Spaces:
Runtime error

Runtime error
Commit
·
95a3ca6
1
Parent(s):
4b4ab36
Initial commit
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +9 -0
- 12e12d_last.pt +3 -0
- LICENSE +21 -0
- README.md +162 -11
- __pycache__/ConSTtester.cpython-310.pyc +0 -0
- __pycache__/ConSTtester.cpython-311.pyc +0 -0
- __pycache__/mRASPloader.cpython-310.pyc +0 -0
- __pycache__/mRASPloader.cpython-311.pyc +0 -0
- app +0 -0
- app.py +420 -0
- bpe_vocab +0 -0
- cfg.txt +0 -0
- cfgDefault.txt +1 -0
- codes.bpe.32000 +0 -0
- data-bin/dict.ar.txt +0 -0
- data-bin/dict.en.txt +0 -0
- data-bin/dict.es.txt +0 -0
- data-bin/dict.fr.txt +0 -0
- data-bin/dict.ru.txt +0 -0
- data-bin/dict.zh.txt +0 -0
- data-bin/preprocess.log +106 -0
- data-bin/test.en-ar.ar +1 -0
- data-bin/test.en-ar.en +1 -0
- data-bin/test.en-en.en +1 -0
- data-bin/test.en-es.en +1 -0
- data-bin/test.en-es.es +1 -0
- data-bin/test.en-fr.en +1 -0
- data-bin/test.en-fr.fr +1 -0
- data-bin/test.en-ru.en +1 -0
- data-bin/test.en-ru.ru +1 -0
- data-bin/test.en-zh.en +1 -0
- data-bin/test.en-zh.zh +1 -0
- data-bin/test.es-en.en +1 -0
- data-bin/test.es-en.es +1 -0
- data-bin/test.es-ru.es +1 -0
- data-bin/test.es-ru.ru +1 -0
- data-bin/test.es-zh.es +1 -0
- data-bin/test.es-zh.zh +1 -0
- data-bin/test.zh-en.en +1 -0
- data-bin/test.zh-en.zh +1 -0
- docs/img.png +0 -0
- eval.sh +166 -0
- examples/configs/eval_benchmarks.yml +80 -0
- examples/configs/parallel_mono_12e12d_contrastive.yml +44 -0
- fairseq +1 -0
- hubconf.py +69 -0
- input.ar +1 -0
- input.en +1 -0
- input.es +1 -0
- input.fr +1 -0
.gitignore
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
12e12d_no_mono.pt
|
| 2 |
+
6e6d_no_mono.pt
|
| 3 |
+
ConST/
|
| 4 |
+
ConSTtester.py
|
| 5 |
+
appCopy.py
|
| 6 |
+
bpe_vocab.1
|
| 7 |
+
codes.bpe.32000.1
|
| 8 |
+
constcaller.py
|
| 9 |
+
requirements.apt.txt
|
12e12d_last.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f4e378559de68a6b82c7d2e0a48ce4054fbb943305682b6ad389378013e888e2
|
| 3 |
+
size 5586588620
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Facebook, Inc. and its affiliates.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,13 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contrastive Learning for Many-to-many Multilingual Neural Machine Translation(mCOLT/mRASP2), ACL2021
|
| 2 |
+
The code for training mCOLT/mRASP2, a multilingual neural machine translation training method, implemented based on [fairseq](https://github.com/pytorch/fairseq).
|
| 3 |
+
|
| 4 |
+
**mRASP2**: [paper](https://arxiv.org/abs/2105.09501) [blog](https://medium.com/@panxiao1994/mrasp2-multilingual-nmt-advances-via-contrastive-learning-ac8c4c35d63)
|
| 5 |
+
|
| 6 |
+
**mRASP**: [paper](https://www.aclweb.org/anthology/2020.emnlp-main.210.pdf),
|
| 7 |
+
[code](https://github.com/linzehui/mRASP)
|
| 8 |
+
|
| 9 |
---
|
| 10 |
+
## News
|
| 11 |
+
We have released two versions, this version is the original one. In this implementation:
|
| 12 |
+
- You should first merge all data, by pre-pending language token before each sentence to indicate the language.
|
| 13 |
+
- AA/RAS muse be done off-line (before binarize), check [this toolkit](https://github.com/linzehui/mRASP/blob/master/preprocess).
|
| 14 |
+
|
| 15 |
+
**New implementation**: https://github.com/PANXiao1994/mRASP2/tree/new_impl
|
| 16 |
+
|
| 17 |
+
* Acknowledgement: This work is supported by [Bytedance](https://bytedance.com). We thank [Chengqi](https://github.com/zhaocq-nlp) for uploading all files and checkpoints.
|
| 18 |
+
|
| 19 |
+
## Introduction
|
| 20 |
+
|
| 21 |
+
mRASP2/mCOLT, representing multilingual Contrastive Learning for Transformer, is a multilingual neural machine translation model that supports complete many-to-many multilingual machine translation. It employs both parallel corpora and multilingual corpora in a unified training framework. For detailed information please refer to the paper.
|
| 22 |
+
|
| 23 |
+

|
| 24 |
+
|
| 25 |
+
## Pre-requisite
|
| 26 |
+
```bash
|
| 27 |
+
pip install -r requirements.txt
|
| 28 |
+
# install fairseq
|
| 29 |
+
git clone https://github.com/pytorch/fairseq
|
| 30 |
+
cd fairseq
|
| 31 |
+
pip install --editable ./
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
## Training Data and Checkpoints
|
| 35 |
+
We release our preprocessed training data and checkpoints in the following.
|
| 36 |
+
### Dataset
|
| 37 |
+
|
| 38 |
+
We merge 32 English-centric language pairs, resulting in 64 directed translation pairs in total. The original 32 language pairs corpus contains about 197M pairs of sentences. We get about 262M pairs of sentences after applying RAS, since we keep both the original sentences and the substituted sentences. We release both the original dataset and dataset after applying RAS.
|
| 39 |
+
|
| 40 |
+
| Dataset | #Pair |
|
| 41 |
+
| --- | --- |
|
| 42 |
+
| [32-lang-pairs-TRAIN](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_parallel/download.sh) | 197603294 |
|
| 43 |
+
| [32-lang-pairs-RAS-TRAIN](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_parallel_ras/download.sh) | 262662792 |
|
| 44 |
+
| [mono-split-a](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_a/download.sh) | - |
|
| 45 |
+
| [mono-split-b](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_b/download.sh) | - |
|
| 46 |
+
| [mono-split-c](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_c/download.sh) | - |
|
| 47 |
+
| [mono-split-d](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_d/download.sh) | - |
|
| 48 |
+
| [mono-split-e](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_split_e/download.sh) | - |
|
| 49 |
+
| [mono-split-de-fr-en](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_de_fr_en/download.sh) | - |
|
| 50 |
+
| [mono-split-nl-pl-pt](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_mono_nl_pl_pt/download.sh) | - |
|
| 51 |
+
| [32-lang-pairs-DEV-en-centric](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_dev_en_centric/download.sh) | - |
|
| 52 |
+
| [32-lang-pairs-DEV-many-to-many](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bin_dev_m2m/download.sh) | - |
|
| 53 |
+
| [Vocab](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/bpe_vocab) | - |
|
| 54 |
+
| [BPE Code](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/emnlp2020/mrasp/pretrain/dataset/codes.bpe.32000) | - |
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
### Checkpoints & Results
|
| 58 |
+
* **Please note that the provided checkpoint is sightly different from that in the paper.** In the following sections, we report the results of the provided checkpoints.
|
| 59 |
+
|
| 60 |
+
#### English-centric Directions
|
| 61 |
+
We report **tokenized BLEU** in the following table. Please click the model links to download. It is in pytorch format. (check eval.sh for details)
|
| 62 |
+
|
| 63 |
+
|Models | [6e6d-no-mono](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/6e6d_no_mono.pt) | [12e12d-no-mono](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/12e12d_no_mono.pt) | [12e12d](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/12e12d_last.pt) |
|
| 64 |
+
| --- | --- | --- | --- |
|
| 65 |
+
| en2cs/wmt16 | 21.0 | 22.3 | 23.8 |
|
| 66 |
+
| cs2en/wmt16 | 29.6 | 32.4 | 33.2 |
|
| 67 |
+
| en2fr/wmt14 | 42.0 | 43.3 | 43.4 |
|
| 68 |
+
| fr2en/wmt14 | 37.8 | 39.3 | 39.5 |
|
| 69 |
+
| en2de/wmt14 | 27.4 | 29.2 | 29.5 |
|
| 70 |
+
| de2en/wmt14 | 32.2 | 34.9 | 35.2 |
|
| 71 |
+
| en2zh/wmt17 | 33.0 | 34.9 | 34.1 |
|
| 72 |
+
| zh2en/wmt17 | 22.4 | 24.0 | 24.4 |
|
| 73 |
+
| en2ro/wmt16 | 26.6 | 28.1 | 28.7 |
|
| 74 |
+
| ro2en/wmt16 | 36.8 | 39.0 | 39.1 |
|
| 75 |
+
| en2tr/wmt16 | 18.6 | 20.3 | 21.2 |
|
| 76 |
+
| tr2en/wmt16 | 22.2 | 25.5 | 26.1 |
|
| 77 |
+
| en2ru/wmt19 | 17.4 | 18.5 | 19.2 |
|
| 78 |
+
| ru2en/wmt19 | 22.0 | 23.2 | 23.6 |
|
| 79 |
+
| en2fi/wmt17 | 20.2 | 22.1 | 22.9 |
|
| 80 |
+
| fi2en/wmt17 | 26.1 | 29.5 | 29.7 |
|
| 81 |
+
| en2es/wmt13 | 32.8 | 34.1 | 34.6 |
|
| 82 |
+
| es2en/wmt13 | 32.8 | 34.6 | 34.7 |
|
| 83 |
+
| en2it/wmt09 | 28.9 | 30.0 | 30.8 |
|
| 84 |
+
| it2en/wmt09 | 31.4 | 32.7 | 32.8 |
|
| 85 |
+
|
| 86 |
+
#### Unsupervised Directions
|
| 87 |
+
We report **tokenized BLEU** in the following table. (check eval.sh for details)
|
| 88 |
+
|
| 89 |
+
| | 12e12d |
|
| 90 |
+
| --- | --- |
|
| 91 |
+
| en2pl/wmt20 | 6.2 |
|
| 92 |
+
| pl2en/wmt20 | 13.5 |
|
| 93 |
+
| en2nl/iwslt14 | 8.8 |
|
| 94 |
+
| nl2en/iwslt14 | 27.1 |
|
| 95 |
+
| en2pt/opus100 | 18.9 |
|
| 96 |
+
| pt2en/opus100 | 29.2 |
|
| 97 |
+
|
| 98 |
+
#### Zero-shot Directions
|
| 99 |
+
* row: source language
|
| 100 |
+
* column: target language
|
| 101 |
+
We report **[sacreBLEU](https://github.com/mozilla/sacreBLEU)** in the following table.
