diff --git a/README.md b/README.md
index 300e19f4f108231fbfb3167e2ac456a594a0d93a..cd87a5528018f8bf38b8ab3be592dac3aaf30d5c 100644
--- a/README.md
+++ b/README.md
@@ -1,8 +1,8 @@
---
-title: Tango2 Full
-emoji: 🏆
+title: Tango2
+emoji: 🐠
colorFrom: indigo
-colorTo: red
+colorTo: pink
sdk: gradio
sdk_version: 4.26.0
app_file: app.py
diff --git a/app.py b/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bf8c4abe42dc5ca2217adbf85b61ae18866b3a3
--- /dev/null
+++ b/app.py
@@ -0,0 +1,143 @@
+import gradio as gr
+import json
+import torch
+import wavio
+from tqdm import tqdm
+from huggingface_hub import snapshot_download
+from models import AudioDiffusion, DDPMScheduler
+from audioldm.audio.stft import TacotronSTFT
+from audioldm.variational_autoencoder import AutoencoderKL
+from gradio import Markdown
+import spaces
+
+class Tango:
+ def __init__(self, name="declare-lab/tango2-full", device="cuda:0"):
+
+ path = snapshot_download(repo_id=name)
+
+ vae_config = json.load(open("{}/vae_config.json".format(path)))
+ stft_config = json.load(open("{}/stft_config.json".format(path)))
+ main_config = json.load(open("{}/main_config.json".format(path)))
+
+ self.vae = AutoencoderKL(**vae_config).to(device)
+ self.stft = TacotronSTFT(**stft_config).to(device)
+ self.model = AudioDiffusion(**main_config).to(device)
+
+ vae_weights = torch.load("{}/pytorch_model_vae.bin".format(path), map_location=device)
+ stft_weights = torch.load("{}/pytorch_model_stft.bin".format(path), map_location=device)
+ main_weights = torch.load("{}/pytorch_model_main.bin".format(path), map_location=device)
+
+ self.vae.load_state_dict(vae_weights)
+ self.stft.load_state_dict(stft_weights)
+ self.model.load_state_dict(main_weights)
+
+ print ("Successfully loaded checkpoint from:", name)
+
+ self.vae.eval()
+ self.stft.eval()
+ self.model.eval()
+
+ self.scheduler = DDPMScheduler.from_pretrained(main_config["scheduler_name"], subfolder="scheduler")
+
+ def chunks(self, lst, n):
+ """ Yield successive n-sized chunks from a list. """
+ for i in range(0, len(lst), n):
+ yield lst[i:i + n]
+
+ def generate(self, prompt, steps=100, guidance=3, samples=1, disable_progress=True):
+ """ Genrate audio for a single prompt string. """
+ with torch.no_grad():
+ latents = self.model.inference([prompt], self.scheduler, steps, guidance, samples, disable_progress=disable_progress)
+ mel = self.vae.decode_first_stage(latents)
+ wave = self.vae.decode_to_waveform(mel)
+ return wave[0]
+
+ def generate_for_batch(self, prompts, steps=200, guidance=3, samples=1, batch_size=8, disable_progress=True):
+ """ Genrate audio for a list of prompt strings. """
+ outputs = []
+ for k in tqdm(range(0, len(prompts), batch_size)):
+ batch = prompts[k: k+batch_size]
+ with torch.no_grad():
+ latents = self.model.inference(batch, self.scheduler, steps, guidance, samples, disable_progress=disable_progress)
+ mel = self.vae.decode_first_stage(latents)
+ wave = self.vae.decode_to_waveform(mel)
+ outputs += [item for item in wave]
+ if samples == 1:
+ return outputs
+ else:
+ return list(self.chunks(outputs, samples))
+
+# Initialize TANGO
+
+tango = Tango(device="cpu")
+tango.vae.to("cuda")
+tango.stft.to("cuda")
+tango.model.to("cuda")
+
+@spaces.GPU(duration=60)
+def gradio_generate(prompt, steps, guidance):
+ output_wave = tango.generate(prompt, steps, guidance)
+ # output_filename = f"{prompt.replace(' ', '_')}_{steps}_{guidance}"[:250] + ".wav"
+ output_filename = "temp.wav"
+ wavio.write(output_filename, output_wave, rate=16000, sampwidth=2)
+
+ return output_filename
+
+# description_text = """
+#  For faster inference without waiting in queue, you may duplicate the space and upgrade to a GPU in the settings.
For faster inference without waiting in queue, you may duplicate the space and upgrade to a GPU in the settings.
+# Generate audio using TANGO by providing a text prompt.
+#
Limitations: TANGO is trained on the small AudioCaps dataset so it may not generate good audio \
+# samples related to concepts that it has not seen in training (e.g. singing). For the same reason, TANGO \
+# is not always able to finely control its generations over textual control prompts. For example, \
+# the generations from TANGO for prompts Chopping tomatoes on a wooden table and Chopping potatoes \
+# on a metal table are very similar. \
+#
We are currently training another version of TANGO on larger datasets to enhance its generalization, \
+# compositional and controllable generation ability.
+#
We recommend using a guidance scale of 3. The default number of steps is set to 100. More steps generally lead to better quality of generated audios but will take longer.
+#
+#
ChatGPT-enhanced audio generation
+#
+# As TANGO consists of an instruction-tuned LLM, it is able to process complex sound descriptions allowing us to provide more detailed instructions to improve the generation quality.
+# For example, ``A boat is moving on the sea'' vs ``The sound of the water lapping against the hull of the boat or splashing as you move through the waves''. The latter is obtained by prompting ChatGPT to explain the sound generated when a boat moves on the sea.
+# Using this ChatGPT-generated description of the sound, TANGO provides superior results.
+#
+# """
+description_text = ""
+# Gradio input and output components
+input_text = gr.Textbox(lines=2, label="Prompt")
+output_audio = gr.Audio(label="Generated Audio", type="filepath")
+denoising_steps = gr.Slider(minimum=100, maximum=200, value=100, step=1, label="Steps", interactive=True)
+guidance_scale = gr.Slider(minimum=1, maximum=10, value=3, step=0.1, label="Guidance Scale", interactive=True)
+
+# Gradio interface
+gr_interface = gr.Interface(
+ fn=gradio_generate,
+ inputs=[input_text, denoising_steps, guidance_scale],
+ outputs=[output_audio],
+ title="TANGO2: Aligning Diffusion-based Text-to-Audio Generative Models through Direct Preference Optimization",
+ description=description_text,
+ allow_flagging=False,
+ examples=[
+ ["A lady is singing a song with a kid"],
+ ["The sound of the water lapping against the hull of the boat or splashing as you move through the waves"],
+ ["An audience cheering and clapping"],
+ ["Rolling thunder with lightning strikes"],
+ ["Gentle water stream, birds chirping and sudden gun shot"],
+ ["A car engine revving"],
+ ["A dog barking"],
+ ["A cat meowing"],
+ ["Wooden table tapping sound while water pouring"],
+ ["Emergency sirens wailing"],
+ ["two gunshots followed by birds flying away while chirping"],
+ ["Whistling with birds chirping"],
+ ["A person snoring"],
+ ["Motor vehicles are driving with loud engines and a person whistles"],
+ ["People cheering in a stadium while thunder and lightning strikes"],
+ ["A helicopter is in flight"],
+ ["A dog barking and a man talking and a racing car passes by"],
+ ],
+ cache_examples=False, # Turn on to cache.
+)
+
+# Launch Gradio app
+gr_interface.queue(10).launch()
\ No newline at end of file
diff --git a/audioldm/__init__.py b/audioldm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2bbf85f01ccc72b6f18e7405d940adf07a26b500
--- /dev/null
+++ b/audioldm/__init__.py
@@ -0,0 +1,8 @@
+from .ldm import LatentDiffusion
+from .utils import seed_everything, save_wave, get_time, get_duration
+from .pipeline import *
+
+
+
+
+
diff --git a/audioldm/__main__.py b/audioldm/__main__.py
new file mode 100644
index 0000000000000000000000000000000000000000..13f8bafa839f512a156dd6380d2cf43c573a970a
--- /dev/null
+++ b/audioldm/__main__.py
@@ -0,0 +1,183 @@
+#!/usr/bin/python3
+import os
+from audioldm import text_to_audio, style_transfer, build_model, save_wave, get_time, round_up_duration, get_duration
+import argparse
+
+CACHE_DIR = os.getenv(
+ "AUDIOLDM_CACHE_DIR",
+ os.path.join(os.path.expanduser("~"), ".cache/audioldm"))
+
+parser = argparse.ArgumentParser()
+
+parser.add_argument(
+ "--mode",
+ type=str,
+ required=False,
+ default="generation",
+ help="generation: text-to-audio generation; transfer: style transfer",
+ choices=["generation", "transfer"]
+)
+
+parser.add_argument(
+ "-t",
+ "--text",
+ type=str,
+ required=False,
+ default="",
+ help="Text prompt to the model for audio generation",
+)
+
+parser.add_argument(
+ "-f",
+ "--file_path",
+ type=str,
+ required=False,
+ default=None,
+ help="(--mode transfer): Original audio file for style transfer; Or (--mode generation): the guidance audio file for generating simialr audio",
+)
+
+parser.add_argument(
+ "--transfer_strength",
+ type=float,
+ required=False,
+ default=0.5,
+ help="A value between 0 and 1. 0 means original audio without transfer, 1 means completely transfer to the audio indicated by text",
+)
+
+parser.add_argument(
+ "-s",
+ "--save_path",
+ type=str,
+ required=False,
+ help="The path to save model output",
+ default="./output",
+)
+
+parser.add_argument(
+ "--model_name",
+ type=str,
+ required=False,
+ help="The checkpoint you gonna use",
+ default="audioldm-s-full",
+ choices=["audioldm-s-full", "audioldm-l-full", "audioldm-s-full-v2"]
+)
+
+parser.add_argument(
+ "-ckpt",
+ "--ckpt_path",
+ type=str,
+ required=False,
+ help="The path to the pretrained .ckpt model",
+ default=None,
+)
+
+parser.add_argument(
+ "-b",
+ "--batchsize",
+ type=int,
+ required=False,
+ default=1,
+ help="Generate how many samples at the same time",
+)
+
+parser.add_argument(
+ "--ddim_steps",
+ type=int,
+ required=False,
+ default=200,
+ help="The sampling step for DDIM",
+)
+
+parser.add_argument(
+ "-gs",
+ "--guidance_scale",
+ type=float,
+ required=False,
+ default=2.5,
+ help="Guidance scale (Large => better quality and relavancy to text; Small => better diversity)",
+)
+
+parser.add_argument(
+ "-dur",
+ "--duration",
+ type=float,
+ required=False,
+ default=10.0,
+ help="The duration of the samples",
+)
+
+parser.add_argument(
+ "-n",
+ "--n_candidate_gen_per_text",
+ type=int,
+ required=False,
+ default=3,
+ help="Automatic quality control. This number control the number of candidates (e.g., generate three audios and choose the best to show you). A Larger value usually lead to better quality with heavier computation",
+)
+
+parser.add_argument(
+ "--seed",
+ type=int,
+ required=False,
+ default=42,
+ help="Change this value (any integer number) will lead to a different generation result.",
+)
+
+args = parser.parse_args()
+
+if(args.ckpt_path is not None):
+ print("Warning: ckpt_path has no effect after version 0.0.20.")
+
+assert args.duration % 2.5 == 0, "Duration must be a multiple of 2.5"
+
+mode = args.mode
+if(mode == "generation" and args.file_path is not None):
+ mode = "generation_audio_to_audio"
+ if(len(args.text) > 0):
+ print("Warning: You have specified the --file_path. --text will be ignored")
+ args.text = ""
+
+save_path = os.path.join(args.save_path, mode)
+
+if(args.file_path is not None):
+ save_path = os.path.join(save_path, os.path.basename(args.file_path.split(".")[0]))
+
+text = args.text
+random_seed = args.seed
+duration = args.duration
+guidance_scale = args.guidance_scale
+n_candidate_gen_per_text = args.n_candidate_gen_per_text
+
+os.makedirs(save_path, exist_ok=True)
+audioldm = build_model(model_name=args.model_name)
+
+if(args.mode == "generation"):
+ waveform = text_to_audio(
+ audioldm,
+ text,
+ args.file_path,
+ random_seed,
+ duration=duration,
+ guidance_scale=guidance_scale,
+ ddim_steps=args.ddim_steps,
+ n_candidate_gen_per_text=n_candidate_gen_per_text,
+ batchsize=args.batchsize,
+ )
+
+elif(args.mode == "transfer"):
+ assert args.file_path is not None
+ assert os.path.exists(args.file_path), "The original audio file \'%s\' for style transfer does not exist." % args.file_path
+ waveform = style_transfer(
+ audioldm,
+ text,
+ args.file_path,
+ args.transfer_strength,
+ random_seed,
+ duration=duration,
+ guidance_scale=guidance_scale,
+ ddim_steps=args.ddim_steps,
+ batchsize=args.batchsize,
+ )
+ waveform = waveform[:,None,:]
+
+save_wave(waveform, save_path, name="%s_%s" % (get_time(), text))
diff --git a/audioldm/__pycache__/__init__.cpython-310.pyc b/audioldm/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..067501d8389f25b3dd5e94e094dee4fec6b020d8
Binary files /dev/null and b/audioldm/__pycache__/__init__.cpython-310.pyc differ
diff --git a/audioldm/__pycache__/__init__.cpython-39.pyc b/audioldm/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0d328b3eaf9f4eacac868e98967a5dc9c1986348
Binary files /dev/null and b/audioldm/__pycache__/__init__.cpython-39.pyc differ
diff --git a/audioldm/__pycache__/ldm.cpython-310.pyc b/audioldm/__pycache__/ldm.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7d60ccb9c75da0ff674a2c1552d5705ddaac72f1
Binary files /dev/null and b/audioldm/__pycache__/ldm.cpython-310.pyc differ
diff --git a/audioldm/__pycache__/ldm.cpython-39.pyc b/audioldm/__pycache__/ldm.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..221430f46af091948a712bd53e3f433848410f2e
Binary files /dev/null and b/audioldm/__pycache__/ldm.cpython-39.pyc differ
diff --git a/audioldm/__pycache__/pipeline.cpython-310.pyc b/audioldm/__pycache__/pipeline.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8d924469b8abbd5e9069d4adf6ef3d74dcd0228c
Binary files /dev/null and b/audioldm/__pycache__/pipeline.cpython-310.pyc differ
diff --git a/audioldm/__pycache__/pipeline.cpython-39.pyc b/audioldm/__pycache__/pipeline.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..84b7d927277281ad53ed68755a069b5e34d2c4f5
Binary files /dev/null and b/audioldm/__pycache__/pipeline.cpython-39.pyc differ
diff --git a/audioldm/__pycache__/utils.cpython-310.pyc b/audioldm/__pycache__/utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2a8ef89a18f16551116fe36a17fa3f71c9abc33e
Binary files /dev/null and b/audioldm/__pycache__/utils.cpython-310.pyc differ
diff --git a/audioldm/__pycache__/utils.cpython-39.pyc b/audioldm/__pycache__/utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..832b2699578046b4ca139fe2a01a8105c5b05068
Binary files /dev/null and b/audioldm/__pycache__/utils.cpython-39.pyc differ
diff --git a/audioldm/audio/__init__.py b/audioldm/audio/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..56902e96f041bc4ba6bfadd7a7742023b9560233
--- /dev/null
+++ b/audioldm/audio/__init__.py
@@ -0,0 +1,2 @@
+from .tools import wav_to_fbank, read_wav_file
+from .stft import TacotronSTFT
diff --git a/audioldm/audio/__pycache__/__init__.cpython-310.pyc b/audioldm/audio/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7c3a56530f805df37d002bde85f7cc955af7501e
Binary files /dev/null and b/audioldm/audio/__pycache__/__init__.cpython-310.pyc differ
diff --git a/audioldm/audio/__pycache__/__init__.cpython-39.pyc b/audioldm/audio/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..90462df03852001507606b9849462d919c8804bf
Binary files /dev/null and b/audioldm/audio/__pycache__/__init__.cpython-39.pyc differ
diff --git a/audioldm/audio/__pycache__/audio_processing.cpython-310.pyc b/audioldm/audio/__pycache__/audio_processing.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3fc766bc8f667260cf35d199a33fb6ea2214ae34
Binary files /dev/null and b/audioldm/audio/__pycache__/audio_processing.cpython-310.pyc differ
diff --git a/audioldm/audio/__pycache__/audio_processing.cpython-39.pyc b/audioldm/audio/__pycache__/audio_processing.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2c0834d7e33b8705ffbe6f53fcc1718f10fa3505
Binary files /dev/null and b/audioldm/audio/__pycache__/audio_processing.cpython-39.pyc differ
diff --git a/audioldm/audio/__pycache__/mix.cpython-39.pyc b/audioldm/audio/__pycache__/mix.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..003a82b3753e63a56273c14c523d2124d7447630
Binary files /dev/null and b/audioldm/audio/__pycache__/mix.cpython-39.pyc differ
diff --git a/audioldm/audio/__pycache__/stft.cpython-310.pyc b/audioldm/audio/__pycache__/stft.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..65c75413e11a5619dbf04269b313abbfcd32097c
Binary files /dev/null and b/audioldm/audio/__pycache__/stft.cpython-310.pyc differ
diff --git a/audioldm/audio/__pycache__/stft.cpython-39.pyc b/audioldm/audio/__pycache__/stft.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3a01acfda6f67baa8f452abf9cfea52a158569b1
Binary files /dev/null and b/audioldm/audio/__pycache__/stft.cpython-39.pyc differ
diff --git a/audioldm/audio/__pycache__/tools.cpython-310.pyc b/audioldm/audio/__pycache__/tools.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bd5a6802eeb0092dac35393c9bf86669bcccf3a5
Binary files /dev/null and b/audioldm/audio/__pycache__/tools.cpython-310.pyc differ
diff --git a/audioldm/audio/__pycache__/tools.cpython-39.pyc b/audioldm/audio/__pycache__/tools.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1ce3a469b3afaaa3f82fb3a2f73cdac0a08a1df3
Binary files /dev/null and b/audioldm/audio/__pycache__/tools.cpython-39.pyc differ
diff --git a/audioldm/audio/__pycache__/torch_tools.cpython-39.pyc b/audioldm/audio/__pycache__/torch_tools.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d12585156ae7b45619271b60b313cb6b7c9b3682
Binary files /dev/null and b/audioldm/audio/__pycache__/torch_tools.cpython-39.pyc differ
diff --git a/audioldm/audio/audio_processing.py b/audioldm/audio/audio_processing.py
new file mode 100644
index 0000000000000000000000000000000000000000..77a4057aa82f226f68474f4c2a19eba84510d663
--- /dev/null
+++ b/audioldm/audio/audio_processing.py
@@ -0,0 +1,100 @@
+import torch
+import numpy as np
+import librosa.util as librosa_util
+from scipy.signal import get_window
+
+
+def window_sumsquare(
+ window,
+ n_frames,
+ hop_length,
+ win_length,
+ n_fft,
+ dtype=np.float32,
+ norm=None,
+):
+ """
+ # from librosa 0.6
+ Compute the sum-square envelope of a window function at a given hop length.
+
+ This is used to estimate modulation effects induced by windowing
+ observations in short-time fourier transforms.
+
+ Parameters
+ ----------
+ window : string, tuple, number, callable, or list-like
+ Window specification, as in `get_window`
+
+ n_frames : int > 0
+ The number of analysis frames
+
+ hop_length : int > 0
+ The number of samples to advance between frames
+
+ win_length : [optional]
+ The length of the window function. By default, this matches `n_fft`.
+
+ n_fft : int > 0
+ The length of each analysis frame.
+
+ dtype : np.dtype
+ The data type of the output
+
+ Returns
+ -------
+ wss : np.ndarray, shape=`(n_fft + hop_length * (n_frames - 1))`
+ The sum-squared envelope of the window function
+ """
+ if win_length is None:
+ win_length = n_fft
+
+ n = n_fft + hop_length * (n_frames - 1)
+ x = np.zeros(n, dtype=dtype)
+
+ # Compute the squared window at the desired length
+ win_sq = get_window(window, win_length, fftbins=True)
+ win_sq = librosa_util.normalize(win_sq, norm=norm) ** 2
+ win_sq = librosa_util.pad_center(win_sq, n_fft)
+
+ # Fill the envelope
+ for i in range(n_frames):
+ sample = i * hop_length
+ x[sample : min(n, sample + n_fft)] += win_sq[: max(0, min(n_fft, n - sample))]
+ return x
+
+
+def griffin_lim(magnitudes, stft_fn, n_iters=30):
+ """
+ PARAMS
+ ------
+ magnitudes: spectrogram magnitudes
+ stft_fn: STFT class with transform (STFT) and inverse (ISTFT) methods
+ """
+
+ angles = np.angle(np.exp(2j * np.pi * np.random.rand(*magnitudes.size())))
+ angles = angles.astype(np.float32)
+ angles = torch.autograd.Variable(torch.from_numpy(angles))
+ signal = stft_fn.inverse(magnitudes, angles).squeeze(1)
+
+ for i in range(n_iters):
+ _, angles = stft_fn.transform(signal)
+ signal = stft_fn.inverse(magnitudes, angles).squeeze(1)
+ return signal
+
+
+def dynamic_range_compression(x, normalize_fun=torch.log, C=1, clip_val=1e-5):
+ """
+ PARAMS
+ ------
+ C: compression factor
+ """
+ return normalize_fun(torch.clamp(x, min=clip_val) * C)
+
+
+def dynamic_range_decompression(x, C=1):
+ """
+ PARAMS
+ ------
+ C: compression factor used to compress
+ """
+ return torch.exp(x) / C
diff --git a/audioldm/audio/stft.py b/audioldm/audio/stft.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4acef4e7823f5b8ecc58a770b9f3400906864aa
--- /dev/null
+++ b/audioldm/audio/stft.py
@@ -0,0 +1,186 @@
+import torch
+import torch.nn.functional as F
+import numpy as np
+from scipy.signal import get_window
+from librosa.util import pad_center, tiny
+from librosa.filters import mel as librosa_mel_fn
+
+from audioldm.audio.audio_processing import (
+ dynamic_range_compression,
+ dynamic_range_decompression,
+ window_sumsquare,
+)
+
+
+class STFT(torch.nn.Module):
+ """adapted from Prem Seetharaman's https://github.com/pseeth/pytorch-stft"""
+
+ def __init__(self, filter_length, hop_length, win_length, window="hann"):
+ super(STFT, self).__init__()
+ self.filter_length = filter_length
+ self.hop_length = hop_length
+ self.win_length = win_length
+ self.window = window
+ self.forward_transform = None
+ scale = self.filter_length / self.hop_length
+ fourier_basis = np.fft.fft(np.eye(self.filter_length))
+
+ cutoff = int((self.filter_length / 2 + 1))
+ fourier_basis = np.vstack(
+ [np.real(fourier_basis[:cutoff, :]), np.imag(fourier_basis[:cutoff, :])]
+ )
+
+ forward_basis = torch.FloatTensor(fourier_basis[:, None, :])
+ inverse_basis = torch.FloatTensor(
+ np.linalg.pinv(scale * fourier_basis).T[:, None, :]
+ )
+
+ if window is not None:
+ assert filter_length >= win_length
+ # get window and zero center pad it to filter_length
+ fft_window = get_window(window, win_length, fftbins=True)
+ fft_window = pad_center(fft_window, filter_length)
+ fft_window = torch.from_numpy(fft_window).float()
+
+ # window the bases
+ forward_basis *= fft_window
+ inverse_basis *= fft_window
+
+ self.register_buffer("forward_basis", forward_basis.float())
+ self.register_buffer("inverse_basis", inverse_basis.float())
+
+ def transform(self, input_data):
+ device = self.forward_basis.device
+ input_data = input_data.to(device)
+
+ num_batches = input_data.size(0)
+ num_samples = input_data.size(1)
+
+ self.num_samples = num_samples
+
+ # similar to librosa, reflect-pad the input
+ input_data = input_data.view(num_batches, 1, num_samples)
+ input_data = F.pad(
+ input_data.unsqueeze(1),
+ (int(self.filter_length / 2), int(self.filter_length / 2), 0, 0),
+ mode="reflect",
+ )
+ input_data = input_data.squeeze(1)
+
+ forward_transform = F.conv1d(
+ input_data,
+ torch.autograd.Variable(self.forward_basis, requires_grad=False),
+ stride=self.hop_length,
+ padding=0,
+ )#.cpu()
+
+ cutoff = int((self.filter_length / 2) + 1)
+ real_part = forward_transform[:, :cutoff, :]
+ imag_part = forward_transform[:, cutoff:, :]
+
+ magnitude = torch.sqrt(real_part**2 + imag_part**2)
+ phase = torch.autograd.Variable(torch.atan2(imag_part.data, real_part.data))
+
+ return magnitude, phase
+
+ def inverse(self, magnitude, phase):
+ device = self.forward_basis.device
+ magnitude, phase = magnitude.to(device), phase.to(device)
+
+ recombine_magnitude_phase = torch.cat(
+ [magnitude * torch.cos(phase), magnitude * torch.sin(phase)], dim=1
+ )
+
+ inverse_transform = F.conv_transpose1d(
+ recombine_magnitude_phase,
+ torch.autograd.Variable(self.inverse_basis, requires_grad=False),
+ stride=self.hop_length,
+ padding=0,
+ )
+
+ if self.window is not None:
+ window_sum = window_sumsquare(
+ self.window,
+ magnitude.size(-1),
+ hop_length=self.hop_length,
+ win_length=self.win_length,
+ n_fft=self.filter_length,
+ dtype=np.float32,
+ )
+ # remove modulation effects
+ approx_nonzero_indices = torch.from_numpy(
+ np.where(window_sum > tiny(window_sum))[0]
+ )
+ window_sum = torch.autograd.Variable(
+ torch.from_numpy(window_sum), requires_grad=False
+ )
+ window_sum = window_sum
+ inverse_transform[:, :, approx_nonzero_indices] /= window_sum[
+ approx_nonzero_indices
+ ]
+
+ # scale by hop ratio
+ inverse_transform *= float(self.filter_length) / self.hop_length
+
+ inverse_transform = inverse_transform[:, :, int(self.filter_length / 2) :]
+ inverse_transform = inverse_transform[:, :, : -int(self.filter_length / 2) :]
+
+ return inverse_transform
+
+ def forward(self, input_data):
+ self.magnitude, self.phase = self.transform(input_data)
+ reconstruction = self.inverse(self.magnitude, self.phase)
+ return reconstruction
+
+
+class TacotronSTFT(torch.nn.Module):
+ def __init__(
+ self,
+ filter_length,
+ hop_length,
+ win_length,
+ n_mel_channels,
+ sampling_rate,
+ mel_fmin,
+ mel_fmax,
+ ):
+ super(TacotronSTFT, self).__init__()
+ self.n_mel_channels = n_mel_channels
+ self.sampling_rate = sampling_rate
+ self.stft_fn = STFT(filter_length, hop_length, win_length)
+ mel_basis = librosa_mel_fn(
+ sampling_rate, filter_length, n_mel_channels, mel_fmin, mel_fmax
+ )
+ mel_basis = torch.from_numpy(mel_basis).float()
+ self.register_buffer("mel_basis", mel_basis)
+
+ def spectral_normalize(self, magnitudes, normalize_fun):
+ output = dynamic_range_compression(magnitudes, normalize_fun)
+ return output
+
+ def spectral_de_normalize(self, magnitudes):
+ output = dynamic_range_decompression(magnitudes)
+ return output
+
+ def mel_spectrogram(self, y, normalize_fun=torch.log):
+ """Computes mel-spectrograms from a batch of waves
+ PARAMS
+ ------
+ y: Variable(torch.FloatTensor) with shape (B, T) in range [-1, 1]
+
+ RETURNS
+ -------
+ mel_output: torch.FloatTensor of shape (B, n_mel_channels, T)
+ """
+ assert torch.min(y.data) >= -1, torch.min(y.data)
+ assert torch.max(y.data) <= 1, torch.max(y.data)
+
+ magnitudes, phases = self.stft_fn.transform(y)
+ magnitudes = magnitudes.data
+ mel_output = torch.matmul(self.mel_basis, magnitudes)
+ mel_output = self.spectral_normalize(mel_output, normalize_fun)
+ energy = torch.norm(magnitudes, dim=1)
+
+ log_magnitudes = self.spectral_normalize(magnitudes, normalize_fun)
+
+ return mel_output, log_magnitudes, energy
diff --git a/audioldm/audio/tools.py b/audioldm/audio/tools.py
new file mode 100644
index 0000000000000000000000000000000000000000..d641a982664b6673822c8528a1929c593f011b11
--- /dev/null
+++ b/audioldm/audio/tools.py
@@ -0,0 +1,85 @@
+import torch
+import numpy as np
+import torchaudio
+
+
+def get_mel_from_wav(audio, _stft):
+ audio = torch.clip(torch.FloatTensor(audio).unsqueeze(0), -1, 1)
+ audio = torch.autograd.Variable(audio, requires_grad=False)
+ melspec, log_magnitudes_stft, energy = _stft.mel_spectrogram(audio)
+ melspec = torch.squeeze(melspec, 0).numpy().astype(np.float32)
+ log_magnitudes_stft = (
+ torch.squeeze(log_magnitudes_stft, 0).numpy().astype(np.float32)
+ )
+ energy = torch.squeeze(energy, 0).numpy().astype(np.float32)
+ return melspec, log_magnitudes_stft, energy
+
+
+def _pad_spec(fbank, target_length=1024):
+ n_frames = fbank.shape[0]
+ p = target_length - n_frames
+ # cut and pad
+ if p > 0:
+ m = torch.nn.ZeroPad2d((0, 0, 0, p))
+ fbank = m(fbank)
+ elif p < 0:
+ fbank = fbank[0:target_length, :]
+
+ if fbank.size(-1) % 2 != 0:
+ fbank = fbank[..., :-1]
+
+ return fbank
+
+
+def pad_wav(waveform, segment_length):
+ waveform_length = waveform.shape[-1]
+ assert waveform_length > 100, "Waveform is too short, %s" % waveform_length
+ if segment_length is None or waveform_length == segment_length:
+ return waveform
+ elif waveform_length > segment_length:
+ return waveform[:segment_length]
+ elif waveform_length < segment_length:
+ temp_wav = np.zeros((1, segment_length))
+ temp_wav[:, :waveform_length] = waveform
+ return temp_wav
+
+def normalize_wav(waveform):
+ waveform = waveform - np.mean(waveform)
+ waveform = waveform / (np.max(np.abs(waveform)) + 1e-8)
+ return waveform * 0.5
+
+
+def read_wav_file(filename, segment_length):
+ # waveform, sr = librosa.load(filename, sr=None, mono=True) # 4 times slower
+ waveform, sr = torchaudio.load(filename) # Faster!!!
+ waveform = torchaudio.functional.resample(waveform, orig_freq=sr, new_freq=16000)
+ waveform = waveform.numpy()[0, ...]
+ waveform = normalize_wav(waveform)
+ waveform = waveform[None, ...]
+ waveform = pad_wav(waveform, segment_length)
+
+ waveform = waveform / np.max(np.abs(waveform))
+ waveform = 0.5 * waveform
+
+ return waveform
+
+
+def wav_to_fbank(filename, target_length=1024, fn_STFT=None):
+ assert fn_STFT is not None
+
+ # mixup
+ waveform = read_wav_file(filename, target_length * 160) # hop size is 160
+
+ waveform = waveform[0, ...]
+ waveform = torch.FloatTensor(waveform)
+
+ fbank, log_magnitudes_stft, energy = get_mel_from_wav(waveform, fn_STFT)
+
+ fbank = torch.FloatTensor(fbank.T)
+ log_magnitudes_stft = torch.FloatTensor(log_magnitudes_stft.T)
+
+ fbank, log_magnitudes_stft = _pad_spec(fbank, target_length), _pad_spec(
+ log_magnitudes_stft, target_length
+ )
+
+ return fbank, log_magnitudes_stft, waveform
diff --git a/audioldm/hifigan/__init__.py b/audioldm/hifigan/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0ae476fe58c48e998c56234a55b871beba4042d
--- /dev/null
+++ b/audioldm/hifigan/__init__.py
@@ -0,0 +1,7 @@
+from .models import Generator
+
+
+class AttrDict(dict):
+ def __init__(self, *args, **kwargs):
+ super(AttrDict, self).__init__(*args, **kwargs)
+ self.__dict__ = self
diff --git a/audioldm/hifigan/__pycache__/__init__.cpython-310.pyc b/audioldm/hifigan/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1a403925383d5a573c33bf61d86a3709a36e3ca5
Binary files /dev/null and b/audioldm/hifigan/__pycache__/__init__.cpython-310.pyc differ
diff --git a/audioldm/hifigan/__pycache__/__init__.cpython-39.pyc b/audioldm/hifigan/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fd2381df60d4e38d483db28feb5589f312583bb3
Binary files /dev/null and b/audioldm/hifigan/__pycache__/__init__.cpython-39.pyc differ
diff --git a/audioldm/hifigan/__pycache__/models.cpython-310.pyc b/audioldm/hifigan/__pycache__/models.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c1b63b58c1017dd96c5fb5175e5ef880957a05eb
Binary files /dev/null and b/audioldm/hifigan/__pycache__/models.cpython-310.pyc differ
diff --git a/audioldm/hifigan/__pycache__/models.cpython-39.pyc b/audioldm/hifigan/__pycache__/models.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5d4b61d15155828febf38dfb2608cbba9739cb61
Binary files /dev/null and b/audioldm/hifigan/__pycache__/models.cpython-39.pyc differ
diff --git a/audioldm/hifigan/__pycache__/utilities.cpython-310.pyc b/audioldm/hifigan/__pycache__/utilities.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a792563d905f7552462d7bca2ce3e9578995a747
Binary files /dev/null and b/audioldm/hifigan/__pycache__/utilities.cpython-310.pyc differ
diff --git a/audioldm/hifigan/__pycache__/utilities.cpython-39.pyc b/audioldm/hifigan/__pycache__/utilities.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..77760ca357a29f69e25c6cc64f97a590d6ca9453
Binary files /dev/null and b/audioldm/hifigan/__pycache__/utilities.cpython-39.pyc differ
diff --git a/audioldm/hifigan/models.py b/audioldm/hifigan/models.py
new file mode 100644
index 0000000000000000000000000000000000000000..c4382cc39de0463f9b7c0f33f037dbc233e7cb36
--- /dev/null
+++ b/audioldm/hifigan/models.py
@@ -0,0 +1,174 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn import Conv1d, ConvTranspose1d
+from torch.nn.utils import weight_norm, remove_weight_norm
+
+LRELU_SLOPE = 0.1
+
+
+def init_weights(m, mean=0.0, std=0.01):
+ classname = m.__class__.__name__
+ if classname.find("Conv") != -1:
+ m.weight.data.normal_(mean, std)
+
+
+def get_padding(kernel_size, dilation=1):
+ return int((kernel_size * dilation - dilation) / 2)
+
+
+class ResBlock(torch.nn.Module):
+ def __init__(self, h, channels, kernel_size=3, dilation=(1, 3, 5)):
+ super(ResBlock, self).__init__()
+ self.h = h
+ self.convs1 = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[0],
+ padding=get_padding(kernel_size, dilation[0]),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[1],
+ padding=get_padding(kernel_size, dilation[1]),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=dilation[2],
+ padding=get_padding(kernel_size, dilation[2]),
+ )
+ ),
+ ]
+ )
+ self.convs1.apply(init_weights)
+
+ self.convs2 = nn.ModuleList(
+ [
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=get_padding(kernel_size, 1),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=get_padding(kernel_size, 1),
+ )
+ ),
+ weight_norm(
+ Conv1d(
+ channels,
+ channels,
+ kernel_size,
+ 1,
+ dilation=1,
+ padding=get_padding(kernel_size, 1),
+ )
+ ),
+ ]
+ )
+ self.convs2.apply(init_weights)
+
+ def forward(self, x):
+ for c1, c2 in zip(self.convs1, self.convs2):
+ xt = F.leaky_relu(x, LRELU_SLOPE)
+ xt = c1(xt)
+ xt = F.leaky_relu(xt, LRELU_SLOPE)
+ xt = c2(xt)
+ x = xt + x
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.convs1:
+ remove_weight_norm(l)
+ for l in self.convs2:
+ remove_weight_norm(l)
+
+
+class Generator(torch.nn.Module):
+ def __init__(self, h):
+ super(Generator, self).__init__()
+ self.h = h
+ self.num_kernels = len(h.resblock_kernel_sizes)
+ self.num_upsamples = len(h.upsample_rates)
+ self.conv_pre = weight_norm(
+ Conv1d(h.num_mels, h.upsample_initial_channel, 7, 1, padding=3)
+ )
+ resblock = ResBlock
+
+ self.ups = nn.ModuleList()
+ for i, (u, k) in enumerate(zip(h.upsample_rates, h.upsample_kernel_sizes)):
+ self.ups.append(
+ weight_norm(
+ ConvTranspose1d(
+ h.upsample_initial_channel // (2**i),
+ h.upsample_initial_channel // (2 ** (i + 1)),
+ k,
+ u,
+ padding=(k - u) // 2,
+ )
+ )
+ )
+
+ self.resblocks = nn.ModuleList()
+ for i in range(len(self.ups)):
+ ch = h.upsample_initial_channel // (2 ** (i + 1))
+ for j, (k, d) in enumerate(
+ zip(h.resblock_kernel_sizes, h.resblock_dilation_sizes)
+ ):
+ self.resblocks.append(resblock(h, ch, k, d))
+
+ self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3))
+ self.ups.apply(init_weights)
+ self.conv_post.apply(init_weights)
+
+ def forward(self, x):
+ x = self.conv_pre(x)
+ for i in range(self.num_upsamples):
+ x = F.leaky_relu(x, LRELU_SLOPE)
+ x = self.ups[i](x)
+ xs = None
+ for j in range(self.num_kernels):
+ if xs is None:
+ xs = self.resblocks[i * self.num_kernels + j](x)
+ else:
+ xs += self.resblocks[i * self.num_kernels + j](x)
+ x = xs / self.num_kernels
+ x = F.leaky_relu(x)
+ x = self.conv_post(x)
+ x = torch.tanh(x)
+
+ return x
+
+ def remove_weight_norm(self):
+ # print("Removing weight norm...")
+ for l in self.ups:
+ remove_weight_norm(l)
+ for l in self.resblocks:
+ l.remove_weight_norm()
+ remove_weight_norm(self.conv_pre)
+ remove_weight_norm(self.conv_post)
diff --git a/audioldm/hifigan/utilities.py b/audioldm/hifigan/utilities.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea9f958e460a77fd4936a6edf59403dd3ea617ab
--- /dev/null
+++ b/audioldm/hifigan/utilities.py
@@ -0,0 +1,86 @@
+import os
+import json
+
+import torch
+import numpy as np
+
+import audioldm.hifigan as hifigan
+
+HIFIGAN_16K_64 = {
+ "resblock": "1",
+ "num_gpus": 6,
+ "batch_size": 16,
+ "learning_rate": 0.0002,
+ "adam_b1": 0.8,
+ "adam_b2": 0.99,
+ "lr_decay": 0.999,
+ "seed": 1234,
+ "upsample_rates": [5, 4, 2, 2, 2],
+ "upsample_kernel_sizes": [16, 16, 8, 4, 4],
+ "upsample_initial_channel": 1024,
+ "resblock_kernel_sizes": [3, 7, 11],
+ "resblock_dilation_sizes": [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ "segment_size": 8192,
+ "num_mels": 64,
+ "num_freq": 1025,
+ "n_fft": 1024,
+ "hop_size": 160,
+ "win_size": 1024,
+ "sampling_rate": 16000,
+ "fmin": 0,
+ "fmax": 8000,
+ "fmax_for_loss": None,
+ "num_workers": 4,
+ "dist_config": {
+ "dist_backend": "nccl",
+ "dist_url": "tcp://localhost:54321",
+ "world_size": 1,
+ },
+}
+
+
+def get_available_checkpoint_keys(model, ckpt):
+ print("==> Attemp to reload from %s" % ckpt)
+ state_dict = torch.load(ckpt)["state_dict"]
+ current_state_dict = model.state_dict()
+ new_state_dict = {}
+ for k in state_dict.keys():
+ if (
+ k in current_state_dict.keys()
+ and current_state_dict[k].size() == state_dict[k].size()
+ ):
+ new_state_dict[k] = state_dict[k]
+ else:
+ print("==> WARNING: Skipping %s" % k)
+ print(
+ "%s out of %s keys are matched"
+ % (len(new_state_dict.keys()), len(state_dict.keys()))
+ )
+ return new_state_dict
+
+
+def get_param_num(model):
+ num_param = sum(param.numel() for param in model.parameters())
+ return num_param
+
+
+def get_vocoder(config, device):
+ config = hifigan.AttrDict(HIFIGAN_16K_64)
+ vocoder = hifigan.Generator(config)
+ vocoder.eval()
+ vocoder.remove_weight_norm()
+ vocoder.to(device)
+ return vocoder
+
+
+def vocoder_infer(mels, vocoder, lengths=None):
+ vocoder.eval()
+ with torch.no_grad():
+ wavs = vocoder(mels).squeeze(1)
+
+ wavs = (wavs.cpu().numpy() * 32768).astype("int16")
+
+ if lengths is not None:
+ wavs = wavs[:, :lengths]
+
+ return wavs
diff --git a/audioldm/latent_diffusion/__init__.py b/audioldm/latent_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/audioldm/latent_diffusion/__pycache__/__init__.cpython-310.pyc b/audioldm/latent_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..69dda1d4c0fe34cd2f5990d187aadb12877ad088
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/__init__.cpython-39.pyc b/audioldm/latent_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7c3c3cc14c48e8229474b8f7ec8876ae477e1abe
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/attention.cpython-310.pyc b/audioldm/latent_diffusion/__pycache__/attention.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0310e33bf9928fcbb3e61406c593745d2ec64b49
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/attention.cpython-310.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/attention.cpython-39.pyc b/audioldm/latent_diffusion/__pycache__/attention.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6adedcc3563899d776cacda3dda199afed484dc9
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/attention.cpython-39.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/ddim.cpython-310.pyc b/audioldm/latent_diffusion/__pycache__/ddim.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3e632ada673b33b0d7830b5afc4b5522ee2bb220
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/ddim.cpython-310.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/ddim.cpython-39.pyc b/audioldm/latent_diffusion/__pycache__/ddim.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4c31097ababd05e919c92bb083a8695e6ca69956
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/ddim.cpython-39.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/ddpm.cpython-310.pyc b/audioldm/latent_diffusion/__pycache__/ddpm.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3fc22cfb5c33e81d5bd9b8f28fe2008f07f71e76
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/ddpm.cpython-310.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/ddpm.cpython-39.pyc b/audioldm/latent_diffusion/__pycache__/ddpm.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ccb475d005326564fc9cb8c9faac0a6a704d1663
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/ddpm.cpython-39.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/ema.cpython-310.pyc b/audioldm/latent_diffusion/__pycache__/ema.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4a09c1f7e92c0a5d3e0f58d38bcb719eb8a24926
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/ema.cpython-310.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/ema.cpython-39.pyc b/audioldm/latent_diffusion/__pycache__/ema.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c7c12ddcfd0fb7808997eb6503c23d34b3c53dd5
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/ema.cpython-39.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/openaimodel.cpython-39.pyc b/audioldm/latent_diffusion/__pycache__/openaimodel.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0633fd9040ad48672c165c50d720b2fa57efffab
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/openaimodel.cpython-39.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/util.cpython-310.pyc b/audioldm/latent_diffusion/__pycache__/util.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2f52f59f8b8cf775ea355bfaff317c3c2180a2a5
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/util.cpython-310.pyc differ
diff --git a/audioldm/latent_diffusion/__pycache__/util.cpython-39.pyc b/audioldm/latent_diffusion/__pycache__/util.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..035b771c97a223a8ab77d3ab7ca2b8bf8a28eb75
Binary files /dev/null and b/audioldm/latent_diffusion/__pycache__/util.cpython-39.pyc differ
diff --git a/audioldm/latent_diffusion/attention.py b/audioldm/latent_diffusion/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..27886f5ee3c7eb856100503b838399106ef00051
--- /dev/null
+++ b/audioldm/latent_diffusion/attention.py
@@ -0,0 +1,469 @@
+from inspect import isfunction
+import math
+import torch
+import torch.nn.functional as F
+from torch import nn
+from einops import rearrange
+
+from audioldm.latent_diffusion.util import checkpoint
+
+
+def exists(val):
+ return val is not None
+
+
+def uniq(arr):
+ return {el: True for el in arr}.keys()
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if isfunction(d) else d
+
+
+def max_neg_value(t):
+ return -torch.finfo(t.dtype).max
+
+
+def init_(tensor):
+ dim = tensor.shape[-1]
+ std = 1 / math.sqrt(dim)
+ tensor.uniform_(-std, std)
+ return tensor
+
+
+# feedforward
+class GEGLU(nn.Module):
+ def __init__(self, dim_in, dim_out):
+ super().__init__()
+ self.proj = nn.Linear(dim_in, dim_out * 2)
+
+ def forward(self, x):
+ x, gate = self.proj(x).chunk(2, dim=-1)
+ return x * F.gelu(gate)
+
+
+class FeedForward(nn.Module):
+ def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.0):
+ super().__init__()
+ inner_dim = int(dim * mult)
+ dim_out = default(dim_out, dim)
+ project_in = (
+ nn.Sequential(nn.Linear(dim, inner_dim), nn.GELU())
+ if not glu
+ else GEGLU(dim, inner_dim)
+ )
+
+ self.net = nn.Sequential(
+ project_in, nn.Dropout(dropout), nn.Linear(inner_dim, dim_out)
+ )
+
+ def forward(self, x):
+ return self.net(x)
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def Normalize(in_channels):
+ return torch.nn.GroupNorm(
+ num_groups=32, num_channels=in_channels, eps=1e-6, affine=True
+ )
+
+
+class LinearAttention(nn.Module):
+ def __init__(self, dim, heads=4, dim_head=32):
+ super().__init__()
+ self.heads = heads
+ hidden_dim = dim_head * heads
+ self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
+ self.to_out = nn.Conv2d(hidden_dim, dim, 1)
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+ qkv = self.to_qkv(x)
+ q, k, v = rearrange(
+ qkv, "b (qkv heads c) h w -> qkv b heads c (h w)", heads=self.heads, qkv=3
+ )
+ k = k.softmax(dim=-1)
+ context = torch.einsum("bhdn,bhen->bhde", k, v)
+ out = torch.einsum("bhde,bhdn->bhen", context, q)
+ out = rearrange(
+ out, "b heads c (h w) -> b (heads c) h w", heads=self.heads, h=h, w=w
+ )
+ return self.to_out(out)
+
+
+class SpatialSelfAttention(nn.Module):
+ def __init__(self, in_channels):
+ super().__init__()
+ self.in_channels = in_channels
+
+ self.norm = Normalize(in_channels)
+ self.q = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.k = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.v = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.proj_out = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+
+ def forward(self, x):
+ h_ = x
+ h_ = self.norm(h_)
+ q = self.q(h_)
+ k = self.k(h_)
+ v = self.v(h_)
+
+ # compute attention
+ b, c, h, w = q.shape
+ q = rearrange(q, "b c h w -> b (h w) c")
+ k = rearrange(k, "b c h w -> b c (h w)")
+ w_ = torch.einsum("bij,bjk->bik", q, k)
+
+ w_ = w_ * (int(c) ** (-0.5))
+ w_ = torch.nn.functional.softmax(w_, dim=2)
+
+ # attend to values
+ v = rearrange(v, "b c h w -> b c (h w)")
+ w_ = rearrange(w_, "b i j -> b j i")
+ h_ = torch.einsum("bij,bjk->bik", v, w_)
+ h_ = rearrange(h_, "b c (h w) -> b c h w", h=h)
+ h_ = self.proj_out(h_)
+
+ return x + h_
+
+
+class CrossAttention(nn.Module):
+ """
+ ### Cross Attention Layer
+ This falls-back to self-attention when conditional embeddings are not specified.
+ """
+
+ # use_flash_attention: bool = True
+ use_flash_attention: bool = False
+
+ def __init__(
+ self,
+ query_dim,
+ context_dim=None,
+ heads=8,
+ dim_head=64,
+ dropout=0.0,
+ is_inplace: bool = True,
+ ):
+ # def __init__(self, d_model: int, d_cond: int, n_heads: int, d_head: int, is_inplace: bool = True):
+ """
+ :param d_model: is the input embedding size
+ :param n_heads: is the number of attention heads
+ :param d_head: is the size of a attention head
+ :param d_cond: is the size of the conditional embeddings
+ :param is_inplace: specifies whether to perform the attention softmax computation inplace to
+ save memory
+ """
+ super().__init__()
+
+ self.is_inplace = is_inplace
+ self.n_heads = heads
+ self.d_head = dim_head
+
+ # Attention scaling factor
+ self.scale = dim_head**-0.5
+
+ # The normal self-attention layer
+ if context_dim is None:
+ context_dim = query_dim
+
+ # Query, key and value mappings
+ d_attn = dim_head * heads
+ self.to_q = nn.Linear(query_dim, d_attn, bias=False)
+ self.to_k = nn.Linear(context_dim, d_attn, bias=False)
+ self.to_v = nn.Linear(context_dim, d_attn, bias=False)
+
+ # Final linear layer
+ self.to_out = nn.Sequential(nn.Linear(d_attn, query_dim), nn.Dropout(dropout))
+
+ # Setup [flash attention](https://github.com/HazyResearch/flash-attention).
+ # Flash attention is only used if it's installed
+ # and `CrossAttention.use_flash_attention` is set to `True`.
+ try:
+ # You can install flash attention by cloning their Github repo,
+ # [https://github.com/HazyResearch/flash-attention](https://github.com/HazyResearch/flash-attention)
+ # and then running `python setup.py install`
+ from flash_attn.flash_attention import FlashAttention
+
+ self.flash = FlashAttention()
+ # Set the scale for scaled dot-product attention.
+ self.flash.softmax_scale = self.scale
+ # Set to `None` if it's not installed
+ except ImportError:
+ self.flash = None
+
+ def forward(self, x, context=None, mask=None):
+ """
+ :param x: are the input embeddings of shape `[batch_size, height * width, d_model]`
+ :param cond: is the conditional embeddings of shape `[batch_size, n_cond, d_cond]`
+ """
+
+ # If `cond` is `None` we perform self attention
+ has_cond = context is not None
+ if not has_cond:
+ context = x
+
+ # Get query, key and value vectors
+ q = self.to_q(x)
+ k = self.to_k(context)
+ v = self.to_v(context)
+
+ # Use flash attention if it's available and the head size is less than or equal to `128`
+ if (
+ CrossAttention.use_flash_attention
+ and self.flash is not None
+ and not has_cond
+ and self.d_head <= 128
+ ):
+ return self.flash_attention(q, k, v)
+ # Otherwise, fallback to normal attention
+ else:
+ return self.normal_attention(q, k, v)
+
+ def flash_attention(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
+ """
+ #### Flash Attention
+ :param q: are the query vectors before splitting heads, of shape `[batch_size, seq, d_attn]`
+ :param k: are the query vectors before splitting heads, of shape `[batch_size, seq, d_attn]`
+ :param v: are the query vectors before splitting heads, of shape `[batch_size, seq, d_attn]`
+ """
+
+ # Get batch size and number of elements along sequence axis (`width * height`)
+ batch_size, seq_len, _ = q.shape
+
+ # Stack `q`, `k`, `v` vectors for flash attention, to get a single tensor of
+ # shape `[batch_size, seq_len, 3, n_heads * d_head]`
+ qkv = torch.stack((q, k, v), dim=2)
+ # Split the heads
+ qkv = qkv.view(batch_size, seq_len, 3, self.n_heads, self.d_head)
+
+ # Flash attention works for head sizes `32`, `64` and `128`, so we have to pad the heads to
+ # fit this size.
+ if self.d_head <= 32:
+ pad = 32 - self.d_head
+ elif self.d_head <= 64:
+ pad = 64 - self.d_head
+ elif self.d_head <= 128:
+ pad = 128 - self.d_head
+ else:
+ raise ValueError(f"Head size ${self.d_head} too large for Flash Attention")
+
+ # Pad the heads
+ if pad:
+ qkv = torch.cat(
+ (qkv, qkv.new_zeros(batch_size, seq_len, 3, self.n_heads, pad)), dim=-1
+ )
+
+ # Compute attention
+ # $$\underset{seq}{softmax}\Bigg(\frac{Q K^\top}{\sqrt{d_{key}}}\Bigg)V$$
+ # This gives a tensor of shape `[batch_size, seq_len, n_heads, d_padded]`
+ # TODO here I add the dtype changing
+ out, _ = self.flash(qkv.type(torch.float16))
+ # Truncate the extra head size
+ out = out[:, :, :, : self.d_head].float()
+ # Reshape to `[batch_size, seq_len, n_heads * d_head]`
+ out = out.reshape(batch_size, seq_len, self.n_heads * self.d_head)
+
+ # Map to `[batch_size, height * width, d_model]` with a linear layer
+ return self.to_out(out)
+
+ def normal_attention(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
+ """
+ #### Normal Attention
+
+ :param q: are the query vectors before splitting heads, of shape `[batch_size, seq, d_attn]`
+ :param k: are the query vectors before splitting heads, of shape `[batch_size, seq, d_attn]`
+ :param v: are the query vectors before splitting heads, of shape `[batch_size, seq, d_attn]`
+ """
+
+ # Split them to heads of shape `[batch_size, seq_len, n_heads, d_head]`
+ q = q.view(*q.shape[:2], self.n_heads, -1) # [bs, 64, 20, 32]
+ k = k.view(*k.shape[:2], self.n_heads, -1) # [bs, 1, 20, 32]
+ v = v.view(*v.shape[:2], self.n_heads, -1)
+
+ # Calculate attention $\frac{Q K^\top}{\sqrt{d_{key}}}$
+ attn = torch.einsum("bihd,bjhd->bhij", q, k) * self.scale
+
+ # Compute softmax
+ # $$\underset{seq}{softmax}\Bigg(\frac{Q K^\top}{\sqrt{d_{key}}}\Bigg)$$
+ if self.is_inplace:
+ half = attn.shape[0] // 2
+ attn[half:] = attn[half:].softmax(dim=-1)
+ attn[:half] = attn[:half].softmax(dim=-1)
+ else:
+ attn = attn.softmax(dim=-1)
+
+ # Compute attention output
+ # $$\underset{seq}{softmax}\Bigg(\frac{Q K^\top}{\sqrt{d_{key}}}\Bigg)V$$
+ # attn: [bs, 20, 64, 1]
+ # v: [bs, 1, 20, 32]
+ out = torch.einsum("bhij,bjhd->bihd", attn, v)
+ # Reshape to `[batch_size, height * width, n_heads * d_head]`
+ out = out.reshape(*out.shape[:2], -1)
+ # Map to `[batch_size, height * width, d_model]` with a linear layer
+ return self.to_out(out)
+
+
+# class CrossAttention(nn.Module):
+# def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
+# super().__init__()
+# inner_dim = dim_head * heads
+# context_dim = default(context_dim, query_dim)
+
+# self.scale = dim_head ** -0.5
+# self.heads = heads
+
+# self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
+# self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
+# self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
+
+# self.to_out = nn.Sequential(
+# nn.Linear(inner_dim, query_dim),
+# nn.Dropout(dropout)
+# )
+
+# def forward(self, x, context=None, mask=None):
+# h = self.heads
+
+# q = self.to_q(x)
+# context = default(context, x)
+# k = self.to_k(context)
+# v = self.to_v(context)
+
+# q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
+
+# sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
+
+# if exists(mask):
+# mask = rearrange(mask, 'b ... -> b (...)')
+# max_neg_value = -torch.finfo(sim.dtype).max
+# mask = repeat(mask, 'b j -> (b h) () j', h=h)
+# sim.masked_fill_(~mask, max_neg_value)
+
+# # attention, what we cannot get enough of
+# attn = sim.softmax(dim=-1)
+
+# out = einsum('b i j, b j d -> b i d', attn, v)
+# out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
+# return self.to_out(out)
+
+
+class BasicTransformerBlock(nn.Module):
+ def __init__(
+ self,
+ dim,
+ n_heads,
+ d_head,
+ dropout=0.0,
+ context_dim=None,
+ gated_ff=True,
+ checkpoint=True,
+ ):
+ super().__init__()
+ self.attn1 = CrossAttention(
+ query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout
+ ) # is a self-attention
+ self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
+ self.attn2 = CrossAttention(
+ query_dim=dim,
+ context_dim=context_dim,
+ heads=n_heads,
+ dim_head=d_head,
+ dropout=dropout,
+ ) # is self-attn if context is none
+ self.norm1 = nn.LayerNorm(dim)
+ self.norm2 = nn.LayerNorm(dim)
+ self.norm3 = nn.LayerNorm(dim)
+ self.checkpoint = checkpoint
+
+ def forward(self, x, context=None):
+ if context is None:
+ return checkpoint(self._forward, (x,), self.parameters(), self.checkpoint)
+ else:
+ return checkpoint(
+ self._forward, (x, context), self.parameters(), self.checkpoint
+ )
+
+ def _forward(self, x, context=None):
+ x = self.attn1(self.norm1(x)) + x
+ x = self.attn2(self.norm2(x), context=context) + x
+ x = self.ff(self.norm3(x)) + x
+ return x
+
+
+class SpatialTransformer(nn.Module):
+ """
+ Transformer block for image-like data.
+ First, project the input (aka embedding)
+ and reshape to b, t, d.
+ Then apply standard transformer action.
+ Finally, reshape to image
+ """
+
+ def __init__(
+ self,
+ in_channels,
+ n_heads,
+ d_head,
+ depth=1,
+ dropout=0.0,
+ context_dim=None,
+ no_context=False,
+ ):
+ super().__init__()
+
+ if no_context:
+ context_dim = None
+
+ self.in_channels = in_channels
+ inner_dim = n_heads * d_head
+ self.norm = Normalize(in_channels)
+
+ self.proj_in = nn.Conv2d(
+ in_channels, inner_dim, kernel_size=1, stride=1, padding=0
+ )
+
+ self.transformer_blocks = nn.ModuleList(
+ [
+ BasicTransformerBlock(
+ inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim
+ )
+ for d in range(depth)
+ ]
+ )
+
+ self.proj_out = zero_module(
+ nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
+ )
+
+ def forward(self, x, context=None):
+ # note: if no context is given, cross-attention defaults to self-attention
+ b, c, h, w = x.shape
+ x_in = x
+ x = self.norm(x)
+ x = self.proj_in(x)
+ x = rearrange(x, "b c h w -> b (h w) c")
+ for block in self.transformer_blocks:
+ x = block(x, context=context)
+ x = rearrange(x, "b (h w) c -> b c h w", h=h, w=w)
+ x = self.proj_out(x)
+ return x + x_in
diff --git a/audioldm/latent_diffusion/ddim.py b/audioldm/latent_diffusion/ddim.py
new file mode 100644
index 0000000000000000000000000000000000000000..732002b048e9a193313aa0ef9a353d4fc078be72
--- /dev/null
+++ b/audioldm/latent_diffusion/ddim.py
@@ -0,0 +1,377 @@
+"""SAMPLING ONLY."""
+
+import torch
+import numpy as np
+from tqdm import tqdm
+
+from audioldm.latent_diffusion.util import (
+ make_ddim_sampling_parameters,
+ make_ddim_timesteps,
+ noise_like,
+ extract_into_tensor,
+)
+
+
+class DDIMSampler(object):
+ def __init__(self, model, schedule="linear", **kwargs):
+ super().__init__()
+ self.model = model
+ self.ddpm_num_timesteps = model.num_timesteps
+ self.schedule = schedule
+
+ def register_buffer(self, name, attr):
+ if type(attr) == torch.Tensor:
+ if attr.device != torch.device("cuda"):
+ attr = attr.to(torch.device("cuda"))
+ setattr(self, name, attr)
+
+ def make_schedule(
+ self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0.0, verbose=True
+ ):
+ self.ddim_timesteps = make_ddim_timesteps(
+ ddim_discr_method=ddim_discretize,
+ num_ddim_timesteps=ddim_num_steps,
+ num_ddpm_timesteps=self.ddpm_num_timesteps,
+ verbose=verbose,
+ )
+ alphas_cumprod = self.model.alphas_cumprod
+ assert (
+ alphas_cumprod.shape[0] == self.ddpm_num_timesteps
+ ), "alphas have to be defined for each timestep"
+ to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
+
+ self.register_buffer("betas", to_torch(self.model.betas))
+ self.register_buffer("alphas_cumprod", to_torch(alphas_cumprod))
+ self.register_buffer(
+ "alphas_cumprod_prev", to_torch(self.model.alphas_cumprod_prev)
+ )
+
+ # calculations for diffusion q(x_t | x_{t-1}) and others
+ self.register_buffer(
+ "sqrt_alphas_cumprod", to_torch(np.sqrt(alphas_cumprod.cpu()))
+ )
+ self.register_buffer(
+ "sqrt_one_minus_alphas_cumprod",
+ to_torch(np.sqrt(1.0 - alphas_cumprod.cpu())),
+ )
+ self.register_buffer(
+ "log_one_minus_alphas_cumprod", to_torch(np.log(1.0 - alphas_cumprod.cpu()))
+ )
+ self.register_buffer(
+ "sqrt_recip_alphas_cumprod", to_torch(np.sqrt(1.0 / alphas_cumprod.cpu()))
+ )
+ self.register_buffer(
+ "sqrt_recipm1_alphas_cumprod",
+ to_torch(np.sqrt(1.0 / alphas_cumprod.cpu() - 1)),
+ )
+
+ # ddim sampling parameters
+ ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(
+ alphacums=alphas_cumprod.cpu(),
+ ddim_timesteps=self.ddim_timesteps,
+ eta=ddim_eta,
+ verbose=verbose,
+ )
+ self.register_buffer("ddim_sigmas", ddim_sigmas)
+ self.register_buffer("ddim_alphas", ddim_alphas)
+ self.register_buffer("ddim_alphas_prev", ddim_alphas_prev)
+ self.register_buffer("ddim_sqrt_one_minus_alphas", np.sqrt(1.0 - ddim_alphas))
+ sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt(
+ (1 - self.alphas_cumprod_prev)
+ / (1 - self.alphas_cumprod)
+ * (1 - self.alphas_cumprod / self.alphas_cumprod_prev)
+ )
+ self.register_buffer(
+ "ddim_sigmas_for_original_num_steps", sigmas_for_original_sampling_steps
+ )
+
+ @torch.no_grad()
+ def sample(
+ self,
+ S,
+ batch_size,
+ shape,
+ conditioning=None,
+ callback=None,
+ normals_sequence=None,
+ img_callback=None,
+ quantize_x0=False,
+ eta=0.0,
+ mask=None,
+ x0=None,
+ temperature=1.0,
+ noise_dropout=0.0,
+ score_corrector=None,
+ corrector_kwargs=None,
+ verbose=True,
+ x_T=None,
+ log_every_t=100,
+ unconditional_guidance_scale=1.0,
+ unconditional_conditioning=None,
+ # this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
+ **kwargs,
+ ):
+ if conditioning is not None:
+ if isinstance(conditioning, dict):
+ cbs = conditioning[list(conditioning.keys())[0]].shape[0]
+ if cbs != batch_size:
+ print(
+ f"Warning: Got {cbs} conditionings but batch-size is {batch_size}"
+ )
+ else:
+ if conditioning.shape[0] != batch_size:
+ print(
+ f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}"
+ )
+
+ self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose)
+ # sampling
+ C, H, W = shape
+ size = (batch_size, C, H, W)
+ samples, intermediates = self.ddim_sampling(
+ conditioning,
+ size,
+ callback=callback,
+ img_callback=img_callback,
+ quantize_denoised=quantize_x0,
+ mask=mask,
+ x0=x0,
+ ddim_use_original_steps=False,
+ noise_dropout=noise_dropout,
+ temperature=temperature,
+ score_corrector=score_corrector,
+ corrector_kwargs=corrector_kwargs,
+ x_T=x_T,
+ log_every_t=log_every_t,
+ unconditional_guidance_scale=unconditional_guidance_scale,
+ unconditional_conditioning=unconditional_conditioning,
+ )
+ return samples, intermediates
+
+ @torch.no_grad()
+ def ddim_sampling(
+ self,
+ cond,
+ shape,
+ x_T=None,
+ ddim_use_original_steps=False,
+ callback=None,
+ timesteps=None,
+ quantize_denoised=False,
+ mask=None,
+ x0=None,
+ img_callback=None,
+ log_every_t=100,
+ temperature=1.0,
+ noise_dropout=0.0,
+ score_corrector=None,
+ corrector_kwargs=None,
+ unconditional_guidance_scale=1.0,
+ unconditional_conditioning=None,
+ ):
+ device = self.model.betas.device
+ b = shape[0]
+ if x_T is None:
+ img = torch.randn(shape, device=device)
+ else:
+ img = x_T
+
+ if timesteps is None:
+ timesteps = (
+ self.ddpm_num_timesteps
+ if ddim_use_original_steps
+ else self.ddim_timesteps
+ )
+ elif timesteps is not None and not ddim_use_original_steps:
+ subset_end = (
+ int(
+ min(timesteps / self.ddim_timesteps.shape[0], 1)
+ * self.ddim_timesteps.shape[0]
+ )
+ - 1
+ )
+ timesteps = self.ddim_timesteps[:subset_end]
+
+ intermediates = {"x_inter": [img], "pred_x0": [img]}
+ time_range = (
+ reversed(range(0, timesteps))
+ if ddim_use_original_steps
+ else np.flip(timesteps)
+ )
+ total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0]
+ # print(f"Running DDIM Sampling with {total_steps} timesteps")
+
+ # iterator = gr.Progress().tqdm(time_range, desc="DDIM Sampler", total=total_steps)
+ iterator = tqdm(time_range, desc="DDIM Sampler", total=total_steps, leave=False)
+
+ for i, step in enumerate(iterator):
+ index = total_steps - i - 1
+ ts = torch.full((b,), step, device=device, dtype=torch.long)
+ if mask is not None:
+ assert x0 is not None
+ img_orig = self.model.q_sample(
+ x0, ts
+ ) # TODO deterministic forward pass?
+ img = (
+ img_orig * mask + (1.0 - mask) * img
+ ) # In the first sampling step, img is pure gaussian noise
+
+ outs = self.p_sample_ddim(
+ img,
+ cond,
+ ts,
+ index=index,
+ use_original_steps=ddim_use_original_steps,
+ quantize_denoised=quantize_denoised,
+ temperature=temperature,
+ noise_dropout=noise_dropout,
+ score_corrector=score_corrector,
+ corrector_kwargs=corrector_kwargs,
+ unconditional_guidance_scale=unconditional_guidance_scale,
+ unconditional_conditioning=unconditional_conditioning,
+ )
+ img, pred_x0 = outs
+ if callback:
+ callback(i)
+ if img_callback:
+ img_callback(pred_x0, i)
+
+ if index % log_every_t == 0 or index == total_steps - 1:
+ intermediates["x_inter"].append(img)
+ intermediates["pred_x0"].append(pred_x0)
+
+ return img, intermediates
+
+ @torch.no_grad()
+ def stochastic_encode(self, x0, t, use_original_steps=False, noise=None):
+ # fast, but does not allow for exact reconstruction
+ # t serves as an index to gather the correct alphas
+ if use_original_steps:
+ sqrt_alphas_cumprod = self.sqrt_alphas_cumprod
+ sqrt_one_minus_alphas_cumprod = self.sqrt_one_minus_alphas_cumprod
+ else:
+ sqrt_alphas_cumprod = torch.sqrt(self.ddim_alphas)
+ sqrt_one_minus_alphas_cumprod = self.ddim_sqrt_one_minus_alphas
+
+ if noise is None:
+ noise = torch.randn_like(x0)
+
+ return (
+ extract_into_tensor(sqrt_alphas_cumprod, t, x0.shape) * x0
+ + extract_into_tensor(sqrt_one_minus_alphas_cumprod, t, x0.shape) * noise
+ )
+
+ @torch.no_grad()
+ def decode(
+ self,
+ x_latent,
+ cond,
+ t_start,
+ unconditional_guidance_scale=1.0,
+ unconditional_conditioning=None,
+ use_original_steps=False,
+ ):
+
+ timesteps = (
+ np.arange(self.ddpm_num_timesteps)
+ if use_original_steps
+ else self.ddim_timesteps
+ )
+ timesteps = timesteps[:t_start]
+
+ time_range = np.flip(timesteps)
+ total_steps = timesteps.shape[0]
+ # print(f"Running DDIM Sampling with {total_steps} timesteps")
+
+ # iterator = gr.Progress().tqdm(time_range, desc="Decoding image", total=total_steps)
+ iterator = tqdm(time_range, desc="Decoding image", total=total_steps)
+ x_dec = x_latent
+
+ for i, step in enumerate(iterator):
+ index = total_steps - i - 1
+ ts = torch.full(
+ (x_latent.shape[0],), step, device=x_latent.device, dtype=torch.long
+ )
+ x_dec, _ = self.p_sample_ddim(
+ x_dec,
+ cond,
+ ts,
+ index=index,
+ use_original_steps=use_original_steps,
+ unconditional_guidance_scale=unconditional_guidance_scale,
+ unconditional_conditioning=unconditional_conditioning,
+ )
+ return x_dec
+
+ @torch.no_grad()
+ def p_sample_ddim(
+ self,
+ x,
+ c,
+ t,
+ index,
+ repeat_noise=False,
+ use_original_steps=False,
+ quantize_denoised=False,
+ temperature=1.0,
+ noise_dropout=0.0,
+ score_corrector=None,
+ corrector_kwargs=None,
+ unconditional_guidance_scale=1.0,
+ unconditional_conditioning=None,
+ ):
+ b, *_, device = *x.shape, x.device
+
+ if unconditional_conditioning is None or unconditional_guidance_scale == 1.0:
+ e_t = self.model.apply_model(x, t, c)
+ else:
+ x_in = torch.cat([x] * 2)
+ t_in = torch.cat([t] * 2)
+ c_in = torch.cat([unconditional_conditioning, c])
+ e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
+ # When unconditional_guidance_scale == 1: only e_t
+ # When unconditional_guidance_scale == 0: only unconditional
+ # When unconditional_guidance_scale > 1: add more unconditional guidance
+ e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
+
+ if score_corrector is not None:
+ assert self.model.parameterization == "eps"
+ e_t = score_corrector.modify_score(
+ self.model, e_t, x, t, c, **corrector_kwargs
+ )
+
+ alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
+ alphas_prev = (
+ self.model.alphas_cumprod_prev
+ if use_original_steps
+ else self.ddim_alphas_prev
+ )
+ sqrt_one_minus_alphas = (
+ self.model.sqrt_one_minus_alphas_cumprod
+ if use_original_steps
+ else self.ddim_sqrt_one_minus_alphas
+ )
+ sigmas = (
+ self.model.ddim_sigmas_for_original_num_steps
+ if use_original_steps
+ else self.ddim_sigmas
+ )
+ # select parameters corresponding to the currently considered timestep
+ a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
+ a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
+ sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
+ sqrt_one_minus_at = torch.full(
+ (b, 1, 1, 1), sqrt_one_minus_alphas[index], device=device
+ )
+
+ # current prediction for x_0
+ pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
+ if quantize_denoised:
+ pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
+ # direction pointing to x_t
+ dir_xt = (1.0 - a_prev - sigma_t**2).sqrt() * e_t
+ noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
+ if noise_dropout > 0.0:
+ noise = torch.nn.functional.dropout(noise, p=noise_dropout)
+ x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise # TODO
+ return x_prev, pred_x0
diff --git a/audioldm/latent_diffusion/ddpm.py b/audioldm/latent_diffusion/ddpm.py
new file mode 100644
index 0000000000000000000000000000000000000000..ffca031c27d413698adee5a58547b7d0ea4069c3
--- /dev/null
+++ b/audioldm/latent_diffusion/ddpm.py
@@ -0,0 +1,441 @@
+"""
+wild mixture of
+https://github.com/lucidrains/denoising-diffusion-pytorch/blob/7706bdfc6f527f58d33f84b7b522e61e6e3164b3/denoising_diffusion_pytorch/denoising_diffusion_pytorch.py
+https://github.com/openai/improved-diffusion/blob/e94489283bb876ac1477d5dd7709bbbd2d9902ce/improved_diffusion/gaussian_diffusion.py
+https://github.com/CompVis/taming-transformers
+-- merci
+"""
+import sys
+import os
+
+import torch
+import torch.nn as nn
+import numpy as np
+from contextlib import contextmanager
+from functools import partial
+from tqdm import tqdm
+
+from audioldm.utils import exists, default, count_params, instantiate_from_config
+from audioldm.latent_diffusion.ema import LitEma
+from audioldm.latent_diffusion.util import (
+ make_beta_schedule,
+ extract_into_tensor,
+ noise_like,
+)
+import soundfile as sf
+import os
+
+
+__conditioning_keys__ = {"concat": "c_concat", "crossattn": "c_crossattn", "adm": "y"}
+
+
+def disabled_train(self, mode=True):
+ """Overwrite model.train with this function to make sure train/eval mode
+ does not change anymore."""
+ return self
+
+
+def uniform_on_device(r1, r2, shape, device):
+ return (r1 - r2) * torch.rand(*shape, device=device) + r2
+
+
+class DiffusionWrapper(nn.Module):
+ def __init__(self, diff_model_config, conditioning_key):
+ super().__init__()
+ self.diffusion_model = instantiate_from_config(diff_model_config)
+ self.conditioning_key = conditioning_key
+ assert self.conditioning_key in [
+ None,
+ "concat",
+ "crossattn",
+ "hybrid",
+ "adm",
+ "film",
+ ]
+
+ def forward(
+ self, x, t, c_concat: list = None, c_crossattn: list = None, c_film: list = None
+ ):
+ x = x.contiguous()
+ t = t.contiguous()
+
+ if self.conditioning_key is None:
+ out = self.diffusion_model(x, t)
+ elif self.conditioning_key == "concat":
+ xc = torch.cat([x] + c_concat, dim=1)
+ out = self.diffusion_model(xc, t)
+ elif self.conditioning_key == "crossattn":
+ cc = torch.cat(c_crossattn, 1)
+ out = self.diffusion_model(x, t, context=cc)
+ elif self.conditioning_key == "hybrid":
+ xc = torch.cat([x] + c_concat, dim=1)
+ cc = torch.cat(c_crossattn, 1)
+ out = self.diffusion_model(xc, t, context=cc)
+ elif (
+ self.conditioning_key == "film"
+ ): # The condition is assumed to be a global token, which wil pass through a linear layer and added with the time embedding for the FILM
+ cc = c_film[0].squeeze(1) # only has one token
+ out = self.diffusion_model(x, t, y=cc)
+ elif self.conditioning_key == "adm":
+ cc = c_crossattn[0]
+ out = self.diffusion_model(x, t, y=cc)
+ else:
+ raise NotImplementedError()
+
+ return out
+
+
+class DDPM(nn.Module):
+ # classic DDPM with Gaussian diffusion, in image space
+ def __init__(
+ self,
+ unet_config,
+ timesteps=1000,
+ beta_schedule="linear",
+ loss_type="l2",
+ ckpt_path=None,
+ ignore_keys=[],
+ load_only_unet=False,
+ monitor="val/loss",
+ use_ema=True,
+ first_stage_key="image",
+ latent_t_size=256,
+ latent_f_size=16,
+ channels=3,
+ log_every_t=100,
+ clip_denoised=True,
+ linear_start=1e-4,
+ linear_end=2e-2,
+ cosine_s=8e-3,
+ given_betas=None,
+ original_elbo_weight=0.0,
+ v_posterior=0.0, # weight for choosing posterior variance as sigma = (1-v) * beta_tilde + v * beta
+ l_simple_weight=1.0,
+ conditioning_key=None,
+ parameterization="eps", # all assuming fixed variance schedules
+ scheduler_config=None,
+ use_positional_encodings=False,
+ learn_logvar=False,
+ logvar_init=0.0,
+ ):
+ super().__init__()
+ assert parameterization in [
+ "eps",
+ "x0",
+ ], 'currently only supporting "eps" and "x0"'
+ self.parameterization = parameterization
+ self.state = None
+ # print(f"{self.__class__.__name__}: Running in {self.parameterization}-prediction mode")
+ self.cond_stage_model = None
+ self.clip_denoised = clip_denoised
+ self.log_every_t = log_every_t
+ self.first_stage_key = first_stage_key
+
+ self.latent_t_size = latent_t_size
+ self.latent_f_size = latent_f_size
+
+ self.channels = channels
+ self.use_positional_encodings = use_positional_encodings
+ self.model = DiffusionWrapper(unet_config, conditioning_key)
+ count_params(self.model, verbose=True)
+ self.use_ema = use_ema
+ if self.use_ema:
+ self.model_ema = LitEma(self.model)
+ # print(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}.")
+
+ self.use_scheduler = scheduler_config is not None
+ if self.use_scheduler:
+ self.scheduler_config = scheduler_config
+
+ self.v_posterior = v_posterior
+ self.original_elbo_weight = original_elbo_weight
+ self.l_simple_weight = l_simple_weight
+
+ if monitor is not None:
+ self.monitor = monitor
+
+ self.register_schedule(
+ given_betas=given_betas,
+ beta_schedule=beta_schedule,
+ timesteps=timesteps,
+ linear_start=linear_start,
+ linear_end=linear_end,
+ cosine_s=cosine_s,
+ )
+
+ self.loss_type = loss_type
+
+ self.learn_logvar = learn_logvar
+ self.logvar = torch.full(fill_value=logvar_init, size=(self.num_timesteps,))
+ if self.learn_logvar:
+ self.logvar = nn.Parameter(self.logvar, requires_grad=True)
+ else:
+ self.logvar = nn.Parameter(self.logvar, requires_grad=False)
+
+ self.logger_save_dir = None
+ self.logger_project = None
+ self.logger_version = None
+ self.label_indices_total = None
+ # To avoid the system cannot find metric value for checkpoint
+ self.metrics_buffer = {
+ "val/kullback_leibler_divergence_sigmoid": 15.0,
+ "val/kullback_leibler_divergence_softmax": 10.0,
+ "val/psnr": 0.0,
+ "val/ssim": 0.0,
+ "val/inception_score_mean": 1.0,
+ "val/inception_score_std": 0.0,
+ "val/kernel_inception_distance_mean": 0.0,
+ "val/kernel_inception_distance_std": 0.0,
+ "val/frechet_inception_distance": 133.0,
+ "val/frechet_audio_distance": 32.0,
+ }
+ self.initial_learning_rate = None
+
+ def get_log_dir(self):
+ if (
+ self.logger_save_dir is None
+ and self.logger_project is None
+ and self.logger_version is None
+ ):
+ return os.path.join(
+ self.logger.save_dir, self.logger._project, self.logger.version
+ )
+ else:
+ return os.path.join(
+ self.logger_save_dir, self.logger_project, self.logger_version
+ )
+
+ def set_log_dir(self, save_dir, project, version):
+ self.logger_save_dir = save_dir
+ self.logger_project = project
+ self.logger_version = version
+
+ def register_schedule(
+ self,
+ given_betas=None,
+ beta_schedule="linear",
+ timesteps=1000,
+ linear_start=1e-4,
+ linear_end=2e-2,
+ cosine_s=8e-3,
+ ):
+ if exists(given_betas):
+ betas = given_betas
+ else:
+ betas = make_beta_schedule(
+ beta_schedule,
+ timesteps,
+ linear_start=linear_start,
+ linear_end=linear_end,
+ cosine_s=cosine_s,
+ )
+ alphas = 1.0 - betas
+ alphas_cumprod = np.cumprod(alphas, axis=0)
+ alphas_cumprod_prev = np.append(1.0, alphas_cumprod[:-1])
+
+ (timesteps,) = betas.shape
+ self.num_timesteps = int(timesteps)
+ self.linear_start = linear_start
+ self.linear_end = linear_end
+ assert (
+ alphas_cumprod.shape[0] == self.num_timesteps
+ ), "alphas have to be defined for each timestep"
+
+ to_torch = partial(torch.tensor, dtype=torch.float32)
+
+ self.register_buffer("betas", to_torch(betas))
+ self.register_buffer("alphas_cumprod", to_torch(alphas_cumprod))
+ self.register_buffer("alphas_cumprod_prev", to_torch(alphas_cumprod_prev))
+
+ # calculations for diffusion q(x_t | x_{t-1}) and others
+ self.register_buffer("sqrt_alphas_cumprod", to_torch(np.sqrt(alphas_cumprod)))
+ self.register_buffer(
+ "sqrt_one_minus_alphas_cumprod", to_torch(np.sqrt(1.0 - alphas_cumprod))
+ )
+ self.register_buffer(
+ "log_one_minus_alphas_cumprod", to_torch(np.log(1.0 - alphas_cumprod))
+ )
+ self.register_buffer(
+ "sqrt_recip_alphas_cumprod", to_torch(np.sqrt(1.0 / alphas_cumprod))
+ )
+ self.register_buffer(
+ "sqrt_recipm1_alphas_cumprod", to_torch(np.sqrt(1.0 / alphas_cumprod - 1))
+ )
+
+ # calculations for posterior q(x_{t-1} | x_t, x_0)
+ posterior_variance = (1 - self.v_posterior) * betas * (
+ 1.0 - alphas_cumprod_prev
+ ) / (1.0 - alphas_cumprod) + self.v_posterior * betas
+ # above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t)
+ self.register_buffer("posterior_variance", to_torch(posterior_variance))
+ # below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
+ self.register_buffer(
+ "posterior_log_variance_clipped",
+ to_torch(np.log(np.maximum(posterior_variance, 1e-20))),
+ )
+ self.register_buffer(
+ "posterior_mean_coef1",
+ to_torch(betas * np.sqrt(alphas_cumprod_prev) / (1.0 - alphas_cumprod)),
+ )
+ self.register_buffer(
+ "posterior_mean_coef2",
+ to_torch(
+ (1.0 - alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - alphas_cumprod)
+ ),
+ )
+
+ if self.parameterization == "eps":
+ lvlb_weights = self.betas**2 / (
+ 2
+ * self.posterior_variance
+ * to_torch(alphas)
+ * (1 - self.alphas_cumprod)
+ )
+ elif self.parameterization == "x0":
+ lvlb_weights = (
+ 0.5
+ * np.sqrt(torch.Tensor(alphas_cumprod))
+ / (2.0 * 1 - torch.Tensor(alphas_cumprod))
+ )
+ else:
+ raise NotImplementedError("mu not supported")
+ # TODO how to choose this term
+ lvlb_weights[0] = lvlb_weights[1]
+ self.register_buffer("lvlb_weights", lvlb_weights, persistent=False)
+ assert not torch.isnan(self.lvlb_weights).all()
+
+ @contextmanager
+ def ema_scope(self, context=None):
+ if self.use_ema:
+ self.model_ema.store(self.model.parameters())
+ self.model_ema.copy_to(self.model)
+ if context is not None:
+ # print(f"{context}: Switched to EMA weights")
+ pass
+ try:
+ yield None
+ finally:
+ if self.use_ema:
+ self.model_ema.restore(self.model.parameters())
+ if context is not None:
+ # print(f"{context}: Restored training weights")
+ pass
+
+ def q_mean_variance(self, x_start, t):
+ """
+ Get the distribution q(x_t | x_0).
+ :param x_start: the [N x C x ...] tensor of noiseless inputs.
+ :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
+ :return: A tuple (mean, variance, log_variance), all of x_start's shape.
+ """
+ mean = extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
+ variance = extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
+ log_variance = extract_into_tensor(
+ self.log_one_minus_alphas_cumprod, t, x_start.shape
+ )
+ return mean, variance, log_variance
+
+ def predict_start_from_noise(self, x_t, t, noise):
+ return (
+ extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t
+ - extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
+ * noise
+ )
+
+ def q_posterior(self, x_start, x_t, t):
+ posterior_mean = (
+ extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start
+ + extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t
+ )
+ posterior_variance = extract_into_tensor(self.posterior_variance, t, x_t.shape)
+ posterior_log_variance_clipped = extract_into_tensor(
+ self.posterior_log_variance_clipped, t, x_t.shape
+ )
+ return posterior_mean, posterior_variance, posterior_log_variance_clipped
+
+ def p_mean_variance(self, x, t, clip_denoised: bool):
+ model_out = self.model(x, t)
+ if self.parameterization == "eps":
+ x_recon = self.predict_start_from_noise(x, t=t, noise=model_out)
+ elif self.parameterization == "x0":
+ x_recon = model_out
+ if clip_denoised:
+ x_recon.clamp_(-1.0, 1.0)
+
+ model_mean, posterior_variance, posterior_log_variance = self.q_posterior(
+ x_start=x_recon, x_t=x, t=t
+ )
+ return model_mean, posterior_variance, posterior_log_variance
+
+ @torch.no_grad()
+ def p_sample(self, x, t, clip_denoised=True, repeat_noise=False):
+ b, *_, device = *x.shape, x.device
+ model_mean, _, model_log_variance = self.p_mean_variance(
+ x=x, t=t, clip_denoised=clip_denoised
+ )
+ noise = noise_like(x.shape, device, repeat_noise)
+ # no noise when t == 0
+ nonzero_mask = (
+ (1 - (t == 0).float()).reshape(b, *((1,) * (len(x.shape) - 1))).contiguous()
+ )
+ return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
+
+ @torch.no_grad()
+ def p_sample_loop(self, shape, return_intermediates=False):
+ device = self.betas.device
+ b = shape[0]
+ img = torch.randn(shape, device=device)
+ intermediates = [img]
+ for i in tqdm(
+ reversed(range(0, self.num_timesteps)),
+ desc="Sampling t",
+ total=self.num_timesteps,
+ ):
+ img = self.p_sample(
+ img,
+ torch.full((b,), i, device=device, dtype=torch.long),
+ clip_denoised=self.clip_denoised,
+ )
+ if i % self.log_every_t == 0 or i == self.num_timesteps - 1:
+ intermediates.append(img)
+ if return_intermediates:
+ return img, intermediates
+ return img
+
+ @torch.no_grad()
+ def sample(self, batch_size=16, return_intermediates=False):
+ shape = (batch_size, channels, self.latent_t_size, self.latent_f_size)
+ channels = self.channels
+ return self.p_sample_loop(shape, return_intermediates=return_intermediates)
+
+ def q_sample(self, x_start, t, noise=None):
+ noise = default(noise, lambda: torch.randn_like(x_start))
+ return (
+ extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
+ + extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape)
+ * noise
+ )
+
+ def forward(self, x, *args, **kwargs):
+ t = torch.randint(
+ 0, self.num_timesteps, (x.shape[0],), device=self.device
+ ).long()
+ return self.p_losses(x, t, *args, **kwargs)
+
+ def get_input(self, batch, k):
+ # fbank, log_magnitudes_stft, label_indices, fname, waveform, clip_label, text = batch
+ fbank, log_magnitudes_stft, label_indices, fname, waveform, text = batch
+ ret = {}
+
+ ret["fbank"] = (
+ fbank.unsqueeze(1).to(memory_format=torch.contiguous_format).float()
+ )
+ ret["stft"] = log_magnitudes_stft.to(
+ memory_format=torch.contiguous_format
+ ).float()
+ # ret["clip_label"] = clip_label.to(memory_format=torch.contiguous_format).float()
+ ret["waveform"] = waveform.to(memory_format=torch.contiguous_format).float()
+ ret["text"] = list(text)
+ ret["fname"] = fname
+
+ return ret[k]
diff --git a/audioldm/latent_diffusion/ema.py b/audioldm/latent_diffusion/ema.py
new file mode 100644
index 0000000000000000000000000000000000000000..880ca3d205d9b4d7450e146930a93f2e63c58b70
--- /dev/null
+++ b/audioldm/latent_diffusion/ema.py
@@ -0,0 +1,82 @@
+import torch
+from torch import nn
+
+
+class LitEma(nn.Module):
+ def __init__(self, model, decay=0.9999, use_num_upates=True):
+ super().__init__()
+ if decay < 0.0 or decay > 1.0:
+ raise ValueError("Decay must be between 0 and 1")
+
+ self.m_name2s_name = {}
+ self.register_buffer("decay", torch.tensor(decay, dtype=torch.float32))
+ self.register_buffer(
+ "num_updates",
+ torch.tensor(0, dtype=torch.int)
+ if use_num_upates
+ else torch.tensor(-1, dtype=torch.int),
+ )
+
+ for name, p in model.named_parameters():
+ if p.requires_grad:
+ # remove as '.'-character is not allowed in buffers
+ s_name = name.replace(".", "")
+ self.m_name2s_name.update({name: s_name})
+ self.register_buffer(s_name, p.clone().detach().data)
+
+ self.collected_params = []
+
+ def forward(self, model):
+ decay = self.decay
+
+ if self.num_updates >= 0:
+ self.num_updates += 1
+ decay = min(self.decay, (1 + self.num_updates) / (10 + self.num_updates))
+
+ one_minus_decay = 1.0 - decay
+
+ with torch.no_grad():
+ m_param = dict(model.named_parameters())
+ shadow_params = dict(self.named_buffers())
+
+ for key in m_param:
+ if m_param[key].requires_grad:
+ sname = self.m_name2s_name[key]
+ shadow_params[sname] = shadow_params[sname].type_as(m_param[key])
+ shadow_params[sname].sub_(
+ one_minus_decay * (shadow_params[sname] - m_param[key])
+ )
+ else:
+ assert not key in self.m_name2s_name
+
+ def copy_to(self, model):
+ m_param = dict(model.named_parameters())
+ shadow_params = dict(self.named_buffers())
+ for key in m_param:
+ if m_param[key].requires_grad:
+ m_param[key].data.copy_(shadow_params[self.m_name2s_name[key]].data)
+ else:
+ assert not key in self.m_name2s_name
+
+ def store(self, parameters):
+ """
+ Save the current parameters for restoring later.
+ Args:
+ parameters: Iterable of `torch.nn.Parameter`; the parameters to be
+ temporarily stored.
+ """
+ self.collected_params = [param.clone() for param in parameters]
+
+ def restore(self, parameters):
+ """
+ Restore the parameters stored with the `store` method.
+ Useful to validate the model with EMA parameters without affecting the
+ original optimization process. Store the parameters before the
+ `copy_to` method. After validation (or model saving), use this to
+ restore the former parameters.
+ Args:
+ parameters: Iterable of `torch.nn.Parameter`; the parameters to be
+ updated with the stored parameters.
+ """
+ for c_param, param in zip(self.collected_params, parameters):
+ param.data.copy_(c_param.data)
diff --git a/audioldm/latent_diffusion/openaimodel.py b/audioldm/latent_diffusion/openaimodel.py
new file mode 100644
index 0000000000000000000000000000000000000000..831d7aafb36bba16888e4389153979a6c13639f5
--- /dev/null
+++ b/audioldm/latent_diffusion/openaimodel.py
@@ -0,0 +1,1069 @@
+from abc import abstractmethod
+import math
+
+import numpy as np
+import torch as th
+import torch.nn as nn
+import torch.nn.functional as F
+
+from audioldm.latent_diffusion.util import (
+ checkpoint,
+ conv_nd,
+ linear,
+ avg_pool_nd,
+ zero_module,
+ normalization,
+ timestep_embedding,
+)
+from audioldm.latent_diffusion.attention import SpatialTransformer
+
+
+# dummy replace
+def convert_module_to_f16(x):
+ pass
+
+
+def convert_module_to_f32(x):
+ pass
+
+
+## go
+class AttentionPool2d(nn.Module):
+ """
+ Adapted from CLIP: https://github.com/openai/CLIP/blob/main/clip/model.py
+ """
+
+ def __init__(
+ self,
+ spacial_dim: int,
+ embed_dim: int,
+ num_heads_channels: int,
+ output_dim: int = None,
+ ):
+ super().__init__()
+ self.positional_embedding = nn.Parameter(
+ th.randn(embed_dim, spacial_dim**2 + 1) / embed_dim**0.5
+ )
+ self.qkv_proj = conv_nd(1, embed_dim, 3 * embed_dim, 1)
+ self.c_proj = conv_nd(1, embed_dim, output_dim or embed_dim, 1)
+ self.num_heads = embed_dim // num_heads_channels
+ self.attention = QKVAttention(self.num_heads)
+
+ def forward(self, x):
+ b, c, *_spatial = x.shape
+ x = x.reshape(b, c, -1).contiguous() # NC(HW)
+ x = th.cat([x.mean(dim=-1, keepdim=True), x], dim=-1) # NC(HW+1)
+ x = x + self.positional_embedding[None, :, :].to(x.dtype) # NC(HW+1)
+ x = self.qkv_proj(x)
+ x = self.attention(x)
+ x = self.c_proj(x)
+ return x[:, :, 0]
+
+
+class TimestepBlock(nn.Module):
+ """
+ Any module where forward() takes timestep embeddings as a second argument.
+ """
+
+ @abstractmethod
+ def forward(self, x, emb):
+ """
+ Apply the module to `x` given `emb` timestep embeddings.
+ """
+
+
+class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
+ """
+ A sequential module that passes timestep embeddings to the children that
+ support it as an extra input.
+ """
+
+ def forward(self, x, emb, context=None):
+ for layer in self:
+ if isinstance(layer, TimestepBlock):
+ x = layer(x, emb)
+ elif isinstance(layer, SpatialTransformer):
+ x = layer(x, context)
+ else:
+ x = layer(x)
+ return x
+
+
+class Upsample(nn.Module):
+ """
+ An upsampling layer with an optional convolution.
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ upsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ if use_conv:
+ self.conv = conv_nd(
+ dims, self.channels, self.out_channels, 3, padding=padding
+ )
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.dims == 3:
+ x = F.interpolate(
+ x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest"
+ )
+ else:
+ x = F.interpolate(x, scale_factor=2, mode="nearest")
+ if self.use_conv:
+ x = self.conv(x)
+ return x
+
+
+class TransposedUpsample(nn.Module):
+ "Learned 2x upsampling without padding"
+
+ def __init__(self, channels, out_channels=None, ks=5):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+
+ self.up = nn.ConvTranspose2d(
+ self.channels, self.out_channels, kernel_size=ks, stride=2
+ )
+
+ def forward(self, x):
+ return self.up(x)
+
+
+class Downsample(nn.Module):
+ """
+ A downsampling layer with an optional convolution.
+ :param channels: channels in the inputs and outputs.
+ :param use_conv: a bool determining if a convolution is applied.
+ :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
+ downsampling occurs in the inner-two dimensions.
+ """
+
+ def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.dims = dims
+ stride = 2 if dims != 3 else (1, 2, 2)
+ if use_conv:
+ self.op = conv_nd(
+ dims,
+ self.channels,
+ self.out_channels,
+ 3,
+ stride=stride,
+ padding=padding,
+ )
+ else:
+ assert self.channels == self.out_channels
+ self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ return self.op(x)
+
+
+class ResBlock(TimestepBlock):
+ """
+ A residual block that can optionally change the number of channels.
+ :param channels: the number of input channels.
+ :param emb_channels: the number of timestep embedding channels.
+ :param dropout: the rate of dropout.
+ :param out_channels: if specified, the number of out channels.
+ :param use_conv: if True and out_channels is specified, use a spatial
+ convolution instead of a smaller 1x1 convolution to change the
+ channels in the skip connection.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param use_checkpoint: if True, use gradient checkpointing on this module.
+ :param up: if True, use this block for upsampling.
+ :param down: if True, use this block for downsampling.
+ """
+
+ def __init__(
+ self,
+ channels,
+ emb_channels,
+ dropout,
+ out_channels=None,
+ use_conv=False,
+ use_scale_shift_norm=False,
+ dims=2,
+ use_checkpoint=False,
+ up=False,
+ down=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ self.emb_channels = emb_channels
+ self.dropout = dropout
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_checkpoint = use_checkpoint
+ self.use_scale_shift_norm = use_scale_shift_norm
+
+ self.in_layers = nn.Sequential(
+ normalization(channels),
+ nn.SiLU(),
+ conv_nd(dims, channels, self.out_channels, 3, padding=1),
+ )
+
+ self.updown = up or down
+
+ if up:
+ self.h_upd = Upsample(channels, False, dims)
+ self.x_upd = Upsample(channels, False, dims)
+ elif down:
+ self.h_upd = Downsample(channels, False, dims)
+ self.x_upd = Downsample(channels, False, dims)
+ else:
+ self.h_upd = self.x_upd = nn.Identity()
+
+ self.emb_layers = nn.Sequential(
+ nn.SiLU(),
+ linear(
+ emb_channels,
+ 2 * self.out_channels if use_scale_shift_norm else self.out_channels,
+ ),
+ )
+ self.out_layers = nn.Sequential(
+ normalization(self.out_channels),
+ nn.SiLU(),
+ nn.Dropout(p=dropout),
+ zero_module(
+ conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)
+ ),
+ )
+
+ if self.out_channels == channels:
+ self.skip_connection = nn.Identity()
+ elif use_conv:
+ self.skip_connection = conv_nd(
+ dims, channels, self.out_channels, 3, padding=1
+ )
+ else:
+ self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
+
+ def forward(self, x, emb):
+ """
+ Apply the block to a Tensor, conditioned on a timestep embedding.
+ :param x: an [N x C x ...] Tensor of features.
+ :param emb: an [N x emb_channels] Tensor of timestep embeddings.
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ return checkpoint(
+ self._forward, (x, emb), self.parameters(), self.use_checkpoint
+ )
+
+ def _forward(self, x, emb):
+ if self.updown:
+ in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
+ h = in_rest(x)
+ h = self.h_upd(h)
+ x = self.x_upd(x)
+ h = in_conv(h)
+ else:
+ h = self.in_layers(x)
+ emb_out = self.emb_layers(emb).type(h.dtype)
+ while len(emb_out.shape) < len(h.shape):
+ emb_out = emb_out[..., None]
+ if self.use_scale_shift_norm:
+ out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
+ scale, shift = th.chunk(emb_out, 2, dim=1)
+ h = out_norm(h) * (1 + scale) + shift
+ h = out_rest(h)
+ else:
+ h = h + emb_out
+ h = self.out_layers(h)
+ return self.skip_connection(x) + h
+
+
+class AttentionBlock(nn.Module):
+ """
+ An attention block that allows spatial positions to attend to each other.
+ Originally ported from here, but adapted to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ """
+
+ def __init__(
+ self,
+ channels,
+ num_heads=1,
+ num_head_channels=-1,
+ use_checkpoint=False,
+ use_new_attention_order=False,
+ ):
+ super().__init__()
+ self.channels = channels
+ if num_head_channels == -1:
+ self.num_heads = num_heads
+ else:
+ assert (
+ channels % num_head_channels == 0
+ ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
+ self.num_heads = channels // num_head_channels
+ self.use_checkpoint = use_checkpoint
+ self.norm = normalization(channels)
+ self.qkv = conv_nd(1, channels, channels * 3, 1)
+ if use_new_attention_order:
+ # split qkv before split heads
+ self.attention = QKVAttention(self.num_heads)
+ else:
+ # split heads before split qkv
+ self.attention = QKVAttentionLegacy(self.num_heads)
+
+ self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
+
+ def forward(self, x):
+ return checkpoint(
+ self._forward, (x,), self.parameters(), True
+ ) # TODO: check checkpoint usage, is True # TODO: fix the .half call!!!
+ # return pt_checkpoint(self._forward, x) # pytorch
+
+ def _forward(self, x):
+ b, c, *spatial = x.shape
+ x = x.reshape(b, c, -1).contiguous()
+ qkv = self.qkv(self.norm(x)).contiguous()
+ h = self.attention(qkv).contiguous()
+ h = self.proj_out(h).contiguous()
+ return (x + h).reshape(b, c, *spatial).contiguous()
+
+
+def count_flops_attn(model, _x, y):
+ """
+ A counter for the `thop` package to count the operations in an
+ attention operation.
+ Meant to be used like:
+ macs, params = thop.profile(
+ model,
+ inputs=(inputs, timestamps),
+ custom_ops={QKVAttention: QKVAttention.count_flops},
+ )
+ """
+ b, c, *spatial = y[0].shape
+ num_spatial = int(np.prod(spatial))
+ # We perform two matmuls with the same number of ops.
+ # The first computes the weight matrix, the second computes
+ # the combination of the value vectors.
+ matmul_ops = 2 * b * (num_spatial**2) * c
+ model.total_ops += th.DoubleTensor([matmul_ops])
+
+
+class QKVAttentionLegacy(nn.Module):
+ """
+ A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+ :param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = (
+ qkv.reshape(bs * self.n_heads, ch * 3, length).contiguous().split(ch, dim=1)
+ )
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = th.einsum(
+ "bct,bcs->bts", q * scale, k * scale
+ ) # More stable with f16 than dividing afterwards
+ weight = th.softmax(weight.float(), dim=-1).type(weight.dtype)
+ a = th.einsum("bts,bcs->bct", weight, v)
+ return a.reshape(bs, -1, length).contiguous()
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class QKVAttention(nn.Module):
+ """
+ A module which performs QKV attention and splits in a different order.
+ """
+
+ def __init__(self, n_heads):
+ super().__init__()
+ self.n_heads = n_heads
+
+ def forward(self, qkv):
+ """
+ Apply QKV attention.
+ :param qkv: an [N x (3 * H * C) x T] tensor of Qs, Ks, and Vs.
+ :return: an [N x (H * C) x T] tensor after attention.
+ """
+ bs, width, length = qkv.shape
+ assert width % (3 * self.n_heads) == 0
+ ch = width // (3 * self.n_heads)
+ q, k, v = qkv.chunk(3, dim=1)
+ scale = 1 / math.sqrt(math.sqrt(ch))
+ weight = th.einsum(
+ "bct,bcs->bts",
+ (q * scale).view(bs * self.n_heads, ch, length),
+ (k * scale).view(bs * self.n_heads, ch, length),
+ ) # More stable with f16 than dividing afterwards
+ weight = th.softmax(weight.float(), dim=-1).type(weight.dtype)
+ a = th.einsum(
+ "bts,bcs->bct",
+ weight,
+ v.reshape(bs * self.n_heads, ch, length).contiguous(),
+ )
+ return a.reshape(bs, -1, length).contiguous()
+
+ @staticmethod
+ def count_flops(model, _x, y):
+ return count_flops_attn(model, _x, y)
+
+
+class UNetModel(nn.Module):
+ """
+ The full UNet model with attention and timestep embedding.
+ :param in_channels: channels in the input Tensor.
+ :param model_channels: base channel count for the model.
+ :param out_channels: channels in the output Tensor.
+ :param num_res_blocks: number of residual blocks per downsample.
+ :param attention_resolutions: a collection of downsample rates at which
+ attention will take place. May be a set, list, or tuple.
+ For example, if this contains 4, then at 4x downsampling, attention
+ will be used.
+ :param dropout: the dropout probability.
+ :param channel_mult: channel multiplier for each level of the UNet.
+ :param conv_resample: if True, use learned convolutions for upsampling and
+ downsampling.
+ :param dims: determines if the signal is 1D, 2D, or 3D.
+ :param num_classes: if specified (as an int), then this model will be
+ class-conditional with `num_classes` classes.
+ :param use_checkpoint: use gradient checkpointing to reduce memory usage.
+ :param num_heads: the number of attention heads in each attention layer.
+ :param num_heads_channels: if specified, ignore num_heads and instead use
+ a fixed channel width per attention head.
+ :param num_heads_upsample: works with num_heads to set a different number
+ of heads for upsampling. Deprecated.
+ :param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
+ :param resblock_updown: use residual blocks for up/downsampling.
+ :param use_new_attention_order: use a different attention pattern for potentially
+ increased efficiency.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ num_classes=None,
+ extra_film_condition_dim=None,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=-1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ extra_film_use_concat=False, # If true, concatenate extrafilm condition with time embedding, else addition
+ resblock_updown=False,
+ use_new_attention_order=False,
+ use_spatial_transformer=False, # custom transformer support
+ transformer_depth=1, # custom transformer support
+ context_dim=None, # custom transformer support
+ n_embed=None, # custom support for prediction of discrete ids into codebook of first stage vq model
+ legacy=True,
+ ):
+ super().__init__()
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ if num_heads == -1:
+ assert (
+ num_head_channels != -1
+ ), "Either num_heads or num_head_channels has to be set"
+
+ if num_head_channels == -1:
+ assert (
+ num_heads != -1
+ ), "Either num_heads or num_head_channels has to be set"
+
+ self.image_size = image_size
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.num_classes = num_classes
+ self.extra_film_condition_dim = extra_film_condition_dim
+ self.use_checkpoint = use_checkpoint
+ self.dtype = th.float16 if use_fp16 else th.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+ self.predict_codebook_ids = n_embed is not None
+ self.extra_film_use_concat = extra_film_use_concat
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ assert not (
+ self.num_classes is not None and self.extra_film_condition_dim is not None
+ ), "As for the condition of theh UNet model, you can only set using class label or an extra embedding vector (such as from CLAP). You cannot set both num_classes and extra_film_condition_dim."
+
+ if self.num_classes is not None:
+ self.label_emb = nn.Embedding(num_classes, time_embed_dim)
+
+ self.use_extra_film_by_concat = (
+ self.extra_film_condition_dim is not None and self.extra_film_use_concat
+ )
+ self.use_extra_film_by_addition = (
+ self.extra_film_condition_dim is not None and not self.extra_film_use_concat
+ )
+
+ if self.extra_film_condition_dim is not None:
+ self.film_emb = nn.Linear(self.extra_film_condition_dim, time_embed_dim)
+ # print("+ Use extra condition on UNet channel using Film. Extra condition dimension is %s. " % self.extra_film_condition_dim)
+ # if(self.use_extra_film_by_concat):
+ # print("\t By concatenation with time embedding")
+ # elif(self.use_extra_film_by_concat):
+ # print("\t By addition with time embedding")
+
+ if use_spatial_transformer and (
+ self.use_extra_film_by_concat or self.use_extra_film_by_addition
+ ):
+ # print("+ Spatial transformer will only be used as self-attention. Because you have choose to use film as your global condition.")
+ spatial_transformer_no_context = True
+ else:
+ spatial_transformer_no_context = False
+
+ if use_spatial_transformer and not spatial_transformer_no_context:
+ assert (
+ context_dim is not None
+ ), "Fool!! You forgot to include the dimension of your cross-attention conditioning..."
+
+ if context_dim is not None and not spatial_transformer_no_context:
+ assert (
+ use_spatial_transformer
+ ), "Fool!! You forgot to use the spatial transformer for your cross-attention conditioning..."
+ from omegaconf.listconfig import ListConfig
+
+ if type(context_dim) == ListConfig:
+ context_dim = list(context_dim)
+
+ self.input_blocks = nn.ModuleList(
+ [
+ TimestepEmbedSequential(
+ conv_nd(dims, in_channels, model_channels, 3, padding=1)
+ )
+ ]
+ )
+ self._feature_size = model_channels
+ input_block_chans = [model_channels]
+ ch = model_channels
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim
+ if (not self.use_extra_film_by_concat)
+ else time_embed_dim * 2,
+ dropout,
+ out_channels=mult * model_channels,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = mult * model_channels
+ if ds in attention_resolutions:
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+ if legacy:
+ dim_head = (
+ ch // num_heads
+ if use_spatial_transformer
+ else num_head_channels
+ )
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=dim_head,
+ use_new_attention_order=use_new_attention_order,
+ )
+ if not use_spatial_transformer
+ else SpatialTransformer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth,
+ context_dim=context_dim,
+ no_context=spatial_transformer_no_context,
+ )
+ )
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim
+ if (not self.use_extra_film_by_concat)
+ else time_embed_dim * 2,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ )
+ if resblock_updown
+ else Downsample(
+ ch, conv_resample, dims=dims, out_channels=out_ch
+ )
+ )
+ )
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+ if legacy:
+ # num_heads = 1
+ dim_head = ch // num_heads if use_spatial_transformer else num_head_channels
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim
+ if (not self.use_extra_film_by_concat)
+ else time_embed_dim * 2,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=dim_head,
+ use_new_attention_order=use_new_attention_order,
+ )
+ if not use_spatial_transformer
+ else SpatialTransformer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth,
+ context_dim=context_dim,
+ no_context=spatial_transformer_no_context,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim
+ if (not self.use_extra_film_by_concat)
+ else time_embed_dim * 2,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+
+ self.output_blocks = nn.ModuleList([])
+ for level, mult in list(enumerate(channel_mult))[::-1]:
+ for i in range(num_res_blocks + 1):
+ ich = input_block_chans.pop()
+ layers = [
+ ResBlock(
+ ch + ich,
+ time_embed_dim
+ if (not self.use_extra_film_by_concat)
+ else time_embed_dim * 2,
+ dropout,
+ out_channels=model_channels * mult,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = model_channels * mult
+ if ds in attention_resolutions:
+ if num_head_channels == -1:
+ dim_head = ch // num_heads
+ else:
+ num_heads = ch // num_head_channels
+ dim_head = num_head_channels
+ if legacy:
+ # num_heads = 1
+ dim_head = (
+ ch // num_heads
+ if use_spatial_transformer
+ else num_head_channels
+ )
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads_upsample,
+ num_head_channels=dim_head,
+ use_new_attention_order=use_new_attention_order,
+ )
+ if not use_spatial_transformer
+ else SpatialTransformer(
+ ch,
+ num_heads,
+ dim_head,
+ depth=transformer_depth,
+ context_dim=context_dim,
+ no_context=spatial_transformer_no_context,
+ )
+ )
+ if level and i == num_res_blocks:
+ out_ch = ch
+ layers.append(
+ ResBlock(
+ ch,
+ time_embed_dim
+ if (not self.use_extra_film_by_concat)
+ else time_embed_dim * 2,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ up=True,
+ )
+ if resblock_updown
+ else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch)
+ )
+ ds //= 2
+ self.output_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+
+ self.out = nn.Sequential(
+ normalization(ch),
+ nn.SiLU(),
+ zero_module(conv_nd(dims, model_channels, out_channels, 3, padding=1)),
+ )
+ if self.predict_codebook_ids:
+ self.id_predictor = nn.Sequential(
+ normalization(ch),
+ conv_nd(dims, model_channels, n_embed, 1),
+ # nn.LogSoftmax(dim=1) # change to cross_entropy and produce non-normalized logits
+ )
+
+ self.shape_reported = False
+
+ def convert_to_fp16(self):
+ """
+ Convert the torso of the model to float16.
+ """
+ self.input_blocks.apply(convert_module_to_f16)
+ self.middle_block.apply(convert_module_to_f16)
+ self.output_blocks.apply(convert_module_to_f16)
+
+ def convert_to_fp32(self):
+ """
+ Convert the torso of the model to float32.
+ """
+ self.input_blocks.apply(convert_module_to_f32)
+ self.middle_block.apply(convert_module_to_f32)
+ self.output_blocks.apply(convert_module_to_f32)
+
+ def forward(self, x, timesteps=None, context=None, y=None, **kwargs):
+ """
+ Apply the model to an input batch.
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :param context: conditioning plugged in via crossattn
+ :param y: an [N] Tensor of labels, if class-conditional. an [N, extra_film_condition_dim] Tensor if film-embed conditional
+ :return: an [N x C x ...] Tensor of outputs.
+ """
+ if not self.shape_reported:
+ # print("The shape of UNet input is", x.size())
+ self.shape_reported = True
+
+ assert (y is not None) == (
+ self.num_classes is not None or self.extra_film_condition_dim is not None
+ ), "must specify y if and only if the model is class-conditional or film embedding conditional"
+ hs = []
+ t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
+ emb = self.time_embed(t_emb)
+
+ if self.num_classes is not None:
+ assert y.shape == (x.shape[0],)
+ emb = emb + self.label_emb(y)
+
+ if self.use_extra_film_by_addition:
+ emb = emb + self.film_emb(y)
+ elif self.use_extra_film_by_concat:
+ emb = th.cat([emb, self.film_emb(y)], dim=-1)
+
+ h = x.type(self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb, context)
+ hs.append(h)
+ h = self.middle_block(h, emb, context)
+ for module in self.output_blocks:
+ h = th.cat([h, hs.pop()], dim=1)
+ h = module(h, emb, context)
+ h = h.type(x.dtype)
+ if self.predict_codebook_ids:
+ return self.id_predictor(h)
+ else:
+ return self.out(h)
+
+
+class EncoderUNetModel(nn.Module):
+ """
+ The half UNet model with attention and timestep embedding.
+ For usage, see UNet.
+ """
+
+ def __init__(
+ self,
+ image_size,
+ in_channels,
+ model_channels,
+ out_channels,
+ num_res_blocks,
+ attention_resolutions,
+ dropout=0,
+ channel_mult=(1, 2, 4, 8),
+ conv_resample=True,
+ dims=2,
+ use_checkpoint=False,
+ use_fp16=False,
+ num_heads=1,
+ num_head_channels=-1,
+ num_heads_upsample=-1,
+ use_scale_shift_norm=False,
+ resblock_updown=False,
+ use_new_attention_order=False,
+ pool="adaptive",
+ *args,
+ **kwargs,
+ ):
+ super().__init__()
+
+ if num_heads_upsample == -1:
+ num_heads_upsample = num_heads
+
+ self.in_channels = in_channels
+ self.model_channels = model_channels
+ self.out_channels = out_channels
+ self.num_res_blocks = num_res_blocks
+ self.attention_resolutions = attention_resolutions
+ self.dropout = dropout
+ self.channel_mult = channel_mult
+ self.conv_resample = conv_resample
+ self.use_checkpoint = use_checkpoint
+ self.dtype = th.float16 if use_fp16 else th.float32
+ self.num_heads = num_heads
+ self.num_head_channels = num_head_channels
+ self.num_heads_upsample = num_heads_upsample
+
+ time_embed_dim = model_channels * 4
+ self.time_embed = nn.Sequential(
+ linear(model_channels, time_embed_dim),
+ nn.SiLU(),
+ linear(time_embed_dim, time_embed_dim),
+ )
+
+ self.input_blocks = nn.ModuleList(
+ [
+ TimestepEmbedSequential(
+ conv_nd(dims, in_channels, model_channels, 3, padding=1)
+ )
+ ]
+ )
+ self._feature_size = model_channels
+ input_block_chans = [model_channels]
+ ch = model_channels
+ ds = 1
+ for level, mult in enumerate(channel_mult):
+ for _ in range(num_res_blocks):
+ layers = [
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=mult * model_channels,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ )
+ ]
+ ch = mult * model_channels
+ if ds in attention_resolutions:
+ layers.append(
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ )
+ )
+ self.input_blocks.append(TimestepEmbedSequential(*layers))
+ self._feature_size += ch
+ input_block_chans.append(ch)
+ if level != len(channel_mult) - 1:
+ out_ch = ch
+ self.input_blocks.append(
+ TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ out_channels=out_ch,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ down=True,
+ )
+ if resblock_updown
+ else Downsample(
+ ch, conv_resample, dims=dims, out_channels=out_ch
+ )
+ )
+ )
+ ch = out_ch
+ input_block_chans.append(ch)
+ ds *= 2
+ self._feature_size += ch
+
+ self.middle_block = TimestepEmbedSequential(
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ AttentionBlock(
+ ch,
+ use_checkpoint=use_checkpoint,
+ num_heads=num_heads,
+ num_head_channels=num_head_channels,
+ use_new_attention_order=use_new_attention_order,
+ ),
+ ResBlock(
+ ch,
+ time_embed_dim,
+ dropout,
+ dims=dims,
+ use_checkpoint=use_checkpoint,
+ use_scale_shift_norm=use_scale_shift_norm,
+ ),
+ )
+ self._feature_size += ch
+ self.pool = pool
+ if pool == "adaptive":
+ self.out = nn.Sequential(
+ normalization(ch),
+ nn.SiLU(),
+ nn.AdaptiveAvgPool2d((1, 1)),
+ zero_module(conv_nd(dims, ch, out_channels, 1)),
+ nn.Flatten(),
+ )
+ elif pool == "attention":
+ assert num_head_channels != -1
+ self.out = nn.Sequential(
+ normalization(ch),
+ nn.SiLU(),
+ AttentionPool2d(
+ (image_size // ds), ch, num_head_channels, out_channels
+ ),
+ )
+ elif pool == "spatial":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ nn.ReLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ elif pool == "spatial_v2":
+ self.out = nn.Sequential(
+ nn.Linear(self._feature_size, 2048),
+ normalization(2048),
+ nn.SiLU(),
+ nn.Linear(2048, self.out_channels),
+ )
+ else:
+ raise NotImplementedError(f"Unexpected {pool} pooling")
+
+ def convert_to_fp16(self):
+ """
+ Convert the torso of the model to float16.
+ """
+ self.input_blocks.apply(convert_module_to_f16)
+ self.middle_block.apply(convert_module_to_f16)
+
+ def convert_to_fp32(self):
+ """
+ Convert the torso of the model to float32.
+ """
+ self.input_blocks.apply(convert_module_to_f32)
+ self.middle_block.apply(convert_module_to_f32)
+
+ def forward(self, x, timesteps):
+ """
+ Apply the model to an input batch.
+ :param x: an [N x C x ...] Tensor of inputs.
+ :param timesteps: a 1-D batch of timesteps.
+ :return: an [N x K] Tensor of outputs.
+ """
+ emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
+
+ results = []
+ h = x.type(self.dtype)
+ for module in self.input_blocks:
+ h = module(h, emb)
+ if self.pool.startswith("spatial"):
+ results.append(h.type(x.dtype).mean(dim=(2, 3)))
+ h = self.middle_block(h, emb)
+ if self.pool.startswith("spatial"):
+ results.append(h.type(x.dtype).mean(dim=(2, 3)))
+ h = th.cat(results, axis=-1)
+ return self.out(h)
+ else:
+ h = h.type(x.dtype)
+ return self.out(h)
diff --git a/audioldm/latent_diffusion/util.py b/audioldm/latent_diffusion/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b289f6aa7f22a070870d8a706f944dc8547e936
--- /dev/null
+++ b/audioldm/latent_diffusion/util.py
@@ -0,0 +1,295 @@
+# adopted from
+# https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
+# and
+# https://github.com/lucidrains/denoising-diffusion-pytorch/blob/7706bdfc6f527f58d33f84b7b522e61e6e3164b3/denoising_diffusion_pytorch/denoising_diffusion_pytorch.py
+# and
+# https://github.com/openai/guided-diffusion/blob/0ba878e517b276c45d1195eb29f6f5f72659a05b/guided_diffusion/nn.py
+#
+# thanks!
+
+
+import os
+import math
+import torch
+import torch.nn as nn
+import numpy as np
+from einops import repeat
+
+from audioldm.utils import instantiate_from_config
+
+
+def make_beta_schedule(
+ schedule, n_timestep, linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3
+):
+ if schedule == "linear":
+ betas = (
+ torch.linspace(
+ linear_start**0.5, linear_end**0.5, n_timestep, dtype=torch.float64
+ )
+ ** 2
+ )
+
+ elif schedule == "cosine":
+ timesteps = (
+ torch.arange(n_timestep + 1, dtype=torch.float64) / n_timestep + cosine_s
+ )
+ alphas = timesteps / (1 + cosine_s) * np.pi / 2
+ alphas = torch.cos(alphas).pow(2)
+ alphas = alphas / alphas[0]
+ betas = 1 - alphas[1:] / alphas[:-1]
+ betas = np.clip(betas, a_min=0, a_max=0.999)
+
+ elif schedule == "sqrt_linear":
+ betas = torch.linspace(
+ linear_start, linear_end, n_timestep, dtype=torch.float64
+ )
+ elif schedule == "sqrt":
+ betas = (
+ torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64)
+ ** 0.5
+ )
+ else:
+ raise ValueError(f"schedule '{schedule}' unknown.")
+ return betas.numpy()
+
+
+def make_ddim_timesteps(
+ ddim_discr_method, num_ddim_timesteps, num_ddpm_timesteps, verbose=True
+):
+ if ddim_discr_method == "uniform":
+ c = num_ddpm_timesteps // num_ddim_timesteps
+ ddim_timesteps = np.asarray(list(range(0, num_ddpm_timesteps, c)))
+ elif ddim_discr_method == "quad":
+ ddim_timesteps = (
+ (np.linspace(0, np.sqrt(num_ddpm_timesteps * 0.8), num_ddim_timesteps)) ** 2
+ ).astype(int)
+ else:
+ raise NotImplementedError(
+ f'There is no ddim discretization method called "{ddim_discr_method}"'
+ )
+
+ # assert ddim_timesteps.shape[0] == num_ddim_timesteps
+ # add one to get the final alpha values right (the ones from first scale to data during sampling)
+ steps_out = ddim_timesteps + 1
+ if verbose:
+ print(f"Selected timesteps for ddim sampler: {steps_out}")
+ return steps_out
+
+
+def make_ddim_sampling_parameters(alphacums, ddim_timesteps, eta, verbose=True):
+ # select alphas for computing the variance schedule
+ alphas = alphacums[ddim_timesteps]
+ alphas_prev = np.asarray([alphacums[0]] + alphacums[ddim_timesteps[:-1]].tolist())
+
+ # according the the formula provided in https://arxiv.org/abs/2010.02502
+ sigmas = eta * np.sqrt(
+ (1 - alphas_prev) / (1 - alphas) * (1 - alphas / alphas_prev)
+ )
+ if verbose:
+ print(
+ f"Selected alphas for ddim sampler: a_t: {alphas}; a_(t-1): {alphas_prev}"
+ )
+ print(
+ f"For the chosen value of eta, which is {eta}, "
+ f"this results in the following sigma_t schedule for ddim sampler {sigmas}"
+ )
+ return sigmas, alphas, alphas_prev
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function,
+ which defines the cumulative product of (1-beta) over time from t = [0,1].
+ :param num_diffusion_timesteps: the number of betas to produce.
+ :param alpha_bar: a lambda that takes an argument t from 0 to 1 and
+ produces the cumulative product of (1-beta) up to that
+ part of the diffusion process.
+ :param max_beta: the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+ """
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return np.array(betas)
+
+
+def extract_into_tensor(a, t, x_shape):
+ b, *_ = t.shape
+ out = a.gather(-1, t).contiguous()
+ return out.reshape(b, *((1,) * (len(x_shape) - 1))).contiguous()
+
+
+def checkpoint(func, inputs, params, flag):
+ """
+ Evaluate a function without caching intermediate activations, allowing for
+ reduced memory at the expense of extra compute in the backward pass.
+ :param func: the function to evaluate.
+ :param inputs: the argument sequence to pass to `func`.
+ :param params: a sequence of parameters `func` depends on but does not
+ explicitly take as arguments.
+ :param flag: if False, disable gradient checkpointing.
+ """
+ if flag:
+ args = tuple(inputs) + tuple(params)
+ return CheckpointFunction.apply(func, len(inputs), *args)
+ else:
+ return func(*inputs)
+
+
+class CheckpointFunction(torch.autograd.Function):
+ @staticmethod
+ def forward(ctx, run_function, length, *args):
+ ctx.run_function = run_function
+ ctx.input_tensors = list(args[:length])
+ ctx.input_params = list(args[length:])
+
+ with torch.no_grad():
+ output_tensors = ctx.run_function(*ctx.input_tensors)
+ return output_tensors
+
+ @staticmethod
+ def backward(ctx, *output_grads):
+ ctx.input_tensors = [x.detach().requires_grad_(True) for x in ctx.input_tensors]
+ with torch.enable_grad():
+ # Fixes a bug where the first op in run_function modifies the
+ # Tensor storage in place, which is not allowed for detach()'d
+ # Tensors.
+ shallow_copies = [x.view_as(x) for x in ctx.input_tensors]
+ output_tensors = ctx.run_function(*shallow_copies)
+ input_grads = torch.autograd.grad(
+ output_tensors,
+ ctx.input_tensors + ctx.input_params,
+ output_grads,
+ allow_unused=True,
+ )
+ del ctx.input_tensors
+ del ctx.input_params
+ del output_tensors
+ return (None, None) + input_grads
+
+
+def timestep_embedding(timesteps, dim, max_period=10000, repeat_only=False):
+ """
+ Create sinusoidal timestep embeddings.
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param dim: the dimension of the output.
+ :param max_period: controls the minimum frequency of the embeddings.
+ :return: an [N x dim] Tensor of positional embeddings.
+ """
+ if not repeat_only:
+ half = dim // 2
+ freqs = torch.exp(
+ -math.log(max_period)
+ * torch.arange(start=0, end=half, dtype=torch.float32)
+ / half
+ ).to(device=timesteps.device)
+ args = timesteps[:, None].float() * freqs[None]
+ embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
+ if dim % 2:
+ embedding = torch.cat(
+ [embedding, torch.zeros_like(embedding[:, :1])], dim=-1
+ )
+ else:
+ embedding = repeat(timesteps, "b -> b d", d=dim)
+ return embedding
+
+
+def zero_module(module):
+ """
+ Zero out the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().zero_()
+ return module
+
+
+def scale_module(module, scale):
+ """
+ Scale the parameters of a module and return it.
+ """
+ for p in module.parameters():
+ p.detach().mul_(scale)
+ return module
+
+
+def mean_flat(tensor):
+ """
+ Take the mean over all non-batch dimensions.
+ """
+ return tensor.mean(dim=list(range(1, len(tensor.shape))))
+
+
+def normalization(channels):
+ """
+ Make a standard normalization layer.
+ :param channels: number of input channels.
+ :return: an nn.Module for normalization.
+ """
+ return GroupNorm32(32, channels)
+
+
+# PyTorch 1.7 has SiLU, but we support PyTorch 1.5.
+class SiLU(nn.Module):
+ def forward(self, x):
+ return x * torch.sigmoid(x)
+
+
+class GroupNorm32(nn.GroupNorm):
+ def forward(self, x):
+ return super().forward(x.float()).type(x.dtype)
+
+
+def conv_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D convolution module.
+ """
+ if dims == 1:
+ return nn.Conv1d(*args, **kwargs)
+ elif dims == 2:
+ return nn.Conv2d(*args, **kwargs)
+ elif dims == 3:
+ return nn.Conv3d(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+def linear(*args, **kwargs):
+ """
+ Create a linear module.
+ """
+ return nn.Linear(*args, **kwargs)
+
+
+def avg_pool_nd(dims, *args, **kwargs):
+ """
+ Create a 1D, 2D, or 3D average pooling module.
+ """
+ if dims == 1:
+ return nn.AvgPool1d(*args, **kwargs)
+ elif dims == 2:
+ return nn.AvgPool2d(*args, **kwargs)
+ elif dims == 3:
+ return nn.AvgPool3d(*args, **kwargs)
+ raise ValueError(f"unsupported dimensions: {dims}")
+
+
+class HybridConditioner(nn.Module):
+ def __init__(self, c_concat_config, c_crossattn_config):
+ super().__init__()
+ self.concat_conditioner = instantiate_from_config(c_concat_config)
+ self.crossattn_conditioner = instantiate_from_config(c_crossattn_config)
+
+ def forward(self, c_concat, c_crossattn):
+ c_concat = self.concat_conditioner(c_concat)
+ c_crossattn = self.crossattn_conditioner(c_crossattn)
+ return {"c_concat": [c_concat], "c_crossattn": [c_crossattn]}
+
+
+def noise_like(shape, device, repeat=False):
+ repeat_noise = lambda: torch.randn((1, *shape[1:]), device=device).repeat(
+ shape[0], *((1,) * (len(shape) - 1))
+ )
+ noise = lambda: torch.randn(shape, device=device)
+ return repeat_noise() if repeat else noise()
diff --git a/audioldm/ldm.py b/audioldm/ldm.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0179fd5a506052ac9db22bd37f3db6b910aded5
--- /dev/null
+++ b/audioldm/ldm.py
@@ -0,0 +1,818 @@
+import os
+
+import torch
+import numpy as np
+from tqdm import tqdm
+from audioldm.utils import default, instantiate_from_config, save_wave
+from audioldm.latent_diffusion.ddpm import DDPM
+from audioldm.variational_autoencoder.distributions import DiagonalGaussianDistribution
+from audioldm.latent_diffusion.util import noise_like
+from audioldm.latent_diffusion.ddim import DDIMSampler
+import os
+
+
+def disabled_train(self, mode=True):
+ """Overwrite model.train with this function to make sure train/eval mode
+ does not change anymore."""
+ return self
+
+
+class LatentDiffusion(DDPM):
+ """main class"""
+
+ def __init__(
+ self,
+ device="cuda",
+ first_stage_config=None,
+ cond_stage_config=None,
+ num_timesteps_cond=None,
+ cond_stage_key="image",
+ cond_stage_trainable=False,
+ concat_mode=True,
+ cond_stage_forward=None,
+ conditioning_key=None,
+ scale_factor=1.0,
+ scale_by_std=False,
+ base_learning_rate=None,
+ *args,
+ **kwargs,
+ ):
+ self.device = device
+ self.learning_rate = base_learning_rate
+ self.num_timesteps_cond = default(num_timesteps_cond, 1)
+ self.scale_by_std = scale_by_std
+ assert self.num_timesteps_cond <= kwargs["timesteps"]
+ # for backwards compatibility after implementation of DiffusionWrapper
+ if conditioning_key is None:
+ conditioning_key = "concat" if concat_mode else "crossattn"
+ if cond_stage_config == "__is_unconditional__":
+ conditioning_key = None
+ ckpt_path = kwargs.pop("ckpt_path", None)
+ ignore_keys = kwargs.pop("ignore_keys", [])
+ super().__init__(conditioning_key=conditioning_key, *args, **kwargs)
+ self.concat_mode = concat_mode
+ self.cond_stage_trainable = cond_stage_trainable
+ self.cond_stage_key = cond_stage_key
+ self.cond_stage_key_orig = cond_stage_key
+ try:
+ self.num_downs = len(first_stage_config.params.ddconfig.ch_mult) - 1
+ except:
+ self.num_downs = 0
+ if not scale_by_std:
+ self.scale_factor = scale_factor
+ else:
+ self.register_buffer("scale_factor", torch.tensor(scale_factor))
+ self.instantiate_first_stage(first_stage_config)
+ self.instantiate_cond_stage(cond_stage_config)
+ self.cond_stage_forward = cond_stage_forward
+ self.clip_denoised = False
+
+ def make_cond_schedule(
+ self,
+ ):
+ self.cond_ids = torch.full(
+ size=(self.num_timesteps,),
+ fill_value=self.num_timesteps - 1,
+ dtype=torch.long,
+ )
+ ids = torch.round(
+ torch.linspace(0, self.num_timesteps - 1, self.num_timesteps_cond)
+ ).long()
+ self.cond_ids[: self.num_timesteps_cond] = ids
+
+ def register_schedule(
+ self,
+ given_betas=None,
+ beta_schedule="linear",
+ timesteps=1000,
+ linear_start=1e-4,
+ linear_end=2e-2,
+ cosine_s=8e-3,
+ ):
+ super().register_schedule(
+ given_betas, beta_schedule, timesteps, linear_start, linear_end, cosine_s
+ )
+
+ self.shorten_cond_schedule = self.num_timesteps_cond > 1
+ if self.shorten_cond_schedule:
+ self.make_cond_schedule()
+
+ def instantiate_first_stage(self, config):
+ model = instantiate_from_config(config)
+ self.first_stage_model = model.eval()
+ self.first_stage_model.train = disabled_train
+ for param in self.first_stage_model.parameters():
+ param.requires_grad = False
+
+ def instantiate_cond_stage(self, config):
+ if not self.cond_stage_trainable:
+ if config == "__is_first_stage__":
+ print("Using first stage also as cond stage.")
+ self.cond_stage_model = self.first_stage_model
+ elif config == "__is_unconditional__":
+ print(f"Training {self.__class__.__name__} as an unconditional model.")
+ self.cond_stage_model = None
+ # self.be_unconditional = True
+ else:
+ model = instantiate_from_config(config)
+ self.cond_stage_model = model.eval()
+ self.cond_stage_model.train = disabled_train
+ for param in self.cond_stage_model.parameters():
+ param.requires_grad = False
+ else:
+ assert config != "__is_first_stage__"
+ assert config != "__is_unconditional__"
+ model = instantiate_from_config(config)
+ self.cond_stage_model = model
+ self.cond_stage_model = self.cond_stage_model.to(self.device)
+
+ def get_first_stage_encoding(self, encoder_posterior):
+ if isinstance(encoder_posterior, DiagonalGaussianDistribution):
+ z = encoder_posterior.sample()
+ elif isinstance(encoder_posterior, torch.Tensor):
+ z = encoder_posterior
+ else:
+ raise NotImplementedError(
+ f"encoder_posterior of type '{type(encoder_posterior)}' not yet implemented"
+ )
+ return self.scale_factor * z
+
+ def get_learned_conditioning(self, c):
+ if self.cond_stage_forward is None:
+ if hasattr(self.cond_stage_model, "encode") and callable(
+ self.cond_stage_model.encode
+ ):
+ c = self.cond_stage_model.encode(c)
+ if isinstance(c, DiagonalGaussianDistribution):
+ c = c.mode()
+ else:
+ # Text input is list
+ if type(c) == list and len(c) == 1:
+ c = self.cond_stage_model([c[0], c[0]])
+ c = c[0:1]
+ else:
+ c = self.cond_stage_model(c)
+ else:
+ assert hasattr(self.cond_stage_model, self.cond_stage_forward)
+ c = getattr(self.cond_stage_model, self.cond_stage_forward)(c)
+ return c
+
+ @torch.no_grad()
+ def get_input(
+ self,
+ batch,
+ k,
+ return_first_stage_encode=True,
+ return_first_stage_outputs=False,
+ force_c_encode=False,
+ cond_key=None,
+ return_original_cond=False,
+ bs=None,
+ ):
+ x = super().get_input(batch, k)
+
+ if bs is not None:
+ x = x[:bs]
+
+ x = x.to(self.device)
+
+ if return_first_stage_encode:
+ encoder_posterior = self.encode_first_stage(x)
+ z = self.get_first_stage_encoding(encoder_posterior).detach()
+ else:
+ z = None
+
+ if self.model.conditioning_key is not None:
+ if cond_key is None:
+ cond_key = self.cond_stage_key
+ if cond_key != self.first_stage_key:
+ if cond_key in ["caption", "coordinates_bbox"]:
+ xc = batch[cond_key]
+ elif cond_key == "class_label":
+ xc = batch
+ else:
+ # [bs, 1, 527]
+ xc = super().get_input(batch, cond_key)
+ if type(xc) == torch.Tensor:
+ xc = xc.to(self.device)
+ else:
+ xc = x
+ if not self.cond_stage_trainable or force_c_encode:
+ if isinstance(xc, dict) or isinstance(xc, list):
+ c = self.get_learned_conditioning(xc)
+ else:
+ c = self.get_learned_conditioning(xc.to(self.device))
+ else:
+ c = xc
+
+ if bs is not None:
+ c = c[:bs]
+
+ else:
+ c = None
+ xc = None
+ if self.use_positional_encodings:
+ pos_x, pos_y = self.compute_latent_shifts(batch)
+ c = {"pos_x": pos_x, "pos_y": pos_y}
+ out = [z, c]
+ if return_first_stage_outputs:
+ xrec = self.decode_first_stage(z)
+ out.extend([x, xrec])
+ if return_original_cond:
+ out.append(xc)
+ return out
+
+ @torch.no_grad()
+ def decode_first_stage(self, z, predict_cids=False, force_not_quantize=False):
+ if predict_cids:
+ if z.dim() == 4:
+ z = torch.argmax(z.exp(), dim=1).long()
+ z = self.first_stage_model.quantize.get_codebook_entry(z, shape=None)
+ z = rearrange(z, "b h w c -> b c h w").contiguous()
+
+ z = 1.0 / self.scale_factor * z
+ return self.first_stage_model.decode(z)
+
+ def mel_spectrogram_to_waveform(self, mel):
+ # Mel: [bs, 1, t-steps, fbins]
+ if len(mel.size()) == 4:
+ mel = mel.squeeze(1)
+ mel = mel.permute(0, 2, 1)
+ waveform = self.first_stage_model.vocoder(mel)
+ waveform = waveform.cpu().detach().numpy()
+ return waveform
+
+ @torch.no_grad()
+ def encode_first_stage(self, x):
+ return self.first_stage_model.encode(x)
+
+ def apply_model(self, x_noisy, t, cond, return_ids=False):
+
+ if isinstance(cond, dict):
+ # hybrid case, cond is exptected to be a dict
+ pass
+ else:
+ if not isinstance(cond, list):
+ cond = [cond]
+ if self.model.conditioning_key == "concat":
+ key = "c_concat"
+ elif self.model.conditioning_key == "crossattn":
+ key = "c_crossattn"
+ else:
+ key = "c_film"
+
+ cond = {key: cond}
+
+ x_recon = self.model(x_noisy, t, **cond)
+
+ if isinstance(x_recon, tuple) and not return_ids:
+ return x_recon[0]
+ else:
+ return x_recon
+
+ def p_mean_variance(
+ self,
+ x,
+ c,
+ t,
+ clip_denoised: bool,
+ return_codebook_ids=False,
+ quantize_denoised=False,
+ return_x0=False,
+ score_corrector=None,
+ corrector_kwargs=None,
+ ):
+ t_in = t
+ model_out = self.apply_model(x, t_in, c, return_ids=return_codebook_ids)
+
+ if score_corrector is not None:
+ assert self.parameterization == "eps"
+ model_out = score_corrector.modify_score(
+ self, model_out, x, t, c, **corrector_kwargs
+ )
+
+ if return_codebook_ids:
+ model_out, logits = model_out
+
+ if self.parameterization == "eps":
+ x_recon = self.predict_start_from_noise(x, t=t, noise=model_out)
+ elif self.parameterization == "x0":
+ x_recon = model_out
+ else:
+ raise NotImplementedError()
+
+ if clip_denoised:
+ x_recon.clamp_(-1.0, 1.0)
+ if quantize_denoised:
+ x_recon, _, [_, _, indices] = self.first_stage_model.quantize(x_recon)
+ model_mean, posterior_variance, posterior_log_variance = self.q_posterior(
+ x_start=x_recon, x_t=x, t=t
+ )
+ if return_codebook_ids:
+ return model_mean, posterior_variance, posterior_log_variance, logits
+ elif return_x0:
+ return model_mean, posterior_variance, posterior_log_variance, x_recon
+ else:
+ return model_mean, posterior_variance, posterior_log_variance
+
+ @torch.no_grad()
+ def p_sample(
+ self,
+ x,
+ c,
+ t,
+ clip_denoised=False,
+ repeat_noise=False,
+ return_codebook_ids=False,
+ quantize_denoised=False,
+ return_x0=False,
+ temperature=1.0,
+ noise_dropout=0.0,
+ score_corrector=None,
+ corrector_kwargs=None,
+ ):
+ b, *_, device = *x.shape, x.device
+ outputs = self.p_mean_variance(
+ x=x,
+ c=c,
+ t=t,
+ clip_denoised=clip_denoised,
+ return_codebook_ids=return_codebook_ids,
+ quantize_denoised=quantize_denoised,
+ return_x0=return_x0,
+ score_corrector=score_corrector,
+ corrector_kwargs=corrector_kwargs,
+ )
+ if return_codebook_ids:
+ raise DeprecationWarning("Support dropped.")
+ model_mean, _, model_log_variance, logits = outputs
+ elif return_x0:
+ model_mean, _, model_log_variance, x0 = outputs
+ else:
+ model_mean, _, model_log_variance = outputs
+
+ noise = noise_like(x.shape, device, repeat_noise) * temperature
+ if noise_dropout > 0.0:
+ noise = torch.nn.functional.dropout(noise, p=noise_dropout)
+ # no noise when t == 0
+ nonzero_mask = (
+ (1 - (t == 0).float()).reshape(b, *((1,) * (len(x.shape) - 1))).contiguous()
+ )
+
+ if return_codebook_ids:
+ return model_mean + nonzero_mask * (
+ 0.5 * model_log_variance
+ ).exp() * noise, logits.argmax(dim=1)
+ if return_x0:
+ return (
+ model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise,
+ x0,
+ )
+ else:
+ return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
+
+ @torch.no_grad()
+ def progressive_denoising(
+ self,
+ cond,
+ shape,
+ verbose=True,
+ callback=None,
+ quantize_denoised=False,
+ img_callback=None,
+ mask=None,
+ x0=None,
+ temperature=1.0,
+ noise_dropout=0.0,
+ score_corrector=None,
+ corrector_kwargs=None,
+ batch_size=None,
+ x_T=None,
+ start_T=None,
+ log_every_t=None,
+ ):
+ if not log_every_t:
+ log_every_t = self.log_every_t
+ timesteps = self.num_timesteps
+ if batch_size is not None:
+ b = batch_size if batch_size is not None else shape[0]
+ shape = [batch_size] + list(shape)
+ else:
+ b = batch_size = shape[0]
+ if x_T is None:
+ img = torch.randn(shape, device=self.device)
+ else:
+ img = x_T
+ intermediates = []
+ if cond is not None:
+ if isinstance(cond, dict):
+ cond = {
+ key: cond[key][:batch_size]
+ if not isinstance(cond[key], list)
+ else list(map(lambda x: x[:batch_size], cond[key]))
+ for key in cond
+ }
+ else:
+ cond = (
+ [c[:batch_size] for c in cond]
+ if isinstance(cond, list)
+ else cond[:batch_size]
+ )
+
+ if start_T is not None:
+ timesteps = min(timesteps, start_T)
+ iterator = (
+ tqdm(
+ reversed(range(0, timesteps)),
+ desc="Progressive Generation",
+ total=timesteps,
+ )
+ if verbose
+ else reversed(range(0, timesteps))
+ )
+ if type(temperature) == float:
+ temperature = [temperature] * timesteps
+
+ for i in iterator:
+ ts = torch.full((b,), i, device=self.device, dtype=torch.long)
+ if self.shorten_cond_schedule:
+ assert self.model.conditioning_key != "hybrid"
+ tc = self.cond_ids[ts].to(cond.device)
+ cond = self.q_sample(x_start=cond, t=tc, noise=torch.randn_like(cond))
+
+ img, x0_partial = self.p_sample(
+ img,
+ cond,
+ ts,
+ clip_denoised=self.clip_denoised,
+ quantize_denoised=quantize_denoised,
+ return_x0=True,
+ temperature=temperature[i],
+ noise_dropout=noise_dropout,
+ score_corrector=score_corrector,
+ corrector_kwargs=corrector_kwargs,
+ )
+ if mask is not None:
+ assert x0 is not None
+ img_orig = self.q_sample(x0, ts)
+ img = img_orig * mask + (1.0 - mask) * img
+
+ if i % log_every_t == 0 or i == timesteps - 1:
+ intermediates.append(x0_partial)
+ if callback:
+ callback(i)
+ if img_callback:
+ img_callback(img, i)
+ return img, intermediates
+
+ @torch.no_grad()
+ def p_sample_loop(
+ self,
+ cond,
+ shape,
+ return_intermediates=False,
+ x_T=None,
+ verbose=True,
+ callback=None,
+ timesteps=None,
+ quantize_denoised=False,
+ mask=None,
+ x0=None,
+ img_callback=None,
+ start_T=None,
+ log_every_t=None,
+ ):
+
+ if not log_every_t:
+ log_every_t = self.log_every_t
+ device = self.betas.device
+ b = shape[0]
+ if x_T is None:
+ img = torch.randn(shape, device=device)
+ else:
+ img = x_T
+
+ intermediates = [img]
+ if timesteps is None:
+ timesteps = self.num_timesteps
+
+ if start_T is not None:
+ timesteps = min(timesteps, start_T)
+ iterator = (
+ tqdm(reversed(range(0, timesteps)), desc="Sampling t", total=timesteps)
+ if verbose
+ else reversed(range(0, timesteps))
+ )
+
+ if mask is not None:
+ assert x0 is not None
+ assert x0.shape[2:3] == mask.shape[2:3] # spatial size has to match
+
+ for i in iterator:
+ ts = torch.full((b,), i, device=device, dtype=torch.long)
+ if self.shorten_cond_schedule:
+ assert self.model.conditioning_key != "hybrid"
+ tc = self.cond_ids[ts].to(cond.device)
+ cond = self.q_sample(x_start=cond, t=tc, noise=torch.randn_like(cond))
+
+ img = self.p_sample(
+ img,
+ cond,
+ ts,
+ clip_denoised=self.clip_denoised,
+ quantize_denoised=quantize_denoised,
+ )
+ if mask is not None:
+ img_orig = self.q_sample(x0, ts)
+ img = img_orig * mask + (1.0 - mask) * img
+
+ if i % log_every_t == 0 or i == timesteps - 1:
+ intermediates.append(img)
+ if callback:
+ callback(i)
+ if img_callback:
+ img_callback(img, i)
+
+ if return_intermediates:
+ return img, intermediates
+ return img
+
+ @torch.no_grad()
+ def sample(
+ self,
+ cond,
+ batch_size=16,
+ return_intermediates=False,
+ x_T=None,
+ verbose=True,
+ timesteps=None,
+ quantize_denoised=False,
+ mask=None,
+ x0=None,
+ shape=None,
+ **kwargs,
+ ):
+ if shape is None:
+ shape = (batch_size, self.channels, self.latent_t_size, self.latent_f_size)
+ if cond is not None:
+ if isinstance(cond, dict):
+ cond = {
+ key: cond[key][:batch_size]
+ if not isinstance(cond[key], list)
+ else list(map(lambda x: x[:batch_size], cond[key]))
+ for key in cond
+ }
+ else:
+ cond = (
+ [c[:batch_size] for c in cond]
+ if isinstance(cond, list)
+ else cond[:batch_size]
+ )
+ return self.p_sample_loop(
+ cond,
+ shape,
+ return_intermediates=return_intermediates,
+ x_T=x_T,
+ verbose=verbose,
+ timesteps=timesteps,
+ quantize_denoised=quantize_denoised,
+ mask=mask,
+ x0=x0,
+ **kwargs,
+ )
+
+ @torch.no_grad()
+ def sample_log(
+ self,
+ cond,
+ batch_size,
+ ddim,
+ ddim_steps,
+ unconditional_guidance_scale=1.0,
+ unconditional_conditioning=None,
+ use_plms=False,
+ mask=None,
+ **kwargs,
+ ):
+
+ if mask is not None:
+ shape = (self.channels, mask.size()[-2], mask.size()[-1])
+ else:
+ shape = (self.channels, self.latent_t_size, self.latent_f_size)
+
+ intermediate = None
+ if ddim and not use_plms:
+ # print("Use ddim sampler")
+
+ ddim_sampler = DDIMSampler(self)
+ samples, intermediates = ddim_sampler.sample(
+ ddim_steps,
+ batch_size,
+ shape,
+ cond,
+ verbose=False,
+ unconditional_guidance_scale=unconditional_guidance_scale,
+ unconditional_conditioning=unconditional_conditioning,
+ mask=mask,
+ **kwargs,
+ )
+
+ else:
+ # print("Use DDPM sampler")
+ samples, intermediates = self.sample(
+ cond=cond,
+ batch_size=batch_size,
+ return_intermediates=True,
+ unconditional_guidance_scale=unconditional_guidance_scale,
+ mask=mask,
+ unconditional_conditioning=unconditional_conditioning,
+ **kwargs,
+ )
+
+ return samples, intermediate
+
+ @torch.no_grad()
+ def generate_sample(
+ self,
+ batchs,
+ ddim_steps=200,
+ ddim_eta=1.0,
+ x_T=None,
+ n_candidate_gen_per_text=1,
+ unconditional_guidance_scale=1.0,
+ unconditional_conditioning=None,
+ name="waveform",
+ use_plms=False,
+ save=False,
+ **kwargs,
+ ):
+ # Generate n_candidate_gen_per_text times and select the best
+ # Batch: audio, text, fnames
+ assert x_T is None
+ try:
+ batchs = iter(batchs)
+ except TypeError:
+ raise ValueError("The first input argument should be an iterable object")
+
+ if use_plms:
+ assert ddim_steps is not None
+ use_ddim = ddim_steps is not None
+ # waveform_save_path = os.path.join(self.get_log_dir(), name)
+ # os.makedirs(waveform_save_path, exist_ok=True)
+ # print("Waveform save path: ", waveform_save_path)
+
+ with self.ema_scope("Generate"):
+ for batch in batchs:
+ z, c = self.get_input(
+ batch,
+ self.first_stage_key,
+ cond_key=self.cond_stage_key,
+ return_first_stage_outputs=False,
+ force_c_encode=True,
+ return_original_cond=False,
+ bs=None,
+ )
+ text = super().get_input(batch, "text")
+
+ # Generate multiple samples
+ batch_size = z.shape[0] * n_candidate_gen_per_text
+ c = torch.cat([c] * n_candidate_gen_per_text, dim=0)
+ text = text * n_candidate_gen_per_text
+
+ if unconditional_guidance_scale != 1.0:
+ unconditional_conditioning = (
+ self.cond_stage_model.get_unconditional_condition(batch_size)
+ )
+
+ samples, _ = self.sample_log(
+ cond=c,
+ batch_size=batch_size,
+ x_T=x_T,
+ ddim=use_ddim,
+ ddim_steps=ddim_steps,
+ eta=ddim_eta,
+ unconditional_guidance_scale=unconditional_guidance_scale,
+ unconditional_conditioning=unconditional_conditioning,
+ use_plms=use_plms,
+ )
+
+ if(torch.max(torch.abs(samples)) > 1e2):
+ samples = torch.clip(samples, min=-10, max=10)
+
+ mel = self.decode_first_stage(samples)
+
+ waveform = self.mel_spectrogram_to_waveform(mel)
+
+ if waveform.shape[0] > 1:
+ similarity = self.cond_stage_model.cos_similarity(
+ torch.FloatTensor(waveform).squeeze(1), text
+ )
+
+ best_index = []
+ for i in range(z.shape[0]):
+ candidates = similarity[i :: z.shape[0]]
+ max_index = torch.argmax(candidates).item()
+ best_index.append(i + max_index * z.shape[0])
+
+ waveform = waveform[best_index]
+ # print("Similarity between generated audio and text", similarity)
+ # print("Choose the following indexes:", best_index)
+
+ return waveform
+
+ @torch.no_grad()
+ def generate_sample_masked(
+ self,
+ batchs,
+ ddim_steps=200,
+ ddim_eta=1.0,
+ x_T=None,
+ n_candidate_gen_per_text=1,
+ unconditional_guidance_scale=1.0,
+ unconditional_conditioning=None,
+ name="waveform",
+ use_plms=False,
+ time_mask_ratio_start_and_end=(0.25, 0.75),
+ freq_mask_ratio_start_and_end=(0.75, 1.0),
+ save=False,
+ **kwargs,
+ ):
+ # Generate n_candidate_gen_per_text times and select the best
+ # Batch: audio, text, fnames
+ assert x_T is None
+ try:
+ batchs = iter(batchs)
+ except TypeError:
+ raise ValueError("The first input argument should be an iterable object")
+
+ if use_plms:
+ assert ddim_steps is not None
+ use_ddim = ddim_steps is not None
+ # waveform_save_path = os.path.join(self.get_log_dir(), name)
+ # os.makedirs(waveform_save_path, exist_ok=True)
+ # print("Waveform save path: ", waveform_save_path)
+
+ with self.ema_scope("Generate"):
+ for batch in batchs:
+ z, c = self.get_input(
+ batch,
+ self.first_stage_key,
+ cond_key=self.cond_stage_key,
+ return_first_stage_outputs=False,
+ force_c_encode=True,
+ return_original_cond=False,
+ bs=None,
+ )
+ text = super().get_input(batch, "text")
+
+ # Generate multiple samples
+ batch_size = z.shape[0] * n_candidate_gen_per_text
+
+ _, h, w = z.shape[0], z.shape[2], z.shape[3]
+
+ mask = torch.ones(batch_size, h, w).to(self.device)
+
+ mask[:, int(h * time_mask_ratio_start_and_end[0]) : int(h * time_mask_ratio_start_and_end[1]), :] = 0
+ mask[:, :, int(w * freq_mask_ratio_start_and_end[0]) : int(w * freq_mask_ratio_start_and_end[1])] = 0
+ mask = mask[:, None, ...]
+
+ c = torch.cat([c] * n_candidate_gen_per_text, dim=0)
+ text = text * n_candidate_gen_per_text
+
+ if unconditional_guidance_scale != 1.0:
+ unconditional_conditioning = (
+ self.cond_stage_model.get_unconditional_condition(batch_size)
+ )
+
+ samples, _ = self.sample_log(
+ cond=c,
+ batch_size=batch_size,
+ x_T=x_T,
+ ddim=use_ddim,
+ ddim_steps=ddim_steps,
+ eta=ddim_eta,
+ unconditional_guidance_scale=unconditional_guidance_scale,
+ unconditional_conditioning=unconditional_conditioning,
+ use_plms=use_plms, mask=mask, x0=torch.cat([z] * n_candidate_gen_per_text)
+ )
+
+ mel = self.decode_first_stage(samples)
+
+ waveform = self.mel_spectrogram_to_waveform(mel)
+
+ if waveform.shape[0] > 1:
+ similarity = self.cond_stage_model.cos_similarity(
+ torch.FloatTensor(waveform).squeeze(1), text
+ )
+
+ best_index = []
+ for i in range(z.shape[0]):
+ candidates = similarity[i :: z.shape[0]]
+ max_index = torch.argmax(candidates).item()
+ best_index.append(i + max_index * z.shape[0])
+
+ waveform = waveform[best_index]
+ # print("Similarity between generated audio and text", similarity)
+ # print("Choose the following indexes:", best_index)
+
+ return waveform
\ No newline at end of file
diff --git a/audioldm/pipeline.py b/audioldm/pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..b08e1f77206483025ce027588c2dea1de78ae26c
--- /dev/null
+++ b/audioldm/pipeline.py
@@ -0,0 +1,301 @@
+import os
+
+import argparse
+import yaml
+import torch
+from torch import autocast
+from tqdm import tqdm, trange
+
+from audioldm import LatentDiffusion, seed_everything
+from audioldm.utils import default_audioldm_config, get_duration, get_bit_depth, get_metadata, download_checkpoint
+from audioldm.audio import wav_to_fbank, TacotronSTFT, read_wav_file
+from audioldm.latent_diffusion.ddim import DDIMSampler
+from einops import repeat
+import os
+
+def make_batch_for_text_to_audio(text, waveform=None, fbank=None, batchsize=1):
+ text = [text] * batchsize
+ if batchsize < 1:
+ print("Warning: Batchsize must be at least 1. Batchsize is set to .")
+
+ if(fbank is None):
+ fbank = torch.zeros((batchsize, 1024, 64)) # Not used, here to keep the code format
+ else:
+ fbank = torch.FloatTensor(fbank)
+ fbank = fbank.expand(batchsize, 1024, 64)
+ assert fbank.size(0) == batchsize
+
+ stft = torch.zeros((batchsize, 1024, 512)) # Not used
+
+ if(waveform is None):
+ waveform = torch.zeros((batchsize, 160000)) # Not used
+ else:
+ waveform = torch.FloatTensor(waveform)
+ waveform = waveform.expand(batchsize, -1)
+ assert waveform.size(0) == batchsize
+
+ fname = [""] * batchsize # Not used
+
+ batch = (
+ fbank,
+ stft,
+ None,
+ fname,
+ waveform,
+ text,
+ )
+ return batch
+
+def round_up_duration(duration):
+ return int(round(duration/2.5) + 1) * 2.5
+
+def build_model(
+ ckpt_path=None,
+ config=None,
+ model_name="audioldm-s-full"
+):
+ print("Load AudioLDM: %s", model_name)
+
+ if(ckpt_path is None):
+ ckpt_path = get_metadata()[model_name]["path"]
+
+ if(not os.path.exists(ckpt_path)):
+ download_checkpoint(model_name)
+
+ if torch.cuda.is_available():
+ device = torch.device("cuda:0")
+ else:
+ device = torch.device("cpu")
+
+ if config is not None:
+ assert type(config) is str
+ config = yaml.load(open(config, "r"), Loader=yaml.FullLoader)
+ else:
+ config = default_audioldm_config(model_name)
+
+ # Use text as condition instead of using waveform during training
+ config["model"]["params"]["device"] = device
+ config["model"]["params"]["cond_stage_key"] = "text"
+
+ # No normalization here
+ latent_diffusion = LatentDiffusion(**config["model"]["params"])
+
+ resume_from_checkpoint = ckpt_path
+
+ checkpoint = torch.load(resume_from_checkpoint, map_location=device)
+ latent_diffusion.load_state_dict(checkpoint["state_dict"])
+
+ latent_diffusion.eval()
+ latent_diffusion = latent_diffusion.to(device)
+
+ latent_diffusion.cond_stage_model.embed_mode = "text"
+ return latent_diffusion
+
+def duration_to_latent_t_size(duration):
+ return int(duration * 25.6)
+
+def set_cond_audio(latent_diffusion):
+ latent_diffusion.cond_stage_key = "waveform"
+ latent_diffusion.cond_stage_model.embed_mode="audio"
+ return latent_diffusion
+
+def set_cond_text(latent_diffusion):
+ latent_diffusion.cond_stage_key = "text"
+ latent_diffusion.cond_stage_model.embed_mode="text"
+ return latent_diffusion
+
+def text_to_audio(
+ latent_diffusion,
+ text,
+ original_audio_file_path = None,
+ seed=42,
+ ddim_steps=200,
+ duration=10,
+ batchsize=1,
+ guidance_scale=2.5,
+ n_candidate_gen_per_text=3,
+ config=None,
+):
+ seed_everything(int(seed))
+ waveform = None
+ if(original_audio_file_path is not None):
+ waveform = read_wav_file(original_audio_file_path, int(duration * 102.4) * 160)
+
+ batch = make_batch_for_text_to_audio(text, waveform=waveform, batchsize=batchsize)
+
+ latent_diffusion.latent_t_size = duration_to_latent_t_size(duration)
+
+ if(waveform is not None):
+ print("Generate audio that has similar content as %s" % original_audio_file_path)
+ latent_diffusion = set_cond_audio(latent_diffusion)
+ else:
+ print("Generate audio using text %s" % text)
+ latent_diffusion = set_cond_text(latent_diffusion)
+
+ with torch.no_grad():
+ waveform = latent_diffusion.generate_sample(
+ [batch],
+ unconditional_guidance_scale=guidance_scale,
+ ddim_steps=ddim_steps,
+ n_candidate_gen_per_text=n_candidate_gen_per_text,
+ duration=duration,
+ )
+ return waveform
+
+def style_transfer(
+ latent_diffusion,
+ text,
+ original_audio_file_path,
+ transfer_strength,
+ seed=42,
+ duration=10,
+ batchsize=1,
+ guidance_scale=2.5,
+ ddim_steps=200,
+ config=None,
+):
+ if torch.cuda.is_available():
+ device = torch.device("cuda:0")
+ else:
+ device = torch.device("cpu")
+
+ assert original_audio_file_path is not None, "You need to provide the original audio file path"
+
+ audio_file_duration = get_duration(original_audio_file_path)
+
+ assert get_bit_depth(original_audio_file_path) == 16, "The bit depth of the original audio file %s must be 16" % original_audio_file_path
+
+ # if(duration > 20):
+ # print("Warning: The duration of the audio file %s must be less than 20 seconds. Longer duration will result in Nan in model output (we are still debugging that); Automatically set duration to 20 seconds")
+ # duration = 20
+
+ if(duration >= audio_file_duration):
+ print("Warning: Duration you specified %s-seconds must equal or smaller than the audio file duration %ss" % (duration, audio_file_duration))
+ duration = round_up_duration(audio_file_duration)
+ print("Set new duration as %s-seconds" % duration)
+
+ # duration = round_up_duration(duration)
+
+ latent_diffusion = set_cond_text(latent_diffusion)
+
+ if config is not None:
+ assert type(config) is str
+ config = yaml.load(open(config, "r"), Loader=yaml.FullLoader)
+ else:
+ config = default_audioldm_config()
+
+ seed_everything(int(seed))
+ # latent_diffusion.latent_t_size = duration_to_latent_t_size(duration)
+ latent_diffusion.cond_stage_model.embed_mode = "text"
+
+ fn_STFT = TacotronSTFT(
+ config["preprocessing"]["stft"]["filter_length"],
+ config["preprocessing"]["stft"]["hop_length"],
+ config["preprocessing"]["stft"]["win_length"],
+ config["preprocessing"]["mel"]["n_mel_channels"],
+ config["preprocessing"]["audio"]["sampling_rate"],
+ config["preprocessing"]["mel"]["mel_fmin"],
+ config["preprocessing"]["mel"]["mel_fmax"],
+ )
+
+ mel, _, _ = wav_to_fbank(
+ original_audio_file_path, target_length=int(duration * 102.4), fn_STFT=fn_STFT
+ )
+ mel = mel.unsqueeze(0).unsqueeze(0).to(device)
+ mel = repeat(mel, "1 ... -> b ...", b=batchsize)
+ init_latent = latent_diffusion.get_first_stage_encoding(
+ latent_diffusion.encode_first_stage(mel)
+ ) # move to latent space, encode and sample
+ if(torch.max(torch.abs(init_latent)) > 1e2):
+ init_latent = torch.clip(init_latent, min=-10, max=10)
+ sampler = DDIMSampler(latent_diffusion)
+ sampler.make_schedule(ddim_num_steps=ddim_steps, ddim_eta=1.0, verbose=False)
+
+ t_enc = int(transfer_strength * ddim_steps)
+ prompts = text
+
+ with torch.no_grad():
+ with autocast("cuda"):
+ with latent_diffusion.ema_scope():
+ uc = None
+ if guidance_scale != 1.0:
+ uc = latent_diffusion.cond_stage_model.get_unconditional_condition(
+ batchsize
+ )
+
+ c = latent_diffusion.get_learned_conditioning([prompts] * batchsize)
+ z_enc = sampler.stochastic_encode(
+ init_latent, torch.tensor([t_enc] * batchsize).to(device)
+ )
+ samples = sampler.decode(
+ z_enc,
+ c,
+ t_enc,
+ unconditional_guidance_scale=guidance_scale,
+ unconditional_conditioning=uc,
+ )
+ # x_samples = latent_diffusion.decode_first_stage(samples) # Will result in Nan in output
+ # print(torch.sum(torch.isnan(samples)))
+ x_samples = latent_diffusion.decode_first_stage(samples)
+ # print(x_samples)
+ x_samples = latent_diffusion.decode_first_stage(samples[:,:,:-3,:])
+ # print(x_samples)
+ waveform = latent_diffusion.first_stage_model.decode_to_waveform(
+ x_samples
+ )
+
+ return waveform
+
+def super_resolution_and_inpainting(
+ latent_diffusion,
+ text,
+ original_audio_file_path = None,
+ seed=42,
+ ddim_steps=200,
+ duration=None,
+ batchsize=1,
+ guidance_scale=2.5,
+ n_candidate_gen_per_text=3,
+ time_mask_ratio_start_and_end=(0.10, 0.15), # regenerate the 10% to 15% of the time steps in the spectrogram
+ # time_mask_ratio_start_and_end=(1.0, 1.0), # no inpainting
+ # freq_mask_ratio_start_and_end=(0.75, 1.0), # regenerate the higher 75% to 100% mel bins
+ freq_mask_ratio_start_and_end=(1.0, 1.0), # no super-resolution
+ config=None,
+):
+ seed_everything(int(seed))
+ if config is not None:
+ assert type(config) is str
+ config = yaml.load(open(config, "r"), Loader=yaml.FullLoader)
+ else:
+ config = default_audioldm_config()
+ fn_STFT = TacotronSTFT(
+ config["preprocessing"]["stft"]["filter_length"],
+ config["preprocessing"]["stft"]["hop_length"],
+ config["preprocessing"]["stft"]["win_length"],
+ config["preprocessing"]["mel"]["n_mel_channels"],
+ config["preprocessing"]["audio"]["sampling_rate"],
+ config["preprocessing"]["mel"]["mel_fmin"],
+ config["preprocessing"]["mel"]["mel_fmax"],
+ )
+
+ # waveform = read_wav_file(original_audio_file_path, None)
+ mel, _, _ = wav_to_fbank(
+ original_audio_file_path, target_length=int(duration * 102.4), fn_STFT=fn_STFT
+ )
+
+ batch = make_batch_for_text_to_audio(text, fbank=mel[None,...], batchsize=batchsize)
+
+ # latent_diffusion.latent_t_size = duration_to_latent_t_size(duration)
+ latent_diffusion = set_cond_text(latent_diffusion)
+
+ with torch.no_grad():
+ waveform = latent_diffusion.generate_sample_masked(
+ [batch],
+ unconditional_guidance_scale=guidance_scale,
+ ddim_steps=ddim_steps,
+ n_candidate_gen_per_text=n_candidate_gen_per_text,
+ duration=duration,
+ time_mask_ratio_start_and_end=time_mask_ratio_start_and_end,
+ freq_mask_ratio_start_and_end=freq_mask_ratio_start_and_end
+ )
+ return waveform
\ No newline at end of file
diff --git a/audioldm/utils.py b/audioldm/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..5401b29d4366774233f1bf4a9e7fcb7ce214187e
--- /dev/null
+++ b/audioldm/utils.py
@@ -0,0 +1,281 @@
+import contextlib
+import importlib
+
+from inspect import isfunction
+import os
+import soundfile as sf
+import time
+import wave
+
+import urllib.request
+import progressbar
+
+CACHE_DIR = os.getenv(
+ "AUDIOLDM_CACHE_DIR",
+ os.path.join(os.path.expanduser("~"), ".cache/audioldm"))
+
+def get_duration(fname):
+ with contextlib.closing(wave.open(fname, 'r')) as f:
+ frames = f.getnframes()
+ rate = f.getframerate()
+ return frames / float(rate)
+
+def get_bit_depth(fname):
+ with contextlib.closing(wave.open(fname, 'r')) as f:
+ bit_depth = f.getsampwidth() * 8
+ return bit_depth
+
+def get_time():
+ t = time.localtime()
+ return time.strftime("%d_%m_%Y_%H_%M_%S", t)
+
+def seed_everything(seed):
+ import random, os
+ import numpy as np
+ import torch
+
+ random.seed(seed)
+ os.environ["PYTHONHASHSEED"] = str(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed(seed)
+ torch.backends.cudnn.deterministic = True
+ torch.backends.cudnn.benchmark = True
+
+
+def save_wave(waveform, savepath, name="outwav"):
+ if type(name) is not list:
+ name = [name] * waveform.shape[0]
+
+ for i in range(waveform.shape[0]):
+ path = os.path.join(
+ savepath,
+ "%s_%s.wav"
+ % (
+ os.path.basename(name[i])
+ if (not ".wav" in name[i])
+ else os.path.basename(name[i]).split(".")[0],
+ i,
+ ),
+ )
+ print("Save audio to %s" % path)
+ sf.write(path, waveform[i, 0], samplerate=16000)
+
+
+def exists(x):
+ return x is not None
+
+
+def default(val, d):
+ if exists(val):
+ return val
+ return d() if isfunction(d) else d
+
+
+def count_params(model, verbose=False):
+ total_params = sum(p.numel() for p in model.parameters())
+ if verbose:
+ print(f"{model.__class__.__name__} has {total_params * 1.e-6:.2f} M params.")
+ return total_params
+
+
+def get_obj_from_str(string, reload=False):
+ module, cls = string.rsplit(".", 1)
+ if reload:
+ module_imp = importlib.import_module(module)
+ importlib.reload(module_imp)
+ return getattr(importlib.import_module(module, package=None), cls)
+
+
+def instantiate_from_config(config):
+ if not "target" in config:
+ if config == "__is_first_stage__":
+ return None
+ elif config == "__is_unconditional__":
+ return None
+ raise KeyError("Expected key `target` to instantiate.")
+ return get_obj_from_str(config["target"])(**config.get("params", dict()))
+
+
+def default_audioldm_config(model_name="audioldm-s-full"):
+ basic_config = {
+ "wave_file_save_path": "./output",
+ "id": {
+ "version": "v1",
+ "name": "default",
+ "root": "/mnt/fast/nobackup/users/hl01486/projects/general_audio_generation/AudioLDM-python/config/default/latent_diffusion.yaml",
+ },
+ "preprocessing": {
+ "audio": {"sampling_rate": 16000, "max_wav_value": 32768},
+ "stft": {"filter_length": 1024, "hop_length": 160, "win_length": 1024},
+ "mel": {
+ "n_mel_channels": 64,
+ "mel_fmin": 0,
+ "mel_fmax": 8000,
+ "freqm": 0,
+ "timem": 0,
+ "blur": False,
+ "mean": -4.63,
+ "std": 2.74,
+ "target_length": 1024,
+ },
+ },
+ "model": {
+ "device": "cuda",
+ "target": "audioldm.pipline.LatentDiffusion",
+ "params": {
+ "base_learning_rate": 5e-06,
+ "linear_start": 0.0015,
+ "linear_end": 0.0195,
+ "num_timesteps_cond": 1,
+ "log_every_t": 200,
+ "timesteps": 1000,
+ "first_stage_key": "fbank",
+ "cond_stage_key": "waveform",
+ "latent_t_size": 256,
+ "latent_f_size": 16,
+ "channels": 8,
+ "cond_stage_trainable": True,
+ "conditioning_key": "film",
+ "monitor": "val/loss_simple_ema",
+ "scale_by_std": True,
+ "unet_config": {
+ "target": "audioldm.latent_diffusion.openaimodel.UNetModel",
+ "params": {
+ "image_size": 64,
+ "extra_film_condition_dim": 512,
+ "extra_film_use_concat": True,
+ "in_channels": 8,
+ "out_channels": 8,
+ "model_channels": 128,
+ "attention_resolutions": [8, 4, 2],
+ "num_res_blocks": 2,
+ "channel_mult": [1, 2, 3, 5],
+ "num_head_channels": 32,
+ "use_spatial_transformer": True,
+ },
+ },
+ "first_stage_config": {
+ "base_learning_rate": 4.5e-05,
+ "target": "audioldm.variational_autoencoder.autoencoder.AutoencoderKL",
+ "params": {
+ "monitor": "val/rec_loss",
+ "image_key": "fbank",
+ "subband": 1,
+ "embed_dim": 8,
+ "time_shuffle": 1,
+ "ddconfig": {
+ "double_z": True,
+ "z_channels": 8,
+ "resolution": 256,
+ "downsample_time": False,
+ "in_channels": 1,
+ "out_ch": 1,
+ "ch": 128,
+ "ch_mult": [1, 2, 4],
+ "num_res_blocks": 2,
+ "attn_resolutions": [],
+ "dropout": 0.0,
+ },
+ },
+ },
+ "cond_stage_config": {
+ "target": "audioldm.clap.encoders.CLAPAudioEmbeddingClassifierFreev2",
+ "params": {
+ "key": "waveform",
+ "sampling_rate": 16000,
+ "embed_mode": "audio",
+ "unconditional_prob": 0.1,
+ },
+ },
+ },
+ },
+ }
+
+ if("-l-" in model_name):
+ basic_config["model"]["params"]["unet_config"]["params"]["model_channels"] = 256
+ basic_config["model"]["params"]["unet_config"]["params"]["num_head_channels"] = 64
+ elif("-m-" in model_name):
+ basic_config["model"]["params"]["unet_config"]["params"]["model_channels"] = 192
+ basic_config["model"]["params"]["cond_stage_config"]["params"]["amodel"] = "HTSAT-base" # This model use a larger HTAST
+
+ return basic_config
+
+def get_metadata():
+ return {
+ "audioldm-s-full": {
+ "path": os.path.join(
+ CACHE_DIR,
+ "audioldm-s-full.ckpt",
+ ),
+ "url": "https://zenodo.org/record/7600541/files/audioldm-s-full?download=1",
+ },
+ "audioldm-l-full": {
+ "path": os.path.join(
+ CACHE_DIR,
+ "audioldm-l-full.ckpt",
+ ),
+ "url": "https://zenodo.org/record/7698295/files/audioldm-full-l.ckpt?download=1",
+ },
+ "audioldm-s-full-v2": {
+ "path": os.path.join(
+ CACHE_DIR,
+ "audioldm-s-full-v2.ckpt",
+ ),
+ "url": "https://zenodo.org/record/7698295/files/audioldm-full-s-v2.ckpt?download=1",
+ },
+ "audioldm-m-text-ft": {
+ "path": os.path.join(
+ CACHE_DIR,
+ "audioldm-m-text-ft.ckpt",
+ ),
+ "url": "https://zenodo.org/record/7813012/files/audioldm-m-text-ft.ckpt?download=1",
+ },
+ "audioldm-s-text-ft": {
+ "path": os.path.join(
+ CACHE_DIR,
+ "audioldm-s-text-ft.ckpt",
+ ),
+ "url": "https://zenodo.org/record/7813012/files/audioldm-s-text-ft.ckpt?download=1",
+ },
+ "audioldm-m-full": {
+ "path": os.path.join(
+ CACHE_DIR,
+ "audioldm-m-full.ckpt",
+ ),
+ "url": "https://zenodo.org/record/7813012/files/audioldm-m-full.ckpt?download=1",
+ },
+ }
+
+class MyProgressBar():
+ def __init__(self):
+ self.pbar = None
+
+ def __call__(self, block_num, block_size, total_size):
+ if not self.pbar:
+ self.pbar=progressbar.ProgressBar(maxval=total_size)
+ self.pbar.start()
+
+ downloaded = block_num * block_size
+ if downloaded < total_size:
+ self.pbar.update(downloaded)
+ else:
+ self.pbar.finish()
+
+def download_checkpoint(checkpoint_name="audioldm-s-full"):
+ meta = get_metadata()
+ if(checkpoint_name not in meta.keys()):
+ print("The model name you provided is not supported. Please use one of the following: ", meta.keys())
+
+ if not os.path.exists(meta[checkpoint_name]["path"]) or os.path.getsize(meta[checkpoint_name]["path"]) < 2*10**9:
+ os.makedirs(os.path.dirname(meta[checkpoint_name]["path"]), exist_ok=True)
+ print(f"Downloading the main structure of {checkpoint_name} into {os.path.dirname(meta[checkpoint_name]['path'])}")
+
+ urllib.request.urlretrieve(meta[checkpoint_name]["url"], meta[checkpoint_name]["path"], MyProgressBar())
+ print(
+ "Weights downloaded in: {} Size: {}".format(
+ meta[checkpoint_name]["path"],
+ os.path.getsize(meta[checkpoint_name]["path"]),
+ )
+ )
+
\ No newline at end of file
diff --git a/audioldm/variational_autoencoder/__init__.py b/audioldm/variational_autoencoder/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..08b2a9b9698e02918d7b0dd9fe0431b2847e5aa2
--- /dev/null
+++ b/audioldm/variational_autoencoder/__init__.py
@@ -0,0 +1 @@
+from .autoencoder import AutoencoderKL
\ No newline at end of file
diff --git a/audioldm/variational_autoencoder/__pycache__/__init__.cpython-310.pyc b/audioldm/variational_autoencoder/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..664998b7317187af866ea398c5037533c6f9565c
Binary files /dev/null and b/audioldm/variational_autoencoder/__pycache__/__init__.cpython-310.pyc differ
diff --git a/audioldm/variational_autoencoder/__pycache__/__init__.cpython-39.pyc b/audioldm/variational_autoencoder/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b14ebed636cb1eb73079742be13481f06ec412e4
Binary files /dev/null and b/audioldm/variational_autoencoder/__pycache__/__init__.cpython-39.pyc differ
diff --git a/audioldm/variational_autoencoder/__pycache__/autoencoder.cpython-310.pyc b/audioldm/variational_autoencoder/__pycache__/autoencoder.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b51f97f7f15fd63d7fa96f70ccf043059df61ded
Binary files /dev/null and b/audioldm/variational_autoencoder/__pycache__/autoencoder.cpython-310.pyc differ
diff --git a/audioldm/variational_autoencoder/__pycache__/autoencoder.cpython-39.pyc b/audioldm/variational_autoencoder/__pycache__/autoencoder.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4fabd42e758859017d638e88391ed2e6980b7c5e
Binary files /dev/null and b/audioldm/variational_autoencoder/__pycache__/autoencoder.cpython-39.pyc differ
diff --git a/audioldm/variational_autoencoder/__pycache__/distributions.cpython-310.pyc b/audioldm/variational_autoencoder/__pycache__/distributions.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7ed7c551dbf9bdb4c6dd6379c7a3f3b9dd697c26
Binary files /dev/null and b/audioldm/variational_autoencoder/__pycache__/distributions.cpython-310.pyc differ
diff --git a/audioldm/variational_autoencoder/__pycache__/distributions.cpython-39.pyc b/audioldm/variational_autoencoder/__pycache__/distributions.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ac0a06b06153c96d3707bf474dee8d580c0295db
Binary files /dev/null and b/audioldm/variational_autoencoder/__pycache__/distributions.cpython-39.pyc differ
diff --git a/audioldm/variational_autoencoder/__pycache__/modules.cpython-310.pyc b/audioldm/variational_autoencoder/__pycache__/modules.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5947c8f265a0b1384438112b2193e03268fd0036
Binary files /dev/null and b/audioldm/variational_autoencoder/__pycache__/modules.cpython-310.pyc differ
diff --git a/audioldm/variational_autoencoder/__pycache__/modules.cpython-39.pyc b/audioldm/variational_autoencoder/__pycache__/modules.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..26fbb358274b085b3ab72074d1789f87d397ab4b
Binary files /dev/null and b/audioldm/variational_autoencoder/__pycache__/modules.cpython-39.pyc differ
diff --git a/audioldm/variational_autoencoder/autoencoder.py b/audioldm/variational_autoencoder/autoencoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..9dadc849da65d1f9eb82dc75dc777250bf738151
--- /dev/null
+++ b/audioldm/variational_autoencoder/autoencoder.py
@@ -0,0 +1,135 @@
+import torch
+from audioldm.latent_diffusion.ema import *
+from audioldm.variational_autoencoder.modules import Encoder, Decoder
+from audioldm.variational_autoencoder.distributions import DiagonalGaussianDistribution
+
+from audioldm.hifigan.utilities import get_vocoder, vocoder_infer
+
+
+class AutoencoderKL(nn.Module):
+ def __init__(
+ self,
+ ddconfig=None,
+ lossconfig=None,
+ image_key="fbank",
+ embed_dim=None,
+ time_shuffle=1,
+ subband=1,
+ ckpt_path=None,
+ reload_from_ckpt=None,
+ ignore_keys=[],
+ colorize_nlabels=None,
+ monitor=None,
+ base_learning_rate=1e-5,
+ scale_factor=1
+ ):
+ super().__init__()
+
+ self.encoder = Encoder(**ddconfig)
+ self.decoder = Decoder(**ddconfig)
+
+ self.subband = int(subband)
+
+ if self.subband > 1:
+ print("Use subband decomposition %s" % self.subband)
+
+ self.quant_conv = torch.nn.Conv2d(2 * ddconfig["z_channels"], 2 * embed_dim, 1)
+ self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
+
+ self.vocoder = get_vocoder(None, "cpu")
+ self.embed_dim = embed_dim
+
+ if monitor is not None:
+ self.monitor = monitor
+
+ self.time_shuffle = time_shuffle
+ self.reload_from_ckpt = reload_from_ckpt
+ self.reloaded = False
+ self.mean, self.std = None, None
+
+ self.scale_factor = scale_factor
+
+ def encode(self, x):
+ # x = self.time_shuffle_operation(x)
+ x = self.freq_split_subband(x)
+ h = self.encoder(x)
+ moments = self.quant_conv(h)
+ posterior = DiagonalGaussianDistribution(moments)
+ return posterior
+
+ def decode(self, z):
+ z = self.post_quant_conv(z)
+ dec = self.decoder(z)
+ dec = self.freq_merge_subband(dec)
+ return dec
+
+ def decode_to_waveform(self, dec):
+ dec = dec.squeeze(1).permute(0, 2, 1)
+ wav_reconstruction = vocoder_infer(dec, self.vocoder)
+ return wav_reconstruction
+
+ def forward(self, input, sample_posterior=True):
+ posterior = self.encode(input)
+ if sample_posterior:
+ z = posterior.sample()
+ else:
+ z = posterior.mode()
+
+ if self.flag_first_run:
+ print("Latent size: ", z.size())
+ self.flag_first_run = False
+
+ dec = self.decode(z)
+
+ return dec, posterior
+
+ def freq_split_subband(self, fbank):
+ if self.subband == 1 or self.image_key != "stft":
+ return fbank
+
+ bs, ch, tstep, fbins = fbank.size()
+
+ assert fbank.size(-1) % self.subband == 0
+ assert ch == 1
+
+ return (
+ fbank.squeeze(1)
+ .reshape(bs, tstep, self.subband, fbins // self.subband)
+ .permute(0, 2, 1, 3)
+ )
+
+ def freq_merge_subband(self, subband_fbank):
+ if self.subband == 1 or self.image_key != "stft":
+ return subband_fbank
+ assert subband_fbank.size(1) == self.subband # Channel dimension
+ bs, sub_ch, tstep, fbins = subband_fbank.size()
+ return subband_fbank.permute(0, 2, 1, 3).reshape(bs, tstep, -1).unsqueeze(1)
+
+ def device(self):
+ return next(self.parameters()).device
+
+ @torch.no_grad()
+ def encode_first_stage(self, x):
+ return self.encode(x)
+
+ @torch.no_grad()
+ def decode_first_stage(self, z, predict_cids=False, force_not_quantize=False):
+ if predict_cids:
+ if z.dim() == 4:
+ z = torch.argmax(z.exp(), dim=1).long()
+ z = self.first_stage_model.quantize.get_codebook_entry(z, shape=None)
+ z = rearrange(z, "b h w c -> b c h w").contiguous()
+
+ z = 1.0 / self.scale_factor * z
+ return self.decode(z)
+
+ def get_first_stage_encoding(self, encoder_posterior):
+ if isinstance(encoder_posterior, DiagonalGaussianDistribution):
+ z = encoder_posterior.sample()
+ elif isinstance(encoder_posterior, torch.Tensor):
+ z = encoder_posterior
+ else:
+ raise NotImplementedError(
+ f"encoder_posterior of type '{type(encoder_posterior)}' not yet implemented"
+ )
+ return self.scale_factor * z
\ No newline at end of file
diff --git a/audioldm/variational_autoencoder/distributions.py b/audioldm/variational_autoencoder/distributions.py
new file mode 100644
index 0000000000000000000000000000000000000000..58eb535e7769f402169ddff77ee45c96ba3650d9
--- /dev/null
+++ b/audioldm/variational_autoencoder/distributions.py
@@ -0,0 +1,102 @@
+import torch
+import numpy as np
+
+
+class AbstractDistribution:
+ def sample(self):
+ raise NotImplementedError()
+
+ def mode(self):
+ raise NotImplementedError()
+
+
+class DiracDistribution(AbstractDistribution):
+ def __init__(self, value):
+ self.value = value
+
+ def sample(self):
+ return self.value
+
+ def mode(self):
+ return self.value
+
+
+class DiagonalGaussianDistribution(object):
+ def __init__(self, parameters, deterministic=False):
+ self.parameters = parameters
+ self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
+ self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
+ self.deterministic = deterministic
+ self.std = torch.exp(0.5 * self.logvar)
+ self.var = torch.exp(self.logvar)
+ if self.deterministic:
+ self.var = self.std = torch.zeros_like(self.mean).to(
+ device=self.parameters.device
+ )
+
+ def sample(self):
+ x = self.mean + self.std * torch.randn(self.mean.shape).to(
+ device=self.parameters.device
+ )
+ return x
+
+ def kl(self, other=None):
+ if self.deterministic:
+ return torch.Tensor([0.0])
+ else:
+ if other is None:
+ return 0.5 * torch.mean(
+ torch.pow(self.mean, 2) + self.var - 1.0 - self.logvar,
+ dim=[1, 2, 3],
+ )
+ else:
+ return 0.5 * torch.mean(
+ torch.pow(self.mean - other.mean, 2) / other.var
+ + self.var / other.var
+ - 1.0
+ - self.logvar
+ + other.logvar,
+ dim=[1, 2, 3],
+ )
+
+ def nll(self, sample, dims=[1, 2, 3]):
+ if self.deterministic:
+ return torch.Tensor([0.0])
+ logtwopi = np.log(2.0 * np.pi)
+ return 0.5 * torch.sum(
+ logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var,
+ dim=dims,
+ )
+
+ def mode(self):
+ return self.mean
+
+
+def normal_kl(mean1, logvar1, mean2, logvar2):
+ """
+ source: https://github.com/openai/guided-diffusion/blob/27c20a8fab9cb472df5d6bdd6c8d11c8f430b924/guided_diffusion/losses.py#L12
+ Compute the KL divergence between two gaussians.
+ Shapes are automatically broadcasted, so batches can be compared to
+ scalars, among other use cases.
+ """
+ tensor = None
+ for obj in (mean1, logvar1, mean2, logvar2):
+ if isinstance(obj, torch.Tensor):
+ tensor = obj
+ break
+ assert tensor is not None, "at least one argument must be a Tensor"
+
+ # Force variances to be Tensors. Broadcasting helps convert scalars to
+ # Tensors, but it does not work for torch.exp().
+ logvar1, logvar2 = [
+ x if isinstance(x, torch.Tensor) else torch.tensor(x).to(tensor)
+ for x in (logvar1, logvar2)
+ ]
+
+ return 0.5 * (
+ -1.0
+ + logvar2
+ - logvar1
+ + torch.exp(logvar1 - logvar2)
+ + ((mean1 - mean2) ** 2) * torch.exp(-logvar2)
+ )
diff --git a/audioldm/variational_autoencoder/modules.py b/audioldm/variational_autoencoder/modules.py
new file mode 100644
index 0000000000000000000000000000000000000000..e48386d045c1d0e159de33db02af1035159c3447
--- /dev/null
+++ b/audioldm/variational_autoencoder/modules.py
@@ -0,0 +1,1066 @@
+# pytorch_diffusion + derived encoder decoder
+import math
+import torch
+import torch.nn as nn
+import numpy as np
+from einops import rearrange
+
+from audioldm.utils import instantiate_from_config
+from audioldm.latent_diffusion.attention import LinearAttention
+
+
+def get_timestep_embedding(timesteps, embedding_dim):
+ """
+ This matches the implementation in Denoising Diffusion Probabilistic Models:
+ From Fairseq.
+ Build sinusoidal embeddings.
+ This matches the implementation in tensor2tensor, but differs slightly
+ from the description in Section 3.5 of "Attention Is All You Need".
+ """
+ assert len(timesteps.shape) == 1
+
+ half_dim = embedding_dim // 2
+ emb = math.log(10000) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
+ emb = emb.to(device=timesteps.device)
+ emb = timesteps.float()[:, None] * emb[None, :]
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
+ if embedding_dim % 2 == 1: # zero pad
+ emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
+ return emb
+
+
+def nonlinearity(x):
+ # swish
+ return x * torch.sigmoid(x)
+
+
+def Normalize(in_channels, num_groups=32):
+ return torch.nn.GroupNorm(
+ num_groups=num_groups, num_channels=in_channels, eps=1e-6, affine=True
+ )
+
+
+class Upsample(nn.Module):
+ def __init__(self, in_channels, with_conv):
+ super().__init__()
+ self.with_conv = with_conv
+ if self.with_conv:
+ self.conv = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=3, stride=1, padding=1
+ )
+
+ def forward(self, x):
+ x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
+ if self.with_conv:
+ x = self.conv(x)
+ return x
+
+
+class UpsampleTimeStride4(nn.Module):
+ def __init__(self, in_channels, with_conv):
+ super().__init__()
+ self.with_conv = with_conv
+ if self.with_conv:
+ self.conv = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=5, stride=1, padding=2
+ )
+
+ def forward(self, x):
+ x = torch.nn.functional.interpolate(x, scale_factor=(4.0, 2.0), mode="nearest")
+ if self.with_conv:
+ x = self.conv(x)
+ return x
+
+
+class Downsample(nn.Module):
+ def __init__(self, in_channels, with_conv):
+ super().__init__()
+ self.with_conv = with_conv
+ if self.with_conv:
+ # Do time downsampling here
+ # no asymmetric padding in torch conv, must do it ourselves
+ self.conv = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=3, stride=2, padding=0
+ )
+
+ def forward(self, x):
+ if self.with_conv:
+ pad = (0, 1, 0, 1)
+ x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
+ x = self.conv(x)
+ else:
+ x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
+ return x
+
+
+class DownsampleTimeStride4(nn.Module):
+ def __init__(self, in_channels, with_conv):
+ super().__init__()
+ self.with_conv = with_conv
+ if self.with_conv:
+ # Do time downsampling here
+ # no asymmetric padding in torch conv, must do it ourselves
+ self.conv = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=5, stride=(4, 2), padding=1
+ )
+
+ def forward(self, x):
+ if self.with_conv:
+ pad = (0, 1, 0, 1)
+ x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
+ x = self.conv(x)
+ else:
+ x = torch.nn.functional.avg_pool2d(x, kernel_size=(4, 2), stride=(4, 2))
+ return x
+
+
+class ResnetBlock(nn.Module):
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout,
+ temb_channels=512,
+ ):
+ super().__init__()
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+
+ self.norm1 = Normalize(in_channels)
+ self.conv1 = torch.nn.Conv2d(
+ in_channels, out_channels, kernel_size=3, stride=1, padding=1
+ )
+ if temb_channels > 0:
+ self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
+ self.norm2 = Normalize(out_channels)
+ self.dropout = torch.nn.Dropout(dropout)
+ self.conv2 = torch.nn.Conv2d(
+ out_channels, out_channels, kernel_size=3, stride=1, padding=1
+ )
+ if self.in_channels != self.out_channels:
+ if self.use_conv_shortcut:
+ self.conv_shortcut = torch.nn.Conv2d(
+ in_channels, out_channels, kernel_size=3, stride=1, padding=1
+ )
+ else:
+ self.nin_shortcut = torch.nn.Conv2d(
+ in_channels, out_channels, kernel_size=1, stride=1, padding=0
+ )
+
+ def forward(self, x, temb):
+ h = x
+ h = self.norm1(h)
+ h = nonlinearity(h)
+ h = self.conv1(h)
+
+ if temb is not None:
+ h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
+
+ h = self.norm2(h)
+ h = nonlinearity(h)
+ h = self.dropout(h)
+ h = self.conv2(h)
+
+ if self.in_channels != self.out_channels:
+ if self.use_conv_shortcut:
+ x = self.conv_shortcut(x)
+ else:
+ x = self.nin_shortcut(x)
+
+ return x + h
+
+
+class LinAttnBlock(LinearAttention):
+ """to match AttnBlock usage"""
+
+ def __init__(self, in_channels):
+ super().__init__(dim=in_channels, heads=1, dim_head=in_channels)
+
+
+class AttnBlock(nn.Module):
+ def __init__(self, in_channels):
+ super().__init__()
+ self.in_channels = in_channels
+
+ self.norm = Normalize(in_channels)
+ self.q = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.k = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.v = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+ self.proj_out = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=1, stride=1, padding=0
+ )
+
+ def forward(self, x):
+ h_ = x
+ h_ = self.norm(h_)
+ q = self.q(h_)
+ k = self.k(h_)
+ v = self.v(h_)
+
+ # compute attention
+ b, c, h, w = q.shape
+ q = q.reshape(b, c, h * w).contiguous()
+ q = q.permute(0, 2, 1).contiguous() # b,hw,c
+ k = k.reshape(b, c, h * w).contiguous() # b,c,hw
+ w_ = torch.bmm(q, k).contiguous() # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
+ w_ = w_ * (int(c) ** (-0.5))
+ w_ = torch.nn.functional.softmax(w_, dim=2)
+
+ # attend to values
+ v = v.reshape(b, c, h * w).contiguous()
+ w_ = w_.permute(0, 2, 1).contiguous() # b,hw,hw (first hw of k, second of q)
+ h_ = torch.bmm(
+ v, w_
+ ).contiguous() # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
+ h_ = h_.reshape(b, c, h, w).contiguous()
+
+ h_ = self.proj_out(h_)
+
+ return x + h_
+
+
+def make_attn(in_channels, attn_type="vanilla"):
+ assert attn_type in ["vanilla", "linear", "none"], f"attn_type {attn_type} unknown"
+ # print(f"making attention of type '{attn_type}' with {in_channels} in_channels")
+ if attn_type == "vanilla":
+ return AttnBlock(in_channels)
+ elif attn_type == "none":
+ return nn.Identity(in_channels)
+ else:
+ return LinAttnBlock(in_channels)
+
+
+class Model(nn.Module):
+ def __init__(
+ self,
+ *,
+ ch,
+ out_ch,
+ ch_mult=(1, 2, 4, 8),
+ num_res_blocks,
+ attn_resolutions,
+ dropout=0.0,
+ resamp_with_conv=True,
+ in_channels,
+ resolution,
+ use_timestep=True,
+ use_linear_attn=False,
+ attn_type="vanilla",
+ ):
+ super().__init__()
+ if use_linear_attn:
+ attn_type = "linear"
+ self.ch = ch
+ self.temb_ch = self.ch * 4
+ self.num_resolutions = len(ch_mult)
+ self.num_res_blocks = num_res_blocks
+ self.resolution = resolution
+ self.in_channels = in_channels
+
+ self.use_timestep = use_timestep
+ if self.use_timestep:
+ # timestep embedding
+ self.temb = nn.Module()
+ self.temb.dense = nn.ModuleList(
+ [
+ torch.nn.Linear(self.ch, self.temb_ch),
+ torch.nn.Linear(self.temb_ch, self.temb_ch),
+ ]
+ )
+
+ # downsampling
+ self.conv_in = torch.nn.Conv2d(
+ in_channels, self.ch, kernel_size=3, stride=1, padding=1
+ )
+
+ curr_res = resolution
+ in_ch_mult = (1,) + tuple(ch_mult)
+ self.down = nn.ModuleList()
+ for i_level in range(self.num_resolutions):
+ block = nn.ModuleList()
+ attn = nn.ModuleList()
+ block_in = ch * in_ch_mult[i_level]
+ block_out = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks):
+ block.append(
+ ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ if curr_res in attn_resolutions:
+ attn.append(make_attn(block_in, attn_type=attn_type))
+ down = nn.Module()
+ down.block = block
+ down.attn = attn
+ if i_level != self.num_resolutions - 1:
+ down.downsample = Downsample(block_in, resamp_with_conv)
+ curr_res = curr_res // 2
+ self.down.append(down)
+
+ # middle
+ self.mid = nn.Module()
+ self.mid.block_1 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
+ self.mid.block_2 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+
+ # upsampling
+ self.up = nn.ModuleList()
+ for i_level in reversed(range(self.num_resolutions)):
+ block = nn.ModuleList()
+ attn = nn.ModuleList()
+ block_out = ch * ch_mult[i_level]
+ skip_in = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks + 1):
+ if i_block == self.num_res_blocks:
+ skip_in = ch * in_ch_mult[i_level]
+ block.append(
+ ResnetBlock(
+ in_channels=block_in + skip_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ if curr_res in attn_resolutions:
+ attn.append(make_attn(block_in, attn_type=attn_type))
+ up = nn.Module()
+ up.block = block
+ up.attn = attn
+ if i_level != 0:
+ up.upsample = Upsample(block_in, resamp_with_conv)
+ curr_res = curr_res * 2
+ self.up.insert(0, up) # prepend to get consistent order
+
+ # end
+ self.norm_out = Normalize(block_in)
+ self.conv_out = torch.nn.Conv2d(
+ block_in, out_ch, kernel_size=3, stride=1, padding=1
+ )
+
+ def forward(self, x, t=None, context=None):
+ # assert x.shape[2] == x.shape[3] == self.resolution
+ if context is not None:
+ # assume aligned context, cat along channel axis
+ x = torch.cat((x, context), dim=1)
+ if self.use_timestep:
+ # timestep embedding
+ assert t is not None
+ temb = get_timestep_embedding(t, self.ch)
+ temb = self.temb.dense[0](temb)
+ temb = nonlinearity(temb)
+ temb = self.temb.dense[1](temb)
+ else:
+ temb = None
+
+ # downsampling
+ hs = [self.conv_in(x)]
+ for i_level in range(self.num_resolutions):
+ for i_block in range(self.num_res_blocks):
+ h = self.down[i_level].block[i_block](hs[-1], temb)
+ if len(self.down[i_level].attn) > 0:
+ h = self.down[i_level].attn[i_block](h)
+ hs.append(h)
+ if i_level != self.num_resolutions - 1:
+ hs.append(self.down[i_level].downsample(hs[-1]))
+
+ # middle
+ h = hs[-1]
+ h = self.mid.block_1(h, temb)
+ h = self.mid.attn_1(h)
+ h = self.mid.block_2(h, temb)
+
+ # upsampling
+ for i_level in reversed(range(self.num_resolutions)):
+ for i_block in range(self.num_res_blocks + 1):
+ h = self.up[i_level].block[i_block](
+ torch.cat([h, hs.pop()], dim=1), temb
+ )
+ if len(self.up[i_level].attn) > 0:
+ h = self.up[i_level].attn[i_block](h)
+ if i_level != 0:
+ h = self.up[i_level].upsample(h)
+
+ # end
+ h = self.norm_out(h)
+ h = nonlinearity(h)
+ h = self.conv_out(h)
+ return h
+
+ def get_last_layer(self):
+ return self.conv_out.weight
+
+
+class Encoder(nn.Module):
+ def __init__(
+ self,
+ *,
+ ch,
+ out_ch,
+ ch_mult=(1, 2, 4, 8),
+ num_res_blocks,
+ attn_resolutions,
+ dropout=0.0,
+ resamp_with_conv=True,
+ in_channels,
+ resolution,
+ z_channels,
+ double_z=True,
+ use_linear_attn=False,
+ attn_type="vanilla",
+ downsample_time_stride4_levels=[],
+ **ignore_kwargs,
+ ):
+ super().__init__()
+ if use_linear_attn:
+ attn_type = "linear"
+ self.ch = ch
+ self.temb_ch = 0
+ self.num_resolutions = len(ch_mult)
+ self.num_res_blocks = num_res_blocks
+ self.resolution = resolution
+ self.in_channels = in_channels
+ self.downsample_time_stride4_levels = downsample_time_stride4_levels
+
+ if len(self.downsample_time_stride4_levels) > 0:
+ assert max(self.downsample_time_stride4_levels) < self.num_resolutions, (
+ "The level to perform downsample 4 operation need to be smaller than the total resolution number %s"
+ % str(self.num_resolutions)
+ )
+
+ # downsampling
+ self.conv_in = torch.nn.Conv2d(
+ in_channels, self.ch, kernel_size=3, stride=1, padding=1
+ )
+
+ curr_res = resolution
+ in_ch_mult = (1,) + tuple(ch_mult)
+ self.in_ch_mult = in_ch_mult
+ self.down = nn.ModuleList()
+ for i_level in range(self.num_resolutions):
+ block = nn.ModuleList()
+ attn = nn.ModuleList()
+ block_in = ch * in_ch_mult[i_level]
+ block_out = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks):
+ block.append(
+ ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ if curr_res in attn_resolutions:
+ attn.append(make_attn(block_in, attn_type=attn_type))
+ down = nn.Module()
+ down.block = block
+ down.attn = attn
+ if i_level != self.num_resolutions - 1:
+ if i_level in self.downsample_time_stride4_levels:
+ down.downsample = DownsampleTimeStride4(block_in, resamp_with_conv)
+ else:
+ down.downsample = Downsample(block_in, resamp_with_conv)
+ curr_res = curr_res // 2
+ self.down.append(down)
+
+ # middle
+ self.mid = nn.Module()
+ self.mid.block_1 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
+ self.mid.block_2 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+
+ # end
+ self.norm_out = Normalize(block_in)
+ self.conv_out = torch.nn.Conv2d(
+ block_in,
+ 2 * z_channels if double_z else z_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ )
+
+ def forward(self, x):
+ # timestep embedding
+ temb = None
+ # downsampling
+ hs = [self.conv_in(x)]
+ for i_level in range(self.num_resolutions):
+ for i_block in range(self.num_res_blocks):
+ h = self.down[i_level].block[i_block](hs[-1], temb)
+ if len(self.down[i_level].attn) > 0:
+ h = self.down[i_level].attn[i_block](h)
+ hs.append(h)
+ if i_level != self.num_resolutions - 1:
+ hs.append(self.down[i_level].downsample(hs[-1]))
+
+ # middle
+ h = hs[-1]
+ h = self.mid.block_1(h, temb)
+ h = self.mid.attn_1(h)
+ h = self.mid.block_2(h, temb)
+
+ # end
+ h = self.norm_out(h)
+ h = nonlinearity(h)
+ h = self.conv_out(h)
+ return h
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self,
+ *,
+ ch,
+ out_ch,
+ ch_mult=(1, 2, 4, 8),
+ num_res_blocks,
+ attn_resolutions,
+ dropout=0.0,
+ resamp_with_conv=True,
+ in_channels,
+ resolution,
+ z_channels,
+ give_pre_end=False,
+ tanh_out=False,
+ use_linear_attn=False,
+ downsample_time_stride4_levels=[],
+ attn_type="vanilla",
+ **ignorekwargs,
+ ):
+ super().__init__()
+ if use_linear_attn:
+ attn_type = "linear"
+ self.ch = ch
+ self.temb_ch = 0
+ self.num_resolutions = len(ch_mult)
+ self.num_res_blocks = num_res_blocks
+ self.resolution = resolution
+ self.in_channels = in_channels
+ self.give_pre_end = give_pre_end
+ self.tanh_out = tanh_out
+ self.downsample_time_stride4_levels = downsample_time_stride4_levels
+
+ if len(self.downsample_time_stride4_levels) > 0:
+ assert max(self.downsample_time_stride4_levels) < self.num_resolutions, (
+ "The level to perform downsample 4 operation need to be smaller than the total resolution number %s"
+ % str(self.num_resolutions)
+ )
+
+ # compute in_ch_mult, block_in and curr_res at lowest res
+ in_ch_mult = (1,) + tuple(ch_mult)
+ block_in = ch * ch_mult[self.num_resolutions - 1]
+ curr_res = resolution // 2 ** (self.num_resolutions - 1)
+ self.z_shape = (1, z_channels, curr_res, curr_res)
+ # print("Working with z of shape {} = {} dimensions.".format(
+ # self.z_shape, np.prod(self.z_shape)))
+
+ # z to block_in
+ self.conv_in = torch.nn.Conv2d(
+ z_channels, block_in, kernel_size=3, stride=1, padding=1
+ )
+
+ # middle
+ self.mid = nn.Module()
+ self.mid.block_1 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
+ self.mid.block_2 = ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_in,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+
+ # upsampling
+ self.up = nn.ModuleList()
+ for i_level in reversed(range(self.num_resolutions)):
+ block = nn.ModuleList()
+ attn = nn.ModuleList()
+ block_out = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks + 1):
+ block.append(
+ ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ if curr_res in attn_resolutions:
+ attn.append(make_attn(block_in, attn_type=attn_type))
+ up = nn.Module()
+ up.block = block
+ up.attn = attn
+ if i_level != 0:
+ if i_level - 1 in self.downsample_time_stride4_levels:
+ up.upsample = UpsampleTimeStride4(block_in, resamp_with_conv)
+ else:
+ up.upsample = Upsample(block_in, resamp_with_conv)
+ curr_res = curr_res * 2
+ self.up.insert(0, up) # prepend to get consistent order
+
+ # end
+ self.norm_out = Normalize(block_in)
+ self.conv_out = torch.nn.Conv2d(
+ block_in, out_ch, kernel_size=3, stride=1, padding=1
+ )
+
+ def forward(self, z):
+ # assert z.shape[1:] == self.z_shape[1:]
+ self.last_z_shape = z.shape
+
+ # timestep embedding
+ temb = None
+
+ # z to block_in
+ h = self.conv_in(z)
+
+ # middle
+ h = self.mid.block_1(h, temb)
+ h = self.mid.attn_1(h)
+ h = self.mid.block_2(h, temb)
+
+ # upsampling
+ for i_level in reversed(range(self.num_resolutions)):
+ for i_block in range(self.num_res_blocks + 1):
+ h = self.up[i_level].block[i_block](h, temb)
+ if len(self.up[i_level].attn) > 0:
+ h = self.up[i_level].attn[i_block](h)
+ if i_level != 0:
+ h = self.up[i_level].upsample(h)
+
+ # end
+ if self.give_pre_end:
+ return h
+
+ h = self.norm_out(h)
+ h = nonlinearity(h)
+ h = self.conv_out(h)
+ if self.tanh_out:
+ h = torch.tanh(h)
+ return h
+
+
+class SimpleDecoder(nn.Module):
+ def __init__(self, in_channels, out_channels, *args, **kwargs):
+ super().__init__()
+ self.model = nn.ModuleList(
+ [
+ nn.Conv2d(in_channels, in_channels, 1),
+ ResnetBlock(
+ in_channels=in_channels,
+ out_channels=2 * in_channels,
+ temb_channels=0,
+ dropout=0.0,
+ ),
+ ResnetBlock(
+ in_channels=2 * in_channels,
+ out_channels=4 * in_channels,
+ temb_channels=0,
+ dropout=0.0,
+ ),
+ ResnetBlock(
+ in_channels=4 * in_channels,
+ out_channels=2 * in_channels,
+ temb_channels=0,
+ dropout=0.0,
+ ),
+ nn.Conv2d(2 * in_channels, in_channels, 1),
+ Upsample(in_channels, with_conv=True),
+ ]
+ )
+ # end
+ self.norm_out = Normalize(in_channels)
+ self.conv_out = torch.nn.Conv2d(
+ in_channels, out_channels, kernel_size=3, stride=1, padding=1
+ )
+
+ def forward(self, x):
+ for i, layer in enumerate(self.model):
+ if i in [1, 2, 3]:
+ x = layer(x, None)
+ else:
+ x = layer(x)
+
+ h = self.norm_out(x)
+ h = nonlinearity(h)
+ x = self.conv_out(h)
+ return x
+
+
+class UpsampleDecoder(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ ch,
+ num_res_blocks,
+ resolution,
+ ch_mult=(2, 2),
+ dropout=0.0,
+ ):
+ super().__init__()
+ # upsampling
+ self.temb_ch = 0
+ self.num_resolutions = len(ch_mult)
+ self.num_res_blocks = num_res_blocks
+ block_in = in_channels
+ curr_res = resolution // 2 ** (self.num_resolutions - 1)
+ self.res_blocks = nn.ModuleList()
+ self.upsample_blocks = nn.ModuleList()
+ for i_level in range(self.num_resolutions):
+ res_block = []
+ block_out = ch * ch_mult[i_level]
+ for i_block in range(self.num_res_blocks + 1):
+ res_block.append(
+ ResnetBlock(
+ in_channels=block_in,
+ out_channels=block_out,
+ temb_channels=self.temb_ch,
+ dropout=dropout,
+ )
+ )
+ block_in = block_out
+ self.res_blocks.append(nn.ModuleList(res_block))
+ if i_level != self.num_resolutions - 1:
+ self.upsample_blocks.append(Upsample(block_in, True))
+ curr_res = curr_res * 2
+
+ # end
+ self.norm_out = Normalize(block_in)
+ self.conv_out = torch.nn.Conv2d(
+ block_in, out_channels, kernel_size=3, stride=1, padding=1
+ )
+
+ def forward(self, x):
+ # upsampling
+ h = x
+ for k, i_level in enumerate(range(self.num_resolutions)):
+ for i_block in range(self.num_res_blocks + 1):
+ h = self.res_blocks[i_level][i_block](h, None)
+ if i_level != self.num_resolutions - 1:
+ h = self.upsample_blocks[k](h)
+ h = self.norm_out(h)
+ h = nonlinearity(h)
+ h = self.conv_out(h)
+ return h
+
+
+class LatentRescaler(nn.Module):
+ def __init__(self, factor, in_channels, mid_channels, out_channels, depth=2):
+ super().__init__()
+ # residual block, interpolate, residual block
+ self.factor = factor
+ self.conv_in = nn.Conv2d(
+ in_channels, mid_channels, kernel_size=3, stride=1, padding=1
+ )
+ self.res_block1 = nn.ModuleList(
+ [
+ ResnetBlock(
+ in_channels=mid_channels,
+ out_channels=mid_channels,
+ temb_channels=0,
+ dropout=0.0,
+ )
+ for _ in range(depth)
+ ]
+ )
+ self.attn = AttnBlock(mid_channels)
+ self.res_block2 = nn.ModuleList(
+ [
+ ResnetBlock(
+ in_channels=mid_channels,
+ out_channels=mid_channels,
+ temb_channels=0,
+ dropout=0.0,
+ )
+ for _ in range(depth)
+ ]
+ )
+
+ self.conv_out = nn.Conv2d(
+ mid_channels,
+ out_channels,
+ kernel_size=1,
+ )
+
+ def forward(self, x):
+ x = self.conv_in(x)
+ for block in self.res_block1:
+ x = block(x, None)
+ x = torch.nn.functional.interpolate(
+ x,
+ size=(
+ int(round(x.shape[2] * self.factor)),
+ int(round(x.shape[3] * self.factor)),
+ ),
+ )
+ x = self.attn(x).contiguous()
+ for block in self.res_block2:
+ x = block(x, None)
+ x = self.conv_out(x)
+ return x
+
+
+class MergedRescaleEncoder(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ ch,
+ resolution,
+ out_ch,
+ num_res_blocks,
+ attn_resolutions,
+ dropout=0.0,
+ resamp_with_conv=True,
+ ch_mult=(1, 2, 4, 8),
+ rescale_factor=1.0,
+ rescale_module_depth=1,
+ ):
+ super().__init__()
+ intermediate_chn = ch * ch_mult[-1]
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ num_res_blocks=num_res_blocks,
+ ch=ch,
+ ch_mult=ch_mult,
+ z_channels=intermediate_chn,
+ double_z=False,
+ resolution=resolution,
+ attn_resolutions=attn_resolutions,
+ dropout=dropout,
+ resamp_with_conv=resamp_with_conv,
+ out_ch=None,
+ )
+ self.rescaler = LatentRescaler(
+ factor=rescale_factor,
+ in_channels=intermediate_chn,
+ mid_channels=intermediate_chn,
+ out_channels=out_ch,
+ depth=rescale_module_depth,
+ )
+
+ def forward(self, x):
+ x = self.encoder(x)
+ x = self.rescaler(x)
+ return x
+
+
+class MergedRescaleDecoder(nn.Module):
+ def __init__(
+ self,
+ z_channels,
+ out_ch,
+ resolution,
+ num_res_blocks,
+ attn_resolutions,
+ ch,
+ ch_mult=(1, 2, 4, 8),
+ dropout=0.0,
+ resamp_with_conv=True,
+ rescale_factor=1.0,
+ rescale_module_depth=1,
+ ):
+ super().__init__()
+ tmp_chn = z_channels * ch_mult[-1]
+ self.decoder = Decoder(
+ out_ch=out_ch,
+ z_channels=tmp_chn,
+ attn_resolutions=attn_resolutions,
+ dropout=dropout,
+ resamp_with_conv=resamp_with_conv,
+ in_channels=None,
+ num_res_blocks=num_res_blocks,
+ ch_mult=ch_mult,
+ resolution=resolution,
+ ch=ch,
+ )
+ self.rescaler = LatentRescaler(
+ factor=rescale_factor,
+ in_channels=z_channels,
+ mid_channels=tmp_chn,
+ out_channels=tmp_chn,
+ depth=rescale_module_depth,
+ )
+
+ def forward(self, x):
+ x = self.rescaler(x)
+ x = self.decoder(x)
+ return x
+
+
+class Upsampler(nn.Module):
+ def __init__(self, in_size, out_size, in_channels, out_channels, ch_mult=2):
+ super().__init__()
+ assert out_size >= in_size
+ num_blocks = int(np.log2(out_size // in_size)) + 1
+ factor_up = 1.0 + (out_size % in_size)
+ print(
+ f"Building {self.__class__.__name__} with in_size: {in_size} --> out_size {out_size} and factor {factor_up}"
+ )
+ self.rescaler = LatentRescaler(
+ factor=factor_up,
+ in_channels=in_channels,
+ mid_channels=2 * in_channels,
+ out_channels=in_channels,
+ )
+ self.decoder = Decoder(
+ out_ch=out_channels,
+ resolution=out_size,
+ z_channels=in_channels,
+ num_res_blocks=2,
+ attn_resolutions=[],
+ in_channels=None,
+ ch=in_channels,
+ ch_mult=[ch_mult for _ in range(num_blocks)],
+ )
+
+ def forward(self, x):
+ x = self.rescaler(x)
+ x = self.decoder(x)
+ return x
+
+
+class Resize(nn.Module):
+ def __init__(self, in_channels=None, learned=False, mode="bilinear"):
+ super().__init__()
+ self.with_conv = learned
+ self.mode = mode
+ if self.with_conv:
+ print(
+ f"Note: {self.__class__.__name} uses learned downsampling and will ignore the fixed {mode} mode"
+ )
+ raise NotImplementedError()
+ assert in_channels is not None
+ # no asymmetric padding in torch conv, must do it ourselves
+ self.conv = torch.nn.Conv2d(
+ in_channels, in_channels, kernel_size=4, stride=2, padding=1
+ )
+
+ def forward(self, x, scale_factor=1.0):
+ if scale_factor == 1.0:
+ return x
+ else:
+ x = torch.nn.functional.interpolate(
+ x, mode=self.mode, align_corners=False, scale_factor=scale_factor
+ )
+ return x
+
+
+class FirstStagePostProcessor(nn.Module):
+ def __init__(
+ self,
+ ch_mult: list,
+ in_channels,
+ pretrained_model: nn.Module = None,
+ reshape=False,
+ n_channels=None,
+ dropout=0.0,
+ pretrained_config=None,
+ ):
+ super().__init__()
+ if pretrained_config is None:
+ assert (
+ pretrained_model is not None
+ ), 'Either "pretrained_model" or "pretrained_config" must not be None'
+ self.pretrained_model = pretrained_model
+ else:
+ assert (
+ pretrained_config is not None
+ ), 'Either "pretrained_model" or "pretrained_config" must not be None'
+ self.instantiate_pretrained(pretrained_config)
+
+ self.do_reshape = reshape
+
+ if n_channels is None:
+ n_channels = self.pretrained_model.encoder.ch
+
+ self.proj_norm = Normalize(in_channels, num_groups=in_channels // 2)
+ self.proj = nn.Conv2d(
+ in_channels, n_channels, kernel_size=3, stride=1, padding=1
+ )
+
+ blocks = []
+ downs = []
+ ch_in = n_channels
+ for m in ch_mult:
+ blocks.append(
+ ResnetBlock(
+ in_channels=ch_in, out_channels=m * n_channels, dropout=dropout
+ )
+ )
+ ch_in = m * n_channels
+ downs.append(Downsample(ch_in, with_conv=False))
+
+ self.model = nn.ModuleList(blocks)
+ self.downsampler = nn.ModuleList(downs)
+
+ def instantiate_pretrained(self, config):
+ model = instantiate_from_config(config)
+ self.pretrained_model = model.eval()
+ # self.pretrained_model.train = False
+ for param in self.pretrained_model.parameters():
+ param.requires_grad = False
+
+ @torch.no_grad()
+ def encode_with_pretrained(self, x):
+ c = self.pretrained_model.encode(x)
+ if isinstance(c, DiagonalGaussianDistribution):
+ c = c.mode()
+ return c
+
+ def forward(self, x):
+ z_fs = self.encode_with_pretrained(x)
+ z = self.proj_norm(z_fs)
+ z = self.proj(z)
+ z = nonlinearity(z)
+
+ for submodel, downmodel in zip(self.model, self.downsampler):
+ z = submodel(z, temb=None)
+ z = downmodel(z)
+
+ if self.do_reshape:
+ z = rearrange(z, "b c h w -> b (h w) c")
+ return z
diff --git a/configs/.ipynb_checkpoints/diffusion_model_config-checkpoint.json b/configs/.ipynb_checkpoints/diffusion_model_config-checkpoint.json
new file mode 100644
index 0000000000000000000000000000000000000000..efc3539cb2c9fd041301cc9aa073d0c64f3aac72
--- /dev/null
+++ b/configs/.ipynb_checkpoints/diffusion_model_config-checkpoint.json
@@ -0,0 +1,46 @@
+{
+ "_class_name": "UNet2DConditionModel",
+ "_diffusers_version": "0.10.0.dev0",
+ "act_fn": "silu",
+ "attention_head_dim": [
+ 5,
+ 10,
+ 20,
+ 20
+ ],
+ "block_out_channels": [
+ 320,
+ 640,
+ 1280,
+ 1280
+ ],
+ "center_input_sample": false,
+ "cross_attention_dim": 1024,
+ "down_block_types": [
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D"
+ ],
+ "downsample_padding": 1,
+ "dual_cross_attention": false,
+ "flip_sin_to_cos": true,
+ "freq_shift": 0,
+ "in_channels": 8,
+ "layers_per_block": 2,
+ "mid_block_scale_factor": 1,
+ "norm_eps": 1e-05,
+ "norm_num_groups": 32,
+ "num_class_embeds": null,
+ "only_cross_attention": false,
+ "out_channels": 8,
+ "sample_size": [32, 2],
+ "up_block_types": [
+ "UpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D"
+ ],
+ "use_linear_projection": true,
+ "upcast_attention": true
+}
diff --git a/configs/.ipynb_checkpoints/stable_diffusion_2.1-checkpoint.json b/configs/.ipynb_checkpoints/stable_diffusion_2.1-checkpoint.json
new file mode 100644
index 0000000000000000000000000000000000000000..9b1458658e8651398962171a8c5c56c5c0bd5aea
--- /dev/null
+++ b/configs/.ipynb_checkpoints/stable_diffusion_2.1-checkpoint.json
@@ -0,0 +1,46 @@
+{
+ "_class_name": "UNet2DConditionModel",
+ "_diffusers_version": "0.10.0.dev0",
+ "act_fn": "silu",
+ "attention_head_dim": [
+ 5,
+ 10,
+ 20,
+ 20
+ ],
+ "block_out_channels": [
+ 320,
+ 640,
+ 1280,
+ 1280
+ ],
+ "center_input_sample": false,
+ "cross_attention_dim": 1024,
+ "down_block_types": [
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D"
+ ],
+ "downsample_padding": 1,
+ "dual_cross_attention": false,
+ "flip_sin_to_cos": true,
+ "freq_shift": 0,
+ "in_channels": 4,
+ "layers_per_block": 2,
+ "mid_block_scale_factor": 1,
+ "norm_eps": 1e-05,
+ "norm_num_groups": 32,
+ "num_class_embeds": null,
+ "only_cross_attention": false,
+ "out_channels": 4,
+ "sample_size": 96,
+ "up_block_types": [
+ "UpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D"
+ ],
+ "use_linear_projection": true,
+ "upcast_attention": true
+}
diff --git a/configs/diffusion_model_config.json b/configs/diffusion_model_config.json
new file mode 100644
index 0000000000000000000000000000000000000000..efc3539cb2c9fd041301cc9aa073d0c64f3aac72
--- /dev/null
+++ b/configs/diffusion_model_config.json
@@ -0,0 +1,46 @@
+{
+ "_class_name": "UNet2DConditionModel",
+ "_diffusers_version": "0.10.0.dev0",
+ "act_fn": "silu",
+ "attention_head_dim": [
+ 5,
+ 10,
+ 20,
+ 20
+ ],
+ "block_out_channels": [
+ 320,
+ 640,
+ 1280,
+ 1280
+ ],
+ "center_input_sample": false,
+ "cross_attention_dim": 1024,
+ "down_block_types": [
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D"
+ ],
+ "downsample_padding": 1,
+ "dual_cross_attention": false,
+ "flip_sin_to_cos": true,
+ "freq_shift": 0,
+ "in_channels": 8,
+ "layers_per_block": 2,
+ "mid_block_scale_factor": 1,
+ "norm_eps": 1e-05,
+ "norm_num_groups": 32,
+ "num_class_embeds": null,
+ "only_cross_attention": false,
+ "out_channels": 8,
+ "sample_size": [32, 2],
+ "up_block_types": [
+ "UpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D"
+ ],
+ "use_linear_projection": true,
+ "upcast_attention": true
+}
diff --git a/configs/diffusion_model_xl_config.json b/configs/diffusion_model_xl_config.json
new file mode 100644
index 0000000000000000000000000000000000000000..2da2eeb0a3f7815233c737d0d3e908dd446091e5
--- /dev/null
+++ b/configs/diffusion_model_xl_config.json
@@ -0,0 +1,46 @@
+{
+ "_class_name": "UNet2DConditionModel",
+ "_diffusers_version": "0.10.0.dev0",
+ "act_fn": "silu",
+ "attention_head_dim": [
+ 5,
+ 10,
+ 20,
+ 20
+ ],
+ "block_out_channels": [
+ 320,
+ 640,
+ 1280,
+ 1280
+ ],
+ "center_input_sample": false,
+ "cross_attention_dim": 2048,
+ "down_block_types": [
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D"
+ ],
+ "downsample_padding": 1,
+ "dual_cross_attention": false,
+ "flip_sin_to_cos": true,
+ "freq_shift": 0,
+ "in_channels": 8,
+ "layers_per_block": 2,
+ "mid_block_scale_factor": 1,
+ "norm_eps": 1e-05,
+ "norm_num_groups": 32,
+ "num_class_embeds": null,
+ "only_cross_attention": false,
+ "out_channels": 8,
+ "sample_size": [32, 2],
+ "up_block_types": [
+ "UpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D"
+ ],
+ "use_linear_projection": true,
+ "upcast_attention": true
+}
diff --git a/configs/stable_diffusion_2.1.json b/configs/stable_diffusion_2.1.json
new file mode 100644
index 0000000000000000000000000000000000000000..9b1458658e8651398962171a8c5c56c5c0bd5aea
--- /dev/null
+++ b/configs/stable_diffusion_2.1.json
@@ -0,0 +1,46 @@
+{
+ "_class_name": "UNet2DConditionModel",
+ "_diffusers_version": "0.10.0.dev0",
+ "act_fn": "silu",
+ "attention_head_dim": [
+ 5,
+ 10,
+ 20,
+ 20
+ ],
+ "block_out_channels": [
+ 320,
+ 640,
+ 1280,
+ 1280
+ ],
+ "center_input_sample": false,
+ "cross_attention_dim": 1024,
+ "down_block_types": [
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D"
+ ],
+ "downsample_padding": 1,
+ "dual_cross_attention": false,
+ "flip_sin_to_cos": true,
+ "freq_shift": 0,
+ "in_channels": 4,
+ "layers_per_block": 2,
+ "mid_block_scale_factor": 1,
+ "norm_eps": 1e-05,
+ "norm_num_groups": 32,
+ "num_class_embeds": null,
+ "only_cross_attention": false,
+ "out_channels": 4,
+ "sample_size": 96,
+ "up_block_types": [
+ "UpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D",
+ "CrossAttnUpBlock2D"
+ ],
+ "use_linear_projection": true,
+ "upcast_attention": true
+}
diff --git a/diffusers/CITATION.cff b/diffusers/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..18c0151d10a2a4c86cbc0d35841dc328cb7298b3
--- /dev/null
+++ b/diffusers/CITATION.cff
@@ -0,0 +1,40 @@
+cff-version: 1.2.0
+title: 'Diffusers: State-of-the-art diffusion models'
+message: >-
+ If you use this software, please cite it using the
+ metadata from this file.
+type: software
+authors:
+ - given-names: Patrick
+ family-names: von Platen
+ - given-names: Suraj
+ family-names: Patil
+ - given-names: Anton
+ family-names: Lozhkov
+ - given-names: Pedro
+ family-names: Cuenca
+ - given-names: Nathan
+ family-names: Lambert
+ - given-names: Kashif
+ family-names: Rasul
+ - given-names: Mishig
+ family-names: Davaadorj
+ - given-names: Thomas
+ family-names: Wolf
+repository-code: 'https://github.com/huggingface/diffusers'
+abstract: >-
+ Diffusers provides pretrained diffusion models across
+ multiple modalities, such as vision and audio, and serves
+ as a modular toolbox for inference and training of
+ diffusion models.
+keywords:
+ - deep-learning
+ - pytorch
+ - image-generation
+ - diffusion
+ - text2image
+ - image2image
+ - score-based-generative-modeling
+ - stable-diffusion
+license: Apache-2.0
+version: 0.12.1
diff --git a/diffusers/CODE_OF_CONDUCT.md b/diffusers/CODE_OF_CONDUCT.md
new file mode 100644
index 0000000000000000000000000000000000000000..05954dfae2798fd0707c3c100ced94855a938eac
--- /dev/null
+++ b/diffusers/CODE_OF_CONDUCT.md
@@ -0,0 +1,130 @@
+
+# Contributor Covenant Code of Conduct
+
+## Our Pledge
+
+We as members, contributors, and leaders pledge to make participation in our
+community a harassment-free experience for everyone, regardless of age, body
+size, visible or invisible disability, ethnicity, sex characteristics, gender
+identity and expression, level of experience, education, socio-economic status,
+nationality, personal appearance, race, religion, or sexual identity
+and orientation.
+
+We pledge to act and interact in ways that contribute to an open, welcoming,
+diverse, inclusive, and healthy community.
+
+## Our Standards
+
+Examples of behavior that contributes to a positive environment for our
+community include:
+
+* Demonstrating empathy and kindness toward other people
+* Being respectful of differing opinions, viewpoints, and experiences
+* Giving and gracefully accepting constructive feedback
+* Accepting responsibility and apologizing to those affected by our mistakes,
+ and learning from the experience
+* Focusing on what is best not just for us as individuals, but for the
+ overall diffusers community
+
+Examples of unacceptable behavior include:
+
+* The use of sexualized language or imagery, and sexual attention or
+ advances of any kind
+* Trolling, insulting or derogatory comments, and personal or political attacks
+* Public or private harassment
+* Publishing others' private information, such as a physical or email
+ address, without their explicit permission
+* Spamming issues or PRs with links to projects unrelated to this library
+* Other conduct which could reasonably be considered inappropriate in a
+ professional setting
+
+## Enforcement Responsibilities
+
+Community leaders are responsible for clarifying and enforcing our standards of
+acceptable behavior and will take appropriate and fair corrective action in
+response to any behavior that they deem inappropriate, threatening, offensive,
+or harmful.
+
+Community leaders have the right and responsibility to remove, edit, or reject
+comments, commits, code, wiki edits, issues, and other contributions that are
+not aligned to this Code of Conduct, and will communicate reasons for moderation
+decisions when appropriate.
+
+## Scope
+
+This Code of Conduct applies within all community spaces, and also applies when
+an individual is officially representing the community in public spaces.
+Examples of representing our community include using an official e-mail address,
+posting via an official social media account, or acting as an appointed
+representative at an online or offline event.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be
+reported to the community leaders responsible for enforcement at
+feedback@huggingface.co.
+All complaints will be reviewed and investigated promptly and fairly.
+
+All community leaders are obligated to respect the privacy and security of the
+reporter of any incident.
+
+## Enforcement Guidelines
+
+Community leaders will follow these Community Impact Guidelines in determining
+the consequences for any action they deem in violation of this Code of Conduct:
+
+### 1. Correction
+
+**Community Impact**: Use of inappropriate language or other behavior deemed
+unprofessional or unwelcome in the community.
+
+**Consequence**: A private, written warning from community leaders, providing
+clarity around the nature of the violation and an explanation of why the
+behavior was inappropriate. A public apology may be requested.
+
+### 2. Warning
+
+**Community Impact**: A violation through a single incident or series
+of actions.
+
+**Consequence**: A warning with consequences for continued behavior. No
+interaction with the people involved, including unsolicited interaction with
+those enforcing the Code of Conduct, for a specified period of time. This
+includes avoiding interactions in community spaces as well as external channels
+like social media. Violating these terms may lead to a temporary or
+permanent ban.
+
+### 3. Temporary Ban
+
+**Community Impact**: A serious violation of community standards, including
+sustained inappropriate behavior.
+
+**Consequence**: A temporary ban from any sort of interaction or public
+communication with the community for a specified period of time. No public or
+private interaction with the people involved, including unsolicited interaction
+with those enforcing the Code of Conduct, is allowed during this period.
+Violating these terms may lead to a permanent ban.
+
+### 4. Permanent Ban
+
+**Community Impact**: Demonstrating a pattern of violation of community
+standards, including sustained inappropriate behavior, harassment of an
+individual, or aggression toward or disparagement of classes of individuals.
+
+**Consequence**: A permanent ban from any sort of public interaction within
+the community.
+
+## Attribution
+
+This Code of Conduct is adapted from the [Contributor Covenant][homepage],
+version 2.0, available at
+https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
+
+Community Impact Guidelines were inspired by [Mozilla's code of conduct
+enforcement ladder](https://github.com/mozilla/diversity).
+
+[homepage]: https://www.contributor-covenant.org
+
+For answers to common questions about this code of conduct, see the FAQ at
+https://www.contributor-covenant.org/faq. Translations are available at
+https://www.contributor-covenant.org/translations.
diff --git a/diffusers/CONTRIBUTING.md b/diffusers/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..e9aa10a871d3afff3dbb9426db05baf6a0be3817
--- /dev/null
+++ b/diffusers/CONTRIBUTING.md
@@ -0,0 +1,498 @@
+
+
+# How to contribute to Diffusers 🧨
+
+We ❤️ contributions from the open-source community! Everyone is welcome, and all types of participation –not just code– are valued and appreciated. Answering questions, helping others, reaching out, and improving the documentation are all immensely valuable to the community, so don't be afraid and get involved if you're up for it!
+
+Everyone is encouraged to start by saying 👋 in our public Discord channel. We discuss the latest trends in diffusion models, ask questions, show off personal projects, help each other with contributions, or just hang out ☕.  +
+Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
+
+We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
+
+## Overview
+
+You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
+the core library.
+
+In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
+
+* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
+* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose)
+* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues)
+* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
+* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
+* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
+* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
+
+As said before, **all contributions are valuable to the community**.
+In the following, we will explain each contribution a bit more in detail.
+
+For all contributions 4.-9. you will need to open a PR. It is explained in detail how to do so in [Opening a pull requst](#how-to-open-a-pr)
+
+### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
+
+Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
+- Reports of training or inference experiments in an attempt to share knowledge
+- Presentation of personal projects
+- Questions to non-official training examples
+- Project proposals
+- General feedback
+- Paper summaries
+- Asking for help on personal projects that build on top of the Diffusers library
+- General questions
+- Ethical questions regarding diffusion models
+- ...
+
+Every question that is asked on the forum or on Discord actively encourages the community to publicly
+share knowledge and might very well help a beginner in the future that has the same question you're
+having. Please do pose any questions you might have.
+In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
+
+**Please** keep in mind that the more effort you put into asking or answering a question, the higher
+the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
+In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accesible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+**NOTE about channels**:
+[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
+In addition, questions and answers posted in the forum can easily be linked to.
+In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
+While it will most likely take less time for you to get an answer to your question on Discord, your
+question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
+
+### 2. Opening new issues on the GitHub issues tab
+
+The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
+the problems they encounter. So thank you for reporting an issue.
+
+Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
+
+In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
+
+**Please consider the following guidelines when opening a new issue**:
+- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
+- Please never report a new issue on another (related) issue. If another issue is highly related, please
+open a new issue nevertheless and link to the related issue.
+- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
+- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
+- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
+
+New issues usually include the following.
+
+#### 2.1. Reproducible, minimal bug reports.
+
+A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
+This means in more detail:
+- Narrow the bug down as much as you can, **do not just dump your whole code file**
+- Format your code
+- Do not include any external libraries except for Diffusers depending on them.
+- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
+- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
+- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
+- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
+
+For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new/choose).
+
+#### 2.2. Feature requests.
+
+A world-class feature request addresses the following points:
+
+1. Motivation first:
+* Is it related to a problem/frustration with the library? If so, please explain
+why. Providing a code snippet that demonstrates the problem is best.
+* Is it related to something you would need for a project? We'd love to hear
+about it!
+* Is it something you worked on and think could benefit the community?
+Awesome! Tell us what problem it solved for you.
+2. Write a *full paragraph* describing the feature;
+3. Provide a **code snippet** that demonstrates its future use;
+4. In case this is related to a paper, please attach a link;
+5. Attach any additional information (drawings, screenshots, etc.) you think may help.
+
+You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
+
+#### 2.3 Feedback.
+
+Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
+If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
+
+You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
+
+#### 2.4 Technical questions.
+
+Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
+why this part of the code is difficult to understand.
+
+You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
+
+#### 2.5 Proposal to add a new model, scheduler, or pipeline.
+
+If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
+
+* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
+* Link to any of its open-source implementation.
+* Link to the model weights if they are available.
+
+If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
+to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
+
+You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
+
+### 3. Answering issues on the GitHub issues tab
+
+Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
+Some tips to give a high-quality answer to an issue:
+- Be as concise and minimal as possible
+- Stay on topic. An answer to the issue should concern the issue and only the issue.
+- Provide links to code, papers, or other sources that prove or encourage your point.
+- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
+
+Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
+help to the maintainers if you can answer such issues, encouraging the author of the issue to be
+more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR)
+
+If you have verified that the issued bug report is correct and requires a correction in the source code,
+please have a look at the next sections.
+
+For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull requst](#how-to-open-a-pr) section.
+
+### 4. Fixing a "Good first issue"
+
+*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
+explains how a potential solution should look so that it is easier to fix.
+If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
+- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
+- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
+- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
+
+
+### 5. Contribute to the documentation
+
+A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
+valuable contribution**.
+
+Contributing to the library can have many forms:
+
+- Correcting spelling or grammatical errors.
+- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
+- Correct the shape or dimensions of a docstring input or output tensor.
+- Clarify documentation that is hard to understand or incorrect.
+- Update outdated code examples.
+- Translating the documentation to another language.
+
+Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
+
+Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
+
+
+### 6. Contribute a community pipeline
+
+[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
+Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
+We support two types of pipelines:
+
+- Official Pipelines
+- Community Pipelines
+
+Both official and community pipelines follow the same design and consist of the same type of components.
+
+Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
+resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
+In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
+They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
+
+The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
+possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
+Officially released diffusion pipelines,
+such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
+high quality of maintenance, no backward-breaking code changes, and testing.
+More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
+
+To add a community pipeline, one should add a .py file to [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and adapt the [examples/community/README.md](https://github.com/huggingface/diffusers/tree/main/examples/community/README.md) to include an example of the new pipeline.
+
+An example can be seen [here](https://github.com/huggingface/diffusers/pull/2400).
+
+Community pipeline PRs are only checked at a superficial level and ideally they should be maintained by their original authors.
+
+Contributing a community pipeline is a great way to understand how Diffusers models and schedulers work. Having contributed a community pipeline is usually the first stepping stone to contributing an official pipeline to the
+core package.
+
+### 7. Contribute to training examples
+
+Diffusers examples are a collection of training scripts that reside in [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+
+We support two types of training examples:
+
+- Official training examples
+- Research training examples
+
+Research training examples are located in [examples/research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects) whereas official training examples include all folders under [examples](https://github.com/huggingface/diffusers/tree/main/examples) except the `research_projects` and `community` folders.
+The official training examples are maintained by the Diffusers' core maintainers whereas the research training examples are maintained by the community.
+This is because of the same reasons put forward in [6. Contribute a community pipeline](#contribute-a-community-pipeline) for official pipelines vs. community pipelines: It is not feasible for the core maintainers to maintain all possible training methods for diffusion models.
+If the Diffusers core maintainers and the community consider a certain training paradigm to be too experimental or not popular enough, the corresponding training code should be put in the `research_projects` folder and maintained by the author.
+
+Both official training and research examples consist of a directory that contains one or more training scripts, a requirements.txt file, and a README.md file. In order for the user to make use of the
+training examples, it is required to clone the repository:
+
+```
+git clone https://github.com/huggingface/diffusers
+```
+
+as well as to install all additional dependencies required for training:
+
+```
+pip install -r /examples//requirements.txt
+```
+
+Therefore when adding an example, the `requirements.txt` file shall define all pip dependencies required for your training example so that once all those are installed, the user can run the example's training script. See, for example, the [DreamBooth `requirements.txt` file](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/requirements.txt).
+
+Training examples of the Diffusers library should adhere to the following philosophy:
+- All the code necessary to run the examples should be found in a single Python file
+- One should be able to run the example from the command line with `python .py --args`
+- Examples should be kept simple and serve as **an example** on how to use Diffusers for training. The purpose of example scripts is **not** to create state-of-the-art diffusion models, but rather to reproduce known training schemes without adding too much custom logic. As a byproduct of this point, our examples also strive to serve as good educational materials.
+
+To contribute an example, it is highly recommended to look at already existing examples such as [dreambooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py) to get an idea of how they should look like.
+We strongly advise contributors to make use of the [Accelerate library](https://github.com/huggingface/accelerate) as it's tightly integrated
+with Diffusers.
+Once an example script works, please make sure to add a comprehensive `README.md` that states how to use the example exactly. This README should include:
+- An example command on how to run the example script as shown [here e.g.](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#running-locally-with-pytorch).
+- A link to some training results (logs, models, ...) that show what the user can expect as shown [here e.g.](https://api.wandb.ai/report/patrickvonplaten/xm6cd5q5).
+- If you are adding a non-official/research training example, **please don't forget** to add a sentence that you are maintaining this training example which includes your git handle as shown [here](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/intel_opts#diffusers-examples-with-intel-optimizations).
+
+If you are contributing to the official training examples, please also make sure to add a test to [examples/test_examples.py](https://github.com/huggingface/diffusers/blob/main/examples/test_examples.py). This is not necessary for non-official training examples.
+
+### 8. Fixing a "Good second issue"
+
+*Good second issues* are marked by the [Good second issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) label. Good second issues are
+usually more complicated to solve than [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+The issue description usually gives less guidance on how to fix the issue and requires
+a decent understanding of the library by the interested contributor.
+If you are interested in tackling a second good issue, feel free to open a PR to fix it and link the PR to the issue. If you see that a PR has already been opened for this issue but did not get merged, have a look to understand why it wasn't merged and try to open an improved PR.
+Good second issues are usually more difficult to get merged compared to good first issues, so don't hesitate to ask for help from the core maintainers. If your PR is almost finished the core maintainers can also jump into your PR and commit to it in order to get it merged.
+
+### 9. Adding pipelines, models, schedulers
+
+Pipelines, models, and schedulers are the most important pieces of the Diffusers library.
+They provide easy access to state-of-the-art diffusion technologies and thus allow the community to
+build powerful generative AI applications.
+
+By adding a new model, pipeline, or scheduler you might enable a new powerful use case for any of the user interfaces relying on Diffusers which can be of immense value for the whole generative AI ecosystem.
+
+Diffusers has a couple of open feature requests for all three components - feel free to gloss over them
+if you don't know yet what specific component you would like to add:
+- [Model or pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22)
+- [Scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
+
+Before adding any of the three components, it is strongly recommended that you give the [Philosophy guide](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) a read to better understand the design of any of the three components. Please be aware that
+we cannot merge model, scheduler, or pipeline additions that strongly diverge from our design philosophy
+as it will lead to API inconsistencies. If you fundamentally disagree with a design choice, please
+open a [Feedback issue](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=) instead so that it can be discussed whether a certain design
+pattern/design choice shall be changed everywhere in the library and whether we shall update our design philosophy. Consistency across the library is very important for us.
+
+Please make sure to add links to the original codebase/paper to the PR and ideally also ping the
+original author directly on the PR so that they can follow the progress and potentially help with questions.
+
+If you are unsure or stuck in the PR, don't hesitate to leave a message to ask for a first review or help.
+
+## How to write a good issue
+
+**The better your issue is written, the higher the chances that it will be quickly resolved.**
+
+1. Make sure that you've used the correct template for your issue. You can pick between *Bug Report*, *Feature Request*, *Feedback about API Design*, *New model/pipeline/scheduler addition*, *Forum*, or a blank issue. Make sure to pick the correct one when opening [a new issue](https://github.com/huggingface/diffusers/issues/new/choose).
+2. **Be precise**: Give your issue a fitting title. Try to formulate your issue description as simple as possible. The more precise you are when submitting an issue, the less time it takes to understand the issue and potentially solve it. Make sure to open an issue for one issue only and not for multiple issues. If you found multiple issues, simply open multiple issues. If your issue is a bug, try to be as precise as possible about what bug it is - you should not just write "Error in diffusers".
+3. **Reproducibility**: No reproducible code snippet == no solution. If you encounter a bug, maintainers **have to be able to reproduce** it. Make sure that you include a code snippet that can be copy-pasted into a Python interpreter to reproduce the issue. Make sure that your code snippet works, *i.e.* that there are no missing imports or missing links to images, ... Your issue should contain an error message **and** a code snippet that can be copy-pasted without any changes to reproduce the exact same error message. If your issue is using local model weights or local data that cannot be accessed by the reader, the issue cannot be solved. If you cannot share your data or model, try to make a dummy model or dummy data.
+4. **Minimalistic**: Try to help the reader as much as you can to understand the issue as quickly as possible by staying as concise as possible. Remove all code / all information that is irrelevant to the issue. If you have found a bug, try to create the easiest code example you can to demonstrate your issue, do not just dump your whole workflow into the issue as soon as you have found a bug. E.g., if you train a model and get an error at some point during the training, you should first try to understand what part of the training code is responsible for the error and try to reproduce it with a couple of lines. Try to use dummy data instead of full datasets.
+5. Add links. If you are referring to a certain naming, method, or model make sure to provide a link so that the reader can better understand what you mean. If you are referring to a specific PR or issue, make sure to link it to your issue. Do not assume that the reader knows what you are talking about. The more links you add to your issue the better.
+6. Formatting. Make sure to nicely format your issue by formatting code into Python code syntax, and error messages into normal code syntax. See the [official GitHub formatting docs](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) for more information.
+7. Think of your issue not as a ticket to be solved, but rather as a beautiful entry to a well-written encyclopedia. Every added issue is a contribution to publicly available knowledge. By adding a nicely written issue you not only make it easier for maintainers to solve your issue, but you are helping the whole community to better understand a certain aspect of the library.
+
+## How to write a good PR
+
+1. Be a chameleon. Understand existing design patterns and syntax and make sure your code additions flow seamlessly into the existing code base. Pull requests that significantly diverge from existing design patterns or user interfaces will not be merged.
+2. Be laser focused. A pull request should solve one problem and one problem only. Make sure to not fall into the trap of "also fixing another problem while we're adding it". It is much more difficult to review pull requests that solve multiple, unrelated problems at once.
+3. If helpful, try to add a code snippet that displays an example of how your addition can be used.
+4. The title of your pull request should be a summary of its contribution.
+5. If your pull request addresses an issue, please mention the issue number in
+the pull request description to make sure they are linked (and people
+consulting the issue know you are working on it);
+6. To indicate a work in progress please prefix the title with `[WIP]`. These
+are useful to avoid duplicated work, and to differentiate it from PRs ready
+to be merged;
+7. Try to formulate and format your text as explained in [How to write a good issue](#how-to-write-a-good-issue).
+8. Make sure existing tests pass;
+9. Add high-coverage tests. No quality testing = no merge.
+- If you are adding new `@slow` tests, make sure they pass using
+`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
+CircleCI does not run the slow tests, but GitHub actions does every night!
+10. All public methods must have informative docstrings that work nicely with markdown. See `[pipeline_latent_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py)` for an example.
+11. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
+[`hf-internal-testing`](https://huggingface.co/hf-internal-testing) or [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images) to place these files.
+If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
+to this dataset.
+
+## How to open a PR
+
+Before writing code, we strongly advise you to search through the existing PRs or
+issues to make sure that nobody is already working on the same thing. If you are
+unsure, it is always a good idea to open an issue to get some feedback.
+
+You will need basic `git` proficiency to be able to contribute to
+🧨 Diffusers. `git` is not the easiest tool to use but it has the greatest
+manual. Type `git --help` in a shell and enjoy. If you prefer books, [Pro
+Git](https://git-scm.com/book/en/v2) is a very good reference.
+
+Follow these steps to start contributing ([supported Python versions](https://github.com/huggingface/diffusers/blob/main/setup.py#L244)):
+
+1. Fork the [repository](https://github.com/huggingface/diffusers) by
+clicking on the 'Fork' button on the repository's page. This creates a copy of the code
+under your GitHub user account.
+
+2. Clone your fork to your local disk, and add the base repository as a remote:
+
+ ```bash
+ $ git clone git@github.com:/diffusers.git
+ $ cd diffusers
+ $ git remote add upstream https://github.com/huggingface/diffusers.git
+ ```
+
+3. Create a new branch to hold your development changes:
+
+ ```bash
+ $ git checkout -b a-descriptive-name-for-my-changes
+ ```
+
+**Do not** work on the `main` branch.
+
+4. Set up a development environment by running the following command in a virtual environment:
+
+ ```bash
+ $ pip install -e ".[dev]"
+ ```
+
+If you have already cloned the repo, you might need to `git pull` to get the most recent changes in the
+library.
+
+5. Develop the features on your branch.
+
+As you work on the features, you should make sure that the test suite
+passes. You should run the tests impacted by your changes like this:
+
+ ```bash
+ $ pytest tests/.py
+ ```
+
+You can also run the full suite with the following command, but it takes
+a beefy machine to produce a result in a decent amount of time now that
+Diffusers has grown a lot. Here is the command for it:
+
+ ```bash
+ $ make test
+ ```
+
+🧨 Diffusers relies on `black` and `isort` to format its source code
+consistently. After you make changes, apply automatic style corrections and code verifications
+that can't be automated in one go with:
+
+ ```bash
+ $ make style
+ ```
+
+🧨 Diffusers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
+control runs in CI, however, you can also run the same checks with:
+
+ ```bash
+ $ make quality
+ ```
+
+Once you're happy with your changes, add changed files using `git add` and
+make a commit with `git commit` to record your changes locally:
+
+ ```bash
+ $ git add modified_file.py
+ $ git commit
+ ```
+
+It is a good idea to sync your copy of the code with the original
+repository regularly. This way you can quickly account for changes:
+
+ ```bash
+ $ git pull upstream main
+ ```
+
+Push the changes to your account using:
+
+ ```bash
+ $ git push -u origin a-descriptive-name-for-my-changes
+ ```
+
+6. Once you are satisfied, go to the
+webpage of your fork on GitHub. Click on 'Pull request' to send your changes
+to the project maintainers for review.
+
+7. It's ok if maintainers ask you for changes. It happens to core contributors
+too! So everyone can see the changes in the Pull request, work in your local
+branch and push the changes to your fork. They will automatically appear in
+the pull request.
+
+### Tests
+
+An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
+the [tests folder](https://github.com/huggingface/diffusers/tree/main/tests).
+
+We like `pytest` and `pytest-xdist` because it's faster. From the root of the
+repository, here's how to run tests with `pytest` for the library:
+
+```bash
+$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
+```
+
+In fact, that's how `make test` is implemented!
+
+You can specify a smaller set of tests in order to test only the feature
+you're working on.
+
+By default, slow tests are skipped. Set the `RUN_SLOW` environment variable to
+`yes` to run them. This will download many gigabytes of models — make sure you
+have enough disk space and a good Internet connection, or a lot of patience!
+
+```bash
+$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
+```
+
+`unittest` is fully supported, here's how to run tests with it:
+
+```bash
+$ python -m unittest discover -s tests -t . -v
+$ python -m unittest discover -s examples -t examples -v
+```
+
+### Syncing forked main with upstream (HuggingFace) main
+
+To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
+when syncing the main branch of a forked repository, please, follow these steps:
+1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
+2. If a PR is absolutely necessary, use the following steps after checking out your branch:
+```
+$ git checkout -b your-branch-for-syncing
+$ git pull --squash --no-commit upstream main
+$ git commit -m ''
+$ git push --set-upstream origin your-branch-for-syncing
+```
+
+### Style guide
+
+For documentation strings, 🧨 Diffusers follows the [google style](https://google.github.io/styleguide/pyguide.html).
diff --git a/diffusers/LICENSE b/diffusers/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/diffusers/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/diffusers/MANIFEST.in b/diffusers/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..b22fe1a28a1ef881fdb36af3c30b14c0a5d10aa5
--- /dev/null
+++ b/diffusers/MANIFEST.in
@@ -0,0 +1,2 @@
+include LICENSE
+include src/diffusers/utils/model_card_template.md
diff --git a/diffusers/Makefile b/diffusers/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..94af6d2f12724c9e22a09143be9277aaace3cd85
--- /dev/null
+++ b/diffusers/Makefile
@@ -0,0 +1,96 @@
+.PHONY: deps_table_update modified_only_fixup extra_style_checks quality style fixup fix-copies test test-examples
+
+# make sure to test the local checkout in scripts and not the pre-installed one (don't use quotes!)
+export PYTHONPATH = src
+
+check_dirs := examples scripts src tests utils
+
+modified_only_fixup:
+ $(eval modified_py_files := $(shell python utils/get_modified_files.py $(check_dirs)))
+ @if test -n "$(modified_py_files)"; then \
+ echo "Checking/fixing $(modified_py_files)"; \
+ black $(modified_py_files); \
+ ruff $(modified_py_files); \
+ else \
+ echo "No library .py files were modified"; \
+ fi
+
+# Update src/diffusers/dependency_versions_table.py
+
+deps_table_update:
+ @python setup.py deps_table_update
+
+deps_table_check_updated:
+ @md5sum src/diffusers/dependency_versions_table.py > md5sum.saved
+ @python setup.py deps_table_update
+ @md5sum -c --quiet md5sum.saved || (printf "\nError: the version dependency table is outdated.\nPlease run 'make fixup' or 'make style' and commit the changes.\n\n" && exit 1)
+ @rm md5sum.saved
+
+# autogenerating code
+
+autogenerate_code: deps_table_update
+
+# Check that the repo is in a good state
+
+repo-consistency:
+ python utils/check_dummies.py
+ python utils/check_repo.py
+ python utils/check_inits.py
+
+# this target runs checks on all files
+
+quality:
+ black --check $(check_dirs)
+ ruff $(check_dirs)
+ doc-builder style src/diffusers docs/source --max_len 119 --check_only --path_to_docs docs/source
+ python utils/check_doc_toc.py
+
+# Format source code automatically and check is there are any problems left that need manual fixing
+
+extra_style_checks:
+ python utils/custom_init_isort.py
+ doc-builder style src/diffusers docs/source --max_len 119 --path_to_docs docs/source
+ python utils/check_doc_toc.py --fix_and_overwrite
+
+# this target runs checks on all files and potentially modifies some of them
+
+style:
+ black $(check_dirs)
+ ruff $(check_dirs) --fix
+ ${MAKE} autogenerate_code
+ ${MAKE} extra_style_checks
+
+# Super fast fix and check target that only works on relevant modified files since the branch was made
+
+fixup: modified_only_fixup extra_style_checks autogenerate_code repo-consistency
+
+# Make marked copies of snippets of codes conform to the original
+
+fix-copies:
+ python utils/check_copies.py --fix_and_overwrite
+ python utils/check_dummies.py --fix_and_overwrite
+
+# Run tests for the library
+
+test:
+ python -m pytest -n auto --dist=loadfile -s -v ./tests/
+
+# Run tests for examples
+
+test-examples:
+ python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/
+
+
+# Release stuff
+
+pre-release:
+ python utils/release.py
+
+pre-patch:
+ python utils/release.py --patch
+
+post-release:
+ python utils/release.py --post_release
+
+post-patch:
+ python utils/release.py --post_release --patch
diff --git a/diffusers/PHILOSOPHY.md b/diffusers/PHILOSOPHY.md
new file mode 100644
index 0000000000000000000000000000000000000000..fbad5948e17e576d902176202060e8077b4198ec
--- /dev/null
+++ b/diffusers/PHILOSOPHY.md
@@ -0,0 +1,110 @@
+
+
+# Philosophy
+
+🧨 Diffusers provides **state-of-the-art** pretrained diffusion models across multiple modalities.
+Its purpose is to serve as a **modular toolbox** for both inference and training.
+
+We aim at building a library that stands the test of time and therefore take API design very seriously.
+
+In a nutshell, Diffusers is built to be a natural extension of PyTorch. Therefore, most of our design choices are based on [PyTorch's Design Principles](https://pytorch.org/docs/stable/community/design.html#pytorch-design-philosophy). Let's go over the most important ones:
+
+## Usability over Performance
+
+- While Diffusers has many built-in performance-enhancing features (see [Memory and Speed](https://huggingface.co/docs/diffusers/optimization/fp16)), models are always loaded with the highest precision and lowest optimization. Therefore, by default diffusion pipelines are always instantiated on CPU with float32 precision if not otherwise defined by the user. This ensures usability across different platforms and accelerators and means that no complex installations are required to run the library.
+- Diffusers aim at being a **light-weight** package and therefore has very few required dependencies, but many soft dependencies that can improve performance (such as `accelerate`, `safetensors`, `onnx`, etc...). We strive to keep the library as lightweight as possible so that it can be added without much concern as a dependency on other packages.
+- Diffusers prefers simple, self-explainable code over condensed, magic code. This means that short-hand code syntaxes such as lambda functions, and advanced PyTorch operators are often not desired.
+
+## Simple over easy
+
+As PyTorch states, **explicit is better than implicit** and **simple is better than complex**. This design philosophy is reflected in multiple parts of the library:
+- We follow PyTorch's API with methods like [`DiffusionPipeline.to`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.to) to let the user handle device management.
+- Raising concise error messages is preferred to silently correct erroneous input. Diffusers aims at teaching the user, rather than making the library as easy to use as possible.
+- Complex model vs. scheduler logic is exposed instead of magically handled inside. Schedulers/Samplers are separated from diffusion models with minimal dependencies on each other. This forces the user to write the unrolled denoising loop. However, the separation allows for easier debugging and gives the user more control over adapting the denoising process or switching out diffusion models or schedulers.
+- Separately trained components of the diffusion pipeline, *e.g.* the text encoder, the unet, and the variational autoencoder, each have their own model class. This forces the user to handle the interaction between the different model components, and the serialization format separates the model components into different files. However, this allows for easier debugging and customization. Dreambooth or textual inversion training
+is very simple thanks to diffusers' ability to separate single components of the diffusion pipeline.
+
+## Tweakable, contributor-friendly over abstraction
+
+For large parts of the library, Diffusers adopts an important design principle of the [Transformers library](https://github.com/huggingface/transformers), which is to prefer copy-pasted code over hasty abstractions. This design principle is very opinionated and stands in stark contrast to popular design principles such as [Don't repeat yourself (DRY)](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself).
+In short, just like Transformers does for modeling files, diffusers prefers to keep an extremely low level of abstraction and very self-contained code for pipelines and schedulers.
+Functions, long code blocks, and even classes can be copied across multiple files which at first can look like a bad, sloppy design choice that makes the library unmaintainable.
+**However**, this design has proven to be extremely successful for Transformers and makes a lot of sense for community-driven, open-source machine learning libraries because:
+- Machine Learning is an extremely fast-moving field in which paradigms, model architectures, and algorithms are changing rapidly, which therefore makes it very difficult to define long-lasting code abstractions.
+- Machine Learning practitioners like to be able to quickly tweak existing code for ideation and research and therefore prefer self-contained code over one that contains many abstractions.
+- Open-source libraries rely on community contributions and therefore must build a library that is easy to contribute to. The more abstract the code, the more dependencies, the harder to read, and the harder to contribute to. Contributors simply stop contributing to very abstract libraries out of fear of breaking vital functionality. If contributing to a library cannot break other fundamental code, not only is it more inviting for potential new contributors, but it is also easier to review and contribute to multiple parts in parallel.
+
+At Hugging Face, we call this design the **single-file policy** which means that almost all of the code of a certain class should be written in a single, self-contained file. To read more about the philosophy, you can have a look
+at [this blog post](https://huggingface.co/blog/transformers-design-philosophy).
+
+In diffusers, we follow this philosophy for both pipelines and schedulers, but only partly for diffusion models. The reason we don't follow this design fully for diffusion models is because almost all diffusion pipelines, such
+as [DDPM](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/ddpm), [Stable Diffusion](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/stable_diffusion/overview#stable-diffusion-pipelines), [UnCLIP (Dalle-2)](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/unclip#overview) and [Imagen](https://imagen.research.google/) all rely on the same diffusion model, the [UNet](https://huggingface.co/docs/diffusers/api/models#diffusers.UNet2DConditionModel).
+
+Great, now you should have generally understood why 🧨 Diffusers is designed the way it is 🤗.
+We try to apply these design principles consistently across the library. Nevertheless, there are some minor exceptions to the philosophy or some unlucky design choices. If you have feedback regarding the design, we would ❤️ to hear it [directly on GitHub](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
+
+## Design Philosophy in Details
+
+Now, let's look a bit into the nitty-gritty details of the design philosophy. Diffusers essentially consist of three major classes, [pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines), [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models), and [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
+Let's walk through more in-detail design decisions for each class.
+
+### Pipelines
+
+Pipelines are designed to be easy to use (therefore do not follow [*Simple over easy*](#simple-over-easy) 100%)), are not feature complete, and should loosely be seen as examples of how to use [models](#models) and [schedulers](#schedulers) for inference.
+
+The following design principles are followed:
+- Pipelines follow the single-file policy. All pipelines can be found in individual directories under src/diffusers/pipelines. One pipeline folder corresponds to one diffusion paper/project/release. Multiple pipeline files can be gathered in one pipeline folder, as it’s done for [`src/diffusers/pipelines/stable-diffusion`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/stable_diffusion). If pipelines share similar functionality, one can make use of the [#Copied from mechanism](https://github.com/huggingface/diffusers/blob/125d783076e5bd9785beb05367a2d2566843a271/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py#L251).
+- Pipelines all inherit from [`DiffusionPipeline`]
+- Every pipeline consists of different model and scheduler components, that are documented in the [`model_index.json` file](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json), are accessible under the same name as attributes of the pipeline and can be shared between pipelines with [`DiffusionPipeline.components`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.components) function.
+- Every pipeline should be loadable via the [`DiffusionPipeline.from_pretrained`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained) function.
+- Pipelines should be used **only** for inference.
+- Pipelines should be very readable, self-explanatory, and easy to tweak.
+- Pipelines should be designed to build on top of each other and be easy to integrate into higher-level APIs.
+- Pipelines are **not** intended to be feature-complete user interfaces. For future complete user interfaces one should rather have a look at [InvokeAI](https://github.com/invoke-ai/InvokeAI), [Diffuzers](https://github.com/abhishekkrthakur/diffuzers), and [lama-cleaner](https://github.com/Sanster/lama-cleaner)
+- Every pipeline should have one and only one way to run it via a `__call__` method. The naming of the `__call__` arguments should be shared across all pipelines.
+- Pipelines should be named after the task they are intended to solve.
+- In almost all cases, novel diffusion pipelines shall be implemented in a new pipeline folder/file.
+
+### Models
+
+Models are designed as configurable toolboxes that are natural extensions of [PyTorch's Module class](https://pytorch.org/docs/stable/generated/torch.nn.Module.html). They only partly follow the **single-file policy**.
+
+The following design principles are followed:
+- Models correspond to **a type of model architecture**. *E.g.* the [`UNet2DConditionModel`] class is used for all UNet variations that expect 2D image inputs and are conditioned on some context.
+- All models can be found in [`src/diffusers/models`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and every model architecture shall be defined in its file, e.g. [`unet_2d_condition.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_condition.py), [`transformer_2d.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/transformer_2d.py), etc...
+- Models **do not** follow the single-file policy and should make use of smaller model building blocks, such as [`attention.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention.py), [`resnet.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/resnet.py), [`embeddings.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/embeddings.py), etc... **Note**: This is in stark contrast to Transformers' modeling files and shows that models do not really follow the single-file policy.
+- Models intend to expose complexity, just like PyTorch's module does, and give clear error messages.
+- Models all inherit from `ModelMixin` and `ConfigMixin`.
+- Models can be optimized for performance when it doesn’t demand major code changes, keeps backward compatibility, and gives significant memory or compute gain.
+- Models should by default have the highest precision and lowest performance setting.
+- To integrate new model checkpoints whose general architecture can be classified as an architecture that already exists in Diffusers, the existing model architecture shall be adapted to make it work with the new checkpoint. One should only create a new file if the model architecture is fundamentally different.
+- Models should be designed to be easily extendable to future changes. This can be achieved by limiting public function arguments, configuration arguments, and "foreseeing" future changes, *e.g.* it is usually better to add `string` "...type" arguments that can easily be extended to new future types instead of boolean `is_..._type` arguments. Only the minimum amount of changes shall be made to existing architectures to make a new model checkpoint work.
+- The model design is a difficult trade-off between keeping code readable and concise and supporting many model checkpoints. For most parts of the modeling code, classes shall be adapted for new model checkpoints, while there are some exceptions where it is preferred to add new classes to make sure the code is kept concise and
+readable longterm, such as [UNet blocks](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_blocks.py) and [Attention processors](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+### Schedulers
+
+Schedulers are responsible to guide the denoising process for inference as well as to define a noise schedule for training. They are designed as individual classes with loadable configuration files and strongly follow the **single-file policy**.
+
+The following design principles are followed:
+- All schedulers are found in [`src/diffusers/schedulers`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
+- Schedulers are **not** allowed to import from large utils files and shall be kept very self-contained.
+- One scheduler python file corresponds to one scheduler algorithm (as might be defined in a paper).
+- If schedulers share similar functionalities, we can make use of the `#Copied from` mechanism.
+- Schedulers all inherit from `SchedulerMixin` and `ConfigMixin`.
+- Schedulers can be easily swapped out with the [`ConfigMixin.from_config`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config) method as explained in detail [here](./using-diffusers/schedulers.mdx).
+- Every scheduler has to have a `set_num_inference_steps`, and a `step` function. `set_num_inference_steps(...)` has to be called before every denoising process, *i.e.* before `step(...)` is called.
+- Every scheduler exposes the timesteps to be "looped over" via a `timesteps` attribute, which is an array of timesteps the model will be called upon
+- The `step(...)` function takes a predicted model output and the "current" sample (x_t) and returns the "previous", slightly more denoised sample (x_t-1).
+- Given the complexity of diffusion schedulers, the `step` function does not expose all the complexity and can be a bit of a "black box".
+- In almost all cases, novel schedulers shall be implemented in a new scheduling file.
diff --git a/diffusers/README.md b/diffusers/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..76d7df79c813d86e5c7a4b6f8a7b6b3c878afa26
--- /dev/null
+++ b/diffusers/README.md
@@ -0,0 +1,185 @@
+
+
+Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
+
+We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
+
+## Overview
+
+You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
+the core library.
+
+In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
+
+* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
+* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose)
+* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues)
+* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
+* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
+* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
+* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
+
+As said before, **all contributions are valuable to the community**.
+In the following, we will explain each contribution a bit more in detail.
+
+For all contributions 4.-9. you will need to open a PR. It is explained in detail how to do so in [Opening a pull requst](#how-to-open-a-pr)
+
+### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
+
+Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
+- Reports of training or inference experiments in an attempt to share knowledge
+- Presentation of personal projects
+- Questions to non-official training examples
+- Project proposals
+- General feedback
+- Paper summaries
+- Asking for help on personal projects that build on top of the Diffusers library
+- General questions
+- Ethical questions regarding diffusion models
+- ...
+
+Every question that is asked on the forum or on Discord actively encourages the community to publicly
+share knowledge and might very well help a beginner in the future that has the same question you're
+having. Please do pose any questions you might have.
+In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
+
+**Please** keep in mind that the more effort you put into asking or answering a question, the higher
+the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
+In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accesible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+**NOTE about channels**:
+[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
+In addition, questions and answers posted in the forum can easily be linked to.
+In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
+While it will most likely take less time for you to get an answer to your question on Discord, your
+question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
+
+### 2. Opening new issues on the GitHub issues tab
+
+The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
+the problems they encounter. So thank you for reporting an issue.
+
+Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
+
+In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
+
+**Please consider the following guidelines when opening a new issue**:
+- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
+- Please never report a new issue on another (related) issue. If another issue is highly related, please
+open a new issue nevertheless and link to the related issue.
+- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
+- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
+- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
+
+New issues usually include the following.
+
+#### 2.1. Reproducible, minimal bug reports.
+
+A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
+This means in more detail:
+- Narrow the bug down as much as you can, **do not just dump your whole code file**
+- Format your code
+- Do not include any external libraries except for Diffusers depending on them.
+- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
+- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
+- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
+- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
+
+For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new/choose).
+
+#### 2.2. Feature requests.
+
+A world-class feature request addresses the following points:
+
+1. Motivation first:
+* Is it related to a problem/frustration with the library? If so, please explain
+why. Providing a code snippet that demonstrates the problem is best.
+* Is it related to something you would need for a project? We'd love to hear
+about it!
+* Is it something you worked on and think could benefit the community?
+Awesome! Tell us what problem it solved for you.
+2. Write a *full paragraph* describing the feature;
+3. Provide a **code snippet** that demonstrates its future use;
+4. In case this is related to a paper, please attach a link;
+5. Attach any additional information (drawings, screenshots, etc.) you think may help.
+
+You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
+
+#### 2.3 Feedback.
+
+Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
+If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
+
+You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
+
+#### 2.4 Technical questions.
+
+Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
+why this part of the code is difficult to understand.
+
+You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
+
+#### 2.5 Proposal to add a new model, scheduler, or pipeline.
+
+If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
+
+* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
+* Link to any of its open-source implementation.
+* Link to the model weights if they are available.
+
+If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
+to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
+
+You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
+
+### 3. Answering issues on the GitHub issues tab
+
+Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
+Some tips to give a high-quality answer to an issue:
+- Be as concise and minimal as possible
+- Stay on topic. An answer to the issue should concern the issue and only the issue.
+- Provide links to code, papers, or other sources that prove or encourage your point.
+- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
+
+Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
+help to the maintainers if you can answer such issues, encouraging the author of the issue to be
+more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR)
+
+If you have verified that the issued bug report is correct and requires a correction in the source code,
+please have a look at the next sections.
+
+For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull requst](#how-to-open-a-pr) section.
+
+### 4. Fixing a "Good first issue"
+
+*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
+explains how a potential solution should look so that it is easier to fix.
+If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
+- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
+- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
+- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
+
+
+### 5. Contribute to the documentation
+
+A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
+valuable contribution**.
+
+Contributing to the library can have many forms:
+
+- Correcting spelling or grammatical errors.
+- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
+- Correct the shape or dimensions of a docstring input or output tensor.
+- Clarify documentation that is hard to understand or incorrect.
+- Update outdated code examples.
+- Translating the documentation to another language.
+
+Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
+
+Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
+
+
+### 6. Contribute a community pipeline
+
+[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
+Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
+We support two types of pipelines:
+
+- Official Pipelines
+- Community Pipelines
+
+Both official and community pipelines follow the same design and consist of the same type of components.
+
+Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
+resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
+In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
+They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
+
+The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
+possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
+Officially released diffusion pipelines,
+such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
+high quality of maintenance, no backward-breaking code changes, and testing.
+More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
+
+To add a community pipeline, one should add a .py file to [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and adapt the [examples/community/README.md](https://github.com/huggingface/diffusers/tree/main/examples/community/README.md) to include an example of the new pipeline.
+
+An example can be seen [here](https://github.com/huggingface/diffusers/pull/2400).
+
+Community pipeline PRs are only checked at a superficial level and ideally they should be maintained by their original authors.
+
+Contributing a community pipeline is a great way to understand how Diffusers models and schedulers work. Having contributed a community pipeline is usually the first stepping stone to contributing an official pipeline to the
+core package.
+
+### 7. Contribute to training examples
+
+Diffusers examples are a collection of training scripts that reside in [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+
+We support two types of training examples:
+
+- Official training examples
+- Research training examples
+
+Research training examples are located in [examples/research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects) whereas official training examples include all folders under [examples](https://github.com/huggingface/diffusers/tree/main/examples) except the `research_projects` and `community` folders.
+The official training examples are maintained by the Diffusers' core maintainers whereas the research training examples are maintained by the community.
+This is because of the same reasons put forward in [6. Contribute a community pipeline](#contribute-a-community-pipeline) for official pipelines vs. community pipelines: It is not feasible for the core maintainers to maintain all possible training methods for diffusion models.
+If the Diffusers core maintainers and the community consider a certain training paradigm to be too experimental or not popular enough, the corresponding training code should be put in the `research_projects` folder and maintained by the author.
+
+Both official training and research examples consist of a directory that contains one or more training scripts, a requirements.txt file, and a README.md file. In order for the user to make use of the
+training examples, it is required to clone the repository:
+
+```
+git clone https://github.com/huggingface/diffusers
+```
+
+as well as to install all additional dependencies required for training:
+
+```
+pip install -r /examples//requirements.txt
+```
+
+Therefore when adding an example, the `requirements.txt` file shall define all pip dependencies required for your training example so that once all those are installed, the user can run the example's training script. See, for example, the [DreamBooth `requirements.txt` file](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/requirements.txt).
+
+Training examples of the Diffusers library should adhere to the following philosophy:
+- All the code necessary to run the examples should be found in a single Python file
+- One should be able to run the example from the command line with `python .py --args`
+- Examples should be kept simple and serve as **an example** on how to use Diffusers for training. The purpose of example scripts is **not** to create state-of-the-art diffusion models, but rather to reproduce known training schemes without adding too much custom logic. As a byproduct of this point, our examples also strive to serve as good educational materials.
+
+To contribute an example, it is highly recommended to look at already existing examples such as [dreambooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py) to get an idea of how they should look like.
+We strongly advise contributors to make use of the [Accelerate library](https://github.com/huggingface/accelerate) as it's tightly integrated
+with Diffusers.
+Once an example script works, please make sure to add a comprehensive `README.md` that states how to use the example exactly. This README should include:
+- An example command on how to run the example script as shown [here e.g.](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#running-locally-with-pytorch).
+- A link to some training results (logs, models, ...) that show what the user can expect as shown [here e.g.](https://api.wandb.ai/report/patrickvonplaten/xm6cd5q5).
+- If you are adding a non-official/research training example, **please don't forget** to add a sentence that you are maintaining this training example which includes your git handle as shown [here](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/intel_opts#diffusers-examples-with-intel-optimizations).
+
+If you are contributing to the official training examples, please also make sure to add a test to [examples/test_examples.py](https://github.com/huggingface/diffusers/blob/main/examples/test_examples.py). This is not necessary for non-official training examples.
+
+### 8. Fixing a "Good second issue"
+
+*Good second issues* are marked by the [Good second issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) label. Good second issues are
+usually more complicated to solve than [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+The issue description usually gives less guidance on how to fix the issue and requires
+a decent understanding of the library by the interested contributor.
+If you are interested in tackling a second good issue, feel free to open a PR to fix it and link the PR to the issue. If you see that a PR has already been opened for this issue but did not get merged, have a look to understand why it wasn't merged and try to open an improved PR.
+Good second issues are usually more difficult to get merged compared to good first issues, so don't hesitate to ask for help from the core maintainers. If your PR is almost finished the core maintainers can also jump into your PR and commit to it in order to get it merged.
+
+### 9. Adding pipelines, models, schedulers
+
+Pipelines, models, and schedulers are the most important pieces of the Diffusers library.
+They provide easy access to state-of-the-art diffusion technologies and thus allow the community to
+build powerful generative AI applications.
+
+By adding a new model, pipeline, or scheduler you might enable a new powerful use case for any of the user interfaces relying on Diffusers which can be of immense value for the whole generative AI ecosystem.
+
+Diffusers has a couple of open feature requests for all three components - feel free to gloss over them
+if you don't know yet what specific component you would like to add:
+- [Model or pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22)
+- [Scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
+
+Before adding any of the three components, it is strongly recommended that you give the [Philosophy guide](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) a read to better understand the design of any of the three components. Please be aware that
+we cannot merge model, scheduler, or pipeline additions that strongly diverge from our design philosophy
+as it will lead to API inconsistencies. If you fundamentally disagree with a design choice, please
+open a [Feedback issue](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=) instead so that it can be discussed whether a certain design
+pattern/design choice shall be changed everywhere in the library and whether we shall update our design philosophy. Consistency across the library is very important for us.
+
+Please make sure to add links to the original codebase/paper to the PR and ideally also ping the
+original author directly on the PR so that they can follow the progress and potentially help with questions.
+
+If you are unsure or stuck in the PR, don't hesitate to leave a message to ask for a first review or help.
+
+## How to write a good issue
+
+**The better your issue is written, the higher the chances that it will be quickly resolved.**
+
+1. Make sure that you've used the correct template for your issue. You can pick between *Bug Report*, *Feature Request*, *Feedback about API Design*, *New model/pipeline/scheduler addition*, *Forum*, or a blank issue. Make sure to pick the correct one when opening [a new issue](https://github.com/huggingface/diffusers/issues/new/choose).
+2. **Be precise**: Give your issue a fitting title. Try to formulate your issue description as simple as possible. The more precise you are when submitting an issue, the less time it takes to understand the issue and potentially solve it. Make sure to open an issue for one issue only and not for multiple issues. If you found multiple issues, simply open multiple issues. If your issue is a bug, try to be as precise as possible about what bug it is - you should not just write "Error in diffusers".
+3. **Reproducibility**: No reproducible code snippet == no solution. If you encounter a bug, maintainers **have to be able to reproduce** it. Make sure that you include a code snippet that can be copy-pasted into a Python interpreter to reproduce the issue. Make sure that your code snippet works, *i.e.* that there are no missing imports or missing links to images, ... Your issue should contain an error message **and** a code snippet that can be copy-pasted without any changes to reproduce the exact same error message. If your issue is using local model weights or local data that cannot be accessed by the reader, the issue cannot be solved. If you cannot share your data or model, try to make a dummy model or dummy data.
+4. **Minimalistic**: Try to help the reader as much as you can to understand the issue as quickly as possible by staying as concise as possible. Remove all code / all information that is irrelevant to the issue. If you have found a bug, try to create the easiest code example you can to demonstrate your issue, do not just dump your whole workflow into the issue as soon as you have found a bug. E.g., if you train a model and get an error at some point during the training, you should first try to understand what part of the training code is responsible for the error and try to reproduce it with a couple of lines. Try to use dummy data instead of full datasets.
+5. Add links. If you are referring to a certain naming, method, or model make sure to provide a link so that the reader can better understand what you mean. If you are referring to a specific PR or issue, make sure to link it to your issue. Do not assume that the reader knows what you are talking about. The more links you add to your issue the better.
+6. Formatting. Make sure to nicely format your issue by formatting code into Python code syntax, and error messages into normal code syntax. See the [official GitHub formatting docs](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) for more information.
+7. Think of your issue not as a ticket to be solved, but rather as a beautiful entry to a well-written encyclopedia. Every added issue is a contribution to publicly available knowledge. By adding a nicely written issue you not only make it easier for maintainers to solve your issue, but you are helping the whole community to better understand a certain aspect of the library.
+
+## How to write a good PR
+
+1. Be a chameleon. Understand existing design patterns and syntax and make sure your code additions flow seamlessly into the existing code base. Pull requests that significantly diverge from existing design patterns or user interfaces will not be merged.
+2. Be laser focused. A pull request should solve one problem and one problem only. Make sure to not fall into the trap of "also fixing another problem while we're adding it". It is much more difficult to review pull requests that solve multiple, unrelated problems at once.
+3. If helpful, try to add a code snippet that displays an example of how your addition can be used.
+4. The title of your pull request should be a summary of its contribution.
+5. If your pull request addresses an issue, please mention the issue number in
+the pull request description to make sure they are linked (and people
+consulting the issue know you are working on it);
+6. To indicate a work in progress please prefix the title with `[WIP]`. These
+are useful to avoid duplicated work, and to differentiate it from PRs ready
+to be merged;
+7. Try to formulate and format your text as explained in [How to write a good issue](#how-to-write-a-good-issue).
+8. Make sure existing tests pass;
+9. Add high-coverage tests. No quality testing = no merge.
+- If you are adding new `@slow` tests, make sure they pass using
+`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
+CircleCI does not run the slow tests, but GitHub actions does every night!
+10. All public methods must have informative docstrings that work nicely with markdown. See `[pipeline_latent_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py)` for an example.
+11. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
+[`hf-internal-testing`](https://huggingface.co/hf-internal-testing) or [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images) to place these files.
+If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
+to this dataset.
+
+## How to open a PR
+
+Before writing code, we strongly advise you to search through the existing PRs or
+issues to make sure that nobody is already working on the same thing. If you are
+unsure, it is always a good idea to open an issue to get some feedback.
+
+You will need basic `git` proficiency to be able to contribute to
+🧨 Diffusers. `git` is not the easiest tool to use but it has the greatest
+manual. Type `git --help` in a shell and enjoy. If you prefer books, [Pro
+Git](https://git-scm.com/book/en/v2) is a very good reference.
+
+Follow these steps to start contributing ([supported Python versions](https://github.com/huggingface/diffusers/blob/main/setup.py#L244)):
+
+1. Fork the [repository](https://github.com/huggingface/diffusers) by
+clicking on the 'Fork' button on the repository's page. This creates a copy of the code
+under your GitHub user account.
+
+2. Clone your fork to your local disk, and add the base repository as a remote:
+
+ ```bash
+ $ git clone git@github.com:/diffusers.git
+ $ cd diffusers
+ $ git remote add upstream https://github.com/huggingface/diffusers.git
+ ```
+
+3. Create a new branch to hold your development changes:
+
+ ```bash
+ $ git checkout -b a-descriptive-name-for-my-changes
+ ```
+
+**Do not** work on the `main` branch.
+
+4. Set up a development environment by running the following command in a virtual environment:
+
+ ```bash
+ $ pip install -e ".[dev]"
+ ```
+
+If you have already cloned the repo, you might need to `git pull` to get the most recent changes in the
+library.
+
+5. Develop the features on your branch.
+
+As you work on the features, you should make sure that the test suite
+passes. You should run the tests impacted by your changes like this:
+
+ ```bash
+ $ pytest tests/.py
+ ```
+
+You can also run the full suite with the following command, but it takes
+a beefy machine to produce a result in a decent amount of time now that
+Diffusers has grown a lot. Here is the command for it:
+
+ ```bash
+ $ make test
+ ```
+
+🧨 Diffusers relies on `black` and `isort` to format its source code
+consistently. After you make changes, apply automatic style corrections and code verifications
+that can't be automated in one go with:
+
+ ```bash
+ $ make style
+ ```
+
+🧨 Diffusers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
+control runs in CI, however, you can also run the same checks with:
+
+ ```bash
+ $ make quality
+ ```
+
+Once you're happy with your changes, add changed files using `git add` and
+make a commit with `git commit` to record your changes locally:
+
+ ```bash
+ $ git add modified_file.py
+ $ git commit
+ ```
+
+It is a good idea to sync your copy of the code with the original
+repository regularly. This way you can quickly account for changes:
+
+ ```bash
+ $ git pull upstream main
+ ```
+
+Push the changes to your account using:
+
+ ```bash
+ $ git push -u origin a-descriptive-name-for-my-changes
+ ```
+
+6. Once you are satisfied, go to the
+webpage of your fork on GitHub. Click on 'Pull request' to send your changes
+to the project maintainers for review.
+
+7. It's ok if maintainers ask you for changes. It happens to core contributors
+too! So everyone can see the changes in the Pull request, work in your local
+branch and push the changes to your fork. They will automatically appear in
+the pull request.
+
+### Tests
+
+An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
+the [tests folder](https://github.com/huggingface/diffusers/tree/main/tests).
+
+We like `pytest` and `pytest-xdist` because it's faster. From the root of the
+repository, here's how to run tests with `pytest` for the library:
+
+```bash
+$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
+```
+
+In fact, that's how `make test` is implemented!
+
+You can specify a smaller set of tests in order to test only the feature
+you're working on.
+
+By default, slow tests are skipped. Set the `RUN_SLOW` environment variable to
+`yes` to run them. This will download many gigabytes of models — make sure you
+have enough disk space and a good Internet connection, or a lot of patience!
+
+```bash
+$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
+```
+
+`unittest` is fully supported, here's how to run tests with it:
+
+```bash
+$ python -m unittest discover -s tests -t . -v
+$ python -m unittest discover -s examples -t examples -v
+```
+
+### Syncing forked main with upstream (HuggingFace) main
+
+To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
+when syncing the main branch of a forked repository, please, follow these steps:
+1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
+2. If a PR is absolutely necessary, use the following steps after checking out your branch:
+```
+$ git checkout -b your-branch-for-syncing
+$ git pull --squash --no-commit upstream main
+$ git commit -m ''
+$ git push --set-upstream origin your-branch-for-syncing
+```
+
+### Style guide
+
+For documentation strings, 🧨 Diffusers follows the [google style](https://google.github.io/styleguide/pyguide.html).
diff --git a/diffusers/LICENSE b/diffusers/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/diffusers/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/diffusers/MANIFEST.in b/diffusers/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..b22fe1a28a1ef881fdb36af3c30b14c0a5d10aa5
--- /dev/null
+++ b/diffusers/MANIFEST.in
@@ -0,0 +1,2 @@
+include LICENSE
+include src/diffusers/utils/model_card_template.md
diff --git a/diffusers/Makefile b/diffusers/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..94af6d2f12724c9e22a09143be9277aaace3cd85
--- /dev/null
+++ b/diffusers/Makefile
@@ -0,0 +1,96 @@
+.PHONY: deps_table_update modified_only_fixup extra_style_checks quality style fixup fix-copies test test-examples
+
+# make sure to test the local checkout in scripts and not the pre-installed one (don't use quotes!)
+export PYTHONPATH = src
+
+check_dirs := examples scripts src tests utils
+
+modified_only_fixup:
+ $(eval modified_py_files := $(shell python utils/get_modified_files.py $(check_dirs)))
+ @if test -n "$(modified_py_files)"; then \
+ echo "Checking/fixing $(modified_py_files)"; \
+ black $(modified_py_files); \
+ ruff $(modified_py_files); \
+ else \
+ echo "No library .py files were modified"; \
+ fi
+
+# Update src/diffusers/dependency_versions_table.py
+
+deps_table_update:
+ @python setup.py deps_table_update
+
+deps_table_check_updated:
+ @md5sum src/diffusers/dependency_versions_table.py > md5sum.saved
+ @python setup.py deps_table_update
+ @md5sum -c --quiet md5sum.saved || (printf "\nError: the version dependency table is outdated.\nPlease run 'make fixup' or 'make style' and commit the changes.\n\n" && exit 1)
+ @rm md5sum.saved
+
+# autogenerating code
+
+autogenerate_code: deps_table_update
+
+# Check that the repo is in a good state
+
+repo-consistency:
+ python utils/check_dummies.py
+ python utils/check_repo.py
+ python utils/check_inits.py
+
+# this target runs checks on all files
+
+quality:
+ black --check $(check_dirs)
+ ruff $(check_dirs)
+ doc-builder style src/diffusers docs/source --max_len 119 --check_only --path_to_docs docs/source
+ python utils/check_doc_toc.py
+
+# Format source code automatically and check is there are any problems left that need manual fixing
+
+extra_style_checks:
+ python utils/custom_init_isort.py
+ doc-builder style src/diffusers docs/source --max_len 119 --path_to_docs docs/source
+ python utils/check_doc_toc.py --fix_and_overwrite
+
+# this target runs checks on all files and potentially modifies some of them
+
+style:
+ black $(check_dirs)
+ ruff $(check_dirs) --fix
+ ${MAKE} autogenerate_code
+ ${MAKE} extra_style_checks
+
+# Super fast fix and check target that only works on relevant modified files since the branch was made
+
+fixup: modified_only_fixup extra_style_checks autogenerate_code repo-consistency
+
+# Make marked copies of snippets of codes conform to the original
+
+fix-copies:
+ python utils/check_copies.py --fix_and_overwrite
+ python utils/check_dummies.py --fix_and_overwrite
+
+# Run tests for the library
+
+test:
+ python -m pytest -n auto --dist=loadfile -s -v ./tests/
+
+# Run tests for examples
+
+test-examples:
+ python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/
+
+
+# Release stuff
+
+pre-release:
+ python utils/release.py
+
+pre-patch:
+ python utils/release.py --patch
+
+post-release:
+ python utils/release.py --post_release
+
+post-patch:
+ python utils/release.py --post_release --patch
diff --git a/diffusers/PHILOSOPHY.md b/diffusers/PHILOSOPHY.md
new file mode 100644
index 0000000000000000000000000000000000000000..fbad5948e17e576d902176202060e8077b4198ec
--- /dev/null
+++ b/diffusers/PHILOSOPHY.md
@@ -0,0 +1,110 @@
+
+
+# Philosophy
+
+🧨 Diffusers provides **state-of-the-art** pretrained diffusion models across multiple modalities.
+Its purpose is to serve as a **modular toolbox** for both inference and training.
+
+We aim at building a library that stands the test of time and therefore take API design very seriously.
+
+In a nutshell, Diffusers is built to be a natural extension of PyTorch. Therefore, most of our design choices are based on [PyTorch's Design Principles](https://pytorch.org/docs/stable/community/design.html#pytorch-design-philosophy). Let's go over the most important ones:
+
+## Usability over Performance
+
+- While Diffusers has many built-in performance-enhancing features (see [Memory and Speed](https://huggingface.co/docs/diffusers/optimization/fp16)), models are always loaded with the highest precision and lowest optimization. Therefore, by default diffusion pipelines are always instantiated on CPU with float32 precision if not otherwise defined by the user. This ensures usability across different platforms and accelerators and means that no complex installations are required to run the library.
+- Diffusers aim at being a **light-weight** package and therefore has very few required dependencies, but many soft dependencies that can improve performance (such as `accelerate`, `safetensors`, `onnx`, etc...). We strive to keep the library as lightweight as possible so that it can be added without much concern as a dependency on other packages.
+- Diffusers prefers simple, self-explainable code over condensed, magic code. This means that short-hand code syntaxes such as lambda functions, and advanced PyTorch operators are often not desired.
+
+## Simple over easy
+
+As PyTorch states, **explicit is better than implicit** and **simple is better than complex**. This design philosophy is reflected in multiple parts of the library:
+- We follow PyTorch's API with methods like [`DiffusionPipeline.to`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.to) to let the user handle device management.
+- Raising concise error messages is preferred to silently correct erroneous input. Diffusers aims at teaching the user, rather than making the library as easy to use as possible.
+- Complex model vs. scheduler logic is exposed instead of magically handled inside. Schedulers/Samplers are separated from diffusion models with minimal dependencies on each other. This forces the user to write the unrolled denoising loop. However, the separation allows for easier debugging and gives the user more control over adapting the denoising process or switching out diffusion models or schedulers.
+- Separately trained components of the diffusion pipeline, *e.g.* the text encoder, the unet, and the variational autoencoder, each have their own model class. This forces the user to handle the interaction between the different model components, and the serialization format separates the model components into different files. However, this allows for easier debugging and customization. Dreambooth or textual inversion training
+is very simple thanks to diffusers' ability to separate single components of the diffusion pipeline.
+
+## Tweakable, contributor-friendly over abstraction
+
+For large parts of the library, Diffusers adopts an important design principle of the [Transformers library](https://github.com/huggingface/transformers), which is to prefer copy-pasted code over hasty abstractions. This design principle is very opinionated and stands in stark contrast to popular design principles such as [Don't repeat yourself (DRY)](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself).
+In short, just like Transformers does for modeling files, diffusers prefers to keep an extremely low level of abstraction and very self-contained code for pipelines and schedulers.
+Functions, long code blocks, and even classes can be copied across multiple files which at first can look like a bad, sloppy design choice that makes the library unmaintainable.
+**However**, this design has proven to be extremely successful for Transformers and makes a lot of sense for community-driven, open-source machine learning libraries because:
+- Machine Learning is an extremely fast-moving field in which paradigms, model architectures, and algorithms are changing rapidly, which therefore makes it very difficult to define long-lasting code abstractions.
+- Machine Learning practitioners like to be able to quickly tweak existing code for ideation and research and therefore prefer self-contained code over one that contains many abstractions.
+- Open-source libraries rely on community contributions and therefore must build a library that is easy to contribute to. The more abstract the code, the more dependencies, the harder to read, and the harder to contribute to. Contributors simply stop contributing to very abstract libraries out of fear of breaking vital functionality. If contributing to a library cannot break other fundamental code, not only is it more inviting for potential new contributors, but it is also easier to review and contribute to multiple parts in parallel.
+
+At Hugging Face, we call this design the **single-file policy** which means that almost all of the code of a certain class should be written in a single, self-contained file. To read more about the philosophy, you can have a look
+at [this blog post](https://huggingface.co/blog/transformers-design-philosophy).
+
+In diffusers, we follow this philosophy for both pipelines and schedulers, but only partly for diffusion models. The reason we don't follow this design fully for diffusion models is because almost all diffusion pipelines, such
+as [DDPM](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/ddpm), [Stable Diffusion](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/stable_diffusion/overview#stable-diffusion-pipelines), [UnCLIP (Dalle-2)](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/unclip#overview) and [Imagen](https://imagen.research.google/) all rely on the same diffusion model, the [UNet](https://huggingface.co/docs/diffusers/api/models#diffusers.UNet2DConditionModel).
+
+Great, now you should have generally understood why 🧨 Diffusers is designed the way it is 🤗.
+We try to apply these design principles consistently across the library. Nevertheless, there are some minor exceptions to the philosophy or some unlucky design choices. If you have feedback regarding the design, we would ❤️ to hear it [directly on GitHub](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
+
+## Design Philosophy in Details
+
+Now, let's look a bit into the nitty-gritty details of the design philosophy. Diffusers essentially consist of three major classes, [pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines), [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models), and [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
+Let's walk through more in-detail design decisions for each class.
+
+### Pipelines
+
+Pipelines are designed to be easy to use (therefore do not follow [*Simple over easy*](#simple-over-easy) 100%)), are not feature complete, and should loosely be seen as examples of how to use [models](#models) and [schedulers](#schedulers) for inference.
+
+The following design principles are followed:
+- Pipelines follow the single-file policy. All pipelines can be found in individual directories under src/diffusers/pipelines. One pipeline folder corresponds to one diffusion paper/project/release. Multiple pipeline files can be gathered in one pipeline folder, as it’s done for [`src/diffusers/pipelines/stable-diffusion`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/stable_diffusion). If pipelines share similar functionality, one can make use of the [#Copied from mechanism](https://github.com/huggingface/diffusers/blob/125d783076e5bd9785beb05367a2d2566843a271/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py#L251).
+- Pipelines all inherit from [`DiffusionPipeline`]
+- Every pipeline consists of different model and scheduler components, that are documented in the [`model_index.json` file](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json), are accessible under the same name as attributes of the pipeline and can be shared between pipelines with [`DiffusionPipeline.components`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.components) function.
+- Every pipeline should be loadable via the [`DiffusionPipeline.from_pretrained`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained) function.
+- Pipelines should be used **only** for inference.
+- Pipelines should be very readable, self-explanatory, and easy to tweak.
+- Pipelines should be designed to build on top of each other and be easy to integrate into higher-level APIs.
+- Pipelines are **not** intended to be feature-complete user interfaces. For future complete user interfaces one should rather have a look at [InvokeAI](https://github.com/invoke-ai/InvokeAI), [Diffuzers](https://github.com/abhishekkrthakur/diffuzers), and [lama-cleaner](https://github.com/Sanster/lama-cleaner)
+- Every pipeline should have one and only one way to run it via a `__call__` method. The naming of the `__call__` arguments should be shared across all pipelines.
+- Pipelines should be named after the task they are intended to solve.
+- In almost all cases, novel diffusion pipelines shall be implemented in a new pipeline folder/file.
+
+### Models
+
+Models are designed as configurable toolboxes that are natural extensions of [PyTorch's Module class](https://pytorch.org/docs/stable/generated/torch.nn.Module.html). They only partly follow the **single-file policy**.
+
+The following design principles are followed:
+- Models correspond to **a type of model architecture**. *E.g.* the [`UNet2DConditionModel`] class is used for all UNet variations that expect 2D image inputs and are conditioned on some context.
+- All models can be found in [`src/diffusers/models`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and every model architecture shall be defined in its file, e.g. [`unet_2d_condition.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_condition.py), [`transformer_2d.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/transformer_2d.py), etc...
+- Models **do not** follow the single-file policy and should make use of smaller model building blocks, such as [`attention.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention.py), [`resnet.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/resnet.py), [`embeddings.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/embeddings.py), etc... **Note**: This is in stark contrast to Transformers' modeling files and shows that models do not really follow the single-file policy.
+- Models intend to expose complexity, just like PyTorch's module does, and give clear error messages.
+- Models all inherit from `ModelMixin` and `ConfigMixin`.
+- Models can be optimized for performance when it doesn’t demand major code changes, keeps backward compatibility, and gives significant memory or compute gain.
+- Models should by default have the highest precision and lowest performance setting.
+- To integrate new model checkpoints whose general architecture can be classified as an architecture that already exists in Diffusers, the existing model architecture shall be adapted to make it work with the new checkpoint. One should only create a new file if the model architecture is fundamentally different.
+- Models should be designed to be easily extendable to future changes. This can be achieved by limiting public function arguments, configuration arguments, and "foreseeing" future changes, *e.g.* it is usually better to add `string` "...type" arguments that can easily be extended to new future types instead of boolean `is_..._type` arguments. Only the minimum amount of changes shall be made to existing architectures to make a new model checkpoint work.
+- The model design is a difficult trade-off between keeping code readable and concise and supporting many model checkpoints. For most parts of the modeling code, classes shall be adapted for new model checkpoints, while there are some exceptions where it is preferred to add new classes to make sure the code is kept concise and
+readable longterm, such as [UNet blocks](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_blocks.py) and [Attention processors](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+### Schedulers
+
+Schedulers are responsible to guide the denoising process for inference as well as to define a noise schedule for training. They are designed as individual classes with loadable configuration files and strongly follow the **single-file policy**.
+
+The following design principles are followed:
+- All schedulers are found in [`src/diffusers/schedulers`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
+- Schedulers are **not** allowed to import from large utils files and shall be kept very self-contained.
+- One scheduler python file corresponds to one scheduler algorithm (as might be defined in a paper).
+- If schedulers share similar functionalities, we can make use of the `#Copied from` mechanism.
+- Schedulers all inherit from `SchedulerMixin` and `ConfigMixin`.
+- Schedulers can be easily swapped out with the [`ConfigMixin.from_config`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config) method as explained in detail [here](./using-diffusers/schedulers.mdx).
+- Every scheduler has to have a `set_num_inference_steps`, and a `step` function. `set_num_inference_steps(...)` has to be called before every denoising process, *i.e.* before `step(...)` is called.
+- Every scheduler exposes the timesteps to be "looped over" via a `timesteps` attribute, which is an array of timesteps the model will be called upon
+- The `step(...)` function takes a predicted model output and the "current" sample (x_t) and returns the "previous", slightly more denoised sample (x_t-1).
+- Given the complexity of diffusion schedulers, the `step` function does not expose all the complexity and can be a bit of a "black box".
+- In almost all cases, novel schedulers shall be implemented in a new scheduling file.
diff --git a/diffusers/README.md b/diffusers/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..76d7df79c813d86e5c7a4b6f8a7b6b3c878afa26
--- /dev/null
+++ b/diffusers/README.md
@@ -0,0 +1,185 @@
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or training your own diffusion models, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](https://huggingface.co/docs/diffusers/conceptual/philosophy#usability-over-performance), [simple over easy](https://huggingface.co/docs/diffusers/conceptual/philosophy#simple-over-easy), and [customizability over abstractions](https://huggingface.co/docs/diffusers/conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
+
+🤗 Diffusers offers three core components:
+
+- State-of-the-art [diffusion pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) that can be run in inference with just a few lines of code.
+- Interchangeable noise [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview) for different diffusion speeds and output quality.
+- Pretrained [models](https://huggingface.co/docs/diffusers/api/models) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
+
+## Installation
+
+We recommend installing 🤗 Diffusers in a virtual environment from PyPi or Conda. For more details about installing [PyTorch](https://pytorch.org/get-started/locally/) and [Flax](https://flax.readthedocs.io/en/latest/installation.html), please refer to their official documentation.
+
+### PyTorch
+
+With `pip` (official package):
+
+```bash
+pip install --upgrade diffusers[torch]
+```
+
+With `conda` (maintained by the community):
+
+```sh
+conda install -c conda-forge diffusers
+```
+
+### Flax
+
+With `pip` (official package):
+
+```bash
+pip install --upgrade diffusers[flax]
+```
+
+### Apple Silicon (M1/M2) support
+
+Please refer to the [How to use Stable Diffusion in Apple Silicon](https://huggingface.co/docs/diffusers/optimization/mps) guide.
+
+## Quickstart
+
+Generating outputs is super easy with 🤗 Diffusers. To generate an image from text, use the `from_pretrained` method to load any pretrained diffusion model (browse the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) for 4000+ checkpoints):
+
+```python
+from diffusers import DiffusionPipeline
+
+pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+pipeline.to("cuda")
+pipeline("An image of a squirrel in Picasso style").images[0]
+```
+
+You can also dig into the models and schedulers toolbox to build your own diffusion system:
+
+```python
+from diffusers import DDPMScheduler, UNet2DModel
+from PIL import Image
+import torch
+import numpy as np
+
+scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
+model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
+scheduler.set_timesteps(50)
+
+sample_size = model.config.sample_size
+noise = torch.randn((1, 3, sample_size, sample_size)).to("cuda")
+input = noise
+
+for t in scheduler.timesteps:
+ with torch.no_grad():
+ noisy_residual = model(input, t).sample
+ prev_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
+ input = prev_noisy_sample
+
+image = (input / 2 + 0.5).clamp(0, 1)
+image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
+image = Image.fromarray((image * 255).round().astype("uint8"))
+image
+```
+
+Check out the [Quickstart](https://huggingface.co/docs/diffusers/quicktour) to launch your diffusion journey today!
+
+## How to navigate the documentation
+
+| **Documentation** | **What can I learn?** |
+|---------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| Tutorial | A basic crash course for learning how to use the library's most important features like using models and schedulers to build your own diffusion system, and training your own diffusion model. |
+| Loading | Guides for how to load and configure all the components (pipelines, models, and schedulers) of the library, as well as how to use different schedulers. |
+| Pipelines for inference | Guides for how to use pipelines for different inference tasks, batched generation, controlling generated outputs and randomness, and how to contribute a pipeline to the library. |
+| Optimization | Guides for how to optimize your diffusion model to run faster and consume less memory. |
+| [Training](https://huggingface.co/docs/diffusers/training/overview) | Guides for how to train a diffusion model for different tasks with different training techniques. |
+
+## Supported pipelines
+
+| Pipeline | Paper | Tasks |
+|---|---|:---:|
+| [alt_diffusion](./api/pipelines/alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
+| [audio_diffusion](./api/pipelines/audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
+| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [dance_diffusion](./api/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
+| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
+| [ddim](./api/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./api/pipelines/paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./api/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [score_sde_ve](./api/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [score_sde_vp](./api/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [**Semantic Guidance**](https://arxiv.org/abs/2301.12247) | Text-Guided Generation |
+| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation |
+| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation |
+| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [**MultiDiffusion**](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
+| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [**InstructPix2Pix**](https://github.com/timothybrooks/instruct-pix2pix) | Text-Guided Image Editing|
+| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [**Zero-shot Image-to-Image Translation**](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
+| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [**Attend and Excite for Stable Diffusion**](https://attendandexcite.github.io/Attend-and-Excite/) | Text-to-Image Generation |
+| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [**Self-Attention Guidance**](https://ku-cvlab.github.io/Self-Attention-Guidance) | Text-to-Image Generation |
+| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [**Stable Diffusion Image Variations**](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
+| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [**Stable Diffusion Latent Upscaler**](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Depth-Conditional Stable Diffusion**](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation |
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
+| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
+
+## Contribution
+
+We ❤️ contributions from the open-source community!
+If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md).
+You can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library.
+- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
+- See [New model/pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models / diffusion pipelines
+- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
+
+Also, say 👋 in our public Discord channel  . We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or
+just hang out ☕.
+
+## Credits
+
+This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
+
+- @CompVis' latent diffusion models library, available [here](https://github.com/CompVis/latent-diffusion)
+- @hojonathanho original DDPM implementation, available [here](https://github.com/hojonathanho/diffusion) as well as the extremely useful translation into PyTorch by @pesser, available [here](https://github.com/pesser/pytorch_diffusion)
+- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim)
+- @yang-song's Score-VE and Score-VP implementations, available [here](https://github.com/yang-song/score_sde_pytorch)
+
+We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available [here](https://github.com/heejkoo/Awesome-Diffusion-Models) as well as @crowsonkb and @rromb for useful discussions and insights.
+
+## Citation
+
+```bibtex
+@misc{von-platen-etal-2022-diffusers,
+ author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Thomas Wolf},
+ title = {Diffusers: State-of-the-art diffusion models},
+ year = {2022},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ howpublished = {\url{https://github.com/huggingface/diffusers}}
+}
+```
diff --git a/diffusers/_typos.toml b/diffusers/_typos.toml
new file mode 100644
index 0000000000000000000000000000000000000000..551099f981e7885fbda9ed28e297bace0e13407b
--- /dev/null
+++ b/diffusers/_typos.toml
@@ -0,0 +1,13 @@
+# Files for typos
+# Instruction: https://github.com/marketplace/actions/typos-action#getting-started
+
+[default.extend-identifiers]
+
+[default.extend-words]
+NIN="NIN" # NIN is used in scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py
+nd="np" # nd may be np (numpy)
+parms="parms" # parms is used in scripts/convert_original_stable_diffusion_to_diffusers.py
+
+
+[files]
+extend-exclude = ["_typos.toml"]
diff --git a/diffusers/docker/diffusers-flax-cpu/Dockerfile b/diffusers/docker/diffusers-flax-cpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..57a9c1ec742200b48f8c2f906d1152e85e60584a
--- /dev/null
+++ b/diffusers/docker/diffusers-flax-cpu/Dockerfile
@@ -0,0 +1,44 @@
+FROM ubuntu:20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+# follow the instructions here: https://cloud.google.com/tpu/docs/run-in-container#train_a_jax_model_in_a_docker_container
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --upgrade --no-cache-dir \
+ clu \
+ "jax[cpu]>=0.2.16,!=0.3.2" \
+ "flax>=0.4.1" \
+ "jaxlib>=0.1.65" && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-flax-tpu/Dockerfile b/diffusers/docker/diffusers-flax-tpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..2517da586d74b43c4c94a0eca4651f047345ec4d
--- /dev/null
+++ b/diffusers/docker/diffusers-flax-tpu/Dockerfile
@@ -0,0 +1,46 @@
+FROM ubuntu:20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+# follow the instructions here: https://cloud.google.com/tpu/docs/run-in-container#train_a_jax_model_in_a_docker_container
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ "jax[tpu]>=0.2.16,!=0.3.2" \
+ -f https://storage.googleapis.com/jax-releases/libtpu_releases.html && \
+ python3 -m pip install --upgrade --no-cache-dir \
+ clu \
+ "flax>=0.4.1" \
+ "jaxlib>=0.1.65" && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-onnxruntime-cpu/Dockerfile b/diffusers/docker/diffusers-onnxruntime-cpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..75f45be87a033e9476c4038218c9c2fd2f1255a5
--- /dev/null
+++ b/diffusers/docker/diffusers-onnxruntime-cpu/Dockerfile
@@ -0,0 +1,44 @@
+FROM ubuntu:20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ torch \
+ torchvision \
+ torchaudio \
+ onnxruntime \
+ --extra-index-url https://download.pytorch.org/whl/cpu && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-onnxruntime-cuda/Dockerfile b/diffusers/docker/diffusers-onnxruntime-cuda/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..2129dbcaf68c57755485e1e54e867af05b937336
--- /dev/null
+++ b/diffusers/docker/diffusers-onnxruntime-cuda/Dockerfile
@@ -0,0 +1,44 @@
+FROM nvidia/cuda:11.6.2-cudnn8-devel-ubuntu20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ torch \
+ torchvision \
+ torchaudio \
+ "onnxruntime-gpu>=1.13.1" \
+ --extra-index-url https://download.pytorch.org/whl/cu117 && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-pytorch-cpu/Dockerfile b/diffusers/docker/diffusers-pytorch-cpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..a70eff4c852b21e51c576e1e43172dd8dc25e1a0
--- /dev/null
+++ b/diffusers/docker/diffusers-pytorch-cpu/Dockerfile
@@ -0,0 +1,43 @@
+FROM ubuntu:20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ torch \
+ torchvision \
+ torchaudio \
+ --extra-index-url https://download.pytorch.org/whl/cpu && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-pytorch-cuda/Dockerfile b/diffusers/docker/diffusers-pytorch-cuda/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..8087be4299967c535e9d34590118113f001721bd
--- /dev/null
+++ b/diffusers/docker/diffusers-pytorch-cuda/Dockerfile
@@ -0,0 +1,42 @@
+FROM nvidia/cuda:11.7.1-cudnn8-runtime-ubuntu20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ torch \
+ torchvision \
+ torchaudio \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
diff --git a/diffusers/docs/README.md b/diffusers/docs/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..739f880f65650b5249bdce7539664e53b51d7496
--- /dev/null
+++ b/diffusers/docs/README.md
@@ -0,0 +1,271 @@
+
+
+# Generating the documentation
+
+To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
+you can install them with the following command, at the root of the code repository:
+
+```bash
+pip install -e ".[docs]"
+```
+
+Then you need to install our open source documentation builder tool:
+
+```bash
+pip install git+https://github.com/huggingface/doc-builder
+```
+
+---
+**NOTE**
+
+You only need to generate the documentation to inspect it locally (if you're planning changes and want to
+check how they look before committing for instance). You don't have to commit the built documentation.
+
+---
+
+## Previewing the documentation
+
+To preview the docs, first install the `watchdog` module with:
+
+```bash
+pip install watchdog
+```
+
+Then run the following command:
+
+```bash
+doc-builder preview {package_name} {path_to_docs}
+```
+
+For example:
+
+```bash
+doc-builder preview diffusers docs/source/en
+```
+
+The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
+
+---
+**NOTE**
+
+The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
+
+---
+
+## Adding a new element to the navigation bar
+
+Accepted files are Markdown (.md or .mdx).
+
+Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
+the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/diffusers/blob/main/docs/source/_toctree.yml) file.
+
+## Renaming section headers and moving sections
+
+It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
+
+Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
+
+So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
+
+```
+Sections that were moved:
+
+[ Section A ]
+```
+and of course, if you moved it to another file, then:
+
+```
+Sections that were moved:
+
+[ Section A ]
+```
+
+Use the relative style to link to the new file so that the versioned docs continue to work.
+
+For an example of a rich moved section set please see the very end of [the transformers Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.mdx).
+
+
+## Writing Documentation - Specification
+
+The `huggingface/diffusers` documentation follows the
+[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
+although we can write them directly in Markdown.
+
+### Adding a new tutorial
+
+Adding a new tutorial or section is done in two steps:
+
+- Add a new file under `docs/source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
+- Link that file in `docs/source/_toctree.yml` on the correct toc-tree.
+
+Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
+depending on the intended targets (beginners, more advanced users, or researchers) it should go in sections two, three, or four.
+
+### Adding a new pipeline/scheduler
+
+When adding a new pipeline:
+
+- create a file `xxx.mdx` under `docs/source/api/pipelines` (don't hesitate to copy an existing file as template).
+- Link that file in (*Diffusers Summary*) section in `docs/source/api/pipelines/overview.mdx`, along with the link to the paper, and a colab notebook (if available).
+- Write a short overview of the diffusion model:
+ - Overview with paper & authors
+ - Paper abstract
+ - Tips and tricks and how to use it best
+ - Possible an end-to-end example of how to use it
+- Add all the pipeline classes that should be linked in the diffusion model. These classes should be added using our Markdown syntax. By default as follows:
+
+```
+## XXXPipeline
+
+[[autodoc]] XXXPipeline
+ - all
+ - __call__
+```
+
+This will include every public method of the pipeline that is documented, as well as the `__call__` method that is not documented by default. If you just want to add additional methods that are not documented, you can put the list of all methods to add in a list that contains `all`.
+
+```
+[[autodoc]] XXXPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+```
+
+You can follow the same process to create a new scheduler under the `docs/source/api/schedulers` folder
+
+### Writing source documentation
+
+Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
+and objects like True, None, or any strings should usually be put in `code`.
+
+When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
+adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
+function to be in the main package.
+
+If you want to create a link to some internal class or function, you need to
+provide its path. For instance: \[\`pipelines.ImagePipelineOutput\`\]. This will be converted into a link with
+`pipelines.ImagePipelineOutput` in the description. To get rid of the path and only keep the name of the object you are
+linking to in the description, add a ~: \[\`~pipelines.ImagePipelineOutput\`\] will generate a link with `ImagePipelineOutput` in the description.
+
+The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
+
+#### Defining arguments in a method
+
+Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
+an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
+description:
+
+```
+ Args:
+ n_layers (`int`): The number of layers of the model.
+```
+
+If the description is too long to fit in one line, another indentation is necessary before writing the description
+after the argument.
+
+Here's an example showcasing everything so far:
+
+```
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
+ [`~PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+```
+
+For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
+following signature:
+
+```
+def my_function(x: str = None, a: float = 1):
+```
+
+then its documentation should look like this:
+
+```
+ Args:
+ x (`str`, *optional*):
+ This argument controls ...
+ a (`float`, *optional*, defaults to 1):
+ This argument is used to ...
+```
+
+Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
+if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
+however write as many lines as you want in the indented description (see the example above with `input_ids`).
+
+#### Writing a multi-line code block
+
+Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
+
+
+````
+```
+# first line of code
+# second line
+# etc
+```
+````
+
+#### Writing a return block
+
+The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
+The first line should be the type of the return, followed by a line return. No need to indent further for the elements
+building the return.
+
+Here's an example of a single value return:
+
+```
+ Returns:
+ `List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
+```
+
+Here's an example of a tuple return, comprising several objects:
+
+```
+ Returns:
+ `tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
+ - ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
+ Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
+ - **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+```
+
+#### Adding an image
+
+Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
+the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
+them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
+If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
+to this dataset.
+
+## Styling the docstring
+
+We have an automatic script running with the `make style` command that will make sure that:
+- the docstrings fully take advantage of the line width
+- all code examples are formatted using black, like the code of the Transformers library
+
+This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
+recommended to commit your changes before running `make style`, so you can revert the changes done by that script
+easily.
+
diff --git a/diffusers/docs/TRANSLATING.md b/diffusers/docs/TRANSLATING.md
new file mode 100644
index 0000000000000000000000000000000000000000..32cd95f2ade9ba90ed6a10b1c54169b26a79d01d
--- /dev/null
+++ b/diffusers/docs/TRANSLATING.md
@@ -0,0 +1,57 @@
+### Translating the Diffusers documentation into your language
+
+As part of our mission to democratize machine learning, we'd love to make the Diffusers library available in many more languages! Follow the steps below if you want to help translate the documentation into your language 🙏.
+
+**🗞️ Open an issue**
+
+To get started, navigate to the [Issues](https://github.com/huggingface/diffusers/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the "Translation template" from the "New issue" button.
+
+Once an issue exists, post a comment to indicate which chapters you'd like to work on, and we'll add your name to the list.
+
+
+**🍴 Fork the repository**
+
+First, you'll need to [fork the Diffusers repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page.
+
+Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
+
+```bash
+git clone https://github.com/YOUR-USERNAME/diffusers.git
+```
+
+**📋 Copy-paste the English version with a new language code**
+
+The documentation files are in one leading directory:
+
+- [`docs/source`](https://github.com/huggingface/diffusers/tree/main/docs/source): All the documentation materials are organized here by language.
