Spaces:
Build error

Build error
brayden-gg
commited on
Commit
·
a21775a
1
Parent(s):
b34cf94
added rest of files
Browse files- LICENSE +20 -0
- README.md +211 -0
- example_outputs/grid_ysun.jpeg +0 -0
- requirements.txt +10 -0
- samples/20.png +0 -0
- samples/25.png +0 -0
- samples/original.png +0 -0
LICENSE
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright 2022, Brown University, Providence, RI.
|
| 2 |
+
|
| 3 |
+
All Rights Reserved
|
| 4 |
+
|
| 5 |
+
Permission to use, copy, modify, and distribute this software and
|
| 6 |
+
its documentation for any purpose other than its incorporation into a
|
| 7 |
+
commercial product or service is hereby granted without fee, provided
|
| 8 |
+
that the above copyright notice appear in all copies and that both
|
| 9 |
+
that copyright notice and this permission notice appear in supporting
|
| 10 |
+
documentation, and that the name of Brown University not be used in
|
| 11 |
+
advertising or publicity pertaining to distribution of the software
|
| 12 |
+
without specific, written prior permission.
|
| 13 |
+
|
| 14 |
+
BROWN UNIVERSITY DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE,
|
| 15 |
+
INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR ANY
|
| 16 |
+
PARTICULAR PURPOSE. IN NO EVENT SHALL BROWN UNIVERSITY BE LIABLE FOR
|
| 17 |
+
ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
| 18 |
+
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
| 19 |
+
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF
|
| 20 |
+
OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
README.md
CHANGED
|
@@ -9,4 +9,215 @@ app_file: app.py
|
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
|
|
|
|
| 12 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
pinned: false
|
| 10 |
---
|
| 11 |
|
| 12 |
+
<!--
|
| 13 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
| 14 |
+
-->
|
| 15 |
+
|
| 16 |
+
# Generating Handwriting via Decoupled Style Descriptors
|
| 17 |
+
|
| 18 |
+
[Atsunobu Kotani](http://www.atsunobukotani.com/research/), [Stefanie Tellex](http://cs.brown.edu/people/stellex/), [James Tompkin](www.jamestompkin.com)
|
| 19 |
+
|
| 20 |
+
ECCV 2020
|
| 21 |
+
|
| 22 |
+
http://dsd.cs.brown.edu/
|
| 23 |
+
|
| 24 |
+

|
| 25 |
+
|
| 26 |
+
We synthesize handwriting (bottom) in a target style (top) via learned spaces of style and content,
|
| 27 |
+
and can exploit any available reference samples (middle) to improve output quality.
|
| 28 |
+
|
| 29 |
+
# License
|
| 30 |
+
|
| 31 |
+
This project is licenced under the Brown Computer Science Department Copyright Notice, which does not allow commercial use. Please see details in [here](LICENSE).
|
| 32 |
+
|
| 33 |
+
# Preparation (Before you run the code)
|
| 34 |
+
|
| 35 |
+
In the root of a project directory of your choice, create `./model`, `./data`, and `./results` subdirectories.
|
| 36 |
+
Then, download our pretrained model from [here](https://drive.google.com/file/d/1LlRHdm4GV9rfuVZazgx6HtnQg6x7mezR/view?usp=sharing) and save it under the `./model` directory.
|
| 37 |
+
|
| 38 |
+
Further, please download the dataset from [here](https://drive.google.com/file/d/1pfUKaYkFu8HpX4f5rlg0spgTk2wwbKzP/view?usp=sharing) and decompress the zip file into the `./data` directory. The folder should be located as `'./data/writers'`.
|
| 39 |
+
|
| 40 |
+
Finally, please install dependencies with your python virtual environment:
|
| 41 |
+
|
| 42 |
+
```
|
| 43 |
+
pip install -r requirements.txt
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
We tested our codes run in Python 3.8.5 and 3.9.12 without issues.
|
| 47 |
+
|
| 48 |
+
# Code
|
| 49 |
+
|
| 50 |
+
You can generate handwriting samples with:
|
| 51 |
+
|
| 52 |
+
```
|
| 53 |
+
python sample.py
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
Please check out [the script](sample.py) for potential arguments.