|
| 102 |
+
|
| 103 |
+
| 12e12d | ar | zh | nl | fr | de | ru |
|
| 104 |
+
| --- | --- | --- | --- | --- | --- | --- |
|
| 105 |
+
| ar | - | 32.5 | 3.2 | 22.8 | 11.2 | 16.7 |
|
| 106 |
+
| zh | 6.5 | - | 1.9 | 32.9 | 7.6 | 23.7 |
|
| 107 |
+
| nl | 1.7 | 8.2 | - | 7.5 | 10.2 | 2.9 |
|
| 108 |
+
| fr | 6.2 | 42.3 | 7.5 | - | 18.9 | 24.4 |
|
| 109 |
+
| de | 4.9 | 21.6 | 9.2 | 24.7 | - | 14.4 |
|
| 110 |
+
| ru | 7.1 | 40.6 | 4.5 | 29.9 | 13.5 | - |
|
| 111 |
+
|
| 112 |
+
## Training
|
| 113 |
+
```bash
|
| 114 |
+
export NUM_GPU=4 && bash train_w_mono.sh ${model_config}
|
| 115 |
+
```
|
| 116 |
+
* We give example of `${model_config}` in `${PROJECT_REPO}/examples/configs/parallel_mono_12e12d_contrastive.yml`
|
| 117 |
+
|
| 118 |
+
## Inference
|
| 119 |
+
* You must pre-pend the corresponding language token to the source side before binarize the test data.
|
| 120 |
+
```bash
|
| 121 |
+
fairseq-generate ${test_path} \
|
| 122 |
+
--user-dir ${repo_dir}/mcolt \
|
| 123 |
+
-s ${src} \
|
| 124 |
+
-t ${tgt} \
|
| 125 |
+
--skip-invalid-size-inputs-valid-test \
|
| 126 |
+
--path ${ckpts} \
|
| 127 |
+
--max-tokens ${batch_size} \
|
| 128 |
+
--task translation_w_langtok \
|
| 129 |
+
${options} \
|
| 130 |
+
--lang-prefix-tok "LANG_TOK_"`echo "${tgt} " | tr '[a-z]' '[A-Z]'` \
|
| 131 |
+
--max-source-positions ${max_source_positions} \
|
| 132 |
+
--max-target-positions ${max_target_positions} \
|
| 133 |
+
--nbest 1 | grep -E '[S|H|P|T]-[0-9]+' > ${final_res_file}
|
| 134 |
+
python3 ${repo_dir}/scripts/utils.py ${res_file} ${ref_file} || exit 1;
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
## Synonym dictionaries
|
| 138 |
+
We use the bilingual synonym dictionaries provised by [MUSE](https://github.com/facebookresearch/MUSE).
|
| 139 |
+
|
| 140 |
+
We generate multilingual synonym dictionaries using [this script](https://github.com/linzehui/mRASP/blob/master/preprocess/tools/ras/multi_way_word_graph.py), and apply
|
| 141 |
+
RAS using [this script](https://github.com/linzehui/mRASP/blob/master/preprocess/tools/ras/random_alignment_substitution_w_multi.sh).
|
| 142 |
+
|
| 143 |
+
| Description | File | Size |
|
| 144 |
+
| --- | --- | --- |
|
| 145 |
+
| dep=1 | [synonym_dict_raw_dep1](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/synonym_dict_raw_dep1) | 138.0 M |
|
| 146 |
+
| dep=2 | [synonym_dict_raw_dep2](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/synonym_dict_raw_dep2) | 1.6 G |
|
| 147 |
+
| dep=3 | [synonym_dict_raw_dep3](https://lf3-nlp-opensource.bytetos.com/obj/nlp-opensource/acl2021/mrasp2/synonym_dict_raw_dep3) | 2.2 G |
|
| 148 |
+
|
| 149 |
+
## Contact
|
| 150 |
+
Please contact me via e-mail `[email protected]` or via [wechat/zhihu](https://fork-ball-95c.notion.site/mRASP2-4e9b3450d5aa4137ae1a2c46d5f3c1fa) or join [the slack group](https://mrasp2.slack.com/join/shared_invite/zt-10k9710mb-MbDHzDboXfls2Omd8cuWqA)!
|
| 151 |
|
| 152 |
+
## Citation
|
| 153 |
+
Please cite as:
|
| 154 |
+
```
|
| 155 |
+
@inproceedings{mrasp2,
|
| 156 |
+
title = {Contrastive Learning for Many-to-many Multilingual Neural Machine Translation},
|
| 157 |
+
author= {Xiao Pan and
|
| 158 |
+
Mingxuan Wang and
|
| 159 |
+
Liwei Wu and
|
| 160 |
+
Lei Li},
|
| 161 |
+
booktitle = {Proceedings of ACL 2021},
|
| 162 |
+
year = {2021},
|
| 163 |
+
}
|
| 164 |
+
```
|
__pycache__/ConSTtester.cpython-310.pyc
ADDED
|
Binary file (1.1 kB). View file
|
|
|
__pycache__/ConSTtester.cpython-311.pyc
ADDED
|
Binary file (1.03 kB). View file
|
|
|
__pycache__/mRASPloader.cpython-310.pyc
ADDED
|
Binary file (7.61 kB). View file
|
|
|
__pycache__/mRASPloader.cpython-311.pyc
ADDED
|
Binary file (14.6 kB). View file
|
|
|
app
ADDED
|
File without changes
|
app.py
ADDED
|
@@ -0,0 +1,420 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# imports
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import whisper
|
| 6 |
+
import torch
|
| 7 |
+
import traceback
|
| 8 |
+
import shutil
|
| 9 |
+
import yaml
|
| 10 |
+
import re
|
| 11 |
+
from pydub import AudioSegment
|
| 12 |
+
from huggingface_hub import snapshot_download
|
| 13 |
+
import json
|
| 14 |
+
import requests
|
| 15 |
+
import wave
|
| 16 |
+
from pynvml import *
|
| 17 |
+
import time
|
| 18 |
+
|
| 19 |
+
import mRASPloader
|
| 20 |
+
|
| 21 |
+
torch.cuda.empty_cache()
|
| 22 |
+
|
| 23 |
+
# TTS header and url
|
| 24 |
+
headers = {"Authorization": "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjoiYTI5NDFhMmEtYzA5ZS00YTcyLWI5ZGItODM5ODEzZDIwMGEwIiwidHlwZSI6ImFwaV90b2tlbiJ9.StBap5nQtNqjh1BMz9DledR5tg5FTWdUMVBrDwY6DjY"}
|
| 25 |
+
url ="https://api.edenai.run/v2/audio/text_to_speech"
|
| 26 |
+
|
| 27 |
+
# the model we are using for ASR, options are small, medium, large and largev2 (large and largev2 don't fit on huggingface cpu)
|
| 28 |
+
model = whisper.load_model("medium")
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
# A table to look up all the languages
|
| 33 |
+
language_id_lookup = {
|
| 34 |
+
"Arabic" : "ar",
|
| 35 |
+
"English" : "en",
|
| 36 |
+
"Chinese" : "zh",
|
| 37 |
+
"Spanish" : "es",
|
| 38 |
+
"Russian" : "ru",
|
| 39 |
+
"French" : "fr",
|
| 40 |
+
"German" : "de",
|
| 41 |
+
"Italian" : "it",
|
| 42 |
+
"Netherlands": "nl",
|
| 43 |
+
"Portuguese": "pt",
|
| 44 |
+
"Romanian" : "ro",
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# A lookup table for ConST
|
| 49 |
+
|
| 50 |
+
LANG_GEN_SETUPS = {
|
| 51 |
+
"de": {"beam": 10, "lenpen": 0.7},
|
| 52 |
+
"es": {"beam": 10, "lenpen": 0.1},
|
| 53 |
+
"fr": {"beam": 10, "lenpen": 1.0},
|
| 54 |
+
"it": {"beam": 10, "lenpen": 0.5},
|
| 55 |
+
"nl": {"beam": 10, "lenpen": 0.4},
|
| 56 |
+
"pt": {"beam": 10, "lenpen": 0.9},
|
| 57 |
+
"ro": {"beam": 10, "lenpen": 1.0},
|
| 58 |
+
"ru": {"beam": 10, "lenpen": 0.3},
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# A lookup table for TTS (edenai)
|
| 63 |
+
lang2voice = {
|
| 64 |
+
"Arabic" : ["ar-XA", "MALE"],
|
| 65 |
+
"English" : ["en-US", "FEMALE"],
|
| 66 |
+
"Chinese" : ["cmn-TW", "MALE"],
|
| 67 |
+
"Spanish" : ["es-ES","MALE"],
|
| 68 |
+
"Russian" : ["ru-RU,", "FEMALE"],
|
| 69 |
+
"French" : ["fr-FR", "FEMALE"],
|
| 70 |
+
"German" : ["de-DE", "MALE"],
|
| 71 |
+
"Italian" : ["it-IT", "FEMALE"],
|
| 72 |
+
"Netherlands": ["nl-NL", "MALE"],
|
| 73 |
+
"Portuguese": ["pt-BR", "FEMALE"],
|
| 74 |
+
"Romanian" : ["ro-RO", "MALE"],
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
# load whisper
|
| 80 |
+
os.system("pip install git+https://github.com/openai/whisper.git")
|
| 81 |
+
|
| 82 |
+
# load mRASP2
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
# load ConST
|
| 88 |
+
#os.system("git clone https://github.com/ReneeYe/ConST")
|
| 89 |
+
#os.system("mv ConST ConST_git")
|
| 90 |
+
#os.system('mv -n ConST_git/* ./')
|
| 91 |
+
#os.system("rm -rf ConST_git")
|
| 92 |
+
#os.system("pip3 install --editable ./")
|
| 93 |