+
+You'll only need to copy the files in the [`docs/source/en`](https://github.com/huggingface/diffusers/tree/main/docs/source/en) directory, so first navigate to your fork of the repo and run the following:
+
+```bash
+cd ~/path/to/diffusers/docs
+cp -r source/en source/LANG-ID
+```
+
+Here, `LANG-ID` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
+
+**✍️ Start translating**
+
+The fun part comes - translating the text!
+
+The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your doc chapter. This file is used to render the table of contents on the website.
+
+> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can create one by copy-pasting from the English version and deleting the sections unrelated to your chapter. Just make sure it exists in the `docs/source/LANG-ID/` directory!
+
+The fields you should add are `local` (with the name of the file containing the translation; e.g. `autoclass_tutorial`), and `title` (with the title of the doc in your language; e.g. `Load pretrained instances with an AutoClass`) -- as a reference, here is the `_toctree.yml` for [English](https://github.com/huggingface/diffusers/blob/main/docs/source/en/_toctree.yml):
+
+```yaml
+- sections:
+ - local: pipeline_tutorial # Do not change this! Use the same name for your .md file
+ title: Pipelines for inference # Translate this!
+ ...
+ title: Tutorials # Translate this!
+```
+
+Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your docs chapter.
+
+> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/diffusers/issues) and tag @patrickvonplaten.
diff --git a/diffusers/docs/source/_config.py b/diffusers/docs/source/_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a4818ea8b1e19007c9e6440a3a98383031278cb
--- /dev/null
+++ b/diffusers/docs/source/_config.py
@@ -0,0 +1,9 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# Diffusers installation
+! pip install diffusers transformers datasets accelerate
+# To install from source instead of the last release, comment the command above and uncomment the following one.
+# ! pip install git+https://github.com/huggingface/diffusers.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
\ No newline at end of file
diff --git a/diffusers/docs/source/en/_toctree.yml b/diffusers/docs/source/en/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..dc40d9b142baf2e8b0ab0298a90131d353216c04
--- /dev/null
+++ b/diffusers/docs/source/en/_toctree.yml
@@ -0,0 +1,264 @@
+- sections:
+ - local: index
+ title: 🧨 Diffusers
+ - local: quicktour
+ title: Quicktour
+ - local: stable_diffusion
+ title: Effective and efficient diffusion
+ - local: installation
+ title: Installation
+ title: Get started
+- sections:
+ - local: tutorials/tutorial_overview
+ title: Overview
+ - local: using-diffusers/write_own_pipeline
+ title: Understanding models and schedulers
+ - local: tutorials/basic_training
+ title: Train a diffusion model
+ title: Tutorials
+- sections:
+ - sections:
+ - local: using-diffusers/loading_overview
+ title: Overview
+ - local: using-diffusers/loading
+ title: Load pipelines, models, and schedulers
+ - local: using-diffusers/schedulers
+ title: Load and compare different schedulers
+ - local: using-diffusers/custom_pipeline_overview
+ title: Load and add custom pipelines
+ - local: using-diffusers/kerascv
+ title: Load KerasCV Stable Diffusion checkpoints
+ title: Loading & Hub
+ - sections:
+ - local: using-diffusers/pipeline_overview
+ title: Overview
+ - local: using-diffusers/unconditional_image_generation
+ title: Unconditional image generation
+ - local: using-diffusers/conditional_image_generation
+ title: Text-to-image generation
+ - local: using-diffusers/img2img
+ title: Text-guided image-to-image
+ - local: using-diffusers/inpaint
+ title: Text-guided image-inpainting
+ - local: using-diffusers/depth2img
+ title: Text-guided depth-to-image
+ - local: using-diffusers/reusing_seeds
+ title: Improve image quality with deterministic generation
+ - local: using-diffusers/reproducibility
+ title: Create reproducible pipelines
+ - local: using-diffusers/custom_pipeline_examples
+ title: Community Pipelines
+ - local: using-diffusers/contribute_pipeline
+ title: How to contribute a Pipeline
+ - local: using-diffusers/using_safetensors
+ title: Using safetensors
+ - local: using-diffusers/stable_diffusion_jax_how_to
+ title: Stable Diffusion in JAX/Flax
+ - local: using-diffusers/weighted_prompts
+ title: Weighting Prompts
+ title: Pipelines for Inference
+ - sections:
+ - local: training/overview
+ title: Overview
+ - local: training/unconditional_training
+ title: Unconditional image generation
+ - local: training/text_inversion
+ title: Textual Inversion
+ - local: training/dreambooth
+ title: DreamBooth
+ - local: training/text2image
+ title: Text-to-image
+ - local: training/lora
+ title: Low-Rank Adaptation of Large Language Models (LoRA)
+ - local: training/controlnet
+ title: ControlNet
+ - local: training/instructpix2pix
+ title: InstructPix2Pix Training
+ title: Training
+ - sections:
+ - local: using-diffusers/rl
+ title: Reinforcement Learning
+ - local: using-diffusers/audio
+ title: Audio
+ - local: using-diffusers/other-modalities
+ title: Other Modalities
+ title: Taking Diffusers Beyond Images
+ title: Using Diffusers
+- sections:
+ - local: optimization/opt_overview
+ title: Overview
+ - local: optimization/fp16
+ title: Memory and Speed
+ - local: optimization/torch2.0
+ title: Torch2.0 support
+ - local: optimization/xformers
+ title: xFormers
+ - local: optimization/onnx
+ title: ONNX
+ - local: optimization/open_vino
+ title: OpenVINO
+ - local: optimization/mps
+ title: MPS
+ - local: optimization/habana
+ title: Habana Gaudi
+ title: Optimization/Special Hardware
+- sections:
+ - local: conceptual/philosophy
+ title: Philosophy
+ - local: using-diffusers/controlling_generation
+ title: Controlled generation
+ - local: conceptual/contribution
+ title: How to contribute?
+ - local: conceptual/ethical_guidelines
+ title: Diffusers' Ethical Guidelines
+ - local: conceptual/evaluation
+ title: Evaluating Diffusion Models
+ title: Conceptual Guides
+- sections:
+ - sections:
+ - local: api/models
+ title: Models
+ - local: api/diffusion_pipeline
+ title: Diffusion Pipeline
+ - local: api/logging
+ title: Logging
+ - local: api/configuration
+ title: Configuration
+ - local: api/outputs
+ title: Outputs
+ - local: api/loaders
+ title: Loaders
+ title: Main Classes
+ - sections:
+ - local: api/pipelines/overview
+ title: Overview
+ - local: api/pipelines/alt_diffusion
+ title: AltDiffusion
+ - local: api/pipelines/audio_diffusion
+ title: Audio Diffusion
+ - local: api/pipelines/audioldm
+ title: AudioLDM
+ - local: api/pipelines/cycle_diffusion
+ title: Cycle Diffusion
+ - local: api/pipelines/dance_diffusion
+ title: Dance Diffusion
+ - local: api/pipelines/ddim
+ title: DDIM
+ - local: api/pipelines/ddpm
+ title: DDPM
+ - local: api/pipelines/dit
+ title: DiT
+ - local: api/pipelines/latent_diffusion
+ title: Latent Diffusion
+ - local: api/pipelines/paint_by_example
+ title: PaintByExample
+ - local: api/pipelines/pndm
+ title: PNDM
+ - local: api/pipelines/repaint
+ title: RePaint
+ - local: api/pipelines/stable_diffusion_safe
+ title: Safe Stable Diffusion
+ - local: api/pipelines/score_sde_ve
+ title: Score SDE VE
+ - local: api/pipelines/semantic_stable_diffusion
+ title: Semantic Guidance
+ - local: api/pipelines/spectrogram_diffusion
+ title: "Spectrogram Diffusion"
+ - sections:
+ - local: api/pipelines/stable_diffusion/overview
+ title: Overview
+ - local: api/pipelines/stable_diffusion/text2img
+ title: Text-to-Image
+ - local: api/pipelines/stable_diffusion/img2img
+ title: Image-to-Image
+ - local: api/pipelines/stable_diffusion/inpaint
+ title: Inpaint
+ - local: api/pipelines/stable_diffusion/depth2img
+ title: Depth-to-Image
+ - local: api/pipelines/stable_diffusion/image_variation
+ title: Image-Variation
+ - local: api/pipelines/stable_diffusion/upscale
+ title: Super-Resolution
+ - local: api/pipelines/stable_diffusion/latent_upscale
+ title: Stable-Diffusion-Latent-Upscaler
+ - local: api/pipelines/stable_diffusion/pix2pix
+ title: InstructPix2Pix
+ - local: api/pipelines/stable_diffusion/attend_and_excite
+ title: Attend and Excite
+ - local: api/pipelines/stable_diffusion/pix2pix_zero
+ title: Pix2Pix Zero
+ - local: api/pipelines/stable_diffusion/self_attention_guidance
+ title: Self-Attention Guidance
+ - local: api/pipelines/stable_diffusion/panorama
+ title: MultiDiffusion Panorama
+ - local: api/pipelines/stable_diffusion/controlnet
+ title: Text-to-Image Generation with ControlNet Conditioning
+ - local: api/pipelines/stable_diffusion/model_editing
+ title: Text-to-Image Model Editing
+ title: Stable Diffusion
+ - local: api/pipelines/stable_diffusion_2
+ title: Stable Diffusion 2
+ - local: api/pipelines/stable_unclip
+ title: Stable unCLIP
+ - local: api/pipelines/stochastic_karras_ve
+ title: Stochastic Karras VE
+ - local: api/pipelines/text_to_video
+ title: Text-to-Video
+ - local: api/pipelines/unclip
+ title: UnCLIP
+ - local: api/pipelines/latent_diffusion_uncond
+ title: Unconditional Latent Diffusion
+ - local: api/pipelines/versatile_diffusion
+ title: Versatile Diffusion
+ - local: api/pipelines/vq_diffusion
+ title: VQ Diffusion
+ title: Pipelines
+ - sections:
+ - local: api/schedulers/overview
+ title: Overview
+ - local: api/schedulers/ddim
+ title: DDIM
+ - local: api/schedulers/ddim_inverse
+ title: DDIMInverse
+ - local: api/schedulers/ddpm
+ title: DDPM
+ - local: api/schedulers/deis
+ title: DEIS
+ - local: api/schedulers/dpm_discrete
+ title: DPM Discrete Scheduler
+ - local: api/schedulers/dpm_discrete_ancestral
+ title: DPM Discrete Scheduler with ancestral sampling
+ - local: api/schedulers/euler_ancestral
+ title: Euler Ancestral Scheduler
+ - local: api/schedulers/euler
+ title: Euler scheduler
+ - local: api/schedulers/heun
+ title: Heun Scheduler
+ - local: api/schedulers/ipndm
+ title: IPNDM
+ - local: api/schedulers/lms_discrete
+ title: Linear Multistep
+ - local: api/schedulers/multistep_dpm_solver
+ title: Multistep DPM-Solver
+ - local: api/schedulers/pndm
+ title: PNDM
+ - local: api/schedulers/repaint
+ title: RePaint Scheduler
+ - local: api/schedulers/singlestep_dpm_solver
+ title: Singlestep DPM-Solver
+ - local: api/schedulers/stochastic_karras_ve
+ title: Stochastic Kerras VE
+ - local: api/schedulers/unipc
+ title: UniPCMultistepScheduler
+ - local: api/schedulers/score_sde_ve
+ title: VE-SDE
+ - local: api/schedulers/score_sde_vp
+ title: VP-SDE
+ - local: api/schedulers/vq_diffusion
+ title: VQDiffusionScheduler
+ title: Schedulers
+ - sections:
+ - local: api/experimental/rl
+ title: RL Planning
+ title: Experimental Features
+ title: API
diff --git a/diffusers/docs/source/en/api/configuration.mdx b/diffusers/docs/source/en/api/configuration.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..2bbb42d9253804170a2312fa01522336a5cd7307
--- /dev/null
+++ b/diffusers/docs/source/en/api/configuration.mdx
@@ -0,0 +1,25 @@
+
+
+# Configuration
+
+Schedulers from [`~schedulers.scheduling_utils.SchedulerMixin`] and models from [`ModelMixin`] inherit from [`ConfigMixin`] which conveniently takes care of storing all the parameters that are
+passed to their respective `__init__` methods in a JSON-configuration file.
+
+## ConfigMixin
+
+[[autodoc]] ConfigMixin
+ - load_config
+ - from_config
+ - save_config
+ - to_json_file
+ - to_json_string
diff --git a/diffusers/docs/source/en/api/diffusion_pipeline.mdx b/diffusers/docs/source/en/api/diffusion_pipeline.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..280802d6a89ab8bd9181cb02d008d3f8970e220a
--- /dev/null
+++ b/diffusers/docs/source/en/api/diffusion_pipeline.mdx
@@ -0,0 +1,47 @@
+
+
+# Pipelines
+
+The [`DiffusionPipeline`] is the easiest way to load any pretrained diffusion pipeline from the [Hub](https://huggingface.co/models?library=diffusers) and to use it in inference.
+
+
+
+ One should not use the Diffusion Pipeline class for training or fine-tuning a diffusion model. Individual
+ components of diffusion pipelines are usually trained individually, so we suggest to directly work
+ with [`UNetModel`] and [`UNetConditionModel`].
+
+
+
+Any diffusion pipeline that is loaded with [`~DiffusionPipeline.from_pretrained`] will automatically
+detect the pipeline type, *e.g.* [`StableDiffusionPipeline`] and consequently load each component of the
+pipeline and pass them into the `__init__` function of the pipeline, *e.g.* [`~StableDiffusionPipeline.__init__`].
+
+Any pipeline object can be saved locally with [`~DiffusionPipeline.save_pretrained`].
+
+## DiffusionPipeline
+[[autodoc]] DiffusionPipeline
+ - all
+ - __call__
+ - device
+ - to
+ - components
+
+## ImagePipelineOutput
+By default diffusion pipelines return an object of class
+
+[[autodoc]] pipelines.ImagePipelineOutput
+
+## AudioPipelineOutput
+By default diffusion pipelines return an object of class
+
+[[autodoc]] pipelines.AudioPipelineOutput
diff --git a/diffusers/docs/source/en/api/experimental/rl.mdx b/diffusers/docs/source/en/api/experimental/rl.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..66c8db311b4ef8d34089ddfe31c7496b08be3416
--- /dev/null
+++ b/diffusers/docs/source/en/api/experimental/rl.mdx
@@ -0,0 +1,15 @@
+
+
+# TODO
+
+Coming soon!
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/loaders.mdx b/diffusers/docs/source/en/api/loaders.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..1d55bd03c0641d1a63e79e2fd26c444727595b23
--- /dev/null
+++ b/diffusers/docs/source/en/api/loaders.mdx
@@ -0,0 +1,30 @@
+
+
+# Loaders
+
+There are many ways to train adapter neural networks for diffusion models, such as
+- [Textual Inversion](./training/text_inversion.mdx)
+- [LoRA](https://github.com/cloneofsimo/lora)
+- [Hypernetworks](https://arxiv.org/abs/1609.09106)
+
+Such adapter neural networks often only consist of a fraction of the number of weights compared
+to the pretrained model and as such are very portable. The Diffusers library offers an easy-to-use
+API to load such adapter neural networks via the [`loaders.py` module](https://github.com/huggingface/diffusers/blob/main/src/diffusers/loaders.py).
+
+**Note**: This module is still highly experimental and prone to future changes.
+
+## LoaderMixins
+
+### UNet2DConditionLoadersMixin
+
+[[autodoc]] loaders.UNet2DConditionLoadersMixin
diff --git a/diffusers/docs/source/en/api/logging.mdx b/diffusers/docs/source/en/api/logging.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b52c0434f42d06de3085f3816a9093df14ea0212
--- /dev/null
+++ b/diffusers/docs/source/en/api/logging.mdx
@@ -0,0 +1,98 @@
+
+
+# Logging
+
+🧨 Diffusers has a centralized logging system, so that you can setup the verbosity of the library easily.
+
+Currently the default verbosity of the library is `WARNING`.
+
+To change the level of verbosity, just use one of the direct setters. For instance, here is how to change the verbosity
+to the INFO level.
+
+```python
+import diffusers
+
+diffusers.logging.set_verbosity_info()
+```
+
+You can also use the environment variable `DIFFUSERS_VERBOSITY` to override the default verbosity. You can set it
+to one of the following: `debug`, `info`, `warning`, `error`, `critical`. For example:
+
+```bash
+DIFFUSERS_VERBOSITY=error ./myprogram.py
+```
+
+Additionally, some `warnings` can be disabled by setting the environment variable
+`DIFFUSERS_NO_ADVISORY_WARNINGS` to a true value, like *1*. This will disable any warning that is logged using
+[`logger.warning_advice`]. For example:
+
+```bash
+DIFFUSERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
+```
+
+Here is an example of how to use the same logger as the library in your own module or script:
+
+```python
+from diffusers.utils import logging
+
+logging.set_verbosity_info()
+logger = logging.get_logger("diffusers")
+logger.info("INFO")
+logger.warning("WARN")
+```
+
+
+All the methods of this logging module are documented below, the main ones are
+[`logging.get_verbosity`] to get the current level of verbosity in the logger and
+[`logging.set_verbosity`] to set the verbosity to the level of your choice. In order (from the least
+verbose to the most verbose), those levels (with their corresponding int values in parenthesis) are:
+
+- `diffusers.logging.CRITICAL` or `diffusers.logging.FATAL` (int value, 50): only report the most
+ critical errors.
+- `diffusers.logging.ERROR` (int value, 40): only report errors.
+- `diffusers.logging.WARNING` or `diffusers.logging.WARN` (int value, 30): only reports error and
+ warnings. This the default level used by the library.
+- `diffusers.logging.INFO` (int value, 20): reports error, warnings and basic information.
+- `diffusers.logging.DEBUG` (int value, 10): report all information.
+
+By default, `tqdm` progress bars will be displayed during model download. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] can be used to suppress or unsuppress this behavior.
+
+## Base setters
+
+[[autodoc]] logging.set_verbosity_error
+
+[[autodoc]] logging.set_verbosity_warning
+
+[[autodoc]] logging.set_verbosity_info
+
+[[autodoc]] logging.set_verbosity_debug
+
+## Other functions
+
+[[autodoc]] logging.get_verbosity
+
+[[autodoc]] logging.set_verbosity
+
+[[autodoc]] logging.get_logger
+
+[[autodoc]] logging.enable_default_handler
+
+[[autodoc]] logging.disable_default_handler
+
+[[autodoc]] logging.enable_explicit_format
+
+[[autodoc]] logging.reset_format
+
+[[autodoc]] logging.enable_progress_bar
+
+[[autodoc]] logging.disable_progress_bar
diff --git a/diffusers/docs/source/en/api/models.mdx b/diffusers/docs/source/en/api/models.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..2361fd4f65972342f105d70d3317af126cd4e14c
--- /dev/null
+++ b/diffusers/docs/source/en/api/models.mdx
@@ -0,0 +1,107 @@
+
+
+# Models
+
+Diffusers contains pretrained models for popular algorithms and modules for creating the next set of diffusion models.
+The primary function of these models is to denoise an input sample, by modeling the distribution $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$.
+The models are built on the base class ['ModelMixin'] that is a `torch.nn.module` with basic functionality for saving and loading models both locally and from the HuggingFace hub.
+
+## ModelMixin
+[[autodoc]] ModelMixin
+
+## UNet2DOutput
+[[autodoc]] models.unet_2d.UNet2DOutput
+
+## UNet2DModel
+[[autodoc]] UNet2DModel
+
+## UNet1DOutput
+[[autodoc]] models.unet_1d.UNet1DOutput
+
+## UNet1DModel
+[[autodoc]] UNet1DModel
+
+## UNet2DConditionOutput
+[[autodoc]] models.unet_2d_condition.UNet2DConditionOutput
+
+## UNet2DConditionModel
+[[autodoc]] UNet2DConditionModel
+
+## UNet3DConditionOutput
+[[autodoc]] models.unet_3d_condition.UNet3DConditionOutput
+
+## UNet3DConditionModel
+[[autodoc]] UNet3DConditionModel
+
+## DecoderOutput
+[[autodoc]] models.vae.DecoderOutput
+
+## VQEncoderOutput
+[[autodoc]] models.vq_model.VQEncoderOutput
+
+## VQModel
+[[autodoc]] VQModel
+
+## AutoencoderKLOutput
+[[autodoc]] models.autoencoder_kl.AutoencoderKLOutput
+
+## AutoencoderKL
+[[autodoc]] AutoencoderKL
+
+## Transformer2DModel
+[[autodoc]] Transformer2DModel
+
+## Transformer2DModelOutput
+[[autodoc]] models.transformer_2d.Transformer2DModelOutput
+
+## TransformerTemporalModel
+[[autodoc]] models.transformer_temporal.TransformerTemporalModel
+
+## Transformer2DModelOutput
+[[autodoc]] models.transformer_temporal.TransformerTemporalModelOutput
+
+## PriorTransformer
+[[autodoc]] models.prior_transformer.PriorTransformer
+
+## PriorTransformerOutput
+[[autodoc]] models.prior_transformer.PriorTransformerOutput
+
+## ControlNetOutput
+[[autodoc]] models.controlnet.ControlNetOutput
+
+## ControlNetModel
+[[autodoc]] ControlNetModel
+
+## FlaxModelMixin
+[[autodoc]] FlaxModelMixin
+
+## FlaxUNet2DConditionOutput
+[[autodoc]] models.unet_2d_condition_flax.FlaxUNet2DConditionOutput
+
+## FlaxUNet2DConditionModel
+[[autodoc]] FlaxUNet2DConditionModel
+
+## FlaxDecoderOutput
+[[autodoc]] models.vae_flax.FlaxDecoderOutput
+
+## FlaxAutoencoderKLOutput
+[[autodoc]] models.vae_flax.FlaxAutoencoderKLOutput
+
+## FlaxAutoencoderKL
+[[autodoc]] FlaxAutoencoderKL
+
+## FlaxControlNetOutput
+[[autodoc]] models.controlnet_flax.FlaxControlNetOutput
+
+## FlaxControlNetModel
+[[autodoc]] FlaxControlNetModel
diff --git a/diffusers/docs/source/en/api/outputs.mdx b/diffusers/docs/source/en/api/outputs.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..9466f354541d55e66b65ef96ae2567f881d63fc0
--- /dev/null
+++ b/diffusers/docs/source/en/api/outputs.mdx
@@ -0,0 +1,55 @@
+
+
+# BaseOutputs
+
+All models have outputs that are instances of subclasses of [`~utils.BaseOutput`]. Those are
+data structures containing all the information returned by the model, but that can also be used as tuples or
+dictionaries.
+
+Let's see how this looks in an example:
+
+```python
+from diffusers import DDIMPipeline
+
+pipeline = DDIMPipeline.from_pretrained("google/ddpm-cifar10-32")
+outputs = pipeline()
+```
+
+The `outputs` object is a [`~pipelines.ImagePipelineOutput`], as we can see in the
+documentation of that class below, it means it has an image attribute.
+
+You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you will get `None`:
+
+```python
+outputs.images
+```
+
+or via keyword lookup
+
+```python
+outputs["images"]
+```
+
+When considering our `outputs` object as tuple, it only considers the attributes that don't have `None` values.
+Here for instance, we could retrieve images via indexing:
+
+```python
+outputs[:1]
+```
+
+which will return the tuple `(outputs.images)` for instance.
+
+## BaseOutput
+
+[[autodoc]] utils.BaseOutput
+ - to_tuple
diff --git a/diffusers/docs/source/en/api/pipelines/alt_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/alt_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..dbe3b079a201638b0129087b3f0de0de22323551
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/alt_diffusion.mdx
@@ -0,0 +1,83 @@
+
+
+# AltDiffusion
+
+AltDiffusion was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu.
+
+The abstract of the paper is the following:
+
+*In this work, we present a conceptually simple and effective method to train a strong bilingual multimodal representation model. Starting from the pretrained multimodal representation model CLIP released by OpenAI, we switched its text encoder with a pretrained multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art performances on a bunch of tasks including ImageNet-CN, Flicker30k- CN, and COCO-CN. Further, we obtain very close performances with CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding.*
+
+
+*Overview*:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [pipeline_alt_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion.py) | *Text-to-Image Generation* | - | -
+| [pipeline_alt_diffusion_img2img.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion_img2img.py) | *Image-to-Image Text-Guided Generation* | - |-
+
+## Tips
+
+- AltDiffusion is conceptually exactly the same as [Stable Diffusion](./api/pipelines/stable_diffusion/overview).
+
+- *Run AltDiffusion*
+
+AltDiffusion can be tested very easily with the [`AltDiffusionPipeline`], [`AltDiffusionImg2ImgPipeline`] and the `"BAAI/AltDiffusion-m9"` checkpoint exactly in the same way it is shown in the [Conditional Image Generation Guide](./using-diffusers/conditional_image_generation) and the [Image-to-Image Generation Guide](./using-diffusers/img2img).
+
+- *How to load and use different schedulers.*
+
+The alt diffusion pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the alt diffusion pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import AltDiffusionPipeline, EulerDiscreteScheduler
+
+>>> pipeline = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion-m9")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("BAAI/AltDiffusion-m9", subfolder="scheduler")
+>>> pipeline = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion-m9", scheduler=euler_scheduler)
+```
+
+
+- *How to convert all use cases with multiple or single pipeline*
+
+If you want to use all possible use cases in a single `DiffusionPipeline` we recommend using the `components` functionality to instantiate all components in the most memory-efficient way:
+
+```python
+>>> from diffusers import (
+... AltDiffusionPipeline,
+... AltDiffusionImg2ImgPipeline,
+... )
+
+>>> text2img = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion-m9")
+>>> img2img = AltDiffusionImg2ImgPipeline(**text2img.components)
+
+>>> # now you can use text2img(...) and img2img(...) just like the call methods of each respective pipeline
+```
+
+## AltDiffusionPipelineOutput
+[[autodoc]] pipelines.alt_diffusion.AltDiffusionPipelineOutput
+ - all
+ - __call__
+
+## AltDiffusionPipeline
+[[autodoc]] AltDiffusionPipeline
+ - all
+ - __call__
+
+## AltDiffusionImg2ImgPipeline
+[[autodoc]] AltDiffusionImg2ImgPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/audio_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/audio_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..9c7725367e8fd5eedae1fbd1412f43af76a1cf59
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/audio_diffusion.mdx
@@ -0,0 +1,98 @@
+
+
+# Audio Diffusion
+
+## Overview
+
+[Audio Diffusion](https://github.com/teticio/audio-diffusion) by Robert Dargavel Smith.
+
+Audio Diffusion leverages the recent advances in image generation using diffusion models by converting audio samples to
+and from mel spectrogram images.
+
+The original codebase of this implementation can be found [here](https://github.com/teticio/audio-diffusion), including
+training scripts and example notebooks.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_audio_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/audio_diffusion/pipeline_audio_diffusion.py) | *Unconditional Audio Generation* | [](https://colab.research.google.com/github/teticio/audio-diffusion/blob/master/notebooks/audio_diffusion_pipeline.ipynb) |
+
+
+## Examples:
+
+### Audio Diffusion
+
+```python
+import torch
+from IPython.display import Audio
+from diffusers import DiffusionPipeline
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-256").to(device)
+
+output = pipe()
+display(output.images[0])
+display(Audio(output.audios[0], rate=mel.get_sample_rate()))
+```
+
+### Latent Audio Diffusion
+
+```python
+import torch
+from IPython.display import Audio
+from diffusers import DiffusionPipeline
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+pipe = DiffusionPipeline.from_pretrained("teticio/latent-audio-diffusion-256").to(device)
+
+output = pipe()
+display(output.images[0])
+display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
+```
+
+### Audio Diffusion with DDIM (faster)
+
+```python
+import torch
+from IPython.display import Audio
+from diffusers import DiffusionPipeline
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-ddim-256").to(device)
+
+output = pipe()
+display(output.images[0])
+display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
+```
+
+### Variations, in-painting, out-painting etc.
+
+```python
+output = pipe(
+ raw_audio=output.audios[0, 0],
+ start_step=int(pipe.get_default_steps() / 2),
+ mask_start_secs=1,
+ mask_end_secs=1,
+)
+display(output.images[0])
+display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
+```
+
+## AudioDiffusionPipeline
+[[autodoc]] AudioDiffusionPipeline
+ - all
+ - __call__
+
+## Mel
+[[autodoc]] Mel
diff --git a/diffusers/docs/source/en/api/pipelines/audioldm.mdx b/diffusers/docs/source/en/api/pipelines/audioldm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f3987d2263ac649ee5a0c89a2152d54db5d9a323
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/audioldm.mdx
@@ -0,0 +1,82 @@
+
+
+# AudioLDM
+
+## Overview
+
+AudioLDM was proposed in [AudioLDM: Text-to-Audio Generation with Latent Diffusion Models](https://arxiv.org/abs/2301.12503) by Haohe Liu et al.
+
+Inspired by [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview), AudioLDM
+is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from [CLAP](https://huggingface.co/docs/transformers/main/model_doc/clap)
+latents. AudioLDM takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional
+sound effects, human speech and music.
+
+This pipeline was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original codebase can be found [here](https://github.com/haoheliu/AudioLDM).
+
+## Text-to-Audio
+
+The [`AudioLDMPipeline`] can be used to load pre-trained weights from [cvssp/audioldm](https://huggingface.co/cvssp/audioldm) and generate text-conditional audio outputs:
+
+```python
+from diffusers import AudioLDMPipeline
+import torch
+import scipy
+
+repo_id = "cvssp/audioldm"
+pipe = AudioLDMPipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
+pipe = pipe.to("cuda")
+
+prompt = "Techno music with a strong, upbeat tempo and high melodic riffs"
+audio = pipe(prompt, num_inference_steps=10, audio_length_in_s=5.0).audios[0]
+
+# save the audio sample as a .wav file
+scipy.io.wavfile.write("techno.wav", rate=16000, data=audio)
+```
+
+### Tips
+
+Prompts:
+* Descriptive prompt inputs work best: you can use adjectives to describe the sound (e.g. "high quality" or "clear") and make the prompt context specific (e.g., "water stream in a forest" instead of "stream").
+* It's best to use general terms like 'cat' or 'dog' instead of specific names or abstract objects that the model may not be familiar with.
+
+Inference:
+* The _quality_ of the predicted audio sample can be controlled by the `num_inference_steps` argument: higher steps give higher quality audio at the expense of slower inference.
+* The _length_ of the predicted audio sample can be controlled by varying the `audio_length_in_s` argument.
+
+### How to load and use different schedulers
+
+The AudioLDM pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers
+that can be used with the AudioLDM pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`],
+[`EulerAncestralDiscreteScheduler`] etc. We recommend using the [`DPMSolverMultistepScheduler`] as it's currently the fastest
+scheduler there is.
+
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`]
+method, or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the
+[`DPMSolverMultistepScheduler`], you can do the following:
+
+```python
+>>> from diffusers import AudioLDMPipeline, DPMSolverMultistepScheduler
+>>> import torch
+
+>>> pipeline = AudioLDMPipeline.from_pretrained("cvssp/audioldm", torch_dtype=torch.float16)
+>>> pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> dpm_scheduler = DPMSolverMultistepScheduler.from_pretrained("cvssp/audioldm", subfolder="scheduler")
+>>> pipeline = AudioLDMPipeline.from_pretrained("cvssp/audioldm", scheduler=dpm_scheduler, torch_dtype=torch.float16)
+```
+
+## AudioLDMPipeline
+[[autodoc]] AudioLDMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/cycle_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/cycle_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b8fbff5d7157dc08cf15ea051f4d019b74c39ff5
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/cycle_diffusion.mdx
@@ -0,0 +1,100 @@
+
+
+# Cycle Diffusion
+
+## Overview
+
+Cycle Diffusion is a Text-Guided Image-to-Image Generation model proposed in [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) by Chen Henry Wu, Fernando De la Torre.
+
+The abstract of the paper is the following:
+
+*Diffusion models have achieved unprecedented performance in generative modeling. The commonly-adopted formulation of the latent code of diffusion models is a sequence of gradually denoised samples, as opposed to the simpler (e.g., Gaussian) latent space of GANs, VAEs, and normalizing flows. This paper provides an alternative, Gaussian formulation of the latent space of various diffusion models, as well as an invertible DPM-Encoder that maps images into the latent space. While our formulation is purely based on the definition of diffusion models, we demonstrate several intriguing consequences. (1) Empirically, we observe that a common latent space emerges from two diffusion models trained independently on related domains. In light of this finding, we propose CycleDiffusion, which uses DPM-Encoder for unpaired image-to-image translation. Furthermore, applying CycleDiffusion to text-to-image diffusion models, we show that large-scale text-to-image diffusion models can be used as zero-shot image-to-image editors. (2) One can guide pre-trained diffusion models and GANs by controlling the latent codes in a unified, plug-and-play formulation based on energy-based models. Using the CLIP model and a face recognition model as guidance, we demonstrate that diffusion models have better coverage of low-density sub-populations and individuals than GANs.*
+
+*Tips*:
+- The Cycle Diffusion pipeline is fully compatible with any [Stable Diffusion](./stable_diffusion) checkpoints
+- Currently Cycle Diffusion only works with the [`DDIMScheduler`].
+
+*Example*:
+
+In the following we should how to best use the [`CycleDiffusionPipeline`]
+
+```python
+import requests
+import torch
+from PIL import Image
+from io import BytesIO
+
+from diffusers import CycleDiffusionPipeline, DDIMScheduler
+
+# load the pipeline
+# make sure you're logged in with `huggingface-cli login`
+model_id_or_path = "CompVis/stable-diffusion-v1-4"
+scheduler = DDIMScheduler.from_pretrained(model_id_or_path, subfolder="scheduler")
+pipe = CycleDiffusionPipeline.from_pretrained(model_id_or_path, scheduler=scheduler).to("cuda")
+
+# let's download an initial image
+url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/An%20astronaut%20riding%20a%20horse.png"
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((512, 512))
+init_image.save("horse.png")
+
+# let's specify a prompt
+source_prompt = "An astronaut riding a horse"
+prompt = "An astronaut riding an elephant"
+
+# call the pipeline
+image = pipe(
+ prompt=prompt,
+ source_prompt=source_prompt,
+ image=init_image,
+ num_inference_steps=100,
+ eta=0.1,
+ strength=0.8,
+ guidance_scale=2,
+ source_guidance_scale=1,
+).images[0]
+
+image.save("horse_to_elephant.png")
+
+# let's try another example
+# See more samples at the original repo: https://github.com/ChenWu98/cycle-diffusion
+url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/A%20black%20colored%20car.png"
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((512, 512))
+init_image.save("black.png")
+
+source_prompt = "A black colored car"
+prompt = "A blue colored car"
+
+# call the pipeline
+torch.manual_seed(0)
+image = pipe(
+ prompt=prompt,
+ source_prompt=source_prompt,
+ image=init_image,
+ num_inference_steps=100,
+ eta=0.1,
+ strength=0.85,
+ guidance_scale=3,
+ source_guidance_scale=1,
+).images[0]
+
+image.save("black_to_blue.png")
+```
+
+## CycleDiffusionPipeline
+[[autodoc]] CycleDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/dance_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/dance_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..92b5b9f877bc8474ad61d5f6815615e3922e23b8
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/dance_diffusion.mdx
@@ -0,0 +1,34 @@
+
+
+# Dance Diffusion
+
+## Overview
+
+[Dance Diffusion](https://github.com/Harmonai-org/sample-generator) by Zach Evans.
+
+Dance Diffusion is the first in a suite of generative audio tools for producers and musicians to be released by Harmonai.
+For more info or to get involved in the development of these tools, please visit https://harmonai.org and fill out the form on the front page.
+
+The original codebase of this implementation can be found [here](https://github.com/Harmonai-org/sample-generator).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_dance_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/dance_diffusion/pipeline_dance_diffusion.py) | *Unconditional Audio Generation* | - |
+
+
+## DanceDiffusionPipeline
+[[autodoc]] DanceDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/ddim.mdx b/diffusers/docs/source/en/api/pipelines/ddim.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..3adcb375b4481b0047479929c9cd1f89034aae99
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/ddim.mdx
@@ -0,0 +1,36 @@
+
+
+# DDIM
+
+## Overview
+
+[Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) (DDIM) by Jiaming Song, Chenlin Meng and Stefano Ermon.
+
+The abstract of the paper is the following:
+
+Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples 10× to 50× faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.
+
+The original codebase of this paper can be found here: [ermongroup/ddim](https://github.com/ermongroup/ddim).
+For questions, feel free to contact the author on [tsong.me](https://tsong.me/).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddim/pipeline_ddim.py) | *Unconditional Image Generation* | - |
+
+
+## DDIMPipeline
+[[autodoc]] DDIMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/ddpm.mdx b/diffusers/docs/source/en/api/pipelines/ddpm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..1be71964041c7bce5300d7177657594a90cdbf2f
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/ddpm.mdx
@@ -0,0 +1,37 @@
+
+
+# DDPM
+
+## Overview
+
+[Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
+ (DDPM) by Jonathan Ho, Ajay Jain and Pieter Abbeel proposes the diffusion based model of the same name, but in the context of the 🤗 Diffusers library, DDPM refers to the discrete denoising scheduler from the paper as well as the pipeline.
+
+The abstract of the paper is the following:
+
+We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.
+
+The original codebase of this paper can be found [here](https://github.com/hojonathanho/diffusion).
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddpm/pipeline_ddpm.py) | *Unconditional Image Generation* | - |
+
+
+# DDPMPipeline
+[[autodoc]] DDPMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/dit.mdx b/diffusers/docs/source/en/api/pipelines/dit.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..ce96749a1720ba3ee0da67728cd702292f6b6637
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/dit.mdx
@@ -0,0 +1,59 @@
+
+
+# Scalable Diffusion Models with Transformers (DiT)
+
+## Overview
+
+[Scalable Diffusion Models with Transformers](https://arxiv.org/abs/2212.09748) (DiT) by William Peebles and Saining Xie.
+
+The abstract of the paper is the following:
+
+*We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops -- through increased transformer depth/width or increased number of input tokens -- consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.*
+
+The original codebase of this paper can be found here: [facebookresearch/dit](https://github.com/facebookresearch/dit).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_dit.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/dit/pipeline_dit.py) | *Conditional Image Generation* | - |
+
+
+## Usage example
+
+```python
+from diffusers import DiTPipeline, DPMSolverMultistepScheduler
+import torch
+
+pipe = DiTPipeline.from_pretrained("facebook/DiT-XL-2-256", torch_dtype=torch.float16)
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+
+# pick words from Imagenet class labels
+pipe.labels # to print all available words
+
+# pick words that exist in ImageNet
+words = ["white shark", "umbrella"]
+
+class_ids = pipe.get_label_ids(words)
+
+generator = torch.manual_seed(33)
+output = pipe(class_labels=class_ids, num_inference_steps=25, generator=generator)
+
+image = output.images[0] # label 'white shark'
+```
+
+## DiTPipeline
+[[autodoc]] DiTPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/latent_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/latent_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..72c159e90d92ac31ccaeda3869687313ae0593ed
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/latent_diffusion.mdx
@@ -0,0 +1,49 @@
+
+
+# Latent Diffusion
+
+## Overview
+
+Latent Diffusion was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer.
+
+The abstract of the paper is the following:
+
+*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
+
+The original codebase can be found [here](https://github.com/CompVis/latent-diffusion).
+
+## Tips:
+
+-
+-
+-
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_latent_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py) | *Text-to-Image Generation* | - |
+| [pipeline_latent_diffusion_superresolution.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py) | *Super Resolution* | - |
+
+## Examples:
+
+
+## LDMTextToImagePipeline
+[[autodoc]] LDMTextToImagePipeline
+ - all
+ - __call__
+
+## LDMSuperResolutionPipeline
+[[autodoc]] LDMSuperResolutionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/latent_diffusion_uncond.mdx b/diffusers/docs/source/en/api/pipelines/latent_diffusion_uncond.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..c293ebb9400e7235ac79b510430fbf3662ed2240
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/latent_diffusion_uncond.mdx
@@ -0,0 +1,42 @@
+
+
+# Unconditional Latent Diffusion
+
+## Overview
+
+Unconditional Latent Diffusion was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer.
+
+The abstract of the paper is the following:
+
+*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
+
+The original codebase can be found [here](https://github.com/CompVis/latent-diffusion).
+
+## Tips:
+
+-
+-
+-
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_latent_diffusion_uncond.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion_uncond/pipeline_latent_diffusion_uncond.py) | *Unconditional Image Generation* | - |
+
+## Examples:
+
+## LDMPipeline
+[[autodoc]] LDMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/overview.mdx b/diffusers/docs/source/en/api/pipelines/overview.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..3b0e7c66152f5506418e3cfe9aa1861fa7e7e20b
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/overview.mdx
@@ -0,0 +1,213 @@
+
+
+# Pipelines
+
+Pipelines provide a simple way to run state-of-the-art diffusion models in inference.
+Most diffusion systems consist of multiple independently-trained models and highly adaptable scheduler
+components - all of which are needed to have a functioning end-to-end diffusion system.
+
+As an example, [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) has three independently trained models:
+- [Autoencoder](./api/models#vae)
+- [Conditional Unet](./api/models#UNet2DConditionModel)
+- [CLIP text encoder](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/clip#transformers.CLIPTextModel)
+- a scheduler component, [scheduler](./api/scheduler#pndm),
+- a [CLIPImageProcessor](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/clip#transformers.CLIPImageProcessor),
+- as well as a [safety checker](./stable_diffusion#safety_checker).
+All of these components are necessary to run stable diffusion in inference even though they were trained
+or created independently from each other.
+
+To that end, we strive to offer all open-sourced, state-of-the-art diffusion system under a unified API.
+More specifically, we strive to provide pipelines that
+- 1. can load the officially published weights and yield 1-to-1 the same outputs as the original implementation according to the corresponding paper (*e.g.* [LDMTextToImagePipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/latent_diffusion), uses the officially released weights of [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)),
+- 2. have a simple user interface to run the model in inference (see the [Pipelines API](#pipelines-api) section),
+- 3. are easy to understand with code that is self-explanatory and can be read along-side the official paper (see [Pipelines summary](#pipelines-summary)),
+- 4. can easily be contributed by the community (see the [Contribution](#contribution) section).
+
+**Note** that pipelines do not (and should not) offer any training functionality.
+If you are looking for *official* training examples, please have a look at [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+
+## 🧨 Diffusers Summary
+
+The following table summarizes all officially supported pipelines, their corresponding paper, and if
+available a colab notebook to directly try them out.
+
+
+| Pipeline | Paper | Tasks | Colab
+|---|---|:---:|:---:|
+| [alt_diffusion](./alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation | -
+| [audio_diffusion](./audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio_diffusion.git) | Unconditional Audio Generation |
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+| [cycle_diffusion](./cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [dance_diffusion](./dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
+| [ddpm](./ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
+| [ddim](./ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [latent_diffusion](./latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [score_sde_ve](./score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [score_sde_vp](./score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [semantic_stable_diffusion](./semantic_stable_diffusion) | [**SEGA: Instructing Diffusion using Semantic Dimensions**](https://arxiv.org/abs/2301.12247) | Text-to-Image Generation |
+| [stable_diffusion_text2img](./stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
+| [stable_diffusion_img2img](./stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+| [stable_diffusion_inpaint](./stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
+| [stable_diffusion_panorama](./stable_diffusion/panorama) | [**MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation**](https://arxiv.org/abs/2302.08113) | Text-Guided Panorama View Generation |
+| [stable_diffusion_pix2pix](./stable_diffusion/pix2pix) | [**InstructPix2Pix: Learning to Follow Image Editing Instructions**](https://arxiv.org/abs/2211.09800) | Text-Based Image Editing |
+| [stable_diffusion_pix2pix_zero](./stable_diffusion/pix2pix_zero) | [**Zero-shot Image-to-Image Translation**](https://arxiv.org/abs/2302.03027) | Text-Based Image Editing |
+| [stable_diffusion_attend_and_excite](./stable_diffusion/attend_and_excite) | [**Attend and Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models**](https://arxiv.org/abs/2301.13826) | Text-to-Image Generation |
+| [stable_diffusion_self_attention_guidance](./stable_diffusion/self_attention_guidance) | [**Self-Attention Guidance**](https://arxiv.org/abs/2210.00939) | Text-to-Image Generation |
+| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [**Stable Diffusion Image Variations**](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
+| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [**Stable Diffusion Latent Upscaler**](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_2](./stable_diffusion_2/) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
+| [stable_diffusion_2](./stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_2](./stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Depth-to-Image Text-Guided Generation |
+| [stable_diffusion_2](./stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_safe](./stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb)
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
+| [stochastic_karras_ve](./stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [text_to_video_sd](./api/pipelines/text_to_video) | [Modelscope's Text-to-video-synthesis Model in Open Domain](https://modelscope.cn/models/damo/text-to-video-synthesis/summary) | Text-to-Video Generation |
+| [unclip](./unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
+| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
+
+
+**Note**: Pipelines are simple examples of how to play around with the diffusion systems as described in the corresponding papers.
+
+However, most of them can be adapted to use different scheduler components or even different model components. Some pipeline examples are shown in the [Examples](#examples) below.
+
+## Pipelines API
+
+Diffusion models often consist of multiple independently-trained models or other previously existing components.
+
+
+Each model has been trained independently on a different task and the scheduler can easily be swapped out and replaced with a different one.
+During inference, we however want to be able to easily load all components and use them in inference - even if one component, *e.g.* CLIP's text encoder, originates from a different library, such as [Transformers](https://github.com/huggingface/transformers). To that end, all pipelines provide the following functionality:
+
+- [`from_pretrained` method](../diffusion_pipeline) that accepts a Hugging Face Hub repository id, *e.g.* [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) or a path to a local directory, *e.g.*
+"./stable-diffusion". To correctly retrieve which models and components should be loaded, one has to provide a `model_index.json` file, *e.g.* [runwayml/stable-diffusion-v1-5/model_index.json](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json), which defines all components that should be
+loaded into the pipelines. More specifically, for each model/component one needs to define the format `: ["", ""]`. `` is the attribute name given to the loaded instance of `` which can be found in the library or pipeline folder called `""`.
+- [`save_pretrained`](../diffusion_pipeline) that accepts a local path, *e.g.* `./stable-diffusion` under which all models/components of the pipeline will be saved. For each component/model a folder is created inside the local path that is named after the given attribute name, *e.g.* `./stable_diffusion/unet`.
+In addition, a `model_index.json` file is created at the root of the local path, *e.g.* `./stable_diffusion/model_index.json` so that the complete pipeline can again be instantiated
+from the local path.
+- [`to`](../diffusion_pipeline) which accepts a `string` or `torch.device` to move all models that are of type `torch.nn.Module` to the passed device. The behavior is fully analogous to [PyTorch's `to` method](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.to).
+- [`__call__`] method to use the pipeline in inference. `__call__` defines inference logic of the pipeline and should ideally encompass all aspects of it, from pre-processing to forwarding tensors to the different models and schedulers, as well as post-processing. The API of the `__call__` method can strongly vary from pipeline to pipeline. *E.g.* a text-to-image pipeline, such as [`StableDiffusionPipeline`](./stable_diffusion) should accept among other things the text prompt to generate the image. A pure image generation pipeline, such as [DDPMPipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/ddpm) on the other hand can be run without providing any inputs. To better understand what inputs can be adapted for
+each pipeline, one should look directly into the respective pipeline.
+
+**Note**: All pipelines have PyTorch's autograd disabled by decorating the `__call__` method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should
+not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community).
+
+## Contribution
+
+We are more than happy about any contribution to the officially supported pipelines 🤗. We aspire
+all of our pipelines to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
+
+- **Self-contained**: A pipeline shall be as self-contained as possible. More specifically, this means that all functionality should be either directly defined in the pipeline file itself, should be inherited from (and only from) the [`DiffusionPipeline` class](.../diffusion_pipeline) or be directly attached to the model and scheduler components of the pipeline.
+- **Easy-to-use**: Pipelines should be extremely easy to use - one should be able to load the pipeline and
+use it for its designated task, *e.g.* text-to-image generation, in just a couple of lines of code. Most
+logic including pre-processing, an unrolled diffusion loop, and post-processing should all happen inside the `__call__` method.
+- **Easy-to-tweak**: Certain pipelines will not be able to handle all use cases and tasks that you might like them to. If you want to use a certain pipeline for a specific use case that is not yet supported, you might have to copy the pipeline file and tweak the code to your needs. We try to make the pipeline code as readable as possible so that each part –from pre-processing to diffusing to post-processing– can easily be adapted. If you would like the community to benefit from your customized pipeline, we would love to see a contribution to our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community). If you feel that an important pipeline should be part of the official pipelines but isn't, a contribution to the [official pipelines](./overview) would be even better.
+- **One-purpose-only**: Pipelines should be used for one task and one task only. Even if two tasks are very similar from a modeling point of view, *e.g.* image2image translation and in-painting, pipelines shall be used for one task only to keep them *easy-to-tweak* and *readable*.
+
+## Examples
+
+### Text-to-Image generation with Stable Diffusion
+
+```python
+# make sure you're logged in with `huggingface-cli login`
+from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
+
+pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+pipe = pipe.to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+image = pipe(prompt).images[0]
+
+image.save("astronaut_rides_horse.png")
+```
+
+### Image-to-Image text-guided generation with Stable Diffusion
+
+The `StableDiffusionImg2ImgPipeline` lets you pass a text prompt and an initial image to condition the generation of new images.
+
+```python
+import requests
+from PIL import Image
+from io import BytesIO
+
+from diffusers import StableDiffusionImg2ImgPipeline
+
+# load the pipeline
+device = "cuda"
+pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to(
+ device
+)
+
+# let's download an initial image
+url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((768, 512))
+
+prompt = "A fantasy landscape, trending on artstation"
+
+images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
+
+images[0].save("fantasy_landscape.png")
+```
+You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+
+### Tweak prompts reusing seeds and latents
+
+You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
+
+
+### In-painting using Stable Diffusion
+
+The `StableDiffusionInpaintPipeline` lets you edit specific parts of an image by providing a mask and text prompt.
+
+```python
+import PIL
+import requests
+import torch
+from io import BytesIO
+
+from diffusers import StableDiffusionInpaintPipeline
+
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+init_image = download_image(img_url).resize((512, 512))
+mask_image = download_image(mask_url).resize((512, 512))
+
+pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting",
+ torch_dtype=torch.float16,
+)
+pipe = pipe.to("cuda")
+
+prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
+```
+
+You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
diff --git a/diffusers/docs/source/en/api/pipelines/paint_by_example.mdx b/diffusers/docs/source/en/api/pipelines/paint_by_example.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..5abb3406db448fdbeab14b2626bd17621214d819
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/paint_by_example.mdx
@@ -0,0 +1,74 @@
+
+
+# PaintByExample
+
+## Overview
+
+[Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) by Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, Fang Wen.
+
+The abstract of the paper is the following:
+
+*Language-guided image editing has achieved great success recently. In this paper, for the first time, we investigate exemplar-guided image editing for more precise control. We achieve this goal by leveraging self-supervised training to disentangle and re-organize the source image and the exemplar. However, the naive approach will cause obvious fusing artifacts. We carefully analyze it and propose an information bottleneck and strong augmentations to avoid the trivial solution of directly copying and pasting the exemplar image. Meanwhile, to ensure the controllability of the editing process, we design an arbitrary shape mask for the exemplar image and leverage the classifier-free guidance to increase the similarity to the exemplar image. The whole framework involves a single forward of the diffusion model without any iterative optimization. We demonstrate that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity.*
+
+The original codebase can be found [here](https://github.com/Fantasy-Studio/Paint-by-Example).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_paint_by_example.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py) | *Image-Guided Image Painting* | - |
+
+## Tips
+
+- PaintByExample is supported by the official [Fantasy-Studio/Paint-by-Example](https://huggingface.co/Fantasy-Studio/Paint-by-Example) checkpoint. The checkpoint has been warm-started from the [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4) and with the objective to inpaint partly masked images conditioned on example / reference images
+- To quickly demo *PaintByExample*, please have a look at [this demo](https://huggingface.co/spaces/Fantasy-Studio/Paint-by-Example)
+- You can run the following code snippet as an example:
+
+
+```python
+# !pip install diffusers transformers
+
+import PIL
+import requests
+import torch
+from io import BytesIO
+from diffusers import DiffusionPipeline
+
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+img_url = "https://raw.githubusercontent.com/Fantasy-Studio/Paint-by-Example/main/examples/image/example_1.png"
+mask_url = "https://raw.githubusercontent.com/Fantasy-Studio/Paint-by-Example/main/examples/mask/example_1.png"
+example_url = "https://raw.githubusercontent.com/Fantasy-Studio/Paint-by-Example/main/examples/reference/example_1.jpg"
+
+init_image = download_image(img_url).resize((512, 512))
+mask_image = download_image(mask_url).resize((512, 512))
+example_image = download_image(example_url).resize((512, 512))
+
+pipe = DiffusionPipeline.from_pretrained(
+ "Fantasy-Studio/Paint-by-Example",
+ torch_dtype=torch.float16,
+)
+pipe = pipe.to("cuda")
+
+image = pipe(image=init_image, mask_image=mask_image, example_image=example_image).images[0]
+image
+```
+
+## PaintByExamplePipeline
+[[autodoc]] PaintByExamplePipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/pndm.mdx b/diffusers/docs/source/en/api/pipelines/pndm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..43625fdfbe5206e01dcb11c85e86d31737d3c6ee
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/pndm.mdx
@@ -0,0 +1,35 @@
+
+
+# PNDM
+
+## Overview
+
+[Pseudo Numerical methods for Diffusion Models on manifolds](https://arxiv.org/abs/2202.09778) (PNDM) by Luping Liu, Yi Ren, Zhijie Lin and Zhou Zhao.
+
+The abstract of the paper is the following:
+
+Denoising Diffusion Probabilistic Models (DDPMs) can generate high-quality samples such as image and audio samples. However, DDPMs require hundreds to thousands of iterations to produce final samples. Several prior works have successfully accelerated DDPMs through adjusting the variance schedule (e.g., Improved Denoising Diffusion Probabilistic Models) or the denoising equation (e.g., Denoising Diffusion Implicit Models (DDIMs)). However, these acceleration methods cannot maintain the quality of samples and even introduce new noise at a high speedup rate, which limit their practicability. To accelerate the inference process while keeping the sample quality, we provide a fresh perspective that DDPMs should be treated as solving differential equations on manifolds. Under such a perspective, we propose pseudo numerical methods for diffusion models (PNDMs). Specifically, we figure out how to solve differential equations on manifolds and show that DDIMs are simple cases of pseudo numerical methods. We change several classical numerical methods to corresponding pseudo numerical methods and find that the pseudo linear multi-step method is the best in most situations. According to our experiments, by directly using pre-trained models on Cifar10, CelebA and LSUN, PNDMs can generate higher quality synthetic images with only 50 steps compared with 1000-step DDIMs (20x speedup), significantly outperform DDIMs with 250 steps (by around 0.4 in FID) and have good generalization on different variance schedules.
+
+The original codebase can be found [here](https://github.com/luping-liu/PNDM).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pndm/pipeline_pndm.py) | *Unconditional Image Generation* | - |
+
+
+## PNDMPipeline
+[[autodoc]] PNDMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/repaint.mdx b/diffusers/docs/source/en/api/pipelines/repaint.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..927398d0bf54119684dae652ce9d2c86ba34bc5c
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/repaint.mdx
@@ -0,0 +1,77 @@
+
+
+# RePaint
+
+## Overview
+
+[RePaint: Inpainting using Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2201.09865) (PNDM) by Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, Luc Van Gool.
+
+The abstract of the paper is the following:
+
+Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks.
+RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions.
+
+The original codebase can be found [here](https://github.com/andreas128/RePaint).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|-------------------------------------------------------------------------------------------------------------------------------|--------------------|:---:|
+| [pipeline_repaint.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/repaint/pipeline_repaint.py) | *Image Inpainting* | - |
+
+## Usage example
+
+```python
+from io import BytesIO
+
+import torch
+
+import PIL
+import requests
+from diffusers import RePaintPipeline, RePaintScheduler
+
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+img_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/celeba_hq_256.png"
+mask_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/mask_256.png"
+
+# Load the original image and the mask as PIL images
+original_image = download_image(img_url).resize((256, 256))
+mask_image = download_image(mask_url).resize((256, 256))
+
+# Load the RePaint scheduler and pipeline based on a pretrained DDPM model
+scheduler = RePaintScheduler.from_pretrained("google/ddpm-ema-celebahq-256")
+pipe = RePaintPipeline.from_pretrained("google/ddpm-ema-celebahq-256", scheduler=scheduler)
+pipe = pipe.to("cuda")
+
+generator = torch.Generator(device="cuda").manual_seed(0)
+output = pipe(
+ original_image=original_image,
+ mask_image=mask_image,
+ num_inference_steps=250,
+ eta=0.0,
+ jump_length=10,
+ jump_n_sample=10,
+ generator=generator,
+)
+inpainted_image = output.images[0]
+```
+
+## RePaintPipeline
+[[autodoc]] RePaintPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/score_sde_ve.mdx b/diffusers/docs/source/en/api/pipelines/score_sde_ve.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..42253e301f4eaf0d34976439e5539201eb257237
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/score_sde_ve.mdx
@@ -0,0 +1,36 @@
+
+
+# Score SDE VE
+
+## Overview
+
+[Score-Based Generative Modeling through Stochastic Differential Equations](https://arxiv.org/abs/2011.13456) (Score SDE) by Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon and Ben Poole.
+
+The abstract of the paper is the following:
+
+Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (\aka, score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in score-based generative modeling and diffusion probabilistic modeling, allowing for new sampling procedures and new modeling capabilities. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, but additionally enables exact likelihood computation, and improved sampling efficiency. In addition, we provide a new way to solve inverse problems with score-based models, as demonstrated with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 2.99 bits/dim, and demonstrate high fidelity generation of 1024 x 1024 images for the first time from a score-based generative model.
+
+The original codebase can be found [here](https://github.com/yang-song/score_sde_pytorch).
+
+This pipeline implements the Variance Expanding (VE) variant of the method.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_score_sde_ve.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_ve/pipeline_score_sde_ve.py) | *Unconditional Image Generation* | - |
+
+## ScoreSdeVePipeline
+[[autodoc]] ScoreSdeVePipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/semantic_stable_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/semantic_stable_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b4562cf0c389bb917b3f075f279c347442dfdfa9
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/semantic_stable_diffusion.mdx
@@ -0,0 +1,79 @@
+
+
+# Semantic Guidance
+
+Semantic Guidance for Diffusion Models was proposed in [SEGA: Instructing Diffusion using Semantic Dimensions](https://arxiv.org/abs/2301.12247) and provides strong semantic control over the image generation.
+Small changes to the text prompt usually result in entirely different output images. However, with SEGA a variety of changes to the image are enabled that can be controlled easily and intuitively, and stay true to the original image composition.
+
+The abstract of the paper is the following:
+
+*Text-to-image diffusion models have recently received a lot of interest for their astonishing ability to produce high-fidelity images from text only. However, achieving one-shot generation that aligns with the user's intent is nearly impossible, yet small changes to the input prompt often result in very different images. This leaves the user with little semantic control. To put the user in control, we show how to interact with the diffusion process to flexibly steer it along semantic directions. This semantic guidance (SEGA) allows for subtle and extensive edits, changes in composition and style, as well as optimizing the overall artistic conception. We demonstrate SEGA's effectiveness on a variety of tasks and provide evidence for its versatility and flexibility.*
+
+
+*Overview*:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [pipeline_semantic_stable_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/ml-research/semantic-image-editing/blob/main/examples/SemanticGuidance.ipynb) | [Coming Soon](https://huggingface.co/AIML-TUDA)
+
+## Tips
+
+- The Semantic Guidance pipeline can be used with any [Stable Diffusion](./stable_diffusion/text2img) checkpoint.
+
+### Run Semantic Guidance
+
+The interface of [`SemanticStableDiffusionPipeline`] provides several additional parameters to influence the image generation.
+Exemplary usage may look like this:
+
+```python
+import torch
+from diffusers import SemanticStableDiffusionPipeline
+
+pipe = SemanticStableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
+pipe = pipe.to("cuda")
+
+out = pipe(
+ prompt="a photo of the face of a woman",
+ num_images_per_prompt=1,
+ guidance_scale=7,
+ editing_prompt=[
+ "smiling, smile", # Concepts to apply
+ "glasses, wearing glasses",
+ "curls, wavy hair, curly hair",
+ "beard, full beard, mustache",
+ ],
+ reverse_editing_direction=[False, False, False, False], # Direction of guidance i.e. increase all concepts
+ edit_warmup_steps=[10, 10, 10, 10], # Warmup period for each concept
+ edit_guidance_scale=[4, 5, 5, 5.4], # Guidance scale for each concept
+ edit_threshold=[
+ 0.99,
+ 0.975,
+ 0.925,
+ 0.96,
+ ], # Threshold for each concept. Threshold equals the percentile of the latent space that will be discarded. I.e. threshold=0.99 uses 1% of the latent dimensions
+ edit_momentum_scale=0.3, # Momentum scale that will be added to the latent guidance
+ edit_mom_beta=0.6, # Momentum beta
+ edit_weights=[1, 1, 1, 1, 1], # Weights of the individual concepts against each other
+)
+```
+
+For more examples check the Colab notebook.
+
+## StableDiffusionSafePipelineOutput
+[[autodoc]] pipelines.semantic_stable_diffusion.SemanticStableDiffusionPipelineOutput
+ - all
+
+## SemanticStableDiffusionPipeline
+[[autodoc]] SemanticStableDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/spectrogram_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/spectrogram_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..c98300fe791f054807665373b70d6526b5219682
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/spectrogram_diffusion.mdx
@@ -0,0 +1,54 @@
+
+
+# Multi-instrument Music Synthesis with Spectrogram Diffusion
+
+## Overview
+
+[Spectrogram Diffusion](https://arxiv.org/abs/2206.05408) by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
+
+An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
+
+The original codebase of this implementation can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion).
+
+## Model
+
+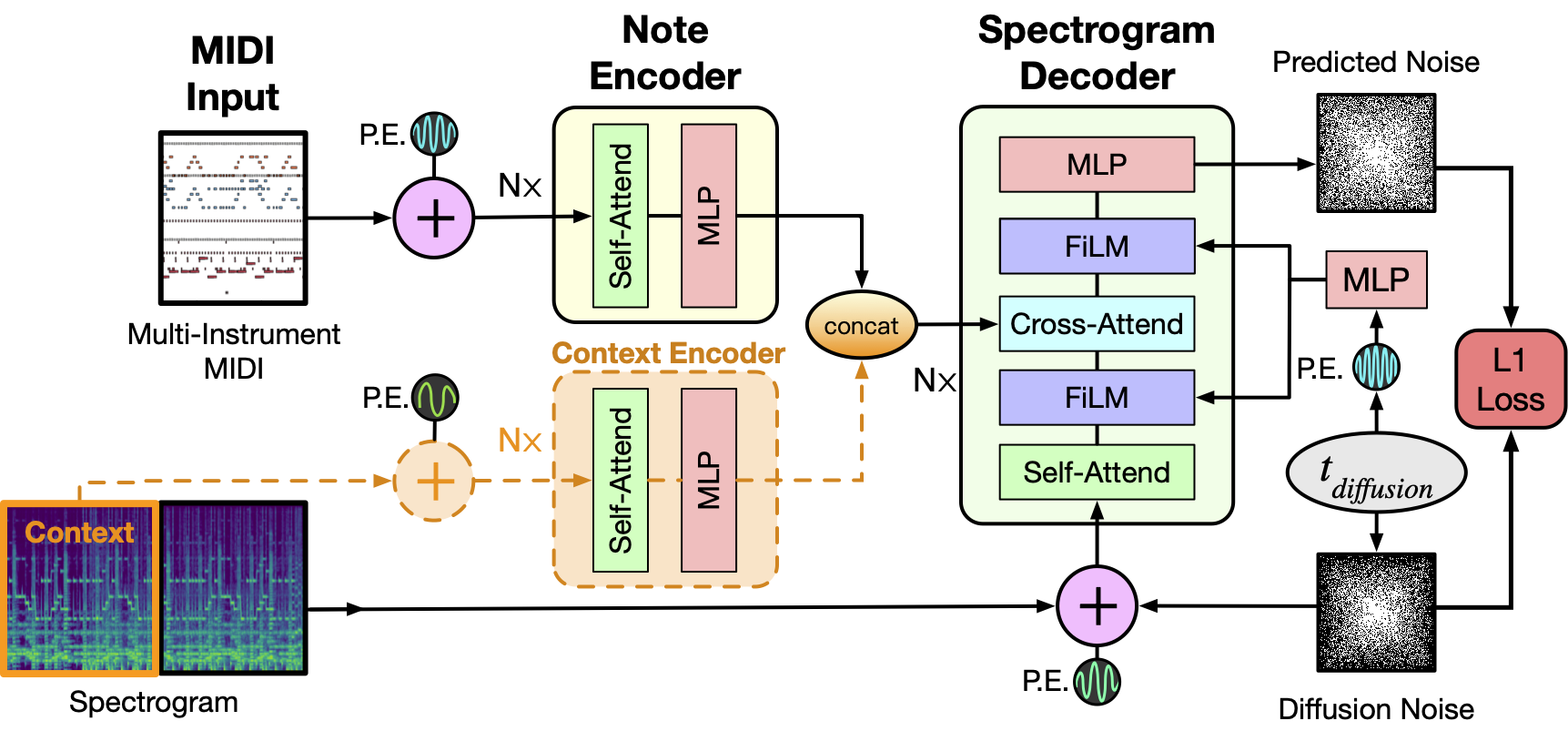
+
+As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_spectrogram_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion) | *Unconditional Audio Generation* | - |
+
+
+## Example usage
+
+```python
+from diffusers import SpectrogramDiffusionPipeline, MidiProcessor
+
+pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
+pipe = pipe.to("cuda")
+processor = MidiProcessor()
+
+# Download MIDI from: wget http://www.piano-midi.de/midis/beethoven/beethoven_hammerklavier_2.mid
+output = pipe(processor("beethoven_hammerklavier_2.mid"))
+
+audio = output.audios[0]
+```
+
+## SpectrogramDiffusionPipeline
+[[autodoc]] SpectrogramDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/attend_and_excite.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/attend_and_excite.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..1a329bc442e7bb6f5e20d60a679c12acf1855c90
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/attend_and_excite.mdx
@@ -0,0 +1,75 @@
+
+
+# Attend and Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
+
+## Overview
+
+Attend and Excite for Stable Diffusion was proposed in [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://attendandexcite.github.io/Attend-and-Excite/) and provides textual attention control over the image generation.
+
+The abstract of the paper is the following:
+
+*Text-to-image diffusion models have recently received a lot of interest for their astonishing ability to produce high-fidelity images from text only. However, achieving one-shot generation that aligns with the user's intent is nearly impossible, yet small changes to the input prompt often result in very different images. This leaves the user with little semantic control. To put the user in control, we show how to interact with the diffusion process to flexibly steer it along semantic directions. This semantic guidance (SEGA) allows for subtle and extensive edits, changes in composition and style, as well as optimizing the overall artistic conception. We demonstrate SEGA's effectiveness on a variety of tasks and provide evidence for its versatility and flexibility.*
+
+Resources
+
+* [Project Page](https://attendandexcite.github.io/Attend-and-Excite/)
+* [Paper](https://arxiv.org/abs/2301.13826)
+* [Original Code](https://github.com/AttendAndExcite/Attend-and-Excite)
+* [Demo](https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite)
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [pipeline_semantic_stable_diffusion_attend_and_excite.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_semantic_stable_diffusion_attend_and_excite) | *Text-to-Image Generation* | - | https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite
+
+
+### Usage example
+
+
+```python
+import torch
+from diffusers import StableDiffusionAttendAndExcitePipeline
+
+model_id = "CompVis/stable-diffusion-v1-4"
+pipe = StableDiffusionAttendAndExcitePipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+pipe = pipe.to("cuda")
+
+prompt = "a cat and a frog"
+
+# use get_indices function to find out indices of the tokens you want to alter
+pipe.get_indices(prompt)
+
+token_indices = [2, 5]
+seed = 6141
+generator = torch.Generator("cuda").manual_seed(seed)
+
+images = pipe(
+ prompt=prompt,
+ token_indices=token_indices,
+ guidance_scale=7.5,
+ generator=generator,
+ num_inference_steps=50,
+ max_iter_to_alter=25,
+).images
+
+image = images[0]
+image.save(f"../images/{prompt}_{seed}.png")
+```
+
+
+## StableDiffusionAttendAndExcitePipeline
+[[autodoc]] StableDiffusionAttendAndExcitePipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..5a4cfa41ca43d7fe0cf6f12fc7e8c155af92a960
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
@@ -0,0 +1,280 @@
+
+
+# Text-to-Image Generation with ControlNet Conditioning
+
+## Overview
+
+[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
+
+Using the pretrained models we can provide control images (for example, a depth map) to control Stable Diffusion text-to-image generation so that it follows the structure of the depth image and fills in the details.
+
+The abstract of the paper is the following:
+
+*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.*
+
+This model was contributed by the amazing community contributor [takuma104](https://huggingface.co/takuma104) ❤️ .
+
+Resources:
+
+* [Paper](https://arxiv.org/abs/2302.05543)
+* [Original Code](https://github.com/lllyasviel/ControlNet)
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionControlNetPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py) | *Text-to-Image Generation with ControlNet Conditioning* | [Colab Example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+
+## Usage example
+
+In the following we give a simple example of how to use a *ControlNet* checkpoint with Diffusers for inference.
+The inference pipeline is the same for all pipelines:
+
+* 1. Take an image and run it through a pre-conditioning processor.
+* 2. Run the pre-processed image through the [`StableDiffusionControlNetPipeline`].
+
+Let's have a look at a simple example using the [Canny Edge ControlNet](https://huggingface.co/lllyasviel/sd-controlnet-canny).
+
+```python
+from diffusers import StableDiffusionControlNetPipeline
+from diffusers.utils import load_image
+
+# Let's load the popular vermeer image
+image = load_image(
+ "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
+)
+```
+
+
+
+Next, we process the image to get the canny image. This is step *1.* - running the pre-conditioning processor. The pre-conditioning processor is different for every ControlNet. Please see the model cards of the [official checkpoints](#controlnet-with-stable-diffusion-1.5) for more information about other models.
+
+First, we need to install opencv:
+
+```
+pip install opencv-contrib-python
+```
+
+Next, let's also install all required Hugging Face libraries:
+
+```
+pip install diffusers transformers git+https://github.com/huggingface/accelerate.git
+```
+
+Then we can retrieve the canny edges of the image.
+
+```python
+import cv2
+from PIL import Image
+import numpy as np
+
+image = np.array(image)
+
+low_threshold = 100
+high_threshold = 200
+
+image = cv2.Canny(image, low_threshold, high_threshold)
+image = image[:, :, None]
+image = np.concatenate([image, image, image], axis=2)
+canny_image = Image.fromarray(image)
+```
+
+Let's take a look at the processed image.
+
+
+
+Now, we load the official [Stable Diffusion 1.5 Model](runwayml/stable-diffusion-v1-5) as well as the ControlNet for canny edges.
+
+```py
+from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
+import torch
+
+controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+)
+```
+
+To speed-up things and reduce memory, let's enable model offloading and use the fast [`UniPCMultistepScheduler`].
+
+```py
+from diffusers import UniPCMultistepScheduler
+
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+# this command loads the individual model components on GPU on-demand.
+pipe.enable_model_cpu_offload()
+```
+
+Finally, we can run the pipeline:
+
+```py
+generator = torch.manual_seed(0)
+
+out_image = pipe(
+ "disco dancer with colorful lights", num_inference_steps=20, generator=generator, image=canny_image
+).images[0]
+```
+
+This should take only around 3-4 seconds on GPU (depending on hardware). The output image then looks as follows:
+
+
+
+
+**Note**: To see how to run all other ControlNet checkpoints, please have a look at [ControlNet with Stable Diffusion 1.5](#controlnet-with-stable-diffusion-1.5).
+
+
+
+## Combining multiple conditionings
+
+Multiple ControlNet conditionings can be combined for a single image generation. Pass a list of ControlNets to the pipeline's constructor and a corresponding list of conditionings to `__call__`.
+
+When combining conditionings, it is helpful to mask conditionings such that they do not overlap. In the example, we mask the middle of the canny map where the pose conditioning is located.
+
+It can also be helpful to vary the `controlnet_conditioning_scales` to emphasize one conditioning over the other.
+
+### Canny conditioning
+
+The original image:
+
+
. We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or
+just hang out ☕.
+
+## Credits
+
+This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
+
+- @CompVis' latent diffusion models library, available [here](https://github.com/CompVis/latent-diffusion)
+- @hojonathanho original DDPM implementation, available [here](https://github.com/hojonathanho/diffusion) as well as the extremely useful translation into PyTorch by @pesser, available [here](https://github.com/pesser/pytorch_diffusion)
+- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim)
+- @yang-song's Score-VE and Score-VP implementations, available [here](https://github.com/yang-song/score_sde_pytorch)
+
+We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available [here](https://github.com/heejkoo/Awesome-Diffusion-Models) as well as @crowsonkb and @rromb for useful discussions and insights.
+
+## Citation
+
+```bibtex
+@misc{von-platen-etal-2022-diffusers,
+ author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Thomas Wolf},
+ title = {Diffusers: State-of-the-art diffusion models},
+ year = {2022},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ howpublished = {\url{https://github.com/huggingface/diffusers}}
+}
+```
diff --git a/diffusers/_typos.toml b/diffusers/_typos.toml
new file mode 100644
index 0000000000000000000000000000000000000000..551099f981e7885fbda9ed28e297bace0e13407b
--- /dev/null
+++ b/diffusers/_typos.toml
@@ -0,0 +1,13 @@
+# Files for typos
+# Instruction: https://github.com/marketplace/actions/typos-action#getting-started
+
+[default.extend-identifiers]
+
+[default.extend-words]
+NIN="NIN" # NIN is used in scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py
+nd="np" # nd may be np (numpy)
+parms="parms" # parms is used in scripts/convert_original_stable_diffusion_to_diffusers.py
+
+
+[files]
+extend-exclude = ["_typos.toml"]
diff --git a/diffusers/docker/diffusers-flax-cpu/Dockerfile b/diffusers/docker/diffusers-flax-cpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..57a9c1ec742200b48f8c2f906d1152e85e60584a
--- /dev/null
+++ b/diffusers/docker/diffusers-flax-cpu/Dockerfile
@@ -0,0 +1,44 @@
+FROM ubuntu:20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+# follow the instructions here: https://cloud.google.com/tpu/docs/run-in-container#train_a_jax_model_in_a_docker_container
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --upgrade --no-cache-dir \
+ clu \
+ "jax[cpu]>=0.2.16,!=0.3.2" \
+ "flax>=0.4.1" \
+ "jaxlib>=0.1.65" && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-flax-tpu/Dockerfile b/diffusers/docker/diffusers-flax-tpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..2517da586d74b43c4c94a0eca4651f047345ec4d
--- /dev/null
+++ b/diffusers/docker/diffusers-flax-tpu/Dockerfile
@@ -0,0 +1,46 @@
+FROM ubuntu:20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+# follow the instructions here: https://cloud.google.com/tpu/docs/run-in-container#train_a_jax_model_in_a_docker_container
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ "jax[tpu]>=0.2.16,!=0.3.2" \
+ -f https://storage.googleapis.com/jax-releases/libtpu_releases.html && \
+ python3 -m pip install --upgrade --no-cache-dir \
+ clu \
+ "flax>=0.4.1" \
+ "jaxlib>=0.1.65" && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-onnxruntime-cpu/Dockerfile b/diffusers/docker/diffusers-onnxruntime-cpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..75f45be87a033e9476c4038218c9c2fd2f1255a5
--- /dev/null
+++ b/diffusers/docker/diffusers-onnxruntime-cpu/Dockerfile
@@ -0,0 +1,44 @@
+FROM ubuntu:20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ torch \
+ torchvision \
+ torchaudio \
+ onnxruntime \
+ --extra-index-url https://download.pytorch.org/whl/cpu && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-onnxruntime-cuda/Dockerfile b/diffusers/docker/diffusers-onnxruntime-cuda/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..2129dbcaf68c57755485e1e54e867af05b937336
--- /dev/null
+++ b/diffusers/docker/diffusers-onnxruntime-cuda/Dockerfile
@@ -0,0 +1,44 @@
+FROM nvidia/cuda:11.6.2-cudnn8-devel-ubuntu20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ torch \
+ torchvision \
+ torchaudio \
+ "onnxruntime-gpu>=1.13.1" \
+ --extra-index-url https://download.pytorch.org/whl/cu117 && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-pytorch-cpu/Dockerfile b/diffusers/docker/diffusers-pytorch-cpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..a70eff4c852b21e51c576e1e43172dd8dc25e1a0
--- /dev/null
+++ b/diffusers/docker/diffusers-pytorch-cpu/Dockerfile
@@ -0,0 +1,43 @@
+FROM ubuntu:20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ torch \
+ torchvision \
+ torchaudio \
+ --extra-index-url https://download.pytorch.org/whl/cpu && \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
\ No newline at end of file
diff --git a/diffusers/docker/diffusers-pytorch-cuda/Dockerfile b/diffusers/docker/diffusers-pytorch-cuda/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..8087be4299967c535e9d34590118113f001721bd
--- /dev/null
+++ b/diffusers/docker/diffusers-pytorch-cuda/Dockerfile
@@ -0,0 +1,42 @@
+FROM nvidia/cuda:11.7.1-cudnn8-runtime-ubuntu20.04
+LABEL maintainer="Hugging Face"
+LABEL repository="diffusers"
+
+ENV DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ git-lfs \
+ curl \
+ ca-certificates \
+ libsndfile1-dev \
+ python3.8 \
+ python3-pip \
+ python3.8-venv && \
+ rm -rf /var/lib/apt/lists
+
+# make sure to use venv
+RUN python3 -m venv /opt/venv
+ENV PATH="/opt/venv/bin:$PATH"
+
+# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ torch \
+ torchvision \
+ torchaudio \
+ python3 -m pip install --no-cache-dir \
+ accelerate \
+ datasets \
+ hf-doc-builder \
+ huggingface-hub \
+ Jinja2 \
+ librosa \
+ numpy \
+ scipy \
+ tensorboard \
+ transformers
+
+CMD ["/bin/bash"]
diff --git a/diffusers/docs/README.md b/diffusers/docs/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..739f880f65650b5249bdce7539664e53b51d7496
--- /dev/null
+++ b/diffusers/docs/README.md
@@ -0,0 +1,271 @@
+
+
+# Generating the documentation
+
+To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
+you can install them with the following command, at the root of the code repository:
+
+```bash
+pip install -e ".[docs]"
+```
+
+Then you need to install our open source documentation builder tool:
+
+```bash
+pip install git+https://github.com/huggingface/doc-builder
+```
+
+---
+**NOTE**
+
+You only need to generate the documentation to inspect it locally (if you're planning changes and want to
+check how they look before committing for instance). You don't have to commit the built documentation.
+
+---
+
+## Previewing the documentation
+
+To preview the docs, first install the `watchdog` module with:
+
+```bash
+pip install watchdog
+```
+
+Then run the following command:
+
+```bash
+doc-builder preview {package_name} {path_to_docs}
+```
+
+For example:
+
+```bash
+doc-builder preview diffusers docs/source/en
+```
+
+The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
+
+---
+**NOTE**
+
+The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
+
+---
+
+## Adding a new element to the navigation bar
+
+Accepted files are Markdown (.md or .mdx).
+
+Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
+the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/diffusers/blob/main/docs/source/_toctree.yml) file.
+
+## Renaming section headers and moving sections
+
+It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
+
+Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
+
+So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
+
+```
+Sections that were moved:
+
+[ Section A ]
+```
+and of course, if you moved it to another file, then:
+
+```
+Sections that were moved:
+
+[ Section A ]
+```
+
+Use the relative style to link to the new file so that the versioned docs continue to work.
+
+For an example of a rich moved section set please see the very end of [the transformers Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.mdx).
+
+
+## Writing Documentation - Specification
+
+The `huggingface/diffusers` documentation follows the
+[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
+although we can write them directly in Markdown.
+
+### Adding a new tutorial
+
+Adding a new tutorial or section is done in two steps:
+
+- Add a new file under `docs/source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
+- Link that file in `docs/source/_toctree.yml` on the correct toc-tree.
+
+Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
+depending on the intended targets (beginners, more advanced users, or researchers) it should go in sections two, three, or four.
+
+### Adding a new pipeline/scheduler
+
+When adding a new pipeline:
+
+- create a file `xxx.mdx` under `docs/source/api/pipelines` (don't hesitate to copy an existing file as template).
+- Link that file in (*Diffusers Summary*) section in `docs/source/api/pipelines/overview.mdx`, along with the link to the paper, and a colab notebook (if available).
+- Write a short overview of the diffusion model:
+ - Overview with paper & authors
+ - Paper abstract
+ - Tips and tricks and how to use it best
+ - Possible an end-to-end example of how to use it
+- Add all the pipeline classes that should be linked in the diffusion model. These classes should be added using our Markdown syntax. By default as follows:
+
+```
+## XXXPipeline
+
+[[autodoc]] XXXPipeline
+ - all
+ - __call__
+```
+
+This will include every public method of the pipeline that is documented, as well as the `__call__` method that is not documented by default. If you just want to add additional methods that are not documented, you can put the list of all methods to add in a list that contains `all`.
+
+```
+[[autodoc]] XXXPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+```
+
+You can follow the same process to create a new scheduler under the `docs/source/api/schedulers` folder
+
+### Writing source documentation
+
+Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
+and objects like True, None, or any strings should usually be put in `code`.
+
+When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
+adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
+function to be in the main package.
+
+If you want to create a link to some internal class or function, you need to
+provide its path. For instance: \[\`pipelines.ImagePipelineOutput\`\]. This will be converted into a link with
+`pipelines.ImagePipelineOutput` in the description. To get rid of the path and only keep the name of the object you are
+linking to in the description, add a ~: \[\`~pipelines.ImagePipelineOutput\`\] will generate a link with `ImagePipelineOutput` in the description.
+
+The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
+
+#### Defining arguments in a method
+
+Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
+an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
+description:
+
+```
+ Args:
+ n_layers (`int`): The number of layers of the model.
+```
+
+If the description is too long to fit in one line, another indentation is necessary before writing the description
+after the argument.
+
+Here's an example showcasing everything so far:
+
+```
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
+ [`~PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+```
+
+For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
+following signature:
+
+```
+def my_function(x: str = None, a: float = 1):
+```
+
+then its documentation should look like this:
+
+```
+ Args:
+ x (`str`, *optional*):
+ This argument controls ...
+ a (`float`, *optional*, defaults to 1):
+ This argument is used to ...
+```
+
+Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
+if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
+however write as many lines as you want in the indented description (see the example above with `input_ids`).
+
+#### Writing a multi-line code block
+
+Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
+
+
+````
+```
+# first line of code
+# second line
+# etc
+```
+````
+
+#### Writing a return block
+
+The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
+The first line should be the type of the return, followed by a line return. No need to indent further for the elements
+building the return.
+
+Here's an example of a single value return:
+
+```
+ Returns:
+ `List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
+```
+
+Here's an example of a tuple return, comprising several objects:
+
+```
+ Returns:
+ `tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
+ - ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
+ Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
+ - **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+```
+
+#### Adding an image
+
+Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
+the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
+them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
+If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
+to this dataset.
+
+## Styling the docstring
+
+We have an automatic script running with the `make style` command that will make sure that:
+- the docstrings fully take advantage of the line width
+- all code examples are formatted using black, like the code of the Transformers library
+
+This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
+recommended to commit your changes before running `make style`, so you can revert the changes done by that script
+easily.
+
diff --git a/diffusers/docs/TRANSLATING.md b/diffusers/docs/TRANSLATING.md
new file mode 100644
index 0000000000000000000000000000000000000000..32cd95f2ade9ba90ed6a10b1c54169b26a79d01d
--- /dev/null
+++ b/diffusers/docs/TRANSLATING.md
@@ -0,0 +1,57 @@
+### Translating the Diffusers documentation into your language
+
+As part of our mission to democratize machine learning, we'd love to make the Diffusers library available in many more languages! Follow the steps below if you want to help translate the documentation into your language 🙏.
+
+**🗞️ Open an issue**
+
+To get started, navigate to the [Issues](https://github.com/huggingface/diffusers/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the "Translation template" from the "New issue" button.
+
+Once an issue exists, post a comment to indicate which chapters you'd like to work on, and we'll add your name to the list.
+
+
+**🍴 Fork the repository**
+
+First, you'll need to [fork the Diffusers repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page.
+
+Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
+
+```bash
+git clone https://github.com/YOUR-USERNAME/diffusers.git
+```
+
+**📋 Copy-paste the English version with a new language code**
+
+The documentation files are in one leading directory:
+
+- [`docs/source`](https://github.com/huggingface/diffusers/tree/main/docs/source): All the documentation materials are organized here by language.
+
+You'll only need to copy the files in the [`docs/source/en`](https://github.com/huggingface/diffusers/tree/main/docs/source/en) directory, so first navigate to your fork of the repo and run the following:
+
+```bash
+cd ~/path/to/diffusers/docs
+cp -r source/en source/LANG-ID
+```
+
+Here, `LANG-ID` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
+
+**✍️ Start translating**
+
+The fun part comes - translating the text!
+
+The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your doc chapter. This file is used to render the table of contents on the website.
+
+> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can create one by copy-pasting from the English version and deleting the sections unrelated to your chapter. Just make sure it exists in the `docs/source/LANG-ID/` directory!
+
+The fields you should add are `local` (with the name of the file containing the translation; e.g. `autoclass_tutorial`), and `title` (with the title of the doc in your language; e.g. `Load pretrained instances with an AutoClass`) -- as a reference, here is the `_toctree.yml` for [English](https://github.com/huggingface/diffusers/blob/main/docs/source/en/_toctree.yml):
+
+```yaml
+- sections:
+ - local: pipeline_tutorial # Do not change this! Use the same name for your .md file
+ title: Pipelines for inference # Translate this!
+ ...
+ title: Tutorials # Translate this!
+```
+
+Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your docs chapter.
+
+> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/diffusers/issues) and tag @patrickvonplaten.
diff --git a/diffusers/docs/source/_config.py b/diffusers/docs/source/_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a4818ea8b1e19007c9e6440a3a98383031278cb
--- /dev/null
+++ b/diffusers/docs/source/_config.py
@@ -0,0 +1,9 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# Diffusers installation
+! pip install diffusers transformers datasets accelerate
+# To install from source instead of the last release, comment the command above and uncomment the following one.
+# ! pip install git+https://github.com/huggingface/diffusers.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
\ No newline at end of file
diff --git a/diffusers/docs/source/en/_toctree.yml b/diffusers/docs/source/en/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..dc40d9b142baf2e8b0ab0298a90131d353216c04
--- /dev/null
+++ b/diffusers/docs/source/en/_toctree.yml
@@ -0,0 +1,264 @@
+- sections:
+ - local: index
+ title: 🧨 Diffusers
+ - local: quicktour
+ title: Quicktour
+ - local: stable_diffusion
+ title: Effective and efficient diffusion
+ - local: installation
+ title: Installation
+ title: Get started
+- sections:
+ - local: tutorials/tutorial_overview
+ title: Overview
+ - local: using-diffusers/write_own_pipeline
+ title: Understanding models and schedulers
+ - local: tutorials/basic_training
+ title: Train a diffusion model
+ title: Tutorials
+- sections:
+ - sections:
+ - local: using-diffusers/loading_overview
+ title: Overview
+ - local: using-diffusers/loading
+ title: Load pipelines, models, and schedulers
+ - local: using-diffusers/schedulers
+ title: Load and compare different schedulers
+ - local: using-diffusers/custom_pipeline_overview
+ title: Load and add custom pipelines
+ - local: using-diffusers/kerascv
+ title: Load KerasCV Stable Diffusion checkpoints
+ title: Loading & Hub
+ - sections:
+ - local: using-diffusers/pipeline_overview
+ title: Overview
+ - local: using-diffusers/unconditional_image_generation
+ title: Unconditional image generation
+ - local: using-diffusers/conditional_image_generation
+ title: Text-to-image generation
+ - local: using-diffusers/img2img
+ title: Text-guided image-to-image
+ - local: using-diffusers/inpaint
+ title: Text-guided image-inpainting
+ - local: using-diffusers/depth2img
+ title: Text-guided depth-to-image
+ - local: using-diffusers/reusing_seeds
+ title: Improve image quality with deterministic generation
+ - local: using-diffusers/reproducibility
+ title: Create reproducible pipelines
+ - local: using-diffusers/custom_pipeline_examples
+ title: Community Pipelines
+ - local: using-diffusers/contribute_pipeline
+ title: How to contribute a Pipeline
+ - local: using-diffusers/using_safetensors
+ title: Using safetensors
+ - local: using-diffusers/stable_diffusion_jax_how_to
+ title: Stable Diffusion in JAX/Flax
+ - local: using-diffusers/weighted_prompts
+ title: Weighting Prompts
+ title: Pipelines for Inference
+ - sections:
+ - local: training/overview
+ title: Overview
+ - local: training/unconditional_training
+ title: Unconditional image generation
+ - local: training/text_inversion
+ title: Textual Inversion
+ - local: training/dreambooth
+ title: DreamBooth
+ - local: training/text2image
+ title: Text-to-image
+ - local: training/lora
+ title: Low-Rank Adaptation of Large Language Models (LoRA)
+ - local: training/controlnet
+ title: ControlNet
+ - local: training/instructpix2pix
+ title: InstructPix2Pix Training
+ title: Training
+ - sections:
+ - local: using-diffusers/rl
+ title: Reinforcement Learning
+ - local: using-diffusers/audio
+ title: Audio
+ - local: using-diffusers/other-modalities
+ title: Other Modalities
+ title: Taking Diffusers Beyond Images
+ title: Using Diffusers
+- sections:
+ - local: optimization/opt_overview
+ title: Overview
+ - local: optimization/fp16
+ title: Memory and Speed
+ - local: optimization/torch2.0
+ title: Torch2.0 support
+ - local: optimization/xformers
+ title: xFormers
+ - local: optimization/onnx
+ title: ONNX
+ - local: optimization/open_vino
+ title: OpenVINO
+ - local: optimization/mps
+ title: MPS
+ - local: optimization/habana
+ title: Habana Gaudi
+ title: Optimization/Special Hardware
+- sections:
+ - local: conceptual/philosophy
+ title: Philosophy
+ - local: using-diffusers/controlling_generation
+ title: Controlled generation
+ - local: conceptual/contribution
+ title: How to contribute?
+ - local: conceptual/ethical_guidelines
+ title: Diffusers' Ethical Guidelines
+ - local: conceptual/evaluation
+ title: Evaluating Diffusion Models
+ title: Conceptual Guides
+- sections:
+ - sections:
+ - local: api/models
+ title: Models
+ - local: api/diffusion_pipeline
+ title: Diffusion Pipeline
+ - local: api/logging
+ title: Logging
+ - local: api/configuration
+ title: Configuration
+ - local: api/outputs
+ title: Outputs
+ - local: api/loaders
+ title: Loaders
+ title: Main Classes
+ - sections:
+ - local: api/pipelines/overview
+ title: Overview
+ - local: api/pipelines/alt_diffusion
+ title: AltDiffusion
+ - local: api/pipelines/audio_diffusion
+ title: Audio Diffusion
+ - local: api/pipelines/audioldm
+ title: AudioLDM
+ - local: api/pipelines/cycle_diffusion
+ title: Cycle Diffusion
+ - local: api/pipelines/dance_diffusion
+ title: Dance Diffusion
+ - local: api/pipelines/ddim
+ title: DDIM
+ - local: api/pipelines/ddpm
+ title: DDPM
+ - local: api/pipelines/dit
+ title: DiT
+ - local: api/pipelines/latent_diffusion
+ title: Latent Diffusion
+ - local: api/pipelines/paint_by_example
+ title: PaintByExample
+ - local: api/pipelines/pndm
+ title: PNDM
+ - local: api/pipelines/repaint
+ title: RePaint
+ - local: api/pipelines/stable_diffusion_safe
+ title: Safe Stable Diffusion
+ - local: api/pipelines/score_sde_ve
+ title: Score SDE VE
+ - local: api/pipelines/semantic_stable_diffusion
+ title: Semantic Guidance
+ - local: api/pipelines/spectrogram_diffusion
+ title: "Spectrogram Diffusion"
+ - sections:
+ - local: api/pipelines/stable_diffusion/overview
+ title: Overview
+ - local: api/pipelines/stable_diffusion/text2img
+ title: Text-to-Image
+ - local: api/pipelines/stable_diffusion/img2img
+ title: Image-to-Image
+ - local: api/pipelines/stable_diffusion/inpaint
+ title: Inpaint
+ - local: api/pipelines/stable_diffusion/depth2img
+ title: Depth-to-Image
+ - local: api/pipelines/stable_diffusion/image_variation
+ title: Image-Variation
+ - local: api/pipelines/stable_diffusion/upscale
+ title: Super-Resolution
+ - local: api/pipelines/stable_diffusion/latent_upscale
+ title: Stable-Diffusion-Latent-Upscaler
+ - local: api/pipelines/stable_diffusion/pix2pix
+ title: InstructPix2Pix
+ - local: api/pipelines/stable_diffusion/attend_and_excite
+ title: Attend and Excite
+ - local: api/pipelines/stable_diffusion/pix2pix_zero
+ title: Pix2Pix Zero
+ - local: api/pipelines/stable_diffusion/self_attention_guidance
+ title: Self-Attention Guidance
+ - local: api/pipelines/stable_diffusion/panorama
+ title: MultiDiffusion Panorama
+ - local: api/pipelines/stable_diffusion/controlnet
+ title: Text-to-Image Generation with ControlNet Conditioning
+ - local: api/pipelines/stable_diffusion/model_editing
+ title: Text-to-Image Model Editing
+ title: Stable Diffusion
+ - local: api/pipelines/stable_diffusion_2
+ title: Stable Diffusion 2
+ - local: api/pipelines/stable_unclip
+ title: Stable unCLIP
+ - local: api/pipelines/stochastic_karras_ve
+ title: Stochastic Karras VE
+ - local: api/pipelines/text_to_video
+ title: Text-to-Video
+ - local: api/pipelines/unclip
+ title: UnCLIP
+ - local: api/pipelines/latent_diffusion_uncond
+ title: Unconditional Latent Diffusion
+ - local: api/pipelines/versatile_diffusion
+ title: Versatile Diffusion
+ - local: api/pipelines/vq_diffusion
+ title: VQ Diffusion
+ title: Pipelines
+ - sections:
+ - local: api/schedulers/overview
+ title: Overview
+ - local: api/schedulers/ddim
+ title: DDIM
+ - local: api/schedulers/ddim_inverse
+ title: DDIMInverse
+ - local: api/schedulers/ddpm
+ title: DDPM
+ - local: api/schedulers/deis
+ title: DEIS
+ - local: api/schedulers/dpm_discrete
+ title: DPM Discrete Scheduler
+ - local: api/schedulers/dpm_discrete_ancestral
+ title: DPM Discrete Scheduler with ancestral sampling
+ - local: api/schedulers/euler_ancestral
+ title: Euler Ancestral Scheduler
+ - local: api/schedulers/euler
+ title: Euler scheduler
+ - local: api/schedulers/heun
+ title: Heun Scheduler
+ - local: api/schedulers/ipndm
+ title: IPNDM
+ - local: api/schedulers/lms_discrete
+ title: Linear Multistep
+ - local: api/schedulers/multistep_dpm_solver
+ title: Multistep DPM-Solver
+ - local: api/schedulers/pndm
+ title: PNDM
+ - local: api/schedulers/repaint
+ title: RePaint Scheduler
+ - local: api/schedulers/singlestep_dpm_solver
+ title: Singlestep DPM-Solver
+ - local: api/schedulers/stochastic_karras_ve
+ title: Stochastic Kerras VE
+ - local: api/schedulers/unipc
+ title: UniPCMultistepScheduler
+ - local: api/schedulers/score_sde_ve
+ title: VE-SDE
+ - local: api/schedulers/score_sde_vp
+ title: VP-SDE
+ - local: api/schedulers/vq_diffusion
+ title: VQDiffusionScheduler
+ title: Schedulers
+ - sections:
+ - local: api/experimental/rl
+ title: RL Planning
+ title: Experimental Features
+ title: API
diff --git a/diffusers/docs/source/en/api/configuration.mdx b/diffusers/docs/source/en/api/configuration.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..2bbb42d9253804170a2312fa01522336a5cd7307
--- /dev/null
+++ b/diffusers/docs/source/en/api/configuration.mdx
@@ -0,0 +1,25 @@
+
+
+# Configuration
+
+Schedulers from [`~schedulers.scheduling_utils.SchedulerMixin`] and models from [`ModelMixin`] inherit from [`ConfigMixin`] which conveniently takes care of storing all the parameters that are
+passed to their respective `__init__` methods in a JSON-configuration file.
+
+## ConfigMixin
+
+[[autodoc]] ConfigMixin
+ - load_config
+ - from_config
+ - save_config
+ - to_json_file
+ - to_json_string
diff --git a/diffusers/docs/source/en/api/diffusion_pipeline.mdx b/diffusers/docs/source/en/api/diffusion_pipeline.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..280802d6a89ab8bd9181cb02d008d3f8970e220a
--- /dev/null
+++ b/diffusers/docs/source/en/api/diffusion_pipeline.mdx
@@ -0,0 +1,47 @@
+
+
+# Pipelines
+
+The [`DiffusionPipeline`] is the easiest way to load any pretrained diffusion pipeline from the [Hub](https://huggingface.co/models?library=diffusers) and to use it in inference.
+
+
+
+ One should not use the Diffusion Pipeline class for training or fine-tuning a diffusion model. Individual
+ components of diffusion pipelines are usually trained individually, so we suggest to directly work
+ with [`UNetModel`] and [`UNetConditionModel`].
+
+
+
+Any diffusion pipeline that is loaded with [`~DiffusionPipeline.from_pretrained`] will automatically
+detect the pipeline type, *e.g.* [`StableDiffusionPipeline`] and consequently load each component of the
+pipeline and pass them into the `__init__` function of the pipeline, *e.g.* [`~StableDiffusionPipeline.__init__`].
+
+Any pipeline object can be saved locally with [`~DiffusionPipeline.save_pretrained`].
+
+## DiffusionPipeline
+[[autodoc]] DiffusionPipeline
+ - all
+ - __call__
+ - device
+ - to
+ - components
+
+## ImagePipelineOutput
+By default diffusion pipelines return an object of class
+
+[[autodoc]] pipelines.ImagePipelineOutput
+
+## AudioPipelineOutput
+By default diffusion pipelines return an object of class
+
+[[autodoc]] pipelines.AudioPipelineOutput
diff --git a/diffusers/docs/source/en/api/experimental/rl.mdx b/diffusers/docs/source/en/api/experimental/rl.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..66c8db311b4ef8d34089ddfe31c7496b08be3416
--- /dev/null
+++ b/diffusers/docs/source/en/api/experimental/rl.mdx
@@ -0,0 +1,15 @@
+
+
+# TODO
+
+Coming soon!
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/loaders.mdx b/diffusers/docs/source/en/api/loaders.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..1d55bd03c0641d1a63e79e2fd26c444727595b23
--- /dev/null
+++ b/diffusers/docs/source/en/api/loaders.mdx
@@ -0,0 +1,30 @@
+
+
+# Loaders
+
+There are many ways to train adapter neural networks for diffusion models, such as
+- [Textual Inversion](./training/text_inversion.mdx)
+- [LoRA](https://github.com/cloneofsimo/lora)
+- [Hypernetworks](https://arxiv.org/abs/1609.09106)
+
+Such adapter neural networks often only consist of a fraction of the number of weights compared
+to the pretrained model and as such are very portable. The Diffusers library offers an easy-to-use
+API to load such adapter neural networks via the [`loaders.py` module](https://github.com/huggingface/diffusers/blob/main/src/diffusers/loaders.py).
+
+**Note**: This module is still highly experimental and prone to future changes.
+
+## LoaderMixins
+
+### UNet2DConditionLoadersMixin
+
+[[autodoc]] loaders.UNet2DConditionLoadersMixin
diff --git a/diffusers/docs/source/en/api/logging.mdx b/diffusers/docs/source/en/api/logging.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b52c0434f42d06de3085f3816a9093df14ea0212
--- /dev/null
+++ b/diffusers/docs/source/en/api/logging.mdx
@@ -0,0 +1,98 @@
+
+
+# Logging
+
+🧨 Diffusers has a centralized logging system, so that you can setup the verbosity of the library easily.
+
+Currently the default verbosity of the library is `WARNING`.
+
+To change the level of verbosity, just use one of the direct setters. For instance, here is how to change the verbosity
+to the INFO level.
+
+```python
+import diffusers
+
+diffusers.logging.set_verbosity_info()
+```
+
+You can also use the environment variable `DIFFUSERS_VERBOSITY` to override the default verbosity. You can set it
+to one of the following: `debug`, `info`, `warning`, `error`, `critical`. For example:
+
+```bash
+DIFFUSERS_VERBOSITY=error ./myprogram.py
+```
+
+Additionally, some `warnings` can be disabled by setting the environment variable
+`DIFFUSERS_NO_ADVISORY_WARNINGS` to a true value, like *1*. This will disable any warning that is logged using
+[`logger.warning_advice`]. For example:
+
+```bash
+DIFFUSERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
+```
+
+Here is an example of how to use the same logger as the library in your own module or script:
+
+```python
+from diffusers.utils import logging
+
+logging.set_verbosity_info()
+logger = logging.get_logger("diffusers")
+logger.info("INFO")
+logger.warning("WARN")
+```
+
+
+All the methods of this logging module are documented below, the main ones are
+[`logging.get_verbosity`] to get the current level of verbosity in the logger and
+[`logging.set_verbosity`] to set the verbosity to the level of your choice. In order (from the least
+verbose to the most verbose), those levels (with their corresponding int values in parenthesis) are:
+
+- `diffusers.logging.CRITICAL` or `diffusers.logging.FATAL` (int value, 50): only report the most
+ critical errors.
+- `diffusers.logging.ERROR` (int value, 40): only report errors.
+- `diffusers.logging.WARNING` or `diffusers.logging.WARN` (int value, 30): only reports error and
+ warnings. This the default level used by the library.
+- `diffusers.logging.INFO` (int value, 20): reports error, warnings and basic information.
+- `diffusers.logging.DEBUG` (int value, 10): report all information.
+
+By default, `tqdm` progress bars will be displayed during model download. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] can be used to suppress or unsuppress this behavior.
+
+## Base setters
+
+[[autodoc]] logging.set_verbosity_error
+
+[[autodoc]] logging.set_verbosity_warning
+
+[[autodoc]] logging.set_verbosity_info
+
+[[autodoc]] logging.set_verbosity_debug
+
+## Other functions
+
+[[autodoc]] logging.get_verbosity
+
+[[autodoc]] logging.set_verbosity
+
+[[autodoc]] logging.get_logger
+
+[[autodoc]] logging.enable_default_handler
+
+[[autodoc]] logging.disable_default_handler
+
+[[autodoc]] logging.enable_explicit_format
+
+[[autodoc]] logging.reset_format
+
+[[autodoc]] logging.enable_progress_bar
+
+[[autodoc]] logging.disable_progress_bar
diff --git a/diffusers/docs/source/en/api/models.mdx b/diffusers/docs/source/en/api/models.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..2361fd4f65972342f105d70d3317af126cd4e14c
--- /dev/null
+++ b/diffusers/docs/source/en/api/models.mdx
@@ -0,0 +1,107 @@
+
+
+# Models
+
+Diffusers contains pretrained models for popular algorithms and modules for creating the next set of diffusion models.
+The primary function of these models is to denoise an input sample, by modeling the distribution $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$.
+The models are built on the base class ['ModelMixin'] that is a `torch.nn.module` with basic functionality for saving and loading models both locally and from the HuggingFace hub.
+
+## ModelMixin
+[[autodoc]] ModelMixin
+
+## UNet2DOutput
+[[autodoc]] models.unet_2d.UNet2DOutput
+
+## UNet2DModel
+[[autodoc]] UNet2DModel
+
+## UNet1DOutput
+[[autodoc]] models.unet_1d.UNet1DOutput
+
+## UNet1DModel
+[[autodoc]] UNet1DModel
+
+## UNet2DConditionOutput
+[[autodoc]] models.unet_2d_condition.UNet2DConditionOutput
+
+## UNet2DConditionModel
+[[autodoc]] UNet2DConditionModel
+
+## UNet3DConditionOutput
+[[autodoc]] models.unet_3d_condition.UNet3DConditionOutput
+
+## UNet3DConditionModel
+[[autodoc]] UNet3DConditionModel
+
+## DecoderOutput
+[[autodoc]] models.vae.DecoderOutput
+
+## VQEncoderOutput
+[[autodoc]] models.vq_model.VQEncoderOutput
+
+## VQModel
+[[autodoc]] VQModel
+
+## AutoencoderKLOutput
+[[autodoc]] models.autoencoder_kl.AutoencoderKLOutput
+
+## AutoencoderKL
+[[autodoc]] AutoencoderKL
+
+## Transformer2DModel
+[[autodoc]] Transformer2DModel
+
+## Transformer2DModelOutput
+[[autodoc]] models.transformer_2d.Transformer2DModelOutput
+
+## TransformerTemporalModel
+[[autodoc]] models.transformer_temporal.TransformerTemporalModel
+
+## Transformer2DModelOutput
+[[autodoc]] models.transformer_temporal.TransformerTemporalModelOutput
+
+## PriorTransformer
+[[autodoc]] models.prior_transformer.PriorTransformer
+
+## PriorTransformerOutput
+[[autodoc]] models.prior_transformer.PriorTransformerOutput
+
+## ControlNetOutput
+[[autodoc]] models.controlnet.ControlNetOutput
+
+## ControlNetModel
+[[autodoc]] ControlNetModel
+
+## FlaxModelMixin
+[[autodoc]] FlaxModelMixin
+
+## FlaxUNet2DConditionOutput
+[[autodoc]] models.unet_2d_condition_flax.FlaxUNet2DConditionOutput
+
+## FlaxUNet2DConditionModel
+[[autodoc]] FlaxUNet2DConditionModel
+
+## FlaxDecoderOutput
+[[autodoc]] models.vae_flax.FlaxDecoderOutput
+
+## FlaxAutoencoderKLOutput
+[[autodoc]] models.vae_flax.FlaxAutoencoderKLOutput
+
+## FlaxAutoencoderKL
+[[autodoc]] FlaxAutoencoderKL
+
+## FlaxControlNetOutput
+[[autodoc]] models.controlnet_flax.FlaxControlNetOutput
+
+## FlaxControlNetModel
+[[autodoc]] FlaxControlNetModel
diff --git a/diffusers/docs/source/en/api/outputs.mdx b/diffusers/docs/source/en/api/outputs.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..9466f354541d55e66b65ef96ae2567f881d63fc0
--- /dev/null
+++ b/diffusers/docs/source/en/api/outputs.mdx
@@ -0,0 +1,55 @@
+
+
+# BaseOutputs
+
+All models have outputs that are instances of subclasses of [`~utils.BaseOutput`]. Those are
+data structures containing all the information returned by the model, but that can also be used as tuples or
+dictionaries.
+
+Let's see how this looks in an example:
+
+```python
+from diffusers import DDIMPipeline
+
+pipeline = DDIMPipeline.from_pretrained("google/ddpm-cifar10-32")
+outputs = pipeline()
+```
+
+The `outputs` object is a [`~pipelines.ImagePipelineOutput`], as we can see in the
+documentation of that class below, it means it has an image attribute.
+
+You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you will get `None`:
+
+```python
+outputs.images
+```
+
+or via keyword lookup
+
+```python
+outputs["images"]
+```
+
+When considering our `outputs` object as tuple, it only considers the attributes that don't have `None` values.
+Here for instance, we could retrieve images via indexing:
+
+```python
+outputs[:1]
+```
+
+which will return the tuple `(outputs.images)` for instance.
+
+## BaseOutput
+
+[[autodoc]] utils.BaseOutput
+ - to_tuple
diff --git a/diffusers/docs/source/en/api/pipelines/alt_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/alt_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..dbe3b079a201638b0129087b3f0de0de22323551
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/alt_diffusion.mdx
@@ -0,0 +1,83 @@
+
+
+# AltDiffusion
+
+AltDiffusion was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu.
+
+The abstract of the paper is the following:
+
+*In this work, we present a conceptually simple and effective method to train a strong bilingual multimodal representation model. Starting from the pretrained multimodal representation model CLIP released by OpenAI, we switched its text encoder with a pretrained multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art performances on a bunch of tasks including ImageNet-CN, Flicker30k- CN, and COCO-CN. Further, we obtain very close performances with CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding.*
+
+
+*Overview*:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [pipeline_alt_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion.py) | *Text-to-Image Generation* | - | -
+| [pipeline_alt_diffusion_img2img.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion_img2img.py) | *Image-to-Image Text-Guided Generation* | - |-
+
+## Tips
+
+- AltDiffusion is conceptually exactly the same as [Stable Diffusion](./api/pipelines/stable_diffusion/overview).
+
+- *Run AltDiffusion*
+
+AltDiffusion can be tested very easily with the [`AltDiffusionPipeline`], [`AltDiffusionImg2ImgPipeline`] and the `"BAAI/AltDiffusion-m9"` checkpoint exactly in the same way it is shown in the [Conditional Image Generation Guide](./using-diffusers/conditional_image_generation) and the [Image-to-Image Generation Guide](./using-diffusers/img2img).
+
+- *How to load and use different schedulers.*
+
+The alt diffusion pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the alt diffusion pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import AltDiffusionPipeline, EulerDiscreteScheduler
+
+>>> pipeline = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion-m9")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("BAAI/AltDiffusion-m9", subfolder="scheduler")
+>>> pipeline = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion-m9", scheduler=euler_scheduler)
+```
+
+
+- *How to convert all use cases with multiple or single pipeline*
+
+If you want to use all possible use cases in a single `DiffusionPipeline` we recommend using the `components` functionality to instantiate all components in the most memory-efficient way:
+
+```python
+>>> from diffusers import (
+... AltDiffusionPipeline,
+... AltDiffusionImg2ImgPipeline,
+... )
+
+>>> text2img = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion-m9")
+>>> img2img = AltDiffusionImg2ImgPipeline(**text2img.components)
+
+>>> # now you can use text2img(...) and img2img(...) just like the call methods of each respective pipeline
+```
+
+## AltDiffusionPipelineOutput
+[[autodoc]] pipelines.alt_diffusion.AltDiffusionPipelineOutput
+ - all
+ - __call__
+
+## AltDiffusionPipeline
+[[autodoc]] AltDiffusionPipeline
+ - all
+ - __call__
+
+## AltDiffusionImg2ImgPipeline
+[[autodoc]] AltDiffusionImg2ImgPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/audio_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/audio_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..9c7725367e8fd5eedae1fbd1412f43af76a1cf59
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/audio_diffusion.mdx
@@ -0,0 +1,98 @@
+
+
+# Audio Diffusion
+
+## Overview
+
+[Audio Diffusion](https://github.com/teticio/audio-diffusion) by Robert Dargavel Smith.
+
+Audio Diffusion leverages the recent advances in image generation using diffusion models by converting audio samples to
+and from mel spectrogram images.
+
+The original codebase of this implementation can be found [here](https://github.com/teticio/audio-diffusion), including
+training scripts and example notebooks.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_audio_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/audio_diffusion/pipeline_audio_diffusion.py) | *Unconditional Audio Generation* | [](https://colab.research.google.com/github/teticio/audio-diffusion/blob/master/notebooks/audio_diffusion_pipeline.ipynb) |
+
+
+## Examples:
+
+### Audio Diffusion
+
+```python
+import torch
+from IPython.display import Audio
+from diffusers import DiffusionPipeline
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-256").to(device)
+
+output = pipe()
+display(output.images[0])
+display(Audio(output.audios[0], rate=mel.get_sample_rate()))
+```
+
+### Latent Audio Diffusion
+
+```python
+import torch
+from IPython.display import Audio
+from diffusers import DiffusionPipeline
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+pipe = DiffusionPipeline.from_pretrained("teticio/latent-audio-diffusion-256").to(device)
+
+output = pipe()
+display(output.images[0])
+display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
+```
+
+### Audio Diffusion with DDIM (faster)
+
+```python
+import torch
+from IPython.display import Audio
+from diffusers import DiffusionPipeline
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-ddim-256").to(device)
+
+output = pipe()
+display(output.images[0])
+display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
+```
+
+### Variations, in-painting, out-painting etc.
+
+```python
+output = pipe(
+ raw_audio=output.audios[0, 0],
+ start_step=int(pipe.get_default_steps() / 2),
+ mask_start_secs=1,
+ mask_end_secs=1,
+)
+display(output.images[0])
+display(Audio(output.audios[0], rate=pipe.mel.get_sample_rate()))
+```
+
+## AudioDiffusionPipeline
+[[autodoc]] AudioDiffusionPipeline
+ - all
+ - __call__
+
+## Mel
+[[autodoc]] Mel
diff --git a/diffusers/docs/source/en/api/pipelines/audioldm.mdx b/diffusers/docs/source/en/api/pipelines/audioldm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f3987d2263ac649ee5a0c89a2152d54db5d9a323
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/audioldm.mdx
@@ -0,0 +1,82 @@
+
+
+# AudioLDM
+
+## Overview
+
+AudioLDM was proposed in [AudioLDM: Text-to-Audio Generation with Latent Diffusion Models](https://arxiv.org/abs/2301.12503) by Haohe Liu et al.
+
+Inspired by [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview), AudioLDM
+is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from [CLAP](https://huggingface.co/docs/transformers/main/model_doc/clap)
+latents. AudioLDM takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional
+sound effects, human speech and music.
+
+This pipeline was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original codebase can be found [here](https://github.com/haoheliu/AudioLDM).
+
+## Text-to-Audio
+
+The [`AudioLDMPipeline`] can be used to load pre-trained weights from [cvssp/audioldm](https://huggingface.co/cvssp/audioldm) and generate text-conditional audio outputs:
+
+```python
+from diffusers import AudioLDMPipeline
+import torch
+import scipy
+
+repo_id = "cvssp/audioldm"
+pipe = AudioLDMPipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
+pipe = pipe.to("cuda")
+
+prompt = "Techno music with a strong, upbeat tempo and high melodic riffs"
+audio = pipe(prompt, num_inference_steps=10, audio_length_in_s=5.0).audios[0]
+
+# save the audio sample as a .wav file
+scipy.io.wavfile.write("techno.wav", rate=16000, data=audio)
+```
+
+### Tips
+
+Prompts:
+* Descriptive prompt inputs work best: you can use adjectives to describe the sound (e.g. "high quality" or "clear") and make the prompt context specific (e.g., "water stream in a forest" instead of "stream").
+* It's best to use general terms like 'cat' or 'dog' instead of specific names or abstract objects that the model may not be familiar with.
+
+Inference:
+* The _quality_ of the predicted audio sample can be controlled by the `num_inference_steps` argument: higher steps give higher quality audio at the expense of slower inference.
+* The _length_ of the predicted audio sample can be controlled by varying the `audio_length_in_s` argument.
+
+### How to load and use different schedulers
+
+The AudioLDM pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers
+that can be used with the AudioLDM pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`],
+[`EulerAncestralDiscreteScheduler`] etc. We recommend using the [`DPMSolverMultistepScheduler`] as it's currently the fastest
+scheduler there is.
+
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`]
+method, or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the
+[`DPMSolverMultistepScheduler`], you can do the following:
+
+```python
+>>> from diffusers import AudioLDMPipeline, DPMSolverMultistepScheduler
+>>> import torch
+
+>>> pipeline = AudioLDMPipeline.from_pretrained("cvssp/audioldm", torch_dtype=torch.float16)
+>>> pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> dpm_scheduler = DPMSolverMultistepScheduler.from_pretrained("cvssp/audioldm", subfolder="scheduler")
+>>> pipeline = AudioLDMPipeline.from_pretrained("cvssp/audioldm", scheduler=dpm_scheduler, torch_dtype=torch.float16)
+```
+
+## AudioLDMPipeline
+[[autodoc]] AudioLDMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/cycle_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/cycle_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b8fbff5d7157dc08cf15ea051f4d019b74c39ff5
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/cycle_diffusion.mdx
@@ -0,0 +1,100 @@
+
+
+# Cycle Diffusion
+
+## Overview
+
+Cycle Diffusion is a Text-Guided Image-to-Image Generation model proposed in [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) by Chen Henry Wu, Fernando De la Torre.
+
+The abstract of the paper is the following:
+
+*Diffusion models have achieved unprecedented performance in generative modeling. The commonly-adopted formulation of the latent code of diffusion models is a sequence of gradually denoised samples, as opposed to the simpler (e.g., Gaussian) latent space of GANs, VAEs, and normalizing flows. This paper provides an alternative, Gaussian formulation of the latent space of various diffusion models, as well as an invertible DPM-Encoder that maps images into the latent space. While our formulation is purely based on the definition of diffusion models, we demonstrate several intriguing consequences. (1) Empirically, we observe that a common latent space emerges from two diffusion models trained independently on related domains. In light of this finding, we propose CycleDiffusion, which uses DPM-Encoder for unpaired image-to-image translation. Furthermore, applying CycleDiffusion to text-to-image diffusion models, we show that large-scale text-to-image diffusion models can be used as zero-shot image-to-image editors. (2) One can guide pre-trained diffusion models and GANs by controlling the latent codes in a unified, plug-and-play formulation based on energy-based models. Using the CLIP model and a face recognition model as guidance, we demonstrate that diffusion models have better coverage of low-density sub-populations and individuals than GANs.*
+
+*Tips*:
+- The Cycle Diffusion pipeline is fully compatible with any [Stable Diffusion](./stable_diffusion) checkpoints
+- Currently Cycle Diffusion only works with the [`DDIMScheduler`].
+
+*Example*:
+
+In the following we should how to best use the [`CycleDiffusionPipeline`]
+
+```python
+import requests
+import torch
+from PIL import Image
+from io import BytesIO
+
+from diffusers import CycleDiffusionPipeline, DDIMScheduler
+
+# load the pipeline
+# make sure you're logged in with `huggingface-cli login`
+model_id_or_path = "CompVis/stable-diffusion-v1-4"
+scheduler = DDIMScheduler.from_pretrained(model_id_or_path, subfolder="scheduler")
+pipe = CycleDiffusionPipeline.from_pretrained(model_id_or_path, scheduler=scheduler).to("cuda")
+
+# let's download an initial image
+url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/An%20astronaut%20riding%20a%20horse.png"
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((512, 512))
+init_image.save("horse.png")
+
+# let's specify a prompt
+source_prompt = "An astronaut riding a horse"
+prompt = "An astronaut riding an elephant"
+
+# call the pipeline
+image = pipe(
+ prompt=prompt,
+ source_prompt=source_prompt,
+ image=init_image,
+ num_inference_steps=100,
+ eta=0.1,
+ strength=0.8,
+ guidance_scale=2,
+ source_guidance_scale=1,
+).images[0]
+
+image.save("horse_to_elephant.png")
+
+# let's try another example
+# See more samples at the original repo: https://github.com/ChenWu98/cycle-diffusion
+url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/A%20black%20colored%20car.png"
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((512, 512))
+init_image.save("black.png")
+
+source_prompt = "A black colored car"
+prompt = "A blue colored car"
+
+# call the pipeline
+torch.manual_seed(0)
+image = pipe(
+ prompt=prompt,
+ source_prompt=source_prompt,
+ image=init_image,
+ num_inference_steps=100,
+ eta=0.1,
+ strength=0.85,
+ guidance_scale=3,
+ source_guidance_scale=1,
+).images[0]
+
+image.save("black_to_blue.png")
+```
+
+## CycleDiffusionPipeline
+[[autodoc]] CycleDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/dance_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/dance_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..92b5b9f877bc8474ad61d5f6815615e3922e23b8
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/dance_diffusion.mdx
@@ -0,0 +1,34 @@
+
+
+# Dance Diffusion
+
+## Overview
+
+[Dance Diffusion](https://github.com/Harmonai-org/sample-generator) by Zach Evans.
+
+Dance Diffusion is the first in a suite of generative audio tools for producers and musicians to be released by Harmonai.
+For more info or to get involved in the development of these tools, please visit https://harmonai.org and fill out the form on the front page.
+
+The original codebase of this implementation can be found [here](https://github.com/Harmonai-org/sample-generator).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_dance_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/dance_diffusion/pipeline_dance_diffusion.py) | *Unconditional Audio Generation* | - |
+
+
+## DanceDiffusionPipeline
+[[autodoc]] DanceDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/ddim.mdx b/diffusers/docs/source/en/api/pipelines/ddim.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..3adcb375b4481b0047479929c9cd1f89034aae99
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/ddim.mdx
@@ -0,0 +1,36 @@
+
+
+# DDIM
+
+## Overview
+
+[Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) (DDIM) by Jiaming Song, Chenlin Meng and Stefano Ermon.
+
+The abstract of the paper is the following:
+
+Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples 10× to 50× faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.
+
+The original codebase of this paper can be found here: [ermongroup/ddim](https://github.com/ermongroup/ddim).
+For questions, feel free to contact the author on [tsong.me](https://tsong.me/).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddim/pipeline_ddim.py) | *Unconditional Image Generation* | - |
+
+
+## DDIMPipeline
+[[autodoc]] DDIMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/ddpm.mdx b/diffusers/docs/source/en/api/pipelines/ddpm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..1be71964041c7bce5300d7177657594a90cdbf2f
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/ddpm.mdx
@@ -0,0 +1,37 @@
+
+
+# DDPM
+
+## Overview
+
+[Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
+ (DDPM) by Jonathan Ho, Ajay Jain and Pieter Abbeel proposes the diffusion based model of the same name, but in the context of the 🤗 Diffusers library, DDPM refers to the discrete denoising scheduler from the paper as well as the pipeline.
+
+The abstract of the paper is the following:
+
+We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.
+
+The original codebase of this paper can be found [here](https://github.com/hojonathanho/diffusion).
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddpm/pipeline_ddpm.py) | *Unconditional Image Generation* | - |
+
+
+# DDPMPipeline
+[[autodoc]] DDPMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/dit.mdx b/diffusers/docs/source/en/api/pipelines/dit.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..ce96749a1720ba3ee0da67728cd702292f6b6637
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/dit.mdx
@@ -0,0 +1,59 @@
+
+
+# Scalable Diffusion Models with Transformers (DiT)
+
+## Overview
+
+[Scalable Diffusion Models with Transformers](https://arxiv.org/abs/2212.09748) (DiT) by William Peebles and Saining Xie.
+
+The abstract of the paper is the following:
+
+*We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops -- through increased transformer depth/width or increased number of input tokens -- consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.*
+
+The original codebase of this paper can be found here: [facebookresearch/dit](https://github.com/facebookresearch/dit).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_dit.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/dit/pipeline_dit.py) | *Conditional Image Generation* | - |
+
+
+## Usage example
+
+```python
+from diffusers import DiTPipeline, DPMSolverMultistepScheduler
+import torch
+
+pipe = DiTPipeline.from_pretrained("facebook/DiT-XL-2-256", torch_dtype=torch.float16)
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+
+# pick words from Imagenet class labels
+pipe.labels # to print all available words
+
+# pick words that exist in ImageNet
+words = ["white shark", "umbrella"]
+
+class_ids = pipe.get_label_ids(words)
+
+generator = torch.manual_seed(33)
+output = pipe(class_labels=class_ids, num_inference_steps=25, generator=generator)
+
+image = output.images[0] # label 'white shark'
+```
+
+## DiTPipeline
+[[autodoc]] DiTPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/latent_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/latent_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..72c159e90d92ac31ccaeda3869687313ae0593ed
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/latent_diffusion.mdx
@@ -0,0 +1,49 @@
+
+
+# Latent Diffusion
+
+## Overview
+
+Latent Diffusion was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer.
+
+The abstract of the paper is the following:
+
+*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
+
+The original codebase can be found [here](https://github.com/CompVis/latent-diffusion).
+
+## Tips:
+
+-
+-
+-
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_latent_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py) | *Text-to-Image Generation* | - |
+| [pipeline_latent_diffusion_superresolution.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py) | *Super Resolution* | - |
+
+## Examples:
+
+
+## LDMTextToImagePipeline
+[[autodoc]] LDMTextToImagePipeline
+ - all
+ - __call__
+
+## LDMSuperResolutionPipeline
+[[autodoc]] LDMSuperResolutionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/latent_diffusion_uncond.mdx b/diffusers/docs/source/en/api/pipelines/latent_diffusion_uncond.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..c293ebb9400e7235ac79b510430fbf3662ed2240
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/latent_diffusion_uncond.mdx
@@ -0,0 +1,42 @@
+
+
+# Unconditional Latent Diffusion
+
+## Overview
+
+Unconditional Latent Diffusion was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer.
+
+The abstract of the paper is the following:
+
+*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
+
+The original codebase can be found [here](https://github.com/CompVis/latent-diffusion).
+
+## Tips:
+
+-
+-
+-
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_latent_diffusion_uncond.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion_uncond/pipeline_latent_diffusion_uncond.py) | *Unconditional Image Generation* | - |
+
+## Examples:
+
+## LDMPipeline
+[[autodoc]] LDMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/overview.mdx b/diffusers/docs/source/en/api/pipelines/overview.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..3b0e7c66152f5506418e3cfe9aa1861fa7e7e20b
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/overview.mdx
@@ -0,0 +1,213 @@
+
+
+# Pipelines
+
+Pipelines provide a simple way to run state-of-the-art diffusion models in inference.
+Most diffusion systems consist of multiple independently-trained models and highly adaptable scheduler
+components - all of which are needed to have a functioning end-to-end diffusion system.
+
+As an example, [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) has three independently trained models:
+- [Autoencoder](./api/models#vae)
+- [Conditional Unet](./api/models#UNet2DConditionModel)
+- [CLIP text encoder](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/clip#transformers.CLIPTextModel)
+- a scheduler component, [scheduler](./api/scheduler#pndm),
+- a [CLIPImageProcessor](https://huggingface.co/docs/transformers/v4.27.1/en/model_doc/clip#transformers.CLIPImageProcessor),
+- as well as a [safety checker](./stable_diffusion#safety_checker).
+All of these components are necessary to run stable diffusion in inference even though they were trained
+or created independently from each other.
+
+To that end, we strive to offer all open-sourced, state-of-the-art diffusion system under a unified API.
+More specifically, we strive to provide pipelines that
+- 1. can load the officially published weights and yield 1-to-1 the same outputs as the original implementation according to the corresponding paper (*e.g.* [LDMTextToImagePipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/latent_diffusion), uses the officially released weights of [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)),
+- 2. have a simple user interface to run the model in inference (see the [Pipelines API](#pipelines-api) section),
+- 3. are easy to understand with code that is self-explanatory and can be read along-side the official paper (see [Pipelines summary](#pipelines-summary)),
+- 4. can easily be contributed by the community (see the [Contribution](#contribution) section).
+
+**Note** that pipelines do not (and should not) offer any training functionality.
+If you are looking for *official* training examples, please have a look at [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+
+## 🧨 Diffusers Summary
+
+The following table summarizes all officially supported pipelines, their corresponding paper, and if
+available a colab notebook to directly try them out.
+
+
+| Pipeline | Paper | Tasks | Colab
+|---|---|:---:|:---:|
+| [alt_diffusion](./alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation | -
+| [audio_diffusion](./audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio_diffusion.git) | Unconditional Audio Generation |
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+| [cycle_diffusion](./cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [dance_diffusion](./dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
+| [ddpm](./ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
+| [ddim](./ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [latent_diffusion](./latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [score_sde_ve](./score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [score_sde_vp](./score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [semantic_stable_diffusion](./semantic_stable_diffusion) | [**SEGA: Instructing Diffusion using Semantic Dimensions**](https://arxiv.org/abs/2301.12247) | Text-to-Image Generation |
+| [stable_diffusion_text2img](./stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
+| [stable_diffusion_img2img](./stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+| [stable_diffusion_inpaint](./stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
+| [stable_diffusion_panorama](./stable_diffusion/panorama) | [**MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation**](https://arxiv.org/abs/2302.08113) | Text-Guided Panorama View Generation |
+| [stable_diffusion_pix2pix](./stable_diffusion/pix2pix) | [**InstructPix2Pix: Learning to Follow Image Editing Instructions**](https://arxiv.org/abs/2211.09800) | Text-Based Image Editing |
+| [stable_diffusion_pix2pix_zero](./stable_diffusion/pix2pix_zero) | [**Zero-shot Image-to-Image Translation**](https://arxiv.org/abs/2302.03027) | Text-Based Image Editing |
+| [stable_diffusion_attend_and_excite](./stable_diffusion/attend_and_excite) | [**Attend and Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models**](https://arxiv.org/abs/2301.13826) | Text-to-Image Generation |
+| [stable_diffusion_self_attention_guidance](./stable_diffusion/self_attention_guidance) | [**Self-Attention Guidance**](https://arxiv.org/abs/2210.00939) | Text-to-Image Generation |
+| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [**Stable Diffusion Image Variations**](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
+| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [**Stable Diffusion Latent Upscaler**](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_2](./stable_diffusion_2/) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
+| [stable_diffusion_2](./stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_2](./stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Depth-to-Image Text-Guided Generation |
+| [stable_diffusion_2](./stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_safe](./stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb)
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
+| [stochastic_karras_ve](./stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [text_to_video_sd](./api/pipelines/text_to_video) | [Modelscope's Text-to-video-synthesis Model in Open Domain](https://modelscope.cn/models/damo/text-to-video-synthesis/summary) | Text-to-Video Generation |
+| [unclip](./unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
+| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
+
+
+**Note**: Pipelines are simple examples of how to play around with the diffusion systems as described in the corresponding papers.
+
+However, most of them can be adapted to use different scheduler components or even different model components. Some pipeline examples are shown in the [Examples](#examples) below.
+
+## Pipelines API
+
+Diffusion models often consist of multiple independently-trained models or other previously existing components.
+
+
+Each model has been trained independently on a different task and the scheduler can easily be swapped out and replaced with a different one.
+During inference, we however want to be able to easily load all components and use them in inference - even if one component, *e.g.* CLIP's text encoder, originates from a different library, such as [Transformers](https://github.com/huggingface/transformers). To that end, all pipelines provide the following functionality:
+
+- [`from_pretrained` method](../diffusion_pipeline) that accepts a Hugging Face Hub repository id, *e.g.* [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) or a path to a local directory, *e.g.*
+"./stable-diffusion". To correctly retrieve which models and components should be loaded, one has to provide a `model_index.json` file, *e.g.* [runwayml/stable-diffusion-v1-5/model_index.json](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json), which defines all components that should be
+loaded into the pipelines. More specifically, for each model/component one needs to define the format `: ["", ""]`. `` is the attribute name given to the loaded instance of `` which can be found in the library or pipeline folder called `""`.
+- [`save_pretrained`](../diffusion_pipeline) that accepts a local path, *e.g.* `./stable-diffusion` under which all models/components of the pipeline will be saved. For each component/model a folder is created inside the local path that is named after the given attribute name, *e.g.* `./stable_diffusion/unet`.
+In addition, a `model_index.json` file is created at the root of the local path, *e.g.* `./stable_diffusion/model_index.json` so that the complete pipeline can again be instantiated
+from the local path.
+- [`to`](../diffusion_pipeline) which accepts a `string` or `torch.device` to move all models that are of type `torch.nn.Module` to the passed device. The behavior is fully analogous to [PyTorch's `to` method](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.to).
+- [`__call__`] method to use the pipeline in inference. `__call__` defines inference logic of the pipeline and should ideally encompass all aspects of it, from pre-processing to forwarding tensors to the different models and schedulers, as well as post-processing. The API of the `__call__` method can strongly vary from pipeline to pipeline. *E.g.* a text-to-image pipeline, such as [`StableDiffusionPipeline`](./stable_diffusion) should accept among other things the text prompt to generate the image. A pure image generation pipeline, such as [DDPMPipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/ddpm) on the other hand can be run without providing any inputs. To better understand what inputs can be adapted for
+each pipeline, one should look directly into the respective pipeline.
+
+**Note**: All pipelines have PyTorch's autograd disabled by decorating the `__call__` method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should
+not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community).
+
+## Contribution
+
+We are more than happy about any contribution to the officially supported pipelines 🤗. We aspire
+all of our pipelines to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
+
+- **Self-contained**: A pipeline shall be as self-contained as possible. More specifically, this means that all functionality should be either directly defined in the pipeline file itself, should be inherited from (and only from) the [`DiffusionPipeline` class](.../diffusion_pipeline) or be directly attached to the model and scheduler components of the pipeline.
+- **Easy-to-use**: Pipelines should be extremely easy to use - one should be able to load the pipeline and
+use it for its designated task, *e.g.* text-to-image generation, in just a couple of lines of code. Most
+logic including pre-processing, an unrolled diffusion loop, and post-processing should all happen inside the `__call__` method.
+- **Easy-to-tweak**: Certain pipelines will not be able to handle all use cases and tasks that you might like them to. If you want to use a certain pipeline for a specific use case that is not yet supported, you might have to copy the pipeline file and tweak the code to your needs. We try to make the pipeline code as readable as possible so that each part –from pre-processing to diffusing to post-processing– can easily be adapted. If you would like the community to benefit from your customized pipeline, we would love to see a contribution to our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community). If you feel that an important pipeline should be part of the official pipelines but isn't, a contribution to the [official pipelines](./overview) would be even better.
+- **One-purpose-only**: Pipelines should be used for one task and one task only. Even if two tasks are very similar from a modeling point of view, *e.g.* image2image translation and in-painting, pipelines shall be used for one task only to keep them *easy-to-tweak* and *readable*.
+
+## Examples
+
+### Text-to-Image generation with Stable Diffusion
+
+```python
+# make sure you're logged in with `huggingface-cli login`
+from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
+
+pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+pipe = pipe.to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+image = pipe(prompt).images[0]
+
+image.save("astronaut_rides_horse.png")
+```
+
+### Image-to-Image text-guided generation with Stable Diffusion
+
+The `StableDiffusionImg2ImgPipeline` lets you pass a text prompt and an initial image to condition the generation of new images.
+
+```python
+import requests
+from PIL import Image
+from io import BytesIO
+
+from diffusers import StableDiffusionImg2ImgPipeline
+
+# load the pipeline
+device = "cuda"
+pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to(
+ device
+)
+
+# let's download an initial image
+url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((768, 512))
+
+prompt = "A fantasy landscape, trending on artstation"
+
+images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
+
+images[0].save("fantasy_landscape.png")
+```
+You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+
+### Tweak prompts reusing seeds and latents
+
+You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
+
+
+### In-painting using Stable Diffusion
+
+The `StableDiffusionInpaintPipeline` lets you edit specific parts of an image by providing a mask and text prompt.
+
+```python
+import PIL
+import requests
+import torch
+from io import BytesIO
+
+from diffusers import StableDiffusionInpaintPipeline
+
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+init_image = download_image(img_url).resize((512, 512))
+mask_image = download_image(mask_url).resize((512, 512))
+
+pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting",
+ torch_dtype=torch.float16,
+)
+pipe = pipe.to("cuda")
+
+prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
+```
+
+You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
diff --git a/diffusers/docs/source/en/api/pipelines/paint_by_example.mdx b/diffusers/docs/source/en/api/pipelines/paint_by_example.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..5abb3406db448fdbeab14b2626bd17621214d819
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/paint_by_example.mdx
@@ -0,0 +1,74 @@
+
+
+# PaintByExample
+
+## Overview
+
+[Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) by Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, Fang Wen.
+
+The abstract of the paper is the following:
+
+*Language-guided image editing has achieved great success recently. In this paper, for the first time, we investigate exemplar-guided image editing for more precise control. We achieve this goal by leveraging self-supervised training to disentangle and re-organize the source image and the exemplar. However, the naive approach will cause obvious fusing artifacts. We carefully analyze it and propose an information bottleneck and strong augmentations to avoid the trivial solution of directly copying and pasting the exemplar image. Meanwhile, to ensure the controllability of the editing process, we design an arbitrary shape mask for the exemplar image and leverage the classifier-free guidance to increase the similarity to the exemplar image. The whole framework involves a single forward of the diffusion model without any iterative optimization. We demonstrate that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity.*
+
+The original codebase can be found [here](https://github.com/Fantasy-Studio/Paint-by-Example).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_paint_by_example.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py) | *Image-Guided Image Painting* | - |
+
+## Tips
+
+- PaintByExample is supported by the official [Fantasy-Studio/Paint-by-Example](https://huggingface.co/Fantasy-Studio/Paint-by-Example) checkpoint. The checkpoint has been warm-started from the [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4) and with the objective to inpaint partly masked images conditioned on example / reference images
+- To quickly demo *PaintByExample*, please have a look at [this demo](https://huggingface.co/spaces/Fantasy-Studio/Paint-by-Example)
+- You can run the following code snippet as an example:
+
+
+```python
+# !pip install diffusers transformers
+
+import PIL
+import requests
+import torch
+from io import BytesIO
+from diffusers import DiffusionPipeline
+
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+img_url = "https://raw.githubusercontent.com/Fantasy-Studio/Paint-by-Example/main/examples/image/example_1.png"
+mask_url = "https://raw.githubusercontent.com/Fantasy-Studio/Paint-by-Example/main/examples/mask/example_1.png"
+example_url = "https://raw.githubusercontent.com/Fantasy-Studio/Paint-by-Example/main/examples/reference/example_1.jpg"
+
+init_image = download_image(img_url).resize((512, 512))
+mask_image = download_image(mask_url).resize((512, 512))
+example_image = download_image(example_url).resize((512, 512))
+
+pipe = DiffusionPipeline.from_pretrained(
+ "Fantasy-Studio/Paint-by-Example",
+ torch_dtype=torch.float16,
+)
+pipe = pipe.to("cuda")
+
+image = pipe(image=init_image, mask_image=mask_image, example_image=example_image).images[0]
+image
+```
+
+## PaintByExamplePipeline
+[[autodoc]] PaintByExamplePipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/pndm.mdx b/diffusers/docs/source/en/api/pipelines/pndm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..43625fdfbe5206e01dcb11c85e86d31737d3c6ee
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/pndm.mdx
@@ -0,0 +1,35 @@
+
+
+# PNDM
+
+## Overview
+
+[Pseudo Numerical methods for Diffusion Models on manifolds](https://arxiv.org/abs/2202.09778) (PNDM) by Luping Liu, Yi Ren, Zhijie Lin and Zhou Zhao.
+
+The abstract of the paper is the following:
+
+Denoising Diffusion Probabilistic Models (DDPMs) can generate high-quality samples such as image and audio samples. However, DDPMs require hundreds to thousands of iterations to produce final samples. Several prior works have successfully accelerated DDPMs through adjusting the variance schedule (e.g., Improved Denoising Diffusion Probabilistic Models) or the denoising equation (e.g., Denoising Diffusion Implicit Models (DDIMs)). However, these acceleration methods cannot maintain the quality of samples and even introduce new noise at a high speedup rate, which limit their practicability. To accelerate the inference process while keeping the sample quality, we provide a fresh perspective that DDPMs should be treated as solving differential equations on manifolds. Under such a perspective, we propose pseudo numerical methods for diffusion models (PNDMs). Specifically, we figure out how to solve differential equations on manifolds and show that DDIMs are simple cases of pseudo numerical methods. We change several classical numerical methods to corresponding pseudo numerical methods and find that the pseudo linear multi-step method is the best in most situations. According to our experiments, by directly using pre-trained models on Cifar10, CelebA and LSUN, PNDMs can generate higher quality synthetic images with only 50 steps compared with 1000-step DDIMs (20x speedup), significantly outperform DDIMs with 250 steps (by around 0.4 in FID) and have good generalization on different variance schedules.
+
+The original codebase can be found [here](https://github.com/luping-liu/PNDM).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pndm/pipeline_pndm.py) | *Unconditional Image Generation* | - |
+
+
+## PNDMPipeline
+[[autodoc]] PNDMPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/repaint.mdx b/diffusers/docs/source/en/api/pipelines/repaint.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..927398d0bf54119684dae652ce9d2c86ba34bc5c
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/repaint.mdx
@@ -0,0 +1,77 @@
+
+
+# RePaint
+
+## Overview
+
+[RePaint: Inpainting using Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2201.09865) (PNDM) by Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, Luc Van Gool.
+
+The abstract of the paper is the following:
+
+Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks.
+RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions.
+
+The original codebase can be found [here](https://github.com/andreas128/RePaint).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|-------------------------------------------------------------------------------------------------------------------------------|--------------------|:---:|
+| [pipeline_repaint.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/repaint/pipeline_repaint.py) | *Image Inpainting* | - |
+
+## Usage example
+
+```python
+from io import BytesIO
+
+import torch
+
+import PIL
+import requests
+from diffusers import RePaintPipeline, RePaintScheduler
+
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+img_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/celeba_hq_256.png"
+mask_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/mask_256.png"
+
+# Load the original image and the mask as PIL images
+original_image = download_image(img_url).resize((256, 256))
+mask_image = download_image(mask_url).resize((256, 256))
+
+# Load the RePaint scheduler and pipeline based on a pretrained DDPM model
+scheduler = RePaintScheduler.from_pretrained("google/ddpm-ema-celebahq-256")
+pipe = RePaintPipeline.from_pretrained("google/ddpm-ema-celebahq-256", scheduler=scheduler)
+pipe = pipe.to("cuda")
+
+generator = torch.Generator(device="cuda").manual_seed(0)
+output = pipe(
+ original_image=original_image,
+ mask_image=mask_image,
+ num_inference_steps=250,
+ eta=0.0,
+ jump_length=10,
+ jump_n_sample=10,
+ generator=generator,
+)
+inpainted_image = output.images[0]
+```
+
+## RePaintPipeline
+[[autodoc]] RePaintPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/score_sde_ve.mdx b/diffusers/docs/source/en/api/pipelines/score_sde_ve.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..42253e301f4eaf0d34976439e5539201eb257237
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/score_sde_ve.mdx
@@ -0,0 +1,36 @@
+
+
+# Score SDE VE
+
+## Overview
+
+[Score-Based Generative Modeling through Stochastic Differential Equations](https://arxiv.org/abs/2011.13456) (Score SDE) by Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon and Ben Poole.
+
+The abstract of the paper is the following:
+
+Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (\aka, score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in score-based generative modeling and diffusion probabilistic modeling, allowing for new sampling procedures and new modeling capabilities. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, but additionally enables exact likelihood computation, and improved sampling efficiency. In addition, we provide a new way to solve inverse problems with score-based models, as demonstrated with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 2.99 bits/dim, and demonstrate high fidelity generation of 1024 x 1024 images for the first time from a score-based generative model.
+
+The original codebase can be found [here](https://github.com/yang-song/score_sde_pytorch).
+
+This pipeline implements the Variance Expanding (VE) variant of the method.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_score_sde_ve.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_ve/pipeline_score_sde_ve.py) | *Unconditional Image Generation* | - |
+
+## ScoreSdeVePipeline
+[[autodoc]] ScoreSdeVePipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/semantic_stable_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/semantic_stable_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b4562cf0c389bb917b3f075f279c347442dfdfa9
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/semantic_stable_diffusion.mdx
@@ -0,0 +1,79 @@
+
+
+# Semantic Guidance
+
+Semantic Guidance for Diffusion Models was proposed in [SEGA: Instructing Diffusion using Semantic Dimensions](https://arxiv.org/abs/2301.12247) and provides strong semantic control over the image generation.
+Small changes to the text prompt usually result in entirely different output images. However, with SEGA a variety of changes to the image are enabled that can be controlled easily and intuitively, and stay true to the original image composition.
+
+The abstract of the paper is the following:
+
+*Text-to-image diffusion models have recently received a lot of interest for their astonishing ability to produce high-fidelity images from text only. However, achieving one-shot generation that aligns with the user's intent is nearly impossible, yet small changes to the input prompt often result in very different images. This leaves the user with little semantic control. To put the user in control, we show how to interact with the diffusion process to flexibly steer it along semantic directions. This semantic guidance (SEGA) allows for subtle and extensive edits, changes in composition and style, as well as optimizing the overall artistic conception. We demonstrate SEGA's effectiveness on a variety of tasks and provide evidence for its versatility and flexibility.*
+
+
+*Overview*:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [pipeline_semantic_stable_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/ml-research/semantic-image-editing/blob/main/examples/SemanticGuidance.ipynb) | [Coming Soon](https://huggingface.co/AIML-TUDA)
+
+## Tips
+
+- The Semantic Guidance pipeline can be used with any [Stable Diffusion](./stable_diffusion/text2img) checkpoint.
+
+### Run Semantic Guidance
+
+The interface of [`SemanticStableDiffusionPipeline`] provides several additional parameters to influence the image generation.
+Exemplary usage may look like this:
+
+```python
+import torch
+from diffusers import SemanticStableDiffusionPipeline
+
+pipe = SemanticStableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
+pipe = pipe.to("cuda")
+
+out = pipe(
+ prompt="a photo of the face of a woman",
+ num_images_per_prompt=1,
+ guidance_scale=7,
+ editing_prompt=[
+ "smiling, smile", # Concepts to apply
+ "glasses, wearing glasses",
+ "curls, wavy hair, curly hair",
+ "beard, full beard, mustache",
+ ],
+ reverse_editing_direction=[False, False, False, False], # Direction of guidance i.e. increase all concepts
+ edit_warmup_steps=[10, 10, 10, 10], # Warmup period for each concept
+ edit_guidance_scale=[4, 5, 5, 5.4], # Guidance scale for each concept
+ edit_threshold=[
+ 0.99,
+ 0.975,
+ 0.925,
+ 0.96,
+ ], # Threshold for each concept. Threshold equals the percentile of the latent space that will be discarded. I.e. threshold=0.99 uses 1% of the latent dimensions
+ edit_momentum_scale=0.3, # Momentum scale that will be added to the latent guidance
+ edit_mom_beta=0.6, # Momentum beta
+ edit_weights=[1, 1, 1, 1, 1], # Weights of the individual concepts against each other
+)
+```
+
+For more examples check the Colab notebook.
+
+## StableDiffusionSafePipelineOutput
+[[autodoc]] pipelines.semantic_stable_diffusion.SemanticStableDiffusionPipelineOutput
+ - all
+
+## SemanticStableDiffusionPipeline
+[[autodoc]] SemanticStableDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/spectrogram_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/spectrogram_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..c98300fe791f054807665373b70d6526b5219682
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/spectrogram_diffusion.mdx
@@ -0,0 +1,54 @@
+
+
+# Multi-instrument Music Synthesis with Spectrogram Diffusion
+
+## Overview
+
+[Spectrogram Diffusion](https://arxiv.org/abs/2206.05408) by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
+
+An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
+
+The original codebase of this implementation can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion).
+
+## Model
+
+
+
+As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_spectrogram_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion) | *Unconditional Audio Generation* | - |
+
+
+## Example usage
+
+```python
+from diffusers import SpectrogramDiffusionPipeline, MidiProcessor
+
+pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
+pipe = pipe.to("cuda")
+processor = MidiProcessor()
+
+# Download MIDI from: wget http://www.piano-midi.de/midis/beethoven/beethoven_hammerklavier_2.mid
+output = pipe(processor("beethoven_hammerklavier_2.mid"))
+
+audio = output.audios[0]
+```
+
+## SpectrogramDiffusionPipeline
+[[autodoc]] SpectrogramDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/attend_and_excite.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/attend_and_excite.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..1a329bc442e7bb6f5e20d60a679c12acf1855c90
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/attend_and_excite.mdx
@@ -0,0 +1,75 @@
+
+
+# Attend and Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
+
+## Overview
+
+Attend and Excite for Stable Diffusion was proposed in [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://attendandexcite.github.io/Attend-and-Excite/) and provides textual attention control over the image generation.
+
+The abstract of the paper is the following:
+
+*Text-to-image diffusion models have recently received a lot of interest for their astonishing ability to produce high-fidelity images from text only. However, achieving one-shot generation that aligns with the user's intent is nearly impossible, yet small changes to the input prompt often result in very different images. This leaves the user with little semantic control. To put the user in control, we show how to interact with the diffusion process to flexibly steer it along semantic directions. This semantic guidance (SEGA) allows for subtle and extensive edits, changes in composition and style, as well as optimizing the overall artistic conception. We demonstrate SEGA's effectiveness on a variety of tasks and provide evidence for its versatility and flexibility.*
+
+Resources
+
+* [Project Page](https://attendandexcite.github.io/Attend-and-Excite/)
+* [Paper](https://arxiv.org/abs/2301.13826)
+* [Original Code](https://github.com/AttendAndExcite/Attend-and-Excite)
+* [Demo](https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite)
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [pipeline_semantic_stable_diffusion_attend_and_excite.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_semantic_stable_diffusion_attend_and_excite) | *Text-to-Image Generation* | - | https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite
+
+
+### Usage example
+
+
+```python
+import torch
+from diffusers import StableDiffusionAttendAndExcitePipeline
+
+model_id = "CompVis/stable-diffusion-v1-4"
+pipe = StableDiffusionAttendAndExcitePipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+pipe = pipe.to("cuda")
+
+prompt = "a cat and a frog"
+
+# use get_indices function to find out indices of the tokens you want to alter
+pipe.get_indices(prompt)
+
+token_indices = [2, 5]
+seed = 6141
+generator = torch.Generator("cuda").manual_seed(seed)
+
+images = pipe(
+ prompt=prompt,
+ token_indices=token_indices,
+ guidance_scale=7.5,
+ generator=generator,
+ num_inference_steps=50,
+ max_iter_to_alter=25,
+).images
+
+image = images[0]
+image.save(f"../images/{prompt}_{seed}.png")
+```
+
+
+## StableDiffusionAttendAndExcitePipeline
+[[autodoc]] StableDiffusionAttendAndExcitePipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..5a4cfa41ca43d7fe0cf6f12fc7e8c155af92a960
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/controlnet.mdx
@@ -0,0 +1,280 @@
+
+
+# Text-to-Image Generation with ControlNet Conditioning
+
+## Overview
+
+[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
+
+Using the pretrained models we can provide control images (for example, a depth map) to control Stable Diffusion text-to-image generation so that it follows the structure of the depth image and fills in the details.
+
+The abstract of the paper is the following:
+
+*We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.*
+
+This model was contributed by the amazing community contributor [takuma104](https://huggingface.co/takuma104) ❤️ .
+
+Resources:
+
+* [Paper](https://arxiv.org/abs/2302.05543)
+* [Original Code](https://github.com/lllyasviel/ControlNet)
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionControlNetPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py) | *Text-to-Image Generation with ControlNet Conditioning* | [Colab Example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+
+## Usage example
+
+In the following we give a simple example of how to use a *ControlNet* checkpoint with Diffusers for inference.
+The inference pipeline is the same for all pipelines:
+
+* 1. Take an image and run it through a pre-conditioning processor.
+* 2. Run the pre-processed image through the [`StableDiffusionControlNetPipeline`].
+
+Let's have a look at a simple example using the [Canny Edge ControlNet](https://huggingface.co/lllyasviel/sd-controlnet-canny).
+
+```python
+from diffusers import StableDiffusionControlNetPipeline
+from diffusers.utils import load_image
+
+# Let's load the popular vermeer image
+image = load_image(
+ "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
+)
+```
+
+
+
+Next, we process the image to get the canny image. This is step *1.* - running the pre-conditioning processor. The pre-conditioning processor is different for every ControlNet. Please see the model cards of the [official checkpoints](#controlnet-with-stable-diffusion-1.5) for more information about other models.
+
+First, we need to install opencv:
+
+```
+pip install opencv-contrib-python
+```
+
+Next, let's also install all required Hugging Face libraries:
+
+```
+pip install diffusers transformers git+https://github.com/huggingface/accelerate.git
+```
+
+Then we can retrieve the canny edges of the image.
+
+```python
+import cv2
+from PIL import Image
+import numpy as np
+
+image = np.array(image)
+
+low_threshold = 100
+high_threshold = 200
+
+image = cv2.Canny(image, low_threshold, high_threshold)
+image = image[:, :, None]
+image = np.concatenate([image, image, image], axis=2)
+canny_image = Image.fromarray(image)
+```
+
+Let's take a look at the processed image.
+
+
+
+Now, we load the official [Stable Diffusion 1.5 Model](runwayml/stable-diffusion-v1-5) as well as the ControlNet for canny edges.
+
+```py
+from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
+import torch
+
+controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+)
+```
+
+To speed-up things and reduce memory, let's enable model offloading and use the fast [`UniPCMultistepScheduler`].
+
+```py
+from diffusers import UniPCMultistepScheduler
+
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+# this command loads the individual model components on GPU on-demand.
+pipe.enable_model_cpu_offload()
+```
+
+Finally, we can run the pipeline:
+
+```py
+generator = torch.manual_seed(0)
+
+out_image = pipe(
+ "disco dancer with colorful lights", num_inference_steps=20, generator=generator, image=canny_image
+).images[0]
+```
+
+This should take only around 3-4 seconds on GPU (depending on hardware). The output image then looks as follows:
+
+
+
+
+**Note**: To see how to run all other ControlNet checkpoints, please have a look at [ControlNet with Stable Diffusion 1.5](#controlnet-with-stable-diffusion-1.5).
+
+
+
+## Combining multiple conditionings
+
+Multiple ControlNet conditionings can be combined for a single image generation. Pass a list of ControlNets to the pipeline's constructor and a corresponding list of conditionings to `__call__`.
+
+When combining conditionings, it is helpful to mask conditionings such that they do not overlap. In the example, we mask the middle of the canny map where the pose conditioning is located.
+
+It can also be helpful to vary the `controlnet_conditioning_scales` to emphasize one conditioning over the other.
+
+### Canny conditioning
+
+The original image:
+
+ +
+Prepare the conditioning:
+
+```python
+from diffusers.utils import load_image
+from PIL import Image
+import cv2
+import numpy as np
+from diffusers.utils import load_image
+
+canny_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
+)
+canny_image = np.array(canny_image)
+
+low_threshold = 100
+high_threshold = 200
+
+canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
+
+# zero out middle columns of image where pose will be overlayed
+zero_start = canny_image.shape[1] // 4
+zero_end = zero_start + canny_image.shape[1] // 2
+canny_image[:, zero_start:zero_end] = 0
+
+canny_image = canny_image[:, :, None]
+canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
+canny_image = Image.fromarray(canny_image)
+```
+
+
+
+Prepare the conditioning:
+
+```python
+from diffusers.utils import load_image
+from PIL import Image
+import cv2
+import numpy as np
+from diffusers.utils import load_image
+
+canny_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
+)
+canny_image = np.array(canny_image)
+
+low_threshold = 100
+high_threshold = 200
+
+canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
+
+# zero out middle columns of image where pose will be overlayed
+zero_start = canny_image.shape[1] // 4
+zero_end = zero_start + canny_image.shape[1] // 2
+canny_image[:, zero_start:zero_end] = 0
+
+canny_image = canny_image[:, :, None]
+canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
+canny_image = Image.fromarray(canny_image)
+```
+
+ +
+### Openpose conditioning
+
+The original image:
+
+
+
+### Openpose conditioning
+
+The original image:
+
+ +
+Prepare the conditioning:
+
+```python
+from controlnet_aux import OpenposeDetector
+from diffusers.utils import load_image
+
+openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
+
+openpose_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
+)
+openpose_image = openpose(openpose_image)
+```
+
+
+
+Prepare the conditioning:
+
+```python
+from controlnet_aux import OpenposeDetector
+from diffusers.utils import load_image
+
+openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
+
+openpose_image = load_image(
+ "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
+)
+openpose_image = openpose(openpose_image)
+```
+
+ +
+### Running ControlNet with multiple conditionings
+
+```python
+from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+import torch
+
+controlnet = [
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
+]
+
+pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+)
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+pipe.enable_xformers_memory_efficient_attention()
+pipe.enable_model_cpu_offload()
+
+prompt = "a giant standing in a fantasy landscape, best quality"
+negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+generator = torch.Generator(device="cpu").manual_seed(1)
+
+images = [openpose_image, canny_image]
+
+image = pipe(
+ prompt,
+ images,
+ num_inference_steps=20,
+ generator=generator,
+ negative_prompt=negative_prompt,
+ controlnet_conditioning_scale=[1.0, 0.8],
+).images[0]
+
+image.save("./multi_controlnet_output.png")
+```
+
+
+
+### Running ControlNet with multiple conditionings
+
+```python
+from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+import torch
+
+controlnet = [
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
+ ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
+]
+
+pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+)
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+pipe.enable_xformers_memory_efficient_attention()
+pipe.enable_model_cpu_offload()
+
+prompt = "a giant standing in a fantasy landscape, best quality"
+negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+generator = torch.Generator(device="cpu").manual_seed(1)
+
+images = [openpose_image, canny_image]
+
+image = pipe(
+ prompt,
+ images,
+ num_inference_steps=20,
+ generator=generator,
+ negative_prompt=negative_prompt,
+ controlnet_conditioning_scale=[1.0, 0.8],
+).images[0]
+
+image.save("./multi_controlnet_output.png")
+```
+
+ +
+## Available checkpoints
+
+ControlNet requires a *control image* in addition to the text-to-image *prompt*.
+Each pretrained model is trained using a different conditioning method that requires different images for conditioning the generated outputs. For example, Canny edge conditioning requires the control image to be the output of a Canny filter, while depth conditioning requires the control image to be a depth map. See the overview and image examples below to know more.
+
+All checkpoints can be found under the authors' namespace [lllyasviel](https://huggingface.co/lllyasviel).
+
+### ControlNet with Stable Diffusion 1.5
+
+| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
+|---|---|---|---|
+|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)
+
+## Available checkpoints
+
+ControlNet requires a *control image* in addition to the text-to-image *prompt*.
+Each pretrained model is trained using a different conditioning method that requires different images for conditioning the generated outputs. For example, Canny edge conditioning requires the control image to be the output of a Canny filter, while depth conditioning requires the control image to be a depth map. See the overview and image examples below to know more.
+
+All checkpoints can be found under the authors' namespace [lllyasviel](https://huggingface.co/lllyasviel).
+
+### ControlNet with Stable Diffusion 1.5
+
+| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
+|---|---|---|---|
+|[lllyasviel/sd-controlnet-canny](https://huggingface.co/lllyasviel/sd-controlnet-canny)
*Trained with canny edge detection* | A monochrome image with white edges on a black background.| |
| |
+|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)
|
+|[lllyasviel/sd-controlnet-depth](https://huggingface.co/lllyasviel/sd-controlnet-depth)
*Trained with Midas depth estimation* |A grayscale image with black representing deep areas and white representing shallow areas.| |
| |
+|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)
|
+|[lllyasviel/sd-controlnet-hed](https://huggingface.co/lllyasviel/sd-controlnet-hed)
*Trained with HED edge detection (soft edge)* |A monochrome image with white soft edges on a black background.| |
| |
+|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)
|
+|[lllyasviel/sd-controlnet-mlsd](https://huggingface.co/lllyasviel/sd-controlnet-mlsd)
*Trained with M-LSD line detection* |A monochrome image composed only of white straight lines on a black background.| |
| |
+|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)
|
+|[lllyasviel/sd-controlnet-normal](https://huggingface.co/lllyasviel/sd-controlnet-normal)
*Trained with normal map* |A [normal mapped](https://en.wikipedia.org/wiki/Normal_mapping) image.| |
| |
+|[lllyasviel/sd-controlnet-openpose](https://huggingface.co/lllyasviel/sd-controlnet_openpose)
|
+|[lllyasviel/sd-controlnet-openpose](https://huggingface.co/lllyasviel/sd-controlnet_openpose)
*Trained with OpenPose bone image* |A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.| |
| |
+|[lllyasviel/sd-controlnet-scribble](https://huggingface.co/lllyasviel/sd-controlnet_scribble)
|
+|[lllyasviel/sd-controlnet-scribble](https://huggingface.co/lllyasviel/sd-controlnet_scribble)
*Trained with human scribbles* |A hand-drawn monochrome image with white outlines on a black background.| |
| |
+|[lllyasviel/sd-controlnet-seg](https://huggingface.co/lllyasviel/sd-controlnet_seg)
|
+|[lllyasviel/sd-controlnet-seg](https://huggingface.co/lllyasviel/sd-controlnet_seg)
*Trained with semantic segmentation* |An [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/)'s segmentation protocol image.| |
| |
+
+## StableDiffusionControlNetPipeline
+[[autodoc]] StableDiffusionControlNetPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+## FlaxStableDiffusionControlNetPipeline
+[[autodoc]] FlaxStableDiffusionControlNetPipeline
+ - all
+ - __call__
+
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..c46576ff288757a316a5efa0ec3b753fd9ce2bd4
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx
@@ -0,0 +1,33 @@
+
+
+# Depth-to-Image Generation
+
+## StableDiffusionDepth2ImgPipeline
+
+The depth-guided stable diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), as part of Stable Diffusion 2.0. It uses [MiDas](https://github.com/isl-org/MiDaS) to infer depth based on an image.
+
+[`StableDiffusionDepth2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images as well as a `depth_map` to preserve the images’ structure.
+
+The original codebase can be found here:
+- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion)
+
+Available Checkpoints are:
+- *stable-diffusion-2-depth*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth)
+
+[[autodoc]] StableDiffusionDepth2ImgPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..8ca69ff69aec6a74e22beade70b5ef2ef42a0e3c
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx
@@ -0,0 +1,31 @@
+
+
+# Image Variation
+
+## StableDiffusionImageVariationPipeline
+
+[`StableDiffusionImageVariationPipeline`] lets you generate variations from an input image using Stable Diffusion. It uses a fine-tuned version of Stable Diffusion model, trained by [Justin Pinkney](https://www.justinpinkney.com/) (@Buntworthy) at [Lambda](https://lambdalabs.com/).
+
+The original codebase can be found here:
+[Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations)
+
+Available Checkpoints are:
+- *sd-image-variations-diffusers*: [lambdalabs/sd-image-variations-diffusers](https://huggingface.co/lambdalabs/sd-image-variations-diffusers)
+
+[[autodoc]] StableDiffusionImageVariationPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..09bfb853f9c9bdce1fbd4b4ae3571557d2a5bfc1
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx
@@ -0,0 +1,36 @@
+
+
+# Image-to-Image Generation
+
+## StableDiffusionImg2ImgPipeline
+
+The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images using Stable Diffusion.
+
+The original codebase can be found here: [CampVis/stable-diffusion](https://github.com/CompVis/stable-diffusion/blob/main/scripts/img2img.py)
+
+[`StableDiffusionImg2ImgPipeline`] is compatible with all Stable Diffusion checkpoints for [Text-to-Image](./text2img)
+
+The pipeline uses the diffusion-denoising mechanism proposed by SDEdit ([SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations](https://arxiv.org/abs/2108.01073)
+proposed by Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, Stefano Ermon).
+
+[[autodoc]] StableDiffusionImg2ImgPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+[[autodoc]] FlaxStableDiffusionImg2ImgPipeline
+ - all
+ - __call__
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..33e84a63261fbf9c370e2d5e22ffbf4a1256bbb4
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx
@@ -0,0 +1,37 @@
+
+
+# Text-Guided Image Inpainting
+
+## StableDiffusionInpaintPipeline
+
+The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionInpaintPipeline`] lets you edit specific parts of an image by providing a mask and a text prompt using Stable Diffusion.
+
+The original codebase can be found here:
+- *Stable Diffusion V1*: [CampVis/stable-diffusion](https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion)
+- *Stable Diffusion V2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#image-inpainting-with-stable-diffusion)
+
+Available checkpoints are:
+- *stable-diffusion-inpainting (512x512 resolution)*: [runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting)
+- *stable-diffusion-2-inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting)
+
+[[autodoc]] StableDiffusionInpaintPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+[[autodoc]] FlaxStableDiffusionInpaintPipeline
+ - all
+ - __call__
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..61fd2f799114de345400a692c115811fbf222871
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx
@@ -0,0 +1,33 @@
+
+
+# Stable Diffusion Latent Upscaler
+
+## StableDiffusionLatentUpscalePipeline
+
+The Stable Diffusion Latent Upscaler model was created by [Katherine Crowson](https://github.com/crowsonkb/k-diffusion) in collaboration with [Stability AI](https://stability.ai/). It can be used on top of any [`StableDiffusionUpscalePipeline`] checkpoint to enhance its output image resolution by a factor of 2.
+
+A notebook that demonstrates the original implementation can be found here:
+- [Stable Diffusion Upscaler Demo](https://colab.research.google.com/drive/1o1qYJcFeywzCIdkfKJy7cTpgZTCM2EI4)
+
+Available Checkpoints are:
+- *stabilityai/latent-upscaler*: [stabilityai/sd-x2-latent-upscaler](https://huggingface.co/stabilityai/sd-x2-latent-upscaler)
+
+
+[[autodoc]] StableDiffusionLatentUpscalePipeline
+ - all
+ - __call__
+ - enable_sequential_cpu_offload
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..7aae35ba2a91774a4297ee7ada6d13a40fed6f32
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
@@ -0,0 +1,61 @@
+
+
+# Editing Implicit Assumptions in Text-to-Image Diffusion Models
+
+## Overview
+
+[Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084) by Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov.
+
+The abstract of the paper is the following:
+
+*Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.*
+
+Resources:
+
+* [Project Page](https://time-diffusion.github.io/).
+* [Paper](https://arxiv.org/abs/2303.08084).
+* [Original Code](https://github.com/bahjat-kawar/time-diffusion).
+* [Demo](https://huggingface.co/spaces/bahjat-kawar/time-diffusion).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionModelEditingPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py) | *Text-to-Image Model Editing* | [🤗 Space](https://huggingface.co/spaces/bahjat-kawar/time-diffusion)) |
+
+This pipeline enables editing the diffusion model weights, such that its assumptions on a given concept are changed. The resulting change is expected to take effect in all prompt generations pertaining to the edited concept.
+
+## Usage example
+
+```python
+import torch
+from diffusers import StableDiffusionModelEditingPipeline
+
+model_ckpt = "CompVis/stable-diffusion-v1-4"
+pipe = StableDiffusionModelEditingPipeline.from_pretrained(model_ckpt)
+
+pipe = pipe.to("cuda")
+
+source_prompt = "A pack of roses"
+destination_prompt = "A pack of blue roses"
+pipe.edit_model(source_prompt, destination_prompt)
+
+prompt = "A field of roses"
+image = pipe(prompt).images[0]
+image.save("field_of_roses.png")
+```
+
+## StableDiffusionModelEditingPipeline
+[[autodoc]] StableDiffusionModelEditingPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..70731fd294b91c8bca9bb1726c14011507c22a4a
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
@@ -0,0 +1,82 @@
+
+
+# Stable diffusion pipelines
+
+Stable Diffusion is a text-to-image _latent diffusion_ model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/). It's trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) dataset. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and can run on consumer GPUs.
+
+Latent diffusion is the research on top of which Stable Diffusion was built. It was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. You can learn more details about it in the [specific pipeline for latent diffusion](pipelines/latent_diffusion) that is part of 🤗 Diffusers.
+
+For more details about how Stable Diffusion works and how it differs from the base latent diffusion model, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-announcement) and [this section of our own blog post](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work).
+
+*Tips*:
+- To tweak your prompts on a specific result you liked, you can generate your own latents, as demonstrated in the following notebook: [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
+
+*Overview*:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [StableDiffusionPipeline](./text2img) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb) | [🤗 Stable Diffusion](https://huggingface.co/spaces/stabilityai/stable-diffusion)
+| [StableDiffusionImg2ImgPipeline](./img2img) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb) | [🤗 Diffuse the Rest](https://huggingface.co/spaces/huggingface/diffuse-the-rest)
+| [StableDiffusionInpaintPipeline](./inpaint) | **Experimental** – *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb) | Coming soon
+| [StableDiffusionDepth2ImgPipeline](./depth2img) | **Experimental** – *Depth-to-Image Text-Guided Generation * | | Coming soon
+| [StableDiffusionImageVariationPipeline](./image_variation) | **Experimental** – *Image Variation Generation * | | [🤗 Stable Diffusion Image Variations](https://huggingface.co/spaces/lambdalabs/stable-diffusion-image-variations)
+| [StableDiffusionUpscalePipeline](./upscale) | **Experimental** – *Text-Guided Image Super-Resolution * | | Coming soon
+| [StableDiffusionLatentUpscalePipeline](./latent_upscale) | **Experimental** – *Text-Guided Image Super-Resolution * | | Coming soon
+| [StableDiffusionInstructPix2PixPipeline](./pix2pix) | **Experimental** – *Text-Based Image Editing * | | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/spaces/timbrooks/instruct-pix2pix)
+| [StableDiffusionAttendAndExcitePipeline](./attend_and_excite) | **Experimental** – *Text-to-Image Generation * | | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite)
+| [StableDiffusionPix2PixZeroPipeline](./pix2pix_zero) | **Experimental** – *Text-Based Image Editing * | | [Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027)
+| [StableDiffusionModelEditingPipeline](./model_editing) | **Experimental** – *Text-to-Image Model Editing * | | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084)
+
+
+
+## Tips
+
+### How to load and use different schedulers.
+
+The stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
+
+>>> pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
+>>> pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=euler_scheduler)
+```
+
+
+### How to convert all use cases with multiple or single pipeline
+
+If you want to use all possible use cases in a single `DiffusionPipeline` you can either:
+- Make use of the [Stable Diffusion Mega Pipeline](https://github.com/huggingface/diffusers/tree/main/examples/community#stable-diffusion-mega) or
+- Make use of the `components` functionality to instantiate all components in the most memory-efficient way:
+
+```python
+>>> from diffusers import (
+... StableDiffusionPipeline,
+... StableDiffusionImg2ImgPipeline,
+... StableDiffusionInpaintPipeline,
+... )
+
+>>> text2img = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+>>> img2img = StableDiffusionImg2ImgPipeline(**text2img.components)
+>>> inpaint = StableDiffusionInpaintPipeline(**text2img.components)
+
+>>> # now you can use text2img(...), img2img(...), inpaint(...) just like the call methods of each respective pipeline
+```
+
+## StableDiffusionPipelineOutput
+[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e0c7747a0193013507ccc28e3d48c7ee5ab8ca11
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx
@@ -0,0 +1,58 @@
+
+
+# MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
+
+## Overview
+
+[MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation](https://arxiv.org/abs/2302.08113) by Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel.
+
+The abstract of the paper is the following:
+
+*Recent advances in text-to-image generation with diffusion models present transformative capabilities in image quality. However, user controllability of the generated image, and fast adaptation to new tasks still remains an open challenge, currently mostly addressed by costly and long re-training and fine-tuning or ad-hoc adaptations to specific image generation tasks. In this work, we present MultiDiffusion, a unified framework that enables versatile and controllable image generation, using a pre-trained text-to-image diffusion model, without any further training or finetuning. At the center of our approach is a new generation process, based on an optimization task that binds together multiple diffusion generation processes with a shared set of parameters or constraints. We show that MultiDiffusion can be readily applied to generate high quality and diverse images that adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes.
+
+Resources:
+
+* [Project Page](https://multidiffusion.github.io/).
+* [Paper](https://arxiv.org/abs/2302.08113).
+* [Original Code](https://github.com/omerbt/MultiDiffusion).
+* [Demo](https://huggingface.co/spaces/weizmannscience/MultiDiffusion).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionPanoramaPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_panorama.py) | *Text-Guided Panorama View Generation* | [🤗 Space](https://huggingface.co/spaces/weizmannscience/MultiDiffusion)) |
+
+
+
+## Usage example
+
+```python
+import torch
+from diffusers import StableDiffusionPanoramaPipeline, DDIMScheduler
+
+model_ckpt = "stabilityai/stable-diffusion-2-base"
+scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
+pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, torch_dtype=torch.float16)
+
+pipe = pipe.to("cuda")
+
+prompt = "a photo of the dolomites"
+image = pipe(prompt).images[0]
+image.save("dolomites.png")
+```
+
+## StableDiffusionPanoramaPipeline
+[[autodoc]] StableDiffusionPanoramaPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..42cd4b896b2e4603aaf826efc7201672c016563f
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx
@@ -0,0 +1,70 @@
+
+
+# InstructPix2Pix: Learning to Follow Image Editing Instructions
+
+## Overview
+
+[InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) by Tim Brooks, Aleksander Holynski and Alexei A. Efros.
+
+The abstract of the paper is the following:
+
+*We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models -- a language model (GPT-3) and a text-to-image model (Stable Diffusion) -- to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.*
+
+Resources:
+
+* [Project Page](https://www.timothybrooks.com/instruct-pix2pix).
+* [Paper](https://arxiv.org/abs/2211.09800).
+* [Original Code](https://github.com/timothybrooks/instruct-pix2pix).
+* [Demo](https://huggingface.co/spaces/timbrooks/instruct-pix2pix).
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionInstructPix2PixPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/timbrooks/instruct-pix2pix) |
+
+
+
+## Usage example
+
+```python
+import PIL
+import requests
+import torch
+from diffusers import StableDiffusionInstructPix2PixPipeline
+
+model_id = "timbrooks/instruct-pix2pix"
+pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+
+url = "https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
+
+
+def download_image(url):
+ image = PIL.Image.open(requests.get(url, stream=True).raw)
+ image = PIL.ImageOps.exif_transpose(image)
+ image = image.convert("RGB")
+ return image
+
+
+image = download_image(url)
+
+prompt = "make the mountains snowy"
+images = pipe(prompt, image=image, num_inference_steps=20, image_guidance_scale=1.5, guidance_scale=7).images
+images[0].save("snowy_mountains.png")
+```
+
+## StableDiffusionInstructPix2PixPipeline
+[[autodoc]] StableDiffusionInstructPix2PixPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f04a54f242acade990415a1ed7c240c37a828dd7
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx
@@ -0,0 +1,291 @@
+
+
+# Zero-shot Image-to-Image Translation
+
+## Overview
+
+[Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027).
+
+The abstract of the paper is the following:
+
+*Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.*
+
+Resources:
+
+* [Project Page](https://pix2pixzero.github.io/).
+* [Paper](https://arxiv.org/abs/2302.03027).
+* [Original Code](https://github.com/pix2pixzero/pix2pix-zero).
+* [Demo](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo).
+
+## Tips
+
+* The pipeline can be conditioned on real input images. Check out the code examples below to know more.
+* The pipeline exposes two arguments namely `source_embeds` and `target_embeds`
+that let you control the direction of the semantic edits in the final image to be generated. Let's say,
+you wanted to translate from "cat" to "dog". In this case, the edit direction will be "cat -> dog". To reflect
+this in the pipeline, you simply have to set the embeddings related to the phrases including "cat" to
+`source_embeds` and "dog" to `target_embeds`. Refer to the code example below for more details.
+* When you're using this pipeline from a prompt, specify the _source_ concept in the prompt. Taking
+the above example, a valid input prompt would be: "a high resolution painting of a **cat** in the style of van gough".
+* If you wanted to reverse the direction in the example above, i.e., "dog -> cat", then it's recommended to:
+ * Swap the `source_embeds` and `target_embeds`.
+ * Change the input prompt to include "dog".
+* To learn more about how the source and target embeddings are generated, refer to the [original
+paper](https://arxiv.org/abs/2302.03027). Below, we also provide some directions on how to generate the embeddings.
+* Note that the quality of the outputs generated with this pipeline is dependent on how good the `source_embeds` and `target_embeds` are. Please, refer to [this discussion](#generating-source-and-target-embeddings) for some suggestions on the topic.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionPix2PixZeroPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo) |
+
+
+
+## Usage example
+
+### Based on an image generated with the input prompt
+
+```python
+import requests
+import torch
+
+from diffusers import DDIMScheduler, StableDiffusionPix2PixZeroPipeline
+
+
+def download(embedding_url, local_filepath):
+ r = requests.get(embedding_url)
+ with open(local_filepath, "wb") as f:
+ f.write(r.content)
+
+
+model_ckpt = "CompVis/stable-diffusion-v1-4"
+pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ model_ckpt, conditions_input_image=False, torch_dtype=torch.float16
+)
+pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+pipeline.to("cuda")
+
+prompt = "a high resolution painting of a cat in the style of van gogh"
+src_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/cat.pt"
+target_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/dog.pt"
+
+for url in [src_embs_url, target_embs_url]:
+ download(url, url.split("/")[-1])
+
+src_embeds = torch.load(src_embs_url.split("/")[-1])
+target_embeds = torch.load(target_embs_url.split("/")[-1])
+
+images = pipeline(
+ prompt,
+ source_embeds=src_embeds,
+ target_embeds=target_embeds,
+ num_inference_steps=50,
+ cross_attention_guidance_amount=0.15,
+).images
+images[0].save("edited_image_dog.png")
+```
+
+### Based on an input image
+
+When the pipeline is conditioned on an input image, we first obtain an inverted
+noise from it using a `DDIMInverseScheduler` with the help of a generated caption. Then
+the inverted noise is used to start the generation process.
+
+First, let's load our pipeline:
+
+```py
+import torch
+from transformers import BlipForConditionalGeneration, BlipProcessor
+from diffusers import DDIMScheduler, DDIMInverseScheduler, StableDiffusionPix2PixZeroPipeline
+
+captioner_id = "Salesforce/blip-image-captioning-base"
+processor = BlipProcessor.from_pretrained(captioner_id)
+model = BlipForConditionalGeneration.from_pretrained(captioner_id, torch_dtype=torch.float16, low_cpu_mem_usage=True)
+
+sd_model_ckpt = "CompVis/stable-diffusion-v1-4"
+pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ sd_model_ckpt,
+ caption_generator=model,
+ caption_processor=processor,
+ torch_dtype=torch.float16,
+ safety_checker=None,
+)
+pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+pipeline.inverse_scheduler = DDIMInverseScheduler.from_config(pipeline.scheduler.config)
+pipeline.enable_model_cpu_offload()
+```
+
+Then, we load an input image for conditioning and obtain a suitable caption for it:
+
+```py
+import requests
+from PIL import Image
+
+img_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/test_images/cats/cat_6.png"
+raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB").resize((512, 512))
+caption = pipeline.generate_caption(raw_image)
+```
+
+Then we employ the generated caption and the input image to get the inverted noise:
+
+```py
+generator = torch.manual_seed(0)
+inv_latents = pipeline.invert(caption, image=raw_image, generator=generator).latents
+```
+
+Now, generate the image with edit directions:
+
+```py
+# See the "Generating source and target embeddings" section below to
+# automate the generation of these captions with a pre-trained model like Flan-T5 as explained below.
+source_prompts = ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
+target_prompts = ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
+
+source_embeds = pipeline.get_embeds(source_prompts, batch_size=2)
+target_embeds = pipeline.get_embeds(target_prompts, batch_size=2)
+
+
+image = pipeline(
+ caption,
+ source_embeds=source_embeds,
+ target_embeds=target_embeds,
+ num_inference_steps=50,
+ cross_attention_guidance_amount=0.15,
+ generator=generator,
+ latents=inv_latents,
+ negative_prompt=caption,
+).images[0]
+image.save("edited_image.png")
+```
+
+## Generating source and target embeddings
+
+The authors originally used the [GPT-3 API](https://openai.com/api/) to generate the source and target captions for discovering
+edit directions. However, we can also leverage open source and public models for the same purpose.
+Below, we provide an end-to-end example with the [Flan-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5) model
+for generating captions and [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for
+computing embeddings on the generated captions.
+
+**1. Load the generation model**:
+
+```py
+import torch
+from transformers import AutoTokenizer, T5ForConditionalGeneration
+
+tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xl")
+model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xl", device_map="auto", torch_dtype=torch.float16)
+```
+
+**2. Construct a starting prompt**:
+
+```py
+source_concept = "cat"
+target_concept = "dog"
+
+source_text = f"Provide a caption for images containing a {source_concept}. "
+"The captions should be in English and should be no longer than 150 characters."
+
+target_text = f"Provide a caption for images containing a {target_concept}. "
+"The captions should be in English and should be no longer than 150 characters."
+```
+
+Here, we're interested in the "cat -> dog" direction.
+
+**3. Generate captions**:
+
+We can use a utility like so for this purpose.
+
+```py
+def generate_captions(input_prompt):
+ input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.to("cuda")
+
+ outputs = model.generate(
+ input_ids, temperature=0.8, num_return_sequences=16, do_sample=True, max_new_tokens=128, top_k=10
+ )
+ return tokenizer.batch_decode(outputs, skip_special_tokens=True)
+```
+
+And then we just call it to generate our captions:
+
+```py
+source_captions = generate_captions(source_text)
+target_captions = generate_captions(target_concept)
+```
+
+We encourage you to play around with the different parameters supported by the
+`generate()` method ([documentation](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_tf_utils.TFGenerationMixin.generate)) for the generation quality you are looking for.
+
+**4. Load the embedding model**:
+
+Here, we need to use the same text encoder model used by the subsequent Stable Diffusion model.
+
+```py
+from diffusers import StableDiffusionPix2PixZeroPipeline
+
+pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
+)
+pipeline = pipeline.to("cuda")
+tokenizer = pipeline.tokenizer
+text_encoder = pipeline.text_encoder
+```
+
+**5. Compute embeddings**:
+
+```py
+import torch
+
+def embed_captions(sentences, tokenizer, text_encoder, device="cuda"):
+ with torch.no_grad():
+ embeddings = []
+ for sent in sentences:
+ text_inputs = tokenizer(
+ sent,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ prompt_embeds = text_encoder(text_input_ids.to(device), attention_mask=None)[0]
+ embeddings.append(prompt_embeds)
+ return torch.concatenate(embeddings, dim=0).mean(dim=0).unsqueeze(0)
+
+source_embeddings = embed_captions(source_captions, tokenizer, text_encoder)
+target_embeddings = embed_captions(target_captions, tokenizer, text_encoder)
+```
+
+And you're done! [Here](https://colab.research.google.com/drive/1tz2C1EdfZYAPlzXXbTnf-5PRBiR8_R1F?usp=sharing) is a Colab Notebook that you can use to interact with the entire process.
+
+Now, you can use these embeddings directly while calling the pipeline:
+
+```py
+from diffusers import DDIMScheduler
+
+pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+
+images = pipeline(
+ prompt,
+ source_embeds=source_embeddings,
+ target_embeds=target_embeddings,
+ num_inference_steps=50,
+ cross_attention_guidance_amount=0.15,
+).images
+images[0].save("edited_image_dog.png")
+```
+
+## StableDiffusionPix2PixZeroPipeline
+[[autodoc]] StableDiffusionPix2PixZeroPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b34c1f51cf668b289ca000719828addb88f6a20e
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx
@@ -0,0 +1,64 @@
+
+
+# Self-Attention Guidance (SAG)
+
+## Overview
+
+[Self-Attention Guidance](https://arxiv.org/abs/2210.00939) by Susung Hong et al.
+
+The abstract of the paper is the following:
+
+*Denoising diffusion models (DDMs) have been drawing much attention for their appreciable sample quality and diversity. Despite their remarkable performance, DDMs remain black boxes on which further study is necessary to take a profound step. Motivated by this, we delve into the design of conventional U-shaped diffusion models. More specifically, we investigate the self-attention modules within these models through carefully designed experiments and explore their characteristics. In addition, inspired by the studies that substantiate the effectiveness of the guidance schemes, we present plug-and-play diffusion guidance, namely Self-Attention Guidance (SAG), that can drastically boost the performance of existing diffusion models. Our method, SAG, extracts the intermediate attention map from a diffusion model at every iteration and selects tokens above a certain attention score for masking and blurring to obtain a partially blurred input. Subsequently, we measure the dissimilarity between the predicted noises obtained from feeding the blurred and original input to the diffusion model and leverage it as guidance. With this guidance, we observe apparent improvements in a wide range of diffusion models, e.g., ADM, IDDPM, and Stable Diffusion, and show that the results further improve by combining our method with the conventional guidance scheme. We provide extensive ablation studies to verify our choices.*
+
+Resources:
+
+* [Project Page](https://ku-cvlab.github.io/Self-Attention-Guidance).
+* [Paper](https://arxiv.org/abs/2210.00939).
+* [Original Code](https://github.com/KU-CVLAB/Self-Attention-Guidance).
+* [Demo](https://colab.research.google.com/github/SusungHong/Self-Attention-Guidance/blob/main/SAG_Stable.ipynb).
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionSAGPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py) | *Text-to-Image Generation* | [Colab](https://colab.research.google.com/github/SusungHong/Self-Attention-Guidance/blob/main/SAG_Stable.ipynb) |
+
+## Usage example
+
+```python
+import torch
+from diffusers import StableDiffusionSAGPipeline
+from accelerate.utils import set_seed
+
+pipe = StableDiffusionSAGPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+pipe = pipe.to("cuda")
+
+seed = 8978
+prompt = "."
+guidance_scale = 7.5
+num_images_per_prompt = 1
+
+sag_scale = 1.0
+
+set_seed(seed)
+images = pipe(
+ prompt, num_images_per_prompt=num_images_per_prompt, guidance_scale=guidance_scale, sag_scale=sag_scale
+).images
+images[0].save("example.png")
+```
+
+## StableDiffusionSAGPipeline
+[[autodoc]] StableDiffusionSAGPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6b8d53bf6510a0b122529170e0de3cbddcc40690
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx
@@ -0,0 +1,45 @@
+
+
+# Text-to-Image Generation
+
+## StableDiffusionPipeline
+
+The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionPipeline`] is capable of generating photo-realistic images given any text input using Stable Diffusion.
+
+The original codebase can be found here:
+- *Stable Diffusion V1*: [CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion)
+- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion)
+
+Available Checkpoints are:
+- *stable-diffusion-v1-4 (512x512 resolution)* [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)
+- *stable-diffusion-v1-5 (512x512 resolution)* [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
+- *stable-diffusion-2-base (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base)
+- *stable-diffusion-2 (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2)
+- *stable-diffusion-2-1-base (512x512 resolution)* [stabilityai/stable-diffusion-2-1-base](https://huggingface.co/stabilityai/stable-diffusion-2-1-base)
+- *stable-diffusion-2-1 (768x768 resolution)*: [stabilityai/stable-diffusion-2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1)
+
+[[autodoc]] StableDiffusionPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+ - enable_vae_tiling
+ - disable_vae_tiling
+
+[[autodoc]] FlaxStableDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f70d8f445fd95fb49e7a92c7566951c40ec74933
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx
@@ -0,0 +1,32 @@
+
+
+# Super-Resolution
+
+## StableDiffusionUpscalePipeline
+
+The upscaler diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), as part of Stable Diffusion 2.0. [`StableDiffusionUpscalePipeline`] can be used to enhance the resolution of input images by a factor of 4.
+
+The original codebase can be found here:
+- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#image-upscaling-with-stable-diffusion)
+
+Available Checkpoints are:
+- *stabilityai/stable-diffusion-x4-upscaler (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler)
+
+
+[[autodoc]] StableDiffusionUpscalePipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e922072e4e3185f9de4a0d6e734e0c46a4fe3215
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx
@@ -0,0 +1,176 @@
+
+
+# Stable diffusion 2
+
+Stable Diffusion 2 is a text-to-image _latent diffusion_ model built upon the work of [Stable Diffusion 1](https://stability.ai/blog/stable-diffusion-public-release).
+The project to train Stable Diffusion 2 was led by Robin Rombach and Katherine Crowson from [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/).
+
+*The Stable Diffusion 2.0 release includes robust text-to-image models trained using a brand new text encoder (OpenCLIP), developed by LAION with support from Stability AI, which greatly improves the quality of the generated images compared to earlier V1 releases. The text-to-image models in this release can generate images with default resolutions of both 512x512 pixels and 768x768 pixels.
+These models are trained on an aesthetic subset of the [LAION-5B dataset](https://laion.ai/blog/laion-5b/) created by the DeepFloyd team at Stability AI, which is then further filtered to remove adult content using [LAION’s NSFW filter](https://openreview.net/forum?id=M3Y74vmsMcY).*
+
+For more details about how Stable Diffusion 2 works and how it differs from Stable Diffusion 1, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-v2-release).
+
+## Tips
+
+### Available checkpoints:
+
+Note that the architecture is more or less identical to [Stable Diffusion 1](./stable_diffusion/overview) so please refer to [this page](./stable_diffusion/overview) for API documentation.
+
+- *Text-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) with [`StableDiffusionPipeline`]
+- *Text-to-Image (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) with [`StableDiffusionPipeline`]
+- *Image Inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) with [`StableDiffusionInpaintPipeline`]
+- *Super-Resolution (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) [`StableDiffusionUpscalePipeline`]
+- *Depth-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) with [`StableDiffusionDepth2ImagePipeline`]
+
+We recommend using the [`DPMSolverMultistepScheduler`] as it's currently the fastest scheduler there is.
+
+
+### Text-to-Image
+
+- *Text-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) with [`StableDiffusionPipeline`]
+
+```python
+from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
+import torch
+
+repo_id = "stabilityai/stable-diffusion-2-base"
+pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
+
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+
+prompt = "High quality photo of an astronaut riding a horse in space"
+image = pipe(prompt, num_inference_steps=25).images[0]
+image.save("astronaut.png")
+```
+
+- *Text-to-Image (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) with [`StableDiffusionPipeline`]
+
+```python
+from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
+import torch
+
+repo_id = "stabilityai/stable-diffusion-2"
+pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
+
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+
+prompt = "High quality photo of an astronaut riding a horse in space"
+image = pipe(prompt, guidance_scale=9, num_inference_steps=25).images[0]
+image.save("astronaut.png")
+```
+
+### Image Inpainting
+
+- *Image Inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) with [`StableDiffusionInpaintPipeline`]
+
+```python
+import PIL
+import requests
+import torch
+from io import BytesIO
+
+from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
+
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+init_image = download_image(img_url).resize((512, 512))
+mask_image = download_image(mask_url).resize((512, 512))
+
+repo_id = "stabilityai/stable-diffusion-2-inpainting"
+pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
+
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+
+prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+image = pipe(prompt=prompt, image=init_image, mask_image=mask_image, num_inference_steps=25).images[0]
+
+image.save("yellow_cat.png")
+```
+
+### Super-Resolution
+
+- *Image Upscaling (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) with [`StableDiffusionUpscalePipeline`]
+
+
+```python
+import requests
+from PIL import Image
+from io import BytesIO
+from diffusers import StableDiffusionUpscalePipeline
+import torch
+
+# load model and scheduler
+model_id = "stabilityai/stable-diffusion-x4-upscaler"
+pipeline = StableDiffusionUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
+pipeline = pipeline.to("cuda")
+
+# let's download an image
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
+response = requests.get(url)
+low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
+low_res_img = low_res_img.resize((128, 128))
+prompt = "a white cat"
+upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
+upscaled_image.save("upsampled_cat.png")
+```
+
+### Depth-to-Image
+
+- *Depth-Guided Text-to-Image*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) [`StableDiffusionDepth2ImagePipeline`]
+
+
+```python
+import torch
+import requests
+from PIL import Image
+
+from diffusers import StableDiffusionDepth2ImgPipeline
+
+pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-depth",
+ torch_dtype=torch.float16,
+).to("cuda")
+
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+init_image = Image.open(requests.get(url, stream=True).raw)
+prompt = "two tigers"
+n_propmt = "bad, deformed, ugly, bad anotomy"
+image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
+```
+
+### How to load and use different schedulers.
+
+The stable diffusion pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
+
+>>> pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("stabilityai/stable-diffusion-2", subfolder="scheduler")
+>>> pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", scheduler=euler_scheduler)
+```
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..688eb5013c6a287c77722f006eea59bab73343e6
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
@@ -0,0 +1,90 @@
+
+
+# Safe Stable Diffusion
+
+Safe Stable Diffusion was proposed in [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://arxiv.org/abs/2211.05105) and mitigates the well known issue that models like Stable Diffusion that are trained on unfiltered, web-crawled datasets tend to suffer from inappropriate degeneration. For instance Stable Diffusion may unexpectedly generate nudity, violence, images depicting self-harm, or otherwise offensive content.
+Safe Stable Diffusion is an extension to the Stable Diffusion that drastically reduces content like this.
+
+The abstract of the paper is the following:
+
+*Text-conditioned image generation models have recently achieved astonishing results in image quality and text alignment and are consequently employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer, as we demonstrate, from degenerated and biased human behavior. In turn, they may even reinforce such biases. To help combat these undesired side effects, we present safe latent diffusion (SLD). Specifically, to measure the inappropriate degeneration due to unfiltered and imbalanced training sets, we establish a novel image generation test bed-inappropriate image prompts (I2P)-containing dedicated, real-world image-to-text prompts covering concepts such as nudity and violence. As our exhaustive empirical evaluation demonstrates, the introduced SLD removes and suppresses inappropriate image parts during the diffusion process, with no additional training required and no adverse effect on overall image quality or text alignment.*
+
+
+*Overview*:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [pipeline_stable_diffusion_safe.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb) | [](https://huggingface.co/spaces/AIML-TUDA/unsafe-vs-safe-stable-diffusion)
+
+## Tips
+
+- Safe Stable Diffusion may also be used with weights of [Stable Diffusion](./api/pipelines/stable_diffusion/text2img).
+
+### Run Safe Stable Diffusion
+
+Safe Stable Diffusion can be tested very easily with the [`StableDiffusionPipelineSafe`], and the `"AIML-TUDA/stable-diffusion-safe"` checkpoint exactly in the same way it is shown in the [Conditional Image Generation Guide](./using-diffusers/conditional_image_generation).
+
+### Interacting with the Safety Concept
+
+To check and edit the currently used safety concept, use the `safety_concept` property of [`StableDiffusionPipelineSafe`]:
+```python
+>>> from diffusers import StableDiffusionPipelineSafe
+
+>>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
+>>> pipeline.safety_concept
+```
+For each image generation the active concept is also contained in [`StableDiffusionSafePipelineOutput`].
+
+### Using pre-defined safety configurations
+
+You may use the 4 configurations defined in the [Safe Latent Diffusion paper](https://arxiv.org/abs/2211.05105) as follows:
+
+```python
+>>> from diffusers import StableDiffusionPipelineSafe
+>>> from diffusers.pipelines.stable_diffusion_safe import SafetyConfig
+
+>>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
+>>> prompt = "the four horsewomen of the apocalypse, painting by tom of finland, gaston bussiere, craig mullins, j. c. leyendecker"
+>>> out = pipeline(prompt=prompt, **SafetyConfig.MAX)
+```
+
+The following configurations are available: `SafetyConfig.WEAK`, `SafetyConfig.MEDIUM`, `SafetyConfig.STRONG`, and `SafetyConfig.MAX`.
+
+### How to load and use different schedulers
+
+The safe stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import StableDiffusionPipelineSafe, EulerDiscreteScheduler
+
+>>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("AIML-TUDA/stable-diffusion-safe", subfolder="scheduler")
+>>> pipeline = StableDiffusionPipelineSafe.from_pretrained(
+... "AIML-TUDA/stable-diffusion-safe", scheduler=euler_scheduler
+... )
+```
+
+
+## StableDiffusionSafePipelineOutput
+[[autodoc]] pipelines.stable_diffusion_safe.StableDiffusionSafePipelineOutput
+ - all
+ - __call__
+
+## StableDiffusionPipelineSafe
+[[autodoc]] StableDiffusionPipelineSafe
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx b/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..ee359d0ba486a30fb732fe3d191e7088c6c69a1e
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx
@@ -0,0 +1,175 @@
+
+
+# Stable unCLIP
+
+Stable unCLIP checkpoints are finetuned from [stable diffusion 2.1](./stable_diffusion_2) checkpoints to condition on CLIP image embeddings.
+Stable unCLIP also still conditions on text embeddings. Given the two separate conditionings, stable unCLIP can be used
+for text guided image variation. When combined with an unCLIP prior, it can also be used for full text to image generation.
+
+To know more about the unCLIP process, check out the following paper:
+
+[Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) by Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen.
+
+## Tips
+
+Stable unCLIP takes a `noise_level` as input during inference. `noise_level` determines how much noise is added
+to the image embeddings. A higher `noise_level` increases variation in the final un-noised images. By default,
+we do not add any additional noise to the image embeddings i.e. `noise_level = 0`.
+
+### Available checkpoints:
+
+* Image variation
+ * [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip)
+ * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
+* Text-to-image
+ * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
+
+### Text-to-Image Generation
+Stable unCLIP can be leveraged for text-to-image generation by pipelining it with the prior model of KakaoBrain's open source DALL-E 2 replication [Karlo](https://huggingface.co/kakaobrain/karlo-v1-alpha)
+
+```python
+import torch
+from diffusers import UnCLIPScheduler, DDPMScheduler, StableUnCLIPPipeline
+from diffusers.models import PriorTransformer
+from transformers import CLIPTokenizer, CLIPTextModelWithProjection
+
+prior_model_id = "kakaobrain/karlo-v1-alpha"
+data_type = torch.float16
+prior = PriorTransformer.from_pretrained(prior_model_id, subfolder="prior", torch_dtype=data_type)
+
+prior_text_model_id = "openai/clip-vit-large-patch14"
+prior_tokenizer = CLIPTokenizer.from_pretrained(prior_text_model_id)
+prior_text_model = CLIPTextModelWithProjection.from_pretrained(prior_text_model_id, torch_dtype=data_type)
+prior_scheduler = UnCLIPScheduler.from_pretrained(prior_model_id, subfolder="prior_scheduler")
+prior_scheduler = DDPMScheduler.from_config(prior_scheduler.config)
+
+stable_unclip_model_id = "stabilityai/stable-diffusion-2-1-unclip-small"
+
+pipe = StableUnCLIPPipeline.from_pretrained(
+ stable_unclip_model_id,
+ torch_dtype=data_type,
+ variant="fp16",
+ prior_tokenizer=prior_tokenizer,
+ prior_text_encoder=prior_text_model,
+ prior=prior,
+ prior_scheduler=prior_scheduler,
+)
+
+pipe = pipe.to("cuda")
+wave_prompt = "dramatic wave, the Oceans roar, Strong wave spiral across the oceans as the waves unfurl into roaring crests; perfect wave form; perfect wave shape; dramatic wave shape; wave shape unbelievable; wave; wave shape spectacular"
+
+images = pipe(prompt=wave_prompt).images
+images[0].save("waves.png")
+```
+
+
+For text-to-image we use `stabilityai/stable-diffusion-2-1-unclip-small` as it was trained on CLIP ViT-L/14 embedding, the same as the Karlo model prior. [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip) was trained on OpenCLIP ViT-H, so we don't recommend its use.
+
+
+
+### Text guided Image-to-Image Variation
+
+```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
+
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+pipe = pipe.to("cuda")
+
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
+
+images = pipe(init_image).images
+images[0].save("variation_image.png")
+```
+
+Optionally, you can also pass a prompt to `pipe` such as:
+
+```python
+prompt = "A fantasy landscape, trending on artstation"
+
+images = pipe(init_image, prompt=prompt).images
+images[0].save("variation_image_two.png")
+```
+
+### Memory optimization
+
+If you are short on GPU memory, you can enable smart CPU offloading so that models that are not needed
+immediately for a computation can be offloaded to CPU:
+
+```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
+
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+# Offload to CPU.
+pipe.enable_model_cpu_offload()
+
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
+
+images = pipe(init_image).images
+images[0]
+```
+
+Further memory optimizations are possible by enabling VAE slicing on the pipeline:
+
+```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
+
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+pipe.enable_model_cpu_offload()
+pipe.enable_vae_slicing()
+
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
+
+images = pipe(init_image).images
+images[0]
+```
+
+### StableUnCLIPPipeline
+
+[[autodoc]] StableUnCLIPPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+
+### StableUnCLIPImg2ImgPipeline
+
+[[autodoc]] StableUnCLIPImg2ImgPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stochastic_karras_ve.mdx b/diffusers/docs/source/en/api/pipelines/stochastic_karras_ve.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..17a414303b9c8670361258e52047db4aff399cf7
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stochastic_karras_ve.mdx
@@ -0,0 +1,36 @@
+
+
+# Stochastic Karras VE
+
+## Overview
+
+[Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) by Tero Karras, Miika Aittala, Timo Aila and Samuli Laine.
+
+The abstract of the paper is the following:
+
+We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of an existing ImageNet-64 model from 2.07 to near-SOTA 1.55.
+
+This pipeline implements the Stochastic sampling tailored to the Variance-Expanding (VE) models.
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_stochastic_karras_ve.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stochastic_karras_ve/pipeline_stochastic_karras_ve.py) | *Unconditional Image Generation* | - |
+
+
+## KarrasVePipeline
+[[autodoc]] KarrasVePipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/text_to_video.mdx b/diffusers/docs/source/en/api/pipelines/text_to_video.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..82b2f19ce1b2eb0456906ecf9ed1dfde4f6a0d26
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/text_to_video.mdx
@@ -0,0 +1,130 @@
+
+
+
+
+This pipeline is for research purposes only.
+
+
+
+# Text-to-video synthesis
+
+## Overview
+
+[VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation](https://arxiv.org/abs/2303.08320) by Zhengxiong Luo, Dayou Chen, Yingya Zhang, Yan Huang, Liang Wang, Yujun Shen, Deli Zhao, Jingren Zhou, Tieniu Tan.
+
+The abstract of the paper is the following:
+
+*A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to high-dimensional data spaces. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.*
+
+Resources:
+
+* [Website](https://modelscope.cn/models/damo/text-to-video-synthesis/summary)
+* [GitHub repository](https://github.com/modelscope/modelscope/)
+* [🤗 Spaces](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis)
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [TextToVideoSDPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py) | *Text-to-Video Generation* | [🤗 Spaces](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis)
+
+## Usage example
+
+Let's start by generating a short video with the default length of 16 frames (2s at 8 fps):
+
+```python
+import torch
+from diffusers import DiffusionPipeline
+from diffusers.utils import export_to_video
+
+pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
+pipe = pipe.to("cuda")
+
+prompt = "Spiderman is surfing"
+video_frames = pipe(prompt).frames
+video_path = export_to_video(video_frames)
+video_path
+```
+
+Diffusers supports different optimization techniques to improve the latency
+and memory footprint of a pipeline. Since videos are often more memory-heavy than images,
+we can enable CPU offloading and VAE slicing to keep the memory footprint at bay.
+
+Let's generate a video of 8 seconds (64 frames) on the same GPU using CPU offloading and VAE slicing:
+
+```python
+import torch
+from diffusers import DiffusionPipeline
+from diffusers.utils import export_to_video
+
+pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
+pipe.enable_model_cpu_offload()
+
+# memory optimization
+pipe.enable_vae_slicing()
+
+prompt = "Darth Vader surfing a wave"
+video_frames = pipe(prompt, num_frames=64).frames
+video_path = export_to_video(video_frames)
+video_path
+```
+
+It just takes **7 GBs of GPU memory** to generate the 64 video frames using PyTorch 2.0, "fp16" precision and the techniques mentioned above.
+
+We can also use a different scheduler easily, using the same method we'd use for Stable Diffusion:
+
+```python
+import torch
+from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
+from diffusers.utils import export_to_video
+
+pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe.enable_model_cpu_offload()
+
+prompt = "Spiderman is surfing"
+video_frames = pipe(prompt, num_inference_steps=25).frames
+video_path = export_to_video(video_frames)
+video_path
+```
+
+Here are some sample outputs:
+
+
|
+
+## StableDiffusionControlNetPipeline
+[[autodoc]] StableDiffusionControlNetPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+## FlaxStableDiffusionControlNetPipeline
+[[autodoc]] FlaxStableDiffusionControlNetPipeline
+ - all
+ - __call__
+
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..c46576ff288757a316a5efa0ec3b753fd9ce2bd4
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/depth2img.mdx
@@ -0,0 +1,33 @@
+
+
+# Depth-to-Image Generation
+
+## StableDiffusionDepth2ImgPipeline
+
+The depth-guided stable diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), as part of Stable Diffusion 2.0. It uses [MiDas](https://github.com/isl-org/MiDaS) to infer depth based on an image.
+
+[`StableDiffusionDepth2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images as well as a `depth_map` to preserve the images’ structure.
+
+The original codebase can be found here:
+- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion)
+
+Available Checkpoints are:
+- *stable-diffusion-2-depth*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth)
+
+[[autodoc]] StableDiffusionDepth2ImgPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..8ca69ff69aec6a74e22beade70b5ef2ef42a0e3c
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/image_variation.mdx
@@ -0,0 +1,31 @@
+
+
+# Image Variation
+
+## StableDiffusionImageVariationPipeline
+
+[`StableDiffusionImageVariationPipeline`] lets you generate variations from an input image using Stable Diffusion. It uses a fine-tuned version of Stable Diffusion model, trained by [Justin Pinkney](https://www.justinpinkney.com/) (@Buntworthy) at [Lambda](https://lambdalabs.com/).
+
+The original codebase can be found here:
+[Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations)
+
+Available Checkpoints are:
+- *sd-image-variations-diffusers*: [lambdalabs/sd-image-variations-diffusers](https://huggingface.co/lambdalabs/sd-image-variations-diffusers)
+
+[[autodoc]] StableDiffusionImageVariationPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..09bfb853f9c9bdce1fbd4b4ae3571557d2a5bfc1
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/img2img.mdx
@@ -0,0 +1,36 @@
+
+
+# Image-to-Image Generation
+
+## StableDiffusionImg2ImgPipeline
+
+The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images using Stable Diffusion.
+
+The original codebase can be found here: [CampVis/stable-diffusion](https://github.com/CompVis/stable-diffusion/blob/main/scripts/img2img.py)
+
+[`StableDiffusionImg2ImgPipeline`] is compatible with all Stable Diffusion checkpoints for [Text-to-Image](./text2img)
+
+The pipeline uses the diffusion-denoising mechanism proposed by SDEdit ([SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations](https://arxiv.org/abs/2108.01073)
+proposed by Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, Stefano Ermon).
+
+[[autodoc]] StableDiffusionImg2ImgPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+[[autodoc]] FlaxStableDiffusionImg2ImgPipeline
+ - all
+ - __call__
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..33e84a63261fbf9c370e2d5e22ffbf4a1256bbb4
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.mdx
@@ -0,0 +1,37 @@
+
+
+# Text-Guided Image Inpainting
+
+## StableDiffusionInpaintPipeline
+
+The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionInpaintPipeline`] lets you edit specific parts of an image by providing a mask and a text prompt using Stable Diffusion.
+
+The original codebase can be found here:
+- *Stable Diffusion V1*: [CampVis/stable-diffusion](https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion)
+- *Stable Diffusion V2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#image-inpainting-with-stable-diffusion)
+
+Available checkpoints are:
+- *stable-diffusion-inpainting (512x512 resolution)*: [runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting)
+- *stable-diffusion-2-inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting)
+
+[[autodoc]] StableDiffusionInpaintPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+[[autodoc]] FlaxStableDiffusionInpaintPipeline
+ - all
+ - __call__
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..61fd2f799114de345400a692c115811fbf222871
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/latent_upscale.mdx
@@ -0,0 +1,33 @@
+
+
+# Stable Diffusion Latent Upscaler
+
+## StableDiffusionLatentUpscalePipeline
+
+The Stable Diffusion Latent Upscaler model was created by [Katherine Crowson](https://github.com/crowsonkb/k-diffusion) in collaboration with [Stability AI](https://stability.ai/). It can be used on top of any [`StableDiffusionUpscalePipeline`] checkpoint to enhance its output image resolution by a factor of 2.
+
+A notebook that demonstrates the original implementation can be found here:
+- [Stable Diffusion Upscaler Demo](https://colab.research.google.com/drive/1o1qYJcFeywzCIdkfKJy7cTpgZTCM2EI4)
+
+Available Checkpoints are:
+- *stabilityai/latent-upscaler*: [stabilityai/sd-x2-latent-upscaler](https://huggingface.co/stabilityai/sd-x2-latent-upscaler)
+
+
+[[autodoc]] StableDiffusionLatentUpscalePipeline
+ - all
+ - __call__
+ - enable_sequential_cpu_offload
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..7aae35ba2a91774a4297ee7ada6d13a40fed6f32
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/model_editing.mdx
@@ -0,0 +1,61 @@
+
+
+# Editing Implicit Assumptions in Text-to-Image Diffusion Models
+
+## Overview
+
+[Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084) by Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov.
+
+The abstract of the paper is the following:
+
+*Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.*
+
+Resources:
+
+* [Project Page](https://time-diffusion.github.io/).
+* [Paper](https://arxiv.org/abs/2303.08084).
+* [Original Code](https://github.com/bahjat-kawar/time-diffusion).
+* [Demo](https://huggingface.co/spaces/bahjat-kawar/time-diffusion).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionModelEditingPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py) | *Text-to-Image Model Editing* | [🤗 Space](https://huggingface.co/spaces/bahjat-kawar/time-diffusion)) |
+
+This pipeline enables editing the diffusion model weights, such that its assumptions on a given concept are changed. The resulting change is expected to take effect in all prompt generations pertaining to the edited concept.
+
+## Usage example
+
+```python
+import torch
+from diffusers import StableDiffusionModelEditingPipeline
+
+model_ckpt = "CompVis/stable-diffusion-v1-4"
+pipe = StableDiffusionModelEditingPipeline.from_pretrained(model_ckpt)
+
+pipe = pipe.to("cuda")
+
+source_prompt = "A pack of roses"
+destination_prompt = "A pack of blue roses"
+pipe.edit_model(source_prompt, destination_prompt)
+
+prompt = "A field of roses"
+image = pipe(prompt).images[0]
+image.save("field_of_roses.png")
+```
+
+## StableDiffusionModelEditingPipeline
+[[autodoc]] StableDiffusionModelEditingPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..70731fd294b91c8bca9bb1726c14011507c22a4a
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/overview.mdx
@@ -0,0 +1,82 @@
+
+
+# Stable diffusion pipelines
+
+Stable Diffusion is a text-to-image _latent diffusion_ model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/). It's trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) dataset. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and can run on consumer GPUs.
+
+Latent diffusion is the research on top of which Stable Diffusion was built. It was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. You can learn more details about it in the [specific pipeline for latent diffusion](pipelines/latent_diffusion) that is part of 🤗 Diffusers.
+
+For more details about how Stable Diffusion works and how it differs from the base latent diffusion model, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-announcement) and [this section of our own blog post](https://huggingface.co/blog/stable_diffusion#how-does-stable-diffusion-work).
+
+*Tips*:
+- To tweak your prompts on a specific result you liked, you can generate your own latents, as demonstrated in the following notebook: [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
+
+*Overview*:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [StableDiffusionPipeline](./text2img) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb) | [🤗 Stable Diffusion](https://huggingface.co/spaces/stabilityai/stable-diffusion)
+| [StableDiffusionImg2ImgPipeline](./img2img) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb) | [🤗 Diffuse the Rest](https://huggingface.co/spaces/huggingface/diffuse-the-rest)
+| [StableDiffusionInpaintPipeline](./inpaint) | **Experimental** – *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb) | Coming soon
+| [StableDiffusionDepth2ImgPipeline](./depth2img) | **Experimental** – *Depth-to-Image Text-Guided Generation * | | Coming soon
+| [StableDiffusionImageVariationPipeline](./image_variation) | **Experimental** – *Image Variation Generation * | | [🤗 Stable Diffusion Image Variations](https://huggingface.co/spaces/lambdalabs/stable-diffusion-image-variations)
+| [StableDiffusionUpscalePipeline](./upscale) | **Experimental** – *Text-Guided Image Super-Resolution * | | Coming soon
+| [StableDiffusionLatentUpscalePipeline](./latent_upscale) | **Experimental** – *Text-Guided Image Super-Resolution * | | Coming soon
+| [StableDiffusionInstructPix2PixPipeline](./pix2pix) | **Experimental** – *Text-Based Image Editing * | | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/spaces/timbrooks/instruct-pix2pix)
+| [StableDiffusionAttendAndExcitePipeline](./attend_and_excite) | **Experimental** – *Text-to-Image Generation * | | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://huggingface.co/spaces/AttendAndExcite/Attend-and-Excite)
+| [StableDiffusionPix2PixZeroPipeline](./pix2pix_zero) | **Experimental** – *Text-Based Image Editing * | | [Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027)
+| [StableDiffusionModelEditingPipeline](./model_editing) | **Experimental** – *Text-to-Image Model Editing * | | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://arxiv.org/abs/2303.08084)
+
+
+
+## Tips
+
+### How to load and use different schedulers.
+
+The stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
+
+>>> pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
+>>> pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=euler_scheduler)
+```
+
+
+### How to convert all use cases with multiple or single pipeline
+
+If you want to use all possible use cases in a single `DiffusionPipeline` you can either:
+- Make use of the [Stable Diffusion Mega Pipeline](https://github.com/huggingface/diffusers/tree/main/examples/community#stable-diffusion-mega) or
+- Make use of the `components` functionality to instantiate all components in the most memory-efficient way:
+
+```python
+>>> from diffusers import (
+... StableDiffusionPipeline,
+... StableDiffusionImg2ImgPipeline,
+... StableDiffusionInpaintPipeline,
+... )
+
+>>> text2img = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+>>> img2img = StableDiffusionImg2ImgPipeline(**text2img.components)
+>>> inpaint = StableDiffusionInpaintPipeline(**text2img.components)
+
+>>> # now you can use text2img(...), img2img(...), inpaint(...) just like the call methods of each respective pipeline
+```
+
+## StableDiffusionPipelineOutput
+[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e0c7747a0193013507ccc28e3d48c7ee5ab8ca11
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/panorama.mdx
@@ -0,0 +1,58 @@
+
+
+# MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
+
+## Overview
+
+[MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation](https://arxiv.org/abs/2302.08113) by Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel.
+
+The abstract of the paper is the following:
+
+*Recent advances in text-to-image generation with diffusion models present transformative capabilities in image quality. However, user controllability of the generated image, and fast adaptation to new tasks still remains an open challenge, currently mostly addressed by costly and long re-training and fine-tuning or ad-hoc adaptations to specific image generation tasks. In this work, we present MultiDiffusion, a unified framework that enables versatile and controllable image generation, using a pre-trained text-to-image diffusion model, without any further training or finetuning. At the center of our approach is a new generation process, based on an optimization task that binds together multiple diffusion generation processes with a shared set of parameters or constraints. We show that MultiDiffusion can be readily applied to generate high quality and diverse images that adhere to user-provided controls, such as desired aspect ratio (e.g., panorama), and spatial guiding signals, ranging from tight segmentation masks to bounding boxes.
+
+Resources:
+
+* [Project Page](https://multidiffusion.github.io/).
+* [Paper](https://arxiv.org/abs/2302.08113).
+* [Original Code](https://github.com/omerbt/MultiDiffusion).
+* [Demo](https://huggingface.co/spaces/weizmannscience/MultiDiffusion).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionPanoramaPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_panorama.py) | *Text-Guided Panorama View Generation* | [🤗 Space](https://huggingface.co/spaces/weizmannscience/MultiDiffusion)) |
+
+
+
+## Usage example
+
+```python
+import torch
+from diffusers import StableDiffusionPanoramaPipeline, DDIMScheduler
+
+model_ckpt = "stabilityai/stable-diffusion-2-base"
+scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
+pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, torch_dtype=torch.float16)
+
+pipe = pipe.to("cuda")
+
+prompt = "a photo of the dolomites"
+image = pipe(prompt).images[0]
+image.save("dolomites.png")
+```
+
+## StableDiffusionPanoramaPipeline
+[[autodoc]] StableDiffusionPanoramaPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..42cd4b896b2e4603aaf826efc7201672c016563f
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix.mdx
@@ -0,0 +1,70 @@
+
+
+# InstructPix2Pix: Learning to Follow Image Editing Instructions
+
+## Overview
+
+[InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) by Tim Brooks, Aleksander Holynski and Alexei A. Efros.
+
+The abstract of the paper is the following:
+
+*We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models -- a language model (GPT-3) and a text-to-image model (Stable Diffusion) -- to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.*
+
+Resources:
+
+* [Project Page](https://www.timothybrooks.com/instruct-pix2pix).
+* [Paper](https://arxiv.org/abs/2211.09800).
+* [Original Code](https://github.com/timothybrooks/instruct-pix2pix).
+* [Demo](https://huggingface.co/spaces/timbrooks/instruct-pix2pix).
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionInstructPix2PixPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/timbrooks/instruct-pix2pix) |
+
+
+
+## Usage example
+
+```python
+import PIL
+import requests
+import torch
+from diffusers import StableDiffusionInstructPix2PixPipeline
+
+model_id = "timbrooks/instruct-pix2pix"
+pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+
+url = "https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
+
+
+def download_image(url):
+ image = PIL.Image.open(requests.get(url, stream=True).raw)
+ image = PIL.ImageOps.exif_transpose(image)
+ image = image.convert("RGB")
+ return image
+
+
+image = download_image(url)
+
+prompt = "make the mountains snowy"
+images = pipe(prompt, image=image, num_inference_steps=20, image_guidance_scale=1.5, guidance_scale=7).images
+images[0].save("snowy_mountains.png")
+```
+
+## StableDiffusionInstructPix2PixPipeline
+[[autodoc]] StableDiffusionInstructPix2PixPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f04a54f242acade990415a1ed7c240c37a828dd7
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/pix2pix_zero.mdx
@@ -0,0 +1,291 @@
+
+
+# Zero-shot Image-to-Image Translation
+
+## Overview
+
+[Zero-shot Image-to-Image Translation](https://arxiv.org/abs/2302.03027).
+
+The abstract of the paper is the following:
+
+*Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.*
+
+Resources:
+
+* [Project Page](https://pix2pixzero.github.io/).
+* [Paper](https://arxiv.org/abs/2302.03027).
+* [Original Code](https://github.com/pix2pixzero/pix2pix-zero).
+* [Demo](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo).
+
+## Tips
+
+* The pipeline can be conditioned on real input images. Check out the code examples below to know more.
+* The pipeline exposes two arguments namely `source_embeds` and `target_embeds`
+that let you control the direction of the semantic edits in the final image to be generated. Let's say,
+you wanted to translate from "cat" to "dog". In this case, the edit direction will be "cat -> dog". To reflect
+this in the pipeline, you simply have to set the embeddings related to the phrases including "cat" to
+`source_embeds` and "dog" to `target_embeds`. Refer to the code example below for more details.
+* When you're using this pipeline from a prompt, specify the _source_ concept in the prompt. Taking
+the above example, a valid input prompt would be: "a high resolution painting of a **cat** in the style of van gough".
+* If you wanted to reverse the direction in the example above, i.e., "dog -> cat", then it's recommended to:
+ * Swap the `source_embeds` and `target_embeds`.
+ * Change the input prompt to include "dog".
+* To learn more about how the source and target embeddings are generated, refer to the [original
+paper](https://arxiv.org/abs/2302.03027). Below, we also provide some directions on how to generate the embeddings.
+* Note that the quality of the outputs generated with this pipeline is dependent on how good the `source_embeds` and `target_embeds` are. Please, refer to [this discussion](#generating-source-and-target-embeddings) for some suggestions on the topic.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionPix2PixZeroPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo) |
+
+
+
+## Usage example
+
+### Based on an image generated with the input prompt
+
+```python
+import requests
+import torch
+
+from diffusers import DDIMScheduler, StableDiffusionPix2PixZeroPipeline
+
+
+def download(embedding_url, local_filepath):
+ r = requests.get(embedding_url)
+ with open(local_filepath, "wb") as f:
+ f.write(r.content)
+
+
+model_ckpt = "CompVis/stable-diffusion-v1-4"
+pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ model_ckpt, conditions_input_image=False, torch_dtype=torch.float16
+)
+pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+pipeline.to("cuda")
+
+prompt = "a high resolution painting of a cat in the style of van gogh"
+src_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/cat.pt"
+target_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/dog.pt"
+
+for url in [src_embs_url, target_embs_url]:
+ download(url, url.split("/")[-1])
+
+src_embeds = torch.load(src_embs_url.split("/")[-1])
+target_embeds = torch.load(target_embs_url.split("/")[-1])
+
+images = pipeline(
+ prompt,
+ source_embeds=src_embeds,
+ target_embeds=target_embeds,
+ num_inference_steps=50,
+ cross_attention_guidance_amount=0.15,
+).images
+images[0].save("edited_image_dog.png")
+```
+
+### Based on an input image
+
+When the pipeline is conditioned on an input image, we first obtain an inverted
+noise from it using a `DDIMInverseScheduler` with the help of a generated caption. Then
+the inverted noise is used to start the generation process.
+
+First, let's load our pipeline:
+
+```py
+import torch
+from transformers import BlipForConditionalGeneration, BlipProcessor
+from diffusers import DDIMScheduler, DDIMInverseScheduler, StableDiffusionPix2PixZeroPipeline
+
+captioner_id = "Salesforce/blip-image-captioning-base"
+processor = BlipProcessor.from_pretrained(captioner_id)
+model = BlipForConditionalGeneration.from_pretrained(captioner_id, torch_dtype=torch.float16, low_cpu_mem_usage=True)
+
+sd_model_ckpt = "CompVis/stable-diffusion-v1-4"
+pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ sd_model_ckpt,
+ caption_generator=model,
+ caption_processor=processor,
+ torch_dtype=torch.float16,
+ safety_checker=None,
+)
+pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+pipeline.inverse_scheduler = DDIMInverseScheduler.from_config(pipeline.scheduler.config)
+pipeline.enable_model_cpu_offload()
+```
+
+Then, we load an input image for conditioning and obtain a suitable caption for it:
+
+```py
+import requests
+from PIL import Image
+
+img_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/test_images/cats/cat_6.png"
+raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB").resize((512, 512))
+caption = pipeline.generate_caption(raw_image)
+```
+
+Then we employ the generated caption and the input image to get the inverted noise:
+
+```py
+generator = torch.manual_seed(0)
+inv_latents = pipeline.invert(caption, image=raw_image, generator=generator).latents
+```
+
+Now, generate the image with edit directions:
+
+```py
+# See the "Generating source and target embeddings" section below to
+# automate the generation of these captions with a pre-trained model like Flan-T5 as explained below.
+source_prompts = ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
+target_prompts = ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
+
+source_embeds = pipeline.get_embeds(source_prompts, batch_size=2)
+target_embeds = pipeline.get_embeds(target_prompts, batch_size=2)
+
+
+image = pipeline(
+ caption,
+ source_embeds=source_embeds,
+ target_embeds=target_embeds,
+ num_inference_steps=50,
+ cross_attention_guidance_amount=0.15,
+ generator=generator,
+ latents=inv_latents,
+ negative_prompt=caption,
+).images[0]
+image.save("edited_image.png")
+```
+
+## Generating source and target embeddings
+
+The authors originally used the [GPT-3 API](https://openai.com/api/) to generate the source and target captions for discovering
+edit directions. However, we can also leverage open source and public models for the same purpose.
+Below, we provide an end-to-end example with the [Flan-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5) model
+for generating captions and [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for
+computing embeddings on the generated captions.
+
+**1. Load the generation model**:
+
+```py
+import torch
+from transformers import AutoTokenizer, T5ForConditionalGeneration
+
+tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xl")
+model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xl", device_map="auto", torch_dtype=torch.float16)
+```
+
+**2. Construct a starting prompt**:
+
+```py
+source_concept = "cat"
+target_concept = "dog"
+
+source_text = f"Provide a caption for images containing a {source_concept}. "
+"The captions should be in English and should be no longer than 150 characters."
+
+target_text = f"Provide a caption for images containing a {target_concept}. "
+"The captions should be in English and should be no longer than 150 characters."
+```
+
+Here, we're interested in the "cat -> dog" direction.
+
+**3. Generate captions**:
+
+We can use a utility like so for this purpose.
+
+```py
+def generate_captions(input_prompt):
+ input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.to("cuda")
+
+ outputs = model.generate(
+ input_ids, temperature=0.8, num_return_sequences=16, do_sample=True, max_new_tokens=128, top_k=10
+ )
+ return tokenizer.batch_decode(outputs, skip_special_tokens=True)
+```
+
+And then we just call it to generate our captions:
+
+```py
+source_captions = generate_captions(source_text)
+target_captions = generate_captions(target_concept)
+```
+
+We encourage you to play around with the different parameters supported by the
+`generate()` method ([documentation](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_tf_utils.TFGenerationMixin.generate)) for the generation quality you are looking for.
+
+**4. Load the embedding model**:
+
+Here, we need to use the same text encoder model used by the subsequent Stable Diffusion model.
+
+```py
+from diffusers import StableDiffusionPix2PixZeroPipeline
+
+pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
+)
+pipeline = pipeline.to("cuda")
+tokenizer = pipeline.tokenizer
+text_encoder = pipeline.text_encoder
+```
+
+**5. Compute embeddings**:
+
+```py
+import torch
+
+def embed_captions(sentences, tokenizer, text_encoder, device="cuda"):
+ with torch.no_grad():
+ embeddings = []
+ for sent in sentences:
+ text_inputs = tokenizer(
+ sent,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ prompt_embeds = text_encoder(text_input_ids.to(device), attention_mask=None)[0]
+ embeddings.append(prompt_embeds)
+ return torch.concatenate(embeddings, dim=0).mean(dim=0).unsqueeze(0)
+
+source_embeddings = embed_captions(source_captions, tokenizer, text_encoder)
+target_embeddings = embed_captions(target_captions, tokenizer, text_encoder)
+```
+
+And you're done! [Here](https://colab.research.google.com/drive/1tz2C1EdfZYAPlzXXbTnf-5PRBiR8_R1F?usp=sharing) is a Colab Notebook that you can use to interact with the entire process.
+
+Now, you can use these embeddings directly while calling the pipeline:
+
+```py
+from diffusers import DDIMScheduler
+
+pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+
+images = pipeline(
+ prompt,
+ source_embeds=source_embeddings,
+ target_embeds=target_embeddings,
+ num_inference_steps=50,
+ cross_attention_guidance_amount=0.15,
+).images
+images[0].save("edited_image_dog.png")
+```
+
+## StableDiffusionPix2PixZeroPipeline
+[[autodoc]] StableDiffusionPix2PixZeroPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b34c1f51cf668b289ca000719828addb88f6a20e
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/self_attention_guidance.mdx
@@ -0,0 +1,64 @@
+
+
+# Self-Attention Guidance (SAG)
+
+## Overview
+
+[Self-Attention Guidance](https://arxiv.org/abs/2210.00939) by Susung Hong et al.
+
+The abstract of the paper is the following:
+
+*Denoising diffusion models (DDMs) have been drawing much attention for their appreciable sample quality and diversity. Despite their remarkable performance, DDMs remain black boxes on which further study is necessary to take a profound step. Motivated by this, we delve into the design of conventional U-shaped diffusion models. More specifically, we investigate the self-attention modules within these models through carefully designed experiments and explore their characteristics. In addition, inspired by the studies that substantiate the effectiveness of the guidance schemes, we present plug-and-play diffusion guidance, namely Self-Attention Guidance (SAG), that can drastically boost the performance of existing diffusion models. Our method, SAG, extracts the intermediate attention map from a diffusion model at every iteration and selects tokens above a certain attention score for masking and blurring to obtain a partially blurred input. Subsequently, we measure the dissimilarity between the predicted noises obtained from feeding the blurred and original input to the diffusion model and leverage it as guidance. With this guidance, we observe apparent improvements in a wide range of diffusion models, e.g., ADM, IDDPM, and Stable Diffusion, and show that the results further improve by combining our method with the conventional guidance scheme. We provide extensive ablation studies to verify our choices.*
+
+Resources:
+
+* [Project Page](https://ku-cvlab.github.io/Self-Attention-Guidance).
+* [Paper](https://arxiv.org/abs/2210.00939).
+* [Original Code](https://github.com/KU-CVLAB/Self-Attention-Guidance).
+* [Demo](https://colab.research.google.com/github/SusungHong/Self-Attention-Guidance/blob/main/SAG_Stable.ipynb).
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [StableDiffusionSAGPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py) | *Text-to-Image Generation* | [Colab](https://colab.research.google.com/github/SusungHong/Self-Attention-Guidance/blob/main/SAG_Stable.ipynb) |
+
+## Usage example
+
+```python
+import torch
+from diffusers import StableDiffusionSAGPipeline
+from accelerate.utils import set_seed
+
+pipe = StableDiffusionSAGPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+pipe = pipe.to("cuda")
+
+seed = 8978
+prompt = "."
+guidance_scale = 7.5
+num_images_per_prompt = 1
+
+sag_scale = 1.0
+
+set_seed(seed)
+images = pipe(
+ prompt, num_images_per_prompt=num_images_per_prompt, guidance_scale=guidance_scale, sag_scale=sag_scale
+).images
+images[0].save("example.png")
+```
+
+## StableDiffusionSAGPipeline
+[[autodoc]] StableDiffusionSAGPipeline
+ - __call__
+ - all
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6b8d53bf6510a0b122529170e0de3cbddcc40690
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/text2img.mdx
@@ -0,0 +1,45 @@
+
+
+# Text-to-Image Generation
+
+## StableDiffusionPipeline
+
+The Stable Diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), [runway](https://github.com/runwayml), and [LAION](https://laion.ai/). The [`StableDiffusionPipeline`] is capable of generating photo-realistic images given any text input using Stable Diffusion.
+
+The original codebase can be found here:
+- *Stable Diffusion V1*: [CompVis/stable-diffusion](https://github.com/CompVis/stable-diffusion)
+- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion)
+
+Available Checkpoints are:
+- *stable-diffusion-v1-4 (512x512 resolution)* [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)
+- *stable-diffusion-v1-5 (512x512 resolution)* [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)
+- *stable-diffusion-2-base (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base)
+- *stable-diffusion-2 (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2)
+- *stable-diffusion-2-1-base (512x512 resolution)* [stabilityai/stable-diffusion-2-1-base](https://huggingface.co/stabilityai/stable-diffusion-2-1-base)
+- *stable-diffusion-2-1 (768x768 resolution)*: [stabilityai/stable-diffusion-2-1](https://huggingface.co/stabilityai/stable-diffusion-2-1)
+
+[[autodoc]] StableDiffusionPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+ - enable_vae_tiling
+ - disable_vae_tiling
+
+[[autodoc]] FlaxStableDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f70d8f445fd95fb49e7a92c7566951c40ec74933
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion/upscale.mdx
@@ -0,0 +1,32 @@
+
+
+# Super-Resolution
+
+## StableDiffusionUpscalePipeline
+
+The upscaler diffusion model was created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), as part of Stable Diffusion 2.0. [`StableDiffusionUpscalePipeline`] can be used to enhance the resolution of input images by a factor of 4.
+
+The original codebase can be found here:
+- *Stable Diffusion v2*: [Stability-AI/stablediffusion](https://github.com/Stability-AI/stablediffusion#image-upscaling-with-stable-diffusion)
+
+Available Checkpoints are:
+- *stabilityai/stable-diffusion-x4-upscaler (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler)
+
+
+[[autodoc]] StableDiffusionUpscalePipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e922072e4e3185f9de4a0d6e734e0c46a4fe3215
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion_2.mdx
@@ -0,0 +1,176 @@
+
+
+# Stable diffusion 2
+
+Stable Diffusion 2 is a text-to-image _latent diffusion_ model built upon the work of [Stable Diffusion 1](https://stability.ai/blog/stable-diffusion-public-release).
+The project to train Stable Diffusion 2 was led by Robin Rombach and Katherine Crowson from [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/).
+
+*The Stable Diffusion 2.0 release includes robust text-to-image models trained using a brand new text encoder (OpenCLIP), developed by LAION with support from Stability AI, which greatly improves the quality of the generated images compared to earlier V1 releases. The text-to-image models in this release can generate images with default resolutions of both 512x512 pixels and 768x768 pixels.
+These models are trained on an aesthetic subset of the [LAION-5B dataset](https://laion.ai/blog/laion-5b/) created by the DeepFloyd team at Stability AI, which is then further filtered to remove adult content using [LAION’s NSFW filter](https://openreview.net/forum?id=M3Y74vmsMcY).*
+
+For more details about how Stable Diffusion 2 works and how it differs from Stable Diffusion 1, please refer to the official [launch announcement post](https://stability.ai/blog/stable-diffusion-v2-release).
+
+## Tips
+
+### Available checkpoints:
+
+Note that the architecture is more or less identical to [Stable Diffusion 1](./stable_diffusion/overview) so please refer to [this page](./stable_diffusion/overview) for API documentation.
+
+- *Text-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) with [`StableDiffusionPipeline`]
+- *Text-to-Image (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) with [`StableDiffusionPipeline`]
+- *Image Inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) with [`StableDiffusionInpaintPipeline`]
+- *Super-Resolution (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) [`StableDiffusionUpscalePipeline`]
+- *Depth-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) with [`StableDiffusionDepth2ImagePipeline`]
+
+We recommend using the [`DPMSolverMultistepScheduler`] as it's currently the fastest scheduler there is.
+
+
+### Text-to-Image
+
+- *Text-to-Image (512x512 resolution)*: [stabilityai/stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) with [`StableDiffusionPipeline`]
+
+```python
+from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
+import torch
+
+repo_id = "stabilityai/stable-diffusion-2-base"
+pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
+
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+
+prompt = "High quality photo of an astronaut riding a horse in space"
+image = pipe(prompt, num_inference_steps=25).images[0]
+image.save("astronaut.png")
+```
+
+- *Text-to-Image (768x768 resolution)*: [stabilityai/stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) with [`StableDiffusionPipeline`]
+
+```python
+from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
+import torch
+
+repo_id = "stabilityai/stable-diffusion-2"
+pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
+
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+
+prompt = "High quality photo of an astronaut riding a horse in space"
+image = pipe(prompt, guidance_scale=9, num_inference_steps=25).images[0]
+image.save("astronaut.png")
+```
+
+### Image Inpainting
+
+- *Image Inpainting (512x512 resolution)*: [stabilityai/stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) with [`StableDiffusionInpaintPipeline`]
+
+```python
+import PIL
+import requests
+import torch
+from io import BytesIO
+
+from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
+
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+init_image = download_image(img_url).resize((512, 512))
+mask_image = download_image(mask_url).resize((512, 512))
+
+repo_id = "stabilityai/stable-diffusion-2-inpainting"
+pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16, revision="fp16")
+
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+
+prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+image = pipe(prompt=prompt, image=init_image, mask_image=mask_image, num_inference_steps=25).images[0]
+
+image.save("yellow_cat.png")
+```
+
+### Super-Resolution
+
+- *Image Upscaling (x4 resolution resolution)*: [stable-diffusion-x4-upscaler](https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler) with [`StableDiffusionUpscalePipeline`]
+
+
+```python
+import requests
+from PIL import Image
+from io import BytesIO
+from diffusers import StableDiffusionUpscalePipeline
+import torch
+
+# load model and scheduler
+model_id = "stabilityai/stable-diffusion-x4-upscaler"
+pipeline = StableDiffusionUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
+pipeline = pipeline.to("cuda")
+
+# let's download an image
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
+response = requests.get(url)
+low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
+low_res_img = low_res_img.resize((128, 128))
+prompt = "a white cat"
+upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
+upscaled_image.save("upsampled_cat.png")
+```
+
+### Depth-to-Image
+
+- *Depth-Guided Text-to-Image*: [stabilityai/stable-diffusion-2-depth](https://huggingface.co/stabilityai/stable-diffusion-2-depth) [`StableDiffusionDepth2ImagePipeline`]
+
+
+```python
+import torch
+import requests
+from PIL import Image
+
+from diffusers import StableDiffusionDepth2ImgPipeline
+
+pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-depth",
+ torch_dtype=torch.float16,
+).to("cuda")
+
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+init_image = Image.open(requests.get(url, stream=True).raw)
+prompt = "two tigers"
+n_propmt = "bad, deformed, ugly, bad anotomy"
+image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
+```
+
+### How to load and use different schedulers.
+
+The stable diffusion pipeline uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
+
+>>> pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("stabilityai/stable-diffusion-2", subfolder="scheduler")
+>>> pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", scheduler=euler_scheduler)
+```
diff --git a/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx b/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..688eb5013c6a287c77722f006eea59bab73343e6
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_diffusion_safe.mdx
@@ -0,0 +1,90 @@
+
+
+# Safe Stable Diffusion
+
+Safe Stable Diffusion was proposed in [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://arxiv.org/abs/2211.05105) and mitigates the well known issue that models like Stable Diffusion that are trained on unfiltered, web-crawled datasets tend to suffer from inappropriate degeneration. For instance Stable Diffusion may unexpectedly generate nudity, violence, images depicting self-harm, or otherwise offensive content.
+Safe Stable Diffusion is an extension to the Stable Diffusion that drastically reduces content like this.
+
+The abstract of the paper is the following:
+
+*Text-conditioned image generation models have recently achieved astonishing results in image quality and text alignment and are consequently employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the internet, they also suffer, as we demonstrate, from degenerated and biased human behavior. In turn, they may even reinforce such biases. To help combat these undesired side effects, we present safe latent diffusion (SLD). Specifically, to measure the inappropriate degeneration due to unfiltered and imbalanced training sets, we establish a novel image generation test bed-inappropriate image prompts (I2P)-containing dedicated, real-world image-to-text prompts covering concepts such as nudity and violence. As our exhaustive empirical evaluation demonstrates, the introduced SLD removes and suppresses inappropriate image parts during the diffusion process, with no additional training required and no adverse effect on overall image quality or text alignment.*
+
+
+*Overview*:
+
+| Pipeline | Tasks | Colab | Demo
+|---|---|:---:|:---:|
+| [pipeline_stable_diffusion_safe.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb) | [](https://huggingface.co/spaces/AIML-TUDA/unsafe-vs-safe-stable-diffusion)
+
+## Tips
+
+- Safe Stable Diffusion may also be used with weights of [Stable Diffusion](./api/pipelines/stable_diffusion/text2img).
+
+### Run Safe Stable Diffusion
+
+Safe Stable Diffusion can be tested very easily with the [`StableDiffusionPipelineSafe`], and the `"AIML-TUDA/stable-diffusion-safe"` checkpoint exactly in the same way it is shown in the [Conditional Image Generation Guide](./using-diffusers/conditional_image_generation).
+
+### Interacting with the Safety Concept
+
+To check and edit the currently used safety concept, use the `safety_concept` property of [`StableDiffusionPipelineSafe`]:
+```python
+>>> from diffusers import StableDiffusionPipelineSafe
+
+>>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
+>>> pipeline.safety_concept
+```
+For each image generation the active concept is also contained in [`StableDiffusionSafePipelineOutput`].
+
+### Using pre-defined safety configurations
+
+You may use the 4 configurations defined in the [Safe Latent Diffusion paper](https://arxiv.org/abs/2211.05105) as follows:
+
+```python
+>>> from diffusers import StableDiffusionPipelineSafe
+>>> from diffusers.pipelines.stable_diffusion_safe import SafetyConfig
+
+>>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
+>>> prompt = "the four horsewomen of the apocalypse, painting by tom of finland, gaston bussiere, craig mullins, j. c. leyendecker"
+>>> out = pipeline(prompt=prompt, **SafetyConfig.MAX)
+```
+
+The following configurations are available: `SafetyConfig.WEAK`, `SafetyConfig.MEDIUM`, `SafetyConfig.STRONG`, and `SafetyConfig.MAX`.
+
+### How to load and use different schedulers
+
+The safe stable diffusion pipeline uses [`PNDMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the stable diffusion pipeline such as [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import StableDiffusionPipelineSafe, EulerDiscreteScheduler
+
+>>> pipeline = StableDiffusionPipelineSafe.from_pretrained("AIML-TUDA/stable-diffusion-safe")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("AIML-TUDA/stable-diffusion-safe", subfolder="scheduler")
+>>> pipeline = StableDiffusionPipelineSafe.from_pretrained(
+... "AIML-TUDA/stable-diffusion-safe", scheduler=euler_scheduler
+... )
+```
+
+
+## StableDiffusionSafePipelineOutput
+[[autodoc]] pipelines.stable_diffusion_safe.StableDiffusionSafePipelineOutput
+ - all
+ - __call__
+
+## StableDiffusionPipelineSafe
+[[autodoc]] StableDiffusionPipelineSafe
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx b/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..ee359d0ba486a30fb732fe3d191e7088c6c69a1e
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stable_unclip.mdx
@@ -0,0 +1,175 @@
+
+
+# Stable unCLIP
+
+Stable unCLIP checkpoints are finetuned from [stable diffusion 2.1](./stable_diffusion_2) checkpoints to condition on CLIP image embeddings.
+Stable unCLIP also still conditions on text embeddings. Given the two separate conditionings, stable unCLIP can be used
+for text guided image variation. When combined with an unCLIP prior, it can also be used for full text to image generation.
+
+To know more about the unCLIP process, check out the following paper:
+
+[Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) by Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen.
+
+## Tips
+
+Stable unCLIP takes a `noise_level` as input during inference. `noise_level` determines how much noise is added
+to the image embeddings. A higher `noise_level` increases variation in the final un-noised images. By default,
+we do not add any additional noise to the image embeddings i.e. `noise_level = 0`.
+
+### Available checkpoints:
+
+* Image variation
+ * [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip)
+ * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
+* Text-to-image
+ * [stabilityai/stable-diffusion-2-1-unclip-small](https://hf.co/stabilityai/stable-diffusion-2-1-unclip-small)
+
+### Text-to-Image Generation
+Stable unCLIP can be leveraged for text-to-image generation by pipelining it with the prior model of KakaoBrain's open source DALL-E 2 replication [Karlo](https://huggingface.co/kakaobrain/karlo-v1-alpha)
+
+```python
+import torch
+from diffusers import UnCLIPScheduler, DDPMScheduler, StableUnCLIPPipeline
+from diffusers.models import PriorTransformer
+from transformers import CLIPTokenizer, CLIPTextModelWithProjection
+
+prior_model_id = "kakaobrain/karlo-v1-alpha"
+data_type = torch.float16
+prior = PriorTransformer.from_pretrained(prior_model_id, subfolder="prior", torch_dtype=data_type)
+
+prior_text_model_id = "openai/clip-vit-large-patch14"
+prior_tokenizer = CLIPTokenizer.from_pretrained(prior_text_model_id)
+prior_text_model = CLIPTextModelWithProjection.from_pretrained(prior_text_model_id, torch_dtype=data_type)
+prior_scheduler = UnCLIPScheduler.from_pretrained(prior_model_id, subfolder="prior_scheduler")
+prior_scheduler = DDPMScheduler.from_config(prior_scheduler.config)
+
+stable_unclip_model_id = "stabilityai/stable-diffusion-2-1-unclip-small"
+
+pipe = StableUnCLIPPipeline.from_pretrained(
+ stable_unclip_model_id,
+ torch_dtype=data_type,
+ variant="fp16",
+ prior_tokenizer=prior_tokenizer,
+ prior_text_encoder=prior_text_model,
+ prior=prior,
+ prior_scheduler=prior_scheduler,
+)
+
+pipe = pipe.to("cuda")
+wave_prompt = "dramatic wave, the Oceans roar, Strong wave spiral across the oceans as the waves unfurl into roaring crests; perfect wave form; perfect wave shape; dramatic wave shape; wave shape unbelievable; wave; wave shape spectacular"
+
+images = pipe(prompt=wave_prompt).images
+images[0].save("waves.png")
+```
+
+
+For text-to-image we use `stabilityai/stable-diffusion-2-1-unclip-small` as it was trained on CLIP ViT-L/14 embedding, the same as the Karlo model prior. [stabilityai/stable-diffusion-2-1-unclip](https://hf.co/stabilityai/stable-diffusion-2-1-unclip) was trained on OpenCLIP ViT-H, so we don't recommend its use.
+
+
+
+### Text guided Image-to-Image Variation
+
+```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
+
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+pipe = pipe.to("cuda")
+
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
+
+images = pipe(init_image).images
+images[0].save("variation_image.png")
+```
+
+Optionally, you can also pass a prompt to `pipe` such as:
+
+```python
+prompt = "A fantasy landscape, trending on artstation"
+
+images = pipe(init_image, prompt=prompt).images
+images[0].save("variation_image_two.png")
+```
+
+### Memory optimization
+
+If you are short on GPU memory, you can enable smart CPU offloading so that models that are not needed
+immediately for a computation can be offloaded to CPU:
+
+```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
+
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+# Offload to CPU.
+pipe.enable_model_cpu_offload()
+
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
+
+images = pipe(init_image).images
+images[0]
+```
+
+Further memory optimizations are possible by enabling VAE slicing on the pipeline:
+
+```python
+from diffusers import StableUnCLIPImg2ImgPipeline
+from diffusers.utils import load_image
+import torch
+
+pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1-unclip", torch_dtype=torch.float16, variation="fp16"
+)
+pipe.enable_model_cpu_offload()
+pipe.enable_vae_slicing()
+
+url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/tarsila_do_amaral.png"
+init_image = load_image(url)
+
+images = pipe(init_image).images
+images[0]
+```
+
+### StableUnCLIPPipeline
+
+[[autodoc]] StableUnCLIPPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
+
+### StableUnCLIPImg2ImgPipeline
+
+[[autodoc]] StableUnCLIPImg2ImgPipeline
+ - all
+ - __call__
+ - enable_attention_slicing
+ - disable_attention_slicing
+ - enable_vae_slicing
+ - disable_vae_slicing
+ - enable_xformers_memory_efficient_attention
+ - disable_xformers_memory_efficient_attention
+
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/pipelines/stochastic_karras_ve.mdx b/diffusers/docs/source/en/api/pipelines/stochastic_karras_ve.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..17a414303b9c8670361258e52047db4aff399cf7
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/stochastic_karras_ve.mdx
@@ -0,0 +1,36 @@
+
+
+# Stochastic Karras VE
+
+## Overview
+
+[Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) by Tero Karras, Miika Aittala, Timo Aila and Samuli Laine.
+
+The abstract of the paper is the following:
+
+We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of an existing ImageNet-64 model from 2.07 to near-SOTA 1.55.
+
+This pipeline implements the Stochastic sampling tailored to the Variance-Expanding (VE) models.
+
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_stochastic_karras_ve.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stochastic_karras_ve/pipeline_stochastic_karras_ve.py) | *Unconditional Image Generation* | - |
+
+
+## KarrasVePipeline
+[[autodoc]] KarrasVePipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/text_to_video.mdx b/diffusers/docs/source/en/api/pipelines/text_to_video.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..82b2f19ce1b2eb0456906ecf9ed1dfde4f6a0d26
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/text_to_video.mdx
@@ -0,0 +1,130 @@
+
+
+
+
+This pipeline is for research purposes only.
+
+
+
+# Text-to-video synthesis
+
+## Overview
+
+[VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation](https://arxiv.org/abs/2303.08320) by Zhengxiong Luo, Dayou Chen, Yingya Zhang, Yan Huang, Liang Wang, Yujun Shen, Deli Zhao, Jingren Zhou, Tieniu Tan.
+
+The abstract of the paper is the following:
+
+*A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to high-dimensional data spaces. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.*
+
+Resources:
+
+* [Website](https://modelscope.cn/models/damo/text-to-video-synthesis/summary)
+* [GitHub repository](https://github.com/modelscope/modelscope/)
+* [🤗 Spaces](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis)
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Demo
+|---|---|:---:|
+| [TextToVideoSDPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py) | *Text-to-Video Generation* | [🤗 Spaces](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis)
+
+## Usage example
+
+Let's start by generating a short video with the default length of 16 frames (2s at 8 fps):
+
+```python
+import torch
+from diffusers import DiffusionPipeline
+from diffusers.utils import export_to_video
+
+pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
+pipe = pipe.to("cuda")
+
+prompt = "Spiderman is surfing"
+video_frames = pipe(prompt).frames
+video_path = export_to_video(video_frames)
+video_path
+```
+
+Diffusers supports different optimization techniques to improve the latency
+and memory footprint of a pipeline. Since videos are often more memory-heavy than images,
+we can enable CPU offloading and VAE slicing to keep the memory footprint at bay.
+
+Let's generate a video of 8 seconds (64 frames) on the same GPU using CPU offloading and VAE slicing:
+
+```python
+import torch
+from diffusers import DiffusionPipeline
+from diffusers.utils import export_to_video
+
+pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
+pipe.enable_model_cpu_offload()
+
+# memory optimization
+pipe.enable_vae_slicing()
+
+prompt = "Darth Vader surfing a wave"
+video_frames = pipe(prompt, num_frames=64).frames
+video_path = export_to_video(video_frames)
+video_path
+```
+
+It just takes **7 GBs of GPU memory** to generate the 64 video frames using PyTorch 2.0, "fp16" precision and the techniques mentioned above.
+
+We can also use a different scheduler easily, using the same method we'd use for Stable Diffusion:
+
+```python
+import torch
+from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
+from diffusers.utils import export_to_video
+
+pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
+pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe.enable_model_cpu_offload()
+
+prompt = "Spiderman is surfing"
+video_frames = pipe(prompt, num_inference_steps=25).frames
+video_path = export_to_video(video_frames)
+video_path
+```
+
+Here are some sample outputs:
+
+
+
+
+ An astronaut riding a horse.
+
+  +
+ |
+
+ Darth vader surfing in waves.
+
+  +
+ |
+
+
+
+## Available checkpoints
+
+* [damo-vilab/text-to-video-ms-1.7b](https://huggingface.co/damo-vilab/text-to-video-ms-1.7b/)
+* [damo-vilab/text-to-video-ms-1.7b-legacy](https://huggingface.co/damo-vilab/text-to-video-ms-1.7b-legacy)
+
+## TextToVideoSDPipeline
+[[autodoc]] TextToVideoSDPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/unclip.mdx b/diffusers/docs/source/en/api/pipelines/unclip.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..13a578a0ab4857c38dd37598b334c731ba184f46
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/unclip.mdx
@@ -0,0 +1,37 @@
+
+
+# unCLIP
+
+## Overview
+
+[Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) by Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, Mark Chen
+
+The abstract of the paper is the following:
+
+Contrastive models like CLIP have been shown to learn robust representations of images that capture both semantics and style. To leverage these representations for image generation, we propose a two-stage model: a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding. We show that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity. Our decoders conditioned on image representations can also produce variations of an image that preserve both its semantics and style, while varying the non-essential details absent from the image representation. Moreover, the joint embedding space of CLIP enables language-guided image manipulations in a zero-shot fashion. We use diffusion models for the decoder and experiment with both autoregressive and diffusion models for the prior, finding that the latter are computationally more efficient and produce higher-quality samples.
+
+The unCLIP model in diffusers comes from kakaobrain's karlo and the original codebase can be found [here](https://github.com/kakaobrain/karlo). Additionally, lucidrains has a DALL-E 2 recreation [here](https://github.com/lucidrains/DALLE2-pytorch).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_unclip.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/unclip/pipeline_unclip.py) | *Text-to-Image Generation* | - |
+| [pipeline_unclip_image_variation.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/unclip/pipeline_unclip_image_variation.py) | *Image-Guided Image Generation* | - |
+
+
+## UnCLIPPipeline
+[[autodoc]] UnCLIPPipeline
+ - all
+ - __call__
+
+[[autodoc]] UnCLIPImageVariationPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/versatile_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/versatile_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..bfafa8e8f1fc8b36e1488b917922ff676222db98
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/versatile_diffusion.mdx
@@ -0,0 +1,70 @@
+
+
+# VersatileDiffusion
+
+VersatileDiffusion was proposed in [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) by Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi .
+
+The abstract of the paper is the following:
+
+*The recent advances in diffusion models have set an impressive milestone in many generation tasks. Trending works such as DALL-E2, Imagen, and Stable Diffusion have attracted great interest in academia and industry. Despite the rapid landscape changes, recent new approaches focus on extensions and performance rather than capacity, thus requiring separate models for separate tasks. In this work, we expand the existing single-flow diffusion pipeline into a multi-flow network, dubbed Versatile Diffusion (VD), that handles text-to-image, image-to-text, image-variation, and text-variation in one unified model. Moreover, we generalize VD to a unified multi-flow multimodal diffusion framework with grouped layers, swappable streams, and other propositions that can process modalities beyond images and text. Through our experiments, we demonstrate that VD and its underlying framework have the following merits: a) VD handles all subtasks with competitive quality; b) VD initiates novel extensions and applications such as disentanglement of style and semantic, image-text dual-guided generation, etc.; c) Through these experiments and applications, VD provides more semantic insights of the generated outputs.*
+
+## Tips
+
+- VersatileDiffusion is conceptually very similar as [Stable Diffusion](./api/pipelines/stable_diffusion/overview), but instead of providing just a image data stream conditioned on text, VersatileDiffusion provides both a image and text data stream and can be conditioned on both text and image.
+
+### *Run VersatileDiffusion*
+
+You can both load the memory intensive "all-in-one" [`VersatileDiffusionPipeline`] that can run all tasks
+with the same class as shown in [`VersatileDiffusionPipeline.text_to_image`], [`VersatileDiffusionPipeline.image_variation`], and [`VersatileDiffusionPipeline.dual_guided`]
+
+**or**
+
+You can run the individual pipelines which are much more memory efficient:
+
+- *Text-to-Image*: [`VersatileDiffusionTextToImagePipeline.__call__`]
+- *Image Variation*: [`VersatileDiffusionImageVariationPipeline.__call__`]
+- *Dual Text and Image Guided Generation*: [`VersatileDiffusionDualGuidedPipeline.__call__`]
+
+### *How to load and use different schedulers.*
+
+The versatile diffusion pipelines uses [`DDIMScheduler`] scheduler by default. But `diffusers` provides many other schedulers that can be used with the alt diffusion pipeline such as [`PNDMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`] etc.
+To use a different scheduler, you can either change it via the [`ConfigMixin.from_config`] method or pass the `scheduler` argument to the `from_pretrained` method of the pipeline. For example, to use the [`EulerDiscreteScheduler`], you can do the following:
+
+```python
+>>> from diffusers import VersatileDiffusionPipeline, EulerDiscreteScheduler
+
+>>> pipeline = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion")
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+>>> # or
+>>> euler_scheduler = EulerDiscreteScheduler.from_pretrained("shi-labs/versatile-diffusion", subfolder="scheduler")
+>>> pipeline = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion", scheduler=euler_scheduler)
+```
+
+## VersatileDiffusionPipeline
+[[autodoc]] VersatileDiffusionPipeline
+
+## VersatileDiffusionTextToImagePipeline
+[[autodoc]] VersatileDiffusionTextToImagePipeline
+ - all
+ - __call__
+
+## VersatileDiffusionImageVariationPipeline
+[[autodoc]] VersatileDiffusionImageVariationPipeline
+ - all
+ - __call__
+
+## VersatileDiffusionDualGuidedPipeline
+[[autodoc]] VersatileDiffusionDualGuidedPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/pipelines/vq_diffusion.mdx b/diffusers/docs/source/en/api/pipelines/vq_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f8182c674f7a75eff8bb9276d191a156c0ba6741
--- /dev/null
+++ b/diffusers/docs/source/en/api/pipelines/vq_diffusion.mdx
@@ -0,0 +1,35 @@
+
+
+# VQDiffusion
+
+## Overview
+
+[Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) by Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, Baining Guo
+
+The abstract of the paper is the following:
+
+We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
+
+The original codebase can be found [here](https://github.com/microsoft/VQ-Diffusion).
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_vq_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/vq_diffusion/pipeline_vq_diffusion.py) | *Text-to-Image Generation* | - |
+
+
+## VQDiffusionPipeline
+[[autodoc]] VQDiffusionPipeline
+ - all
+ - __call__
diff --git a/diffusers/docs/source/en/api/schedulers/ddim.mdx b/diffusers/docs/source/en/api/schedulers/ddim.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..51b0cc3e9a09c85215b03f2af18430962cd2ba88
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/ddim.mdx
@@ -0,0 +1,27 @@
+
+
+# Denoising Diffusion Implicit Models (DDIM)
+
+## Overview
+
+[Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) (DDIM) by Jiaming Song, Chenlin Meng and Stefano Ermon.
+
+The abstract of the paper is the following:
+
+Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples 10× to 50× faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.
+
+The original codebase of this paper can be found here: [ermongroup/ddim](https://github.com/ermongroup/ddim).
+For questions, feel free to contact the author on [tsong.me](https://tsong.me/).
+
+## DDIMScheduler
+[[autodoc]] DDIMScheduler
diff --git a/diffusers/docs/source/en/api/schedulers/ddim_inverse.mdx b/diffusers/docs/source/en/api/schedulers/ddim_inverse.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..5096a3cee283d7a59eeedc48b1dea5080c46aa21
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/ddim_inverse.mdx
@@ -0,0 +1,21 @@
+
+
+# Inverse Denoising Diffusion Implicit Models (DDIMInverse)
+
+## Overview
+
+This scheduler is the inverted scheduler of [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) (DDIM) by Jiaming Song, Chenlin Meng and Stefano Ermon.
+The implementation is mostly based on the DDIM inversion definition of [Null-text Inversion for Editing Real Images using Guided Diffusion Models](https://arxiv.org/pdf/2211.09794.pdf)
+
+## DDIMInverseScheduler
+[[autodoc]] DDIMInverseScheduler
diff --git a/diffusers/docs/source/en/api/schedulers/ddpm.mdx b/diffusers/docs/source/en/api/schedulers/ddpm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6c4058b941fab8ec7177f9635aecc7b924b39d68
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/ddpm.mdx
@@ -0,0 +1,27 @@
+
+
+# Denoising Diffusion Probabilistic Models (DDPM)
+
+## Overview
+
+[Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
+ (DDPM) by Jonathan Ho, Ajay Jain and Pieter Abbeel proposes the diffusion based model of the same name, but in the context of the 🤗 Diffusers library, DDPM refers to the discrete denoising scheduler from the paper as well as the pipeline.
+
+The abstract of the paper is the following:
+
+We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.
+
+The original paper can be found [here](https://arxiv.org/abs/2010.02502).
+
+## DDPMScheduler
+[[autodoc]] DDPMScheduler
diff --git a/diffusers/docs/source/en/api/schedulers/deis.mdx b/diffusers/docs/source/en/api/schedulers/deis.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..9ab8418210983d4920c677de1aa4a865ab2bfca8
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/deis.mdx
@@ -0,0 +1,22 @@
+
+
+# DEIS
+
+Fast Sampling of Diffusion Models with Exponential Integrator.
+
+## Overview
+
+Original paper can be found [here](https://arxiv.org/abs/2204.13902). The original implementation can be found [here](https://github.com/qsh-zh/deis).
+
+## DEISMultistepScheduler
+[[autodoc]] DEISMultistepScheduler
diff --git a/diffusers/docs/source/en/api/schedulers/dpm_discrete.mdx b/diffusers/docs/source/en/api/schedulers/dpm_discrete.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b57c478adf0c97373279b5ad834dd01bd30a6b13
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/dpm_discrete.mdx
@@ -0,0 +1,22 @@
+
+
+# DPM Discrete Scheduler inspired by Karras et. al paper
+
+## Overview
+
+Inspired by [Karras et. al](https://arxiv.org/abs/2206.00364). Scheduler ported from @crowsonkb's https://github.com/crowsonkb/k-diffusion library:
+
+All credit for making this scheduler work goes to [Katherine Crowson](https://github.com/crowsonkb/)
+
+## KDPM2DiscreteScheduler
+[[autodoc]] KDPM2DiscreteScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/dpm_discrete_ancestral.mdx b/diffusers/docs/source/en/api/schedulers/dpm_discrete_ancestral.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e341a68b553b53601d22e61df35dd58aca00fdfc
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/dpm_discrete_ancestral.mdx
@@ -0,0 +1,22 @@
+
+
+# DPM Discrete Scheduler with ancestral sampling inspired by Karras et. al paper
+
+## Overview
+
+Inspired by [Karras et. al](https://arxiv.org/abs/2206.00364). Scheduler ported from @crowsonkb's https://github.com/crowsonkb/k-diffusion library:
+
+All credit for making this scheduler work goes to [Katherine Crowson](https://github.com/crowsonkb/)
+
+## KDPM2AncestralDiscreteScheduler
+[[autodoc]] KDPM2AncestralDiscreteScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/euler.mdx b/diffusers/docs/source/en/api/schedulers/euler.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f107623363bf49763fc0552bbccd70f7529592f7
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/euler.mdx
@@ -0,0 +1,21 @@
+
+
+# Euler scheduler
+
+## Overview
+
+Euler scheduler (Algorithm 2) from the paper [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) by Karras et al. (2022). Based on the original [k-diffusion](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L51) implementation by Katherine Crowson.
+Fast scheduler which often times generates good outputs with 20-30 steps.
+
+## EulerDiscreteScheduler
+[[autodoc]] EulerDiscreteScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/euler_ancestral.mdx b/diffusers/docs/source/en/api/schedulers/euler_ancestral.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..60fd524b195593608f1d2a900ad86756f8fd25ba
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/euler_ancestral.mdx
@@ -0,0 +1,21 @@
+
+
+# Euler Ancestral scheduler
+
+## Overview
+
+Ancestral sampling with Euler method steps. Based on the original [k-diffusion](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L72) implementation by Katherine Crowson.
+Fast scheduler which often times generates good outputs with 20-30 steps.
+
+## EulerAncestralDiscreteScheduler
+[[autodoc]] EulerAncestralDiscreteScheduler
diff --git a/diffusers/docs/source/en/api/schedulers/heun.mdx b/diffusers/docs/source/en/api/schedulers/heun.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..245c20584c6d4e35e2f0f12afd6ea5da7c220ffe
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/heun.mdx
@@ -0,0 +1,23 @@
+
+
+# Heun scheduler inspired by Karras et. al paper
+
+## Overview
+
+Algorithm 1 of [Karras et. al](https://arxiv.org/abs/2206.00364).
+Scheduler ported from @crowsonkb's https://github.com/crowsonkb/k-diffusion library:
+
+All credit for making this scheduler work goes to [Katherine Crowson](https://github.com/crowsonkb/)
+
+## HeunDiscreteScheduler
+[[autodoc]] HeunDiscreteScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/ipndm.mdx b/diffusers/docs/source/en/api/schedulers/ipndm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..854713d22d77b5d179eb93a97b7a7e0082c7b543
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/ipndm.mdx
@@ -0,0 +1,20 @@
+
+
+# improved pseudo numerical methods for diffusion models (iPNDM)
+
+## Overview
+
+Original implementation can be found [here](https://github.com/crowsonkb/v-diffusion-pytorch/blob/987f8985e38208345c1959b0ea767a625831cc9b/diffusion/sampling.py#L296).
+
+## IPNDMScheduler
+[[autodoc]] IPNDMScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/lms_discrete.mdx b/diffusers/docs/source/en/api/schedulers/lms_discrete.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..a7a6e87c85daed0ba5024ff2474c444ab6171068
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/lms_discrete.mdx
@@ -0,0 +1,20 @@
+
+
+# Linear multistep scheduler for discrete beta schedules
+
+## Overview
+
+Original implementation can be found [here](https://arxiv.org/abs/2206.00364).
+
+## LMSDiscreteScheduler
+[[autodoc]] LMSDiscreteScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/multistep_dpm_solver.mdx b/diffusers/docs/source/en/api/schedulers/multistep_dpm_solver.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..588b453a0b00627315db8daa96582d754661c21e
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/multistep_dpm_solver.mdx
@@ -0,0 +1,20 @@
+
+
+# Multistep DPM-Solver
+
+## Overview
+
+Original paper can be found [here](https://arxiv.org/abs/2206.00927) and the [improved version](https://arxiv.org/abs/2211.01095). The original implementation can be found [here](https://github.com/LuChengTHU/dpm-solver).
+
+## DPMSolverMultistepScheduler
+[[autodoc]] DPMSolverMultistepScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/overview.mdx b/diffusers/docs/source/en/api/schedulers/overview.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..a8f4dcd4d0b06023ff3c4526416cc7947f271e15
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/overview.mdx
@@ -0,0 +1,92 @@
+
+
+# Schedulers
+
+Diffusers contains multiple pre-built schedule functions for the diffusion process.
+
+## What is a scheduler?
+
+The schedule functions, denoted *Schedulers* in the library take in the output of a trained model, a sample which the diffusion process is iterating on, and a timestep to return a denoised sample. That's why schedulers may also be called *Samplers* in other diffusion models implementations.
+
+- Schedulers define the methodology for iteratively adding noise to an image or for updating a sample based on model outputs.
+ - adding noise in different manners represent the algorithmic processes to train a diffusion model by adding noise to images.
+ - for inference, the scheduler defines how to update a sample based on an output from a pretrained model.
+- Schedulers are often defined by a *noise schedule* and an *update rule* to solve the differential equation solution.
+
+### Discrete versus continuous schedulers
+
+All schedulers take in a timestep to predict the updated version of the sample being diffused.
+The timesteps dictate where in the diffusion process the step is, where data is generated by iterating forward in time and inference is executed by propagating backwards through timesteps.
+Different algorithms use timesteps that can be discrete (accepting `int` inputs), such as the [`DDPMScheduler`] or [`PNDMScheduler`], or continuous (accepting `float` inputs), such as the score-based schedulers [`ScoreSdeVeScheduler`] or [`ScoreSdeVpScheduler`].
+
+## Designing Re-usable schedulers
+
+The core design principle between the schedule functions is to be model, system, and framework independent.
+This allows for rapid experimentation and cleaner abstractions in the code, where the model prediction is separated from the sample update.
+To this end, the design of schedulers is such that:
+
+- Schedulers can be used interchangeably between diffusion models in inference to find the preferred trade-off between speed and generation quality.
+- Schedulers are currently by default in PyTorch, but are designed to be framework independent (partial Jax support currently exists).
+- Many diffusion pipelines, such as [`StableDiffusionPipeline`] and [`DiTPipeline`] can use any of [`KarrasDiffusionSchedulers`]
+
+## Schedulers Summary
+
+The following table summarizes all officially supported schedulers, their corresponding paper
+
+| Scheduler | Paper |
+|---|---|
+| [ddim](./ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) |
+| [ddim_inverse](./ddim_inverse) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) |
+| [ddpm](./ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) |
+| [deis](./deis) | [**DEISMultistepScheduler**](https://arxiv.org/abs/2204.13902) |
+| [singlestep_dpm_solver](./singlestep_dpm_solver) | [**Singlestep DPM-Solver**](https://arxiv.org/abs/2206.00927) |
+| [multistep_dpm_solver](./multistep_dpm_solver) | [**Multistep DPM-Solver**](https://arxiv.org/abs/2206.00927) |
+| [heun](./heun) | [**Heun scheduler inspired by Karras et. al paper**](https://arxiv.org/abs/2206.00364) |
+| [dpm_discrete](./dpm_discrete) | [**DPM Discrete Scheduler inspired by Karras et. al paper**](https://arxiv.org/abs/2206.00364) |
+| [dpm_discrete_ancestral](./dpm_discrete_ancestral) | [**DPM Discrete Scheduler with ancestral sampling inspired by Karras et. al paper**](https://arxiv.org/abs/2206.00364) |
+| [stochastic_karras_ve](./stochastic_karras_ve) | [**Variance exploding, stochastic sampling from Karras et. al**](https://arxiv.org/abs/2206.00364) |
+| [lms_discrete](./lms_discrete) | [**Linear multistep scheduler for discrete beta schedules**](https://arxiv.org/abs/2206.00364) |
+| [pndm](./pndm) | [**Pseudo numerical methods for diffusion models (PNDM)**](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L181) |
+| [score_sde_ve](./score_sde_ve) | [**variance exploding stochastic differential equation (VE-SDE) scheduler**](https://arxiv.org/abs/2011.13456) |
+| [ipndm](./ipndm) | [**improved pseudo numerical methods for diffusion models (iPNDM)**](https://github.com/crowsonkb/v-diffusion-pytorch/blob/987f8985e38208345c1959b0ea767a625831cc9b/diffusion/sampling.py#L296) |
+| [score_sde_vp](./score_sde_vp) | [**Variance preserving stochastic differential equation (VP-SDE) scheduler**](https://arxiv.org/abs/2011.13456) |
+| [euler](./euler) | [**Euler scheduler**](https://arxiv.org/abs/2206.00364) |
+| [euler_ancestral](./euler_ancestral) | [**Euler Ancestral scheduler**](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L72) |
+| [vq_diffusion](./vq_diffusion) | [**VQDiffusionScheduler**](https://arxiv.org/abs/2111.14822) |
+| [unipc](./unipc) | [**UniPCMultistepScheduler**](https://arxiv.org/abs/2302.04867) |
+| [repaint](./repaint) | [**RePaint scheduler**](https://arxiv.org/abs/2201.09865) |
+
+## API
+
+The core API for any new scheduler must follow a limited structure.
+- Schedulers should provide one or more `def step(...)` functions that should be called to update the generated sample iteratively.
+- Schedulers should provide a `set_timesteps(...)` method that configures the parameters of a schedule function for a specific inference task.
+- Schedulers should be framework-specific.
+
+The base class [`SchedulerMixin`] implements low level utilities used by multiple schedulers.
+
+### SchedulerMixin
+[[autodoc]] SchedulerMixin
+
+### SchedulerOutput
+The class [`SchedulerOutput`] contains the outputs from any schedulers `step(...)` call.
+
+[[autodoc]] schedulers.scheduling_utils.SchedulerOutput
+
+### KarrasDiffusionSchedulers
+
+`KarrasDiffusionSchedulers` encompasses the main generalization of schedulers in Diffusers. The schedulers in this class are distinguished, at a high level, by their noise sampling strategy; the type of network and scaling; and finally the training strategy or how the loss is weighed.
+
+The different schedulers, depending on the type of ODE solver, fall into the above taxonomy and provide a good abstraction for the design of the main schedulers implemented in Diffusers. The schedulers in this class are given below:
+
+[[autodoc]] schedulers.scheduling_utils.KarrasDiffusionSchedulers
diff --git a/diffusers/docs/source/en/api/schedulers/pndm.mdx b/diffusers/docs/source/en/api/schedulers/pndm.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6670914b7ac0a0fd77224b06805fed2e463866e4
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/pndm.mdx
@@ -0,0 +1,20 @@
+
+
+# Pseudo numerical methods for diffusion models (PNDM)
+
+## Overview
+
+Original implementation can be found [here](https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L181).
+
+## PNDMScheduler
+[[autodoc]] PNDMScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/repaint.mdx b/diffusers/docs/source/en/api/schedulers/repaint.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b7e2bcf119c12ce63fde95a2c5c689bb97da8db5
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/repaint.mdx
@@ -0,0 +1,23 @@
+
+
+# RePaint scheduler
+
+## Overview
+
+DDPM-based inpainting scheduler for unsupervised inpainting with extreme masks.
+Intended for use with [`RePaintPipeline`].
+Based on the paper [RePaint: Inpainting using Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2201.09865)
+and the original implementation by Andreas Lugmayr et al.: https://github.com/andreas128/RePaint
+
+## RePaintScheduler
+[[autodoc]] RePaintScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/score_sde_ve.mdx b/diffusers/docs/source/en/api/schedulers/score_sde_ve.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..66a00c69e3b42d42093ca0434e0b56f9cb9aae52
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/score_sde_ve.mdx
@@ -0,0 +1,20 @@
+
+
+# Variance Exploding Stochastic Differential Equation (VE-SDE) scheduler
+
+## Overview
+
+Original paper can be found [here](https://arxiv.org/abs/2011.13456).
+
+## ScoreSdeVeScheduler
+[[autodoc]] ScoreSdeVeScheduler
diff --git a/diffusers/docs/source/en/api/schedulers/score_sde_vp.mdx b/diffusers/docs/source/en/api/schedulers/score_sde_vp.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..ac1d2f109c81d1ab81b2b1d87e5280c6f870dc43
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/score_sde_vp.mdx
@@ -0,0 +1,26 @@
+
+
+# Variance Preserving Stochastic Differential Equation (VP-SDE) scheduler
+
+## Overview
+
+Original paper can be found [here](https://arxiv.org/abs/2011.13456).
+
+
+
+Score SDE-VP is under construction.
+
+
+
+## ScoreSdeVpScheduler
+[[autodoc]] schedulers.scheduling_sde_vp.ScoreSdeVpScheduler
diff --git a/diffusers/docs/source/en/api/schedulers/singlestep_dpm_solver.mdx b/diffusers/docs/source/en/api/schedulers/singlestep_dpm_solver.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..7142e0ded5a7833fd61bcbc1ae7018e0472c6fde
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/singlestep_dpm_solver.mdx
@@ -0,0 +1,20 @@
+
+
+# Singlestep DPM-Solver
+
+## Overview
+
+Original paper can be found [here](https://arxiv.org/abs/2206.00927) and the [improved version](https://arxiv.org/abs/2211.01095). The original implementation can be found [here](https://github.com/LuChengTHU/dpm-solver).
+
+## DPMSolverSinglestepScheduler
+[[autodoc]] DPMSolverSinglestepScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/stochastic_karras_ve.mdx b/diffusers/docs/source/en/api/schedulers/stochastic_karras_ve.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b8e4f9ff7e99c897c78a2a43e50ae047564460e9
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/stochastic_karras_ve.mdx
@@ -0,0 +1,20 @@
+
+
+# Variance exploding, stochastic sampling from Karras et. al
+
+## Overview
+
+Original paper can be found [here](https://arxiv.org/abs/2206.00364).
+
+## KarrasVeScheduler
+[[autodoc]] KarrasVeScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/api/schedulers/unipc.mdx b/diffusers/docs/source/en/api/schedulers/unipc.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..134dc1ef3170b7ee15b9af2c98eedec719ea8c98
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/unipc.mdx
@@ -0,0 +1,24 @@
+
+
+# UniPC
+
+## Overview
+
+UniPC is a training-free framework designed for the fast sampling of diffusion models, which consists of a corrector (UniC) and a predictor (UniP) that share a unified analytical form and support arbitrary orders.
+
+For more details about the method, please refer to the [paper](https://arxiv.org/abs/2302.04867) and the [code](https://github.com/wl-zhao/UniPC).
+
+Fast Sampling of Diffusion Models with Exponential Integrator.
+
+## UniPCMultistepScheduler
+[[autodoc]] UniPCMultistepScheduler
diff --git a/diffusers/docs/source/en/api/schedulers/vq_diffusion.mdx b/diffusers/docs/source/en/api/schedulers/vq_diffusion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..0ed145119fd2b513a4a1e33af894ae1c0f71df49
--- /dev/null
+++ b/diffusers/docs/source/en/api/schedulers/vq_diffusion.mdx
@@ -0,0 +1,20 @@
+
+
+# VQDiffusionScheduler
+
+## Overview
+
+Original paper can be found [here](https://arxiv.org/abs/2111.14822)
+
+## VQDiffusionScheduler
+[[autodoc]] VQDiffusionScheduler
\ No newline at end of file
diff --git a/diffusers/docs/source/en/conceptual/contribution.mdx b/diffusers/docs/source/en/conceptual/contribution.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e9aa10a871d3afff3dbb9426db05baf6a0be3817
--- /dev/null
+++ b/diffusers/docs/source/en/conceptual/contribution.mdx
@@ -0,0 +1,498 @@
+
+
+# How to contribute to Diffusers 🧨
+
+We ❤️ contributions from the open-source community! Everyone is welcome, and all types of participation –not just code– are valued and appreciated. Answering questions, helping others, reaching out, and improving the documentation are all immensely valuable to the community, so don't be afraid and get involved if you're up for it!
+
+Everyone is encouraged to start by saying 👋 in our public Discord channel. We discuss the latest trends in diffusion models, ask questions, show off personal projects, help each other with contributions, or just hang out ☕.
+
+Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
+
+We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
+
+## Overview
+
+You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
+the core library.
+
+In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
+
+* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
+* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose)
+* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues)
+* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
+* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
+* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
+* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
+
+As said before, **all contributions are valuable to the community**.
+In the following, we will explain each contribution a bit more in detail.
+
+For all contributions 4.-9. you will need to open a PR. It is explained in detail how to do so in [Opening a pull requst](#how-to-open-a-pr)
+
+### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
+
+Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
+- Reports of training or inference experiments in an attempt to share knowledge
+- Presentation of personal projects
+- Questions to non-official training examples
+- Project proposals
+- General feedback
+- Paper summaries
+- Asking for help on personal projects that build on top of the Diffusers library
+- General questions
+- Ethical questions regarding diffusion models
+- ...
+
+Every question that is asked on the forum or on Discord actively encourages the community to publicly
+share knowledge and might very well help a beginner in the future that has the same question you're
+having. Please do pose any questions you might have.
+In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
+
+**Please** keep in mind that the more effort you put into asking or answering a question, the higher
+the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
+In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accesible*, and *well-formated/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+**NOTE about channels**:
+[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
+In addition, questions and answers posted in the forum can easily be linked to.
+In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
+While it will most likely take less time for you to get an answer to your question on Discord, your
+question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
+
+### 2. Opening new issues on the GitHub issues tab
+
+The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
+the problems they encounter. So thank you for reporting an issue.
+
+Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
+
+In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
+
+**Please consider the following guidelines when opening a new issue**:
+- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
+- Please never report a new issue on another (related) issue. If another issue is highly related, please
+open a new issue nevertheless and link to the related issue.
+- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
+- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
+- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
+
+New issues usually include the following.
+
+#### 2.1. Reproducible, minimal bug reports.
+
+A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
+This means in more detail:
+- Narrow the bug down as much as you can, **do not just dump your whole code file**
+- Format your code
+- Do not include any external libraries except for Diffusers depending on them.
+- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
+- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
+- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
+- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
+
+For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
+
+You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new/choose).
+
+#### 2.2. Feature requests.
+
+A world-class feature request addresses the following points:
+
+1. Motivation first:
+* Is it related to a problem/frustration with the library? If so, please explain
+why. Providing a code snippet that demonstrates the problem is best.
+* Is it related to something you would need for a project? We'd love to hear
+about it!
+* Is it something you worked on and think could benefit the community?
+Awesome! Tell us what problem it solved for you.
+2. Write a *full paragraph* describing the feature;
+3. Provide a **code snippet** that demonstrates its future use;
+4. In case this is related to a paper, please attach a link;
+5. Attach any additional information (drawings, screenshots, etc.) you think may help.
+
+You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
+
+#### 2.3 Feedback.
+
+Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
+If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
+
+You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
+
+#### 2.4 Technical questions.
+
+Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
+why this part of the code is difficult to understand.
+
+You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
+
+#### 2.5 Proposal to add a new model, scheduler, or pipeline.
+
+If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
+
+* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
+* Link to any of its open-source implementation.
+* Link to the model weights if they are available.
+
+If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
+to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
+
+You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
+
+### 3. Answering issues on the GitHub issues tab
+
+Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
+Some tips to give a high-quality answer to an issue:
+- Be as concise and minimal as possible
+- Stay on topic. An answer to the issue should concern the issue and only the issue.
+- Provide links to code, papers, or other sources that prove or encourage your point.
+- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
+
+Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
+help to the maintainers if you can answer such issues, encouraging the author of the issue to be
+more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR)
+
+If you have verified that the issued bug report is correct and requires a correction in the source code,
+please have a look at the next sections.
+
+For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull requst](#how-to-open-a-pr) section.
+
+### 4. Fixing a "Good first issue"
+
+*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
+explains how a potential solution should look so that it is easier to fix.
+If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
+- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
+- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
+- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
+
+
+### 5. Contribute to the documentation
+
+A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
+valuable contribution**.
+
+Contributing to the library can have many forms:
+
+- Correcting spelling or grammatical errors.
+- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
+- Correct the shape or dimensions of a docstring input or output tensor.
+- Clarify documentation that is hard to understand or incorrect.
+- Update outdated code examples.
+- Translating the documentation to another language.
+
+Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
+
+Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
+
+
+### 6. Contribute a community pipeline
+
+[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
+Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
+We support two types of pipelines:
+
+- Official Pipelines
+- Community Pipelines
+
+Both official and community pipelines follow the same design and consist of the same type of components.
+
+Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
+resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
+In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
+They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
+
+The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
+possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
+Officially released diffusion pipelines,
+such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
+high quality of maintenance, no backward-breaking code changes, and testing.
+More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
+
+To add a community pipeline, one should add a .py file to [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and adapt the [examples/community/README.md](https://github.com/huggingface/diffusers/tree/main/examples/community/README.md) to include an example of the new pipeline.
+
+An example can be seen [here](https://github.com/huggingface/diffusers/pull/2400).
+
+Community pipeline PRs are only checked at a superficial level and ideally they should be maintained by their original authors.
+
+Contributing a community pipeline is a great way to understand how Diffusers models and schedulers work. Having contributed a community pipeline is usually the first stepping stone to contributing an official pipeline to the
+core package.
+
+### 7. Contribute to training examples
+
+Diffusers examples are a collection of training scripts that reside in [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+
+We support two types of training examples:
+
+- Official training examples
+- Research training examples
+
+Research training examples are located in [examples/research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects) whereas official training examples include all folders under [examples](https://github.com/huggingface/diffusers/tree/main/examples) except the `research_projects` and `community` folders.
+The official training examples are maintained by the Diffusers' core maintainers whereas the research training examples are maintained by the community.
+This is because of the same reasons put forward in [6. Contribute a community pipeline](#contribute-a-community-pipeline) for official pipelines vs. community pipelines: It is not feasible for the core maintainers to maintain all possible training methods for diffusion models.
+If the Diffusers core maintainers and the community consider a certain training paradigm to be too experimental or not popular enough, the corresponding training code should be put in the `research_projects` folder and maintained by the author.
+
+Both official training and research examples consist of a directory that contains one or more training scripts, a requirements.txt file, and a README.md file. In order for the user to make use of the
+training examples, it is required to clone the repository:
+
+```
+git clone https://github.com/huggingface/diffusers
+```
+
+as well as to install all additional dependencies required for training:
+
+```
+pip install -r /examples//requirements.txt
+```
+
+Therefore when adding an example, the `requirements.txt` file shall define all pip dependencies required for your training example so that once all those are installed, the user can run the example's training script. See, for example, the [DreamBooth `requirements.txt` file](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/requirements.txt).
+
+Training examples of the Diffusers library should adhere to the following philosophy:
+- All the code necessary to run the examples should be found in a single Python file
+- One should be able to run the example from the command line with `python .py --args`
+- Examples should be kept simple and serve as **an example** on how to use Diffusers for training. The purpose of example scripts is **not** to create state-of-the-art diffusion models, but rather to reproduce known training schemes without adding too much custom logic. As a byproduct of this point, our examples also strive to serve as good educational materials.
+
+To contribute an example, it is highly recommended to look at already existing examples such as [dreambooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py) to get an idea of how they should look like.
+We strongly advise contributors to make use of the [Accelerate library](https://github.com/huggingface/accelerate) as it's tightly integrated
+with Diffusers.
+Once an example script works, please make sure to add a comprehensive `README.md` that states how to use the example exactly. This README should include:
+- An example command on how to run the example script as shown [here e.g.](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#running-locally-with-pytorch).
+- A link to some training results (logs, models, ...) that show what the user can expect as shown [here e.g.](https://api.wandb.ai/report/patrickvonplaten/xm6cd5q5).
+- If you are adding a non-official/research training example, **please don't forget** to add a sentence that you are maintaining this training example which includes your git handle as shown [here](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/intel_opts#diffusers-examples-with-intel-optimizations).
+
+If you are contributing to the official training examples, please also make sure to add a test to [examples/test_examples.py](https://github.com/huggingface/diffusers/blob/main/examples/test_examples.py). This is not necessary for non-official training examples.
+
+### 8. Fixing a "Good second issue"
+
+*Good second issues* are marked by the [Good second issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) label. Good second issues are
+usually more complicated to solve than [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
+The issue description usually gives less guidance on how to fix the issue and requires
+a decent understanding of the library by the interested contributor.
+If you are interested in tackling a second good issue, feel free to open a PR to fix it and link the PR to the issue. If you see that a PR has already been opened for this issue but did not get merged, have a look to understand why it wasn't merged and try to open an improved PR.
+Good second issues are usually more difficult to get merged compared to good first issues, so don't hesitate to ask for help from the core maintainers. If your PR is almost finished the core maintainers can also jump into your PR and commit to it in order to get it merged.
+
+### 9. Adding pipelines, models, schedulers
+
+Pipelines, models, and schedulers are the most important pieces of the Diffusers library.
+They provide easy access to state-of-the-art diffusion technologies and thus allow the community to
+build powerful generative AI applications.
+
+By adding a new model, pipeline, or scheduler you might enable a new powerful use case for any of the user interfaces relying on Diffusers which can be of immense value for the whole generative AI ecosystem.
+
+Diffusers has a couple of open feature requests for all three components - feel free to gloss over them
+if you don't know yet what specific component you would like to add:
+- [Model or pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22)
+- [Scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
+
+Before adding any of the three components, it is strongly recommended that you give the [Philosophy guide](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) a read to better understand the design of any of the three components. Please be aware that
+we cannot merge model, scheduler, or pipeline additions that strongly diverge from our design philosophy
+as it will lead to API inconsistencies. If you fundamentally disagree with a design choice, please
+open a [Feedback issue](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=) instead so that it can be discussed whether a certain design
+pattern/design choice shall be changed everywhere in the library and whether we shall update our design philosophy. Consistency across the library is very important for us.
+
+Please make sure to add links to the original codebase/paper to the PR and ideally also ping the
+original author directly on the PR so that they can follow the progress and potentially help with questions.
+
+If you are unsure or stuck in the PR, don't hesitate to leave a message to ask for a first review or help.
+
+## How to write a good issue
+
+**The better your issue is written, the higher the chances that it will be quickly resolved.**
+
+1. Make sure that you've used the correct template for your issue. You can pick between *Bug Report*, *Feature Request*, *Feedback about API Design*, *New model/pipeline/scheduler addition*, *Forum*, or a blank issue. Make sure to pick the correct one when opening [a new issue](https://github.com/huggingface/diffusers/issues/new/choose).
+2. **Be precise**: Give your issue a fitting title. Try to formulate your issue description as simple as possible. The more precise you are when submitting an issue, the less time it takes to understand the issue and potentially solve it. Make sure to open an issue for one issue only and not for multiple issues. If you found multiple issues, simply open multiple issues. If your issue is a bug, try to be as precise as possible about what bug it is - you should not just write "Error in diffusers".
+3. **Reproducibility**: No reproducible code snippet == no solution. If you encounter a bug, maintainers **have to be able to reproduce** it. Make sure that you include a code snippet that can be copy-pasted into a Python interpreter to reproduce the issue. Make sure that your code snippet works, *i.e.* that there are no missing imports or missing links to images, ... Your issue should contain an error message **and** a code snippet that can be copy-pasted without any changes to reproduce the exact same error message. If your issue is using local model weights or local data that cannot be accessed by the reader, the issue cannot be solved. If you cannot share your data or model, try to make a dummy model or dummy data.
+4. **Minimalistic**: Try to help the reader as much as you can to understand the issue as quickly as possible by staying as concise as possible. Remove all code / all information that is irrelevant to the issue. If you have found a bug, try to create the easiest code example you can to demonstrate your issue, do not just dump your whole workflow into the issue as soon as you have found a bug. E.g., if you train a model and get an error at some point during the training, you should first try to understand what part of the training code is responsible for the error and try to reproduce it with a couple of lines. Try to use dummy data instead of full datasets.
+5. Add links. If you are referring to a certain naming, method, or model make sure to provide a link so that the reader can better understand what you mean. If you are referring to a specific PR or issue, make sure to link it to your issue. Do not assume that the reader knows what you are talking about. The more links you add to your issue the better.
+6. Formatting. Make sure to nicely format your issue by formatting code into Python code syntax, and error messages into normal code syntax. See the [official GitHub formatting docs](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) for more information.
+7. Think of your issue not as a ticket to be solved, but rather as a beautiful entry to a well-written encyclopedia. Every added issue is a contribution to publicly available knowledge. By adding a nicely written issue you not only make it easier for maintainers to solve your issue, but you are helping the whole community to better understand a certain aspect of the library.
+
+## How to write a good PR
+
+1. Be a chameleon. Understand existing design patterns and syntax and make sure your code additions flow seamlessly into the existing code base. Pull requests that significantly diverge from existing design patterns or user interfaces will not be merged.
+2. Be laser focused. A pull request should solve one problem and one problem only. Make sure to not fall into the trap of "also fixing another problem while we're adding it". It is much more difficult to review pull requests that solve multiple, unrelated problems at once.
+3. If helpful, try to add a code snippet that displays an example of how your addition can be used.
+4. The title of your pull request should be a summary of its contribution.
+5. If your pull request addresses an issue, please mention the issue number in
+the pull request description to make sure they are linked (and people
+consulting the issue know you are working on it);
+6. To indicate a work in progress please prefix the title with `[WIP]`. These
+are useful to avoid duplicated work, and to differentiate it from PRs ready
+to be merged;
+7. Try to formulate and format your text as explained in [How to write a good issue](#how-to-write-a-good-issue).
+8. Make sure existing tests pass;
+9. Add high-coverage tests. No quality testing = no merge.
+- If you are adding new `@slow` tests, make sure they pass using
+`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
+CircleCI does not run the slow tests, but GitHub actions does every night!
+10. All public methods must have informative docstrings that work nicely with markdown. See `[pipeline_latent_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py)` for an example.
+11. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
+[`hf-internal-testing`](https://huggingface.co/hf-internal-testing) or [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images) to place these files.
+If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
+to this dataset.
+
+## How to open a PR
+
+Before writing code, we strongly advise you to search through the existing PRs or
+issues to make sure that nobody is already working on the same thing. If you are
+unsure, it is always a good idea to open an issue to get some feedback.
+
+You will need basic `git` proficiency to be able to contribute to
+🧨 Diffusers. `git` is not the easiest tool to use but it has the greatest
+manual. Type `git --help` in a shell and enjoy. If you prefer books, [Pro
+Git](https://git-scm.com/book/en/v2) is a very good reference.
+
+Follow these steps to start contributing ([supported Python versions](https://github.com/huggingface/diffusers/blob/main/setup.py#L244)):
+
+1. Fork the [repository](https://github.com/huggingface/diffusers) by
+clicking on the 'Fork' button on the repository's page. This creates a copy of the code
+under your GitHub user account.
+
+2. Clone your fork to your local disk, and add the base repository as a remote:
+
+ ```bash
+ $ git clone git@github.com:/diffusers.git
+ $ cd diffusers
+ $ git remote add upstream https://github.com/huggingface/diffusers.git
+ ```
+
+3. Create a new branch to hold your development changes:
+
+ ```bash
+ $ git checkout -b a-descriptive-name-for-my-changes
+ ```
+
+**Do not** work on the `main` branch.
+
+4. Set up a development environment by running the following command in a virtual environment:
+
+ ```bash
+ $ pip install -e ".[dev]"
+ ```
+
+If you have already cloned the repo, you might need to `git pull` to get the most recent changes in the
+library.
+
+5. Develop the features on your branch.
+
+As you work on the features, you should make sure that the test suite
+passes. You should run the tests impacted by your changes like this:
+
+ ```bash
+ $ pytest tests/.py
+ ```
+
+You can also run the full suite with the following command, but it takes
+a beefy machine to produce a result in a decent amount of time now that
+Diffusers has grown a lot. Here is the command for it:
+
+ ```bash
+ $ make test
+ ```
+
+🧨 Diffusers relies on `black` and `isort` to format its source code
+consistently. After you make changes, apply automatic style corrections and code verifications
+that can't be automated in one go with:
+
+ ```bash
+ $ make style
+ ```
+
+🧨 Diffusers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
+control runs in CI, however, you can also run the same checks with:
+
+ ```bash
+ $ make quality
+ ```
+
+Once you're happy with your changes, add changed files using `git add` and
+make a commit with `git commit` to record your changes locally:
+
+ ```bash
+ $ git add modified_file.py
+ $ git commit
+ ```
+
+It is a good idea to sync your copy of the code with the original
+repository regularly. This way you can quickly account for changes:
+
+ ```bash
+ $ git pull upstream main
+ ```
+
+Push the changes to your account using:
+
+ ```bash
+ $ git push -u origin a-descriptive-name-for-my-changes
+ ```
+
+6. Once you are satisfied, go to the
+webpage of your fork on GitHub. Click on 'Pull request' to send your changes
+to the project maintainers for review.
+
+7. It's ok if maintainers ask you for changes. It happens to core contributors
+too! So everyone can see the changes in the Pull request, work in your local
+branch and push the changes to your fork. They will automatically appear in
+the pull request.
+
+### Tests
+
+An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
+the [tests folder](https://github.com/huggingface/diffusers/tree/main/tests).
+
+We like `pytest` and `pytest-xdist` because it's faster. From the root of the
+repository, here's how to run tests with `pytest` for the library:
+
+```bash
+$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
+```
+
+In fact, that's how `make test` is implemented!
+
+You can specify a smaller set of tests in order to test only the feature
+you're working on.
+
+By default, slow tests are skipped. Set the `RUN_SLOW` environment variable to
+`yes` to run them. This will download many gigabytes of models — make sure you
+have enough disk space and a good Internet connection, or a lot of patience!
+
+```bash
+$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
+```
+
+`unittest` is fully supported, here's how to run tests with it:
+
+```bash
+$ python -m unittest discover -s tests -t . -v
+$ python -m unittest discover -s examples -t examples -v
+```
+
+### Syncing forked main with upstream (HuggingFace) main
+
+To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
+when syncing the main branch of a forked repository, please, follow these steps:
+1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
+2. If a PR is absolutely necessary, use the following steps after checking out your branch:
+```
+$ git checkout -b your-branch-for-syncing
+$ git pull --squash --no-commit upstream main
+$ git commit -m ''
+$ git push --set-upstream origin your-branch-for-syncing
+```
+
+### Style guide
+
+For documentation strings, 🧨 Diffusers follows the [google style](https://google.github.io/styleguide/pyguide.html).
diff --git a/diffusers/docs/source/en/conceptual/ethical_guidelines.mdx b/diffusers/docs/source/en/conceptual/ethical_guidelines.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..100a92152f000d6d2f05055735a385c6391152ce
--- /dev/null
+++ b/diffusers/docs/source/en/conceptual/ethical_guidelines.mdx
@@ -0,0 +1,51 @@
+# 🧨 Diffusers’ Ethical Guidelines
+
+## Preamble
+
+[Diffusers](https://huggingface.co/docs/diffusers/index) provides pre-trained diffusion models and serves as a modular toolbox for inference and training.
+
+Given its real case applications in the world and potential negative impacts on society, we think it is important to provide the project with ethical guidelines to guide the development, users’ contributions, and usage of the Diffusers library.
+
+The risks associated with using this technology are still being examined, but to name a few: copyrights issues for artists; deep-fake exploitation; sexual content generation in inappropriate contexts; non-consensual impersonation; harmful social biases perpetuating the oppression of marginalized groups.
+We will keep tracking risks and adapt the following guidelines based on the community's responsiveness and valuable feedback.
+
+
+## Scope
+
+The Diffusers community will apply the following ethical guidelines to the project’s development and help coordinate how the community will integrate the contributions, especially concerning sensitive topics related to ethical concerns.
+
+
+## Ethical guidelines
+
+The following ethical guidelines apply generally, but we will primarily implement them when dealing with ethically sensitive issues while making a technical choice. Furthermore, we commit to adapting those ethical principles over time following emerging harms related to the state of the art of the technology in question.
+
+- **Transparency**: we are committed to being transparent in managing PRs, explaining our choices to users, and making technical decisions.
+
+- **Consistency**: we are committed to guaranteeing our users the same level of attention in project management, keeping it technically stable and consistent.
+
+- **Simplicity**: with a desire to make it easy to use and exploit the Diffusers library, we are committed to keeping the project’s goals lean and coherent.
+
+- **Accessibility**: the Diffusers project helps lower the entry bar for contributors who can help run it even without technical expertise. Doing so makes research artifacts more accessible to the community.
+
+- **Reproducibility**: we aim to be transparent about the reproducibility of upstream code, models, and datasets when made available through the Diffusers library.
+
+- **Responsibility**: as a community and through teamwork, we hold a collective responsibility to our users by anticipating and mitigating this technology's potential risks and dangers.
+
+
+## Examples of implementations: Safety features and Mechanisms
+
+The team works daily to make the technical and non-technical tools available to deal with the potential ethical and social risks associated with diffusion technology. Moreover, the community's input is invaluable in ensuring these features' implementation and raising awareness with us.
+
+- [**Community tab**](https://huggingface.co/docs/hub/repositories-pull-requests-discussions): it enables the community to discuss and better collaborate on a project.
+
+- **Bias exploration and evaluation**: the Hugging Face team provides a [space](https://huggingface.co/spaces/society-ethics/DiffusionBiasExplorer) to demonstrate the biases in Stable Diffusion interactively. In this sense, we support and encourage bias explorers and evaluations.
+
+- **Encouraging safety in deployment**
+
+ - [**Safe Stable Diffusion**](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion_safe): It mitigates the well-known issue that models, like Stable Diffusion, that are trained on unfiltered, web-crawled datasets tend to suffer from inappropriate degeneration. Related paper: [Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models](https://arxiv.org/abs/2211.05105).
+
+ - [**Safety Checker**](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py): It checks and compares the class probability of a set of hard-coded harmful concepts in the embedding space against an image after it has been generated. The harmful concepts are intentionally hidden to prevent reverse engineering of the checker.
+
+- **Staged released on the Hub**: in particularly sensitive situations, access to some repositories should be restricted. This staged release is an intermediary step that allows the repository’s authors to have more control over its use.
+
+- **Licensing**: [OpenRAILs](https://huggingface.co/blog/open_rail), a new type of licensing, allow us to ensure free access while having a set of restrictions that ensure more responsible use.
diff --git a/diffusers/docs/source/en/conceptual/evaluation.mdx b/diffusers/docs/source/en/conceptual/evaluation.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..2721adea0c160bfb0d80dd078364df60d8e19e10
--- /dev/null
+++ b/diffusers/docs/source/en/conceptual/evaluation.mdx
@@ -0,0 +1,565 @@
+
+
+# Evaluating Diffusion Models
+
+
+  +
+
+Evaluation of generative models like [Stable Diffusion](https://huggingface.co/docs/diffusers/stable_diffusion) is subjective in nature. But as practitioners and researchers, we often have to make careful choices amongst many different possibilities. So, when working with different generative models (like GANs, Diffusion, etc.), how do we choose one over the other?
+
+Qualitative evaluation of such models can be error-prone and might incorrectly influence a decision.
+However, quantitative metrics don't necessarily correspond to image quality. So, usually, a combination
+of both qualitative and quantitative evaluations provides a stronger signal when choosing one model
+over the other.
+
+In this document, we provide a non-exhaustive overview of qualitative and quantitative methods to evaluate Diffusion models. For quantitative methods, we specifically focus on how to implement them alongside `diffusers`.
+
+The methods shown in this document can also be used to evaluate different [noise schedulers](https://huggingface.co/docs/diffusers/main/en/api/schedulers/overview) keeping the underlying generation model fixed.
+
+## Scenarios
+
+We cover Diffusion models with the following pipelines:
+
+- Text-guided image generation (such as the [`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/text2img)).
+- Text-guided image generation, additionally conditioned on an input image (such as the [`StableDiffusionImg2ImgPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/img2img), and [`StableDiffusionInstructPix2PixPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix)).
+- Class-conditioned image generation models (such as the [`DiTPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/dit)).
+
+## Qualitative Evaluation
+
+Qualitative evaluation typically involves human assessment of generated images. Quality is measured across aspects such as compositionality, image-text alignment, and spatial relations. Common prompts provide a degree of uniformity for subjective metrics. DrawBench and PartiPrompts are prompt datasets used for qualitative benchmarking. DrawBench and PartiPrompts were introduced by [Imagen](https://imagen.research.google/) and [Parti](https://parti.research.google/) respectively.
+
+From the [official Parti website](https://parti.research.google/):
+
+> PartiPrompts (P2) is a rich set of over 1600 prompts in English that we release as part of this work. P2 can be used to measure model capabilities across various categories and challenge aspects.
+
+
+
+PartiPrompts has the following columns:
+
+- Prompt
+- Category of the prompt (such as “Abstract”, “World Knowledge”, etc.)
+- Challenge reflecting the difficulty (such as “Basic”, “Complex”, “Writing & Symbols”, etc.)
+
+These benchmarks allow for side-by-side human evaluation of different image generation models. Let’s see how we can use `diffusers` on a couple of PartiPrompts.
+
+Below we show some prompts sampled across different challenges: Basic, Complex, Linguistic Structures, Imagination, and Writing & Symbols. Here we are using PartiPrompts as a [dataset](https://huggingface.co/datasets/nateraw/parti-prompts).
+
+```python
+from datasets import load_dataset
+
+# prompts = load_dataset("nateraw/parti-prompts", split="train")
+# prompts = prompts.shuffle()
+# sample_prompts = [prompts[i]["Prompt"] for i in range(5)]
+
+# Fixing these sample prompts in the interest of reproducibility.
+sample_prompts = [
+ "a corgi",
+ "a hot air balloon with a yin-yang symbol, with the moon visible in the daytime sky",
+ "a car with no windows",
+ "a cube made of porcupine",
+ 'The saying "BE EXCELLENT TO EACH OTHER" written on a red brick wall with a graffiti image of a green alien wearing a tuxedo. A yellow fire hydrant is on a sidewalk in the foreground.',
+]
+```
+
+Now we can use these prompts to generate some images using Stable Diffusion ([v1-4 checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4)):
+
+```python
+import torch
+
+seed = 0
+generator = torch.manual_seed(seed)
+
+images = sd_pipeline(sample_prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
+```
+
+
+
+We can also set `num_images_per_prompt` accordingly to compare different images for the same prompt. Running the same pipeline but with a different checkpoint ([v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)), yields:
+
+
+
+Once several images are generated from all the prompts using multiple models (under evaluation), these results are presented to human evaluators for scoring. For
+more details on the DrawBench and PartiPrompts benchmarks, refer to their respective papers.
+
+
+
+It is useful to look at some inference samples while a model is training to measure the
+training progress. In our [training scripts](https://github.com/huggingface/diffusers/tree/main/examples/), we support this utility with additional support for
+logging to TensorBoard and Weights & Biases.
+
+
+
+## Quantitative Evaluation
+
+In this section, we will walk you through how to evaluate three different diffusion pipelines using:
+
+- CLIP score
+- CLIP directional similarity
+- FID
+
+### Text-guided image generation
+
+[CLIP score](https://arxiv.org/abs/2104.08718) measures the compatibility of image-caption pairs. Higher CLIP scores imply higher compatibility 🔼. The CLIP score is a quantitative measurement of the qualitative concept "compatibility". Image-caption pair compatibility can also be thought of as the semantic similarity between the image and the caption. CLIP score was found to have high correlation with human judgement.
+
+Let's first load a [`StableDiffusionPipeline`]:
+
+```python
+from diffusers import StableDiffusionPipeline
+import torch
+
+model_ckpt = "CompVis/stable-diffusion-v1-4"
+sd_pipeline = StableDiffusionPipeline.from_pretrained(model_ckpt, torch_dtype=torch.float16).to("cuda")
+```
+
+Generate some images with multiple prompts:
+
+```python
+prompts = [
+ "a photo of an astronaut riding a horse on mars",
+ "A high tech solarpunk utopia in the Amazon rainforest",
+ "A pikachu fine dining with a view to the Eiffel Tower",
+ "A mecha robot in a favela in expressionist style",
+ "an insect robot preparing a delicious meal",
+ "A small cabin on top of a snowy mountain in the style of Disney, artstation",
+]
+
+images = sd_pipeline(prompts, num_images_per_prompt=1, output_type="numpy").images
+
+print(images.shape)
+# (6, 512, 512, 3)
+```
+
+And then, we calculate the CLIP score.
+
+```python
+from torchmetrics.functional.multimodal import clip_score
+from functools import partial
+
+clip_score_fn = partial(clip_score, model_name_or_path="openai/clip-vit-base-patch16")
+
+
+def calculate_clip_score(images, prompts):
+ images_int = (images * 255).astype("uint8")
+ clip_score = clip_score_fn(torch.from_numpy(images_int).permute(0, 3, 1, 2), prompts).detach()
+ return round(float(clip_score), 4)
+
+
+sd_clip_score = calculate_clip_score(images, prompts)
+print(f"CLIP score: {sd_clip_score}")
+# CLIP score: 35.7038
+```
+
+In the above example, we generated one image per prompt. If we generated multiple images per prompt, we would have to take the average score from the generated images per prompt.
+
+Now, if we wanted to compare two checkpoints compatible with the [`StableDiffusionPipeline`] we should pass a generator while calling the pipeline. First, we generate images with a
+fixed seed with the [v1-4 Stable Diffusion checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4):
+
+```python
+seed = 0
+generator = torch.manual_seed(seed)
+
+images = sd_pipeline(prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
+```
+
+Then we load the [v1-5 checkpoint](https://huggingface.co/runwayml/stable-diffusion-v1-5) to generate images:
+
+```python
+model_ckpt_1_5 = "runwayml/stable-diffusion-v1-5"
+sd_pipeline_1_5 = StableDiffusionPipeline.from_pretrained(model_ckpt_1_5, torch_dtype=weight_dtype).to(device)
+
+images_1_5 = sd_pipeline_1_5(prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
+```
+
+And finally, we compare their CLIP scores:
+
+```python
+sd_clip_score_1_4 = calculate_clip_score(images, prompts)
+print(f"CLIP Score with v-1-4: {sd_clip_score_1_4}")
+# CLIP Score with v-1-4: 34.9102
+
+sd_clip_score_1_5 = calculate_clip_score(images_1_5, prompts)
+print(f"CLIP Score with v-1-5: {sd_clip_score_1_5}")
+# CLIP Score with v-1-5: 36.2137
+```
+
+It seems like the [v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint performs better than its predecessor. Note, however, that the number of prompts we used to compute the CLIP scores is quite low. For a more practical evaluation, this number should be way higher, and the prompts should be diverse.
+
+
+
+By construction, there are some limitations in this score. The captions in the training dataset
+were crawled from the web and extracted from `alt` and similar tags associated an image on the internet.
+They are not necessarily representative of what a human being would use to describe an image. Hence we
+had to "engineer" some prompts here.
+
+
+
+### Image-conditioned text-to-image generation
+
+In this case, we condition the generation pipeline with an input image as well as a text prompt. Let's take the [`StableDiffusionInstructPix2PixPipeline`], as an example. It takes an edit instruction as an input prompt and an input image to be edited.
+
+Here is one example:
+
+
+
+One strategy to evaluate such a model is to measure the consistency of the change between the two images (in [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) space) with the change between the two image captions (as shown in [CLIP-Guided Domain Adaptation of Image Generators](https://arxiv.org/abs/2108.00946)). This is referred to as the "**CLIP directional similarity**".
+
+- Caption 1 corresponds to the input image (image 1) that is to be edited.
+- Caption 2 corresponds to the edited image (image 2). It should reflect the edit instruction.
+
+Following is a pictorial overview:
+
+
+
+We have prepared a mini dataset to implement this metric. Let's first load the dataset.
+
+```python
+from datasets import load_dataset
+
+dataset = load_dataset("sayakpaul/instructpix2pix-demo", split="train")
+dataset.features
+```
+
+```bash
+{'input': Value(dtype='string', id=None),
+ 'edit': Value(dtype='string', id=None),
+ 'output': Value(dtype='string', id=None),
+ 'image': Image(decode=True, id=None)}
+```
+
+Here we have:
+
+- `input` is a caption corresponding to the `image`.
+- `edit` denotes the edit instruction.
+- `output` denotes the modified caption reflecting the `edit` instruction.
+
+Let's take a look at a sample.
+
+```python
+idx = 0
+print(f"Original caption: {dataset[idx]['input']}")
+print(f"Edit instruction: {dataset[idx]['edit']}")
+print(f"Modified caption: {dataset[idx]['output']}")
+```
+
+```bash
+Original caption: 2. FAROE ISLANDS: An archipelago of 18 mountainous isles in the North Atlantic Ocean between Norway and Iceland, the Faroe Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
+Edit instruction: make the isles all white marble
+Modified caption: 2. WHITE MARBLE ISLANDS: An archipelago of 18 mountainous white marble isles in the North Atlantic Ocean between Norway and Iceland, the White Marble Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
+```
+
+And here is the image:
+
+```python
+dataset[idx]["image"]
+```
+
+
+
+We will first edit the images of our dataset with the edit instruction and compute the directional similarity.
+
+Let's first load the [`StableDiffusionInstructPix2PixPipeline`]:
+
+```python
+from diffusers import StableDiffusionInstructPix2PixPipeline
+
+instruct_pix2pix_pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ "timbrooks/instruct-pix2pix", torch_dtype=torch.float16
+).to(device)
+```
+
+Now, we perform the edits:
+
+```python
+import numpy as np
+
+
+def edit_image(input_image, instruction):
+ image = instruct_pix2pix_pipeline(
+ instruction,
+ image=input_image,
+ output_type="numpy",
+ generator=generator,
+ ).images[0]
+ return image
+
+
+input_images = []
+original_captions = []
+modified_captions = []
+edited_images = []
+
+for idx in range(len(dataset)):
+ input_image = dataset[idx]["image"]
+ edit_instruction = dataset[idx]["edit"]
+ edited_image = edit_image(input_image, edit_instruction)
+
+ input_images.append(np.array(input_image))
+ original_captions.append(dataset[idx]["input"])
+ modified_captions.append(dataset[idx]["output"])
+ edited_images.append(edited_image)
+```
+
+To measure the directional similarity, we first load CLIP's image and text encoders:
+
+```python
+from transformers import (
+ CLIPTokenizer,
+ CLIPTextModelWithProjection,
+ CLIPVisionModelWithProjection,
+ CLIPImageProcessor,
+)
+
+clip_id = "openai/clip-vit-large-patch14"
+tokenizer = CLIPTokenizer.from_pretrained(clip_id)
+text_encoder = CLIPTextModelWithProjection.from_pretrained(clip_id).to(device)
+image_processor = CLIPImageProcessor.from_pretrained(clip_id)
+image_encoder = CLIPVisionModelWithProjection.from_pretrained(clip_id).to(device)
+```
+
+Notice that we are using a particular CLIP checkpoint, i.e., `openai/clip-vit-large-patch14`. This is because the Stable Diffusion pre-training was performed with this CLIP variant. For more details, refer to the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix#diffusers.StableDiffusionInstructPix2PixPipeline.text_encoder).
+
+Next, we prepare a PyTorch `nn.Module` to compute directional similarity:
+
+```python
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class DirectionalSimilarity(nn.Module):
+ def __init__(self, tokenizer, text_encoder, image_processor, image_encoder):
+ super().__init__()
+ self.tokenizer = tokenizer
+ self.text_encoder = text_encoder
+ self.image_processor = image_processor
+ self.image_encoder = image_encoder
+
+ def preprocess_image(self, image):
+ image = self.image_processor(image, return_tensors="pt")["pixel_values"]
+ return {"pixel_values": image.to(device)}
+
+ def tokenize_text(self, text):
+ inputs = self.tokenizer(
+ text,
+ max_length=self.tokenizer.model_max_length,
+ padding="max_length",
+ truncation=True,
+ return_tensors="pt",
+ )
+ return {"input_ids": inputs.input_ids.to(device)}
+
+ def encode_image(self, image):
+ preprocessed_image = self.preprocess_image(image)
+ image_features = self.image_encoder(**preprocessed_image).image_embeds
+ image_features = image_features / image_features.norm(dim=1, keepdim=True)
+ return image_features
+
+ def encode_text(self, text):
+ tokenized_text = self.tokenize_text(text)
+ text_features = self.text_encoder(**tokenized_text).text_embeds
+ text_features = text_features / text_features.norm(dim=1, keepdim=True)
+ return text_features
+
+ def compute_directional_similarity(self, img_feat_one, img_feat_two, text_feat_one, text_feat_two):
+ sim_direction = F.cosine_similarity(img_feat_two - img_feat_one, text_feat_two - text_feat_one)
+ return sim_direction
+
+ def forward(self, image_one, image_two, caption_one, caption_two):
+ img_feat_one = self.encode_image(image_one)
+ img_feat_two = self.encode_image(image_two)
+ text_feat_one = self.encode_text(caption_one)
+ text_feat_two = self.encode_text(caption_two)
+ directional_similarity = self.compute_directional_similarity(
+ img_feat_one, img_feat_two, text_feat_one, text_feat_two
+ )
+ return directional_similarity
+```
+
+Let's put `DirectionalSimilarity` to use now.
