diff --git a/.gitattributes b/.gitattributes
new file mode 100644
index 0000000000000000000000000000000000000000..d7f73cd45e8a703a1efca7ee367e37d0ec268788
--- /dev/null
+++ b/.gitattributes
@@ -0,0 +1,36 @@
+*.7z filter=lfs diff=lfs merge=lfs -text
+*.arrow filter=lfs diff=lfs merge=lfs -text
+*.bin filter=lfs diff=lfs merge=lfs -text
+*.bz2 filter=lfs diff=lfs merge=lfs -text
+*.ckpt filter=lfs diff=lfs merge=lfs -text
+*.ftz filter=lfs diff=lfs merge=lfs -text
+*.gz filter=lfs diff=lfs merge=lfs -text
+*.h5 filter=lfs diff=lfs merge=lfs -text
+*.joblib filter=lfs diff=lfs merge=lfs -text
+*.lfs.* filter=lfs diff=lfs merge=lfs -text
+*.mlmodel filter=lfs diff=lfs merge=lfs -text
+*.model filter=lfs diff=lfs merge=lfs -text
+*.msgpack filter=lfs diff=lfs merge=lfs -text
+*.npy filter=lfs diff=lfs merge=lfs -text
+*.npz filter=lfs diff=lfs merge=lfs -text
+*.onnx filter=lfs diff=lfs merge=lfs -text
+*.ot filter=lfs diff=lfs merge=lfs -text
+*.parquet filter=lfs diff=lfs merge=lfs -text
+*.pb filter=lfs diff=lfs merge=lfs -text
+*.pickle filter=lfs diff=lfs merge=lfs -text
+*.pkl filter=lfs diff=lfs merge=lfs -text
+*.pt filter=lfs diff=lfs merge=lfs -text
+*.pth filter=lfs diff=lfs merge=lfs -text
+*.rar filter=lfs diff=lfs merge=lfs -text
+*.safetensors filter=lfs diff=lfs merge=lfs -text
+saved_model/**/* filter=lfs diff=lfs merge=lfs -text
+*.tar.* filter=lfs diff=lfs merge=lfs -text
+*.tflite filter=lfs diff=lfs merge=lfs -text
+*.tgz filter=lfs diff=lfs merge=lfs -text
+*.wasm filter=lfs diff=lfs merge=lfs -text
+*.xz filter=lfs diff=lfs merge=lfs -text
+*.zip filter=lfs diff=lfs merge=lfs -text
+*.zst filter=lfs diff=lfs merge=lfs -text
+*.zstandard filter=lfs diff=lfs merge=lfs -text
+*tfevents* filter=lfs diff=lfs merge=lfs -text
+*.glb filter=lfs diff=lfs merge=lfs -text
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..aff6d155226dd90c0b489e0d5c5af2b3e24ca382
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,47 @@
+results/
+# Python build
+.eggs/
+gradio.egg-info/*
+!gradio.egg-info/requires.txt
+!gradio.egg-info/PKG-INFO
+dist/
+*.pyc
+__pycache__/
+*.py[cod]
+*$py.class
+build/
+
+# JS build
+gradio/templates/frontend
+# Secrets
+.env
+
+# Gradio run artifacts
+*.db
+*.sqlite3
+gradio/launches.json
+flagged/
+# gradio_cached_examples/
+
+# Tests
+.coverage
+coverage.xml
+test.txt
+
+# Demos
+demo/tmp.zip
+demo/files/*.avi
+demo/files/*.mp4
+
+# Etc
+.idea/*
+.DS_Store
+*.bak
+workspace.code-workspace
+*.h5
+.vscode/
+
+# log files
+.pnpm-debug.log
+venv/
+*.db-journal
diff --git a/PIFu/.gitignore b/PIFu/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..e708e040236215f149585d154acc3d1cc9827569
--- /dev/null
+++ b/PIFu/.gitignore
@@ -0,0 +1 @@
+checkpoints/*
diff --git a/PIFu/LICENSE.txt b/PIFu/LICENSE.txt
new file mode 100755
index 0000000000000000000000000000000000000000..e19263f8ae04d1aaa5a98ce6c42c1ed6c8734ea3
--- /dev/null
+++ b/PIFu/LICENSE.txt
@@ -0,0 +1,48 @@
+MIT License
+
+Copyright (c) 2019 Shunsuke Saito, Zeng Huang, and Ryota Natsume
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
+
+anyabagomo
+
+-------------------- LICENSE FOR ResBlk Image Encoder -----------------------
+Copyright (c) 2017, Jun-Yan Zhu and Taesung Park
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are met:
+
+* Redistributions of source code must retain the above copyright notice, this
+ list of conditions and the following disclaimer.
+
+* Redistributions in binary form must reproduce the above copyright notice,
+ this list of conditions and the following disclaimer in the documentation
+ and/or other materials provided with the distribution.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
+AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
+IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
+DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
+FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
+DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
+SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
+CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
+OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
\ No newline at end of file
diff --git a/PIFu/README.md b/PIFu/README.md
new file mode 100755
index 0000000000000000000000000000000000000000..5eae12f2a370027de6c46fbf78ec68a1ecb1c01c
--- /dev/null
+++ b/PIFu/README.md
@@ -0,0 +1,167 @@
+# PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
+
+[](https://arxiv.org/abs/1905.05172) [](https://colab.research.google.com/drive/1GFSsqP2BWz4gtq0e-nki00ZHSirXwFyY)
+
+News:
+* \[2020/05/04\] Added EGL rendering option for training data generation. Now you can create your own training data with headless machines!
+* \[2020/04/13\] Demo with Google Colab (incl. visualization) is available. Special thanks to [@nanopoteto](https://github.com/nanopoteto)!!!
+* \[2020/02/26\] License is updated to MIT license! Enjoy!
+
+This repository contains a pytorch implementation of "[PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization](https://arxiv.org/abs/1905.05172)".
+
+[Project Page](https://shunsukesaito.github.io/PIFu/)
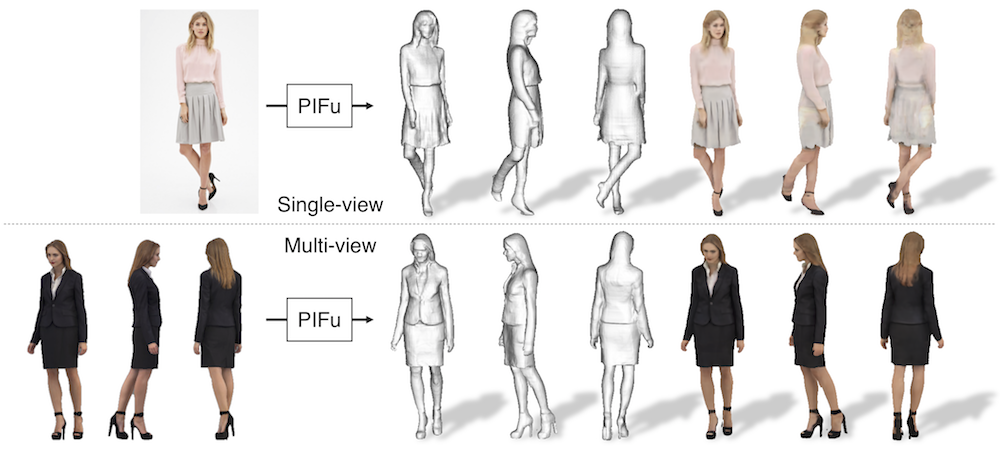
+
+
+If you find the code useful in your research, please consider citing the paper.
+
+```
+@InProceedings{saito2019pifu,
+author = {Saito, Shunsuke and Huang, Zeng and Natsume, Ryota and Morishima, Shigeo and Kanazawa, Angjoo and Li, Hao},
+title = {PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization},
+booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
+month = {October},
+year = {2019}
+}
+```
+
+
+This codebase provides:
+- test code
+- training code
+- data generation code
+
+## Requirements
+- Python 3
+- [PyTorch](https://pytorch.org/) tested on 1.4.0
+- json
+- PIL
+- skimage
+- tqdm
+- numpy
+- cv2
+
+for training and data generation
+- [trimesh](https://trimsh.org/) with [pyembree](https://github.com/scopatz/pyembree)
+- [pyexr](https://github.com/tvogels/pyexr)
+- PyOpenGL
+- freeglut (use `sudo apt-get install freeglut3-dev` for ubuntu users)
+- (optional) egl related packages for rendering with headless machines. (use `apt install libgl1-mesa-dri libegl1-mesa libgbm1` for ubuntu users)
+
+Warning: I found that outdated NVIDIA drivers may cause errors with EGL. If you want to try out the EGL version, please update your NVIDIA driver to the latest!!
+
+## Windows demo installation instuction
+
+- Install [miniconda](https://docs.conda.io/en/latest/miniconda.html)
+- Add `conda` to PATH
+- Install [git bash](https://git-scm.com/downloads)
+- Launch `Git\bin\bash.exe`
+- `eval "$(conda shell.bash hook)"` then `conda activate my_env` because of [this](https://github.com/conda/conda-build/issues/3371)
+- Automatic `env create -f environment.yml` (look [this](https://github.com/conda/conda/issues/3417))
+- OR manually setup [environment](https://towardsdatascience.com/a-guide-to-conda-environments-bc6180fc533)
+ - `conda create —name pifu python` where `pifu` is name of your environment
+ - `conda activate`
+ - `conda install pytorch torchvision cudatoolkit=10.1 -c pytorch`
+ - `conda install pillow`
+ - `conda install scikit-image`
+ - `conda install tqdm`
+ - `conda install -c menpo opencv`
+- Download [wget.exe](https://eternallybored.org/misc/wget/)
+- Place it into `Git\mingw64\bin`
+- `sh ./scripts/download_trained_model.sh`
+- Remove background from your image ([this](https://www.remove.bg/), for example)
+- Create black-white mask .png
+- Replace original from sample_images/
+- Try it out - `sh ./scripts/test.sh`
+- Download [Meshlab](http://www.meshlab.net/) because of [this](https://github.com/shunsukesaito/PIFu/issues/1)
+- Open .obj file in Meshlab
+
+
+## Demo
+Warning: The released model is trained with mostly upright standing scans with weak perspectie projection and the pitch angle of 0 degree. Reconstruction quality may degrade for images highly deviated from trainining data.
+1. run the following script to download the pretrained models from the following link and copy them under `./PIFu/checkpoints/`.
+```
+sh ./scripts/download_trained_model.sh
+```
+
+2. run the following script. the script creates a textured `.obj` file under `./PIFu/eval_results/`. You may need to use `./apps/crop_img.py` to roughly align an input image and the corresponding mask to the training data for better performance. For background removal, you can use any off-the-shelf tools such as [removebg](https://www.remove.bg/).
+```
+sh ./scripts/test.sh
+```
+
+## Demo on Google Colab
+If you do not have a setup to run PIFu, we offer Google Colab version to give it a try, allowing you to run PIFu in the cloud, free of charge. Try our Colab demo using the following notebook:
+[](https://colab.research.google.com/drive/1GFSsqP2BWz4gtq0e-nki00ZHSirXwFyY)
+
+## Data Generation (Linux Only)
+While we are unable to release the full training data due to the restriction of commertial scans, we provide rendering code using free models in [RenderPeople](https://renderpeople.com/free-3d-people/).
+This tutorial uses `rp_dennis_posed_004` model. Please download the model from [this link](https://renderpeople.com/sample/free/rp_dennis_posed_004_OBJ.zip) and unzip the content under a folder named `rp_dennis_posed_004_OBJ`. The same process can be applied to other RenderPeople data.
+
+Warning: the following code becomes extremely slow without [pyembree](https://github.com/scopatz/pyembree). Please make sure you install pyembree.
+
+1. run the following script to compute spherical harmonics coefficients for [precomputed radiance transfer (PRT)](https://sites.fas.harvard.edu/~cs278/papers/prt.pdf). In a nutshell, PRT is used to account for accurate light transport including ambient occlusion without compromising online rendering time, which significantly improves the photorealism compared with [a common sperical harmonics rendering using surface normals](https://cseweb.ucsd.edu/~ravir/papers/envmap/envmap.pdf). This process has to be done once for each obj file.
+```
+python -m apps.prt_util -i {path_to_rp_dennis_posed_004_OBJ}
+```
+
+2. run the following script. Under the specified data path, the code creates folders named `GEO`, `RENDER`, `MASK`, `PARAM`, `UV_RENDER`, `UV_MASK`, `UV_NORMAL`, and `UV_POS`. Note that you may need to list validation subjects to exclude from training in `{path_to_training_data}/val.txt` (this tutorial has only one subject and leave it empty). If you wish to render images with headless servers equipped with NVIDIA GPU, add -e to enable EGL rendering.
+```
+python -m apps.render_data -i {path_to_rp_dennis_posed_004_OBJ} -o {path_to_training_data} [-e]
+```
+
+## Training (Linux Only)
+
+Warning: the following code becomes extremely slow without [pyembree](https://github.com/scopatz/pyembree). Please make sure you install pyembree.
+
+1. run the following script to train the shape module. The intermediate results and checkpoints are saved under `./results` and `./checkpoints` respectively. You can add `--batch_size` and `--num_sample_input` flags to adjust the batch size and the number of sampled points based on available GPU memory.
+```
+python -m apps.train_shape --dataroot {path_to_training_data} --random_flip --random_scale --random_trans
+```
+
+2. run the following script to train the color module.
+```
+python -m apps.train_color --dataroot {path_to_training_data} --num_sample_inout 0 --num_sample_color 5000 --sigma 0.1 --random_flip --random_scale --random_trans
+```
+
+## Related Research
+**[Monocular Real-Time Volumetric Performance Capture (ECCV 2020)](https://project-splinter.github.io/)**
+*Ruilong Li\*, Yuliang Xiu\*, Shunsuke Saito, Zeng Huang, Kyle Olszewski, Hao Li*
+
+The first real-time PIFu by accelerating reconstruction and rendering!!
+
+**[PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization (CVPR 2020)](https://shunsukesaito.github.io/PIFuHD/)**
+*Shunsuke Saito, Tomas Simon, Jason Saragih, Hanbyul Joo*
+
+We further improve the quality of reconstruction by leveraging multi-level approach!
+
+**[ARCH: Animatable Reconstruction of Clothed Humans (CVPR 2020)](https://arxiv.org/pdf/2004.04572.pdf)**
+*Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, Tony Tung*
+
+Learning PIFu in canonical space for animatable avatar generation!
+
+**[Robust 3D Self-portraits in Seconds (CVPR 2020)](http://www.liuyebin.com/portrait/portrait.html)**
+*Zhe Li, Tao Yu, Chuanyu Pan, Zerong Zheng, Yebin Liu*
+
+They extend PIFu to RGBD + introduce "PIFusion" utilizing PIFu reconstruction for non-rigid fusion.
+
+**[Learning to Infer Implicit Surfaces without 3d Supervision (NeurIPS 2019)](http://papers.nips.cc/paper/9039-learning-to-infer-implicit-surfaces-without-3d-supervision.pdf)**
+*Shichen Liu, Shunsuke Saito, Weikai Chen, Hao Li*
+
+We answer to the question of "how can we learn implicit function if we don't have 3D ground truth?"
+
+**[SiCloPe: Silhouette-Based Clothed People (CVPR 2019, best paper finalist)](https://arxiv.org/pdf/1901.00049.pdf)**
+*Ryota Natsume\*, Shunsuke Saito\*, Zeng Huang, Weikai Chen, Chongyang Ma, Hao Li, Shigeo Morishima*
+
+Our first attempt to reconstruct 3D clothed human body with texture from a single image!
+
+**[Deep Volumetric Video from Very Sparse Multi-view Performance Capture (ECCV 2018)](http://openaccess.thecvf.com/content_ECCV_2018/papers/Zeng_Huang_Deep_Volumetric_Video_ECCV_2018_paper.pdf)**
+*Zeng Huang, Tianye Li, Weikai Chen, Yajie Zhao, Jun Xing, Chloe LeGendre, Linjie Luo, Chongyang Ma, Hao Li*
+
+Implict surface learning for sparse view human performance capture!
+
+------
+
+
+
+For commercial queries, please contact:
+
+Hao Li: hao@hao-li.com ccto: saitos@usc.edu Baker!!
diff --git a/PIFu/apps/__init__.py b/PIFu/apps/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/PIFu/apps/crop_img.py b/PIFu/apps/crop_img.py
new file mode 100755
index 0000000000000000000000000000000000000000..4854d1f5a6361963659a9d79f41c404d801e9193
--- /dev/null
+++ b/PIFu/apps/crop_img.py
@@ -0,0 +1,75 @@
+import os
+import cv2
+import numpy as np
+
+from pathlib import Path
+import argparse
+
+def get_bbox(msk):
+ rows = np.any(msk, axis=1)
+ cols = np.any(msk, axis=0)
+ rmin, rmax = np.where(rows)[0][[0,-1]]
+ cmin, cmax = np.where(cols)[0][[0,-1]]
+
+ return rmin, rmax, cmin, cmax
+
+def process_img(img, msk, bbox=None):
+ if bbox is None:
+ bbox = get_bbox(msk > 100)
+ cx = (bbox[3] + bbox[2])//2
+ cy = (bbox[1] + bbox[0])//2
+
+ w = img.shape[1]
+ h = img.shape[0]
+ height = int(1.138*(bbox[1] - bbox[0]))
+ hh = height//2
+
+ # crop
+ dw = min(cx, w-cx, hh)
+ if cy-hh < 0:
+ img = cv2.copyMakeBorder(img,hh-cy,0,0,0,cv2.BORDER_CONSTANT,value=[0,0,0])
+ msk = cv2.copyMakeBorder(msk,hh-cy,0,0,0,cv2.BORDER_CONSTANT,value=0)
+ cy = hh
+ if cy+hh > h:
+ img = cv2.copyMakeBorder(img,0,cy+hh-h,0,0,cv2.BORDER_CONSTANT,value=[0,0,0])
+ msk = cv2.copyMakeBorder(msk,0,cy+hh-h,0,0,cv2.BORDER_CONSTANT,value=0)
+ img = img[cy-hh:(cy+hh),cx-dw:cx+dw,:]
+ msk = msk[cy-hh:(cy+hh),cx-dw:cx+dw]
+ dw = img.shape[0] - img.shape[1]
+ if dw != 0:
+ img = cv2.copyMakeBorder(img,0,0,dw//2,dw//2,cv2.BORDER_CONSTANT,value=[0,0,0])
+ msk = cv2.copyMakeBorder(msk,0,0,dw//2,dw//2,cv2.BORDER_CONSTANT,value=0)
+ img = cv2.resize(img, (512, 512))
+ msk = cv2.resize(msk, (512, 512))
+
+ kernel = np.ones((3,3),np.uint8)
+ msk = cv2.erode((255*(msk > 100)).astype(np.uint8), kernel, iterations = 1)
+
+ return img, msk
+
+def main():
+ '''
+ given foreground mask, this script crops and resizes an input image and mask for processing.
+ '''
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-i', '--input_image', type=str, help='if the image has alpha channel, it will be used as mask')
+ parser.add_argument('-m', '--input_mask', type=str)
+ parser.add_argument('-o', '--out_path', type=str, default='./sample_images')
+ args = parser.parse_args()
+
+ img = cv2.imread(args.input_image, cv2.IMREAD_UNCHANGED)
+ if img.shape[2] == 4:
+ msk = img[:,:,3:]
+ img = img[:,:,:3]
+ else:
+ msk = cv2.imread(args.input_mask, cv2.IMREAD_GRAYSCALE)
+
+ img_new, msk_new = process_img(img, msk)
+
+ img_name = Path(args.input_image).stem
+
+ cv2.imwrite(os.path.join(args.out_path, img_name + '.png'), img_new)
+ cv2.imwrite(os.path.join(args.out_path, img_name + '_mask.png'), msk_new)
+
+if __name__ == "__main__":
+ main()
\ No newline at end of file
diff --git a/PIFu/apps/eval.py b/PIFu/apps/eval.py
new file mode 100755
index 0000000000000000000000000000000000000000..a0ee3fa66c75a144da5c155b927f63170b7e923c
--- /dev/null
+++ b/PIFu/apps/eval.py
@@ -0,0 +1,153 @@
+import tqdm
+import glob
+import torchvision.transforms as transforms
+from PIL import Image
+from lib.model import *
+from lib.train_util import *
+from lib.sample_util import *
+from lib.mesh_util import *
+# from lib.options import BaseOptions
+from torch.utils.data import DataLoader
+import torch
+import numpy as np
+import json
+import time
+import sys
+import os
+
+sys.path.insert(0, os.path.abspath(
+ os.path.join(os.path.dirname(__file__), '..')))
+ROOT_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+
+
+# # get options
+# opt = BaseOptions().parse()
+
+class Evaluator:
+ def __init__(self, opt, projection_mode='orthogonal'):
+ self.opt = opt
+ self.load_size = self.opt.loadSize
+ self.to_tensor = transforms.Compose([
+ transforms.Resize(self.load_size),
+ transforms.ToTensor(),
+ transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
+ ])
+ # set cuda
+ cuda = torch.device(
+ 'cuda:%d' % opt.gpu_id) if torch.cuda.is_available() else torch.device('cpu')
+
+ # create net
+ netG = HGPIFuNet(opt, projection_mode).to(device=cuda)
+ print('Using Network: ', netG.name)
+
+ if opt.load_netG_checkpoint_path:
+ netG.load_state_dict(torch.load(
+ opt.load_netG_checkpoint_path, map_location=cuda))
+
+ if opt.load_netC_checkpoint_path is not None:
+ print('loading for net C ...', opt.load_netC_checkpoint_path)
+ netC = ResBlkPIFuNet(opt).to(device=cuda)
+ netC.load_state_dict(torch.load(
+ opt.load_netC_checkpoint_path, map_location=cuda))
+ else:
+ netC = None
+
+ os.makedirs(opt.results_path, exist_ok=True)
+ os.makedirs('%s/%s' % (opt.results_path, opt.name), exist_ok=True)
+
+ opt_log = os.path.join(opt.results_path, opt.name, 'opt.txt')
+ with open(opt_log, 'w') as outfile:
+ outfile.write(json.dumps(vars(opt), indent=2))
+
+ self.cuda = cuda
+ self.netG = netG
+ self.netC = netC
+
+ def load_image(self, image_path, mask_path):
+ # Name
+ img_name = os.path.splitext(os.path.basename(image_path))[0]
+ # Calib
+ B_MIN = np.array([-1, -1, -1])
+ B_MAX = np.array([1, 1, 1])
+ projection_matrix = np.identity(4)
+ projection_matrix[1, 1] = -1
+ calib = torch.Tensor(projection_matrix).float()
+ # Mask
+ mask = Image.open(mask_path).convert('L')
+ mask = transforms.Resize(self.load_size)(mask)
+ mask = transforms.ToTensor()(mask).float()
+ # image
+ image = Image.open(image_path).convert('RGB')
+ image = self.to_tensor(image)
+ image = mask.expand_as(image) * image
+ return {
+ 'name': img_name,
+ 'img': image.unsqueeze(0),
+ 'calib': calib.unsqueeze(0),
+ 'mask': mask.unsqueeze(0),
+ 'b_min': B_MIN,
+ 'b_max': B_MAX,
+ }
+
+ def load_image_from_memory(self, image_path, mask_path, img_name):
+ # Calib
+ B_MIN = np.array([-1, -1, -1])
+ B_MAX = np.array([1, 1, 1])
+ projection_matrix = np.identity(4)
+ projection_matrix[1, 1] = -1
+ calib = torch.Tensor(projection_matrix).float()
+ # Mask
+ mask = Image.fromarray(mask_path).convert('L')
+ mask = transforms.Resize(self.load_size)(mask)
+ mask = transforms.ToTensor()(mask).float()
+ # image
+ image = Image.fromarray(image_path).convert('RGB')
+ image = self.to_tensor(image)
+ image = mask.expand_as(image) * image
+ return {
+ 'name': img_name,
+ 'img': image.unsqueeze(0),
+ 'calib': calib.unsqueeze(0),
+ 'mask': mask.unsqueeze(0),
+ 'b_min': B_MIN,
+ 'b_max': B_MAX,
+ }
+
+ def eval(self, data, use_octree=False):
+ '''
+ Evaluate a data point
+ :param data: a dict containing at least ['name'], ['image'], ['calib'], ['b_min'] and ['b_max'] tensors.
+ :return:
+ '''
+ opt = self.opt
+ with torch.no_grad():
+ self.netG.eval()
+ if self.netC:
+ self.netC.eval()
+ save_path = '%s/%s/result_%s.obj' % (
+ opt.results_path, opt.name, data['name'])
+ if self.netC:
+ gen_mesh_color(opt, self.netG, self.netC, self.cuda,
+ data, save_path, use_octree=use_octree)
+ else:
+ gen_mesh(opt, self.netG, self.cuda, data,
+ save_path, use_octree=use_octree)
+
+
+if __name__ == '__main__':
+ evaluator = Evaluator(opt)
+
+ test_images = glob.glob(os.path.join(opt.test_folder_path, '*'))
+ test_images = [f for f in test_images if (
+ 'png' in f or 'jpg' in f) and (not 'mask' in f)]
+ test_masks = [f[:-4]+'_mask.png' for f in test_images]
+
+ print("num; ", len(test_masks))
+
+ for image_path, mask_path in tqdm.tqdm(zip(test_images, test_masks)):
+ try:
+ print(image_path, mask_path)
+ data = evaluator.load_image(image_path, mask_path)
+ evaluator.eval(data, True)
+ except Exception as e:
+ print("error:", e.args)
diff --git a/PIFu/apps/eval_spaces.py b/PIFu/apps/eval_spaces.py
new file mode 100755
index 0000000000000000000000000000000000000000..b0cf689d24f70d95aa0d491fd04987296802e492
--- /dev/null
+++ b/PIFu/apps/eval_spaces.py
@@ -0,0 +1,138 @@
+import sys
+import os
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+ROOT_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+
+import time
+import json
+import numpy as np
+import torch
+from torch.utils.data import DataLoader
+
+from lib.options import BaseOptions
+from lib.mesh_util import *
+from lib.sample_util import *
+from lib.train_util import *
+from lib.model import *
+
+from PIL import Image
+import torchvision.transforms as transforms
+
+import trimesh
+from datetime import datetime
+
+# get options
+opt = BaseOptions().parse()
+
+class Evaluator:
+ def __init__(self, opt, projection_mode='orthogonal'):
+ self.opt = opt
+ self.load_size = self.opt.loadSize
+ self.to_tensor = transforms.Compose([
+ transforms.Resize(self.load_size),
+ transforms.ToTensor(),
+ transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
+ ])
+ # set cuda
+ cuda = torch.device('cuda:%d' % opt.gpu_id) if torch.cuda.is_available() else torch.device('cpu')
+ print("CUDDAAAAA ???", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "NO ONLY CPU")
+
+ # create net
+ netG = HGPIFuNet(opt, projection_mode).to(device=cuda)
+ print('Using Network: ', netG.name)
+
+ if opt.load_netG_checkpoint_path:
+ netG.load_state_dict(torch.load(opt.load_netG_checkpoint_path, map_location=cuda))
+
+ if opt.load_netC_checkpoint_path is not None:
+ print('loading for net C ...', opt.load_netC_checkpoint_path)
+ netC = ResBlkPIFuNet(opt).to(device=cuda)
+ netC.load_state_dict(torch.load(opt.load_netC_checkpoint_path, map_location=cuda))
+ else:
+ netC = None
+
+ os.makedirs(opt.results_path, exist_ok=True)
+ os.makedirs('%s/%s' % (opt.results_path, opt.name), exist_ok=True)
+
+ opt_log = os.path.join(opt.results_path, opt.name, 'opt.txt')
+ with open(opt_log, 'w') as outfile:
+ outfile.write(json.dumps(vars(opt), indent=2))
+
+ self.cuda = cuda
+ self.netG = netG
+ self.netC = netC
+
+ def load_image(self, image_path, mask_path):
+ # Name
+ img_name = os.path.splitext(os.path.basename(image_path))[0]
+ # Calib
+ B_MIN = np.array([-1, -1, -1])
+ B_MAX = np.array([1, 1, 1])
+ projection_matrix = np.identity(4)
+ projection_matrix[1, 1] = -1
+ calib = torch.Tensor(projection_matrix).float()
+ # Mask
+ mask = Image.open(mask_path).convert('L')
+ mask = transforms.Resize(self.load_size)(mask)
+ mask = transforms.ToTensor()(mask).float()
+ # image
+ image = Image.open(image_path).convert('RGB')
+ image = self.to_tensor(image)
+ image = mask.expand_as(image) * image
+ return {
+ 'name': img_name,
+ 'img': image.unsqueeze(0),
+ 'calib': calib.unsqueeze(0),
+ 'mask': mask.unsqueeze(0),
+ 'b_min': B_MIN,
+ 'b_max': B_MAX,
+ }
+
+ def eval(self, data, use_octree=False):
+ '''
+ Evaluate a data point
+ :param data: a dict containing at least ['name'], ['image'], ['calib'], ['b_min'] and ['b_max'] tensors.
+ :return:
+ '''
+ opt = self.opt
+ with torch.no_grad():
+ self.netG.eval()
+ if self.netC:
+ self.netC.eval()
+ save_path = '%s/%s/result_%s.obj' % (opt.results_path, opt.name, data['name'])
+ if self.netC:
+ gen_mesh_color(opt, self.netG, self.netC, self.cuda, data, save_path, use_octree=use_octree)
+ else:
+ gen_mesh(opt, self.netG, self.cuda, data, save_path, use_octree=use_octree)
+
+
+if __name__ == '__main__':
+ evaluator = Evaluator(opt)
+
+ results_path = opt.results_path
+ name = opt.name
+ test_image_path = opt.img_path
+ test_mask_path = test_image_path[:-4] +'_mask.png'
+ test_img_name = os.path.splitext(os.path.basename(test_image_path))[0]
+ print("test_image: ", test_image_path)
+ print("test_mask: ", test_mask_path)
+
+ try:
+ time = datetime.now()
+ print("evaluating" , time)
+ data = evaluator.load_image(test_image_path, test_mask_path)
+ evaluator.eval(data, False)
+ print("done evaluating" , datetime.now() - time)
+ except Exception as e:
+ print("error:", e.args)
+
+ try:
+ mesh = trimesh.load(f'{results_path}/{name}/result_{test_img_name}.obj')
+ mesh.apply_transform([[1, 0, 0, 0],
+ [0, 1, 0, 0],
+ [0, 0, -1, 0],
+ [0, 0, 0, 1]])
+ mesh.export(file_obj=f'{results_path}/{name}/result_{test_img_name}.glb')
+ except Exception as e:
+ print("error generating MESH", e)
diff --git a/PIFu/apps/prt_util.py b/PIFu/apps/prt_util.py
new file mode 100755
index 0000000000000000000000000000000000000000..7eba32fa0b396f420b2e332abbb67135dbc14d6b
--- /dev/null
+++ b/PIFu/apps/prt_util.py
@@ -0,0 +1,142 @@
+import os
+import trimesh
+import numpy as np
+import math
+from scipy.special import sph_harm
+import argparse
+from tqdm import tqdm
+
+def factratio(N, D):
+ if N >= D:
+ prod = 1.0
+ for i in range(D+1, N+1):
+ prod *= i
+ return prod
+ else:
+ prod = 1.0
+ for i in range(N+1, D+1):
+ prod *= i
+ return 1.0 / prod
+
+def KVal(M, L):
+ return math.sqrt(((2 * L + 1) / (4 * math.pi)) * (factratio(L - M, L + M)))
+
+def AssociatedLegendre(M, L, x):
+ if M < 0 or M > L or np.max(np.abs(x)) > 1.0:
+ return np.zeros_like(x)
+
+ pmm = np.ones_like(x)
+ if M > 0:
+ somx2 = np.sqrt((1.0 + x) * (1.0 - x))
+ fact = 1.0
+ for i in range(1, M+1):
+ pmm = -pmm * fact * somx2
+ fact = fact + 2
+
+ if L == M:
+ return pmm
+ else:
+ pmmp1 = x * (2 * M + 1) * pmm
+ if L == M+1:
+ return pmmp1
+ else:
+ pll = np.zeros_like(x)
+ for i in range(M+2, L+1):
+ pll = (x * (2 * i - 1) * pmmp1 - (i + M - 1) * pmm) / (i - M)
+ pmm = pmmp1
+ pmmp1 = pll
+ return pll
+
+def SphericalHarmonic(M, L, theta, phi):
+ if M > 0:
+ return math.sqrt(2.0) * KVal(M, L) * np.cos(M * phi) * AssociatedLegendre(M, L, np.cos(theta))
+ elif M < 0:
+ return math.sqrt(2.0) * KVal(-M, L) * np.sin(-M * phi) * AssociatedLegendre(-M, L, np.cos(theta))
+ else:
+ return KVal(0, L) * AssociatedLegendre(0, L, np.cos(theta))
+
+def save_obj(mesh_path, verts):
+ file = open(mesh_path, 'w')
+ for v in verts:
+ file.write('v %.4f %.4f %.4f\n' % (v[0], v[1], v[2]))
+ file.close()
+
+def sampleSphericalDirections(n):
+ xv = np.random.rand(n,n)
+ yv = np.random.rand(n,n)
+ theta = np.arccos(1-2 * xv)
+ phi = 2.0 * math.pi * yv
+
+ phi = phi.reshape(-1)
+ theta = theta.reshape(-1)
+
+ vx = -np.sin(theta) * np.cos(phi)
+ vy = -np.sin(theta) * np.sin(phi)
+ vz = np.cos(theta)
+ return np.stack([vx, vy, vz], 1), phi, theta
+
+def getSHCoeffs(order, phi, theta):
+ shs = []
+ for n in range(0, order+1):
+ for m in range(-n,n+1):
+ s = SphericalHarmonic(m, n, theta, phi)
+ shs.append(s)
+
+ return np.stack(shs, 1)
+
+def computePRT(mesh_path, n, order):
+ mesh = trimesh.load(mesh_path, process=False)
+ vectors_orig, phi, theta = sampleSphericalDirections(n)
+ SH_orig = getSHCoeffs(order, phi, theta)
+
+ w = 4.0 * math.pi / (n*n)
+
+ origins = mesh.vertices
+ normals = mesh.vertex_normals
+ n_v = origins.shape[0]
+
+ origins = np.repeat(origins[:,None], n, axis=1).reshape(-1,3)
+ normals = np.repeat(normals[:,None], n, axis=1).reshape(-1,3)
+ PRT_all = None
+ for i in tqdm(range(n)):
+ SH = np.repeat(SH_orig[None,(i*n):((i+1)*n)], n_v, axis=0).reshape(-1,SH_orig.shape[1])
+ vectors = np.repeat(vectors_orig[None,(i*n):((i+1)*n)], n_v, axis=0).reshape(-1,3)
+
+ dots = (vectors * normals).sum(1)
+ front = (dots > 0.0)
+
+ delta = 1e-3*min(mesh.bounding_box.extents)
+ hits = mesh.ray.intersects_any(origins + delta * normals, vectors)
+ nohits = np.logical_and(front, np.logical_not(hits))
+
+ PRT = (nohits.astype(np.float) * dots)[:,None] * SH
+
+ if PRT_all is not None:
+ PRT_all += (PRT.reshape(-1, n, SH.shape[1]).sum(1))
+ else:
+ PRT_all = (PRT.reshape(-1, n, SH.shape[1]).sum(1))
+
+ PRT = w * PRT_all
+
+ # NOTE: trimesh sometimes break the original vertex order, but topology will not change.
+ # when loading PRT in other program, use the triangle list from trimesh.