+
#os.system("mkdir -p data checkpoint")
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
huggingface_model_dir = snapshot_download(repo_id="ReneeYe/ConST_en2x_models")
|
| 97 |
+
print(huggingface_model_dir)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def restrict_src_options(model_type):
|
| 102 |
+
if model_type == 'Whisper+mRASP2':
|
| 103 |
+
return gr.Dropdown.update(visible= True), gr.Dropdown.update(visible= True), gr.Dropdown.update(visible= False), gr.Button.update(visible= True)
|
| 104 |
+
else:
|
| 105 |
+
return gr.Dropdown.update(visible= False), gr.Dropdown.update(visible= False), gr.Dropdown.update(visible= True), gr.Button.update(visible= False)
|
| 106 |
+
|
| 107 |
+
def switchLang(src_lang, tgt_lang):
|
| 108 |
+
return tgt_lang, src_lang
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
# The predict function. audio, language and mic_audio are all parameters directly passed by gradio
|
| 112 |
+
# which means they are user inputted. They are specified in gr.inputs[] block at the bottom. The
|
| 113 |
+
# gr.outputs[] block will specify the output type.
|
| 114 |
+
|
| 115 |
+
def predict(audio, src_language, tgt_language_mRASP, tgt_language_ConST, model_type, mic_audio=None):
|
| 116 |
+
# checks if mic_audio is used, otherwise feeds model uploaded audio
|
| 117 |
+
start_predict = time.time()
|
| 118 |
+
if mic_audio is not None:
|
| 119 |
+
input_audio = mic_audio
|
| 120 |
+
elif audio is not None:
|
| 121 |
+
input_audio = audio
|
| 122 |
+
else:
|
| 123 |
+
return "(please provide audio)"
|
| 124 |
+
|
| 125 |
+
transcript = "Undefined"
|
| 126 |
+
translation = "Undefined"
|
| 127 |
+
|
| 128 |
+
if model_type == 'Whisper+mRASP2':
|
| 129 |
+
transcript, translation = predictWithmRASP2(input_audio, src_language, tgt_language_mRASP)
|
| 130 |
+
language = tgt_language_mRASP
|
| 131 |
+
elif model_type == 'ConST':
|
| 132 |
+
predictWithConST(input_audio, tgt_language_ConST)
|
| 133 |
+
language = tgt_language_ConST
|
| 134 |
+
|
| 135 |
+
start_tts = time.time()
|
| 136 |
+
|
| 137 |
+
payload={
|
| 138 |
+
"providers": "google",
|
| 139 |
+
"language": lang2voice[language][0],
|
| 140 |
+
"option": lang2voice[language][1],
|
| 141 |
+
"text": translation,
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
response = requests.post(url, json=payload, headers=headers)
|
| 145 |
+
|
| 146 |
+
result = json.loads(response.text)
|
| 147 |
+
|
| 148 |
+
os.system('wget -O output.wav "{}"'.format(result['google']['audio_resource_url']))
|
| 149 |
+
|
| 150 |
+
tts_time = time.time() - start_tts
|
| 151 |
+
print(f"Took {tts_time} to do text to speech")
|
| 152 |
+
|
| 153 |
+
total_time = time.time() - start_predict
|
| 154 |
+
print(f"Took {total_time} to do entire prediction")
|
| 155 |
+
|
| 156 |
+
return transcript, translation, "output.wav"
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def predictWithmRASP2(input_audio, src_language, tgt_language):
|
| 161 |
+
print("Called predictWithmRASP2")
|
| 162 |
+
# Uses the model's preprocessing methods to preprocess audio
|
| 163 |
+
asr_start = time.time()
|
| 164 |
+
|
| 165 |
+
audio = whisper.load_audio(input_audio)
|
| 166 |
+
audio = whisper.pad_or_trim(audio)
|
| 167 |
+
|
| 168 |
+
# Calculates the mel frequency spectogram
|
| 169 |
+
mel = whisper.log_mel_spectrogram(audio).to(model.device)
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
# if model is supposed to detect language, set outLanguage to None
|
| 173 |
+
# otherwise set to specified language
|
| 174 |
+
if(src_language == "Detect Language"):
|
| 175 |
+
src_language = None
|
| 176 |
+
else:
|
| 177 |
+
src_language = language_id_lookup[src_language.split()[0]]
|
| 178 |
+
tgt_language = language_id_lookup[tgt_language.split()[0]]
|
| 179 |
+
|
| 180 |
+
# Runs the audio through the whisper model and gets the DecodingResult object, which has the features:
|
| 181 |
+
# audio_features (Tensor), language, language_probs, tokens, text, avg_logprob, no_speech_prob, temperature, compression_ratio
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
# asr
|
| 185 |
+
|
| 186 |
+
options = whisper.DecodingOptions(fp16 = True, language = src_language)
|
| 187 |
+
result = whisper.decode(model, mel, options)
|
| 188 |
+
if src_language is None:
|
| 189 |
+
src_language = result.language
|
| 190 |
+
|
| 191 |
+
transcript = result.text
|
| 192 |
+
|
| 193 |
+
asr_time = time.time() - asr_start
|
| 194 |
+
mt_start_time = time.time()
|
| 195 |
+
# mt
|
| 196 |
+
with open("input." + src_language, 'w') as w:
|
| 197 |
+
w.write(result.text)
|
| 198 |
+
with open("input." + tgt_language, 'w') as w:
|
| 199 |
+
w.write('LANG_TOK_' + src_language.upper())
|
| 200 |
+
|
| 201 |
+
#os.system("python3 fairseq/fairseq_cli/preprocess.py --dataset-impl raw \
|
| 202 |
+
# --srcdict bpe_vocab --tgtdict bpe_vocab --testpref input -s {} -t {}".format( \
|
| 203 |
+
# src_language, tgt_language))
|
| 204 |
+
|
| 205 |
+
#previous way of doing it
|
| 206 |
+
old_way = """os.system("python3 fairseq/fairseq_cli/interactive.py ./data-bin \
|
| 207 |
+
--user-dir mcolt \
|
| 208 |
+
-s zh \
|
| 209 |
+
-t en \
|
| 210 |
+
--skip-invalid-size-inputs-valid-test \
|
| 211 |
+
--path {} \
|
| 212 |
+
--max-tokens 1024 \
|
| 213 |
+
--task translation_w_langtok \
|
| 214 |
+
--lang-prefix-tok \"LANG_TOK_{}\" \
|
| 215 |
+
--max-source-positions 1024 \
|
| 216 |
+
--max-target-positions 1024 \
|
| 217 |
+
--nbest 1 \
|
| 218 |
+
--bpe subword_nmt \
|
| 219 |
+
--bpe-codes codes.bpe.32000 \
|
| 220 |
+
--post-process --tokenizer moses \
|
| 221 |
+
--input input.{} | grep -E '[D]-[0-9]+' > output".format(
|
| 222 |
+
model_name, tgt_language.upper(), src_language))"""
|
| 223 |
+
|
| 224 |
+
translation = mRASPloader.infer(cfg, models, task, max_positions, tokenizer, bpe, use_cuda, generator, src_dict, tgt_dict, align_dict, start_time, start_id, src_language, tgt_language)
|
| 225 |
+
translation = (' '.join(translation.split(' ')[1:])).strip()
|
| 226 |
+
|
| 227 |
+
mt_time = time.time() - mt_start_time
|
| 228 |
+
print(f"Took {mt_time} to do Machine Translation")
|
| 229 |
+
#print(model_name)
|
| 230 |
+
|
| 231 |
+
#with open("output", 'r') as r:
|
| 232 |
+
# translation = "Undefined"
|
| 233 |
+
# translation = (' '.join(r.readline().split(' ')[1:])).strip()
|
| 234 |
+
# print(translation)
|
| 235 |
+
|
| 236 |
+
# Returns the text
|
| 237 |
+
print("returning transcript: " + transcript + " and the translation: " + translation)
|
| 238 |
+
return transcript, translation
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
# Helper methods for ConST (as written in https://huggingface.co/spaces/ReneeYe/ConST-speech2text-translator/blob/main/app.py)
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
def convert_audio_to_16k_wav(audio_input):
|
| 246 |
+
sound = AudioSegment.from_file(audio_input)
|
| 247 |
+