+
+```python
+dir_similarity = DirectionalSimilarity(tokenizer, text_encoder, image_processor, image_encoder)
+scores = []
+
+for i in range(len(input_images)):
+ original_image = input_images[i]
+ original_caption = original_captions[i]
+ edited_image = edited_images[i]
+ modified_caption = modified_captions[i]
+
+ similarity_score = dir_similarity(original_image, edited_image, original_caption, modified_caption)
+ scores.append(float(similarity_score.detach().cpu()))
+
+print(f"CLIP directional similarity: {np.mean(scores)}")
+# CLIP directional similarity: 0.0797976553440094
+```
+
+Like the CLIP Score, the higher the CLIP directional similarity, the better it is.
+
+It should be noted that the `StableDiffusionInstructPix2PixPipeline` exposes two arguments, namely, `image_guidance_scale` and `guidance_scale` that let you control the quality of the final edited image. We encourage you to experiment with these two arguments and see the impact of that on the directional similarity.
+
+We can extend the idea of this metric to measure how similar the original image and edited version are. To do that, we can just do `F.cosine_similarity(img_feat_two, img_feat_one)`. For these kinds of edits, we would still want the primary semantics of the images to be preserved as much as possible, i.e., a high similarity score.
+
+We can use these metrics for similar pipelines such as the [`StableDiffusionPix2PixZeroPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix_zero#diffusers.StableDiffusionPix2PixZeroPipeline).
+
+
+
+Both CLIP score and CLIP direction similarity rely on the CLIP model, which can make the evaluations biased.
+
+
+
+***Extending metrics like IS, FID (discussed later), or KID can be difficult*** when the model under evaluation was pre-trained on a large image-captioning dataset (such as the [LAION-5B dataset](https://laion.ai/blog/laion-5b/)). This is because underlying these metrics is an InceptionNet (pre-trained on the ImageNet-1k dataset) used for extracting intermediate image features. The pre-training dataset of Stable Diffusion may have limited overlap with the pre-training dataset of InceptionNet, so it is not a good candidate here for feature extraction.
+
+***Using the above metrics helps evaluate models that are class-conditioned. For example, [DiT](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/overview). It was pre-trained being conditioned on the ImageNet-1k classes.***
+
+### Class-conditioned image generation
+
+Class-conditioned generative models are usually pre-trained on a class-labeled dataset such as [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k). Popular metrics for evaluating these models include Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and Inception Score (IS). In this document, we focus on FID ([Heusel et al.](https://arxiv.org/abs/1706.08500)). We show how to compute it with the [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit), which uses the [DiT model](https://arxiv.org/abs/2212.09748) under the hood.
+
+FID aims to measure how similar are two datasets of images. As per [this resource](https://mmgeneration.readthedocs.io/en/latest/quick_run.html#fid):
+
+> Fréchet Inception Distance is a measure of similarity between two datasets of images. It was shown to correlate well with the human judgment of visual quality and is most often used to evaluate the quality of samples of Generative Adversarial Networks. FID is calculated by computing the Fréchet distance between two Gaussians fitted to feature representations of the Inception network.
+
+These two datasets are essentially the dataset of real images and the dataset of fake images (generated images in our case). FID is usually calculated with two large datasets. However, for this document, we will work with two mini datasets.
+
+Let's first download a few images from the ImageNet-1k training set:
+
+```python
+from zipfile import ZipFile
+import requests
+
+
+def download(url, local_filepath):
+ r = requests.get(url)
+ with open(local_filepath, "wb") as f:
+ f.write(r.content)
+ return local_filepath
+
+
+dummy_dataset_url = "https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/sample-imagenet-images.zip"
+local_filepath = download(dummy_dataset_url, dummy_dataset_url.split("/")[-1])
+
+with ZipFile(local_filepath, "r") as zipper:
+ zipper.extractall(".")
+```
+
+```python
+from PIL import Image
+import os
+
+dataset_path = "sample-imagenet-images"
+image_paths = sorted([os.path.join(dataset_path, x) for x in os.listdir(dataset_path)])
+
+real_images = [np.array(Image.open(path).convert("RGB")) for path in image_paths]
+```
+
+These are 10 images from the following Imagenet-1k classes: "cassette_player", "chain_saw" (x2), "church", "gas_pump" (x3), "parachute" (x2), and "tench".
+
+
+
+
+Evaluation of generative models like [Stable Diffusion](https://huggingface.co/docs/diffusers/stable_diffusion) is subjective in nature. But as practitioners and researchers, we often have to make careful choices amongst many different possibilities. So, when working with different generative models (like GANs, Diffusion, etc.), how do we choose one over the other?
+
+Qualitative evaluation of such models can be error-prone and might incorrectly influence a decision.
+However, quantitative metrics don't necessarily correspond to image quality. So, usually, a combination
+of both qualitative and quantitative evaluations provides a stronger signal when choosing one model
+over the other.
+
+In this document, we provide a non-exhaustive overview of qualitative and quantitative methods to evaluate Diffusion models. For quantitative methods, we specifically focus on how to implement them alongside `diffusers`.
+
+The methods shown in this document can also be used to evaluate different [noise schedulers](https://huggingface.co/docs/diffusers/main/en/api/schedulers/overview) keeping the underlying generation model fixed.
+
+## Scenarios
+
+We cover Diffusion models with the following pipelines:
+
+- Text-guided image generation (such as the [`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/text2img)).
+- Text-guided image generation, additionally conditioned on an input image (such as the [`StableDiffusionImg2ImgPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/img2img), and [`StableDiffusionInstructPix2PixPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix)).
+- Class-conditioned image generation models (such as the [`DiTPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/dit)).
+
+## Qualitative Evaluation
+
+Qualitative evaluation typically involves human assessment of generated images. Quality is measured across aspects such as compositionality, image-text alignment, and spatial relations. Common prompts provide a degree of uniformity for subjective metrics. DrawBench and PartiPrompts are prompt datasets used for qualitative benchmarking. DrawBench and PartiPrompts were introduced by [Imagen](https://imagen.research.google/) and [Parti](https://parti.research.google/) respectively.
+
+From the [official Parti website](https://parti.research.google/):
+
+> PartiPrompts (P2) is a rich set of over 1600 prompts in English that we release as part of this work. P2 can be used to measure model capabilities across various categories and challenge aspects.
+
+
+
+PartiPrompts has the following columns:
+
+- Prompt
+- Category of the prompt (such as “Abstract”, “World Knowledge”, etc.)
+- Challenge reflecting the difficulty (such as “Basic”, “Complex”, “Writing & Symbols”, etc.)
+
+These benchmarks allow for side-by-side human evaluation of different image generation models. Let’s see how we can use `diffusers` on a couple of PartiPrompts.
+
+Below we show some prompts sampled across different challenges: Basic, Complex, Linguistic Structures, Imagination, and Writing & Symbols. Here we are using PartiPrompts as a [dataset](https://huggingface.co/datasets/nateraw/parti-prompts).
+
+```python
+from datasets import load_dataset
+
+# prompts = load_dataset("nateraw/parti-prompts", split="train")
+# prompts = prompts.shuffle()
+# sample_prompts = [prompts[i]["Prompt"] for i in range(5)]
+
+# Fixing these sample prompts in the interest of reproducibility.
+sample_prompts = [
+ "a corgi",
+ "a hot air balloon with a yin-yang symbol, with the moon visible in the daytime sky",
+ "a car with no windows",
+ "a cube made of porcupine",
+ 'The saying "BE EXCELLENT TO EACH OTHER" written on a red brick wall with a graffiti image of a green alien wearing a tuxedo. A yellow fire hydrant is on a sidewalk in the foreground.',
+]
+```
+
+Now we can use these prompts to generate some images using Stable Diffusion ([v1-4 checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4)):
+
+```python
+import torch
+
+seed = 0
+generator = torch.manual_seed(seed)
+
+images = sd_pipeline(sample_prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
+```
+
+
+
+We can also set `num_images_per_prompt` accordingly to compare different images for the same prompt. Running the same pipeline but with a different checkpoint ([v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5)), yields:
+
+
+
+Once several images are generated from all the prompts using multiple models (under evaluation), these results are presented to human evaluators for scoring. For
+more details on the DrawBench and PartiPrompts benchmarks, refer to their respective papers.
+
+
+
+It is useful to look at some inference samples while a model is training to measure the
+training progress. In our [training scripts](https://github.com/huggingface/diffusers/tree/main/examples/), we support this utility with additional support for
+logging to TensorBoard and Weights & Biases.
+
+
+
+## Quantitative Evaluation
+
+In this section, we will walk you through how to evaluate three different diffusion pipelines using:
+
+- CLIP score
+- CLIP directional similarity
+- FID
+
+### Text-guided image generation
+
+[CLIP score](https://arxiv.org/abs/2104.08718) measures the compatibility of image-caption pairs. Higher CLIP scores imply higher compatibility 🔼. The CLIP score is a quantitative measurement of the qualitative concept "compatibility". Image-caption pair compatibility can also be thought of as the semantic similarity between the image and the caption. CLIP score was found to have high correlation with human judgement.
+
+Let's first load a [`StableDiffusionPipeline`]:
+
+```python
+from diffusers import StableDiffusionPipeline
+import torch
+
+model_ckpt = "CompVis/stable-diffusion-v1-4"
+sd_pipeline = StableDiffusionPipeline.from_pretrained(model_ckpt, torch_dtype=torch.float16).to("cuda")
+```
+
+Generate some images with multiple prompts:
+
+```python
+prompts = [
+ "a photo of an astronaut riding a horse on mars",
+ "A high tech solarpunk utopia in the Amazon rainforest",
+ "A pikachu fine dining with a view to the Eiffel Tower",
+ "A mecha robot in a favela in expressionist style",
+ "an insect robot preparing a delicious meal",
+ "A small cabin on top of a snowy mountain in the style of Disney, artstation",
+]
+
+images = sd_pipeline(prompts, num_images_per_prompt=1, output_type="numpy").images
+
+print(images.shape)
+# (6, 512, 512, 3)
+```
+
+And then, we calculate the CLIP score.
+
+```python
+from torchmetrics.functional.multimodal import clip_score
+from functools import partial
+
+clip_score_fn = partial(clip_score, model_name_or_path="openai/clip-vit-base-patch16")
+
+
+def calculate_clip_score(images, prompts):
+ images_int = (images * 255).astype("uint8")
+ clip_score = clip_score_fn(torch.from_numpy(images_int).permute(0, 3, 1, 2), prompts).detach()
+ return round(float(clip_score), 4)
+
+
+sd_clip_score = calculate_clip_score(images, prompts)
+print(f"CLIP score: {sd_clip_score}")
+# CLIP score: 35.7038
+```
+
+In the above example, we generated one image per prompt. If we generated multiple images per prompt, we would have to take the average score from the generated images per prompt.
+
+Now, if we wanted to compare two checkpoints compatible with the [`StableDiffusionPipeline`] we should pass a generator while calling the pipeline. First, we generate images with a
+fixed seed with the [v1-4 Stable Diffusion checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4):
+
+```python
+seed = 0
+generator = torch.manual_seed(seed)
+
+images = sd_pipeline(prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
+```
+
+Then we load the [v1-5 checkpoint](https://huggingface.co/runwayml/stable-diffusion-v1-5) to generate images:
+
+```python
+model_ckpt_1_5 = "runwayml/stable-diffusion-v1-5"
+sd_pipeline_1_5 = StableDiffusionPipeline.from_pretrained(model_ckpt_1_5, torch_dtype=weight_dtype).to(device)
+
+images_1_5 = sd_pipeline_1_5(prompts, num_images_per_prompt=1, generator=generator, output_type="numpy").images
+```
+
+And finally, we compare their CLIP scores:
+
+```python
+sd_clip_score_1_4 = calculate_clip_score(images, prompts)
+print(f"CLIP Score with v-1-4: {sd_clip_score_1_4}")
+# CLIP Score with v-1-4: 34.9102
+
+sd_clip_score_1_5 = calculate_clip_score(images_1_5, prompts)
+print(f"CLIP Score with v-1-5: {sd_clip_score_1_5}")
+# CLIP Score with v-1-5: 36.2137
+```
+
+It seems like the [v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint performs better than its predecessor. Note, however, that the number of prompts we used to compute the CLIP scores is quite low. For a more practical evaluation, this number should be way higher, and the prompts should be diverse.
+
+
+
+By construction, there are some limitations in this score. The captions in the training dataset
+were crawled from the web and extracted from `alt` and similar tags associated an image on the internet.
+They are not necessarily representative of what a human being would use to describe an image. Hence we
+had to "engineer" some prompts here.
+
+
+
+### Image-conditioned text-to-image generation
+
+In this case, we condition the generation pipeline with an input image as well as a text prompt. Let's take the [`StableDiffusionInstructPix2PixPipeline`], as an example. It takes an edit instruction as an input prompt and an input image to be edited.
+
+Here is one example:
+
+
+
+One strategy to evaluate such a model is to measure the consistency of the change between the two images (in [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) space) with the change between the two image captions (as shown in [CLIP-Guided Domain Adaptation of Image Generators](https://arxiv.org/abs/2108.00946)). This is referred to as the "**CLIP directional similarity**".
+
+- Caption 1 corresponds to the input image (image 1) that is to be edited.
+- Caption 2 corresponds to the edited image (image 2). It should reflect the edit instruction.
+
+Following is a pictorial overview:
+
+
+
+We have prepared a mini dataset to implement this metric. Let's first load the dataset.
+
+```python
+from datasets import load_dataset
+
+dataset = load_dataset("sayakpaul/instructpix2pix-demo", split="train")
+dataset.features
+```
+
+```bash
+{'input': Value(dtype='string', id=None),
+ 'edit': Value(dtype='string', id=None),
+ 'output': Value(dtype='string', id=None),
+ 'image': Image(decode=True, id=None)}
+```
+
+Here we have:
+
+- `input` is a caption corresponding to the `image`.
+- `edit` denotes the edit instruction.
+- `output` denotes the modified caption reflecting the `edit` instruction.
+
+Let's take a look at a sample.
+
+```python
+idx = 0
+print(f"Original caption: {dataset[idx]['input']}")
+print(f"Edit instruction: {dataset[idx]['edit']}")
+print(f"Modified caption: {dataset[idx]['output']}")
+```
+
+```bash
+Original caption: 2. FAROE ISLANDS: An archipelago of 18 mountainous isles in the North Atlantic Ocean between Norway and Iceland, the Faroe Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
+Edit instruction: make the isles all white marble
+Modified caption: 2. WHITE MARBLE ISLANDS: An archipelago of 18 mountainous white marble isles in the North Atlantic Ocean between Norway and Iceland, the White Marble Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
+```
+
+And here is the image:
+
+```python
+dataset[idx]["image"]
+```
+
+
+
+We will first edit the images of our dataset with the edit instruction and compute the directional similarity.
+
+Let's first load the [`StableDiffusionInstructPix2PixPipeline`]:
+
+```python
+from diffusers import StableDiffusionInstructPix2PixPipeline
+
+instruct_pix2pix_pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ "timbrooks/instruct-pix2pix", torch_dtype=torch.float16
+).to(device)
+```
+
+Now, we perform the edits:
+
+```python
+import numpy as np
+
+
+def edit_image(input_image, instruction):
+ image = instruct_pix2pix_pipeline(
+ instruction,
+ image=input_image,
+ output_type="numpy",
+ generator=generator,
+ ).images[0]
+ return image
+
+
+input_images = []
+original_captions = []
+modified_captions = []
+edited_images = []
+
+for idx in range(len(dataset)):
+ input_image = dataset[idx]["image"]
+ edit_instruction = dataset[idx]["edit"]
+ edited_image = edit_image(input_image, edit_instruction)
+
+ input_images.append(np.array(input_image))
+ original_captions.append(dataset[idx]["input"])
+ modified_captions.append(dataset[idx]["output"])
+ edited_images.append(edited_image)
+```
+
+To measure the directional similarity, we first load CLIP's image and text encoders:
+
+```python
+from transformers import (
+ CLIPTokenizer,
+ CLIPTextModelWithProjection,
+ CLIPVisionModelWithProjection,
+ CLIPImageProcessor,
+)
+
+clip_id = "openai/clip-vit-large-patch14"
+tokenizer = CLIPTokenizer.from_pretrained(clip_id)
+text_encoder = CLIPTextModelWithProjection.from_pretrained(clip_id).to(device)
+image_processor = CLIPImageProcessor.from_pretrained(clip_id)
+image_encoder = CLIPVisionModelWithProjection.from_pretrained(clip_id).to(device)
+```
+
+Notice that we are using a particular CLIP checkpoint, i.e., `openai/clip-vit-large-patch14`. This is because the Stable Diffusion pre-training was performed with this CLIP variant. For more details, refer to the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix#diffusers.StableDiffusionInstructPix2PixPipeline.text_encoder).
+
+Next, we prepare a PyTorch `nn.Module` to compute directional similarity:
+
+```python
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class DirectionalSimilarity(nn.Module):
+ def __init__(self, tokenizer, text_encoder, image_processor, image_encoder):
+ super().__init__()
+ self.tokenizer = tokenizer
+ self.text_encoder = text_encoder
+ self.image_processor = image_processor
+ self.image_encoder = image_encoder
+
+ def preprocess_image(self, image):
+ image = self.image_processor(image, return_tensors="pt")["pixel_values"]
+ return {"pixel_values": image.to(device)}
+
+ def tokenize_text(self, text):
+ inputs = self.tokenizer(
+ text,
+ max_length=self.tokenizer.model_max_length,
+ padding="max_length",
+ truncation=True,
+ return_tensors="pt",
+ )
+ return {"input_ids": inputs.input_ids.to(device)}
+
+ def encode_image(self, image):
+ preprocessed_image = self.preprocess_image(image)
+ image_features = self.image_encoder(**preprocessed_image).image_embeds
+ image_features = image_features / image_features.norm(dim=1, keepdim=True)
+ return image_features
+
+ def encode_text(self, text):
+ tokenized_text = self.tokenize_text(text)
+ text_features = self.text_encoder(**tokenized_text).text_embeds
+ text_features = text_features / text_features.norm(dim=1, keepdim=True)
+ return text_features
+
+ def compute_directional_similarity(self, img_feat_one, img_feat_two, text_feat_one, text_feat_two):
+ sim_direction = F.cosine_similarity(img_feat_two - img_feat_one, text_feat_two - text_feat_one)
+ return sim_direction
+
+ def forward(self, image_one, image_two, caption_one, caption_two):
+ img_feat_one = self.encode_image(image_one)
+ img_feat_two = self.encode_image(image_two)
+ text_feat_one = self.encode_text(caption_one)
+ text_feat_two = self.encode_text(caption_two)
+ directional_similarity = self.compute_directional_similarity(
+ img_feat_one, img_feat_two, text_feat_one, text_feat_two
+ )
+ return directional_similarity
+```
+
+Let's put `DirectionalSimilarity` to use now.
+
+```python
+dir_similarity = DirectionalSimilarity(tokenizer, text_encoder, image_processor, image_encoder)
+scores = []
+
+for i in range(len(input_images)):
+ original_image = input_images[i]
+ original_caption = original_captions[i]
+ edited_image = edited_images[i]
+ modified_caption = modified_captions[i]
+
+ similarity_score = dir_similarity(original_image, edited_image, original_caption, modified_caption)
+ scores.append(float(similarity_score.detach().cpu()))
+
+print(f"CLIP directional similarity: {np.mean(scores)}")
+# CLIP directional similarity: 0.0797976553440094
+```
+
+Like the CLIP Score, the higher the CLIP directional similarity, the better it is.
+
+It should be noted that the `StableDiffusionInstructPix2PixPipeline` exposes two arguments, namely, `image_guidance_scale` and `guidance_scale` that let you control the quality of the final edited image. We encourage you to experiment with these two arguments and see the impact of that on the directional similarity.
+
+We can extend the idea of this metric to measure how similar the original image and edited version are. To do that, we can just do `F.cosine_similarity(img_feat_two, img_feat_one)`. For these kinds of edits, we would still want the primary semantics of the images to be preserved as much as possible, i.e., a high similarity score.
+
+We can use these metrics for similar pipelines such as the [`StableDiffusionPix2PixZeroPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/pix2pix_zero#diffusers.StableDiffusionPix2PixZeroPipeline).
+
+
+
+Both CLIP score and CLIP direction similarity rely on the CLIP model, which can make the evaluations biased.
+
+
+
+***Extending metrics like IS, FID (discussed later), or KID can be difficult*** when the model under evaluation was pre-trained on a large image-captioning dataset (such as the [LAION-5B dataset](https://laion.ai/blog/laion-5b/)). This is because underlying these metrics is an InceptionNet (pre-trained on the ImageNet-1k dataset) used for extracting intermediate image features. The pre-training dataset of Stable Diffusion may have limited overlap with the pre-training dataset of InceptionNet, so it is not a good candidate here for feature extraction.
+
+***Using the above metrics helps evaluate models that are class-conditioned. For example, [DiT](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/overview). It was pre-trained being conditioned on the ImageNet-1k classes.***
+
+### Class-conditioned image generation
+
+Class-conditioned generative models are usually pre-trained on a class-labeled dataset such as [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k). Popular metrics for evaluating these models include Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and Inception Score (IS). In this document, we focus on FID ([Heusel et al.](https://arxiv.org/abs/1706.08500)). We show how to compute it with the [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit), which uses the [DiT model](https://arxiv.org/abs/2212.09748) under the hood.
+
+FID aims to measure how similar are two datasets of images. As per [this resource](https://mmgeneration.readthedocs.io/en/latest/quick_run.html#fid):
+
+> Fréchet Inception Distance is a measure of similarity between two datasets of images. It was shown to correlate well with the human judgment of visual quality and is most often used to evaluate the quality of samples of Generative Adversarial Networks. FID is calculated by computing the Fréchet distance between two Gaussians fitted to feature representations of the Inception network.
+
+These two datasets are essentially the dataset of real images and the dataset of fake images (generated images in our case). FID is usually calculated with two large datasets. However, for this document, we will work with two mini datasets.
+
+Let's first download a few images from the ImageNet-1k training set:
+
+```python
+from zipfile import ZipFile
+import requests
+
+
+def download(url, local_filepath):
+ r = requests.get(url)
+ with open(local_filepath, "wb") as f:
+ f.write(r.content)
+ return local_filepath
+
+
+dummy_dataset_url = "https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/sample-imagenet-images.zip"
+local_filepath = download(dummy_dataset_url, dummy_dataset_url.split("/")[-1])
+
+with ZipFile(local_filepath, "r") as zipper:
+ zipper.extractall(".")
+```
+
+```python
+from PIL import Image
+import os
+
+dataset_path = "sample-imagenet-images"
+image_paths = sorted([os.path.join(dataset_path, x) for x in os.listdir(dataset_path)])
+
+real_images = [np.array(Image.open(path).convert("RGB")) for path in image_paths]
+```
+
+These are 10 images from the following Imagenet-1k classes: "cassette_player", "chain_saw" (x2), "church", "gas_pump" (x3), "parachute" (x2), and "tench".
+
+
+ 
+ Real images.
+
+
+Now that the images are loaded, let's apply some lightweight pre-processing on them to use them for FID calculation.
+
+```python
+from torchvision.transforms import functional as F
+
+
+def preprocess_image(image):
+ image = torch.tensor(image).unsqueeze(0)
+ image = image.permute(0, 3, 1, 2) / 255.0
+ return F.center_crop(image, (256, 256))
+
+
+real_images = torch.cat([preprocess_image(image) for image in real_images])
+print(real_images.shape)
+# torch.Size([10, 3, 256, 256])
+```
+
+We now load the [`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit) to generate images conditioned on the above-mentioned classes.
+
+```python
+from diffusers import DiTPipeline, DPMSolverMultistepScheduler
+
+dit_pipeline = DiTPipeline.from_pretrained("facebook/DiT-XL-2-256", torch_dtype=torch.float16)
+dit_pipeline.scheduler = DPMSolverMultistepScheduler.from_config(dit_pipeline.scheduler.config)
+dit_pipeline = dit_pipeline.to("cuda")
+
+words = [
+ "cassette player",
+ "chainsaw",
+ "chainsaw",
+ "church",
+ "gas pump",
+ "gas pump",
+ "gas pump",
+ "parachute",
+ "parachute",
+ "tench",
+]
+
+class_ids = dit_pipeline.get_label_ids(words)
+output = dit_pipeline(class_labels=class_ids, generator=generator, output_type="numpy")
+
+fake_images = output.images
+fake_images = torch.tensor(fake_images)
+fake_images = fake_images.permute(0, 3, 1, 2)
+print(fake_images.shape)
+# torch.Size([10, 3, 256, 256])
+```
+
+Now, we can compute the FID using [`torchmetrics`](https://torchmetrics.readthedocs.io/).
+
+```python
+from torchmetrics.image.fid import FrechetInceptionDistance
+
+fid = FrechetInceptionDistance(normalize=True)
+fid.update(real_images, real=True)
+fid.update(fake_images, real=False)
+
+print(f"FID: {float(fid.compute())}")
+# FID: 177.7147216796875
+```
+
+The lower the FID, the better it is. Several things can influence FID here:
+
+- Number of images (both real and fake)
+- Randomness induced in the diffusion process
+- Number of inference steps in the diffusion process
+- The scheduler being used in the diffusion process
+
+For the last two points, it is, therefore, a good practice to run the evaluation across different seeds and inference steps, and then report an average result.
+
+
+
+FID results tend to be fragile as they depend on a lot of factors:
+
+* The specific Inception model used during computation.
+* The implementation accuracy of the computation.
+* The image format (not the same if we start from PNGs vs JPGs).
+
+Keeping that in mind, FID is often most useful when comparing similar runs, but it is
+hard to reproduce paper results unless the authors carefully disclose the FID
+measurement code.
+
+These points apply to other related metrics too, such as KID and IS.
+
+
+
+As a final step, let's visually inspect the `fake_images`.
+
+
+ 
+ Fake images.
+
diff --git a/diffusers/docs/source/en/conceptual/philosophy.mdx b/diffusers/docs/source/en/conceptual/philosophy.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..564530f2cb489f652f8a0870f313659c8469cfcf
--- /dev/null
+++ b/diffusers/docs/source/en/conceptual/philosophy.mdx
@@ -0,0 +1,110 @@
+
+
+# Philosophy
+
+🧨 Diffusers provides **state-of-the-art** pretrained diffusion models across multiple modalities.
+Its purpose is to serve as a **modular toolbox** for both inference and training.
+
+We aim at building a library that stands the test of time and therefore take API design very seriously.
+
+In a nutshell, Diffusers is built to be a natural extension of PyTorch. Therefore, most of our design choices are based on [PyTorch's Design Principles](https://pytorch.org/docs/stable/community/design.html#pytorch-design-philosophy). Let's go over the most important ones:
+
+## Usability over Performance
+
+- While Diffusers has many built-in performance-enhancing features (see [Memory and Speed](https://huggingface.co/docs/diffusers/optimization/fp16)), models are always loaded with the highest precision and lowest optimization. Therefore, by default diffusion pipelines are always instantiated on CPU with float32 precision if not otherwise defined by the user. This ensures usability across different platforms and accelerators and means that no complex installations are required to run the library.
+- Diffusers aim at being a **light-weight** package and therefore has very few required dependencies, but many soft dependencies that can improve performance (such as `accelerate`, `safetensors`, `onnx`, etc...). We strive to keep the library as lightweight as possible so that it can be added without much concern as a dependency on other packages.
+- Diffusers prefers simple, self-explainable code over condensed, magic code. This means that short-hand code syntaxes such as lambda functions, and advanced PyTorch operators are often not desired.
+
+## Simple over easy
+
+As PyTorch states, **explicit is better than implicit** and **simple is better than complex**. This design philosophy is reflected in multiple parts of the library:
+- We follow PyTorch's API with methods like [`DiffusionPipeline.to`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.to) to let the user handle device management.
+- Raising concise error messages is preferred to silently correct erroneous input. Diffusers aims at teaching the user, rather than making the library as easy to use as possible.
+- Complex model vs. scheduler logic is exposed instead of magically handled inside. Schedulers/Samplers are separated from diffusion models with minimal dependencies on each other. This forces the user to write the unrolled denoising loop. However, the separation allows for easier debugging and gives the user more control over adapting the denoising process or switching out diffusion models or schedulers.
+- Separately trained components of the diffusion pipeline, *e.g.* the text encoder, the unet, and the variational autoencoder, each have their own model class. This forces the user to handle the interaction between the different model components, and the serialization format separates the model components into different files. However, this allows for easier debugging and customization. Dreambooth or textual inversion training
+is very simple thanks to diffusers' ability to separate single components of the diffusion pipeline.
+
+## Tweakable, contributor-friendly over abstraction
+
+For large parts of the library, Diffusers adopts an important design principle of the [Transformers library](https://github.com/huggingface/transformers), which is to prefer copy-pasted code over hasty abstractions. This design principle is very opinionated and stands in stark contrast to popular design principles such as [Don't repeat yourself (DRY)](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself).
+In short, just like Transformers does for modeling files, diffusers prefers to keep an extremely low level of abstraction and very self-contained code for pipelines and schedulers.
+Functions, long code blocks, and even classes can be copied across multiple files which at first can look like a bad, sloppy design choice that makes the library unmaintainable.
+**However**, this design has proven to be extremely successful for Transformers and makes a lot of sense for community-driven, open-source machine learning libraries because:
+- Machine Learning is an extremely fast-moving field in which paradigms, model architectures, and algorithms are changing rapidly, which therefore makes it very difficult to define long-lasting code abstractions.
+- Machine Learning practitioners like to be able to quickly tweak existing code for ideation and research and therefore prefer self-contained code over one that contains many abstractions.
+- Open-source libraries rely on community contributions and therefore must build a library that is easy to contribute to. The more abstract the code, the more dependencies, the harder to read, and the harder to contribute to. Contributors simply stop contributing to very abstract libraries out of fear of breaking vital functionality. If contributing to a library cannot break other fundamental code, not only is it more inviting for potential new contributors, but it is also easier to review and contribute to multiple parts in parallel.
+
+At Hugging Face, we call this design the **single-file policy** which means that almost all of the code of a certain class should be written in a single, self-contained file. To read more about the philosophy, you can have a look
+at [this blog post](https://huggingface.co/blog/transformers-design-philosophy).
+
+In diffusers, we follow this philosophy for both pipelines and schedulers, but only partly for diffusion models. The reason we don't follow this design fully for diffusion models is because almost all diffusion pipelines, such
+as [DDPM](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/ddpm), [Stable Diffusion](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/stable_diffusion/overview#stable-diffusion-pipelines), [UnCLIP (Dalle-2)](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/unclip#overview) and [Imagen](https://imagen.research.google/) all rely on the same diffusion model, the [UNet](https://huggingface.co/docs/diffusers/api/models#diffusers.UNet2DConditionModel).
+
+Great, now you should have generally understood why 🧨 Diffusers is designed the way it is 🤗.
+We try to apply these design principles consistently across the library. Nevertheless, there are some minor exceptions to the philosophy or some unlucky design choices. If you have feedback regarding the design, we would ❤️ to hear it [directly on GitHub](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
+
+## Design Philosophy in Details
+
+Now, let's look a bit into the nitty-gritty details of the design philosophy. Diffusers essentially consist of three major classes, [pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines), [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models), and [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
+Let's walk through more in-detail design decisions for each class.
+
+### Pipelines
+
+Pipelines are designed to be easy to use (therefore do not follow [*Simple over easy*](#simple-over-easy) 100%), are not feature complete, and should loosely be seen as examples of how to use [models](#models) and [schedulers](#schedulers) for inference.
+
+The following design principles are followed:
+- Pipelines follow the single-file policy. All pipelines can be found in individual directories under src/diffusers/pipelines. One pipeline folder corresponds to one diffusion paper/project/release. Multiple pipeline files can be gathered in one pipeline folder, as it’s done for [`src/diffusers/pipelines/stable-diffusion`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/stable_diffusion). If pipelines share similar functionality, one can make use of the [#Copied from mechanism](https://github.com/huggingface/diffusers/blob/125d783076e5bd9785beb05367a2d2566843a271/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py#L251).
+- Pipelines all inherit from [`DiffusionPipeline`].
+- Every pipeline consists of different model and scheduler components, that are documented in the [`model_index.json` file](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json), are accessible under the same name as attributes of the pipeline and can be shared between pipelines with [`DiffusionPipeline.components`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.components) function.
+- Every pipeline should be loadable via the [`DiffusionPipeline.from_pretrained`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained) function.
+- Pipelines should be used **only** for inference.
+- Pipelines should be very readable, self-explanatory, and easy to tweak.
+- Pipelines should be designed to build on top of each other and be easy to integrate into higher-level APIs.
+- Pipelines are **not** intended to be feature-complete user interfaces. For future complete user interfaces one should rather have a look at [InvokeAI](https://github.com/invoke-ai/InvokeAI), [Diffuzers](https://github.com/abhishekkrthakur/diffuzers), and [lama-cleaner](https://github.com/Sanster/lama-cleaner).
+- Every pipeline should have one and only one way to run it via a `__call__` method. The naming of the `__call__` arguments should be shared across all pipelines.
+- Pipelines should be named after the task they are intended to solve.
+- In almost all cases, novel diffusion pipelines shall be implemented in a new pipeline folder/file.
+
+### Models
+
+Models are designed as configurable toolboxes that are natural extensions of [PyTorch's Module class](https://pytorch.org/docs/stable/generated/torch.nn.Module.html). They only partly follow the **single-file policy**.
+
+The following design principles are followed:
+- Models correspond to **a type of model architecture**. *E.g.* the [`UNet2DConditionModel`] class is used for all UNet variations that expect 2D image inputs and are conditioned on some context.
+- All models can be found in [`src/diffusers/models`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and every model architecture shall be defined in its file, e.g. [`unet_2d_condition.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_condition.py), [`transformer_2d.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/transformer_2d.py), etc...
+- Models **do not** follow the single-file policy and should make use of smaller model building blocks, such as [`attention.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention.py), [`resnet.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/resnet.py), [`embeddings.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/embeddings.py), etc... **Note**: This is in stark contrast to Transformers' modeling files and shows that models do not really follow the single-file policy.
+- Models intend to expose complexity, just like PyTorch's module does, and give clear error messages.
+- Models all inherit from `ModelMixin` and `ConfigMixin`.
+- Models can be optimized for performance when it doesn’t demand major code changes, keeps backward compatibility, and gives significant memory or compute gain.
+- Models should by default have the highest precision and lowest performance setting.
+- To integrate new model checkpoints whose general architecture can be classified as an architecture that already exists in Diffusers, the existing model architecture shall be adapted to make it work with the new checkpoint. One should only create a new file if the model architecture is fundamentally different.
+- Models should be designed to be easily extendable to future changes. This can be achieved by limiting public function arguments, configuration arguments, and "foreseeing" future changes, *e.g.* it is usually better to add `string` "...type" arguments that can easily be extended to new future types instead of boolean `is_..._type` arguments. Only the minimum amount of changes shall be made to existing architectures to make a new model checkpoint work.
+- The model design is a difficult trade-off between keeping code readable and concise and supporting many model checkpoints. For most parts of the modeling code, classes shall be adapted for new model checkpoints, while there are some exceptions where it is preferred to add new classes to make sure the code is kept concise and
+readable longterm, such as [UNet blocks](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_blocks.py) and [Attention processors](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+### Schedulers
+
+Schedulers are responsible to guide the denoising process for inference as well as to define a noise schedule for training. They are designed as individual classes with loadable configuration files and strongly follow the **single-file policy**.
+
+The following design principles are followed:
+- All schedulers are found in [`src/diffusers/schedulers`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
+- Schedulers are **not** allowed to import from large utils files and shall be kept very self-contained.
+- One scheduler python file corresponds to one scheduler algorithm (as might be defined in a paper).
+- If schedulers share similar functionalities, we can make use of the `#Copied from` mechanism.
+- Schedulers all inherit from `SchedulerMixin` and `ConfigMixin`.
+- Schedulers can be easily swapped out with the [`ConfigMixin.from_config`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config) method as explained in detail [here](./using-diffusers/schedulers.mdx).
+- Every scheduler has to have a `set_num_inference_steps`, and a `step` function. `set_num_inference_steps(...)` has to be called before every denoising process, *i.e.* before `step(...)` is called.
+- Every scheduler exposes the timesteps to be "looped over" via a `timesteps` attribute, which is an array of timesteps the model will be called upon.
+- The `step(...)` function takes a predicted model output and the "current" sample (x_t) and returns the "previous", slightly more denoised sample (x_t-1).
+- Given the complexity of diffusion schedulers, the `step` function does not expose all the complexity and can be a bit of a "black box".
+- In almost all cases, novel schedulers shall be implemented in a new scheduling file.
diff --git a/diffusers/docs/source/en/imgs/access_request.png b/diffusers/docs/source/en/imgs/access_request.png
new file mode 100644
index 0000000000000000000000000000000000000000..33c6abc88dfb226e929b44c30c173c787b407045
Binary files /dev/null and b/diffusers/docs/source/en/imgs/access_request.png differ
diff --git a/diffusers/docs/source/en/imgs/diffusers_library.jpg b/diffusers/docs/source/en/imgs/diffusers_library.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..07ba9c6571a3f070d9d10b78dccfd4d4537dd539
Binary files /dev/null and b/diffusers/docs/source/en/imgs/diffusers_library.jpg differ
diff --git a/diffusers/docs/source/en/index.mdx b/diffusers/docs/source/en/index.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..d020eb5d7d174da5a0d291b1efd4e810d3c1dc90
--- /dev/null
+++ b/diffusers/docs/source/en/index.mdx
@@ -0,0 +1,93 @@
+
+
+
+
+  +
+
+
+
+# Diffusers
+
+🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or want to train your own diffusion model, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](conceptual/philosophy#usability-over-performance), [simple over easy](conceptual/philosophy#simple-over-easy), and [customizability over abstractions](conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
+
+The library has three main components:
+
+- State-of-the-art [diffusion pipelines](api/pipelines/overview) for inference with just a few lines of code.
+- Interchangeable [noise schedulers](api/schedulers/overview) for balancing trade-offs between generation speed and quality.
+- Pretrained [models](api/models) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
+
+
+
+## Supported pipelines
+
+| Pipeline | Paper/Repository | Tasks |
+|---|---|:---:|
+| [alt_diffusion](./api/pipelines/alt_diffusion) | [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
+| [audio_diffusion](./api/pipelines/audio_diffusion) | [Audio Diffusion](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
+| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [dance_diffusion](./api/pipelines/dance_diffusion) | [Dance Diffusion](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
+| [ddpm](./api/pipelines/ddpm) | [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
+| [ddim](./api/pipelines/ddim) | [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./api/pipelines/paint_by_example) | [Paint by Example: Exemplar-based Image Editing with Diffusion Models](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./api/pipelines/pndm) | [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [score_sde_ve](./api/pipelines/score_sde_ve) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [score_sde_vp](./api/pipelines/score_sde_vp) | [Score-Based Generative Modeling through Stochastic Differential Equations](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [Semantic Guidance](https://arxiv.org/abs/2301.12247) | Text-Guided Generation |
+| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation |
+| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation |
+| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [Stable Diffusion](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [MultiDiffusion](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
+| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://arxiv.org/abs/2211.09800) | Text-Guided Image Editing|
+| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [Zero-shot Image-to-Image Translation](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
+| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models](https://arxiv.org/abs/2301.13826) | Text-to-Image Generation |
+| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [Improving Sample Quality of Diffusion Models Using Self-Attention Guidance](https://arxiv.org/abs/2210.00939) | Text-to-Image Generation |
+| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [Stable Diffusion Image Variations](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
+| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [Stable Diffusion Latent Upscaler](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_model_editing](./api/pipelines/stable_diffusion/model_editing) | [Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://time-diffusion.github.io/) | Text-to-Image Model Editing |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Depth-Conditional Stable Diffusion](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [Stable Diffusion 2](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [Safe Stable Diffusion](https://arxiv.org/abs/2211.05105) | Text-Guided Generation |
+| [stable_unclip](./stable_unclip) | Stable unCLIP | Text-to-Image Generation |
+| [stable_unclip](./stable_unclip) | Stable unCLIP | Image-to-Image Text-Guided Generation |
+| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [text_to_video_sd](./api/pipelines/text_to_video) | [Modelscope's Text-to-video-synthesis Model in Open Domain](https://modelscope.cn/models/damo/text-to-video-synthesis/summary) | Text-to-Video Generation |
+| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125)(implementation by [kakaobrain](https://github.com/kakaobrain/karlo)) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
\ No newline at end of file
diff --git a/diffusers/docs/source/en/installation.mdx b/diffusers/docs/source/en/installation.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..8639bcfca95b47cfa9d0116c4fae4f3f3cbe888a
--- /dev/null
+++ b/diffusers/docs/source/en/installation.mdx
@@ -0,0 +1,144 @@
+
+
+# Installation
+
+Install 🤗 Diffusers for whichever deep learning library you’re working with.
+
+🤗 Diffusers is tested on Python 3.7+, PyTorch 1.7.0+ and flax. Follow the installation instructions below for the deep learning library you are using:
+
+- [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
+- [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
+
+## Install with pip
+
+You should install 🤗 Diffusers in a [virtual environment](https://docs.python.org/3/library/venv.html).
+If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
+
+Start by creating a virtual environment in your project directory:
+
+```bash
+python -m venv .env
+```
+
+Activate the virtual environment:
+
+```bash
+source .env/bin/activate
+```
+
+Now you're ready to install 🤗 Diffusers with the following command:
+
+**For PyTorch**
+
+```bash
+pip install diffusers["torch"]
+```
+
+**For Flax**
+
+```bash
+pip install diffusers["flax"]
+```
+
+## Install from source
+
+Before intsalling `diffusers` from source, make sure you have `torch` and `accelerate` installed.
+
+For `torch` installation refer to the `torch` [docs](https://pytorch.org/get-started/locally/#start-locally).
+
+To install `accelerate`
+
+```bash
+pip install accelerate
+```
+
+Install 🤗 Diffusers from source with the following command:
+
+```bash
+pip install git+https://github.com/huggingface/diffusers
+```
+
+This command installs the bleeding edge `main` version rather than the latest `stable` version.
+The `main` version is useful for staying up-to-date with the latest developments.
+For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet.
+However, this means the `main` version may not always be stable.
+We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day.
+If you run into a problem, please open an [Issue](https://github.com/huggingface/transformers/issues), so we can fix it even sooner!
+
+## Editable install
+
+You will need an editable install if you'd like to:
+
+* Use the `main` version of the source code.
+* Contribute to 🤗 Diffusers and need to test changes in the code.
+
+Clone the repository and install 🤗 Diffusers with the following commands:
+
+```bash
+git clone https://github.com/huggingface/diffusers.git
+cd diffusers
+```
+
+**For PyTorch**
+
+```
+pip install -e ".[torch]"
+```
+
+**For Flax**
+
+```
+pip install -e ".[flax]"
+```
+
+These commands will link the folder you cloned the repository to and your Python library paths.
+Python will now look inside the folder you cloned to in addition to the normal library paths.
+For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python will also search the folder you cloned to: `~/diffusers/`.
+
+
+
+You must keep the `diffusers` folder if you want to keep using the library.
+
+
+
+Now you can easily update your clone to the latest version of 🤗 Diffusers with the following command:
+
+```bash
+cd ~/diffusers/
+git pull
+```
+
+Your Python environment will find the `main` version of 🤗 Diffusers on the next run.
+
+## Notice on telemetry logging
+
+Our library gathers telemetry information during `from_pretrained()` requests.
+This data includes the version of Diffusers and PyTorch/Flax, the requested model or pipeline class,
+and the path to a pretrained checkpoint if it is hosted on the Hub.
+This usage data helps us debug issues and prioritize new features.
+Telemetry is only sent when loading models and pipelines from the HuggingFace Hub,
+and is not collected during local usage.
+
+We understand that not everyone wants to share additional information, and we respect your privacy,
+so you can disable telemetry collection by setting the `DISABLE_TELEMETRY` environment variable from your terminal:
+
+On Linux/MacOS:
+```bash
+export DISABLE_TELEMETRY=YES
+```
+
+On Windows:
+```bash
+set DISABLE_TELEMETRY=YES
+```
\ No newline at end of file
diff --git a/diffusers/docs/source/en/optimization/fp16.mdx b/diffusers/docs/source/en/optimization/fp16.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..d05c5aabea2b473ee0398eb331470c344826859a
--- /dev/null
+++ b/diffusers/docs/source/en/optimization/fp16.mdx
@@ -0,0 +1,423 @@
+
+
+# Memory and speed
+
+We present some techniques and ideas to optimize 🤗 Diffusers _inference_ for memory or speed. As a general rule, we recommend the use of [xFormers](https://github.com/facebookresearch/xformers) for memory efficient attention, please see the recommended [installation instructions](xformers).
+
+We'll discuss how the following settings impact performance and memory.
+
+| | Latency | Speedup |
+| ---------------- | ------- | ------- |
+| original | 9.50s | x1 |
+| fp16 | 3.61s | x2.63 |
+| channels last | 3.30s | x2.88 |
+| traced UNet | 3.21s | x2.96 |
+| memory efficient attention | 2.63s | x3.61 |
+
+
+ obtained on NVIDIA TITAN RTX by generating a single image of size 512x512 from
+ the prompt "a photo of an astronaut riding a horse on mars" with 50 DDIM
+ steps.
+
+
+### Use tf32 instead of fp32 (on Ampere and later CUDA devices)
+
+On Ampere and later CUDA devices matrix multiplications and convolutions can use the TensorFloat32 (TF32) mode for faster but slightly less accurate computations. By default PyTorch enables TF32 mode for convolutions but not matrix multiplications, and unless a network requires full float32 precision we recommend enabling this setting for matrix multiplications, too. It can significantly speed up computations with typically negligible loss of numerical accuracy. You can read more about it [here](https://huggingface.co/docs/transformers/v4.18.0/en/performance#tf32). All you need to do is to add this before your inference:
+
+```python
+import torch
+
+torch.backends.cuda.matmul.allow_tf32 = True
+```
+
+## Half precision weights
+
+To save more GPU memory and get more speed, you can load and run the model weights directly in half precision. This involves loading the float16 version of the weights, which was saved to a branch named `fp16`, and telling PyTorch to use the `float16` type when loading them:
+
+```Python
+import torch
+from diffusers import DiffusionPipeline
+
+pipe = DiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+
+ torch_dtype=torch.float16,
+)
+pipe = pipe.to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+image = pipe(prompt).images[0]
+```
+
+
+ It is strongly discouraged to make use of [`torch.autocast`](https://pytorch.org/docs/stable/amp.html#torch.autocast) in any of the pipelines as it can lead to black images and is always slower than using pure
+ float16 precision.
+
+
+## Sliced attention for additional memory savings
+
+For even additional memory savings, you can use a sliced version of attention that performs the computation in steps instead of all at once.
+
+
+ Attention slicing is useful even if a batch size of just 1 is used - as long
+ as the model uses more than one attention head. If there is more than one
+ attention head the *QK^T* attention matrix can be computed sequentially for
+ each head which can save a significant amount of memory.
+
+
+To perform the attention computation sequentially over each head, you only need to invoke [`~DiffusionPipeline.enable_attention_slicing`] in your pipeline before inference, like here:
+
+```Python
+import torch
+from diffusers import DiffusionPipeline
+
+pipe = DiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+
+ torch_dtype=torch.float16,
+)
+pipe = pipe.to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+pipe.enable_attention_slicing()
+image = pipe(prompt).images[0]
+```
+
+There's a small performance penalty of about 10% slower inference times, but this method allows you to use Stable Diffusion in as little as 3.2 GB of VRAM!
+
+
+## Sliced VAE decode for larger batches
+
+To decode large batches of images with limited VRAM, or to enable batches with 32 images or more, you can use sliced VAE decode that decodes the batch latents one image at a time.
+
+You likely want to couple this with [`~StableDiffusionPipeline.enable_attention_slicing`] or [`~StableDiffusionPipeline.enable_xformers_memory_efficient_attention`] to further minimize memory use.
+
+To perform the VAE decode one image at a time, invoke [`~StableDiffusionPipeline.enable_vae_slicing`] in your pipeline before inference. For example:
+
+```Python
+import torch
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+
+ torch_dtype=torch.float16,
+)
+pipe = pipe.to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+pipe.enable_vae_slicing()
+images = pipe([prompt] * 32).images
+```
+
+You may see a small performance boost in VAE decode on multi-image batches. There should be no performance impact on single-image batches.
+
+
+## Tiled VAE decode and encode for large images
+
+Tiled VAE processing makes it possible to work with large images on limited VRAM. For example, generating 4k images in 8GB of VRAM. Tiled VAE decoder splits the image into overlapping tiles, decodes the tiles, and blends the outputs to make the final image.
+
+You want to couple this with [`~StableDiffusionPipeline.enable_attention_slicing`] or [`~StableDiffusionPipeline.enable_xformers_memory_efficient_attention`] to further minimize memory use.
+
+To use tiled VAE processing, invoke [`~StableDiffusionPipeline.enable_vae_tiling`] in your pipeline before inference. For example:
+
+```python
+import torch
+from diffusers import StableDiffusionPipeline, UniPCMultistepScheduler
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ torch_dtype=torch.float16,
+)
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to("cuda")
+prompt = "a beautiful landscape photograph"
+pipe.enable_vae_tiling()
+pipe.enable_xformers_memory_efficient_attention()
+
+image = pipe([prompt], width=3840, height=2224, num_inference_steps=20).images[0]
+```
+
+The output image will have some tile-to-tile tone variation from the tiles having separate decoders, but you shouldn't see sharp seams between the tiles. The tiling is turned off for images that are 512x512 or smaller.
+
+
+
+## Offloading to CPU with accelerate for memory savings
+
+For additional memory savings, you can offload the weights to CPU and only load them to GPU when performing the forward pass.
+
+To perform CPU offloading, all you have to do is invoke [`~StableDiffusionPipeline.enable_sequential_cpu_offload`]:
+
+```Python
+import torch
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+
+ torch_dtype=torch.float16,
+)
+
+prompt = "a photo of an astronaut riding a horse on mars"
+pipe.enable_sequential_cpu_offload()
+image = pipe(prompt).images[0]
+```
+
+And you can get the memory consumption to < 3GB.
+
+Note that this method works at the submodule level, not on whole models. This is the best way to minimize memory consumption, but inference is much slower due to the iterative nature of the process. The UNet component of the pipeline runs several times (as many as `num_inference_steps`); each time, the different submodules of the UNet are sequentially onloaded and then offloaded as they are needed, so the number of memory transfers is large.
+
+
+Consider using model offloading as another point in the optimization space: it will be much faster, but memory savings won't be as large.
+
+
+It is also possible to chain offloading with attention slicing for minimal memory consumption (< 2GB).
+
+```Python
+import torch
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+
+ torch_dtype=torch.float16,
+)
+
+prompt = "a photo of an astronaut riding a horse on mars"
+pipe.enable_sequential_cpu_offload()
+pipe.enable_attention_slicing(1)
+
+image = pipe(prompt).images[0]
+```
+
+**Note**: When using `enable_sequential_cpu_offload()`, it is important to **not** move the pipeline to CUDA beforehand or else the gain in memory consumption will only be minimal. See [this issue](https://github.com/huggingface/diffusers/issues/1934) for more information.
+
+
+
+## Model offloading for fast inference and memory savings
+
+[Sequential CPU offloading](#sequential_offloading), as discussed in the previous section, preserves a lot of memory but makes inference slower, because submodules are moved to GPU as needed, and immediately returned to CPU when a new module runs.
+
+Full-model offloading is an alternative that moves whole models to the GPU, instead of handling each model's constituent _modules_. This results in a negligible impact on inference time (compared with moving the pipeline to `cuda`), while still providing some memory savings.
+
+In this scenario, only one of the main components of the pipeline (typically: text encoder, unet and vae)
+will be in the GPU while the others wait in the CPU. Components like the UNet that run for multiple iterations will stay on GPU until they are no longer needed.
+
+This feature can be enabled by invoking `enable_model_cpu_offload()` on the pipeline, as shown below.
+
+```Python
+import torch
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ torch_dtype=torch.float16,
+)
+
+prompt = "a photo of an astronaut riding a horse on mars"
+pipe.enable_model_cpu_offload()
+image = pipe(prompt).images[0]
+```
+
+This is also compatible with attention slicing for additional memory savings.
+
+```Python
+import torch
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ torch_dtype=torch.float16,
+)
+
+prompt = "a photo of an astronaut riding a horse on mars"
+pipe.enable_model_cpu_offload()
+pipe.enable_attention_slicing(1)
+
+image = pipe(prompt).images[0]
+```
+
+
+This feature requires `accelerate` version 0.17.0 or larger.
+
+
+## Using Channels Last memory format
+
+Channels last memory format is an alternative way of ordering NCHW tensors in memory preserving dimensions ordering. Channels last tensors ordered in such a way that channels become the densest dimension (aka storing images pixel-per-pixel). Since not all operators currently support channels last format it may result in a worst performance, so it's better to try it and see if it works for your model.
+
+For example, in order to set the UNet model in our pipeline to use channels last format, we can use the following:
+
+```python
+print(pipe.unet.conv_out.state_dict()["weight"].stride()) # (2880, 9, 3, 1)
+pipe.unet.to(memory_format=torch.channels_last) # in-place operation
+print(
+ pipe.unet.conv_out.state_dict()["weight"].stride()
+) # (2880, 1, 960, 320) having a stride of 1 for the 2nd dimension proves that it works
+```
+
+## Tracing
+
+Tracing runs an example input tensor through your model, and captures the operations that are invoked as that input makes its way through the model's layers so that an executable or `ScriptFunction` is returned that will be optimized using just-in-time compilation.
+
+To trace our UNet model, we can use the following:
+
+```python
+import time
+import torch
+from diffusers import StableDiffusionPipeline
+import functools
+
+# torch disable grad
+torch.set_grad_enabled(False)
+
+# set variables
+n_experiments = 2
+unet_runs_per_experiment = 50
+
+
+# load inputs
+def generate_inputs():
+ sample = torch.randn(2, 4, 64, 64).half().cuda()
+ timestep = torch.rand(1).half().cuda() * 999
+ encoder_hidden_states = torch.randn(2, 77, 768).half().cuda()
+ return sample, timestep, encoder_hidden_states
+
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ torch_dtype=torch.float16,
+).to("cuda")
+unet = pipe.unet
+unet.eval()
+unet.to(memory_format=torch.channels_last) # use channels_last memory format
+unet.forward = functools.partial(unet.forward, return_dict=False) # set return_dict=False as default
+
+# warmup
+for _ in range(3):
+ with torch.inference_mode():
+ inputs = generate_inputs()
+ orig_output = unet(*inputs)
+
+# trace
+print("tracing..")
+unet_traced = torch.jit.trace(unet, inputs)
+unet_traced.eval()
+print("done tracing")
+
+
+# warmup and optimize graph
+for _ in range(5):
+ with torch.inference_mode():
+ inputs = generate_inputs()
+ orig_output = unet_traced(*inputs)
+
+
+# benchmarking
+with torch.inference_mode():
+ for _ in range(n_experiments):
+ torch.cuda.synchronize()
+ start_time = time.time()
+ for _ in range(unet_runs_per_experiment):
+ orig_output = unet_traced(*inputs)
+ torch.cuda.synchronize()
+ print(f"unet traced inference took {time.time() - start_time:.2f} seconds")
+ for _ in range(n_experiments):
+ torch.cuda.synchronize()
+ start_time = time.time()
+ for _ in range(unet_runs_per_experiment):
+ orig_output = unet(*inputs)
+ torch.cuda.synchronize()
+ print(f"unet inference took {time.time() - start_time:.2f} seconds")
+
+# save the model
+unet_traced.save("unet_traced.pt")
+```
+
+Then we can replace the `unet` attribute of the pipeline with the traced model like the following
+
+```python
+from diffusers import StableDiffusionPipeline
+import torch
+from dataclasses import dataclass
+
+
+@dataclass
+class UNet2DConditionOutput:
+ sample: torch.FloatTensor
+
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ torch_dtype=torch.float16,
+).to("cuda")
+
+# use jitted unet
+unet_traced = torch.jit.load("unet_traced.pt")
+
+
+# del pipe.unet
+class TracedUNet(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.in_channels = pipe.unet.in_channels
+ self.device = pipe.unet.device
+
+ def forward(self, latent_model_input, t, encoder_hidden_states):
+ sample = unet_traced(latent_model_input, t, encoder_hidden_states)[0]
+ return UNet2DConditionOutput(sample=sample)
+
+
+pipe.unet = TracedUNet()
+
+with torch.inference_mode():
+ image = pipe([prompt] * 1, num_inference_steps=50).images[0]
+```
+
+
+## Memory Efficient Attention
+
+Recent work on optimizing the bandwitdh in the attention block has generated huge speed ups and gains in GPU memory usage. The most recent being Flash Attention from @tridao: [code](https://github.com/HazyResearch/flash-attention), [paper](https://arxiv.org/pdf/2205.14135.pdf).
+
+Here are the speedups we obtain on a few Nvidia GPUs when running the inference at 512x512 with a batch size of 1 (one prompt):
+
+| GPU | Base Attention FP16 | Memory Efficient Attention FP16 |
+|------------------ |--------------------- |--------------------------------- |
+| NVIDIA Tesla T4 | 3.5it/s | 5.5it/s |
+| NVIDIA 3060 RTX | 4.6it/s | 7.8it/s |
+| NVIDIA A10G | 8.88it/s | 15.6it/s |
+| NVIDIA RTX A6000 | 11.7it/s | 21.09it/s |
+| NVIDIA TITAN RTX | 12.51it/s | 18.22it/s |
+| A100-SXM4-40GB | 18.6it/s | 29.it/s |
+| A100-SXM-80GB | 18.7it/s | 29.5it/s |
+
+To leverage it just make sure you have:
+ - PyTorch > 1.12
+ - Cuda available
+ - [Installed the xformers library](xformers).
+```python
+from diffusers import DiffusionPipeline
+import torch
+
+pipe = DiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ torch_dtype=torch.float16,
+).to("cuda")
+
+pipe.enable_xformers_memory_efficient_attention()
+
+with torch.inference_mode():
+ sample = pipe("a small cat")
+
+# optional: You can disable it via
+# pipe.disable_xformers_memory_efficient_attention()
+```
diff --git a/diffusers/docs/source/en/optimization/habana.mdx b/diffusers/docs/source/en/optimization/habana.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..a5f476b0cef2ad8ddb457ef1dc4b10a9da072a59
--- /dev/null
+++ b/diffusers/docs/source/en/optimization/habana.mdx
@@ -0,0 +1,70 @@
+
+
+# How to use Stable Diffusion on Habana Gaudi
+
+🤗 Diffusers is compatible with Habana Gaudi through 🤗 [Optimum Habana](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion).
+
+## Requirements
+
+- Optimum Habana 1.4 or later, [here](https://huggingface.co/docs/optimum/habana/installation) is how to install it.
+- SynapseAI 1.8.
+
+
+## Inference Pipeline
+
+To generate images with Stable Diffusion 1 and 2 on Gaudi, you need to instantiate two instances:
+- A pipeline with [`GaudiStableDiffusionPipeline`](https://huggingface.co/docs/optimum/habana/package_reference/stable_diffusion_pipeline). This pipeline supports *text-to-image generation*.
+- A scheduler with [`GaudiDDIMScheduler`](https://huggingface.co/docs/optimum/habana/package_reference/stable_diffusion_pipeline#optimum.habana.diffusers.GaudiDDIMScheduler). This scheduler has been optimized for Habana Gaudi.
+
+When initializing the pipeline, you have to specify `use_habana=True` to deploy it on HPUs.
+Furthermore, in order to get the fastest possible generations you should enable **HPU graphs** with `use_hpu_graphs=True`.
+Finally, you will need to specify a [Gaudi configuration](https://huggingface.co/docs/optimum/habana/package_reference/gaudi_config) which can be downloaded from the [Hugging Face Hub](https://huggingface.co/Habana).
+
+```python
+from optimum.habana import GaudiConfig
+from optimum.habana.diffusers import GaudiDDIMScheduler, GaudiStableDiffusionPipeline
+
+model_name = "stabilityai/stable-diffusion-2-base"
+scheduler = GaudiDDIMScheduler.from_pretrained(model_name, subfolder="scheduler")
+pipeline = GaudiStableDiffusionPipeline.from_pretrained(
+ model_name,
+ scheduler=scheduler,
+ use_habana=True,
+ use_hpu_graphs=True,
+ gaudi_config="Habana/stable-diffusion",
+)
+```
+
+You can then call the pipeline to generate images by batches from one or several prompts:
+```python
+outputs = pipeline(
+ prompt=[
+ "High quality photo of an astronaut riding a horse in space",
+ "Face of a yellow cat, high resolution, sitting on a park bench",
+ ],
+ num_images_per_prompt=10,
+ batch_size=4,
+)
+```
+
+For more information, check out Optimum Habana's [documentation](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion) and the [example](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) provided in the official Github repository.
+
+
+## Benchmark
+
+Here are the latencies for Habana first-generation Gaudi and Gaudi2 with the [Habana/stable-diffusion](https://huggingface.co/Habana/stable-diffusion) Gaudi configuration (mixed precision bf16/fp32):
+
+| | Latency (batch size = 1) | Throughput (batch size = 8) |
+| ---------------------- |:------------------------:|:---------------------------:|
+| first-generation Gaudi | 4.29s | 0.283 images/s |
+| Gaudi2 | 1.54s | 0.904 images/s |
diff --git a/diffusers/docs/source/en/optimization/mps.mdx b/diffusers/docs/source/en/optimization/mps.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..3be8c621ee3e27b019f8cbe87d5718aebd310f19
--- /dev/null
+++ b/diffusers/docs/source/en/optimization/mps.mdx
@@ -0,0 +1,67 @@
+
+
+# How to use Stable Diffusion in Apple Silicon (M1/M2)
+
+🤗 Diffusers is compatible with Apple silicon for Stable Diffusion inference, using the PyTorch `mps` device. These are the steps you need to follow to use your M1 or M2 computer with Stable Diffusion.
+
+## Requirements
+
+- Mac computer with Apple silicon (M1/M2) hardware.
+- macOS 12.6 or later (13.0 or later recommended).
+- arm64 version of Python.
+- PyTorch 2.0 (recommended) or 1.13 (minimum version supported for `mps`). You can install it with `pip` or `conda` using the instructions in https://pytorch.org/get-started/locally/.
+
+
+## Inference Pipeline
+
+The snippet below demonstrates how to use the `mps` backend using the familiar `to()` interface to move the Stable Diffusion pipeline to your M1 or M2 device.
+
+
+
+**If you are using PyTorch 1.13** you need to "prime" the pipeline using an additional one-time pass through it. This is a temporary workaround for a weird issue we detected: the first inference pass produces slightly different results than subsequent ones. You only need to do this pass once, and it's ok to use just one inference step and discard the result.
+
+
+
+We strongly recommend you use PyTorch 2 or better, as it solves a number of problems like the one described in the previous tip.
+
+```python
+from diffusers import DiffusionPipeline
+
+pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+pipe = pipe.to("mps")
+
+# Recommended if your computer has < 64 GB of RAM
+pipe.enable_attention_slicing()
+
+prompt = "a photo of an astronaut riding a horse on mars"
+
+# First-time "warmup" pass if PyTorch version is 1.13 (see explanation above)
+_ = pipe(prompt, num_inference_steps=1)
+
+# Results match those from the CPU device after the warmup pass.
+image = pipe(prompt).images[0]
+```
+
+## Performance Recommendations
+
+M1/M2 performance is very sensitive to memory pressure. The system will automatically swap if it needs to, but performance will degrade significantly when it does.
+
+We recommend you use _attention slicing_ to reduce memory pressure during inference and prevent swapping, particularly if your computer has less than 64 GB of system RAM, or if you generate images at non-standard resolutions larger than 512 × 512 pixels. Attention slicing performs the costly attention operation in multiple steps instead of all at once. It usually has a performance impact of ~20% in computers without universal memory, but we have observed _better performance_ in most Apple Silicon computers, unless you have 64 GB or more.
+
+```python
+pipeline.enable_attention_slicing()
+```
+
+## Known Issues
+
+- Generating multiple prompts in a batch [crashes or doesn't work reliably](https://github.com/huggingface/diffusers/issues/363). We believe this is related to the [`mps` backend in PyTorch](https://github.com/pytorch/pytorch/issues/84039). This is being resolved, but for now we recommend to iterate instead of batching.
diff --git a/diffusers/docs/source/en/optimization/onnx.mdx b/diffusers/docs/source/en/optimization/onnx.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6f96ba0cc1941ba0709d3ee672fa09725ff459a2
--- /dev/null
+++ b/diffusers/docs/source/en/optimization/onnx.mdx
@@ -0,0 +1,65 @@
+
+
+
+# How to use the ONNX Runtime for inference
+
+🤗 [Optimum](https://github.com/huggingface/optimum) provides a Stable Diffusion pipeline compatible with ONNX Runtime.
+
+## Installation
+
+Install 🤗 Optimum with the following command for ONNX Runtime support:
+
+```
+pip install optimum["onnxruntime"]
+```
+
+## Stable Diffusion Inference
+
+To load an ONNX model and run inference with the ONNX Runtime, you need to replace [`StableDiffusionPipeline`] with `ORTStableDiffusionPipeline`. In case you want to load
+a PyTorch model and convert it to the ONNX format on-the-fly, you can set `export=True`.
+
+```python
+from optimum.onnxruntime import ORTStableDiffusionPipeline
+
+model_id = "runwayml/stable-diffusion-v1-5"
+pipe = ORTStableDiffusionPipeline.from_pretrained(model_id, export=True)
+prompt = "a photo of an astronaut riding a horse on mars"
+images = pipe(prompt).images[0]
+pipe.save_pretrained("./onnx-stable-diffusion-v1-5")
+```
+
+If you want to export the pipeline in the ONNX format offline and later use it for inference,
+you can use the [`optimum-cli export`](https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) command:
+
+```bash
+optimum-cli export onnx --model runwayml/stable-diffusion-v1-5 sd_v15_onnx/
+```
+
+Then perform inference:
+
+```python
+from optimum.onnxruntime import ORTStableDiffusionPipeline
+
+model_id = "sd_v15_onnx"
+pipe = ORTStableDiffusionPipeline.from_pretrained(model_id)
+prompt = "a photo of an astronaut riding a horse on mars"
+images = pipe(prompt).images[0]
+```
+
+Notice that we didn't have to specify `export=True` above.
+
+You can find more examples in [optimum documentation](https://huggingface.co/docs/optimum/).
+
+## Known Issues
+
+- Generating multiple prompts in a batch seems to take too much memory. While we look into it, you may need to iterate instead of batching.
diff --git a/diffusers/docs/source/en/optimization/open_vino.mdx b/diffusers/docs/source/en/optimization/open_vino.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..5366e86b4a54d110805df5aa5b400662f4b4bfaa
--- /dev/null
+++ b/diffusers/docs/source/en/optimization/open_vino.mdx
@@ -0,0 +1,39 @@
+
+
+
+# How to use OpenVINO for inference
+
+🤗 [Optimum](https://github.com/huggingface/optimum-intel) provides a Stable Diffusion pipeline compatible with OpenVINO. You can now easily perform inference with OpenVINO Runtime on a variety of Intel processors ([see](https://docs.openvino.ai/latest/openvino_docs_OV_UG_supported_plugins_Supported_Devices.html) the full list of supported devices).
+
+## Installation
+
+Install 🤗 Optimum Intel with the following command:
+
+```
+pip install optimum["openvino"]
+```
+
+## Stable Diffusion Inference
+
+To load an OpenVINO model and run inference with OpenVINO Runtime, you need to replace `StableDiffusionPipeline` with `OVStableDiffusionPipeline`. In case you want to load a PyTorch model and convert it to the OpenVINO format on-the-fly, you can set `export=True`.
+
+```python
+from optimum.intel.openvino import OVStableDiffusionPipeline
+
+model_id = "runwayml/stable-diffusion-v1-5"
+pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
+prompt = "a photo of an astronaut riding a horse on mars"
+images = pipe(prompt).images[0]
+```
+
+You can find more examples (such as static reshaping and model compilation) in [optimum documentation](https://huggingface.co/docs/optimum/intel/inference#export-and-inference-of-stable-diffusion-models).
diff --git a/diffusers/docs/source/en/optimization/opt_overview.mdx b/diffusers/docs/source/en/optimization/opt_overview.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..8d8386f85f43df2d22c00a9b54df5de59e07fe01
--- /dev/null
+++ b/diffusers/docs/source/en/optimization/opt_overview.mdx
@@ -0,0 +1,17 @@
+
+
+# Overview
+
+Generating high-quality outputs is computationally intensive, especially during each iterative step where you go from a noisy output to a less noisy output. One of 🧨 Diffuser's goal is to make this technology widely accessible to everyone, which includes enabling fast inference on consumer and specialized hardware.
+
+This section will cover tips and tricks - like half-precision weights and sliced attention - for optimizing inference speed and reducing memory-consumption. You can also learn how to speed up your PyTorch code with [`torch.compile`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) or [ONNX Runtime](https://onnxruntime.ai/docs/), and enable memory-efficient attention with [xFormers](https://facebookresearch.github.io/xformers/). There are also guides for running inference on specific hardware like Apple Silicon, and Intel or Habana processors.
\ No newline at end of file
diff --git a/diffusers/docs/source/en/optimization/torch2.0.mdx b/diffusers/docs/source/en/optimization/torch2.0.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..206ac4e447ccae0dbed2c269587be3c98e5829f1
--- /dev/null
+++ b/diffusers/docs/source/en/optimization/torch2.0.mdx
@@ -0,0 +1,210 @@
+
+
+# Accelerated PyTorch 2.0 support in Diffusers
+
+Starting from version `0.13.0`, Diffusers supports the latest optimization from the upcoming [PyTorch 2.0](https://pytorch.org/get-started/pytorch-2.0/) release. These include:
+1. Support for accelerated transformers implementation with memory-efficient attention – no extra dependencies required.
+2. [torch.compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) support for extra performance boost when individual models are compiled.
+
+
+## Installation
+To benefit from the accelerated attention implementation and `torch.compile`, you just need to install the latest versions of PyTorch 2.0 from `pip`, and make sure you are on diffusers 0.13.0 or later. As explained below, `diffusers` automatically uses the attention optimizations (but not `torch.compile`) when available.
+
+```bash
+pip install --upgrade torch torchvision diffusers
+```
+
+## Using accelerated transformers and torch.compile.
+
+
+1. **Accelerated Transformers implementation**
+
+ PyTorch 2.0 includes an optimized and memory-efficient attention implementation through the [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) function, which automatically enables several optimizations depending on the inputs and the GPU type. This is similar to the `memory_efficient_attention` from [xFormers](https://github.com/facebookresearch/xformers), but built natively into PyTorch.
+
+ These optimizations will be enabled by default in Diffusers if PyTorch 2.0 is installed and if `torch.nn.functional.scaled_dot_product_attention` is available. To use it, just install `torch 2.0` as suggested above and simply use the pipeline. For example:
+
+ ```Python
+ import torch
+ from diffusers import DiffusionPipeline
+
+ pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
+ pipe = pipe.to("cuda")
+
+ prompt = "a photo of an astronaut riding a horse on mars"
+ image = pipe(prompt).images[0]
+ ```
+
+ If you want to enable it explicitly (which is not required), you can do so as shown below.
+
+ ```Python
+ import torch
+ from diffusers import DiffusionPipeline
+ from diffusers.models.attention_processor import AttnProcessor2_0
+
+ pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
+ pipe.unet.set_attn_processor(AttnProcessor2_0())
+
+ prompt = "a photo of an astronaut riding a horse on mars"
+ image = pipe(prompt).images[0]
+ ```
+
+ This should be as fast and memory efficient as `xFormers`. More details [in our benchmark](#benchmark).
+
+
+2. **torch.compile**
+
+ To get an additional speedup, we can use the new `torch.compile` feature. To do so, we simply wrap our `unet` with `torch.compile`. For more information and different options, refer to the
+ [torch compile docs](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html).
+
+ ```python
+ import torch
+ from diffusers import DiffusionPipeline
+
+ pipe = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
+ pipe.unet = torch.compile(pipe.unet)
+
+ batch_size = 10
+ prompt = "A photo of an astronaut riding a horse on marse."
+ images = pipe(prompt, num_inference_steps=steps, num_images_per_prompt=batch_size).images
+ ```
+
+ Depending on the type of GPU, `compile()` can yield between 2-9% of _additional speed-up_ over the accelerated transformer optimizations. Note, however, that compilation is able to squeeze more performance improvements in more recent GPU architectures such as Ampere (A100, 3090), Ada (4090) and Hopper (H100).
+
+ Compilation takes some time to complete, so it is best suited for situations where you need to prepare your pipeline once and then perform the same type of inference operations multiple times.
+
+
+## Benchmark
+
+We conducted a simple benchmark on different GPUs to compare vanilla attention, xFormers, `torch.nn.functional.scaled_dot_product_attention` and `torch.compile+torch.nn.functional.scaled_dot_product_attention`.
+For the benchmark we used the [stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4) model with 50 steps. The `xFormers` benchmark is done using the `torch==1.13.1` version, while the accelerated transformers optimizations are tested using nightly versions of PyTorch 2.0. The tables below summarize the results we got.
+
+Please refer to [our featured blog post in the PyTorch site](https://pytorch.org/blog/accelerated-diffusers-pt-20/) for more details.
+
+### FP16 benchmark
+
+The table below shows the benchmark results for inference using `fp16`. As we can see, `torch.nn.functional.scaled_dot_product_attention` is as fast as `xFormers` (sometimes slightly faster/slower) on all the GPUs we tested.
+And using `torch.compile` gives further speed-up of up of 10% over `xFormers`, but it's mostly noticeable on the A100 GPU.
+
+___The time reported is in seconds.___
+
+| GPU | Batch Size | Vanilla Attention | xFormers | PyTorch2.0 SDPA | SDPA + torch.compile | Speed over xformers (%) |
+| --- | --- | --- | --- | --- | --- | --- |
+| A100 | 1 | 2.69 | 2.7 | 1.98 | 2.47 | 8.52 |
+| A100 | 2 | 3.21 | 3.04 | 2.38 | 2.78 | 8.55 |
+| A100 | 4 | 5.27 | 3.91 | 3.89 | 3.53 | 9.72 |
+| A100 | 8 | 9.74 | 7.03 | 7.04 | 6.62 | 5.83 |
+| A100 | 10 | 12.02 | 8.7 | 8.67 | 8.45 | 2.87 |
+| A100 | 16 | 18.95 | 13.57 | 13.55 | 13.20 | 2.73 |
+| A100 | 32 (1) | OOM | 26.56 | 26.68 | 25.85 | 2.67 |
+| A100 | 64 | | 52.51 | 53.03 | 50.93 | 3.01 |
+| | | | | | | |
+| A10 | 4 | 13.94 | 9.81 | 10.01 | 9.35 | 4.69 |
+| A10 | 8 | 27.09 | 19 | 19.53 | 18.33 | 3.53 |
+| A10 | 10 | 33.69 | 23.53 | 24.19 | 22.52 | 4.29 |
+| A10 | 16 | OOM | 37.55 | 38.31 | 36.81 | 1.97 |
+| A10 | 32 (1) | | 77.19 | 78.43 | 76.64 | 0.71 |
+| A10 | 64 (1) | | 173.59 | 158.99 | 155.14 | 10.63 |
+| | | | | | | |
+| T4 | 4 | 38.81 | 30.09 | 29.74 | 27.55 | 8.44 |
+| T4 | 8 | OOM | 55.71 | 55.99 | 53.85 | 3.34 |
+| T4 | 10 | OOM | 68.96 | 69.86 | 65.35 | 5.23 |
+| T4 | 16 | OOM | 111.47 | 113.26 | 106.93 | 4.07 |
+| | | | | | | |
+| V100 | 4 | 9.84 | 8.16 | 8.09 | 7.65 | 6.25 |
+| V100 | 8 | OOM | 15.62 | 15.44 | 14.59 | 6.59 |
+| V100 | 10 | OOM | 19.52 | 19.28 | 18.18 | 6.86 |
+| V100 | 16 | OOM | 30.29 | 29.84 | 28.22 | 6.83 |
+| | | | | | | |
+| 3090 | 1 | 2.94 | 2.5 | 2.42 | 2.33 | 6.80 |
+| 3090 | 4 | 10.04 | 7.82 | 7.72 | 7.38 | 5.63 |
+| 3090 | 8 | 19.27 | 14.97 | 14.88 | 14.15 | 5.48 |
+| 3090 | 10| 24.08 | 18.7 | 18.62 | 18.12 | 3.10 |
+| 3090 | 16 | OOM | 29.06 | 28.88 | 28.2 | 2.96 |
+| 3090 | 32 (1) | | 58.05 | 57.42 | 56.28 | 3.05 |
+| 3090 | 64 (1) | | 126.54 | 114.27 | 112.21 | 11.32 |
+| | | | | | | |
+| 3090 Ti | 1 | 2.7 | 2.26 | 2.19 | 2.12 | 6.19 |
+| 3090 Ti | 4 | 9.07 | 7.14 | 7.00 | 6.71 | 6.02 |
+| 3090 Ti | 8 | 17.51 | 13.65 | 13.53 | 12.94 | 5.20 |
+| 3090 Ti | 10 (2) | 21.79 | 16.85 | 16.77 | 16.44 | 2.43 |
+| 3090 Ti | 16 | OOM | 26.1 | 26.04 | 25.53 | 2.18 |
+| 3090 Ti | 32 (1) | | 51.78 | 51.71 | 50.91 | 1.68 |
+| 3090 Ti | 64 (1) | | 112.02 | 102.78 | 100.89 | 9.94 |
+| | | | | | | |
+| 4090 | 1 | 4.47 | 3.98 | 1.28 | 1.21 | 69.60 |
+| 4090 | 4 | 10.48 | 8.37 | 3.76 | 3.56 | 57.47 |
+| 4090 | 8 | 14.33 | 10.22 | 7.43 | 6.99 | 31.60 |
+| 4090 | 16 | | 17.07 | 14.98 | 14.58 | 14.59 |
+| 4090 | 32 (1) | | 39.03 | 30.18 | 29.49 | 24.44 |
+| 4090 | 64 (1) | | 77.29 | 61.34 | 59.96 | 22.42 |
+
+
+
+### FP32 benchmark
+
+The table below shows the benchmark results for inference using `fp32`. In this case, `torch.nn.functional.scaled_dot_product_attention` is faster than `xFormers` on all the GPUs we tested.
+
+Using `torch.compile` in addition to the accelerated transformers implementation can yield up to 19% performance improvement over `xFormers` in Ampere and Ada cards, and up to 20% (Ampere) or 28% (Ada) over vanilla attention.
+
+| GPU | Batch Size | Vanilla Attention | xFormers | PyTorch2.0 SDPA | SDPA + torch.compile | Speed over xformers (%) | Speed over vanilla (%) |
+| --- | --- | --- | --- | --- | --- | --- | --- |
+| A100 | 1 | 4.97 | 3.86 | 2.6 | 2.86 | 25.91 | 42.45 |
+| A100 | 2 | 9.03 | 6.76 | 4.41 | 4.21 | 37.72 | 53.38 |
+| A100 | 4 | 16.70 | 12.42 | 7.94 | 7.54 | 39.29 | 54.85 |
+| A100 | 10 | OOM | 29.93 | 18.70 | 18.46 | 38.32 | |
+| A100 | 16 | | 47.08 | 29.41 | 29.04 | 38.32 | |
+| A100 | 32 | | 92.89 | 57.55 | 56.67 | 38.99 | |
+| A100 | 64 | | 185.3 | 114.8 | 112.98 | 39.03 | |
+| | | | | | | |
+| A10 | 1 | 10.59 | 8.81 | 7.51 | 7.35 | 16.57 | 30.59 |
+| A10 | 4 | 34.77 | 27.63 | 22.77 | 22.07 | 20.12 | 36.53 |
+| A10 | 8 | | 56.19 | 43.53 | 43.86 | 21.94 | |
+| A10 | 16 | | 116.49 | 88.56 | 86.64 | 25.62 | |
+| A10 | 32 | | 221.95 | 175.74 | 168.18 | 24.23 | |
+| A10 | 48 | | 333.23 | 264.84 | | 20.52 | |
+| | | | | | | |
+| T4 | 1 | 28.2 | 24.49 | 23.93 | 23.56 | 3.80 | 16.45 |
+| T4 | 2 | 52.77 | 45.7 | 45.88 | 45.06 | 1.40 | 14.61 |
+| T4 | 4 | OOM | 85.72 | 85.78 | 84.48 | 1.45 | |
+| T4 | 8 | | 149.64 | 150.75 | 148.4 | 0.83 | |
+| | | | | | | |
+| V100 | 1 | 7.4 | 6.84 | 6.8 | 6.66 | 2.63 | 10.00 |
+| V100 | 2 | 13.85 | 12.81 | 12.66 | 12.35 | 3.59 | 10.83 |
+| V100 | 4 | OOM | 25.73 | 25.31 | 24.78 | 3.69 | |
+| V100 | 8 | | 43.95 | 43.37 | 42.25 | 3.87 | |
+| V100 | 16 | | 84.99 | 84.73 | 82.55 | 2.87 | |
+| | | | | | | |
+| 3090 | 1 | 7.09 | 6.78 | 5.34 | 5.35 | 21.09 | 24.54 |
+| 3090 | 4 | 22.69 | 21.45 | 18.56 | 18.18 | 15.24 | 19.88 |
+| 3090 | 8 | | 42.59 | 36.68 | 35.61 | 16.39 | |
+| 3090 | 16 | | 85.35 | 72.93 | 70.18 | 17.77 | |
+| 3090 | 32 (1) | | 162.05 | 143.46 | 138.67 | 14.43 | |
+| | | | | | | |
+| 3090 Ti | 1 | 6.45 | 6.19 | 4.99 | 4.89 | 21.00 | 24.19 |
+| 3090 Ti | 4 | 20.32 | 19.31 | 17.02 | 16.48 | 14.66 | 18.90 |
+| 3090 Ti | 8 | | 37.93 | 33.21 | 32.24 | 15.00 | |
+| 3090 Ti | 16 | | 75.37 | 66.63 | 64.5 | 14.42 | |
+| 3090 Ti | 32 (1) | | 142.55 | 128.89 | 124.92 | 12.37 | |
+| | | | | | | |
+| 4090 | 1 | 5.54 | 4.99 | 2.66 | 2.58 | 48.30 | 53.43 |
+| 4090 | 4 | 13.67 | 11.4 | 8.81 | 8.46 | 25.79 | 38.11 |
+| 4090 | 8 | | 19.79 | 17.55 | 16.62 | 16.02 | |
+| 4090 | 16 | | 38.62 | 35.65 | 34.07 | 11.78 | |
+| 4090 | 32 (1) | | 76.57 | 69.48 | 65.35 | 14.65 | |
+| 4090 | 48 | | 114.44 | 106.3 | | 7.11 | |
+
+
+(1) Batch Size >= 32 requires enable_vae_slicing() because of https://github.com/pytorch/pytorch/issues/81665.
+This is required for PyTorch 1.13.1, and also for PyTorch 2.0 and large batch sizes.
+
+For more details about how this benchmark was run, please refer to [this PR](https://github.com/huggingface/diffusers/pull/2303) and to [the blog post](https://pytorch.org/blog/accelerated-diffusers-pt-20/).
diff --git a/diffusers/docs/source/en/optimization/xformers.mdx b/diffusers/docs/source/en/optimization/xformers.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..ede074a59fa9e05d216a01801042a342a24ca254
--- /dev/null
+++ b/diffusers/docs/source/en/optimization/xformers.mdx
@@ -0,0 +1,35 @@
+
+
+# Installing xFormers
+
+We recommend the use of [xFormers](https://github.com/facebookresearch/xformers) for both inference and training. In our tests, the optimizations performed in the attention blocks allow for both faster speed and reduced memory consumption.
+
+Starting from version `0.0.16` of xFormers, released on January 2023, installation can be easily performed using pre-built pip wheels:
+
+```bash
+pip install xformers
+```
+
+
+
+The xFormers PIP package requires the latest version of PyTorch (1.13.1 as of xFormers 0.0.16). If you need to use a previous version of PyTorch, then we recommend you install xFormers from source using [the project instructions](https://github.com/facebookresearch/xformers#installing-xformers).
+
+
+
+After xFormers is installed, you can use `enable_xformers_memory_efficient_attention()` for faster inference and reduced memory consumption, as discussed [here](fp16#memory-efficient-attention).
+
+
+
+According to [this issue](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212), xFormers `v0.0.16` cannot be used for training (fine-tune or Dreambooth) in some GPUs. If you observe that problem, please install a development version as indicated in that comment.
+
+
diff --git a/diffusers/docs/source/en/quicktour.mdx b/diffusers/docs/source/en/quicktour.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..d494b79dccd567e8fae61b23d88743e6a5e7d019
--- /dev/null
+++ b/diffusers/docs/source/en/quicktour.mdx
@@ -0,0 +1,313 @@
+
+
+[[open-in-colab]]
+
+# Quicktour
+
+Diffusion models are trained to denoise random Gaussian noise step-by-step to generate a sample of interest, such as an image or audio. This has sparked a tremendous amount of interest in generative AI, and you have probably seen examples of diffusion generated images on the internet. 🧨 Diffusers is a library aimed at making diffusion models widely accessible to everyone.
+
+Whether you're a developer or an everyday user, this quicktour will introduce you to 🧨 Diffusers and help you get up and generating quickly! There are three main components of the library to know about:
+
+* The [`DiffusionPipeline`] is a high-level end-to-end class designed to rapidly generate samples from pretrained diffusion models for inference.
+* Popular pretrained [model](./api/models) architectures and modules that can be used as building blocks for creating diffusion systems.
+* Many different [schedulers](./api/schedulers/overview) - algorithms that control how noise is added for training, and how to generate denoised images during inference.
+
+The quicktour will show you how to use the [`DiffusionPipeline`] for inference, and then walk you through how to combine a model and scheduler to replicate what's happening inside the [`DiffusionPipeline`].
+
+
+
+The quicktour is a simplified version of the introductory 🧨 Diffusers [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) to help you get started quickly. If you want to learn more about 🧨 Diffusers goal, design philosophy, and additional details about it's core API, check out the notebook!
+
+
+
+Before you begin, make sure you have all the necessary libraries installed:
+
+```bash
+pip install --upgrade diffusers accelerate transformers
+```
+
+- [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) speeds up model loading for inference and training.
+- [🤗 Transformers](https://huggingface.co/docs/transformers/index) is required to run the most popular diffusion models, such as [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview).
+
+## DiffusionPipeline
+
+The [`DiffusionPipeline`] is the easiest way to use a pretrained diffusion system for inference. It is an end-to-end system containing the model and the scheduler. You can use the [`DiffusionPipeline`] out-of-the-box for many tasks. Take a look at the table below for some supported tasks, and for a complete list of supported tasks, check out the [🧨 Diffusers Summary](./api/pipelines/overview#diffusers-summary) table.
+
+| **Task** | **Description** | **Pipeline**
+|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|
+| Unconditional Image Generation | generate an image from Gaussian noise | [unconditional_image_generation](./using-diffusers/unconditional_image_generation) |
+| Text-Guided Image Generation | generate an image given a text prompt | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
+| Text-Guided Image-to-Image Translation | adapt an image guided by a text prompt | [img2img](./using-diffusers/img2img) |
+| Text-Guided Image-Inpainting | fill the masked part of an image given the image, the mask and a text prompt | [inpaint](./using-diffusers/inpaint) |
+| Text-Guided Depth-to-Image Translation | adapt parts of an image guided by a text prompt while preserving structure via depth estimation | [depth2img](./using-diffusers/depth2img) |
+
+Start by creating an instance of a [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
+You can use the [`DiffusionPipeline`] for any [checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads) stored on the Hugging Face Hub.
+In this quicktour, you'll load the [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) checkpoint for text-to-image generation.
+
+
+
+For [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion) models, please carefully read the [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) first before running the model. 🧨 Diffusers implements a [`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) to prevent offensive or harmful content, but the model's improved image generation capabilities can still produce potentially harmful content.
+
+
+
+Load the model with the [`~DiffusionPipeline.from_pretrained`] method:
+
+```python
+>>> from diffusers import DiffusionPipeline
+
+>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+```
+
+The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components. You'll see that the Stable Diffusion pipeline is composed of the [`UNet2DConditionModel`] and [`PNDMScheduler`] among other things:
+
+```py
+>>> pipeline
+StableDiffusionPipeline {
+ "_class_name": "StableDiffusionPipeline",
+ "_diffusers_version": "0.13.1",
+ ...,
+ "scheduler": [
+ "diffusers",
+ "PNDMScheduler"
+ ],
+ ...,
+ "unet": [
+ "diffusers",
+ "UNet2DConditionModel"
+ ],
+ "vae": [
+ "diffusers",
+ "AutoencoderKL"
+ ]
+}
+```
+
+We strongly recommend running the pipeline on a GPU because the model consists of roughly 1.4 billion parameters.
+You can move the generator object to a GPU, just like you would in PyTorch:
+
+```python
+>>> pipeline.to("cuda")
+```
+
+Now you can pass a text prompt to the `pipeline` to generate an image, and then access the denoised image. By default, the image output is wrapped in a [`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class) object.
+
+```python
+>>> image = pipeline("An image of a squirrel in Picasso style").images[0]
+>>> image
+```
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+  +
+
+
+The output is an "edited" image that reflects the edit instruction applied on the input image:
+
+
+  +
+
+
+The `train_instruct_pix2pix.py` script shows how to implement the training procedure and adapt it for Stable Diffusion.
+
+***Disclaimer: Even though `train_instruct_pix2pix.py` implements the InstructPix2Pix
+training procedure while being faithful to the [original implementation](https://github.com/timothybrooks/instruct-pix2pix) we have only tested it on a [small-scale dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples). This can impact the end results. For better results, we recommend longer training runs with a larger dataset. [Here](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) you can find a large dataset for InstructPix2Pix training.***
+
+## Running locally with PyTorch
+
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install -e .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+Or for a default accelerate configuration without answering questions about your environment
+
+```bash
+accelerate config default
+```
+
+Or if your environment doesn't support an interactive shell e.g. a notebook
+
+```python
+from accelerate.utils import write_basic_config
+
+write_basic_config()
+```
+
+### Toy example
+
+As mentioned before, we'll use a [small toy dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) for training. The dataset
+is a smaller version of the [original dataset](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) used in the InstructPix2Pix paper.
+
+Configure environment variables such as the dataset identifier and the Stable Diffusion
+checkpoint:
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export DATASET_ID="fusing/instructpix2pix-1000-samples"
+```
+
+Now, we can launch training:
+
+```bash
+accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$DATASET_ID \
+ --enable_xformers_memory_efficient_attention \
+ --resolution=256 --random_flip \
+ --train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
+ --max_train_steps=15000 \
+ --checkpointing_steps=5000 --checkpoints_total_limit=1 \
+ --learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
+ --conditioning_dropout_prob=0.05 \
+ --mixed_precision=fp16 \
+ --seed=42
+```
+
+Additionally, we support performing validation inference to monitor training progress
+with Weights and Biases. You can enable this feature with `report_to="wandb"`:
+
+```bash
+accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$DATASET_ID \
+ --enable_xformers_memory_efficient_attention \
+ --resolution=256 --random_flip \
+ --train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
+ --max_train_steps=15000 \
+ --checkpointing_steps=5000 --checkpoints_total_limit=1 \
+ --learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
+ --conditioning_dropout_prob=0.05 \
+ --mixed_precision=fp16 \
+ --val_image_url="https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png" \
+ --validation_prompt="make the mountains snowy" \
+ --seed=42 \
+ --report_to=wandb
+ ```
+
+ We recommend this type of validation as it can be useful for model debugging. Note that you need `wandb` installed to use this. You can install `wandb` by running `pip install wandb`.
+
+ [Here](https://wandb.ai/sayakpaul/instruct-pix2pix/runs/ctr3kovq), you can find an example training run that includes some validation samples and the training hyperparameters.
+
+ ***Note: In the original paper, the authors observed that even when the model is trained with an image resolution of 256x256, it generalizes well to bigger resolutions such as 512x512. This is likely because of the larger dataset they used during training.***
+
+ ## Inference
+
+ Once training is complete, we can perform inference:
+
+ ```python
+import PIL
+import requests
+import torch
+from diffusers import StableDiffusionInstructPix2PixPipeline
+
+model_id = "your_model_id" # <- replace this
+pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+generator = torch.Generator("cuda").manual_seed(0)
+
+url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/test_pix2pix_4.png"
+
+
+def download_image(url):
+ image = PIL.Image.open(requests.get(url, stream=True).raw)
+ image = PIL.ImageOps.exif_transpose(image)
+ image = image.convert("RGB")
+ return image
+
+
+image = download_image(url)
+prompt = "wipe out the lake"
+num_inference_steps = 20
+image_guidance_scale = 1.5
+guidance_scale = 10
+
+edited_image = pipe(
+ prompt,
+ image=image,
+ num_inference_steps=num_inference_steps,
+ image_guidance_scale=image_guidance_scale,
+ guidance_scale=guidance_scale,
+ generator=generator,
+).images[0]
+edited_image.save("edited_image.png")
+```
+
+An example model repo obtained using this training script can be found
+here - [sayakpaul/instruct-pix2pix](https://huggingface.co/sayakpaul/instruct-pix2pix).
+
+We encourage you to play with the following three parameters to control
+speed and quality during performance:
+
+* `num_inference_steps`
+* `image_guidance_scale`
+* `guidance_scale`
+
+Particularly, `image_guidance_scale` and `guidance_scale` can have a profound impact
+on the generated ("edited") image (see [here](https://twitter.com/RisingSayak/status/1628392199196151808?s=20) for an example).
diff --git a/diffusers/docs/source/en/training/lora.mdx b/diffusers/docs/source/en/training/lora.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..1c72fbbc8d584128fabcfd8e29226df2db86d527
--- /dev/null
+++ b/diffusers/docs/source/en/training/lora.mdx
@@ -0,0 +1,214 @@
+
+
+# Low-Rank Adaptation of Large Language Models (LoRA)
+
+[[open-in-colab]]
+
+
+
+Currently, LoRA is only supported for the attention layers of the [`UNet2DConditionalModel`].
+
+
+
+[Low-Rank Adaptation of Large Language Models (LoRA)](https://arxiv.org/abs/2106.09685) is a training method that accelerates the training of large models while consuming less memory. It adds pairs of rank-decomposition weight matrices (called **update matrices**) to existing weights, and **only** trains those newly added weights. This has a couple of advantages:
+
+- Previous pretrained weights are kept frozen so the model is not as prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
+- Rank-decomposition matrices have significantly fewer parameters than the original model, which means that trained LoRA weights are easily portable.
+- LoRA matrices are generally added to the attention layers of the original model. 🧨 Diffusers provides the [`~diffusers.loaders.UNet2DConditionLoadersMixin.load_attn_procs`] method to load the LoRA weights into a model's attention layers. You can control the extent to which the model is adapted toward new training images via a `scale` parameter.
+- The greater memory-efficiency allows you to run fine-tuning on consumer GPUs like the Tesla T4, RTX 3080 or even the RTX 2080 Ti! GPUs like the T4 are free and readily accessible in Kaggle or Google Colab notebooks.
+
+
+
+💡 LoRA is not only limited to attention layers. The authors found that amending
+the attention layers of a language model is sufficient to obtain good downstream performance with great efficiency. This is why it's common to just add the LoRA weights to the attention layers of a model. Check out the [Using LoRA for efficient Stable Diffusion fine-tuning](https://huggingface.co/blog/lora) blog for more information about how LoRA works!
+
+
+
+[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository. 🧨 Diffusers now supports finetuning with LoRA for [text-to-image generation](https://github.com/huggingface/diffusers/tree/main/examples/text_to_image#training-with-lora) and [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#training-with-low-rank-adaptation-of-large-language-models-lora). This guide will show you how to do both.
+
+If you'd like to store or share your model with the community, login to your Hugging Face account (create [one](hf.co/join) if you don't have one already):
+
+```bash
+huggingface-cli login
+```
+
+## Text-to-image
+
+Finetuning a model like Stable Diffusion, which has billions of parameters, can be slow and difficult. With LoRA, it is much easier and faster to finetune a diffusion model. It can run on hardware with as little as 11GB of GPU RAM without resorting to tricks such as 8-bit optimizers.
+
+### Training[[text-to-image-training]]
+
+Let's finetune [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) on the [Pokémon BLIP captions](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) dataset to generate your own Pokémon.
+
+To start, make sure you have the `MODEL_NAME` and `DATASET_NAME` environment variables set. The `OUTPUT_DIR` and `HUB_MODEL_ID` variables are optional and specify where to save the model to on the Hub:
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export OUTPUT_DIR="/sddata/finetune/lora/pokemon"
+export HUB_MODEL_ID="pokemon-lora"
+export DATASET_NAME="lambdalabs/pokemon-blip-captions"
+```
+
+There are some flags to be aware of before you start training:
+
+* `--push_to_hub` stores the trained LoRA embeddings on the Hub.
+* `--report_to=wandb` reports and logs the training results to your Weights & Biases dashboard (as an example, take a look at this [report](https://wandb.ai/pcuenq/text2image-fine-tune/runs/b4k1w0tn?workspace=user-pcuenq)).
+* `--learning_rate=1e-04`, you can afford to use a higher learning rate than you normally would with LoRA.
+
+Now you're ready to launch the training (you can find the full training script [here](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py)):
+
+```bash
+accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$DATASET_NAME \
+ --dataloader_num_workers=8 \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --max_train_steps=15000 \
+ --learning_rate=1e-04 \
+ --max_grad_norm=1 \
+ --lr_scheduler="cosine" --lr_warmup_steps=0 \
+ --output_dir=${OUTPUT_DIR} \
+ --push_to_hub \
+ --hub_model_id=${HUB_MODEL_ID} \
+ --report_to=wandb \
+ --checkpointing_steps=500 \
+ --validation_prompt="A pokemon with blue eyes." \
+ --seed=1337
+```
+
+### Inference[[text-to-image-inference]]
+
+Now you can use the model for inference by loading the base model in the [`StableDiffusionPipeline`] and then the [`DPMSolverMultistepScheduler`]:
+
+```py
+>>> import torch
+>>> from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
+
+>>> model_base = "runwayml/stable-diffusion-v1-5"
+
+>>> pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16)
+>>> pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+```
+
+Load the LoRA weights from your finetuned model *on top of the base model weights*, and then move the pipeline to a GPU for faster inference. When you merge the LoRA weights with the frozen pretrained model weights, you can optionally adjust how much of the weights to merge with the `scale` parameter:
+
+
+
+💡 A `scale` value of `0` is the same as not using your LoRA weights and you're only using the base model weights, and a `scale` value of `1` means you're only using the fully finetuned LoRA weights. Values between `0` and `1` interpolates between the two weights.
+
+
+
+```py
+>>> pipe.unet.load_attn_procs(model_path)
+>>> pipe.to("cuda")
+# use half the weights from the LoRA finetuned model and half the weights from the base model
+
+>>> image = pipe(
+... "A pokemon with blue eyes.", num_inference_steps=25, guidance_scale=7.5, cross_attention_kwargs={"scale": 0.5}
+... ).images[0]
+# use the weights from the fully finetuned LoRA model
+
+>>> image = pipe("A pokemon with blue eyes.", num_inference_steps=25, guidance_scale=7.5).images[0]
+>>> image.save("blue_pokemon.png")
+```
+
+## DreamBooth
+
+[DreamBooth](https://arxiv.org/abs/2208.12242) is a finetuning technique for personalizing a text-to-image model like Stable Diffusion to generate photorealistic images of a subject in different contexts, given a few images of the subject. However, DreamBooth is very sensitive to hyperparameters and it is easy to overfit. Some important hyperparameters to consider include those that affect the training time (learning rate, number of training steps), and inference time (number of steps, scheduler type).
+
+
+
+💡 Take a look at the [Training Stable Diffusion with DreamBooth using 🧨 Diffusers](https://huggingface.co/blog/dreambooth) blog for an in-depth analysis of DreamBooth experiments and recommended settings.
+
+
+
+### Training[[dreambooth-training]]
+
+Let's finetune [`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) with DreamBooth and LoRA with some 🐶 [dog images](https://drive.google.com/drive/folders/1BO_dyz-p65qhBRRMRA4TbZ8qW4rB99JZ). Download and save these images to a directory.
+
+To start, make sure you have the `MODEL_NAME` and `INSTANCE_DIR` (path to directory containing images) environment variables set. The `OUTPUT_DIR` variables is optional and specifies where to save the model to on the Hub:
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export INSTANCE_DIR="path-to-instance-images"
+export OUTPUT_DIR="path-to-save-model"
+```
+
+There are some flags to be aware of before you start training:
+
+* `--push_to_hub` stores the trained LoRA embeddings on the Hub.
+* `--report_to=wandb` reports and logs the training results to your Weights & Biases dashboard (as an example, take a look at this [report](https://wandb.ai/pcuenq/text2image-fine-tune/runs/b4k1w0tn?workspace=user-pcuenq)).
+* `--learning_rate=1e-04`, you can afford to use a higher learning rate than you normally would with LoRA.
+
+Now you're ready to launch the training (you can find the full training script [here](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py)):
+
+```bash
+accelerate launch train_dreambooth_lora.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --instance_prompt="a photo of sks dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=1 \
+ --checkpointing_steps=100 \
+ --learning_rate=1e-4 \
+ --report_to="wandb" \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=500 \
+ --validation_prompt="A photo of sks dog in a bucket" \
+ --validation_epochs=50 \
+ --seed="0" \
+ --push_to_hub
+```
+
+### Inference[[dreambooth-inference]]
+
+Now you can use the model for inference by loading the base model in the [`StableDiffusionPipeline`]:
+
+```py
+>>> import torch
+>>> from diffusers import StableDiffusionPipeline
+
+>>> model_base = "runwayml/stable-diffusion-v1-5"
+
+>>> pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16)
+```
+
+Load the LoRA weights from your finetuned DreamBooth model *on top of the base model weights*, and then move the pipeline to a GPU for faster inference. When you merge the LoRA weights with the frozen pretrained model weights, you can optionally adjust how much of the weights to merge with the `scale` parameter:
+
+
+
+💡 A `scale` value of `0` is the same as not using your LoRA weights and you're only using the base model weights, and a `scale` value of `1` means you're only using the fully finetuned LoRA weights. Values between `0` and `1` interpolates between the two weights.
+
+
+
+```py
+>>> pipe.unet.load_attn_procs(model_path)
+>>> pipe.to("cuda")
+# use half the weights from the LoRA finetuned model and half the weights from the base model
+
+>>> image = pipe(
+... "A picture of a sks dog in a bucket.",
+... num_inference_steps=25,
+... guidance_scale=7.5,
+... cross_attention_kwargs={"scale": 0.5},
+... ).images[0]
+# use the weights from the fully finetuned LoRA model
+
+>>> image = pipe("A picture of a sks dog in a bucket.", num_inference_steps=25, guidance_scale=7.5).images[0]
+>>> image.save("bucket-dog.png")
+```
\ No newline at end of file
diff --git a/diffusers/docs/source/en/training/overview.mdx b/diffusers/docs/source/en/training/overview.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..5ad3a1f06cc1cd7c4ec8b66923186f80e714790a
--- /dev/null
+++ b/diffusers/docs/source/en/training/overview.mdx
@@ -0,0 +1,76 @@
+
+
+# 🧨 Diffusers Training Examples
+
+Diffusers training examples are a collection of scripts to demonstrate how to effectively use the `diffusers` library
+for a variety of use cases.
+
+**Note**: If you are looking for **official** examples on how to use `diffusers` for inference,
+please have a look at [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)
+
+Our examples aspire to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
+More specifically, this means:
+
+- **Self-contained**: An example script shall only depend on "pip-install-able" Python packages that can be found in a `requirements.txt` file. Example scripts shall **not** depend on any local files. This means that one can simply download an example script, *e.g.* [train_unconditional.py](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py), install the required dependencies, *e.g.* [requirements.txt](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/requirements.txt) and execute the example script.
+- **Easy-to-tweak**: While we strive to present as many use cases as possible, the example scripts are just that - examples. It is expected that they won't work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs. To help you with that, most of the examples fully expose the preprocessing of the data and the training loop to allow you to tweak and edit them as required.
+- **Beginner-friendly**: We do not aim for providing state-of-the-art training scripts for the newest models, but rather examples that can be used as a way to better understand diffusion models and how to use them with the `diffusers` library. We often purposefully leave out certain state-of-the-art methods if we consider them too complex for beginners.
+- **One-purpose-only**: Examples should show one task and one task only. Even if a task is from a modeling
+point of view very similar, *e.g.* image super-resolution and image modification tend to use the same model and training method, we want examples to showcase only one task to keep them as readable and easy-to-understand as possible.
+
+We provide **official** examples that cover the most popular tasks of diffusion models.
+*Official* examples are **actively** maintained by the `diffusers` maintainers and we try to rigorously follow our example philosophy as defined above.
+If you feel like another important example should exist, we are more than happy to welcome a [Feature Request](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=) or directly a [Pull Request](https://github.com/huggingface/diffusers/compare) from you!
+
+Training examples show how to pretrain or fine-tune diffusion models for a variety of tasks. Currently we support:
+
+- [Unconditional Training](./unconditional_training)
+- [Text-to-Image Training](./text2image)
+- [Text Inversion](./text_inversion)
+- [Dreambooth](./dreambooth)
+- [LoRA Support](./lora)
+- [ControlNet](./controlnet)
+
+If possible, please [install xFormers](../optimization/xformers) for memory efficient attention. This could help make your training faster and less memory intensive.
+
+| Task | 🤗 Accelerate | 🤗 Datasets | Colab
+|---|---|:---:|:---:|
+| [**Unconditional Image Generation**](./unconditional_training) | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
+| [**Text-to-Image fine-tuning**](./text2image) | ✅ | ✅ |
+| [**Textual Inversion**](./text_inversion) | ✅ | - | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
+| [**Dreambooth**](./dreambooth) | ✅ | - | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb)
+| [**Training with LoRA**](./lora) | ✅ | - | - |
+| [**ControlNet**](./controlnet) | ✅ | ✅ | - |
+
+## Community
+
+In addition, we provide **community** examples, which are examples added and maintained by our community.
+Community examples can consist of both *training* examples or *inference* pipelines.
+For such examples, we are more lenient regarding the philosophy defined above and also cannot guarantee to provide maintenance for every issue.
+Examples that are useful for the community, but are either not yet deemed popular or not yet following our above philosophy should go into the [community examples](https://github.com/huggingface/diffusers/tree/main/examples/community) folder. The community folder therefore includes training examples and inference pipelines.
+**Note**: Community examples can be a [great first contribution](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) to show to the community how you like to use `diffusers` 🪄.
+
+## Important note
+
+To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install .
+```
+
+Then cd in the example folder of your choice and run
+
+```bash
+pip install -r requirements.txt
+```
diff --git a/diffusers/docs/source/en/training/text2image.mdx b/diffusers/docs/source/en/training/text2image.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..851be61bcf973d46d7a57bd6efd39802899ab46b
--- /dev/null
+++ b/diffusers/docs/source/en/training/text2image.mdx
@@ -0,0 +1,208 @@
+
+
+
+# Text-to-image
+
+
+
+The text-to-image fine-tuning script is experimental. It's easy to overfit and run into issues like catastrophic forgetting. We recommend you explore different hyperparameters to get the best results on your dataset.
+
+
+
+Text-to-image models like Stable Diffusion generate an image from a text prompt. This guide will show you how to finetune the [`CompVis/stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) model on your own dataset with PyTorch and Flax. All the training scripts for text-to-image finetuning used in this guide can be found in this [repository](https://github.com/huggingface/diffusers/tree/main/examples/text_to_image) if you're interested in taking a closer look.
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+```bash
+pip install git+https://github.com/huggingface/diffusers.git
+pip install -U -r requirements.txt
+```
+
+And initialize an [🤗 Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+If you have already cloned the repo, then you won't need to go through these steps. Instead, you can pass the path to your local checkout to the training script and it will be loaded from there.
+
+## Hardware requirements
+
+Using `gradient_checkpointing` and `mixed_precision`, it should be possible to finetune the model on a single 24GB GPU. For higher `batch_size`'s and faster training, it's better to use GPUs with more than 30GB of GPU memory. You can also use JAX/Flax for fine-tuning on TPUs or GPUs, which will be covered [below](#flax-jax-finetuning).
+
+You can reduce your memory footprint even more by enabling memory efficient attention with xFormers. Make sure you have [xFormers installed](./optimization/xformers) and pass the `--enable_xformers_memory_efficient_attention` flag to the training script.
+
+xFormers is not available for Flax.
+
+## Upload model to Hub
+
+Store your model on the Hub by adding the following argument to the training script:
+
+```bash
+ --push_to_hub
+```
+
+## Save and load checkpoints
+
+It is a good idea to regularly save checkpoints in case anything happens during training. To save a checkpoint, pass the following argument to the training script:
+
+```bash
+ --checkpointing_steps=500
+```
+
+Every 500 steps, the full training state is saved in a subfolder in the `output_dir`. The checkpoint has the format `checkpoint-` followed by the number of steps trained so far. For example, `checkpoint-1500` is a checkpoint saved after 1500 training steps.
+
+To load a checkpoint to resume training, pass the argument `--resume_from_checkpoint` to the training script and specify the checkpoint you want to resume from. For example, the following argument resumes training from the checkpoint saved after 1500 training steps:
+
+```bash
+ --resume_from_checkpoint="checkpoint-1500"
+```
+
+## Fine-tuning
+
+
+
+Launch the [PyTorch training script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py) for a fine-tuning run on the [Pokémon BLIP captions](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions) dataset like this:
+
+
+{"path": "../../../../examples/text_to_image/README.md",
+"language": "bash",
+"start-after": "accelerate_snippet_start",
+"end-before": "accelerate_snippet_end",
+"dedent": 0}
+
+
+To finetune on your own dataset, prepare the dataset according to the format required by 🤗 [Datasets](https://huggingface.co/docs/datasets/index). You can [upload your dataset to the Hub](https://huggingface.co/docs/datasets/image_dataset#upload-dataset-to-the-hub), or you can [prepare a local folder with your files](https://huggingface.co/docs/datasets/image_dataset#imagefolder).
+
+Modify the script if you want to use custom loading logic. We left pointers in the code in the appropriate places to help you. 🤗 The example script below shows how to finetune on a local dataset in `TRAIN_DIR` and where to save the model to in `OUTPUT_DIR`:
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export TRAIN_DIR="path_to_your_dataset"
+export OUTPUT_DIR="path_to_save_model"
+
+accelerate launch train_text_to_image.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$TRAIN_DIR \
+ --use_ema \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --gradient_checkpointing \
+ --mixed_precision="fp16" \
+ --max_train_steps=15000 \
+ --learning_rate=1e-05 \
+ --max_grad_norm=1 \
+ --lr_scheduler="constant" --lr_warmup_steps=0 \
+ --output_dir=${OUTPUT_DIR}
+```
+
+
+With Flax, it's possible to train a Stable Diffusion model faster on TPUs and GPUs thanks to [@duongna211](https://github.com/duongna21). This is very efficient on TPU hardware but works great on GPUs too. The Flax training script doesn't support features like gradient checkpointing or gradient accumulation yet, so you'll need a GPU with at least 30GB of memory or a TPU v3.
+
+Before running the script, make sure you have the requirements installed:
+
+```bash
+pip install -U -r requirements_flax.txt
+```
+
+Now you can launch the [Flax training script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_flax.py) like this:
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export dataset_name="lambdalabs/pokemon-blip-captions"
+
+python train_text_to_image_flax.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$dataset_name \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --max_train_steps=15000 \
+ --learning_rate=1e-05 \
+ --max_grad_norm=1 \
+ --output_dir="sd-pokemon-model"
+```
+
+To finetune on your own dataset, prepare the dataset according to the format required by 🤗 [Datasets](https://huggingface.co/docs/datasets/index). You can [upload your dataset to the Hub](https://huggingface.co/docs/datasets/image_dataset#upload-dataset-to-the-hub), or you can [prepare a local folder with your files](https://huggingface.co/docs/datasets/image_dataset#imagefolder).
+
+Modify the script if you want to use custom loading logic. We left pointers in the code in the appropriate places to help you. 🤗 The example script below shows how to finetune on a local dataset in `TRAIN_DIR`:
+
+```bash
+export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
+export TRAIN_DIR="path_to_your_dataset"
+
+python train_text_to_image_flax.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$TRAIN_DIR \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --mixed_precision="fp16" \
+ --max_train_steps=15000 \
+ --learning_rate=1e-05 \
+ --max_grad_norm=1 \
+ --output_dir="sd-pokemon-model"
+```
+
+
+
+## LoRA
+
+You can also use Low-Rank Adaptation of Large Language Models (LoRA), a fine-tuning technique for accelerating training large models, for fine-tuning text-to-image models. For more details, take a look at the [LoRA training](lora#text-to-image) guide.
+
+## Inference
+
+Now you can load the fine-tuned model for inference by passing the model path or model name on the Hub to the [`StableDiffusionPipeline`]:
+
+
+
+```python
+from diffusers import StableDiffusionPipeline
+
+model_path = "path_to_saved_model"
+pipe = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
+pipe.to("cuda")
+
+image = pipe(prompt="yoda").images[0]
+image.save("yoda-pokemon.png")
+```
+
+
+```python
+import jax
+import numpy as np
+from flax.jax_utils import replicate
+from flax.training.common_utils import shard
+from diffusers import FlaxStableDiffusionPipeline
+
+model_path = "path_to_saved_model"
+pipe, params = FlaxStableDiffusionPipeline.from_pretrained(model_path, dtype=jax.numpy.bfloat16)
+
+prompt = "yoda pokemon"
+prng_seed = jax.random.PRNGKey(0)
+num_inference_steps = 50
+
+num_samples = jax.device_count()
+prompt = num_samples * [prompt]
+prompt_ids = pipeline.prepare_inputs(prompt)
+
+# shard inputs and rng
+params = replicate(params)
+prng_seed = jax.random.split(prng_seed, jax.device_count())
+prompt_ids = shard(prompt_ids)
+
+images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
+images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
+image.save("yoda-pokemon.png")
+```
+
+
diff --git a/diffusers/docs/source/en/training/text_inversion.mdx b/diffusers/docs/source/en/training/text_inversion.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..68c613849301934579d5b2353b7ec902e6cad76f
--- /dev/null
+++ b/diffusers/docs/source/en/training/text_inversion.mdx
@@ -0,0 +1,215 @@
+
+
+
+
+# Textual Inversion
+
+[[open-in-colab]]
+
+[Textual Inversion](https://arxiv.org/abs/2208.01618) is a technique for capturing novel concepts from a small number of example images. While the technique was originally demonstrated with a [latent diffusion model](https://github.com/CompVis/latent-diffusion), it has since been applied to other model variants like [Stable Diffusion](https://huggingface.co/docs/diffusers/main/en/conceptual/stable_diffusion). The learned concepts can be used to better control the images generated from text-to-image pipelines. It learns new "words" in the text encoder's embedding space, which are used within text prompts for personalized image generation.
+
+
+By using just 3-5 images you can teach new concepts to a model such as Stable Diffusion for personalized image generation (image source).
+
+This guide will show you how to train a [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) model with Textual Inversion. All the training scripts for Textual Inversion used in this guide can be found [here](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion) if you're interested in taking a closer look at how things work under the hood.
+
+
+
+There is a community-created collection of trained Textual Inversion models in the [Stable Diffusion Textual Inversion Concepts Library](https://huggingface.co/sd-concepts-library) which are readily available for inference. Over time, this'll hopefully grow into a useful resource as more concepts are added!
+
+
+
+Before you begin, make sure you install the library's training dependencies:
+
+```bash
+pip install diffusers accelerate transformers
+```
+
+After all the dependencies have been set up, initialize a [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+To setup a default 🤗 Accelerate environment without choosing any configurations:
+
+```bash
+accelerate config default
+```
+
+Or if your environment doesn't support an interactive shell like a notebook, you can use:
+
+```bash
+from accelerate.utils import write_basic_config
+
+write_basic_config()
+```
+
+Finally, you try and [install xFormers](https://huggingface.co/docs/diffusers/main/en/training/optimization/xformers) to reduce your memory footprint with xFormers memory-efficient attention. Once you have xFormers installed, add the `--enable_xformers_memory_efficient_attention` argument to the training script. xFormers is not supported for Flax.
+
+## Upload model to Hub
+
+If you want to store your model on the Hub, add the following argument to the training script:
+
+```bash
+--push_to_hub
+```
+
+## Save and load checkpoints
+
+It is often a good idea to regularly save checkpoints of your model during training. This way, you can resume training from a saved checkpoint if your training is interrupted for any reason. To save a checkpoint, pass the following argument to the training script to save the full training state in a subfolder in `output_dir` every 500 steps:
+
+```bash
+--checkpointing_steps=500
+```
+
+To resume training from a saved checkpoint, pass the following argument to the training script and the specific checkpoint you'd like to resume from:
+
+```bash
+--resume_from_checkpoint="checkpoint-1500"
+```
+
+## Finetuning
+
+For your training dataset, download these [images of a cat statue](https://drive.google.com/drive/folders/1fmJMs25nxS_rSNqS5hTcRdLem_YQXbq5) and store them in a directory.
+
+Set the `MODEL_NAME` environment variable to the model repository id, and the `DATA_DIR` environment variable to the path of the directory containing the images. Now you can launch the [training script](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py):
+
+
+
+💡 A full training run takes ~1 hour on one V100 GPU. While you're waiting for the training to complete, feel free to check out [how Textual Inversion works](#how-it-works) in the section below if you're curious!
+
+
+
+
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export DATA_DIR="path-to-dir-containing-images"
+
+accelerate launch textual_inversion.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --max_train_steps=3000 \
+ --learning_rate=5.0e-04 --scale_lr \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --output_dir="textual_inversion_cat"
+```
+
+
+If you have access to TPUs, try out the [Flax training script](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion_flax.py) to train even faster (this'll also work for GPUs). With the same configuration settings, the Flax training script should be at least 70% faster than the PyTorch training script! ⚡️
+
+Before you begin, make sure you install the Flax specific dependencies:
+
+```bash
+pip install -U -r requirements_flax.txt
+```
+
+Then you can launch the [training script](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion_flax.py):
+
+```bash
+export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
+export DATA_DIR="path-to-dir-containing-images"
+
+python textual_inversion_flax.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --max_train_steps=3000 \
+ --learning_rate=5.0e-04 --scale_lr \
+ --output_dir="textual_inversion_cat"
+```
+
+
+
+### Intermediate logging
+
+If you're interested in following along with your model training progress, you can save the generated images from the training process. Add the following arguments to the training script to enable intermediate logging:
+
+- `validation_prompt`, the prompt used to generate samples (this is set to `None` by default and intermediate logging is disabled)
+- `num_validation_images`, the number of sample images to generate
+- `validation_steps`, the number of steps before generating `num_validation_images` from the `validation_prompt`
+
+```bash
+--validation_prompt="A backpack"
+--num_validation_images=4
+--validation_steps=100
+```
+
+## Inference
+
+Once you have trained a model, you can use it for inference with the [`StableDiffusionPipeline`]. Make sure you include the `placeholder_token` in your prompt, in this case, it is ``.
+
+
+
+```python
+from diffusers import StableDiffusionPipeline
+
+model_id = "path-to-your-trained-model"
+pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+
+prompt = "A backpack"
+
+image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
+
+image.save("cat-backpack.png")
+```
+
+
+```python
+import jax
+import numpy as np
+from flax.jax_utils import replicate
+from flax.training.common_utils import shard
+from diffusers import FlaxStableDiffusionPipeline
+
+model_path = "path-to-your-trained-model"
+pipe, params = FlaxStableDiffusionPipeline.from_pretrained(model_path, dtype=jax.numpy.bfloat16)
+
+prompt = "A backpack"
+prng_seed = jax.random.PRNGKey(0)
+num_inference_steps = 50
+
+num_samples = jax.device_count()
+prompt = num_samples * [prompt]
+prompt_ids = pipeline.prepare_inputs(prompt)
+
+# shard inputs and rng
+params = replicate(params)
+prng_seed = jax.random.split(prng_seed, jax.device_count())
+prompt_ids = shard(prompt_ids)
+
+images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
+images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
+image.save("cat-backpack.png")
+```
+
+
+
+## How it works
+
+
+Architecture overview from the Textual Inversion blog post.
+
+Usually, text prompts are tokenized into an embedding before being passed to a model, which is often a transformer. Textual Inversion does something similar, but it learns a new token embedding, `v*`, from a special token `S*` in the diagram above. The model output is used to condition the diffusion model, which helps the diffusion model understand the prompt and new concepts from just a few example images.
+
+To do this, Textual Inversion uses a generator model and noisy versions of the training images. The generator tries to predict less noisy versions of the images, and the token embedding `v*` is optimized based on how well the generator does. If the token embedding successfully captures the new concept, it gives more useful information to the diffusion model and helps create clearer images with less noise. This optimization process typically occurs after several thousand steps of exposure to a variety of prompt and image variants.
diff --git a/diffusers/docs/source/en/training/unconditional_training.mdx b/diffusers/docs/source/en/training/unconditional_training.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..26517fd1fcf8cf00819817a3630b570be041affd
--- /dev/null
+++ b/diffusers/docs/source/en/training/unconditional_training.mdx
@@ -0,0 +1,201 @@
+
+
+# Unconditional image generation
+
+Unconditional image generation is not conditioned on any text or images, unlike text- or image-to-image models. It only generates images that resemble its training data distribution.
+
+
+
+
+This guide will show you how to train an unconditional image generation model on existing datasets as well as your own custom dataset. All the training scripts for unconditional image generation can be found [here](https://github.com/huggingface/diffusers/tree/main/examples/unconditional_image_generation) if you're interested in learning more about the training details.
+
+Before running the script, make sure you install the library's training dependencies:
+
+```bash
+pip install diffusers[training] accelerate datasets
+```
+
+Next, initialize an 🤗 [Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+To setup a default 🤗 Accelerate environment without choosing any configurations:
+
+```bash
+accelerate config default
+```
+
+Or if your environment doesn't support an interactive shell like a notebook, you can use:
+
+```bash
+from accelerate.utils import write_basic_config
+
+write_basic_config()
+```
+
+## Upload model to Hub
+
+You can upload your model on the Hub by adding the following argument to the training script:
+
+```bash
+--push_to_hub
+```
+
+## Save and load checkpoints
+
+It is a good idea to regularly save checkpoints in case anything happens during training. To save a checkpoint, pass the following argument to the training script:
+
+```bash
+--checkpointing_steps=500
+```
+
+The full training state is saved in a subfolder in the `output_dir` every 500 steps, which allows you to load a checkpoint and resume training if you pass the `--resume_from_checkpoint` argument to the training script:
+
+```bash
+--resume_from_checkpoint="checkpoint-1500"
+```
+
+## Finetuning
+
+You're ready to launch the [training script](https://github.com/huggingface/diffusers/blob/main/examples/unconditional_image_generation/train_unconditional.py) now! Specify the dataset name to finetune on with the `--dataset_name` argument and then save it to the path in `--output_dir`.
+
+
+
+💡 A full training run takes 2 hours on 4xV100 GPUs.
+
+
+
+For example, to finetune on the [Oxford Flowers](https://huggingface.co/datasets/huggan/flowers-102-categories) dataset:
+
+```bash
+accelerate launch train_unconditional.py \
+ --dataset_name="huggan/flowers-102-categories" \
+ --resolution=64 \
+ --output_dir="ddpm-ema-flowers-64" \
+ --train_batch_size=16 \
+ --num_epochs=100 \
+ --gradient_accumulation_steps=1 \
+ --learning_rate=1e-4 \
+ --lr_warmup_steps=500 \
+ --mixed_precision=no \
+ --push_to_hub
+```
+
+
+

+
+

+
+

+
+

+
+

+
 |
|  |
+
+Play around with the Spaces below and see if you notice a difference between generated images with and without a depth map!
+
+
diff --git a/diffusers/docs/source/en/using-diffusers/img2img.mdx b/diffusers/docs/source/en/using-diffusers/img2img.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..71540fbf5dd9ef203158bf5531e327b27915d5a4
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/img2img.mdx
@@ -0,0 +1,99 @@
+
+
+# Text-guided image-to-image generation
+
+[[open-in-colab]]
+
+The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images.
+
+Before you begin, make sure you have all the necessary libraries installed:
+
+```bash
+!pip install diffusers transformers ftfy accelerate
+```
+
+Get started by creating a [`StableDiffusionImg2ImgPipeline`] with a pretrained Stable Diffusion model like [`nitrosocke/Ghibli-Diffusion`](https://huggingface.co/nitrosocke/Ghibli-Diffusion).
+
+```python
+import torch
+import requests
+from PIL import Image
+from io import BytesIO
+from diffusers import StableDiffusionImg2ImgPipeline
+
+device = "cuda"
+pipe = StableDiffusionImg2ImgPipeline.from_pretrained("nitrosocke/Ghibli-Diffusion", torch_dtype=torch.float16).to(
+ device
+)
+```
+
+Download and preprocess an initial image so you can pass it to the pipeline:
+
+```python
+url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image.thumbnail((768, 768))
+init_image
+```
+
+
|
+
+Play around with the Spaces below and see if you notice a difference between generated images with and without a depth map!
+
+
diff --git a/diffusers/docs/source/en/using-diffusers/img2img.mdx b/diffusers/docs/source/en/using-diffusers/img2img.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..71540fbf5dd9ef203158bf5531e327b27915d5a4
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/img2img.mdx
@@ -0,0 +1,99 @@
+
+
+# Text-guided image-to-image generation
+
+[[open-in-colab]]
+
+The [`StableDiffusionImg2ImgPipeline`] lets you pass a text prompt and an initial image to condition the generation of new images.
+
+Before you begin, make sure you have all the necessary libraries installed:
+
+```bash
+!pip install diffusers transformers ftfy accelerate
+```
+
+Get started by creating a [`StableDiffusionImg2ImgPipeline`] with a pretrained Stable Diffusion model like [`nitrosocke/Ghibli-Diffusion`](https://huggingface.co/nitrosocke/Ghibli-Diffusion).
+
+```python
+import torch
+import requests
+from PIL import Image
+from io import BytesIO
+from diffusers import StableDiffusionImg2ImgPipeline
+
+device = "cuda"
+pipe = StableDiffusionImg2ImgPipeline.from_pretrained("nitrosocke/Ghibli-Diffusion", torch_dtype=torch.float16).to(
+ device
+)
+```
+
+Download and preprocess an initial image so you can pass it to the pipeline:
+
+```python
+url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image.thumbnail((768, 768))
+init_image
+```
+
+
+

+
+

+
+

+
 |
|  | ***Face of a yellow cat, high resolution, sitting on a park bench*** |
| ***Face of a yellow cat, high resolution, sitting on a park bench*** |  |
+
+
+
+
+A previous experimental implementation of inpainting used a different, lower-quality process. To ensure backwards compatibility, loading a pretrained pipeline that doesn't contain the new model will still apply the old inpainting method.
+
+
+
+Check out the Spaces below to try out image inpainting yourself!
+
+
diff --git a/diffusers/docs/source/en/using-diffusers/kerascv.mdx b/diffusers/docs/source/en/using-diffusers/kerascv.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..06981cc8fdd1c5dca658c5f8a6379a020514ae7f
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/kerascv.mdx
@@ -0,0 +1,179 @@
+
+
+# Using KerasCV Stable Diffusion Checkpoints in Diffusers
+
+
+
+This is an experimental feature.
+
+
+
+[KerasCV](https://github.com/keras-team/keras-cv/) provides APIs for implementing various computer vision workflows. It
+also provides the Stable Diffusion [v1 and v2](https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion)
+models. Many practitioners find it easy to fine-tune the Stable Diffusion models shipped by KerasCV. However, as of this writing, KerasCV offers limited support to experiment with Stable Diffusion models for inference and deployment. On the other hand,
+Diffusers provides tooling dedicated to this purpose (and more), such as different [noise schedulers](https://huggingface.co/docs/diffusers/using-diffusers/schedulers), [flash attention](https://huggingface.co/docs/diffusers/optimization/xformers), and [other
+optimization techniques](https://huggingface.co/docs/diffusers/optimization/fp16).
+
+How about fine-tuning Stable Diffusion models in KerasCV and exporting them such that they become compatible with Diffusers to combine the
+best of both worlds? We have created a [tool](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) that
+lets you do just that! It takes KerasCV Stable Diffusion checkpoints and exports them to Diffusers-compatible checkpoints.
+More specifically, it first converts the checkpoints to PyTorch and then wraps them into a
+[`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview) which is ready
+for inference. Finally, it pushes the converted checkpoints to a repository on the Hugging Face Hub.
+
+We welcome you to try out the tool [here](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers)
+and share feedback via [discussions](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers/discussions/new).
+
+## Getting Started
+
+First, you need to obtain the fine-tuned KerasCV Stable Diffusion checkpoints. We provide an
+overview of the different ways Stable Diffusion models can be fine-tuned [using `diffusers`](https://huggingface.co/docs/diffusers/training/overview). For the Keras implementation of some of these methods, you can check out these resources:
+
+* [Teach StableDiffusion new concepts via Textual Inversion](https://keras.io/examples/generative/fine_tune_via_textual_inversion/)
+* [Fine-tuning Stable Diffusion](https://keras.io/examples/generative/finetune_stable_diffusion/)
+* [DreamBooth](https://keras.io/examples/generative/dreambooth/)
+* [Prompt-to-Prompt editing](https://github.com/miguelCalado/prompt-to-prompt-tensorflow)
+
+Stable Diffusion is comprised of the following models:
+
+* Text encoder
+* UNet
+* VAE
+
+Depending on the fine-tuning task, we may fine-tune one or more of these components (the VAE is almost always left untouched). Here are some common combinations:
+
+* DreamBooth: UNet and text encoder
+* Classical text to image fine-tuning: UNet
+* Textual Inversion: Just the newly initialized embeddings in the text encoder
+
+### Performing the Conversion
+
+Let's use [this checkpoint](https://huggingface.co/sayakpaul/textual-inversion-kerasio/resolve/main/textual_inversion_kerasio.h5) which was generated
+by conducting Textual Inversion with the following "placeholder token": ``.
+
+On the tool, we supply the following things:
+
+* Path(s) to download the fine-tuned checkpoint(s) (KerasCV)
+* An HF token
+* Placeholder token (only applicable for Textual Inversion)
+
+
|
+
+
+
+
+A previous experimental implementation of inpainting used a different, lower-quality process. To ensure backwards compatibility, loading a pretrained pipeline that doesn't contain the new model will still apply the old inpainting method.
+
+
+
+Check out the Spaces below to try out image inpainting yourself!
+
+
diff --git a/diffusers/docs/source/en/using-diffusers/kerascv.mdx b/diffusers/docs/source/en/using-diffusers/kerascv.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..06981cc8fdd1c5dca658c5f8a6379a020514ae7f
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/kerascv.mdx
@@ -0,0 +1,179 @@
+
+
+# Using KerasCV Stable Diffusion Checkpoints in Diffusers
+
+
+
+This is an experimental feature.
+
+
+
+[KerasCV](https://github.com/keras-team/keras-cv/) provides APIs for implementing various computer vision workflows. It
+also provides the Stable Diffusion [v1 and v2](https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion)
+models. Many practitioners find it easy to fine-tune the Stable Diffusion models shipped by KerasCV. However, as of this writing, KerasCV offers limited support to experiment with Stable Diffusion models for inference and deployment. On the other hand,
+Diffusers provides tooling dedicated to this purpose (and more), such as different [noise schedulers](https://huggingface.co/docs/diffusers/using-diffusers/schedulers), [flash attention](https://huggingface.co/docs/diffusers/optimization/xformers), and [other
+optimization techniques](https://huggingface.co/docs/diffusers/optimization/fp16).
+
+How about fine-tuning Stable Diffusion models in KerasCV and exporting them such that they become compatible with Diffusers to combine the
+best of both worlds? We have created a [tool](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) that
+lets you do just that! It takes KerasCV Stable Diffusion checkpoints and exports them to Diffusers-compatible checkpoints.
+More specifically, it first converts the checkpoints to PyTorch and then wraps them into a
+[`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview) which is ready
+for inference. Finally, it pushes the converted checkpoints to a repository on the Hugging Face Hub.
+
+We welcome you to try out the tool [here](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers)
+and share feedback via [discussions](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers/discussions/new).
+
+## Getting Started
+
+First, you need to obtain the fine-tuned KerasCV Stable Diffusion checkpoints. We provide an
+overview of the different ways Stable Diffusion models can be fine-tuned [using `diffusers`](https://huggingface.co/docs/diffusers/training/overview). For the Keras implementation of some of these methods, you can check out these resources:
+
+* [Teach StableDiffusion new concepts via Textual Inversion](https://keras.io/examples/generative/fine_tune_via_textual_inversion/)
+* [Fine-tuning Stable Diffusion](https://keras.io/examples/generative/finetune_stable_diffusion/)
+* [DreamBooth](https://keras.io/examples/generative/dreambooth/)
+* [Prompt-to-Prompt editing](https://github.com/miguelCalado/prompt-to-prompt-tensorflow)
+
+Stable Diffusion is comprised of the following models:
+
+* Text encoder
+* UNet
+* VAE
+
+Depending on the fine-tuning task, we may fine-tune one or more of these components (the VAE is almost always left untouched). Here are some common combinations:
+
+* DreamBooth: UNet and text encoder
+* Classical text to image fine-tuning: UNet
+* Textual Inversion: Just the newly initialized embeddings in the text encoder
+
+### Performing the Conversion
+
+Let's use [this checkpoint](https://huggingface.co/sayakpaul/textual-inversion-kerasio/resolve/main/textual_inversion_kerasio.h5) which was generated
+by conducting Textual Inversion with the following "placeholder token": ``.
+
+On the tool, we supply the following things:
+
+* Path(s) to download the fine-tuned checkpoint(s) (KerasCV)
+* An HF token
+* Placeholder token (only applicable for Textual Inversion)
+
+
+
+
+

+
+
+
+
+
+
+
+

+
+

+
+
+  +
+
+
+
+
+## Changing the scheduler
+
+Now we show how easy it is to change the scheduler of a pipeline. Every scheduler has a property [`SchedulerMixin.compatibles`]
+which defines all compatible schedulers. You can take a look at all available, compatible schedulers for the Stable Diffusion pipeline as follows.
+
+```python
+pipeline.scheduler.compatibles
+```
+
+**Output**:
+```
+[diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
+ diffusers.schedulers.scheduling_ddim.DDIMScheduler,
+ diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
+ diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
+ diffusers.schedulers.scheduling_pndm.PNDMScheduler,
+ diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
+ diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler]
+```
+
+Cool, lots of schedulers to look at. Feel free to have a look at their respective class definitions:
+
+- [`LMSDiscreteScheduler`],
+- [`DDIMScheduler`],
+- [`DPMSolverMultistepScheduler`],
+- [`EulerDiscreteScheduler`],
+- [`PNDMScheduler`],
+- [`DDPMScheduler`],
+- [`EulerAncestralDiscreteScheduler`].
+
+We will now compare the input prompt with all other schedulers. To change the scheduler of the pipeline you can make use of the
+convenient [`ConfigMixin.config`] property in combination with the [`ConfigMixin.from_config`] function.
+
+```python
+pipeline.scheduler.config
+```
+
+returns a dictionary of the configuration of the scheduler:
+
+**Output**:
+```
+FrozenDict([('num_train_timesteps', 1000),
+ ('beta_start', 0.00085),
+ ('beta_end', 0.012),
+ ('beta_schedule', 'scaled_linear'),
+ ('trained_betas', None),
+ ('skip_prk_steps', True),
+ ('set_alpha_to_one', False),
+ ('steps_offset', 1),
+ ('_class_name', 'PNDMScheduler'),
+ ('_diffusers_version', '0.8.0.dev0'),
+ ('clip_sample', False)])
+```
+
+This configuration can then be used to instantiate a scheduler
+of a different class that is compatible with the pipeline. Here,
+we change the scheduler to the [`DDIMScheduler`].
+
+```python
+from diffusers import DDIMScheduler
+
+pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+```
+
+Cool, now we can run the pipeline again to compare the generation quality.
+
+```python
+generator = torch.Generator(device="cuda").manual_seed(8)
+image = pipeline(prompt, generator=generator).images[0]
+image
+```
+
+
+
+  +
+
+
+
+If you are a JAX/Flax user, please check [this section](#changing-the-scheduler-in-flax) instead.
+
+## Compare schedulers
+
+So far we have tried running the stable diffusion pipeline with two schedulers: [`PNDMScheduler`] and [`DDIMScheduler`].
+A number of better schedulers have been released that can be run with much fewer steps, let's compare them here:
+
+[`LMSDiscreteScheduler`] usually leads to better results:
+
+```python
+from diffusers import LMSDiscreteScheduler
+
+pipeline.scheduler = LMSDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+generator = torch.Generator(device="cuda").manual_seed(8)
+image = pipeline(prompt, generator=generator).images[0]
+image
+```
+
+
+
+  +
+
+
+
+
+[`EulerDiscreteScheduler`] and [`EulerAncestralDiscreteScheduler`] can generate high quality results with as little as 30 steps.
+
+```python
+from diffusers import EulerDiscreteScheduler
+
+pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+generator = torch.Generator(device="cuda").manual_seed(8)
+image = pipeline(prompt, generator=generator, num_inference_steps=30).images[0]
+image
+```
+
+
+
+  +
+
+
+
+
+and:
+
+```python
+from diffusers import EulerAncestralDiscreteScheduler
+
+pipeline.scheduler = EulerAncestralDiscreteScheduler.from_config(pipeline.scheduler.config)
+
+generator = torch.Generator(device="cuda").manual_seed(8)
+image = pipeline(prompt, generator=generator, num_inference_steps=30).images[0]
+image
+```
+
+
+
+  +
+
+
+
+
+At the time of writing this doc [`DPMSolverMultistepScheduler`] gives arguably the best speed/quality trade-off and can be run with as little
+as 20 steps.
+
+```python
+from diffusers import DPMSolverMultistepScheduler
+
+pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
+
+generator = torch.Generator(device="cuda").manual_seed(8)
+image = pipeline(prompt, generator=generator, num_inference_steps=20).images[0]
+image
+```
+
+
+
+  +
+
+
+
+As you can see most images look very similar and are arguably of very similar quality. It often really depends on the specific use case which scheduler to choose. A good approach is always to run multiple different
+schedulers to compare results.
+
+## Changing the Scheduler in Flax
+
+If you are a JAX/Flax user, you can also change the default pipeline scheduler. This is a complete example of how to run inference using the Flax Stable Diffusion pipeline and the super-fast [DDPM-Solver++ scheduler](../api/schedulers/multistep_dpm_solver):
+
+```Python
+import jax
+import numpy as np
+from flax.jax_utils import replicate
+from flax.training.common_utils import shard
+
+from diffusers import FlaxStableDiffusionPipeline, FlaxDPMSolverMultistepScheduler
+
+model_id = "runwayml/stable-diffusion-v1-5"
+scheduler, scheduler_state = FlaxDPMSolverMultistepScheduler.from_pretrained(
+ model_id,
+ subfolder="scheduler"
+)
+pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
+ model_id,
+ scheduler=scheduler,
+ revision="bf16",
+ dtype=jax.numpy.bfloat16,
+)
+params["scheduler"] = scheduler_state
+
+# Generate 1 image per parallel device (8 on TPUv2-8 or TPUv3-8)
+prompt = "a photo of an astronaut riding a horse on mars"
+num_samples = jax.device_count()
+prompt_ids = pipeline.prepare_inputs([prompt] * num_samples)
+
+prng_seed = jax.random.PRNGKey(0)
+num_inference_steps = 25
+
+# shard inputs and rng
+params = replicate(params)
+prng_seed = jax.random.split(prng_seed, jax.device_count())
+prompt_ids = shard(prompt_ids)
+
+images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
+images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
+```
+
+
+
+The following Flax schedulers are _not yet compatible_ with the Flax Stable Diffusion Pipeline:
+
+- `FlaxLMSDiscreteScheduler`
+- `FlaxDDPMScheduler`
+
+
diff --git a/diffusers/docs/source/en/using-diffusers/stable_diffusion_jax_how_to.mdx b/diffusers/docs/source/en/using-diffusers/stable_diffusion_jax_how_to.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e0332fdc6496cd0193320617afc9e8a55b78cc73
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/stable_diffusion_jax_how_to.mdx
@@ -0,0 +1,250 @@
+# 🧨 Stable Diffusion in JAX / Flax !
+
+[[open-in-colab]]
+
+🤗 Hugging Face [Diffusers](https://github.com/huggingface/diffusers) supports Flax since version `0.5.1`! This allows for super fast inference on Google TPUs, such as those available in Colab, Kaggle or Google Cloud Platform.
+
+This notebook shows how to run inference using JAX / Flax. If you want more details about how Stable Diffusion works or want to run it in GPU, please refer to [this notebook](https://huggingface.co/docs/diffusers/stable_diffusion).
+
+First, make sure you are using a TPU backend. If you are running this notebook in Colab, select `Runtime` in the menu above, then select the option "Change runtime type" and then select `TPU` under the `Hardware accelerator` setting.
+
+Note that JAX is not exclusive to TPUs, but it shines on that hardware because each TPU server has 8 TPU accelerators working in parallel.
+
+## Setup
+
+First make sure diffusers is installed.
+
+```bash
+!pip install jax==0.3.25 jaxlib==0.3.25 flax transformers ftfy
+!pip install diffusers
+```
+
+```python
+import jax.tools.colab_tpu
+
+jax.tools.colab_tpu.setup_tpu()
+import jax
+```
+
+```python
+num_devices = jax.device_count()
+device_type = jax.devices()[0].device_kind
+
+print(f"Found {num_devices} JAX devices of type {device_type}.")
+assert (
+ "TPU" in device_type
+), "Available device is not a TPU, please select TPU from Edit > Notebook settings > Hardware accelerator"
+```
+
+```python out
+Found 8 JAX devices of type Cloud TPU.
+```
+
+Then we import all the dependencies.
+
+```python
+import numpy as np
+import jax
+import jax.numpy as jnp
+
+from pathlib import Path
+from jax import pmap
+from flax.jax_utils import replicate
+from flax.training.common_utils import shard
+from PIL import Image
+
+from huggingface_hub import notebook_login
+from diffusers import FlaxStableDiffusionPipeline
+```
+
+## Model Loading
+
+TPU devices support `bfloat16`, an efficient half-float type. We'll use it for our tests, but you can also use `float32` to use full precision instead.
+
+```python
+dtype = jnp.bfloat16
+```
+
+Flax is a functional framework, so models are stateless and parameters are stored outside them. Loading the pre-trained Flax pipeline will return both the pipeline itself and the model weights (or parameters). We are using a `bf16` version of the weights, which leads to type warnings that you can safely ignore.
+
+```python
+pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ revision="bf16",
+ dtype=dtype,
+)
+```
+
+## Inference
+
+Since TPUs usually have 8 devices working in parallel, we'll replicate our prompt as many times as devices we have. Then we'll perform inference on the 8 devices at once, each responsible for generating one image. Thus, we'll get 8 images in the same amount of time it takes for one chip to generate a single one.
+
+After replicating the prompt, we obtain the tokenized text ids by invoking the `prepare_inputs` function of the pipeline. The length of the tokenized text is set to 77 tokens, as required by the configuration of the underlying CLIP Text model.
+
+```python
+prompt = "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of field, close up, split lighting, cinematic"
+prompt = [prompt] * jax.device_count()
+prompt_ids = pipeline.prepare_inputs(prompt)
+prompt_ids.shape
+```
+
+```python out
+(8, 77)
+```
+
+### Replication and parallelization
+
+Model parameters and inputs have to be replicated across the 8 parallel devices we have. The parameters dictionary is replicated using `flax.jax_utils.replicate`, which traverses the dictionary and changes the shape of the weights so they are repeated 8 times. Arrays are replicated using `shard`.
+
+```python
+p_params = replicate(params)
+```
+
+```python
+prompt_ids = shard(prompt_ids)
+prompt_ids.shape
+```
+
+```python out
+(8, 1, 77)
+```
+
+That shape means that each one of the `8` devices will receive as an input a `jnp` array with shape `(1, 77)`. `1` is therefore the batch size per device. In TPUs with sufficient memory, it could be larger than `1` if we wanted to generate multiple images (per chip) at once.
+
+We are almost ready to generate images! We just need to create a random number generator to pass to the generation function. This is the standard procedure in Flax, which is very serious and opinionated about random numbers – all functions that deal with random numbers are expected to receive a generator. This ensures reproducibility, even when we are training across multiple distributed devices.
+
+The helper function below uses a seed to initialize a random number generator. As long as we use the same seed, we'll get the exact same results. Feel free to use different seeds when exploring results later in the notebook.
+
+```python
+def create_key(seed=0):
+ return jax.random.PRNGKey(seed)
+```
+
+We obtain a rng and then "split" it 8 times so each device receives a different generator. Therefore, each device will create a different image, and the full process is reproducible.
+
+```python
+rng = create_key(0)
+rng = jax.random.split(rng, jax.device_count())
+```
+
+JAX code can be compiled to an efficient representation that runs very fast. However, we need to ensure that all inputs have the same shape in subsequent calls; otherwise, JAX will have to recompile the code, and we wouldn't be able to take advantage of the optimized speed.
+
+The Flax pipeline can compile the code for us if we pass `jit = True` as an argument. It will also ensure that the model runs in parallel in the 8 available devices.
+
+The first time we run the following cell it will take a long time to compile, but subequent calls (even with different inputs) will be much faster. For example, it took more than a minute to compile in a TPU v2-8 when I tested, but then it takes about **`7s`** for future inference runs.
+
+```
+%%time
+images = pipeline(prompt_ids, p_params, rng, jit=True)[0]
+```
+
+```python out
+CPU times: user 56.2 s, sys: 42.5 s, total: 1min 38s
+Wall time: 1min 29s
+```
+
+The returned array has shape `(8, 1, 512, 512, 3)`. We reshape it to get rid of the second dimension and obtain 8 images of `512 × 512 × 3` and then convert them to PIL.
+
+```python
+images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
+images = pipeline.numpy_to_pil(images)
+```
+
+### Visualization
+
+Let's create a helper function to display images in a grid.
+
+```python
+def image_grid(imgs, rows, cols):
+ w, h = imgs[0].size
+ grid = Image.new("RGB", size=(cols * w, rows * h))
+ for i, img in enumerate(imgs):
+ grid.paste(img, box=(i % cols * w, i // cols * h))
+ return grid
+```
+
+```python
+image_grid(images, 2, 4)
+```
+
+
+
+
+## Using different prompts
+
+We don't have to replicate the _same_ prompt in all the devices. We can do whatever we want: generate 2 prompts 4 times each, or even generate 8 different prompts at once. Let's do that!
+
+First, we'll refactor the input preparation code into a handy function:
+
+```python
+prompts = [
+ "Labrador in the style of Hokusai",
+ "Painting of a squirrel skating in New York",
+ "HAL-9000 in the style of Van Gogh",
+ "Times Square under water, with fish and a dolphin swimming around",
+ "Ancient Roman fresco showing a man working on his laptop",
+ "Close-up photograph of young black woman against urban background, high quality, bokeh",
+ "Armchair in the shape of an avocado",
+ "Clown astronaut in space, with Earth in the background",
+]
+```
+
+```python
+prompt_ids = pipeline.prepare_inputs(prompts)
+prompt_ids = shard(prompt_ids)
+
+images = pipeline(prompt_ids, p_params, rng, jit=True).images
+images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
+images = pipeline.numpy_to_pil(images)
+
+image_grid(images, 2, 4)
+```
+
+
+
+
+## How does parallelization work?
+
+We said before that the `diffusers` Flax pipeline automatically compiles the model and runs it in parallel on all available devices. We'll now briefly look inside that process to show how it works.
+
+JAX parallelization can be done in multiple ways. The easiest one revolves around using the `jax.pmap` function to achieve single-program, multiple-data (SPMD) parallelization. It means we'll run several copies of the same code, each on different data inputs. More sophisticated approaches are possible, we invite you to go over the [JAX documentation](https://jax.readthedocs.io/en/latest/index.html) and the [`pjit` pages](https://jax.readthedocs.io/en/latest/jax-101/08-pjit.html?highlight=pjit) to explore this topic if you are interested!
+
+`jax.pmap` does two things for us:
+- Compiles (or `jit`s) the code, as if we had invoked `jax.jit()`. This does not happen when we call `pmap`, but the first time the pmapped function is invoked.
+- Ensures the compiled code runs in parallel in all the available devices.
+
+To show how it works we `pmap` the `_generate` method of the pipeline, which is the private method that runs generates images. Please, note that this method may be renamed or removed in future releases of `diffusers`.
+
+```python
+p_generate = pmap(pipeline._generate)
+```
+
+After we use `pmap`, the prepared function `p_generate` will conceptually do the following:
+* Invoke a copy of the underlying function `pipeline._generate` in each device.
+* Send each device a different portion of the input arguments. That's what sharding is used for. In our case, `prompt_ids` has shape `(8, 1, 77, 768)`. This array will be split in `8` and each copy of `_generate` will receive an input with shape `(1, 77, 768)`.
+
+We can code `_generate` completely ignoring the fact that it will be invoked in parallel. We just care about our batch size (`1` in this example) and the dimensions that make sense for our code, and don't have to change anything to make it work in parallel.
+
+The same way as when we used the pipeline call, the first time we run the following cell it will take a while, but then it will be much faster.
+
+```
+%%time
+images = p_generate(prompt_ids, p_params, rng)
+images = images.block_until_ready()
+images.shape
+```
+
+```python out
+CPU times: user 1min 15s, sys: 18.2 s, total: 1min 34s
+Wall time: 1min 15s
+```
+
+```python
+images.shape
+```
+
+```python out
+(8, 1, 512, 512, 3)
+```
+
+We use `block_until_ready()` to correctly measure inference time, because JAX uses asynchronous dispatch and returns control to the Python loop as soon as it can. You don't need to use that in your code; blocking will occur automatically when you want to use the result of a computation that has not yet been materialized.
\ No newline at end of file
diff --git a/diffusers/docs/source/en/using-diffusers/unconditional_image_generation.mdx b/diffusers/docs/source/en/using-diffusers/unconditional_image_generation.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..c0888f94c6c135e429feb42d2026962d3a257f5f
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/unconditional_image_generation.mdx
@@ -0,0 +1,69 @@
+
+
+# Unconditional image generation
+
+[[open-in-colab]]
+
+Unconditional image generation is a relatively straightforward task. The model only generates images - without any additional context like text or an image - resembling the training data it was trained on.
+
+The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion system for inference.
+
+Start by creating an instance of [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
+You can use any of the 🧨 Diffusers [checkpoints](https://huggingface.co/models?library=diffusers&sort=downloads) from the Hub (the checkpoint you'll use generates images of butterflies).
+
+
+
+💡 Want to train your own unconditional image generation model? Take a look at the training [guide](training/unconditional_training) to learn how to generate your own images.
+
+
+
+In this guide, you'll use [`DiffusionPipeline`] for unconditional image generation with [DDPM](https://arxiv.org/abs/2006.11239):
+
+```python
+>>> from diffusers import DiffusionPipeline
+
+>>> generator = DiffusionPipeline.from_pretrained("anton-l/ddpm-butterflies-128")
+```
+
+The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components.
+Because the model consists of roughly 1.4 billion parameters, we strongly recommend running it on a GPU.
+You can move the generator object to a GPU, just like you would in PyTorch:
+
+```python
+>>> generator.to("cuda")
+```
+
+Now you can use the `generator` to generate an image:
+
+```python
+>>> image = generator().images[0]
+```
+
+The output is by default wrapped into a [`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class) object.
+
+You can save the image by calling:
+
+```python
+>>> image.save("generated_image.png")
+```
+
+Try out the Spaces below, and feel free to play around with the inference steps parameter to see how it affects the image quality!
+
+
+
+
diff --git a/diffusers/docs/source/en/using-diffusers/using_safetensors b/diffusers/docs/source/en/using-diffusers/using_safetensors
new file mode 100644
index 0000000000000000000000000000000000000000..b6b165dabc728b885d8f7f097af808d8a2270b2c
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/using_safetensors
@@ -0,0 +1,19 @@
+# What is safetensors ?
+
+[safetensors](https://github.com/huggingface/safetensors) is a different format
+from the classic `.bin` which uses Pytorch which uses pickle.
+
+Pickle is notoriously unsafe which allow any malicious file to execute arbitrary code.
+The hub itself tries to prevent issues from it, but it's not a silver bullet.
+
+`safetensors` first and foremost goal is to make loading machine learning models *safe*
+in the sense that no takeover of your computer can be done.
+
+# Why use safetensors ?
+
+**Safety** can be one reason, if you're attempting to use a not well known model and
+you're not sure about the source of the file.
+
+And a secondary reason, is **the speed of loading**. Safetensors can load models much faster
+than regular pickle files. If you spend a lot of times switching models, this can be
+a huge timesave.
diff --git a/diffusers/docs/source/en/using-diffusers/using_safetensors.mdx b/diffusers/docs/source/en/using-diffusers/using_safetensors.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..b522f3236fbb43ea19b088adede40c9677fb274a
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/using_safetensors.mdx
@@ -0,0 +1,87 @@
+# What is safetensors ?
+
+[safetensors](https://github.com/huggingface/safetensors) is a different format
+from the classic `.bin` which uses Pytorch which uses pickle. It contains the
+exact same data, which is just the model weights (or tensors).
+
+Pickle is notoriously unsafe which allow any malicious file to execute arbitrary code.
+The hub itself tries to prevent issues from it, but it's not a silver bullet.
+
+`safetensors` first and foremost goal is to make loading machine learning models *safe*
+in the sense that no takeover of your computer can be done.
+
+Hence the name.
+
+# Why use safetensors ?
+
+**Safety** can be one reason, if you're attempting to use a not well known model and
+you're not sure about the source of the file.
+
+And a secondary reason, is **the speed of loading**. Safetensors can load models much faster
+than regular pickle files. If you spend a lot of times switching models, this can be
+a huge timesave.
+
+Numbers taken AMD EPYC 7742 64-Core Processor
+```
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1")
+
+# Loaded in safetensors 0:00:02.033658
+# Loaded in Pytorch 0:00:02.663379
+```
+
+This is for the entire loading time, the actual weights loading time to load 500MB:
+
+```
+Safetensors: 3.4873ms
+PyTorch: 172.7537ms
+```
+
+Performance in general is a tricky business, and there are a few things to understand:
+
+- If you're using the model for the first time from the hub, you will have to download the weights.
+ That's extremely likely to be much slower than any loading method, therefore you will not see any difference
+- If you're loading the model for the first time (let's say after a reboot) then your machine will have to
+ actually read the disk. It's likely to be as slow in both cases. Again the speed difference may not be as visible (this depends on hardware and the actual model).
+- The best performance benefit is when the model was already loaded previously on your computer and you're switching from one model to another. Your OS, is trying really hard not to read from disk, since this is slow, so it will keep the files around in RAM, making it loading again much faster. Since safetensors is doing zero-copy of the tensors, reloading will be faster than pytorch since it has at least once extra copy to do.
+
+# How to use safetensors ?
+
+If you have `safetensors` installed, and all the weights are available in `safetensors` format, \
+then by default it will use that instead of the pytorch weights.
+
+If you are really paranoid about this, the ultimate weapon would be disabling `torch.load`:
+```python
+import torch
+
+
+def _raise():
+ raise RuntimeError("I don't want to use pickle")
+
+
+torch.load = lambda *args, **kwargs: _raise()
+```
+
+# I want to use model X but it doesn't have safetensors weights.
+
+Just go to this [space](https://huggingface.co/spaces/diffusers/convert).
+This will create a new PR with the weights, let's say `refs/pr/22`.
+
+This space will download the pickled version, convert it, and upload it on the hub as a PR.
+If anything bad is contained in the file, it's Huggingface hub that will get issues, not your own computer.
+And we're equipped with dealing with it.
+
+Then in order to use the model, even before the branch gets accepted by the original author you can do:
+
+```python
+from diffusers import DiffusionPipeline
+
+pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", revision="refs/pr/22")
+```
+
+or you can test it directly online with this [space](https://huggingface.co/spaces/diffusers/check_pr).
+
+And that's it !
+
+Anything unclear, concerns, or found a bugs ? [Open an issue](https://github.com/huggingface/diffusers/issues/new/choose)
diff --git a/diffusers/docs/source/en/using-diffusers/weighted_prompts.mdx b/diffusers/docs/source/en/using-diffusers/weighted_prompts.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..c1316dc9f47d867e7f500e6f882977bcbadf97cb
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/weighted_prompts.mdx
@@ -0,0 +1,98 @@
+
+
+# Weighting prompts
+
+Text-guided diffusion models generate images based on a given text prompt. The text prompt
+can include multiple concepts that the model should generate and it's often desirable to weight
+certain parts of the prompt more or less.
+
+Diffusion models work by conditioning the cross attention layers of the diffusion model with contextualized text embeddings (see the [Stable Diffusion Guide for more information](../stable-diffusion)).
+Thus a simple way to emphasize (or de-emphasize) certain parts of the prompt is by increasing or reducing the scale of the text embedding vector that corresponds to the relevant part of the prompt.
+This is called "prompt-weighting" and has been a highly demanded feature by the community (see issue [here](https://github.com/huggingface/diffusers/issues/2431)).
+
+## How to do prompt-weighting in Diffusers
+
+We believe the role of `diffusers` is to be a toolbox that provides essential features that enable other projects, such as [InvokeAI](https://github.com/invoke-ai/InvokeAI) or [diffuzers](https://github.com/abhishekkrthakur/diffuzers), to build powerful UIs. In order to support arbitrary methods to manipulate prompts, `diffusers` exposes a [`prompt_embeds`](https://huggingface.co/docs/diffusers/v0.14.0/en/api/pipelines/stable_diffusion/text2img#diffusers.StableDiffusionPipeline.__call__.prompt_embeds) function argument to many pipelines such as [`StableDiffusionPipeline`], allowing to directly pass the "prompt-weighted"/scaled text embeddings to the pipeline.
+
+The [compel library](https://github.com/damian0815/compel) provides an easy way to emphasize or de-emphasize portions of the prompt for you. We strongly recommend it instead of preparing the embeddings yourself.
+
+Let's look at a simple example. Imagine you want to generate an image of `"a red cat playing with a ball"` as
+follows:
+
+```py
+from diffusers import StableDiffusionPipeline, UniPCMultistepScheduler
+
+pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+
+prompt = "a red cat playing with a ball"
+
+generator = torch.Generator(device="cpu").manual_seed(33)
+
+image = pipe(prompt, generator=generator, num_inference_steps=20).images[0]
+image
+```
+
+This gives you:
+
+
+
+As you can see, there is no "ball" in the image. Let's emphasize this part!
+
+For this we should install the `compel` library:
+
+```
+pip install compel
+```
+
+and then create a `Compel` object:
+
+```py
+from compel import Compel
+
+compel_proc = Compel(tokenizer=pipe.tokenizer, text_encoder=pipe.text_encoder)
+```
+
+Now we emphasize the part "ball" with the `"++"` syntax:
+
+```py
+prompt = "a red cat playing with a ball++"
+```
+
+and instead of passing this to the pipeline directly, we have to process it using `compel_proc`:
+
+```py
+prompt_embeds = compel_proc(prompt)
+```
+
+Now we can pass `prompt_embeds` directly to the pipeline:
+
+```py
+generator = torch.Generator(device="cpu").manual_seed(33)
+
+images = pipe(prompt_embeds=prompt_embeds, generator=generator, num_inference_steps=20).images[0]
+image
+```
+
+We now get the following image which has a "ball"!
+
+
+
+Similarly, we de-emphasize parts of the sentence by using the `--` suffix for words, feel free to give it
+a try!
+
+If your favorite pipeline does not have a `prompt_embeds` input, please make sure to open an issue, the
+diffusers team tries to be as responsive as possible.
+
+Also, please check out the documentation of the [compel](https://github.com/damian0815/compel) library for
+more information.
diff --git a/diffusers/docs/source/en/using-diffusers/write_own_pipeline.mdx b/diffusers/docs/source/en/using-diffusers/write_own_pipeline.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..3c993ed53a2ab3f15fb2053d42be60573d6e4b42
--- /dev/null
+++ b/diffusers/docs/source/en/using-diffusers/write_own_pipeline.mdx
@@ -0,0 +1,290 @@
+
+
+# Understanding pipelines, models and schedulers
+
+[[open-in-colab]]
+
+🧨 Diffusers is designed to be a user-friendly and flexible toolbox for building diffusion systems tailored to your use-case. At the core of the toolbox are models and schedulers. While the [`DiffusionPipeline`] bundles these components together for convenience, you can also unbundle the pipeline and use the models and schedulers separately to create new diffusion systems.
+
+In this tutorial, you'll learn how to use models and schedulers to assemble a diffusion system for inference, starting with a basic pipeline and then progressing to the Stable Diffusion pipeline.
+
+## Deconstruct a basic pipeline
+
+A pipeline is a quick and easy way to run a model for inference, requiring no more than four lines of code to generate an image:
+
+```py
+>>> from diffusers import DDPMPipeline
+
+>>> ddpm = DDPMPipeline.from_pretrained("google/ddpm-cat-256").to("cuda")
+>>> image = ddpm(num_inference_steps=25).images[0]
+>>> image
+```
+
+
+

+
+

+
+
+
+
+
+
+# 🧨 Diffusers
+
+🤗 Diffusers는 사전학습된 비전 및 오디오 확산 모델을 제공하고, 추론 및 학습을 위한 모듈식 도구 상자 역할을 합니다.
+
+보다 정확하게, 🤗 Diffusers는 다음을 제공합니다:
+
+- 단 몇 줄의 코드로 추론을 실행할 수 있는 최신 확산 파이프라인을 제공합니다. ([**Using Diffusers**](./using-diffusers/conditional_image_generation)를 살펴보세요) 지원되는 모든 파이프라인과 해당 논문에 대한 개요를 보려면 [**Pipelines**](#pipelines)을 살펴보세요.
+- 추론에서 속도 vs 품질의 절충을 위해 상호교환적으로 사용할 수 있는 다양한 노이즈 스케줄러를 제공합니다. 자세한 내용은 [**Schedulers**](./api/schedulers/overview)를 참고하세요.
+- UNet과 같은 여러 유형의 모델을 end-to-end 확산 시스템의 구성 요소로 사용할 수 있습니다. 자세한 내용은 [**Models**](./api/models)을 참고하세요.
+- 가장 인기있는 확산 모델 테스크를 학습하는 방법을 보여주는 예제들을 제공합니다. 자세한 내용은 [**Training**](./training/overview)를 참고하세요.
+
+## 🧨 Diffusers 파이프라인
+
+다음 표에는 공시적으로 지원되는 모든 파이프라인, 관련 논문, 직접 사용해 볼 수 있는 Colab 노트북(사용 가능한 경우)이 요약되어 있습니다.
+
+| Pipeline | Paper | Tasks | Colab
+|---|---|:---:|:---:|
+| [alt_diffusion](./api/pipelines/alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
+| [audio_diffusion](./api/pipelines/audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation | [](https://colab.research.google.com/github/teticio/audio-diffusion/blob/master/notebooks/audio_diffusion_pipeline.ipynb)
+| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [dance_diffusion](./api/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
+| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
+| [ddim](./api/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./api/pipelines/paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./api/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [score_sde_ve](./api/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [score_sde_vp](./api/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [stable_diffusion](./api/pipelines/stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
+| [stable_diffusion](./api/pipelines/stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+| [stable_diffusion](./api/pipelines/stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb)
+| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
+
+**참고**: 파이프라인은 해당 문서에 설명된 대로 확산 시스템을 사용한 방법에 대한 간단한 예입니다.
diff --git a/diffusers/docs/source/ko/installation.mdx b/diffusers/docs/source/ko/installation.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..a10f9f8d1b52c0281433356f03f81039d4356f91
--- /dev/null
+++ b/diffusers/docs/source/ko/installation.mdx
@@ -0,0 +1,142 @@
+
+
+# 설치
+
+사용하시는 라이브러리에 맞는 🤗 Diffusers를 설치하세요.
+
+🤗 Diffusers는 Python 3.7+, PyTorch 1.7.0+ 및 flax에서 테스트되었습니다. 사용중인 딥러닝 라이브러리에 대한 아래의 설치 안내를 따르세요.
+
+- [PyTorch 설치 안내](https://pytorch.org/get-started/locally/)
+- [Flax 설치 안내](https://flax.readthedocs.io/en/latest/)
+
+## pip를 이용한 설치
+
+[가상 환경](https://docs.python.org/3/library/venv.html)에 🤗 Diffusers를 설치해야 합니다.
+Python 가상 환경에 익숙하지 않은 경우 [가상환경 pip 설치 가이드](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)를 살펴보세요.
+가상 환경을 사용하면 서로 다른 프로젝트를 더 쉽게 관리하고, 종속성간의 호환성 문제를 피할 수 있습니다.
+
+프로젝트 디렉토리에 가상 환경을 생성하는 것으로 시작하세요:
+
+```bash
+python -m venv .env
+```
+
+그리고 가상 환경을 활성화합니다:
+
+```bash
+source .env/bin/activate
+```
+
+이제 다음의 명령어로 🤗 Diffusers를 설치할 준비가 되었습니다:
+
+**PyTorch의 경우**
+
+```bash
+pip install diffusers["torch"]
+```
+
+**Flax의 경우**
+
+```bash
+pip install diffusers["flax"]
+```
+
+## 소스로부터 설치
+
+소스에서 `diffusers`를 설치하기 전에, `torch` 및 `accelerate`이 설치되어 있는지 확인하세요.
+
+`torch` 설치에 대해서는 [torch docs](https://pytorch.org/get-started/locally/#start-locally)를 참고하세요.
+
+다음과 같이 `accelerate`을 설치하세요.
+
+```bash
+pip install accelerate
+```
+
+다음 명령어를 사용하여 소스에서 🤗 Diffusers를 설치하세요:
+
+```bash
+pip install git+https://github.com/huggingface/diffusers
+```
+
+이 명령어는 최신 `stable` 버전이 아닌 최첨단 `main` 버전을 설치합니다.
+`main` 버전은 최신 개발 정보를 최신 상태로 유지하는 데 유용합니다.
+예를 들어 마지막 공식 릴리즈 이후 버그가 수정되었지만, 새 릴리즈가 아직 출시되지 않은 경우입니다.
+그러나 이는 `main` 버전이 항상 안정적이지 않을 수 있음을 의미합니다.
+우리는 `main` 버전이 지속적으로 작동하도록 노력하고 있으며, 대부분의 문제는 보통 몇 시간 또는 하루 안에 해결됩니다.
+문제가 발생하면 더 빨리 해결할 수 있도록 [Issue](https://github.com/huggingface/transformers/issues)를 열어주세요!
+
+
+## 편집가능한 설치
+
+다음을 수행하려면 편집가능한 설치가 필요합니다:
+
+* 소스 코드의 `main` 버전을 사용
+* 🤗 Diffusers에 기여 (코드의 변경 사항을 테스트하기 위해 필요)
+
+저장소를 복제하고 다음 명령어를 사용하여 🤗 Diffusers를 설치합니다:
+
+```bash
+git clone https://github.com/huggingface/diffusers.git
+cd diffusers
+```
+
+**PyTorch의 경우**
+
+```
+pip install -e ".[torch]"
+```
+
+**Flax의 경우**
+
+```
+pip install -e ".[flax]"
+```
+
+이러한 명령어들은 저장소를 복제한 폴더와 Python 라이브러리 경로를 연결합니다.
+Python은 이제 일반 라이브러리 경로에 더하여 복제한 폴더 내부를 살펴봅니다.
+예를들어 Python 패키지가 `~/anaconda3/envs/main/lib/python3.7/site-packages/`에 설치되어 있는 경우 Python은 복제한 폴더인 `~/diffusers/`도 검색합니다.
+
+
+
+라이브러리를 계속 사용하려면 `diffusers` 폴더를 유지해야 합니다.
+
+
+
+이제 다음 명령어를 사용하여 최신 버전의 🤗 Diffusers로 쉽게 업데이트할 수 있습니다:
+
+```bash
+cd ~/diffusers/
+git pull
+```
+
+이렇게 하면, 다음에 실행할 때 Python 환경이 🤗 Diffusers의 `main` 버전을 찾게 됩니다.
+
+## 텔레메트리 로깅에 대한 알림
+
+우리 라이브러리는 `from_pretrained()` 요청 중에 텔레메트리 정보를 원격으로 수집합니다.
+이 데이터에는 Diffusers 및 PyTorch/Flax의 버전, 요청된 모델 또는 파이프라인 클래스, 그리고 허브에서 호스팅되는 경우 사전학습된 체크포인트에 대한 경로를 포함합니다.
+이 사용 데이터는 문제를 디버깅하고 새로운 기능의 우선순위를 지정하는데 도움이 됩니다.
+텔레메트리는 HuggingFace 허브에서 모델과 파이프라인을 불러올 때만 전송되며, 로컬 사용 중에는 수집되지 않습니다.
+
+우리는 추가 정보를 공유하지 않기를 원하는 사람이 있다는 것을 이해하고 개인 정보를 존중하므로, 터미널에서 `DISABLE_TELEMETRY` 환경 변수를 설정하여 텔레메트리 수집을 비활성화할 수 있습니다.
+
+Linux/MacOS에서:
+```bash
+export DISABLE_TELEMETRY=YES
+```
+
+Windows에서:
+```bash
+set DISABLE_TELEMETRY=YES
+```
\ No newline at end of file
diff --git a/diffusers/docs/source/ko/quicktour.mdx b/diffusers/docs/source/ko/quicktour.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e0676ce2a9ca169322c79c17c4cfd224b6163f43
--- /dev/null
+++ b/diffusers/docs/source/ko/quicktour.mdx
@@ -0,0 +1,123 @@
+
+
+# 훑어보기
+
+🧨 Diffusers로 빠르게 시작하고 실행하세요!
+이 훑어보기는 여러분이 개발자, 일반사용자 상관없이 시작하는 데 도움을 주며, 추론을 위해 [`DiffusionPipeline`] 사용하는 방법을 보여줍니다.
+
+시작하기에 앞서서, 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install --upgrade diffusers accelerate transformers
+```
+
+- [`accelerate`](https://huggingface.co/docs/accelerate/index)은 추론 및 학습을 위한 모델 불러오기 속도를 높입니다.
+- [`transformers`](https://huggingface.co/docs/transformers/index)는 [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview)과 같이 가장 널리 사용되는 확산 모델을 실행하기 위해 필요합니다.
+
+## DiffusionPipeline
+
+[`DiffusionPipeline`]은 추론을 위해 사전학습된 확산 시스템을 사용하는 가장 쉬운 방법입니다. 다양한 양식의 많은 작업에 [`DiffusionPipeline`]을 바로 사용할 수 있습니다. 지원되는 작업은 아래의 표를 참고하세요:
+
+| **Task** | **Description** | **Pipeline**
+|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|
+| Unconditional Image Generation | 가우시안 노이즈에서 이미지 생성 | [unconditional_image_generation](./using-diffusers/unconditional_image_generation`) |
+| Text-Guided Image Generation | 텍스트 프롬프트로 이미지 생성 | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
+| Text-Guided Image-to-Image Translation | 텍스트 프롬프트에 따라 이미지 조정 | [img2img](./using-diffusers/img2img) |
+| Text-Guided Image-Inpainting | 마스크 및 텍스트 프롬프트가 주어진 이미지의 마스킹된 부분을 채우기 | [inpaint](./using-diffusers/inpaint) |
+| Text-Guided Depth-to-Image Translation | 깊이 추정을 통해 구조를 유지하면서 텍스트 프롬프트에 따라 이미지의 일부를 조정 | [depth2image](./using-diffusers/depth2image) |
+
+확산 파이프라인이 다양한 작업에 대해 어떻게 작동하는지는 [**Using Diffusers**](./using-diffusers/overview)를 참고하세요.
+
+예를들어, [`DiffusionPipeline`] 인스턴스를 생성하여 시작하고, 다운로드하려는 파이프라인 체크포인트를 지정합니다.
+모든 [Diffusers' checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads)에 대해 [`DiffusionPipeline`]을 사용할 수 있습니다.
+하지만, 이 가이드에서는 [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion)을 사용하여 text-to-image를 하는데 [`DiffusionPipeline`]을 사용합니다.
+
+[Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion) 기반 모델을 실행하기 전에 [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license)를 주의 깊게 읽으세요.
+이는 모델의 향상된 이미지 생성 기능과 이것으로 생성될 수 있는 유해한 콘텐츠 때문입니다. 선택한 Stable Diffusion 모델(*예*: [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5))로 이동하여 라이센스를 읽으세요.
+
+다음과 같이 모델을 로드할 수 있습니다:
+
+```python
+>>> from diffusers import DiffusionPipeline
+
+>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+```
+
+[`DiffusionPipeline`]은 모든 모델링, 토큰화 및 스케줄링 구성요소를 다운로드하고 캐시합니다.
+모델은 약 14억개의 매개변수로 구성되어 있으므로 GPU에서 실행하는 것이 좋습니다.
+PyTorch에서와 마찬가지로 생성기 객체를 GPU로 옮길 수 있습니다.
+
+```python
+>>> pipeline.to("cuda")
+```
+
+이제 `pipeline`을 사용할 수 있습니다:
+
+```python
+>>> image = pipeline("An image of a squirrel in Picasso style").images[0]
+```
+
+출력은 기본적으로 [PIL Image object](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class)로 래핑됩니다.
+
+다음과 같이 함수를 호출하여 이미지를 저장할 수 있습니다:
+
+```python
+>>> image.save("image_of_squirrel_painting.png")
+```
+
+**참고**: 다음을 통해 가중치를 다운로드하여 로컬에서 파이프라인을 사용할 수도 있습니다:
+
+```
+git lfs install
+git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
+```
+
+그리고 저장된 가중치를 파이프라인에 불러옵니다.
+
+```python
+>>> pipeline = DiffusionPipeline.from_pretrained("./stable-diffusion-v1-5")
+```
+
+파이프라인 실행은 동일한 모델 아키텍처이므로 위의 코드와 동일합니다.
+
+```python
+>>> generator.to("cuda")
+>>> image = generator("An image of a squirrel in Picasso style").images[0]
+>>> image.save("image_of_squirrel_painting.png")
+```
+
+확산 시스템은 각각 장점이 있는 여러 다른 [schedulers](./api/schedulers/overview)와 함께 사용할 수 있습니다. 기본적으로 Stable Diffusion은 `PNDMScheduler`로 실행되지만 다른 스케줄러를 사용하는 방법은 매우 간단합니다. *예* [`EulerDiscreteScheduler`] 스케줄러를 사용하려는 경우, 다음과 같이 사용할 수 있습니다:
+
+```python
+>>> from diffusers import EulerDiscreteScheduler
+
+>>> pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+
+>>> # change scheduler to Euler
+>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
+```
+
+스케줄러 변경 방법에 대한 자세한 내용은 [Using Schedulers](./using-diffusers/schedulers) 가이드를 참고하세요.
+
+[Stability AI's](https://stability.ai/)의 Stable Diffusion 모델은 인상적인 이미지 생성 모델이며 텍스트에서 이미지를 생성하는 것보다 훨씬 더 많은 작업을 수행할 수 있습니다. 우리는 Stable Diffusion만을 위한 전체 문서 페이지를 제공합니다 [link](./conceptual/stable_diffusion).
+
+만약 더 적은 메모리, 더 높은 추론 속도, Mac과 같은 특정 하드웨어 또는 ONNX 런타임에서 실행되도록 Stable Diffusion을 최적화하는 방법을 알고 싶다면 최적화 페이지를 살펴보세요:
+
+- [Optimized PyTorch on GPU](./optimization/fp16)
+- [Mac OS with PyTorch](./optimization/mps)
+- [ONNX](./optimization/onnx)
+- [OpenVINO](./optimization/open_vino)
+
+확산 모델을 미세조정하거나 학습시키려면, [**training section**](./training/overview)을 살펴보세요.
+
+마지막으로, 생성된 이미지를 공개적으로 배포할 때 신중을 기해 주세요 🤗.
\ No newline at end of file
diff --git a/diffusers/docs/source/zh/_toctree.yml b/diffusers/docs/source/zh/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..2d67d9c4a025104a13e0de3851e53a690ac86fc5
--- /dev/null
+++ b/diffusers/docs/source/zh/_toctree.yml
@@ -0,0 +1,238 @@
+- sections:
+ - local: index
+ title: 🧨 Diffusers
+ - local: quicktour
+ title: 快速入门
+ - local: stable_diffusion
+ title: Stable Diffusion
+ - local: installation
+ title: 安装
+ title: 开始
+- sections:
+ - local: tutorials/basic_training
+ title: Train a diffusion model
+ title: Tutorials
+- sections:
+ - sections:
+ - local: using-diffusers/loading
+ title: Loading Pipelines, Models, and Schedulers
+ - local: using-diffusers/schedulers
+ title: Using different Schedulers
+ - local: using-diffusers/configuration
+ title: Configuring Pipelines, Models, and Schedulers
+ - local: using-diffusers/custom_pipeline_overview
+ title: Loading and Adding Custom Pipelines
+ - local: using-diffusers/kerascv
+ title: Using KerasCV Stable Diffusion Checkpoints in Diffusers
+ title: Loading & Hub
+ - sections:
+ - local: using-diffusers/unconditional_image_generation
+ title: Unconditional Image Generation
+ - local: using-diffusers/conditional_image_generation
+ title: Text-to-Image Generation
+ - local: using-diffusers/img2img
+ title: Text-Guided Image-to-Image
+ - local: using-diffusers/inpaint
+ title: Text-Guided Image-Inpainting
+ - local: using-diffusers/depth2img
+ title: Text-Guided Depth-to-Image
+ - local: using-diffusers/controlling_generation
+ title: Controlling generation
+ - local: using-diffusers/reusing_seeds
+ title: Reusing seeds for deterministic generation
+ - local: using-diffusers/reproducibility
+ title: Reproducibility
+ - local: using-diffusers/custom_pipeline_examples
+ title: Community Pipelines
+ - local: using-diffusers/contribute_pipeline
+ title: How to contribute a Pipeline
+ - local: using-diffusers/using_safetensors
+ title: Using safetensors
+ title: Pipelines for Inference
+ - sections:
+ - local: using-diffusers/rl
+ title: Reinforcement Learning
+ - local: using-diffusers/audio
+ title: Audio
+ - local: using-diffusers/other-modalities
+ title: Other Modalities
+ title: Taking Diffusers Beyond Images
+ title: Using Diffusers
+- sections:
+ - local: optimization/fp16
+ title: Memory and Speed
+ - local: optimization/torch2.0
+ title: Torch2.0 support
+ - local: optimization/xformers
+ title: xFormers
+ - local: optimization/onnx
+ title: ONNX
+ - local: optimization/open_vino
+ title: OpenVINO
+ - local: optimization/mps
+ title: MPS
+ - local: optimization/habana
+ title: Habana Gaudi
+ title: Optimization/Special Hardware
+- sections:
+ - local: training/overview
+ title: Overview
+ - local: training/unconditional_training
+ title: Unconditional Image Generation
+ - local: training/text_inversion
+ title: Textual Inversion
+ - local: training/dreambooth
+ title: DreamBooth
+ - local: training/text2image
+ title: Text-to-image
+ - local: training/lora
+ title: Low-Rank Adaptation of Large Language Models (LoRA)
+ title: Training
+- sections:
+ - local: conceptual/philosophy
+ title: Philosophy
+ - local: conceptual/contribution
+ title: How to contribute?
+ - local: conceptual/ethical_guidelines
+ title: Diffusers' Ethical Guidelines
+ title: Conceptual Guides
+- sections:
+ - sections:
+ - local: api/models
+ title: Models
+ - local: api/diffusion_pipeline
+ title: Diffusion Pipeline
+ - local: api/logging
+ title: Logging
+ - local: api/configuration
+ title: Configuration
+ - local: api/outputs
+ title: Outputs
+ - local: api/loaders
+ title: Loaders
+ title: Main Classes
+ - sections:
+ - local: api/pipelines/overview
+ title: Overview
+ - local: api/pipelines/alt_diffusion
+ title: AltDiffusion
+ - local: api/pipelines/audio_diffusion
+ title: Audio Diffusion
+ - local: api/pipelines/cycle_diffusion
+ title: Cycle Diffusion
+ - local: api/pipelines/dance_diffusion
+ title: Dance Diffusion
+ - local: api/pipelines/ddim
+ title: DDIM
+ - local: api/pipelines/ddpm
+ title: DDPM
+ - local: api/pipelines/dit
+ title: DiT
+ - local: api/pipelines/latent_diffusion
+ title: Latent Diffusion
+ - local: api/pipelines/paint_by_example
+ title: PaintByExample
+ - local: api/pipelines/pndm
+ title: PNDM
+ - local: api/pipelines/repaint
+ title: RePaint
+ - local: api/pipelines/stable_diffusion_safe
+ title: Safe Stable Diffusion
+ - local: api/pipelines/score_sde_ve
+ title: Score SDE VE
+ - local: api/pipelines/semantic_stable_diffusion
+ title: Semantic Guidance
+ - sections:
+ - local: api/pipelines/stable_diffusion/overview
+ title: Overview
+ - local: api/pipelines/stable_diffusion/text2img
+ title: Text-to-Image
+ - local: api/pipelines/stable_diffusion/img2img
+ title: Image-to-Image
+ - local: api/pipelines/stable_diffusion/inpaint
+ title: Inpaint
+ - local: api/pipelines/stable_diffusion/depth2img
+ title: Depth-to-Image
+ - local: api/pipelines/stable_diffusion/image_variation
+ title: Image-Variation
+ - local: api/pipelines/stable_diffusion/upscale
+ title: Super-Resolution
+ - local: api/pipelines/stable_diffusion/latent_upscale
+ title: Stable-Diffusion-Latent-Upscaler
+ - local: api/pipelines/stable_diffusion/pix2pix
+ title: InstructPix2Pix
+ - local: api/pipelines/stable_diffusion/attend_and_excite
+ title: Attend and Excite
+ - local: api/pipelines/stable_diffusion/pix2pix_zero
+ title: Pix2Pix Zero
+ - local: api/pipelines/stable_diffusion/self_attention_guidance
+ title: Self-Attention Guidance
+ - local: api/pipelines/stable_diffusion/panorama
+ title: MultiDiffusion Panorama
+ - local: api/pipelines/stable_diffusion/controlnet
+ title: Text-to-Image Generation with ControlNet Conditioning
+ title: Stable Diffusion
+ - local: api/pipelines/stable_diffusion_2
+ title: Stable Diffusion 2
+ - local: api/pipelines/stable_unclip
+ title: Stable unCLIP
+ - local: api/pipelines/stochastic_karras_ve
+ title: Stochastic Karras VE
+ - local: api/pipelines/unclip
+ title: UnCLIP
+ - local: api/pipelines/latent_diffusion_uncond
+ title: Unconditional Latent Diffusion
+ - local: api/pipelines/versatile_diffusion
+ title: Versatile Diffusion
+ - local: api/pipelines/vq_diffusion
+ title: VQ Diffusion
+ title: Pipelines
+ - sections:
+ - local: api/schedulers/overview
+ title: Overview
+ - local: api/schedulers/ddim
+ title: DDIM
+ - local: api/schedulers/ddim_inverse
+ title: DDIMInverse
+ - local: api/schedulers/ddpm
+ title: DDPM
+ - local: api/schedulers/deis
+ title: DEIS
+ - local: api/schedulers/dpm_discrete
+ title: DPM Discrete Scheduler
+ - local: api/schedulers/dpm_discrete_ancestral
+ title: DPM Discrete Scheduler with ancestral sampling
+ - local: api/schedulers/euler_ancestral
+ title: Euler Ancestral Scheduler
+ - local: api/schedulers/euler
+ title: Euler scheduler
+ - local: api/schedulers/heun
+ title: Heun Scheduler
+ - local: api/schedulers/ipndm
+ title: IPNDM
+ - local: api/schedulers/lms_discrete
+ title: Linear Multistep
+ - local: api/schedulers/multistep_dpm_solver
+ title: Multistep DPM-Solver
+ - local: api/schedulers/pndm
+ title: PNDM
+ - local: api/schedulers/repaint
+ title: RePaint Scheduler
+ - local: api/schedulers/singlestep_dpm_solver
+ title: Singlestep DPM-Solver
+ - local: api/schedulers/stochastic_karras_ve
+ title: Stochastic Kerras VE
+ - local: api/schedulers/unipc
+ title: UniPCMultistepScheduler
+ - local: api/schedulers/score_sde_ve
+ title: VE-SDE
+ - local: api/schedulers/score_sde_vp
+ title: VP-SDE
+ - local: api/schedulers/vq_diffusion
+ title: VQDiffusionScheduler
+ title: Schedulers
+ - sections:
+ - local: api/experimental/rl
+ title: RL Planning
+ title: Experimental Features
+ title: API
diff --git a/diffusers/docs/source/zh/index.mdx b/diffusers/docs/source/zh/index.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..4f952c5db79ccfa120fb23e11303a9a878a887f5
--- /dev/null
+++ b/diffusers/docs/source/zh/index.mdx
@@ -0,0 +1,78 @@
+
+
+
+
+
+
+
+
+# 🧨 Diffusers
+
+🤗Diffusers提供了预训练好的视觉和音频扩散模型,并可以作为推理和训练的模块化工具箱。
+
+更准确地说,🤗Diffusers提供了:
+
+- 最先进的扩散管道,可以在推理中仅用几行代码运行(详情看[**Using Diffusers**](./using-diffusers/conditional_image_generation))或看[**管道**](#pipelines) 以获取所有支持的管道及其对应的论文的概述。
+- 可以在推理中交替使用的各种噪声调度程序,以便在推理过程中权衡如何选择速度和质量。有关更多信息,可以看[**Schedulers**](./api/schedulers/overview)。
+- 多种类型的模型,如U-Net,可用作端到端扩散系统中的构建模块。有关更多详细信息,可以看 [**Models**](./api/models) 。
+- 训练示例,展示如何训练最流行的扩散模型任务。更多相关信息,可以看[**Training**](./training/overview)。
+
+
+## 🧨 Diffusers pipelines
+
+下表总结了所有官方支持的pipelines及其对应的论文,部分提供了colab,可以直接尝试一下。
+
+
+| 管道 | 论文 | 任务 | Colab
+|---|---|:---:|:---:|
+| [alt_diffusion](./api/pipelines/alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
+| [audio_diffusion](./api/pipelines/audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation | [](https://colab.research.google.com/github/teticio/audio-diffusion/blob/master/notebooks/audio_diffusion_pipeline.ipynb)
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb)
+| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [dance_diffusion](./api/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
+| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
+| [ddim](./api/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./api/pipelines/paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./api/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [score_sde_ve](./api/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [score_sde_vp](./api/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [**Semantic Guidance**](https://arxiv.org/abs/2301.12247) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/semantic-image-editing/blob/main/examples/SemanticGuidance.ipynb)
+| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
+| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
+| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [**MultiDiffusion**](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
+| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [**InstructPix2Pix**](https://github.com/timothybrooks/instruct-pix2pix) | Text-Guided Image Editing|
+| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [**Zero-shot Image-to-Image Translation**](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
+| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [**Attend and Excite for Stable Diffusion**](https://attendandexcite.github.io/Attend-and-Excite/) | Text-to-Image Generation |
+| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [**Self-Attention Guidance**](https://ku-cvlab.github.io/Self-Attention-Guidance) | Text-to-Image Generation |
+| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [**Stable Diffusion Image Variations**](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
+| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [**Stable Diffusion Latent Upscaler**](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Depth-Conditional Stable Diffusion**](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation | [](https://colab.research.google.com/github/ml-research/safe-latent-diffusion/blob/main/examples/Safe%20Latent%20Diffusion.ipynb)
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
+| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
+
+
+**注意**: 管道是如何使用相应论文中提出的扩散模型的简单示例。
\ No newline at end of file
diff --git a/diffusers/docs/source/zh/installation.mdx b/diffusers/docs/source/zh/installation.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..cda91df8a6cd6fa99dd8710adca08ed08844dafb
--- /dev/null
+++ b/diffusers/docs/source/zh/installation.mdx
@@ -0,0 +1,147 @@
+
+
+# 安装
+
+安装🤗 Diffusers 到你正在使用的任何深度学习框架中。
+
+🤗 Diffusers已在Python 3.7+、PyTorch 1.7.0+和Flax上进行了测试。按照下面的安装说明,针对你正在使用的深度学习框架进行安装:
+
+- [PyTorch](https://pytorch.org/get-started/locally/) installation instructions.
+- [Flax](https://flax.readthedocs.io/en/latest/) installation instructions.
+
+## 使用pip安装
+
+你需要在[虚拟环境](https://docs.python.org/3/library/venv.html)中安装🤗 Diffusers 。
+
+如果你对 Python 虚拟环境不熟悉,可以看看这个[教程](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+
+使用虚拟环境你可以轻松管理不同的项目,避免了依赖项之间的兼容性问题。
+
+首先,在你的项目目录下创建一个虚拟环境:
+
+```bash
+python -m venv .env
+```
+
+激活虚拟环境:
+
+```bash
+source .env/bin/activate
+```
+
+现在你就可以安装 🤗 Diffusers了!使用下边这个命令:
+
+**PyTorch**
+
+```bash
+pip install diffusers["torch"]
+```
+
+**Flax**
+
+```bash
+pip install diffusers["flax"]
+```
+
+## 从源代码安装
+
+在从源代码安装 `diffusers` 之前,你先确定你已经安装了 `torch` 和 `accelerate`。
+
+`torch`的安装教程可以看 `torch` [文档](https://pytorch.org/get-started/locally/#start-locally).
+
+安装 `accelerate`
+
+```bash
+pip install accelerate
+```
+
+从源码安装 🤗 Diffusers 使用以下命令:
+
+```bash
+pip install git+https://github.com/huggingface/diffusers
+```
+
+这个命令安装的是最新的 `main`版本,而不是最近的`stable`版。
+`main`是一直和最新进展保持一致的。比如,上次正式版发布了,有bug,新的正式版还没推出,但是`main`中可以看到这个bug被修复了。
+但是这也意味着 `main`版本并不总是稳定的。
+
+我们努力保持`main`版本正常运行,大多数问题都能在几个小时或一天之内解决
+
+如果你遇到了问题,可以提 [Issue](https://github.com/huggingface/transformers/issues),这样我们就能更快修复问题了。
+
+## 可修改安装
+
+如果你想做以下两件事,那你可能需要一个可修改代码的安装方式:
+
+* 使用 `main`版本的源代码。
+* 为 🤗 Diffusers 贡献,需要测试代码中的变化。
+
+使用以下命令克隆并安装 🤗 Diffusers:
+
+```bash
+git clone https://github.com/huggingface/diffusers.git
+cd diffusers
+```
+
+**PyTorch**
+
+```
+pip install -e ".[torch]"
+```
+
+**Flax**
+
+```
+pip install -e ".[flax]"
+```
+
+这些命令将连接你克隆的版本库和你的 Python 库路径。
+现在,除了正常的库路径外,Python 还会在你克隆的文件夹内寻找。
+例如,如果你的 Python 包通常安装在 `~/anaconda3/envs/main/lib/python3.7/Site-packages/`,Python 也会搜索你克隆到的文件夹。`~/diffusers/`。
+
+
+
+如果你想继续使用这个库,你必须保留 `diffusers` 文件夹。
+
+
+
+
+现在你可以用下面的命令轻松地将你克隆的🤗Diffusers仓库更新到最新版本。
+
+```bash
+cd ~/diffusers/
+git pull
+```
+
+你的Python环境将在下次运行时找到`main`版本的🤗 Diffusers。
+
+## 注意遥测日志
+
+我们的库会在使用`from_pretrained()`请求期间收集信息。这些数据包括Diffusers和PyTorch/Flax的版本,请求的模型或管道,以及预训练检查点的路径(如果它被托管在Hub上)。
+
+这些使用数据有助于我们调试问题并优先考虑新功能。
+当从HuggingFace Hub加载模型和管道时才会发送遥测数据,并且在本地使用时不会收集数据。
+
+我们知道并不是每个人都想分享这些的信息,我们尊重您的隐私,
+因此您可以通过在终端中设置“DISABLE_TELEMETRY”环境变量来禁用遥测数据的收集:
+
+
+在Linux/MacOS中:
+```bash
+export DISABLE_TELEMETRY=YES
+```
+
+在Windows中:
+```bash
+set DISABLE_TELEMETRY=YES
+```
\ No newline at end of file
diff --git a/diffusers/docs/source/zh/quicktour.mdx b/diffusers/docs/source/zh/quicktour.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..68ab56c55a85a53c6b444d7831a059f7bed745f4
--- /dev/null
+++ b/diffusers/docs/source/zh/quicktour.mdx
@@ -0,0 +1,331 @@
+
+
+[[open-in-colab]]
+
+# 快速上手
+
+训练扩散模型,是为了对随机高斯噪声进行逐步去噪,以生成令人感兴趣的样本,比如图像或者语音。
+
+扩散模型的发展引起了人们对生成式人工智能的极大兴趣,你可能已经在网上见过扩散生成的图像了。🧨 Diffusers库的目的是让大家更易上手扩散模型。
+
+无论你是开发人员还是普通用户,本文将向你介绍🧨 Diffusers 并帮助你快速开始生成内容!
+
+🧨 Diffusers 库的三个主要组件:
+
+
+无论你是开发者还是普通用户,这个快速指南将向你介绍🧨 Diffusers,并帮助你快速使用和生成!该库三个主要部分如下:
+
+* [`DiffusionPipeline`]是一个高级的端到端类,旨在通过预训练的扩散模型快速生成样本进行推理。
+* 作为创建扩散系统做组件的流行的预训练[模型](./api/models)框架和模块。
+* 许多不同的[调度器](./api/schedulers/overview):控制如何在训练过程中添加噪声的算法,以及如何在推理过程中生成去噪图像的算法。
+
+快速入门将告诉你如何使用[`DiffusionPipeline`]进行推理,然后指导你如何结合模型和调度器以复现[`DiffusionPipeline`]内部发生的事情。
+
+
+
+快速入门是🧨[Diffusers入门](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)的简化版,可以帮助你快速上手。如果你想了解更多关于🧨 Diffusers的目标、设计理念以及关于它的核心API的更多细节,可以点击🧨[Diffusers入门](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)查看。
+
+
+
+在开始之前,确认一下你已经安装好了所需要的库:
+
+```bash
+pip install --upgrade diffusers accelerate transformers
+```
+
+- [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) 在推理和训练过程中加速模型加载。
+- [🤗 Transformers](https://huggingface.co/docs/transformers/index) 是运行最流行的扩散模型所必须的库,比如[Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview).
+
+## 扩散模型管道
+
+[`DiffusionPipeline`]是用预训练的扩散系统进行推理的最简单方法。它是一个包含模型和调度器的端到端系统。你可以直接使用[`DiffusionPipeline`]完成许多任务。请查看下面的表格以了解一些支持的任务,要获取完整的支持任务列表,请查看[🧨 Diffusers 总结](./api/pipelines/overview#diffusers-summary) 。
+
+| **任务** | **描述** | **管道**
+|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|
+| Unconditional Image Generation | 从高斯噪声中生成图片 | [unconditional_image_generation](./using-diffusers/unconditional_image_generation) |
+| Text-Guided Image Generation | 给定文本提示生成图像 | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
+| Text-Guided Image-to-Image Translation | 在文本提示的指导下调整图像 | [img2img](./using-diffusers/img2img) |
+| Text-Guided Image-Inpainting | 给出图像、遮罩和文本提示,填充图像的遮罩部分 | [inpaint](./using-diffusers/inpaint) |
+| Text-Guided Depth-to-Image Translation | 在文本提示的指导下调整图像的部分内容,同时通过深度估计保留其结构 | [depth2img](./using-diffusers/depth2img) |
+
+首先创建一个[`DiffusionPipeline`]的实例,并指定要下载的pipeline检查点。
+你可以使用存储在Hugging Face Hub上的任何[`DiffusionPipeline`][检查点](https://huggingface.co/models?library=diffusers&sort=downloads)。
+在教程中,你将加载[`stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)检查点,用于文本到图像的生成。
+
+首先创建一个[DiffusionPipeline]实例,并指定要下载的管道检查点。
+您可以在Hugging Face Hub上使用[DiffusionPipeline]的任何检查点。
+在本快速入门中,您将加载stable-diffusion-v1-5检查点,用于文本到图像生成。
+
+。
+
+对于[Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion)模型,在运行该模型之前,请先仔细阅读[许可证](https://huggingface.co/spaces/CompVis/stable-diffusion-license)。🧨 Diffusers实现了一个[`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py),以防止有攻击性的或有害的内容,但Stable Diffusion模型改进图像的生成能力仍有可能产生潜在的有害内容。
+
+
+
+用[`~DiffusionPipeline.from_pretrained`]方法加载模型。
+
+```python
+>>> from diffusers import DiffusionPipeline
+
+>>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+```
+[`DiffusionPipeline`]会下载并缓存所有的建模、标记化和调度组件。你可以看到Stable Diffusion的pipeline是由[`UNet2DConditionModel`]和[`PNDMScheduler`]等组件组成的:
+
+```py
+>>> pipeline
+StableDiffusionPipeline {
+ "_class_name": "StableDiffusionPipeline",
+ "_diffusers_version": "0.13.1",
+ ...,
+ "scheduler": [
+ "diffusers",
+ "PNDMScheduler"
+ ],
+ ...,
+ "unet": [
+ "diffusers",
+ "UNet2DConditionModel"
+ ],
+ "vae": [
+ "diffusers",
+ "AutoencoderKL"
+ ]
+}
+```
+
+我们强烈建议你在GPU上运行这个pipeline,因为该模型由大约14亿个参数组成。
+
+你可以像在Pytorch里那样把生成器对象移到GPU上:
+
+```python
+>>> pipeline.to("cuda")
+```
+
+现在你可以向`pipeline`传递一个文本提示来生成图像,然后获得去噪的图像。默认情况下,图像输出被放在一个[`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class)对象中。
+
+```python
+>>> image = pipeline("An image of a squirrel in Picasso style").images[0]
+>>> image
+```
+
+
+
+
+
+
+
+
+
+The output is an "edited" image that reflects the edit instruction applied on the input image:
+
+
+
+
+
+The `train_instruct_pix2pix.py` script shows how to implement the training procedure and adapt it for Stable Diffusion.
+
+***Disclaimer: Even though `train_instruct_pix2pix.py` implements the InstructPix2Pix
+training procedure while being faithful to the [original implementation](https://github.com/timothybrooks/instruct-pix2pix) we have only tested it on a [small-scale dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples). This can impact the end results. For better results, we recommend longer training runs with a larger dataset. [Here](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) you can find a large dataset for InstructPix2Pix training.***
+
+## Running locally with PyTorch
+
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install -e .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+Or for a default accelerate configuration without answering questions about your environment
+
+```bash
+accelerate config default
+```
+
+Or if your environment doesn't support an interactive shell e.g. a notebook
+
+```python
+from accelerate.utils import write_basic_config
+write_basic_config()
+```
+
+### Toy example
+
+As mentioned before, we'll use a [small toy dataset](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) for training. The dataset
+is a smaller version of the [original dataset](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) used in the InstructPix2Pix paper.
+
+Configure environment variables such as the dataset identifier and the Stable Diffusion
+checkpoint:
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export DATASET_ID="fusing/instructpix2pix-1000-samples"
+```
+
+Now, we can launch training:
+
+```bash
+accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$DATASET_ID \
+ --enable_xformers_memory_efficient_attention \
+ --resolution=256 --random_flip \
+ --train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
+ --max_train_steps=15000 \
+ --checkpointing_steps=5000 --checkpoints_total_limit=1 \
+ --learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
+ --conditioning_dropout_prob=0.05 \
+ --mixed_precision=fp16 \
+ --seed=42
+```
+
+Additionally, we support performing validation inference to monitor training progress
+with Weights and Biases. You can enable this feature with `report_to="wandb"`:
+
+```bash
+accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$DATASET_ID \
+ --enable_xformers_memory_efficient_attention \
+ --resolution=256 --random_flip \
+ --train_batch_size=4 --gradient_accumulation_steps=4 --gradient_checkpointing \
+ --max_train_steps=15000 \
+ --checkpointing_steps=5000 --checkpoints_total_limit=1 \
+ --learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
+ --conditioning_dropout_prob=0.05 \
+ --mixed_precision=fp16 \
+ --val_image_url="https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png" \
+ --validation_prompt="make the mountains snowy" \
+ --seed=42 \
+ --report_to=wandb
+ ```
+
+ We recommend this type of validation as it can be useful for model debugging. Note that you need `wandb` installed to use this. You can install `wandb` by running `pip install wandb`.
+
+ [Here](https://wandb.ai/sayakpaul/instruct-pix2pix/runs/ctr3kovq), you can find an example training run that includes some validation samples and the training hyperparameters.
+
+ ***Note: In the original paper, the authors observed that even when the model is trained with an image resolution of 256x256, it generalizes well to bigger resolutions such as 512x512. This is likely because of the larger dataset they used during training.***
+
+ ## Inference
+
+ Once training is complete, we can perform inference:
+
+ ```python
+import PIL
+import requests
+import torch
+from diffusers import StableDiffusionInstructPix2PixPipeline
+
+model_id = "your_model_id" # <- replace this
+pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+generator = torch.Generator("cuda").manual_seed(0)
+
+url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/test_pix2pix_4.png"
+
+
+def download_image(url):
+ image = PIL.Image.open(requests.get(url, stream=True).raw)
+ image = PIL.ImageOps.exif_transpose(image)
+ image = image.convert("RGB")
+ return image
+
+image = download_image(url)
+prompt = "wipe out the lake"
+num_inference_steps = 20
+image_guidance_scale = 1.5
+guidance_scale = 10
+
+edited_image = pipe(prompt,
+ image=image,
+ num_inference_steps=num_inference_steps,
+ image_guidance_scale=image_guidance_scale,
+ guidance_scale=guidance_scale,
+ generator=generator,
+).images[0]
+edited_image.save("edited_image.png")
+```
+
+An example model repo obtained using this training script can be found
+here - [sayakpaul/instruct-pix2pix](https://huggingface.co/sayakpaul/instruct-pix2pix).
+
+We encourage you to play with the following three parameters to control
+speed and quality during performance:
+
+* `num_inference_steps`
+* `image_guidance_scale`
+* `guidance_scale`
+
+Particularly, `image_guidance_scale` and `guidance_scale` can have a profound impact
+on the generated ("edited") image (see [here](https://twitter.com/RisingSayak/status/1628392199196151808?s=20) for an example).
diff --git a/diffusers/examples/instruct_pix2pix/requirements.txt b/diffusers/examples/instruct_pix2pix/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..176ef92a1424045016a37252ef35fa1c7865701b
--- /dev/null
+++ b/diffusers/examples/instruct_pix2pix/requirements.txt
@@ -0,0 +1,6 @@
+accelerate
+torchvision
+transformers>=4.25.1
+datasets
+ftfy
+tensorboard
\ No newline at end of file
diff --git a/diffusers/examples/instruct_pix2pix/train_instruct_pix2pix.py b/diffusers/examples/instruct_pix2pix/train_instruct_pix2pix.py
new file mode 100644
index 0000000000000000000000000000000000000000..a119e12f73d1aaec4e383e8f8acf1b5a496ee1d7
--- /dev/null
+++ b/diffusers/examples/instruct_pix2pix/train_instruct_pix2pix.py
@@ -0,0 +1,988 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Script to fine-tune Stable Diffusion for InstructPix2Pix."""
+
+import argparse
+import logging
+import math
+import os
+from pathlib import Path
+
+import accelerate
+import datasets
+import numpy as np
+import PIL
+import requests
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from datasets import load_dataset
+from huggingface_hub import create_repo, upload_folder
+from packaging import version
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+import diffusers
+from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionInstructPix2PixPipeline, UNet2DConditionModel
+from diffusers.optimization import get_scheduler
+from diffusers.training_utils import EMAModel
+from diffusers.utils import check_min_version, deprecate, is_wandb_available
+from diffusers.utils.import_utils import is_xformers_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.15.0.dev0")
+
+logger = get_logger(__name__, log_level="INFO")
+
+DATASET_NAME_MAPPING = {
+ "fusing/instructpix2pix-1000-samples": ("input_image", "edit_prompt", "edited_image"),
+}
+WANDB_TABLE_COL_NAMES = ["original_image", "edited_image", "edit_prompt"]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script for InstructPix2Pix.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that 🤗 Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--original_image_column",
+ type=str,
+ default="input_image",
+ help="The column of the dataset containing the original image on which edits where made.",
+ )
+ parser.add_argument(
+ "--edited_image_column",
+ type=str,
+ default="edited_image",
+ help="The column of the dataset containing the edited image.",
+ )
+ parser.add_argument(
+ "--edit_prompt_column",
+ type=str,
+ default="edit_prompt",
+ help="The column of the dataset containing the edit instruction.",
+ )
+ parser.add_argument(
+ "--val_image_url",
+ type=str,
+ default=None,
+ help="URL to the original image that you would like to edit (used during inference for debugging purposes).",
+ )
+ parser.add_argument(
+ "--validation_prompt", type=str, default=None, help="A prompt that is sampled during training for inference."
+ )
+ parser.add_argument(
+ "--num_validation_images",
+ type=int,
+ default=4,
+ help="Number of images that should be generated during validation with `validation_prompt`.",
+ )
+ parser.add_argument(
+ "--validation_epochs",
+ type=int,
+ default=1,
+ help=(
+ "Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
+ " `args.validation_prompt` multiple times: `args.num_validation_images`."
+ ),
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="instruct-pix2pix-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=256,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--conditioning_dropout_prob",
+ type=float,
+ default=None,
+ help="Conditioning dropout probability. Drops out the conditionings (image and edit prompt) used in training InstructPix2Pix. See section 3.2.1 in the paper: https://arxiv.org/abs/2211.09800.",
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
+ parser.add_argument(
+ "--non_ema_revision",
+ type=str,
+ default=None,
+ required=False,
+ help=(
+ "Revision of pretrained non-ema model identifier. Must be a branch, tag or git identifier of the local or"
+ " remote repository specified with --pretrained_model_name_or_path."
+ ),
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_data_dir is None:
+ raise ValueError("Need either a dataset name or a training folder.")
+
+ # default to using the same revision for the non-ema model if not specified
+ if args.non_ema_revision is None:
+ args.non_ema_revision = args.revision
+
+ return args
+
+
+def convert_to_np(image, resolution):
+ image = image.convert("RGB").resize((resolution, resolution))
+ return np.array(image).transpose(2, 0, 1)
+
+
+def download_image(url):
+ image = PIL.Image.open(requests.get(url, stream=True).raw)
+ image = PIL.ImageOps.exif_transpose(image)
+ image = image.convert("RGB")
+ return image
+
+
+def main():
+ args = parse_args()
+
+ if args.non_ema_revision is not None:
+ deprecate(
+ "non_ema_revision!=None",
+ "0.15.0",
+ message=(
+ "Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
+ " use `--variant=non_ema` instead."
+ ),
+ )
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+
+ generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
+
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+ import wandb
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load scheduler, tokenizer and models.
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ tokenizer = CLIPTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
+ )
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
+ )
+
+ # InstructPix2Pix uses an additional image for conditioning. To accommodate that,
+ # it uses 8 channels (instead of 4) in the first (conv) layer of the UNet. This UNet is
+ # then fine-tuned on the custom InstructPix2Pix dataset. This modified UNet is initialized
+ # from the pre-trained checkpoints. For the extra channels added to the first layer, they are
+ # initialized to zero.
+ if accelerator.is_main_process:
+ logger.info("Initializing the InstructPix2Pix UNet from the pretrained UNet.")
+ in_channels = 8
+ out_channels = unet.conv_in.out_channels
+ unet.register_to_config(in_channels=in_channels)
+
+ with torch.no_grad():
+ new_conv_in = nn.Conv2d(
+ in_channels, out_channels, unet.conv_in.kernel_size, unet.conv_in.stride, unet.conv_in.padding
+ )
+ new_conv_in.weight.zero_()
+ new_conv_in.weight[:, :4, :, :].copy_(unet.conv_in.weight)
+ unet.conv_in = new_conv_in
+
+ # Freeze vae and text_encoder
+ vae.requires_grad_(False)
+ text_encoder.requires_grad_(False)
+
+ # Create EMA for the unet.
+ if args.use_ema:
+ ema_unet = EMAModel(unet.parameters(), model_cls=UNet2DConditionModel, model_config=unet.config)
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # `accelerate` 0.16.0 will have better support for customized saving
+ if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
+ # create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
+ def save_model_hook(models, weights, output_dir):
+ if args.use_ema:
+ ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
+
+ for i, model in enumerate(models):
+ model.save_pretrained(os.path.join(output_dir, "unet"))
+
+ # make sure to pop weight so that corresponding model is not saved again
+ weights.pop()
+
+ def load_model_hook(models, input_dir):
+ if args.use_ema:
+ load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DConditionModel)
+ ema_unet.load_state_dict(load_model.state_dict())
+ ema_unet.to(accelerator.device)
+ del load_model
+
+ for i in range(len(models)):
+ # pop models so that they are not loaded again
+ model = models.pop()
+
+ # load diffusers style into model
+ load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
+ model.register_to_config(**load_model.config)
+
+ model.load_state_dict(load_model.state_dict())
+ del load_model
+
+ accelerator.register_save_state_pre_hook(save_model_hook)
+ accelerator.register_load_state_pre_hook(load_model_hook)
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
+ )
+
+ optimizer_cls = bnb.optim.AdamW8bit
+ else:
+ optimizer_cls = torch.optim.AdamW
+
+ optimizer = optimizer_cls(
+ unet.parameters(),
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ )
+ else:
+ data_files = {}
+ if args.train_data_dir is not None:
+ data_files["train"] = os.path.join(args.train_data_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=args.cache_dir,
+ )
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/main/en/image_load#imagefolder
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ column_names = dataset["train"].column_names
+
+ # 6. Get the column names for input/target.
+ dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
+ if args.original_image_column is None:
+ original_image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ original_image_column = args.original_image_column
+ if original_image_column not in column_names:
+ raise ValueError(
+ f"--original_image_column' value '{args.original_image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.edit_prompt_column is None:
+ edit_prompt_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ edit_prompt_column = args.edit_prompt_column
+ if edit_prompt_column not in column_names:
+ raise ValueError(
+ f"--edit_prompt_column' value '{args.edit_prompt_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.edited_image_column is None:
+ edited_image_column = dataset_columns[2] if dataset_columns is not None else column_names[2]
+ else:
+ edited_image_column = args.edited_image_column
+ if edited_image_column not in column_names:
+ raise ValueError(
+ f"--edited_image_column' value '{args.edited_image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Preprocessing the datasets.
+ # We need to tokenize input captions and transform the images.
+ def tokenize_captions(captions):
+ inputs = tokenizer(
+ captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
+ )
+ return inputs.input_ids
+
+ # Preprocessing the datasets.
+ train_transforms = transforms.Compose(
+ [
+ transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
+ transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
+ ]
+ )
+
+ def preprocess_images(examples):
+ original_images = np.concatenate(
+ [convert_to_np(image, args.resolution) for image in examples[original_image_column]]
+ )
+ edited_images = np.concatenate(
+ [convert_to_np(image, args.resolution) for image in examples[edited_image_column]]
+ )
+ # We need to ensure that the original and the edited images undergo the same
+ # augmentation transforms.
+ images = np.concatenate([original_images, edited_images])
+ images = torch.tensor(images)
+ images = 2 * (images / 255) - 1
+ return train_transforms(images)
+
+ def preprocess_train(examples):
+ # Preprocess images.
+ preprocessed_images = preprocess_images(examples)
+ # Since the original and edited images were concatenated before
+ # applying the transformations, we need to separate them and reshape
+ # them accordingly.
+ original_images, edited_images = preprocessed_images.chunk(2)
+ original_images = original_images.reshape(-1, 3, args.resolution, args.resolution)
+ edited_images = edited_images.reshape(-1, 3, args.resolution, args.resolution)
+
+ # Collate the preprocessed images into the `examples`.
+ examples["original_pixel_values"] = original_images
+ examples["edited_pixel_values"] = edited_images
+
+ # Preprocess the captions.
+ captions = list(examples[edit_prompt_column])
+ examples["input_ids"] = tokenize_captions(captions)
+ return examples
+
+ with accelerator.main_process_first():
+ if args.max_train_samples is not None:
+ dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ train_dataset = dataset["train"].with_transform(preprocess_train)
+
+ def collate_fn(examples):
+ original_pixel_values = torch.stack([example["original_pixel_values"] for example in examples])
+ original_pixel_values = original_pixel_values.to(memory_format=torch.contiguous_format).float()
+ edited_pixel_values = torch.stack([example["edited_pixel_values"] for example in examples])
+ edited_pixel_values = edited_pixel_values.to(memory_format=torch.contiguous_format).float()
+ input_ids = torch.stack([example["input_ids"] for example in examples])
+ return {
+ "original_pixel_values": original_pixel_values,
+ "edited_pixel_values": edited_pixel_values,
+ "input_ids": input_ids,
+ }
+
+ # DataLoaders creation:
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ shuffle=True,
+ collate_fn=collate_fn,
+ batch_size=args.train_batch_size,
+ num_workers=args.dataloader_num_workers,
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+
+ if args.use_ema:
+ ema_unet.to(accelerator.device)
+
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move text_encode and vae to gpu and cast to weight_dtype
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+ vae.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("instruct-pix2pix", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ train_loss = 0.0
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(unet):
+ # We want to learn the denoising process w.r.t the edited images which
+ # are conditioned on the original image (which was edited) and the edit instruction.
+ # So, first, convert images to latent space.
+ latents = vae.encode(batch["edited_pixel_values"].to(weight_dtype)).latent_dist.sample()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning.
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Get the additional image embedding for conditioning.
+ # Instead of getting a diagonal Gaussian here, we simply take the mode.
+ original_image_embeds = vae.encode(batch["original_pixel_values"].to(weight_dtype)).latent_dist.mode()
+
+ # Conditioning dropout to support classifier-free guidance during inference. For more details
+ # check out the section 3.2.1 of the original paper https://arxiv.org/abs/2211.09800.
+ if args.conditioning_dropout_prob is not None:
+ random_p = torch.rand(bsz, device=latents.device, generator=generator)
+ # Sample masks for the edit prompts.
+ prompt_mask = random_p < 2 * args.conditioning_dropout_prob
+ prompt_mask = prompt_mask.reshape(bsz, 1, 1)
+ # Final text conditioning.
+ null_conditioning = text_encoder(tokenize_captions([""]).to(accelerator.device))[0]
+ encoder_hidden_states = torch.where(prompt_mask, null_conditioning, encoder_hidden_states)
+
+ # Sample masks for the original images.
+ image_mask_dtype = original_image_embeds.dtype
+ image_mask = 1 - (
+ (random_p >= args.conditioning_dropout_prob).to(image_mask_dtype)
+ * (random_p < 3 * args.conditioning_dropout_prob).to(image_mask_dtype)
+ )
+ image_mask = image_mask.reshape(bsz, 1, 1, 1)
+ # Final image conditioning.
+ original_image_embeds = image_mask * original_image_embeds
+
+ # Concatenate the `original_image_embeds` with the `noisy_latents`.
+ concatenated_noisy_latents = torch.cat([noisy_latents, original_image_embeds], dim=1)
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ # Predict the noise residual and compute loss
+ model_pred = unet(concatenated_noisy_latents, timesteps, encoder_hidden_states).sample
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ # Gather the losses across all processes for logging (if we use distributed training).
+ avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
+ train_loss += avg_loss.item() / args.gradient_accumulation_steps
+
+ # Backpropagate
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ if args.use_ema:
+ ema_unet.step(unet.parameters())
+ progress_bar.update(1)
+ global_step += 1
+ accelerator.log({"train_loss": train_loss}, step=global_step)
+ train_loss = 0.0
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if accelerator.is_main_process:
+ if (
+ (args.val_image_url is not None)
+ and (args.validation_prompt is not None)
+ and (epoch % args.validation_epochs == 0)
+ ):
+ logger.info(
+ f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
+ f" {args.validation_prompt}."
+ )
+ # create pipeline
+ if args.use_ema:
+ # Store the UNet parameters temporarily and load the EMA parameters to perform inference.
+ ema_unet.store(unet.parameters())
+ ema_unet.copy_to(unet.parameters())
+ pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=unet,
+ revision=args.revision,
+ torch_dtype=weight_dtype,
+ )
+ pipeline = pipeline.to(accelerator.device)
+ pipeline.set_progress_bar_config(disable=True)
+
+ # run inference
+ original_image = download_image(args.val_image_url)
+ edited_images = []
+ with torch.autocast(str(accelerator.device), enabled=accelerator.mixed_precision == "fp16"):
+ for _ in range(args.num_validation_images):
+ edited_images.append(
+ pipeline(
+ args.validation_prompt,
+ image=original_image,
+ num_inference_steps=20,
+ image_guidance_scale=1.5,
+ guidance_scale=7,
+ generator=generator,
+ ).images[0]
+ )
+
+ for tracker in accelerator.trackers:
+ if tracker.name == "wandb":
+ wandb_table = wandb.Table(columns=WANDB_TABLE_COL_NAMES)
+ for edited_image in edited_images:
+ wandb_table.add_data(
+ wandb.Image(original_image), wandb.Image(edited_image), args.validation_prompt
+ )
+ tracker.log({"validation": wandb_table})
+ if args.use_ema:
+ # Switch back to the original UNet parameters.
+ ema_unet.restore(unet.parameters())
+
+ del pipeline
+ torch.cuda.empty_cache()
+
+ # Create the pipeline using the trained modules and save it.
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ unet = accelerator.unwrap_model(unet)
+ if args.use_ema:
+ ema_unet.copy_to(unet.parameters())
+
+ pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ vae=accelerator.unwrap_model(vae),
+ unet=unet,
+ revision=args.revision,
+ )
+ pipeline.save_pretrained(args.output_dir)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ if args.validation_prompt is not None:
+ edited_images = []
+ pipeline = pipeline.to(accelerator.device)
+ with torch.autocast(str(accelerator.device)):
+ for _ in range(args.num_validation_images):
+ edited_images.append(
+ pipeline(
+ args.validation_prompt,
+ image=original_image,
+ num_inference_steps=20,
+ image_guidance_scale=1.5,
+ guidance_scale=7,
+ generator=generator,
+ ).images[0]
+ )
+
+ for tracker in accelerator.trackers:
+ if tracker.name == "wandb":
+ wandb_table = wandb.Table(columns=WANDB_TABLE_COL_NAMES)
+ for edited_image in edited_images:
+ wandb_table.add_data(
+ wandb.Image(original_image), wandb.Image(edited_image), args.validation_prompt
+ )
+ tracker.log({"test": wandb_table})
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/README.md b/diffusers/examples/research_projects/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ef50d423e68ff5c641e4419bd30f84787aebf839
--- /dev/null
+++ b/diffusers/examples/research_projects/README.md
@@ -0,0 +1,14 @@
+# Research projects
+
+This folder contains various research projects using 🧨 Diffusers.
+They are not really maintained by the core maintainers of this library and often require a specific version of Diffusers that is indicated in the requirements file of each folder.
+Updating them to the most recent version of the library will require some work.
+
+To use any of them, just run the command
+
+```
+pip install -r requirements.txt
+```
+inside the folder of your choice.
+
+If you need help with any of those, please open an issue where you directly ping the author(s), as indicated at the top of the README of each folder.
diff --git a/diffusers/examples/research_projects/colossalai/README.md b/diffusers/examples/research_projects/colossalai/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..7c428bbce736de2ba25f189ff19d4c8216c53fc5
--- /dev/null
+++ b/diffusers/examples/research_projects/colossalai/README.md
@@ -0,0 +1,111 @@
+# [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) by [colossalai](https://github.com/hpcaitech/ColossalAI.git)
+
+[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
+The `train_dreambooth_colossalai.py` script shows how to implement the training procedure and adapt it for stable diffusion.
+
+By accommodating model data in CPU and GPU and moving the data to the computing device when necessary, [Gemini](https://www.colossalai.org/docs/advanced_tutorials/meet_gemini), the Heterogeneous Memory Manager of [Colossal-AI](https://github.com/hpcaitech/ColossalAI) can breakthrough the GPU memory wall by using GPU and CPU memory (composed of CPU DRAM or nvme SSD memory) together at the same time. Moreover, the model scale can be further improved by combining heterogeneous training with the other parallel approaches, such as data parallel, tensor parallel and pipeline parallel.
+
+## Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+```bash
+pip install -r requirements.txt
+```
+
+## Install [ColossalAI](https://github.com/hpcaitech/ColossalAI.git)
+
+**From PyPI**
+```bash
+pip install colossalai
+```
+
+**From source**
+
+```bash
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI
+
+# install colossalai
+pip install .
+```
+
+## Dataset for Teyvat BLIP captions
+Dataset used to train [Teyvat characters text to image model](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion).
+
+BLIP generated captions for characters images from [genshin-impact fandom wiki](https://genshin-impact.fandom.com/wiki/Character#Playable_Characters)and [biligame wiki for genshin impact](https://wiki.biligame.com/ys/%E8%A7%92%E8%89%B2).
+
+For each row the dataset contains `image` and `text` keys. `image` is a varying size PIL png, and `text` is the accompanying text caption. Only a train split is provided.
+
+The `text` include the tag `Teyvat`, `Name`,`Element`, `Weapon`, `Region`, `Model type`, and `Description`, the `Description` is captioned with the [pre-trained BLIP model](https://github.com/salesforce/BLIP).
+
+## Training
+
+The arguement `placement` can be `cpu`, `auto`, `cuda`, with `cpu` the GPU RAM required can be minimized to 4GB but will deceleration, with `cuda` you can also reduce GPU memory by half but accelerated training, with `auto` a more balanced solution for speed and memory can be obtained。
+
+**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export INSTANCE_DIR="path-to-instance-images"
+export OUTPUT_DIR="path-to-save-model"
+
+torchrun --nproc_per_node 2 train_dreambooth_colossalai.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --instance_prompt="a photo of sks dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=400 \
+ --placement="cuda"
+```
+
+
+### Training with prior-preservation loss
+
+Prior-preservation is used to avoid overfitting and language-drift. Refer to the paper to learn more about it. For prior-preservation we first generate images using the model with a class prompt and then use those during training along with our data.
+According to the paper, it's recommended to generate `num_epochs * num_samples` images for prior-preservation. 200-300 works well for most cases. The `num_class_images` flag sets the number of images to generate with the class prompt. You can place existing images in `class_data_dir`, and the training script will generate any additional images so that `num_class_images` are present in `class_data_dir` during training time.
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export INSTANCE_DIR="path-to-instance-images"
+export CLASS_DIR="path-to-class-images"
+export OUTPUT_DIR="path-to-save-model"
+
+torchrun --nproc_per_node 2 train_dreambooth_colossalai.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --class_data_dir=$CLASS_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --with_prior_preservation --prior_loss_weight=1.0 \
+ --instance_prompt="a photo of sks dog" \
+ --class_prompt="a photo of dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=800 \
+ --placement="cuda"
+```
+
+## Inference
+
+Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `identifier`(e.g. sks in above example) in your prompt.
+
+```python
+from diffusers import StableDiffusionPipeline
+import torch
+
+model_id = "path-to-save-model"
+pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+
+prompt = "A photo of sks dog in a bucket"
+image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
+
+image.save("dog-bucket.png")
+```
diff --git a/diffusers/examples/research_projects/colossalai/inference.py b/diffusers/examples/research_projects/colossalai/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b115c2d2b8f5bcdb3a0c053a6c71b91a965c573
--- /dev/null
+++ b/diffusers/examples/research_projects/colossalai/inference.py
@@ -0,0 +1,12 @@
+import torch
+
+from diffusers import StableDiffusionPipeline
+
+
+model_id = "path-to-your-trained-model"
+pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+
+prompt = "A photo of sks dog in a bucket"
+image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
+
+image.save("dog-bucket.png")
diff --git a/diffusers/examples/research_projects/colossalai/requirement.txt b/diffusers/examples/research_projects/colossalai/requirement.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f80467dcff521bfed1fa72109e1e01e92ab05646
--- /dev/null
+++ b/diffusers/examples/research_projects/colossalai/requirement.txt
@@ -0,0 +1,7 @@
+diffusers
+torch
+torchvision
+ftfy
+tensorboard
+Jinja2
+transformers
\ No newline at end of file
diff --git a/diffusers/examples/research_projects/colossalai/train_dreambooth_colossalai.py b/diffusers/examples/research_projects/colossalai/train_dreambooth_colossalai.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d4466bf94b74c5b324b970913c142342871cf78
--- /dev/null
+++ b/diffusers/examples/research_projects/colossalai/train_dreambooth_colossalai.py
@@ -0,0 +1,673 @@
+import argparse
+import hashlib
+import math
+import os
+from pathlib import Path
+
+import colossalai
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.logging import disable_existing_loggers, get_dist_logger
+from colossalai.nn.optimizer.gemini_optimizer import GeminiAdamOptimizer
+from colossalai.nn.parallel.utils import get_static_torch_model
+from colossalai.utils import get_current_device
+from colossalai.utils.model.colo_init_context import ColoInitContext
+from huggingface_hub import create_repo, upload_folder
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import AutoTokenizer, PretrainedConfig
+
+from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, UNet2DConditionModel
+from diffusers.optimization import get_scheduler
+
+
+disable_existing_loggers()
+logger = get_dist_logger()
+
+
+def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str):
+ text_encoder_config = PretrainedConfig.from_pretrained(
+ pretrained_model_name_or_path,
+ subfolder="text_encoder",
+ revision=args.revision,
+ )
+ model_class = text_encoder_config.architectures[0]
+
+ if model_class == "CLIPTextModel":
+ from transformers import CLIPTextModel
+
+ return CLIPTextModel
+ elif model_class == "RobertaSeriesModelWithTransformation":
+ from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
+
+ return RobertaSeriesModelWithTransformation
+ else:
+ raise ValueError(f"{model_class} is not supported.")
+
+
+def parse_args(input_args=None):
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--instance_data_dir",
+ type=str,
+ default=None,
+ required=True,
+ help="A folder containing the training data of instance images.",
+ )
+ parser.add_argument(
+ "--class_data_dir",
+ type=str,
+ default=None,
+ required=False,
+ help="A folder containing the training data of class images.",
+ )
+ parser.add_argument(
+ "--instance_prompt",
+ type=str,
+ default="a photo of sks dog",
+ required=False,
+ help="The prompt with identifier specifying the instance",
+ )
+ parser.add_argument(
+ "--class_prompt",
+ type=str,
+ default=None,
+ help="The prompt to specify images in the same class as provided instance images.",
+ )
+ parser.add_argument(
+ "--with_prior_preservation",
+ default=False,
+ action="store_true",
+ help="Flag to add prior preservation loss.",
+ )
+ parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
+ parser.add_argument(
+ "--num_class_images",
+ type=int,
+ default=100,
+ help=(
+ "Minimal class images for prior preservation loss. If there are not enough images already present in"
+ " class_data_dir, additional images will be sampled with class_prompt."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--placement",
+ type=str,
+ default="cpu",
+ help="Placement Policy for Gemini. Valid when using colossalai as dist plan.",
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument(
+ "--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=1)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument("--save_steps", type=int, default=500, help="Save checkpoint every X updates steps.")
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-6,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+
+ if input_args is not None:
+ args = parser.parse_args(input_args)
+ else:
+ args = parser.parse_args()
+
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.with_prior_preservation:
+ if args.class_data_dir is None:
+ raise ValueError("You must specify a data directory for class images.")
+ if args.class_prompt is None:
+ raise ValueError("You must specify prompt for class images.")
+ else:
+ if args.class_data_dir is not None:
+ logger.warning("You need not use --class_data_dir without --with_prior_preservation.")
+ if args.class_prompt is not None:
+ logger.warning("You need not use --class_prompt without --with_prior_preservation.")
+
+ return args
+
+
+class DreamBoothDataset(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images and the tokenizes prompts.
+ """
+
+ def __init__(
+ self,
+ instance_data_root,
+ instance_prompt,
+ tokenizer,
+ class_data_root=None,
+ class_prompt=None,
+ size=512,
+ center_crop=False,
+ ):
+ self.size = size
+ self.center_crop = center_crop
+ self.tokenizer = tokenizer
+
+ self.instance_data_root = Path(instance_data_root)
+ if not self.instance_data_root.exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ self.instance_images_path = list(Path(instance_data_root).iterdir())
+ self.num_instance_images = len(self.instance_images_path)
+ self.instance_prompt = instance_prompt
+ self._length = self.num_instance_images
+
+ if class_data_root is not None:
+ self.class_data_root = Path(class_data_root)
+ self.class_data_root.mkdir(parents=True, exist_ok=True)
+ self.class_images_path = list(self.class_data_root.iterdir())
+ self.num_class_images = len(self.class_images_path)
+ self._length = max(self.num_class_images, self.num_instance_images)
+ self.class_prompt = class_prompt
+ else:
+ self.class_data_root = None
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, index):
+ example = {}
+ instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
+ if not instance_image.mode == "RGB":
+ instance_image = instance_image.convert("RGB")
+ example["instance_images"] = self.image_transforms(instance_image)
+ example["instance_prompt_ids"] = self.tokenizer(
+ self.instance_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ if self.class_data_root:
+ class_image = Image.open(self.class_images_path[index % self.num_class_images])
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ example["class_images"] = self.image_transforms(class_image)
+ example["class_prompt_ids"] = self.tokenizer(
+ self.class_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ return example
+
+
+class PromptDataset(Dataset):
+ "A simple dataset to prepare the prompts to generate class images on multiple GPUs."
+
+ def __init__(self, prompt, num_samples):
+ self.prompt = prompt
+ self.num_samples = num_samples
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, index):
+ example = {}
+ example["prompt"] = self.prompt
+ example["index"] = index
+ return example
+
+
+# Gemini + ZeRO DDP
+def gemini_zero_dpp(model: torch.nn.Module, placememt_policy: str = "auto"):
+ from colossalai.nn.parallel import GeminiDDP
+
+ model = GeminiDDP(
+ model, device=get_current_device(), placement_policy=placememt_policy, pin_memory=True, search_range_mb=64
+ )
+ return model
+
+
+def main(args):
+ if args.seed is None:
+ colossalai.launch_from_torch(config={})
+ else:
+ colossalai.launch_from_torch(config={}, seed=args.seed)
+
+ local_rank = gpc.get_local_rank(ParallelMode.DATA)
+ world_size = gpc.get_world_size(ParallelMode.DATA)
+
+ if args.with_prior_preservation:
+ class_images_dir = Path(args.class_data_dir)
+ if not class_images_dir.exists():
+ class_images_dir.mkdir(parents=True)
+ cur_class_images = len(list(class_images_dir.iterdir()))
+
+ if cur_class_images < args.num_class_images:
+ torch_dtype = torch.float16 if get_current_device() == "cuda" else torch.float32
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ torch_dtype=torch_dtype,
+ safety_checker=None,
+ revision=args.revision,
+ )
+ pipeline.set_progress_bar_config(disable=True)
+
+ num_new_images = args.num_class_images - cur_class_images
+ logger.info(f"Number of class images to sample: {num_new_images}.")
+
+ sample_dataset = PromptDataset(args.class_prompt, num_new_images)
+ sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
+
+ pipeline.to(get_current_device())
+
+ for example in tqdm(
+ sample_dataloader,
+ desc="Generating class images",
+ disable=not local_rank == 0,
+ ):
+ images = pipeline(example["prompt"]).images
+
+ for i, image in enumerate(images):
+ hash_image = hashlib.sha1(image.tobytes()).hexdigest()
+ image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
+ image.save(image_filename)
+
+ del pipeline
+
+ # Handle the repository creation
+ if local_rank == 0:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load the tokenizer
+ if args.tokenizer_name:
+ logger.info(f"Loading tokenizer from {args.tokenizer_name}", ranks=[0])
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name,
+ revision=args.revision,
+ use_fast=False,
+ )
+ elif args.pretrained_model_name_or_path:
+ logger.info("Loading tokenizer from pretrained model", ranks=[0])
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="tokenizer",
+ revision=args.revision,
+ use_fast=False,
+ )
+ # import correct text encoder class
+ text_encoder_cls = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path)
+
+ # Load models and create wrapper for stable diffusion
+
+ logger.info(f"Loading text_encoder from {args.pretrained_model_name_or_path}", ranks=[0])
+
+ text_encoder = text_encoder_cls.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="text_encoder",
+ revision=args.revision,
+ )
+
+ logger.info(f"Loading AutoencoderKL from {args.pretrained_model_name_or_path}", ranks=[0])
+ vae = AutoencoderKL.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="vae",
+ revision=args.revision,
+ )
+
+ logger.info(f"Loading UNet2DConditionModel from {args.pretrained_model_name_or_path}", ranks=[0])
+ with ColoInitContext(device=get_current_device()):
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, low_cpu_mem_usage=False
+ )
+
+ vae.requires_grad_(False)
+ text_encoder.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+
+ if args.scale_lr:
+ args.learning_rate = args.learning_rate * args.train_batch_size * world_size
+
+ unet = gemini_zero_dpp(unet, args.placement)
+
+ # config optimizer for colossalai zero
+ optimizer = GeminiAdamOptimizer(
+ unet, lr=args.learning_rate, initial_scale=2**5, clipping_norm=args.max_grad_norm
+ )
+
+ # load noise_scheduler
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+
+ # prepare dataset
+ logger.info(f"Prepare dataset from {args.instance_data_dir}", ranks=[0])
+ train_dataset = DreamBoothDataset(
+ instance_data_root=args.instance_data_dir,
+ instance_prompt=args.instance_prompt,
+ class_data_root=args.class_data_dir if args.with_prior_preservation else None,
+ class_prompt=args.class_prompt,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ center_crop=args.center_crop,
+ )
+
+ def collate_fn(examples):
+ input_ids = [example["instance_prompt_ids"] for example in examples]
+ pixel_values = [example["instance_images"] for example in examples]
+
+ # Concat class and instance examples for prior preservation.
+ # We do this to avoid doing two forward passes.
+ if args.with_prior_preservation:
+ input_ids += [example["class_prompt_ids"] for example in examples]
+ pixel_values += [example["class_images"] for example in examples]
+
+ pixel_values = torch.stack(pixel_values)
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+
+ input_ids = tokenizer.pad(
+ {"input_ids": input_ids},
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ return_tensors="pt",
+ ).input_ids
+
+ batch = {
+ "input_ids": input_ids,
+ "pixel_values": pixel_values,
+ }
+ return batch
+
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=args.train_batch_size, shuffle=True, collate_fn=collate_fn, num_workers=1
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader))
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps,
+ num_training_steps=args.max_train_steps,
+ )
+ weight_dtype = torch.float32
+ if args.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif args.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move text_encode and vae to gpu.
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ vae.to(get_current_device(), dtype=weight_dtype)
+ text_encoder.to(get_current_device(), dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader))
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Train!
+ total_batch_size = args.train_batch_size * world_size
+
+ logger.info("***** Running training *****", ranks=[0])
+ logger.info(f" Num examples = {len(train_dataset)}", ranks=[0])
+ logger.info(f" Num batches each epoch = {len(train_dataloader)}", ranks=[0])
+ logger.info(f" Num Epochs = {args.num_train_epochs}", ranks=[0])
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}", ranks=[0])
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}", ranks=[0])
+ logger.info(f" Total optimization steps = {args.max_train_steps}", ranks=[0])
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not local_rank == 0)
+ progress_bar.set_description("Steps")
+ global_step = 0
+
+ torch.cuda.synchronize()
+ for epoch in range(args.num_train_epochs):
+ unet.train()
+ for step, batch in enumerate(train_dataloader):
+ torch.cuda.reset_peak_memory_stats()
+ # Move batch to gpu
+ for key, value in batch.items():
+ batch[key] = value.to(get_current_device(), non_blocking=True)
+
+ # Convert images to latent space
+ optimizer.zero_grad()
+
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
+ latents = latents * 0.18215
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Predict the noise residual
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ if args.with_prior_preservation:
+ # Chunk the noise and model_pred into two parts and compute the loss on each part separately.
+ model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
+ target, target_prior = torch.chunk(target, 2, dim=0)
+
+ # Compute instance loss
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="none").mean([1, 2, 3]).mean()
+
+ # Compute prior loss
+ prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
+
+ # Add the prior loss to the instance loss.
+ loss = loss + args.prior_loss_weight * prior_loss
+ else:
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ optimizer.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ logger.info(f"max GPU_mem cost is {torch.cuda.max_memory_allocated()/2**20} MB", ranks=[0])
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ progress_bar.update(1)
+ global_step += 1
+ logs = {
+ "loss": loss.detach().item(),
+ "lr": optimizer.param_groups[0]["lr"],
+ } # lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+
+ if global_step % args.save_steps == 0:
+ torch.cuda.synchronize()
+ torch_unet = get_static_torch_model(unet)
+ if local_rank == 0:
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=torch_unet,
+ revision=args.revision,
+ )
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ pipeline.save_pretrained(save_path)
+ logger.info(f"Saving model checkpoint to {save_path}", ranks=[0])
+ if global_step >= args.max_train_steps:
+ break
+
+ torch.cuda.synchronize()
+ unet = get_static_torch_model(unet)
+
+ if local_rank == 0:
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=unet,
+ revision=args.revision,
+ )
+
+ pipeline.save_pretrained(args.output_dir)
+ logger.info(f"Saving model checkpoint to {args.output_dir}", ranks=[0])
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/diffusers/examples/research_projects/dreambooth_inpaint/README.md b/diffusers/examples/research_projects/dreambooth_inpaint/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..dec919587935ec6e08a08e9299d62b0edc17449c
--- /dev/null
+++ b/diffusers/examples/research_projects/dreambooth_inpaint/README.md
@@ -0,0 +1,118 @@
+# Dreambooth for the inpainting model
+
+This script was added by @thedarkzeno .
+
+Please note that this script is not actively maintained, you can open an issue and tag @thedarkzeno or @patil-suraj though.
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-inpainting"
+export INSTANCE_DIR="path-to-instance-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch train_dreambooth_inpaint.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --instance_prompt="a photo of sks dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=1 \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=400
+```
+
+### Training with prior-preservation loss
+
+Prior-preservation is used to avoid overfitting and language-drift. Refer to the paper to learn more about it. For prior-preservation we first generate images using the model with a class prompt and then use those during training along with our data.
+According to the paper, it's recommended to generate `num_epochs * num_samples` images for prior-preservation. 200-300 works well for most cases.
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-inpainting"
+export INSTANCE_DIR="path-to-instance-images"
+export CLASS_DIR="path-to-class-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch train_dreambooth_inpaint.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --class_data_dir=$CLASS_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --with_prior_preservation --prior_loss_weight=1.0 \
+ --instance_prompt="a photo of sks dog" \
+ --class_prompt="a photo of dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=1 \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --num_class_images=200 \
+ --max_train_steps=800
+```
+
+
+### Training with gradient checkpointing and 8-bit optimizer:
+
+With the help of gradient checkpointing and the 8-bit optimizer from bitsandbytes it's possible to run train dreambooth on a 16GB GPU.
+
+To install `bitandbytes` please refer to this [readme](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-inpainting"
+export INSTANCE_DIR="path-to-instance-images"
+export CLASS_DIR="path-to-class-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch train_dreambooth_inpaint.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --class_data_dir=$CLASS_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --with_prior_preservation --prior_loss_weight=1.0 \
+ --instance_prompt="a photo of sks dog" \
+ --class_prompt="a photo of dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=2 --gradient_checkpointing \
+ --use_8bit_adam \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --num_class_images=200 \
+ --max_train_steps=800
+```
+
+### Fine-tune text encoder with the UNet.
+
+The script also allows to fine-tune the `text_encoder` along with the `unet`. It's been observed experimentally that fine-tuning `text_encoder` gives much better results especially on faces.
+Pass the `--train_text_encoder` argument to the script to enable training `text_encoder`.
+
+___Note: Training text encoder requires more memory, with this option the training won't fit on 16GB GPU. It needs at least 24GB VRAM.___
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-inpainting"
+export INSTANCE_DIR="path-to-instance-images"
+export CLASS_DIR="path-to-class-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch train_dreambooth_inpaint.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_text_encoder \
+ --instance_data_dir=$INSTANCE_DIR \
+ --class_data_dir=$CLASS_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --with_prior_preservation --prior_loss_weight=1.0 \
+ --instance_prompt="a photo of sks dog" \
+ --class_prompt="a photo of dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --use_8bit_adam \
+ --gradient_checkpointing \
+ --learning_rate=2e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --num_class_images=200 \
+ --max_train_steps=800
+```
diff --git a/diffusers/examples/research_projects/dreambooth_inpaint/requirements.txt b/diffusers/examples/research_projects/dreambooth_inpaint/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f17dfab9653b70b379d36dae1103eb0f4728806e
--- /dev/null
+++ b/diffusers/examples/research_projects/dreambooth_inpaint/requirements.txt
@@ -0,0 +1,7 @@
+diffusers==0.9.0
+accelerate
+torchvision
+transformers>=4.21.0
+ftfy
+tensorboard
+Jinja2
diff --git a/diffusers/examples/research_projects/dreambooth_inpaint/train_dreambooth_inpaint.py b/diffusers/examples/research_projects/dreambooth_inpaint/train_dreambooth_inpaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..c9b9211415b8637679dfc8e977a76661a4f1c48b
--- /dev/null
+++ b/diffusers/examples/research_projects/dreambooth_inpaint/train_dreambooth_inpaint.py
@@ -0,0 +1,811 @@
+import argparse
+import hashlib
+import itertools
+import math
+import os
+import random
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from huggingface_hub import create_repo, upload_folder
+from PIL import Image, ImageDraw
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDPMScheduler,
+ StableDiffusionInpaintPipeline,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.13.0.dev0")
+
+logger = get_logger(__name__)
+
+
+def prepare_mask_and_masked_image(image, mask):
+ image = np.array(image.convert("RGB"))
+ image = image[None].transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+
+ mask = np.array(mask.convert("L"))
+ mask = mask.astype(np.float32) / 255.0
+ mask = mask[None, None]
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+ mask = torch.from_numpy(mask)
+
+ masked_image = image * (mask < 0.5)
+
+ return mask, masked_image
+
+
+# generate random masks
+def random_mask(im_shape, ratio=1, mask_full_image=False):
+ mask = Image.new("L", im_shape, 0)
+ draw = ImageDraw.Draw(mask)
+ size = (random.randint(0, int(im_shape[0] * ratio)), random.randint(0, int(im_shape[1] * ratio)))
+ # use this to always mask the whole image
+ if mask_full_image:
+ size = (int(im_shape[0] * ratio), int(im_shape[1] * ratio))
+ limits = (im_shape[0] - size[0] // 2, im_shape[1] - size[1] // 2)
+ center = (random.randint(size[0] // 2, limits[0]), random.randint(size[1] // 2, limits[1]))
+ draw_type = random.randint(0, 1)
+ if draw_type == 0 or mask_full_image:
+ draw.rectangle(
+ (center[0] - size[0] // 2, center[1] - size[1] // 2, center[0] + size[0] // 2, center[1] + size[1] // 2),
+ fill=255,
+ )
+ else:
+ draw.ellipse(
+ (center[0] - size[0] // 2, center[1] - size[1] // 2, center[0] + size[0] // 2, center[1] + size[1] // 2),
+ fill=255,
+ )
+
+ return mask
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--instance_data_dir",
+ type=str,
+ default=None,
+ required=True,
+ help="A folder containing the training data of instance images.",
+ )
+ parser.add_argument(
+ "--class_data_dir",
+ type=str,
+ default=None,
+ required=False,
+ help="A folder containing the training data of class images.",
+ )
+ parser.add_argument(
+ "--instance_prompt",
+ type=str,
+ default=None,
+ help="The prompt with identifier specifying the instance",
+ )
+ parser.add_argument(
+ "--class_prompt",
+ type=str,
+ default=None,
+ help="The prompt to specify images in the same class as provided instance images.",
+ )
+ parser.add_argument(
+ "--with_prior_preservation",
+ default=False,
+ action="store_true",
+ help="Flag to add prior preservation loss.",
+ )
+ parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
+ parser.add_argument(
+ "--num_class_images",
+ type=int,
+ default=100,
+ help=(
+ "Minimal class images for prior preservation loss. If not have enough images, additional images will be"
+ " sampled with class_prompt."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument("--train_text_encoder", action="store_true", help="Whether to train the text encoder")
+ parser.add_argument(
+ "--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument(
+ "--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=1)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-6,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
+ " checkpoints in case they are better than the last checkpoint and are suitable for resuming training"
+ " using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.instance_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ if args.with_prior_preservation:
+ if args.class_data_dir is None:
+ raise ValueError("You must specify a data directory for class images.")
+ if args.class_prompt is None:
+ raise ValueError("You must specify prompt for class images.")
+
+ return args
+
+
+class DreamBoothDataset(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images and the tokenizes prompts.
+ """
+
+ def __init__(
+ self,
+ instance_data_root,
+ instance_prompt,
+ tokenizer,
+ class_data_root=None,
+ class_prompt=None,
+ size=512,
+ center_crop=False,
+ ):
+ self.size = size
+ self.center_crop = center_crop
+ self.tokenizer = tokenizer
+
+ self.instance_data_root = Path(instance_data_root)
+ if not self.instance_data_root.exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ self.instance_images_path = list(Path(instance_data_root).iterdir())
+ self.num_instance_images = len(self.instance_images_path)
+ self.instance_prompt = instance_prompt
+ self._length = self.num_instance_images
+
+ if class_data_root is not None:
+ self.class_data_root = Path(class_data_root)
+ self.class_data_root.mkdir(parents=True, exist_ok=True)
+ self.class_images_path = list(self.class_data_root.iterdir())
+ self.num_class_images = len(self.class_images_path)
+ self._length = max(self.num_class_images, self.num_instance_images)
+ self.class_prompt = class_prompt
+ else:
+ self.class_data_root = None
+
+ self.image_transforms_resize_and_crop = transforms.Compose(
+ [
+ transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
+ ]
+ )
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, index):
+ example = {}
+ instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
+ if not instance_image.mode == "RGB":
+ instance_image = instance_image.convert("RGB")
+ instance_image = self.image_transforms_resize_and_crop(instance_image)
+
+ example["PIL_images"] = instance_image
+ example["instance_images"] = self.image_transforms(instance_image)
+
+ example["instance_prompt_ids"] = self.tokenizer(
+ self.instance_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ if self.class_data_root:
+ class_image = Image.open(self.class_images_path[index % self.num_class_images])
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ class_image = self.image_transforms_resize_and_crop(class_image)
+ example["class_images"] = self.image_transforms(class_image)
+ example["class_PIL_images"] = class_image
+ example["class_prompt_ids"] = self.tokenizer(
+ self.class_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ return example
+
+
+class PromptDataset(Dataset):
+ "A simple dataset to prepare the prompts to generate class images on multiple GPUs."
+
+ def __init__(self, prompt, num_samples):
+ self.prompt = prompt
+ self.num_samples = num_samples
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, index):
+ example = {}
+ example["prompt"] = self.prompt
+ example["index"] = index
+ return example
+
+
+def main():
+ args = parse_args()
+ logging_dir = Path(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with="tensorboard",
+ logging_dir=logging_dir,
+ accelerator_project_config=accelerator_project_config,
+ )
+
+ # Currently, it's not possible to do gradient accumulation when training two models with accelerate.accumulate
+ # This will be enabled soon in accelerate. For now, we don't allow gradient accumulation when training two models.
+ # TODO (patil-suraj): Remove this check when gradient accumulation with two models is enabled in accelerate.
+ if args.train_text_encoder and args.gradient_accumulation_steps > 1 and accelerator.num_processes > 1:
+ raise ValueError(
+ "Gradient accumulation is not supported when training the text encoder in distributed training. "
+ "Please set gradient_accumulation_steps to 1. This feature will be supported in the future."
+ )
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ if args.with_prior_preservation:
+ class_images_dir = Path(args.class_data_dir)
+ if not class_images_dir.exists():
+ class_images_dir.mkdir(parents=True)
+ cur_class_images = len(list(class_images_dir.iterdir()))
+
+ if cur_class_images < args.num_class_images:
+ torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
+ pipeline = StableDiffusionInpaintPipeline.from_pretrained(
+ args.pretrained_model_name_or_path, torch_dtype=torch_dtype, safety_checker=None
+ )
+ pipeline.set_progress_bar_config(disable=True)
+
+ num_new_images = args.num_class_images - cur_class_images
+ logger.info(f"Number of class images to sample: {num_new_images}.")
+
+ sample_dataset = PromptDataset(args.class_prompt, num_new_images)
+ sample_dataloader = torch.utils.data.DataLoader(
+ sample_dataset, batch_size=args.sample_batch_size, num_workers=1
+ )
+
+ sample_dataloader = accelerator.prepare(sample_dataloader)
+ pipeline.to(accelerator.device)
+ transform_to_pil = transforms.ToPILImage()
+ for example in tqdm(
+ sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
+ ):
+ bsz = len(example["prompt"])
+ fake_images = torch.rand((3, args.resolution, args.resolution))
+ transform_to_pil = transforms.ToPILImage()
+ fake_pil_images = transform_to_pil(fake_images)
+
+ fake_mask = random_mask((args.resolution, args.resolution), ratio=1, mask_full_image=True)
+
+ images = pipeline(prompt=example["prompt"], mask_image=fake_mask, image=fake_pil_images).images
+
+ for i, image in enumerate(images):
+ hash_image = hashlib.sha1(image.tobytes()).hexdigest()
+ image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
+ image.save(image_filename)
+
+ del pipeline
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load the tokenizer
+ if args.tokenizer_name:
+ tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Load models and create wrapper for stable diffusion
+ text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae")
+ unet = UNet2DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
+
+ vae.requires_grad_(False)
+ if not args.train_text_encoder:
+ text_encoder.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+ if args.train_text_encoder:
+ text_encoder.gradient_checkpointing_enable()
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ params_to_optimize = (
+ itertools.chain(unet.parameters(), text_encoder.parameters()) if args.train_text_encoder else unet.parameters()
+ )
+ optimizer = optimizer_class(
+ params_to_optimize,
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+
+ train_dataset = DreamBoothDataset(
+ instance_data_root=args.instance_data_dir,
+ instance_prompt=args.instance_prompt,
+ class_data_root=args.class_data_dir if args.with_prior_preservation else None,
+ class_prompt=args.class_prompt,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ center_crop=args.center_crop,
+ )
+
+ def collate_fn(examples):
+ input_ids = [example["instance_prompt_ids"] for example in examples]
+ pixel_values = [example["instance_images"] for example in examples]
+
+ # Concat class and instance examples for prior preservation.
+ # We do this to avoid doing two forward passes.
+ if args.with_prior_preservation:
+ input_ids += [example["class_prompt_ids"] for example in examples]
+ pixel_values += [example["class_images"] for example in examples]
+ pior_pil = [example["class_PIL_images"] for example in examples]
+
+ masks = []
+ masked_images = []
+ for example in examples:
+ pil_image = example["PIL_images"]
+ # generate a random mask
+ mask = random_mask(pil_image.size, 1, False)
+ # prepare mask and masked image
+ mask, masked_image = prepare_mask_and_masked_image(pil_image, mask)
+
+ masks.append(mask)
+ masked_images.append(masked_image)
+
+ if args.with_prior_preservation:
+ for pil_image in pior_pil:
+ # generate a random mask
+ mask = random_mask(pil_image.size, 1, False)
+ # prepare mask and masked image
+ mask, masked_image = prepare_mask_and_masked_image(pil_image, mask)
+
+ masks.append(mask)
+ masked_images.append(masked_image)
+
+ pixel_values = torch.stack(pixel_values)
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+
+ input_ids = tokenizer.pad({"input_ids": input_ids}, padding=True, return_tensors="pt").input_ids
+ masks = torch.stack(masks)
+ masked_images = torch.stack(masked_images)
+ batch = {"input_ids": input_ids, "pixel_values": pixel_values, "masks": masks, "masked_images": masked_images}
+ return batch
+
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=args.train_batch_size, shuffle=True, collate_fn=collate_fn
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ if args.train_text_encoder:
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+ else:
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+ accelerator.register_for_checkpointing(lr_scheduler)
+
+ weight_dtype = torch.float32
+ if args.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif args.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move text_encode and vae to gpu.
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ vae.to(accelerator.device, dtype=weight_dtype)
+ if not args.train_text_encoder:
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("dreambooth", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num batches each epoch = {len(train_dataloader)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
+ latents = latents * vae.config.scaling_factor
+
+ # Convert masked images to latent space
+ masked_latents = vae.encode(
+ batch["masked_images"].reshape(batch["pixel_values"].shape).to(dtype=weight_dtype)
+ ).latent_dist.sample()
+ masked_latents = masked_latents * vae.config.scaling_factor
+
+ masks = batch["masks"]
+ # resize the mask to latents shape as we concatenate the mask to the latents
+ mask = torch.stack(
+ [
+ torch.nn.functional.interpolate(mask, size=(args.resolution // 8, args.resolution // 8))
+ for mask in masks
+ ]
+ )
+ mask = mask.reshape(-1, 1, args.resolution // 8, args.resolution // 8)
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # concatenate the noised latents with the mask and the masked latents
+ latent_model_input = torch.cat([noisy_latents, mask, masked_latents], dim=1)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Predict the noise residual
+ noise_pred = unet(latent_model_input, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ if args.with_prior_preservation:
+ # Chunk the noise and noise_pred into two parts and compute the loss on each part separately.
+ noise_pred, noise_pred_prior = torch.chunk(noise_pred, 2, dim=0)
+ target, target_prior = torch.chunk(target, 2, dim=0)
+
+ # Compute instance loss
+ loss = F.mse_loss(noise_pred.float(), target.float(), reduction="none").mean([1, 2, 3]).mean()
+
+ # Compute prior loss
+ prior_loss = F.mse_loss(noise_pred_prior.float(), target_prior.float(), reduction="mean")
+
+ # Add the prior loss to the instance loss.
+ loss = loss + args.prior_loss_weight * prior_loss
+ else:
+ loss = F.mse_loss(noise_pred.float(), target.float(), reduction="mean")
+
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ params_to_clip = (
+ itertools.chain(unet.parameters(), text_encoder.parameters())
+ if args.train_text_encoder
+ else unet.parameters()
+ )
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ accelerator.wait_for_everyone()
+
+ # Create the pipeline using using the trained modules and save it.
+ if accelerator.is_main_process:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ pipeline.save_pretrained(args.output_dir)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/dreambooth_inpaint/train_dreambooth_inpaint_lora.py b/diffusers/examples/research_projects/dreambooth_inpaint/train_dreambooth_inpaint_lora.py
new file mode 100644
index 0000000000000000000000000000000000000000..0522488f2882c87bf552b8deed24c232657ed3e7
--- /dev/null
+++ b/diffusers/examples/research_projects/dreambooth_inpaint/train_dreambooth_inpaint_lora.py
@@ -0,0 +1,830 @@
+import argparse
+import hashlib
+import math
+import os
+import random
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from huggingface_hub import create_repo, upload_folder
+from PIL import Image, ImageDraw
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionInpaintPipeline, UNet2DConditionModel
+from diffusers.loaders import AttnProcsLayers
+from diffusers.models.attention_processor import LoRAAttnProcessor
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version
+from diffusers.utils.import_utils import is_xformers_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.13.0.dev0")
+
+logger = get_logger(__name__)
+
+
+def prepare_mask_and_masked_image(image, mask):
+ image = np.array(image.convert("RGB"))
+ image = image[None].transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+
+ mask = np.array(mask.convert("L"))
+ mask = mask.astype(np.float32) / 255.0
+ mask = mask[None, None]
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+ mask = torch.from_numpy(mask)
+
+ masked_image = image * (mask < 0.5)
+
+ return mask, masked_image
+
+
+# generate random masks
+def random_mask(im_shape, ratio=1, mask_full_image=False):
+ mask = Image.new("L", im_shape, 0)
+ draw = ImageDraw.Draw(mask)
+ size = (random.randint(0, int(im_shape[0] * ratio)), random.randint(0, int(im_shape[1] * ratio)))
+ # use this to always mask the whole image
+ if mask_full_image:
+ size = (int(im_shape[0] * ratio), int(im_shape[1] * ratio))
+ limits = (im_shape[0] - size[0] // 2, im_shape[1] - size[1] // 2)
+ center = (random.randint(size[0] // 2, limits[0]), random.randint(size[1] // 2, limits[1]))
+ draw_type = random.randint(0, 1)
+ if draw_type == 0 or mask_full_image:
+ draw.rectangle(
+ (center[0] - size[0] // 2, center[1] - size[1] // 2, center[0] + size[0] // 2, center[1] + size[1] // 2),
+ fill=255,
+ )
+ else:
+ draw.ellipse(
+ (center[0] - size[0] // 2, center[1] - size[1] // 2, center[0] + size[0] // 2, center[1] + size[1] // 2),
+ fill=255,
+ )
+
+ return mask
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--instance_data_dir",
+ type=str,
+ default=None,
+ required=True,
+ help="A folder containing the training data of instance images.",
+ )
+ parser.add_argument(
+ "--class_data_dir",
+ type=str,
+ default=None,
+ required=False,
+ help="A folder containing the training data of class images.",
+ )
+ parser.add_argument(
+ "--instance_prompt",
+ type=str,
+ default=None,
+ help="The prompt with identifier specifying the instance",
+ )
+ parser.add_argument(
+ "--class_prompt",
+ type=str,
+ default=None,
+ help="The prompt to specify images in the same class as provided instance images.",
+ )
+ parser.add_argument(
+ "--with_prior_preservation",
+ default=False,
+ action="store_true",
+ help="Flag to add prior preservation loss.",
+ )
+ parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
+ parser.add_argument(
+ "--num_class_images",
+ type=int,
+ default=100,
+ help=(
+ "Minimal class images for prior preservation loss. If not have enough images, additional images will be"
+ " sampled with class_prompt."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="dreambooth-inpaint-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument("--train_text_encoder", action="store_true", help="Whether to train the text encoder")
+ parser.add_argument(
+ "--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument(
+ "--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=1)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-6,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
+ " checkpoints in case they are better than the last checkpoint and are suitable for resuming training"
+ " using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.instance_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ if args.with_prior_preservation:
+ if args.class_data_dir is None:
+ raise ValueError("You must specify a data directory for class images.")
+ if args.class_prompt is None:
+ raise ValueError("You must specify prompt for class images.")
+
+ return args
+
+
+class DreamBoothDataset(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images and the tokenizes prompts.
+ """
+
+ def __init__(
+ self,
+ instance_data_root,
+ instance_prompt,
+ tokenizer,
+ class_data_root=None,
+ class_prompt=None,
+ size=512,
+ center_crop=False,
+ ):
+ self.size = size
+ self.center_crop = center_crop
+ self.tokenizer = tokenizer
+
+ self.instance_data_root = Path(instance_data_root)
+ if not self.instance_data_root.exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ self.instance_images_path = list(Path(instance_data_root).iterdir())
+ self.num_instance_images = len(self.instance_images_path)
+ self.instance_prompt = instance_prompt
+ self._length = self.num_instance_images
+
+ if class_data_root is not None:
+ self.class_data_root = Path(class_data_root)
+ self.class_data_root.mkdir(parents=True, exist_ok=True)
+ self.class_images_path = list(self.class_data_root.iterdir())
+ self.num_class_images = len(self.class_images_path)
+ self._length = max(self.num_class_images, self.num_instance_images)
+ self.class_prompt = class_prompt
+ else:
+ self.class_data_root = None
+
+ self.image_transforms_resize_and_crop = transforms.Compose(
+ [
+ transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
+ ]
+ )
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, index):
+ example = {}
+ instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
+ if not instance_image.mode == "RGB":
+ instance_image = instance_image.convert("RGB")
+ instance_image = self.image_transforms_resize_and_crop(instance_image)
+
+ example["PIL_images"] = instance_image
+ example["instance_images"] = self.image_transforms(instance_image)
+
+ example["instance_prompt_ids"] = self.tokenizer(
+ self.instance_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ if self.class_data_root:
+ class_image = Image.open(self.class_images_path[index % self.num_class_images])
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ class_image = self.image_transforms_resize_and_crop(class_image)
+ example["class_images"] = self.image_transforms(class_image)
+ example["class_PIL_images"] = class_image
+ example["class_prompt_ids"] = self.tokenizer(
+ self.class_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ return example
+
+
+class PromptDataset(Dataset):
+ "A simple dataset to prepare the prompts to generate class images on multiple GPUs."
+
+ def __init__(self, prompt, num_samples):
+ self.prompt = prompt
+ self.num_samples = num_samples
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, index):
+ example = {}
+ example["prompt"] = self.prompt
+ example["index"] = index
+ return example
+
+
+def main():
+ args = parse_args()
+ logging_dir = Path(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with="tensorboard",
+ logging_dir=logging_dir,
+ accelerator_project_config=accelerator_project_config,
+ )
+
+ # Currently, it's not possible to do gradient accumulation when training two models with accelerate.accumulate
+ # This will be enabled soon in accelerate. For now, we don't allow gradient accumulation when training two models.
+ # TODO (patil-suraj): Remove this check when gradient accumulation with two models is enabled in accelerate.
+ if args.train_text_encoder and args.gradient_accumulation_steps > 1 and accelerator.num_processes > 1:
+ raise ValueError(
+ "Gradient accumulation is not supported when training the text encoder in distributed training. "
+ "Please set gradient_accumulation_steps to 1. This feature will be supported in the future."
+ )
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ if args.with_prior_preservation:
+ class_images_dir = Path(args.class_data_dir)
+ if not class_images_dir.exists():
+ class_images_dir.mkdir(parents=True)
+ cur_class_images = len(list(class_images_dir.iterdir()))
+
+ if cur_class_images < args.num_class_images:
+ torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
+ pipeline = StableDiffusionInpaintPipeline.from_pretrained(
+ args.pretrained_model_name_or_path, torch_dtype=torch_dtype, safety_checker=None
+ )
+ pipeline.set_progress_bar_config(disable=True)
+
+ num_new_images = args.num_class_images - cur_class_images
+ logger.info(f"Number of class images to sample: {num_new_images}.")
+
+ sample_dataset = PromptDataset(args.class_prompt, num_new_images)
+ sample_dataloader = torch.utils.data.DataLoader(
+ sample_dataset, batch_size=args.sample_batch_size, num_workers=1
+ )
+
+ sample_dataloader = accelerator.prepare(sample_dataloader)
+ pipeline.to(accelerator.device)
+ transform_to_pil = transforms.ToPILImage()
+ for example in tqdm(
+ sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
+ ):
+ bsz = len(example["prompt"])
+ fake_images = torch.rand((3, args.resolution, args.resolution))
+ transform_to_pil = transforms.ToPILImage()
+ fake_pil_images = transform_to_pil(fake_images)
+
+ fake_mask = random_mask((args.resolution, args.resolution), ratio=1, mask_full_image=True)
+
+ images = pipeline(prompt=example["prompt"], mask_image=fake_mask, image=fake_pil_images).images
+
+ for i, image in enumerate(images):
+ hash_image = hashlib.sha1(image.tobytes()).hexdigest()
+ image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
+ image.save(image_filename)
+
+ del pipeline
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load the tokenizer
+ if args.tokenizer_name:
+ tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Load models and create wrapper for stable diffusion
+ text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae")
+ unet = UNet2DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
+
+ # We only train the additional adapter LoRA layers
+ vae.requires_grad_(False)
+ text_encoder.requires_grad_(False)
+ unet.requires_grad_(False)
+
+ weight_dtype = torch.float32
+ if args.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif args.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move text_encode and vae to gpu.
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ unet.to(accelerator.device, dtype=weight_dtype)
+ vae.to(accelerator.device, dtype=weight_dtype)
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # now we will add new LoRA weights to the attention layers
+ # It's important to realize here how many attention weights will be added and of which sizes
+ # The sizes of the attention layers consist only of two different variables:
+ # 1) - the "hidden_size", which is increased according to `unet.config.block_out_channels`.
+ # 2) - the "cross attention size", which is set to `unet.config.cross_attention_dim`.
+
+ # Let's first see how many attention processors we will have to set.
+ # For Stable Diffusion, it should be equal to:
+ # - down blocks (2x attention layers) * (2x transformer layers) * (3x down blocks) = 12
+ # - mid blocks (2x attention layers) * (1x transformer layers) * (1x mid blocks) = 2
+ # - up blocks (2x attention layers) * (3x transformer layers) * (3x down blocks) = 18
+ # => 32 layers
+
+ # Set correct lora layers
+ lora_attn_procs = {}
+ for name in unet.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = unet.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = unet.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+
+ unet.set_attn_processor(lora_attn_procs)
+ lora_layers = AttnProcsLayers(unet.attn_processors)
+
+ accelerator.register_for_checkpointing(lora_layers)
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ optimizer = optimizer_class(
+ lora_layers.parameters(),
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+
+ train_dataset = DreamBoothDataset(
+ instance_data_root=args.instance_data_dir,
+ instance_prompt=args.instance_prompt,
+ class_data_root=args.class_data_dir if args.with_prior_preservation else None,
+ class_prompt=args.class_prompt,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ center_crop=args.center_crop,
+ )
+
+ def collate_fn(examples):
+ input_ids = [example["instance_prompt_ids"] for example in examples]
+ pixel_values = [example["instance_images"] for example in examples]
+
+ # Concat class and instance examples for prior preservation.
+ # We do this to avoid doing two forward passes.
+ if args.with_prior_preservation:
+ input_ids += [example["class_prompt_ids"] for example in examples]
+ pixel_values += [example["class_images"] for example in examples]
+ pior_pil = [example["class_PIL_images"] for example in examples]
+
+ masks = []
+ masked_images = []
+ for example in examples:
+ pil_image = example["PIL_images"]
+ # generate a random mask
+ mask = random_mask(pil_image.size, 1, False)
+ # prepare mask and masked image
+ mask, masked_image = prepare_mask_and_masked_image(pil_image, mask)
+
+ masks.append(mask)
+ masked_images.append(masked_image)
+
+ if args.with_prior_preservation:
+ for pil_image in pior_pil:
+ # generate a random mask
+ mask = random_mask(pil_image.size, 1, False)
+ # prepare mask and masked image
+ mask, masked_image = prepare_mask_and_masked_image(pil_image, mask)
+
+ masks.append(mask)
+ masked_images.append(masked_image)
+
+ pixel_values = torch.stack(pixel_values)
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+
+ input_ids = tokenizer.pad({"input_ids": input_ids}, padding=True, return_tensors="pt").input_ids
+ masks = torch.stack(masks)
+ masked_images = torch.stack(masked_images)
+ batch = {"input_ids": input_ids, "pixel_values": pixel_values, "masks": masks, "masked_images": masked_images}
+ return batch
+
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=args.train_batch_size, shuffle=True, collate_fn=collate_fn
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ lora_layers, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ lora_layers, optimizer, train_dataloader, lr_scheduler
+ )
+ # accelerator.register_for_checkpointing(lr_scheduler)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("dreambooth-inpaint-lora", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num batches each epoch = {len(train_dataloader)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
+ latents = latents * vae.config.scaling_factor
+
+ # Convert masked images to latent space
+ masked_latents = vae.encode(
+ batch["masked_images"].reshape(batch["pixel_values"].shape).to(dtype=weight_dtype)
+ ).latent_dist.sample()
+ masked_latents = masked_latents * vae.config.scaling_factor
+
+ masks = batch["masks"]
+ # resize the mask to latents shape as we concatenate the mask to the latents
+ mask = torch.stack(
+ [
+ torch.nn.functional.interpolate(mask, size=(args.resolution // 8, args.resolution // 8))
+ for mask in masks
+ ]
+ )
+ mask = mask.reshape(-1, 1, args.resolution // 8, args.resolution // 8)
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # concatenate the noised latents with the mask and the masked latents
+ latent_model_input = torch.cat([noisy_latents, mask, masked_latents], dim=1)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Predict the noise residual
+ noise_pred = unet(latent_model_input, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ if args.with_prior_preservation:
+ # Chunk the noise and noise_pred into two parts and compute the loss on each part separately.
+ noise_pred, noise_pred_prior = torch.chunk(noise_pred, 2, dim=0)
+ target, target_prior = torch.chunk(target, 2, dim=0)
+
+ # Compute instance loss
+ loss = F.mse_loss(noise_pred.float(), target.float(), reduction="none").mean([1, 2, 3]).mean()
+
+ # Compute prior loss
+ prior_loss = F.mse_loss(noise_pred_prior.float(), target_prior.float(), reduction="mean")
+
+ # Add the prior loss to the instance loss.
+ loss = loss + args.prior_loss_weight * prior_loss
+ else:
+ loss = F.mse_loss(noise_pred.float(), target.float(), reduction="mean")
+
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ params_to_clip = lora_layers.parameters()
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ accelerator.wait_for_everyone()
+
+ # Save the lora layers
+ if accelerator.is_main_process:
+ unet = unet.to(torch.float32)
+ unet.save_attn_procs(args.output_dir)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/intel_opts/README.md b/diffusers/examples/research_projects/intel_opts/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6b25679efbe90d556244e7aa6bee3e863c28b069
--- /dev/null
+++ b/diffusers/examples/research_projects/intel_opts/README.md
@@ -0,0 +1,37 @@
+## Diffusers examples with Intel optimizations
+
+**This research project is not actively maintained by the diffusers team. For any questions or comments, please make sure to tag @hshen14 .**
+
+This aims to provide diffusers examples with Intel optimizations such as Bfloat16 for training/fine-tuning acceleration and 8-bit integer (INT8) for inference acceleration on Intel platforms.
+
+## Accelerating the fine-tuning for textual inversion
+
+We accelereate the fine-tuning for textual inversion with Intel Extension for PyTorch. The [examples](textual_inversion) enable both single node and multi-node distributed training with Bfloat16 support on Intel Xeon Scalable Processor.
+
+## Accelerating the inference for Stable Diffusion using Bfloat16
+
+We start the inference acceleration with Bfloat16 using Intel Extension for PyTorch. The [script](inference_bf16.py) is generally designed to support standard Stable Diffusion models with Bfloat16 support.
+```bash
+pip install diffusers transformers accelerate scipy safetensors
+
+export KMP_BLOCKTIME=1
+export KMP_SETTINGS=1
+export KMP_AFFINITY=granularity=fine,compact,1,0
+
+# Intel OpenMP
+export OMP_NUM_THREADS=< Cores to use >
+export LD_PRELOAD=${LD_PRELOAD}:/path/to/lib/libiomp5.so
+# Jemalloc is a recommended malloc implementation that emphasizes fragmentation avoidance and scalable concurrency support.
+export LD_PRELOAD=${LD_PRELOAD}:/path/to/lib/libjemalloc.so
+export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:-1,muzzy_decay_ms:9000000000"
+
+# Launch with default DDIM
+numactl --membind -C python python inference_bf16.py
+# Launch with DPMSolverMultistepScheduler
+numactl --membind -C python python inference_bf16.py --dpm
+
+```
+
+## Accelerating the inference for Stable Diffusion using INT8
+
+Coming soon ...
diff --git a/diffusers/examples/research_projects/intel_opts/inference_bf16.py b/diffusers/examples/research_projects/intel_opts/inference_bf16.py
new file mode 100644
index 0000000000000000000000000000000000000000..96ec709f433cd13dad0b93d5368d61e169b9df28
--- /dev/null
+++ b/diffusers/examples/research_projects/intel_opts/inference_bf16.py
@@ -0,0 +1,56 @@
+import argparse
+
+import intel_extension_for_pytorch as ipex
+import torch
+
+from diffusers import DPMSolverMultistepScheduler, StableDiffusionPipeline
+
+
+parser = argparse.ArgumentParser("Stable Diffusion script with intel optimization", add_help=False)
+parser.add_argument("--dpm", action="store_true", help="Enable DPMSolver or not")
+parser.add_argument("--steps", default=None, type=int, help="Num inference steps")
+args = parser.parse_args()
+
+
+device = "cpu"
+prompt = "a lovely in red dress and hat, in the snowly and brightly night, with many brighly buildings"
+
+model_id = "path-to-your-trained-model"
+pipe = StableDiffusionPipeline.from_pretrained(model_id)
+if args.dpm:
+ pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+pipe = pipe.to(device)
+
+# to channels last
+pipe.unet = pipe.unet.to(memory_format=torch.channels_last)
+pipe.vae = pipe.vae.to(memory_format=torch.channels_last)
+pipe.text_encoder = pipe.text_encoder.to(memory_format=torch.channels_last)
+if pipe.requires_safety_checker:
+ pipe.safety_checker = pipe.safety_checker.to(memory_format=torch.channels_last)
+
+# optimize with ipex
+sample = torch.randn(2, 4, 64, 64)
+timestep = torch.rand(1) * 999
+encoder_hidden_status = torch.randn(2, 77, 768)
+input_example = (sample, timestep, encoder_hidden_status)
+try:
+ pipe.unet = ipex.optimize(pipe.unet.eval(), dtype=torch.bfloat16, inplace=True, sample_input=input_example)
+except Exception:
+ pipe.unet = ipex.optimize(pipe.unet.eval(), dtype=torch.bfloat16, inplace=True)
+pipe.vae = ipex.optimize(pipe.vae.eval(), dtype=torch.bfloat16, inplace=True)
+pipe.text_encoder = ipex.optimize(pipe.text_encoder.eval(), dtype=torch.bfloat16, inplace=True)
+if pipe.requires_safety_checker:
+ pipe.safety_checker = ipex.optimize(pipe.safety_checker.eval(), dtype=torch.bfloat16, inplace=True)
+
+# compute
+seed = 666
+generator = torch.Generator(device).manual_seed(seed)
+generate_kwargs = {"generator": generator}
+if args.steps is not None:
+ generate_kwargs["num_inference_steps"] = args.steps
+
+with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
+ image = pipe(prompt, **generate_kwargs).images[0]
+
+# save image
+image.save("generated.png")
diff --git a/diffusers/examples/research_projects/intel_opts/textual_inversion/README.md b/diffusers/examples/research_projects/intel_opts/textual_inversion/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..14e8b160fb1fb2de72cd37ddb4e4abcab83356fa
--- /dev/null
+++ b/diffusers/examples/research_projects/intel_opts/textual_inversion/README.md
@@ -0,0 +1,68 @@
+## Textual Inversion fine-tuning example
+
+[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
+The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
+
+## Training with Intel Extension for PyTorch
+
+Intel Extension for PyTorch provides the optimizations for faster training and inference on CPUs. You can leverage the training example "textual_inversion.py". Follow the [instructions](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion) to get the model and [dataset](https://huggingface.co/sd-concepts-library/dicoo2) before running the script.
+
+The example supports both single node and multi-node distributed training:
+
+### Single node training
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export DATA_DIR="path-to-dir-containing-dicoo-images"
+
+python textual_inversion.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --seed=7 \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=1 \
+ --max_train_steps=3000 \
+ --learning_rate=2.5e-03 --scale_lr \
+ --output_dir="textual_inversion_dicoo"
+```
+
+Note: Bfloat16 is available on Intel Xeon Scalable Processors Cooper Lake or Sapphire Rapids. You may not get performance speedup without Bfloat16 support.
+
+### Multi-node distributed training
+
+Before running the scripts, make sure to install the library's training dependencies successfully:
+
+```bash
+python -m pip install oneccl_bind_pt==1.13 -f https://developer.intel.com/ipex-whl-stable-cpu
+```
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export DATA_DIR="path-to-dir-containing-dicoo-images"
+
+oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
+source $oneccl_bindings_for_pytorch_path/env/setvars.sh
+
+python -m intel_extension_for_pytorch.cpu.launch --distributed \
+ --hostfile hostfile --nnodes 2 --nproc_per_node 2 textual_inversion.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --seed=7 \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=1 \
+ --max_train_steps=750 \
+ --learning_rate=2.5e-03 --scale_lr \
+ --output_dir="textual_inversion_dicoo"
+```
+The above is a simple distributed training usage on 2 nodes with 2 processes on each node. Add the right hostname or ip address in the "hostfile" and make sure these 2 nodes are reachable from each other. For more details, please refer to the [user guide](https://github.com/intel/torch-ccl).
+
+
+### Reference
+
+We publish a [Medium blog](https://medium.com/intel-analytics-software/personalized-stable-diffusion-with-few-shot-fine-tuning-on-a-single-cpu-f01a3316b13) on how to create your own Stable Diffusion model on CPUs using textual inversion. Try it out now, if you have interests.
diff --git a/diffusers/examples/research_projects/intel_opts/textual_inversion/requirements.txt b/diffusers/examples/research_projects/intel_opts/textual_inversion/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..17b32ea8a2714f1e1d6cf6442aa0f0b65f8d58c0
--- /dev/null
+++ b/diffusers/examples/research_projects/intel_opts/textual_inversion/requirements.txt
@@ -0,0 +1,7 @@
+accelerate
+torchvision
+transformers>=4.21.0
+ftfy
+tensorboard
+Jinja2
+intel_extension_for_pytorch>=1.13
diff --git a/diffusers/examples/research_projects/intel_opts/textual_inversion/textual_inversion_bf16.py b/diffusers/examples/research_projects/intel_opts/textual_inversion/textual_inversion_bf16.py
new file mode 100644
index 0000000000000000000000000000000000000000..1580cb392e8d87bda23d7db8eb88318a4f8e6bf6
--- /dev/null
+++ b/diffusers/examples/research_projects/intel_opts/textual_inversion/textual_inversion_bf16.py
@@ -0,0 +1,635 @@
+import argparse
+import itertools
+import math
+import os
+import random
+from pathlib import Path
+
+import intel_extension_for_pytorch as ipex
+import numpy as np
+import PIL
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from huggingface_hub import create_repo, upload_folder
+
+# TODO: remove and import from diffusers.utils when the new version of diffusers is released
+from packaging import version
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from diffusers import AutoencoderKL, DDPMScheduler, PNDMScheduler, StableDiffusionPipeline, UNet2DConditionModel
+from diffusers.optimization import get_scheduler
+from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
+from diffusers.utils import check_min_version
+
+
+if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.Resampling.BILINEAR,
+ "bilinear": PIL.Image.Resampling.BILINEAR,
+ "bicubic": PIL.Image.Resampling.BICUBIC,
+ "lanczos": PIL.Image.Resampling.LANCZOS,
+ "nearest": PIL.Image.Resampling.NEAREST,
+ }
+else:
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.LINEAR,
+ "bilinear": PIL.Image.BILINEAR,
+ "bicubic": PIL.Image.BICUBIC,
+ "lanczos": PIL.Image.LANCZOS,
+ "nearest": PIL.Image.NEAREST,
+ }
+# ------------------------------------------------------------------------------
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.13.0.dev0")
+
+
+logger = get_logger(__name__)
+
+
+def save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path):
+ logger.info("Saving embeddings")
+ learned_embeds = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[placeholder_token_id]
+ learned_embeds_dict = {args.placeholder_token: learned_embeds.detach().cpu()}
+ torch.save(learned_embeds_dict, save_path)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--save_steps",
+ type=int,
+ default=500,
+ help="Save learned_embeds.bin every X updates steps.",
+ )
+ parser.add_argument(
+ "--only_save_embeds",
+ action="store_true",
+ default=False,
+ help="Save only the embeddings for the new concept.",
+ )
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
+ )
+ parser.add_argument(
+ "--placeholder_token",
+ type=str,
+ default=None,
+ required=True,
+ help="A token to use as a placeholder for the concept.",
+ )
+ parser.add_argument(
+ "--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
+ )
+ parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
+ parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=5000,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=True,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.train_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ return args
+
+
+imagenet_templates_small = [
+ "a photo of a {}",
+ "a rendering of a {}",
+ "a cropped photo of the {}",
+ "the photo of a {}",
+ "a photo of a clean {}",
+ "a photo of a dirty {}",
+ "a dark photo of the {}",
+ "a photo of my {}",
+ "a photo of the cool {}",
+ "a close-up photo of a {}",
+ "a bright photo of the {}",
+ "a cropped photo of a {}",
+ "a photo of the {}",
+ "a good photo of the {}",
+ "a photo of one {}",
+ "a close-up photo of the {}",
+ "a rendition of the {}",
+ "a photo of the clean {}",
+ "a rendition of a {}",
+ "a photo of a nice {}",
+ "a good photo of a {}",
+ "a photo of the nice {}",
+ "a photo of the small {}",
+ "a photo of the weird {}",
+ "a photo of the large {}",
+ "a photo of a cool {}",
+ "a photo of a small {}",
+]
+
+imagenet_style_templates_small = [
+ "a painting in the style of {}",
+ "a rendering in the style of {}",
+ "a cropped painting in the style of {}",
+ "the painting in the style of {}",
+ "a clean painting in the style of {}",
+ "a dirty painting in the style of {}",
+ "a dark painting in the style of {}",
+ "a picture in the style of {}",
+ "a cool painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a bright painting in the style of {}",
+ "a cropped painting in the style of {}",
+ "a good painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a rendition in the style of {}",
+ "a nice painting in the style of {}",
+ "a small painting in the style of {}",
+ "a weird painting in the style of {}",
+ "a large painting in the style of {}",
+]
+
+
+class TextualInversionDataset(Dataset):
+ def __init__(
+ self,
+ data_root,
+ tokenizer,
+ learnable_property="object", # [object, style]
+ size=512,
+ repeats=100,
+ interpolation="bicubic",
+ flip_p=0.5,
+ set="train",
+ placeholder_token="*",
+ center_crop=False,
+ ):
+ self.data_root = data_root
+ self.tokenizer = tokenizer
+ self.learnable_property = learnable_property
+ self.size = size
+ self.placeholder_token = placeholder_token
+ self.center_crop = center_crop
+ self.flip_p = flip_p
+
+ self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
+
+ self.num_images = len(self.image_paths)
+ self._length = self.num_images
+
+ if set == "train":
+ self._length = self.num_images * repeats
+
+ self.interpolation = {
+ "linear": PIL_INTERPOLATION["linear"],
+ "bilinear": PIL_INTERPOLATION["bilinear"],
+ "bicubic": PIL_INTERPOLATION["bicubic"],
+ "lanczos": PIL_INTERPOLATION["lanczos"],
+ }[interpolation]
+
+ self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
+ self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, i):
+ example = {}
+ image = Image.open(self.image_paths[i % self.num_images])
+
+ if not image.mode == "RGB":
+ image = image.convert("RGB")
+
+ placeholder_string = self.placeholder_token
+ text = random.choice(self.templates).format(placeholder_string)
+
+ example["input_ids"] = self.tokenizer(
+ text,
+ padding="max_length",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ ).input_ids[0]
+
+ # default to score-sde preprocessing
+ img = np.array(image).astype(np.uint8)
+
+ if self.center_crop:
+ crop = min(img.shape[0], img.shape[1])
+ (
+ h,
+ w,
+ ) = (
+ img.shape[0],
+ img.shape[1],
+ )
+ img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
+
+ image = Image.fromarray(img)
+ image = image.resize((self.size, self.size), resample=self.interpolation)
+
+ image = self.flip_transform(image)
+ image = np.array(image).astype(np.uint8)
+ image = (image / 127.5 - 1.0).astype(np.float32)
+
+ example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
+ return example
+
+
+def freeze_params(params):
+ for param in params:
+ param.requires_grad = False
+
+
+def main():
+ args = parse_args()
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with="tensorboard",
+ logging_dir=logging_dir,
+ )
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load the tokenizer and add the placeholder token as a additional special token
+ if args.tokenizer_name:
+ tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Add the placeholder token in tokenizer
+ num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
+ if num_added_tokens == 0:
+ raise ValueError(
+ f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
+ " `placeholder_token` that is not already in the tokenizer."
+ )
+
+ # Convert the initializer_token, placeholder_token to ids
+ token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
+ # Check if initializer_token is a single token or a sequence of tokens
+ if len(token_ids) > 1:
+ raise ValueError("The initializer token must be a single token.")
+
+ initializer_token_id = token_ids[0]
+ placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
+
+ # Load models and create wrapper for stable diffusion
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="text_encoder",
+ revision=args.revision,
+ )
+ vae = AutoencoderKL.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="vae",
+ revision=args.revision,
+ )
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="unet",
+ revision=args.revision,
+ )
+
+ # Resize the token embeddings as we are adding new special tokens to the tokenizer
+ text_encoder.resize_token_embeddings(len(tokenizer))
+
+ # Initialise the newly added placeholder token with the embeddings of the initializer token
+ token_embeds = text_encoder.get_input_embeddings().weight.data
+ token_embeds[placeholder_token_id] = token_embeds[initializer_token_id]
+
+ # Freeze vae and unet
+ freeze_params(vae.parameters())
+ freeze_params(unet.parameters())
+ # Freeze all parameters except for the token embeddings in text encoder
+ params_to_freeze = itertools.chain(
+ text_encoder.text_model.encoder.parameters(),
+ text_encoder.text_model.final_layer_norm.parameters(),
+ text_encoder.text_model.embeddings.position_embedding.parameters(),
+ )
+ freeze_params(params_to_freeze)
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ optimizer = torch.optim.AdamW(
+ text_encoder.get_input_embeddings().parameters(), # only optimize the embeddings
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+
+ train_dataset = TextualInversionDataset(
+ data_root=args.train_data_dir,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ placeholder_token=args.placeholder_token,
+ repeats=args.repeats,
+ learnable_property=args.learnable_property,
+ center_crop=args.center_crop,
+ set="train",
+ )
+ train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=args.train_batch_size, shuffle=True)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+
+ # Move vae and unet to device
+ vae.to(accelerator.device)
+ unet.to(accelerator.device)
+
+ # Keep vae and unet in eval model as we don't train these
+ vae.eval()
+ unet.eval()
+
+ unet = ipex.optimize(unet, dtype=torch.bfloat16, inplace=True)
+ vae = ipex.optimize(vae, dtype=torch.bfloat16, inplace=True)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("textual_inversion", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+ global_step = 0
+
+ text_encoder.train()
+ text_encoder, optimizer = ipex.optimize(text_encoder, optimizer=optimizer, dtype=torch.bfloat16)
+
+ for epoch in range(args.num_train_epochs):
+ for step, batch in enumerate(train_dataloader):
+ with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
+ with accelerator.accumulate(text_encoder):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"]).latent_dist.sample().detach()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn(latents.shape).to(latents.device)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(
+ 0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device
+ ).long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Predict the noise residual
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ loss = F.mse_loss(model_pred, target, reduction="none").mean([1, 2, 3]).mean()
+ accelerator.backward(loss)
+
+ # Zero out the gradients for all token embeddings except the newly added
+ # embeddings for the concept, as we only want to optimize the concept embeddings
+ if accelerator.num_processes > 1:
+ grads = text_encoder.module.get_input_embeddings().weight.grad
+ else:
+ grads = text_encoder.get_input_embeddings().weight.grad
+ # Get the index for tokens that we want to zero the grads for
+ index_grads_to_zero = torch.arange(len(tokenizer)) != placeholder_token_id
+ grads.data[index_grads_to_zero, :] = grads.data[index_grads_to_zero, :].fill_(0)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+ if global_step % args.save_steps == 0:
+ save_path = os.path.join(args.output_dir, f"learned_embeds-steps-{global_step}.bin")
+ save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ accelerator.wait_for_everyone()
+
+ # Create the pipeline using using the trained modules and save it.
+ if accelerator.is_main_process:
+ if args.push_to_hub and args.only_save_embeds:
+ logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
+ save_full_model = True
+ else:
+ save_full_model = not args.only_save_embeds
+ if save_full_model:
+ pipeline = StableDiffusionPipeline(
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ vae=vae,
+ unet=unet,
+ tokenizer=tokenizer,
+ scheduler=PNDMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler"),
+ safety_checker=StableDiffusionSafetyChecker.from_pretrained("CompVis/stable-diffusion-safety-checker"),
+ feature_extractor=CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch32"),
+ )
+ pipeline.save_pretrained(args.output_dir)
+ # Save the newly trained embeddings
+ save_path = os.path.join(args.output_dir, "learned_embeds.bin")
+ save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/lora/README.md b/diffusers/examples/research_projects/lora/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b5d72403166f9b4017751c3d47f79a9eb3f535d8
--- /dev/null
+++ b/diffusers/examples/research_projects/lora/README.md
@@ -0,0 +1,83 @@
+# Stable Diffusion text-to-image fine-tuning
+This extended LoRA training script was authored by [haofanwang](https://github.com/haofanwang).
+This is an experimental LoRA extension of [this example](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py). We further support add LoRA layers for text encoder.
+
+## Training with LoRA
+
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+
+In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
+
+- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
+- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
+- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
+
+[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
+
+With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
+on consumer GPUs like Tesla T4, Tesla V100.
+
+### Training
+
+First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables. Here, we will use [Stable Diffusion v1-4](https://hf.co/CompVis/stable-diffusion-v1-4) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
+
+**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
+
+**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export DATASET_NAME="lambdalabs/pokemon-blip-captions"
+```
+
+For this example we want to directly store the trained LoRA embeddings on the Hub, so
+we need to be logged in and add the `--push_to_hub` flag.
+
+```bash
+huggingface-cli login
+```
+
+Now we can start training!
+
+```bash
+accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$DATASET_NAME --caption_column="text" \
+ --resolution=512 --random_flip \
+ --train_batch_size=1 \
+ --num_train_epochs=100 --checkpointing_steps=5000 \
+ --learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
+ --seed=42 \
+ --output_dir="sd-pokemon-model-lora" \
+ --validation_prompt="cute dragon creature" --report_to="wandb"
+ --use_peft \
+ --lora_r=4 --lora_alpha=32 \
+ --lora_text_encoder_r=4 --lora_text_encoder_alpha=32
+```
+
+The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
+
+**___Note: When using LoRA we can use a much higher learning rate compared to non-LoRA fine-tuning. Here we use *1e-4* instead of the usual *1e-5*. Also, by using LoRA, it's possible to run `train_text_to_image_lora.py` in consumer GPUs like T4 or V100.___**
+
+The final LoRA embedding weights have been uploaded to [sayakpaul/sd-model-finetuned-lora-t4](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4). **___Note: [The final weights](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) are only 3 MB in size, which is orders of magnitudes smaller than the original model.___**
+
+You can check some inference samples that were logged during the course of the fine-tuning process [here](https://wandb.ai/sayakpaul/text2image-fine-tune/runs/q4lc0xsw).
+
+### Inference
+
+Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline` after loading the trained LoRA weights. You
+need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora`.
+
+```python
+from diffusers import StableDiffusionPipeline
+import torch
+
+model_path = "sayakpaul/sd-model-finetuned-lora-t4"
+pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+pipe.unet.load_attn_procs(model_path)
+pipe.to("cuda")
+
+prompt = "A pokemon with green eyes and red legs."
+image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
+image.save("pokemon.png")
+```
\ No newline at end of file
diff --git a/diffusers/examples/research_projects/lora/requirements.txt b/diffusers/examples/research_projects/lora/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..13b6feeec964cb5ee53f3a0c8b4d2e06614e2d6a
--- /dev/null
+++ b/diffusers/examples/research_projects/lora/requirements.txt
@@ -0,0 +1,8 @@
+accelerate
+torchvision
+transformers>=4.25.1
+datasets
+ftfy
+tensorboard
+Jinja2
+git+https://github.com/huggingface/peft.git
\ No newline at end of file
diff --git a/diffusers/examples/research_projects/lora/train_text_to_image_lora.py b/diffusers/examples/research_projects/lora/train_text_to_image_lora.py
new file mode 100644
index 0000000000000000000000000000000000000000..9db2024bde1e1d8f7e1cf7fbf396f0d7e82778fd
--- /dev/null
+++ b/diffusers/examples/research_projects/lora/train_text_to_image_lora.py
@@ -0,0 +1,1013 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fine-tuning script for Stable Diffusion for text2image with support for LoRA."""
+
+import argparse
+import itertools
+import json
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from datasets import load_dataset
+from huggingface_hub import create_repo, upload_folder
+from packaging import version
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+import diffusers
+from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, UNet2DConditionModel
+from diffusers.loaders import AttnProcsLayers
+from diffusers.models.attention_processor import LoRAAttnProcessor
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version, is_wandb_available
+from diffusers.utils.import_utils import is_xformers_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.14.0.dev0")
+
+logger = get_logger(__name__, log_level="INFO")
+
+
+def save_model_card(repo_id: str, images=None, base_model=str, dataset_name=str, repo_folder=None):
+ img_str = ""
+ for i, image in enumerate(images):
+ image.save(os.path.join(repo_folder, f"image_{i}.png"))
+ img_str += f"\n"
+
+ yaml = f"""
+---
+license: creativeml-openrail-m
+base_model: {base_model}
+tags:
+- stable-diffusion
+- stable-diffusion-diffusers
+- text-to-image
+- diffusers
+- lora
+inference: true
+---
+ """
+ model_card = f"""
+# LoRA text2image fine-tuning - {repo_id}
+These are LoRA adaption weights for {base_model}. The weights were fine-tuned on the {dataset_name} dataset. You can find some example images in the following. \n
+{img_str}
+"""
+ with open(os.path.join(repo_folder, "README.md"), "w") as f:
+ f.write(yaml + model_card)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that 🤗 Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--image_column", type=str, default="image", help="The column of the dataset containing an image."
+ )
+ parser.add_argument(
+ "--caption_column",
+ type=str,
+ default="text",
+ help="The column of the dataset containing a caption or a list of captions.",
+ )
+ parser.add_argument(
+ "--validation_prompt", type=str, default=None, help="A prompt that is sampled during training for inference."
+ )
+ parser.add_argument(
+ "--num_validation_images",
+ type=int,
+ default=4,
+ help="Number of images that should be generated during validation with `validation_prompt`.",
+ )
+ parser.add_argument(
+ "--validation_epochs",
+ type=int,
+ default=1,
+ help=(
+ "Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
+ " `args.validation_prompt` multiple times: `args.num_validation_images`."
+ ),
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="sd-model-finetuned-lora",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument("--train_text_encoder", action="store_true", help="Whether to train the text encoder")
+
+ # lora args
+ parser.add_argument("--use_peft", action="store_true", help="Whether to use peft to support lora")
+ parser.add_argument("--lora_r", type=int, default=4, help="Lora rank, only used if use_lora is True")
+ parser.add_argument("--lora_alpha", type=int, default=32, help="Lora alpha, only used if lora is True")
+ parser.add_argument("--lora_dropout", type=float, default=0.0, help="Lora dropout, only used if use_lora is True")
+ parser.add_argument(
+ "--lora_bias",
+ type=str,
+ default="none",
+ help="Bias type for Lora. Can be 'none', 'all' or 'lora_only', only used if use_lora is True",
+ )
+ parser.add_argument(
+ "--lora_text_encoder_r",
+ type=int,
+ default=4,
+ help="Lora rank for text encoder, only used if `use_lora` and `train_text_encoder` are True",
+ )
+ parser.add_argument(
+ "--lora_text_encoder_alpha",
+ type=int,
+ default=32,
+ help="Lora alpha for text encoder, only used if `use_lora` and `train_text_encoder` are True",
+ )
+ parser.add_argument(
+ "--lora_text_encoder_dropout",
+ type=float,
+ default=0.0,
+ help="Lora dropout for text encoder, only used if `use_lora` and `train_text_encoder` are True",
+ )
+ parser.add_argument(
+ "--lora_text_encoder_bias",
+ type=str,
+ default="none",
+ help="Bias type for Lora. Can be 'none', 'all' or 'lora_only', only used if use_lora and `train_text_encoder` are True",
+ )
+
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_data_dir is None:
+ raise ValueError("Need either a dataset name or a training folder.")
+
+ return args
+
+
+DATASET_NAME_MAPPING = {
+ "lambdalabs/pokemon-blip-captions": ("image", "text"),
+}
+
+
+def main():
+ args = parse_args()
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+ import wandb
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load scheduler, tokenizer and models.
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ tokenizer = CLIPTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
+ )
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ if args.use_peft:
+ from peft import LoraConfig, LoraModel, get_peft_model_state_dict, set_peft_model_state_dict
+
+ UNET_TARGET_MODULES = ["to_q", "to_v", "query", "value"]
+ TEXT_ENCODER_TARGET_MODULES = ["q_proj", "v_proj"]
+
+ config = LoraConfig(
+ r=args.lora_r,
+ lora_alpha=args.lora_alpha,
+ target_modules=UNET_TARGET_MODULES,
+ lora_dropout=args.lora_dropout,
+ bias=args.lora_bias,
+ )
+ unet = LoraModel(config, unet)
+
+ vae.requires_grad_(False)
+ if args.train_text_encoder:
+ config = LoraConfig(
+ r=args.lora_text_encoder_r,
+ lora_alpha=args.lora_text_encoder_alpha,
+ target_modules=TEXT_ENCODER_TARGET_MODULES,
+ lora_dropout=args.lora_text_encoder_dropout,
+ bias=args.lora_text_encoder_bias,
+ )
+ text_encoder = LoraModel(config, text_encoder)
+ else:
+ # freeze parameters of models to save more memory
+ unet.requires_grad_(False)
+ vae.requires_grad_(False)
+
+ text_encoder.requires_grad_(False)
+
+ # now we will add new LoRA weights to the attention layers
+ # It's important to realize here how many attention weights will be added and of which sizes
+ # The sizes of the attention layers consist only of two different variables:
+ # 1) - the "hidden_size", which is increased according to `unet.config.block_out_channels`.
+ # 2) - the "cross attention size", which is set to `unet.config.cross_attention_dim`.
+
+ # Let's first see how many attention processors we will have to set.
+ # For Stable Diffusion, it should be equal to:
+ # - down blocks (2x attention layers) * (2x transformer layers) * (3x down blocks) = 12
+ # - mid blocks (2x attention layers) * (1x transformer layers) * (1x mid blocks) = 2
+ # - up blocks (2x attention layers) * (3x transformer layers) * (3x down blocks) = 18
+ # => 32 layers
+
+ # Set correct lora layers
+ lora_attn_procs = {}
+ for name in unet.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = unet.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = unet.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+
+ unet.set_attn_processor(lora_attn_procs)
+ lora_layers = AttnProcsLayers(unet.attn_processors)
+
+ # Move unet, vae and text_encoder to device and cast to weight_dtype
+ vae.to(accelerator.device, dtype=weight_dtype)
+ if not args.train_text_encoder:
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
+ )
+
+ optimizer_cls = bnb.optim.AdamW8bit
+ else:
+ optimizer_cls = torch.optim.AdamW
+
+ if args.use_peft:
+ # Optimizer creation
+ params_to_optimize = (
+ itertools.chain(unet.parameters(), text_encoder.parameters())
+ if args.train_text_encoder
+ else unet.parameters()
+ )
+ optimizer = optimizer_cls(
+ params_to_optimize,
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+ else:
+ optimizer = optimizer_cls(
+ lora_layers.parameters(),
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ )
+ else:
+ data_files = {}
+ if args.train_data_dir is not None:
+ data_files["train"] = os.path.join(args.train_data_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=args.cache_dir,
+ )
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ column_names = dataset["train"].column_names
+
+ # 6. Get the column names for input/target.
+ dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
+ if args.image_column is None:
+ image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ image_column = args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.caption_column is None:
+ caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ caption_column = args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Preprocessing the datasets.
+ # We need to tokenize input captions and transform the images.
+ def tokenize_captions(examples, is_train=True):
+ captions = []
+ for caption in examples[caption_column]:
+ if isinstance(caption, str):
+ captions.append(caption)
+ elif isinstance(caption, (list, np.ndarray)):
+ # take a random caption if there are multiple
+ captions.append(random.choice(caption) if is_train else caption[0])
+ else:
+ raise ValueError(
+ f"Caption column `{caption_column}` should contain either strings or lists of strings."
+ )
+ inputs = tokenizer(
+ captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
+ )
+ return inputs.input_ids
+
+ # Preprocessing the datasets.
+ train_transforms = transforms.Compose(
+ [
+ transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
+ transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def preprocess_train(examples):
+ images = [image.convert("RGB") for image in examples[image_column]]
+ examples["pixel_values"] = [train_transforms(image) for image in images]
+ examples["input_ids"] = tokenize_captions(examples)
+ return examples
+
+ with accelerator.main_process_first():
+ if args.max_train_samples is not None:
+ dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ train_dataset = dataset["train"].with_transform(preprocess_train)
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+ input_ids = torch.stack([example["input_ids"] for example in examples])
+ return {"pixel_values": pixel_values, "input_ids": input_ids}
+
+ # DataLoaders creation:
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ shuffle=True,
+ collate_fn=collate_fn,
+ batch_size=args.train_batch_size,
+ num_workers=args.dataloader_num_workers,
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ if args.use_peft:
+ if args.train_text_encoder:
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+ else:
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+ else:
+ lora_layers, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ lora_layers, optimizer, train_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("text2image-fine-tune", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ if args.train_text_encoder:
+ text_encoder.train()
+ train_loss = 0.0
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ # Predict the noise residual and compute loss
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ # Gather the losses across all processes for logging (if we use distributed training).
+ avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
+ train_loss += avg_loss.item() / args.gradient_accumulation_steps
+
+ # Backpropagate
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ if args.use_peft:
+ params_to_clip = (
+ itertools.chain(unet.parameters(), text_encoder.parameters())
+ if args.train_text_encoder
+ else unet.parameters()
+ )
+ else:
+ params_to_clip = lora_layers.parameters()
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+ accelerator.log({"train_loss": train_loss}, step=global_step)
+ train_loss = 0.0
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if accelerator.is_main_process:
+ if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
+ logger.info(
+ f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
+ f" {args.validation_prompt}."
+ )
+ # create pipeline
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ revision=args.revision,
+ torch_dtype=weight_dtype,
+ )
+ pipeline = pipeline.to(accelerator.device)
+ pipeline.set_progress_bar_config(disable=True)
+
+ # run inference
+ generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
+ images = []
+ for _ in range(args.num_validation_images):
+ images.append(
+ pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0]
+ )
+
+ if accelerator.is_main_process:
+ for tracker in accelerator.trackers:
+ if tracker.name == "tensorboard":
+ np_images = np.stack([np.asarray(img) for img in images])
+ tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "validation": [
+ wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
+ for i, image in enumerate(images)
+ ]
+ }
+ )
+
+ del pipeline
+ torch.cuda.empty_cache()
+
+ # Save the lora layers
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ if args.use_peft:
+ lora_config = {}
+ unwarpped_unet = accelerator.unwrap_model(unet)
+ state_dict = get_peft_model_state_dict(unwarpped_unet, state_dict=accelerator.get_state_dict(unet))
+ lora_config["peft_config"] = unwarpped_unet.get_peft_config_as_dict(inference=True)
+ if args.train_text_encoder:
+ unwarpped_text_encoder = accelerator.unwrap_model(text_encoder)
+ text_encoder_state_dict = get_peft_model_state_dict(
+ unwarpped_text_encoder, state_dict=accelerator.get_state_dict(text_encoder)
+ )
+ text_encoder_state_dict = {f"text_encoder_{k}": v for k, v in text_encoder_state_dict.items()}
+ state_dict.update(text_encoder_state_dict)
+ lora_config["text_encoder_peft_config"] = unwarpped_text_encoder.get_peft_config_as_dict(
+ inference=True
+ )
+
+ accelerator.save(state_dict, os.path.join(args.output_dir, f"{global_step}_lora.pt"))
+ with open(os.path.join(args.output_dir, f"{global_step}_lora_config.json"), "w") as f:
+ json.dump(lora_config, f)
+ else:
+ unet = unet.to(torch.float32)
+ unet.save_attn_procs(args.output_dir)
+
+ if args.push_to_hub:
+ save_model_card(
+ repo_id,
+ images=images,
+ base_model=args.pretrained_model_name_or_path,
+ dataset_name=args.dataset_name,
+ repo_folder=args.output_dir,
+ )
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ # Final inference
+ # Load previous pipeline
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path, revision=args.revision, torch_dtype=weight_dtype
+ )
+
+ if args.use_peft:
+
+ def load_and_set_lora_ckpt(pipe, ckpt_dir, global_step, device, dtype):
+ with open(os.path.join(args.output_dir, f"{global_step}_lora_config.json"), "r") as f:
+ lora_config = json.load(f)
+ print(lora_config)
+
+ checkpoint = os.path.join(args.output_dir, f"{global_step}_lora.pt")
+ lora_checkpoint_sd = torch.load(checkpoint)
+ unet_lora_ds = {k: v for k, v in lora_checkpoint_sd.items() if "text_encoder_" not in k}
+ text_encoder_lora_ds = {
+ k.replace("text_encoder_", ""): v for k, v in lora_checkpoint_sd.items() if "text_encoder_" in k
+ }
+
+ unet_config = LoraConfig(**lora_config["peft_config"])
+ pipe.unet = LoraModel(unet_config, pipe.unet)
+ set_peft_model_state_dict(pipe.unet, unet_lora_ds)
+
+ if "text_encoder_peft_config" in lora_config:
+ text_encoder_config = LoraConfig(**lora_config["text_encoder_peft_config"])
+ pipe.text_encoder = LoraModel(text_encoder_config, pipe.text_encoder)
+ set_peft_model_state_dict(pipe.text_encoder, text_encoder_lora_ds)
+
+ if dtype in (torch.float16, torch.bfloat16):
+ pipe.unet.half()
+ pipe.text_encoder.half()
+
+ pipe.to(device)
+ return pipe
+
+ pipeline = load_and_set_lora_ckpt(pipeline, args.output_dir, global_step, accelerator.device, weight_dtype)
+
+ else:
+ pipeline = pipeline.to(accelerator.device)
+ # load attention processors
+ pipeline.unet.load_attn_procs(args.output_dir)
+
+ # run inference
+ if args.seed is not None:
+ generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
+ else:
+ generator = None
+ images = []
+ for _ in range(args.num_validation_images):
+ images.append(pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0])
+
+ if accelerator.is_main_process:
+ for tracker in accelerator.trackers:
+ if tracker.name == "tensorboard":
+ np_images = np.stack([np.asarray(img) for img in images])
+ tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "test": [
+ wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
+ for i, image in enumerate(images)
+ ]
+ }
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/mulit_token_textual_inversion/README.md b/diffusers/examples/research_projects/mulit_token_textual_inversion/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..540e4a705f192002958d901d14c5120b5d2fa681
--- /dev/null
+++ b/diffusers/examples/research_projects/mulit_token_textual_inversion/README.md
@@ -0,0 +1,140 @@
+## Multi Token Textual Inversion
+The author of this project is [Isamu Isozaki](https://github.com/isamu-isozaki) - please make sure to tag the author for issue and PRs as well as @patrickvonplaten.
+
+We add multi token support to textual inversion. I added
+1. num_vec_per_token for the number of used to reference that token
+2. progressive_tokens for progressively training the token from 1 token to 2 token etc
+3. progressive_tokens_max_steps for the max number of steps until we start full training
+4. vector_shuffle to shuffle vectors
+
+Feel free to add these options to your training! In practice num_vec_per_token around 10+vector shuffle works great!
+
+## Textual Inversion fine-tuning example
+
+[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
+The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
+
+## Running on Colab
+
+Colab for training
+[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
+
+Colab for inference
+[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
+
+## Running locally with PyTorch
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+
+### Cat toy example
+
+You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-5`, so you'll need to visit [its card](https://huggingface.co/runwayml/stable-diffusion-v1-5), read the license and tick the checkbox if you agree.
+
+You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
+
+Run the following command to authenticate your token
+
+```bash
+huggingface-cli login
+```
+
+If you have already cloned the repo, then you won't need to go through these steps.
+
+
+
+Now let's get our dataset.Download 3-4 images from [here](https://drive.google.com/drive/folders/1fmJMs25nxS_rSNqS5hTcRdLem_YQXbq5) and save them in a directory. This will be our training data.
+
+And launch the training using
+
+**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export DATA_DIR="path-to-dir-containing-images"
+
+accelerate launch textual_inversion.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --max_train_steps=3000 \
+ --learning_rate=5.0e-04 --scale_lr \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --output_dir="textual_inversion_cat"
+```
+
+A full training run takes ~1 hour on one V100 GPU.
+
+### Inference
+
+Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `placeholder_token` in your prompt.
+
+```python
+from diffusers import StableDiffusionPipeline
+
+model_id = "path-to-your-trained-model"
+pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16).to("cuda")
+
+prompt = "A backpack"
+
+image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
+
+image.save("cat-backpack.png")
+```
+
+
+## Training with Flax/JAX
+
+For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+```bash
+pip install -U -r requirements_flax.txt
+```
+
+```bash
+export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
+export DATA_DIR="path-to-dir-containing-images"
+
+python textual_inversion_flax.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --max_train_steps=3000 \
+ --learning_rate=5.0e-04 --scale_lr \
+ --output_dir="textual_inversion_cat"
+```
+It should be at least 70% faster than the PyTorch script with the same configuration.
+
+### Training with xformers:
+You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script. This is not available with the Flax/JAX implementation.
diff --git a/diffusers/examples/research_projects/mulit_token_textual_inversion/multi_token_clip.py b/diffusers/examples/research_projects/mulit_token_textual_inversion/multi_token_clip.py
new file mode 100644
index 0000000000000000000000000000000000000000..4388771b840df36ffa3a986dc9a2ad81ac7ee425
--- /dev/null
+++ b/diffusers/examples/research_projects/mulit_token_textual_inversion/multi_token_clip.py
@@ -0,0 +1,103 @@
+"""
+The main idea for this code is to provide a way for users to not need to bother with the hassle of multiple tokens for a concept by typing
+a photo of _0 _1 ... and so on
+and instead just do
+a photo of
+which gets translated to the above. This needs to work for both inference and training.
+For inference,
+the tokenizer encodes the text. So, we would want logic for our tokenizer to replace the placeholder token with
+it's underlying vectors
+For training,
+we would want to abstract away some logic like
+1. Adding tokens
+2. Updating gradient mask
+3. Saving embeddings
+to our Util class here.