+ return PRT, mesh.faces
+
+def testPRT(dir_path, n=40):
+ if dir_path[-1] == '/':
+ dir_path = dir_path[:-1]
+ sub_name = dir_path.split('/')[-1][:-4]
+ obj_path = os.path.join(dir_path, sub_name + '_100k.obj')
+ os.makedirs(os.path.join(dir_path, 'bounce'), exist_ok=True)
+
+ PRT, F = computePRT(obj_path, n, 2)
+ np.savetxt(os.path.join(dir_path, 'bounce', 'bounce0.txt'), PRT, fmt='%.8f')
+ np.save(os.path.join(dir_path, 'bounce', 'face.npy'), F)
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-i', '--input', type=str, default='/home/shunsuke/Downloads/rp_dennis_posed_004_OBJ')
+ parser.add_argument('-n', '--n_sample', type=int, default=40, help='squared root of number of sampling. the higher, the more accurate, but slower')
+ args = parser.parse_args()
+
+ testPRT(args.input)
diff --git a/PIFu/apps/render_data.py b/PIFu/apps/render_data.py
new file mode 100755
index 0000000000000000000000000000000000000000..563c03fba6e304eced73ca283152a968a65c3b8e
--- /dev/null
+++ b/PIFu/apps/render_data.py
@@ -0,0 +1,290 @@
+#from data.config import raw_dataset, render_dataset, archive_dataset, model_list, zip_path
+
+from lib.renderer.camera import Camera
+import numpy as np
+from lib.renderer.mesh import load_obj_mesh, compute_tangent, compute_normal, load_obj_mesh_mtl
+from lib.renderer.camera import Camera
+import os
+import cv2
+import time
+import math
+import random
+import pyexr
+import argparse
+from tqdm import tqdm
+
+
+def make_rotate(rx, ry, rz):
+ sinX = np.sin(rx)
+ sinY = np.sin(ry)
+ sinZ = np.sin(rz)
+
+ cosX = np.cos(rx)
+ cosY = np.cos(ry)
+ cosZ = np.cos(rz)
+
+ Rx = np.zeros((3,3))
+ Rx[0, 0] = 1.0
+ Rx[1, 1] = cosX
+ Rx[1, 2] = -sinX
+ Rx[2, 1] = sinX
+ Rx[2, 2] = cosX
+
+ Ry = np.zeros((3,3))
+ Ry[0, 0] = cosY
+ Ry[0, 2] = sinY
+ Ry[1, 1] = 1.0
+ Ry[2, 0] = -sinY
+ Ry[2, 2] = cosY
+
+ Rz = np.zeros((3,3))
+ Rz[0, 0] = cosZ
+ Rz[0, 1] = -sinZ
+ Rz[1, 0] = sinZ
+ Rz[1, 1] = cosZ
+ Rz[2, 2] = 1.0
+
+ R = np.matmul(np.matmul(Rz,Ry),Rx)
+ return R
+
+def rotateSH(SH, R):
+ SHn = SH
+
+ # 1st order
+ SHn[1] = R[1,1]*SH[1] - R[1,2]*SH[2] + R[1,0]*SH[3]
+ SHn[2] = -R[2,1]*SH[1] + R[2,2]*SH[2] - R[2,0]*SH[3]
+ SHn[3] = R[0,1]*SH[1] - R[0,2]*SH[2] + R[0,0]*SH[3]
+
+ # 2nd order
+ SHn[4:,0] = rotateBand2(SH[4:,0],R)
+ SHn[4:,1] = rotateBand2(SH[4:,1],R)
+ SHn[4:,2] = rotateBand2(SH[4:,2],R)
+
+ return SHn
+
+def rotateBand2(x, R):
+ s_c3 = 0.94617469575
+ s_c4 = -0.31539156525
+ s_c5 = 0.54627421529
+
+ s_c_scale = 1.0/0.91529123286551084
+ s_c_scale_inv = 0.91529123286551084
+
+ s_rc2 = 1.5853309190550713*s_c_scale
+ s_c4_div_c3 = s_c4/s_c3
+ s_c4_div_c3_x2 = (s_c4/s_c3)*2.0
+
+ s_scale_dst2 = s_c3 * s_c_scale_inv
+ s_scale_dst4 = s_c5 * s_c_scale_inv
+
+ sh0 = x[3] + x[4] + x[4] - x[1]
+ sh1 = x[0] + s_rc2*x[2] + x[3] + x[4]
+ sh2 = x[0]
+ sh3 = -x[3]
+ sh4 = -x[1]
+
+ r2x = R[0][0] + R[0][1]
+ r2y = R[1][0] + R[1][1]
+ r2z = R[2][0] + R[2][1]
+
+ r3x = R[0][0] + R[0][2]
+ r3y = R[1][0] + R[1][2]
+ r3z = R[2][0] + R[2][2]
+
+ r4x = R[0][1] + R[0][2]
+ r4y = R[1][1] + R[1][2]
+ r4z = R[2][1] + R[2][2]
+
+ sh0_x = sh0 * R[0][0]
+ sh0_y = sh0 * R[1][0]
+ d0 = sh0_x * R[1][0]
+ d1 = sh0_y * R[2][0]
+ d2 = sh0 * (R[2][0] * R[2][0] + s_c4_div_c3)
+ d3 = sh0_x * R[2][0]
+ d4 = sh0_x * R[0][0] - sh0_y * R[1][0]
+
+ sh1_x = sh1 * R[0][2]
+ sh1_y = sh1 * R[1][2]
+ d0 += sh1_x * R[1][2]
+ d1 += sh1_y * R[2][2]
+ d2 += sh1 * (R[2][2] * R[2][2] + s_c4_div_c3)
+ d3 += sh1_x * R[2][2]
+ d4 += sh1_x * R[0][2] - sh1_y * R[1][2]
+
+ sh2_x = sh2 * r2x
+ sh2_y = sh2 * r2y
+ d0 += sh2_x * r2y
+ d1 += sh2_y * r2z
+ d2 += sh2 * (r2z * r2z + s_c4_div_c3_x2)
+ d3 += sh2_x * r2z
+ d4 += sh2_x * r2x - sh2_y * r2y
+
+ sh3_x = sh3 * r3x
+ sh3_y = sh3 * r3y
+ d0 += sh3_x * r3y
+ d1 += sh3_y * r3z
+ d2 += sh3 * (r3z * r3z + s_c4_div_c3_x2)
+ d3 += sh3_x * r3z
+ d4 += sh3_x * r3x - sh3_y * r3y
+
+ sh4_x = sh4 * r4x
+ sh4_y = sh4 * r4y
+ d0 += sh4_x * r4y
+ d1 += sh4_y * r4z
+ d2 += sh4 * (r4z * r4z + s_c4_div_c3_x2)
+ d3 += sh4_x * r4z
+ d4 += sh4_x * r4x - sh4_y * r4y
+
+ dst = x
+ dst[0] = d0
+ dst[1] = -d1
+ dst[2] = d2 * s_scale_dst2
+ dst[3] = -d3
+ dst[4] = d4 * s_scale_dst4
+
+ return dst
+
+def render_prt_ortho(out_path, folder_name, subject_name, shs, rndr, rndr_uv, im_size, angl_step=4, n_light=1, pitch=[0]):
+ cam = Camera(width=im_size, height=im_size)
+ cam.ortho_ratio = 0.4 * (512 / im_size)
+ cam.near = -100
+ cam.far = 100
+ cam.sanity_check()
+
+ # set path for obj, prt
+ mesh_file = os.path.join(folder_name, subject_name + '_100k.obj')
+ if not os.path.exists(mesh_file):
+ print('ERROR: obj file does not exist!!', mesh_file)
+ return
+ prt_file = os.path.join(folder_name, 'bounce', 'bounce0.txt')
+ if not os.path.exists(prt_file):
+ print('ERROR: prt file does not exist!!!', prt_file)
+ return
+ face_prt_file = os.path.join(folder_name, 'bounce', 'face.npy')
+ if not os.path.exists(face_prt_file):
+ print('ERROR: face prt file does not exist!!!', prt_file)
+ return
+ text_file = os.path.join(folder_name, 'tex', subject_name + '_dif_2k.jpg')
+ if not os.path.exists(text_file):
+ print('ERROR: dif file does not exist!!', text_file)
+ return
+
+ texture_image = cv2.imread(text_file)
+ texture_image = cv2.cvtColor(texture_image, cv2.COLOR_BGR2RGB)
+
+ vertices, faces, normals, faces_normals, textures, face_textures = load_obj_mesh(mesh_file, with_normal=True, with_texture=True)
+ vmin = vertices.min(0)
+ vmax = vertices.max(0)
+ up_axis = 1 if (vmax-vmin).argmax() == 1 else 2
+
+ vmed = np.median(vertices, 0)
+ vmed[up_axis] = 0.5*(vmax[up_axis]+vmin[up_axis])
+ y_scale = 180/(vmax[up_axis] - vmin[up_axis])
+
+ rndr.set_norm_mat(y_scale, vmed)
+ rndr_uv.set_norm_mat(y_scale, vmed)
+
+ tan, bitan = compute_tangent(vertices, faces, normals, textures, face_textures)
+ prt = np.loadtxt(prt_file)
+ face_prt = np.load(face_prt_file)
+ rndr.set_mesh(vertices, faces, normals, faces_normals, textures, face_textures, prt, face_prt, tan, bitan)
+ rndr.set_albedo(texture_image)
+
+ rndr_uv.set_mesh(vertices, faces, normals, faces_normals, textures, face_textures, prt, face_prt, tan, bitan)
+ rndr_uv.set_albedo(texture_image)
+
+ os.makedirs(os.path.join(out_path, 'GEO', 'OBJ', subject_name),exist_ok=True)
+ os.makedirs(os.path.join(out_path, 'PARAM', subject_name),exist_ok=True)
+ os.makedirs(os.path.join(out_path, 'RENDER', subject_name),exist_ok=True)
+ os.makedirs(os.path.join(out_path, 'MASK', subject_name),exist_ok=True)
+ os.makedirs(os.path.join(out_path, 'UV_RENDER', subject_name),exist_ok=True)
+ os.makedirs(os.path.join(out_path, 'UV_MASK', subject_name),exist_ok=True)
+ os.makedirs(os.path.join(out_path, 'UV_POS', subject_name),exist_ok=True)
+ os.makedirs(os.path.join(out_path, 'UV_NORMAL', subject_name),exist_ok=True)
+
+ if not os.path.exists(os.path.join(out_path, 'val.txt')):
+ f = open(os.path.join(out_path, 'val.txt'), 'w')
+ f.close()
+
+ # copy obj file
+ cmd = 'cp %s %s' % (mesh_file, os.path.join(out_path, 'GEO', 'OBJ', subject_name))
+ print(cmd)
+ os.system(cmd)
+
+ for p in pitch:
+ for y in tqdm(range(0, 360, angl_step)):
+ R = np.matmul(make_rotate(math.radians(p), 0, 0), make_rotate(0, math.radians(y), 0))
+ if up_axis == 2:
+ R = np.matmul(R, make_rotate(math.radians(90),0,0))
+
+ rndr.rot_matrix = R
+ rndr_uv.rot_matrix = R
+ rndr.set_camera(cam)
+ rndr_uv.set_camera(cam)
+
+ for j in range(n_light):
+ sh_id = random.randint(0,shs.shape[0]-1)
+ sh = shs[sh_id]
+ sh_angle = 0.2*np.pi*(random.random()-0.5)
+ sh = rotateSH(sh, make_rotate(0, sh_angle, 0).T)
+
+ dic = {'sh': sh, 'ortho_ratio': cam.ortho_ratio, 'scale': y_scale, 'center': vmed, 'R': R}
+
+ rndr.set_sh(sh)
+ rndr.analytic = False
+ rndr.use_inverse_depth = False
+ rndr.display()
+
+ out_all_f = rndr.get_color(0)
+ out_mask = out_all_f[:,:,3]
+ out_all_f = cv2.cvtColor(out_all_f, cv2.COLOR_RGBA2BGR)
+
+ np.save(os.path.join(out_path, 'PARAM', subject_name, '%d_%d_%02d.npy'%(y,p,j)),dic)
+ cv2.imwrite(os.path.join(out_path, 'RENDER', subject_name, '%d_%d_%02d.jpg'%(y,p,j)),255.0*out_all_f)
+ cv2.imwrite(os.path.join(out_path, 'MASK', subject_name, '%d_%d_%02d.png'%(y,p,j)),255.0*out_mask)
+
+ rndr_uv.set_sh(sh)
+ rndr_uv.analytic = False
+ rndr_uv.use_inverse_depth = False
+ rndr_uv.display()
+
+ uv_color = rndr_uv.get_color(0)
+ uv_color = cv2.cvtColor(uv_color, cv2.COLOR_RGBA2BGR)
+ cv2.imwrite(os.path.join(out_path, 'UV_RENDER', subject_name, '%d_%d_%02d.jpg'%(y,p,j)),255.0*uv_color)
+
+ if y == 0 and j == 0 and p == pitch[0]:
+ uv_pos = rndr_uv.get_color(1)
+ uv_mask = uv_pos[:,:,3]
+ cv2.imwrite(os.path.join(out_path, 'UV_MASK', subject_name, '00.png'),255.0*uv_mask)
+
+ data = {'default': uv_pos[:,:,:3]} # default is a reserved name
+ pyexr.write(os.path.join(out_path, 'UV_POS', subject_name, '00.exr'), data)
+
+ uv_nml = rndr_uv.get_color(2)
+ uv_nml = cv2.cvtColor(uv_nml, cv2.COLOR_RGBA2BGR)
+ cv2.imwrite(os.path.join(out_path, 'UV_NORMAL', subject_name, '00.png'),255.0*uv_nml)
+
+
+if __name__ == '__main__':
+ shs = np.load('./env_sh.npy')
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-i', '--input', type=str, default='/home/shunsuke/Downloads/rp_dennis_posed_004_OBJ')
+ parser.add_argument('-o', '--out_dir', type=str, default='/home/shunsuke/Documents/hf_human')
+ parser.add_argument('-m', '--ms_rate', type=int, default=1, help='higher ms rate results in less aliased output. MESA renderer only supports ms_rate=1.')
+ parser.add_argument('-e', '--egl', action='store_true', help='egl rendering option. use this when rendering with headless server with NVIDIA GPU')
+ parser.add_argument('-s', '--size', type=int, default=512, help='rendering image size')
+ args = parser.parse_args()
+
+ # NOTE: GL context has to be created before any other OpenGL function loads.
+ from lib.renderer.gl.init_gl import initialize_GL_context
+ initialize_GL_context(width=args.size, height=args.size, egl=args.egl)
+
+ from lib.renderer.gl.prt_render import PRTRender
+ rndr = PRTRender(width=args.size, height=args.size, ms_rate=args.ms_rate, egl=args.egl)
+ rndr_uv = PRTRender(width=args.size, height=args.size, uv_mode=True, egl=args.egl)
+
+ if args.input[-1] == '/':
+ args.input = args.input[:-1]
+ subject_name = args.input.split('/')[-1][:-4]
+ render_prt_ortho(args.out_dir, args.input, subject_name, shs, rndr, rndr_uv, args.size, 1, 1, pitch=[0])
\ No newline at end of file
diff --git a/PIFu/apps/train_color.py b/PIFu/apps/train_color.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c1aeb9f33ff7ebf95489cef9a3e96e8af7ee3d7
--- /dev/null
+++ b/PIFu/apps/train_color.py
@@ -0,0 +1,191 @@
+import sys
+import os
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+ROOT_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+
+import time
+import json
+import numpy as np
+import cv2
+import random
+import torch
+import torch.nn as nn
+from torch.utils.data import DataLoader
+from tqdm import tqdm
+
+from lib.options import BaseOptions
+from lib.mesh_util import *
+from lib.sample_util import *
+from lib.train_util import *
+from lib.data import *
+from lib.model import *
+from lib.geometry import index
+
+# get options
+opt = BaseOptions().parse()
+
+def train_color(opt):
+ # set cuda
+ cuda = torch.device('cuda:%d' % opt.gpu_id)
+
+ train_dataset = TrainDataset(opt, phase='train')
+ test_dataset = TrainDataset(opt, phase='test')
+
+ projection_mode = train_dataset.projection_mode
+
+ # create data loader
+ train_data_loader = DataLoader(train_dataset,
+ batch_size=opt.batch_size, shuffle=not opt.serial_batches,
+ num_workers=opt.num_threads, pin_memory=opt.pin_memory)
+
+ print('train data size: ', len(train_data_loader))
+
+ # NOTE: batch size should be 1 and use all the points for evaluation
+ test_data_loader = DataLoader(test_dataset,
+ batch_size=1, shuffle=False,
+ num_workers=opt.num_threads, pin_memory=opt.pin_memory)
+ print('test data size: ', len(test_data_loader))
+
+ # create net
+ netG = HGPIFuNet(opt, projection_mode).to(device=cuda)
+
+ lr = opt.learning_rate
+
+ # Always use resnet for color regression
+ netC = ResBlkPIFuNet(opt).to(device=cuda)
+ optimizerC = torch.optim.Adam(netC.parameters(), lr=opt.learning_rate)
+
+ def set_train():
+ netG.eval()
+ netC.train()
+
+ def set_eval():
+ netG.eval()
+ netC.eval()
+
+ print('Using NetworkG: ', netG.name, 'networkC: ', netC.name)
+
+ # load checkpoints
+ if opt.load_netG_checkpoint_path is not None:
+ print('loading for net G ...', opt.load_netG_checkpoint_path)
+ netG.load_state_dict(torch.load(opt.load_netG_checkpoint_path, map_location=cuda))
+ else:
+ model_path_G = '%s/%s/netG_latest' % (opt.checkpoints_path, opt.name)
+ print('loading for net G ...', model_path_G)
+ netG.load_state_dict(torch.load(model_path_G, map_location=cuda))
+
+ if opt.load_netC_checkpoint_path is not None:
+ print('loading for net C ...', opt.load_netC_checkpoint_path)
+ netC.load_state_dict(torch.load(opt.load_netC_checkpoint_path, map_location=cuda))
+
+ if opt.continue_train:
+ if opt.resume_epoch < 0:
+ model_path_C = '%s/%s/netC_latest' % (opt.checkpoints_path, opt.name)
+ else:
+ model_path_C = '%s/%s/netC_epoch_%d' % (opt.checkpoints_path, opt.name, opt.resume_epoch)
+
+ print('Resuming from ', model_path_C)
+ netC.load_state_dict(torch.load(model_path_C, map_location=cuda))
+
+ os.makedirs(opt.checkpoints_path, exist_ok=True)
+ os.makedirs(opt.results_path, exist_ok=True)
+ os.makedirs('%s/%s' % (opt.checkpoints_path, opt.name), exist_ok=True)
+ os.makedirs('%s/%s' % (opt.results_path, opt.name), exist_ok=True)
+
+ opt_log = os.path.join(opt.results_path, opt.name, 'opt.txt')
+ with open(opt_log, 'w') as outfile:
+ outfile.write(json.dumps(vars(opt), indent=2))
+
+ # training
+ start_epoch = 0 if not opt.continue_train else max(opt.resume_epoch,0)
+ for epoch in range(start_epoch, opt.num_epoch):
+ epoch_start_time = time.time()
+
+ set_train()
+ iter_data_time = time.time()
+ for train_idx, train_data in enumerate(train_data_loader):
+ iter_start_time = time.time()
+ # retrieve the data
+ image_tensor = train_data['img'].to(device=cuda)
+ calib_tensor = train_data['calib'].to(device=cuda)
+ color_sample_tensor = train_data['color_samples'].to(device=cuda)
+
+ image_tensor, calib_tensor = reshape_multiview_tensors(image_tensor, calib_tensor)
+
+ if opt.num_views > 1:
+ color_sample_tensor = reshape_sample_tensor(color_sample_tensor, opt.num_views)
+
+ rgb_tensor = train_data['rgbs'].to(device=cuda)
+
+ with torch.no_grad():
+ netG.filter(image_tensor)
+ resC, error = netC.forward(image_tensor, netG.get_im_feat(), color_sample_tensor, calib_tensor, labels=rgb_tensor)
+
+ optimizerC.zero_grad()
+ error.backward()
+ optimizerC.step()
+
+ iter_net_time = time.time()
+ eta = ((iter_net_time - epoch_start_time) / (train_idx + 1)) * len(train_data_loader) - (
+ iter_net_time - epoch_start_time)
+
+ if train_idx % opt.freq_plot == 0:
+ print(
+ 'Name: {0} | Epoch: {1} | {2}/{3} | Err: {4:.06f} | LR: {5:.06f} | dataT: {6:.05f} | netT: {7:.05f} | ETA: {8:02d}:{9:02d}'.format(
+ opt.name, epoch, train_idx, len(train_data_loader),
+ error.item(),
+ lr,
+ iter_start_time - iter_data_time,
+ iter_net_time - iter_start_time, int(eta // 60),
+ int(eta - 60 * (eta // 60))))
+
+ if train_idx % opt.freq_save == 0 and train_idx != 0:
+ torch.save(netC.state_dict(), '%s/%s/netC_latest' % (opt.checkpoints_path, opt.name))
+ torch.save(netC.state_dict(), '%s/%s/netC_epoch_%d' % (opt.checkpoints_path, opt.name, epoch))
+
+ if train_idx % opt.freq_save_ply == 0:
+ save_path = '%s/%s/pred_col.ply' % (opt.results_path, opt.name)
+ rgb = resC[0].transpose(0, 1).cpu() * 0.5 + 0.5
+ points = color_sample_tensor[0].transpose(0, 1).cpu()
+ save_samples_rgb(save_path, points.detach().numpy(), rgb.detach().numpy())
+
+ iter_data_time = time.time()
+
+ #### test
+ with torch.no_grad():
+ set_eval()
+
+ if not opt.no_num_eval:
+ test_losses = {}
+ print('calc error (test) ...')
+ test_color_error = calc_error_color(opt, netG, netC, cuda, test_dataset, 100)
+ print('eval test | color error:', test_color_error)
+ test_losses['test_color'] = test_color_error
+
+ print('calc error (train) ...')
+ train_dataset.is_train = False
+ train_color_error = calc_error_color(opt, netG, netC, cuda, train_dataset, 100)
+ train_dataset.is_train = True
+ print('eval train | color error:', train_color_error)
+ test_losses['train_color'] = train_color_error
+
+ if not opt.no_gen_mesh:
+ print('generate mesh (test) ...')
+ for gen_idx in tqdm(range(opt.num_gen_mesh_test)):
+ test_data = random.choice(test_dataset)
+ save_path = '%s/%s/test_eval_epoch%d_%s.obj' % (
+ opt.results_path, opt.name, epoch, test_data['name'])
+ gen_mesh_color(opt, netG, netC, cuda, test_data, save_path)
+
+ print('generate mesh (train) ...')
+ train_dataset.is_train = False
+ for gen_idx in tqdm(range(opt.num_gen_mesh_test)):
+ train_data = random.choice(train_dataset)
+ save_path = '%s/%s/train_eval_epoch%d_%s.obj' % (
+ opt.results_path, opt.name, epoch, train_data['name'])
+ gen_mesh_color(opt, netG, netC, cuda, train_data, save_path)
+ train_dataset.is_train = True
+
+if __name__ == '__main__':
+ train_color(opt)
\ No newline at end of file
diff --git a/PIFu/apps/train_shape.py b/PIFu/apps/train_shape.py
new file mode 100644
index 0000000000000000000000000000000000000000..241ce543c956ce51f6f8445739ef41f4ddf7a7d5
--- /dev/null
+++ b/PIFu/apps/train_shape.py
@@ -0,0 +1,183 @@
+import sys
+import os
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
+ROOT_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+
+import time
+import json
+import numpy as np
+import cv2
+import random
+import torch
+from torch.utils.data import DataLoader
+from tqdm import tqdm
+
+from lib.options import BaseOptions
+from lib.mesh_util import *
+from lib.sample_util import *
+from lib.train_util import *
+from lib.data import *
+from lib.model import *
+from lib.geometry import index
+
+# get options
+opt = BaseOptions().parse()
+
+def train(opt):
+ # set cuda
+ cuda = torch.device('cuda:%d' % opt.gpu_id)
+
+ train_dataset = TrainDataset(opt, phase='train')
+ test_dataset = TrainDataset(opt, phase='test')
+
+ projection_mode = train_dataset.projection_mode
+
+ # create data loader
+ train_data_loader = DataLoader(train_dataset,
+ batch_size=opt.batch_size, shuffle=not opt.serial_batches,
+ num_workers=opt.num_threads, pin_memory=opt.pin_memory)
+
+ print('train data size: ', len(train_data_loader))
+
+ # NOTE: batch size should be 1 and use all the points for evaluation
+ test_data_loader = DataLoader(test_dataset,
+ batch_size=1, shuffle=False,
+ num_workers=opt.num_threads, pin_memory=opt.pin_memory)
+ print('test data size: ', len(test_data_loader))
+
+ # create net
+ netG = HGPIFuNet(opt, projection_mode).to(device=cuda)
+ optimizerG = torch.optim.RMSprop(netG.parameters(), lr=opt.learning_rate, momentum=0, weight_decay=0)
+ lr = opt.learning_rate
+ print('Using Network: ', netG.name)
+
+ def set_train():
+ netG.train()
+
+ def set_eval():
+ netG.eval()
+
+ # load checkpoints
+ if opt.load_netG_checkpoint_path is not None:
+ print('loading for net G ...', opt.load_netG_checkpoint_path)
+ netG.load_state_dict(torch.load(opt.load_netG_checkpoint_path, map_location=cuda))
+
+ if opt.continue_train:
+ if opt.resume_epoch < 0:
+ model_path = '%s/%s/netG_latest' % (opt.checkpoints_path, opt.name)
+ else:
+ model_path = '%s/%s/netG_epoch_%d' % (opt.checkpoints_path, opt.name, opt.resume_epoch)
+ print('Resuming from ', model_path)
+ netG.load_state_dict(torch.load(model_path, map_location=cuda))
+
+ os.makedirs(opt.checkpoints_path, exist_ok=True)
+ os.makedirs(opt.results_path, exist_ok=True)
+ os.makedirs('%s/%s' % (opt.checkpoints_path, opt.name), exist_ok=True)
+ os.makedirs('%s/%s' % (opt.results_path, opt.name), exist_ok=True)
+
+ opt_log = os.path.join(opt.results_path, opt.name, 'opt.txt')
+ with open(opt_log, 'w') as outfile:
+ outfile.write(json.dumps(vars(opt), indent=2))
+
+ # training
+ start_epoch = 0 if not opt.continue_train else max(opt.resume_epoch,0)
+ for epoch in range(start_epoch, opt.num_epoch):
+ epoch_start_time = time.time()
+
+ set_train()
+ iter_data_time = time.time()
+ for train_idx, train_data in enumerate(train_data_loader):
+ iter_start_time = time.time()
+
+ # retrieve the data
+ image_tensor = train_data['img'].to(device=cuda)
+ calib_tensor = train_data['calib'].to(device=cuda)
+ sample_tensor = train_data['samples'].to(device=cuda)
+
+ image_tensor, calib_tensor = reshape_multiview_tensors(image_tensor, calib_tensor)
+
+ if opt.num_views > 1:
+ sample_tensor = reshape_sample_tensor(sample_tensor, opt.num_views)
+
+ label_tensor = train_data['labels'].to(device=cuda)
+
+ res, error = netG.forward(image_tensor, sample_tensor, calib_tensor, labels=label_tensor)
+
+ optimizerG.zero_grad()
+ error.backward()
+ optimizerG.step()
+
+ iter_net_time = time.time()
+ eta = ((iter_net_time - epoch_start_time) / (train_idx + 1)) * len(train_data_loader) - (
+ iter_net_time - epoch_start_time)
+
+ if train_idx % opt.freq_plot == 0:
+ print(
+ 'Name: {0} | Epoch: {1} | {2}/{3} | Err: {4:.06f} | LR: {5:.06f} | Sigma: {6:.02f} | dataT: {7:.05f} | netT: {8:.05f} | ETA: {9:02d}:{10:02d}'.format(
+ opt.name, epoch, train_idx, len(train_data_loader), error.item(), lr, opt.sigma,
+ iter_start_time - iter_data_time,
+ iter_net_time - iter_start_time, int(eta // 60),
+ int(eta - 60 * (eta // 60))))
+
+ if train_idx % opt.freq_save == 0 and train_idx != 0:
+ torch.save(netG.state_dict(), '%s/%s/netG_latest' % (opt.checkpoints_path, opt.name))
+ torch.save(netG.state_dict(), '%s/%s/netG_epoch_%d' % (opt.checkpoints_path, opt.name, epoch))
+
+ if train_idx % opt.freq_save_ply == 0:
+ save_path = '%s/%s/pred.ply' % (opt.results_path, opt.name)
+ r = res[0].cpu()
+ points = sample_tensor[0].transpose(0, 1).cpu()
+ save_samples_truncted_prob(save_path, points.detach().numpy(), r.detach().numpy())
+
+ iter_data_time = time.time()
+
+ # update learning rate
+ lr = adjust_learning_rate(optimizerG, epoch, lr, opt.schedule, opt.gamma)
+
+ #### test
+ with torch.no_grad():
+ set_eval()
+
+ if not opt.no_num_eval:
+ test_losses = {}
+ print('calc error (test) ...')
+ test_errors = calc_error(opt, netG, cuda, test_dataset, 100)
+ print('eval test MSE: {0:06f} IOU: {1:06f} prec: {2:06f} recall: {3:06f}'.format(*test_errors))
+ MSE, IOU, prec, recall = test_errors
+ test_losses['MSE(test)'] = MSE
+ test_losses['IOU(test)'] = IOU
+ test_losses['prec(test)'] = prec
+ test_losses['recall(test)'] = recall
+
+ print('calc error (train) ...')
+ train_dataset.is_train = False
+ train_errors = calc_error(opt, netG, cuda, train_dataset, 100)
+ train_dataset.is_train = True
+ print('eval train MSE: {0:06f} IOU: {1:06f} prec: {2:06f} recall: {3:06f}'.format(*train_errors))
+ MSE, IOU, prec, recall = train_errors
+ test_losses['MSE(train)'] = MSE
+ test_losses['IOU(train)'] = IOU
+ test_losses['prec(train)'] = prec
+ test_losses['recall(train)'] = recall
+
+ if not opt.no_gen_mesh:
+ print('generate mesh (test) ...')
+ for gen_idx in tqdm(range(opt.num_gen_mesh_test)):
+ test_data = random.choice(test_dataset)
+ save_path = '%s/%s/test_eval_epoch%d_%s.obj' % (
+ opt.results_path, opt.name, epoch, test_data['name'])
+ gen_mesh(opt, netG, cuda, test_data, save_path)
+
+ print('generate mesh (train) ...')
+ train_dataset.is_train = False
+ for gen_idx in tqdm(range(opt.num_gen_mesh_test)):
+ train_data = random.choice(train_dataset)
+ save_path = '%s/%s/train_eval_epoch%d_%s.obj' % (
+ opt.results_path, opt.name, epoch, train_data['name'])
+ gen_mesh(opt, netG, cuda, train_data, save_path)
+ train_dataset.is_train = True
+
+
+if __name__ == '__main__':
+ train(opt)
\ No newline at end of file
diff --git a/PIFu/env_sh.npy b/PIFu/env_sh.npy
new file mode 100755
index 0000000000000000000000000000000000000000..6841e757f9035f97d392925e09a5e202a45a7701
Binary files /dev/null and b/PIFu/env_sh.npy differ
diff --git a/PIFu/environment.yml b/PIFu/environment.yml
new file mode 100755
index 0000000000000000000000000000000000000000..80b2e05ef59c6f5377c70af584837e495c9cf690
--- /dev/null
+++ b/PIFu/environment.yml
@@ -0,0 +1,19 @@
+name: PIFu
+channels:
+- pytorch
+- defaults
+dependencies:
+- opencv
+- pytorch
+- json
+- pyexr
+- cv2
+- PIL
+- skimage
+- tqdm
+- pyembree
+- shapely
+- rtree
+- xxhash
+- trimesh
+- PyOpenGL
\ No newline at end of file
diff --git a/PIFu/lib/__init__.py b/PIFu/lib/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/PIFu/lib/colab_util.py b/PIFu/lib/colab_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..608227b228647e7b1bc16676fadf22d68e381f57
--- /dev/null
+++ b/PIFu/lib/colab_util.py
@@ -0,0 +1,114 @@
+import io
+import os
+import torch
+from skimage.io import imread
+import numpy as np
+import cv2
+from tqdm import tqdm_notebook as tqdm
+import base64
+from IPython.display import HTML
+
+# Util function for loading meshes
+from pytorch3d.io import load_objs_as_meshes
+
+from IPython.display import HTML
+from base64 import b64encode
+
+# Data structures and functions for rendering
+from pytorch3d.structures import Meshes
+from pytorch3d.renderer import (
+ look_at_view_transform,
+ OpenGLOrthographicCameras,
+ PointLights,
+ DirectionalLights,
+ Materials,
+ RasterizationSettings,
+ MeshRenderer,
+ MeshRasterizer,
+ SoftPhongShader,
+ HardPhongShader,
+ TexturesVertex
+)
+
+def set_renderer():
+ # Setup
+ device = torch.device("cuda:0")
+ torch.cuda.set_device(device)
+
+ # Initialize an OpenGL perspective camera.
+ R, T = look_at_view_transform(2.0, 0, 180)
+ cameras = OpenGLOrthographicCameras(device=device, R=R, T=T)
+
+ raster_settings = RasterizationSettings(
+ image_size=512,
+ blur_radius=0.0,
+ faces_per_pixel=1,
+ bin_size = None,
+ max_faces_per_bin = None
+ )
+
+ lights = PointLights(device=device, location=((2.0, 2.0, 2.0),))
+
+ renderer = MeshRenderer(
+ rasterizer=MeshRasterizer(
+ cameras=cameras,
+ raster_settings=raster_settings
+ ),
+ shader=HardPhongShader(
+ device=device,
+ cameras=cameras,
+ lights=lights
+ )
+ )
+ return renderer
+
+def get_verts_rgb_colors(obj_path):
+ rgb_colors = []
+
+ f = open(obj_path)
+ lines = f.readlines()
+ for line in lines:
+ ls = line.split(' ')
+ if len(ls) == 7:
+ rgb_colors.append(ls[-3:])
+
+ return np.array(rgb_colors, dtype='float32')[None, :, :]
+
+def generate_video_from_obj(obj_path, video_path, renderer):
+ # Setup
+ device = torch.device("cuda:0")
+ torch.cuda.set_device(device)
+
+ # Load obj file
+ verts_rgb_colors = get_verts_rgb_colors(obj_path)
+ verts_rgb_colors = torch.from_numpy(verts_rgb_colors).to(device)
+ textures = TexturesVertex(verts_features=verts_rgb_colors)
+ wo_textures = TexturesVertex(verts_features=torch.ones_like(verts_rgb_colors)*0.75)
+
+ # Load obj
+ mesh = load_objs_as_meshes([obj_path], device=device)
+
+ # Set mesh
+ vers = mesh._verts_list
+ faces = mesh._faces_list
+ mesh_w_tex = Meshes(vers, faces, textures)
+ mesh_wo_tex = Meshes(vers, faces, wo_textures)
+
+ # create VideoWriter
+ fourcc = cv2. VideoWriter_fourcc(*'MP4V')
+ out = cv2.VideoWriter(video_path, fourcc, 20.0, (1024,512))
+
+ for i in tqdm(range(90)):
+ R, T = look_at_view_transform(1.8, 0, i*4, device=device)
+ images_w_tex = renderer(mesh_w_tex, R=R, T=T)
+ images_w_tex = np.clip(images_w_tex[0, ..., :3].cpu().numpy(), 0.0, 1.0)[:, :, ::-1] * 255
+ images_wo_tex = renderer(mesh_wo_tex, R=R, T=T)
+ images_wo_tex = np.clip(images_wo_tex[0, ..., :3].cpu().numpy(), 0.0, 1.0)[:, :, ::-1] * 255
+ image = np.concatenate([images_w_tex, images_wo_tex], axis=1)
+ out.write(image.astype('uint8'))
+ out.release()
+
+def video(path):
+ mp4 = open(path,'rb').read()
+ data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
+ return HTML('' % data_url)
diff --git a/PIFu/lib/data/BaseDataset.py b/PIFu/lib/data/BaseDataset.py
new file mode 100755
index 0000000000000000000000000000000000000000..2d3e842341ecd51514ac96ce51a13fcaa12d1733
--- /dev/null
+++ b/PIFu/lib/data/BaseDataset.py
@@ -0,0 +1,46 @@
+from torch.utils.data import Dataset
+import random
+
+
+class BaseDataset(Dataset):
+ '''
+ This is the Base Datasets.
+ Itself does nothing and is not runnable.
+ Check self.get_item function to see what it should return.
+ '''
+
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ return parser
+
+ def __init__(self, opt, phase='train'):
+ self.opt = opt
+ self.is_train = self.phase == 'train'
+ self.projection_mode = 'orthogonal' # Declare projection mode here
+
+ def __len__(self):
+ return 0
+
+ def get_item(self, index):
+ # In case of a missing file or IO error, switch to a random sample instead
+ try:
+ res = {
+ 'name': None, # name of this subject
+ 'b_min': None, # Bounding box (x_min, y_min, z_min) of target space
+ 'b_max': None, # Bounding box (x_max, y_max, z_max) of target space
+
+ 'samples': None, # [3, N] samples
+ 'labels': None, # [1, N] labels
+
+ 'img': None, # [num_views, C, H, W] input images
+ 'calib': None, # [num_views, 4, 4] calibration matrix
+ 'extrinsic': None, # [num_views, 4, 4] extrinsic matrix
+ 'mask': None, # [num_views, 1, H, W] segmentation masks
+ }
+ return res
+ except:
+ print("Requested index %s has missing files. Using a random sample instead." % index)
+ return self.get_item(index=random.randint(0, self.__len__() - 1))
+
+ def __getitem__(self, index):
+ return self.get_item(index)
diff --git a/PIFu/lib/data/EvalDataset.py b/PIFu/lib/data/EvalDataset.py
new file mode 100755
index 0000000000000000000000000000000000000000..ad42b46459aa099ed48780b5cff0cb9099f82b71
--- /dev/null
+++ b/PIFu/lib/data/EvalDataset.py
@@ -0,0 +1,166 @@
+from torch.utils.data import Dataset
+import numpy as np
+import os
+import random
+import torchvision.transforms as transforms
+from PIL import Image, ImageOps
+import cv2
+import torch
+from PIL.ImageFilter import GaussianBlur
+import trimesh
+import cv2
+
+
+class EvalDataset(Dataset):
+ @staticmethod
+ def modify_commandline_options(parser):
+ return parser
+
+ def __init__(self, opt, root=None):
+ self.opt = opt
+ self.projection_mode = 'orthogonal'
+
+ # Path setup
+ self.root = self.opt.dataroot
+ if root is not None:
+ self.root = root
+ self.RENDER = os.path.join(self.root, 'RENDER')
+ self.MASK = os.path.join(self.root, 'MASK')
+ self.PARAM = os.path.join(self.root, 'PARAM')
+ self.OBJ = os.path.join(self.root, 'GEO', 'OBJ')
+
+ self.phase = 'val'
+ self.load_size = self.opt.loadSize
+
+ self.num_views = self.opt.num_views
+
+ self.max_view_angle = 360
+ self.interval = 1
+ self.subjects = self.get_subjects()
+
+ # PIL to tensor
+ self.to_tensor = transforms.Compose([
+ transforms.Resize(self.load_size),
+ transforms.ToTensor(),
+ transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
+ ])
+
+ def get_subjects(self):
+ var_file = os.path.join(self.root, 'val.txt')
+ if os.path.exists(var_file):
+ var_subjects = np.loadtxt(var_file, dtype=str)
+ return sorted(list(var_subjects))
+ all_subjects = os.listdir(self.RENDER)
+ return sorted(list(all_subjects))
+
+ def __len__(self):
+ return len(self.subjects) * self.max_view_angle // self.interval
+
+ def get_render(self, subject, num_views, view_id=None, random_sample=False):
+ '''
+ Return the render data
+ :param subject: subject name
+ :param num_views: how many views to return
+ :param view_id: the first view_id. If None, select a random one.