|
| 57 |
+
|
| 58 |
+
The provided model has been trained using the following command:
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
python -u main.py --divider 5.0 --weight_dim 256 --sample 5 --device 0 --num_layers 3 --num_writer 1 --lr 0.001 --VALIDATION 1 --datadir 2 --TYPE_B 0 --TYPE_C 0
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
You can also interpolate between pre-set handwriting styles as well as between characters with:
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
python interpolation.py
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
Some notable arguments are:
|
| 71 |
+
|
| 72 |
+
`--interpolate`:
|
| 73 |
+
Allows the user to choose whether to interpolate between characters or writer styles as well as to adjust the randomness (MDN sampling)
|
| 74 |
+
|
| 75 |
+
`--output`:
|
| 76 |
+
The program can output a video of the interpolation, a single image, or a grid of characters.
|
| 77 |
+
|
| 78 |
+
To specify the word used for interpolation, a list of characters to be interpolated, or the characters at the corners of the grid, use `--target_word`, `--blend_chars`, or `--grid_chars` respectively.
|
| 79 |
+
|
| 80 |
+
`--writer_ids`:
|
| 81 |
+
A list of (0 to 169) representing the ids of writer styles to use. If `--interpolation` is not set to `writer`, the first writer id provided will be used.
|
| 82 |
+
|
| 83 |
+
`--blend_weights` (for when `--interpolation=writer`):
|
| 84 |
+
How much to weight each of the writers (typically summing to 1)
|
| 85 |
+
|
| 86 |
+
`--max_randomness` (for when `--interpolation=randomness`):
|
| 87 |
+
Adjusts the maximum amount of randomness allowed (clamps the MDN sampling at a percent of the distribution)
|
| 88 |
+
|
| 89 |
+
`--scale_randomness` (for when `--interpolation=randomness`)::
|
| 90 |
+
Adjusts scale of the randomness allowed (scales the standard deviations of MDN sampling)
|
| 91 |
+
|
| 92 |
+
`--num_random_samples` (for when `--interpolation=randomness`)::
|
| 93 |
+
Number of random samples to take, each will be a single frame of the outputted video
|
| 94 |
+
|
| 95 |
+
In addition, we have provided some convenience functions in `style.py` that can be used to extract the style/character information as well as recombine them into the desired image or video.
|
| 96 |
+
|
| 97 |
+
# Example Interpolations:
|
| 98 |
+
|
| 99 |
+
A video interpolation between writers 80 and 120 generated with the following command:
|
| 100 |
+
|
| 101 |
+
```
|
| 102 |
+
python interpolation.py --interpolate writer --output video --writer_ids 80 120 --target_word "hello world"
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
Result
|
| 106 |
+
|
| 107 |
+

|
| 108 |
+
|
| 109 |
+
A grid that interpolates bilinearly between four letters, one at each corner can be generated with the following command:
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
python interpolation.py --interpolate character --output grid --grid_chars y s u n
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
Result:
|
| 116 |
+
|
| 117 |
+

|
| 118 |
+
|
| 119 |
+
Character interpolation between the first few letters of the alphabet:
|
| 120 |
+
|
| 121 |
+
```
|
| 122 |
+
python3 interpolation.py --interpolate character --output video --blend_chars a b c d e
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
Result:
|
| 126 |
+
|
| 127 |
+

|
| 128 |
+
|
| 129 |
+
Uses random sampling to make minor variations in the letters
|
| 130 |
+
|
| 131 |
+
```
|
| 132 |
+
python interpolation.py --output video --interpolate randomness --scale_randomness 1 --max_randomness 1 --num_samples 10
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
Result:
|
| 136 |
+
|
| 137 |
+

|
| 138 |
+
|
| 139 |
+
# Insights
|
| 140 |
+
|
| 141 |
+
The current model, as published at ECCV 2020 and for consistency with it, does not include a supervised character loss.
|
| 142 |
+
Adding this can improve quality in cases where generation does not terminate as expected (characters run on).
