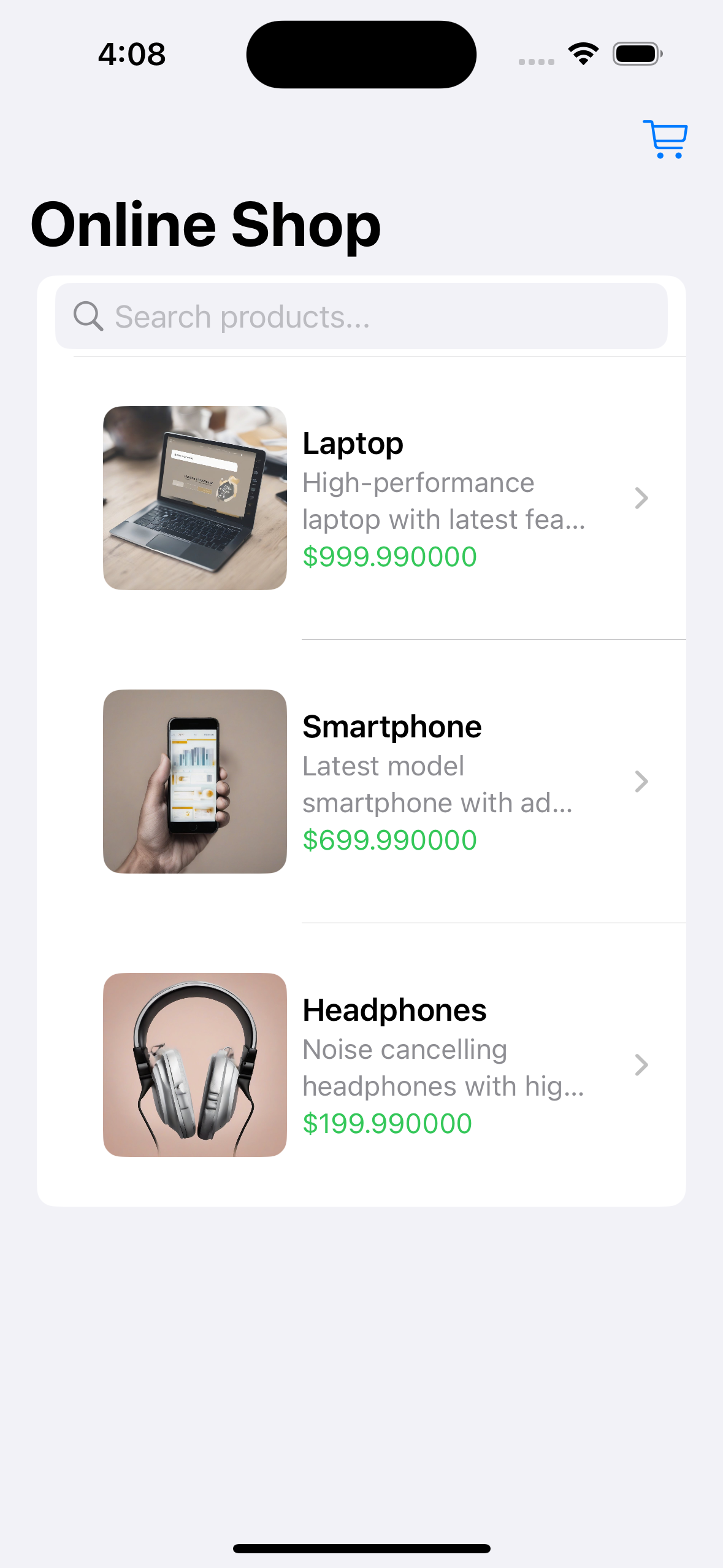
["testcases/original.png", "testcases/formaterror.png", "ui screenshot. well-designed. e-commerce shopping app"],
|
| 59 |
+
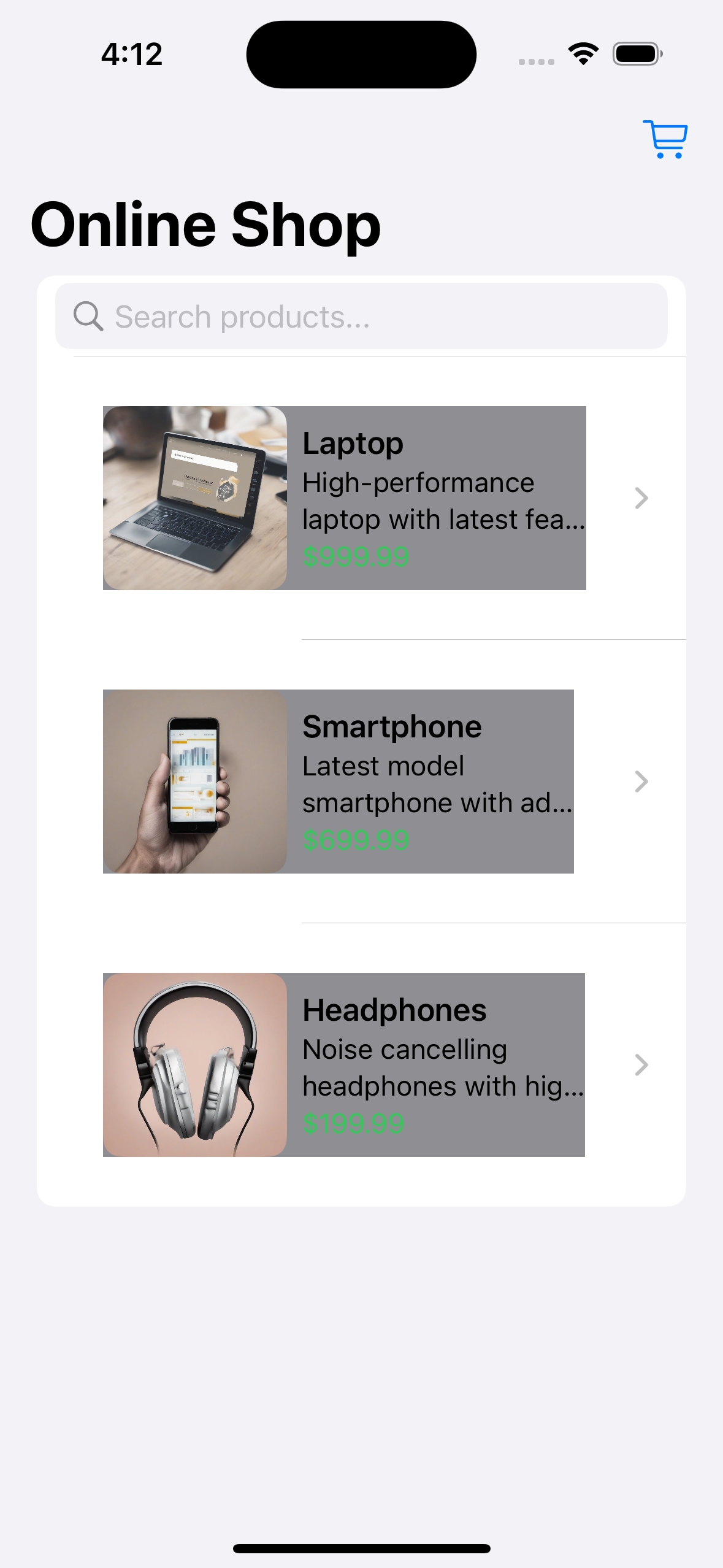
["testcases/original.png", "testcases/greybackground.png", "ui screenshot. well-designed. e-commerce shopping app"],
|
| 60 |
+
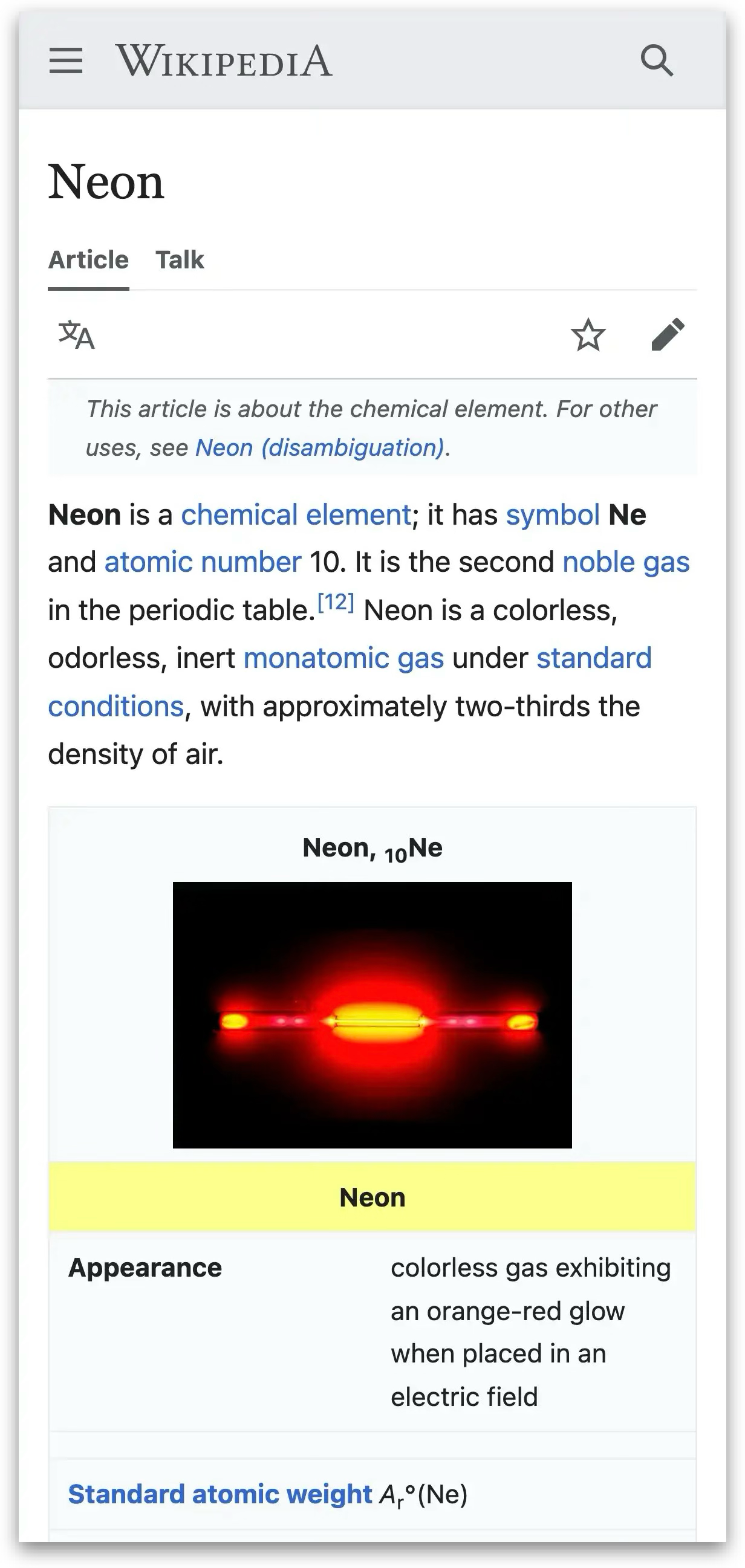
["testcases/wiki-original.png", "testcases/wiki-color.png", "ui screenshot. well-designed. page displaying information about neon"],
|
| 61 |
+
