
Commit
·
6cda05c
1
Parent(s):
9e478e3
updated
Browse files- .vscode/settings.json +3 -0
- README.md +26 -1
- app/app.py +212 -0
- requirements.txt +5 -0
- screenshots/1.png +0 -0
- screenshots/2.png +0 -0
- screenshots/3.png +0 -0
- screenshots/4.png +0 -0
.vscode/settings.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"window.title": "${dirty}${activeEditorShort}${separator}${rootName}${separator}${profileName}${separator}${appName}${separator}[Branch: main]"
|
| 3 |
+
}
|
README.md
CHANGED
|
@@ -1 +1,26 @@
|
|
| 1 |
-
#
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Prompt And Output Separation Utility
|
| 2 |
+
|
| 3 |
+
This is a utility that was generated by Claude Anthropic with prompting by me in order to generate a Streamlit Community Cloud utility for automatically separating prompts and outputs when they are recorded together in one continuous string of text.
|
| 4 |
+
|
| 5 |
+
## Author
|
| 6 |
+
|
| 7 |
+
Daniel Rosehill
|
| 8 |
+
(public at danielrosehill dot com)
|
| 9 |
+
|
| 10 |
+
## Licensing
|
| 11 |
+
|
| 12 |
+
This repository is licensed under CC-BY-4.0 (Attribution 4.0 International)
|
| 13 |
+
[License](https://creativecommons.org/licenses/by/4.0/)
|
| 14 |
+
|
| 15 |
+
### Summary of the License
|
| 16 |
+
The Creative Commons Attribution 4.0 International (CC BY 4.0) license allows others to:
|
| 17 |
+
- **Share**: Copy and redistribute the material in any medium or format.
|
| 18 |
+
- **Adapt**: Remix, transform, and build upon the material for any purpose, even commercially.
|
| 19 |
+
|
| 20 |
+
The licensor cannot revoke these freedoms as long as you follow the license terms.
|
| 21 |
+
|
| 22 |
+
#### License Terms
|
| 23 |
+
- **Attribution**: You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
|
| 24 |
+
- **No additional restrictions**: You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
|
| 25 |
+
|
| 26 |
+
For the full legal code, please visit the [Creative Commons website](https://creativecommons.org/licenses/by/4.0/legalcode).
|
app/app.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import re
|
| 4 |
+
import time
|
| 5 |
+
import os
|
| 6 |
+
from io import StringIO
|
| 7 |
+
import pyperclip
|
| 8 |
+
import nltk
|
| 9 |
+
from openai import OpenAI
|
| 10 |
+
import json
|
| 11 |
+
|
| 12 |
+
# OpenAI configuration
|
| 13 |
+
if 'openai_api_key' not in st.session_state:
|
| 14 |
+
st.session_state.openai_api_key = None
|
| 15 |
+
|
| 16 |
+
# Sidebar for API key configuration
|
| 17 |
+
with st.sidebar:
|
| 18 |
+
st.markdown("## Configuration")
|
| 19 |
+
api_key = st.text_input("Enter OpenAI API Key", type="password")
|
| 20 |
+
if api_key:
|
| 21 |
+
st.session_state.openai_api_key = api_key
|
| 22 |
+
client = OpenAI(api_key=api_key)
|
| 23 |
+
|
| 24 |
+
def analyze_with_llm(text):
|
| 25 |
+
if not st.session_state.openai_api_key:
|
| 26 |
+
st.error("Please provide an OpenAI API key in the sidebar")
|
| 27 |
+
return None, None
|
| 28 |
+
|
| 29 |
+
try:
|
| 30 |
+
client = OpenAI(api_key=st.session_state.openai_api_key)
|
| 31 |
+
|
| 32 |
+
response = client.chat.completions.create(
|
| 33 |
+
model="gpt-3.5-turbo-1106",
|
| 34 |
+
messages=[
|
| 35 |
+
{
|
| 36 |
+
"role": "system",
|
| 37 |
+
"content": """You are a text analysis expert. Your task is to separate a conversation into the prompt/question and the response/answer.
|
| 38 |
+
Return ONLY a JSON object with two fields:
|
| 39 |
+
- prompt: the user's question or prompt
|
| 40 |
+
- output: the response or answer
|
| 41 |
+
If you cannot clearly identify both parts, set the unknown part to null."""