+ :return:
+ 'img': [num_views, C, W, H] images
+ 'calib': [num_views, 4, 4] calibration matrix
+ 'extrinsic': [num_views, 4, 4] extrinsic matrix
+ 'mask': [num_views, 1, W, H] masks
+ '''
+ # For now we only have pitch = 00. Hard code it here
+ pitch = 0
+ # Select a random view_id from self.max_view_angle if not given
+ if view_id is None:
+ view_id = np.random.randint(self.max_view_angle)
+ # The ids are an even distribution of num_views around view_id
+ view_ids = [(view_id + self.max_view_angle // num_views * offset) % self.max_view_angle
+ for offset in range(num_views)]
+ if random_sample:
+ view_ids = np.random.choice(self.max_view_angle, num_views, replace=False)
+
+ calib_list = []
+ render_list = []
+ mask_list = []
+ extrinsic_list = []
+
+ for vid in view_ids:
+ param_path = os.path.join(self.PARAM, subject, '%d_%02d.npy' % (vid, pitch))
+ render_path = os.path.join(self.RENDER, subject, '%d_%02d.jpg' % (vid, pitch))
+ mask_path = os.path.join(self.MASK, subject, '%d_%02d.png' % (vid, pitch))
+
+ # loading calibration data
+ param = np.load(param_path)
+ # pixel unit / world unit
+ ortho_ratio = param.item().get('ortho_ratio')
+ # world unit / model unit
+ scale = param.item().get('scale')
+ # camera center world coordinate
+ center = param.item().get('center')
+ # model rotation
+ R = param.item().get('R')
+
+ translate = -np.matmul(R, center).reshape(3, 1)
+ extrinsic = np.concatenate([R, translate], axis=1)
+ extrinsic = np.concatenate([extrinsic, np.array([0, 0, 0, 1]).reshape(1, 4)], 0)
+ # Match camera space to image pixel space
+ scale_intrinsic = np.identity(4)
+ scale_intrinsic[0, 0] = scale / ortho_ratio
+ scale_intrinsic[1, 1] = -scale / ortho_ratio
+ scale_intrinsic[2, 2] = -scale / ortho_ratio
+ # Match image pixel space to image uv space
+ uv_intrinsic = np.identity(4)
+ uv_intrinsic[0, 0] = 1.0 / float(self.opt.loadSize // 2)
+ uv_intrinsic[1, 1] = 1.0 / float(self.opt.loadSize // 2)
+ uv_intrinsic[2, 2] = 1.0 / float(self.opt.loadSize // 2)
+ # Transform under image pixel space
+ trans_intrinsic = np.identity(4)
+
+ mask = Image.open(mask_path).convert('L')
+ render = Image.open(render_path).convert('RGB')
+
+ intrinsic = np.matmul(trans_intrinsic, np.matmul(uv_intrinsic, scale_intrinsic))
+ calib = torch.Tensor(np.matmul(intrinsic, extrinsic)).float()
+ extrinsic = torch.Tensor(extrinsic).float()
+
+ mask = transforms.Resize(self.load_size)(mask)
+ mask = transforms.ToTensor()(mask).float()
+ mask_list.append(mask)
+
+ render = self.to_tensor(render)
+ render = mask.expand_as(render) * render
+
+ render_list.append(render)
+ calib_list.append(calib)
+ extrinsic_list.append(extrinsic)
+
+ return {
+ 'img': torch.stack(render_list, dim=0),
+ 'calib': torch.stack(calib_list, dim=0),
+ 'extrinsic': torch.stack(extrinsic_list, dim=0),
+ 'mask': torch.stack(mask_list, dim=0)
+ }
+
+ def get_item(self, index):
+ # In case of a missing file or IO error, switch to a random sample instead
+ try:
+ sid = index % len(self.subjects)
+ vid = (index // len(self.subjects)) * self.interval
+ # name of the subject 'rp_xxxx_xxx'
+ subject = self.subjects[sid]
+ res = {
+ 'name': subject,
+ 'mesh_path': os.path.join(self.OBJ, subject + '.obj'),
+ 'sid': sid,
+ 'vid': vid,
+ }
+ render_data = self.get_render(subject, num_views=self.num_views, view_id=vid,
+ random_sample=self.opt.random_multiview)
+ res.update(render_data)
+ return res
+ except Exception as e:
+ print(e)
+ return self.get_item(index=random.randint(0, self.__len__() - 1))
+
+ def __getitem__(self, index):
+ return self.get_item(index)
diff --git a/PIFu/lib/data/TrainDataset.py b/PIFu/lib/data/TrainDataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..47a639bc644ba7a26e0f2799ffb5f170eed93318
--- /dev/null
+++ b/PIFu/lib/data/TrainDataset.py
@@ -0,0 +1,390 @@
+from torch.utils.data import Dataset
+import numpy as np
+import os
+import random
+import torchvision.transforms as transforms
+from PIL import Image, ImageOps
+import cv2
+import torch
+from PIL.ImageFilter import GaussianBlur
+import trimesh
+import logging
+
+log = logging.getLogger('trimesh')
+log.setLevel(40)
+
+def load_trimesh(root_dir):
+ folders = os.listdir(root_dir)
+ meshs = {}
+ for i, f in enumerate(folders):
+ sub_name = f
+ meshs[sub_name] = trimesh.load(os.path.join(root_dir, f, '%s_100k.obj' % sub_name))
+
+ return meshs
+
+def save_samples_truncted_prob(fname, points, prob):
+ '''
+ Save the visualization of sampling to a ply file.
+ Red points represent positive predictions.
+ Green points represent negative predictions.
+ :param fname: File name to save
+ :param points: [N, 3] array of points
+ :param prob: [N, 1] array of predictions in the range [0~1]
+ :return:
+ '''
+ r = (prob > 0.5).reshape([-1, 1]) * 255
+ g = (prob < 0.5).reshape([-1, 1]) * 255
+ b = np.zeros(r.shape)
+
+ to_save = np.concatenate([points, r, g, b], axis=-1)
+ return np.savetxt(fname,
+ to_save,
+ fmt='%.6f %.6f %.6f %d %d %d',
+ comments='',
+ header=(
+ 'ply\nformat ascii 1.0\nelement vertex {:d}\nproperty float x\nproperty float y\nproperty float z\nproperty uchar red\nproperty uchar green\nproperty uchar blue\nend_header').format(
+ points.shape[0])
+ )
+
+
+class TrainDataset(Dataset):
+ @staticmethod
+ def modify_commandline_options(parser, is_train):
+ return parser
+
+ def __init__(self, opt, phase='train'):
+ self.opt = opt
+ self.projection_mode = 'orthogonal'
+
+ # Path setup
+ self.root = self.opt.dataroot
+ self.RENDER = os.path.join(self.root, 'RENDER')
+ self.MASK = os.path.join(self.root, 'MASK')
+ self.PARAM = os.path.join(self.root, 'PARAM')
+ self.UV_MASK = os.path.join(self.root, 'UV_MASK')
+ self.UV_NORMAL = os.path.join(self.root, 'UV_NORMAL')
+ self.UV_RENDER = os.path.join(self.root, 'UV_RENDER')
+ self.UV_POS = os.path.join(self.root, 'UV_POS')
+ self.OBJ = os.path.join(self.root, 'GEO', 'OBJ')
+
+ self.B_MIN = np.array([-128, -28, -128])
+ self.B_MAX = np.array([128, 228, 128])
+
+ self.is_train = (phase == 'train')
+ self.load_size = self.opt.loadSize
+
+ self.num_views = self.opt.num_views
+
+ self.num_sample_inout = self.opt.num_sample_inout
+ self.num_sample_color = self.opt.num_sample_color
+
+ self.yaw_list = list(range(0,360,1))
+ self.pitch_list = [0]
+ self.subjects = self.get_subjects()
+
+ # PIL to tensor
+ self.to_tensor = transforms.Compose([
+ transforms.Resize(self.load_size),
+ transforms.ToTensor(),
+ transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
+ ])
+
+ # augmentation
+ self.aug_trans = transforms.Compose([
+ transforms.ColorJitter(brightness=opt.aug_bri, contrast=opt.aug_con, saturation=opt.aug_sat,
+ hue=opt.aug_hue)
+ ])
+
+ self.mesh_dic = load_trimesh(self.OBJ)
+
+ def get_subjects(self):
+ all_subjects = os.listdir(self.RENDER)
+ var_subjects = np.loadtxt(os.path.join(self.root, 'val.txt'), dtype=str)
+ if len(var_subjects) == 0:
+ return all_subjects
+
+ if self.is_train:
+ return sorted(list(set(all_subjects) - set(var_subjects)))
+ else:
+ return sorted(list(var_subjects))
+
+ def __len__(self):
+ return len(self.subjects) * len(self.yaw_list) * len(self.pitch_list)
+
+ def get_render(self, subject, num_views, yid=0, pid=0, random_sample=False):
+ '''
+ Return the render data
+ :param subject: subject name
+ :param num_views: how many views to return
+ :param view_id: the first view_id. If None, select a random one.
+ :return:
+ 'img': [num_views, C, W, H] images
+ 'calib': [num_views, 4, 4] calibration matrix
+ 'extrinsic': [num_views, 4, 4] extrinsic matrix
+ 'mask': [num_views, 1, W, H] masks
+ '''
+ pitch = self.pitch_list[pid]
+
+ # The ids are an even distribution of num_views around view_id
+ view_ids = [self.yaw_list[(yid + len(self.yaw_list) // num_views * offset) % len(self.yaw_list)]
+ for offset in range(num_views)]
+ if random_sample:
+ view_ids = np.random.choice(self.yaw_list, num_views, replace=False)
+
+ calib_list = []
+ render_list = []
+ mask_list = []
+ extrinsic_list = []
+
+ for vid in view_ids:
+ param_path = os.path.join(self.PARAM, subject, '%d_%d_%02d.npy' % (vid, pitch, 0))
+ render_path = os.path.join(self.RENDER, subject, '%d_%d_%02d.jpg' % (vid, pitch, 0))
+ mask_path = os.path.join(self.MASK, subject, '%d_%d_%02d.png' % (vid, pitch, 0))
+
+ # loading calibration data
+ param = np.load(param_path, allow_pickle=True)
+ # pixel unit / world unit
+ ortho_ratio = param.item().get('ortho_ratio')
+ # world unit / model unit
+ scale = param.item().get('scale')
+ # camera center world coordinate
+ center = param.item().get('center')
+ # model rotation
+ R = param.item().get('R')
+
+ translate = -np.matmul(R, center).reshape(3, 1)
+ extrinsic = np.concatenate([R, translate], axis=1)
+ extrinsic = np.concatenate([extrinsic, np.array([0, 0, 0, 1]).reshape(1, 4)], 0)
+ # Match camera space to image pixel space
+ scale_intrinsic = np.identity(4)
+ scale_intrinsic[0, 0] = scale / ortho_ratio
+ scale_intrinsic[1, 1] = -scale / ortho_ratio
+ scale_intrinsic[2, 2] = scale / ortho_ratio
+ # Match image pixel space to image uv space
+ uv_intrinsic = np.identity(4)
+ uv_intrinsic[0, 0] = 1.0 / float(self.opt.loadSize // 2)
+ uv_intrinsic[1, 1] = 1.0 / float(self.opt.loadSize // 2)
+ uv_intrinsic[2, 2] = 1.0 / float(self.opt.loadSize // 2)
+ # Transform under image pixel space
+ trans_intrinsic = np.identity(4)
+
+ mask = Image.open(mask_path).convert('L')
+ render = Image.open(render_path).convert('RGB')
+
+ if self.is_train:
+ # Pad images
+ pad_size = int(0.1 * self.load_size)
+ render = ImageOps.expand(render, pad_size, fill=0)
+ mask = ImageOps.expand(mask, pad_size, fill=0)
+
+ w, h = render.size
+ th, tw = self.load_size, self.load_size
+
+ # random flip
+ if self.opt.random_flip and np.random.rand() > 0.5:
+ scale_intrinsic[0, 0] *= -1
+ render = transforms.RandomHorizontalFlip(p=1.0)(render)
+ mask = transforms.RandomHorizontalFlip(p=1.0)(mask)
+
+ # random scale
+ if self.opt.random_scale:
+ rand_scale = random.uniform(0.9, 1.1)
+ w = int(rand_scale * w)
+ h = int(rand_scale * h)
+ render = render.resize((w, h), Image.BILINEAR)
+ mask = mask.resize((w, h), Image.NEAREST)
+ scale_intrinsic *= rand_scale
+ scale_intrinsic[3, 3] = 1
+
+ # random translate in the pixel space
+ if self.opt.random_trans:
+ dx = random.randint(-int(round((w - tw) / 10.)),
+ int(round((w - tw) / 10.)))
+ dy = random.randint(-int(round((h - th) / 10.)),
+ int(round((h - th) / 10.)))
+ else:
+ dx = 0
+ dy = 0
+
+ trans_intrinsic[0, 3] = -dx / float(self.opt.loadSize // 2)
+ trans_intrinsic[1, 3] = -dy / float(self.opt.loadSize // 2)
+
+ x1 = int(round((w - tw) / 2.)) + dx
+ y1 = int(round((h - th) / 2.)) + dy
+
+ render = render.crop((x1, y1, x1 + tw, y1 + th))
+ mask = mask.crop((x1, y1, x1 + tw, y1 + th))
+
+ render = self.aug_trans(render)
+
+ # random blur
+ if self.opt.aug_blur > 0.00001:
+ blur = GaussianBlur(np.random.uniform(0, self.opt.aug_blur))
+ render = render.filter(blur)
+
+ intrinsic = np.matmul(trans_intrinsic, np.matmul(uv_intrinsic, scale_intrinsic))
+ calib = torch.Tensor(np.matmul(intrinsic, extrinsic)).float()
+ extrinsic = torch.Tensor(extrinsic).float()
+
+ mask = transforms.Resize(self.load_size)(mask)
+ mask = transforms.ToTensor()(mask).float()
+ mask_list.append(mask)
+
+ render = self.to_tensor(render)
+ render = mask.expand_as(render) * render
+
+ render_list.append(render)
+ calib_list.append(calib)
+ extrinsic_list.append(extrinsic)
+
+ return {
+ 'img': torch.stack(render_list, dim=0),
+ 'calib': torch.stack(calib_list, dim=0),
+ 'extrinsic': torch.stack(extrinsic_list, dim=0),
+ 'mask': torch.stack(mask_list, dim=0)
+ }
+
+ def select_sampling_method(self, subject):
+ if not self.is_train:
+ random.seed(1991)
+ np.random.seed(1991)
+ torch.manual_seed(1991)
+ mesh = self.mesh_dic[subject]
+ surface_points, _ = trimesh.sample.sample_surface(mesh, 4 * self.num_sample_inout)
+ sample_points = surface_points + np.random.normal(scale=self.opt.sigma, size=surface_points.shape)
+
+ # add random points within image space
+ length = self.B_MAX - self.B_MIN
+ random_points = np.random.rand(self.num_sample_inout // 4, 3) * length + self.B_MIN
+ sample_points = np.concatenate([sample_points, random_points], 0)
+ np.random.shuffle(sample_points)
+
+ inside = mesh.contains(sample_points)
+ inside_points = sample_points[inside]
+ outside_points = sample_points[np.logical_not(inside)]
+
+ nin = inside_points.shape[0]
+ inside_points = inside_points[
+ :self.num_sample_inout // 2] if nin > self.num_sample_inout // 2 else inside_points
+ outside_points = outside_points[
+ :self.num_sample_inout // 2] if nin > self.num_sample_inout // 2 else outside_points[
+ :(self.num_sample_inout - nin)]
+
+ samples = np.concatenate([inside_points, outside_points], 0).T
+ labels = np.concatenate([np.ones((1, inside_points.shape[0])), np.zeros((1, outside_points.shape[0]))], 1)
+
+ # save_samples_truncted_prob('out.ply', samples.T, labels.T)
+ # exit()
+
+ samples = torch.Tensor(samples).float()
+ labels = torch.Tensor(labels).float()
+
+ del mesh
+
+ return {
+ 'samples': samples,
+ 'labels': labels
+ }
+
+
+ def get_color_sampling(self, subject, yid, pid=0):
+ yaw = self.yaw_list[yid]
+ pitch = self.pitch_list[pid]
+ uv_render_path = os.path.join(self.UV_RENDER, subject, '%d_%d_%02d.jpg' % (yaw, pitch, 0))
+ uv_mask_path = os.path.join(self.UV_MASK, subject, '%02d.png' % (0))
+ uv_pos_path = os.path.join(self.UV_POS, subject, '%02d.exr' % (0))
+ uv_normal_path = os.path.join(self.UV_NORMAL, subject, '%02d.png' % (0))
+
+ # Segmentation mask for the uv render.
+ # [H, W] bool
+ uv_mask = cv2.imread(uv_mask_path)
+ uv_mask = uv_mask[:, :, 0] != 0
+ # UV render. each pixel is the color of the point.
+ # [H, W, 3] 0 ~ 1 float
+ uv_render = cv2.imread(uv_render_path)
+ uv_render = cv2.cvtColor(uv_render, cv2.COLOR_BGR2RGB) / 255.0
+
+ # Normal render. each pixel is the surface normal of the point.
+ # [H, W, 3] -1 ~ 1 float
+ uv_normal = cv2.imread(uv_normal_path)
+ uv_normal = cv2.cvtColor(uv_normal, cv2.COLOR_BGR2RGB) / 255.0
+ uv_normal = 2.0 * uv_normal - 1.0
+ # Position render. each pixel is the xyz coordinates of the point
+ uv_pos = cv2.imread(uv_pos_path, 2 | 4)[:, :, ::-1]
+
+ ### In these few lines we flattern the masks, positions, and normals
+ uv_mask = uv_mask.reshape((-1))
+ uv_pos = uv_pos.reshape((-1, 3))
+ uv_render = uv_render.reshape((-1, 3))
+ uv_normal = uv_normal.reshape((-1, 3))
+
+ surface_points = uv_pos[uv_mask]
+ surface_colors = uv_render[uv_mask]
+ surface_normal = uv_normal[uv_mask]
+
+ if self.num_sample_color:
+ sample_list = random.sample(range(0, surface_points.shape[0] - 1), self.num_sample_color)
+ surface_points = surface_points[sample_list].T
+ surface_colors = surface_colors[sample_list].T
+ surface_normal = surface_normal[sample_list].T
+
+ # Samples are around the true surface with an offset
+ normal = torch.Tensor(surface_normal).float()
+ samples = torch.Tensor(surface_points).float() \
+ + torch.normal(mean=torch.zeros((1, normal.size(1))), std=self.opt.sigma).expand_as(normal) * normal
+
+ # Normalized to [-1, 1]
+ rgbs_color = 2.0 * torch.Tensor(surface_colors).float() - 1.0
+
+ return {
+ 'color_samples': samples,
+ 'rgbs': rgbs_color
+ }
+
+ def get_item(self, index):
+ # In case of a missing file or IO error, switch to a random sample instead
+ # try:
+ sid = index % len(self.subjects)
+ tmp = index // len(self.subjects)
+ yid = tmp % len(self.yaw_list)
+ pid = tmp // len(self.yaw_list)
+
+ # name of the subject 'rp_xxxx_xxx'
+ subject = self.subjects[sid]
+ res = {
+ 'name': subject,
+ 'mesh_path': os.path.join(self.OBJ, subject + '.obj'),
+ 'sid': sid,
+ 'yid': yid,
+ 'pid': pid,
+ 'b_min': self.B_MIN,
+ 'b_max': self.B_MAX,
+ }
+ render_data = self.get_render(subject, num_views=self.num_views, yid=yid, pid=pid,
+ random_sample=self.opt.random_multiview)
+ res.update(render_data)
+
+ if self.opt.num_sample_inout:
+ sample_data = self.select_sampling_method(subject)
+ res.update(sample_data)
+
+ # img = np.uint8((np.transpose(render_data['img'][0].numpy(), (1, 2, 0)) * 0.5 + 0.5)[:, :, ::-1] * 255.0)
+ # rot = render_data['calib'][0,:3, :3]
+ # trans = render_data['calib'][0,:3, 3:4]
+ # pts = torch.addmm(trans, rot, sample_data['samples'][:, sample_data['labels'][0] > 0.5]) # [3, N]
+ # pts = 0.5 * (pts.numpy().T + 1.0) * render_data['img'].size(2)
+ # for p in pts:
+ # img = cv2.circle(img, (p[0], p[1]), 2, (0,255,0), -1)
+ # cv2.imshow('test', img)
+ # cv2.waitKey(1)
+
+ if self.num_sample_color:
+ color_data = self.get_color_sampling(subject, yid=yid, pid=pid)
+ res.update(color_data)
+ return res
+ # except Exception as e:
+ # print(e)
+ # return self.get_item(index=random.randint(0, self.__len__() - 1))
+
+ def __getitem__(self, index):
+ return self.get_item(index)
\ No newline at end of file
diff --git a/PIFu/lib/data/__init__.py b/PIFu/lib/data/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..f87dc45d179d82778d6187ae1ffe9a18371296e8
--- /dev/null
+++ b/PIFu/lib/data/__init__.py
@@ -0,0 +1,2 @@
+from .EvalDataset import EvalDataset
+from .TrainDataset import TrainDataset
\ No newline at end of file
diff --git a/PIFu/lib/ext_transform.py b/PIFu/lib/ext_transform.py
new file mode 100755
index 0000000000000000000000000000000000000000..7e1104bd7b1a24303370c066d1487f83a9bfece0
--- /dev/null
+++ b/PIFu/lib/ext_transform.py
@@ -0,0 +1,78 @@
+import random
+
+import numpy as np
+from skimage.filters import gaussian
+import torch
+from PIL import Image, ImageFilter
+
+
+class RandomVerticalFlip(object):
+ def __call__(self, img):
+ if random.random() < 0.5:
+ return img.transpose(Image.FLIP_TOP_BOTTOM)
+ return img
+
+
+class DeNormalize(object):
+ def __init__(self, mean, std):
+ self.mean = mean
+ self.std = std
+
+ def __call__(self, tensor):
+ for t, m, s in zip(tensor, self.mean, self.std):
+ t.mul_(s).add_(m)
+ return tensor
+
+
+class MaskToTensor(object):
+ def __call__(self, img):
+ return torch.from_numpy(np.array(img, dtype=np.int32)).long()
+
+
+class FreeScale(object):
+ def __init__(self, size, interpolation=Image.BILINEAR):
+ self.size = tuple(reversed(size)) # size: (h, w)
+ self.interpolation = interpolation
+
+ def __call__(self, img):
+ return img.resize(self.size, self.interpolation)
+
+
+class FlipChannels(object):
+ def __call__(self, img):
+ img = np.array(img)[:, :, ::-1]
+ return Image.fromarray(img.astype(np.uint8))
+
+
+class RandomGaussianBlur(object):
+ def __call__(self, img):
+ sigma = 0.15 + random.random() * 1.15
+ blurred_img = gaussian(np.array(img), sigma=sigma, multichannel=True)
+ blurred_img *= 255
+ return Image.fromarray(blurred_img.astype(np.uint8))
+
+# Lighting data augmentation take from here - https://github.com/eladhoffer/convNet.pytorch/blob/master/preprocess.py
+
+
+class Lighting(object):
+ """Lighting noise(AlexNet - style PCA - based noise)"""
+
+ def __init__(self, alphastd,
+ eigval=(0.2175, 0.0188, 0.0045),
+ eigvec=((-0.5675, 0.7192, 0.4009),
+ (-0.5808, -0.0045, -0.8140),
+ (-0.5836, -0.6948, 0.4203))):
+ self.alphastd = alphastd
+ self.eigval = torch.Tensor(eigval)
+ self.eigvec = torch.Tensor(eigvec)
+
+ def __call__(self, img):
+ if self.alphastd == 0:
+ return img
+
+ alpha = img.new().resize_(3).normal_(0, self.alphastd)
+ rgb = self.eigvec.type_as(img).clone()\
+ .mul(alpha.view(1, 3).expand(3, 3))\
+ .mul(self.eigval.view(1, 3).expand(3, 3))\
+ .sum(1).squeeze()
+ return img.add(rgb.view(3, 1, 1).expand_as(img))
diff --git a/PIFu/lib/geometry.py b/PIFu/lib/geometry.py
new file mode 100755
index 0000000000000000000000000000000000000000..5e88b38602ae00d9c20343f21efb019b8fba1cc0
--- /dev/null
+++ b/PIFu/lib/geometry.py
@@ -0,0 +1,55 @@
+import torch
+
+
+def index(feat, uv):
+ '''
+
+ :param feat: [B, C, H, W] image features
+ :param uv: [B, 2, N] uv coordinates in the image plane, range [-1, 1]
+ :return: [B, C, N] image features at the uv coordinates
+ '''
+ uv = uv.transpose(1, 2) # [B, N, 2]
+ uv = uv.unsqueeze(2) # [B, N, 1, 2]
+ # NOTE: for newer PyTorch, it seems that training results are degraded due to implementation diff in F.grid_sample
+ # for old versions, simply remove the aligned_corners argument.
+ samples = torch.nn.functional.grid_sample(feat, uv, align_corners=True) # [B, C, N, 1]
+ return samples[:, :, :, 0] # [B, C, N]
+
+
+def orthogonal(points, calibrations, transforms=None):
+ '''
+ Compute the orthogonal projections of 3D points into the image plane by given projection matrix
+ :param points: [B, 3, N] Tensor of 3D points
+ :param calibrations: [B, 4, 4] Tensor of projection matrix
+ :param transforms: [B, 2, 3] Tensor of image transform matrix
+ :return: xyz: [B, 3, N] Tensor of xyz coordinates in the image plane
+ '''
+ rot = calibrations[:, :3, :3]
+ trans = calibrations[:, :3, 3:4]
+ pts = torch.baddbmm(trans, rot, points) # [B, 3, N]
+ if transforms is not None:
+ scale = transforms[:2, :2]
+ shift = transforms[:2, 2:3]
+ pts[:, :2, :] = torch.baddbmm(shift, scale, pts[:, :2, :])
+ return pts
+
+
+def perspective(points, calibrations, transforms=None):
+ '''
+ Compute the perspective projections of 3D points into the image plane by given projection matrix
+ :param points: [Bx3xN] Tensor of 3D points
+ :param calibrations: [Bx4x4] Tensor of projection matrix
+ :param transforms: [Bx2x3] Tensor of image transform matrix
+ :return: xy: [Bx2xN] Tensor of xy coordinates in the image plane
+ '''
+ rot = calibrations[:, :3, :3]
+ trans = calibrations[:, :3, 3:4]
+ homo = torch.baddbmm(trans, rot, points) # [B, 3, N]
+ xy = homo[:, :2, :] / homo[:, 2:3, :]
+ if transforms is not None:
+ scale = transforms[:2, :2]
+ shift = transforms[:2, 2:3]
+ xy = torch.baddbmm(shift, scale, xy)
+
+ xyz = torch.cat([xy, homo[:, 2:3, :]], 1)
+ return xyz
diff --git a/PIFu/lib/mesh_util.py b/PIFu/lib/mesh_util.py
new file mode 100755
index 0000000000000000000000000000000000000000..39934219011401e194c61cc00034b12dad4072d3
--- /dev/null
+++ b/PIFu/lib/mesh_util.py
@@ -0,0 +1,91 @@
+from skimage import measure
+import numpy as np
+import torch
+from .sdf import create_grid, eval_grid_octree, eval_grid
+from skimage import measure
+
+
+def reconstruction(net, cuda, calib_tensor,
+ resolution, b_min, b_max,
+ use_octree=False, num_samples=10000, transform=None):
+ '''
+ Reconstruct meshes from sdf predicted by the network.
+ :param net: a BasePixImpNet object. call image filter beforehead.
+ :param cuda: cuda device
+ :param calib_tensor: calibration tensor
+ :param resolution: resolution of the grid cell
+ :param b_min: bounding box corner [x_min, y_min, z_min]
+ :param b_max: bounding box corner [x_max, y_max, z_max]
+ :param use_octree: whether to use octree acceleration
+ :param num_samples: how many points to query each gpu iteration
+ :return: marching cubes results.
+ '''
+ # First we create a grid by resolution
+ # and transforming matrix for grid coordinates to real world xyz
+ coords, mat = create_grid(resolution, resolution, resolution,
+ b_min, b_max, transform=transform)
+
+ # Then we define the lambda function for cell evaluation
+ def eval_func(points):
+ points = np.expand_dims(points, axis=0)
+ points = np.repeat(points, net.num_views, axis=0)
+ samples = torch.from_numpy(points).to(device=cuda).float()
+ net.query(samples, calib_tensor)
+ pred = net.get_preds()[0][0]
+ return pred.detach().cpu().numpy()
+
+ # Then we evaluate the grid
+ if use_octree:
+ sdf = eval_grid_octree(coords, eval_func, num_samples=num_samples)
+ else:
+ sdf = eval_grid(coords, eval_func, num_samples=num_samples)
+
+ # Finally we do marching cubes
+ try:
+ verts, faces, normals, values = measure.marching_cubes_lewiner(sdf, 0.5)
+ # transform verts into world coordinate system
+ verts = np.matmul(mat[:3, :3], verts.T) + mat[:3, 3:4]
+ verts = verts.T
+ return verts, faces, normals, values
+ except:
+ print('error cannot marching cubes')
+ return -1
+
+
+def save_obj_mesh(mesh_path, verts, faces):
+ file = open(mesh_path, 'w')
+
+ for v in verts:
+ file.write('v %.4f %.4f %.4f\n' % (v[0], v[1], v[2]))
+ for f in faces:
+ f_plus = f + 1
+ file.write('f %d %d %d\n' % (f_plus[0], f_plus[2], f_plus[1]))
+ file.close()
+
+
+def save_obj_mesh_with_color(mesh_path, verts, faces, colors):
+ file = open(mesh_path, 'w')
+
+ for idx, v in enumerate(verts):
+ c = colors[idx]
+ file.write('v %.4f %.4f %.4f %.4f %.4f %.4f\n' % (v[0], v[1], v[2], c[0], c[1], c[2]))
+ for f in faces:
+ f_plus = f + 1
+ file.write('f %d %d %d\n' % (f_plus[0], f_plus[2], f_plus[1]))
+ file.close()
+
+
+def save_obj_mesh_with_uv(mesh_path, verts, faces, uvs):
+ file = open(mesh_path, 'w')
+
+ for idx, v in enumerate(verts):
+ vt = uvs[idx]
+ file.write('v %.4f %.4f %.4f\n' % (v[0], v[1], v[2]))
+ file.write('vt %.4f %.4f\n' % (vt[0], vt[1]))
+
+ for f in faces:
+ f_plus = f + 1
+ file.write('f %d/%d %d/%d %d/%d\n' % (f_plus[0], f_plus[0],
+ f_plus[2], f_plus[2],
+ f_plus[1], f_plus[1]))
+ file.close()
diff --git a/PIFu/lib/model/BasePIFuNet.py b/PIFu/lib/model/BasePIFuNet.py
new file mode 100755
index 0000000000000000000000000000000000000000..cb8423ea7120b09d0627bab40a90bf8ce7d13e14
--- /dev/null
+++ b/PIFu/lib/model/BasePIFuNet.py
@@ -0,0 +1,76 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..geometry import index, orthogonal, perspective
+
+class BasePIFuNet(nn.Module):
+ def __init__(self,
+ projection_mode='orthogonal',
+ error_term=nn.MSELoss(),
+ ):
+ """
+ :param projection_mode:
+ Either orthogonal or perspective.
+ It will call the corresponding function for projection.
+ :param error_term:
+ nn Loss between the predicted [B, Res, N] and the label [B, Res, N]
+ """
+ super(BasePIFuNet, self).__init__()
+ self.name = 'base'
+
+ self.error_term = error_term
+
+ self.index = index
+ self.projection = orthogonal if projection_mode == 'orthogonal' else perspective
+
+ self.preds = None
+ self.labels = None
+
+ def forward(self, points, images, calibs, transforms=None):
+ '''
+ :param points: [B, 3, N] world space coordinates of points
+ :param images: [B, C, H, W] input images
+ :param calibs: [B, 3, 4] calibration matrices for each image
+ :param transforms: Optional [B, 2, 3] image space coordinate transforms
+ :return: [B, Res, N] predictions for each point
+ '''
+ self.filter(images)
+ self.query(points, calibs, transforms)
+ return self.get_preds()
+
+ def filter(self, images):
+ '''
+ Filter the input images
+ store all intermediate features.
+ :param images: [B, C, H, W] input images
+ '''
+ None
+
+ def query(self, points, calibs, transforms=None, labels=None):
+ '''
+ Given 3D points, query the network predictions for each point.
+ Image features should be pre-computed before this call.
+ store all intermediate features.
+ query() function may behave differently during training/testing.
+ :param points: [B, 3, N] world space coordinates of points
+ :param calibs: [B, 3, 4] calibration matrices for each image
+ :param transforms: Optional [B, 2, 3] image space coordinate transforms
+ :param labels: Optional [B, Res, N] gt labeling
+ :return: [B, Res, N] predictions for each point
+ '''
+ None
+
+ def get_preds(self):
+ '''
+ Get the predictions from the last query
+ :return: [B, Res, N] network prediction for the last query
+ '''
+ return self.preds
+
+ def get_error(self):
+ '''
+ Get the network loss from the last query
+ :return: loss term
+ '''
+ return self.error_term(self.preds, self.labels)
diff --git a/PIFu/lib/model/ConvFilters.py b/PIFu/lib/model/ConvFilters.py
new file mode 100755
index 0000000000000000000000000000000000000000..1348ddea27e1bb3b0a65592bf78c92305dce0bd7
--- /dev/null
+++ b/PIFu/lib/model/ConvFilters.py
@@ -0,0 +1,112 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torchvision.models.resnet as resnet
+import torchvision.models.vgg as vgg
+
+
+class MultiConv(nn.Module):
+ def __init__(self, filter_channels):
+ super(MultiConv, self).__init__()
+ self.filters = []
+
+ for l in range(0, len(filter_channels) - 1):
+ self.filters.append(
+ nn.Conv2d(filter_channels[l], filter_channels[l + 1], kernel_size=4, stride=2))
+ self.add_module("conv%d" % l, self.filters[l])
+
+ def forward(self, image):
+ '''
+ :param image: [BxC_inxHxW] tensor of input image
+ :return: list of [BxC_outxHxW] tensors of output features
+ '''
+ y = image
+ # y = F.relu(self.bn0(self.conv0(y)), True)
+ feat_pyramid = [y]
+ for i, f in enumerate(self.filters):
+ y = f(y)
+ if i != len(self.filters) - 1:
+ y = F.leaky_relu(y)
+ # y = F.max_pool2d(y, kernel_size=2, stride=2)
+ feat_pyramid.append(y)
+ return feat_pyramid
+
+
+class Vgg16(torch.nn.Module):
+ def __init__(self):
+ super(Vgg16, self).__init__()
+ vgg_pretrained_features = vgg.vgg16(pretrained=True).features
+ self.slice1 = torch.nn.Sequential()
+ self.slice2 = torch.nn.Sequential()
+ self.slice3 = torch.nn.Sequential()
+ self.slice4 = torch.nn.Sequential()
+ self.slice5 = torch.nn.Sequential()
+
+ for x in range(4):
+ self.slice1.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(4, 9):
+ self.slice2.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(9, 16):
+ self.slice3.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(16, 23):
+ self.slice4.add_module(str(x), vgg_pretrained_features[x])
+ for x in range(23, 30):
+ self.slice5.add_module(str(x), vgg_pretrained_features[x])
+
+ def forward(self, X):
+ h = self.slice1(X)
+ h_relu1_2 = h
+ h = self.slice2(h)
+ h_relu2_2 = h
+ h = self.slice3(h)
+ h_relu3_3 = h
+ h = self.slice4(h)
+ h_relu4_3 = h
+ h = self.slice5(h)
+ h_relu5_3 = h
+
+ return [h_relu1_2, h_relu2_2, h_relu3_3, h_relu4_3, h_relu5_3]
+
+
+class ResNet(nn.Module):
+ def __init__(self, model='resnet18'):
+ super(ResNet, self).__init__()
+
+ if model == 'resnet18':
+ net = resnet.resnet18(pretrained=True)
+ elif model == 'resnet34':
+ net = resnet.resnet34(pretrained=True)
+ elif model == 'resnet50':
+ net = resnet.resnet50(pretrained=True)
+ else:
+ raise NameError('Unknown Fan Filter setting!')
+
+ self.conv1 = net.conv1
+
+ self.pool = net.maxpool
+ self.layer0 = nn.Sequential(net.conv1, net.bn1, net.relu)
+ self.layer1 = net.layer1
+ self.layer2 = net.layer2
+ self.layer3 = net.layer3
+ self.layer4 = net.layer4
+
+ def forward(self, image):
+ '''
+ :param image: [BxC_inxHxW] tensor of input image
+ :return: list of [BxC_outxHxW] tensors of output features
+ '''
+
+ y = image
+ feat_pyramid = []
+ y = self.layer0(y)
+ feat_pyramid.append(y)
+ y = self.layer1(self.pool(y))
+ feat_pyramid.append(y)
+ y = self.layer2(y)
+ feat_pyramid.append(y)
+ y = self.layer3(y)
+ feat_pyramid.append(y)
+ y = self.layer4(y)
+ feat_pyramid.append(y)
+
+ return feat_pyramid
diff --git a/PIFu/lib/model/ConvPIFuNet.py b/PIFu/lib/model/ConvPIFuNet.py
new file mode 100755
index 0000000000000000000000000000000000000000..1d43d262aa237d03db0cf329b4d199061ee6a006
--- /dev/null
+++ b/PIFu/lib/model/ConvPIFuNet.py
@@ -0,0 +1,99 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from .BasePIFuNet import BasePIFuNet
+from .SurfaceClassifier import SurfaceClassifier
+from .DepthNormalizer import DepthNormalizer
+from .ConvFilters import *
+from ..net_util import init_net
+
+class ConvPIFuNet(BasePIFuNet):
+ '''
+ Conv Piximp network is the standard 3-phase network that we will use.