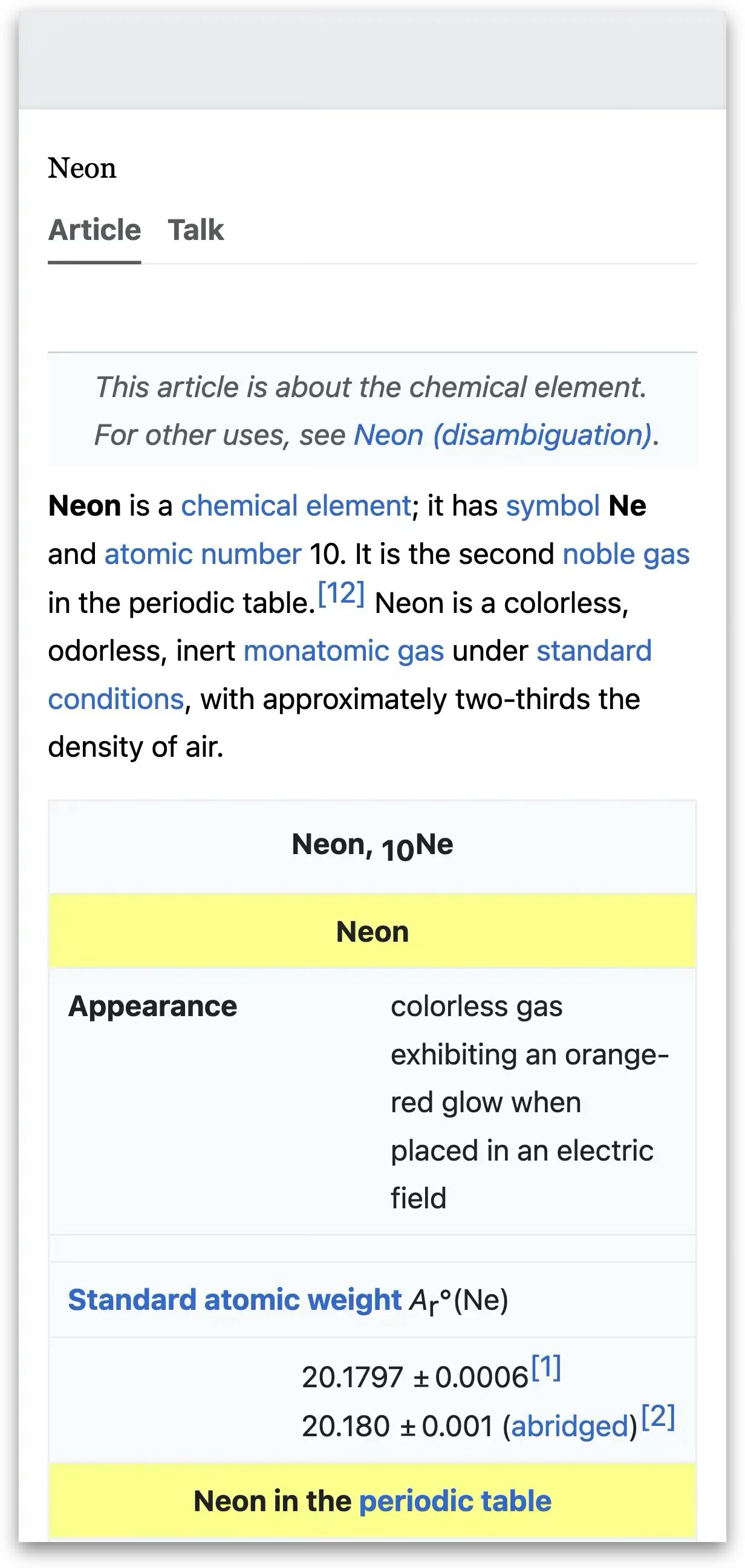
["testcases/wiki-original.png", "testcases/wiki-font.png", "ui screenshot. well-designed. page displaying information about neon"],
|
| 62 |
+
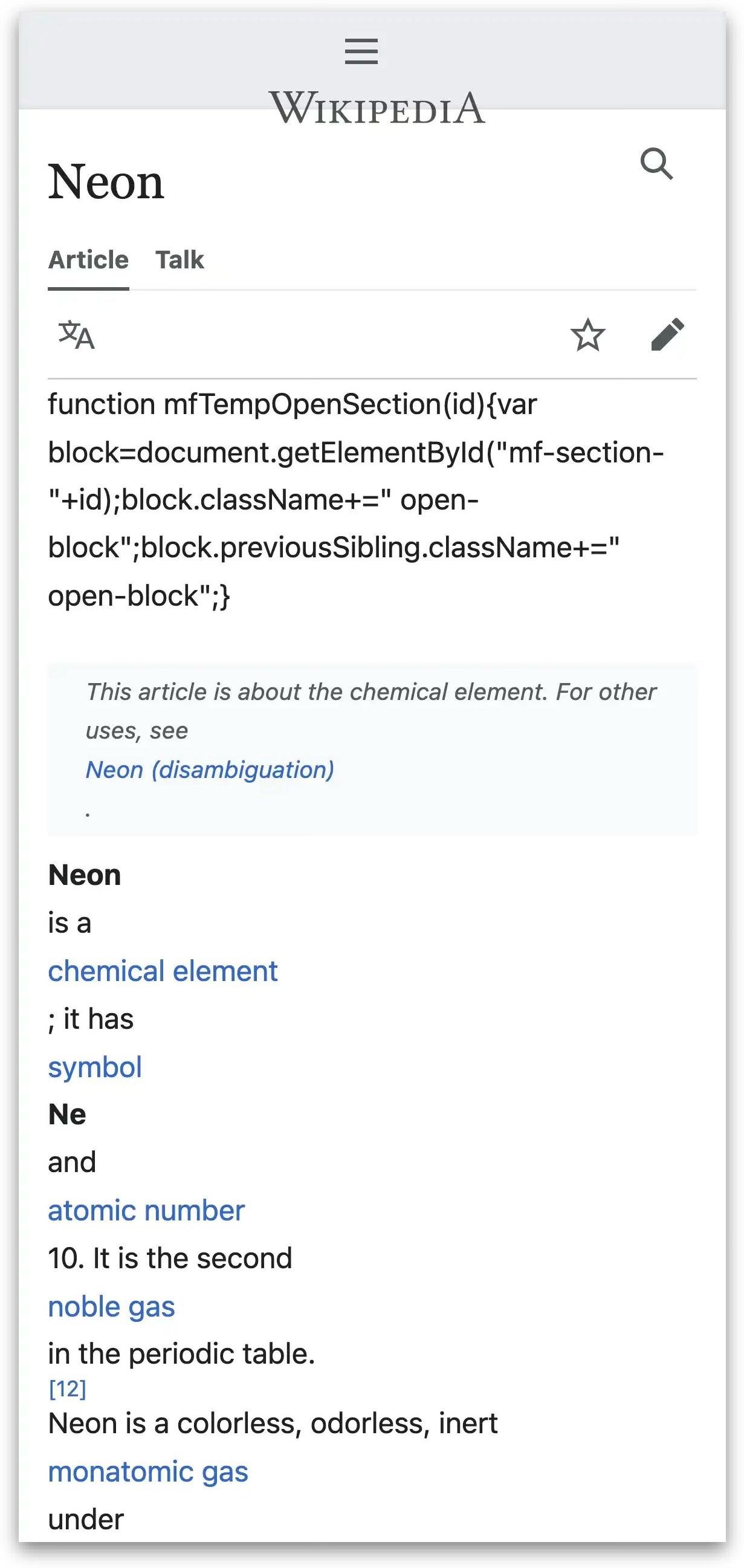
["testcases/wiki-original.png", "testcases/wiki-layout.png", "ui screenshot. well-designed. page displaying information about neon"],
|
| 63 |
+
]
|
| 64 |
+
|
| 65 |
+
# Set up the Gradio interface
|
| 66 |
+
demo = gr.Interface(
|
| 67 |
+
fn=clip_predict_comparison,
|
| 68 |
+
inputs=[
|
| 69 |
+