+so
+TODO:
+1. have tokenizer keep track of concept, multiconcept pairs and replace during encode call x
+2. have mechanism for adding tokens x
+3. have mech for saving emebeddings x
+4. get mask to update x
+5. Loading tokens from embedding x
+6. Integrate to training x
+7. Test
+"""
+import copy
+import random
+
+from transformers import CLIPTokenizer
+
+
+class MultiTokenCLIPTokenizer(CLIPTokenizer):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.token_map = {}
+
+ def try_adding_tokens(self, placeholder_token, *args, **kwargs):
+ num_added_tokens = super().add_tokens(placeholder_token, *args, **kwargs)
+ if num_added_tokens == 0:
+ raise ValueError(
+ f"The tokenizer already contains the token {placeholder_token}. Please pass a different"
+ " `placeholder_token` that is not already in the tokenizer."
+ )
+
+ def add_placeholder_tokens(self, placeholder_token, *args, num_vec_per_token=1, **kwargs):
+ output = []
+ if num_vec_per_token == 1:
+ self.try_adding_tokens(placeholder_token, *args, **kwargs)
+ output.append(placeholder_token)
+ else:
+ output = []
+ for i in range(num_vec_per_token):
+ ith_token = placeholder_token + f"_{i}"
+ self.try_adding_tokens(ith_token, *args, **kwargs)
+ output.append(ith_token)
+ # handle cases where there is a new placeholder token that contains the current placeholder token but is larger
+ for token in self.token_map:
+ if token in placeholder_token:
+ raise ValueError(
+ f"The tokenizer already has placeholder token {token} that can get confused with"
+ f" {placeholder_token}keep placeholder tokens independent"
+ )
+ self.token_map[placeholder_token] = output
+
+ def replace_placeholder_tokens_in_text(self, text, vector_shuffle=False, prop_tokens_to_load=1.0):
+ """
+ Here, we replace the placeholder tokens in text recorded in token_map so that the text_encoder
+ can encode them
+ vector_shuffle was inspired by https://github.com/rinongal/textual_inversion/pull/119
+ where shuffling tokens were found to force the model to learn the concepts more descriptively.
+ """
+ if isinstance(text, list):
+ output = []
+ for i in range(len(text)):
+ output.append(self.replace_placeholder_tokens_in_text(text[i], vector_shuffle=vector_shuffle))
+ return output
+ for placeholder_token in self.token_map:
+ if placeholder_token in text:
+ tokens = self.token_map[placeholder_token]
+ tokens = tokens[: 1 + int(len(tokens) * prop_tokens_to_load)]
+ if vector_shuffle:
+ tokens = copy.copy(tokens)
+ random.shuffle(tokens)
+ text = text.replace(placeholder_token, " ".join(tokens))
+ return text
+
+ def __call__(self, text, *args, vector_shuffle=False, prop_tokens_to_load=1.0, **kwargs):
+ return super().__call__(
+ self.replace_placeholder_tokens_in_text(
+ text, vector_shuffle=vector_shuffle, prop_tokens_to_load=prop_tokens_to_load
+ ),
+ *args,
+ **kwargs,
+ )
+
+ def encode(self, text, *args, vector_shuffle=False, prop_tokens_to_load=1.0, **kwargs):
+ return super().encode(
+ self.replace_placeholder_tokens_in_text(
+ text, vector_shuffle=vector_shuffle, prop_tokens_to_load=prop_tokens_to_load
+ ),
+ *args,
+ **kwargs,
+ )
diff --git a/diffusers/examples/research_projects/mulit_token_textual_inversion/requirements.txt b/diffusers/examples/research_projects/mulit_token_textual_inversion/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7d93f3d03bd8eba09b8cab5e570d15380456b66a
--- /dev/null
+++ b/diffusers/examples/research_projects/mulit_token_textual_inversion/requirements.txt
@@ -0,0 +1,6 @@
+accelerate
+torchvision
+transformers>=4.25.1
+ftfy
+tensorboard
+Jinja2
diff --git a/diffusers/examples/research_projects/mulit_token_textual_inversion/requirements_flax.txt b/diffusers/examples/research_projects/mulit_token_textual_inversion/requirements_flax.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8f85ad523a3b46b65abf0138c05ecdd656e6845c
--- /dev/null
+++ b/diffusers/examples/research_projects/mulit_token_textual_inversion/requirements_flax.txt
@@ -0,0 +1,8 @@
+transformers>=4.25.1
+flax
+optax
+torch
+torchvision
+ftfy
+tensorboard
+Jinja2
diff --git a/diffusers/examples/research_projects/mulit_token_textual_inversion/textual_inversion.py b/diffusers/examples/research_projects/mulit_token_textual_inversion/textual_inversion.py
new file mode 100644
index 0000000000000000000000000000000000000000..622c51d2e52e37d91e9551138efaac54f76fcd0d
--- /dev/null
+++ b/diffusers/examples/research_projects/mulit_token_textual_inversion/textual_inversion.py
@@ -0,0 +1,927 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import argparse
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import numpy as np
+import PIL
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from huggingface_hub import create_repo, upload_folder
+from multi_token_clip import MultiTokenCLIPTokenizer
+
+# TODO: remove and import from diffusers.utils when the new version of diffusers is released
+from packaging import version
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel
+
+import diffusers
+from diffusers import (
+ AutoencoderKL,
+ DDPMScheduler,
+ DiffusionPipeline,
+ DPMSolverMultistepScheduler,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version, is_wandb_available
+from diffusers.utils.import_utils import is_xformers_available
+
+
+if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.Resampling.BILINEAR,
+ "bilinear": PIL.Image.Resampling.BILINEAR,
+ "bicubic": PIL.Image.Resampling.BICUBIC,
+ "lanczos": PIL.Image.Resampling.LANCZOS,
+ "nearest": PIL.Image.Resampling.NEAREST,
+ }
+else:
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.LINEAR,
+ "bilinear": PIL.Image.BILINEAR,
+ "bicubic": PIL.Image.BICUBIC,
+ "lanczos": PIL.Image.LANCZOS,
+ "nearest": PIL.Image.NEAREST,
+ }
+# ------------------------------------------------------------------------------
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.14.0.dev0")
+
+logger = get_logger(__name__)
+
+
+def add_tokens(tokenizer, text_encoder, placeholder_token, num_vec_per_token=1, initializer_token=None):
+ """
+ Add tokens to the tokenizer and set the initial value of token embeddings
+ """
+ tokenizer.add_placeholder_tokens(placeholder_token, num_vec_per_token=num_vec_per_token)
+ text_encoder.resize_token_embeddings(len(tokenizer))
+ token_embeds = text_encoder.get_input_embeddings().weight.data
+ placeholder_token_ids = tokenizer.encode(placeholder_token, add_special_tokens=False)
+ if initializer_token:
+ token_ids = tokenizer.encode(initializer_token, add_special_tokens=False)
+ for i, placeholder_token_id in enumerate(placeholder_token_ids):
+ token_embeds[placeholder_token_id] = token_embeds[token_ids[i * len(token_ids) // num_vec_per_token]]
+ else:
+ for i, placeholder_token_id in enumerate(placeholder_token_ids):
+ token_embeds[placeholder_token_id] = torch.randn_like(token_embeds[placeholder_token_id])
+ return placeholder_token
+
+
+def save_progress(tokenizer, text_encoder, accelerator, save_path):
+ for placeholder_token in tokenizer.token_map:
+ placeholder_token_ids = tokenizer.encode(placeholder_token, add_special_tokens=False)
+ learned_embeds = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[placeholder_token_ids]
+ if len(placeholder_token_ids) == 1:
+ learned_embeds = learned_embeds[None]
+ learned_embeds_dict = {placeholder_token: learned_embeds.detach().cpu()}
+ torch.save(learned_embeds_dict, save_path)
+
+
+def load_multitoken_tokenizer(tokenizer, text_encoder, learned_embeds_dict):
+ for placeholder_token in learned_embeds_dict:
+ placeholder_embeds = learned_embeds_dict[placeholder_token]
+ num_vec_per_token = placeholder_embeds.shape[0]
+ placeholder_embeds = placeholder_embeds.to(dtype=text_encoder.dtype)
+ add_tokens(tokenizer, text_encoder, placeholder_token, num_vec_per_token=num_vec_per_token)
+ placeholder_token_ids = tokenizer.encode(placeholder_token, add_special_tokens=False)
+ token_embeds = text_encoder.get_input_embeddings().weight.data
+ for i, placeholder_token_id in enumerate(placeholder_token_ids):
+ token_embeds[placeholder_token_id] = placeholder_embeds[i]
+
+
+def load_multitoken_tokenizer_from_automatic(tokenizer, text_encoder, automatic_dict, placeholder_token):
+ """
+ Automatic1111's tokens have format
+ {'string_to_token': {'*': 265}, 'string_to_param': {'*': tensor([[ 0.0833, 0.0030, 0.0057, ..., -0.0264, -0.0616, -0.0529],
+ [ 0.0058, -0.0190, -0.0584, ..., -0.0025, -0.0945, -0.0490],
+ [ 0.0916, 0.0025, 0.0365, ..., -0.0685, -0.0124, 0.0728],
+ [ 0.0812, -0.0199, -0.0100, ..., -0.0581, -0.0780, 0.0254]],
+ requires_grad=True)}, 'name': 'FloralMarble-400', 'step': 399, 'sd_checkpoint': '4bdfc29c', 'sd_checkpoint_name': 'SD2.1-768'}
+ """
+ learned_embeds_dict = {}
+ learned_embeds_dict[placeholder_token] = automatic_dict["string_to_param"]["*"]
+ load_multitoken_tokenizer(tokenizer, text_encoder, learned_embeds_dict)
+
+
+def get_mask(tokenizer, accelerator):
+ # Get the mask of the weights that won't change
+ mask = torch.ones(len(tokenizer)).to(accelerator.device, dtype=torch.bool)
+ for placeholder_token in tokenizer.token_map:
+ placeholder_token_ids = tokenizer.encode(placeholder_token, add_special_tokens=False)
+ for i in range(len(placeholder_token_ids)):
+ mask = mask & (torch.arange(len(tokenizer)) != placeholder_token_ids[i]).to(accelerator.device)
+ return mask
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--progressive_tokens_max_steps",
+ type=int,
+ default=2000,
+ help="The number of steps until all tokens will be used.",
+ )
+ parser.add_argument(
+ "--progressive_tokens",
+ action="store_true",
+ help="Progressively train the tokens. For example, first train for 1 token, then 2 tokens and so on.",
+ )
+ parser.add_argument("--vector_shuffle", action="store_true", help="Shuffling tokens durint training")
+ parser.add_argument(
+ "--num_vec_per_token",
+ type=int,
+ default=1,
+ help=(
+ "The number of vectors used to represent the placeholder token. The higher the number, the better the"
+ " result at the cost of editability. This can be fixed by prompt editing."
+ ),
+ )
+ parser.add_argument(
+ "--save_steps",
+ type=int,
+ default=500,
+ help="Save learned_embeds.bin every X updates steps.",
+ )
+ parser.add_argument(
+ "--only_save_embeds",
+ action="store_true",
+ default=False,
+ help="Save only the embeddings for the new concept.",
+ )
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
+ )
+ parser.add_argument(
+ "--placeholder_token",
+ type=str,
+ default=None,
+ required=True,
+ help="A token to use as a placeholder for the concept.",
+ )
+ parser.add_argument(
+ "--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
+ )
+ parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
+ parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=5000,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument(
+ "--validation_prompt",
+ type=str,
+ default=None,
+ help="A prompt that is used during validation to verify that the model is learning.",
+ )
+ parser.add_argument(
+ "--num_validation_images",
+ type=int,
+ default=4,
+ help="Number of images that should be generated during validation with `validation_prompt`.",
+ )
+ parser.add_argument(
+ "--validation_epochs",
+ type=int,
+ default=50,
+ help=(
+ "Run validation every X epochs. Validation consists of running the prompt"
+ " `args.validation_prompt` multiple times: `args.num_validation_images`"
+ " and logging the images."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.train_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ return args
+
+
+imagenet_templates_small = [
+ "a photo of a {}",
+ "a rendering of a {}",
+ "a cropped photo of the {}",
+ "the photo of a {}",
+ "a photo of a clean {}",
+ "a photo of a dirty {}",
+ "a dark photo of the {}",
+ "a photo of my {}",
+ "a photo of the cool {}",
+ "a close-up photo of a {}",
+ "a bright photo of the {}",
+ "a cropped photo of a {}",
+ "a photo of the {}",
+ "a good photo of the {}",
+ "a photo of one {}",
+ "a close-up photo of the {}",
+ "a rendition of the {}",
+ "a photo of the clean {}",
+ "a rendition of a {}",
+ "a photo of a nice {}",
+ "a good photo of a {}",
+ "a photo of the nice {}",
+ "a photo of the small {}",
+ "a photo of the weird {}",
+ "a photo of the large {}",
+ "a photo of a cool {}",
+ "a photo of a small {}",
+]
+
+imagenet_style_templates_small = [
+ "a painting in the style of {}",
+ "a rendering in the style of {}",
+ "a cropped painting in the style of {}",
+ "the painting in the style of {}",
+ "a clean painting in the style of {}",
+ "a dirty painting in the style of {}",
+ "a dark painting in the style of {}",
+ "a picture in the style of {}",
+ "a cool painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a bright painting in the style of {}",
+ "a cropped painting in the style of {}",
+ "a good painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a rendition in the style of {}",
+ "a nice painting in the style of {}",
+ "a small painting in the style of {}",
+ "a weird painting in the style of {}",
+ "a large painting in the style of {}",
+]
+
+
+class TextualInversionDataset(Dataset):
+ def __init__(
+ self,
+ data_root,
+ tokenizer,
+ learnable_property="object", # [object, style]
+ size=512,
+ repeats=100,
+ interpolation="bicubic",
+ flip_p=0.5,
+ set="train",
+ placeholder_token="*",
+ center_crop=False,
+ vector_shuffle=False,
+ progressive_tokens=False,
+ ):
+ self.data_root = data_root
+ self.tokenizer = tokenizer
+ self.learnable_property = learnable_property
+ self.size = size
+ self.placeholder_token = placeholder_token
+ self.center_crop = center_crop
+ self.flip_p = flip_p
+ self.vector_shuffle = vector_shuffle
+ self.progressive_tokens = progressive_tokens
+ self.prop_tokens_to_load = 0
+
+ self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
+
+ self.num_images = len(self.image_paths)
+ self._length = self.num_images
+
+ if set == "train":
+ self._length = self.num_images * repeats
+
+ self.interpolation = {
+ "linear": PIL_INTERPOLATION["linear"],
+ "bilinear": PIL_INTERPOLATION["bilinear"],
+ "bicubic": PIL_INTERPOLATION["bicubic"],
+ "lanczos": PIL_INTERPOLATION["lanczos"],
+ }[interpolation]
+
+ self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
+ self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, i):
+ example = {}
+ image = Image.open(self.image_paths[i % self.num_images])
+
+ if not image.mode == "RGB":
+ image = image.convert("RGB")
+
+ placeholder_string = self.placeholder_token
+ text = random.choice(self.templates).format(placeholder_string)
+
+ example["input_ids"] = self.tokenizer.encode(
+ text,
+ padding="max_length",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ vector_shuffle=self.vector_shuffle,
+ prop_tokens_to_load=self.prop_tokens_to_load if self.progressive_tokens else 1.0,
+ )[0]
+
+ # default to score-sde preprocessing
+ img = np.array(image).astype(np.uint8)
+
+ if self.center_crop:
+ crop = min(img.shape[0], img.shape[1])
+ (
+ h,
+ w,
+ ) = (
+ img.shape[0],
+ img.shape[1],
+ )
+ img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
+
+ image = Image.fromarray(img)
+ image = image.resize((self.size, self.size), resample=self.interpolation)
+
+ image = self.flip_transform(image)
+ image = np.array(image).astype(np.uint8)
+ image = (image / 127.5 - 1.0).astype(np.float32)
+
+ example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
+ return example
+
+
+def main():
+ args = parse_args()
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+ import wandb
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load tokenizer
+ if args.tokenizer_name:
+ tokenizer = MultiTokenCLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = MultiTokenCLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Load scheduler and models
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+ if is_xformers_available():
+ try:
+ unet.enable_xformers_memory_efficient_attention()
+ except Exception as e:
+ logger.warning(
+ "Could not enable memory efficient attention. Make sure xformers is installed"
+ f" correctly and a GPU is available: {e}"
+ )
+ add_tokens(tokenizer, text_encoder, args.placeholder_token, args.num_vec_per_token, args.initializer_token)
+
+ # Freeze vae and unet
+ vae.requires_grad_(False)
+ unet.requires_grad_(False)
+ # Freeze all parameters except for the token embeddings in text encoder
+ text_encoder.text_model.encoder.requires_grad_(False)
+ text_encoder.text_model.final_layer_norm.requires_grad_(False)
+ text_encoder.text_model.embeddings.position_embedding.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ # Keep unet in train mode if we are using gradient checkpointing to save memory.
+ # The dropout cannot be != 0 so it doesn't matter if we are in eval or train mode.
+ unet.train()
+ text_encoder.gradient_checkpointing_enable()
+ unet.enable_gradient_checkpointing()
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ optimizer = torch.optim.AdamW(
+ text_encoder.get_input_embeddings().parameters(), # only optimize the embeddings
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Dataset and DataLoaders creation:
+ train_dataset = TextualInversionDataset(
+ data_root=args.train_data_dir,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ placeholder_token=args.placeholder_token,
+ repeats=args.repeats,
+ learnable_property=args.learnable_property,
+ center_crop=args.center_crop,
+ set="train",
+ )
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+
+ # For mixed precision training we cast the unet and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move vae and unet to device and cast to weight_dtype
+ unet.to(accelerator.device, dtype=weight_dtype)
+ vae.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("textual_inversion", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ # keep original embeddings as reference
+ orig_embeds_params = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight.data.clone()
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ text_encoder.train()
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+ if args.progressive_tokens:
+ train_dataset.prop_tokens_to_load = float(global_step) / args.progressive_tokens_max_steps
+
+ with accelerator.accumulate(text_encoder):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample().detach()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0].to(dtype=weight_dtype)
+
+ # Predict the noise residual
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Let's make sure we don't update any embedding weights besides the newly added token
+ index_no_updates = get_mask(tokenizer, accelerator)
+ with torch.no_grad():
+ accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[
+ index_no_updates
+ ] = orig_embeds_params[index_no_updates]
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+ if global_step % args.save_steps == 0:
+ save_path = os.path.join(args.output_dir, f"learned_embeds-steps-{global_step}.bin")
+ save_progress(tokenizer, text_encoder, accelerator, save_path)
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if accelerator.is_main_process and args.validation_prompt is not None and epoch % args.validation_epochs == 0:
+ logger.info(
+ f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
+ f" {args.validation_prompt}."
+ )
+ # create pipeline (note: unet and vae are loaded again in float32)
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ tokenizer=tokenizer,
+ unet=unet,
+ vae=vae,
+ revision=args.revision,
+ torch_dtype=weight_dtype,
+ )
+ pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
+ pipeline = pipeline.to(accelerator.device)
+ pipeline.set_progress_bar_config(disable=True)
+
+ # run inference
+ generator = (
+ None if args.seed is None else torch.Generator(device=accelerator.device).manual_seed(args.seed)
+ )
+ images = []
+ for _ in range(args.num_validation_images):
+ with torch.autocast("cuda"):
+ image = pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
+ images.append(image)
+
+ for tracker in accelerator.trackers:
+ if tracker.name == "tensorboard":
+ np_images = np.stack([np.asarray(img) for img in images])
+ tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "validation": [
+ wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
+ for i, image in enumerate(images)
+ ]
+ }
+ )
+
+ del pipeline
+ torch.cuda.empty_cache()
+
+ # Create the pipeline using using the trained modules and save it.
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ if args.push_to_hub and args.only_save_embeds:
+ logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
+ save_full_model = True
+ else:
+ save_full_model = not args.only_save_embeds
+ if save_full_model:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ vae=vae,
+ unet=unet,
+ tokenizer=tokenizer,
+ )
+ pipeline.save_pretrained(args.output_dir)
+ # Save the newly trained embeddings
+ save_path = os.path.join(args.output_dir, "learned_embeds.bin")
+ save_progress(tokenizer, text_encoder, accelerator, save_path)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/mulit_token_textual_inversion/textual_inversion_flax.py b/diffusers/examples/research_projects/mulit_token_textual_inversion/textual_inversion_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..ecc89f98298e3e4205581fee1689761c519bc4e4
--- /dev/null
+++ b/diffusers/examples/research_projects/mulit_token_textual_inversion/textual_inversion_flax.py
@@ -0,0 +1,654 @@
+import argparse
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+import PIL
+import torch
+import torch.utils.checkpoint
+import transformers
+from flax import jax_utils
+from flax.training import train_state
+from flax.training.common_utils import shard
+from huggingface_hub import create_repo, upload_folder
+
+# TODO: remove and import from diffusers.utils when the new version of diffusers is released
+from packaging import version
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel, set_seed
+
+from diffusers import (
+ FlaxAutoencoderKL,
+ FlaxDDPMScheduler,
+ FlaxPNDMScheduler,
+ FlaxStableDiffusionPipeline,
+ FlaxUNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion import FlaxStableDiffusionSafetyChecker
+from diffusers.utils import check_min_version
+
+
+if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.Resampling.BILINEAR,
+ "bilinear": PIL.Image.Resampling.BILINEAR,
+ "bicubic": PIL.Image.Resampling.BICUBIC,
+ "lanczos": PIL.Image.Resampling.LANCZOS,
+ "nearest": PIL.Image.Resampling.NEAREST,
+ }
+else:
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.LINEAR,
+ "bilinear": PIL.Image.BILINEAR,
+ "bicubic": PIL.Image.BICUBIC,
+ "lanczos": PIL.Image.LANCZOS,
+ "nearest": PIL.Image.NEAREST,
+ }
+# ------------------------------------------------------------------------------
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.14.0.dev0")
+
+logger = logging.getLogger(__name__)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
+ )
+ parser.add_argument(
+ "--placeholder_token",
+ type=str,
+ default=None,
+ required=True,
+ help="A token to use as a placeholder for the concept.",
+ )
+ parser.add_argument(
+ "--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
+ )
+ parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
+ parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=42, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=5000,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=True,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--use_auth_token",
+ action="store_true",
+ help=(
+ "Will use the token generated when running `huggingface-cli login` (necessary to use this script with"
+ " private models)."
+ ),
+ )
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.train_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ return args
+
+
+imagenet_templates_small = [
+ "a photo of a {}",
+ "a rendering of a {}",
+ "a cropped photo of the {}",
+ "the photo of a {}",
+ "a photo of a clean {}",
+ "a photo of a dirty {}",
+ "a dark photo of the {}",
+ "a photo of my {}",
+ "a photo of the cool {}",
+ "a close-up photo of a {}",
+ "a bright photo of the {}",
+ "a cropped photo of a {}",
+ "a photo of the {}",
+ "a good photo of the {}",
+ "a photo of one {}",
+ "a close-up photo of the {}",
+ "a rendition of the {}",
+ "a photo of the clean {}",
+ "a rendition of a {}",
+ "a photo of a nice {}",
+ "a good photo of a {}",
+ "a photo of the nice {}",
+ "a photo of the small {}",
+ "a photo of the weird {}",
+ "a photo of the large {}",
+ "a photo of a cool {}",
+ "a photo of a small {}",
+]
+
+imagenet_style_templates_small = [
+ "a painting in the style of {}",
+ "a rendering in the style of {}",
+ "a cropped painting in the style of {}",
+ "the painting in the style of {}",
+ "a clean painting in the style of {}",
+ "a dirty painting in the style of {}",
+ "a dark painting in the style of {}",
+ "a picture in the style of {}",
+ "a cool painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a bright painting in the style of {}",
+ "a cropped painting in the style of {}",
+ "a good painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a rendition in the style of {}",
+ "a nice painting in the style of {}",
+ "a small painting in the style of {}",
+ "a weird painting in the style of {}",
+ "a large painting in the style of {}",
+]
+
+
+class TextualInversionDataset(Dataset):
+ def __init__(
+ self,
+ data_root,
+ tokenizer,
+ learnable_property="object", # [object, style]
+ size=512,
+ repeats=100,
+ interpolation="bicubic",
+ flip_p=0.5,
+ set="train",
+ placeholder_token="*",
+ center_crop=False,
+ ):
+ self.data_root = data_root
+ self.tokenizer = tokenizer
+ self.learnable_property = learnable_property
+ self.size = size
+ self.placeholder_token = placeholder_token
+ self.center_crop = center_crop
+ self.flip_p = flip_p
+
+ self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
+
+ self.num_images = len(self.image_paths)
+ self._length = self.num_images
+
+ if set == "train":
+ self._length = self.num_images * repeats
+
+ self.interpolation = {
+ "linear": PIL_INTERPOLATION["linear"],
+ "bilinear": PIL_INTERPOLATION["bilinear"],
+ "bicubic": PIL_INTERPOLATION["bicubic"],
+ "lanczos": PIL_INTERPOLATION["lanczos"],
+ }[interpolation]
+
+ self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
+ self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, i):
+ example = {}
+ image = Image.open(self.image_paths[i % self.num_images])
+
+ if not image.mode == "RGB":
+ image = image.convert("RGB")
+
+ placeholder_string = self.placeholder_token
+ text = random.choice(self.templates).format(placeholder_string)
+
+ example["input_ids"] = self.tokenizer(
+ text,
+ padding="max_length",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ ).input_ids[0]
+
+ # default to score-sde preprocessing
+ img = np.array(image).astype(np.uint8)
+
+ if self.center_crop:
+ crop = min(img.shape[0], img.shape[1])
+ (
+ h,
+ w,
+ ) = (
+ img.shape[0],
+ img.shape[1],
+ )
+ img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
+
+ image = Image.fromarray(img)
+ image = image.resize((self.size, self.size), resample=self.interpolation)
+
+ image = self.flip_transform(image)
+ image = np.array(image).astype(np.uint8)
+ image = (image / 127.5 - 1.0).astype(np.float32)
+
+ example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
+ return example
+
+
+def resize_token_embeddings(model, new_num_tokens, initializer_token_id, placeholder_token_id, rng):
+ if model.config.vocab_size == new_num_tokens or new_num_tokens is None:
+ return
+ model.config.vocab_size = new_num_tokens
+
+ params = model.params
+ old_embeddings = params["text_model"]["embeddings"]["token_embedding"]["embedding"]
+ old_num_tokens, emb_dim = old_embeddings.shape
+
+ initializer = jax.nn.initializers.normal()
+
+ new_embeddings = initializer(rng, (new_num_tokens, emb_dim))
+ new_embeddings = new_embeddings.at[:old_num_tokens].set(old_embeddings)
+ new_embeddings = new_embeddings.at[placeholder_token_id].set(new_embeddings[initializer_token_id])
+ params["text_model"]["embeddings"]["token_embedding"]["embedding"] = new_embeddings
+
+ model.params = params
+ return model
+
+
+def get_params_to_save(params):
+ return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
+
+
+def main():
+ args = parse_args()
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ if jax.process_index() == 0:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+
+ # Load the tokenizer and add the placeholder token as a additional special token
+ if args.tokenizer_name:
+ tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Add the placeholder token in tokenizer
+ num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
+ if num_added_tokens == 0:
+ raise ValueError(
+ f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
+ " `placeholder_token` that is not already in the tokenizer."
+ )
+
+ # Convert the initializer_token, placeholder_token to ids
+ token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
+ # Check if initializer_token is a single token or a sequence of tokens
+ if len(token_ids) > 1:
+ raise ValueError("The initializer token must be a single token.")
+
+ initializer_token_id = token_ids[0]
+ placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
+
+ # Load models and create wrapper for stable diffusion
+ text_encoder = FlaxCLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
+ vae, vae_params = FlaxAutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae")
+ unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
+
+ # Create sampling rng
+ rng = jax.random.PRNGKey(args.seed)
+ rng, _ = jax.random.split(rng)
+ # Resize the token embeddings as we are adding new special tokens to the tokenizer
+ text_encoder = resize_token_embeddings(
+ text_encoder, len(tokenizer), initializer_token_id, placeholder_token_id, rng
+ )
+ original_token_embeds = text_encoder.params["text_model"]["embeddings"]["token_embedding"]["embedding"]
+
+ train_dataset = TextualInversionDataset(
+ data_root=args.train_data_dir,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ placeholder_token=args.placeholder_token,
+ repeats=args.repeats,
+ learnable_property=args.learnable_property,
+ center_crop=args.center_crop,
+ set="train",
+ )
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ input_ids = torch.stack([example["input_ids"] for example in examples])
+
+ batch = {"pixel_values": pixel_values, "input_ids": input_ids}
+ batch = {k: v.numpy() for k, v in batch.items()}
+
+ return batch
+
+ total_train_batch_size = args.train_batch_size * jax.local_device_count()
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=total_train_batch_size, shuffle=True, drop_last=True, collate_fn=collate_fn
+ )
+
+ # Optimization
+ if args.scale_lr:
+ args.learning_rate = args.learning_rate * total_train_batch_size
+
+ constant_scheduler = optax.constant_schedule(args.learning_rate)
+
+ optimizer = optax.adamw(
+ learning_rate=constant_scheduler,
+ b1=args.adam_beta1,
+ b2=args.adam_beta2,
+ eps=args.adam_epsilon,
+ weight_decay=args.adam_weight_decay,
+ )
+
+ def create_mask(params, label_fn):
+ def _map(params, mask, label_fn):
+ for k in params:
+ if label_fn(k):
+ mask[k] = "token_embedding"
+ else:
+ if isinstance(params[k], dict):
+ mask[k] = {}
+ _map(params[k], mask[k], label_fn)
+ else:
+ mask[k] = "zero"
+
+ mask = {}
+ _map(params, mask, label_fn)
+ return mask
+
+ def zero_grads():
+ # from https://github.com/deepmind/optax/issues/159#issuecomment-896459491
+ def init_fn(_):
+ return ()
+
+ def update_fn(updates, state, params=None):
+ return jax.tree_util.tree_map(jnp.zeros_like, updates), ()
+
+ return optax.GradientTransformation(init_fn, update_fn)
+
+ # Zero out gradients of layers other than the token embedding layer
+ tx = optax.multi_transform(
+ {"token_embedding": optimizer, "zero": zero_grads()},
+ create_mask(text_encoder.params, lambda s: s == "token_embedding"),
+ )
+
+ state = train_state.TrainState.create(apply_fn=text_encoder.__call__, params=text_encoder.params, tx=tx)
+
+ noise_scheduler = FlaxDDPMScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000
+ )
+ noise_scheduler_state = noise_scheduler.create_state()
+
+ # Initialize our training
+ train_rngs = jax.random.split(rng, jax.local_device_count())
+
+ # Define gradient train step fn
+ def train_step(state, vae_params, unet_params, batch, train_rng):
+ dropout_rng, sample_rng, new_train_rng = jax.random.split(train_rng, 3)
+
+ def compute_loss(params):
+ vae_outputs = vae.apply(
+ {"params": vae_params}, batch["pixel_values"], deterministic=True, method=vae.encode
+ )
+ latents = vae_outputs.latent_dist.sample(sample_rng)
+ # (NHWC) -> (NCHW)
+ latents = jnp.transpose(latents, (0, 3, 1, 2))
+ latents = latents * vae.config.scaling_factor
+
+ noise_rng, timestep_rng = jax.random.split(sample_rng)
+ noise = jax.random.normal(noise_rng, latents.shape)
+ bsz = latents.shape[0]
+ timesteps = jax.random.randint(
+ timestep_rng,
+ (bsz,),
+ 0,
+ noise_scheduler.config.num_train_timesteps,
+ )
+ noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
+ encoder_hidden_states = state.apply_fn(
+ batch["input_ids"], params=params, dropout_rng=dropout_rng, train=True
+ )[0]
+ # Predict the noise residual and compute loss
+ model_pred = unet.apply(
+ {"params": unet_params}, noisy_latents, timesteps, encoder_hidden_states, train=False
+ ).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ loss = (target - model_pred) ** 2
+ loss = loss.mean()
+
+ return loss
+
+ grad_fn = jax.value_and_grad(compute_loss)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+ new_state = state.apply_gradients(grads=grad)
+
+ # Keep the token embeddings fixed except the newly added embeddings for the concept,
+ # as we only want to optimize the concept embeddings
+ token_embeds = original_token_embeds.at[placeholder_token_id].set(
+ new_state.params["text_model"]["embeddings"]["token_embedding"]["embedding"][placeholder_token_id]
+ )
+ new_state.params["text_model"]["embeddings"]["token_embedding"]["embedding"] = token_embeds
+
+ metrics = {"loss": loss}
+ metrics = jax.lax.pmean(metrics, axis_name="batch")
+ return new_state, metrics, new_train_rng
+
+ # Create parallel version of the train and eval step
+ p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
+
+ # Replicate the train state on each device
+ state = jax_utils.replicate(state)
+ vae_params = jax_utils.replicate(vae_params)
+ unet_params = jax_utils.replicate(unet_params)
+
+ # Train!
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader))
+
+ # Scheduler and math around the number of training steps.
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ global_step = 0
+
+ epochs = tqdm(range(args.num_train_epochs), desc=f"Epoch ... (1/{args.num_train_epochs})", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+
+ train_metrics = []
+
+ steps_per_epoch = len(train_dataset) // total_train_batch_size
+ train_step_progress_bar = tqdm(total=steps_per_epoch, desc="Training...", position=1, leave=False)
+ # train
+ for batch in train_dataloader:
+ batch = shard(batch)
+ state, train_metric, train_rngs = p_train_step(state, vae_params, unet_params, batch, train_rngs)
+ train_metrics.append(train_metric)
+
+ train_step_progress_bar.update(1)
+ global_step += 1
+
+ if global_step >= args.max_train_steps:
+ break
+
+ train_metric = jax_utils.unreplicate(train_metric)
+
+ train_step_progress_bar.close()
+ epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
+
+ # Create the pipeline using using the trained modules and save it.
+ if jax.process_index() == 0:
+ scheduler = FlaxPNDMScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", skip_prk_steps=True
+ )
+ safety_checker = FlaxStableDiffusionSafetyChecker.from_pretrained(
+ "CompVis/stable-diffusion-safety-checker", from_pt=True
+ )
+ pipeline = FlaxStableDiffusionPipeline(
+ text_encoder=text_encoder,
+ vae=vae,
+ unet=unet,
+ tokenizer=tokenizer,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch32"),
+ )
+
+ pipeline.save_pretrained(
+ args.output_dir,
+ params={
+ "text_encoder": get_params_to_save(state.params),
+ "vae": get_params_to_save(vae_params),
+ "unet": get_params_to_save(unet_params),
+ "safety_checker": safety_checker.params,
+ },
+ )
+
+ # Also save the newly trained embeddings
+ learned_embeds = get_params_to_save(state.params)["text_model"]["embeddings"]["token_embedding"]["embedding"][
+ placeholder_token_id
+ ]
+ learned_embeds_dict = {args.placeholder_token: learned_embeds}
+ jnp.save(os.path.join(args.output_dir, "learned_embeds.npy"), learned_embeds_dict)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/multi_subject_dreambooth/README.md b/diffusers/examples/research_projects/multi_subject_dreambooth/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..cf7dd31d0797ad1e22fb7d5ab192de2dada490df
--- /dev/null
+++ b/diffusers/examples/research_projects/multi_subject_dreambooth/README.md
@@ -0,0 +1,291 @@
+# Multi Subject DreamBooth training
+
+[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few(3~5) images of a subject.
+This `train_multi_subject_dreambooth.py` script shows how to implement the training procedure for one or more subjects and adapt it for stable diffusion. Note that this code is based off of the `examples/dreambooth/train_dreambooth.py` script as of 01/06/2022.
+
+This script was added by @kopsahlong, and is not actively maintained. However, if you come across anything that could use fixing, feel free to open an issue and tag @kopsahlong.
+
+## Running locally with PyTorch
+### Installing the dependencies
+
+Before running the script, make sure to install the library's training dependencies:
+
+To start, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install -e .
+```
+
+Then cd into the folder `diffusers/examples/research_projects/multi_subject_dreambooth` and run the following:
+```bash
+pip install -r requirements.txt
+```
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+Or for a default accelerate configuration without answering questions about your environment
+
+```bash
+accelerate config default
+```
+
+Or if your environment doesn't support an interactive shell e.g. a notebook
+
+```python
+from accelerate.utils import write_basic_config
+write_basic_config()
+```
+
+### Multi Subject Training Example
+In order to have your model learn multiple concepts at once, we simply add in the additional data directories and prompts to our `instance_data_dir` and `instance_prompt` (as well as `class_data_dir` and `class_prompt` if `--with_prior_preservation` is specified) as one comma separated string.
+
+See an example with 2 subjects below, which learns a model for one dog subject and one human subject:
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export OUTPUT_DIR="path-to-save-model"
+
+# Subject 1
+export INSTANCE_DIR_1="path-to-instance-images-concept-1"
+export INSTANCE_PROMPT_1="a photo of a sks dog"
+export CLASS_DIR_1="path-to-class-images-dog"
+export CLASS_PROMPT_1="a photo of a dog"
+
+# Subject 2
+export INSTANCE_DIR_2="path-to-instance-images-concept-2"
+export INSTANCE_PROMPT_2="a photo of a t@y person"
+export CLASS_DIR_2="path-to-class-images-person"
+export CLASS_PROMPT_2="a photo of a person"
+
+accelerate launch train_multi_subject_dreambooth.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir="$INSTANCE_DIR_1,$INSTANCE_DIR_2" \
+ --output_dir=$OUTPUT_DIR \
+ --train_text_encoder \
+ --instance_prompt="$INSTANCE_PROMPT_1,$INSTANCE_PROMPT_2" \
+ --with_prior_preservation \
+ --prior_loss_weight=1.0 \
+ --class_data_dir="$CLASS_DIR_1,$CLASS_DIR_2" \
+ --class_prompt="$CLASS_PROMPT_1,$CLASS_PROMPT_2"\
+ --num_class_images=50 \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=1 \
+ --learning_rate=1e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=1500
+```
+
+This example shows training for 2 subjects, but please note that the model can be trained on any number of new concepts. This can be done by continuing to add in the corresponding directories and prompts to the corresponding comma separated string.
+
+Note also that in this script, `sks` and `t@y` were used as tokens to learn the new subjects ([this thread](https://github.com/XavierXiao/Dreambooth-Stable-Diffusion/issues/71) inspired the use of `t@y` as our second identifier). However, there may be better rare tokens to experiment with, and results also seemed to be good when more intuitive words are used.
+
+### Inference
+
+Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `identifier`(e.g. sks in above example) in your prompt.
+
+```python
+from diffusers import StableDiffusionPipeline
+import torch
+
+model_id = "path-to-your-trained-model"
+pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
+
+prompt = "A photo of a t@y person petting an sks dog"
+image = pipe(prompt, num_inference_steps=200, guidance_scale=7.5).images[0]
+
+image.save("person-petting-dog.png")
+```
+
+### Inference from a training checkpoint
+
+You can also perform inference from one of the checkpoints saved during the training process, if you used the `--checkpointing_steps` argument. Please, refer to [the documentation](https://huggingface.co/docs/diffusers/main/en/training/dreambooth#performing-inference-using-a-saved-checkpoint) to see how to do it.
+
+## Additional Dreambooth documentation
+Because the `train_multi_subject_dreambooth.py` script here was forked from an original version of `train_dreambooth.py` in the `examples/dreambooth` folder, I've included the original applicable training documentation for single subject examples below.
+
+This should explain how to play with training variables such as prior preservation, fine tuning the text encoder, etc. which is still applicable to our multi subject training code. Note also that the examples below, which are single subject examples, also work with `train_multi_subject_dreambooth.py`, as this script supports 1 (or more) subjects.
+
+### Single subject dog toy example
+
+Let's get our dataset. Download images from [here](https://drive.google.com/drive/folders/1BO_dyz-p65qhBRRMRA4TbZ8qW4rB99JZ) and save them in a directory. This will be our training data.
+
+And launch the training using
+
+**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export INSTANCE_DIR="path-to-instance-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch train_dreambooth.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --instance_prompt="a photo of sks dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=1 \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --max_train_steps=400
+```
+
+### Training with prior-preservation loss
+
+Prior-preservation is used to avoid overfitting and language-drift. Refer to the paper to learn more about it. For prior-preservation we first generate images using the model with a class prompt and then use those during training along with our data.
+According to the paper, it's recommended to generate `num_epochs * num_samples` images for prior-preservation. 200-300 works well for most cases. The `num_class_images` flag sets the number of images to generate with the class prompt. You can place existing images in `class_data_dir`, and the training script will generate any additional images so that `num_class_images` are present in `class_data_dir` during training time.
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export INSTANCE_DIR="path-to-instance-images"
+export CLASS_DIR="path-to-class-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch train_dreambooth.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --class_data_dir=$CLASS_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --with_prior_preservation --prior_loss_weight=1.0 \
+ --instance_prompt="a photo of sks dog" \
+ --class_prompt="a photo of dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=1 \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --num_class_images=200 \
+ --max_train_steps=800
+```
+
+
+### Training on a 16GB GPU:
+
+With the help of gradient checkpointing and the 8-bit optimizer from bitsandbytes it's possible to run train dreambooth on a 16GB GPU.
+
+To install `bitandbytes` please refer to this [readme](https://github.com/TimDettmers/bitsandbytes#requirements--installation).
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export INSTANCE_DIR="path-to-instance-images"
+export CLASS_DIR="path-to-class-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch train_dreambooth.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --class_data_dir=$CLASS_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --with_prior_preservation --prior_loss_weight=1.0 \
+ --instance_prompt="a photo of sks dog" \
+ --class_prompt="a photo of dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=2 --gradient_checkpointing \
+ --use_8bit_adam \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --num_class_images=200 \
+ --max_train_steps=800
+```
+
+### Training on a 8 GB GPU:
+
+By using [DeepSpeed](https://www.deepspeed.ai/) it's possible to offload some
+tensors from VRAM to either CPU or NVME allowing to train with less VRAM.
+
+DeepSpeed needs to be enabled with `accelerate config`. During configuration
+answer yes to "Do you want to use DeepSpeed?". With DeepSpeed stage 2, fp16
+mixed precision and offloading both parameters and optimizer state to cpu it's
+possible to train on under 8 GB VRAM with a drawback of requiring significantly
+more RAM (about 25 GB). See [documentation](https://huggingface.co/docs/accelerate/usage_guides/deepspeed) for more DeepSpeed configuration options.
+
+Changing the default Adam optimizer to DeepSpeed's special version of Adam
+`deepspeed.ops.adam.DeepSpeedCPUAdam` gives a substantial speedup but enabling
+it requires CUDA toolchain with the same version as pytorch. 8-bit optimizer
+does not seem to be compatible with DeepSpeed at the moment.
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export INSTANCE_DIR="path-to-instance-images"
+export CLASS_DIR="path-to-class-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch --mixed_precision="fp16" train_dreambooth.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --instance_data_dir=$INSTANCE_DIR \
+ --class_data_dir=$CLASS_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --with_prior_preservation --prior_loss_weight=1.0 \
+ --instance_prompt="a photo of sks dog" \
+ --class_prompt="a photo of dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --sample_batch_size=1 \
+ --gradient_accumulation_steps=1 --gradient_checkpointing \
+ --learning_rate=5e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --num_class_images=200 \
+ --max_train_steps=800
+```
+
+### Fine-tune text encoder with the UNet.
+
+The script also allows to fine-tune the `text_encoder` along with the `unet`. It's been observed experimentally that fine-tuning `text_encoder` gives much better results especially on faces.
+Pass the `--train_text_encoder` argument to the script to enable training `text_encoder`.
+
+___Note: Training text encoder requires more memory, with this option the training won't fit on 16GB GPU. It needs at least 24GB VRAM.___
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export INSTANCE_DIR="path-to-instance-images"
+export CLASS_DIR="path-to-class-images"
+export OUTPUT_DIR="path-to-save-model"
+
+accelerate launch train_dreambooth.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_text_encoder \
+ --instance_data_dir=$INSTANCE_DIR \
+ --class_data_dir=$CLASS_DIR \
+ --output_dir=$OUTPUT_DIR \
+ --with_prior_preservation --prior_loss_weight=1.0 \
+ --instance_prompt="a photo of sks dog" \
+ --class_prompt="a photo of dog" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --use_8bit_adam \
+ --gradient_checkpointing \
+ --learning_rate=2e-6 \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --num_class_images=200 \
+ --max_train_steps=800
+```
+
+### Using DreamBooth for other pipelines than Stable Diffusion
+
+Altdiffusion also support dreambooth now, the runing comman is basically the same as abouve, all you need to do is replace the `MODEL_NAME` like this:
+One can now simply change the `pretrained_model_name_or_path` to another architecture such as [`AltDiffusion`](https://huggingface.co/docs/diffusers/api/pipelines/alt_diffusion).
+
+```
+export MODEL_NAME="CompVis/stable-diffusion-v1-4" --> export MODEL_NAME="BAAI/AltDiffusion-m9"
+or
+export MODEL_NAME="CompVis/stable-diffusion-v1-4" --> export MODEL_NAME="BAAI/AltDiffusion"
+```
+
+### Training with xformers:
+You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script. This is not available with the Flax/JAX implementation.
+
+You can also use Dreambooth to train the specialized in-painting model. See [the script in the research folder for details](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/dreambooth_inpaint).
\ No newline at end of file
diff --git a/diffusers/examples/research_projects/multi_subject_dreambooth/requirements.txt b/diffusers/examples/research_projects/multi_subject_dreambooth/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bbf6c5bec69c6d473db01ff4f15f38e3d7d7a1b3
--- /dev/null
+++ b/diffusers/examples/research_projects/multi_subject_dreambooth/requirements.txt
@@ -0,0 +1,6 @@
+accelerate
+torchvision
+transformers>=4.25.1
+ftfy
+tensorboard
+Jinja2
\ No newline at end of file
diff --git a/diffusers/examples/research_projects/multi_subject_dreambooth/train_multi_subject_dreambooth.py b/diffusers/examples/research_projects/multi_subject_dreambooth/train_multi_subject_dreambooth.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1016b50e7b2b3757fcf1f0b2baa6601888f5eb8
--- /dev/null
+++ b/diffusers/examples/research_projects/multi_subject_dreambooth/train_multi_subject_dreambooth.py
@@ -0,0 +1,882 @@
+import argparse
+import hashlib
+import itertools
+import logging
+import math
+import os
+import warnings
+from pathlib import Path
+
+import datasets
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from huggingface_hub import create_repo, upload_folder
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import AutoTokenizer, PretrainedConfig
+
+import diffusers
+from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, UNet2DConditionModel
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version
+from diffusers.utils.import_utils import is_xformers_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.13.0.dev0")
+
+logger = get_logger(__name__)
+
+
+def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
+ text_encoder_config = PretrainedConfig.from_pretrained(
+ pretrained_model_name_or_path,
+ subfolder="text_encoder",
+ revision=revision,
+ )
+ model_class = text_encoder_config.architectures[0]
+
+ if model_class == "CLIPTextModel":
+ from transformers import CLIPTextModel
+
+ return CLIPTextModel
+ elif model_class == "RobertaSeriesModelWithTransformation":
+ from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
+
+ return RobertaSeriesModelWithTransformation
+ else:
+ raise ValueError(f"{model_class} is not supported.")
+
+
+def parse_args(input_args=None):
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--instance_data_dir",
+ type=str,
+ default=None,
+ required=True,
+ help="A folder containing the training data of instance images.",
+ )
+ parser.add_argument(
+ "--class_data_dir",
+ type=str,
+ default=None,
+ required=False,
+ help="A folder containing the training data of class images.",
+ )
+ parser.add_argument(
+ "--instance_prompt",
+ type=str,
+ default=None,
+ required=True,
+ help="The prompt with identifier specifying the instance",
+ )
+ parser.add_argument(
+ "--class_prompt",
+ type=str,
+ default=None,
+ help="The prompt to specify images in the same class as provided instance images.",
+ )
+ parser.add_argument(
+ "--with_prior_preservation",
+ default=False,
+ action="store_true",
+ help="Flag to add prior preservation loss.",
+ )
+ parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
+ parser.add_argument(
+ "--num_class_images",
+ type=int,
+ default=100,
+ help=(
+ "Minimal class images for prior preservation loss. If there are not enough images already present in"
+ " class_data_dir, additional images will be sampled with class_prompt."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument("--train_text_encoder", action="store_true", help="Whether to train the text encoder")
+ parser.add_argument(
+ "--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument(
+ "--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=1)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
+ " checkpoints in case they are better than the last checkpoint, and are also suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-6,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--lr_num_cycles",
+ type=int,
+ default=1,
+ help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
+ )
+ parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument(
+ "--prior_generation_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp32", "fp16", "bf16"],
+ help=(
+ "Choose prior generation precision between fp32, fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to fp16 if a GPU is available else fp32."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ if input_args is not None:
+ args = parser.parse_args(input_args)
+ else:
+ args = parser.parse_args()
+
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.with_prior_preservation:
+ if args.class_data_dir is None:
+ raise ValueError("You must specify a data directory for class images.")
+ if args.class_prompt is None:
+ raise ValueError("You must specify prompt for class images.")
+ else:
+ # logger is not available yet
+ if args.class_data_dir is not None:
+ warnings.warn("You need not use --class_data_dir without --with_prior_preservation.")
+ if args.class_prompt is not None:
+ warnings.warn("You need not use --class_prompt without --with_prior_preservation.")
+
+ return args
+
+
+class DreamBoothDataset(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images and the tokenizes prompts.
+ """
+
+ def __init__(
+ self,
+ instance_data_root,
+ instance_prompt,
+ tokenizer,
+ class_data_root=None,
+ class_prompt=None,
+ size=512,
+ center_crop=False,
+ ):
+ self.size = size
+ self.center_crop = center_crop
+ self.tokenizer = tokenizer
+
+ self.instance_data_root = []
+ self.instance_images_path = []
+ self.num_instance_images = []
+ self.instance_prompt = []
+ self.class_data_root = []
+ self.class_images_path = []
+ self.num_class_images = []
+ self.class_prompt = []
+ self._length = 0
+
+ for i in range(len(instance_data_root)):
+ self.instance_data_root.append(Path(instance_data_root[i]))
+ if not self.instance_data_root[i].exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ self.instance_images_path.append(list(Path(instance_data_root[i]).iterdir()))
+ self.num_instance_images.append(len(self.instance_images_path[i]))
+ self.instance_prompt.append(instance_prompt[i])
+ self._length += self.num_instance_images[i]
+
+ if class_data_root is not None:
+ self.class_data_root.append(Path(class_data_root[i]))
+ self.class_data_root[i].mkdir(parents=True, exist_ok=True)
+ self.class_images_path.append(list(self.class_data_root[i].iterdir()))
+ self.num_class_images.append(len(self.class_images_path))
+ if self.num_class_images[i] > self.num_instance_images[i]:
+ self._length -= self.num_instance_images[i]
+ self._length += self.num_class_images[i]
+ self.class_prompt.append(class_prompt[i])
+ else:
+ self.class_data_root = None
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, index):
+ example = {}
+ for i in range(len(self.instance_images_path)):
+ instance_image = Image.open(self.instance_images_path[i][index % self.num_instance_images[i]])
+ if not instance_image.mode == "RGB":
+ instance_image = instance_image.convert("RGB")
+ example[f"instance_images_{i}"] = self.image_transforms(instance_image)
+ example[f"instance_prompt_ids_{i}"] = self.tokenizer(
+ self.instance_prompt[i],
+ truncation=True,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ ).input_ids
+
+ if self.class_data_root:
+ for i in range(len(self.class_data_root)):
+ class_image = Image.open(self.class_images_path[i][index % self.num_class_images[i]])
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ example[f"class_images_{i}"] = self.image_transforms(class_image)
+ example[f"class_prompt_ids_{i}"] = self.tokenizer(
+ self.class_prompt[i],
+ truncation=True,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ ).input_ids
+
+ return example
+
+
+def collate_fn(num_instances, examples, with_prior_preservation=False):
+ input_ids = []
+ pixel_values = []
+
+ for i in range(num_instances):
+ input_ids += [example[f"instance_prompt_ids_{i}"] for example in examples]
+ pixel_values += [example[f"instance_images_{i}"] for example in examples]
+
+ # Concat class and instance examples for prior preservation.
+ # We do this to avoid doing two forward passes.
+ if with_prior_preservation:
+ for i in range(num_instances):
+ input_ids += [example[f"class_prompt_ids_{i}"] for example in examples]
+ pixel_values += [example[f"class_images_{i}"] for example in examples]
+
+ pixel_values = torch.stack(pixel_values)
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+
+ input_ids = torch.cat(input_ids, dim=0)
+
+ batch = {
+ "input_ids": input_ids,
+ "pixel_values": pixel_values,
+ }
+ return batch
+
+
+class PromptDataset(Dataset):
+ "A simple dataset to prepare the prompts to generate class images on multiple GPUs."
+
+ def __init__(self, prompt, num_samples):
+ self.prompt = prompt
+ self.num_samples = num_samples
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, index):
+ example = {}
+ example["prompt"] = self.prompt
+ example["index"] = index
+ return example
+
+
+def main(args):
+ logging_dir = Path(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+
+ # Currently, it's not possible to do gradient accumulation when training two models with accelerate.accumulate
+ # This will be enabled soon in accelerate. For now, we don't allow gradient accumulation when training two models.
+ # TODO (patil-suraj): Remove this check when gradient accumulation with two models is enabled in accelerate.
+ if args.train_text_encoder and args.gradient_accumulation_steps > 1 and accelerator.num_processes > 1:
+ raise ValueError(
+ "Gradient accumulation is not supported when training the text encoder in distributed training. "
+ "Please set gradient_accumulation_steps to 1. This feature will be supported in the future."
+ )
+
+ # Parse instance and class inputs, and double check that lengths match
+ instance_data_dir = args.instance_data_dir.split(",")
+ instance_prompt = args.instance_prompt.split(",")
+ assert all(
+ x == len(instance_data_dir) for x in [len(instance_data_dir), len(instance_prompt)]
+ ), "Instance data dir and prompt inputs are not of the same length."
+
+ if args.with_prior_preservation:
+ class_data_dir = args.class_data_dir.split(",")
+ class_prompt = args.class_prompt.split(",")
+ assert all(
+ x == len(instance_data_dir)
+ for x in [len(instance_data_dir), len(instance_prompt), len(class_data_dir), len(class_prompt)]
+ ), "Instance & class data dir or prompt inputs are not of the same length."
+ else:
+ class_data_dir = args.class_data_dir
+ class_prompt = args.class_prompt
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Generate class images if prior preservation is enabled.
+ if args.with_prior_preservation:
+ for i in range(len(class_data_dir)):
+ class_images_dir = Path(class_data_dir[i])
+ if not class_images_dir.exists():
+ class_images_dir.mkdir(parents=True)
+ cur_class_images = len(list(class_images_dir.iterdir()))
+
+ if cur_class_images < args.num_class_images:
+ torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
+ if args.prior_generation_precision == "fp32":
+ torch_dtype = torch.float32
+ elif args.prior_generation_precision == "fp16":
+ torch_dtype = torch.float16
+ elif args.prior_generation_precision == "bf16":
+ torch_dtype = torch.bfloat16
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ torch_dtype=torch_dtype,
+ safety_checker=None,
+ revision=args.revision,
+ )
+ pipeline.set_progress_bar_config(disable=True)
+
+ num_new_images = args.num_class_images - cur_class_images
+ logger.info(f"Number of class images to sample: {num_new_images}.")
+
+ sample_dataset = PromptDataset(class_prompt[i], num_new_images)
+ sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
+
+ sample_dataloader = accelerator.prepare(sample_dataloader)
+ pipeline.to(accelerator.device)
+
+ for example in tqdm(
+ sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
+ ):
+ images = pipeline(example["prompt"]).images
+
+ for i, image in enumerate(images):
+ hash_image = hashlib.sha1(image.tobytes()).hexdigest()
+ image_filename = (
+ class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
+ )
+ image.save(image_filename)
+
+ del pipeline
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load the tokenizer
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, revision=args.revision, use_fast=False)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="tokenizer",
+ revision=args.revision,
+ use_fast=False,
+ )
+
+ # import correct text encoder class
+ text_encoder_cls = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path, args.revision)
+
+ # Load scheduler and models
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ text_encoder = text_encoder_cls.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+
+ vae.requires_grad_(False)
+ if not args.train_text_encoder:
+ text_encoder.requires_grad_(False)
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+ if args.train_text_encoder:
+ text_encoder.gradient_checkpointing_enable()
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ # Optimizer creation
+ params_to_optimize = (
+ itertools.chain(unet.parameters(), text_encoder.parameters()) if args.train_text_encoder else unet.parameters()
+ )
+ optimizer = optimizer_class(
+ params_to_optimize,
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Dataset and DataLoaders creation:
+ train_dataset = DreamBoothDataset(
+ instance_data_root=instance_data_dir,
+ instance_prompt=instance_prompt,
+ class_data_root=class_data_dir if args.with_prior_preservation else None,
+ class_prompt=class_prompt,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ center_crop=args.center_crop,
+ )
+
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ batch_size=args.train_batch_size,
+ shuffle=True,
+ collate_fn=lambda examples: collate_fn(len(instance_data_dir), examples, args.with_prior_preservation),
+ num_workers=1,
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_cycles=args.lr_num_cycles,
+ power=args.lr_power,
+ )
+
+ # Prepare everything with our `accelerator`.
+ if args.train_text_encoder:
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+ else:
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move vae and text_encoder to device and cast to weight_dtype
+ vae.to(accelerator.device, dtype=weight_dtype)
+ if not args.train_text_encoder:
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("dreambooth", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num batches each epoch = {len(train_dataloader)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the mos recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ if args.train_text_encoder:
+ text_encoder.train()
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Predict the noise residual
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ if args.with_prior_preservation:
+ # Chunk the noise and model_pred into two parts and compute the loss on each part separately.
+ model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
+ target, target_prior = torch.chunk(target, 2, dim=0)
+
+ # Compute instance loss
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ # Compute prior loss
+ prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
+
+ # Add the prior loss to the instance loss.
+ loss = loss + args.prior_loss_weight * prior_loss
+ else:
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ params_to_clip = (
+ itertools.chain(unet.parameters(), text_encoder.parameters())
+ if args.train_text_encoder
+ else unet.parameters()
+ )
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ # Create the pipeline using using the trained modules and save it.
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ revision=args.revision,
+ )
+ pipeline.save_pretrained(args.output_dir)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/diffusers/examples/research_projects/onnxruntime/README.md b/diffusers/examples/research_projects/onnxruntime/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..204d9c951c996fedabc169d9a32781be9f4c4cc1
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/README.md
@@ -0,0 +1,5 @@
+## Diffusers examples with ONNXRuntime optimizations
+
+**This research project is not actively maintained by the diffusers team. For any questions or comments, please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions.**
+
+This aims to provide diffusers examples with ONNXRuntime optimizations for training/fine-tuning unconditional image generation, text to image, and textual inversion. Please see individual directories for more details on how to run each task using ONNXRuntime.
\ No newline at end of file
diff --git a/diffusers/examples/research_projects/onnxruntime/text_to_image/README.md b/diffusers/examples/research_projects/onnxruntime/text_to_image/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..cd9397939ac2399ac161f19623430636a4c3c9ad
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/text_to_image/README.md
@@ -0,0 +1,74 @@
+# Stable Diffusion text-to-image fine-tuning
+
+The `train_text_to_image.py` script shows how to fine-tune stable diffusion model on your own dataset.
+
+___Note___:
+
+___This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparamters to get the best result on your dataset.___
+
+
+## Running locally with PyTorch
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+### Pokemon example
+
+You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-4`, so you'll need to visit [its card](https://huggingface.co/CompVis/stable-diffusion-v1-4), read the license and tick the checkbox if you agree.
+
+You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
+
+Run the following command to authenticate your token
+
+```bash
+huggingface-cli login
+```
+
+If you have already cloned the repo, then you won't need to go through these steps.
+
+
+
+## Use ONNXRuntime to accelerate training
+In order to leverage onnxruntime to accelerate training, please use train_text_to_image.py
+
+The command to train a DDPM UNetCondition model on the Pokemon dataset with onnxruntime:
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export dataset_name="lambdalabs/pokemon-blip-captions"
+accelerate launch --mixed_precision="fp16" train_text_to_image.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$dataset_name \
+ --use_ema \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --gradient_checkpointing \
+ --max_train_steps=15000 \
+ --learning_rate=1e-05 \
+ --max_grad_norm=1 \
+ --lr_scheduler="constant" --lr_warmup_steps=0 \
+ --output_dir="sd-pokemon-model"
+```
+
+Please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions.
\ No newline at end of file
diff --git a/diffusers/examples/research_projects/onnxruntime/text_to_image/requirements.txt b/diffusers/examples/research_projects/onnxruntime/text_to_image/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b597d5464f1ebe39f0b1f51a23b2237925263a4a
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/text_to_image/requirements.txt
@@ -0,0 +1,7 @@
+accelerate
+torchvision
+transformers>=4.25.1
+datasets
+ftfy
+tensorboard
+modelcards
diff --git a/diffusers/examples/research_projects/onnxruntime/text_to_image/train_text_to_image.py b/diffusers/examples/research_projects/onnxruntime/text_to_image/train_text_to_image.py
new file mode 100644
index 0000000000000000000000000000000000000000..aba9020f58b651a8f3445b2ae1f5b1abeeba0fa7
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/text_to_image/train_text_to_image.py
@@ -0,0 +1,727 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import argparse
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from datasets import load_dataset
+from huggingface_hub import create_repo, upload_folder
+from onnxruntime.training.ortmodule import ORTModule
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+import diffusers
+from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel
+from diffusers.optimization import get_scheduler
+from diffusers.training_utils import EMAModel
+from diffusers.utils import check_min_version
+from diffusers.utils.import_utils import is_xformers_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.13.0.dev0")
+
+logger = get_logger(__name__, log_level="INFO")
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that 🤗 Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--image_column", type=str, default="image", help="The column of the dataset containing an image."
+ )
+ parser.add_argument(
+ "--caption_column",
+ type=str,
+ default="text",
+ help="The column of the dataset containing a caption or a list of captions.",
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="sd-model-finetuned",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
+ parser.add_argument(
+ "--non_ema_revision",
+ type=str,
+ default=None,
+ required=False,
+ help=(
+ "Revision of pretrained non-ema model identifier. Must be a branch, tag or git identifier of the local or"
+ " remote repository specified with --pretrained_model_name_or_path."
+ ),
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_data_dir is None:
+ raise ValueError("Need either a dataset name or a training folder.")
+
+ # default to using the same revision for the non-ema model if not specified
+ if args.non_ema_revision is None:
+ args.non_ema_revision = args.revision
+
+ return args
+
+
+dataset_name_mapping = {
+ "lambdalabs/pokemon-blip-captions": ("image", "text"),
+}
+
+
+def main():
+ args = parse_args()
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ accelerator_project_config=accelerator_project_config,
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load scheduler, tokenizer and models.
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ tokenizer = CLIPTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
+ )
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
+ )
+
+ # Freeze vae and text_encoder
+ vae.requires_grad_(False)
+ text_encoder.requires_grad_(False)
+
+ # Create EMA for the unet.
+ if args.use_ema:
+ ema_unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+ ema_unet = EMAModel(ema_unet.parameters())
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+ vae.enable_gradient_checkpointing()
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
+ )
+
+ optimizer_cls = bnb.optim.AdamW8bit
+ else:
+ optimizer_cls = torch.optim.AdamW
+
+ optimizer = optimizer_cls(
+ unet.parameters(),
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ )
+ else:
+ data_files = {}
+ if args.train_data_dir is not None:
+ data_files["train"] = os.path.join(args.train_data_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=args.cache_dir,
+ )
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ column_names = dataset["train"].column_names
+
+ # 6. Get the column names for input/target.
+ dataset_columns = dataset_name_mapping.get(args.dataset_name, None)
+ if args.image_column is None:
+ image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ image_column = args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.caption_column is None:
+ caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ caption_column = args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Preprocessing the datasets.
+ # We need to tokenize input captions and transform the images.
+ def tokenize_captions(examples, is_train=True):
+ captions = []
+ for caption in examples[caption_column]:
+ if isinstance(caption, str):
+ captions.append(caption)
+ elif isinstance(caption, (list, np.ndarray)):
+ # take a random caption if there are multiple
+ captions.append(random.choice(caption) if is_train else caption[0])
+ else:
+ raise ValueError(
+ f"Caption column `{caption_column}` should contain either strings or lists of strings."
+ )
+ inputs = tokenizer(
+ captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
+ )
+ return inputs.input_ids
+
+ # Preprocessing the datasets.
+ train_transforms = transforms.Compose(
+ [
+ transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
+ transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def preprocess_train(examples):
+ images = [image.convert("RGB") for image in examples[image_column]]
+ examples["pixel_values"] = [train_transforms(image) for image in images]
+ examples["input_ids"] = tokenize_captions(examples)
+ return examples
+
+ with accelerator.main_process_first():
+ if args.max_train_samples is not None:
+ dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ train_dataset = dataset["train"].with_transform(preprocess_train)
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+ input_ids = torch.stack([example["input_ids"] for example in examples])
+ return {"pixel_values": pixel_values, "input_ids": input_ids}
+
+ # DataLoaders creation:
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ shuffle=True,
+ collate_fn=collate_fn,
+ batch_size=args.train_batch_size,
+ num_workers=args.dataloader_num_workers,
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+
+ unet = ORTModule(unet)
+
+ if args.use_ema:
+ accelerator.register_for_checkpointing(ema_unet)
+
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move text_encode and vae to gpu and cast to weight_dtype
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+ vae.to(accelerator.device, dtype=weight_dtype)
+ if args.use_ema:
+ ema_unet.to(accelerator.device)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("text2image-fine-tune", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ train_loss = 0.0
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(weight_dtype)).latent_dist.sample()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ # Predict the noise residual and compute loss
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states, return_dict=False)[0]
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ # Gather the losses across all processes for logging (if we use distributed training).
+ avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
+ train_loss += avg_loss.item() / args.gradient_accumulation_steps
+
+ # Backpropagate
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ if args.use_ema:
+ ema_unet.step(unet.parameters())
+ progress_bar.update(1)
+ global_step += 1
+ accelerator.log({"train_loss": train_loss}, step=global_step)
+ train_loss = 0.0
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ # Create the pipeline using the trained modules and save it.
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ unet = accelerator.unwrap_model(unet)
+ if args.use_ema:
+ ema_unet.copy_to(unet.parameters())
+
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=text_encoder,
+ vae=vae,
+ unet=unet,
+ revision=args.revision,
+ )
+ pipeline.save_pretrained(args.output_dir)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/onnxruntime/textual_inversion/README.md b/diffusers/examples/research_projects/onnxruntime/textual_inversion/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0ed34966e9f1836d9744edf77f46c84bb8609e97
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/textual_inversion/README.md
@@ -0,0 +1,82 @@
+## Textual Inversion fine-tuning example
+
+[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
+The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
+
+## Running on Colab
+
+Colab for training
+[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
+
+Colab for inference
+[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
+
+## Running locally with PyTorch
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+
+### Cat toy example
+
+You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-5`, so you'll need to visit [its card](https://huggingface.co/runwayml/stable-diffusion-v1-5), read the license and tick the checkbox if you agree.
+
+You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
+
+Run the following command to authenticate your token
+
+```bash
+huggingface-cli login
+```
+
+If you have already cloned the repo, then you won't need to go through these steps.
+
+
+
+Now let's get our dataset.Download 3-4 images from [here](https://drive.google.com/drive/folders/1fmJMs25nxS_rSNqS5hTcRdLem_YQXbq5) and save them in a directory. This will be our training data.
+
+## Use ONNXRuntime to accelerate training
+In order to leverage onnxruntime to accelerate training, please use textual_inversion.py
+
+The command to train on custom data with onnxruntime:
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export DATA_DIR="path-to-dir-containing-images"
+
+accelerate launch textual_inversion.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --max_train_steps=3000 \
+ --learning_rate=5.0e-04 --scale_lr \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --output_dir="textual_inversion_cat"
+```
+
+Please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions.
\ No newline at end of file
diff --git a/diffusers/examples/research_projects/onnxruntime/textual_inversion/requirements.txt b/diffusers/examples/research_projects/onnxruntime/textual_inversion/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3a1731c228fd4f103c2e5e32735304d0d1bbaa2d
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/textual_inversion/requirements.txt
@@ -0,0 +1,6 @@
+accelerate
+torchvision
+transformers>=4.25.1
+ftfy
+tensorboard
+modelcards
diff --git a/diffusers/examples/research_projects/onnxruntime/textual_inversion/textual_inversion.py b/diffusers/examples/research_projects/onnxruntime/textual_inversion/textual_inversion.py
new file mode 100644
index 0000000000000000000000000000000000000000..a3d24066ad7aded3afa8945e26a2e96ed34efe33
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/textual_inversion/textual_inversion.py
@@ -0,0 +1,846 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import argparse
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import numpy as np
+import PIL
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from huggingface_hub import create_repo, upload_folder
+from onnxruntime.training.ortmodule import ORTModule
+
+# TODO: remove and import from diffusers.utils when the new version of diffusers is released
+from packaging import version
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+import diffusers
+from diffusers import (
+ AutoencoderKL,
+ DDPMScheduler,
+ DiffusionPipeline,
+ DPMSolverMultistepScheduler,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version, is_wandb_available
+from diffusers.utils.import_utils import is_xformers_available
+
+
+if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.Resampling.BILINEAR,
+ "bilinear": PIL.Image.Resampling.BILINEAR,
+ "bicubic": PIL.Image.Resampling.BICUBIC,
+ "lanczos": PIL.Image.Resampling.LANCZOS,
+ "nearest": PIL.Image.Resampling.NEAREST,
+ }
+else:
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.LINEAR,
+ "bilinear": PIL.Image.BILINEAR,
+ "bicubic": PIL.Image.BICUBIC,
+ "lanczos": PIL.Image.LANCZOS,
+ "nearest": PIL.Image.NEAREST,
+ }
+# ------------------------------------------------------------------------------
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.13.0.dev0")
+
+logger = get_logger(__name__)
+
+
+def save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path):
+ logger.info("Saving embeddings")
+ learned_embeds = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[placeholder_token_id]
+ learned_embeds_dict = {args.placeholder_token: learned_embeds.detach().cpu()}
+ torch.save(learned_embeds_dict, save_path)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--save_steps",
+ type=int,
+ default=500,
+ help="Save learned_embeds.bin every X updates steps.",
+ )
+ parser.add_argument(
+ "--only_save_embeds",
+ action="store_true",
+ default=False,
+ help="Save only the embeddings for the new concept.",
+ )
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
+ )
+ parser.add_argument(
+ "--placeholder_token",
+ type=str,
+ default=None,
+ required=True,
+ help="A token to use as a placeholder for the concept.",
+ )
+ parser.add_argument(
+ "--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
+ )
+ parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
+ parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=5000,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument(
+ "--validation_prompt",
+ type=str,
+ default=None,
+ help="A prompt that is used during validation to verify that the model is learning.",
+ )
+ parser.add_argument(
+ "--num_validation_images",
+ type=int,
+ default=4,
+ help="Number of images that should be generated during validation with `validation_prompt`.",
+ )
+ parser.add_argument(
+ "--validation_epochs",
+ type=int,
+ default=50,
+ help=(
+ "Run validation every X epochs. Validation consists of running the prompt"
+ " `args.validation_prompt` multiple times: `args.num_validation_images`"
+ " and logging the images."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.train_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ return args
+
+
+imagenet_templates_small = [
+ "a photo of a {}",
+ "a rendering of a {}",
+ "a cropped photo of the {}",
+ "the photo of a {}",
+ "a photo of a clean {}",
+ "a photo of a dirty {}",
+ "a dark photo of the {}",
+ "a photo of my {}",
+ "a photo of the cool {}",
+ "a close-up photo of a {}",
+ "a bright photo of the {}",
+ "a cropped photo of a {}",
+ "a photo of the {}",
+ "a good photo of the {}",
+ "a photo of one {}",
+ "a close-up photo of the {}",
+ "a rendition of the {}",
+ "a photo of the clean {}",
+ "a rendition of a {}",
+ "a photo of a nice {}",
+ "a good photo of a {}",
+ "a photo of the nice {}",
+ "a photo of the small {}",
+ "a photo of the weird {}",
+ "a photo of the large {}",
+ "a photo of a cool {}",
+ "a photo of a small {}",
+]
+
+imagenet_style_templates_small = [
+ "a painting in the style of {}",
+ "a rendering in the style of {}",
+ "a cropped painting in the style of {}",
+ "the painting in the style of {}",
+ "a clean painting in the style of {}",
+ "a dirty painting in the style of {}",
+ "a dark painting in the style of {}",
+ "a picture in the style of {}",
+ "a cool painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a bright painting in the style of {}",
+ "a cropped painting in the style of {}",
+ "a good painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a rendition in the style of {}",
+ "a nice painting in the style of {}",
+ "a small painting in the style of {}",
+ "a weird painting in the style of {}",
+ "a large painting in the style of {}",
+]
+
+
+class TextualInversionDataset(Dataset):
+ def __init__(
+ self,
+ data_root,
+ tokenizer,
+ learnable_property="object", # [object, style]
+ size=512,
+ repeats=100,
+ interpolation="bicubic",
+ flip_p=0.5,
+ set="train",
+ placeholder_token="*",
+ center_crop=False,
+ ):
+ self.data_root = data_root
+ self.tokenizer = tokenizer
+ self.learnable_property = learnable_property
+ self.size = size
+ self.placeholder_token = placeholder_token
+ self.center_crop = center_crop
+ self.flip_p = flip_p
+
+ self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
+
+ self.num_images = len(self.image_paths)
+ self._length = self.num_images
+
+ if set == "train":
+ self._length = self.num_images * repeats
+
+ self.interpolation = {
+ "linear": PIL_INTERPOLATION["linear"],
+ "bilinear": PIL_INTERPOLATION["bilinear"],
+ "bicubic": PIL_INTERPOLATION["bicubic"],
+ "lanczos": PIL_INTERPOLATION["lanczos"],
+ }[interpolation]
+
+ self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
+ self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, i):
+ example = {}
+ image = Image.open(self.image_paths[i % self.num_images])
+
+ if not image.mode == "RGB":
+ image = image.convert("RGB")
+
+ placeholder_string = self.placeholder_token
+ text = random.choice(self.templates).format(placeholder_string)
+
+ example["input_ids"] = self.tokenizer(
+ text,
+ padding="max_length",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ ).input_ids[0]
+
+ # default to score-sde preprocessing
+ img = np.array(image).astype(np.uint8)
+
+ if self.center_crop:
+ crop = min(img.shape[0], img.shape[1])
+ (
+ h,
+ w,
+ ) = (
+ img.shape[0],
+ img.shape[1],
+ )
+ img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
+
+ image = Image.fromarray(img)
+ image = image.resize((self.size, self.size), resample=self.interpolation)
+
+ image = self.flip_transform(image)
+ image = np.array(image).astype(np.uint8)
+ image = (image / 127.5 - 1.0).astype(np.float32)
+
+ example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
+ return example
+
+
+def main():
+ args = parse_args()
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+ import wandb
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load tokenizer
+ if args.tokenizer_name:
+ tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Load scheduler and models
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+
+ # Add the placeholder token in tokenizer
+ num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
+ if num_added_tokens == 0:
+ raise ValueError(
+ f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
+ " `placeholder_token` that is not already in the tokenizer."
+ )
+
+ # Convert the initializer_token, placeholder_token to ids
+ token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
+ # Check if initializer_token is a single token or a sequence of tokens
+ if len(token_ids) > 1:
+ raise ValueError("The initializer token must be a single token.")
+
+ initializer_token_id = token_ids[0]
+ placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
+
+ # Resize the token embeddings as we are adding new special tokens to the tokenizer
+ text_encoder.resize_token_embeddings(len(tokenizer))
+
+ # Initialise the newly added placeholder token with the embeddings of the initializer token
+ token_embeds = text_encoder.get_input_embeddings().weight.data
+ token_embeds[placeholder_token_id] = token_embeds[initializer_token_id]
+
+ # Freeze vae and unet
+ vae.requires_grad_(False)
+ unet.requires_grad_(False)
+ # Freeze all parameters except for the token embeddings in text encoder
+ text_encoder.text_model.encoder.requires_grad_(False)
+ text_encoder.text_model.final_layer_norm.requires_grad_(False)
+ text_encoder.text_model.embeddings.position_embedding.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ # Keep unet in train mode if we are using gradient checkpointing to save memory.
+ # The dropout cannot be != 0 so it doesn't matter if we are in eval or train mode.
+ unet.train()
+ text_encoder.gradient_checkpointing_enable()
+ unet.enable_gradient_checkpointing()
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ optimizer = torch.optim.AdamW(
+ text_encoder.get_input_embeddings().parameters(), # only optimize the embeddings
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Dataset and DataLoaders creation:
+ train_dataset = TextualInversionDataset(
+ data_root=args.train_data_dir,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ placeholder_token=args.placeholder_token,
+ repeats=args.repeats,
+ learnable_property=args.learnable_property,
+ center_crop=args.center_crop,
+ set="train",
+ )
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+
+ text_encoder = ORTModule(text_encoder)
+
+ # For mixed precision training we cast the unet and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move vae and unet to device and cast to weight_dtype
+ unet.to(accelerator.device, dtype=weight_dtype)
+ vae.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("textual_inversion", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ # keep original embeddings as reference
+ orig_embeds_params = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight.data.clone()
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ text_encoder.train()
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(text_encoder):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample().detach()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0].to(dtype=weight_dtype)
+
+ # Predict the noise residual
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Let's make sure we don't update any embedding weights besides the newly added token
+ index_no_updates = torch.arange(len(tokenizer)) != placeholder_token_id
+ with torch.no_grad():
+ accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[
+ index_no_updates
+ ] = orig_embeds_params[index_no_updates]
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+ if global_step % args.save_steps == 0:
+ save_path = os.path.join(args.output_dir, f"learned_embeds-steps-{global_step}.bin")
+ save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if accelerator.is_main_process and args.validation_prompt is not None and epoch % args.validation_epochs == 0:
+ logger.info(
+ f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
+ f" {args.validation_prompt}."
+ )
+ # create pipeline (note: unet and vae are loaded again in float32)
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ revision=args.revision,
+ )
+ pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
+ pipeline = pipeline.to(accelerator.device)
+ pipeline.set_progress_bar_config(disable=True)
+
+ # run inference
+ generator = (
+ None if args.seed is None else torch.Generator(device=accelerator.device).manual_seed(args.seed)
+ )
+ prompt = args.num_validation_images * [args.validation_prompt]
+ images = pipeline(prompt, num_inference_steps=25, generator=generator).images
+
+ for tracker in accelerator.trackers:
+ if tracker.name == "tensorboard":
+ np_images = np.stack([np.asarray(img) for img in images])
+ tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "validation": [
+ wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
+ for i, image in enumerate(images)
+ ]
+ }
+ )
+
+ del pipeline
+ torch.cuda.empty_cache()
+
+ # Create the pipeline using using the trained modules and save it.
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ if args.push_to_hub and args.only_save_embeds:
+ logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
+ save_full_model = True
+ else:
+ save_full_model = not args.only_save_embeds
+ if save_full_model:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ vae=vae,
+ unet=unet,
+ tokenizer=tokenizer,
+ )
+ pipeline.save_pretrained(args.output_dir)
+ # Save the newly trained embeddings
+ save_path = os.path.join(args.output_dir, "learned_embeds.bin")
+ save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/README.md b/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..621e9a2fd69a97046230fb7561571d1484d47710
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/README.md
@@ -0,0 +1,50 @@
+## Training examples
+
+Creating a training image set is [described in a different document](https://huggingface.co/docs/datasets/image_process#image-datasets).
+
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+#### Use ONNXRuntime to accelerate training
+
+In order to leverage onnxruntime to accelerate training, please use train_unconditional_ort.py
+
+The command to train a DDPM UNet model on the Oxford Flowers dataset with onnxruntime:
+
+```bash
+accelerate launch train_unconditional_ort.py \
+ --dataset_name="huggan/flowers-102-categories" \
+ --resolution=64 --center_crop --random_flip \
+ --output_dir="ddpm-ema-flowers-64" \
+ --use_ema \
+ --train_batch_size=16 \
+ --num_epochs=1 \
+ --gradient_accumulation_steps=1 \
+ --learning_rate=1e-4 \
+ --lr_warmup_steps=500 \
+ --mixed_precision=fp16
+ ```
+
+Please contact Prathik Rao (prathikr), Sunghoon Choi (hanbitmyths), Ashwini Khade (askhade), or Peng Wang (pengwa) on github with any questions.
diff --git a/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/requirements.txt b/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bbc6905560209d6b9c957d8c6bb61cde4462365b
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/requirements.txt
@@ -0,0 +1,3 @@
+accelerate
+torchvision
+datasets
diff --git a/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/train_unconditional.py b/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/train_unconditional.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b38036d82c03b9d8be3e0cd35d91be14558b1b5
--- /dev/null
+++ b/diffusers/examples/research_projects/onnxruntime/unconditional_image_generation/train_unconditional.py
@@ -0,0 +1,606 @@
+import argparse
+import inspect
+import logging
+import math
+import os
+from pathlib import Path
+from typing import Optional
+
+import datasets
+import torch
+import torch.nn.functional as F
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration
+from datasets import load_dataset
+from huggingface_hub import HfFolder, Repository, create_repo, whoami
+from onnxruntime.training.ortmodule import ORTModule
+from torchvision import transforms
+from tqdm.auto import tqdm
+
+import diffusers
+from diffusers import DDPMPipeline, DDPMScheduler, UNet2DModel
+from diffusers.optimization import get_scheduler
+from diffusers.training_utils import EMAModel
+from diffusers.utils import check_min_version, is_tensorboard_available, is_wandb_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.13.0.dev0")
+
+logger = get_logger(__name__, log_level="INFO")
+
+
+def _extract_into_tensor(arr, timesteps, broadcast_shape):
+ """
+ Extract values from a 1-D numpy array for a batch of indices.
+ :param arr: the 1-D numpy array.
+ :param timesteps: a tensor of indices into the array to extract.
+ :param broadcast_shape: a larger shape of K dimensions with the batch
+ dimension equal to the length of timesteps.
+ :return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
+ """
+ if not isinstance(arr, torch.Tensor):
+ arr = torch.from_numpy(arr)
+ res = arr[timesteps].float().to(timesteps.device)
+ while len(res.shape) < len(broadcast_shape):
+ res = res[..., None]
+ return res.expand(broadcast_shape)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that HF Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="ddpm-model-64",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--overwrite_output_dir", action="store_true")
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=64,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ default=False,
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument(
+ "--eval_batch_size", type=int, default=16, help="The number of images to generate for evaluation."
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "The number of subprocesses to use for data loading. 0 means that the data will be loaded in the main"
+ " process."
+ ),
+ )
+ parser.add_argument("--num_epochs", type=int, default=100)
+ parser.add_argument("--save_images_epochs", type=int, default=10, help="How often to save images during training.")
+ parser.add_argument(
+ "--save_model_epochs", type=int, default=10, help="How often to save the model during training."
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="cosine",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.95, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument(
+ "--adam_weight_decay", type=float, default=1e-6, help="Weight decay magnitude for the Adam optimizer."
+ )
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer.")
+ parser.add_argument(
+ "--use_ema",
+ action="store_true",
+ help="Whether to use Exponential Moving Average for the final model weights.",
+ )
+ parser.add_argument("--ema_inv_gamma", type=float, default=1.0, help="The inverse gamma value for the EMA decay.")
+ parser.add_argument("--ema_power", type=float, default=3 / 4, help="The power value for the EMA decay.")
+ parser.add_argument("--ema_max_decay", type=float, default=0.9999, help="The maximum decay magnitude for EMA.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--hub_private_repo", action="store_true", help="Whether or not to create a private repository."
+ )
+ parser.add_argument(
+ "--logger",
+ type=str,
+ default="tensorboard",
+ choices=["tensorboard", "wandb"],
+ help=(
+ "Whether to use [tensorboard](https://www.tensorflow.org/tensorboard) or [wandb](https://www.wandb.ai)"
+ " for experiment tracking and logging of model metrics and model checkpoints"
+ ),
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument(
+ "--prediction_type",
+ type=str,
+ default="epsilon",
+ choices=["epsilon", "sample"],
+ help="Whether the model should predict the 'epsilon'/noise error or directly the reconstructed image 'x0'.",
+ )
+ parser.add_argument("--ddpm_num_steps", type=int, default=1000)
+ parser.add_argument("--ddpm_num_inference_steps", type=int, default=1000)
+ parser.add_argument("--ddpm_beta_schedule", type=str, default="linear")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.dataset_name is None and args.train_data_dir is None:
+ raise ValueError("You must specify either a dataset name from the hub or a train data directory.")
+
+ return args
+
+
+def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
+ if token is None:
+ token = HfFolder.get_token()
+ if organization is None:
+ username = whoami(token)["name"]
+ return f"{username}/{model_id}"
+ else:
+ return f"{organization}/{model_id}"
+
+
+def main(args):
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.logger,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+
+ if args.logger == "tensorboard":
+ if not is_tensorboard_available():
+ raise ImportError("Make sure to install tensorboard if you want to use it for logging during training.")
+
+ elif args.logger == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+ import wandb
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ if args.hub_model_id is None:
+ repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
+ else:
+ repo_name = args.hub_model_id
+ create_repo(repo_name, exist_ok=True, token=args.hub_token)
+ repo = Repository(args.output_dir, clone_from=repo_name, token=args.hub_token)
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ # Initialize the model
+ model = UNet2DModel(
+ sample_size=args.resolution,
+ in_channels=3,
+ out_channels=3,
+ layers_per_block=2,
+ block_out_channels=(128, 128, 256, 256, 512, 512),
+ down_block_types=(
+ "DownBlock2D",
+ "DownBlock2D",
+ "DownBlock2D",
+ "DownBlock2D",
+ "AttnDownBlock2D",
+ "DownBlock2D",
+ ),
+ up_block_types=(
+ "UpBlock2D",
+ "AttnUpBlock2D",
+ "UpBlock2D",
+ "UpBlock2D",
+ "UpBlock2D",
+ "UpBlock2D",
+ ),
+ )
+
+ # Create EMA for the model.
+ if args.use_ema:
+ ema_model = EMAModel(
+ model.parameters(),
+ decay=args.ema_max_decay,
+ use_ema_warmup=True,
+ inv_gamma=args.ema_inv_gamma,
+ power=args.ema_power,
+ )
+
+ # Initialize the scheduler
+ accepts_prediction_type = "prediction_type" in set(inspect.signature(DDPMScheduler.__init__).parameters.keys())
+ if accepts_prediction_type:
+ noise_scheduler = DDPMScheduler(
+ num_train_timesteps=args.ddpm_num_steps,
+ beta_schedule=args.ddpm_beta_schedule,
+ prediction_type=args.prediction_type,
+ )
+ else:
+ noise_scheduler = DDPMScheduler(num_train_timesteps=args.ddpm_num_steps, beta_schedule=args.ddpm_beta_schedule)
+
+ # Initialize the optimizer
+ optimizer = torch.optim.AdamW(
+ model.parameters(),
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ split="train",
+ )
+ else:
+ dataset = load_dataset("imagefolder", data_dir=args.train_data_dir, cache_dir=args.cache_dir, split="train")
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
+
+ # Preprocessing the datasets and DataLoaders creation.
+ augmentations = transforms.Compose(
+ [
+ transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
+ transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def transform_images(examples):
+ images = [augmentations(image.convert("RGB")) for image in examples["image"]]
+ return {"input": images}
+
+ logger.info(f"Dataset size: {len(dataset)}")
+
+ dataset.set_transform(transform_images)
+ train_dataloader = torch.utils.data.DataLoader(
+ dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
+ )
+
+ # Initialize the learning rate scheduler
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=(len(train_dataloader) * args.num_epochs),
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, lr_scheduler
+ )
+
+ model = ORTModule(model)
+
+ if args.use_ema:
+ accelerator.register_for_checkpointing(ema_model)
+ ema_model.to(accelerator.device)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ run = os.path.split(__file__)[-1].split(".")[0]
+ accelerator.init_trackers(run)
+
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ max_train_steps = args.num_epochs * num_update_steps_per_epoch
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(dataset)}")
+ logger.info(f" Num Epochs = {args.num_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {max_train_steps}")
+
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Train!
+ for epoch in range(first_epoch, args.num_epochs):
+ model.train()
+ progress_bar = tqdm(total=num_update_steps_per_epoch, disable=not accelerator.is_local_main_process)
+ progress_bar.set_description(f"Epoch {epoch}")
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ clean_images = batch["input"]
+ # Sample noise that we'll add to the images
+ noise = torch.randn(clean_images.shape).to(clean_images.device)
+ bsz = clean_images.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(
+ 0, noise_scheduler.config.num_train_timesteps, (bsz,), device=clean_images.device
+ ).long()
+
+ # Add noise to the clean images according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
+
+ with accelerator.accumulate(model):
+ # Predict the noise residual
+ model_output = model(noisy_images, timesteps, return_dict=False)[0]
+
+ if args.prediction_type == "epsilon":
+ loss = F.mse_loss(model_output, noise) # this could have different weights!
+ elif args.prediction_type == "sample":
+ alpha_t = _extract_into_tensor(
+ noise_scheduler.alphas_cumprod, timesteps, (clean_images.shape[0], 1, 1, 1)
+ )
+ snr_weights = alpha_t / (1 - alpha_t)
+ loss = snr_weights * F.mse_loss(
+ model_output, clean_images, reduction="none"
+ ) # use SNR weighting from distillation paper
+ loss = loss.mean()
+ else:
+ raise ValueError(f"Unsupported prediction type: {args.prediction_type}")
+
+ accelerator.backward(loss)
+
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(model.parameters(), 1.0)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ if args.use_ema:
+ ema_model.step(model.parameters())
+ progress_bar.update(1)
+ global_step += 1
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
+ if args.use_ema:
+ logs["ema_decay"] = ema_model.decay
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+ progress_bar.close()
+
+ accelerator.wait_for_everyone()
+
+ # Generate sample images for visual inspection
+ if accelerator.is_main_process:
+ if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1:
+ unet = accelerator.unwrap_model(model)
+ if args.use_ema:
+ ema_model.copy_to(unet.parameters())
+ pipeline = DDPMPipeline(
+ unet=unet,
+ scheduler=noise_scheduler,
+ )
+
+ generator = torch.Generator(device=pipeline.device).manual_seed(0)
+ # run pipeline in inference (sample random noise and denoise)
+ images = pipeline(
+ generator=generator,
+ batch_size=args.eval_batch_size,
+ output_type="numpy",
+ num_inference_steps=args.ddpm_num_inference_steps,
+ ).images
+
+ # denormalize the images and save to tensorboard
+ images_processed = (images * 255).round().astype("uint8")
+
+ if args.logger == "tensorboard":
+ accelerator.get_tracker("tensorboard").add_images(
+ "test_samples", images_processed.transpose(0, 3, 1, 2), epoch
+ )
+ elif args.logger == "wandb":
+ accelerator.get_tracker("wandb").log(
+ {"test_samples": [wandb.Image(img) for img in images_processed], "epoch": epoch},
+ step=global_step,
+ )
+
+ if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:
+ # save the model
+ pipeline.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ repo.push_to_hub(commit_message=f"Epoch {epoch}", blocking=False)
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/diffusers/examples/rl/README.md b/diffusers/examples/rl/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..17881d584a4043156b784a152253b0f83598ced9
--- /dev/null
+++ b/diffusers/examples/rl/README.md
@@ -0,0 +1,22 @@
+# Overview
+
+These examples show how to run [Diffuser](https://arxiv.org/abs/2205.09991) in Diffusers.
+There are two ways to use the script, `run_diffuser_locomotion.py`.
+
+The key option is a change of the variable `n_guide_steps`.
+When `n_guide_steps=0`, the trajectories are sampled from the diffusion model, but not fine-tuned to maximize reward in the environment.
+By default, `n_guide_steps=2` to match the original implementation.
+
+
+You will need some RL specific requirements to run the examples:
+
+```
+pip install -f https://download.pytorch.org/whl/torch_stable.html \
+ free-mujoco-py \
+ einops \
+ gym==0.24.1 \
+ protobuf==3.20.1 \
+ git+https://github.com/rail-berkeley/d4rl.git \
+ mediapy \
+ Pillow==9.0.0
+```
diff --git a/diffusers/examples/rl/run_diffuser_locomotion.py b/diffusers/examples/rl/run_diffuser_locomotion.py
new file mode 100644
index 0000000000000000000000000000000000000000..adf6d1443d1c2e7caca7bdc1a26da1f2f186b8f9
--- /dev/null
+++ b/diffusers/examples/rl/run_diffuser_locomotion.py
@@ -0,0 +1,59 @@
+import d4rl # noqa
+import gym
+import tqdm
+from diffusers.experimental import ValueGuidedRLPipeline
+
+
+config = {
+ "n_samples": 64,
+ "horizon": 32,
+ "num_inference_steps": 20,
+ "n_guide_steps": 2, # can set to 0 for faster sampling, does not use value network
+ "scale_grad_by_std": True,
+ "scale": 0.1,
+ "eta": 0.0,
+ "t_grad_cutoff": 2,
+ "device": "cpu",
+}
+
+
+if __name__ == "__main__":
+ env_name = "hopper-medium-v2"
+ env = gym.make(env_name)
+
+ pipeline = ValueGuidedRLPipeline.from_pretrained(
+ "bglick13/hopper-medium-v2-value-function-hor32",
+ env=env,
+ )
+
+ env.seed(0)
+ obs = env.reset()
+ total_reward = 0
+ total_score = 0
+ T = 1000
+ rollout = [obs.copy()]
+ try:
+ for t in tqdm.tqdm(range(T)):
+ # call the policy
+ denorm_actions = pipeline(obs, planning_horizon=32)
+
+ # execute action in environment
+ next_observation, reward, terminal, _ = env.step(denorm_actions)
+ score = env.get_normalized_score(total_reward)
+
+ # update return
+ total_reward += reward
+ total_score += score
+ print(
+ f"Step: {t}, Reward: {reward}, Total Reward: {total_reward}, Score: {score}, Total Score:"
+ f" {total_score}"
+ )
+
+ # save observations for rendering
+ rollout.append(next_observation.copy())
+
+ obs = next_observation
+ except KeyboardInterrupt:
+ pass
+
+ print(f"Total reward: {total_reward}")
diff --git a/diffusers/examples/test_examples.py b/diffusers/examples/test_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9a1f86e53aac33257848084e52107c00b60f373
--- /dev/null
+++ b/diffusers/examples/test_examples.py
@@ -0,0 +1,408 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc..
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import logging
+import os
+import shutil
+import subprocess
+import sys
+import tempfile
+import unittest
+from typing import List
+
+from accelerate.utils import write_basic_config
+
+from diffusers import DiffusionPipeline, UNet2DConditionModel
+
+
+logging.basicConfig(level=logging.DEBUG)
+
+logger = logging.getLogger()
+
+
+# These utils relate to ensuring the right error message is received when running scripts
+class SubprocessCallException(Exception):
+ pass
+
+
+def run_command(command: List[str], return_stdout=False):
+ """
+ Runs `command` with `subprocess.check_output` and will potentially return the `stdout`. Will also properly capture
+ if an error occurred while running `command`
+ """
+ try:
+ output = subprocess.check_output(command, stderr=subprocess.STDOUT)
+ if return_stdout:
+ if hasattr(output, "decode"):
+ output = output.decode("utf-8")
+ return output
+ except subprocess.CalledProcessError as e:
+ raise SubprocessCallException(
+ f"Command `{' '.join(command)}` failed with the following error:\n\n{e.output.decode()}"
+ ) from e
+
+
+stream_handler = logging.StreamHandler(sys.stdout)
+logger.addHandler(stream_handler)
+
+
+class ExamplesTestsAccelerate(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+ cls._tmpdir = tempfile.mkdtemp()
+ cls.configPath = os.path.join(cls._tmpdir, "default_config.yml")
+
+ write_basic_config(save_location=cls.configPath)
+ cls._launch_args = ["accelerate", "launch", "--config_file", cls.configPath]
+
+ @classmethod
+ def tearDownClass(cls):
+ super().tearDownClass()
+ shutil.rmtree(cls._tmpdir)
+
+ def test_train_unconditional(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ test_args = f"""
+ examples/unconditional_image_generation/train_unconditional.py
+ --dataset_name hf-internal-testing/dummy_image_class_data
+ --model_config_name_or_path diffusers/ddpm_dummy
+ --resolution 64
+ --output_dir {tmpdir}
+ --train_batch_size 2
+ --num_epochs 1
+ --gradient_accumulation_steps 1
+ --ddpm_num_inference_steps 2
+ --learning_rate 1e-3
+ --lr_warmup_steps 5
+ """.split()
+
+ run_command(self._launch_args + test_args, return_stdout=True)
+ # save_pretrained smoke test
+ self.assertTrue(os.path.isfile(os.path.join(tmpdir, "unet", "diffusion_pytorch_model.bin")))
+ self.assertTrue(os.path.isfile(os.path.join(tmpdir, "scheduler", "scheduler_config.json")))
+
+ def test_textual_inversion(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ test_args = f"""
+ examples/textual_inversion/textual_inversion.py
+ --pretrained_model_name_or_path hf-internal-testing/tiny-stable-diffusion-pipe
+ --train_data_dir docs/source/en/imgs
+ --learnable_property object
+ --placeholder_token
+ --initializer_token a
+ --resolution 64
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 2
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ """.split()
+
+ run_command(self._launch_args + test_args)
+ # save_pretrained smoke test
+ self.assertTrue(os.path.isfile(os.path.join(tmpdir, "learned_embeds.bin")))
+
+ def test_dreambooth(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ test_args = f"""
+ examples/dreambooth/train_dreambooth.py
+ --pretrained_model_name_or_path hf-internal-testing/tiny-stable-diffusion-pipe
+ --instance_data_dir docs/source/en/imgs
+ --instance_prompt photo
+ --resolution 64
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 2
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ """.split()
+
+ run_command(self._launch_args + test_args)
+ # save_pretrained smoke test
+ self.assertTrue(os.path.isfile(os.path.join(tmpdir, "unet", "diffusion_pytorch_model.bin")))
+ self.assertTrue(os.path.isfile(os.path.join(tmpdir, "scheduler", "scheduler_config.json")))
+
+ def test_dreambooth_checkpointing(self):
+ instance_prompt = "photo"
+ pretrained_model_name_or_path = "hf-internal-testing/tiny-stable-diffusion-pipe"
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ # Run training script with checkpointing
+ # max_train_steps == 5, checkpointing_steps == 2
+ # Should create checkpoints at steps 2, 4
+
+ initial_run_args = f"""
+ examples/dreambooth/train_dreambooth.py
+ --pretrained_model_name_or_path {pretrained_model_name_or_path}
+ --instance_data_dir docs/source/en/imgs
+ --instance_prompt {instance_prompt}
+ --resolution 64
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 5
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ --checkpointing_steps=2
+ --seed=0
+ """.split()
+
+ run_command(self._launch_args + initial_run_args)
+
+ # check can run the original fully trained output pipeline
+ pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
+ pipe(instance_prompt, num_inference_steps=2)
+
+ # check checkpoint directories exist
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-2")))
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-4")))
+
+ # check can run an intermediate checkpoint
+ unet = UNet2DConditionModel.from_pretrained(tmpdir, subfolder="checkpoint-2/unet")
+ pipe = DiffusionPipeline.from_pretrained(pretrained_model_name_or_path, unet=unet, safety_checker=None)
+ pipe(instance_prompt, num_inference_steps=2)
+
+ # Remove checkpoint 2 so that we can check only later checkpoints exist after resuming
+ shutil.rmtree(os.path.join(tmpdir, "checkpoint-2"))
+
+ # Run training script for 7 total steps resuming from checkpoint 4
+
+ resume_run_args = f"""
+ examples/dreambooth/train_dreambooth.py
+ --pretrained_model_name_or_path {pretrained_model_name_or_path}
+ --instance_data_dir docs/source/en/imgs
+ --instance_prompt {instance_prompt}
+ --resolution 64
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 7
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ --checkpointing_steps=2
+ --resume_from_checkpoint=checkpoint-4
+ --seed=0
+ """.split()
+
+ run_command(self._launch_args + resume_run_args)
+
+ # check can run new fully trained pipeline
+ pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
+ pipe(instance_prompt, num_inference_steps=2)
+
+ # check old checkpoints do not exist
+ self.assertFalse(os.path.isdir(os.path.join(tmpdir, "checkpoint-2")))
+
+ # check new checkpoints exist
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-4")))
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-6")))
+
+ def test_text_to_image(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ test_args = f"""
+ examples/text_to_image/train_text_to_image.py
+ --pretrained_model_name_or_path hf-internal-testing/tiny-stable-diffusion-pipe
+ --dataset_name hf-internal-testing/dummy_image_text_data
+ --resolution 64
+ --center_crop
+ --random_flip
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 2
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ """.split()
+
+ run_command(self._launch_args + test_args)
+ # save_pretrained smoke test
+ self.assertTrue(os.path.isfile(os.path.join(tmpdir, "unet", "diffusion_pytorch_model.bin")))
+ self.assertTrue(os.path.isfile(os.path.join(tmpdir, "scheduler", "scheduler_config.json")))
+
+ def test_text_to_image_checkpointing(self):
+ pretrained_model_name_or_path = "hf-internal-testing/tiny-stable-diffusion-pipe"
+ prompt = "a prompt"
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ # Run training script with checkpointing
+ # max_train_steps == 5, checkpointing_steps == 2
+ # Should create checkpoints at steps 2, 4
+
+ initial_run_args = f"""
+ examples/text_to_image/train_text_to_image.py
+ --pretrained_model_name_or_path {pretrained_model_name_or_path}
+ --dataset_name hf-internal-testing/dummy_image_text_data
+ --resolution 64
+ --center_crop
+ --random_flip
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 5
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ --checkpointing_steps=2
+ --seed=0
+ """.split()
+
+ run_command(self._launch_args + initial_run_args)
+
+ pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
+ pipe(prompt, num_inference_steps=2)
+
+ # check checkpoint directories exist
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-2")))
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-4")))
+
+ # check can run an intermediate checkpoint
+ unet = UNet2DConditionModel.from_pretrained(tmpdir, subfolder="checkpoint-2/unet")
+ pipe = DiffusionPipeline.from_pretrained(pretrained_model_name_or_path, unet=unet, safety_checker=None)
+ pipe(prompt, num_inference_steps=2)
+
+ # Remove checkpoint 2 so that we can check only later checkpoints exist after resuming
+ shutil.rmtree(os.path.join(tmpdir, "checkpoint-2"))
+
+ # Run training script for 7 total steps resuming from checkpoint 4
+
+ resume_run_args = f"""
+ examples/text_to_image/train_text_to_image.py
+ --pretrained_model_name_or_path {pretrained_model_name_or_path}
+ --dataset_name hf-internal-testing/dummy_image_text_data
+ --resolution 64
+ --center_crop
+ --random_flip
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 7
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ --checkpointing_steps=2
+ --resume_from_checkpoint=checkpoint-4
+ --seed=0
+ """.split()
+
+ run_command(self._launch_args + resume_run_args)
+
+ # check can run new fully trained pipeline
+ pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
+ pipe(prompt, num_inference_steps=2)
+
+ # check old checkpoints do not exist
+ self.assertFalse(os.path.isdir(os.path.join(tmpdir, "checkpoint-2")))
+
+ # check new checkpoints exist
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-4")))
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-6")))
+
+ def test_text_to_image_checkpointing_use_ema(self):
+ pretrained_model_name_or_path = "hf-internal-testing/tiny-stable-diffusion-pipe"
+ prompt = "a prompt"
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ # Run training script with checkpointing
+ # max_train_steps == 5, checkpointing_steps == 2
+ # Should create checkpoints at steps 2, 4
+
+ initial_run_args = f"""
+ examples/text_to_image/train_text_to_image.py
+ --pretrained_model_name_or_path {pretrained_model_name_or_path}
+ --dataset_name hf-internal-testing/dummy_image_text_data
+ --resolution 64
+ --center_crop
+ --random_flip
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 5
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ --checkpointing_steps=2
+ --use_ema
+ --seed=0
+ """.split()
+
+ run_command(self._launch_args + initial_run_args)
+
+ pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
+ pipe(prompt, num_inference_steps=2)
+
+ # check checkpoint directories exist
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-2")))
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-4")))
+
+ # check can run an intermediate checkpoint
+ unet = UNet2DConditionModel.from_pretrained(tmpdir, subfolder="checkpoint-2/unet")
+ pipe = DiffusionPipeline.from_pretrained(pretrained_model_name_or_path, unet=unet, safety_checker=None)
+ pipe(prompt, num_inference_steps=2)
+
+ # Remove checkpoint 2 so that we can check only later checkpoints exist after resuming
+ shutil.rmtree(os.path.join(tmpdir, "checkpoint-2"))
+
+ # Run training script for 7 total steps resuming from checkpoint 4
+
+ resume_run_args = f"""
+ examples/text_to_image/train_text_to_image.py
+ --pretrained_model_name_or_path {pretrained_model_name_or_path}
+ --dataset_name hf-internal-testing/dummy_image_text_data
+ --resolution 64
+ --center_crop
+ --random_flip
+ --train_batch_size 1
+ --gradient_accumulation_steps 1
+ --max_train_steps 7
+ --learning_rate 5.0e-04
+ --scale_lr
+ --lr_scheduler constant
+ --lr_warmup_steps 0
+ --output_dir {tmpdir}
+ --checkpointing_steps=2
+ --resume_from_checkpoint=checkpoint-4
+ --use_ema
+ --seed=0
+ """.split()
+
+ run_command(self._launch_args + resume_run_args)
+
+ # check can run new fully trained pipeline
+ pipe = DiffusionPipeline.from_pretrained(tmpdir, safety_checker=None)
+ pipe(prompt, num_inference_steps=2)
+
+ # check old checkpoints do not exist
+ self.assertFalse(os.path.isdir(os.path.join(tmpdir, "checkpoint-2")))
+
+ # check new checkpoints exist
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-4")))
+ self.assertTrue(os.path.isdir(os.path.join(tmpdir, "checkpoint-6")))
diff --git a/diffusers/examples/text_to_image/README.md b/diffusers/examples/text_to_image/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0c378ffde2e59c2d26c2db4783fce3f6ef695a08
--- /dev/null
+++ b/diffusers/examples/text_to_image/README.md
@@ -0,0 +1,247 @@
+# Stable Diffusion text-to-image fine-tuning
+
+The `train_text_to_image.py` script shows how to fine-tune stable diffusion model on your own dataset.
+
+___Note___:
+
+___This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparamters to get the best result on your dataset.___
+
+
+## Running locally with PyTorch
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+### Pokemon example
+
+You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-4`, so you'll need to visit [its card](https://huggingface.co/CompVis/stable-diffusion-v1-4), read the license and tick the checkbox if you agree.
+
+You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
+
+Run the following command to authenticate your token
+
+```bash
+huggingface-cli login
+```
+
+If you have already cloned the repo, then you won't need to go through these steps.
+
+
+
+#### Hardware
+With `gradient_checkpointing` and `mixed_precision` it should be possible to fine tune the model on a single 24GB GPU. For higher `batch_size` and faster training it's better to use GPUs with >30GB memory.
+
+**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export dataset_name="lambdalabs/pokemon-blip-captions"
+
+accelerate launch --mixed_precision="fp16" train_text_to_image.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$dataset_name \
+ --use_ema \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --gradient_checkpointing \
+ --max_train_steps=15000 \
+ --learning_rate=1e-05 \
+ --max_grad_norm=1 \
+ --lr_scheduler="constant" --lr_warmup_steps=0 \
+ --output_dir="sd-pokemon-model"
+```
+
+
+
+To run on your own training files prepare the dataset according to the format required by `datasets`, you can find the instructions for how to do that in this [document](https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder-with-metadata).
+If you wish to use custom loading logic, you should modify the script, we have left pointers for that in the training script.
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export TRAIN_DIR="path_to_your_dataset"
+
+accelerate launch --mixed_precision="fp16" train_text_to_image.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$TRAIN_DIR \
+ --use_ema \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --gradient_checkpointing \
+ --max_train_steps=15000 \
+ --learning_rate=1e-05 \
+ --max_grad_norm=1 \
+ --lr_scheduler="constant" --lr_warmup_steps=0 \
+ --output_dir="sd-pokemon-model"
+```
+
+
+Once the training is finished the model will be saved in the `output_dir` specified in the command. In this example it's `sd-pokemon-model`. To load the fine-tuned model for inference just pass that path to `StableDiffusionPipeline`
+
+
+```python
+from diffusers import StableDiffusionPipeline
+
+model_path = "path_to_saved_model"
+pipe = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
+pipe.to("cuda")
+
+image = pipe(prompt="yoda").images[0]
+image.save("yoda-pokemon.png")
+```
+
+## Training with LoRA
+
+Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
+
+In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
+
+- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
+- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
+- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
+
+[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
+
+With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
+on consumer GPUs like Tesla T4, Tesla V100.
+
+### Training
+
+First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables. Here, we will use [Stable Diffusion v1-4](https://hf.co/CompVis/stable-diffusion-v1-4) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
+
+**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
+
+**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
+
+```bash
+export MODEL_NAME="CompVis/stable-diffusion-v1-4"
+export DATASET_NAME="lambdalabs/pokemon-blip-captions"
+```
+
+For this example we want to directly store the trained LoRA embeddings on the Hub, so
+we need to be logged in and add the `--push_to_hub` flag.
+
+```bash
+huggingface-cli login
+```
+
+Now we can start training!
+
+```bash
+accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$DATASET_NAME --caption_column="text" \
+ --resolution=512 --random_flip \
+ --train_batch_size=1 \
+ --num_train_epochs=100 --checkpointing_steps=5000 \
+ --learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
+ --seed=42 \
+ --output_dir="sd-pokemon-model-lora" \
+ --validation_prompt="cute dragon creature" --report_to="wandb"
+```
+
+The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
+
+**___Note: When using LoRA we can use a much higher learning rate compared to non-LoRA fine-tuning. Here we use *1e-4* instead of the usual *1e-5*. Also, by using LoRA, it's possible to run `train_text_to_image_lora.py` in consumer GPUs like T4 or V100.___**
+
+The final LoRA embedding weights have been uploaded to [sayakpaul/sd-model-finetuned-lora-t4](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4). **___Note: [The final weights](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) are only 3 MB in size, which is orders of magnitudes smaller than the original model.___**
+
+You can check some inference samples that were logged during the course of the fine-tuning process [here](https://wandb.ai/sayakpaul/text2image-fine-tune/runs/q4lc0xsw).
+
+### Inference
+
+Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline` after loading the trained LoRA weights. You
+need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora`.
+
+```python
+from diffusers import StableDiffusionPipeline
+import torch
+
+model_path = "sayakpaul/sd-model-finetuned-lora-t4"
+pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+pipe.unet.load_attn_procs(model_path)
+pipe.to("cuda")
+
+prompt = "A pokemon with green eyes and red legs."
+image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
+image.save("pokemon.png")
+```
+
+## Training with Flax/JAX
+
+For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
+
+**___Note: The flax example doesn't yet support features like gradient checkpoint, gradient accumulation etc, so to use flax for faster training we will need >30GB cards or TPU v3.___**
+
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+```bash
+pip install -U -r requirements_flax.txt
+```
+
+```bash
+export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
+export dataset_name="lambdalabs/pokemon-blip-captions"
+
+python train_text_to_image_flax.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --dataset_name=$dataset_name \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --mixed_precision="fp16" \
+ --max_train_steps=15000 \
+ --learning_rate=1e-05 \
+ --max_grad_norm=1 \
+ --output_dir="sd-pokemon-model"
+```
+
+To run on your own training files prepare the dataset according to the format required by `datasets`, you can find the instructions for how to do that in this [document](https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder-with-metadata).
+If you wish to use custom loading logic, you should modify the script, we have left pointers for that in the training script.
+
+```bash
+export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
+export TRAIN_DIR="path_to_your_dataset"
+
+python train_text_to_image_flax.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$TRAIN_DIR \
+ --resolution=512 --center_crop --random_flip \
+ --train_batch_size=1 \
+ --mixed_precision="fp16" \
+ --max_train_steps=15000 \
+ --learning_rate=1e-05 \
+ --max_grad_norm=1 \
+ --output_dir="sd-pokemon-model"
+```
+
+### Training with xFormers:
+
+You can enable memory efficient attention by [installing xFormers](https://huggingface.co/docs/diffusers/main/en/optimization/xformers) and passing the `--enable_xformers_memory_efficient_attention` argument to the script.
+
+xFormers training is not available for Flax/JAX.
+
+**Note**:
+
+According to [this issue](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212), xFormers `v0.0.16` cannot be used for training in some GPUs. If you observe that problem, please install a development version as indicated in that comment.
diff --git a/diffusers/examples/text_to_image/requirements.txt b/diffusers/examples/text_to_image/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a71be6715c15bb3fe81ad940c68e106797ba0759
--- /dev/null
+++ b/diffusers/examples/text_to_image/requirements.txt
@@ -0,0 +1,7 @@
+accelerate
+torchvision
+transformers>=4.25.1
+datasets
+ftfy
+tensorboard
+Jinja2
diff --git a/diffusers/examples/text_to_image/requirements_flax.txt b/diffusers/examples/text_to_image/requirements_flax.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b6eb64e254625ee8eff2ef126d67adfd5b6994dc
--- /dev/null
+++ b/diffusers/examples/text_to_image/requirements_flax.txt
@@ -0,0 +1,9 @@
+transformers>=4.25.1
+datasets
+flax
+optax
+torch
+torchvision
+ftfy
+tensorboard
+Jinja2
diff --git a/diffusers/examples/text_to_image/train_text_to_image.py b/diffusers/examples/text_to_image/train_text_to_image.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf2d1e81912e5c1448c217bf6b4d23c3d8fd7640
--- /dev/null
+++ b/diffusers/examples/text_to_image/train_text_to_image.py
@@ -0,0 +1,781 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import argparse
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import accelerate
+import datasets
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from datasets import load_dataset
+from huggingface_hub import create_repo, upload_folder
+from packaging import version
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+import diffusers
+from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel
+from diffusers.optimization import get_scheduler
+from diffusers.training_utils import EMAModel
+from diffusers.utils import check_min_version, deprecate
+from diffusers.utils.import_utils import is_xformers_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.15.0.dev0")
+
+logger = get_logger(__name__, log_level="INFO")
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that 🤗 Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--image_column", type=str, default="image", help="The column of the dataset containing an image."
+ )
+ parser.add_argument(
+ "--caption_column",
+ type=str,
+ default="text",
+ help="The column of the dataset containing a caption or a list of captions.",
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="sd-model-finetuned",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument("--use_ema", action="store_true", help="Whether to use EMA model.")
+ parser.add_argument(
+ "--non_ema_revision",
+ type=str,
+ default=None,
+ required=False,
+ help=(
+ "Revision of pretrained non-ema model identifier. Must be a branch, tag or git identifier of the local or"
+ " remote repository specified with --pretrained_model_name_or_path."
+ ),
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+ parser.add_argument("--noise_offset", type=float, default=0, help="The scale of noise offset.")
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_data_dir is None:
+ raise ValueError("Need either a dataset name or a training folder.")
+
+ # default to using the same revision for the non-ema model if not specified
+ if args.non_ema_revision is None:
+ args.non_ema_revision = args.revision
+
+ return args
+
+
+dataset_name_mapping = {
+ "lambdalabs/pokemon-blip-captions": ("image", "text"),
+}
+
+
+def main():
+ args = parse_args()
+
+ if args.non_ema_revision is not None:
+ deprecate(
+ "non_ema_revision!=None",
+ "0.15.0",
+ message=(
+ "Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
+ " use `--variant=non_ema` instead."
+ ),
+ )
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load scheduler, tokenizer and models.
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ tokenizer = CLIPTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
+ )
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
+ )
+
+ # Freeze vae and text_encoder
+ vae.requires_grad_(False)
+ text_encoder.requires_grad_(False)
+
+ # Create EMA for the unet.
+ if args.use_ema:
+ ema_unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+ ema_unet = EMAModel(ema_unet.parameters(), model_cls=UNet2DConditionModel, model_config=ema_unet.config)
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # `accelerate` 0.16.0 will have better support for customized saving
+ if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
+ # create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
+ def save_model_hook(models, weights, output_dir):
+ if args.use_ema:
+ ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
+
+ for i, model in enumerate(models):
+ model.save_pretrained(os.path.join(output_dir, "unet"))
+
+ # make sure to pop weight so that corresponding model is not saved again
+ weights.pop()
+
+ def load_model_hook(models, input_dir):
+ if args.use_ema:
+ load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DConditionModel)
+ ema_unet.load_state_dict(load_model.state_dict())
+ ema_unet.to(accelerator.device)
+ del load_model
+
+ for i in range(len(models)):
+ # pop models so that they are not loaded again
+ model = models.pop()
+
+ # load diffusers style into model
+ load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
+ model.register_to_config(**load_model.config)
+
+ model.load_state_dict(load_model.state_dict())
+ del load_model
+
+ accelerator.register_save_state_pre_hook(save_model_hook)
+ accelerator.register_load_state_pre_hook(load_model_hook)
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
+ )
+
+ optimizer_cls = bnb.optim.AdamW8bit
+ else:
+ optimizer_cls = torch.optim.AdamW
+
+ optimizer = optimizer_cls(
+ unet.parameters(),
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ )
+ else:
+ data_files = {}
+ if args.train_data_dir is not None:
+ data_files["train"] = os.path.join(args.train_data_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=args.cache_dir,
+ )
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ column_names = dataset["train"].column_names
+
+ # 6. Get the column names for input/target.
+ dataset_columns = dataset_name_mapping.get(args.dataset_name, None)
+ if args.image_column is None:
+ image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ image_column = args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.caption_column is None:
+ caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ caption_column = args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Preprocessing the datasets.
+ # We need to tokenize input captions and transform the images.
+ def tokenize_captions(examples, is_train=True):
+ captions = []
+ for caption in examples[caption_column]:
+ if isinstance(caption, str):
+ captions.append(caption)
+ elif isinstance(caption, (list, np.ndarray)):
+ # take a random caption if there are multiple
+ captions.append(random.choice(caption) if is_train else caption[0])
+ else:
+ raise ValueError(
+ f"Caption column `{caption_column}` should contain either strings or lists of strings."
+ )
+ inputs = tokenizer(
+ captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
+ )
+ return inputs.input_ids
+
+ # Preprocessing the datasets.
+ train_transforms = transforms.Compose(
+ [
+ transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
+ transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def preprocess_train(examples):
+ images = [image.convert("RGB") for image in examples[image_column]]
+ examples["pixel_values"] = [train_transforms(image) for image in images]
+ examples["input_ids"] = tokenize_captions(examples)
+ return examples
+
+ with accelerator.main_process_first():
+ if args.max_train_samples is not None:
+ dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ train_dataset = dataset["train"].with_transform(preprocess_train)
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+ input_ids = torch.stack([example["input_ids"] for example in examples])
+ return {"pixel_values": pixel_values, "input_ids": input_ids}
+
+ # DataLoaders creation:
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ shuffle=True,
+ collate_fn=collate_fn,
+ batch_size=args.train_batch_size,
+ num_workers=args.dataloader_num_workers,
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+
+ if args.use_ema:
+ ema_unet.to(accelerator.device)
+
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move text_encode and vae to gpu and cast to weight_dtype
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+ vae.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("text2image-fine-tune", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ train_loss = 0.0
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(weight_dtype)).latent_dist.sample()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ if args.noise_offset:
+ # https://www.crosslabs.org//blog/diffusion-with-offset-noise
+ noise += args.noise_offset * torch.randn(
+ (latents.shape[0], latents.shape[1], 1, 1), device=latents.device
+ )
+
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ # Predict the noise residual and compute loss
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ # Gather the losses across all processes for logging (if we use distributed training).
+ avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
+ train_loss += avg_loss.item() / args.gradient_accumulation_steps
+
+ # Backpropagate
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ if args.use_ema:
+ ema_unet.step(unet.parameters())
+ progress_bar.update(1)
+ global_step += 1
+ accelerator.log({"train_loss": train_loss}, step=global_step)
+ train_loss = 0.0
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ # Create the pipeline using the trained modules and save it.
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ unet = accelerator.unwrap_model(unet)
+ if args.use_ema:
+ ema_unet.copy_to(unet.parameters())
+
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=text_encoder,
+ vae=vae,
+ unet=unet,
+ revision=args.revision,
+ )
+ pipeline.save_pretrained(args.output_dir)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/text_to_image/train_text_to_image_flax.py b/diffusers/examples/text_to_image/train_text_to_image_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..cbd236c5ea15586f1f826daf12d238c9ac29bb9f
--- /dev/null
+++ b/diffusers/examples/text_to_image/train_text_to_image_flax.py
@@ -0,0 +1,574 @@
+import argparse
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+import torch
+import torch.utils.checkpoint
+import transformers
+from datasets import load_dataset
+from flax import jax_utils
+from flax.training import train_state
+from flax.training.common_utils import shard
+from huggingface_hub import create_repo, upload_folder
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel, set_seed
+
+from diffusers import (
+ FlaxAutoencoderKL,
+ FlaxDDPMScheduler,
+ FlaxPNDMScheduler,
+ FlaxStableDiffusionPipeline,
+ FlaxUNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion import FlaxStableDiffusionSafetyChecker
+from diffusers.utils import check_min_version
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.15.0.dev0")
+
+logger = logging.getLogger(__name__)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that 🤗 Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--image_column", type=str, default="image", help="The column of the dataset containing an image."
+ )
+ parser.add_argument(
+ "--caption_column",
+ type=str,
+ default="text",
+ help="The column of the dataset containing a caption or a list of captions.",
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="sd-model-finetuned",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument("--seed", type=int, default=0, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_data_dir is None:
+ raise ValueError("Need either a dataset name or a training folder.")
+
+ return args
+
+
+dataset_name_mapping = {
+ "lambdalabs/pokemon-blip-captions": ("image", "text"),
+}
+
+
+def get_params_to_save(params):
+ return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
+
+
+def main():
+ args = parse_args()
+
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if jax.process_index() == 0:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ )
+ else:
+ data_files = {}
+ if args.train_data_dir is not None:
+ data_files["train"] = os.path.join(args.train_data_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=args.cache_dir,
+ )
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ column_names = dataset["train"].column_names
+
+ # 6. Get the column names for input/target.
+ dataset_columns = dataset_name_mapping.get(args.dataset_name, None)
+ if args.image_column is None:
+ image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ image_column = args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.caption_column is None:
+ caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ caption_column = args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Preprocessing the datasets.
+ # We need to tokenize input captions and transform the images.
+ def tokenize_captions(examples, is_train=True):
+ captions = []
+ for caption in examples[caption_column]:
+ if isinstance(caption, str):
+ captions.append(caption)
+ elif isinstance(caption, (list, np.ndarray)):
+ # take a random caption if there are multiple
+ captions.append(random.choice(caption) if is_train else caption[0])
+ else:
+ raise ValueError(
+ f"Caption column `{caption_column}` should contain either strings or lists of strings."
+ )
+ inputs = tokenizer(captions, max_length=tokenizer.model_max_length, padding="do_not_pad", truncation=True)
+ input_ids = inputs.input_ids
+ return input_ids
+
+ train_transforms = transforms.Compose(
+ [
+ transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
+ transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def preprocess_train(examples):
+ images = [image.convert("RGB") for image in examples[image_column]]
+ examples["pixel_values"] = [train_transforms(image) for image in images]
+ examples["input_ids"] = tokenize_captions(examples)
+
+ return examples
+
+ if jax.process_index() == 0:
+ if args.max_train_samples is not None:
+ dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ train_dataset = dataset["train"].with_transform(preprocess_train)
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+ input_ids = [example["input_ids"] for example in examples]
+
+ padded_tokens = tokenizer.pad(
+ {"input_ids": input_ids}, padding="max_length", max_length=tokenizer.model_max_length, return_tensors="pt"
+ )
+ batch = {
+ "pixel_values": pixel_values,
+ "input_ids": padded_tokens.input_ids,
+ }
+ batch = {k: v.numpy() for k, v in batch.items()}
+
+ return batch
+
+ total_train_batch_size = args.train_batch_size * jax.local_device_count()
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=total_train_batch_size, drop_last=True
+ )
+
+ weight_dtype = jnp.float32
+ if args.mixed_precision == "fp16":
+ weight_dtype = jnp.float16
+ elif args.mixed_precision == "bf16":
+ weight_dtype = jnp.bfloat16
+
+ # Load models and create wrapper for stable diffusion
+ tokenizer = CLIPTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path, revision=args.revision, subfolder="tokenizer"
+ )
+ text_encoder = FlaxCLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, revision=args.revision, subfolder="text_encoder", dtype=weight_dtype
+ )
+ vae, vae_params = FlaxAutoencoderKL.from_pretrained(
+ args.pretrained_model_name_or_path, revision=args.revision, subfolder="vae", dtype=weight_dtype
+ )
+ unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, revision=args.revision, subfolder="unet", dtype=weight_dtype
+ )
+
+ # Optimization
+ if args.scale_lr:
+ args.learning_rate = args.learning_rate * total_train_batch_size
+
+ constant_scheduler = optax.constant_schedule(args.learning_rate)
+
+ adamw = optax.adamw(
+ learning_rate=constant_scheduler,
+ b1=args.adam_beta1,
+ b2=args.adam_beta2,
+ eps=args.adam_epsilon,
+ weight_decay=args.adam_weight_decay,
+ )
+
+ optimizer = optax.chain(
+ optax.clip_by_global_norm(args.max_grad_norm),
+ adamw,
+ )
+
+ state = train_state.TrainState.create(apply_fn=unet.__call__, params=unet_params, tx=optimizer)
+
+ noise_scheduler = FlaxDDPMScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000
+ )
+ noise_scheduler_state = noise_scheduler.create_state()
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(args.seed)
+ train_rngs = jax.random.split(rng, jax.local_device_count())
+
+ def train_step(state, text_encoder_params, vae_params, batch, train_rng):
+ dropout_rng, sample_rng, new_train_rng = jax.random.split(train_rng, 3)
+
+ def compute_loss(params):
+ # Convert images to latent space
+ vae_outputs = vae.apply(
+ {"params": vae_params}, batch["pixel_values"], deterministic=True, method=vae.encode
+ )
+ latents = vae_outputs.latent_dist.sample(sample_rng)
+ # (NHWC) -> (NCHW)
+ latents = jnp.transpose(latents, (0, 3, 1, 2))
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise_rng, timestep_rng = jax.random.split(sample_rng)
+ noise = jax.random.normal(noise_rng, latents.shape)
+ # Sample a random timestep for each image
+ bsz = latents.shape[0]
+ timesteps = jax.random.randint(
+ timestep_rng,
+ (bsz,),
+ 0,
+ noise_scheduler.config.num_train_timesteps,
+ )
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(
+ batch["input_ids"],
+ params=text_encoder_params,
+ train=False,
+ )[0]
+
+ # Predict the noise residual and compute loss
+ model_pred = unet.apply(
+ {"params": params}, noisy_latents, timesteps, encoder_hidden_states, train=True
+ ).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ loss = (target - model_pred) ** 2
+ loss = loss.mean()
+
+ return loss
+
+ grad_fn = jax.value_and_grad(compute_loss)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+
+ new_state = state.apply_gradients(grads=grad)
+
+ metrics = {"loss": loss}
+ metrics = jax.lax.pmean(metrics, axis_name="batch")
+
+ return new_state, metrics, new_train_rng
+
+ # Create parallel version of the train step
+ p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
+
+ # Replicate the train state on each device
+ state = jax_utils.replicate(state)
+ text_encoder_params = jax_utils.replicate(text_encoder.params)
+ vae_params = jax_utils.replicate(vae_params)
+
+ # Train!
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader))
+
+ # Scheduler and math around the number of training steps.
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ global_step = 0
+
+ epochs = tqdm(range(args.num_train_epochs), desc="Epoch ... ", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+
+ train_metrics = []
+
+ steps_per_epoch = len(train_dataset) // total_train_batch_size
+ train_step_progress_bar = tqdm(total=steps_per_epoch, desc="Training...", position=1, leave=False)
+ # train
+ for batch in train_dataloader:
+ batch = shard(batch)
+ state, train_metric, train_rngs = p_train_step(state, text_encoder_params, vae_params, batch, train_rngs)
+ train_metrics.append(train_metric)
+
+ train_step_progress_bar.update(1)
+
+ global_step += 1
+ if global_step >= args.max_train_steps:
+ break
+
+ train_metric = jax_utils.unreplicate(train_metric)
+
+ train_step_progress_bar.close()
+ epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
+
+ # Create the pipeline using using the trained modules and save it.
+ if jax.process_index() == 0:
+ scheduler = FlaxPNDMScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", skip_prk_steps=True
+ )
+ safety_checker = FlaxStableDiffusionSafetyChecker.from_pretrained(
+ "CompVis/stable-diffusion-safety-checker", from_pt=True
+ )
+ pipeline = FlaxStableDiffusionPipeline(
+ text_encoder=text_encoder,
+ vae=vae,
+ unet=unet,
+ tokenizer=tokenizer,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch32"),
+ )
+
+ pipeline.save_pretrained(
+ args.output_dir,
+ params={
+ "text_encoder": get_params_to_save(text_encoder_params),
+ "vae": get_params_to_save(vae_params),
+ "unet": get_params_to_save(state.params),
+ "safety_checker": safety_checker.params,
+ },
+ )
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/text_to_image/train_text_to_image_lora.py b/diffusers/examples/text_to_image/train_text_to_image_lora.py
new file mode 100644
index 0000000000000000000000000000000000000000..c85b339d5b7ac07c7191c66888465c75c2c3a3bb
--- /dev/null
+++ b/diffusers/examples/text_to_image/train_text_to_image_lora.py
@@ -0,0 +1,861 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fine-tuning script for Stable Diffusion for text2image with support for LoRA."""
+
+import argparse
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from datasets import load_dataset
+from huggingface_hub import create_repo, upload_folder
+from packaging import version
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+import diffusers
+from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, UNet2DConditionModel
+from diffusers.loaders import AttnProcsLayers
+from diffusers.models.attention_processor import LoRAAttnProcessor
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version, is_wandb_available
+from diffusers.utils.import_utils import is_xformers_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.15.0.dev0")
+
+logger = get_logger(__name__, log_level="INFO")
+
+
+def save_model_card(repo_id: str, images=None, base_model=str, dataset_name=str, repo_folder=None):
+ img_str = ""
+ for i, image in enumerate(images):
+ image.save(os.path.join(repo_folder, f"image_{i}.png"))
+ img_str += f"\n"
+
+ yaml = f"""
+---
+license: creativeml-openrail-m
+base_model: {base_model}
+tags:
+- stable-diffusion
+- stable-diffusion-diffusers
+- text-to-image
+- diffusers
+- lora
+inference: true
+---
+ """
+ model_card = f"""
+# LoRA text2image fine-tuning - {repo_id}
+These are LoRA adaption weights for {base_model}. The weights were fine-tuned on the {dataset_name} dataset. You can find some example images in the following. \n
+{img_str}
+"""
+ with open(os.path.join(repo_folder, "README.md"), "w") as f:
+ f.write(yaml + model_card)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that 🤗 Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--image_column", type=str, default="image", help="The column of the dataset containing an image."
+ )
+ parser.add_argument(
+ "--caption_column",
+ type=str,
+ default="text",
+ help="The column of the dataset containing a caption or a list of captions.",
+ )
+ parser.add_argument(
+ "--validation_prompt", type=str, default=None, help="A prompt that is sampled during training for inference."
+ )
+ parser.add_argument(
+ "--num_validation_images",
+ type=int,
+ default=4,
+ help="Number of images that should be generated during validation with `validation_prompt`.",
+ )
+ parser.add_argument(
+ "--validation_epochs",
+ type=int,
+ default=1,
+ help=(
+ "Run fine-tuning validation every X epochs. The validation process consists of running the prompt"
+ " `args.validation_prompt` multiple times: `args.num_validation_images`."
+ ),
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="sd-model-finetuned-lora",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default=None,
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
+ " 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
+ " flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+ parser.add_argument("--noise_offset", type=float, default=0, help="The scale of noise offset.")
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_data_dir is None:
+ raise ValueError("Need either a dataset name or a training folder.")
+
+ return args
+
+
+DATASET_NAME_MAPPING = {
+ "lambdalabs/pokemon-blip-captions": ("image", "text"),
+}
+
+
+def main():
+ args = parse_args()
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+ import wandb
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+ # Load scheduler, tokenizer and models.
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ tokenizer = CLIPTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
+ )
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+ # freeze parameters of models to save more memory
+ unet.requires_grad_(False)
+ vae.requires_grad_(False)
+
+ text_encoder.requires_grad_(False)
+
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move unet, vae and text_encoder to device and cast to weight_dtype
+ unet.to(accelerator.device, dtype=weight_dtype)
+ vae.to(accelerator.device, dtype=weight_dtype)
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+
+ # now we will add new LoRA weights to the attention layers
+ # It's important to realize here how many attention weights will be added and of which sizes
+ # The sizes of the attention layers consist only of two different variables:
+ # 1) - the "hidden_size", which is increased according to `unet.config.block_out_channels`.
+ # 2) - the "cross attention size", which is set to `unet.config.cross_attention_dim`.
+
+ # Let's first see how many attention processors we will have to set.
+ # For Stable Diffusion, it should be equal to:
+ # - down blocks (2x attention layers) * (2x transformer layers) * (3x down blocks) = 12
+ # - mid blocks (2x attention layers) * (1x transformer layers) * (1x mid blocks) = 2
+ # - up blocks (2x attention layers) * (3x transformer layers) * (3x down blocks) = 18
+ # => 32 layers
+
+ # Set correct lora layers
+ lora_attn_procs = {}
+ for name in unet.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = unet.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = unet.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+
+ unet.set_attn_processor(lora_attn_procs)
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ lora_layers = AttnProcsLayers(unet.attn_processors)
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "Please install bitsandbytes to use 8-bit Adam. You can do so by running `pip install bitsandbytes`"
+ )
+
+ optimizer_cls = bnb.optim.AdamW8bit
+ else:
+ optimizer_cls = torch.optim.AdamW
+
+ optimizer = optimizer_cls(
+ lora_layers.parameters(),
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ )
+ else:
+ data_files = {}
+ if args.train_data_dir is not None:
+ data_files["train"] = os.path.join(args.train_data_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=args.cache_dir,
+ )
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ column_names = dataset["train"].column_names
+
+ # 6. Get the column names for input/target.
+ dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
+ if args.image_column is None:
+ image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ image_column = args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.caption_column is None:
+ caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ caption_column = args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Preprocessing the datasets.
+ # We need to tokenize input captions and transform the images.
+ def tokenize_captions(examples, is_train=True):
+ captions = []
+ for caption in examples[caption_column]:
+ if isinstance(caption, str):
+ captions.append(caption)
+ elif isinstance(caption, (list, np.ndarray)):
+ # take a random caption if there are multiple
+ captions.append(random.choice(caption) if is_train else caption[0])
+ else:
+ raise ValueError(
+ f"Caption column `{caption_column}` should contain either strings or lists of strings."
+ )
+ inputs = tokenizer(
+ captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
+ )
+ return inputs.input_ids
+
+ # Preprocessing the datasets.
+ train_transforms = transforms.Compose(
+ [
+ transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
+ transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def preprocess_train(examples):
+ images = [image.convert("RGB") for image in examples[image_column]]
+ examples["pixel_values"] = [train_transforms(image) for image in images]
+ examples["input_ids"] = tokenize_captions(examples)
+ return examples
+
+ with accelerator.main_process_first():
+ if args.max_train_samples is not None:
+ dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ train_dataset = dataset["train"].with_transform(preprocess_train)
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+ input_ids = torch.stack([example["input_ids"] for example in examples])
+ return {"pixel_values": pixel_values, "input_ids": input_ids}
+
+ # DataLoaders creation:
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ shuffle=True,
+ collate_fn=collate_fn,
+ batch_size=args.train_batch_size,
+ num_workers=args.dataloader_num_workers,
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ lora_layers, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ lora_layers, optimizer, train_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("text2image-fine-tune", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ train_loss = 0.0
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ if args.noise_offset:
+ # https://www.crosslabs.org//blog/diffusion-with-offset-noise
+ noise += args.noise_offset * torch.randn(
+ (latents.shape[0], latents.shape[1], 1, 1), device=latents.device
+ )
+
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ # Predict the noise residual and compute loss
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ # Gather the losses across all processes for logging (if we use distributed training).
+ avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
+ train_loss += avg_loss.item() / args.gradient_accumulation_steps
+
+ # Backpropagate
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ params_to_clip = lora_layers.parameters()
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+ accelerator.log({"train_loss": train_loss}, step=global_step)
+ train_loss = 0.0
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"step_loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if accelerator.is_main_process:
+ if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
+ logger.info(
+ f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
+ f" {args.validation_prompt}."
+ )
+ # create pipeline
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ revision=args.revision,
+ torch_dtype=weight_dtype,
+ )
+ pipeline = pipeline.to(accelerator.device)
+ pipeline.set_progress_bar_config(disable=True)
+
+ # run inference
+ generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
+ images = []
+ for _ in range(args.num_validation_images):
+ images.append(
+ pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0]
+ )
+
+ for tracker in accelerator.trackers:
+ if tracker.name == "tensorboard":
+ np_images = np.stack([np.asarray(img) for img in images])
+ tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "validation": [
+ wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
+ for i, image in enumerate(images)
+ ]
+ }
+ )
+
+ del pipeline
+ torch.cuda.empty_cache()
+
+ # Save the lora layers
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ unet = unet.to(torch.float32)
+ unet.save_attn_procs(args.output_dir)
+
+ if args.push_to_hub:
+ save_model_card(
+ repo_id,
+ images=images,
+ base_model=args.pretrained_model_name_or_path,
+ dataset_name=args.dataset_name,
+ repo_folder=args.output_dir,
+ )
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ # Final inference
+ # Load previous pipeline
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path, revision=args.revision, torch_dtype=weight_dtype
+ )
+ pipeline = pipeline.to(accelerator.device)
+
+ # load attention processors
+ pipeline.unet.load_attn_procs(args.output_dir)
+
+ # run inference
+ generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
+ images = []
+ for _ in range(args.num_validation_images):
+ images.append(pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0])
+
+ if accelerator.is_main_process:
+ for tracker in accelerator.trackers:
+ if tracker.name == "tensorboard":
+ np_images = np.stack([np.asarray(img) for img in images])
+ tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "test": [
+ wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
+ for i, image in enumerate(images)
+ ]
+ }
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/textual_inversion/README.md b/diffusers/examples/textual_inversion/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..3a7c96be69fbe198479a866523dc9c867a15339f
--- /dev/null
+++ b/diffusers/examples/textual_inversion/README.md
@@ -0,0 +1,129 @@
+## Textual Inversion fine-tuning example
+
+[Textual inversion](https://arxiv.org/abs/2208.01618) is a method to personalize text2image models like stable diffusion on your own images using just 3-5 examples.
+The `textual_inversion.py` script shows how to implement the training procedure and adapt it for stable diffusion.
+
+## Running on Colab
+
+Colab for training
+[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb)
+
+Colab for inference
+[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb)
+
+## Running locally with PyTorch
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+
+### Cat toy example
+
+You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-5`, so you'll need to visit [its card](https://huggingface.co/runwayml/stable-diffusion-v1-5), read the license and tick the checkbox if you agree.
+
+You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
+
+Run the following command to authenticate your token
+
+```bash
+huggingface-cli login
+```
+
+If you have already cloned the repo, then you won't need to go through these steps.
+
+
+
+Now let's get our dataset.Download 3-4 images from [here](https://drive.google.com/drive/folders/1fmJMs25nxS_rSNqS5hTcRdLem_YQXbq5) and save them in a directory. This will be our training data.
+
+And launch the training using
+
+**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
+
+```bash
+export MODEL_NAME="runwayml/stable-diffusion-v1-5"
+export DATA_DIR="path-to-dir-containing-images"
+
+accelerate launch textual_inversion.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --gradient_accumulation_steps=4 \
+ --max_train_steps=3000 \
+ --learning_rate=5.0e-04 --scale_lr \
+ --lr_scheduler="constant" \
+ --lr_warmup_steps=0 \
+ --output_dir="textual_inversion_cat"
+```
+
+A full training run takes ~1 hour on one V100 GPU.
+
+### Inference
+
+Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline`. Make sure to include the `placeholder_token` in your prompt.
+
+```python
+from diffusers import StableDiffusionPipeline
+
+model_id = "path-to-your-trained-model"
+pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16).to("cuda")
+
+prompt = "A backpack"
+
+image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
+
+image.save("cat-backpack.png")
+```
+
+
+## Training with Flax/JAX
+
+For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+```bash
+pip install -U -r requirements_flax.txt
+```
+
+```bash
+export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
+export DATA_DIR="path-to-dir-containing-images"
+
+python textual_inversion_flax.py \
+ --pretrained_model_name_or_path=$MODEL_NAME \
+ --train_data_dir=$DATA_DIR \
+ --learnable_property="object" \
+ --placeholder_token="" --initializer_token="toy" \
+ --resolution=512 \
+ --train_batch_size=1 \
+ --max_train_steps=3000 \
+ --learning_rate=5.0e-04 --scale_lr \
+ --output_dir="textual_inversion_cat"
+```
+It should be at least 70% faster than the PyTorch script with the same configuration.
+
+### Training with xformers:
+You can enable memory efficient attention by [installing xFormers](https://github.com/facebookresearch/xformers#installing-xformers) and padding the `--enable_xformers_memory_efficient_attention` argument to the script. This is not available with the Flax/JAX implementation.
diff --git a/diffusers/examples/textual_inversion/requirements.txt b/diffusers/examples/textual_inversion/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7d93f3d03bd8eba09b8cab5e570d15380456b66a
--- /dev/null
+++ b/diffusers/examples/textual_inversion/requirements.txt
@@ -0,0 +1,6 @@
+accelerate
+torchvision
+transformers>=4.25.1
+ftfy
+tensorboard
+Jinja2
diff --git a/diffusers/examples/textual_inversion/requirements_flax.txt b/diffusers/examples/textual_inversion/requirements_flax.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8f85ad523a3b46b65abf0138c05ecdd656e6845c
--- /dev/null
+++ b/diffusers/examples/textual_inversion/requirements_flax.txt
@@ -0,0 +1,8 @@
+transformers>=4.25.1
+flax
+optax
+torch
+torchvision
+ftfy
+tensorboard
+Jinja2
diff --git a/diffusers/examples/textual_inversion/textual_inversion.py b/diffusers/examples/textual_inversion/textual_inversion.py
new file mode 100644
index 0000000000000000000000000000000000000000..42ea9c946c47aba12c2207ef6a57d868f05ad86b
--- /dev/null
+++ b/diffusers/examples/textual_inversion/textual_inversion.py
@@ -0,0 +1,875 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import argparse
+import logging
+import math
+import os
+import random
+import warnings
+from pathlib import Path
+
+import numpy as np
+import PIL
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration, set_seed
+from huggingface_hub import create_repo, upload_folder
+
+# TODO: remove and import from diffusers.utils when the new version of diffusers is released
+from packaging import version
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+import diffusers
+from diffusers import (
+ AutoencoderKL,
+ DDPMScheduler,
+ DiffusionPipeline,
+ DPMSolverMultistepScheduler,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.optimization import get_scheduler
+from diffusers.utils import check_min_version, is_wandb_available
+from diffusers.utils.import_utils import is_xformers_available
+
+
+if is_wandb_available():
+ import wandb
+
+if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.Resampling.BILINEAR,
+ "bilinear": PIL.Image.Resampling.BILINEAR,
+ "bicubic": PIL.Image.Resampling.BICUBIC,
+ "lanczos": PIL.Image.Resampling.LANCZOS,
+ "nearest": PIL.Image.Resampling.NEAREST,
+ }
+else:
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.LINEAR,
+ "bilinear": PIL.Image.BILINEAR,
+ "bicubic": PIL.Image.BICUBIC,
+ "lanczos": PIL.Image.LANCZOS,
+ "nearest": PIL.Image.NEAREST,
+ }
+# ------------------------------------------------------------------------------
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.15.0.dev0")
+
+logger = get_logger(__name__)
+
+
+def log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch):
+ logger.info(
+ f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
+ f" {args.validation_prompt}."
+ )
+ # create pipeline (note: unet and vae are loaded again in float32)
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ tokenizer=tokenizer,
+ unet=unet,
+ vae=vae,
+ revision=args.revision,
+ torch_dtype=weight_dtype,
+ )
+ pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
+ pipeline = pipeline.to(accelerator.device)
+ pipeline.set_progress_bar_config(disable=True)
+
+ # run inference
+ generator = None if args.seed is None else torch.Generator(device=accelerator.device).manual_seed(args.seed)
+ images = []
+ for _ in range(args.num_validation_images):
+ with torch.autocast("cuda"):
+ image = pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
+ images.append(image)
+
+ for tracker in accelerator.trackers:
+ if tracker.name == "tensorboard":
+ np_images = np.stack([np.asarray(img) for img in images])
+ tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
+ if tracker.name == "wandb":
+ tracker.log(
+ {
+ "validation": [
+ wandb.Image(image, caption=f"{i}: {args.validation_prompt}") for i, image in enumerate(images)
+ ]
+ }
+ )
+
+ del pipeline
+ torch.cuda.empty_cache()
+
+
+def save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path):
+ logger.info("Saving embeddings")
+ learned_embeds = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[placeholder_token_id]
+ learned_embeds_dict = {args.placeholder_token: learned_embeds.detach().cpu()}
+ torch.save(learned_embeds_dict, save_path)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--save_steps",
+ type=int,
+ default=500,
+ help="Save learned_embeds.bin every X updates steps.",
+ )
+ parser.add_argument(
+ "--only_save_embeds",
+ action="store_true",
+ default=False,
+ help="Save only the embeddings for the new concept.",
+ )
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
+ )
+ parser.add_argument(
+ "--placeholder_token",
+ type=str,
+ default=None,
+ required=True,
+ help="A token to use as a placeholder for the concept.",
+ )
+ parser.add_argument(
+ "--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
+ )
+ parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
+ parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=5000,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument(
+ "--allow_tf32",
+ action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="tensorboard",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument(
+ "--validation_prompt",
+ type=str,
+ default=None,
+ help="A prompt that is used during validation to verify that the model is learning.",
+ )
+ parser.add_argument(
+ "--num_validation_images",
+ type=int,
+ default=4,
+ help="Number of images that should be generated during validation with `validation_prompt`.",
+ )
+ parser.add_argument(
+ "--validation_steps",
+ type=int,
+ default=100,
+ help=(
+ "Run validation every X steps. Validation consists of running the prompt"
+ " `args.validation_prompt` multiple times: `args.num_validation_images`"
+ " and logging the images."
+ ),
+ )
+ parser.add_argument(
+ "--validation_epochs",
+ type=int,
+ default=None,
+ help=(
+ "Deprecated in favor of validation_steps. Run validation every X epochs. Validation consists of running the prompt"
+ " `args.validation_prompt` multiple times: `args.num_validation_images`"
+ " and logging the images."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.train_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ return args
+
+
+imagenet_templates_small = [
+ "a photo of a {}",
+ "a rendering of a {}",
+ "a cropped photo of the {}",
+ "the photo of a {}",
+ "a photo of a clean {}",
+ "a photo of a dirty {}",
+ "a dark photo of the {}",
+ "a photo of my {}",
+ "a photo of the cool {}",
+ "a close-up photo of a {}",
+ "a bright photo of the {}",
+ "a cropped photo of a {}",
+ "a photo of the {}",
+ "a good photo of the {}",
+ "a photo of one {}",
+ "a close-up photo of the {}",
+ "a rendition of the {}",
+ "a photo of the clean {}",
+ "a rendition of a {}",
+ "a photo of a nice {}",
+ "a good photo of a {}",
+ "a photo of the nice {}",
+ "a photo of the small {}",
+ "a photo of the weird {}",
+ "a photo of the large {}",
+ "a photo of a cool {}",
+ "a photo of a small {}",
+]
+
+imagenet_style_templates_small = [
+ "a painting in the style of {}",
+ "a rendering in the style of {}",
+ "a cropped painting in the style of {}",
+ "the painting in the style of {}",
+ "a clean painting in the style of {}",
+ "a dirty painting in the style of {}",
+ "a dark painting in the style of {}",
+ "a picture in the style of {}",
+ "a cool painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a bright painting in the style of {}",
+ "a cropped painting in the style of {}",
+ "a good painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a rendition in the style of {}",
+ "a nice painting in the style of {}",
+ "a small painting in the style of {}",
+ "a weird painting in the style of {}",
+ "a large painting in the style of {}",
+]
+
+
+class TextualInversionDataset(Dataset):
+ def __init__(
+ self,
+ data_root,
+ tokenizer,
+ learnable_property="object", # [object, style]
+ size=512,
+ repeats=100,
+ interpolation="bicubic",
+ flip_p=0.5,
+ set="train",
+ placeholder_token="*",
+ center_crop=False,
+ ):
+ self.data_root = data_root
+ self.tokenizer = tokenizer
+ self.learnable_property = learnable_property
+ self.size = size
+ self.placeholder_token = placeholder_token
+ self.center_crop = center_crop
+ self.flip_p = flip_p
+
+ self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
+
+ self.num_images = len(self.image_paths)
+ self._length = self.num_images
+
+ if set == "train":
+ self._length = self.num_images * repeats
+
+ self.interpolation = {
+ "linear": PIL_INTERPOLATION["linear"],
+ "bilinear": PIL_INTERPOLATION["bilinear"],
+ "bicubic": PIL_INTERPOLATION["bicubic"],
+ "lanczos": PIL_INTERPOLATION["lanczos"],
+ }[interpolation]
+
+ self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
+ self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, i):
+ example = {}
+ image = Image.open(self.image_paths[i % self.num_images])
+
+ if not image.mode == "RGB":
+ image = image.convert("RGB")
+
+ placeholder_string = self.placeholder_token
+ text = random.choice(self.templates).format(placeholder_string)
+
+ example["input_ids"] = self.tokenizer(
+ text,
+ padding="max_length",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ ).input_ids[0]
+
+ # default to score-sde preprocessing
+ img = np.array(image).astype(np.uint8)
+
+ if self.center_crop:
+ crop = min(img.shape[0], img.shape[1])
+ (
+ h,
+ w,
+ ) = (
+ img.shape[0],
+ img.shape[1],
+ )
+ img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
+
+ image = Image.fromarray(img)
+ image = image.resize((self.size, self.size), resample=self.interpolation)
+
+ image = self.flip_transform(image)
+ image = np.array(image).astype(np.uint8)
+ image = (image / 127.5 - 1.0).astype(np.float32)
+
+ example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
+ return example
+
+
+def main():
+ args = parse_args()
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+
+ if args.report_to == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Load tokenizer
+ if args.tokenizer_name:
+ tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Load scheduler and models
+ noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
+ text_encoder = CLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+
+ # Add the placeholder token in tokenizer
+ num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
+ if num_added_tokens == 0:
+ raise ValueError(
+ f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
+ " `placeholder_token` that is not already in the tokenizer."
+ )
+
+ # Convert the initializer_token, placeholder_token to ids
+ token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
+ # Check if initializer_token is a single token or a sequence of tokens
+ if len(token_ids) > 1:
+ raise ValueError("The initializer token must be a single token.")
+
+ initializer_token_id = token_ids[0]
+ placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
+
+ # Resize the token embeddings as we are adding new special tokens to the tokenizer
+ text_encoder.resize_token_embeddings(len(tokenizer))
+
+ # Initialise the newly added placeholder token with the embeddings of the initializer token
+ token_embeds = text_encoder.get_input_embeddings().weight.data
+ token_embeds[placeholder_token_id] = token_embeds[initializer_token_id]
+
+ # Freeze vae and unet
+ vae.requires_grad_(False)
+ unet.requires_grad_(False)
+ # Freeze all parameters except for the token embeddings in text encoder
+ text_encoder.text_model.encoder.requires_grad_(False)
+ text_encoder.text_model.final_layer_norm.requires_grad_(False)
+ text_encoder.text_model.embeddings.position_embedding.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ # Keep unet in train mode if we are using gradient checkpointing to save memory.
+ # The dropout cannot be != 0 so it doesn't matter if we are in eval or train mode.
+ unet.train()
+ text_encoder.gradient_checkpointing_enable()
+ unet.enable_gradient_checkpointing()
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # Enable TF32 for faster training on Ampere GPUs,
+ # cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Initialize the optimizer
+ optimizer = torch.optim.AdamW(
+ text_encoder.get_input_embeddings().parameters(), # only optimize the embeddings
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Dataset and DataLoaders creation:
+ train_dataset = TextualInversionDataset(
+ data_root=args.train_data_dir,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ placeholder_token=args.placeholder_token,
+ repeats=args.repeats,
+ learnable_property=args.learnable_property,
+ center_crop=args.center_crop,
+ set="train",
+ )
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
+ )
+ if args.validation_epochs is not None:
+ warnings.warn(
+ f"FutureWarning: You are doing logging with validation_epochs={args.validation_epochs}."
+ " Deprecated validation_epochs in favor of `validation_steps`"
+ f"Setting `args.validation_steps` to {args.validation_epochs * len(train_dataset)}",
+ FutureWarning,
+ stacklevel=2,
+ )
+ args.validation_steps = args.validation_epochs * len(train_dataset)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+
+ # For mixed precision training we cast the unet and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move vae and unet to device and cast to weight_dtype
+ unet.to(accelerator.device, dtype=weight_dtype)
+ vae.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("textual_inversion", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ global_step = 0
+ first_epoch = 0
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+
+ # keep original embeddings as reference
+ orig_embeds_params = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight.data.clone()
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ text_encoder.train()
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ with accelerator.accumulate(text_encoder):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample().detach()
+ latents = latents * vae.config.scaling_factor
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0].to(dtype=weight_dtype)
+
+ # Predict the noise residual
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Let's make sure we don't update any embedding weights besides the newly added token
+ index_no_updates = torch.arange(len(tokenizer)) != placeholder_token_id
+ with torch.no_grad():
+ accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[
+ index_no_updates
+ ] = orig_embeds_params[index_no_updates]
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+ if global_step % args.save_steps == 0:
+ save_path = os.path.join(args.output_dir, f"learned_embeds-steps-{global_step}.bin")
+ save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
+
+ if accelerator.is_main_process:
+ if global_step % args.checkpointing_steps == 0:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ if args.validation_prompt is not None and global_step % args.validation_steps == 0:
+ log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch)
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+ # Create the pipeline using using the trained modules and save it.
+ accelerator.wait_for_everyone()
+ if accelerator.is_main_process:
+ if args.push_to_hub and args.only_save_embeds:
+ logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
+ save_full_model = True
+ else:
+ save_full_model = not args.only_save_embeds
+ if save_full_model:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ vae=vae,
+ unet=unet,
+ tokenizer=tokenizer,
+ )
+ pipeline.save_pretrained(args.output_dir)
+ # Save the newly trained embeddings
+ save_path = os.path.join(args.output_dir, "learned_embeds.bin")
+ save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/textual_inversion/textual_inversion_flax.py b/diffusers/examples/textual_inversion/textual_inversion_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..988b67866fe9667d47c66a13eb402af5d9986a14
--- /dev/null
+++ b/diffusers/examples/textual_inversion/textual_inversion_flax.py
@@ -0,0 +1,681 @@
+import argparse
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+import PIL
+import torch
+import torch.utils.checkpoint
+import transformers
+from flax import jax_utils
+from flax.training import train_state
+from flax.training.common_utils import shard
+from huggingface_hub import create_repo, upload_folder
+
+# TODO: remove and import from diffusers.utils when the new version of diffusers is released
+from packaging import version
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel, set_seed
+
+from diffusers import (
+ FlaxAutoencoderKL,
+ FlaxDDPMScheduler,
+ FlaxPNDMScheduler,
+ FlaxStableDiffusionPipeline,
+ FlaxUNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion import FlaxStableDiffusionSafetyChecker
+from diffusers.utils import check_min_version
+
+
+if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.Resampling.BILINEAR,
+ "bilinear": PIL.Image.Resampling.BILINEAR,
+ "bicubic": PIL.Image.Resampling.BICUBIC,
+ "lanczos": PIL.Image.Resampling.LANCZOS,
+ "nearest": PIL.Image.Resampling.NEAREST,
+ }
+else:
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.LINEAR,
+ "bilinear": PIL.Image.BILINEAR,
+ "bicubic": PIL.Image.BICUBIC,
+ "lanczos": PIL.Image.LANCZOS,
+ "nearest": PIL.Image.NEAREST,
+ }
+# ------------------------------------------------------------------------------
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.15.0.dev0")
+
+logger = logging.getLogger(__name__)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--train_data_dir", type=str, default=None, required=True, help="A folder containing the training data."
+ )
+ parser.add_argument(
+ "--placeholder_token",
+ type=str,
+ default=None,
+ required=True,
+ help="A token to use as a placeholder for the concept.",
+ )
+ parser.add_argument(
+ "--initializer_token", type=str, default=None, required=True, help="A token to use as initializer word."
+ )
+ parser.add_argument("--learnable_property", type=str, default="object", help="Choose between 'object' and 'style'")
+ parser.add_argument("--repeats", type=int, default=100, help="How many times to repeat the training data.")
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="text-inversion-model",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=42, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution."
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=100)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=5000,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--save_steps",
+ type=int,
+ default=500,
+ help="Save learned_embeds.bin every X updates steps.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=True,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--revision",
+ type=str,
+ default=None,
+ required=False,
+ help="Revision of pretrained model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--use_auth_token",
+ action="store_true",
+ help=(
+ "Will use the token generated when running `huggingface-cli login` (necessary to use this script with"
+ " private models)."
+ ),
+ )
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.train_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ return args
+
+
+imagenet_templates_small = [
+ "a photo of a {}",
+ "a rendering of a {}",
+ "a cropped photo of the {}",
+ "the photo of a {}",
+ "a photo of a clean {}",
+ "a photo of a dirty {}",
+ "a dark photo of the {}",
+ "a photo of my {}",
+ "a photo of the cool {}",
+ "a close-up photo of a {}",
+ "a bright photo of the {}",
+ "a cropped photo of a {}",
+ "a photo of the {}",
+ "a good photo of the {}",
+ "a photo of one {}",
+ "a close-up photo of the {}",
+ "a rendition of the {}",
+ "a photo of the clean {}",
+ "a rendition of a {}",
+ "a photo of a nice {}",
+ "a good photo of a {}",
+ "a photo of the nice {}",
+ "a photo of the small {}",
+ "a photo of the weird {}",
+ "a photo of the large {}",
+ "a photo of a cool {}",
+ "a photo of a small {}",
+]
+
+imagenet_style_templates_small = [
+ "a painting in the style of {}",
+ "a rendering in the style of {}",
+ "a cropped painting in the style of {}",
+ "the painting in the style of {}",
+ "a clean painting in the style of {}",
+ "a dirty painting in the style of {}",
+ "a dark painting in the style of {}",
+ "a picture in the style of {}",
+ "a cool painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a bright painting in the style of {}",
+ "a cropped painting in the style of {}",
+ "a good painting in the style of {}",
+ "a close-up painting in the style of {}",
+ "a rendition in the style of {}",
+ "a nice painting in the style of {}",
+ "a small painting in the style of {}",
+ "a weird painting in the style of {}",
+ "a large painting in the style of {}",
+]
+
+
+class TextualInversionDataset(Dataset):
+ def __init__(
+ self,
+ data_root,
+ tokenizer,
+ learnable_property="object", # [object, style]
+ size=512,
+ repeats=100,
+ interpolation="bicubic",
+ flip_p=0.5,
+ set="train",
+ placeholder_token="*",
+ center_crop=False,
+ ):
+ self.data_root = data_root
+ self.tokenizer = tokenizer
+ self.learnable_property = learnable_property
+ self.size = size
+ self.placeholder_token = placeholder_token
+ self.center_crop = center_crop
+ self.flip_p = flip_p
+
+ self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
+
+ self.num_images = len(self.image_paths)
+ self._length = self.num_images
+
+ if set == "train":
+ self._length = self.num_images * repeats
+
+ self.interpolation = {
+ "linear": PIL_INTERPOLATION["linear"],
+ "bilinear": PIL_INTERPOLATION["bilinear"],
+ "bicubic": PIL_INTERPOLATION["bicubic"],
+ "lanczos": PIL_INTERPOLATION["lanczos"],
+ }[interpolation]
+
+ self.templates = imagenet_style_templates_small if learnable_property == "style" else imagenet_templates_small
+ self.flip_transform = transforms.RandomHorizontalFlip(p=self.flip_p)
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, i):
+ example = {}
+ image = Image.open(self.image_paths[i % self.num_images])
+
+ if not image.mode == "RGB":
+ image = image.convert("RGB")
+
+ placeholder_string = self.placeholder_token
+ text = random.choice(self.templates).format(placeholder_string)
+
+ example["input_ids"] = self.tokenizer(
+ text,
+ padding="max_length",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ ).input_ids[0]
+
+ # default to score-sde preprocessing
+ img = np.array(image).astype(np.uint8)
+
+ if self.center_crop:
+ crop = min(img.shape[0], img.shape[1])
+ (
+ h,
+ w,
+ ) = (
+ img.shape[0],
+ img.shape[1],
+ )
+ img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
+
+ image = Image.fromarray(img)
+ image = image.resize((self.size, self.size), resample=self.interpolation)
+
+ image = self.flip_transform(image)
+ image = np.array(image).astype(np.uint8)
+ image = (image / 127.5 - 1.0).astype(np.float32)
+
+ example["pixel_values"] = torch.from_numpy(image).permute(2, 0, 1)
+ return example
+
+
+def resize_token_embeddings(model, new_num_tokens, initializer_token_id, placeholder_token_id, rng):
+ if model.config.vocab_size == new_num_tokens or new_num_tokens is None:
+ return
+ model.config.vocab_size = new_num_tokens
+
+ params = model.params
+ old_embeddings = params["text_model"]["embeddings"]["token_embedding"]["embedding"]
+ old_num_tokens, emb_dim = old_embeddings.shape
+
+ initializer = jax.nn.initializers.normal()
+
+ new_embeddings = initializer(rng, (new_num_tokens, emb_dim))
+ new_embeddings = new_embeddings.at[:old_num_tokens].set(old_embeddings)
+ new_embeddings = new_embeddings.at[placeholder_token_id].set(new_embeddings[initializer_token_id])
+ params["text_model"]["embeddings"]["token_embedding"]["embedding"] = new_embeddings
+
+ model.params = params
+ return model
+
+
+def get_params_to_save(params):
+ return jax.device_get(jax.tree_util.tree_map(lambda x: x[0], params))
+
+
+def main():
+ args = parse_args()
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ if jax.process_index() == 0:
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ if args.push_to_hub:
+ repo_id = create_repo(
+ repo_id=args.hub_model_id or Path(args.output_dir).name, exist_ok=True, token=args.hub_token
+ ).repo_id
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+
+ # Load the tokenizer and add the placeholder token as a additional special token
+ if args.tokenizer_name:
+ tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Add the placeholder token in tokenizer
+ num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
+ if num_added_tokens == 0:
+ raise ValueError(
+ f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
+ " `placeholder_token` that is not already in the tokenizer."
+ )
+
+ # Convert the initializer_token, placeholder_token to ids
+ token_ids = tokenizer.encode(args.initializer_token, add_special_tokens=False)
+ # Check if initializer_token is a single token or a sequence of tokens
+ if len(token_ids) > 1:
+ raise ValueError("The initializer token must be a single token.")
+
+ initializer_token_id = token_ids[0]
+ placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
+
+ # Load models and create wrapper for stable diffusion
+ text_encoder = FlaxCLIPTextModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
+ )
+ vae, vae_params = FlaxAutoencoderKL.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision
+ )
+ unet, unet_params = FlaxUNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
+ )
+
+ # Create sampling rng
+ rng = jax.random.PRNGKey(args.seed)
+ rng, _ = jax.random.split(rng)
+ # Resize the token embeddings as we are adding new special tokens to the tokenizer
+ text_encoder = resize_token_embeddings(
+ text_encoder, len(tokenizer), initializer_token_id, placeholder_token_id, rng
+ )
+ original_token_embeds = text_encoder.params["text_model"]["embeddings"]["token_embedding"]["embedding"]
+
+ train_dataset = TextualInversionDataset(
+ data_root=args.train_data_dir,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ placeholder_token=args.placeholder_token,
+ repeats=args.repeats,
+ learnable_property=args.learnable_property,
+ center_crop=args.center_crop,
+ set="train",
+ )
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ input_ids = torch.stack([example["input_ids"] for example in examples])
+
+ batch = {"pixel_values": pixel_values, "input_ids": input_ids}
+ batch = {k: v.numpy() for k, v in batch.items()}
+
+ return batch
+
+ total_train_batch_size = args.train_batch_size * jax.local_device_count()
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=total_train_batch_size, shuffle=True, drop_last=True, collate_fn=collate_fn
+ )
+
+ # Optimization
+ if args.scale_lr:
+ args.learning_rate = args.learning_rate * total_train_batch_size
+
+ constant_scheduler = optax.constant_schedule(args.learning_rate)
+
+ optimizer = optax.adamw(
+ learning_rate=constant_scheduler,
+ b1=args.adam_beta1,
+ b2=args.adam_beta2,
+ eps=args.adam_epsilon,
+ weight_decay=args.adam_weight_decay,
+ )
+
+ def create_mask(params, label_fn):
+ def _map(params, mask, label_fn):
+ for k in params:
+ if label_fn(k):
+ mask[k] = "token_embedding"
+ else:
+ if isinstance(params[k], dict):
+ mask[k] = {}
+ _map(params[k], mask[k], label_fn)
+ else:
+ mask[k] = "zero"
+
+ mask = {}
+ _map(params, mask, label_fn)
+ return mask
+
+ def zero_grads():
+ # from https://github.com/deepmind/optax/issues/159#issuecomment-896459491
+ def init_fn(_):
+ return ()
+
+ def update_fn(updates, state, params=None):
+ return jax.tree_util.tree_map(jnp.zeros_like, updates), ()
+
+ return optax.GradientTransformation(init_fn, update_fn)
+
+ # Zero out gradients of layers other than the token embedding layer
+ tx = optax.multi_transform(
+ {"token_embedding": optimizer, "zero": zero_grads()},
+ create_mask(text_encoder.params, lambda s: s == "token_embedding"),
+ )
+
+ state = train_state.TrainState.create(apply_fn=text_encoder.__call__, params=text_encoder.params, tx=tx)
+
+ noise_scheduler = FlaxDDPMScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000
+ )
+ noise_scheduler_state = noise_scheduler.create_state()
+
+ # Initialize our training
+ train_rngs = jax.random.split(rng, jax.local_device_count())
+
+ # Define gradient train step fn
+ def train_step(state, vae_params, unet_params, batch, train_rng):
+ dropout_rng, sample_rng, new_train_rng = jax.random.split(train_rng, 3)
+
+ def compute_loss(params):
+ vae_outputs = vae.apply(
+ {"params": vae_params}, batch["pixel_values"], deterministic=True, method=vae.encode
+ )
+ latents = vae_outputs.latent_dist.sample(sample_rng)
+ # (NHWC) -> (NCHW)
+ latents = jnp.transpose(latents, (0, 3, 1, 2))
+ latents = latents * vae.config.scaling_factor
+
+ noise_rng, timestep_rng = jax.random.split(sample_rng)
+ noise = jax.random.normal(noise_rng, latents.shape)
+ bsz = latents.shape[0]
+ timesteps = jax.random.randint(
+ timestep_rng,
+ (bsz,),
+ 0,
+ noise_scheduler.config.num_train_timesteps,
+ )
+ noisy_latents = noise_scheduler.add_noise(noise_scheduler_state, latents, noise, timesteps)
+ encoder_hidden_states = state.apply_fn(
+ batch["input_ids"], params=params, dropout_rng=dropout_rng, train=True
+ )[0]
+ # Predict the noise residual and compute loss
+ model_pred = unet.apply(
+ {"params": unet_params}, noisy_latents, timesteps, encoder_hidden_states, train=False
+ ).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(noise_scheduler_state, latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ loss = (target - model_pred) ** 2
+ loss = loss.mean()
+
+ return loss
+
+ grad_fn = jax.value_and_grad(compute_loss)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+ new_state = state.apply_gradients(grads=grad)
+
+ # Keep the token embeddings fixed except the newly added embeddings for the concept,
+ # as we only want to optimize the concept embeddings
+ token_embeds = original_token_embeds.at[placeholder_token_id].set(
+ new_state.params["text_model"]["embeddings"]["token_embedding"]["embedding"][placeholder_token_id]
+ )
+ new_state.params["text_model"]["embeddings"]["token_embedding"]["embedding"] = token_embeds
+
+ metrics = {"loss": loss}
+ metrics = jax.lax.pmean(metrics, axis_name="batch")
+ return new_state, metrics, new_train_rng
+
+ # Create parallel version of the train and eval step
+ p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
+
+ # Replicate the train state on each device
+ state = jax_utils.replicate(state)
+ vae_params = jax_utils.replicate(vae_params)
+ unet_params = jax_utils.replicate(unet_params)
+
+ # Train!
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader))
+
+ # Scheduler and math around the number of training steps.
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel & distributed) = {total_train_batch_size}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ global_step = 0
+
+ epochs = tqdm(range(args.num_train_epochs), desc=f"Epoch ... (1/{args.num_train_epochs})", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+
+ train_metrics = []
+
+ steps_per_epoch = len(train_dataset) // total_train_batch_size
+ train_step_progress_bar = tqdm(total=steps_per_epoch, desc="Training...", position=1, leave=False)
+ # train
+ for batch in train_dataloader:
+ batch = shard(batch)
+ state, train_metric, train_rngs = p_train_step(state, vae_params, unet_params, batch, train_rngs)
+ train_metrics.append(train_metric)
+
+ train_step_progress_bar.update(1)
+ global_step += 1
+
+ if global_step >= args.max_train_steps:
+ break
+ if global_step % args.save_steps == 0:
+ learned_embeds = get_params_to_save(state.params)["text_model"]["embeddings"]["token_embedding"][
+ "embedding"
+ ][placeholder_token_id]
+ learned_embeds_dict = {args.placeholder_token: learned_embeds}
+ jnp.save(
+ os.path.join(args.output_dir, "learned_embeds-" + str(global_step) + ".npy"), learned_embeds_dict
+ )
+
+ train_metric = jax_utils.unreplicate(train_metric)
+
+ train_step_progress_bar.close()
+ epochs.write(f"Epoch... ({epoch + 1}/{args.num_train_epochs} | Loss: {train_metric['loss']})")
+
+ # Create the pipeline using using the trained modules and save it.
+ if jax.process_index() == 0:
+ scheduler = FlaxPNDMScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", skip_prk_steps=True
+ )
+ safety_checker = FlaxStableDiffusionSafetyChecker.from_pretrained(
+ "CompVis/stable-diffusion-safety-checker", from_pt=True
+ )
+ pipeline = FlaxStableDiffusionPipeline(
+ text_encoder=text_encoder,
+ vae=vae,
+ unet=unet,
+ tokenizer=tokenizer,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch32"),
+ )
+
+ pipeline.save_pretrained(
+ args.output_dir,
+ params={
+ "text_encoder": get_params_to_save(state.params),
+ "vae": get_params_to_save(vae_params),
+ "unet": get_params_to_save(unet_params),
+ "safety_checker": safety_checker.params,
+ },
+ )
+
+ # Also save the newly trained embeddings
+ learned_embeds = get_params_to_save(state.params)["text_model"]["embeddings"]["token_embedding"]["embedding"][
+ placeholder_token_id
+ ]
+ learned_embeds_dict = {args.placeholder_token: learned_embeds}
+ jnp.save(os.path.join(args.output_dir, "learned_embeds.npy"), learned_embeds_dict)
+
+ if args.push_to_hub:
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=args.output_dir,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/examples/unconditional_image_generation/README.md b/diffusers/examples/unconditional_image_generation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..db06d901168104c47d86415f42a24f3e738362e9
--- /dev/null
+++ b/diffusers/examples/unconditional_image_generation/README.md
@@ -0,0 +1,142 @@
+## Training examples
+
+Creating a training image set is [described in a different document](https://huggingface.co/docs/datasets/image_process#image-datasets).
+
+### Installing the dependencies
+
+Before running the scripts, make sure to install the library's training dependencies:
+
+**Important**
+
+To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
+```bash
+git clone https://github.com/huggingface/diffusers
+cd diffusers
+pip install .
+```
+
+Then cd in the example folder and run
+```bash
+pip install -r requirements.txt
+```
+
+
+And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
+
+```bash
+accelerate config
+```
+
+### Unconditional Flowers
+
+The command to train a DDPM UNet model on the Oxford Flowers dataset:
+
+```bash
+accelerate launch train_unconditional.py \
+ --dataset_name="huggan/flowers-102-categories" \
+ --resolution=64 --center_crop --random_flip \
+ --output_dir="ddpm-ema-flowers-64" \
+ --train_batch_size=16 \
+ --num_epochs=100 \
+ --gradient_accumulation_steps=1 \
+ --use_ema \
+ --learning_rate=1e-4 \
+ --lr_warmup_steps=500 \
+ --mixed_precision=no \
+ --push_to_hub
+```
+An example trained model: https://huggingface.co/anton-l/ddpm-ema-flowers-64
+
+A full training run takes 2 hours on 4xV100 GPUs.
+
+
+
+
+### Unconditional Pokemon
+
+The command to train a DDPM UNet model on the Pokemon dataset:
+
+```bash
+accelerate launch train_unconditional.py \
+ --dataset_name="huggan/pokemon" \
+ --resolution=64 --center_crop --random_flip \
+ --output_dir="ddpm-ema-pokemon-64" \
+ --train_batch_size=16 \
+ --num_epochs=100 \
+ --gradient_accumulation_steps=1 \
+ --use_ema \
+ --learning_rate=1e-4 \
+ --lr_warmup_steps=500 \
+ --mixed_precision=no \
+ --push_to_hub
+```
+An example trained model: https://huggingface.co/anton-l/ddpm-ema-pokemon-64
+
+A full training run takes 2 hours on 4xV100 GPUs.
+
+
+
+
+### Using your own data
+
+To use your own dataset, there are 2 ways:
+- you can either provide your own folder as `--train_data_dir`
+- or you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
+
+Below, we explain both in more detail.
+
+#### Provide the dataset as a folder
+
+If you provide your own folders with images, the script expects the following directory structure:
+
+```bash
+data_dir/xxx.png
+data_dir/xxy.png
+data_dir/[...]/xxz.png
+```
+
+In other words, the script will take care of gathering all images inside the folder. You can then run the script like this:
+
+```bash
+accelerate launch train_unconditional.py \
+ --train_data_dir \
+
+```
+
+Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
+
+#### Upload your data to the hub, as a (possibly private) repo
+
+It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
+
+```python
+from datasets import load_dataset
+
+# example 1: local folder
+dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
+
+# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
+dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
+
+# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
+dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
+
+# example 4: providing several splits
+dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
+```
+
+`ImageFolder` will create an `image` column containing the PIL-encoded images.
+
+Next, push it to the hub!
+
+```python
+# assuming you have ran the huggingface-cli login command in a terminal
+dataset.push_to_hub("name_of_your_dataset")
+
+# if you want to push to a private repo, simply pass private=True:
+dataset.push_to_hub("name_of_your_dataset", private=True)
+```
+
+and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub.
+
+More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
diff --git a/diffusers/examples/unconditional_image_generation/requirements.txt b/diffusers/examples/unconditional_image_generation/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bbc6905560209d6b9c957d8c6bb61cde4462365b
--- /dev/null
+++ b/diffusers/examples/unconditional_image_generation/requirements.txt
@@ -0,0 +1,3 @@
+accelerate
+torchvision
+datasets
diff --git a/diffusers/examples/unconditional_image_generation/train_unconditional.py b/diffusers/examples/unconditional_image_generation/train_unconditional.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b784eda6a34b20644fed253f9e64df01b26893e
--- /dev/null
+++ b/diffusers/examples/unconditional_image_generation/train_unconditional.py
@@ -0,0 +1,692 @@
+import argparse
+import inspect
+import logging
+import math
+import os
+from pathlib import Path
+from typing import Optional
+
+import accelerate
+import datasets
+import torch
+import torch.nn.functional as F
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import ProjectConfiguration
+from datasets import load_dataset
+from huggingface_hub import HfFolder, Repository, create_repo, whoami
+from packaging import version
+from torchvision import transforms
+from tqdm.auto import tqdm
+
+import diffusers
+from diffusers import DDPMPipeline, DDPMScheduler, UNet2DModel
+from diffusers.optimization import get_scheduler
+from diffusers.training_utils import EMAModel
+from diffusers.utils import check_min_version, is_accelerate_version, is_tensorboard_available, is_wandb_available
+from diffusers.utils.import_utils import is_xformers_available
+
+
+# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
+check_min_version("0.15.0.dev0")
+
+logger = get_logger(__name__, log_level="INFO")
+
+
+def _extract_into_tensor(arr, timesteps, broadcast_shape):
+ """
+ Extract values from a 1-D numpy array for a batch of indices.
+
+ :param arr: the 1-D numpy array.
+ :param timesteps: a tensor of indices into the array to extract.
+ :param broadcast_shape: a larger shape of K dimensions with the batch
+ dimension equal to the length of timesteps.
+ :return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
+ """
+ if not isinstance(arr, torch.Tensor):
+ arr = torch.from_numpy(arr)
+ res = arr[timesteps].float().to(timesteps.device)
+ while len(res.shape) < len(broadcast_shape):
+ res = res[..., None]
+ return res.expand(broadcast_shape)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
+ " or to a folder containing files that HF Datasets can understand."
+ ),
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The config of the Dataset, leave as None if there's only one config.",
+ )
+ parser.add_argument(
+ "--model_config_name_or_path",
+ type=str,
+ default=None,
+ help="The config of the UNet model to train, leave as None to use standard DDPM configuration.",
+ )
+ parser.add_argument(
+ "--train_data_dir",
+ type=str,
+ default=None,
+ help=(
+ "A folder containing the training data. Folder contents must follow the structure described in"
+ " https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
+ " must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="ddpm-model-64",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--overwrite_output_dir", action="store_true")
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="The directory where the downloaded models and datasets will be stored.",
+ )
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=64,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop",
+ default=False,
+ action="store_true",
+ help=(
+ "Whether to center crop the input images to the resolution. If not set, the images will be randomly"
+ " cropped. The images will be resized to the resolution first before cropping."
+ ),
+ )
+ parser.add_argument(
+ "--random_flip",
+ default=False,
+ action="store_true",
+ help="whether to randomly flip images horizontally",
+ )
+ parser.add_argument(
+ "--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument(
+ "--eval_batch_size", type=int, default=16, help="The number of images to generate for evaluation."
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=0,
+ help=(
+ "The number of subprocesses to use for data loading. 0 means that the data will be loaded in the main"
+ " process."
+ ),
+ )
+ parser.add_argument("--num_epochs", type=int, default=100)
+ parser.add_argument("--save_images_epochs", type=int, default=10, help="How often to save images during training.")
+ parser.add_argument(
+ "--save_model_epochs", type=int, default=10, help="How often to save the model during training."
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="cosine",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.95, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument(
+ "--adam_weight_decay", type=float, default=1e-6, help="Weight decay magnitude for the Adam optimizer."
+ )
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer.")
+ parser.add_argument(
+ "--use_ema",
+ action="store_true",
+ help="Whether to use Exponential Moving Average for the final model weights.",
+ )
+ parser.add_argument("--ema_inv_gamma", type=float, default=1.0, help="The inverse gamma value for the EMA decay.")
+ parser.add_argument("--ema_power", type=float, default=3 / 4, help="The power value for the EMA decay.")
+ parser.add_argument("--ema_max_decay", type=float, default=0.9999, help="The maximum decay magnitude for EMA.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--hub_private_repo", action="store_true", help="Whether or not to create a private repository."
+ )
+ parser.add_argument(
+ "--logger",
+ type=str,
+ default="tensorboard",
+ choices=["tensorboard", "wandb"],
+ help=(
+ "Whether to use [tensorboard](https://www.tensorflow.org/tensorboard) or [wandb](https://www.wandb.ai)"
+ " for experiment tracking and logging of model metrics and model checkpoints"
+ ),
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+ parser.add_argument(
+ "--prediction_type",
+ type=str,
+ default="epsilon",
+ choices=["epsilon", "sample"],
+ help="Whether the model should predict the 'epsilon'/noise error or directly the reconstructed image 'x0'.",
+ )
+ parser.add_argument("--ddpm_num_steps", type=int, default=1000)
+ parser.add_argument("--ddpm_num_inference_steps", type=int, default=1000)
+ parser.add_argument("--ddpm_beta_schedule", type=str, default="linear")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=int,
+ default=500,
+ help=(
+ "Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
+ " training using `--resume_from_checkpoint`."
+ ),
+ )
+ parser.add_argument(
+ "--checkpoints_total_limit",
+ type=int,
+ default=None,
+ help=(
+ "Max number of checkpoints to store. Passed as `total_limit` to the `Accelerator` `ProjectConfiguration`."
+ " See Accelerator::save_state https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.save_state"
+ " for more docs"
+ ),
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help=(
+ "Whether training should be resumed from a previous checkpoint. Use a path saved by"
+ ' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
+ ),
+ )
+ parser.add_argument(
+ "--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
+ )
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.dataset_name is None and args.train_data_dir is None:
+ raise ValueError("You must specify either a dataset name from the hub or a train data directory.")
+
+ return args
+
+
+def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
+ if token is None:
+ token = HfFolder.get_token()
+ if organization is None:
+ username = whoami(token)["name"]
+ return f"{username}/{model_id}"
+ else:
+ return f"{organization}/{model_id}"
+
+
+def main(args):
+ logging_dir = os.path.join(args.output_dir, args.logging_dir)
+
+ accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.logger,
+ logging_dir=logging_dir,
+ project_config=accelerator_project_config,
+ )
+
+ if args.logger == "tensorboard":
+ if not is_tensorboard_available():
+ raise ImportError("Make sure to install tensorboard if you want to use it for logging during training.")
+
+ elif args.logger == "wandb":
+ if not is_wandb_available():
+ raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
+ import wandb
+
+ # `accelerate` 0.16.0 will have better support for customized saving
+ if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
+ # create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
+ def save_model_hook(models, weights, output_dir):
+ if args.use_ema:
+ ema_model.save_pretrained(os.path.join(output_dir, "unet_ema"))
+
+ for i, model in enumerate(models):
+ model.save_pretrained(os.path.join(output_dir, "unet"))
+
+ # make sure to pop weight so that corresponding model is not saved again
+ weights.pop()
+
+ def load_model_hook(models, input_dir):
+ if args.use_ema:
+ load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DModel)
+ ema_model.load_state_dict(load_model.state_dict())
+ ema_model.to(accelerator.device)
+ del load_model
+
+ for i in range(len(models)):
+ # pop models so that they are not loaded again
+ model = models.pop()
+
+ # load diffusers style into model
+ load_model = UNet2DModel.from_pretrained(input_dir, subfolder="unet")
+ model.register_to_config(**load_model.config)
+
+ model.load_state_dict(load_model.state_dict())
+ del load_model
+
+ accelerator.register_save_state_pre_hook(save_model_hook)
+ accelerator.register_load_state_pre_hook(load_model_hook)
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ if args.hub_model_id is None:
+ repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
+ else:
+ repo_name = args.hub_model_id
+ create_repo(repo_name, exist_ok=True, token=args.hub_token)
+ repo = Repository(args.output_dir, clone_from=repo_name, token=args.hub_token)
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ # Initialize the model
+ if args.model_config_name_or_path is None:
+ model = UNet2DModel(
+ sample_size=args.resolution,
+ in_channels=3,
+ out_channels=3,
+ layers_per_block=2,
+ block_out_channels=(128, 128, 256, 256, 512, 512),
+ down_block_types=(
+ "DownBlock2D",
+ "DownBlock2D",
+ "DownBlock2D",
+ "DownBlock2D",
+ "AttnDownBlock2D",
+ "DownBlock2D",
+ ),
+ up_block_types=(
+ "UpBlock2D",
+ "AttnUpBlock2D",
+ "UpBlock2D",
+ "UpBlock2D",
+ "UpBlock2D",
+ "UpBlock2D",
+ ),
+ )
+ else:
+ config = UNet2DModel.load_config(args.model_config_name_or_path)
+ model = UNet2DModel.from_config(config)
+
+ # Create EMA for the model.
+ if args.use_ema:
+ ema_model = EMAModel(
+ model.parameters(),
+ decay=args.ema_max_decay,
+ use_ema_warmup=True,
+ inv_gamma=args.ema_inv_gamma,
+ power=args.ema_power,
+ model_cls=UNet2DModel,
+ model_config=model.config,
+ )
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ model.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+ # Initialize the scheduler
+ accepts_prediction_type = "prediction_type" in set(inspect.signature(DDPMScheduler.__init__).parameters.keys())
+ if accepts_prediction_type:
+ noise_scheduler = DDPMScheduler(
+ num_train_timesteps=args.ddpm_num_steps,
+ beta_schedule=args.ddpm_beta_schedule,
+ prediction_type=args.prediction_type,
+ )
+ else:
+ noise_scheduler = DDPMScheduler(num_train_timesteps=args.ddpm_num_steps, beta_schedule=args.ddpm_beta_schedule)
+
+ # Initialize the optimizer
+ optimizer = torch.optim.AdamW(
+ model.parameters(),
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ dataset = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ cache_dir=args.cache_dir,
+ split="train",
+ )
+ else:
+ dataset = load_dataset("imagefolder", data_dir=args.train_data_dir, cache_dir=args.cache_dir, split="train")
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder
+
+ # Preprocessing the datasets and DataLoaders creation.
+ augmentations = transforms.Compose(
+ [
+ transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),
+ transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def transform_images(examples):
+ images = [augmentations(image.convert("RGB")) for image in examples["image"]]
+ return {"input": images}
+
+ logger.info(f"Dataset size: {len(dataset)}")
+
+ dataset.set_transform(transform_images)
+ train_dataloader = torch.utils.data.DataLoader(
+ dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
+ )
+
+ # Initialize the learning rate scheduler
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=(len(train_dataloader) * args.num_epochs),
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, lr_scheduler
+ )
+
+ if args.use_ema:
+ ema_model.to(accelerator.device)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ run = os.path.split(__file__)[-1].split(".")[0]
+ accelerator.init_trackers(run)
+
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ max_train_steps = args.num_epochs * num_update_steps_per_epoch
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(dataset)}")
+ logger.info(f" Num Epochs = {args.num_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {max_train_steps}")
+
+ global_step = 0
+ first_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint != "latest":
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = os.listdir(args.output_dir)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ accelerator.print(
+ f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ args.resume_from_checkpoint = None
+ else:
+ accelerator.print(f"Resuming from checkpoint {path}")
+ accelerator.load_state(os.path.join(args.output_dir, path))
+ global_step = int(path.split("-")[1])
+
+ resume_global_step = global_step * args.gradient_accumulation_steps
+ first_epoch = global_step // num_update_steps_per_epoch
+ resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
+
+ # Train!
+ for epoch in range(first_epoch, args.num_epochs):
+ model.train()
+ progress_bar = tqdm(total=num_update_steps_per_epoch, disable=not accelerator.is_local_main_process)
+ progress_bar.set_description(f"Epoch {epoch}")
+ for step, batch in enumerate(train_dataloader):
+ # Skip steps until we reach the resumed step
+ if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
+ if step % args.gradient_accumulation_steps == 0:
+ progress_bar.update(1)
+ continue
+
+ clean_images = batch["input"]
+ # Sample noise that we'll add to the images
+ noise = torch.randn(clean_images.shape).to(clean_images.device)
+ bsz = clean_images.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(
+ 0, noise_scheduler.config.num_train_timesteps, (bsz,), device=clean_images.device
+ ).long()
+
+ # Add noise to the clean images according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
+
+ with accelerator.accumulate(model):
+ # Predict the noise residual
+ model_output = model(noisy_images, timesteps).sample
+
+ if args.prediction_type == "epsilon":
+ loss = F.mse_loss(model_output, noise) # this could have different weights!
+ elif args.prediction_type == "sample":
+ alpha_t = _extract_into_tensor(
+ noise_scheduler.alphas_cumprod, timesteps, (clean_images.shape[0], 1, 1, 1)
+ )
+ snr_weights = alpha_t / (1 - alpha_t)
+ loss = snr_weights * F.mse_loss(
+ model_output, clean_images, reduction="none"
+ ) # use SNR weighting from distillation paper
+ loss = loss.mean()
+ else:
+ raise ValueError(f"Unsupported prediction type: {args.prediction_type}")
+
+ accelerator.backward(loss)
+
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(model.parameters(), 1.0)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ if args.use_ema:
+ ema_model.step(model.parameters())
+ progress_bar.update(1)
+ global_step += 1
+
+ if global_step % args.checkpointing_steps == 0:
+ if accelerator.is_main_process:
+ save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
+ if args.use_ema:
+ logs["ema_decay"] = ema_model.cur_decay_value
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+ progress_bar.close()
+
+ accelerator.wait_for_everyone()
+
+ # Generate sample images for visual inspection
+ if accelerator.is_main_process:
+ if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1:
+ unet = accelerator.unwrap_model(model)
+
+ if args.use_ema:
+ ema_model.store(unet.parameters())
+ ema_model.copy_to(unet.parameters())
+
+ pipeline = DDPMPipeline(
+ unet=unet,
+ scheduler=noise_scheduler,
+ )
+
+ generator = torch.Generator(device=pipeline.device).manual_seed(0)
+ # run pipeline in inference (sample random noise and denoise)
+ images = pipeline(
+ generator=generator,
+ batch_size=args.eval_batch_size,
+ num_inference_steps=args.ddpm_num_inference_steps,
+ output_type="numpy",
+ ).images
+
+ if args.use_ema:
+ ema_model.restore(unet.parameters())
+
+ # denormalize the images and save to tensorboard
+ images_processed = (images * 255).round().astype("uint8")
+
+ if args.logger == "tensorboard":
+ if is_accelerate_version(">=", "0.17.0.dev0"):
+ tracker = accelerator.get_tracker("tensorboard", unwrap=True)
+ else:
+ tracker = accelerator.get_tracker("tensorboard")
+ tracker.add_images("test_samples", images_processed.transpose(0, 3, 1, 2), epoch)
+ elif args.logger == "wandb":
+ # Upcoming `log_images` helper coming in https://github.com/huggingface/accelerate/pull/962/files
+ accelerator.get_tracker("wandb").log(
+ {"test_samples": [wandb.Image(img) for img in images_processed], "epoch": epoch},
+ step=global_step,
+ )
+
+ if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:
+ # save the model
+ unet = accelerator.unwrap_model(model)
+
+ if args.use_ema:
+ ema_model.store(unet.parameters())
+ ema_model.copy_to(unet.parameters())
+
+ pipeline = DDPMPipeline(
+ unet=unet,
+ scheduler=noise_scheduler,
+ )
+
+ pipeline.save_pretrained(args.output_dir)
+
+ if args.use_ema:
+ ema_model.restore(unet.parameters())
+
+ if args.push_to_hub:
+ repo.push_to_hub(commit_message=f"Epoch {epoch}", blocking=False)
+
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/diffusers/pyproject.toml b/diffusers/pyproject.toml
new file mode 100644
index 0000000000000000000000000000000000000000..a5fe70af9ca71bb76eeb79eddc6c7afb11037d17
--- /dev/null
+++ b/diffusers/pyproject.toml
@@ -0,0 +1,18 @@
+[tool.black]
+line-length = 119
+target-version = ['py37']
+
+[tool.ruff]
+# Never enforce `E501` (line length violations).
+ignore = ["C901", "E501", "E741", "W605"]
+select = ["C", "E", "F", "I", "W"]
+line-length = 119
+
+# Ignore import violations in all `__init__.py` files.
+[tool.ruff.per-file-ignores]
+"__init__.py" = ["E402", "F401", "F403", "F811"]
+"src/diffusers/utils/dummy_*.py" = ["F401"]
+
+[tool.ruff.isort]
+lines-after-imports = 2
+known-first-party = ["diffusers"]
diff --git a/diffusers/scripts/__init__.py b/diffusers/scripts/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/scripts/change_naming_configs_and_checkpoints.py b/diffusers/scripts/change_naming_configs_and_checkpoints.py
new file mode 100644
index 0000000000000000000000000000000000000000..01c4f88c2daf8b40f695bde7b07367e11ae4e3a2
--- /dev/null
+++ b/diffusers/scripts/change_naming_configs_and_checkpoints.py
@@ -0,0 +1,113 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the LDM checkpoints. """
+
+import argparse
+import json
+import os
+
+import torch
+from transformers.file_utils import has_file
+
+from diffusers import UNet2DConditionModel, UNet2DModel
+
+
+do_only_config = False
+do_only_weights = True
+do_only_renaming = False
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--repo_path",
+ default=None,
+ type=str,
+ required=True,
+ help="The config json file corresponding to the architecture.",
+ )
+
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+
+ args = parser.parse_args()
+
+ config_parameters_to_change = {
+ "image_size": "sample_size",
+ "num_res_blocks": "layers_per_block",
+ "block_channels": "block_out_channels",
+ "down_blocks": "down_block_types",
+ "up_blocks": "up_block_types",
+ "downscale_freq_shift": "freq_shift",
+ "resnet_num_groups": "norm_num_groups",
+ "resnet_act_fn": "act_fn",
+ "resnet_eps": "norm_eps",
+ "num_head_channels": "attention_head_dim",
+ }
+
+ key_parameters_to_change = {
+ "time_steps": "time_proj",
+ "mid": "mid_block",
+ "downsample_blocks": "down_blocks",
+ "upsample_blocks": "up_blocks",
+ }
+
+ subfolder = "" if has_file(args.repo_path, "config.json") else "unet"
+
+ with open(os.path.join(args.repo_path, subfolder, "config.json"), "r", encoding="utf-8") as reader:
+ text = reader.read()
+ config = json.loads(text)
+
+ if do_only_config:
+ for key in config_parameters_to_change.keys():
+ config.pop(key, None)
+
+ if has_file(args.repo_path, "config.json"):
+ model = UNet2DModel(**config)
+ else:
+ class_name = UNet2DConditionModel if "ldm-text2im-large-256" in args.repo_path else UNet2DModel
+ model = class_name(**config)
+
+ if do_only_config:
+ model.save_config(os.path.join(args.repo_path, subfolder))
+
+ config = dict(model.config)
+
+ if do_only_renaming:
+ for key, value in config_parameters_to_change.items():
+ if key in config:
+ config[value] = config[key]
+ del config[key]
+
+ config["down_block_types"] = [k.replace("UNetRes", "") for k in config["down_block_types"]]
+ config["up_block_types"] = [k.replace("UNetRes", "") for k in config["up_block_types"]]
+
+ if do_only_weights:
+ state_dict = torch.load(os.path.join(args.repo_path, subfolder, "diffusion_pytorch_model.bin"))
+
+ new_state_dict = {}
+ for param_key, param_value in state_dict.items():
+ if param_key.endswith(".op.bias") or param_key.endswith(".op.weight"):
+ continue
+ has_changed = False
+ for key, new_key in key_parameters_to_change.items():
+ if not has_changed and param_key.split(".")[0] == key:
+ new_state_dict[".".join([new_key] + param_key.split(".")[1:])] = param_value
+ has_changed = True
+ if not has_changed:
+ new_state_dict[param_key] = param_value
+
+ model.load_state_dict(new_state_dict)
+ model.save_pretrained(os.path.join(args.repo_path, subfolder))
diff --git a/diffusers/scripts/conversion_ldm_uncond.py b/diffusers/scripts/conversion_ldm_uncond.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2ebb3934b6696fd427c9bf09eb051cf7befe7f4
--- /dev/null
+++ b/diffusers/scripts/conversion_ldm_uncond.py
@@ -0,0 +1,56 @@
+import argparse
+
+import OmegaConf
+import torch
+
+from diffusers import DDIMScheduler, LDMPipeline, UNetLDMModel, VQModel
+
+
+def convert_ldm_original(checkpoint_path, config_path, output_path):
+ config = OmegaConf.load(config_path)
+ state_dict = torch.load(checkpoint_path, map_location="cpu")["model"]
+ keys = list(state_dict.keys())
+
+ # extract state_dict for VQVAE
+ first_stage_dict = {}
+ first_stage_key = "first_stage_model."
+ for key in keys:
+ if key.startswith(first_stage_key):
+ first_stage_dict[key.replace(first_stage_key, "")] = state_dict[key]
+
+ # extract state_dict for UNetLDM
+ unet_state_dict = {}
+ unet_key = "model.diffusion_model."
+ for key in keys:
+ if key.startswith(unet_key):
+ unet_state_dict[key.replace(unet_key, "")] = state_dict[key]
+
+ vqvae_init_args = config.model.params.first_stage_config.params
+ unet_init_args = config.model.params.unet_config.params
+
+ vqvae = VQModel(**vqvae_init_args).eval()
+ vqvae.load_state_dict(first_stage_dict)
+
+ unet = UNetLDMModel(**unet_init_args).eval()
+ unet.load_state_dict(unet_state_dict)
+
+ noise_scheduler = DDIMScheduler(
+ timesteps=config.model.params.timesteps,
+ beta_schedule="scaled_linear",
+ beta_start=config.model.params.linear_start,
+ beta_end=config.model.params.linear_end,
+ clip_sample=False,
+ )
+
+ pipeline = LDMPipeline(vqvae, unet, noise_scheduler)
+ pipeline.save_pretrained(output_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--checkpoint_path", type=str, required=True)
+ parser.add_argument("--config_path", type=str, required=True)
+ parser.add_argument("--output_path", type=str, required=True)
+ args = parser.parse_args()
+
+ convert_ldm_original(args.checkpoint_path, args.config_path, args.output_path)
diff --git a/diffusers/scripts/convert_dance_diffusion_to_diffusers.py b/diffusers/scripts/convert_dance_diffusion_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..d53d1f792e89be30e26cd701c178083e94699f00
--- /dev/null
+++ b/diffusers/scripts/convert_dance_diffusion_to_diffusers.py
@@ -0,0 +1,339 @@
+#!/usr/bin/env python3
+import argparse
+import math
+import os
+from copy import deepcopy
+
+import torch
+from audio_diffusion.models import DiffusionAttnUnet1D
+from diffusion import sampling
+from torch import nn
+
+from diffusers import DanceDiffusionPipeline, IPNDMScheduler, UNet1DModel
+
+
+MODELS_MAP = {
+ "gwf-440k": {
+ "url": "https://model-server.zqevans2.workers.dev/gwf-440k.ckpt",
+ "sample_rate": 48000,
+ "sample_size": 65536,
+ },
+ "jmann-small-190k": {
+ "url": "https://model-server.zqevans2.workers.dev/jmann-small-190k.ckpt",
+ "sample_rate": 48000,
+ "sample_size": 65536,
+ },
+ "jmann-large-580k": {
+ "url": "https://model-server.zqevans2.workers.dev/jmann-large-580k.ckpt",
+ "sample_rate": 48000,
+ "sample_size": 131072,
+ },
+ "maestro-uncond-150k": {
+ "url": "https://model-server.zqevans2.workers.dev/maestro-uncond-150k.ckpt",
+ "sample_rate": 16000,
+ "sample_size": 65536,
+ },
+ "unlocked-uncond-250k": {
+ "url": "https://model-server.zqevans2.workers.dev/unlocked-uncond-250k.ckpt",
+ "sample_rate": 16000,
+ "sample_size": 65536,
+ },
+ "honk-140k": {
+ "url": "https://model-server.zqevans2.workers.dev/honk-140k.ckpt",
+ "sample_rate": 16000,
+ "sample_size": 65536,
+ },
+}
+
+
+def alpha_sigma_to_t(alpha, sigma):
+ """Returns a timestep, given the scaling factors for the clean image and for
+ the noise."""
+ return torch.atan2(sigma, alpha) / math.pi * 2
+
+
+def get_crash_schedule(t):
+ sigma = torch.sin(t * math.pi / 2) ** 2
+ alpha = (1 - sigma**2) ** 0.5
+ return alpha_sigma_to_t(alpha, sigma)
+
+
+class Object(object):
+ pass
+
+
+class DiffusionUncond(nn.Module):
+ def __init__(self, global_args):
+ super().__init__()
+
+ self.diffusion = DiffusionAttnUnet1D(global_args, n_attn_layers=4)
+ self.diffusion_ema = deepcopy(self.diffusion)
+ self.rng = torch.quasirandom.SobolEngine(1, scramble=True)
+
+
+def download(model_name):
+ url = MODELS_MAP[model_name]["url"]
+ os.system(f"wget {url} ./")
+
+ return f"./{model_name}.ckpt"
+
+
+DOWN_NUM_TO_LAYER = {
+ "1": "resnets.0",
+ "2": "attentions.0",
+ "3": "resnets.1",
+ "4": "attentions.1",
+ "5": "resnets.2",
+ "6": "attentions.2",
+}
+UP_NUM_TO_LAYER = {
+ "8": "resnets.0",
+ "9": "attentions.0",
+ "10": "resnets.1",
+ "11": "attentions.1",
+ "12": "resnets.2",
+ "13": "attentions.2",
+}
+MID_NUM_TO_LAYER = {
+ "1": "resnets.0",
+ "2": "attentions.0",
+ "3": "resnets.1",
+ "4": "attentions.1",
+ "5": "resnets.2",
+ "6": "attentions.2",
+ "8": "resnets.3",
+ "9": "attentions.3",
+ "10": "resnets.4",
+ "11": "attentions.4",
+ "12": "resnets.5",
+ "13": "attentions.5",
+}
+DEPTH_0_TO_LAYER = {
+ "0": "resnets.0",
+ "1": "resnets.1",
+ "2": "resnets.2",
+ "4": "resnets.0",
+ "5": "resnets.1",
+ "6": "resnets.2",
+}
+
+RES_CONV_MAP = {
+ "skip": "conv_skip",
+ "main.0": "conv_1",
+ "main.1": "group_norm_1",
+ "main.3": "conv_2",
+ "main.4": "group_norm_2",
+}
+
+ATTN_MAP = {
+ "norm": "group_norm",
+ "qkv_proj": ["query", "key", "value"],
+ "out_proj": ["proj_attn"],
+}
+
+
+def convert_resconv_naming(name):
+ if name.startswith("skip"):
+ return name.replace("skip", RES_CONV_MAP["skip"])
+
+ # name has to be of format main.{digit}
+ if not name.startswith("main."):
+ raise ValueError(f"ResConvBlock error with {name}")
+
+ return name.replace(name[:6], RES_CONV_MAP[name[:6]])
+
+
+def convert_attn_naming(name):
+ for key, value in ATTN_MAP.items():
+ if name.startswith(key) and not isinstance(value, list):
+ return name.replace(key, value)
+ elif name.startswith(key):
+ return [name.replace(key, v) for v in value]
+ raise ValueError(f"Attn error with {name}")
+
+
+def rename(input_string, max_depth=13):
+ string = input_string
+
+ if string.split(".")[0] == "timestep_embed":
+ return string.replace("timestep_embed", "time_proj")
+
+ depth = 0
+ if string.startswith("net.3."):
+ depth += 1
+ string = string[6:]
+ elif string.startswith("net."):
+ string = string[4:]
+
+ while string.startswith("main.7."):
+ depth += 1
+ string = string[7:]
+
+ if string.startswith("main."):
+ string = string[5:]
+
+ # mid block
+ if string[:2].isdigit():
+ layer_num = string[:2]
+ string_left = string[2:]
+ else:
+ layer_num = string[0]
+ string_left = string[1:]
+
+ if depth == max_depth:
+ new_layer = MID_NUM_TO_LAYER[layer_num]
+ prefix = "mid_block"
+ elif depth > 0 and int(layer_num) < 7:
+ new_layer = DOWN_NUM_TO_LAYER[layer_num]
+ prefix = f"down_blocks.{depth}"
+ elif depth > 0 and int(layer_num) > 7:
+ new_layer = UP_NUM_TO_LAYER[layer_num]
+ prefix = f"up_blocks.{max_depth - depth - 1}"
+ elif depth == 0:
+ new_layer = DEPTH_0_TO_LAYER[layer_num]
+ prefix = f"up_blocks.{max_depth - 1}" if int(layer_num) > 3 else "down_blocks.0"
+
+ if not string_left.startswith("."):
+ raise ValueError(f"Naming error with {input_string} and string_left: {string_left}.")
+
+ string_left = string_left[1:]
+
+ if "resnets" in new_layer:
+ string_left = convert_resconv_naming(string_left)
+ elif "attentions" in new_layer:
+ new_string_left = convert_attn_naming(string_left)
+ string_left = new_string_left
+
+ if not isinstance(string_left, list):
+ new_string = prefix + "." + new_layer + "." + string_left
+ else:
+ new_string = [prefix + "." + new_layer + "." + s for s in string_left]
+ return new_string
+
+
+def rename_orig_weights(state_dict):
+ new_state_dict = {}
+ for k, v in state_dict.items():
+ if k.endswith("kernel"):
+ # up- and downsample layers, don't have trainable weights
+ continue
+
+ new_k = rename(k)
+
+ # check if we need to transform from Conv => Linear for attention
+ if isinstance(new_k, list):
+ new_state_dict = transform_conv_attns(new_state_dict, new_k, v)
+ else:
+ new_state_dict[new_k] = v
+
+ return new_state_dict
+
+
+def transform_conv_attns(new_state_dict, new_k, v):
+ if len(new_k) == 1:
+ if len(v.shape) == 3:
+ # weight
+ new_state_dict[new_k[0]] = v[:, :, 0]
+ else:
+ # bias
+ new_state_dict[new_k[0]] = v
+ else:
+ # qkv matrices
+ trippled_shape = v.shape[0]
+ single_shape = trippled_shape // 3
+ for i in range(3):
+ if len(v.shape) == 3:
+ new_state_dict[new_k[i]] = v[i * single_shape : (i + 1) * single_shape, :, 0]
+ else:
+ new_state_dict[new_k[i]] = v[i * single_shape : (i + 1) * single_shape]
+ return new_state_dict
+
+
+def main(args):
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+ model_name = args.model_path.split("/")[-1].split(".")[0]
+ if not os.path.isfile(args.model_path):
+ assert (
+ model_name == args.model_path
+ ), f"Make sure to provide one of the official model names {MODELS_MAP.keys()}"
+ args.model_path = download(model_name)
+
+ sample_rate = MODELS_MAP[model_name]["sample_rate"]
+ sample_size = MODELS_MAP[model_name]["sample_size"]
+
+ config = Object()
+ config.sample_size = sample_size
+ config.sample_rate = sample_rate
+ config.latent_dim = 0
+
+ diffusers_model = UNet1DModel(sample_size=sample_size, sample_rate=sample_rate)
+ diffusers_state_dict = diffusers_model.state_dict()
+
+ orig_model = DiffusionUncond(config)
+ orig_model.load_state_dict(torch.load(args.model_path, map_location=device)["state_dict"])
+ orig_model = orig_model.diffusion_ema.eval()
+ orig_model_state_dict = orig_model.state_dict()
+ renamed_state_dict = rename_orig_weights(orig_model_state_dict)
+
+ renamed_minus_diffusers = set(renamed_state_dict.keys()) - set(diffusers_state_dict.keys())
+ diffusers_minus_renamed = set(diffusers_state_dict.keys()) - set(renamed_state_dict.keys())
+
+ assert len(renamed_minus_diffusers) == 0, f"Problem with {renamed_minus_diffusers}"
+ assert all(k.endswith("kernel") for k in list(diffusers_minus_renamed)), f"Problem with {diffusers_minus_renamed}"
+
+ for key, value in renamed_state_dict.items():
+ assert (
+ diffusers_state_dict[key].squeeze().shape == value.squeeze().shape
+ ), f"Shape for {key} doesn't match. Diffusers: {diffusers_state_dict[key].shape} vs. {value.shape}"
+ if key == "time_proj.weight":
+ value = value.squeeze()
+
+ diffusers_state_dict[key] = value
+
+ diffusers_model.load_state_dict(diffusers_state_dict)
+
+ steps = 100
+ seed = 33
+
+ diffusers_scheduler = IPNDMScheduler(num_train_timesteps=steps)
+
+ generator = torch.manual_seed(seed)
+ noise = torch.randn([1, 2, config.sample_size], generator=generator).to(device)
+
+ t = torch.linspace(1, 0, steps + 1, device=device)[:-1]
+ step_list = get_crash_schedule(t)
+
+ pipe = DanceDiffusionPipeline(unet=diffusers_model, scheduler=diffusers_scheduler)
+
+ generator = torch.manual_seed(33)
+ audio = pipe(num_inference_steps=steps, generator=generator).audios
+
+ generated = sampling.iplms_sample(orig_model, noise, step_list, {})
+ generated = generated.clamp(-1, 1)
+
+ diff_sum = (generated - audio).abs().sum()
+ diff_max = (generated - audio).abs().max()
+
+ if args.save:
+ pipe.save_pretrained(args.checkpoint_path)
+
+ print("Diff sum", diff_sum)
+ print("Diff max", diff_max)
+
+ assert diff_max < 1e-3, f"Diff max: {diff_max} is too much :-/"
+
+ print(f"Conversion for {model_name} successful!")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument("--model_path", default=None, type=str, required=True, help="Path to the model to convert.")
+ parser.add_argument(
+ "--save", default=True, type=bool, required=False, help="Whether to save the converted model or not."
+ )
+ parser.add_argument("--checkpoint_path", default=None, type=str, required=True, help="Path to the output model.")
+ args = parser.parse_args()
+
+ main(args)
diff --git a/diffusers/scripts/convert_ddpm_original_checkpoint_to_diffusers.py b/diffusers/scripts/convert_ddpm_original_checkpoint_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..46595784b0bac0016b623b7122082275248363e9
--- /dev/null
+++ b/diffusers/scripts/convert_ddpm_original_checkpoint_to_diffusers.py
@@ -0,0 +1,431 @@
+import argparse
+import json
+
+import torch
+
+from diffusers import AutoencoderKL, DDPMPipeline, DDPMScheduler, UNet2DModel, VQModel
+
+
+def shave_segments(path, n_shave_prefix_segments=1):
+ """
+ Removes segments. Positive values shave the first segments, negative shave the last segments.
+ """
+ if n_shave_prefix_segments >= 0:
+ return ".".join(path.split(".")[n_shave_prefix_segments:])
+ else:
+ return ".".join(path.split(".")[:n_shave_prefix_segments])
+
+
+def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+ new_item = new_item.replace("block.", "resnets.")
+ new_item = new_item.replace("conv_shorcut", "conv1")
+ new_item = new_item.replace("in_shortcut", "conv_shortcut")
+ new_item = new_item.replace("temb_proj", "time_emb_proj")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_attention_paths(old_list, n_shave_prefix_segments=0, in_mid=False):
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ # In `model.mid`, the layer is called `attn`.
+ if not in_mid:
+ new_item = new_item.replace("attn", "attentions")
+ new_item = new_item.replace(".k.", ".key.")
+ new_item = new_item.replace(".v.", ".value.")
+ new_item = new_item.replace(".q.", ".query.")
+
+ new_item = new_item.replace("proj_out", "proj_attn")
+ new_item = new_item.replace("norm", "group_norm")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def assign_to_checkpoint(
+ paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
+):
+ assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
+
+ if attention_paths_to_split is not None:
+ if config is None:
+ raise ValueError("Please specify the config if setting 'attention_paths_to_split' to 'True'.")
+
+ for path, path_map in attention_paths_to_split.items():
+ old_tensor = old_checkpoint[path]
+ channels = old_tensor.shape[0] // 3
+
+ target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
+
+ num_heads = old_tensor.shape[0] // config.get("num_head_channels", 1) // 3
+
+ old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
+ query, key, value = old_tensor.split(channels // num_heads, dim=1)
+
+ checkpoint[path_map["query"]] = query.reshape(target_shape).squeeze()
+ checkpoint[path_map["key"]] = key.reshape(target_shape).squeeze()
+ checkpoint[path_map["value"]] = value.reshape(target_shape).squeeze()
+
+ for path in paths:
+ new_path = path["new"]
+
+ if attention_paths_to_split is not None and new_path in attention_paths_to_split:
+ continue
+
+ new_path = new_path.replace("down.", "down_blocks.")
+ new_path = new_path.replace("up.", "up_blocks.")
+
+ if additional_replacements is not None:
+ for replacement in additional_replacements:
+ new_path = new_path.replace(replacement["old"], replacement["new"])
+
+ if "attentions" in new_path:
+ checkpoint[new_path] = old_checkpoint[path["old"]].squeeze()
+ else:
+ checkpoint[new_path] = old_checkpoint[path["old"]]
+
+
+def convert_ddpm_checkpoint(checkpoint, config):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint.
+ """
+ new_checkpoint = {}
+
+ new_checkpoint["time_embedding.linear_1.weight"] = checkpoint["temb.dense.0.weight"]
+ new_checkpoint["time_embedding.linear_1.bias"] = checkpoint["temb.dense.0.bias"]
+ new_checkpoint["time_embedding.linear_2.weight"] = checkpoint["temb.dense.1.weight"]
+ new_checkpoint["time_embedding.linear_2.bias"] = checkpoint["temb.dense.1.bias"]
+
+ new_checkpoint["conv_norm_out.weight"] = checkpoint["norm_out.weight"]
+ new_checkpoint["conv_norm_out.bias"] = checkpoint["norm_out.bias"]
+
+ new_checkpoint["conv_in.weight"] = checkpoint["conv_in.weight"]
+ new_checkpoint["conv_in.bias"] = checkpoint["conv_in.bias"]
+ new_checkpoint["conv_out.weight"] = checkpoint["conv_out.weight"]
+ new_checkpoint["conv_out.bias"] = checkpoint["conv_out.bias"]
+
+ num_down_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "down" in layer})
+ down_blocks = {
+ layer_id: [key for key in checkpoint if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
+ }
+
+ num_up_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "up" in layer})
+ up_blocks = {layer_id: [key for key in checkpoint if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)}
+
+ for i in range(num_down_blocks):
+ block_id = (i - 1) // (config["layers_per_block"] + 1)
+
+ if any("downsample" in layer for layer in down_blocks[i]):
+ new_checkpoint[f"down_blocks.{i}.downsamplers.0.conv.weight"] = checkpoint[
+ f"down.{i}.downsample.op.weight"
+ ]
+ new_checkpoint[f"down_blocks.{i}.downsamplers.0.conv.bias"] = checkpoint[f"down.{i}.downsample.op.bias"]
+ # new_checkpoint[f'down_blocks.{i}.downsamplers.0.op.weight'] = checkpoint[f'down.{i}.downsample.conv.weight']
+ # new_checkpoint[f'down_blocks.{i}.downsamplers.0.op.bias'] = checkpoint[f'down.{i}.downsample.conv.bias']
+
+ if any("block" in layer for layer in down_blocks[i]):
+ num_blocks = len(
+ {".".join(shave_segments(layer, 2).split(".")[:2]) for layer in down_blocks[i] if "block" in layer}
+ )
+ blocks = {
+ layer_id: [key for key in down_blocks[i] if f"block.{layer_id}" in key]
+ for layer_id in range(num_blocks)
+ }
+
+ if num_blocks > 0:
+ for j in range(config["layers_per_block"]):
+ paths = renew_resnet_paths(blocks[j])
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint)
+
+ if any("attn" in layer for layer in down_blocks[i]):
+ num_attn = len(
+ {".".join(shave_segments(layer, 2).split(".")[:2]) for layer in down_blocks[i] if "attn" in layer}
+ )
+ attns = {
+ layer_id: [key for key in down_blocks[i] if f"attn.{layer_id}" in key]
+ for layer_id in range(num_blocks)
+ }
+
+ if num_attn > 0:
+ for j in range(config["layers_per_block"]):
+ paths = renew_attention_paths(attns[j])
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint, config=config)
+
+ mid_block_1_layers = [key for key in checkpoint if "mid.block_1" in key]
+ mid_block_2_layers = [key for key in checkpoint if "mid.block_2" in key]
+ mid_attn_1_layers = [key for key in checkpoint if "mid.attn_1" in key]
+
+ # Mid new 2
+ paths = renew_resnet_paths(mid_block_1_layers)
+ assign_to_checkpoint(
+ paths,
+ new_checkpoint,
+ checkpoint,
+ additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "block_1", "new": "resnets.0"}],
+ )
+
+ paths = renew_resnet_paths(mid_block_2_layers)
+ assign_to_checkpoint(
+ paths,
+ new_checkpoint,
+ checkpoint,
+ additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "block_2", "new": "resnets.1"}],
+ )
+
+ paths = renew_attention_paths(mid_attn_1_layers, in_mid=True)
+ assign_to_checkpoint(
+ paths,
+ new_checkpoint,
+ checkpoint,
+ additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "attn_1", "new": "attentions.0"}],
+ )
+
+ for i in range(num_up_blocks):
+ block_id = num_up_blocks - 1 - i
+
+ if any("upsample" in layer for layer in up_blocks[i]):
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = checkpoint[
+ f"up.{i}.upsample.conv.weight"
+ ]
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = checkpoint[f"up.{i}.upsample.conv.bias"]
+
+ if any("block" in layer for layer in up_blocks[i]):
+ num_blocks = len(
+ {".".join(shave_segments(layer, 2).split(".")[:2]) for layer in up_blocks[i] if "block" in layer}
+ )
+ blocks = {
+ layer_id: [key for key in up_blocks[i] if f"block.{layer_id}" in key] for layer_id in range(num_blocks)
+ }
+
+ if num_blocks > 0:
+ for j in range(config["layers_per_block"] + 1):
+ replace_indices = {"old": f"up_blocks.{i}", "new": f"up_blocks.{block_id}"}
+ paths = renew_resnet_paths(blocks[j])
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
+
+ if any("attn" in layer for layer in up_blocks[i]):
+ num_attn = len(
+ {".".join(shave_segments(layer, 2).split(".")[:2]) for layer in up_blocks[i] if "attn" in layer}
+ )
+ attns = {
+ layer_id: [key for key in up_blocks[i] if f"attn.{layer_id}" in key] for layer_id in range(num_blocks)
+ }
+
+ if num_attn > 0:
+ for j in range(config["layers_per_block"] + 1):
+ replace_indices = {"old": f"up_blocks.{i}", "new": f"up_blocks.{block_id}"}
+ paths = renew_attention_paths(attns[j])
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
+
+ new_checkpoint = {k.replace("mid_new_2", "mid_block"): v for k, v in new_checkpoint.items()}
+ return new_checkpoint
+
+
+def convert_vq_autoenc_checkpoint(checkpoint, config):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint.
+ """
+ new_checkpoint = {}
+
+ new_checkpoint["encoder.conv_norm_out.weight"] = checkpoint["encoder.norm_out.weight"]
+ new_checkpoint["encoder.conv_norm_out.bias"] = checkpoint["encoder.norm_out.bias"]
+
+ new_checkpoint["encoder.conv_in.weight"] = checkpoint["encoder.conv_in.weight"]
+ new_checkpoint["encoder.conv_in.bias"] = checkpoint["encoder.conv_in.bias"]
+ new_checkpoint["encoder.conv_out.weight"] = checkpoint["encoder.conv_out.weight"]
+ new_checkpoint["encoder.conv_out.bias"] = checkpoint["encoder.conv_out.bias"]
+
+ new_checkpoint["decoder.conv_norm_out.weight"] = checkpoint["decoder.norm_out.weight"]
+ new_checkpoint["decoder.conv_norm_out.bias"] = checkpoint["decoder.norm_out.bias"]
+
+ new_checkpoint["decoder.conv_in.weight"] = checkpoint["decoder.conv_in.weight"]
+ new_checkpoint["decoder.conv_in.bias"] = checkpoint["decoder.conv_in.bias"]
+ new_checkpoint["decoder.conv_out.weight"] = checkpoint["decoder.conv_out.weight"]
+ new_checkpoint["decoder.conv_out.bias"] = checkpoint["decoder.conv_out.bias"]
+
+ num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in checkpoint if "down" in layer})
+ down_blocks = {
+ layer_id: [key for key in checkpoint if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
+ }
+
+ num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in checkpoint if "up" in layer})
+ up_blocks = {layer_id: [key for key in checkpoint if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)}
+
+ for i in range(num_down_blocks):
+ block_id = (i - 1) // (config["layers_per_block"] + 1)
+
+ if any("downsample" in layer for layer in down_blocks[i]):
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = checkpoint[
+ f"encoder.down.{i}.downsample.conv.weight"
+ ]
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = checkpoint[
+ f"encoder.down.{i}.downsample.conv.bias"
+ ]
+
+ if any("block" in layer for layer in down_blocks[i]):
+ num_blocks = len(
+ {".".join(shave_segments(layer, 3).split(".")[:3]) for layer in down_blocks[i] if "block" in layer}
+ )
+ blocks = {
+ layer_id: [key for key in down_blocks[i] if f"block.{layer_id}" in key]
+ for layer_id in range(num_blocks)
+ }
+
+ if num_blocks > 0:
+ for j in range(config["layers_per_block"]):
+ paths = renew_resnet_paths(blocks[j])
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint)
+
+ if any("attn" in layer for layer in down_blocks[i]):
+ num_attn = len(
+ {".".join(shave_segments(layer, 3).split(".")[:3]) for layer in down_blocks[i] if "attn" in layer}
+ )
+ attns = {
+ layer_id: [key for key in down_blocks[i] if f"attn.{layer_id}" in key]
+ for layer_id in range(num_blocks)
+ }
+
+ if num_attn > 0:
+ for j in range(config["layers_per_block"]):
+ paths = renew_attention_paths(attns[j])
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint, config=config)
+
+ mid_block_1_layers = [key for key in checkpoint if "mid.block_1" in key]
+ mid_block_2_layers = [key for key in checkpoint if "mid.block_2" in key]
+ mid_attn_1_layers = [key for key in checkpoint if "mid.attn_1" in key]
+
+ # Mid new 2
+ paths = renew_resnet_paths(mid_block_1_layers)
+ assign_to_checkpoint(
+ paths,
+ new_checkpoint,
+ checkpoint,
+ additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "block_1", "new": "resnets.0"}],
+ )
+
+ paths = renew_resnet_paths(mid_block_2_layers)
+ assign_to_checkpoint(
+ paths,
+ new_checkpoint,
+ checkpoint,
+ additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "block_2", "new": "resnets.1"}],
+ )
+
+ paths = renew_attention_paths(mid_attn_1_layers, in_mid=True)
+ assign_to_checkpoint(
+ paths,
+ new_checkpoint,
+ checkpoint,
+ additional_replacements=[{"old": "mid.", "new": "mid_new_2."}, {"old": "attn_1", "new": "attentions.0"}],
+ )
+
+ for i in range(num_up_blocks):
+ block_id = num_up_blocks - 1 - i
+
+ if any("upsample" in layer for layer in up_blocks[i]):
+ new_checkpoint[f"decoder.up_blocks.{block_id}.upsamplers.0.conv.weight"] = checkpoint[
+ f"decoder.up.{i}.upsample.conv.weight"
+ ]
+ new_checkpoint[f"decoder.up_blocks.{block_id}.upsamplers.0.conv.bias"] = checkpoint[
+ f"decoder.up.{i}.upsample.conv.bias"
+ ]
+
+ if any("block" in layer for layer in up_blocks[i]):
+ num_blocks = len(
+ {".".join(shave_segments(layer, 3).split(".")[:3]) for layer in up_blocks[i] if "block" in layer}
+ )
+ blocks = {
+ layer_id: [key for key in up_blocks[i] if f"block.{layer_id}" in key] for layer_id in range(num_blocks)
+ }
+
+ if num_blocks > 0:
+ for j in range(config["layers_per_block"] + 1):
+ replace_indices = {"old": f"up_blocks.{i}", "new": f"up_blocks.{block_id}"}
+ paths = renew_resnet_paths(blocks[j])
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
+
+ if any("attn" in layer for layer in up_blocks[i]):
+ num_attn = len(
+ {".".join(shave_segments(layer, 3).split(".")[:3]) for layer in up_blocks[i] if "attn" in layer}
+ )
+ attns = {
+ layer_id: [key for key in up_blocks[i] if f"attn.{layer_id}" in key] for layer_id in range(num_blocks)
+ }
+
+ if num_attn > 0:
+ for j in range(config["layers_per_block"] + 1):
+ replace_indices = {"old": f"up_blocks.{i}", "new": f"up_blocks.{block_id}"}
+ paths = renew_attention_paths(attns[j])
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
+
+ new_checkpoint = {k.replace("mid_new_2", "mid_block"): v for k, v in new_checkpoint.items()}
+ new_checkpoint["quant_conv.weight"] = checkpoint["quant_conv.weight"]
+ new_checkpoint["quant_conv.bias"] = checkpoint["quant_conv.bias"]
+ if "quantize.embedding.weight" in checkpoint:
+ new_checkpoint["quantize.embedding.weight"] = checkpoint["quantize.embedding.weight"]
+ new_checkpoint["post_quant_conv.weight"] = checkpoint["post_quant_conv.weight"]
+ new_checkpoint["post_quant_conv.bias"] = checkpoint["post_quant_conv.bias"]
+
+ return new_checkpoint
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+
+ parser.add_argument(
+ "--config_file",
+ default=None,
+ type=str,
+ required=True,
+ help="The config json file corresponding to the architecture.",
+ )
+
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+
+ args = parser.parse_args()
+ checkpoint = torch.load(args.checkpoint_path)
+
+ with open(args.config_file) as f:
+ config = json.loads(f.read())
+
+ # unet case
+ key_prefix_set = {key.split(".")[0] for key in checkpoint.keys()}
+ if "encoder" in key_prefix_set and "decoder" in key_prefix_set:
+ converted_checkpoint = convert_vq_autoenc_checkpoint(checkpoint, config)
+ else:
+ converted_checkpoint = convert_ddpm_checkpoint(checkpoint, config)
+
+ if "ddpm" in config:
+ del config["ddpm"]
+
+ if config["_class_name"] == "VQModel":
+ model = VQModel(**config)
+ model.load_state_dict(converted_checkpoint)
+ model.save_pretrained(args.dump_path)
+ elif config["_class_name"] == "AutoencoderKL":
+ model = AutoencoderKL(**config)
+ model.load_state_dict(converted_checkpoint)
+ model.save_pretrained(args.dump_path)
+ else:
+ model = UNet2DModel(**config)
+ model.load_state_dict(converted_checkpoint)
+
+ scheduler = DDPMScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
+
+ pipe = DDPMPipeline(unet=model, scheduler=scheduler)
+ pipe.save_pretrained(args.dump_path)
diff --git a/diffusers/scripts/convert_diffusers_to_original_stable_diffusion.py b/diffusers/scripts/convert_diffusers_to_original_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..9da45211551e32acf34c883c1d6c5218a7bd6dd7
--- /dev/null
+++ b/diffusers/scripts/convert_diffusers_to_original_stable_diffusion.py
@@ -0,0 +1,333 @@
+# Script for converting a HF Diffusers saved pipeline to a Stable Diffusion checkpoint.
+# *Only* converts the UNet, VAE, and Text Encoder.
+# Does not convert optimizer state or any other thing.
+
+import argparse
+import os.path as osp
+import re
+
+import torch
+from safetensors.torch import load_file, save_file
+
+
+# =================#
+# UNet Conversion #
+# =================#
+
+unet_conversion_map = [
+ # (stable-diffusion, HF Diffusers)
+ ("time_embed.0.weight", "time_embedding.linear_1.weight"),
+ ("time_embed.0.bias", "time_embedding.linear_1.bias"),
+ ("time_embed.2.weight", "time_embedding.linear_2.weight"),
+ ("time_embed.2.bias", "time_embedding.linear_2.bias"),
+ ("input_blocks.0.0.weight", "conv_in.weight"),
+ ("input_blocks.0.0.bias", "conv_in.bias"),
+ ("out.0.weight", "conv_norm_out.weight"),
+ ("out.0.bias", "conv_norm_out.bias"),
+ ("out.2.weight", "conv_out.weight"),
+ ("out.2.bias", "conv_out.bias"),
+]
+
+unet_conversion_map_resnet = [
+ # (stable-diffusion, HF Diffusers)
+ ("in_layers.0", "norm1"),
+ ("in_layers.2", "conv1"),
+ ("out_layers.0", "norm2"),
+ ("out_layers.3", "conv2"),
+ ("emb_layers.1", "time_emb_proj"),
+ ("skip_connection", "conv_shortcut"),
+]
+
+unet_conversion_map_layer = []
+# hardcoded number of downblocks and resnets/attentions...
+# would need smarter logic for other networks.
+for i in range(4):
+ # loop over downblocks/upblocks
+
+ for j in range(2):
+ # loop over resnets/attentions for downblocks
+ hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
+ sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
+ unet_conversion_map_layer.append((sd_down_res_prefix, hf_down_res_prefix))
+
+ if i < 3:
+ # no attention layers in down_blocks.3
+ hf_down_atn_prefix = f"down_blocks.{i}.attentions.{j}."
+ sd_down_atn_prefix = f"input_blocks.{3*i + j + 1}.1."
+ unet_conversion_map_layer.append((sd_down_atn_prefix, hf_down_atn_prefix))
+
+ for j in range(3):
+ # loop over resnets/attentions for upblocks
+ hf_up_res_prefix = f"up_blocks.{i}.resnets.{j}."
+ sd_up_res_prefix = f"output_blocks.{3*i + j}.0."
+ unet_conversion_map_layer.append((sd_up_res_prefix, hf_up_res_prefix))
+
+ if i > 0:
+ # no attention layers in up_blocks.0
+ hf_up_atn_prefix = f"up_blocks.{i}.attentions.{j}."
+ sd_up_atn_prefix = f"output_blocks.{3*i + j}.1."
+ unet_conversion_map_layer.append((sd_up_atn_prefix, hf_up_atn_prefix))
+
+ if i < 3:
+ # no downsample in down_blocks.3
+ hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
+ sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
+ unet_conversion_map_layer.append((sd_downsample_prefix, hf_downsample_prefix))
+
+ # no upsample in up_blocks.3
+ hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
+ sd_upsample_prefix = f"output_blocks.{3*i + 2}.{1 if i == 0 else 2}."
+ unet_conversion_map_layer.append((sd_upsample_prefix, hf_upsample_prefix))
+
+hf_mid_atn_prefix = "mid_block.attentions.0."
+sd_mid_atn_prefix = "middle_block.1."
+unet_conversion_map_layer.append((sd_mid_atn_prefix, hf_mid_atn_prefix))
+
+for j in range(2):
+ hf_mid_res_prefix = f"mid_block.resnets.{j}."
+ sd_mid_res_prefix = f"middle_block.{2*j}."
+ unet_conversion_map_layer.append((sd_mid_res_prefix, hf_mid_res_prefix))
+
+
+def convert_unet_state_dict(unet_state_dict):
+ # buyer beware: this is a *brittle* function,
+ # and correct output requires that all of these pieces interact in
+ # the exact order in which I have arranged them.
+ mapping = {k: k for k in unet_state_dict.keys()}
+ for sd_name, hf_name in unet_conversion_map:
+ mapping[hf_name] = sd_name
+ for k, v in mapping.items():
+ if "resnets" in k:
+ for sd_part, hf_part in unet_conversion_map_resnet:
+ v = v.replace(hf_part, sd_part)
+ mapping[k] = v
+ for k, v in mapping.items():
+ for sd_part, hf_part in unet_conversion_map_layer:
+ v = v.replace(hf_part, sd_part)
+ mapping[k] = v
+ new_state_dict = {v: unet_state_dict[k] for k, v in mapping.items()}
+ return new_state_dict
+
+
+# ================#
+# VAE Conversion #
+# ================#
+
+vae_conversion_map = [
+ # (stable-diffusion, HF Diffusers)
+ ("nin_shortcut", "conv_shortcut"),
+ ("norm_out", "conv_norm_out"),
+ ("mid.attn_1.", "mid_block.attentions.0."),
+]
+
+for i in range(4):
+ # down_blocks have two resnets
+ for j in range(2):
+ hf_down_prefix = f"encoder.down_blocks.{i}.resnets.{j}."
+ sd_down_prefix = f"encoder.down.{i}.block.{j}."
+ vae_conversion_map.append((sd_down_prefix, hf_down_prefix))
+
+ if i < 3:
+ hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0."
+ sd_downsample_prefix = f"down.{i}.downsample."
+ vae_conversion_map.append((sd_downsample_prefix, hf_downsample_prefix))
+
+ hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
+ sd_upsample_prefix = f"up.{3-i}.upsample."
+ vae_conversion_map.append((sd_upsample_prefix, hf_upsample_prefix))
+
+ # up_blocks have three resnets
+ # also, up blocks in hf are numbered in reverse from sd
+ for j in range(3):
+ hf_up_prefix = f"decoder.up_blocks.{i}.resnets.{j}."
+ sd_up_prefix = f"decoder.up.{3-i}.block.{j}."
+ vae_conversion_map.append((sd_up_prefix, hf_up_prefix))
+
+# this part accounts for mid blocks in both the encoder and the decoder
+for i in range(2):
+ hf_mid_res_prefix = f"mid_block.resnets.{i}."
+ sd_mid_res_prefix = f"mid.block_{i+1}."
+ vae_conversion_map.append((sd_mid_res_prefix, hf_mid_res_prefix))
+
+
+vae_conversion_map_attn = [
+ # (stable-diffusion, HF Diffusers)
+ ("norm.", "group_norm."),
+ ("q.", "query."),
+ ("k.", "key."),
+ ("v.", "value."),
+ ("proj_out.", "proj_attn."),
+]
+
+
+def reshape_weight_for_sd(w):
+ # convert HF linear weights to SD conv2d weights
+ return w.reshape(*w.shape, 1, 1)
+
+
+def convert_vae_state_dict(vae_state_dict):
+ mapping = {k: k for k in vae_state_dict.keys()}
+ for k, v in mapping.items():
+ for sd_part, hf_part in vae_conversion_map:
+ v = v.replace(hf_part, sd_part)
+ mapping[k] = v
+ for k, v in mapping.items():
+ if "attentions" in k:
+ for sd_part, hf_part in vae_conversion_map_attn:
+ v = v.replace(hf_part, sd_part)
+ mapping[k] = v
+ new_state_dict = {v: vae_state_dict[k] for k, v in mapping.items()}
+ weights_to_convert = ["q", "k", "v", "proj_out"]
+ for k, v in new_state_dict.items():
+ for weight_name in weights_to_convert:
+ if f"mid.attn_1.{weight_name}.weight" in k:
+ print(f"Reshaping {k} for SD format")
+ new_state_dict[k] = reshape_weight_for_sd(v)
+ return new_state_dict
+
+
+# =========================#
+# Text Encoder Conversion #
+# =========================#
+
+
+textenc_conversion_lst = [
+ # (stable-diffusion, HF Diffusers)
+ ("resblocks.", "text_model.encoder.layers."),
+ ("ln_1", "layer_norm1"),
+ ("ln_2", "layer_norm2"),
+ (".c_fc.", ".fc1."),
+ (".c_proj.", ".fc2."),
+ (".attn", ".self_attn"),
+ ("ln_final.", "transformer.text_model.final_layer_norm."),
+ ("token_embedding.weight", "transformer.text_model.embeddings.token_embedding.weight"),
+ ("positional_embedding", "transformer.text_model.embeddings.position_embedding.weight"),
+]
+protected = {re.escape(x[1]): x[0] for x in textenc_conversion_lst}
+textenc_pattern = re.compile("|".join(protected.keys()))
+
+# Ordering is from https://github.com/pytorch/pytorch/blob/master/test/cpp/api/modules.cpp
+code2idx = {"q": 0, "k": 1, "v": 2}
+
+
+def convert_text_enc_state_dict_v20(text_enc_dict):
+ new_state_dict = {}
+ capture_qkv_weight = {}
+ capture_qkv_bias = {}
+ for k, v in text_enc_dict.items():
+ if (
+ k.endswith(".self_attn.q_proj.weight")
+ or k.endswith(".self_attn.k_proj.weight")
+ or k.endswith(".self_attn.v_proj.weight")
+ ):
+ k_pre = k[: -len(".q_proj.weight")]
+ k_code = k[-len("q_proj.weight")]
+ if k_pre not in capture_qkv_weight:
+ capture_qkv_weight[k_pre] = [None, None, None]
+ capture_qkv_weight[k_pre][code2idx[k_code]] = v
+ continue
+
+ if (
+ k.endswith(".self_attn.q_proj.bias")
+ or k.endswith(".self_attn.k_proj.bias")
+ or k.endswith(".self_attn.v_proj.bias")
+ ):
+ k_pre = k[: -len(".q_proj.bias")]
+ k_code = k[-len("q_proj.bias")]
+ if k_pre not in capture_qkv_bias:
+ capture_qkv_bias[k_pre] = [None, None, None]
+ capture_qkv_bias[k_pre][code2idx[k_code]] = v
+ continue
+
+ relabelled_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], k)
+ new_state_dict[relabelled_key] = v
+
+ for k_pre, tensors in capture_qkv_weight.items():
+ if None in tensors:
+ raise Exception("CORRUPTED MODEL: one of the q-k-v values for the text encoder was missing")
+ relabelled_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], k_pre)
+ new_state_dict[relabelled_key + ".in_proj_weight"] = torch.cat(tensors)
+
+ for k_pre, tensors in capture_qkv_bias.items():
+ if None in tensors:
+ raise Exception("CORRUPTED MODEL: one of the q-k-v values for the text encoder was missing")
+ relabelled_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], k_pre)
+ new_state_dict[relabelled_key + ".in_proj_bias"] = torch.cat(tensors)
+
+ return new_state_dict
+
+
+def convert_text_enc_state_dict(text_enc_dict):
+ return text_enc_dict
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument("--model_path", default=None, type=str, required=True, help="Path to the model to convert.")
+ parser.add_argument("--checkpoint_path", default=None, type=str, required=True, help="Path to the output model.")
+ parser.add_argument("--half", action="store_true", help="Save weights in half precision.")
+ parser.add_argument(
+ "--use_safetensors", action="store_true", help="Save weights use safetensors, default is ckpt."
+ )
+
+ args = parser.parse_args()
+
+ assert args.model_path is not None, "Must provide a model path!"
+
+ assert args.checkpoint_path is not None, "Must provide a checkpoint path!"
+
+ # Path for safetensors
+ unet_path = osp.join(args.model_path, "unet", "diffusion_pytorch_model.safetensors")
+ vae_path = osp.join(args.model_path, "vae", "diffusion_pytorch_model.safetensors")
+ text_enc_path = osp.join(args.model_path, "text_encoder", "model.safetensors")
+
+ # Load models from safetensors if it exists, if it doesn't pytorch
+ if osp.exists(unet_path):
+ unet_state_dict = load_file(unet_path, device="cpu")
+ else:
+ unet_path = osp.join(args.model_path, "unet", "diffusion_pytorch_model.bin")
+ unet_state_dict = torch.load(unet_path, map_location="cpu")
+
+ if osp.exists(vae_path):
+ vae_state_dict = load_file(vae_path, device="cpu")
+ else:
+ vae_path = osp.join(args.model_path, "vae", "diffusion_pytorch_model.bin")
+ vae_state_dict = torch.load(vae_path, map_location="cpu")
+
+ if osp.exists(text_enc_path):
+ text_enc_dict = load_file(text_enc_path, device="cpu")
+ else:
+ text_enc_path = osp.join(args.model_path, "text_encoder", "pytorch_model.bin")
+ text_enc_dict = torch.load(text_enc_path, map_location="cpu")
+
+ # Convert the UNet model
+ unet_state_dict = convert_unet_state_dict(unet_state_dict)
+ unet_state_dict = {"model.diffusion_model." + k: v for k, v in unet_state_dict.items()}
+
+ # Convert the VAE model
+ vae_state_dict = convert_vae_state_dict(vae_state_dict)
+ vae_state_dict = {"first_stage_model." + k: v for k, v in vae_state_dict.items()}
+
+ # Easiest way to identify v2.0 model seems to be that the text encoder (OpenCLIP) is deeper
+ is_v20_model = "text_model.encoder.layers.22.layer_norm2.bias" in text_enc_dict
+
+ if is_v20_model:
+ # Need to add the tag 'transformer' in advance so we can knock it out from the final layer-norm
+ text_enc_dict = {"transformer." + k: v for k, v in text_enc_dict.items()}
+ text_enc_dict = convert_text_enc_state_dict_v20(text_enc_dict)
+ text_enc_dict = {"cond_stage_model.model." + k: v for k, v in text_enc_dict.items()}
+ else:
+ text_enc_dict = convert_text_enc_state_dict(text_enc_dict)
+ text_enc_dict = {"cond_stage_model.transformer." + k: v for k, v in text_enc_dict.items()}
+
+ # Put together new checkpoint
+ state_dict = {**unet_state_dict, **vae_state_dict, **text_enc_dict}
+ if args.half:
+ state_dict = {k: v.half() for k, v in state_dict.items()}
+
+ if args.use_safetensors:
+ save_file(state_dict, args.checkpoint_path)
+ else:
+ state_dict = {"state_dict": state_dict}
+ torch.save(state_dict, args.checkpoint_path)
diff --git a/diffusers/scripts/convert_dit_to_diffusers.py b/diffusers/scripts/convert_dit_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc127f69555c260f594e70444b1540faa196e3fb
--- /dev/null
+++ b/diffusers/scripts/convert_dit_to_diffusers.py
@@ -0,0 +1,162 @@
+import argparse
+import os
+
+import torch
+from torchvision.datasets.utils import download_url
+
+from diffusers import AutoencoderKL, DDIMScheduler, DiTPipeline, Transformer2DModel
+
+
+pretrained_models = {512: "DiT-XL-2-512x512.pt", 256: "DiT-XL-2-256x256.pt"}
+
+
+def download_model(model_name):
+ """
+ Downloads a pre-trained DiT model from the web.
+ """
+ local_path = f"pretrained_models/{model_name}"
+ if not os.path.isfile(local_path):
+ os.makedirs("pretrained_models", exist_ok=True)
+ web_path = f"https://dl.fbaipublicfiles.com/DiT/models/{model_name}"
+ download_url(web_path, "pretrained_models")
+ model = torch.load(local_path, map_location=lambda storage, loc: storage)
+ return model
+
+
+def main(args):
+ state_dict = download_model(pretrained_models[args.image_size])
+
+ state_dict["pos_embed.proj.weight"] = state_dict["x_embedder.proj.weight"]
+ state_dict["pos_embed.proj.bias"] = state_dict["x_embedder.proj.bias"]
+ state_dict.pop("x_embedder.proj.weight")
+ state_dict.pop("x_embedder.proj.bias")
+
+ for depth in range(28):
+ state_dict[f"transformer_blocks.{depth}.norm1.emb.timestep_embedder.linear_1.weight"] = state_dict[
+ "t_embedder.mlp.0.weight"
+ ]
+ state_dict[f"transformer_blocks.{depth}.norm1.emb.timestep_embedder.linear_1.bias"] = state_dict[
+ "t_embedder.mlp.0.bias"
+ ]
+ state_dict[f"transformer_blocks.{depth}.norm1.emb.timestep_embedder.linear_2.weight"] = state_dict[
+ "t_embedder.mlp.2.weight"
+ ]
+ state_dict[f"transformer_blocks.{depth}.norm1.emb.timestep_embedder.linear_2.bias"] = state_dict[
+ "t_embedder.mlp.2.bias"
+ ]
+ state_dict[f"transformer_blocks.{depth}.norm1.emb.class_embedder.embedding_table.weight"] = state_dict[
+ "y_embedder.embedding_table.weight"
+ ]
+
+ state_dict[f"transformer_blocks.{depth}.norm1.linear.weight"] = state_dict[
+ f"blocks.{depth}.adaLN_modulation.1.weight"
+ ]
+ state_dict[f"transformer_blocks.{depth}.norm1.linear.bias"] = state_dict[
+ f"blocks.{depth}.adaLN_modulation.1.bias"
+ ]
+
+ q, k, v = torch.chunk(state_dict[f"blocks.{depth}.attn.qkv.weight"], 3, dim=0)
+ q_bias, k_bias, v_bias = torch.chunk(state_dict[f"blocks.{depth}.attn.qkv.bias"], 3, dim=0)
+
+ state_dict[f"transformer_blocks.{depth}.attn1.to_q.weight"] = q
+ state_dict[f"transformer_blocks.{depth}.attn1.to_q.bias"] = q_bias
+ state_dict[f"transformer_blocks.{depth}.attn1.to_k.weight"] = k
+ state_dict[f"transformer_blocks.{depth}.attn1.to_k.bias"] = k_bias
+ state_dict[f"transformer_blocks.{depth}.attn1.to_v.weight"] = v
+ state_dict[f"transformer_blocks.{depth}.attn1.to_v.bias"] = v_bias
+
+ state_dict[f"transformer_blocks.{depth}.attn1.to_out.0.weight"] = state_dict[
+ f"blocks.{depth}.attn.proj.weight"
+ ]
+ state_dict[f"transformer_blocks.{depth}.attn1.to_out.0.bias"] = state_dict[f"blocks.{depth}.attn.proj.bias"]
+
+ state_dict[f"transformer_blocks.{depth}.ff.net.0.proj.weight"] = state_dict[f"blocks.{depth}.mlp.fc1.weight"]
+ state_dict[f"transformer_blocks.{depth}.ff.net.0.proj.bias"] = state_dict[f"blocks.{depth}.mlp.fc1.bias"]
+ state_dict[f"transformer_blocks.{depth}.ff.net.2.weight"] = state_dict[f"blocks.{depth}.mlp.fc2.weight"]
+ state_dict[f"transformer_blocks.{depth}.ff.net.2.bias"] = state_dict[f"blocks.{depth}.mlp.fc2.bias"]
+
+ state_dict.pop(f"blocks.{depth}.attn.qkv.weight")
+ state_dict.pop(f"blocks.{depth}.attn.qkv.bias")
+ state_dict.pop(f"blocks.{depth}.attn.proj.weight")
+ state_dict.pop(f"blocks.{depth}.attn.proj.bias")
+ state_dict.pop(f"blocks.{depth}.mlp.fc1.weight")
+ state_dict.pop(f"blocks.{depth}.mlp.fc1.bias")
+ state_dict.pop(f"blocks.{depth}.mlp.fc2.weight")
+ state_dict.pop(f"blocks.{depth}.mlp.fc2.bias")
+ state_dict.pop(f"blocks.{depth}.adaLN_modulation.1.weight")
+ state_dict.pop(f"blocks.{depth}.adaLN_modulation.1.bias")
+
+ state_dict.pop("t_embedder.mlp.0.weight")
+ state_dict.pop("t_embedder.mlp.0.bias")
+ state_dict.pop("t_embedder.mlp.2.weight")
+ state_dict.pop("t_embedder.mlp.2.bias")
+ state_dict.pop("y_embedder.embedding_table.weight")
+
+ state_dict["proj_out_1.weight"] = state_dict["final_layer.adaLN_modulation.1.weight"]
+ state_dict["proj_out_1.bias"] = state_dict["final_layer.adaLN_modulation.1.bias"]
+ state_dict["proj_out_2.weight"] = state_dict["final_layer.linear.weight"]
+ state_dict["proj_out_2.bias"] = state_dict["final_layer.linear.bias"]
+
+ state_dict.pop("final_layer.linear.weight")
+ state_dict.pop("final_layer.linear.bias")
+ state_dict.pop("final_layer.adaLN_modulation.1.weight")
+ state_dict.pop("final_layer.adaLN_modulation.1.bias")
+
+ # DiT XL/2
+ transformer = Transformer2DModel(
+ sample_size=args.image_size // 8,
+ num_layers=28,
+ attention_head_dim=72,
+ in_channels=4,
+ out_channels=8,
+ patch_size=2,
+ attention_bias=True,
+ num_attention_heads=16,
+ activation_fn="gelu-approximate",
+ num_embeds_ada_norm=1000,
+ norm_type="ada_norm_zero",
+ norm_elementwise_affine=False,
+ )
+ transformer.load_state_dict(state_dict, strict=True)
+
+ scheduler = DDIMScheduler(
+ num_train_timesteps=1000,
+ beta_schedule="linear",
+ prediction_type="epsilon",
+ clip_sample=False,
+ )
+
+ vae = AutoencoderKL.from_pretrained(args.vae_model)
+
+ pipeline = DiTPipeline(transformer=transformer, vae=vae, scheduler=scheduler)
+
+ if args.save:
+ pipeline.save_pretrained(args.checkpoint_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--image_size",
+ default=256,
+ type=int,
+ required=False,
+ help="Image size of pretrained model, either 256 or 512.",
+ )
+ parser.add_argument(
+ "--vae_model",
+ default="stabilityai/sd-vae-ft-ema",
+ type=str,
+ required=False,
+ help="Path to pretrained VAE model, either stabilityai/sd-vae-ft-mse or stabilityai/sd-vae-ft-ema.",
+ )
+ parser.add_argument(
+ "--save", default=True, type=bool, required=False, help="Whether to save the converted pipeline or not."
+ )
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the output pipeline."
+ )
+
+ args = parser.parse_args()
+ main(args)
diff --git a/diffusers/scripts/convert_k_upscaler_to_diffusers.py b/diffusers/scripts/convert_k_upscaler_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..62abedd737855ca0b0bc9abb75c9b6fb91d5bde2
--- /dev/null
+++ b/diffusers/scripts/convert_k_upscaler_to_diffusers.py
@@ -0,0 +1,297 @@
+import argparse
+
+import huggingface_hub
+import k_diffusion as K
+import torch
+
+from diffusers import UNet2DConditionModel
+
+
+UPSCALER_REPO = "pcuenq/k-upscaler"
+
+
+def resnet_to_diffusers_checkpoint(resnet, checkpoint, *, diffusers_resnet_prefix, resnet_prefix):
+ rv = {
+ # norm1
+ f"{diffusers_resnet_prefix}.norm1.linear.weight": checkpoint[f"{resnet_prefix}.main.0.mapper.weight"],
+ f"{diffusers_resnet_prefix}.norm1.linear.bias": checkpoint[f"{resnet_prefix}.main.0.mapper.bias"],
+ # conv1
+ f"{diffusers_resnet_prefix}.conv1.weight": checkpoint[f"{resnet_prefix}.main.2.weight"],
+ f"{diffusers_resnet_prefix}.conv1.bias": checkpoint[f"{resnet_prefix}.main.2.bias"],
+ # norm2
+ f"{diffusers_resnet_prefix}.norm2.linear.weight": checkpoint[f"{resnet_prefix}.main.4.mapper.weight"],
+ f"{diffusers_resnet_prefix}.norm2.linear.bias": checkpoint[f"{resnet_prefix}.main.4.mapper.bias"],
+ # conv2
+ f"{diffusers_resnet_prefix}.conv2.weight": checkpoint[f"{resnet_prefix}.main.6.weight"],
+ f"{diffusers_resnet_prefix}.conv2.bias": checkpoint[f"{resnet_prefix}.main.6.bias"],
+ }
+
+ if resnet.conv_shortcut is not None:
+ rv.update(
+ {
+ f"{diffusers_resnet_prefix}.conv_shortcut.weight": checkpoint[f"{resnet_prefix}.skip.weight"],
+ }
+ )
+
+ return rv
+
+
+def self_attn_to_diffusers_checkpoint(checkpoint, *, diffusers_attention_prefix, attention_prefix):
+ weight_q, weight_k, weight_v = checkpoint[f"{attention_prefix}.qkv_proj.weight"].chunk(3, dim=0)
+ bias_q, bias_k, bias_v = checkpoint[f"{attention_prefix}.qkv_proj.bias"].chunk(3, dim=0)
+ rv = {
+ # norm
+ f"{diffusers_attention_prefix}.norm1.linear.weight": checkpoint[f"{attention_prefix}.norm_in.mapper.weight"],
+ f"{diffusers_attention_prefix}.norm1.linear.bias": checkpoint[f"{attention_prefix}.norm_in.mapper.bias"],
+ # to_q
+ f"{diffusers_attention_prefix}.attn1.to_q.weight": weight_q.squeeze(-1).squeeze(-1),
+ f"{diffusers_attention_prefix}.attn1.to_q.bias": bias_q,
+ # to_k
+ f"{diffusers_attention_prefix}.attn1.to_k.weight": weight_k.squeeze(-1).squeeze(-1),
+ f"{diffusers_attention_prefix}.attn1.to_k.bias": bias_k,
+ # to_v
+ f"{diffusers_attention_prefix}.attn1.to_v.weight": weight_v.squeeze(-1).squeeze(-1),
+ f"{diffusers_attention_prefix}.attn1.to_v.bias": bias_v,
+ # to_out
+ f"{diffusers_attention_prefix}.attn1.to_out.0.weight": checkpoint[f"{attention_prefix}.out_proj.weight"]
+ .squeeze(-1)
+ .squeeze(-1),
+ f"{diffusers_attention_prefix}.attn1.to_out.0.bias": checkpoint[f"{attention_prefix}.out_proj.bias"],
+ }
+
+ return rv
+
+
+def cross_attn_to_diffusers_checkpoint(
+ checkpoint, *, diffusers_attention_prefix, diffusers_attention_index, attention_prefix
+):
+ weight_k, weight_v = checkpoint[f"{attention_prefix}.kv_proj.weight"].chunk(2, dim=0)
+ bias_k, bias_v = checkpoint[f"{attention_prefix}.kv_proj.bias"].chunk(2, dim=0)
+
+ rv = {
+ # norm2 (ada groupnorm)
+ f"{diffusers_attention_prefix}.norm{diffusers_attention_index}.linear.weight": checkpoint[
+ f"{attention_prefix}.norm_dec.mapper.weight"
+ ],
+ f"{diffusers_attention_prefix}.norm{diffusers_attention_index}.linear.bias": checkpoint[
+ f"{attention_prefix}.norm_dec.mapper.bias"
+ ],
+ # layernorm on encoder_hidden_state
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.norm_cross.weight": checkpoint[
+ f"{attention_prefix}.norm_enc.weight"
+ ],
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.norm_cross.bias": checkpoint[
+ f"{attention_prefix}.norm_enc.bias"
+ ],
+ # to_q
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.to_q.weight": checkpoint[
+ f"{attention_prefix}.q_proj.weight"
+ ]
+ .squeeze(-1)
+ .squeeze(-1),
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.to_q.bias": checkpoint[
+ f"{attention_prefix}.q_proj.bias"
+ ],
+ # to_k
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.to_k.weight": weight_k.squeeze(-1).squeeze(-1),
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.to_k.bias": bias_k,
+ # to_v
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.to_v.weight": weight_v.squeeze(-1).squeeze(-1),
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.to_v.bias": bias_v,
+ # to_out
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.to_out.0.weight": checkpoint[
+ f"{attention_prefix}.out_proj.weight"
+ ]
+ .squeeze(-1)
+ .squeeze(-1),
+ f"{diffusers_attention_prefix}.attn{diffusers_attention_index}.to_out.0.bias": checkpoint[
+ f"{attention_prefix}.out_proj.bias"
+ ],
+ }
+
+ return rv
+
+
+def block_to_diffusers_checkpoint(block, checkpoint, block_idx, block_type):
+ block_prefix = "inner_model.u_net.u_blocks" if block_type == "up" else "inner_model.u_net.d_blocks"
+ block_prefix = f"{block_prefix}.{block_idx}"
+
+ diffusers_checkpoint = {}
+
+ if not hasattr(block, "attentions"):
+ n = 1 # resnet only
+ elif not block.attentions[0].add_self_attention:
+ n = 2 # resnet -> cross-attention
+ else:
+ n = 3 # resnet -> self-attention -> cross-attention)
+
+ for resnet_idx, resnet in enumerate(block.resnets):
+ # diffusers_resnet_prefix = f"{diffusers_up_block_prefix}.resnets.{resnet_idx}"
+ diffusers_resnet_prefix = f"{block_type}_blocks.{block_idx}.resnets.{resnet_idx}"
+ idx = n * resnet_idx if block_type == "up" else n * resnet_idx + 1
+ resnet_prefix = f"{block_prefix}.{idx}" if block_type == "up" else f"{block_prefix}.{idx}"
+
+ diffusers_checkpoint.update(
+ resnet_to_diffusers_checkpoint(
+ resnet, checkpoint, diffusers_resnet_prefix=diffusers_resnet_prefix, resnet_prefix=resnet_prefix
+ )
+ )
+
+ if hasattr(block, "attentions"):
+ for attention_idx, attention in enumerate(block.attentions):
+ diffusers_attention_prefix = f"{block_type}_blocks.{block_idx}.attentions.{attention_idx}"
+ idx = n * attention_idx + 1 if block_type == "up" else n * attention_idx + 2
+ self_attention_prefix = f"{block_prefix}.{idx}"
+ cross_attention_prefix = f"{block_prefix}.{idx }"
+ cross_attention_index = 1 if not attention.add_self_attention else 2
+ idx = (
+ n * attention_idx + cross_attention_index
+ if block_type == "up"
+ else n * attention_idx + cross_attention_index + 1
+ )
+ cross_attention_prefix = f"{block_prefix}.{idx }"
+
+ diffusers_checkpoint.update(
+ cross_attn_to_diffusers_checkpoint(
+ checkpoint,
+ diffusers_attention_prefix=diffusers_attention_prefix,
+ diffusers_attention_index=2,
+ attention_prefix=cross_attention_prefix,
+ )
+ )
+
+ if attention.add_self_attention is True:
+ diffusers_checkpoint.update(
+ self_attn_to_diffusers_checkpoint(
+ checkpoint,
+ diffusers_attention_prefix=diffusers_attention_prefix,
+ attention_prefix=self_attention_prefix,
+ )
+ )
+
+ return diffusers_checkpoint
+
+
+def unet_to_diffusers_checkpoint(model, checkpoint):
+ diffusers_checkpoint = {}
+
+ # pre-processing
+ diffusers_checkpoint.update(
+ {
+ "conv_in.weight": checkpoint["inner_model.proj_in.weight"],
+ "conv_in.bias": checkpoint["inner_model.proj_in.bias"],
+ }
+ )
+
+ # timestep and class embedding
+ diffusers_checkpoint.update(
+ {
+ "time_proj.weight": checkpoint["inner_model.timestep_embed.weight"].squeeze(-1),
+ "time_embedding.linear_1.weight": checkpoint["inner_model.mapping.0.weight"],
+ "time_embedding.linear_1.bias": checkpoint["inner_model.mapping.0.bias"],
+ "time_embedding.linear_2.weight": checkpoint["inner_model.mapping.2.weight"],
+ "time_embedding.linear_2.bias": checkpoint["inner_model.mapping.2.bias"],
+ "time_embedding.cond_proj.weight": checkpoint["inner_model.mapping_cond.weight"],
+ }
+ )
+
+ # down_blocks
+ for down_block_idx, down_block in enumerate(model.down_blocks):
+ diffusers_checkpoint.update(block_to_diffusers_checkpoint(down_block, checkpoint, down_block_idx, "down"))
+
+ # up_blocks
+ for up_block_idx, up_block in enumerate(model.up_blocks):
+ diffusers_checkpoint.update(block_to_diffusers_checkpoint(up_block, checkpoint, up_block_idx, "up"))
+
+ # post-processing
+ diffusers_checkpoint.update(
+ {
+ "conv_out.weight": checkpoint["inner_model.proj_out.weight"],
+ "conv_out.bias": checkpoint["inner_model.proj_out.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+def unet_model_from_original_config(original_config):
+ in_channels = original_config["input_channels"] + original_config["unet_cond_dim"]
+ out_channels = original_config["input_channels"] + (1 if original_config["has_variance"] else 0)
+
+ block_out_channels = original_config["channels"]
+
+ assert (
+ len(set(original_config["depths"])) == 1
+ ), "UNet2DConditionModel currently do not support blocks with different number of layers"
+ layers_per_block = original_config["depths"][0]
+
+ class_labels_dim = original_config["mapping_cond_dim"]
+ cross_attention_dim = original_config["cross_cond_dim"]
+
+ attn1_types = []
+ attn2_types = []
+ for s, c in zip(original_config["self_attn_depths"], original_config["cross_attn_depths"]):
+ if s:
+ a1 = "self"
+ a2 = "cross" if c else None
+ elif c:
+ a1 = "cross"
+ a2 = None
+ else:
+ a1 = None
+ a2 = None
+ attn1_types.append(a1)
+ attn2_types.append(a2)
+
+ unet = UNet2DConditionModel(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ down_block_types=("KDownBlock2D", "KCrossAttnDownBlock2D", "KCrossAttnDownBlock2D", "KCrossAttnDownBlock2D"),
+ mid_block_type=None,
+ up_block_types=("KCrossAttnUpBlock2D", "KCrossAttnUpBlock2D", "KCrossAttnUpBlock2D", "KUpBlock2D"),
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn="gelu",
+ norm_num_groups=None,
+ cross_attention_dim=cross_attention_dim,
+ attention_head_dim=64,
+ time_cond_proj_dim=class_labels_dim,
+ resnet_time_scale_shift="scale_shift",
+ time_embedding_type="fourier",
+ timestep_post_act="gelu",
+ conv_in_kernel=1,
+ conv_out_kernel=1,
+ )
+
+ return unet
+
+
+def main(args):
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+ orig_config_path = huggingface_hub.hf_hub_download(UPSCALER_REPO, "config_laion_text_cond_latent_upscaler_2.json")
+ orig_weights_path = huggingface_hub.hf_hub_download(
+ UPSCALER_REPO, "laion_text_cond_latent_upscaler_2_1_00470000_slim.pth"
+ )
+ print(f"loading original model configuration from {orig_config_path}")
+ print(f"loading original model checkpoint from {orig_weights_path}")
+
+ print("converting to diffusers unet")
+ orig_config = K.config.load_config(open(orig_config_path))["model"]
+ model = unet_model_from_original_config(orig_config)
+
+ orig_checkpoint = torch.load(orig_weights_path, map_location=device)["model_ema"]
+ converted_checkpoint = unet_to_diffusers_checkpoint(model, orig_checkpoint)
+
+ model.load_state_dict(converted_checkpoint, strict=True)
+ model.save_pretrained(args.dump_path)
+ print(f"saving converted unet model in {args.dump_path}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+ args = parser.parse_args()
+
+ main(args)
diff --git a/diffusers/scripts/convert_kakao_brain_unclip_to_diffusers.py b/diffusers/scripts/convert_kakao_brain_unclip_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..85d983dea686f26d0196be94c3ef35496161eb24
--- /dev/null
+++ b/diffusers/scripts/convert_kakao_brain_unclip_to_diffusers.py
@@ -0,0 +1,1159 @@
+import argparse
+import tempfile
+
+import torch
+from accelerate import load_checkpoint_and_dispatch
+from transformers import CLIPTextModelWithProjection, CLIPTokenizer
+
+from diffusers import UnCLIPPipeline, UNet2DConditionModel, UNet2DModel
+from diffusers.models.prior_transformer import PriorTransformer
+from diffusers.pipelines.unclip.text_proj import UnCLIPTextProjModel
+from diffusers.schedulers.scheduling_unclip import UnCLIPScheduler
+
+
+"""
+Example - From the diffusers root directory:
+
+Download weights:
+```sh
+$ wget https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/efdf6206d8ed593961593dc029a8affa/decoder-ckpt-step%3D01000000-of-01000000.ckpt
+$ wget https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/4226b831ae0279020d134281f3c31590/improved-sr-ckpt-step%3D1.2M.ckpt
+$ wget https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/85626483eaca9f581e2a78d31ff905ca/prior-ckpt-step%3D01000000-of-01000000.ckpt
+$ wget https://arena.kakaocdn.net/brainrepo/models/karlo-public/v1.0.0.alpha/0b62380a75e56f073e2844ab5199153d/ViT-L-14_stats.th
+```
+
+Convert the model:
+```sh
+$ python scripts/convert_kakao_brain_unclip_to_diffusers.py \
+ --decoder_checkpoint_path ./decoder-ckpt-step\=01000000-of-01000000.ckpt \
+ --super_res_unet_checkpoint_path ./improved-sr-ckpt-step\=1.2M.ckpt \
+ --prior_checkpoint_path ./prior-ckpt-step\=01000000-of-01000000.ckpt \
+ --clip_stat_path ./ViT-L-14_stats.th \
+ --dump_path
+```
+"""
+
+
+# prior
+
+PRIOR_ORIGINAL_PREFIX = "model"
+
+# Uses default arguments
+PRIOR_CONFIG = {}
+
+
+def prior_model_from_original_config():
+ model = PriorTransformer(**PRIOR_CONFIG)
+
+ return model
+
+
+def prior_original_checkpoint_to_diffusers_checkpoint(model, checkpoint, clip_stats_checkpoint):
+ diffusers_checkpoint = {}
+
+ # .time_embed.0 -> .time_embedding.linear_1
+ diffusers_checkpoint.update(
+ {
+ "time_embedding.linear_1.weight": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.time_embed.0.weight"],
+ "time_embedding.linear_1.bias": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.time_embed.0.bias"],
+ }
+ )
+
+ # .clip_img_proj -> .proj_in
+ diffusers_checkpoint.update(
+ {
+ "proj_in.weight": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.clip_img_proj.weight"],
+ "proj_in.bias": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.clip_img_proj.bias"],
+ }
+ )
+
+ # .text_emb_proj -> .embedding_proj
+ diffusers_checkpoint.update(
+ {
+ "embedding_proj.weight": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.text_emb_proj.weight"],
+ "embedding_proj.bias": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.text_emb_proj.bias"],
+ }
+ )
+
+ # .text_enc_proj -> .encoder_hidden_states_proj
+ diffusers_checkpoint.update(
+ {
+ "encoder_hidden_states_proj.weight": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.text_enc_proj.weight"],
+ "encoder_hidden_states_proj.bias": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.text_enc_proj.bias"],
+ }
+ )
+
+ # .positional_embedding -> .positional_embedding
+ diffusers_checkpoint.update({"positional_embedding": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.positional_embedding"]})
+
+ # .prd_emb -> .prd_embedding
+ diffusers_checkpoint.update({"prd_embedding": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.prd_emb"]})
+
+ # .time_embed.2 -> .time_embedding.linear_2
+ diffusers_checkpoint.update(
+ {
+ "time_embedding.linear_2.weight": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.time_embed.2.weight"],
+ "time_embedding.linear_2.bias": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.time_embed.2.bias"],
+ }
+ )
+
+ # .resblocks. -> .transformer_blocks.
+ for idx in range(len(model.transformer_blocks)):
+ diffusers_transformer_prefix = f"transformer_blocks.{idx}"
+ original_transformer_prefix = f"{PRIOR_ORIGINAL_PREFIX}.transformer.resblocks.{idx}"
+
+ # .attn -> .attn1
+ diffusers_attention_prefix = f"{diffusers_transformer_prefix}.attn1"
+ original_attention_prefix = f"{original_transformer_prefix}.attn"
+ diffusers_checkpoint.update(
+ prior_attention_to_diffusers(
+ checkpoint,
+ diffusers_attention_prefix=diffusers_attention_prefix,
+ original_attention_prefix=original_attention_prefix,
+ attention_head_dim=model.attention_head_dim,
+ )
+ )
+
+ # .mlp -> .ff
+ diffusers_ff_prefix = f"{diffusers_transformer_prefix}.ff"
+ original_ff_prefix = f"{original_transformer_prefix}.mlp"
+ diffusers_checkpoint.update(
+ prior_ff_to_diffusers(
+ checkpoint, diffusers_ff_prefix=diffusers_ff_prefix, original_ff_prefix=original_ff_prefix
+ )
+ )
+
+ # .ln_1 -> .norm1
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_transformer_prefix}.norm1.weight": checkpoint[
+ f"{original_transformer_prefix}.ln_1.weight"
+ ],
+ f"{diffusers_transformer_prefix}.norm1.bias": checkpoint[f"{original_transformer_prefix}.ln_1.bias"],
+ }
+ )
+
+ # .ln_2 -> .norm3
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_transformer_prefix}.norm3.weight": checkpoint[
+ f"{original_transformer_prefix}.ln_2.weight"
+ ],
+ f"{diffusers_transformer_prefix}.norm3.bias": checkpoint[f"{original_transformer_prefix}.ln_2.bias"],
+ }
+ )
+
+ # .final_ln -> .norm_out
+ diffusers_checkpoint.update(
+ {
+ "norm_out.weight": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.final_ln.weight"],
+ "norm_out.bias": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.final_ln.bias"],
+ }
+ )
+
+ # .out_proj -> .proj_to_clip_embeddings
+ diffusers_checkpoint.update(
+ {
+ "proj_to_clip_embeddings.weight": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.out_proj.weight"],
+ "proj_to_clip_embeddings.bias": checkpoint[f"{PRIOR_ORIGINAL_PREFIX}.out_proj.bias"],
+ }
+ )
+
+ # clip stats
+ clip_mean, clip_std = clip_stats_checkpoint
+ clip_mean = clip_mean[None, :]
+ clip_std = clip_std[None, :]
+
+ diffusers_checkpoint.update({"clip_mean": clip_mean, "clip_std": clip_std})
+
+ return diffusers_checkpoint
+
+
+def prior_attention_to_diffusers(
+ checkpoint, *, diffusers_attention_prefix, original_attention_prefix, attention_head_dim
+):
+ diffusers_checkpoint = {}
+
+ # .c_qkv -> .{to_q, to_k, to_v}
+ [q_weight, k_weight, v_weight], [q_bias, k_bias, v_bias] = split_attentions(
+ weight=checkpoint[f"{original_attention_prefix}.c_qkv.weight"],
+ bias=checkpoint[f"{original_attention_prefix}.c_qkv.bias"],
+ split=3,
+ chunk_size=attention_head_dim,
+ )
+
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_attention_prefix}.to_q.weight": q_weight,
+ f"{diffusers_attention_prefix}.to_q.bias": q_bias,
+ f"{diffusers_attention_prefix}.to_k.weight": k_weight,
+ f"{diffusers_attention_prefix}.to_k.bias": k_bias,
+ f"{diffusers_attention_prefix}.to_v.weight": v_weight,
+ f"{diffusers_attention_prefix}.to_v.bias": v_bias,
+ }
+ )
+
+ # .c_proj -> .to_out.0
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_attention_prefix}.to_out.0.weight": checkpoint[f"{original_attention_prefix}.c_proj.weight"],
+ f"{diffusers_attention_prefix}.to_out.0.bias": checkpoint[f"{original_attention_prefix}.c_proj.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+def prior_ff_to_diffusers(checkpoint, *, diffusers_ff_prefix, original_ff_prefix):
+ diffusers_checkpoint = {
+ # .c_fc -> .net.0.proj
+ f"{diffusers_ff_prefix}.net.{0}.proj.weight": checkpoint[f"{original_ff_prefix}.c_fc.weight"],
+ f"{diffusers_ff_prefix}.net.{0}.proj.bias": checkpoint[f"{original_ff_prefix}.c_fc.bias"],
+ # .c_proj -> .net.2
+ f"{diffusers_ff_prefix}.net.{2}.weight": checkpoint[f"{original_ff_prefix}.c_proj.weight"],
+ f"{diffusers_ff_prefix}.net.{2}.bias": checkpoint[f"{original_ff_prefix}.c_proj.bias"],
+ }
+
+ return diffusers_checkpoint
+
+
+# done prior
+
+
+# decoder
+
+DECODER_ORIGINAL_PREFIX = "model"
+
+# We are hardcoding the model configuration for now. If we need to generalize to more model configurations, we can
+# update then.
+DECODER_CONFIG = {
+ "sample_size": 64,
+ "layers_per_block": 3,
+ "down_block_types": (
+ "ResnetDownsampleBlock2D",
+ "SimpleCrossAttnDownBlock2D",
+ "SimpleCrossAttnDownBlock2D",
+ "SimpleCrossAttnDownBlock2D",
+ ),
+ "up_block_types": (
+ "SimpleCrossAttnUpBlock2D",
+ "SimpleCrossAttnUpBlock2D",
+ "SimpleCrossAttnUpBlock2D",
+ "ResnetUpsampleBlock2D",
+ ),
+ "mid_block_type": "UNetMidBlock2DSimpleCrossAttn",
+ "block_out_channels": (320, 640, 960, 1280),
+ "in_channels": 3,
+ "out_channels": 6,
+ "cross_attention_dim": 1536,
+ "class_embed_type": "identity",
+ "attention_head_dim": 64,
+ "resnet_time_scale_shift": "scale_shift",
+}
+
+
+def decoder_model_from_original_config():
+ model = UNet2DConditionModel(**DECODER_CONFIG)
+
+ return model
+
+
+def decoder_original_checkpoint_to_diffusers_checkpoint(model, checkpoint):
+ diffusers_checkpoint = {}
+
+ original_unet_prefix = DECODER_ORIGINAL_PREFIX
+ num_head_channels = DECODER_CONFIG["attention_head_dim"]
+
+ diffusers_checkpoint.update(unet_time_embeddings(checkpoint, original_unet_prefix))
+ diffusers_checkpoint.update(unet_conv_in(checkpoint, original_unet_prefix))
+
+ # .input_blocks -> .down_blocks
+
+ original_down_block_idx = 1
+
+ for diffusers_down_block_idx in range(len(model.down_blocks)):
+ checkpoint_update, num_original_down_blocks = unet_downblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ diffusers_down_block_idx=diffusers_down_block_idx,
+ original_down_block_idx=original_down_block_idx,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=num_head_channels,
+ )
+
+ original_down_block_idx += num_original_down_blocks
+
+ diffusers_checkpoint.update(checkpoint_update)
+
+ # done .input_blocks -> .down_blocks
+
+ diffusers_checkpoint.update(
+ unet_midblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=num_head_channels,
+ )
+ )
+
+ # .output_blocks -> .up_blocks
+
+ original_up_block_idx = 0
+
+ for diffusers_up_block_idx in range(len(model.up_blocks)):
+ checkpoint_update, num_original_up_blocks = unet_upblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ diffusers_up_block_idx=diffusers_up_block_idx,
+ original_up_block_idx=original_up_block_idx,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=num_head_channels,
+ )
+
+ original_up_block_idx += num_original_up_blocks
+
+ diffusers_checkpoint.update(checkpoint_update)
+
+ # done .output_blocks -> .up_blocks
+
+ diffusers_checkpoint.update(unet_conv_norm_out(checkpoint, original_unet_prefix))
+ diffusers_checkpoint.update(unet_conv_out(checkpoint, original_unet_prefix))
+
+ return diffusers_checkpoint
+
+
+# done decoder
+
+# text proj
+
+
+def text_proj_from_original_config():
+ # From the conditional unet constructor where the dimension of the projected time embeddings is
+ # constructed
+ time_embed_dim = DECODER_CONFIG["block_out_channels"][0] * 4
+
+ cross_attention_dim = DECODER_CONFIG["cross_attention_dim"]
+
+ model = UnCLIPTextProjModel(time_embed_dim=time_embed_dim, cross_attention_dim=cross_attention_dim)
+
+ return model
+
+
+# Note that the input checkpoint is the original decoder checkpoint
+def text_proj_original_checkpoint_to_diffusers_checkpoint(checkpoint):
+ diffusers_checkpoint = {
+ # .text_seq_proj.0 -> .encoder_hidden_states_proj
+ "encoder_hidden_states_proj.weight": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.text_seq_proj.0.weight"],
+ "encoder_hidden_states_proj.bias": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.text_seq_proj.0.bias"],
+ # .text_seq_proj.1 -> .text_encoder_hidden_states_norm
+ "text_encoder_hidden_states_norm.weight": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.text_seq_proj.1.weight"],
+ "text_encoder_hidden_states_norm.bias": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.text_seq_proj.1.bias"],
+ # .clip_tok_proj -> .clip_extra_context_tokens_proj
+ "clip_extra_context_tokens_proj.weight": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.clip_tok_proj.weight"],
+ "clip_extra_context_tokens_proj.bias": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.clip_tok_proj.bias"],
+ # .text_feat_proj -> .embedding_proj
+ "embedding_proj.weight": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.text_feat_proj.weight"],
+ "embedding_proj.bias": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.text_feat_proj.bias"],
+ # .cf_param -> .learned_classifier_free_guidance_embeddings
+ "learned_classifier_free_guidance_embeddings": checkpoint[f"{DECODER_ORIGINAL_PREFIX}.cf_param"],
+ # .clip_emb -> .clip_image_embeddings_project_to_time_embeddings
+ "clip_image_embeddings_project_to_time_embeddings.weight": checkpoint[
+ f"{DECODER_ORIGINAL_PREFIX}.clip_emb.weight"
+ ],
+ "clip_image_embeddings_project_to_time_embeddings.bias": checkpoint[
+ f"{DECODER_ORIGINAL_PREFIX}.clip_emb.bias"
+ ],
+ }
+
+ return diffusers_checkpoint
+
+
+# done text proj
+
+# super res unet first steps
+
+SUPER_RES_UNET_FIRST_STEPS_PREFIX = "model_first_steps"
+
+SUPER_RES_UNET_FIRST_STEPS_CONFIG = {
+ "sample_size": 256,
+ "layers_per_block": 3,
+ "down_block_types": (
+ "ResnetDownsampleBlock2D",
+ "ResnetDownsampleBlock2D",
+ "ResnetDownsampleBlock2D",
+ "ResnetDownsampleBlock2D",
+ ),
+ "up_block_types": (
+ "ResnetUpsampleBlock2D",
+ "ResnetUpsampleBlock2D",
+ "ResnetUpsampleBlock2D",
+ "ResnetUpsampleBlock2D",
+ ),
+ "block_out_channels": (320, 640, 960, 1280),
+ "in_channels": 6,
+ "out_channels": 3,
+ "add_attention": False,
+}
+
+
+def super_res_unet_first_steps_model_from_original_config():
+ model = UNet2DModel(**SUPER_RES_UNET_FIRST_STEPS_CONFIG)
+
+ return model
+
+
+def super_res_unet_first_steps_original_checkpoint_to_diffusers_checkpoint(model, checkpoint):
+ diffusers_checkpoint = {}
+
+ original_unet_prefix = SUPER_RES_UNET_FIRST_STEPS_PREFIX
+
+ diffusers_checkpoint.update(unet_time_embeddings(checkpoint, original_unet_prefix))
+ diffusers_checkpoint.update(unet_conv_in(checkpoint, original_unet_prefix))
+
+ # .input_blocks -> .down_blocks
+
+ original_down_block_idx = 1
+
+ for diffusers_down_block_idx in range(len(model.down_blocks)):
+ checkpoint_update, num_original_down_blocks = unet_downblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ diffusers_down_block_idx=diffusers_down_block_idx,
+ original_down_block_idx=original_down_block_idx,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=None,
+ )
+
+ original_down_block_idx += num_original_down_blocks
+
+ diffusers_checkpoint.update(checkpoint_update)
+
+ diffusers_checkpoint.update(
+ unet_midblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=None,
+ )
+ )
+
+ # .output_blocks -> .up_blocks
+
+ original_up_block_idx = 0
+
+ for diffusers_up_block_idx in range(len(model.up_blocks)):
+ checkpoint_update, num_original_up_blocks = unet_upblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ diffusers_up_block_idx=diffusers_up_block_idx,
+ original_up_block_idx=original_up_block_idx,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=None,
+ )
+
+ original_up_block_idx += num_original_up_blocks
+
+ diffusers_checkpoint.update(checkpoint_update)
+
+ # done .output_blocks -> .up_blocks
+
+ diffusers_checkpoint.update(unet_conv_norm_out(checkpoint, original_unet_prefix))
+ diffusers_checkpoint.update(unet_conv_out(checkpoint, original_unet_prefix))
+
+ return diffusers_checkpoint
+
+
+# done super res unet first steps
+
+# super res unet last step
+
+SUPER_RES_UNET_LAST_STEP_PREFIX = "model_last_step"
+
+SUPER_RES_UNET_LAST_STEP_CONFIG = {
+ "sample_size": 256,
+ "layers_per_block": 3,
+ "down_block_types": (
+ "ResnetDownsampleBlock2D",
+ "ResnetDownsampleBlock2D",
+ "ResnetDownsampleBlock2D",
+ "ResnetDownsampleBlock2D",
+ ),
+ "up_block_types": (
+ "ResnetUpsampleBlock2D",
+ "ResnetUpsampleBlock2D",
+ "ResnetUpsampleBlock2D",
+ "ResnetUpsampleBlock2D",
+ ),
+ "block_out_channels": (320, 640, 960, 1280),
+ "in_channels": 6,
+ "out_channels": 3,
+ "add_attention": False,
+}
+
+
+def super_res_unet_last_step_model_from_original_config():
+ model = UNet2DModel(**SUPER_RES_UNET_LAST_STEP_CONFIG)
+
+ return model
+
+
+def super_res_unet_last_step_original_checkpoint_to_diffusers_checkpoint(model, checkpoint):
+ diffusers_checkpoint = {}
+
+ original_unet_prefix = SUPER_RES_UNET_LAST_STEP_PREFIX
+
+ diffusers_checkpoint.update(unet_time_embeddings(checkpoint, original_unet_prefix))
+ diffusers_checkpoint.update(unet_conv_in(checkpoint, original_unet_prefix))
+
+ # .input_blocks -> .down_blocks
+
+ original_down_block_idx = 1
+
+ for diffusers_down_block_idx in range(len(model.down_blocks)):
+ checkpoint_update, num_original_down_blocks = unet_downblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ diffusers_down_block_idx=diffusers_down_block_idx,
+ original_down_block_idx=original_down_block_idx,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=None,
+ )
+
+ original_down_block_idx += num_original_down_blocks
+
+ diffusers_checkpoint.update(checkpoint_update)
+
+ diffusers_checkpoint.update(
+ unet_midblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=None,
+ )
+ )
+
+ # .output_blocks -> .up_blocks
+
+ original_up_block_idx = 0
+
+ for diffusers_up_block_idx in range(len(model.up_blocks)):
+ checkpoint_update, num_original_up_blocks = unet_upblock_to_diffusers_checkpoint(
+ model,
+ checkpoint,
+ diffusers_up_block_idx=diffusers_up_block_idx,
+ original_up_block_idx=original_up_block_idx,
+ original_unet_prefix=original_unet_prefix,
+ num_head_channels=None,
+ )
+
+ original_up_block_idx += num_original_up_blocks
+
+ diffusers_checkpoint.update(checkpoint_update)
+
+ # done .output_blocks -> .up_blocks
+
+ diffusers_checkpoint.update(unet_conv_norm_out(checkpoint, original_unet_prefix))
+ diffusers_checkpoint.update(unet_conv_out(checkpoint, original_unet_prefix))
+
+ return diffusers_checkpoint
+
+
+# done super res unet last step
+
+
+# unet utils
+
+
+# .time_embed -> .time_embedding
+def unet_time_embeddings(checkpoint, original_unet_prefix):
+ diffusers_checkpoint = {}
+
+ diffusers_checkpoint.update(
+ {
+ "time_embedding.linear_1.weight": checkpoint[f"{original_unet_prefix}.time_embed.0.weight"],
+ "time_embedding.linear_1.bias": checkpoint[f"{original_unet_prefix}.time_embed.0.bias"],
+ "time_embedding.linear_2.weight": checkpoint[f"{original_unet_prefix}.time_embed.2.weight"],
+ "time_embedding.linear_2.bias": checkpoint[f"{original_unet_prefix}.time_embed.2.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+# .input_blocks.0 -> .conv_in
+def unet_conv_in(checkpoint, original_unet_prefix):
+ diffusers_checkpoint = {}
+
+ diffusers_checkpoint.update(
+ {
+ "conv_in.weight": checkpoint[f"{original_unet_prefix}.input_blocks.0.0.weight"],
+ "conv_in.bias": checkpoint[f"{original_unet_prefix}.input_blocks.0.0.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+# .out.0 -> .conv_norm_out
+def unet_conv_norm_out(checkpoint, original_unet_prefix):
+ diffusers_checkpoint = {}
+
+ diffusers_checkpoint.update(
+ {
+ "conv_norm_out.weight": checkpoint[f"{original_unet_prefix}.out.0.weight"],
+ "conv_norm_out.bias": checkpoint[f"{original_unet_prefix}.out.0.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+# .out.2 -> .conv_out
+def unet_conv_out(checkpoint, original_unet_prefix):
+ diffusers_checkpoint = {}
+
+ diffusers_checkpoint.update(
+ {
+ "conv_out.weight": checkpoint[f"{original_unet_prefix}.out.2.weight"],
+ "conv_out.bias": checkpoint[f"{original_unet_prefix}.out.2.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+# .input_blocks -> .down_blocks
+def unet_downblock_to_diffusers_checkpoint(
+ model, checkpoint, *, diffusers_down_block_idx, original_down_block_idx, original_unet_prefix, num_head_channels
+):
+ diffusers_checkpoint = {}
+
+ diffusers_resnet_prefix = f"down_blocks.{diffusers_down_block_idx}.resnets"
+ original_down_block_prefix = f"{original_unet_prefix}.input_blocks"
+
+ down_block = model.down_blocks[diffusers_down_block_idx]
+
+ num_resnets = len(down_block.resnets)
+
+ if down_block.downsamplers is None:
+ downsampler = False
+ else:
+ assert len(down_block.downsamplers) == 1
+ downsampler = True
+ # The downsample block is also a resnet
+ num_resnets += 1
+
+ for resnet_idx_inc in range(num_resnets):
+ full_resnet_prefix = f"{original_down_block_prefix}.{original_down_block_idx + resnet_idx_inc}.0"
+
+ if downsampler and resnet_idx_inc == num_resnets - 1:
+ # this is a downsample block
+ full_diffusers_resnet_prefix = f"down_blocks.{diffusers_down_block_idx}.downsamplers.0"
+ else:
+ # this is a regular resnet block
+ full_diffusers_resnet_prefix = f"{diffusers_resnet_prefix}.{resnet_idx_inc}"
+
+ diffusers_checkpoint.update(
+ resnet_to_diffusers_checkpoint(
+ checkpoint, resnet_prefix=full_resnet_prefix, diffusers_resnet_prefix=full_diffusers_resnet_prefix
+ )
+ )
+
+ if hasattr(down_block, "attentions"):
+ num_attentions = len(down_block.attentions)
+ diffusers_attention_prefix = f"down_blocks.{diffusers_down_block_idx}.attentions"
+
+ for attention_idx_inc in range(num_attentions):
+ full_attention_prefix = f"{original_down_block_prefix}.{original_down_block_idx + attention_idx_inc}.1"
+ full_diffusers_attention_prefix = f"{diffusers_attention_prefix}.{attention_idx_inc}"
+
+ diffusers_checkpoint.update(
+ attention_to_diffusers_checkpoint(
+ checkpoint,
+ attention_prefix=full_attention_prefix,
+ diffusers_attention_prefix=full_diffusers_attention_prefix,
+ num_head_channels=num_head_channels,
+ )
+ )
+
+ num_original_down_blocks = num_resnets
+
+ return diffusers_checkpoint, num_original_down_blocks
+
+
+# .middle_block -> .mid_block
+def unet_midblock_to_diffusers_checkpoint(model, checkpoint, *, original_unet_prefix, num_head_channels):
+ diffusers_checkpoint = {}
+
+ # block 0
+
+ original_block_idx = 0
+
+ diffusers_checkpoint.update(
+ resnet_to_diffusers_checkpoint(
+ checkpoint,
+ diffusers_resnet_prefix="mid_block.resnets.0",
+ resnet_prefix=f"{original_unet_prefix}.middle_block.{original_block_idx}",
+ )
+ )
+
+ original_block_idx += 1
+
+ # optional block 1
+
+ if hasattr(model.mid_block, "attentions") and model.mid_block.attentions[0] is not None:
+ diffusers_checkpoint.update(
+ attention_to_diffusers_checkpoint(
+ checkpoint,
+ diffusers_attention_prefix="mid_block.attentions.0",
+ attention_prefix=f"{original_unet_prefix}.middle_block.{original_block_idx}",
+ num_head_channels=num_head_channels,
+ )
+ )
+ original_block_idx += 1
+
+ # block 1 or block 2
+
+ diffusers_checkpoint.update(
+ resnet_to_diffusers_checkpoint(
+ checkpoint,
+ diffusers_resnet_prefix="mid_block.resnets.1",
+ resnet_prefix=f"{original_unet_prefix}.middle_block.{original_block_idx}",
+ )
+ )
+
+ return diffusers_checkpoint
+
+
+# .output_blocks -> .up_blocks
+def unet_upblock_to_diffusers_checkpoint(
+ model, checkpoint, *, diffusers_up_block_idx, original_up_block_idx, original_unet_prefix, num_head_channels
+):
+ diffusers_checkpoint = {}
+
+ diffusers_resnet_prefix = f"up_blocks.{diffusers_up_block_idx}.resnets"
+ original_up_block_prefix = f"{original_unet_prefix}.output_blocks"
+
+ up_block = model.up_blocks[diffusers_up_block_idx]
+
+ num_resnets = len(up_block.resnets)
+
+ if up_block.upsamplers is None:
+ upsampler = False
+ else:
+ assert len(up_block.upsamplers) == 1
+ upsampler = True
+ # The upsample block is also a resnet
+ num_resnets += 1
+
+ has_attentions = hasattr(up_block, "attentions")
+
+ for resnet_idx_inc in range(num_resnets):
+ if upsampler and resnet_idx_inc == num_resnets - 1:
+ # this is an upsample block
+ if has_attentions:
+ # There is a middle attention block that we skip
+ original_resnet_block_idx = 2
+ else:
+ original_resnet_block_idx = 1
+
+ # we add the `minus 1` because the last two resnets are stuck together in the same output block
+ full_resnet_prefix = (
+ f"{original_up_block_prefix}.{original_up_block_idx + resnet_idx_inc - 1}.{original_resnet_block_idx}"
+ )
+
+ full_diffusers_resnet_prefix = f"up_blocks.{diffusers_up_block_idx}.upsamplers.0"
+ else:
+ # this is a regular resnet block
+ full_resnet_prefix = f"{original_up_block_prefix}.{original_up_block_idx + resnet_idx_inc}.0"
+ full_diffusers_resnet_prefix = f"{diffusers_resnet_prefix}.{resnet_idx_inc}"
+
+ diffusers_checkpoint.update(
+ resnet_to_diffusers_checkpoint(
+ checkpoint, resnet_prefix=full_resnet_prefix, diffusers_resnet_prefix=full_diffusers_resnet_prefix
+ )
+ )
+
+ if has_attentions:
+ num_attentions = len(up_block.attentions)
+ diffusers_attention_prefix = f"up_blocks.{diffusers_up_block_idx}.attentions"
+
+ for attention_idx_inc in range(num_attentions):
+ full_attention_prefix = f"{original_up_block_prefix}.{original_up_block_idx + attention_idx_inc}.1"
+ full_diffusers_attention_prefix = f"{diffusers_attention_prefix}.{attention_idx_inc}"
+
+ diffusers_checkpoint.update(
+ attention_to_diffusers_checkpoint(
+ checkpoint,
+ attention_prefix=full_attention_prefix,
+ diffusers_attention_prefix=full_diffusers_attention_prefix,
+ num_head_channels=num_head_channels,
+ )
+ )
+
+ num_original_down_blocks = num_resnets - 1 if upsampler else num_resnets
+
+ return diffusers_checkpoint, num_original_down_blocks
+
+
+def resnet_to_diffusers_checkpoint(checkpoint, *, diffusers_resnet_prefix, resnet_prefix):
+ diffusers_checkpoint = {
+ f"{diffusers_resnet_prefix}.norm1.weight": checkpoint[f"{resnet_prefix}.in_layers.0.weight"],
+ f"{diffusers_resnet_prefix}.norm1.bias": checkpoint[f"{resnet_prefix}.in_layers.0.bias"],
+ f"{diffusers_resnet_prefix}.conv1.weight": checkpoint[f"{resnet_prefix}.in_layers.2.weight"],
+ f"{diffusers_resnet_prefix}.conv1.bias": checkpoint[f"{resnet_prefix}.in_layers.2.bias"],
+ f"{diffusers_resnet_prefix}.time_emb_proj.weight": checkpoint[f"{resnet_prefix}.emb_layers.1.weight"],
+ f"{diffusers_resnet_prefix}.time_emb_proj.bias": checkpoint[f"{resnet_prefix}.emb_layers.1.bias"],
+ f"{diffusers_resnet_prefix}.norm2.weight": checkpoint[f"{resnet_prefix}.out_layers.0.weight"],
+ f"{diffusers_resnet_prefix}.norm2.bias": checkpoint[f"{resnet_prefix}.out_layers.0.bias"],
+ f"{diffusers_resnet_prefix}.conv2.weight": checkpoint[f"{resnet_prefix}.out_layers.3.weight"],
+ f"{diffusers_resnet_prefix}.conv2.bias": checkpoint[f"{resnet_prefix}.out_layers.3.bias"],
+ }
+
+ skip_connection_prefix = f"{resnet_prefix}.skip_connection"
+
+ if f"{skip_connection_prefix}.weight" in checkpoint:
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_resnet_prefix}.conv_shortcut.weight": checkpoint[f"{skip_connection_prefix}.weight"],
+ f"{diffusers_resnet_prefix}.conv_shortcut.bias": checkpoint[f"{skip_connection_prefix}.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+def attention_to_diffusers_checkpoint(checkpoint, *, diffusers_attention_prefix, attention_prefix, num_head_channels):
+ diffusers_checkpoint = {}
+
+ # .norm -> .group_norm
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_attention_prefix}.group_norm.weight": checkpoint[f"{attention_prefix}.norm.weight"],
+ f"{diffusers_attention_prefix}.group_norm.bias": checkpoint[f"{attention_prefix}.norm.bias"],
+ }
+ )
+
+ # .qkv -> .{query, key, value}
+ [q_weight, k_weight, v_weight], [q_bias, k_bias, v_bias] = split_attentions(
+ weight=checkpoint[f"{attention_prefix}.qkv.weight"][:, :, 0],
+ bias=checkpoint[f"{attention_prefix}.qkv.bias"],
+ split=3,
+ chunk_size=num_head_channels,
+ )
+
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_attention_prefix}.to_q.weight": q_weight,
+ f"{diffusers_attention_prefix}.to_q.bias": q_bias,
+ f"{diffusers_attention_prefix}.to_k.weight": k_weight,
+ f"{diffusers_attention_prefix}.to_k.bias": k_bias,
+ f"{diffusers_attention_prefix}.to_v.weight": v_weight,
+ f"{diffusers_attention_prefix}.to_v.bias": v_bias,
+ }
+ )
+
+ # .encoder_kv -> .{context_key, context_value}
+ [encoder_k_weight, encoder_v_weight], [encoder_k_bias, encoder_v_bias] = split_attentions(
+ weight=checkpoint[f"{attention_prefix}.encoder_kv.weight"][:, :, 0],
+ bias=checkpoint[f"{attention_prefix}.encoder_kv.bias"],
+ split=2,
+ chunk_size=num_head_channels,
+ )
+
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_attention_prefix}.add_k_proj.weight": encoder_k_weight,
+ f"{diffusers_attention_prefix}.add_k_proj.bias": encoder_k_bias,
+ f"{diffusers_attention_prefix}.add_v_proj.weight": encoder_v_weight,
+ f"{diffusers_attention_prefix}.add_v_proj.bias": encoder_v_bias,
+ }
+ )
+
+ # .proj_out (1d conv) -> .proj_attn (linear)
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_attention_prefix}.to_out.0.weight": checkpoint[f"{attention_prefix}.proj_out.weight"][
+ :, :, 0
+ ],
+ f"{diffusers_attention_prefix}.to_out.0.bias": checkpoint[f"{attention_prefix}.proj_out.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+# TODO maybe document and/or can do more efficiently (build indices in for loop and extract once for each split?)
+def split_attentions(*, weight, bias, split, chunk_size):
+ weights = [None] * split
+ biases = [None] * split
+
+ weights_biases_idx = 0
+
+ for starting_row_index in range(0, weight.shape[0], chunk_size):
+ row_indices = torch.arange(starting_row_index, starting_row_index + chunk_size)
+
+ weight_rows = weight[row_indices, :]
+ bias_rows = bias[row_indices]
+
+ if weights[weights_biases_idx] is None:
+ assert weights[weights_biases_idx] is None
+ weights[weights_biases_idx] = weight_rows
+ biases[weights_biases_idx] = bias_rows
+ else:
+ assert weights[weights_biases_idx] is not None
+ weights[weights_biases_idx] = torch.concat([weights[weights_biases_idx], weight_rows])
+ biases[weights_biases_idx] = torch.concat([biases[weights_biases_idx], bias_rows])
+
+ weights_biases_idx = (weights_biases_idx + 1) % split
+
+ return weights, biases
+
+
+# done unet utils
+
+
+# Driver functions
+
+
+def text_encoder():
+ print("loading CLIP text encoder")
+
+ clip_name = "openai/clip-vit-large-patch14"
+
+ # sets pad_value to 0
+ pad_token = "!"
+
+ tokenizer_model = CLIPTokenizer.from_pretrained(clip_name, pad_token=pad_token, device_map="auto")
+
+ assert tokenizer_model.convert_tokens_to_ids(pad_token) == 0
+
+ text_encoder_model = CLIPTextModelWithProjection.from_pretrained(
+ clip_name,
+ # `CLIPTextModel` does not support device_map="auto"
+ # device_map="auto"
+ )
+
+ print("done loading CLIP text encoder")
+
+ return text_encoder_model, tokenizer_model
+
+
+def prior(*, args, checkpoint_map_location):
+ print("loading prior")
+
+ prior_checkpoint = torch.load(args.prior_checkpoint_path, map_location=checkpoint_map_location)
+ prior_checkpoint = prior_checkpoint["state_dict"]
+
+ clip_stats_checkpoint = torch.load(args.clip_stat_path, map_location=checkpoint_map_location)
+
+ prior_model = prior_model_from_original_config()
+
+ prior_diffusers_checkpoint = prior_original_checkpoint_to_diffusers_checkpoint(
+ prior_model, prior_checkpoint, clip_stats_checkpoint
+ )
+
+ del prior_checkpoint
+ del clip_stats_checkpoint
+
+ load_checkpoint_to_model(prior_diffusers_checkpoint, prior_model, strict=True)
+
+ print("done loading prior")
+
+ return prior_model
+
+
+def decoder(*, args, checkpoint_map_location):
+ print("loading decoder")
+
+ decoder_checkpoint = torch.load(args.decoder_checkpoint_path, map_location=checkpoint_map_location)
+ decoder_checkpoint = decoder_checkpoint["state_dict"]
+
+ decoder_model = decoder_model_from_original_config()
+
+ decoder_diffusers_checkpoint = decoder_original_checkpoint_to_diffusers_checkpoint(
+ decoder_model, decoder_checkpoint
+ )
+
+ # text proj interlude
+
+ # The original decoder implementation includes a set of parameters that are used
+ # for creating the `encoder_hidden_states` which are what the U-net is conditioned
+ # on. The diffusers conditional unet directly takes the encoder_hidden_states. We pull
+ # the parameters into the UnCLIPTextProjModel class
+ text_proj_model = text_proj_from_original_config()
+
+ text_proj_checkpoint = text_proj_original_checkpoint_to_diffusers_checkpoint(decoder_checkpoint)
+
+ load_checkpoint_to_model(text_proj_checkpoint, text_proj_model, strict=True)
+
+ # done text proj interlude
+
+ del decoder_checkpoint
+
+ load_checkpoint_to_model(decoder_diffusers_checkpoint, decoder_model, strict=True)
+
+ print("done loading decoder")
+
+ return decoder_model, text_proj_model
+
+
+def super_res_unet(*, args, checkpoint_map_location):
+ print("loading super resolution unet")
+
+ super_res_checkpoint = torch.load(args.super_res_unet_checkpoint_path, map_location=checkpoint_map_location)
+ super_res_checkpoint = super_res_checkpoint["state_dict"]
+
+ # model_first_steps
+
+ super_res_first_model = super_res_unet_first_steps_model_from_original_config()
+
+ super_res_first_steps_checkpoint = super_res_unet_first_steps_original_checkpoint_to_diffusers_checkpoint(
+ super_res_first_model, super_res_checkpoint
+ )
+
+ # model_last_step
+ super_res_last_model = super_res_unet_last_step_model_from_original_config()
+
+ super_res_last_step_checkpoint = super_res_unet_last_step_original_checkpoint_to_diffusers_checkpoint(
+ super_res_last_model, super_res_checkpoint
+ )
+
+ del super_res_checkpoint
+
+ load_checkpoint_to_model(super_res_first_steps_checkpoint, super_res_first_model, strict=True)
+
+ load_checkpoint_to_model(super_res_last_step_checkpoint, super_res_last_model, strict=True)
+
+ print("done loading super resolution unet")
+
+ return super_res_first_model, super_res_last_model
+
+
+def load_checkpoint_to_model(checkpoint, model, strict=False):
+ with tempfile.NamedTemporaryFile() as file:
+ torch.save(checkpoint, file.name)
+ del checkpoint
+ if strict:
+ model.load_state_dict(torch.load(file.name), strict=True)
+ else:
+ load_checkpoint_and_dispatch(model, file.name, device_map="auto")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+
+ parser.add_argument(
+ "--prior_checkpoint_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to the prior checkpoint to convert.",
+ )
+
+ parser.add_argument(
+ "--decoder_checkpoint_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to the decoder checkpoint to convert.",
+ )
+
+ parser.add_argument(
+ "--super_res_unet_checkpoint_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to the super resolution checkpoint to convert.",
+ )
+
+ parser.add_argument(
+ "--clip_stat_path", default=None, type=str, required=True, help="Path to the clip stats checkpoint to convert."
+ )
+
+ parser.add_argument(
+ "--checkpoint_load_device",
+ default="cpu",
+ type=str,
+ required=False,
+ help="The device passed to `map_location` when loading checkpoints.",
+ )
+
+ parser.add_argument(
+ "--debug",
+ default=None,
+ type=str,
+ required=False,
+ help="Only run a specific stage of the convert script. Used for debugging",
+ )
+
+ args = parser.parse_args()
+
+ print(f"loading checkpoints to {args.checkpoint_load_device}")
+
+ checkpoint_map_location = torch.device(args.checkpoint_load_device)
+
+ if args.debug is not None:
+ print(f"debug: only executing {args.debug}")
+
+ if args.debug is None:
+ text_encoder_model, tokenizer_model = text_encoder()
+
+ prior_model = prior(args=args, checkpoint_map_location=checkpoint_map_location)
+
+ decoder_model, text_proj_model = decoder(args=args, checkpoint_map_location=checkpoint_map_location)
+
+ super_res_first_model, super_res_last_model = super_res_unet(
+ args=args, checkpoint_map_location=checkpoint_map_location
+ )
+
+ prior_scheduler = UnCLIPScheduler(
+ variance_type="fixed_small_log",
+ prediction_type="sample",
+ num_train_timesteps=1000,
+ clip_sample_range=5.0,
+ )
+
+ decoder_scheduler = UnCLIPScheduler(
+ variance_type="learned_range",
+ prediction_type="epsilon",
+ num_train_timesteps=1000,
+ )
+
+ super_res_scheduler = UnCLIPScheduler(
+ variance_type="fixed_small_log",
+ prediction_type="epsilon",
+ num_train_timesteps=1000,
+ )
+
+ print(f"saving Kakao Brain unCLIP to {args.dump_path}")
+
+ pipe = UnCLIPPipeline(
+ prior=prior_model,
+ decoder=decoder_model,
+ text_proj=text_proj_model,
+ tokenizer=tokenizer_model,
+ text_encoder=text_encoder_model,
+ super_res_first=super_res_first_model,
+ super_res_last=super_res_last_model,
+ prior_scheduler=prior_scheduler,
+ decoder_scheduler=decoder_scheduler,
+ super_res_scheduler=super_res_scheduler,
+ )
+ pipe.save_pretrained(args.dump_path)
+
+ print("done writing Kakao Brain unCLIP")
+ elif args.debug == "text_encoder":
+ text_encoder_model, tokenizer_model = text_encoder()
+ elif args.debug == "prior":
+ prior_model = prior(args=args, checkpoint_map_location=checkpoint_map_location)
+ elif args.debug == "decoder":
+ decoder_model, text_proj_model = decoder(args=args, checkpoint_map_location=checkpoint_map_location)
+ elif args.debug == "super_res_unet":
+ super_res_first_model, super_res_last_model = super_res_unet(
+ args=args, checkpoint_map_location=checkpoint_map_location
+ )
+ else:
+ raise ValueError(f"unknown debug value : {args.debug}")
diff --git a/diffusers/scripts/convert_ldm_original_checkpoint_to_diffusers.py b/diffusers/scripts/convert_ldm_original_checkpoint_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..0624ac66dd7ea8f0bd867db606562daacb878247
--- /dev/null
+++ b/diffusers/scripts/convert_ldm_original_checkpoint_to_diffusers.py
@@ -0,0 +1,359 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the LDM checkpoints. """
+
+import argparse
+import json
+
+import torch
+
+from diffusers import DDPMScheduler, LDMPipeline, UNet2DModel, VQModel
+
+
+def shave_segments(path, n_shave_prefix_segments=1):
+ """
+ Removes segments. Positive values shave the first segments, negative shave the last segments.
+ """
+ if n_shave_prefix_segments >= 0:
+ return ".".join(path.split(".")[n_shave_prefix_segments:])
+ else:
+ return ".".join(path.split(".")[:n_shave_prefix_segments])
+
+
+def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item.replace("in_layers.0", "norm1")
+ new_item = new_item.replace("in_layers.2", "conv1")
+
+ new_item = new_item.replace("out_layers.0", "norm2")
+ new_item = new_item.replace("out_layers.3", "conv2")
+
+ new_item = new_item.replace("emb_layers.1", "time_emb_proj")
+ new_item = new_item.replace("skip_connection", "conv_shortcut")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("norm.weight", "group_norm.weight")
+ new_item = new_item.replace("norm.bias", "group_norm.bias")
+
+ new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
+ new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def assign_to_checkpoint(
+ paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
+):
+ """
+ This does the final conversion step: take locally converted weights and apply a global renaming
+ to them. It splits attention layers, and takes into account additional replacements
+ that may arise.
+
+ Assigns the weights to the new checkpoint.
+ """
+ assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
+
+ # Splits the attention layers into three variables.
+ if attention_paths_to_split is not None:
+ for path, path_map in attention_paths_to_split.items():
+ old_tensor = old_checkpoint[path]
+ channels = old_tensor.shape[0] // 3
+
+ target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
+
+ num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
+
+ old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
+ query, key, value = old_tensor.split(channels // num_heads, dim=1)
+
+ checkpoint[path_map["query"]] = query.reshape(target_shape)
+ checkpoint[path_map["key"]] = key.reshape(target_shape)
+ checkpoint[path_map["value"]] = value.reshape(target_shape)
+
+ for path in paths:
+ new_path = path["new"]
+
+ # These have already been assigned
+ if attention_paths_to_split is not None and new_path in attention_paths_to_split:
+ continue
+
+ # Global renaming happens here
+ new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
+ new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
+ new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
+
+ if additional_replacements is not None:
+ for replacement in additional_replacements:
+ new_path = new_path.replace(replacement["old"], replacement["new"])
+
+ # proj_attn.weight has to be converted from conv 1D to linear
+ if "proj_attn.weight" in new_path:
+ checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
+ else:
+ checkpoint[new_path] = old_checkpoint[path["old"]]
+
+
+def convert_ldm_checkpoint(checkpoint, config):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint.
+ """
+ new_checkpoint = {}
+
+ new_checkpoint["time_embedding.linear_1.weight"] = checkpoint["time_embed.0.weight"]
+ new_checkpoint["time_embedding.linear_1.bias"] = checkpoint["time_embed.0.bias"]
+ new_checkpoint["time_embedding.linear_2.weight"] = checkpoint["time_embed.2.weight"]
+ new_checkpoint["time_embedding.linear_2.bias"] = checkpoint["time_embed.2.bias"]
+
+ new_checkpoint["conv_in.weight"] = checkpoint["input_blocks.0.0.weight"]
+ new_checkpoint["conv_in.bias"] = checkpoint["input_blocks.0.0.bias"]
+
+ new_checkpoint["conv_norm_out.weight"] = checkpoint["out.0.weight"]
+ new_checkpoint["conv_norm_out.bias"] = checkpoint["out.0.bias"]
+ new_checkpoint["conv_out.weight"] = checkpoint["out.2.weight"]
+ new_checkpoint["conv_out.bias"] = checkpoint["out.2.bias"]
+
+ # Retrieves the keys for the input blocks only
+ num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "input_blocks" in layer})
+ input_blocks = {
+ layer_id: [key for key in checkpoint if f"input_blocks.{layer_id}" in key]
+ for layer_id in range(num_input_blocks)
+ }
+
+ # Retrieves the keys for the middle blocks only
+ num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "middle_block" in layer})
+ middle_blocks = {
+ layer_id: [key for key in checkpoint if f"middle_block.{layer_id}" in key]
+ for layer_id in range(num_middle_blocks)
+ }
+
+ # Retrieves the keys for the output blocks only
+ num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in checkpoint if "output_blocks" in layer})
+ output_blocks = {
+ layer_id: [key for key in checkpoint if f"output_blocks.{layer_id}" in key]
+ for layer_id in range(num_output_blocks)
+ }
+
+ for i in range(1, num_input_blocks):
+ block_id = (i - 1) // (config["num_res_blocks"] + 1)
+ layer_in_block_id = (i - 1) % (config["num_res_blocks"] + 1)
+
+ resnets = [key for key in input_blocks[i] if f"input_blocks.{i}.0" in key]
+ attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
+
+ if f"input_blocks.{i}.0.op.weight" in checkpoint:
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = checkpoint[
+ f"input_blocks.{i}.0.op.weight"
+ ]
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = checkpoint[
+ f"input_blocks.{i}.0.op.bias"
+ ]
+ continue
+
+ paths = renew_resnet_paths(resnets)
+ meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ resnet_op = {"old": "resnets.2.op", "new": "downsamplers.0.op"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, checkpoint, additional_replacements=[meta_path, resnet_op], config=config
+ )
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"input_blocks.{i}.1",
+ "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ to_split = {
+ f"input_blocks.{i}.1.qkv.bias": {
+ "key": f"down_blocks.{block_id}.attentions.{layer_in_block_id}.key.bias",
+ "query": f"down_blocks.{block_id}.attentions.{layer_in_block_id}.query.bias",
+ "value": f"down_blocks.{block_id}.attentions.{layer_in_block_id}.value.bias",
+ },
+ f"input_blocks.{i}.1.qkv.weight": {
+ "key": f"down_blocks.{block_id}.attentions.{layer_in_block_id}.key.weight",
+ "query": f"down_blocks.{block_id}.attentions.{layer_in_block_id}.query.weight",
+ "value": f"down_blocks.{block_id}.attentions.{layer_in_block_id}.value.weight",
+ },
+ }
+ assign_to_checkpoint(
+ paths,
+ new_checkpoint,
+ checkpoint,
+ additional_replacements=[meta_path],
+ attention_paths_to_split=to_split,
+ config=config,
+ )
+
+ resnet_0 = middle_blocks[0]
+ attentions = middle_blocks[1]
+ resnet_1 = middle_blocks[2]
+
+ resnet_0_paths = renew_resnet_paths(resnet_0)
+ assign_to_checkpoint(resnet_0_paths, new_checkpoint, checkpoint, config=config)
+
+ resnet_1_paths = renew_resnet_paths(resnet_1)
+ assign_to_checkpoint(resnet_1_paths, new_checkpoint, checkpoint, config=config)
+
+ attentions_paths = renew_attention_paths(attentions)
+ to_split = {
+ "middle_block.1.qkv.bias": {
+ "key": "mid_block.attentions.0.key.bias",
+ "query": "mid_block.attentions.0.query.bias",
+ "value": "mid_block.attentions.0.value.bias",
+ },
+ "middle_block.1.qkv.weight": {
+ "key": "mid_block.attentions.0.key.weight",
+ "query": "mid_block.attentions.0.query.weight",
+ "value": "mid_block.attentions.0.value.weight",
+ },
+ }
+ assign_to_checkpoint(
+ attentions_paths, new_checkpoint, checkpoint, attention_paths_to_split=to_split, config=config
+ )
+
+ for i in range(num_output_blocks):
+ block_id = i // (config["num_res_blocks"] + 1)
+ layer_in_block_id = i % (config["num_res_blocks"] + 1)
+ output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
+ output_block_list = {}
+
+ for layer in output_block_layers:
+ layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
+ if layer_id in output_block_list:
+ output_block_list[layer_id].append(layer_name)
+ else:
+ output_block_list[layer_id] = [layer_name]
+
+ if len(output_block_list) > 1:
+ resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
+ attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
+
+ resnet_0_paths = renew_resnet_paths(resnets)
+ paths = renew_resnet_paths(resnets)
+
+ meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[meta_path], config=config)
+
+ if ["conv.weight", "conv.bias"] in output_block_list.values():
+ index = list(output_block_list.values()).index(["conv.weight", "conv.bias"])
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = checkpoint[
+ f"output_blocks.{i}.{index}.conv.weight"
+ ]
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = checkpoint[
+ f"output_blocks.{i}.{index}.conv.bias"
+ ]
+
+ # Clear attentions as they have been attributed above.