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"role": "user",
|
| 45 |
+
"content": f"Please analyze this text and separate it into prompt and output: {text}"
|
| 46 |
+
}
|
| 47 |
+
],
|
| 48 |
+
temperature=0,
|
| 49 |
+
response_format={ "type": "json_object" }
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
result = response.choices[0].message.content
|
| 53 |
+
parsed = json.loads(result)
|
| 54 |
+
return parsed.get("prompt"), parsed.get("output")
|
| 55 |
+
|
| 56 |
+
except Exception as e:
|
| 57 |
+
st.error(f"Error analyzing text: {str(e)}")
|
| 58 |
+
return None, None
|
| 59 |
+
|
| 60 |
+
# Processing function
|
| 61 |
+
def separate_prompt_output(text):
|
| 62 |
+
if not text:
|
| 63 |
+
return "", ""
|
| 64 |
+
|
| 65 |
+
# Use LLM if API key is available
|
| 66 |
+
if st.session_state.openai_api_key:
|
| 67 |
+
prompt, output = analyze_with_llm(text)
|
| 68 |
+
if prompt is not None and output is not None:
|
| 69 |
+
return prompt, output
|
| 70 |
+
|
| 71 |
+
# Fallback to basic separation if LLM fails or no API key
|
| 72 |
+
parts = text.split('\n\n', 1)
|
| 73 |
+
if len(parts) == 2:
|
| 74 |
+
return parts[0].strip(), parts[1].strip()
|
| 75 |
+
return text.strip(), ""
|
| 76 |
+
|
| 77 |
+
# Column processing function
|
| 78 |
+