+ The image filter is a pure multi-layer convolutional network,
+ while during feature extraction phase all features in the pyramid at the projected location
+ will be aggregated.
+ It does the following:
+ 1. Compute image feature pyramids and store it in self.im_feat_list
+ 2. Calculate calibration and indexing on each of the feat, and append them together
+ 3. Classification.
+ '''
+
+ def __init__(self,
+ opt,
+ projection_mode='orthogonal',
+ error_term=nn.MSELoss(),
+ ):
+ super(ConvPIFuNet, self).__init__(
+ projection_mode=projection_mode,
+ error_term=error_term)
+
+ self.name = 'convpifu'
+
+ self.opt = opt
+ self.num_views = self.opt.num_views
+
+ self.image_filter = self.define_imagefilter(opt)
+
+ self.surface_classifier = SurfaceClassifier(
+ filter_channels=self.opt.mlp_dim,
+ num_views=self.opt.num_views,
+ no_residual=self.opt.no_residual,
+ last_op=nn.Sigmoid())
+
+ self.normalizer = DepthNormalizer(opt)
+
+ # This is a list of [B x Feat_i x H x W] features
+ self.im_feat_list = []
+
+ init_net(self)
+
+ def define_imagefilter(self, opt):
+ net = None
+ if opt.netIMF == 'multiconv':
+ net = MultiConv(opt.enc_dim)
+ elif 'resnet' in opt.netIMF:
+ net = ResNet(model=opt.netIMF)
+ elif opt.netIMF == 'vgg16':
+ net = Vgg16()
+ else:
+ raise NotImplementedError('model name [%s] is not recognized' % opt.imf_type)
+
+ return net
+
+ def filter(self, images):
+ '''
+ Filter the input images
+ store all intermediate features.
+ :param images: [B, C, H, W] input images
+ '''
+ self.im_feat_list = self.image_filter(images)
+
+ def query(self, points, calibs, transforms=None, labels=None):
+ '''
+ Given 3D points, query the network predictions for each point.
+ Image features should be pre-computed before this call.
+ store all intermediate features.
+ query() function may behave differently during training/testing.
+ :param points: [B, 3, N] world space coordinates of points
+ :param calibs: [B, 3, 4] calibration matrices for each image
+ :param transforms: Optional [B, 2, 3] image space coordinate transforms
+ :param labels: Optional [B, Res, N] gt labeling
+ :return: [B, Res, N] predictions for each point
+ '''
+ if labels is not None:
+ self.labels = labels
+
+ xyz = self.projection(points, calibs, transforms)
+ xy = xyz[:, :2, :]
+ z = xyz[:, 2:3, :]
+
+ z_feat = self.normalizer(z)
+
+ # This is a list of [B, Feat_i, N] features
+ point_local_feat_list = [self.index(im_feat, xy) for im_feat in self.im_feat_list]
+ point_local_feat_list.append(z_feat)
+ # [B, Feat_all, N]
+ point_local_feat = torch.cat(point_local_feat_list, 1)
+
+ self.preds = self.surface_classifier(point_local_feat)
diff --git a/PIFu/lib/model/DepthNormalizer.py b/PIFu/lib/model/DepthNormalizer.py
new file mode 100755
index 0000000000000000000000000000000000000000..84908ec131771b8d42f32535ab856017fe1143a1
--- /dev/null
+++ b/PIFu/lib/model/DepthNormalizer.py
@@ -0,0 +1,18 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class DepthNormalizer(nn.Module):
+ def __init__(self, opt):
+ super(DepthNormalizer, self).__init__()
+ self.opt = opt
+
+ def forward(self, z, calibs=None, index_feat=None):
+ '''
+ Normalize z_feature
+ :param z_feat: [B, 1, N] depth value for z in the image coordinate system
+ :return:
+ '''
+ z_feat = z * (self.opt.loadSize // 2) / self.opt.z_size
+ return z_feat
diff --git a/PIFu/lib/model/HGFilters.py b/PIFu/lib/model/HGFilters.py
new file mode 100755
index 0000000000000000000000000000000000000000..870b3c43c82d66df001eb1bc24af9ce21ec60c83
--- /dev/null
+++ b/PIFu/lib/model/HGFilters.py
@@ -0,0 +1,146 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from ..net_util import *
+
+
+class HourGlass(nn.Module):
+ def __init__(self, num_modules, depth, num_features, norm='batch'):
+ super(HourGlass, self).__init__()
+ self.num_modules = num_modules
+ self.depth = depth
+ self.features = num_features
+ self.norm = norm
+
+ self._generate_network(self.depth)
+
+ def _generate_network(self, level):
+ self.add_module('b1_' + str(level), ConvBlock(self.features, self.features, norm=self.norm))
+
+ self.add_module('b2_' + str(level), ConvBlock(self.features, self.features, norm=self.norm))
+
+ if level > 1:
+ self._generate_network(level - 1)
+ else:
+ self.add_module('b2_plus_' + str(level), ConvBlock(self.features, self.features, norm=self.norm))
+
+ self.add_module('b3_' + str(level), ConvBlock(self.features, self.features, norm=self.norm))
+
+ def _forward(self, level, inp):
+ # Upper branch
+ up1 = inp
+ up1 = self._modules['b1_' + str(level)](up1)
+
+ # Lower branch
+ low1 = F.avg_pool2d(inp, 2, stride=2)
+ low1 = self._modules['b2_' + str(level)](low1)
+
+ if level > 1:
+ low2 = self._forward(level - 1, low1)
+ else:
+ low2 = low1
+ low2 = self._modules['b2_plus_' + str(level)](low2)
+
+ low3 = low2
+ low3 = self._modules['b3_' + str(level)](low3)
+
+ # NOTE: for newer PyTorch (1.3~), it seems that training results are degraded due to implementation diff in F.grid_sample
+ # if the pretrained model behaves weirdly, switch with the commented line.
+ # NOTE: I also found that "bicubic" works better.
+ up2 = F.interpolate(low3, scale_factor=2, mode='bicubic', align_corners=True)
+ # up2 = F.interpolate(low3, scale_factor=2, mode='nearest)
+
+ return up1 + up2
+
+ def forward(self, x):
+ return self._forward(self.depth, x)
+
+
+class HGFilter(nn.Module):
+ def __init__(self, opt):
+ super(HGFilter, self).__init__()
+ self.num_modules = opt.num_stack
+
+ self.opt = opt
+
+ # Base part
+ self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
+
+ if self.opt.norm == 'batch':
+ self.bn1 = nn.BatchNorm2d(64)
+ elif self.opt.norm == 'group':
+ self.bn1 = nn.GroupNorm(32, 64)
+
+ if self.opt.hg_down == 'conv64':
+ self.conv2 = ConvBlock(64, 64, self.opt.norm)
+ self.down_conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
+ elif self.opt.hg_down == 'conv128':
+ self.conv2 = ConvBlock(64, 128, self.opt.norm)
+ self.down_conv2 = nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1)
+ elif self.opt.hg_down == 'ave_pool':
+ self.conv2 = ConvBlock(64, 128, self.opt.norm)
+ else:
+ raise NameError('Unknown Fan Filter setting!')
+
+ self.conv3 = ConvBlock(128, 128, self.opt.norm)
+ self.conv4 = ConvBlock(128, 256, self.opt.norm)
+
+ # Stacking part
+ for hg_module in range(self.num_modules):
+ self.add_module('m' + str(hg_module), HourGlass(1, opt.num_hourglass, 256, self.opt.norm))
+
+ self.add_module('top_m_' + str(hg_module), ConvBlock(256, 256, self.opt.norm))
+ self.add_module('conv_last' + str(hg_module),
+ nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0))
+ if self.opt.norm == 'batch':
+ self.add_module('bn_end' + str(hg_module), nn.BatchNorm2d(256))
+ elif self.opt.norm == 'group':
+ self.add_module('bn_end' + str(hg_module), nn.GroupNorm(32, 256))
+
+ self.add_module('l' + str(hg_module), nn.Conv2d(256,
+ opt.hourglass_dim, kernel_size=1, stride=1, padding=0))
+
+ if hg_module < self.num_modules - 1:
+ self.add_module(
+ 'bl' + str(hg_module), nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0))
+ self.add_module('al' + str(hg_module), nn.Conv2d(opt.hourglass_dim,
+ 256, kernel_size=1, stride=1, padding=0))
+
+ def forward(self, x):
+ x = F.relu(self.bn1(self.conv1(x)), True)
+ tmpx = x
+ if self.opt.hg_down == 'ave_pool':
+ x = F.avg_pool2d(self.conv2(x), 2, stride=2)
+ elif self.opt.hg_down in ['conv64', 'conv128']:
+ x = self.conv2(x)
+ x = self.down_conv2(x)
+ else:
+ raise NameError('Unknown Fan Filter setting!')
+
+ normx = x
+
+ x = self.conv3(x)
+ x = self.conv4(x)
+
+ previous = x
+
+ outputs = []
+ for i in range(self.num_modules):
+ hg = self._modules['m' + str(i)](previous)
+
+ ll = hg
+ ll = self._modules['top_m_' + str(i)](ll)
+
+ ll = F.relu(self._modules['bn_end' + str(i)]
+ (self._modules['conv_last' + str(i)](ll)), True)
+
+ # Predict heatmaps
+ tmp_out = self._modules['l' + str(i)](ll)
+ outputs.append(tmp_out)
+
+ if i < self.num_modules - 1:
+ ll = self._modules['bl' + str(i)](ll)
+ tmp_out_ = self._modules['al' + str(i)](tmp_out)
+ previous = previous + ll + tmp_out_
+
+ return outputs, tmpx.detach(), normx
diff --git a/PIFu/lib/model/HGPIFuNet.py b/PIFu/lib/model/HGPIFuNet.py
new file mode 100755
index 0000000000000000000000000000000000000000..4771715345afcf326b3b0e64717517801fe75a1c
--- /dev/null
+++ b/PIFu/lib/model/HGPIFuNet.py
@@ -0,0 +1,142 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from .BasePIFuNet import BasePIFuNet
+from .SurfaceClassifier import SurfaceClassifier
+from .DepthNormalizer import DepthNormalizer
+from .HGFilters import *
+from ..net_util import init_net
+
+
+class HGPIFuNet(BasePIFuNet):
+ '''
+ HG PIFu network uses Hourglass stacks as the image filter.
+ It does the following:
+ 1. Compute image feature stacks and store it in self.im_feat_list
+ self.im_feat_list[-1] is the last stack (output stack)
+ 2. Calculate calibration
+ 3. If training, it index on every intermediate stacks,
+ If testing, it index on the last stack.
+ 4. Classification.
+ 5. During training, error is calculated on all stacks.
+ '''
+
+ def __init__(self,
+ opt,
+ projection_mode='orthogonal',
+ error_term=nn.MSELoss(),
+ ):
+ super(HGPIFuNet, self).__init__(
+ projection_mode=projection_mode,
+ error_term=error_term)
+
+ self.name = 'hgpifu'
+
+ self.opt = opt
+ self.num_views = self.opt.num_views
+
+ self.image_filter = HGFilter(opt)
+
+ self.surface_classifier = SurfaceClassifier(
+ filter_channels=self.opt.mlp_dim,
+ num_views=self.opt.num_views,
+ no_residual=self.opt.no_residual,
+ last_op=nn.Sigmoid())
+
+ self.normalizer = DepthNormalizer(opt)
+
+ # This is a list of [B x Feat_i x H x W] features
+ self.im_feat_list = []
+ self.tmpx = None
+ self.normx = None
+
+ self.intermediate_preds_list = []
+
+ init_net(self)
+
+ def filter(self, images):
+ '''
+ Filter the input images
+ store all intermediate features.
+ :param images: [B, C, H, W] input images
+ '''
+ self.im_feat_list, self.tmpx, self.normx = self.image_filter(images)
+ # If it is not in training, only produce the last im_feat
+ if not self.training:
+ self.im_feat_list = [self.im_feat_list[-1]]
+
+ def query(self, points, calibs, transforms=None, labels=None):
+ '''
+ Given 3D points, query the network predictions for each point.
+ Image features should be pre-computed before this call.
+ store all intermediate features.
+ query() function may behave differently during training/testing.
+ :param points: [B, 3, N] world space coordinates of points
+ :param calibs: [B, 3, 4] calibration matrices for each image
+ :param transforms: Optional [B, 2, 3] image space coordinate transforms
+ :param labels: Optional [B, Res, N] gt labeling
+ :return: [B, Res, N] predictions for each point
+ '''
+ if labels is not None:
+ self.labels = labels
+
+ xyz = self.projection(points, calibs, transforms)
+ xy = xyz[:, :2, :]
+ z = xyz[:, 2:3, :]
+
+ in_img = (xy[:, 0] >= -1.0) & (xy[:, 0] <= 1.0) & (xy[:, 1] >= -1.0) & (xy[:, 1] <= 1.0)
+
+ z_feat = self.normalizer(z, calibs=calibs)
+
+ if self.opt.skip_hourglass:
+ tmpx_local_feature = self.index(self.tmpx, xy)
+
+ self.intermediate_preds_list = []
+
+ for im_feat in self.im_feat_list:
+ # [B, Feat_i + z, N]
+ point_local_feat_list = [self.index(im_feat, xy), z_feat]
+
+ if self.opt.skip_hourglass:
+ point_local_feat_list.append(tmpx_local_feature)
+
+ point_local_feat = torch.cat(point_local_feat_list, 1)
+
+ # out of image plane is always set to 0
+ pred = in_img[:,None].float() * self.surface_classifier(point_local_feat)
+ self.intermediate_preds_list.append(pred)
+
+ self.preds = self.intermediate_preds_list[-1]
+
+ def get_im_feat(self):
+ '''
+ Get the image filter
+ :return: [B, C_feat, H, W] image feature after filtering
+ '''
+ return self.im_feat_list[-1]
+
+ def get_error(self):
+ '''
+ Hourglass has its own intermediate supervision scheme
+ '''
+ error = 0
+ for preds in self.intermediate_preds_list:
+ error += self.error_term(preds, self.labels)
+ error /= len(self.intermediate_preds_list)
+
+ return error
+
+ def forward(self, images, points, calibs, transforms=None, labels=None):
+ # Get image feature
+ self.filter(images)
+
+ # Phase 2: point query
+ self.query(points=points, calibs=calibs, transforms=transforms, labels=labels)
+
+ # get the prediction
+ res = self.get_preds()
+
+ # get the error
+ error = self.get_error()
+
+ return res, error
\ No newline at end of file
diff --git a/PIFu/lib/model/ResBlkPIFuNet.py b/PIFu/lib/model/ResBlkPIFuNet.py
new file mode 100755
index 0000000000000000000000000000000000000000..26848408569fd3903a338e023aefb832f942f0e3
--- /dev/null
+++ b/PIFu/lib/model/ResBlkPIFuNet.py
@@ -0,0 +1,201 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from .BasePIFuNet import BasePIFuNet
+import functools
+from .SurfaceClassifier import SurfaceClassifier
+from .DepthNormalizer import DepthNormalizer
+from ..net_util import *
+
+
+class ResBlkPIFuNet(BasePIFuNet):
+ def __init__(self, opt,
+ projection_mode='orthogonal'):
+ if opt.color_loss_type == 'l1':
+ error_term = nn.L1Loss()
+ elif opt.color_loss_type == 'mse':
+ error_term = nn.MSELoss()
+
+ super(ResBlkPIFuNet, self).__init__(
+ projection_mode=projection_mode,
+ error_term=error_term)
+
+ self.name = 'respifu'
+ self.opt = opt
+
+ norm_type = get_norm_layer(norm_type=opt.norm_color)
+ self.image_filter = ResnetFilter(opt, norm_layer=norm_type)
+
+ self.surface_classifier = SurfaceClassifier(
+ filter_channels=self.opt.mlp_dim_color,
+ num_views=self.opt.num_views,
+ no_residual=self.opt.no_residual,
+ last_op=nn.Tanh())
+
+ self.normalizer = DepthNormalizer(opt)
+
+ init_net(self)
+
+ def filter(self, images):
+ '''
+ Filter the input images
+ store all intermediate features.
+ :param images: [B, C, H, W] input images
+ '''
+ self.im_feat = self.image_filter(images)
+
+ def attach(self, im_feat):
+ self.im_feat = torch.cat([im_feat, self.im_feat], 1)
+
+ def query(self, points, calibs, transforms=None, labels=None):
+ '''
+ Given 3D points, query the network predictions for each point.
+ Image features should be pre-computed before this call.
+ store all intermediate features.
+ query() function may behave differently during training/testing.
+ :param points: [B, 3, N] world space coordinates of points
+ :param calibs: [B, 3, 4] calibration matrices for each image
+ :param transforms: Optional [B, 2, 3] image space coordinate transforms
+ :param labels: Optional [B, Res, N] gt labeling
+ :return: [B, Res, N] predictions for each point
+ '''
+ if labels is not None:
+ self.labels = labels
+
+ xyz = self.projection(points, calibs, transforms)
+ xy = xyz[:, :2, :]
+ z = xyz[:, 2:3, :]
+
+ z_feat = self.normalizer(z)
+
+ # This is a list of [B, Feat_i, N] features
+ point_local_feat_list = [self.index(self.im_feat, xy), z_feat]
+ # [B, Feat_all, N]
+ point_local_feat = torch.cat(point_local_feat_list, 1)
+
+ self.preds = self.surface_classifier(point_local_feat)
+
+ def forward(self, images, im_feat, points, calibs, transforms=None, labels=None):
+ self.filter(images)
+
+ self.attach(im_feat)
+
+ self.query(points, calibs, transforms, labels)
+
+ res = self.get_preds()
+ error = self.get_error()
+
+ return res, error
+
+class ResnetBlock(nn.Module):
+ """Define a Resnet block"""
+
+ def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias, last=False):
+ """Initialize the Resnet block
+ A resnet block is a conv block with skip connections
+ We construct a conv block with build_conv_block function,
+ and implement skip connections in function.
+ Original Resnet paper: https://arxiv.org/pdf/1512.03385.pdf
+ """
+ super(ResnetBlock, self).__init__()
+ self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias, last)
+
+ def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias, last=False):
+ """Construct a convolutional block.
+ Parameters:
+ dim (int) -- the number of channels in the conv layer.
+ padding_type (str) -- the name of padding layer: reflect | replicate | zero
+ norm_layer -- normalization layer
+ use_dropout (bool) -- if use dropout layers.
+ use_bias (bool) -- if the conv layer uses bias or not
+ Returns a conv block (with a conv layer, a normalization layer, and a non-linearity layer (ReLU))
+ """
+ conv_block = []
+ p = 0
+ if padding_type == 'reflect':
+ conv_block += [nn.ReflectionPad2d(1)]
+ elif padding_type == 'replicate':
+ conv_block += [nn.ReplicationPad2d(1)]
+ elif padding_type == 'zero':
+ p = 1
+ else:
+ raise NotImplementedError('padding [%s] is not implemented' % padding_type)
+
+ conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
+ if use_dropout:
+ conv_block += [nn.Dropout(0.5)]
+
+ p = 0
+ if padding_type == 'reflect':
+ conv_block += [nn.ReflectionPad2d(1)]
+ elif padding_type == 'replicate':
+ conv_block += [nn.ReplicationPad2d(1)]
+ elif padding_type == 'zero':
+ p = 1
+ else:
+ raise NotImplementedError('padding [%s] is not implemented' % padding_type)
+ if last:
+ conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias)]
+ else:
+ conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
+
+ return nn.Sequential(*conv_block)
+
+ def forward(self, x):
+ """Forward function (with skip connections)"""
+ out = x + self.conv_block(x) # add skip connections
+ return out
+
+
+class ResnetFilter(nn.Module):
+ """Resnet-based generator that consists of Resnet blocks between a few downsampling/upsampling operations.
+ We adapt Torch code and idea from Justin Johnson's neural style transfer project(https://github.com/jcjohnson/fast-neural-style)
+ """
+
+ def __init__(self, opt, input_nc=3, output_nc=256, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False,
+ n_blocks=6, padding_type='reflect'):
+ """Construct a Resnet-based generator
+ Parameters:
+ input_nc (int) -- the number of channels in input images
+ output_nc (int) -- the number of channels in output images
+ ngf (int) -- the number of filters in the last conv layer
+ norm_layer -- normalization layer
+ use_dropout (bool) -- if use dropout layers
+ n_blocks (int) -- the number of ResNet blocks
+ padding_type (str) -- the name of padding layer in conv layers: reflect | replicate | zero
+ """
+ assert (n_blocks >= 0)
+ super(ResnetFilter, self).__init__()
+ if type(norm_layer) == functools.partial:
+ use_bias = norm_layer.func == nn.InstanceNorm2d
+ else:
+ use_bias = norm_layer == nn.InstanceNorm2d
+
+ model = [nn.ReflectionPad2d(3),
+ nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias),
+ norm_layer(ngf),
+ nn.ReLU(True)]
+
+ n_downsampling = 2
+ for i in range(n_downsampling): # add downsampling layers
+ mult = 2 ** i
+ model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, bias=use_bias),
+ norm_layer(ngf * mult * 2),
+ nn.ReLU(True)]
+
+ mult = 2 ** n_downsampling
+ for i in range(n_blocks): # add ResNet blocks
+ if i == n_blocks - 1:
+ model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer,
+ use_dropout=use_dropout, use_bias=use_bias, last=True)]
+ else:
+ model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer,
+ use_dropout=use_dropout, use_bias=use_bias)]
+
+ if opt.use_tanh:
+ model += [nn.Tanh()]
+ self.model = nn.Sequential(*model)
+
+ def forward(self, input):
+ """Standard forward"""
+ return self.model(input)
diff --git a/PIFu/lib/model/SurfaceClassifier.py b/PIFu/lib/model/SurfaceClassifier.py
new file mode 100755
index 0000000000000000000000000000000000000000..af5afe4fdd4767f72549df258e5b67dea6ac671d
--- /dev/null
+++ b/PIFu/lib/model/SurfaceClassifier.py
@@ -0,0 +1,71 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class SurfaceClassifier(nn.Module):
+ def __init__(self, filter_channels, num_views=1, no_residual=True, last_op=None):
+ super(SurfaceClassifier, self).__init__()
+
+ self.filters = []
+ self.num_views = num_views
+ self.no_residual = no_residual
+ filter_channels = filter_channels
+ self.last_op = last_op
+
+ if self.no_residual:
+ for l in range(0, len(filter_channels) - 1):
+ self.filters.append(nn.Conv1d(
+ filter_channels[l],
+ filter_channels[l + 1],
+ 1))
+ self.add_module("conv%d" % l, self.filters[l])
+ else:
+ for l in range(0, len(filter_channels) - 1):
+ if 0 != l:
+ self.filters.append(
+ nn.Conv1d(
+ filter_channels[l] + filter_channels[0],
+ filter_channels[l + 1],
+ 1))
+ else:
+ self.filters.append(nn.Conv1d(
+ filter_channels[l],
+ filter_channels[l + 1],
+ 1))
+
+ self.add_module("conv%d" % l, self.filters[l])
+
+ def forward(self, feature):
+ '''
+
+ :param feature: list of [BxC_inxHxW] tensors of image features
+ :param xy: [Bx3xN] tensor of (x,y) coodinates in the image plane
+ :return: [BxC_outxN] tensor of features extracted at the coordinates
+ '''
+
+ y = feature
+ tmpy = feature
+ for i, f in enumerate(self.filters):
+ if self.no_residual:
+ y = self._modules['conv' + str(i)](y)
+ else:
+ y = self._modules['conv' + str(i)](
+ y if i == 0
+ else torch.cat([y, tmpy], 1)
+ )
+ if i != len(self.filters) - 1:
+ y = F.leaky_relu(y)
+
+ if self.num_views > 1 and i == len(self.filters) // 2:
+ y = y.view(
+ -1, self.num_views, y.shape[1], y.shape[2]
+ ).mean(dim=1)
+ tmpy = feature.view(
+ -1, self.num_views, feature.shape[1], feature.shape[2]
+ ).mean(dim=1)
+
+ if self.last_op:
+ y = self.last_op(y)
+
+ return y
diff --git a/PIFu/lib/model/VhullPIFuNet.py b/PIFu/lib/model/VhullPIFuNet.py
new file mode 100755
index 0000000000000000000000000000000000000000..3bd30dc40722f8aff8403990b04f4fdba34fdc29
--- /dev/null
+++ b/PIFu/lib/model/VhullPIFuNet.py
@@ -0,0 +1,70 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from .BasePIFuNet import BasePIFuNet
+
+
+class VhullPIFuNet(BasePIFuNet):
+ '''
+ Vhull Piximp network is a minimal network demonstrating how the template works
+ also, it helps debugging the training/test schemes
+ It does the following:
+ 1. Compute the masks of images and stores under self.im_feats
+ 2. Calculate calibration and indexing
+ 3. Return if the points fall into the intersection of all masks
+ '''
+
+ def __init__(self,
+ num_views,
+ projection_mode='orthogonal',
+ error_term=nn.MSELoss(),
+ ):
+ super(VhullPIFuNet, self).__init__(
+ projection_mode=projection_mode,
+ error_term=error_term)
+ self.name = 'vhull'
+
+ self.num_views = num_views
+
+ self.im_feat = None
+
+ def filter(self, images):
+ '''
+ Filter the input images
+ store all intermediate features.
+ :param images: [B, C, H, W] input images
+ '''
+ # If the image has alpha channel, use the alpha channel
+ if images.shape[1] > 3:
+ self.im_feat = images[:, 3:4, :, :]
+ # Else, tell if it's not white
+ else:
+ self.im_feat = images[:, 0:1, :, :]
+
+ def query(self, points, calibs, transforms=None, labels=None):
+ '''
+ Given 3D points, query the network predictions for each point.
+ Image features should be pre-computed before this call.
+ store all intermediate features.
+ query() function may behave differently during training/testing.
+ :param points: [B, 3, N] world space coordinates of points
+ :param calibs: [B, 3, 4] calibration matrices for each image
+ :param transforms: Optional [B, 2, 3] image space coordinate transforms
+ :param labels: Optional [B, Res, N] gt labeling
+ :return: [B, Res, N] predictions for each point
+ '''
+ if labels is not None:
+ self.labels = labels
+
+ xyz = self.projection(points, calibs, transforms)
+ xy = xyz[:, :2, :]
+
+ point_local_feat = self.index(self.im_feat, xy)
+ local_shape = point_local_feat.shape
+ point_feat = point_local_feat.view(
+ local_shape[0] // self.num_views,
+ local_shape[1] * self.num_views,
+ -1)
+ pred = torch.prod(point_feat, dim=1)
+
+ self.preds = pred.unsqueeze(1)
diff --git a/PIFu/lib/model/__init__.py b/PIFu/lib/model/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..6709327c4ef99c510a6dbe3ec9fec57a47bb9245
--- /dev/null
+++ b/PIFu/lib/model/__init__.py
@@ -0,0 +1,5 @@
+from .BasePIFuNet import BasePIFuNet
+from .VhullPIFuNet import VhullPIFuNet
+from .ConvPIFuNet import ConvPIFuNet
+from .HGPIFuNet import HGPIFuNet
+from .ResBlkPIFuNet import ResBlkPIFuNet
diff --git a/PIFu/lib/net_util.py b/PIFu/lib/net_util.py
new file mode 100755
index 0000000000000000000000000000000000000000..3345c10335a0216c5ca3b3c02300911600771b52
--- /dev/null
+++ b/PIFu/lib/net_util.py
@@ -0,0 +1,396 @@
+import torch
+from torch.nn import init
+import torch.nn as nn
+import torch.nn.functional as F
+import functools
+
+import numpy as np
+from .mesh_util import *
+from .sample_util import *
+from .geometry import index
+import cv2
+from PIL import Image
+from tqdm import tqdm
+
+
+def reshape_multiview_tensors(image_tensor, calib_tensor):
+ # Careful here! Because we put single view and multiview together,
+ # the returned tensor.shape is 5-dim: [B, num_views, C, W, H]
+ # So we need to convert it back to 4-dim [B*num_views, C, W, H]
+ # Don't worry classifier will handle multi-view cases
+ image_tensor = image_tensor.view(
+ image_tensor.shape[0] * image_tensor.shape[1],
+ image_tensor.shape[2],
+ image_tensor.shape[3],
+ image_tensor.shape[4]
+ )
+ calib_tensor = calib_tensor.view(
+ calib_tensor.shape[0] * calib_tensor.shape[1],
+ calib_tensor.shape[2],
+ calib_tensor.shape[3]
+ )
+
+ return image_tensor, calib_tensor
+
+
+def reshape_sample_tensor(sample_tensor, num_views):
+ if num_views == 1:
+ return sample_tensor
+ # Need to repeat sample_tensor along the batch dim num_views times
+ sample_tensor = sample_tensor.unsqueeze(dim=1)
+ sample_tensor = sample_tensor.repeat(1, num_views, 1, 1)
+ sample_tensor = sample_tensor.view(
+ sample_tensor.shape[0] * sample_tensor.shape[1],
+ sample_tensor.shape[2],
+ sample_tensor.shape[3]
+ )
+ return sample_tensor
+
+
+def gen_mesh(opt, net, cuda, data, save_path, use_octree=True):
+ image_tensor = data['img'].to(device=cuda)
+ calib_tensor = data['calib'].to(device=cuda)
+
+ net.filter(image_tensor)
+
+ b_min = data['b_min']
+ b_max = data['b_max']
+ try:
+ save_img_path = save_path[:-4] + '.png'
+ save_img_list = []
+ for v in range(image_tensor.shape[0]):
+ save_img = (np.transpose(image_tensor[v].detach().cpu().numpy(), (1, 2, 0)) * 0.5 + 0.5)[:, :, ::-1] * 255.0
+ save_img_list.append(save_img)
+ save_img = np.concatenate(save_img_list, axis=1)
+ Image.fromarray(np.uint8(save_img[:,:,::-1])).save(save_img_path)
+
+ verts, faces, _, _ = reconstruction(
+ net, cuda, calib_tensor, opt.resolution, b_min, b_max, use_octree=use_octree)
+ verts_tensor = torch.from_numpy(verts.T).unsqueeze(0).to(device=cuda).float()
+ xyz_tensor = net.projection(verts_tensor, calib_tensor[:1])
+ uv = xyz_tensor[:, :2, :]
+ color = index(image_tensor[:1], uv).detach().cpu().numpy()[0].T
+ color = color * 0.5 + 0.5
+ save_obj_mesh_with_color(save_path, verts, faces, color)
+ except Exception as e:
+ print(e)
+ print('Can not create marching cubes at this time.')
+
+def gen_mesh_color(opt, netG, netC, cuda, data, save_path, use_octree=True):
+ image_tensor = data['img'].to(device=cuda)
+ calib_tensor = data['calib'].to(device=cuda)
+
+ netG.filter(image_tensor)
+ netC.filter(image_tensor)
+ netC.attach(netG.get_im_feat())
+
+ b_min = data['b_min']
+ b_max = data['b_max']
+ try:
+ save_img_path = save_path[:-4] + '.png'
+ save_img_list = []
+ for v in range(image_tensor.shape[0]):
+ save_img = (np.transpose(image_tensor[v].detach().cpu().numpy(), (1, 2, 0)) * 0.5 + 0.5)[:, :, ::-1] * 255.0
+ save_img_list.append(save_img)
+ save_img = np.concatenate(save_img_list, axis=1)
+ Image.fromarray(np.uint8(save_img[:,:,::-1])).save(save_img_path)
+
+ verts, faces, _, _ = reconstruction(
+ netG, cuda, calib_tensor, opt.resolution, b_min, b_max, use_octree=use_octree)
+
+ # Now Getting colors
+ verts_tensor = torch.from_numpy(verts.T).unsqueeze(0).to(device=cuda).float()
+ verts_tensor = reshape_sample_tensor(verts_tensor, opt.num_views)
+
+ color = np.zeros(verts.shape)
+ interval = opt.num_sample_color
+ for i in range(len(color) // interval):
+ left = i * interval
+ right = i * interval + interval
+ if i == len(color) // interval - 1:
+ right = -1
+ netC.query(verts_tensor[:, :, left:right], calib_tensor)
+ rgb = netC.get_preds()[0].detach().cpu().numpy() * 0.5 + 0.5
+ color[left:right] = rgb.T
+
+ save_obj_mesh_with_color(save_path, verts, faces, color)
+ except Exception as e:
+ print(e)
+ print('Can not create marching cubes at this time.')
+
+def adjust_learning_rate(optimizer, epoch, lr, schedule, gamma):
+ """Sets the learning rate to the initial LR decayed by schedule"""
+ if epoch in schedule:
+ lr *= gamma
+ for param_group in optimizer.param_groups:
+ param_group['lr'] = lr
+ return lr
+
+
+def compute_acc(pred, gt, thresh=0.5):
+ '''
+ return:
+ IOU, precision, and recall
+ '''
+ with torch.no_grad():
+ vol_pred = pred > thresh
+ vol_gt = gt > thresh
+
+ union = vol_pred | vol_gt
+ inter = vol_pred & vol_gt
+
+ true_pos = inter.sum().float()
+
+ union = union.sum().float()
+ if union == 0:
+ union = 1
+ vol_pred = vol_pred.sum().float()
+ if vol_pred == 0:
+ vol_pred = 1
+ vol_gt = vol_gt.sum().float()
+ if vol_gt == 0:
+ vol_gt = 1
+ return true_pos / union, true_pos / vol_pred, true_pos / vol_gt
+
+
+def calc_error(opt, net, cuda, dataset, num_tests):
+ if num_tests > len(dataset):
+ num_tests = len(dataset)
+ with torch.no_grad():
+ erorr_arr, IOU_arr, prec_arr, recall_arr = [], [], [], []
+ for idx in tqdm(range(num_tests)):
+ data = dataset[idx * len(dataset) // num_tests]
+ # retrieve the data
+ image_tensor = data['img'].to(device=cuda)
+ calib_tensor = data['calib'].to(device=cuda)
+ sample_tensor = data['samples'].to(device=cuda).unsqueeze(0)
+ if opt.num_views > 1:
+ sample_tensor = reshape_sample_tensor(sample_tensor, opt.num_views)
+ label_tensor = data['labels'].to(device=cuda).unsqueeze(0)
+
+ res, error = net.forward(image_tensor, sample_tensor, calib_tensor, labels=label_tensor)
+
+ IOU, prec, recall = compute_acc(res, label_tensor)
+
+ # print(
+ # '{0}/{1} | Error: {2:06f} IOU: {3:06f} prec: {4:06f} recall: {5:06f}'
+ # .format(idx, num_tests, error.item(), IOU.item(), prec.item(), recall.item()))
+ erorr_arr.append(error.item())
+ IOU_arr.append(IOU.item())
+ prec_arr.append(prec.item())
+ recall_arr.append(recall.item())
+
+ return np.average(erorr_arr), np.average(IOU_arr), np.average(prec_arr), np.average(recall_arr)
+
+def calc_error_color(opt, netG, netC, cuda, dataset, num_tests):
+ if num_tests > len(dataset):
+ num_tests = len(dataset)
+ with torch.no_grad():
+ error_color_arr = []
+
+ for idx in tqdm(range(num_tests)):
+ data = dataset[idx * len(dataset) // num_tests]
+ # retrieve the data
+ image_tensor = data['img'].to(device=cuda)
+ calib_tensor = data['calib'].to(device=cuda)
+ color_sample_tensor = data['color_samples'].to(device=cuda).unsqueeze(0)
+
+ if opt.num_views > 1:
+ color_sample_tensor = reshape_sample_tensor(color_sample_tensor, opt.num_views)
+
+ rgb_tensor = data['rgbs'].to(device=cuda).unsqueeze(0)
+
+ netG.filter(image_tensor)
+ _, errorC = netC.forward(image_tensor, netG.get_im_feat(), color_sample_tensor, calib_tensor, labels=rgb_tensor)
+
+ # print('{0}/{1} | Error inout: {2:06f} | Error color: {3:06f}'
+ # .format(idx, num_tests, errorG.item(), errorC.item()))
+ error_color_arr.append(errorC.item())
+
+ return np.average(error_color_arr)
+
+
+def conv3x3(in_planes, out_planes, strd=1, padding=1, bias=False):
+ "3x3 convolution with padding"
+ return nn.Conv2d(in_planes, out_planes, kernel_size=3,
+ stride=strd, padding=padding, bias=bias)
+
+def init_weights(net, init_type='normal', init_gain=0.02):
+ """Initialize network weights.
+
+ Parameters:
+ net (network) -- network to be initialized
+ init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
+ init_gain (float) -- scaling factor for normal, xavier and orthogonal.
+
+ We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
+ work better for some applications. Feel free to try yourself.
+ """
+
+ def init_func(m): # define the initialization function
+ classname = m.__class__.__name__
+ if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
+ if init_type == 'normal':
+ init.normal_(m.weight.data, 0.0, init_gain)
+ elif init_type == 'xavier':
+ init.xavier_normal_(m.weight.data, gain=init_gain)
+ elif init_type == 'kaiming':
+ init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
+ elif init_type == 'orthogonal':
+ init.orthogonal_(m.weight.data, gain=init_gain)
+ else:
+ raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
+ if hasattr(m, 'bias') and m.bias is not None:
+ init.constant_(m.bias.data, 0.0)
+ elif classname.find(
+ 'BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
+ init.normal_(m.weight.data, 1.0, init_gain)
+ init.constant_(m.bias.data, 0.0)
+
+ print('initialize network with %s' % init_type)
+ net.apply(init_func) # apply the initialization function
+
+
+def init_net(net, init_type='normal', init_gain=0.02, gpu_ids=[]):
+ """Initialize a network: 1. register CPU/GPU device (with multi-GPU support); 2. initialize the network weights
+ Parameters:
+ net (network) -- the network to be initialized
+ init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
+ gain (float) -- scaling factor for normal, xavier and orthogonal.
+ gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
+
+ Return an initialized network.
+ """
+ if len(gpu_ids) > 0:
+ assert (torch.cuda.is_available())
+ net.to(gpu_ids[0])
+ net = torch.nn.DataParallel(net, gpu_ids) # multi-GPUs
+ init_weights(net, init_type, init_gain=init_gain)
+ return net
+
+
+def imageSpaceRotation(xy, rot):
+ '''
+ args:
+ xy: (B, 2, N) input
+ rot: (B, 2) x,y axis rotation angles
+
+ rotation center will be always image center (other rotation center can be represented by additional z translation)
+ '''
+ disp = rot.unsqueeze(2).sin().expand_as(xy)
+ return (disp * xy).sum(dim=1)
+
+
+def cal_gradient_penalty(netD, real_data, fake_data, device, type='mixed', constant=1.0, lambda_gp=10.0):
+ """Calculate the gradient penalty loss, used in WGAN-GP paper https://arxiv.org/abs/1704.00028
+
+ Arguments:
+ netD (network) -- discriminator network
+ real_data (tensor array) -- real images
+ fake_data (tensor array) -- generated images from the generator
+ device (str) -- GPU / CPU: from torch.device('cuda:{}'.format(self.gpu_ids[0])) if self.gpu_ids else torch.device('cpu')
+ type (str) -- if we mix real and fake data or not [real | fake | mixed].
+ constant (float) -- the constant used in formula ( | |gradient||_2 - constant)^2
+ lambda_gp (float) -- weight for this loss
+
+ Returns the gradient penalty loss
+ """
+ if lambda_gp > 0.0:
+ if type == 'real': # either use real images, fake images, or a linear interpolation of two.
+ interpolatesv = real_data
+ elif type == 'fake':
+ interpolatesv = fake_data
+ elif type == 'mixed':
+ alpha = torch.rand(real_data.shape[0], 1)
+ alpha = alpha.expand(real_data.shape[0], real_data.nelement() // real_data.shape[0]).contiguous().view(
+ *real_data.shape)
+ alpha = alpha.to(device)
+ interpolatesv = alpha * real_data + ((1 - alpha) * fake_data)
+ else:
+ raise NotImplementedError('{} not implemented'.format(type))
+ interpolatesv.requires_grad_(True)
+ disc_interpolates = netD(interpolatesv)
+ gradients = torch.autograd.grad(outputs=disc_interpolates, inputs=interpolatesv,
+ grad_outputs=torch.ones(disc_interpolates.size()).to(device),
+ create_graph=True, retain_graph=True, only_inputs=True)
+ gradients = gradients[0].view(real_data.size(0), -1) # flat the data
+ gradient_penalty = (((gradients + 1e-16).norm(2, dim=1) - constant) ** 2).mean() * lambda_gp # added eps
+ return gradient_penalty, gradients
+ else:
+ return 0.0, None
+
+def get_norm_layer(norm_type='instance'):
+ """Return a normalization layer
+ Parameters:
+ norm_type (str) -- the name of the normalization layer: batch | instance | none
+ For BatchNorm, we use learnable affine parameters and track running statistics (mean/stddev).
+ For InstanceNorm, we do not use learnable affine parameters. We do not track running statistics.
+ """
+ if norm_type == 'batch':
+ norm_layer = functools.partial(nn.BatchNorm2d, affine=True, track_running_stats=True)
+ elif norm_type == 'instance':
+ norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
+ elif norm_type == 'group':
+ norm_layer = functools.partial(nn.GroupNorm, 32)
+ elif norm_type == 'none':
+ norm_layer = None
+ else:
+ raise NotImplementedError('normalization layer [%s] is not found' % norm_type)
+ return norm_layer
+
+class Flatten(nn.Module):
+ def forward(self, input):
+ return input.view(input.size(0), -1)
+
+class ConvBlock(nn.Module):
+ def __init__(self, in_planes, out_planes, norm='batch'):
+ super(ConvBlock, self).__init__()
+ self.conv1 = conv3x3(in_planes, int(out_planes / 2))
+ self.conv2 = conv3x3(int(out_planes / 2), int(out_planes / 4))
+ self.conv3 = conv3x3(int(out_planes / 4), int(out_planes / 4))
+
+ if norm == 'batch':
+ self.bn1 = nn.BatchNorm2d(in_planes)
+ self.bn2 = nn.BatchNorm2d(int(out_planes / 2))
+ self.bn3 = nn.BatchNorm2d(int(out_planes / 4))
+ self.bn4 = nn.BatchNorm2d(in_planes)
+ elif norm == 'group':
+ self.bn1 = nn.GroupNorm(32, in_planes)
+ self.bn2 = nn.GroupNorm(32, int(out_planes / 2))
+ self.bn3 = nn.GroupNorm(32, int(out_planes / 4))
+ self.bn4 = nn.GroupNorm(32, in_planes)
+
+ if in_planes != out_planes:
+ self.downsample = nn.Sequential(
+ self.bn4,
+ nn.ReLU(True),
+ nn.Conv2d(in_planes, out_planes,
+ kernel_size=1, stride=1, bias=False),
+ )
+ else:
+ self.downsample = None
+
+ def forward(self, x):
+ residual = x
+
+ out1 = self.bn1(x)
+ out1 = F.relu(out1, True)
+ out1 = self.conv1(out1)
+
+ out2 = self.bn2(out1)
+ out2 = F.relu(out2, True)
+ out2 = self.conv2(out2)
+
+ out3 = self.bn3(out2)
+ out3 = F.relu(out3, True)
+ out3 = self.conv3(out3)
+
+ out3 = torch.cat((out1, out2, out3), 1)
+
+ if self.downsample is not None:
+ residual = self.downsample(residual)
+
+ out3 += residual
+
+ return out3
+
\ No newline at end of file
diff --git a/PIFu/lib/options.py b/PIFu/lib/options.py
new file mode 100755
index 0000000000000000000000000000000000000000..3c76097b6a0b2a312c161bd634a4a137b5929bf3
--- /dev/null
+++ b/PIFu/lib/options.py
@@ -0,0 +1,161 @@
+import argparse
+import os
+
+
+class BaseOptions():
+ def __init__(self):
+ self.initialized = False
+ argparse
+ def initialize(self, parser):
+ # Datasets related
+ g_data = parser.add_argument_group('Data')
+ g_data.add_argument('--dataroot', type=str, default='./data',
+ help='path to images (data folder)')
+
+ g_data.add_argument('--loadSize', type=int, default=512, help='load size of input image')
+
+ # Experiment related
+ g_exp = parser.add_argument_group('Experiment')
+ g_exp.add_argument('--name', type=str, default='example',
+ help='name of the experiment. It decides where to store samples and models')
+ g_exp.add_argument('--debug', action='store_true', help='debug mode or not')
+
+ g_exp.add_argument('--num_views', type=int, default=1, help='How many views to use for multiview network.')
+ g_exp.add_argument('--random_multiview', action='store_true', help='Select random multiview combination.')
+
+ # Training related
+ g_train = parser.add_argument_group('Training')
+ g_train.add_argument('--gpu_id', type=int, default=0, help='gpu id for cuda')
+ g_train.add_argument('--gpu_ids', type=str, default='0', help='gpu ids: e.g. 0 0,1,2, 0,2, -1 for CPU mode')
+
+ g_train.add_argument('--num_threads', default=1, type=int, help='# sthreads for loading data')
+ g_train.add_argument('--serial_batches', action='store_true',
+ help='if true, takes images in order to make batches, otherwise takes them randomly')
+ g_train.add_argument('--pin_memory', action='store_true', help='pin_memory')
+
+ g_train.add_argument('--batch_size', type=int, default=2, help='input batch size')
+ g_train.add_argument('--learning_rate', type=float, default=1e-3, help='adam learning rate')
+ g_train.add_argument('--learning_rateC', type=float, default=1e-3, help='adam learning rate')
+ g_train.add_argument('--num_epoch', type=int, default=100, help='num epoch to train')
+
+ g_train.add_argument('--freq_plot', type=int, default=10, help='freqency of the error plot')
+ g_train.add_argument('--freq_save', type=int, default=50, help='freqency of the save_checkpoints')
+ g_train.add_argument('--freq_save_ply', type=int, default=100, help='freqency of the save ply')
+
+ g_train.add_argument('--no_gen_mesh', action='store_true')
+ g_train.add_argument('--no_num_eval', action='store_true')
+
+ g_train.add_argument('--resume_epoch', type=int, default=-1, help='epoch resuming the training')
+ g_train.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
+
+ # Testing related
+ g_test = parser.add_argument_group('Testing')
+ g_test.add_argument('--resolution', type=int, default=256, help='# of grid in mesh reconstruction')
+ g_test.add_argument('--test_folder_path', type=str, default=None, help='the folder of test image')
+
+ # Sampling related
+ g_sample = parser.add_argument_group('Sampling')
+ g_sample.add_argument('--sigma', type=float, default=5.0, help='perturbation standard deviation for positions')
+
+ g_sample.add_argument('--num_sample_inout', type=int, default=5000, help='# of sampling points')
+ g_sample.add_argument('--num_sample_color', type=int, default=0, help='# of sampling points')
+
+ g_sample.add_argument('--z_size', type=float, default=200.0, help='z normalization factor')
+
+ # Model related
+ g_model = parser.add_argument_group('Model')
+ # General
+ g_model.add_argument('--norm', type=str, default='group',
+ help='instance normalization or batch normalization or group normalization')
+ g_model.add_argument('--norm_color', type=str, default='instance',
+ help='instance normalization or batch normalization or group normalization')
+
+ # hg filter specify
+ g_model.add_argument('--num_stack', type=int, default=4, help='# of hourglass')
+ g_model.add_argument('--num_hourglass', type=int, default=2, help='# of stacked layer of hourglass')
+ g_model.add_argument('--skip_hourglass', action='store_true', help='skip connection in hourglass')
+ g_model.add_argument('--hg_down', type=str, default='ave_pool', help='ave pool || conv64 || conv128')
+ g_model.add_argument('--hourglass_dim', type=int, default='256', help='256 | 512')
+
+ # Classification General
+ g_model.add_argument('--mlp_dim', nargs='+', default=[257, 1024, 512, 256, 128, 1], type=int,
+ help='# of dimensions of mlp')
+ g_model.add_argument('--mlp_dim_color', nargs='+', default=[513, 1024, 512, 256, 128, 3],
+ type=int, help='# of dimensions of color mlp')
+
+ g_model.add_argument('--use_tanh', action='store_true',
+ help='using tanh after last conv of image_filter network')
+
+ # for train
+ parser.add_argument('--random_flip', action='store_true', help='if random flip')
+ parser.add_argument('--random_trans', action='store_true', help='if random flip')
+ parser.add_argument('--random_scale', action='store_true', help='if random flip')
+ parser.add_argument('--no_residual', action='store_true', help='no skip connection in mlp')
+ parser.add_argument('--schedule', type=int, nargs='+', default=[60, 80],
+ help='Decrease learning rate at these epochs.')
+ parser.add_argument('--gamma', type=float, default=0.1, help='LR is multiplied by gamma on schedule.')
+ parser.add_argument('--color_loss_type', type=str, default='l1', help='mse | l1')
+
+ # for eval
+ parser.add_argument('--val_test_error', action='store_true', help='validate errors of test data')
+ parser.add_argument('--val_train_error', action='store_true', help='validate errors of train data')
+ parser.add_argument('--gen_test_mesh', action='store_true', help='generate test mesh')
+ parser.add_argument('--gen_train_mesh', action='store_true', help='generate train mesh')
+ parser.add_argument('--all_mesh', action='store_true', help='generate meshs from all hourglass output')
+ parser.add_argument('--num_gen_mesh_test', type=int, default=1,
+ help='how many meshes to generate during testing')
+
+ # path
+ parser.add_argument('--checkpoints_path', type=str, default='./checkpoints', help='path to save checkpoints')
+ parser.add_argument('--load_netG_checkpoint_path', type=str, default=None, help='path to save checkpoints')
+ parser.add_argument('--load_netC_checkpoint_path', type=str, default=None, help='path to save checkpoints')
+ parser.add_argument('--results_path', type=str, default='./results', help='path to save results ply')
+ parser.add_argument('--load_checkpoint_path', type=str, help='path to save results ply')
+ parser.add_argument('--single', type=str, default='', help='single data for training')
+ # for single image reconstruction
+ parser.add_argument('--mask_path', type=str, help='path for input mask')
+ parser.add_argument('--img_path', type=str, help='path for input image')
+
+ # aug
+ group_aug = parser.add_argument_group('aug')
+ group_aug.add_argument('--aug_alstd', type=float, default=0.0, help='augmentation pca lighting alpha std')
+ group_aug.add_argument('--aug_bri', type=float, default=0.0, help='augmentation brightness')
+ group_aug.add_argument('--aug_con', type=float, default=0.0, help='augmentation contrast')
+ group_aug.add_argument('--aug_sat', type=float, default=0.0, help='augmentation saturation')
+ group_aug.add_argument('--aug_hue', type=float, default=0.0, help='augmentation hue')
+ group_aug.add_argument('--aug_blur', type=float, default=0.0, help='augmentation blur')
+
+ # special tasks
+ self.initialized = True
+ return parser
+
+ def gather_options(self):
+ # initialize parser with basic options
+ if not self.initialized:
+ parser = argparse.ArgumentParser(
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter)
+ parser = self.initialize(parser)
+
+ self.parser = parser
+
+ return parser.parse_args()
+
+ def print_options(self, opt):
+ message = ''
+ message += '----------------- Options ---------------\n'
+ for k, v in sorted(vars(opt).items()):
+ comment = ''
+ default = self.parser.get_default(k)
+ if v != default:
+ comment = '\t[default: %s]' % str(default)
+ message += '{:>25}: {:<30}{}\n'.format(str(k), str(v), comment)
+ message += '----------------- End -------------------'
+ print(message)
+
+ def parse(self):
+ opt = self.gather_options()
+ return opt
+
+ def parse_to_dict(self):
+ opt = self.gather_options()
+ return opt.__dict__
\ No newline at end of file
diff --git a/PIFu/lib/renderer/__init__.py b/PIFu/lib/renderer/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/PIFu/lib/renderer/camera.py b/PIFu/lib/renderer/camera.py
new file mode 100755
index 0000000000000000000000000000000000000000..c15deb629801cc7f692631fae7e1312c7cc3dbd9
--- /dev/null
+++ b/PIFu/lib/renderer/camera.py
@@ -0,0 +1,207 @@
+import cv2
+import numpy as np
+
+from .glm import ortho
+
+
+class Camera:
+ def __init__(self, width=1600, height=1200):
+ # Focal Length
+ # equivalent 50mm
+ focal = np.sqrt(width * width + height * height)
+ self.focal_x = focal
+ self.focal_y = focal
+ # Principal Point Offset
+ self.principal_x = width / 2
+ self.principal_y = height / 2
+ # Axis Skew
+ self.skew = 0
+ # Image Size
+ self.width = width
+ self.height = height
+
+ self.near = 1
+ self.far = 10
+
+ # Camera Center
+ self.center = np.array([0, 0, 1.6])
+ self.direction = np.array([0, 0, -1])
+ self.right = np.array([1, 0, 0])
+ self.up = np.array([0, 1, 0])
+
+ self.ortho_ratio = None
+
+ def sanity_check(self):
+ self.center = self.center.reshape([-1])
+ self.direction = self.direction.reshape([-1])
+ self.right = self.right.reshape([-1])
+ self.up = self.up.reshape([-1])
+
+ assert len(self.center) == 3
+ assert len(self.direction) == 3
+ assert len(self.right) == 3
+ assert len(self.up) == 3
+
+ @staticmethod
+ def normalize_vector(v):
+ v_norm = np.linalg.norm(v)
+ return v if v_norm == 0 else v / v_norm
+
+ def get_real_z_value(self, z):
+ z_near = self.near
+ z_far = self.far
+ z_n = 2.0 * z - 1.0
+ z_e = 2.0 * z_near * z_far / (z_far + z_near - z_n * (z_far - z_near))
+ return z_e
+
+ def get_rotation_matrix(self):
+ rot_mat = np.eye(3)
+ s = self.right
+ s = self.normalize_vector(s)
+ rot_mat[0, :] = s
+ u = self.up
+ u = self.normalize_vector(u)
+ rot_mat[1, :] = -u
+ rot_mat[2, :] = self.normalize_vector(self.direction)
+
+ return rot_mat
+
+ def get_translation_vector(self):
+ rot_mat = self.get_rotation_matrix()
+ trans = -np.dot(rot_mat, self.center)
+ return trans
+
+ def get_intrinsic_matrix(self):
+ int_mat = np.eye(3)
+
+ int_mat[0, 0] = self.focal_x
+ int_mat[1, 1] = self.focal_y
+ int_mat[0, 1] = self.skew
+ int_mat[0, 2] = self.principal_x
+ int_mat[1, 2] = self.principal_y
+
+ return int_mat
+
+ def get_projection_matrix(self):
+ ext_mat = self.get_extrinsic_matrix()
+ int_mat = self.get_intrinsic_matrix()
+
+ return np.matmul(int_mat, ext_mat)
+
+ def get_extrinsic_matrix(self):
+ rot_mat = self.get_rotation_matrix()
+ int_mat = self.get_intrinsic_matrix()
+ trans = self.get_translation_vector()
+
+ extrinsic = np.eye(4)
+ extrinsic[:3, :3] = rot_mat
+ extrinsic[:3, 3] = trans
+
+ return extrinsic[:3, :]
+
+ def set_rotation_matrix(self, rot_mat):
+ self.direction = rot_mat[2, :]
+ self.up = -rot_mat[1, :]
+ self.right = rot_mat[0, :]
+
+ def set_intrinsic_matrix(self, int_mat):
+ self.focal_x = int_mat[0, 0]
+ self.focal_y = int_mat[1, 1]
+ self.skew = int_mat[0, 1]
+ self.principal_x = int_mat[0, 2]
+ self.principal_y = int_mat[1, 2]
+
+ def set_projection_matrix(self, proj_mat):
+ res = cv2.decomposeProjectionMatrix(proj_mat)
+ int_mat, rot_mat, camera_center_homo = res[0], res[1], res[2]
+ camera_center = camera_center_homo[0:3] / camera_center_homo[3]
+ camera_center = camera_center.reshape(-1)
+ int_mat = int_mat / int_mat[2][2]
+
+ self.set_intrinsic_matrix(int_mat)
+ self.set_rotation_matrix(rot_mat)
+ self.center = camera_center
+
+ self.sanity_check()
+
+ def get_gl_matrix(self):
+ z_near = self.near
+ z_far = self.far
+ rot_mat = self.get_rotation_matrix()
+ int_mat = self.get_intrinsic_matrix()
+ trans = self.get_translation_vector()
+
+ extrinsic = np.eye(4)
+ extrinsic[:3, :3] = rot_mat
+ extrinsic[:3, 3] = trans
+ axis_adj = np.eye(4)
+ axis_adj[2, 2] = -1
+ axis_adj[1, 1] = -1
+ model_view = np.matmul(axis_adj, extrinsic)
+
+ projective = np.zeros([4, 4])
+ projective[:2, :2] = int_mat[:2, :2]
+ projective[:2, 2:3] = -int_mat[:2, 2:3]
+ projective[3, 2] = -1
+ projective[2, 2] = (z_near + z_far)
+ projective[2, 3] = (z_near * z_far)
+
+ if self.ortho_ratio is None:
+ ndc = ortho(0, self.width, 0, self.height, z_near, z_far)
+ perspective = np.matmul(ndc, projective)
+ else:
+ perspective = ortho(-self.width * self.ortho_ratio / 2, self.width * self.ortho_ratio / 2,
+ -self.height * self.ortho_ratio / 2, self.height * self.ortho_ratio / 2,
+ z_near, z_far)
+
+ return perspective, model_view
+
+
+def KRT_from_P(proj_mat, normalize_K=True):
+ res = cv2.decomposeProjectionMatrix(proj_mat)
+ K, Rot, camera_center_homog = res[0], res[1], res[2]
+ camera_center = camera_center_homog[0:3] / camera_center_homog[3]
+ trans = -Rot.dot(camera_center)
+ if normalize_K:
+ K = K / K[2][2]
+ return K, Rot, trans
+
+
+def MVP_from_P(proj_mat, width, height, near=0.1, far=10000):
+ '''
+ Convert OpenCV camera calibration matrix to OpenGL projection and model view matrix
+ :param proj_mat: OpenCV camera projeciton matrix
+ :param width: Image width
+ :param height: Image height
+ :param near: Z near value
+ :param far: Z far value
+ :return: OpenGL projection matrix and model view matrix
+ '''
+ res = cv2.decomposeProjectionMatrix(proj_mat)
+ K, Rot, camera_center_homog = res[0], res[1], res[2]
+ camera_center = camera_center_homog[0:3] / camera_center_homog[3]
+ trans = -Rot.dot(camera_center)
+ K = K / K[2][2]
+
+ extrinsic = np.eye(4)
+ extrinsic[:3, :3] = Rot
+ extrinsic[:3, 3:4] = trans
+ axis_adj = np.eye(4)
+ axis_adj[2, 2] = -1
+ axis_adj[1, 1] = -1
+ model_view = np.matmul(axis_adj, extrinsic)
+
+ zFar = far
+ zNear = near
+ projective = np.zeros([4, 4])
+ projective[:2, :2] = K[:2, :2]
+ projective[:2, 2:3] = -K[:2, 2:3]
+ projective[3, 2] = -1
+ projective[2, 2] = (zNear + zFar)
+ projective[2, 3] = (zNear * zFar)
+
+ ndc = ortho(0, width, 0, height, zNear, zFar)
+
+ perspective = np.matmul(ndc, projective)
+
+ return perspective, model_view
diff --git a/PIFu/lib/renderer/gl/__init__.py b/PIFu/lib/renderer/gl/__init__.py
new file mode 100755
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/PIFu/lib/renderer/gl/cam_render.py b/PIFu/lib/renderer/gl/cam_render.py
new file mode 100755
index 0000000000000000000000000000000000000000..7b766af057b9c052388aceb152b0191fa2e4ea25
--- /dev/null
+++ b/PIFu/lib/renderer/gl/cam_render.py
@@ -0,0 +1,48 @@
+from .render import Render
+
+GLUT = None
+
+class CamRender(Render):
+ def __init__(self, width=1600, height=1200, name='Cam Renderer',
+ program_files=['simple.fs', 'simple.vs'], color_size=1, ms_rate=1, egl=False):
+ Render.__init__(self, width, height, name, program_files, color_size, ms_rate=ms_rate, egl=egl)
+ self.camera = None
+
+ if not egl:
+ global GLUT
+ import OpenGL.GLUT as GLUT
+ GLUT.glutDisplayFunc(self.display)
+ GLUT.glutKeyboardFunc(self.keyboard)
+
+ def set_camera(self, camera):
+ self.camera = camera
+ self.projection_matrix, self.model_view_matrix = camera.get_gl_matrix()
+
+ def keyboard(self, key, x, y):
+ # up
+ eps = 1
+ # print(key)
+ if key == b'w':
+ self.camera.center += eps * self.camera.direction
+ elif key == b's':
+ self.camera.center -= eps * self.camera.direction
+ if key == b'a':
+ self.camera.center -= eps * self.camera.right
+ elif key == b'd':
+ self.camera.center += eps * self.camera.right
+ if key == b' ':
+ self.camera.center += eps * self.camera.up
+ elif key == b'x':
+ self.camera.center -= eps * self.camera.up
+ elif key == b'i':
+ self.camera.near += 0.1 * eps
+ self.camera.far += 0.1 * eps
+ elif key == b'o':
+ self.camera.near -= 0.1 * eps
+ self.camera.far -= 0.1 * eps
+
+ self.projection_matrix, self.model_view_matrix = self.camera.get_gl_matrix()
+
+ def show(self):
+ if GLUT is not None:
+ GLUT.glutMainLoop()
diff --git a/PIFu/lib/renderer/gl/data/prt.fs b/PIFu/lib/renderer/gl/data/prt.fs
new file mode 100755
index 0000000000000000000000000000000000000000..b1cc3807df0710eeb7c4e5bbe22b359196d2825e
--- /dev/null
+++ b/PIFu/lib/renderer/gl/data/prt.fs
@@ -0,0 +1,153 @@
+#version 330
+
+uniform vec3 SHCoeffs[9];
+uniform uint analytic;
+
+uniform uint hasNormalMap;
+uniform uint hasAlbedoMap;
+
+uniform sampler2D AlbedoMap;
+uniform sampler2D NormalMap;
+
+in VertexData {
+ vec3 Position;
+ vec3 Depth;
+ vec3 ModelNormal;
+ vec2 Texcoord;
+ vec3 Tangent;
+ vec3 Bitangent;
+ vec3 PRT1;
+ vec3 PRT2;
+ vec3 PRT3;
+} VertexIn;
+
+layout (location = 0) out vec4 FragColor;
+layout (location = 1) out vec4 FragNormal;
+layout (location = 2) out vec4 FragPosition;
+layout (location = 3) out vec4 FragAlbedo;
+layout (location = 4) out vec4 FragShading;
+layout (location = 5) out vec4 FragPRT1;
+layout (location = 6) out vec4 FragPRT2;
+layout (location = 7) out vec4 FragPRT3;
+
+vec4 gammaCorrection(vec4 vec, float g)
+{
+ return vec4(pow(vec.x, 1.0/g), pow(vec.y, 1.0/g), pow(vec.z, 1.0/g), vec.w);
+}
+
+vec3 gammaCorrection(vec3 vec, float g)
+{
+ return vec3(pow(vec.x, 1.0/g), pow(vec.y, 1.0/g), pow(vec.z, 1.0/g));
+}
+
+void evaluateH(vec3 n, out float H[9])
+{
+ float c1 = 0.429043, c2 = 0.511664,
+ c3 = 0.743125, c4 = 0.886227, c5 = 0.247708;
+
+ H[0] = c4;
+ H[1] = 2.0 * c2 * n[1];
+ H[2] = 2.0 * c2 * n[2];
+ H[3] = 2.0 * c2 * n[0];
+ H[4] = 2.0 * c1 * n[0] * n[1];
+ H[5] = 2.0 * c1 * n[1] * n[2];
+ H[6] = c3 * n[2] * n[2] - c5;
+ H[7] = 2.0 * c1 * n[2] * n[0];
+ H[8] = c1 * (n[0] * n[0] - n[1] * n[1]);
+}
+
+vec3 evaluateLightingModel(vec3 normal)
+{
+ float H[9];
+ evaluateH(normal, H);
+ vec3 res = vec3(0.0);
+ for (int i = 0; i < 9; i++) {
+ res += H[i] * SHCoeffs[i];
+ }
+ return res;
+}
+
+// nC: coarse geometry normal, nH: fine normal from normal map
+vec3 evaluateLightingModelHybrid(vec3 nC, vec3 nH, mat3 prt)
+{
+ float HC[9], HH[9];
+ evaluateH(nC, HC);
+ evaluateH(nH, HH);
+
+ vec3 res = vec3(0.0);
+ vec3 shadow = vec3(0.0);
+ vec3 unshadow = vec3(0.0);
+ for(int i = 0; i < 3; ++i){
+ for(int j = 0; j < 3; ++j){
+ int id = i*3+j;
+ res += HH[id]* SHCoeffs[id];
+ shadow += prt[i][j] * SHCoeffs[id];
+ unshadow += HC[id] * SHCoeffs[id];
+ }
+ }
+ vec3 ratio = clamp(shadow/unshadow,0.0,1.0);
+ res = ratio * res;
+
+ return res;
+}
+
+vec3 evaluateLightingModelPRT(mat3 prt)
+{
+ vec3 res = vec3(0.0);
+ for(int i = 0; i < 3; ++i){
+ for(int j = 0; j < 3; ++j){
+ res += prt[i][j] * SHCoeffs[i*3+j];
+ }
+ }
+
+ return res;
+}
+
+void main()
+{
+ vec2 uv = VertexIn.Texcoord;
+ vec3 nC = normalize(VertexIn.ModelNormal);
+ vec3 nml = nC;
+ mat3 prt = mat3(VertexIn.PRT1, VertexIn.PRT2, VertexIn.PRT3);
+
+ if(hasAlbedoMap == uint(0))
+ FragAlbedo = vec4(1.0);
+ else
+ FragAlbedo = texture(AlbedoMap, uv);//gammaCorrection(texture(AlbedoMap, uv), 1.0/2.2);
+
+ if(hasNormalMap == uint(0))
+ {
+ if(analytic == uint(0))
+ FragShading = vec4(evaluateLightingModelPRT(prt), 1.0f);
+ else
+ FragShading = vec4(evaluateLightingModel(nC), 1.0f);
+ }
+ else
+ {
+ vec3 n_tan = normalize(texture(NormalMap, uv).rgb*2.0-vec3(1.0));
+
+ mat3 TBN = mat3(normalize(VertexIn.Tangent),normalize(VertexIn.Bitangent),nC);
+ vec3 nH = normalize(TBN * n_tan);
+
+ if(analytic == uint(0))
+ FragShading = vec4(evaluateLightingModelHybrid(nC,nH,prt),1.0f);
+ else
+ FragShading = vec4(evaluateLightingModel(nH), 1.0f);
+
+ nml = nH;
+ }
+
+ FragShading = gammaCorrection(FragShading, 2.2);
+ FragColor = clamp(FragAlbedo * FragShading, 0.0, 1.0);
+ FragNormal = vec4(0.5*(nml+vec3(1.0)), 1.0);
+ FragPosition = vec4(VertexIn.Position,VertexIn.Depth.x);
+ FragShading = vec4(clamp(0.5*FragShading.xyz, 0.0, 1.0),1.0);
+ // FragColor = gammaCorrection(clamp(FragAlbedo * FragShading, 0.0, 1.0),2.2);
+ // FragNormal = vec4(0.5*(nml+vec3(1.0)), 1.0);
+ // FragPosition = vec4(VertexIn.Position,VertexIn.Depth.x);
+ // FragShading = vec4(gammaCorrection(clamp(0.5*FragShading.xyz, 0.0, 1.0),2.2),1.0);
+ // FragAlbedo = gammaCorrection(FragAlbedo,2.2);
+ FragPRT1 = vec4(VertexIn.PRT1,1.0);
+ FragPRT2 = vec4(VertexIn.PRT2,1.0);
+ FragPRT3 = vec4(VertexIn.PRT3,1.0);
+}
\ No newline at end of file
diff --git a/PIFu/lib/renderer/gl/data/prt.vs b/PIFu/lib/renderer/gl/data/prt.vs
new file mode 100755
index 0000000000000000000000000000000000000000..71e7b96986e9a7fca3c059c97904d1960bc156dc
--- /dev/null
+++ b/PIFu/lib/renderer/gl/data/prt.vs
@@ -0,0 +1,167 @@
+#version 330
+
+layout (location = 0) in vec3 a_Position;
+layout (location = 1) in vec3 a_Normal;
+layout (location = 2) in vec2 a_TextureCoord;
+layout (location = 3) in vec3 a_Tangent;
+layout (location = 4) in vec3 a_Bitangent;
+layout (location = 5) in vec3 a_PRT1;
+layout (location = 6) in vec3 a_PRT2;
+layout (location = 7) in vec3 a_PRT3;
+
+out VertexData {
+ vec3 Position;
+ vec3 Depth;
+ vec3 ModelNormal;
+ vec2 Texcoord;
+ vec3 Tangent;
+ vec3 Bitangent;
+ vec3 PRT1;
+ vec3 PRT2;
+ vec3 PRT3;
+} VertexOut;
+
+uniform mat3 RotMat;
+uniform mat4 NormMat;
+uniform mat4 ModelMat;
+uniform mat4 PerspMat;
+
+float s_c3 = 0.94617469575; // (3*sqrt(5))/(4*sqrt(pi))
+float s_c4 = -0.31539156525;// (-sqrt(5))/(4*sqrt(pi))
+float s_c5 = 0.54627421529; // (sqrt(15))/(4*sqrt(pi))
+
+float s_c_scale = 1.0/0.91529123286551084;
+float s_c_scale_inv = 0.91529123286551084;
+
+float s_rc2 = 1.5853309190550713*s_c_scale;
+float s_c4_div_c3 = s_c4/s_c3;
+float s_c4_div_c3_x2 = (s_c4/s_c3)*2.0;
+
+float s_scale_dst2 = s_c3 * s_c_scale_inv;
+float s_scale_dst4 = s_c5 * s_c_scale_inv;
+
+void OptRotateBand0(float x[1], mat3 R, out float dst[1])
+{
+ dst[0] = x[0];
+}
+
+// 9 multiplies
+void OptRotateBand1(float x[3], mat3 R, out float dst[3])
+{
+ // derived from SlowRotateBand1
+ dst[0] = ( R[1][1])*x[0] + (-R[1][2])*x[1] + ( R[1][0])*x[2];
+ dst[1] = (-R[2][1])*x[0] + ( R[2][2])*x[1] + (-R[2][0])*x[2];
+ dst[2] = ( R[0][1])*x[0] + (-R[0][2])*x[1] + ( R[0][0])*x[2];
+}
+
+// 48 multiplies
+void OptRotateBand2(float x[5], mat3 R, out float dst[5])
+{
+ // Sparse matrix multiply
+ float sh0 = x[3] + x[4] + x[4] - x[1];
+ float sh1 = x[0] + s_rc2*x[2] + x[3] + x[4];
+ float sh2 = x[0];
+ float sh3 = -x[3];
+ float sh4 = -x[1];
+
+ // Rotations. R0 and R1 just use the raw matrix columns
+ float r2x = R[0][0] + R[0][1];
+ float r2y = R[1][0] + R[1][1];
+ float r2z = R[2][0] + R[2][1];
+
+ float r3x = R[0][0] + R[0][2];
+ float r3y = R[1][0] + R[1][2];
+ float r3z = R[2][0] + R[2][2];
+
+ float r4x = R[0][1] + R[0][2];
+ float r4y = R[1][1] + R[1][2];
+ float r4z = R[2][1] + R[2][2];
+
+ // dense matrix multiplication one column at a time
+
+ // column 0
+ float sh0_x = sh0 * R[0][0];
+ float sh0_y = sh0 * R[1][0];
+ float d0 = sh0_x * R[1][0];
+ float d1 = sh0_y * R[2][0];
+ float d2 = sh0 * (R[2][0] * R[2][0] + s_c4_div_c3);
+ float d3 = sh0_x * R[2][0];
+ float d4 = sh0_x * R[0][0] - sh0_y * R[1][0];
+
+ // column 1
+ float sh1_x = sh1 * R[0][2];
+ float sh1_y = sh1 * R[1][2];
+ d0 += sh1_x * R[1][2];
+ d1 += sh1_y * R[2][2];
+ d2 += sh1 * (R[2][2] * R[2][2] + s_c4_div_c3);
+ d3 += sh1_x * R[2][2];
+ d4 += sh1_x * R[0][2] - sh1_y * R[1][2];
+
+ // column 2
+ float sh2_x = sh2 * r2x;
+ float sh2_y = sh2 * r2y;
+ d0 += sh2_x * r2y;
+ d1 += sh2_y * r2z;
+ d2 += sh2 * (r2z * r2z + s_c4_div_c3_x2);
+ d3 += sh2_x * r2z;
+ d4 += sh2_x * r2x - sh2_y * r2y;
+
+ // column 3
+ float sh3_x = sh3 * r3x;
+ float sh3_y = sh3 * r3y;
+ d0 += sh3_x * r3y;
+ d1 += sh3_y * r3z;
+ d2 += sh3 * (r3z * r3z + s_c4_div_c3_x2);
+ d3 += sh3_x * r3z;
+ d4 += sh3_x * r3x - sh3_y * r3y;
+
+ // column 4
+ float sh4_x = sh4 * r4x;
+ float sh4_y = sh4 * r4y;
+ d0 += sh4_x * r4y;
+ d1 += sh4_y * r4z;
+ d2 += sh4 * (r4z * r4z + s_c4_div_c3_x2);
+ d3 += sh4_x * r4z;
+ d4 += sh4_x * r4x - sh4_y * r4y;
+
+ // extra multipliers
+ dst[0] = d0;
+ dst[1] = -d1;
+ dst[2] = d2 * s_scale_dst2;
+ dst[3] = -d3;
+ dst[4] = d4 * s_scale_dst4;
+}
+
+void main()
+{
+ // normalization
+ vec3 pos = (NormMat * vec4(a_Position,1.0)).xyz;
+
+ mat3 R = mat3(ModelMat) * RotMat;
+ VertexOut.ModelNormal = (R * a_Normal);
+ VertexOut.Position = R * pos;
+ VertexOut.Texcoord = a_TextureCoord;
+ VertexOut.Tangent = (R * a_Tangent);
+ VertexOut.Bitangent = (R * a_Bitangent);
+ float PRT0, PRT1[3], PRT2[5];
+ PRT0 = a_PRT1[0];
+ PRT1[0] = a_PRT1[1];
+ PRT1[1] = a_PRT1[2];
+ PRT1[2] = a_PRT2[0];
+ PRT2[0] = a_PRT2[1];
+ PRT2[1] = a_PRT2[2];
+ PRT2[2] = a_PRT3[0];
+ PRT2[3] = a_PRT3[1];
+ PRT2[4] = a_PRT3[2];
+
+ OptRotateBand1(PRT1, R, PRT1);
+ OptRotateBand2(PRT2, R, PRT2);
+
+ VertexOut.PRT1 = vec3(PRT0,PRT1[0],PRT1[1]);
+ VertexOut.PRT2 = vec3(PRT1[2],PRT2[0],PRT2[1]);
+ VertexOut.PRT3 = vec3(PRT2[2],PRT2[3],PRT2[4]);
+
+ gl_Position = PerspMat * ModelMat * vec4(RotMat * pos, 1.0);
+
+ VertexOut.Depth = vec3(gl_Position.z / gl_Position.w);
+}
diff --git a/PIFu/lib/renderer/gl/data/prt_uv.fs b/PIFu/lib/renderer/gl/data/prt_uv.fs
new file mode 100755
index 0000000000000000000000000000000000000000..6e90b25c62b41c8cf61afd29333372193047d5f1
--- /dev/null
+++ b/PIFu/lib/renderer/gl/data/prt_uv.fs
@@ -0,0 +1,141 @@
+#version 330
+
+uniform vec3 SHCoeffs[9];
+uniform uint analytic;
+
+uniform uint hasNormalMap;
+uniform uint hasAlbedoMap;
+
+uniform sampler2D AlbedoMap;
+uniform sampler2D NormalMap;
+
+in VertexData {
+ vec3 Position;
+ vec3 ModelNormal;
+ vec3 CameraNormal;
+ vec2 Texcoord;
+ vec3 Tangent;
+ vec3 Bitangent;
+ vec3 PRT1;
+ vec3 PRT2;
+ vec3 PRT3;
+} VertexIn;
+
+layout (location = 0) out vec4 FragColor;
+layout (location = 1) out vec4 FragPosition;
+layout (location = 2) out vec4 FragNormal;
+
+vec4 gammaCorrection(vec4 vec, float g)
+{
+ return vec4(pow(vec.x, 1.0/g), pow(vec.y, 1.0/g), pow(vec.z, 1.0/g), vec.w);