+ if len(attentions) == 2:
+ attentions = []
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"output_blocks.{i}.1",
+ "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ to_split = {
+ f"output_blocks.{i}.1.qkv.bias": {
+ "key": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.key.bias",
+ "query": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.query.bias",
+ "value": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.value.bias",
+ },
+ f"output_blocks.{i}.1.qkv.weight": {
+ "key": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.key.weight",
+ "query": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.query.weight",
+ "value": f"up_blocks.{block_id}.attentions.{layer_in_block_id}.value.weight",
+ },
+ }
+ assign_to_checkpoint(
+ paths,
+ new_checkpoint,
+ checkpoint,
+ additional_replacements=[meta_path],
+ attention_paths_to_split=to_split if any("qkv" in key for key in attentions) else None,
+ config=config,
+ )
+ else:
+ resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
+ for path in resnet_0_paths:
+ old_path = ".".join(["output_blocks", str(i), path["old"]])
+ new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
+
+ new_checkpoint[new_path] = checkpoint[old_path]
+
+ return new_checkpoint
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+
+ parser.add_argument(
+ "--config_file",
+ default=None,
+ type=str,
+ required=True,
+ help="The config json file corresponding to the architecture.",
+ )
+
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+
+ args = parser.parse_args()
+
+ checkpoint = torch.load(args.checkpoint_path)
+
+ with open(args.config_file) as f:
+ config = json.loads(f.read())
+
+ converted_checkpoint = convert_ldm_checkpoint(checkpoint, config)
+
+ if "ldm" in config:
+ del config["ldm"]
+
+ model = UNet2DModel(**config)
+ model.load_state_dict(converted_checkpoint)
+
+ try:
+ scheduler = DDPMScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
+ vqvae = VQModel.from_pretrained("/".join(args.checkpoint_path.split("/")[:-1]))
+
+ pipe = LDMPipeline(unet=model, scheduler=scheduler, vae=vqvae)
+ pipe.save_pretrained(args.dump_path)
+ except: # noqa: E722
+ model.save_pretrained(args.dump_path)
diff --git a/diffusers/scripts/convert_lora_safetensor_to_diffusers.py b/diffusers/scripts/convert_lora_safetensor_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8e05d62bd2ac35cad31e750ba590afec7f614e6
--- /dev/null
+++ b/diffusers/scripts/convert_lora_safetensor_to_diffusers.py
@@ -0,0 +1,128 @@
+# coding=utf-8
+# Copyright 2023, Haofan Wang, Qixun Wang, All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+""" Conversion script for the LoRA's safetensors checkpoints. """
+
+import argparse
+
+import torch
+from safetensors.torch import load_file
+
+from diffusers import StableDiffusionPipeline
+
+
+def convert(base_model_path, checkpoint_path, LORA_PREFIX_UNET, LORA_PREFIX_TEXT_ENCODER, alpha):
+ # load base model
+ pipeline = StableDiffusionPipeline.from_pretrained(base_model_path, torch_dtype=torch.float32)
+
+ # load LoRA weight from .safetensors
+ state_dict = load_file(checkpoint_path)
+
+ visited = []
+
+ # directly update weight in diffusers model
+ for key in state_dict:
+ # it is suggested to print out the key, it usually will be something like below
+ # "lora_te_text_model_encoder_layers_0_self_attn_k_proj.lora_down.weight"
+
+ # as we have set the alpha beforehand, so just skip
+ if ".alpha" in key or key in visited:
+ continue
+
+ if "text" in key:
+ layer_infos = key.split(".")[0].split(LORA_PREFIX_TEXT_ENCODER + "_")[-1].split("_")
+ curr_layer = pipeline.text_encoder
+ else:
+ layer_infos = key.split(".")[0].split(LORA_PREFIX_UNET + "_")[-1].split("_")
+ curr_layer = pipeline.unet
+
+ # find the target layer
+ temp_name = layer_infos.pop(0)
+ while len(layer_infos) > -1:
+ try:
+ curr_layer = curr_layer.__getattr__(temp_name)
+ if len(layer_infos) > 0:
+ temp_name = layer_infos.pop(0)
+ elif len(layer_infos) == 0:
+ break
+ except Exception:
+ if len(temp_name) > 0:
+ temp_name += "_" + layer_infos.pop(0)
+ else:
+ temp_name = layer_infos.pop(0)
+
+ pair_keys = []
+ if "lora_down" in key:
+ pair_keys.append(key.replace("lora_down", "lora_up"))
+ pair_keys.append(key)
+ else:
+ pair_keys.append(key)
+ pair_keys.append(key.replace("lora_up", "lora_down"))
+
+ # update weight
+ if len(state_dict[pair_keys[0]].shape) == 4:
+ weight_up = state_dict[pair_keys[0]].squeeze(3).squeeze(2).to(torch.float32)
+ weight_down = state_dict[pair_keys[1]].squeeze(3).squeeze(2).to(torch.float32)
+ curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down).unsqueeze(2).unsqueeze(3)
+ else:
+ weight_up = state_dict[pair_keys[0]].to(torch.float32)
+ weight_down = state_dict[pair_keys[1]].to(torch.float32)
+ curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down)
+
+ # update visited list
+ for item in pair_keys:
+ visited.append(item)
+
+ return pipeline
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--base_model_path", default=None, type=str, required=True, help="Path to the base model in diffusers format."
+ )
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+ parser.add_argument(
+ "--lora_prefix_unet", default="lora_unet", type=str, help="The prefix of UNet weight in safetensors"
+ )
+ parser.add_argument(
+ "--lora_prefix_text_encoder",
+ default="lora_te",
+ type=str,
+ help="The prefix of text encoder weight in safetensors",
+ )
+ parser.add_argument("--alpha", default=0.75, type=float, help="The merging ratio in W = W0 + alpha * deltaW")
+ parser.add_argument(
+ "--to_safetensors", action="store_true", help="Whether to store pipeline in safetensors format or not."
+ )
+ parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
+
+ args = parser.parse_args()
+
+ base_model_path = args.base_model_path
+ checkpoint_path = args.checkpoint_path
+ dump_path = args.dump_path
+ lora_prefix_unet = args.lora_prefix_unet
+ lora_prefix_text_encoder = args.lora_prefix_text_encoder
+ alpha = args.alpha
+
+ pipe = convert(base_model_path, checkpoint_path, lora_prefix_unet, lora_prefix_text_encoder, alpha)
+
+ pipe = pipe.to(args.device)
+ pipe.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
diff --git a/diffusers/scripts/convert_models_diffuser_to_diffusers.py b/diffusers/scripts/convert_models_diffuser_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc5321e33fe088c652f6014c6dab813bb8d5f246
--- /dev/null
+++ b/diffusers/scripts/convert_models_diffuser_to_diffusers.py
@@ -0,0 +1,100 @@
+import json
+import os
+
+import torch
+
+from diffusers import UNet1DModel
+
+
+os.makedirs("hub/hopper-medium-v2/unet/hor32", exist_ok=True)
+os.makedirs("hub/hopper-medium-v2/unet/hor128", exist_ok=True)
+
+os.makedirs("hub/hopper-medium-v2/value_function", exist_ok=True)
+
+
+def unet(hor):
+ if hor == 128:
+ down_block_types = ("DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D")
+ block_out_channels = (32, 128, 256)
+ up_block_types = ("UpResnetBlock1D", "UpResnetBlock1D")
+
+ elif hor == 32:
+ down_block_types = ("DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D")
+ block_out_channels = (32, 64, 128, 256)
+ up_block_types = ("UpResnetBlock1D", "UpResnetBlock1D", "UpResnetBlock1D")
+ model = torch.load(f"/Users/bglickenhaus/Documents/diffuser/temporal_unet-hopper-mediumv2-hor{hor}.torch")
+ state_dict = model.state_dict()
+ config = {
+ "down_block_types": down_block_types,
+ "block_out_channels": block_out_channels,
+ "up_block_types": up_block_types,
+ "layers_per_block": 1,
+ "use_timestep_embedding": True,
+ "out_block_type": "OutConv1DBlock",
+ "norm_num_groups": 8,
+ "downsample_each_block": False,
+ "in_channels": 14,
+ "out_channels": 14,
+ "extra_in_channels": 0,
+ "time_embedding_type": "positional",
+ "flip_sin_to_cos": False,
+ "freq_shift": 1,
+ "sample_size": 65536,
+ "mid_block_type": "MidResTemporalBlock1D",
+ "act_fn": "mish",
+ }
+ hf_value_function = UNet1DModel(**config)
+ print(f"length of state dict: {len(state_dict.keys())}")
+ print(f"length of value function dict: {len(hf_value_function.state_dict().keys())}")
+ mapping = dict(zip(model.state_dict().keys(), hf_value_function.state_dict().keys()))
+ for k, v in mapping.items():
+ state_dict[v] = state_dict.pop(k)
+ hf_value_function.load_state_dict(state_dict)
+
+ torch.save(hf_value_function.state_dict(), f"hub/hopper-medium-v2/unet/hor{hor}/diffusion_pytorch_model.bin")
+ with open(f"hub/hopper-medium-v2/unet/hor{hor}/config.json", "w") as f:
+ json.dump(config, f)
+
+
+def value_function():
+ config = {
+ "in_channels": 14,
+ "down_block_types": ("DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D"),
+ "up_block_types": (),
+ "out_block_type": "ValueFunction",
+ "mid_block_type": "ValueFunctionMidBlock1D",
+ "block_out_channels": (32, 64, 128, 256),
+ "layers_per_block": 1,
+ "downsample_each_block": True,
+ "sample_size": 65536,
+ "out_channels": 14,
+ "extra_in_channels": 0,
+ "time_embedding_type": "positional",
+ "use_timestep_embedding": True,
+ "flip_sin_to_cos": False,
+ "freq_shift": 1,
+ "norm_num_groups": 8,
+ "act_fn": "mish",
+ }
+
+ model = torch.load("/Users/bglickenhaus/Documents/diffuser/value_function-hopper-mediumv2-hor32.torch")
+ state_dict = model
+ hf_value_function = UNet1DModel(**config)
+ print(f"length of state dict: {len(state_dict.keys())}")
+ print(f"length of value function dict: {len(hf_value_function.state_dict().keys())}")
+
+ mapping = dict(zip(state_dict.keys(), hf_value_function.state_dict().keys()))
+ for k, v in mapping.items():
+ state_dict[v] = state_dict.pop(k)
+
+ hf_value_function.load_state_dict(state_dict)
+
+ torch.save(hf_value_function.state_dict(), "hub/hopper-medium-v2/value_function/diffusion_pytorch_model.bin")
+ with open("hub/hopper-medium-v2/value_function/config.json", "w") as f:
+ json.dump(config, f)
+
+
+if __name__ == "__main__":
+ unet(32)
+ # unet(128)
+ value_function()
diff --git a/diffusers/scripts/convert_ms_text_to_video_to_diffusers.py b/diffusers/scripts/convert_ms_text_to_video_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..3102c7eede9bf72ce460599f3bf47446230a836b
--- /dev/null
+++ b/diffusers/scripts/convert_ms_text_to_video_to_diffusers.py
@@ -0,0 +1,428 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the LDM checkpoints. """
+
+import argparse
+
+import torch
+
+from diffusers import UNet3DConditionModel
+
+
+def assign_to_checkpoint(
+ paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
+):
+ """
+ This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
+ attention layers, and takes into account additional replacements that may arise.
+
+ Assigns the weights to the new checkpoint.
+ """
+ assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
+
+ # Splits the attention layers into three variables.
+ if attention_paths_to_split is not None:
+ for path, path_map in attention_paths_to_split.items():
+ old_tensor = old_checkpoint[path]
+ channels = old_tensor.shape[0] // 3
+
+ target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
+
+ num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
+
+ old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
+ query, key, value = old_tensor.split(channels // num_heads, dim=1)
+
+ checkpoint[path_map["query"]] = query.reshape(target_shape)
+ checkpoint[path_map["key"]] = key.reshape(target_shape)
+ checkpoint[path_map["value"]] = value.reshape(target_shape)
+
+ for path in paths:
+ new_path = path["new"]
+
+ # These have already been assigned
+ if attention_paths_to_split is not None and new_path in attention_paths_to_split:
+ continue
+
+ if additional_replacements is not None:
+ for replacement in additional_replacements:
+ new_path = new_path.replace(replacement["old"], replacement["new"])
+
+ # proj_attn.weight has to be converted from conv 1D to linear
+ weight = old_checkpoint[path["old"]]
+ names = ["proj_attn.weight"]
+ names_2 = ["proj_out.weight", "proj_in.weight"]
+ if any(k in new_path for k in names):
+ checkpoint[new_path] = weight[:, :, 0]
+ elif any(k in new_path for k in names_2) and len(weight.shape) > 2 and ".attentions." not in new_path:
+ checkpoint[new_path] = weight[:, :, 0]
+ else:
+ checkpoint[new_path] = weight
+
+
+def renew_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ # new_item = new_item.replace('norm.weight', 'group_norm.weight')
+ # new_item = new_item.replace('norm.bias', 'group_norm.bias')
+
+ # new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
+ # new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
+
+ # new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def shave_segments(path, n_shave_prefix_segments=1):
+ """
+ Removes segments. Positive values shave the first segments, negative shave the last segments.
+ """
+ if n_shave_prefix_segments >= 0:
+ return ".".join(path.split(".")[n_shave_prefix_segments:])
+ else:
+ return ".".join(path.split(".")[:n_shave_prefix_segments])
+
+
+def renew_temp_conv_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ mapping.append({"old": old_item, "new": old_item})
+
+ return mapping
+
+
+def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item.replace("in_layers.0", "norm1")
+ new_item = new_item.replace("in_layers.2", "conv1")
+
+ new_item = new_item.replace("out_layers.0", "norm2")
+ new_item = new_item.replace("out_layers.3", "conv2")
+
+ new_item = new_item.replace("emb_layers.1", "time_emb_proj")
+ new_item = new_item.replace("skip_connection", "conv_shortcut")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ if "temopral_conv" not in old_item:
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def convert_ldm_unet_checkpoint(checkpoint, config, path=None, extract_ema=False):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint.
+ """
+
+ # extract state_dict for UNet
+ unet_state_dict = {}
+ keys = list(checkpoint.keys())
+
+ unet_key = "model.diffusion_model."
+
+ # at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
+ if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
+ print(f"Checkpoint {path} has both EMA and non-EMA weights.")
+ print(
+ "In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
+ " weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
+ )
+ for key in keys:
+ if key.startswith("model.diffusion_model"):
+ flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
+ else:
+ if sum(k.startswith("model_ema") for k in keys) > 100:
+ print(
+ "In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
+ " weights (usually better for inference), please make sure to add the `--extract_ema` flag."
+ )
+
+ for key in keys:
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
+ new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
+ new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
+ new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
+
+ if config["class_embed_type"] is None:
+ # No parameters to port
+ ...
+ elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
+ new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
+ new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
+ new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
+ new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
+ else:
+ raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
+
+ new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
+ new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
+
+ first_temp_attention = [v for v in unet_state_dict if v.startswith("input_blocks.0.1")]
+ paths = renew_attention_paths(first_temp_attention)
+ meta_path = {"old": "input_blocks.0.1", "new": "transformer_in"}
+ assign_to_checkpoint(paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config)
+
+ new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
+ new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
+ new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
+ new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
+
+ # Retrieves the keys for the input blocks only
+ num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
+ input_blocks = {
+ layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
+ for layer_id in range(num_input_blocks)
+ }
+
+ # Retrieves the keys for the middle blocks only
+ num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
+ middle_blocks = {
+ layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
+ for layer_id in range(num_middle_blocks)
+ }
+
+ # Retrieves the keys for the output blocks only
+ num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
+ output_blocks = {
+ layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
+ for layer_id in range(num_output_blocks)
+ }
+
+ for i in range(1, num_input_blocks):
+ block_id = (i - 1) // (config["layers_per_block"] + 1)
+ layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
+
+ resnets = [
+ key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
+ ]
+ attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
+ temp_attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.2" in key]
+
+ if f"input_blocks.{i}.op.weight" in unet_state_dict:
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
+ f"input_blocks.{i}.op.weight"
+ )
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
+ f"input_blocks.{i}.op.bias"
+ )
+
+ paths = renew_resnet_paths(resnets)
+ meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ temporal_convs = [key for key in resnets if "temopral_conv" in key]
+ paths = renew_temp_conv_paths(temporal_convs)
+ meta_path = {
+ "old": f"input_blocks.{i}.0.temopral_conv",
+ "new": f"down_blocks.{block_id}.temp_convs.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if len(temp_attentions):
+ paths = renew_attention_paths(temp_attentions)
+ meta_path = {
+ "old": f"input_blocks.{i}.2",
+ "new": f"down_blocks.{block_id}.temp_attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ resnet_0 = middle_blocks[0]
+ temporal_convs_0 = [key for key in resnet_0 if "temopral_conv" in key]
+ attentions = middle_blocks[1]
+ temp_attentions = middle_blocks[2]
+ resnet_1 = middle_blocks[3]
+ temporal_convs_1 = [key for key in resnet_1 if "temopral_conv" in key]
+
+ resnet_0_paths = renew_resnet_paths(resnet_0)
+ meta_path = {"old": "middle_block.0", "new": "mid_block.resnets.0"}
+ assign_to_checkpoint(
+ resnet_0_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
+ )
+
+ temp_conv_0_paths = renew_temp_conv_paths(temporal_convs_0)
+ meta_path = {"old": "middle_block.0.temopral_conv", "new": "mid_block.temp_convs.0"}
+ assign_to_checkpoint(
+ temp_conv_0_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
+ )
+
+ resnet_1_paths = renew_resnet_paths(resnet_1)
+ meta_path = {"old": "middle_block.3", "new": "mid_block.resnets.1"}
+ assign_to_checkpoint(
+ resnet_1_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
+ )
+
+ temp_conv_1_paths = renew_temp_conv_paths(temporal_convs_1)
+ meta_path = {"old": "middle_block.3.temopral_conv", "new": "mid_block.temp_convs.1"}
+ assign_to_checkpoint(
+ temp_conv_1_paths, new_checkpoint, unet_state_dict, config=config, additional_replacements=[meta_path]
+ )
+
+ attentions_paths = renew_attention_paths(attentions)
+ meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ temp_attentions_paths = renew_attention_paths(temp_attentions)
+ meta_path = {"old": "middle_block.2", "new": "mid_block.temp_attentions.0"}
+ assign_to_checkpoint(
+ temp_attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ for i in range(num_output_blocks):
+ block_id = i // (config["layers_per_block"] + 1)
+ layer_in_block_id = i % (config["layers_per_block"] + 1)
+ output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
+ output_block_list = {}
+
+ for layer in output_block_layers:
+ layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
+ if layer_id in output_block_list:
+ output_block_list[layer_id].append(layer_name)
+ else:
+ output_block_list[layer_id] = [layer_name]
+
+ if len(output_block_list) > 1:
+ resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
+ attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
+ temp_attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.2" in key]
+
+ resnet_0_paths = renew_resnet_paths(resnets)
+ paths = renew_resnet_paths(resnets)
+
+ meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ temporal_convs = [key for key in resnets if "temopral_conv" in key]
+ paths = renew_temp_conv_paths(temporal_convs)
+ meta_path = {
+ "old": f"output_blocks.{i}.0.temopral_conv",
+ "new": f"up_blocks.{block_id}.temp_convs.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
+ if ["conv.bias", "conv.weight"] in output_block_list.values():
+ index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.weight"
+ ]
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.bias"
+ ]
+
+ # Clear attentions as they have been attributed above.
+ if len(attentions) == 2:
+ attentions = []
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"output_blocks.{i}.1",
+ "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if len(temp_attentions):
+ paths = renew_attention_paths(temp_attentions)
+ meta_path = {
+ "old": f"output_blocks.{i}.2",
+ "new": f"up_blocks.{block_id}.temp_attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+ else:
+ resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
+ for path in resnet_0_paths:
+ old_path = ".".join(["output_blocks", str(i), path["old"]])
+ new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
+ new_checkpoint[new_path] = unet_state_dict[old_path]
+
+ temopral_conv_paths = [l for l in output_block_layers if "temopral_conv" in l]
+ for path in temopral_conv_paths:
+ pruned_path = path.split("temopral_conv.")[-1]
+ old_path = ".".join(["output_blocks", str(i), str(block_id), "temopral_conv", pruned_path])
+ new_path = ".".join(["up_blocks", str(block_id), "temp_convs", str(layer_in_block_id), pruned_path])
+ new_checkpoint[new_path] = unet_state_dict[old_path]
+
+ return new_checkpoint
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+ args = parser.parse_args()
+
+ unet_checkpoint = torch.load(args.checkpoint_path, map_location="cpu")
+ unet = UNet3DConditionModel()
+
+ converted_ckpt = convert_ldm_unet_checkpoint(unet_checkpoint, unet.config)
+
+ diff_0 = set(unet.state_dict().keys()) - set(converted_ckpt.keys())
+ diff_1 = set(converted_ckpt.keys()) - set(unet.state_dict().keys())
+
+ assert len(diff_0) == len(diff_1) == 0, "Converted weights don't match"
+
+ # load state_dict
+ unet.load_state_dict(converted_ckpt)
+
+ unet.save_pretrained(args.dump_path)
+
+ # -- finish converting the unet --
diff --git a/diffusers/scripts/convert_music_spectrogram_to_diffusers.py b/diffusers/scripts/convert_music_spectrogram_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..41ee8b914774de09193f866c406057a92744bf51
--- /dev/null
+++ b/diffusers/scripts/convert_music_spectrogram_to_diffusers.py
@@ -0,0 +1,213 @@
+#!/usr/bin/env python3
+import argparse
+import os
+
+import jax as jnp
+import numpy as onp
+import torch
+import torch.nn as nn
+from music_spectrogram_diffusion import inference
+from t5x import checkpoints
+
+from diffusers import DDPMScheduler, OnnxRuntimeModel, SpectrogramDiffusionPipeline
+from diffusers.pipelines.spectrogram_diffusion import SpectrogramContEncoder, SpectrogramNotesEncoder, T5FilmDecoder
+
+
+MODEL = "base_with_context"
+
+
+def load_notes_encoder(weights, model):
+ model.token_embedder.weight = nn.Parameter(torch.FloatTensor(weights["token_embedder"]["embedding"]))
+ model.position_encoding.weight = nn.Parameter(
+ torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False
+ )
+ for lyr_num, lyr in enumerate(model.encoders):
+ ly_weight = weights[f"layers_{lyr_num}"]
+ lyr.layer[0].layer_norm.weight = nn.Parameter(
+ torch.FloatTensor(ly_weight["pre_attention_layer_norm"]["scale"])
+ )
+
+ attention_weights = ly_weight["attention"]
+ lyr.layer[0].SelfAttention.q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T))
+ lyr.layer[0].SelfAttention.k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T))
+ lyr.layer[0].SelfAttention.v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T))
+ lyr.layer[0].SelfAttention.o.weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T))
+
+ lyr.layer[1].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"]))
+
+ lyr.layer[1].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T))
+ lyr.layer[1].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T))
+ lyr.layer[1].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T))
+
+ model.layer_norm.weight = nn.Parameter(torch.FloatTensor(weights["encoder_norm"]["scale"]))
+ return model
+
+
+def load_continuous_encoder(weights, model):
+ model.input_proj.weight = nn.Parameter(torch.FloatTensor(weights["input_proj"]["kernel"].T))
+
+ model.position_encoding.weight = nn.Parameter(
+ torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False
+ )
+
+ for lyr_num, lyr in enumerate(model.encoders):
+ ly_weight = weights[f"layers_{lyr_num}"]
+ attention_weights = ly_weight["attention"]
+
+ lyr.layer[0].SelfAttention.q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T))
+ lyr.layer[0].SelfAttention.k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T))
+ lyr.layer[0].SelfAttention.v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T))
+ lyr.layer[0].SelfAttention.o.weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T))
+ lyr.layer[0].layer_norm.weight = nn.Parameter(
+ torch.FloatTensor(ly_weight["pre_attention_layer_norm"]["scale"])
+ )
+
+ lyr.layer[1].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T))
+ lyr.layer[1].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T))
+ lyr.layer[1].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T))
+ lyr.layer[1].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"]))
+
+ model.layer_norm.weight = nn.Parameter(torch.FloatTensor(weights["encoder_norm"]["scale"]))
+
+ return model
+
+
+def load_decoder(weights, model):
+ model.conditioning_emb[0].weight = nn.Parameter(torch.FloatTensor(weights["time_emb_dense0"]["kernel"].T))
+ model.conditioning_emb[2].weight = nn.Parameter(torch.FloatTensor(weights["time_emb_dense1"]["kernel"].T))
+
+ model.position_encoding.weight = nn.Parameter(
+ torch.FloatTensor(weights["Embed_0"]["embedding"]), requires_grad=False
+ )
+
+ model.continuous_inputs_projection.weight = nn.Parameter(
+ torch.FloatTensor(weights["continuous_inputs_projection"]["kernel"].T)
+ )
+
+ for lyr_num, lyr in enumerate(model.decoders):
+ ly_weight = weights[f"layers_{lyr_num}"]
+ lyr.layer[0].layer_norm.weight = nn.Parameter(
+ torch.FloatTensor(ly_weight["pre_self_attention_layer_norm"]["scale"])
+ )
+
+ lyr.layer[0].FiLMLayer.scale_bias.weight = nn.Parameter(
+ torch.FloatTensor(ly_weight["FiLMLayer_0"]["DenseGeneral_0"]["kernel"].T)
+ )
+
+ attention_weights = ly_weight["self_attention"]
+ lyr.layer[0].attention.to_q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T))
+ lyr.layer[0].attention.to_k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T))
+ lyr.layer[0].attention.to_v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T))
+ lyr.layer[0].attention.to_out[0].weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T))
+
+ attention_weights = ly_weight["MultiHeadDotProductAttention_0"]
+ lyr.layer[1].attention.to_q.weight = nn.Parameter(torch.FloatTensor(attention_weights["query"]["kernel"].T))
+ lyr.layer[1].attention.to_k.weight = nn.Parameter(torch.FloatTensor(attention_weights["key"]["kernel"].T))
+ lyr.layer[1].attention.to_v.weight = nn.Parameter(torch.FloatTensor(attention_weights["value"]["kernel"].T))
+ lyr.layer[1].attention.to_out[0].weight = nn.Parameter(torch.FloatTensor(attention_weights["out"]["kernel"].T))
+ lyr.layer[1].layer_norm.weight = nn.Parameter(
+ torch.FloatTensor(ly_weight["pre_cross_attention_layer_norm"]["scale"])
+ )
+
+ lyr.layer[2].layer_norm.weight = nn.Parameter(torch.FloatTensor(ly_weight["pre_mlp_layer_norm"]["scale"]))
+ lyr.layer[2].film.scale_bias.weight = nn.Parameter(
+ torch.FloatTensor(ly_weight["FiLMLayer_1"]["DenseGeneral_0"]["kernel"].T)
+ )
+ lyr.layer[2].DenseReluDense.wi_0.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_0"]["kernel"].T))
+ lyr.layer[2].DenseReluDense.wi_1.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wi_1"]["kernel"].T))
+ lyr.layer[2].DenseReluDense.wo.weight = nn.Parameter(torch.FloatTensor(ly_weight["mlp"]["wo"]["kernel"].T))
+
+ model.decoder_norm.weight = nn.Parameter(torch.FloatTensor(weights["decoder_norm"]["scale"]))
+
+ model.spec_out.weight = nn.Parameter(torch.FloatTensor(weights["spec_out_dense"]["kernel"].T))
+
+ return model
+
+
+def main(args):
+ t5_checkpoint = checkpoints.load_t5x_checkpoint(args.checkpoint_path)
+ t5_checkpoint = jnp.tree_util.tree_map(onp.array, t5_checkpoint)
+
+ gin_overrides = [
+ "from __gin__ import dynamic_registration",
+ "from music_spectrogram_diffusion.models.diffusion import diffusion_utils",
+ "diffusion_utils.ClassifierFreeGuidanceConfig.eval_condition_weight = 2.0",
+ "diffusion_utils.DiffusionConfig.classifier_free_guidance = @diffusion_utils.ClassifierFreeGuidanceConfig()",
+ ]
+
+ gin_file = os.path.join(args.checkpoint_path, "..", "config.gin")
+ gin_config = inference.parse_training_gin_file(gin_file, gin_overrides)
+ synth_model = inference.InferenceModel(args.checkpoint_path, gin_config)
+
+ scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2", variance_type="fixed_large")
+
+ notes_encoder = SpectrogramNotesEncoder(
+ max_length=synth_model.sequence_length["inputs"],
+ vocab_size=synth_model.model.module.config.vocab_size,
+ d_model=synth_model.model.module.config.emb_dim,
+ dropout_rate=synth_model.model.module.config.dropout_rate,
+ num_layers=synth_model.model.module.config.num_encoder_layers,
+ num_heads=synth_model.model.module.config.num_heads,
+ d_kv=synth_model.model.module.config.head_dim,
+ d_ff=synth_model.model.module.config.mlp_dim,
+ feed_forward_proj="gated-gelu",
+ )
+
+ continuous_encoder = SpectrogramContEncoder(
+ input_dims=synth_model.audio_codec.n_dims,
+ targets_context_length=synth_model.sequence_length["targets_context"],
+ d_model=synth_model.model.module.config.emb_dim,
+ dropout_rate=synth_model.model.module.config.dropout_rate,
+ num_layers=synth_model.model.module.config.num_encoder_layers,
+ num_heads=synth_model.model.module.config.num_heads,
+ d_kv=synth_model.model.module.config.head_dim,
+ d_ff=synth_model.model.module.config.mlp_dim,
+ feed_forward_proj="gated-gelu",
+ )
+
+ decoder = T5FilmDecoder(
+ input_dims=synth_model.audio_codec.n_dims,
+ targets_length=synth_model.sequence_length["targets_context"],
+ max_decoder_noise_time=synth_model.model.module.config.max_decoder_noise_time,
+ d_model=synth_model.model.module.config.emb_dim,
+ num_layers=synth_model.model.module.config.num_decoder_layers,
+ num_heads=synth_model.model.module.config.num_heads,
+ d_kv=synth_model.model.module.config.head_dim,
+ d_ff=synth_model.model.module.config.mlp_dim,
+ dropout_rate=synth_model.model.module.config.dropout_rate,
+ )
+
+ notes_encoder = load_notes_encoder(t5_checkpoint["target"]["token_encoder"], notes_encoder)
+ continuous_encoder = load_continuous_encoder(t5_checkpoint["target"]["continuous_encoder"], continuous_encoder)
+ decoder = load_decoder(t5_checkpoint["target"]["decoder"], decoder)
+
+ melgan = OnnxRuntimeModel.from_pretrained("kashif/soundstream_mel_decoder")
+
+ pipe = SpectrogramDiffusionPipeline(
+ notes_encoder=notes_encoder,
+ continuous_encoder=continuous_encoder,
+ decoder=decoder,
+ scheduler=scheduler,
+ melgan=melgan,
+ )
+ if args.save:
+ pipe.save_pretrained(args.output_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument("--output_path", default=None, type=str, required=True, help="Path to the converted model.")
+ parser.add_argument(
+ "--save", default=True, type=bool, required=False, help="Whether to save the converted model or not."
+ )
+ parser.add_argument(
+ "--checkpoint_path",
+ default=f"{MODEL}/checkpoint_500000",
+ type=str,
+ required=False,
+ help="Path to the original jax model checkpoint.",
+ )
+ args = parser.parse_args()
+
+ main(args)
diff --git a/diffusers/scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py b/diffusers/scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..22e4271eba3aa859e4220b6f69e81c06550e9548
--- /dev/null
+++ b/diffusers/scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py
@@ -0,0 +1,185 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the NCSNPP checkpoints. """
+
+import argparse
+import json
+
+import torch
+
+from diffusers import ScoreSdeVePipeline, ScoreSdeVeScheduler, UNet2DModel
+
+
+def convert_ncsnpp_checkpoint(checkpoint, config):
+ """
+ Takes a state dict and the path to
+ """
+ new_model_architecture = UNet2DModel(**config)
+ new_model_architecture.time_proj.W.data = checkpoint["all_modules.0.W"].data
+ new_model_architecture.time_proj.weight.data = checkpoint["all_modules.0.W"].data
+ new_model_architecture.time_embedding.linear_1.weight.data = checkpoint["all_modules.1.weight"].data
+ new_model_architecture.time_embedding.linear_1.bias.data = checkpoint["all_modules.1.bias"].data
+
+ new_model_architecture.time_embedding.linear_2.weight.data = checkpoint["all_modules.2.weight"].data
+ new_model_architecture.time_embedding.linear_2.bias.data = checkpoint["all_modules.2.bias"].data
+
+ new_model_architecture.conv_in.weight.data = checkpoint["all_modules.3.weight"].data
+ new_model_architecture.conv_in.bias.data = checkpoint["all_modules.3.bias"].data
+
+ new_model_architecture.conv_norm_out.weight.data = checkpoint[list(checkpoint.keys())[-4]].data
+ new_model_architecture.conv_norm_out.bias.data = checkpoint[list(checkpoint.keys())[-3]].data
+ new_model_architecture.conv_out.weight.data = checkpoint[list(checkpoint.keys())[-2]].data
+ new_model_architecture.conv_out.bias.data = checkpoint[list(checkpoint.keys())[-1]].data
+
+ module_index = 4
+
+ def set_attention_weights(new_layer, old_checkpoint, index):
+ new_layer.query.weight.data = old_checkpoint[f"all_modules.{index}.NIN_0.W"].data.T
+ new_layer.key.weight.data = old_checkpoint[f"all_modules.{index}.NIN_1.W"].data.T
+ new_layer.value.weight.data = old_checkpoint[f"all_modules.{index}.NIN_2.W"].data.T
+
+ new_layer.query.bias.data = old_checkpoint[f"all_modules.{index}.NIN_0.b"].data
+ new_layer.key.bias.data = old_checkpoint[f"all_modules.{index}.NIN_1.b"].data
+ new_layer.value.bias.data = old_checkpoint[f"all_modules.{index}.NIN_2.b"].data
+
+ new_layer.proj_attn.weight.data = old_checkpoint[f"all_modules.{index}.NIN_3.W"].data.T
+ new_layer.proj_attn.bias.data = old_checkpoint[f"all_modules.{index}.NIN_3.b"].data
+
+ new_layer.group_norm.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.weight"].data
+ new_layer.group_norm.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.bias"].data
+
+ def set_resnet_weights(new_layer, old_checkpoint, index):
+ new_layer.conv1.weight.data = old_checkpoint[f"all_modules.{index}.Conv_0.weight"].data
+ new_layer.conv1.bias.data = old_checkpoint[f"all_modules.{index}.Conv_0.bias"].data
+ new_layer.norm1.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.weight"].data
+ new_layer.norm1.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.bias"].data
+
+ new_layer.conv2.weight.data = old_checkpoint[f"all_modules.{index}.Conv_1.weight"].data
+ new_layer.conv2.bias.data = old_checkpoint[f"all_modules.{index}.Conv_1.bias"].data
+ new_layer.norm2.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_1.weight"].data
+ new_layer.norm2.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_1.bias"].data
+
+ new_layer.time_emb_proj.weight.data = old_checkpoint[f"all_modules.{index}.Dense_0.weight"].data
+ new_layer.time_emb_proj.bias.data = old_checkpoint[f"all_modules.{index}.Dense_0.bias"].data
+
+ if new_layer.in_channels != new_layer.out_channels or new_layer.up or new_layer.down:
+ new_layer.conv_shortcut.weight.data = old_checkpoint[f"all_modules.{index}.Conv_2.weight"].data
+ new_layer.conv_shortcut.bias.data = old_checkpoint[f"all_modules.{index}.Conv_2.bias"].data
+
+ for i, block in enumerate(new_model_architecture.downsample_blocks):
+ has_attentions = hasattr(block, "attentions")
+ for j in range(len(block.resnets)):
+ set_resnet_weights(block.resnets[j], checkpoint, module_index)
+ module_index += 1
+ if has_attentions:
+ set_attention_weights(block.attentions[j], checkpoint, module_index)
+ module_index += 1
+
+ if hasattr(block, "downsamplers") and block.downsamplers is not None:
+ set_resnet_weights(block.resnet_down, checkpoint, module_index)
+ module_index += 1
+ block.skip_conv.weight.data = checkpoint[f"all_modules.{module_index}.Conv_0.weight"].data
+ block.skip_conv.bias.data = checkpoint[f"all_modules.{module_index}.Conv_0.bias"].data
+ module_index += 1
+
+ set_resnet_weights(new_model_architecture.mid_block.resnets[0], checkpoint, module_index)
+ module_index += 1
+ set_attention_weights(new_model_architecture.mid_block.attentions[0], checkpoint, module_index)
+ module_index += 1
+ set_resnet_weights(new_model_architecture.mid_block.resnets[1], checkpoint, module_index)
+ module_index += 1
+
+ for i, block in enumerate(new_model_architecture.up_blocks):
+ has_attentions = hasattr(block, "attentions")
+ for j in range(len(block.resnets)):
+ set_resnet_weights(block.resnets[j], checkpoint, module_index)
+ module_index += 1
+ if has_attentions:
+ set_attention_weights(
+ block.attentions[0], checkpoint, module_index
+ ) # why can there only be a single attention layer for up?
+ module_index += 1
+
+ if hasattr(block, "resnet_up") and block.resnet_up is not None:
+ block.skip_norm.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
+ block.skip_norm.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
+ module_index += 1
+ block.skip_conv.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
+ block.skip_conv.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
+ module_index += 1
+ set_resnet_weights(block.resnet_up, checkpoint, module_index)
+ module_index += 1
+
+ new_model_architecture.conv_norm_out.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
+ new_model_architecture.conv_norm_out.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
+ module_index += 1
+ new_model_architecture.conv_out.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
+ new_model_architecture.conv_out.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
+
+ return new_model_architecture.state_dict()
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--checkpoint_path",
+ default="/Users/arthurzucker/Work/diffusers/ArthurZ/diffusion_pytorch_model.bin",
+ type=str,
+ required=False,
+ help="Path to the checkpoint to convert.",
+ )
+
+ parser.add_argument(
+ "--config_file",
+ default="/Users/arthurzucker/Work/diffusers/ArthurZ/config.json",
+ type=str,
+ required=False,
+ help="The config json file corresponding to the architecture.",
+ )
+
+ parser.add_argument(
+ "--dump_path",
+ default="/Users/arthurzucker/Work/diffusers/ArthurZ/diffusion_model_new.pt",
+ type=str,
+ required=False,
+ help="Path to the output model.",
+ )
+
+ args = parser.parse_args()
+
+ checkpoint = torch.load(args.checkpoint_path, map_location="cpu")
+
+ with open(args.config_file) as f:
+ config = json.loads(f.read())
+
+ converted_checkpoint = convert_ncsnpp_checkpoint(
+ checkpoint,
+ config,
+ )
+
+ if "sde" in config:
+ del config["sde"]
+
+ model = UNet2DModel(**config)
+ model.load_state_dict(converted_checkpoint)
+
+ try:
+ scheduler = ScoreSdeVeScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
+
+ pipe = ScoreSdeVePipeline(unet=model, scheduler=scheduler)
+ pipe.save_pretrained(args.dump_path)
+ except: # noqa: E722
+ model.save_pretrained(args.dump_path)
diff --git a/diffusers/scripts/convert_original_audioldm_to_diffusers.py b/diffusers/scripts/convert_original_audioldm_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..189b165c0a017067026c8b8919c5c33fe0f0ae87
--- /dev/null
+++ b/diffusers/scripts/convert_original_audioldm_to_diffusers.py
@@ -0,0 +1,1015 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the AudioLDM checkpoints."""
+
+import argparse
+import re
+
+import torch
+from transformers import (
+ AutoTokenizer,
+ ClapTextConfig,
+ ClapTextModelWithProjection,
+ SpeechT5HifiGan,
+ SpeechT5HifiGanConfig,
+)
+
+from diffusers import (
+ AudioLDMPipeline,
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ HeunDiscreteScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ UNet2DConditionModel,
+)
+from diffusers.utils import is_omegaconf_available, is_safetensors_available
+from diffusers.utils.import_utils import BACKENDS_MAPPING
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.shave_segments
+def shave_segments(path, n_shave_prefix_segments=1):
+ """
+ Removes segments. Positive values shave the first segments, negative shave the last segments.
+ """
+ if n_shave_prefix_segments >= 0:
+ return ".".join(path.split(".")[n_shave_prefix_segments:])
+ else:
+ return ".".join(path.split(".")[:n_shave_prefix_segments])
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.renew_resnet_paths
+def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item.replace("in_layers.0", "norm1")
+ new_item = new_item.replace("in_layers.2", "conv1")
+
+ new_item = new_item.replace("out_layers.0", "norm2")
+ new_item = new_item.replace("out_layers.3", "conv2")
+
+ new_item = new_item.replace("emb_layers.1", "time_emb_proj")
+ new_item = new_item.replace("skip_connection", "conv_shortcut")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.renew_vae_resnet_paths
+def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("nin_shortcut", "conv_shortcut")
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.renew_attention_paths
+def renew_attention_paths(old_list):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ # new_item = new_item.replace('norm.weight', 'group_norm.weight')
+ # new_item = new_item.replace('norm.bias', 'group_norm.bias')
+
+ # new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
+ # new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
+
+ # new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.renew_vae_attention_paths
+def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("norm.weight", "group_norm.weight")
+ new_item = new_item.replace("norm.bias", "group_norm.bias")
+
+ new_item = new_item.replace("q.weight", "query.weight")
+ new_item = new_item.replace("q.bias", "query.bias")
+
+ new_item = new_item.replace("k.weight", "key.weight")
+ new_item = new_item.replace("k.bias", "key.bias")
+
+ new_item = new_item.replace("v.weight", "value.weight")
+ new_item = new_item.replace("v.bias", "value.bias")
+
+ new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
+ new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.assign_to_checkpoint
+def assign_to_checkpoint(
+ paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
+):
+ """
+ This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
+ attention layers, and takes into account additional replacements that may arise.
+
+ Assigns the weights to the new checkpoint.
+ """
+ assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
+
+ # Splits the attention layers into three variables.
+ if attention_paths_to_split is not None:
+ for path, path_map in attention_paths_to_split.items():
+ old_tensor = old_checkpoint[path]
+ channels = old_tensor.shape[0] // 3
+
+ target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
+
+ num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
+
+ old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
+ query, key, value = old_tensor.split(channels // num_heads, dim=1)
+
+ checkpoint[path_map["query"]] = query.reshape(target_shape)
+ checkpoint[path_map["key"]] = key.reshape(target_shape)
+ checkpoint[path_map["value"]] = value.reshape(target_shape)
+
+ for path in paths:
+ new_path = path["new"]
+
+ # These have already been assigned
+ if attention_paths_to_split is not None and new_path in attention_paths_to_split:
+ continue
+
+ # Global renaming happens here
+ new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
+ new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
+ new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
+
+ if additional_replacements is not None:
+ for replacement in additional_replacements:
+ new_path = new_path.replace(replacement["old"], replacement["new"])
+
+ # proj_attn.weight has to be converted from conv 1D to linear
+ if "proj_attn.weight" in new_path:
+ checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
+ else:
+ checkpoint[new_path] = old_checkpoint[path["old"]]
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.conv_attn_to_linear
+def conv_attn_to_linear(checkpoint):
+ keys = list(checkpoint.keys())
+ attn_keys = ["query.weight", "key.weight", "value.weight"]
+ for key in keys:
+ if ".".join(key.split(".")[-2:]) in attn_keys:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0, 0]
+ elif "proj_attn.weight" in key:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0]
+
+
+def create_unet_diffusers_config(original_config, image_size: int):
+ """
+ Creates a UNet config for diffusers based on the config of the original AudioLDM model.
+ """
+ unet_params = original_config.model.params.unet_config.params
+ vae_params = original_config.model.params.first_stage_config.params.ddconfig
+
+ block_out_channels = [unet_params.model_channels * mult for mult in unet_params.channel_mult]
+
+ down_block_types = []
+ resolution = 1
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnDownBlock2D" if resolution in unet_params.attention_resolutions else "DownBlock2D"
+ down_block_types.append(block_type)
+ if i != len(block_out_channels) - 1:
+ resolution *= 2
+
+ up_block_types = []
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnUpBlock2D" if resolution in unet_params.attention_resolutions else "UpBlock2D"
+ up_block_types.append(block_type)
+ resolution //= 2
+
+ vae_scale_factor = 2 ** (len(vae_params.ch_mult) - 1)
+
+ cross_attention_dim = (
+ unet_params.cross_attention_dim if "cross_attention_dim" in unet_params else block_out_channels
+ )
+
+ class_embed_type = "simple_projection" if "extra_film_condition_dim" in unet_params else None
+ projection_class_embeddings_input_dim = (
+ unet_params.extra_film_condition_dim if "extra_film_condition_dim" in unet_params else None
+ )
+ class_embeddings_concat = unet_params.extra_film_use_concat if "extra_film_use_concat" in unet_params else None
+
+ config = {
+ "sample_size": image_size // vae_scale_factor,
+ "in_channels": unet_params.in_channels,
+ "out_channels": unet_params.out_channels,
+ "down_block_types": tuple(down_block_types),
+ "up_block_types": tuple(up_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "layers_per_block": unet_params.num_res_blocks,
+ "cross_attention_dim": cross_attention_dim,
+ "class_embed_type": class_embed_type,
+ "projection_class_embeddings_input_dim": projection_class_embeddings_input_dim,
+ "class_embeddings_concat": class_embeddings_concat,
+ }
+
+ return config
+
+
+# Adapted from diffusers.pipelines.stable_diffusion.convert_from_ckpt.create_vae_diffusers_config
+def create_vae_diffusers_config(original_config, checkpoint, image_size: int):
+ """
+ Creates a VAE config for diffusers based on the config of the original AudioLDM model. Compared to the original
+ Stable Diffusion conversion, this function passes a *learnt* VAE scaling factor to the diffusers VAE.
+ """
+ vae_params = original_config.model.params.first_stage_config.params.ddconfig
+ _ = original_config.model.params.first_stage_config.params.embed_dim
+
+ block_out_channels = [vae_params.ch * mult for mult in vae_params.ch_mult]
+ down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels)
+ up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels)
+
+ scaling_factor = checkpoint["scale_factor"] if "scale_by_std" in original_config.model.params else 0.18215
+
+ config = {
+ "sample_size": image_size,
+ "in_channels": vae_params.in_channels,
+ "out_channels": vae_params.out_ch,
+ "down_block_types": tuple(down_block_types),
+ "up_block_types": tuple(up_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "latent_channels": vae_params.z_channels,
+ "layers_per_block": vae_params.num_res_blocks,
+ "scaling_factor": float(scaling_factor),
+ }
+ return config
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.create_diffusers_schedular
+def create_diffusers_schedular(original_config):
+ schedular = DDIMScheduler(
+ num_train_timesteps=original_config.model.params.timesteps,
+ beta_start=original_config.model.params.linear_start,
+ beta_end=original_config.model.params.linear_end,
+ beta_schedule="scaled_linear",
+ )
+ return schedular
+
+
+# Adapted from diffusers.pipelines.stable_diffusion.convert_from_ckpt.convert_ldm_unet_checkpoint
+def convert_ldm_unet_checkpoint(checkpoint, config, path=None, extract_ema=False):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint. Compared to the original Stable Diffusion
+ conversion, this function additionally converts the learnt film embedding linear layer.
+ """
+
+ # extract state_dict for UNet
+ unet_state_dict = {}
+ keys = list(checkpoint.keys())
+
+ unet_key = "model.diffusion_model."
+ # at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
+ if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
+ print(f"Checkpoint {path} has both EMA and non-EMA weights.")
+ print(
+ "In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
+ " weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
+ )
+ for key in keys:
+ if key.startswith("model.diffusion_model"):
+ flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
+ else:
+ if sum(k.startswith("model_ema") for k in keys) > 100:
+ print(
+ "In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
+ " weights (usually better for inference), please make sure to add the `--extract_ema` flag."
+ )
+
+ for key in keys:
+ if key.startswith(unet_key):
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
+ new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
+ new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
+ new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
+
+ new_checkpoint["class_embedding.weight"] = unet_state_dict["film_emb.weight"]
+ new_checkpoint["class_embedding.bias"] = unet_state_dict["film_emb.bias"]
+
+ new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
+ new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
+
+ new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
+ new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
+ new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
+ new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
+
+ # Retrieves the keys for the input blocks only
+ num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
+ input_blocks = {
+ layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
+ for layer_id in range(num_input_blocks)
+ }
+
+ # Retrieves the keys for the middle blocks only
+ num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
+ middle_blocks = {
+ layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
+ for layer_id in range(num_middle_blocks)
+ }
+
+ # Retrieves the keys for the output blocks only
+ num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
+ output_blocks = {
+ layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
+ for layer_id in range(num_output_blocks)
+ }
+
+ for i in range(1, num_input_blocks):
+ block_id = (i - 1) // (config["layers_per_block"] + 1)
+ layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
+
+ resnets = [
+ key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
+ ]
+ attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
+
+ if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.weight"
+ )
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.bias"
+ )
+
+ paths = renew_resnet_paths(resnets)
+ meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ resnet_0 = middle_blocks[0]
+ attentions = middle_blocks[1]
+ resnet_1 = middle_blocks[2]
+
+ resnet_0_paths = renew_resnet_paths(resnet_0)
+ assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
+
+ resnet_1_paths = renew_resnet_paths(resnet_1)
+ assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
+
+ attentions_paths = renew_attention_paths(attentions)
+ meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ for i in range(num_output_blocks):
+ block_id = i // (config["layers_per_block"] + 1)
+ layer_in_block_id = i % (config["layers_per_block"] + 1)
+ output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
+ output_block_list = {}
+
+ for layer in output_block_layers:
+ layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
+ if layer_id in output_block_list:
+ output_block_list[layer_id].append(layer_name)
+ else:
+ output_block_list[layer_id] = [layer_name]
+
+ if len(output_block_list) > 1:
+ resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
+ attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
+
+ resnet_0_paths = renew_resnet_paths(resnets)
+ paths = renew_resnet_paths(resnets)
+
+ meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
+ if ["conv.bias", "conv.weight"] in output_block_list.values():
+ index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.weight"
+ ]
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.bias"
+ ]
+
+ # Clear attentions as they have been attributed above.
+ if len(attentions) == 2:
+ attentions = []
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"output_blocks.{i}.1",
+ "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+ else:
+ resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
+ for path in resnet_0_paths:
+ old_path = ".".join(["output_blocks", str(i), path["old"]])
+ new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
+
+ new_checkpoint[new_path] = unet_state_dict[old_path]
+
+ return new_checkpoint
+
+
+# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.convert_ldm_vae_checkpoint
+def convert_ldm_vae_checkpoint(checkpoint, config):
+ # extract state dict for VAE
+ vae_state_dict = {}
+ vae_key = "first_stage_model."
+ keys = list(checkpoint.keys())
+ for key in keys:
+ if key.startswith(vae_key):
+ vae_state_dict[key.replace(vae_key, "")] = checkpoint.get(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
+ new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
+ new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
+ new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
+ new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
+ new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
+
+ new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
+ new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
+ new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
+ new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
+ new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
+ new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
+
+ new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
+ new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
+ new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
+ new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
+
+ # Retrieves the keys for the encoder down blocks only
+ num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer})
+ down_blocks = {
+ layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
+ }
+
+ # Retrieves the keys for the decoder up blocks only
+ num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
+ up_blocks = {
+ layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
+ }
+
+ for i in range(num_down_blocks):
+ resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
+
+ if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.weight"
+ )
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.bias"
+ )
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+ conv_attn_to_linear(new_checkpoint)
+
+ for i in range(num_up_blocks):
+ block_id = num_up_blocks - 1 - i
+ resnets = [
+ key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
+ ]
+
+ if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.weight"
+ ]
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.bias"
+ ]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+ conv_attn_to_linear(new_checkpoint)
+ return new_checkpoint
+
+
+CLAP_KEYS_TO_MODIFY_MAPPING = {
+ "text_branch": "text_model",
+ "attn": "attention.self",
+ "self.proj": "output.dense",
+ "attention.self_mask": "attn_mask",
+ "mlp.fc1": "intermediate.dense",
+ "mlp.fc2": "output.dense",
+ "norm1": "layernorm_before",
+ "norm2": "layernorm_after",
+ "bn0": "batch_norm",
+}
+
+CLAP_KEYS_TO_IGNORE = ["text_transform"]
+
+CLAP_EXPECTED_MISSING_KEYS = ["text_model.embeddings.token_type_ids"]
+
+
+def convert_open_clap_checkpoint(checkpoint):
+ """
+ Takes a state dict and returns a converted CLAP checkpoint.
+ """
+ # extract state dict for CLAP text embedding model, discarding the audio component
+ model_state_dict = {}
+ model_key = "cond_stage_model.model.text_"
+ keys = list(checkpoint.keys())
+ for key in keys:
+ if key.startswith(model_key):
+ model_state_dict[key.replace(model_key, "text_")] = checkpoint.get(key)
+
+ new_checkpoint = {}
+
+ sequential_layers_pattern = r".*sequential.(\d+).*"
+ text_projection_pattern = r".*_projection.(\d+).*"
+
+ for key, value in model_state_dict.items():
+ # check if key should be ignored in mapping
+ if key.split(".")[0] in CLAP_KEYS_TO_IGNORE:
+ continue
+
+ # check if any key needs to be modified
+ for key_to_modify, new_key in CLAP_KEYS_TO_MODIFY_MAPPING.items():
+ if key_to_modify in key:
+ key = key.replace(key_to_modify, new_key)
+
+ if re.match(sequential_layers_pattern, key):
+ # replace sequential layers with list
+ sequential_layer = re.match(sequential_layers_pattern, key).group(1)
+
+ key = key.replace(f"sequential.{sequential_layer}.", f"layers.{int(sequential_layer)//3}.linear.")
+ elif re.match(text_projection_pattern, key):
+ projecton_layer = int(re.match(text_projection_pattern, key).group(1))
+
+ # Because in CLAP they use `nn.Sequential`...
+ transformers_projection_layer = 1 if projecton_layer == 0 else 2
+
+ key = key.replace(f"_projection.{projecton_layer}.", f"_projection.linear{transformers_projection_layer}.")
+
+ if "audio" and "qkv" in key:
+ # split qkv into query key and value
+ mixed_qkv = value
+ qkv_dim = mixed_qkv.size(0) // 3
+
+ query_layer = mixed_qkv[:qkv_dim]
+ key_layer = mixed_qkv[qkv_dim : qkv_dim * 2]
+ value_layer = mixed_qkv[qkv_dim * 2 :]
+
+ new_checkpoint[key.replace("qkv", "query")] = query_layer
+ new_checkpoint[key.replace("qkv", "key")] = key_layer
+ new_checkpoint[key.replace("qkv", "value")] = value_layer
+ else:
+ new_checkpoint[key] = value
+
+ return new_checkpoint
+
+
+def create_transformers_vocoder_config(original_config):
+ """
+ Creates a config for transformers SpeechT5HifiGan based on the config of the vocoder model.
+ """
+ vocoder_params = original_config.model.params.vocoder_config.params
+
+ config = {
+ "model_in_dim": vocoder_params.num_mels,
+ "sampling_rate": vocoder_params.sampling_rate,
+ "upsample_initial_channel": vocoder_params.upsample_initial_channel,
+ "upsample_rates": list(vocoder_params.upsample_rates),
+ "upsample_kernel_sizes": list(vocoder_params.upsample_kernel_sizes),
+ "resblock_kernel_sizes": list(vocoder_params.resblock_kernel_sizes),
+ "resblock_dilation_sizes": [
+ list(resblock_dilation) for resblock_dilation in vocoder_params.resblock_dilation_sizes
+ ],
+ "normalize_before": False,
+ }
+
+ return config
+
+
+def convert_hifigan_checkpoint(checkpoint, config):
+ """
+ Takes a state dict and config, and returns a converted HiFiGAN vocoder checkpoint.
+ """
+ # extract state dict for vocoder
+ vocoder_state_dict = {}
+ vocoder_key = "first_stage_model.vocoder."
+ keys = list(checkpoint.keys())
+ for key in keys:
+ if key.startswith(vocoder_key):
+ vocoder_state_dict[key.replace(vocoder_key, "")] = checkpoint.get(key)
+
+ # fix upsampler keys, everything else is correct already
+ for i in range(len(config.upsample_rates)):
+ vocoder_state_dict[f"upsampler.{i}.weight"] = vocoder_state_dict.pop(f"ups.{i}.weight")
+ vocoder_state_dict[f"upsampler.{i}.bias"] = vocoder_state_dict.pop(f"ups.{i}.bias")
+
+ if not config.normalize_before:
+ # if we don't set normalize_before then these variables are unused, so we set them to their initialised values
+ vocoder_state_dict["mean"] = torch.zeros(config.model_in_dim)
+ vocoder_state_dict["scale"] = torch.ones(config.model_in_dim)
+
+ return vocoder_state_dict
+
+
+# Adapted from https://huggingface.co/spaces/haoheliu/audioldm-text-to-audio-generation/blob/84a0384742a22bd80c44e903e241f0623e874f1d/audioldm/utils.py#L72-L73
+DEFAULT_CONFIG = {
+ "model": {
+ "params": {
+ "linear_start": 0.0015,
+ "linear_end": 0.0195,
+ "timesteps": 1000,
+ "channels": 8,
+ "scale_by_std": True,
+ "unet_config": {
+ "target": "audioldm.latent_diffusion.openaimodel.UNetModel",
+ "params": {
+ "extra_film_condition_dim": 512,
+ "extra_film_use_concat": True,
+ "in_channels": 8,
+ "out_channels": 8,
+ "model_channels": 128,
+ "attention_resolutions": [8, 4, 2],
+ "num_res_blocks": 2,
+ "channel_mult": [1, 2, 3, 5],
+ "num_head_channels": 32,
+ },
+ },
+ "first_stage_config": {
+ "target": "audioldm.variational_autoencoder.autoencoder.AutoencoderKL",
+ "params": {
+ "embed_dim": 8,
+ "ddconfig": {
+ "z_channels": 8,
+ "resolution": 256,
+ "in_channels": 1,
+ "out_ch": 1,
+ "ch": 128,
+ "ch_mult": [1, 2, 4],
+ "num_res_blocks": 2,
+ },
+ },
+ },
+ "vocoder_config": {
+ "target": "audioldm.first_stage_model.vocoder",
+ "params": {
+ "upsample_rates": [5, 4, 2, 2, 2],
+ "upsample_kernel_sizes": [16, 16, 8, 4, 4],
+ "upsample_initial_channel": 1024,
+ "resblock_kernel_sizes": [3, 7, 11],
+ "resblock_dilation_sizes": [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
+ "num_mels": 64,
+ "sampling_rate": 16000,
+ },
+ },
+ },
+ },
+}
+
+
+def load_pipeline_from_original_audioldm_ckpt(
+ checkpoint_path: str,
+ original_config_file: str = None,
+ image_size: int = 512,
+ prediction_type: str = None,
+ extract_ema: bool = False,
+ scheduler_type: str = "ddim",
+ num_in_channels: int = None,
+ device: str = None,
+ from_safetensors: bool = False,
+) -> AudioLDMPipeline:
+ """
+ Load an AudioLDM pipeline object from a `.ckpt`/`.safetensors` file and (ideally) a `.yaml` config file.
+
+ Although many of the arguments can be automatically inferred, some of these rely on brittle checks against the
+ global step count, which will likely fail for models that have undergone further fine-tuning. Therefore, it is
+ recommended that you override the default values and/or supply an `original_config_file` wherever possible.
+
+ :param checkpoint_path: Path to `.ckpt` file. :param original_config_file: Path to `.yaml` config file
+ corresponding to the original architecture.
+ If `None`, will be automatically instantiated based on default values.
+ :param image_size: The image size that the model was trained on. Use 512 for original AudioLDM checkpoints. :param
+ prediction_type: The prediction type that the model was trained on. Use `'epsilon'` for original
+ AudioLDM checkpoints.
+ :param num_in_channels: The number of input channels. If `None` number of input channels will be automatically
+ inferred.
+ :param scheduler_type: Type of scheduler to use. Should be one of `["pndm", "lms", "heun", "euler",
+ "euler-ancestral", "dpm", "ddim"]`.
+ :param extract_ema: Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract
+ the EMA weights or not. Defaults to `False`. Pass `True` to extract the EMA weights. EMA weights usually
+ yield higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning.
+ :param device: The device to use. Pass `None` to determine automatically. :param from_safetensors: If
+ `checkpoint_path` is in `safetensors` format, load checkpoint with safetensors
+ instead of PyTorch.
+ :return: An AudioLDMPipeline object representing the passed-in `.ckpt`/`.safetensors` file.
+ """
+
+ if not is_omegaconf_available():
+ raise ValueError(BACKENDS_MAPPING["omegaconf"][1])
+
+ from omegaconf import OmegaConf
+
+ if from_safetensors:
+ if not is_safetensors_available():
+ raise ValueError(BACKENDS_MAPPING["safetensors"][1])
+
+ from safetensors import safe_open
+
+ checkpoint = {}
+ with safe_open(checkpoint_path, framework="pt", device="cpu") as f:
+ for key in f.keys():
+ checkpoint[key] = f.get_tensor(key)
+ else:
+ if device is None:
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ checkpoint = torch.load(checkpoint_path, map_location=device)
+ else:
+ checkpoint = torch.load(checkpoint_path, map_location=device)
+
+ if "state_dict" in checkpoint:
+ checkpoint = checkpoint["state_dict"]
+
+ if original_config_file is None:
+ original_config = DEFAULT_CONFIG
+ original_config = OmegaConf.create(original_config)
+ else:
+ original_config = OmegaConf.load(original_config_file)
+
+ if num_in_channels is not None:
+ original_config["model"]["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
+
+ if (
+ "parameterization" in original_config["model"]["params"]
+ and original_config["model"]["params"]["parameterization"] == "v"
+ ):
+ if prediction_type is None:
+ prediction_type = "v_prediction"
+ else:
+ if prediction_type is None:
+ prediction_type = "epsilon"
+
+ if image_size is None:
+ image_size = 512
+
+ num_train_timesteps = original_config.model.params.timesteps
+ beta_start = original_config.model.params.linear_start
+ beta_end = original_config.model.params.linear_end
+
+ scheduler = DDIMScheduler(
+ beta_end=beta_end,
+ beta_schedule="scaled_linear",
+ beta_start=beta_start,
+ num_train_timesteps=num_train_timesteps,
+ steps_offset=1,
+ clip_sample=False,
+ set_alpha_to_one=False,
+ prediction_type=prediction_type,
+ )
+ # make sure scheduler works correctly with DDIM
+ scheduler.register_to_config(clip_sample=False)
+
+ if scheduler_type == "pndm":
+ config = dict(scheduler.config)
+ config["skip_prk_steps"] = True
+ scheduler = PNDMScheduler.from_config(config)
+ elif scheduler_type == "lms":
+ scheduler = LMSDiscreteScheduler.from_config(scheduler.config)
+ elif scheduler_type == "heun":
+ scheduler = HeunDiscreteScheduler.from_config(scheduler.config)
+ elif scheduler_type == "euler":
+ scheduler = EulerDiscreteScheduler.from_config(scheduler.config)
+ elif scheduler_type == "euler-ancestral":
+ scheduler = EulerAncestralDiscreteScheduler.from_config(scheduler.config)
+ elif scheduler_type == "dpm":
+ scheduler = DPMSolverMultistepScheduler.from_config(scheduler.config)
+ elif scheduler_type == "ddim":
+ scheduler = scheduler
+ else:
+ raise ValueError(f"Scheduler of type {scheduler_type} doesn't exist!")
+
+ # Convert the UNet2DModel
+ unet_config = create_unet_diffusers_config(original_config, image_size=image_size)
+ unet = UNet2DConditionModel(**unet_config)
+
+ converted_unet_checkpoint = convert_ldm_unet_checkpoint(
+ checkpoint, unet_config, path=checkpoint_path, extract_ema=extract_ema
+ )
+
+ unet.load_state_dict(converted_unet_checkpoint)
+
+ # Convert the VAE model
+ vae_config = create_vae_diffusers_config(original_config, checkpoint=checkpoint, image_size=image_size)
+ converted_vae_checkpoint = convert_ldm_vae_checkpoint(checkpoint, vae_config)
+
+ vae = AutoencoderKL(**vae_config)
+ vae.load_state_dict(converted_vae_checkpoint)
+
+ # Convert the text model
+ # AudioLDM uses the same configuration and tokenizer as the original CLAP model
+ config = ClapTextConfig.from_pretrained("laion/clap-htsat-unfused")
+ tokenizer = AutoTokenizer.from_pretrained("laion/clap-htsat-unfused")
+
+ converted_text_model = convert_open_clap_checkpoint(checkpoint)
+ text_model = ClapTextModelWithProjection(config)
+
+ missing_keys, unexpected_keys = text_model.load_state_dict(converted_text_model, strict=False)
+ # we expect not to have token_type_ids in our original state dict so let's ignore them
+ missing_keys = list(set(missing_keys) - set(CLAP_EXPECTED_MISSING_KEYS))
+
+ if len(unexpected_keys) > 0:
+ raise ValueError(f"Unexpected keys when loading CLAP model: {unexpected_keys}")
+
+ if len(missing_keys) > 0:
+ raise ValueError(f"Missing keys when loading CLAP model: {missing_keys}")
+
+ # Convert the vocoder model
+ vocoder_config = create_transformers_vocoder_config(original_config)
+ vocoder_config = SpeechT5HifiGanConfig(**vocoder_config)
+ converted_vocoder_checkpoint = convert_hifigan_checkpoint(checkpoint, vocoder_config)
+
+ vocoder = SpeechT5HifiGan(vocoder_config)
+ vocoder.load_state_dict(converted_vocoder_checkpoint)
+
+ # Instantiate the diffusers pipeline
+ pipe = AudioLDMPipeline(
+ vae=vae,
+ text_encoder=text_model,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ vocoder=vocoder,
+ )
+
+ return pipe
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument(
+ "--original_config_file",
+ default=None,
+ type=str,
+ help="The YAML config file corresponding to the original architecture.",
+ )
+ parser.add_argument(
+ "--num_in_channels",
+ default=None,
+ type=int,
+ help="The number of input channels. If `None` number of input channels will be automatically inferred.",
+ )
+ parser.add_argument(
+ "--scheduler_type",
+ default="ddim",
+ type=str,
+ help="Type of scheduler to use. Should be one of ['pndm', 'lms', 'ddim', 'euler', 'euler-ancestral', 'dpm']",
+ )
+ parser.add_argument(
+ "--image_size",
+ default=None,
+ type=int,
+ help=("The image size that the model was trained on."),
+ )
+ parser.add_argument(
+ "--prediction_type",
+ default=None,
+ type=str,
+ help=("The prediction type that the model was trained on."),
+ )
+ parser.add_argument(
+ "--extract_ema",
+ action="store_true",
+ help=(
+ "Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
+ " or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
+ " higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
+ ),
+ )
+ parser.add_argument(
+ "--from_safetensors",
+ action="store_true",
+ help="If `--checkpoint_path` is in `safetensors` format, load checkpoint with safetensors instead of PyTorch.",
+ )
+ parser.add_argument(
+ "--to_safetensors",
+ action="store_true",
+ help="Whether to store pipeline in safetensors format or not.",
+ )
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+ parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
+ args = parser.parse_args()
+
+ pipe = load_pipeline_from_original_audioldm_ckpt(
+ checkpoint_path=args.checkpoint_path,
+ original_config_file=args.original_config_file,
+ image_size=args.image_size,
+ prediction_type=args.prediction_type,
+ extract_ema=args.extract_ema,
+ scheduler_type=args.scheduler_type,
+ num_in_channels=args.num_in_channels,
+ from_safetensors=args.from_safetensors,
+ device=args.device,
+ )
+ pipe.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
diff --git a/diffusers/scripts/convert_original_controlnet_to_diffusers.py b/diffusers/scripts/convert_original_controlnet_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..a9e05abd4cf13a0fe629698f969698e95e913c4a
--- /dev/null
+++ b/diffusers/scripts/convert_original_controlnet_to_diffusers.py
@@ -0,0 +1,91 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for stable diffusion checkpoints which _only_ contain a contrlnet. """
+
+import argparse
+
+from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_controlnet_from_original_ckpt
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument(
+ "--original_config_file",
+ type=str,
+ required=True,
+ help="The YAML config file corresponding to the original architecture.",
+ )
+ parser.add_argument(
+ "--num_in_channels",
+ default=None,
+ type=int,
+ help="The number of input channels. If `None` number of input channels will be automatically inferred.",
+ )
+ parser.add_argument(
+ "--image_size",
+ default=512,
+ type=int,
+ help=(
+ "The image size that the model was trained on. Use 512 for Stable Diffusion v1.X and Stable Siffusion v2"
+ " Base. Use 768 for Stable Diffusion v2."
+ ),
+ )
+ parser.add_argument(
+ "--extract_ema",
+ action="store_true",
+ help=(
+ "Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
+ " or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
+ " higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
+ ),
+ )
+ parser.add_argument(
+ "--upcast_attention",
+ action="store_true",
+ help=(
+ "Whether the attention computation should always be upcasted. This is necessary when running stable"
+ " diffusion 2.1."
+ ),
+ )
+ parser.add_argument(
+ "--from_safetensors",
+ action="store_true",
+ help="If `--checkpoint_path` is in `safetensors` format, load checkpoint with safetensors instead of PyTorch.",
+ )
+ parser.add_argument(
+ "--to_safetensors",
+ action="store_true",
+ help="Whether to store pipeline in safetensors format or not.",
+ )
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+ parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
+ args = parser.parse_args()
+
+ controlnet = download_controlnet_from_original_ckpt(
+ checkpoint_path=args.checkpoint_path,
+ original_config_file=args.original_config_file,
+ image_size=args.image_size,
+ extract_ema=args.extract_ema,
+ num_in_channels=args.num_in_channels,
+ upcast_attention=args.upcast_attention,
+ from_safetensors=args.from_safetensors,
+ device=args.device,
+ )
+
+ controlnet.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
diff --git a/diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py b/diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..de64095523b6cfc0acd25e36b44a03f99885f261
--- /dev/null
+++ b/diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py
@@ -0,0 +1,156 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the LDM checkpoints. """
+
+import argparse
+
+import torch
+
+from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_from_original_stable_diffusion_ckpt
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+ # !wget https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml
+ parser.add_argument(
+ "--original_config_file",
+ default=None,
+ type=str,
+ help="The YAML config file corresponding to the original architecture.",
+ )
+ parser.add_argument(
+ "--num_in_channels",
+ default=None,
+ type=int,
+ help="The number of input channels. If `None` number of input channels will be automatically inferred.",
+ )
+ parser.add_argument(
+ "--scheduler_type",
+ default="pndm",
+ type=str,
+ help="Type of scheduler to use. Should be one of ['pndm', 'lms', 'ddim', 'euler', 'euler-ancestral', 'dpm']",
+ )
+ parser.add_argument(
+ "--pipeline_type",
+ default=None,
+ type=str,
+ help=(
+ "The pipeline type. One of 'FrozenOpenCLIPEmbedder', 'FrozenCLIPEmbedder', 'PaintByExample'"
+ ". If `None` pipeline will be automatically inferred."
+ ),
+ )
+ parser.add_argument(
+ "--image_size",
+ default=None,
+ type=int,
+ help=(
+ "The image size that the model was trained on. Use 512 for Stable Diffusion v1.X and Stable Siffusion v2"
+ " Base. Use 768 for Stable Diffusion v2."
+ ),
+ )
+ parser.add_argument(
+ "--prediction_type",
+ default=None,
+ type=str,
+ help=(
+ "The prediction type that the model was trained on. Use 'epsilon' for Stable Diffusion v1.X and Stable"
+ " Diffusion v2 Base. Use 'v_prediction' for Stable Diffusion v2."
+ ),
+ )
+ parser.add_argument(
+ "--extract_ema",
+ action="store_true",
+ help=(
+ "Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
+ " or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
+ " higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
+ ),
+ )
+ parser.add_argument(
+ "--upcast_attention",
+ action="store_true",
+ help=(
+ "Whether the attention computation should always be upcasted. This is necessary when running stable"
+ " diffusion 2.1."
+ ),
+ )
+ parser.add_argument(
+ "--from_safetensors",
+ action="store_true",
+ help="If `--checkpoint_path` is in `safetensors` format, load checkpoint with safetensors instead of PyTorch.",
+ )
+ parser.add_argument(
+ "--to_safetensors",
+ action="store_true",
+ help="Whether to store pipeline in safetensors format or not.",
+ )
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+ parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
+ parser.add_argument(
+ "--stable_unclip",
+ type=str,
+ default=None,
+ required=False,
+ help="Set if this is a stable unCLIP model. One of 'txt2img' or 'img2img'.",
+ )
+ parser.add_argument(
+ "--stable_unclip_prior",
+ type=str,
+ default=None,
+ required=False,
+ help="Set if this is a stable unCLIP txt2img model. Selects which prior to use. If `--stable_unclip` is set to `txt2img`, the karlo prior (https://huggingface.co/kakaobrain/karlo-v1-alpha/tree/main/prior) is selected by default.",
+ )
+ parser.add_argument(
+ "--clip_stats_path",
+ type=str,
+ help="Path to the clip stats file. Only required if the stable unclip model's config specifies `model.params.noise_aug_config.params.clip_stats_path`.",
+ required=False,
+ )
+ parser.add_argument(
+ "--controlnet", action="store_true", default=None, help="Set flag if this is a controlnet checkpoint."
+ )
+ parser.add_argument("--half", action="store_true", help="Save weights in half precision.")
+ args = parser.parse_args()
+
+ pipe = download_from_original_stable_diffusion_ckpt(
+ checkpoint_path=args.checkpoint_path,
+ original_config_file=args.original_config_file,
+ image_size=args.image_size,
+ prediction_type=args.prediction_type,
+ model_type=args.pipeline_type,
+ extract_ema=args.extract_ema,
+ scheduler_type=args.scheduler_type,
+ num_in_channels=args.num_in_channels,
+ upcast_attention=args.upcast_attention,
+ from_safetensors=args.from_safetensors,
+ device=args.device,
+ stable_unclip=args.stable_unclip,
+ stable_unclip_prior=args.stable_unclip_prior,
+ clip_stats_path=args.clip_stats_path,
+ controlnet=args.controlnet,
+ )
+
+ if args.half:
+ pipe.to(torch_dtype=torch.float16)
+
+ if args.controlnet:
+ # only save the controlnet model
+ pipe.controlnet.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
+ else:
+ pipe.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
diff --git a/diffusers/scripts/convert_stable_diffusion_checkpoint_to_onnx.py b/diffusers/scripts/convert_stable_diffusion_checkpoint_to_onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..c527c8037b77d9fe9c10b0dabb505fb4a2657f0c
--- /dev/null
+++ b/diffusers/scripts/convert_stable_diffusion_checkpoint_to_onnx.py
@@ -0,0 +1,265 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import os
+import shutil
+from pathlib import Path
+
+import onnx
+import torch
+from packaging import version
+from torch.onnx import export
+
+from diffusers import OnnxRuntimeModel, OnnxStableDiffusionPipeline, StableDiffusionPipeline
+
+
+is_torch_less_than_1_11 = version.parse(version.parse(torch.__version__).base_version) < version.parse("1.11")
+
+
+def onnx_export(
+ model,
+ model_args: tuple,
+ output_path: Path,
+ ordered_input_names,
+ output_names,
+ dynamic_axes,
+ opset,
+ use_external_data_format=False,
+):
+ output_path.parent.mkdir(parents=True, exist_ok=True)
+ # PyTorch deprecated the `enable_onnx_checker` and `use_external_data_format` arguments in v1.11,
+ # so we check the torch version for backwards compatibility
+ if is_torch_less_than_1_11:
+ export(
+ model,
+ model_args,
+ f=output_path.as_posix(),
+ input_names=ordered_input_names,
+ output_names=output_names,
+ dynamic_axes=dynamic_axes,
+ do_constant_folding=True,
+ use_external_data_format=use_external_data_format,
+ enable_onnx_checker=True,
+ opset_version=opset,
+ )
+ else:
+ export(
+ model,
+ model_args,
+ f=output_path.as_posix(),
+ input_names=ordered_input_names,
+ output_names=output_names,
+ dynamic_axes=dynamic_axes,
+ do_constant_folding=True,
+ opset_version=opset,
+ )
+
+
+@torch.no_grad()
+def convert_models(model_path: str, output_path: str, opset: int, fp16: bool = False):
+ dtype = torch.float16 if fp16 else torch.float32
+ if fp16 and torch.cuda.is_available():
+ device = "cuda"
+ elif fp16 and not torch.cuda.is_available():
+ raise ValueError("`float16` model export is only supported on GPUs with CUDA")
+ else:
+ device = "cpu"
+ pipeline = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=dtype).to(device)
+ output_path = Path(output_path)
+
+ # TEXT ENCODER
+ num_tokens = pipeline.text_encoder.config.max_position_embeddings
+ text_hidden_size = pipeline.text_encoder.config.hidden_size
+ text_input = pipeline.tokenizer(
+ "A sample prompt",
+ padding="max_length",
+ max_length=pipeline.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ onnx_export(
+ pipeline.text_encoder,
+ # casting to torch.int32 until the CLIP fix is released: https://github.com/huggingface/transformers/pull/18515/files
+ model_args=(text_input.input_ids.to(device=device, dtype=torch.int32)),
+ output_path=output_path / "text_encoder" / "model.onnx",
+ ordered_input_names=["input_ids"],
+ output_names=["last_hidden_state", "pooler_output"],
+ dynamic_axes={
+ "input_ids": {0: "batch", 1: "sequence"},
+ },
+ opset=opset,
+ )
+ del pipeline.text_encoder
+
+ # UNET
+ unet_in_channels = pipeline.unet.config.in_channels
+ unet_sample_size = pipeline.unet.config.sample_size
+ unet_path = output_path / "unet" / "model.onnx"
+ onnx_export(
+ pipeline.unet,
+ model_args=(
+ torch.randn(2, unet_in_channels, unet_sample_size, unet_sample_size).to(device=device, dtype=dtype),
+ torch.randn(2).to(device=device, dtype=dtype),
+ torch.randn(2, num_tokens, text_hidden_size).to(device=device, dtype=dtype),
+ False,
+ ),
+ output_path=unet_path,
+ ordered_input_names=["sample", "timestep", "encoder_hidden_states", "return_dict"],
+ output_names=["out_sample"], # has to be different from "sample" for correct tracing
+ dynamic_axes={
+ "sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
+ "timestep": {0: "batch"},
+ "encoder_hidden_states": {0: "batch", 1: "sequence"},
+ },
+ opset=opset,
+ use_external_data_format=True, # UNet is > 2GB, so the weights need to be split
+ )
+ unet_model_path = str(unet_path.absolute().as_posix())
+ unet_dir = os.path.dirname(unet_model_path)
+ unet = onnx.load(unet_model_path)
+ # clean up existing tensor files
+ shutil.rmtree(unet_dir)
+ os.mkdir(unet_dir)
+ # collate external tensor files into one
+ onnx.save_model(
+ unet,
+ unet_model_path,
+ save_as_external_data=True,
+ all_tensors_to_one_file=True,
+ location="weights.pb",
+ convert_attribute=False,
+ )
+ del pipeline.unet
+
+ # VAE ENCODER
+ vae_encoder = pipeline.vae
+ vae_in_channels = vae_encoder.config.in_channels
+ vae_sample_size = vae_encoder.config.sample_size
+ # need to get the raw tensor output (sample) from the encoder
+ vae_encoder.forward = lambda sample, return_dict: vae_encoder.encode(sample, return_dict)[0].sample()
+ onnx_export(
+ vae_encoder,
+ model_args=(
+ torch.randn(1, vae_in_channels, vae_sample_size, vae_sample_size).to(device=device, dtype=dtype),
+ False,
+ ),
+ output_path=output_path / "vae_encoder" / "model.onnx",
+ ordered_input_names=["sample", "return_dict"],
+ output_names=["latent_sample"],
+ dynamic_axes={
+ "sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
+ },
+ opset=opset,
+ )
+
+ # VAE DECODER
+ vae_decoder = pipeline.vae
+ vae_latent_channels = vae_decoder.config.latent_channels
+ vae_out_channels = vae_decoder.config.out_channels
+ # forward only through the decoder part
+ vae_decoder.forward = vae_encoder.decode
+ onnx_export(
+ vae_decoder,
+ model_args=(
+ torch.randn(1, vae_latent_channels, unet_sample_size, unet_sample_size).to(device=device, dtype=dtype),
+ False,
+ ),
+ output_path=output_path / "vae_decoder" / "model.onnx",
+ ordered_input_names=["latent_sample", "return_dict"],
+ output_names=["sample"],
+ dynamic_axes={
+ "latent_sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
+ },
+ opset=opset,
+ )
+ del pipeline.vae
+
+ # SAFETY CHECKER
+ if pipeline.safety_checker is not None:
+ safety_checker = pipeline.safety_checker
+ clip_num_channels = safety_checker.config.vision_config.num_channels
+ clip_image_size = safety_checker.config.vision_config.image_size
+ safety_checker.forward = safety_checker.forward_onnx
+ onnx_export(
+ pipeline.safety_checker,
+ model_args=(
+ torch.randn(
+ 1,
+ clip_num_channels,
+ clip_image_size,
+ clip_image_size,
+ ).to(device=device, dtype=dtype),
+ torch.randn(1, vae_sample_size, vae_sample_size, vae_out_channels).to(device=device, dtype=dtype),
+ ),
+ output_path=output_path / "safety_checker" / "model.onnx",
+ ordered_input_names=["clip_input", "images"],
+ output_names=["out_images", "has_nsfw_concepts"],
+ dynamic_axes={
+ "clip_input": {0: "batch", 1: "channels", 2: "height", 3: "width"},
+ "images": {0: "batch", 1: "height", 2: "width", 3: "channels"},
+ },
+ opset=opset,
+ )
+ del pipeline.safety_checker
+ safety_checker = OnnxRuntimeModel.from_pretrained(output_path / "safety_checker")
+ feature_extractor = pipeline.feature_extractor
+ else:
+ safety_checker = None
+ feature_extractor = None
+
+ onnx_pipeline = OnnxStableDiffusionPipeline(
+ vae_encoder=OnnxRuntimeModel.from_pretrained(output_path / "vae_encoder"),
+ vae_decoder=OnnxRuntimeModel.from_pretrained(output_path / "vae_decoder"),
+ text_encoder=OnnxRuntimeModel.from_pretrained(output_path / "text_encoder"),
+ tokenizer=pipeline.tokenizer,
+ unet=OnnxRuntimeModel.from_pretrained(output_path / "unet"),
+ scheduler=pipeline.scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ requires_safety_checker=safety_checker is not None,
+ )
+
+ onnx_pipeline.save_pretrained(output_path)
+ print("ONNX pipeline saved to", output_path)
+
+ del pipeline
+ del onnx_pipeline
+ _ = OnnxStableDiffusionPipeline.from_pretrained(output_path, provider="CPUExecutionProvider")
+ print("ONNX pipeline is loadable")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--model_path",
+ type=str,
+ required=True,
+ help="Path to the `diffusers` checkpoint to convert (either a local directory or on the Hub).",
+ )
+
+ parser.add_argument("--output_path", type=str, required=True, help="Path to the output model.")
+
+ parser.add_argument(
+ "--opset",
+ default=14,
+ type=int,
+ help="The version of the ONNX operator set to use.",
+ )
+ parser.add_argument("--fp16", action="store_true", default=False, help="Export the models in `float16` mode")
+
+ args = parser.parse_args()
+
+ convert_models(args.model_path, args.output_path, args.opset, args.fp16)
diff --git a/diffusers/scripts/convert_unclip_txt2img_to_image_variation.py b/diffusers/scripts/convert_unclip_txt2img_to_image_variation.py
new file mode 100644
index 0000000000000000000000000000000000000000..07f8ebf2a3d012600a533dcfa642b609c31a3d8c
--- /dev/null
+++ b/diffusers/scripts/convert_unclip_txt2img_to_image_variation.py
@@ -0,0 +1,41 @@
+import argparse
+
+from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
+
+from diffusers import UnCLIPImageVariationPipeline, UnCLIPPipeline
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+
+ parser.add_argument(
+ "--txt2img_unclip",
+ default="kakaobrain/karlo-v1-alpha",
+ type=str,
+ required=False,
+ help="The pretrained txt2img unclip.",
+ )
+
+ args = parser.parse_args()
+
+ txt2img = UnCLIPPipeline.from_pretrained(args.txt2img_unclip)
+
+ feature_extractor = CLIPImageProcessor()
+ image_encoder = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
+
+ img2img = UnCLIPImageVariationPipeline(
+ decoder=txt2img.decoder,
+ text_encoder=txt2img.text_encoder,
+ tokenizer=txt2img.tokenizer,
+ text_proj=txt2img.text_proj,
+ feature_extractor=feature_extractor,
+ image_encoder=image_encoder,
+ super_res_first=txt2img.super_res_first,
+ super_res_last=txt2img.super_res_last,
+ decoder_scheduler=txt2img.decoder_scheduler,
+ super_res_scheduler=txt2img.super_res_scheduler,
+ )
+
+ img2img.save_pretrained(args.dump_path)
diff --git a/diffusers/scripts/convert_vae_diff_to_onnx.py b/diffusers/scripts/convert_vae_diff_to_onnx.py
new file mode 100644
index 0000000000000000000000000000000000000000..e023e04b94973f26ff6a93b6fa3e2b7b3661b829
--- /dev/null
+++ b/diffusers/scripts/convert_vae_diff_to_onnx.py
@@ -0,0 +1,122 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+from pathlib import Path
+
+import torch
+from packaging import version
+from torch.onnx import export
+
+from diffusers import AutoencoderKL
+
+
+is_torch_less_than_1_11 = version.parse(version.parse(torch.__version__).base_version) < version.parse("1.11")
+
+
+def onnx_export(
+ model,
+ model_args: tuple,
+ output_path: Path,
+ ordered_input_names,
+ output_names,
+ dynamic_axes,
+ opset,
+ use_external_data_format=False,
+):
+ output_path.parent.mkdir(parents=True, exist_ok=True)
+ # PyTorch deprecated the `enable_onnx_checker` and `use_external_data_format` arguments in v1.11,
+ # so we check the torch version for backwards compatibility
+ if is_torch_less_than_1_11:
+ export(
+ model,
+ model_args,
+ f=output_path.as_posix(),
+ input_names=ordered_input_names,
+ output_names=output_names,
+ dynamic_axes=dynamic_axes,
+ do_constant_folding=True,
+ use_external_data_format=use_external_data_format,
+ enable_onnx_checker=True,
+ opset_version=opset,
+ )
+ else:
+ export(
+ model,
+ model_args,
+ f=output_path.as_posix(),
+ input_names=ordered_input_names,
+ output_names=output_names,
+ dynamic_axes=dynamic_axes,
+ do_constant_folding=True,
+ opset_version=opset,
+ )
+
+
+@torch.no_grad()
+def convert_models(model_path: str, output_path: str, opset: int, fp16: bool = False):
+ dtype = torch.float16 if fp16 else torch.float32
+ if fp16 and torch.cuda.is_available():
+ device = "cuda"
+ elif fp16 and not torch.cuda.is_available():
+ raise ValueError("`float16` model export is only supported on GPUs with CUDA")
+ else:
+ device = "cpu"
+ output_path = Path(output_path)
+
+ # VAE DECODER
+ vae_decoder = AutoencoderKL.from_pretrained(model_path + "/vae")
+ vae_latent_channels = vae_decoder.config.latent_channels
+ # forward only through the decoder part
+ vae_decoder.forward = vae_decoder.decode
+ onnx_export(
+ vae_decoder,
+ model_args=(
+ torch.randn(1, vae_latent_channels, 25, 25).to(device=device, dtype=dtype),
+ False,
+ ),
+ output_path=output_path / "vae_decoder" / "model.onnx",
+ ordered_input_names=["latent_sample", "return_dict"],
+ output_names=["sample"],
+ dynamic_axes={
+ "latent_sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
+ },
+ opset=opset,
+ )
+ del vae_decoder
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--model_path",
+ type=str,
+ required=True,
+ help="Path to the `diffusers` checkpoint to convert (either a local directory or on the Hub).",
+ )
+
+ parser.add_argument("--output_path", type=str, required=True, help="Path to the output model.")
+ parser.add_argument(
+ "--opset",
+ default=14,
+ type=int,
+ help="The version of the ONNX operator set to use.",
+ )
+ parser.add_argument("--fp16", action="store_true", default=False, help="Export the models in `float16` mode")
+
+ args = parser.parse_args()
+ print(args.output_path)
+ convert_models(args.model_path, args.output_path, args.opset, args.fp16)
+ print("SD: Done: ONNX")
diff --git a/diffusers/scripts/convert_vae_pt_to_diffusers.py b/diffusers/scripts/convert_vae_pt_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..4762ffcf8d00dd2ec18fd1779e7eebe472392b7d
--- /dev/null
+++ b/diffusers/scripts/convert_vae_pt_to_diffusers.py
@@ -0,0 +1,151 @@
+import argparse
+import io
+
+import requests
+import torch
+from omegaconf import OmegaConf
+
+from diffusers import AutoencoderKL
+from diffusers.pipelines.stable_diffusion.convert_from_ckpt import (
+ assign_to_checkpoint,
+ conv_attn_to_linear,
+ create_vae_diffusers_config,
+ renew_vae_attention_paths,
+ renew_vae_resnet_paths,
+)
+
+
+def custom_convert_ldm_vae_checkpoint(checkpoint, config):
+ vae_state_dict = checkpoint
+
+ new_checkpoint = {}
+
+ new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
+ new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
+ new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
+ new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
+ new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
+ new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
+
+ new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
+ new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
+ new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
+ new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
+ new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
+ new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
+
+ new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
+ new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
+ new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
+ new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
+
+ # Retrieves the keys for the encoder down blocks only
+ num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer})
+ down_blocks = {
+ layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
+ }
+
+ # Retrieves the keys for the decoder up blocks only
+ num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
+ up_blocks = {
+ layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
+ }
+
+ for i in range(num_down_blocks):
+ resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
+
+ if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.weight"
+ )
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.bias"
+ )
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+ conv_attn_to_linear(new_checkpoint)
+
+ for i in range(num_up_blocks):
+ block_id = num_up_blocks - 1 - i
+ resnets = [
+ key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
+ ]
+
+ if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.weight"
+ ]
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.bias"
+ ]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+ conv_attn_to_linear(new_checkpoint)
+ return new_checkpoint
+
+
+def vae_pt_to_vae_diffuser(
+ checkpoint_path: str,
+ output_path: str,
+):
+ # Only support V1
+ r = requests.get(
+ " https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml"
+ )
+ io_obj = io.BytesIO(r.content)
+
+ original_config = OmegaConf.load(io_obj)
+ image_size = 512
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ checkpoint = torch.load(checkpoint_path, map_location=device)
+
+ # Convert the VAE model.
+ vae_config = create_vae_diffusers_config(original_config, image_size=image_size)
+ converted_vae_checkpoint = custom_convert_ldm_vae_checkpoint(checkpoint["state_dict"], vae_config)
+
+ vae = AutoencoderKL(**vae_config)
+ vae.load_state_dict(converted_vae_checkpoint)
+ vae.save_pretrained(output_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument("--vae_pt_path", default=None, type=str, required=True, help="Path to the VAE.pt to convert.")
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the VAE.pt to convert.")
+
+ args = parser.parse_args()
+
+ vae_pt_to_vae_diffuser(args.vae_pt_path, args.dump_path)
diff --git a/diffusers/scripts/convert_versatile_diffusion_to_diffusers.py b/diffusers/scripts/convert_versatile_diffusion_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..b895e08e9de9cc8ee1910bdb84336ee644c2a559
--- /dev/null
+++ b/diffusers/scripts/convert_versatile_diffusion_to_diffusers.py
@@ -0,0 +1,791 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the Versatile Stable Diffusion checkpoints. """
+
+import argparse
+from argparse import Namespace
+
+import torch
+from transformers import (
+ CLIPImageProcessor,
+ CLIPTextModelWithProjection,
+ CLIPTokenizer,
+ CLIPVisionModelWithProjection,
+)
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ UNet2DConditionModel,
+ VersatileDiffusionPipeline,
+)
+from diffusers.pipelines.versatile_diffusion.modeling_text_unet import UNetFlatConditionModel
+
+
+SCHEDULER_CONFIG = Namespace(
+ **{
+ "beta_linear_start": 0.00085,
+ "beta_linear_end": 0.012,
+ "timesteps": 1000,
+ "scale_factor": 0.18215,
+ }
+)
+
+IMAGE_UNET_CONFIG = Namespace(
+ **{
+ "input_channels": 4,
+ "model_channels": 320,
+ "output_channels": 4,
+ "num_noattn_blocks": [2, 2, 2, 2],
+ "channel_mult": [1, 2, 4, 4],
+ "with_attn": [True, True, True, False],
+ "num_heads": 8,
+ "context_dim": 768,
+ "use_checkpoint": True,
+ }
+)
+
+TEXT_UNET_CONFIG = Namespace(
+ **{
+ "input_channels": 768,
+ "model_channels": 320,
+ "output_channels": 768,
+ "num_noattn_blocks": [2, 2, 2, 2],
+ "channel_mult": [1, 2, 4, 4],
+ "second_dim": [4, 4, 4, 4],
+ "with_attn": [True, True, True, False],
+ "num_heads": 8,
+ "context_dim": 768,
+ "use_checkpoint": True,
+ }
+)
+
+AUTOENCODER_CONFIG = Namespace(
+ **{
+ "double_z": True,
+ "z_channels": 4,
+ "resolution": 256,
+ "in_channels": 3,
+ "out_ch": 3,
+ "ch": 128,
+ "ch_mult": [1, 2, 4, 4],
+ "num_res_blocks": 2,
+ "attn_resolutions": [],
+ "dropout": 0.0,
+ }
+)
+
+
+def shave_segments(path, n_shave_prefix_segments=1):
+ """
+ Removes segments. Positive values shave the first segments, negative shave the last segments.
+ """
+ if n_shave_prefix_segments >= 0:
+ return ".".join(path.split(".")[n_shave_prefix_segments:])
+ else:
+ return ".".join(path.split(".")[:n_shave_prefix_segments])
+
+
+def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item.replace("in_layers.0", "norm1")
+ new_item = new_item.replace("in_layers.2", "conv1")
+
+ new_item = new_item.replace("out_layers.0", "norm2")
+ new_item = new_item.replace("out_layers.3", "conv2")
+
+ new_item = new_item.replace("emb_layers.1", "time_emb_proj")
+ new_item = new_item.replace("skip_connection", "conv_shortcut")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("nin_shortcut", "conv_shortcut")
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ # new_item = new_item.replace('norm.weight', 'group_norm.weight')
+ # new_item = new_item.replace('norm.bias', 'group_norm.bias')
+
+ # new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
+ # new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
+
+ # new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("norm.weight", "group_norm.weight")
+ new_item = new_item.replace("norm.bias", "group_norm.bias")
+
+ new_item = new_item.replace("q.weight", "query.weight")
+ new_item = new_item.replace("q.bias", "query.bias")
+
+ new_item = new_item.replace("k.weight", "key.weight")
+ new_item = new_item.replace("k.bias", "key.bias")
+
+ new_item = new_item.replace("v.weight", "value.weight")
+ new_item = new_item.replace("v.bias", "value.bias")
+
+ new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
+ new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def assign_to_checkpoint(
+ paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
+):
+ """
+ This does the final conversion step: take locally converted weights and apply a global renaming
+ to them. It splits attention layers, and takes into account additional replacements
+ that may arise.
+
+ Assigns the weights to the new checkpoint.
+ """
+ assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
+
+ # Splits the attention layers into three variables.
+ if attention_paths_to_split is not None:
+ for path, path_map in attention_paths_to_split.items():
+ old_tensor = old_checkpoint[path]
+ channels = old_tensor.shape[0] // 3
+
+ target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
+
+ num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
+
+ old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
+ query, key, value = old_tensor.split(channels // num_heads, dim=1)
+
+ checkpoint[path_map["query"]] = query.reshape(target_shape)
+ checkpoint[path_map["key"]] = key.reshape(target_shape)
+ checkpoint[path_map["value"]] = value.reshape(target_shape)
+
+ for path in paths:
+ new_path = path["new"]
+
+ # These have already been assigned
+ if attention_paths_to_split is not None and new_path in attention_paths_to_split:
+ continue
+
+ # Global renaming happens here
+ new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
+ new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
+ new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
+
+ if additional_replacements is not None:
+ for replacement in additional_replacements:
+ new_path = new_path.replace(replacement["old"], replacement["new"])
+
+ # proj_attn.weight has to be converted from conv 1D to linear
+ if "proj_attn.weight" in new_path:
+ checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
+ elif path["old"] in old_checkpoint:
+ checkpoint[new_path] = old_checkpoint[path["old"]]
+
+
+def conv_attn_to_linear(checkpoint):
+ keys = list(checkpoint.keys())
+ attn_keys = ["query.weight", "key.weight", "value.weight"]
+ for key in keys:
+ if ".".join(key.split(".")[-2:]) in attn_keys:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0, 0]
+ elif "proj_attn.weight" in key:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0]
+
+
+def create_image_unet_diffusers_config(unet_params):
+ """
+ Creates a config for the diffusers based on the config of the VD model.
+ """
+
+ block_out_channels = [unet_params.model_channels * mult for mult in unet_params.channel_mult]
+
+ down_block_types = []
+ resolution = 1
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnDownBlock2D" if unet_params.with_attn[i] else "DownBlock2D"
+ down_block_types.append(block_type)
+ if i != len(block_out_channels) - 1:
+ resolution *= 2
+
+ up_block_types = []
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnUpBlock2D" if unet_params.with_attn[-i - 1] else "UpBlock2D"
+ up_block_types.append(block_type)
+ resolution //= 2
+
+ if not all(n == unet_params.num_noattn_blocks[0] for n in unet_params.num_noattn_blocks):
+ raise ValueError("Not all num_res_blocks are equal, which is not supported in this script.")
+
+ config = {
+ "sample_size": None,
+ "in_channels": unet_params.input_channels,
+ "out_channels": unet_params.output_channels,
+ "down_block_types": tuple(down_block_types),
+ "up_block_types": tuple(up_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "layers_per_block": unet_params.num_noattn_blocks[0],
+ "cross_attention_dim": unet_params.context_dim,
+ "attention_head_dim": unet_params.num_heads,
+ }
+
+ return config
+
+
+def create_text_unet_diffusers_config(unet_params):
+ """
+ Creates a config for the diffusers based on the config of the VD model.
+ """
+
+ block_out_channels = [unet_params.model_channels * mult for mult in unet_params.channel_mult]
+
+ down_block_types = []
+ resolution = 1
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnDownBlockFlat" if unet_params.with_attn[i] else "DownBlockFlat"
+ down_block_types.append(block_type)
+ if i != len(block_out_channels) - 1:
+ resolution *= 2
+
+ up_block_types = []
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnUpBlockFlat" if unet_params.with_attn[-i - 1] else "UpBlockFlat"
+ up_block_types.append(block_type)
+ resolution //= 2
+
+ if not all(n == unet_params.num_noattn_blocks[0] for n in unet_params.num_noattn_blocks):
+ raise ValueError("Not all num_res_blocks are equal, which is not supported in this script.")
+
+ config = {
+ "sample_size": None,
+ "in_channels": (unet_params.input_channels, 1, 1),
+ "out_channels": (unet_params.output_channels, 1, 1),
+ "down_block_types": tuple(down_block_types),
+ "up_block_types": tuple(up_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "layers_per_block": unet_params.num_noattn_blocks[0],
+ "cross_attention_dim": unet_params.context_dim,
+ "attention_head_dim": unet_params.num_heads,
+ }
+
+ return config
+
+
+def create_vae_diffusers_config(vae_params):
+ """
+ Creates a config for the diffusers based on the config of the VD model.
+ """
+
+ block_out_channels = [vae_params.ch * mult for mult in vae_params.ch_mult]
+ down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels)
+ up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels)
+
+ config = {
+ "sample_size": vae_params.resolution,
+ "in_channels": vae_params.in_channels,
+ "out_channels": vae_params.out_ch,
+ "down_block_types": tuple(down_block_types),
+ "up_block_types": tuple(up_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "latent_channels": vae_params.z_channels,
+ "layers_per_block": vae_params.num_res_blocks,
+ }
+ return config
+
+
+def create_diffusers_scheduler(original_config):
+ schedular = DDIMScheduler(
+ num_train_timesteps=original_config.model.params.timesteps,
+ beta_start=original_config.model.params.linear_start,
+ beta_end=original_config.model.params.linear_end,
+ beta_schedule="scaled_linear",
+ )
+ return schedular
+
+
+def convert_vd_unet_checkpoint(checkpoint, config, unet_key, extract_ema=False):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint.
+ """
+
+ # extract state_dict for UNet
+ unet_state_dict = {}
+ keys = list(checkpoint.keys())
+
+ # at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
+ if sum(k.startswith("model_ema") for k in keys) > 100:
+ print("Checkpoint has both EMA and non-EMA weights.")
+ if extract_ema:
+ print(
+ "In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
+ " weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
+ )
+ for key in keys:
+ if key.startswith("model.diffusion_model"):
+ flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
+ else:
+ print(
+ "In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
+ " weights (usually better for inference), please make sure to add the `--extract_ema` flag."
+ )
+
+ for key in keys:
+ if key.startswith(unet_key):
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["time_embedding.linear_1.weight"] = checkpoint["model.diffusion_model.time_embed.0.weight"]
+ new_checkpoint["time_embedding.linear_1.bias"] = checkpoint["model.diffusion_model.time_embed.0.bias"]
+ new_checkpoint["time_embedding.linear_2.weight"] = checkpoint["model.diffusion_model.time_embed.2.weight"]
+ new_checkpoint["time_embedding.linear_2.bias"] = checkpoint["model.diffusion_model.time_embed.2.bias"]
+
+ new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
+ new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
+
+ new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
+ new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
+ new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
+ new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
+
+ # Retrieves the keys for the input blocks only
+ num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
+ input_blocks = {
+ layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
+ for layer_id in range(num_input_blocks)
+ }
+
+ # Retrieves the keys for the middle blocks only
+ num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
+ middle_blocks = {
+ layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
+ for layer_id in range(num_middle_blocks)
+ }
+
+ # Retrieves the keys for the output blocks only
+ num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
+ output_blocks = {
+ layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
+ for layer_id in range(num_output_blocks)
+ }
+
+ for i in range(1, num_input_blocks):
+ block_id = (i - 1) // (config["layers_per_block"] + 1)
+ layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
+
+ resnets = [
+ key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
+ ]
+ attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
+
+ if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.weight"
+ )
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.bias"
+ )
+ elif f"input_blocks.{i}.0.weight" in unet_state_dict:
+ # text_unet uses linear layers in place of downsamplers
+ shape = unet_state_dict[f"input_blocks.{i}.0.weight"].shape
+ if shape[0] != shape[1]:
+ continue
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.weight"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.weight"
+ )
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.bias"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.bias"
+ )
+
+ paths = renew_resnet_paths(resnets)
+ meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ resnet_0 = middle_blocks[0]
+ attentions = middle_blocks[1]
+ resnet_1 = middle_blocks[2]
+
+ resnet_0_paths = renew_resnet_paths(resnet_0)
+ assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
+
+ resnet_1_paths = renew_resnet_paths(resnet_1)
+ assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
+
+ attentions_paths = renew_attention_paths(attentions)
+ meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ for i in range(num_output_blocks):
+ block_id = i // (config["layers_per_block"] + 1)
+ layer_in_block_id = i % (config["layers_per_block"] + 1)
+ output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
+ output_block_list = {}
+
+ for layer in output_block_layers:
+ layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
+ if layer_id in output_block_list:
+ output_block_list[layer_id].append(layer_name)
+ else:
+ output_block_list[layer_id] = [layer_name]
+
+ if len(output_block_list) > 1:
+ resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
+ attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
+
+ paths = renew_resnet_paths(resnets)
+
+ meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if ["conv.weight", "conv.bias"] in output_block_list.values():
+ index = list(output_block_list.values()).index(["conv.weight", "conv.bias"])
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.weight"
+ ]
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.bias"
+ ]
+ # Clear attentions as they have been attributed above.
+ if len(attentions) == 2:
+ attentions = []
+ elif f"output_blocks.{i}.1.weight" in unet_state_dict:
+ # text_unet uses linear layers in place of upsamplers
+ shape = unet_state_dict[f"output_blocks.{i}.1.weight"].shape
+ if shape[0] != shape[1]:
+ continue
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.weight"] = unet_state_dict.pop(
+ f"output_blocks.{i}.1.weight"
+ )
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.bias"] = unet_state_dict.pop(
+ f"output_blocks.{i}.1.bias"
+ )
+ # Clear attentions as they have been attributed above.
+ if len(attentions) == 2:
+ attentions = []
+ elif f"output_blocks.{i}.2.weight" in unet_state_dict:
+ # text_unet uses linear layers in place of upsamplers
+ shape = unet_state_dict[f"output_blocks.{i}.2.weight"].shape
+ if shape[0] != shape[1]:
+ continue
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.weight"] = unet_state_dict.pop(
+ f"output_blocks.{i}.2.weight"
+ )
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.bias"] = unet_state_dict.pop(
+ f"output_blocks.{i}.2.bias"
+ )
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"output_blocks.{i}.1",
+ "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+ else:
+ resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
+ for path in resnet_0_paths:
+ old_path = ".".join(["output_blocks", str(i), path["old"]])
+ new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
+
+ new_checkpoint[new_path] = unet_state_dict[old_path]
+
+ return new_checkpoint
+
+
+def convert_vd_vae_checkpoint(checkpoint, config):
+ # extract state dict for VAE
+ vae_state_dict = {}
+ keys = list(checkpoint.keys())
+ for key in keys:
+ vae_state_dict[key] = checkpoint.get(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
+ new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
+ new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
+ new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
+ new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
+ new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
+
+ new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
+ new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
+ new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
+ new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
+ new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
+ new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
+
+ new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
+ new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
+ new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
+ new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
+
+ # Retrieves the keys for the encoder down blocks only
+ num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer})
+ down_blocks = {
+ layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
+ }
+
+ # Retrieves the keys for the decoder up blocks only
+ num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
+ up_blocks = {
+ layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
+ }
+
+ for i in range(num_down_blocks):
+ resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
+
+ if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.weight"
+ )
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.bias"
+ )
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+ conv_attn_to_linear(new_checkpoint)
+
+ for i in range(num_up_blocks):
+ block_id = num_up_blocks - 1 - i
+ resnets = [
+ key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
+ ]
+
+ if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.weight"
+ ]
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.bias"
+ ]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+ conv_attn_to_linear(new_checkpoint)
+ return new_checkpoint
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--unet_checkpoint_path", default=None, type=str, required=False, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument(
+ "--vae_checkpoint_path", default=None, type=str, required=False, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument(
+ "--optimus_checkpoint_path", default=None, type=str, required=False, help="Path to the checkpoint to convert."
+ )
+ parser.add_argument(
+ "--scheduler_type",
+ default="pndm",
+ type=str,
+ help="Type of scheduler to use. Should be one of ['pndm', 'lms', 'ddim', 'euler', 'euler-ancestral', 'dpm']",
+ )
+ parser.add_argument(
+ "--extract_ema",
+ action="store_true",
+ help=(
+ "Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
+ " or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
+ " higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
+ ),
+ )
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+
+ args = parser.parse_args()
+
+ scheduler_config = SCHEDULER_CONFIG
+
+ num_train_timesteps = scheduler_config.timesteps
+ beta_start = scheduler_config.beta_linear_start
+ beta_end = scheduler_config.beta_linear_end
+ if args.scheduler_type == "pndm":
+ scheduler = PNDMScheduler(
+ beta_end=beta_end,
+ beta_schedule="scaled_linear",
+ beta_start=beta_start,
+ num_train_timesteps=num_train_timesteps,
+ skip_prk_steps=True,
+ steps_offset=1,
+ )
+ elif args.scheduler_type == "lms":
+ scheduler = LMSDiscreteScheduler(beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear")
+ elif args.scheduler_type == "euler":
+ scheduler = EulerDiscreteScheduler(beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear")
+ elif args.scheduler_type == "euler-ancestral":
+ scheduler = EulerAncestralDiscreteScheduler(
+ beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear"
+ )
+ elif args.scheduler_type == "dpm":
+ scheduler = DPMSolverMultistepScheduler(
+ beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear"
+ )
+ elif args.scheduler_type == "ddim":
+ scheduler = DDIMScheduler(
+ beta_start=beta_start,
+ beta_end=beta_end,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ steps_offset=1,
+ )
+ else:
+ raise ValueError(f"Scheduler of type {args.scheduler_type} doesn't exist!")
+
+ # Convert the UNet2DConditionModel models.
+ if args.unet_checkpoint_path is not None:
+ # image UNet
+ image_unet_config = create_image_unet_diffusers_config(IMAGE_UNET_CONFIG)
+ checkpoint = torch.load(args.unet_checkpoint_path)
+ converted_image_unet_checkpoint = convert_vd_unet_checkpoint(
+ checkpoint, image_unet_config, unet_key="model.diffusion_model.unet_image.", extract_ema=args.extract_ema
+ )
+ image_unet = UNet2DConditionModel(**image_unet_config)
+ image_unet.load_state_dict(converted_image_unet_checkpoint)
+
+ # text UNet
+ text_unet_config = create_text_unet_diffusers_config(TEXT_UNET_CONFIG)
+ converted_text_unet_checkpoint = convert_vd_unet_checkpoint(
+ checkpoint, text_unet_config, unet_key="model.diffusion_model.unet_text.", extract_ema=args.extract_ema
+ )
+ text_unet = UNetFlatConditionModel(**text_unet_config)
+ text_unet.load_state_dict(converted_text_unet_checkpoint)
+
+ # Convert the VAE model.
+ if args.vae_checkpoint_path is not None:
+ vae_config = create_vae_diffusers_config(AUTOENCODER_CONFIG)
+ checkpoint = torch.load(args.vae_checkpoint_path)
+ converted_vae_checkpoint = convert_vd_vae_checkpoint(checkpoint, vae_config)
+
+ vae = AutoencoderKL(**vae_config)
+ vae.load_state_dict(converted_vae_checkpoint)
+
+ tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
+ image_feature_extractor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14")
+ text_encoder = CLIPTextModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
+ image_encoder = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
+
+ pipe = VersatileDiffusionPipeline(
+ scheduler=scheduler,
+ tokenizer=tokenizer,
+ image_feature_extractor=image_feature_extractor,
+ text_encoder=text_encoder,
+ image_encoder=image_encoder,
+ image_unet=image_unet,
+ text_unet=text_unet,
+ vae=vae,
+ )
+ pipe.save_pretrained(args.dump_path)
diff --git a/diffusers/scripts/convert_vq_diffusion_to_diffusers.py b/diffusers/scripts/convert_vq_diffusion_to_diffusers.py
new file mode 100644
index 0000000000000000000000000000000000000000..58ed2d93d5df4bd486b7485e1dc5e3cd255f2d99
--- /dev/null
+++ b/diffusers/scripts/convert_vq_diffusion_to_diffusers.py
@@ -0,0 +1,925 @@
+"""
+This script ports models from VQ-diffusion (https://github.com/microsoft/VQ-Diffusion) to diffusers.
+
+It currently only supports porting the ITHQ dataset.
+
+ITHQ dataset:
+```sh
+# From the root directory of diffusers.
+
+# Download the VQVAE checkpoint
+$ wget https://facevcstandard.blob.core.windows.net/v-zhictang/Improved-VQ-Diffusion_model_release/ithq_vqvae.pth?sv=2020-10-02&st=2022-05-30T15%3A17%3A18Z&se=2030-05-31T15%3A17%3A00Z&sr=b&sp=r&sig=1jVavHFPpUjDs%2FTO1V3PTezaNbPp2Nx8MxiWI7y6fEY%3D -O ithq_vqvae.pth
+
+# Download the VQVAE config
+# NOTE that in VQ-diffusion the documented file is `configs/ithq.yaml` but the target class
+# `image_synthesis.modeling.codecs.image_codec.ema_vqvae.PatchVQVAE`
+# loads `OUTPUT/pretrained_model/taming_dvae/config.yaml`
+$ wget https://raw.githubusercontent.com/microsoft/VQ-Diffusion/main/OUTPUT/pretrained_model/taming_dvae/config.yaml -O ithq_vqvae.yaml
+
+# Download the main model checkpoint
+$ wget https://facevcstandard.blob.core.windows.net/v-zhictang/Improved-VQ-Diffusion_model_release/ithq_learnable.pth?sv=2020-10-02&st=2022-05-30T10%3A22%3A06Z&se=2030-05-31T10%3A22%3A00Z&sr=b&sp=r&sig=GOE%2Bza02%2FPnGxYVOOPtwrTR4RA3%2F5NVgMxdW4kjaEZ8%3D -O ithq_learnable.pth
+
+# Download the main model config
+$ wget https://raw.githubusercontent.com/microsoft/VQ-Diffusion/main/configs/ithq.yaml -O ithq.yaml
+
+# run the convert script
+$ python ./scripts/convert_vq_diffusion_to_diffusers.py \
+ --checkpoint_path ./ithq_learnable.pth \
+ --original_config_file ./ithq.yaml \
+ --vqvae_checkpoint_path ./ithq_vqvae.pth \
+ --vqvae_original_config_file ./ithq_vqvae.yaml \
+ --dump_path
+```
+"""
+
+import argparse
+import tempfile
+
+import torch
+import yaml
+from accelerate import init_empty_weights, load_checkpoint_and_dispatch
+from transformers import CLIPTextModel, CLIPTokenizer
+from yaml.loader import FullLoader
+
+from diffusers import Transformer2DModel, VQDiffusionPipeline, VQDiffusionScheduler, VQModel
+from diffusers.pipelines.vq_diffusion.pipeline_vq_diffusion import LearnedClassifierFreeSamplingEmbeddings
+
+
+try:
+ from omegaconf import OmegaConf
+except ImportError:
+ raise ImportError(
+ "OmegaConf is required to convert the VQ Diffusion checkpoints. Please install it with `pip install"
+ " OmegaConf`."
+ )
+
+# vqvae model
+
+PORTED_VQVAES = ["image_synthesis.modeling.codecs.image_codec.patch_vqgan.PatchVQGAN"]
+
+
+def vqvae_model_from_original_config(original_config):
+ assert original_config.target in PORTED_VQVAES, f"{original_config.target} has not yet been ported to diffusers."
+
+ original_config = original_config.params
+
+ original_encoder_config = original_config.encoder_config.params
+ original_decoder_config = original_config.decoder_config.params
+
+ in_channels = original_encoder_config.in_channels
+ out_channels = original_decoder_config.out_ch
+
+ down_block_types = get_down_block_types(original_encoder_config)
+ up_block_types = get_up_block_types(original_decoder_config)
+
+ assert original_encoder_config.ch == original_decoder_config.ch
+ assert original_encoder_config.ch_mult == original_decoder_config.ch_mult
+ block_out_channels = tuple(
+ [original_encoder_config.ch * a_ch_mult for a_ch_mult in original_encoder_config.ch_mult]
+ )
+
+ assert original_encoder_config.num_res_blocks == original_decoder_config.num_res_blocks
+ layers_per_block = original_encoder_config.num_res_blocks
+
+ assert original_encoder_config.z_channels == original_decoder_config.z_channels
+ latent_channels = original_encoder_config.z_channels
+
+ num_vq_embeddings = original_config.n_embed
+
+ # Hard coded value for ResnetBlock.GoupNorm(num_groups) in VQ-diffusion
+ norm_num_groups = 32
+
+ e_dim = original_config.embed_dim
+
+ model = VQModel(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ down_block_types=down_block_types,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ latent_channels=latent_channels,
+ num_vq_embeddings=num_vq_embeddings,
+ norm_num_groups=norm_num_groups,
+ vq_embed_dim=e_dim,
+ )
+
+ return model
+
+
+def get_down_block_types(original_encoder_config):
+ attn_resolutions = coerce_attn_resolutions(original_encoder_config.attn_resolutions)
+ num_resolutions = len(original_encoder_config.ch_mult)
+ resolution = coerce_resolution(original_encoder_config.resolution)
+
+ curr_res = resolution
+ down_block_types = []
+
+ for _ in range(num_resolutions):
+ if curr_res in attn_resolutions:
+ down_block_type = "AttnDownEncoderBlock2D"
+ else:
+ down_block_type = "DownEncoderBlock2D"
+
+ down_block_types.append(down_block_type)
+
+ curr_res = [r // 2 for r in curr_res]
+
+ return down_block_types
+
+
+def get_up_block_types(original_decoder_config):
+ attn_resolutions = coerce_attn_resolutions(original_decoder_config.attn_resolutions)
+ num_resolutions = len(original_decoder_config.ch_mult)
+ resolution = coerce_resolution(original_decoder_config.resolution)
+
+ curr_res = [r // 2 ** (num_resolutions - 1) for r in resolution]
+ up_block_types = []
+
+ for _ in reversed(range(num_resolutions)):
+ if curr_res in attn_resolutions:
+ up_block_type = "AttnUpDecoderBlock2D"
+ else:
+ up_block_type = "UpDecoderBlock2D"
+
+ up_block_types.append(up_block_type)
+
+ curr_res = [r * 2 for r in curr_res]
+
+ return up_block_types
+
+
+def coerce_attn_resolutions(attn_resolutions):
+ attn_resolutions = OmegaConf.to_object(attn_resolutions)
+ attn_resolutions_ = []
+ for ar in attn_resolutions:
+ if isinstance(ar, (list, tuple)):
+ attn_resolutions_.append(list(ar))
+ else:
+ attn_resolutions_.append([ar, ar])
+ return attn_resolutions_
+
+
+def coerce_resolution(resolution):
+ resolution = OmegaConf.to_object(resolution)
+ if isinstance(resolution, int):
+ resolution = [resolution, resolution] # H, W
+ elif isinstance(resolution, (tuple, list)):
+ resolution = list(resolution)
+ else:
+ raise ValueError("Unknown type of resolution:", resolution)
+ return resolution
+
+
+# done vqvae model
+
+# vqvae checkpoint
+
+
+def vqvae_original_checkpoint_to_diffusers_checkpoint(model, checkpoint):
+ diffusers_checkpoint = {}
+
+ diffusers_checkpoint.update(vqvae_encoder_to_diffusers_checkpoint(model, checkpoint))
+
+ # quant_conv
+
+ diffusers_checkpoint.update(
+ {
+ "quant_conv.weight": checkpoint["quant_conv.weight"],
+ "quant_conv.bias": checkpoint["quant_conv.bias"],
+ }
+ )
+
+ # quantize
+ diffusers_checkpoint.update({"quantize.embedding.weight": checkpoint["quantize.embedding"]})
+
+ # post_quant_conv
+ diffusers_checkpoint.update(
+ {
+ "post_quant_conv.weight": checkpoint["post_quant_conv.weight"],
+ "post_quant_conv.bias": checkpoint["post_quant_conv.bias"],
+ }
+ )
+
+ # decoder
+ diffusers_checkpoint.update(vqvae_decoder_to_diffusers_checkpoint(model, checkpoint))
+
+ return diffusers_checkpoint
+
+
+def vqvae_encoder_to_diffusers_checkpoint(model, checkpoint):
+ diffusers_checkpoint = {}
+
+ # conv_in
+ diffusers_checkpoint.update(
+ {
+ "encoder.conv_in.weight": checkpoint["encoder.conv_in.weight"],
+ "encoder.conv_in.bias": checkpoint["encoder.conv_in.bias"],
+ }
+ )
+
+ # down_blocks
+ for down_block_idx, down_block in enumerate(model.encoder.down_blocks):
+ diffusers_down_block_prefix = f"encoder.down_blocks.{down_block_idx}"
+ down_block_prefix = f"encoder.down.{down_block_idx}"
+
+ # resnets
+ for resnet_idx, resnet in enumerate(down_block.resnets):
+ diffusers_resnet_prefix = f"{diffusers_down_block_prefix}.resnets.{resnet_idx}"
+ resnet_prefix = f"{down_block_prefix}.block.{resnet_idx}"
+
+ diffusers_checkpoint.update(
+ vqvae_resnet_to_diffusers_checkpoint(
+ resnet, checkpoint, diffusers_resnet_prefix=diffusers_resnet_prefix, resnet_prefix=resnet_prefix
+ )
+ )
+
+ # downsample
+
+ # do not include the downsample when on the last down block
+ # There is no downsample on the last down block
+ if down_block_idx != len(model.encoder.down_blocks) - 1:
+ # There's a single downsample in the original checkpoint but a list of downsamples
+ # in the diffusers model.
+ diffusers_downsample_prefix = f"{diffusers_down_block_prefix}.downsamplers.0.conv"
+ downsample_prefix = f"{down_block_prefix}.downsample.conv"
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_downsample_prefix}.weight": checkpoint[f"{downsample_prefix}.weight"],
+ f"{diffusers_downsample_prefix}.bias": checkpoint[f"{downsample_prefix}.bias"],
+ }
+ )
+
+ # attentions
+
+ if hasattr(down_block, "attentions"):
+ for attention_idx, _ in enumerate(down_block.attentions):
+ diffusers_attention_prefix = f"{diffusers_down_block_prefix}.attentions.{attention_idx}"
+ attention_prefix = f"{down_block_prefix}.attn.{attention_idx}"
+ diffusers_checkpoint.update(
+ vqvae_attention_to_diffusers_checkpoint(
+ checkpoint,
+ diffusers_attention_prefix=diffusers_attention_prefix,
+ attention_prefix=attention_prefix,
+ )
+ )
+
+ # mid block
+
+ # mid block attentions
+
+ # There is a single hardcoded attention block in the middle of the VQ-diffusion encoder
+ diffusers_attention_prefix = "encoder.mid_block.attentions.0"
+ attention_prefix = "encoder.mid.attn_1"
+ diffusers_checkpoint.update(
+ vqvae_attention_to_diffusers_checkpoint(
+ checkpoint, diffusers_attention_prefix=diffusers_attention_prefix, attention_prefix=attention_prefix
+ )
+ )
+
+ # mid block resnets
+
+ for diffusers_resnet_idx, resnet in enumerate(model.encoder.mid_block.resnets):
+ diffusers_resnet_prefix = f"encoder.mid_block.resnets.{diffusers_resnet_idx}"
+
+ # the hardcoded prefixes to `block_` are 1 and 2
+ orig_resnet_idx = diffusers_resnet_idx + 1
+ # There are two hardcoded resnets in the middle of the VQ-diffusion encoder
+ resnet_prefix = f"encoder.mid.block_{orig_resnet_idx}"
+
+ diffusers_checkpoint.update(
+ vqvae_resnet_to_diffusers_checkpoint(
+ resnet, checkpoint, diffusers_resnet_prefix=diffusers_resnet_prefix, resnet_prefix=resnet_prefix
+ )
+ )
+
+ diffusers_checkpoint.update(
+ {
+ # conv_norm_out
+ "encoder.conv_norm_out.weight": checkpoint["encoder.norm_out.weight"],
+ "encoder.conv_norm_out.bias": checkpoint["encoder.norm_out.bias"],
+ # conv_out
+ "encoder.conv_out.weight": checkpoint["encoder.conv_out.weight"],
+ "encoder.conv_out.bias": checkpoint["encoder.conv_out.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+def vqvae_decoder_to_diffusers_checkpoint(model, checkpoint):
+ diffusers_checkpoint = {}
+
+ # conv in
+ diffusers_checkpoint.update(
+ {
+ "decoder.conv_in.weight": checkpoint["decoder.conv_in.weight"],
+ "decoder.conv_in.bias": checkpoint["decoder.conv_in.bias"],
+ }
+ )
+
+ # up_blocks
+
+ for diffusers_up_block_idx, up_block in enumerate(model.decoder.up_blocks):
+ # up_blocks are stored in reverse order in the VQ-diffusion checkpoint
+ orig_up_block_idx = len(model.decoder.up_blocks) - 1 - diffusers_up_block_idx
+
+ diffusers_up_block_prefix = f"decoder.up_blocks.{diffusers_up_block_idx}"
+ up_block_prefix = f"decoder.up.{orig_up_block_idx}"
+
+ # resnets
+ for resnet_idx, resnet in enumerate(up_block.resnets):
+ diffusers_resnet_prefix = f"{diffusers_up_block_prefix}.resnets.{resnet_idx}"
+ resnet_prefix = f"{up_block_prefix}.block.{resnet_idx}"
+
+ diffusers_checkpoint.update(
+ vqvae_resnet_to_diffusers_checkpoint(
+ resnet, checkpoint, diffusers_resnet_prefix=diffusers_resnet_prefix, resnet_prefix=resnet_prefix
+ )
+ )
+
+ # upsample
+
+ # there is no up sample on the last up block
+ if diffusers_up_block_idx != len(model.decoder.up_blocks) - 1:
+ # There's a single upsample in the VQ-diffusion checkpoint but a list of downsamples
+ # in the diffusers model.
+ diffusers_downsample_prefix = f"{diffusers_up_block_prefix}.upsamplers.0.conv"
+ downsample_prefix = f"{up_block_prefix}.upsample.conv"
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_downsample_prefix}.weight": checkpoint[f"{downsample_prefix}.weight"],
+ f"{diffusers_downsample_prefix}.bias": checkpoint[f"{downsample_prefix}.bias"],
+ }
+ )
+
+ # attentions
+
+ if hasattr(up_block, "attentions"):
+ for attention_idx, _ in enumerate(up_block.attentions):
+ diffusers_attention_prefix = f"{diffusers_up_block_prefix}.attentions.{attention_idx}"
+ attention_prefix = f"{up_block_prefix}.attn.{attention_idx}"
+ diffusers_checkpoint.update(
+ vqvae_attention_to_diffusers_checkpoint(
+ checkpoint,
+ diffusers_attention_prefix=diffusers_attention_prefix,
+ attention_prefix=attention_prefix,
+ )
+ )
+
+ # mid block
+
+ # mid block attentions
+
+ # There is a single hardcoded attention block in the middle of the VQ-diffusion decoder
+ diffusers_attention_prefix = "decoder.mid_block.attentions.0"
+ attention_prefix = "decoder.mid.attn_1"
+ diffusers_checkpoint.update(
+ vqvae_attention_to_diffusers_checkpoint(
+ checkpoint, diffusers_attention_prefix=diffusers_attention_prefix, attention_prefix=attention_prefix
+ )
+ )
+
+ # mid block resnets
+
+ for diffusers_resnet_idx, resnet in enumerate(model.encoder.mid_block.resnets):
+ diffusers_resnet_prefix = f"decoder.mid_block.resnets.{diffusers_resnet_idx}"
+
+ # the hardcoded prefixes to `block_` are 1 and 2
+ orig_resnet_idx = diffusers_resnet_idx + 1
+ # There are two hardcoded resnets in the middle of the VQ-diffusion decoder
+ resnet_prefix = f"decoder.mid.block_{orig_resnet_idx}"
+
+ diffusers_checkpoint.update(
+ vqvae_resnet_to_diffusers_checkpoint(
+ resnet, checkpoint, diffusers_resnet_prefix=diffusers_resnet_prefix, resnet_prefix=resnet_prefix
+ )
+ )
+
+ diffusers_checkpoint.update(
+ {
+ # conv_norm_out
+ "decoder.conv_norm_out.weight": checkpoint["decoder.norm_out.weight"],
+ "decoder.conv_norm_out.bias": checkpoint["decoder.norm_out.bias"],
+ # conv_out
+ "decoder.conv_out.weight": checkpoint["decoder.conv_out.weight"],
+ "decoder.conv_out.bias": checkpoint["decoder.conv_out.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+def vqvae_resnet_to_diffusers_checkpoint(resnet, checkpoint, *, diffusers_resnet_prefix, resnet_prefix):
+ rv = {
+ # norm1
+ f"{diffusers_resnet_prefix}.norm1.weight": checkpoint[f"{resnet_prefix}.norm1.weight"],
+ f"{diffusers_resnet_prefix}.norm1.bias": checkpoint[f"{resnet_prefix}.norm1.bias"],
+ # conv1
+ f"{diffusers_resnet_prefix}.conv1.weight": checkpoint[f"{resnet_prefix}.conv1.weight"],
+ f"{diffusers_resnet_prefix}.conv1.bias": checkpoint[f"{resnet_prefix}.conv1.bias"],
+ # norm2
+ f"{diffusers_resnet_prefix}.norm2.weight": checkpoint[f"{resnet_prefix}.norm2.weight"],
+ f"{diffusers_resnet_prefix}.norm2.bias": checkpoint[f"{resnet_prefix}.norm2.bias"],
+ # conv2
+ f"{diffusers_resnet_prefix}.conv2.weight": checkpoint[f"{resnet_prefix}.conv2.weight"],
+ f"{diffusers_resnet_prefix}.conv2.bias": checkpoint[f"{resnet_prefix}.conv2.bias"],
+ }
+
+ if resnet.conv_shortcut is not None:
+ rv.update(
+ {
+ f"{diffusers_resnet_prefix}.conv_shortcut.weight": checkpoint[f"{resnet_prefix}.nin_shortcut.weight"],
+ f"{diffusers_resnet_prefix}.conv_shortcut.bias": checkpoint[f"{resnet_prefix}.nin_shortcut.bias"],
+ }
+ )
+
+ return rv
+
+
+def vqvae_attention_to_diffusers_checkpoint(checkpoint, *, diffusers_attention_prefix, attention_prefix):
+ return {
+ # group_norm
+ f"{diffusers_attention_prefix}.group_norm.weight": checkpoint[f"{attention_prefix}.norm.weight"],
+ f"{diffusers_attention_prefix}.group_norm.bias": checkpoint[f"{attention_prefix}.norm.bias"],
+ # query
+ f"{diffusers_attention_prefix}.query.weight": checkpoint[f"{attention_prefix}.q.weight"][:, :, 0, 0],
+ f"{diffusers_attention_prefix}.query.bias": checkpoint[f"{attention_prefix}.q.bias"],
+ # key
+ f"{diffusers_attention_prefix}.key.weight": checkpoint[f"{attention_prefix}.k.weight"][:, :, 0, 0],
+ f"{diffusers_attention_prefix}.key.bias": checkpoint[f"{attention_prefix}.k.bias"],
+ # value
+ f"{diffusers_attention_prefix}.value.weight": checkpoint[f"{attention_prefix}.v.weight"][:, :, 0, 0],
+ f"{diffusers_attention_prefix}.value.bias": checkpoint[f"{attention_prefix}.v.bias"],
+ # proj_attn
+ f"{diffusers_attention_prefix}.proj_attn.weight": checkpoint[f"{attention_prefix}.proj_out.weight"][
+ :, :, 0, 0
+ ],
+ f"{diffusers_attention_prefix}.proj_attn.bias": checkpoint[f"{attention_prefix}.proj_out.bias"],
+ }
+
+
+# done vqvae checkpoint
+
+# transformer model
+
+PORTED_DIFFUSIONS = ["image_synthesis.modeling.transformers.diffusion_transformer.DiffusionTransformer"]
+PORTED_TRANSFORMERS = ["image_synthesis.modeling.transformers.transformer_utils.Text2ImageTransformer"]
+PORTED_CONTENT_EMBEDDINGS = ["image_synthesis.modeling.embeddings.dalle_mask_image_embedding.DalleMaskImageEmbedding"]
+
+
+def transformer_model_from_original_config(
+ original_diffusion_config, original_transformer_config, original_content_embedding_config
+):
+ assert (
+ original_diffusion_config.target in PORTED_DIFFUSIONS
+ ), f"{original_diffusion_config.target} has not yet been ported to diffusers."
+ assert (
+ original_transformer_config.target in PORTED_TRANSFORMERS
+ ), f"{original_transformer_config.target} has not yet been ported to diffusers."
+ assert (
+ original_content_embedding_config.target in PORTED_CONTENT_EMBEDDINGS
+ ), f"{original_content_embedding_config.target} has not yet been ported to diffusers."
+
+ original_diffusion_config = original_diffusion_config.params
+ original_transformer_config = original_transformer_config.params
+ original_content_embedding_config = original_content_embedding_config.params
+
+ inner_dim = original_transformer_config["n_embd"]
+
+ n_heads = original_transformer_config["n_head"]
+
+ # VQ-Diffusion gives dimension of the multi-headed attention layers as the
+ # number of attention heads times the sequence length (the dimension) of a
+ # single head. We want to specify our attention blocks with those values
+ # specified separately
+ assert inner_dim % n_heads == 0
+ d_head = inner_dim // n_heads
+
+ depth = original_transformer_config["n_layer"]
+ context_dim = original_transformer_config["condition_dim"]
+
+ num_embed = original_content_embedding_config["num_embed"]
+ # the number of embeddings in the transformer includes the mask embedding.
+ # the content embedding (the vqvae) does not include the mask embedding.
+ num_embed = num_embed + 1
+
+ height = original_transformer_config["content_spatial_size"][0]
+ width = original_transformer_config["content_spatial_size"][1]
+
+ assert width == height, "width has to be equal to height"
+ dropout = original_transformer_config["resid_pdrop"]
+ num_embeds_ada_norm = original_diffusion_config["diffusion_step"]
+
+ model_kwargs = {
+ "attention_bias": True,
+ "cross_attention_dim": context_dim,
+ "attention_head_dim": d_head,
+ "num_layers": depth,
+ "dropout": dropout,
+ "num_attention_heads": n_heads,
+ "num_vector_embeds": num_embed,
+ "num_embeds_ada_norm": num_embeds_ada_norm,
+ "norm_num_groups": 32,
+ "sample_size": width,
+ "activation_fn": "geglu-approximate",
+ }
+
+ model = Transformer2DModel(**model_kwargs)
+ return model
+
+
+# done transformer model
+
+# transformer checkpoint
+
+
+def transformer_original_checkpoint_to_diffusers_checkpoint(model, checkpoint):
+ diffusers_checkpoint = {}
+
+ transformer_prefix = "transformer.transformer"
+
+ diffusers_latent_image_embedding_prefix = "latent_image_embedding"
+ latent_image_embedding_prefix = f"{transformer_prefix}.content_emb"
+
+ # DalleMaskImageEmbedding
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_latent_image_embedding_prefix}.emb.weight": checkpoint[
+ f"{latent_image_embedding_prefix}.emb.weight"
+ ],
+ f"{diffusers_latent_image_embedding_prefix}.height_emb.weight": checkpoint[
+ f"{latent_image_embedding_prefix}.height_emb.weight"
+ ],
+ f"{diffusers_latent_image_embedding_prefix}.width_emb.weight": checkpoint[
+ f"{latent_image_embedding_prefix}.width_emb.weight"
+ ],
+ }
+ )
+
+ # transformer blocks
+ for transformer_block_idx, transformer_block in enumerate(model.transformer_blocks):
+ diffusers_transformer_block_prefix = f"transformer_blocks.{transformer_block_idx}"
+ transformer_block_prefix = f"{transformer_prefix}.blocks.{transformer_block_idx}"
+
+ # ada norm block
+ diffusers_ada_norm_prefix = f"{diffusers_transformer_block_prefix}.norm1"
+ ada_norm_prefix = f"{transformer_block_prefix}.ln1"
+
+ diffusers_checkpoint.update(
+ transformer_ada_norm_to_diffusers_checkpoint(
+ checkpoint, diffusers_ada_norm_prefix=diffusers_ada_norm_prefix, ada_norm_prefix=ada_norm_prefix
+ )
+ )
+
+ # attention block
+ diffusers_attention_prefix = f"{diffusers_transformer_block_prefix}.attn1"
+ attention_prefix = f"{transformer_block_prefix}.attn1"
+
+ diffusers_checkpoint.update(
+ transformer_attention_to_diffusers_checkpoint(
+ checkpoint, diffusers_attention_prefix=diffusers_attention_prefix, attention_prefix=attention_prefix
+ )
+ )
+
+ # ada norm block
+ diffusers_ada_norm_prefix = f"{diffusers_transformer_block_prefix}.norm2"
+ ada_norm_prefix = f"{transformer_block_prefix}.ln1_1"
+
+ diffusers_checkpoint.update(
+ transformer_ada_norm_to_diffusers_checkpoint(
+ checkpoint, diffusers_ada_norm_prefix=diffusers_ada_norm_prefix, ada_norm_prefix=ada_norm_prefix
+ )
+ )
+
+ # attention block
+ diffusers_attention_prefix = f"{diffusers_transformer_block_prefix}.attn2"
+ attention_prefix = f"{transformer_block_prefix}.attn2"
+
+ diffusers_checkpoint.update(
+ transformer_attention_to_diffusers_checkpoint(
+ checkpoint, diffusers_attention_prefix=diffusers_attention_prefix, attention_prefix=attention_prefix
+ )
+ )
+
+ # norm block
+ diffusers_norm_block_prefix = f"{diffusers_transformer_block_prefix}.norm3"
+ norm_block_prefix = f"{transformer_block_prefix}.ln2"
+
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_norm_block_prefix}.weight": checkpoint[f"{norm_block_prefix}.weight"],
+ f"{diffusers_norm_block_prefix}.bias": checkpoint[f"{norm_block_prefix}.bias"],
+ }
+ )
+
+ # feedforward block
+ diffusers_feedforward_prefix = f"{diffusers_transformer_block_prefix}.ff"
+ feedforward_prefix = f"{transformer_block_prefix}.mlp"
+
+ diffusers_checkpoint.update(
+ transformer_feedforward_to_diffusers_checkpoint(
+ checkpoint,
+ diffusers_feedforward_prefix=diffusers_feedforward_prefix,
+ feedforward_prefix=feedforward_prefix,
+ )
+ )
+
+ # to logits
+
+ diffusers_norm_out_prefix = "norm_out"
+ norm_out_prefix = f"{transformer_prefix}.to_logits.0"
+
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_norm_out_prefix}.weight": checkpoint[f"{norm_out_prefix}.weight"],
+ f"{diffusers_norm_out_prefix}.bias": checkpoint[f"{norm_out_prefix}.bias"],
+ }
+ )
+
+ diffusers_out_prefix = "out"
+ out_prefix = f"{transformer_prefix}.to_logits.1"
+
+ diffusers_checkpoint.update(
+ {
+ f"{diffusers_out_prefix}.weight": checkpoint[f"{out_prefix}.weight"],
+ f"{diffusers_out_prefix}.bias": checkpoint[f"{out_prefix}.bias"],
+ }
+ )
+
+ return diffusers_checkpoint
+
+
+def transformer_ada_norm_to_diffusers_checkpoint(checkpoint, *, diffusers_ada_norm_prefix, ada_norm_prefix):
+ return {
+ f"{diffusers_ada_norm_prefix}.emb.weight": checkpoint[f"{ada_norm_prefix}.emb.weight"],
+ f"{diffusers_ada_norm_prefix}.linear.weight": checkpoint[f"{ada_norm_prefix}.linear.weight"],
+ f"{diffusers_ada_norm_prefix}.linear.bias": checkpoint[f"{ada_norm_prefix}.linear.bias"],
+ }
+
+
+def transformer_attention_to_diffusers_checkpoint(checkpoint, *, diffusers_attention_prefix, attention_prefix):
+ return {
+ # key
+ f"{diffusers_attention_prefix}.to_k.weight": checkpoint[f"{attention_prefix}.key.weight"],
+ f"{diffusers_attention_prefix}.to_k.bias": checkpoint[f"{attention_prefix}.key.bias"],
+ # query
+ f"{diffusers_attention_prefix}.to_q.weight": checkpoint[f"{attention_prefix}.query.weight"],
+ f"{diffusers_attention_prefix}.to_q.bias": checkpoint[f"{attention_prefix}.query.bias"],
+ # value
+ f"{diffusers_attention_prefix}.to_v.weight": checkpoint[f"{attention_prefix}.value.weight"],
+ f"{diffusers_attention_prefix}.to_v.bias": checkpoint[f"{attention_prefix}.value.bias"],
+ # linear out
+ f"{diffusers_attention_prefix}.to_out.0.weight": checkpoint[f"{attention_prefix}.proj.weight"],
+ f"{diffusers_attention_prefix}.to_out.0.bias": checkpoint[f"{attention_prefix}.proj.bias"],
+ }
+
+
+def transformer_feedforward_to_diffusers_checkpoint(checkpoint, *, diffusers_feedforward_prefix, feedforward_prefix):
+ return {
+ f"{diffusers_feedforward_prefix}.net.0.proj.weight": checkpoint[f"{feedforward_prefix}.0.weight"],
+ f"{diffusers_feedforward_prefix}.net.0.proj.bias": checkpoint[f"{feedforward_prefix}.0.bias"],
+ f"{diffusers_feedforward_prefix}.net.2.weight": checkpoint[f"{feedforward_prefix}.2.weight"],
+ f"{diffusers_feedforward_prefix}.net.2.bias": checkpoint[f"{feedforward_prefix}.2.bias"],
+ }
+
+
+# done transformer checkpoint
+
+
+def read_config_file(filename):
+ # The yaml file contains annotations that certain values should
+ # loaded as tuples. By default, OmegaConf will panic when reading
+ # these. Instead, we can manually read the yaml with the FullLoader and then
+ # construct the OmegaConf object.
+ with open(filename) as f:
+ original_config = yaml.load(f, FullLoader)
+
+ return OmegaConf.create(original_config)
+
+
+# We take separate arguments for the vqvae because the ITHQ vqvae config file
+# is separate from the config file for the rest of the model.
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ "--vqvae_checkpoint_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to the vqvae checkpoint to convert.",
+ )
+
+ parser.add_argument(
+ "--vqvae_original_config_file",
+ default=None,
+ type=str,
+ required=True,
+ help="The YAML config file corresponding to the original architecture for the vqvae.",
+ )
+
+ parser.add_argument(
+ "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
+ )
+
+ parser.add_argument(
+ "--original_config_file",
+ default=None,
+ type=str,
+ required=True,
+ help="The YAML config file corresponding to the original architecture.",
+ )
+
+ parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
+
+ parser.add_argument(
+ "--checkpoint_load_device",
+ default="cpu",
+ type=str,
+ required=False,
+ help="The device passed to `map_location` when loading checkpoints.",
+ )
+
+ # See link for how ema weights are always selected
+ # https://github.com/microsoft/VQ-Diffusion/blob/3c98e77f721db7c787b76304fa2c96a36c7b00af/inference_VQ_Diffusion.py#L65
+ parser.add_argument(
+ "--no_use_ema",
+ action="store_true",
+ required=False,
+ help=(
+ "Set to not use the ema weights from the original VQ-Diffusion checkpoint. You probably do not want to set"
+ " it as the original VQ-Diffusion always uses the ema weights when loading models."
+ ),
+ )
+
+ args = parser.parse_args()
+
+ use_ema = not args.no_use_ema
+
+ print(f"loading checkpoints to {args.checkpoint_load_device}")
+
+ checkpoint_map_location = torch.device(args.checkpoint_load_device)
+
+ # vqvae_model
+
+ print(f"loading vqvae, config: {args.vqvae_original_config_file}, checkpoint: {args.vqvae_checkpoint_path}")
+
+ vqvae_original_config = read_config_file(args.vqvae_original_config_file).model
+ vqvae_checkpoint = torch.load(args.vqvae_checkpoint_path, map_location=checkpoint_map_location)["model"]
+
+ with init_empty_weights():
+ vqvae_model = vqvae_model_from_original_config(vqvae_original_config)
+
+ vqvae_diffusers_checkpoint = vqvae_original_checkpoint_to_diffusers_checkpoint(vqvae_model, vqvae_checkpoint)
+
+ with tempfile.NamedTemporaryFile() as vqvae_diffusers_checkpoint_file:
+ torch.save(vqvae_diffusers_checkpoint, vqvae_diffusers_checkpoint_file.name)
+ del vqvae_diffusers_checkpoint
+ del vqvae_checkpoint
+ load_checkpoint_and_dispatch(vqvae_model, vqvae_diffusers_checkpoint_file.name, device_map="auto")
+
+ print("done loading vqvae")
+
+ # done vqvae_model
+
+ # transformer_model
+
+ print(
+ f"loading transformer, config: {args.original_config_file}, checkpoint: {args.checkpoint_path}, use ema:"
+ f" {use_ema}"
+ )
+
+ original_config = read_config_file(args.original_config_file).model
+
+ diffusion_config = original_config.params.diffusion_config
+ transformer_config = original_config.params.diffusion_config.params.transformer_config
+ content_embedding_config = original_config.params.diffusion_config.params.content_emb_config
+
+ pre_checkpoint = torch.load(args.checkpoint_path, map_location=checkpoint_map_location)
+
+ if use_ema:
+ if "ema" in pre_checkpoint:
+ checkpoint = {}
+ for k, v in pre_checkpoint["model"].items():
+ checkpoint[k] = v
+
+ for k, v in pre_checkpoint["ema"].items():
+ # The ema weights are only used on the transformer. To mimic their key as if they came
+ # from the state_dict for the top level model, we prefix with an additional "transformer."
+ # See the source linked in the args.use_ema config for more information.
+ checkpoint[f"transformer.{k}"] = v
+ else:
+ print("attempted to load ema weights but no ema weights are specified in the loaded checkpoint.")
+ checkpoint = pre_checkpoint["model"]
+ else:
+ checkpoint = pre_checkpoint["model"]
+
+ del pre_checkpoint
+
+ with init_empty_weights():
+ transformer_model = transformer_model_from_original_config(
+ diffusion_config, transformer_config, content_embedding_config
+ )
+
+ diffusers_transformer_checkpoint = transformer_original_checkpoint_to_diffusers_checkpoint(
+ transformer_model, checkpoint
+ )
+
+ # classifier free sampling embeddings interlude
+
+ # The learned embeddings are stored on the transformer in the original VQ-diffusion. We store them on a separate
+ # model, so we pull them off the checkpoint before the checkpoint is deleted.
+
+ learnable_classifier_free_sampling_embeddings = diffusion_config.params.learnable_cf
+
+ if learnable_classifier_free_sampling_embeddings:
+ learned_classifier_free_sampling_embeddings_embeddings = checkpoint["transformer.empty_text_embed"]
+ else:
+ learned_classifier_free_sampling_embeddings_embeddings = None
+
+ # done classifier free sampling embeddings interlude
+
+ with tempfile.NamedTemporaryFile() as diffusers_transformer_checkpoint_file:
+ torch.save(diffusers_transformer_checkpoint, diffusers_transformer_checkpoint_file.name)
+ del diffusers_transformer_checkpoint
+ del checkpoint
+ load_checkpoint_and_dispatch(transformer_model, diffusers_transformer_checkpoint_file.name, device_map="auto")
+
+ print("done loading transformer")
+
+ # done transformer_model
+
+ # text encoder
+
+ print("loading CLIP text encoder")
+
+ clip_name = "openai/clip-vit-base-patch32"
+
+ # The original VQ-Diffusion specifies the pad value by the int used in the
+ # returned tokens. Each model uses `0` as the pad value. The transformers clip api
+ # specifies the pad value via the token before it has been tokenized. The `!` pad
+ # token is the same as padding with the `0` pad value.
+ pad_token = "!"
+
+ tokenizer_model = CLIPTokenizer.from_pretrained(clip_name, pad_token=pad_token, device_map="auto")
+
+ assert tokenizer_model.convert_tokens_to_ids(pad_token) == 0
+
+ text_encoder_model = CLIPTextModel.from_pretrained(
+ clip_name,
+ # `CLIPTextModel` does not support device_map="auto"
+ # device_map="auto"
+ )
+
+ print("done loading CLIP text encoder")
+
+ # done text encoder
+
+ # scheduler
+
+ scheduler_model = VQDiffusionScheduler(
+ # the scheduler has the same number of embeddings as the transformer
+ num_vec_classes=transformer_model.num_vector_embeds
+ )
+
+ # done scheduler
+
+ # learned classifier free sampling embeddings
+
+ with init_empty_weights():
+ learned_classifier_free_sampling_embeddings_model = LearnedClassifierFreeSamplingEmbeddings(
+ learnable_classifier_free_sampling_embeddings,
+ hidden_size=text_encoder_model.config.hidden_size,
+ length=tokenizer_model.model_max_length,
+ )
+
+ learned_classifier_free_sampling_checkpoint = {
+ "embeddings": learned_classifier_free_sampling_embeddings_embeddings.float()
+ }
+
+ with tempfile.NamedTemporaryFile() as learned_classifier_free_sampling_checkpoint_file:
+ torch.save(learned_classifier_free_sampling_checkpoint, learned_classifier_free_sampling_checkpoint_file.name)
+ del learned_classifier_free_sampling_checkpoint
+ del learned_classifier_free_sampling_embeddings_embeddings
+ load_checkpoint_and_dispatch(
+ learned_classifier_free_sampling_embeddings_model,
+ learned_classifier_free_sampling_checkpoint_file.name,
+ device_map="auto",
+ )
+
+ # done learned classifier free sampling embeddings
+
+ print(f"saving VQ diffusion model, path: {args.dump_path}")
+
+ pipe = VQDiffusionPipeline(
+ vqvae=vqvae_model,
+ transformer=transformer_model,
+ tokenizer=tokenizer_model,
+ text_encoder=text_encoder_model,
+ learned_classifier_free_sampling_embeddings=learned_classifier_free_sampling_embeddings_model,
+ scheduler=scheduler_model,
+ )
+ pipe.save_pretrained(args.dump_path)
+
+ print("done writing VQ diffusion model")
diff --git a/diffusers/scripts/generate_logits.py b/diffusers/scripts/generate_logits.py
new file mode 100644
index 0000000000000000000000000000000000000000..89dce0e78d4ef50e060ac554ac3f7e760f55983f
--- /dev/null
+++ b/diffusers/scripts/generate_logits.py
@@ -0,0 +1,127 @@
+import random
+
+import torch
+from huggingface_hub import HfApi
+
+from diffusers import UNet2DModel
+
+
+api = HfApi()
+
+results = {}
+# fmt: off
+results["google_ddpm_cifar10_32"] = torch.tensor([
+ -0.7515, -1.6883, 0.2420, 0.0300, 0.6347, 1.3433, -1.1743, -3.7467,
+ 1.2342, -2.2485, 0.4636, 0.8076, -0.7991, 0.3969, 0.8498, 0.9189,
+ -1.8887, -3.3522, 0.7639, 0.2040, 0.6271, -2.7148, -1.6316, 3.0839,
+ 0.3186, 0.2721, -0.9759, -1.2461, 2.6257, 1.3557
+])
+results["google_ddpm_ema_bedroom_256"] = torch.tensor([
+ -2.3639, -2.5344, 0.0054, -0.6674, 1.5990, 1.0158, 0.3124, -2.1436,
+ 1.8795, -2.5429, -0.1566, -0.3973, 1.2490, 2.6447, 1.2283, -0.5208,
+ -2.8154, -3.5119, 2.3838, 1.2033, 1.7201, -2.1256, -1.4576, 2.7948,
+ 2.4204, -0.9752, -1.2546, 0.8027, 3.2758, 3.1365
+])
+results["CompVis_ldm_celebahq_256"] = torch.tensor([
+ -0.6531, -0.6891, -0.3172, -0.5375, -0.9140, -0.5367, -0.1175, -0.7869,
+ -0.3808, -0.4513, -0.2098, -0.0083, 0.3183, 0.5140, 0.2247, -0.1304,
+ -0.1302, -0.2802, -0.2084, -0.2025, -0.4967, -0.4873, -0.0861, 0.6925,
+ 0.0250, 0.1290, -0.1543, 0.6316, 1.0460, 1.4943
+])
+results["google_ncsnpp_ffhq_1024"] = torch.tensor([
+ 0.0911, 0.1107, 0.0182, 0.0435, -0.0805, -0.0608, 0.0381, 0.2172,
+ -0.0280, 0.1327, -0.0299, -0.0255, -0.0050, -0.1170, -0.1046, 0.0309,
+ 0.1367, 0.1728, -0.0533, -0.0748, -0.0534, 0.1624, 0.0384, -0.1805,
+ -0.0707, 0.0642, 0.0220, -0.0134, -0.1333, -0.1505
+])
+results["google_ncsnpp_bedroom_256"] = torch.tensor([
+ 0.1321, 0.1337, 0.0440, 0.0622, -0.0591, -0.0370, 0.0503, 0.2133,
+ -0.0177, 0.1415, -0.0116, -0.0112, 0.0044, -0.0980, -0.0789, 0.0395,
+ 0.1502, 0.1785, -0.0488, -0.0514, -0.0404, 0.1539, 0.0454, -0.1559,
+ -0.0665, 0.0659, 0.0383, -0.0005, -0.1266, -0.1386
+])
+results["google_ncsnpp_celebahq_256"] = torch.tensor([
+ 0.1154, 0.1218, 0.0307, 0.0526, -0.0711, -0.0541, 0.0366, 0.2078,
+ -0.0267, 0.1317, -0.0226, -0.0193, -0.0014, -0.1055, -0.0902, 0.0330,
+ 0.1391, 0.1709, -0.0562, -0.0693, -0.0560, 0.1482, 0.0381, -0.1683,
+ -0.0681, 0.0661, 0.0331, -0.0046, -0.1268, -0.1431
+])
+results["google_ncsnpp_church_256"] = torch.tensor([
+ 0.1192, 0.1240, 0.0414, 0.0606, -0.0557, -0.0412, 0.0430, 0.2042,
+ -0.0200, 0.1385, -0.0115, -0.0132, 0.0017, -0.0965, -0.0802, 0.0398,
+ 0.1433, 0.1747, -0.0458, -0.0533, -0.0407, 0.1545, 0.0419, -0.1574,
+ -0.0645, 0.0626, 0.0341, -0.0010, -0.1199, -0.1390
+])
+results["google_ncsnpp_ffhq_256"] = torch.tensor([
+ 0.1075, 0.1074, 0.0205, 0.0431, -0.0774, -0.0607, 0.0298, 0.2042,
+ -0.0320, 0.1267, -0.0281, -0.0250, -0.0064, -0.1091, -0.0946, 0.0290,
+ 0.1328, 0.1650, -0.0580, -0.0738, -0.0586, 0.1440, 0.0337, -0.1746,
+ -0.0712, 0.0605, 0.0250, -0.0099, -0.1316, -0.1473
+])
+results["google_ddpm_cat_256"] = torch.tensor([
+ -1.4572, -2.0481, -0.0414, -0.6005, 1.4136, 0.5848, 0.4028, -2.7330,
+ 1.2212, -2.1228, 0.2155, 0.4039, 0.7662, 2.0535, 0.7477, -0.3243,
+ -2.1758, -2.7648, 1.6947, 0.7026, 1.2338, -1.6078, -0.8682, 2.2810,
+ 1.8574, -0.5718, -0.5586, -0.0186, 2.3415, 2.1251])
+results["google_ddpm_celebahq_256"] = torch.tensor([
+ -1.3690, -1.9720, -0.4090, -0.6966, 1.4660, 0.9938, -0.1385, -2.7324,
+ 0.7736, -1.8917, 0.2923, 0.4293, 0.1693, 1.4112, 1.1887, -0.3181,
+ -2.2160, -2.6381, 1.3170, 0.8163, 0.9240, -1.6544, -0.6099, 2.5259,
+ 1.6430, -0.9090, -0.9392, -0.0126, 2.4268, 2.3266
+])
+results["google_ddpm_ema_celebahq_256"] = torch.tensor([
+ -1.3525, -1.9628, -0.3956, -0.6860, 1.4664, 1.0014, -0.1259, -2.7212,
+ 0.7772, -1.8811, 0.2996, 0.4388, 0.1704, 1.4029, 1.1701, -0.3027,
+ -2.2053, -2.6287, 1.3350, 0.8131, 0.9274, -1.6292, -0.6098, 2.5131,
+ 1.6505, -0.8958, -0.9298, -0.0151, 2.4257, 2.3355
+])
+results["google_ddpm_church_256"] = torch.tensor([
+ -2.0585, -2.7897, -0.2850, -0.8940, 1.9052, 0.5702, 0.6345, -3.8959,
+ 1.5932, -3.2319, 0.1974, 0.0287, 1.7566, 2.6543, 0.8387, -0.5351,
+ -3.2736, -4.3375, 2.9029, 1.6390, 1.4640, -2.1701, -1.9013, 2.9341,
+ 3.4981, -0.6255, -1.1644, -0.1591, 3.7097, 3.2066
+])
+results["google_ddpm_bedroom_256"] = torch.tensor([
+ -2.3139, -2.5594, -0.0197, -0.6785, 1.7001, 1.1606, 0.3075, -2.1740,
+ 1.8071, -2.5630, -0.0926, -0.3811, 1.2116, 2.6246, 1.2731, -0.5398,
+ -2.8153, -3.6140, 2.3893, 1.3262, 1.6258, -2.1856, -1.3267, 2.8395,
+ 2.3779, -1.0623, -1.2468, 0.8959, 3.3367, 3.2243
+])
+results["google_ddpm_ema_church_256"] = torch.tensor([
+ -2.0628, -2.7667, -0.2089, -0.8263, 2.0539, 0.5992, 0.6495, -3.8336,
+ 1.6025, -3.2817, 0.1721, -0.0633, 1.7516, 2.7039, 0.8100, -0.5908,
+ -3.2113, -4.4343, 2.9257, 1.3632, 1.5562, -2.1489, -1.9894, 3.0560,
+ 3.3396, -0.7328, -1.0417, 0.0383, 3.7093, 3.2343
+])
+results["google_ddpm_ema_cat_256"] = torch.tensor([
+ -1.4574, -2.0569, -0.0473, -0.6117, 1.4018, 0.5769, 0.4129, -2.7344,
+ 1.2241, -2.1397, 0.2000, 0.3937, 0.7616, 2.0453, 0.7324, -0.3391,
+ -2.1746, -2.7744, 1.6963, 0.6921, 1.2187, -1.6172, -0.8877, 2.2439,
+ 1.8471, -0.5839, -0.5605, -0.0464, 2.3250, 2.1219
+])
+# fmt: on
+
+models = api.list_models(filter="diffusers")
+for mod in models:
+ if "google" in mod.author or mod.modelId == "CompVis/ldm-celebahq-256":
+ local_checkpoint = "/home/patrick/google_checkpoints/" + mod.modelId.split("/")[-1]
+
+ print(f"Started running {mod.modelId}!!!")
+
+ if mod.modelId.startswith("CompVis"):
+ model = UNet2DModel.from_pretrained(local_checkpoint, subfolder="unet")
+ else:
+ model = UNet2DModel.from_pretrained(local_checkpoint)
+
+ torch.manual_seed(0)
+ random.seed(0)
+
+ noise = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
+ time_step = torch.tensor([10] * noise.shape[0])
+ with torch.no_grad():
+ logits = model(noise, time_step).sample
+
+ assert torch.allclose(
+ logits[0, 0, 0, :30], results["_".join("_".join(mod.modelId.split("/")).split("-"))], atol=1e-3
+ )
+ print(f"{mod.modelId} has passed successfully!!!")
diff --git a/diffusers/setup.cfg b/diffusers/setup.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..fe555d61c69ae01d96d862039ca1867cfffdd6f5
--- /dev/null
+++ b/diffusers/setup.cfg
@@ -0,0 +1,20 @@
+[isort]
+default_section = FIRSTPARTY
+ensure_newline_before_comments = True
+force_grid_wrap = 0
+include_trailing_comma = True
+known_first_party = accelerate
+known_third_party =
+ numpy
+ torch
+ torch_xla
+
+line_length = 119
+lines_after_imports = 2
+multi_line_output = 3
+use_parentheses = True
+
+[flake8]
+ignore = E203, E722, E501, E741, W503, W605
+max-line-length = 119
+per-file-ignores = __init__.py:F401
diff --git a/diffusers/setup.py b/diffusers/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..972f9a5b4a2480a594c84daf7840ab26edf51a2c
--- /dev/null
+++ b/diffusers/setup.py
@@ -0,0 +1,279 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""
+Simple check list from AllenNLP repo: https://github.com/allenai/allennlp/blob/main/setup.py
+
+To create the package for pypi.
+
+1. Run `make pre-release` (or `make pre-patch` for a patch release) then run `make fix-copies` to fix the index of the
+ documentation.
+
+ If releasing on a special branch, copy the updated README.md on the main branch for your the commit you will make
+ for the post-release and run `make fix-copies` on the main branch as well.
+
+2. Run Tests for Amazon Sagemaker. The documentation is located in `./tests/sagemaker/README.md`, otherwise @philschmid.
+
+3. Unpin specific versions from setup.py that use a git install.
+
+4. Checkout the release branch (v-release, for example v4.19-release), and commit these changes with the
+ message: "Release: " and push.
+
+5. Wait for the tests on main to be completed and be green (otherwise revert and fix bugs)
+
+6. Add a tag in git to mark the release: "git tag v -m 'Adds tag v for pypi' "
+ Push the tag to git: git push --tags origin v-release
+
+7. Build both the sources and the wheel. Do not change anything in setup.py between
+ creating the wheel and the source distribution (obviously).
+
+ For the wheel, run: "python setup.py bdist_wheel" in the top level directory.
+ (this will build a wheel for the python version you use to build it).
+
+ For the sources, run: "python setup.py sdist"
+ You should now have a /dist directory with both .whl and .tar.gz source versions.
+
+8. Check that everything looks correct by uploading the package to the pypi test server:
+
+ twine upload dist/* -r pypitest
+ (pypi suggest using twine as other methods upload files via plaintext.)
+ You may have to specify the repository url, use the following command then:
+ twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/
+
+ Check that you can install it in a virtualenv by running:
+ pip install -i https://testpypi.python.org/pypi diffusers
+
+ Check you can run the following commands:
+ python -c "from diffusers import pipeline; classifier = pipeline('text-classification'); print(classifier('What a nice release'))"
+ python -c "from diffusers import *"
+
+9. Upload the final version to actual pypi:
+ twine upload dist/* -r pypi
+
+10. Copy the release notes from RELEASE.md to the tag in github once everything is looking hunky-dory.
+
+11. Run `make post-release` (or, for a patch release, `make post-patch`). If you were on a branch for the release,
+ you need to go back to main before executing this.
+"""
+
+import os
+import re
+from distutils.core import Command
+
+from setuptools import find_packages, setup
+
+
+# IMPORTANT:
+# 1. all dependencies should be listed here with their version requirements if any
+# 2. once modified, run: `make deps_table_update` to update src/diffusers/dependency_versions_table.py
+_deps = [
+ "Pillow", # keep the PIL.Image.Resampling deprecation away
+ "accelerate>=0.11.0",
+ "compel==0.1.8",
+ "black~=23.1",
+ "datasets",
+ "filelock",
+ "flax>=0.4.1",
+ "hf-doc-builder>=0.3.0",
+ "huggingface-hub>=0.13.2",
+ "requests-mock==1.10.0",
+ "importlib_metadata",
+ "isort>=5.5.4",
+ "jax>=0.2.8,!=0.3.2",
+ "jaxlib>=0.1.65",
+ "Jinja2",
+ "k-diffusion>=0.0.12",
+ "librosa",
+ "note-seq",
+ "numpy",
+ "parameterized",
+ "protobuf>=3.20.3,<4",
+ "pytest",
+ "pytest-timeout",
+ "pytest-xdist",
+ "ruff>=0.0.241",
+ "safetensors",
+ "sentencepiece>=0.1.91,!=0.1.92",
+ "scipy",
+ "regex!=2019.12.17",
+ "requests",
+ "tensorboard",
+ "torch>=1.4",
+ "torchvision",
+ "transformers>=4.25.1",
+]
+
+# this is a lookup table with items like:
+#
+# tokenizers: "huggingface-hub==0.8.0"
+# packaging: "packaging"
+#
+# some of the values are versioned whereas others aren't.
+deps = {b: a for a, b in (re.findall(r"^(([^!=<>~]+)(?:[!=<>~].*)?$)", x)[0] for x in _deps)}
+
+# since we save this data in src/diffusers/dependency_versions_table.py it can be easily accessed from
+# anywhere. If you need to quickly access the data from this table in a shell, you can do so easily with:
+#
+# python -c 'import sys; from diffusers.dependency_versions_table import deps; \
+# print(" ".join([ deps[x] for x in sys.argv[1:]]))' tokenizers datasets
+#
+# Just pass the desired package names to that script as it's shown with 2 packages above.
+#
+# If diffusers is not yet installed and the work is done from the cloned repo remember to add `PYTHONPATH=src` to the script above
+#
+# You can then feed this for example to `pip`:
+#
+# pip install -U $(python -c 'import sys; from diffusers.dependency_versions_table import deps; \
+# print(" ".join([ deps[x] for x in sys.argv[1:]]))' tokenizers datasets)
+#
+
+
+def deps_list(*pkgs):
+ return [deps[pkg] for pkg in pkgs]
+
+
+class DepsTableUpdateCommand(Command):
+ """
+ A custom distutils command that updates the dependency table.
+ usage: python setup.py deps_table_update
+ """
+
+ description = "build runtime dependency table"
+ user_options = [
+ # format: (long option, short option, description).
+ ("dep-table-update", None, "updates src/diffusers/dependency_versions_table.py"),
+ ]
+
+ def initialize_options(self):
+ pass
+
+ def finalize_options(self):
+ pass
+
+ def run(self):
+ entries = "\n".join([f' "{k}": "{v}",' for k, v in deps.items()])
+ content = [
+ "# THIS FILE HAS BEEN AUTOGENERATED. To update:",
+ "# 1. modify the `_deps` dict in setup.py",
+ "# 2. run `make deps_table_update``",
+ "deps = {",
+ entries,
+ "}",
+ "",
+ ]
+ target = "src/diffusers/dependency_versions_table.py"
+ print(f"updating {target}")
+ with open(target, "w", encoding="utf-8", newline="\n") as f:
+ f.write("\n".join(content))
+
+
+extras = {}
+
+
+extras = {}
+extras["quality"] = deps_list("black", "isort", "ruff", "hf-doc-builder")
+extras["docs"] = deps_list("hf-doc-builder")
+extras["training"] = deps_list("accelerate", "datasets", "protobuf", "tensorboard", "Jinja2")
+extras["test"] = deps_list(
+ "compel",
+ "datasets",
+ "Jinja2",
+ "k-diffusion",
+ "librosa",
+ "note-seq",
+ "parameterized",
+ "pytest",
+ "pytest-timeout",
+ "pytest-xdist",
+ "requests-mock",
+ "safetensors",
+ "sentencepiece",
+ "scipy",
+ "torchvision",
+ "transformers",
+)
+extras["torch"] = deps_list("torch", "accelerate")
+
+if os.name == "nt": # windows
+ extras["flax"] = [] # jax is not supported on windows
+else:
+ extras["flax"] = deps_list("jax", "jaxlib", "flax")
+
+extras["dev"] = (
+ extras["quality"] + extras["test"] + extras["training"] + extras["docs"] + extras["torch"] + extras["flax"]
+)
+
+install_requires = [
+ deps["importlib_metadata"],
+ deps["filelock"],
+ deps["huggingface-hub"],
+ deps["numpy"],
+ deps["regex"],
+ deps["requests"],
+ deps["Pillow"],
+]
+
+setup(
+ name="diffusers",
+ version="0.15.0.dev0", # expected format is one of x.y.z.dev0, or x.y.z.rc1 or x.y.z (no to dashes, yes to dots)
+ description="Diffusers",
+ long_description=open("README.md", "r", encoding="utf-8").read(),
+ long_description_content_type="text/markdown",
+ keywords="deep learning",
+ license="Apache",
+ author="The HuggingFace team",
+ author_email="patrick@huggingface.co",
+ url="https://github.com/huggingface/diffusers",
+ package_dir={"": "src"},
+ packages=find_packages("src"),
+ include_package_data=True,
+ python_requires=">=3.7.0",
+ install_requires=install_requires,
+ extras_require=extras,
+ entry_points={"console_scripts": ["diffusers-cli=diffusers.commands.diffusers_cli:main"]},
+ classifiers=[
+ "Development Status :: 5 - Production/Stable",
+ "Intended Audience :: Developers",
+ "Intended Audience :: Education",
+ "Intended Audience :: Science/Research",
+ "License :: OSI Approved :: Apache Software License",
+ "Operating System :: OS Independent",
+ "Programming Language :: Python :: 3",
+ "Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
+ "Programming Language :: Python :: 3.9",
+ "Topic :: Scientific/Engineering :: Artificial Intelligence",
+ ],
+ cmdclass={"deps_table_update": DepsTableUpdateCommand},
+)
+
+# Release checklist
+# 1. Change the version in __init__.py and setup.py.
+# 2. Commit these changes with the message: "Release: Release"
+# 3. Add a tag in git to mark the release: "git tag RELEASE -m 'Adds tag RELEASE for pypi' "
+# Push the tag to git: git push --tags origin main
+# 4. Run the following commands in the top-level directory:
+# python setup.py bdist_wheel
+# python setup.py sdist
+# 5. Upload the package to the pypi test server first:
+# twine upload dist/* -r pypitest
+# twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/
+# 6. Check that you can install it in a virtualenv by running:
+# pip install -i https://testpypi.python.org/pypi diffusers
+# diffusers env
+# diffusers test
+# 7. Upload the final version to actual pypi:
+# twine upload dist/* -r pypi
+# 8. Add release notes to the tag in github once everything is looking hunky-dory.
+# 9. Update the version in __init__.py, setup.py to the new version "-dev" and push to master
diff --git a/diffusers/src/diffusers.egg-info/PKG-INFO b/diffusers/src/diffusers.egg-info/PKG-INFO
new file mode 100644
index 0000000000000000000000000000000000000000..ecf097814ac73fd2867633c5138b73dc0886e395
--- /dev/null
+++ b/diffusers/src/diffusers.egg-info/PKG-INFO
@@ -0,0 +1,216 @@
+Metadata-Version: 2.1
+Name: diffusers
+Version: 0.15.0.dev0
+Summary: Diffusers
+Home-page: https://github.com/huggingface/diffusers
+Author: The HuggingFace team
+Author-email: patrick@huggingface.co
+License: Apache
+Keywords: deep learning
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Intended Audience :: Developers
+Classifier: Intended Audience :: Education
+Classifier: Intended Audience :: Science/Research
+Classifier: License :: OSI Approved :: Apache Software License
+Classifier: Operating System :: OS Independent
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3.7
+Classifier: Programming Language :: Python :: 3.8
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
+Requires-Python: >=3.7.0
+Description-Content-Type: text/markdown
+Provides-Extra: quality
+Provides-Extra: docs
+Provides-Extra: training
+Provides-Extra: test
+Provides-Extra: torch
+Provides-Extra: flax
+Provides-Extra: dev
+License-File: LICENSE
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or training your own diffusion models, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](https://huggingface.co/docs/diffusers/conceptual/philosophy#usability-over-performance), [simple over easy](https://huggingface.co/docs/diffusers/conceptual/philosophy#simple-over-easy), and [customizability over abstractions](https://huggingface.co/docs/diffusers/conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
+
+🤗 Diffusers offers three core components:
+
+- State-of-the-art [diffusion pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) that can be run in inference with just a few lines of code.
+- Interchangeable noise [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview) for different diffusion speeds and output quality.
+- Pretrained [models](https://huggingface.co/docs/diffusers/api/models) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
+
+## Installation
+
+We recommend installing 🤗 Diffusers in a virtual environment from PyPi or Conda. For more details about installing [PyTorch](https://pytorch.org/get-started/locally/) and [Flax](https://flax.readthedocs.io/en/latest/installation.html), please refer to their official documentation.
+
+### PyTorch
+
+With `pip` (official package):
+
+```bash
+pip install --upgrade diffusers[torch]
+```
+
+With `conda` (maintained by the community):
+
+```sh
+conda install -c conda-forge diffusers
+```
+
+### Flax
+
+With `pip` (official package):
+
+```bash
+pip install --upgrade diffusers[flax]
+```
+
+### Apple Silicon (M1/M2) support
+
+Please refer to the [How to use Stable Diffusion in Apple Silicon](https://huggingface.co/docs/diffusers/optimization/mps) guide.
+
+## Quickstart
+
+Generating outputs is super easy with 🤗 Diffusers. To generate an image from text, use the `from_pretrained` method to load any pretrained diffusion model (browse the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) for 4000+ checkpoints):
+
+```python
+from diffusers import DiffusionPipeline
+
+pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+pipeline.to("cuda")
+pipeline("An image of a squirrel in Picasso style").images[0]
+```
+
+You can also dig into the models and schedulers toolbox to build your own diffusion system:
+
+```python
+from diffusers import DDPMScheduler, UNet2DModel
+from PIL import Image
+import torch
+import numpy as np
+
+scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
+model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
+scheduler.set_timesteps(50)
+
+sample_size = model.config.sample_size
+noise = torch.randn((1, 3, sample_size, sample_size)).to("cuda")
+input = noise
+
+for t in scheduler.timesteps:
+ with torch.no_grad():
+ noisy_residual = model(input, t).sample
+ prev_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
+ input = prev_noisy_sample
+
+image = (input / 2 + 0.5).clamp(0, 1)
+image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
+image = Image.fromarray((image * 255).round().astype("uint8"))
+image
+```
+
+Check out the [Quickstart](https://huggingface.co/docs/diffusers/quicktour) to launch your diffusion journey today!
+
+## How to navigate the documentation
+
+| **Documentation** | **What can I learn?** |
+|---------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| Tutorial | A basic crash course for learning how to use the library's most important features like using models and schedulers to build your own diffusion system, and training your own diffusion model. |
+| Loading | Guides for how to load and configure all the components (pipelines, models, and schedulers) of the library, as well as how to use different schedulers. |
+| Pipelines for inference | Guides for how to use pipelines for different inference tasks, batched generation, controlling generated outputs and randomness, and how to contribute a pipeline to the library. |
+| Optimization | Guides for how to optimize your diffusion model to run faster and consume less memory. |
+| [Training](https://huggingface.co/docs/diffusers/training/overview) | Guides for how to train a diffusion model for different tasks with different training techniques. |
+
+## Supported pipelines
+
+| Pipeline | Paper | Tasks |
+|---|---|:---:|
+| [alt_diffusion](./api/pipelines/alt_diffusion) | [**AltDiffusion**](https://arxiv.org/abs/2211.06679) | Image-to-Image Text-Guided Generation |
+| [audio_diffusion](./api/pipelines/audio_diffusion) | [**Audio Diffusion**](https://github.com/teticio/audio-diffusion.git) | Unconditional Audio Generation |
+| [controlnet](./api/pipelines/stable_diffusion/controlnet) | [**ControlNet with Stable Diffusion**](https://arxiv.org/abs/2302.05543) | Image-to-Image Text-Guided Generation |
+| [cycle_diffusion](./api/pipelines/cycle_diffusion) | [**Cycle Diffusion**](https://arxiv.org/abs/2210.05559) | Image-to-Image Text-Guided Generation |
+| [dance_diffusion](./api/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/williamberman/diffusers.git) | Unconditional Audio Generation |
+| [ddpm](./api/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | Unconditional Image Generation |
+| [ddim](./api/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | Unconditional Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Text-to-Image Generation |
+| [latent_diffusion](./api/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752)| Super Resolution Image-to-Image |
+| [latent_diffusion_uncond](./api/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | Unconditional Image Generation |
+| [paint_by_example](./api/pipelines/paint_by_example) | [**Paint by Example: Exemplar-based Image Editing with Diffusion Models**](https://arxiv.org/abs/2211.13227) | Image-Guided Image Inpainting |
+| [pndm](./api/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | Unconditional Image Generation |
+| [score_sde_ve](./api/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [score_sde_vp](./api/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | Unconditional Image Generation |
+| [semantic_stable_diffusion](./api/pipelines/semantic_stable_diffusion) | [**Semantic Guidance**](https://arxiv.org/abs/2301.12247) | Text-Guided Generation |
+| [stable_diffusion_text2img](./api/pipelines/stable_diffusion/text2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-to-Image Generation |
+| [stable_diffusion_img2img](./api/pipelines/stable_diffusion/img2img) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Image-to-Image Text-Guided Generation |
+| [stable_diffusion_inpaint](./api/pipelines/stable_diffusion/inpaint) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_panorama](./api/pipelines/stable_diffusion/panorama) | [**MultiDiffusion**](https://multidiffusion.github.io/) | Text-to-Panorama Generation |
+| [stable_diffusion_pix2pix](./api/pipelines/stable_diffusion/pix2pix) | [**InstructPix2Pix**](https://github.com/timothybrooks/instruct-pix2pix) | Text-Guided Image Editing|
+| [stable_diffusion_pix2pix_zero](./api/pipelines/stable_diffusion/pix2pix_zero) | [**Zero-shot Image-to-Image Translation**](https://pix2pixzero.github.io/) | Text-Guided Image Editing |
+| [stable_diffusion_attend_and_excite](./api/pipelines/stable_diffusion/attend_and_excite) | [**Attend and Excite for Stable Diffusion**](https://attendandexcite.github.io/Attend-and-Excite/) | Text-to-Image Generation |
+| [stable_diffusion_self_attention_guidance](./api/pipelines/stable_diffusion/self_attention_guidance) | [**Self-Attention Guidance**](https://ku-cvlab.github.io/Self-Attention-Guidance) | Text-to-Image Generation |
+| [stable_diffusion_image_variation](./stable_diffusion/image_variation) | [**Stable Diffusion Image Variations**](https://github.com/LambdaLabsML/lambda-diffusers#stable-diffusion-image-variations) | Image-to-Image Generation |
+| [stable_diffusion_latent_upscale](./stable_diffusion/latent_upscale) | [**Stable Diffusion Latent Upscaler**](https://twitter.com/StabilityAI/status/1590531958815064065) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Image Inpainting |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Depth-Conditional Stable Diffusion**](https://github.com/Stability-AI/stablediffusion#depth-conditional-stable-diffusion) | Depth-to-Image Generation |
+| [stable_diffusion_2](./api/pipelines/stable_diffusion_2) | [**Stable Diffusion 2**](https://stability.ai/blog/stable-diffusion-v2-release) | Text-Guided Super Resolution Image-to-Image |
+| [stable_diffusion_safe](./api/pipelines/stable_diffusion_safe) | [**Safe Stable Diffusion**](https://arxiv.org/abs/2211.05105) | Text-Guided Generation |
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Text-to-Image Generation |
+| [stable_unclip](./stable_unclip) | **Stable unCLIP** | Image-to-Image Text-Guided Generation |
+| [stochastic_karras_ve](./api/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | Unconditional Image Generation |
+| [unclip](./api/pipelines/unclip) | [Hierarchical Text-Conditional Image Generation with CLIP Latents](https://arxiv.org/abs/2204.06125) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Text-to-Image Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Image Variations Generation |
+| [versatile_diffusion](./api/pipelines/versatile_diffusion) | [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://arxiv.org/abs/2211.08332) | Dual Image and Text Guided Generation |
+| [vq_diffusion](./api/pipelines/vq_diffusion) | [Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://arxiv.org/abs/2111.14822) | Text-to-Image Generation |
+
+## Contribution
+
+We ❤️ contributions from the open-source community!
+If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md).
+You can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library.
+- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
+- See [New model/pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models / diffusion pipelines
+- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
+
+Also, say 👋 in our public Discord channel . We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or
+just hang out ☕.
+
+## Credits
+
+This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
+
+- @CompVis' latent diffusion models library, available [here](https://github.com/CompVis/latent-diffusion)
+- @hojonathanho original DDPM implementation, available [here](https://github.com/hojonathanho/diffusion) as well as the extremely useful translation into PyTorch by @pesser, available [here](https://github.com/pesser/pytorch_diffusion)
+- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim)
+- @yang-song's Score-VE and Score-VP implementations, available [here](https://github.com/yang-song/score_sde_pytorch)
+
+We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available [here](https://github.com/heejkoo/Awesome-Diffusion-Models) as well as @crowsonkb and @rromb for useful discussions and insights.
+
+## Citation
+
+```bibtex
+@misc{von-platen-etal-2022-diffusers,
+ author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Thomas Wolf},
+ title = {Diffusers: State-of-the-art diffusion models},
+ year = {2022},
+ publisher = {GitHub},
+ journal = {GitHub repository},
+ howpublished = {\url{https://github.com/huggingface/diffusers}}
+}
+```
diff --git a/diffusers/src/diffusers.egg-info/SOURCES.txt b/diffusers/src/diffusers.egg-info/SOURCES.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3a9909157e907b4eaaa7b00d9e992e8ee1217e28
--- /dev/null
+++ b/diffusers/src/diffusers.egg-info/SOURCES.txt
@@ -0,0 +1,226 @@
+LICENSE
+MANIFEST.in
+README.md
+pyproject.toml
+setup.cfg
+setup.py
+src/diffusers/__init__.py
+src/diffusers/configuration_utils.py
+src/diffusers/dependency_versions_check.py
+src/diffusers/dependency_versions_table.py
+src/diffusers/image_processor.py
+src/diffusers/loaders.py
+src/diffusers/optimization.py
+src/diffusers/pipeline_utils.py
+src/diffusers/training_utils.py
+src/diffusers.egg-info/PKG-INFO
+src/diffusers.egg-info/SOURCES.txt
+src/diffusers.egg-info/dependency_links.txt
+src/diffusers.egg-info/entry_points.txt
+src/diffusers.egg-info/requires.txt
+src/diffusers.egg-info/top_level.txt
+src/diffusers/commands/__init__.py
+src/diffusers/commands/diffusers_cli.py
+src/diffusers/commands/env.py
+src/diffusers/experimental/__init__.py
+src/diffusers/experimental/rl/__init__.py
+src/diffusers/experimental/rl/value_guided_sampling.py
+src/diffusers/models/__init__.py
+src/diffusers/models/attention.py
+src/diffusers/models/attention_flax.py
+src/diffusers/models/attention_processor.py
+src/diffusers/models/autoencoder_kl.py
+src/diffusers/models/controlnet.py
+src/diffusers/models/controlnet_flax.py
+src/diffusers/models/cross_attention.py
+src/diffusers/models/dual_transformer_2d.py
+src/diffusers/models/embeddings.py
+src/diffusers/models/embeddings_flax.py
+src/diffusers/models/modeling_flax_pytorch_utils.py
+src/diffusers/models/modeling_flax_utils.py
+src/diffusers/models/modeling_pytorch_flax_utils.py
+src/diffusers/models/modeling_utils.py
+src/diffusers/models/prior_transformer.py
+src/diffusers/models/resnet.py
+src/diffusers/models/resnet_flax.py
+src/diffusers/models/t5_film_transformer.py
+src/diffusers/models/transformer_2d.py
+src/diffusers/models/transformer_temporal.py
+src/diffusers/models/unet_1d.py
+src/diffusers/models/unet_1d_blocks.py
+src/diffusers/models/unet_2d.py
+src/diffusers/models/unet_2d_blocks.py
+src/diffusers/models/unet_2d_blocks_flax.py
+src/diffusers/models/unet_2d_condition.py
+src/diffusers/models/unet_2d_condition_flax.py
+src/diffusers/models/unet_3d_blocks.py
+src/diffusers/models/unet_3d_condition.py
+src/diffusers/models/vae.py
+src/diffusers/models/vae_flax.py
+src/diffusers/models/vq_model.py
+src/diffusers/pipelines/__init__.py
+src/diffusers/pipelines/onnx_utils.py
+src/diffusers/pipelines/pipeline_flax_utils.py
+src/diffusers/pipelines/pipeline_utils.py
+src/diffusers/pipelines/alt_diffusion/__init__.py
+src/diffusers/pipelines/alt_diffusion/modeling_roberta_series.py
+src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion.py
+src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion_img2img.py
+src/diffusers/pipelines/audio_diffusion/__init__.py
+src/diffusers/pipelines/audio_diffusion/mel.py
+src/diffusers/pipelines/audio_diffusion/pipeline_audio_diffusion.py
+src/diffusers/pipelines/audioldm/__init__.py
+src/diffusers/pipelines/audioldm/pipeline_audioldm.py
+src/diffusers/pipelines/dance_diffusion/__init__.py
+src/diffusers/pipelines/dance_diffusion/pipeline_dance_diffusion.py
+src/diffusers/pipelines/ddim/__init__.py
+src/diffusers/pipelines/ddim/pipeline_ddim.py
+src/diffusers/pipelines/ddpm/__init__.py
+src/diffusers/pipelines/ddpm/pipeline_ddpm.py
+src/diffusers/pipelines/dit/__init__.py
+src/diffusers/pipelines/dit/pipeline_dit.py
+src/diffusers/pipelines/latent_diffusion/__init__.py
+src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py
+src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py
+src/diffusers/pipelines/latent_diffusion_uncond/__init__.py
+src/diffusers/pipelines/latent_diffusion_uncond/pipeline_latent_diffusion_uncond.py
+src/diffusers/pipelines/paint_by_example/__init__.py
+src/diffusers/pipelines/paint_by_example/image_encoder.py
+src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py
+src/diffusers/pipelines/pndm/__init__.py
+src/diffusers/pipelines/pndm/pipeline_pndm.py
+src/diffusers/pipelines/repaint/__init__.py
+src/diffusers/pipelines/repaint/pipeline_repaint.py
+src/diffusers/pipelines/score_sde_ve/__init__.py
+src/diffusers/pipelines/score_sde_ve/pipeline_score_sde_ve.py
+src/diffusers/pipelines/semantic_stable_diffusion/__init__.py
+src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
+src/diffusers/pipelines/spectrogram_diffusion/__init__.py
+src/diffusers/pipelines/spectrogram_diffusion/continous_encoder.py
+src/diffusers/pipelines/spectrogram_diffusion/midi_utils.py
+src/diffusers/pipelines/spectrogram_diffusion/notes_encoder.py
+src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion.py
+src/diffusers/pipelines/stable_diffusion/__init__.py
+src/diffusers/pipelines/stable_diffusion/convert_from_ckpt.py
+src/diffusers/pipelines/stable_diffusion/pipeline_cycle_diffusion.py
+src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion.py
+src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
+src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_img2img.py
+src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_inpaint.py
+src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion.py
+src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py
+src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint.py
+src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint_legacy.py
+src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_attend_and_excite.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint_legacy.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_k_diffusion.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_latent_upscale.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_panorama.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_upscale.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip.py
+src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip_img2img.py
+src/diffusers/pipelines/stable_diffusion/safety_checker.py
+src/diffusers/pipelines/stable_diffusion/safety_checker_flax.py
+src/diffusers/pipelines/stable_diffusion/stable_unclip_image_normalizer.py
+src/diffusers/pipelines/stable_diffusion_safe/__init__.py
+src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py
+src/diffusers/pipelines/stable_diffusion_safe/safety_checker.py
+src/diffusers/pipelines/stochastic_karras_ve/__init__.py
+src/diffusers/pipelines/stochastic_karras_ve/pipeline_stochastic_karras_ve.py
+src/diffusers/pipelines/text_to_video_synthesis/__init__.py
+src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py
+src/diffusers/pipelines/unclip/__init__.py
+src/diffusers/pipelines/unclip/pipeline_unclip.py
+src/diffusers/pipelines/unclip/pipeline_unclip_image_variation.py
+src/diffusers/pipelines/unclip/text_proj.py
+src/diffusers/pipelines/versatile_diffusion/__init__.py
+src/diffusers/pipelines/versatile_diffusion/modeling_text_unet.py
+src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion.py
+src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_dual_guided.py
+src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_image_variation.py
+src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
+src/diffusers/pipelines/vq_diffusion/__init__.py
+src/diffusers/pipelines/vq_diffusion/pipeline_vq_diffusion.py
+src/diffusers/schedulers/__init__.py
+src/diffusers/schedulers/scheduling_ddim.py
+src/diffusers/schedulers/scheduling_ddim_flax.py
+src/diffusers/schedulers/scheduling_ddim_inverse.py
+src/diffusers/schedulers/scheduling_ddpm.py
+src/diffusers/schedulers/scheduling_ddpm_flax.py
+src/diffusers/schedulers/scheduling_deis_multistep.py
+src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
+src/diffusers/schedulers/scheduling_dpmsolver_multistep_flax.py
+src/diffusers/schedulers/scheduling_dpmsolver_singlestep.py
+src/diffusers/schedulers/scheduling_euler_ancestral_discrete.py
+src/diffusers/schedulers/scheduling_euler_discrete.py
+src/diffusers/schedulers/scheduling_heun_discrete.py
+src/diffusers/schedulers/scheduling_ipndm.py
+src/diffusers/schedulers/scheduling_k_dpm_2_ancestral_discrete.py
+src/diffusers/schedulers/scheduling_k_dpm_2_discrete.py
+src/diffusers/schedulers/scheduling_karras_ve.py
+src/diffusers/schedulers/scheduling_karras_ve_flax.py
+src/diffusers/schedulers/scheduling_lms_discrete.py
+src/diffusers/schedulers/scheduling_lms_discrete_flax.py
+src/diffusers/schedulers/scheduling_pndm.py
+src/diffusers/schedulers/scheduling_pndm_flax.py
+src/diffusers/schedulers/scheduling_repaint.py
+src/diffusers/schedulers/scheduling_sde_ve.py
+src/diffusers/schedulers/scheduling_sde_ve_flax.py
+src/diffusers/schedulers/scheduling_sde_vp.py
+src/diffusers/schedulers/scheduling_unclip.py
+src/diffusers/schedulers/scheduling_unipc_multistep.py
+src/diffusers/schedulers/scheduling_utils.py
+src/diffusers/schedulers/scheduling_utils_flax.py
+src/diffusers/schedulers/scheduling_vq_diffusion.py
+src/diffusers/utils/__init__.py
+src/diffusers/utils/accelerate_utils.py
+src/diffusers/utils/constants.py
+src/diffusers/utils/deprecation_utils.py
+src/diffusers/utils/doc_utils.py
+src/diffusers/utils/dummy_flax_and_transformers_objects.py
+src/diffusers/utils/dummy_flax_objects.py
+src/diffusers/utils/dummy_note_seq_objects.py
+src/diffusers/utils/dummy_onnx_objects.py
+src/diffusers/utils/dummy_pt_objects.py
+src/diffusers/utils/dummy_torch_and_librosa_objects.py
+src/diffusers/utils/dummy_torch_and_scipy_objects.py
+src/diffusers/utils/dummy_torch_and_transformers_and_k_diffusion_objects.py
+src/diffusers/utils/dummy_torch_and_transformers_and_onnx_objects.py
+src/diffusers/utils/dummy_torch_and_transformers_objects1.py
+src/diffusers/utils/dummy_transformers_and_torch_and_note_seq_objects.py
+src/diffusers/utils/dynamic_modules_utils.py
+src/diffusers/utils/hub_utils.py
+src/diffusers/utils/import_utils.py
+src/diffusers/utils/logging.py
+src/diffusers/utils/model_card_template.md
+src/diffusers/utils/outputs.py
+src/diffusers/utils/pil_utils.py
+src/diffusers/utils/testing_utils.py
+src/diffusers/utils/torch_utils.py
+tests/test_config.py
+tests/test_ema.py
+tests/test_hub_utils.py
+tests/test_image_processor.py
+tests/test_layers_utils.py
+tests/test_modeling_common.py
+tests/test_modeling_common_flax.py
+tests/test_outputs.py
+tests/test_pipelines.py
+tests/test_pipelines_common.py
+tests/test_pipelines_flax.py
+tests/test_pipelines_onnx_common.py
+tests/test_training.py
+tests/test_unet_2d_blocks.py
+tests/test_unet_blocks_common.py
+tests/test_utils.py
\ No newline at end of file
diff --git a/diffusers/src/diffusers.egg-info/dependency_links.txt b/diffusers/src/diffusers.egg-info/dependency_links.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/diffusers/src/diffusers.egg-info/dependency_links.txt
@@ -0,0 +1 @@
+
diff --git a/diffusers/src/diffusers.egg-info/entry_points.txt b/diffusers/src/diffusers.egg-info/entry_points.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4d8cdefa4968bbed7a122fa7a34940bf9a15360b
--- /dev/null
+++ b/diffusers/src/diffusers.egg-info/entry_points.txt
@@ -0,0 +1,2 @@
+[console_scripts]
+diffusers-cli = diffusers.commands.diffusers_cli:main
diff --git a/diffusers/src/diffusers.egg-info/requires.txt b/diffusers/src/diffusers.egg-info/requires.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ae96abe9a73c49cf8595a83b99ffa7b45a6c960b
--- /dev/null
+++ b/diffusers/src/diffusers.egg-info/requires.txt
@@ -0,0 +1,79 @@
+importlib_metadata
+filelock
+huggingface-hub>=0.13.2
+numpy
+regex!=2019.12.17
+requests
+Pillow
+
+[dev]
+black~=23.1
+isort>=5.5.4
+ruff>=0.0.241
+hf-doc-builder>=0.3.0
+compel==0.1.8
+datasets
+Jinja2
+k-diffusion>=0.0.12
+librosa
+note-seq
+parameterized
+pytest
+pytest-timeout
+pytest-xdist
+requests-mock==1.10.0
+safetensors
+sentencepiece!=0.1.92,>=0.1.91
+scipy
+torchvision
+transformers>=4.25.1
+accelerate>=0.11.0
+protobuf<4,>=3.20.3
+tensorboard
+torch>=1.4
+jax!=0.3.2,>=0.2.8
+jaxlib>=0.1.65
+flax>=0.4.1
+
+[docs]
+hf-doc-builder>=0.3.0
+
+[flax]
+jax!=0.3.2,>=0.2.8
+jaxlib>=0.1.65
+flax>=0.4.1
+
+[quality]
+black~=23.1
+isort>=5.5.4
+ruff>=0.0.241
+hf-doc-builder>=0.3.0
+
+[test]
+compel==0.1.8
+datasets
+Jinja2
+k-diffusion>=0.0.12
+librosa
+note-seq
+parameterized
+pytest
+pytest-timeout
+pytest-xdist
+requests-mock==1.10.0
+safetensors
+sentencepiece!=0.1.92,>=0.1.91
+scipy
+torchvision
+transformers>=4.25.1
+
+[torch]
+torch>=1.4
+accelerate>=0.11.0
+
+[training]
+accelerate>=0.11.0
+datasets
+protobuf<4,>=3.20.3
+tensorboard
+Jinja2
diff --git a/diffusers/src/diffusers.egg-info/top_level.txt b/diffusers/src/diffusers.egg-info/top_level.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6033efb6dbaaff9bc81792fd75a6b39d9f195aeb
--- /dev/null
+++ b/diffusers/src/diffusers.egg-info/top_level.txt
@@ -0,0 +1 @@
+diffusers
diff --git a/diffusers/src/diffusers/.ipynb_checkpoints/pipeline_utils-checkpoint.py b/diffusers/src/diffusers/.ipynb_checkpoints/pipeline_utils-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c0c2337dc048dd9ef164ac5cb92e4bf5e62d764
--- /dev/null
+++ b/diffusers/src/diffusers/.ipynb_checkpoints/pipeline_utils-checkpoint.py
@@ -0,0 +1,19 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+# limitations under the License.
+
+# NOTE: This file is deprecated and will be removed in a future version.
+# It only exists so that temporarely `from diffusers.pipelines import DiffusionPipeline` works
+
+from .pipelines import DiffusionPipeline, ImagePipelineOutput # noqa: F401
diff --git a/diffusers/src/diffusers/__init__.py b/diffusers/src/diffusers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8ac91c0eb95fffec92f57a658622ce5702a3d24
--- /dev/null
+++ b/diffusers/src/diffusers/__init__.py
@@ -0,0 +1,230 @@
+__version__ = "0.15.0.dev0"
+
+from .configuration_utils import ConfigMixin
+from .utils import (
+ OptionalDependencyNotAvailable,
+ is_flax_available,
+ is_inflect_available,
+ is_k_diffusion_available,
+ is_k_diffusion_version,
+ is_librosa_available,
+ is_note_seq_available,
+ is_onnx_available,
+ is_scipy_available,
+ is_torch_available,
+ is_transformers_available,
+ is_transformers_version,
+ is_unidecode_available,
+ logging,
+)
+
+
+try:
+ if not is_onnx_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_onnx_objects import * # noqa F403
+else:
+ from .pipelines import OnnxRuntimeModel
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_pt_objects import * # noqa F403
+else:
+ from .models import (
+ AutoencoderKL,
+ ControlNetModel,
+ ModelMixin,
+ PriorTransformer,
+ T5FilmDecoder,
+ Transformer2DModel,
+ UNet1DModel,
+ UNet2DConditionModel,
+ UNet2DModel,
+ UNet3DConditionModel,
+ VQModel,
+ )
+ from .optimization import (
+ get_constant_schedule,
+ get_constant_schedule_with_warmup,
+ get_cosine_schedule_with_warmup,
+ get_cosine_with_hard_restarts_schedule_with_warmup,
+ get_linear_schedule_with_warmup,
+ get_polynomial_decay_schedule_with_warmup,
+ get_scheduler,
+ )
+ from .pipelines import (
+ AudioPipelineOutput,
+ DanceDiffusionPipeline,
+ DDIMPipeline,
+ DDPMPipeline,
+ DiffusionPipeline,
+ DiTPipeline,
+ ImagePipelineOutput,
+ KarrasVePipeline,
+ LDMPipeline,
+ LDMSuperResolutionPipeline,
+ PNDMPipeline,
+ RePaintPipeline,
+ ScoreSdeVePipeline,
+ )
+ from .schedulers import (
+ DDIMInverseScheduler,
+ DDIMScheduler,
+ DDPMScheduler,
+ DEISMultistepScheduler,
+ DPMSolverMultistepScheduler,
+ DPMSolverSinglestepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ HeunDiscreteScheduler,
+ IPNDMScheduler,
+ KarrasVeScheduler,
+ KDPM2AncestralDiscreteScheduler,
+ KDPM2DiscreteScheduler,
+ PNDMScheduler,
+ RePaintScheduler,
+ SchedulerMixin,
+ ScoreSdeVeScheduler,
+ UnCLIPScheduler,
+ UniPCMultistepScheduler,
+ VQDiffusionScheduler,
+ )
+ from .training_utils import EMAModel
+
+try:
+ if not (is_torch_available() and is_scipy_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_torch_and_scipy_objects import * # noqa F403
+else:
+ from .schedulers import LMSDiscreteScheduler
+
+
+try:
+ if not (is_torch_available() and is_transformers_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_torch_and_transformers_objects import * # noqa F403
+else:
+ from .loaders import TextualInversionLoaderMixin
+ from .pipelines import (
+ AltDiffusionImg2ImgPipeline,
+ AltDiffusionPipeline,
+ AudioLDMPipeline,
+ CycleDiffusionPipeline,
+ LDMTextToImagePipeline,
+ PaintByExamplePipeline,
+ SemanticStableDiffusionPipeline,
+ StableDiffusionAttendAndExcitePipeline,
+ StableDiffusionControlNetPipeline,
+ StableDiffusionDepth2ImgPipeline,
+ StableDiffusionImageVariationPipeline,
+ StableDiffusionImg2ImgPipeline,
+ StableDiffusionInpaintPipeline,
+ StableDiffusionInpaintPipelineLegacy,
+ StableDiffusionInstructPix2PixPipeline,
+ StableDiffusionLatentUpscalePipeline,
+ StableDiffusionModelEditingPipeline,
+ StableDiffusionPanoramaPipeline,
+ StableDiffusionPipeline,
+ StableDiffusionPipelineSafe,
+ StableDiffusionPix2PixZeroPipeline,
+ StableDiffusionSAGPipeline,
+ StableDiffusionUpscalePipeline,
+ StableUnCLIPImg2ImgPipeline,
+ StableUnCLIPPipeline,
+ TextToVideoSDPipeline,
+ UnCLIPImageVariationPipeline,
+ UnCLIPPipeline,
+ VersatileDiffusionDualGuidedPipeline,
+ VersatileDiffusionImageVariationPipeline,
+ VersatileDiffusionPipeline,
+ VersatileDiffusionTextToImagePipeline,
+ VQDiffusionPipeline,
+ )
+
+try:
+ if not (is_torch_available() and is_transformers_available() and is_k_diffusion_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_torch_and_transformers_and_k_diffusion_objects import * # noqa F403
+else:
+ from .pipelines import StableDiffusionKDiffusionPipeline
+
+try:
+ if not (is_torch_available() and is_transformers_available() and is_onnx_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_torch_and_transformers_and_onnx_objects import * # noqa F403
+else:
+ from .pipelines import (
+ OnnxStableDiffusionImg2ImgPipeline,
+ OnnxStableDiffusionInpaintPipeline,
+ OnnxStableDiffusionInpaintPipelineLegacy,
+ OnnxStableDiffusionPipeline,
+ OnnxStableDiffusionUpscalePipeline,
+ StableDiffusionOnnxPipeline,
+ )
+
+try:
+ if not (is_torch_available() and is_librosa_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_torch_and_librosa_objects import * # noqa F403
+else:
+ from .pipelines import AudioDiffusionPipeline, Mel
+
+try:
+ if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_transformers_and_torch_and_note_seq_objects import * # noqa F403
+else:
+ from .pipelines import SpectrogramDiffusionPipeline
+
+try:
+ if not is_flax_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_flax_objects import * # noqa F403
+else:
+ from .models.controlnet_flax import FlaxControlNetModel
+ from .models.modeling_flax_utils import FlaxModelMixin
+ from .models.unet_2d_condition_flax import FlaxUNet2DConditionModel
+ from .models.vae_flax import FlaxAutoencoderKL
+ from .pipelines import FlaxDiffusionPipeline
+ from .schedulers import (
+ FlaxDDIMScheduler,
+ FlaxDDPMScheduler,
+ FlaxDPMSolverMultistepScheduler,
+ FlaxKarrasVeScheduler,
+ FlaxLMSDiscreteScheduler,
+ FlaxPNDMScheduler,
+ FlaxSchedulerMixin,
+ FlaxScoreSdeVeScheduler,
+ )
+
+
+try:
+ if not (is_flax_available() and is_transformers_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_flax_and_transformers_objects import * # noqa F403
+else:
+ from .pipelines import (
+ FlaxStableDiffusionControlNetPipeline,
+ FlaxStableDiffusionImg2ImgPipeline,
+ FlaxStableDiffusionInpaintPipeline,
+ FlaxStableDiffusionPipeline,
+ )
+
+try:
+ if not (is_note_seq_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils.dummy_note_seq_objects import * # noqa F403
+else:
+ from .pipelines import MidiProcessor
diff --git a/diffusers/src/diffusers/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a5f9083ae72d8a4bb2624295ff9bc24b3c31d43f
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..239da5c5f258cf51ce2f7f56dc74f58805e795f1
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/configuration_utils.cpython-310.pyc b/diffusers/src/diffusers/__pycache__/configuration_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d1eb24af8af771e7b8b27fb83c6dc714785e50cc
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/configuration_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/configuration_utils.cpython-39.pyc b/diffusers/src/diffusers/__pycache__/configuration_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5ec0585204a7dc4a3fc169b3842c704edc460360
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/configuration_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/image_processor.cpython-310.pyc b/diffusers/src/diffusers/__pycache__/image_processor.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8f61c78fb3f62707ad9961988d1a7bf4972d75cb
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/image_processor.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/image_processor.cpython-39.pyc b/diffusers/src/diffusers/__pycache__/image_processor.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8a400d514d27ed4d9d3b495a6fd9deca91a95c8b
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/image_processor.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/loaders.cpython-310.pyc b/diffusers/src/diffusers/__pycache__/loaders.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..471cce26117fd8ab2da5c787dc85631cc19dbca7
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/loaders.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/loaders.cpython-39.pyc b/diffusers/src/diffusers/__pycache__/loaders.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6b87f11a64bda0f10d37bcae1d2b0348cc6cb961
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/loaders.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/optimization.cpython-310.pyc b/diffusers/src/diffusers/__pycache__/optimization.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8834662145115f5c5d0515218a50ad5b9532734d
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/optimization.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/optimization.cpython-39.pyc b/diffusers/src/diffusers/__pycache__/optimization.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b98f80d8e52625373bb877e35ef992471709ceb6
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/optimization.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/pipeline_utils.cpython-310.pyc b/diffusers/src/diffusers/__pycache__/pipeline_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6d8029b8f80d6116d22889a6a00fe51f4dad1bec
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/pipeline_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/pipeline_utils.cpython-39.pyc b/diffusers/src/diffusers/__pycache__/pipeline_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..54a94cf354ca828515b250eb398d4198c36ecbbc
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/pipeline_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/training_utils.cpython-310.pyc b/diffusers/src/diffusers/__pycache__/training_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..88073d9fa11fd6261231ef729c62ac301873c1c4
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/training_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/__pycache__/training_utils.cpython-39.pyc b/diffusers/src/diffusers/__pycache__/training_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..462f5fcec9bc22c97a976902e68ff8075736adcb
Binary files /dev/null and b/diffusers/src/diffusers/__pycache__/training_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/commands/__init__.py b/diffusers/src/diffusers/commands/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ad4af9199bbe297dbc6679fd9ecb46baa976053
--- /dev/null
+++ b/diffusers/src/diffusers/commands/__init__.py
@@ -0,0 +1,27 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from abc import ABC, abstractmethod
+from argparse import ArgumentParser
+
+
+class BaseDiffusersCLICommand(ABC):
+ @staticmethod
+ @abstractmethod
+ def register_subcommand(parser: ArgumentParser):
+ raise NotImplementedError()
+
+ @abstractmethod
+ def run(self):
+ raise NotImplementedError()
diff --git a/diffusers/src/diffusers/commands/diffusers_cli.py b/diffusers/src/diffusers/commands/diffusers_cli.py
new file mode 100644
index 0000000000000000000000000000000000000000..74ad29a786d7f77e982242d7020170cb4d031c41
--- /dev/null
+++ b/diffusers/src/diffusers/commands/diffusers_cli.py
@@ -0,0 +1,41 @@
+#!/usr/bin/env python
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from argparse import ArgumentParser
+
+from .env import EnvironmentCommand
+
+
+def main():
+ parser = ArgumentParser("Diffusers CLI tool", usage="diffusers-cli []")
+ commands_parser = parser.add_subparsers(help="diffusers-cli command helpers")
+
+ # Register commands
+ EnvironmentCommand.register_subcommand(commands_parser)
+
+ # Let's go
+ args = parser.parse_args()
+
+ if not hasattr(args, "func"):
+ parser.print_help()
+ exit(1)
+
+ # Run
+ service = args.func(args)
+ service.run()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/diffusers/src/diffusers/commands/env.py b/diffusers/src/diffusers/commands/env.py
new file mode 100644
index 0000000000000000000000000000000000000000..db9de720942b5efcff921d7e2503e3ae8813561e
--- /dev/null
+++ b/diffusers/src/diffusers/commands/env.py
@@ -0,0 +1,84 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import platform
+from argparse import ArgumentParser
+
+import huggingface_hub
+
+from .. import __version__ as version
+from ..utils import is_accelerate_available, is_torch_available, is_transformers_available, is_xformers_available
+from . import BaseDiffusersCLICommand
+
+
+def info_command_factory(_):
+ return EnvironmentCommand()
+
+
+class EnvironmentCommand(BaseDiffusersCLICommand):
+ @staticmethod
+ def register_subcommand(parser: ArgumentParser):
+ download_parser = parser.add_parser("env")
+ download_parser.set_defaults(func=info_command_factory)
+
+ def run(self):
+ hub_version = huggingface_hub.__version__
+
+ pt_version = "not installed"
+ pt_cuda_available = "NA"
+ if is_torch_available():
+ import torch
+
+ pt_version = torch.__version__
+ pt_cuda_available = torch.cuda.is_available()
+
+ transformers_version = "not installed"
+ if is_transformers_available():
+ import transformers
+
+ transformers_version = transformers.__version__
+
+ accelerate_version = "not installed"
+ if is_accelerate_available():
+ import accelerate
+
+ accelerate_version = accelerate.__version__
+
+ xformers_version = "not installed"
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = xformers.__version__
+
+ info = {
+ "`diffusers` version": version,
+ "Platform": platform.platform(),
+ "Python version": platform.python_version(),
+ "PyTorch version (GPU?)": f"{pt_version} ({pt_cuda_available})",
+ "Huggingface_hub version": hub_version,
+ "Transformers version": transformers_version,
+ "Accelerate version": accelerate_version,
+ "xFormers version": xformers_version,
+ "Using GPU in script?": "",
+ "Using distributed or parallel set-up in script?": "",
+ }
+
+ print("\nCopy-and-paste the text below in your GitHub issue and FILL OUT the two last points.\n")
+ print(self.format_dict(info))
+
+ return info
+
+ @staticmethod
+ def format_dict(d):
+ return "\n".join([f"- {prop}: {val}" for prop, val in d.items()]) + "\n"
diff --git a/diffusers/src/diffusers/configuration_utils.py b/diffusers/src/diffusers/configuration_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce6e77b03f579b49312f004710391ca63588d872
--- /dev/null
+++ b/diffusers/src/diffusers/configuration_utils.py
@@ -0,0 +1,642 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" ConfigMixin base class and utilities."""
+import dataclasses
+import functools
+import importlib
+import inspect
+import json
+import os
+import re
+from collections import OrderedDict
+from pathlib import PosixPath
+from typing import Any, Dict, Tuple, Union
+
+import numpy as np
+from huggingface_hub import hf_hub_download
+from huggingface_hub.utils import EntryNotFoundError, RepositoryNotFoundError, RevisionNotFoundError
+from requests import HTTPError
+
+from . import __version__
+from .utils import (
+ DIFFUSERS_CACHE,
+ HUGGINGFACE_CO_RESOLVE_ENDPOINT,
+ DummyObject,
+ deprecate,
+ extract_commit_hash,
+ http_user_agent,
+ logging,
+)
+
+
+logger = logging.get_logger(__name__)
+
+_re_configuration_file = re.compile(r"config\.(.*)\.json")
+
+
+class FrozenDict(OrderedDict):
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ for key, value in self.items():
+ setattr(self, key, value)
+
+ self.__frozen = True
+
+ def __delitem__(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
+
+ def setdefault(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
+
+ def pop(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
+
+ def update(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
+
+ def __setattr__(self, name, value):
+ if hasattr(self, "__frozen") and self.__frozen:
+ raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
+ super().__setattr__(name, value)
+
+ def __setitem__(self, name, value):
+ if hasattr(self, "__frozen") and self.__frozen:
+ raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
+ super().__setitem__(name, value)
+
+
+class ConfigMixin:
+ r"""
+ Base class for all configuration classes. Stores all configuration parameters under `self.config` Also handles all
+ methods for loading/downloading/saving classes inheriting from [`ConfigMixin`] with
+ - [`~ConfigMixin.from_config`]
+ - [`~ConfigMixin.save_config`]
+
+ Class attributes:
+ - **config_name** (`str`) -- A filename under which the config should stored when calling
+ [`~ConfigMixin.save_config`] (should be overridden by parent class).
+ - **ignore_for_config** (`List[str]`) -- A list of attributes that should not be saved in the config (should be
+ overridden by subclass).
+ - **has_compatibles** (`bool`) -- Whether the class has compatible classes (should be overridden by subclass).
+ - **_deprecated_kwargs** (`List[str]`) -- Keyword arguments that are deprecated. Note that the init function
+ should only have a `kwargs` argument if at least one argument is deprecated (should be overridden by
+ subclass).
+ """
+ config_name = None
+ ignore_for_config = []
+ has_compatibles = False
+
+ _deprecated_kwargs = []
+
+ def register_to_config(self, **kwargs):
+ if self.config_name is None:
+ raise NotImplementedError(f"Make sure that {self.__class__} has defined a class name `config_name`")
+ # Special case for `kwargs` used in deprecation warning added to schedulers
+ # TODO: remove this when we remove the deprecation warning, and the `kwargs` argument,
+ # or solve in a more general way.
+ kwargs.pop("kwargs", None)
+ for key, value in kwargs.items():
+ try:
+ setattr(self, key, value)
+ except AttributeError as err:
+ logger.error(f"Can't set {key} with value {value} for {self}")
+ raise err
+
+ if not hasattr(self, "_internal_dict"):
+ internal_dict = kwargs
+ else:
+ previous_dict = dict(self._internal_dict)
+ internal_dict = {**self._internal_dict, **kwargs}
+ logger.debug(f"Updating config from {previous_dict} to {internal_dict}")
+
+ self._internal_dict = FrozenDict(internal_dict)
+
+ def save_config(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
+ """
+ Save a configuration object to the directory `save_directory`, so that it can be re-loaded using the
+ [`~ConfigMixin.from_config`] class method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the configuration JSON file will be saved (will be created if it does not exist).
+ """
+ if os.path.isfile(save_directory):
+ raise AssertionError(f"Provided path ({save_directory}) should be a directory, not a file")
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ # If we save using the predefined names, we can load using `from_config`
+ output_config_file = os.path.join(save_directory, self.config_name)
+
+ self.to_json_file(output_config_file)
+ logger.info(f"Configuration saved in {output_config_file}")
+
+ @classmethod
+ def from_config(cls, config: Union[FrozenDict, Dict[str, Any]] = None, return_unused_kwargs=False, **kwargs):
+ r"""
+ Instantiate a Python class from a config dictionary
+
+ Parameters:
+ config (`Dict[str, Any]`):
+ A config dictionary from which the Python class will be instantiated. Make sure to only load
+ configuration files of compatible classes.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ Whether kwargs that are not consumed by the Python class should be returned or not.
+
+ kwargs (remaining dictionary of keyword arguments, *optional*):
+ Can be used to update the configuration object (after it being loaded) and initiate the Python class.
+ `**kwargs` will be directly passed to the underlying scheduler/model's `__init__` method and eventually
+ overwrite same named arguments of `config`.
+
+ Examples:
+
+ ```python
+ >>> from diffusers import DDPMScheduler, DDIMScheduler, PNDMScheduler
+
+ >>> # Download scheduler from huggingface.co and cache.
+ >>> scheduler = DDPMScheduler.from_pretrained("google/ddpm-cifar10-32")
+
+ >>> # Instantiate DDIM scheduler class with same config as DDPM
+ >>> scheduler = DDIMScheduler.from_config(scheduler.config)
+
+ >>> # Instantiate PNDM scheduler class with same config as DDPM
+ >>> scheduler = PNDMScheduler.from_config(scheduler.config)
+ ```
+ """
+ # <===== TO BE REMOVED WITH DEPRECATION
+ # TODO(Patrick) - make sure to remove the following lines when config=="model_path" is deprecated
+ if "pretrained_model_name_or_path" in kwargs:
+ config = kwargs.pop("pretrained_model_name_or_path")
+
+ if config is None:
+ raise ValueError("Please make sure to provide a config as the first positional argument.")
+ # ======>
+
+ if not isinstance(config, dict):
+ deprecation_message = "It is deprecated to pass a pretrained model name or path to `from_config`."
+ if "Scheduler" in cls.__name__:
+ deprecation_message += (
+ f"If you were trying to load a scheduler, please use {cls}.from_pretrained(...) instead."
+ " Otherwise, please make sure to pass a configuration dictionary instead. This functionality will"
+ " be removed in v1.0.0."
+ )
+ elif "Model" in cls.__name__:
+ deprecation_message += (
+ f"If you were trying to load a model, please use {cls}.load_config(...) followed by"
+ f" {cls}.from_config(...) instead. Otherwise, please make sure to pass a configuration dictionary"
+ " instead. This functionality will be removed in v1.0.0."
+ )
+ deprecate("config-passed-as-path", "1.0.0", deprecation_message, standard_warn=False)
+ config, kwargs = cls.load_config(pretrained_model_name_or_path=config, return_unused_kwargs=True, **kwargs)
+
+ init_dict, unused_kwargs, hidden_dict = cls.extract_init_dict(config, **kwargs)
+
+ # Allow dtype to be specified on initialization
+ if "dtype" in unused_kwargs:
+ init_dict["dtype"] = unused_kwargs.pop("dtype")
+
+ # add possible deprecated kwargs
+ for deprecated_kwarg in cls._deprecated_kwargs:
+ if deprecated_kwarg in unused_kwargs:
+ init_dict[deprecated_kwarg] = unused_kwargs.pop(deprecated_kwarg)
+
+ # Return model and optionally state and/or unused_kwargs
+ model = cls(**init_dict)
+
+ # make sure to also save config parameters that might be used for compatible classes
+ model.register_to_config(**hidden_dict)
+
+ # add hidden kwargs of compatible classes to unused_kwargs
+ unused_kwargs = {**unused_kwargs, **hidden_dict}
+
+ if return_unused_kwargs:
+ return (model, unused_kwargs)
+ else:
+ return model
+
+ @classmethod
+ def get_config_dict(cls, *args, **kwargs):
+ deprecation_message = (
+ f" The function get_config_dict is deprecated. Please use {cls}.load_config instead. This function will be"
+ " removed in version v1.0.0"
+ )
+ deprecate("get_config_dict", "1.0.0", deprecation_message, standard_warn=False)
+ return cls.load_config(*args, **kwargs)
+
+ @classmethod
+ def load_config(
+ cls,
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ return_unused_kwargs=False,
+ return_commit_hash=False,
+ **kwargs,
+ ) -> Tuple[Dict[str, Any], Dict[str, Any]]:
+ r"""
+ Instantiate a Python class from a config dictionary
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
+ Can be either:
+
+ - A string, the *model id* of a model repo on huggingface.co. Valid model ids should have an
+ organization name, like `google/ddpm-celebahq-256`.
+ - A path to a *directory* containing model weights saved using [`~ConfigMixin.save_config`], e.g.,
+ `./my_model_directory/`.
+
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `transformers-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo (either remote in
+ huggingface.co or downloaded locally), you can specify the folder name here.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False):
+ Whether unused keyword arguments of the config shall be returned.
+ return_commit_hash (`bool`, *optional*, defaults to `False):
+ Whether the commit_hash of the loaded configuration shall be returned.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models).
+
+
+
+
+
+ Activate the special ["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to
+ use this method in a firewalled environment.
+
+
+ """
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ revision = kwargs.pop("revision", None)
+ _ = kwargs.pop("mirror", None)
+ subfolder = kwargs.pop("subfolder", None)
+ user_agent = kwargs.pop("user_agent", {})
+
+ user_agent = {**user_agent, "file_type": "config"}
+ user_agent = http_user_agent(user_agent)
+
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+
+ if cls.config_name is None:
+ raise ValueError(
+ "`self.config_name` is not defined. Note that one should not load a config from "
+ "`ConfigMixin`. Please make sure to define `config_name` in a class inheriting from `ConfigMixin`"
+ )
+
+ if os.path.isfile(pretrained_model_name_or_path):
+ config_file = pretrained_model_name_or_path
+ elif os.path.isdir(pretrained_model_name_or_path):
+ if os.path.isfile(os.path.join(pretrained_model_name_or_path, cls.config_name)):
+ # Load from a PyTorch checkpoint
+ config_file = os.path.join(pretrained_model_name_or_path, cls.config_name)
+ elif subfolder is not None and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
+ ):
+ config_file = os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
+ else:
+ raise EnvironmentError(
+ f"Error no file named {cls.config_name} found in directory {pretrained_model_name_or_path}."
+ )
+ else:
+ try:
+ # Load from URL or cache if already cached
+ config_file = hf_hub_download(
+ pretrained_model_name_or_path,
+ filename=cls.config_name,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ subfolder=subfolder,
+ revision=revision,
+ )
+ except RepositoryNotFoundError:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier"
+ " listed on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a"
+ " token having permission to this repo with `use_auth_token` or log in with `huggingface-cli"
+ " login`."
+ )
+ except RevisionNotFoundError:
+ raise EnvironmentError(
+ f"{revision} is not a valid git identifier (branch name, tag name or commit id) that exists for"
+ " this model name. Check the model page at"
+ f" 'https://huggingface.co/{pretrained_model_name_or_path}' for available revisions."
+ )
+ except EntryNotFoundError:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named {cls.config_name}."
+ )
+ except HTTPError as err:
+ raise EnvironmentError(
+ "There was a specific connection error when trying to load"
+ f" {pretrained_model_name_or_path}:\n{err}"
+ )
+ except ValueError:
+ raise EnvironmentError(
+ f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this model, couldn't find it"
+ f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
+ f" directory containing a {cls.config_name} file.\nCheckout your internet connection or see how to"
+ " run the library in offline mode at"
+ " 'https://huggingface.co/docs/diffusers/installation#offline-mode'."
+ )
+ except EnvironmentError:
+ raise EnvironmentError(
+ f"Can't load config for '{pretrained_model_name_or_path}'. If you were trying to load it from "
+ "'https://huggingface.co/models', make sure you don't have a local directory with the same name. "
+ f"Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory "
+ f"containing a {cls.config_name} file"
+ )
+
+ try:
+ # Load config dict
+ config_dict = cls._dict_from_json_file(config_file)
+
+ commit_hash = extract_commit_hash(config_file)
+ except (json.JSONDecodeError, UnicodeDecodeError):
+ raise EnvironmentError(f"It looks like the config file at '{config_file}' is not a valid JSON file.")
+
+ if not (return_unused_kwargs or return_commit_hash):
+ return config_dict
+
+ outputs = (config_dict,)
+
+ if return_unused_kwargs:
+ outputs += (kwargs,)
+
+ if return_commit_hash:
+ outputs += (commit_hash,)
+
+ return outputs
+
+ @staticmethod
+ def _get_init_keys(cls):
+ return set(dict(inspect.signature(cls.__init__).parameters).keys())
+
+ @classmethod
+ def extract_init_dict(cls, config_dict, **kwargs):
+ # 0. Copy origin config dict
+ original_dict = dict(config_dict.items())
+
+ # 1. Retrieve expected config attributes from __init__ signature
+ expected_keys = cls._get_init_keys(cls)
+ expected_keys.remove("self")
+ # remove general kwargs if present in dict
+ if "kwargs" in expected_keys:
+ expected_keys.remove("kwargs")
+ # remove flax internal keys
+ if hasattr(cls, "_flax_internal_args"):
+ for arg in cls._flax_internal_args:
+ expected_keys.remove(arg)
+
+ # 2. Remove attributes that cannot be expected from expected config attributes
+ # remove keys to be ignored
+ if len(cls.ignore_for_config) > 0:
+ expected_keys = expected_keys - set(cls.ignore_for_config)
+
+ # load diffusers library to import compatible and original scheduler
+ diffusers_library = importlib.import_module(__name__.split(".")[0])
+
+ if cls.has_compatibles:
+ compatible_classes = [c for c in cls._get_compatibles() if not isinstance(c, DummyObject)]
+ else:
+ compatible_classes = []
+
+ expected_keys_comp_cls = set()
+ for c in compatible_classes:
+ expected_keys_c = cls._get_init_keys(c)
+ expected_keys_comp_cls = expected_keys_comp_cls.union(expected_keys_c)
+ expected_keys_comp_cls = expected_keys_comp_cls - cls._get_init_keys(cls)
+ config_dict = {k: v for k, v in config_dict.items() if k not in expected_keys_comp_cls}
+
+ # remove attributes from orig class that cannot be expected
+ orig_cls_name = config_dict.pop("_class_name", cls.__name__)
+ if orig_cls_name != cls.__name__ and hasattr(diffusers_library, orig_cls_name):
+ orig_cls = getattr(diffusers_library, orig_cls_name)
+ unexpected_keys_from_orig = cls._get_init_keys(orig_cls) - expected_keys
+ config_dict = {k: v for k, v in config_dict.items() if k not in unexpected_keys_from_orig}
+
+ # remove private attributes
+ config_dict = {k: v for k, v in config_dict.items() if not k.startswith("_")}
+
+ # 3. Create keyword arguments that will be passed to __init__ from expected keyword arguments
+ init_dict = {}
+ for key in expected_keys:
+ # if config param is passed to kwarg and is present in config dict
+ # it should overwrite existing config dict key
+ if key in kwargs and key in config_dict:
+ config_dict[key] = kwargs.pop(key)
+
+ if key in kwargs:
+ # overwrite key
+ init_dict[key] = kwargs.pop(key)
+ elif key in config_dict:
+ # use value from config dict
+ init_dict[key] = config_dict.pop(key)
+
+ # 4. Give nice warning if unexpected values have been passed
+ if len(config_dict) > 0:
+ logger.warning(
+ f"The config attributes {config_dict} were passed to {cls.__name__}, "
+ "but are not expected and will be ignored. Please verify your "
+ f"{cls.config_name} configuration file."
+ )
+
+ # 5. Give nice info if config attributes are initiliazed to default because they have not been passed
+ passed_keys = set(init_dict.keys())
+ if len(expected_keys - passed_keys) > 0:
+ logger.info(
+ f"{expected_keys - passed_keys} was not found in config. Values will be initialized to default values."
+ )
+
+ # 6. Define unused keyword arguments
+ unused_kwargs = {**config_dict, **kwargs}
+
+ # 7. Define "hidden" config parameters that were saved for compatible classes
+ hidden_config_dict = {k: v for k, v in original_dict.items() if k not in init_dict}
+
+ return init_dict, unused_kwargs, hidden_config_dict
+
+ @classmethod
+ def _dict_from_json_file(cls, json_file: Union[str, os.PathLike]):
+ with open(json_file, "r", encoding="utf-8") as reader:
+ text = reader.read()
+ return json.loads(text)
+
+ def __repr__(self):
+ return f"{self.__class__.__name__} {self.to_json_string()}"
+
+ @property
+ def config(self) -> Dict[str, Any]:
+ """
+ Returns the config of the class as a frozen dictionary
+
+ Returns:
+ `Dict[str, Any]`: Config of the class.
+ """
+ return self._internal_dict
+
+ def to_json_string(self) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this configuration instance in JSON format.
+ """
+ config_dict = self._internal_dict if hasattr(self, "_internal_dict") else {}
+ config_dict["_class_name"] = self.__class__.__name__
+ config_dict["_diffusers_version"] = __version__
+
+ def to_json_saveable(value):
+ if isinstance(value, np.ndarray):
+ value = value.tolist()
+ elif isinstance(value, PosixPath):
+ value = str(value)
+ return value
+
+ config_dict = {k: to_json_saveable(v) for k, v in config_dict.items()}
+ return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this configuration instance's parameters will be saved.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ writer.write(self.to_json_string())
+
+
+def register_to_config(init):
+ r"""
+ Decorator to apply on the init of classes inheriting from [`ConfigMixin`] so that all the arguments are
+ automatically sent to `self.register_for_config`. To ignore a specific argument accepted by the init but that
+ shouldn't be registered in the config, use the `ignore_for_config` class variable
+
+ Warning: Once decorated, all private arguments (beginning with an underscore) are trashed and not sent to the init!
+ """
+
+ @functools.wraps(init)
+ def inner_init(self, *args, **kwargs):
+ # Ignore private kwargs in the init.
+ init_kwargs = {k: v for k, v in kwargs.items() if not k.startswith("_")}
+ config_init_kwargs = {k: v for k, v in kwargs.items() if k.startswith("_")}
+ if not isinstance(self, ConfigMixin):
+ raise RuntimeError(
+ f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
+ "not inherit from `ConfigMixin`."
+ )
+
+ ignore = getattr(self, "ignore_for_config", [])
+ # Get positional arguments aligned with kwargs
+ new_kwargs = {}
+ signature = inspect.signature(init)
+ parameters = {
+ name: p.default for i, (name, p) in enumerate(signature.parameters.items()) if i > 0 and name not in ignore
+ }
+ for arg, name in zip(args, parameters.keys()):
+ new_kwargs[name] = arg
+
+ # Then add all kwargs
+ new_kwargs.update(
+ {
+ k: init_kwargs.get(k, default)
+ for k, default in parameters.items()
+ if k not in ignore and k not in new_kwargs
+ }
+ )
+ new_kwargs = {**config_init_kwargs, **new_kwargs}
+ getattr(self, "register_to_config")(**new_kwargs)
+ init(self, *args, **init_kwargs)
+
+ return inner_init
+
+
+def flax_register_to_config(cls):
+ original_init = cls.__init__
+
+ @functools.wraps(original_init)
+ def init(self, *args, **kwargs):
+ if not isinstance(self, ConfigMixin):
+ raise RuntimeError(
+ f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
+ "not inherit from `ConfigMixin`."
+ )
+
+ # Ignore private kwargs in the init. Retrieve all passed attributes
+ init_kwargs = dict(kwargs.items())
+
+ # Retrieve default values
+ fields = dataclasses.fields(self)
+ default_kwargs = {}
+ for field in fields:
+ # ignore flax specific attributes
+ if field.name in self._flax_internal_args:
+ continue
+ if type(field.default) == dataclasses._MISSING_TYPE:
+ default_kwargs[field.name] = None
+ else:
+ default_kwargs[field.name] = getattr(self, field.name)
+
+ # Make sure init_kwargs override default kwargs
+ new_kwargs = {**default_kwargs, **init_kwargs}
+ # dtype should be part of `init_kwargs`, but not `new_kwargs`
+ if "dtype" in new_kwargs:
+ new_kwargs.pop("dtype")
+
+ # Get positional arguments aligned with kwargs
+ for i, arg in enumerate(args):
+ name = fields[i].name
+ new_kwargs[name] = arg
+
+ getattr(self, "register_to_config")(**new_kwargs)
+ original_init(self, *args, **kwargs)
+
+ cls.__init__ = init
+ return cls
diff --git a/diffusers/src/diffusers/dependency_versions_check.py b/diffusers/src/diffusers/dependency_versions_check.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f8578c52957bf6c06decb0d97d3139437f0078f
--- /dev/null
+++ b/diffusers/src/diffusers/dependency_versions_check.py
@@ -0,0 +1,47 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import sys
+
+from .dependency_versions_table import deps
+from .utils.versions import require_version, require_version_core
+
+
+# define which module versions we always want to check at run time
+# (usually the ones defined in `install_requires` in setup.py)
+#
+# order specific notes:
+# - tqdm must be checked before tokenizers
+
+pkgs_to_check_at_runtime = "python tqdm regex requests packaging filelock numpy tokenizers".split()
+if sys.version_info < (3, 7):
+ pkgs_to_check_at_runtime.append("dataclasses")
+if sys.version_info < (3, 8):
+ pkgs_to_check_at_runtime.append("importlib_metadata")
+
+for pkg in pkgs_to_check_at_runtime:
+ if pkg in deps:
+ if pkg == "tokenizers":
+ # must be loaded here, or else tqdm check may fail
+ from .utils import is_tokenizers_available
+
+ if not is_tokenizers_available():
+ continue # not required, check version only if installed
+
+ require_version_core(deps[pkg])
+ else:
+ raise ValueError(f"can't find {pkg} in {deps.keys()}, check dependency_versions_table.py")
+
+
+def dep_version_check(pkg, hint=None):
+ require_version(deps[pkg], hint)
diff --git a/diffusers/src/diffusers/dependency_versions_table.py b/diffusers/src/diffusers/dependency_versions_table.py
new file mode 100644
index 0000000000000000000000000000000000000000..1269cf1578a6bbfc38a02d6e1850bad0fefd1375
--- /dev/null
+++ b/diffusers/src/diffusers/dependency_versions_table.py
@@ -0,0 +1,39 @@
+# THIS FILE HAS BEEN AUTOGENERATED. To update:
+# 1. modify the `_deps` dict in setup.py
+# 2. run `make deps_table_update``
+deps = {
+ "Pillow": "Pillow",
+ "accelerate": "accelerate>=0.11.0",
+ "compel": "compel==0.1.8",
+ "black": "black~=23.1",
+ "datasets": "datasets",
+ "filelock": "filelock",
+ "flax": "flax>=0.4.1",
+ "hf-doc-builder": "hf-doc-builder>=0.3.0",
+ "huggingface-hub": "huggingface-hub>=0.13.2",
+ "requests-mock": "requests-mock==1.10.0",
+ "importlib_metadata": "importlib_metadata",
+ "isort": "isort>=5.5.4",
+ "jax": "jax>=0.2.8,!=0.3.2",
+ "jaxlib": "jaxlib>=0.1.65",
+ "Jinja2": "Jinja2",
+ "k-diffusion": "k-diffusion>=0.0.12",
+ "librosa": "librosa",
+ "note-seq": "note-seq",
+ "numpy": "numpy",
+ "parameterized": "parameterized",
+ "protobuf": "protobuf>=3.20.3,<4",
+ "pytest": "pytest",
+ "pytest-timeout": "pytest-timeout",
+ "pytest-xdist": "pytest-xdist",
+ "ruff": "ruff>=0.0.241",
+ "safetensors": "safetensors",
+ "sentencepiece": "sentencepiece>=0.1.91,!=0.1.92",
+ "scipy": "scipy",
+ "regex": "regex!=2019.12.17",
+ "requests": "requests",
+ "tensorboard": "tensorboard",
+ "torch": "torch>=1.4",
+ "torchvision": "torchvision",
+ "transformers": "transformers>=4.25.1",
+}
diff --git a/diffusers/src/diffusers/experimental/README.md b/diffusers/src/diffusers/experimental/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..81a9de81c73728ea41eb6e8617a5429c3c9645ff
--- /dev/null
+++ b/diffusers/src/diffusers/experimental/README.md
@@ -0,0 +1,5 @@
+# 🧨 Diffusers Experimental
+
+We are adding experimental code to support novel applications and usages of the Diffusers library.
+Currently, the following experiments are supported:
+* Reinforcement learning via an implementation of the [Diffuser](https://arxiv.org/abs/2205.09991) model.
\ No newline at end of file
diff --git a/diffusers/src/diffusers/experimental/__init__.py b/diffusers/src/diffusers/experimental/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ebc8155403016dfd8ad7fb78d246f9da9098ac50
--- /dev/null
+++ b/diffusers/src/diffusers/experimental/__init__.py
@@ -0,0 +1 @@
+from .rl import ValueGuidedRLPipeline
diff --git a/diffusers/src/diffusers/experimental/rl/__init__.py b/diffusers/src/diffusers/experimental/rl/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b338d3173e12d478b6b6d6fd0e50650a0ab5a4c
--- /dev/null
+++ b/diffusers/src/diffusers/experimental/rl/__init__.py
@@ -0,0 +1 @@
+from .value_guided_sampling import ValueGuidedRLPipeline
diff --git a/diffusers/src/diffusers/experimental/rl/value_guided_sampling.py b/diffusers/src/diffusers/experimental/rl/value_guided_sampling.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4af4986faad9c1e81a5cf4ee76138f3db00ab44
--- /dev/null
+++ b/diffusers/src/diffusers/experimental/rl/value_guided_sampling.py
@@ -0,0 +1,152 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import torch
+import tqdm
+
+from ...models.unet_1d import UNet1DModel
+from ...pipelines import DiffusionPipeline
+from ...utils import randn_tensor
+from ...utils.dummy_pt_objects import DDPMScheduler
+
+
+class ValueGuidedRLPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+ Pipeline for sampling actions from a diffusion model trained to predict sequences of states.
+
+ Original implementation inspired by this repository: https://github.com/jannerm/diffuser.
+
+ Parameters:
+ value_function ([`UNet1DModel`]): A specialized UNet for fine-tuning trajectories base on reward.
+ unet ([`UNet1DModel`]): U-Net architecture to denoise the encoded trajectories.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded trajectories. Default for this
+ application is [`DDPMScheduler`].
+ env: An environment following the OpenAI gym API to act in. For now only Hopper has pretrained models.
+ """
+
+ def __init__(
+ self,
+ value_function: UNet1DModel,
+ unet: UNet1DModel,
+ scheduler: DDPMScheduler,
+ env,
+ ):
+ super().__init__()
+ self.value_function = value_function
+ self.unet = unet
+ self.scheduler = scheduler
+ self.env = env
+ self.data = env.get_dataset()
+ self.means = {}
+ for key in self.data.keys():
+ try:
+ self.means[key] = self.data[key].mean()
+ except: # noqa: E722
+ pass
+ self.stds = {}
+ for key in self.data.keys():
+ try:
+ self.stds[key] = self.data[key].std()
+ except: # noqa: E722
+ pass
+ self.state_dim = env.observation_space.shape[0]
+ self.action_dim = env.action_space.shape[0]
+
+ def normalize(self, x_in, key):
+ return (x_in - self.means[key]) / self.stds[key]
+
+ def de_normalize(self, x_in, key):
+ return x_in * self.stds[key] + self.means[key]
+
+ def to_torch(self, x_in):
+ if type(x_in) is dict:
+ return {k: self.to_torch(v) for k, v in x_in.items()}
+ elif torch.is_tensor(x_in):
+ return x_in.to(self.unet.device)
+ return torch.tensor(x_in, device=self.unet.device)
+
+ def reset_x0(self, x_in, cond, act_dim):
+ for key, val in cond.items():
+ x_in[:, key, act_dim:] = val.clone()
+ return x_in
+
+ def run_diffusion(self, x, conditions, n_guide_steps, scale):
+ batch_size = x.shape[0]
+ y = None
+ for i in tqdm.tqdm(self.scheduler.timesteps):
+ # create batch of timesteps to pass into model
+ timesteps = torch.full((batch_size,), i, device=self.unet.device, dtype=torch.long)
+ for _ in range(n_guide_steps):
+ with torch.enable_grad():
+ x.requires_grad_()
+
+ # permute to match dimension for pre-trained models
+ y = self.value_function(x.permute(0, 2, 1), timesteps).sample
+ grad = torch.autograd.grad([y.sum()], [x])[0]
+
+ posterior_variance = self.scheduler._get_variance(i)
+ model_std = torch.exp(0.5 * posterior_variance)
+ grad = model_std * grad
+
+ grad[timesteps < 2] = 0
+ x = x.detach()
+ x = x + scale * grad
+ x = self.reset_x0(x, conditions, self.action_dim)
+
+ prev_x = self.unet(x.permute(0, 2, 1), timesteps).sample.permute(0, 2, 1)
+
+ # TODO: verify deprecation of this kwarg
+ x = self.scheduler.step(prev_x, i, x, predict_epsilon=False)["prev_sample"]
+
+ # apply conditions to the trajectory (set the initial state)
+ x = self.reset_x0(x, conditions, self.action_dim)
+ x = self.to_torch(x)
+ return x, y
+
+ def __call__(self, obs, batch_size=64, planning_horizon=32, n_guide_steps=2, scale=0.1):
+ # normalize the observations and create batch dimension
+ obs = self.normalize(obs, "observations")
+ obs = obs[None].repeat(batch_size, axis=0)
+
+ conditions = {0: self.to_torch(obs)}
+ shape = (batch_size, planning_horizon, self.state_dim + self.action_dim)
+
+ # generate initial noise and apply our conditions (to make the trajectories start at current state)
+ x1 = randn_tensor(shape, device=self.unet.device)
+ x = self.reset_x0(x1, conditions, self.action_dim)
+ x = self.to_torch(x)
+
+ # run the diffusion process
+ x, y = self.run_diffusion(x, conditions, n_guide_steps, scale)
+
+ # sort output trajectories by value
+ sorted_idx = y.argsort(0, descending=True).squeeze()
+ sorted_values = x[sorted_idx]
+ actions = sorted_values[:, :, : self.action_dim]
+ actions = actions.detach().cpu().numpy()
+ denorm_actions = self.de_normalize(actions, key="actions")
+
+ # select the action with the highest value
+ if y is not None:
+ selected_index = 0
+ else:
+ # if we didn't run value guiding, select a random action
+ selected_index = np.random.randint(0, batch_size)
+
+ denorm_actions = denorm_actions[selected_index, 0]
+ return denorm_actions
diff --git a/diffusers/src/diffusers/image_processor.py b/diffusers/src/diffusers/image_processor.py
new file mode 100644
index 0000000000000000000000000000000000000000..80e3412991cfb925816eda85e38210292802ceef
--- /dev/null
+++ b/diffusers/src/diffusers/image_processor.py
@@ -0,0 +1,177 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import warnings
+from typing import Union
+
+import numpy as np
+import PIL
+import torch
+from PIL import Image
+
+from .configuration_utils import ConfigMixin, register_to_config
+from .utils import CONFIG_NAME, PIL_INTERPOLATION
+
+
+class VaeImageProcessor(ConfigMixin):
+ """
+ Image Processor for VAE
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to downscale the image's (height, width) dimensions to multiples of `vae_scale_factor`.
+ vae_scale_factor (`int`, *optional*, defaults to `8`):
+ VAE scale factor. If `do_resize` is True, the image will be automatically resized to multiples of this
+ factor.
+ resample (`str`, *optional*, defaults to `lanczos`):
+ Resampling filter to use when resizing the image.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image to [-1,1]
+ """
+
+ config_name = CONFIG_NAME
+
+ @register_to_config
+ def __init__(
+ self,
+ do_resize: bool = True,
+ vae_scale_factor: int = 8,
+ resample: str = "lanczos",
+ do_normalize: bool = True,
+ ):
+ super().__init__()
+
+ @staticmethod
+ def numpy_to_pil(images):
+ """
+ Convert a numpy image or a batch of images to a PIL image.
+ """
+ if images.ndim == 3:
+ images = images[None, ...]
+ images = (images * 255).round().astype("uint8")
+ if images.shape[-1] == 1:
+ # special case for grayscale (single channel) images
+ pil_images = [Image.fromarray(image.squeeze(), mode="L") for image in images]
+ else:
+ pil_images = [Image.fromarray(image) for image in images]
+
+ return pil_images
+
+ @staticmethod
+ def numpy_to_pt(images):
+ """
+ Convert a numpy image to a pytorch tensor
+ """
+ if images.ndim == 3:
+ images = images[..., None]
+
+ images = torch.from_numpy(images.transpose(0, 3, 1, 2))
+ return images
+
+ @staticmethod
+ def pt_to_numpy(images):
+ """
+ Convert a numpy image to a pytorch tensor
+ """
+ images = images.cpu().permute(0, 2, 3, 1).float().numpy()
+ return images
+
+ @staticmethod
+ def normalize(images):
+ """
+ Normalize an image array to [-1,1]
+ """
+ return 2.0 * images - 1.0
+
+ def resize(self, images: PIL.Image.Image) -> PIL.Image.Image:
+ """
+ Resize a PIL image. Both height and width will be downscaled to the next integer multiple of `vae_scale_factor`
+ """
+ w, h = images.size
+ w, h = (x - x % self.vae_scale_factor for x in (w, h)) # resize to integer multiple of vae_scale_factor
+ images = images.resize((w, h), resample=PIL_INTERPOLATION[self.resample])
+ return images
+
+ def preprocess(
+ self,
+ image: Union[torch.FloatTensor, PIL.Image.Image, np.ndarray],
+ ) -> torch.Tensor:
+ """
+ Preprocess the image input, accepted formats are PIL images, numpy arrays or pytorch tensors"
+ """
+ supported_formats = (PIL.Image.Image, np.ndarray, torch.Tensor)
+ if isinstance(image, supported_formats):
+ image = [image]
+ elif not (isinstance(image, list) and all(isinstance(i, supported_formats) for i in image)):
+ raise ValueError(
+ f"Input is in incorrect format: {[type(i) for i in image]}. Currently, we only support {', '.join(supported_formats)}"
+ )
+
+ if isinstance(image[0], PIL.Image.Image):
+ if self.do_resize:
+ image = [self.resize(i) for i in image]
+ image = [np.array(i).astype(np.float32) / 255.0 for i in image]
+ image = np.stack(image, axis=0) # to np
+ image = self.numpy_to_pt(image) # to pt
+
+ elif isinstance(image[0], np.ndarray):
+ image = np.concatenate(image, axis=0) if image[0].ndim == 4 else np.stack(image, axis=0)
+ image = self.numpy_to_pt(image)
+ _, _, height, width = image.shape
+ if self.do_resize and (height % self.vae_scale_factor != 0 or width % self.vae_scale_factor != 0):
+ raise ValueError(
+ f"Currently we only support resizing for PIL image - please resize your numpy array to be divisible by {self.vae_scale_factor}"
+ f"currently the sizes are {height} and {width}. You can also pass a PIL image instead to use resize option in VAEImageProcessor"
+ )
+
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, axis=0) if image[0].ndim == 4 else torch.stack(image, axis=0)
+ _, _, height, width = image.shape
+ if self.do_resize and (height % self.vae_scale_factor != 0 or width % self.vae_scale_factor != 0):
+ raise ValueError(
+ f"Currently we only support resizing for PIL image - please resize your pytorch tensor to be divisible by {self.vae_scale_factor}"
+ f"currently the sizes are {height} and {width}. You can also pass a PIL image instead to use resize option in VAEImageProcessor"
+ )
+
+ # expected range [0,1], normalize to [-1,1]
+ do_normalize = self.do_normalize
+ if image.min() < 0:
+ warnings.warn(
+ "Passing `image` as torch tensor with value range in [-1,1] is deprecated. The expected value range for image tensor is [0,1] "
+ f"when passing as pytorch tensor or numpy Array. You passed `image` with value range [{image.min()},{image.max()}]",
+ FutureWarning,
+ )
+ do_normalize = False
+
+ if do_normalize:
+ image = self.normalize(image)
+
+ return image
+
+ def postprocess(
+ self,
+ image,
+ output_type: str = "pil",
+ ):
+ if isinstance(image, torch.Tensor) and output_type == "pt":
+ return image
+
+ image = self.pt_to_numpy(image)
+
+ if output_type == "np":
+ return image
+ elif output_type == "pil":
+ return self.numpy_to_pil(image)
+ else:
+ raise ValueError(f"Unsupported output_type {output_type}.")
diff --git a/diffusers/src/diffusers/loaders.py b/diffusers/src/diffusers/loaders.py
new file mode 100644
index 0000000000000000000000000000000000000000..a262833938e7c65cbc626e964e732cb56073e319
--- /dev/null
+++ b/diffusers/src/diffusers/loaders.py
@@ -0,0 +1,569 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from collections import defaultdict
+from typing import Callable, Dict, List, Optional, Union
+
+import torch
+
+from .models.attention_processor import LoRAAttnProcessor
+from .utils import (
+ DIFFUSERS_CACHE,
+ HF_HUB_OFFLINE,
+ _get_model_file,
+ deprecate,
+ is_safetensors_available,
+ is_transformers_available,
+ logging,
+)
+
+
+if is_safetensors_available():
+ import safetensors
+
+if is_transformers_available():
+ from transformers import PreTrainedModel, PreTrainedTokenizer
+
+
+logger = logging.get_logger(__name__)
+
+
+LORA_WEIGHT_NAME = "pytorch_lora_weights.bin"
+LORA_WEIGHT_NAME_SAFE = "pytorch_lora_weights.safetensors"
+
+TEXT_INVERSION_NAME = "learned_embeds.bin"
+TEXT_INVERSION_NAME_SAFE = "learned_embeds.safetensors"
+
+
+class AttnProcsLayers(torch.nn.Module):
+ def __init__(self, state_dict: Dict[str, torch.Tensor]):
+ super().__init__()
+ self.layers = torch.nn.ModuleList(state_dict.values())
+ self.mapping = dict(enumerate(state_dict.keys()))
+ self.rev_mapping = {v: k for k, v in enumerate(state_dict.keys())}
+
+ # we add a hook to state_dict() and load_state_dict() so that the
+ # naming fits with `unet.attn_processors`
+ def map_to(module, state_dict, *args, **kwargs):
+ new_state_dict = {}
+ for key, value in state_dict.items():
+ num = int(key.split(".")[1]) # 0 is always "layers"
+ new_key = key.replace(f"layers.{num}", module.mapping[num])
+ new_state_dict[new_key] = value
+
+ return new_state_dict
+
+ def map_from(module, state_dict, *args, **kwargs):
+ all_keys = list(state_dict.keys())
+ for key in all_keys:
+ replace_key = key.split(".processor")[0] + ".processor"
+ new_key = key.replace(replace_key, f"layers.{module.rev_mapping[replace_key]}")
+ state_dict[new_key] = state_dict[key]
+ del state_dict[key]
+
+ self._register_state_dict_hook(map_to)
+ self._register_load_state_dict_pre_hook(map_from, with_module=True)
+
+
+class UNet2DConditionLoadersMixin:
+ def load_attn_procs(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
+ r"""
+ Load pretrained attention processor layers into `UNet2DConditionModel`. Attention processor layers have to be
+ defined in
+ [cross_attention.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py)
+ and be a `torch.nn.Module` class.
+
+
+
+ This function is experimental and might change in the future.
+
+
+
+ Parameters:
+ pretrained_model_name_or_path_or_dict (`str` or `os.PathLike` or `dict`):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ Valid model ids should have an organization name, like `google/ddpm-celebahq-256`.
+ - A path to a *directory* containing model weights saved using [`~ModelMixin.save_config`], e.g.,
+ `./my_model_directory/`.
+ - A [torch state
+ dict](https://pytorch.org/tutorials/beginner/saving_loading_models.html#what-is-a-state-dict).
+
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `diffusers-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo (either remote in
+ huggingface.co or downloaded locally), you can specify the folder name here.
+
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models).
+
+
+ """
+
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ subfolder = kwargs.pop("subfolder", None)
+ weight_name = kwargs.pop("weight_name", None)
+ use_safetensors = kwargs.pop("use_safetensors", None)
+
+ if use_safetensors and not is_safetensors_available():
+ raise ValueError(
+ "`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
+ )
+
+ allow_pickle = False
+ if use_safetensors is None:
+ use_safetensors = is_safetensors_available()
+ allow_pickle = True
+
+ user_agent = {
+ "file_type": "attn_procs_weights",
+ "framework": "pytorch",
+ }
+
+ model_file = None
+ if not isinstance(pretrained_model_name_or_path_or_dict, dict):
+ # Let's first try to load .safetensors weights
+ if (use_safetensors and weight_name is None) or (
+ weight_name is not None and weight_name.endswith(".safetensors")
+ ):
+ try:
+ model_file = _get_model_file(
+ pretrained_model_name_or_path_or_dict,
+ weights_name=weight_name or LORA_WEIGHT_NAME_SAFE,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ user_agent=user_agent,
+ )
+ state_dict = safetensors.torch.load_file(model_file, device="cpu")
+ except IOError as e:
+ if not allow_pickle:
+ raise e
+ # try loading non-safetensors weights
+ pass
+ if model_file is None:
+ model_file = _get_model_file(
+ pretrained_model_name_or_path_or_dict,
+ weights_name=weight_name or LORA_WEIGHT_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ user_agent=user_agent,
+ )
+ state_dict = torch.load(model_file, map_location="cpu")
+ else:
+ state_dict = pretrained_model_name_or_path_or_dict
+
+ # fill attn processors
+ attn_processors = {}
+
+ is_lora = all("lora" in k for k in state_dict.keys())
+
+ if is_lora:
+ lora_grouped_dict = defaultdict(dict)
+ for key, value in state_dict.items():
+ attn_processor_key, sub_key = ".".join(key.split(".")[:-3]), ".".join(key.split(".")[-3:])
+ lora_grouped_dict[attn_processor_key][sub_key] = value
+
+ for key, value_dict in lora_grouped_dict.items():
+ rank = value_dict["to_k_lora.down.weight"].shape[0]
+ cross_attention_dim = value_dict["to_k_lora.down.weight"].shape[1]
+ hidden_size = value_dict["to_k_lora.up.weight"].shape[0]
+
+ attn_processors[key] = LoRAAttnProcessor(
+ hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, rank=rank
+ )
+ attn_processors[key].load_state_dict(value_dict)
+
+ else:
+ raise ValueError(f"{model_file} does not seem to be in the correct format expected by LoRA training.")
+
+ # set correct dtype & device
+ attn_processors = {k: v.to(device=self.device, dtype=self.dtype) for k, v in attn_processors.items()}
+
+ # set layers
+ self.set_attn_processor(attn_processors)
+
+ def save_attn_procs(
+ self,
+ save_directory: Union[str, os.PathLike],
+ is_main_process: bool = True,
+ weight_name: str = None,
+ save_function: Callable = None,
+ safe_serialization: bool = False,
+ **kwargs,
+ ):
+ r"""
+ Save an attention processor to a directory, so that it can be re-loaded using the
+ `[`~loaders.UNet2DConditionLoadersMixin.load_attn_procs`]` method.
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ is_main_process (`bool`, *optional*, defaults to `True`):
+ Whether the process calling this is the main process or not. Useful when in distributed training like
+ TPUs and need to call this function on all processes. In this case, set `is_main_process=True` only on
+ the main process to avoid race conditions.
+ save_function (`Callable`):
+ The function to use to save the state dictionary. Useful on distributed training like TPUs when one
+ need to replace `torch.save` by another method. Can be configured with the environment variable
+ `DIFFUSERS_SAVE_MODE`.
+ """
+ weight_name = weight_name or deprecate(
+ "weights_name",
+ "0.18.0",
+ "`weights_name` is deprecated, please use `weight_name` instead.",
+ take_from=kwargs,
+ )
+ if os.path.isfile(save_directory):
+ logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
+ return
+
+ if save_function is None:
+ if safe_serialization:
+
+ def save_function(weights, filename):
+ return safetensors.torch.save_file(weights, filename, metadata={"format": "pt"})
+
+ else:
+ save_function = torch.save
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ model_to_save = AttnProcsLayers(self.attn_processors)
+
+ # Save the model
+ state_dict = model_to_save.state_dict()
+
+ if weight_name is None:
+ if safe_serialization:
+ weight_name = LORA_WEIGHT_NAME_SAFE
+ else:
+ weight_name = LORA_WEIGHT_NAME
+
+ # Save the model
+ save_function(state_dict, os.path.join(save_directory, weight_name))
+ logger.info(f"Model weights saved in {os.path.join(save_directory, weight_name)}")
+
+
+class TextualInversionLoaderMixin:
+ r"""
+ Mixin class for loading textual inversion tokens and embeddings to the tokenizer and text encoder.
+ """
+
+ def maybe_convert_prompt(self, prompt: Union[str, List[str]], tokenizer: "PreTrainedTokenizer"):
+ r"""
+ Maybe convert a prompt into a "multi vector"-compatible prompt. If the prompt includes a token that corresponds
+ to a multi-vector textual inversion embedding, this function will process the prompt so that the special token
+ is replaced with multiple special tokens each corresponding to one of the vectors. If the prompt has no textual
+ inversion token or a textual inversion token that is a single vector, the input prompt is simply returned.
+
+ Parameters:
+ prompt (`str` or list of `str`):
+ The prompt or prompts to guide the image generation.
+ tokenizer (`PreTrainedTokenizer`):
+ The tokenizer responsible for encoding the prompt into input tokens.
+
+ Returns:
+ `str` or list of `str`: The converted prompt
+ """
+ if not isinstance(prompt, List):
+ prompts = [prompt]
+ else:
+ prompts = prompt
+
+ prompts = [self._maybe_convert_prompt(p, tokenizer) for p in prompts]
+
+ if not isinstance(prompt, List):
+ return prompts[0]
+
+ return prompts
+
+ def _maybe_convert_prompt(self, prompt: str, tokenizer: "PreTrainedTokenizer"):
+ r"""
+ Maybe convert a prompt into a "multi vector"-compatible prompt. If the prompt includes a token that corresponds
+ to a multi-vector textual inversion embedding, this function will process the prompt so that the special token
+ is replaced with multiple special tokens each corresponding to one of the vectors. If the prompt has no textual
+ inversion token or a textual inversion token that is a single vector, the input prompt is simply returned.
+
+ Parameters:
+ prompt (`str`):
+ The prompt to guide the image generation.
+ tokenizer (`PreTrainedTokenizer`):
+ The tokenizer responsible for encoding the prompt into input tokens.
+
+ Returns:
+ `str`: The converted prompt
+ """
+ tokens = tokenizer.tokenize(prompt)
+ for token in tokens:
+ if token in tokenizer.added_tokens_encoder:
+ replacement = token
+ i = 1
+ while f"{token}_{i}" in tokenizer.added_tokens_encoder:
+ replacement += f"{token}_{i}"
+ i += 1
+
+ prompt = prompt.replace(token, replacement)
+
+ return prompt
+
+ def load_textual_inversion(
+ self, pretrained_model_name_or_path: Union[str, Dict[str, torch.Tensor]], token: Optional[str] = None, **kwargs
+ ):
+ r"""
+ Load textual inversion embeddings into the text encoder of stable diffusion pipelines. Both `diffusers` and
+ `Automatic1111` formats are supported.
+
+
+
+ This function is experimental and might change in the future.
+
+
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ Valid model ids should have an organization name, like
+ `"sd-concepts-library/low-poly-hd-logos-icons"`.
+ - A path to a *directory* containing textual inversion weights, e.g.
+ `./my_text_inversion_directory/`.
+ weight_name (`str`, *optional*):
+ Name of a custom weight file. This should be used in two cases:
+
+ - The saved textual inversion file is in `diffusers` format, but was saved under a specific weight
+ name, such as `text_inv.bin`.
+ - The saved textual inversion file is in the "Automatic1111" form.
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `diffusers-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo (either remote in
+ huggingface.co or downloaded locally), you can specify the folder name here.
+
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models).
+
+
+ """
+ if not hasattr(self, "tokenizer") or not isinstance(self.tokenizer, PreTrainedTokenizer):
+ raise ValueError(
+ f"{self.__class__.__name__} requires `self.tokenizer` of type `PreTrainedTokenizer` for calling"
+ f" `{self.load_textual_inversion.__name__}`"
+ )
+
+ if not hasattr(self, "text_encoder") or not isinstance(self.text_encoder, PreTrainedModel):
+ raise ValueError(
+ f"{self.__class__.__name__} requires `self.text_encoder` of type `PreTrainedModel` for calling"
+ f" `{self.load_textual_inversion.__name__}`"
+ )
+
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ force_download = kwargs.pop("force_download", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ subfolder = kwargs.pop("subfolder", None)
+ weight_name = kwargs.pop("weight_name", None)
+ use_safetensors = kwargs.pop("use_safetensors", None)
+
+ if use_safetensors and not is_safetensors_available():
+ raise ValueError(
+ "`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
+ )
+
+ allow_pickle = False
+ if use_safetensors is None:
+ use_safetensors = is_safetensors_available()
+ allow_pickle = True
+
+ user_agent = {
+ "file_type": "text_inversion",
+ "framework": "pytorch",
+ }
+
+ # 1. Load textual inversion file
+ model_file = None
+ # Let's first try to load .safetensors weights
+ if (use_safetensors and weight_name is None) or (
+ weight_name is not None and weight_name.endswith(".safetensors")
+ ):
+ try:
+ model_file = _get_model_file(
+ pretrained_model_name_or_path,
+ weights_name=weight_name or TEXT_INVERSION_NAME_SAFE,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ user_agent=user_agent,
+ )
+ state_dict = safetensors.torch.load_file(model_file, device="cpu")
+ except Exception as e:
+ if not allow_pickle:
+ raise e
+
+ model_file = None
+
+ if model_file is None:
+ model_file = _get_model_file(
+ pretrained_model_name_or_path,
+ weights_name=weight_name or TEXT_INVERSION_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ user_agent=user_agent,
+ )
+ state_dict = torch.load(model_file, map_location="cpu")
+
+ # 2. Load token and embedding correcly from file
+ if isinstance(state_dict, torch.Tensor):
+ if token is None:
+ raise ValueError(
+ "You are trying to load a textual inversion embedding that has been saved as a PyTorch tensor. Make sure to pass the name of the corresponding token in this case: `token=...`."
+ )
+ embedding = state_dict
+ elif len(state_dict) == 1:
+ # diffusers
+ loaded_token, embedding = next(iter(state_dict.items()))
+ elif "string_to_param" in state_dict:
+ # A1111
+ loaded_token = state_dict["name"]
+ embedding = state_dict["string_to_param"]["*"]
+
+ if token is not None and loaded_token != token:
+ logger.warn(f"The loaded token: {loaded_token} is overwritten by the passed token {token}.")
+ else:
+ token = loaded_token
+
+ embedding = embedding.to(dtype=self.text_encoder.dtype, device=self.text_encoder.device)
+
+ # 3. Make sure we don't mess up the tokenizer or text encoder
+ vocab = self.tokenizer.get_vocab()
+ if token in vocab:
+ raise ValueError(
+ f"Token {token} already in tokenizer vocabulary. Please choose a different token name or remove {token} and embedding from the tokenizer and text encoder."
+ )
+ elif f"{token}_1" in vocab:
+ multi_vector_tokens = [token]
+ i = 1
+ while f"{token}_{i}" in self.tokenizer.added_tokens_encoder:
+ multi_vector_tokens.append(f"{token}_{i}")
+ i += 1
+
+ raise ValueError(
+ f"Multi-vector Token {multi_vector_tokens} already in tokenizer vocabulary. Please choose a different token name or remove the {multi_vector_tokens} and embedding from the tokenizer and text encoder."
+ )
+
+ is_multi_vector = len(embedding.shape) > 1 and embedding.shape[0] > 1
+
+ if is_multi_vector:
+ tokens = [token] + [f"{token}_{i}" for i in range(1, embedding.shape[0])]
+ embeddings = [e for e in embedding] # noqa: C416
+ else:
+ tokens = [token]
+ embeddings = [embedding[0]] if len(embedding.shape) > 1 else [embedding]
+
+ # add tokens and get ids
+ self.tokenizer.add_tokens(tokens)
+ token_ids = self.tokenizer.convert_tokens_to_ids(tokens)
+
+ # resize token embeddings and set new embeddings
+ self.text_encoder.resize_token_embeddings(len(self.tokenizer))
+ for token_id, embedding in zip(token_ids, embeddings):
+ self.text_encoder.get_input_embeddings().weight.data[token_id] = embedding
+
+ logger.info("Loaded textual inversion embedding for {token}.")
diff --git a/diffusers/src/diffusers/models/.ipynb_checkpoints/unet_2d_condition-checkpoint.py b/diffusers/src/diffusers/models/.ipynb_checkpoints/unet_2d_condition-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..01116ad1b0baa4e3a75d07fcd0a76b34c81ee9aa
--- /dev/null
+++ b/diffusers/src/diffusers/models/.ipynb_checkpoints/unet_2d_condition-checkpoint.py
@@ -0,0 +1,707 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..loaders import UNet2DConditionLoadersMixin
+from ..utils import BaseOutput, logging
+from .attention_processor import AttentionProcessor, AttnProcessor
+from .embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
+from .modeling_utils import ModelMixin
+from .unet_2d_blocks import (
+ CrossAttnDownBlock2D,
+ CrossAttnUpBlock2D,
+ DownBlock2D,
+ UNetMidBlock2DCrossAttn,
+ UNetMidBlock2DSimpleCrossAttn,
+ UpBlock2D,
+ get_down_block,
+ get_up_block,
+)
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class UNet2DConditionOutput(BaseOutput):
+ """
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Hidden states conditioned on `encoder_hidden_states` input. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor
+
+
+class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
+ r"""
+ UNet2DConditionModel is a conditional 2D UNet model that takes in a noisy sample, conditional state, and a timestep
+ and returns sample shaped output.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the models (such as downloading or saving, etc.)
+
+ Parameters:
+ sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
+ Height and width of input/output sample.
+ in_channels (`int`, *optional*, defaults to 4): The number of channels in the input sample.
+ out_channels (`int`, *optional*, defaults to 4): The number of channels in the output.
+ center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
+ flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
+ Whether to flip the sin to cos in the time embedding.
+ freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
+ down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
+ The tuple of downsample blocks to use.
+ mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
+ The mid block type. Choose from `UNetMidBlock2DCrossAttn` or `UNetMidBlock2DSimpleCrossAttn`, will skip the
+ mid block layer if `None`.
+ up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D",)`):
+ The tuple of upsample blocks to use.
+ only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
+ Whether to include self-attention in the basic transformer blocks, see
+ [`~models.attention.BasicTransformerBlock`].
+ block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
+ The tuple of output channels for each block.
+ layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
+ downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
+ mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
+ act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
+ norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
+ If `None`, it will skip the normalization and activation layers in post-processing
+ norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
+ cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
+ The dimension of the cross attention features.
+ attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
+ resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
+ for resnet blocks, see [`~models.resnet.ResnetBlock2D`]. Choose from `default` or `scale_shift`.
+ class_embed_type (`str`, *optional*, defaults to None):
+ The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
+ `"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
+ num_class_embeds (`int`, *optional*, defaults to None):
+ Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
+ class conditioning with `class_embed_type` equal to `None`.
+ time_embedding_type (`str`, *optional*, default to `positional`):
+ The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
+ timestep_post_act (`str, *optional*, default to `None`):
+ The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
+ time_cond_proj_dim (`int`, *optional*, default to `None`):
+ The dimension of `cond_proj` layer in timestep embedding.
+ conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer.
+ conv_out_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_out` layer.
+ projection_class_embeddings_input_dim (`int`, *optional*): The dimension of the `class_labels` input when
+ using the "projection" `class_embed_type`. Required when using the "projection" `class_embed_type`.
+ class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
+ embeddings with the class embeddings.
+ """
+
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[int] = None,
+ in_channels: int = 4,
+ out_channels: int = 4,
+ center_input_sample: bool = False,
+ flip_sin_to_cos: bool = True,
+ freq_shift: int = 0,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D",
+ ),
+ mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
+ up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
+ only_cross_attention: Union[bool, Tuple[bool]] = False,
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: int = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: Union[int, Tuple[int]] = 1280,
+ attention_head_dim: Union[int, Tuple[int]] = 8,
+ dual_cross_attention: bool = False,
+ use_linear_projection: bool = False,
+ class_embed_type: Optional[str] = None,
+ num_class_embeds: Optional[int] = None,
+ upcast_attention: bool = False,
+ resnet_time_scale_shift: str = "default",
+ time_embedding_type: str = "positional",
+ timestep_post_act: Optional[str] = None,
+ time_cond_proj_dim: Optional[int] = None,
+ conv_in_kernel: int = 3,
+ conv_out_kernel: int = 3,
+ projection_class_embeddings_input_dim: Optional[int] = None,
+ class_embeddings_concat: bool = False,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_padding = (conv_in_kernel - 1) // 2
+ self.conv_in = nn.Conv2d(
+ in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
+ )
+
+ # time
+ if time_embedding_type == "fourier":
+ time_embed_dim = block_out_channels[0] * 2
+ if time_embed_dim % 2 != 0:
+ raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
+ self.time_proj = GaussianFourierProjection(
+ time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
+ )
+ timestep_input_dim = time_embed_dim
+ elif time_embedding_type == "positional":
+ time_embed_dim = block_out_channels[0] * 4
+
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+ else:
+ raise ValueError(
+ f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
+ )
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ post_act_fn=timestep_post_act,
+ cond_proj_dim=time_cond_proj_dim,
+ )
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ elif class_embed_type == "projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
+ # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
+ # 2. it projects from an arbitrary input dimension.
+ #
+ # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
+ # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
+ # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
+ self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif class_embed_type == "simple_projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ self.down_blocks = nn.ModuleList([])
+ self.up_blocks = nn.ModuleList([])
+
+ if isinstance(only_cross_attention, bool):
+ only_cross_attention = [only_cross_attention] * len(down_block_types)
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ if isinstance(cross_attention_dim, int):
+ cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
+
+ if class_embeddings_concat:
+ # The time embeddings are concatenated with the class embeddings. The dimension of the
+ # time embeddings passed to the down, middle, and up blocks is twice the dimension of the
+ # regular time embeddings
+ blocks_time_embed_dim = time_embed_dim * 2
+ else:
+ blocks_time_embed_dim = time_embed_dim
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim[i],
+ attn_num_head_channels=attention_head_dim[i],
+ downsample_padding=downsample_padding,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ if mid_block_type == "UNetMidBlock2DCrossAttn":
+ self.mid_block = UNetMidBlock2DCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ cross_attention_dim=cross_attention_dim[-1],
+ attn_num_head_channels=attention_head_dim[-1],
+ resnet_groups=norm_num_groups,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
+ self.mid_block = UNetMidBlock2DSimpleCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ cross_attention_dim=cross_attention_dim[-1],
+ attn_num_head_channels=attention_head_dim[-1],
+ resnet_groups=norm_num_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif mid_block_type is None:
+ self.mid_block = None
+ else:
+ raise ValueError(f"unknown mid_block_type : {mid_block_type}")
+
+ # count how many layers upsample the images
+ self.num_upsamplers = 0
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_attention_head_dim = list(reversed(attention_head_dim))
+ reversed_cross_attention_dim = list(reversed(cross_attention_dim))
+ only_cross_attention = list(reversed(only_cross_attention))
+
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ is_final_block = i == len(block_out_channels) - 1
+
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ # add upsample block for all BUT final layer
+ if not is_final_block:
+ add_upsample = True
+ self.num_upsamplers += 1
+ else:
+ add_upsample = False
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_upsample=add_upsample,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=reversed_cross_attention_dim[i],
+ attn_num_head_channels=reversed_attention_head_dim[i],
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ if norm_num_groups is not None:
+ self.conv_norm_out = nn.GroupNorm(
+ num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
+ )
+ self.conv_act = nn.SiLU()
+ else:
+ self.conv_norm_out = None
+ self.conv_act = None
+
+ conv_out_padding = (conv_out_kernel - 1) // 2
+ self.conv_out = nn.Conv2d(
+ block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
+ )
+
+ @property
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
+ r"""
+ Parameters:
+ `processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ of **all** `Attention` layers.
+ In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainable attention processors.:
+
+ """
+ count = len(self.attn_processors.keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module will split the input tensor in slices, to compute attention
+ in several steps. This is useful to save some memory in exchange for a small speed decrease.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
+ `"max"`, maximum amount of memory will be saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlock2D, DownBlock2D, CrossAttnUpBlock2D, UpBlock2D)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
+ mid_block_additional_residual: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ) -> Union[UNet2DConditionOutput, Tuple]:
+ r"""
+ Args:
+ sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
+ timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
+ encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
+ encoder_attention_mask (`torch.Tensor`):
+ (batch, sequence_length) cross-attention mask (or bias), applied to encoder_hidden_states. If a
+ BoolTensor is provided, it will be turned into a bias, by adding a large negative value. False = hide
+ token. Other tensor types will be used as-is as bias values.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Returns:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ # By default samples have to be AT least a multiple of the overall upsampling factor.
+ # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
+ # However, the upsampling interpolation output size can be forced to fit any upsampling size
+ # on the fly if necessary.
+ default_overall_up_factor = 2**self.num_upsamplers
+
+ # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
+ forward_upsample_size = False
+ upsample_size = None
+
+ if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
+ logger.info("Forward upsample size to force interpolation output size.")
+ forward_upsample_size = True
+
+ # prepare attention_mask
+ if attention_mask is not None:
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # ensure encoder_attention_mask is a bias, and make it broadcastable over multi-head-attention channels
+ if encoder_attention_mask is not None:
+ # if it's a mask: turn it into a bias. otherwise: assume it's already a bias
+ if encoder_attention_mask.dtype is torch.bool:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # timesteps does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=self.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when num_class_embeds > 0")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
+
+ if self.config.class_embeddings_concat:
+ emb = torch.cat([emb, class_emb], dim=-1)
+ else:
+ emb = emb + class_emb
+
+ # 2. pre-process
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample = down_block_res_sample + down_block_additional_residual
+ new_down_block_res_samples += (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+
+ if mid_block_additional_residual is not None:
+ sample = sample + mid_block_additional_residual
+
+ # 5. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ is_final_block = i == len(self.up_blocks) - 1
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ # if we have not reached the final block and need to forward the
+ # upsample size, we do it here
+ if not is_final_block and forward_upsample_size:
+ upsample_size = down_block_res_samples[-1].shape[2:]
+
+ if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ upsample_size=upsample_size,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ else:
+ sample = upsample_block(
+ hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
+ )
+
+ # 6. post-process
+ if self.conv_norm_out:
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet2DConditionOutput(sample=sample)
diff --git a/diffusers/src/diffusers/models/README.md b/diffusers/src/diffusers/models/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..80fe0bc381406457665d632816891fe364efd71f
--- /dev/null
+++ b/diffusers/src/diffusers/models/README.md
@@ -0,0 +1,3 @@
+# Models
+
+For more detail on the models, please refer to the [docs](https://huggingface.co/docs/diffusers/api/models).
\ No newline at end of file
diff --git a/diffusers/src/diffusers/models/__init__.py b/diffusers/src/diffusers/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..23839c84af45777df5bfb2cfa1a727dfefdc1897
--- /dev/null
+++ b/diffusers/src/diffusers/models/__init__.py
@@ -0,0 +1,35 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from ..utils import is_flax_available, is_torch_available
+
+
+if is_torch_available():
+ from .autoencoder_kl import AutoencoderKL
+ from .controlnet import ControlNetModel
+ from .dual_transformer_2d import DualTransformer2DModel
+ from .modeling_utils import ModelMixin
+ from .prior_transformer import PriorTransformer
+ from .t5_film_transformer import T5FilmDecoder
+ from .transformer_2d import Transformer2DModel
+ from .unet_1d import UNet1DModel
+ from .unet_2d import UNet2DModel
+ from .unet_2d_condition import UNet2DConditionModel
+ from .unet_3d_condition import UNet3DConditionModel
+ from .vq_model import VQModel
+
+if is_flax_available():
+ from .controlnet_flax import FlaxControlNetModel
+ from .unet_2d_condition_flax import FlaxUNet2DConditionModel
+ from .vae_flax import FlaxAutoencoderKL
diff --git a/diffusers/src/diffusers/models/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d8b94768b185e08d063dc457c104759f0c57d438
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2ad41aa50ba4885320a457e1a5260903d852d656
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/attention.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/attention.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..985cd02a52df0d87294830c988069ac9fb2bbcbf
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/attention.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/attention.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/attention.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2cd2ab1881e2b890f8be6b0a657bee028f84b0c6
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/attention.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/attention_processor.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/attention_processor.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ccd0fc139b5c7a7289bf2d6075f8b933740dcc62
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/attention_processor.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/attention_processor.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/attention_processor.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0bb61f9bc804c3ced81b93015c73f4588d947267
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/attention_processor.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/autoencoder_kl.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/autoencoder_kl.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ca031ae7a9d63103f0b8ae9978aec4752d4d4eb6
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/autoencoder_kl.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/autoencoder_kl.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/autoencoder_kl.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..25e995516ba673c427cd6fc3a6532de16c18c9ab
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/autoencoder_kl.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/controlnet.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/controlnet.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0cc1a72b2f2c9df53133a49343647d1d7f3497e4
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/controlnet.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/controlnet.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/controlnet.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8cdfbe2ba4bcec17db8c88addcfcabb09feb112c
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/controlnet.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/dual_transformer_2d.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/dual_transformer_2d.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..84ade8726ebf874553c1199223fc7f31367bfef2
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/dual_transformer_2d.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/dual_transformer_2d.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/dual_transformer_2d.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..242ee0f5cb7a1ba3f3151fba2c379afd3b5db44a
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/dual_transformer_2d.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/embeddings.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/embeddings.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e732cbf5d56a2fda08780288805fde737d2d3f10
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/embeddings.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/embeddings.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/embeddings.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3f0b4b1233a73a05cbba0b43050f7d9713fc3a41
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/embeddings.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/modeling_utils.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/modeling_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..644def7905f98895f401f4ee7987479736b62c4f
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/modeling_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/modeling_utils.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/modeling_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e22a404daf61c08c4f6b8bea714dc377ca614717
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/modeling_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/prior_transformer.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/prior_transformer.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..59af505f5a1ce4a92789cdd0cceca1f063a180b5
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/prior_transformer.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/prior_transformer.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/prior_transformer.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1cefcf6ef5fd4c25534115dd4b189282d6ad5eb5
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/prior_transformer.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/resnet.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/resnet.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8107d1f95a5aefdbbf75e47de6b13e092b9bac90
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/resnet.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/resnet.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/resnet.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b0ca9ebb5c50c4ce35f1c465f2d6ad25b3522456
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/resnet.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/t5_film_transformer.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/t5_film_transformer.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1b706c7eb82c0c8265d38389b961b9ea732f6dd3
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/t5_film_transformer.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/t5_film_transformer.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/t5_film_transformer.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..eb9cec0c0a5d73be1ce7bf3d47011dec8513039d
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/t5_film_transformer.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/transformer_2d.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/transformer_2d.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..10197513ee2c8a94501590d07e846e759f375f00
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/transformer_2d.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/transformer_2d.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/transformer_2d.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..219bb51fd5e0d2e6797d10d4a34562eb44945998
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/transformer_2d.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/transformer_temporal.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/transformer_temporal.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a2c467dbd60676b5e992da180bcc01e4735d0843
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/transformer_temporal.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/transformer_temporal.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/transformer_temporal.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..110db4a14f5359525517d0b25239dcbe86c85d0b
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/transformer_temporal.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_1d.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/unet_1d.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cee561b711acade10e4f3429ba0afe9ae95b7012
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_1d.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_1d.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/unet_1d.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..96a314aa98d0a18ca146652c176a832db30fa73b
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_1d.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_1d_blocks.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/unet_1d_blocks.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1ad9685e668fcdd304995f292d29a553b841a87a
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_1d_blocks.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_1d_blocks.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/unet_1d_blocks.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..267482479949474abe5b31c02ddc686ec002419d
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_1d_blocks.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_2d.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/unet_2d.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..311f01d4273199aba9de6300dacc74e5738c3695
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_2d.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_2d.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/unet_2d.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..351402c328dea79e60e4dfe23f264ffd719468c0
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_2d.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_2d_blocks.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/unet_2d_blocks.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..750d83f805b2bb1041bb98d90b369187ceb378c7
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_2d_blocks.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_2d_blocks.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/unet_2d_blocks.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..887947cc22b69b8d71be2f9f083aae2c27b88e9f
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_2d_blocks.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_2d_condition.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/unet_2d_condition.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c65c0409af7dc7dac3815d700f20e8defb0b0ee2
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_2d_condition.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_2d_condition.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/unet_2d_condition.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9aed041fe8f27925cd1b3fbf2220e64f54e636e0
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_2d_condition.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_3d_blocks.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/unet_3d_blocks.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1c956445af446858a8a115a644e7cd3a8767149b
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_3d_blocks.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_3d_blocks.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/unet_3d_blocks.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d9aebd6b60a44c2d9cb2a2971f33296f4db0eb77
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_3d_blocks.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_3d_condition.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/unet_3d_condition.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b24bb6199ff303b4fae296725cf850c12ce42508
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_3d_condition.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/unet_3d_condition.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/unet_3d_condition.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9f722d66a50bef8fb98f57e8e48d93db097bca15
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/unet_3d_condition.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/vae.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/vae.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e60bdb95dca91d8f162f8f3d1e965d7e3f6b4ef7
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/vae.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/vae.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/vae.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..64d79f3ecca2f14397de34f442fb0075ce63b4ec
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/vae.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/vq_model.cpython-310.pyc b/diffusers/src/diffusers/models/__pycache__/vq_model.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8d34e95cb045cf1572fa703749c7a0352caa1bf7
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/vq_model.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/models/__pycache__/vq_model.cpython-39.pyc b/diffusers/src/diffusers/models/__pycache__/vq_model.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5fdddcd956af44a0f6d851b603f1bc2b8c2f0270
Binary files /dev/null and b/diffusers/src/diffusers/models/__pycache__/vq_model.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/models/attention.py b/diffusers/src/diffusers/models/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..008cd5d5484e0985ee58b5a072af7f3006ca4bef
--- /dev/null
+++ b/diffusers/src/diffusers/models/attention.py
@@ -0,0 +1,523 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+from typing import Any, Callable, Dict, Optional
+
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from ..utils.import_utils import is_xformers_available
+from .attention_processor import Attention
+from .embeddings import CombinedTimestepLabelEmbeddings
+
+
+if is_xformers_available():
+ import xformers
+ import xformers.ops
+else:
+ xformers = None
+
+
+class AttentionBlock(nn.Module):
+ """
+ An attention block that allows spatial positions to attend to each other. Originally ported from here, but adapted
+ to the N-d case.
+ https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
+ Uses three q, k, v linear layers to compute attention.
+
+ Parameters:
+ channels (`int`): The number of channels in the input and output.
+ num_head_channels (`int`, *optional*):
+ The number of channels in each head. If None, then `num_heads` = 1.
+ norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for group norm.
+ rescale_output_factor (`float`, *optional*, defaults to 1.0): The factor to rescale the output by.
+ eps (`float`, *optional*, defaults to 1e-5): The epsilon value to use for group norm.
+ """
+
+ # IMPORTANT;TODO(Patrick, William) - this class will be deprecated soon. Do not use it anymore
+
+ def __init__(
+ self,
+ channels: int,
+ num_head_channels: Optional[int] = None,
+ norm_num_groups: int = 32,
+ rescale_output_factor: float = 1.0,
+ eps: float = 1e-5,
+ ):
+ super().__init__()
+ self.channels = channels
+
+ self.num_heads = channels // num_head_channels if num_head_channels is not None else 1
+ self.num_head_size = num_head_channels
+ self.group_norm = nn.GroupNorm(num_channels=channels, num_groups=norm_num_groups, eps=eps, affine=True)
+
+ # define q,k,v as linear layers
+ self.query = nn.Linear(channels, channels)
+ self.key = nn.Linear(channels, channels)
+ self.value = nn.Linear(channels, channels)
+
+ self.rescale_output_factor = rescale_output_factor
+ self.proj_attn = nn.Linear(channels, channels, bias=True)
+
+ self._use_memory_efficient_attention_xformers = False
+ self._attention_op = None
+
+ def reshape_heads_to_batch_dim(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.num_heads
+ tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
+ tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size * head_size, seq_len, dim // head_size)
+ return tensor
+
+ def reshape_batch_dim_to_heads(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.num_heads
+ tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
+ tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
+ return tensor
+
+ def set_use_memory_efficient_attention_xformers(
+ self, use_memory_efficient_attention_xformers: bool, attention_op: Optional[Callable] = None
+ ):
+ if use_memory_efficient_attention_xformers:
+ if not is_xformers_available():
+ raise ModuleNotFoundError(
+ (
+ "Refer to https://github.com/facebookresearch/xformers for more information on how to install"
+ " xformers"
+ ),
+ name="xformers",
+ )
+ elif not torch.cuda.is_available():
+ raise ValueError(
+ "torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is"
+ " only available for GPU "
+ )
+ else:
+ try:
+ # Make sure we can run the memory efficient attention
+ _ = xformers.ops.memory_efficient_attention(
+ torch.randn((1, 2, 40), device="cuda"),
+ torch.randn((1, 2, 40), device="cuda"),
+ torch.randn((1, 2, 40), device="cuda"),
+ )
+ except Exception as e:
+ raise e
+ self._use_memory_efficient_attention_xformers = use_memory_efficient_attention_xformers
+ self._attention_op = attention_op
+
+ def forward(self, hidden_states):
+ residual = hidden_states
+ batch, channel, height, width = hidden_states.shape
+
+ # norm
+ hidden_states = self.group_norm(hidden_states)
+
+ hidden_states = hidden_states.view(batch, channel, height * width).transpose(1, 2)
+
+ # proj to q, k, v
+ query_proj = self.query(hidden_states)
+ key_proj = self.key(hidden_states)
+ value_proj = self.value(hidden_states)
+
+ scale = 1 / math.sqrt(self.channels / self.num_heads)
+
+ query_proj = self.reshape_heads_to_batch_dim(query_proj)
+ key_proj = self.reshape_heads_to_batch_dim(key_proj)
+ value_proj = self.reshape_heads_to_batch_dim(value_proj)
+
+ if self._use_memory_efficient_attention_xformers:
+ # Memory efficient attention
+ hidden_states = xformers.ops.memory_efficient_attention(
+ query_proj, key_proj, value_proj, attn_bias=None, op=self._attention_op
+ )
+ hidden_states = hidden_states.to(query_proj.dtype)
+ else:
+ attention_scores = torch.baddbmm(
+ torch.empty(
+ query_proj.shape[0],
+ query_proj.shape[1],
+ key_proj.shape[1],
+ dtype=query_proj.dtype,
+ device=query_proj.device,
+ ),
+ query_proj,
+ key_proj.transpose(-1, -2),
+ beta=0,
+ alpha=scale,
+ )
+ attention_probs = torch.softmax(attention_scores.float(), dim=-1).type(attention_scores.dtype)
+ hidden_states = torch.bmm(attention_probs, value_proj)
+
+ # reshape hidden_states
+ hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
+
+ # compute next hidden_states
+ hidden_states = self.proj_attn(hidden_states)
+
+ hidden_states = hidden_states.transpose(-1, -2).reshape(batch, channel, height, width)
+
+ # res connect and rescale
+ hidden_states = (hidden_states + residual) / self.rescale_output_factor
+ return hidden_states
+
+
+class BasicTransformerBlock(nn.Module):
+ r"""
+ A basic Transformer block.
+
+ Parameters:
+ dim (`int`): The number of channels in the input and output.
+ num_attention_heads (`int`): The number of heads to use for multi-head attention.
+ attention_head_dim (`int`): The number of channels in each head.
+ dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
+ cross_attention_dim (`int`, *optional*): The size of the encoder_hidden_states vector for cross attention.
+ only_cross_attention (`bool`, *optional*):
+ Whether to use only cross-attention layers. In this case two cross attention layers are used.
+ double_self_attention (`bool`, *optional*):
+ Whether to use two self-attention layers. In this case no cross attention layers are used.
+ activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
+ num_embeds_ada_norm (:
+ obj: `int`, *optional*): The number of diffusion steps used during training. See `Transformer2DModel`.
+ attention_bias (:
+ obj: `bool`, *optional*, defaults to `False`): Configure if the attentions should contain a bias parameter.
+ """
+
+ def __init__(
+ self,
+ dim: int,
+ num_attention_heads: int,
+ attention_head_dim: int,
+ dropout=0.0,
+ cross_attention_dim: Optional[int] = None,
+ activation_fn: str = "geglu",
+ num_embeds_ada_norm: Optional[int] = None,
+ attention_bias: bool = False,
+ only_cross_attention: bool = False,
+ double_self_attention: bool = False,
+ upcast_attention: bool = False,
+ norm_elementwise_affine: bool = True,
+ norm_type: str = "layer_norm",
+ final_dropout: bool = False,
+ ):
+ super().__init__()
+ self.only_cross_attention = only_cross_attention
+
+ self.use_ada_layer_norm_zero = (num_embeds_ada_norm is not None) and norm_type == "ada_norm_zero"
+ self.use_ada_layer_norm = (num_embeds_ada_norm is not None) and norm_type == "ada_norm"
+
+ if norm_type in ("ada_norm", "ada_norm_zero") and num_embeds_ada_norm is None:
+ raise ValueError(
+ f"`norm_type` is set to {norm_type}, but `num_embeds_ada_norm` is not defined. Please make sure to"
+ f" define `num_embeds_ada_norm` if setting `norm_type` to {norm_type}."
+ )
+
+ # 1. Self-Attn
+ self.attn1 = Attention(
+ query_dim=dim,
+ heads=num_attention_heads,
+ dim_head=attention_head_dim,
+ dropout=dropout,
+ bias=attention_bias,
+ cross_attention_dim=cross_attention_dim if only_cross_attention else None,
+ upcast_attention=upcast_attention,
+ )
+
+ self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn, final_dropout=final_dropout)
+
+ # 2. Cross-Attn
+ if cross_attention_dim is not None or double_self_attention:
+ self.attn2 = Attention(
+ query_dim=dim,
+ cross_attention_dim=cross_attention_dim if not double_self_attention else None,
+ heads=num_attention_heads,
+ dim_head=attention_head_dim,
+ dropout=dropout,
+ bias=attention_bias,
+ upcast_attention=upcast_attention,
+ ) # is self-attn if encoder_hidden_states is none
+ else:
+ self.attn2 = None
+
+ if self.use_ada_layer_norm:
+ self.norm1 = AdaLayerNorm(dim, num_embeds_ada_norm)
+ elif self.use_ada_layer_norm_zero:
+ self.norm1 = AdaLayerNormZero(dim, num_embeds_ada_norm)
+ else:
+ self.norm1 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine)
+
+ if cross_attention_dim is not None or double_self_attention:
+ # We currently only use AdaLayerNormZero for self attention where there will only be one attention block.
+ # I.e. the number of returned modulation chunks from AdaLayerZero would not make sense if returned during
+ # the second cross attention block.
+ self.norm2 = (
+ AdaLayerNorm(dim, num_embeds_ada_norm)
+ if self.use_ada_layer_norm
+ else nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine)
+ )
+ else:
+ self.norm2 = None
+
+ # 3. Feed-forward
+ self.norm3 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine)
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ timestep: Optional[torch.LongTensor] = None,
+ cross_attention_kwargs: Dict[str, Any] = None,
+ class_labels: Optional[torch.LongTensor] = None,
+ ):
+ if self.use_ada_layer_norm:
+ norm_hidden_states = self.norm1(hidden_states, timestep)
+ elif self.use_ada_layer_norm_zero:
+ norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
+ hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
+ )
+ else:
+ norm_hidden_states = self.norm1(hidden_states)
+
+ # 1. Self-Attention
+ cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
+ attn_output = self.attn1(
+ norm_hidden_states,
+ encoder_hidden_states=encoder_hidden_states if self.only_cross_attention else None,
+ attention_mask=attention_mask,
+ **cross_attention_kwargs,
+ )
+ if self.use_ada_layer_norm_zero:
+ attn_output = gate_msa.unsqueeze(1) * attn_output
+ hidden_states = attn_output + hidden_states
+
+ if self.attn2 is not None:
+ norm_hidden_states = (
+ self.norm2(hidden_states, timestep) if self.use_ada_layer_norm else self.norm2(hidden_states)
+ )
+
+ # 2. Cross-Attention
+ attn_output = self.attn2(
+ norm_hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=encoder_attention_mask,
+ **cross_attention_kwargs,
+ )
+ hidden_states = attn_output + hidden_states
+
+ # 3. Feed-forward
+ norm_hidden_states = self.norm3(hidden_states)
+
+ if self.use_ada_layer_norm_zero:
+ norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
+
+ ff_output = self.ff(norm_hidden_states)
+
+ if self.use_ada_layer_norm_zero:
+ ff_output = gate_mlp.unsqueeze(1) * ff_output
+
+ hidden_states = ff_output + hidden_states
+
+ return hidden_states
+
+
+class FeedForward(nn.Module):
+ r"""
+ A feed-forward layer.
+
+ Parameters:
+ dim (`int`): The number of channels in the input.
+ dim_out (`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`.
+ mult (`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension.
+ dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
+ activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
+ final_dropout (`bool` *optional*, defaults to False): Apply a final dropout.
+ """
+
+ def __init__(
+ self,
+ dim: int,
+ dim_out: Optional[int] = None,
+ mult: int = 4,
+ dropout: float = 0.0,
+ activation_fn: str = "geglu",
+ final_dropout: bool = False,
+ ):
+ super().__init__()
+ inner_dim = int(dim * mult)
+ dim_out = dim_out if dim_out is not None else dim
+
+ if activation_fn == "gelu":
+ act_fn = GELU(dim, inner_dim)
+ if activation_fn == "gelu-approximate":
+ act_fn = GELU(dim, inner_dim, approximate="tanh")
+ elif activation_fn == "geglu":
+ act_fn = GEGLU(dim, inner_dim)
+ elif activation_fn == "geglu-approximate":
+ act_fn = ApproximateGELU(dim, inner_dim)
+
+ self.net = nn.ModuleList([])
+ # project in
+ self.net.append(act_fn)
+ # project dropout
+ self.net.append(nn.Dropout(dropout))
+ # project out
+ self.net.append(nn.Linear(inner_dim, dim_out))
+ # FF as used in Vision Transformer, MLP-Mixer, etc. have a final dropout
+ if final_dropout:
+ self.net.append(nn.Dropout(dropout))
+
+ def forward(self, hidden_states):
+ for module in self.net:
+ hidden_states = module(hidden_states)
+ return hidden_states
+
+
+class GELU(nn.Module):
+ r"""
+ GELU activation function with tanh approximation support with `approximate="tanh"`.
+ """
+
+ def __init__(self, dim_in: int, dim_out: int, approximate: str = "none"):
+ super().__init__()
+ self.proj = nn.Linear(dim_in, dim_out)
+ self.approximate = approximate
+
+ def gelu(self, gate):
+ if gate.device.type != "mps":
+ return F.gelu(gate, approximate=self.approximate)
+ # mps: gelu is not implemented for float16
+ return F.gelu(gate.to(dtype=torch.float32), approximate=self.approximate).to(dtype=gate.dtype)
+
+ def forward(self, hidden_states):
+ hidden_states = self.proj(hidden_states)
+ hidden_states = self.gelu(hidden_states)
+ return hidden_states
+
+
+class GEGLU(nn.Module):
+ r"""
+ A variant of the gated linear unit activation function from https://arxiv.org/abs/2002.05202.
+
+ Parameters:
+ dim_in (`int`): The number of channels in the input.
+ dim_out (`int`): The number of channels in the output.
+ """
+
+ def __init__(self, dim_in: int, dim_out: int):
+ super().__init__()
+ self.proj = nn.Linear(dim_in, dim_out * 2)
+
+ def gelu(self, gate):
+ if gate.device.type != "mps":
+ return F.gelu(gate)
+ # mps: gelu is not implemented for float16
+ return F.gelu(gate.to(dtype=torch.float32)).to(dtype=gate.dtype)
+
+ def forward(self, hidden_states):
+ hidden_states, gate = self.proj(hidden_states).chunk(2, dim=-1)
+ return hidden_states * self.gelu(gate)
+
+
+class ApproximateGELU(nn.Module):
+ """
+ The approximate form of Gaussian Error Linear Unit (GELU)
+
+ For more details, see section 2: https://arxiv.org/abs/1606.08415
+ """
+
+ def __init__(self, dim_in: int, dim_out: int):
+ super().__init__()
+ self.proj = nn.Linear(dim_in, dim_out)
+
+ def forward(self, x):
+ x = self.proj(x)
+ return x * torch.sigmoid(1.702 * x)
+
+
+class AdaLayerNorm(nn.Module):
+ """
+ Norm layer modified to incorporate timestep embeddings.
+ """
+
+ def __init__(self, embedding_dim, num_embeddings):
+ super().__init__()
+ self.emb = nn.Embedding(num_embeddings, embedding_dim)
+ self.silu = nn.SiLU()
+ self.linear = nn.Linear(embedding_dim, embedding_dim * 2)
+ self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False)
+
+ def forward(self, x, timestep):
+ emb = self.linear(self.silu(self.emb(timestep)))
+ scale, shift = torch.chunk(emb, 2)
+ x = self.norm(x) * (1 + scale) + shift
+ return x
+
+
+class AdaLayerNormZero(nn.Module):
+ """
+ Norm layer adaptive layer norm zero (adaLN-Zero).
+ """
+
+ def __init__(self, embedding_dim, num_embeddings):
+ super().__init__()
+
+ self.emb = CombinedTimestepLabelEmbeddings(num_embeddings, embedding_dim)
+
+ self.silu = nn.SiLU()
+ self.linear = nn.Linear(embedding_dim, 6 * embedding_dim, bias=True)
+ self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False, eps=1e-6)
+
+ def forward(self, x, timestep, class_labels, hidden_dtype=None):
+ emb = self.linear(self.silu(self.emb(timestep, class_labels, hidden_dtype=hidden_dtype)))
+ shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = emb.chunk(6, dim=1)
+ x = self.norm(x) * (1 + scale_msa[:, None]) + shift_msa[:, None]
+ return x, gate_msa, shift_mlp, scale_mlp, gate_mlp
+
+
+class AdaGroupNorm(nn.Module):
+ """
+ GroupNorm layer modified to incorporate timestep embeddings.
+ """
+
+ def __init__(
+ self, embedding_dim: int, out_dim: int, num_groups: int, act_fn: Optional[str] = None, eps: float = 1e-5
+ ):
+ super().__init__()
+ self.num_groups = num_groups
+ self.eps = eps
+ self.act = None
+ if act_fn == "swish":
+ self.act = lambda x: F.silu(x)
+ elif act_fn == "mish":
+ self.act = nn.Mish()
+ elif act_fn == "silu":
+ self.act = nn.SiLU()
+ elif act_fn == "gelu":
+ self.act = nn.GELU()
+
+ self.linear = nn.Linear(embedding_dim, out_dim * 2)
+
+ def forward(self, x, emb):
+ if self.act:
+ emb = self.act(emb)
+ emb = self.linear(emb)
+ emb = emb[:, :, None, None]
+ scale, shift = emb.chunk(2, dim=1)
+
+ x = F.group_norm(x, self.num_groups, eps=self.eps)
+ x = x * (1 + scale) + shift
+ return x
diff --git a/diffusers/src/diffusers/models/attention_flax.py b/diffusers/src/diffusers/models/attention_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a47d728c2f911cbc24e353f8c500909c960f159
--- /dev/null
+++ b/diffusers/src/diffusers/models/attention_flax.py
@@ -0,0 +1,302 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import flax.linen as nn
+import jax.numpy as jnp
+
+
+class FlaxAttention(nn.Module):
+ r"""
+ A Flax multi-head attention module as described in: https://arxiv.org/abs/1706.03762
+
+ Parameters:
+ query_dim (:obj:`int`):
+ Input hidden states dimension
+ heads (:obj:`int`, *optional*, defaults to 8):
+ Number of heads
+ dim_head (:obj:`int`, *optional*, defaults to 64):
+ Hidden states dimension inside each head
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+
+ """
+ query_dim: int
+ heads: int = 8
+ dim_head: int = 64
+ dropout: float = 0.0
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ inner_dim = self.dim_head * self.heads
+ self.scale = self.dim_head**-0.5
+
+ # Weights were exported with old names {to_q, to_k, to_v, to_out}
+ self.query = nn.Dense(inner_dim, use_bias=False, dtype=self.dtype, name="to_q")
+ self.key = nn.Dense(inner_dim, use_bias=False, dtype=self.dtype, name="to_k")
+ self.value = nn.Dense(inner_dim, use_bias=False, dtype=self.dtype, name="to_v")
+
+ self.proj_attn = nn.Dense(self.query_dim, dtype=self.dtype, name="to_out_0")
+
+ def reshape_heads_to_batch_dim(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.heads
+ tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
+ tensor = jnp.transpose(tensor, (0, 2, 1, 3))
+ tensor = tensor.reshape(batch_size * head_size, seq_len, dim // head_size)
+ return tensor
+
+ def reshape_batch_dim_to_heads(self, tensor):
+ batch_size, seq_len, dim = tensor.shape
+ head_size = self.heads
+ tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
+ tensor = jnp.transpose(tensor, (0, 2, 1, 3))
+ tensor = tensor.reshape(batch_size // head_size, seq_len, dim * head_size)
+ return tensor
+
+ def __call__(self, hidden_states, context=None, deterministic=True):
+ context = hidden_states if context is None else context
+
+ query_proj = self.query(hidden_states)
+ key_proj = self.key(context)
+ value_proj = self.value(context)
+
+ query_states = self.reshape_heads_to_batch_dim(query_proj)
+ key_states = self.reshape_heads_to_batch_dim(key_proj)
+ value_states = self.reshape_heads_to_batch_dim(value_proj)
+
+ # compute attentions
+ attention_scores = jnp.einsum("b i d, b j d->b i j", query_states, key_states)
+ attention_scores = attention_scores * self.scale
+ attention_probs = nn.softmax(attention_scores, axis=2)
+
+ # attend to values
+ hidden_states = jnp.einsum("b i j, b j d -> b i d", attention_probs, value_states)
+ hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
+ hidden_states = self.proj_attn(hidden_states)
+ return hidden_states
+
+
+class FlaxBasicTransformerBlock(nn.Module):
+ r"""
+ A Flax transformer block layer with `GLU` (Gated Linear Unit) activation function as described in:
+ https://arxiv.org/abs/1706.03762
+
+
+ Parameters:
+ dim (:obj:`int`):
+ Inner hidden states dimension
+ n_heads (:obj:`int`):
+ Number of heads
+ d_head (:obj:`int`):
+ Hidden states dimension inside each head
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ only_cross_attention (`bool`, defaults to `False`):
+ Whether to only apply cross attention.
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ dim: int
+ n_heads: int
+ d_head: int
+ dropout: float = 0.0
+ only_cross_attention: bool = False
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ # self attention (or cross_attention if only_cross_attention is True)
+ self.attn1 = FlaxAttention(self.dim, self.n_heads, self.d_head, self.dropout, dtype=self.dtype)
+ # cross attention
+ self.attn2 = FlaxAttention(self.dim, self.n_heads, self.d_head, self.dropout, dtype=self.dtype)
+ self.ff = FlaxFeedForward(dim=self.dim, dropout=self.dropout, dtype=self.dtype)
+ self.norm1 = nn.LayerNorm(epsilon=1e-5, dtype=self.dtype)
+ self.norm2 = nn.LayerNorm(epsilon=1e-5, dtype=self.dtype)
+ self.norm3 = nn.LayerNorm(epsilon=1e-5, dtype=self.dtype)
+
+ def __call__(self, hidden_states, context, deterministic=True):
+ # self attention
+ residual = hidden_states
+ if self.only_cross_attention:
+ hidden_states = self.attn1(self.norm1(hidden_states), context, deterministic=deterministic)
+ else:
+ hidden_states = self.attn1(self.norm1(hidden_states), deterministic=deterministic)
+ hidden_states = hidden_states + residual
+
+ # cross attention
+ residual = hidden_states
+ hidden_states = self.attn2(self.norm2(hidden_states), context, deterministic=deterministic)
+ hidden_states = hidden_states + residual
+
+ # feed forward
+ residual = hidden_states
+ hidden_states = self.ff(self.norm3(hidden_states), deterministic=deterministic)
+ hidden_states = hidden_states + residual
+
+ return hidden_states
+
+
+class FlaxTransformer2DModel(nn.Module):
+ r"""
+ A Spatial Transformer layer with Gated Linear Unit (GLU) activation function as described in:
+ https://arxiv.org/pdf/1506.02025.pdf
+
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input number of channels
+ n_heads (:obj:`int`):
+ Number of heads
+ d_head (:obj:`int`):
+ Hidden states dimension inside each head
+ depth (:obj:`int`, *optional*, defaults to 1):
+ Number of transformers block
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ use_linear_projection (`bool`, defaults to `False`): tbd
+ only_cross_attention (`bool`, defaults to `False`): tbd
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ n_heads: int
+ d_head: int
+ depth: int = 1
+ dropout: float = 0.0
+ use_linear_projection: bool = False
+ only_cross_attention: bool = False
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.norm = nn.GroupNorm(num_groups=32, epsilon=1e-5)
+
+ inner_dim = self.n_heads * self.d_head
+ if self.use_linear_projection:
+ self.proj_in = nn.Dense(inner_dim, dtype=self.dtype)
+ else:
+ self.proj_in = nn.Conv(
+ inner_dim,
+ kernel_size=(1, 1),
+ strides=(1, 1),
+ padding="VALID",
+ dtype=self.dtype,
+ )
+
+ self.transformer_blocks = [
+ FlaxBasicTransformerBlock(
+ inner_dim,
+ self.n_heads,
+ self.d_head,
+ dropout=self.dropout,
+ only_cross_attention=self.only_cross_attention,
+ dtype=self.dtype,
+ )
+ for _ in range(self.depth)
+ ]
+
+ if self.use_linear_projection:
+ self.proj_out = nn.Dense(inner_dim, dtype=self.dtype)
+ else:
+ self.proj_out = nn.Conv(
+ inner_dim,
+ kernel_size=(1, 1),
+ strides=(1, 1),
+ padding="VALID",
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states, context, deterministic=True):
+ batch, height, width, channels = hidden_states.shape
+ residual = hidden_states
+ hidden_states = self.norm(hidden_states)
+ if self.use_linear_projection:
+ hidden_states = hidden_states.reshape(batch, height * width, channels)
+ hidden_states = self.proj_in(hidden_states)
+ else:
+ hidden_states = self.proj_in(hidden_states)
+ hidden_states = hidden_states.reshape(batch, height * width, channels)
+
+ for transformer_block in self.transformer_blocks:
+ hidden_states = transformer_block(hidden_states, context, deterministic=deterministic)
+
+ if self.use_linear_projection:
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = hidden_states.reshape(batch, height, width, channels)
+ else:
+ hidden_states = hidden_states.reshape(batch, height, width, channels)
+ hidden_states = self.proj_out(hidden_states)
+
+ hidden_states = hidden_states + residual
+ return hidden_states
+
+
+class FlaxFeedForward(nn.Module):
+ r"""
+ Flax module that encapsulates two Linear layers separated by a non-linearity. It is the counterpart of PyTorch's
+ [`FeedForward`] class, with the following simplifications:
+ - The activation function is currently hardcoded to a gated linear unit from:
+ https://arxiv.org/abs/2002.05202
+ - `dim_out` is equal to `dim`.
+ - The number of hidden dimensions is hardcoded to `dim * 4` in [`FlaxGELU`].
+
+ Parameters:
+ dim (:obj:`int`):
+ Inner hidden states dimension
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ dim: int
+ dropout: float = 0.0
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ # The second linear layer needs to be called
+ # net_2 for now to match the index of the Sequential layer
+ self.net_0 = FlaxGEGLU(self.dim, self.dropout, self.dtype)
+ self.net_2 = nn.Dense(self.dim, dtype=self.dtype)
+
+ def __call__(self, hidden_states, deterministic=True):
+ hidden_states = self.net_0(hidden_states)
+ hidden_states = self.net_2(hidden_states)
+ return hidden_states
+
+
+class FlaxGEGLU(nn.Module):
+ r"""
+ Flax implementation of a Linear layer followed by the variant of the gated linear unit activation function from
+ https://arxiv.org/abs/2002.05202.
+
+ Parameters:
+ dim (:obj:`int`):
+ Input hidden states dimension
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ dim: int
+ dropout: float = 0.0
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ inner_dim = self.dim * 4
+ self.proj = nn.Dense(inner_dim * 2, dtype=self.dtype)
+
+ def __call__(self, hidden_states, deterministic=True):
+ hidden_states = self.proj(hidden_states)
+ hidden_linear, hidden_gelu = jnp.split(hidden_states, 2, axis=2)
+ return hidden_linear * nn.gelu(hidden_gelu)
diff --git a/diffusers/src/diffusers/models/attention_processor.py b/diffusers/src/diffusers/models/attention_processor.py
new file mode 100644
index 0000000000000000000000000000000000000000..dffca50fced3e39598c5ec54cb6b54dc494333a2
--- /dev/null
+++ b/diffusers/src/diffusers/models/attention_processor.py
@@ -0,0 +1,712 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Callable, Optional, Union
+
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from ..utils import deprecate, logging
+from ..utils.import_utils import is_xformers_available
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+if is_xformers_available():
+ import xformers
+ import xformers.ops
+else:
+ xformers = None
+
+
+class Attention(nn.Module):
+ r"""
+ A cross attention layer.
+
+ Parameters:
+ query_dim (`int`): The number of channels in the query.
+ cross_attention_dim (`int`, *optional*):
+ The number of channels in the encoder_hidden_states. If not given, defaults to `query_dim`.
+ heads (`int`, *optional*, defaults to 8): The number of heads to use for multi-head attention.
+ dim_head (`int`, *optional*, defaults to 64): The number of channels in each head.
+ dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
+ bias (`bool`, *optional*, defaults to False):
+ Set to `True` for the query, key, and value linear layers to contain a bias parameter.
+ """
+
+ def __init__(
+ self,
+ query_dim: int,
+ cross_attention_dim: Optional[int] = None,
+ heads: int = 8,
+ dim_head: int = 64,
+ dropout: float = 0.0,
+ bias=False,
+ upcast_attention: bool = False,
+ upcast_softmax: bool = False,
+ cross_attention_norm: bool = False,
+ added_kv_proj_dim: Optional[int] = None,
+ norm_num_groups: Optional[int] = None,
+ out_bias: bool = True,
+ scale_qk: bool = True,
+ processor: Optional["AttnProcessor"] = None,
+ ):
+ super().__init__()
+ inner_dim = dim_head * heads
+ cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
+ self.upcast_attention = upcast_attention
+ self.upcast_softmax = upcast_softmax
+ self.cross_attention_norm = cross_attention_norm
+
+ self.scale = dim_head**-0.5 if scale_qk else 1.0
+
+ self.heads = heads
+ # for slice_size > 0 the attention score computation
+ # is split across the batch axis to save memory
+ # You can set slice_size with `set_attention_slice`
+ self.sliceable_head_dim = heads
+
+ self.added_kv_proj_dim = added_kv_proj_dim
+
+ if norm_num_groups is not None:
+ self.group_norm = nn.GroupNorm(num_channels=inner_dim, num_groups=norm_num_groups, eps=1e-5, affine=True)
+ else:
+ self.group_norm = None
+
+ if cross_attention_norm:
+ self.norm_cross = nn.LayerNorm(cross_attention_dim)
+
+ self.to_q = nn.Linear(query_dim, inner_dim, bias=bias)
+ self.to_k = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
+ self.to_v = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
+
+ if self.added_kv_proj_dim is not None:
+ self.add_k_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
+ self.add_v_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
+
+ self.to_out = nn.ModuleList([])
+ self.to_out.append(nn.Linear(inner_dim, query_dim, bias=out_bias))
+ self.to_out.append(nn.Dropout(dropout))
+
+ # set attention processor
+ # We use the AttnProcessor2_0 by default when torch 2.x is used which uses
+ # torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
+ # but only if it has the default `scale` argument. TODO remove scale_qk check when we move to torch 2.1
+ if processor is None:
+ processor = (
+ AttnProcessor2_0() if hasattr(F, "scaled_dot_product_attention") and scale_qk else AttnProcessor()
+ )
+ self.set_processor(processor)
+
+ def set_use_memory_efficient_attention_xformers(
+ self, use_memory_efficient_attention_xformers: bool, attention_op: Optional[Callable] = None
+ ):
+ is_lora = hasattr(self, "processor") and isinstance(
+ self.processor, (LoRAAttnProcessor, LoRAXFormersAttnProcessor)
+ )
+
+ if use_memory_efficient_attention_xformers:
+ if self.added_kv_proj_dim is not None:
+ # TODO(Anton, Patrick, Suraj, William) - currently xformers doesn't work for UnCLIP
+ # which uses this type of cross attention ONLY because the attention mask of format
+ # [0, ..., -10.000, ..., 0, ...,] is not supported
+ raise NotImplementedError(
+ "Memory efficient attention with `xformers` is currently not supported when"
+ " `self.added_kv_proj_dim` is defined."