sample_rate = sound.frame_rate
|
| 248 |
+
num_channels = sound.channels
|
| 249 |
+
num_frames = int(sound.frame_count())
|
| 250 |
+
filename = audio_input.split("/")[-1]
|
| 251 |
+
print("original file is at:", audio_input)
|
| 252 |
+
if (num_channels > 1) or (sample_rate != 16000): # convert to mono-channel 16k wav
|
| 253 |
+
if num_channels > 1:
|
| 254 |
+
sound = sound.set_channels(1)
|
| 255 |
+
if sample_rate != 16000:
|
| 256 |
+
sound = sound.set_frame_rate(16000)
|
| 257 |
+
num_frames = int(sound.frame_count())
|
| 258 |
+
filename = filename.replace(".wav", "") + "_16k.wav"
|
| 259 |
+
sound.export(f"data/{filename}", format="wav")
|
| 260 |
+
else:
|
| 261 |
+
shutil.copy(audio_input, f'data/{filename}')
|
| 262 |
+
return filename, num_frames
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
def prepare_tsv(file_name, n_frame, language, task="ST"):
|
| 266 |
+
tgt_lang = language_id_lookup[language]
|
| 267 |
+
with open("data/test_case.tsv", "w") as f:
|
| 268 |
+
f.write("id\taudio\tn_frames\ttgt_text\tspeaker\tsrc_lang\ttgt_lang\tsrc_text\n")
|
| 269 |
+
f.write(f"sample\t{file_name}\t{n_frame}\tThis is in {tgt_lang}.\tspk.1\ten\t{tgt_lang}\tThis is English.\n")
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def get_vocab_and_yaml(language):
|
| 273 |
+
tgt_lang = language_id_lookup[language]
|
| 274 |
+
# get: spm_ende.model and spm_ende.txt, and save to data/xxx
|
| 275 |
+
# if exist, no need to download
|
| 276 |
+
shutil.copy(os.path.join(huggingface_model_dir, f"vocabulary/spm_en{tgt_lang}.model"), "./data")
|
| 277 |
+
shutil.copy(os.path.join(huggingface_model_dir, f"vocabulary/spm_en{tgt_lang}.txt"), "./data")
|
| 278 |
+
|
| 279 |
+
# write yaml file
|
| 280 |
+
abs_path = os.popen("pwd").read().strip()
|
| 281 |
+
yaml_dict = LANG_GEN_SETUPS[tgt_lang]
|
| 282 |
+
yaml_dict["input_channels"] = 1
|
| 283 |
+
yaml_dict["use_audio_input"] = True
|
| 284 |
+
yaml_dict["prepend_tgt_lang_tag"] = True
|
| 285 |
+
yaml_dict["prepend_src_lang_tag"] = True
|
| 286 |
+
yaml_dict["audio_root"] = os.path.join(abs_path, "data")
|
| 287 |
+
yaml_dict["vocab_filename"] = f"spm_en{tgt_lang}.txt"
|
| 288 |
+
yaml_dict["bpe_tokenizer"] = {"bpe": "sentencepiece",
|
| 289 |
+
"sentencepiece_model": os.path.join(abs_path, f"data/spm_en{tgt_lang}.model")}
|
| 290 |
+
with open("data/config.yaml", "w") as f:
|
| 291 |
+
yaml.dump(yaml_dict, f)
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
def get_model(language):
|
| 295 |
+
# download models to checkpoint/xxx
|
| 296 |
+
return os.path.join(huggingface_model_dir, f"models/const_en{language_id_lookup[language]}.pt")
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
def generate(model_path):
|
| 300 |
+
os.system(f"python3 fairseq/fairseq_cli/generate.py data/ --gen-subset test_case --task speech_to_text --prefix-size 1 \
|
| 301 |
+
--max-source-positions 4000000 \
|
| 302 |
+
--config-yaml config.yaml --path {model_path} | tee temp.txt")
|
| 303 |
+
print("No problem with 1st line")
|
| 304 |
+
output = os.popen("grep ^D temp.txt | sort -n -k 2 -t '-' | cut -f 3")
|
| 305 |
+
return output.read().strip()
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
def post_processing(raw_sentence):
|
| 309 |
+
output_sentence = raw_sentence
|
| 310 |
+
if ":" in raw_sentence:
|
| 311 |
+
splited_sent = raw_sentence.split(":")
|
| 312 |
+
if len(splited_sent) == 2:
|
| 313 |
+
prefix = splited_sent[0].strip()
|
| 314 |
+
if len(prefix) <= 3:
|
| 315 |
+
output_sentence = splited_sent[1].strip()
|
| 316 |
+
elif ("(" in prefix) and (")" in prefix):
|
| 317 |
+
bgm = re.findall(r"\(.*?\)", prefix)[0]
|
| 318 |
+
if len(prefix.replace(bgm, "").strip()) <= 3:
|
| 319 |
+
output_sentence = splited_sent[1].strip()
|
| 320 |
+
elif len(splited_sent[1].strip()) > 8:
|
| 321 |
+
output_sentence = splited_sent[1].strip()
|
| 322 |
+
|
| 323 |
+
elif ("(" in raw_sentence) and (")" in raw_sentence):
|
| 324 |
+
bgm_list = re.findall(r"\(.*?\)", raw_sentence)
|
| 325 |
+
for bgm in bgm_list:
|
| 326 |
+
if len(raw_sentence.replace(bgm, "").strip()) > 5:
|
| 327 |
+
output_sentence = output_sentence.replace(bgm, "").strip()
|
| 328 |
+
if len(output_sentence) <= 5:
|
| 329 |
+
output_sentence = raw_sentence
|
| 330 |
+
return output_sentence
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
def remove_temp_files(audio_file):
|
| 334 |
+
os.remove("temp.txt")
|
| 335 |
+
os.remove("data/test_case.tsv")
|
| 336 |
+
os.remove(f"data/{audio_file}")
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
def error_output(language):
|
| 341 |
+
return f"Fail to translate the audio into {language}, you may use the examples I provide."
|
| 342 |
+
|
| 343 |
+
# Predicting the translation with ConST
|
| 344 |
+
def predictWithConST(audio_file, language):
|
| 345 |
+
try:
|
| 346 |
+
converted_audio_file, n_frame = convert_audio_to_16k_wav(audio_file)
|
| 347 |
+
prepare_tsv(converted_audio_file, n_frame, language)
|
| 348 |
+
get_vocab_and_yaml(language)
|
| 349 |
+
model_path = get_model(language)
|
| 350 |
+
print("This is the model path: " + model_path)
|
| 351 |
+
generate_model_path = generate(model_path)
|
| 352 |
+
print("No problem generating model path")
|
| 353 |
+
generated_output = post_processing(generate_model_path)
|
| 354 |
+
print("No problem generating output")
|
| 355 |
+
remove_temp_files(converted_audio_file)
|
| 356 |
+
print("No problem removing_temp")
|
| 357 |
+
return generated_output
|
| 358 |
+
except:
|
| 359 |
+
traceback.print_exc()
|
| 360 |
+
return error_output(language)
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
title = "Demo for Speech Translation (Whisper+mRASP2 and ConST)"
|
| 364 |
+
|
| 365 |
+
description = """
|
| 366 |
+
<b>How to use:</b> Upload an audio file or record using the microphone. The audio is either processed by being inputted into the openai whisper model for transcription
|
| 367 |
+
and then mRASP2 for translation, or by ConST, which directly takes the audio input and produces text in the desired language. When using Whisper+mRASP2,
|
| 368 |
+
you can ask the model to detect a language, it will tell you what language it detected. ConST only supports translating from English to another language.
|
| 369 |
+
"""
|
| 370 |
+
|
| 371 |
+
# The gradio block
|
| 372 |
+
|
| 373 |
+
cfg = mRASPloader.createCFG()
|
| 374 |
+
print(cfg)
|
| 375 |
+
models, task, max_positions, tokenizer, bpe, use_cuda, generator, src_dict, tgt_dict, align_dict, start_time, start_id = mRASPloader.loadmRASP2(cfg)
|
| 376 |
+
|
| 377 |
+
demo = gr.Blocks()
|
| 378 |
+
|
| 379 |
+
with demo:
|
| 380 |
+
gr.Markdown("# " + title)
|
| 381 |
+
gr.Markdown("###" + description)
|
| 382 |
+
with gr.Row():
|
| 383 |
+
with gr.Column():
|
| 384 |
+
model_type = gr.Dropdown(['Whisper+mRASP2', 'ConST'], type = "value", value = 'Whisper+mRASP2', label = "Select the model you want to use.")