|
| 143 |
+
|
| 144 |
+
# BRUSH dataset
|
| 145 |
+
|
| 146 |
+
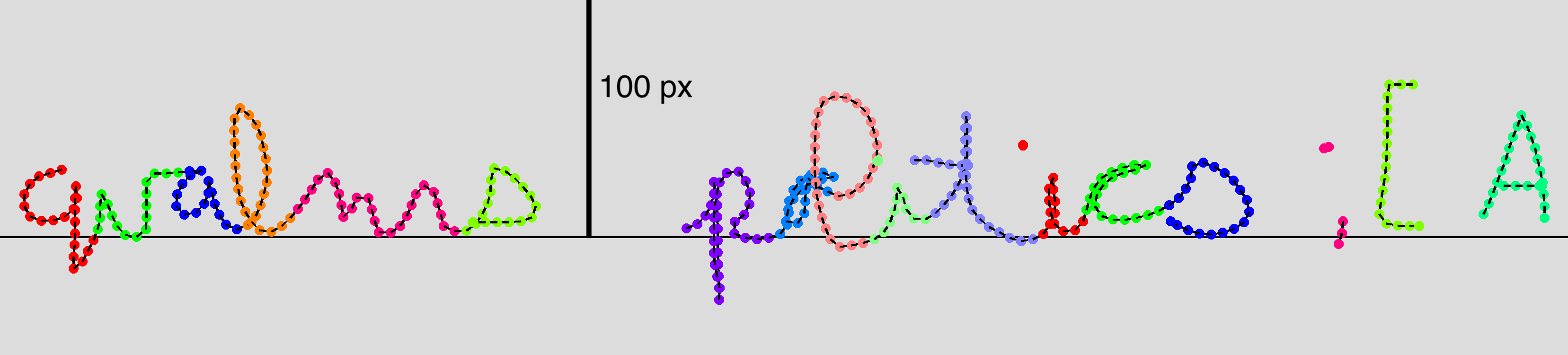
This is the BRUSH dataset (BRown University Stylus Handwriting) from the paper "[Generating Handwriting via Decoupled Style Descriptors](http://dsd.cs.brown.edu/)" by Atsunobu Kotani, Stefanie Tellex, James Tompkin from Brown University, presented at European Conference on Computer Vision (ECCV) 2020. This dataset contains 27,649 online handwriting samples, and the total of 170 writers contributed to create this dataset. Every sequence is labeled with characters (i.e. users can identify what character a point in a sequence corresponds with.
|
| 147 |
+
|
| 148 |
+
The BRUSH dataset can be downloaded from
|
| 149 |
+
[this link](https://drive.google.com/file/d/1NIIXDfmpUhI6i80Dg2363PIdllY7FRVQ/view?usp=sharing) (compressed ZIP 566.6MB). (The original dataset used for ECCV paper is also in [here](https://drive.google.com/file/d/1pfUKaYkFu8HpX4f5rlg0spgTk2wwbKzP/view?usp=sharing), which has slightly less cleaning and fewer alternative resamplings.)
|
| 150 |
+
|
| 151 |
+
## Terms of Use
|
| 152 |
+
|
| 153 |
+
The BRUSH dataset may only be used for non-commercial research purposes.
|
| 154 |
+
Anyone wanting to use it for other purposes should contact [Prof. James Tompkin](www.jamestompkin.com).
|
| 155 |
+
If you publish materials based on this database, we request that you please include a reference to our paper.
|
| 156 |
+
|
| 157 |
+
```
|
| 158 |
+
@inproceedings{kotani2020generating,
|
| 159 |
+
title={Generating Handwriting via Decoupled Style Descriptors},
|
| 160 |
+
author={Kotani, Atsunobu and Tellex, Stefanie and Tompkin, James},
|
| 161 |
+
booktitle={European Conference on Computer Vision},
|
| 162 |
+
pages={764--780},
|
| 163 |
+
year={2020},
|
| 164 |
+
organization={Springer}
|
| 165 |
+
}
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
## Data specification
|
| 169 |
+
|
| 170 |
+
Each folder contains drawings by the same writer, and each file is compressed with Python 3.8.5 pickle as it follows.