gr.Image(type="pil", label="Upload Image 1", height=400), # First image input with max height 400px
|
| 70 |
+
gr.Image(type="pil", label="Upload Image 2", height=400), # Second image input with max height 400px
|
| 71 |
+
gr.Textbox(label="Enter text description") # Text input
|
| 72 |
+
],
|
| 73 |
+
outputs=[
|
| 74 |
+
gr.Textbox(label="OpenAI CLIP"), # Output for the original model
|
| 75 |
+
gr.Textbox(label="UIClip"), # Output for variant 1
|
| 76 |
+
gr.Textbox(label="UIClip + Webpairs"), # Output for variant 2
|
| 77 |
+
gr.Textbox(label="UIClip + Webpairs + Humanpairs") # Output for variant 3
|
| 78 |
+
],
|
| 79 |
+
title="Score and Compare the Design Quality of two UI Screenshots",
|
| 80 |
+
description="Upload two UI screenshots and provide a prompt in the format \"ui screenshot. well-designed. DESCRIPTION\". A generic description such as \"mobile app screen\" can also be used. The pair of screenshots are scored with CLIP and three variants of UIClip. The numbers in the output pane represent that probability (normalized via softmax) that one image is better designed than the other.",
|
| 81 |
+
examples=examples # Include the example inputs
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
# Launch the Gradio demo app
|
| 85 |
+
demo.launch()
|
testcases/bigtitle.png
ADDED
|
testcases/formaterror.png
ADDED
|
testcases/greybackground.png
ADDED
|
testcases/original.png
ADDED
|
testcases/wiki-color.png
ADDED

|
Git LFS Details
|
testcases/wiki-font.png
ADDED
|
testcases/wiki-layout.png
ADDED
|
testcases/wiki-original.png
ADDED
|