|
| 385 |
+
audio_file = gr.Audio(label="Upload Speech", source="upload", type="filepath")
|
| 386 |
+
src_language = gr.Dropdown(['Arabic',
|
| 387 |
+
'Chinese',
|
| 388 |
+
'English',
|
| 389 |
+
'Spanish',
|
| 390 |
+
'Russian',
|
| 391 |
+
'French',
|
| 392 |
+
'Detect Language'], value = 'English', label="Select the language of input")
|
| 393 |
+
tgt_language_mRASP = gr.Dropdown(['Arabic',
|
| 394 |
+
'Chinese',
|
| 395 |
+
'English',
|
| 396 |
+
'Spanish',
|
| 397 |
+
'Russian',
|
| 398 |
+
'French'], type="value", value='English', label="Select the language of output")
|
| 399 |
+
tgt_language_ConST = gr.Dropdown(['German',
|
| 400 |
+
'Spanish',
|
| 401 |
+
'French',
|
| 402 |
+
'Italian',
|
| 403 |
+
'Netherlands',
|
| 404 |
+
'Portugese',
|
| 405 |
+
'Romanian',
|
| 406 |
+
'Russian'], type = 'value', value='German', label="Select the language of output", visible= False)
|
| 407 |
+
switch_lang_button = gr.Button("Switch input and output languages")
|
| 408 |
+
mic_audio = gr.Audio(label="Record Speech", source="microphone", type="filepath")
|
| 409 |
+
|
| 410 |
+
model_type.change(fn = restrict_src_options, inputs=[model_type], outputs=[src_language, tgt_language_mRASP, tgt_language_ConST, switch_lang_button])
|
| 411 |
+
submit_button = gr.Button("Submit")
|
| 412 |
+
with gr.Column():
|
| 413 |
+
transcript = gr.Text(label= "Transcription")
|
| 414 |
+
translate = gr.Text(label= "Translation")
|
| 415 |
+
translated_speech = gr.Audio(label="Translation Speech")
|
| 416 |
+
|
| 417 |
+
submit_button.click(fn = predict, inputs=[audio_file, src_language, tgt_language_mRASP, tgt_language_ConST, model_type, mic_audio], outputs=[transcript, translate, translated_speech])
|
| 418 |
+
switch_lang_button.click(switchLang, [src_language, tgt_language_mRASP], [src_language, tgt_language_mRASP])
|
| 419 |
+
|
| 420 |
+
demo.launch(share= True)
|
bpe_vocab
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
cfg.txt
ADDED
|
Binary file (23.4 kB). View file
|
|
|
cfgDefault.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
FairseqConfig(_name=None, common=CommonConfig(_name=None, no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma'), common_eval=CommonEvalConfig(_name=None, path=None, post_process=None, quiet=False, model_overrides='{}', results_path=None), distributed_training=DistributedTrainingConfig(_name=None, distributed_world_size=8, distributed_num_procs=8, distributed_rank=0, distributed_backend='nccl', distributed_init_method=None, distributed_port=-1, device_id=0, distributed_no_spawn=False, ddp_backend='pytorch_ddp', ddp_comm_hook='none', bucket_cap_mb=25, fix_batches_to_gpus=False, find_unused_parameters=False, gradient_as_bucket_view=False, fast_stat_sync=False, heartbeat_timeout=-1, broadcast_buffers=False, slowmo_momentum=None, slowmo_base_algorithm='localsgd', localsgd_frequency=3, nprocs_per_node=8, pipeline_model_parallel=False, pipeline_balance=None, pipeline_devices=None, pipeline_chunks=0, pipeline_encoder_balance=None, pipeline_encoder_devices=None, pipeline_decoder_balance=None, pipeline_decoder_devices=None, pipeline_checkpoint='never', zero_sharding='none', fp16='${common.fp16}', memory_efficient_fp16='${common.memory_efficient_fp16}', tpu='${common.tpu}', no_reshard_after_forward=False, fp32_reduce_scatter=False, cpu_offload=False, use_sharded_state=False, not_fsdp_flatten_parameters=False), dataset=DatasetConfig(_name=None, num_workers=1, skip_invalid_size_inputs_valid_test=False, max_tokens=None, batch_size=None, required_batch_size_multiple=8, required_seq_len_multiple=1, dataset_impl=None, data_buffer_size=10, train_subset='train', valid_subset='valid', combine_valid_subsets=None, ignore_unused_valid_subsets=False, validate_interval=1, validate_interval_updates=0, validate_after_updates=0, fixed_validation_seed=None, disable_validation=False, max_tokens_valid='${dataset.max_tokens}', batch_size_valid='${dataset.batch_size}', max_valid_steps=None, curriculum=0, gen_subset='test', num_shards=1, shard_id=0, grouped_shuffling=False, update_epoch_batch_itr='${dataset.grouped_shuffling}', update_ordered_indices_seed=False), optimization=OptimizationConfig(_name=None, max_epoch=0, max_update=0, stop_time_hours=0, clip_norm=0.0, sentence_avg=False, update_freq=[1], lr=[0.25], stop_min_lr=-1.0, use_bmuf=False, skip_remainder_batch=False, debug_param_names=False), checkpoint=CheckpointConfig(_name=None, save_dir='checkpoints', restore_file='checkpoint_last.pt', continue_once=None, finetune_from_model=None, reset_dataloader=False, reset_lr_scheduler=False, reset_meters=False, reset_optimizer=False, optimizer_overrides='{}', save_interval=1, save_interval_updates=0, keep_interval_updates=-1, keep_interval_updates_pattern=-1, keep_last_epochs=-1, keep_best_checkpoints=-1, no_save=False, no_epoch_checkpoints=False, no_last_checkpoints=False, no_save_optimizer_state=False, best_checkpoint_metric='loss', maximize_best_checkpoint_metric=False, patience=-1, checkpoint_suffix='', checkpoint_shard_count=1, load_checkpoint_on_all_dp_ranks=False, write_checkpoints_asynchronously=False, model_parallel_size='${common.model_parallel_size}'), bmuf=FairseqBMUFConfig(_name=None, block_lr=1, block_momentum=0.875, global_sync_iter=50, warmup_iterations=500, use_nbm=False, average_sync=False, distributed_world_size='${distributed_training.distributed_world_size}'), generation=GenerationConfig(_name=None, beam=5, beam_mt=0, nbest=1, max_len_a=0, max_len_b=200, max_len_a_mt=0, max_len_b_mt=200, min_len=1, match_source_len=False, unnormalized=False, no_early_stop=False, no_beamable_mm=False, lenpen=1, lenpen_mt=1, unkpen=0, replace_unk=None, sacrebleu=False, score_reference=False, prefix_size=0, no_repeat_ngram_size=0, sampling=False, sampling_topk=-1, sampling_topp=-1.0, constraints=None, temperature=1.0, diverse_beam_groups=-1, diverse_beam_strength=0.5, diversity_rate=-1.0, print_alignment=None, print_step=False, lm_path=None, lm_weight=0.0, iter_decode_eos_penalty=0.0, iter_decode_max_iter=10, iter_decode_force_max_iter=False, iter_decode_with_beam=1, iter_decode_with_external_reranker=False, retain_iter_history=False, retain_dropout=False, retain_dropout_modules=None, decoding_format=None, no_seed_provided=False, eos_token=None), eval_lm=EvalLMConfig(_name=None, output_word_probs=False, output_word_stats=False, context_window=0, softmax_batch=9223372036854775807), interactive=InteractiveConfig(_name=None, buffer_size=0, input='-'), model='???', task=None, criterion=None, optimizer=None, lr_scheduler=None, scoring=None, bpe=None, tokenizer=None, ema=EMAConfig(_name=None, store_ema=False, ema_decay=0.9999, ema_start_update=0, ema_seed_model=None, ema_update_freq=1, ema_fp32=False))
|
codes.bpe.32000
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/dict.ar.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/dict.en.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/dict.es.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/dict.fr.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/dict.ru.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/dict.zh.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data-bin/preprocess.log
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='ru', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 2 |
+
Wrote preprocessed data to data-bin
|
| 3 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='zh', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 4 |
+
Wrote preprocessed data to data-bin
|
| 5 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 6 |
+
Wrote preprocessed data to data-bin
|
| 7 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='zh', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 8 |
+
Wrote preprocessed data to data-bin
|
| 9 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 10 |