def process_column(column):
|
| 79 |
+
processed_data = []
|
| 80 |
+
for item in column:
|
| 81 |
+
prompt, output = separate_prompt_output(str(item))
|
| 82 |
+
processed_data.append({"Prompt": prompt, "Output": output})
|
| 83 |
+
return pd.DataFrame(processed_data)
|
| 84 |
+
|
| 85 |
+
# Download NLTK resources
|
| 86 |
+
nltk.download('punkt')
|
| 87 |
+
|
| 88 |
+
# Session state management
|
| 89 |
+
if 'history' not in st.session_state:
|
| 90 |
+
st.session_state.history = []
|
| 91 |
+
|
| 92 |
+
if 'mode' not in st.session_state:
|
| 93 |
+
st.session_state.mode = 'light'
|
| 94 |
+
|
| 95 |
+
# Styling
|
| 96 |
+
st.markdown("""
|
| 97 |
+
<style>
|
| 98 |
+
body {
|
| 99 |
+
font-family: Arial, sans-serif;
|
| 100 |
+
color: #333;
|
| 101 |
+
background-color: #f4f4f9;
|
| 102 |
+
}
|
| 103 |
+
.stTextInput > div > div > input {
|
| 104 |
+
font-size: 16px;
|
| 105 |
+
}
|
| 106 |
+
.stButton > button {
|
| 107 |
+
font-size: 16px;
|
| 108 |
+
padding: 0.5rem 1rem;
|
| 109 |
+
}
|
| 110 |
+
.stMarkdown {
|
| 111 |
+
font-size: 14px;
|
| 112 |
+
}
|
| 113 |
+
</style>
|
| 114 |
+
""", unsafe_allow_html=True)
|
| 115 |
+
|
| 116 |
+
# Dark mode toggle
|
| 117 |
+
if st.sidebar.button("Toggle Dark Mode"):
|
| 118 |
+
st.session_state.mode = 'dark' if st.session_state.mode == 'light' else 'light'