+}
+
+vec3 gammaCorrection(vec3 vec, float g)
+{
+ return vec3(pow(vec.x, 1.0/g), pow(vec.y, 1.0/g), pow(vec.z, 1.0/g));
+}
+
+void evaluateH(vec3 n, out float H[9])
+{
+ float c1 = 0.429043, c2 = 0.511664,
+ c3 = 0.743125, c4 = 0.886227, c5 = 0.247708;
+
+ H[0] = c4;
+ H[1] = 2.0 * c2 * n[1];
+ H[2] = 2.0 * c2 * n[2];
+ H[3] = 2.0 * c2 * n[0];
+ H[4] = 2.0 * c1 * n[0] * n[1];
+ H[5] = 2.0 * c1 * n[1] * n[2];
+ H[6] = c3 * n[2] * n[2] - c5;
+ H[7] = 2.0 * c1 * n[2] * n[0];
+ H[8] = c1 * (n[0] * n[0] - n[1] * n[1]);
+}
+
+vec3 evaluateLightingModel(vec3 normal)
+{
+ float H[9];
+ evaluateH(normal, H);
+ vec3 res = vec3(0.0);
+ for (int i = 0; i < 9; i++) {
+ res += H[i] * SHCoeffs[i];
+ }
+ return res;
+}
+
+// nC: coarse geometry normal, nH: fine normal from normal map
+vec3 evaluateLightingModelHybrid(vec3 nC, vec3 nH, mat3 prt)
+{
+ float HC[9], HH[9];
+ evaluateH(nC, HC);
+ evaluateH(nH, HH);
+
+ vec3 res = vec3(0.0);
+ vec3 shadow = vec3(0.0);
+ vec3 unshadow = vec3(0.0);
+ for(int i = 0; i < 3; ++i){
+ for(int j = 0; j < 3; ++j){
+ int id = i*3+j;
+ res += HH[id]* SHCoeffs[id];
+ shadow += prt[i][j] * SHCoeffs[id];
+ unshadow += HC[id] * SHCoeffs[id];
+ }
+ }
+ vec3 ratio = clamp(shadow/unshadow,0.0,1.0);
+ res = ratio * res;
+
+ return res;
+}
+
+vec3 evaluateLightingModelPRT(mat3 prt)
+{
+ vec3 res = vec3(0.0);
+ for(int i = 0; i < 3; ++i){
+ for(int j = 0; j < 3; ++j){
+ res += prt[i][j] * SHCoeffs[i*3+j];
+ }
+ }
+
+ return res;
+}
+
+void main()
+{
+ vec2 uv = VertexIn.Texcoord;
+ vec3 nM = normalize(VertexIn.ModelNormal);
+ vec3 nC = normalize(VertexIn.CameraNormal);
+ vec3 nml = nC;
+ mat3 prt = mat3(VertexIn.PRT1, VertexIn.PRT2, VertexIn.PRT3);
+
+ vec4 albedo, shading;
+ if(hasAlbedoMap == uint(0))
+ albedo = vec4(1.0);
+ else
+ albedo = texture(AlbedoMap, uv);//gammaCorrection(texture(AlbedoMap, uv), 1.0/2.2);
+
+ if(hasNormalMap == uint(0))
+ {
+ if(analytic == uint(0))
+ shading = vec4(evaluateLightingModelPRT(prt), 1.0f);
+ else
+ shading = vec4(evaluateLightingModel(nC), 1.0f);
+ }
+ else
+ {
+ vec3 n_tan = normalize(texture(NormalMap, uv).rgb*2.0-vec3(1.0));
+
+ mat3 TBN = mat3(normalize(VertexIn.Tangent),normalize(VertexIn.Bitangent),nC);
+ vec3 nH = normalize(TBN * n_tan);
+
+ if(analytic == uint(0))
+ shading = vec4(evaluateLightingModelHybrid(nC,nH,prt),1.0f);
+ else
+ shading = vec4(evaluateLightingModel(nH), 1.0f);
+
+ nml = nH;
+ }
+
+ shading = gammaCorrection(shading, 2.2);
+ FragColor = clamp(albedo * shading, 0.0, 1.0);
+ FragPosition = vec4(VertexIn.Position,1.0);
+ FragNormal = vec4(0.5*(nM+vec3(1.0)),1.0);
+}
\ No newline at end of file
diff --git a/PIFu/lib/renderer/gl/data/prt_uv.vs b/PIFu/lib/renderer/gl/data/prt_uv.vs
new file mode 100755
index 0000000000000000000000000000000000000000..22a03564bd95158c3fb9edf513c0717975b93ee0
--- /dev/null
+++ b/PIFu/lib/renderer/gl/data/prt_uv.vs
@@ -0,0 +1,168 @@
+#version 330
+
+layout (location = 0) in vec3 a_Position;
+layout (location = 1) in vec3 a_Normal;
+layout (location = 2) in vec2 a_TextureCoord;
+layout (location = 3) in vec3 a_Tangent;
+layout (location = 4) in vec3 a_Bitangent;
+layout (location = 5) in vec3 a_PRT1;
+layout (location = 6) in vec3 a_PRT2;
+layout (location = 7) in vec3 a_PRT3;
+
+out VertexData {
+ vec3 Position;
+ vec3 ModelNormal;
+ vec3 CameraNormal;
+ vec2 Texcoord;
+ vec3 Tangent;
+ vec3 Bitangent;
+ vec3 PRT1;
+ vec3 PRT2;
+ vec3 PRT3;
+} VertexOut;
+
+uniform mat3 RotMat;
+uniform mat4 NormMat;
+uniform mat4 ModelMat;
+uniform mat4 PerspMat;
+
+#define pi 3.1415926535897932384626433832795
+
+float s_c3 = 0.94617469575; // (3*sqrt(5))/(4*sqrt(pi))
+float s_c4 = -0.31539156525;// (-sqrt(5))/(4*sqrt(pi))
+float s_c5 = 0.54627421529; // (sqrt(15))/(4*sqrt(pi))
+
+float s_c_scale = 1.0/0.91529123286551084;
+float s_c_scale_inv = 0.91529123286551084;
+
+float s_rc2 = 1.5853309190550713*s_c_scale;
+float s_c4_div_c3 = s_c4/s_c3;
+float s_c4_div_c3_x2 = (s_c4/s_c3)*2.0;
+
+float s_scale_dst2 = s_c3 * s_c_scale_inv;
+float s_scale_dst4 = s_c5 * s_c_scale_inv;
+
+void OptRotateBand0(float x[1], mat3 R, out float dst[1])
+{
+ dst[0] = x[0];
+}
+
+// 9 multiplies
+void OptRotateBand1(float x[3], mat3 R, out float dst[3])
+{
+ // derived from SlowRotateBand1
+ dst[0] = ( R[1][1])*x[0] + (-R[1][2])*x[1] + ( R[1][0])*x[2];
+ dst[1] = (-R[2][1])*x[0] + ( R[2][2])*x[1] + (-R[2][0])*x[2];
+ dst[2] = ( R[0][1])*x[0] + (-R[0][2])*x[1] + ( R[0][0])*x[2];
+}
+
+// 48 multiplies
+void OptRotateBand2(float x[5], mat3 R, out float dst[5])
+{
+ // Sparse matrix multiply
+ float sh0 = x[3] + x[4] + x[4] - x[1];
+ float sh1 = x[0] + s_rc2*x[2] + x[3] + x[4];
+ float sh2 = x[0];
+ float sh3 = -x[3];
+ float sh4 = -x[1];
+
+ // Rotations. R0 and R1 just use the raw matrix columns
+ float r2x = R[0][0] + R[0][1];
+ float r2y = R[1][0] + R[1][1];
+ float r2z = R[2][0] + R[2][1];
+
+ float r3x = R[0][0] + R[0][2];
+ float r3y = R[1][0] + R[1][2];
+ float r3z = R[2][0] + R[2][2];
+
+ float r4x = R[0][1] + R[0][2];
+ float r4y = R[1][1] + R[1][2];
+ float r4z = R[2][1] + R[2][2];
+
+ // dense matrix multiplication one column at a time
+
+ // column 0
+ float sh0_x = sh0 * R[0][0];
+ float sh0_y = sh0 * R[1][0];
+ float d0 = sh0_x * R[1][0];
+ float d1 = sh0_y * R[2][0];
+ float d2 = sh0 * (R[2][0] * R[2][0] + s_c4_div_c3);
+ float d3 = sh0_x * R[2][0];
+ float d4 = sh0_x * R[0][0] - sh0_y * R[1][0];
+
+ // column 1
+ float sh1_x = sh1 * R[0][2];
+ float sh1_y = sh1 * R[1][2];
+ d0 += sh1_x * R[1][2];
+ d1 += sh1_y * R[2][2];
+ d2 += sh1 * (R[2][2] * R[2][2] + s_c4_div_c3);
+ d3 += sh1_x * R[2][2];
+ d4 += sh1_x * R[0][2] - sh1_y * R[1][2];
+
+ // column 2
+ float sh2_x = sh2 * r2x;
+ float sh2_y = sh2 * r2y;
+ d0 += sh2_x * r2y;
+ d1 += sh2_y * r2z;
+ d2 += sh2 * (r2z * r2z + s_c4_div_c3_x2);
+ d3 += sh2_x * r2z;
+ d4 += sh2_x * r2x - sh2_y * r2y;
+
+ // column 3
+ float sh3_x = sh3 * r3x;
+ float sh3_y = sh3 * r3y;
+ d0 += sh3_x * r3y;
+ d1 += sh3_y * r3z;
+ d2 += sh3 * (r3z * r3z + s_c4_div_c3_x2);
+ d3 += sh3_x * r3z;
+ d4 += sh3_x * r3x - sh3_y * r3y;
+
+ // column 4
+ float sh4_x = sh4 * r4x;
+ float sh4_y = sh4 * r4y;
+ d0 += sh4_x * r4y;
+ d1 += sh4_y * r4z;
+ d2 += sh4 * (r4z * r4z + s_c4_div_c3_x2);
+ d3 += sh4_x * r4z;
+ d4 += sh4_x * r4x - sh4_y * r4y;
+
+ // extra multipliers
+ dst[0] = d0;
+ dst[1] = -d1;
+ dst[2] = d2 * s_scale_dst2;
+ dst[3] = -d3;
+ dst[4] = d4 * s_scale_dst4;
+}
+
+void main()
+{
+ // normalization
+ mat3 R = mat3(ModelMat) * RotMat;
+ VertexOut.ModelNormal = a_Normal;
+ VertexOut.CameraNormal = (R * a_Normal);
+ VertexOut.Position = a_Position;
+ VertexOut.Texcoord = a_TextureCoord;
+ VertexOut.Tangent = (R * a_Tangent);
+ VertexOut.Bitangent = (R * a_Bitangent);
+ float PRT0, PRT1[3], PRT2[5];
+ PRT0 = a_PRT1[0];
+ PRT1[0] = a_PRT1[1];
+ PRT1[1] = a_PRT1[2];
+ PRT1[2] = a_PRT2[0];
+ PRT2[0] = a_PRT2[1];
+ PRT2[1] = a_PRT2[2];
+ PRT2[2] = a_PRT3[0];
+ PRT2[3] = a_PRT3[1];
+ PRT2[4] = a_PRT3[2];
+
+ OptRotateBand1(PRT1, R, PRT1);
+ OptRotateBand2(PRT2, R, PRT2);
+
+ VertexOut.PRT1 = vec3(PRT0,PRT1[0],PRT1[1]);
+ VertexOut.PRT2 = vec3(PRT1[2],PRT2[0],PRT2[1]);
+ VertexOut.PRT3 = vec3(PRT2[2],PRT2[3],PRT2[4]);
+
+ gl_Position = vec4(a_TextureCoord, 0.0, 1.0) - vec4(0.5, 0.5, 0, 0);
+ gl_Position[0] *= 2.0;
+ gl_Position[1] *= 2.0;
+}
diff --git a/PIFu/lib/renderer/gl/data/quad.fs b/PIFu/lib/renderer/gl/data/quad.fs
new file mode 100755
index 0000000000000000000000000000000000000000..f43502f2352ca2adf19d11e809946b51498df5a5
--- /dev/null
+++ b/PIFu/lib/renderer/gl/data/quad.fs
@@ -0,0 +1,11 @@
+#version 330 core
+out vec4 FragColor;
+
+in vec2 TexCoord;
+
+uniform sampler2D screenTexture;
+
+void main()
+{
+ FragColor = texture(screenTexture, TexCoord);
+}
\ No newline at end of file
diff --git a/PIFu/lib/renderer/gl/data/quad.vs b/PIFu/lib/renderer/gl/data/quad.vs
new file mode 100755
index 0000000000000000000000000000000000000000..811044631a1f29f5b45c490b2d40297f3127b6ea
--- /dev/null
+++ b/PIFu/lib/renderer/gl/data/quad.vs
@@ -0,0 +1,11 @@
+#version 330 core
+layout (location = 0) in vec2 aPos;
+layout (location = 1) in vec2 aTexCoord;
+
+out vec2 TexCoord;
+
+void main()
+{
+ gl_Position = vec4(aPos.x, aPos.y, 0.0, 1.0);
+ TexCoord = aTexCoord;
+}
\ No newline at end of file
diff --git a/PIFu/lib/renderer/gl/framework.py b/PIFu/lib/renderer/gl/framework.py
new file mode 100755
index 0000000000000000000000000000000000000000..a4375b659a91267d3db9278f72bd1f0b030a4655
--- /dev/null
+++ b/PIFu/lib/renderer/gl/framework.py
@@ -0,0 +1,90 @@
+# Mario Rosasco, 2016
+# adapted from framework.cpp, Copyright (C) 2010-2012 by Jason L. McKesson
+# This file is licensed under the MIT License.
+#
+# NB: Unlike in the framework.cpp organization, the main loop is contained
+# in the tutorial files, not in this framework file. Additionally, a copy of
+# this module file must exist in the same directory as the tutorial files
+# to be imported properly.
+
+import os
+from OpenGL.GL import *
+
+# Function that creates and compiles shaders according to the given type (a GL enum value) and
+# shader program (a file containing a GLSL program).
+def loadShader(shaderType, shaderFile):
+ # check if file exists, get full path name
+ strFilename = findFileOrThrow(shaderFile)
+ shaderData = None
+ with open(strFilename, 'r') as f:
+ shaderData = f.read()
+
+ shader = glCreateShader(shaderType)
+ glShaderSource(shader, shaderData) # note that this is a simpler function call than in C
+
+ # This shader compilation is more explicit than the one used in
+ # framework.cpp, which relies on a glutil wrapper function.
+ # This is made explicit here mainly to decrease dependence on pyOpenGL
+ # utilities and wrappers, which docs caution may change in future versions.
+ glCompileShader(shader)
+
+ status = glGetShaderiv(shader, GL_COMPILE_STATUS)
+ if status == GL_FALSE:
+ # Note that getting the error log is much simpler in Python than in C/C++
+ # and does not require explicit handling of the string buffer
+ strInfoLog = glGetShaderInfoLog(shader)
+ strShaderType = ""
+ if shaderType is GL_VERTEX_SHADER:
+ strShaderType = "vertex"
+ elif shaderType is GL_GEOMETRY_SHADER:
+ strShaderType = "geometry"
+ elif shaderType is GL_FRAGMENT_SHADER:
+ strShaderType = "fragment"
+
+ print("Compilation failure for " + strShaderType + " shader:\n" + str(strInfoLog))
+
+ return shader
+
+
+# Function that accepts a list of shaders, compiles them, and returns a handle to the compiled program
+def createProgram(shaderList):
+ program = glCreateProgram()
+
+ for shader in shaderList:
+ glAttachShader(program, shader)
+
+ glLinkProgram(program)
+
+ status = glGetProgramiv(program, GL_LINK_STATUS)
+ if status == GL_FALSE:
+ # Note that getting the error log is much simpler in Python than in C/C++
+ # and does not require explicit handling of the string buffer
+ strInfoLog = glGetProgramInfoLog(program)
+ print("Linker failure: \n" + str(strInfoLog))
+
+ for shader in shaderList:
+ glDetachShader(program, shader)
+
+ return program
+
+
+# Helper function to locate and open the target file (passed in as a string).
+# Returns the full path to the file as a string.
+def findFileOrThrow(strBasename):
+ # Keep constant names in C-style convention, for readability
+ # when comparing to C(/C++) code.
+ if os.path.isfile(strBasename):
+ return strBasename
+
+ LOCAL_FILE_DIR = "data" + os.sep
+ GLOBAL_FILE_DIR = os.path.dirname(os.path.abspath(__file__)) + os.sep + "data" + os.sep
+
+ strFilename = LOCAL_FILE_DIR + strBasename
+ if os.path.isfile(strFilename):
+ return strFilename
+
+ strFilename = GLOBAL_FILE_DIR + strBasename
+ if os.path.isfile(strFilename):
+ return strFilename
+
+ raise IOError('Could not find target file ' + strBasename)
\ No newline at end of file
diff --git a/PIFu/lib/renderer/gl/glcontext.py b/PIFu/lib/renderer/gl/glcontext.py
new file mode 100755
index 0000000000000000000000000000000000000000..f55156b568dcd672498d7582fb4ca58ecdbe523d
--- /dev/null
+++ b/PIFu/lib/renderer/gl/glcontext.py
@@ -0,0 +1,142 @@
+"""Headless GPU-accelerated OpenGL context creation on Google Colaboratory.
+
+Typical usage:
+
+ # Optional PyOpenGL configuratiopn can be done here.
+ # import OpenGL
+ # OpenGL.ERROR_CHECKING = True
+
+ # 'glcontext' must be imported before any OpenGL.* API.
+ from lucid.misc.gl.glcontext import create_opengl_context
+
+ # Now it's safe to import OpenGL and EGL functions
+ import OpenGL.GL as gl
+
+ # create_opengl_context() creates a GL context that is attached to an
+ # offscreen surface of the specified size. Note that rendering to buffers
+ # of other sizes and formats is still possible with OpenGL Framebuffers.
+ #
+ # Users are expected to directly use the EGL API in case more advanced
+ # context management is required.
+ width, height = 640, 480
+ create_opengl_context((width, height))
+
+ # OpenGL context is available here.
+
+"""
+
+from __future__ import print_function
+
+# pylint: disable=unused-import,g-import-not-at-top,g-statement-before-imports
+
+try:
+ import OpenGL
+except:
+ print('This module depends on PyOpenGL.')
+ print('Please run "\033[1m!pip install -q pyopengl\033[0m" '
+ 'prior importing this module.')
+ raise
+
+import ctypes
+from ctypes import pointer, util
+import os
+
+os.environ['PYOPENGL_PLATFORM'] = 'egl'
+
+# OpenGL loading workaround.
+#
+# * PyOpenGL tries to load libGL, but we need libOpenGL, see [1,2].
+# This could have been solved by a symlink libGL->libOpenGL, but:
+#
+# * Python 2.7 can't find libGL and linEGL due to a bug (see [3])
+# in ctypes.util, that was only wixed in Python 3.6.
+#
+# So, the only solution I've found is to monkeypatch ctypes.util
+# [1] https://devblogs.nvidia.com/egl-eye-opengl-visualization-without-x-server/
+# [2] https://devblogs.nvidia.com/linking-opengl-server-side-rendering/
+# [3] https://bugs.python.org/issue9998
+_find_library_old = ctypes.util.find_library
+try:
+
+ def _find_library_new(name):
+ return {
+ 'GL': 'libOpenGL.so',
+ 'EGL': 'libEGL.so',
+ }.get(name, _find_library_old(name))
+ util.find_library = _find_library_new
+ import OpenGL.GL as gl
+ import OpenGL.EGL as egl
+ from OpenGL import error
+ from OpenGL.EGL.EXT.device_base import egl_get_devices
+ from OpenGL.raw.EGL.EXT.platform_device import EGL_PLATFORM_DEVICE_EXT
+except:
+ print('Unable to load OpenGL libraries. '
+ 'Make sure you use GPU-enabled backend.')
+ print('Press "Runtime->Change runtime type" and set '
+ '"Hardware accelerator" to GPU.')
+ raise
+finally:
+ util.find_library = _find_library_old
+
+def create_initialized_headless_egl_display():
+ """Creates an initialized EGL display directly on a device."""
+ for device in egl_get_devices():
+ display = egl.eglGetPlatformDisplayEXT(EGL_PLATFORM_DEVICE_EXT, device, None)
+
+ if display != egl.EGL_NO_DISPLAY and egl.eglGetError() == egl.EGL_SUCCESS:
+ # `eglInitialize` may or may not raise an exception on failure depending
+ # on how PyOpenGL is configured. We therefore catch a `GLError` and also
+ # manually check the output of `eglGetError()` here.
+ try:
+ initialized = egl.eglInitialize(display, None, None)
+ except error.GLError:
+ pass
+ else:
+ if initialized == egl.EGL_TRUE and egl.eglGetError() == egl.EGL_SUCCESS:
+ return display
+ return egl.EGL_NO_DISPLAY
+
+def create_opengl_context(surface_size=(640, 480)):
+ """Create offscreen OpenGL context and make it current.
+
+ Users are expected to directly use EGL API in case more advanced
+ context management is required.
+
+ Args:
+ surface_size: (width, height), size of the offscreen rendering surface.
+ """
+ egl_display = create_initialized_headless_egl_display()
+ if egl_display == egl.EGL_NO_DISPLAY:
+ raise ImportError('Cannot initialize a headless EGL display.')
+
+ major, minor = egl.EGLint(), egl.EGLint()
+ egl.eglInitialize(egl_display, pointer(major), pointer(minor))
+
+ config_attribs = [
+ egl.EGL_SURFACE_TYPE, egl.EGL_PBUFFER_BIT, egl.EGL_BLUE_SIZE, 8,
+ egl.EGL_GREEN_SIZE, 8, egl.EGL_RED_SIZE, 8, egl.EGL_DEPTH_SIZE, 24,
+ egl.EGL_RENDERABLE_TYPE, egl.EGL_OPENGL_BIT, egl.EGL_NONE
+ ]
+ config_attribs = (egl.EGLint * len(config_attribs))(*config_attribs)
+
+ num_configs = egl.EGLint()
+ egl_cfg = egl.EGLConfig()
+ egl.eglChooseConfig(egl_display, config_attribs, pointer(egl_cfg), 1,
+ pointer(num_configs))
+
+ width, height = surface_size
+ pbuffer_attribs = [
+ egl.EGL_WIDTH,
+ width,
+ egl.EGL_HEIGHT,
+ height,
+ egl.EGL_NONE,
+ ]
+ pbuffer_attribs = (egl.EGLint * len(pbuffer_attribs))(*pbuffer_attribs)
+ egl_surf = egl.eglCreatePbufferSurface(egl_display, egl_cfg, pbuffer_attribs)
+
+ egl.eglBindAPI(egl.EGL_OPENGL_API)
+
+ egl_context = egl.eglCreateContext(egl_display, egl_cfg, egl.EGL_NO_CONTEXT,
+ None)
+ egl.eglMakeCurrent(egl_display, egl_surf, egl_surf, egl_context)
diff --git a/PIFu/lib/renderer/gl/init_gl.py b/PIFu/lib/renderer/gl/init_gl.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d2c7e6ba0be20136b2be2e2f644894bee4af9c1
--- /dev/null
+++ b/PIFu/lib/renderer/gl/init_gl.py
@@ -0,0 +1,24 @@
+_glut_window = None
+_context_inited = None
+
+def initialize_GL_context(width=512, height=512, egl=False):
+ '''
+ default context uses GLUT
+ '''
+ if not egl:
+ import OpenGL.GLUT as GLUT
+ display_mode = GLUT.GLUT_DOUBLE | GLUT.GLUT_RGB | GLUT.GLUT_DEPTH
+ global _glut_window
+ if _glut_window is None:
+ GLUT.glutInit()
+ GLUT.glutInitDisplayMode(display_mode)
+ GLUT.glutInitWindowSize(width, height)
+ GLUT.glutInitWindowPosition(0, 0)
+ _glut_window = GLUT.glutCreateWindow("My Render.")
+ else:
+ from .glcontext import create_opengl_context
+ global _context_inited
+ if _context_inited is None:
+ create_opengl_context((width, height))
+ _context_inited = True
+
diff --git a/PIFu/lib/renderer/gl/prt_render.py b/PIFu/lib/renderer/gl/prt_render.py
new file mode 100755
index 0000000000000000000000000000000000000000..92c8a6257f776ab0c803a78a3af7c43a4333c3f9
--- /dev/null
+++ b/PIFu/lib/renderer/gl/prt_render.py
@@ -0,0 +1,350 @@
+import numpy as np
+import random
+
+from .framework import *
+from .cam_render import CamRender
+
+class PRTRender(CamRender):
+ def __init__(self, width=1600, height=1200, name='PRT Renderer', uv_mode=False, ms_rate=1, egl=False):
+ program_files = ['prt.vs', 'prt.fs'] if not uv_mode else ['prt_uv.vs', 'prt_uv.fs']
+ CamRender.__init__(self, width, height, name, program_files=program_files, color_size=8, ms_rate=ms_rate, egl=egl)
+
+ # WARNING: this differs from vertex_buffer and vertex_data in Render
+ self.vert_buffer = {}
+ self.vert_data = {}
+
+ self.norm_buffer = {}
+ self.norm_data = {}
+
+ self.tan_buffer = {}
+ self.tan_data = {}
+
+ self.btan_buffer = {}
+ self.btan_data = {}
+
+ self.prt1_buffer = {}
+ self.prt1_data = {}
+ self.prt2_buffer = {}
+ self.prt2_data = {}
+ self.prt3_buffer = {}
+ self.prt3_data = {}
+
+ self.uv_buffer = {}
+ self.uv_data = {}
+
+ self.render_texture_mat = {}
+
+ self.vertex_dim = {}
+ self.n_vertices = {}
+
+ self.norm_mat_unif = glGetUniformLocation(self.program, 'NormMat')
+ self.normalize_matrix = np.eye(4)
+
+ self.shcoeff_unif = glGetUniformLocation(self.program, 'SHCoeffs')
+ self.shcoeffs = np.zeros((9,3))
+ self.shcoeffs[0,:] = 1.0
+ #self.shcoeffs[1:,:] = np.random.rand(8,3)
+
+ self.hasAlbedoUnif = glGetUniformLocation(self.program, 'hasAlbedoMap')
+ self.hasNormalUnif = glGetUniformLocation(self.program, 'hasNormalMap')
+
+ self.analyticUnif = glGetUniformLocation(self.program, 'analytic')
+ self.analytic = False
+
+ self.rot_mat_unif = glGetUniformLocation(self.program, 'RotMat')
+ self.rot_matrix = np.eye(3)
+
+ def set_texture(self, mat_name, smplr_name, texture):
+ # texture_image: H x W x 3
+ width = texture.shape[1]
+ height = texture.shape[0]
+ texture = np.flip(texture, 0)
+ img_data = np.fromstring(texture.tostring(), np.uint8)
+
+ if mat_name not in self.render_texture_mat:
+ self.render_texture_mat[mat_name] = {}
+ if smplr_name in self.render_texture_mat[mat_name].keys():
+ glDeleteTextures([self.render_texture_mat[mat_name][smplr_name]])
+ del self.render_texture_mat[mat_name][smplr_name]
+ self.render_texture_mat[mat_name][smplr_name] = glGenTextures(1)
+ glActiveTexture(GL_TEXTURE0)
+
+ glPixelStorei(GL_UNPACK_ALIGNMENT, 1)
+ glBindTexture(GL_TEXTURE_2D, self.render_texture_mat[mat_name][smplr_name])
+
+ glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, img_data)
+
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAX_LEVEL, 3)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR)
+
+ glGenerateMipmap(GL_TEXTURE_2D)
+
+ def set_albedo(self, texture_image, mat_name='all'):
+ self.set_texture(mat_name, 'AlbedoMap', texture_image)
+
+ def set_normal_map(self, texture_image, mat_name='all'):
+ self.set_texture(mat_name, 'NormalMap', texture_image)
+
+ def set_mesh(self, vertices, faces, norms, faces_nml, uvs, faces_uvs, prt, faces_prt, tans, bitans, mat_name='all'):
+ self.vert_data[mat_name] = vertices[faces.reshape([-1])]
+ self.n_vertices[mat_name] = self.vert_data[mat_name].shape[0]
+ self.vertex_dim[mat_name] = self.vert_data[mat_name].shape[1]
+
+ if mat_name not in self.vert_buffer.keys():
+ self.vert_buffer[mat_name] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.vert_buffer[mat_name])
+ glBufferData(GL_ARRAY_BUFFER, self.vert_data[mat_name], GL_STATIC_DRAW)
+
+ self.uv_data[mat_name] = uvs[faces_uvs.reshape([-1])]
+ if mat_name not in self.uv_buffer.keys():
+ self.uv_buffer[mat_name] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.uv_buffer[mat_name])
+ glBufferData(GL_ARRAY_BUFFER, self.uv_data[mat_name], GL_STATIC_DRAW)
+
+ self.norm_data[mat_name] = norms[faces_nml.reshape([-1])]
+ if mat_name not in self.norm_buffer.keys():
+ self.norm_buffer[mat_name] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.norm_buffer[mat_name])
+ glBufferData(GL_ARRAY_BUFFER, self.norm_data[mat_name], GL_STATIC_DRAW)
+
+ self.tan_data[mat_name] = tans[faces_nml.reshape([-1])]
+ if mat_name not in self.tan_buffer.keys():
+ self.tan_buffer[mat_name] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.tan_buffer[mat_name])
+ glBufferData(GL_ARRAY_BUFFER, self.tan_data[mat_name], GL_STATIC_DRAW)
+
+ self.btan_data[mat_name] = bitans[faces_nml.reshape([-1])]
+ if mat_name not in self.btan_buffer.keys():
+ self.btan_buffer[mat_name] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.btan_buffer[mat_name])
+ glBufferData(GL_ARRAY_BUFFER, self.btan_data[mat_name], GL_STATIC_DRAW)
+
+ self.prt1_data[mat_name] = prt[faces_prt.reshape([-1])][:,:3]
+ self.prt2_data[mat_name] = prt[faces_prt.reshape([-1])][:,3:6]
+ self.prt3_data[mat_name] = prt[faces_prt.reshape([-1])][:,6:]
+
+ if mat_name not in self.prt1_buffer.keys():
+ self.prt1_buffer[mat_name] = glGenBuffers(1)
+ if mat_name not in self.prt2_buffer.keys():
+ self.prt2_buffer[mat_name] = glGenBuffers(1)
+ if mat_name not in self.prt3_buffer.keys():
+ self.prt3_buffer[mat_name] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt1_buffer[mat_name])
+ glBufferData(GL_ARRAY_BUFFER, self.prt1_data[mat_name], GL_STATIC_DRAW)
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt2_buffer[mat_name])
+ glBufferData(GL_ARRAY_BUFFER, self.prt2_data[mat_name], GL_STATIC_DRAW)
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt3_buffer[mat_name])
+ glBufferData(GL_ARRAY_BUFFER, self.prt3_data[mat_name], GL_STATIC_DRAW)
+
+ glBindBuffer(GL_ARRAY_BUFFER, 0)
+
+ def set_mesh_mtl(self, vertices, faces, norms, faces_nml, uvs, faces_uvs, tans, bitans, prt):
+ for key in faces:
+ self.vert_data[key] = vertices[faces[key].reshape([-1])]
+ self.n_vertices[key] = self.vert_data[key].shape[0]
+ self.vertex_dim[key] = self.vert_data[key].shape[1]
+
+ if key not in self.vert_buffer.keys():
+ self.vert_buffer[key] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.vert_buffer[key])
+ glBufferData(GL_ARRAY_BUFFER, self.vert_data[key], GL_STATIC_DRAW)
+
+ self.uv_data[key] = uvs[faces_uvs[key].reshape([-1])]
+ if key not in self.uv_buffer.keys():
+ self.uv_buffer[key] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.uv_buffer[key])
+ glBufferData(GL_ARRAY_BUFFER, self.uv_data[key], GL_STATIC_DRAW)
+
+ self.norm_data[key] = norms[faces_nml[key].reshape([-1])]
+ if key not in self.norm_buffer.keys():
+ self.norm_buffer[key] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.norm_buffer[key])
+ glBufferData(GL_ARRAY_BUFFER, self.norm_data[key], GL_STATIC_DRAW)
+
+ self.tan_data[key] = tans[faces_nml[key].reshape([-1])]
+ if key not in self.tan_buffer.keys():
+ self.tan_buffer[key] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.tan_buffer[key])
+ glBufferData(GL_ARRAY_BUFFER, self.tan_data[key], GL_STATIC_DRAW)
+
+ self.btan_data[key] = bitans[faces_nml[key].reshape([-1])]
+ if key not in self.btan_buffer.keys():
+ self.btan_buffer[key] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.btan_buffer[key])
+ glBufferData(GL_ARRAY_BUFFER, self.btan_data[key], GL_STATIC_DRAW)
+
+ self.prt1_data[key] = prt[faces[key].reshape([-1])][:,:3]
+ self.prt2_data[key] = prt[faces[key].reshape([-1])][:,3:6]
+ self.prt3_data[key] = prt[faces[key].reshape([-1])][:,6:]
+
+ if key not in self.prt1_buffer.keys():
+ self.prt1_buffer[key] = glGenBuffers(1)
+ if key not in self.prt2_buffer.keys():
+ self.prt2_buffer[key] = glGenBuffers(1)
+ if key not in self.prt3_buffer.keys():
+ self.prt3_buffer[key] = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt1_buffer[key])
+ glBufferData(GL_ARRAY_BUFFER, self.prt1_data[key], GL_STATIC_DRAW)
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt2_buffer[key])
+ glBufferData(GL_ARRAY_BUFFER, self.prt2_data[key], GL_STATIC_DRAW)
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt3_buffer[key])
+ glBufferData(GL_ARRAY_BUFFER, self.prt3_data[key], GL_STATIC_DRAW)
+
+ glBindBuffer(GL_ARRAY_BUFFER, 0)
+
+ def cleanup(self):
+
+ glBindBuffer(GL_ARRAY_BUFFER, 0)
+ for key in self.vert_data:
+ glDeleteBuffers(1, [self.vert_buffer[key]])
+ glDeleteBuffers(1, [self.norm_buffer[key]])
+ glDeleteBuffers(1, [self.uv_buffer[key]])
+
+ glDeleteBuffers(1, [self.tan_buffer[key]])
+ glDeleteBuffers(1, [self.btan_buffer[key]])
+ glDeleteBuffers(1, [self.prt1_buffer[key]])
+ glDeleteBuffers(1, [self.prt2_buffer[key]])
+ glDeleteBuffers(1, [self.prt3_buffer[key]])
+
+ glDeleteBuffers(1, [])
+
+ for smplr in self.render_texture_mat[key]:
+ glDeleteTextures([self.render_texture_mat[key][smplr]])
+
+ self.vert_buffer = {}
+ self.vert_data = {}
+
+ self.norm_buffer = {}
+ self.norm_data = {}
+
+ self.tan_buffer = {}
+ self.tan_data = {}
+
+ self.btan_buffer = {}
+ self.btan_data = {}
+
+ self.prt1_buffer = {}
+ self.prt1_data = {}
+
+ self.prt2_buffer = {}
+ self.prt2_data = {}
+
+ self.prt3_buffer = {}
+ self.prt3_data = {}
+
+ self.uv_buffer = {}
+ self.uv_data = {}
+
+ self.render_texture_mat = {}
+
+ self.vertex_dim = {}
+ self.n_vertices = {}
+
+ def randomize_sh(self):
+ self.shcoeffs[0,:] = 0.8
+ self.shcoeffs[1:,:] = 1.0*np.random.rand(8,3)
+
+ def set_sh(self, sh):
+ self.shcoeffs = sh
+
+ def set_norm_mat(self, scale, center):
+ N = np.eye(4)
+ N[:3, :3] = scale*np.eye(3)
+ N[:3, 3] = -scale*center
+
+ self.normalize_matrix = N
+
+ def draw(self):
+ self.draw_init()
+
+ glDisable(GL_BLEND)
+ #glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)
+ glEnable(GL_MULTISAMPLE)
+
+ glUseProgram(self.program)
+ glUniformMatrix4fv(self.norm_mat_unif, 1, GL_FALSE, self.normalize_matrix.transpose())
+ glUniformMatrix4fv(self.model_mat_unif, 1, GL_FALSE, self.model_view_matrix.transpose())
+ glUniformMatrix4fv(self.persp_mat_unif, 1, GL_FALSE, self.projection_matrix.transpose())
+
+ if 'AlbedoMap' in self.render_texture_mat['all']:
+ glUniform1ui(self.hasAlbedoUnif, GLuint(1))
+ else:
+ glUniform1ui(self.hasAlbedoUnif, GLuint(0))
+
+ if 'NormalMap' in self.render_texture_mat['all']:
+ glUniform1ui(self.hasNormalUnif, GLuint(1))
+ else:
+ glUniform1ui(self.hasNormalUnif, GLuint(0))
+
+ glUniform1ui(self.analyticUnif, GLuint(1) if self.analytic else GLuint(0))
+
+ glUniform3fv(self.shcoeff_unif, 9, self.shcoeffs)
+
+ glUniformMatrix3fv(self.rot_mat_unif, 1, GL_FALSE, self.rot_matrix.transpose())
+
+ for mat in self.vert_buffer:
+ # Handle vertex buffer
+ glBindBuffer(GL_ARRAY_BUFFER, self.vert_buffer[mat])
+ glEnableVertexAttribArray(0)
+ glVertexAttribPointer(0, self.vertex_dim[mat], GL_DOUBLE, GL_FALSE, 0, None)
+
+ # Handle normal buffer
+ glBindBuffer(GL_ARRAY_BUFFER, self.norm_buffer[mat])
+ glEnableVertexAttribArray(1)
+ glVertexAttribPointer(1, 3, GL_DOUBLE, GL_FALSE, 0, None)
+
+ # Handle uv buffer
+ glBindBuffer(GL_ARRAY_BUFFER, self.uv_buffer[mat])
+ glEnableVertexAttribArray(2)
+ glVertexAttribPointer(2, 2, GL_DOUBLE, GL_FALSE, 0, None)
+
+ # Handle tan buffer
+ glBindBuffer(GL_ARRAY_BUFFER, self.tan_buffer[mat])
+ glEnableVertexAttribArray(3)
+ glVertexAttribPointer(3, 3, GL_DOUBLE, GL_FALSE, 0, None)
+
+ # Handle btan buffer
+ glBindBuffer(GL_ARRAY_BUFFER, self.btan_buffer[mat])
+ glEnableVertexAttribArray(4)
+ glVertexAttribPointer(4, 3, GL_DOUBLE, GL_FALSE, 0, None)
+
+ # Handle PTR buffer
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt1_buffer[mat])
+ glEnableVertexAttribArray(5)
+ glVertexAttribPointer(5, 3, GL_DOUBLE, GL_FALSE, 0, None)
+
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt2_buffer[mat])
+ glEnableVertexAttribArray(6)
+ glVertexAttribPointer(6, 3, GL_DOUBLE, GL_FALSE, 0, None)
+
+ glBindBuffer(GL_ARRAY_BUFFER, self.prt3_buffer[mat])
+ glEnableVertexAttribArray(7)
+ glVertexAttribPointer(7, 3, GL_DOUBLE, GL_FALSE, 0, None)
+
+ for i, smplr in enumerate(self.render_texture_mat[mat]):
+ glActiveTexture(GL_TEXTURE0 + i)
+ glBindTexture(GL_TEXTURE_2D, self.render_texture_mat[mat][smplr])
+ glUniform1i(glGetUniformLocation(self.program, smplr), i)
+
+ glDrawArrays(GL_TRIANGLES, 0, self.n_vertices[mat])
+
+ glDisableVertexAttribArray(7)
+ glDisableVertexAttribArray(6)
+ glDisableVertexAttribArray(5)
+ glDisableVertexAttribArray(4)
+ glDisableVertexAttribArray(3)
+ glDisableVertexAttribArray(2)
+ glDisableVertexAttribArray(1)
+ glDisableVertexAttribArray(0)
+
+ glBindBuffer(GL_ARRAY_BUFFER, 0)
+
+ glUseProgram(0)
+
+ glDisable(GL_BLEND)
+ glDisable(GL_MULTISAMPLE)
+
+ self.draw_end()
diff --git a/PIFu/lib/renderer/gl/render.py b/PIFu/lib/renderer/gl/render.py
new file mode 100755
index 0000000000000000000000000000000000000000..57c219386c9bc0adb1ee78dd1c31a6fbf0dd1b3d
--- /dev/null
+++ b/PIFu/lib/renderer/gl/render.py
@@ -0,0 +1,310 @@
+from ctypes import *
+
+import numpy as np
+from .framework import *
+
+GLUT = None
+
+# NOTE: Render class assumes GL context is created already.