+
Wrote preprocessed data to data-bin
|
| 11 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='ru', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 12 |
+
Wrote preprocessed data to data-bin
|
| 13 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='fr', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 14 |
+
Wrote preprocessed data to data-bin
|
| 15 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 16 |
+
Wrote preprocessed data to data-bin
|
| 17 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='zh', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 18 |
+
Wrote preprocessed data to data-bin
|
| 19 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 20 |
+
Wrote preprocessed data to data-bin
|
| 21 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 22 |
+
Wrote preprocessed data to data-bin
|
| 23 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 24 |
+
Wrote preprocessed data to data-bin
|
| 25 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 26 |
+
Wrote preprocessed data to data-bin
|
| 27 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 28 |
+
Wrote preprocessed data to data-bin
|
| 29 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 30 |
+
Wrote preprocessed data to data-bin
|
| 31 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 32 |
+
Wrote preprocessed data to data-bin
|
| 33 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 34 |
+
Wrote preprocessed data to data-bin
|
| 35 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 36 |
+
Wrote preprocessed data to data-bin
|
| 37 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 38 |
+
Wrote preprocessed data to data-bin
|
| 39 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 40 |
+
Wrote preprocessed data to data-bin
|
| 41 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 42 |
+
Wrote preprocessed data to data-bin
|
| 43 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 44 |
+
Wrote preprocessed data to data-bin
|
| 45 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 46 |
+
Wrote preprocessed data to data-bin
|
| 47 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 48 |
+
Wrote preprocessed data to data-bin
|
| 49 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 50 |
+
Wrote preprocessed data to data-bin
|
| 51 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 52 |
+
Wrote preprocessed data to data-bin
|
| 53 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 54 |
+
Wrote preprocessed data to data-bin
|
| 55 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 56 |
+
Wrote preprocessed data to data-bin
|
| 57 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 58 |
+
Wrote preprocessed data to data-bin
|
| 59 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 60 |
+
Wrote preprocessed data to data-bin
|
| 61 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 62 |
+
Wrote preprocessed data to data-bin
|
| 63 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 64 |
+
Wrote preprocessed data to data-bin
|
| 65 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 66 |
+
Wrote preprocessed data to data-bin
|
| 67 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 68 |
+
Wrote preprocessed data to data-bin
|
| 69 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 70 |
+
Wrote preprocessed data to data-bin
|
| 71 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 72 |
+
Wrote preprocessed data to data-bin
|
| 73 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 74 |
+
Wrote preprocessed data to data-bin
|
| 75 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 76 |
+
Wrote preprocessed data to data-bin
|
| 77 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='ru', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 78 |
+
Wrote preprocessed data to data-bin
|
| 79 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='ru', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 80 |
+
Wrote preprocessed data to data-bin
|
| 81 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 82 |
+
Wrote preprocessed data to data-bin
|
| 83 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 84 |
+
Wrote preprocessed data to data-bin
|
| 85 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 86 |
+
Wrote preprocessed data to data-bin
|
| 87 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 88 |
+
Wrote preprocessed data to data-bin
|
| 89 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='es', target_lang='en', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 90 |
+
Wrote preprocessed data to data-bin
|
| 91 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='ru', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 92 |
+
Wrote preprocessed data to data-bin
|
| 93 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='ru', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 94 |
+
Wrote preprocessed data to data-bin
|
| 95 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='ru', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 96 |
+
Wrote preprocessed data to data-bin
|
| 97 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='ar', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 98 |
+
Wrote preprocessed data to data-bin
|
| 99 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='zh', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 100 |
+
Wrote preprocessed data to data-bin
|
| 101 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='es', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 102 |
+
Wrote preprocessed data to data-bin
|
| 103 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='ru', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 104 |
+
Wrote preprocessed data to data-bin
|
| 105 |
+
Namespace(no_progress_bar=False, log_interval=100, log_format=None, log_file=None, aim_repo=None, aim_run_hash=None, tensorboard_logdir=None, wandb_project=None, azureml_logging=False, seed=1, cpu=False, tpu=False, bf16=False, memory_efficient_bf16=False, fp16=False, memory_efficient_fp16=False, fp16_no_flatten_grads=False, fp16_init_scale=128, fp16_scale_window=None, fp16_scale_tolerance=0.0, on_cpu_convert_precision=False, min_loss_scale=0.0001, threshold_loss_scale=None, amp=False, amp_batch_retries=2, amp_init_scale=128, amp_scale_window=None, user_dir=None, empty_cache_freq=0, all_gather_list_size=16384, model_parallel_size=1, quantization_config_path=None, profile=False, reset_logging=False, suppress_crashes=False, use_plasma_view=False, plasma_path='/tmp/plasma', criterion='cross_entropy', tokenizer=None, bpe=None, optimizer=None, lr_scheduler='fixed', scoring='bleu', task='translation', source_lang='en', target_lang='fr', trainpref=None, validpref=None, testpref='input', align_suffix=None, destdir='data-bin', thresholdtgt=0, thresholdsrc=0, tgtdict='bpe_vocab', srcdict='bpe_vocab', nwordstgt=-1, nwordssrc=-1, alignfile=None, dataset_impl='raw', joined_dictionary=False, only_source=False, padding_factor=8, workers=1, dict_only=False)
|
| 106 |
+
Wrote preprocessed data to data-bin
|
data-bin/test.en-ar.ar
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|
data-bin/test.en-ar.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Hello.
|
data-bin/test.en-en.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|
data-bin/test.en-es.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Hello.
|
data-bin/test.en-es.es
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|
data-bin/test.en-fr.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Hello.
|
data-bin/test.en-fr.fr
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|
data-bin/test.en-ru.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Hello.
|
data-bin/test.en-ru.ru
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|
data-bin/test.en-zh.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Hello.