|
| 119 |
+
|
| 120 |
+
if st.session_state.mode == 'dark':
|
| 121 |
+
st.markdown("""
|
| 122 |
+
<style>
|
| 123 |
+
body {
|
| 124 |
+
color: #fff;
|
| 125 |
+
background-color: #121212;
|
| 126 |
+
}
|
| 127 |
+
.stTextInput > div > div > input {
|
| 128 |
+
color: #fff;
|
| 129 |
+
background-color: #333;
|
| 130 |
+
}
|
| 131 |
+
.stButton > button {
|
| 132 |
+
color: #fff;
|
| 133 |
+
background-color: #6200ea;
|
| 134 |
+
}
|
| 135 |
+
.stMarkdown {
|
| 136 |
+
color: #fff;
|
| 137 |
+
}
|
| 138 |
+
</style>
|
| 139 |
+
""", unsafe_allow_html=True)
|
| 140 |
+
|
| 141 |
+
# Header
|
| 142 |
+
st.title("Prompt Output Separator")
|
| 143 |
+
st.markdown("A utility to separate user prompts from AI responses")
|
| 144 |
+
|
| 145 |
+
# Add API key status indicator
|
| 146 |
+
if st.session_state.openai_api_key:
|
| 147 |
+
st.sidebar.success("✓ API Key configured")
|
| 148 |
+
else:
|
| 149 |
+
st.sidebar.warning("⚠ No API Key provided - using basic separation")
|
| 150 |
+
|
| 151 |
+
# GitHub badge
|
| 152 |
+
st.sidebar.markdown("[](https://github.com/danielrosehill)")
|
| 153 |
+
|
| 154 |
+
# Tabs
|
| 155 |
+
tabs = st.tabs(["Manual Input", "File Processing"])
|
| 156 |
+
|
| 157 |
+
# Manual Input Tab
|
| 158 |
+
with tabs[0]:
|
| 159 |
+
st.subheader("Manual Input")
|
| 160 |
+
input_text = st.text_area("Enter text here", height=300)
|
| 161 |
+
|
| 162 |
+
col1, col2 = st.columns(2)
|
| 163 |
+
|
| 164 |
+
with col1:
|
| 165 |
+
if st.button("Separate Now"):
|
| 166 |
+
if input_text:
|
| 167 |
+
st.session_state.history.append(input_text)
|
| 168 |
+
prompt, output = separate_prompt_output(input_text)
|
| 169 |
+
st.session_state.prompt = prompt
|
| 170 |
+
st.session_state.output = output
|
| 171 |
+
else:
|
| 172 |
+
st.error("Please enter some text")
|
| 173 |
+
|
| 174 |
+
if st.button("Clear"):
|
| 175 |
+
st.session_state.prompt = ""
|
| 176 |
+
st.session_state.output = ""
|
| 177 |
+
input_text = ""
|
| 178 |
+
|
| 179 |
+
with col2:
|
| 180 |
+
st.text_area("Prompt", value=st.session_state.get('prompt', ""), height=150)
|
| 181 |
+
st.text_area("Output", value=st.session_state.get('output', ""), height=150)
|
| 182 |
+
|
| 183 |
+
if st.button("Copy Prompt to Clipboard"):
|
| 184 |
+
pyperclip.copy(st.session_state.get('prompt', ""))
|
| 185 |
+
st.success("Copied to clipboard")
|
| 186 |
+
|
| 187 |
+
if st.button("Copy Output to Clipboard"):
|
| 188 |
+
pyperclip.copy(st.session_state.get('output', ""))
|
| 189 |
+
st.success("Copied to clipboard")
|
| 190 |
+
|
| 191 |
+
