Spaces:
Runtime error

Runtime error
File size: 11,905 Bytes
a1d409e |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 |
<!---
Copyright 2022 The Microsoft Inc. and The HuggingFace Inc. Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Run Table Tasks with TAPEX
TAPEX is a table pre-training approach for table-related tasks. By learning a neural SQL executor over a synthetic corpus based on generative language models (e.g., BART), it achieves state-of-the-art performance on several table-based question answering benchmarks and table-based fact verification benchmark. More details can be found in the original paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/pdf/2107.07653.pdf).
> If you are also familiar with [fairseq](https://github.com/pytorch/fairseq), you may also find [the official implementation](https://github.com/microsoft/Table-Pretraining) useful, which leverages the framework.
## Table Question Answering Tasks
### What is Table Question Answering

The task of Table Question Answering (TableQA) is to empower machines to answer users' questions over a given table. The resulting answer(s) can be a region in the table, or a number calculated by applying aggregation operators to a specific region.
### What Questions Can be Answered
Benefiting from the powerfulness of generative models, TAPEX can deal with almost all kinds of questions over tables (if there is training data). Below are some typical question and their answers taken from [WikiTableQuestion](https://nlp.stanford.edu/blog/wikitablequestions-a-complex-real-world-question-understanding-dataset).
| Question | Answer |
| :---: | :---: |
| What is the years won for each team? | 2004, 2008, 2012 |
| How long did Taiki Tsuchiya last? | 4:27 |
| What is the total amount of matches drawn? | 1 |
| Besides Tiger Woods, what other player won between 2007 and 2009? | Camilo Villegas |
| What was the last Baekje Temple? | Uija |
| What is the difference between White voters and Black voters in 1948? | 0 |
| What is the average number of sailors for each country during the worlds qualification tournament? | 2 |
### How to Fine-tune TAPEX on TableQA
We provide a fine-tuning script of tapex for TableQA on the WikiSQL benchmark: [WikiSQL](https://github.com/salesforce/WikiSQL).
This script is customized for tapex models, and can be easily adapted to other benchmarks such as WikiTableQuestion
(only some tweaks in the function `preprocess_tableqa_function`).
#### TAPEX-Base on WikiSQL
Here is how to run the script on the WikiSQL with `tapex-base`:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
```bash
export EXP_NAME=wikisql_tapex_base
python run_wikisql_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000
```
#### TAPEX-Large on WikiSQL
Here is how to run the script on the WikiSQL with `tapex-large`:
> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
```bash
export EXP_NAME=wikisql_tapex_large
python run_wikisql_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 32 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000 \
--fp16
```
#### TAPEX-Base on WikiTableQuestions
Here is how to run the script on the WikiTableQuestions with `tapex-base`:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
```bash
export EXP_NAME=wikitablequestions_tapex_base
python run_wikitablequestions_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000
```
#### TAPEX-Large on WikiTableQuestions
Here is how to run the script on the WikiTableQuestions with `tapex-large`:
> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could reduce the `per_device_train_batch_size` and `per_device_eval_batch_size` and have another try. Or you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
```bash
export EXP_NAME=wikitablequestions_tapex_large
python run_wikitablequestions_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 12 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000 \
--fp16
```
### How to Evaluate TAPEX Fine-tuned Models on TableQA
We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
> You can also replace `microsoft/tapex-base-finetuned-wikisql` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
```bash
export EXP_NAME=wikisql_tapex_base_eval
python run_wikisql_with_tapex.py \
--do_eval \
--model_name_or_path microsoft/tapex-base-finetuned-wikisql \
--output_dir $EXP_NAME \
--per_device_eval_batch_size 4 \
--predict_with_generate \
--num_beams 5
```
## Table Fact Verification Tasks
### What is Table Fact Verification
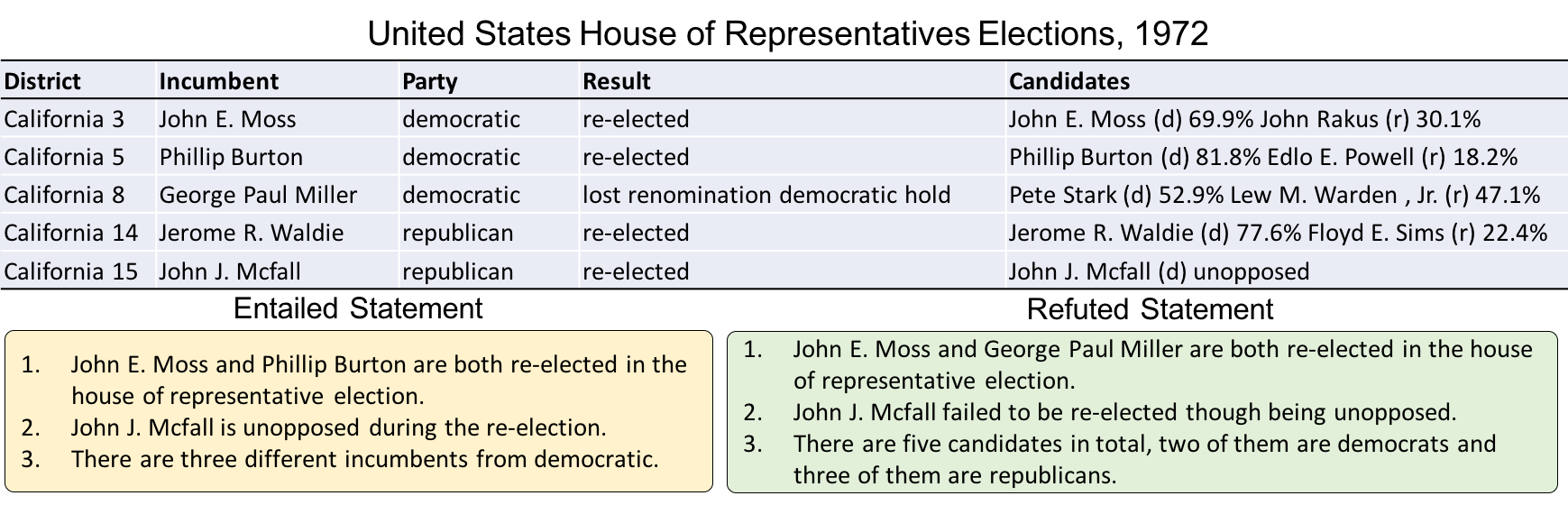
The task of Table Fact Verification (TableFV) is to empower machines to justify if a statement follows facts in a given table. The result is a binary classification belonging to `1` (entailed) or `0` (refused).
### How to Fine-tune TAPEX on TableFV
#### TAPEX-Base on TabFact
We provide a fine-tuning script of tapex for TableFV on the TabFact benchmark: [TabFact](https://github.com/wenhuchen/Table-Fact-Checking).
Here is how to run the script on the TabFact:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
```bash
export EXP_NAME=tabfact_tapex_base
python run_tabfact_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 3 \
--gradient_accumulation_steps 16 \
--per_device_eval_batch_size 12 \
--eval_accumulation_steps 6 \
--warm_steps 1000 \
--logging_steps 10 \
--learning_rate 3e-5 \
--eval_steps 1000 \
--save_steps 1000 \
--evaluation_strategy steps \
--weight_decay 1e-2 \
--max_steps 30000 \
--max_grad_norm 0.1
```
#### TAPEX-Large on TabFact
Here is how to run the script on the TabFact:
> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 24GB and 1 GPU card. Sorry we cannot reduce the memory consumption since the model input in TabFact usually contains nearly ~1000 tokens. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
```bash
export EXP_NAME=tabfact_tapex_large
python run_tabfact_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 18 \
--per_device_eval_batch_size 4 \
--eval_accumulation_steps 12 \
--warm_steps 1000 \
--logging_steps 10 \
--learning_rate 3e-5 \
--eval_steps 1000 \
--save_steps 1000 \
--evaluation_strategy steps \
--weight_decay 1e-2 \
--max_steps 30000 \
--max_grad_norm 0.1
```
### How to Evaluate TAPEX Fine-tuned Models on TableFV
We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
> You can also replace `microsoft/tapex-base-finetuned-tabfact` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
```bash
export EXP_NAME=tabfact_tapex_base_eval
python run_tabfact_with_tapex.py \
--do_eval \
--model_name_or_path microsoft/tapex-base-finetuned-tabfact \
--output_dir $EXP_NAME \
--per_device_eval_batch_size 12 \
--eval_accumulation_steps 6
```
## Reproduced Results
We get the following results on the dev set of the benchmark with the previous commands:
| Task | Model Size | Metric | Result |
|:---:|:---:|:---:|:---:|
| WikiSQL (Weak) | Base | Denotation Accuracy | 88.1 |
| WikiSQL (Weak) | Large | Denotation Accuracy | 89.5 |
| WikiTableQuestion | Base | Denotation Accuracy | 47.1 |
| WikiTableQuestion | Large | Denotation Accuracy | 57.2 |
| TabFact | Base | Accuracy | 78.7 |
| TabFact | Large | Accuracy | 83.6 |
|