|
data-bin/test.en-zh.zh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|
data-bin/test.es-en.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_ES
|
data-bin/test.es-en.es
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
necesito un carro para ver mi comida
|
data-bin/test.es-ru.es
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Hola, soy Jeff. ¿Cómo estás?
|
data-bin/test.es-ru.ru
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_ES
|
data-bin/test.es-zh.es
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Hoy vamos a hacer un menú mexicano. Vamos a hacer un apetizer, una entree y un deser. Ahora vamos a hacer el deser, que es la flan. Lo estamos haciendo ahora porque se tiende muy largo. Así que vamos a seguir. Estos son nuestros ingredientes para hacer el flan, nuestro deser. Ahora ponemos el azúcar para que lo caramelizemos y lo ponemos en la flan.
|
data-bin/test.es-zh.zh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_ES
|
data-bin/test.zh-en.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_ZH
|
data-bin/test.zh-en.zh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
天气真好
|
docs/img.png
ADDED
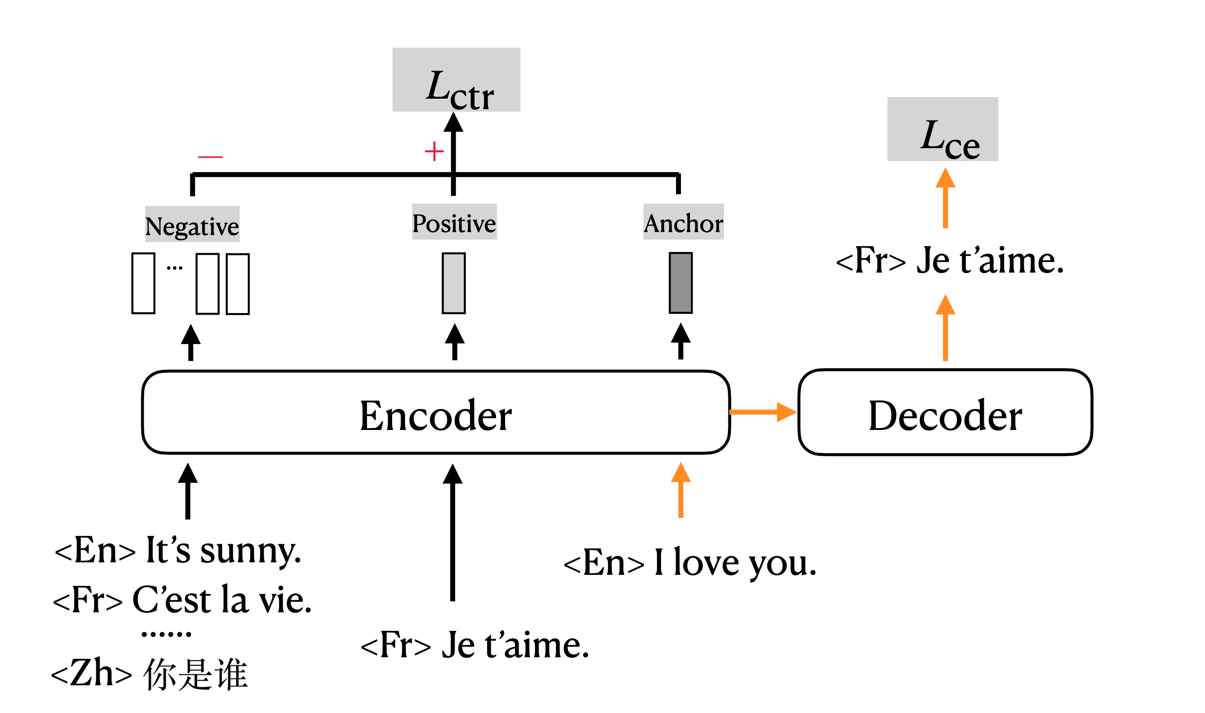
|
eval.sh
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
|
| 3 |
+
# repo_dir: root directory of the project
|
| 4 |
+
repo_dir="$( cd "$( dirname "$0" )" && pwd )"
|
| 5 |
+
echo "==== Working directory: ====" >&2
|
| 6 |
+
echo "${repo_dir}" >&2
|
| 7 |
+
echo "============================" >&2
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
test_config=$1
|
| 11 |
+
source ${repo_dir}/scripts/load_config.sh ${test_config} ${repo_dir}
|
| 12 |
+
model_dir=$2
|
| 13 |
+
choice=$3 # all|best|last
|
| 14 |
+
|
| 15 |
+
model_dir=${repo_dir}/model
|
| 16 |
+
data_dir=${repo_dir}/data
|
| 17 |
+
res_path=${model_dir}/results
|
| 18 |
+
|
| 19 |
+
mkdir -p ${model_dir} ${data_dir} ${res_path}
|
| 20 |
+
|
| 21 |
+
testset_name=data_testset_1_name
|
| 22 |
+
testset_path=data_testset_1_path
|
| 23 |
+
testset_ref=data_testset_1_ref
|
| 24 |
+
testset_direc=data_testset_1_direction
|
| 25 |
+
i=1
|
| 26 |
+
testsets=""
|
| 27 |
+
while [[ ! -z ${!testset_path} && ! -z ${!testset_direc} ]]; do
|
| 28 |
+
dataname=${!testset_name}
|
| 29 |
+
mkdir -p ${data_dir}/${!testset_direc}/${dataname} ${data_dir}/ref/${!testset_direc}/${dataname}
|
| 30 |
+
cp ${!testset_path}/* ${data_dir}/${!testset_direc}/${dataname}/
|
| 31 |
+
cp ${!testset_ref}/* ${data_dir}/ref/${!testset_direc}/${dataname}/
|
| 32 |
+
if [[ $testsets == "" ]]; then
|
| 33 |
+
testsets=${!testset_direc}/${dataname}
|
| 34 |
+
else
|
| 35 |
+
testsets=${testsets}:${!testset_direc}/${dataname}
|
| 36 |
+
fi
|
| 37 |
+
i=$((i+1))
|
| 38 |
+
testset_name=testset_${i}_name
|
| 39 |
+
testset_path=testset_${i}_path
|
| 40 |
+
testset_ref=testset_${i}_ref
|
| 41 |
+
testset_direc=testset_${i}_direction
|
| 42 |
+
done
|
| 43 |
+
|
| 44 |
+
IFS=':' read -r -a testset_list <<< ${testsets}
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
bleu () {
|
| 48 |
+
src=$1
|
| 49 |
+
tgt=$2
|
| 50 |
+
res_file=$3
|
| 51 |
+
ref_file=$4
|
| 52 |
+
if [[ -f ${res_file} ]]; then
|
| 53 |
+
f_dirname=`dirname ${res_file}`
|
| 54 |
+
python3 ${repo_dir}/scripts/utils.py ${res_file} ${ref_file} || exit 1;
|
| 55 |
+
input_file="${f_dirname}/hypo.out.nobpe"
|
| 56 |
+
output_file="${f_dirname}/hypo.out.nobpe.final"
|
| 57 |
+
# form command
|
| 58 |
+
cmd="cat ${input_file}"
|
| 59 |
+
lang_token="LANG_TOK_"`echo "${tgt} " | tr '[a-z]' '[A-Z]'`
|
| 60 |
+
if [[ $tgt == "fr" ]]; then
|
| 61 |
+
cmd=$cmd" | sed -Ee 's/\"([^\"]*)\"/« \1 »/g'"
|
| 62 |
+
elif [[ $tgt == "zh" ]]; then
|
| 63 |
+
tokenizer="zh"
|
| 64 |
+
elif [[ $tgt == "ja" ]]; then
|
| 65 |
+
tokenizer="ja-mecab"
|
| 66 |
+
fi
|
| 67 |
+
[[ -z $tokenizer ]] && tokenizer="none"
|
| 68 |
+
cmd=$cmd" | sed -e s'|${lang_token} ||g' > ${output_file}"
|
| 69 |
+
eval $cmd || { echo "$cmd FAILED !"; exit 1; }
|
| 70 |
+
cat ${output_file} | sacrebleu -l ${src}-${tgt} -tok $tokenizer --short "${f_dirname}/ref.out" | awk '{print $3}'
|
| 71 |
+
else
|
| 72 |
+
echo "${res_file} not exist!" >&2 && exit 1;
|
| 73 |
+
fi
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
# monitor
|
| 77 |
+
# ${ckptname}/${direction}/${testname}/orig.txt
|
| 78 |
+
(inotifywait -r -m -e close_write ${res_path} |
|
| 79 |
+
while read path action file; do
|
| 80 |
+
if [[ "$file" =~ .*txt$ ]]; then
|
| 81 |
+
tmp_str="${path%/*}"
|
| 82 |
+
testname="${tmp_str##*/}"
|
| 83 |
+
tmp_str="${tmp_str%/*}"
|
| 84 |
+
direction="${tmp_str##*/}"
|
| 85 |
+
tmp_str="${tmp_str%/*}"
|
| 86 |
+
ckptname="${tmp_str##*/}"
|
| 87 |
+
src_lang="${direction%2*}"
|
| 88 |
+
tgt_lang="${direction##*2}"
|
| 89 |
+
res_file=$path$file
|
| 90 |
+
ref_file=${data_dir}/ref/${direction}/${testname}/dev.${tgt_lang}
|
| 91 |
+
bleuscore=`bleu ${src_lang} ${tgt_lang} ${res_file} ${ref_file}`
|
| 92 |
+
bleu_str="$(date "+%Y-%m-%d %H:%M:%S")\t${ckptname}\t${direction}/${testname}\t$bleuscore"
|
| 93 |
+
echo -e ${bleu_str} # to stdout
|
| 94 |
+
echo -e ${bleu_str} >> ${model_dir}/summary.log
|
| 95 |
+
fi
|
| 96 |
+
done) &
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
if [[ ${choice} == "all" ]]; then
|
| 100 |
+
filelist=`ls -la ${model_dir} | sort -k6,7 -r | awk '{print $NF}' | grep .pt$ | tr '\n' ' '`
|
| 101 |
+
elif [[ ${choice} == "best" ]]; then
|
| 102 |
+
filelist="${model_dir}/checkpoint_best.pt"
|
| 103 |
+
elif [[ ${choice} == "last" ]]; then
|
| 104 |
+
filelist="${model_dir}/checkpoint_last.pt"
|
| 105 |
+
else
|
| 106 |
+
echo "invalid choice!" && exit 2;
|
| 107 |
+
fi
|
| 108 |
+
|
| 109 |
+
N=${NUM_GPU}
|
| 110 |
+
#export CUDA_VISIBLE_DEVICES=$(seq -s ',' 0 $(($N - 1)) )
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
infer_test () {
|
| 114 |
+
test_path=$1
|
| 115 |
+
ckpts=$2
|
| 116 |
+
gpu=$3
|
| 117 |
+
final_res_file=$4
|
| 118 |
+
src=$5
|
| 119 |
+
tgt=$6
|
| 120 |
+
gpu_cmd="CUDA_VISIBLE_DEVICES=$gpu "
|
| 121 |
+
lang_token="LANG_TOK_"`echo "${tgt} " | tr '[a-z]' '[A-Z]'`
|
| 122 |
+
[[ -z ${max_source_positions} ]] && max_source_positions=1024
|
| 123 |
+
[[ -z ${max_target_positions} ]] && max_target_positions=1024
|
| 124 |
+
command=${gpu_cmd}"fairseq-generate ${test_path} \
|
| 125 |
+
--user-dir ${repo_dir}/mcolt \
|
| 126 |
+
-s ${src} \
|
| 127 |
+
-t ${tgt} \
|
| 128 |
+
--skip-invalid-size-inputs-valid-test \
|
| 129 |
+
--path ${ckpts} \
|
| 130 |
+
--max-tokens 1024 \
|
| 131 |
+
--task translation_w_langtok \
|
| 132 |
+
${options} \
|
| 133 |
+
--lang-prefix-tok ${lang_token} \
|
| 134 |
+
--max-source-positions ${max_source_positions} \
|
| 135 |
+
--max-target-positions ${max_target_positions} \
|
| 136 |
+
--nbest 1 | grep -E '[S|H|P|T]-[0-9]+' > ${final_res_file}
|
| 137 |
+
"
|
| 138 |
+
echo "$command"
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
export -f infer_test
|
| 142 |
+
i=0
|
| 143 |
+
(for ckpt in ${filelist}
|
| 144 |
+
do
|
| 145 |
+
for testset in "${testset_list[@]}"
|
| 146 |
+
do
|
| 147 |
+
ckptbase=`basename $ckpt`
|
| 148 |
+
ckptname="${ckptbase%.*}"
|
| 149 |
+
direction="${testset%/*}"
|
| 150 |
+
testname="${testset##*/}"
|
| 151 |
+
src_lang="${direction%2*}"
|
| 152 |
+
tgt_lang="${direction##*2}"
|
| 153 |
+
|
| 154 |
+
((i=i%N)); ((i++==0)) && wait
|
| 155 |
+
test_path=${data_dir}/${testset}
|
| 156 |
+
|
| 157 |
+
echo "-----> "${ckptname}" | "${direction}/$testname" <-----" >&2
|
| 158 |
+
if [[ ! -d ${res_path}/${ckptname}/${direction}/${testname} ]]; then
|
| 159 |
+
mkdir -p ${res_path}/${ckptname}/${direction}/${testname}
|
| 160 |
+
fi
|
| 161 |
+
final_res_file="${res_path}/${ckptname}/${direction}/${testname}/orig.txt"
|
| 162 |
+
command=`infer_test ${test_path} ${model_dir}/${ckptname}.pt $((i-1)) ${final_res_file} ${src_lang} ${tgt_lang}`