# File Processing Tab
|
| 192 |
+
with tabs[1]:
|
| 193 |
+
st.subheader("File Processing")
|
| 194 |
+
uploaded_files = st.file_uploader("Upload files", type=["txt", "md", "csv"], accept_multiple_files=True)
|
| 195 |
+
|
| 196 |
+
if uploaded_files:
|
| 197 |
+
for file in uploaded_files:
|
| 198 |
+
file_content = file.read().decode("utf-8")
|
| 199 |
+
if file.name.endswith(".csv"):
|
| 200 |
+
df = pd.read_csv(StringIO(file_content))
|
| 201 |
+
for col in df.columns:
|
| 202 |
+
processed_df = process_column(df[col])
|
| 203 |
+
st.write(f"Processed column: {col}")
|
| 204 |
+
st.write(processed_df)
|
| 205 |
+
else:
|
| 206 |
+
processed_text = separate_prompt_output(file_content)
|
| 207 |
+
st.write("Processed text file:")
|
| 208 |
+
st.write({"Prompt": processed_text[0], "Output": processed_text[1]})
|
| 209 |
+
|
| 210 |
+
# Footer
|
| 211 |
+
st.markdown("---")
|
| 212 |
+
st.write("Version 1.0.0")
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
openai>=1.0.0
|
| 2 |
+
streamlit
|
| 3 |
+
pandas
|
| 4 |
+
pyperclip
|
| 5 |
+
nltk
|
screenshots/1.png
ADDED
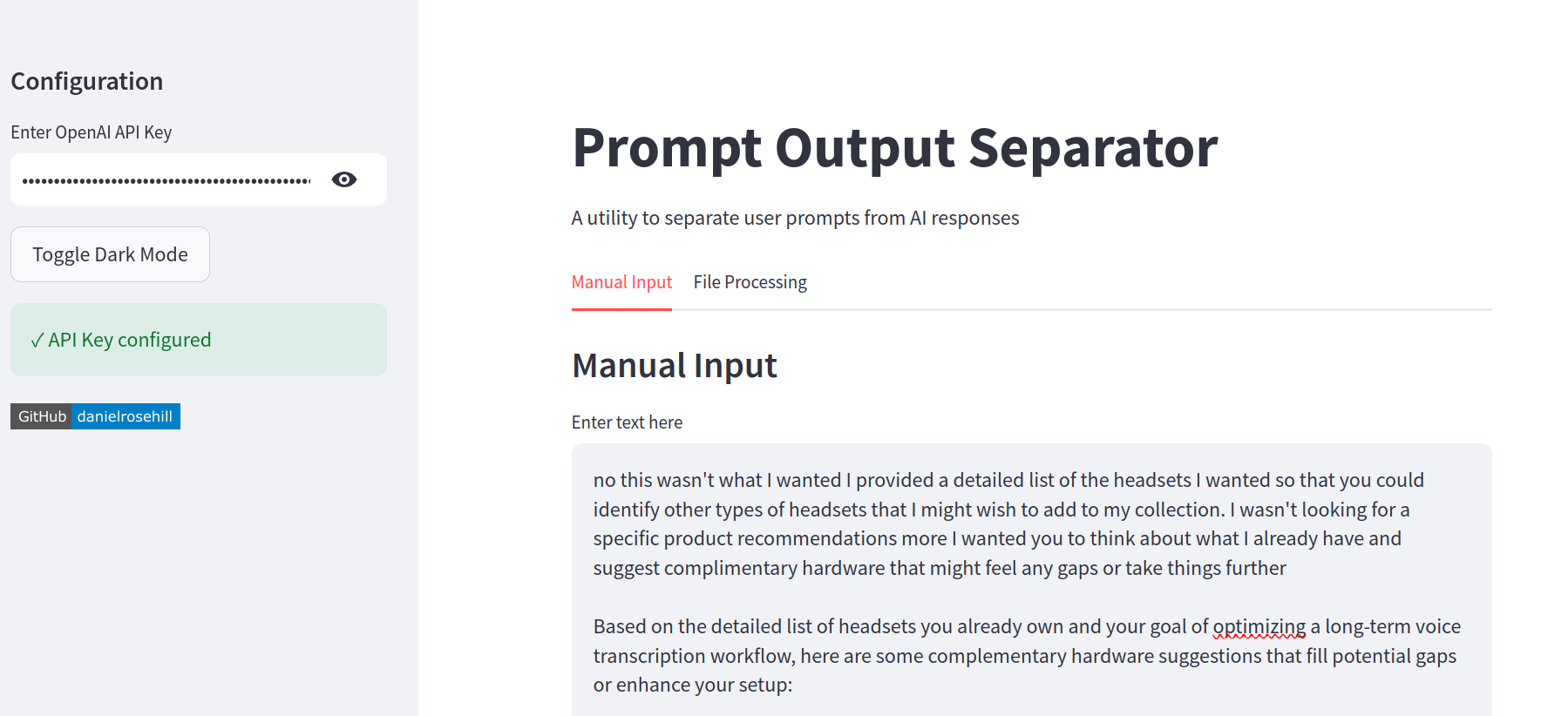
|
screenshots/2.png
ADDED
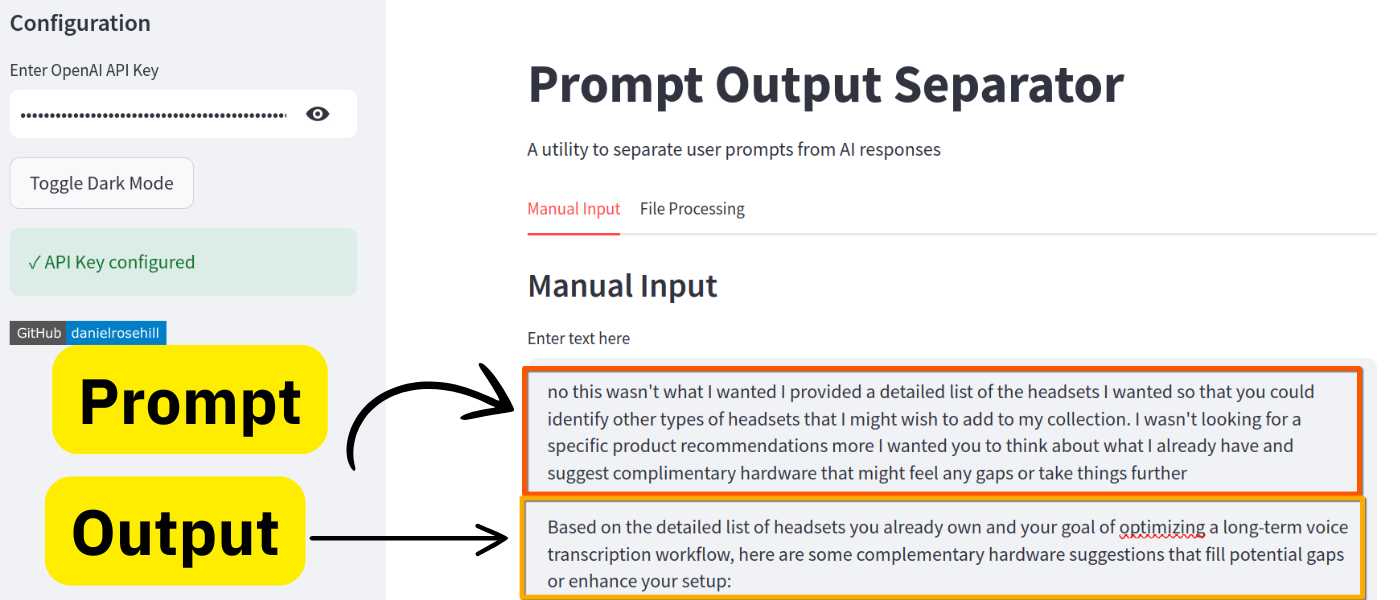
|
screenshots/3.png
ADDED

|
screenshots/4.png
ADDED
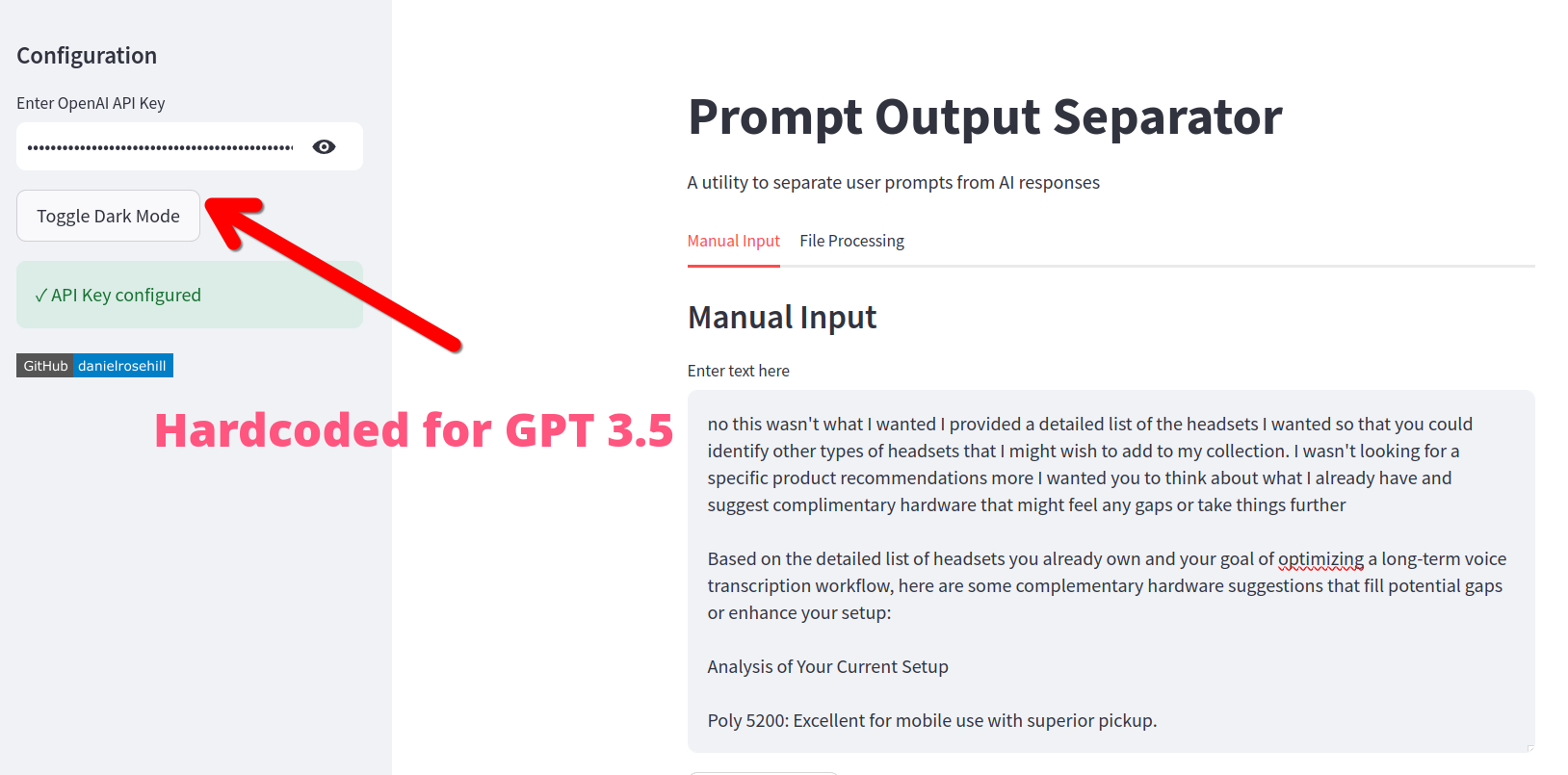
|