+ )
+ elif not is_xformers_available():
+ raise ModuleNotFoundError(
+ (
+ "Refer to https://github.com/facebookresearch/xformers for more information on how to install"
+ " xformers"
+ ),
+ name="xformers",
+ )
+ elif not torch.cuda.is_available():
+ raise ValueError(
+ "torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is"
+ " only available for GPU "
+ )
+ else:
+ try:
+ # Make sure we can run the memory efficient attention
+ _ = xformers.ops.memory_efficient_attention(
+ torch.randn((1, 2, 40), device="cuda"),
+ torch.randn((1, 2, 40), device="cuda"),
+ torch.randn((1, 2, 40), device="cuda"),
+ )
+ except Exception as e:
+ raise e
+
+ if is_lora:
+ processor = LoRAXFormersAttnProcessor(
+ hidden_size=self.processor.hidden_size,
+ cross_attention_dim=self.processor.cross_attention_dim,
+ rank=self.processor.rank,
+ attention_op=attention_op,
+ )
+ processor.load_state_dict(self.processor.state_dict())
+ processor.to(self.processor.to_q_lora.up.weight.device)
+ else:
+ processor = XFormersAttnProcessor(attention_op=attention_op)
+ else:
+ if is_lora:
+ processor = LoRAAttnProcessor(
+ hidden_size=self.processor.hidden_size,
+ cross_attention_dim=self.processor.cross_attention_dim,
+ rank=self.processor.rank,
+ )
+ processor.load_state_dict(self.processor.state_dict())
+ processor.to(self.processor.to_q_lora.up.weight.device)
+ else:
+ processor = AttnProcessor()
+
+ self.set_processor(processor)
+
+ def set_attention_slice(self, slice_size):
+ if slice_size is not None and slice_size > self.sliceable_head_dim:
+ raise ValueError(f"slice_size {slice_size} has to be smaller or equal to {self.sliceable_head_dim}.")
+
+ if slice_size is not None and self.added_kv_proj_dim is not None:
+ processor = SlicedAttnAddedKVProcessor(slice_size)
+ elif slice_size is not None:
+ processor = SlicedAttnProcessor(slice_size)
+ elif self.added_kv_proj_dim is not None:
+ processor = AttnAddedKVProcessor()
+ else:
+ processor = AttnProcessor()
+
+ self.set_processor(processor)
+
+ def set_processor(self, processor: "AttnProcessor"):
+ # if current processor is in `self._modules` and if passed `processor` is not, we need to
+ # pop `processor` from `self._modules`
+ if (
+ hasattr(self, "processor")
+ and isinstance(self.processor, torch.nn.Module)
+ and not isinstance(processor, torch.nn.Module)
+ ):
+ logger.info(f"You are removing possibly trained weights of {self.processor} with {processor}")
+ self._modules.pop("processor")
+
+ self.processor = processor
+
+ def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, **cross_attention_kwargs):
+ # The `Attention` class can call different attention processors / attention functions
+ # here we simply pass along all tensors to the selected processor class
+ # For standard processors that are defined here, `**cross_attention_kwargs` is empty
+ return self.processor(
+ self,
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ **cross_attention_kwargs,
+ )
+
+ def batch_to_head_dim(self, tensor):
+ head_size = self.heads
+ batch_size, seq_len, dim = tensor.shape
+ tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
+ tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
+ return tensor
+
+ def head_to_batch_dim(self, tensor):
+ head_size = self.heads
+ batch_size, seq_len, dim = tensor.shape
+ tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
+ tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size * head_size, seq_len, dim // head_size)
+ return tensor
+
+ def get_attention_scores(self, query, key, attention_mask=None):
+ dtype = query.dtype
+ if self.upcast_attention:
+ query = query.float()
+ key = key.float()
+
+ if attention_mask is None:
+ baddbmm_input = torch.empty(
+ query.shape[0], query.shape[1], key.shape[1], dtype=query.dtype, device=query.device
+ )
+ beta = 0
+ else:
+ baddbmm_input = attention_mask
+ beta = 1
+
+ attention_scores = torch.baddbmm(
+ baddbmm_input,
+ query,
+ key.transpose(-1, -2),
+ beta=beta,
+ alpha=self.scale,
+ )
+
+ if self.upcast_softmax:
+ attention_scores = attention_scores.float()
+
+ attention_probs = attention_scores.softmax(dim=-1)
+ attention_probs = attention_probs.to(dtype)
+
+ return attention_probs
+
+ def prepare_attention_mask(self, attention_mask, target_length, batch_size=None):
+ if batch_size is None:
+ deprecate(
+ "batch_size=None",
+ "0.0.15",
+ (
+ "Not passing the `batch_size` parameter to `prepare_attention_mask` can lead to incorrect"
+ " attention mask preparation and is deprecated behavior. Please make sure to pass `batch_size` to"
+ " `prepare_attention_mask` when preparing the attention_mask."
+ ),
+ )
+ batch_size = 1
+
+ head_size = self.heads
+ if attention_mask is None:
+ return attention_mask
+
+ current_length: int = attention_mask.shape[-1]
+ if current_length > target_length:
+ # we *could* trim the mask with:
+ # attention_mask = attention_mask[:,:target_length]
+ # but this is weird enough that it's more likely to be a mistake than a shortcut
+ raise ValueError(f"mask's length ({current_length}) exceeds the sequence length ({target_length}).")
+ elif current_length < target_length:
+ if attention_mask.device.type == "mps":
+ # HACK: MPS: Does not support padding by greater than dimension of input tensor.
+ # Instead, we can manually construct the padding tensor.
+ padding_shape = (attention_mask.shape[0], attention_mask.shape[1], target_length)
+ padding = torch.zeros(padding_shape, dtype=attention_mask.dtype, device=attention_mask.device)
+ attention_mask = torch.cat([attention_mask, padding], dim=2)
+ else:
+ remaining_length: int = target_length - current_length
+ attention_mask = F.pad(attention_mask, (0, remaining_length), value=0.0)
+
+ if attention_mask.shape[0] < batch_size * head_size:
+ attention_mask = attention_mask.repeat_interleave(head_size, dim=0)
+ return attention_mask
+
+
+class AttnProcessor:
+ def __call__(
+ self,
+ attn: Attention,
+ hidden_states,
+ encoder_hidden_states=None,
+ attention_mask=None,
+ ):
+ batch_size, sequence_length, _ = (
+ hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
+ )
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+ query = attn.to_q(hidden_states)
+
+ if encoder_hidden_states is None:
+ encoder_hidden_states = hidden_states
+ elif attn.cross_attention_norm:
+ encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
+
+ key = attn.to_k(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states)
+
+ query = attn.head_to_batch_dim(query)
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+
+ attention_probs = attn.get_attention_scores(query, key, attention_mask)
+ hidden_states = torch.bmm(attention_probs, value)
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ return hidden_states
+
+
+class LoRALinearLayer(nn.Module):
+ def __init__(self, in_features, out_features, rank=4):
+ super().__init__()
+
+ if rank > min(in_features, out_features):
+ raise ValueError(f"LoRA rank {rank} must be less or equal than {min(in_features, out_features)}")
+
+ self.down = nn.Linear(in_features, rank, bias=False)
+ self.up = nn.Linear(rank, out_features, bias=False)
+
+ nn.init.normal_(self.down.weight, std=1 / rank)
+ nn.init.zeros_(self.up.weight)
+
+ def forward(self, hidden_states):
+ orig_dtype = hidden_states.dtype
+ dtype = self.down.weight.dtype
+
+ down_hidden_states = self.down(hidden_states.to(dtype))
+ up_hidden_states = self.up(down_hidden_states)
+
+ return up_hidden_states.to(orig_dtype)
+
+
+class LoRAAttnProcessor(nn.Module):
+ def __init__(self, hidden_size, cross_attention_dim=None, rank=4):
+ super().__init__()
+
+ self.hidden_size = hidden_size
+ self.cross_attention_dim = cross_attention_dim
+ self.rank = rank
+
+ self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
+ self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
+ self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
+ self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
+
+ def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0):
+ batch_size, sequence_length, _ = (
+ hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
+ )
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+
+ query = attn.to_q(hidden_states) + scale * self.to_q_lora(hidden_states)
+ query = attn.head_to_batch_dim(query)
+
+ encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
+
+ key = attn.to_k(encoder_hidden_states) + scale * self.to_k_lora(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states) + scale * self.to_v_lora(encoder_hidden_states)
+
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+
+ attention_probs = attn.get_attention_scores(query, key, attention_mask)
+ hidden_states = torch.bmm(attention_probs, value)
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states) + scale * self.to_out_lora(hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ return hidden_states
+
+
+class AttnAddedKVProcessor:
+ def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
+ residual = hidden_states
+ hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
+ batch_size, sequence_length, _ = hidden_states.shape
+ encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
+
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+
+ hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
+
+ query = attn.to_q(hidden_states)
+ query = attn.head_to_batch_dim(query)
+
+ key = attn.to_k(hidden_states)
+ value = attn.to_v(hidden_states)
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+
+ encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
+ encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
+ encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
+ encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
+
+ key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
+ value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
+
+ attention_probs = attn.get_attention_scores(query, key, attention_mask)
+ hidden_states = torch.bmm(attention_probs, value)
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
+ hidden_states = hidden_states + residual
+
+ return hidden_states
+
+
+class XFormersAttnProcessor:
+ def __init__(self, attention_op: Optional[Callable] = None):
+ self.attention_op = attention_op
+
+ def __call__(
+ self,
+ attn: Attention,
+ hidden_states: torch.FloatTensor,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ ):
+ batch_size, key_tokens, _ = (
+ hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
+ )
+
+ attention_mask = attn.prepare_attention_mask(attention_mask, key_tokens, batch_size)
+ if attention_mask is not None:
+ # xformers doesn't broadcast for us, so we expand our singleton dimension manually
+ _, query_tokens, _ = hidden_states.shape
+ attention_mask = attention_mask.expand(-1, query_tokens, -1)
+
+ query = attn.to_q(hidden_states)
+
+ if encoder_hidden_states is None:
+ encoder_hidden_states = hidden_states
+ elif attn.cross_attention_norm:
+ encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
+
+ key = attn.to_k(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states)
+
+ query = attn.head_to_batch_dim(query).contiguous()
+ key = attn.head_to_batch_dim(key).contiguous()
+ value = attn.head_to_batch_dim(value).contiguous()
+
+ hidden_states = xformers.ops.memory_efficient_attention(
+ query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
+ )
+ hidden_states = hidden_states.to(query.dtype)
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+ return hidden_states
+
+
+class AttnProcessor2_0:
+ def __init__(self):
+ if not hasattr(F, "scaled_dot_product_attention"):
+ raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
+
+ def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
+ batch_size, sequence_length, _ = (
+ hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
+ )
+ inner_dim = hidden_states.shape[-1]
+
+ if attention_mask is not None:
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+ # scaled_dot_product_attention expects attention_mask shape to be
+ # (batch, heads, source_length, target_length)
+ attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
+
+ query = attn.to_q(hidden_states)
+
+ if encoder_hidden_states is None:
+ encoder_hidden_states = hidden_states
+ elif attn.cross_attention_norm:
+ encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
+
+ key = attn.to_k(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states)
+
+ head_dim = inner_dim // attn.heads
+ query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+ value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
+
+ # the output of sdp = (batch, num_heads, seq_len, head_dim)
+ # TODO: add support for attn.scale when we move to Torch 2.1
+ hidden_states = F.scaled_dot_product_attention(
+ query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
+ )
+
+ hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
+ hidden_states = hidden_states.to(query.dtype)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+ return hidden_states
+
+
+class LoRAXFormersAttnProcessor(nn.Module):
+ def __init__(self, hidden_size, cross_attention_dim, rank=4, attention_op: Optional[Callable] = None):
+ super().__init__()
+
+ self.hidden_size = hidden_size
+ self.cross_attention_dim = cross_attention_dim
+ self.rank = rank
+ self.attention_op = attention_op
+
+ self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
+ self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
+ self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
+ self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
+
+ def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0):
+ batch_size, sequence_length, _ = (
+ hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
+ )
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+
+ query = attn.to_q(hidden_states) + scale * self.to_q_lora(hidden_states)
+ query = attn.head_to_batch_dim(query).contiguous()
+
+ encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
+
+ key = attn.to_k(encoder_hidden_states) + scale * self.to_k_lora(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states) + scale * self.to_v_lora(encoder_hidden_states)
+
+ key = attn.head_to_batch_dim(key).contiguous()
+ value = attn.head_to_batch_dim(value).contiguous()
+
+ hidden_states = xformers.ops.memory_efficient_attention(
+ query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
+ )
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states) + scale * self.to_out_lora(hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ return hidden_states
+
+
+class SlicedAttnProcessor:
+ def __init__(self, slice_size):
+ self.slice_size = slice_size
+
+ def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
+ batch_size, sequence_length, _ = (
+ hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
+ )
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+
+ query = attn.to_q(hidden_states)
+ dim = query.shape[-1]
+ query = attn.head_to_batch_dim(query)
+
+ if encoder_hidden_states is None:
+ encoder_hidden_states = hidden_states
+ elif attn.cross_attention_norm:
+ encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
+
+ key = attn.to_k(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states)
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+
+ batch_size_attention, query_tokens, _ = query.shape
+ hidden_states = torch.zeros(
+ (batch_size_attention, query_tokens, dim // attn.heads), device=query.device, dtype=query.dtype
+ )
+
+ for i in range(batch_size_attention // self.slice_size):
+ start_idx = i * self.slice_size
+ end_idx = (i + 1) * self.slice_size
+
+ query_slice = query[start_idx:end_idx]
+ key_slice = key[start_idx:end_idx]
+ attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
+
+ attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
+
+ attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
+
+ hidden_states[start_idx:end_idx] = attn_slice
+
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ return hidden_states
+
+
+class SlicedAttnAddedKVProcessor:
+ def __init__(self, slice_size):
+ self.slice_size = slice_size
+
+ def __call__(self, attn: "Attention", hidden_states, encoder_hidden_states=None, attention_mask=None):
+ residual = hidden_states
+ hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
+ encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
+
+ batch_size, sequence_length, _ = hidden_states.shape
+
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+
+ hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
+
+ query = attn.to_q(hidden_states)
+ dim = query.shape[-1]
+ query = attn.head_to_batch_dim(query)
+
+ key = attn.to_k(hidden_states)
+ value = attn.to_v(hidden_states)
+ encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
+ encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
+
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+ encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
+ encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
+
+ key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
+ value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
+
+ batch_size_attention, query_tokens, _ = query.shape
+ hidden_states = torch.zeros(
+ (batch_size_attention, query_tokens, dim // attn.heads), device=query.device, dtype=query.dtype
+ )
+
+ for i in range(batch_size_attention // self.slice_size):
+ start_idx = i * self.slice_size
+ end_idx = (i + 1) * self.slice_size
+
+ query_slice = query[start_idx:end_idx]
+ key_slice = key[start_idx:end_idx]
+ attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
+
+ attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
+
+ attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
+
+ hidden_states[start_idx:end_idx] = attn_slice
+
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
+ hidden_states = hidden_states + residual
+
+ return hidden_states
+
+
+AttentionProcessor = Union[
+ AttnProcessor,
+ XFormersAttnProcessor,
+ SlicedAttnProcessor,
+ AttnAddedKVProcessor,
+ SlicedAttnAddedKVProcessor,
+ LoRAAttnProcessor,
+ LoRAXFormersAttnProcessor,
+]
diff --git a/diffusers/src/diffusers/models/autoencoder_kl.py b/diffusers/src/diffusers/models/autoencoder_kl.py
new file mode 100644
index 0000000000000000000000000000000000000000..8f65c2357cac4c86380451bc794856e0b5f31550
--- /dev/null
+++ b/diffusers/src/diffusers/models/autoencoder_kl.py
@@ -0,0 +1,328 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, apply_forward_hook
+from .modeling_utils import ModelMixin
+from .vae import Decoder, DecoderOutput, DiagonalGaussianDistribution, Encoder
+
+
+@dataclass
+class AutoencoderKLOutput(BaseOutput):
+ """
+ Output of AutoencoderKL encoding method.
+
+ Args:
+ latent_dist (`DiagonalGaussianDistribution`):
+ Encoded outputs of `Encoder` represented as the mean and logvar of `DiagonalGaussianDistribution`.
+ `DiagonalGaussianDistribution` allows for sampling latents from the distribution.
+ """
+
+ latent_dist: "DiagonalGaussianDistribution"
+
+
+class AutoencoderKL(ModelMixin, ConfigMixin):
+ r"""Variational Autoencoder (VAE) model with KL loss from the paper Auto-Encoding Variational Bayes by Diederik P. Kingma
+ and Max Welling.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the model (such as downloading or saving, etc.)
+
+ Parameters:
+ in_channels (int, *optional*, defaults to 3): Number of channels in the input image.
+ out_channels (int, *optional*, defaults to 3): Number of channels in the output.
+ down_block_types (`Tuple[str]`, *optional*, defaults to :
+ obj:`("DownEncoderBlock2D",)`): Tuple of downsample block types.
+ up_block_types (`Tuple[str]`, *optional*, defaults to :
+ obj:`("UpDecoderBlock2D",)`): Tuple of upsample block types.
+ block_out_channels (`Tuple[int]`, *optional*, defaults to :
+ obj:`(64,)`): Tuple of block output channels.
+ act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
+ latent_channels (`int`, *optional*, defaults to 4): Number of channels in the latent space.
+ sample_size (`int`, *optional*, defaults to `32`): TODO
+ scaling_factor (`float`, *optional*, defaults to 0.18215):
+ The component-wise standard deviation of the trained latent space computed using the first batch of the
+ training set. This is used to scale the latent space to have unit variance when training the diffusion
+ model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
+ diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
+ / scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
+ Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ """
+
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels: int = 3,
+ out_channels: int = 3,
+ down_block_types: Tuple[str] = ("DownEncoderBlock2D",),
+ up_block_types: Tuple[str] = ("UpDecoderBlock2D",),
+ block_out_channels: Tuple[int] = (64,),
+ layers_per_block: int = 1,
+ act_fn: str = "silu",
+ latent_channels: int = 4,
+ norm_num_groups: int = 32,
+ sample_size: int = 32,
+ scaling_factor: float = 0.18215,
+ ):
+ super().__init__()
+
+ # pass init params to Encoder
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ out_channels=latent_channels,
+ down_block_types=down_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ norm_num_groups=norm_num_groups,
+ double_z=True,
+ )
+
+ # pass init params to Decoder
+ self.decoder = Decoder(
+ in_channels=latent_channels,
+ out_channels=out_channels,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ norm_num_groups=norm_num_groups,
+ act_fn=act_fn,
+ )
+
+ self.quant_conv = nn.Conv2d(2 * latent_channels, 2 * latent_channels, 1)
+ self.post_quant_conv = nn.Conv2d(latent_channels, latent_channels, 1)
+
+ self.use_slicing = False
+ self.use_tiling = False
+
+ # only relevant if vae tiling is enabled
+ self.tile_sample_min_size = self.config.sample_size
+ sample_size = (
+ self.config.sample_size[0]
+ if isinstance(self.config.sample_size, (list, tuple))
+ else self.config.sample_size
+ )
+ self.tile_latent_min_size = int(sample_size / (2 ** (len(self.block_out_channels) - 1)))
+ self.tile_overlap_factor = 0.25
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (Encoder, Decoder)):
+ module.gradient_checkpointing = value
+
+ def enable_tiling(self, use_tiling: bool = True):
+ r"""
+ Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
+ compute decoding and encoding in several steps. This is useful to save a large amount of memory and to allow
+ the processing of larger images.
+ """
+ self.use_tiling = use_tiling
+
+ def disable_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.enable_tiling(False)
+
+ def enable_slicing(self):
+ r"""
+ Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
+ compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.use_slicing = True
+
+ def disable_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_slicing` was previously invoked, this method will go back to computing
+ decoding in one step.
+ """
+ self.use_slicing = False
+
+ @apply_forward_hook
+ def encode(self, x: torch.FloatTensor, return_dict: bool = True) -> AutoencoderKLOutput:
+ if self.use_tiling and (x.shape[-1] > self.tile_sample_min_size or x.shape[-2] > self.tile_sample_min_size):
+ return self.tiled_encode(x, return_dict=return_dict)
+
+ h = self.encoder(x)
+ moments = self.quant_conv(h)
+ posterior = DiagonalGaussianDistribution(moments)
+
+ if not return_dict:
+ return (posterior,)
+
+ return AutoencoderKLOutput(latent_dist=posterior)
+
+ def _decode(self, z: torch.FloatTensor, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
+ if self.use_tiling and (z.shape[-1] > self.tile_latent_min_size or z.shape[-2] > self.tile_latent_min_size):
+ return self.tiled_decode(z, return_dict=return_dict)
+
+ z = self.post_quant_conv(z)
+ dec = self.decoder(z)
+
+ if not return_dict:
+ return (dec,)
+
+ return DecoderOutput(sample=dec)
+
+ @apply_forward_hook
+ def decode(self, z: torch.FloatTensor, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
+ if self.use_slicing and z.shape[0] > 1:
+ decoded_slices = [self._decode(z_slice).sample for z_slice in z.split(1)]
+ decoded = torch.cat(decoded_slices)
+ else:
+ decoded = self._decode(z).sample
+
+ if not return_dict:
+ return (decoded,)
+
+ return DecoderOutput(sample=decoded)
+
+ def blend_v(self, a, b, blend_extent):
+ for y in range(min(a.shape[2], b.shape[2], blend_extent)):
+ b[:, :, y, :] = a[:, :, -blend_extent + y, :] * (1 - y / blend_extent) + b[:, :, y, :] * (y / blend_extent)
+ return b
+
+ def blend_h(self, a, b, blend_extent):
+ for x in range(min(a.shape[3], b.shape[3], blend_extent)):
+ b[:, :, :, x] = a[:, :, :, -blend_extent + x] * (1 - x / blend_extent) + b[:, :, :, x] * (x / blend_extent)
+ return b
+
+ def tiled_encode(self, x: torch.FloatTensor, return_dict: bool = True) -> AutoencoderKLOutput:
+ r"""Encode a batch of images using a tiled encoder.
+
+ Args:
+ When this option is enabled, the VAE will split the input tensor into tiles to compute encoding in several
+ steps. This is useful to keep memory use constant regardless of image size. The end result of tiled encoding is:
+ different from non-tiled encoding due to each tile using a different encoder. To avoid tiling artifacts, the
+ tiles overlap and are blended together to form a smooth output. You may still see tile-sized changes in the
+ look of the output, but they should be much less noticeable.
+ x (`torch.FloatTensor`): Input batch of images. return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`AutoencoderKLOutput`] instead of a plain tuple.
+ """
+ overlap_size = int(self.tile_sample_min_size * (1 - self.tile_overlap_factor))
+ blend_extent = int(self.tile_latent_min_size * self.tile_overlap_factor)
+ row_limit = self.tile_latent_min_size - blend_extent
+
+ # Split the image into 512x512 tiles and encode them separately.
+ rows = []
+ for i in range(0, x.shape[2], overlap_size):
+ row = []
+ for j in range(0, x.shape[3], overlap_size):
+ tile = x[:, :, i : i + self.tile_sample_min_size, j : j + self.tile_sample_min_size]
+ tile = self.encoder(tile)
+ tile = self.quant_conv(tile)
+ row.append(tile)
+ rows.append(row)
+ result_rows = []
+ for i, row in enumerate(rows):
+ result_row = []
+ for j, tile in enumerate(row):
+ # blend the above tile and the left tile
+ # to the current tile and add the current tile to the result row
+ if i > 0:
+ tile = self.blend_v(rows[i - 1][j], tile, blend_extent)
+ if j > 0:
+ tile = self.blend_h(row[j - 1], tile, blend_extent)
+ result_row.append(tile[:, :, :row_limit, :row_limit])
+ result_rows.append(torch.cat(result_row, dim=3))
+
+ moments = torch.cat(result_rows, dim=2)
+ posterior = DiagonalGaussianDistribution(moments)
+
+ if not return_dict:
+ return (posterior,)
+
+ return AutoencoderKLOutput(latent_dist=posterior)
+
+ def tiled_decode(self, z: torch.FloatTensor, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
+ r"""Decode a batch of images using a tiled decoder.
+
+ Args:
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding in several
+ steps. This is useful to keep memory use constant regardless of image size. The end result of tiled decoding is:
+ different from non-tiled decoding due to each tile using a different decoder. To avoid tiling artifacts, the
+ tiles overlap and are blended together to form a smooth output. You may still see tile-sized changes in the
+ look of the output, but they should be much less noticeable.
+ z (`torch.FloatTensor`): Input batch of latent vectors. return_dict (`bool`, *optional*, defaults to
+ `True`):
+ Whether or not to return a [`DecoderOutput`] instead of a plain tuple.
+ """
+ overlap_size = int(self.tile_latent_min_size * (1 - self.tile_overlap_factor))
+ blend_extent = int(self.tile_sample_min_size * self.tile_overlap_factor)
+ row_limit = self.tile_sample_min_size - blend_extent
+
+ # Split z into overlapping 64x64 tiles and decode them separately.
+ # The tiles have an overlap to avoid seams between tiles.
+ rows = []
+ for i in range(0, z.shape[2], overlap_size):
+ row = []
+ for j in range(0, z.shape[3], overlap_size):
+ tile = z[:, :, i : i + self.tile_latent_min_size, j : j + self.tile_latent_min_size]
+ tile = self.post_quant_conv(tile)
+ decoded = self.decoder(tile)
+ row.append(decoded)
+ rows.append(row)
+ result_rows = []
+ for i, row in enumerate(rows):
+ result_row = []
+ for j, tile in enumerate(row):
+ # blend the above tile and the left tile
+ # to the current tile and add the current tile to the result row
+ if i > 0:
+ tile = self.blend_v(rows[i - 1][j], tile, blend_extent)
+ if j > 0:
+ tile = self.blend_h(row[j - 1], tile, blend_extent)
+ result_row.append(tile[:, :, :row_limit, :row_limit])
+ result_rows.append(torch.cat(result_row, dim=3))
+
+ dec = torch.cat(result_rows, dim=2)
+ if not return_dict:
+ return (dec,)
+
+ return DecoderOutput(sample=dec)
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ sample_posterior: bool = False,
+ return_dict: bool = True,
+ generator: Optional[torch.Generator] = None,
+ ) -> Union[DecoderOutput, torch.FloatTensor]:
+ r"""
+ Args:
+ sample (`torch.FloatTensor`): Input sample.
+ sample_posterior (`bool`, *optional*, defaults to `False`):
+ Whether to sample from the posterior.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`DecoderOutput`] instead of a plain tuple.
+ """
+ x = sample
+ posterior = self.encode(x).latent_dist
+ if sample_posterior:
+ z = posterior.sample(generator=generator)
+ else:
+ z = posterior.mode()
+ dec = self.decode(z).sample
+
+ if not return_dict:
+ return (dec,)
+
+ return DecoderOutput(sample=dec)
diff --git a/diffusers/src/diffusers/models/controlnet.py b/diffusers/src/diffusers/models/controlnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb608ad82a7a38d940ae4f381fe7a81f42957ca8
--- /dev/null
+++ b/diffusers/src/diffusers/models/controlnet.py
@@ -0,0 +1,573 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, logging
+from .attention_processor import AttentionProcessor, AttnProcessor
+from .embeddings import TimestepEmbedding, Timesteps
+from .modeling_utils import ModelMixin
+from .unet_2d_blocks import (
+ CrossAttnDownBlock2D,
+ DownBlock2D,
+ UNetMidBlock2DCrossAttn,
+ get_down_block,
+)
+from .unet_2d_condition import UNet2DConditionModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class ControlNetOutput(BaseOutput):
+ down_block_res_samples: Tuple[torch.Tensor]
+ mid_block_res_sample: torch.Tensor
+
+
+class ControlNetConditioningEmbedding(nn.Module):
+ """
+ Quoting from https://arxiv.org/abs/2302.05543: "Stable Diffusion uses a pre-processing method similar to VQ-GAN
+ [11] to convert the entire dataset of 512 × 512 images into smaller 64 × 64 “latent images” for stabilized
+ training. This requires ControlNets to convert image-based conditions to 64 × 64 feature space to match the
+ convolution size. We use a tiny network E(·) of four convolution layers with 4 × 4 kernels and 2 × 2 strides
+ (activated by ReLU, channels are 16, 32, 64, 128, initialized with Gaussian weights, trained jointly with the full
+ model) to encode image-space conditions ... into feature maps ..."
+ """
+
+ def __init__(
+ self,
+ conditioning_embedding_channels: int,
+ conditioning_channels: int = 3,
+ block_out_channels: Tuple[int] = (16, 32, 96, 256),
+ ):
+ super().__init__()
+
+ self.conv_in = nn.Conv2d(conditioning_channels, block_out_channels[0], kernel_size=3, padding=1)
+
+ self.blocks = nn.ModuleList([])
+
+ for i in range(len(block_out_channels) - 1):
+ channel_in = block_out_channels[i]
+ channel_out = block_out_channels[i + 1]
+ self.blocks.append(nn.Conv2d(channel_in, channel_in, kernel_size=3, padding=1))
+ self.blocks.append(nn.Conv2d(channel_in, channel_out, kernel_size=3, padding=1, stride=2))
+
+ self.conv_out = zero_module(
+ nn.Conv2d(block_out_channels[-1], conditioning_embedding_channels, kernel_size=3, padding=1)
+ )
+
+ def forward(self, conditioning):
+ embedding = self.conv_in(conditioning)
+ embedding = F.silu(embedding)
+
+ for block in self.blocks:
+ embedding = block(embedding)
+ embedding = F.silu(embedding)
+
+ embedding = self.conv_out(embedding)
+
+ return embedding
+
+
+class ControlNetModel(ModelMixin, ConfigMixin):
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels: int = 4,
+ flip_sin_to_cos: bool = True,
+ freq_shift: int = 0,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D",
+ ),
+ only_cross_attention: Union[bool, Tuple[bool]] = False,
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: int = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: int = 1280,
+ attention_head_dim: Union[int, Tuple[int]] = 8,
+ use_linear_projection: bool = False,
+ class_embed_type: Optional[str] = None,
+ num_class_embeds: Optional[int] = None,
+ upcast_attention: bool = False,
+ resnet_time_scale_shift: str = "default",
+ projection_class_embeddings_input_dim: Optional[int] = None,
+ controlnet_conditioning_channel_order: str = "rgb",
+ conditioning_embedding_out_channels: Optional[Tuple[int]] = (16, 32, 96, 256),
+ ):
+ super().__init__()
+
+ # Check inputs
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_kernel = 3
+ conv_in_padding = (conv_in_kernel - 1) // 2
+ self.conv_in = nn.Conv2d(
+ in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
+ )
+
+ # time
+ time_embed_dim = block_out_channels[0] * 4
+
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ )
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ elif class_embed_type == "projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
+ # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
+ # 2. it projects from an arbitrary input dimension.
+ #
+ # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
+ # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
+ # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
+ self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ # control net conditioning embedding
+ self.controlnet_cond_embedding = ControlNetConditioningEmbedding(
+ conditioning_embedding_channels=block_out_channels[0],
+ block_out_channels=conditioning_embedding_out_channels,
+ )
+
+ self.down_blocks = nn.ModuleList([])
+ self.controlnet_down_blocks = nn.ModuleList([])
+
+ if isinstance(only_cross_attention, bool):
+ only_cross_attention = [only_cross_attention] * len(down_block_types)
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ # down
+ output_channel = block_out_channels[0]
+
+ controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
+ controlnet_block = zero_module(controlnet_block)
+ self.controlnet_down_blocks.append(controlnet_block)
+
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim[i],
+ downsample_padding=downsample_padding,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.down_blocks.append(down_block)
+
+ for _ in range(layers_per_block):
+ controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
+ controlnet_block = zero_module(controlnet_block)
+ self.controlnet_down_blocks.append(controlnet_block)
+
+ if not is_final_block:
+ controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
+ controlnet_block = zero_module(controlnet_block)
+ self.controlnet_down_blocks.append(controlnet_block)
+
+ # mid
+ mid_block_channel = block_out_channels[-1]
+
+ controlnet_block = nn.Conv2d(mid_block_channel, mid_block_channel, kernel_size=1)
+ controlnet_block = zero_module(controlnet_block)
+ self.controlnet_mid_block = controlnet_block
+
+ self.mid_block = UNetMidBlock2DCrossAttn(
+ in_channels=mid_block_channel,
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim[-1],
+ resnet_groups=norm_num_groups,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+
+ @classmethod
+ def from_unet(
+ cls,
+ unet: UNet2DConditionModel,
+ controlnet_conditioning_channel_order: str = "rgb",
+ conditioning_embedding_out_channels: Optional[Tuple[int]] = (16, 32, 96, 256),
+ load_weights_from_unet: bool = True,
+ ):
+ r"""
+ Instantiate Controlnet class from UNet2DConditionModel.
+
+ Parameters:
+ unet (`UNet2DConditionModel`):
+ UNet model which weights are copied to the ControlNet. Note that all configuration options are also
+ copied where applicable.
+ """
+ controlnet = cls(
+ in_channels=unet.config.in_channels,
+ flip_sin_to_cos=unet.config.flip_sin_to_cos,
+ freq_shift=unet.config.freq_shift,
+ down_block_types=unet.config.down_block_types,
+ only_cross_attention=unet.config.only_cross_attention,
+ block_out_channels=unet.config.block_out_channels,
+ layers_per_block=unet.config.layers_per_block,
+ downsample_padding=unet.config.downsample_padding,
+ mid_block_scale_factor=unet.config.mid_block_scale_factor,
+ act_fn=unet.config.act_fn,
+ norm_num_groups=unet.config.norm_num_groups,
+ norm_eps=unet.config.norm_eps,
+ cross_attention_dim=unet.config.cross_attention_dim,
+ attention_head_dim=unet.config.attention_head_dim,
+ use_linear_projection=unet.config.use_linear_projection,
+ class_embed_type=unet.config.class_embed_type,
+ num_class_embeds=unet.config.num_class_embeds,
+ upcast_attention=unet.config.upcast_attention,
+ resnet_time_scale_shift=unet.config.resnet_time_scale_shift,
+ projection_class_embeddings_input_dim=unet.config.projection_class_embeddings_input_dim,
+ controlnet_conditioning_channel_order=controlnet_conditioning_channel_order,
+ conditioning_embedding_out_channels=conditioning_embedding_out_channels,
+ )
+
+ if load_weights_from_unet:
+ controlnet.conv_in.load_state_dict(unet.conv_in.state_dict())
+ controlnet.time_proj.load_state_dict(unet.time_proj.state_dict())
+ controlnet.time_embedding.load_state_dict(unet.time_embedding.state_dict())
+
+ if controlnet.class_embedding:
+ controlnet.class_embedding.load_state_dict(unet.class_embedding.state_dict())
+
+ controlnet.down_blocks.load_state_dict(unet.down_blocks.state_dict())
+ controlnet.mid_block.load_state_dict(unet.mid_block.state_dict())
+
+ return controlnet
+
+ @property
+ # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.attn_processors
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attn_processor
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
+ r"""
+ Parameters:
+ `processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ of **all** `Attention` layers.
+ In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainable attention processors.:
+
+ """
+ count = len(self.attn_processors.keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attention_slice
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module will split the input tensor in slices, to compute attention
+ in several steps. This is useful to save some memory in exchange for a small speed decrease.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
+ `"max"`, maximum amount of memory will be saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlock2D, DownBlock2D)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ controlnet_cond: torch.FloatTensor,
+ conditioning_scale: float = 1.0,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ return_dict: bool = True,
+ ) -> Union[ControlNetOutput, Tuple]:
+ # check channel order
+ channel_order = self.config.controlnet_conditioning_channel_order
+
+ if channel_order == "rgb":
+ # in rgb order by default
+ ...
+ elif channel_order == "bgr":
+ controlnet_cond = torch.flip(controlnet_cond, dims=[1])
+ else:
+ raise ValueError(f"unknown `controlnet_conditioning_channel_order`: {channel_order}")
+
+ # prepare attention_mask
+ if attention_mask is not None:
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # timesteps does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=self.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when num_class_embeds > 0")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
+ emb = emb + class_emb
+
+ # 2. pre-process
+ sample = self.conv_in(sample)
+
+ controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
+
+ sample += controlnet_cond
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+
+ # 5. Control net blocks
+
+ controlnet_down_block_res_samples = ()
+
+ for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks):
+ down_block_res_sample = controlnet_block(down_block_res_sample)
+ controlnet_down_block_res_samples += (down_block_res_sample,)
+
+ down_block_res_samples = controlnet_down_block_res_samples
+
+ mid_block_res_sample = self.controlnet_mid_block(sample)
+
+ # 6. scaling
+ down_block_res_samples = [sample * conditioning_scale for sample in down_block_res_samples]
+ mid_block_res_sample *= conditioning_scale
+
+ if not return_dict:
+ return (down_block_res_samples, mid_block_res_sample)
+
+ return ControlNetOutput(
+ down_block_res_samples=down_block_res_samples, mid_block_res_sample=mid_block_res_sample
+ )
+
+
+def zero_module(module):
+ for p in module.parameters():
+ nn.init.zeros_(p)
+ return module
diff --git a/diffusers/src/diffusers/models/controlnet_flax.py b/diffusers/src/diffusers/models/controlnet_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..3adefa84ea680c521a1dea505e3ece26dc122efa
--- /dev/null
+++ b/diffusers/src/diffusers/models/controlnet_flax.py
@@ -0,0 +1,383 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Tuple, Union
+
+import flax
+import flax.linen as nn
+import jax
+import jax.numpy as jnp
+from flax.core.frozen_dict import FrozenDict
+
+from ..configuration_utils import ConfigMixin, flax_register_to_config
+from ..utils import BaseOutput
+from .embeddings_flax import FlaxTimestepEmbedding, FlaxTimesteps
+from .modeling_flax_utils import FlaxModelMixin
+from .unet_2d_blocks_flax import (
+ FlaxCrossAttnDownBlock2D,
+ FlaxDownBlock2D,
+ FlaxUNetMidBlock2DCrossAttn,
+)
+
+
+@flax.struct.dataclass
+class FlaxControlNetOutput(BaseOutput):
+ down_block_res_samples: jnp.ndarray
+ mid_block_res_sample: jnp.ndarray
+
+
+class FlaxControlNetConditioningEmbedding(nn.Module):
+ conditioning_embedding_channels: int
+ block_out_channels: Tuple[int] = (16, 32, 96, 256)
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.conv_in = nn.Conv(
+ self.block_out_channels[0],
+ kernel_size=(3, 3),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ blocks = []
+ for i in range(len(self.block_out_channels) - 1):
+ channel_in = self.block_out_channels[i]
+ channel_out = self.block_out_channels[i + 1]
+ conv1 = nn.Conv(
+ channel_in,
+ kernel_size=(3, 3),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+ blocks.append(conv1)
+ conv2 = nn.Conv(
+ channel_out,
+ kernel_size=(3, 3),
+ strides=(2, 2),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+ blocks.append(conv2)
+ self.blocks = blocks
+
+ self.conv_out = nn.Conv(
+ self.conditioning_embedding_channels,
+ kernel_size=(3, 3),
+ padding=((1, 1), (1, 1)),
+ kernel_init=nn.initializers.zeros_init(),
+ bias_init=nn.initializers.zeros_init(),
+ dtype=self.dtype,
+ )
+
+ def __call__(self, conditioning):
+ embedding = self.conv_in(conditioning)
+ embedding = nn.silu(embedding)
+
+ for block in self.blocks:
+ embedding = block(embedding)
+ embedding = nn.silu(embedding)
+
+ embedding = self.conv_out(embedding)
+
+ return embedding
+
+
+@flax_register_to_config
+class FlaxControlNetModel(nn.Module, FlaxModelMixin, ConfigMixin):
+ r"""
+ Quoting from https://arxiv.org/abs/2302.05543: "Stable Diffusion uses a pre-processing method similar to VQ-GAN
+ [11] to convert the entire dataset of 512 × 512 images into smaller 64 × 64 “latent images” for stabilized
+ training. This requires ControlNets to convert image-based conditions to 64 × 64 feature space to match the
+ convolution size. We use a tiny network E(·) of four convolution layers with 4 × 4 kernels and 2 × 2 strides
+ (activated by ReLU, channels are 16, 32, 64, 128, initialized with Gaussian weights, trained jointly with the full
+ model) to encode image-space conditions ... into feature maps ..."
+
+ This model inherits from [`FlaxModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the models (such as downloading or saving, etc.)
+
+ Also, this model is a Flax Linen [flax.linen.Module](https://flax.readthedocs.io/en/latest/flax.linen.html#module)
+ subclass. Use it as a regular Flax linen Module and refer to the Flax documentation for all matter related to
+ general usage and behavior.
+
+ Finally, this model supports inherent JAX features such as:
+ - [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
+ - [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
+ - [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
+ - [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
+
+ Parameters:
+ sample_size (`int`, *optional*):
+ The size of the input sample.
+ in_channels (`int`, *optional*, defaults to 4):
+ The number of channels in the input sample.
+ down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
+ The tuple of downsample blocks to use. The corresponding class names will be: "FlaxCrossAttnDownBlock2D",
+ "FlaxCrossAttnDownBlock2D", "FlaxCrossAttnDownBlock2D", "FlaxDownBlock2D"
+ block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
+ The tuple of output channels for each block.
+ layers_per_block (`int`, *optional*, defaults to 2):
+ The number of layers per block.
+ attention_head_dim (`int` or `Tuple[int]`, *optional*, defaults to 8):
+ The dimension of the attention heads.
+ cross_attention_dim (`int`, *optional*, defaults to 768):
+ The dimension of the cross attention features.
+ dropout (`float`, *optional*, defaults to 0):
+ Dropout probability for down, up and bottleneck blocks.
+ flip_sin_to_cos (`bool`, *optional*, defaults to `True`):
+ Whether to flip the sin to cos in the time embedding.
+ freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
+ controlnet_conditioning_channel_order (`str`, *optional*, defaults to `rgb`):
+ The channel order of conditional image. Will convert it to `rgb` if it's `bgr`
+ conditioning_embedding_out_channels (`tuple`, *optional*, defaults to `(16, 32, 96, 256)`):
+ The tuple of output channel for each block in conditioning_embedding layer
+
+
+ """
+ sample_size: int = 32
+ in_channels: int = 4
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D",
+ )
+ only_cross_attention: Union[bool, Tuple[bool]] = False
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280)
+ layers_per_block: int = 2
+ attention_head_dim: Union[int, Tuple[int]] = 8
+ cross_attention_dim: int = 1280
+ dropout: float = 0.0
+ use_linear_projection: bool = False
+ dtype: jnp.dtype = jnp.float32
+ flip_sin_to_cos: bool = True
+ freq_shift: int = 0
+ controlnet_conditioning_channel_order: str = "rgb"
+ conditioning_embedding_out_channels: Tuple[int] = (16, 32, 96, 256)
+
+ def init_weights(self, rng: jax.random.KeyArray) -> FrozenDict:
+ # init input tensors
+ sample_shape = (1, self.in_channels, self.sample_size, self.sample_size)
+ sample = jnp.zeros(sample_shape, dtype=jnp.float32)
+ timesteps = jnp.ones((1,), dtype=jnp.int32)
+ encoder_hidden_states = jnp.zeros((1, 1, self.cross_attention_dim), dtype=jnp.float32)
+ controlnet_cond_shape = (1, 3, self.sample_size * 8, self.sample_size * 8)
+ controlnet_cond = jnp.zeros(controlnet_cond_shape, dtype=jnp.float32)
+
+ params_rng, dropout_rng = jax.random.split(rng)
+ rngs = {"params": params_rng, "dropout": dropout_rng}
+
+ return self.init(rngs, sample, timesteps, encoder_hidden_states, controlnet_cond)["params"]
+
+ def setup(self):
+ block_out_channels = self.block_out_channels
+ time_embed_dim = block_out_channels[0] * 4
+
+ # input
+ self.conv_in = nn.Conv(
+ block_out_channels[0],
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ # time
+ self.time_proj = FlaxTimesteps(
+ block_out_channels[0], flip_sin_to_cos=self.flip_sin_to_cos, freq_shift=self.config.freq_shift
+ )
+ self.time_embedding = FlaxTimestepEmbedding(time_embed_dim, dtype=self.dtype)
+
+ self.controlnet_cond_embedding = FlaxControlNetConditioningEmbedding(
+ conditioning_embedding_channels=block_out_channels[0],
+ block_out_channels=self.conditioning_embedding_out_channels,
+ )
+
+ only_cross_attention = self.only_cross_attention
+ if isinstance(only_cross_attention, bool):
+ only_cross_attention = (only_cross_attention,) * len(self.down_block_types)
+
+ attention_head_dim = self.attention_head_dim
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(self.down_block_types)
+
+ # down
+ down_blocks = []
+ controlnet_down_blocks = []
+
+ output_channel = block_out_channels[0]
+
+ controlnet_block = nn.Conv(
+ output_channel,
+ kernel_size=(1, 1),
+ padding="VALID",
+ kernel_init=nn.initializers.zeros_init(),
+ bias_init=nn.initializers.zeros_init(),
+ dtype=self.dtype,
+ )
+ controlnet_down_blocks.append(controlnet_block)
+
+ for i, down_block_type in enumerate(self.down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ if down_block_type == "CrossAttnDownBlock2D":
+ down_block = FlaxCrossAttnDownBlock2D(
+ in_channels=input_channel,
+ out_channels=output_channel,
+ dropout=self.dropout,
+ num_layers=self.layers_per_block,
+ attn_num_head_channels=attention_head_dim[i],
+ add_downsample=not is_final_block,
+ use_linear_projection=self.use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ dtype=self.dtype,
+ )
+ else:
+ down_block = FlaxDownBlock2D(
+ in_channels=input_channel,
+ out_channels=output_channel,
+ dropout=self.dropout,
+ num_layers=self.layers_per_block,
+ add_downsample=not is_final_block,
+ dtype=self.dtype,
+ )
+
+ down_blocks.append(down_block)
+
+ for _ in range(self.layers_per_block):
+ controlnet_block = nn.Conv(
+ output_channel,
+ kernel_size=(1, 1),
+ padding="VALID",
+ kernel_init=nn.initializers.zeros_init(),
+ bias_init=nn.initializers.zeros_init(),
+ dtype=self.dtype,
+ )
+ controlnet_down_blocks.append(controlnet_block)
+
+ if not is_final_block:
+ controlnet_block = nn.Conv(
+ output_channel,
+ kernel_size=(1, 1),
+ padding="VALID",
+ kernel_init=nn.initializers.zeros_init(),
+ bias_init=nn.initializers.zeros_init(),
+ dtype=self.dtype,
+ )
+ controlnet_down_blocks.append(controlnet_block)
+
+ self.down_blocks = down_blocks
+ self.controlnet_down_blocks = controlnet_down_blocks
+
+ # mid
+ mid_block_channel = block_out_channels[-1]
+ self.mid_block = FlaxUNetMidBlock2DCrossAttn(
+ in_channels=mid_block_channel,
+ dropout=self.dropout,
+ attn_num_head_channels=attention_head_dim[-1],
+ use_linear_projection=self.use_linear_projection,
+ dtype=self.dtype,
+ )
+
+ self.controlnet_mid_block = nn.Conv(
+ mid_block_channel,
+ kernel_size=(1, 1),
+ padding="VALID",
+ kernel_init=nn.initializers.zeros_init(),
+ bias_init=nn.initializers.zeros_init(),
+ dtype=self.dtype,
+ )
+
+ def __call__(
+ self,
+ sample,
+ timesteps,
+ encoder_hidden_states,
+ controlnet_cond,
+ conditioning_scale: float = 1.0,
+ return_dict: bool = True,
+ train: bool = False,
+ ) -> Union[FlaxControlNetOutput, Tuple]:
+ r"""
+ Args:
+ sample (`jnp.ndarray`): (batch, channel, height, width) noisy inputs tensor
+ timestep (`jnp.ndarray` or `float` or `int`): timesteps
+ encoder_hidden_states (`jnp.ndarray`): (batch_size, sequence_length, hidden_size) encoder hidden states
+ controlnet_cond (`jnp.ndarray`): (batch, channel, height, width) the conditional input tensor
+ conditioning_scale: (`float`) the scale factor for controlnet outputs
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition_flax.FlaxUNet2DConditionOutput`] instead of a
+ plain tuple.
+ train (`bool`, *optional*, defaults to `False`):
+ Use deterministic functions and disable dropout when not training.
+
+ Returns:
+ [`~models.unet_2d_condition_flax.FlaxUNet2DConditionOutput`] or `tuple`:
+ [`~models.unet_2d_condition_flax.FlaxUNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`.
+ When returning a tuple, the first element is the sample tensor.
+ """
+ channel_order = self.controlnet_conditioning_channel_order
+ if channel_order == "bgr":
+ controlnet_cond = jnp.flip(controlnet_cond, axis=1)
+
+ # 1. time
+ if not isinstance(timesteps, jnp.ndarray):
+ timesteps = jnp.array([timesteps], dtype=jnp.int32)
+ elif isinstance(timesteps, jnp.ndarray) and len(timesteps.shape) == 0:
+ timesteps = timesteps.astype(dtype=jnp.float32)
+ timesteps = jnp.expand_dims(timesteps, 0)
+
+ t_emb = self.time_proj(timesteps)
+ t_emb = self.time_embedding(t_emb)
+
+ # 2. pre-process
+ sample = jnp.transpose(sample, (0, 2, 3, 1))
+ sample = self.conv_in(sample)
+
+ controlnet_cond = jnp.transpose(controlnet_cond, (0, 2, 3, 1))
+ controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
+ sample += controlnet_cond
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for down_block in self.down_blocks:
+ if isinstance(down_block, FlaxCrossAttnDownBlock2D):
+ sample, res_samples = down_block(sample, t_emb, encoder_hidden_states, deterministic=not train)
+ else:
+ sample, res_samples = down_block(sample, t_emb, deterministic=not train)
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, t_emb, encoder_hidden_states, deterministic=not train)
+
+ # 5. contronet blocks
+ controlnet_down_block_res_samples = ()
+ for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks):
+ down_block_res_sample = controlnet_block(down_block_res_sample)
+ controlnet_down_block_res_samples += (down_block_res_sample,)
+
+ down_block_res_samples = controlnet_down_block_res_samples
+
+ mid_block_res_sample = self.controlnet_mid_block(sample)
+
+ # 6. scaling
+ down_block_res_samples = [sample * conditioning_scale for sample in down_block_res_samples]
+ mid_block_res_sample *= conditioning_scale
+
+ if not return_dict:
+ return (down_block_res_samples, mid_block_res_sample)
+
+ return FlaxControlNetOutput(
+ down_block_res_samples=down_block_res_samples, mid_block_res_sample=mid_block_res_sample
+ )
diff --git a/diffusers/src/diffusers/models/cross_attention.py b/diffusers/src/diffusers/models/cross_attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..4fdb2acaabed20c1cf8ca2a9fa9ce4a29a0c3a00
--- /dev/null
+++ b/diffusers/src/diffusers/models/cross_attention.py
@@ -0,0 +1,94 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from ..utils import deprecate
+from .attention_processor import ( # noqa: F401
+ Attention,
+ AttentionProcessor,
+ AttnAddedKVProcessor,
+ AttnProcessor2_0,
+ LoRAAttnProcessor,
+ LoRALinearLayer,
+ LoRAXFormersAttnProcessor,
+ SlicedAttnAddedKVProcessor,
+ SlicedAttnProcessor,
+ XFormersAttnProcessor,
+)
+from .attention_processor import AttnProcessor as AttnProcessorRename # noqa: F401
+
+
+deprecate(
+ "cross_attention",
+ "0.18.0",
+ "Importing from cross_attention is deprecated. Please import from diffusers.models.attention_processor instead.",
+ standard_warn=False,
+)
+
+
+AttnProcessor = AttentionProcessor
+
+
+class CrossAttention(Attention):
+ def __init__(self, *args, **kwargs):
+ deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
+ deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
+ super().__init__(*args, **kwargs)
+
+
+class CrossAttnProcessor(AttnProcessorRename):
+ def __init__(self, *args, **kwargs):
+ deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
+ deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
+ super().__init__(*args, **kwargs)
+
+
+class LoRACrossAttnProcessor(LoRAAttnProcessor):
+ def __init__(self, *args, **kwargs):
+ deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
+ deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
+ super().__init__(*args, **kwargs)
+
+
+class CrossAttnAddedKVProcessor(AttnAddedKVProcessor):
+ def __init__(self, *args, **kwargs):
+ deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
+ deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
+ super().__init__(*args, **kwargs)
+
+
+class XFormersCrossAttnProcessor(XFormersAttnProcessor):
+ def __init__(self, *args, **kwargs):
+ deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
+ deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
+ super().__init__(*args, **kwargs)
+
+
+class LoRAXFormersCrossAttnProcessor(LoRAXFormersAttnProcessor):
+ def __init__(self, *args, **kwargs):
+ deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
+ deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
+ super().__init__(*args, **kwargs)
+
+
+class SlicedCrossAttnProcessor(SlicedAttnProcessor):
+ def __init__(self, *args, **kwargs):
+ deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
+ deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
+ super().__init__(*args, **kwargs)
+
+
+class SlicedCrossAttnAddedKVProcessor(SlicedAttnAddedKVProcessor):
+ def __init__(self, *args, **kwargs):
+ deprecation_message = f"{self.__class__.__name__} is deprecated and will be removed in `0.18.0`. Please use `from diffusers.models.attention_processor import {''.join(self.__class__.__name__.split('Cross'))} instead."
+ deprecate("cross_attention", "0.18.0", deprecation_message, standard_warn=False)
+ super().__init__(*args, **kwargs)
diff --git a/diffusers/src/diffusers/models/dual_transformer_2d.py b/diffusers/src/diffusers/models/dual_transformer_2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..3db7e73ca6afc5fa7c67c1902d79e67c1aa728bc
--- /dev/null
+++ b/diffusers/src/diffusers/models/dual_transformer_2d.py
@@ -0,0 +1,151 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Optional
+
+from torch import nn
+
+from .transformer_2d import Transformer2DModel, Transformer2DModelOutput
+
+
+class DualTransformer2DModel(nn.Module):
+ """
+ Dual transformer wrapper that combines two `Transformer2DModel`s for mixed inference.
+
+ Parameters:
+ num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
+ attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
+ in_channels (`int`, *optional*):
+ Pass if the input is continuous. The number of channels in the input and output.
+ num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
+ dropout (`float`, *optional*, defaults to 0.1): The dropout probability to use.
+ cross_attention_dim (`int`, *optional*): The number of encoder_hidden_states dimensions to use.
+ sample_size (`int`, *optional*): Pass if the input is discrete. The width of the latent images.
+ Note that this is fixed at training time as it is used for learning a number of position embeddings. See
+ `ImagePositionalEmbeddings`.
+ num_vector_embeds (`int`, *optional*):
+ Pass if the input is discrete. The number of classes of the vector embeddings of the latent pixels.
+ Includes the class for the masked latent pixel.
+ activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
+ num_embeds_ada_norm ( `int`, *optional*): Pass if at least one of the norm_layers is `AdaLayerNorm`.
+ The number of diffusion steps used during training. Note that this is fixed at training time as it is used
+ to learn a number of embeddings that are added to the hidden states. During inference, you can denoise for
+ up to but not more than steps than `num_embeds_ada_norm`.
+ attention_bias (`bool`, *optional*):
+ Configure if the TransformerBlocks' attention should contain a bias parameter.
+ """
+
+ def __init__(
+ self,
+ num_attention_heads: int = 16,
+ attention_head_dim: int = 88,
+ in_channels: Optional[int] = None,
+ num_layers: int = 1,
+ dropout: float = 0.0,
+ norm_num_groups: int = 32,
+ cross_attention_dim: Optional[int] = None,
+ attention_bias: bool = False,
+ sample_size: Optional[int] = None,
+ num_vector_embeds: Optional[int] = None,
+ activation_fn: str = "geglu",
+ num_embeds_ada_norm: Optional[int] = None,
+ ):
+ super().__init__()
+ self.transformers = nn.ModuleList(
+ [
+ Transformer2DModel(
+ num_attention_heads=num_attention_heads,
+ attention_head_dim=attention_head_dim,
+ in_channels=in_channels,
+ num_layers=num_layers,
+ dropout=dropout,
+ norm_num_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim,
+ attention_bias=attention_bias,
+ sample_size=sample_size,
+ num_vector_embeds=num_vector_embeds,
+ activation_fn=activation_fn,
+ num_embeds_ada_norm=num_embeds_ada_norm,
+ )
+ for _ in range(2)
+ ]
+ )
+
+ # Variables that can be set by a pipeline:
+
+ # The ratio of transformer1 to transformer2's output states to be combined during inference
+ self.mix_ratio = 0.5
+
+ # The shape of `encoder_hidden_states` is expected to be
+ # `(batch_size, condition_lengths[0]+condition_lengths[1], num_features)`
+ self.condition_lengths = [77, 257]
+
+ # Which transformer to use to encode which condition.
+ # E.g. `(1, 0)` means that we'll use `transformers[1](conditions[0])` and `transformers[0](conditions[1])`
+ self.transformer_index_for_condition = [1, 0]
+
+ def forward(
+ self,
+ hidden_states,
+ encoder_hidden_states,
+ timestep=None,
+ attention_mask=None,
+ cross_attention_kwargs=None,
+ return_dict: bool = True,
+ ):
+ """
+ Args:
+ hidden_states ( When discrete, `torch.LongTensor` of shape `(batch size, num latent pixels)`.
+ When continuous, `torch.FloatTensor` of shape `(batch size, channel, height, width)`): Input
+ hidden_states
+ encoder_hidden_states ( `torch.LongTensor` of shape `(batch size, encoder_hidden_states dim)`, *optional*):
+ Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
+ self-attention.
+ timestep ( `torch.long`, *optional*):
+ Optional timestep to be applied as an embedding in AdaLayerNorm's. Used to indicate denoising step.
+ attention_mask (`torch.FloatTensor`, *optional*):
+ Optional attention mask to be applied in Attention
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~models.transformer_2d.Transformer2DModelOutput`] or `tuple`:
+ [`~models.transformer_2d.Transformer2DModelOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ input_states = hidden_states
+
+ encoded_states = []
+ tokens_start = 0
+ # attention_mask is not used yet
+ for i in range(2):
+ # for each of the two transformers, pass the corresponding condition tokens
+ condition_state = encoder_hidden_states[:, tokens_start : tokens_start + self.condition_lengths[i]]
+ transformer_index = self.transformer_index_for_condition[i]
+ encoded_state = self.transformers[transformer_index](
+ input_states,
+ encoder_hidden_states=condition_state,
+ timestep=timestep,
+ cross_attention_kwargs=cross_attention_kwargs,
+ return_dict=False,
+ )[0]
+ encoded_states.append(encoded_state - input_states)
+ tokens_start += self.condition_lengths[i]
+
+ output_states = encoded_states[0] * self.mix_ratio + encoded_states[1] * (1 - self.mix_ratio)
+ output_states = output_states + input_states
+
+ if not return_dict:
+ return (output_states,)
+
+ return Transformer2DModelOutput(sample=output_states)
diff --git a/diffusers/src/diffusers/models/embeddings.py b/diffusers/src/diffusers/models/embeddings.py
new file mode 100644
index 0000000000000000000000000000000000000000..7fbadb471f9275545f687b0f631eab74582f32d8
--- /dev/null
+++ b/diffusers/src/diffusers/models/embeddings.py
@@ -0,0 +1,379 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+from typing import Optional
+
+import numpy as np
+import torch
+from torch import nn
+
+
+def get_timestep_embedding(
+ timesteps: torch.Tensor,
+ embedding_dim: int,
+ flip_sin_to_cos: bool = False,
+ downscale_freq_shift: float = 1,
+ scale: float = 1,
+ max_period: int = 10000,
+):
+ """
+ This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
+
+ :param timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ :param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
+ embeddings. :return: an [N x dim] Tensor of positional embeddings.
+ """
+ assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
+
+ half_dim = embedding_dim // 2
+ exponent = -math.log(max_period) * torch.arange(
+ start=0, end=half_dim, dtype=torch.float32, device=timesteps.device
+ )
+ exponent = exponent / (half_dim - downscale_freq_shift)
+
+ emb = torch.exp(exponent)
+ emb = timesteps[:, None].float() * emb[None, :]
+
+ # scale embeddings
+ emb = scale * emb
+
+ # concat sine and cosine embeddings
+ emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
+
+ # flip sine and cosine embeddings
+ if flip_sin_to_cos:
+ emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
+
+ # zero pad
+ if embedding_dim % 2 == 1:
+ emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
+ return emb
+
+
+def get_2d_sincos_pos_embed(embed_dim, grid_size, cls_token=False, extra_tokens=0):
+ """
+ grid_size: int of the grid height and width return: pos_embed: [grid_size*grid_size, embed_dim] or
+ [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
+ """
+ grid_h = np.arange(grid_size, dtype=np.float32)
+ grid_w = np.arange(grid_size, dtype=np.float32)
+ grid = np.meshgrid(grid_w, grid_h) # here w goes first
+ grid = np.stack(grid, axis=0)
+
+ grid = grid.reshape([2, 1, grid_size, grid_size])
+ pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
+ if cls_token and extra_tokens > 0:
+ pos_embed = np.concatenate([np.zeros([extra_tokens, embed_dim]), pos_embed], axis=0)
+ return pos_embed
+
+
+def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
+ if embed_dim % 2 != 0:
+ raise ValueError("embed_dim must be divisible by 2")
+
+ # use half of dimensions to encode grid_h
+ emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
+ emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
+
+ emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
+ return emb
+
+
+def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
+ """
+ embed_dim: output dimension for each position pos: a list of positions to be encoded: size (M,) out: (M, D)
+ """
+ if embed_dim % 2 != 0:
+ raise ValueError("embed_dim must be divisible by 2")
+
+ omega = np.arange(embed_dim // 2, dtype=np.float64)
+ omega /= embed_dim / 2.0
+ omega = 1.0 / 10000**omega # (D/2,)
+
+ pos = pos.reshape(-1) # (M,)
+ out = np.einsum("m,d->md", pos, omega) # (M, D/2), outer product
+
+ emb_sin = np.sin(out) # (M, D/2)
+ emb_cos = np.cos(out) # (M, D/2)
+
+ emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
+ return emb
+
+
+class PatchEmbed(nn.Module):
+ """2D Image to Patch Embedding"""
+
+ def __init__(
+ self,
+ height=224,
+ width=224,
+ patch_size=16,
+ in_channels=3,
+ embed_dim=768,
+ layer_norm=False,
+ flatten=True,
+ bias=True,
+ ):
+ super().__init__()
+
+ num_patches = (height // patch_size) * (width // patch_size)
+ self.flatten = flatten
+ self.layer_norm = layer_norm
+
+ self.proj = nn.Conv2d(
+ in_channels, embed_dim, kernel_size=(patch_size, patch_size), stride=patch_size, bias=bias
+ )
+ if layer_norm:
+ self.norm = nn.LayerNorm(embed_dim, elementwise_affine=False, eps=1e-6)
+ else:
+ self.norm = None
+
+ pos_embed = get_2d_sincos_pos_embed(embed_dim, int(num_patches**0.5))
+ self.register_buffer("pos_embed", torch.from_numpy(pos_embed).float().unsqueeze(0), persistent=False)
+
+ def forward(self, latent):
+ latent = self.proj(latent)
+ if self.flatten:
+ latent = latent.flatten(2).transpose(1, 2) # BCHW -> BNC
+ if self.layer_norm:
+ latent = self.norm(latent)
+ return latent + self.pos_embed
+
+
+class TimestepEmbedding(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ time_embed_dim: int,
+ act_fn: str = "silu",
+ out_dim: int = None,
+ post_act_fn: Optional[str] = None,
+ cond_proj_dim=None,
+ ):
+ super().__init__()
+
+ self.linear_1 = nn.Linear(in_channels, time_embed_dim)
+
+ if cond_proj_dim is not None:
+ self.cond_proj = nn.Linear(cond_proj_dim, in_channels, bias=False)
+ else:
+ self.cond_proj = None
+
+ if act_fn == "silu":
+ self.act = nn.SiLU()
+ elif act_fn == "mish":
+ self.act = nn.Mish()
+ elif act_fn == "gelu":
+ self.act = nn.GELU()
+ else:
+ raise ValueError(f"{act_fn} does not exist. Make sure to define one of 'silu', 'mish', or 'gelu'")
+
+ if out_dim is not None:
+ time_embed_dim_out = out_dim
+ else:
+ time_embed_dim_out = time_embed_dim
+ self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim_out)
+
+ if post_act_fn is None:
+ self.post_act = None
+ elif post_act_fn == "silu":
+ self.post_act = nn.SiLU()
+ elif post_act_fn == "mish":
+ self.post_act = nn.Mish()
+ elif post_act_fn == "gelu":
+ self.post_act = nn.GELU()
+ else:
+ raise ValueError(f"{post_act_fn} does not exist. Make sure to define one of 'silu', 'mish', or 'gelu'")
+
+ def forward(self, sample, condition=None):
+ if condition is not None:
+ sample = sample + self.cond_proj(condition)
+ sample = self.linear_1(sample)
+
+ if self.act is not None:
+ sample = self.act(sample)
+
+ sample = self.linear_2(sample)
+
+ if self.post_act is not None:
+ sample = self.post_act(sample)
+ return sample
+
+
+class Timesteps(nn.Module):
+ def __init__(self, num_channels: int, flip_sin_to_cos: bool, downscale_freq_shift: float):
+ super().__init__()
+ self.num_channels = num_channels
+ self.flip_sin_to_cos = flip_sin_to_cos
+ self.downscale_freq_shift = downscale_freq_shift
+
+ def forward(self, timesteps):
+ t_emb = get_timestep_embedding(
+ timesteps,
+ self.num_channels,
+ flip_sin_to_cos=self.flip_sin_to_cos,
+ downscale_freq_shift=self.downscale_freq_shift,
+ )
+ return t_emb
+
+
+class GaussianFourierProjection(nn.Module):
+ """Gaussian Fourier embeddings for noise levels."""
+
+ def __init__(
+ self, embedding_size: int = 256, scale: float = 1.0, set_W_to_weight=True, log=True, flip_sin_to_cos=False
+ ):
+ super().__init__()
+ self.weight = nn.Parameter(torch.randn(embedding_size) * scale, requires_grad=False)
+ self.log = log
+ self.flip_sin_to_cos = flip_sin_to_cos
+
+ if set_W_to_weight:
+ # to delete later
+ self.W = nn.Parameter(torch.randn(embedding_size) * scale, requires_grad=False)
+
+ self.weight = self.W
+
+ def forward(self, x):
+ if self.log:
+ x = torch.log(x)
+
+ x_proj = x[:, None] * self.weight[None, :] * 2 * np.pi
+
+ if self.flip_sin_to_cos:
+ out = torch.cat([torch.cos(x_proj), torch.sin(x_proj)], dim=-1)
+ else:
+ out = torch.cat([torch.sin(x_proj), torch.cos(x_proj)], dim=-1)
+ return out
+
+
+class ImagePositionalEmbeddings(nn.Module):
+ """
+ Converts latent image classes into vector embeddings. Sums the vector embeddings with positional embeddings for the
+ height and width of the latent space.
+
+ For more details, see figure 10 of the dall-e paper: https://arxiv.org/abs/2102.12092
+
+ For VQ-diffusion:
+
+ Output vector embeddings are used as input for the transformer.
+
+ Note that the vector embeddings for the transformer are different than the vector embeddings from the VQVAE.
+
+ Args:
+ num_embed (`int`):
+ Number of embeddings for the latent pixels embeddings.
+ height (`int`):
+ Height of the latent image i.e. the number of height embeddings.
+ width (`int`):
+ Width of the latent image i.e. the number of width embeddings.
+ embed_dim (`int`):
+ Dimension of the produced vector embeddings. Used for the latent pixel, height, and width embeddings.
+ """
+
+ def __init__(
+ self,
+ num_embed: int,
+ height: int,
+ width: int,
+ embed_dim: int,
+ ):
+ super().__init__()
+
+ self.height = height
+ self.width = width
+ self.num_embed = num_embed
+ self.embed_dim = embed_dim
+
+ self.emb = nn.Embedding(self.num_embed, embed_dim)
+ self.height_emb = nn.Embedding(self.height, embed_dim)
+ self.width_emb = nn.Embedding(self.width, embed_dim)
+
+ def forward(self, index):
+ emb = self.emb(index)
+
+ height_emb = self.height_emb(torch.arange(self.height, device=index.device).view(1, self.height))
+
+ # 1 x H x D -> 1 x H x 1 x D
+ height_emb = height_emb.unsqueeze(2)
+
+ width_emb = self.width_emb(torch.arange(self.width, device=index.device).view(1, self.width))
+
+ # 1 x W x D -> 1 x 1 x W x D
+ width_emb = width_emb.unsqueeze(1)
+
+ pos_emb = height_emb + width_emb
+
+ # 1 x H x W x D -> 1 x L xD
+ pos_emb = pos_emb.view(1, self.height * self.width, -1)
+
+ emb = emb + pos_emb[:, : emb.shape[1], :]
+
+ return emb
+
+
+class LabelEmbedding(nn.Module):
+ """
+ Embeds class labels into vector representations. Also handles label dropout for classifier-free guidance.
+
+ Args:
+ num_classes (`int`): The number of classes.
+ hidden_size (`int`): The size of the vector embeddings.
+ dropout_prob (`float`): The probability of dropping a label.
+ """
+
+ def __init__(self, num_classes, hidden_size, dropout_prob):
+ super().__init__()
+ use_cfg_embedding = dropout_prob > 0
+ self.embedding_table = nn.Embedding(num_classes + use_cfg_embedding, hidden_size)
+ self.num_classes = num_classes
+ self.dropout_prob = dropout_prob
+
+ def token_drop(self, labels, force_drop_ids=None):
+ """
+ Drops labels to enable classifier-free guidance.
+ """
+ if force_drop_ids is None:
+ drop_ids = torch.rand(labels.shape[0], device=labels.device) < self.dropout_prob
+ else:
+ drop_ids = torch.tensor(force_drop_ids == 1)
+ labels = torch.where(drop_ids, self.num_classes, labels)
+ return labels
+
+ def forward(self, labels: torch.LongTensor, force_drop_ids=None):
+ use_dropout = self.dropout_prob > 0
+ if (self.training and use_dropout) or (force_drop_ids is not None):
+ labels = self.token_drop(labels, force_drop_ids)
+ embeddings = self.embedding_table(labels)
+ return embeddings
+
+
+class CombinedTimestepLabelEmbeddings(nn.Module):
+ def __init__(self, num_classes, embedding_dim, class_dropout_prob=0.1):
+ super().__init__()
+
+ self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=1)
+ self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
+ self.class_embedder = LabelEmbedding(num_classes, embedding_dim, class_dropout_prob)
+
+ def forward(self, timestep, class_labels, hidden_dtype=None):
+ timesteps_proj = self.time_proj(timestep)
+ timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=hidden_dtype)) # (N, D)
+
+ class_labels = self.class_embedder(class_labels) # (N, D)
+
+ conditioning = timesteps_emb + class_labels # (N, D)
+
+ return conditioning
diff --git a/diffusers/src/diffusers/models/embeddings_flax.py b/diffusers/src/diffusers/models/embeddings_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..88c2c45e4655b8013fa96e0b4408e3ec0a87c2c7
--- /dev/null
+++ b/diffusers/src/diffusers/models/embeddings_flax.py
@@ -0,0 +1,95 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+
+import flax.linen as nn
+import jax.numpy as jnp
+
+
+def get_sinusoidal_embeddings(
+ timesteps: jnp.ndarray,
+ embedding_dim: int,
+ freq_shift: float = 1,
+ min_timescale: float = 1,
+ max_timescale: float = 1.0e4,
+ flip_sin_to_cos: bool = False,
+ scale: float = 1.0,
+) -> jnp.ndarray:
+ """Returns the positional encoding (same as Tensor2Tensor).
+
+ Args:
+ timesteps: a 1-D Tensor of N indices, one per batch element.
+ These may be fractional.
+ embedding_dim: The number of output channels.
+ min_timescale: The smallest time unit (should probably be 0.0).
+ max_timescale: The largest time unit.
+ Returns:
+ a Tensor of timing signals [N, num_channels]
+ """
+ assert timesteps.ndim == 1, "Timesteps should be a 1d-array"
+ assert embedding_dim % 2 == 0, f"Embedding dimension {embedding_dim} should be even"
+ num_timescales = float(embedding_dim // 2)
+ log_timescale_increment = math.log(max_timescale / min_timescale) / (num_timescales - freq_shift)
+ inv_timescales = min_timescale * jnp.exp(jnp.arange(num_timescales, dtype=jnp.float32) * -log_timescale_increment)
+ emb = jnp.expand_dims(timesteps, 1) * jnp.expand_dims(inv_timescales, 0)
+
+ # scale embeddings
+ scaled_time = scale * emb
+
+ if flip_sin_to_cos:
+ signal = jnp.concatenate([jnp.cos(scaled_time), jnp.sin(scaled_time)], axis=1)
+ else:
+ signal = jnp.concatenate([jnp.sin(scaled_time), jnp.cos(scaled_time)], axis=1)
+ signal = jnp.reshape(signal, [jnp.shape(timesteps)[0], embedding_dim])
+ return signal
+
+
+class FlaxTimestepEmbedding(nn.Module):
+ r"""
+ Time step Embedding Module. Learns embeddings for input time steps.
+
+ Args:
+ time_embed_dim (`int`, *optional*, defaults to `32`):
+ Time step embedding dimension
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ time_embed_dim: int = 32
+ dtype: jnp.dtype = jnp.float32
+
+ @nn.compact
+ def __call__(self, temb):
+ temb = nn.Dense(self.time_embed_dim, dtype=self.dtype, name="linear_1")(temb)
+ temb = nn.silu(temb)
+ temb = nn.Dense(self.time_embed_dim, dtype=self.dtype, name="linear_2")(temb)
+ return temb
+
+
+class FlaxTimesteps(nn.Module):
+ r"""
+ Wrapper Module for sinusoidal Time step Embeddings as described in https://arxiv.org/abs/2006.11239
+
+ Args:
+ dim (`int`, *optional*, defaults to `32`):
+ Time step embedding dimension
+ """
+ dim: int = 32
+ flip_sin_to_cos: bool = False
+ freq_shift: float = 1
+
+ @nn.compact
+ def __call__(self, timesteps):
+ return get_sinusoidal_embeddings(
+ timesteps, embedding_dim=self.dim, flip_sin_to_cos=self.flip_sin_to_cos, freq_shift=self.freq_shift
+ )
diff --git a/diffusers/src/diffusers/models/modeling_flax_pytorch_utils.py b/diffusers/src/diffusers/models/modeling_flax_pytorch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9de83f87dab84d2e7fdd77b835db787cb4f1cb6
--- /dev/null
+++ b/diffusers/src/diffusers/models/modeling_flax_pytorch_utils.py
@@ -0,0 +1,118 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch - Flax general utilities."""
+import re
+
+import jax.numpy as jnp
+from flax.traverse_util import flatten_dict, unflatten_dict
+from jax.random import PRNGKey
+
+from ..utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+def rename_key(key):
+ regex = r"\w+[.]\d+"
+ pats = re.findall(regex, key)
+ for pat in pats:
+ key = key.replace(pat, "_".join(pat.split(".")))
+ return key
+
+
+#####################
+# PyTorch => Flax #
+#####################
+
+
+# Adapted from https://github.com/huggingface/transformers/blob/c603c80f46881ae18b2ca50770ef65fa4033eacd/src/transformers/modeling_flax_pytorch_utils.py#L69
+# and https://github.com/patil-suraj/stable-diffusion-jax/blob/main/stable_diffusion_jax/convert_diffusers_to_jax.py
+def rename_key_and_reshape_tensor(pt_tuple_key, pt_tensor, random_flax_state_dict):
+ """Rename PT weight names to corresponding Flax weight names and reshape tensor if necessary"""
+
+ # conv norm or layer norm
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("scale",)
+ if (
+ any("norm" in str_ for str_ in pt_tuple_key)
+ and (pt_tuple_key[-1] == "bias")
+ and (pt_tuple_key[:-1] + ("bias",) not in random_flax_state_dict)
+ and (pt_tuple_key[:-1] + ("scale",) in random_flax_state_dict)
+ ):
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("scale",)
+ return renamed_pt_tuple_key, pt_tensor
+ elif pt_tuple_key[-1] in ["weight", "gamma"] and pt_tuple_key[:-1] + ("scale",) in random_flax_state_dict:
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("scale",)
+ return renamed_pt_tuple_key, pt_tensor
+
+ # embedding
+ if pt_tuple_key[-1] == "weight" and pt_tuple_key[:-1] + ("embedding",) in random_flax_state_dict:
+ pt_tuple_key = pt_tuple_key[:-1] + ("embedding",)
+ return renamed_pt_tuple_key, pt_tensor
+
+ # conv layer
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
+ if pt_tuple_key[-1] == "weight" and pt_tensor.ndim == 4:
+ pt_tensor = pt_tensor.transpose(2, 3, 1, 0)
+ return renamed_pt_tuple_key, pt_tensor
+
+ # linear layer
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
+ if pt_tuple_key[-1] == "weight":
+ pt_tensor = pt_tensor.T
+ return renamed_pt_tuple_key, pt_tensor
+
+ # old PyTorch layer norm weight
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("weight",)
+ if pt_tuple_key[-1] == "gamma":
+ return renamed_pt_tuple_key, pt_tensor
+
+ # old PyTorch layer norm bias
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("bias",)
+ if pt_tuple_key[-1] == "beta":
+ return renamed_pt_tuple_key, pt_tensor
+
+ return pt_tuple_key, pt_tensor
+
+
+def convert_pytorch_state_dict_to_flax(pt_state_dict, flax_model, init_key=42):
+ # Step 1: Convert pytorch tensor to numpy
+ pt_state_dict = {k: v.numpy() for k, v in pt_state_dict.items()}
+
+ # Step 2: Since the model is stateless, get random Flax params
+ random_flax_params = flax_model.init_weights(PRNGKey(init_key))
+
+ random_flax_state_dict = flatten_dict(random_flax_params)
+ flax_state_dict = {}
+
+ # Need to change some parameters name to match Flax names
+ for pt_key, pt_tensor in pt_state_dict.items():
+ renamed_pt_key = rename_key(pt_key)
+ pt_tuple_key = tuple(renamed_pt_key.split("."))
+
+ # Correctly rename weight parameters
+ flax_key, flax_tensor = rename_key_and_reshape_tensor(pt_tuple_key, pt_tensor, random_flax_state_dict)
+
+ if flax_key in random_flax_state_dict:
+ if flax_tensor.shape != random_flax_state_dict[flax_key].shape:
+ raise ValueError(
+ f"PyTorch checkpoint seems to be incorrect. Weight {pt_key} was expected to be of shape "
+ f"{random_flax_state_dict[flax_key].shape}, but is {flax_tensor.shape}."
+ )
+
+ # also add unexpected weight so that warning is thrown
+ flax_state_dict[flax_key] = jnp.asarray(flax_tensor)
+
+ return unflatten_dict(flax_state_dict)
diff --git a/diffusers/src/diffusers/models/modeling_flax_utils.py b/diffusers/src/diffusers/models/modeling_flax_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..58c492a974a30624cbf1bd638ad3ed5202ef3862
--- /dev/null
+++ b/diffusers/src/diffusers/models/modeling_flax_utils.py
@@ -0,0 +1,526 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from pickle import UnpicklingError
+from typing import Any, Dict, Union
+
+import jax
+import jax.numpy as jnp
+import msgpack.exceptions
+from flax.core.frozen_dict import FrozenDict, unfreeze
+from flax.serialization import from_bytes, to_bytes
+from flax.traverse_util import flatten_dict, unflatten_dict
+from huggingface_hub import hf_hub_download
+from huggingface_hub.utils import EntryNotFoundError, RepositoryNotFoundError, RevisionNotFoundError
+from requests import HTTPError
+
+from .. import __version__, is_torch_available
+from ..utils import (
+ CONFIG_NAME,
+ DIFFUSERS_CACHE,
+ FLAX_WEIGHTS_NAME,
+ HUGGINGFACE_CO_RESOLVE_ENDPOINT,
+ WEIGHTS_NAME,
+ logging,
+)
+from .modeling_flax_pytorch_utils import convert_pytorch_state_dict_to_flax
+
+
+logger = logging.get_logger(__name__)
+
+
+class FlaxModelMixin:
+ r"""
+ Base class for all flax models.
+
+ [`FlaxModelMixin`] takes care of storing the configuration of the models and handles methods for loading,
+ downloading and saving models.
+ """
+ config_name = CONFIG_NAME
+ _automatically_saved_args = ["_diffusers_version", "_class_name", "_name_or_path"]
+ _flax_internal_args = ["name", "parent", "dtype"]
+
+ @classmethod
+ def _from_config(cls, config, **kwargs):
+ """
+ All context managers that the model should be initialized under go here.
+ """
+ return cls(config, **kwargs)
+
+ def _cast_floating_to(self, params: Union[Dict, FrozenDict], dtype: jnp.dtype, mask: Any = None) -> Any:
+ """
+ Helper method to cast floating-point values of given parameter `PyTree` to given `dtype`.
+ """
+
+ # taken from https://github.com/deepmind/jmp/blob/3a8318abc3292be38582794dbf7b094e6583b192/jmp/_src/policy.py#L27
+ def conditional_cast(param):
+ if isinstance(param, jnp.ndarray) and jnp.issubdtype(param.dtype, jnp.floating):
+ param = param.astype(dtype)
+ return param
+
+ if mask is None:
+ return jax.tree_map(conditional_cast, params)
+
+ flat_params = flatten_dict(params)
+ flat_mask, _ = jax.tree_flatten(mask)
+
+ for masked, key in zip(flat_mask, flat_params.keys()):
+ if masked:
+ param = flat_params[key]
+ flat_params[key] = conditional_cast(param)
+
+ return unflatten_dict(flat_params)
+
+ def to_bf16(self, params: Union[Dict, FrozenDict], mask: Any = None):
+ r"""
+ Cast the floating-point `params` to `jax.numpy.bfloat16`. This returns a new `params` tree and does not cast
+ the `params` in place.
+
+ This method can be used on TPU to explicitly convert the model parameters to bfloat16 precision to do full
+ half-precision training or to save weights in bfloat16 for inference in order to save memory and improve speed.
+
+ Arguments:
+ params (`Union[Dict, FrozenDict]`):
+ A `PyTree` of model parameters.
+ mask (`Union[Dict, FrozenDict]`):
+ A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
+ you want to cast, and should be `False` for those you want to skip.
+
+ Examples:
+
+ ```python
+ >>> from diffusers import FlaxUNet2DConditionModel
+
+ >>> # load model
+ >>> model, params = FlaxUNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5")
+ >>> # By default, the model parameters will be in fp32 precision, to cast these to bfloat16 precision
+ >>> params = model.to_bf16(params)
+ >>> # If you don't want to cast certain parameters (for example layer norm bias and scale)
+ >>> # then pass the mask as follows
+ >>> from flax import traverse_util
+
+ >>> model, params = FlaxUNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5")
+ >>> flat_params = traverse_util.flatten_dict(params)
+ >>> mask = {
+ ... path: (path[-2] != ("LayerNorm", "bias") and path[-2:] != ("LayerNorm", "scale"))
+ ... for path in flat_params
+ ... }
+ >>> mask = traverse_util.unflatten_dict(mask)
+ >>> params = model.to_bf16(params, mask)
+ ```"""
+ return self._cast_floating_to(params, jnp.bfloat16, mask)
+
+ def to_fp32(self, params: Union[Dict, FrozenDict], mask: Any = None):
+ r"""
+ Cast the floating-point `params` to `jax.numpy.float32`. This method can be used to explicitly convert the
+ model parameters to fp32 precision. This returns a new `params` tree and does not cast the `params` in place.
+
+ Arguments:
+ params (`Union[Dict, FrozenDict]`):
+ A `PyTree` of model parameters.
+ mask (`Union[Dict, FrozenDict]`):
+ A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
+ you want to cast, and should be `False` for those you want to skip
+
+ Examples:
+
+ ```python
+ >>> from diffusers import FlaxUNet2DConditionModel
+
+ >>> # Download model and configuration from huggingface.co
+ >>> model, params = FlaxUNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5")
+ >>> # By default, the model params will be in fp32, to illustrate the use of this method,
+ >>> # we'll first cast to fp16 and back to fp32
+ >>> params = model.to_f16(params)
+ >>> # now cast back to fp32
+ >>> params = model.to_fp32(params)
+ ```"""
+ return self._cast_floating_to(params, jnp.float32, mask)
+
+ def to_fp16(self, params: Union[Dict, FrozenDict], mask: Any = None):
+ r"""
+ Cast the floating-point `params` to `jax.numpy.float16`. This returns a new `params` tree and does not cast the
+ `params` in place.
+
+ This method can be used on GPU to explicitly convert the model parameters to float16 precision to do full
+ half-precision training or to save weights in float16 for inference in order to save memory and improve speed.
+
+ Arguments:
+ params (`Union[Dict, FrozenDict]`):
+ A `PyTree` of model parameters.
+ mask (`Union[Dict, FrozenDict]`):
+ A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
+ you want to cast, and should be `False` for those you want to skip
+
+ Examples:
+
+ ```python
+ >>> from diffusers import FlaxUNet2DConditionModel
+
+ >>> # load model
+ >>> model, params = FlaxUNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5")
+ >>> # By default, the model params will be in fp32, to cast these to float16
+ >>> params = model.to_fp16(params)
+ >>> # If you want don't want to cast certain parameters (for example layer norm bias and scale)
+ >>> # then pass the mask as follows
+ >>> from flax import traverse_util
+
+ >>> model, params = FlaxUNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5")
+ >>> flat_params = traverse_util.flatten_dict(params)
+ >>> mask = {
+ ... path: (path[-2] != ("LayerNorm", "bias") and path[-2:] != ("LayerNorm", "scale"))
+ ... for path in flat_params
+ ... }
+ >>> mask = traverse_util.unflatten_dict(mask)
+ >>> params = model.to_fp16(params, mask)
+ ```"""
+ return self._cast_floating_to(params, jnp.float16, mask)
+
+ def init_weights(self, rng: jax.random.KeyArray) -> Dict:
+ raise NotImplementedError(f"init_weights method has to be implemented for {self}")
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ dtype: jnp.dtype = jnp.float32,
+ *model_args,
+ **kwargs,
+ ):
+ r"""
+ Instantiate a pretrained flax model from a pre-trained model configuration.
+
+ The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
+ pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
+ task.
+
+ The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
+ weights are discarded.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ Valid model ids are namespaced under a user or organization name, like
+ `runwayml/stable-diffusion-v1-5`.
+ - A path to a *directory* containing model weights saved using [`~ModelMixin.save_pretrained`],
+ e.g., `./my_model_directory/`.
+ dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
+ The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on GPUs) and
+ `jax.numpy.bfloat16` (on TPUs).
+
+ This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
+ specified all the computation will be performed with the given `dtype`.
+
+ **Note that this only specifies the dtype of the computation and does not influence the dtype of model
+ parameters.**
+
+ If you wish to change the dtype of the model parameters, see [`~ModelMixin.to_fp16`] and
+ [`~ModelMixin.to_bf16`].
+ model_args (sequence of positional arguments, *optional*):
+ All remaining positional arguments will be passed to the underlying model's `__init__` method.
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ from_pt (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a PyTorch checkpoint save file.
+ kwargs (remaining dictionary of keyword arguments, *optional*):
+ Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
+ `output_attentions=True`). Behaves differently depending on whether a `config` is provided or
+ automatically loaded:
+
+ - If a configuration is provided with `config`, `**kwargs` will be directly passed to the
+ underlying model's `__init__` method (we assume all relevant updates to the configuration have
+ already been done)
+ - If a configuration is not provided, `kwargs` will be first passed to the configuration class
+ initialization function ([`~ConfigMixin.from_config`]). Each key of `kwargs` that corresponds to
+ a configuration attribute will be used to override said attribute with the supplied `kwargs`
+ value. Remaining keys that do not correspond to any configuration attribute will be passed to the
+ underlying model's `__init__` function.
+
+ Examples:
+
+ ```python
+ >>> from diffusers import FlaxUNet2DConditionModel
+
+ >>> # Download model and configuration from huggingface.co and cache.
+ >>> model, params = FlaxUNet2DConditionModel.from_pretrained("runwayml/stable-diffusion-v1-5")
+ >>> # Model was saved using *save_pretrained('./test/saved_model/')* (for example purposes, not runnable).
+ >>> model, params = FlaxUNet2DConditionModel.from_pretrained("./test/saved_model/")
+ ```"""
+ config = kwargs.pop("config", None)
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ force_download = kwargs.pop("force_download", False)
+ from_pt = kwargs.pop("from_pt", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ subfolder = kwargs.pop("subfolder", None)
+
+ user_agent = {
+ "diffusers": __version__,
+ "file_type": "model",
+ "framework": "flax",
+ }
+
+ # Load config if we don't provide a configuration
+ config_path = config if config is not None else pretrained_model_name_or_path
+ model, model_kwargs = cls.from_config(
+ config_path,
+ cache_dir=cache_dir,
+ return_unused_kwargs=True,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ # model args
+ dtype=dtype,
+ **kwargs,
+ )
+
+ # Load model
+ pretrained_path_with_subfolder = (
+ pretrained_model_name_or_path
+ if subfolder is None
+ else os.path.join(pretrained_model_name_or_path, subfolder)
+ )
+ if os.path.isdir(pretrained_path_with_subfolder):
+ if from_pt:
+ if not os.path.isfile(os.path.join(pretrained_path_with_subfolder, WEIGHTS_NAME)):
+ raise EnvironmentError(
+ f"Error no file named {WEIGHTS_NAME} found in directory {pretrained_path_with_subfolder} "
+ )
+ model_file = os.path.join(pretrained_path_with_subfolder, WEIGHTS_NAME)
+ elif os.path.isfile(os.path.join(pretrained_path_with_subfolder, FLAX_WEIGHTS_NAME)):
+ # Load from a Flax checkpoint
+ model_file = os.path.join(pretrained_path_with_subfolder, FLAX_WEIGHTS_NAME)
+ # Check if pytorch weights exist instead
+ elif os.path.isfile(os.path.join(pretrained_path_with_subfolder, WEIGHTS_NAME)):
+ raise EnvironmentError(
+ f"{WEIGHTS_NAME} file found in directory {pretrained_path_with_subfolder}. Please load the model"
+ " using `from_pt=True`."
+ )
+ else:
+ raise EnvironmentError(
+ f"Error no file named {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME} found in directory "
+ f"{pretrained_path_with_subfolder}."
+ )
+ else:
+ try:
+ model_file = hf_hub_download(
+ pretrained_model_name_or_path,
+ filename=FLAX_WEIGHTS_NAME if not from_pt else WEIGHTS_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ subfolder=subfolder,
+ revision=revision,
+ )
+
+ except RepositoryNotFoundError:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier "
+ "listed on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a "
+ "token having permission to this repo with `use_auth_token` or log in with `huggingface-cli "
+ "login`."
+ )
+ except RevisionNotFoundError:
+ raise EnvironmentError(
+ f"{revision} is not a valid git identifier (branch name, tag name or commit id) that exists for "
+ "this model name. Check the model page at "
+ f"'https://huggingface.co/{pretrained_model_name_or_path}' for available revisions."
+ )
+ except EntryNotFoundError:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named {FLAX_WEIGHTS_NAME}."
+ )
+ except HTTPError as err:
+ raise EnvironmentError(
+ f"There was a specific connection error when trying to load {pretrained_model_name_or_path}:\n"
+ f"{err}"
+ )
+ except ValueError:
+ raise EnvironmentError(
+ f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this model, couldn't find it"
+ f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
+ f" directory containing a file named {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME}.\nCheckout your"
+ " internet connection or see how to run the library in offline mode at"
+ " 'https://huggingface.co/docs/transformers/installation#offline-mode'."
+ )
+ except EnvironmentError:
+ raise EnvironmentError(
+ f"Can't load the model for '{pretrained_model_name_or_path}'. If you were trying to load it from "
+ "'https://huggingface.co/models', make sure you don't have a local directory with the same name. "
+ f"Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory "
+ f"containing a file named {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME}."
+ )
+
+ if from_pt:
+ if is_torch_available():
+ from .modeling_utils import load_state_dict
+ else:
+ raise EnvironmentError(
+ "Can't load the model in PyTorch format because PyTorch is not installed. "
+ "Please, install PyTorch or use native Flax weights."
+ )
+
+ # Step 1: Get the pytorch file
+ pytorch_model_file = load_state_dict(model_file)
+
+ # Step 2: Convert the weights
+ state = convert_pytorch_state_dict_to_flax(pytorch_model_file, model)
+ else:
+ try:
+ with open(model_file, "rb") as state_f:
+ state = from_bytes(cls, state_f.read())
+ except (UnpicklingError, msgpack.exceptions.ExtraData) as e:
+ try:
+ with open(model_file) as f:
+ if f.read().startswith("version"):
+ raise OSError(
+ "You seem to have cloned a repository without having git-lfs installed. Please"
+ " install git-lfs and run `git lfs install` followed by `git lfs pull` in the"
+ " folder you cloned."
+ )
+ else:
+ raise ValueError from e
+ except (UnicodeDecodeError, ValueError):
+ raise EnvironmentError(f"Unable to convert {model_file} to Flax deserializable object. ")
+ # make sure all arrays are stored as jnp.ndarray
+ # NOTE: This is to prevent a bug this will be fixed in Flax >= v0.3.4:
+ # https://github.com/google/flax/issues/1261
+ state = jax.tree_util.tree_map(lambda x: jax.device_put(x, jax.devices("cpu")[0]), state)
+
+ # flatten dicts
+ state = flatten_dict(state)
+
+ params_shape_tree = jax.eval_shape(model.init_weights, rng=jax.random.PRNGKey(0))
+ required_params = set(flatten_dict(unfreeze(params_shape_tree)).keys())
+
+ shape_state = flatten_dict(unfreeze(params_shape_tree))
+
+ missing_keys = required_params - set(state.keys())
+ unexpected_keys = set(state.keys()) - required_params
+
+ if missing_keys:
+ logger.warning(
+ f"The checkpoint {pretrained_model_name_or_path} is missing required keys: {missing_keys}. "
+ "Make sure to call model.init_weights to initialize the missing weights."
+ )
+ cls._missing_keys = missing_keys
+
+ for key in state.keys():
+ if key in shape_state and state[key].shape != shape_state[key].shape:
+ raise ValueError(
+ f"Trying to load the pretrained weight for {key} failed: checkpoint has shape "
+ f"{state[key].shape} which is incompatible with the model shape {shape_state[key].shape}. "
+ )
+
+ # remove unexpected keys to not be saved again
+ for unexpected_key in unexpected_keys:
+ del state[unexpected_key]
+
+ if len(unexpected_keys) > 0:
+ logger.warning(
+ f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
+ f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
+ f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
+ " with another architecture."
+ )
+ else:
+ logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
+
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
+ " TRAIN this model on a down-stream task to be able to use it for predictions and inference."
+ )
+ else:
+ logger.info(
+ f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
+ f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
+ " training."
+ )
+
+ return model, unflatten_dict(state)
+
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ params: Union[Dict, FrozenDict],
+ is_main_process: bool = True,
+ ):
+ """
+ Save a model and its configuration file to a directory, so that it can be re-loaded using the
+ `[`~FlaxModelMixin.from_pretrained`]` class method
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ params (`Union[Dict, FrozenDict]`):
+ A `PyTree` of model parameters.
+ is_main_process (`bool`, *optional*, defaults to `True`):
+ Whether the process calling this is the main process or not. Useful when in distributed training like
+ TPUs and need to call this function on all processes. In this case, set `is_main_process=True` only on
+ the main process to avoid race conditions.
+ """
+ if os.path.isfile(save_directory):
+ logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
+ return
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ model_to_save = self
+
+ # Attach architecture to the config
+ # Save the config
+ if is_main_process:
+ model_to_save.save_config(save_directory)
+
+ # save model
+ output_model_file = os.path.join(save_directory, FLAX_WEIGHTS_NAME)
+ with open(output_model_file, "wb") as f:
+ model_bytes = to_bytes(params)
+ f.write(model_bytes)
+
+ logger.info(f"Model weights saved in {output_model_file}")
diff --git a/diffusers/src/diffusers/models/modeling_pytorch_flax_utils.py b/diffusers/src/diffusers/models/modeling_pytorch_flax_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..80975641412b79e5f75040c14a5a18df429acfe6
--- /dev/null
+++ b/diffusers/src/diffusers/models/modeling_pytorch_flax_utils.py
@@ -0,0 +1,155 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch - Flax general utilities."""
+
+from pickle import UnpicklingError
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.serialization import from_bytes
+from flax.traverse_util import flatten_dict
+
+from ..utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+#####################
+# Flax => PyTorch #
+#####################
+
+
+# from https://github.com/huggingface/transformers/blob/main/src/transformers/modeling_flax_pytorch_utils.py#L224-L352
+def load_flax_checkpoint_in_pytorch_model(pt_model, model_file):
+ try:
+ with open(model_file, "rb") as flax_state_f:
+ flax_state = from_bytes(None, flax_state_f.read())
+ except UnpicklingError as e:
+ try:
+ with open(model_file) as f:
+ if f.read().startswith("version"):
+ raise OSError(
+ "You seem to have cloned a repository without having git-lfs installed. Please"
+ " install git-lfs and run `git lfs install` followed by `git lfs pull` in the"
+ " folder you cloned."
+ )
+ else:
+ raise ValueError from e
+ except (UnicodeDecodeError, ValueError):
+ raise EnvironmentError(f"Unable to convert {model_file} to Flax deserializable object. ")
+
+ return load_flax_weights_in_pytorch_model(pt_model, flax_state)
+
+
+def load_flax_weights_in_pytorch_model(pt_model, flax_state):
+ """Load flax checkpoints in a PyTorch model"""
+
+ try:
+ import torch # noqa: F401
+ except ImportError:
+ logger.error(
+ "Loading Flax weights in PyTorch requires both PyTorch and Flax to be installed. Please see"
+ " https://pytorch.org/ and https://flax.readthedocs.io/en/latest/installation.html for installation"
+ " instructions."
+ )
+ raise
+
+ # check if we have bf16 weights
+ is_type_bf16 = flatten_dict(jax.tree_util.tree_map(lambda x: x.dtype == jnp.bfloat16, flax_state)).values()
+ if any(is_type_bf16):
+ # convert all weights to fp32 if they are bf16 since torch.from_numpy can-not handle bf16
+
+ # and bf16 is not fully supported in PT yet.
+ logger.warning(
+ "Found ``bfloat16`` weights in Flax model. Casting all ``bfloat16`` weights to ``float32`` "
+ "before loading those in PyTorch model."
+ )
+ flax_state = jax.tree_util.tree_map(
+ lambda params: params.astype(np.float32) if params.dtype == jnp.bfloat16 else params, flax_state
+ )
+
+ pt_model.base_model_prefix = ""
+
+ flax_state_dict = flatten_dict(flax_state, sep=".")
+ pt_model_dict = pt_model.state_dict()
+
+ # keep track of unexpected & missing keys
+ unexpected_keys = []
+ missing_keys = set(pt_model_dict.keys())
+
+ for flax_key_tuple, flax_tensor in flax_state_dict.items():
+ flax_key_tuple_array = flax_key_tuple.split(".")
+
+ if flax_key_tuple_array[-1] == "kernel" and flax_tensor.ndim == 4:
+ flax_key_tuple_array = flax_key_tuple_array[:-1] + ["weight"]
+ flax_tensor = jnp.transpose(flax_tensor, (3, 2, 0, 1))
+ elif flax_key_tuple_array[-1] == "kernel":
+ flax_key_tuple_array = flax_key_tuple_array[:-1] + ["weight"]
+ flax_tensor = flax_tensor.T
+ elif flax_key_tuple_array[-1] == "scale":
+ flax_key_tuple_array = flax_key_tuple_array[:-1] + ["weight"]
+
+ if "time_embedding" not in flax_key_tuple_array:
+ for i, flax_key_tuple_string in enumerate(flax_key_tuple_array):
+ flax_key_tuple_array[i] = (
+ flax_key_tuple_string.replace("_0", ".0")
+ .replace("_1", ".1")
+ .replace("_2", ".2")
+ .replace("_3", ".3")
+ )
+
+ flax_key = ".".join(flax_key_tuple_array)
+
+ if flax_key in pt_model_dict:
+ if flax_tensor.shape != pt_model_dict[flax_key].shape:
+ raise ValueError(
+ f"Flax checkpoint seems to be incorrect. Weight {flax_key_tuple} was expected "
+ f"to be of shape {pt_model_dict[flax_key].shape}, but is {flax_tensor.shape}."
+ )
+ else:
+ # add weight to pytorch dict
+ flax_tensor = np.asarray(flax_tensor) if not isinstance(flax_tensor, np.ndarray) else flax_tensor
+ pt_model_dict[flax_key] = torch.from_numpy(flax_tensor)
+ # remove from missing keys
+ missing_keys.remove(flax_key)
+ else:
+ # weight is not expected by PyTorch model
+ unexpected_keys.append(flax_key)
+
+ pt_model.load_state_dict(pt_model_dict)
+
+ # re-transform missing_keys to list
+ missing_keys = list(missing_keys)
+
+ if len(unexpected_keys) > 0:
+ logger.warning(
+ "Some weights of the Flax model were not used when initializing the PyTorch model"
+ f" {pt_model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are initializing"
+ f" {pt_model.__class__.__name__} from a Flax model trained on another task or with another architecture"
+ " (e.g. initializing a BertForSequenceClassification model from a FlaxBertForPreTraining model).\n- This"
+ f" IS NOT expected if you are initializing {pt_model.__class__.__name__} from a Flax model that you expect"
+ " to be exactly identical (e.g. initializing a BertForSequenceClassification model from a"
+ " FlaxBertForSequenceClassification model)."
+ )
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some weights of {pt_model.__class__.__name__} were not initialized from the Flax model and are newly"
+ f" initialized: {missing_keys}\nYou should probably TRAIN this model on a down-stream task to be able to"
+ " use it for predictions and inference."
+ )
+
+ return pt_model
diff --git a/diffusers/src/diffusers/models/modeling_utils.py b/diffusers/src/diffusers/models/modeling_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a849f6f0e45a1ef48625043fc9d70b119b1fbf5
--- /dev/null
+++ b/diffusers/src/diffusers/models/modeling_utils.py
@@ -0,0 +1,777 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+import os
+from functools import partial
+from typing import Callable, List, Optional, Tuple, Union
+
+import torch
+from torch import Tensor, device
+
+from .. import __version__
+from ..utils import (
+ CONFIG_NAME,
+ DIFFUSERS_CACHE,
+ FLAX_WEIGHTS_NAME,
+ HF_HUB_OFFLINE,
+ SAFETENSORS_WEIGHTS_NAME,
+ WEIGHTS_NAME,
+ _add_variant,
+ _get_model_file,
+ is_accelerate_available,
+ is_safetensors_available,
+ is_torch_version,
+ logging,
+)
+
+
+logger = logging.get_logger(__name__)
+
+
+if is_torch_version(">=", "1.9.0"):
+ _LOW_CPU_MEM_USAGE_DEFAULT = True
+else:
+ _LOW_CPU_MEM_USAGE_DEFAULT = False
+
+
+if is_accelerate_available():
+ import accelerate
+ from accelerate.utils import set_module_tensor_to_device
+ from accelerate.utils.versions import is_torch_version
+
+if is_safetensors_available():
+ import safetensors
+
+
+def get_parameter_device(parameter: torch.nn.Module):
+ try:
+ return next(parameter.parameters()).device
+ except StopIteration:
+ # For torch.nn.DataParallel compatibility in PyTorch 1.5
+
+ def find_tensor_attributes(module: torch.nn.Module) -> List[Tuple[str, Tensor]]:
+ tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
+ return tuples
+
+ gen = parameter._named_members(get_members_fn=find_tensor_attributes)
+ first_tuple = next(gen)
+ return first_tuple[1].device
+
+
+def get_parameter_dtype(parameter: torch.nn.Module):
+ try:
+ return next(parameter.parameters()).dtype
+ except StopIteration:
+ # For torch.nn.DataParallel compatibility in PyTorch 1.5
+
+ def find_tensor_attributes(module: torch.nn.Module) -> List[Tuple[str, Tensor]]:
+ tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
+ return tuples
+
+ gen = parameter._named_members(get_members_fn=find_tensor_attributes)
+ first_tuple = next(gen)
+ return first_tuple[1].dtype
+
+
+def load_state_dict(checkpoint_file: Union[str, os.PathLike], variant: Optional[str] = None):
+ """
+ Reads a checkpoint file, returning properly formatted errors if they arise.
+ """
+ try:
+ if os.path.basename(checkpoint_file) == _add_variant(WEIGHTS_NAME, variant):
+ return torch.load(checkpoint_file, map_location="cpu")
+ else:
+ return safetensors.torch.load_file(checkpoint_file, device="cpu")
+ except Exception as e:
+ try:
+ with open(checkpoint_file) as f:
+ if f.read().startswith("version"):
+ raise OSError(
+ "You seem to have cloned a repository without having git-lfs installed. Please install "
+ "git-lfs and run `git lfs install` followed by `git lfs pull` in the folder "
+ "you cloned."
+ )
+ else:
+ raise ValueError(
+ f"Unable to locate the file {checkpoint_file} which is necessary to load this pretrained "
+ "model. Make sure you have saved the model properly."
+ ) from e
+ except (UnicodeDecodeError, ValueError):
+ raise OSError(
+ f"Unable to load weights from checkpoint file for '{checkpoint_file}' "
+ f"at '{checkpoint_file}'. "
+ "If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True."
+ )
+
+
+def _load_state_dict_into_model(model_to_load, state_dict):
+ # Convert old format to new format if needed from a PyTorch state_dict
+ # copy state_dict so _load_from_state_dict can modify it
+ state_dict = state_dict.copy()
+ error_msgs = []
+
+ # PyTorch's `_load_from_state_dict` does not copy parameters in a module's descendants
+ # so we need to apply the function recursively.
+ def load(module: torch.nn.Module, prefix=""):
+ args = (state_dict, prefix, {}, True, [], [], error_msgs)
+ module._load_from_state_dict(*args)
+
+ for name, child in module._modules.items():
+ if child is not None:
+ load(child, prefix + name + ".")
+
+ load(model_to_load)
+
+ return error_msgs
+
+
+class ModelMixin(torch.nn.Module):
+ r"""
+ Base class for all models.
+
+ [`ModelMixin`] takes care of storing the configuration of the models and handles methods for loading, downloading
+ and saving models.
+
+ - **config_name** ([`str`]) -- A filename under which the model should be stored when calling
+ [`~models.ModelMixin.save_pretrained`].
+ """
+ config_name = CONFIG_NAME
+ _automatically_saved_args = ["_diffusers_version", "_class_name", "_name_or_path"]
+ _supports_gradient_checkpointing = False
+
+ def __init__(self):
+ super().__init__()
+
+ @property
+ def is_gradient_checkpointing(self) -> bool:
+ """
+ Whether gradient checkpointing is activated for this model or not.
+
+ Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
+ activations".
+ """
+ return any(hasattr(m, "gradient_checkpointing") and m.gradient_checkpointing for m in self.modules())
+
+ def enable_gradient_checkpointing(self):
+ """
+ Activates gradient checkpointing for the current model.
+
+ Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
+ activations".
+ """
+ if not self._supports_gradient_checkpointing:
+ raise ValueError(f"{self.__class__.__name__} does not support gradient checkpointing.")
+ self.apply(partial(self._set_gradient_checkpointing, value=True))
+
+ def disable_gradient_checkpointing(self):
+ """
+ Deactivates gradient checkpointing for the current model.
+
+ Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
+ activations".
+ """
+ if self._supports_gradient_checkpointing:
+ self.apply(partial(self._set_gradient_checkpointing, value=False))
+
+ def set_use_memory_efficient_attention_xformers(
+ self, valid: bool, attention_op: Optional[Callable] = None
+ ) -> None:
+ # Recursively walk through all the children.
+ # Any children which exposes the set_use_memory_efficient_attention_xformers method
+ # gets the message
+ def fn_recursive_set_mem_eff(module: torch.nn.Module):
+ if hasattr(module, "set_use_memory_efficient_attention_xformers"):
+ module.set_use_memory_efficient_attention_xformers(valid, attention_op)
+
+ for child in module.children():
+ fn_recursive_set_mem_eff(child)
+
+ for module in self.children():
+ if isinstance(module, torch.nn.Module):
+ fn_recursive_set_mem_eff(module)
+
+ def enable_xformers_memory_efficient_attention(self, attention_op: Optional[Callable] = None):
+ r"""
+ Enable memory efficient attention as implemented in xformers.
+
+ When this option is enabled, you should observe lower GPU memory usage and a potential speed up at inference
+ time. Speed up at training time is not guaranteed.
+
+ Warning: When Memory Efficient Attention and Sliced attention are both enabled, the Memory Efficient Attention
+ is used.
+
+ Parameters:
+ attention_op (`Callable`, *optional*):
+ Override the default `None` operator for use as `op` argument to the
+ [`memory_efficient_attention()`](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.memory_efficient_attention)
+ function of xFormers.
+
+ Examples:
+
+ ```py
+ >>> import torch
+ >>> from diffusers import UNet2DConditionModel
+ >>> from xformers.ops import MemoryEfficientAttentionFlashAttentionOp
+
+ >>> model = UNet2DConditionModel.from_pretrained(
+ ... "stabilityai/stable-diffusion-2-1", subfolder="unet", torch_dtype=torch.float16
+ ... )
+ >>> model = model.to("cuda")
+ >>> model.enable_xformers_memory_efficient_attention(attention_op=MemoryEfficientAttentionFlashAttentionOp)
+ ```
+ """
+ self.set_use_memory_efficient_attention_xformers(True, attention_op)
+
+ def disable_xformers_memory_efficient_attention(self):
+ r"""
+ Disable memory efficient attention as implemented in xformers.
+ """
+ self.set_use_memory_efficient_attention_xformers(False)
+
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ is_main_process: bool = True,
+ save_function: Callable = None,
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ """
+ Save a model and its configuration file to a directory, so that it can be re-loaded using the
+ `[`~models.ModelMixin.from_pretrained`]` class method.
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ is_main_process (`bool`, *optional*, defaults to `True`):
+ Whether the process calling this is the main process or not. Useful when in distributed training like
+ TPUs and need to call this function on all processes. In this case, set `is_main_process=True` only on
+ the main process to avoid race conditions.
+ save_function (`Callable`):
+ The function to use to save the state dictionary. Useful on distributed training like TPUs when one
+ need to replace `torch.save` by another method. Can be configured with the environment variable
+ `DIFFUSERS_SAVE_MODE`.
+ safe_serialization (`bool`, *optional*, defaults to `False`):
+ Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
+ variant (`str`, *optional*):
+ If specified, weights are saved in the format pytorch_model..bin.
+ """
+ if safe_serialization and not is_safetensors_available():
+ raise ImportError("`safe_serialization` requires the `safetensors library: `pip install safetensors`.")
+
+ if os.path.isfile(save_directory):
+ logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
+ return
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ model_to_save = self
+
+ # Attach architecture to the config
+ # Save the config
+ if is_main_process:
+ model_to_save.save_config(save_directory)
+
+ # Save the model
+ state_dict = model_to_save.state_dict()
+
+ weights_name = SAFETENSORS_WEIGHTS_NAME if safe_serialization else WEIGHTS_NAME
+ weights_name = _add_variant(weights_name, variant)
+
+ # Save the model
+ if safe_serialization:
+ safetensors.torch.save_file(
+ state_dict, os.path.join(save_directory, weights_name), metadata={"format": "pt"}
+ )
+ else:
+ torch.save(state_dict, os.path.join(save_directory, weights_name))
+
+ logger.info(f"Model weights saved in {os.path.join(save_directory, weights_name)}")
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
+ r"""
+ Instantiate a pretrained pytorch model from a pre-trained model configuration.
+
+ The model is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated). To train
+ the model, you should first set it back in training mode with `model.train()`.
+
+ The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
+ pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
+ task.
+
+ The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
+ weights are discarded.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ Valid model ids should have an organization name, like `google/ddpm-celebahq-256`.
+ - A path to a *directory* containing model weights saved using [`~ModelMixin.save_config`], e.g.,
+ `./my_model_directory/`.
+
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ torch_dtype (`str` or `torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
+ will be automatically derived from the model's weights.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `diffusers-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ from_flax (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a Flax checkpoint save file.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo (either remote in
+ huggingface.co or downloaded locally), you can specify the folder name here.
+
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information.
+ device_map (`str` or `Dict[str, Union[int, str, torch.device]]`, *optional*):
+ A map that specifies where each submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every submodule of it will be sent to the
+ same device.
+
+ To have Accelerate compute the most optimized `device_map` automatically, set `device_map="auto"`. For
+ more information about each option see [designing a device
+ map](https://hf.co/docs/accelerate/main/en/usage_guides/big_modeling#designing-a-device-map).
+ low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
+ Speed up model loading by not initializing the weights and only loading the pre-trained weights. This
+ also tries to not use more than 1x model size in CPU memory (including peak memory) while loading the
+ model. This is only supported when torch version >= 1.9.0. If you are using an older version of torch,
+ setting this argument to `True` will raise an error.
+ variant (`str`, *optional*):
+ If specified load weights from `variant` filename, *e.g.* pytorch_model..bin. `variant` is
+ ignored when using `from_flax`.
+ use_safetensors (`bool`, *optional* ):
+ If set to `True`, the pipeline will forcibly load the models from `safetensors` weights. If set to
+ `None` (the default). The pipeline will load using `safetensors` if safetensors weights are available
+ *and* if `safetensors` is installed. If the to `False` the pipeline will *not* use `safetensors`.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models).
+
+
+
+
+
+ Activate the special ["offline-mode"](https://huggingface.co/diffusers/installation.html#offline-mode) to use
+ this method in a firewalled environment.
+
+
+
+ """
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ ignore_mismatched_sizes = kwargs.pop("ignore_mismatched_sizes", False)
+ force_download = kwargs.pop("force_download", False)
+ from_flax = kwargs.pop("from_flax", False)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ output_loading_info = kwargs.pop("output_loading_info", False)
+ local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ torch_dtype = kwargs.pop("torch_dtype", None)
+ subfolder = kwargs.pop("subfolder", None)
+ device_map = kwargs.pop("device_map", None)
+ low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", _LOW_CPU_MEM_USAGE_DEFAULT)
+ variant = kwargs.pop("variant", None)
+ use_safetensors = kwargs.pop("use_safetensors", None)
+
+ if use_safetensors and not is_safetensors_available():
+ raise ValueError(
+ "`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
+ )
+
+ allow_pickle = False
+ if use_safetensors is None:
+ use_safetensors = is_safetensors_available()
+ allow_pickle = True
+
+ if low_cpu_mem_usage and not is_accelerate_available():
+ low_cpu_mem_usage = False
+ logger.warning(
+ "Cannot initialize model with low cpu memory usage because `accelerate` was not found in the"
+ " environment. Defaulting to `low_cpu_mem_usage=False`. It is strongly recommended to install"
+ " `accelerate` for faster and less memory-intense model loading. You can do so with: \n```\npip"
+ " install accelerate\n```\n."
+ )
+
+ if device_map is not None and not is_accelerate_available():
+ raise NotImplementedError(
+ "Loading and dispatching requires `accelerate`. Please make sure to install accelerate or set"
+ " `device_map=None`. You can install accelerate with `pip install accelerate`."
+ )
+
+ # Check if we can handle device_map and dispatching the weights
+ if device_map is not None and not is_torch_version(">=", "1.9.0"):
+ raise NotImplementedError(
+ "Loading and dispatching requires torch >= 1.9.0. Please either update your PyTorch version or set"
+ " `device_map=None`."
+ )
+
+ if low_cpu_mem_usage is True and not is_torch_version(">=", "1.9.0"):
+ raise NotImplementedError(
+ "Low memory initialization requires torch >= 1.9.0. Please either update your PyTorch version or set"
+ " `low_cpu_mem_usage=False`."
+ )
+
+ if low_cpu_mem_usage is False and device_map is not None:
+ raise ValueError(
+ f"You cannot set `low_cpu_mem_usage` to `False` while using device_map={device_map} for loading and"
+ " dispatching. Please make sure to set `low_cpu_mem_usage=True`."
+ )
+
+ # Load config if we don't provide a configuration
+ config_path = pretrained_model_name_or_path
+
+ user_agent = {
+ "diffusers": __version__,
+ "file_type": "model",
+ "framework": "pytorch",
+ }
+
+ # load config
+ config, unused_kwargs, commit_hash = cls.load_config(
+ config_path,
+ cache_dir=cache_dir,
+ return_unused_kwargs=True,
+ return_commit_hash=True,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ device_map=device_map,
+ user_agent=user_agent,
+ **kwargs,
+ )
+
+ # load model
+ model_file = None
+ if from_flax:
+ model_file = _get_model_file(
+ pretrained_model_name_or_path,
+ weights_name=FLAX_WEIGHTS_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ user_agent=user_agent,
+ commit_hash=commit_hash,
+ )
+ model = cls.from_config(config, **unused_kwargs)
+
+ # Convert the weights
+ from .modeling_pytorch_flax_utils import load_flax_checkpoint_in_pytorch_model
+
+ model = load_flax_checkpoint_in_pytorch_model(model, model_file)
+ else:
+ if use_safetensors:
+ try:
+ model_file = _get_model_file(
+ pretrained_model_name_or_path,
+ weights_name=_add_variant(SAFETENSORS_WEIGHTS_NAME, variant),
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ user_agent=user_agent,
+ commit_hash=commit_hash,
+ )
+ except IOError as e:
+ if not allow_pickle:
+ raise e
+ pass
+ if model_file is None:
+ model_file = _get_model_file(
+ pretrained_model_name_or_path,
+ weights_name=_add_variant(WEIGHTS_NAME, variant),
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ subfolder=subfolder,
+ user_agent=user_agent,
+ commit_hash=commit_hash,
+ )
+
+ if low_cpu_mem_usage:
+ # Instantiate model with empty weights
+ with accelerate.init_empty_weights():
+ model = cls.from_config(config, **unused_kwargs)
+
+ # if device_map is None, load the state dict and move the params from meta device to the cpu
+ if device_map is None:
+ param_device = "cpu"
+ state_dict = load_state_dict(model_file, variant=variant)
+ # move the params from meta device to cpu
+ missing_keys = set(model.state_dict().keys()) - set(state_dict.keys())
+ if len(missing_keys) > 0:
+ raise ValueError(
+ f"Cannot load {cls} from {pretrained_model_name_or_path} because the following keys are"
+ f" missing: \n {', '.join(missing_keys)}. \n Please make sure to pass"
+ " `low_cpu_mem_usage=False` and `device_map=None` if you want to randomly initialize"
+ " those weights or else make sure your checkpoint file is correct."
+ )
+
+ empty_state_dict = model.state_dict()
+ for param_name, param in state_dict.items():
+ accepts_dtype = "dtype" in set(
+ inspect.signature(set_module_tensor_to_device).parameters.keys()
+ )
+
+ if empty_state_dict[param_name].shape != param.shape:
+ raise ValueError(
+ f"Cannot load {pretrained_model_name_or_path} because {param_name} expected shape {empty_state_dict[param_name]}, but got {param.shape}. If you want to instead overwrite randomly initialized weights, please make sure to pass both `low_cpu_mem_usage=False` and `ignore_mismatched_sizes=True`. For more information, see also: https://github.com/huggingface/diffusers/issues/1619#issuecomment-1345604389 as an example."
+ )
+
+ if accepts_dtype:
+ set_module_tensor_to_device(
+ model, param_name, param_device, value=param, dtype=torch_dtype
+ )
+ else:
+ set_module_tensor_to_device(model, param_name, param_device, value=param)
+ else: # else let accelerate handle loading and dispatching.
+ # Load weights and dispatch according to the device_map
+ # by default the device_map is None and the weights are loaded on the CPU
+ accelerate.load_checkpoint_and_dispatch(model, model_file, device_map, dtype=torch_dtype)
+
+ loading_info = {
+ "missing_keys": [],
+ "unexpected_keys": [],
+ "mismatched_keys": [],
+ "error_msgs": [],
+ }
+ else:
+ model = cls.from_config(config, **unused_kwargs)
+
+ state_dict = load_state_dict(model_file, variant=variant)
+
+ model, missing_keys, unexpected_keys, mismatched_keys, error_msgs = cls._load_pretrained_model(
+ model,
+ state_dict,
+ model_file,
+ pretrained_model_name_or_path,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ )
+
+ loading_info = {
+ "missing_keys": missing_keys,
+ "unexpected_keys": unexpected_keys,
+ "mismatched_keys": mismatched_keys,
+ "error_msgs": error_msgs,
+ }
+
+ if torch_dtype is not None and not isinstance(torch_dtype, torch.dtype):
+ raise ValueError(
+ f"{torch_dtype} needs to be of type `torch.dtype`, e.g. `torch.float16`, but is {type(torch_dtype)}."
+ )
+ elif torch_dtype is not None:
+ model = model.to(torch_dtype)
+
+ model.register_to_config(_name_or_path=pretrained_model_name_or_path)
+
+ # Set model in evaluation mode to deactivate DropOut modules by default
+ model.eval()
+ if output_loading_info:
+ return model, loading_info
+
+ return model
+
+ @classmethod
+ def _load_pretrained_model(
+ cls,
+ model,
+ state_dict,
+ resolved_archive_file,
+ pretrained_model_name_or_path,
+ ignore_mismatched_sizes=False,
+ ):
+ # Retrieve missing & unexpected_keys
+ model_state_dict = model.state_dict()
+ loaded_keys = list(state_dict.keys())
+
+ expected_keys = list(model_state_dict.keys())
+
+ original_loaded_keys = loaded_keys
+
+ missing_keys = list(set(expected_keys) - set(loaded_keys))
+ unexpected_keys = list(set(loaded_keys) - set(expected_keys))
+
+ # Make sure we are able to load base models as well as derived models (with heads)
+ model_to_load = model
+
+ def _find_mismatched_keys(
+ state_dict,
+ model_state_dict,
+ loaded_keys,
+ ignore_mismatched_sizes,
+ ):
+ mismatched_keys = []
+ if ignore_mismatched_sizes:
+ for checkpoint_key in loaded_keys:
+ model_key = checkpoint_key
+
+ if (
+ model_key in model_state_dict
+ and state_dict[checkpoint_key].shape != model_state_dict[model_key].shape
+ ):
+ mismatched_keys.append(
+ (checkpoint_key, state_dict[checkpoint_key].shape, model_state_dict[model_key].shape)
+ )
+ del state_dict[checkpoint_key]
+ return mismatched_keys
+
+ if state_dict is not None:
+ # Whole checkpoint
+ mismatched_keys = _find_mismatched_keys(
+ state_dict,
+ model_state_dict,
+ original_loaded_keys,
+ ignore_mismatched_sizes,
+ )
+ error_msgs = _load_state_dict_into_model(model_to_load, state_dict)
+
+ if len(error_msgs) > 0:
+ error_msg = "\n\t".join(error_msgs)
+ if "size mismatch" in error_msg:
+ error_msg += (
+ "\n\tYou may consider adding `ignore_mismatched_sizes=True` in the model `from_pretrained` method."
+ )
+ raise RuntimeError(f"Error(s) in loading state_dict for {model.__class__.__name__}:\n\t{error_msg}")
+
+ if len(unexpected_keys) > 0:
+ logger.warning(
+ f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
+ f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
+ f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task"
+ " or with another architecture (e.g. initializing a BertForSequenceClassification model from a"
+ " BertForPreTraining model).\n- This IS NOT expected if you are initializing"
+ f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly"
+ " identical (initializing a BertForSequenceClassification model from a"
+ " BertForSequenceClassification model)."
+ )
+ else:
+ logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
+ " TRAIN this model on a down-stream task to be able to use it for predictions and inference."
+ )
+ elif len(mismatched_keys) == 0:
+ logger.info(
+ f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the"
+ f" checkpoint was trained on, you can already use {model.__class__.__name__} for predictions"
+ " without further training."
+ )
+ if len(mismatched_keys) > 0:
+ mismatched_warning = "\n".join(
+ [
+ f"- {key}: found shape {shape1} in the checkpoint and {shape2} in the model instantiated"
+ for key, shape1, shape2 in mismatched_keys
+ ]
+ )
+ logger.warning(
+ f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not"
+ f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be"
+ " able to use it for predictions and inference."
+ )
+
+ return model, missing_keys, unexpected_keys, mismatched_keys, error_msgs
+
+ @property
+ def device(self) -> device:
+ """
+ `torch.device`: The device on which the module is (assuming that all the module parameters are on the same
+ device).
+ """
+ return get_parameter_device(self)
+
+ @property
+ def dtype(self) -> torch.dtype:
+ """
+ `torch.dtype`: The dtype of the module (assuming that all the module parameters have the same dtype).
+ """
+ return get_parameter_dtype(self)
+
+ def num_parameters(self, only_trainable: bool = False, exclude_embeddings: bool = False) -> int:
+ """
+ Get number of (optionally, trainable or non-embeddings) parameters in the module.
+
+ Args:
+ only_trainable (`bool`, *optional*, defaults to `False`):
+ Whether or not to return only the number of trainable parameters
+
+ exclude_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether or not to return only the number of non-embeddings parameters
+
+ Returns:
+ `int`: The number of parameters.
+ """
+
+ if exclude_embeddings:
+ embedding_param_names = [
+ f"{name}.weight"
+ for name, module_type in self.named_modules()
+ if isinstance(module_type, torch.nn.Embedding)
+ ]
+ non_embedding_parameters = [
+ parameter for name, parameter in self.named_parameters() if name not in embedding_param_names
+ ]
+ return sum(p.numel() for p in non_embedding_parameters if p.requires_grad or not only_trainable)
+ else:
+ return sum(p.numel() for p in self.parameters() if p.requires_grad or not only_trainable)
diff --git a/diffusers/src/diffusers/models/prior_transformer.py b/diffusers/src/diffusers/models/prior_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b245612e6fc16800cd6f0cb2560d681f1360d60b
--- /dev/null
+++ b/diffusers/src/diffusers/models/prior_transformer.py
@@ -0,0 +1,194 @@
+from dataclasses import dataclass
+from typing import Optional, Union
+
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput
+from .attention import BasicTransformerBlock
+from .embeddings import TimestepEmbedding, Timesteps
+from .modeling_utils import ModelMixin
+
+
+@dataclass
+class PriorTransformerOutput(BaseOutput):
+ """
+ Args:
+ predicted_image_embedding (`torch.FloatTensor` of shape `(batch_size, embedding_dim)`):
+ The predicted CLIP image embedding conditioned on the CLIP text embedding input.
+ """
+
+ predicted_image_embedding: torch.FloatTensor
+
+
+class PriorTransformer(ModelMixin, ConfigMixin):
+ """
+ The prior transformer from unCLIP is used to predict CLIP image embeddings from CLIP text embeddings. Note that the
+ transformer predicts the image embeddings through a denoising diffusion process.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the models (such as downloading or saving, etc.)
+
+ For more details, see the original paper: https://arxiv.org/abs/2204.06125
+
+ Parameters:
+ num_attention_heads (`int`, *optional*, defaults to 32): The number of heads to use for multi-head attention.
+ attention_head_dim (`int`, *optional*, defaults to 64): The number of channels in each head.
+ num_layers (`int`, *optional*, defaults to 20): The number of layers of Transformer blocks to use.
+ embedding_dim (`int`, *optional*, defaults to 768): The dimension of the CLIP embeddings. Note that CLIP
+ image embeddings and text embeddings are both the same dimension.
+ num_embeddings (`int`, *optional*, defaults to 77): The max number of clip embeddings allowed. I.e. the
+ length of the prompt after it has been tokenized.
+ additional_embeddings (`int`, *optional*, defaults to 4): The number of additional tokens appended to the
+ projected hidden_states. The actual length of the used hidden_states is `num_embeddings +
+ additional_embeddings`.
+ dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
+
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ num_attention_heads: int = 32,
+ attention_head_dim: int = 64,
+ num_layers: int = 20,
+ embedding_dim: int = 768,
+ num_embeddings=77,
+ additional_embeddings=4,
+ dropout: float = 0.0,
+ ):
+ super().__init__()
+ self.num_attention_heads = num_attention_heads
+ self.attention_head_dim = attention_head_dim
+ inner_dim = num_attention_heads * attention_head_dim
+ self.additional_embeddings = additional_embeddings
+
+ self.time_proj = Timesteps(inner_dim, True, 0)
+ self.time_embedding = TimestepEmbedding(inner_dim, inner_dim)
+
+ self.proj_in = nn.Linear(embedding_dim, inner_dim)
+
+ self.embedding_proj = nn.Linear(embedding_dim, inner_dim)
+ self.encoder_hidden_states_proj = nn.Linear(embedding_dim, inner_dim)
+
+ self.positional_embedding = nn.Parameter(torch.zeros(1, num_embeddings + additional_embeddings, inner_dim))
+
+ self.prd_embedding = nn.Parameter(torch.zeros(1, 1, inner_dim))
+
+ self.transformer_blocks = nn.ModuleList(
+ [
+ BasicTransformerBlock(
+ inner_dim,
+ num_attention_heads,
+ attention_head_dim,
+ dropout=dropout,
+ activation_fn="gelu",
+ attention_bias=True,
+ )
+ for d in range(num_layers)
+ ]
+ )
+
+ self.norm_out = nn.LayerNorm(inner_dim)
+ self.proj_to_clip_embeddings = nn.Linear(inner_dim, embedding_dim)
+
+ causal_attention_mask = torch.full(
+ [num_embeddings + additional_embeddings, num_embeddings + additional_embeddings], -10000.0
+ )
+ causal_attention_mask.triu_(1)
+ causal_attention_mask = causal_attention_mask[None, ...]
+ self.register_buffer("causal_attention_mask", causal_attention_mask, persistent=False)
+
+ self.clip_mean = nn.Parameter(torch.zeros(1, embedding_dim))
+ self.clip_std = nn.Parameter(torch.zeros(1, embedding_dim))
+
+ def forward(
+ self,
+ hidden_states,
+ timestep: Union[torch.Tensor, float, int],
+ proj_embedding: torch.FloatTensor,
+ encoder_hidden_states: torch.FloatTensor,
+ attention_mask: Optional[torch.BoolTensor] = None,
+ return_dict: bool = True,
+ ):
+ """
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, embedding_dim)`):
+ x_t, the currently predicted image embeddings.
+ timestep (`torch.long`):
+ Current denoising step.
+ proj_embedding (`torch.FloatTensor` of shape `(batch_size, embedding_dim)`):
+ Projected embedding vector the denoising process is conditioned on.
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, num_embeddings, embedding_dim)`):
+ Hidden states of the text embeddings the denoising process is conditioned on.
+ attention_mask (`torch.BoolTensor` of shape `(batch_size, num_embeddings)`):
+ Text mask for the text embeddings.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.prior_transformer.PriorTransformerOutput`] instead of a plain
+ tuple.
+
+ Returns:
+ [`~models.prior_transformer.PriorTransformerOutput`] or `tuple`:
+ [`~models.prior_transformer.PriorTransformerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ batch_size = hidden_states.shape[0]
+
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ timesteps = torch.tensor([timesteps], dtype=torch.long, device=hidden_states.device)
+ elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(hidden_states.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps * torch.ones(batch_size, dtype=timesteps.dtype, device=timesteps.device)
+
+ timesteps_projected = self.time_proj(timesteps)
+
+ # timesteps does not contain any weights and will always return f32 tensors
+ # but time_embedding might be fp16, so we need to cast here.
+ timesteps_projected = timesteps_projected.to(dtype=self.dtype)
+ time_embeddings = self.time_embedding(timesteps_projected)
+
+ proj_embeddings = self.embedding_proj(proj_embedding)
+ encoder_hidden_states = self.encoder_hidden_states_proj(encoder_hidden_states)
+ hidden_states = self.proj_in(hidden_states)
+ prd_embedding = self.prd_embedding.to(hidden_states.dtype).expand(batch_size, -1, -1)
+ positional_embeddings = self.positional_embedding.to(hidden_states.dtype)
+
+ hidden_states = torch.cat(
+ [
+ encoder_hidden_states,
+ proj_embeddings[:, None, :],
+ time_embeddings[:, None, :],
+ hidden_states[:, None, :],
+ prd_embedding,
+ ],
+ dim=1,
+ )
+
+ hidden_states = hidden_states + positional_embeddings
+
+ if attention_mask is not None:
+ attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
+ attention_mask = F.pad(attention_mask, (0, self.additional_embeddings), value=0.0)
+ attention_mask = (attention_mask[:, None, :] + self.causal_attention_mask).to(hidden_states.dtype)
+ attention_mask = attention_mask.repeat_interleave(self.config.num_attention_heads, dim=0)
+
+ for block in self.transformer_blocks:
+ hidden_states = block(hidden_states, attention_mask=attention_mask)
+
+ hidden_states = self.norm_out(hidden_states)
+ hidden_states = hidden_states[:, -1]
+ predicted_image_embedding = self.proj_to_clip_embeddings(hidden_states)
+
+ if not return_dict:
+ return (predicted_image_embedding,)
+
+ return PriorTransformerOutput(predicted_image_embedding=predicted_image_embedding)
+
+ def post_process_latents(self, prior_latents):
+ prior_latents = (prior_latents * self.clip_std) + self.clip_mean
+ return prior_latents
diff --git a/diffusers/src/diffusers/models/resnet.py b/diffusers/src/diffusers/models/resnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..98f8f19c896a3567e12e59ee02c20168e94ff0f0
--- /dev/null
+++ b/diffusers/src/diffusers/models/resnet.py
@@ -0,0 +1,839 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+# `TemporalConvLayer` Copyright 2023 Alibaba DAMO-VILAB, The ModelScope Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from functools import partial
+from typing import Optional
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from .attention import AdaGroupNorm
+
+
+class Upsample1D(nn.Module):
+ """
+ An upsampling layer with an optional convolution.
+
+ Parameters:
+ channels: channels in the inputs and outputs.
+ use_conv: a bool determining if a convolution is applied.
+ use_conv_transpose:
+ out_channels:
+ """
+
+ def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_conv_transpose = use_conv_transpose
+ self.name = name
+
+ self.conv = None
+ if use_conv_transpose:
+ self.conv = nn.ConvTranspose1d(channels, self.out_channels, 4, 2, 1)
+ elif use_conv:
+ self.conv = nn.Conv1d(self.channels, self.out_channels, 3, padding=1)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ if self.use_conv_transpose:
+ return self.conv(x)
+
+ x = F.interpolate(x, scale_factor=2.0, mode="nearest")
+
+ if self.use_conv:
+ x = self.conv(x)
+
+ return x
+
+
+class Downsample1D(nn.Module):
+ """
+ A downsampling layer with an optional convolution.
+
+ Parameters:
+ channels: channels in the inputs and outputs.
+ use_conv: a bool determining if a convolution is applied.
+ out_channels:
+ padding:
+ """
+
+ def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.padding = padding
+ stride = 2
+ self.name = name
+
+ if use_conv:
+ self.conv = nn.Conv1d(self.channels, self.out_channels, 3, stride=stride, padding=padding)
+ else:
+ assert self.channels == self.out_channels
+ self.conv = nn.AvgPool1d(kernel_size=stride, stride=stride)
+
+ def forward(self, x):
+ assert x.shape[1] == self.channels
+ return self.conv(x)
+
+
+class Upsample2D(nn.Module):
+ """
+ An upsampling layer with an optional convolution.
+
+ Parameters:
+ channels: channels in the inputs and outputs.
+ use_conv: a bool determining if a convolution is applied.
+ use_conv_transpose:
+ out_channels:
+ """
+
+ def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.use_conv_transpose = use_conv_transpose
+ self.name = name
+
+ conv = None
+ if use_conv_transpose:
+ conv = nn.ConvTranspose2d(channels, self.out_channels, 4, 2, 1)
+ elif use_conv:
+ conv = nn.Conv2d(self.channels, self.out_channels, 3, padding=1)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if name == "conv":
+ self.conv = conv
+ else:
+ self.Conv2d_0 = conv
+
+ def forward(self, hidden_states, output_size=None):
+ assert hidden_states.shape[1] == self.channels
+
+ if self.use_conv_transpose:
+ return self.conv(hidden_states)
+
+ # Cast to float32 to as 'upsample_nearest2d_out_frame' op does not support bfloat16
+ # TODO(Suraj): Remove this cast once the issue is fixed in PyTorch
+ # https://github.com/pytorch/pytorch/issues/86679
+ dtype = hidden_states.dtype
+ if dtype == torch.bfloat16:
+ hidden_states = hidden_states.to(torch.float32)
+
+ # upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
+ if hidden_states.shape[0] >= 64:
+ hidden_states = hidden_states.contiguous()
+
+ # if `output_size` is passed we force the interpolation output
+ # size and do not make use of `scale_factor=2`
+ if output_size is None:
+ hidden_states = F.interpolate(hidden_states, scale_factor=2.0, mode="nearest")
+ else:
+ hidden_states = F.interpolate(hidden_states, size=output_size, mode="nearest")
+
+ # If the input is bfloat16, we cast back to bfloat16
+ if dtype == torch.bfloat16:
+ hidden_states = hidden_states.to(dtype)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if self.use_conv:
+ if self.name == "conv":
+ hidden_states = self.conv(hidden_states)
+ else:
+ hidden_states = self.Conv2d_0(hidden_states)
+
+ return hidden_states
+
+
+class Downsample2D(nn.Module):
+ """
+ A downsampling layer with an optional convolution.
+
+ Parameters:
+ channels: channels in the inputs and outputs.
+ use_conv: a bool determining if a convolution is applied.
+ out_channels:
+ padding:
+ """
+
+ def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
+ super().__init__()
+ self.channels = channels
+ self.out_channels = out_channels or channels
+ self.use_conv = use_conv
+ self.padding = padding
+ stride = 2
+ self.name = name
+
+ if use_conv:
+ conv = nn.Conv2d(self.channels, self.out_channels, 3, stride=stride, padding=padding)
+ else:
+ assert self.channels == self.out_channels
+ conv = nn.AvgPool2d(kernel_size=stride, stride=stride)
+
+ # TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
+ if name == "conv":
+ self.Conv2d_0 = conv
+ self.conv = conv
+ elif name == "Conv2d_0":
+ self.conv = conv
+ else:
+ self.conv = conv
+
+ def forward(self, hidden_states):
+ assert hidden_states.shape[1] == self.channels
+ if self.use_conv and self.padding == 0:
+ pad = (0, 1, 0, 1)
+ hidden_states = F.pad(hidden_states, pad, mode="constant", value=0)
+
+ assert hidden_states.shape[1] == self.channels
+ hidden_states = self.conv(hidden_states)
+
+ return hidden_states
+
+
+class FirUpsample2D(nn.Module):
+ def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
+ super().__init__()
+ out_channels = out_channels if out_channels else channels
+ if use_conv:
+ self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.use_conv = use_conv
+ self.fir_kernel = fir_kernel
+ self.out_channels = out_channels
+
+ def _upsample_2d(self, hidden_states, weight=None, kernel=None, factor=2, gain=1):
+ """Fused `upsample_2d()` followed by `Conv2d()`.
+
+ Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
+ efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of
+ arbitrary order.
+
+ Args:
+ hidden_states: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
+ weight: Weight tensor of the shape `[filterH, filterW, inChannels,
+ outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] // numGroups`.
+ kernel: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
+ factor: Integer upsampling factor (default: 2).
+ gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ output: Tensor of the shape `[N, C, H * factor, W * factor]` or `[N, H * factor, W * factor, C]`, and same
+ datatype as `hidden_states`.
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+
+ # Setup filter kernel.
+ if kernel is None:
+ kernel = [1] * factor
+
+ # setup kernel
+ kernel = torch.tensor(kernel, dtype=torch.float32)
+ if kernel.ndim == 1:
+ kernel = torch.outer(kernel, kernel)
+ kernel /= torch.sum(kernel)
+
+ kernel = kernel * (gain * (factor**2))
+
+ if self.use_conv:
+ convH = weight.shape[2]
+ convW = weight.shape[3]
+ inC = weight.shape[1]
+
+ pad_value = (kernel.shape[0] - factor) - (convW - 1)
+
+ stride = (factor, factor)
+ # Determine data dimensions.
+ output_shape = (
+ (hidden_states.shape[2] - 1) * factor + convH,
+ (hidden_states.shape[3] - 1) * factor + convW,
+ )
+ output_padding = (
+ output_shape[0] - (hidden_states.shape[2] - 1) * stride[0] - convH,
+ output_shape[1] - (hidden_states.shape[3] - 1) * stride[1] - convW,
+ )
+ assert output_padding[0] >= 0 and output_padding[1] >= 0
+ num_groups = hidden_states.shape[1] // inC
+
+ # Transpose weights.
+ weight = torch.reshape(weight, (num_groups, -1, inC, convH, convW))
+ weight = torch.flip(weight, dims=[3, 4]).permute(0, 2, 1, 3, 4)
+ weight = torch.reshape(weight, (num_groups * inC, -1, convH, convW))
+
+ inverse_conv = F.conv_transpose2d(
+ hidden_states, weight, stride=stride, output_padding=output_padding, padding=0
+ )
+
+ output = upfirdn2d_native(
+ inverse_conv,
+ torch.tensor(kernel, device=inverse_conv.device),
+ pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2 + 1),
+ )
+ else:
+ pad_value = kernel.shape[0] - factor
+ output = upfirdn2d_native(
+ hidden_states,
+ torch.tensor(kernel, device=hidden_states.device),
+ up=factor,
+ pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2),
+ )
+
+ return output
+
+ def forward(self, hidden_states):
+ if self.use_conv:
+ height = self._upsample_2d(hidden_states, self.Conv2d_0.weight, kernel=self.fir_kernel)
+ height = height + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
+ else:
+ height = self._upsample_2d(hidden_states, kernel=self.fir_kernel, factor=2)
+
+ return height
+
+
+class FirDownsample2D(nn.Module):
+ def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
+ super().__init__()
+ out_channels = out_channels if out_channels else channels
+ if use_conv:
+ self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
+ self.fir_kernel = fir_kernel
+ self.use_conv = use_conv
+ self.out_channels = out_channels
+
+ def _downsample_2d(self, hidden_states, weight=None, kernel=None, factor=2, gain=1):
+ """Fused `Conv2d()` followed by `downsample_2d()`.
+ Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
+ efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of
+ arbitrary order.
+
+ Args:
+ hidden_states: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
+ weight:
+ Weight tensor of the shape `[filterH, filterW, inChannels, outChannels]`. Grouped convolution can be
+ performed by `inChannels = x.shape[0] // numGroups`.
+ kernel: FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] *
+ factor`, which corresponds to average pooling.
+ factor: Integer downsampling factor (default: 2).
+ gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ output: Tensor of the shape `[N, C, H // factor, W // factor]` or `[N, H // factor, W // factor, C]`, and
+ same datatype as `x`.
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+ if kernel is None:
+ kernel = [1] * factor
+
+ # setup kernel
+ kernel = torch.tensor(kernel, dtype=torch.float32)
+ if kernel.ndim == 1:
+ kernel = torch.outer(kernel, kernel)
+ kernel /= torch.sum(kernel)
+
+ kernel = kernel * gain
+
+ if self.use_conv:
+ _, _, convH, convW = weight.shape
+ pad_value = (kernel.shape[0] - factor) + (convW - 1)
+ stride_value = [factor, factor]
+ upfirdn_input = upfirdn2d_native(
+ hidden_states,
+ torch.tensor(kernel, device=hidden_states.device),
+ pad=((pad_value + 1) // 2, pad_value // 2),
+ )
+ output = F.conv2d(upfirdn_input, weight, stride=stride_value, padding=0)
+ else:
+ pad_value = kernel.shape[0] - factor
+ output = upfirdn2d_native(
+ hidden_states,
+ torch.tensor(kernel, device=hidden_states.device),
+ down=factor,
+ pad=((pad_value + 1) // 2, pad_value // 2),
+ )
+
+ return output
+
+ def forward(self, hidden_states):
+ if self.use_conv:
+ downsample_input = self._downsample_2d(hidden_states, weight=self.Conv2d_0.weight, kernel=self.fir_kernel)
+ hidden_states = downsample_input + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
+ else:
+ hidden_states = self._downsample_2d(hidden_states, kernel=self.fir_kernel, factor=2)
+
+ return hidden_states
+
+
+# downsample/upsample layer used in k-upscaler, might be able to use FirDownsample2D/DirUpsample2D instead
+class KDownsample2D(nn.Module):
+ def __init__(self, pad_mode="reflect"):
+ super().__init__()
+ self.pad_mode = pad_mode
+ kernel_1d = torch.tensor([[1 / 8, 3 / 8, 3 / 8, 1 / 8]])
+ self.pad = kernel_1d.shape[1] // 2 - 1
+ self.register_buffer("kernel", kernel_1d.T @ kernel_1d, persistent=False)
+
+ def forward(self, x):
+ x = F.pad(x, (self.pad,) * 4, self.pad_mode)
+ weight = x.new_zeros([x.shape[1], x.shape[1], self.kernel.shape[0], self.kernel.shape[1]])
+ indices = torch.arange(x.shape[1], device=x.device)
+ weight[indices, indices] = self.kernel.to(weight)
+ return F.conv2d(x, weight, stride=2)
+
+
+class KUpsample2D(nn.Module):
+ def __init__(self, pad_mode="reflect"):
+ super().__init__()
+ self.pad_mode = pad_mode
+ kernel_1d = torch.tensor([[1 / 8, 3 / 8, 3 / 8, 1 / 8]]) * 2
+ self.pad = kernel_1d.shape[1] // 2 - 1
+ self.register_buffer("kernel", kernel_1d.T @ kernel_1d, persistent=False)
+
+ def forward(self, x):
+ x = F.pad(x, ((self.pad + 1) // 2,) * 4, self.pad_mode)
+ weight = x.new_zeros([x.shape[1], x.shape[1], self.kernel.shape[0], self.kernel.shape[1]])
+ indices = torch.arange(x.shape[1], device=x.device)
+ weight[indices, indices] = self.kernel.to(weight)
+ return F.conv_transpose2d(x, weight, stride=2, padding=self.pad * 2 + 1)
+
+
+class ResnetBlock2D(nn.Module):
+ r"""
+ A Resnet block.
+
+ Parameters:
+ in_channels (`int`): The number of channels in the input.
+ out_channels (`int`, *optional*, default to be `None`):
+ The number of output channels for the first conv2d layer. If None, same as `in_channels`.
+ dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
+ temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
+ groups (`int`, *optional*, default to `32`): The number of groups to use for the first normalization layer.
+ groups_out (`int`, *optional*, default to None):
+ The number of groups to use for the second normalization layer. if set to None, same as `groups`.
+ eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
+ non_linearity (`str`, *optional*, default to `"swish"`): the activation function to use.
+ time_embedding_norm (`str`, *optional*, default to `"default"` ): Time scale shift config.
+ By default, apply timestep embedding conditioning with a simple shift mechanism. Choose "scale_shift" or
+ "ada_group" for a stronger conditioning with scale and shift.
+ kernel (`torch.FloatTensor`, optional, default to None): FIR filter, see
+ [`~models.resnet.FirUpsample2D`] and [`~models.resnet.FirDownsample2D`].
+ output_scale_factor (`float`, *optional*, default to be `1.0`): the scale factor to use for the output.
+ use_in_shortcut (`bool`, *optional*, default to `True`):
+ If `True`, add a 1x1 nn.conv2d layer for skip-connection.
+ up (`bool`, *optional*, default to `False`): If `True`, add an upsample layer.
+ down (`bool`, *optional*, default to `False`): If `True`, add a downsample layer.
+ conv_shortcut_bias (`bool`, *optional*, default to `True`): If `True`, adds a learnable bias to the
+ `conv_shortcut` output.
+ conv_2d_out_channels (`int`, *optional*, default to `None`): the number of channels in the output.
+ If None, same as `out_channels`.
+ """
+
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ conv_shortcut=False,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ non_linearity="swish",
+ time_embedding_norm="default", # default, scale_shift, ada_group
+ kernel=None,
+ output_scale_factor=1.0,
+ use_in_shortcut=None,
+ up=False,
+ down=False,
+ conv_shortcut_bias: bool = True,
+ conv_2d_out_channels: Optional[int] = None,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.up = up
+ self.down = down
+ self.output_scale_factor = output_scale_factor
+ self.time_embedding_norm = time_embedding_norm
+
+ if groups_out is None:
+ groups_out = groups
+
+ if self.time_embedding_norm == "ada_group":
+ self.norm1 = AdaGroupNorm(temb_channels, in_channels, groups, eps=eps)
+ else:
+ self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
+
+ self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
+
+ if temb_channels is not None:
+ if self.time_embedding_norm == "default":
+ self.time_emb_proj = torch.nn.Linear(temb_channels, out_channels)
+ elif self.time_embedding_norm == "scale_shift":
+ self.time_emb_proj = torch.nn.Linear(temb_channels, 2 * out_channels)
+ elif self.time_embedding_norm == "ada_group":
+ self.time_emb_proj = None
+ else:
+ raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
+ else:
+ self.time_emb_proj = None
+
+ if self.time_embedding_norm == "ada_group":
+ self.norm2 = AdaGroupNorm(temb_channels, out_channels, groups_out, eps=eps)
+ else:
+ self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
+
+ self.dropout = torch.nn.Dropout(dropout)
+ conv_2d_out_channels = conv_2d_out_channels or out_channels
+ self.conv2 = torch.nn.Conv2d(out_channels, conv_2d_out_channels, kernel_size=3, stride=1, padding=1)
+
+ if non_linearity == "swish":
+ self.nonlinearity = lambda x: F.silu(x)
+ elif non_linearity == "mish":
+ self.nonlinearity = nn.Mish()
+ elif non_linearity == "silu":
+ self.nonlinearity = nn.SiLU()
+ elif non_linearity == "gelu":
+ self.nonlinearity = nn.GELU()
+
+ self.upsample = self.downsample = None
+ if self.up:
+ if kernel == "fir":
+ fir_kernel = (1, 3, 3, 1)
+ self.upsample = lambda x: upsample_2d(x, kernel=fir_kernel)
+ elif kernel == "sde_vp":
+ self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
+ else:
+ self.upsample = Upsample2D(in_channels, use_conv=False)
+ elif self.down:
+ if kernel == "fir":
+ fir_kernel = (1, 3, 3, 1)
+ self.downsample = lambda x: downsample_2d(x, kernel=fir_kernel)
+ elif kernel == "sde_vp":
+ self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
+ else:
+ self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
+
+ self.use_in_shortcut = self.in_channels != conv_2d_out_channels if use_in_shortcut is None else use_in_shortcut
+
+ self.conv_shortcut = None
+ if self.use_in_shortcut:
+ self.conv_shortcut = torch.nn.Conv2d(
+ in_channels, conv_2d_out_channels, kernel_size=1, stride=1, padding=0, bias=conv_shortcut_bias
+ )
+
+ def forward(self, input_tensor, temb):
+ hidden_states = input_tensor
+
+ if self.time_embedding_norm == "ada_group":
+ hidden_states = self.norm1(hidden_states, temb)
+ else:
+ hidden_states = self.norm1(hidden_states)
+
+ hidden_states = self.nonlinearity(hidden_states)
+
+ if self.upsample is not None:
+ # upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
+ if hidden_states.shape[0] >= 64:
+ input_tensor = input_tensor.contiguous()
+ hidden_states = hidden_states.contiguous()
+ input_tensor = self.upsample(input_tensor)
+ hidden_states = self.upsample(hidden_states)
+ elif self.downsample is not None:
+ input_tensor = self.downsample(input_tensor)
+ hidden_states = self.downsample(hidden_states)
+
+ hidden_states = self.conv1(hidden_states)
+
+ if self.time_emb_proj is not None:
+ temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None]
+
+ if temb is not None and self.time_embedding_norm == "default":
+ hidden_states = hidden_states + temb
+
+ if self.time_embedding_norm == "ada_group":
+ hidden_states = self.norm2(hidden_states, temb)
+ else:
+ hidden_states = self.norm2(hidden_states)
+
+ if temb is not None and self.time_embedding_norm == "scale_shift":
+ scale, shift = torch.chunk(temb, 2, dim=1)
+ hidden_states = hidden_states * (1 + scale) + shift
+
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+
+ if self.conv_shortcut is not None:
+ input_tensor = self.conv_shortcut(input_tensor)
+
+ output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
+
+ return output_tensor
+
+
+class Mish(torch.nn.Module):
+ def forward(self, hidden_states):
+ return hidden_states * torch.tanh(torch.nn.functional.softplus(hidden_states))
+
+
+# unet_rl.py
+def rearrange_dims(tensor):
+ if len(tensor.shape) == 2:
+ return tensor[:, :, None]
+ if len(tensor.shape) == 3:
+ return tensor[:, :, None, :]
+ elif len(tensor.shape) == 4:
+ return tensor[:, :, 0, :]
+ else:
+ raise ValueError(f"`len(tensor)`: {len(tensor)} has to be 2, 3 or 4.")
+
+
+class Conv1dBlock(nn.Module):
+ """
+ Conv1d --> GroupNorm --> Mish
+ """
+
+ def __init__(self, inp_channels, out_channels, kernel_size, n_groups=8):
+ super().__init__()
+
+ self.conv1d = nn.Conv1d(inp_channels, out_channels, kernel_size, padding=kernel_size // 2)
+ self.group_norm = nn.GroupNorm(n_groups, out_channels)
+ self.mish = nn.Mish()
+
+ def forward(self, x):
+ x = self.conv1d(x)
+ x = rearrange_dims(x)
+ x = self.group_norm(x)
+ x = rearrange_dims(x)
+ x = self.mish(x)
+ return x
+
+
+# unet_rl.py
+class ResidualTemporalBlock1D(nn.Module):
+ def __init__(self, inp_channels, out_channels, embed_dim, kernel_size=5):
+ super().__init__()
+ self.conv_in = Conv1dBlock(inp_channels, out_channels, kernel_size)
+ self.conv_out = Conv1dBlock(out_channels, out_channels, kernel_size)
+
+ self.time_emb_act = nn.Mish()
+ self.time_emb = nn.Linear(embed_dim, out_channels)
+
+ self.residual_conv = (
+ nn.Conv1d(inp_channels, out_channels, 1) if inp_channels != out_channels else nn.Identity()
+ )
+
+ def forward(self, x, t):
+ """
+ Args:
+ x : [ batch_size x inp_channels x horizon ]
+ t : [ batch_size x embed_dim ]
+
+ returns:
+ out : [ batch_size x out_channels x horizon ]
+ """
+ t = self.time_emb_act(t)
+ t = self.time_emb(t)
+ out = self.conv_in(x) + rearrange_dims(t)
+ out = self.conv_out(out)
+ return out + self.residual_conv(x)
+
+
+def upsample_2d(hidden_states, kernel=None, factor=2, gain=1):
+ r"""Upsample2D a batch of 2D images with the given filter.
+ Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and upsamples each image with the given
+ filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the specified
+ `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its shape is
+ a: multiple of the upsampling factor.
+
+ Args:
+ hidden_states: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
+ kernel: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
+ factor: Integer upsampling factor (default: 2).
+ gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ output: Tensor of the shape `[N, C, H * factor, W * factor]`
+ """
+ assert isinstance(factor, int) and factor >= 1
+ if kernel is None:
+ kernel = [1] * factor
+
+ kernel = torch.tensor(kernel, dtype=torch.float32)
+ if kernel.ndim == 1:
+ kernel = torch.outer(kernel, kernel)
+ kernel /= torch.sum(kernel)
+
+ kernel = kernel * (gain * (factor**2))
+ pad_value = kernel.shape[0] - factor
+ output = upfirdn2d_native(
+ hidden_states,
+ kernel.to(device=hidden_states.device),
+ up=factor,
+ pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2),
+ )
+ return output
+
+
+def downsample_2d(hidden_states, kernel=None, factor=2, gain=1):
+ r"""Downsample2D a batch of 2D images with the given filter.
+ Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and downsamples each image with the
+ given filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the
+ specified `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its
+ shape is a multiple of the downsampling factor.
+
+ Args:
+ hidden_states: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
+ kernel: FIR filter of the shape `[firH, firW]` or `[firN]`
+ (separable). The default is `[1] * factor`, which corresponds to average pooling.
+ factor: Integer downsampling factor (default: 2).
+ gain: Scaling factor for signal magnitude (default: 1.0).
+
+ Returns:
+ output: Tensor of the shape `[N, C, H // factor, W // factor]`
+ """
+
+ assert isinstance(factor, int) and factor >= 1
+ if kernel is None:
+ kernel = [1] * factor
+
+ kernel = torch.tensor(kernel, dtype=torch.float32)
+ if kernel.ndim == 1:
+ kernel = torch.outer(kernel, kernel)
+ kernel /= torch.sum(kernel)
+
+ kernel = kernel * gain
+ pad_value = kernel.shape[0] - factor
+ output = upfirdn2d_native(
+ hidden_states, kernel.to(device=hidden_states.device), down=factor, pad=((pad_value + 1) // 2, pad_value // 2)
+ )
+ return output
+
+
+def upfirdn2d_native(tensor, kernel, up=1, down=1, pad=(0, 0)):
+ up_x = up_y = up
+ down_x = down_y = down
+ pad_x0 = pad_y0 = pad[0]
+ pad_x1 = pad_y1 = pad[1]
+
+ _, channel, in_h, in_w = tensor.shape
+ tensor = tensor.reshape(-1, in_h, in_w, 1)
+
+ _, in_h, in_w, minor = tensor.shape
+ kernel_h, kernel_w = kernel.shape
+
+ out = tensor.view(-1, in_h, 1, in_w, 1, minor)
+ out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
+ out = out.view(-1, in_h * up_y, in_w * up_x, minor)
+
+ out = F.pad(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
+ out = out.to(tensor.device) # Move back to mps if necessary
+ out = out[
+ :,
+ max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
+ max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
+ :,
+ ]
+
+ out = out.permute(0, 3, 1, 2)
+ out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
+ w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
+ out = F.conv2d(out, w)
+ out = out.reshape(
+ -1,
+ minor,
+ in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
+ in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
+ )
+ out = out.permute(0, 2, 3, 1)
+ out = out[:, ::down_y, ::down_x, :]
+
+ out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
+ out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
+
+ return out.view(-1, channel, out_h, out_w)
+
+
+class TemporalConvLayer(nn.Module):
+ """
+ Temporal convolutional layer that can be used for video (sequence of images) input Code mostly copied from:
+ https://github.com/modelscope/modelscope/blob/1509fdb973e5871f37148a4b5e5964cafd43e64d/modelscope/models/multi_modal/video_synthesis/unet_sd.py#L1016
+ """
+
+ def __init__(self, in_dim, out_dim=None, dropout=0.0):
+ super().__init__()
+ out_dim = out_dim or in_dim
+ self.in_dim = in_dim
+ self.out_dim = out_dim
+
+ # conv layers
+ self.conv1 = nn.Sequential(
+ nn.GroupNorm(32, in_dim), nn.SiLU(), nn.Conv3d(in_dim, out_dim, (3, 1, 1), padding=(1, 0, 0))
+ )
+ self.conv2 = nn.Sequential(
+ nn.GroupNorm(32, out_dim),
+ nn.SiLU(),
+ nn.Dropout(dropout),
+ nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
+ )
+ self.conv3 = nn.Sequential(
+ nn.GroupNorm(32, out_dim),
+ nn.SiLU(),
+ nn.Dropout(dropout),
+ nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
+ )
+ self.conv4 = nn.Sequential(
+ nn.GroupNorm(32, out_dim),
+ nn.SiLU(),
+ nn.Dropout(dropout),
+ nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
+ )
+
+ # zero out the last layer params,so the conv block is identity
+ nn.init.zeros_(self.conv4[-1].weight)
+ nn.init.zeros_(self.conv4[-1].bias)
+
+ def forward(self, hidden_states, num_frames=1):
+ hidden_states = (
+ hidden_states[None, :].reshape((-1, num_frames) + hidden_states.shape[1:]).permute(0, 2, 1, 3, 4)
+ )
+
+ identity = hidden_states
+ hidden_states = self.conv1(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+ hidden_states = self.conv3(hidden_states)
+ hidden_states = self.conv4(hidden_states)
+
+ hidden_states = identity + hidden_states
+
+ hidden_states = hidden_states.permute(0, 2, 1, 3, 4).reshape(
+ (hidden_states.shape[0] * hidden_states.shape[2], -1) + hidden_states.shape[3:]
+ )
+ return hidden_states
diff --git a/diffusers/src/diffusers/models/resnet_flax.py b/diffusers/src/diffusers/models/resnet_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a391f4b947e74beda03f26e376141b2b3c21502
--- /dev/null
+++ b/diffusers/src/diffusers/models/resnet_flax.py
@@ -0,0 +1,124 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import flax.linen as nn
+import jax
+import jax.numpy as jnp
+
+
+class FlaxUpsample2D(nn.Module):
+ out_channels: int
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.conv = nn.Conv(
+ self.out_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states):
+ batch, height, width, channels = hidden_states.shape
+ hidden_states = jax.image.resize(
+ hidden_states,
+ shape=(batch, height * 2, width * 2, channels),
+ method="nearest",
+ )
+ hidden_states = self.conv(hidden_states)
+ return hidden_states
+
+
+class FlaxDownsample2D(nn.Module):
+ out_channels: int
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.conv = nn.Conv(
+ self.out_channels,
+ kernel_size=(3, 3),
+ strides=(2, 2),
+ padding=((1, 1), (1, 1)), # padding="VALID",
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states):
+ # pad = ((0, 0), (0, 1), (0, 1), (0, 0)) # pad height and width dim
+ # hidden_states = jnp.pad(hidden_states, pad_width=pad)
+ hidden_states = self.conv(hidden_states)
+ return hidden_states
+
+
+class FlaxResnetBlock2D(nn.Module):
+ in_channels: int
+ out_channels: int = None
+ dropout_prob: float = 0.0
+ use_nin_shortcut: bool = None
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ out_channels = self.in_channels if self.out_channels is None else self.out_channels
+
+ self.norm1 = nn.GroupNorm(num_groups=32, epsilon=1e-5)
+ self.conv1 = nn.Conv(
+ out_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ self.time_emb_proj = nn.Dense(out_channels, dtype=self.dtype)
+
+ self.norm2 = nn.GroupNorm(num_groups=32, epsilon=1e-5)
+ self.dropout = nn.Dropout(self.dropout_prob)
+ self.conv2 = nn.Conv(
+ out_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ use_nin_shortcut = self.in_channels != out_channels if self.use_nin_shortcut is None else self.use_nin_shortcut
+
+ self.conv_shortcut = None
+ if use_nin_shortcut:
+ self.conv_shortcut = nn.Conv(
+ out_channels,
+ kernel_size=(1, 1),
+ strides=(1, 1),
+ padding="VALID",
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states, temb, deterministic=True):
+ residual = hidden_states
+ hidden_states = self.norm1(hidden_states)
+ hidden_states = nn.swish(hidden_states)
+ hidden_states = self.conv1(hidden_states)
+
+ temb = self.time_emb_proj(nn.swish(temb))
+ temb = jnp.expand_dims(jnp.expand_dims(temb, 1), 1)
+ hidden_states = hidden_states + temb
+
+ hidden_states = self.norm2(hidden_states)
+ hidden_states = nn.swish(hidden_states)
+ hidden_states = self.dropout(hidden_states, deterministic)
+ hidden_states = self.conv2(hidden_states)
+
+ if self.conv_shortcut is not None:
+ residual = self.conv_shortcut(residual)
+
+ return hidden_states + residual
diff --git a/diffusers/src/diffusers/models/t5_film_transformer.py b/diffusers/src/diffusers/models/t5_film_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c41e656a9dbe81edafd5a2958d49ff28e84fd01
--- /dev/null
+++ b/diffusers/src/diffusers/models/t5_film_transformer.py
@@ -0,0 +1,321 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+
+import torch
+from torch import nn
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .attention_processor import Attention
+from .embeddings import get_timestep_embedding
+from .modeling_utils import ModelMixin
+
+
+class T5FilmDecoder(ModelMixin, ConfigMixin):
+ @register_to_config
+ def __init__(
+ self,
+ input_dims: int = 128,
+ targets_length: int = 256,
+ max_decoder_noise_time: float = 2000.0,
+ d_model: int = 768,
+ num_layers: int = 12,
+ num_heads: int = 12,
+ d_kv: int = 64,
+ d_ff: int = 2048,
+ dropout_rate: float = 0.1,
+ ):
+ super().__init__()
+
+ self.conditioning_emb = nn.Sequential(
+ nn.Linear(d_model, d_model * 4, bias=False),
+ nn.SiLU(),
+ nn.Linear(d_model * 4, d_model * 4, bias=False),
+ nn.SiLU(),
+ )
+
+ self.position_encoding = nn.Embedding(targets_length, d_model)
+ self.position_encoding.weight.requires_grad = False
+
+ self.continuous_inputs_projection = nn.Linear(input_dims, d_model, bias=False)
+
+ self.dropout = nn.Dropout(p=dropout_rate)
+
+ self.decoders = nn.ModuleList()
+ for lyr_num in range(num_layers):
+ # FiLM conditional T5 decoder
+ lyr = DecoderLayer(d_model=d_model, d_kv=d_kv, num_heads=num_heads, d_ff=d_ff, dropout_rate=dropout_rate)
+ self.decoders.append(lyr)
+
+ self.decoder_norm = T5LayerNorm(d_model)
+
+ self.post_dropout = nn.Dropout(p=dropout_rate)
+ self.spec_out = nn.Linear(d_model, input_dims, bias=False)
+
+ def encoder_decoder_mask(self, query_input, key_input):
+ mask = torch.mul(query_input.unsqueeze(-1), key_input.unsqueeze(-2))
+ return mask.unsqueeze(-3)
+
+ def forward(self, encodings_and_masks, decoder_input_tokens, decoder_noise_time):
+ batch, _, _ = decoder_input_tokens.shape
+ assert decoder_noise_time.shape == (batch,)
+
+ # decoder_noise_time is in [0, 1), so rescale to expected timing range.
+ time_steps = get_timestep_embedding(
+ decoder_noise_time * self.config.max_decoder_noise_time,
+ embedding_dim=self.config.d_model,
+ max_period=self.config.max_decoder_noise_time,
+ ).to(dtype=self.dtype)
+
+ conditioning_emb = self.conditioning_emb(time_steps).unsqueeze(1)
+
+ assert conditioning_emb.shape == (batch, 1, self.config.d_model * 4)
+
+ seq_length = decoder_input_tokens.shape[1]
+
+ # If we want to use relative positions for audio context, we can just offset
+ # this sequence by the length of encodings_and_masks.
+ decoder_positions = torch.broadcast_to(
+ torch.arange(seq_length, device=decoder_input_tokens.device),
+ (batch, seq_length),
+ )
+
+ position_encodings = self.position_encoding(decoder_positions)
+
+ inputs = self.continuous_inputs_projection(decoder_input_tokens)
+ inputs += position_encodings
+ y = self.dropout(inputs)
+
+ # decoder: No padding present.
+ decoder_mask = torch.ones(
+ decoder_input_tokens.shape[:2], device=decoder_input_tokens.device, dtype=inputs.dtype
+ )
+
+ # Translate encoding masks to encoder-decoder masks.
+ encodings_and_encdec_masks = [(x, self.encoder_decoder_mask(decoder_mask, y)) for x, y in encodings_and_masks]
+
+ # cross attend style: concat encodings
+ encoded = torch.cat([x[0] for x in encodings_and_encdec_masks], dim=1)
+ encoder_decoder_mask = torch.cat([x[1] for x in encodings_and_encdec_masks], dim=-1)
+
+ for lyr in self.decoders:
+ y = lyr(
+ y,
+ conditioning_emb=conditioning_emb,
+ encoder_hidden_states=encoded,
+ encoder_attention_mask=encoder_decoder_mask,
+ )[0]
+
+ y = self.decoder_norm(y)
+ y = self.post_dropout(y)
+
+ spec_out = self.spec_out(y)
+ return spec_out
+
+
+class DecoderLayer(nn.Module):
+ def __init__(self, d_model, d_kv, num_heads, d_ff, dropout_rate, layer_norm_epsilon=1e-6):
+ super().__init__()
+ self.layer = nn.ModuleList()
+
+ # cond self attention: layer 0
+ self.layer.append(
+ T5LayerSelfAttentionCond(d_model=d_model, d_kv=d_kv, num_heads=num_heads, dropout_rate=dropout_rate)
+ )
+
+ # cross attention: layer 1
+ self.layer.append(
+ T5LayerCrossAttention(
+ d_model=d_model,
+ d_kv=d_kv,
+ num_heads=num_heads,
+ dropout_rate=dropout_rate,
+ layer_norm_epsilon=layer_norm_epsilon,
+ )
+ )
+
+ # Film Cond MLP + dropout: last layer
+ self.layer.append(
+ T5LayerFFCond(d_model=d_model, d_ff=d_ff, dropout_rate=dropout_rate, layer_norm_epsilon=layer_norm_epsilon)
+ )
+
+ def forward(
+ self,
+ hidden_states,
+ conditioning_emb=None,
+ attention_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ encoder_decoder_position_bias=None,
+ ):
+ hidden_states = self.layer[0](
+ hidden_states,
+ conditioning_emb=conditioning_emb,
+ attention_mask=attention_mask,
+ )
+
+ if encoder_hidden_states is not None:
+ encoder_extended_attention_mask = torch.where(encoder_attention_mask > 0, 0, -1e10).to(
+ encoder_hidden_states.dtype
+ )
+
+ hidden_states = self.layer[1](
+ hidden_states,
+ key_value_states=encoder_hidden_states,
+ attention_mask=encoder_extended_attention_mask,
+ )
+
+ # Apply Film Conditional Feed Forward layer
+ hidden_states = self.layer[-1](hidden_states, conditioning_emb)
+
+ return (hidden_states,)
+
+
+class T5LayerSelfAttentionCond(nn.Module):
+ def __init__(self, d_model, d_kv, num_heads, dropout_rate):
+ super().__init__()
+ self.layer_norm = T5LayerNorm(d_model)
+ self.FiLMLayer = T5FiLMLayer(in_features=d_model * 4, out_features=d_model)
+ self.attention = Attention(query_dim=d_model, heads=num_heads, dim_head=d_kv, out_bias=False, scale_qk=False)
+ self.dropout = nn.Dropout(dropout_rate)
+
+ def forward(
+ self,
+ hidden_states,
+ conditioning_emb=None,
+ attention_mask=None,
+ ):
+ # pre_self_attention_layer_norm
+ normed_hidden_states = self.layer_norm(hidden_states)
+
+ if conditioning_emb is not None:
+ normed_hidden_states = self.FiLMLayer(normed_hidden_states, conditioning_emb)
+
+ # Self-attention block
+ attention_output = self.attention(normed_hidden_states)
+
+ hidden_states = hidden_states + self.dropout(attention_output)
+
+ return hidden_states
+
+
+class T5LayerCrossAttention(nn.Module):
+ def __init__(self, d_model, d_kv, num_heads, dropout_rate, layer_norm_epsilon):
+ super().__init__()
+ self.attention = Attention(query_dim=d_model, heads=num_heads, dim_head=d_kv, out_bias=False, scale_qk=False)
+ self.layer_norm = T5LayerNorm(d_model, eps=layer_norm_epsilon)
+ self.dropout = nn.Dropout(dropout_rate)
+
+ def forward(
+ self,
+ hidden_states,
+ key_value_states=None,
+ attention_mask=None,
+ ):
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.attention(
+ normed_hidden_states,
+ encoder_hidden_states=key_value_states,
+ attention_mask=attention_mask.squeeze(1),
+ )
+ layer_output = hidden_states + self.dropout(attention_output)
+ return layer_output
+
+
+class T5LayerFFCond(nn.Module):
+ def __init__(self, d_model, d_ff, dropout_rate, layer_norm_epsilon):
+ super().__init__()
+ self.DenseReluDense = T5DenseGatedActDense(d_model=d_model, d_ff=d_ff, dropout_rate=dropout_rate)
+ self.film = T5FiLMLayer(in_features=d_model * 4, out_features=d_model)
+ self.layer_norm = T5LayerNorm(d_model, eps=layer_norm_epsilon)
+ self.dropout = nn.Dropout(dropout_rate)
+
+ def forward(self, hidden_states, conditioning_emb=None):
+ forwarded_states = self.layer_norm(hidden_states)
+ if conditioning_emb is not None:
+ forwarded_states = self.film(forwarded_states, conditioning_emb)
+
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ hidden_states = hidden_states + self.dropout(forwarded_states)
+ return hidden_states
+
+
+class T5DenseGatedActDense(nn.Module):
+ def __init__(self, d_model, d_ff, dropout_rate):
+ super().__init__()
+ self.wi_0 = nn.Linear(d_model, d_ff, bias=False)
+ self.wi_1 = nn.Linear(d_model, d_ff, bias=False)
+ self.wo = nn.Linear(d_ff, d_model, bias=False)
+ self.dropout = nn.Dropout(dropout_rate)
+ self.act = NewGELUActivation()
+
+ def forward(self, hidden_states):
+ hidden_gelu = self.act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+
+
+class T5LayerNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ Construct a layernorm module in the T5 style. No bias and no subtraction of mean.
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ # T5 uses a layer_norm which only scales and doesn't shift, which is also known as Root Mean
+ # Square Layer Normalization https://arxiv.org/abs/1910.07467 thus variance is calculated
+ # w/o mean and there is no bias. Additionally we want to make sure that the accumulation for
+ # half-precision inputs is done in fp32
+
+ variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+
+ # convert into half-precision if necessary
+ if self.weight.dtype in [torch.float16, torch.bfloat16]:
+ hidden_states = hidden_states.to(self.weight.dtype)
+
+ return self.weight * hidden_states
+
+
+class NewGELUActivation(nn.Module):
+ """
+ Implementation of the GELU activation function currently in Google BERT repo (identical to OpenAI GPT). Also see
+ the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ """
+
+ def forward(self, input: torch.Tensor) -> torch.Tensor:
+ return 0.5 * input * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (input + 0.044715 * torch.pow(input, 3.0))))
+
+
+class T5FiLMLayer(nn.Module):
+ """
+ FiLM Layer
+ """
+
+ def __init__(self, in_features, out_features):
+ super().__init__()
+ self.scale_bias = nn.Linear(in_features, out_features * 2, bias=False)
+
+ def forward(self, x, conditioning_emb):
+ emb = self.scale_bias(conditioning_emb)
+ scale, shift = torch.chunk(emb, 2, -1)
+ x = x * (1 + scale) + shift
+ return x
diff --git a/diffusers/src/diffusers/models/transformer_2d.py b/diffusers/src/diffusers/models/transformer_2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..d590b1d0978104719e987504244ec60c53882539
--- /dev/null
+++ b/diffusers/src/diffusers/models/transformer_2d.py
@@ -0,0 +1,321 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Any, Dict, Optional
+
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..models.embeddings import ImagePositionalEmbeddings
+from ..utils import BaseOutput, deprecate
+from .attention import BasicTransformerBlock
+from .embeddings import PatchEmbed
+from .modeling_utils import ModelMixin
+
+
+@dataclass
+class Transformer2DModelOutput(BaseOutput):
+ """
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` or `(batch size, num_vector_embeds - 1, num_latent_pixels)` if [`Transformer2DModel`] is discrete):
+ Hidden states conditioned on `encoder_hidden_states` input. If discrete, returns probability distributions
+ for the unnoised latent pixels.
+ """
+
+ sample: torch.FloatTensor
+
+
+class Transformer2DModel(ModelMixin, ConfigMixin):
+ """
+ Transformer model for image-like data. Takes either discrete (classes of vector embeddings) or continuous (actual
+ embeddings) inputs.
+
+ When input is continuous: First, project the input (aka embedding) and reshape to b, t, d. Then apply standard
+ transformer action. Finally, reshape to image.
+
+ When input is discrete: First, input (classes of latent pixels) is converted to embeddings and has positional
+ embeddings applied, see `ImagePositionalEmbeddings`. Then apply standard transformer action. Finally, predict
+ classes of unnoised image.
+
+ Note that it is assumed one of the input classes is the masked latent pixel. The predicted classes of the unnoised
+ image do not contain a prediction for the masked pixel as the unnoised image cannot be masked.
+
+ Parameters:
+ num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
+ attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
+ in_channels (`int`, *optional*):
+ Pass if the input is continuous. The number of channels in the input and output.
+ num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
+ dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
+ cross_attention_dim (`int`, *optional*): The number of encoder_hidden_states dimensions to use.
+ sample_size (`int`, *optional*): Pass if the input is discrete. The width of the latent images.
+ Note that this is fixed at training time as it is used for learning a number of position embeddings. See
+ `ImagePositionalEmbeddings`.
+ num_vector_embeds (`int`, *optional*):
+ Pass if the input is discrete. The number of classes of the vector embeddings of the latent pixels.
+ Includes the class for the masked latent pixel.
+ activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
+ num_embeds_ada_norm ( `int`, *optional*): Pass if at least one of the norm_layers is `AdaLayerNorm`.
+ The number of diffusion steps used during training. Note that this is fixed at training time as it is used
+ to learn a number of embeddings that are added to the hidden states. During inference, you can denoise for
+ up to but not more than steps than `num_embeds_ada_norm`.
+ attention_bias (`bool`, *optional*):
+ Configure if the TransformerBlocks' attention should contain a bias parameter.
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ num_attention_heads: int = 16,
+ attention_head_dim: int = 88,
+ in_channels: Optional[int] = None,
+ out_channels: Optional[int] = None,
+ num_layers: int = 1,
+ dropout: float = 0.0,
+ norm_num_groups: int = 32,
+ cross_attention_dim: Optional[int] = None,
+ attention_bias: bool = False,
+ sample_size: Optional[int] = None,
+ num_vector_embeds: Optional[int] = None,
+ patch_size: Optional[int] = None,
+ activation_fn: str = "geglu",
+ num_embeds_ada_norm: Optional[int] = None,
+ use_linear_projection: bool = False,
+ only_cross_attention: bool = False,
+ upcast_attention: bool = False,
+ norm_type: str = "layer_norm",
+ norm_elementwise_affine: bool = True,
+ ):
+ super().__init__()
+ self.use_linear_projection = use_linear_projection
+ self.num_attention_heads = num_attention_heads
+ self.attention_head_dim = attention_head_dim
+ inner_dim = num_attention_heads * attention_head_dim
+
+ # 1. Transformer2DModel can process both standard continuous images of shape `(batch_size, num_channels, width, height)` as well as quantized image embeddings of shape `(batch_size, num_image_vectors)`
+ # Define whether input is continuous or discrete depending on configuration
+ self.is_input_continuous = (in_channels is not None) and (patch_size is None)
+ self.is_input_vectorized = num_vector_embeds is not None
+ self.is_input_patches = in_channels is not None and patch_size is not None
+
+ if norm_type == "layer_norm" and num_embeds_ada_norm is not None:
+ deprecation_message = (
+ f"The configuration file of this model: {self.__class__} is outdated. `norm_type` is either not set or"
+ " incorrectly set to `'layer_norm'`.Make sure to set `norm_type` to `'ada_norm'` in the config."
+ " Please make sure to update the config accordingly as leaving `norm_type` might led to incorrect"
+ " results in future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it"
+ " would be very nice if you could open a Pull request for the `transformer/config.json` file"
+ )
+ deprecate("norm_type!=num_embeds_ada_norm", "1.0.0", deprecation_message, standard_warn=False)
+ norm_type = "ada_norm"
+
+ if self.is_input_continuous and self.is_input_vectorized:
+ raise ValueError(
+ f"Cannot define both `in_channels`: {in_channels} and `num_vector_embeds`: {num_vector_embeds}. Make"
+ " sure that either `in_channels` or `num_vector_embeds` is None."
+ )
+ elif self.is_input_vectorized and self.is_input_patches:
+ raise ValueError(
+ f"Cannot define both `num_vector_embeds`: {num_vector_embeds} and `patch_size`: {patch_size}. Make"
+ " sure that either `num_vector_embeds` or `num_patches` is None."
+ )
+ elif not self.is_input_continuous and not self.is_input_vectorized and not self.is_input_patches:
+ raise ValueError(
+ f"Has to define `in_channels`: {in_channels}, `num_vector_embeds`: {num_vector_embeds}, or patch_size:"
+ f" {patch_size}. Make sure that `in_channels`, `num_vector_embeds` or `num_patches` is not None."
+ )
+
+ # 2. Define input layers
+ if self.is_input_continuous:
+ self.in_channels = in_channels
+
+ self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
+ if use_linear_projection:
+ self.proj_in = nn.Linear(in_channels, inner_dim)
+ else:
+ self.proj_in = nn.Conv2d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
+ elif self.is_input_vectorized:
+ assert sample_size is not None, "Transformer2DModel over discrete input must provide sample_size"
+ assert num_vector_embeds is not None, "Transformer2DModel over discrete input must provide num_embed"
+
+ self.height = sample_size
+ self.width = sample_size
+ self.num_vector_embeds = num_vector_embeds
+ self.num_latent_pixels = self.height * self.width
+
+ self.latent_image_embedding = ImagePositionalEmbeddings(
+ num_embed=num_vector_embeds, embed_dim=inner_dim, height=self.height, width=self.width
+ )
+ elif self.is_input_patches:
+ assert sample_size is not None, "Transformer2DModel over patched input must provide sample_size"
+
+ self.height = sample_size
+ self.width = sample_size
+
+ self.patch_size = patch_size
+ self.pos_embed = PatchEmbed(
+ height=sample_size,
+ width=sample_size,
+ patch_size=patch_size,
+ in_channels=in_channels,
+ embed_dim=inner_dim,
+ )
+
+ # 3. Define transformers blocks
+ self.transformer_blocks = nn.ModuleList(
+ [
+ BasicTransformerBlock(
+ inner_dim,
+ num_attention_heads,
+ attention_head_dim,
+ dropout=dropout,
+ cross_attention_dim=cross_attention_dim,
+ activation_fn=activation_fn,
+ num_embeds_ada_norm=num_embeds_ada_norm,
+ attention_bias=attention_bias,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ norm_type=norm_type,
+ norm_elementwise_affine=norm_elementwise_affine,
+ )
+ for d in range(num_layers)
+ ]
+ )
+
+ # 4. Define output layers
+ self.out_channels = in_channels if out_channels is None else out_channels
+ if self.is_input_continuous:
+ # TODO: should use out_channels for continuous projections
+ if use_linear_projection:
+ self.proj_out = nn.Linear(inner_dim, in_channels)
+ else:
+ self.proj_out = nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
+ elif self.is_input_vectorized:
+ self.norm_out = nn.LayerNorm(inner_dim)
+ self.out = nn.Linear(inner_dim, self.num_vector_embeds - 1)
+ elif self.is_input_patches:
+ self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
+ self.proj_out_1 = nn.Linear(inner_dim, 2 * inner_dim)
+ self.proj_out_2 = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ timestep: Optional[torch.LongTensor] = None,
+ class_labels: Optional[torch.LongTensor] = None,
+ cross_attention_kwargs: Dict[str, Any] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ):
+ """
+ Args:
+ hidden_states ( When discrete, `torch.LongTensor` of shape `(batch size, num latent pixels)`.
+ When continuous, `torch.FloatTensor` of shape `(batch size, channel, height, width)`): Input
+ hidden_states
+ encoder_hidden_states ( `torch.LongTensor` of shape `(batch size, encoder_hidden_states dim)`, *optional*):
+ Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
+ self-attention.
+ timestep ( `torch.LongTensor`, *optional*):
+ Optional timestep to be applied as an embedding in AdaLayerNorm's. Used to indicate denoising step.
+ class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
+ Optional class labels to be applied as an embedding in AdaLayerZeroNorm. Used to indicate class labels
+ conditioning.
+ attention_mask ( `torch.Tensor` of shape (batch size, num latent pixels), *optional* ).
+ Bias to add to attention scores.
+ encoder_attention_mask ( `torch.Tensor` of shape (batch size, num encoder tokens), *optional* ).
+ Bias to add to cross-attention scores.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~models.transformer_2d.Transformer2DModelOutput`] or `tuple`:
+ [`~models.transformer_2d.Transformer2DModelOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ # 1. Input
+ if self.is_input_continuous:
+ batch, _, height, width = hidden_states.shape
+ residual = hidden_states
+
+ hidden_states = self.norm(hidden_states)
+ if not self.use_linear_projection:
+ hidden_states = self.proj_in(hidden_states)
+ inner_dim = hidden_states.shape[1]
+ hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
+ else:
+ inner_dim = hidden_states.shape[1]
+ hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
+ hidden_states = self.proj_in(hidden_states)
+ elif self.is_input_vectorized:
+ hidden_states = self.latent_image_embedding(hidden_states)
+ elif self.is_input_patches:
+ hidden_states = self.pos_embed(hidden_states)
+
+ # 2. Blocks
+ for block in self.transformer_blocks:
+ hidden_states = block(
+ hidden_states,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ timestep=timestep,
+ cross_attention_kwargs=cross_attention_kwargs,
+ class_labels=class_labels,
+ )
+
+ # 3. Output
+ if self.is_input_continuous:
+ if not self.use_linear_projection:
+ hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
+ hidden_states = self.proj_out(hidden_states)
+ else:
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
+
+ output = hidden_states + residual
+ elif self.is_input_vectorized:
+ hidden_states = self.norm_out(hidden_states)
+ logits = self.out(hidden_states)
+ # (batch, self.num_vector_embeds - 1, self.num_latent_pixels)
+ logits = logits.permute(0, 2, 1)
+
+ # log(p(x_0))
+ output = F.log_softmax(logits.double(), dim=1).float()
+ elif self.is_input_patches:
+ # TODO: cleanup!
+ conditioning = self.transformer_blocks[0].norm1.emb(
+ timestep, class_labels, hidden_dtype=hidden_states.dtype
+ )
+ shift, scale = self.proj_out_1(F.silu(conditioning)).chunk(2, dim=1)
+ hidden_states = self.norm_out(hidden_states) * (1 + scale[:, None]) + shift[:, None]
+ hidden_states = self.proj_out_2(hidden_states)
+
+ # unpatchify
+ height = width = int(hidden_states.shape[1] ** 0.5)
+ hidden_states = hidden_states.reshape(
+ shape=(-1, height, width, self.patch_size, self.patch_size, self.out_channels)
+ )
+ hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
+ output = hidden_states.reshape(
+ shape=(-1, self.out_channels, height * self.patch_size, width * self.patch_size)
+ )
+
+ if not return_dict:
+ return (output,)
+
+ return Transformer2DModelOutput(sample=output)
diff --git a/diffusers/src/diffusers/models/transformer_temporal.py b/diffusers/src/diffusers/models/transformer_temporal.py
new file mode 100644
index 0000000000000000000000000000000000000000..ece88b8db2d503809e3f020fc2f2420d00d98342
--- /dev/null
+++ b/diffusers/src/diffusers/models/transformer_temporal.py
@@ -0,0 +1,176 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Optional
+
+import torch
+from torch import nn
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput
+from .attention import BasicTransformerBlock
+from .modeling_utils import ModelMixin
+
+
+@dataclass
+class TransformerTemporalModelOutput(BaseOutput):
+ """
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size x num_frames, num_channels, height, width)`)
+ Hidden states conditioned on `encoder_hidden_states` input.
+ """
+
+ sample: torch.FloatTensor
+
+
+class TransformerTemporalModel(ModelMixin, ConfigMixin):
+ """
+ Transformer model for video-like data.
+
+ Parameters:
+ num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
+ attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
+ in_channels (`int`, *optional*):
+ Pass if the input is continuous. The number of channels in the input and output.
+ num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
+ dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
+ cross_attention_dim (`int`, *optional*): The number of encoder_hidden_states dimensions to use.
+ sample_size (`int`, *optional*): Pass if the input is discrete. The width of the latent images.
+ Note that this is fixed at training time as it is used for learning a number of position embeddings. See
+ `ImagePositionalEmbeddings`.
+ activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
+ attention_bias (`bool`, *optional*):
+ Configure if the TransformerBlocks' attention should contain a bias parameter.
+ double_self_attention (`bool`, *optional*):
+ Configure if each TransformerBlock should contain two self-attention layers
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ num_attention_heads: int = 16,
+ attention_head_dim: int = 88,
+ in_channels: Optional[int] = None,
+ out_channels: Optional[int] = None,
+ num_layers: int = 1,
+ dropout: float = 0.0,
+ norm_num_groups: int = 32,
+ cross_attention_dim: Optional[int] = None,
+ attention_bias: bool = False,
+ sample_size: Optional[int] = None,
+ activation_fn: str = "geglu",
+ norm_elementwise_affine: bool = True,
+ double_self_attention: bool = True,
+ ):
+ super().__init__()
+ self.num_attention_heads = num_attention_heads
+ self.attention_head_dim = attention_head_dim
+ inner_dim = num_attention_heads * attention_head_dim
+
+ self.in_channels = in_channels
+
+ self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
+ self.proj_in = nn.Linear(in_channels, inner_dim)
+
+ # 3. Define transformers blocks
+ self.transformer_blocks = nn.ModuleList(
+ [
+ BasicTransformerBlock(
+ inner_dim,
+ num_attention_heads,
+ attention_head_dim,
+ dropout=dropout,
+ cross_attention_dim=cross_attention_dim,
+ activation_fn=activation_fn,
+ attention_bias=attention_bias,
+ double_self_attention=double_self_attention,
+ norm_elementwise_affine=norm_elementwise_affine,
+ )
+ for d in range(num_layers)
+ ]
+ )
+
+ self.proj_out = nn.Linear(inner_dim, in_channels)
+
+ def forward(
+ self,
+ hidden_states,
+ encoder_hidden_states=None,
+ timestep=None,
+ class_labels=None,
+ num_frames=1,
+ cross_attention_kwargs=None,
+ return_dict: bool = True,
+ ):
+ """
+ Args:
+ hidden_states ( When discrete, `torch.LongTensor` of shape `(batch size, num latent pixels)`.
+ When continous, `torch.FloatTensor` of shape `(batch size, channel, height, width)`): Input
+ hidden_states
+ encoder_hidden_states ( `torch.LongTensor` of shape `(batch size, encoder_hidden_states dim)`, *optional*):
+ Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
+ self-attention.
+ timestep ( `torch.long`, *optional*):
+ Optional timestep to be applied as an embedding in AdaLayerNorm's. Used to indicate denoising step.
+ class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
+ Optional class labels to be applied as an embedding in AdaLayerZeroNorm. Used to indicate class labels
+ conditioning.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~models.transformer_2d.TransformerTemporalModelOutput`] or `tuple`:
+ [`~models.transformer_2d.TransformerTemporalModelOutput`] if `return_dict` is True, otherwise a `tuple`.
+ When returning a tuple, the first element is the sample tensor.
+ """
+ # 1. Input
+ batch_frames, channel, height, width = hidden_states.shape
+ batch_size = batch_frames // num_frames
+
+ residual = hidden_states
+
+ hidden_states = hidden_states[None, :].reshape(batch_size, num_frames, channel, height, width)
+ hidden_states = hidden_states.permute(0, 2, 1, 3, 4)
+
+ hidden_states = self.norm(hidden_states)
+ hidden_states = hidden_states.permute(0, 3, 4, 2, 1).reshape(batch_size * height * width, num_frames, channel)
+
+ hidden_states = self.proj_in(hidden_states)
+
+ # 2. Blocks
+ for block in self.transformer_blocks:
+ hidden_states = block(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ timestep=timestep,
+ cross_attention_kwargs=cross_attention_kwargs,
+ class_labels=class_labels,
+ )
+
+ # 3. Output
+ hidden_states = self.proj_out(hidden_states)
+ hidden_states = (
+ hidden_states[None, None, :]
+ .reshape(batch_size, height, width, channel, num_frames)
+ .permute(0, 3, 4, 1, 2)
+ .contiguous()
+ )
+ hidden_states = hidden_states.reshape(batch_frames, channel, height, width)
+
+ output = hidden_states + residual
+
+ if not return_dict:
+ return (output,)
+
+ return TransformerTemporalModelOutput(sample=output)
diff --git a/diffusers/src/diffusers/models/unet_1d.py b/diffusers/src/diffusers/models/unet_1d.py
new file mode 100644
index 0000000000000000000000000000000000000000..34a1d2b5160eef54d4cec9596b87d233f5938e80
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_1d.py
@@ -0,0 +1,249 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput
+from .embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
+from .modeling_utils import ModelMixin
+from .unet_1d_blocks import get_down_block, get_mid_block, get_out_block, get_up_block
+
+
+@dataclass
+class UNet1DOutput(BaseOutput):
+ """
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, sample_size)`):
+ Hidden states output. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor
+
+
+class UNet1DModel(ModelMixin, ConfigMixin):
+ r"""
+ UNet1DModel is a 1D UNet model that takes in a noisy sample and a timestep and returns sample shaped output.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the model (such as downloading or saving, etc.)
+
+ Parameters:
+ sample_size (`int`, *optional*): Default length of sample. Should be adaptable at runtime.
+ in_channels (`int`, *optional*, defaults to 2): Number of channels in the input sample.
+ out_channels (`int`, *optional*, defaults to 2): Number of channels in the output.
+ extra_in_channels (`int`, *optional*, defaults to 0):
+ Number of additional channels to be added to the input of the first down block. Useful for cases where the
+ input data has more channels than what the model is initially designed for.
+ time_embedding_type (`str`, *optional*, defaults to `"fourier"`): Type of time embedding to use.
+ freq_shift (`float`, *optional*, defaults to 0.0): Frequency shift for fourier time embedding.
+ flip_sin_to_cos (`bool`, *optional*, defaults to :
+ obj:`False`): Whether to flip sin to cos for fourier time embedding.
+ down_block_types (`Tuple[str]`, *optional*, defaults to :
+ obj:`("DownBlock1D", "DownBlock1DNoSkip", "AttnDownBlock1D")`): Tuple of downsample block types.
+ up_block_types (`Tuple[str]`, *optional*, defaults to :
+ obj:`("UpBlock1D", "UpBlock1DNoSkip", "AttnUpBlock1D")`): Tuple of upsample block types.
+ block_out_channels (`Tuple[int]`, *optional*, defaults to :
+ obj:`(32, 32, 64)`): Tuple of block output channels.
+ mid_block_type (`str`, *optional*, defaults to "UNetMidBlock1D"): block type for middle of UNet.
+ out_block_type (`str`, *optional*, defaults to `None`): optional output processing of UNet.
+ act_fn (`str`, *optional*, defaults to None): optional activation function in UNet blocks.
+ norm_num_groups (`int`, *optional*, defaults to 8): group norm member count in UNet blocks.
+ layers_per_block (`int`, *optional*, defaults to 1): added number of layers in a UNet block.
+ downsample_each_block (`int`, *optional*, defaults to False:
+ experimental feature for using a UNet without upsampling.
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: int = 65536,
+ sample_rate: Optional[int] = None,
+ in_channels: int = 2,
+ out_channels: int = 2,
+ extra_in_channels: int = 0,
+ time_embedding_type: str = "fourier",
+ flip_sin_to_cos: bool = True,
+ use_timestep_embedding: bool = False,
+ freq_shift: float = 0.0,
+ down_block_types: Tuple[str] = ("DownBlock1DNoSkip", "DownBlock1D", "AttnDownBlock1D"),
+ up_block_types: Tuple[str] = ("AttnUpBlock1D", "UpBlock1D", "UpBlock1DNoSkip"),
+ mid_block_type: Tuple[str] = "UNetMidBlock1D",
+ out_block_type: str = None,
+ block_out_channels: Tuple[int] = (32, 32, 64),
+ act_fn: str = None,
+ norm_num_groups: int = 8,
+ layers_per_block: int = 1,
+ downsample_each_block: bool = False,
+ ):
+ super().__init__()
+ self.sample_size = sample_size
+
+ # time
+ if time_embedding_type == "fourier":
+ self.time_proj = GaussianFourierProjection(
+ embedding_size=8, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
+ )
+ timestep_input_dim = 2 * block_out_channels[0]
+ elif time_embedding_type == "positional":
+ self.time_proj = Timesteps(
+ block_out_channels[0], flip_sin_to_cos=flip_sin_to_cos, downscale_freq_shift=freq_shift
+ )
+ timestep_input_dim = block_out_channels[0]
+
+ if use_timestep_embedding:
+ time_embed_dim = block_out_channels[0] * 4
+ self.time_mlp = TimestepEmbedding(
+ in_channels=timestep_input_dim,
+ time_embed_dim=time_embed_dim,
+ act_fn=act_fn,
+ out_dim=block_out_channels[0],
+ )
+
+ self.down_blocks = nn.ModuleList([])
+ self.mid_block = None
+ self.up_blocks = nn.ModuleList([])
+ self.out_block = None
+
+ # down
+ output_channel = in_channels
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+
+ if i == 0:
+ input_channel += extra_in_channels
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=block_out_channels[0],
+ add_downsample=not is_final_block or downsample_each_block,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = get_mid_block(
+ mid_block_type,
+ in_channels=block_out_channels[-1],
+ mid_channels=block_out_channels[-1],
+ out_channels=block_out_channels[-1],
+ embed_dim=block_out_channels[0],
+ num_layers=layers_per_block,
+ add_downsample=downsample_each_block,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ if out_block_type is None:
+ final_upsample_channels = out_channels
+ else:
+ final_upsample_channels = block_out_channels[0]
+
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = (
+ reversed_block_out_channels[i + 1] if i < len(up_block_types) - 1 else final_upsample_channels
+ )
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block,
+ in_channels=prev_output_channel,
+ out_channels=output_channel,
+ temb_channels=block_out_channels[0],
+ add_upsample=not is_final_block,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ num_groups_out = norm_num_groups if norm_num_groups is not None else min(block_out_channels[0] // 4, 32)
+ self.out_block = get_out_block(
+ out_block_type=out_block_type,
+ num_groups_out=num_groups_out,
+ embed_dim=block_out_channels[0],
+ out_channels=out_channels,
+ act_fn=act_fn,
+ fc_dim=block_out_channels[-1] // 4,
+ )
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ return_dict: bool = True,
+ ) -> Union[UNet1DOutput, Tuple]:
+ r"""
+ Args:
+ sample (`torch.FloatTensor`): `(batch_size, num_channels, sample_size)` noisy inputs tensor
+ timestep (`torch.FloatTensor` or `float` or `int): (batch) timesteps
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~models.unet_1d.UNet1DOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~models.unet_1d.UNet1DOutput`] or `tuple`: [`~models.unet_1d.UNet1DOutput`] if `return_dict` is True,
+ otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+ """
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device)
+ elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ timestep_embed = self.time_proj(timesteps)
+ if self.config.use_timestep_embedding:
+ timestep_embed = self.time_mlp(timestep_embed)
+ else:
+ timestep_embed = timestep_embed[..., None]
+ timestep_embed = timestep_embed.repeat([1, 1, sample.shape[2]]).to(sample.dtype)
+ timestep_embed = timestep_embed.broadcast_to((sample.shape[:1] + timestep_embed.shape[1:]))
+
+ # 2. down
+ down_block_res_samples = ()
+ for downsample_block in self.down_blocks:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=timestep_embed)
+ down_block_res_samples += res_samples
+
+ # 3. mid
+ if self.mid_block:
+ sample = self.mid_block(sample, timestep_embed)
+
+ # 4. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ res_samples = down_block_res_samples[-1:]
+ down_block_res_samples = down_block_res_samples[:-1]
+ sample = upsample_block(sample, res_hidden_states_tuple=res_samples, temb=timestep_embed)
+
+ # 5. post-process
+ if self.out_block:
+ sample = self.out_block(sample, timestep_embed)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet1DOutput(sample=sample)
diff --git a/diffusers/src/diffusers/models/unet_1d_blocks.py b/diffusers/src/diffusers/models/unet_1d_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0f0e58f91032daf4ab3d34c448a200ed85c75ae
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_1d_blocks.py
@@ -0,0 +1,668 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+
+import torch
+import torch.nn.functional as F
+from torch import nn
+
+from .resnet import Downsample1D, ResidualTemporalBlock1D, Upsample1D, rearrange_dims
+
+
+class DownResnetBlock1D(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels=None,
+ num_layers=1,
+ conv_shortcut=False,
+ temb_channels=32,
+ groups=32,
+ groups_out=None,
+ non_linearity=None,
+ time_embedding_norm="default",
+ output_scale_factor=1.0,
+ add_downsample=True,
+ ):
+ super().__init__()
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.use_conv_shortcut = conv_shortcut
+ self.time_embedding_norm = time_embedding_norm
+ self.add_downsample = add_downsample
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ # there will always be at least one resnet
+ resnets = [ResidualTemporalBlock1D(in_channels, out_channels, embed_dim=temb_channels)]
+
+ for _ in range(num_layers):
+ resnets.append(ResidualTemporalBlock1D(out_channels, out_channels, embed_dim=temb_channels))
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if non_linearity == "swish":
+ self.nonlinearity = lambda x: F.silu(x)
+ elif non_linearity == "mish":
+ self.nonlinearity = nn.Mish()
+ elif non_linearity == "silu":
+ self.nonlinearity = nn.SiLU()
+ else:
+ self.nonlinearity = None
+
+ self.downsample = None
+ if add_downsample:
+ self.downsample = Downsample1D(out_channels, use_conv=True, padding=1)
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for resnet in self.resnets[1:]:
+ hidden_states = resnet(hidden_states, temb)
+
+ output_states += (hidden_states,)
+
+ if self.nonlinearity is not None:
+ hidden_states = self.nonlinearity(hidden_states)
+
+ if self.downsample is not None:
+ hidden_states = self.downsample(hidden_states)
+
+ return hidden_states, output_states
+
+
+class UpResnetBlock1D(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels=None,
+ num_layers=1,
+ temb_channels=32,
+ groups=32,
+ groups_out=None,
+ non_linearity=None,
+ time_embedding_norm="default",
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ self.in_channels = in_channels
+ out_channels = in_channels if out_channels is None else out_channels
+ self.out_channels = out_channels
+ self.time_embedding_norm = time_embedding_norm
+ self.add_upsample = add_upsample
+ self.output_scale_factor = output_scale_factor
+
+ if groups_out is None:
+ groups_out = groups
+
+ # there will always be at least one resnet
+ resnets = [ResidualTemporalBlock1D(2 * in_channels, out_channels, embed_dim=temb_channels)]
+
+ for _ in range(num_layers):
+ resnets.append(ResidualTemporalBlock1D(out_channels, out_channels, embed_dim=temb_channels))
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if non_linearity == "swish":
+ self.nonlinearity = lambda x: F.silu(x)
+ elif non_linearity == "mish":
+ self.nonlinearity = nn.Mish()
+ elif non_linearity == "silu":
+ self.nonlinearity = nn.SiLU()
+ else:
+ self.nonlinearity = None
+
+ self.upsample = None
+ if add_upsample:
+ self.upsample = Upsample1D(out_channels, use_conv_transpose=True)
+
+ def forward(self, hidden_states, res_hidden_states_tuple=None, temb=None):
+ if res_hidden_states_tuple is not None:
+ res_hidden_states = res_hidden_states_tuple[-1]
+ hidden_states = torch.cat((hidden_states, res_hidden_states), dim=1)
+
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for resnet in self.resnets[1:]:
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.nonlinearity is not None:
+ hidden_states = self.nonlinearity(hidden_states)
+
+ if self.upsample is not None:
+ hidden_states = self.upsample(hidden_states)
+
+ return hidden_states
+
+
+class ValueFunctionMidBlock1D(nn.Module):
+ def __init__(self, in_channels, out_channels, embed_dim):
+ super().__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.embed_dim = embed_dim
+
+ self.res1 = ResidualTemporalBlock1D(in_channels, in_channels // 2, embed_dim=embed_dim)
+ self.down1 = Downsample1D(out_channels // 2, use_conv=True)
+ self.res2 = ResidualTemporalBlock1D(in_channels // 2, in_channels // 4, embed_dim=embed_dim)
+ self.down2 = Downsample1D(out_channels // 4, use_conv=True)
+
+ def forward(self, x, temb=None):
+ x = self.res1(x, temb)
+ x = self.down1(x)
+ x = self.res2(x, temb)
+ x = self.down2(x)
+ return x
+
+
+class MidResTemporalBlock1D(nn.Module):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ embed_dim,
+ num_layers: int = 1,
+ add_downsample: bool = False,
+ add_upsample: bool = False,
+ non_linearity=None,
+ ):
+ super().__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.add_downsample = add_downsample
+
+ # there will always be at least one resnet
+ resnets = [ResidualTemporalBlock1D(in_channels, out_channels, embed_dim=embed_dim)]
+
+ for _ in range(num_layers):
+ resnets.append(ResidualTemporalBlock1D(out_channels, out_channels, embed_dim=embed_dim))
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if non_linearity == "swish":
+ self.nonlinearity = lambda x: F.silu(x)
+ elif non_linearity == "mish":
+ self.nonlinearity = nn.Mish()
+ elif non_linearity == "silu":
+ self.nonlinearity = nn.SiLU()
+ else:
+ self.nonlinearity = None
+
+ self.upsample = None
+ if add_upsample:
+ self.upsample = Downsample1D(out_channels, use_conv=True)
+
+ self.downsample = None
+ if add_downsample:
+ self.downsample = Downsample1D(out_channels, use_conv=True)
+
+ if self.upsample and self.downsample:
+ raise ValueError("Block cannot downsample and upsample")
+
+ def forward(self, hidden_states, temb):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for resnet in self.resnets[1:]:
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.upsample:
+ hidden_states = self.upsample(hidden_states)
+ if self.downsample:
+ self.downsample = self.downsample(hidden_states)
+
+ return hidden_states
+
+
+class OutConv1DBlock(nn.Module):
+ def __init__(self, num_groups_out, out_channels, embed_dim, act_fn):
+ super().__init__()
+ self.final_conv1d_1 = nn.Conv1d(embed_dim, embed_dim, 5, padding=2)
+ self.final_conv1d_gn = nn.GroupNorm(num_groups_out, embed_dim)
+ if act_fn == "silu":
+ self.final_conv1d_act = nn.SiLU()
+ if act_fn == "mish":
+ self.final_conv1d_act = nn.Mish()
+ self.final_conv1d_2 = nn.Conv1d(embed_dim, out_channels, 1)
+
+ def forward(self, hidden_states, temb=None):
+ hidden_states = self.final_conv1d_1(hidden_states)
+ hidden_states = rearrange_dims(hidden_states)
+ hidden_states = self.final_conv1d_gn(hidden_states)
+ hidden_states = rearrange_dims(hidden_states)
+ hidden_states = self.final_conv1d_act(hidden_states)
+ hidden_states = self.final_conv1d_2(hidden_states)
+ return hidden_states
+
+
+class OutValueFunctionBlock(nn.Module):
+ def __init__(self, fc_dim, embed_dim):
+ super().__init__()
+ self.final_block = nn.ModuleList(
+ [
+ nn.Linear(fc_dim + embed_dim, fc_dim // 2),
+ nn.Mish(),
+ nn.Linear(fc_dim // 2, 1),
+ ]
+ )
+
+ def forward(self, hidden_states, temb):
+ hidden_states = hidden_states.view(hidden_states.shape[0], -1)
+ hidden_states = torch.cat((hidden_states, temb), dim=-1)
+ for layer in self.final_block:
+ hidden_states = layer(hidden_states)
+
+ return hidden_states
+
+
+_kernels = {
+ "linear": [1 / 8, 3 / 8, 3 / 8, 1 / 8],
+ "cubic": [-0.01171875, -0.03515625, 0.11328125, 0.43359375, 0.43359375, 0.11328125, -0.03515625, -0.01171875],
+ "lanczos3": [
+ 0.003689131001010537,
+ 0.015056144446134567,
+ -0.03399861603975296,
+ -0.066637322306633,
+ 0.13550527393817902,
+ 0.44638532400131226,
+ 0.44638532400131226,
+ 0.13550527393817902,
+ -0.066637322306633,
+ -0.03399861603975296,
+ 0.015056144446134567,
+ 0.003689131001010537,
+ ],
+}
+
+
+class Downsample1d(nn.Module):
+ def __init__(self, kernel="linear", pad_mode="reflect"):
+ super().__init__()
+ self.pad_mode = pad_mode
+ kernel_1d = torch.tensor(_kernels[kernel])
+ self.pad = kernel_1d.shape[0] // 2 - 1
+ self.register_buffer("kernel", kernel_1d)
+
+ def forward(self, hidden_states):
+ hidden_states = F.pad(hidden_states, (self.pad,) * 2, self.pad_mode)
+ weight = hidden_states.new_zeros([hidden_states.shape[1], hidden_states.shape[1], self.kernel.shape[0]])
+ indices = torch.arange(hidden_states.shape[1], device=hidden_states.device)
+ weight[indices, indices] = self.kernel.to(weight)
+ return F.conv1d(hidden_states, weight, stride=2)
+
+
+class Upsample1d(nn.Module):
+ def __init__(self, kernel="linear", pad_mode="reflect"):
+ super().__init__()
+ self.pad_mode = pad_mode
+ kernel_1d = torch.tensor(_kernels[kernel]) * 2
+ self.pad = kernel_1d.shape[0] // 2 - 1
+ self.register_buffer("kernel", kernel_1d)
+
+ def forward(self, hidden_states, temb=None):
+ hidden_states = F.pad(hidden_states, ((self.pad + 1) // 2,) * 2, self.pad_mode)
+ weight = hidden_states.new_zeros([hidden_states.shape[1], hidden_states.shape[1], self.kernel.shape[0]])
+ indices = torch.arange(hidden_states.shape[1], device=hidden_states.device)
+ weight[indices, indices] = self.kernel.to(weight)
+ return F.conv_transpose1d(hidden_states, weight, stride=2, padding=self.pad * 2 + 1)
+
+
+class SelfAttention1d(nn.Module):
+ def __init__(self, in_channels, n_head=1, dropout_rate=0.0):
+ super().__init__()
+ self.channels = in_channels
+ self.group_norm = nn.GroupNorm(1, num_channels=in_channels)
+ self.num_heads = n_head
+
+ self.query = nn.Linear(self.channels, self.channels)
+ self.key = nn.Linear(self.channels, self.channels)
+ self.value = nn.Linear(self.channels, self.channels)
+
+ self.proj_attn = nn.Linear(self.channels, self.channels, bias=True)
+
+ self.dropout = nn.Dropout(dropout_rate, inplace=True)
+
+ def transpose_for_scores(self, projection: torch.Tensor) -> torch.Tensor:
+ new_projection_shape = projection.size()[:-1] + (self.num_heads, -1)
+ # move heads to 2nd position (B, T, H * D) -> (B, T, H, D) -> (B, H, T, D)
+ new_projection = projection.view(new_projection_shape).permute(0, 2, 1, 3)
+ return new_projection
+
+ def forward(self, hidden_states):
+ residual = hidden_states
+ batch, channel_dim, seq = hidden_states.shape
+
+ hidden_states = self.group_norm(hidden_states)
+ hidden_states = hidden_states.transpose(1, 2)
+
+ query_proj = self.query(hidden_states)
+ key_proj = self.key(hidden_states)
+ value_proj = self.value(hidden_states)
+
+ query_states = self.transpose_for_scores(query_proj)
+ key_states = self.transpose_for_scores(key_proj)
+ value_states = self.transpose_for_scores(value_proj)
+
+ scale = 1 / math.sqrt(math.sqrt(key_states.shape[-1]))
+
+ attention_scores = torch.matmul(query_states * scale, key_states.transpose(-1, -2) * scale)
+ attention_probs = torch.softmax(attention_scores, dim=-1)
+
+ # compute attention output
+ hidden_states = torch.matmul(attention_probs, value_states)
+
+ hidden_states = hidden_states.permute(0, 2, 1, 3).contiguous()
+ new_hidden_states_shape = hidden_states.size()[:-2] + (self.channels,)
+ hidden_states = hidden_states.view(new_hidden_states_shape)
+
+ # compute next hidden_states
+ hidden_states = self.proj_attn(hidden_states)
+ hidden_states = hidden_states.transpose(1, 2)
+ hidden_states = self.dropout(hidden_states)
+
+ output = hidden_states + residual
+
+ return output
+
+
+class ResConvBlock(nn.Module):
+ def __init__(self, in_channels, mid_channels, out_channels, is_last=False):
+ super().__init__()
+ self.is_last = is_last
+ self.has_conv_skip = in_channels != out_channels
+
+ if self.has_conv_skip:
+ self.conv_skip = nn.Conv1d(in_channels, out_channels, 1, bias=False)
+
+ self.conv_1 = nn.Conv1d(in_channels, mid_channels, 5, padding=2)
+ self.group_norm_1 = nn.GroupNorm(1, mid_channels)
+ self.gelu_1 = nn.GELU()
+ self.conv_2 = nn.Conv1d(mid_channels, out_channels, 5, padding=2)
+
+ if not self.is_last:
+ self.group_norm_2 = nn.GroupNorm(1, out_channels)
+ self.gelu_2 = nn.GELU()
+
+ def forward(self, hidden_states):
+ residual = self.conv_skip(hidden_states) if self.has_conv_skip else hidden_states
+
+ hidden_states = self.conv_1(hidden_states)
+ hidden_states = self.group_norm_1(hidden_states)
+ hidden_states = self.gelu_1(hidden_states)
+ hidden_states = self.conv_2(hidden_states)
+
+ if not self.is_last:
+ hidden_states = self.group_norm_2(hidden_states)
+ hidden_states = self.gelu_2(hidden_states)
+
+ output = hidden_states + residual
+ return output
+
+
+class UNetMidBlock1D(nn.Module):
+ def __init__(self, mid_channels, in_channels, out_channels=None):
+ super().__init__()
+
+ out_channels = in_channels if out_channels is None else out_channels
+
+ # there is always at least one resnet
+ self.down = Downsample1d("cubic")
+ resnets = [
+ ResConvBlock(in_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, out_channels),
+ ]
+ attentions = [
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(out_channels, out_channels // 32),
+ ]
+ self.up = Upsample1d(kernel="cubic")
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None):
+ hidden_states = self.down(hidden_states)
+ for attn, resnet in zip(self.attentions, self.resnets):
+ hidden_states = resnet(hidden_states)
+ hidden_states = attn(hidden_states)
+
+ hidden_states = self.up(hidden_states)
+
+ return hidden_states
+
+
+class AttnDownBlock1D(nn.Module):
+ def __init__(self, out_channels, in_channels, mid_channels=None):
+ super().__init__()
+ mid_channels = out_channels if mid_channels is None else mid_channels
+
+ self.down = Downsample1d("cubic")
+ resnets = [
+ ResConvBlock(in_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, out_channels),
+ ]
+ attentions = [
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(out_channels, out_channels // 32),
+ ]
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None):
+ hidden_states = self.down(hidden_states)
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states)
+ hidden_states = attn(hidden_states)
+
+ return hidden_states, (hidden_states,)
+
+
+class DownBlock1D(nn.Module):
+ def __init__(self, out_channels, in_channels, mid_channels=None):
+ super().__init__()
+ mid_channels = out_channels if mid_channels is None else mid_channels
+
+ self.down = Downsample1d("cubic")
+ resnets = [
+ ResConvBlock(in_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, out_channels),
+ ]
+
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None):
+ hidden_states = self.down(hidden_states)
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states)
+
+ return hidden_states, (hidden_states,)
+
+
+class DownBlock1DNoSkip(nn.Module):
+ def __init__(self, out_channels, in_channels, mid_channels=None):
+ super().__init__()
+ mid_channels = out_channels if mid_channels is None else mid_channels
+
+ resnets = [
+ ResConvBlock(in_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, out_channels),
+ ]
+
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None):
+ hidden_states = torch.cat([hidden_states, temb], dim=1)
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states)
+
+ return hidden_states, (hidden_states,)
+
+
+class AttnUpBlock1D(nn.Module):
+ def __init__(self, in_channels, out_channels, mid_channels=None):
+ super().__init__()
+ mid_channels = out_channels if mid_channels is None else mid_channels
+
+ resnets = [
+ ResConvBlock(2 * in_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, out_channels),
+ ]
+ attentions = [
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(mid_channels, mid_channels // 32),
+ SelfAttention1d(out_channels, out_channels // 32),
+ ]
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+ self.up = Upsample1d(kernel="cubic")
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ res_hidden_states = res_hidden_states_tuple[-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states)
+ hidden_states = attn(hidden_states)
+
+ hidden_states = self.up(hidden_states)
+
+ return hidden_states
+
+
+class UpBlock1D(nn.Module):
+ def __init__(self, in_channels, out_channels, mid_channels=None):
+ super().__init__()
+ mid_channels = in_channels if mid_channels is None else mid_channels
+
+ resnets = [
+ ResConvBlock(2 * in_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, out_channels),
+ ]
+
+ self.resnets = nn.ModuleList(resnets)
+ self.up = Upsample1d(kernel="cubic")
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ res_hidden_states = res_hidden_states_tuple[-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states)
+
+ hidden_states = self.up(hidden_states)
+
+ return hidden_states
+
+
+class UpBlock1DNoSkip(nn.Module):
+ def __init__(self, in_channels, out_channels, mid_channels=None):
+ super().__init__()
+ mid_channels = in_channels if mid_channels is None else mid_channels
+
+ resnets = [
+ ResConvBlock(2 * in_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, mid_channels),
+ ResConvBlock(mid_channels, mid_channels, out_channels, is_last=True),
+ ]
+
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ res_hidden_states = res_hidden_states_tuple[-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states)
+
+ return hidden_states
+
+
+def get_down_block(down_block_type, num_layers, in_channels, out_channels, temb_channels, add_downsample):
+ if down_block_type == "DownResnetBlock1D":
+ return DownResnetBlock1D(
+ in_channels=in_channels,
+ num_layers=num_layers,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ )
+ elif down_block_type == "DownBlock1D":
+ return DownBlock1D(out_channels=out_channels, in_channels=in_channels)
+ elif down_block_type == "AttnDownBlock1D":
+ return AttnDownBlock1D(out_channels=out_channels, in_channels=in_channels)
+ elif down_block_type == "DownBlock1DNoSkip":
+ return DownBlock1DNoSkip(out_channels=out_channels, in_channels=in_channels)
+ raise ValueError(f"{down_block_type} does not exist.")
+
+
+def get_up_block(up_block_type, num_layers, in_channels, out_channels, temb_channels, add_upsample):
+ if up_block_type == "UpResnetBlock1D":
+ return UpResnetBlock1D(
+ in_channels=in_channels,
+ num_layers=num_layers,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ )
+ elif up_block_type == "UpBlock1D":
+ return UpBlock1D(in_channels=in_channels, out_channels=out_channels)
+ elif up_block_type == "AttnUpBlock1D":
+ return AttnUpBlock1D(in_channels=in_channels, out_channels=out_channels)
+ elif up_block_type == "UpBlock1DNoSkip":
+ return UpBlock1DNoSkip(in_channels=in_channels, out_channels=out_channels)
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+def get_mid_block(mid_block_type, num_layers, in_channels, mid_channels, out_channels, embed_dim, add_downsample):
+ if mid_block_type == "MidResTemporalBlock1D":
+ return MidResTemporalBlock1D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ embed_dim=embed_dim,
+ add_downsample=add_downsample,
+ )
+ elif mid_block_type == "ValueFunctionMidBlock1D":
+ return ValueFunctionMidBlock1D(in_channels=in_channels, out_channels=out_channels, embed_dim=embed_dim)
+ elif mid_block_type == "UNetMidBlock1D":
+ return UNetMidBlock1D(in_channels=in_channels, mid_channels=mid_channels, out_channels=out_channels)
+ raise ValueError(f"{mid_block_type} does not exist.")
+
+
+def get_out_block(*, out_block_type, num_groups_out, embed_dim, out_channels, act_fn, fc_dim):
+ if out_block_type == "OutConv1DBlock":
+ return OutConv1DBlock(num_groups_out, out_channels, embed_dim, act_fn)
+ elif out_block_type == "ValueFunction":
+ return OutValueFunctionBlock(fc_dim, embed_dim)
+ return None
diff --git a/diffusers/src/diffusers/models/unet_2d.py b/diffusers/src/diffusers/models/unet_2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..2df6e60d88c98738905d157caac0aa00c5b16db6
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_2d.py
@@ -0,0 +1,315 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput
+from .embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
+from .modeling_utils import ModelMixin
+from .unet_2d_blocks import UNetMidBlock2D, get_down_block, get_up_block
+
+
+@dataclass
+class UNet2DOutput(BaseOutput):
+ """
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Hidden states output. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor
+
+
+class UNet2DModel(ModelMixin, ConfigMixin):
+ r"""
+ UNet2DModel is a 2D UNet model that takes in a noisy sample and a timestep and returns sample shaped output.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the model (such as downloading or saving, etc.)
+
+ Parameters:
+ sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
+ Height and width of input/output sample.
+ in_channels (`int`, *optional*, defaults to 3): Number of channels in the input image.
+ out_channels (`int`, *optional*, defaults to 3): Number of channels in the output.
+ center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
+ time_embedding_type (`str`, *optional*, defaults to `"positional"`): Type of time embedding to use.
+ freq_shift (`int`, *optional*, defaults to 0): Frequency shift for fourier time embedding.
+ flip_sin_to_cos (`bool`, *optional*, defaults to :
+ obj:`True`): Whether to flip sin to cos for fourier time embedding.
+ down_block_types (`Tuple[str]`, *optional*, defaults to :
+ obj:`("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D")`): Tuple of downsample block
+ types.
+ mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2D"`):
+ The mid block type. Choose from `UNetMidBlock2D` or `UnCLIPUNetMidBlock2D`.
+ up_block_types (`Tuple[str]`, *optional*, defaults to :
+ obj:`("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D")`): Tuple of upsample block types.
+ block_out_channels (`Tuple[int]`, *optional*, defaults to :
+ obj:`(224, 448, 672, 896)`): Tuple of block output channels.
+ layers_per_block (`int`, *optional*, defaults to `2`): The number of layers per block.
+ mid_block_scale_factor (`float`, *optional*, defaults to `1`): The scale factor for the mid block.
+ downsample_padding (`int`, *optional*, defaults to `1`): The padding for the downsample convolution.
+ act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
+ attention_head_dim (`int`, *optional*, defaults to `8`): The attention head dimension.
+ norm_num_groups (`int`, *optional*, defaults to `32`): The number of groups for the normalization.
+ norm_eps (`float`, *optional*, defaults to `1e-5`): The epsilon for the normalization.
+ resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
+ for resnet blocks, see [`~models.resnet.ResnetBlock2D`]. Choose from `default` or `scale_shift`.
+ class_embed_type (`str`, *optional*, defaults to None):
+ The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
+ `"timestep"`, or `"identity"`.
+ num_class_embeds (`int`, *optional*, defaults to None):
+ Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
+ class conditioning with `class_embed_type` equal to `None`.
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[Union[int, Tuple[int, int]]] = None,
+ in_channels: int = 3,
+ out_channels: int = 3,
+ center_input_sample: bool = False,
+ time_embedding_type: str = "positional",
+ freq_shift: int = 0,
+ flip_sin_to_cos: bool = True,
+ down_block_types: Tuple[str] = ("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D"),
+ up_block_types: Tuple[str] = ("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D"),
+ block_out_channels: Tuple[int] = (224, 448, 672, 896),
+ layers_per_block: int = 2,
+ mid_block_scale_factor: float = 1,
+ downsample_padding: int = 1,
+ act_fn: str = "silu",
+ attention_head_dim: Optional[int] = 8,
+ norm_num_groups: int = 32,
+ norm_eps: float = 1e-5,
+ resnet_time_scale_shift: str = "default",
+ add_attention: bool = True,
+ class_embed_type: Optional[str] = None,
+ num_class_embeds: Optional[int] = None,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+ time_embed_dim = block_out_channels[0] * 4
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ self.conv_in = nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
+
+ # time
+ if time_embedding_type == "fourier":
+ self.time_proj = GaussianFourierProjection(embedding_size=block_out_channels[0], scale=16)
+ timestep_input_dim = 2 * block_out_channels[0]
+ elif time_embedding_type == "positional":
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ self.down_blocks = nn.ModuleList([])
+ self.mid_block = None
+ self.up_blocks = nn.ModuleList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ attn_num_head_channels=attention_head_dim,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ attn_num_head_channels=attention_head_dim,
+ resnet_groups=norm_num_groups,
+ add_attention=add_attention,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=time_embed_dim,
+ add_upsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ attn_num_head_channels=attention_head_dim,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ num_groups_out = norm_num_groups if norm_num_groups is not None else min(block_out_channels[0] // 4, 32)
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=num_groups_out, eps=norm_eps)
+ self.conv_act = nn.SiLU()
+ self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, kernel_size=3, padding=1)
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ class_labels: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ) -> Union[UNet2DOutput, Tuple]:
+ r"""
+ Args:
+ sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
+ timestep (`torch.FloatTensor` or `float` or `int): (batch) timesteps
+ class_labels (`torch.FloatTensor`, *optional*, defaults to `None`):
+ Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~models.unet_2d.UNet2DOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~models.unet_2d.UNet2DOutput`] or `tuple`: [`~models.unet_2d.UNet2DOutput`] if `return_dict` is True,
+ otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+ """
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device)
+ elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps * torch.ones(sample.shape[0], dtype=timesteps.dtype, device=timesteps.device)
+
+ t_emb = self.time_proj(timesteps)
+
+ # timesteps does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=self.dtype)
+ emb = self.time_embedding(t_emb)
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when doing class conditioning")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
+ emb = emb + class_emb
+
+ # 2. pre-process
+ skip_sample = sample
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "skip_conv"):
+ sample, res_samples, skip_sample = downsample_block(
+ hidden_states=sample, temb=emb, skip_sample=skip_sample
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, emb)
+
+ # 5. up
+ skip_sample = None
+ for upsample_block in self.up_blocks:
+ res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ if hasattr(upsample_block, "skip_conv"):
+ sample, skip_sample = upsample_block(sample, res_samples, emb, skip_sample)
+ else:
+ sample = upsample_block(sample, res_samples, emb)
+
+ # 6. post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ if skip_sample is not None:
+ sample += skip_sample
+
+ if self.config.time_embedding_type == "fourier":
+ timesteps = timesteps.reshape((sample.shape[0], *([1] * len(sample.shape[1:]))))
+ sample = sample / timesteps
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet2DOutput(sample=sample)
diff --git a/diffusers/src/diffusers/models/unet_2d_blocks.py b/diffusers/src/diffusers/models/unet_2d_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..70cc75b51200b53a89f48bec92fa5dd66209f43e
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_2d_blocks.py
@@ -0,0 +1,2775 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Any, Dict, Optional, Tuple
+
+import numpy as np
+import torch
+from torch import nn
+
+from .attention import AdaGroupNorm, AttentionBlock
+from .attention_processor import Attention, AttnAddedKVProcessor
+from .dual_transformer_2d import DualTransformer2DModel
+from .resnet import Downsample2D, FirDownsample2D, FirUpsample2D, KDownsample2D, KUpsample2D, ResnetBlock2D, Upsample2D
+from .transformer_2d import Transformer2DModel, Transformer2DModelOutput
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ downsample_padding=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlock2D":
+ return DownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "ResnetDownsampleBlock2D":
+ return ResnetDownsampleBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "AttnDownBlock2D":
+ return AttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "CrossAttnDownBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock2D")
+ return CrossAttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "SimpleCrossAttnDownBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for SimpleCrossAttnDownBlock2D")
+ return SimpleCrossAttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "SkipDownBlock2D":
+ return SkipDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "AttnSkipDownBlock2D":
+ return AttnSkipDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "DownEncoderBlock2D":
+ return DownEncoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "AttnDownEncoderBlock2D":
+ return AttnDownEncoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ attn_num_head_channels=attn_num_head_channels,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "KDownBlock2D":
+ return KDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ elif down_block_type == "KCrossAttnDownBlock2D":
+ return KCrossAttnDownBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ add_self_attention=True if not add_downsample else False,
+ )
+ raise ValueError(f"{down_block_type} does not exist.")
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlock2D":
+ return UpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "ResnetUpsampleBlock2D":
+ return ResnetUpsampleBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "CrossAttnUpBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock2D")
+ return CrossAttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "SimpleCrossAttnUpBlock2D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for SimpleCrossAttnUpBlock2D")
+ return SimpleCrossAttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "AttnUpBlock2D":
+ return AttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ attn_num_head_channels=attn_num_head_channels,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "SkipUpBlock2D":
+ return SkipUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "AttnSkipUpBlock2D":
+ return AttnSkipUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ attn_num_head_channels=attn_num_head_channels,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "UpDecoderBlock2D":
+ return UpDecoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "AttnUpDecoderBlock2D":
+ return AttnUpDecoderBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ attn_num_head_channels=attn_num_head_channels,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "KUpBlock2D":
+ return KUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ )
+ elif up_block_type == "KCrossAttnUpBlock2D":
+ return KCrossAttnUpBlock2D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ )
+
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ add_attention: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ ):
+ super().__init__()
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+ self.add_attention = add_attention
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ if self.add_attention:
+ attentions.append(
+ AttentionBlock(
+ in_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ else:
+ attentions.append(None)
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(self, hidden_states, temb=None):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ if attn is not None:
+ hidden_states = attn(hidden_states)
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class UNetMidBlock2DCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ if not dual_cross_attention:
+ attentions.append(
+ Transformer2DModel(
+ attn_num_head_channels,
+ in_channels // attn_num_head_channels,
+ in_channels=in_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ )
+ else:
+ attentions.append(
+ DualTransformer2DModel(
+ attn_num_head_channels,
+ in_channels // attn_num_head_channels,
+ in_channels=in_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ temb: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ ) -> torch.FloatTensor:
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ output: Transformer2DModelOutput = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ hidden_states = output.sample
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class UNetMidBlock2DSimpleCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+
+ self.attn_num_head_channels = attn_num_head_channels
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ self.num_heads = in_channels // self.attn_num_head_channels
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ Attention(
+ query_dim=in_channels,
+ cross_attention_dim=in_channels,
+ heads=self.num_heads,
+ dim_head=attn_num_head_channels,
+ added_kv_proj_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ bias=True,
+ upcast_softmax=True,
+ processor=AttnAddedKVProcessor(),
+ )
+ )
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(
+ self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None, cross_attention_kwargs=None
+ ):
+ cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ # attn
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ **cross_attention_kwargs,
+ )
+
+ # resnet
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+class AttnDownBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ attentions.append(
+ AttentionBlock(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ norm_num_groups=resnet_groups,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample2D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class CrossAttnDownBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if not dual_cross_attention:
+ attentions.append(
+ Transformer2DModel(
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ else:
+ attentions.append(
+ DualTransformer2DModel(
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample2D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ temb: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ ):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ None, # timestep
+ None, # class_labels
+ cross_attention_kwargs,
+ attention_mask,
+ encoder_attention_mask,
+ )[0]
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ ).sample
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class DownBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample2D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class DownEncoderBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample2D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb=None)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnDownEncoderBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ attentions.append(
+ AttentionBlock(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ norm_num_groups=resnet_groups,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample2D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb=None)
+ hidden_states = attn(hidden_states)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnSkipDownBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=np.sqrt(2.0),
+ downsample_padding=1,
+ add_downsample=True,
+ ):
+ super().__init__()
+ self.attentions = nn.ModuleList([])
+ self.resnets = nn.ModuleList([])
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ self.resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(in_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ self.attentions.append(
+ AttentionBlock(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ )
+ )
+
+ if add_downsample:
+ self.resnet_down = ResnetBlock2D(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_in_shortcut=True,
+ down=True,
+ kernel="fir",
+ )
+ self.downsamplers = nn.ModuleList([FirDownsample2D(out_channels, out_channels=out_channels)])
+ self.skip_conv = nn.Conv2d(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
+ else:
+ self.resnet_down = None
+ self.downsamplers = None
+ self.skip_conv = None
+
+ def forward(self, hidden_states, temb=None, skip_sample=None):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ hidden_states = self.resnet_down(hidden_states, temb)
+ for downsampler in self.downsamplers:
+ skip_sample = downsampler(skip_sample)
+
+ hidden_states = self.skip_conv(skip_sample) + hidden_states
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states, skip_sample
+
+
+class SkipDownBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ output_scale_factor=np.sqrt(2.0),
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ self.resnets = nn.ModuleList([])
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ self.resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(in_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ if add_downsample:
+ self.resnet_down = ResnetBlock2D(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_in_shortcut=True,
+ down=True,
+ kernel="fir",
+ )
+ self.downsamplers = nn.ModuleList([FirDownsample2D(out_channels, out_channels=out_channels)])
+ self.skip_conv = nn.Conv2d(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
+ else:
+ self.resnet_down = None
+ self.downsamplers = None
+ self.skip_conv = None
+
+ def forward(self, hidden_states, temb=None, skip_sample=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb)
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ hidden_states = self.resnet_down(hidden_states, temb)
+ for downsampler in self.downsamplers:
+ skip_sample = downsampler(skip_sample)
+
+ hidden_states = self.skip_conv(skip_sample) + hidden_states
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states, skip_sample
+
+
+class ResnetDownsampleBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ ResnetBlock2D(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ down=True,
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states, temb)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class SimpleCrossAttnDownBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+
+ resnets = []
+ attentions = []
+
+ self.attn_num_head_channels = attn_num_head_channels
+ self.num_heads = out_channels // self.attn_num_head_channels
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ attentions.append(
+ Attention(
+ query_dim=out_channels,
+ cross_attention_dim=out_channels,
+ heads=self.num_heads,
+ dim_head=attn_num_head_channels,
+ added_kv_proj_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ bias=True,
+ upcast_softmax=True,
+ processor=AttnAddedKVProcessor(),
+ )
+ )
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ ResnetBlock2D(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ down=True,
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None, cross_attention_kwargs=None
+ ):
+ output_states = ()
+ cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ # resnet
+ hidden_states = resnet(hidden_states, temb)
+
+ # attn
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ **cross_attention_kwargs,
+ )
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states, temb)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class KDownBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 4,
+ resnet_eps: float = 1e-5,
+ resnet_act_fn: str = "gelu",
+ resnet_group_size: int = 32,
+ add_downsample=False,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ groups = in_channels // resnet_group_size
+ groups_out = out_channels // resnet_group_size
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ dropout=dropout,
+ temb_channels=temb_channels,
+ groups=groups,
+ groups_out=groups_out,
+ eps=resnet_eps,
+ non_linearity=resnet_act_fn,
+ time_embedding_norm="ada_group",
+ conv_shortcut_bias=False,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ # YiYi's comments- might be able to use FirDownsample2D, look into details later
+ self.downsamplers = nn.ModuleList([KDownsample2D()])
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states, output_states
+
+
+class KCrossAttnDownBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ cross_attention_dim: int,
+ dropout: float = 0.0,
+ num_layers: int = 4,
+ resnet_group_size: int = 32,
+ add_downsample=True,
+ attn_num_head_channels: int = 64,
+ add_self_attention: bool = False,
+ resnet_eps: float = 1e-5,
+ resnet_act_fn: str = "gelu",
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.has_cross_attention = True
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ groups = in_channels // resnet_group_size
+ groups_out = out_channels // resnet_group_size
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ dropout=dropout,
+ temb_channels=temb_channels,
+ groups=groups,
+ groups_out=groups_out,
+ eps=resnet_eps,
+ non_linearity=resnet_act_fn,
+ time_embedding_norm="ada_group",
+ conv_shortcut_bias=False,
+ )
+ )
+ attentions.append(
+ KAttentionBlock(
+ out_channels,
+ out_channels // attn_num_head_channels,
+ attn_num_head_channels,
+ cross_attention_dim=cross_attention_dim,
+ temb_channels=temb_channels,
+ attention_bias=True,
+ add_self_attention=add_self_attention,
+ cross_attention_norm=True,
+ group_size=resnet_group_size,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.attentions = nn.ModuleList(attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList([KDownsample2D()])
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None, cross_attention_kwargs=None
+ ):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ attention_mask,
+ cross_attention_kwargs,
+ )
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ emb=temb,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+
+ if self.downsamplers is None:
+ output_states += (None,)
+ else:
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ return hidden_states, output_states
+
+
+class AttnUpBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ attentions.append(
+ AttentionBlock(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ norm_num_groups=resnet_groups,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class CrossAttnUpBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if not dual_cross_attention:
+ attentions.append(
+ Transformer2DModel(
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ else:
+ attentions.append(
+ DualTransformer2DModel(
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
+ temb: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ upsample_size: Optional[int] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ ):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ None, # timestep
+ None, # class_labels
+ cross_attention_kwargs,
+ attention_mask,
+ encoder_attention_mask,
+ )[0]
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ ).sample
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+
+class UpBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+
+class UpDecoderBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ input_channels = in_channels if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=input_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb=None)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnUpDecoderBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ for i in range(num_layers):
+ input_channels = in_channels if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=input_channels,
+ out_channels=out_channels,
+ temb_channels=None,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ attentions.append(
+ AttentionBlock(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ norm_num_groups=resnet_groups,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ def forward(self, hidden_states):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb=None)
+ hidden_states = attn(hidden_states)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class AttnSkipUpBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=np.sqrt(2.0),
+ upsample_padding=1,
+ add_upsample=True,
+ ):
+ super().__init__()
+ self.attentions = nn.ModuleList([])
+ self.resnets = nn.ModuleList([])
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ self.resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(resnet_in_channels + res_skip_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions.append(
+ AttentionBlock(
+ out_channels,
+ num_head_channels=attn_num_head_channels,
+ rescale_output_factor=output_scale_factor,
+ eps=resnet_eps,
+ )
+ )
+
+ self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
+ if add_upsample:
+ self.resnet_up = ResnetBlock2D(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_in_shortcut=True,
+ up=True,
+ kernel="fir",
+ )
+ self.skip_conv = nn.Conv2d(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ self.skip_norm = torch.nn.GroupNorm(
+ num_groups=min(out_channels // 4, 32), num_channels=out_channels, eps=resnet_eps, affine=True
+ )
+ self.act = nn.SiLU()
+ else:
+ self.resnet_up = None
+ self.skip_conv = None
+ self.skip_norm = None
+ self.act = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, skip_sample=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ hidden_states = self.attentions[0](hidden_states)
+
+ if skip_sample is not None:
+ skip_sample = self.upsampler(skip_sample)
+ else:
+ skip_sample = 0
+
+ if self.resnet_up is not None:
+ skip_sample_states = self.skip_norm(hidden_states)
+ skip_sample_states = self.act(skip_sample_states)
+ skip_sample_states = self.skip_conv(skip_sample_states)
+
+ skip_sample = skip_sample + skip_sample_states
+
+ hidden_states = self.resnet_up(hidden_states, temb)
+
+ return hidden_states, skip_sample
+
+
+class SkipUpBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_pre_norm: bool = True,
+ output_scale_factor=np.sqrt(2.0),
+ add_upsample=True,
+ upsample_padding=1,
+ ):
+ super().__init__()
+ self.resnets = nn.ModuleList([])
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ self.resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min((resnet_in_channels + res_skip_channels) // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
+ if add_upsample:
+ self.resnet_up = ResnetBlock2D(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=min(out_channels // 4, 32),
+ groups_out=min(out_channels // 4, 32),
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ use_in_shortcut=True,
+ up=True,
+ kernel="fir",
+ )
+ self.skip_conv = nn.Conv2d(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ self.skip_norm = torch.nn.GroupNorm(
+ num_groups=min(out_channels // 4, 32), num_channels=out_channels, eps=resnet_eps, affine=True
+ )
+ self.act = nn.SiLU()
+ else:
+ self.resnet_up = None
+ self.skip_conv = None
+ self.skip_norm = None
+ self.act = None
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, skip_sample=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ if skip_sample is not None:
+ skip_sample = self.upsampler(skip_sample)
+ else:
+ skip_sample = 0
+
+ if self.resnet_up is not None:
+ skip_sample_states = self.skip_norm(hidden_states)
+ skip_sample_states = self.act(skip_sample_states)
+ skip_sample_states = self.skip_conv(skip_sample_states)
+
+ skip_sample = skip_sample + skip_sample_states
+
+ hidden_states = self.resnet_up(hidden_states, temb)
+
+ return hidden_states, skip_sample
+
+
+class ResnetUpsampleBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList(
+ [
+ ResnetBlock2D(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ up=True,
+ )
+ ]
+ )
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, temb)
+
+ return hidden_states
+
+
+class SimpleCrossAttnUpBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+
+ self.num_heads = out_channels // self.attn_num_head_channels
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ attentions.append(
+ Attention(
+ query_dim=out_channels,
+ cross_attention_dim=out_channels,
+ heads=self.num_heads,
+ dim_head=attn_num_head_channels,
+ added_kv_proj_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ bias=True,
+ upcast_softmax=True,
+ processor=AttnAddedKVProcessor(),
+ )
+ )
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList(
+ [
+ ResnetBlock2D(
+ in_channels=out_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ up=True,
+ )
+ ]
+ )
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ res_hidden_states_tuple,
+ temb=None,
+ encoder_hidden_states=None,
+ upsample_size=None,
+ attention_mask=None,
+ cross_attention_kwargs=None,
+ ):
+ cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
+ for resnet, attn in zip(self.resnets, self.attentions):
+ # resnet
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ hidden_states = resnet(hidden_states, temb)
+
+ # attn
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ **cross_attention_kwargs,
+ )
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, temb)
+
+ return hidden_states
+
+
+class KUpBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 5,
+ resnet_eps: float = 1e-5,
+ resnet_act_fn: str = "gelu",
+ resnet_group_size: Optional[int] = 32,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ k_in_channels = 2 * out_channels
+ k_out_channels = in_channels
+ num_layers = num_layers - 1
+
+ for i in range(num_layers):
+ in_channels = k_in_channels if i == 0 else out_channels
+ groups = in_channels // resnet_group_size
+ groups_out = out_channels // resnet_group_size
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=k_out_channels if (i == num_layers - 1) else out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=groups,
+ groups_out=groups_out,
+ dropout=dropout,
+ non_linearity=resnet_act_fn,
+ time_embedding_norm="ada_group",
+ conv_shortcut_bias=False,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([KUpsample2D()])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None):
+ res_hidden_states_tuple = res_hidden_states_tuple[-1]
+ if res_hidden_states_tuple is not None:
+ hidden_states = torch.cat([hidden_states, res_hidden_states_tuple], dim=1)
+
+ for resnet in self.resnets:
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+class KCrossAttnUpBlock2D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 4,
+ resnet_eps: float = 1e-5,
+ resnet_act_fn: str = "gelu",
+ resnet_group_size: int = 32,
+ attn_num_head_channels=1, # attention dim_head
+ cross_attention_dim: int = 768,
+ add_upsample: bool = True,
+ upcast_attention: bool = False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ is_first_block = in_channels == out_channels == temb_channels
+ is_middle_block = in_channels != out_channels
+ add_self_attention = True if is_first_block else False
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+
+ # in_channels, and out_channels for the block (k-unet)
+ k_in_channels = out_channels if is_first_block else 2 * out_channels
+ k_out_channels = in_channels
+
+ num_layers = num_layers - 1
+
+ for i in range(num_layers):
+ in_channels = k_in_channels if i == 0 else out_channels
+ groups = in_channels // resnet_group_size
+ groups_out = out_channels // resnet_group_size
+
+ if is_middle_block and (i == num_layers - 1):
+ conv_2d_out_channels = k_out_channels
+ else:
+ conv_2d_out_channels = None
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ conv_2d_out_channels=conv_2d_out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=groups,
+ groups_out=groups_out,
+ dropout=dropout,
+ non_linearity=resnet_act_fn,
+ time_embedding_norm="ada_group",
+ conv_shortcut_bias=False,
+ )
+ )
+ attentions.append(
+ KAttentionBlock(
+ k_out_channels if (i == num_layers - 1) else out_channels,
+ k_out_channels // attn_num_head_channels
+ if (i == num_layers - 1)
+ else out_channels // attn_num_head_channels,
+ attn_num_head_channels,
+ cross_attention_dim=cross_attention_dim,
+ temb_channels=temb_channels,
+ attention_bias=True,
+ add_self_attention=add_self_attention,
+ cross_attention_norm=True,
+ upcast_attention=upcast_attention,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.attentions = nn.ModuleList(attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([KUpsample2D()])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ res_hidden_states_tuple,
+ temb=None,
+ encoder_hidden_states=None,
+ cross_attention_kwargs=None,
+ upsample_size=None,
+ attention_mask=None,
+ ):
+ res_hidden_states_tuple = res_hidden_states_tuple[-1]
+ if res_hidden_states_tuple is not None:
+ hidden_states = torch.cat([hidden_states, res_hidden_states_tuple], dim=1)
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ attention_mask,
+ cross_attention_kwargs,
+ )[0]
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ emb=temb,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states)
+
+ return hidden_states
+
+
+# can potentially later be renamed to `No-feed-forward` attention
+class KAttentionBlock(nn.Module):
+ r"""
+ A basic Transformer block.
+
+ Parameters:
+ dim (`int`): The number of channels in the input and output.
+ num_attention_heads (`int`): The number of heads to use for multi-head attention.
+ attention_head_dim (`int`): The number of channels in each head.
+ dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
+ cross_attention_dim (`int`, *optional*): The size of the encoder_hidden_states vector for cross attention.
+ activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
+ num_embeds_ada_norm (:
+ obj: `int`, *optional*): The number of diffusion steps used during training. See `Transformer2DModel`.
+ attention_bias (:
+ obj: `bool`, *optional*, defaults to `False`): Configure if the attentions should contain a bias parameter.
+ """
+
+ def __init__(
+ self,
+ dim: int,
+ num_attention_heads: int,
+ attention_head_dim: int,
+ dropout: float = 0.0,
+ cross_attention_dim: Optional[int] = None,
+ attention_bias: bool = False,
+ upcast_attention: bool = False,
+ temb_channels: int = 768, # for ada_group_norm
+ add_self_attention: bool = False,
+ cross_attention_norm: bool = False,
+ group_size: int = 32,
+ ):
+ super().__init__()
+ self.add_self_attention = add_self_attention
+
+ # 1. Self-Attn
+ if add_self_attention:
+ self.norm1 = AdaGroupNorm(temb_channels, dim, max(1, dim // group_size))
+ self.attn1 = Attention(
+ query_dim=dim,
+ heads=num_attention_heads,
+ dim_head=attention_head_dim,
+ dropout=dropout,
+ bias=attention_bias,
+ cross_attention_dim=None,
+ cross_attention_norm=False,
+ )
+
+ # 2. Cross-Attn
+ self.norm2 = AdaGroupNorm(temb_channels, dim, max(1, dim // group_size))
+ self.attn2 = Attention(
+ query_dim=dim,
+ cross_attention_dim=cross_attention_dim,
+ heads=num_attention_heads,
+ dim_head=attention_head_dim,
+ dropout=dropout,
+ bias=attention_bias,
+ upcast_attention=upcast_attention,
+ cross_attention_norm=cross_attention_norm,
+ )
+
+ def _to_3d(self, hidden_states, height, weight):
+ return hidden_states.permute(0, 2, 3, 1).reshape(hidden_states.shape[0], height * weight, -1)
+
+ def _to_4d(self, hidden_states, height, weight):
+ return hidden_states.permute(0, 2, 1).reshape(hidden_states.shape[0], -1, height, weight)
+
+ def forward(
+ self,
+ hidden_states,
+ encoder_hidden_states=None,
+ emb=None,
+ attention_mask=None,
+ cross_attention_kwargs=None,
+ ):
+ cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
+
+ # 1. Self-Attention
+ if self.add_self_attention:
+ norm_hidden_states = self.norm1(hidden_states, emb)
+
+ height, weight = norm_hidden_states.shape[2:]
+ norm_hidden_states = self._to_3d(norm_hidden_states, height, weight)
+
+ attn_output = self.attn1(
+ norm_hidden_states,
+ encoder_hidden_states=None,
+ **cross_attention_kwargs,
+ )
+ attn_output = self._to_4d(attn_output, height, weight)
+
+ hidden_states = attn_output + hidden_states
+
+ # 2. Cross-Attention/None
+ norm_hidden_states = self.norm2(hidden_states, emb)
+
+ height, weight = norm_hidden_states.shape[2:]
+ norm_hidden_states = self._to_3d(norm_hidden_states, height, weight)
+ attn_output = self.attn2(
+ norm_hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ **cross_attention_kwargs,
+ )
+ attn_output = self._to_4d(attn_output, height, weight)
+
+ hidden_states = attn_output + hidden_states
+
+ return hidden_states
diff --git a/diffusers/src/diffusers/models/unet_2d_blocks_flax.py b/diffusers/src/diffusers/models/unet_2d_blocks_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e9690d332c9743ff0411b170238e9c8c37699e1
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_2d_blocks_flax.py
@@ -0,0 +1,365 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import flax.linen as nn
+import jax.numpy as jnp
+
+from .attention_flax import FlaxTransformer2DModel
+from .resnet_flax import FlaxDownsample2D, FlaxResnetBlock2D, FlaxUpsample2D
+
+
+class FlaxCrossAttnDownBlock2D(nn.Module):
+ r"""
+ Cross Attention 2D Downsizing block - original architecture from Unet transformers:
+ https://arxiv.org/abs/2103.06104
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input channels
+ out_channels (:obj:`int`):
+ Output channels
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ num_layers (:obj:`int`, *optional*, defaults to 1):
+ Number of attention blocks layers
+ attn_num_head_channels (:obj:`int`, *optional*, defaults to 1):
+ Number of attention heads of each spatial transformer block
+ add_downsample (:obj:`bool`, *optional*, defaults to `True`):
+ Whether to add downsampling layer before each final output
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ out_channels: int
+ dropout: float = 0.0
+ num_layers: int = 1
+ attn_num_head_channels: int = 1
+ add_downsample: bool = True
+ use_linear_projection: bool = False
+ only_cross_attention: bool = False
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ resnets = []
+ attentions = []
+
+ for i in range(self.num_layers):
+ in_channels = self.in_channels if i == 0 else self.out_channels
+
+ res_block = FlaxResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=self.out_channels,
+ dropout_prob=self.dropout,
+ dtype=self.dtype,
+ )
+ resnets.append(res_block)
+
+ attn_block = FlaxTransformer2DModel(
+ in_channels=self.out_channels,
+ n_heads=self.attn_num_head_channels,
+ d_head=self.out_channels // self.attn_num_head_channels,
+ depth=1,
+ use_linear_projection=self.use_linear_projection,
+ only_cross_attention=self.only_cross_attention,
+ dtype=self.dtype,
+ )
+ attentions.append(attn_block)
+
+ self.resnets = resnets
+ self.attentions = attentions
+
+ if self.add_downsample:
+ self.downsamplers_0 = FlaxDownsample2D(self.out_channels, dtype=self.dtype)
+
+ def __call__(self, hidden_states, temb, encoder_hidden_states, deterministic=True):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ hidden_states = resnet(hidden_states, temb, deterministic=deterministic)
+ hidden_states = attn(hidden_states, encoder_hidden_states, deterministic=deterministic)
+ output_states += (hidden_states,)
+
+ if self.add_downsample:
+ hidden_states = self.downsamplers_0(hidden_states)
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class FlaxDownBlock2D(nn.Module):
+ r"""
+ Flax 2D downsizing block
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input channels
+ out_channels (:obj:`int`):
+ Output channels
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ num_layers (:obj:`int`, *optional*, defaults to 1):
+ Number of attention blocks layers
+ add_downsample (:obj:`bool`, *optional*, defaults to `True`):
+ Whether to add downsampling layer before each final output
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ out_channels: int
+ dropout: float = 0.0
+ num_layers: int = 1
+ add_downsample: bool = True
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ resnets = []
+
+ for i in range(self.num_layers):
+ in_channels = self.in_channels if i == 0 else self.out_channels
+
+ res_block = FlaxResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=self.out_channels,
+ dropout_prob=self.dropout,
+ dtype=self.dtype,
+ )
+ resnets.append(res_block)
+ self.resnets = resnets
+
+ if self.add_downsample:
+ self.downsamplers_0 = FlaxDownsample2D(self.out_channels, dtype=self.dtype)
+
+ def __call__(self, hidden_states, temb, deterministic=True):
+ output_states = ()
+
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, temb, deterministic=deterministic)
+ output_states += (hidden_states,)
+
+ if self.add_downsample:
+ hidden_states = self.downsamplers_0(hidden_states)
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class FlaxCrossAttnUpBlock2D(nn.Module):
+ r"""
+ Cross Attention 2D Upsampling block - original architecture from Unet transformers:
+ https://arxiv.org/abs/2103.06104
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input channels
+ out_channels (:obj:`int`):
+ Output channels
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ num_layers (:obj:`int`, *optional*, defaults to 1):
+ Number of attention blocks layers
+ attn_num_head_channels (:obj:`int`, *optional*, defaults to 1):
+ Number of attention heads of each spatial transformer block
+ add_upsample (:obj:`bool`, *optional*, defaults to `True`):
+ Whether to add upsampling layer before each final output
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ out_channels: int
+ prev_output_channel: int
+ dropout: float = 0.0
+ num_layers: int = 1
+ attn_num_head_channels: int = 1
+ add_upsample: bool = True
+ use_linear_projection: bool = False
+ only_cross_attention: bool = False
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ resnets = []
+ attentions = []
+
+ for i in range(self.num_layers):
+ res_skip_channels = self.in_channels if (i == self.num_layers - 1) else self.out_channels
+ resnet_in_channels = self.prev_output_channel if i == 0 else self.out_channels
+
+ res_block = FlaxResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=self.out_channels,
+ dropout_prob=self.dropout,
+ dtype=self.dtype,
+ )
+ resnets.append(res_block)
+
+ attn_block = FlaxTransformer2DModel(
+ in_channels=self.out_channels,
+ n_heads=self.attn_num_head_channels,
+ d_head=self.out_channels // self.attn_num_head_channels,
+ depth=1,
+ use_linear_projection=self.use_linear_projection,
+ only_cross_attention=self.only_cross_attention,
+ dtype=self.dtype,
+ )
+ attentions.append(attn_block)
+
+ self.resnets = resnets
+ self.attentions = attentions
+
+ if self.add_upsample:
+ self.upsamplers_0 = FlaxUpsample2D(self.out_channels, dtype=self.dtype)
+
+ def __call__(self, hidden_states, res_hidden_states_tuple, temb, encoder_hidden_states, deterministic=True):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = jnp.concatenate((hidden_states, res_hidden_states), axis=-1)
+
+ hidden_states = resnet(hidden_states, temb, deterministic=deterministic)
+ hidden_states = attn(hidden_states, encoder_hidden_states, deterministic=deterministic)
+
+ if self.add_upsample:
+ hidden_states = self.upsamplers_0(hidden_states)
+
+ return hidden_states
+
+
+class FlaxUpBlock2D(nn.Module):
+ r"""
+ Flax 2D upsampling block
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input channels
+ out_channels (:obj:`int`):
+ Output channels
+ prev_output_channel (:obj:`int`):
+ Output channels from the previous block
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ num_layers (:obj:`int`, *optional*, defaults to 1):
+ Number of attention blocks layers
+ add_downsample (:obj:`bool`, *optional*, defaults to `True`):
+ Whether to add downsampling layer before each final output
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ out_channels: int
+ prev_output_channel: int
+ dropout: float = 0.0
+ num_layers: int = 1
+ add_upsample: bool = True
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ resnets = []
+
+ for i in range(self.num_layers):
+ res_skip_channels = self.in_channels if (i == self.num_layers - 1) else self.out_channels
+ resnet_in_channels = self.prev_output_channel if i == 0 else self.out_channels
+
+ res_block = FlaxResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=self.out_channels,
+ dropout_prob=self.dropout,
+ dtype=self.dtype,
+ )
+ resnets.append(res_block)
+
+ self.resnets = resnets
+
+ if self.add_upsample:
+ self.upsamplers_0 = FlaxUpsample2D(self.out_channels, dtype=self.dtype)
+
+ def __call__(self, hidden_states, res_hidden_states_tuple, temb, deterministic=True):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = jnp.concatenate((hidden_states, res_hidden_states), axis=-1)
+
+ hidden_states = resnet(hidden_states, temb, deterministic=deterministic)
+
+ if self.add_upsample:
+ hidden_states = self.upsamplers_0(hidden_states)
+
+ return hidden_states
+
+
+class FlaxUNetMidBlock2DCrossAttn(nn.Module):
+ r"""
+ Cross Attention 2D Mid-level block - original architecture from Unet transformers: https://arxiv.org/abs/2103.06104
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input channels
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ num_layers (:obj:`int`, *optional*, defaults to 1):
+ Number of attention blocks layers
+ attn_num_head_channels (:obj:`int`, *optional*, defaults to 1):
+ Number of attention heads of each spatial transformer block
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ dropout: float = 0.0
+ num_layers: int = 1
+ attn_num_head_channels: int = 1
+ use_linear_projection: bool = False
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ # there is always at least one resnet
+ resnets = [
+ FlaxResnetBlock2D(
+ in_channels=self.in_channels,
+ out_channels=self.in_channels,
+ dropout_prob=self.dropout,
+ dtype=self.dtype,
+ )
+ ]
+
+ attentions = []
+
+ for _ in range(self.num_layers):
+ attn_block = FlaxTransformer2DModel(
+ in_channels=self.in_channels,
+ n_heads=self.attn_num_head_channels,
+ d_head=self.in_channels // self.attn_num_head_channels,
+ depth=1,
+ use_linear_projection=self.use_linear_projection,
+ dtype=self.dtype,
+ )
+ attentions.append(attn_block)
+
+ res_block = FlaxResnetBlock2D(
+ in_channels=self.in_channels,
+ out_channels=self.in_channels,
+ dropout_prob=self.dropout,
+ dtype=self.dtype,
+ )
+ resnets.append(res_block)
+
+ self.resnets = resnets
+ self.attentions = attentions
+
+ def __call__(self, hidden_states, temb, encoder_hidden_states, deterministic=True):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states, encoder_hidden_states, deterministic=deterministic)
+ hidden_states = resnet(hidden_states, temb, deterministic=deterministic)
+
+ return hidden_states
diff --git a/diffusers/src/diffusers/models/unet_2d_condition.py b/diffusers/src/diffusers/models/unet_2d_condition.py
new file mode 100644
index 0000000000000000000000000000000000000000..01116ad1b0baa4e3a75d07fcd0a76b34c81ee9aa
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_2d_condition.py
@@ -0,0 +1,707 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..loaders import UNet2DConditionLoadersMixin
+from ..utils import BaseOutput, logging
+from .attention_processor import AttentionProcessor, AttnProcessor
+from .embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
+from .modeling_utils import ModelMixin
+from .unet_2d_blocks import (
+ CrossAttnDownBlock2D,
+ CrossAttnUpBlock2D,
+ DownBlock2D,
+ UNetMidBlock2DCrossAttn,
+ UNetMidBlock2DSimpleCrossAttn,
+ UpBlock2D,
+ get_down_block,
+ get_up_block,
+)
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class UNet2DConditionOutput(BaseOutput):
+ """
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Hidden states conditioned on `encoder_hidden_states` input. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor
+
+
+class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
+ r"""
+ UNet2DConditionModel is a conditional 2D UNet model that takes in a noisy sample, conditional state, and a timestep
+ and returns sample shaped output.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the models (such as downloading or saving, etc.)
+
+ Parameters:
+ sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
+ Height and width of input/output sample.
+ in_channels (`int`, *optional*, defaults to 4): The number of channels in the input sample.
+ out_channels (`int`, *optional*, defaults to 4): The number of channels in the output.
+ center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
+ flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
+ Whether to flip the sin to cos in the time embedding.
+ freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
+ down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
+ The tuple of downsample blocks to use.
+ mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
+ The mid block type. Choose from `UNetMidBlock2DCrossAttn` or `UNetMidBlock2DSimpleCrossAttn`, will skip the
+ mid block layer if `None`.
+ up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D",)`):
+ The tuple of upsample blocks to use.
+ only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
+ Whether to include self-attention in the basic transformer blocks, see
+ [`~models.attention.BasicTransformerBlock`].
+ block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
+ The tuple of output channels for each block.
+ layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
+ downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
+ mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
+ act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
+ norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
+ If `None`, it will skip the normalization and activation layers in post-processing
+ norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
+ cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
+ The dimension of the cross attention features.
+ attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
+ resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
+ for resnet blocks, see [`~models.resnet.ResnetBlock2D`]. Choose from `default` or `scale_shift`.
+ class_embed_type (`str`, *optional*, defaults to None):
+ The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
+ `"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
+ num_class_embeds (`int`, *optional*, defaults to None):
+ Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
+ class conditioning with `class_embed_type` equal to `None`.
+ time_embedding_type (`str`, *optional*, default to `positional`):
+ The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
+ timestep_post_act (`str, *optional*, default to `None`):
+ The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
+ time_cond_proj_dim (`int`, *optional*, default to `None`):
+ The dimension of `cond_proj` layer in timestep embedding.
+ conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer.
+ conv_out_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_out` layer.
+ projection_class_embeddings_input_dim (`int`, *optional*): The dimension of the `class_labels` input when
+ using the "projection" `class_embed_type`. Required when using the "projection" `class_embed_type`.
+ class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
+ embeddings with the class embeddings.
+ """
+
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[int] = None,
+ in_channels: int = 4,
+ out_channels: int = 4,
+ center_input_sample: bool = False,
+ flip_sin_to_cos: bool = True,
+ freq_shift: int = 0,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D",
+ ),
+ mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
+ up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
+ only_cross_attention: Union[bool, Tuple[bool]] = False,
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: int = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: Union[int, Tuple[int]] = 1280,
+ attention_head_dim: Union[int, Tuple[int]] = 8,
+ dual_cross_attention: bool = False,
+ use_linear_projection: bool = False,
+ class_embed_type: Optional[str] = None,
+ num_class_embeds: Optional[int] = None,
+ upcast_attention: bool = False,
+ resnet_time_scale_shift: str = "default",
+ time_embedding_type: str = "positional",
+ timestep_post_act: Optional[str] = None,
+ time_cond_proj_dim: Optional[int] = None,
+ conv_in_kernel: int = 3,
+ conv_out_kernel: int = 3,
+ projection_class_embeddings_input_dim: Optional[int] = None,
+ class_embeddings_concat: bool = False,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_padding = (conv_in_kernel - 1) // 2
+ self.conv_in = nn.Conv2d(
+ in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
+ )
+
+ # time
+ if time_embedding_type == "fourier":
+ time_embed_dim = block_out_channels[0] * 2
+ if time_embed_dim % 2 != 0:
+ raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
+ self.time_proj = GaussianFourierProjection(
+ time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
+ )
+ timestep_input_dim = time_embed_dim
+ elif time_embedding_type == "positional":
+ time_embed_dim = block_out_channels[0] * 4
+
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+ else:
+ raise ValueError(
+ f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
+ )
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ post_act_fn=timestep_post_act,
+ cond_proj_dim=time_cond_proj_dim,
+ )
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ elif class_embed_type == "projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
+ # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
+ # 2. it projects from an arbitrary input dimension.
+ #
+ # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
+ # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
+ # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
+ self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif class_embed_type == "simple_projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ self.down_blocks = nn.ModuleList([])
+ self.up_blocks = nn.ModuleList([])
+
+ if isinstance(only_cross_attention, bool):
+ only_cross_attention = [only_cross_attention] * len(down_block_types)
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ if isinstance(cross_attention_dim, int):
+ cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
+
+ if class_embeddings_concat:
+ # The time embeddings are concatenated with the class embeddings. The dimension of the
+ # time embeddings passed to the down, middle, and up blocks is twice the dimension of the
+ # regular time embeddings
+ blocks_time_embed_dim = time_embed_dim * 2
+ else:
+ blocks_time_embed_dim = time_embed_dim
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim[i],
+ attn_num_head_channels=attention_head_dim[i],
+ downsample_padding=downsample_padding,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ if mid_block_type == "UNetMidBlock2DCrossAttn":
+ self.mid_block = UNetMidBlock2DCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ cross_attention_dim=cross_attention_dim[-1],
+ attn_num_head_channels=attention_head_dim[-1],
+ resnet_groups=norm_num_groups,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
+ self.mid_block = UNetMidBlock2DSimpleCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ cross_attention_dim=cross_attention_dim[-1],
+ attn_num_head_channels=attention_head_dim[-1],
+ resnet_groups=norm_num_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif mid_block_type is None:
+ self.mid_block = None
+ else:
+ raise ValueError(f"unknown mid_block_type : {mid_block_type}")
+
+ # count how many layers upsample the images
+ self.num_upsamplers = 0
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_attention_head_dim = list(reversed(attention_head_dim))
+ reversed_cross_attention_dim = list(reversed(cross_attention_dim))
+ only_cross_attention = list(reversed(only_cross_attention))
+
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ is_final_block = i == len(block_out_channels) - 1
+
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ # add upsample block for all BUT final layer
+ if not is_final_block:
+ add_upsample = True
+ self.num_upsamplers += 1
+ else:
+ add_upsample = False
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_upsample=add_upsample,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=reversed_cross_attention_dim[i],
+ attn_num_head_channels=reversed_attention_head_dim[i],
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ if norm_num_groups is not None:
+ self.conv_norm_out = nn.GroupNorm(
+ num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
+ )
+ self.conv_act = nn.SiLU()
+ else:
+ self.conv_norm_out = None
+ self.conv_act = None
+
+ conv_out_padding = (conv_out_kernel - 1) // 2
+ self.conv_out = nn.Conv2d(
+ block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
+ )
+
+ @property
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
+ r"""
+ Parameters:
+ `processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ of **all** `Attention` layers.
+ In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainable attention processors.:
+
+ """
+ count = len(self.attn_processors.keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module will split the input tensor in slices, to compute attention
+ in several steps. This is useful to save some memory in exchange for a small speed decrease.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
+ `"max"`, maximum amount of memory will be saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlock2D, DownBlock2D, CrossAttnUpBlock2D, UpBlock2D)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
+ mid_block_additional_residual: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ) -> Union[UNet2DConditionOutput, Tuple]:
+ r"""
+ Args:
+ sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
+ timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
+ encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
+ encoder_attention_mask (`torch.Tensor`):
+ (batch, sequence_length) cross-attention mask (or bias), applied to encoder_hidden_states. If a
+ BoolTensor is provided, it will be turned into a bias, by adding a large negative value. False = hide
+ token. Other tensor types will be used as-is as bias values.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Returns:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ # By default samples have to be AT least a multiple of the overall upsampling factor.
+ # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
+ # However, the upsampling interpolation output size can be forced to fit any upsampling size
+ # on the fly if necessary.
+ default_overall_up_factor = 2**self.num_upsamplers
+
+ # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
+ forward_upsample_size = False
+ upsample_size = None
+
+ if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
+ logger.info("Forward upsample size to force interpolation output size.")
+ forward_upsample_size = True
+
+ # prepare attention_mask
+ if attention_mask is not None:
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # ensure encoder_attention_mask is a bias, and make it broadcastable over multi-head-attention channels
+ if encoder_attention_mask is not None:
+ # if it's a mask: turn it into a bias. otherwise: assume it's already a bias
+ if encoder_attention_mask.dtype is torch.bool:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # timesteps does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=self.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when num_class_embeds > 0")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
+
+ if self.config.class_embeddings_concat:
+ emb = torch.cat([emb, class_emb], dim=-1)
+ else:
+ emb = emb + class_emb
+
+ # 2. pre-process
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample = down_block_res_sample + down_block_additional_residual
+ new_down_block_res_samples += (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+
+ if mid_block_additional_residual is not None:
+ sample = sample + mid_block_additional_residual
+
+ # 5. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ is_final_block = i == len(self.up_blocks) - 1
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ # if we have not reached the final block and need to forward the
+ # upsample size, we do it here
+ if not is_final_block and forward_upsample_size:
+ upsample_size = down_block_res_samples[-1].shape[2:]
+
+ if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ upsample_size=upsample_size,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ else:
+ sample = upsample_block(
+ hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
+ )
+
+ # 6. post-process
+ if self.conv_norm_out:
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet2DConditionOutput(sample=sample)
diff --git a/diffusers/src/diffusers/models/unet_2d_condition_flax.py b/diffusers/src/diffusers/models/unet_2d_condition_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..812ca079db384b3ca46ac4ecb73644dfdf2b0a11
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_2d_condition_flax.py
@@ -0,0 +1,337 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Tuple, Union
+
+import flax
+import flax.linen as nn
+import jax
+import jax.numpy as jnp
+from flax.core.frozen_dict import FrozenDict
+
+from ..configuration_utils import ConfigMixin, flax_register_to_config
+from ..utils import BaseOutput
+from .embeddings_flax import FlaxTimestepEmbedding, FlaxTimesteps
+from .modeling_flax_utils import FlaxModelMixin
+from .unet_2d_blocks_flax import (
+ FlaxCrossAttnDownBlock2D,
+ FlaxCrossAttnUpBlock2D,
+ FlaxDownBlock2D,
+ FlaxUNetMidBlock2DCrossAttn,
+ FlaxUpBlock2D,
+)
+
+
+@flax.struct.dataclass
+class FlaxUNet2DConditionOutput(BaseOutput):
+ """
+ Args:
+ sample (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
+ Hidden states conditioned on `encoder_hidden_states` input. Output of last layer of model.
+ """
+
+ sample: jnp.ndarray
+
+
+@flax_register_to_config
+class FlaxUNet2DConditionModel(nn.Module, FlaxModelMixin, ConfigMixin):
+ r"""
+ FlaxUNet2DConditionModel is a conditional 2D UNet model that takes in a noisy sample, conditional state, and a
+ timestep and returns sample shaped output.
+
+ This model inherits from [`FlaxModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the models (such as downloading or saving, etc.)
+
+ Also, this model is a Flax Linen [flax.linen.Module](https://flax.readthedocs.io/en/latest/flax.linen.html#module)
+ subclass. Use it as a regular Flax linen Module and refer to the Flax documentation for all matter related to
+ general usage and behavior.
+
+ Finally, this model supports inherent JAX features such as:
+ - [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
+ - [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
+ - [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
+ - [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
+
+ Parameters:
+ sample_size (`int`, *optional*):
+ The size of the input sample.
+ in_channels (`int`, *optional*, defaults to 4):
+ The number of channels in the input sample.
+ out_channels (`int`, *optional*, defaults to 4):
+ The number of channels in the output.
+ down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
+ The tuple of downsample blocks to use. The corresponding class names will be: "FlaxCrossAttnDownBlock2D",
+ "FlaxCrossAttnDownBlock2D", "FlaxCrossAttnDownBlock2D", "FlaxDownBlock2D"
+ up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D",)`):
+ The tuple of upsample blocks to use. The corresponding class names will be: "FlaxUpBlock2D",
+ "FlaxCrossAttnUpBlock2D", "FlaxCrossAttnUpBlock2D", "FlaxCrossAttnUpBlock2D"
+ block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
+ The tuple of output channels for each block.
+ layers_per_block (`int`, *optional*, defaults to 2):
+ The number of layers per block.
+ attention_head_dim (`int` or `Tuple[int]`, *optional*, defaults to 8):
+ The dimension of the attention heads.
+ cross_attention_dim (`int`, *optional*, defaults to 768):
+ The dimension of the cross attention features.
+ dropout (`float`, *optional*, defaults to 0):
+ Dropout probability for down, up and bottleneck blocks.
+ flip_sin_to_cos (`bool`, *optional*, defaults to `True`):
+ Whether to flip the sin to cos in the time embedding.
+ freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
+
+ """
+
+ sample_size: int = 32
+ in_channels: int = 4
+ out_channels: int = 4
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "CrossAttnDownBlock2D",
+ "DownBlock2D",
+ )
+ up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")
+ only_cross_attention: Union[bool, Tuple[bool]] = False
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280)
+ layers_per_block: int = 2
+ attention_head_dim: Union[int, Tuple[int]] = 8
+ cross_attention_dim: int = 1280
+ dropout: float = 0.0
+ use_linear_projection: bool = False
+ dtype: jnp.dtype = jnp.float32
+ flip_sin_to_cos: bool = True
+ freq_shift: int = 0
+
+ def init_weights(self, rng: jax.random.KeyArray) -> FrozenDict:
+ # init input tensors
+ sample_shape = (1, self.in_channels, self.sample_size, self.sample_size)
+ sample = jnp.zeros(sample_shape, dtype=jnp.float32)
+ timesteps = jnp.ones((1,), dtype=jnp.int32)
+ encoder_hidden_states = jnp.zeros((1, 1, self.cross_attention_dim), dtype=jnp.float32)
+
+ params_rng, dropout_rng = jax.random.split(rng)
+ rngs = {"params": params_rng, "dropout": dropout_rng}
+
+ return self.init(rngs, sample, timesteps, encoder_hidden_states)["params"]
+
+ def setup(self):
+ block_out_channels = self.block_out_channels
+ time_embed_dim = block_out_channels[0] * 4
+
+ # input
+ self.conv_in = nn.Conv(
+ block_out_channels[0],
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ # time
+ self.time_proj = FlaxTimesteps(
+ block_out_channels[0], flip_sin_to_cos=self.flip_sin_to_cos, freq_shift=self.config.freq_shift
+ )
+ self.time_embedding = FlaxTimestepEmbedding(time_embed_dim, dtype=self.dtype)
+
+ only_cross_attention = self.only_cross_attention
+ if isinstance(only_cross_attention, bool):
+ only_cross_attention = (only_cross_attention,) * len(self.down_block_types)
+
+ attention_head_dim = self.attention_head_dim
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(self.down_block_types)
+
+ # down
+ down_blocks = []
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(self.down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ if down_block_type == "CrossAttnDownBlock2D":
+ down_block = FlaxCrossAttnDownBlock2D(
+ in_channels=input_channel,
+ out_channels=output_channel,
+ dropout=self.dropout,
+ num_layers=self.layers_per_block,
+ attn_num_head_channels=attention_head_dim[i],
+ add_downsample=not is_final_block,
+ use_linear_projection=self.use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ dtype=self.dtype,
+ )
+ else:
+ down_block = FlaxDownBlock2D(
+ in_channels=input_channel,
+ out_channels=output_channel,
+ dropout=self.dropout,
+ num_layers=self.layers_per_block,
+ add_downsample=not is_final_block,
+ dtype=self.dtype,
+ )
+
+ down_blocks.append(down_block)
+ self.down_blocks = down_blocks
+
+ # mid
+ self.mid_block = FlaxUNetMidBlock2DCrossAttn(
+ in_channels=block_out_channels[-1],
+ dropout=self.dropout,
+ attn_num_head_channels=attention_head_dim[-1],
+ use_linear_projection=self.use_linear_projection,
+ dtype=self.dtype,
+ )
+
+ # up
+ up_blocks = []
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_attention_head_dim = list(reversed(attention_head_dim))
+ only_cross_attention = list(reversed(only_cross_attention))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(self.up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ if up_block_type == "CrossAttnUpBlock2D":
+ up_block = FlaxCrossAttnUpBlock2D(
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ num_layers=self.layers_per_block + 1,
+ attn_num_head_channels=reversed_attention_head_dim[i],
+ add_upsample=not is_final_block,
+ dropout=self.dropout,
+ use_linear_projection=self.use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ dtype=self.dtype,
+ )
+ else:
+ up_block = FlaxUpBlock2D(
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ num_layers=self.layers_per_block + 1,
+ add_upsample=not is_final_block,
+ dropout=self.dropout,
+ dtype=self.dtype,
+ )
+
+ up_blocks.append(up_block)
+ prev_output_channel = output_channel
+ self.up_blocks = up_blocks
+
+ # out
+ self.conv_norm_out = nn.GroupNorm(num_groups=32, epsilon=1e-5)
+ self.conv_out = nn.Conv(
+ self.out_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ def __call__(
+ self,
+ sample,
+ timesteps,
+ encoder_hidden_states,
+ down_block_additional_residuals=None,
+ mid_block_additional_residual=None,
+ return_dict: bool = True,
+ train: bool = False,
+ ) -> Union[FlaxUNet2DConditionOutput, Tuple]:
+ r"""
+ Args:
+ sample (`jnp.ndarray`): (batch, channel, height, width) noisy inputs tensor
+ timestep (`jnp.ndarray` or `float` or `int`): timesteps
+ encoder_hidden_states (`jnp.ndarray`): (batch_size, sequence_length, hidden_size) encoder hidden states
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition_flax.FlaxUNet2DConditionOutput`] instead of a
+ plain tuple.
+ train (`bool`, *optional*, defaults to `False`):
+ Use deterministic functions and disable dropout when not training.
+
+ Returns:
+ [`~models.unet_2d_condition_flax.FlaxUNet2DConditionOutput`] or `tuple`:
+ [`~models.unet_2d_condition_flax.FlaxUNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`.
+ When returning a tuple, the first element is the sample tensor.
+ """
+ # 1. time
+ if not isinstance(timesteps, jnp.ndarray):
+ timesteps = jnp.array([timesteps], dtype=jnp.int32)
+ elif isinstance(timesteps, jnp.ndarray) and len(timesteps.shape) == 0:
+ timesteps = timesteps.astype(dtype=jnp.float32)
+ timesteps = jnp.expand_dims(timesteps, 0)
+
+ t_emb = self.time_proj(timesteps)
+ t_emb = self.time_embedding(t_emb)
+
+ # 2. pre-process
+ sample = jnp.transpose(sample, (0, 2, 3, 1))
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for down_block in self.down_blocks:
+ if isinstance(down_block, FlaxCrossAttnDownBlock2D):
+ sample, res_samples = down_block(sample, t_emb, encoder_hidden_states, deterministic=not train)
+ else:
+ sample, res_samples = down_block(sample, t_emb, deterministic=not train)
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample += down_block_additional_residual
+ new_down_block_res_samples += (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ sample = self.mid_block(sample, t_emb, encoder_hidden_states, deterministic=not train)
+
+ if mid_block_additional_residual is not None:
+ sample += mid_block_additional_residual
+
+ # 5. up
+ for up_block in self.up_blocks:
+ res_samples = down_block_res_samples[-(self.layers_per_block + 1) :]
+ down_block_res_samples = down_block_res_samples[: -(self.layers_per_block + 1)]
+ if isinstance(up_block, FlaxCrossAttnUpBlock2D):
+ sample = up_block(
+ sample,
+ temb=t_emb,
+ encoder_hidden_states=encoder_hidden_states,
+ res_hidden_states_tuple=res_samples,
+ deterministic=not train,
+ )
+ else:
+ sample = up_block(sample, temb=t_emb, res_hidden_states_tuple=res_samples, deterministic=not train)
+
+ # 6. post-process
+ sample = self.conv_norm_out(sample)
+ sample = nn.silu(sample)
+ sample = self.conv_out(sample)
+ sample = jnp.transpose(sample, (0, 3, 1, 2))
+
+ if not return_dict:
+ return (sample,)
+
+ return FlaxUNet2DConditionOutput(sample=sample)
diff --git a/diffusers/src/diffusers/models/unet_3d_blocks.py b/diffusers/src/diffusers/models/unet_3d_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f8ee2a22aab482d51ef8848120372668a5a896c
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_3d_blocks.py
@@ -0,0 +1,670 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+from torch import nn
+
+from .resnet import Downsample2D, ResnetBlock2D, TemporalConvLayer, Upsample2D
+from .transformer_2d import Transformer2DModel
+from .transformer_temporal import TransformerTemporalModel
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ downsample_padding=None,
+ dual_cross_attention=False,
+ use_linear_projection=True,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+):
+ if down_block_type == "DownBlock3D":
+ return DownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "CrossAttnDownBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock3D")
+ return CrossAttnDownBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{down_block_type} does not exist.")
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ dual_cross_attention=False,
+ use_linear_projection=True,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+):
+ if up_block_type == "UpBlock3D":
+ return UpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "CrossAttnUpBlock3D":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock3D")
+ return CrossAttnUpBlock3D(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{up_block_type} does not exist.")
+
+
+class UNetMidBlock3DCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ dual_cross_attention=False,
+ use_linear_projection=True,
+ upcast_attention=False,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ temp_convs = [
+ TemporalConvLayer(
+ in_channels,
+ in_channels,
+ dropout=0.1,
+ )
+ ]
+ attentions = []
+ temp_attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ Transformer2DModel(
+ in_channels // attn_num_head_channels,
+ attn_num_head_channels,
+ in_channels=in_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temp_attentions.append(
+ TransformerTemporalModel(
+ in_channels // attn_num_head_channels,
+ attn_num_head_channels,
+ in_channels=in_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temp_convs.append(
+ TemporalConvLayer(
+ in_channels,
+ in_channels,
+ dropout=0.1,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temp_convs = nn.ModuleList(temp_convs)
+ self.attentions = nn.ModuleList(attentions)
+ self.temp_attentions = nn.ModuleList(temp_attentions)
+
+ def forward(
+ self,
+ hidden_states,
+ temb=None,
+ encoder_hidden_states=None,
+ attention_mask=None,
+ num_frames=1,
+ cross_attention_kwargs=None,
+ ):
+ hidden_states = self.resnets[0](hidden_states, temb)
+ hidden_states = self.temp_convs[0](hidden_states, num_frames=num_frames)
+ for attn, temp_attn, resnet, temp_conv in zip(
+ self.attentions, self.temp_attentions, self.resnets[1:], self.temp_convs[1:]
+ ):
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+ hidden_states = temp_attn(hidden_states, num_frames=num_frames).sample
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temp_conv(hidden_states, num_frames=num_frames)
+
+ return hidden_states
+
+
+class CrossAttnDownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+ temp_attentions = []
+ temp_convs = []
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temp_convs.append(
+ TemporalConvLayer(
+ out_channels,
+ out_channels,
+ dropout=0.1,
+ )
+ )
+ attentions.append(
+ Transformer2DModel(
+ out_channels // attn_num_head_channels,
+ attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temp_attentions.append(
+ TransformerTemporalModel(
+ out_channels // attn_num_head_channels,
+ attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ self.resnets = nn.ModuleList(resnets)
+ self.temp_convs = nn.ModuleList(temp_convs)
+ self.attentions = nn.ModuleList(attentions)
+ self.temp_attentions = nn.ModuleList(temp_attentions)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample2D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ temb=None,
+ encoder_hidden_states=None,
+ attention_mask=None,
+ num_frames=1,
+ cross_attention_kwargs=None,
+ ):
+ # TODO(Patrick, William) - attention mask is not used
+ output_states = ()
+
+ for resnet, temp_conv, attn, temp_attn in zip(
+ self.resnets, self.temp_convs, self.attentions, self.temp_attentions
+ ):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temp_conv(hidden_states, num_frames=num_frames)
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+ hidden_states = temp_attn(hidden_states, num_frames=num_frames).sample
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class DownBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+ temp_convs = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temp_convs.append(
+ TemporalConvLayer(
+ out_channels,
+ out_channels,
+ dropout=0.1,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temp_convs = nn.ModuleList(temp_convs)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ Downsample2D(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None, num_frames=1):
+ output_states = ()
+
+ for resnet, temp_conv in zip(self.resnets, self.temp_convs):
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temp_conv(hidden_states, num_frames=num_frames)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+class CrossAttnUpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ temp_convs = []
+ attentions = []
+ temp_attentions = []
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temp_convs.append(
+ TemporalConvLayer(
+ out_channels,
+ out_channels,
+ dropout=0.1,
+ )
+ )
+ attentions.append(
+ Transformer2DModel(
+ out_channels // attn_num_head_channels,
+ attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ temp_attentions.append(
+ TransformerTemporalModel(
+ out_channels // attn_num_head_channels,
+ attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ self.resnets = nn.ModuleList(resnets)
+ self.temp_convs = nn.ModuleList(temp_convs)
+ self.attentions = nn.ModuleList(attentions)
+ self.temp_attentions = nn.ModuleList(temp_attentions)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ res_hidden_states_tuple,
+ temb=None,
+ encoder_hidden_states=None,
+ upsample_size=None,
+ attention_mask=None,
+ num_frames=1,
+ cross_attention_kwargs=None,
+ ):
+ # TODO(Patrick, William) - attention mask is not used
+ for resnet, temp_conv, attn, temp_attn in zip(
+ self.resnets, self.temp_convs, self.attentions, self.temp_attentions
+ ):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temp_conv(hidden_states, num_frames=num_frames)
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+ hidden_states = temp_attn(hidden_states, num_frames=num_frames).sample
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+
+class UpBlock3D(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+ temp_convs = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlock2D(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ temp_convs.append(
+ TemporalConvLayer(
+ out_channels,
+ out_channels,
+ dropout=0.1,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+ self.temp_convs = nn.ModuleList(temp_convs)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None, num_frames=1):
+ for resnet, temp_conv in zip(self.resnets, self.temp_convs):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = temp_conv(hidden_states, num_frames=num_frames)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
diff --git a/diffusers/src/diffusers/models/unet_3d_condition.py b/diffusers/src/diffusers/models/unet_3d_condition.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec8865f31031f9415f46fad166d6cb06aa1c7445
--- /dev/null
+++ b/diffusers/src/diffusers/models/unet_3d_condition.py
@@ -0,0 +1,557 @@
+# Copyright 2023 Alibaba DAMO-VILAB and The HuggingFace Team. All rights reserved.
+# Copyright 2023 The ModelScope Team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, logging
+from .attention_processor import AttentionProcessor, AttnProcessor
+from .embeddings import TimestepEmbedding, Timesteps
+from .modeling_utils import ModelMixin
+from .transformer_temporal import TransformerTemporalModel
+from .unet_3d_blocks import (
+ CrossAttnDownBlock3D,
+ CrossAttnUpBlock3D,
+ DownBlock3D,
+ UNetMidBlock3DCrossAttn,
+ UpBlock3D,
+ get_down_block,
+ get_up_block,
+)
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class UNet3DConditionOutput(BaseOutput):
+ """
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_frames, num_channels, height, width)`):
+ Hidden states conditioned on `encoder_hidden_states` input. Output of last layer of model.
+ """
+
+ sample: torch.FloatTensor
+
+
+class UNet3DConditionModel(ModelMixin, ConfigMixin):
+ r"""
+ UNet3DConditionModel is a conditional 2D UNet model that takes in a noisy sample, conditional state, and a timestep
+ and returns sample shaped output.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the models (such as downloading or saving, etc.)
+
+ Parameters:
+ sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
+ Height and width of input/output sample.
+ in_channels (`int`, *optional*, defaults to 4): The number of channels in the input sample.
+ out_channels (`int`, *optional*, defaults to 4): The number of channels in the output.
+ down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
+ The tuple of downsample blocks to use.
+ up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D",)`):
+ The tuple of upsample blocks to use.
+ block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
+ The tuple of output channels for each block.
+ layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
+ downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
+ mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
+ act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
+ norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
+ If `None`, it will skip the normalization and activation layers in post-processing
+ norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
+ cross_attention_dim (`int`, *optional*, defaults to 1280): The dimension of the cross attention features.
+ attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
+ """
+
+ _supports_gradient_checkpointing = False
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[int] = None,
+ in_channels: int = 4,
+ out_channels: int = 4,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ "CrossAttnDownBlock3D",
+ "DownBlock3D",
+ ),
+ up_block_types: Tuple[str] = ("UpBlock3D", "CrossAttnUpBlock3D", "CrossAttnUpBlock3D", "CrossAttnUpBlock3D"),
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: int = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: int = 1024,
+ attention_head_dim: Union[int, Tuple[int]] = 64,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_kernel = 3
+ conv_out_kernel = 3
+ conv_in_padding = (conv_in_kernel - 1) // 2
+ self.conv_in = nn.Conv2d(
+ in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
+ )
+
+ # time
+ time_embed_dim = block_out_channels[0] * 4
+ self.time_proj = Timesteps(block_out_channels[0], True, 0)
+ timestep_input_dim = block_out_channels[0]
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ )
+
+ self.transformer_in = TransformerTemporalModel(
+ num_attention_heads=8,
+ attention_head_dim=attention_head_dim,
+ in_channels=block_out_channels[0],
+ num_layers=1,
+ )
+
+ # class embedding
+ self.down_blocks = nn.ModuleList([])
+ self.up_blocks = nn.ModuleList([])
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim[i],
+ downsample_padding=downsample_padding,
+ dual_cross_attention=False,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock3DCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attention_head_dim[-1],
+ resnet_groups=norm_num_groups,
+ dual_cross_attention=False,
+ )
+
+ # count how many layers upsample the images
+ self.num_upsamplers = 0
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_attention_head_dim = list(reversed(attention_head_dim))
+
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ is_final_block = i == len(block_out_channels) - 1
+
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ # add upsample block for all BUT final layer
+ if not is_final_block:
+ add_upsample = True
+ self.num_upsamplers += 1
+ else:
+ add_upsample = False
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=time_embed_dim,
+ add_upsample=add_upsample,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=reversed_attention_head_dim[i],
+ dual_cross_attention=False,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ if norm_num_groups is not None:
+ self.conv_norm_out = nn.GroupNorm(
+ num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
+ )
+ self.conv_act = nn.SiLU()
+ else:
+ self.conv_norm_out = None
+ self.conv_act = None
+
+ conv_out_padding = (conv_out_kernel - 1) // 2
+ self.conv_out = nn.Conv2d(
+ block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
+ )
+
+ @property
+ # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.attn_processors
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attention_slice
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module will split the input tensor in slices, to compute attention
+ in several steps. This is useful to save some memory in exchange for a small speed decrease.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
+ `"max"`, maximum amount of memory will be saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attn_processor
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
+ r"""
+ Parameters:
+ `processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ of **all** `Attention` layers.
+ In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainable attention processors.:
+
+ """
+ count = len(self.attn_processors.keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlock3D, DownBlock3D, CrossAttnUpBlock3D, UpBlock3D)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
+ mid_block_additional_residual: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ) -> Union[UNet3DConditionOutput, Tuple]:
+ r"""
+ Args:
+ sample (`torch.FloatTensor`): (batch, num_frames, channel, height, width) noisy inputs tensor
+ timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
+ encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition.UNet3DConditionOutput`] instead of a plain tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Returns:
+ [`~models.unet_2d_condition.UNet3DConditionOutput`] or `tuple`:
+ [`~models.unet_2d_condition.UNet3DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ # By default samples have to be AT least a multiple of the overall upsampling factor.
+ # The overall upsampling factor is equal to 2 ** (# num of upsampling layears).
+ # However, the upsampling interpolation output size can be forced to fit any upsampling size
+ # on the fly if necessary.
+ default_overall_up_factor = 2**self.num_upsamplers
+
+ # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
+ forward_upsample_size = False
+ upsample_size = None
+
+ if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
+ logger.info("Forward upsample size to force interpolation output size.")
+ forward_upsample_size = True
+
+ # prepare attention_mask
+ if attention_mask is not None:
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ num_frames = sample.shape[2]
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # timesteps does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=self.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+ emb = emb.repeat_interleave(repeats=num_frames, dim=0)
+ encoder_hidden_states = encoder_hidden_states.repeat_interleave(repeats=num_frames, dim=0)
+
+ # 2. pre-process
+ sample = sample.permute(0, 2, 1, 3, 4).reshape((sample.shape[0] * num_frames, -1) + sample.shape[3:])
+ sample = self.conv_in(sample)
+
+ sample = self.transformer_in(sample, num_frames=num_frames).sample
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ num_frames=num_frames,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb, num_frames=num_frames)
+
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample = down_block_res_sample + down_block_additional_residual
+ new_down_block_res_samples += (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ num_frames=num_frames,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+
+ if mid_block_additional_residual is not None:
+ sample = sample + mid_block_additional_residual
+
+ # 5. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ is_final_block = i == len(self.up_blocks) - 1
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ # if we have not reached the final block and need to forward the
+ # upsample size, we do it here
+ if not is_final_block and forward_upsample_size:
+ upsample_size = down_block_res_samples[-1].shape[2:]
+
+ if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ upsample_size=upsample_size,
+ attention_mask=attention_mask,
+ num_frames=num_frames,
+ cross_attention_kwargs=cross_attention_kwargs,
+ )
+ else:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ upsample_size=upsample_size,
+ num_frames=num_frames,
+ )
+
+ # 6. post-process
+ if self.conv_norm_out:
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+
+ sample = self.conv_out(sample)
+
+ # reshape to (batch, channel, framerate, width, height)
+ sample = sample[None, :].reshape((-1, num_frames) + sample.shape[1:]).permute(0, 2, 1, 3, 4)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet3DConditionOutput(sample=sample)
diff --git a/diffusers/src/diffusers/models/vae.py b/diffusers/src/diffusers/models/vae.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4484823ac3dacbabbe150fd3106215f773a12da
--- /dev/null
+++ b/diffusers/src/diffusers/models/vae.py
@@ -0,0 +1,403 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Optional
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+from ..utils import BaseOutput, randn_tensor
+from .unet_2d_blocks import UNetMidBlock2D, get_down_block, get_up_block
+
+
+@dataclass
+class DecoderOutput(BaseOutput):
+ """
+ Output of decoding method.
+
+ Args:
+ sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Decoded output sample of the model. Output of the last layer of the model.
+ """
+
+ sample: torch.FloatTensor
+
+
+class Encoder(nn.Module):
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D",),
+ block_out_channels=(64,),
+ layers_per_block=2,
+ norm_num_groups=32,
+ act_fn="silu",
+ double_z=True,
+ ):
+ super().__init__()
+ self.layers_per_block = layers_per_block
+
+ self.conv_in = torch.nn.Conv2d(
+ in_channels,
+ block_out_channels[0],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ )
+
+ self.mid_block = None
+ self.down_blocks = nn.ModuleList([])
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=self.layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ add_downsample=not is_final_block,
+ resnet_eps=1e-6,
+ downsample_padding=0,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ attn_num_head_channels=None,
+ temb_channels=None,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ output_scale_factor=1,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=None,
+ resnet_groups=norm_num_groups,
+ temb_channels=None,
+ )
+
+ # out
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[-1], num_groups=norm_num_groups, eps=1e-6)
+ self.conv_act = nn.SiLU()
+
+ conv_out_channels = 2 * out_channels if double_z else out_channels
+ self.conv_out = nn.Conv2d(block_out_channels[-1], conv_out_channels, 3, padding=1)
+
+ self.gradient_checkpointing = False
+
+ def forward(self, x):
+ sample = x
+ sample = self.conv_in(sample)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ # down
+ for down_block in self.down_blocks:
+ sample = torch.utils.checkpoint.checkpoint(create_custom_forward(down_block), sample)
+
+ # middle
+ sample = torch.utils.checkpoint.checkpoint(create_custom_forward(self.mid_block), sample)
+
+ else:
+ # down
+ for down_block in self.down_blocks:
+ sample = down_block(sample)
+
+ # middle
+ sample = self.mid_block(sample)
+
+ # post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class Decoder(nn.Module):
+ def __init__(
+ self,
+ in_channels=3,
+ out_channels=3,
+ up_block_types=("UpDecoderBlock2D",),
+ block_out_channels=(64,),
+ layers_per_block=2,
+ norm_num_groups=32,
+ act_fn="silu",
+ ):
+ super().__init__()
+ self.layers_per_block = layers_per_block
+
+ self.conv_in = nn.Conv2d(
+ in_channels,
+ block_out_channels[-1],
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ )
+
+ self.mid_block = None
+ self.up_blocks = nn.ModuleList([])
+
+ # mid
+ self.mid_block = UNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ output_scale_factor=1,
+ resnet_time_scale_shift="default",
+ attn_num_head_channels=None,
+ resnet_groups=norm_num_groups,
+ temb_channels=None,
+ )
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=self.layers_per_block + 1,
+ in_channels=prev_output_channel,
+ out_channels=output_channel,
+ prev_output_channel=None,
+ add_upsample=not is_final_block,
+ resnet_eps=1e-6,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ attn_num_head_channels=None,
+ temb_channels=None,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=1e-6)
+ self.conv_act = nn.SiLU()
+ self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
+
+ self.gradient_checkpointing = False
+
+ def forward(self, z):
+ sample = z
+ sample = self.conv_in(sample)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ # middle
+ sample = torch.utils.checkpoint.checkpoint(create_custom_forward(self.mid_block), sample)
+
+ # up
+ for up_block in self.up_blocks:
+ sample = torch.utils.checkpoint.checkpoint(create_custom_forward(up_block), sample)
+ else:
+ # middle
+ sample = self.mid_block(sample)
+
+ # up
+ for up_block in self.up_blocks:
+ sample = up_block(sample)
+
+ # post-process
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class VectorQuantizer(nn.Module):
+ """
+ Improved version over VectorQuantizer, can be used as a drop-in replacement. Mostly avoids costly matrix
+ multiplications and allows for post-hoc remapping of indices.
+ """
+
+ # NOTE: due to a bug the beta term was applied to the wrong term. for
+ # backwards compatibility we use the buggy version by default, but you can
+ # specify legacy=False to fix it.
+ def __init__(
+ self, n_e, vq_embed_dim, beta, remap=None, unknown_index="random", sane_index_shape=False, legacy=True
+ ):
+ super().__init__()
+ self.n_e = n_e
+ self.vq_embed_dim = vq_embed_dim
+ self.beta = beta
+ self.legacy = legacy
+
+ self.embedding = nn.Embedding(self.n_e, self.vq_embed_dim)
+ self.embedding.weight.data.uniform_(-1.0 / self.n_e, 1.0 / self.n_e)
+
+ self.remap = remap
+ if self.remap is not None:
+ self.register_buffer("used", torch.tensor(np.load(self.remap)))
+ self.re_embed = self.used.shape[0]
+ self.unknown_index = unknown_index # "random" or "extra" or integer
+ if self.unknown_index == "extra":
+ self.unknown_index = self.re_embed
+ self.re_embed = self.re_embed + 1
+ print(
+ f"Remapping {self.n_e} indices to {self.re_embed} indices. "
+ f"Using {self.unknown_index} for unknown indices."
+ )
+ else:
+ self.re_embed = n_e
+
+ self.sane_index_shape = sane_index_shape
+
+ def remap_to_used(self, inds):
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape(ishape[0], -1)
+ used = self.used.to(inds)
+ match = (inds[:, :, None] == used[None, None, ...]).long()
+ new = match.argmax(-1)
+ unknown = match.sum(2) < 1
+ if self.unknown_index == "random":
+ new[unknown] = torch.randint(0, self.re_embed, size=new[unknown].shape).to(device=new.device)
+ else:
+ new[unknown] = self.unknown_index
+ return new.reshape(ishape)
+
+ def unmap_to_all(self, inds):
+ ishape = inds.shape
+ assert len(ishape) > 1
+ inds = inds.reshape(ishape[0], -1)
+ used = self.used.to(inds)
+ if self.re_embed > self.used.shape[0]: # extra token
+ inds[inds >= self.used.shape[0]] = 0 # simply set to zero
+ back = torch.gather(used[None, :][inds.shape[0] * [0], :], 1, inds)
+ return back.reshape(ishape)
+
+ def forward(self, z):
+ # reshape z -> (batch, height, width, channel) and flatten
+ z = z.permute(0, 2, 3, 1).contiguous()
+ z_flattened = z.view(-1, self.vq_embed_dim)
+
+ # distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
+ min_encoding_indices = torch.argmin(torch.cdist(z_flattened, self.embedding.weight), dim=1)
+
+ z_q = self.embedding(min_encoding_indices).view(z.shape)
+ perplexity = None
+ min_encodings = None
+
+ # compute loss for embedding
+ if not self.legacy:
+ loss = self.beta * torch.mean((z_q.detach() - z) ** 2) + torch.mean((z_q - z.detach()) ** 2)
+ else:
+ loss = torch.mean((z_q.detach() - z) ** 2) + self.beta * torch.mean((z_q - z.detach()) ** 2)
+
+ # preserve gradients
+ z_q = z + (z_q - z).detach()
+
+ # reshape back to match original input shape
+ z_q = z_q.permute(0, 3, 1, 2).contiguous()
+
+ if self.remap is not None:
+ min_encoding_indices = min_encoding_indices.reshape(z.shape[0], -1) # add batch axis
+ min_encoding_indices = self.remap_to_used(min_encoding_indices)
+ min_encoding_indices = min_encoding_indices.reshape(-1, 1) # flatten
+
+ if self.sane_index_shape:
+ min_encoding_indices = min_encoding_indices.reshape(z_q.shape[0], z_q.shape[2], z_q.shape[3])
+
+ return z_q, loss, (perplexity, min_encodings, min_encoding_indices)
+
+ def get_codebook_entry(self, indices, shape):
+ # shape specifying (batch, height, width, channel)
+ if self.remap is not None:
+ indices = indices.reshape(shape[0], -1) # add batch axis
+ indices = self.unmap_to_all(indices)
+ indices = indices.reshape(-1) # flatten again
+
+ # get quantized latent vectors
+ z_q = self.embedding(indices)
+
+ if shape is not None:
+ z_q = z_q.view(shape)
+ # reshape back to match original input shape
+ z_q = z_q.permute(0, 3, 1, 2).contiguous()
+
+ return z_q
+
+
+class DiagonalGaussianDistribution(object):
+ def __init__(self, parameters, deterministic=False):
+ self.parameters = parameters
+ self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
+ self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
+ self.deterministic = deterministic
+ self.std = torch.exp(0.5 * self.logvar)
+ self.var = torch.exp(self.logvar)
+ if self.deterministic:
+ self.var = self.std = torch.zeros_like(
+ self.mean, device=self.parameters.device, dtype=self.parameters.dtype
+ )
+
+ def sample(self, generator: Optional[torch.Generator] = None) -> torch.FloatTensor:
+ # make sure sample is on the same device as the parameters and has same dtype
+ sample = randn_tensor(
+ self.mean.shape, generator=generator, device=self.parameters.device, dtype=self.parameters.dtype
+ )
+ x = self.mean + self.std * sample
+ return x
+
+ def kl(self, other=None):
+ if self.deterministic:
+ return torch.Tensor([0.0])
+ else:
+ if other is None:
+ return 0.5 * torch.sum(torch.pow(self.mean, 2) + self.var - 1.0 - self.logvar, dim=[1, 2, 3])
+ else:
+ return 0.5 * torch.sum(
+ torch.pow(self.mean - other.mean, 2) / other.var
+ + self.var / other.var
+ - 1.0
+ - self.logvar
+ + other.logvar,
+ dim=[1, 2, 3],
+ )
+
+ def nll(self, sample, dims=[1, 2, 3]):
+ if self.deterministic:
+ return torch.Tensor([0.0])
+ logtwopi = np.log(2.0 * np.pi)
+ return 0.5 * torch.sum(logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var, dim=dims)
+
+ def mode(self):
+ return self.mean
diff --git a/diffusers/src/diffusers/models/vae_flax.py b/diffusers/src/diffusers/models/vae_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..994e3bb06adc0318acade07a4c29f95d71552320
--- /dev/null
+++ b/diffusers/src/diffusers/models/vae_flax.py
@@ -0,0 +1,866 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# JAX implementation of VQGAN from taming-transformers https://github.com/CompVis/taming-transformers
+
+import math
+from functools import partial
+from typing import Tuple
+
+import flax
+import flax.linen as nn
+import jax
+import jax.numpy as jnp
+from flax.core.frozen_dict import FrozenDict
+
+from ..configuration_utils import ConfigMixin, flax_register_to_config
+from ..utils import BaseOutput
+from .modeling_flax_utils import FlaxModelMixin
+
+
+@flax.struct.dataclass
+class FlaxDecoderOutput(BaseOutput):
+ """
+ Output of decoding method.
+
+ Args:
+ sample (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
+ Decoded output sample of the model. Output of the last layer of the model.
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+
+ sample: jnp.ndarray
+
+
+@flax.struct.dataclass
+class FlaxAutoencoderKLOutput(BaseOutput):
+ """
+ Output of AutoencoderKL encoding method.
+
+ Args:
+ latent_dist (`FlaxDiagonalGaussianDistribution`):
+ Encoded outputs of `Encoder` represented as the mean and logvar of `FlaxDiagonalGaussianDistribution`.
+ `FlaxDiagonalGaussianDistribution` allows for sampling latents from the distribution.
+ """
+
+ latent_dist: "FlaxDiagonalGaussianDistribution"
+
+
+class FlaxUpsample2D(nn.Module):
+ """
+ Flax implementation of 2D Upsample layer
+
+ Args:
+ in_channels (`int`):
+ Input channels
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+
+ in_channels: int
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.conv = nn.Conv(
+ self.in_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states):
+ batch, height, width, channels = hidden_states.shape
+ hidden_states = jax.image.resize(
+ hidden_states,
+ shape=(batch, height * 2, width * 2, channels),
+ method="nearest",
+ )
+ hidden_states = self.conv(hidden_states)
+ return hidden_states
+
+
+class FlaxDownsample2D(nn.Module):
+ """
+ Flax implementation of 2D Downsample layer
+
+ Args:
+ in_channels (`int`):
+ Input channels
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+
+ in_channels: int
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.conv = nn.Conv(
+ self.in_channels,
+ kernel_size=(3, 3),
+ strides=(2, 2),
+ padding="VALID",
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states):
+ pad = ((0, 0), (0, 1), (0, 1), (0, 0)) # pad height and width dim
+ hidden_states = jnp.pad(hidden_states, pad_width=pad)
+ hidden_states = self.conv(hidden_states)
+ return hidden_states
+
+
+class FlaxResnetBlock2D(nn.Module):
+ """
+ Flax implementation of 2D Resnet Block.
+
+ Args:
+ in_channels (`int`):
+ Input channels
+ out_channels (`int`):
+ Output channels
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ groups (:obj:`int`, *optional*, defaults to `32`):
+ The number of groups to use for group norm.
+ use_nin_shortcut (:obj:`bool`, *optional*, defaults to `None`):
+ Whether to use `nin_shortcut`. This activates a new layer inside ResNet block
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+
+ in_channels: int
+ out_channels: int = None
+ dropout: float = 0.0
+ groups: int = 32
+ use_nin_shortcut: bool = None
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ out_channels = self.in_channels if self.out_channels is None else self.out_channels
+
+ self.norm1 = nn.GroupNorm(num_groups=self.groups, epsilon=1e-6)
+ self.conv1 = nn.Conv(
+ out_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ self.norm2 = nn.GroupNorm(num_groups=self.groups, epsilon=1e-6)
+ self.dropout_layer = nn.Dropout(self.dropout)
+ self.conv2 = nn.Conv(
+ out_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ use_nin_shortcut = self.in_channels != out_channels if self.use_nin_shortcut is None else self.use_nin_shortcut
+
+ self.conv_shortcut = None
+ if use_nin_shortcut:
+ self.conv_shortcut = nn.Conv(
+ out_channels,
+ kernel_size=(1, 1),
+ strides=(1, 1),
+ padding="VALID",
+ dtype=self.dtype,
+ )
+
+ def __call__(self, hidden_states, deterministic=True):
+ residual = hidden_states
+ hidden_states = self.norm1(hidden_states)
+ hidden_states = nn.swish(hidden_states)
+ hidden_states = self.conv1(hidden_states)
+
+ hidden_states = self.norm2(hidden_states)
+ hidden_states = nn.swish(hidden_states)
+ hidden_states = self.dropout_layer(hidden_states, deterministic)
+ hidden_states = self.conv2(hidden_states)
+
+ if self.conv_shortcut is not None:
+ residual = self.conv_shortcut(residual)
+
+ return hidden_states + residual
+
+
+class FlaxAttentionBlock(nn.Module):
+ r"""
+ Flax Convolutional based multi-head attention block for diffusion-based VAE.
+
+ Parameters:
+ channels (:obj:`int`):
+ Input channels
+ num_head_channels (:obj:`int`, *optional*, defaults to `None`):
+ Number of attention heads
+ num_groups (:obj:`int`, *optional*, defaults to `32`):
+ The number of groups to use for group norm
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+
+ """
+ channels: int
+ num_head_channels: int = None
+ num_groups: int = 32
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.num_heads = self.channels // self.num_head_channels if self.num_head_channels is not None else 1
+
+ dense = partial(nn.Dense, self.channels, dtype=self.dtype)
+
+ self.group_norm = nn.GroupNorm(num_groups=self.num_groups, epsilon=1e-6)
+ self.query, self.key, self.value = dense(), dense(), dense()
+ self.proj_attn = dense()
+
+ def transpose_for_scores(self, projection):
+ new_projection_shape = projection.shape[:-1] + (self.num_heads, -1)
+ # move heads to 2nd position (B, T, H * D) -> (B, T, H, D)
+ new_projection = projection.reshape(new_projection_shape)
+ # (B, T, H, D) -> (B, H, T, D)
+ new_projection = jnp.transpose(new_projection, (0, 2, 1, 3))
+ return new_projection
+
+ def __call__(self, hidden_states):
+ residual = hidden_states
+ batch, height, width, channels = hidden_states.shape
+
+ hidden_states = self.group_norm(hidden_states)
+
+ hidden_states = hidden_states.reshape((batch, height * width, channels))
+
+ query = self.query(hidden_states)
+ key = self.key(hidden_states)
+ value = self.value(hidden_states)
+
+ # transpose
+ query = self.transpose_for_scores(query)
+ key = self.transpose_for_scores(key)
+ value = self.transpose_for_scores(value)
+
+ # compute attentions
+ scale = 1 / math.sqrt(math.sqrt(self.channels / self.num_heads))
+ attn_weights = jnp.einsum("...qc,...kc->...qk", query * scale, key * scale)
+ attn_weights = nn.softmax(attn_weights, axis=-1)
+
+ # attend to values
+ hidden_states = jnp.einsum("...kc,...qk->...qc", value, attn_weights)
+
+ hidden_states = jnp.transpose(hidden_states, (0, 2, 1, 3))
+ new_hidden_states_shape = hidden_states.shape[:-2] + (self.channels,)
+ hidden_states = hidden_states.reshape(new_hidden_states_shape)
+
+ hidden_states = self.proj_attn(hidden_states)
+ hidden_states = hidden_states.reshape((batch, height, width, channels))
+ hidden_states = hidden_states + residual
+ return hidden_states
+
+
+class FlaxDownEncoderBlock2D(nn.Module):
+ r"""
+ Flax Resnet blocks-based Encoder block for diffusion-based VAE.