|
| 163 |
+
echo "${command}"
|
| 164 |
+
eval $command &
|
| 165 |
+
done
|
| 166 |
+
done)
|
examples/configs/eval_benchmarks.yml
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data_testset_1:
|
| 2 |
+
direction: en2de
|
| 3 |
+
name: wmt14
|
| 4 |
+
path: data/binarized/en_de/en2de/wmt14
|
| 5 |
+
ref: data/dev/en2de/wmt14
|
| 6 |
+
data_testset_10:
|
| 7 |
+
direction: ru2en
|
| 8 |
+
name: newstest2019
|
| 9 |
+
path: data/binarized/en_ru/ru2en/newstest2019
|
| 10 |
+
ref: data/dev/ru2en/newstest2019
|
| 11 |
+
data_testset_11:
|
| 12 |
+
direction: en2fi
|
| 13 |
+
name: newstest2017
|
| 14 |
+
path: data/binarized/en_fi/en2fi/newstest2017
|
| 15 |
+
ref: data/dev/en2fi/newstest2017
|
| 16 |
+
data_testset_12:
|
| 17 |
+
direction: fi2en
|
| 18 |
+
name: newstest2017
|
| 19 |
+
path: data/binarized/en_fi/fi2en/newstest2017
|
| 20 |
+
ref: data/dev/fi2en/newstest2017
|
| 21 |
+
data_testset_13:
|
| 22 |
+
direction: en2cs
|
| 23 |
+
name: newstest2016
|
| 24 |
+
path: data/binarized/en_cs/en2cs/newstest2016
|
| 25 |
+
ref: data/dev/en2cs/newstest2016
|
| 26 |
+
data_testset_14:
|
| 27 |
+
direction: cs2en
|
| 28 |
+
name: newstest2016
|
| 29 |
+
path: data/binarized/en_cs/cs2en/newstest2016
|
| 30 |
+
ref: data/dev/cs2en/newstest2016
|
| 31 |
+
data_testset_15:
|
| 32 |
+
direction: en2et
|
| 33 |
+
name: newstest2018
|
| 34 |
+
path: data/binarized/en_et/en2et/newstest2018
|
| 35 |
+
ref: data/dev/en2et/newstest2018
|
| 36 |
+
data_testset_16:
|
| 37 |
+
direction: et2en
|
| 38 |
+
name: newstest2018
|
| 39 |
+
path: data/binarized/en_et/et2en/newstest2018
|
| 40 |
+
ref: data/dev/et2en/newstest2018
|
| 41 |
+
data_testset_2:
|
| 42 |
+
direction: de2en
|
| 43 |
+
name: wmt14
|
| 44 |
+
path: data/binarized/en_de/de2en/wmt14
|
| 45 |
+
ref: data/dev/de2en/wmt14
|
| 46 |
+
data_testset_3:
|
| 47 |
+
direction: en2fr
|
| 48 |
+
name: newstest2014
|
| 49 |
+
path: data/binarized/en_fr/en2fr/newstest2014
|
| 50 |
+
ref: data/dev/en2fr/newstest2014
|
| 51 |
+
data_testset_4:
|
| 52 |
+
direction: fr2en
|
| 53 |
+
name: newstest2014
|
| 54 |
+
path: data/binarized/en_fr/fr2en/newstest2014
|
| 55 |
+
ref: data/dev/fr2en/newstest2014
|
| 56 |
+
data_testset_5:
|
| 57 |
+
direction: en2ro
|
| 58 |
+
name: wmt16
|
| 59 |
+
path: data/binarized/en_ro/en_ro/wmt16
|
| 60 |
+
ref: data/dev/en_ro/wmt16
|
| 61 |
+
data_testset_6:
|
| 62 |
+
direction: ro2en
|
| 63 |
+
name: wmt16
|
| 64 |
+
path: data/binarized/en_ro/en_ro/wmt16
|
| 65 |
+
ref: data/dev/en_ro/wmt16
|
| 66 |
+
data_testset_7:
|
| 67 |
+
direction: en2zh
|
| 68 |
+
name: wmt17
|
| 69 |
+
path: data/binarized/en_zh/en2zh/wmt17
|
| 70 |
+
ref: data/dev/en2zh/wmt17
|
| 71 |
+
data_testset_8:
|
| 72 |
+
direction: zh2en
|
| 73 |
+
name: wmt17
|
| 74 |
+
path: data/binarized/en_zh/zh2en/wmt17
|
| 75 |
+
ref: data/dev/zh2en/wmt17
|
| 76 |
+
data_testset_9:
|
| 77 |
+
direction: en2ru
|
| 78 |
+
name: newstest2019
|
| 79 |
+
path: data/binarized/en_ru/en2ru/newstest2019
|
| 80 |
+
ref: data/dev/en2ru/newstest2019
|
examples/configs/parallel_mono_12e12d_contrastive.yml
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_dir: model/pretrain/lab/multilingual/l2r/multi_bpe32k/parallel_mono_contrastive_1/transformer_big_t2t_12e12d
|
| 2 |
+
data_1: data/multilingual/bin/merged_deduped_ras
|
| 3 |
+
data_mono_1: data/multilingual/bin/mono_only/splitaa
|
| 4 |
+
data_mono_2: data/multilingual/bin/mono_only/splitab
|
| 5 |
+
data_mono_3: data/multilingual/bin/mono_only/splitac
|
| 6 |
+
data_mono_4: data/multilingual/bin/mono_only/splitad
|
| 7 |
+
data_mono_5: data/multilingual/bin/mono_only/splitae
|
| 8 |
+
data_mono_6: data/multilingual/bin/mono_only/mono_de_fr_en
|
| 9 |
+
data_mono_7: data/multilingual/bin/mono_only/mono_nl_pl_pt
|
| 10 |
+
source_lang: src
|
| 11 |
+
target_lang: trg
|
| 12 |
+
task: translation_w_mono
|
| 13 |
+
parallel_ratio: 0.2
|
| 14 |
+
mono_ratio: 0.07
|
| 15 |
+
arch: transformer_big_t2t_12e12d
|
| 16 |
+
share_all_embeddings: true
|
| 17 |
+
encoder_learned_pos: true
|
| 18 |
+
decoder_learned_pos: true
|
| 19 |
+
max_source_positions: 1024
|
| 20 |
+
max_target_positions: 1024
|
| 21 |
+
dropout: 0.1
|
| 22 |
+
criterion: label_smoothed_cross_entropy_with_contrastive
|
| 23 |
+
contrastive_lambda: 1.0
|
| 24 |
+
temperature: 0.1
|
| 25 |
+
lr: 0.0003
|
| 26 |
+
clip_norm: 10.0
|
| 27 |
+
optimizer: adam
|
| 28 |
+
adam_eps: 1e-06
|
| 29 |
+
weight_decay: 0.01
|
| 30 |
+
warmup_updates: 10000
|
| 31 |
+
label_smoothing: 0.1
|
| 32 |
+
lr_scheduler: polynomial_decay
|
| 33 |
+
min_lr: -1
|
| 34 |
+
max_tokens: 1536
|
| 35 |
+
update_freq: 30
|
| 36 |
+
max_update: 5000000
|
| 37 |
+
no_scale_embedding: true
|
| 38 |
+
layernorm_embedding: true
|
| 39 |
+
save_interval_updates: 2000
|
| 40 |
+
skip_invalid_size_inputs_valid_test: true
|
| 41 |
+
log_interval: 500
|
| 42 |
+
num_workers: 1
|
| 43 |
+
fp16: true
|
| 44 |
+
seed: 33122
|
fairseq
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Subproject commit 4db264940f281a6f47558d17387b1455d4abd8d9
|
hubconf.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the MIT license found in the
|
| 4 |
+
# LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import functools
|
| 7 |
+
import importlib
|
| 8 |
+
|
| 9 |
+
from fairseq.hub_utils import ( # noqa; noqa
|
| 10 |
+
BPEHubInterface as bpe,
|
| 11 |
+
TokenizerHubInterface as tokenizer,
|
| 12 |
+
)
|
| 13 |
+
from fairseq.models import MODEL_REGISTRY # noqa
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
dependencies = [
|
| 17 |
+
"dataclasses",
|
| 18 |
+
"hydra",
|
| 19 |
+
"numpy",
|
| 20 |
+
"regex",
|
| 21 |
+
"requests",
|
| 22 |
+
"torch",
|
| 23 |
+
]
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# Check for required dependencies and raise a RuntimeError if any are missing.
|
| 27 |
+
missing_deps = []
|
| 28 |
+
for dep in dependencies:
|
| 29 |
+
try:
|
| 30 |
+
importlib.import_module(dep)
|
| 31 |
+
except ImportError:
|
| 32 |
+
# Hack: the hydra package is provided under the "hydra-core" name in
|
| 33 |
+
# pypi. We don't want the user mistakenly calling `pip install hydra`
|
| 34 |
+
# since that will install an unrelated package.
|
| 35 |
+
if dep == "hydra":
|
| 36 |
+
dep = "hydra-core"
|
| 37 |
+
missing_deps.append(dep)
|
| 38 |
+
if len(missing_deps) > 0:
|
| 39 |
+
raise RuntimeError("Missing dependencies: {}".format(", ".join(missing_deps)))
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
# torch.hub doesn't build Cython components, so if they are not found then try
|
| 43 |
+
# to build them here
|
| 44 |
+
try:
|
| 45 |
+
import fairseq.data.token_block_utils_fast # noqa
|
| 46 |
+
except ImportError:
|
| 47 |
+
try:
|
| 48 |
+
import cython # noqa
|
| 49 |
+
import os
|
| 50 |
+
from setuptools import sandbox
|
| 51 |
+
|
| 52 |
+
sandbox.run_setup(
|
| 53 |
+
os.path.join(os.path.dirname(__file__), "setup.py"),
|
| 54 |
+
["build_ext", "--inplace"],
|
| 55 |
+
)
|
| 56 |
+
except ImportError:
|
| 57 |
+
print(
|
| 58 |
+
"Unable to build Cython components. Please make sure Cython is "
|
| 59 |
+
"installed if the torch.hub model you are loading depends on it."
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# automatically expose models defined in FairseqModel::hub_models
|
| 64 |
+
for _model_type, _cls in MODEL_REGISTRY.items():
|
| 65 |
+
for model_name in _cls.hub_models().keys():
|
| 66 |
+
globals()[model_name] = functools.partial(
|
| 67 |
+
_cls.from_pretrained,
|
| 68 |
+
model_name,
|
| 69 |
+
)
|
input.ar
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|
input.en
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Why are you such a sussy fucker?
|
input.es
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|
input.fr
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
LANG_TOK_EN
|