+class Render:
+ def __init__(self, width=1600, height=1200, name='GL Renderer',
+ program_files=['simple.fs', 'simple.vs'], color_size=1, ms_rate=1, egl=False):
+ self.width = width
+ self.height = height
+ self.name = name
+ self.use_inverse_depth = False
+ self.egl = egl
+
+ glEnable(GL_DEPTH_TEST)
+
+ glClampColor(GL_CLAMP_READ_COLOR, GL_FALSE)
+ glClampColor(GL_CLAMP_FRAGMENT_COLOR, GL_FALSE)
+ glClampColor(GL_CLAMP_VERTEX_COLOR, GL_FALSE)
+
+ # init program
+ shader_list = []
+
+ for program_file in program_files:
+ _, ext = os.path.splitext(program_file)
+ if ext == '.vs':
+ shader_list.append(loadShader(GL_VERTEX_SHADER, program_file))
+ elif ext == '.fs':
+ shader_list.append(loadShader(GL_FRAGMENT_SHADER, program_file))
+ elif ext == '.gs':
+ shader_list.append(loadShader(GL_GEOMETRY_SHADER, program_file))
+
+ self.program = createProgram(shader_list)
+
+ for shader in shader_list:
+ glDeleteShader(shader)
+
+ # Init uniform variables
+ self.model_mat_unif = glGetUniformLocation(self.program, 'ModelMat')
+ self.persp_mat_unif = glGetUniformLocation(self.program, 'PerspMat')
+
+ self.vertex_buffer = glGenBuffers(1)
+
+ # Init screen quad program and buffer
+ self.quad_program, self.quad_buffer = self.init_quad_program()
+
+ # Configure frame buffer
+ self.frame_buffer = glGenFramebuffers(1)
+ glBindFramebuffer(GL_FRAMEBUFFER, self.frame_buffer)
+
+ self.intermediate_fbo = None
+ if ms_rate > 1:
+ # Configure texture buffer to render to
+ self.color_buffer = []
+ for i in range(color_size):
+ color_buffer = glGenTextures(1)
+ multi_sample_rate = ms_rate
+ glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, color_buffer)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR)
+ glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, multi_sample_rate, GL_RGBA32F, self.width, self.height, GL_TRUE)
+ glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, 0)
+ glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0 + i, GL_TEXTURE_2D_MULTISAMPLE, color_buffer, 0)
+ self.color_buffer.append(color_buffer)
+
+ self.render_buffer = glGenRenderbuffers(1)
+ glBindRenderbuffer(GL_RENDERBUFFER, self.render_buffer)
+ glRenderbufferStorageMultisample(GL_RENDERBUFFER, multi_sample_rate, GL_DEPTH24_STENCIL8, self.width, self.height)
+ glBindRenderbuffer(GL_RENDERBUFFER, 0)
+ glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, self.render_buffer)
+
+ attachments = []
+ for i in range(color_size):
+ attachments.append(GL_COLOR_ATTACHMENT0 + i)
+ glDrawBuffers(color_size, attachments)
+ glBindFramebuffer(GL_FRAMEBUFFER, 0)
+
+ self.intermediate_fbo = glGenFramebuffers(1)
+ glBindFramebuffer(GL_FRAMEBUFFER, self.intermediate_fbo)
+
+ self.screen_texture = []
+ for i in range(color_size):
+ screen_texture = glGenTextures(1)
+ glBindTexture(GL_TEXTURE_2D, screen_texture)
+ glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA32F, self.width, self.height, 0, GL_RGBA, GL_FLOAT, None)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR)
+ glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0 + i, GL_TEXTURE_2D, screen_texture, 0)
+ self.screen_texture.append(screen_texture)
+
+ glDrawBuffers(color_size, attachments)
+ glBindFramebuffer(GL_FRAMEBUFFER, 0)
+ else:
+ self.color_buffer = []
+ for i in range(color_size):
+ color_buffer = glGenTextures(1)
+ glBindTexture(GL_TEXTURE_2D, color_buffer)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST)
+ glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA32F, self.width, self.height, 0, GL_RGBA, GL_FLOAT, None)
+ glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0 + i, GL_TEXTURE_2D, color_buffer, 0)
+ self.color_buffer.append(color_buffer)
+
+ # Configure depth texture map to render to
+ self.depth_buffer = glGenTextures(1)
+ glBindTexture(GL_TEXTURE_2D, self.depth_buffer)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST)
+ glTexParameteri(GL_TEXTURE_2D, GL_DEPTH_TEXTURE_MODE, GL_INTENSITY)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_COMPARE_MODE, GL_COMPARE_R_TO_TEXTURE)
+ glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_COMPARE_FUNC, GL_LEQUAL)
+ glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT, self.width, self.height, 0, GL_DEPTH_COMPONENT, GL_FLOAT, None)
+ glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, GL_TEXTURE_2D, self.depth_buffer, 0)
+
+ attachments = []
+ for i in range(color_size):
+ attachments.append(GL_COLOR_ATTACHMENT0 + i)
+ glDrawBuffers(color_size, attachments)
+ self.screen_texture = self.color_buffer
+
+ glBindFramebuffer(GL_FRAMEBUFFER, 0)
+
+
+ # Configure texture buffer if needed
+ self.render_texture = None
+
+ # NOTE: original render_texture only support one input
+ # this is tentative member of this issue
+ self.render_texture_v2 = {}
+
+ # Inner storage for buffer data
+ self.vertex_data = None
+ self.vertex_dim = None
+ self.n_vertices = None
+
+ self.model_view_matrix = None
+ self.projection_matrix = None
+
+ if not egl:
+ global GLUT
+ import OpenGL.GLUT as GLUT
+ GLUT.glutDisplayFunc(self.display)
+
+
+ def init_quad_program(self):
+ shader_list = []
+
+ shader_list.append(loadShader(GL_VERTEX_SHADER, "quad.vs"))
+ shader_list.append(loadShader(GL_FRAGMENT_SHADER, "quad.fs"))
+
+ the_program = createProgram(shader_list)
+
+ for shader in shader_list:
+ glDeleteShader(shader)
+
+ # vertex attributes for a quad that fills the entire screen in Normalized Device Coordinates.
+ # positions # texCoords
+ quad_vertices = np.array(
+ [-1.0, 1.0, 0.0, 1.0,
+ -1.0, -1.0, 0.0, 0.0,
+ 1.0, -1.0, 1.0, 0.0,
+
+ -1.0, 1.0, 0.0, 1.0,
+ 1.0, -1.0, 1.0, 0.0,
+ 1.0, 1.0, 1.0, 1.0]
+ )
+
+ quad_buffer = glGenBuffers(1)
+ glBindBuffer(GL_ARRAY_BUFFER, quad_buffer)
+ glBufferData(GL_ARRAY_BUFFER, quad_vertices, GL_STATIC_DRAW)
+
+ glBindBuffer(GL_ARRAY_BUFFER, 0)
+
+ return the_program, quad_buffer
+
+ def set_mesh(self, vertices, faces):
+ self.vertex_data = vertices[faces.reshape([-1])]
+ self.vertex_dim = self.vertex_data.shape[1]
+ self.n_vertices = self.vertex_data.shape[0]
+
+ glBindBuffer(GL_ARRAY_BUFFER, self.vertex_buffer)
+ glBufferData(GL_ARRAY_BUFFER, self.vertex_data, GL_STATIC_DRAW)
+
+ glBindBuffer(GL_ARRAY_BUFFER, 0)
+
+ def set_viewpoint(self, projection, model_view):
+ self.projection_matrix = projection
+ self.model_view_matrix = model_view
+
+ def draw_init(self):
+ glBindFramebuffer(GL_FRAMEBUFFER, self.frame_buffer)
+ glEnable(GL_DEPTH_TEST)
+
+ glClearColor(0.0, 0.0, 0.0, 0.0)
+ if self.use_inverse_depth:
+ glDepthFunc(GL_GREATER)
+ glClearDepth(0.0)
+ else:
+ glDepthFunc(GL_LESS)
+ glClearDepth(1.0)
+ glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT)
+
+ def draw_end(self):
+ if self.intermediate_fbo is not None:
+ for i in range(len(self.color_buffer)):
+ glBindFramebuffer(GL_READ_FRAMEBUFFER, self.frame_buffer)
+ glReadBuffer(GL_COLOR_ATTACHMENT0 + i)
+ glBindFramebuffer(GL_DRAW_FRAMEBUFFER, self.intermediate_fbo)
+ glDrawBuffer(GL_COLOR_ATTACHMENT0 + i)
+ glBlitFramebuffer(0, 0, self.width, self.height, 0, 0, self.width, self.height, GL_COLOR_BUFFER_BIT, GL_NEAREST)
+
+ glBindFramebuffer(GL_FRAMEBUFFER, 0)
+ glDepthFunc(GL_LESS)
+ glClearDepth(1.0)
+
+ def draw(self):
+ self.draw_init()
+
+ glUseProgram(self.program)
+ glUniformMatrix4fv(self.model_mat_unif, 1, GL_FALSE, self.model_view_matrix.transpose())
+ glUniformMatrix4fv(self.persp_mat_unif, 1, GL_FALSE, self.projection_matrix.transpose())
+
+ glBindBuffer(GL_ARRAY_BUFFER, self.vertex_buffer)
+
+ glEnableVertexAttribArray(0)
+ glVertexAttribPointer(0, self.vertex_dim, GL_DOUBLE, GL_FALSE, 0, None)
+
+ glDrawArrays(GL_TRIANGLES, 0, self.n_vertices)
+
+ glDisableVertexAttribArray(0)
+
+ glBindBuffer(GL_ARRAY_BUFFER, 0)
+
+ glUseProgram(0)
+
+ self.draw_end()
+
+ def get_color(self, color_id=0):
+ glBindFramebuffer(GL_FRAMEBUFFER, self.intermediate_fbo if self.intermediate_fbo is not None else self.frame_buffer)
+ glReadBuffer(GL_COLOR_ATTACHMENT0 + color_id)
+ data = glReadPixels(0, 0, self.width, self.height, GL_RGBA, GL_FLOAT, outputType=None)
+ glBindFramebuffer(GL_FRAMEBUFFER, 0)
+ rgb = data.reshape(self.height, self.width, -1)
+ rgb = np.flip(rgb, 0)
+ return rgb
+
+ def get_z_value(self):
+ glBindFramebuffer(GL_FRAMEBUFFER, self.frame_buffer)
+ data = glReadPixels(0, 0, self.width, self.height, GL_DEPTH_COMPONENT, GL_FLOAT, outputType=None)
+ glBindFramebuffer(GL_FRAMEBUFFER, 0)
+ z = data.reshape(self.height, self.width)
+ z = np.flip(z, 0)
+ return z
+
+ def display(self):
+ self.draw()
+
+ if not self.egl:
+ # First we draw a scene.
+ # Notice the result is stored in the texture buffer.
+
+ # Then we return to the default frame buffer since we will display on the screen.
+ glBindFramebuffer(GL_FRAMEBUFFER, 0)
+
+ # Do the clean-up.
+ glClearColor(0.0, 0.0, 0.0, 0.0)
+ glClear(GL_COLOR_BUFFER_BIT)
+
+ # We draw a rectangle which covers the whole screen.
+ glUseProgram(self.quad_program)
+ glBindBuffer(GL_ARRAY_BUFFER, self.quad_buffer)
+
+ size_of_double = 8
+ glEnableVertexAttribArray(0)
+ glVertexAttribPointer(0, 2, GL_DOUBLE, GL_FALSE, 4 * size_of_double, None)
+ glEnableVertexAttribArray(1)
+ glVertexAttribPointer(1, 2, GL_DOUBLE, GL_FALSE, 4 * size_of_double, c_void_p(2 * size_of_double))
+
+ glDisable(GL_DEPTH_TEST)
+
+ # The stored texture is then mapped to this rectangle.
+ # properly assing color buffer texture
+ glActiveTexture(GL_TEXTURE0)
+ glBindTexture(GL_TEXTURE_2D, self.screen_texture[0])
+ glUniform1i(glGetUniformLocation(self.quad_program, 'screenTexture'), 0)
+
+ glDrawArrays(GL_TRIANGLES, 0, 6)
+
+ glDisableVertexAttribArray(1)
+ glDisableVertexAttribArray(0)
+
+ glEnable(GL_DEPTH_TEST)
+ glBindBuffer(GL_ARRAY_BUFFER, 0)
+ glUseProgram(0)
+
+ GLUT.glutSwapBuffers()
+ GLUT.glutPostRedisplay()
+
+ def show(self):
+ if not self.egl:
+ GLUT.glutMainLoop()
diff --git a/PIFu/lib/renderer/glm.py b/PIFu/lib/renderer/glm.py
new file mode 100755
index 0000000000000000000000000000000000000000..8be14b50f0d7edcde6328f1f805b392c8e3ab7e2
--- /dev/null
+++ b/PIFu/lib/renderer/glm.py
@@ -0,0 +1,125 @@
+import numpy as np
+
+
+def vec3(x, y, z):
+ return np.array([x, y, z], dtype=np.float32)
+
+
+def radians(v):
+ return np.radians(v)
+
+
+def identity():
+ return np.identity(4, dtype=np.float32)
+
+
+def empty():
+ return np.zeros([4, 4], dtype=np.float32)
+
+
+def magnitude(v):
+ return np.linalg.norm(v)
+
+
+def normalize(v):
+ m = magnitude(v)
+ return v if m == 0 else v / m
+
+
+def dot(u, v):
+ return np.sum(u * v)
+
+
+def cross(u, v):
+ res = vec3(0, 0, 0)
+ res[0] = u[1] * v[2] - u[2] * v[1]
+ res[1] = u[2] * v[0] - u[0] * v[2]
+ res[2] = u[0] * v[1] - u[1] * v[0]
+ return res
+
+
+# below functions can be optimized
+
+def translate(m, v):
+ res = np.copy(m)
+ res[:, 3] = m[:, 0] * v[0] + m[:, 1] * v[1] + m[:, 2] * v[2] + m[:, 3]
+ return res
+
+
+def rotate(m, angle, v):
+ a = angle
+ c = np.cos(a)
+ s = np.sin(a)
+
+ axis = normalize(v)
+ temp = (1 - c) * axis
+
+ rot = empty()
+ rot[0][0] = c + temp[0] * axis[0]
+ rot[0][1] = temp[0] * axis[1] + s * axis[2]
+ rot[0][2] = temp[0] * axis[2] - s * axis[1]
+
+ rot[1][0] = temp[1] * axis[0] - s * axis[2]
+ rot[1][1] = c + temp[1] * axis[1]
+ rot[1][2] = temp[1] * axis[2] + s * axis[0]
+
+ rot[2][0] = temp[2] * axis[0] + s * axis[1]
+ rot[2][1] = temp[2] * axis[1] - s * axis[0]
+ rot[2][2] = c + temp[2] * axis[2]
+
+ res = empty()
+ res[:, 0] = m[:, 0] * rot[0][0] + m[:, 1] * rot[0][1] + m[:, 2] * rot[0][2]
+ res[:, 1] = m[:, 0] * rot[1][0] + m[:, 1] * rot[1][1] + m[:, 2] * rot[1][2]
+ res[:, 2] = m[:, 0] * rot[2][0] + m[:, 1] * rot[2][1] + m[:, 2] * rot[2][2]
+ res[:, 3] = m[:, 3]
+ return res
+
+
+def perspective(fovy, aspect, zNear, zFar):
+ tanHalfFovy = np.tan(fovy / 2)
+
+ res = empty()
+ res[0][0] = 1 / (aspect * tanHalfFovy)
+ res[1][1] = 1 / (tanHalfFovy)
+ res[2][3] = -1
+ res[2][2] = - (zFar + zNear) / (zFar - zNear)
+ res[3][2] = -(2 * zFar * zNear) / (zFar - zNear)
+
+ return res.T
+
+
+def ortho(left, right, bottom, top, zNear, zFar):
+ # res = np.ones([4, 4], dtype=np.float32)
+ res = identity()
+ res[0][0] = 2 / (right - left)
+ res[1][1] = 2 / (top - bottom)
+ res[2][2] = - 2 / (zFar - zNear)
+ res[3][0] = - (right + left) / (right - left)
+ res[3][1] = - (top + bottom) / (top - bottom)
+ res[3][2] = - (zFar + zNear) / (zFar - zNear)
+ return res.T
+
+
+def lookat(eye, center, up):
+ f = normalize(center - eye)
+ s = normalize(cross(f, up))
+ u = cross(s, f)
+
+ res = identity()
+ res[0][0] = s[0]
+ res[1][0] = s[1]
+ res[2][0] = s[2]
+ res[0][1] = u[0]
+ res[1][1] = u[1]
+ res[2][1] = u[2]
+ res[0][2] = -f[0]
+ res[1][2] = -f[1]
+ res[2][2] = -f[2]
+ res[3][0] = -dot(s, eye)
+ res[3][1] = -dot(u, eye)
+ res[3][2] = -dot(f, eye)
+ return res.T
+
+
+def transform(d, m):
+ return np.dot(m, d.T).T
diff --git a/PIFu/lib/renderer/mesh.py b/PIFu/lib/renderer/mesh.py
new file mode 100755
index 0000000000000000000000000000000000000000..a76ec5838d08d109dc24f58ca8ef3aff2ade552b
--- /dev/null
+++ b/PIFu/lib/renderer/mesh.py
@@ -0,0 +1,345 @@
+import numpy as np
+
+
+def save_obj_mesh(mesh_path, verts, faces):
+ file = open(mesh_path, 'w')
+ for v in verts:
+ file.write('v %.4f %.4f %.4f\n' % (v[0], v[1], v[2]))
+ for f in faces:
+ f_plus = f + 1
+ file.write('f %d %d %d\n' % (f_plus[0], f_plus[1], f_plus[2]))
+ file.close()
+
+# https://github.com/ratcave/wavefront_reader
+def read_mtlfile(fname):
+ materials = {}
+ with open(fname) as f:
+ lines = f.read().splitlines()
+
+ for line in lines:
+ if line:
+ split_line = line.strip().split(' ', 1)
+ if len(split_line) < 2:
+ continue
+
+ prefix, data = split_line[0], split_line[1]
+ if 'newmtl' in prefix:
+ material = {}
+ materials[data] = material
+ elif materials:
+ if data:
+ split_data = data.strip().split(' ')
+
+ # assume texture maps are in the same level
+ # WARNING: do not include space in your filename!!
+ if 'map' in prefix:
+ material[prefix] = split_data[-1].split('\\')[-1]
+ elif len(split_data) > 1:
+ material[prefix] = tuple(float(d) for d in split_data)
+ else:
+ try:
+ material[prefix] = int(data)
+ except ValueError:
+ material[prefix] = float(data)
+
+ return materials
+
+
+def load_obj_mesh_mtl(mesh_file):
+ vertex_data = []
+ norm_data = []
+ uv_data = []
+
+ face_data = []
+ face_norm_data = []
+ face_uv_data = []
+
+ # face per material
+ face_data_mat = {}
+ face_norm_data_mat = {}
+ face_uv_data_mat = {}
+
+ # current material name
+ mtl_data = None
+ cur_mat = None
+
+ if isinstance(mesh_file, str):
+ f = open(mesh_file, "r")
+ else:
+ f = mesh_file
+ for line in f:
+ if isinstance(line, bytes):
+ line = line.decode("utf-8")
+ if line.startswith('#'):
+ continue
+ values = line.split()
+ if not values:
+ continue
+
+ if values[0] == 'v':
+ v = list(map(float, values[1:4]))
+ vertex_data.append(v)
+ elif values[0] == 'vn':
+ vn = list(map(float, values[1:4]))
+ norm_data.append(vn)
+ elif values[0] == 'vt':
+ vt = list(map(float, values[1:3]))
+ uv_data.append(vt)
+ elif values[0] == 'mtllib':
+ mtl_data = read_mtlfile(mesh_file.replace(mesh_file.split('/')[-1],values[1]))
+ elif values[0] == 'usemtl':
+ cur_mat = values[1]
+ elif values[0] == 'f':
+ # local triangle data
+ l_face_data = []
+ l_face_uv_data = []
+ l_face_norm_data = []
+
+ # quad mesh
+ if len(values) > 4:
+ f = list(map(lambda x: int(x.split('/')[0]) if int(x.split('/')[0]) < 0 else int(x.split('/')[0])-1, values[1:4]))
+ l_face_data.append(f)
+ f = list(map(lambda x: int(x.split('/')[0]) if int(x.split('/')[0]) < 0 else int(x.split('/')[0])-1, [values[3], values[4], values[1]]))
+ l_face_data.append(f)
+ # tri mesh
+ else:
+ f = list(map(lambda x: int(x.split('/')[0]) if int(x.split('/')[0]) < 0 else int(x.split('/')[0])-1, values[1:4]))
+ l_face_data.append(f)
+ # deal with texture
+ if len(values[1].split('/')) >= 2:
+ # quad mesh
+ if len(values) > 4:
+ f = list(map(lambda x: int(x.split('/')[1]) if int(x.split('/')[1]) < 0 else int(x.split('/')[1])-1, values[1:4]))
+ l_face_uv_data.append(f)
+ f = list(map(lambda x: int(x.split('/')[1]) if int(x.split('/')[1]) < 0 else int(x.split('/')[1])-1, [values[3], values[4], values[1]]))
+ l_face_uv_data.append(f)
+ # tri mesh
+ elif len(values[1].split('/')[1]) != 0:
+ f = list(map(lambda x: int(x.split('/')[1]) if int(x.split('/')[1]) < 0 else int(x.split('/')[1])-1, values[1:4]))
+ l_face_uv_data.append(f)
+ # deal with normal
+ if len(values[1].split('/')) == 3:
+ # quad mesh
+ if len(values) > 4:
+ f = list(map(lambda x: int(x.split('/')[2]) if int(x.split('/')[2]) < 0 else int(x.split('/')[2])-1, values[1:4]))
+ l_face_norm_data.append(f)
+ f = list(map(lambda x: int(x.split('/')[2]) if int(x.split('/')[2]) < 0 else int(x.split('/')[2])-1, [values[3], values[4], values[1]]))
+ l_face_norm_data.append(f)
+ # tri mesh
+ elif len(values[1].split('/')[2]) != 0:
+ f = list(map(lambda x: int(x.split('/')[2]) if int(x.split('/')[2]) < 0 else int(x.split('/')[2])-1, values[1:4]))
+ l_face_norm_data.append(f)
+
+ face_data += l_face_data
+ face_uv_data += l_face_uv_data
+ face_norm_data += l_face_norm_data
+
+ if cur_mat is not None:
+ if cur_mat not in face_data_mat.keys():
+ face_data_mat[cur_mat] = []
+ if cur_mat not in face_uv_data_mat.keys():
+ face_uv_data_mat[cur_mat] = []
+ if cur_mat not in face_norm_data_mat.keys():
+ face_norm_data_mat[cur_mat] = []
+ face_data_mat[cur_mat] += l_face_data
+ face_uv_data_mat[cur_mat] += l_face_uv_data
+ face_norm_data_mat[cur_mat] += l_face_norm_data
+
+ vertices = np.array(vertex_data)
+ faces = np.array(face_data)
+
+ norms = np.array(norm_data)
+ norms = normalize_v3(norms)
+ face_normals = np.array(face_norm_data)
+
+ uvs = np.array(uv_data)
+ face_uvs = np.array(face_uv_data)
+
+ out_tuple = (vertices, faces, norms, face_normals, uvs, face_uvs)
+
+ if cur_mat is not None and mtl_data is not None:
+ for key in face_data_mat:
+ face_data_mat[key] = np.array(face_data_mat[key])
+ face_uv_data_mat[key] = np.array(face_uv_data_mat[key])
+ face_norm_data_mat[key] = np.array(face_norm_data_mat[key])
+
+ out_tuple += (face_data_mat, face_norm_data_mat, face_uv_data_mat, mtl_data)
+
+ return out_tuple
+
+
+def load_obj_mesh(mesh_file, with_normal=False, with_texture=False):
+ vertex_data = []
+ norm_data = []
+ uv_data = []
+
+ face_data = []
+ face_norm_data = []
+ face_uv_data = []
+
+ if isinstance(mesh_file, str):
+ f = open(mesh_file, "r")
+ else:
+ f = mesh_file
+ for line in f:
+ if isinstance(line, bytes):
+ line = line.decode("utf-8")
+ if line.startswith('#'):
+ continue
+ values = line.split()
+ if not values:
+ continue
+
+ if values[0] == 'v':
+ v = list(map(float, values[1:4]))
+ vertex_data.append(v)
+ elif values[0] == 'vn':
+ vn = list(map(float, values[1:4]))
+ norm_data.append(vn)
+ elif values[0] == 'vt':
+ vt = list(map(float, values[1:3]))
+ uv_data.append(vt)
+
+ elif values[0] == 'f':
+ # quad mesh
+ if len(values) > 4:
+ f = list(map(lambda x: int(x.split('/')[0]), values[1:4]))
+ face_data.append(f)
+ f = list(map(lambda x: int(x.split('/')[0]), [values[3], values[4], values[1]]))
+ face_data.append(f)
+ # tri mesh
+ else:
+ f = list(map(lambda x: int(x.split('/')[0]), values[1:4]))
+ face_data.append(f)
+
+ # deal with texture
+ if len(values[1].split('/')) >= 2:
+ # quad mesh
+ if len(values) > 4:
+ f = list(map(lambda x: int(x.split('/')[1]), values[1:4]))
+ face_uv_data.append(f)
+ f = list(map(lambda x: int(x.split('/')[1]), [values[3], values[4], values[1]]))
+ face_uv_data.append(f)
+ # tri mesh
+ elif len(values[1].split('/')[1]) != 0:
+ f = list(map(lambda x: int(x.split('/')[1]), values[1:4]))
+ face_uv_data.append(f)
+ # deal with normal
+ if len(values[1].split('/')) == 3:
+ # quad mesh
+ if len(values) > 4:
+ f = list(map(lambda x: int(x.split('/')[2]), values[1:4]))
+ face_norm_data.append(f)
+ f = list(map(lambda x: int(x.split('/')[2]), [values[3], values[4], values[1]]))
+ face_norm_data.append(f)
+ # tri mesh
+ elif len(values[1].split('/')[2]) != 0:
+ f = list(map(lambda x: int(x.split('/')[2]), values[1:4]))
+ face_norm_data.append(f)
+
+ vertices = np.array(vertex_data)
+ faces = np.array(face_data) - 1
+
+ if with_texture and with_normal:
+ uvs = np.array(uv_data)
+ face_uvs = np.array(face_uv_data) - 1
+ norms = np.array(norm_data)
+ if norms.shape[0] == 0:
+ norms = compute_normal(vertices, faces)
+ face_normals = faces
+ else:
+ norms = normalize_v3(norms)
+ face_normals = np.array(face_norm_data) - 1
+ return vertices, faces, norms, face_normals, uvs, face_uvs
+
+ if with_texture:
+ uvs = np.array(uv_data)
+ face_uvs = np.array(face_uv_data) - 1
+ return vertices, faces, uvs, face_uvs
+
+ if with_normal:
+ norms = np.array(norm_data)
+ norms = normalize_v3(norms)
+ face_normals = np.array(face_norm_data) - 1
+ return vertices, faces, norms, face_normals
+
+ return vertices, faces
+
+
+def normalize_v3(arr):
+ ''' Normalize a numpy array of 3 component vectors shape=(n,3) '''
+ lens = np.sqrt(arr[:, 0] ** 2 + arr[:, 1] ** 2 + arr[:, 2] ** 2)
+ eps = 0.00000001
+ lens[lens < eps] = eps
+ arr[:, 0] /= lens
+ arr[:, 1] /= lens
+ arr[:, 2] /= lens
+ return arr
+
+
+def compute_normal(vertices, faces):
+ # Create a zeroed array with the same type and shape as our vertices i.e., per vertex normal
+ norm = np.zeros(vertices.shape, dtype=vertices.dtype)
+ # Create an indexed view into the vertex array using the array of three indices for triangles
+ tris = vertices[faces]
+ # Calculate the normal for all the triangles, by taking the cross product of the vectors v1-v0, and v2-v0 in each triangle
+ n = np.cross(tris[::, 1] - tris[::, 0], tris[::, 2] - tris[::, 0])
+ # n is now an array of normals per triangle. The length of each normal is dependent the vertices,
+ # we need to normalize these, so that our next step weights each normal equally.
+ normalize_v3(n)
+ # now we have a normalized array of normals, one per triangle, i.e., per triangle normals.
+ # But instead of one per triangle (i.e., flat shading), we add to each vertex in that triangle,
+ # the triangles' normal. Multiple triangles would then contribute to every vertex, so we need to normalize again afterwards.
+ # The cool part, we can actually add the normals through an indexed view of our (zeroed) per vertex normal array
+ norm[faces[:, 0]] += n
+ norm[faces[:, 1]] += n
+ norm[faces[:, 2]] += n
+ normalize_v3(norm)
+
+ return norm
+
+# compute tangent and bitangent
+def compute_tangent(vertices, faces, normals, uvs, faceuvs):
+ # NOTE: this could be numerically unstable around [0,0,1]
+ # but other current solutions are pretty freaky somehow
+ c1 = np.cross(normals, np.array([0,1,0.0]))
+ tan = c1
+ normalize_v3(tan)
+ btan = np.cross(normals, tan)
+
+ # NOTE: traditional version is below
+
+ # pts_tris = vertices[faces]
+ # uv_tris = uvs[faceuvs]
+
+ # W = np.stack([pts_tris[::, 1] - pts_tris[::, 0], pts_tris[::, 2] - pts_tris[::, 0]],2)
+ # UV = np.stack([uv_tris[::, 1] - uv_tris[::, 0], uv_tris[::, 2] - uv_tris[::, 0]], 1)
+
+ # for i in range(W.shape[0]):
+ # W[i,::] = W[i,::].dot(np.linalg.inv(UV[i,::]))
+
+ # tan = np.zeros(vertices.shape, dtype=vertices.dtype)
+ # tan[faces[:,0]] += W[:,:,0]
+ # tan[faces[:,1]] += W[:,:,0]
+ # tan[faces[:,2]] += W[:,:,0]
+
+ # btan = np.zeros(vertices.shape, dtype=vertices.dtype)
+ # btan[faces[:,0]] += W[:,:,1]
+ # btan[faces[:,1]] += W[:,:,1]
+ # btan[faces[:,2]] += W[:,:,1]
+
+ # normalize_v3(tan)
+
+ # ndott = np.sum(normals*tan, 1, keepdims=True)
+ # tan = tan - ndott * normals
+
+ # normalize_v3(btan)
+ # normalize_v3(tan)
+
+ # tan[np.sum(np.cross(normals, tan) * btan, 1) < 0,:] *= -1.0
+
+ return tan, btan
+
+if __name__ == '__main__':
+ pts, tri, nml, trin, uvs, triuv = load_obj_mesh('/home/ICT2000/ssaito/Documents/Body/tmp/Baseball_Pitching/0012.obj', True, True)
+ compute_tangent(pts, tri, uvs, triuv)
\ No newline at end of file
diff --git a/PIFu/lib/sample_util.py b/PIFu/lib/sample_util.py
new file mode 100755
index 0000000000000000000000000000000000000000..d0b105d148d6d8fddc461d1c04f659200957c189
--- /dev/null
+++ b/PIFu/lib/sample_util.py
@@ -0,0 +1,47 @@
+import numpy as np
+
+
+def save_samples_truncted_prob(fname, points, prob):
+ '''
+ Save the visualization of sampling to a ply file.
+ Red points represent positive predictions.
+ Green points represent negative predictions.
+ :param fname: File name to save
+ :param points: [N, 3] array of points
+ :param prob: [N, 1] array of predictions in the range [0~1]
+ :return:
+ '''
+ r = (prob > 0.5).reshape([-1, 1]) * 255
+ g = (prob < 0.5).reshape([-1, 1]) * 255
+ b = np.zeros(r.shape)
+
+ to_save = np.concatenate([points, r, g, b], axis=-1)
+ return np.savetxt(fname,
+ to_save,
+ fmt='%.6f %.6f %.6f %d %d %d',
+ comments='',
+ header=(
+ 'ply\nformat ascii 1.0\nelement vertex {:d}\nproperty float x\nproperty float y\nproperty float z\nproperty uchar red\nproperty uchar green\nproperty uchar blue\nend_header').format(
+ points.shape[0])
+ )
+
+
+def save_samples_rgb(fname, points, rgb):
+ '''
+ Save the visualization of sampling to a ply file.
+ Red points represent positive predictions.
+ Green points represent negative predictions.