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input channels
+ out_channels (:obj:`int`):
+ Output channels
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ num_layers (:obj:`int`, *optional*, defaults to 1):
+ Number of Resnet layer block
+ resnet_groups (:obj:`int`, *optional*, defaults to `32`):
+ The number of groups to use for the Resnet block group norm
+ add_downsample (:obj:`bool`, *optional*, defaults to `True`):
+ Whether to add downsample layer
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ out_channels: int
+ dropout: float = 0.0
+ num_layers: int = 1
+ resnet_groups: int = 32
+ add_downsample: bool = True
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ resnets = []
+ for i in range(self.num_layers):
+ in_channels = self.in_channels if i == 0 else self.out_channels
+
+ res_block = FlaxResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=self.out_channels,
+ dropout=self.dropout,
+ groups=self.resnet_groups,
+ dtype=self.dtype,
+ )
+ resnets.append(res_block)
+ self.resnets = resnets
+
+ if self.add_downsample:
+ self.downsamplers_0 = FlaxDownsample2D(self.out_channels, dtype=self.dtype)
+
+ def __call__(self, hidden_states, deterministic=True):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, deterministic=deterministic)
+
+ if self.add_downsample:
+ hidden_states = self.downsamplers_0(hidden_states)
+
+ return hidden_states
+
+
+class FlaxUpDecoderBlock2D(nn.Module):
+ r"""
+ Flax Resnet blocks-based Decoder block for diffusion-based VAE.
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input channels
+ out_channels (:obj:`int`):
+ Output channels
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ num_layers (:obj:`int`, *optional*, defaults to 1):
+ Number of Resnet layer block
+ resnet_groups (:obj:`int`, *optional*, defaults to `32`):
+ The number of groups to use for the Resnet block group norm
+ add_upsample (:obj:`bool`, *optional*, defaults to `True`):
+ Whether to add upsample layer
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ out_channels: int
+ dropout: float = 0.0
+ num_layers: int = 1
+ resnet_groups: int = 32
+ add_upsample: bool = True
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ resnets = []
+ for i in range(self.num_layers):
+ in_channels = self.in_channels if i == 0 else self.out_channels
+ res_block = FlaxResnetBlock2D(
+ in_channels=in_channels,
+ out_channels=self.out_channels,
+ dropout=self.dropout,
+ groups=self.resnet_groups,
+ dtype=self.dtype,
+ )
+ resnets.append(res_block)
+
+ self.resnets = resnets
+
+ if self.add_upsample:
+ self.upsamplers_0 = FlaxUpsample2D(self.out_channels, dtype=self.dtype)
+
+ def __call__(self, hidden_states, deterministic=True):
+ for resnet in self.resnets:
+ hidden_states = resnet(hidden_states, deterministic=deterministic)
+
+ if self.add_upsample:
+ hidden_states = self.upsamplers_0(hidden_states)
+
+ return hidden_states
+
+
+class FlaxUNetMidBlock2D(nn.Module):
+ r"""
+ Flax Unet Mid-Block module.
+
+ Parameters:
+ in_channels (:obj:`int`):
+ Input channels
+ dropout (:obj:`float`, *optional*, defaults to 0.0):
+ Dropout rate
+ num_layers (:obj:`int`, *optional*, defaults to 1):
+ Number of Resnet layer block
+ resnet_groups (:obj:`int`, *optional*, defaults to `32`):
+ The number of groups to use for the Resnet and Attention block group norm
+ attn_num_head_channels (:obj:`int`, *optional*, defaults to `1`):
+ Number of attention heads for each attention block
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int
+ dropout: float = 0.0
+ num_layers: int = 1
+ resnet_groups: int = 32
+ attn_num_head_channels: int = 1
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ resnet_groups = self.resnet_groups if self.resnet_groups is not None else min(self.in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ FlaxResnetBlock2D(
+ in_channels=self.in_channels,
+ out_channels=self.in_channels,
+ dropout=self.dropout,
+ groups=resnet_groups,
+ dtype=self.dtype,
+ )
+ ]
+
+ attentions = []
+
+ for _ in range(self.num_layers):
+ attn_block = FlaxAttentionBlock(
+ channels=self.in_channels,
+ num_head_channels=self.attn_num_head_channels,
+ num_groups=resnet_groups,
+ dtype=self.dtype,
+ )
+ attentions.append(attn_block)
+
+ res_block = FlaxResnetBlock2D(
+ in_channels=self.in_channels,
+ out_channels=self.in_channels,
+ dropout=self.dropout,
+ groups=resnet_groups,
+ dtype=self.dtype,
+ )
+ resnets.append(res_block)
+
+ self.resnets = resnets
+ self.attentions = attentions
+
+ def __call__(self, hidden_states, deterministic=True):
+ hidden_states = self.resnets[0](hidden_states, deterministic=deterministic)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ hidden_states = attn(hidden_states)
+ hidden_states = resnet(hidden_states, deterministic=deterministic)
+
+ return hidden_states
+
+
+class FlaxEncoder(nn.Module):
+ r"""
+ Flax Implementation of VAE Encoder.
+
+ This model is a Flax Linen [flax.linen.Module](https://flax.readthedocs.io/en/latest/flax.linen.html#module)
+ subclass. Use it as a regular Flax linen Module and refer to the Flax documentation for all matter related to
+ general usage and behavior.
+
+ Finally, this model supports inherent JAX features such as:
+ - [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
+ - [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
+ - [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
+ - [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
+
+ Parameters:
+ in_channels (:obj:`int`, *optional*, defaults to 3):
+ Input channels
+ out_channels (:obj:`int`, *optional*, defaults to 3):
+ Output channels
+ down_block_types (:obj:`Tuple[str]`, *optional*, defaults to `(DownEncoderBlock2D)`):
+ DownEncoder block type
+ block_out_channels (:obj:`Tuple[str]`, *optional*, defaults to `(64,)`):
+ Tuple containing the number of output channels for each block
+ layers_per_block (:obj:`int`, *optional*, defaults to `2`):
+ Number of Resnet layer for each block
+ norm_num_groups (:obj:`int`, *optional*, defaults to `32`):
+ norm num group
+ act_fn (:obj:`str`, *optional*, defaults to `silu`):
+ Activation function
+ double_z (:obj:`bool`, *optional*, defaults to `False`):
+ Whether to double the last output channels
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ Parameters `dtype`
+ """
+ in_channels: int = 3
+ out_channels: int = 3
+ down_block_types: Tuple[str] = ("DownEncoderBlock2D",)
+ block_out_channels: Tuple[int] = (64,)
+ layers_per_block: int = 2
+ norm_num_groups: int = 32
+ act_fn: str = "silu"
+ double_z: bool = False
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ block_out_channels = self.block_out_channels
+ # in
+ self.conv_in = nn.Conv(
+ block_out_channels[0],
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ # downsampling
+ down_blocks = []
+ output_channel = block_out_channels[0]
+ for i, _ in enumerate(self.down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = FlaxDownEncoderBlock2D(
+ in_channels=input_channel,
+ out_channels=output_channel,
+ num_layers=self.layers_per_block,
+ resnet_groups=self.norm_num_groups,
+ add_downsample=not is_final_block,
+ dtype=self.dtype,
+ )
+ down_blocks.append(down_block)
+ self.down_blocks = down_blocks
+
+ # middle
+ self.mid_block = FlaxUNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_groups=self.norm_num_groups,
+ attn_num_head_channels=None,
+ dtype=self.dtype,
+ )
+
+ # end
+ conv_out_channels = 2 * self.out_channels if self.double_z else self.out_channels
+ self.conv_norm_out = nn.GroupNorm(num_groups=self.norm_num_groups, epsilon=1e-6)
+ self.conv_out = nn.Conv(
+ conv_out_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ def __call__(self, sample, deterministic: bool = True):
+ # in
+ sample = self.conv_in(sample)
+
+ # downsampling
+ for block in self.down_blocks:
+ sample = block(sample, deterministic=deterministic)
+
+ # middle
+ sample = self.mid_block(sample, deterministic=deterministic)
+
+ # end
+ sample = self.conv_norm_out(sample)
+ sample = nn.swish(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class FlaxDecoder(nn.Module):
+ r"""
+ Flax Implementation of VAE Decoder.
+
+ This model is a Flax Linen [flax.linen.Module](https://flax.readthedocs.io/en/latest/flax.linen.html#module)
+ subclass. Use it as a regular Flax linen Module and refer to the Flax documentation for all matter related to
+ general usage and behavior.
+
+ Finally, this model supports inherent JAX features such as:
+ - [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
+ - [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
+ - [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
+ - [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
+
+ Parameters:
+ in_channels (:obj:`int`, *optional*, defaults to 3):
+ Input channels
+ out_channels (:obj:`int`, *optional*, defaults to 3):
+ Output channels
+ up_block_types (:obj:`Tuple[str]`, *optional*, defaults to `(UpDecoderBlock2D)`):
+ UpDecoder block type
+ block_out_channels (:obj:`Tuple[str]`, *optional*, defaults to `(64,)`):
+ Tuple containing the number of output channels for each block
+ layers_per_block (:obj:`int`, *optional*, defaults to `2`):
+ Number of Resnet layer for each block
+ norm_num_groups (:obj:`int`, *optional*, defaults to `32`):
+ norm num group
+ act_fn (:obj:`str`, *optional*, defaults to `silu`):
+ Activation function
+ double_z (:obj:`bool`, *optional*, defaults to `False`):
+ Whether to double the last output channels
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ parameters `dtype`
+ """
+ in_channels: int = 3
+ out_channels: int = 3
+ up_block_types: Tuple[str] = ("UpDecoderBlock2D",)
+ block_out_channels: int = (64,)
+ layers_per_block: int = 2
+ norm_num_groups: int = 32
+ act_fn: str = "silu"
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ block_out_channels = self.block_out_channels
+
+ # z to block_in
+ self.conv_in = nn.Conv(
+ block_out_channels[-1],
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ # middle
+ self.mid_block = FlaxUNetMidBlock2D(
+ in_channels=block_out_channels[-1],
+ resnet_groups=self.norm_num_groups,
+ attn_num_head_channels=None,
+ dtype=self.dtype,
+ )
+
+ # upsampling
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ output_channel = reversed_block_out_channels[0]
+ up_blocks = []
+ for i, _ in enumerate(self.up_block_types):
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+
+ is_final_block = i == len(block_out_channels) - 1
+
+ up_block = FlaxUpDecoderBlock2D(
+ in_channels=prev_output_channel,
+ out_channels=output_channel,
+ num_layers=self.layers_per_block + 1,
+ resnet_groups=self.norm_num_groups,
+ add_upsample=not is_final_block,
+ dtype=self.dtype,
+ )
+ up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ self.up_blocks = up_blocks
+
+ # end
+ self.conv_norm_out = nn.GroupNorm(num_groups=self.norm_num_groups, epsilon=1e-6)
+ self.conv_out = nn.Conv(
+ self.out_channels,
+ kernel_size=(3, 3),
+ strides=(1, 1),
+ padding=((1, 1), (1, 1)),
+ dtype=self.dtype,
+ )
+
+ def __call__(self, sample, deterministic: bool = True):
+ # z to block_in
+ sample = self.conv_in(sample)
+
+ # middle
+ sample = self.mid_block(sample, deterministic=deterministic)
+
+ # upsampling
+ for block in self.up_blocks:
+ sample = block(sample, deterministic=deterministic)
+
+ sample = self.conv_norm_out(sample)
+ sample = nn.swish(sample)
+ sample = self.conv_out(sample)
+
+ return sample
+
+
+class FlaxDiagonalGaussianDistribution(object):
+ def __init__(self, parameters, deterministic=False):
+ # Last axis to account for channels-last
+ self.mean, self.logvar = jnp.split(parameters, 2, axis=-1)
+ self.logvar = jnp.clip(self.logvar, -30.0, 20.0)
+ self.deterministic = deterministic
+ self.std = jnp.exp(0.5 * self.logvar)
+ self.var = jnp.exp(self.logvar)
+ if self.deterministic:
+ self.var = self.std = jnp.zeros_like(self.mean)
+
+ def sample(self, key):
+ return self.mean + self.std * jax.random.normal(key, self.mean.shape)
+
+ def kl(self, other=None):
+ if self.deterministic:
+ return jnp.array([0.0])
+
+ if other is None:
+ return 0.5 * jnp.sum(self.mean**2 + self.var - 1.0 - self.logvar, axis=[1, 2, 3])
+
+ return 0.5 * jnp.sum(
+ jnp.square(self.mean - other.mean) / other.var + self.var / other.var - 1.0 - self.logvar + other.logvar,
+ axis=[1, 2, 3],
+ )
+
+ def nll(self, sample, axis=[1, 2, 3]):
+ if self.deterministic:
+ return jnp.array([0.0])
+
+ logtwopi = jnp.log(2.0 * jnp.pi)
+ return 0.5 * jnp.sum(logtwopi + self.logvar + jnp.square(sample - self.mean) / self.var, axis=axis)
+
+ def mode(self):
+ return self.mean
+
+
+@flax_register_to_config
+class FlaxAutoencoderKL(nn.Module, FlaxModelMixin, ConfigMixin):
+ r"""
+ Flax Implementation of Variational Autoencoder (VAE) model with KL loss from the paper Auto-Encoding Variational
+ Bayes by Diederik P. Kingma and Max Welling.
+
+ This model is a Flax Linen [flax.linen.Module](https://flax.readthedocs.io/en/latest/flax.linen.html#module)
+ subclass. Use it as a regular Flax linen Module and refer to the Flax documentation for all matter related to
+ general usage and behavior.
+
+ Finally, this model supports inherent JAX features such as:
+ - [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
+ - [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
+ - [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
+ - [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
+
+ Parameters:
+ in_channels (:obj:`int`, *optional*, defaults to 3):
+ Input channels
+ out_channels (:obj:`int`, *optional*, defaults to 3):
+ Output channels
+ down_block_types (:obj:`Tuple[str]`, *optional*, defaults to `(DownEncoderBlock2D)`):
+ DownEncoder block type
+ up_block_types (:obj:`Tuple[str]`, *optional*, defaults to `(UpDecoderBlock2D)`):
+ UpDecoder block type
+ block_out_channels (:obj:`Tuple[str]`, *optional*, defaults to `(64,)`):
+ Tuple containing the number of output channels for each block
+ layers_per_block (:obj:`int`, *optional*, defaults to `2`):
+ Number of Resnet layer for each block
+ act_fn (:obj:`str`, *optional*, defaults to `silu`):
+ Activation function
+ latent_channels (:obj:`int`, *optional*, defaults to `4`):
+ Latent space channels
+ norm_num_groups (:obj:`int`, *optional*, defaults to `32`):
+ Norm num group
+ sample_size (:obj:`int`, *optional*, defaults to 32):
+ Sample input size
+ scaling_factor (`float`, *optional*, defaults to 0.18215):
+ The component-wise standard deviation of the trained latent space computed using the first batch of the
+ training set. This is used to scale the latent space to have unit variance when training the diffusion
+ model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
+ diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
+ / scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
+ Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ dtype (:obj:`jnp.dtype`, *optional*, defaults to jnp.float32):
+ parameters `dtype`
+ """
+ in_channels: int = 3
+ out_channels: int = 3
+ down_block_types: Tuple[str] = ("DownEncoderBlock2D",)
+ up_block_types: Tuple[str] = ("UpDecoderBlock2D",)
+ block_out_channels: Tuple[int] = (64,)
+ layers_per_block: int = 1
+ act_fn: str = "silu"
+ latent_channels: int = 4
+ norm_num_groups: int = 32
+ sample_size: int = 32
+ scaling_factor: float = 0.18215
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.encoder = FlaxEncoder(
+ in_channels=self.config.in_channels,
+ out_channels=self.config.latent_channels,
+ down_block_types=self.config.down_block_types,
+ block_out_channels=self.config.block_out_channels,
+ layers_per_block=self.config.layers_per_block,
+ act_fn=self.config.act_fn,
+ norm_num_groups=self.config.norm_num_groups,
+ double_z=True,
+ dtype=self.dtype,
+ )
+ self.decoder = FlaxDecoder(
+ in_channels=self.config.latent_channels,
+ out_channels=self.config.out_channels,
+ up_block_types=self.config.up_block_types,
+ block_out_channels=self.config.block_out_channels,
+ layers_per_block=self.config.layers_per_block,
+ norm_num_groups=self.config.norm_num_groups,
+ act_fn=self.config.act_fn,
+ dtype=self.dtype,
+ )
+ self.quant_conv = nn.Conv(
+ 2 * self.config.latent_channels,
+ kernel_size=(1, 1),
+ strides=(1, 1),
+ padding="VALID",
+ dtype=self.dtype,
+ )
+ self.post_quant_conv = nn.Conv(
+ self.config.latent_channels,
+ kernel_size=(1, 1),
+ strides=(1, 1),
+ padding="VALID",
+ dtype=self.dtype,
+ )
+
+ def init_weights(self, rng: jax.random.KeyArray) -> FrozenDict:
+ # init input tensors
+ sample_shape = (1, self.in_channels, self.sample_size, self.sample_size)
+ sample = jnp.zeros(sample_shape, dtype=jnp.float32)
+
+ params_rng, dropout_rng, gaussian_rng = jax.random.split(rng, 3)
+ rngs = {"params": params_rng, "dropout": dropout_rng, "gaussian": gaussian_rng}
+
+ return self.init(rngs, sample)["params"]
+
+ def encode(self, sample, deterministic: bool = True, return_dict: bool = True):
+ sample = jnp.transpose(sample, (0, 2, 3, 1))
+
+ hidden_states = self.encoder(sample, deterministic=deterministic)
+ moments = self.quant_conv(hidden_states)
+ posterior = FlaxDiagonalGaussianDistribution(moments)
+
+ if not return_dict:
+ return (posterior,)
+
+ return FlaxAutoencoderKLOutput(latent_dist=posterior)
+
+ def decode(self, latents, deterministic: bool = True, return_dict: bool = True):
+ if latents.shape[-1] != self.config.latent_channels:
+ latents = jnp.transpose(latents, (0, 2, 3, 1))
+
+ hidden_states = self.post_quant_conv(latents)
+ hidden_states = self.decoder(hidden_states, deterministic=deterministic)
+
+ hidden_states = jnp.transpose(hidden_states, (0, 3, 1, 2))
+
+ if not return_dict:
+ return (hidden_states,)
+
+ return FlaxDecoderOutput(sample=hidden_states)
+
+ def __call__(self, sample, sample_posterior=False, deterministic: bool = True, return_dict: bool = True):
+ posterior = self.encode(sample, deterministic=deterministic, return_dict=return_dict)
+ if sample_posterior:
+ rng = self.make_rng("gaussian")
+ hidden_states = posterior.latent_dist.sample(rng)
+ else:
+ hidden_states = posterior.latent_dist.mode()
+
+ sample = self.decode(hidden_states, return_dict=return_dict).sample
+
+ if not return_dict:
+ return (sample,)
+
+ return FlaxDecoderOutput(sample=sample)
diff --git a/diffusers/src/diffusers/models/vq_model.py b/diffusers/src/diffusers/models/vq_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..65f734dccb2dd48174a48134294b597a2c0b8ea4
--- /dev/null
+++ b/diffusers/src/diffusers/models/vq_model.py
@@ -0,0 +1,156 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput
+from .modeling_utils import ModelMixin
+from .vae import Decoder, DecoderOutput, Encoder, VectorQuantizer
+
+
+@dataclass
+class VQEncoderOutput(BaseOutput):
+ """
+ Output of VQModel encoding method.
+
+ Args:
+ latents (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Encoded output sample of the model. Output of the last layer of the model.
+ """
+
+ latents: torch.FloatTensor
+
+
+class VQModel(ModelMixin, ConfigMixin):
+ r"""VQ-VAE model from the paper Neural Discrete Representation Learning by Aaron van den Oord, Oriol Vinyals and Koray
+ Kavukcuoglu.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the model (such as downloading or saving, etc.)
+
+ Parameters:
+ in_channels (int, *optional*, defaults to 3): Number of channels in the input image.
+ out_channels (int, *optional*, defaults to 3): Number of channels in the output.
+ down_block_types (`Tuple[str]`, *optional*, defaults to :
+ obj:`("DownEncoderBlock2D",)`): Tuple of downsample block types.
+ up_block_types (`Tuple[str]`, *optional*, defaults to :
+ obj:`("UpDecoderBlock2D",)`): Tuple of upsample block types.
+ block_out_channels (`Tuple[int]`, *optional*, defaults to :
+ obj:`(64,)`): Tuple of block output channels.
+ act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
+ latent_channels (`int`, *optional*, defaults to `3`): Number of channels in the latent space.
+ sample_size (`int`, *optional*, defaults to `32`): TODO
+ num_vq_embeddings (`int`, *optional*, defaults to `256`): Number of codebook vectors in the VQ-VAE.
+ vq_embed_dim (`int`, *optional*): Hidden dim of codebook vectors in the VQ-VAE.
+ scaling_factor (`float`, *optional*, defaults to `0.18215`):
+ The component-wise standard deviation of the trained latent space computed using the first batch of the
+ training set. This is used to scale the latent space to have unit variance when training the diffusion
+ model. The latents are scaled with the formula `z = z * scaling_factor` before being passed to the
+ diffusion model. When decoding, the latents are scaled back to the original scale with the formula: `z = 1
+ / scaling_factor * z`. For more details, refer to sections 4.3.2 and D.1 of the [High-Resolution Image
+ Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752) paper.
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ in_channels: int = 3,
+ out_channels: int = 3,
+ down_block_types: Tuple[str] = ("DownEncoderBlock2D",),
+ up_block_types: Tuple[str] = ("UpDecoderBlock2D",),
+ block_out_channels: Tuple[int] = (64,),
+ layers_per_block: int = 1,
+ act_fn: str = "silu",
+ latent_channels: int = 3,
+ sample_size: int = 32,
+ num_vq_embeddings: int = 256,
+ norm_num_groups: int = 32,
+ vq_embed_dim: Optional[int] = None,
+ scaling_factor: float = 0.18215,
+ ):
+ super().__init__()
+
+ # pass init params to Encoder
+ self.encoder = Encoder(
+ in_channels=in_channels,
+ out_channels=latent_channels,
+ down_block_types=down_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ norm_num_groups=norm_num_groups,
+ double_z=False,
+ )
+
+ vq_embed_dim = vq_embed_dim if vq_embed_dim is not None else latent_channels
+
+ self.quant_conv = nn.Conv2d(latent_channels, vq_embed_dim, 1)
+ self.quantize = VectorQuantizer(num_vq_embeddings, vq_embed_dim, beta=0.25, remap=None, sane_index_shape=False)
+ self.post_quant_conv = nn.Conv2d(vq_embed_dim, latent_channels, 1)
+
+ # pass init params to Decoder
+ self.decoder = Decoder(
+ in_channels=latent_channels,
+ out_channels=out_channels,
+ up_block_types=up_block_types,
+ block_out_channels=block_out_channels,
+ layers_per_block=layers_per_block,
+ act_fn=act_fn,
+ norm_num_groups=norm_num_groups,
+ )
+
+ def encode(self, x: torch.FloatTensor, return_dict: bool = True) -> VQEncoderOutput:
+ h = self.encoder(x)
+ h = self.quant_conv(h)
+
+ if not return_dict:
+ return (h,)
+
+ return VQEncoderOutput(latents=h)
+
+ def decode(
+ self, h: torch.FloatTensor, force_not_quantize: bool = False, return_dict: bool = True
+ ) -> Union[DecoderOutput, torch.FloatTensor]:
+ # also go through quantization layer
+ if not force_not_quantize:
+ quant, emb_loss, info = self.quantize(h)
+ else:
+ quant = h
+ quant = self.post_quant_conv(quant)
+ dec = self.decoder(quant)
+
+ if not return_dict:
+ return (dec,)
+
+ return DecoderOutput(sample=dec)
+
+ def forward(self, sample: torch.FloatTensor, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
+ r"""
+ Args:
+ sample (`torch.FloatTensor`): Input sample.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`DecoderOutput`] instead of a plain tuple.
+ """
+ x = sample
+ h = self.encode(x).latents
+ dec = self.decode(h).sample
+
+ if not return_dict:
+ return (dec,)
+
+ return DecoderOutput(sample=dec)
diff --git a/diffusers/src/diffusers/optimization.py b/diffusers/src/diffusers/optimization.py
new file mode 100644
index 0000000000000000000000000000000000000000..657e085062e051ddf68c060575d696419ac6c1d2
--- /dev/null
+++ b/diffusers/src/diffusers/optimization.py
@@ -0,0 +1,304 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch optimization for diffusion models."""
+
+import math
+from enum import Enum
+from typing import Optional, Union
+
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import LambdaLR
+
+from .utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class SchedulerType(Enum):
+ LINEAR = "linear"
+ COSINE = "cosine"
+ COSINE_WITH_RESTARTS = "cosine_with_restarts"
+ POLYNOMIAL = "polynomial"
+ CONSTANT = "constant"
+ CONSTANT_WITH_WARMUP = "constant_with_warmup"
+
+
+def get_constant_schedule(optimizer: Optimizer, last_epoch: int = -1):
+ """
+ Create a schedule with a constant learning rate, using the learning rate set in optimizer.
+
+ Args:
+ optimizer ([`~torch.optim.Optimizer`]):
+ The optimizer for which to schedule the learning rate.
+ last_epoch (`int`, *optional*, defaults to -1):
+ The index of the last epoch when resuming training.
+
+ Return:
+ `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
+ """
+ return LambdaLR(optimizer, lambda _: 1, last_epoch=last_epoch)
+
+
+def get_constant_schedule_with_warmup(optimizer: Optimizer, num_warmup_steps: int, last_epoch: int = -1):
+ """
+ Create a schedule with a constant learning rate preceded by a warmup period during which the learning rate
+ increases linearly between 0 and the initial lr set in the optimizer.
+
+ Args:
+ optimizer ([`~torch.optim.Optimizer`]):
+ The optimizer for which to schedule the learning rate.
+ num_warmup_steps (`int`):
+ The number of steps for the warmup phase.
+ last_epoch (`int`, *optional*, defaults to -1):
+ The index of the last epoch when resuming training.
+
+ Return:
+ `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
+ """
+
+ def lr_lambda(current_step: int):
+ if current_step < num_warmup_steps:
+ return float(current_step) / float(max(1.0, num_warmup_steps))
+ return 1.0
+
+ return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
+
+
+def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, last_epoch=-1):
+ """
+ Create a schedule with a learning rate that decreases linearly from the initial lr set in the optimizer to 0, after
+ a warmup period during which it increases linearly from 0 to the initial lr set in the optimizer.
+
+ Args:
+ optimizer ([`~torch.optim.Optimizer`]):
+ The optimizer for which to schedule the learning rate.
+ num_warmup_steps (`int`):
+ The number of steps for the warmup phase.
+ num_training_steps (`int`):
+ The total number of training steps.
+ last_epoch (`int`, *optional*, defaults to -1):
+ The index of the last epoch when resuming training.
+
+ Return:
+ `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
+ """
+
+ def lr_lambda(current_step: int):
+ if current_step < num_warmup_steps:
+ return float(current_step) / float(max(1, num_warmup_steps))
+ return max(
+ 0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))
+ )
+
+ return LambdaLR(optimizer, lr_lambda, last_epoch)
+
+
+def get_cosine_schedule_with_warmup(
+ optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1
+):
+ """
+ Create a schedule with a learning rate that decreases following the values of the cosine function between the
+ initial lr set in the optimizer to 0, after a warmup period during which it increases linearly between 0 and the
+ initial lr set in the optimizer.
+
+ Args:
+ optimizer ([`~torch.optim.Optimizer`]):
+ The optimizer for which to schedule the learning rate.
+ num_warmup_steps (`int`):
+ The number of steps for the warmup phase.
+ num_training_steps (`int`):
+ The total number of training steps.
+ num_periods (`float`, *optional*, defaults to 0.5):
+ The number of periods of the cosine function in a schedule (the default is to just decrease from the max
+ value to 0 following a half-cosine).
+ last_epoch (`int`, *optional*, defaults to -1):
+ The index of the last epoch when resuming training.
+
+ Return:
+ `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
+ """
+
+ def lr_lambda(current_step):
+ if current_step < num_warmup_steps:
+ return float(current_step) / float(max(1, num_warmup_steps))
+ progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
+ return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
+
+ return LambdaLR(optimizer, lr_lambda, last_epoch)
+
+
+def get_cosine_with_hard_restarts_schedule_with_warmup(
+ optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: int = 1, last_epoch: int = -1
+):
+ """
+ Create a schedule with a learning rate that decreases following the values of the cosine function between the
+ initial lr set in the optimizer to 0, with several hard restarts, after a warmup period during which it increases
+ linearly between 0 and the initial lr set in the optimizer.
+
+ Args:
+ optimizer ([`~torch.optim.Optimizer`]):
+ The optimizer for which to schedule the learning rate.
+ num_warmup_steps (`int`):
+ The number of steps for the warmup phase.
+ num_training_steps (`int`):
+ The total number of training steps.
+ num_cycles (`int`, *optional*, defaults to 1):
+ The number of hard restarts to use.
+ last_epoch (`int`, *optional*, defaults to -1):
+ The index of the last epoch when resuming training.
+
+ Return:
+ `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
+ """
+
+ def lr_lambda(current_step):
+ if current_step < num_warmup_steps:
+ return float(current_step) / float(max(1, num_warmup_steps))
+ progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
+ if progress >= 1.0:
+ return 0.0
+ return max(0.0, 0.5 * (1.0 + math.cos(math.pi * ((float(num_cycles) * progress) % 1.0))))
+
+ return LambdaLR(optimizer, lr_lambda, last_epoch)
+
+
+def get_polynomial_decay_schedule_with_warmup(
+ optimizer, num_warmup_steps, num_training_steps, lr_end=1e-7, power=1.0, last_epoch=-1
+):
+ """
+ Create a schedule with a learning rate that decreases as a polynomial decay from the initial lr set in the
+ optimizer to end lr defined by *lr_end*, after a warmup period during which it increases linearly from 0 to the
+ initial lr set in the optimizer.
+
+ Args:
+ optimizer ([`~torch.optim.Optimizer`]):
+ The optimizer for which to schedule the learning rate.
+ num_warmup_steps (`int`):
+ The number of steps for the warmup phase.
+ num_training_steps (`int`):
+ The total number of training steps.
+ lr_end (`float`, *optional*, defaults to 1e-7):
+ The end LR.
+ power (`float`, *optional*, defaults to 1.0):
+ Power factor.
+ last_epoch (`int`, *optional*, defaults to -1):
+ The index of the last epoch when resuming training.
+
+ Note: *power* defaults to 1.0 as in the fairseq implementation, which in turn is based on the original BERT
+ implementation at
+ https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/optimization.py#L37
+
+ Return:
+ `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
+
+ """
+
+ lr_init = optimizer.defaults["lr"]
+ if not (lr_init > lr_end):
+ raise ValueError(f"lr_end ({lr_end}) must be be smaller than initial lr ({lr_init})")
+
+ def lr_lambda(current_step: int):
+ if current_step < num_warmup_steps:
+ return float(current_step) / float(max(1, num_warmup_steps))
+ elif current_step > num_training_steps:
+ return lr_end / lr_init # as LambdaLR multiplies by lr_init
+ else:
+ lr_range = lr_init - lr_end
+ decay_steps = num_training_steps - num_warmup_steps
+ pct_remaining = 1 - (current_step - num_warmup_steps) / decay_steps
+ decay = lr_range * pct_remaining**power + lr_end
+ return decay / lr_init # as LambdaLR multiplies by lr_init
+
+ return LambdaLR(optimizer, lr_lambda, last_epoch)
+
+
+TYPE_TO_SCHEDULER_FUNCTION = {
+ SchedulerType.LINEAR: get_linear_schedule_with_warmup,
+ SchedulerType.COSINE: get_cosine_schedule_with_warmup,
+ SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_hard_restarts_schedule_with_warmup,
+ SchedulerType.POLYNOMIAL: get_polynomial_decay_schedule_with_warmup,
+ SchedulerType.CONSTANT: get_constant_schedule,
+ SchedulerType.CONSTANT_WITH_WARMUP: get_constant_schedule_with_warmup,
+}
+
+
+def get_scheduler(
+ name: Union[str, SchedulerType],
+ optimizer: Optimizer,
+ num_warmup_steps: Optional[int] = None,
+ num_training_steps: Optional[int] = None,
+ num_cycles: int = 1,
+ power: float = 1.0,
+ last_epoch: int = -1,
+):
+ """
+ Unified API to get any scheduler from its name.
+
+ Args:
+ name (`str` or `SchedulerType`):
+ The name of the scheduler to use.
+ optimizer (`torch.optim.Optimizer`):
+ The optimizer that will be used during training.
+ num_warmup_steps (`int`, *optional*):
+ The number of warmup steps to do. This is not required by all schedulers (hence the argument being
+ optional), the function will raise an error if it's unset and the scheduler type requires it.
+ num_training_steps (`int``, *optional*):
+ The number of training steps to do. This is not required by all schedulers (hence the argument being
+ optional), the function will raise an error if it's unset and the scheduler type requires it.
+ num_cycles (`int`, *optional*):
+ The number of hard restarts used in `COSINE_WITH_RESTARTS` scheduler.
+ power (`float`, *optional*, defaults to 1.0):
+ Power factor. See `POLYNOMIAL` scheduler
+ last_epoch (`int`, *optional*, defaults to -1):
+ The index of the last epoch when resuming training.
+ """
+ name = SchedulerType(name)
+ schedule_func = TYPE_TO_SCHEDULER_FUNCTION[name]
+ if name == SchedulerType.CONSTANT:
+ return schedule_func(optimizer, last_epoch=last_epoch)
+
+ # All other schedulers require `num_warmup_steps`
+ if num_warmup_steps is None:
+ raise ValueError(f"{name} requires `num_warmup_steps`, please provide that argument.")
+
+ if name == SchedulerType.CONSTANT_WITH_WARMUP:
+ return schedule_func(optimizer, num_warmup_steps=num_warmup_steps, last_epoch=last_epoch)
+
+ # All other schedulers require `num_training_steps`
+ if num_training_steps is None:
+ raise ValueError(f"{name} requires `num_training_steps`, please provide that argument.")
+
+ if name == SchedulerType.COSINE_WITH_RESTARTS:
+ return schedule_func(
+ optimizer,
+ num_warmup_steps=num_warmup_steps,
+ num_training_steps=num_training_steps,
+ num_cycles=num_cycles,
+ last_epoch=last_epoch,
+ )
+
+ if name == SchedulerType.POLYNOMIAL:
+ return schedule_func(
+ optimizer,
+ num_warmup_steps=num_warmup_steps,
+ num_training_steps=num_training_steps,
+ power=power,
+ last_epoch=last_epoch,
+ )
+
+ return schedule_func(
+ optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps, last_epoch=last_epoch
+ )
diff --git a/diffusers/src/diffusers/pipeline_utils.py b/diffusers/src/diffusers/pipeline_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c0c2337dc048dd9ef164ac5cb92e4bf5e62d764
--- /dev/null
+++ b/diffusers/src/diffusers/pipeline_utils.py
@@ -0,0 +1,19 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+# limitations under the License.
+
+# NOTE: This file is deprecated and will be removed in a future version.
+# It only exists so that temporarely `from diffusers.pipelines import DiffusionPipeline` works
+
+from .pipelines import DiffusionPipeline, ImagePipelineOutput # noqa: F401
diff --git a/diffusers/src/diffusers/pipelines/.ipynb_checkpoints/__init__-checkpoint.py b/diffusers/src/diffusers/pipelines/.ipynb_checkpoints/__init__-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..421099a6d746f072222567bbe5f313da5de36206
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/.ipynb_checkpoints/__init__-checkpoint.py
@@ -0,0 +1,139 @@
+from ..utils import (
+ OptionalDependencyNotAvailable,
+ is_flax_available,
+ is_k_diffusion_available,
+ is_librosa_available,
+ is_note_seq_available,
+ is_onnx_available,
+ is_torch_available,
+ is_transformers_available,
+)
+
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_pt_objects import * # noqa F403
+else:
+ from .dance_diffusion import DanceDiffusionPipeline
+ from .ddim import DDIMPipeline
+ from .ddpm import DDPMPipeline
+ from .dit import DiTPipeline
+ from .latent_diffusion import LDMSuperResolutionPipeline
+ from .latent_diffusion_uncond import LDMPipeline
+ from .pipeline_utils import AudioPipelineOutput, DiffusionPipeline, ImagePipelineOutput
+ from .pndm import PNDMPipeline
+ from .repaint import RePaintPipeline
+ from .score_sde_ve import ScoreSdeVePipeline
+ from .stochastic_karras_ve import KarrasVePipeline
+
+try:
+ if not (is_torch_available() and is_librosa_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_librosa_objects import * # noqa F403
+else:
+ from .audio_diffusion import AudioDiffusionPipeline, Mel
+
+try:
+ if not (is_torch_available() and is_transformers_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_transformers_objects import * # noqa F403
+else:
+ from .alt_diffusion import AltDiffusionImg2ImgPipeline, AltDiffusionPipeline
+ from .audioldm import AudioLDMPipeline
+ from .latent_diffusion import LDMTextToImagePipeline
+ from .paint_by_example import PaintByExamplePipeline
+ from .semantic_stable_diffusion import SemanticStableDiffusionPipeline
+ from .stable_diffusion import (
+ CycleDiffusionPipeline,
+ StableDiffusionAttendAndExcitePipeline,
+ StableDiffusionControlNetPipeline,
+ StableDiffusionDepth2ImgPipeline,
+ StableDiffusionImageVariationPipeline,
+ StableDiffusionImg2ImgPipeline,
+ StableDiffusionInpaintPipeline,
+ StableDiffusionInpaintPipelineLegacy,
+ StableDiffusionInstructPix2PixPipeline,
+ StableDiffusionLatentUpscalePipeline,
+ StableDiffusionModelEditingPipeline,
+ StableDiffusionPanoramaPipeline,
+ StableDiffusionPipeline,
+ StableDiffusionPix2PixZeroPipeline,
+ StableDiffusionSAGPipeline,
+ StableDiffusionUpscalePipeline,
+ StableUnCLIPImg2ImgPipeline,
+ StableUnCLIPPipeline,
+ )
+ from .stable_diffusion_safe import StableDiffusionPipelineSafe
+ from .text_to_video_synthesis import TextToVideoSDPipeline
+ from .unclip import UnCLIPImageVariationPipeline, UnCLIPPipeline
+ from .versatile_diffusion import (
+ VersatileDiffusionDualGuidedPipeline,
+ VersatileDiffusionImageVariationPipeline,
+ VersatileDiffusionPipeline,
+ VersatileDiffusionTextToImagePipeline,
+ )
+ from .vq_diffusion import VQDiffusionPipeline
+
+try:
+ if not is_onnx_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_onnx_objects import * # noqa F403
+else:
+ from .onnx_utils import OnnxRuntimeModel
+
+try:
+ if not (is_torch_available() and is_transformers_available() and is_onnx_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_transformers_and_onnx_objects import * # noqa F403
+else:
+ from .stable_diffusion import (
+ OnnxStableDiffusionImg2ImgPipeline,
+ OnnxStableDiffusionInpaintPipeline,
+ OnnxStableDiffusionInpaintPipelineLegacy,
+ OnnxStableDiffusionPipeline,
+ OnnxStableDiffusionUpscalePipeline,
+ StableDiffusionOnnxPipeline,
+ )
+
+try:
+ if not (is_torch_available() and is_transformers_available() and is_k_diffusion_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_transformers_and_k_diffusion_objects import * # noqa F403
+else:
+ from .stable_diffusion import StableDiffusionKDiffusionPipeline
+
+try:
+ if not is_flax_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_flax_objects import * # noqa F403
+else:
+ from .pipeline_flax_utils import FlaxDiffusionPipeline
+
+
+try:
+ if not (is_flax_available() and is_transformers_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_flax_and_transformers_objects import * # noqa F403
+else:
+ from .stable_diffusion import (
+ FlaxStableDiffusionControlNetPipeline,
+ FlaxStableDiffusionImg2ImgPipeline,
+ FlaxStableDiffusionInpaintPipeline,
+ FlaxStableDiffusionPipeline,
+ )
+try:
+ if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_transformers_and_torch_and_note_seq_objects import * # noqa F403
+else:
+ from .spectrogram_diffusion import MidiProcessor, SpectrogramDiffusionPipeline
diff --git a/diffusers/src/diffusers/pipelines/.ipynb_checkpoints/pipeline_utils-checkpoint.py b/diffusers/src/diffusers/pipelines/.ipynb_checkpoints/pipeline_utils-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..a03c454e9244e28e98bdcdcc8cdeb340da3f7903
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/.ipynb_checkpoints/pipeline_utils-checkpoint.py
@@ -0,0 +1,1396 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import fnmatch
+import importlib
+import inspect
+import os
+import re
+import warnings
+from dataclasses import dataclass
+from pathlib import Path
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from huggingface_hub import hf_hub_download, model_info, snapshot_download
+from packaging import version
+from PIL import Image
+from tqdm.auto import tqdm
+
+import diffusers
+
+from .. import __version__
+from ..configuration_utils import ConfigMixin
+from ..models.modeling_utils import _LOW_CPU_MEM_USAGE_DEFAULT
+from ..schedulers.scheduling_utils import SCHEDULER_CONFIG_NAME
+from ..utils import (
+ CONFIG_NAME,
+ DEPRECATED_REVISION_ARGS,
+ DIFFUSERS_CACHE,
+ HF_HUB_OFFLINE,
+ SAFETENSORS_WEIGHTS_NAME,
+ WEIGHTS_NAME,
+ BaseOutput,
+ deprecate,
+ get_class_from_dynamic_module,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_compiled_module,
+ is_safetensors_available,
+ is_torch_version,
+ is_transformers_available,
+ logging,
+)
+
+
+if is_transformers_available():
+ import transformers
+ from transformers import PreTrainedModel
+ from transformers.utils import FLAX_WEIGHTS_NAME as TRANSFORMERS_FLAX_WEIGHTS_NAME
+ from transformers.utils import SAFE_WEIGHTS_NAME as TRANSFORMERS_SAFE_WEIGHTS_NAME
+ from transformers.utils import WEIGHTS_NAME as TRANSFORMERS_WEIGHTS_NAME
+
+from ..utils import FLAX_WEIGHTS_NAME, ONNX_EXTERNAL_WEIGHTS_NAME, ONNX_WEIGHTS_NAME
+
+
+if is_accelerate_available():
+ import accelerate
+
+
+INDEX_FILE = "diffusion_pytorch_model.bin"
+CUSTOM_PIPELINE_FILE_NAME = "pipeline.py"
+DUMMY_MODULES_FOLDER = "diffusers.utils"
+TRANSFORMERS_DUMMY_MODULES_FOLDER = "transformers.utils"
+
+
+logger = logging.get_logger(__name__)
+
+
+LOADABLE_CLASSES = {
+ "diffusers": {
+ "ModelMixin": ["save_pretrained", "from_pretrained"],
+ "SchedulerMixin": ["save_pretrained", "from_pretrained"],
+ "DiffusionPipeline": ["save_pretrained", "from_pretrained"],
+ "OnnxRuntimeModel": ["save_pretrained", "from_pretrained"],
+ },
+ "transformers": {
+ "PreTrainedTokenizer": ["save_pretrained", "from_pretrained"],
+ "PreTrainedTokenizerFast": ["save_pretrained", "from_pretrained"],
+ "PreTrainedModel": ["save_pretrained", "from_pretrained"],
+ "FeatureExtractionMixin": ["save_pretrained", "from_pretrained"],
+ "ProcessorMixin": ["save_pretrained", "from_pretrained"],
+ "ImageProcessingMixin": ["save_pretrained", "from_pretrained"],
+ },
+ "onnxruntime.training": {
+ "ORTModule": ["save_pretrained", "from_pretrained"],
+ },
+}
+
+ALL_IMPORTABLE_CLASSES = {}
+for library in LOADABLE_CLASSES:
+ ALL_IMPORTABLE_CLASSES.update(LOADABLE_CLASSES[library])
+
+
+@dataclass
+class ImagePipelineOutput(BaseOutput):
+ """
+ Output class for image pipelines.
+
+ Args:
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
+ num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
+ """
+
+ images: Union[List[PIL.Image.Image], np.ndarray]
+
+
+@dataclass
+class AudioPipelineOutput(BaseOutput):
+ """
+ Output class for audio pipelines.
+
+ Args:
+ audios (`np.ndarray`)
+ List of denoised samples of shape `(batch_size, num_channels, sample_rate)`. Numpy array present the
+ denoised audio samples of the diffusion pipeline.
+ """
+
+ audios: np.ndarray
+
+
+def is_safetensors_compatible(filenames, variant=None) -> bool:
+ """
+ Checking for safetensors compatibility:
+ - By default, all models are saved with the default pytorch serialization, so we use the list of default pytorch
+ files to know which safetensors files are needed.
+ - The model is safetensors compatible only if there is a matching safetensors file for every default pytorch file.
+
+ Converting default pytorch serialized filenames to safetensors serialized filenames:
+ - For models from the diffusers library, just replace the ".bin" extension with ".safetensors"
+ - For models from the transformers library, the filename changes from "pytorch_model" to "model", and the ".bin"
+ extension is replaced with ".safetensors"
+ """
+ pt_filenames = []
+
+ sf_filenames = set()
+
+ for filename in filenames:
+ _, extension = os.path.splitext(filename)
+
+ if extension == ".bin":
+ pt_filenames.append(filename)
+ elif extension == ".safetensors":
+ sf_filenames.add(filename)
+
+ for filename in pt_filenames:
+ # filename = 'foo/bar/baz.bam' -> path = 'foo/bar', filename = 'baz', extention = '.bam'
+ path, filename = os.path.split(filename)
+ filename, extension = os.path.splitext(filename)
+
+ if filename == "pytorch_model":
+ filename = "model"
+ elif filename == f"pytorch_model.{variant}":
+ filename = f"model.{variant}"
+ else:
+ filename = filename
+
+ expected_sf_filename = os.path.join(path, filename)
+ expected_sf_filename = f"{expected_sf_filename}.safetensors"
+
+ if expected_sf_filename not in sf_filenames:
+ logger.warning(f"{expected_sf_filename} not found")
+ return False
+
+ return True
+
+
+def variant_compatible_siblings(filenames, variant=None) -> Union[List[os.PathLike], str]:
+ weight_names = [
+ WEIGHTS_NAME,
+ SAFETENSORS_WEIGHTS_NAME,
+ FLAX_WEIGHTS_NAME,
+ ONNX_WEIGHTS_NAME,
+ ONNX_EXTERNAL_WEIGHTS_NAME,
+ ]
+
+ if is_transformers_available():
+ weight_names += [TRANSFORMERS_WEIGHTS_NAME, TRANSFORMERS_SAFE_WEIGHTS_NAME, TRANSFORMERS_FLAX_WEIGHTS_NAME]
+
+ # model_pytorch, diffusion_model_pytorch, ...
+ weight_prefixes = [w.split(".")[0] for w in weight_names]
+ # .bin, .safetensors, ...
+ weight_suffixs = [w.split(".")[-1] for w in weight_names]
+
+ variant_file_regex = (
+ re.compile(f"({'|'.join(weight_prefixes)})(.{variant}.)({'|'.join(weight_suffixs)})")
+ if variant is not None
+ else None
+ )
+ non_variant_file_regex = re.compile(f"{'|'.join(weight_names)}")
+
+ if variant is not None:
+ variant_filenames = {f for f in filenames if variant_file_regex.match(f.split("/")[-1]) is not None}
+ else:
+ variant_filenames = set()
+
+ non_variant_filenames = {f for f in filenames if non_variant_file_regex.match(f.split("/")[-1]) is not None}
+
+ usable_filenames = set(variant_filenames)
+ for f in non_variant_filenames:
+ variant_filename = f"{f.split('.')[0]}.{variant}.{f.split('.')[1]}"
+ if variant_filename not in usable_filenames:
+ usable_filenames.add(f)
+
+ return usable_filenames, variant_filenames
+
+
+def warn_deprecated_model_variant(pretrained_model_name_or_path, use_auth_token, variant, revision, model_filenames):
+ info = model_info(
+ pretrained_model_name_or_path,
+ use_auth_token=use_auth_token,
+ revision=None,
+ )
+ filenames = {sibling.rfilename for sibling in info.siblings}
+ comp_model_filenames, _ = variant_compatible_siblings(filenames, variant=revision)
+ comp_model_filenames = [".".join(f.split(".")[:1] + f.split(".")[2:]) for f in comp_model_filenames]
+
+ if set(comp_model_filenames) == set(model_filenames):
+ warnings.warn(
+ f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'` even though you can load it via `variant=`{revision}`. Loading model variants via `revision='{revision}'` is deprecated and will be removed in diffusers v1. Please use `variant='{revision}'` instead.",
+ FutureWarning,
+ )
+ else:
+ warnings.warn(
+ f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'`. This behavior is deprecated and will be removed in diffusers v1. One should use `variant='{revision}'` instead. However, it appears that {pretrained_model_name_or_path} currently does not have the required variant filenames in the 'main' branch. \n The Diffusers team and community would be very grateful if you could open an issue: https://github.com/huggingface/diffusers/issues/new with the title '{pretrained_model_name_or_path} is missing {revision} files' so that the correct variant file can be added.",
+ FutureWarning,
+ )
+
+
+def maybe_raise_or_warn(
+ library_name, library, class_name, importable_classes, passed_class_obj, name, is_pipeline_module
+):
+ """Simple helper method to raise or warn in case incorrect module has been passed"""
+ if not is_pipeline_module:
+ library = importlib.import_module(library_name)
+ class_obj = getattr(library, class_name)
+ class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
+
+ expected_class_obj = None
+ for class_name, class_candidate in class_candidates.items():
+ if class_candidate is not None and issubclass(class_obj, class_candidate):
+ expected_class_obj = class_candidate
+
+ # Dynamo wraps the original model in a private class.
+ # I didn't find a public API to get the original class.
+ sub_model = passed_class_obj[name]
+ model_cls = sub_model.__class__
+ if is_compiled_module(sub_model):
+ model_cls = sub_model._orig_mod.__class__
+
+ if not issubclass(model_cls, expected_class_obj):
+ raise ValueError(
+ f"{passed_class_obj[name]} is of type: {type(passed_class_obj[name])}, but should be"
+ f" {expected_class_obj}"
+ )
+ else:
+ logger.warning(
+ f"You have passed a non-standard module {passed_class_obj[name]}. We cannot verify whether it"
+ " has the correct type"
+ )
+
+
+def get_class_obj_and_candidates(library_name, class_name, importable_classes, pipelines, is_pipeline_module):
+ """Simple helper method to retrieve class object of module as well as potential parent class objects"""
+ if is_pipeline_module:
+ pipeline_module = getattr(pipelines, library_name)
+
+ class_obj = getattr(pipeline_module, class_name)
+ class_candidates = {c: class_obj for c in importable_classes.keys()}
+ else:
+ # else we just import it from the library.
+ library = importlib.import_module(library_name)
+
+ class_obj = getattr(library, class_name)
+ class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
+
+ return class_obj, class_candidates
+
+
+def load_sub_model(
+ library_name: str,
+ class_name: str,
+ importable_classes: List[Any],
+ pipelines: Any,
+ is_pipeline_module: bool,
+ pipeline_class: Any,
+ torch_dtype: torch.dtype,
+ provider: Any,
+ sess_options: Any,
+ device_map: Optional[Union[Dict[str, torch.device], str]],
+ model_variants: Dict[str, str],
+ name: str,
+ from_flax: bool,
+ variant: str,
+ low_cpu_mem_usage: bool,
+ cached_folder: Union[str, os.PathLike],
+):
+ """Helper method to load the module `name` from `library_name` and `class_name`"""
+ # retrieve class candidates
+ class_obj, class_candidates = get_class_obj_and_candidates(
+ library_name, class_name, importable_classes, pipelines, is_pipeline_module
+ )
+
+ load_method_name = None
+ # retrive load method name
+ for class_name, class_candidate in class_candidates.items():
+ if class_candidate is not None and issubclass(class_obj, class_candidate):
+ load_method_name = importable_classes[class_name][1]
+
+ # if load method name is None, then we have a dummy module -> raise Error
+ if load_method_name is None:
+ none_module = class_obj.__module__
+ is_dummy_path = none_module.startswith(DUMMY_MODULES_FOLDER) or none_module.startswith(
+ TRANSFORMERS_DUMMY_MODULES_FOLDER
+ )
+ if is_dummy_path and "dummy" in none_module:
+ # call class_obj for nice error message of missing requirements
+ class_obj()
+
+ raise ValueError(
+ f"The component {class_obj} of {pipeline_class} cannot be loaded as it does not seem to have"
+ f" any of the loading methods defined in {ALL_IMPORTABLE_CLASSES}."
+ )
+
+ load_method = getattr(class_obj, load_method_name)
+
+ # add kwargs to loading method
+ loading_kwargs = {}
+ if issubclass(class_obj, torch.nn.Module):
+ loading_kwargs["torch_dtype"] = torch_dtype
+ if issubclass(class_obj, diffusers.OnnxRuntimeModel):
+ loading_kwargs["provider"] = provider
+ loading_kwargs["sess_options"] = sess_options
+
+ is_diffusers_model = issubclass(class_obj, diffusers.ModelMixin)
+
+ if is_transformers_available():
+ transformers_version = version.parse(version.parse(transformers.__version__).base_version)
+ else:
+ transformers_version = "N/A"
+
+ is_transformers_model = (
+ is_transformers_available()
+ and issubclass(class_obj, PreTrainedModel)
+ and transformers_version >= version.parse("4.20.0")
+ )
+
+ # When loading a transformers model, if the device_map is None, the weights will be initialized as opposed to diffusers.
+ # To make default loading faster we set the `low_cpu_mem_usage=low_cpu_mem_usage` flag which is `True` by default.
+ # This makes sure that the weights won't be initialized which significantly speeds up loading.
+ if is_diffusers_model or is_transformers_model:
+ loading_kwargs["device_map"] = device_map
+ loading_kwargs["variant"] = model_variants.pop(name, None)
+ if from_flax:
+ loading_kwargs["from_flax"] = True
+
+ # the following can be deleted once the minimum required `transformers` version
+ # is higher than 4.27
+ if (
+ is_transformers_model
+ and loading_kwargs["variant"] is not None
+ and transformers_version < version.parse("4.27.0")
+ ):
+ raise ImportError(
+ f"When passing `variant='{variant}'`, please make sure to upgrade your `transformers` version to at least 4.27.0.dev0"
+ )
+ elif is_transformers_model and loading_kwargs["variant"] is None:
+ loading_kwargs.pop("variant")
+
+ # if `from_flax` and model is transformer model, can currently not load with `low_cpu_mem_usage`
+ if not (from_flax and is_transformers_model):
+ loading_kwargs["low_cpu_mem_usage"] = low_cpu_mem_usage
+ else:
+ loading_kwargs["low_cpu_mem_usage"] = False
+
+ # check if the module is in a subdirectory
+ if os.path.isdir(os.path.join(cached_folder, name)):
+ loaded_sub_model = load_method(os.path.join(cached_folder, name), **loading_kwargs)
+ else:
+ # else load from the root directory
+ loaded_sub_model = load_method(cached_folder, **loading_kwargs)
+
+ return loaded_sub_model
+
+
+class DiffusionPipeline(ConfigMixin):
+ r"""
+ Base class for all models.
+
+ [`DiffusionPipeline`] takes care of storing all components (models, schedulers, processors) for diffusion pipelines
+ and handles methods for loading, downloading and saving models as well as a few methods common to all pipelines to:
+
+ - move all PyTorch modules to the device of your choice
+ - enabling/disabling the progress bar for the denoising iteration
+
+ Class attributes:
+
+ - **config_name** (`str`) -- name of the config file that will store the class and module names of all
+ components of the diffusion pipeline.
+ - **_optional_components** (List[`str`]) -- list of all components that are optional so they don't have to be
+ passed for the pipeline to function (should be overridden by subclasses).
+ """
+ config_name = "model_index.json"
+ _optional_components = []
+
+ def register_modules(self, **kwargs):
+ # import it here to avoid circular import
+ from diffusers import pipelines
+
+ for name, module in kwargs.items():
+ # retrieve library
+ if module is None:
+ register_dict = {name: (None, None)}
+ else:
+ # register the original module, not the dynamo compiled one
+ if is_compiled_module(module):
+ module = module._orig_mod
+
+ library = module.__module__.split(".")[0]
+
+ # check if the module is a pipeline module
+ pipeline_dir = module.__module__.split(".")[-2] if len(module.__module__.split(".")) > 2 else None
+ path = module.__module__.split(".")
+ is_pipeline_module = pipeline_dir in path and hasattr(pipelines, pipeline_dir)
+
+ # if library is not in LOADABLE_CLASSES, then it is a custom module.
+ # Or if it's a pipeline module, then the module is inside the pipeline
+ # folder so we set the library to module name.
+ if library not in LOADABLE_CLASSES or is_pipeline_module:
+ library = pipeline_dir
+
+ # retrieve class_name
+ class_name = module.__class__.__name__
+
+ register_dict = {name: (library, class_name)}
+
+ # save model index config
+ self.register_to_config(**register_dict)
+
+ # set models
+ setattr(self, name, module)
+
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ """
+ Save all variables of the pipeline that can be saved and loaded as well as the pipelines configuration file to
+ a directory. A pipeline variable can be saved and loaded if its class implements both a save and loading
+ method. The pipeline can easily be re-loaded using the `[`~DiffusionPipeline.from_pretrained`]` class method.
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ safe_serialization (`bool`, *optional*, defaults to `False`):
+ Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
+ variant (`str`, *optional*):
+ If specified, weights are saved in the format pytorch_model..bin.
+ """
+ self.save_config(save_directory)
+
+ model_index_dict = dict(self.config)
+ model_index_dict.pop("_class_name")
+ model_index_dict.pop("_diffusers_version")
+ model_index_dict.pop("_module", None)
+
+ expected_modules, optional_kwargs = self._get_signature_keys(self)
+
+ def is_saveable_module(name, value):
+ if name not in expected_modules:
+ return False
+ if name in self._optional_components and value[0] is None:
+ return False
+ return True
+
+ model_index_dict = {k: v for k, v in model_index_dict.items() if is_saveable_module(k, v)}
+
+ for pipeline_component_name in model_index_dict.keys():
+ sub_model = getattr(self, pipeline_component_name)
+ model_cls = sub_model.__class__
+
+ # Dynamo wraps the original model in a private class.
+ # I didn't find a public API to get the original class.
+ if is_compiled_module(sub_model):
+ sub_model = sub_model._orig_mod
+ model_cls = sub_model.__class__
+
+ save_method_name = None
+ # search for the model's base class in LOADABLE_CLASSES
+ for library_name, library_classes in LOADABLE_CLASSES.items():
+ library = importlib.import_module(library_name)
+ for base_class, save_load_methods in library_classes.items():
+ class_candidate = getattr(library, base_class, None)
+ if class_candidate is not None and issubclass(model_cls, class_candidate):
+ # if we found a suitable base class in LOADABLE_CLASSES then grab its save method
+ save_method_name = save_load_methods[0]
+ break
+ if save_method_name is not None:
+ break
+
+ save_method = getattr(sub_model, save_method_name)
+
+ # Call the save method with the argument safe_serialization only if it's supported
+ save_method_signature = inspect.signature(save_method)
+ save_method_accept_safe = "safe_serialization" in save_method_signature.parameters
+ save_method_accept_variant = "variant" in save_method_signature.parameters
+
+ save_kwargs = {}
+ if save_method_accept_safe:
+ save_kwargs["safe_serialization"] = safe_serialization
+ if save_method_accept_variant:
+ save_kwargs["variant"] = variant
+
+ save_method(os.path.join(save_directory, pipeline_component_name), **save_kwargs)
+
+ def to(
+ self,
+ torch_device: Optional[Union[str, torch.device]] = None,
+ torch_dtype: Optional[torch.dtype] = None,
+ silence_dtype_warnings: bool = False,
+ ):
+ if torch_device is None and torch_dtype is None:
+ return self
+
+ # throw warning if pipeline is in "offloaded"-mode but user tries to manually set to GPU.
+ def module_is_sequentially_offloaded(module):
+ if not is_accelerate_available() or is_accelerate_version("<", "0.14.0"):
+ return False
+
+ return hasattr(module, "_hf_hook") and not isinstance(module._hf_hook, accelerate.hooks.CpuOffload)
+
+ def module_is_offloaded(module):
+ if not is_accelerate_available() or is_accelerate_version("<", "0.17.0.dev0"):
+ return False
+
+ return hasattr(module, "_hf_hook") and isinstance(module._hf_hook, accelerate.hooks.CpuOffload)
+
+ # .to("cuda") would raise an error if the pipeline is sequentially offloaded, so we raise our own to make it clearer
+ pipeline_is_sequentially_offloaded = any(
+ module_is_sequentially_offloaded(module) for _, module in self.components.items()
+ )
+ if pipeline_is_sequentially_offloaded and torch.device(torch_device).type == "cuda":
+ raise ValueError(
+ "It seems like you have activated sequential model offloading by calling `enable_sequential_cpu_offload`, but are now attempting to move the pipeline to GPU. This is not compatible with offloading. Please, move your pipeline `.to('cpu')` or consider removing the move altogether if you use sequential offloading."
+ )
+
+ # Display a warning in this case (the operation succeeds but the benefits are lost)
+ pipeline_is_offloaded = any(module_is_offloaded(module) for _, module in self.components.items())
+ if pipeline_is_offloaded and torch.device(torch_device).type == "cuda":
+ logger.warning(
+ f"It seems like you have activated model offloading by calling `enable_model_cpu_offload`, but are now manually moving the pipeline to GPU. It is strongly recommended against doing so as memory gains from offloading are likely to be lost. Offloading automatically takes care of moving the individual components {', '.join(self.components.keys())} to GPU when needed. To make sure offloading works as expected, you should consider moving the pipeline back to CPU: `pipeline.to('cpu')` or removing the move altogether if you use offloading."
+ )
+
+ module_names, _, _ = self.extract_init_dict(dict(self.config))
+ is_offloaded = pipeline_is_offloaded or pipeline_is_sequentially_offloaded
+ for name in module_names.keys():
+ module = getattr(self, name)
+ if isinstance(module, torch.nn.Module):
+ module.to(torch_device, torch_dtype)
+ if (
+ module.dtype == torch.float16
+ and str(torch_device) in ["cpu"]
+ and not silence_dtype_warnings
+ and not is_offloaded
+ ):
+ logger.warning(
+ "Pipelines loaded with `torch_dtype=torch.float16` cannot run with `cpu` device. It"
+ " is not recommended to move them to `cpu` as running them will fail. Please make"
+ " sure to use an accelerator to run the pipeline in inference, due to the lack of"
+ " support for`float16` operations on this device in PyTorch. Please, remove the"
+ " `torch_dtype=torch.float16` argument, or use another device for inference."
+ )
+ return self
+
+ @property
+ def device(self) -> torch.device:
+ r"""
+ Returns:
+ `torch.device`: The torch device on which the pipeline is located.
+ """
+ module_names, _, _ = self.extract_init_dict(dict(self.config))
+ for name in module_names.keys():
+ module = getattr(self, name)
+ if isinstance(module, torch.nn.Module):
+ return module.device
+ return torch.device("cpu")
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
+ r"""
+ Instantiate a PyTorch diffusion pipeline from pre-trained pipeline weights.
+
+ The pipeline is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated).
+
+ The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
+ pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
+ task.
+
+ The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
+ weights are discarded.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
+ Can be either:
+
+ - A string, the *repo id* of a pretrained pipeline hosted inside a model repo on
+ https://huggingface.co/ Valid repo ids have to be located under a user or organization name, like
+ `CompVis/ldm-text2im-large-256`.
+ - A path to a *directory* containing pipeline weights saved using
+ [`~DiffusionPipeline.save_pretrained`], e.g., `./my_pipeline_directory/`.
+ torch_dtype (`str` or `torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
+ will be automatically derived from the model's weights.
+ custom_pipeline (`str`, *optional*):
+
+
+
+ This is an experimental feature and is likely to change in the future.
+
+
+
+ Can be either:
+
+ - A string, the *repo id* of a custom pipeline hosted inside a model repo on
+ https://huggingface.co/. Valid repo ids have to be located under a user or organization name,
+ like `hf-internal-testing/diffusers-dummy-pipeline`.
+
+
+
+ It is required that the model repo has a file, called `pipeline.py` that defines the custom
+ pipeline.
+
+
+
+ - A string, the *file name* of a community pipeline hosted on GitHub under
+ https://github.com/huggingface/diffusers/tree/main/examples/community. Valid file names have to
+ match exactly the file name without `.py` located under the above link, *e.g.*
+ `clip_guided_stable_diffusion`.
+
+
+
+ Community pipelines are always loaded from the current `main` branch of GitHub.
+
+
+
+ - A path to a *directory* containing a custom pipeline, e.g., `./my_pipeline_directory/`.
+
+
+
+ It is required that the directory has a file, called `pipeline.py` that defines the custom
+ pipeline.
+
+
+
+ For more information on how to load and create custom pipelines, please have a look at [Loading and
+ Adding Custom
+ Pipelines](https://huggingface.co/docs/diffusers/using-diffusers/custom_pipeline_overview)
+
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ custom_revision (`str`, *optional*, defaults to `"main"` when loading from the Hub and to local version of `diffusers` when loading from GitHub):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id similar to
+ `revision` when loading a custom pipeline from the Hub. It can be a diffusers version when loading a
+ custom pipeline from GitHub.
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information. specify the folder name here.
+ device_map (`str` or `Dict[str, Union[int, str, torch.device]]`, *optional*):
+ A map that specifies where each submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every submodule of it will be sent to the
+ same device.
+
+ To have Accelerate compute the most optimized `device_map` automatically, set `device_map="auto"`. For
+ more information about each option see [designing a device
+ map](https://hf.co/docs/accelerate/main/en/usage_guides/big_modeling#designing-a-device-map).
+ low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
+ Speed up model loading by not initializing the weights and only loading the pre-trained weights. This
+ also tries to not use more than 1x model size in CPU memory (including peak memory) while loading the
+ model. This is only supported when torch version >= 1.9.0. If you are using an older version of torch,
+ setting this argument to `True` will raise an error.
+ use_safetensors (`bool`, *optional* ):
+ If set to `True`, the pipeline will be loaded from `safetensors` weights. If set to `None` (the
+ default). The pipeline will load using `safetensors` if the safetensors weights are available *and* if
+ `safetensors` is installed. If the to `False` the pipeline will *not* use `safetensors`.
+ kwargs (remaining dictionary of keyword arguments, *optional*):
+ Can be used to overwrite load - and saveable variables - *i.e.* the pipeline components - of the
+ specific pipeline class. The overwritten components are then directly passed to the pipelines
+ `__init__` method. See example below for more information.
+ variant (`str`, *optional*):
+ If specified load weights from `variant` filename, *e.g.* pytorch_model..bin. `variant` is
+ ignored when using `from_flax`.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models), *e.g.* `"runwayml/stable-diffusion-v1-5"`
+
+
+
+
+
+ Activate the special ["offline-mode"](https://huggingface.co/diffusers/installation.html#offline-mode) to use
+ this method in a firewalled environment.
+
+
+
+ Examples:
+
+ ```py
+ >>> from diffusers import DiffusionPipeline
+
+ >>> # Download pipeline from huggingface.co and cache.
+ >>> pipeline = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
+
+ >>> # Download pipeline that requires an authorization token
+ >>> # For more information on access tokens, please refer to this section
+ >>> # of the documentation](https://huggingface.co/docs/hub/security-tokens)
+ >>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+
+ >>> # Use a different scheduler
+ >>> from diffusers import LMSDiscreteScheduler
+
+ >>> scheduler = LMSDiscreteScheduler.from_config(pipeline.scheduler.config)
+ >>> pipeline.scheduler = scheduler
+ ```
+ """
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ resume_download = kwargs.pop("resume_download", False)
+ force_download = kwargs.pop("force_download", False)
+ proxies = kwargs.pop("proxies", None)
+ local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ from_flax = kwargs.pop("from_flax", False)
+ torch_dtype = kwargs.pop("torch_dtype", None)
+ custom_pipeline = kwargs.pop("custom_pipeline", None)
+ custom_revision = kwargs.pop("custom_revision", None)
+ provider = kwargs.pop("provider", None)
+ sess_options = kwargs.pop("sess_options", None)
+ device_map = kwargs.pop("device_map", None)
+ low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", _LOW_CPU_MEM_USAGE_DEFAULT)
+ variant = kwargs.pop("variant", None)
+ kwargs.pop("use_safetensors", None if is_safetensors_available() else False)
+
+ # 1. Download the checkpoints and configs
+ # use snapshot download here to get it working from from_pretrained
+ if not os.path.isdir(pretrained_model_name_or_path):
+ cached_folder = cls.download(
+ pretrained_model_name_or_path,
+ cache_dir=cache_dir,
+ resume_download=resume_download,
+ force_download=force_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ from_flax=from_flax,
+ custom_pipeline=custom_pipeline,
+ variant=variant,
+ )
+ else:
+ cached_folder = pretrained_model_name_or_path
+
+ config_dict = cls.load_config(cached_folder)
+
+ # 2. Define which model components should load variants
+ # We retrieve the information by matching whether variant
+ # model checkpoints exist in the subfolders
+ model_variants = {}
+ if variant is not None:
+ for folder in os.listdir(cached_folder):
+ folder_path = os.path.join(cached_folder, folder)
+ is_folder = os.path.isdir(folder_path) and folder in config_dict
+ variant_exists = is_folder and any(path.split(".")[1] == variant for path in os.listdir(folder_path))
+ if variant_exists:
+ model_variants[folder] = variant
+
+ # 3. Load the pipeline class, if using custom module then load it from the hub
+ # if we load from explicit class, let's use it
+ if custom_pipeline is not None:
+ if custom_pipeline.endswith(".py"):
+ path = Path(custom_pipeline)
+ # decompose into folder & file
+ file_name = path.name
+ custom_pipeline = path.parent.absolute()
+ else:
+ file_name = CUSTOM_PIPELINE_FILE_NAME
+
+ pipeline_class = get_class_from_dynamic_module(
+ custom_pipeline, module_file=file_name, cache_dir=cache_dir, revision=custom_revision
+ )
+ elif cls != DiffusionPipeline:
+ pipeline_class = cls
+ else:
+ diffusers_module = importlib.import_module(cls.__module__.split(".")[0])
+ pipeline_class = getattr(diffusers_module, config_dict["_class_name"])
+
+ # DEPRECATED: To be removed in 1.0.0
+ if pipeline_class.__name__ == "StableDiffusionInpaintPipeline" and version.parse(
+ version.parse(config_dict["_diffusers_version"]).base_version
+ ) <= version.parse("0.5.1"):
+ from diffusers import StableDiffusionInpaintPipeline, StableDiffusionInpaintPipelineLegacy
+
+ pipeline_class = StableDiffusionInpaintPipelineLegacy
+
+ deprecation_message = (
+ "You are using a legacy checkpoint for inpainting with Stable Diffusion, therefore we are loading the"
+ f" {StableDiffusionInpaintPipelineLegacy} class instead of {StableDiffusionInpaintPipeline}. For"
+ " better inpainting results, we strongly suggest using Stable Diffusion's official inpainting"
+ " checkpoint: https://huggingface.co/runwayml/stable-diffusion-inpainting instead or adapting your"
+ f" checkpoint {pretrained_model_name_or_path} to the format of"
+ " https://huggingface.co/runwayml/stable-diffusion-inpainting. Note that we do not actively maintain"
+ " the {StableDiffusionInpaintPipelineLegacy} class and will likely remove it in version 1.0.0."
+ )
+ deprecate("StableDiffusionInpaintPipelineLegacy", "1.0.0", deprecation_message, standard_warn=False)
+
+ # 4. Define expected modules given pipeline signature
+ # and define non-None initialized modules (=`init_kwargs`)
+
+ # some modules can be passed directly to the init
+ # in this case they are already instantiated in `kwargs`
+ # extract them here
+ expected_modules, optional_kwargs = cls._get_signature_keys(pipeline_class)
+ passed_class_obj = {k: kwargs.pop(k) for k in expected_modules if k in kwargs}
+ passed_pipe_kwargs = {k: kwargs.pop(k) for k in optional_kwargs if k in kwargs}
+
+ init_dict, unused_kwargs, _ = pipeline_class.extract_init_dict(config_dict, **kwargs)
+
+ # define init kwargs
+ init_kwargs = {k: init_dict.pop(k) for k in optional_kwargs if k in init_dict}
+ init_kwargs = {**init_kwargs, **passed_pipe_kwargs}
+
+ # remove `null` components
+ def load_module(name, value):
+ if value[0] is None:
+ return False
+ if name in passed_class_obj and passed_class_obj[name] is None:
+ return False
+ return True
+
+ init_dict = {k: v for k, v in init_dict.items() if load_module(k, v)}
+
+ # Special case: safety_checker must be loaded separately when using `from_flax`
+ if from_flax and "safety_checker" in init_dict and "safety_checker" not in passed_class_obj:
+ raise NotImplementedError(
+ "The safety checker cannot be automatically loaded when loading weights `from_flax`."
+ " Please, pass `safety_checker=None` to `from_pretrained`, and load the safety checker"
+ " separately if you need it."
+ )
+
+ # 5. Throw nice warnings / errors for fast accelerate loading
+ if len(unused_kwargs) > 0:
+ logger.warning(
+ f"Keyword arguments {unused_kwargs} are not expected by {pipeline_class.__name__} and will be ignored."
+ )
+
+ if low_cpu_mem_usage and not is_accelerate_available():
+ low_cpu_mem_usage = False
+ logger.warning(
+ "Cannot initialize model with low cpu memory usage because `accelerate` was not found in the"
+ " environment. Defaulting to `low_cpu_mem_usage=False`. It is strongly recommended to install"
+ " `accelerate` for faster and less memory-intense model loading. You can do so with: \n```\npip"
+ " install accelerate\n```\n."
+ )
+
+ if device_map is not None and not is_torch_version(">=", "1.9.0"):
+ raise NotImplementedError(
+ "Loading and dispatching requires torch >= 1.9.0. Please either update your PyTorch version or set"
+ " `device_map=None`."
+ )
+
+ if low_cpu_mem_usage is True and not is_torch_version(">=", "1.9.0"):
+ raise NotImplementedError(
+ "Low memory initialization requires torch >= 1.9.0. Please either update your PyTorch version or set"
+ " `low_cpu_mem_usage=False`."
+ )
+
+ if low_cpu_mem_usage is False and device_map is not None:
+ raise ValueError(
+ f"You cannot set `low_cpu_mem_usage` to False while using device_map={device_map} for loading and"
+ " dispatching. Please make sure to set `low_cpu_mem_usage=True`."
+ )
+
+ # import it here to avoid circular import
+ from diffusers import pipelines
+
+ # 6. Load each module in the pipeline
+ for name, (library_name, class_name) in init_dict.items():
+ # 6.1 - now that JAX/Flax is an official framework of the library, we might load from Flax names
+ if class_name.startswith("Flax"):
+ class_name = class_name[4:]
+
+ # 6.2 Define all importable classes
+ is_pipeline_module = hasattr(pipelines, library_name)
+ importable_classes = ALL_IMPORTABLE_CLASSES if is_pipeline_module else LOADABLE_CLASSES[library_name]
+ loaded_sub_model = None
+
+ # 6.3 Use passed sub model or load class_name from library_name
+ if name in passed_class_obj:
+ # if the model is in a pipeline module, then we load it from the pipeline
+ # check that passed_class_obj has correct parent class
+ maybe_raise_or_warn(
+ library_name, library, class_name, importable_classes, passed_class_obj, name, is_pipeline_module
+ )
+
+ loaded_sub_model = passed_class_obj[name]
+ else:
+ # load sub model
+ loaded_sub_model = load_sub_model(
+ library_name=library_name,
+ class_name=class_name,
+ importable_classes=importable_classes,
+ pipelines=pipelines,
+ is_pipeline_module=is_pipeline_module,
+ pipeline_class=pipeline_class,
+ torch_dtype=torch_dtype,
+ provider=provider,
+ sess_options=sess_options,
+ device_map=device_map,
+ model_variants=model_variants,
+ name=name,
+ from_flax=from_flax,
+ variant=variant,
+ low_cpu_mem_usage=low_cpu_mem_usage,
+ cached_folder=cached_folder,
+ )
+
+ init_kwargs[name] = loaded_sub_model # UNet(...), # DiffusionSchedule(...)
+
+ # 7. Potentially add passed objects if expected
+ missing_modules = set(expected_modules) - set(init_kwargs.keys())
+ passed_modules = list(passed_class_obj.keys())
+ optional_modules = pipeline_class._optional_components
+ if len(missing_modules) > 0 and missing_modules <= set(passed_modules + optional_modules):
+ for module in missing_modules:
+ init_kwargs[module] = passed_class_obj.get(module, None)
+ elif len(missing_modules) > 0:
+ passed_modules = set(list(init_kwargs.keys()) + list(passed_class_obj.keys())) - optional_kwargs
+ raise ValueError(
+ f"Pipeline {pipeline_class} expected {expected_modules}, but only {passed_modules} were passed."
+ )
+
+ # 8. Instantiate the pipeline
+ model = pipeline_class(**init_kwargs)
+
+ return_cached_folder = kwargs.pop("return_cached_folder", False)
+ if return_cached_folder:
+ message = f"Passing `return_cached_folder=True` is deprecated and will be removed in `diffusers=0.17.0`. Please do the following instead: \n 1. Load the cached_folder via `cached_folder={cls}.download({pretrained_model_name_or_path})`. \n 2. Load the pipeline by loading from the cached folder: `pipeline={cls}.from_pretrained(cached_folder)`."
+ deprecate("return_cached_folder", "0.17.0", message, take_from=kwargs)
+ return model, cached_folder
+
+ return model
+
+ @classmethod
+ def download(cls, pretrained_model_name, **kwargs) -> Union[str, os.PathLike]:
+ r"""
+ Download and cache a PyTorch diffusion pipeline from pre-trained pipeline weights.
+
+ Parameters:
+ pretrained_model_name (`str` or `os.PathLike`, *optional*):
+ Should be a string, the *repo id* of a pretrained pipeline hosted inside a model repo on
+ https://huggingface.co/ Valid repo ids have to be located under a user or organization name, like
+ `CompVis/ldm-text2im-large-256`.
+ custom_pipeline (`str`, *optional*):
+
+
+
+ This is an experimental feature and is likely to change in the future.
+
+
+
+ Can be either:
+
+ - A string, the *repo id* of a custom pipeline hosted inside a model repo on
+ https://huggingface.co/. Valid repo ids have to be located under a user or organization name,
+ like `hf-internal-testing/diffusers-dummy-pipeline`.
+
+
+
+ It is required that the model repo has a file, called `pipeline.py` that defines the custom
+ pipeline.
+
+
+
+ - A string, the *file name* of a community pipeline hosted on GitHub under
+ https://github.com/huggingface/diffusers/tree/main/examples/community. Valid file names have to
+ match exactly the file name without `.py` located under the above link, *e.g.*
+ `clip_guided_stable_diffusion`.
+
+
+
+ Community pipelines are always loaded from the current `main` branch of GitHub.
+
+
+
+ - A path to a *directory* containing a custom pipeline, e.g., `./my_pipeline_directory/`.
+
+
+
+ It is required that the directory has a file, called `pipeline.py` that defines the custom
+ pipeline.
+
+
+
+ For more information on how to load and create custom pipelines, please have a look at [Loading and
+ Adding Custom
+ Pipelines](https://huggingface.co/docs/diffusers/using-diffusers/custom_pipeline_overview)
+
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ custom_revision (`str`, *optional*, defaults to `"main"` when loading from the Hub and to local version of
+ `diffusers` when loading from GitHub):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id similar to
+ `revision` when loading a custom pipeline from the Hub. It can be a diffusers version when loading a
+ custom pipeline from GitHub.
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information. specify the folder name here.
+ variant (`str`, *optional*):
+ If specified load weights from `variant` filename, *e.g.* pytorch_model..bin. `variant` is
+ ignored when using `from_flax`.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models)
+
+
+
+ """
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ resume_download = kwargs.pop("resume_download", False)
+ force_download = kwargs.pop("force_download", False)
+ proxies = kwargs.pop("proxies", None)
+ local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ from_flax = kwargs.pop("from_flax", False)
+ custom_pipeline = kwargs.pop("custom_pipeline", None)
+ variant = kwargs.pop("variant", None)
+ use_safetensors = kwargs.pop("use_safetensors", None)
+
+ if use_safetensors and not is_safetensors_available():
+ raise ValueError(
+ "`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
+ )
+
+ allow_pickle = False
+ if use_safetensors is None:
+ use_safetensors = is_safetensors_available()
+ allow_pickle = True
+
+ pipeline_is_cached = False
+ allow_patterns = None
+ ignore_patterns = None
+
+ if not local_files_only:
+ config_file = hf_hub_download(
+ pretrained_model_name,
+ cls.config_name,
+ cache_dir=cache_dir,
+ revision=revision,
+ proxies=proxies,
+ force_download=force_download,
+ resume_download=resume_download,
+ use_auth_token=use_auth_token,
+ )
+ info = model_info(
+ pretrained_model_name,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ )
+
+ config_dict = cls._dict_from_json_file(config_file)
+ # retrieve all folder_names that contain relevant files
+ folder_names = [k for k, v in config_dict.items() if isinstance(v, list)]
+
+ filenames = {sibling.rfilename for sibling in info.siblings}
+ model_filenames, variant_filenames = variant_compatible_siblings(filenames, variant=variant)
+
+ # if the whole pipeline is cached we don't have to ping the Hub
+ if revision in DEPRECATED_REVISION_ARGS and version.parse(
+ version.parse(__version__).base_version
+ ) >= version.parse("0.17.0"):
+ warn_deprecated_model_variant(
+ pretrained_model_name, use_auth_token, variant, revision, model_filenames
+ )
+
+ model_folder_names = {os.path.split(f)[0] for f in model_filenames}
+
+ # all filenames compatible with variant will be added
+ allow_patterns = list(model_filenames)
+
+ # allow all patterns from non-model folders
+ # this enables downloading schedulers, tokenizers, ...
+ allow_patterns += [os.path.join(k, "*") for k in folder_names if k not in model_folder_names]
+ # also allow downloading config.json files with the model
+ allow_patterns += [os.path.join(k, "*.json") for k in model_folder_names]
+
+ allow_patterns += [
+ SCHEDULER_CONFIG_NAME,
+ CONFIG_NAME,
+ cls.config_name,
+ CUSTOM_PIPELINE_FILE_NAME,
+ ]
+
+ if (
+ use_safetensors
+ and not allow_pickle
+ and not is_safetensors_compatible(model_filenames, variant=variant)
+ ):
+ raise EnvironmentError(
+ f"Could not found the necessary `safetensors` weights in {model_filenames} (variant={variant})"
+ )
+ if from_flax:
+ ignore_patterns = ["*.bin", "*.safetensors", "*.onnx", "*.pb"]
+ elif use_safetensors and is_safetensors_compatible(model_filenames, variant=variant):
+ ignore_patterns = ["*.bin", "*.msgpack"]
+
+ safetensors_variant_filenames = {f for f in variant_filenames if f.endswith(".safetensors")}
+ safetensors_model_filenames = {f for f in model_filenames if f.endswith(".safetensors")}
+ if (
+ len(safetensors_variant_filenames) > 0
+ and safetensors_model_filenames != safetensors_variant_filenames
+ ):
+ logger.warn(
+ f"\nA mixture of {variant} and non-{variant} filenames will be loaded.\nLoaded {variant} filenames:\n[{', '.join(safetensors_variant_filenames)}]\nLoaded non-{variant} filenames:\n[{', '.join(safetensors_model_filenames - safetensors_variant_filenames)}\nIf this behavior is not expected, please check your folder structure."
+ )
+ else:
+ ignore_patterns = ["*.safetensors", "*.msgpack"]
+
+ bin_variant_filenames = {f for f in variant_filenames if f.endswith(".bin")}
+ bin_model_filenames = {f for f in model_filenames if f.endswith(".bin")}
+ if len(bin_variant_filenames) > 0 and bin_model_filenames != bin_variant_filenames:
+ logger.warn(
+ f"\nA mixture of {variant} and non-{variant} filenames will be loaded.\nLoaded {variant} filenames:\n[{', '.join(bin_variant_filenames)}]\nLoaded non-{variant} filenames:\n[{', '.join(bin_model_filenames - bin_variant_filenames)}\nIf this behavior is not expected, please check your folder structure."
+ )
+
+ re_ignore_pattern = [re.compile(fnmatch.translate(p)) for p in ignore_patterns]
+ re_allow_pattern = [re.compile(fnmatch.translate(p)) for p in allow_patterns]
+
+ expected_files = [f for f in filenames if not any(p.match(f) for p in re_ignore_pattern)]
+ expected_files = [f for f in expected_files if any(p.match(f) for p in re_allow_pattern)]
+
+ snapshot_folder = Path(config_file).parent
+ pipeline_is_cached = all((snapshot_folder / f).is_file() for f in expected_files)
+
+ if pipeline_is_cached:
+ # if the pipeline is cached, we can directly return it
+ # else call snapshot_download
+ return snapshot_folder
+
+ user_agent = {"pipeline_class": cls.__name__}
+ if custom_pipeline is not None and not custom_pipeline.endswith(".py"):
+ user_agent["custom_pipeline"] = custom_pipeline
+
+ # download all allow_patterns - ignore_patterns
+ cached_folder = snapshot_download(
+ pretrained_model_name,
+ cache_dir=cache_dir,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ allow_patterns=allow_patterns,
+ ignore_patterns=ignore_patterns,
+ user_agent=user_agent,
+ )
+
+ return cached_folder
+
+ @staticmethod
+ def _get_signature_keys(obj):
+ parameters = inspect.signature(obj.__init__).parameters
+ required_parameters = {k: v for k, v in parameters.items() if v.default == inspect._empty}
+ optional_parameters = set({k for k, v in parameters.items() if v.default != inspect._empty})
+ expected_modules = set(required_parameters.keys()) - {"self"}
+ return expected_modules, optional_parameters
+
+ @property
+ def components(self) -> Dict[str, Any]:
+ r"""
+
+ The `self.components` property can be useful to run different pipelines with the same weights and
+ configurations to not have to re-allocate memory.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import (
+ ... StableDiffusionPipeline,
+ ... StableDiffusionImg2ImgPipeline,
+ ... StableDiffusionInpaintPipeline,
+ ... )
+
+ >>> text2img = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ >>> img2img = StableDiffusionImg2ImgPipeline(**text2img.components)
+ >>> inpaint = StableDiffusionInpaintPipeline(**text2img.components)
+ ```
+
+ Returns:
+ A dictionary containing all the modules needed to initialize the pipeline.
+ """
+ expected_modules, optional_parameters = self._get_signature_keys(self)
+ components = {
+ k: getattr(self, k) for k in self.config.keys() if not k.startswith("_") and k not in optional_parameters
+ }
+
+ if set(components.keys()) != expected_modules:
+ raise ValueError(
+ f"{self} has been incorrectly initialized or {self.__class__} is incorrectly implemented. Expected"
+ f" {expected_modules} to be defined, but {components.keys()} are defined."
+ )
+
+ return components
+
+ @staticmethod
+ def numpy_to_pil(images):
+ """
+ Convert a numpy image or a batch of images to a PIL image.
+ """
+ if images.ndim == 3:
+ images = images[None, ...]
+ images = (images * 255).round().astype("uint8")
+ if images.shape[-1] == 1:
+ # special case for grayscale (single channel) images
+ pil_images = [Image.fromarray(image.squeeze(), mode="L") for image in images]
+ else:
+ pil_images = [Image.fromarray(image) for image in images]
+
+ return pil_images
+
+ def progress_bar(self, iterable=None, total=None):
+ if not hasattr(self, "_progress_bar_config"):
+ self._progress_bar_config = {}
+ elif not isinstance(self._progress_bar_config, dict):
+ raise ValueError(
+ f"`self._progress_bar_config` should be of type `dict`, but is {type(self._progress_bar_config)}."
+ )
+
+ if iterable is not None:
+ return tqdm(iterable, **self._progress_bar_config)
+ elif total is not None:
+ return tqdm(total=total, **self._progress_bar_config)
+ else:
+ raise ValueError("Either `total` or `iterable` has to be defined.")
+
+ def set_progress_bar_config(self, **kwargs):
+ self._progress_bar_config = kwargs
+
+ def enable_xformers_memory_efficient_attention(self, attention_op: Optional[Callable] = None):
+ r"""
+ Enable memory efficient attention as implemented in xformers.
+
+ When this option is enabled, you should observe lower GPU memory usage and a potential speed up at inference
+ time. Speed up at training time is not guaranteed.
+
+ Warning: When Memory Efficient Attention and Sliced attention are both enabled, the Memory Efficient Attention
+ is used.
+
+ Parameters:
+ attention_op (`Callable`, *optional*):
+ Override the default `None` operator for use as `op` argument to the
+ [`memory_efficient_attention()`](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.memory_efficient_attention)
+ function of xFormers.
+
+ Examples:
+
+ ```py
+ >>> import torch
+ >>> from diffusers import DiffusionPipeline
+ >>> from xformers.ops import MemoryEfficientAttentionFlashAttentionOp
+
+ >>> pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16)
+ >>> pipe = pipe.to("cuda")
+ >>> pipe.enable_xformers_memory_efficient_attention(attention_op=MemoryEfficientAttentionFlashAttentionOp)
+ >>> # Workaround for not accepting attention shape using VAE for Flash Attention
+ >>> pipe.vae.enable_xformers_memory_efficient_attention(attention_op=None)
+ ```
+ """
+ self.set_use_memory_efficient_attention_xformers(True, attention_op)
+
+ def disable_xformers_memory_efficient_attention(self):
+ r"""
+ Disable memory efficient attention as implemented in xformers.
+ """
+ self.set_use_memory_efficient_attention_xformers(False)
+
+ def set_use_memory_efficient_attention_xformers(
+ self, valid: bool, attention_op: Optional[Callable] = None
+ ) -> None:
+ # Recursively walk through all the children.
+ # Any children which exposes the set_use_memory_efficient_attention_xformers method
+ # gets the message
+ def fn_recursive_set_mem_eff(module: torch.nn.Module):
+ if hasattr(module, "set_use_memory_efficient_attention_xformers"):
+ module.set_use_memory_efficient_attention_xformers(valid, attention_op)
+
+ for child in module.children():
+ fn_recursive_set_mem_eff(child)
+
+ module_names, _, _ = self.extract_init_dict(dict(self.config))
+ for module_name in module_names:
+ module = getattr(self, module_name)
+ if isinstance(module, torch.nn.Module):
+ fn_recursive_set_mem_eff(module)
+
+ def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module will split the input tensor in slices, to compute attention
+ in several steps. This is useful to save some memory in exchange for a small speed decrease.
+
+ Args:
+ slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
+ When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
+ `"max"`, maximum amount of memory will be saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ self.set_attention_slice(slice_size)
+
+ def disable_attention_slicing(self):
+ r"""
+ Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
+ back to computing attention in one step.
+ """
+ # set slice_size = `None` to disable `attention slicing`
+ self.enable_attention_slicing(None)
+
+ def set_attention_slice(self, slice_size: Optional[int]):
+ module_names, _, _ = self.extract_init_dict(dict(self.config))
+ for module_name in module_names:
+ module = getattr(self, module_name)
+ if isinstance(module, torch.nn.Module) and hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size)
diff --git a/diffusers/src/diffusers/pipelines/README.md b/diffusers/src/diffusers/pipelines/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..7562040596e9028ed56431817f42f4379ecf3435
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/README.md
@@ -0,0 +1,171 @@
+# 🧨 Diffusers Pipelines
+
+Pipelines provide a simple way to run state-of-the-art diffusion models in inference.
+Most diffusion systems consist of multiple independently-trained models and highly adaptable scheduler
+components - all of which are needed to have a functioning end-to-end diffusion system.
+
+As an example, [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) has three independently trained models:
+- [Autoencoder](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/models/vae.py#L392)
+- [Conditional Unet](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/models/unet_2d_condition.py#L12)
+- [CLIP text encoder](https://huggingface.co/docs/transformers/main/en/model_doc/clip#transformers.CLIPTextModel)
+- a scheduler component, [scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py),
+- a [CLIPImageProcessor](https://huggingface.co/docs/transformers/main/en/model_doc/clip#transformers.CLIPImageProcessor),
+- as well as a [safety checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py).
+All of these components are necessary to run stable diffusion in inference even though they were trained
+or created independently from each other.
+
+To that end, we strive to offer all open-sourced, state-of-the-art diffusion system under a unified API.
+More specifically, we strive to provide pipelines that
+- 1. can load the officially published weights and yield 1-to-1 the same outputs as the original implementation according to the corresponding paper (*e.g.* [LDMTextToImagePipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/latent_diffusion), uses the officially released weights of [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752)),
+- 2. have a simple user interface to run the model in inference (see the [Pipelines API](#pipelines-api) section),
+- 3. are easy to understand with code that is self-explanatory and can be read along-side the official paper (see [Pipelines summary](#pipelines-summary)),
+- 4. can easily be contributed by the community (see the [Contribution](#contribution) section).
+
+**Note** that pipelines do not (and should not) offer any training functionality.
+If you are looking for *official* training examples, please have a look at [examples](https://github.com/huggingface/diffusers/tree/main/examples).
+
+
+## Pipelines Summary
+
+The following table summarizes all officially supported pipelines, their corresponding paper, and if
+available a colab notebook to directly try them out.
+
+| Pipeline | Source | Tasks | Colab
+|-------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------|:---:|:---:|
+| [dance diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/dance_diffusion) | [**Dance Diffusion**](https://github.com/Harmonai-org/sample-generator) | *Unconditional Audio Generation* |
+| [ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddpm) | [**Denoising Diffusion Probabilistic Models**](https://arxiv.org/abs/2006.11239) | *Unconditional Image Generation* |
+| [ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/ddim) | [**Denoising Diffusion Implicit Models**](https://arxiv.org/abs/2010.02502) | *Unconditional Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
+| [latent_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | *Text-to-Image Generation* |
+| [latent_diffusion_uncond](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion_uncond) | [**High-Resolution Image Synthesis with Latent Diffusion Models**](https://arxiv.org/abs/2112.10752) | *Unconditional Image Generation* |
+| [pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pndm) | [**Pseudo Numerical Methods for Diffusion Models on Manifolds**](https://arxiv.org/abs/2202.09778) | *Unconditional Image Generation* |
+| [score_sde_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_ve) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | *Unconditional Image Generation* |
+| [score_sde_vp](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/score_sde_vp) | [**Score-Based Generative Modeling through Stochastic Differential Equations**](https://openreview.net/forum?id=PxTIG12RRHS) | *Unconditional Image Generation* |
+| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb)
+| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+| [stable_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion) | [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) | *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
+| [stochastic_karras_ve](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stochastic_karras_ve) | [**Elucidating the Design Space of Diffusion-Based Generative Models**](https://arxiv.org/abs/2206.00364) | *Unconditional Image Generation* |
+
+**Note**: Pipelines are simple examples of how to play around with the diffusion systems as described in the corresponding papers.
+However, most of them can be adapted to use different scheduler components or even different model components. Some pipeline examples are shown in the [Examples](#examples) below.
+
+## Pipelines API
+
+Diffusion models often consist of multiple independently-trained models or other previously existing components.
+
+
+Each model has been trained independently on a different task and the scheduler can easily be swapped out and replaced with a different one.
+During inference, we however want to be able to easily load all components and use them in inference - even if one component, *e.g.* CLIP's text encoder, originates from a different library, such as [Transformers](https://github.com/huggingface/transformers). To that end, all pipelines provide the following functionality:
+
+- [`from_pretrained` method](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/pipeline_utils.py#L139) that accepts a Hugging Face Hub repository id, *e.g.* [runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) or a path to a local directory, *e.g.*
+"./stable-diffusion". To correctly retrieve which models and components should be loaded, one has to provide a `model_index.json` file, *e.g.* [runwayml/stable-diffusion-v1-5/model_index.json](https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/model_index.json), which defines all components that should be
+loaded into the pipelines. More specifically, for each model/component one needs to define the format `: ["", ""]`. `` is the attribute name given to the loaded instance of `` which can be found in the library or pipeline folder called `""`.
+- [`save_pretrained`](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/pipeline_utils.py#L90) that accepts a local path, *e.g.* `./stable-diffusion` under which all models/components of the pipeline will be saved. For each component/model a folder is created inside the local path that is named after the given attribute name, *e.g.* `./stable_diffusion/unet`.
+In addition, a `model_index.json` file is created at the root of the local path, *e.g.* `./stable_diffusion/model_index.json` so that the complete pipeline can again be instantiated
+from the local path.
+- [`to`](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/pipeline_utils.py#L118) which accepts a `string` or `torch.device` to move all models that are of type `torch.nn.Module` to the passed device. The behavior is fully analogous to [PyTorch's `to` method](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.to).
+- [`__call__`] method to use the pipeline in inference. `__call__` defines inference logic of the pipeline and should ideally encompass all aspects of it, from pre-processing to forwarding tensors to the different models and schedulers, as well as post-processing. The API of the `__call__` method can strongly vary from pipeline to pipeline. *E.g.* a text-to-image pipeline, such as [`StableDiffusionPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) should accept among other things the text prompt to generate the image. A pure image generation pipeline, such as [DDPMPipeline](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/ddpm) on the other hand can be run without providing any inputs. To better understand what inputs can be adapted for
+each pipeline, one should look directly into the respective pipeline.
+
+**Note**: All pipelines have PyTorch's autograd disabled by decorating the `__call__` method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should
+not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community)
+
+## Contribution
+
+We are more than happy about any contribution to the officially supported pipelines 🤗. We aspire
+all of our pipelines to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
+
+- **Self-contained**: A pipeline shall be as self-contained as possible. More specifically, this means that all functionality should be either directly defined in the pipeline file itself, should be inherited from (and only from) the [`DiffusionPipeline` class](https://github.com/huggingface/diffusers/blob/5cbed8e0d157f65d3ddc2420dfd09f2df630e978/src/diffusers/pipeline_utils.py#L56) or be directly attached to the model and scheduler components of the pipeline.
+- **Easy-to-use**: Pipelines should be extremely easy to use - one should be able to load the pipeline and
+use it for its designated task, *e.g.* text-to-image generation, in just a couple of lines of code. Most
+logic including pre-processing, an unrolled diffusion loop, and post-processing should all happen inside the `__call__` method.
+- **Easy-to-tweak**: Certain pipelines will not be able to handle all use cases and tasks that you might like them to. If you want to use a certain pipeline for a specific use case that is not yet supported, you might have to copy the pipeline file and tweak the code to your needs. We try to make the pipeline code as readable as possible so that each part –from pre-processing to diffusing to post-processing– can easily be adapted. If you would like the community to benefit from your customized pipeline, we would love to see a contribution to our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community). If you feel that an important pipeline should be part of the official pipelines but isn't, a contribution to the [official pipelines](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines) would be even better.
+- **One-purpose-only**: Pipelines should be used for one task and one task only. Even if two tasks are very similar from a modeling point of view, *e.g.* image2image translation and in-painting, pipelines shall be used for one task only to keep them *easy-to-tweak* and *readable*.
+
+## Examples
+
+### Text-to-Image generation with Stable Diffusion
+
+```python
+# make sure you're logged in with `huggingface-cli login`
+from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
+
+pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+pipe = pipe.to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+image = pipe(prompt).images[0]
+
+image.save("astronaut_rides_horse.png")
+```
+
+### Image-to-Image text-guided generation with Stable Diffusion
+
+The `StableDiffusionImg2ImgPipeline` lets you pass a text prompt and an initial image to condition the generation of new images.
+
+```python
+import requests
+from PIL import Image
+from io import BytesIO
+
+from diffusers import StableDiffusionImg2ImgPipeline
+
+# load the pipeline
+device = "cuda"
+pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ torch_dtype=torch.float16,
+).to(device)
+
+# let's download an initial image
+url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((768, 512))
+
+prompt = "A fantasy landscape, trending on artstation"
+
+images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
+
+images[0].save("fantasy_landscape.png")
+```
+You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+
+### Tweak prompts reusing seeds and latents
+
+You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb).
+
+
+### In-painting using Stable Diffusion
+
+The `StableDiffusionInpaintPipeline` lets you edit specific parts of an image by providing a mask and text prompt.
+
+```python
+import PIL
+import requests
+import torch
+from io import BytesIO
+
+from diffusers import StableDiffusionInpaintPipeline
+
+def download_image(url):
+ response = requests.get(url)
+ return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+init_image = download_image(img_url).resize((512, 512))
+mask_image = download_image(mask_url).resize((512, 512))
+
+pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting",
+ torch_dtype=torch.float16,
+)
+pipe = pipe.to("cuda")
+
+prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
+```
+
+You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
diff --git a/diffusers/src/diffusers/pipelines/__init__.py b/diffusers/src/diffusers/pipelines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..421099a6d746f072222567bbe5f313da5de36206
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/__init__.py
@@ -0,0 +1,139 @@
+from ..utils import (
+ OptionalDependencyNotAvailable,
+ is_flax_available,
+ is_k_diffusion_available,
+ is_librosa_available,
+ is_note_seq_available,
+ is_onnx_available,
+ is_torch_available,
+ is_transformers_available,
+)
+
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_pt_objects import * # noqa F403
+else:
+ from .dance_diffusion import DanceDiffusionPipeline
+ from .ddim import DDIMPipeline
+ from .ddpm import DDPMPipeline
+ from .dit import DiTPipeline
+ from .latent_diffusion import LDMSuperResolutionPipeline
+ from .latent_diffusion_uncond import LDMPipeline
+ from .pipeline_utils import AudioPipelineOutput, DiffusionPipeline, ImagePipelineOutput
+ from .pndm import PNDMPipeline
+ from .repaint import RePaintPipeline
+ from .score_sde_ve import ScoreSdeVePipeline
+ from .stochastic_karras_ve import KarrasVePipeline
+
+try:
+ if not (is_torch_available() and is_librosa_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_librosa_objects import * # noqa F403
+else:
+ from .audio_diffusion import AudioDiffusionPipeline, Mel
+
+try:
+ if not (is_torch_available() and is_transformers_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_transformers_objects import * # noqa F403
+else:
+ from .alt_diffusion import AltDiffusionImg2ImgPipeline, AltDiffusionPipeline
+ from .audioldm import AudioLDMPipeline
+ from .latent_diffusion import LDMTextToImagePipeline
+ from .paint_by_example import PaintByExamplePipeline
+ from .semantic_stable_diffusion import SemanticStableDiffusionPipeline
+ from .stable_diffusion import (
+ CycleDiffusionPipeline,
+ StableDiffusionAttendAndExcitePipeline,
+ StableDiffusionControlNetPipeline,
+ StableDiffusionDepth2ImgPipeline,
+ StableDiffusionImageVariationPipeline,
+ StableDiffusionImg2ImgPipeline,
+ StableDiffusionInpaintPipeline,
+ StableDiffusionInpaintPipelineLegacy,
+ StableDiffusionInstructPix2PixPipeline,
+ StableDiffusionLatentUpscalePipeline,
+ StableDiffusionModelEditingPipeline,
+ StableDiffusionPanoramaPipeline,
+ StableDiffusionPipeline,
+ StableDiffusionPix2PixZeroPipeline,
+ StableDiffusionSAGPipeline,
+ StableDiffusionUpscalePipeline,
+ StableUnCLIPImg2ImgPipeline,
+ StableUnCLIPPipeline,
+ )
+ from .stable_diffusion_safe import StableDiffusionPipelineSafe
+ from .text_to_video_synthesis import TextToVideoSDPipeline
+ from .unclip import UnCLIPImageVariationPipeline, UnCLIPPipeline
+ from .versatile_diffusion import (
+ VersatileDiffusionDualGuidedPipeline,
+ VersatileDiffusionImageVariationPipeline,
+ VersatileDiffusionPipeline,
+ VersatileDiffusionTextToImagePipeline,
+ )
+ from .vq_diffusion import VQDiffusionPipeline
+
+try:
+ if not is_onnx_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_onnx_objects import * # noqa F403
+else:
+ from .onnx_utils import OnnxRuntimeModel
+
+try:
+ if not (is_torch_available() and is_transformers_available() and is_onnx_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_transformers_and_onnx_objects import * # noqa F403
+else:
+ from .stable_diffusion import (
+ OnnxStableDiffusionImg2ImgPipeline,
+ OnnxStableDiffusionInpaintPipeline,
+ OnnxStableDiffusionInpaintPipelineLegacy,
+ OnnxStableDiffusionPipeline,
+ OnnxStableDiffusionUpscalePipeline,
+ StableDiffusionOnnxPipeline,
+ )
+
+try:
+ if not (is_torch_available() and is_transformers_available() and is_k_diffusion_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_transformers_and_k_diffusion_objects import * # noqa F403
+else:
+ from .stable_diffusion import StableDiffusionKDiffusionPipeline
+
+try:
+ if not is_flax_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_flax_objects import * # noqa F403
+else:
+ from .pipeline_flax_utils import FlaxDiffusionPipeline
+
+
+try:
+ if not (is_flax_available() and is_transformers_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_flax_and_transformers_objects import * # noqa F403
+else:
+ from .stable_diffusion import (
+ FlaxStableDiffusionControlNetPipeline,
+ FlaxStableDiffusionImg2ImgPipeline,
+ FlaxStableDiffusionInpaintPipeline,
+ FlaxStableDiffusionPipeline,
+ )
+try:
+ if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_transformers_and_torch_and_note_seq_objects import * # noqa F403
+else:
+ from .spectrogram_diffusion import MidiProcessor, SpectrogramDiffusionPipeline
diff --git a/diffusers/src/diffusers/pipelines/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b4429f091bc17f20bc278b27e2b3f3cf98063307
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e7290e3acd18faf2aec66017a5b056bb86528a79
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/__pycache__/pipeline_utils.cpython-310.pyc b/diffusers/src/diffusers/pipelines/__pycache__/pipeline_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..352563855b9c41b41d57653e625fceb62341b4d8
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/__pycache__/pipeline_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/__pycache__/pipeline_utils.cpython-39.pyc b/diffusers/src/diffusers/pipelines/__pycache__/pipeline_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..64a3b2b83c366835d213be1a6e19dbc4e279ba98
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/__pycache__/pipeline_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/alt_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..dab2d8db1045ef27ff5d2234951c1488f547401b
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/alt_diffusion/__init__.py
@@ -0,0 +1,33 @@
+from dataclasses import dataclass
+from typing import List, Optional, Union
+
+import numpy as np
+import PIL
+from PIL import Image
+
+from ...utils import BaseOutput, is_torch_available, is_transformers_available
+
+
+@dataclass
+# Copied from diffusers.pipelines.stable_diffusion.__init__.StableDiffusionPipelineOutput with Stable->Alt
+class AltDiffusionPipelineOutput(BaseOutput):
+ """
+ Output class for Alt Diffusion pipelines.
+
+ Args:
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
+ num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
+ nsfw_content_detected (`List[bool]`)
+ List of flags denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, or `None` if safety checking could not be performed.
+ """
+
+ images: Union[List[PIL.Image.Image], np.ndarray]
+ nsfw_content_detected: Optional[List[bool]]
+
+
+if is_transformers_available() and is_torch_available():
+ from .modeling_roberta_series import RobertaSeriesModelWithTransformation
+ from .pipeline_alt_diffusion import AltDiffusionPipeline
+ from .pipeline_alt_diffusion_img2img import AltDiffusionImg2ImgPipeline
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8a87e47da8b9374eac8677cea09296f7c8f46519
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7c3789f0e14a469434ccf80783b0581dc4b503a5
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/modeling_roberta_series.cpython-310.pyc b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/modeling_roberta_series.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5023dcfed3b7b759d7ad1c76f3b33cad976a61b9
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/modeling_roberta_series.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/modeling_roberta_series.cpython-39.pyc b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/modeling_roberta_series.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b1d06e9a52256f9f51d9e31f98a86a30b9af290b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/modeling_roberta_series.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cae562bd383773046f800823758504aadd85b6f5
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f297d6adf78cfb35ae34bfede6ddb7cd58199109
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion_img2img.cpython-310.pyc b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion_img2img.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5df52df4deb452066c8c5e762557573e2b65bf19
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion_img2img.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion_img2img.cpython-39.pyc b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion_img2img.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..91bb726147bfb776550af68922e2d165c880fcb1
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/alt_diffusion/__pycache__/pipeline_alt_diffusion_img2img.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/modeling_roberta_series.py b/diffusers/src/diffusers/pipelines/alt_diffusion/modeling_roberta_series.py
new file mode 100644
index 0000000000000000000000000000000000000000..637d6dd18698f3c6f1787c5e4d4514e4fc254908
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/alt_diffusion/modeling_roberta_series.py
@@ -0,0 +1,109 @@
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+from torch import nn
+from transformers import RobertaPreTrainedModel, XLMRobertaConfig, XLMRobertaModel
+from transformers.utils import ModelOutput
+
+
+@dataclass
+class TransformationModelOutput(ModelOutput):
+ """
+ Base class for text model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
+ The text embeddings obtained by applying the projection layer to the pooler_output.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ projection_state: Optional[torch.FloatTensor] = None
+ last_hidden_state: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+class RobertaSeriesConfig(XLMRobertaConfig):
+ def __init__(
+ self,
+ pad_token_id=1,
+ bos_token_id=0,
+ eos_token_id=2,
+ project_dim=512,
+ pooler_fn="cls",
+ learn_encoder=False,
+ use_attention_mask=True,
+ **kwargs,
+ ):
+ super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
+ self.project_dim = project_dim
+ self.pooler_fn = pooler_fn
+ self.learn_encoder = learn_encoder
+ self.use_attention_mask = use_attention_mask
+
+
+class RobertaSeriesModelWithTransformation(RobertaPreTrainedModel):
+ _keys_to_ignore_on_load_unexpected = [r"pooler"]
+ _keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
+ base_model_prefix = "roberta"
+ config_class = RobertaSeriesConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.roberta = XLMRobertaModel(config)
+ self.transformation = nn.Linear(config.hidden_size, config.project_dim)
+ self.post_init()
+
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ ):
+ r""" """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.base_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ projection_state = self.transformation(outputs.last_hidden_state)
+
+ return TransformationModelOutput(
+ projection_state=projection_state,
+ last_hidden_state=outputs.last_hidden_state,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion.py b/diffusers/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5bb8f9ac7b133ff4ec674d4156ae527b386f916
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion.py
@@ -0,0 +1,720 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, XLMRobertaTokenizer
+
+from diffusers.utils import is_accelerate_available, is_accelerate_version
+
+from ...configuration_utils import FrozenDict
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import deprecate, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from . import AltDiffusionPipelineOutput, RobertaSeriesModelWithTransformation
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import AltDiffusionPipeline
+
+ >>> pipe = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion-m9", torch_dtype=torch.float16)
+ >>> pipe = pipe.to("cuda")
+
+ >>> # "dark elf princess, highly detailed, d & d, fantasy, highly detailed, digital painting, trending on artstation, concept art, sharp focus, illustration, art by artgerm and greg rutkowski and fuji choko and viktoria gavrilenko and hoang lap"
+ >>> prompt = "黑暗精灵公主,非常详细,幻想,非常详细,数字绘画,概念艺术,敏锐的焦点,插图"
+ >>> image = pipe(prompt).images[0]
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline with Stable->Alt, CLIPTextModel->RobertaSeriesModelWithTransformation, CLIPTokenizer->XLMRobertaTokenizer, AltDiffusionSafetyChecker->StableDiffusionSafetyChecker
+class AltDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Alt Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`RobertaSeriesModelWithTransformation`]):
+ Frozen text-encoder. Alt Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.RobertaSeriesModelWithTransformation),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`XLMRobertaTokenizer`):
+ Tokenizer of class
+ [XLMRobertaTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.XLMRobertaTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: RobertaSeriesModelWithTransformation,
+ tokenizer: XLMRobertaTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Alt Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.AltDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.AltDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.AltDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+ elif output_type == "pil":
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 10. Convert to PIL
+ image = self.numpy_to_pil(image)
+ else:
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return AltDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion_img2img.py b/diffusers/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb8116f2f5d5c23efe7a285a73d8dd13ec69b8c7
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/alt_diffusion/pipeline_alt_diffusion_img2img.py
@@ -0,0 +1,754 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, XLMRobertaTokenizer
+
+from diffusers.utils import is_accelerate_available, is_accelerate_version
+
+from ...configuration_utils import FrozenDict
+from ...image_processor import VaeImageProcessor
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import PIL_INTERPOLATION, deprecate, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from . import AltDiffusionPipelineOutput, RobertaSeriesModelWithTransformation
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import requests
+ >>> import torch
+ >>> from PIL import Image
+ >>> from io import BytesIO
+
+ >>> from diffusers import AltDiffusionImg2ImgPipeline
+
+ >>> device = "cuda"
+ >>> model_id_or_path = "BAAI/AltDiffusion-m9"
+ >>> pipe = AltDiffusionImg2ImgPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
+ >>> pipe = pipe.to(device)
+
+ >>> url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+
+ >>> response = requests.get(url)
+ >>> init_image = Image.open(BytesIO(response.content)).convert("RGB")
+ >>> init_image = init_image.resize((768, 512))
+
+ >>> # "A fantasy landscape, trending on artstation"
+ >>> prompt = "幻想风景, artstation"
+
+ >>> images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
+ >>> images[0].save("幻想风景.png")
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+
+ image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline with Stable->Alt, CLIPTextModel->RobertaSeriesModelWithTransformation, CLIPTokenizer->XLMRobertaTokenizer, AltDiffusionSafetyChecker->StableDiffusionSafetyChecker
+class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-guided image to image generation using Alt Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`RobertaSeriesModelWithTransformation`]):
+ Frozen text-encoder. Alt Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.RobertaSeriesModelWithTransformation),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`XLMRobertaTokenizer`):
+ Tokenizer of class
+ [XLMRobertaTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.XLMRobertaTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: RobertaSeriesModelWithTransformation,
+ tokenizer: XLMRobertaTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Alt Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(
+ requires_safety_checker=requires_safety_checker,
+ )
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def run_safety_checker(self, image, device, dtype):
+ feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
+ safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ return image
+
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self, prompt, strength, callback_steps, negative_prompt=None, prompt_embeds=None, negative_prompt_embeds=None
+ ):
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+
+ def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
+ if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ image = image.to(device=device, dtype=dtype)
+
+ batch_size = batch_size * num_images_per_prompt
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if isinstance(generator, list):
+ init_latents = [
+ self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = self.vae.encode(image).latent_dist.sample(generator)
+
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ deprecation_message = (
+ f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
+ " images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
+ " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
+ " your script to pass as many initial images as text prompts to suppress this warning."
+ )
+ deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
+ additional_image_per_prompt = batch_size // init_latents.shape[0]
+ init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents], dim=0)
+
+ shape = init_latents.shape
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+
+ # get latents
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
+ will be used as a starting point, adding more noise to it the larger the `strength`. The number of
+ denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
+ be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference. This parameter will be modulated by `strength`.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
+ is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.AltDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.AltDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.AltDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(prompt, strength, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds)
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Preprocess image
+ image = self.image_processor.preprocess(image)
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 6. Prepare latent variables
+ latents = self.prepare_latents(
+ image, latent_timestep, batch_size, num_images_per_prompt, prompt_embeds.dtype, device, generator
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ if output_type not in ["latent", "pt", "np", "pil"]:
+ deprecation_message = (
+ f"the output_type {output_type} is outdated. Please make sure to set it to one of these instead: "
+ "`pil`, `np`, `pt`, `latent`"
+ )
+ deprecate("Unsupported output_type", "1.0.0", deprecation_message, standard_warn=False)
+ output_type = "np"
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+
+ else:
+ image = self.decode_latents(latents)
+
+ if self.safety_checker is not None:
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ has_nsfw_concept = False
+
+ image = self.image_processor.postprocess(image, output_type=output_type)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return AltDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/audio_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..58554c45ea52b9897293217652db36fdace7549f
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/audio_diffusion/__init__.py
@@ -0,0 +1,2 @@
+from .mel import Mel
+from .pipeline_audio_diffusion import AudioDiffusionPipeline
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..078f439da7b71c637a186998eedf7ad14870c306
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6af5f57d71da729b6ff7d83c04f309858f4eaded
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/mel.cpython-310.pyc b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/mel.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..af561cc852acd3c6052643e565375a70174e0af4
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/mel.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/mel.cpython-39.pyc b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/mel.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d81bcc23347ba20a027ddce190a76906fdd53851
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/mel.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/pipeline_audio_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/pipeline_audio_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6e3f1a2eece590da06d96105efff45230cb7b006
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/pipeline_audio_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/pipeline_audio_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/pipeline_audio_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ca1d8a10cfbaedab7c2b20ccb1e1363e07d7f27e
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audio_diffusion/__pycache__/pipeline_audio_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/mel.py b/diffusers/src/diffusers/pipelines/audio_diffusion/mel.py
new file mode 100644
index 0000000000000000000000000000000000000000..1bf28fd25a5a5d39416eaf6bfd76b7f6945f4b19
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/audio_diffusion/mel.py
@@ -0,0 +1,160 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import numpy as np # noqa: E402
+
+from ...configuration_utils import ConfigMixin, register_to_config
+from ...schedulers.scheduling_utils import SchedulerMixin
+
+
+try:
+ import librosa # noqa: E402
+
+ _librosa_can_be_imported = True
+ _import_error = ""
+except Exception as e:
+ _librosa_can_be_imported = False
+ _import_error = (
+ f"Cannot import librosa because {e}. Make sure to correctly install librosa to be able to install it."
+ )
+
+
+from PIL import Image # noqa: E402
+
+
+class Mel(ConfigMixin, SchedulerMixin):
+ """
+ Parameters:
+ x_res (`int`): x resolution of spectrogram (time)
+ y_res (`int`): y resolution of spectrogram (frequency bins)
+ sample_rate (`int`): sample rate of audio
+ n_fft (`int`): number of Fast Fourier Transforms
+ hop_length (`int`): hop length (a higher number is recommended for lower than 256 y_res)
+ top_db (`int`): loudest in decibels
+ n_iter (`int`): number of iterations for Griffin Linn mel inversion
+ """
+
+ config_name = "mel_config.json"
+
+ @register_to_config
+ def __init__(
+ self,
+ x_res: int = 256,
+ y_res: int = 256,
+ sample_rate: int = 22050,
+ n_fft: int = 2048,
+ hop_length: int = 512,
+ top_db: int = 80,
+ n_iter: int = 32,
+ ):
+ self.hop_length = hop_length
+ self.sr = sample_rate
+ self.n_fft = n_fft
+ self.top_db = top_db
+ self.n_iter = n_iter
+ self.set_resolution(x_res, y_res)
+ self.audio = None
+
+ if not _librosa_can_be_imported:
+ raise ValueError(_import_error)
+
+ def set_resolution(self, x_res: int, y_res: int):
+ """Set resolution.
+
+ Args:
+ x_res (`int`): x resolution of spectrogram (time)
+ y_res (`int`): y resolution of spectrogram (frequency bins)
+ """
+ self.x_res = x_res
+ self.y_res = y_res
+ self.n_mels = self.y_res
+ self.slice_size = self.x_res * self.hop_length - 1
+
+ def load_audio(self, audio_file: str = None, raw_audio: np.ndarray = None):
+ """Load audio.
+
+ Args:
+ audio_file (`str`): must be a file on disk due to Librosa limitation or
+ raw_audio (`np.ndarray`): audio as numpy array
+ """
+ if audio_file is not None:
+ self.audio, _ = librosa.load(audio_file, mono=True, sr=self.sr)
+ else:
+ self.audio = raw_audio
+
+ # Pad with silence if necessary.
+ if len(self.audio) < self.x_res * self.hop_length:
+ self.audio = np.concatenate([self.audio, np.zeros((self.x_res * self.hop_length - len(self.audio),))])
+
+ def get_number_of_slices(self) -> int:
+ """Get number of slices in audio.
+
+ Returns:
+ `int`: number of spectograms audio can be sliced into
+ """
+ return len(self.audio) // self.slice_size
+
+ def get_audio_slice(self, slice: int = 0) -> np.ndarray:
+ """Get slice of audio.
+
+ Args:
+ slice (`int`): slice number of audio (out of get_number_of_slices())
+
+ Returns:
+ `np.ndarray`: audio as numpy array
+ """
+ return self.audio[self.slice_size * slice : self.slice_size * (slice + 1)]
+
+ def get_sample_rate(self) -> int:
+ """Get sample rate:
+
+ Returns:
+ `int`: sample rate of audio
+ """
+ return self.sr
+
+ def audio_slice_to_image(self, slice: int) -> Image.Image:
+ """Convert slice of audio to spectrogram.
+
+ Args:
+ slice (`int`): slice number of audio to convert (out of get_number_of_slices())
+
+ Returns:
+ `PIL Image`: grayscale image of x_res x y_res
+ """
+ S = librosa.feature.melspectrogram(
+ y=self.get_audio_slice(slice), sr=self.sr, n_fft=self.n_fft, hop_length=self.hop_length, n_mels=self.n_mels
+ )
+ log_S = librosa.power_to_db(S, ref=np.max, top_db=self.top_db)
+ bytedata = (((log_S + self.top_db) * 255 / self.top_db).clip(0, 255) + 0.5).astype(np.uint8)
+ image = Image.fromarray(bytedata)
+ return image
+
+ def image_to_audio(self, image: Image.Image) -> np.ndarray:
+ """Converts spectrogram to audio.
+
+ Args:
+ image (`PIL Image`): x_res x y_res grayscale image
+
+ Returns:
+ audio (`np.ndarray`): raw audio
+ """
+ bytedata = np.frombuffer(image.tobytes(), dtype="uint8").reshape((image.height, image.width))
+ log_S = bytedata.astype("float") * self.top_db / 255 - self.top_db
+ S = librosa.db_to_power(log_S)
+ audio = librosa.feature.inverse.mel_to_audio(
+ S, sr=self.sr, n_fft=self.n_fft, hop_length=self.hop_length, n_iter=self.n_iter
+ )
+ return audio
diff --git a/diffusers/src/diffusers/pipelines/audio_diffusion/pipeline_audio_diffusion.py b/diffusers/src/diffusers/pipelines/audio_diffusion/pipeline_audio_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b88270cbbe6935d9fe01844c73bc14a7abf2e8c
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/audio_diffusion/pipeline_audio_diffusion.py
@@ -0,0 +1,266 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from math import acos, sin
+from typing import List, Tuple, Union
+
+import numpy as np
+import torch
+from PIL import Image
+
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import DDIMScheduler, DDPMScheduler
+from ...utils import randn_tensor
+from ..pipeline_utils import AudioPipelineOutput, BaseOutput, DiffusionPipeline, ImagePipelineOutput
+from .mel import Mel
+
+
+class AudioDiffusionPipeline(DiffusionPipeline):
+ """
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ vqae ([`AutoencoderKL`]): Variational AutoEncoder for Latent Audio Diffusion or None
+ unet ([`UNet2DConditionModel`]): UNET model
+ mel ([`Mel`]): transform audio <-> spectrogram
+ scheduler ([`DDIMScheduler` or `DDPMScheduler`]): de-noising scheduler
+ """
+
+ _optional_components = ["vqvae"]
+
+ def __init__(
+ self,
+ vqvae: AutoencoderKL,
+ unet: UNet2DConditionModel,
+ mel: Mel,
+ scheduler: Union[DDIMScheduler, DDPMScheduler],
+ ):
+ super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler, mel=mel, vqvae=vqvae)
+
+ def get_input_dims(self) -> Tuple:
+ """Returns dimension of input image
+
+ Returns:
+ `Tuple`: (height, width)
+ """
+ input_module = self.vqvae if self.vqvae is not None else self.unet
+ # For backwards compatibility
+ sample_size = (
+ (input_module.sample_size, input_module.sample_size)
+ if type(input_module.sample_size) == int
+ else input_module.sample_size
+ )
+ return sample_size
+
+ def get_default_steps(self) -> int:
+ """Returns default number of steps recommended for inference
+
+ Returns:
+ `int`: number of steps
+ """
+ return 50 if isinstance(self.scheduler, DDIMScheduler) else 1000
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ audio_file: str = None,
+ raw_audio: np.ndarray = None,
+ slice: int = 0,
+ start_step: int = 0,
+ steps: int = None,
+ generator: torch.Generator = None,
+ mask_start_secs: float = 0,
+ mask_end_secs: float = 0,
+ step_generator: torch.Generator = None,
+ eta: float = 0,
+ noise: torch.Tensor = None,
+ encoding: torch.Tensor = None,
+ return_dict=True,
+ ) -> Union[
+ Union[AudioPipelineOutput, ImagePipelineOutput],
+ Tuple[List[Image.Image], Tuple[int, List[np.ndarray]]],
+ ]:
+ """Generate random mel spectrogram from audio input and convert to audio.
+
+ Args:
+ batch_size (`int`): number of samples to generate
+ audio_file (`str`): must be a file on disk due to Librosa limitation or
+ raw_audio (`np.ndarray`): audio as numpy array
+ slice (`int`): slice number of audio to convert
+ start_step (int): step to start from
+ steps (`int`): number of de-noising steps (defaults to 50 for DDIM, 1000 for DDPM)
+ generator (`torch.Generator`): random number generator or None
+ mask_start_secs (`float`): number of seconds of audio to mask (not generate) at start
+ mask_end_secs (`float`): number of seconds of audio to mask (not generate) at end
+ step_generator (`torch.Generator`): random number generator used to de-noise or None
+ eta (`float`): parameter between 0 and 1 used with DDIM scheduler
+ noise (`torch.Tensor`): noise tensor of shape (batch_size, 1, height, width) or None
+ encoding (`torch.Tensor`): for UNet2DConditionModel shape (batch_size, seq_length, cross_attention_dim)
+ return_dict (`bool`): if True return AudioPipelineOutput, ImagePipelineOutput else Tuple
+
+ Returns:
+ `List[PIL Image]`: mel spectrograms (`float`, `List[np.ndarray]`): sample rate and raw audios
+ """
+
+ steps = steps or self.get_default_steps()
+ self.scheduler.set_timesteps(steps)
+ step_generator = step_generator or generator
+ # For backwards compatibility
+ if type(self.unet.sample_size) == int:
+ self.unet.sample_size = (self.unet.sample_size, self.unet.sample_size)
+ input_dims = self.get_input_dims()
+ self.mel.set_resolution(x_res=input_dims[1], y_res=input_dims[0])
+ if noise is None:
+ noise = randn_tensor(
+ (
+ batch_size,
+ self.unet.in_channels,
+ self.unet.sample_size[0],
+ self.unet.sample_size[1],
+ ),
+ generator=generator,
+ device=self.device,
+ )
+ images = noise
+ mask = None
+
+ if audio_file is not None or raw_audio is not None:
+ self.mel.load_audio(audio_file, raw_audio)
+ input_image = self.mel.audio_slice_to_image(slice)
+ input_image = np.frombuffer(input_image.tobytes(), dtype="uint8").reshape(
+ (input_image.height, input_image.width)
+ )
+ input_image = (input_image / 255) * 2 - 1
+ input_images = torch.tensor(input_image[np.newaxis, :, :], dtype=torch.float).to(self.device)
+
+ if self.vqvae is not None:
+ input_images = self.vqvae.encode(torch.unsqueeze(input_images, 0)).latent_dist.sample(
+ generator=generator
+ )[0]
+ input_images = self.vqvae.config.scaling_factor * input_images
+
+ if start_step > 0:
+ images[0, 0] = self.scheduler.add_noise(input_images, noise, self.scheduler.timesteps[start_step - 1])
+
+ pixels_per_second = (
+ self.unet.sample_size[1] * self.mel.get_sample_rate() / self.mel.x_res / self.mel.hop_length
+ )
+ mask_start = int(mask_start_secs * pixels_per_second)
+ mask_end = int(mask_end_secs * pixels_per_second)
+ mask = self.scheduler.add_noise(input_images, noise, torch.tensor(self.scheduler.timesteps[start_step:]))
+
+ for step, t in enumerate(self.progress_bar(self.scheduler.timesteps[start_step:])):
+ if isinstance(self.unet, UNet2DConditionModel):
+ model_output = self.unet(images, t, encoding)["sample"]
+ else:
+ model_output = self.unet(images, t)["sample"]
+
+ if isinstance(self.scheduler, DDIMScheduler):
+ images = self.scheduler.step(
+ model_output=model_output,
+ timestep=t,
+ sample=images,
+ eta=eta,
+ generator=step_generator,
+ )["prev_sample"]
+ else:
+ images = self.scheduler.step(
+ model_output=model_output,
+ timestep=t,
+ sample=images,
+ generator=step_generator,
+ )["prev_sample"]
+
+ if mask is not None:
+ if mask_start > 0:
+ images[:, :, :, :mask_start] = mask[:, step, :, :mask_start]
+ if mask_end > 0:
+ images[:, :, :, -mask_end:] = mask[:, step, :, -mask_end:]
+
+ if self.vqvae is not None:
+ # 0.18215 was scaling factor used in training to ensure unit variance
+ images = 1 / self.vqvae.config.scaling_factor * images
+ images = self.vqvae.decode(images)["sample"]
+
+ images = (images / 2 + 0.5).clamp(0, 1)
+ images = images.cpu().permute(0, 2, 3, 1).numpy()
+ images = (images * 255).round().astype("uint8")
+ images = list(
+ (Image.fromarray(_[:, :, 0]) for _ in images)
+ if images.shape[3] == 1
+ else (Image.fromarray(_, mode="RGB").convert("L") for _ in images)
+ )
+
+ audios = [self.mel.image_to_audio(_) for _ in images]
+ if not return_dict:
+ return images, (self.mel.get_sample_rate(), audios)
+
+ return BaseOutput(**AudioPipelineOutput(np.array(audios)[:, np.newaxis, :]), **ImagePipelineOutput(images))
+
+ @torch.no_grad()
+ def encode(self, images: List[Image.Image], steps: int = 50) -> np.ndarray:
+ """Reverse step process: recover noisy image from generated image.
+
+ Args:
+ images (`List[PIL Image]`): list of images to encode
+ steps (`int`): number of encoding steps to perform (defaults to 50)
+
+ Returns:
+ `np.ndarray`: noise tensor of shape (batch_size, 1, height, width)
+ """
+
+ # Only works with DDIM as this method is deterministic
+ assert isinstance(self.scheduler, DDIMScheduler)
+ self.scheduler.set_timesteps(steps)
+ sample = np.array(
+ [np.frombuffer(image.tobytes(), dtype="uint8").reshape((1, image.height, image.width)) for image in images]
+ )
+ sample = (sample / 255) * 2 - 1
+ sample = torch.Tensor(sample).to(self.device)
+
+ for t in self.progress_bar(torch.flip(self.scheduler.timesteps, (0,))):
+ prev_timestep = t - self.scheduler.num_train_timesteps // self.scheduler.num_inference_steps
+ alpha_prod_t = self.scheduler.alphas_cumprod[t]
+ alpha_prod_t_prev = (
+ self.scheduler.alphas_cumprod[prev_timestep]
+ if prev_timestep >= 0
+ else self.scheduler.final_alpha_cumprod
+ )
+ beta_prod_t = 1 - alpha_prod_t
+ model_output = self.unet(sample, t)["sample"]
+ pred_sample_direction = (1 - alpha_prod_t_prev) ** (0.5) * model_output
+ sample = (sample - pred_sample_direction) * alpha_prod_t_prev ** (-0.5)
+ sample = sample * alpha_prod_t ** (0.5) + beta_prod_t ** (0.5) * model_output
+
+ return sample
+
+ @staticmethod
+ def slerp(x0: torch.Tensor, x1: torch.Tensor, alpha: float) -> torch.Tensor:
+ """Spherical Linear intERPolation
+
+ Args:
+ x0 (`torch.Tensor`): first tensor to interpolate between
+ x1 (`torch.Tensor`): seconds tensor to interpolate between
+ alpha (`float`): interpolation between 0 and 1
+
+ Returns:
+ `torch.Tensor`: interpolated tensor
+ """
+
+ theta = acos(torch.dot(torch.flatten(x0), torch.flatten(x1)) / torch.norm(x0) / torch.norm(x1))
+ return sin((1 - alpha) * theta) * x0 / sin(theta) + sin(alpha * theta) * x1 / sin(theta)
diff --git a/diffusers/src/diffusers/pipelines/audioldm/.ipynb_checkpoints/__init__-checkpoint.py b/diffusers/src/diffusers/pipelines/audioldm/.ipynb_checkpoints/__init__-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa9ae5b8ca12e51ac82040cd9224d8a2fb583e0d
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/audioldm/.ipynb_checkpoints/__init__-checkpoint.py
@@ -0,0 +1,18 @@
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ is_torch_available,
+ is_transformers_available,
+ is_transformers_version,
+)
+
+# from .pipeline_audioldm import AudioLDMPipeline
+
+try:
+ if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.27.0")):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import (
+ AudioLDMPipeline,
+ )
+else:
+ from .pipeline_audioldm import AudioLDMPipeline
diff --git a/diffusers/src/diffusers/pipelines/audioldm/.ipynb_checkpoints/pipeline_audioldm-checkpoint.py b/diffusers/src/diffusers/pipelines/audioldm/.ipynb_checkpoints/pipeline_audioldm-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..b392cd4cc24655a80aae14f0ac922a9a968b1e70
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/audioldm/.ipynb_checkpoints/pipeline_audioldm-checkpoint.py
@@ -0,0 +1,601 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from transformers import ClapTextModelWithProjection, RobertaTokenizer, RobertaTokenizerFast, SpeechT5HifiGan
+
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_available, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import AudioPipelineOutput, DiffusionPipeline
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import AudioLDMPipeline
+
+ >>> pipe = AudioLDMPipeline.from_pretrained("cvssp/audioldm", torch_dtype=torch.float16)
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "A hammer hitting a wooden surface"
+ >>> audio = pipe(prompt).audio[0]
+ ```
+"""
+
+
+class AudioLDMPipeline(DiffusionPipeline):
+ r"""
+ Pipeline for text-to-audio generation using AudioLDM.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode audios to and from latent representations.
+ text_encoder ([`ClapTextModelWithProjection`]):
+ Frozen text-encoder. AudioLDM uses the text portion of
+ [CLAP](https://huggingface.co/docs/transformers/main/model_doc/clap#transformers.ClapTextModelWithProjection),
+ specifically the [RoBERTa HSTAT-unfused](https://huggingface.co/laion/clap-htsat-unfused) variant.
+ tokenizer ([`PreTrainedTokenizer`]):
+ Tokenizer of class
+ [RobertaTokenizer](https://huggingface.co/docs/transformers/model_doc/roberta#transformers.RobertaTokenizer).
+ unet ([`UNet2DConditionModel`]): U-Net architecture to denoise the encoded audio latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded audio latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ vocoder ([`SpeechT5HifiGan`]):
+ Vocoder of class
+ [SpeechT5HifiGan](https://huggingface.co/docs/transformers/main/en/model_doc/speecht5#transformers.SpeechT5HifiGan).
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: ClapTextModelWithProjection,
+ tokenizer: Union[RobertaTokenizer, RobertaTokenizerFast],
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ vocoder: SpeechT5HifiGan,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ vocoder=vocoder,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and vocoder have their state dicts saved to CPU and then are moved to a `torch.device('meta')
+ and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.vocoder]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_waveforms_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device (`torch.device`):
+ torch device
+ num_waveforms_per_prompt (`int`):
+ number of waveforms that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the audio generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ attention_mask = text_inputs.attention_mask
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLAP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask.to(device),
+ )
+ prompt_embeds = prompt_embeds.text_embeds
+ # additional L_2 normalization over each hidden-state
+ prompt_embeds = F.normalize(prompt_embeds, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ (
+ bs_embed,
+ seq_len,
+ ) = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_waveforms_per_prompt)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_waveforms_per_prompt, seq_len)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ uncond_input_ids = uncond_input.input_ids.to(device)
+ attention_mask = uncond_input.attention_mask.to(device)
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input_ids,
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds.text_embeds
+ # additional L_2 normalization over each hidden-state
+ negative_prompt_embeds = F.normalize(negative_prompt_embeds, dim=-1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_waveforms_per_prompt)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_waveforms_per_prompt, seq_len)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ mel_spectrogram = self.vae.decode(latents).sample
+ return mel_spectrogram
+
+ def mel_spectrogram_to_waveform(self, mel_spectrogram):
+ if mel_spectrogram.dim() == 4:
+ mel_spectrogram = mel_spectrogram.squeeze(1)
+
+ waveform = self.vocoder(mel_spectrogram)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ waveform = waveform.cpu()
+ return waveform
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ audio_length_in_s,
+ vocoder_upsample_factor,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ min_audio_length_in_s = vocoder_upsample_factor * self.vae_scale_factor
+ if audio_length_in_s < min_audio_length_in_s:
+ raise ValueError(
+ f"`audio_length_in_s` has to be a positive value greater than or equal to {min_audio_length_in_s}, but "
+ f"is {audio_length_in_s}."
+ )
+
+ if self.vocoder.config.model_in_dim % self.vae_scale_factor != 0:
+ raise ValueError(
+ f"The number of frequency bins in the vocoder's log-mel spectrogram has to be divisible by the "
+ f"VAE scale factor, but got {self.vocoder.config.model_in_dim} bins and a scale factor of "
+ f"{self.vae_scale_factor}."
+ )
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents with width->self.vocoder.config.model_in_dim
+ def prepare_latents(self, batch_size, num_channels_latents, height, dtype, device, generator, latents=None):
+ shape = (
+ batch_size,
+ num_channels_latents,
+ height // self.vae_scale_factor,
+ self.vocoder.config.model_in_dim // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ audio_length_in_s: Optional[float] = None,
+ num_inference_steps: int = 10,
+ guidance_scale: float = 2.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_waveforms_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: Optional[int] = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ output_type: Optional[str] = "np",
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the audio generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ audio_length_in_s (`int`, *optional*, defaults to 5.12):
+ The length of the generated audio sample in seconds.
+ num_inference_steps (`int`, *optional*, defaults to 10):
+ The number of denoising steps. More denoising steps usually lead to a higher quality audio at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 2.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate audios that are closely linked to the text `prompt`,
+ usually at the expense of lower sound quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the audio generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_waveforms_per_prompt (`int`, *optional*, defaults to 1):
+ The number of waveforms to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for audio
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ output_type (`str`, *optional*, defaults to `"np"`):
+ The output format of the generate image. Choose between:
+ - `"np"`: Return Numpy `np.ndarray` objects.
+ - `"pt"`: Return PyTorch `torch.Tensor` objects.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated audios.
+ """
+ # 0. Convert audio input length from seconds to spectrogram height
+ vocoder_upsample_factor = np.prod(self.vocoder.config.upsample_rates) / self.vocoder.config.sampling_rate
+
+ if audio_length_in_s is None:
+ audio_length_in_s = self.unet.config.sample_size * self.vae_scale_factor * vocoder_upsample_factor
+
+ height = int(audio_length_in_s / vocoder_upsample_factor)
+
+ original_waveform_length = int(audio_length_in_s * self.vocoder.config.sampling_rate)
+ if height % self.vae_scale_factor != 0:
+ height = int(np.ceil(height / self.vae_scale_factor)) * self.vae_scale_factor
+ logger.info(
+ f"Audio length in seconds {audio_length_in_s} is increased to {height * vocoder_upsample_factor} "
+ f"so that it can be handled by the model. It will be cut to {audio_length_in_s} after the "
+ f"denoising process."
+ )
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ audio_length_in_s,
+ vocoder_upsample_factor,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_waveforms_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_waveforms_per_prompt,
+ num_channels_latents,
+ height,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=None,
+ class_labels=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ mel_spectrogram = self.decode_latents(latents)
+
+ audio = self.mel_spectrogram_to_waveform(mel_spectrogram)
+
+ audio = audio[:, :original_waveform_length]
+
+ if output_type == "np":
+ audio = audio.numpy()
+
+ if not return_dict:
+ return (audio,)
+
+ return AudioPipelineOutput(audios=audio)
diff --git a/diffusers/src/diffusers/pipelines/audioldm/__init__.py b/diffusers/src/diffusers/pipelines/audioldm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa9ae5b8ca12e51ac82040cd9224d8a2fb583e0d
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/audioldm/__init__.py
@@ -0,0 +1,18 @@
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ is_torch_available,
+ is_transformers_available,
+ is_transformers_version,
+)
+
+# from .pipeline_audioldm import AudioLDMPipeline
+
+try:
+ if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.27.0")):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import (
+ AudioLDMPipeline,
+ )
+else:
+ from .pipeline_audioldm import AudioLDMPipeline
diff --git a/diffusers/src/diffusers/pipelines/audioldm/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/audioldm/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d555b3d513288853638335e723c5944734adca40
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audioldm/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audioldm/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/audioldm/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c64be54d2f62e00f569701b0f03a7b89f2d0b8f4
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audioldm/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audioldm/__pycache__/pipeline_audioldm.cpython-310.pyc b/diffusers/src/diffusers/pipelines/audioldm/__pycache__/pipeline_audioldm.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..270fef0b342d3e5d79d3d76476b2faa2e69b16ef
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audioldm/__pycache__/pipeline_audioldm.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audioldm/__pycache__/pipeline_audioldm.cpython-39.pyc b/diffusers/src/diffusers/pipelines/audioldm/__pycache__/pipeline_audioldm.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d3bcee8e17de7594accc34ee20dd9bf2a5962e0c
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/audioldm/__pycache__/pipeline_audioldm.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/audioldm/pipeline_audioldm.py b/diffusers/src/diffusers/pipelines/audioldm/pipeline_audioldm.py
new file mode 100644
index 0000000000000000000000000000000000000000..b392cd4cc24655a80aae14f0ac922a9a968b1e70
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/audioldm/pipeline_audioldm.py
@@ -0,0 +1,601 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from transformers import ClapTextModelWithProjection, RobertaTokenizer, RobertaTokenizerFast, SpeechT5HifiGan
+
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_available, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import AudioPipelineOutput, DiffusionPipeline
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import AudioLDMPipeline
+
+ >>> pipe = AudioLDMPipeline.from_pretrained("cvssp/audioldm", torch_dtype=torch.float16)
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "A hammer hitting a wooden surface"
+ >>> audio = pipe(prompt).audio[0]
+ ```
+"""
+
+
+class AudioLDMPipeline(DiffusionPipeline):
+ r"""
+ Pipeline for text-to-audio generation using AudioLDM.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode audios to and from latent representations.
+ text_encoder ([`ClapTextModelWithProjection`]):
+ Frozen text-encoder. AudioLDM uses the text portion of
+ [CLAP](https://huggingface.co/docs/transformers/main/model_doc/clap#transformers.ClapTextModelWithProjection),
+ specifically the [RoBERTa HSTAT-unfused](https://huggingface.co/laion/clap-htsat-unfused) variant.
+ tokenizer ([`PreTrainedTokenizer`]):
+ Tokenizer of class
+ [RobertaTokenizer](https://huggingface.co/docs/transformers/model_doc/roberta#transformers.RobertaTokenizer).
+ unet ([`UNet2DConditionModel`]): U-Net architecture to denoise the encoded audio latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded audio latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ vocoder ([`SpeechT5HifiGan`]):
+ Vocoder of class
+ [SpeechT5HifiGan](https://huggingface.co/docs/transformers/main/en/model_doc/speecht5#transformers.SpeechT5HifiGan).
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: ClapTextModelWithProjection,
+ tokenizer: Union[RobertaTokenizer, RobertaTokenizerFast],
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ vocoder: SpeechT5HifiGan,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ vocoder=vocoder,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and vocoder have their state dicts saved to CPU and then are moved to a `torch.device('meta')
+ and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.vocoder]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_waveforms_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device (`torch.device`):
+ torch device
+ num_waveforms_per_prompt (`int`):
+ number of waveforms that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the audio generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ attention_mask = text_inputs.attention_mask
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLAP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask.to(device),
+ )
+ prompt_embeds = prompt_embeds.text_embeds
+ # additional L_2 normalization over each hidden-state
+ prompt_embeds = F.normalize(prompt_embeds, dim=-1)
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ (
+ bs_embed,
+ seq_len,
+ ) = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_waveforms_per_prompt)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_waveforms_per_prompt, seq_len)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ uncond_input_ids = uncond_input.input_ids.to(device)
+ attention_mask = uncond_input.attention_mask.to(device)
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input_ids,
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds.text_embeds
+ # additional L_2 normalization over each hidden-state
+ negative_prompt_embeds = F.normalize(negative_prompt_embeds, dim=-1)
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_waveforms_per_prompt)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_waveforms_per_prompt, seq_len)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ mel_spectrogram = self.vae.decode(latents).sample
+ return mel_spectrogram
+
+ def mel_spectrogram_to_waveform(self, mel_spectrogram):
+ if mel_spectrogram.dim() == 4:
+ mel_spectrogram = mel_spectrogram.squeeze(1)
+
+ waveform = self.vocoder(mel_spectrogram)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ waveform = waveform.cpu()
+ return waveform
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ audio_length_in_s,
+ vocoder_upsample_factor,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ min_audio_length_in_s = vocoder_upsample_factor * self.vae_scale_factor
+ if audio_length_in_s < min_audio_length_in_s:
+ raise ValueError(
+ f"`audio_length_in_s` has to be a positive value greater than or equal to {min_audio_length_in_s}, but "
+ f"is {audio_length_in_s}."
+ )
+
+ if self.vocoder.config.model_in_dim % self.vae_scale_factor != 0:
+ raise ValueError(
+ f"The number of frequency bins in the vocoder's log-mel spectrogram has to be divisible by the "
+ f"VAE scale factor, but got {self.vocoder.config.model_in_dim} bins and a scale factor of "
+ f"{self.vae_scale_factor}."
+ )
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents with width->self.vocoder.config.model_in_dim
+ def prepare_latents(self, batch_size, num_channels_latents, height, dtype, device, generator, latents=None):
+ shape = (
+ batch_size,
+ num_channels_latents,
+ height // self.vae_scale_factor,
+ self.vocoder.config.model_in_dim // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ audio_length_in_s: Optional[float] = None,
+ num_inference_steps: int = 10,
+ guidance_scale: float = 2.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_waveforms_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: Optional[int] = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ output_type: Optional[str] = "np",
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the audio generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ audio_length_in_s (`int`, *optional*, defaults to 5.12):
+ The length of the generated audio sample in seconds.
+ num_inference_steps (`int`, *optional*, defaults to 10):
+ The number of denoising steps. More denoising steps usually lead to a higher quality audio at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 2.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate audios that are closely linked to the text `prompt`,
+ usually at the expense of lower sound quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the audio generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_waveforms_per_prompt (`int`, *optional*, defaults to 1):
+ The number of waveforms to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for audio
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttnProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ output_type (`str`, *optional*, defaults to `"np"`):
+ The output format of the generate image. Choose between:
+ - `"np"`: Return Numpy `np.ndarray` objects.
+ - `"pt"`: Return PyTorch `torch.Tensor` objects.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated audios.
+ """
+ # 0. Convert audio input length from seconds to spectrogram height
+ vocoder_upsample_factor = np.prod(self.vocoder.config.upsample_rates) / self.vocoder.config.sampling_rate
+
+ if audio_length_in_s is None:
+ audio_length_in_s = self.unet.config.sample_size * self.vae_scale_factor * vocoder_upsample_factor
+
+ height = int(audio_length_in_s / vocoder_upsample_factor)
+
+ original_waveform_length = int(audio_length_in_s * self.vocoder.config.sampling_rate)
+ if height % self.vae_scale_factor != 0:
+ height = int(np.ceil(height / self.vae_scale_factor)) * self.vae_scale_factor
+ logger.info(
+ f"Audio length in seconds {audio_length_in_s} is increased to {height * vocoder_upsample_factor} "
+ f"so that it can be handled by the model. It will be cut to {audio_length_in_s} after the "
+ f"denoising process."
+ )
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ audio_length_in_s,
+ vocoder_upsample_factor,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_waveforms_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_waveforms_per_prompt,
+ num_channels_latents,
+ height,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=None,
+ class_labels=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ mel_spectrogram = self.decode_latents(latents)
+
+ audio = self.mel_spectrogram_to_waveform(mel_spectrogram)
+
+ audio = audio[:, :original_waveform_length]
+
+ if output_type == "np":
+ audio = audio.numpy()
+
+ if not return_dict:
+ return (audio,)
+
+ return AudioPipelineOutput(audios=audio)
diff --git a/diffusers/src/diffusers/pipelines/dance_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/dance_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..55d7f8ff9807083a10c844f7003cf0696d8258a3
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/dance_diffusion/__init__.py
@@ -0,0 +1 @@
+from .pipeline_dance_diffusion import DanceDiffusionPipeline
diff --git a/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..33e584666dec65c21b0f5d59cf845f1645e20649
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..58b4b77cdd88f86c033cc9d86bee4b721adaa66d
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/pipeline_dance_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/pipeline_dance_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1b94ffc3222afecb0af085669195d2f519a74e83
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/pipeline_dance_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/pipeline_dance_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/pipeline_dance_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1f7c98a649f0fa42f50924fdcf57cbbd903a39d6
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/dance_diffusion/__pycache__/pipeline_dance_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/dance_diffusion/pipeline_dance_diffusion.py b/diffusers/src/diffusers/pipelines/dance_diffusion/pipeline_dance_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..018e020491ce3711117f9afe13547f12b8ddf48e
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/dance_diffusion/pipeline_dance_diffusion.py
@@ -0,0 +1,123 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from typing import List, Optional, Tuple, Union
+
+import torch
+
+from ...utils import logging, randn_tensor
+from ..pipeline_utils import AudioPipelineOutput, DiffusionPipeline
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class DanceDiffusionPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ unet ([`UNet1DModel`]): U-Net architecture to denoise the encoded image.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
+ [`IPNDMScheduler`].
+ """
+
+ def __init__(self, unet, scheduler):
+ super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ num_inference_steps: int = 100,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ audio_length_in_s: Optional[float] = None,
+ return_dict: bool = True,
+ ) -> Union[AudioPipelineOutput, Tuple]:
+ r"""
+ Args:
+ batch_size (`int`, *optional*, defaults to 1):
+ The number of audio samples to generate.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality audio sample at
+ the expense of slower inference.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ audio_length_in_s (`float`, *optional*, defaults to `self.unet.config.sample_size/self.unet.config.sample_rate`):
+ The length of the generated audio sample in seconds. Note that the output of the pipeline, *i.e.*
+ `sample_size`, will be `audio_length_in_s` * `self.unet.sample_rate`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.AudioPipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.AudioPipelineOutput`] or `tuple`: [`~pipelines.utils.AudioPipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ if audio_length_in_s is None:
+ audio_length_in_s = self.unet.config.sample_size / self.unet.config.sample_rate
+
+ sample_size = audio_length_in_s * self.unet.sample_rate
+
+ down_scale_factor = 2 ** len(self.unet.up_blocks)
+ if sample_size < 3 * down_scale_factor:
+ raise ValueError(
+ f"{audio_length_in_s} is too small. Make sure it's bigger or equal to"
+ f" {3 * down_scale_factor / self.unet.sample_rate}."
+ )
+
+ original_sample_size = int(sample_size)
+ if sample_size % down_scale_factor != 0:
+ sample_size = ((audio_length_in_s * self.unet.sample_rate) // down_scale_factor + 1) * down_scale_factor
+ logger.info(
+ f"{audio_length_in_s} is increased to {sample_size / self.unet.sample_rate} so that it can be handled"
+ f" by the model. It will be cut to {original_sample_size / self.unet.sample_rate} after the denoising"
+ " process."
+ )
+ sample_size = int(sample_size)
+
+ dtype = next(iter(self.unet.parameters())).dtype
+ shape = (batch_size, self.unet.in_channels, sample_size)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ audio = randn_tensor(shape, generator=generator, device=self.device, dtype=dtype)
+
+ # set step values
+ self.scheduler.set_timesteps(num_inference_steps, device=audio.device)
+ self.scheduler.timesteps = self.scheduler.timesteps.to(dtype)
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ # 1. predict noise model_output
+ model_output = self.unet(audio, t).sample
+
+ # 2. compute previous image: x_t -> t_t-1
+ audio = self.scheduler.step(model_output, t, audio).prev_sample
+
+ audio = audio.clamp(-1, 1).float().cpu().numpy()
+
+ audio = audio[:, :, :original_sample_size]
+
+ if not return_dict:
+ return (audio,)
+
+ return AudioPipelineOutput(audios=audio)
diff --git a/diffusers/src/diffusers/pipelines/ddim/__init__.py b/diffusers/src/diffusers/pipelines/ddim/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..85e8118e75e7e4352f8efb12552ba9fff4bf491c
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/ddim/__init__.py
@@ -0,0 +1 @@
+from .pipeline_ddim import DDIMPipeline
diff --git a/diffusers/src/diffusers/pipelines/ddim/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/ddim/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..825033986a4058d8d712f27b1337d9a65151968a
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/ddim/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/ddim/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/ddim/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..485dead53c3865ac59fe1e4a2ef0dd4d6b2d0260
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/ddim/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/ddim/__pycache__/pipeline_ddim.cpython-310.pyc b/diffusers/src/diffusers/pipelines/ddim/__pycache__/pipeline_ddim.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7f488923d4482457f0a159b0975a890faacfe99f
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/ddim/__pycache__/pipeline_ddim.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/ddim/__pycache__/pipeline_ddim.cpython-39.pyc b/diffusers/src/diffusers/pipelines/ddim/__pycache__/pipeline_ddim.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bc73f328c536414a481b19b46e5305b03fa510c3
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/ddim/__pycache__/pipeline_ddim.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/ddim/pipeline_ddim.py b/diffusers/src/diffusers/pipelines/ddim/pipeline_ddim.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e7f2258fa999cc4cdd999a63c287f38eb7ac9a6
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/ddim/pipeline_ddim.py
@@ -0,0 +1,117 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Optional, Tuple, Union
+
+import torch
+
+from ...schedulers import DDIMScheduler
+from ...utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class DDIMPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
+ [`DDPMScheduler`], or [`DDIMScheduler`].
+ """
+
+ def __init__(self, unet, scheduler):
+ super().__init__()
+
+ # make sure scheduler can always be converted to DDIM
+ scheduler = DDIMScheduler.from_config(scheduler.config)
+
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ eta: float = 0.0,
+ num_inference_steps: int = 50,
+ use_clipped_model_output: Optional[bool] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ r"""
+ Args:
+ batch_size (`int`, *optional*, defaults to 1):
+ The number of images to generate.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ eta (`float`, *optional*, defaults to 0.0):
+ The eta parameter which controls the scale of the variance (0 is DDIM and 1 is one type of DDPM).
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ use_clipped_model_output (`bool`, *optional*, defaults to `None`):
+ if `True` or `False`, see documentation for `DDIMScheduler.step`. If `None`, nothing is passed
+ downstream to the scheduler. So use `None` for schedulers which don't support this argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ # Sample gaussian noise to begin loop
+ if isinstance(self.unet.sample_size, int):
+ image_shape = (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size)
+ else:
+ image_shape = (batch_size, self.unet.in_channels, *self.unet.sample_size)
+
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ image = randn_tensor(image_shape, generator=generator, device=self.device, dtype=self.unet.dtype)
+
+ # set step values
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ # 1. predict noise model_output
+ model_output = self.unet(image, t).sample
+
+ # 2. predict previous mean of image x_t-1 and add variance depending on eta
+ # eta corresponds to η in paper and should be between [0, 1]
+ # do x_t -> x_t-1
+ image = self.scheduler.step(
+ model_output, t, image, eta=eta, use_clipped_model_output=use_clipped_model_output, generator=generator
+ ).prev_sample
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/ddpm/__init__.py b/diffusers/src/diffusers/pipelines/ddpm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb228ee012e80493b617b314c867ecadba7ca1ce
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/ddpm/__init__.py
@@ -0,0 +1 @@
+from .pipeline_ddpm import DDPMPipeline
diff --git a/diffusers/src/diffusers/pipelines/ddpm/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/ddpm/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f8f8ac80d644dba0e90544be5b758bc7c4de1ad8
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/ddpm/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/ddpm/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/ddpm/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..aa4690d812010b540c4e3d62a2d79d5a60987982
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/ddpm/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/ddpm/__pycache__/pipeline_ddpm.cpython-310.pyc b/diffusers/src/diffusers/pipelines/ddpm/__pycache__/pipeline_ddpm.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b10d7a47bfc6554c303c094a356d39a29d38a2ff
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/ddpm/__pycache__/pipeline_ddpm.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/ddpm/__pycache__/pipeline_ddpm.cpython-39.pyc b/diffusers/src/diffusers/pipelines/ddpm/__pycache__/pipeline_ddpm.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fd69bed59646b2a24e113e4d11a0d1553a43b2b8
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/ddpm/__pycache__/pipeline_ddpm.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/ddpm/pipeline_ddpm.py b/diffusers/src/diffusers/pipelines/ddpm/pipeline_ddpm.py
new file mode 100644
index 0000000000000000000000000000000000000000..549dbb29d5e7898af4e8883c608c897bb5021cbe
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/ddpm/pipeline_ddpm.py
@@ -0,0 +1,100 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from typing import List, Optional, Tuple, Union
+
+import torch
+
+from ...utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class DDPMPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
+ [`DDPMScheduler`], or [`DDIMScheduler`].
+ """
+
+ def __init__(self, unet, scheduler):
+ super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ num_inference_steps: int = 1000,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ r"""
+ Args:
+ batch_size (`int`, *optional*, defaults to 1):
+ The number of images to generate.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ num_inference_steps (`int`, *optional*, defaults to 1000):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+ # Sample gaussian noise to begin loop
+ if isinstance(self.unet.sample_size, int):
+ image_shape = (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size)
+ else:
+ image_shape = (batch_size, self.unet.in_channels, *self.unet.sample_size)
+
+ if self.device.type == "mps":
+ # randn does not work reproducibly on mps
+ image = randn_tensor(image_shape, generator=generator)
+ image = image.to(self.device)
+ else:
+ image = randn_tensor(image_shape, generator=generator, device=self.device)
+
+ # set step values
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ # 1. predict noise model_output
+ model_output = self.unet(image, t).sample
+
+ # 2. compute previous image: x_t -> x_t-1
+ image = self.scheduler.step(model_output, t, image, generator=generator).prev_sample
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/dit/__init__.py b/diffusers/src/diffusers/pipelines/dit/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ef0729cb4905d5e177ba15533375fce50084406
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/dit/__init__.py
@@ -0,0 +1 @@
+from .pipeline_dit import DiTPipeline
diff --git a/diffusers/src/diffusers/pipelines/dit/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/dit/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1d944fab8d98d4709114ddff19b145a330267a99
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/dit/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/dit/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/dit/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ecdfbc3e2c830c88f9433a814741e69ada976687
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/dit/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/dit/__pycache__/pipeline_dit.cpython-310.pyc b/diffusers/src/diffusers/pipelines/dit/__pycache__/pipeline_dit.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..46868c0ed7d6e31aaa64d37586cf86656d4b607c
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/dit/__pycache__/pipeline_dit.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/dit/__pycache__/pipeline_dit.cpython-39.pyc b/diffusers/src/diffusers/pipelines/dit/__pycache__/pipeline_dit.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..278715a6da15624f05391038b2836c61626fc798
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/dit/__pycache__/pipeline_dit.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/dit/pipeline_dit.py b/diffusers/src/diffusers/pipelines/dit/pipeline_dit.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0d30697af43ca0781e3df8df801bd150078952f
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/dit/pipeline_dit.py
@@ -0,0 +1,199 @@
+# Attribution-NonCommercial 4.0 International (CC BY-NC 4.0)
+# William Peebles and Saining Xie
+#
+# Copyright (c) 2021 OpenAI
+# MIT License
+#
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+
+from ...models import AutoencoderKL, Transformer2DModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class DiTPipeline(DiffusionPipeline):
+ r"""
+ This pipeline inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ transformer ([`Transformer2DModel`]):
+ Class conditioned Transformer in Diffusion model to denoise the encoded image latents.
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ scheduler ([`DDIMScheduler`]):
+ A scheduler to be used in combination with `dit` to denoise the encoded image latents.
+ """
+
+ def __init__(
+ self,
+ transformer: Transformer2DModel,
+ vae: AutoencoderKL,
+ scheduler: KarrasDiffusionSchedulers,
+ id2label: Optional[Dict[int, str]] = None,
+ ):
+ super().__init__()
+ self.register_modules(transformer=transformer, vae=vae, scheduler=scheduler)
+
+ # create a imagenet -> id dictionary for easier use
+ self.labels = {}
+ if id2label is not None:
+ for key, value in id2label.items():
+ for label in value.split(","):
+ self.labels[label.lstrip().rstrip()] = int(key)
+ self.labels = dict(sorted(self.labels.items()))
+
+ def get_label_ids(self, label: Union[str, List[str]]) -> List[int]:
+ r"""
+
+ Map label strings, *e.g.* from ImageNet, to corresponding class ids.
+
+ Parameters:
+ label (`str` or `dict` of `str`): label strings to be mapped to class ids.
+
+ Returns:
+ `list` of `int`: Class ids to be processed by pipeline.
+ """
+
+ if not isinstance(label, list):
+ label = list(label)
+
+ for l in label:
+ if l not in self.labels:
+ raise ValueError(
+ f"{l} does not exist. Please make sure to select one of the following labels: \n {self.labels}."
+ )
+
+ return [self.labels[l] for l in label]
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ class_labels: List[int],
+ guidance_scale: float = 4.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ num_inference_steps: int = 50,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ class_labels (List[int]):
+ List of imagenet class labels for the images to be generated.
+ guidance_scale (`float`, *optional*, defaults to 4.0):
+ Scale of the guidance signal.
+ generator (`torch.Generator`, *optional*):
+ A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
+ deterministic.
+ num_inference_steps (`int`, *optional*, defaults to 250):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`ImagePipelineOutput`] instead of a plain tuple.
+ """
+
+ batch_size = len(class_labels)
+ latent_size = self.transformer.config.sample_size
+ latent_channels = self.transformer.config.in_channels
+
+ latents = randn_tensor(
+ shape=(batch_size, latent_channels, latent_size, latent_size),
+ generator=generator,
+ device=self.device,
+ dtype=self.transformer.dtype,
+ )
+ latent_model_input = torch.cat([latents] * 2) if guidance_scale > 1 else latents
+
+ class_labels = torch.tensor(class_labels, device=self.device).reshape(-1)
+ class_null = torch.tensor([1000] * batch_size, device=self.device)
+ class_labels_input = torch.cat([class_labels, class_null], 0) if guidance_scale > 1 else class_labels
+
+ # set step values
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ if guidance_scale > 1:
+ half = latent_model_input[: len(latent_model_input) // 2]
+ latent_model_input = torch.cat([half, half], dim=0)
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ timesteps = t
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = latent_model_input.device.type == "mps"
+ if isinstance(timesteps, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=latent_model_input.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(latent_model_input.device)
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(latent_model_input.shape[0])
+ # predict noise model_output
+ noise_pred = self.transformer(
+ latent_model_input, timestep=timesteps, class_labels=class_labels_input
+ ).sample
+
+ # perform guidance
+ if guidance_scale > 1:
+ eps, rest = noise_pred[:, :latent_channels], noise_pred[:, latent_channels:]
+ cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)
+
+ half_eps = uncond_eps + guidance_scale * (cond_eps - uncond_eps)
+ eps = torch.cat([half_eps, half_eps], dim=0)
+
+ noise_pred = torch.cat([eps, rest], dim=1)
+
+ # learned sigma
+ if self.transformer.config.out_channels // 2 == latent_channels:
+ model_output, _ = torch.split(noise_pred, latent_channels, dim=1)
+ else:
+ model_output = noise_pred
+
+ # compute previous image: x_t -> x_t-1
+ latent_model_input = self.scheduler.step(model_output, t, latent_model_input).prev_sample
+
+ if guidance_scale > 1:
+ latents, _ = latent_model_input.chunk(2, dim=0)
+ else:
+ latents = latent_model_input
+
+ latents = 1 / self.vae.config.scaling_factor * latents
+ samples = self.vae.decode(latents).sample
+
+ samples = (samples / 2 + 0.5).clamp(0, 1)
+
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ samples = samples.cpu().permute(0, 2, 3, 1).float().numpy()
+
+ if output_type == "pil":
+ samples = self.numpy_to_pil(samples)
+
+ if not return_dict:
+ return (samples,)
+
+ return ImagePipelineOutput(images=samples)
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/latent_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0cce9a89bcbeaac8468d75e9d16c9d3731f738c7
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/latent_diffusion/__init__.py
@@ -0,0 +1,6 @@
+from ...utils import is_transformers_available
+from .pipeline_latent_diffusion_superresolution import LDMSuperResolutionPipeline
+
+
+if is_transformers_available():
+ from .pipeline_latent_diffusion import LDMBertModel, LDMTextToImagePipeline
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6540b5b67551173b6438f6666a1437d9e6ee821e
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..580b16420ac435988727c423963e9672241389ae
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d168c977d554c442b74d1db4baacd098516933b0
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..aadc47130bdafd71198ee252db6728236ce8de7a
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion_superresolution.cpython-310.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion_superresolution.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b08aaf8e242f18429e4650589c98dffe69bf6988
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion_superresolution.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion_superresolution.cpython-39.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion_superresolution.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..11813447cc4492f46f8ae3a3ddc502871ff34abe
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion/__pycache__/pipeline_latent_diffusion_superresolution.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py b/diffusers/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..623b456e52b5bb0c283f943af9bc825863846afe
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py
@@ -0,0 +1,724 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+from transformers import PretrainedConfig, PreTrainedModel, PreTrainedTokenizer
+from transformers.activations import ACT2FN
+from transformers.modeling_outputs import BaseModelOutput
+from transformers.utils import logging
+
+from ...models import AutoencoderKL, UNet2DConditionModel, UNet2DModel, VQModel
+from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
+from ...utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class LDMTextToImagePipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ vqvae ([`VQModel`]):
+ Vector-quantized (VQ) Model to encode and decode images to and from latent representations.
+ bert ([`LDMBertModel`]):
+ Text-encoder model based on [BERT](https://huggingface.co/docs/transformers/model_doc/bert) architecture.
+ tokenizer (`transformers.BertTokenizer`):
+ Tokenizer of class
+ [BertTokenizer](https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vqvae: Union[VQModel, AutoencoderKL],
+ bert: PreTrainedModel,
+ tokenizer: PreTrainedTokenizer,
+ unet: Union[UNet2DModel, UNet2DConditionModel],
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
+ ):
+ super().__init__()
+ self.register_modules(vqvae=vqvae, bert=bert, tokenizer=tokenizer, unet=unet, scheduler=scheduler)
+ self.vae_scale_factor = 2 ** (len(self.vqvae.config.block_out_channels) - 1)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 1.0,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ **kwargs,
+ ) -> Union[Tuple, ImagePipelineOutput]:
+ r"""
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 1.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt` at
+ the, usually at the expense of lower image quality.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ if isinstance(prompt, str):
+ batch_size = 1
+ elif isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ # get unconditional embeddings for classifier free guidance
+ if guidance_scale != 1.0:
+ uncond_input = self.tokenizer(
+ [""] * batch_size, padding="max_length", max_length=77, truncation=True, return_tensors="pt"
+ )
+ negative_prompt_embeds = self.bert(uncond_input.input_ids.to(self.device))[0]
+
+ # get prompt text embeddings
+ text_input = self.tokenizer(prompt, padding="max_length", max_length=77, truncation=True, return_tensors="pt")
+ prompt_embeds = self.bert(text_input.input_ids.to(self.device))[0]
+
+ # get the initial random noise unless the user supplied it
+ latents_shape = (batch_size, self.unet.in_channels, height // 8, width // 8)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(latents_shape, generator=generator, device=self.device, dtype=prompt_embeds.dtype)
+ else:
+ if latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+ latents = latents.to(self.device)
+
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+
+ extra_kwargs = {}
+ if accepts_eta:
+ extra_kwargs["eta"] = eta
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ if guidance_scale == 1.0:
+ # guidance_scale of 1 means no guidance
+ latents_input = latents
+ context = prompt_embeds
+ else:
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ latents_input = torch.cat([latents] * 2)
+ context = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ # predict the noise residual
+ noise_pred = self.unet(latents_input, t, encoder_hidden_states=context).sample
+ # perform guidance
+ if guidance_scale != 1.0:
+ noise_pred_uncond, noise_prediction_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_kwargs).prev_sample
+
+ # scale and decode the image latents with vae
+ latents = 1 / self.vqvae.config.scaling_factor * latents
+ image = self.vqvae.decode(latents).sample
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
+
+
+################################################################################
+# Code for the text transformer model
+################################################################################
+""" PyTorch LDMBERT model."""
+
+
+logger = logging.get_logger(__name__)
+
+LDMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "ldm-bert",
+ # See all LDMBert models at https://huggingface.co/models?filter=ldmbert
+]
+
+
+LDMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "ldm-bert": "https://huggingface.co/valhalla/ldm-bert/blob/main/config.json",
+}
+
+
+""" LDMBERT model configuration"""
+
+
+class LDMBertConfig(PretrainedConfig):
+ model_type = "ldmbert"
+ keys_to_ignore_at_inference = ["past_key_values"]
+ attribute_map = {"num_attention_heads": "encoder_attention_heads", "hidden_size": "d_model"}
+
+ def __init__(
+ self,
+ vocab_size=30522,
+ max_position_embeddings=77,
+ encoder_layers=32,
+ encoder_ffn_dim=5120,
+ encoder_attention_heads=8,
+ head_dim=64,
+ encoder_layerdrop=0.0,
+ activation_function="gelu",
+ d_model=1280,
+ dropout=0.1,
+ attention_dropout=0.0,
+ activation_dropout=0.0,
+ init_std=0.02,
+ classifier_dropout=0.0,
+ scale_embedding=False,
+ use_cache=True,
+ pad_token_id=0,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.d_model = d_model
+ self.encoder_ffn_dim = encoder_ffn_dim
+ self.encoder_layers = encoder_layers
+ self.encoder_attention_heads = encoder_attention_heads
+ self.head_dim = head_dim
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.activation_dropout = activation_dropout
+ self.activation_function = activation_function
+ self.init_std = init_std
+ self.encoder_layerdrop = encoder_layerdrop
+ self.classifier_dropout = classifier_dropout
+ self.use_cache = use_cache
+ self.num_hidden_layers = encoder_layers
+ self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
+
+ super().__init__(pad_token_id=pad_token_id, **kwargs)
+
+
+def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+
+# Copied from transformers.models.bart.modeling_bart.BartAttention with Bart->LDMBert
+class LDMBertAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(
+ self,
+ embed_dim: int,
+ num_heads: int,
+ head_dim: int,
+ dropout: float = 0.0,
+ is_decoder: bool = False,
+ bias: bool = False,
+ ):
+ super().__init__()
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ self.dropout = dropout
+ self.head_dim = head_dim
+ self.inner_dim = head_dim * num_heads
+
+ self.scaling = self.head_dim**-0.5
+ self.is_decoder = is_decoder
+
+ self.k_proj = nn.Linear(embed_dim, self.inner_dim, bias=bias)
+ self.v_proj = nn.Linear(embed_dim, self.inner_dim, bias=bias)
+ self.q_proj = nn.Linear(embed_dim, self.inner_dim, bias=bias)
+ self.out_proj = nn.Linear(self.inner_dim, embed_dim)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states) * self.scaling
+ # get key, value proj
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+ else:
+ # self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
+ key_states = key_states.view(*proj_shape)
+ value_states = value_states.view(*proj_shape)
+
+ src_len = key_states.size(1)
+ attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+
+ if layer_head_mask is not None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(
+ f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}"
+ )
+ attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ if output_attentions:
+ # this operation is a bit awkward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to be reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
+ else:
+ attn_weights_reshaped = None
+
+ attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+
+ attn_output = torch.bmm(attn_probs, value_states)
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+
+ # Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
+ # partitioned across GPUs when using tensor-parallelism.
+ attn_output = attn_output.reshape(bsz, tgt_len, self.inner_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped, past_key_value
+
+
+class LDMBertEncoderLayer(nn.Module):
+ def __init__(self, config: LDMBertConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+ self.self_attn = LDMBertAttention(
+ embed_dim=self.embed_dim,
+ num_heads=config.encoder_attention_heads,
+ head_dim=config.head_dim,
+ dropout=config.attention_dropout,
+ )
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+ self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
+ self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ attention_mask: torch.FloatTensor,
+ layer_head_mask: torch.FloatTensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[torch.FloatTensor]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(seq_len, batch, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ hidden_states, attn_weights, _ = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+
+ residual = hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+
+ if hidden_states.dtype == torch.float16 and (
+ torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()
+ ):
+ clamp_value = torch.finfo(hidden_states.dtype).max - 1000
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+# Copied from transformers.models.bart.modeling_bart.BartPretrainedModel with Bart->LDMBert
+class LDMBertPreTrainedModel(PreTrainedModel):
+ config_class = LDMBertConfig
+ base_model_prefix = "model"
+ _supports_gradient_checkpointing = True
+ _keys_to_ignore_on_load_unexpected = [r"encoder\.version", r"decoder\.version"]
+
+ def _init_weights(self, module):
+ std = self.config.init_std
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (LDMBertEncoder,)):
+ module.gradient_checkpointing = value
+
+ @property
+ def dummy_inputs(self):
+ pad_token = self.config.pad_token_id
+ input_ids = torch.tensor([[0, 6, 10, 4, 2], [0, 8, 12, 2, pad_token]], device=self.device)
+ dummy_inputs = {
+ "attention_mask": input_ids.ne(pad_token),
+ "input_ids": input_ids,
+ }
+ return dummy_inputs
+
+
+class LDMBertEncoder(LDMBertPreTrainedModel):
+ """
+ Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
+ [`LDMBertEncoderLayer`].
+
+ Args:
+ config: LDMBertConfig
+ embed_tokens (nn.Embedding): output embedding
+ """
+
+ def __init__(self, config: LDMBertConfig):
+ super().__init__(config)
+
+ self.dropout = config.dropout
+
+ embed_dim = config.d_model
+ self.padding_idx = config.pad_token_id
+ self.max_source_positions = config.max_position_embeddings
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, embed_dim)
+ self.embed_positions = nn.Embedding(config.max_position_embeddings, embed_dim)
+ self.layers = nn.ModuleList([LDMBertEncoderLayer(config) for _ in range(config.encoder_layers)])
+ self.layer_norm = nn.LayerNorm(embed_dim)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
+ provide it.
+
+ Indices can be obtained using [`BartTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.BaseModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ seq_len = input_shape[1]
+ if position_ids is None:
+ position_ids = torch.arange(seq_len, dtype=torch.long, device=inputs_embeds.device).expand((1, -1))
+ embed_pos = self.embed_positions(position_ids)
+
+ hidden_states = inputs_embeds + embed_pos
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+
+ # expand attention_mask
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ attention_mask = _expand_mask(attention_mask, inputs_embeds.dtype)
+
+ encoder_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ # check if head_mask has a correct number of layers specified if desired
+ if head_mask is not None:
+ if head_mask.size()[0] != (len(self.layers)):
+ raise ValueError(
+ f"The head_mask should be specified for {len(self.layers)} layers, but it is for"
+ f" {head_mask.size()[0]}."
+ )
+
+ for idx, encoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(encoder_layer),
+ hidden_states,
+ attention_mask,
+ (head_mask[idx] if head_mask is not None else None),
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ layer_head_mask=(head_mask[idx] if head_mask is not None else None),
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1],)
+
+ hidden_states = self.layer_norm(hidden_states)
+
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
+ )
+
+
+class LDMBertModel(LDMBertPreTrainedModel):
+ _no_split_modules = []
+
+ def __init__(self, config: LDMBertConfig):
+ super().__init__(config)
+ self.model = LDMBertEncoder(config)
+ self.to_logits = nn.Linear(config.hidden_size, config.vocab_size)
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ return outputs
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py b/diffusers/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py
new file mode 100644
index 0000000000000000000000000000000000000000..6887068f3443e21cf31a3c4a70cd44e7d2117505
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion_superresolution.py
@@ -0,0 +1,159 @@
+import inspect
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import PIL
+import torch
+import torch.utils.checkpoint
+
+from ...models import UNet2DModel, VQModel
+from ...schedulers import (
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+)
+from ...utils import PIL_INTERPOLATION, randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+def preprocess(image):
+ w, h = image.size
+ w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image[None].transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ return 2.0 * image - 1.0
+
+
+class LDMSuperResolutionPipeline(DiffusionPipeline):
+ r"""
+ A pipeline for image super-resolution using Latent
+
+ This class inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ vqvae ([`VQModel`]):
+ Vector-quantized (VQ) VAE Model to encode and decode images to and from latent representations.
+ unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latens. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerDiscreteScheduler`],
+ [`EulerAncestralDiscreteScheduler`], [`DPMSolverMultistepScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vqvae: VQModel,
+ unet: UNet2DModel,
+ scheduler: Union[
+ DDIMScheduler,
+ PNDMScheduler,
+ LMSDiscreteScheduler,
+ EulerDiscreteScheduler,
+ EulerAncestralDiscreteScheduler,
+ DPMSolverMultistepScheduler,
+ ],
+ ):
+ super().__init__()
+ self.register_modules(vqvae=vqvae, unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ image: Union[torch.Tensor, PIL.Image.Image] = None,
+ batch_size: Optional[int] = 1,
+ num_inference_steps: Optional[int] = 100,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ ) -> Union[Tuple, ImagePipelineOutput]:
+ r"""
+ Args:
+ image (`torch.Tensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ batch_size (`int`, *optional*, defaults to 1):
+ Number of images to generate.
+ num_inference_steps (`int`, *optional*, defaults to 100):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+ if isinstance(image, PIL.Image.Image):
+ batch_size = 1
+ elif isinstance(image, torch.Tensor):
+ batch_size = image.shape[0]
+ else:
+ raise ValueError(f"`image` has to be of type `PIL.Image.Image` or `torch.Tensor` but is {type(image)}")
+
+ if isinstance(image, PIL.Image.Image):
+ image = preprocess(image)
+
+ height, width = image.shape[-2:]
+
+ # in_channels should be 6: 3 for latents, 3 for low resolution image
+ latents_shape = (batch_size, self.unet.in_channels // 2, height, width)
+ latents_dtype = next(self.unet.parameters()).dtype
+
+ latents = randn_tensor(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
+
+ image = image.to(device=self.device, dtype=latents_dtype)
+
+ # set timesteps and move to the correct device
+ self.scheduler.set_timesteps(num_inference_steps, device=self.device)
+ timesteps_tensor = self.scheduler.timesteps
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature.
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_kwargs = {}
+ if accepts_eta:
+ extra_kwargs["eta"] = eta
+
+ for t in self.progress_bar(timesteps_tensor):
+ # concat latents and low resolution image in the channel dimension.
+ latents_input = torch.cat([latents, image], dim=1)
+ latents_input = self.scheduler.scale_model_input(latents_input, t)
+ # predict the noise residual
+ noise_pred = self.unet(latents_input, t).sample
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_kwargs).prev_sample
+
+ # decode the image latents with the VQVAE
+ image = self.vqvae.decode(latents).sample
+ image = torch.clamp(image, -1.0, 1.0)
+ image = image / 2 + 0.5
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__init__.py b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b9fc5270a62bbb18d1393263101d4b9f73b7511
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__init__.py
@@ -0,0 +1 @@
+from .pipeline_latent_diffusion_uncond import LDMPipeline
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bfb364e7983a7d8031c25ecae702593a0b598492
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0abf069ff4d38ff0c515905e3d395bbd295e3235
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/pipeline_latent_diffusion_uncond.cpython-310.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/pipeline_latent_diffusion_uncond.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..77f2f7a30e8f1b7e75a38ad74b47f1348e3a4eaf
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/pipeline_latent_diffusion_uncond.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/pipeline_latent_diffusion_uncond.cpython-39.pyc b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/pipeline_latent_diffusion_uncond.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6bfefa3806d2a5b6f2dfb9dd51f0cdcf20c495b5
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/__pycache__/pipeline_latent_diffusion_uncond.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/pipeline_latent_diffusion_uncond.py b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/pipeline_latent_diffusion_uncond.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc0200feedb114a8f2258d72c3f46036d00cd4cb
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/latent_diffusion_uncond/pipeline_latent_diffusion_uncond.py
@@ -0,0 +1,111 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import List, Optional, Tuple, Union
+
+import torch
+
+from ...models import UNet2DModel, VQModel
+from ...schedulers import DDIMScheduler
+from ...utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class LDMPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ vqvae ([`VQModel`]):
+ Vector-quantized (VQ) Model to encode and decode images to and from latent representations.
+ unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ [`DDIMScheduler`] is to be used in combination with `unet` to denoise the encoded image latents.
+ """
+
+ def __init__(self, vqvae: VQModel, unet: UNet2DModel, scheduler: DDIMScheduler):
+ super().__init__()
+ self.register_modules(vqvae=vqvae, unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ eta: float = 0.0,
+ num_inference_steps: int = 50,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ **kwargs,
+ ) -> Union[Tuple, ImagePipelineOutput]:
+ r"""
+ Args:
+ batch_size (`int`, *optional*, defaults to 1):
+ Number of images to generate.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ latents = randn_tensor(
+ (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
+ generator=generator,
+ )
+ latents = latents.to(self.device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+
+ extra_kwargs = {}
+ if accepts_eta:
+ extra_kwargs["eta"] = eta
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ latent_model_input = self.scheduler.scale_model_input(latents, t)
+ # predict the noise residual
+ noise_prediction = self.unet(latent_model_input, t).sample
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_prediction, t, latents, **extra_kwargs).prev_sample
+
+ # decode the image latents with the VAE
+ image = self.vqvae.decode(latents).sample
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/onnx_utils.py b/diffusers/src/diffusers/pipelines/onnx_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..07c32e4e84bfee0241733a077fef9c0dec06905e
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/onnx_utils.py
@@ -0,0 +1,212 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+import shutil
+from pathlib import Path
+from typing import Optional, Union
+
+import numpy as np
+from huggingface_hub import hf_hub_download
+
+from ..utils import ONNX_EXTERNAL_WEIGHTS_NAME, ONNX_WEIGHTS_NAME, is_onnx_available, logging
+
+
+if is_onnx_available():
+ import onnxruntime as ort
+
+
+logger = logging.get_logger(__name__)
+
+ORT_TO_NP_TYPE = {
+ "tensor(bool)": np.bool_,
+ "tensor(int8)": np.int8,
+ "tensor(uint8)": np.uint8,
+ "tensor(int16)": np.int16,
+ "tensor(uint16)": np.uint16,
+ "tensor(int32)": np.int32,
+ "tensor(uint32)": np.uint32,
+ "tensor(int64)": np.int64,
+ "tensor(uint64)": np.uint64,
+ "tensor(float16)": np.float16,
+ "tensor(float)": np.float32,
+ "tensor(double)": np.float64,
+}
+
+
+class OnnxRuntimeModel:
+ def __init__(self, model=None, **kwargs):
+ logger.info("`diffusers.OnnxRuntimeModel` is experimental and might change in the future.")
+ self.model = model
+ self.model_save_dir = kwargs.get("model_save_dir", None)
+ self.latest_model_name = kwargs.get("latest_model_name", ONNX_WEIGHTS_NAME)
+
+ def __call__(self, **kwargs):
+ inputs = {k: np.array(v) for k, v in kwargs.items()}
+ return self.model.run(None, inputs)
+
+ @staticmethod
+ def load_model(path: Union[str, Path], provider=None, sess_options=None):
+ """
+ Loads an ONNX Inference session with an ExecutionProvider. Default provider is `CPUExecutionProvider`
+
+ Arguments:
+ path (`str` or `Path`):
+ Directory from which to load
+ provider(`str`, *optional*):
+ Onnxruntime execution provider to use for loading the model, defaults to `CPUExecutionProvider`
+ """
+ if provider is None:
+ logger.info("No onnxruntime provider specified, using CPUExecutionProvider")
+ provider = "CPUExecutionProvider"
+
+ return ort.InferenceSession(path, providers=[provider], sess_options=sess_options)
+
+ def _save_pretrained(self, save_directory: Union[str, Path], file_name: Optional[str] = None, **kwargs):
+ """
+ Save a model and its configuration file to a directory, so that it can be re-loaded using the
+ [`~optimum.onnxruntime.modeling_ort.ORTModel.from_pretrained`] class method. It will always save the
+ latest_model_name.
+
+ Arguments:
+ save_directory (`str` or `Path`):
+ Directory where to save the model file.
+ file_name(`str`, *optional*):
+ Overwrites the default model file name from `"model.onnx"` to `file_name`. This allows you to save the
+ model with a different name.
+ """
+ model_file_name = file_name if file_name is not None else ONNX_WEIGHTS_NAME
+
+ src_path = self.model_save_dir.joinpath(self.latest_model_name)
+ dst_path = Path(save_directory).joinpath(model_file_name)
+ try:
+ shutil.copyfile(src_path, dst_path)
+ except shutil.SameFileError:
+ pass
+
+ # copy external weights (for models >2GB)
+ src_path = self.model_save_dir.joinpath(ONNX_EXTERNAL_WEIGHTS_NAME)
+ if src_path.exists():
+ dst_path = Path(save_directory).joinpath(ONNX_EXTERNAL_WEIGHTS_NAME)
+ try:
+ shutil.copyfile(src_path, dst_path)
+ except shutil.SameFileError:
+ pass
+
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ **kwargs,
+ ):
+ """
+ Save a model to a directory, so that it can be re-loaded using the [`~OnnxModel.from_pretrained`] class
+ method.:
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ """
+ if os.path.isfile(save_directory):
+ logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
+ return
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ # saving model weights/files
+ self._save_pretrained(save_directory, **kwargs)
+
+ @classmethod
+ def _from_pretrained(
+ cls,
+ model_id: Union[str, Path],
+ use_auth_token: Optional[Union[bool, str, None]] = None,
+ revision: Optional[Union[str, None]] = None,
+ force_download: bool = False,
+ cache_dir: Optional[str] = None,
+ file_name: Optional[str] = None,
+ provider: Optional[str] = None,
+ sess_options: Optional["ort.SessionOptions"] = None,
+ **kwargs,
+ ):
+ """
+ Load a model from a directory or the HF Hub.
+
+ Arguments:
+ model_id (`str` or `Path`):
+ Directory from which to load
+ use_auth_token (`str` or `bool`):
+ Is needed to load models from a private or gated repository
+ revision (`str`):
+ Revision is the specific model version to use. It can be a branch name, a tag name, or a commit id
+ cache_dir (`Union[str, Path]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ file_name(`str`):
+ Overwrites the default model file name from `"model.onnx"` to `file_name`. This allows you to load
+ different model files from the same repository or directory.
+ provider(`str`):
+ The ONNX runtime provider, e.g. `CPUExecutionProvider` or `CUDAExecutionProvider`.
+ kwargs (`Dict`, *optional*):
+ kwargs will be passed to the model during initialization
+ """
+ model_file_name = file_name if file_name is not None else ONNX_WEIGHTS_NAME
+ # load model from local directory
+ if os.path.isdir(model_id):
+ model = OnnxRuntimeModel.load_model(
+ os.path.join(model_id, model_file_name), provider=provider, sess_options=sess_options
+ )
+ kwargs["model_save_dir"] = Path(model_id)
+ # load model from hub
+ else:
+ # download model
+ model_cache_path = hf_hub_download(
+ repo_id=model_id,
+ filename=model_file_name,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ )
+ kwargs["model_save_dir"] = Path(model_cache_path).parent
+ kwargs["latest_model_name"] = Path(model_cache_path).name
+ model = OnnxRuntimeModel.load_model(model_cache_path, provider=provider, sess_options=sess_options)
+ return cls(model=model, **kwargs)
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ model_id: Union[str, Path],
+ force_download: bool = True,
+ use_auth_token: Optional[str] = None,
+ cache_dir: Optional[str] = None,
+ **model_kwargs,
+ ):
+ revision = None
+ if len(str(model_id).split("@")) == 2:
+ model_id, revision = model_id.split("@")
+
+ return cls._from_pretrained(
+ model_id=model_id,
+ revision=revision,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ use_auth_token=use_auth_token,
+ **model_kwargs,
+ )
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/__init__.py b/diffusers/src/diffusers/pipelines/paint_by_example/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0fc8cb71e3f4e1e8baf16c7143658ca64934306
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/paint_by_example/__init__.py
@@ -0,0 +1,13 @@
+from dataclasses import dataclass
+from typing import List, Optional, Union
+
+import numpy as np
+import PIL
+from PIL import Image
+
+from ...utils import is_torch_available, is_transformers_available
+
+
+if is_transformers_available() and is_torch_available():
+ from .image_encoder import PaintByExampleImageEncoder
+ from .pipeline_paint_by_example import PaintByExamplePipeline
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1cb4014adf56c3755605bf69432c24dc86c9ed85
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..77c9f5d305f9533198af2d71f2ab8857d71d9ffd
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/image_encoder.cpython-310.pyc b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/image_encoder.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..699c983e81e64f8bba52acd6f3528d7981db032e
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/image_encoder.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/image_encoder.cpython-39.pyc b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/image_encoder.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6f4f0ba0934e2d260714743edd002bba6e015c72
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/image_encoder.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/pipeline_paint_by_example.cpython-310.pyc b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/pipeline_paint_by_example.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..83e765c9e285463bcfa076d5a60c7ccf684ba61d
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/pipeline_paint_by_example.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/pipeline_paint_by_example.cpython-39.pyc b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/pipeline_paint_by_example.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8ca675ceba91113200d52203b77c6d313eedc399
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/paint_by_example/__pycache__/pipeline_paint_by_example.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/image_encoder.py b/diffusers/src/diffusers/pipelines/paint_by_example/image_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..831489eefed167264c8fd8f57e1ed59610ebb858
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/paint_by_example/image_encoder.py
@@ -0,0 +1,67 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import torch
+from torch import nn
+from transformers import CLIPPreTrainedModel, CLIPVisionModel
+
+from ...models.attention import BasicTransformerBlock
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class PaintByExampleImageEncoder(CLIPPreTrainedModel):
+ def __init__(self, config, proj_size=768):
+ super().__init__(config)
+ self.proj_size = proj_size
+
+ self.model = CLIPVisionModel(config)
+ self.mapper = PaintByExampleMapper(config)
+ self.final_layer_norm = nn.LayerNorm(config.hidden_size)
+ self.proj_out = nn.Linear(config.hidden_size, self.proj_size)
+
+ # uncondition for scaling
+ self.uncond_vector = nn.Parameter(torch.randn((1, 1, self.proj_size)))
+
+ def forward(self, pixel_values, return_uncond_vector=False):
+ clip_output = self.model(pixel_values=pixel_values)
+ latent_states = clip_output.pooler_output
+ latent_states = self.mapper(latent_states[:, None])
+ latent_states = self.final_layer_norm(latent_states)
+ latent_states = self.proj_out(latent_states)
+ if return_uncond_vector:
+ return latent_states, self.uncond_vector
+
+ return latent_states
+
+
+class PaintByExampleMapper(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ num_layers = (config.num_hidden_layers + 1) // 5
+ hid_size = config.hidden_size
+ num_heads = 1
+ self.blocks = nn.ModuleList(
+ [
+ BasicTransformerBlock(hid_size, num_heads, hid_size, activation_fn="gelu", attention_bias=True)
+ for _ in range(num_layers)
+ ]
+ )
+
+ def forward(self, hidden_states):
+ for block in self.blocks:
+ hidden_states = block(hidden_states)
+
+ return hidden_states
diff --git a/diffusers/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py b/diffusers/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py
new file mode 100644
index 0000000000000000000000000000000000000000..ca0a90a5b5ca12120bd6317576d64d21bc275f90
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/paint_by_example/pipeline_paint_by_example.py
@@ -0,0 +1,576 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from transformers import CLIPImageProcessor
+
+from diffusers.utils import is_accelerate_available
+
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
+from ...utils import logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline
+from ..stable_diffusion import StableDiffusionPipelineOutput
+from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from .image_encoder import PaintByExampleImageEncoder
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def prepare_mask_and_masked_image(image, mask):
+ """
+ Prepares a pair (image, mask) to be consumed by the Paint by Example pipeline. This means that those inputs will be
+ converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
+ ``image`` and ``1`` for the ``mask``.
+
+ The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
+ binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
+
+ Args:
+ image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
+ It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
+ ``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
+ mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
+ It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
+ ``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
+
+
+ Raises:
+ ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
+ should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
+ TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
+ (ot the other way around).
+
+ Returns:
+ tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
+ dimensions: ``batch x channels x height x width``.
+ """
+ if isinstance(image, torch.Tensor):
+ if not isinstance(mask, torch.Tensor):
+ raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
+
+ # Batch single image
+ if image.ndim == 3:
+ assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
+ image = image.unsqueeze(0)
+
+ # Batch and add channel dim for single mask
+ if mask.ndim == 2:
+ mask = mask.unsqueeze(0).unsqueeze(0)
+
+ # Batch single mask or add channel dim
+ if mask.ndim == 3:
+ # Batched mask
+ if mask.shape[0] == image.shape[0]:
+ mask = mask.unsqueeze(1)
+ else:
+ mask = mask.unsqueeze(0)
+
+ assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
+ assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
+ assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
+ assert mask.shape[1] == 1, "Mask image must have a single channel"
+
+ # Check image is in [-1, 1]
+ if image.min() < -1 or image.max() > 1:
+ raise ValueError("Image should be in [-1, 1] range")
+
+ # Check mask is in [0, 1]
+ if mask.min() < 0 or mask.max() > 1:
+ raise ValueError("Mask should be in [0, 1] range")
+
+ # paint-by-example inverses the mask
+ mask = 1 - mask
+
+ # Binarize mask
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+
+ # Image as float32
+ image = image.to(dtype=torch.float32)
+ elif isinstance(mask, torch.Tensor):
+ raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
+ else:
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ image = np.concatenate([np.array(i.convert("RGB"))[None, :] for i in image], axis=0)
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+
+ # preprocess mask
+ if isinstance(mask, PIL.Image.Image):
+ mask = [mask]
+
+ mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
+ mask = mask.astype(np.float32) / 255.0
+
+ # paint-by-example inverses the mask
+ mask = 1 - mask
+
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+ mask = torch.from_numpy(mask)
+
+ masked_image = image * mask
+
+ return mask, masked_image
+
+
+class PaintByExamplePipeline(DiffusionPipeline):
+ r"""
+ Pipeline for image-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ image_encoder ([`PaintByExampleImageEncoder`]):
+ Encodes the example input image. The unet is conditioned on the example image instead of a text prompt.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ # TODO: feature_extractor is required to encode initial images (if they are in PIL format),
+ # we should give a descriptive message if the pipeline doesn't have one.
+ _optional_components = ["safety_checker"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ image_encoder: PaintByExampleImageEncoder,
+ unet: UNet2DConditionModel,
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = False,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ image_encoder=image_encoder,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.vae, self.image_encoder]:
+ cpu_offload(cpu_offloaded_model, execution_device=device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_image_variation.StableDiffusionImageVariationPipeline.check_inputs
+ def check_inputs(self, image, height, width, callback_steps):
+ if (
+ not isinstance(image, torch.Tensor)
+ and not isinstance(image, PIL.Image.Image)
+ and not isinstance(image, list)
+ ):
+ raise ValueError(
+ "`image` has to be of type `torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]` but is"
+ f" {type(image)}"
+ )
+
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline.prepare_mask_latents
+ def prepare_mask_latents(
+ self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
+ ):
+ # resize the mask to latents shape as we concatenate the mask to the latents
+ # we do that before converting to dtype to avoid breaking in case we're using cpu_offload
+ # and half precision
+ mask = torch.nn.functional.interpolate(
+ mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
+ )
+ mask = mask.to(device=device, dtype=dtype)
+
+ masked_image = masked_image.to(device=device, dtype=dtype)
+
+ # encode the mask image into latents space so we can concatenate it to the latents
+ if isinstance(generator, list):
+ masked_image_latents = [
+ self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
+ for i in range(batch_size)
+ ]
+ masked_image_latents = torch.cat(masked_image_latents, dim=0)
+ else:
+ masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
+ masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
+
+ # duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
+ if mask.shape[0] < batch_size:
+ if not batch_size % mask.shape[0] == 0:
+ raise ValueError(
+ "The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
+ f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
+ " of masks that you pass is divisible by the total requested batch size."
+ )
+ mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
+ if masked_image_latents.shape[0] < batch_size:
+ if not batch_size % masked_image_latents.shape[0] == 0:
+ raise ValueError(
+ "The passed images and the required batch size don't match. Images are supposed to be duplicated"
+ f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
+ " Make sure the number of images that you pass is divisible by the total requested batch size."
+ )
+ masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
+
+ mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
+ masked_image_latents = (
+ torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
+ )
+
+ # aligning device to prevent device errors when concating it with the latent model input
+ masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
+ return mask, masked_image_latents
+
+ def _encode_image(self, image, device, num_images_per_prompt, do_classifier_free_guidance):
+ dtype = next(self.image_encoder.parameters()).dtype
+
+ if not isinstance(image, torch.Tensor):
+ image = self.feature_extractor(images=image, return_tensors="pt").pixel_values
+
+ image = image.to(device=device, dtype=dtype)
+ image_embeddings, negative_prompt_embeds = self.image_encoder(image, return_uncond_vector=True)
+
+ # duplicate image embeddings for each generation per prompt, using mps friendly method
+ bs_embed, seq_len, _ = image_embeddings.shape
+ image_embeddings = image_embeddings.repeat(1, num_images_per_prompt, 1)
+ image_embeddings = image_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, image_embeddings.shape[0], 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(bs_embed * num_images_per_prompt, 1, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ image_embeddings = torch.cat([negative_prompt_embeds, image_embeddings])
+
+ return image_embeddings
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ example_image: Union[torch.FloatTensor, PIL.Image.Image],
+ image: Union[torch.FloatTensor, PIL.Image.Image],
+ mask_image: Union[torch.FloatTensor, PIL.Image.Image],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 5.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ example_image (`torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]`):
+ The exemplar image to guide the image generation.
+ image (`torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]`):
+ `Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
+ be masked out with `mask_image` and repainted according to `prompt`.
+ mask_image (`torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
+ to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
+ instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 1. Define call parameters
+ if isinstance(image, PIL.Image.Image):
+ batch_size = 1
+ elif isinstance(image, list):
+ batch_size = len(image)
+ else:
+ batch_size = image.shape[0]
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 2. Preprocess mask and image
+ mask, masked_image = prepare_mask_and_masked_image(image, mask_image)
+ height, width = masked_image.shape[-2:]
+
+ # 3. Check inputs
+ self.check_inputs(example_image, height, width, callback_steps)
+
+ # 4. Encode input image
+ image_embeddings = self._encode_image(
+ example_image, device, num_images_per_prompt, do_classifier_free_guidance
+ )
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.vae.config.latent_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ image_embeddings.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare mask latent variables
+ mask, masked_image_latents = self.prepare_mask_latents(
+ mask,
+ masked_image,
+ batch_size * num_images_per_prompt,
+ height,
+ width,
+ image_embeddings.dtype,
+ device,
+ generator,
+ do_classifier_free_guidance,
+ )
+
+ # 8. Check that sizes of mask, masked image and latents match
+ num_channels_mask = mask.shape[1]
+ num_channels_masked_image = masked_image_latents.shape[1]
+ if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
+ raise ValueError(
+ f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
+ f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
+ f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
+ " `pipeline.unet` or your `mask_image` or `image` input."
+ )
+
+ # 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 10. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+
+ # concat latents, mask, masked_image_latents in the channel dimension
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+ latent_model_input = torch.cat([latent_model_input, masked_image_latents, mask], dim=1)
+
+ # predict the noise residual
+ noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=image_embeddings).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 11. Post-processing
+ image = self.decode_latents(latents)
+
+ # 12. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, image_embeddings.dtype)
+
+ # 13. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/pipeline_flax_utils.py b/diffusers/src/diffusers/pipelines/pipeline_flax_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d91ff757799e56942f31dcd7830d96f20e168dc
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/pipeline_flax_utils.py
@@ -0,0 +1,562 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import importlib
+import inspect
+import os
+from typing import Any, Dict, List, Optional, Union
+
+import flax
+import numpy as np
+import PIL
+from flax.core.frozen_dict import FrozenDict
+from huggingface_hub import snapshot_download
+from PIL import Image
+from tqdm.auto import tqdm
+
+from ..configuration_utils import ConfigMixin
+from ..models.modeling_flax_utils import FLAX_WEIGHTS_NAME, FlaxModelMixin
+from ..schedulers.scheduling_utils_flax import SCHEDULER_CONFIG_NAME, FlaxSchedulerMixin
+from ..utils import CONFIG_NAME, DIFFUSERS_CACHE, BaseOutput, http_user_agent, is_transformers_available, logging
+
+
+if is_transformers_available():
+ from transformers import FlaxPreTrainedModel
+
+INDEX_FILE = "diffusion_flax_model.bin"
+
+
+logger = logging.get_logger(__name__)
+
+
+LOADABLE_CLASSES = {
+ "diffusers": {
+ "FlaxModelMixin": ["save_pretrained", "from_pretrained"],
+ "FlaxSchedulerMixin": ["save_pretrained", "from_pretrained"],
+ "FlaxDiffusionPipeline": ["save_pretrained", "from_pretrained"],
+ },
+ "transformers": {
+ "PreTrainedTokenizer": ["save_pretrained", "from_pretrained"],
+ "PreTrainedTokenizerFast": ["save_pretrained", "from_pretrained"],
+ "FlaxPreTrainedModel": ["save_pretrained", "from_pretrained"],
+ "FeatureExtractionMixin": ["save_pretrained", "from_pretrained"],
+ "ProcessorMixin": ["save_pretrained", "from_pretrained"],
+ "ImageProcessingMixin": ["save_pretrained", "from_pretrained"],
+ },
+}
+
+ALL_IMPORTABLE_CLASSES = {}
+for library in LOADABLE_CLASSES:
+ ALL_IMPORTABLE_CLASSES.update(LOADABLE_CLASSES[library])
+
+
+def import_flax_or_no_model(module, class_name):
+ try:
+ # 1. First make sure that if a Flax object is present, import this one
+ class_obj = getattr(module, "Flax" + class_name)
+ except AttributeError:
+ # 2. If this doesn't work, it's not a model and we don't append "Flax"
+ class_obj = getattr(module, class_name)
+ except AttributeError:
+ raise ValueError(f"Neither Flax{class_name} nor {class_name} exist in {module}")
+
+ return class_obj
+
+
+@flax.struct.dataclass
+class FlaxImagePipelineOutput(BaseOutput):
+ """
+ Output class for image pipelines.
+
+ Args:
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
+ num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
+ """
+
+ images: Union[List[PIL.Image.Image], np.ndarray]
+
+
+class FlaxDiffusionPipeline(ConfigMixin):
+ r"""
+ Base class for all models.
+
+ [`FlaxDiffusionPipeline`] takes care of storing all components (models, schedulers, processors) for diffusion
+ pipelines and handles methods for loading, downloading and saving models as well as a few methods common to all
+ pipelines to:
+
+ - enabling/disabling the progress bar for the denoising iteration
+
+ Class attributes:
+
+ - **config_name** ([`str`]) -- name of the config file that will store the class and module names of all
+ components of the diffusion pipeline.
+ """
+ config_name = "model_index.json"
+
+ def register_modules(self, **kwargs):
+ # import it here to avoid circular import
+ from diffusers import pipelines
+
+ for name, module in kwargs.items():
+ if module is None:
+ register_dict = {name: (None, None)}
+ else:
+ # retrieve library
+ library = module.__module__.split(".")[0]
+
+ # check if the module is a pipeline module
+ pipeline_dir = module.__module__.split(".")[-2]
+ path = module.__module__.split(".")
+ is_pipeline_module = pipeline_dir in path and hasattr(pipelines, pipeline_dir)
+
+ # if library is not in LOADABLE_CLASSES, then it is a custom module.
+ # Or if it's a pipeline module, then the module is inside the pipeline
+ # folder so we set the library to module name.
+ if library not in LOADABLE_CLASSES or is_pipeline_module:
+ library = pipeline_dir
+
+ # retrieve class_name
+ class_name = module.__class__.__name__
+
+ register_dict = {name: (library, class_name)}
+
+ # save model index config
+ self.register_to_config(**register_dict)
+
+ # set models
+ setattr(self, name, module)
+
+ def save_pretrained(self, save_directory: Union[str, os.PathLike], params: Union[Dict, FrozenDict]):
+ # TODO: handle inference_state
+ """
+ Save all variables of the pipeline that can be saved and loaded as well as the pipelines configuration file to
+ a directory. A pipeline variable can be saved and loaded if its class implements both a save and loading
+ method. The pipeline can easily be re-loaded using the `[`~FlaxDiffusionPipeline.from_pretrained`]` class
+ method.
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ """
+ self.save_config(save_directory)
+
+ model_index_dict = dict(self.config)
+ model_index_dict.pop("_class_name")
+ model_index_dict.pop("_diffusers_version")
+ model_index_dict.pop("_module", None)
+
+ for pipeline_component_name in model_index_dict.keys():
+ sub_model = getattr(self, pipeline_component_name)
+ if sub_model is None:
+ # edge case for saving a pipeline with safety_checker=None
+ continue
+
+ model_cls = sub_model.__class__
+
+ save_method_name = None
+ # search for the model's base class in LOADABLE_CLASSES
+ for library_name, library_classes in LOADABLE_CLASSES.items():
+ library = importlib.import_module(library_name)
+ for base_class, save_load_methods in library_classes.items():
+ class_candidate = getattr(library, base_class, None)
+ if class_candidate is not None and issubclass(model_cls, class_candidate):
+ # if we found a suitable base class in LOADABLE_CLASSES then grab its save method
+ save_method_name = save_load_methods[0]
+ break
+ if save_method_name is not None:
+ break
+
+ save_method = getattr(sub_model, save_method_name)
+ expects_params = "params" in set(inspect.signature(save_method).parameters.keys())
+
+ if expects_params:
+ save_method(
+ os.path.join(save_directory, pipeline_component_name), params=params[pipeline_component_name]
+ )
+ else:
+ save_method(os.path.join(save_directory, pipeline_component_name))
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
+ r"""
+ Instantiate a Flax diffusion pipeline from pre-trained pipeline weights.
+
+ The pipeline is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated).
+
+ The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
+ pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
+ task.
+
+ The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
+ weights are discarded.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
+ Can be either:
+
+ - A string, the *repo id* of a pretrained pipeline hosted inside a model repo on
+ https://huggingface.co/ Valid repo ids have to be located under a user or organization name, like
+ `CompVis/ldm-text2im-large-256`.
+ - A path to a *directory* containing pipeline weights saved using
+ [`~FlaxDiffusionPipeline.save_pretrained`], e.g., `./my_pipeline_directory/`.
+ dtype (`str` or `jnp.dtype`, *optional*):
+ Override the default `jnp.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
+ will be automatically derived from the model's weights.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information. specify the folder name here.
+
+ kwargs (remaining dictionary of keyword arguments, *optional*):
+ Can be used to overwrite load - and saveable variables - *i.e.* the pipeline components - of the
+ specific pipeline class. The overwritten components are then directly passed to the pipelines
+ `__init__` method. See example below for more information.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models), *e.g.* `"runwayml/stable-diffusion-v1-5"`
+
+
+
+
+
+ Activate the special ["offline-mode"](https://huggingface.co/diffusers/installation.html#offline-mode) to use
+ this method in a firewalled environment.
+
+
+
+ Examples:
+
+ ```py
+ >>> from diffusers import FlaxDiffusionPipeline
+
+ >>> # Download pipeline from huggingface.co and cache.
+ >>> # Requires to be logged in to Hugging Face hub,
+ >>> # see more in [the documentation](https://huggingface.co/docs/hub/security-tokens)
+ >>> pipeline, params = FlaxDiffusionPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5",
+ ... revision="bf16",
+ ... dtype=jnp.bfloat16,
+ ... )
+
+ >>> # Download pipeline, but use a different scheduler
+ >>> from diffusers import FlaxDPMSolverMultistepScheduler
+
+ >>> model_id = "runwayml/stable-diffusion-v1-5"
+ >>> dpmpp, dpmpp_state = FlaxDPMSolverMultistepScheduler.from_pretrained(
+ ... model_id,
+ ... subfolder="scheduler",
+ ... )
+
+ >>> dpm_pipe, dpm_params = FlaxStableDiffusionPipeline.from_pretrained(
+ ... model_id, revision="bf16", dtype=jnp.bfloat16, scheduler=dpmpp
+ ... )
+ >>> dpm_params["scheduler"] = dpmpp_state
+ ```
+ """
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ resume_download = kwargs.pop("resume_download", False)
+ proxies = kwargs.pop("proxies", None)
+ local_files_only = kwargs.pop("local_files_only", False)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ from_pt = kwargs.pop("from_pt", False)
+ dtype = kwargs.pop("dtype", None)
+
+ # 1. Download the checkpoints and configs
+ # use snapshot download here to get it working from from_pretrained
+ if not os.path.isdir(pretrained_model_name_or_path):
+ config_dict = cls.load_config(
+ pretrained_model_name_or_path,
+ cache_dir=cache_dir,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ )
+ # make sure we only download sub-folders and `diffusers` filenames
+ folder_names = [k for k in config_dict.keys() if not k.startswith("_")]
+ allow_patterns = [os.path.join(k, "*") for k in folder_names]
+ allow_patterns += [FLAX_WEIGHTS_NAME, SCHEDULER_CONFIG_NAME, CONFIG_NAME, cls.config_name]
+
+ # make sure we don't download PyTorch weights, unless when using from_pt
+ ignore_patterns = "*.bin" if not from_pt else []
+
+ if cls != FlaxDiffusionPipeline:
+ requested_pipeline_class = cls.__name__
+ else:
+ requested_pipeline_class = config_dict.get("_class_name", cls.__name__)
+ requested_pipeline_class = (
+ requested_pipeline_class
+ if requested_pipeline_class.startswith("Flax")
+ else "Flax" + requested_pipeline_class
+ )
+
+ user_agent = {"pipeline_class": requested_pipeline_class}
+ user_agent = http_user_agent(user_agent)
+
+ # download all allow_patterns
+ cached_folder = snapshot_download(
+ pretrained_model_name_or_path,
+ cache_dir=cache_dir,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ allow_patterns=allow_patterns,
+ ignore_patterns=ignore_patterns,
+ user_agent=user_agent,
+ )
+ else:
+ cached_folder = pretrained_model_name_or_path
+
+ config_dict = cls.load_config(cached_folder)
+
+ # 2. Load the pipeline class, if using custom module then load it from the hub
+ # if we load from explicit class, let's use it
+ if cls != FlaxDiffusionPipeline:
+ pipeline_class = cls
+ else:
+ diffusers_module = importlib.import_module(cls.__module__.split(".")[0])
+ class_name = (
+ config_dict["_class_name"]
+ if config_dict["_class_name"].startswith("Flax")
+ else "Flax" + config_dict["_class_name"]
+ )
+ pipeline_class = getattr(diffusers_module, class_name)
+
+ # some modules can be passed directly to the init
+ # in this case they are already instantiated in `kwargs`
+ # extract them here
+ expected_modules, optional_kwargs = cls._get_signature_keys(pipeline_class)
+ passed_class_obj = {k: kwargs.pop(k) for k in expected_modules if k in kwargs}
+
+ init_dict, _, _ = pipeline_class.extract_init_dict(config_dict, **kwargs)
+
+ init_kwargs = {}
+
+ # inference_params
+ params = {}
+
+ # import it here to avoid circular import
+ from diffusers import pipelines
+
+ # 3. Load each module in the pipeline
+ for name, (library_name, class_name) in init_dict.items():
+ if class_name is None:
+ # edge case for when the pipeline was saved with safety_checker=None
+ init_kwargs[name] = None
+ continue
+
+ is_pipeline_module = hasattr(pipelines, library_name)
+ loaded_sub_model = None
+ sub_model_should_be_defined = True
+
+ # if the model is in a pipeline module, then we load it from the pipeline
+ if name in passed_class_obj:
+ # 1. check that passed_class_obj has correct parent class
+ if not is_pipeline_module:
+ library = importlib.import_module(library_name)
+ class_obj = getattr(library, class_name)
+ importable_classes = LOADABLE_CLASSES[library_name]
+ class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
+
+ expected_class_obj = None
+ for class_name, class_candidate in class_candidates.items():
+ if class_candidate is not None and issubclass(class_obj, class_candidate):
+ expected_class_obj = class_candidate
+
+ if not issubclass(passed_class_obj[name].__class__, expected_class_obj):
+ raise ValueError(
+ f"{passed_class_obj[name]} is of type: {type(passed_class_obj[name])}, but should be"
+ f" {expected_class_obj}"
+ )
+ elif passed_class_obj[name] is None:
+ logger.warning(
+ f"You have passed `None` for {name} to disable its functionality in {pipeline_class}. Note"
+ f" that this might lead to problems when using {pipeline_class} and is not recommended."
+ )
+ sub_model_should_be_defined = False
+ else:
+ logger.warning(
+ f"You have passed a non-standard module {passed_class_obj[name]}. We cannot verify whether it"
+ " has the correct type"
+ )
+
+ # set passed class object
+ loaded_sub_model = passed_class_obj[name]
+ elif is_pipeline_module:
+ pipeline_module = getattr(pipelines, library_name)
+ class_obj = import_flax_or_no_model(pipeline_module, class_name)
+
+ importable_classes = ALL_IMPORTABLE_CLASSES
+ class_candidates = {c: class_obj for c in importable_classes.keys()}
+ else:
+ # else we just import it from the library.
+ library = importlib.import_module(library_name)
+ class_obj = import_flax_or_no_model(library, class_name)
+
+ importable_classes = LOADABLE_CLASSES[library_name]
+ class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
+
+ if loaded_sub_model is None and sub_model_should_be_defined:
+ load_method_name = None
+ for class_name, class_candidate in class_candidates.items():
+ if class_candidate is not None and issubclass(class_obj, class_candidate):
+ load_method_name = importable_classes[class_name][1]
+
+ load_method = getattr(class_obj, load_method_name)
+
+ # check if the module is in a subdirectory
+ if os.path.isdir(os.path.join(cached_folder, name)):
+ loadable_folder = os.path.join(cached_folder, name)
+ else:
+ loaded_sub_model = cached_folder
+
+ if issubclass(class_obj, FlaxModelMixin):
+ loaded_sub_model, loaded_params = load_method(loadable_folder, from_pt=from_pt, dtype=dtype)
+ params[name] = loaded_params
+ elif is_transformers_available() and issubclass(class_obj, FlaxPreTrainedModel):
+ if from_pt:
+ # TODO(Suraj): Fix this in Transformers. We should be able to use `_do_init=False` here
+ loaded_sub_model = load_method(loadable_folder, from_pt=from_pt)
+ loaded_params = loaded_sub_model.params
+ del loaded_sub_model._params
+ else:
+ loaded_sub_model, loaded_params = load_method(loadable_folder, _do_init=False)
+ params[name] = loaded_params
+ elif issubclass(class_obj, FlaxSchedulerMixin):
+ loaded_sub_model, scheduler_state = load_method(loadable_folder)
+ params[name] = scheduler_state
+ else:
+ loaded_sub_model = load_method(loadable_folder)
+
+ init_kwargs[name] = loaded_sub_model # UNet(...), # DiffusionSchedule(...)
+
+ # 4. Potentially add passed objects if expected
+ missing_modules = set(expected_modules) - set(init_kwargs.keys())
+ passed_modules = list(passed_class_obj.keys())
+
+ if len(missing_modules) > 0 and missing_modules <= set(passed_modules):
+ for module in missing_modules:
+ init_kwargs[module] = passed_class_obj.get(module, None)
+ elif len(missing_modules) > 0:
+ passed_modules = set(list(init_kwargs.keys()) + list(passed_class_obj.keys())) - optional_kwargs
+ raise ValueError(
+ f"Pipeline {pipeline_class} expected {expected_modules}, but only {passed_modules} were passed."
+ )
+
+ model = pipeline_class(**init_kwargs, dtype=dtype)
+ return model, params
+
+ @staticmethod
+ def _get_signature_keys(obj):
+ parameters = inspect.signature(obj.__init__).parameters
+ required_parameters = {k: v for k, v in parameters.items() if v.default == inspect._empty}
+ optional_parameters = set({k for k, v in parameters.items() if v.default != inspect._empty})
+ expected_modules = set(required_parameters.keys()) - {"self"}
+ return expected_modules, optional_parameters
+
+ @property
+ def components(self) -> Dict[str, Any]:
+ r"""
+
+ The `self.components` property can be useful to run different pipelines with the same weights and
+ configurations to not have to re-allocate memory.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import (
+ ... FlaxStableDiffusionPipeline,
+ ... FlaxStableDiffusionImg2ImgPipeline,
+ ... )
+
+ >>> text2img = FlaxStableDiffusionPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", revision="bf16", dtype=jnp.bfloat16
+ ... )
+ >>> img2img = FlaxStableDiffusionImg2ImgPipeline(**text2img.components)
+ ```
+
+ Returns:
+ A dictionary containing all the modules needed to initialize the pipeline.
+ """
+ expected_modules, optional_parameters = self._get_signature_keys(self)
+ components = {
+ k: getattr(self, k) for k in self.config.keys() if not k.startswith("_") and k not in optional_parameters
+ }
+
+ if set(components.keys()) != expected_modules:
+ raise ValueError(
+ f"{self} has been incorrectly initialized or {self.__class__} is incorrectly implemented. Expected"
+ f" {expected_modules} to be defined, but {components} are defined."
+ )
+
+ return components
+
+ @staticmethod
+ def numpy_to_pil(images):
+ """
+ Convert a numpy image or a batch of images to a PIL image.
+ """
+ if images.ndim == 3:
+ images = images[None, ...]
+ images = (images * 255).round().astype("uint8")
+ if images.shape[-1] == 1:
+ # special case for grayscale (single channel) images
+ pil_images = [Image.fromarray(image.squeeze(), mode="L") for image in images]
+ else:
+ pil_images = [Image.fromarray(image) for image in images]
+
+ return pil_images
+
+ # TODO: make it compatible with jax.lax
+ def progress_bar(self, iterable):
+ if not hasattr(self, "_progress_bar_config"):
+ self._progress_bar_config = {}
+ elif not isinstance(self._progress_bar_config, dict):
+ raise ValueError(
+ f"`self._progress_bar_config` should be of type `dict`, but is {type(self._progress_bar_config)}."
+ )
+
+ return tqdm(iterable, **self._progress_bar_config)
+
+ def set_progress_bar_config(self, **kwargs):
+ self._progress_bar_config = kwargs
diff --git a/diffusers/src/diffusers/pipelines/pipeline_utils.py b/diffusers/src/diffusers/pipelines/pipeline_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a03c454e9244e28e98bdcdcc8cdeb340da3f7903
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/pipeline_utils.py
@@ -0,0 +1,1396 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import fnmatch
+import importlib
+import inspect
+import os
+import re
+import warnings
+from dataclasses import dataclass
+from pathlib import Path
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from huggingface_hub import hf_hub_download, model_info, snapshot_download
+from packaging import version
+from PIL import Image
+from tqdm.auto import tqdm
+
+import diffusers
+
+from .. import __version__
+from ..configuration_utils import ConfigMixin
+from ..models.modeling_utils import _LOW_CPU_MEM_USAGE_DEFAULT
+from ..schedulers.scheduling_utils import SCHEDULER_CONFIG_NAME
+from ..utils import (
+ CONFIG_NAME,
+ DEPRECATED_REVISION_ARGS,
+ DIFFUSERS_CACHE,
+ HF_HUB_OFFLINE,
+ SAFETENSORS_WEIGHTS_NAME,
+ WEIGHTS_NAME,
+ BaseOutput,
+ deprecate,
+ get_class_from_dynamic_module,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_compiled_module,
+ is_safetensors_available,
+ is_torch_version,
+ is_transformers_available,
+ logging,
+)
+
+
+if is_transformers_available():
+ import transformers
+ from transformers import PreTrainedModel
+ from transformers.utils import FLAX_WEIGHTS_NAME as TRANSFORMERS_FLAX_WEIGHTS_NAME
+ from transformers.utils import SAFE_WEIGHTS_NAME as TRANSFORMERS_SAFE_WEIGHTS_NAME
+ from transformers.utils import WEIGHTS_NAME as TRANSFORMERS_WEIGHTS_NAME
+
+from ..utils import FLAX_WEIGHTS_NAME, ONNX_EXTERNAL_WEIGHTS_NAME, ONNX_WEIGHTS_NAME
+
+
+if is_accelerate_available():
+ import accelerate
+
+
+INDEX_FILE = "diffusion_pytorch_model.bin"
+CUSTOM_PIPELINE_FILE_NAME = "pipeline.py"
+DUMMY_MODULES_FOLDER = "diffusers.utils"
+TRANSFORMERS_DUMMY_MODULES_FOLDER = "transformers.utils"
+
+
+logger = logging.get_logger(__name__)
+
+
+LOADABLE_CLASSES = {
+ "diffusers": {
+ "ModelMixin": ["save_pretrained", "from_pretrained"],
+ "SchedulerMixin": ["save_pretrained", "from_pretrained"],
+ "DiffusionPipeline": ["save_pretrained", "from_pretrained"],
+ "OnnxRuntimeModel": ["save_pretrained", "from_pretrained"],
+ },
+ "transformers": {
+ "PreTrainedTokenizer": ["save_pretrained", "from_pretrained"],
+ "PreTrainedTokenizerFast": ["save_pretrained", "from_pretrained"],
+ "PreTrainedModel": ["save_pretrained", "from_pretrained"],
+ "FeatureExtractionMixin": ["save_pretrained", "from_pretrained"],
+ "ProcessorMixin": ["save_pretrained", "from_pretrained"],
+ "ImageProcessingMixin": ["save_pretrained", "from_pretrained"],
+ },
+ "onnxruntime.training": {
+ "ORTModule": ["save_pretrained", "from_pretrained"],
+ },
+}
+
+ALL_IMPORTABLE_CLASSES = {}
+for library in LOADABLE_CLASSES:
+ ALL_IMPORTABLE_CLASSES.update(LOADABLE_CLASSES[library])
+
+
+@dataclass
+class ImagePipelineOutput(BaseOutput):
+ """
+ Output class for image pipelines.
+
+ Args:
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
+ num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
+ """
+
+ images: Union[List[PIL.Image.Image], np.ndarray]
+
+
+@dataclass
+class AudioPipelineOutput(BaseOutput):
+ """
+ Output class for audio pipelines.
+
+ Args:
+ audios (`np.ndarray`)
+ List of denoised samples of shape `(batch_size, num_channels, sample_rate)`. Numpy array present the
+ denoised audio samples of the diffusion pipeline.
+ """
+
+ audios: np.ndarray
+
+
+def is_safetensors_compatible(filenames, variant=None) -> bool:
+ """
+ Checking for safetensors compatibility:
+ - By default, all models are saved with the default pytorch serialization, so we use the list of default pytorch
+ files to know which safetensors files are needed.
+ - The model is safetensors compatible only if there is a matching safetensors file for every default pytorch file.
+
+ Converting default pytorch serialized filenames to safetensors serialized filenames:
+ - For models from the diffusers library, just replace the ".bin" extension with ".safetensors"
+ - For models from the transformers library, the filename changes from "pytorch_model" to "model", and the ".bin"
+ extension is replaced with ".safetensors"
+ """
+ pt_filenames = []
+
+ sf_filenames = set()
+
+ for filename in filenames:
+ _, extension = os.path.splitext(filename)
+
+ if extension == ".bin":
+ pt_filenames.append(filename)
+ elif extension == ".safetensors":
+ sf_filenames.add(filename)
+
+ for filename in pt_filenames:
+ # filename = 'foo/bar/baz.bam' -> path = 'foo/bar', filename = 'baz', extention = '.bam'
+ path, filename = os.path.split(filename)
+ filename, extension = os.path.splitext(filename)
+
+ if filename == "pytorch_model":
+ filename = "model"
+ elif filename == f"pytorch_model.{variant}":
+ filename = f"model.{variant}"
+ else:
+ filename = filename
+
+ expected_sf_filename = os.path.join(path, filename)
+ expected_sf_filename = f"{expected_sf_filename}.safetensors"
+
+ if expected_sf_filename not in sf_filenames:
+ logger.warning(f"{expected_sf_filename} not found")
+ return False
+
+ return True
+
+
+def variant_compatible_siblings(filenames, variant=None) -> Union[List[os.PathLike], str]:
+ weight_names = [
+ WEIGHTS_NAME,
+ SAFETENSORS_WEIGHTS_NAME,
+ FLAX_WEIGHTS_NAME,
+ ONNX_WEIGHTS_NAME,
+ ONNX_EXTERNAL_WEIGHTS_NAME,
+ ]
+
+ if is_transformers_available():
+ weight_names += [TRANSFORMERS_WEIGHTS_NAME, TRANSFORMERS_SAFE_WEIGHTS_NAME, TRANSFORMERS_FLAX_WEIGHTS_NAME]
+
+ # model_pytorch, diffusion_model_pytorch, ...
+ weight_prefixes = [w.split(".")[0] for w in weight_names]
+ # .bin, .safetensors, ...
+ weight_suffixs = [w.split(".")[-1] for w in weight_names]
+
+ variant_file_regex = (
+ re.compile(f"({'|'.join(weight_prefixes)})(.{variant}.)({'|'.join(weight_suffixs)})")
+ if variant is not None
+ else None
+ )
+ non_variant_file_regex = re.compile(f"{'|'.join(weight_names)}")
+
+ if variant is not None:
+ variant_filenames = {f for f in filenames if variant_file_regex.match(f.split("/")[-1]) is not None}
+ else:
+ variant_filenames = set()
+
+ non_variant_filenames = {f for f in filenames if non_variant_file_regex.match(f.split("/")[-1]) is not None}
+
+ usable_filenames = set(variant_filenames)
+ for f in non_variant_filenames:
+ variant_filename = f"{f.split('.')[0]}.{variant}.{f.split('.')[1]}"
+ if variant_filename not in usable_filenames:
+ usable_filenames.add(f)
+
+ return usable_filenames, variant_filenames
+
+
+def warn_deprecated_model_variant(pretrained_model_name_or_path, use_auth_token, variant, revision, model_filenames):
+ info = model_info(
+ pretrained_model_name_or_path,
+ use_auth_token=use_auth_token,
+ revision=None,
+ )
+ filenames = {sibling.rfilename for sibling in info.siblings}
+ comp_model_filenames, _ = variant_compatible_siblings(filenames, variant=revision)
+ comp_model_filenames = [".".join(f.split(".")[:1] + f.split(".")[2:]) for f in comp_model_filenames]
+
+ if set(comp_model_filenames) == set(model_filenames):
+ warnings.warn(
+ f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'` even though you can load it via `variant=`{revision}`. Loading model variants via `revision='{revision}'` is deprecated and will be removed in diffusers v1. Please use `variant='{revision}'` instead.",
+ FutureWarning,
+ )
+ else:
+ warnings.warn(
+ f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'`. This behavior is deprecated and will be removed in diffusers v1. One should use `variant='{revision}'` instead. However, it appears that {pretrained_model_name_or_path} currently does not have the required variant filenames in the 'main' branch. \n The Diffusers team and community would be very grateful if you could open an issue: https://github.com/huggingface/diffusers/issues/new with the title '{pretrained_model_name_or_path} is missing {revision} files' so that the correct variant file can be added.",
+ FutureWarning,
+ )
+
+
+def maybe_raise_or_warn(
+ library_name, library, class_name, importable_classes, passed_class_obj, name, is_pipeline_module
+):
+ """Simple helper method to raise or warn in case incorrect module has been passed"""
+ if not is_pipeline_module:
+ library = importlib.import_module(library_name)
+ class_obj = getattr(library, class_name)
+ class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
+
+ expected_class_obj = None
+ for class_name, class_candidate in class_candidates.items():
+ if class_candidate is not None and issubclass(class_obj, class_candidate):
+ expected_class_obj = class_candidate
+
+ # Dynamo wraps the original model in a private class.
+ # I didn't find a public API to get the original class.
+ sub_model = passed_class_obj[name]
+ model_cls = sub_model.__class__
+ if is_compiled_module(sub_model):
+ model_cls = sub_model._orig_mod.__class__
+
+ if not issubclass(model_cls, expected_class_obj):
+ raise ValueError(
+ f"{passed_class_obj[name]} is of type: {type(passed_class_obj[name])}, but should be"
+ f" {expected_class_obj}"
+ )
+ else:
+ logger.warning(
+ f"You have passed a non-standard module {passed_class_obj[name]}. We cannot verify whether it"
+ " has the correct type"
+ )
+
+
+def get_class_obj_and_candidates(library_name, class_name, importable_classes, pipelines, is_pipeline_module):
+ """Simple helper method to retrieve class object of module as well as potential parent class objects"""
+ if is_pipeline_module:
+ pipeline_module = getattr(pipelines, library_name)
+
+ class_obj = getattr(pipeline_module, class_name)
+ class_candidates = {c: class_obj for c in importable_classes.keys()}
+ else:
+ # else we just import it from the library.
+ library = importlib.import_module(library_name)
+
+ class_obj = getattr(library, class_name)
+ class_candidates = {c: getattr(library, c, None) for c in importable_classes.keys()}
+
+ return class_obj, class_candidates
+
+
+def load_sub_model(
+ library_name: str,
+ class_name: str,
+ importable_classes: List[Any],
+ pipelines: Any,
+ is_pipeline_module: bool,
+ pipeline_class: Any,
+ torch_dtype: torch.dtype,
+ provider: Any,
+ sess_options: Any,
+ device_map: Optional[Union[Dict[str, torch.device], str]],
+ model_variants: Dict[str, str],
+ name: str,
+ from_flax: bool,
+ variant: str,
+ low_cpu_mem_usage: bool,
+ cached_folder: Union[str, os.PathLike],
+):
+ """Helper method to load the module `name` from `library_name` and `class_name`"""
+ # retrieve class candidates
+ class_obj, class_candidates = get_class_obj_and_candidates(
+ library_name, class_name, importable_classes, pipelines, is_pipeline_module
+ )
+
+ load_method_name = None
+ # retrive load method name
+ for class_name, class_candidate in class_candidates.items():
+ if class_candidate is not None and issubclass(class_obj, class_candidate):
+ load_method_name = importable_classes[class_name][1]
+
+ # if load method name is None, then we have a dummy module -> raise Error
+ if load_method_name is None:
+ none_module = class_obj.__module__
+ is_dummy_path = none_module.startswith(DUMMY_MODULES_FOLDER) or none_module.startswith(
+ TRANSFORMERS_DUMMY_MODULES_FOLDER
+ )
+ if is_dummy_path and "dummy" in none_module:
+ # call class_obj for nice error message of missing requirements
+ class_obj()
+
+ raise ValueError(
+ f"The component {class_obj} of {pipeline_class} cannot be loaded as it does not seem to have"
+ f" any of the loading methods defined in {ALL_IMPORTABLE_CLASSES}."
+ )
+
+ load_method = getattr(class_obj, load_method_name)
+
+ # add kwargs to loading method
+ loading_kwargs = {}
+ if issubclass(class_obj, torch.nn.Module):
+ loading_kwargs["torch_dtype"] = torch_dtype
+ if issubclass(class_obj, diffusers.OnnxRuntimeModel):
+ loading_kwargs["provider"] = provider
+ loading_kwargs["sess_options"] = sess_options
+
+ is_diffusers_model = issubclass(class_obj, diffusers.ModelMixin)
+
+ if is_transformers_available():
+ transformers_version = version.parse(version.parse(transformers.__version__).base_version)
+ else:
+ transformers_version = "N/A"
+
+ is_transformers_model = (
+ is_transformers_available()
+ and issubclass(class_obj, PreTrainedModel)
+ and transformers_version >= version.parse("4.20.0")
+ )
+
+ # When loading a transformers model, if the device_map is None, the weights will be initialized as opposed to diffusers.
+ # To make default loading faster we set the `low_cpu_mem_usage=low_cpu_mem_usage` flag which is `True` by default.
+ # This makes sure that the weights won't be initialized which significantly speeds up loading.
+ if is_diffusers_model or is_transformers_model:
+ loading_kwargs["device_map"] = device_map
+ loading_kwargs["variant"] = model_variants.pop(name, None)
+ if from_flax:
+ loading_kwargs["from_flax"] = True
+
+ # the following can be deleted once the minimum required `transformers` version
+ # is higher than 4.27
+ if (
+ is_transformers_model
+ and loading_kwargs["variant"] is not None
+ and transformers_version < version.parse("4.27.0")
+ ):
+ raise ImportError(
+ f"When passing `variant='{variant}'`, please make sure to upgrade your `transformers` version to at least 4.27.0.dev0"
+ )
+ elif is_transformers_model and loading_kwargs["variant"] is None:
+ loading_kwargs.pop("variant")
+
+ # if `from_flax` and model is transformer model, can currently not load with `low_cpu_mem_usage`
+ if not (from_flax and is_transformers_model):
+ loading_kwargs["low_cpu_mem_usage"] = low_cpu_mem_usage
+ else:
+ loading_kwargs["low_cpu_mem_usage"] = False
+
+ # check if the module is in a subdirectory
+ if os.path.isdir(os.path.join(cached_folder, name)):
+ loaded_sub_model = load_method(os.path.join(cached_folder, name), **loading_kwargs)
+ else:
+ # else load from the root directory
+ loaded_sub_model = load_method(cached_folder, **loading_kwargs)
+
+ return loaded_sub_model
+
+
+class DiffusionPipeline(ConfigMixin):
+ r"""
+ Base class for all models.
+
+ [`DiffusionPipeline`] takes care of storing all components (models, schedulers, processors) for diffusion pipelines
+ and handles methods for loading, downloading and saving models as well as a few methods common to all pipelines to:
+
+ - move all PyTorch modules to the device of your choice
+ - enabling/disabling the progress bar for the denoising iteration
+
+ Class attributes:
+
+ - **config_name** (`str`) -- name of the config file that will store the class and module names of all
+ components of the diffusion pipeline.
+ - **_optional_components** (List[`str`]) -- list of all components that are optional so they don't have to be
+ passed for the pipeline to function (should be overridden by subclasses).
+ """
+ config_name = "model_index.json"
+ _optional_components = []
+
+ def register_modules(self, **kwargs):
+ # import it here to avoid circular import
+ from diffusers import pipelines
+
+ for name, module in kwargs.items():
+ # retrieve library
+ if module is None:
+ register_dict = {name: (None, None)}
+ else:
+ # register the original module, not the dynamo compiled one
+ if is_compiled_module(module):
+ module = module._orig_mod
+
+ library = module.__module__.split(".")[0]
+
+ # check if the module is a pipeline module
+ pipeline_dir = module.__module__.split(".")[-2] if len(module.__module__.split(".")) > 2 else None
+ path = module.__module__.split(".")
+ is_pipeline_module = pipeline_dir in path and hasattr(pipelines, pipeline_dir)
+
+ # if library is not in LOADABLE_CLASSES, then it is a custom module.
+ # Or if it's a pipeline module, then the module is inside the pipeline
+ # folder so we set the library to module name.
+ if library not in LOADABLE_CLASSES or is_pipeline_module:
+ library = pipeline_dir
+
+ # retrieve class_name
+ class_name = module.__class__.__name__
+
+ register_dict = {name: (library, class_name)}
+
+ # save model index config
+ self.register_to_config(**register_dict)
+
+ # set models
+ setattr(self, name, module)
+
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ """
+ Save all variables of the pipeline that can be saved and loaded as well as the pipelines configuration file to
+ a directory. A pipeline variable can be saved and loaded if its class implements both a save and loading
+ method. The pipeline can easily be re-loaded using the `[`~DiffusionPipeline.from_pretrained`]` class method.
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ safe_serialization (`bool`, *optional*, defaults to `False`):
+ Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
+ variant (`str`, *optional*):
+ If specified, weights are saved in the format pytorch_model..bin.
+ """
+ self.save_config(save_directory)
+
+ model_index_dict = dict(self.config)
+ model_index_dict.pop("_class_name")
+ model_index_dict.pop("_diffusers_version")
+ model_index_dict.pop("_module", None)
+
+ expected_modules, optional_kwargs = self._get_signature_keys(self)
+
+ def is_saveable_module(name, value):
+ if name not in expected_modules:
+ return False
+ if name in self._optional_components and value[0] is None:
+ return False
+ return True
+
+ model_index_dict = {k: v for k, v in model_index_dict.items() if is_saveable_module(k, v)}
+
+ for pipeline_component_name in model_index_dict.keys():
+ sub_model = getattr(self, pipeline_component_name)
+ model_cls = sub_model.__class__
+
+ # Dynamo wraps the original model in a private class.
+ # I didn't find a public API to get the original class.
+ if is_compiled_module(sub_model):
+ sub_model = sub_model._orig_mod
+ model_cls = sub_model.__class__
+
+ save_method_name = None
+ # search for the model's base class in LOADABLE_CLASSES
+ for library_name, library_classes in LOADABLE_CLASSES.items():
+ library = importlib.import_module(library_name)
+ for base_class, save_load_methods in library_classes.items():
+ class_candidate = getattr(library, base_class, None)
+ if class_candidate is not None and issubclass(model_cls, class_candidate):
+ # if we found a suitable base class in LOADABLE_CLASSES then grab its save method
+ save_method_name = save_load_methods[0]
+ break
+ if save_method_name is not None:
+ break
+
+ save_method = getattr(sub_model, save_method_name)
+
+ # Call the save method with the argument safe_serialization only if it's supported
+ save_method_signature = inspect.signature(save_method)
+ save_method_accept_safe = "safe_serialization" in save_method_signature.parameters
+ save_method_accept_variant = "variant" in save_method_signature.parameters
+
+ save_kwargs = {}
+ if save_method_accept_safe:
+ save_kwargs["safe_serialization"] = safe_serialization
+ if save_method_accept_variant:
+ save_kwargs["variant"] = variant
+
+ save_method(os.path.join(save_directory, pipeline_component_name), **save_kwargs)
+
+ def to(
+ self,
+ torch_device: Optional[Union[str, torch.device]] = None,
+ torch_dtype: Optional[torch.dtype] = None,
+ silence_dtype_warnings: bool = False,
+ ):
+ if torch_device is None and torch_dtype is None:
+ return self
+
+ # throw warning if pipeline is in "offloaded"-mode but user tries to manually set to GPU.
+ def module_is_sequentially_offloaded(module):
+ if not is_accelerate_available() or is_accelerate_version("<", "0.14.0"):
+ return False
+
+ return hasattr(module, "_hf_hook") and not isinstance(module._hf_hook, accelerate.hooks.CpuOffload)
+
+ def module_is_offloaded(module):
+ if not is_accelerate_available() or is_accelerate_version("<", "0.17.0.dev0"):
+ return False
+
+ return hasattr(module, "_hf_hook") and isinstance(module._hf_hook, accelerate.hooks.CpuOffload)
+
+ # .to("cuda") would raise an error if the pipeline is sequentially offloaded, so we raise our own to make it clearer
+ pipeline_is_sequentially_offloaded = any(
+ module_is_sequentially_offloaded(module) for _, module in self.components.items()
+ )
+ if pipeline_is_sequentially_offloaded and torch.device(torch_device).type == "cuda":
+ raise ValueError(
+ "It seems like you have activated sequential model offloading by calling `enable_sequential_cpu_offload`, but are now attempting to move the pipeline to GPU. This is not compatible with offloading. Please, move your pipeline `.to('cpu')` or consider removing the move altogether if you use sequential offloading."
+ )
+
+ # Display a warning in this case (the operation succeeds but the benefits are lost)
+ pipeline_is_offloaded = any(module_is_offloaded(module) for _, module in self.components.items())
+ if pipeline_is_offloaded and torch.device(torch_device).type == "cuda":
+ logger.warning(
+ f"It seems like you have activated model offloading by calling `enable_model_cpu_offload`, but are now manually moving the pipeline to GPU. It is strongly recommended against doing so as memory gains from offloading are likely to be lost. Offloading automatically takes care of moving the individual components {', '.join(self.components.keys())} to GPU when needed. To make sure offloading works as expected, you should consider moving the pipeline back to CPU: `pipeline.to('cpu')` or removing the move altogether if you use offloading."
+ )
+
+ module_names, _, _ = self.extract_init_dict(dict(self.config))
+ is_offloaded = pipeline_is_offloaded or pipeline_is_sequentially_offloaded
+ for name in module_names.keys():
+ module = getattr(self, name)
+ if isinstance(module, torch.nn.Module):
+ module.to(torch_device, torch_dtype)
+ if (
+ module.dtype == torch.float16
+ and str(torch_device) in ["cpu"]
+ and not silence_dtype_warnings
+ and not is_offloaded
+ ):
+ logger.warning(
+ "Pipelines loaded with `torch_dtype=torch.float16` cannot run with `cpu` device. It"
+ " is not recommended to move them to `cpu` as running them will fail. Please make"
+ " sure to use an accelerator to run the pipeline in inference, due to the lack of"
+ " support for`float16` operations on this device in PyTorch. Please, remove the"
+ " `torch_dtype=torch.float16` argument, or use another device for inference."
+ )
+ return self
+
+ @property
+ def device(self) -> torch.device:
+ r"""
+ Returns:
+ `torch.device`: The torch device on which the pipeline is located.
+ """
+ module_names, _, _ = self.extract_init_dict(dict(self.config))
+ for name in module_names.keys():
+ module = getattr(self, name)
+ if isinstance(module, torch.nn.Module):
+ return module.device
+ return torch.device("cpu")
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path: Optional[Union[str, os.PathLike]], **kwargs):
+ r"""
+ Instantiate a PyTorch diffusion pipeline from pre-trained pipeline weights.
+
+ The pipeline is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated).
+
+ The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
+ pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
+ task.
+
+ The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
+ weights are discarded.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
+ Can be either:
+
+ - A string, the *repo id* of a pretrained pipeline hosted inside a model repo on
+ https://huggingface.co/ Valid repo ids have to be located under a user or organization name, like
+ `CompVis/ldm-text2im-large-256`.
+ - A path to a *directory* containing pipeline weights saved using
+ [`~DiffusionPipeline.save_pretrained`], e.g., `./my_pipeline_directory/`.
+ torch_dtype (`str` or `torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model under this dtype. If `"auto"` is passed the dtype
+ will be automatically derived from the model's weights.
+ custom_pipeline (`str`, *optional*):
+
+
+
+ This is an experimental feature and is likely to change in the future.
+
+
+
+ Can be either:
+
+ - A string, the *repo id* of a custom pipeline hosted inside a model repo on
+ https://huggingface.co/. Valid repo ids have to be located under a user or organization name,
+ like `hf-internal-testing/diffusers-dummy-pipeline`.
+
+
+
+ It is required that the model repo has a file, called `pipeline.py` that defines the custom
+ pipeline.
+
+
+
+ - A string, the *file name* of a community pipeline hosted on GitHub under
+ https://github.com/huggingface/diffusers/tree/main/examples/community. Valid file names have to
+ match exactly the file name without `.py` located under the above link, *e.g.*
+ `clip_guided_stable_diffusion`.
+
+
+
+ Community pipelines are always loaded from the current `main` branch of GitHub.
+
+
+
+ - A path to a *directory* containing a custom pipeline, e.g., `./my_pipeline_directory/`.
+
+
+
+ It is required that the directory has a file, called `pipeline.py` that defines the custom
+ pipeline.
+
+
+
+ For more information on how to load and create custom pipelines, please have a look at [Loading and
+ Adding Custom
+ Pipelines](https://huggingface.co/docs/diffusers/using-diffusers/custom_pipeline_overview)
+
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ custom_revision (`str`, *optional*, defaults to `"main"` when loading from the Hub and to local version of `diffusers` when loading from GitHub):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id similar to
+ `revision` when loading a custom pipeline from the Hub. It can be a diffusers version when loading a
+ custom pipeline from GitHub.
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information. specify the folder name here.
+ device_map (`str` or `Dict[str, Union[int, str, torch.device]]`, *optional*):
+ A map that specifies where each submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every submodule of it will be sent to the
+ same device.
+
+ To have Accelerate compute the most optimized `device_map` automatically, set `device_map="auto"`. For
+ more information about each option see [designing a device
+ map](https://hf.co/docs/accelerate/main/en/usage_guides/big_modeling#designing-a-device-map).
+ low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
+ Speed up model loading by not initializing the weights and only loading the pre-trained weights. This
+ also tries to not use more than 1x model size in CPU memory (including peak memory) while loading the
+ model. This is only supported when torch version >= 1.9.0. If you are using an older version of torch,
+ setting this argument to `True` will raise an error.
+ use_safetensors (`bool`, *optional* ):
+ If set to `True`, the pipeline will be loaded from `safetensors` weights. If set to `None` (the
+ default). The pipeline will load using `safetensors` if the safetensors weights are available *and* if
+ `safetensors` is installed. If the to `False` the pipeline will *not* use `safetensors`.
+ kwargs (remaining dictionary of keyword arguments, *optional*):
+ Can be used to overwrite load - and saveable variables - *i.e.* the pipeline components - of the
+ specific pipeline class. The overwritten components are then directly passed to the pipelines
+ `__init__` method. See example below for more information.
+ variant (`str`, *optional*):
+ If specified load weights from `variant` filename, *e.g.* pytorch_model..bin. `variant` is
+ ignored when using `from_flax`.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models), *e.g.* `"runwayml/stable-diffusion-v1-5"`
+
+
+
+
+
+ Activate the special ["offline-mode"](https://huggingface.co/diffusers/installation.html#offline-mode) to use
+ this method in a firewalled environment.
+
+
+
+ Examples:
+
+ ```py
+ >>> from diffusers import DiffusionPipeline
+
+ >>> # Download pipeline from huggingface.co and cache.
+ >>> pipeline = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
+
+ >>> # Download pipeline that requires an authorization token
+ >>> # For more information on access tokens, please refer to this section
+ >>> # of the documentation](https://huggingface.co/docs/hub/security-tokens)
+ >>> pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+
+ >>> # Use a different scheduler
+ >>> from diffusers import LMSDiscreteScheduler
+
+ >>> scheduler = LMSDiscreteScheduler.from_config(pipeline.scheduler.config)
+ >>> pipeline.scheduler = scheduler
+ ```
+ """
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ resume_download = kwargs.pop("resume_download", False)
+ force_download = kwargs.pop("force_download", False)
+ proxies = kwargs.pop("proxies", None)
+ local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ from_flax = kwargs.pop("from_flax", False)
+ torch_dtype = kwargs.pop("torch_dtype", None)
+ custom_pipeline = kwargs.pop("custom_pipeline", None)
+ custom_revision = kwargs.pop("custom_revision", None)
+ provider = kwargs.pop("provider", None)
+ sess_options = kwargs.pop("sess_options", None)
+ device_map = kwargs.pop("device_map", None)
+ low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", _LOW_CPU_MEM_USAGE_DEFAULT)
+ variant = kwargs.pop("variant", None)
+ kwargs.pop("use_safetensors", None if is_safetensors_available() else False)
+
+ # 1. Download the checkpoints and configs
+ # use snapshot download here to get it working from from_pretrained
+ if not os.path.isdir(pretrained_model_name_or_path):
+ cached_folder = cls.download(
+ pretrained_model_name_or_path,
+ cache_dir=cache_dir,
+ resume_download=resume_download,
+ force_download=force_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ from_flax=from_flax,
+ custom_pipeline=custom_pipeline,
+ variant=variant,
+ )
+ else:
+ cached_folder = pretrained_model_name_or_path
+
+ config_dict = cls.load_config(cached_folder)
+
+ # 2. Define which model components should load variants
+ # We retrieve the information by matching whether variant
+ # model checkpoints exist in the subfolders
+ model_variants = {}
+ if variant is not None:
+ for folder in os.listdir(cached_folder):
+ folder_path = os.path.join(cached_folder, folder)
+ is_folder = os.path.isdir(folder_path) and folder in config_dict
+ variant_exists = is_folder and any(path.split(".")[1] == variant for path in os.listdir(folder_path))
+ if variant_exists:
+ model_variants[folder] = variant
+
+ # 3. Load the pipeline class, if using custom module then load it from the hub
+ # if we load from explicit class, let's use it
+ if custom_pipeline is not None:
+ if custom_pipeline.endswith(".py"):
+ path = Path(custom_pipeline)
+ # decompose into folder & file
+ file_name = path.name
+ custom_pipeline = path.parent.absolute()
+ else:
+ file_name = CUSTOM_PIPELINE_FILE_NAME
+
+ pipeline_class = get_class_from_dynamic_module(
+ custom_pipeline, module_file=file_name, cache_dir=cache_dir, revision=custom_revision
+ )
+ elif cls != DiffusionPipeline:
+ pipeline_class = cls
+ else:
+ diffusers_module = importlib.import_module(cls.__module__.split(".")[0])
+ pipeline_class = getattr(diffusers_module, config_dict["_class_name"])
+
+ # DEPRECATED: To be removed in 1.0.0
+ if pipeline_class.__name__ == "StableDiffusionInpaintPipeline" and version.parse(
+ version.parse(config_dict["_diffusers_version"]).base_version
+ ) <= version.parse("0.5.1"):
+ from diffusers import StableDiffusionInpaintPipeline, StableDiffusionInpaintPipelineLegacy
+
+ pipeline_class = StableDiffusionInpaintPipelineLegacy
+
+ deprecation_message = (
+ "You are using a legacy checkpoint for inpainting with Stable Diffusion, therefore we are loading the"
+ f" {StableDiffusionInpaintPipelineLegacy} class instead of {StableDiffusionInpaintPipeline}. For"
+ " better inpainting results, we strongly suggest using Stable Diffusion's official inpainting"
+ " checkpoint: https://huggingface.co/runwayml/stable-diffusion-inpainting instead or adapting your"
+ f" checkpoint {pretrained_model_name_or_path} to the format of"
+ " https://huggingface.co/runwayml/stable-diffusion-inpainting. Note that we do not actively maintain"
+ " the {StableDiffusionInpaintPipelineLegacy} class and will likely remove it in version 1.0.0."
+ )
+ deprecate("StableDiffusionInpaintPipelineLegacy", "1.0.0", deprecation_message, standard_warn=False)
+
+ # 4. Define expected modules given pipeline signature
+ # and define non-None initialized modules (=`init_kwargs`)
+
+ # some modules can be passed directly to the init
+ # in this case they are already instantiated in `kwargs`
+ # extract them here
+ expected_modules, optional_kwargs = cls._get_signature_keys(pipeline_class)
+ passed_class_obj = {k: kwargs.pop(k) for k in expected_modules if k in kwargs}
+ passed_pipe_kwargs = {k: kwargs.pop(k) for k in optional_kwargs if k in kwargs}
+
+ init_dict, unused_kwargs, _ = pipeline_class.extract_init_dict(config_dict, **kwargs)
+
+ # define init kwargs
+ init_kwargs = {k: init_dict.pop(k) for k in optional_kwargs if k in init_dict}
+ init_kwargs = {**init_kwargs, **passed_pipe_kwargs}
+
+ # remove `null` components
+ def load_module(name, value):
+ if value[0] is None:
+ return False
+ if name in passed_class_obj and passed_class_obj[name] is None:
+ return False
+ return True
+
+ init_dict = {k: v for k, v in init_dict.items() if load_module(k, v)}
+
+ # Special case: safety_checker must be loaded separately when using `from_flax`
+ if from_flax and "safety_checker" in init_dict and "safety_checker" not in passed_class_obj:
+ raise NotImplementedError(
+ "The safety checker cannot be automatically loaded when loading weights `from_flax`."
+ " Please, pass `safety_checker=None` to `from_pretrained`, and load the safety checker"
+ " separately if you need it."
+ )
+
+ # 5. Throw nice warnings / errors for fast accelerate loading
+ if len(unused_kwargs) > 0:
+ logger.warning(
+ f"Keyword arguments {unused_kwargs} are not expected by {pipeline_class.__name__} and will be ignored."
+ )
+
+ if low_cpu_mem_usage and not is_accelerate_available():
+ low_cpu_mem_usage = False
+ logger.warning(
+ "Cannot initialize model with low cpu memory usage because `accelerate` was not found in the"
+ " environment. Defaulting to `low_cpu_mem_usage=False`. It is strongly recommended to install"
+ " `accelerate` for faster and less memory-intense model loading. You can do so with: \n```\npip"
+ " install accelerate\n```\n."
+ )
+
+ if device_map is not None and not is_torch_version(">=", "1.9.0"):
+ raise NotImplementedError(
+ "Loading and dispatching requires torch >= 1.9.0. Please either update your PyTorch version or set"
+ " `device_map=None`."
+ )
+
+ if low_cpu_mem_usage is True and not is_torch_version(">=", "1.9.0"):
+ raise NotImplementedError(
+ "Low memory initialization requires torch >= 1.9.0. Please either update your PyTorch version or set"
+ " `low_cpu_mem_usage=False`."
+ )
+
+ if low_cpu_mem_usage is False and device_map is not None:
+ raise ValueError(
+ f"You cannot set `low_cpu_mem_usage` to False while using device_map={device_map} for loading and"
+ " dispatching. Please make sure to set `low_cpu_mem_usage=True`."
+ )
+
+ # import it here to avoid circular import
+ from diffusers import pipelines
+
+ # 6. Load each module in the pipeline
+ for name, (library_name, class_name) in init_dict.items():
+ # 6.1 - now that JAX/Flax is an official framework of the library, we might load from Flax names
+ if class_name.startswith("Flax"):
+ class_name = class_name[4:]
+
+ # 6.2 Define all importable classes
+ is_pipeline_module = hasattr(pipelines, library_name)
+ importable_classes = ALL_IMPORTABLE_CLASSES if is_pipeline_module else LOADABLE_CLASSES[library_name]
+ loaded_sub_model = None
+
+ # 6.3 Use passed sub model or load class_name from library_name
+ if name in passed_class_obj:
+ # if the model is in a pipeline module, then we load it from the pipeline
+ # check that passed_class_obj has correct parent class
+ maybe_raise_or_warn(
+ library_name, library, class_name, importable_classes, passed_class_obj, name, is_pipeline_module
+ )
+
+ loaded_sub_model = passed_class_obj[name]
+ else:
+ # load sub model
+ loaded_sub_model = load_sub_model(
+ library_name=library_name,
+ class_name=class_name,
+ importable_classes=importable_classes,
+ pipelines=pipelines,
+ is_pipeline_module=is_pipeline_module,
+ pipeline_class=pipeline_class,
+ torch_dtype=torch_dtype,
+ provider=provider,
+ sess_options=sess_options,
+ device_map=device_map,
+ model_variants=model_variants,
+ name=name,
+ from_flax=from_flax,
+ variant=variant,
+ low_cpu_mem_usage=low_cpu_mem_usage,
+ cached_folder=cached_folder,
+ )
+
+ init_kwargs[name] = loaded_sub_model # UNet(...), # DiffusionSchedule(...)
+
+ # 7. Potentially add passed objects if expected
+ missing_modules = set(expected_modules) - set(init_kwargs.keys())
+ passed_modules = list(passed_class_obj.keys())
+ optional_modules = pipeline_class._optional_components
+ if len(missing_modules) > 0 and missing_modules <= set(passed_modules + optional_modules):
+ for module in missing_modules:
+ init_kwargs[module] = passed_class_obj.get(module, None)
+ elif len(missing_modules) > 0:
+ passed_modules = set(list(init_kwargs.keys()) + list(passed_class_obj.keys())) - optional_kwargs
+ raise ValueError(
+ f"Pipeline {pipeline_class} expected {expected_modules}, but only {passed_modules} were passed."
+ )
+
+ # 8. Instantiate the pipeline
+ model = pipeline_class(**init_kwargs)
+
+ return_cached_folder = kwargs.pop("return_cached_folder", False)
+ if return_cached_folder:
+ message = f"Passing `return_cached_folder=True` is deprecated and will be removed in `diffusers=0.17.0`. Please do the following instead: \n 1. Load the cached_folder via `cached_folder={cls}.download({pretrained_model_name_or_path})`. \n 2. Load the pipeline by loading from the cached folder: `pipeline={cls}.from_pretrained(cached_folder)`."
+ deprecate("return_cached_folder", "0.17.0", message, take_from=kwargs)
+ return model, cached_folder
+
+ return model
+
+ @classmethod
+ def download(cls, pretrained_model_name, **kwargs) -> Union[str, os.PathLike]:
+ r"""
+ Download and cache a PyTorch diffusion pipeline from pre-trained pipeline weights.
+
+ Parameters:
+ pretrained_model_name (`str` or `os.PathLike`, *optional*):
+ Should be a string, the *repo id* of a pretrained pipeline hosted inside a model repo on
+ https://huggingface.co/ Valid repo ids have to be located under a user or organization name, like
+ `CompVis/ldm-text2im-large-256`.
+ custom_pipeline (`str`, *optional*):
+
+
+
+ This is an experimental feature and is likely to change in the future.
+
+
+
+ Can be either:
+
+ - A string, the *repo id* of a custom pipeline hosted inside a model repo on
+ https://huggingface.co/. Valid repo ids have to be located under a user or organization name,
+ like `hf-internal-testing/diffusers-dummy-pipeline`.
+
+
+
+ It is required that the model repo has a file, called `pipeline.py` that defines the custom
+ pipeline.
+
+
+
+ - A string, the *file name* of a community pipeline hosted on GitHub under
+ https://github.com/huggingface/diffusers/tree/main/examples/community. Valid file names have to
+ match exactly the file name without `.py` located under the above link, *e.g.*
+ `clip_guided_stable_diffusion`.
+
+
+
+ Community pipelines are always loaded from the current `main` branch of GitHub.
+
+
+
+ - A path to a *directory* containing a custom pipeline, e.g., `./my_pipeline_directory/`.
+
+
+
+ It is required that the directory has a file, called `pipeline.py` that defines the custom
+ pipeline.
+
+
+
+ For more information on how to load and create custom pipelines, please have a look at [Loading and
+ Adding Custom
+ Pipelines](https://huggingface.co/docs/diffusers/using-diffusers/custom_pipeline_overview)
+
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ custom_revision (`str`, *optional*, defaults to `"main"` when loading from the Hub and to local version of
+ `diffusers` when loading from GitHub):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id similar to
+ `revision` when loading a custom pipeline from the Hub. It can be a diffusers version when loading a
+ custom pipeline from GitHub.
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information. specify the folder name here.
+ variant (`str`, *optional*):
+ If specified load weights from `variant` filename, *e.g.* pytorch_model..bin. `variant` is
+ ignored when using `from_flax`.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models)
+
+
+
+ """
+ cache_dir = kwargs.pop("cache_dir", DIFFUSERS_CACHE)
+ resume_download = kwargs.pop("resume_download", False)
+ force_download = kwargs.pop("force_download", False)
+ proxies = kwargs.pop("proxies", None)
+ local_files_only = kwargs.pop("local_files_only", HF_HUB_OFFLINE)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ revision = kwargs.pop("revision", None)
+ from_flax = kwargs.pop("from_flax", False)
+ custom_pipeline = kwargs.pop("custom_pipeline", None)
+ variant = kwargs.pop("variant", None)
+ use_safetensors = kwargs.pop("use_safetensors", None)
+
+ if use_safetensors and not is_safetensors_available():
+ raise ValueError(
+ "`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
+ )
+
+ allow_pickle = False
+ if use_safetensors is None:
+ use_safetensors = is_safetensors_available()
+ allow_pickle = True
+
+ pipeline_is_cached = False
+ allow_patterns = None
+ ignore_patterns = None
+
+ if not local_files_only:
+ config_file = hf_hub_download(
+ pretrained_model_name,
+ cls.config_name,
+ cache_dir=cache_dir,
+ revision=revision,
+ proxies=proxies,
+ force_download=force_download,
+ resume_download=resume_download,
+ use_auth_token=use_auth_token,
+ )
+ info = model_info(
+ pretrained_model_name,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ )
+
+ config_dict = cls._dict_from_json_file(config_file)
+ # retrieve all folder_names that contain relevant files
+ folder_names = [k for k, v in config_dict.items() if isinstance(v, list)]
+
+ filenames = {sibling.rfilename for sibling in info.siblings}
+ model_filenames, variant_filenames = variant_compatible_siblings(filenames, variant=variant)
+
+ # if the whole pipeline is cached we don't have to ping the Hub
+ if revision in DEPRECATED_REVISION_ARGS and version.parse(
+ version.parse(__version__).base_version
+ ) >= version.parse("0.17.0"):
+ warn_deprecated_model_variant(
+ pretrained_model_name, use_auth_token, variant, revision, model_filenames
+ )
+
+ model_folder_names = {os.path.split(f)[0] for f in model_filenames}
+
+ # all filenames compatible with variant will be added
+ allow_patterns = list(model_filenames)
+
+ # allow all patterns from non-model folders
+ # this enables downloading schedulers, tokenizers, ...
+ allow_patterns += [os.path.join(k, "*") for k in folder_names if k not in model_folder_names]
+ # also allow downloading config.json files with the model
+ allow_patterns += [os.path.join(k, "*.json") for k in model_folder_names]
+
+ allow_patterns += [
+ SCHEDULER_CONFIG_NAME,
+ CONFIG_NAME,
+ cls.config_name,
+ CUSTOM_PIPELINE_FILE_NAME,
+ ]
+
+ if (
+ use_safetensors
+ and not allow_pickle
+ and not is_safetensors_compatible(model_filenames, variant=variant)
+ ):
+ raise EnvironmentError(
+ f"Could not found the necessary `safetensors` weights in {model_filenames} (variant={variant})"
+ )
+ if from_flax:
+ ignore_patterns = ["*.bin", "*.safetensors", "*.onnx", "*.pb"]
+ elif use_safetensors and is_safetensors_compatible(model_filenames, variant=variant):
+ ignore_patterns = ["*.bin", "*.msgpack"]
+
+ safetensors_variant_filenames = {f for f in variant_filenames if f.endswith(".safetensors")}
+ safetensors_model_filenames = {f for f in model_filenames if f.endswith(".safetensors")}
+ if (
+ len(safetensors_variant_filenames) > 0
+ and safetensors_model_filenames != safetensors_variant_filenames
+ ):
+ logger.warn(
+ f"\nA mixture of {variant} and non-{variant} filenames will be loaded.\nLoaded {variant} filenames:\n[{', '.join(safetensors_variant_filenames)}]\nLoaded non-{variant} filenames:\n[{', '.join(safetensors_model_filenames - safetensors_variant_filenames)}\nIf this behavior is not expected, please check your folder structure."
+ )
+ else:
+ ignore_patterns = ["*.safetensors", "*.msgpack"]
+
+ bin_variant_filenames = {f for f in variant_filenames if f.endswith(".bin")}
+ bin_model_filenames = {f for f in model_filenames if f.endswith(".bin")}
+ if len(bin_variant_filenames) > 0 and bin_model_filenames != bin_variant_filenames:
+ logger.warn(
+ f"\nA mixture of {variant} and non-{variant} filenames will be loaded.\nLoaded {variant} filenames:\n[{', '.join(bin_variant_filenames)}]\nLoaded non-{variant} filenames:\n[{', '.join(bin_model_filenames - bin_variant_filenames)}\nIf this behavior is not expected, please check your folder structure."
+ )
+
+ re_ignore_pattern = [re.compile(fnmatch.translate(p)) for p in ignore_patterns]
+ re_allow_pattern = [re.compile(fnmatch.translate(p)) for p in allow_patterns]
+
+ expected_files = [f for f in filenames if not any(p.match(f) for p in re_ignore_pattern)]
+ expected_files = [f for f in expected_files if any(p.match(f) for p in re_allow_pattern)]
+
+ snapshot_folder = Path(config_file).parent
+ pipeline_is_cached = all((snapshot_folder / f).is_file() for f in expected_files)
+
+ if pipeline_is_cached:
+ # if the pipeline is cached, we can directly return it
+ # else call snapshot_download
+ return snapshot_folder
+
+ user_agent = {"pipeline_class": cls.__name__}
+ if custom_pipeline is not None and not custom_pipeline.endswith(".py"):
+ user_agent["custom_pipeline"] = custom_pipeline
+
+ # download all allow_patterns - ignore_patterns
+ cached_folder = snapshot_download(
+ pretrained_model_name,
+ cache_dir=cache_dir,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ allow_patterns=allow_patterns,
+ ignore_patterns=ignore_patterns,
+ user_agent=user_agent,
+ )
+
+ return cached_folder
+
+ @staticmethod
+ def _get_signature_keys(obj):
+ parameters = inspect.signature(obj.__init__).parameters
+ required_parameters = {k: v for k, v in parameters.items() if v.default == inspect._empty}
+ optional_parameters = set({k for k, v in parameters.items() if v.default != inspect._empty})
+ expected_modules = set(required_parameters.keys()) - {"self"}
+ return expected_modules, optional_parameters
+
+ @property
+ def components(self) -> Dict[str, Any]:
+ r"""
+
+ The `self.components` property can be useful to run different pipelines with the same weights and
+ configurations to not have to re-allocate memory.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import (
+ ... StableDiffusionPipeline,
+ ... StableDiffusionImg2ImgPipeline,
+ ... StableDiffusionInpaintPipeline,
+ ... )
+
+ >>> text2img = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ >>> img2img = StableDiffusionImg2ImgPipeline(**text2img.components)
+ >>> inpaint = StableDiffusionInpaintPipeline(**text2img.components)
+ ```
+
+ Returns:
+ A dictionary containing all the modules needed to initialize the pipeline.
+ """
+ expected_modules, optional_parameters = self._get_signature_keys(self)
+ components = {
+ k: getattr(self, k) for k in self.config.keys() if not k.startswith("_") and k not in optional_parameters
+ }
+
+ if set(components.keys()) != expected_modules:
+ raise ValueError(
+ f"{self} has been incorrectly initialized or {self.__class__} is incorrectly implemented. Expected"
+ f" {expected_modules} to be defined, but {components.keys()} are defined."
+ )
+
+ return components
+
+ @staticmethod
+ def numpy_to_pil(images):
+ """
+ Convert a numpy image or a batch of images to a PIL image.
+ """
+ if images.ndim == 3:
+ images = images[None, ...]
+ images = (images * 255).round().astype("uint8")
+ if images.shape[-1] == 1:
+ # special case for grayscale (single channel) images
+ pil_images = [Image.fromarray(image.squeeze(), mode="L") for image in images]
+ else:
+ pil_images = [Image.fromarray(image) for image in images]
+
+ return pil_images
+
+ def progress_bar(self, iterable=None, total=None):
+ if not hasattr(self, "_progress_bar_config"):
+ self._progress_bar_config = {}
+ elif not isinstance(self._progress_bar_config, dict):
+ raise ValueError(
+ f"`self._progress_bar_config` should be of type `dict`, but is {type(self._progress_bar_config)}."
+ )
+
+ if iterable is not None:
+ return tqdm(iterable, **self._progress_bar_config)
+ elif total is not None:
+ return tqdm(total=total, **self._progress_bar_config)
+ else:
+ raise ValueError("Either `total` or `iterable` has to be defined.")
+
+ def set_progress_bar_config(self, **kwargs):
+ self._progress_bar_config = kwargs
+
+ def enable_xformers_memory_efficient_attention(self, attention_op: Optional[Callable] = None):
+ r"""
+ Enable memory efficient attention as implemented in xformers.
+
+ When this option is enabled, you should observe lower GPU memory usage and a potential speed up at inference
+ time. Speed up at training time is not guaranteed.
+
+ Warning: When Memory Efficient Attention and Sliced attention are both enabled, the Memory Efficient Attention
+ is used.
+
+ Parameters:
+ attention_op (`Callable`, *optional*):
+ Override the default `None` operator for use as `op` argument to the
+ [`memory_efficient_attention()`](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.memory_efficient_attention)
+ function of xFormers.
+
+ Examples:
+
+ ```py
+ >>> import torch
+ >>> from diffusers import DiffusionPipeline
+ >>> from xformers.ops import MemoryEfficientAttentionFlashAttentionOp
+
+ >>> pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16)
+ >>> pipe = pipe.to("cuda")
+ >>> pipe.enable_xformers_memory_efficient_attention(attention_op=MemoryEfficientAttentionFlashAttentionOp)
+ >>> # Workaround for not accepting attention shape using VAE for Flash Attention
+ >>> pipe.vae.enable_xformers_memory_efficient_attention(attention_op=None)
+ ```
+ """
+ self.set_use_memory_efficient_attention_xformers(True, attention_op)
+
+ def disable_xformers_memory_efficient_attention(self):
+ r"""
+ Disable memory efficient attention as implemented in xformers.
+ """
+ self.set_use_memory_efficient_attention_xformers(False)
+
+ def set_use_memory_efficient_attention_xformers(
+ self, valid: bool, attention_op: Optional[Callable] = None
+ ) -> None:
+ # Recursively walk through all the children.
+ # Any children which exposes the set_use_memory_efficient_attention_xformers method
+ # gets the message
+ def fn_recursive_set_mem_eff(module: torch.nn.Module):
+ if hasattr(module, "set_use_memory_efficient_attention_xformers"):
+ module.set_use_memory_efficient_attention_xformers(valid, attention_op)
+
+ for child in module.children():
+ fn_recursive_set_mem_eff(child)
+
+ module_names, _, _ = self.extract_init_dict(dict(self.config))
+ for module_name in module_names:
+ module = getattr(self, module_name)
+ if isinstance(module, torch.nn.Module):
+ fn_recursive_set_mem_eff(module)
+
+ def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module will split the input tensor in slices, to compute attention
+ in several steps. This is useful to save some memory in exchange for a small speed decrease.
+
+ Args:
+ slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
+ When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
+ `"max"`, maximum amount of memory will be saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ self.set_attention_slice(slice_size)
+
+ def disable_attention_slicing(self):
+ r"""
+ Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
+ back to computing attention in one step.
+ """
+ # set slice_size = `None` to disable `attention slicing`
+ self.enable_attention_slicing(None)
+
+ def set_attention_slice(self, slice_size: Optional[int]):
+ module_names, _, _ = self.extract_init_dict(dict(self.config))
+ for module_name in module_names:
+ module = getattr(self, module_name)
+ if isinstance(module, torch.nn.Module) and hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size)
diff --git a/diffusers/src/diffusers/pipelines/pndm/__init__.py b/diffusers/src/diffusers/pipelines/pndm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..488eb4f5f2b29c071fdc044ef282bc2838148c1e
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/pndm/__init__.py
@@ -0,0 +1 @@
+from .pipeline_pndm import PNDMPipeline
diff --git a/diffusers/src/diffusers/pipelines/pndm/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/pndm/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f34b141893c66d0a6cc7ad56eefa77a4118a7236
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/pndm/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/pndm/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/pndm/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..954b50436670fe9d73f80c55a3f60d6e00c9a91d
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/pndm/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/pndm/__pycache__/pipeline_pndm.cpython-310.pyc b/diffusers/src/diffusers/pipelines/pndm/__pycache__/pipeline_pndm.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2b5280ebd58a3acc51f83f42d39058a8ca50386b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/pndm/__pycache__/pipeline_pndm.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/pndm/__pycache__/pipeline_pndm.cpython-39.pyc b/diffusers/src/diffusers/pipelines/pndm/__pycache__/pipeline_pndm.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..60bc711d92fe252e40eb72b634ae46fa67e57c50
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/pndm/__pycache__/pipeline_pndm.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/pndm/pipeline_pndm.py b/diffusers/src/diffusers/pipelines/pndm/pipeline_pndm.py
new file mode 100644
index 0000000000000000000000000000000000000000..56fb72d3f4ff9827da4b35e2a1ef9095fa741f01
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/pndm/pipeline_pndm.py
@@ -0,0 +1,99 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from typing import List, Optional, Tuple, Union
+
+import torch
+
+from ...models import UNet2DModel
+from ...schedulers import PNDMScheduler
+from ...utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class PNDMPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ unet (`UNet2DModel`): U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ The `PNDMScheduler` to be used in combination with `unet` to denoise the encoded image.
+ """
+
+ unet: UNet2DModel
+ scheduler: PNDMScheduler
+
+ def __init__(self, unet: UNet2DModel, scheduler: PNDMScheduler):
+ super().__init__()
+
+ scheduler = PNDMScheduler.from_config(scheduler.config)
+
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ num_inference_steps: int = 50,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ **kwargs,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ r"""
+ Args:
+ batch_size (`int`, `optional`, defaults to 1): The number of images to generate.
+ num_inference_steps (`int`, `optional`, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ generator (`torch.Generator`, `optional`): A [torch
+ generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
+ deterministic.
+ output_type (`str`, `optional`, defaults to `"pil"`): The output format of the generate image. Choose
+ between [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, `optional`, defaults to `True`): Whether or not to return a
+ [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+ # For more information on the sampling method you can take a look at Algorithm 2 of
+ # the official paper: https://arxiv.org/pdf/2202.09778.pdf
+
+ # Sample gaussian noise to begin loop
+ image = randn_tensor(
+ (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
+ generator=generator,
+ device=self.device,
+ )
+
+ self.scheduler.set_timesteps(num_inference_steps)
+ for t in self.progress_bar(self.scheduler.timesteps):
+ model_output = self.unet(image, t).sample
+
+ image = self.scheduler.step(model_output, t, image).prev_sample
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/repaint/__init__.py b/diffusers/src/diffusers/pipelines/repaint/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..16bc86d1cedf6243fb92f7ba331b5a6188133298
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/repaint/__init__.py
@@ -0,0 +1 @@
+from .pipeline_repaint import RePaintPipeline
diff --git a/diffusers/src/diffusers/pipelines/repaint/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/repaint/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a3dfb3eae2763d227d19dfc468abfce48884b729
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/repaint/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/repaint/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/repaint/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..302ed38c22d7af87b7a5070f2c961c5e7aa69343
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/repaint/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/repaint/__pycache__/pipeline_repaint.cpython-310.pyc b/diffusers/src/diffusers/pipelines/repaint/__pycache__/pipeline_repaint.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9656cd044c3591d67021d5b1d3da9666fb307780
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/repaint/__pycache__/pipeline_repaint.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/repaint/__pycache__/pipeline_repaint.cpython-39.pyc b/diffusers/src/diffusers/pipelines/repaint/__pycache__/pipeline_repaint.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3afef64ba0bc037b208fd97cc45664a4fc5469fd
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/repaint/__pycache__/pipeline_repaint.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/repaint/pipeline_repaint.py b/diffusers/src/diffusers/pipelines/repaint/pipeline_repaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4914c46db51148c60c96f0dde3805092e0cff48
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/repaint/pipeline_repaint.py
@@ -0,0 +1,171 @@
+# Copyright 2023 ETH Zurich Computer Vision Lab and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import PIL
+import torch
+
+from ...models import UNet2DModel
+from ...schedulers import RePaintScheduler
+from ...utils import PIL_INTERPOLATION, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
+def _preprocess_image(image: Union[List, PIL.Image.Image, torch.Tensor]):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+
+ image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+def _preprocess_mask(mask: Union[List, PIL.Image.Image, torch.Tensor]):
+ if isinstance(mask, torch.Tensor):
+ return mask
+ elif isinstance(mask, PIL.Image.Image):
+ mask = [mask]
+
+ if isinstance(mask[0], PIL.Image.Image):
+ w, h = mask[0].size
+ w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
+ mask = [np.array(m.convert("L").resize((w, h), resample=PIL_INTERPOLATION["nearest"]))[None, :] for m in mask]
+ mask = np.concatenate(mask, axis=0)
+ mask = mask.astype(np.float32) / 255.0
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+ mask = torch.from_numpy(mask)
+ elif isinstance(mask[0], torch.Tensor):
+ mask = torch.cat(mask, dim=0)
+ return mask
+
+
+class RePaintPipeline(DiffusionPipeline):
+ unet: UNet2DModel
+ scheduler: RePaintScheduler
+
+ def __init__(self, unet, scheduler):
+ super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ image: Union[torch.Tensor, PIL.Image.Image],
+ mask_image: Union[torch.Tensor, PIL.Image.Image],
+ num_inference_steps: int = 250,
+ eta: float = 0.0,
+ jump_length: int = 10,
+ jump_n_sample: int = 10,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ r"""
+ Args:
+ image (`torch.FloatTensor` or `PIL.Image.Image`):
+ The original image to inpaint on.
+ mask_image (`torch.FloatTensor` or `PIL.Image.Image`):
+ The mask_image where 0.0 values define which part of the original image to inpaint (change).
+ num_inference_steps (`int`, *optional*, defaults to 1000):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ eta (`float`):
+ The weight of noise for added noise in a diffusion step. Its value is between 0.0 and 1.0 - 0.0 is DDIM
+ and 1.0 is DDPM scheduler respectively.
+ jump_length (`int`, *optional*, defaults to 10):
+ The number of steps taken forward in time before going backward in time for a single jump ("j" in
+ RePaint paper). Take a look at Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
+ jump_n_sample (`int`, *optional*, defaults to 10):
+ The number of times we will make forward time jump for a given chosen time sample. Take a look at
+ Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ original_image = image
+
+ original_image = _preprocess_image(original_image)
+ original_image = original_image.to(device=self.device, dtype=self.unet.dtype)
+ mask_image = _preprocess_mask(mask_image)
+ mask_image = mask_image.to(device=self.device, dtype=self.unet.dtype)
+
+ batch_size = original_image.shape[0]
+
+ # sample gaussian noise to begin the loop
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ image_shape = original_image.shape
+ image = randn_tensor(image_shape, generator=generator, device=self.device, dtype=self.unet.dtype)
+
+ # set step values
+ self.scheduler.set_timesteps(num_inference_steps, jump_length, jump_n_sample, self.device)
+ self.scheduler.eta = eta
+
+ t_last = self.scheduler.timesteps[0] + 1
+ generator = generator[0] if isinstance(generator, list) else generator
+ for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
+ if t < t_last:
+ # predict the noise residual
+ model_output = self.unet(image, t).sample
+ # compute previous image: x_t -> x_t-1
+ image = self.scheduler.step(model_output, t, image, original_image, mask_image, generator).prev_sample
+
+ else:
+ # compute the reverse: x_t-1 -> x_t
+ image = self.scheduler.undo_step(image, t_last, generator)
+ t_last = t
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/score_sde_ve/__init__.py b/diffusers/src/diffusers/pipelines/score_sde_ve/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7c2a85c067b707c155e78a3c8b84562999134e7
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/score_sde_ve/__init__.py
@@ -0,0 +1 @@
+from .pipeline_score_sde_ve import ScoreSdeVePipeline
diff --git a/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3fa8e9a1c83e6667c2682893c01f282ba2063c9b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5bad481f6d6f9486cc0f5b70392f99184bceafe9
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/pipeline_score_sde_ve.cpython-310.pyc b/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/pipeline_score_sde_ve.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ec0849fde6016474482d27e5bdd8b2afff2471a9
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/pipeline_score_sde_ve.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/pipeline_score_sde_ve.cpython-39.pyc b/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/pipeline_score_sde_ve.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..17fa07a622f94046fa32f2f319ab60d7ddb70f98
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/score_sde_ve/__pycache__/pipeline_score_sde_ve.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/score_sde_ve/pipeline_score_sde_ve.py b/diffusers/src/diffusers/pipelines/score_sde_ve/pipeline_score_sde_ve.py
new file mode 100644
index 0000000000000000000000000000000000000000..60a6f1e70f4a4b51cec74a315904a4e8e7cf6bfa
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/score_sde_ve/pipeline_score_sde_ve.py
@@ -0,0 +1,101 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Optional, Tuple, Union
+
+import torch
+
+from ...models import UNet2DModel
+from ...schedulers import ScoreSdeVeScheduler
+from ...utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class ScoreSdeVePipeline(DiffusionPipeline):
+ r"""
+ Parameters:
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+ unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image. scheduler ([`SchedulerMixin`]):
+ The [`ScoreSdeVeScheduler`] scheduler to be used in combination with `unet` to denoise the encoded image.
+ """
+ unet: UNet2DModel
+ scheduler: ScoreSdeVeScheduler
+
+ def __init__(self, unet: UNet2DModel, scheduler: DiffusionPipeline):
+ super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ num_inference_steps: int = 2000,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ **kwargs,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ r"""
+ Args:
+ batch_size (`int`, *optional*, defaults to 1):
+ The number of images to generate.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ img_size = self.unet.config.sample_size
+ shape = (batch_size, 3, img_size, img_size)
+
+ model = self.unet
+
+ sample = randn_tensor(shape, generator=generator) * self.scheduler.init_noise_sigma
+ sample = sample.to(self.device)
+
+ self.scheduler.set_timesteps(num_inference_steps)
+ self.scheduler.set_sigmas(num_inference_steps)
+
+ for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
+ sigma_t = self.scheduler.sigmas[i] * torch.ones(shape[0], device=self.device)
+
+ # correction step
+ for _ in range(self.scheduler.config.correct_steps):
+ model_output = self.unet(sample, sigma_t).sample
+ sample = self.scheduler.step_correct(model_output, sample, generator=generator).prev_sample
+
+ # prediction step
+ model_output = model(sample, sigma_t).sample
+ output = self.scheduler.step_pred(model_output, t, sample, generator=generator)
+
+ sample, sample_mean = output.prev_sample, output.prev_sample_mean
+
+ sample = sample_mean.clamp(0, 1)
+ sample = sample.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ sample = self.numpy_to_pil(sample)
+
+ if not return_dict:
+ return (sample,)
+
+ return ImagePipelineOutput(images=sample)
diff --git a/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e312c5e30138e106930421ad8c55c23f01e60e7
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__init__.py
@@ -0,0 +1,31 @@
+from dataclasses import dataclass
+from enum import Enum
+from typing import List, Optional, Union
+
+import numpy as np
+import PIL
+from PIL import Image
+
+from ...utils import BaseOutput, is_torch_available, is_transformers_available
+
+
+@dataclass
+class SemanticStableDiffusionPipelineOutput(BaseOutput):
+ """
+ Output class for Stable Diffusion pipelines.
+
+ Args:
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
+ num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
+ nsfw_content_detected (`List[bool]`)
+ List of flags denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, or `None` if safety checking could not be performed.
+ """
+
+ images: Union[List[PIL.Image.Image], np.ndarray]
+ nsfw_content_detected: Optional[List[bool]]
+
+
+if is_transformers_available() and is_torch_available():
+ from .pipeline_semantic_stable_diffusion import SemanticStableDiffusionPipeline
diff --git a/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..bdc546ceec91e37e883e75a3d26ac73c470354c2
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b7ccac2548e597d09f73bd8c18d664d92b8c4ab4
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/pipeline_semantic_stable_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/pipeline_semantic_stable_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..63c9ab704ed3e3be4c08829f6bd482582881b9ed
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/pipeline_semantic_stable_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/pipeline_semantic_stable_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/pipeline_semantic_stable_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c916db60e3ad73907afa0448d3737ef14ab3d62c
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/__pycache__/pipeline_semantic_stable_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..69703fb8d82c20ea0288d2bf6f6aced2f741c1db
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/semantic_stable_diffusion/pipeline_semantic_stable_diffusion.py
@@ -0,0 +1,702 @@
+import inspect
+from itertools import repeat
+from typing import Callable, List, Optional, Union
+
+import torch
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...pipeline_utils import DiffusionPipeline
+from ...pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import logging, randn_tensor
+from . import SemanticStableDiffusionPipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import SemanticStableDiffusionPipeline
+
+ >>> pipe = SemanticStableDiffusionPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> out = pipe(
+ ... prompt="a photo of the face of a woman",
+ ... num_images_per_prompt=1,
+ ... guidance_scale=7,
+ ... editing_prompt=[
+ ... "smiling, smile", # Concepts to apply
+ ... "glasses, wearing glasses",
+ ... "curls, wavy hair, curly hair",
+ ... "beard, full beard, mustache",
+ ... ],
+ ... reverse_editing_direction=[
+ ... False,
+ ... False,
+ ... False,
+ ... False,
+ ... ], # Direction of guidance i.e. increase all concepts
+ ... edit_warmup_steps=[10, 10, 10, 10], # Warmup period for each concept
+ ... edit_guidance_scale=[4, 5, 5, 5.4], # Guidance scale for each concept
+ ... edit_threshold=[
+ ... 0.99,
+ ... 0.975,
+ ... 0.925,
+ ... 0.96,
+ ... ], # Threshold for each concept. Threshold equals the percentile of the latent space that will be discarded. I.e. threshold=0.99 uses 1% of the latent dimensions
+ ... edit_momentum_scale=0.3, # Momentum scale that will be added to the latent guidance
+ ... edit_mom_beta=0.6, # Momentum beta
+ ... edit_weights=[1, 1, 1, 1, 1], # Weights of the individual concepts against each other
+ ... )
+ >>> image = out.images[0]
+ ```
+"""
+
+
+class SemanticStableDiffusionPipeline(DiffusionPipeline):
+ r"""
+ Pipeline for text-to-image generation with latent editing.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ This model builds on the implementation of ['StableDiffusionPipeline']
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latens. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`Q16SafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: int = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ editing_prompt: Optional[Union[str, List[str]]] = None,
+ editing_prompt_embeddings: Optional[torch.Tensor] = None,
+ reverse_editing_direction: Optional[Union[bool, List[bool]]] = False,
+ edit_guidance_scale: Optional[Union[float, List[float]]] = 5,
+ edit_warmup_steps: Optional[Union[int, List[int]]] = 10,
+ edit_cooldown_steps: Optional[Union[int, List[int]]] = None,
+ edit_threshold: Optional[Union[float, List[float]]] = 0.9,
+ edit_momentum_scale: Optional[float] = 0.1,
+ edit_mom_beta: Optional[float] = 0.4,
+ edit_weights: Optional[List[float]] = None,
+ sem_guidance: Optional[List[torch.Tensor]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ editing_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to use for Semantic guidance. Semantic guidance is disabled by setting
+ `editing_prompt = None`. Guidance direction of prompt should be specified via
+ `reverse_editing_direction`.
+ editing_prompt_embeddings (`torch.Tensor>`, *optional*):
+ Pre-computed embeddings to use for semantic guidance. Guidance direction of embedding should be
+ specified via `reverse_editing_direction`.
+ reverse_editing_direction (`bool` or `List[bool]`, *optional*, defaults to `False`):
+ Whether the corresponding prompt in `editing_prompt` should be increased or decreased.
+ edit_guidance_scale (`float` or `List[float]`, *optional*, defaults to 5):
+ Guidance scale for semantic guidance. If provided as list values should correspond to `editing_prompt`.
+ `edit_guidance_scale` is defined as `s_e` of equation 6 of [SEGA
+ Paper](https://arxiv.org/pdf/2301.12247.pdf).
+ edit_warmup_steps (`float` or `List[float]`, *optional*, defaults to 10):
+ Number of diffusion steps (for each prompt) for which semantic guidance will not be applied. Momentum
+ will still be calculated for those steps and applied once all warmup periods are over.
+ `edit_warmup_steps` is defined as `delta` (δ) of [SEGA Paper](https://arxiv.org/pdf/2301.12247.pdf).
+ edit_cooldown_steps (`float` or `List[float]`, *optional*, defaults to `None`):
+ Number of diffusion steps (for each prompt) after which semantic guidance will no longer be applied.
+ edit_threshold (`float` or `List[float]`, *optional*, defaults to 0.9):
+ Threshold of semantic guidance.
+ edit_momentum_scale (`float`, *optional*, defaults to 0.1):
+ Scale of the momentum to be added to the semantic guidance at each diffusion step. If set to 0.0
+ momentum will be disabled. Momentum is already built up during warmup, i.e. for diffusion steps smaller
+ than `sld_warmup_steps`. Momentum will only be added to latent guidance once all warmup periods are
+ finished. `edit_momentum_scale` is defined as `s_m` of equation 7 of [SEGA
+ Paper](https://arxiv.org/pdf/2301.12247.pdf).
+ edit_mom_beta (`float`, *optional*, defaults to 0.4):
+ Defines how semantic guidance momentum builds up. `edit_mom_beta` indicates how much of the previous
+ momentum will be kept. Momentum is already built up during warmup, i.e. for diffusion steps smaller
+ than `edit_warmup_steps`. `edit_mom_beta` is defined as `beta_m` (β) of equation 8 of [SEGA
+ Paper](https://arxiv.org/pdf/2301.12247.pdf).
+ edit_weights (`List[float]`, *optional*, defaults to `None`):
+ Indicates how much each individual concept should influence the overall guidance. If no weights are
+ provided all concepts are applied equally. `edit_mom_beta` is defined as `g_i` of equation 9 of [SEGA
+ Paper](https://arxiv.org/pdf/2301.12247.pdf).
+ sem_guidance (`List[torch.Tensor]`, *optional*):
+ List of pre-generated guidance vectors to be applied at generation. Length of the list has to
+ correspond to `num_inference_steps`.
+
+ Returns:
+ [`~pipelines.semantic_stable_diffusion.SemanticStableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.semantic_stable_diffusion.SemanticStableDiffusionPipelineOutput`] if `return_dict` is True,
+ otherwise a `tuple. When returning a tuple, the first element is a list with the generated images, and the
+ second element is a list of `bool`s denoting whether the corresponding generated image likely represents
+ "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(prompt, height, width, callback_steps)
+
+ # 2. Define call parameters
+ batch_size = 1 if isinstance(prompt, str) else len(prompt)
+
+ if editing_prompt:
+ enable_edit_guidance = True
+ if isinstance(editing_prompt, str):
+ editing_prompt = [editing_prompt]
+ enabled_editing_prompts = len(editing_prompt)
+ elif editing_prompt_embeddings is not None:
+ enable_edit_guidance = True
+ enabled_editing_prompts = editing_prompt_embeddings.shape[0]
+ else:
+ enabled_editing_prompts = 0
+ enable_edit_guidance = False
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+
+ if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
+ removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+ text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
+ text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
+
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ bs_embed, seq_len, _ = text_embeddings.shape
+ text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
+ text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if enable_edit_guidance:
+ # get safety text embeddings
+ if editing_prompt_embeddings is None:
+ edit_concepts_input = self.tokenizer(
+ [x for item in editing_prompt for x in repeat(item, batch_size)],
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ )
+
+ edit_concepts_input_ids = edit_concepts_input.input_ids
+
+ if edit_concepts_input_ids.shape[-1] > self.tokenizer.model_max_length:
+ removed_text = self.tokenizer.batch_decode(
+ edit_concepts_input_ids[:, self.tokenizer.model_max_length :]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+ edit_concepts_input_ids = edit_concepts_input_ids[:, : self.tokenizer.model_max_length]
+ edit_concepts = self.text_encoder(edit_concepts_input_ids.to(self.device))[0]
+ else:
+ edit_concepts = editing_prompt_embeddings.to(self.device).repeat(batch_size, 1, 1)
+
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ bs_embed_edit, seq_len_edit, _ = edit_concepts.shape
+ edit_concepts = edit_concepts.repeat(1, num_images_per_prompt, 1)
+ edit_concepts = edit_concepts.view(bs_embed_edit * num_images_per_prompt, seq_len_edit, -1)
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+ # get unconditional embeddings for classifier free guidance
+
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""]
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = uncond_embeddings.shape[1]
+ uncond_embeddings = uncond_embeddings.repeat(batch_size, num_images_per_prompt, 1)
+ uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ if enable_edit_guidance:
+ text_embeddings = torch.cat([uncond_embeddings, text_embeddings, edit_concepts])
+ else:
+ text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
+ # get the initial random noise unless the user supplied it
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=self.device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ text_embeddings.dtype,
+ self.device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs.
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # Initialize edit_momentum to None
+ edit_momentum = None
+
+ self.uncond_estimates = None
+ self.text_estimates = None
+ self.edit_estimates = None
+ self.sem_guidance = None
+
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = (
+ torch.cat([latents] * (2 + enabled_editing_prompts)) if do_classifier_free_guidance else latents
+ )
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_out = noise_pred.chunk(2 + enabled_editing_prompts) # [b,4, 64, 64]
+ noise_pred_uncond, noise_pred_text = noise_pred_out[0], noise_pred_out[1]
+ noise_pred_edit_concepts = noise_pred_out[2:]
+
+ # default text guidance
+ noise_guidance = guidance_scale * (noise_pred_text - noise_pred_uncond)
+ # noise_guidance = (noise_pred_text - noise_pred_edit_concepts[0])
+
+ if self.uncond_estimates is None:
+ self.uncond_estimates = torch.zeros((num_inference_steps + 1, *noise_pred_uncond.shape))
+ self.uncond_estimates[i] = noise_pred_uncond.detach().cpu()
+
+ if self.text_estimates is None:
+ self.text_estimates = torch.zeros((num_inference_steps + 1, *noise_pred_text.shape))
+ self.text_estimates[i] = noise_pred_text.detach().cpu()
+
+ if self.edit_estimates is None and enable_edit_guidance:
+ self.edit_estimates = torch.zeros(
+ (num_inference_steps + 1, len(noise_pred_edit_concepts), *noise_pred_edit_concepts[0].shape)
+ )
+
+ if self.sem_guidance is None:
+ self.sem_guidance = torch.zeros((num_inference_steps + 1, *noise_pred_text.shape))
+
+ if edit_momentum is None:
+ edit_momentum = torch.zeros_like(noise_guidance)
+
+ if enable_edit_guidance:
+ concept_weights = torch.zeros(
+ (len(noise_pred_edit_concepts), noise_guidance.shape[0]),
+ device=self.device,
+ dtype=noise_guidance.dtype,
+ )
+ noise_guidance_edit = torch.zeros(
+ (len(noise_pred_edit_concepts), *noise_guidance.shape),
+ device=self.device,
+ dtype=noise_guidance.dtype,
+ )
+ # noise_guidance_edit = torch.zeros_like(noise_guidance)
+ warmup_inds = []
+ for c, noise_pred_edit_concept in enumerate(noise_pred_edit_concepts):
+ self.edit_estimates[i, c] = noise_pred_edit_concept
+ if isinstance(edit_guidance_scale, list):
+ edit_guidance_scale_c = edit_guidance_scale[c]
+ else:
+ edit_guidance_scale_c = edit_guidance_scale
+
+ if isinstance(edit_threshold, list):
+ edit_threshold_c = edit_threshold[c]
+ else:
+ edit_threshold_c = edit_threshold
+ if isinstance(reverse_editing_direction, list):
+ reverse_editing_direction_c = reverse_editing_direction[c]
+ else:
+ reverse_editing_direction_c = reverse_editing_direction
+ if edit_weights:
+ edit_weight_c = edit_weights[c]
+ else:
+ edit_weight_c = 1.0
+ if isinstance(edit_warmup_steps, list):
+ edit_warmup_steps_c = edit_warmup_steps[c]
+ else:
+ edit_warmup_steps_c = edit_warmup_steps
+
+ if isinstance(edit_cooldown_steps, list):
+ edit_cooldown_steps_c = edit_cooldown_steps[c]
+ elif edit_cooldown_steps is None:
+ edit_cooldown_steps_c = i + 1
+ else:
+ edit_cooldown_steps_c = edit_cooldown_steps
+ if i >= edit_warmup_steps_c:
+ warmup_inds.append(c)
+ if i >= edit_cooldown_steps_c:
+ noise_guidance_edit[c, :, :, :, :] = torch.zeros_like(noise_pred_edit_concept)
+ continue
+
+ noise_guidance_edit_tmp = noise_pred_edit_concept - noise_pred_uncond
+ # tmp_weights = (noise_pred_text - noise_pred_edit_concept).sum(dim=(1, 2, 3))
+ tmp_weights = (noise_guidance - noise_pred_edit_concept).sum(dim=(1, 2, 3))
+
+ tmp_weights = torch.full_like(tmp_weights, edit_weight_c) # * (1 / enabled_editing_prompts)
+ if reverse_editing_direction_c:
+ noise_guidance_edit_tmp = noise_guidance_edit_tmp * -1
+ concept_weights[c, :] = tmp_weights
+
+ noise_guidance_edit_tmp = noise_guidance_edit_tmp * edit_guidance_scale_c
+
+ # torch.quantile function expects float32
+ if noise_guidance_edit_tmp.dtype == torch.float32:
+ tmp = torch.quantile(
+ torch.abs(noise_guidance_edit_tmp).flatten(start_dim=2),
+ edit_threshold_c,
+ dim=2,
+ keepdim=False,
+ )
+ else:
+ tmp = torch.quantile(
+ torch.abs(noise_guidance_edit_tmp).flatten(start_dim=2).to(torch.float32),
+ edit_threshold_c,
+ dim=2,
+ keepdim=False,
+ ).to(noise_guidance_edit_tmp.dtype)
+
+ noise_guidance_edit_tmp = torch.where(
+ torch.abs(noise_guidance_edit_tmp) >= tmp[:, :, None, None],
+ noise_guidance_edit_tmp,
+ torch.zeros_like(noise_guidance_edit_tmp),
+ )
+ noise_guidance_edit[c, :, :, :, :] = noise_guidance_edit_tmp
+
+ # noise_guidance_edit = noise_guidance_edit + noise_guidance_edit_tmp
+
+ warmup_inds = torch.tensor(warmup_inds).to(self.device)
+ if len(noise_pred_edit_concepts) > warmup_inds.shape[0] > 0:
+ concept_weights = concept_weights.to("cpu") # Offload to cpu
+ noise_guidance_edit = noise_guidance_edit.to("cpu")
+
+ concept_weights_tmp = torch.index_select(concept_weights.to(self.device), 0, warmup_inds)
+ concept_weights_tmp = torch.where(
+ concept_weights_tmp < 0, torch.zeros_like(concept_weights_tmp), concept_weights_tmp
+ )
+ concept_weights_tmp = concept_weights_tmp / concept_weights_tmp.sum(dim=0)
+ # concept_weights_tmp = torch.nan_to_num(concept_weights_tmp)
+
+ noise_guidance_edit_tmp = torch.index_select(
+ noise_guidance_edit.to(self.device), 0, warmup_inds
+ )
+ noise_guidance_edit_tmp = torch.einsum(
+ "cb,cbijk->bijk", concept_weights_tmp, noise_guidance_edit_tmp
+ )
+ noise_guidance_edit_tmp = noise_guidance_edit_tmp
+ noise_guidance = noise_guidance + noise_guidance_edit_tmp
+
+ self.sem_guidance[i] = noise_guidance_edit_tmp.detach().cpu()
+
+ del noise_guidance_edit_tmp
+ del concept_weights_tmp
+ concept_weights = concept_weights.to(self.device)
+ noise_guidance_edit = noise_guidance_edit.to(self.device)
+
+ concept_weights = torch.where(
+ concept_weights < 0, torch.zeros_like(concept_weights), concept_weights
+ )
+
+ concept_weights = torch.nan_to_num(concept_weights)
+
+ noise_guidance_edit = torch.einsum("cb,cbijk->bijk", concept_weights, noise_guidance_edit)
+
+ noise_guidance_edit = noise_guidance_edit + edit_momentum_scale * edit_momentum
+
+ edit_momentum = edit_mom_beta * edit_momentum + (1 - edit_mom_beta) * noise_guidance_edit
+
+ if warmup_inds.shape[0] == len(noise_pred_edit_concepts):
+ noise_guidance = noise_guidance + noise_guidance_edit
+ self.sem_guidance[i] = noise_guidance_edit.detach().cpu()
+
+ if sem_guidance is not None:
+ edit_guidance = sem_guidance[i].to(self.device)
+ noise_guidance = noise_guidance + edit_guidance
+
+ noise_pred = noise_pred_uncond + noise_guidance
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
+ self.device
+ )
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
+ )
+ else:
+ has_nsfw_concept = None
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return SemanticStableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/spectrogram_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..05b14a857630e7a7c001a8ae4c23772dfc62a08a
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/__init__.py
@@ -0,0 +1,26 @@
+# flake8: noqa
+from ...utils import is_note_seq_available, is_transformers_available, is_torch_available
+from ...utils import OptionalDependencyNotAvailable
+
+
+try:
+ if not (is_transformers_available() and is_torch_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import * # noqa F403
+else:
+ from .notes_encoder import SpectrogramNotesEncoder
+ from .continous_encoder import SpectrogramContEncoder
+ from .pipeline_spectrogram_diffusion import (
+ SpectrogramContEncoder,
+ SpectrogramDiffusionPipeline,
+ T5FilmDecoder,
+ )
+
+try:
+ if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_transformers_and_torch_and_note_seq_objects import * # noqa F403
+else:
+ from .midi_utils import MidiProcessor
diff --git a/diffusers/src/diffusers/pipelines/spectrogram_diffusion/continous_encoder.py b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/continous_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..556136d4023df32e4df2477523463829a0722db4
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/continous_encoder.py
@@ -0,0 +1,92 @@
+# Copyright 2022 The Music Spectrogram Diffusion Authors.
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+import torch.nn as nn
+from transformers.modeling_utils import ModuleUtilsMixin
+from transformers.models.t5.modeling_t5 import (
+ T5Block,
+ T5Config,
+ T5LayerNorm,
+)
+
+from ...configuration_utils import ConfigMixin, register_to_config
+from ...models import ModelMixin
+
+
+class SpectrogramContEncoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
+ @register_to_config
+ def __init__(
+ self,
+ input_dims: int,
+ targets_context_length: int,
+ d_model: int,
+ dropout_rate: float,
+ num_layers: int,
+ num_heads: int,
+ d_kv: int,
+ d_ff: int,
+ feed_forward_proj: str,
+ is_decoder: bool = False,
+ ):
+ super().__init__()
+
+ self.input_proj = nn.Linear(input_dims, d_model, bias=False)
+
+ self.position_encoding = nn.Embedding(targets_context_length, d_model)
+ self.position_encoding.weight.requires_grad = False
+
+ self.dropout_pre = nn.Dropout(p=dropout_rate)
+
+ t5config = T5Config(
+ d_model=d_model,
+ num_heads=num_heads,
+ d_kv=d_kv,
+ d_ff=d_ff,
+ feed_forward_proj=feed_forward_proj,
+ dropout_rate=dropout_rate,
+ is_decoder=is_decoder,
+ is_encoder_decoder=False,
+ )
+ self.encoders = nn.ModuleList()
+ for lyr_num in range(num_layers):
+ lyr = T5Block(t5config)
+ self.encoders.append(lyr)
+
+ self.layer_norm = T5LayerNorm(d_model)
+ self.dropout_post = nn.Dropout(p=dropout_rate)
+
+ def forward(self, encoder_inputs, encoder_inputs_mask):
+ x = self.input_proj(encoder_inputs)
+
+ # terminal relative positional encodings
+ max_positions = encoder_inputs.shape[1]
+ input_positions = torch.arange(max_positions, device=encoder_inputs.device)
+
+ seq_lens = encoder_inputs_mask.sum(-1)
+ input_positions = torch.roll(input_positions.unsqueeze(0), tuple(seq_lens.tolist()), dims=0)
+ x += self.position_encoding(input_positions)
+
+ x = self.dropout_pre(x)
+
+ # inverted the attention mask
+ input_shape = encoder_inputs.size()
+ extended_attention_mask = self.get_extended_attention_mask(encoder_inputs_mask, input_shape)
+
+ for lyr in self.encoders:
+ x = lyr(x, extended_attention_mask)[0]
+ x = self.layer_norm(x)
+
+ return self.dropout_post(x), encoder_inputs_mask
diff --git a/diffusers/src/diffusers/pipelines/spectrogram_diffusion/midi_utils.py b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/midi_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..08d0878db588aa38a2e602a3bc5f6505b9457575
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/midi_utils.py
@@ -0,0 +1,667 @@
+# Copyright 2022 The Music Spectrogram Diffusion Authors.
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import dataclasses
+import math
+import os
+from typing import Any, Callable, List, Mapping, MutableMapping, Optional, Sequence, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+from ...utils import is_note_seq_available
+from .pipeline_spectrogram_diffusion import TARGET_FEATURE_LENGTH
+
+
+if is_note_seq_available():
+ import note_seq
+else:
+ raise ImportError("Please install note-seq via `pip install note-seq`")
+
+
+INPUT_FEATURE_LENGTH = 2048
+
+SAMPLE_RATE = 16000
+HOP_SIZE = 320
+FRAME_RATE = int(SAMPLE_RATE // HOP_SIZE)
+
+DEFAULT_STEPS_PER_SECOND = 100
+DEFAULT_MAX_SHIFT_SECONDS = 10
+DEFAULT_NUM_VELOCITY_BINS = 1
+
+SLAKH_CLASS_PROGRAMS = {
+ "Acoustic Piano": 0,
+ "Electric Piano": 4,
+ "Chromatic Percussion": 8,
+ "Organ": 16,
+ "Acoustic Guitar": 24,
+ "Clean Electric Guitar": 26,
+ "Distorted Electric Guitar": 29,
+ "Acoustic Bass": 32,
+ "Electric Bass": 33,
+ "Violin": 40,
+ "Viola": 41,
+ "Cello": 42,
+ "Contrabass": 43,
+ "Orchestral Harp": 46,
+ "Timpani": 47,
+ "String Ensemble": 48,
+ "Synth Strings": 50,
+ "Choir and Voice": 52,
+ "Orchestral Hit": 55,
+ "Trumpet": 56,
+ "Trombone": 57,
+ "Tuba": 58,
+ "French Horn": 60,
+ "Brass Section": 61,
+ "Soprano/Alto Sax": 64,
+ "Tenor Sax": 66,
+ "Baritone Sax": 67,
+ "Oboe": 68,
+ "English Horn": 69,
+ "Bassoon": 70,
+ "Clarinet": 71,
+ "Pipe": 73,
+ "Synth Lead": 80,
+ "Synth Pad": 88,
+}
+
+
+@dataclasses.dataclass
+class NoteRepresentationConfig:
+ """Configuration note representations."""
+
+ onsets_only: bool
+ include_ties: bool
+
+
+@dataclasses.dataclass
+class NoteEventData:
+ pitch: int
+ velocity: Optional[int] = None
+ program: Optional[int] = None
+ is_drum: Optional[bool] = None
+ instrument: Optional[int] = None
+
+
+@dataclasses.dataclass
+class NoteEncodingState:
+ """Encoding state for note transcription, keeping track of active pitches."""
+
+ # velocity bin for active pitches and programs
+ active_pitches: MutableMapping[Tuple[int, int], int] = dataclasses.field(default_factory=dict)
+
+
+@dataclasses.dataclass
+class EventRange:
+ type: str
+ min_value: int
+ max_value: int
+
+
+@dataclasses.dataclass
+class Event:
+ type: str
+ value: int
+
+
+class Tokenizer:
+ def __init__(self, regular_ids: int):
+ # The special tokens: 0=PAD, 1=EOS, and 2=UNK
+ self._num_special_tokens = 3
+ self._num_regular_tokens = regular_ids
+
+ def encode(self, token_ids):
+ encoded = []
+ for token_id in token_ids:
+ if not 0 <= token_id < self._num_regular_tokens:
+ raise ValueError(
+ f"token_id {token_id} does not fall within valid range of [0, {self._num_regular_tokens})"
+ )
+ encoded.append(token_id + self._num_special_tokens)
+
+ # Add EOS token
+ encoded.append(1)
+
+ # Pad to till INPUT_FEATURE_LENGTH
+ encoded = encoded + [0] * (INPUT_FEATURE_LENGTH - len(encoded))
+
+ return encoded
+
+
+class Codec:
+ """Encode and decode events.
+
+ Useful for declaring what certain ranges of a vocabulary should be used for. This is intended to be used from
+ Python before encoding or after decoding with GenericTokenVocabulary. This class is more lightweight and does not
+ include things like EOS or UNK token handling.
+
+ To ensure that 'shift' events are always the first block of the vocab and start at 0, that event type is required
+ and specified separately.
+ """
+
+ def __init__(self, max_shift_steps: int, steps_per_second: float, event_ranges: List[EventRange]):
+ """Define Codec.
+
+ Args:
+ max_shift_steps: Maximum number of shift steps that can be encoded.
+ steps_per_second: Shift steps will be interpreted as having a duration of
+ 1 / steps_per_second.
+ event_ranges: Other supported event types and their ranges.
+ """
+ self.steps_per_second = steps_per_second
+ self._shift_range = EventRange(type="shift", min_value=0, max_value=max_shift_steps)
+ self._event_ranges = [self._shift_range] + event_ranges
+ # Ensure all event types have unique names.
+ assert len(self._event_ranges) == len({er.type for er in self._event_ranges})
+
+ @property
+ def num_classes(self) -> int:
+ return sum(er.max_value - er.min_value + 1 for er in self._event_ranges)
+
+ # The next couple methods are simplified special case methods just for shift
+ # events that are intended to be used from within autograph functions.
+
+ def is_shift_event_index(self, index: int) -> bool:
+ return (self._shift_range.min_value <= index) and (index <= self._shift_range.max_value)
+
+ @property
+ def max_shift_steps(self) -> int:
+ return self._shift_range.max_value
+
+ def encode_event(self, event: Event) -> int:
+ """Encode an event to an index."""
+ offset = 0
+ for er in self._event_ranges:
+ if event.type == er.type:
+ if not er.min_value <= event.value <= er.max_value:
+ raise ValueError(
+ f"Event value {event.value} is not within valid range "
+ f"[{er.min_value}, {er.max_value}] for type {event.type}"
+ )
+ return offset + event.value - er.min_value
+ offset += er.max_value - er.min_value + 1
+
+ raise ValueError(f"Unknown event type: {event.type}")
+
+ def event_type_range(self, event_type: str) -> Tuple[int, int]:
+ """Return [min_id, max_id] for an event type."""
+ offset = 0
+ for er in self._event_ranges:
+ if event_type == er.type:
+ return offset, offset + (er.max_value - er.min_value)
+ offset += er.max_value - er.min_value + 1
+
+ raise ValueError(f"Unknown event type: {event_type}")
+
+ def decode_event_index(self, index: int) -> Event:
+ """Decode an event index to an Event."""
+ offset = 0
+ for er in self._event_ranges:
+ if offset <= index <= offset + er.max_value - er.min_value:
+ return Event(type=er.type, value=er.min_value + index - offset)
+ offset += er.max_value - er.min_value + 1
+
+ raise ValueError(f"Unknown event index: {index}")
+
+
+@dataclasses.dataclass
+class ProgramGranularity:
+ # both tokens_map_fn and program_map_fn should be idempotent
+ tokens_map_fn: Callable[[Sequence[int], Codec], Sequence[int]]
+ program_map_fn: Callable[[int], int]
+
+
+def drop_programs(tokens, codec: Codec):
+ """Drops program change events from a token sequence."""
+ min_program_id, max_program_id = codec.event_type_range("program")
+ return tokens[(tokens < min_program_id) | (tokens > max_program_id)]
+
+
+def programs_to_midi_classes(tokens, codec):
+ """Modifies program events to be the first program in the MIDI class."""