|
| 171 |
+
|
| 172 |
+
```{python}
|
| 173 |
+
import pickle
|
| 174 |
+
with open("BRUSH/{writer_id}/{drawing_id}", 'rb') as f:
|
| 175 |
+
[sentence, drawing, label] = pickle.load(f)
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
Each file is comprised of the following data.
|
| 179 |
+
|
| 180 |
+
1. **Target sentence** -- a text of length (M).
|
| 181 |
+
|
| 182 |
+
If a sample is a drawing of "hello world", for instance, this value would be "hello world" and
|
| 183 |
+
M=11 as it is.
|
| 184 |
+
|
| 185 |
+
2. **Original drawing** -- a 2D array of size (N, 3).
|
| 186 |
+
|
| 187 |
+
We asked participants to write specific sentences in a box of 120x748 pixels, with a suggested
|
| 188 |
+
baseline at 100 pixels from the top, 20 pixels from the bottom. As every drawing has a different
|
| 189 |
+
sequence length, N can vary, and each point has 3 values; the first two are (x, y) coordinates
|
| 190 |
+
and the last value is a binary end-of-stroke (eos) flag. If this value were 1, it indicates that
|
| 191 |
+
the current stroke (i.e. curve) ends there, instead of being connected with the next point, if
|
| 192 |
+
it exists.
|
| 193 |
+
|
| 194 |
+
3. **Original character label** -- a 2D array of size (N, M).
|
| 195 |
+
|
| 196 |
+
For every point in a sequence, this variable provides an one-hot vector of size (M) to identify
|
| 197 |
+
the corresponding character.
|
| 198 |
+
|
| 199 |
+
As different writers used different kinds of a stylus to produce their data, the sample frequency (i.e.
|
| 200 |
+
the number of sampled points per second) varies per writer. For our original drawing data, we sampled
|
| 201 |
+
points at every 10ms (0.01s) by interpolating between points.
|
| 202 |
+
|
| 203 |
+

|
| 204 |
+
In this example drawing, N=689 and M=19 (i.e. 'qualms politics ;[A'). Different colors indicate different character labels.
|
| 205 |
+
|
| 206 |
+
## Additional formats
|
| 207 |
+
|
| 208 |
+
We also included few other versions of resampled data. Both versions contain 5x rescaled drawings and
|
| 209 |
+
sacrifice temporal information in exchange for a consistence distance between points in a sequence.
|
| 210 |
+
|
| 211 |
+
1. **"BRUSH/{writer_id}/{drawing_id}\_resample20"**
|
| 212 |
+
|
| 213 |
+
Points are resampled in a way that they are distant from their previous point in a stroke sequence
|
| 214 |
+
at maximum of 20 pixels.
|
| 215 |
+

|
| 216 |
+
In this resampled drawing, N=449 and M=19 (i.e. 'qualms politics ;[A').
|
| 217 |
+
|
| 218 |
+
2. **"BRUSH/{writer_id}/{drawing_id}\_resample25"**
|
| 219 |
+
|
| 220 |
+
Points are resampled in a way that they are distant from their previous point in a stroke sequence
|
| 221 |
+
at maximum of 25 pixels.
|
| 222 |
+

|
| 223 |
+
In this resampled drawing, N=360 and M=19 (i.e. 'qualms politics ;[A').
|
example_outputs/grid_ysun.jpeg
ADDED

|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy==1.22.3
|
| 2 |
+
Pillow==9.1.0
|
| 3 |
+
protobuf==3.20.0
|
| 4 |
+
scipy==1.8.0
|
| 5 |
+
six==1.16.0
|
| 6 |
+
tensorboardX==2.5
|
| 7 |
+
torch==1.11.0
|
| 8 |
+
typing_extensions==4.1.1
|
| 9 |
+
ffmpeg-python
|
| 10 |
+
|
samples/20.png
ADDED

|
samples/25.png
ADDED

|
samples/original.png
ADDED
|