+ :param fname: File name to save
+ :param points: [N, 3] array of points
+ :param rgb: [N, 3] array of rgb values in the range [0~1]
+ :return:
+ '''
+ to_save = np.concatenate([points, rgb * 255], axis=-1)
+ return np.savetxt(fname,
+ to_save,
+ fmt='%.6f %.6f %.6f %d %d %d',
+ comments='',
+ header=(
+ 'ply\nformat ascii 1.0\nelement vertex {:d}\nproperty float x\nproperty float y\nproperty float z\nproperty uchar red\nproperty uchar green\nproperty uchar blue\nend_header').format(
+ points.shape[0])
+ )
diff --git a/PIFu/lib/sdf.py b/PIFu/lib/sdf.py
new file mode 100755
index 0000000000000000000000000000000000000000..e87e639eb94993c3e4068d6bd4d21f902aee7694
--- /dev/null
+++ b/PIFu/lib/sdf.py
@@ -0,0 +1,100 @@
+import numpy as np
+
+
+def create_grid(resX, resY, resZ, b_min=np.array([0, 0, 0]), b_max=np.array([1, 1, 1]), transform=None):
+ '''
+ Create a dense grid of given resolution and bounding box
+ :param resX: resolution along X axis
+ :param resY: resolution along Y axis
+ :param resZ: resolution along Z axis
+ :param b_min: vec3 (x_min, y_min, z_min) bounding box corner
+ :param b_max: vec3 (x_max, y_max, z_max) bounding box corner
+ :return: [3, resX, resY, resZ] coordinates of the grid, and transform matrix from mesh index
+ '''
+ coords = np.mgrid[:resX, :resY, :resZ]
+ coords = coords.reshape(3, -1)
+ coords_matrix = np.eye(4)
+ length = b_max - b_min
+ coords_matrix[0, 0] = length[0] / resX
+ coords_matrix[1, 1] = length[1] / resY
+ coords_matrix[2, 2] = length[2] / resZ
+ coords_matrix[0:3, 3] = b_min
+ coords = np.matmul(coords_matrix[:3, :3], coords) + coords_matrix[:3, 3:4]
+ if transform is not None:
+ coords = np.matmul(transform[:3, :3], coords) + transform[:3, 3:4]
+ coords_matrix = np.matmul(transform, coords_matrix)
+ coords = coords.reshape(3, resX, resY, resZ)
+ return coords, coords_matrix
+
+
+def batch_eval(points, eval_func, num_samples=512 * 512 * 512):
+ num_pts = points.shape[1]
+ sdf = np.zeros(num_pts)
+
+ num_batches = num_pts // num_samples
+ for i in range(num_batches):
+ sdf[i * num_samples:i * num_samples + num_samples] = eval_func(
+ points[:, i * num_samples:i * num_samples + num_samples])
+ if num_pts % num_samples:
+ sdf[num_batches * num_samples:] = eval_func(points[:, num_batches * num_samples:])
+
+ return sdf
+
+
+def eval_grid(coords, eval_func, num_samples=512 * 512 * 512):
+ resolution = coords.shape[1:4]
+ coords = coords.reshape([3, -1])
+ sdf = batch_eval(coords, eval_func, num_samples=num_samples)
+ return sdf.reshape(resolution)
+
+
+def eval_grid_octree(coords, eval_func,
+ init_resolution=64, threshold=0.01,
+ num_samples=512 * 512 * 512):
+ resolution = coords.shape[1:4]
+
+ sdf = np.zeros(resolution)
+
+ dirty = np.ones(resolution, dtype=np.bool)
+ grid_mask = np.zeros(resolution, dtype=np.bool)
+
+ reso = resolution[0] // init_resolution
+
+ while reso > 0:
+ # subdivide the grid
+ grid_mask[0:resolution[0]:reso, 0:resolution[1]:reso, 0:resolution[2]:reso] = True
+ # test samples in this iteration
+ test_mask = np.logical_and(grid_mask, dirty)
+ #print('step size:', reso, 'test sample size:', test_mask.sum())
+ points = coords[:, test_mask]
+
+ sdf[test_mask] = batch_eval(points, eval_func, num_samples=num_samples)
+ dirty[test_mask] = False
+
+ # do interpolation
+ if reso <= 1:
+ break
+ for x in range(0, resolution[0] - reso, reso):
+ for y in range(0, resolution[1] - reso, reso):
+ for z in range(0, resolution[2] - reso, reso):
+ # if center marked, return
+ if not dirty[x + reso // 2, y + reso // 2, z + reso // 2]:
+ continue
+ v0 = sdf[x, y, z]
+ v1 = sdf[x, y, z + reso]
+ v2 = sdf[x, y + reso, z]
+ v3 = sdf[x, y + reso, z + reso]
+ v4 = sdf[x + reso, y, z]
+ v5 = sdf[x + reso, y, z + reso]
+ v6 = sdf[x + reso, y + reso, z]
+ v7 = sdf[x + reso, y + reso, z + reso]
+ v = np.array([v0, v1, v2, v3, v4, v5, v6, v7])
+ v_min = v.min()
+ v_max = v.max()
+ # this cell is all the same
+ if (v_max - v_min) < threshold:
+ sdf[x:x + reso, y:y + reso, z:z + reso] = (v_max + v_min) / 2
+ dirty[x:x + reso, y:y + reso, z:z + reso] = False
+ reso //= 2
+
+ return sdf.reshape(resolution)
diff --git a/PIFu/lib/train_util.py b/PIFu/lib/train_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d48cc7beba640703e744112aa2ec458a195a16b
--- /dev/null
+++ b/PIFu/lib/train_util.py
@@ -0,0 +1,204 @@
+import torch
+import numpy as np
+from .mesh_util import *
+from .sample_util import *
+from .geometry import *
+import cv2
+from PIL import Image
+from tqdm import tqdm
+
+def reshape_multiview_tensors(image_tensor, calib_tensor):
+ # Careful here! Because we put single view and multiview together,
+ # the returned tensor.shape is 5-dim: [B, num_views, C, W, H]
+ # So we need to convert it back to 4-dim [B*num_views, C, W, H]
+ # Don't worry classifier will handle multi-view cases
+ image_tensor = image_tensor.view(
+ image_tensor.shape[0] * image_tensor.shape[1],
+ image_tensor.shape[2],
+ image_tensor.shape[3],
+ image_tensor.shape[4]
+ )
+ calib_tensor = calib_tensor.view(
+ calib_tensor.shape[0] * calib_tensor.shape[1],
+ calib_tensor.shape[2],
+ calib_tensor.shape[3]
+ )
+
+ return image_tensor, calib_tensor
+
+
+def reshape_sample_tensor(sample_tensor, num_views):
+ if num_views == 1:
+ return sample_tensor
+ # Need to repeat sample_tensor along the batch dim num_views times
+ sample_tensor = sample_tensor.unsqueeze(dim=1)
+ sample_tensor = sample_tensor.repeat(1, num_views, 1, 1)
+ sample_tensor = sample_tensor.view(
+ sample_tensor.shape[0] * sample_tensor.shape[1],
+ sample_tensor.shape[2],
+ sample_tensor.shape[3]
+ )
+ return sample_tensor
+
+
+def gen_mesh(opt, net, cuda, data, save_path, use_octree=True):
+ image_tensor = data['img'].to(device=cuda)
+ calib_tensor = data['calib'].to(device=cuda)
+
+ net.filter(image_tensor)
+
+ b_min = data['b_min']
+ b_max = data['b_max']
+ try:
+ save_img_path = save_path[:-4] + '.png'
+ save_img_list = []
+ for v in range(image_tensor.shape[0]):
+ save_img = (np.transpose(image_tensor[v].detach().cpu().numpy(), (1, 2, 0)) * 0.5 + 0.5)[:, :, ::-1] * 255.0
+ save_img_list.append(save_img)
+ save_img = np.concatenate(save_img_list, axis=1)
+ Image.fromarray(np.uint8(save_img[:,:,::-1])).save(save_img_path)
+
+ verts, faces, _, _ = reconstruction(
+ net, cuda, calib_tensor, opt.resolution, b_min, b_max, use_octree=use_octree)
+ verts_tensor = torch.from_numpy(verts.T).unsqueeze(0).to(device=cuda).float()
+ xyz_tensor = net.projection(verts_tensor, calib_tensor[:1])
+ uv = xyz_tensor[:, :2, :]
+ color = index(image_tensor[:1], uv).detach().cpu().numpy()[0].T
+ color = color * 0.5 + 0.5
+ save_obj_mesh_with_color(save_path, verts, faces, color)
+ except Exception as e:
+ print(e)
+ print('Can not create marching cubes at this time.')
+
+def gen_mesh_color(opt, netG, netC, cuda, data, save_path, use_octree=True):
+ image_tensor = data['img'].to(device=cuda)
+ calib_tensor = data['calib'].to(device=cuda)
+
+ netG.filter(image_tensor)
+ netC.filter(image_tensor)
+ netC.attach(netG.get_im_feat())
+
+ b_min = data['b_min']
+ b_max = data['b_max']
+ try:
+ save_img_path = save_path[:-4] + '.png'
+ save_img_list = []
+ for v in range(image_tensor.shape[0]):
+ save_img = (np.transpose(image_tensor[v].detach().cpu().numpy(), (1, 2, 0)) * 0.5 + 0.5)[:, :, ::-1] * 255.0
+ save_img_list.append(save_img)
+ save_img = np.concatenate(save_img_list, axis=1)
+ Image.fromarray(np.uint8(save_img[:,:,::-1])).save(save_img_path)
+
+ verts, faces, _, _ = reconstruction(
+ netG, cuda, calib_tensor, opt.resolution, b_min, b_max, use_octree=use_octree)
+
+ # Now Getting colors
+ verts_tensor = torch.from_numpy(verts.T).unsqueeze(0).to(device=cuda).float()
+ verts_tensor = reshape_sample_tensor(verts_tensor, opt.num_views)
+ color = np.zeros(verts.shape)
+ interval = 10000
+ for i in range(len(color) // interval):
+ left = i * interval
+ right = i * interval + interval
+ if i == len(color) // interval - 1:
+ right = -1
+ netC.query(verts_tensor[:, :, left:right], calib_tensor)
+ rgb = netC.get_preds()[0].detach().cpu().numpy() * 0.5 + 0.5
+ color[left:right] = rgb.T
+
+ save_obj_mesh_with_color(save_path, verts, faces, color)
+ except Exception as e:
+ print(e)
+ print('Can not create marching cubes at this time.')
+
+def adjust_learning_rate(optimizer, epoch, lr, schedule, gamma):
+ """Sets the learning rate to the initial LR decayed by schedule"""
+ if epoch in schedule:
+ lr *= gamma
+ for param_group in optimizer.param_groups:
+ param_group['lr'] = lr
+ return lr
+
+
+def compute_acc(pred, gt, thresh=0.5):
+ '''
+ return:
+ IOU, precision, and recall
+ '''
+ with torch.no_grad():
+ vol_pred = pred > thresh
+ vol_gt = gt > thresh
+
+ union = vol_pred | vol_gt
+ inter = vol_pred & vol_gt
+
+ true_pos = inter.sum().float()
+
+ union = union.sum().float()
+ if union == 0:
+ union = 1
+ vol_pred = vol_pred.sum().float()
+ if vol_pred == 0:
+ vol_pred = 1
+ vol_gt = vol_gt.sum().float()
+ if vol_gt == 0:
+ vol_gt = 1
+ return true_pos / union, true_pos / vol_pred, true_pos / vol_gt
+
+
+def calc_error(opt, net, cuda, dataset, num_tests):
+ if num_tests > len(dataset):
+ num_tests = len(dataset)
+ with torch.no_grad():
+ erorr_arr, IOU_arr, prec_arr, recall_arr = [], [], [], []
+ for idx in tqdm(range(num_tests)):
+ data = dataset[idx * len(dataset) // num_tests]
+ # retrieve the data
+ image_tensor = data['img'].to(device=cuda)
+ calib_tensor = data['calib'].to(device=cuda)
+ sample_tensor = data['samples'].to(device=cuda).unsqueeze(0)
+ if opt.num_views > 1:
+ sample_tensor = reshape_sample_tensor(sample_tensor, opt.num_views)
+ label_tensor = data['labels'].to(device=cuda).unsqueeze(0)
+
+ res, error = net.forward(image_tensor, sample_tensor, calib_tensor, labels=label_tensor)
+
+ IOU, prec, recall = compute_acc(res, label_tensor)
+
+ # print(
+ # '{0}/{1} | Error: {2:06f} IOU: {3:06f} prec: {4:06f} recall: {5:06f}'
+ # .format(idx, num_tests, error.item(), IOU.item(), prec.item(), recall.item()))
+ erorr_arr.append(error.item())
+ IOU_arr.append(IOU.item())
+ prec_arr.append(prec.item())
+ recall_arr.append(recall.item())
+
+ return np.average(erorr_arr), np.average(IOU_arr), np.average(prec_arr), np.average(recall_arr)
+
+def calc_error_color(opt, netG, netC, cuda, dataset, num_tests):
+ if num_tests > len(dataset):
+ num_tests = len(dataset)
+ with torch.no_grad():
+ error_color_arr = []
+
+ for idx in tqdm(range(num_tests)):
+ data = dataset[idx * len(dataset) // num_tests]
+ # retrieve the data
+ image_tensor = data['img'].to(device=cuda)
+ calib_tensor = data['calib'].to(device=cuda)
+ color_sample_tensor = data['color_samples'].to(device=cuda).unsqueeze(0)
+
+ if opt.num_views > 1:
+ color_sample_tensor = reshape_sample_tensor(color_sample_tensor, opt.num_views)
+
+ rgb_tensor = data['rgbs'].to(device=cuda).unsqueeze(0)
+
+ netG.filter(image_tensor)
+ _, errorC = netC.forward(image_tensor, netG.get_im_feat(), color_sample_tensor, calib_tensor, labels=rgb_tensor)
+
+ # print('{0}/{1} | Error inout: {2:06f} | Error color: {3:06f}'
+ # .format(idx, num_tests, errorG.item(), errorC.item()))
+ error_color_arr.append(errorC.item())
+
+ return np.average(error_color_arr)
+
diff --git a/PIFu/requirements.txt b/PIFu/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2eff18a890c2ebf689df5d70984880042f8084d1
--- /dev/null
+++ b/PIFu/requirements.txt
@@ -0,0 +1,50 @@
+cycler==0.10.0
+decorator==4.4.1
+imageio==2.8.0
+kiwisolver==1.1.0
+matplotlib==3.1.3
+networkx==2.4
+numpy==1.21.6
+opencv-python==4.1.2.30
+pathlib==1.0.1
+Pillow==9.1.0
+PyOpenGL==3.1.6
+pyparsing==2.4.6
+python-dateutil==2.8.1
+PyWavelets==1.1.1
+scikit-image==0.18.3
+scikit-learn==1.0.2
+scipy==1.4.1
+Shapely==1.7.0
+six==1.14.0
+torch==1.4.0
+torchvision==0.5.0
+git+https://github.com/huggingface/diffusers
+trimesh==3.5.23
+tqdm==4.64.0
+cycler==0.10.0
+decorator==4.4.1
+imageio==2.8.0
+kiwisolver==1.1.0
+matplotlib==3.1.3
+networkx==2.4
+numpy==1.21.6
+opencv-python==4.1.2.30
+pathlib==1.0.1
+Pillow==9.1.0
+PyOpenGL==3.1.6
+pyparsing==2.4.6
+python-dateutil==2.8.1
+PyWavelets==1.1.1
+scikit-image==0.18.3
+scikit-learn==1.0.2
+scipy==1.4.1
+Shapely==1.7.0
+six==1.14.0
+torch==1.4.0
+torchvision==0.5.0
+trimesh==3.5.23
+tqdm==4.64.0
+transformers
+accelerate
+ftfy
\ No newline at end of file
diff --git a/PIFu/sample_images/ryota.png b/PIFu/sample_images/ryota.png
new file mode 100755
index 0000000000000000000000000000000000000000..2ebf1131558c04ce1b8b95e78a86973bb0665f81
Binary files /dev/null and b/PIFu/sample_images/ryota.png differ
diff --git a/PIFu/sample_images/ryota_mask.png b/PIFu/sample_images/ryota_mask.png
new file mode 100755
index 0000000000000000000000000000000000000000..29c4fdc179ed9e00e361ac4b09f03a83a5e31c85
Binary files /dev/null and b/PIFu/sample_images/ryota_mask.png differ
diff --git a/PIFu/scripts/download_trained_model.sh b/PIFu/scripts/download_trained_model.sh
new file mode 100755
index 0000000000000000000000000000000000000000..c652f2c666dc48ff1e2e7a94d559e925ac058dec
--- /dev/null
+++ b/PIFu/scripts/download_trained_model.sh
@@ -0,0 +1,7 @@
+set -ex
+
+mkdir -p checkpoints
+cd checkpoints
+wget "https://drive.google.com/uc?export=download&id=1zEmVXG2VHy0MMzngcRshB4D8Sr_oLHsm" -O net_G
+wget "https://drive.google.com/uc?export=download&id=1V83B6GDIjYMfHdpg-KcCSAPgHxpafHgd" -O net_C
+cd ..
\ No newline at end of file
diff --git a/PIFu/scripts/test.sh b/PIFu/scripts/test.sh
new file mode 100755
index 0000000000000000000000000000000000000000..a7a3d7ec6d2a3572bbb699f935aefd8c575e768e
--- /dev/null
+++ b/PIFu/scripts/test.sh
@@ -0,0 +1,39 @@
+#!/usr/bin/env bash
+set -ex
+
+# Training
+GPU_ID=0
+DISPLAY_ID=$((GPU_ID*10+10))
+NAME='spaces_demo'
+
+# Network configuration
+
+BATCH_SIZE=1
+MLP_DIM='257 1024 512 256 128 1'
+MLP_DIM_COLOR='513 1024 512 256 128 3'
+
+# Reconstruction resolution
+# NOTE: one can change here to reconstruct mesh in a different resolution.
+# VOL_RES=256
+
+# CHECKPOINTS_NETG_PATH='./checkpoints/net_G'
+# CHECKPOINTS_NETC_PATH='./checkpoints/net_C'
+
+# TEST_FOLDER_PATH='./sample_images'
+
+# command
+CUDA_VISIBLE_DEVICES=${GPU_ID} python ./apps/eval_spaces.py \
+ --name ${NAME} \
+ --batch_size ${BATCH_SIZE} \
+ --mlp_dim ${MLP_DIM} \
+ --mlp_dim_color ${MLP_DIM_COLOR} \
+ --num_stack 4 \
+ --num_hourglass 2 \
+ --resolution ${VOL_RES} \
+ --hg_down 'ave_pool' \
+ --norm 'group' \
+ --norm_color 'group' \
+ --load_netG_checkpoint_path ${CHECKPOINTS_NETG_PATH} \
+ --load_netC_checkpoint_path ${CHECKPOINTS_NETC_PATH} \
+ --results_path ${RESULTS_PATH} \
+ --img_path ${INPUT_IMAGE_PATH}
\ No newline at end of file
diff --git a/PIFu/spaces.py b/PIFu/spaces.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c995f77157a5a7c070a360e7d7bb2a7fb9f9803
--- /dev/null
+++ b/PIFu/spaces.py
@@ -0,0 +1,161 @@
+import os
+os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
+os.environ["CUDA_VISIBLE_DEVICES"]="0"
+try:
+ os.system("pip install --upgrade torch==1.11.0+cu113 torchvision==0.12.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html")
+except Exception as e:
+ print(e)
+
+from pydoc import describe
+from huggingface_hub import hf_hub_download
+import gradio as gr
+import os
+from datetime import datetime
+from PIL import Image
+import torch
+import torchvision
+from diffusers import StableDiffusionImg2ImgPipeline
+import skimage
+import paddlehub
+import numpy as np
+from lib.options import BaseOptions
+from apps.crop_img import process_img
+from apps.eval import Evaluator
+from types import SimpleNamespace
+import trimesh
+import glob
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+pipe = StableDiffusionImg2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16, revision="fp16", safety_checker=None) if torch.cuda.is_available() else StableDiffusionImg2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", safety_checker=None)
+pipe = pipe.to(device)
+
+print(
+ "torch: ", torch.__version__,
+ "\ntorchvision: ", torchvision.__version__,
+ "\nskimage:", skimage.__version__
+)
+
+print("EnV", os.environ)
+
+net_C = hf_hub_download("radames/PIFu-upright-standing", filename="net_C")
+net_G = hf_hub_download("radames/PIFu-upright-standing", filename="net_G")
+
+
+opt = BaseOptions()
+opts = opt.parse_to_dict()
+opts['batch_size'] = 1
+opts['mlp_dim'] = [257, 1024, 512, 256, 128, 1]
+opts['mlp_dim_color'] = [513, 1024, 512, 256, 128, 3]
+opts['num_stack'] = 4
+opts['num_hourglass'] = 2
+opts['resolution'] = 128
+opts['hg_down'] = 'ave_pool'
+opts['norm'] = 'group'
+opts['norm_color'] = 'group'
+opts['load_netG_checkpoint_path'] = net_G
+opts['load_netC_checkpoint_path'] = net_C
+opts['results_path'] = "./results"
+opts['name'] = "spaces_demo"
+opts = SimpleNamespace(**opts)
+print("Params", opts)
+evaluator = Evaluator(opts)
+bg_remover_model = paddlehub.Module(name="U2Net")
+
+def resize(value,img):
+ img = Image.open(img)
+ img = img.resize((value,value))
+ return img
+
+def infer(source_img, prompt, negative_prompt, guide, steps, seed, Strength):
+ generator = torch.Generator(device).manual_seed(seed)
+ source_image = resize(768, source_img)
+ source_image.save('source.png')
+ image = pipe(prompt, negative_prompt=negative_prompt, image=source_image, strength=Strength, guidance_scale=guide, num_inference_steps=steps).images[0]
+ return image
+
+def process(img_path):
+ base = os.path.basename(img_path)
+ img_name = os.path.splitext(base)[0]
+ print("\n\n\nStarting Process", datetime.now())
+ print("image name", img_name)
+ img_raw = Image.open(img_path).convert('RGB')
+
+ img = img_raw.resize(
+ (512, int(512 * img_raw.size[1] / img_raw.size[0])),
+ Image.Resampling.LANCZOS)
+
+ try:
+ # remove background
+ print("Removing Background")
+ masks = bg_remover_model.Segmentation(
+ images=[np.array(img)],
+ paths=None,
+ batch_size=1,
+ input_size=320,
+ output_dir='./PIFu/inputs',
+ visualization=False)
+ mask = masks[0]["mask"]
+ front = masks[0]["front"]
+ except Exception as e:
+ print(e)
+
+ print("Aliging mask with input training image")
+ print("Not aligned", front.shape, mask.shape)
+ img_new, msk_new = process_img(front, mask)
+ print("Aligned", img_new.shape, msk_new.shape)
+
+ try:
+ time = datetime.now()
+ data = evaluator.load_image_from_memory(img_new, msk_new, img_name)
+ print("Evaluating via PIFu", time)
+ evaluator.eval(data, True)
+ print("Success Evaluating via PIFu", datetime.now() - time)
+ result_path = f'./{opts.results_path}/{opts.name}/result_{img_name}'
+ except Exception as e:
+ print("Error evaluating via PIFu", e)
+
+ try:
+ mesh = trimesh.load(result_path + '.obj')
+ # flip mesh
+ mesh.apply_transform([[-1, 0, 0, 0],
+ [0, 1, 0, 0],
+ [0, 0, -1, 0],
+ [0, 0, 0, 1]])
+ mesh.export(file_obj=result_path + '.glb')
+ result_gltf = result_path + '.glb'
+ return [result_gltf, result_gltf]
+
+ except Exception as e:
+ print("error generating MESH", e)
+
+
+examples = sorted(glob.glob('examples/*.png'))
+
+iface1 = gr.Interface(fn=infer, inputs=[gr.Image(source="upload", type="filepath", label="Raw Image. Must Be .png"), gr.Textbox(label = 'Prompt Input Text. 77 Token (Keyword or Symbol) Maximum'), gr.Textbox(label='What you Do Not want the AI to generate.'),
+ gr.Slider(2, 15, value = 7, label = 'Guidance Scale'),
+ gr.Slider(1, 25, value = 10, step = 1, label = 'Number of Iterations'),
+ gr.Slider(label = "Seed", minimum = 0, maximum = 987654321987654321, step = 1, randomize = True),
+ gr.Slider(label='Strength', minimum = 0, maximum = 1, step = .05, value = .5)],
+ outputs='image')
+
+iface2 = gr.Interface(
+ fn=process,
+ inputs=gr.Image(type="filepath", label="Input Image"),
+ outputs=[
+ gr.Model3D(
+ clear_color=[0.0, 0.0, 0.0, 0.0], label="3D Model"),
+ gr.File(label="Download 3D Model")
+ ],
+ examples=examples,
+ allow_flagging="never",
+ cache_examples=True
+)
+
+demo = gr.TabbedInterface([iface1, iface2], ["Image-Edit-with-Text", "Image-to-3D-Model"])
+
+if __name__ == "__main__":
+ demo.launch()
+
+# if __name__ == "__main__":
+# iface1.launch(debug=True, enable_queue=False)
+# iface2.launch(debug=True, enable_queue=False)
\ No newline at end of file
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..90f87bc413a5dd0d4039bcfd087c37e851304f98
--- /dev/null
+++ b/README.md
@@ -0,0 +1,14 @@
+---
+title: Image and 3D Model Creator
+emoji: "⭐\_"
+colorFrom: yellow
+colorTo: blue
+sdk: gradio
+sdk_version: 3.0.2
+app_file: ./PIFu/spaces.py
+pinned: false
+python_version: 3.7.13
+duplicated_from: F4RF4R4/Image-and-3D-Model-Creator
+---
+
+Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/examples/0person6.png b/examples/0person6.png
new file mode 100644
index 0000000000000000000000000000000000000000..35a97f0cebb82c7be419b806d0cd43814a8a2a91
Binary files /dev/null and b/examples/0person6.png differ
diff --git a/examples/1person5.png b/examples/1person5.png
new file mode 100644
index 0000000000000000000000000000000000000000..357bb1dabc3e81423dc2e17a0171c4b4456d45fa
Binary files /dev/null and b/examples/1person5.png differ
diff --git a/examples/2person4.png b/examples/2person4.png
new file mode 100644
index 0000000000000000000000000000000000000000..2aa72bfca52c5cd959fa9fe6819b80c1754ec9a9
Binary files /dev/null and b/examples/2person4.png differ
diff --git a/examples/3person.png b/examples/3person.png
new file mode 100644
index 0000000000000000000000000000000000000000..93e6255cde4abf0a84edb64a18af0b4c417520da
Binary files /dev/null and b/examples/3person.png differ
diff --git a/examples/4person1.png b/examples/4person1.png
new file mode 100644
index 0000000000000000000000000000000000000000..7db1c7a763c55606c47f7d80efb05ce3bffa3a0b
Binary files /dev/null and b/examples/4person1.png differ
diff --git a/examples/5person3.png b/examples/5person3.png
new file mode 100644
index 0000000000000000000000000000000000000000..496c1de4ea8fd1f8b06bf11ae5be1b465c6bae5b
Binary files /dev/null and b/examples/5person3.png differ
diff --git a/examples/6person2.png b/examples/6person2.png
new file mode 100644
index 0000000000000000000000000000000000000000..d0d86fdb5faf3a6a9e8f5741a63690f47a7cab8a
Binary files /dev/null and b/examples/6person2.png differ
diff --git a/examples/7a.png b/examples/7a.png
new file mode 100644
index 0000000000000000000000000000000000000000..30d3c09cdeeb5e9c5b64b2fb57d6e8641138c0c2
Binary files /dev/null and b/examples/7a.png differ
diff --git a/examples/8b.png b/examples/8b.png
new file mode 100644
index 0000000000000000000000000000000000000000..3a622a263f388ef10810e670caecdb468189e856
Binary files /dev/null and b/examples/8b.png differ
diff --git a/gradio_cached_examples/.gitattributes b/gradio_cached_examples/.gitattributes
new file mode 100644
index 0000000000000000000000000000000000000000..dbbb4a4159428ad49298a857ee04d91762ef5caf
--- /dev/null
+++ b/gradio_cached_examples/.gitattributes
@@ -0,0 +1,10 @@
+output/1.glb filter=lfs diff=lfs merge=lfs -text
+output/6.glb filter=lfs diff=lfs merge=lfs -text
+output/9.glb filter=lfs diff=lfs merge=lfs -text
+output/5.glb filter=lfs diff=lfs merge=lfs -text
+output/7.glb filter=lfs diff=lfs merge=lfs -text
+output/8.glb filter=lfs diff=lfs merge=lfs -text
+output/0.glb filter=lfs diff=lfs merge=lfs -text
+output/2.glb filter=lfs diff=lfs merge=lfs -text
+output/3.glb filter=lfs diff=lfs merge=lfs -text
+output/4.glb filter=lfs diff=lfs merge=lfs -text
diff --git a/gradio_cached_examples/3D Model/0.glb b/gradio_cached_examples/3D Model/0.glb
new file mode 100644
index 0000000000000000000000000000000000000000..ad0df0336dbb56bb711d48aad5ee2f4085181a50
--- /dev/null
+++ b/gradio_cached_examples/3D Model/0.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1f5ce2e3b8851877d3f2f950148eac0ed4a466fa4ef954954346b0e5ae2adffa
+size 5798824
diff --git a/gradio_cached_examples/3D Model/1.glb b/gradio_cached_examples/3D Model/1.glb
new file mode 100644
index 0000000000000000000000000000000000000000..e817030ce380c56bec3f38bdc8ebd5f860657581
--- /dev/null
+++ b/gradio_cached_examples/3D Model/1.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b2685b1ed8e7a01e902284fd5a8f408576d7776f9cc672de692fa1c838bbbaa6
+size 6432356
diff --git a/gradio_cached_examples/3D Model/2.glb b/gradio_cached_examples/3D Model/2.glb
new file mode 100644
index 0000000000000000000000000000000000000000..9ba667522c33d111f48137d673d2d538dd826d38
--- /dev/null
+++ b/gradio_cached_examples/3D Model/2.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:56607b6879448188a8f6586e5c40cb7199a5cd21bfbf44858d8b2da74fe748c7
+size 6079412
diff --git a/gradio_cached_examples/3D Model/3.glb b/gradio_cached_examples/3D Model/3.glb
new file mode 100644
index 0000000000000000000000000000000000000000..2ebce12df109a42b68b8990e6d9ee2608975bd7a
--- /dev/null
+++ b/gradio_cached_examples/3D Model/3.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:87c7d701abd356f8e271c6f9d79e0348fd6e0a99e298638487febc8bae1c9422
+size 6040496
diff --git a/gradio_cached_examples/3D Model/4.glb b/gradio_cached_examples/3D Model/4.glb
new file mode 100644
index 0000000000000000000000000000000000000000..1866c6e962158589de8b09145426f0da3a8cd902
--- /dev/null
+++ b/gradio_cached_examples/3D Model/4.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e8aa549431270c89bf48b40752f3524edc0973a9a3ed63840afcaac2620ac7af
+size 6910600
diff --git a/gradio_cached_examples/3D Model/5.glb b/gradio_cached_examples/3D Model/5.glb
new file mode 100644
index 0000000000000000000000000000000000000000..f044d4d0705c9e870ed6376413ef71e80cb6a266
--- /dev/null
+++ b/gradio_cached_examples/3D Model/5.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8aa22712df97e6ca38c30ff896ed4f9028c06ecd09c77f608806e11f3faa2650
+size 6823744
diff --git a/gradio_cached_examples/3D Model/6.glb b/gradio_cached_examples/3D Model/6.glb
new file mode 100644
index 0000000000000000000000000000000000000000..94b3853f38cdc3c15cf6aeff2546b64f49f09226
--- /dev/null
+++ b/gradio_cached_examples/3D Model/6.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9620522463d798f8db43eb528a4bc218c475e4e01d0e3ec8f0c0dd5591778511
+size 6346512
diff --git a/gradio_cached_examples/3D Model/7.glb b/gradio_cached_examples/3D Model/7.glb
new file mode 100644
index 0000000000000000000000000000000000000000..4987ae9d504a5a179023049deacb2c33ec32cd4d
--- /dev/null
+++ b/gradio_cached_examples/3D Model/7.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2a522c000d62ee38a0b772c7ec172222fc170003e4f40c77316bc321e503dcba
+size 7694960
diff --git a/gradio_cached_examples/3D Model/8.glb b/gradio_cached_examples/3D Model/8.glb
new file mode 100644
index 0000000000000000000000000000000000000000..f1a92db309c34f4a3626468adfb33960cc28d64b
--- /dev/null
+++ b/gradio_cached_examples/3D Model/8.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ebda9e3c512bb7d54ab320dc8084c7dac4de47a96bbf7639bccbe72e03ad63a0
+size 8251872
diff --git a/gradio_cached_examples/Download 3D Model/0.glb b/gradio_cached_examples/Download 3D Model/0.glb
new file mode 100644
index 0000000000000000000000000000000000000000..ad0df0336dbb56bb711d48aad5ee2f4085181a50
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/0.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1f5ce2e3b8851877d3f2f950148eac0ed4a466fa4ef954954346b0e5ae2adffa
+size 5798824
diff --git a/gradio_cached_examples/Download 3D Model/1.glb b/gradio_cached_examples/Download 3D Model/1.glb
new file mode 100644
index 0000000000000000000000000000000000000000..e817030ce380c56bec3f38bdc8ebd5f860657581
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/1.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b2685b1ed8e7a01e902284fd5a8f408576d7776f9cc672de692fa1c838bbbaa6
+size 6432356
diff --git a/gradio_cached_examples/Download 3D Model/2.glb b/gradio_cached_examples/Download 3D Model/2.glb
new file mode 100644
index 0000000000000000000000000000000000000000..9ba667522c33d111f48137d673d2d538dd826d38
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/2.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:56607b6879448188a8f6586e5c40cb7199a5cd21bfbf44858d8b2da74fe748c7
+size 6079412
diff --git a/gradio_cached_examples/Download 3D Model/3.glb b/gradio_cached_examples/Download 3D Model/3.glb
new file mode 100644
index 0000000000000000000000000000000000000000..2ebce12df109a42b68b8990e6d9ee2608975bd7a
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/3.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:87c7d701abd356f8e271c6f9d79e0348fd6e0a99e298638487febc8bae1c9422
+size 6040496
diff --git a/gradio_cached_examples/Download 3D Model/4.glb b/gradio_cached_examples/Download 3D Model/4.glb
new file mode 100644
index 0000000000000000000000000000000000000000..1866c6e962158589de8b09145426f0da3a8cd902
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/4.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e8aa549431270c89bf48b40752f3524edc0973a9a3ed63840afcaac2620ac7af
+size 6910600
diff --git a/gradio_cached_examples/Download 3D Model/5.glb b/gradio_cached_examples/Download 3D Model/5.glb
new file mode 100644
index 0000000000000000000000000000000000000000..f044d4d0705c9e870ed6376413ef71e80cb6a266
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/5.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8aa22712df97e6ca38c30ff896ed4f9028c06ecd09c77f608806e11f3faa2650
+size 6823744
diff --git a/gradio_cached_examples/Download 3D Model/6.glb b/gradio_cached_examples/Download 3D Model/6.glb
new file mode 100644
index 0000000000000000000000000000000000000000..94b3853f38cdc3c15cf6aeff2546b64f49f09226
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/6.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9620522463d798f8db43eb528a4bc218c475e4e01d0e3ec8f0c0dd5591778511
+size 6346512
diff --git a/gradio_cached_examples/Download 3D Model/7.glb b/gradio_cached_examples/Download 3D Model/7.glb
new file mode 100644
index 0000000000000000000000000000000000000000..4987ae9d504a5a179023049deacb2c33ec32cd4d
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/7.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2a522c000d62ee38a0b772c7ec172222fc170003e4f40c77316bc321e503dcba
+size 7694960
diff --git a/gradio_cached_examples/Download 3D Model/8.glb b/gradio_cached_examples/Download 3D Model/8.glb
new file mode 100644
index 0000000000000000000000000000000000000000..f1a92db309c34f4a3626468adfb33960cc28d64b
--- /dev/null
+++ b/gradio_cached_examples/Download 3D Model/8.glb
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ebda9e3c512bb7d54ab320dc8084c7dac4de47a96bbf7639bccbe72e03ad63a0
+size 8251872
diff --git a/gradio_cached_examples/log.csv b/gradio_cached_examples/log.csv
new file mode 100644
index 0000000000000000000000000000000000000000..c42d0464a63383f9bb190f2b728d6357c0bebd20
--- /dev/null
+++ b/gradio_cached_examples/log.csv
@@ -0,0 +1,10 @@
+'3D Model','Download 3D Model'
+'3D Model/0.glb','Download 3D Model/1.glb'
+'3D Model/1.glb','Download 3D Model/2.glb'
+'3D Model/2.glb','Download 3D Model/3.glb'
+'3D Model/3.glb','Download 3D Model/4.glb'
+'3D Model/4.glb','Download 3D Model/5.glb'
+'3D Model/5.glb','Download 3D Model/6.glb'
+'3D Model/6.glb','Download 3D Model/7.glb'
+'3D Model/7.glb','Download 3D Model/8.glb'
+'3D Model/8.glb','Download 3D Model/8.glb'
diff --git a/packages.txt b/packages.txt
new file mode 100644
index 0000000000000000000000000000000000000000..522fc9eb560ee1b320a6f7afbccf194207b8d3e5
--- /dev/null
+++ b/packages.txt
@@ -0,0 +1,8 @@
+libgl1
+unzip
+ffmpeg
+libsm6
+libxext6
+libgl1-mesa-dri
+libegl1-mesa
+libgbm1
\ No newline at end of file
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..10e800b3af9af68811d6de55206dbdcbd2e7e917
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,30 @@
+cycler==0.10.0
+decorator==4.4.1
+imageio==2.8.0
+kiwisolver==1.1.0
+matplotlib==3.1.3
+networkx==2.4
+numpy==1.21.6
+opencv-python==4.1.2.30
+Pillow==9.1.0
+PyOpenGL==3.1.6
+pyparsing==2.4.6
+python-dateutil==2.8.1
+PyWavelets==1.1.1
+scikit-image==0.18.3
+scikit-learn==1.0.2
+scipy==1.4.1
+Shapely==1.7.0
+six==1.14.0
+torch==1.4.0
+torchvision==0.5.0
+git+https://github.com/huggingface/diffusers
+transformers
+accelerate
+ftfy
+trimesh==3.5.23
+tqdm==4.64.0
+paddlehub
+paddlepaddle
+glob2
+gradio==3.0.2
\ No newline at end of file