+ min_program_id, max_program_id = codec.event_type_range("program")
+ is_program = (tokens >= min_program_id) & (tokens <= max_program_id)
+ return np.where(is_program, min_program_id + 8 * ((tokens - min_program_id) // 8), tokens)
+
+
+PROGRAM_GRANULARITIES = {
+ # "flat" granularity; drop program change tokens and set NoteSequence
+ # programs to zero
+ "flat": ProgramGranularity(tokens_map_fn=drop_programs, program_map_fn=lambda program: 0),
+ # map each program to the first program in its MIDI class
+ "midi_class": ProgramGranularity(
+ tokens_map_fn=programs_to_midi_classes, program_map_fn=lambda program: 8 * (program // 8)
+ ),
+ # leave programs as is
+ "full": ProgramGranularity(tokens_map_fn=lambda tokens, codec: tokens, program_map_fn=lambda program: program),
+}
+
+
+def frame(signal, frame_length, frame_step, pad_end=False, pad_value=0, axis=-1):
+ """
+ equivalent of tf.signal.frame
+ """
+ signal_length = signal.shape[axis]
+ if pad_end:
+ frames_overlap = frame_length - frame_step
+ rest_samples = np.abs(signal_length - frames_overlap) % np.abs(frame_length - frames_overlap)
+ pad_size = int(frame_length - rest_samples)
+
+ if pad_size != 0:
+ pad_axis = [0] * signal.ndim
+ pad_axis[axis] = pad_size
+ signal = F.pad(signal, pad_axis, "constant", pad_value)
+ frames = signal.unfold(axis, frame_length, frame_step)
+ return frames
+
+
+def program_to_slakh_program(program):
+ # this is done very hackily, probably should use a custom mapping
+ for slakh_program in sorted(SLAKH_CLASS_PROGRAMS.values(), reverse=True):
+ if program >= slakh_program:
+ return slakh_program
+
+
+def audio_to_frames(
+ samples,
+ hop_size: int,
+ frame_rate: int,
+) -> Tuple[Sequence[Sequence[int]], torch.Tensor]:
+ """Convert audio samples to non-overlapping frames and frame times."""
+ frame_size = hop_size
+ samples = np.pad(samples, [0, frame_size - len(samples) % frame_size], mode="constant")
+
+ # Split audio into frames.
+ frames = frame(
+ torch.Tensor(samples).unsqueeze(0),
+ frame_length=frame_size,
+ frame_step=frame_size,
+ pad_end=False, # TODO check why its off by 1 here when True
+ )
+
+ num_frames = len(samples) // frame_size
+
+ times = np.arange(num_frames) / frame_rate
+ return frames, times
+
+
+def note_sequence_to_onsets_and_offsets_and_programs(
+ ns: note_seq.NoteSequence,
+) -> Tuple[Sequence[float], Sequence[NoteEventData]]:
+ """Extract onset & offset times and pitches & programs from a NoteSequence.
+
+ The onset & offset times will not necessarily be in sorted order.
+
+ Args:
+ ns: NoteSequence from which to extract onsets and offsets.
+
+ Returns:
+ times: A list of note onset and offset times. values: A list of NoteEventData objects where velocity is zero for
+ note
+ offsets.
+ """
+ # Sort by program and pitch and put offsets before onsets as a tiebreaker for
+ # subsequent stable sort.
+ notes = sorted(ns.notes, key=lambda note: (note.is_drum, note.program, note.pitch))
+ times = [note.end_time for note in notes if not note.is_drum] + [note.start_time for note in notes]
+ values = [
+ NoteEventData(pitch=note.pitch, velocity=0, program=note.program, is_drum=False)
+ for note in notes
+ if not note.is_drum
+ ] + [
+ NoteEventData(pitch=note.pitch, velocity=note.velocity, program=note.program, is_drum=note.is_drum)
+ for note in notes
+ ]
+ return times, values
+
+
+def num_velocity_bins_from_codec(codec: Codec):
+ """Get number of velocity bins from event codec."""
+ lo, hi = codec.event_type_range("velocity")
+ return hi - lo
+
+
+# segment an array into segments of length n
+def segment(a, n):
+ return [a[i : i + n] for i in range(0, len(a), n)]
+
+
+def velocity_to_bin(velocity, num_velocity_bins):
+ if velocity == 0:
+ return 0
+ else:
+ return math.ceil(num_velocity_bins * velocity / note_seq.MAX_MIDI_VELOCITY)
+
+
+def note_event_data_to_events(
+ state: Optional[NoteEncodingState],
+ value: NoteEventData,
+ codec: Codec,
+) -> Sequence[Event]:
+ """Convert note event data to a sequence of events."""
+ if value.velocity is None:
+ # onsets only, no program or velocity
+ return [Event("pitch", value.pitch)]
+ else:
+ num_velocity_bins = num_velocity_bins_from_codec(codec)
+ velocity_bin = velocity_to_bin(value.velocity, num_velocity_bins)
+ if value.program is None:
+ # onsets + offsets + velocities only, no programs
+ if state is not None:
+ state.active_pitches[(value.pitch, 0)] = velocity_bin
+ return [Event("velocity", velocity_bin), Event("pitch", value.pitch)]
+ else:
+ if value.is_drum:
+ # drum events use a separate vocabulary
+ return [Event("velocity", velocity_bin), Event("drum", value.pitch)]
+ else:
+ # program + velocity + pitch
+ if state is not None:
+ state.active_pitches[(value.pitch, value.program)] = velocity_bin
+ return [
+ Event("program", value.program),
+ Event("velocity", velocity_bin),
+ Event("pitch", value.pitch),
+ ]
+
+
+def note_encoding_state_to_events(state: NoteEncodingState) -> Sequence[Event]:
+ """Output program and pitch events for active notes plus a final tie event."""
+ events = []
+ for pitch, program in sorted(state.active_pitches.keys(), key=lambda k: k[::-1]):
+ if state.active_pitches[(pitch, program)]:
+ events += [Event("program", program), Event("pitch", pitch)]
+ events.append(Event("tie", 0))
+ return events
+
+
+def encode_and_index_events(
+ state, event_times, event_values, codec, frame_times, encode_event_fn, encoding_state_to_events_fn=None
+):
+ """Encode a sequence of timed events and index to audio frame times.
+
+ Encodes time shifts as repeated single step shifts for later run length encoding.
+
+ Optionally, also encodes a sequence of "state events", keeping track of the current encoding state at each audio
+ frame. This can be used e.g. to prepend events representing the current state to a targets segment.
+
+ Args:
+ state: Initial event encoding state.
+ event_times: Sequence of event times.
+ event_values: Sequence of event values.
+ encode_event_fn: Function that transforms event value into a sequence of one
+ or more Event objects.
+ codec: An Codec object that maps Event objects to indices.
+ frame_times: Time for every audio frame.
+ encoding_state_to_events_fn: Function that transforms encoding state into a
+ sequence of one or more Event objects.
+
+ Returns:
+ events: Encoded events and shifts. event_start_indices: Corresponding start event index for every audio frame.
+ Note: one event can correspond to multiple audio indices due to sampling rate differences. This makes
+ splitting sequences tricky because the same event can appear at the end of one sequence and the beginning of
+ another.
+ event_end_indices: Corresponding end event index for every audio frame. Used
+ to ensure when slicing that one chunk ends where the next begins. Should always be true that
+ event_end_indices[i] = event_start_indices[i + 1].
+ state_events: Encoded "state" events representing the encoding state before
+ each event.
+ state_event_indices: Corresponding state event index for every audio frame.
+ """
+ indices = np.argsort(event_times, kind="stable")
+ event_steps = [round(event_times[i] * codec.steps_per_second) for i in indices]
+ event_values = [event_values[i] for i in indices]
+
+ events = []
+ state_events = []
+ event_start_indices = []
+ state_event_indices = []
+
+ cur_step = 0
+ cur_event_idx = 0
+ cur_state_event_idx = 0
+
+ def fill_event_start_indices_to_cur_step():
+ while (
+ len(event_start_indices) < len(frame_times)
+ and frame_times[len(event_start_indices)] < cur_step / codec.steps_per_second
+ ):
+ event_start_indices.append(cur_event_idx)
+ state_event_indices.append(cur_state_event_idx)
+
+ for event_step, event_value in zip(event_steps, event_values):
+ while event_step > cur_step:
+ events.append(codec.encode_event(Event(type="shift", value=1)))
+ cur_step += 1
+ fill_event_start_indices_to_cur_step()
+ cur_event_idx = len(events)
+ cur_state_event_idx = len(state_events)
+ if encoding_state_to_events_fn:
+ # Dump state to state events *before* processing the next event, because
+ # we want to capture the state prior to the occurrence of the event.
+ for e in encoding_state_to_events_fn(state):
+ state_events.append(codec.encode_event(e))
+
+ for e in encode_event_fn(state, event_value, codec):
+ events.append(codec.encode_event(e))
+
+ # After the last event, continue filling out the event_start_indices array.
+ # The inequality is not strict because if our current step lines up exactly
+ # with (the start of) an audio frame, we need to add an additional shift event
+ # to "cover" that frame.
+ while cur_step / codec.steps_per_second <= frame_times[-1]:
+ events.append(codec.encode_event(Event(type="shift", value=1)))
+ cur_step += 1
+ fill_event_start_indices_to_cur_step()
+ cur_event_idx = len(events)
+
+ # Now fill in event_end_indices. We need this extra array to make sure that
+ # when we slice events, each slice ends exactly where the subsequent slice
+ # begins.
+ event_end_indices = event_start_indices[1:] + [len(events)]
+
+ events = np.array(events).astype(np.int32)
+ state_events = np.array(state_events).astype(np.int32)
+ event_start_indices = segment(np.array(event_start_indices).astype(np.int32), TARGET_FEATURE_LENGTH)
+ event_end_indices = segment(np.array(event_end_indices).astype(np.int32), TARGET_FEATURE_LENGTH)
+ state_event_indices = segment(np.array(state_event_indices).astype(np.int32), TARGET_FEATURE_LENGTH)
+
+ outputs = []
+ for start_indices, end_indices, event_indices in zip(event_start_indices, event_end_indices, state_event_indices):
+ outputs.append(
+ {
+ "inputs": events,
+ "event_start_indices": start_indices,
+ "event_end_indices": end_indices,
+ "state_events": state_events,
+ "state_event_indices": event_indices,
+ }
+ )
+
+ return outputs
+
+
+def extract_sequence_with_indices(features, state_events_end_token=None, feature_key="inputs"):
+ """Extract target sequence corresponding to audio token segment."""
+ features = features.copy()
+ start_idx = features["event_start_indices"][0]
+ end_idx = features["event_end_indices"][-1]
+
+ features[feature_key] = features[feature_key][start_idx:end_idx]
+
+ if state_events_end_token is not None:
+ # Extract the state events corresponding to the audio start token, and
+ # prepend them to the targets array.
+ state_event_start_idx = features["state_event_indices"][0]
+ state_event_end_idx = state_event_start_idx + 1
+ while features["state_events"][state_event_end_idx - 1] != state_events_end_token:
+ state_event_end_idx += 1
+ features[feature_key] = np.concatenate(
+ [
+ features["state_events"][state_event_start_idx:state_event_end_idx],
+ features[feature_key],
+ ],
+ axis=0,
+ )
+
+ return features
+
+
+def map_midi_programs(
+ feature, codec: Codec, granularity_type: str = "full", feature_key: str = "inputs"
+) -> Mapping[str, Any]:
+ """Apply MIDI program map to token sequences."""
+ granularity = PROGRAM_GRANULARITIES[granularity_type]
+
+ feature[feature_key] = granularity.tokens_map_fn(feature[feature_key], codec)
+ return feature
+
+
+def run_length_encode_shifts_fn(
+ features,
+ codec: Codec,
+ feature_key: str = "inputs",
+ state_change_event_types: Sequence[str] = (),
+) -> Callable[[Mapping[str, Any]], Mapping[str, Any]]:
+ """Return a function that run-length encodes shifts for a given codec.
+
+ Args:
+ codec: The Codec to use for shift events.
+ feature_key: The feature key for which to run-length encode shifts.
+ state_change_event_types: A list of event types that represent state
+ changes; tokens corresponding to these event types will be interpreted as state changes and redundant ones
+ will be removed.
+
+ Returns:
+ A preprocessing function that run-length encodes single-step shifts.
+ """
+ state_change_event_ranges = [codec.event_type_range(event_type) for event_type in state_change_event_types]
+
+ def run_length_encode_shifts(features: MutableMapping[str, Any]) -> Mapping[str, Any]:
+ """Combine leading/interior shifts, trim trailing shifts.
+
+ Args:
+ features: Dict of features to process.
+
+ Returns:
+ A dict of features.
+ """
+ events = features[feature_key]
+
+ shift_steps = 0
+ total_shift_steps = 0
+ output = np.array([], dtype=np.int32)
+
+ current_state = np.zeros(len(state_change_event_ranges), dtype=np.int32)
+
+ for event in events:
+ if codec.is_shift_event_index(event):
+ shift_steps += 1
+ total_shift_steps += 1
+
+ else:
+ # If this event is a state change and has the same value as the current
+ # state, we can skip it entirely.
+ is_redundant = False
+ for i, (min_index, max_index) in enumerate(state_change_event_ranges):
+ if (min_index <= event) and (event <= max_index):
+ if current_state[i] == event:
+ is_redundant = True
+ current_state[i] = event
+ if is_redundant:
+ continue
+
+ # Once we've reached a non-shift event, RLE all previous shift events
+ # before outputting the non-shift event.
+ if shift_steps > 0:
+ shift_steps = total_shift_steps
+ while shift_steps > 0:
+ output_steps = np.minimum(codec.max_shift_steps, shift_steps)
+ output = np.concatenate([output, [output_steps]], axis=0)
+ shift_steps -= output_steps
+ output = np.concatenate([output, [event]], axis=0)
+
+ features[feature_key] = output
+ return features
+
+ return run_length_encode_shifts(features)
+
+
+def note_representation_processor_chain(features, codec: Codec, note_representation_config: NoteRepresentationConfig):
+ tie_token = codec.encode_event(Event("tie", 0))
+ state_events_end_token = tie_token if note_representation_config.include_ties else None
+
+ features = extract_sequence_with_indices(
+ features, state_events_end_token=state_events_end_token, feature_key="inputs"
+ )
+
+ features = map_midi_programs(features, codec)
+
+ features = run_length_encode_shifts_fn(features, codec, state_change_event_types=["velocity", "program"])
+
+ return features
+
+
+class MidiProcessor:
+ def __init__(self):
+ self.codec = Codec(
+ max_shift_steps=DEFAULT_MAX_SHIFT_SECONDS * DEFAULT_STEPS_PER_SECOND,
+ steps_per_second=DEFAULT_STEPS_PER_SECOND,
+ event_ranges=[
+ EventRange("pitch", note_seq.MIN_MIDI_PITCH, note_seq.MAX_MIDI_PITCH),
+ EventRange("velocity", 0, DEFAULT_NUM_VELOCITY_BINS),
+ EventRange("tie", 0, 0),
+ EventRange("program", note_seq.MIN_MIDI_PROGRAM, note_seq.MAX_MIDI_PROGRAM),
+ EventRange("drum", note_seq.MIN_MIDI_PITCH, note_seq.MAX_MIDI_PITCH),
+ ],
+ )
+ self.tokenizer = Tokenizer(self.codec.num_classes)
+ self.note_representation_config = NoteRepresentationConfig(onsets_only=False, include_ties=True)
+
+ def __call__(self, midi: Union[bytes, os.PathLike, str]):
+ if not isinstance(midi, bytes):
+ with open(midi, "rb") as f:
+ midi = f.read()
+
+ ns = note_seq.midi_to_note_sequence(midi)
+ ns_sus = note_seq.apply_sustain_control_changes(ns)
+
+ for note in ns_sus.notes:
+ if not note.is_drum:
+ note.program = program_to_slakh_program(note.program)
+
+ samples = np.zeros(int(ns_sus.total_time * SAMPLE_RATE))
+
+ _, frame_times = audio_to_frames(samples, HOP_SIZE, FRAME_RATE)
+ times, values = note_sequence_to_onsets_and_offsets_and_programs(ns_sus)
+
+ events = encode_and_index_events(
+ state=NoteEncodingState(),
+ event_times=times,
+ event_values=values,
+ frame_times=frame_times,
+ codec=self.codec,
+ encode_event_fn=note_event_data_to_events,
+ encoding_state_to_events_fn=note_encoding_state_to_events,
+ )
+
+ events = [
+ note_representation_processor_chain(event, self.codec, self.note_representation_config) for event in events
+ ]
+ input_tokens = [self.tokenizer.encode(event["inputs"]) for event in events]
+
+ return input_tokens
diff --git a/diffusers/src/diffusers/pipelines/spectrogram_diffusion/notes_encoder.py b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/notes_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..94eaa176f3e5a15f4065e78b4b7714fa8c51ca83
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/notes_encoder.py
@@ -0,0 +1,86 @@
+# Copyright 2022 The Music Spectrogram Diffusion Authors.
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+import torch.nn as nn
+from transformers.modeling_utils import ModuleUtilsMixin
+from transformers.models.t5.modeling_t5 import T5Block, T5Config, T5LayerNorm
+
+from ...configuration_utils import ConfigMixin, register_to_config
+from ...models import ModelMixin
+
+
+class SpectrogramNotesEncoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
+ @register_to_config
+ def __init__(
+ self,
+ max_length: int,
+ vocab_size: int,
+ d_model: int,
+ dropout_rate: float,
+ num_layers: int,
+ num_heads: int,
+ d_kv: int,
+ d_ff: int,
+ feed_forward_proj: str,
+ is_decoder: bool = False,
+ ):
+ super().__init__()
+
+ self.token_embedder = nn.Embedding(vocab_size, d_model)
+
+ self.position_encoding = nn.Embedding(max_length, d_model)
+ self.position_encoding.weight.requires_grad = False
+
+ self.dropout_pre = nn.Dropout(p=dropout_rate)
+
+ t5config = T5Config(
+ vocab_size=vocab_size,
+ d_model=d_model,
+ num_heads=num_heads,
+ d_kv=d_kv,
+ d_ff=d_ff,
+ dropout_rate=dropout_rate,
+ feed_forward_proj=feed_forward_proj,
+ is_decoder=is_decoder,
+ is_encoder_decoder=False,
+ )
+
+ self.encoders = nn.ModuleList()
+ for lyr_num in range(num_layers):
+ lyr = T5Block(t5config)
+ self.encoders.append(lyr)
+
+ self.layer_norm = T5LayerNorm(d_model)
+ self.dropout_post = nn.Dropout(p=dropout_rate)
+
+ def forward(self, encoder_input_tokens, encoder_inputs_mask):
+ x = self.token_embedder(encoder_input_tokens)
+
+ seq_length = encoder_input_tokens.shape[1]
+ inputs_positions = torch.arange(seq_length, device=encoder_input_tokens.device)
+ x += self.position_encoding(inputs_positions)
+
+ x = self.dropout_pre(x)
+
+ # inverted the attention mask
+ input_shape = encoder_input_tokens.size()
+ extended_attention_mask = self.get_extended_attention_mask(encoder_inputs_mask, input_shape)
+
+ for lyr in self.encoders:
+ x = lyr(x, extended_attention_mask)[0]
+ x = self.layer_norm(x)
+
+ return self.dropout_post(x), encoder_inputs_mask
diff --git a/diffusers/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion.py b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..66155ebf7f35cbe224bf21fd54c47f3b5ee32a37
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/spectrogram_diffusion/pipeline_spectrogram_diffusion.py
@@ -0,0 +1,210 @@
+# Copyright 2022 The Music Spectrogram Diffusion Authors.
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from typing import Any, Callable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ...models import T5FilmDecoder
+from ...schedulers import DDPMScheduler
+from ...utils import is_onnx_available, logging, randn_tensor
+
+
+if is_onnx_available():
+ from ..onnx_utils import OnnxRuntimeModel
+
+from ..pipeline_utils import AudioPipelineOutput, DiffusionPipeline
+from .continous_encoder import SpectrogramContEncoder
+from .notes_encoder import SpectrogramNotesEncoder
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+TARGET_FEATURE_LENGTH = 256
+
+
+class SpectrogramDiffusionPipeline(DiffusionPipeline):
+ _optional_components = ["melgan"]
+
+ def __init__(
+ self,
+ notes_encoder: SpectrogramNotesEncoder,
+ continuous_encoder: SpectrogramContEncoder,
+ decoder: T5FilmDecoder,
+ scheduler: DDPMScheduler,
+ melgan: OnnxRuntimeModel if is_onnx_available() else Any,
+ ) -> None:
+ super().__init__()
+
+ # From MELGAN
+ self.min_value = math.log(1e-5) # Matches MelGAN training.
+ self.max_value = 4.0 # Largest value for most examples
+ self.n_dims = 128
+
+ self.register_modules(
+ notes_encoder=notes_encoder,
+ continuous_encoder=continuous_encoder,
+ decoder=decoder,
+ scheduler=scheduler,
+ melgan=melgan,
+ )
+
+ def scale_features(self, features, output_range=(-1.0, 1.0), clip=False):
+ """Linearly scale features to network outputs range."""
+ min_out, max_out = output_range
+ if clip:
+ features = torch.clip(features, self.min_value, self.max_value)
+ # Scale to [0, 1].
+ zero_one = (features - self.min_value) / (self.max_value - self.min_value)
+ # Scale to [min_out, max_out].
+ return zero_one * (max_out - min_out) + min_out
+
+ def scale_to_features(self, outputs, input_range=(-1.0, 1.0), clip=False):
+ """Invert by linearly scaling network outputs to features range."""
+ min_out, max_out = input_range
+ outputs = torch.clip(outputs, min_out, max_out) if clip else outputs
+ # Scale to [0, 1].
+ zero_one = (outputs - min_out) / (max_out - min_out)
+ # Scale to [self.min_value, self.max_value].
+ return zero_one * (self.max_value - self.min_value) + self.min_value
+
+ def encode(self, input_tokens, continuous_inputs, continuous_mask):
+ tokens_mask = input_tokens > 0
+ tokens_encoded, tokens_mask = self.notes_encoder(
+ encoder_input_tokens=input_tokens, encoder_inputs_mask=tokens_mask
+ )
+
+ continuous_encoded, continuous_mask = self.continuous_encoder(
+ encoder_inputs=continuous_inputs, encoder_inputs_mask=continuous_mask
+ )
+
+ return [(tokens_encoded, tokens_mask), (continuous_encoded, continuous_mask)]
+
+ def decode(self, encodings_and_masks, input_tokens, noise_time):
+ timesteps = noise_time
+ if not torch.is_tensor(timesteps):
+ timesteps = torch.tensor([timesteps], dtype=torch.long, device=input_tokens.device)
+ elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(input_tokens.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps * torch.ones(input_tokens.shape[0], dtype=timesteps.dtype, device=timesteps.device)
+
+ logits = self.decoder(
+ encodings_and_masks=encodings_and_masks, decoder_input_tokens=input_tokens, decoder_noise_time=timesteps
+ )
+ return logits
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ input_tokens: List[List[int]],
+ generator: Optional[torch.Generator] = None,
+ num_inference_steps: int = 100,
+ return_dict: bool = True,
+ output_type: str = "numpy",
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ) -> Union[AudioPipelineOutput, Tuple]:
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ pred_mel = np.zeros([1, TARGET_FEATURE_LENGTH, self.n_dims], dtype=np.float32)
+ full_pred_mel = np.zeros([1, 0, self.n_dims], np.float32)
+ ones = torch.ones((1, TARGET_FEATURE_LENGTH), dtype=bool, device=self.device)
+
+ for i, encoder_input_tokens in enumerate(input_tokens):
+ if i == 0:
+ encoder_continuous_inputs = torch.from_numpy(pred_mel[:1].copy()).to(
+ device=self.device, dtype=self.decoder.dtype
+ )
+ # The first chunk has no previous context.
+ encoder_continuous_mask = torch.zeros((1, TARGET_FEATURE_LENGTH), dtype=bool, device=self.device)
+ else:
+ # The full song pipeline does not feed in a context feature, so the mask
+ # will be all 0s after the feature converter. Because we know we're
+ # feeding in a full context chunk from the previous prediction, set it
+ # to all 1s.
+ encoder_continuous_mask = ones
+
+ encoder_continuous_inputs = self.scale_features(
+ encoder_continuous_inputs, output_range=[-1.0, 1.0], clip=True
+ )
+
+ encodings_and_masks = self.encode(
+ input_tokens=torch.IntTensor([encoder_input_tokens]).to(device=self.device),
+ continuous_inputs=encoder_continuous_inputs,
+ continuous_mask=encoder_continuous_mask,
+ )
+
+ # Sample encoder_continuous_inputs shaped gaussian noise to begin loop
+ x = randn_tensor(
+ shape=encoder_continuous_inputs.shape,
+ generator=generator,
+ device=self.device,
+ dtype=self.decoder.dtype,
+ )
+
+ # set step values
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ # Denoising diffusion loop
+ for j, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
+ output = self.decode(
+ encodings_and_masks=encodings_and_masks,
+ input_tokens=x,
+ noise_time=t / self.scheduler.config.num_train_timesteps, # rescale to [0, 1)
+ )
+
+ # Compute previous output: x_t -> x_t-1
+ x = self.scheduler.step(output, t, x, generator=generator).prev_sample
+
+ mel = self.scale_to_features(x, input_range=[-1.0, 1.0])
+ encoder_continuous_inputs = mel[:1]
+ pred_mel = mel.cpu().float().numpy()
+
+ full_pred_mel = np.concatenate([full_pred_mel, pred_mel[:1]], axis=1)
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, full_pred_mel)
+
+ logger.info("Generated segment", i)
+
+ if output_type == "numpy" and not is_onnx_available():
+ raise ValueError(
+ "Cannot return output in 'np' format if ONNX is not available. Make sure to have ONNX installed or set 'output_type' to 'mel'."
+ )
+ elif output_type == "numpy" and self.melgan is None:
+ raise ValueError(
+ "Cannot return output in 'np' format if melgan component is not defined. Make sure to define `self.melgan` or set 'output_type' to 'mel'."
+ )
+
+ if output_type == "numpy":
+ output = self.melgan(input_features=full_pred_mel.astype(np.float32))
+ else:
+ output = full_pred_mel
+
+ if not return_dict:
+ return (output,)
+
+ return AudioPipelineOutput(audios=output)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/.ipynb_checkpoints/pipeline_stable_diffusion-checkpoint.py b/diffusers/src/diffusers/pipelines/stable_diffusion/.ipynb_checkpoints/pipeline_stable_diffusion-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..73b9178e3ab1f9da9c74e3bc97355dbb63ae02b3
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/.ipynb_checkpoints/pipeline_stable_diffusion-checkpoint.py
@@ -0,0 +1,723 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import StableDiffusionPipeline
+
+ >>> pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> image = pipe(prompt).images[0]
+ ```
+"""
+
+
+class StableDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+ elif output_type == "pil":
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 10. Convert to PIL
+ image = self.numpy_to_pil(image)
+ else:
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/README.md b/diffusers/src/diffusers/pipelines/stable_diffusion/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..be4c5d942b2e313ebfac5acc22764de8bae48bf5
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/README.md
@@ -0,0 +1,176 @@
+# Stable Diffusion
+
+## Overview
+
+Stable Diffusion was proposed in [Stable Diffusion Announcement](https://stability.ai/blog/stable-diffusion-announcement) by Patrick Esser and Robin Rombach and the Stability AI team.
+
+The summary of the model is the following:
+
+*Stable Diffusion is a text-to-image model that will empower billions of people to create stunning art within seconds. It is a breakthrough in speed and quality meaning that it can run on consumer GPUs. You can see some of the amazing output that has been created by this model without pre or post-processing on this page. The model itself builds upon the work of the team at CompVis and Runway in their widely used latent diffusion model combined with insights from the conditional diffusion models by our lead generative AI developer Katherine Crowson, Dall-E 2 by Open AI, Imagen by Google Brain and many others. We are delighted that AI media generation is a cooperative field and hope it can continue this way to bring the gift of creativity to all.*
+
+## Tips:
+
+- Stable Diffusion has the same architecture as [Latent Diffusion](https://arxiv.org/abs/2112.10752) but uses a frozen CLIP Text Encoder instead of training the text encoder jointly with the diffusion model.
+- An in-detail explanation of the Stable Diffusion model can be found under [Stable Diffusion with 🧨 Diffusers](https://huggingface.co/blog/stable_diffusion).
+- If you don't want to rely on the Hugging Face Hub and having to pass a authentication token, you can
+download the weights with `git lfs install; git clone https://huggingface.co/runwayml/stable-diffusion-v1-5` and instead pass the local path to the cloned folder to `from_pretrained` as shown below.
+- Stable Diffusion can work with a variety of different samplers as is shown below.
+
+## Available Pipelines:
+
+| Pipeline | Tasks | Colab
+|---|---|:---:|
+| [pipeline_stable_diffusion.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) | *Text-to-Image Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
+| [pipeline_stable_diffusion_img2img](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py) | *Image-to-Image Text-Guided Generation* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
+| [pipeline_stable_diffusion_inpaint](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py) | *Text-Guided Image Inpainting* | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
+
+## Examples:
+
+### Using Stable Diffusion without being logged into the Hub.
+
+If you want to download the model weights using a single Python line, you need to be logged in via `huggingface-cli login`.
+
+```python
+from diffusers import DiffusionPipeline
+
+pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+```
+
+This however can make it difficult to build applications on top of `diffusers` as you will always have to pass the token around. A potential way to solve this issue is by downloading the weights to a local path `"./stable-diffusion-v1-5"`:
+
+```
+git lfs install
+git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
+```
+
+and simply passing the local path to `from_pretrained`:
+
+```python
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained("./stable-diffusion-v1-5")
+```
+
+### Text-to-Image with default PLMS scheduler
+
+```python
+# make sure you're logged in with `huggingface-cli login`
+from diffusers import StableDiffusionPipeline
+
+pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+pipe = pipe.to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+image = pipe(prompt).sample[0]
+
+image.save("astronaut_rides_horse.png")
+```
+
+### Text-to-Image with DDIM scheduler
+
+```python
+# make sure you're logged in with `huggingface-cli login`
+from diffusers import StableDiffusionPipeline, DDIMScheduler
+
+scheduler = DDIMScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ scheduler=scheduler,
+).to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+image = pipe(prompt).sample[0]
+
+image.save("astronaut_rides_horse.png")
+```
+
+### Text-to-Image with K-LMS scheduler
+
+```python
+# make sure you're logged in with `huggingface-cli login`
+from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
+
+lms = LMSDiscreteScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
+
+pipe = StableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ scheduler=lms,
+).to("cuda")
+
+prompt = "a photo of an astronaut riding a horse on mars"
+image = pipe(prompt).sample[0]
+
+image.save("astronaut_rides_horse.png")
+```
+
+### CycleDiffusion using Stable Diffusion and DDIM scheduler
+
+```python
+import requests
+import torch
+from PIL import Image
+from io import BytesIO
+
+from diffusers import CycleDiffusionPipeline, DDIMScheduler
+
+
+# load the scheduler. CycleDiffusion only supports stochastic schedulers.
+
+# load the pipeline
+# make sure you're logged in with `huggingface-cli login`
+model_id_or_path = "CompVis/stable-diffusion-v1-4"
+scheduler = DDIMScheduler.from_pretrained(model_id_or_path, subfolder="scheduler")
+pipe = CycleDiffusionPipeline.from_pretrained(model_id_or_path, scheduler=scheduler).to("cuda")
+
+# let's download an initial image
+url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/An%20astronaut%20riding%20a%20horse.png"
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((512, 512))
+init_image.save("horse.png")
+
+# let's specify a prompt
+source_prompt = "An astronaut riding a horse"
+prompt = "An astronaut riding an elephant"
+
+# call the pipeline
+image = pipe(
+ prompt=prompt,
+ source_prompt=source_prompt,
+ image=init_image,
+ num_inference_steps=100,
+ eta=0.1,
+ strength=0.8,
+ guidance_scale=2,
+ source_guidance_scale=1,
+).images[0]
+
+image.save("horse_to_elephant.png")
+
+# let's try another example
+# See more samples at the original repo: https://github.com/ChenWu98/cycle-diffusion
+url = "https://raw.githubusercontent.com/ChenWu98/cycle-diffusion/main/data/dalle2/A%20black%20colored%20car.png"
+response = requests.get(url)
+init_image = Image.open(BytesIO(response.content)).convert("RGB")
+init_image = init_image.resize((512, 512))
+init_image.save("black.png")
+
+source_prompt = "A black colored car"
+prompt = "A blue colored car"
+
+# call the pipeline
+torch.manual_seed(0)
+image = pipe(
+ prompt=prompt,
+ source_prompt=source_prompt,
+ image=init_image,
+ num_inference_steps=100,
+ eta=0.1,
+ strength=0.85,
+ guidance_scale=3,
+ source_guidance_scale=1,
+).images[0]
+
+image.save("black_to_blue.png")
+```
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/stable_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bc2b58b5feffd53a522594406ab5354f5d57927
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/__init__.py
@@ -0,0 +1,134 @@
+from dataclasses import dataclass
+from typing import List, Optional, Union
+
+import numpy as np
+import PIL
+from PIL import Image
+
+from ...utils import (
+ BaseOutput,
+ OptionalDependencyNotAvailable,
+ is_flax_available,
+ is_k_diffusion_available,
+ is_k_diffusion_version,
+ is_onnx_available,
+ is_torch_available,
+ is_transformers_available,
+ is_transformers_version,
+)
+
+
+@dataclass
+class StableDiffusionPipelineOutput(BaseOutput):
+ """
+ Output class for Stable Diffusion pipelines.
+
+ Args:
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
+ num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
+ nsfw_content_detected (`List[bool]`)
+ List of flags denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, or `None` if safety checking could not be performed.
+ """
+
+ images: Union[List[PIL.Image.Image], np.ndarray]
+ nsfw_content_detected: Optional[List[bool]]
+
+
+try:
+ if not (is_transformers_available() and is_torch_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import * # noqa F403
+else:
+ from .pipeline_cycle_diffusion import CycleDiffusionPipeline
+ from .pipeline_stable_diffusion import StableDiffusionPipeline
+ from .pipeline_stable_diffusion_attend_and_excite import StableDiffusionAttendAndExcitePipeline
+ from .pipeline_stable_diffusion_controlnet import StableDiffusionControlNetPipeline
+ from .pipeline_stable_diffusion_img2img import StableDiffusionImg2ImgPipeline
+ from .pipeline_stable_diffusion_inpaint import StableDiffusionInpaintPipeline
+ from .pipeline_stable_diffusion_inpaint_legacy import StableDiffusionInpaintPipelineLegacy
+ from .pipeline_stable_diffusion_instruct_pix2pix import StableDiffusionInstructPix2PixPipeline
+ from .pipeline_stable_diffusion_latent_upscale import StableDiffusionLatentUpscalePipeline
+ from .pipeline_stable_diffusion_model_editing import StableDiffusionModelEditingPipeline
+ from .pipeline_stable_diffusion_panorama import StableDiffusionPanoramaPipeline
+ from .pipeline_stable_diffusion_sag import StableDiffusionSAGPipeline
+ from .pipeline_stable_diffusion_upscale import StableDiffusionUpscalePipeline
+ from .pipeline_stable_unclip import StableUnCLIPPipeline
+ from .pipeline_stable_unclip_img2img import StableUnCLIPImg2ImgPipeline
+ from .safety_checker import StableDiffusionSafetyChecker
+ from .stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
+
+try:
+ if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.25.0")):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import StableDiffusionImageVariationPipeline
+else:
+ from .pipeline_stable_diffusion_image_variation import StableDiffusionImageVariationPipeline
+
+
+try:
+ if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.26.0")):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import (
+ StableDiffusionDepth2ImgPipeline,
+ StableDiffusionPix2PixZeroPipeline,
+ )
+else:
+ from .pipeline_stable_diffusion_depth2img import StableDiffusionDepth2ImgPipeline
+ from .pipeline_stable_diffusion_pix2pix_zero import StableDiffusionPix2PixZeroPipeline
+
+
+try:
+ if not (
+ is_torch_available()
+ and is_transformers_available()
+ and is_k_diffusion_available()
+ and is_k_diffusion_version(">=", "0.0.12")
+ ):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_and_k_diffusion_objects import * # noqa F403
+else:
+ from .pipeline_stable_diffusion_k_diffusion import StableDiffusionKDiffusionPipeline
+
+try:
+ if not (is_transformers_available() and is_onnx_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_onnx_objects import * # noqa F403
+else:
+ from .pipeline_onnx_stable_diffusion import OnnxStableDiffusionPipeline, StableDiffusionOnnxPipeline
+ from .pipeline_onnx_stable_diffusion_img2img import OnnxStableDiffusionImg2ImgPipeline
+ from .pipeline_onnx_stable_diffusion_inpaint import OnnxStableDiffusionInpaintPipeline
+ from .pipeline_onnx_stable_diffusion_inpaint_legacy import OnnxStableDiffusionInpaintPipelineLegacy
+ from .pipeline_onnx_stable_diffusion_upscale import OnnxStableDiffusionUpscalePipeline
+
+if is_transformers_available() and is_flax_available():
+ import flax
+
+ @flax.struct.dataclass
+ class FlaxStableDiffusionPipelineOutput(BaseOutput):
+ """
+ Output class for Stable Diffusion pipelines.
+
+ Args:
+ images (`np.ndarray`)
+ Array of shape `(batch_size, height, width, num_channels)` with images from the diffusion pipeline.
+ nsfw_content_detected (`List[bool]`)
+ List of flags denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content.
+ """
+
+ images: np.ndarray
+ nsfw_content_detected: List[bool]
+
+ from ...schedulers.scheduling_pndm_flax import PNDMSchedulerState
+ from .pipeline_flax_stable_diffusion import FlaxStableDiffusionPipeline
+ from .pipeline_flax_stable_diffusion_controlnet import FlaxStableDiffusionControlNetPipeline
+ from .pipeline_flax_stable_diffusion_img2img import FlaxStableDiffusionImg2ImgPipeline
+ from .pipeline_flax_stable_diffusion_inpaint import FlaxStableDiffusionInpaintPipeline
+ from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c4a2d7b5e9bbdc4d92822b375724d3693fd8aa90
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8945c144def4e2eb9b80b10a2fcbda8fa15039c4
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_cycle_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_cycle_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ad20c6271690e0d90dafea0ff3cb6e1e53163b85
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_cycle_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_cycle_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_cycle_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b94d7a1b75e6e45aa8cd321c2aa902c995bd763e
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_cycle_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b947c02d61f8a685aa4db187c2bfb52e9f9b4edc
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dcd55ecd6897df3a643c78863d4c63d28c21af88
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_attend_and_excite.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_attend_and_excite.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a080ac0f37569c1f0abf7182fc8cd9cfc4e59520
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_attend_and_excite.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_attend_and_excite.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_attend_and_excite.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6ebc556f49437fe26c95f5aa7d6c9c7ca910a4f9
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_attend_and_excite.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_controlnet.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_controlnet.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7ecbb57839b3aea89c798791bc0fe00ffd6bb27b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_controlnet.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_controlnet.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_controlnet.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d3406060c9850da266091f94c5f255b14d971042
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_controlnet.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_depth2img.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_depth2img.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..268b4eb1906cd47ae0aaa80db3d1166344adc92b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_depth2img.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_depth2img.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_depth2img.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f2264eb17b84e15563684b74559e35964d1754c8
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_depth2img.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_image_variation.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_image_variation.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..68f994bc55ad71d33a783309eebc2b902d6bf80b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_image_variation.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_image_variation.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_image_variation.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..15bdfb8a4e230dab45da994e9d2be31041338afe
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_image_variation.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_img2img.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_img2img.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..daf55b4ba50d532497cf5cdca639f3f407e31e2d
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_img2img.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_img2img.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_img2img.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4d28e2534a5d00a641db8f266bda604092910049
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_img2img.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e8c6a20d5e5a5504b8d00e91f7ad02e096298719
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e305a3f32836bf2ba041fc714cbd5af6d9705d17
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint_legacy.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint_legacy.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c43007037f5caf0b67f892d89521e82bc785e9c4
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint_legacy.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint_legacy.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint_legacy.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2e39ac2da83935893400168c4f652e8116c51bba
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_inpaint_legacy.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_instruct_pix2pix.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_instruct_pix2pix.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ded6c5c2dc00fc6030ae576d51d227bcfe922d73
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_instruct_pix2pix.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_instruct_pix2pix.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_instruct_pix2pix.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..716ac05e7efbc6ced972236eb246fd5b843bcf05
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_instruct_pix2pix.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_latent_upscale.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_latent_upscale.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..98d8982d7f92eca9d4d88fda4cd46fb370d50730
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_latent_upscale.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_latent_upscale.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_latent_upscale.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8c71aaddd55811d048dff15fea5985bd83cfe952
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_latent_upscale.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_model_editing.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_model_editing.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..88a55e25dc49d38739a04d47c299d2718e086c5a
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_model_editing.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_model_editing.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_model_editing.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fb63b75f78a46007d8e02fa8c3b0727ae9839bdb
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_model_editing.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_panorama.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_panorama.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..eac3adc6e7ad1e57f380c34fd9c9497ef1c3378e
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_panorama.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_panorama.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_panorama.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8cabafa1814b6d8d58fde35fff36acf4dc091e31
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_panorama.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_pix2pix_zero.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_pix2pix_zero.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..19d91e5603698d04f5b31bb32d9fad1cbc34ce4d
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_pix2pix_zero.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_pix2pix_zero.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_pix2pix_zero.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6e37d82b59df1d2987202f1ea3447b24643c7c2a
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_pix2pix_zero.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_sag.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_sag.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f20eeb31c9ef9b1db4cd4e21359e6bb2568c2408
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_sag.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_sag.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_sag.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1084e422fbb0b4321ff4c268b8b43157da442cb3
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_sag.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_upscale.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_upscale.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ab34bfb815b56efcaad6f78b3ec0fe0585b6f5b1
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_upscale.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_upscale.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_upscale.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3e6f7e743508780859228af38d8a69430f307671
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_diffusion_upscale.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..80c0a014068666e2ac5d32dd249b2d6568572a1a
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..48e469f11e18a9edd05c8890a0e4b4aaacb1d91a
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip_img2img.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip_img2img.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6abfe47d9b42155e754dbd1afacf771a7cd5c60c
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip_img2img.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip_img2img.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip_img2img.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..443677dac945b23d45c1d29590d0b91f565cd6bf
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/pipeline_stable_unclip_img2img.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/safety_checker.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/safety_checker.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5c10741569cc9d4bf01c3e1ba040b7b377a7970a
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/safety_checker.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/safety_checker.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/safety_checker.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5711b83945ee1e45b8d5be42669329aabbec50a6
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/safety_checker.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/stable_unclip_image_normalizer.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/stable_unclip_image_normalizer.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3cfeeb3613c8039ffd8a62035370d1fcbe058e9b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/stable_unclip_image_normalizer.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/stable_unclip_image_normalizer.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/stable_unclip_image_normalizer.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e356d5e5b8d5a6cf3ae880625a2e5f4d487c3c3e
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion/__pycache__/stable_unclip_image_normalizer.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/convert_from_ckpt.py b/diffusers/src/diffusers/pipelines/stable_diffusion/convert_from_ckpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1621363952699175bd8461ec47e62f53b604457
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/convert_from_ckpt.py
@@ -0,0 +1,1363 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Conversion script for the Stable Diffusion checkpoints."""
+
+import re
+from io import BytesIO
+from typing import Optional
+
+import requests
+import torch
+from transformers import (
+ AutoFeatureExtractor,
+ BertTokenizerFast,
+ CLIPImageProcessor,
+ CLIPTextModel,
+ CLIPTextModelWithProjection,
+ CLIPTokenizer,
+ CLIPVisionConfig,
+ CLIPVisionModelWithProjection,
+)
+
+from diffusers import (
+ AutoencoderKL,
+ ControlNetModel,
+ DDIMScheduler,
+ DDPMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ HeunDiscreteScheduler,
+ LDMTextToImagePipeline,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ PriorTransformer,
+ StableDiffusionControlNetPipeline,
+ StableDiffusionPipeline,
+ StableUnCLIPImg2ImgPipeline,
+ StableUnCLIPPipeline,
+ UnCLIPScheduler,
+ UNet2DConditionModel,
+)
+from diffusers.pipelines.latent_diffusion.pipeline_latent_diffusion import LDMBertConfig, LDMBertModel
+from diffusers.pipelines.paint_by_example import PaintByExampleImageEncoder, PaintByExamplePipeline
+from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
+from diffusers.pipelines.stable_diffusion.stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
+
+from ...utils import is_omegaconf_available, is_safetensors_available, logging
+from ...utils.import_utils import BACKENDS_MAPPING
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def shave_segments(path, n_shave_prefix_segments=1):
+ """
+ Removes segments. Positive values shave the first segments, negative shave the last segments.
+ """
+ if n_shave_prefix_segments >= 0:
+ return ".".join(path.split(".")[n_shave_prefix_segments:])
+ else:
+ return ".".join(path.split(".")[:n_shave_prefix_segments])
+
+
+def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item.replace("in_layers.0", "norm1")
+ new_item = new_item.replace("in_layers.2", "conv1")
+
+ new_item = new_item.replace("out_layers.0", "norm2")
+ new_item = new_item.replace("out_layers.3", "conv2")
+
+ new_item = new_item.replace("emb_layers.1", "time_emb_proj")
+ new_item = new_item.replace("skip_connection", "conv_shortcut")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside resnets to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("nin_shortcut", "conv_shortcut")
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ # new_item = new_item.replace('norm.weight', 'group_norm.weight')
+ # new_item = new_item.replace('norm.bias', 'group_norm.bias')
+
+ # new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
+ # new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
+
+ # new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
+ """
+ Updates paths inside attentions to the new naming scheme (local renaming)
+ """
+ mapping = []
+ for old_item in old_list:
+ new_item = old_item
+
+ new_item = new_item.replace("norm.weight", "group_norm.weight")
+ new_item = new_item.replace("norm.bias", "group_norm.bias")
+
+ new_item = new_item.replace("q.weight", "query.weight")
+ new_item = new_item.replace("q.bias", "query.bias")
+
+ new_item = new_item.replace("k.weight", "key.weight")
+ new_item = new_item.replace("k.bias", "key.bias")
+
+ new_item = new_item.replace("v.weight", "value.weight")
+ new_item = new_item.replace("v.bias", "value.bias")
+
+ new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
+ new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
+
+ new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
+
+ mapping.append({"old": old_item, "new": new_item})
+
+ return mapping
+
+
+def assign_to_checkpoint(
+ paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
+):
+ """
+ This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
+ attention layers, and takes into account additional replacements that may arise.
+
+ Assigns the weights to the new checkpoint.
+ """
+ assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
+
+ # Splits the attention layers into three variables.
+ if attention_paths_to_split is not None:
+ for path, path_map in attention_paths_to_split.items():
+ old_tensor = old_checkpoint[path]
+ channels = old_tensor.shape[0] // 3
+
+ target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
+
+ num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
+
+ old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
+ query, key, value = old_tensor.split(channels // num_heads, dim=1)
+
+ checkpoint[path_map["query"]] = query.reshape(target_shape)
+ checkpoint[path_map["key"]] = key.reshape(target_shape)
+ checkpoint[path_map["value"]] = value.reshape(target_shape)
+
+ for path in paths:
+ new_path = path["new"]
+
+ # These have already been assigned
+ if attention_paths_to_split is not None and new_path in attention_paths_to_split:
+ continue
+
+ # Global renaming happens here
+ new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
+ new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
+ new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
+
+ if additional_replacements is not None:
+ for replacement in additional_replacements:
+ new_path = new_path.replace(replacement["old"], replacement["new"])
+
+ # proj_attn.weight has to be converted from conv 1D to linear
+ if "proj_attn.weight" in new_path:
+ checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
+ else:
+ checkpoint[new_path] = old_checkpoint[path["old"]]
+
+
+def conv_attn_to_linear(checkpoint):
+ keys = list(checkpoint.keys())
+ attn_keys = ["query.weight", "key.weight", "value.weight"]
+ for key in keys:
+ if ".".join(key.split(".")[-2:]) in attn_keys:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0, 0]
+ elif "proj_attn.weight" in key:
+ if checkpoint[key].ndim > 2:
+ checkpoint[key] = checkpoint[key][:, :, 0]
+
+
+def create_unet_diffusers_config(original_config, image_size: int, controlnet=False):
+ """
+ Creates a config for the diffusers based on the config of the LDM model.
+ """
+ if controlnet:
+ unet_params = original_config.model.params.control_stage_config.params
+ else:
+ unet_params = original_config.model.params.unet_config.params
+
+ vae_params = original_config.model.params.first_stage_config.params.ddconfig
+
+ block_out_channels = [unet_params.model_channels * mult for mult in unet_params.channel_mult]
+
+ down_block_types = []
+ resolution = 1
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnDownBlock2D" if resolution in unet_params.attention_resolutions else "DownBlock2D"
+ down_block_types.append(block_type)
+ if i != len(block_out_channels) - 1:
+ resolution *= 2
+
+ up_block_types = []
+ for i in range(len(block_out_channels)):
+ block_type = "CrossAttnUpBlock2D" if resolution in unet_params.attention_resolutions else "UpBlock2D"
+ up_block_types.append(block_type)
+ resolution //= 2
+
+ vae_scale_factor = 2 ** (len(vae_params.ch_mult) - 1)
+
+ head_dim = unet_params.num_heads if "num_heads" in unet_params else None
+ use_linear_projection = (
+ unet_params.use_linear_in_transformer if "use_linear_in_transformer" in unet_params else False
+ )
+ if use_linear_projection:
+ # stable diffusion 2-base-512 and 2-768
+ if head_dim is None:
+ head_dim = [5, 10, 20, 20]
+
+ class_embed_type = None
+ projection_class_embeddings_input_dim = None
+
+ if "num_classes" in unet_params:
+ if unet_params.num_classes == "sequential":
+ class_embed_type = "projection"
+ assert "adm_in_channels" in unet_params
+ projection_class_embeddings_input_dim = unet_params.adm_in_channels
+ else:
+ raise NotImplementedError(f"Unknown conditional unet num_classes config: {unet_params.num_classes}")
+
+ config = {
+ "sample_size": image_size // vae_scale_factor,
+ "in_channels": unet_params.in_channels,
+ "down_block_types": tuple(down_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "layers_per_block": unet_params.num_res_blocks,
+ "cross_attention_dim": unet_params.context_dim,
+ "attention_head_dim": head_dim,
+ "use_linear_projection": use_linear_projection,
+ "class_embed_type": class_embed_type,
+ "projection_class_embeddings_input_dim": projection_class_embeddings_input_dim,
+ }
+
+ if not controlnet:
+ config["out_channels"] = unet_params.out_channels
+ config["up_block_types"] = tuple(up_block_types)
+
+ return config
+
+
+def create_vae_diffusers_config(original_config, image_size: int):
+ """
+ Creates a config for the diffusers based on the config of the LDM model.
+ """
+ vae_params = original_config.model.params.first_stage_config.params.ddconfig
+ _ = original_config.model.params.first_stage_config.params.embed_dim
+
+ block_out_channels = [vae_params.ch * mult for mult in vae_params.ch_mult]
+ down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels)
+ up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels)
+
+ config = {
+ "sample_size": image_size,
+ "in_channels": vae_params.in_channels,
+ "out_channels": vae_params.out_ch,
+ "down_block_types": tuple(down_block_types),
+ "up_block_types": tuple(up_block_types),
+ "block_out_channels": tuple(block_out_channels),
+ "latent_channels": vae_params.z_channels,
+ "layers_per_block": vae_params.num_res_blocks,
+ }
+ return config
+
+
+def create_diffusers_schedular(original_config):
+ schedular = DDIMScheduler(
+ num_train_timesteps=original_config.model.params.timesteps,
+ beta_start=original_config.model.params.linear_start,
+ beta_end=original_config.model.params.linear_end,
+ beta_schedule="scaled_linear",
+ )
+ return schedular
+
+
+def create_ldm_bert_config(original_config):
+ bert_params = original_config.model.parms.cond_stage_config.params
+ config = LDMBertConfig(
+ d_model=bert_params.n_embed,
+ encoder_layers=bert_params.n_layer,
+ encoder_ffn_dim=bert_params.n_embed * 4,
+ )
+ return config
+
+
+def convert_ldm_unet_checkpoint(checkpoint, config, path=None, extract_ema=False, controlnet=False):
+ """
+ Takes a state dict and a config, and returns a converted checkpoint.
+ """
+
+ # extract state_dict for UNet
+ unet_state_dict = {}
+ keys = list(checkpoint.keys())
+
+ if controlnet:
+ unet_key = "control_model."
+ else:
+ unet_key = "model.diffusion_model."
+
+ # at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
+ if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
+ print(f"Checkpoint {path} has both EMA and non-EMA weights.")
+ print(
+ "In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
+ " weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
+ )
+ for key in keys:
+ if key.startswith("model.diffusion_model"):
+ flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
+ else:
+ if sum(k.startswith("model_ema") for k in keys) > 100:
+ print(
+ "In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
+ " weights (usually better for inference), please make sure to add the `--extract_ema` flag."
+ )
+
+ for key in keys:
+ if key.startswith(unet_key):
+ unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
+ new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
+ new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
+ new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
+
+ if config["class_embed_type"] is None:
+ # No parameters to port
+ ...
+ elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
+ new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
+ new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
+ new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
+ new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
+ else:
+ raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
+
+ new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
+ new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
+
+ if not controlnet:
+ new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
+ new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
+ new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
+ new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
+
+ # Retrieves the keys for the input blocks only
+ num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
+ input_blocks = {
+ layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
+ for layer_id in range(num_input_blocks)
+ }
+
+ # Retrieves the keys for the middle blocks only
+ num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
+ middle_blocks = {
+ layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
+ for layer_id in range(num_middle_blocks)
+ }
+
+ # Retrieves the keys for the output blocks only
+ num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
+ output_blocks = {
+ layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
+ for layer_id in range(num_output_blocks)
+ }
+
+ for i in range(1, num_input_blocks):
+ block_id = (i - 1) // (config["layers_per_block"] + 1)
+ layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
+
+ resnets = [
+ key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
+ ]
+ attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
+
+ if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.weight"
+ )
+ new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
+ f"input_blocks.{i}.0.op.bias"
+ )
+
+ paths = renew_resnet_paths(resnets)
+ meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ resnet_0 = middle_blocks[0]
+ attentions = middle_blocks[1]
+ resnet_1 = middle_blocks[2]
+
+ resnet_0_paths = renew_resnet_paths(resnet_0)
+ assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
+
+ resnet_1_paths = renew_resnet_paths(resnet_1)
+ assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
+
+ attentions_paths = renew_attention_paths(attentions)
+ meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(
+ attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ for i in range(num_output_blocks):
+ block_id = i // (config["layers_per_block"] + 1)
+ layer_in_block_id = i % (config["layers_per_block"] + 1)
+ output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
+ output_block_list = {}
+
+ for layer in output_block_layers:
+ layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
+ if layer_id in output_block_list:
+ output_block_list[layer_id].append(layer_name)
+ else:
+ output_block_list[layer_id] = [layer_name]
+
+ if len(output_block_list) > 1:
+ resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
+ attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
+
+ resnet_0_paths = renew_resnet_paths(resnets)
+ paths = renew_resnet_paths(resnets)
+
+ meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+
+ output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
+ if ["conv.bias", "conv.weight"] in output_block_list.values():
+ index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.weight"
+ ]
+ new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
+ f"output_blocks.{i}.{index}.conv.bias"
+ ]
+
+ # Clear attentions as they have been attributed above.
+ if len(attentions) == 2:
+ attentions = []
+
+ if len(attentions):
+ paths = renew_attention_paths(attentions)
+ meta_path = {
+ "old": f"output_blocks.{i}.1",
+ "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
+ }
+ assign_to_checkpoint(
+ paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
+ )
+ else:
+ resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
+ for path in resnet_0_paths:
+ old_path = ".".join(["output_blocks", str(i), path["old"]])
+ new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
+
+ new_checkpoint[new_path] = unet_state_dict[old_path]
+
+ if controlnet:
+ # conditioning embedding
+
+ orig_index = 0
+
+ new_checkpoint["controlnet_cond_embedding.conv_in.weight"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.weight"
+ )
+ new_checkpoint["controlnet_cond_embedding.conv_in.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+
+ orig_index += 2
+
+ diffusers_index = 0
+
+ while diffusers_index < 6:
+ new_checkpoint[f"controlnet_cond_embedding.blocks.{diffusers_index}.weight"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.weight"
+ )
+ new_checkpoint[f"controlnet_cond_embedding.blocks.{diffusers_index}.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+ diffusers_index += 1
+ orig_index += 2
+
+ new_checkpoint["controlnet_cond_embedding.conv_out.weight"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.weight"
+ )
+ new_checkpoint["controlnet_cond_embedding.conv_out.bias"] = unet_state_dict.pop(
+ f"input_hint_block.{orig_index}.bias"
+ )
+
+ # down blocks
+ for i in range(num_input_blocks):
+ new_checkpoint[f"controlnet_down_blocks.{i}.weight"] = unet_state_dict.pop(f"zero_convs.{i}.0.weight")
+ new_checkpoint[f"controlnet_down_blocks.{i}.bias"] = unet_state_dict.pop(f"zero_convs.{i}.0.bias")
+
+ # mid block
+ new_checkpoint["controlnet_mid_block.weight"] = unet_state_dict.pop("middle_block_out.0.weight")
+ new_checkpoint["controlnet_mid_block.bias"] = unet_state_dict.pop("middle_block_out.0.bias")
+
+ return new_checkpoint
+
+
+def convert_ldm_vae_checkpoint(checkpoint, config):
+ # extract state dict for VAE
+ vae_state_dict = {}
+ vae_key = "first_stage_model."
+ keys = list(checkpoint.keys())
+ for key in keys:
+ if key.startswith(vae_key):
+ vae_state_dict[key.replace(vae_key, "")] = checkpoint.get(key)
+
+ new_checkpoint = {}
+
+ new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
+ new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
+ new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
+ new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
+ new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
+ new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
+
+ new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
+ new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
+ new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
+ new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
+ new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
+ new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
+
+ new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
+ new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
+ new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
+ new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
+
+ # Retrieves the keys for the encoder down blocks only
+ num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer})
+ down_blocks = {
+ layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
+ }
+
+ # Retrieves the keys for the decoder up blocks only
+ num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
+ up_blocks = {
+ layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
+ }
+
+ for i in range(num_down_blocks):
+ resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
+
+ if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.weight"
+ )
+ new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
+ f"encoder.down.{i}.downsample.conv.bias"
+ )
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+ conv_attn_to_linear(new_checkpoint)
+
+ for i in range(num_up_blocks):
+ block_id = num_up_blocks - 1 - i
+ resnets = [
+ key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
+ ]
+
+ if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.weight"
+ ]
+ new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
+ f"decoder.up.{block_id}.upsample.conv.bias"
+ ]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
+ num_mid_res_blocks = 2
+ for i in range(1, num_mid_res_blocks + 1):
+ resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
+
+ paths = renew_vae_resnet_paths(resnets)
+ meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+
+ mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
+ paths = renew_vae_attention_paths(mid_attentions)
+ meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
+ assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
+ conv_attn_to_linear(new_checkpoint)
+ return new_checkpoint
+
+
+def convert_ldm_bert_checkpoint(checkpoint, config):
+ def _copy_attn_layer(hf_attn_layer, pt_attn_layer):
+ hf_attn_layer.q_proj.weight.data = pt_attn_layer.to_q.weight
+ hf_attn_layer.k_proj.weight.data = pt_attn_layer.to_k.weight
+ hf_attn_layer.v_proj.weight.data = pt_attn_layer.to_v.weight
+
+ hf_attn_layer.out_proj.weight = pt_attn_layer.to_out.weight
+ hf_attn_layer.out_proj.bias = pt_attn_layer.to_out.bias
+
+ def _copy_linear(hf_linear, pt_linear):
+ hf_linear.weight = pt_linear.weight
+ hf_linear.bias = pt_linear.bias
+
+ def _copy_layer(hf_layer, pt_layer):
+ # copy layer norms
+ _copy_linear(hf_layer.self_attn_layer_norm, pt_layer[0][0])
+ _copy_linear(hf_layer.final_layer_norm, pt_layer[1][0])
+
+ # copy attn
+ _copy_attn_layer(hf_layer.self_attn, pt_layer[0][1])
+
+ # copy MLP
+ pt_mlp = pt_layer[1][1]
+ _copy_linear(hf_layer.fc1, pt_mlp.net[0][0])
+ _copy_linear(hf_layer.fc2, pt_mlp.net[2])
+
+ def _copy_layers(hf_layers, pt_layers):
+ for i, hf_layer in enumerate(hf_layers):
+ if i != 0:
+ i += i
+ pt_layer = pt_layers[i : i + 2]
+ _copy_layer(hf_layer, pt_layer)
+
+ hf_model = LDMBertModel(config).eval()
+
+ # copy embeds
+ hf_model.model.embed_tokens.weight = checkpoint.transformer.token_emb.weight
+ hf_model.model.embed_positions.weight.data = checkpoint.transformer.pos_emb.emb.weight
+
+ # copy layer norm
+ _copy_linear(hf_model.model.layer_norm, checkpoint.transformer.norm)
+
+ # copy hidden layers
+ _copy_layers(hf_model.model.layers, checkpoint.transformer.attn_layers.layers)
+
+ _copy_linear(hf_model.to_logits, checkpoint.transformer.to_logits)
+
+ return hf_model
+
+
+def convert_ldm_clip_checkpoint(checkpoint):
+ text_model = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
+
+ keys = list(checkpoint.keys())
+
+ text_model_dict = {}
+
+ for key in keys:
+ if key.startswith("cond_stage_model.transformer"):
+ text_model_dict[key[len("cond_stage_model.transformer.") :]] = checkpoint[key]
+
+ text_model.load_state_dict(text_model_dict)
+
+ return text_model
+
+
+textenc_conversion_lst = [
+ ("cond_stage_model.model.positional_embedding", "text_model.embeddings.position_embedding.weight"),
+ ("cond_stage_model.model.token_embedding.weight", "text_model.embeddings.token_embedding.weight"),
+ ("cond_stage_model.model.ln_final.weight", "text_model.final_layer_norm.weight"),
+ ("cond_stage_model.model.ln_final.bias", "text_model.final_layer_norm.bias"),
+]
+textenc_conversion_map = {x[0]: x[1] for x in textenc_conversion_lst}
+
+textenc_transformer_conversion_lst = [
+ # (stable-diffusion, HF Diffusers)
+ ("resblocks.", "text_model.encoder.layers."),
+ ("ln_1", "layer_norm1"),
+ ("ln_2", "layer_norm2"),
+ (".c_fc.", ".fc1."),
+ (".c_proj.", ".fc2."),
+ (".attn", ".self_attn"),
+ ("ln_final.", "transformer.text_model.final_layer_norm."),
+ ("token_embedding.weight", "transformer.text_model.embeddings.token_embedding.weight"),
+ ("positional_embedding", "transformer.text_model.embeddings.position_embedding.weight"),
+]
+protected = {re.escape(x[0]): x[1] for x in textenc_transformer_conversion_lst}
+textenc_pattern = re.compile("|".join(protected.keys()))
+
+
+def convert_paint_by_example_checkpoint(checkpoint):
+ config = CLIPVisionConfig.from_pretrained("openai/clip-vit-large-patch14")
+ model = PaintByExampleImageEncoder(config)
+
+ keys = list(checkpoint.keys())
+
+ text_model_dict = {}
+
+ for key in keys:
+ if key.startswith("cond_stage_model.transformer"):
+ text_model_dict[key[len("cond_stage_model.transformer.") :]] = checkpoint[key]
+
+ # load clip vision
+ model.model.load_state_dict(text_model_dict)
+
+ # load mapper
+ keys_mapper = {
+ k[len("cond_stage_model.mapper.res") :]: v
+ for k, v in checkpoint.items()
+ if k.startswith("cond_stage_model.mapper")
+ }
+
+ MAPPING = {
+ "attn.c_qkv": ["attn1.to_q", "attn1.to_k", "attn1.to_v"],
+ "attn.c_proj": ["attn1.to_out.0"],
+ "ln_1": ["norm1"],
+ "ln_2": ["norm3"],
+ "mlp.c_fc": ["ff.net.0.proj"],
+ "mlp.c_proj": ["ff.net.2"],
+ }
+
+ mapped_weights = {}
+ for key, value in keys_mapper.items():
+ prefix = key[: len("blocks.i")]
+ suffix = key.split(prefix)[-1].split(".")[-1]
+ name = key.split(prefix)[-1].split(suffix)[0][1:-1]
+ mapped_names = MAPPING[name]
+
+ num_splits = len(mapped_names)
+ for i, mapped_name in enumerate(mapped_names):
+ new_name = ".".join([prefix, mapped_name, suffix])
+ shape = value.shape[0] // num_splits
+ mapped_weights[new_name] = value[i * shape : (i + 1) * shape]
+
+ model.mapper.load_state_dict(mapped_weights)
+
+ # load final layer norm
+ model.final_layer_norm.load_state_dict(
+ {
+ "bias": checkpoint["cond_stage_model.final_ln.bias"],
+ "weight": checkpoint["cond_stage_model.final_ln.weight"],
+ }
+ )
+
+ # load final proj
+ model.proj_out.load_state_dict(
+ {
+ "bias": checkpoint["proj_out.bias"],
+ "weight": checkpoint["proj_out.weight"],
+ }
+ )
+
+ # load uncond vector
+ model.uncond_vector.data = torch.nn.Parameter(checkpoint["learnable_vector"])
+ return model
+
+
+def convert_open_clip_checkpoint(checkpoint):
+ text_model = CLIPTextModel.from_pretrained("stabilityai/stable-diffusion-2", subfolder="text_encoder")
+
+ keys = list(checkpoint.keys())
+
+ text_model_dict = {}
+
+ if "cond_stage_model.model.text_projection" in checkpoint:
+ d_model = int(checkpoint["cond_stage_model.model.text_projection"].shape[0])
+ else:
+ d_model = 1024
+
+ text_model_dict["text_model.embeddings.position_ids"] = text_model.text_model.embeddings.get_buffer("position_ids")
+
+ for key in keys:
+ if "resblocks.23" in key: # Diffusers drops the final layer and only uses the penultimate layer
+ continue
+ if key in textenc_conversion_map:
+ text_model_dict[textenc_conversion_map[key]] = checkpoint[key]
+ if key.startswith("cond_stage_model.model.transformer."):
+ new_key = key[len("cond_stage_model.model.transformer.") :]
+ if new_key.endswith(".in_proj_weight"):
+ new_key = new_key[: -len(".in_proj_weight")]
+ new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
+ text_model_dict[new_key + ".q_proj.weight"] = checkpoint[key][:d_model, :]
+ text_model_dict[new_key + ".k_proj.weight"] = checkpoint[key][d_model : d_model * 2, :]
+ text_model_dict[new_key + ".v_proj.weight"] = checkpoint[key][d_model * 2 :, :]
+ elif new_key.endswith(".in_proj_bias"):
+ new_key = new_key[: -len(".in_proj_bias")]
+ new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
+ text_model_dict[new_key + ".q_proj.bias"] = checkpoint[key][:d_model]
+ text_model_dict[new_key + ".k_proj.bias"] = checkpoint[key][d_model : d_model * 2]
+ text_model_dict[new_key + ".v_proj.bias"] = checkpoint[key][d_model * 2 :]
+ else:
+ new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
+
+ text_model_dict[new_key] = checkpoint[key]
+
+ text_model.load_state_dict(text_model_dict)
+
+ return text_model
+
+
+def stable_unclip_image_encoder(original_config):
+ """
+ Returns the image processor and clip image encoder for the img2img unclip pipeline.
+
+ We currently know of two types of stable unclip models which separately use the clip and the openclip image
+ encoders.
+ """
+
+ image_embedder_config = original_config.model.params.embedder_config
+
+ sd_clip_image_embedder_class = image_embedder_config.target
+ sd_clip_image_embedder_class = sd_clip_image_embedder_class.split(".")[-1]
+
+ if sd_clip_image_embedder_class == "ClipImageEmbedder":
+ clip_model_name = image_embedder_config.params.model
+
+ if clip_model_name == "ViT-L/14":
+ feature_extractor = CLIPImageProcessor()
+ image_encoder = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
+ else:
+ raise NotImplementedError(f"Unknown CLIP checkpoint name in stable diffusion checkpoint {clip_model_name}")
+
+ elif sd_clip_image_embedder_class == "FrozenOpenCLIPImageEmbedder":
+ feature_extractor = CLIPImageProcessor()
+ image_encoder = CLIPVisionModelWithProjection.from_pretrained("laion/CLIP-ViT-H-14-laion2B-s32B-b79K")
+ else:
+ raise NotImplementedError(
+ f"Unknown CLIP image embedder class in stable diffusion checkpoint {sd_clip_image_embedder_class}"
+ )
+
+ return feature_extractor, image_encoder
+
+
+def stable_unclip_image_noising_components(
+ original_config, clip_stats_path: Optional[str] = None, device: Optional[str] = None
+):
+ """
+ Returns the noising components for the img2img and txt2img unclip pipelines.
+
+ Converts the stability noise augmentor into
+ 1. a `StableUnCLIPImageNormalizer` for holding the CLIP stats
+ 2. a `DDPMScheduler` for holding the noise schedule
+
+ If the noise augmentor config specifies a clip stats path, the `clip_stats_path` must be provided.
+ """
+ noise_aug_config = original_config.model.params.noise_aug_config
+ noise_aug_class = noise_aug_config.target
+ noise_aug_class = noise_aug_class.split(".")[-1]
+
+ if noise_aug_class == "CLIPEmbeddingNoiseAugmentation":
+ noise_aug_config = noise_aug_config.params
+ embedding_dim = noise_aug_config.timestep_dim
+ max_noise_level = noise_aug_config.noise_schedule_config.timesteps
+ beta_schedule = noise_aug_config.noise_schedule_config.beta_schedule
+
+ image_normalizer = StableUnCLIPImageNormalizer(embedding_dim=embedding_dim)
+ image_noising_scheduler = DDPMScheduler(num_train_timesteps=max_noise_level, beta_schedule=beta_schedule)
+
+ if "clip_stats_path" in noise_aug_config:
+ if clip_stats_path is None:
+ raise ValueError("This stable unclip config requires a `clip_stats_path`")
+
+ clip_mean, clip_std = torch.load(clip_stats_path, map_location=device)
+ clip_mean = clip_mean[None, :]
+ clip_std = clip_std[None, :]
+
+ clip_stats_state_dict = {
+ "mean": clip_mean,
+ "std": clip_std,
+ }
+
+ image_normalizer.load_state_dict(clip_stats_state_dict)
+ else:
+ raise NotImplementedError(f"Unknown noise augmentor class: {noise_aug_class}")
+
+ return image_normalizer, image_noising_scheduler
+
+
+def convert_controlnet_checkpoint(
+ checkpoint, original_config, checkpoint_path, image_size, upcast_attention, extract_ema
+):
+ ctrlnet_config = create_unet_diffusers_config(original_config, image_size=image_size, controlnet=True)
+ ctrlnet_config["upcast_attention"] = upcast_attention
+
+ ctrlnet_config.pop("sample_size")
+
+ controlnet_model = ControlNetModel(**ctrlnet_config)
+
+ converted_ctrl_checkpoint = convert_ldm_unet_checkpoint(
+ checkpoint, ctrlnet_config, path=checkpoint_path, extract_ema=extract_ema, controlnet=True
+ )
+
+ controlnet_model.load_state_dict(converted_ctrl_checkpoint)
+
+ return controlnet_model
+
+
+def download_from_original_stable_diffusion_ckpt(
+ checkpoint_path: str,
+ original_config_file: str = None,
+ image_size: int = 512,
+ prediction_type: str = None,
+ model_type: str = None,
+ extract_ema: bool = False,
+ scheduler_type: str = "pndm",
+ num_in_channels: Optional[int] = None,
+ upcast_attention: Optional[bool] = None,
+ device: str = None,
+ from_safetensors: bool = False,
+ stable_unclip: Optional[str] = None,
+ stable_unclip_prior: Optional[str] = None,
+ clip_stats_path: Optional[str] = None,
+ controlnet: Optional[bool] = None,
+ load_safety_checker: bool = True,
+) -> StableDiffusionPipeline:
+ """
+ Load a Stable Diffusion pipeline object from a CompVis-style `.ckpt`/`.safetensors` file and (ideally) a `.yaml`
+ config file.
+
+ Although many of the arguments can be automatically inferred, some of these rely on brittle checks against the
+ global step count, which will likely fail for models that have undergone further fine-tuning. Therefore, it is
+ recommended that you override the default values and/or supply an `original_config_file` wherever possible.
+
+ Args:
+ checkpoint_path (`str`): Path to `.ckpt` file.
+ original_config_file (`str`):
+ Path to `.yaml` config file corresponding to the original architecture. If `None`, will be automatically
+ inferred by looking for a key that only exists in SD2.0 models.
+ image_size (`int`, *optional*, defaults to 512):
+ The image size that the model was trained on. Use 512 for Stable Diffusion v1.X and Stable Diffusion v2
+ Base. Use 768 for Stable Diffusion v2.
+ prediction_type (`str`, *optional*):
+ The prediction type that the model was trained on. Use `'epsilon'` for Stable Diffusion v1.X and Stable
+ Diffusion v2 Base. Use `'v_prediction'` for Stable Diffusion v2.
+ num_in_channels (`int`, *optional*, defaults to None):
+ The number of input channels. If `None`, it will be automatically inferred.
+ scheduler_type (`str`, *optional*, defaults to 'pndm'):
+ Type of scheduler to use. Should be one of `["pndm", "lms", "heun", "euler", "euler-ancestral", "dpm",
+ "ddim"]`.
+ model_type (`str`, *optional*, defaults to `None`):
+ The pipeline type. `None` to automatically infer, or one of `["FrozenOpenCLIPEmbedder",
+ "FrozenCLIPEmbedder", "PaintByExample"]`.
+ extract_ema (`bool`, *optional*, defaults to `False`): Only relevant for
+ checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights or not. Defaults to
+ `False`. Pass `True` to extract the EMA weights. EMA weights usually yield higher quality images for
+ inference. Non-EMA weights are usually better to continue fine-tuning.
+ upcast_attention (`bool`, *optional*, defaults to `None`):
+ Whether the attention computation should always be upcasted. This is necessary when running stable
+ diffusion 2.1.
+ device (`str`, *optional*, defaults to `None`):
+ The device to use. Pass `None` to determine automatically. :param from_safetensors: If `checkpoint_path` is
+ in `safetensors` format, load checkpoint with safetensors instead of PyTorch. :return: A
+ StableDiffusionPipeline object representing the passed-in `.ckpt`/`.safetensors` file.
+ load_safety_checker (`bool`, *optional*, defaults to `True`):
+ Whether to load the safety checker or not. Defaults to `True`.
+ """
+ if prediction_type == "v-prediction":
+ prediction_type = "v_prediction"
+
+ if not is_omegaconf_available():
+ raise ValueError(BACKENDS_MAPPING["omegaconf"][1])
+
+ from omegaconf import OmegaConf
+
+ if from_safetensors:
+ if not is_safetensors_available():
+ raise ValueError(BACKENDS_MAPPING["safetensors"][1])
+
+ from safetensors import safe_open
+
+ checkpoint = {}
+ with safe_open(checkpoint_path, framework="pt", device="cpu") as f:
+ for key in f.keys():
+ checkpoint[key] = f.get_tensor(key)
+ else:
+ if device is None:
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ checkpoint = torch.load(checkpoint_path, map_location=device)
+ else:
+ checkpoint = torch.load(checkpoint_path, map_location=device)
+
+ # Sometimes models don't have the global_step item
+ if "global_step" in checkpoint:
+ global_step = checkpoint["global_step"]
+ else:
+ print("global_step key not found in model")
+ global_step = None
+
+ # NOTE: this while loop isn't great but this controlnet checkpoint has one additional
+ # "state_dict" key https://huggingface.co/thibaud/controlnet-canny-sd21
+ while "state_dict" in checkpoint:
+ checkpoint = checkpoint["state_dict"]
+
+ if original_config_file is None:
+ key_name = "model.diffusion_model.input_blocks.2.1.transformer_blocks.0.attn2.to_k.weight"
+
+ # model_type = "v1"
+ config_url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml"
+
+ if key_name in checkpoint and checkpoint[key_name].shape[-1] == 1024:
+ # model_type = "v2"
+ config_url = "https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml"
+
+ if global_step == 110000:
+ # v2.1 needs to upcast attention
+ upcast_attention = True
+
+ original_config_file = BytesIO(requests.get(config_url).content)
+
+ original_config = OmegaConf.load(original_config_file)
+
+ if num_in_channels is not None:
+ original_config["model"]["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
+
+ if (
+ "parameterization" in original_config["model"]["params"]
+ and original_config["model"]["params"]["parameterization"] == "v"
+ ):
+ if prediction_type is None:
+ # NOTE: For stable diffusion 2 base it is recommended to pass `prediction_type=="epsilon"`
+ # as it relies on a brittle global step parameter here
+ prediction_type = "epsilon" if global_step == 875000 else "v_prediction"
+ if image_size is None:
+ # NOTE: For stable diffusion 2 base one has to pass `image_size==512`
+ # as it relies on a brittle global step parameter here
+ image_size = 512 if global_step == 875000 else 768
+ else:
+ if prediction_type is None:
+ prediction_type = "epsilon"
+ if image_size is None:
+ image_size = 512
+
+ if controlnet is None:
+ controlnet = "control_stage_config" in original_config.model.params
+
+ if controlnet:
+ controlnet_model = convert_controlnet_checkpoint(
+ checkpoint, original_config, checkpoint_path, image_size, upcast_attention, extract_ema
+ )
+
+ num_train_timesteps = original_config.model.params.timesteps
+ beta_start = original_config.model.params.linear_start
+ beta_end = original_config.model.params.linear_end
+
+ scheduler = DDIMScheduler(
+ beta_end=beta_end,
+ beta_schedule="scaled_linear",
+ beta_start=beta_start,
+ num_train_timesteps=num_train_timesteps,
+ steps_offset=1,
+ clip_sample=False,
+ set_alpha_to_one=False,
+ prediction_type=prediction_type,
+ )
+ # make sure scheduler works correctly with DDIM
+ scheduler.register_to_config(clip_sample=False)
+
+ if scheduler_type == "pndm":
+ config = dict(scheduler.config)
+ config["skip_prk_steps"] = True
+ scheduler = PNDMScheduler.from_config(config)
+ elif scheduler_type == "lms":
+ scheduler = LMSDiscreteScheduler.from_config(scheduler.config)
+ elif scheduler_type == "heun":
+ scheduler = HeunDiscreteScheduler.from_config(scheduler.config)
+ elif scheduler_type == "euler":
+ scheduler = EulerDiscreteScheduler.from_config(scheduler.config)
+ elif scheduler_type == "euler-ancestral":
+ scheduler = EulerAncestralDiscreteScheduler.from_config(scheduler.config)
+ elif scheduler_type == "dpm":
+ scheduler = DPMSolverMultistepScheduler.from_config(scheduler.config)
+ elif scheduler_type == "ddim":
+ scheduler = scheduler
+ else:
+ raise ValueError(f"Scheduler of type {scheduler_type} doesn't exist!")
+
+ # Convert the UNet2DConditionModel model.
+ unet_config = create_unet_diffusers_config(original_config, image_size=image_size)
+ unet_config["upcast_attention"] = upcast_attention
+ unet = UNet2DConditionModel(**unet_config)
+
+ converted_unet_checkpoint = convert_ldm_unet_checkpoint(
+ checkpoint, unet_config, path=checkpoint_path, extract_ema=extract_ema
+ )
+
+ unet.load_state_dict(converted_unet_checkpoint)
+
+ # Convert the VAE model.
+ vae_config = create_vae_diffusers_config(original_config, image_size=image_size)
+ converted_vae_checkpoint = convert_ldm_vae_checkpoint(checkpoint, vae_config)
+
+ vae = AutoencoderKL(**vae_config)
+ vae.load_state_dict(converted_vae_checkpoint)
+
+ # Convert the text model.
+ if model_type is None:
+ model_type = original_config.model.params.cond_stage_config.target.split(".")[-1]
+ logger.debug(f"no `model_type` given, `model_type` inferred as: {model_type}")
+
+ if model_type == "FrozenOpenCLIPEmbedder":
+ text_model = convert_open_clip_checkpoint(checkpoint)
+ tokenizer = CLIPTokenizer.from_pretrained("stabilityai/stable-diffusion-2", subfolder="tokenizer")
+
+ if stable_unclip is None:
+ if controlnet:
+ pipe = StableDiffusionControlNetPipeline(
+ vae=vae,
+ text_encoder=text_model,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ controlnet=controlnet_model,
+ safety_checker=None,
+ feature_extractor=None,
+ requires_safety_checker=False,
+ )
+ else:
+ pipe = StableDiffusionPipeline(
+ vae=vae,
+ text_encoder=text_model,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=None,
+ feature_extractor=None,
+ requires_safety_checker=False,
+ )
+ else:
+ image_normalizer, image_noising_scheduler = stable_unclip_image_noising_components(
+ original_config, clip_stats_path=clip_stats_path, device=device
+ )
+
+ if stable_unclip == "img2img":
+ feature_extractor, image_encoder = stable_unclip_image_encoder(original_config)
+
+ pipe = StableUnCLIPImg2ImgPipeline(
+ # image encoding components
+ feature_extractor=feature_extractor,
+ image_encoder=image_encoder,
+ # image noising components
+ image_normalizer=image_normalizer,
+ image_noising_scheduler=image_noising_scheduler,
+ # regular denoising components
+ tokenizer=tokenizer,
+ text_encoder=text_model,
+ unet=unet,
+ scheduler=scheduler,
+ # vae
+ vae=vae,
+ )
+ elif stable_unclip == "txt2img":
+ if stable_unclip_prior is None or stable_unclip_prior == "karlo":
+ karlo_model = "kakaobrain/karlo-v1-alpha"
+ prior = PriorTransformer.from_pretrained(karlo_model, subfolder="prior")
+
+ prior_tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
+ prior_text_model = CLIPTextModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
+
+ prior_scheduler = UnCLIPScheduler.from_pretrained(karlo_model, subfolder="prior_scheduler")
+ prior_scheduler = DDPMScheduler.from_config(prior_scheduler.config)
+ else:
+ raise NotImplementedError(f"unknown prior for stable unclip model: {stable_unclip_prior}")
+
+ pipe = StableUnCLIPPipeline(
+ # prior components
+ prior_tokenizer=prior_tokenizer,
+ prior_text_encoder=prior_text_model,
+ prior=prior,
+ prior_scheduler=prior_scheduler,
+ # image noising components
+ image_normalizer=image_normalizer,
+ image_noising_scheduler=image_noising_scheduler,
+ # regular denoising components
+ tokenizer=tokenizer,
+ text_encoder=text_model,
+ unet=unet,
+ scheduler=scheduler,
+ # vae
+ vae=vae,
+ )
+ else:
+ raise NotImplementedError(f"unknown `stable_unclip` type: {stable_unclip}")
+ elif model_type == "PaintByExample":
+ vision_model = convert_paint_by_example_checkpoint(checkpoint)
+ tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
+ feature_extractor = AutoFeatureExtractor.from_pretrained("CompVis/stable-diffusion-safety-checker")
+ pipe = PaintByExamplePipeline(
+ vae=vae,
+ image_encoder=vision_model,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=None,
+ feature_extractor=feature_extractor,
+ )
+ elif model_type == "FrozenCLIPEmbedder":
+ text_model = convert_ldm_clip_checkpoint(checkpoint)
+ tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
+
+ if load_safety_checker:
+ safety_checker = StableDiffusionSafetyChecker.from_pretrained("CompVis/stable-diffusion-safety-checker")
+ feature_extractor = AutoFeatureExtractor.from_pretrained("CompVis/stable-diffusion-safety-checker")
+ else:
+ safety_checker = None
+ feature_extractor = None
+
+ if controlnet:
+ pipe = StableDiffusionControlNetPipeline(
+ vae=vae,
+ text_encoder=text_model,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet_model,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ else:
+ pipe = StableDiffusionPipeline(
+ vae=vae,
+ text_encoder=text_model,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ else:
+ text_config = create_ldm_bert_config(original_config)
+ text_model = convert_ldm_bert_checkpoint(checkpoint, text_config)
+ tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
+ pipe = LDMTextToImagePipeline(vqvae=vae, bert=text_model, tokenizer=tokenizer, unet=unet, scheduler=scheduler)
+
+ return pipe
+
+
+def download_controlnet_from_original_ckpt(
+ checkpoint_path: str,
+ original_config_file: str,
+ image_size: int = 512,
+ extract_ema: bool = False,
+ num_in_channels: Optional[int] = None,
+ upcast_attention: Optional[bool] = None,
+ device: str = None,
+ from_safetensors: bool = False,
+) -> StableDiffusionPipeline:
+ if not is_omegaconf_available():
+ raise ValueError(BACKENDS_MAPPING["omegaconf"][1])
+
+ from omegaconf import OmegaConf
+
+ if from_safetensors:
+ if not is_safetensors_available():
+ raise ValueError(BACKENDS_MAPPING["safetensors"][1])
+
+ from safetensors import safe_open
+
+ checkpoint = {}
+ with safe_open(checkpoint_path, framework="pt", device="cpu") as f:
+ for key in f.keys():
+ checkpoint[key] = f.get_tensor(key)
+ else:
+ if device is None:
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ checkpoint = torch.load(checkpoint_path, map_location=device)
+ else:
+ checkpoint = torch.load(checkpoint_path, map_location=device)
+
+ # NOTE: this while loop isn't great but this controlnet checkpoint has one additional
+ # "state_dict" key https://huggingface.co/thibaud/controlnet-canny-sd21
+ while "state_dict" in checkpoint:
+ checkpoint = checkpoint["state_dict"]
+
+ original_config = OmegaConf.load(original_config_file)
+
+ if num_in_channels is not None:
+ original_config["model"]["params"]["unet_config"]["params"]["in_channels"] = num_in_channels
+
+ if "control_stage_config" not in original_config.model.params:
+ raise ValueError("`control_stage_config` not present in original config")
+
+ controlnet_model = convert_controlnet_checkpoint(
+ checkpoint, original_config, checkpoint_path, image_size, upcast_attention, extract_ema
+ )
+
+ return controlnet_model
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_cycle_diffusion.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_cycle_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..dd8e4f16dfc0ca359423d8196cc14853bf534755
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_cycle_diffusion.py
@@ -0,0 +1,785 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from diffusers.utils import is_accelerate_available, is_accelerate_version
+
+from ...configuration_utils import FrozenDict
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import DDIMScheduler
+from ...utils import PIL_INTERPOLATION, deprecate, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+
+ image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+def posterior_sample(scheduler, latents, timestep, clean_latents, generator, eta):
+ # 1. get previous step value (=t-1)
+ prev_timestep = timestep - scheduler.config.num_train_timesteps // scheduler.num_inference_steps
+
+ if prev_timestep <= 0:
+ return clean_latents
+
+ # 2. compute alphas, betas
+ alpha_prod_t = scheduler.alphas_cumprod[timestep]
+ alpha_prod_t_prev = (
+ scheduler.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else scheduler.final_alpha_cumprod
+ )
+
+ variance = scheduler._get_variance(timestep, prev_timestep)
+ std_dev_t = eta * variance ** (0.5)
+
+ # direction pointing to x_t
+ e_t = (latents - alpha_prod_t ** (0.5) * clean_latents) / (1 - alpha_prod_t) ** (0.5)
+ dir_xt = (1.0 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * e_t
+ noise = std_dev_t * randn_tensor(
+ clean_latents.shape, dtype=clean_latents.dtype, device=clean_latents.device, generator=generator
+ )
+ prev_latents = alpha_prod_t_prev ** (0.5) * clean_latents + dir_xt + noise
+
+ return prev_latents
+
+
+def compute_noise(scheduler, prev_latents, latents, timestep, noise_pred, eta):
+ # 1. get previous step value (=t-1)
+ prev_timestep = timestep - scheduler.config.num_train_timesteps // scheduler.num_inference_steps
+
+ # 2. compute alphas, betas
+ alpha_prod_t = scheduler.alphas_cumprod[timestep]
+ alpha_prod_t_prev = (
+ scheduler.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else scheduler.final_alpha_cumprod
+ )
+
+ beta_prod_t = 1 - alpha_prod_t
+
+ # 3. compute predicted original sample from predicted noise also called
+ # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
+
+ # 4. Clip "predicted x_0"
+ if scheduler.config.clip_sample:
+ pred_original_sample = torch.clamp(pred_original_sample, -1, 1)
+
+ # 5. compute variance: "sigma_t(η)" -> see formula (16)
+ # σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
+ variance = scheduler._get_variance(timestep, prev_timestep)
+ std_dev_t = eta * variance ** (0.5)
+
+ # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * noise_pred
+
+ noise = (prev_latents - (alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction)) / (
+ variance ** (0.5) * eta
+ )
+ return noise
+
+
+class CycleDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-guided image to image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: DDIMScheduler,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_model_cpu_offload
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.check_inputs
+ def check_inputs(
+ self, prompt, strength, callback_steps, negative_prompt=None, prompt_embeds=None, negative_prompt_embeds=None
+ ):
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+
+ def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
+ image = image.to(device=device, dtype=dtype)
+
+ batch_size = image.shape[0]
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if isinstance(generator, list):
+ init_latents = [
+ self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = self.vae.encode(image).latent_dist.sample(generator)
+
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ deprecation_message = (
+ f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
+ " images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
+ " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
+ " your script to pass as many initial images as text prompts to suppress this warning."
+ )
+ deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
+ additional_image_per_prompt = batch_size // init_latents.shape[0]
+ init_latents = torch.cat([init_latents] * additional_image_per_prompt * num_images_per_prompt, dim=0)
+ elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents] * num_images_per_prompt, dim=0)
+
+ # add noise to latents using the timestep
+ shape = init_latents.shape
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+
+ # get latents
+ clean_latents = init_latents
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+
+ return latents, clean_latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ source_prompt: Union[str, List[str]],
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ source_guidance_scale: Optional[float] = 1,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ image (`torch.FloatTensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
+ will be used as a starting point, adding more noise to it the larger the `strength`. The number of
+ denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
+ be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference. This parameter will be modulated by `strength`.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ source_guidance_scale (`float`, *optional*, defaults to 1):
+ Guidance scale for the source prompt. This is useful to control the amount of influence the source
+ prompt for encoding.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.1):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 1. Check inputs
+ self.check_inputs(prompt, strength, callback_steps)
+
+ # 2. Define call parameters
+ batch_size = 1 if isinstance(prompt, str) else len(prompt)
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ prompt_embeds=prompt_embeds,
+ )
+ source_prompt_embeds = self._encode_prompt(
+ source_prompt, device, num_images_per_prompt, do_classifier_free_guidance, None
+ )
+
+ # 4. Preprocess image
+ image = preprocess(image)
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 6. Prepare latent variables
+ latents, clean_latents = self.prepare_latents(
+ image, latent_timestep, batch_size, num_images_per_prompt, prompt_embeds.dtype, device, generator
+ )
+ source_latents = latents
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+ generator = extra_step_kwargs.pop("generator", None)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2)
+ source_latent_model_input = torch.cat([source_latents] * 2)
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+ source_latent_model_input = self.scheduler.scale_model_input(source_latent_model_input, t)
+
+ # predict the noise residual
+ concat_latent_model_input = torch.stack(
+ [
+ source_latent_model_input[0],
+ latent_model_input[0],
+ source_latent_model_input[1],
+ latent_model_input[1],
+ ],
+ dim=0,
+ )
+ concat_prompt_embeds = torch.stack(
+ [
+ source_prompt_embeds[0],
+ prompt_embeds[0],
+ source_prompt_embeds[1],
+ prompt_embeds[1],
+ ],
+ dim=0,
+ )
+ concat_noise_pred = self.unet(
+ concat_latent_model_input, t, encoder_hidden_states=concat_prompt_embeds
+ ).sample
+
+ # perform guidance
+ (
+ source_noise_pred_uncond,
+ noise_pred_uncond,
+ source_noise_pred_text,
+ noise_pred_text,
+ ) = concat_noise_pred.chunk(4, dim=0)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+ source_noise_pred = source_noise_pred_uncond + source_guidance_scale * (
+ source_noise_pred_text - source_noise_pred_uncond
+ )
+
+ # Sample source_latents from the posterior distribution.
+ prev_source_latents = posterior_sample(
+ self.scheduler, source_latents, t, clean_latents, generator=generator, **extra_step_kwargs
+ )
+ # Compute noise.
+ noise = compute_noise(
+ self.scheduler, prev_source_latents, source_latents, t, source_noise_pred, **extra_step_kwargs
+ )
+ source_latents = prev_source_latents
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(
+ noise_pred, t, latents, variance_noise=noise, **extra_step_kwargs
+ ).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # 10. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 11. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..066d1e99acaaf0785fc817acda8f19397c699af8
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion.py
@@ -0,0 +1,467 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import warnings
+from functools import partial
+from typing import Dict, List, Optional, Union
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.core.frozen_dict import FrozenDict
+from flax.jax_utils import unreplicate
+from flax.training.common_utils import shard
+from packaging import version
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel
+
+from ...models import FlaxAutoencoderKL, FlaxUNet2DConditionModel
+from ...schedulers import (
+ FlaxDDIMScheduler,
+ FlaxDPMSolverMultistepScheduler,
+ FlaxLMSDiscreteScheduler,
+ FlaxPNDMScheduler,
+)
+from ...utils import deprecate, logging, replace_example_docstring
+from ..pipeline_flax_utils import FlaxDiffusionPipeline
+from . import FlaxStableDiffusionPipelineOutput
+from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+# Set to True to use python for loop instead of jax.fori_loop for easier debugging
+DEBUG = False
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import jax
+ >>> import numpy as np
+ >>> from flax.jax_utils import replicate
+ >>> from flax.training.common_utils import shard
+
+ >>> from diffusers import FlaxStableDiffusionPipeline
+
+ >>> pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", revision="bf16", dtype=jax.numpy.bfloat16
+ ... )
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+
+ >>> prng_seed = jax.random.PRNGKey(0)
+ >>> num_inference_steps = 50
+
+ >>> num_samples = jax.device_count()
+ >>> prompt = num_samples * [prompt]
+ >>> prompt_ids = pipeline.prepare_inputs(prompt)
+ # shard inputs and rng
+
+ >>> params = replicate(params)
+ >>> prng_seed = jax.random.split(prng_seed, jax.device_count())
+ >>> prompt_ids = shard(prompt_ids)
+
+ >>> images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
+ >>> images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
+ ```
+"""
+
+
+class FlaxStableDiffusionPipeline(FlaxDiffusionPipeline):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion.
+
+ This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`FlaxAutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`FlaxCLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.FlaxCLIPTextModel),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`FlaxUNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
+ [`FlaxDPMSolverMultistepScheduler`].
+ safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ def __init__(
+ self,
+ vae: FlaxAutoencoderKL,
+ text_encoder: FlaxCLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: FlaxUNet2DConditionModel,
+ scheduler: Union[
+ FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
+ ],
+ safety_checker: FlaxStableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ super().__init__()
+ self.dtype = dtype
+
+ if safety_checker is None:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ def prepare_inputs(self, prompt: Union[str, List[str]]):
+ if not isinstance(prompt, (str, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ return text_input.input_ids
+
+ def _get_has_nsfw_concepts(self, features, params):
+ has_nsfw_concepts = self.safety_checker(features, params)
+ return has_nsfw_concepts
+
+ def _run_safety_checker(self, images, safety_model_params, jit=False):
+ # safety_model_params should already be replicated when jit is True
+ pil_images = [Image.fromarray(image) for image in images]
+ features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
+
+ if jit:
+ features = shard(features)
+ has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
+ has_nsfw_concepts = unshard(has_nsfw_concepts)
+ safety_model_params = unreplicate(safety_model_params)
+ else:
+ has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
+
+ images_was_copied = False
+ for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
+ if has_nsfw_concept:
+ if not images_was_copied:
+ images_was_copied = True
+ images = images.copy()
+
+ images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
+
+ if any(has_nsfw_concepts):
+ warnings.warn(
+ "Potential NSFW content was detected in one or more images. A black image will be returned"
+ " instead. Try again with a different prompt and/or seed."
+ )
+
+ return images, has_nsfw_concepts
+
+ def _generate(
+ self,
+ prompt_ids: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int,
+ height: int,
+ width: int,
+ guidance_scale: float,
+ latents: Optional[jnp.array] = None,
+ neg_prompt_ids: Optional[jnp.array] = None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ # get prompt text embeddings
+ prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
+
+ # TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
+ # implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
+ batch_size = prompt_ids.shape[0]
+
+ max_length = prompt_ids.shape[-1]
+
+ if neg_prompt_ids is None:
+ uncond_input = self.tokenizer(
+ [""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
+ ).input_ids
+ else:
+ uncond_input = neg_prompt_ids
+ negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
+ context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ latents_shape = (
+ batch_size,
+ self.unet.in_channels,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if latents is None:
+ latents = jax.random.normal(prng_seed, shape=latents_shape, dtype=jnp.float32)
+ else:
+ if latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+
+ def loop_body(step, args):
+ latents, scheduler_state = args
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ latents_input = jnp.concatenate([latents] * 2)
+
+ t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
+ timestep = jnp.broadcast_to(t, latents_input.shape[0])
+
+ latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet.apply(
+ {"params": params["unet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ ).sample
+ # perform guidance
+ noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
+ return latents, scheduler_state
+
+ scheduler_state = self.scheduler.set_timesteps(
+ params["scheduler"], num_inference_steps=num_inference_steps, shape=latents.shape
+ )
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * params["scheduler"].init_noise_sigma
+
+ if DEBUG:
+ # run with python for loop
+ for i in range(num_inference_steps):
+ latents, scheduler_state = loop_body(i, (latents, scheduler_state))
+ else:
+ latents, _ = jax.lax.fori_loop(0, num_inference_steps, loop_body, (latents, scheduler_state))
+
+ # scale and decode the image latents with vae
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
+
+ image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
+ return image
+
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt_ids: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int = 50,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ guidance_scale: Union[float, jnp.array] = 7.5,
+ latents: jnp.array = None,
+ neg_prompt_ids: jnp.array = None,
+ return_dict: bool = True,
+ jit: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ latents (`jnp.array`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. tensor will ge generated
+ by sampling using the supplied random `generator`.
+ jit (`bool`, defaults to `False`):
+ Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
+ exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
+ a plain tuple.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
+ `tuple. When returning a tuple, the first element is a list with the generated images, and the second
+ element is a list of `bool`s denoting whether the corresponding generated image likely represents
+ "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ if isinstance(guidance_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ guidance_scale = guidance_scale[:, None]
+
+ if jit:
+ images = _p_generate(
+ self,
+ prompt_ids,
+ params,
+ prng_seed,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ )
+ else:
+ images = self._generate(
+ prompt_ids,
+ params,
+ prng_seed,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ )
+
+ if self.safety_checker is not None:
+ safety_params = params["safety_checker"]
+ images_uint8_casted = (images * 255).round().astype("uint8")
+ num_devices, batch_size = images.shape[:2]
+
+ images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
+ images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
+ images = np.asarray(images)
+
+ # block images
+ if any(has_nsfw_concept):
+ for i, is_nsfw in enumerate(has_nsfw_concept):
+ if is_nsfw:
+ images[i] = np.asarray(images_uint8_casted[i])
+
+ images = images.reshape(num_devices, batch_size, height, width, 3)
+ else:
+ images = np.asarray(images)
+ has_nsfw_concept = False
+
+ if not return_dict:
+ return (images, has_nsfw_concept)
+
+ return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
+
+
+# Static argnums are pipe, num_inference_steps, height, width. A change would trigger recompilation.
+# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
+@partial(
+ jax.pmap,
+ in_axes=(None, 0, 0, 0, None, None, None, 0, 0, 0),
+ static_broadcasted_argnums=(0, 4, 5, 6),
+)
+def _p_generate(
+ pipe,
+ prompt_ids,
+ params,
+ prng_seed,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+):
+ return pipe._generate(
+ prompt_ids,
+ params,
+ prng_seed,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ )
+
+
+@partial(jax.pmap, static_broadcasted_argnums=(0,))
+def _p_get_has_nsfw_concepts(pipe, features, params):
+ return pipe._get_has_nsfw_concepts(features, params)
+
+
+def unshard(x: jnp.ndarray):
+ # einops.rearrange(x, 'd b ... -> (d b) ...')
+ num_devices, batch_size = x.shape[:2]
+ rest = x.shape[2:]
+ return x.reshape(num_devices * batch_size, *rest)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..5af07ec8b9c4ac21c692706a2fa529b2e38f2322
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_controlnet.py
@@ -0,0 +1,537 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import warnings
+from functools import partial
+from typing import Dict, List, Optional, Union
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.core.frozen_dict import FrozenDict
+from flax.jax_utils import unreplicate
+from flax.training.common_utils import shard
+from PIL import Image
+from transformers import CLIPFeatureExtractor, CLIPTokenizer, FlaxCLIPTextModel
+
+from ...models import FlaxAutoencoderKL, FlaxControlNetModel, FlaxUNet2DConditionModel
+from ...schedulers import (
+ FlaxDDIMScheduler,
+ FlaxDPMSolverMultistepScheduler,
+ FlaxLMSDiscreteScheduler,
+ FlaxPNDMScheduler,
+)
+from ...utils import PIL_INTERPOLATION, logging, replace_example_docstring
+from ..pipeline_flax_utils import FlaxDiffusionPipeline
+from . import FlaxStableDiffusionPipelineOutput
+from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+# Set to True to use python for loop instead of jax.fori_loop for easier debugging
+DEBUG = False
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import jax
+ >>> import numpy as np
+ >>> import jax.numpy as jnp
+ >>> from flax.jax_utils import replicate
+ >>> from flax.training.common_utils import shard
+ >>> from diffusers.utils import load_image
+ >>> from PIL import Image
+ >>> from diffusers import FlaxStableDiffusionControlNetPipeline, FlaxControlNetModel
+
+
+ >>> def image_grid(imgs, rows, cols):
+ ... w, h = imgs[0].size
+ ... grid = Image.new("RGB", size=(cols * w, rows * h))
+ ... for i, img in enumerate(imgs):
+ ... grid.paste(img, box=(i % cols * w, i // cols * h))
+ ... return grid
+
+
+ >>> def create_key(seed=0):
+ ... return jax.random.PRNGKey(seed)
+
+
+ >>> rng = create_key(0)
+
+ >>> # get canny image
+ >>> canny_image = load_image(
+ ... "https://huggingface.co/datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_10_output_0.jpeg"
+ ... )
+
+ >>> prompts = "best quality, extremely detailed"
+ >>> negative_prompts = "monochrome, lowres, bad anatomy, worst quality, low quality"
+
+ >>> # load control net and stable diffusion v1-5
+ >>> controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
+ ... "lllyasviel/sd-controlnet-canny", from_pt=True, dtype=jnp.float32
+ ... )
+ >>> pipe, params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, from_pt=True, dtype=jnp.float32
+ ... )
+ >>> params["controlnet"] = controlnet_params
+
+ >>> num_samples = jax.device_count()
+ >>> rng = jax.random.split(rng, jax.device_count())
+
+ >>> prompt_ids = pipe.prepare_text_inputs([prompts] * num_samples)
+ >>> negative_prompt_ids = pipe.prepare_text_inputs([negative_prompts] * num_samples)
+ >>> processed_image = pipe.prepare_image_inputs([canny_image] * num_samples)
+
+ >>> p_params = replicate(params)
+ >>> prompt_ids = shard(prompt_ids)
+ >>> negative_prompt_ids = shard(negative_prompt_ids)
+ >>> processed_image = shard(processed_image)
+
+ >>> output = pipe(
+ ... prompt_ids=prompt_ids,
+ ... image=processed_image,
+ ... params=p_params,
+ ... prng_seed=rng,
+ ... num_inference_steps=50,
+ ... neg_prompt_ids=negative_prompt_ids,
+ ... jit=True,
+ ... ).images
+
+ >>> output_images = pipe.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
+ >>> output_images = image_grid(output_images, num_samples // 4, 4)
+ >>> output_images.save("generated_image.png")
+ ```
+"""
+
+
+class FlaxStableDiffusionControlNetPipeline(FlaxDiffusionPipeline):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet Guidance.
+
+ This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`FlaxAutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`FlaxCLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.FlaxCLIPTextModel),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`FlaxUNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`FlaxControlNetModel`]:
+ Provides additional conditioning to the unet during the denoising process.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
+ [`FlaxDPMSolverMultistepScheduler`].
+ safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPFeatureExtractor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ def __init__(
+ self,
+ vae: FlaxAutoencoderKL,
+ text_encoder: FlaxCLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: FlaxUNet2DConditionModel,
+ controlnet: FlaxControlNetModel,
+ scheduler: Union[
+ FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
+ ],
+ safety_checker: FlaxStableDiffusionSafetyChecker,
+ feature_extractor: CLIPFeatureExtractor,
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ super().__init__()
+ self.dtype = dtype
+
+ if safety_checker is None:
+ logger.warn(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ def prepare_text_inputs(self, prompt: Union[str, List[str]]):
+ if not isinstance(prompt, (str, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+
+ return text_input.input_ids
+
+ def prepare_image_inputs(self, image: Union[Image.Image, List[Image.Image]]):
+ if not isinstance(image, (Image.Image, list)):
+ raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
+
+ if isinstance(image, Image.Image):
+ image = [image]
+
+ processed_images = jnp.concatenate([preprocess(img, jnp.float32) for img in image])
+
+ return processed_images
+
+ def _get_has_nsfw_concepts(self, features, params):
+ has_nsfw_concepts = self.safety_checker(features, params)
+ return has_nsfw_concepts
+
+ def _run_safety_checker(self, images, safety_model_params, jit=False):
+ # safety_model_params should already be replicated when jit is True
+ pil_images = [Image.fromarray(image) for image in images]
+ features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
+
+ if jit:
+ features = shard(features)
+ has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
+ has_nsfw_concepts = unshard(has_nsfw_concepts)
+ safety_model_params = unreplicate(safety_model_params)
+ else:
+ has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
+
+ images_was_copied = False
+ for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
+ if has_nsfw_concept:
+ if not images_was_copied:
+ images_was_copied = True
+ images = images.copy()
+
+ images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
+
+ if any(has_nsfw_concepts):
+ warnings.warn(
+ "Potential NSFW content was detected in one or more images. A black image will be returned"
+ " instead. Try again with a different prompt and/or seed."
+ )
+
+ return images, has_nsfw_concepts
+
+ def _generate(
+ self,
+ prompt_ids: jnp.array,
+ image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int,
+ guidance_scale: float,
+ latents: Optional[jnp.array] = None,
+ neg_prompt_ids: Optional[jnp.array] = None,
+ controlnet_conditioning_scale: float = 1.0,
+ ):
+ height, width = image.shape[-2:]
+ if height % 64 != 0 or width % 64 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 64 but are {height} and {width}.")
+
+ # get prompt text embeddings
+ prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
+
+ # TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
+ # implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
+ batch_size = prompt_ids.shape[0]
+
+ max_length = prompt_ids.shape[-1]
+
+ if neg_prompt_ids is None:
+ uncond_input = self.tokenizer(
+ [""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
+ ).input_ids
+ else:
+ uncond_input = neg_prompt_ids
+ negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
+ context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ image = jnp.concatenate([image] * 2)
+
+ latents_shape = (
+ batch_size,
+ self.unet.in_channels,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if latents is None:
+ latents = jax.random.normal(prng_seed, shape=latents_shape, dtype=jnp.float32)
+ else:
+ if latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+
+ def loop_body(step, args):
+ latents, scheduler_state = args
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ latents_input = jnp.concatenate([latents] * 2)
+
+ t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
+ timestep = jnp.broadcast_to(t, latents_input.shape[0])
+
+ latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
+
+ down_block_res_samples, mid_block_res_sample = self.controlnet.apply(
+ {"params": params["controlnet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ controlnet_cond=image,
+ conditioning_scale=controlnet_conditioning_scale,
+ return_dict=False,
+ )
+
+ # predict the noise residual
+ noise_pred = self.unet.apply(
+ {"params": params["unet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ ).sample
+
+ # perform guidance
+ noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
+ return latents, scheduler_state
+
+ scheduler_state = self.scheduler.set_timesteps(
+ params["scheduler"], num_inference_steps=num_inference_steps, shape=latents_shape
+ )
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * params["scheduler"].init_noise_sigma
+
+ if DEBUG:
+ # run with python for loop
+ for i in range(num_inference_steps):
+ latents, scheduler_state = loop_body(i, (latents, scheduler_state))
+ else:
+ latents, _ = jax.lax.fori_loop(0, num_inference_steps, loop_body, (latents, scheduler_state))
+
+ # scale and decode the image latents with vae
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
+
+ image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
+ return image
+
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt_ids: jnp.array,
+ image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int = 50,
+ guidance_scale: Union[float, jnp.array] = 7.5,
+ latents: jnp.array = None,
+ neg_prompt_ids: jnp.array = None,
+ controlnet_conditioning_scale: Union[float, jnp.array] = 1.0,
+ return_dict: bool = True,
+ jit: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt_ids (`jnp.array`):
+ The prompt or prompts to guide the image generation.
+ image (`jnp.array`):
+ Array representing the ControlNet input condition. ControlNet use this input condition to generate
+ guidance to Unet.
+ params (`Dict` or `FrozenDict`): Dictionary containing the model parameters/weights
+ prng_seed (`jax.random.KeyArray` or `jax.Array`): Array containing random number generator key
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ latents (`jnp.array`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ controlnet_conditioning_scale (`float` or `jnp.array`, *optional*, defaults to 1.0):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
+ a plain tuple.
+ jit (`bool`, defaults to `False`):
+ Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
+ exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
+ `tuple. When returning a tuple, the first element is a list with the generated images, and the second
+ element is a list of `bool`s denoting whether the corresponding generated image likely represents
+ "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
+ """
+
+ height, width = image.shape[-2:]
+
+ if isinstance(guidance_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ guidance_scale = guidance_scale[:, None]
+
+ if isinstance(controlnet_conditioning_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ controlnet_conditioning_scale = jnp.array([controlnet_conditioning_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ controlnet_conditioning_scale = controlnet_conditioning_scale[:, None]
+
+ if jit:
+ images = _p_generate(
+ self,
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+ else:
+ images = self._generate(
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+
+ if self.safety_checker is not None:
+ safety_params = params["safety_checker"]
+ images_uint8_casted = (images * 255).round().astype("uint8")
+ num_devices, batch_size = images.shape[:2]
+
+ images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
+ images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
+ images = np.asarray(images)
+
+ # block images
+ if any(has_nsfw_concept):
+ for i, is_nsfw in enumerate(has_nsfw_concept):
+ if is_nsfw:
+ images[i] = np.asarray(images_uint8_casted[i])
+
+ images = images.reshape(num_devices, batch_size, height, width, 3)
+ else:
+ images = np.asarray(images)
+ has_nsfw_concept = False
+
+ if not return_dict:
+ return (images, has_nsfw_concept)
+
+ return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
+
+
+# Static argnums are pipe, num_inference_steps. A change would trigger recompilation.
+# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
+@partial(
+ jax.pmap,
+ in_axes=(None, 0, 0, 0, 0, None, 0, 0, 0, 0),
+ static_broadcasted_argnums=(0, 5),
+)
+def _p_generate(
+ pipe,
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+):
+ return pipe._generate(
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ controlnet_conditioning_scale,
+ )
+
+
+@partial(jax.pmap, static_broadcasted_argnums=(0,))
+def _p_get_has_nsfw_concepts(pipe, features, params):
+ return pipe._get_has_nsfw_concepts(features, params)
+
+
+def unshard(x: jnp.ndarray):
+ # einops.rearrange(x, 'd b ... -> (d b) ...')
+ num_devices, batch_size = x.shape[:2]
+ rest = x.shape[2:]
+ return x.reshape(num_devices * batch_size, *rest)
+
+
+def preprocess(image, dtype):
+ image = image.convert("RGB")
+ w, h = image.size
+ w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 64
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = jnp.array(image).astype(dtype) / 255.0
+ image = image[None].transpose(0, 3, 1, 2)
+ return image
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_img2img.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..2063238df27a0dd3c795ddc2e03a0ab7657662a0
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_img2img.py
@@ -0,0 +1,527 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import warnings
+from functools import partial
+from typing import Dict, List, Optional, Union
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.core.frozen_dict import FrozenDict
+from flax.jax_utils import unreplicate
+from flax.training.common_utils import shard
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel
+
+from ...models import FlaxAutoencoderKL, FlaxUNet2DConditionModel
+from ...schedulers import (
+ FlaxDDIMScheduler,
+ FlaxDPMSolverMultistepScheduler,
+ FlaxLMSDiscreteScheduler,
+ FlaxPNDMScheduler,
+)
+from ...utils import PIL_INTERPOLATION, logging, replace_example_docstring
+from ..pipeline_flax_utils import FlaxDiffusionPipeline
+from . import FlaxStableDiffusionPipelineOutput
+from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+# Set to True to use python for loop instead of jax.fori_loop for easier debugging
+DEBUG = False
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import jax
+ >>> import numpy as np
+ >>> import jax.numpy as jnp
+ >>> from flax.jax_utils import replicate
+ >>> from flax.training.common_utils import shard
+ >>> import requests
+ >>> from io import BytesIO
+ >>> from PIL import Image
+ >>> from diffusers import FlaxStableDiffusionImg2ImgPipeline
+
+
+ >>> def create_key(seed=0):
+ ... return jax.random.PRNGKey(seed)
+
+
+ >>> rng = create_key(0)
+
+ >>> url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+ >>> response = requests.get(url)
+ >>> init_img = Image.open(BytesIO(response.content)).convert("RGB")
+ >>> init_img = init_img.resize((768, 512))
+
+ >>> prompts = "A fantasy landscape, trending on artstation"
+
+ >>> pipeline, params = FlaxStableDiffusionImg2ImgPipeline.from_pretrained(
+ ... "CompVis/stable-diffusion-v1-4",
+ ... revision="flax",
+ ... dtype=jnp.bfloat16,
+ ... )
+
+ >>> num_samples = jax.device_count()
+ >>> rng = jax.random.split(rng, jax.device_count())
+ >>> prompt_ids, processed_image = pipeline.prepare_inputs(
+ ... prompt=[prompts] * num_samples, image=[init_img] * num_samples
+ ... )
+ >>> p_params = replicate(params)
+ >>> prompt_ids = shard(prompt_ids)
+ >>> processed_image = shard(processed_image)
+
+ >>> output = pipeline(
+ ... prompt_ids=prompt_ids,
+ ... image=processed_image,
+ ... params=p_params,
+ ... prng_seed=rng,
+ ... strength=0.75,
+ ... num_inference_steps=50,
+ ... jit=True,
+ ... height=512,
+ ... width=768,
+ ... ).images
+
+ >>> output_images = pipeline.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
+ ```
+"""
+
+
+class FlaxStableDiffusionImg2ImgPipeline(FlaxDiffusionPipeline):
+ r"""
+ Pipeline for image-to-image generation using Stable Diffusion.
+
+ This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`FlaxAutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`FlaxCLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.FlaxCLIPTextModel),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`FlaxUNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
+ [`FlaxDPMSolverMultistepScheduler`].
+ safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ def __init__(
+ self,
+ vae: FlaxAutoencoderKL,
+ text_encoder: FlaxCLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: FlaxUNet2DConditionModel,
+ scheduler: Union[
+ FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
+ ],
+ safety_checker: FlaxStableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ super().__init__()
+ self.dtype = dtype
+
+ if safety_checker is None:
+ logger.warn(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ def prepare_inputs(self, prompt: Union[str, List[str]], image: Union[Image.Image, List[Image.Image]]):
+ if not isinstance(prompt, (str, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if not isinstance(image, (Image.Image, list)):
+ raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
+
+ if isinstance(image, Image.Image):
+ image = [image]
+
+ processed_images = jnp.concatenate([preprocess(img, jnp.float32) for img in image])
+
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ return text_input.input_ids, processed_images
+
+ def _get_has_nsfw_concepts(self, features, params):
+ has_nsfw_concepts = self.safety_checker(features, params)
+ return has_nsfw_concepts
+
+ def _run_safety_checker(self, images, safety_model_params, jit=False):
+ # safety_model_params should already be replicated when jit is True
+ pil_images = [Image.fromarray(image) for image in images]
+ features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
+
+ if jit:
+ features = shard(features)
+ has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
+ has_nsfw_concepts = unshard(has_nsfw_concepts)
+ safety_model_params = unreplicate(safety_model_params)
+ else:
+ has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
+
+ images_was_copied = False
+ for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
+ if has_nsfw_concept:
+ if not images_was_copied:
+ images_was_copied = True
+ images = images.copy()
+
+ images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
+
+ if any(has_nsfw_concepts):
+ warnings.warn(
+ "Potential NSFW content was detected in one or more images. A black image will be returned"
+ " instead. Try again with a different prompt and/or seed."
+ )
+
+ return images, has_nsfw_concepts
+
+ def get_timestep_start(self, num_inference_steps, strength):
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+
+ return t_start
+
+ def _generate(
+ self,
+ prompt_ids: jnp.array,
+ image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ start_timestep: int,
+ num_inference_steps: int,
+ height: int,
+ width: int,
+ guidance_scale: float,
+ noise: Optional[jnp.array] = None,
+ neg_prompt_ids: Optional[jnp.array] = None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ # get prompt text embeddings
+ prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
+
+ # TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
+ # implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
+ batch_size = prompt_ids.shape[0]
+
+ max_length = prompt_ids.shape[-1]
+
+ if neg_prompt_ids is None:
+ uncond_input = self.tokenizer(
+ [""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
+ ).input_ids
+ else:
+ uncond_input = neg_prompt_ids
+ negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
+ context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ latents_shape = (
+ batch_size,
+ self.unet.in_channels,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if noise is None:
+ noise = jax.random.normal(prng_seed, shape=latents_shape, dtype=jnp.float32)
+ else:
+ if noise.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {noise.shape}, expected {latents_shape}")
+
+ # Create init_latents
+ init_latent_dist = self.vae.apply({"params": params["vae"]}, image, method=self.vae.encode).latent_dist
+ init_latents = init_latent_dist.sample(key=prng_seed).transpose((0, 3, 1, 2))
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ def loop_body(step, args):
+ latents, scheduler_state = args
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ latents_input = jnp.concatenate([latents] * 2)
+
+ t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
+ timestep = jnp.broadcast_to(t, latents_input.shape[0])
+
+ latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet.apply(
+ {"params": params["unet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ ).sample
+ # perform guidance
+ noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
+ return latents, scheduler_state
+
+ scheduler_state = self.scheduler.set_timesteps(
+ params["scheduler"], num_inference_steps=num_inference_steps, shape=latents_shape
+ )
+
+ latent_timestep = scheduler_state.timesteps[start_timestep : start_timestep + 1].repeat(batch_size)
+
+ latents = self.scheduler.add_noise(params["scheduler"], init_latents, noise, latent_timestep)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * params["scheduler"].init_noise_sigma
+
+ if DEBUG:
+ # run with python for loop
+ for i in range(start_timestep, num_inference_steps):
+ latents, scheduler_state = loop_body(i, (latents, scheduler_state))
+ else:
+ latents, _ = jax.lax.fori_loop(start_timestep, num_inference_steps, loop_body, (latents, scheduler_state))
+
+ # scale and decode the image latents with vae
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
+
+ image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
+ return image
+
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt_ids: jnp.array,
+ image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ strength: float = 0.8,
+ num_inference_steps: int = 50,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ guidance_scale: Union[float, jnp.array] = 7.5,
+ noise: jnp.array = None,
+ neg_prompt_ids: jnp.array = None,
+ return_dict: bool = True,
+ jit: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt_ids (`jnp.array`):
+ The prompt or prompts to guide the image generation.
+ image (`jnp.array`):
+ Array representing an image batch, that will be used as the starting point for the process.
+ params (`Dict` or `FrozenDict`): Dictionary containing the model parameters/weights
+ prng_seed (`jax.random.KeyArray` or `jax.Array`): Array containing random number generator key
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
+ will be used as a starting point, adding more noise to it the larger the `strength`. The number of
+ denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
+ be maximum and the denoising process will run for the full number of iterations specified in
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ noise (`jnp.array`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. tensor will ge generated
+ by sampling using the supplied random `generator`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
+ a plain tuple.
+ jit (`bool`, defaults to `False`):
+ Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
+ exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
+ `tuple. When returning a tuple, the first element is a list with the generated images, and the second
+ element is a list of `bool`s denoting whether the corresponding generated image likely represents
+ "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ if isinstance(guidance_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ guidance_scale = guidance_scale[:, None]
+
+ start_timestep = self.get_timestep_start(num_inference_steps, strength)
+
+ if jit:
+ images = _p_generate(
+ self,
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ start_timestep,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ noise,
+ neg_prompt_ids,
+ )
+ else:
+ images = self._generate(
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ start_timestep,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ noise,
+ neg_prompt_ids,
+ )
+
+ if self.safety_checker is not None:
+ safety_params = params["safety_checker"]
+ images_uint8_casted = (images * 255).round().astype("uint8")
+ num_devices, batch_size = images.shape[:2]
+
+ images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
+ images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
+ images = np.asarray(images)
+
+ # block images
+ if any(has_nsfw_concept):
+ for i, is_nsfw in enumerate(has_nsfw_concept):
+ if is_nsfw:
+ images[i] = np.asarray(images_uint8_casted[i])
+
+ images = images.reshape(num_devices, batch_size, height, width, 3)
+ else:
+ images = np.asarray(images)
+ has_nsfw_concept = False
+
+ if not return_dict:
+ return (images, has_nsfw_concept)
+
+ return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
+
+
+# Static argnums are pipe, start_timestep, num_inference_steps, height, width. A change would trigger recompilation.
+# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
+@partial(
+ jax.pmap,
+ in_axes=(None, 0, 0, 0, 0, None, None, None, None, 0, 0, 0),
+ static_broadcasted_argnums=(0, 5, 6, 7, 8),
+)
+def _p_generate(
+ pipe,
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ start_timestep,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ noise,
+ neg_prompt_ids,
+):
+ return pipe._generate(
+ prompt_ids,
+ image,
+ params,
+ prng_seed,
+ start_timestep,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ noise,
+ neg_prompt_ids,
+ )
+
+
+@partial(jax.pmap, static_broadcasted_argnums=(0,))
+def _p_get_has_nsfw_concepts(pipe, features, params):
+ return pipe._get_has_nsfw_concepts(features, params)
+
+
+def unshard(x: jnp.ndarray):
+ # einops.rearrange(x, 'd b ... -> (d b) ...')
+ num_devices, batch_size = x.shape[:2]
+ rest = x.shape[2:]
+ return x.reshape(num_devices * batch_size, *rest)
+
+
+def preprocess(image, dtype):
+ w, h = image.size
+ w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = jnp.array(image).astype(dtype) / 255.0
+ image = image[None].transpose(0, 3, 1, 2)
+ return 2.0 * image - 1.0
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_inpaint.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_inpaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..abb57f8b62e9aab62b7dc83329ab2a3c1f623532
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_flax_stable_diffusion_inpaint.py
@@ -0,0 +1,580 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import warnings
+from functools import partial
+from typing import Dict, List, Optional, Union
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.core.frozen_dict import FrozenDict
+from flax.jax_utils import unreplicate
+from flax.training.common_utils import shard
+from packaging import version
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPTokenizer, FlaxCLIPTextModel
+
+from ...models import FlaxAutoencoderKL, FlaxUNet2DConditionModel
+from ...schedulers import (
+ FlaxDDIMScheduler,
+ FlaxDPMSolverMultistepScheduler,
+ FlaxLMSDiscreteScheduler,
+ FlaxPNDMScheduler,
+)
+from ...utils import PIL_INTERPOLATION, deprecate, logging, replace_example_docstring
+from ..pipeline_flax_utils import FlaxDiffusionPipeline
+from . import FlaxStableDiffusionPipelineOutput
+from .safety_checker_flax import FlaxStableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+# Set to True to use python for loop instead of jax.fori_loop for easier debugging
+DEBUG = False
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import jax
+ >>> import numpy as np
+ >>> from flax.jax_utils import replicate
+ >>> from flax.training.common_utils import shard
+ >>> import PIL
+ >>> import requests
+ >>> from io import BytesIO
+ >>> from diffusers import FlaxStableDiffusionInpaintPipeline
+
+
+ >>> def download_image(url):
+ ... response = requests.get(url)
+ ... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+ >>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+ >>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+ >>> init_image = download_image(img_url).resize((512, 512))
+ >>> mask_image = download_image(mask_url).resize((512, 512))
+
+ >>> pipeline, params = FlaxStableDiffusionInpaintPipeline.from_pretrained(
+ ... "xvjiarui/stable-diffusion-2-inpainting"
+ ... )
+
+ >>> prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+ >>> prng_seed = jax.random.PRNGKey(0)
+ >>> num_inference_steps = 50
+
+ >>> num_samples = jax.device_count()
+ >>> prompt = num_samples * [prompt]
+ >>> init_image = num_samples * [init_image]
+ >>> mask_image = num_samples * [mask_image]
+ >>> prompt_ids, processed_masked_images, processed_masks = pipeline.prepare_inputs(
+ ... prompt, init_image, mask_image
+ ... )
+ # shard inputs and rng
+
+ >>> params = replicate(params)
+ >>> prng_seed = jax.random.split(prng_seed, jax.device_count())
+ >>> prompt_ids = shard(prompt_ids)
+ >>> processed_masked_images = shard(processed_masked_images)
+ >>> processed_masks = shard(processed_masks)
+
+ >>> images = pipeline(
+ ... prompt_ids, processed_masks, processed_masked_images, params, prng_seed, num_inference_steps, jit=True
+ ... ).images
+ >>> images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
+ ```
+"""
+
+
+class FlaxStableDiffusionInpaintPipeline(FlaxDiffusionPipeline):
+ r"""
+ Pipeline for text-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
+
+ This model inherits from [`FlaxDiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`FlaxAutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`FlaxCLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.FlaxCLIPTextModel),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`FlaxUNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`FlaxDDIMScheduler`], [`FlaxLMSDiscreteScheduler`], [`FlaxPNDMScheduler`], or
+ [`FlaxDPMSolverMultistepScheduler`].
+ safety_checker ([`FlaxStableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ def __init__(
+ self,
+ vae: FlaxAutoencoderKL,
+ text_encoder: FlaxCLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: FlaxUNet2DConditionModel,
+ scheduler: Union[
+ FlaxDDIMScheduler, FlaxPNDMScheduler, FlaxLMSDiscreteScheduler, FlaxDPMSolverMultistepScheduler
+ ],
+ safety_checker: FlaxStableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ super().__init__()
+ self.dtype = dtype
+
+ if safety_checker is None:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ def prepare_inputs(
+ self,
+ prompt: Union[str, List[str]],
+ image: Union[Image.Image, List[Image.Image]],
+ mask: Union[Image.Image, List[Image.Image]],
+ ):
+ if not isinstance(prompt, (str, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if not isinstance(image, (Image.Image, list)):
+ raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
+
+ if isinstance(image, Image.Image):
+ image = [image]
+
+ if not isinstance(mask, (Image.Image, list)):
+ raise ValueError(f"image has to be of type `PIL.Image.Image` or list but is {type(image)}")
+
+ if isinstance(mask, Image.Image):
+ mask = [mask]
+
+ processed_images = jnp.concatenate([preprocess_image(img, jnp.float32) for img in image])
+ processed_masks = jnp.concatenate([preprocess_mask(m, jnp.float32) for m in mask])
+ # processed_masks[processed_masks < 0.5] = 0
+ processed_masks = processed_masks.at[processed_masks < 0.5].set(0)
+ # processed_masks[processed_masks >= 0.5] = 1
+ processed_masks = processed_masks.at[processed_masks >= 0.5].set(1)
+
+ processed_masked_images = processed_images * (processed_masks < 0.5)
+
+ text_input = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ return text_input.input_ids, processed_masked_images, processed_masks
+
+ def _get_has_nsfw_concepts(self, features, params):
+ has_nsfw_concepts = self.safety_checker(features, params)
+ return has_nsfw_concepts
+
+ def _run_safety_checker(self, images, safety_model_params, jit=False):
+ # safety_model_params should already be replicated when jit is True
+ pil_images = [Image.fromarray(image) for image in images]
+ features = self.feature_extractor(pil_images, return_tensors="np").pixel_values
+
+ if jit:
+ features = shard(features)
+ has_nsfw_concepts = _p_get_has_nsfw_concepts(self, features, safety_model_params)
+ has_nsfw_concepts = unshard(has_nsfw_concepts)
+ safety_model_params = unreplicate(safety_model_params)
+ else:
+ has_nsfw_concepts = self._get_has_nsfw_concepts(features, safety_model_params)
+
+ images_was_copied = False
+ for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
+ if has_nsfw_concept:
+ if not images_was_copied:
+ images_was_copied = True
+ images = images.copy()
+
+ images[idx] = np.zeros(images[idx].shape, dtype=np.uint8) # black image
+
+ if any(has_nsfw_concepts):
+ warnings.warn(
+ "Potential NSFW content was detected in one or more images. A black image will be returned"
+ " instead. Try again with a different prompt and/or seed."
+ )
+
+ return images, has_nsfw_concepts
+
+ def _generate(
+ self,
+ prompt_ids: jnp.array,
+ mask: jnp.array,
+ masked_image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int,
+ height: int,
+ width: int,
+ guidance_scale: float,
+ latents: Optional[jnp.array] = None,
+ neg_prompt_ids: Optional[jnp.array] = None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ # get prompt text embeddings
+ prompt_embeds = self.text_encoder(prompt_ids, params=params["text_encoder"])[0]
+
+ # TODO: currently it is assumed `do_classifier_free_guidance = guidance_scale > 1.0`
+ # implement this conditional `do_classifier_free_guidance = guidance_scale > 1.0`
+ batch_size = prompt_ids.shape[0]
+
+ max_length = prompt_ids.shape[-1]
+
+ if neg_prompt_ids is None:
+ uncond_input = self.tokenizer(
+ [""] * batch_size, padding="max_length", max_length=max_length, return_tensors="np"
+ ).input_ids
+ else:
+ uncond_input = neg_prompt_ids
+ negative_prompt_embeds = self.text_encoder(uncond_input, params=params["text_encoder"])[0]
+ context = jnp.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ latents_shape = (
+ batch_size,
+ self.vae.config.latent_channels,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if latents is None:
+ latents = jax.random.normal(prng_seed, shape=latents_shape, dtype=self.dtype)
+ else:
+ if latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+
+ prng_seed, mask_prng_seed = jax.random.split(prng_seed)
+
+ masked_image_latent_dist = self.vae.apply(
+ {"params": params["vae"]}, masked_image, method=self.vae.encode
+ ).latent_dist
+ masked_image_latents = masked_image_latent_dist.sample(key=mask_prng_seed).transpose((0, 3, 1, 2))
+ masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
+ del mask_prng_seed
+
+ mask = jax.image.resize(mask, (*mask.shape[:-2], *masked_image_latents.shape[-2:]), method="nearest")
+
+ # 8. Check that sizes of mask, masked image and latents match
+ num_channels_latents = self.vae.config.latent_channels
+ num_channels_mask = mask.shape[1]
+ num_channels_masked_image = masked_image_latents.shape[1]
+ if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
+ raise ValueError(
+ f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
+ f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
+ f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
+ " `pipeline.unet` or your `mask_image` or `image` input."
+ )
+
+ def loop_body(step, args):
+ latents, mask, masked_image_latents, scheduler_state = args
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ latents_input = jnp.concatenate([latents] * 2)
+ mask_input = jnp.concatenate([mask] * 2)
+ masked_image_latents_input = jnp.concatenate([masked_image_latents] * 2)
+
+ t = jnp.array(scheduler_state.timesteps, dtype=jnp.int32)[step]
+ timestep = jnp.broadcast_to(t, latents_input.shape[0])
+
+ latents_input = self.scheduler.scale_model_input(scheduler_state, latents_input, t)
+ # concat latents, mask, masked_image_latents in the channel dimension
+ latents_input = jnp.concatenate([latents_input, mask_input, masked_image_latents_input], axis=1)
+
+ # predict the noise residual
+ noise_pred = self.unet.apply(
+ {"params": params["unet"]},
+ jnp.array(latents_input),
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=context,
+ ).sample
+ # perform guidance
+ noise_pred_uncond, noise_prediction_text = jnp.split(noise_pred, 2, axis=0)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents, scheduler_state = self.scheduler.step(scheduler_state, noise_pred, t, latents).to_tuple()
+ return latents, mask, masked_image_latents, scheduler_state
+
+ scheduler_state = self.scheduler.set_timesteps(
+ params["scheduler"], num_inference_steps=num_inference_steps, shape=latents.shape
+ )
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * params["scheduler"].init_noise_sigma
+
+ if DEBUG:
+ # run with python for loop
+ for i in range(num_inference_steps):
+ latents, mask, masked_image_latents, scheduler_state = loop_body(
+ i, (latents, mask, masked_image_latents, scheduler_state)
+ )
+ else:
+ latents, _, _, _ = jax.lax.fori_loop(
+ 0, num_inference_steps, loop_body, (latents, mask, masked_image_latents, scheduler_state)
+ )
+
+ # scale and decode the image latents with vae
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.apply({"params": params["vae"]}, latents, method=self.vae.decode).sample
+
+ image = (image / 2 + 0.5).clip(0, 1).transpose(0, 2, 3, 1)
+ return image
+
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt_ids: jnp.array,
+ mask: jnp.array,
+ masked_image: jnp.array,
+ params: Union[Dict, FrozenDict],
+ prng_seed: jax.random.KeyArray,
+ num_inference_steps: int = 50,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ guidance_scale: Union[float, jnp.array] = 7.5,
+ latents: jnp.array = None,
+ neg_prompt_ids: jnp.array = None,
+ return_dict: bool = True,
+ jit: bool = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ latents (`jnp.array`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. tensor will ge generated
+ by sampling using the supplied random `generator`.
+ jit (`bool`, defaults to `False`):
+ Whether to run `pmap` versions of the generation and safety scoring functions. NOTE: This argument
+ exists because `__call__` is not yet end-to-end pmap-able. It will be removed in a future release.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] instead of
+ a plain tuple.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a
+ `tuple. When returning a tuple, the first element is a list with the generated images, and the second
+ element is a list of `bool`s denoting whether the corresponding generated image likely represents
+ "not-safe-for-work" (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ masked_image = jax.image.resize(masked_image, (*masked_image.shape[:-2], height, width), method="bicubic")
+ mask = jax.image.resize(mask, (*mask.shape[:-2], height, width), method="nearest")
+
+ if isinstance(guidance_scale, float):
+ # Convert to a tensor so each device gets a copy. Follow the prompt_ids for
+ # shape information, as they may be sharded (when `jit` is `True`), or not.
+ guidance_scale = jnp.array([guidance_scale] * prompt_ids.shape[0])
+ if len(prompt_ids.shape) > 2:
+ # Assume sharded
+ guidance_scale = guidance_scale[:, None]
+
+ if jit:
+ images = _p_generate(
+ self,
+ prompt_ids,
+ mask,
+ masked_image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ )
+ else:
+ images = self._generate(
+ prompt_ids,
+ mask,
+ masked_image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ )
+
+ if self.safety_checker is not None:
+ safety_params = params["safety_checker"]
+ images_uint8_casted = (images * 255).round().astype("uint8")
+ num_devices, batch_size = images.shape[:2]
+
+ images_uint8_casted = np.asarray(images_uint8_casted).reshape(num_devices * batch_size, height, width, 3)
+ images_uint8_casted, has_nsfw_concept = self._run_safety_checker(images_uint8_casted, safety_params, jit)
+ images = np.asarray(images)
+
+ # block images
+ if any(has_nsfw_concept):
+ for i, is_nsfw in enumerate(has_nsfw_concept):
+ if is_nsfw:
+ images[i] = np.asarray(images_uint8_casted[i])
+
+ images = images.reshape(num_devices, batch_size, height, width, 3)
+ else:
+ images = np.asarray(images)
+ has_nsfw_concept = False
+
+ if not return_dict:
+ return (images, has_nsfw_concept)
+
+ return FlaxStableDiffusionPipelineOutput(images=images, nsfw_content_detected=has_nsfw_concept)
+
+
+# Static argnums are pipe, num_inference_steps, height, width. A change would trigger recompilation.
+# Non-static args are (sharded) input tensors mapped over their first dimension (hence, `0`).
+@partial(
+ jax.pmap,
+ in_axes=(None, 0, 0, 0, 0, 0, None, None, None, 0, 0, 0),
+ static_broadcasted_argnums=(0, 6, 7, 8),
+)
+def _p_generate(
+ pipe,
+ prompt_ids,
+ mask,
+ masked_image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+):
+ return pipe._generate(
+ prompt_ids,
+ mask,
+ masked_image,
+ params,
+ prng_seed,
+ num_inference_steps,
+ height,
+ width,
+ guidance_scale,
+ latents,
+ neg_prompt_ids,
+ )
+
+
+@partial(jax.pmap, static_broadcasted_argnums=(0,))
+def _p_get_has_nsfw_concepts(pipe, features, params):
+ return pipe._get_has_nsfw_concepts(features, params)
+
+
+def unshard(x: jnp.ndarray):
+ # einops.rearrange(x, 'd b ... -> (d b) ...')
+ num_devices, batch_size = x.shape[:2]
+ rest = x.shape[2:]
+ return x.reshape(num_devices * batch_size, *rest)
+
+
+def preprocess_image(image, dtype):
+ w, h = image.size
+ w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = jnp.array(image).astype(dtype) / 255.0
+ image = image[None].transpose(0, 3, 1, 2)
+ return 2.0 * image - 1.0
+
+
+def preprocess_mask(mask, dtype):
+ w, h = mask.size
+ w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
+ mask = mask.resize((w, h))
+ mask = jnp.array(mask.convert("L")).astype(dtype) / 255.0
+ mask = jnp.expand_dims(mask, axis=(0, 1))
+
+ return mask
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..99cbc591090ba147ddc6460c9db1de487b573da0
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion.py
@@ -0,0 +1,349 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import torch
+from transformers import CLIPImageProcessor, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
+from ...utils import deprecate, logging
+from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+
+
+logger = logging.get_logger(__name__)
+
+
+class OnnxStableDiffusionPipeline(DiffusionPipeline):
+ vae_encoder: OnnxRuntimeModel
+ vae_decoder: OnnxRuntimeModel
+ text_encoder: OnnxRuntimeModel
+ tokenizer: CLIPTokenizer
+ unet: OnnxRuntimeModel
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler]
+ safety_checker: OnnxRuntimeModel
+ feature_extractor: CLIPImageProcessor
+
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae_encoder: OnnxRuntimeModel,
+ vae_decoder: OnnxRuntimeModel,
+ text_encoder: OnnxRuntimeModel,
+ tokenizer: CLIPTokenizer,
+ unet: OnnxRuntimeModel,
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
+ safety_checker: OnnxRuntimeModel,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae_encoder=vae_encoder,
+ vae_decoder=vae_decoder,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ def _encode_prompt(self, prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ """
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
+
+ if not np.array_equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
+ prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt] * batch_size
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
+ negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ height: Optional[int] = 512,
+ width: Optional[int] = 512,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.0,
+ generator: Optional[np.random.RandomState] = None,
+ latents: Optional[np.ndarray] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
+ callback_steps: int = 1,
+ ):
+ if isinstance(prompt, str):
+ batch_size = 1
+ elif isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if generator is None:
+ generator = np.random
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ prompt_embeds = self._encode_prompt(
+ prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ # get the initial random noise unless the user supplied it
+ latents_dtype = prompt_embeds.dtype
+ latents_shape = (batch_size * num_images_per_prompt, 4, height // 8, width // 8)
+ if latents is None:
+ latents = generator.randn(*latents_shape).astype(latents_dtype)
+ elif latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+
+ # set timesteps
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ latents = latents * np.float64(self.scheduler.init_noise_sigma)
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ timestep_dtype = next(
+ (input.type for input in self.unet.model.get_inputs() if input.name == "timestep"), "tensor(float)"
+ )
+ timestep_dtype = ORT_TO_NP_TYPE[timestep_dtype]
+
+ for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(torch.from_numpy(latent_model_input), t)
+ latent_model_input = latent_model_input.cpu().numpy()
+
+ # predict the noise residual
+ timestep = np.array([t], dtype=timestep_dtype)
+ noise_pred = self.unet(sample=latent_model_input, timestep=timestep, encoder_hidden_states=prompt_embeds)
+ noise_pred = noise_pred[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = np.split(noise_pred, 2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ scheduler_output = self.scheduler.step(
+ torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs
+ )
+ latents = scheduler_output.prev_sample.numpy()
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ latents = 1 / 0.18215 * latents
+ # image = self.vae_decoder(latent_sample=latents)[0]
+ # it seems likes there is a strange result for using half-precision vae decoder if batchsize>1
+ image = np.concatenate(
+ [self.vae_decoder(latent_sample=latents[i : i + 1])[0] for i in range(latents.shape[0])]
+ )
+
+ image = np.clip(image / 2 + 0.5, 0, 1)
+ image = image.transpose((0, 2, 3, 1))
+
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(
+ self.numpy_to_pil(image), return_tensors="np"
+ ).pixel_values.astype(image.dtype)
+
+ images, has_nsfw_concept = [], []
+ for i in range(image.shape[0]):
+ image_i, has_nsfw_concept_i = self.safety_checker(
+ clip_input=safety_checker_input[i : i + 1], images=image[i : i + 1]
+ )
+ images.append(image_i)
+ has_nsfw_concept.append(has_nsfw_concept_i[0])
+ image = np.concatenate(images)
+ else:
+ has_nsfw_concept = None
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
+
+
+class StableDiffusionOnnxPipeline(OnnxStableDiffusionPipeline):
+ def __init__(
+ self,
+ vae_encoder: OnnxRuntimeModel,
+ vae_decoder: OnnxRuntimeModel,
+ text_encoder: OnnxRuntimeModel,
+ tokenizer: CLIPTokenizer,
+ unet: OnnxRuntimeModel,
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
+ safety_checker: OnnxRuntimeModel,
+ feature_extractor: CLIPImageProcessor,
+ ):
+ deprecation_message = "Please use `OnnxStableDiffusionPipeline` instead of `StableDiffusionOnnxPipeline`."
+ deprecate("StableDiffusionOnnxPipeline", "1.0.0", deprecation_message)
+ super().__init__(
+ vae_encoder=vae_encoder,
+ vae_decoder=vae_decoder,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..80c4a8692a05a05ab18029de9fc2ff0f82fcc171
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_img2img.py
@@ -0,0 +1,465 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from transformers import CLIPImageProcessor, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
+from ...utils import PIL_INTERPOLATION, deprecate, logging
+from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess with 8->64
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 64
+
+ image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+class OnnxStableDiffusionImg2ImgPipeline(DiffusionPipeline):
+ r"""
+ Pipeline for text-guided image to image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ vae_encoder: OnnxRuntimeModel
+ vae_decoder: OnnxRuntimeModel
+ text_encoder: OnnxRuntimeModel
+ tokenizer: CLIPTokenizer
+ unet: OnnxRuntimeModel
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler]
+ safety_checker: OnnxRuntimeModel
+ feature_extractor: CLIPImageProcessor
+
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae_encoder: OnnxRuntimeModel,
+ vae_decoder: OnnxRuntimeModel,
+ text_encoder: OnnxRuntimeModel,
+ tokenizer: CLIPTokenizer,
+ unet: OnnxRuntimeModel,
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
+ safety_checker: OnnxRuntimeModel,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae_encoder=vae_encoder,
+ vae_decoder=vae_decoder,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_onnx_stable_diffusion.OnnxStableDiffusionPipeline._encode_prompt
+ def _encode_prompt(self, prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ """
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
+
+ if not np.array_equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
+ prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt] * batch_size
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
+ negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ image: Union[np.ndarray, PIL.Image.Image] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.0,
+ generator: Optional[np.random.RandomState] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ image (`np.ndarray` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
+ will be used as a starting point, adding more noise to it the larger the `strength`. The number of
+ denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
+ be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference. This parameter will be modulated by `strength`.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`np.random.RandomState`, *optional*):
+ A np.random.RandomState to make generation deterministic.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ if isinstance(prompt, str):
+ batch_size = 1
+ elif isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if generator is None:
+ generator = np.random
+
+ # set timesteps
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ image = preprocess(image).cpu().numpy()
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ prompt_embeds = self._encode_prompt(
+ prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ latents_dtype = prompt_embeds.dtype
+ image = image.astype(latents_dtype)
+ # encode the init image into latents and scale the latents
+ init_latents = self.vae_encoder(sample=image)[0]
+ init_latents = 0.18215 * init_latents
+
+ if isinstance(prompt, str):
+ prompt = [prompt]
+ if len(prompt) > init_latents.shape[0] and len(prompt) % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ deprecation_message = (
+ f"You have passed {len(prompt)} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
+ " images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
+ " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
+ " your script to pass as many initial images as text prompts to suppress this warning."
+ )
+ deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
+ additional_image_per_prompt = len(prompt) // init_latents.shape[0]
+ init_latents = np.concatenate([init_latents] * additional_image_per_prompt * num_images_per_prompt, axis=0)
+ elif len(prompt) > init_latents.shape[0] and len(prompt) % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {len(prompt)} text prompts."
+ )
+ else:
+ init_latents = np.concatenate([init_latents] * num_images_per_prompt, axis=0)
+
+ # get the original timestep using init_timestep
+ offset = self.scheduler.config.get("steps_offset", 0)
+ init_timestep = int(num_inference_steps * strength) + offset
+ init_timestep = min(init_timestep, num_inference_steps)
+
+ timesteps = self.scheduler.timesteps.numpy()[-init_timestep]
+ timesteps = np.array([timesteps] * batch_size * num_images_per_prompt)
+
+ # add noise to latents using the timesteps
+ noise = generator.randn(*init_latents.shape).astype(latents_dtype)
+ init_latents = self.scheduler.add_noise(
+ torch.from_numpy(init_latents), torch.from_numpy(noise), torch.from_numpy(timesteps)
+ )
+ init_latents = init_latents.numpy()
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ latents = init_latents
+
+ t_start = max(num_inference_steps - init_timestep + offset, 0)
+ timesteps = self.scheduler.timesteps[t_start:].numpy()
+
+ timestep_dtype = next(
+ (input.type for input in self.unet.model.get_inputs() if input.name == "timestep"), "tensor(float)"
+ )
+ timestep_dtype = ORT_TO_NP_TYPE[timestep_dtype]
+
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(torch.from_numpy(latent_model_input), t)
+ latent_model_input = latent_model_input.cpu().numpy()
+
+ # predict the noise residual
+ timestep = np.array([t], dtype=timestep_dtype)
+ noise_pred = self.unet(sample=latent_model_input, timestep=timestep, encoder_hidden_states=prompt_embeds)[
+ 0
+ ]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = np.split(noise_pred, 2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ scheduler_output = self.scheduler.step(
+ torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs
+ )
+ latents = scheduler_output.prev_sample.numpy()
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ latents = 1 / 0.18215 * latents
+ # image = self.vae_decoder(latent_sample=latents)[0]
+ # it seems likes there is a strange result for using half-precision vae decoder if batchsize>1
+ image = np.concatenate(
+ [self.vae_decoder(latent_sample=latents[i : i + 1])[0] for i in range(latents.shape[0])]
+ )
+
+ image = np.clip(image / 2 + 0.5, 0, 1)
+ image = image.transpose((0, 2, 3, 1))
+
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(
+ self.numpy_to_pil(image), return_tensors="np"
+ ).pixel_values.astype(image.dtype)
+ # safety_checker does not support batched inputs yet
+ images, has_nsfw_concept = [], []
+ for i in range(image.shape[0]):
+ image_i, has_nsfw_concept_i = self.safety_checker(
+ clip_input=safety_checker_input[i : i + 1], images=image[i : i + 1]
+ )
+ images.append(image_i)
+ has_nsfw_concept.append(has_nsfw_concept_i[0])
+ image = np.concatenate(images)
+ else:
+ has_nsfw_concept = None
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..df586d39f648f04573aece93debdf7a93800a39f
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint.py
@@ -0,0 +1,477 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from transformers import CLIPImageProcessor, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
+from ...utils import PIL_INTERPOLATION, deprecate, logging
+from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+NUM_UNET_INPUT_CHANNELS = 9
+NUM_LATENT_CHANNELS = 4
+
+
+def prepare_mask_and_masked_image(image, mask, latents_shape):
+ image = np.array(image.convert("RGB").resize((latents_shape[1] * 8, latents_shape[0] * 8)))
+ image = image[None].transpose(0, 3, 1, 2)
+ image = image.astype(np.float32) / 127.5 - 1.0
+
+ image_mask = np.array(mask.convert("L").resize((latents_shape[1] * 8, latents_shape[0] * 8)))
+ masked_image = image * (image_mask < 127.5)
+
+ mask = mask.resize((latents_shape[1], latents_shape[0]), PIL_INTERPOLATION["nearest"])
+ mask = np.array(mask.convert("L"))
+ mask = mask.astype(np.float32) / 255.0
+ mask = mask[None, None]
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+
+ return mask, masked_image
+
+
+class OnnxStableDiffusionInpaintPipeline(DiffusionPipeline):
+ r"""
+ Pipeline for text-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ vae_encoder: OnnxRuntimeModel
+ vae_decoder: OnnxRuntimeModel
+ text_encoder: OnnxRuntimeModel
+ tokenizer: CLIPTokenizer
+ unet: OnnxRuntimeModel
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler]
+ safety_checker: OnnxRuntimeModel
+ feature_extractor: CLIPImageProcessor
+
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae_encoder: OnnxRuntimeModel,
+ vae_decoder: OnnxRuntimeModel,
+ text_encoder: OnnxRuntimeModel,
+ tokenizer: CLIPTokenizer,
+ unet: OnnxRuntimeModel,
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
+ safety_checker: OnnxRuntimeModel,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+ logger.info("`OnnxStableDiffusionInpaintPipeline` is experimental and will very likely change in the future.")
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae_encoder=vae_encoder,
+ vae_decoder=vae_decoder,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_onnx_stable_diffusion.OnnxStableDiffusionPipeline._encode_prompt
+ def _encode_prompt(self, prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ """
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
+
+ if not np.array_equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
+ prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt] * batch_size
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
+ negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ image: PIL.Image.Image,
+ mask_image: PIL.Image.Image,
+ height: Optional[int] = 512,
+ width: Optional[int] = 512,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[np.random.RandomState] = None,
+ latents: Optional[np.ndarray] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ image (`PIL.Image.Image`):
+ `Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
+ be masked out with `mask_image` and repainted according to `prompt`.
+ mask_image (`PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
+ to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
+ instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ height (`int`, *optional*, defaults to 512):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to 512):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`np.random.RandomState`, *optional*):
+ A np.random.RandomState to make generation deterministic.
+ latents (`np.ndarray`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+
+ if isinstance(prompt, str):
+ batch_size = 1
+ elif isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if generator is None:
+ generator = np.random
+
+ # set timesteps
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ prompt_embeds = self._encode_prompt(
+ prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ num_channels_latents = NUM_LATENT_CHANNELS
+ latents_shape = (batch_size * num_images_per_prompt, num_channels_latents, height // 8, width // 8)
+ latents_dtype = prompt_embeds.dtype
+ if latents is None:
+ latents = generator.randn(*latents_shape).astype(latents_dtype)
+ else:
+ if latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+
+ # prepare mask and masked_image
+ mask, masked_image = prepare_mask_and_masked_image(image, mask_image, latents_shape[-2:])
+ mask = mask.astype(latents.dtype)
+ masked_image = masked_image.astype(latents.dtype)
+
+ masked_image_latents = self.vae_encoder(sample=masked_image)[0]
+ masked_image_latents = 0.18215 * masked_image_latents
+
+ # duplicate mask and masked_image_latents for each generation per prompt
+ mask = mask.repeat(batch_size * num_images_per_prompt, 0)
+ masked_image_latents = masked_image_latents.repeat(batch_size * num_images_per_prompt, 0)
+
+ mask = np.concatenate([mask] * 2) if do_classifier_free_guidance else mask
+ masked_image_latents = (
+ np.concatenate([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
+ )
+
+ num_channels_mask = mask.shape[1]
+ num_channels_masked_image = masked_image_latents.shape[1]
+
+ unet_input_channels = NUM_UNET_INPUT_CHANNELS
+ if num_channels_latents + num_channels_mask + num_channels_masked_image != unet_input_channels:
+ raise ValueError(
+ "Incorrect configuration settings! The config of `pipeline.unet` expects"
+ f" {unet_input_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
+ f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
+ " `pipeline.unet` or your `mask_image` or `image` input."
+ )
+
+ # set timesteps
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * np.float64(self.scheduler.init_noise_sigma)
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ timestep_dtype = next(
+ (input.type for input in self.unet.model.get_inputs() if input.name == "timestep"), "tensor(float)"
+ )
+ timestep_dtype = ORT_TO_NP_TYPE[timestep_dtype]
+
+ for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
+ # concat latents, mask, masked_image_latnets in the channel dimension
+ latent_model_input = self.scheduler.scale_model_input(torch.from_numpy(latent_model_input), t)
+ latent_model_input = latent_model_input.cpu().numpy()
+ latent_model_input = np.concatenate([latent_model_input, mask, masked_image_latents], axis=1)
+
+ # predict the noise residual
+ timestep = np.array([t], dtype=timestep_dtype)
+ noise_pred = self.unet(sample=latent_model_input, timestep=timestep, encoder_hidden_states=prompt_embeds)[
+ 0
+ ]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = np.split(noise_pred, 2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ scheduler_output = self.scheduler.step(
+ torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs
+ )
+ latents = scheduler_output.prev_sample.numpy()
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ latents = 1 / 0.18215 * latents
+ # image = self.vae_decoder(latent_sample=latents)[0]
+ # it seems likes there is a strange result for using half-precision vae decoder if batchsize>1
+ image = np.concatenate(
+ [self.vae_decoder(latent_sample=latents[i : i + 1])[0] for i in range(latents.shape[0])]
+ )
+
+ image = np.clip(image / 2 + 0.5, 0, 1)
+ image = image.transpose((0, 2, 3, 1))
+
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(
+ self.numpy_to_pil(image), return_tensors="np"
+ ).pixel_values.astype(image.dtype)
+ # safety_checker does not support batched inputs yet
+ images, has_nsfw_concept = [], []
+ for i in range(image.shape[0]):
+ image_i, has_nsfw_concept_i = self.safety_checker(
+ clip_input=safety_checker_input[i : i + 1], images=image[i : i + 1]
+ )
+ images.append(image_i)
+ has_nsfw_concept.append(has_nsfw_concept_i[0])
+ image = np.concatenate(images)
+ else:
+ has_nsfw_concept = None
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint_legacy.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint_legacy.py
new file mode 100644
index 0000000000000000000000000000000000000000..5cb3abb4f54e9ae00107bc3354deb1b80d642c9b
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_inpaint_legacy.py
@@ -0,0 +1,460 @@
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from transformers import CLIPImageProcessor, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
+from ...utils import deprecate, logging
+from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def preprocess(image):
+ w, h = image.size
+ w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
+ image = image.resize((w, h), resample=PIL.Image.LANCZOS)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image[None].transpose(0, 3, 1, 2)
+ return 2.0 * image - 1.0
+
+
+def preprocess_mask(mask, scale_factor=8):
+ mask = mask.convert("L")
+ w, h = mask.size
+ w, h = (x - x % 32 for x in (w, h)) # resize to integer multiple of 32
+ mask = mask.resize((w // scale_factor, h // scale_factor), resample=PIL.Image.NEAREST)
+ mask = np.array(mask).astype(np.float32) / 255.0
+ mask = np.tile(mask, (4, 1, 1))
+ mask = mask[None].transpose(0, 1, 2, 3) # what does this step do?
+ mask = 1 - mask # repaint white, keep black
+ return mask
+
+
+class OnnxStableDiffusionInpaintPipelineLegacy(DiffusionPipeline):
+ r"""
+ Pipeline for text-guided image inpainting using Stable Diffusion. This is a *legacy feature* for Onnx pipelines to
+ provide compatibility with StableDiffusionInpaintPipelineLegacy and may be removed in the future.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ vae_encoder: OnnxRuntimeModel
+ vae_decoder: OnnxRuntimeModel
+ text_encoder: OnnxRuntimeModel
+ tokenizer: CLIPTokenizer
+ unet: OnnxRuntimeModel
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler]
+ safety_checker: OnnxRuntimeModel
+ feature_extractor: CLIPImageProcessor
+
+ def __init__(
+ self,
+ vae_encoder: OnnxRuntimeModel,
+ vae_decoder: OnnxRuntimeModel,
+ text_encoder: OnnxRuntimeModel,
+ tokenizer: CLIPTokenizer,
+ unet: OnnxRuntimeModel,
+ scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
+ safety_checker: OnnxRuntimeModel,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae_encoder=vae_encoder,
+ vae_decoder=vae_decoder,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_onnx_stable_diffusion.OnnxStableDiffusionPipeline._encode_prompt
+ def _encode_prompt(self, prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ """
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
+
+ if not np.array_equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
+ prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt] * batch_size
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="np",
+ )
+ negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
+ negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ image: Union[np.ndarray, PIL.Image.Image] = None,
+ mask_image: Union[np.ndarray, PIL.Image.Image] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.0,
+ generator: Optional[np.random.RandomState] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ image (`nd.ndarray` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process. This is the image whose masked region will be inpainted.
+ mask_image (`nd.ndarray` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
+ PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
+ contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.uu
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
+ will be used as a starting point, adding more noise to it the larger the `strength`. The number of
+ denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
+ be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference. This parameter will be modulated by `strength`.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (?) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`np.random.RandomState`, *optional*):
+ A np.random.RandomState to make generation deterministic.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ if isinstance(prompt, str):
+ batch_size = 1
+ elif isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if generator is None:
+ generator = np.random
+
+ # set timesteps
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ if isinstance(image, PIL.Image.Image):
+ image = preprocess(image)
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ prompt_embeds = self._encode_prompt(
+ prompt, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ latents_dtype = prompt_embeds.dtype
+ image = image.astype(latents_dtype)
+
+ # encode the init image into latents and scale the latents
+ init_latents = self.vae_encoder(sample=image)[0]
+ init_latents = 0.18215 * init_latents
+
+ # Expand init_latents for batch_size and num_images_per_prompt
+ init_latents = np.concatenate([init_latents] * num_images_per_prompt, axis=0)
+ init_latents_orig = init_latents
+
+ # preprocess mask
+ if not isinstance(mask_image, np.ndarray):
+ mask_image = preprocess_mask(mask_image, 8)
+ mask_image = mask_image.astype(latents_dtype)
+ mask = np.concatenate([mask_image] * num_images_per_prompt, axis=0)
+
+ # check sizes
+ if not mask.shape == init_latents.shape:
+ raise ValueError("The mask and image should be the same size!")
+
+ # get the original timestep using init_timestep
+ offset = self.scheduler.config.get("steps_offset", 0)
+ init_timestep = int(num_inference_steps * strength) + offset
+ init_timestep = min(init_timestep, num_inference_steps)
+
+ timesteps = self.scheduler.timesteps.numpy()[-init_timestep]
+ timesteps = np.array([timesteps] * batch_size * num_images_per_prompt)
+
+ # add noise to latents using the timesteps
+ noise = generator.randn(*init_latents.shape).astype(latents_dtype)
+ init_latents = self.scheduler.add_noise(
+ torch.from_numpy(init_latents), torch.from_numpy(noise), torch.from_numpy(timesteps)
+ )
+ init_latents = init_latents.numpy()
+
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (?) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to ? in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ latents = init_latents
+
+ t_start = max(num_inference_steps - init_timestep + offset, 0)
+ timesteps = self.scheduler.timesteps[t_start:].numpy()
+ timestep_dtype = next(
+ (input.type for input in self.unet.model.get_inputs() if input.name == "timestep"), "tensor(float)"
+ )
+ timestep_dtype = ORT_TO_NP_TYPE[timestep_dtype]
+
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ timestep = np.array([t], dtype=timestep_dtype)
+ noise_pred = self.unet(sample=latent_model_input, timestep=timestep, encoder_hidden_states=prompt_embeds)[
+ 0
+ ]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = np.split(noise_pred, 2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(
+ torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs
+ ).prev_sample
+
+ latents = latents.numpy()
+
+ init_latents_proper = self.scheduler.add_noise(
+ torch.from_numpy(init_latents_orig), torch.from_numpy(noise), torch.from_numpy(np.array([t]))
+ )
+
+ init_latents_proper = init_latents_proper.numpy()
+
+ latents = (init_latents_proper * mask) + (latents * (1 - mask))
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ latents = 1 / 0.18215 * latents
+ # image = self.vae_decoder(latent_sample=latents)[0]
+ # it seems likes there is a strange result for using half-precision vae decoder if batchsize>1
+ image = np.concatenate(
+ [self.vae_decoder(latent_sample=latents[i : i + 1])[0] for i in range(latents.shape[0])]
+ )
+
+ image = np.clip(image / 2 + 0.5, 0, 1)
+ image = image.transpose((0, 2, 3, 1))
+
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(
+ self.numpy_to_pil(image), return_tensors="np"
+ ).pixel_values.astype(image.dtype)
+ # There will throw an error if use safety_checker batchsize>1
+ images, has_nsfw_concept = [], []
+ for i in range(image.shape[0]):
+ image_i, has_nsfw_concept_i = self.safety_checker(
+ clip_input=safety_checker_input[i : i + 1], images=image[i : i + 1]
+ )
+ images.append(image_i)
+ has_nsfw_concept.append(has_nsfw_concept_i[0])
+ image = np.concatenate(images)
+ else:
+ has_nsfw_concept = None
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..b91262551b0f2fefad50d85782cea5e2dda884ac
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py
@@ -0,0 +1,290 @@
+from logging import getLogger
+from typing import Any, Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+
+from ...schedulers import DDPMScheduler
+from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
+from ..pipeline_utils import ImagePipelineOutput
+from . import StableDiffusionUpscalePipeline
+
+
+logger = getLogger(__name__)
+
+
+NUM_LATENT_CHANNELS = 4
+NUM_UNET_INPUT_CHANNELS = 7
+
+ORT_TO_PT_TYPE = {
+ "float16": torch.float16,
+ "float32": torch.float32,
+}
+
+
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 32
+
+ image = [np.array(i.resize((w, h)))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+
+ return image
+
+
+class OnnxStableDiffusionUpscalePipeline(StableDiffusionUpscalePipeline):
+ def __init__(
+ self,
+ vae: OnnxRuntimeModel,
+ text_encoder: OnnxRuntimeModel,
+ tokenizer: Any,
+ unet: OnnxRuntimeModel,
+ low_res_scheduler: DDPMScheduler,
+ scheduler: Any,
+ max_noise_level: int = 350,
+ ):
+ super().__init__(vae, text_encoder, tokenizer, unet, low_res_scheduler, scheduler, max_noise_level)
+
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ image: Union[torch.FloatTensor, PIL.Image.Image, List[PIL.Image.Image]],
+ num_inference_steps: int = 75,
+ guidance_scale: float = 9.0,
+ noise_level: int = 20,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: Optional[int] = 1,
+ ):
+ # 1. Check inputs
+ self.check_inputs(prompt, image, noise_level, callback_steps)
+
+ # 2. Define call parameters
+ batch_size = 1 if isinstance(prompt, str) else len(prompt)
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ text_embeddings = self._encode_prompt(
+ prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ latents_dtype = ORT_TO_PT_TYPE[str(text_embeddings.dtype)]
+
+ # 4. Preprocess image
+ image = preprocess(image)
+ image = image.cpu()
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Add noise to image
+ noise_level = torch.tensor([noise_level], dtype=torch.long, device=device)
+ noise = torch.randn(image.shape, generator=generator, device=device, dtype=latents_dtype)
+ image = self.low_res_scheduler.add_noise(image, noise, noise_level)
+
+ batch_multiplier = 2 if do_classifier_free_guidance else 1
+ image = np.concatenate([image] * batch_multiplier * num_images_per_prompt)
+ noise_level = np.concatenate([noise_level] * image.shape[0])
+
+ # 6. Prepare latent variables
+ height, width = image.shape[2:]
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ NUM_LATENT_CHANNELS,
+ height,
+ width,
+ latents_dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Check that sizes of image and latents match
+ num_channels_image = image.shape[1]
+ if NUM_LATENT_CHANNELS + num_channels_image != NUM_UNET_INPUT_CHANNELS:
+ raise ValueError(
+ "Incorrect configuration settings! The config of `pipeline.unet` expects"
+ f" {NUM_UNET_INPUT_CHANNELS} but received `num_channels_latents`: {NUM_LATENT_CHANNELS} +"
+ f" `num_channels_image`: {num_channels_image} "
+ f" = {NUM_LATENT_CHANNELS+num_channels_image}. Please verify the config of"
+ " `pipeline.unet` or your `image` input."
+ )
+
+ # 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ timestep_dtype = next(
+ (input.type for input in self.unet.model.get_inputs() if input.name == "timestep"), "tensor(float)"
+ )
+ timestep_dtype = ORT_TO_NP_TYPE[timestep_dtype]
+
+ # 9. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
+
+ # concat latents, mask, masked_image_latents in the channel dimension
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+ latent_model_input = np.concatenate([latent_model_input, image], axis=1)
+
+ # timestep to tensor
+ timestep = np.array([t], dtype=timestep_dtype)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ sample=latent_model_input,
+ timestep=timestep,
+ encoder_hidden_states=text_embeddings,
+ class_labels=noise_level.astype(np.int64),
+ )[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = np.split(noise_pred, 2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(
+ torch.from_numpy(noise_pred), t, latents, **extra_step_kwargs
+ ).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 10. Post-processing
+ image = self.decode_latents(latents.float())
+
+ # 11. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
+
+ def decode_latents(self, latents):
+ latents = 1 / 0.08333 * latents
+ image = self.vae(latent_sample=latents)[0]
+ image = np.clip(image / 2 + 0.5, 0, 1)
+ image = image.transpose((0, 2, 3, 1))
+ return image
+
+ def _encode_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ # if hasattr(text_inputs, "attention_mask"):
+ # attention_mask = text_inputs.attention_mask.to(device)
+ # else:
+ # attention_mask = None
+
+ # no positional arguments to text_encoder
+ text_embeddings = self.text_encoder(
+ input_ids=text_input_ids.int().to(device),
+ # attention_mask=attention_mask,
+ )
+ text_embeddings = text_embeddings[0]
+
+ bs_embed, seq_len, _ = text_embeddings.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ text_embeddings = text_embeddings.repeat(1, num_images_per_prompt)
+ text_embeddings = text_embeddings.reshape(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ # if hasattr(uncond_input, "attention_mask"):
+ # attention_mask = uncond_input.attention_mask.to(device)
+ # else:
+ # attention_mask = None
+
+ uncond_embeddings = self.text_encoder(
+ input_ids=uncond_input.input_ids.int().to(device),
+ # attention_mask=attention_mask,
+ )
+ uncond_embeddings = uncond_embeddings[0]
+
+ seq_len = uncond_embeddings.shape[1]
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt)
+ uncond_embeddings = uncond_embeddings.reshape(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
+
+ return text_embeddings
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..73b9178e3ab1f9da9c74e3bc97355dbb63ae02b3
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py
@@ -0,0 +1,723 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import StableDiffusionPipeline
+
+ >>> pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> image = pipe(prompt).images[0]
+ ```
+"""
+
+
+class StableDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+ elif output_type == "pil":
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 10. Convert to PIL
+ image = self.numpy_to_pil(image)
+ else:
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_attend_and_excite.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_attend_and_excite.py
new file mode 100644
index 0000000000000000000000000000000000000000..46adb69671407174afeeb858ebc911e75b619d7d
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_attend_and_excite.py
@@ -0,0 +1,1050 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+import math
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import torch
+from torch.nn import functional as F
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...models.attention_processor import Attention
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_available, is_accelerate_version, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__)
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import StableDiffusionAttendAndExcitePipeline
+
+ >>> pipe = StableDiffusionAttendAndExcitePipeline.from_pretrained(
+ ... "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
+ ... ).to("cuda")
+
+
+ >>> prompt = "a cat and a frog"
+
+ >>> # use get_indices function to find out indices of the tokens you want to alter
+ >>> pipe.get_indices(prompt)
+ {0: '<|startoftext|>', 1: 'a', 2: 'cat', 3: 'and', 4: 'a', 5: 'frog', 6: '<|endoftext|>'}
+
+ >>> token_indices = [2, 5]
+ >>> seed = 6141
+ >>> generator = torch.Generator("cuda").manual_seed(seed)
+
+ >>> images = pipe(
+ ... prompt=prompt,
+ ... token_indices=token_indices,
+ ... guidance_scale=7.5,
+ ... generator=generator,
+ ... num_inference_steps=50,
+ ... max_iter_to_alter=25,
+ ... ).images
+
+ >>> image = images[0]
+ >>> image.save(f"../images/{prompt}_{seed}.png")
+ ```
+"""
+
+
+class AttentionStore:
+ @staticmethod
+ def get_empty_store():
+ return {"down": [], "mid": [], "up": []}
+
+ def __call__(self, attn, is_cross: bool, place_in_unet: str):
+ if self.cur_att_layer >= 0 and is_cross:
+ if attn.shape[1] == self.attn_res**2:
+ self.step_store[place_in_unet].append(attn)
+
+ self.cur_att_layer += 1
+ if self.cur_att_layer == self.num_att_layers:
+ self.cur_att_layer = 0
+ self.between_steps()
+
+ def between_steps(self):
+ self.attention_store = self.step_store
+ self.step_store = self.get_empty_store()
+
+ def get_average_attention(self):
+ average_attention = self.attention_store
+ return average_attention
+
+ def aggregate_attention(self, from_where: List[str]) -> torch.Tensor:
+ """Aggregates the attention across the different layers and heads at the specified resolution."""
+ out = []
+ attention_maps = self.get_average_attention()
+ for location in from_where:
+ for item in attention_maps[location]:
+ cross_maps = item.reshape(-1, self.attn_res, self.attn_res, item.shape[-1])
+ out.append(cross_maps)
+ out = torch.cat(out, dim=0)
+ out = out.sum(0) / out.shape[0]
+ return out
+
+ def reset(self):
+ self.cur_att_layer = 0
+ self.step_store = self.get_empty_store()
+ self.attention_store = {}
+
+ def __init__(self, attn_res=16):
+ """
+ Initialize an empty AttentionStore :param step_index: used to visualize only a specific step in the diffusion
+ process
+ """
+ self.num_att_layers = -1
+ self.cur_att_layer = 0
+ self.step_store = self.get_empty_store()
+ self.attention_store = {}
+ self.curr_step_index = 0
+ self.attn_res = attn_res
+
+
+class AttendExciteAttnProcessor:
+ def __init__(self, attnstore, place_in_unet):
+ super().__init__()
+ self.attnstore = attnstore
+ self.place_in_unet = place_in_unet
+
+ def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
+ batch_size, sequence_length, _ = hidden_states.shape
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+
+ query = attn.to_q(hidden_states)
+
+ is_cross = encoder_hidden_states is not None
+ encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
+ key = attn.to_k(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states)
+
+ query = attn.head_to_batch_dim(query)
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+
+ attention_probs = attn.get_attention_scores(query, key, attention_mask)
+
+ # only need to store attention maps during the Attend and Excite process
+ if attention_probs.requires_grad:
+ self.attnstore(attention_probs, is_cross, self.place_in_unet)
+
+ hidden_states = torch.bmm(attention_probs, value)
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ return hidden_states
+
+
+class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion and Attend and Excite.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ indices,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ indices_is_list_ints = isinstance(indices, list) and isinstance(indices[0], int)
+ indices_is_list_list_ints = (
+ isinstance(indices, list) and isinstance(indices[0], list) and isinstance(indices[0][0], int)
+ )
+
+ if not indices_is_list_ints and not indices_is_list_list_ints:
+ raise TypeError("`indices` must be a list of ints or a list of a list of ints")
+
+ if indices_is_list_ints:
+ indices_batch_size = 1
+ elif indices_is_list_list_ints:
+ indices_batch_size = len(indices)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if indices_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"indices batch size must be same as prompt batch size. indices batch size: {indices_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @staticmethod
+ def _compute_max_attention_per_index(
+ attention_maps: torch.Tensor,
+ indices: List[int],
+ ) -> List[torch.Tensor]:
+ """Computes the maximum attention value for each of the tokens we wish to alter."""
+ attention_for_text = attention_maps[:, :, 1:-1]
+ attention_for_text *= 100
+ attention_for_text = torch.nn.functional.softmax(attention_for_text, dim=-1)
+
+ # Shift indices since we removed the first token
+ indices = [index - 1 for index in indices]
+
+ # Extract the maximum values
+ max_indices_list = []
+ for i in indices:
+ image = attention_for_text[:, :, i]
+ smoothing = GaussianSmoothing().to(attention_maps.device)
+ input = F.pad(image.unsqueeze(0).unsqueeze(0), (1, 1, 1, 1), mode="reflect")
+ image = smoothing(input).squeeze(0).squeeze(0)
+ max_indices_list.append(image.max())
+ return max_indices_list
+
+ def _aggregate_and_get_max_attention_per_token(
+ self,
+ indices: List[int],
+ ):
+ """Aggregates the attention for each token and computes the max activation value for each token to alter."""
+ attention_maps = self.attention_store.aggregate_attention(
+ from_where=("up", "down", "mid"),
+ )
+ max_attention_per_index = self._compute_max_attention_per_index(
+ attention_maps=attention_maps,
+ indices=indices,
+ )
+ return max_attention_per_index
+
+ @staticmethod
+ def _compute_loss(max_attention_per_index: List[torch.Tensor]) -> torch.Tensor:
+ """Computes the attend-and-excite loss using the maximum attention value for each token."""
+ losses = [max(0, 1.0 - curr_max) for curr_max in max_attention_per_index]
+ loss = max(losses)
+ return loss
+
+ @staticmethod
+ def _update_latent(latents: torch.Tensor, loss: torch.Tensor, step_size: float) -> torch.Tensor:
+ """Update the latent according to the computed loss."""
+ grad_cond = torch.autograd.grad(loss.requires_grad_(True), [latents], retain_graph=True)[0]
+ latents = latents - step_size * grad_cond
+ return latents
+
+ def _perform_iterative_refinement_step(
+ self,
+ latents: torch.Tensor,
+ indices: List[int],
+ loss: torch.Tensor,
+ threshold: float,
+ text_embeddings: torch.Tensor,
+ step_size: float,
+ t: int,
+ max_refinement_steps: int = 20,
+ ):
+ """
+ Performs the iterative latent refinement introduced in the paper. Here, we continuously update the latent code
+ according to our loss objective until the given threshold is reached for all tokens.
+ """
+ iteration = 0
+ target_loss = max(0, 1.0 - threshold)
+ while loss > target_loss:
+ iteration += 1
+
+ latents = latents.clone().detach().requires_grad_(True)
+ self.unet(latents, t, encoder_hidden_states=text_embeddings).sample
+ self.unet.zero_grad()
+
+ # Get max activation value for each subject token
+ max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
+ indices=indices,
+ )
+
+ loss = self._compute_loss(max_attention_per_index)
+
+ if loss != 0:
+ latents = self._update_latent(latents, loss, step_size)
+
+ logger.info(f"\t Try {iteration}. loss: {loss}")
+
+ if iteration >= max_refinement_steps:
+ logger.info(f"\t Exceeded max number of iterations ({max_refinement_steps})! ")
+ break
+
+ # Run one more time but don't compute gradients and update the latents.
+ # We just need to compute the new loss - the grad update will occur below
+ latents = latents.clone().detach().requires_grad_(True)
+ _ = self.unet(latents, t, encoder_hidden_states=text_embeddings).sample
+ self.unet.zero_grad()
+
+ # Get max activation value for each subject token
+ max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
+ indices=indices,
+ )
+ loss = self._compute_loss(max_attention_per_index)
+ logger.info(f"\t Finished with loss of: {loss}")
+ return loss, latents, max_attention_per_index
+
+ def register_attention_control(self):
+ attn_procs = {}
+ cross_att_count = 0
+ for name in self.unet.attn_processors.keys():
+ if name.startswith("mid_block"):
+ place_in_unet = "mid"
+ elif name.startswith("up_blocks"):
+ place_in_unet = "up"
+ elif name.startswith("down_blocks"):
+ place_in_unet = "down"
+ else:
+ continue
+
+ cross_att_count += 1
+ attn_procs[name] = AttendExciteAttnProcessor(attnstore=self.attention_store, place_in_unet=place_in_unet)
+
+ self.unet.set_attn_processor(attn_procs)
+ self.attention_store.num_att_layers = cross_att_count
+
+ def get_indices(self, prompt: str) -> Dict[str, int]:
+ """Utility function to list the indices of the tokens you wish to alte"""
+ ids = self.tokenizer(prompt).input_ids
+ indices = {i: tok for tok, i in zip(self.tokenizer.convert_ids_to_tokens(ids), range(len(ids)))}
+ return indices
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ token_indices: Union[List[int], List[List[int]]],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: int = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ max_iter_to_alter: int = 25,
+ thresholds: dict = {0: 0.05, 10: 0.5, 20: 0.8},
+ scale_factor: int = 20,
+ attn_res: int = 16,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ token_indices (`List[int]`):
+ The token indices to alter with attend-and-excite.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ max_iter_to_alter (`int`, *optional*, defaults to `25`):
+ Number of denoising steps to apply attend-and-excite. The first denoising steps are
+ where the attend-and-excite is applied. I.e. if `max_iter_to_alter` is 25 and there are a total of `30`
+ denoising steps, the first 25 denoising steps will apply attend-and-excite and the last 5 will not
+ apply attend-and-excite.
+ thresholds (`dict`, *optional*, defaults to `{0: 0.05, 10: 0.5, 20: 0.8}`):
+ Dictionary defining the iterations and desired thresholds to apply iterative latent refinement in.
+ scale_factor (`int`, *optional*, default to 20):
+ Scale factor that controls the step size of each Attend and Excite update.
+ attn_res (`int`, *optional*, default to 16):
+ The resolution of most semantic attention map.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`. :type attention_store: object
+ """
+
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ token_indices,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ self.attention_store = AttentionStore(attn_res=attn_res)
+ self.register_attention_control()
+
+ # default config for step size from original repo
+ scale_range = np.linspace(1.0, 0.5, len(self.scheduler.timesteps))
+ step_size = scale_factor * np.sqrt(scale_range)
+
+ text_embeddings = (
+ prompt_embeds[batch_size * num_images_per_prompt :] if do_classifier_free_guidance else prompt_embeds
+ )
+
+ if isinstance(token_indices[0], int):
+ token_indices = [token_indices]
+
+ indices = []
+
+ for ind in token_indices:
+ indices = indices + [ind] * num_images_per_prompt
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # Attend and excite process
+ with torch.enable_grad():
+ latents = latents.clone().detach().requires_grad_(True)
+ updated_latents = []
+ for latent, index, text_embedding in zip(latents, indices, text_embeddings):
+ # Forward pass of denoising with text conditioning
+ latent = latent.unsqueeze(0)
+ text_embedding = text_embedding.unsqueeze(0)
+
+ self.unet(
+ latent,
+ t,
+ encoder_hidden_states=text_embedding,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+ self.unet.zero_grad()
+
+ # Get max activation value for each subject token
+ max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
+ indices=index,
+ )
+
+ loss = self._compute_loss(max_attention_per_index=max_attention_per_index)
+
+ # If this is an iterative refinement step, verify we have reached the desired threshold for all
+ if i in thresholds.keys() and loss > 1.0 - thresholds[i]:
+ loss, latent, max_attention_per_index = self._perform_iterative_refinement_step(
+ latents=latent,
+ indices=index,
+ loss=loss,
+ threshold=thresholds[i],
+ text_embeddings=text_embedding,
+ step_size=step_size[i],
+ t=t,
+ )
+
+ # Perform gradient update
+ if i < max_iter_to_alter:
+ if loss != 0:
+ latent = self._update_latent(
+ latents=latent,
+ loss=loss,
+ step_size=step_size[i],
+ )
+ logger.info(f"Iteration {i} | Loss: {loss:0.4f}")
+
+ updated_latents.append(latent)
+
+ latents = torch.cat(updated_latents, dim=0)
+
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 10. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
+
+
+class GaussianSmoothing(torch.nn.Module):
+ """
+ Arguments:
+ Apply gaussian smoothing on a 1d, 2d or 3d tensor. Filtering is performed seperately for each channel in the input
+ using a depthwise convolution.
+ channels (int, sequence): Number of channels of the input tensors. Output will
+ have this number of channels as well.
+ kernel_size (int, sequence): Size of the gaussian kernel. sigma (float, sequence): Standard deviation of the
+ gaussian kernel. dim (int, optional): The number of dimensions of the data.
+ Default value is 2 (spatial).
+ """
+
+ # channels=1, kernel_size=kernel_size, sigma=sigma, dim=2
+ def __init__(
+ self,
+ channels: int = 1,
+ kernel_size: int = 3,
+ sigma: float = 0.5,
+ dim: int = 2,
+ ):
+ super().__init__()
+
+ if isinstance(kernel_size, int):
+ kernel_size = [kernel_size] * dim
+ if isinstance(sigma, float):
+ sigma = [sigma] * dim
+
+ # The gaussian kernel is the product of the
+ # gaussian function of each dimension.
+ kernel = 1
+ meshgrids = torch.meshgrid([torch.arange(size, dtype=torch.float32) for size in kernel_size])
+ for size, std, mgrid in zip(kernel_size, sigma, meshgrids):
+ mean = (size - 1) / 2
+ kernel *= 1 / (std * math.sqrt(2 * math.pi)) * torch.exp(-(((mgrid - mean) / (2 * std)) ** 2))
+
+ # Make sure sum of values in gaussian kernel equals 1.
+ kernel = kernel / torch.sum(kernel)
+
+ # Reshape to depthwise convolutional weight
+ kernel = kernel.view(1, 1, *kernel.size())
+ kernel = kernel.repeat(channels, *[1] * (kernel.dim() - 1))
+
+ self.register_buffer("weight", kernel)
+ self.groups = channels
+
+ if dim == 1:
+ self.conv = F.conv1d
+ elif dim == 2:
+ self.conv = F.conv2d
+ elif dim == 3:
+ self.conv = F.conv3d
+ else:
+ raise RuntimeError("Only 1, 2 and 3 dimensions are supported. Received {}.".format(dim))
+
+ def forward(self, input):
+ """
+ Arguments:
+ Apply gaussian filter to input.
+ input (torch.Tensor): Input to apply gaussian filter on.
+ Returns:
+ filtered (torch.Tensor): Filtered output.
+ """
+ return self.conv(input, weight=self.weight.to(input.dtype), groups=self.groups)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8272a4ef3d6cb68ac5e973cab6afb96a92e8923
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_controlnet.py
@@ -0,0 +1,1003 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import inspect
+import os
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL.Image
+import torch
+from torch import nn
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
+from ...models.controlnet import ControlNetOutput
+from ...models.modeling_utils import ModelMixin
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> # !pip install opencv-python transformers accelerate
+ >>> from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
+ >>> from diffusers.utils import load_image
+ >>> import numpy as np
+ >>> import torch
+
+ >>> import cv2
+ >>> from PIL import Image
+
+ >>> # download an image
+ >>> image = load_image(
+ ... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
+ ... )
+ >>> image = np.array(image)
+
+ >>> # get canny image
+ >>> image = cv2.Canny(image, 100, 200)
+ >>> image = image[:, :, None]
+ >>> image = np.concatenate([image, image, image], axis=2)
+ >>> canny_image = Image.fromarray(image)
+
+ >>> # load control net and stable diffusion v1-5
+ >>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
+ >>> pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
+ ... )
+
+ >>> # speed up diffusion process with faster scheduler and memory optimization
+ >>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+ >>> # remove following line if xformers is not installed
+ >>> pipe.enable_xformers_memory_efficient_attention()
+
+ >>> pipe.enable_model_cpu_offload()
+
+ >>> # generate image
+ >>> generator = torch.manual_seed(0)
+ >>> image = pipe(
+ ... "futuristic-looking woman", num_inference_steps=20, generator=generator, image=canny_image
+ ... ).images[0]
+ ```
+"""
+
+
+class MultiControlNetModel(ModelMixin):
+ r"""
+ Multiple `ControlNetModel` wrapper class for Multi-ControlNet
+
+ This module is a wrapper for multiple instances of the `ControlNetModel`. The `forward()` API is designed to be
+ compatible with `ControlNetModel`.
+
+ Args:
+ controlnets (`List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. You must set multiple
+ `ControlNetModel` as a list.
+ """
+
+ def __init__(self, controlnets: Union[List[ControlNetModel], Tuple[ControlNetModel]]):
+ super().__init__()
+ self.nets = nn.ModuleList(controlnets)
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ controlnet_cond: List[torch.tensor],
+ conditioning_scale: List[float],
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ return_dict: bool = True,
+ ) -> Union[ControlNetOutput, Tuple]:
+ for i, (image, scale, controlnet) in enumerate(zip(controlnet_cond, conditioning_scale, self.nets)):
+ down_samples, mid_sample = controlnet(
+ sample,
+ timestep,
+ encoder_hidden_states,
+ image,
+ scale,
+ class_labels,
+ timestep_cond,
+ attention_mask,
+ cross_attention_kwargs,
+ return_dict,
+ )
+
+ # merge samples
+ if i == 0:
+ down_block_res_samples, mid_block_res_sample = down_samples, mid_sample
+ else:
+ down_block_res_samples = [
+ samples_prev + samples_curr
+ for samples_prev, samples_curr in zip(down_block_res_samples, down_samples)
+ ]
+ mid_block_res_sample += mid_sample
+
+ return down_block_res_samples, mid_block_res_sample
+
+
+class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
+ Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
+ as a list, the outputs from each ControlNet are added together to create one combined additional
+ conditioning.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ if isinstance(controlnet, (list, tuple)):
+ controlnet = MultiControlNetModel(controlnet)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ controlnet=controlnet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.controlnet]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ # the safety checker can offload the vae again
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # control net hook has be manually offloaded as it alternates with unet
+ cpu_offload_with_hook(self.controlnet, device)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ controlnet_conditioning_scale=1.0,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # `prompt` needs more sophisticated handling when there are multiple
+ # conditionings.
+ if isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(prompt, list):
+ logger.warning(
+ f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
+ " prompts. The conditionings will be fixed across the prompts."
+ )
+
+ # Check `image`
+ if isinstance(self.controlnet, ControlNetModel):
+ self.check_image(image, prompt, prompt_embeds)
+ elif isinstance(self.controlnet, MultiControlNetModel):
+ if not isinstance(image, list):
+ raise TypeError("For multiple controlnets: `image` must be type `list`")
+
+ # When `image` is a nested list:
+ # (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
+ elif any(isinstance(i, list) for i in image):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif len(image) != len(self.controlnet.nets):
+ raise ValueError(
+ "For multiple controlnets: `image` must have the same length as the number of controlnets."
+ )
+
+ for image_ in image:
+ self.check_image(image_, prompt, prompt_embeds)
+ else:
+ assert False
+
+ # Check `controlnet_conditioning_scale`
+ if isinstance(self.controlnet, ControlNetModel):
+ if not isinstance(controlnet_conditioning_scale, float):
+ raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
+ elif isinstance(self.controlnet, MultiControlNetModel):
+ if isinstance(controlnet_conditioning_scale, list):
+ if any(isinstance(i, list) for i in controlnet_conditioning_scale):
+ raise ValueError("A single batch of multiple conditionings are supported at the moment.")
+ elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
+ self.controlnet.nets
+ ):
+ raise ValueError(
+ "For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
+ " the same length as the number of controlnets"
+ )
+ else:
+ assert False
+
+ def check_image(self, image, prompt, prompt_embeds):
+ image_is_pil = isinstance(image, PIL.Image.Image)
+ image_is_tensor = isinstance(image, torch.Tensor)
+ image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
+ image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
+
+ if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
+ raise TypeError(
+ "image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
+ )
+
+ if image_is_pil:
+ image_batch_size = 1
+ elif image_is_tensor:
+ image_batch_size = image.shape[0]
+ elif image_is_pil_list:
+ image_batch_size = len(image)
+ elif image_is_tensor_list:
+ image_batch_size = len(image)
+
+ if prompt is not None and isinstance(prompt, str):
+ prompt_batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ prompt_batch_size = len(prompt)
+ elif prompt_embeds is not None:
+ prompt_batch_size = prompt_embeds.shape[0]
+
+ if image_batch_size != 1 and image_batch_size != prompt_batch_size:
+ raise ValueError(
+ f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
+ )
+
+ def prepare_image(
+ self, image, width, height, batch_size, num_images_per_prompt, device, dtype, do_classifier_free_guidance
+ ):
+ if not isinstance(image, torch.Tensor):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ images = []
+
+ for image_ in image:
+ image_ = image_.convert("RGB")
+ image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
+ image_ = np.array(image_)
+ image_ = image_[None, :]
+ images.append(image_)
+
+ image = images
+
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+
+ image_batch_size = image.shape[0]
+
+ if image_batch_size == 1:
+ repeat_by = batch_size
+ else:
+ # image batch size is the same as prompt batch size
+ repeat_by = num_images_per_prompt
+
+ image = image.repeat_interleave(repeat_by, dim=0)
+
+ image = image.to(device=device, dtype=dtype)
+
+ if do_classifier_free_guidance:
+ image = torch.cat([image] * 2)
+
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def _default_height_width(self, height, width, image):
+ # NOTE: It is possible that a list of images have different
+ # dimensions for each image, so just checking the first image
+ # is not _exactly_ correct, but it is simple.
+ while isinstance(image, list):
+ image = image[0]
+
+ if height is None:
+ if isinstance(image, PIL.Image.Image):
+ height = image.height
+ elif isinstance(image, torch.Tensor):
+ height = image.shape[2]
+
+ height = (height // 8) * 8 # round down to nearest multiple of 8
+
+ if width is None:
+ if isinstance(image, PIL.Image.Image):
+ width = image.width
+ elif isinstance(image, torch.Tensor):
+ width = image.shape[3]
+
+ width = (width // 8) * 8 # round down to nearest multiple of 8
+
+ return height, width
+
+ # override DiffusionPipeline
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ safe_serialization: bool = False,
+ variant: Optional[str] = None,
+ ):
+ if isinstance(self.controlnet, ControlNetModel):
+ super().save_pretrained(save_directory, safe_serialization, variant)
+ else:
+ raise NotImplementedError("Currently, the `save_pretrained()` is not implemented for Multi-ControlNet.")
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
+ `List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
+ The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
+ the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
+ also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
+ height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
+ specified in init, images must be passed as a list such that each element of the list can be correctly
+ batched for input to a single controlnet.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
+ The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
+ to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
+ corresponding scale as a list.
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height, width = self._default_height_width(height, width, image)
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ controlnet_conditioning_scale,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ if isinstance(self.controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
+ controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(self.controlnet.nets)
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare image
+ if isinstance(self.controlnet, ControlNetModel):
+ image = self.prepare_image(
+ image=image,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=self.controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ )
+ elif isinstance(self.controlnet, MultiControlNetModel):
+ images = []
+
+ for image_ in image:
+ image_ = self.prepare_image(
+ image=image_,
+ width=width,
+ height=height,
+ batch_size=batch_size * num_images_per_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ device=device,
+ dtype=self.controlnet.dtype,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ )
+
+ images.append(image_)
+
+ image = images
+ else:
+ assert False
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # controlnet(s) inference
+ down_block_res_samples, mid_block_res_sample = self.controlnet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ controlnet_cond=image,
+ conditioning_scale=controlnet_conditioning_scale,
+ return_dict=False,
+ )
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ down_block_additional_residuals=down_block_res_samples,
+ mid_block_additional_residual=mid_block_res_sample,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # If we do sequential model offloading, let's offload unet and controlnet
+ # manually for max memory savings
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.unet.to("cpu")
+ self.controlnet.to("cpu")
+ torch.cuda.empty_cache()
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+ elif output_type == "pil":
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 10. Convert to PIL
+ image = self.numpy_to_pil(image)
+ else:
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..54f00ebc23f2dff6f379b0349bc8c3b59a222d43
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_depth2img.py
@@ -0,0 +1,699 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import contextlib
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from packaging import version
+from transformers import CLIPTextModel, CLIPTokenizer, DPTFeatureExtractor, DPTForDepthEstimation
+
+from ...configuration_utils import FrozenDict
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import PIL_INTERPOLATION, deprecate, is_accelerate_available, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+
+ image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+class StableDiffusionDepth2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-guided image to image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ depth_estimator: DPTForDepthEstimation,
+ feature_extractor: DPTFeatureExtractor,
+ ):
+ super().__init__()
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ depth_estimator=depth_estimator,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.depth_estimator]:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.check_inputs
+ def check_inputs(
+ self, prompt, strength, callback_steps, negative_prompt=None, prompt_embeds=None, negative_prompt_embeds=None
+ ):
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.prepare_latents
+ def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
+ if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ image = image.to(device=device, dtype=dtype)
+
+ batch_size = batch_size * num_images_per_prompt
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if isinstance(generator, list):
+ init_latents = [
+ self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = self.vae.encode(image).latent_dist.sample(generator)
+
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ deprecation_message = (
+ f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
+ " images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
+ " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
+ " your script to pass as many initial images as text prompts to suppress this warning."
+ )
+ deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
+ additional_image_per_prompt = batch_size // init_latents.shape[0]
+ init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents], dim=0)
+
+ shape = init_latents.shape
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+
+ # get latents
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+
+ return latents
+
+ def prepare_depth_map(self, image, depth_map, batch_size, do_classifier_free_guidance, dtype, device):
+ if isinstance(image, PIL.Image.Image):
+ image = [image]
+ else:
+ image = list(image)
+
+ if isinstance(image[0], PIL.Image.Image):
+ width, height = image[0].size
+ else:
+ height, width = image[0].shape[-2:]
+
+ if depth_map is None:
+ pixel_values = self.feature_extractor(images=image, return_tensors="pt").pixel_values
+ pixel_values = pixel_values.to(device=device)
+ # The DPT-Hybrid model uses batch-norm layers which are not compatible with fp16.
+ # So we use `torch.autocast` here for half precision inference.
+ context_manger = torch.autocast("cuda", dtype=dtype) if device.type == "cuda" else contextlib.nullcontext()
+ with context_manger:
+ depth_map = self.depth_estimator(pixel_values).predicted_depth
+ else:
+ depth_map = depth_map.to(device=device, dtype=dtype)
+
+ depth_map = torch.nn.functional.interpolate(
+ depth_map.unsqueeze(1),
+ size=(height // self.vae_scale_factor, width // self.vae_scale_factor),
+ mode="bicubic",
+ align_corners=False,
+ )
+
+ depth_min = torch.amin(depth_map, dim=[1, 2, 3], keepdim=True)
+ depth_max = torch.amax(depth_map, dim=[1, 2, 3], keepdim=True)
+ depth_map = 2.0 * (depth_map - depth_min) / (depth_max - depth_min) - 1.0
+ depth_map = depth_map.to(dtype)
+
+ # duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
+ if depth_map.shape[0] < batch_size:
+ repeat_by = batch_size // depth_map.shape[0]
+ depth_map = depth_map.repeat(repeat_by, 1, 1, 1)
+
+ depth_map = torch.cat([depth_map] * 2) if do_classifier_free_guidance else depth_map
+ return depth_map
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ depth_map: Optional[torch.FloatTensor] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
+ will be used as a starting point, adding more noise to it the larger the `strength`. The number of
+ denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
+ be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference. This parameter will be modulated by `strength`.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
+ is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> import torch
+ >>> import requests
+ >>> from PIL import Image
+
+ >>> from diffusers import StableDiffusionDepth2ImgPipeline
+
+ >>> pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
+ ... "stabilityai/stable-diffusion-2-depth",
+ ... torch_dtype=torch.float16,
+ ... )
+ >>> pipe.to("cuda")
+
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> init_image = Image.open(requests.get(url, stream=True).raw)
+ >>> prompt = "two tigers"
+ >>> n_propmt = "bad, deformed, ugly, bad anotomy"
+ >>> image = pipe(prompt=prompt, image=init_image, negative_prompt=n_propmt, strength=0.7).images[0]
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 1. Check inputs
+ self.check_inputs(
+ prompt,
+ strength,
+ callback_steps,
+ negative_prompt=negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ if image is None:
+ raise ValueError("`image` input cannot be undefined.")
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare depth mask
+ depth_mask = self.prepare_depth_map(
+ image,
+ depth_map,
+ batch_size * num_images_per_prompt,
+ do_classifier_free_guidance,
+ prompt_embeds.dtype,
+ device,
+ )
+
+ # 5. Preprocess image
+ image = preprocess(image)
+
+ # 6. Set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 7. Prepare latent variables
+ latents = self.prepare_latents(
+ image, latent_timestep, batch_size, num_images_per_prompt, prompt_embeds.dtype, device, generator
+ )
+
+ # 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 9. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+ latent_model_input = torch.cat([latent_model_input, depth_mask], dim=1)
+
+ # predict the noise residual
+ noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 10. Post-processing
+ image = self.decode_latents(latents)
+
+ # 11. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py
new file mode 100644
index 0000000000000000000000000000000000000000..835fba10dee4abefef52403cb6e412926e6ce8d0
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_image_variation.py
@@ -0,0 +1,414 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import PIL
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
+
+from ...configuration_utils import FrozenDict
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import deprecate, is_accelerate_available, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class StableDiffusionImageVariationPipeline(DiffusionPipeline):
+ r"""
+ Pipeline to generate variations from an input image using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ image_encoder ([`CLIPVisionModelWithProjection`]):
+ Frozen CLIP image-encoder. Stable Diffusion Image Variation uses the vision portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPVisionModelWithProjection),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ # TODO: feature_extractor is required to encode images (if they are in PIL format),
+ # we should give a descriptive message if the pipeline doesn't have one.
+ _optional_components = ["safety_checker"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ image_encoder: CLIPVisionModelWithProjection,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warn(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ image_encoder=image_encoder,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.image_encoder, self.vae, self.safety_checker]:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_image(self, image, device, num_images_per_prompt, do_classifier_free_guidance):
+ dtype = next(self.image_encoder.parameters()).dtype
+
+ if not isinstance(image, torch.Tensor):
+ image = self.feature_extractor(images=image, return_tensors="pt").pixel_values
+
+ image = image.to(device=device, dtype=dtype)
+ image_embeddings = self.image_encoder(image).image_embeds
+ image_embeddings = image_embeddings.unsqueeze(1)
+
+ # duplicate image embeddings for each generation per prompt, using mps friendly method
+ bs_embed, seq_len, _ = image_embeddings.shape
+ image_embeddings = image_embeddings.repeat(1, num_images_per_prompt, 1)
+ image_embeddings = image_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ if do_classifier_free_guidance:
+ negative_prompt_embeds = torch.zeros_like(image_embeddings)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ image_embeddings = torch.cat([negative_prompt_embeds, image_embeddings])
+
+ return image_embeddings
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(self, image, height, width, callback_steps):
+ if (
+ not isinstance(image, torch.Tensor)
+ and not isinstance(image, PIL.Image.Image)
+ and not isinstance(image, list)
+ ):
+ raise ValueError(
+ "`image` has to be of type `torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]` but is"
+ f" {type(image)}"
+ )
+
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ image: Union[PIL.Image.Image, List[PIL.Image.Image], torch.FloatTensor],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ image (`PIL.Image.Image` or `List[PIL.Image.Image]` or `torch.FloatTensor`):
+ The image or images to guide the image generation. If you provide a tensor, it needs to comply with the
+ configuration of
+ [this](https://huggingface.co/lambdalabs/sd-image-variations-diffusers/blob/main/feature_extractor/preprocessor_config.json)
+ `CLIPImageProcessor`
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(image, height, width, callback_steps)
+
+ # 2. Define call parameters
+ if isinstance(image, PIL.Image.Image):
+ batch_size = 1
+ elif isinstance(image, list):
+ batch_size = len(image)
+ else:
+ batch_size = image.shape[0]
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input image
+ image_embeddings = self._encode_image(image, device, num_images_per_prompt, do_classifier_free_guidance)
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ image_embeddings.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=image_embeddings).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, image_embeddings.dtype)
+
+ # 10. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0befdae73c4d1c152c0e5180d78d6e708aadc48
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py
@@ -0,0 +1,762 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...image_processor import VaeImageProcessor
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import requests
+ >>> import torch
+ >>> from PIL import Image
+ >>> from io import BytesIO
+
+ >>> from diffusers import StableDiffusionImg2ImgPipeline
+
+ >>> device = "cuda"
+ >>> model_id_or_path = "runwayml/stable-diffusion-v1-5"
+ >>> pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
+ >>> pipe = pipe.to(device)
+
+ >>> url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+
+ >>> response = requests.get(url)
+ >>> init_image = Image.open(BytesIO(response.content)).convert("RGB")
+ >>> init_image = init_image.resize((768, 512))
+
+ >>> prompt = "A fantasy landscape, trending on artstation"
+
+ >>> images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
+ >>> images[0].save("fantasy_landscape.png")
+ ```
+"""
+
+
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+
+ image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+class StableDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-guided image to image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
+ self.register_to_config(
+ requires_safety_checker=requires_safety_checker,
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_model_cpu_offload
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def run_safety_checker(self, image, device, dtype):
+ feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
+ safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ return image, has_nsfw_concept
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self, prompt, strength, callback_steps, negative_prompt=None, prompt_embeds=None, negative_prompt_embeds=None
+ ):
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+
+ def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
+ if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ image = image.to(device=device, dtype=dtype)
+
+ batch_size = batch_size * num_images_per_prompt
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if isinstance(generator, list):
+ init_latents = [
+ self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = self.vae.encode(image).latent_dist.sample(generator)
+
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
+ # expand init_latents for batch_size
+ deprecation_message = (
+ f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
+ " images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
+ " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
+ " your script to pass as many initial images as text prompts to suppress this warning."
+ )
+ deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
+ additional_image_per_prompt = batch_size // init_latents.shape[0]
+ init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents], dim=0)
+
+ shape = init_latents.shape
+ noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+
+ # get latents
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
+ will be used as a starting point, adding more noise to it the larger the `strength`. The number of
+ denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
+ be maximum and the denoising process will run for the full number of iterations specified in
+ `num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference. This parameter will be modulated by `strength`.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
+ is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(prompt, strength, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds)
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Preprocess image
+ image = self.image_processor.preprocess(image)
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 6. Prepare latent variables
+ latents = self.prepare_latents(
+ image, latent_timestep, batch_size, num_images_per_prompt, prompt_embeds.dtype, device, generator
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ if output_type not in ["latent", "pt", "np", "pil"]:
+ deprecation_message = (
+ f"the output_type {output_type} is outdated. Please make sure to set it to one of these instead: "
+ "`pil`, `np`, `pt`, `latent`"
+ )
+ deprecate("Unsupported output_type", "1.0.0", deprecation_message, standard_warn=False)
+ output_type = "np"
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+
+ else:
+ image = self.decode_latents(latents)
+
+ if self.safety_checker is not None:
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+ else:
+ has_nsfw_concept = False
+
+ image = self.image_processor.postprocess(image, output_type=output_type)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e0ea5a8d0795abe77c284c5798ab024d556fa94
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint.py
@@ -0,0 +1,907 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import deprecate, is_accelerate_available, is_accelerate_version, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def prepare_mask_and_masked_image(image, mask):
+ """
+ Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
+ converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
+ ``image`` and ``1`` for the ``mask``.
+
+ The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
+ binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
+
+ Args:
+ image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
+ It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
+ ``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
+ mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
+ It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
+ ``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
+
+
+ Raises:
+ ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
+ should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
+ TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
+ (ot the other way around).
+
+ Returns:
+ tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
+ dimensions: ``batch x channels x height x width``.
+ """
+ if isinstance(image, torch.Tensor):
+ if not isinstance(mask, torch.Tensor):
+ raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
+
+ # Batch single image
+ if image.ndim == 3:
+ assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
+ image = image.unsqueeze(0)
+
+ # Batch and add channel dim for single mask
+ if mask.ndim == 2:
+ mask = mask.unsqueeze(0).unsqueeze(0)
+
+ # Batch single mask or add channel dim
+ if mask.ndim == 3:
+ # Single batched mask, no channel dim or single mask not batched but channel dim
+ if mask.shape[0] == 1:
+ mask = mask.unsqueeze(0)
+
+ # Batched masks no channel dim
+ else:
+ mask = mask.unsqueeze(1)
+
+ assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
+ assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
+ assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
+
+ # Check image is in [-1, 1]
+ if image.min() < -1 or image.max() > 1:
+ raise ValueError("Image should be in [-1, 1] range")
+
+ # Check mask is in [0, 1]
+ if mask.min() < 0 or mask.max() > 1:
+ raise ValueError("Mask should be in [0, 1] range")
+
+ # Binarize mask
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+
+ # Image as float32
+ image = image.to(dtype=torch.float32)
+ elif isinstance(mask, torch.Tensor):
+ raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
+ else:
+ # preprocess image
+ if isinstance(image, (PIL.Image.Image, np.ndarray)):
+ image = [image]
+
+ if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
+ image = [np.array(i.convert("RGB"))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ elif isinstance(image, list) and isinstance(image[0], np.ndarray):
+ image = np.concatenate([i[None, :] for i in image], axis=0)
+
+ image = image.transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+
+ # preprocess mask
+ if isinstance(mask, (PIL.Image.Image, np.ndarray)):
+ mask = [mask]
+
+ if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
+ mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
+ mask = mask.astype(np.float32) / 255.0
+ elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
+ mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
+
+ mask[mask < 0.5] = 0
+ mask[mask >= 0.5] = 1
+ mask = torch.from_numpy(mask)
+
+ masked_image = image * (mask < 0.5)
+
+ return mask, masked_image
+
+
+class StableDiffusionInpaintPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "skip_prk_steps") and scheduler.config.skip_prk_steps is False:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration"
+ " `skip_prk_steps`. `skip_prk_steps` should be set to True in the configuration file. Please make"
+ " sure to update the config accordingly as not setting `skip_prk_steps` in the config might lead to"
+ " incorrect results in future versions. If you have downloaded this checkpoint from the Hugging Face"
+ " Hub, it would be very nice if you could open a Pull request for the"
+ " `scheduler/scheduler_config.json` file"
+ )
+ deprecate("skip_prk_steps not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["skip_prk_steps"] = True
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+ # Check shapes, assume num_channels_latents == 4, num_channels_mask == 1, num_channels_masked == 4
+ if unet.config.in_channels != 9:
+ logger.warning(
+ f"You have loaded a UNet with {unet.config.in_channels} input channels, whereas by default,"
+ f" {self.__class__} assumes that `pipeline.unet` has 9 input channels: 4 for `num_channels_latents`,"
+ " 1 for `num_channels_mask`, and 4 for `num_channels_masked_image`. If you did not intend to modify"
+ " this behavior, please check whether you have loaded the right checkpoint."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_model_cpu_offload
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def prepare_mask_latents(
+ self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
+ ):
+ # resize the mask to latents shape as we concatenate the mask to the latents
+ # we do that before converting to dtype to avoid breaking in case we're using cpu_offload
+ # and half precision
+ mask = torch.nn.functional.interpolate(
+ mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
+ )
+ mask = mask.to(device=device, dtype=dtype)
+
+ masked_image = masked_image.to(device=device, dtype=dtype)
+
+ # encode the mask image into latents space so we can concatenate it to the latents
+ if isinstance(generator, list):
+ masked_image_latents = [
+ self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
+ for i in range(batch_size)
+ ]
+ masked_image_latents = torch.cat(masked_image_latents, dim=0)
+ else:
+ masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
+ masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
+
+ # duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
+ if mask.shape[0] < batch_size:
+ if not batch_size % mask.shape[0] == 0:
+ raise ValueError(
+ "The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
+ f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
+ " of masks that you pass is divisible by the total requested batch size."
+ )
+ mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
+ if masked_image_latents.shape[0] < batch_size:
+ if not batch_size % masked_image_latents.shape[0] == 0:
+ raise ValueError(
+ "The passed images and the required batch size don't match. Images are supposed to be duplicated"
+ f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
+ " Make sure the number of images that you pass is divisible by the total requested batch size."
+ )
+ masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
+
+ mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
+ masked_image_latents = (
+ torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
+ )
+
+ # aligning device to prevent device errors when concating it with the latent model input
+ masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
+ return mask, masked_image_latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ mask_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`PIL.Image.Image`):
+ `Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
+ be masked out with `mask_image` and repainted according to `prompt`.
+ mask_image (`PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
+ to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
+ instead of 3, so the expected shape would be `(B, H, W, 1)`.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
+ is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> import PIL
+ >>> import requests
+ >>> import torch
+ >>> from io import BytesIO
+
+ >>> from diffusers import StableDiffusionInpaintPipeline
+
+
+ >>> def download_image(url):
+ ... response = requests.get(url)
+ ... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+ >>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
+ >>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
+
+ >>> init_image = download_image(img_url).resize((512, 512))
+ >>> mask_image = download_image(mask_url).resize((512, 512))
+
+ >>> pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+ >>> image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs
+ self.check_inputs(
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ )
+
+ if image is None:
+ raise ValueError("`image` input cannot be undefined.")
+
+ if mask_image is None:
+ raise ValueError("`mask_image` input cannot be undefined.")
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Preprocess mask and image
+ mask, masked_image = prepare_mask_and_masked_image(image, mask_image)
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.vae.config.latent_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Prepare mask latent variables
+ mask, masked_image_latents = self.prepare_mask_latents(
+ mask,
+ masked_image,
+ batch_size * num_images_per_prompt,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ do_classifier_free_guidance,
+ )
+
+ # 8. Check that sizes of mask, masked image and latents match
+ num_channels_mask = mask.shape[1]
+ num_channels_masked_image = masked_image_latents.shape[1]
+ if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
+ raise ValueError(
+ f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
+ f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
+ f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
+ " `pipeline.unet` or your `mask_image` or `image` input."
+ )
+
+ # 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 10. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+
+ # concat latents, mask, masked_image_latents in the channel dimension
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+ latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
+
+ # predict the noise residual
+ noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 11. Post-processing
+ image = self.decode_latents(latents)
+
+ # 12. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 13. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint_legacy.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint_legacy.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7a0c942bbe2af808b3f091068d56a61a037e30f
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_inpaint_legacy.py
@@ -0,0 +1,728 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ randn_tensor,
+)
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__)
+
+
+def preprocess_image(image):
+ w, h = image.size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+ image = image.resize((w, h), resample=PIL_INTERPOLATION["lanczos"])
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image[None].transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image)
+ return 2.0 * image - 1.0
+
+
+def preprocess_mask(mask, scale_factor=8):
+ if not isinstance(mask, torch.FloatTensor):
+ mask = mask.convert("L")
+ w, h = mask.size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+ mask = mask.resize((w // scale_factor, h // scale_factor), resample=PIL_INTERPOLATION["nearest"])
+ mask = np.array(mask).astype(np.float32) / 255.0
+ mask = np.tile(mask, (4, 1, 1))
+ mask = mask[None].transpose(0, 1, 2, 3) # what does this step do?
+ mask = 1 - mask # repaint white, keep black
+ mask = torch.from_numpy(mask)
+ return mask
+
+ else:
+ valid_mask_channel_sizes = [1, 3]
+ # if mask channel is fourth tensor dimension, permute dimensions to pytorch standard (B, C, H, W)
+ if mask.shape[3] in valid_mask_channel_sizes:
+ mask = mask.permute(0, 3, 1, 2)
+ elif mask.shape[1] not in valid_mask_channel_sizes:
+ raise ValueError(
+ f"Mask channel dimension of size in {valid_mask_channel_sizes} should be second or fourth dimension,"
+ f" but received mask of shape {tuple(mask.shape)}"
+ )
+ # (potentially) reduce mask channel dimension from 3 to 1 for broadcasting to latent shape
+ mask = mask.mean(dim=1, keepdim=True)
+ h, w = mask.shape[-2:]
+ h, w = (x - x % 8 for x in (h, w)) # resize to integer multiple of 8
+ mask = torch.nn.functional.interpolate(mask, (h // scale_factor, w // scale_factor))
+ return mask
+
+
+class StableDiffusionInpaintPipelineLegacy(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["feature_extractor"]
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.__init__
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely. If your checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_model_cpu_offload
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.check_inputs
+ def check_inputs(
+ self, prompt, strength, callback_steps, negative_prompt=None, prompt_embeds=None, negative_prompt_embeds=None
+ ):
+ if strength < 0 or strength > 1:
+ raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
+ def get_timesteps(self, num_inference_steps, strength, device):
+ # get the original timestep using init_timestep
+ init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
+
+ t_start = max(num_inference_steps - init_timestep, 0)
+ timesteps = self.scheduler.timesteps[t_start:]
+
+ return timesteps, num_inference_steps - t_start
+
+ def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator):
+ image = image.to(device=self.device, dtype=dtype)
+ init_latent_dist = self.vae.encode(image).latent_dist
+ init_latents = init_latent_dist.sample(generator=generator)
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ # Expand init_latents for batch_size and num_images_per_prompt
+ init_latents = torch.cat([init_latents] * batch_size * num_images_per_prompt, dim=0)
+ init_latents_orig = init_latents
+
+ # add noise to latents using the timesteps
+ noise = randn_tensor(init_latents.shape, generator=generator, device=self.device, dtype=dtype)
+ init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
+ latents = init_latents
+ return latents, init_latents_orig, noise
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ mask_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ strength: float = 0.8,
+ num_inference_steps: Optional[int] = 50,
+ guidance_scale: Optional[float] = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ add_predicted_noise: Optional[bool] = False,
+ eta: Optional[float] = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`torch.FloatTensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, that will be used as the starting point for the
+ process. This is the image whose masked region will be inpainted.
+ mask_image (`torch.FloatTensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
+ replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
+ PIL image, it will be converted to a single channel (luminance) before use. If mask is a tensor, the
+ expected shape should be either `(B, H, W, C)` or `(B, C, H, W)`, where C is 1 or 3.
+ strength (`float`, *optional*, defaults to 0.8):
+ Conceptually, indicates how much to inpaint the masked area. Must be between 0 and 1. When `strength`
+ is 1, the denoising process will be run on the masked area for the full number of iterations specified
+ in `num_inference_steps`. `image` will be used as a reference for the masked area, adding more noise to
+ that region the larger the `strength`. If `strength` is 0, no inpainting will occur.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The reference number of denoising steps. More denoising steps usually lead to a higher quality image at
+ the expense of slower inference. This parameter will be modulated by `strength`, as explained above.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
+ is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ add_predicted_noise (`bool`, *optional*, defaults to True):
+ Use predicted noise instead of random noise when constructing noisy versions of the original image in
+ the reverse diffusion process
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 1. Check inputs
+ self.check_inputs(prompt, strength, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds)
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Preprocess image and mask
+ if not isinstance(image, torch.FloatTensor):
+ image = preprocess_image(image)
+
+ mask_image = preprocess_mask(mask_image, self.vae_scale_factor)
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
+ latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
+
+ # 6. Prepare latent variables
+ # encode the init image into latents and scale the latents
+ latents, init_latents_orig, noise = self.prepare_latents(
+ image, latent_timestep, batch_size, num_images_per_prompt, prompt_embeds.dtype, device, generator
+ )
+
+ # 7. Prepare mask latent
+ mask = mask_image.to(device=self.device, dtype=latents.dtype)
+ mask = torch.cat([mask] * batch_size * num_images_per_prompt)
+
+ # 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 9. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+ # masking
+ if add_predicted_noise:
+ init_latents_proper = self.scheduler.add_noise(
+ init_latents_orig, noise_pred_uncond, torch.tensor([t])
+ )
+ else:
+ init_latents_proper = self.scheduler.add_noise(init_latents_orig, noise, torch.tensor([t]))
+
+ latents = (init_latents_proper * mask) + (latents * (1 - mask))
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # use original latents corresponding to unmasked portions of the image
+ latents = (init_latents_orig * mask) + (latents * (1 - mask))
+
+ # 10. Post-processing
+ image = self.decode_latents(latents)
+
+ # 11. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 12. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7999a08dc9b400cf9acf21ff1a91a4179da5306
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_instruct_pix2pix.py
@@ -0,0 +1,758 @@
+# Copyright 2023 The InstructPix2Pix Authors and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ PIL_INTERPOLATION,
+ deprecate,
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ randn_tensor,
+)
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+
+ image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+class StableDiffusionInstructPix2PixPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for pixel-level image editing by following text instructions. Based on Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ num_inference_steps: int = 100,
+ guidance_scale: float = 7.5,
+ image_guidance_scale: float = 1.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`PIL.Image.Image`):
+ `Image`, or tensor representing an image batch which will be repainted according to `prompt`.
+ num_inference_steps (`int`, *optional*, defaults to 100):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality. This pipeline requires a value of at least `1`.
+ image_guidance_scale (`float`, *optional*, defaults to 1.5):
+ Image guidance scale is to push the generated image towards the inital image `image`. Image guidance
+ scale is enabled by setting `image_guidance_scale > 1`. Higher image guidance scale encourages to
+ generate images that are closely linked to the source image `image`, usually at the expense of lower
+ image quality. This pipeline requires a value of at least `1`.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
+ is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> import PIL
+ >>> import requests
+ >>> import torch
+ >>> from io import BytesIO
+
+ >>> from diffusers import StableDiffusionInstructPix2PixPipeline
+
+
+ >>> def download_image(url):
+ ... response = requests.get(url)
+ ... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
+
+
+ >>> img_url = "https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png"
+
+ >>> image = download_image(img_url).resize((512, 512))
+
+ >>> pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ ... "timbrooks/instruct-pix2pix", torch_dtype=torch.float16
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "make the mountains snowy"
+ >>> image = pipe(prompt=prompt, image=image).images[0]
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Check inputs
+ self.check_inputs(prompt, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds)
+
+ if image is None:
+ raise ValueError("`image` input cannot be undefined.")
+
+ # 1. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0 and image_guidance_scale >= 1.0
+ # check if scheduler is in sigmas space
+ scheduler_is_in_sigma_space = hasattr(self.scheduler, "sigmas")
+
+ # 2. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 3. Preprocess image
+ image = preprocess(image)
+ height, width = image.shape[-2:]
+
+ # 4. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare Image latents
+ image_latents = self.prepare_image_latents(
+ image,
+ batch_size,
+ num_images_per_prompt,
+ prompt_embeds.dtype,
+ device,
+ do_classifier_free_guidance,
+ generator,
+ )
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.vae.config.latent_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Check that shapes of latents and image match the UNet channels
+ num_channels_image = image_latents.shape[1]
+ if num_channels_latents + num_channels_image != self.unet.config.in_channels:
+ raise ValueError(
+ f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
+ f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_image`: {num_channels_image} "
+ f" = {num_channels_latents+num_channels_image}. Please verify the config of"
+ " `pipeline.unet` or your `image` input."
+ )
+
+ # 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 9. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # Expand the latents if we are doing classifier free guidance.
+ # The latents are expanded 3 times because for pix2pix the guidance\
+ # is applied for both the text and the input image.
+ latent_model_input = torch.cat([latents] * 3) if do_classifier_free_guidance else latents
+
+ # concat latents, image_latents in the channel dimension
+ scaled_latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+ scaled_latent_model_input = torch.cat([scaled_latent_model_input, image_latents], dim=1)
+
+ # predict the noise residual
+ noise_pred = self.unet(scaled_latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
+
+ # Hack:
+ # For karras style schedulers the model does classifer free guidance using the
+ # predicted_original_sample instead of the noise_pred. So we need to compute the
+ # predicted_original_sample here if we are using a karras style scheduler.
+ if scheduler_is_in_sigma_space:
+ step_index = (self.scheduler.timesteps == t).nonzero().item()
+ sigma = self.scheduler.sigmas[step_index]
+ noise_pred = latent_model_input - sigma * noise_pred
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_text, noise_pred_image, noise_pred_uncond = noise_pred.chunk(3)
+ noise_pred = (
+ noise_pred_uncond
+ + guidance_scale * (noise_pred_text - noise_pred_image)
+ + image_guidance_scale * (noise_pred_image - noise_pred_uncond)
+ )
+
+ # Hack:
+ # For karras style schedulers the model does classifer free guidance using the
+ # predicted_original_sample instead of the noise_pred. But the scheduler.step function
+ # expects the noise_pred and computes the predicted_original_sample internally. So we
+ # need to overwrite the noise_pred here such that the value of the computed
+ # predicted_original_sample is correct.
+ if scheduler_is_in_sigma_space:
+ noise_pred = (noise_pred - latents) / (-sigma)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 10. Post-processing
+ image = self.decode_latents(latents)
+
+ # 11. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 12. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_model_cpu_offload
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ # pix2pix has two negative embeddings, and unlike in other pipelines latents are ordered [prompt_embeds, negative_prompt_embeds, negative_prompt_embeds]
+ prompt_embeds = torch.cat([prompt_embeds, negative_prompt_embeds, negative_prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def check_inputs(
+ self, prompt, callback_steps, negative_prompt=None, prompt_embeds=None, negative_prompt_embeds=None
+ ):
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def prepare_image_latents(
+ self, image, batch_size, num_images_per_prompt, dtype, device, do_classifier_free_guidance, generator=None
+ ):
+ if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ image = image.to(device=device, dtype=dtype)
+
+ batch_size = batch_size * num_images_per_prompt
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if isinstance(generator, list):
+ image_latents = [self.vae.encode(image[i : i + 1]).latent_dist.mode() for i in range(batch_size)]
+ image_latents = torch.cat(image_latents, dim=0)
+ else:
+ image_latents = self.vae.encode(image).latent_dist.mode()
+
+ if batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] == 0:
+ # expand image_latents for batch_size
+ deprecation_message = (
+ f"You have passed {batch_size} text prompts (`prompt`), but only {image_latents.shape[0]} initial"
+ " images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
+ " that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
+ " your script to pass as many initial images as text prompts to suppress this warning."
+ )
+ deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
+ additional_image_per_prompt = batch_size // image_latents.shape[0]
+ image_latents = torch.cat([image_latents] * additional_image_per_prompt, dim=0)
+ elif batch_size > image_latents.shape[0] and batch_size % image_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {image_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ image_latents = torch.cat([image_latents], dim=0)
+
+ if do_classifier_free_guidance:
+ uncond_image_latents = torch.zeros_like(image_latents)
+ image_latents = torch.cat([image_latents, image_latents, uncond_image_latents], dim=0)
+
+ return image_latents
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_k_diffusion.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_k_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..a02eb42750f7db37fa6b247d7d1d99f366867913
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_k_diffusion.py
@@ -0,0 +1,569 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import importlib
+from typing import Callable, List, Optional, Union
+
+import torch
+from k_diffusion.external import CompVisDenoiser, CompVisVDenoiser
+from k_diffusion.sampling import get_sigmas_karras
+
+from ...loaders import TextualInversionLoaderMixin
+from ...pipelines import DiffusionPipeline
+from ...schedulers import LMSDiscreteScheduler
+from ...utils import is_accelerate_available, is_accelerate_version, logging, randn_tensor
+from . import StableDiffusionPipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class ModelWrapper:
+ def __init__(self, model, alphas_cumprod):
+ self.model = model
+ self.alphas_cumprod = alphas_cumprod
+
+ def apply_model(self, *args, **kwargs):
+ if len(args) == 3:
+ encoder_hidden_states = args[-1]
+ args = args[:2]
+ if kwargs.get("cond", None) is not None:
+ encoder_hidden_states = kwargs.pop("cond")
+ return self.model(*args, encoder_hidden_states=encoder_hidden_states, **kwargs).sample
+
+
+class StableDiffusionKDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+
+
+ This is an experimental pipeline and is likely to change in the future.
+
+
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae,
+ text_encoder,
+ tokenizer,
+ unet,
+ scheduler,
+ safety_checker,
+ feature_extractor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ logger.info(
+ f"{self.__class__} is an experimntal pipeline and is likely to change in the future. We recommend to use"
+ " this pipeline for fast experimentation / iteration if needed, but advice to rely on existing pipelines"
+ " as defined in https://huggingface.co/docs/diffusers/api/schedulers#implemented-schedulers for"
+ " production settings."
+ )
+
+ # get correct sigmas from LMS
+ scheduler = LMSDiscreteScheduler.from_config(scheduler.config)
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ model = ModelWrapper(unet, scheduler.alphas_cumprod)
+ if scheduler.prediction_type == "v_prediction":
+ self.k_diffusion_model = CompVisVDenoiser(model)
+ else:
+ self.k_diffusion_model = CompVisDenoiser(model)
+
+ def set_scheduler(self, scheduler_type: str):
+ library = importlib.import_module("k_diffusion")
+ sampling = getattr(library, "sampling")
+ self.sampler = getattr(sampling, scheduler_type)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_model_cpu_offload
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def check_inputs(self, prompt, height, width, callback_steps):
+ if not isinstance(prompt, str) and not isinstance(prompt, list):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ if latents.shape != shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ return latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ use_karras_sigmas: Optional[bool] = False,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
+ is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ use_karras_sigmas (`bool`, *optional*, defaults to `False`):
+ Use karras sigmas. For example, specifying `sample_dpmpp_2m` to `set_scheduler` will be equivalent to
+ `DPM++2M` in stable-diffusion-webui. On top of that, setting this option to True will make it `DPM++2M
+ Karras`.
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(prompt, height, width, callback_steps)
+
+ # 2. Define call parameters
+ batch_size = 1 if isinstance(prompt, str) else len(prompt)
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = True
+ if guidance_scale <= 1.0:
+ raise ValueError("has to use guidance_scale")
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=prompt_embeds.device)
+
+ # 5. Prepare sigmas
+ if use_karras_sigmas:
+ sigma_min: float = self.k_diffusion_model.sigmas[0].item()
+ sigma_max: float = self.k_diffusion_model.sigmas[-1].item()
+ sigmas = get_sigmas_karras(n=num_inference_steps, sigma_min=sigma_min, sigma_max=sigma_max)
+ sigmas = sigmas.to(device)
+ else:
+ sigmas = self.scheduler.sigmas
+ sigmas = sigmas.to(prompt_embeds.dtype)
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+ latents = latents * sigmas[0]
+ self.k_diffusion_model.sigmas = self.k_diffusion_model.sigmas.to(latents.device)
+ self.k_diffusion_model.log_sigmas = self.k_diffusion_model.log_sigmas.to(latents.device)
+
+ # 7. Define model function
+ def model_fn(x, t):
+ latent_model_input = torch.cat([x] * 2)
+ t = torch.cat([t] * 2)
+
+ noise_pred = self.k_diffusion_model(latent_model_input, t, cond=prompt_embeds)
+
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+ return noise_pred
+
+ # 8. Run k-diffusion solver
+ latents = self.sampler(model_fn, latents, sigmas)
+
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # 10. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 11. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_latent_upscale.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_latent_upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..822bd49ce31ca8d6bb53bc41b4f4fa6411e6b319
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_latent_upscale.py
@@ -0,0 +1,518 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+import torch.nn.functional as F
+from transformers import CLIPTextModel, CLIPTokenizer
+
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import EulerDiscreteScheduler
+from ...utils import is_accelerate_available, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.preprocess
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 64
+
+ image = [np.array(i.resize((w, h)))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+class StableDiffusionLatentUpscalePipeline(DiffusionPipeline):
+ r"""
+ Pipeline to upscale the resolution of Stable Diffusion output images by a factor of 2.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/main/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`EulerDiscreteScheduler`].
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: EulerDiscreteScheduler,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ )
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(self, prompt, device, do_classifier_free_guidance, negative_prompt):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `list(int)`):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ """
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_length=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ text_encoder_out = self.text_encoder(
+ text_input_ids.to(device),
+ output_hidden_states=True,
+ )
+ text_embeddings = text_encoder_out.hidden_states[-1]
+ text_pooler_out = text_encoder_out.pooler_output
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_length=True,
+ return_tensors="pt",
+ )
+
+ uncond_encoder_out = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ output_hidden_states=True,
+ )
+
+ uncond_embeddings = uncond_encoder_out.hidden_states[-1]
+ uncond_pooler_out = uncond_encoder_out.pooler_output
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
+ text_pooler_out = torch.cat([uncond_pooler_out, text_pooler_out])
+
+ return text_embeddings, text_pooler_out
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def check_inputs(self, prompt, image, callback_steps):
+ if not isinstance(prompt, str) and not isinstance(prompt, list):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if (
+ not isinstance(image, torch.Tensor)
+ and not isinstance(image, PIL.Image.Image)
+ and not isinstance(image, list)
+ ):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or `list` but is {type(image)}"
+ )
+
+ # verify batch size of prompt and image are same if image is a list or tensor
+ if isinstance(image, list) or isinstance(image, torch.Tensor):
+ if isinstance(prompt, str):
+ batch_size = 1
+ else:
+ batch_size = len(prompt)
+ if isinstance(image, list):
+ image_batch_size = len(image)
+ else:
+ image_batch_size = image.shape[0] if image.ndim == 4 else 1
+ if batch_size != image_batch_size:
+ raise ValueError(
+ f"`prompt` has batch size {batch_size} and `image` has batch size {image_batch_size}."
+ " Please make sure that passed `prompt` matches the batch size of `image`."
+ )
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height, width)
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ if latents.shape != shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ image: Union[torch.FloatTensor, PIL.Image.Image, List[PIL.Image.Image]],
+ num_inference_steps: int = 75,
+ guidance_scale: float = 9.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image upscaling.
+ image (`PIL.Image.Image` or List[`PIL.Image.Image`] or `torch.FloatTensor`):
+ `Image`, or tensor representing an image batch which will be upscaled. If it's a tensor, it can be
+ either a latent output from a stable diffusion model, or an image tensor in the range `[-1, 1]`. It
+ will be considered a `latent` if `image.shape[1]` is `4`; otherwise, it will be considered to be an
+ image representation and encoded using this pipeline's `vae` encoder.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+ ```py
+ >>> from diffusers import StableDiffusionLatentUpscalePipeline, StableDiffusionPipeline
+ >>> import torch
+
+
+ >>> pipeline = StableDiffusionPipeline.from_pretrained(
+ ... "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
+ ... )
+ >>> pipeline.to("cuda")
+
+ >>> model_id = "stabilityai/sd-x2-latent-upscaler"
+ >>> upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
+ >>> upscaler.to("cuda")
+
+ >>> prompt = "a photo of an astronaut high resolution, unreal engine, ultra realistic"
+ >>> generator = torch.manual_seed(33)
+
+ >>> low_res_latents = pipeline(prompt, generator=generator, output_type="latent").images
+
+ >>> with torch.no_grad():
+ ... image = pipeline.decode_latents(low_res_latents)
+ >>> image = pipeline.numpy_to_pil(image)[0]
+
+ >>> image.save("../images/a1.png")
+
+ >>> upscaled_image = upscaler(
+ ... prompt=prompt,
+ ... image=low_res_latents,
+ ... num_inference_steps=20,
+ ... guidance_scale=0,
+ ... generator=generator,
+ ... ).images[0]
+
+ >>> upscaled_image.save("../images/a2.png")
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+
+ # 1. Check inputs
+ self.check_inputs(prompt, image, callback_steps)
+
+ # 2. Define call parameters
+ batch_size = 1 if isinstance(prompt, str) else len(prompt)
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ if guidance_scale == 0:
+ prompt = [""] * batch_size
+
+ # 3. Encode input prompt
+ text_embeddings, text_pooler_out = self._encode_prompt(
+ prompt, device, do_classifier_free_guidance, negative_prompt
+ )
+
+ # 4. Preprocess image
+ image = preprocess(image)
+ image = image.to(dtype=text_embeddings.dtype, device=device)
+ if image.shape[1] == 3:
+ # encode image if not in latent-space yet
+ image = self.vae.encode(image).latent_dist.sample() * self.vae.config.scaling_factor
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ batch_multiplier = 2 if do_classifier_free_guidance else 1
+ image = image[None, :] if image.ndim == 3 else image
+ image = torch.cat([image] * batch_multiplier)
+
+ # 5. Add noise to image (set to be 0):
+ # (see below notes from the author):
+ # "the This step theoretically can make the model work better on out-of-distribution inputs, but mostly just seems to make it match the input less, so it's turned off by default."
+ noise_level = torch.tensor([0.0], dtype=torch.float32, device=device)
+ noise_level = torch.cat([noise_level] * image.shape[0])
+ inv_noise_level = (noise_level**2 + 1) ** (-0.5)
+
+ image_cond = F.interpolate(image, scale_factor=2, mode="nearest") * inv_noise_level[:, None, None, None]
+ image_cond = image_cond.to(text_embeddings.dtype)
+
+ noise_level_embed = torch.cat(
+ [
+ torch.ones(text_pooler_out.shape[0], 64, dtype=text_pooler_out.dtype, device=device),
+ torch.zeros(text_pooler_out.shape[0], 64, dtype=text_pooler_out.dtype, device=device),
+ ],
+ dim=1,
+ )
+
+ timestep_condition = torch.cat([noise_level_embed, text_pooler_out], dim=1)
+
+ # 6. Prepare latent variables
+ height, width = image.shape[2:]
+ num_channels_latents = self.vae.config.latent_channels
+ latents = self.prepare_latents(
+ batch_size,
+ num_channels_latents,
+ height * 2, # 2x upscale
+ width * 2,
+ text_embeddings.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Check that sizes of image and latents match
+ num_channels_image = image.shape[1]
+ if num_channels_latents + num_channels_image != self.unet.config.in_channels:
+ raise ValueError(
+ f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
+ f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_image`: {num_channels_image} "
+ f" = {num_channels_latents+num_channels_image}. Please verify the config of"
+ " `pipeline.unet` or your `image` input."
+ )
+
+ # 9. Denoising loop
+ num_warmup_steps = 0
+
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ sigma = self.scheduler.sigmas[i]
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ scaled_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ scaled_model_input = torch.cat([scaled_model_input, image_cond], dim=1)
+ # preconditioning parameter based on Karras et al. (2022) (table 1)
+ timestep = torch.log(sigma) * 0.25
+
+ noise_pred = self.unet(
+ scaled_model_input,
+ timestep,
+ encoder_hidden_states=text_embeddings,
+ timestep_cond=timestep_condition,
+ ).sample
+
+ # in original repo, the output contains a variance channel that's not used
+ noise_pred = noise_pred[:, :-1]
+
+ # apply preconditioning, based on table 1 in Karras et al. (2022)
+ inv_sigma = 1 / (sigma**2 + 1)
+ noise_pred = inv_sigma * latent_model_input + self.scheduler.scale_model_input(sigma, t) * noise_pred
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 10. Post-processing
+ image = self.decode_latents(latents)
+
+ # 11. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py
new file mode 100644
index 0000000000000000000000000000000000000000..d841bd8a2d268232d02547c64c4b262dbf9d9d89
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_model_editing.py
@@ -0,0 +1,796 @@
+# Copyright 2023 TIME Authors and The HuggingFace Team. All rights reserved."
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import torch
+from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import PNDMScheduler
+from ...schedulers.scheduling_utils import SchedulerMixin
+from ...utils import is_accelerate_available, is_accelerate_version, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+AUGS_CONST = ["A photo of ", "An image of ", "A picture of "]
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import StableDiffusionModelEditingPipeline
+
+ >>> model_ckpt = "CompVis/stable-diffusion-v1-4"
+ >>> pipe = StableDiffusionModelEditingPipeline.from_pretrained(model_ckpt)
+
+ >>> pipe = pipe.to("cuda")
+
+ >>> source_prompt = "A pack of roses"
+ >>> destination_prompt = "A pack of blue roses"
+ >>> pipe.edit_model(source_prompt, destination_prompt)
+
+ >>> prompt = "A field of roses"
+ >>> image = pipe(prompt).images[0]
+ ```
+"""
+
+
+class StableDiffusionModelEditingPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image model editing using "Editing Implicit Assumptions in Text-to-Image Diffusion Models".
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.).
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents.
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPFeatureExtractor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ with_to_k ([`bool`]):
+ Whether to edit the key projection matrices along wiht the value projection matrices.
+ with_augs ([`list`]):
+ Textual augmentations to apply while editing the text-to-image model. Set to [] for no augmentations.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: SchedulerMixin,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPFeatureExtractor,
+ requires_safety_checker: bool = True,
+ with_to_k: bool = True,
+ with_augs: list = AUGS_CONST,
+ ):
+ super().__init__()
+
+ if isinstance(scheduler, PNDMScheduler):
+ logger.error("PNDMScheduler for this pipeline is currently not supported.")
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ self.with_to_k = with_to_k
+ self.with_augs = with_augs
+
+ # get cross-attention layers
+ ca_layers = []
+
+ def append_ca(net_):
+ if net_.__class__.__name__ == "CrossAttention":
+ ca_layers.append(net_)
+ elif hasattr(net_, "children"):
+ for net__ in net_.children():
+ append_ca(net__)
+
+ # recursively find all cross-attention layers in unet
+ for net in self.unet.named_children():
+ if "down" in net[0]:
+ append_ca(net[1])
+ elif "up" in net[0]:
+ append_ca(net[1])
+ elif "mid" in net[0]:
+ append_ca(net[1])
+
+ # get projection matrices
+ self.ca_clip_layers = [l for l in ca_layers if l.to_v.in_features == 768]
+ self.projection_matrices = [l.to_v for l in self.ca_clip_layers]
+ self.og_matrices = [copy.deepcopy(l.to_v) for l in self.ca_clip_layers]
+ if self.with_to_k:
+ self.projection_matrices = self.projection_matrices + [l.to_k for l in self.ca_clip_layers]
+ self.og_matrices = self.og_matrices + [copy.deepcopy(l.to_k) for l in self.ca_clip_layers]
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ def edit_model(
+ self,
+ source_prompt: str,
+ destination_prompt: str,
+ lamb: float = 0.1,
+ restart_params: bool = True,
+ ):
+ r"""
+ Apply model editing via closed-form solution (see Eq. 5 in the TIME paper https://arxiv.org/abs/2303.08084)
+
+ Args:
+ source_prompt (`str`):
+ The source prompt containing the concept to be edited.
+ destination_prompt (`str`):
+ The destination prompt. Must contain all words from source_prompt with additional ones to specify the
+ target edit.
+ lamb (`float`, *optional*, defaults to 0.1):
+ The lambda parameter specifying the regularization intesity. Smaller values increase the editing power.
+ restart_params (`bool`, *optional*, defaults to True):
+ Restart the model parameters to their pre-trained version before editing. This is done to avoid edit
+ compounding. When it is False, edits accumulate.
+ """
+
+ # restart LDM parameters
+ if restart_params:
+ num_ca_clip_layers = len(self.ca_clip_layers)
+ for idx_, l in enumerate(self.ca_clip_layers):
+ l.to_v = copy.deepcopy(self.og_matrices[idx_])
+ self.projection_matrices[idx_] = l.to_v
+ if self.with_to_k:
+ l.to_k = copy.deepcopy(self.og_matrices[num_ca_clip_layers + idx_])
+ self.projection_matrices[num_ca_clip_layers + idx_] = l.to_k
+
+ # set up sentences
+ old_texts = [source_prompt]
+ new_texts = [destination_prompt]
+ # add augmentations
+ base = old_texts[0] if old_texts[0][0:1] != "A" else "a" + old_texts[0][1:]
+ for aug in self.with_augs:
+ old_texts.append(aug + base)
+ base = new_texts[0] if new_texts[0][0:1] != "A" else "a" + new_texts[0][1:]
+ for aug in self.with_augs:
+ new_texts.append(aug + base)
+
+ # prepare input k* and v*
+ old_embs, new_embs = [], []
+ for old_text, new_text in zip(old_texts, new_texts):
+ text_input = self.tokenizer(
+ [old_text, new_text],
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
+ old_emb, new_emb = text_embeddings
+ old_embs.append(old_emb)
+ new_embs.append(new_emb)
+
+ # identify corresponding destinations for each token in old_emb
+ idxs_replaces = []
+ for old_text, new_text in zip(old_texts, new_texts):
+ tokens_a = self.tokenizer(old_text).input_ids
+ tokens_b = self.tokenizer(new_text).input_ids
+ tokens_a = [self.tokenizer.encode("a ")[1] if self.tokenizer.decode(t) == "an" else t for t in tokens_a]
+ tokens_b = [self.tokenizer.encode("a ")[1] if self.tokenizer.decode(t) == "an" else t for t in tokens_b]
+ num_orig_tokens = len(tokens_a)
+ idxs_replace = []
+ j = 0
+ for i in range(num_orig_tokens):
+ curr_token = tokens_a[i]
+ while tokens_b[j] != curr_token:
+ j += 1
+ idxs_replace.append(j)
+ j += 1
+ while j < 77:
+ idxs_replace.append(j)
+ j += 1
+ while len(idxs_replace) < 77:
+ idxs_replace.append(76)
+ idxs_replaces.append(idxs_replace)
+
+ # prepare batch: for each pair of setences, old context and new values
+ contexts, valuess = [], []
+ for old_emb, new_emb, idxs_replace in zip(old_embs, new_embs, idxs_replaces):
+ context = old_emb.detach()
+ values = []
+ with torch.no_grad():
+ for layer in self.projection_matrices:
+ values.append(layer(new_emb[idxs_replace]).detach())
+ contexts.append(context)
+ valuess.append(values)
+
+ # edit the model
+ for layer_num in range(len(self.projection_matrices)):
+ # mat1 = \lambda W + \sum{v k^T}
+ mat1 = lamb * self.projection_matrices[layer_num].weight
+
+ # mat2 = \lambda I + \sum{k k^T}
+ mat2 = lamb * torch.eye(
+ self.projection_matrices[layer_num].weight.shape[1],
+ device=self.projection_matrices[layer_num].weight.device,
+ )
+
+ # aggregate sums for mat1, mat2
+ for context, values in zip(contexts, valuess):
+ context_vector = context.reshape(context.shape[0], context.shape[1], 1)
+ context_vector_T = context.reshape(context.shape[0], 1, context.shape[1])
+ value_vector = values[layer_num].reshape(values[layer_num].shape[0], values[layer_num].shape[1], 1)
+ for_mat1 = (value_vector @ context_vector_T).sum(dim=0)
+ for_mat2 = (context_vector @ context_vector_T).sum(dim=0)
+ mat1 += for_mat1
+ mat2 += for_mat2
+
+ # update projection matrix
+ self.projection_matrices[layer_num].weight = torch.nn.Parameter(mat1 @ torch.inverse(mat2))
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ if output_type == "latent":
+ image = latents
+ has_nsfw_concept = None
+ elif output_type == "pil":
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 10. Convert to PIL
+ image = self.numpy_to_pil(image)
+ else:
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_panorama.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_panorama.py
new file mode 100644
index 0000000000000000000000000000000000000000..c47423bdee5b08255c20a0704467084bd16a0dfd
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_panorama.py
@@ -0,0 +1,673 @@
+# Copyright 2023 MultiDiffusion Authors and The HuggingFace Team. All rights reserved."
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import torch
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import DDIMScheduler, PNDMScheduler
+from ...utils import is_accelerate_available, is_accelerate_version, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import StableDiffusionPanoramaPipeline, DDIMScheduler
+
+ >>> model_ckpt = "stabilityai/stable-diffusion-2-base"
+ >>> scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
+ >>> pipe = StableDiffusionPanoramaPipeline.from_pretrained(
+ ... model_ckpt, scheduler=scheduler, torch_dtype=torch.float16
+ ... )
+
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of the dolomites"
+ >>> image = pipe(prompt).images[0]
+ ```
+"""
+
+
+class StableDiffusionPanoramaPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using "MultiDiffusion: Fusing Diffusion Paths for Controlled Image
+ Generation".
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.).
+
+ To generate panorama-like images, be sure to pass the `width` parameter accordingly when using the pipeline. Our
+ recommendation for the `width` value is 2048. This is the default value of the `width` parameter for this pipeline.
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. The original work
+ on Multi Diffsion used the [`DDIMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: DDIMScheduler,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if isinstance(scheduler, PNDMScheduler):
+ logger.error("PNDMScheduler for this pipeline is currently not supported.")
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def get_views(self, panorama_height, panorama_width, window_size=64, stride=8):
+ # Here, we define the mappings F_i (see Eq. 7 in the MultiDiffusion paper https://arxiv.org/abs/2302.08113)
+ panorama_height /= 8
+ panorama_width /= 8
+ num_blocks_height = (panorama_height - window_size) // stride + 1
+ num_blocks_width = (panorama_width - window_size) // stride + 1
+ total_num_blocks = int(num_blocks_height * num_blocks_width)
+ views = []
+ for i in range(total_num_blocks):
+ h_start = int((i // num_blocks_width) * stride)
+ h_end = h_start + window_size
+ w_start = int((i % num_blocks_width) * stride)
+ w_end = w_start + window_size
+ views.append((h_start, h_end, w_start, w_end))
+ return views
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = 512,
+ width: Optional[int] = 2048,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: Optional[int] = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to 512:
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to 2048):
+ The width in pixels of the generated image. The width is kept to a high number because the
+ pipeline is supposed to be used for generating panorama-like images.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Define panorama grid and initialize views for synthesis.
+ views = self.get_views(height, width)
+ count = torch.zeros_like(latents)
+ value = torch.zeros_like(latents)
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ # Each denoising step also includes refinement of the latents with respect to the
+ # views.
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ count.zero_()
+ value.zero_()
+
+ # generate views
+ # Here, we iterate through different spatial crops of the latents and denoise them. These
+ # denoised (latent) crops are then averaged to produce the final latent
+ # for the current timestep via MultiDiffusion. Please see Sec. 4.1 in the
+ # MultiDiffusion paper for more details: https://arxiv.org/abs/2302.08113
+ for h_start, h_end, w_start, w_end in views:
+ # get the latents corresponding to the current view coordinates
+ latents_for_view = latents[:, :, h_start:h_end, w_start:w_end]
+
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents_for_view] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents_view_denoised = self.scheduler.step(
+ noise_pred, t, latents_for_view, **extra_step_kwargs
+ ).prev_sample
+ value[:, :, h_start:h_end, w_start:w_end] += latents_view_denoised
+ count[:, :, h_start:h_end, w_start:w_end] += 1
+
+ # take the MultiDiffusion step. Eq. 5 in MultiDiffusion paper: https://arxiv.org/abs/2302.08113
+ latents = torch.where(count > 0, value / count, value)
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 10. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py
new file mode 100644
index 0000000000000000000000000000000000000000..6af923cb7743aad6943b5bd924a3c2fbe668ee20
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py
@@ -0,0 +1,1263 @@
+# Copyright 2023 Pix2Pix Zero Authors and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from dataclasses import dataclass
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+import torch.nn.functional as F
+from transformers import (
+ BlipForConditionalGeneration,
+ BlipProcessor,
+ CLIPImageProcessor,
+ CLIPTextModel,
+ CLIPTokenizer,
+)
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...models.attention_processor import Attention
+from ...schedulers import DDIMScheduler, DDPMScheduler, EulerAncestralDiscreteScheduler, LMSDiscreteScheduler
+from ...schedulers.scheduling_ddim_inverse import DDIMInverseScheduler
+from ...utils import (
+ PIL_INTERPOLATION,
+ BaseOutput,
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+class Pix2PixInversionPipelineOutput(BaseOutput, TextualInversionLoaderMixin):
+ """
+ Output class for Stable Diffusion pipelines.
+
+ Args:
+ latents (`torch.FloatTensor`)
+ inverted latents tensor
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
+ num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
+ """
+
+ latents: torch.FloatTensor
+ images: Union[List[PIL.Image.Image], np.ndarray]
+
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import requests
+ >>> import torch
+
+ >>> from diffusers import DDIMScheduler, StableDiffusionPix2PixZeroPipeline
+
+
+ >>> def download(embedding_url, local_filepath):
+ ... r = requests.get(embedding_url)
+ ... with open(local_filepath, "wb") as f:
+ ... f.write(r.content)
+
+
+ >>> model_ckpt = "CompVis/stable-diffusion-v1-4"
+ >>> pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(model_ckpt, torch_dtype=torch.float16)
+ >>> pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+ >>> pipeline.to("cuda")
+
+ >>> prompt = "a high resolution painting of a cat in the style of van gough"
+ >>> source_emb_url = "https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/cat.pt"
+ >>> target_emb_url = "https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/dog.pt"
+
+ >>> for url in [source_emb_url, target_emb_url]:
+ ... download(url, url.split("/")[-1])
+
+ >>> src_embeds = torch.load(source_emb_url.split("/")[-1])
+ >>> target_embeds = torch.load(target_emb_url.split("/")[-1])
+ >>> images = pipeline(
+ ... prompt,
+ ... source_embeds=src_embeds,
+ ... target_embeds=target_embeds,
+ ... num_inference_steps=50,
+ ... cross_attention_guidance_amount=0.15,
+ ... ).images
+
+ >>> images[0].save("edited_image_dog.png")
+ ```
+"""
+
+EXAMPLE_INVERT_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from transformers import BlipForConditionalGeneration, BlipProcessor
+ >>> from diffusers import DDIMScheduler, DDIMInverseScheduler, StableDiffusionPix2PixZeroPipeline
+
+ >>> import requests
+ >>> from PIL import Image
+
+ >>> captioner_id = "Salesforce/blip-image-captioning-base"
+ >>> processor = BlipProcessor.from_pretrained(captioner_id)
+ >>> model = BlipForConditionalGeneration.from_pretrained(
+ ... captioner_id, torch_dtype=torch.float16, low_cpu_mem_usage=True
+ ... )
+
+ >>> sd_model_ckpt = "CompVis/stable-diffusion-v1-4"
+ >>> pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ ... sd_model_ckpt,
+ ... caption_generator=model,
+ ... caption_processor=processor,
+ ... torch_dtype=torch.float16,
+ ... safety_checker=None,
+ ... )
+
+ >>> pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
+ >>> pipeline.inverse_scheduler = DDIMInverseScheduler.from_config(pipeline.scheduler.config)
+ >>> pipeline.enable_model_cpu_offload()
+
+ >>> img_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/test_images/cats/cat_6.png"
+
+ >>> raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB").resize((512, 512))
+ >>> # generate caption
+ >>> caption = pipeline.generate_caption(raw_image)
+
+ >>> # "a photography of a cat with flowers and dai dai daie - daie - daie kasaii"
+ >>> inv_latents = pipeline.invert(caption, image=raw_image).latents
+ >>> # we need to generate source and target embeds
+
+ >>> source_prompts = ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
+
+ >>> target_prompts = ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
+
+ >>> source_embeds = pipeline.get_embeds(source_prompts)
+ >>> target_embeds = pipeline.get_embeds(target_prompts)
+ >>> # the latents can then be used to edit a real image
+ >>> # when using Stable Diffusion 2 or other models that use v-prediction
+ >>> # set `cross_attention_guidance_amount` to 0.01 or less to avoid input latent gradient explosion
+
+ >>> image = pipeline(
+ ... caption,
+ ... source_embeds=source_embeds,
+ ... target_embeds=target_embeds,
+ ... num_inference_steps=50,
+ ... cross_attention_guidance_amount=0.15,
+ ... generator=generator,
+ ... latents=inv_latents,
+ ... negative_prompt=caption,
+ ... ).images[0]
+ >>> image.save("edited_image.png")
+ ```
+"""
+
+
+# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 8 for x in (w, h)) # resize to integer multiple of 8
+
+ image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+def prepare_unet(unet: UNet2DConditionModel):
+ """Modifies the UNet (`unet`) to perform Pix2Pix Zero optimizations."""
+ pix2pix_zero_attn_procs = {}
+ for name in unet.attn_processors.keys():
+ module_name = name.replace(".processor", "")
+ module = unet.get_submodule(module_name)
+ if "attn2" in name:
+ pix2pix_zero_attn_procs[name] = Pix2PixZeroAttnProcessor(is_pix2pix_zero=True)
+ module.requires_grad_(True)
+ else:
+ pix2pix_zero_attn_procs[name] = Pix2PixZeroAttnProcessor(is_pix2pix_zero=False)
+ module.requires_grad_(False)
+
+ unet.set_attn_processor(pix2pix_zero_attn_procs)
+ return unet
+
+
+class Pix2PixZeroL2Loss:
+ def __init__(self):
+ self.loss = 0.0
+
+ def compute_loss(self, predictions, targets):
+ self.loss += ((predictions - targets) ** 2).sum((1, 2)).mean(0)
+
+
+class Pix2PixZeroAttnProcessor:
+ """An attention processor class to store the attention weights.
+ In Pix2Pix Zero, it happens during computations in the cross-attention blocks."""
+
+ def __init__(self, is_pix2pix_zero=False):
+ self.is_pix2pix_zero = is_pix2pix_zero
+ if self.is_pix2pix_zero:
+ self.reference_cross_attn_map = {}
+
+ def __call__(
+ self,
+ attn: Attention,
+ hidden_states,
+ encoder_hidden_states=None,
+ attention_mask=None,
+ timestep=None,
+ loss=None,
+ ):
+ batch_size, sequence_length, _ = hidden_states.shape
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+ query = attn.to_q(hidden_states)
+
+ if encoder_hidden_states is None:
+ encoder_hidden_states = hidden_states
+ elif attn.cross_attention_norm:
+ encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
+
+ key = attn.to_k(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states)
+
+ query = attn.head_to_batch_dim(query)
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+
+ attention_probs = attn.get_attention_scores(query, key, attention_mask)
+ if self.is_pix2pix_zero and timestep is not None:
+ # new bookkeeping to save the attention weights.
+ if loss is None:
+ self.reference_cross_attn_map[timestep.item()] = attention_probs.detach().cpu()
+ # compute loss
+ elif loss is not None:
+ prev_attn_probs = self.reference_cross_attn_map.pop(timestep.item())
+ loss.compute_loss(attention_probs, prev_attn_probs.to(attention_probs.device))
+
+ hidden_states = torch.bmm(attention_probs, value)
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ return hidden_states
+
+
+class StableDiffusionPix2PixZeroPipeline(DiffusionPipeline):
+ r"""
+ Pipeline for pixel-levl image editing using Pix2Pix Zero. Based on Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], [`EulerAncestralDiscreteScheduler`], or [`DDPMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ requires_safety_checker (bool):
+ Whether the pipeline requires a safety checker. We recommend setting it to True if you're using the
+ pipeline publicly.
+ """
+ _optional_components = [
+ "safety_checker",
+ "feature_extractor",
+ "caption_generator",
+ "caption_processor",
+ "inverse_scheduler",
+ ]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: Union[DDPMScheduler, DDIMScheduler, EulerAncestralDiscreteScheduler, LMSDiscreteScheduler],
+ feature_extractor: CLIPImageProcessor,
+ safety_checker: StableDiffusionSafetyChecker,
+ inverse_scheduler: DDIMInverseScheduler,
+ caption_generator: BlipForConditionalGeneration,
+ caption_processor: BlipProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ caption_processor=caption_processor,
+ caption_generator=caption_generator,
+ inverse_scheduler=inverse_scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ hook = None
+ for cpu_offloaded_model in [self.vae, self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ if self.safety_checker is not None:
+ _, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ source_embeds,
+ target_embeds,
+ callback_steps,
+ prompt_embeds=None,
+ ):
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+ if source_embeds is None and target_embeds is None:
+ raise ValueError("`source_embeds` and `target_embeds` cannot be undefined.")
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ def generate_caption(self, images):
+ """Generates caption for a given image."""
+ text = "a photography of"
+
+ prev_device = self.caption_generator.device
+
+ device = self._execution_device
+ inputs = self.caption_processor(images, text, return_tensors="pt").to(
+ device=device, dtype=self.caption_generator.dtype
+ )
+ self.caption_generator.to(device)
+ outputs = self.caption_generator.generate(**inputs, max_new_tokens=128)
+
+ # offload caption generator
+ self.caption_generator.to(prev_device)
+
+ caption = self.caption_processor.batch_decode(outputs, skip_special_tokens=True)[0]
+ return caption
+
+ def construct_direction(self, embs_source: torch.Tensor, embs_target: torch.Tensor):
+ """Constructs the edit direction to steer the image generation process semantically."""
+ return (embs_target.mean(0) - embs_source.mean(0)).unsqueeze(0)
+
+ @torch.no_grad()
+ def get_embeds(self, prompt: List[str], batch_size: int = 16) -> torch.FloatTensor:
+ num_prompts = len(prompt)
+ embeds = []
+ for i in range(0, num_prompts, batch_size):
+ prompt_slice = prompt[i : i + batch_size]
+
+ input_ids = self.tokenizer(
+ prompt_slice,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ ).input_ids
+
+ input_ids = input_ids.to(self.text_encoder.device)
+ embeds.append(self.text_encoder(input_ids)[0])
+
+ return torch.cat(embeds, dim=0).mean(0)[None]
+
+ def prepare_image_latents(self, image, batch_size, dtype, device, generator=None):
+ if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
+ )
+
+ image = image.to(device=device, dtype=dtype)
+
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if isinstance(generator, list):
+ init_latents = [
+ self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
+ ]
+ init_latents = torch.cat(init_latents, dim=0)
+ else:
+ init_latents = self.vae.encode(image).latent_dist.sample(generator)
+
+ init_latents = self.vae.config.scaling_factor * init_latents
+
+ if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
+ raise ValueError(
+ f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
+ )
+ else:
+ init_latents = torch.cat([init_latents], dim=0)
+
+ latents = init_latents
+
+ return latents
+
+ def get_epsilon(self, model_output: torch.Tensor, sample: torch.Tensor, timestep: int):
+ pred_type = self.inverse_scheduler.config.prediction_type
+ alpha_prod_t = self.inverse_scheduler.alphas_cumprod[timestep]
+
+ beta_prod_t = 1 - alpha_prod_t
+
+ if pred_type == "epsilon":
+ return model_output
+ elif pred_type == "sample":
+ return (sample - alpha_prod_t ** (0.5) * model_output) / beta_prod_t ** (0.5)
+ elif pred_type == "v_prediction":
+ return (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
+ else:
+ raise ValueError(
+ f"prediction_type given as {pred_type} must be one of `epsilon`, `sample`, or `v_prediction`"
+ )
+
+ def auto_corr_loss(self, hidden_states, generator=None):
+ batch_size, channel, height, width = hidden_states.shape
+ if batch_size > 1:
+ raise ValueError("Only batch_size 1 is supported for now")
+
+ hidden_states = hidden_states.squeeze(0)
+ # hidden_states must be shape [C,H,W] now
+ reg_loss = 0.0
+ for i in range(hidden_states.shape[0]):
+ noise = hidden_states[i][None, None, :, :]
+ while True:
+ roll_amount = torch.randint(noise.shape[2] // 2, (1,), generator=generator).item()
+ reg_loss += (noise * torch.roll(noise, shifts=roll_amount, dims=2)).mean() ** 2
+ reg_loss += (noise * torch.roll(noise, shifts=roll_amount, dims=3)).mean() ** 2
+
+ if noise.shape[2] <= 8:
+ break
+ noise = F.avg_pool2d(noise, kernel_size=2)
+ return reg_loss
+
+ def kl_divergence(self, hidden_states):
+ mean = hidden_states.mean()
+ var = hidden_states.var()
+ return var + mean**2 - 1 - torch.log(var + 1e-7)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Optional[Union[str, List[str]]] = None,
+ image: Optional[Union[torch.FloatTensor, PIL.Image.Image]] = None,
+ source_embeds: torch.Tensor = None,
+ target_embeds: torch.Tensor = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ cross_attention_guidance_amount: float = 0.1,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: Optional[int] = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ source_embeds (`torch.Tensor`):
+ Source concept embeddings. Generation of the embeddings as per the [original
+ paper](https://arxiv.org/abs/2302.03027). Used in discovering the edit direction.
+ target_embeds (`torch.Tensor`):
+ Target concept embeddings. Generation of the embeddings as per the [original
+ paper](https://arxiv.org/abs/2302.03027). Used in discovering the edit direction.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ cross_attention_guidance_amount (`float`, defaults to 0.1):
+ Amount of guidance needed from the reference cross-attention maps.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Define the spatial resolutions.
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt,
+ image,
+ source_embeds,
+ target_embeds,
+ callback_steps,
+ prompt_embeds,
+ )
+
+ # 3. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+ if cross_attention_kwargs is None:
+ cross_attention_kwargs = {}
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Generate the inverted noise from the input image or any other image
+ # generated from the input prompt.
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+ latents_init = latents.clone()
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Rejig the UNet so that we can obtain the cross-attenion maps and
+ # use them for guiding the subsequent image generation.
+ self.unet = prepare_unet(self.unet)
+
+ # 7. Denoising loop where we obtain the cross-attention maps.
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs={"timestep": t},
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Compute the edit directions.
+ edit_direction = self.construct_direction(source_embeds, target_embeds).to(prompt_embeds.device)
+
+ # 9. Edit the prompt embeddings as per the edit directions discovered.
+ prompt_embeds_edit = prompt_embeds.clone()
+ prompt_embeds_edit[1:2] += edit_direction
+
+ # 10. Second denoising loop to generate the edited image.
+ latents = latents_init
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # we want to learn the latent such that it steers the generation
+ # process towards the edited direction, so make the make initial
+ # noise learnable
+ x_in = latent_model_input.detach().clone()
+ x_in.requires_grad = True
+
+ # optimizer
+ opt = torch.optim.SGD([x_in], lr=cross_attention_guidance_amount)
+
+ with torch.enable_grad():
+ # initialize loss
+ loss = Pix2PixZeroL2Loss()
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ x_in,
+ t,
+ encoder_hidden_states=prompt_embeds_edit.detach(),
+ cross_attention_kwargs={"timestep": t, "loss": loss},
+ ).sample
+
+ loss.loss.backward(retain_graph=False)
+ opt.step()
+
+ # recompute the noise
+ noise_pred = self.unet(
+ x_in.detach(),
+ t,
+ encoder_hidden_states=prompt_embeds_edit,
+ cross_attention_kwargs={"timestep": None},
+ ).sample
+
+ latents = x_in.detach().chunk(2)[0]
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+
+ # 11. Post-process the latents.
+ edited_image = self.decode_latents(latents)
+
+ # 12. Run the safety checker.
+ edited_image, has_nsfw_concept = self.run_safety_checker(edited_image, device, prompt_embeds.dtype)
+
+ # 13. Convert to PIL.
+ if output_type == "pil":
+ edited_image = self.numpy_to_pil(edited_image)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (edited_image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=edited_image, nsfw_content_detected=has_nsfw_concept)
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_INVERT_DOC_STRING)
+ def invert(
+ self,
+ prompt: Optional[str] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ cross_attention_guidance_amount: float = 0.1,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: Optional[int] = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ lambda_auto_corr: float = 20.0,
+ lambda_kl: float = 20.0,
+ num_reg_steps: int = 5,
+ num_auto_corr_rolls: int = 5,
+ ):
+ r"""
+ Function used to generate inverted latents given a prompt and image.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`PIL.Image.Image`, *optional*):
+ `Image`, or tensor representing an image batch which will be used for conditioning.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 1):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ cross_attention_guidance_amount (`float`, defaults to 0.1):
+ Amount of guidance needed from the reference cross-attention maps.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ lambda_auto_corr (`float`, *optional*, defaults to 20.0):
+ Lambda parameter to control auto correction
+ lambda_kl (`float`, *optional*, defaults to 20.0):
+ Lambda parameter to control Kullback–Leibler divergence output
+ num_reg_steps (`int`, *optional*, defaults to 5):
+ Number of regularization loss steps
+ num_auto_corr_rolls (`int`, *optional*, defaults to 5):
+ Number of auto correction roll steps
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.pipeline_stable_diffusion_pix2pix_zero.Pix2PixInversionPipelineOutput`] or
+ `tuple`:
+ [`~pipelines.stable_diffusion.pipeline_stable_diffusion_pix2pix_zero.Pix2PixInversionPipelineOutput`] if
+ `return_dict` is True, otherwise a `tuple. When returning a tuple, the first element is the inverted
+ latents tensor and then second is the corresponding decoded image.
+ """
+ # 1. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+ if cross_attention_kwargs is None:
+ cross_attention_kwargs = {}
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Preprocess image
+ image = preprocess(image)
+
+ # 4. Prepare latent variables
+ latents = self.prepare_image_latents(image, batch_size, self.vae.dtype, device, generator)
+
+ # 5. Encode input prompt
+ num_images_per_prompt = 1
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ prompt_embeds=prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.inverse_scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.inverse_scheduler.timesteps
+
+ # 6. Rejig the UNet so that we can obtain the cross-attenion maps and
+ # use them for guiding the subsequent image generation.
+ self.unet = prepare_unet(self.unet)
+
+ # 7. Denoising loop where we obtain the cross-attention maps.
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.inverse_scheduler.order
+ with self.progress_bar(total=num_inference_steps - 1) as progress_bar:
+ for i, t in enumerate(timesteps[:-1]):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.inverse_scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs={"timestep": t},
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # regularization of the noise prediction
+ with torch.enable_grad():
+ for _ in range(num_reg_steps):
+ if lambda_auto_corr > 0:
+ for _ in range(num_auto_corr_rolls):
+ var = torch.autograd.Variable(noise_pred.detach().clone(), requires_grad=True)
+
+ # Derive epsilon from model output before regularizing to IID standard normal
+ var_epsilon = self.get_epsilon(var, latent_model_input.detach(), t)
+
+ l_ac = self.auto_corr_loss(var_epsilon, generator=generator)
+ l_ac.backward()
+
+ grad = var.grad.detach() / num_auto_corr_rolls
+ noise_pred = noise_pred - lambda_auto_corr * grad
+
+ if lambda_kl > 0:
+ var = torch.autograd.Variable(noise_pred.detach().clone(), requires_grad=True)
+
+ # Derive epsilon from model output before regularizing to IID standard normal
+ var_epsilon = self.get_epsilon(var, latent_model_input.detach(), t)
+
+ l_kld = self.kl_divergence(var_epsilon)
+ l_kld.backward()
+
+ grad = var.grad.detach()
+ noise_pred = noise_pred - lambda_kl * grad
+
+ noise_pred = noise_pred.detach()
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.inverse_scheduler.step(noise_pred, t, latents).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or (
+ (i + 1) > num_warmup_steps and (i + 1) % self.inverse_scheduler.order == 0
+ ):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ inverted_latents = latents.detach().clone()
+
+ # 8. Post-processing
+ image = self.decode_latents(latents.detach())
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ # 9. Convert to PIL.
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (inverted_latents, image)
+
+ return Pix2PixInversionPipelineOutput(latents=inverted_latents, images=image)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b08cf662bb4880f06d935ccfdc3a2841a96f451
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_sag.py
@@ -0,0 +1,788 @@
+# Copyright 2023 Susung Hong and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import torch
+import torch.nn.functional as F
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_available, is_accelerate_version, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionPipelineOutput
+from .safety_checker import StableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import StableDiffusionSAGPipeline
+
+ >>> pipe = StableDiffusionSAGPipeline.from_pretrained(
+ ... "runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> image = pipe(prompt, sag_scale=0.75).images[0]
+ ```
+"""
+
+
+# processes and stores attention probabilities
+class CrossAttnStoreProcessor:
+ def __init__(self):
+ self.attention_probs = None
+
+ def __call__(
+ self,
+ attn,
+ hidden_states,
+ encoder_hidden_states=None,
+ attention_mask=None,
+ ):
+ batch_size, sequence_length, _ = hidden_states.shape
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+ query = attn.to_q(hidden_states)
+
+ if encoder_hidden_states is None:
+ encoder_hidden_states = hidden_states
+ elif attn.cross_attention_norm:
+ encoder_hidden_states = attn.norm_cross(encoder_hidden_states)
+
+ key = attn.to_k(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states)
+
+ query = attn.head_to_batch_dim(query)
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+
+ self.attention_probs = attn.get_attention_scores(query, key, attention_mask)
+ hidden_states = torch.bmm(self.attention_probs, value)
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ return hidden_states
+
+
+# Modified to get self-attention guidance scale in this paper (https://arxiv.org/pdf/2210.00939.pdf) as an input
+class StableDiffusionSAGPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: StableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_sequential_cpu_offload
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ Note that offloading happens on a submodule basis. Memory savings are higher than with
+ `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ if self.safety_checker is not None:
+ cpu_offload(self.safety_checker, execution_device=device, offload_buffers=True)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
+ def run_safety_checker(self, image, device, dtype):
+ if self.safety_checker is not None:
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ else:
+ has_nsfw_concept = None
+ return image, has_nsfw_concept
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ sag_scale: float = 0.75,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: Optional[int] = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ sag_scale (`float`, *optional*, defaults to 0.75):
+ SAG scale as defined in [Improving Sample Quality of Diffusion Models Using Self-Attention Guidance]
+ (https://arxiv.org/abs/2210.00939). `sag_scale` is defined as `s_s` of equation (24) of SAG paper:
+ https://arxiv.org/pdf/2210.00939.pdf. Typically chosen between [0, 1.0] for better quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+ # and `sag_scale` is` `s` of equation (15)
+ # of the self-attentnion guidance paper: https://arxiv.org/pdf/2210.00939.pdf
+ # `sag_scale = 0` means no self-attention guidance
+ do_self_attention_guidance = sag_scale > 0.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ store_processor = CrossAttnStoreProcessor()
+ self.unet.mid_block.attentions[0].transformer_blocks[0].attn1.processor = store_processor
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+
+ map_size = None
+
+ def get_map_size(module, input, output):
+ nonlocal map_size
+ map_size = output.sample.shape[-2:]
+
+ with self.unet.mid_block.attentions[0].register_forward_hook(get_map_size):
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # perform self-attention guidance with the stored self-attentnion map
+ if do_self_attention_guidance:
+ # classifier-free guidance produces two chunks of attention map
+ # and we only use unconditional one according to equation (24)
+ # in https://arxiv.org/pdf/2210.00939.pdf
+ if do_classifier_free_guidance:
+ # DDIM-like prediction of x0
+ pred_x0 = self.pred_x0(latents, noise_pred_uncond, t)
+ # get the stored attention maps
+ uncond_attn, cond_attn = store_processor.attention_probs.chunk(2)
+ # self-attention-based degrading of latents
+ degraded_latents = self.sag_masking(
+ pred_x0, uncond_attn, map_size, t, self.pred_epsilon(latents, noise_pred_uncond, t)
+ )
+ uncond_emb, _ = prompt_embeds.chunk(2)
+ # forward and give guidance
+ degraded_pred = self.unet(degraded_latents, t, encoder_hidden_states=uncond_emb).sample
+ noise_pred += sag_scale * (noise_pred_uncond - degraded_pred)
+ else:
+ # DDIM-like prediction of x0
+ pred_x0 = self.pred_x0(latents, noise_pred, t)
+ # get the stored attention maps
+ cond_attn = store_processor.attention_probs
+ # self-attention-based degrading of latents
+ degraded_latents = self.sag_masking(
+ pred_x0, cond_attn, map_size, t, self.pred_epsilon(latents, noise_pred, t)
+ )
+ # forward and give guidance
+ degraded_pred = self.unet(degraded_latents, t, encoder_hidden_states=prompt_embeds).sample
+ noise_pred += sag_scale * (noise_pred - degraded_pred)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
+
+ # 10. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image, has_nsfw_concept)
+
+ return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
+
+ def sag_masking(self, original_latents, attn_map, map_size, t, eps):
+ # Same masking process as in SAG paper: https://arxiv.org/pdf/2210.00939.pdf
+ bh, hw1, hw2 = attn_map.shape
+ b, latent_channel, latent_h, latent_w = original_latents.shape
+ h = self.unet.attention_head_dim
+ if isinstance(h, list):
+ h = h[-1]
+
+ # Produce attention mask
+ attn_map = attn_map.reshape(b, h, hw1, hw2)
+ attn_mask = attn_map.mean(1, keepdim=False).sum(1, keepdim=False) > 1.0
+ attn_mask = (
+ attn_mask.reshape(b, map_size[0], map_size[1])
+ .unsqueeze(1)
+ .repeat(1, latent_channel, 1, 1)
+ .type(attn_map.dtype)
+ )
+ attn_mask = F.interpolate(attn_mask, (latent_h, latent_w))
+
+ # Blur according to the self-attention mask
+ degraded_latents = gaussian_blur_2d(original_latents, kernel_size=9, sigma=1.0)
+ degraded_latents = degraded_latents * attn_mask + original_latents * (1 - attn_mask)
+
+ # Noise it again to match the noise level
+ degraded_latents = self.scheduler.add_noise(degraded_latents, noise=eps, timesteps=t)
+
+ return degraded_latents
+
+ # Modified from diffusers.schedulers.scheduling_ddim.DDIMScheduler.step
+ # Note: there are some schedulers that clip or do not return x_0 (PNDMScheduler, DDIMScheduler, etc.)
+ def pred_x0(self, sample, model_output, timestep):
+ alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
+
+ beta_prod_t = 1 - alpha_prod_t
+ if self.scheduler.config.prediction_type == "epsilon":
+ pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
+ elif self.scheduler.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ elif self.scheduler.config.prediction_type == "v_prediction":
+ pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
+ # predict V
+ model_output = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.scheduler.config.prediction_type} must be one of `epsilon`, `sample`,"
+ " or `v_prediction`"
+ )
+
+ return pred_original_sample
+
+ def pred_epsilon(self, sample, model_output, timestep):
+ alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
+
+ beta_prod_t = 1 - alpha_prod_t
+ if self.scheduler.config.prediction_type == "epsilon":
+ pred_eps = model_output
+ elif self.scheduler.config.prediction_type == "sample":
+ pred_eps = (sample - (alpha_prod_t**0.5) * model_output) / (beta_prod_t**0.5)
+ elif self.scheduler.config.prediction_type == "v_prediction":
+ pred_eps = (beta_prod_t**0.5) * sample + (alpha_prod_t**0.5) * model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.scheduler.config.prediction_type} must be one of `epsilon`, `sample`,"
+ " or `v_prediction`"
+ )
+
+ return pred_eps
+
+
+# Gaussian blur
+def gaussian_blur_2d(img, kernel_size, sigma):
+ ksize_half = (kernel_size - 1) * 0.5
+
+ x = torch.linspace(-ksize_half, ksize_half, steps=kernel_size)
+
+ pdf = torch.exp(-0.5 * (x / sigma).pow(2))
+
+ x_kernel = pdf / pdf.sum()
+ x_kernel = x_kernel.to(device=img.device, dtype=img.dtype)
+
+ kernel2d = torch.mm(x_kernel[:, None], x_kernel[None, :])
+ kernel2d = kernel2d.expand(img.shape[-3], 1, kernel2d.shape[0], kernel2d.shape[1])
+
+ padding = [kernel_size // 2, kernel_size // 2, kernel_size // 2, kernel_size // 2]
+
+ img = F.pad(img, padding, mode="reflect")
+ img = F.conv2d(img, kernel2d, groups=img.shape[-3])
+
+ return img
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_upscale.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0086b32d6fdd6512241f0ceb23658ca020bc385
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_upscale.py
@@ -0,0 +1,657 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+from transformers import CLIPTextModel, CLIPTokenizer
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import DDPMScheduler, KarrasDiffusionSchedulers
+from ...utils import deprecate, is_accelerate_available, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def preprocess(image):
+ if isinstance(image, torch.Tensor):
+ return image
+ elif isinstance(image, PIL.Image.Image):
+ image = [image]
+
+ if isinstance(image[0], PIL.Image.Image):
+ w, h = image[0].size
+ w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 64
+
+ image = [np.array(i.resize((w, h)))[None, :] for i in image]
+ image = np.concatenate(image, axis=0)
+ image = np.array(image).astype(np.float32) / 255.0
+ image = image.transpose(0, 3, 1, 2)
+ image = 2.0 * image - 1.0
+ image = torch.from_numpy(image)
+ elif isinstance(image[0], torch.Tensor):
+ image = torch.cat(image, dim=0)
+ return image
+
+
+class StableDiffusionUpscalePipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-guided image super-resolution using Stable Diffusion 2.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ low_res_scheduler ([`SchedulerMixin`]):
+ A scheduler used to add initial noise to the low res conditioning image. It must be an instance of
+ [`DDPMScheduler`].
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ low_res_scheduler: DDPMScheduler,
+ scheduler: KarrasDiffusionSchedulers,
+ max_noise_level: int = 350,
+ ):
+ super().__init__()
+
+ if hasattr(vae, "config"):
+ # check if vae has a config attribute `scaling_factor` and if it is set to 0.08333, else set it to 0.08333 and deprecate
+ is_vae_scaling_factor_set_to_0_08333 = (
+ hasattr(vae.config, "scaling_factor") and vae.config.scaling_factor == 0.08333
+ )
+ if not is_vae_scaling_factor_set_to_0_08333:
+ deprecation_message = (
+ "The configuration file of the vae does not contain `scaling_factor` or it is set to"
+ f" {vae.config.scaling_factor}, which seems highly unlikely. If your checkpoint is a fine-tuned"
+ " version of `stabilityai/stable-diffusion-x4-upscaler` you should change 'scaling_factor' to"
+ " 0.08333 Please make sure to update the config accordingly, as not doing so might lead to"
+ " incorrect results in future versions. If you have downloaded this checkpoint from the Hugging"
+ " Face Hub, it would be very nice if you could open a Pull Request for the `vae/config.json` file"
+ )
+ deprecate("wrong scaling_factor", "1.0.0", deprecation_message, standard_warn=False)
+ vae.register_to_config(scaling_factor=0.08333)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ low_res_scheduler=low_res_scheduler,
+ scheduler=scheduler,
+ )
+ self.register_to_config(max_noise_level=max_noise_level)
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder]:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ noise_level,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if (
+ not isinstance(image, torch.Tensor)
+ and not isinstance(image, PIL.Image.Image)
+ and not isinstance(image, list)
+ ):
+ raise ValueError(
+ f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or `list` but is {type(image)}"
+ )
+
+ # verify batch size of prompt and image are same if image is a list or tensor
+ if isinstance(image, list) or isinstance(image, torch.Tensor):
+ if isinstance(prompt, str):
+ batch_size = 1
+ else:
+ batch_size = len(prompt)
+ if isinstance(image, list):
+ image_batch_size = len(image)
+ else:
+ image_batch_size = image.shape[0]
+ if batch_size != image_batch_size:
+ raise ValueError(
+ f"`prompt` has batch size {batch_size} and `image` has batch size {image_batch_size}."
+ " Please make sure that passed `prompt` matches the batch size of `image`."
+ )
+
+ # check noise level
+ if noise_level > self.config.max_noise_level:
+ raise ValueError(f"`noise_level` has to be <= {self.config.max_noise_level} but is {noise_level}")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height, width)
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ if latents.shape != shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ image: Union[torch.FloatTensor, PIL.Image.Image, List[PIL.Image.Image]] = None,
+ num_inference_steps: int = 75,
+ guidance_scale: float = 9.0,
+ noise_level: int = 20,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ image (`PIL.Image.Image` or List[`PIL.Image.Image`] or `torch.FloatTensor`):
+ `Image`, or tensor representing an image batch which will be upscaled. *
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
+ is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+ ```py
+ >>> import requests
+ >>> from PIL import Image
+ >>> from io import BytesIO
+ >>> from diffusers import StableDiffusionUpscalePipeline
+ >>> import torch
+
+ >>> # load model and scheduler
+ >>> model_id = "stabilityai/stable-diffusion-x4-upscaler"
+ >>> pipeline = StableDiffusionUpscalePipeline.from_pretrained(
+ ... model_id, revision="fp16", torch_dtype=torch.float16
+ ... )
+ >>> pipeline = pipeline.to("cuda")
+
+ >>> # let's download an image
+ >>> url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale/low_res_cat.png"
+ >>> response = requests.get(url)
+ >>> low_res_img = Image.open(BytesIO(response.content)).convert("RGB")
+ >>> low_res_img = low_res_img.resize((128, 128))
+ >>> prompt = "a white cat"
+
+ >>> upscaled_image = pipeline(prompt=prompt, image=low_res_img).images[0]
+ >>> upscaled_image.save("upsampled_cat.png")
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+
+ # 1. Check inputs
+ self.check_inputs(
+ prompt,
+ image,
+ noise_level,
+ callback_steps,
+ negative_prompt,
+ prompt_embeds,
+ negative_prompt_embeds,
+ )
+
+ if image is None:
+ raise ValueError("`image` input cannot be undefined.")
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Preprocess image
+ image = preprocess(image)
+ image = image.to(dtype=prompt_embeds.dtype, device=device)
+
+ # 5. set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Add noise to image
+ noise_level = torch.tensor([noise_level], dtype=torch.long, device=device)
+ noise = randn_tensor(image.shape, generator=generator, device=device, dtype=prompt_embeds.dtype)
+ image = self.low_res_scheduler.add_noise(image, noise, noise_level)
+
+ batch_multiplier = 2 if do_classifier_free_guidance else 1
+ image = torch.cat([image] * batch_multiplier * num_images_per_prompt)
+ noise_level = torch.cat([noise_level] * image.shape[0])
+
+ # 6. Prepare latent variables
+ height, width = image.shape[2:]
+ num_channels_latents = self.vae.config.latent_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 7. Check that sizes of image and latents match
+ num_channels_image = image.shape[1]
+ if num_channels_latents + num_channels_image != self.unet.config.in_channels:
+ raise ValueError(
+ f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
+ f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
+ f" `num_channels_image`: {num_channels_image} "
+ f" = {num_channels_latents+num_channels_image}. Please verify the config of"
+ " `pipeline.unet` or your `image` input."
+ )
+
+ # 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 9. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+
+ # concat latents, mask, masked_image_latents in the channel dimension
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+ latent_model_input = torch.cat([latent_model_input, image], dim=1)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input, t, encoder_hidden_states=prompt_embeds, class_labels=noise_level
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 10. Post-processing
+ # make sure the VAE is in float32 mode, as it overflows in float16
+ self.vae.to(dtype=torch.float32)
+ image = self.decode_latents(latents.float())
+
+ # 11. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce41572e683c4a59f4a6c2335875986ca18d9358
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip.py
@@ -0,0 +1,933 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+from transformers.models.clip.modeling_clip import CLIPTextModelOutput
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, PriorTransformer, UNet2DConditionModel
+from ...models.embeddings import get_timestep_embedding
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_available, is_accelerate_version, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+from .stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import StableUnCLIPPipeline
+
+ >>> pipe = StableUnCLIPPipeline.from_pretrained(
+ ... "fusing/stable-unclip-2-1-l", torch_dtype=torch.float16
+ ... ) # TODO update model path
+ >>> pipe = pipe.to("cuda")
+
+ >>> prompt = "a photo of an astronaut riding a horse on mars"
+ >>> images = pipe(prompt).images
+ >>> images[0].save("astronaut_horse.png")
+ ```
+"""
+
+
+class StableUnCLIPPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ """
+ Pipeline for text-to-image generation using stable unCLIP.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ prior_tokenizer ([`CLIPTokenizer`]):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ prior_text_encoder ([`CLIPTextModelWithProjection`]):
+ Frozen text-encoder.
+ prior ([`PriorTransformer`]):
+ The canonincal unCLIP prior to approximate the image embedding from the text embedding.
+ prior_scheduler ([`KarrasDiffusionSchedulers`]):
+ Scheduler used in the prior denoising process.
+ image_normalizer ([`StableUnCLIPImageNormalizer`]):
+ Used to normalize the predicted image embeddings before the noise is applied and un-normalize the image
+ embeddings after the noise has been applied.
+ image_noising_scheduler ([`KarrasDiffusionSchedulers`]):
+ Noise schedule for adding noise to the predicted image embeddings. The amount of noise to add is determined
+ by `noise_level` in `StableUnCLIPPipeline.__call__`.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder.
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`KarrasDiffusionSchedulers`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents.
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ """
+
+ # prior components
+ prior_tokenizer: CLIPTokenizer
+ prior_text_encoder: CLIPTextModelWithProjection
+ prior: PriorTransformer
+ prior_scheduler: KarrasDiffusionSchedulers
+
+ # image noising components
+ image_normalizer: StableUnCLIPImageNormalizer
+ image_noising_scheduler: KarrasDiffusionSchedulers
+
+ # regular denoising components
+ tokenizer: CLIPTokenizer
+ text_encoder: CLIPTextModel
+ unet: UNet2DConditionModel
+ scheduler: KarrasDiffusionSchedulers
+
+ vae: AutoencoderKL
+
+ def __init__(
+ self,
+ # prior components
+ prior_tokenizer: CLIPTokenizer,
+ prior_text_encoder: CLIPTextModelWithProjection,
+ prior: PriorTransformer,
+ prior_scheduler: KarrasDiffusionSchedulers,
+ # image noising components
+ image_normalizer: StableUnCLIPImageNormalizer,
+ image_noising_scheduler: KarrasDiffusionSchedulers,
+ # regular denoising components
+ tokenizer: CLIPTokenizer,
+ text_encoder: CLIPTextModelWithProjection,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ # vae
+ vae: AutoencoderKL,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ prior_tokenizer=prior_tokenizer,
+ prior_text_encoder=prior_text_encoder,
+ prior=prior,
+ prior_scheduler=prior_scheduler,
+ image_normalizer=image_normalizer,
+ image_noising_scheduler=image_noising_scheduler,
+ tokenizer=tokenizer,
+ text_encoder=text_encoder,
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ )
+
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
+ models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
+ when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ # TODO: self.prior.post_process_latents and self.image_noiser.{scale,unscale} are not covered by the offload hooks, so they fails if added to the list
+ models = [
+ self.prior_text_encoder,
+ self.text_encoder,
+ self.unet,
+ self.vae,
+ ]
+ for cpu_offloaded_model in models:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.prior_text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline._encode_prompt with _encode_prompt->_encode_prior_prompt, tokenizer->prior_tokenizer, text_encoder->prior_text_encoder
+ def _encode_prior_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ text_model_output: Optional[Union[CLIPTextModelOutput, Tuple]] = None,
+ text_attention_mask: Optional[torch.Tensor] = None,
+ ):
+ if text_model_output is None:
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+ # get prompt text embeddings
+ text_inputs = self.prior_tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.prior_tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ text_mask = text_inputs.attention_mask.bool().to(device)
+
+ untruncated_ids = self.prior_tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.prior_tokenizer.batch_decode(
+ untruncated_ids[:, self.prior_tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.prior_tokenizer.model_max_length} tokens: {removed_text}"
+ )
+ text_input_ids = text_input_ids[:, : self.prior_tokenizer.model_max_length]
+
+ prior_text_encoder_output = self.prior_text_encoder(text_input_ids.to(device))
+
+ prompt_embeds = prior_text_encoder_output.text_embeds
+ prior_text_encoder_hidden_states = prior_text_encoder_output.last_hidden_state
+
+ else:
+ batch_size = text_model_output[0].shape[0]
+ prompt_embeds, prior_text_encoder_hidden_states = text_model_output[0], text_model_output[1]
+ text_mask = text_attention_mask
+
+ prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
+ prior_text_encoder_hidden_states = prior_text_encoder_hidden_states.repeat_interleave(
+ num_images_per_prompt, dim=0
+ )
+ text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
+
+ if do_classifier_free_guidance:
+ uncond_tokens = [""] * batch_size
+
+ uncond_input = self.prior_tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=self.prior_tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ uncond_text_mask = uncond_input.attention_mask.bool().to(device)
+ negative_prompt_embeds_prior_text_encoder_output = self.prior_text_encoder(
+ uncond_input.input_ids.to(device)
+ )
+
+ negative_prompt_embeds = negative_prompt_embeds_prior_text_encoder_output.text_embeds
+ uncond_prior_text_encoder_hidden_states = (
+ negative_prompt_embeds_prior_text_encoder_output.last_hidden_state
+ )
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
+
+ seq_len = uncond_prior_text_encoder_hidden_states.shape[1]
+ uncond_prior_text_encoder_hidden_states = uncond_prior_text_encoder_hidden_states.repeat(
+ 1, num_images_per_prompt, 1
+ )
+ uncond_prior_text_encoder_hidden_states = uncond_prior_text_encoder_hidden_states.view(
+ batch_size * num_images_per_prompt, seq_len, -1
+ )
+ uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
+
+ # done duplicates
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+ prior_text_encoder_hidden_states = torch.cat(
+ [uncond_prior_text_encoder_hidden_states, prior_text_encoder_hidden_states]
+ )
+
+ text_mask = torch.cat([uncond_text_mask, text_mask])
+
+ return prompt_embeds, prior_text_encoder_hidden_states, text_mask
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs with prepare_extra_step_kwargs->prepare_prior_extra_step_kwargs, scheduler->prior_scheduler
+ def prepare_prior_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the prior_scheduler step, since not all prior_schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other prior_schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.prior_scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the prior_scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.prior_scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ noise_level,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Please make sure to define only one of the two."
+ )
+
+ if prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+
+ if prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ "Provide either `negative_prompt` or `negative_prompt_embeds`. Cannot leave both `negative_prompt` and `negative_prompt_embeds` undefined."
+ )
+
+ if prompt is not None and negative_prompt is not None:
+ if type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if noise_level < 0 or noise_level >= self.image_noising_scheduler.config.num_train_timesteps:
+ raise ValueError(
+ f"`noise_level` must be between 0 and {self.image_noising_scheduler.config.num_train_timesteps - 1}, inclusive."
+ )
+
+ # Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.prepare_latents
+ def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ if latents.shape != shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
+ latents = latents.to(device)
+
+ latents = latents * scheduler.init_noise_sigma
+ return latents
+
+ def noise_image_embeddings(
+ self,
+ image_embeds: torch.Tensor,
+ noise_level: int,
+ noise: Optional[torch.FloatTensor] = None,
+ generator: Optional[torch.Generator] = None,
+ ):
+ """
+ Add noise to the image embeddings. The amount of noise is controlled by a `noise_level` input. A higher
+ `noise_level` increases the variance in the final un-noised images.
+
+ The noise is applied in two ways
+ 1. A noise schedule is applied directly to the embeddings
+ 2. A vector of sinusoidal time embeddings are appended to the output.
+
+ In both cases, the amount of noise is controlled by the same `noise_level`.
+
+ The embeddings are normalized before the noise is applied and un-normalized after the noise is applied.
+ """
+ if noise is None:
+ noise = randn_tensor(
+ image_embeds.shape, generator=generator, device=image_embeds.device, dtype=image_embeds.dtype
+ )
+
+ noise_level = torch.tensor([noise_level] * image_embeds.shape[0], device=image_embeds.device)
+
+ self.image_normalizer.to(image_embeds.device)
+ image_embeds = self.image_normalizer.scale(image_embeds)
+
+ image_embeds = self.image_noising_scheduler.add_noise(image_embeds, timesteps=noise_level, noise=noise)
+
+ image_embeds = self.image_normalizer.unscale(image_embeds)
+
+ noise_level = get_timestep_embedding(
+ timesteps=noise_level, embedding_dim=image_embeds.shape[-1], flip_sin_to_cos=True, downscale_freq_shift=0
+ )
+
+ # `get_timestep_embeddings` does not contain any weights and will always return f32 tensors,
+ # but we might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ noise_level = noise_level.to(image_embeds.dtype)
+
+ image_embeds = torch.cat((image_embeds, noise_level), 1)
+
+ return image_embeds
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ # regular denoising process args
+ prompt: Optional[Union[str, List[str]]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 20,
+ guidance_scale: float = 10.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[torch.Generator] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ noise_level: int = 0,
+ # prior args
+ prior_num_inference_steps: int = 25,
+ prior_guidance_scale: float = 4.0,
+ prior_latents: Optional[torch.FloatTensor] = None,
+ ):
+ """
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 20):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 10.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ noise_level (`int`, *optional*, defaults to `0`):
+ The amount of noise to add to the image embeddings. A higher `noise_level` increases the variance in
+ the final un-noised images. See `StableUnCLIPPipeline.noise_image_embeddings` for details.
+ prior_num_inference_steps (`int`, *optional*, defaults to 25):
+ The number of denoising steps in the prior denoising process. More denoising steps usually lead to a
+ higher quality image at the expense of slower inference.
+ prior_guidance_scale (`float`, *optional*, defaults to 4.0):
+ Guidance scale for the prior denoising process as defined in [Classifier-Free Diffusion
+ Guidance](https://arxiv.org/abs/2207.12598). `prior_guidance_scale` is defined as `w` of equation 2. of
+ [Imagen Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting
+ `guidance_scale > 1`. Higher guidance scale encourages to generate images that are closely linked to
+ the text `prompt`, usually at the expense of lower image quality.
+ prior_latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ embedding generation in the prior denoising process. Can be used to tweak the same generation with
+ different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied
+ random `generator`.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~ pipeline_utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is a list with the generated images.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt=prompt,
+ height=height,
+ width=width,
+ callback_steps=callback_steps,
+ noise_level=noise_level,
+ negative_prompt=negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ batch_size = batch_size * num_images_per_prompt
+
+ device = self._execution_device
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ prior_do_classifier_free_guidance = prior_guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prior_prompt_embeds, prior_text_encoder_hidden_states, prior_text_mask = self._encode_prior_prompt(
+ prompt=prompt,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ do_classifier_free_guidance=prior_do_classifier_free_guidance,
+ )
+
+ # 4. Prepare prior timesteps
+ self.prior_scheduler.set_timesteps(prior_num_inference_steps, device=device)
+ prior_timesteps_tensor = self.prior_scheduler.timesteps
+
+ # 5. Prepare prior latent variables
+ embedding_dim = self.prior.config.embedding_dim
+ prior_latents = self.prepare_latents(
+ (batch_size, embedding_dim),
+ prior_prompt_embeds.dtype,
+ device,
+ generator,
+ prior_latents,
+ self.prior_scheduler,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ prior_extra_step_kwargs = self.prepare_prior_extra_step_kwargs(generator, eta)
+
+ # 7. Prior denoising loop
+ for i, t in enumerate(self.progress_bar(prior_timesteps_tensor)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([prior_latents] * 2) if prior_do_classifier_free_guidance else prior_latents
+ latent_model_input = self.prior_scheduler.scale_model_input(latent_model_input, t)
+
+ predicted_image_embedding = self.prior(
+ latent_model_input,
+ timestep=t,
+ proj_embedding=prior_prompt_embeds,
+ encoder_hidden_states=prior_text_encoder_hidden_states,
+ attention_mask=prior_text_mask,
+ ).predicted_image_embedding
+
+ if prior_do_classifier_free_guidance:
+ predicted_image_embedding_uncond, predicted_image_embedding_text = predicted_image_embedding.chunk(2)
+ predicted_image_embedding = predicted_image_embedding_uncond + prior_guidance_scale * (
+ predicted_image_embedding_text - predicted_image_embedding_uncond
+ )
+
+ prior_latents = self.prior_scheduler.step(
+ predicted_image_embedding,
+ timestep=t,
+ sample=prior_latents,
+ **prior_extra_step_kwargs,
+ ).prev_sample
+
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, prior_latents)
+
+ prior_latents = self.prior.post_process_latents(prior_latents)
+
+ image_embeds = prior_latents
+
+ # done prior
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 8. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt=prompt,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ negative_prompt=negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 9. Prepare image embeddings
+ image_embeds = self.noise_image_embeddings(
+ image_embeds=image_embeds,
+ noise_level=noise_level,
+ generator=generator,
+ )
+
+ if do_classifier_free_guidance:
+ negative_prompt_embeds = torch.zeros_like(image_embeds)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ image_embeds = torch.cat([negative_prompt_embeds, image_embeds])
+
+ # 10. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 11. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ latents = self.prepare_latents(
+ shape=shape,
+ dtype=prompt_embeds.dtype,
+ device=device,
+ generator=generator,
+ latents=latents,
+ scheduler=self.scheduler,
+ )
+
+ # 12. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 13. Denoising loop
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ class_labels=image_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 14. Post-processing
+ image = self.decode_latents(latents)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ # 15. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip_img2img.py b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9bf00bc783561120153a17586b7fc890453cd6a
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_stable_unclip_img2img.py
@@ -0,0 +1,829 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import PIL
+import torch
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
+
+from diffusers.utils.import_utils import is_accelerate_available
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...models.embeddings import get_timestep_embedding
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_version, logging, randn_tensor, replace_example_docstring
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+from .stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import requests
+ >>> import torch
+ >>> from PIL import Image
+ >>> from io import BytesIO
+
+ >>> from diffusers import StableUnCLIPImg2ImgPipeline
+
+ >>> pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ ... "fusing/stable-unclip-2-1-l-img2img", torch_dtype=torch.float16
+ ... ) # TODO update model path
+ >>> pipe = pipe.to("cuda")
+
+ >>> url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
+
+ >>> response = requests.get(url)
+ >>> init_image = Image.open(BytesIO(response.content)).convert("RGB")
+ >>> init_image = init_image.resize((768, 512))
+
+ >>> prompt = "A fantasy landscape, trending on artstation"
+
+ >>> images = pipe(prompt, init_image).images
+ >>> images[0].save("fantasy_landscape.png")
+ ```
+"""
+
+
+class StableUnCLIPImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ """
+ Pipeline for text-guided image to image generation using stable unCLIP.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ feature_extractor ([`CLIPImageProcessor`]):
+ Feature extractor for image pre-processing before being encoded.
+ image_encoder ([`CLIPVisionModelWithProjection`]):
+ CLIP vision model for encoding images.
+ image_normalizer ([`StableUnCLIPImageNormalizer`]):
+ Used to normalize the predicted image embeddings before the noise is applied and un-normalize the image
+ embeddings after the noise has been applied.
+ image_noising_scheduler ([`KarrasDiffusionSchedulers`]):
+ Noise schedule for adding noise to the predicted image embeddings. The amount of noise to add is determined
+ by `noise_level` in `StableUnCLIPPipeline.__call__`.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder.
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`KarrasDiffusionSchedulers`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents.
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ """
+
+ # image encoding components
+ feature_extractor: CLIPImageProcessor
+ image_encoder: CLIPVisionModelWithProjection
+
+ # image noising components
+ image_normalizer: StableUnCLIPImageNormalizer
+ image_noising_scheduler: KarrasDiffusionSchedulers
+
+ # regular denoising components
+ tokenizer: CLIPTokenizer
+ text_encoder: CLIPTextModel
+ unet: UNet2DConditionModel
+ scheduler: KarrasDiffusionSchedulers
+
+ vae: AutoencoderKL
+
+ def __init__(
+ self,
+ # image encoding components
+ feature_extractor: CLIPImageProcessor,
+ image_encoder: CLIPVisionModelWithProjection,
+ # image noising components
+ image_normalizer: StableUnCLIPImageNormalizer,
+ image_noising_scheduler: KarrasDiffusionSchedulers,
+ # regular denoising components
+ tokenizer: CLIPTokenizer,
+ text_encoder: CLIPTextModel,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ # vae
+ vae: AutoencoderKL,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ feature_extractor=feature_extractor,
+ image_encoder=image_encoder,
+ image_normalizer=image_normalizer,
+ image_noising_scheduler=image_noising_scheduler,
+ tokenizer=tokenizer,
+ text_encoder=text_encoder,
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ )
+
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
+ models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
+ when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ # TODO: self.image_normalizer.{scale,unscale} are not covered by the offload hooks, so they fails if added to the list
+ models = [
+ self.image_encoder,
+ self.text_encoder,
+ self.unet,
+ self.vae,
+ ]
+ for cpu_offloaded_model in models:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.image_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def _encode_image(
+ self,
+ image,
+ device,
+ batch_size,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ noise_level,
+ generator,
+ image_embeds,
+ ):
+ dtype = next(self.image_encoder.parameters()).dtype
+
+ if isinstance(image, PIL.Image.Image):
+ # the image embedding should repeated so it matches the total batch size of the prompt
+ repeat_by = batch_size
+ else:
+ # assume the image input is already properly batched and just needs to be repeated so
+ # it matches the num_images_per_prompt.
+ #
+ # NOTE(will) this is probably missing a few number of side cases. I.e. batched/non-batched
+ # `image_embeds`. If those happen to be common use cases, let's think harder about
+ # what the expected dimensions of inputs should be and how we handle the encoding.
+ repeat_by = num_images_per_prompt
+
+ if image_embeds is None:
+ if not isinstance(image, torch.Tensor):
+ image = self.feature_extractor(images=image, return_tensors="pt").pixel_values
+
+ image = image.to(device=device, dtype=dtype)
+ image_embeds = self.image_encoder(image).image_embeds
+
+ image_embeds = self.noise_image_embeddings(
+ image_embeds=image_embeds,
+ noise_level=noise_level,
+ generator=generator,
+ )
+
+ # duplicate image embeddings for each generation per prompt, using mps friendly method
+ image_embeds = image_embeds.unsqueeze(1)
+ bs_embed, seq_len, _ = image_embeds.shape
+ image_embeds = image_embeds.repeat(1, repeat_by, 1)
+ image_embeds = image_embeds.view(bs_embed * repeat_by, seq_len, -1)
+ image_embeds = image_embeds.squeeze(1)
+
+ if do_classifier_free_guidance:
+ negative_prompt_embeds = torch.zeros_like(image_embeds)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ image_embeds = torch.cat([negative_prompt_embeds, image_embeds])
+
+ return image_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(
+ self,
+ prompt,
+ image,
+ height,
+ width,
+ callback_steps,
+ noise_level,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ image_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Please make sure to define only one of the two."
+ )
+
+ if prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+
+ if prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ "Provide either `negative_prompt` or `negative_prompt_embeds`. Cannot leave both `negative_prompt` and `negative_prompt_embeds` undefined."
+ )
+
+ if prompt is not None and negative_prompt is not None:
+ if type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ if noise_level < 0 or noise_level >= self.image_noising_scheduler.config.num_train_timesteps:
+ raise ValueError(
+ f"`noise_level` must be between 0 and {self.image_noising_scheduler.config.num_train_timesteps - 1}, inclusive."
+ )
+
+ if image is not None and image_embeds is not None:
+ raise ValueError(
+ "Provide either `image` or `image_embeds`. Please make sure to define only one of the two."
+ )
+
+ if image is None and image_embeds is None:
+ raise ValueError(
+ "Provide either `image` or `image_embeds`. Cannot leave both `image` and `image_embeds` undefined."
+ )
+
+ if image is not None:
+ if (
+ not isinstance(image, torch.Tensor)
+ and not isinstance(image, PIL.Image.Image)
+ and not isinstance(image, list)
+ ):
+ raise ValueError(
+ "`image` has to be of type `torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]` but is"
+ f" {type(image)}"
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_unclip.StableUnCLIPPipeline.noise_image_embeddings
+ def noise_image_embeddings(
+ self,
+ image_embeds: torch.Tensor,
+ noise_level: int,
+ noise: Optional[torch.FloatTensor] = None,
+ generator: Optional[torch.Generator] = None,
+ ):
+ """
+ Add noise to the image embeddings. The amount of noise is controlled by a `noise_level` input. A higher
+ `noise_level` increases the variance in the final un-noised images.
+
+ The noise is applied in two ways
+ 1. A noise schedule is applied directly to the embeddings
+ 2. A vector of sinusoidal time embeddings are appended to the output.
+
+ In both cases, the amount of noise is controlled by the same `noise_level`.
+
+ The embeddings are normalized before the noise is applied and un-normalized after the noise is applied.
+ """
+ if noise is None:
+ noise = randn_tensor(
+ image_embeds.shape, generator=generator, device=image_embeds.device, dtype=image_embeds.dtype
+ )
+
+ noise_level = torch.tensor([noise_level] * image_embeds.shape[0], device=image_embeds.device)
+
+ self.image_normalizer.to(image_embeds.device)
+ image_embeds = self.image_normalizer.scale(image_embeds)
+
+ image_embeds = self.image_noising_scheduler.add_noise(image_embeds, timesteps=noise_level, noise=noise)
+
+ image_embeds = self.image_normalizer.unscale(image_embeds)
+
+ noise_level = get_timestep_embedding(
+ timesteps=noise_level, embedding_dim=image_embeds.shape[-1], flip_sin_to_cos=True, downscale_freq_shift=0
+ )
+
+ # `get_timestep_embeddings` does not contain any weights and will always return f32 tensors,
+ # but we might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ noise_level = noise_level.to(image_embeds.dtype)
+
+ image_embeds = torch.cat((image_embeds, noise_level), 1)
+
+ return image_embeds
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ image: Union[torch.FloatTensor, PIL.Image.Image] = None,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 20,
+ guidance_scale: float = 10,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[torch.Generator] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ noise_level: int = 0,
+ image_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the image generation. If not defined, either `prompt_embeds` will be
+ used or prompt is initialized to `""`.
+ image (`torch.FloatTensor` or `PIL.Image.Image`):
+ `Image`, or tensor representing an image batch. The image will be encoded to its CLIP embedding which
+ the unet will be conditioned on. Note that the image is _not_ encoded by the vae and then used as the
+ latents in the denoising process such as in the standard stable diffusion text guided image variation
+ process.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 20):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 10.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+ noise_level (`int`, *optional*, defaults to `0`):
+ The amount of noise to add to the image embeddings. A higher `noise_level` increases the variance in
+ the final un-noised images. See `StableUnCLIPPipeline.noise_image_embeddings` for details.
+ image_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated CLIP embeddings to condition the unet on. Note that these are not latents to be used in
+ the denoising process. If you want to provide pre-generated latents, pass them to `__call__` as
+ `latents`.
+
+ Examples:
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~ pipeline_utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is a list with the generated images.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ if prompt is None and prompt_embeds is None:
+ prompt = len(image) * [""] if isinstance(image, list) else ""
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt=prompt,
+ image=image,
+ height=height,
+ width=width,
+ callback_steps=callback_steps,
+ noise_level=noise_level,
+ negative_prompt=negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ image_embeds=image_embeds,
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ batch_size = batch_size * num_images_per_prompt
+
+ device = self._execution_device
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt=prompt,
+ device=device,
+ num_images_per_prompt=num_images_per_prompt,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ negative_prompt=negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Encoder input image
+ noise_level = torch.tensor([noise_level], device=device)
+ image_embeds = self._encode_image(
+ image=image,
+ device=device,
+ batch_size=batch_size,
+ num_images_per_prompt=num_images_per_prompt,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ noise_level=noise_level,
+ generator=generator,
+ image_embeds=image_embeds,
+ )
+
+ # 5. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 6. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size=batch_size,
+ num_channels_latents=num_channels_latents,
+ height=height,
+ width=width,
+ dtype=prompt_embeds.dtype,
+ device=device,
+ generator=generator,
+ latents=latents,
+ )
+
+ # 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 8. Denoising loop
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ class_labels=image_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ # 10. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker.py b/diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker.py
new file mode 100644
index 0000000000000000000000000000000000000000..84b8aeb7bcde36bafd3412a800149f41e0b331c8
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker.py
@@ -0,0 +1,122 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import torch
+import torch.nn as nn
+from transformers import CLIPConfig, CLIPVisionModel, PreTrainedModel
+
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+def cosine_distance(image_embeds, text_embeds):
+ normalized_image_embeds = nn.functional.normalize(image_embeds)
+ normalized_text_embeds = nn.functional.normalize(text_embeds)
+ return torch.mm(normalized_image_embeds, normalized_text_embeds.t())
+
+
+class StableDiffusionSafetyChecker(PreTrainedModel):
+ config_class = CLIPConfig
+
+ _no_split_modules = ["CLIPEncoderLayer"]
+
+ def __init__(self, config: CLIPConfig):
+ super().__init__(config)
+
+ self.vision_model = CLIPVisionModel(config.vision_config)
+ self.visual_projection = nn.Linear(config.vision_config.hidden_size, config.projection_dim, bias=False)
+
+ self.concept_embeds = nn.Parameter(torch.ones(17, config.projection_dim), requires_grad=False)
+ self.special_care_embeds = nn.Parameter(torch.ones(3, config.projection_dim), requires_grad=False)
+
+ self.concept_embeds_weights = nn.Parameter(torch.ones(17), requires_grad=False)
+ self.special_care_embeds_weights = nn.Parameter(torch.ones(3), requires_grad=False)
+
+ @torch.no_grad()
+ def forward(self, clip_input, images):
+ pooled_output = self.vision_model(clip_input)[1] # pooled_output
+ image_embeds = self.visual_projection(pooled_output)
+
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds).cpu().float().numpy()
+ cos_dist = cosine_distance(image_embeds, self.concept_embeds).cpu().float().numpy()
+
+ result = []
+ batch_size = image_embeds.shape[0]
+ for i in range(batch_size):
+ result_img = {"special_scores": {}, "special_care": [], "concept_scores": {}, "bad_concepts": []}
+
+ # increase this value to create a stronger `nfsw` filter
+ # at the cost of increasing the possibility of filtering benign images
+ adjustment = 0.0
+
+ for concept_idx in range(len(special_cos_dist[0])):
+ concept_cos = special_cos_dist[i][concept_idx]
+ concept_threshold = self.special_care_embeds_weights[concept_idx].item()
+ result_img["special_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
+ if result_img["special_scores"][concept_idx] > 0:
+ result_img["special_care"].append({concept_idx, result_img["special_scores"][concept_idx]})
+ adjustment = 0.01
+
+ for concept_idx in range(len(cos_dist[0])):
+ concept_cos = cos_dist[i][concept_idx]
+ concept_threshold = self.concept_embeds_weights[concept_idx].item()
+ result_img["concept_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
+ if result_img["concept_scores"][concept_idx] > 0:
+ result_img["bad_concepts"].append(concept_idx)
+
+ result.append(result_img)
+
+ has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result]
+
+ for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
+ if has_nsfw_concept:
+ images[idx] = np.zeros(images[idx].shape) # black image
+
+ if any(has_nsfw_concepts):
+ logger.warning(
+ "Potential NSFW content was detected in one or more images. A black image will be returned instead."
+ " Try again with a different prompt and/or seed."
+ )
+
+ return images, has_nsfw_concepts
+
+ @torch.no_grad()
+ def forward_onnx(self, clip_input: torch.FloatTensor, images: torch.FloatTensor):
+ pooled_output = self.vision_model(clip_input)[1] # pooled_output
+ image_embeds = self.visual_projection(pooled_output)
+
+ special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds)
+ cos_dist = cosine_distance(image_embeds, self.concept_embeds)
+
+ # increase this value to create a stronger `nsfw` filter
+ # at the cost of increasing the possibility of filtering benign images
+ adjustment = 0.0
+
+ special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment
+ # special_scores = special_scores.round(decimals=3)
+ special_care = torch.any(special_scores > 0, dim=1)
+ special_adjustment = special_care * 0.01
+ special_adjustment = special_adjustment.unsqueeze(1).expand(-1, cos_dist.shape[1])
+
+ concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment
+ # concept_scores = concept_scores.round(decimals=3)
+ has_nsfw_concepts = torch.any(concept_scores > 0, dim=1)
+
+ images[has_nsfw_concepts] = 0.0 # black image
+
+ return images, has_nsfw_concepts
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker_flax.py b/diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a8c3167954016b3b89f16caf8348661cd3a27ef
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/safety_checker_flax.py
@@ -0,0 +1,112 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Optional, Tuple
+
+import jax
+import jax.numpy as jnp
+from flax import linen as nn
+from flax.core.frozen_dict import FrozenDict
+from transformers import CLIPConfig, FlaxPreTrainedModel
+from transformers.models.clip.modeling_flax_clip import FlaxCLIPVisionModule
+
+
+def jax_cosine_distance(emb_1, emb_2, eps=1e-12):
+ norm_emb_1 = jnp.divide(emb_1.T, jnp.clip(jnp.linalg.norm(emb_1, axis=1), a_min=eps)).T
+ norm_emb_2 = jnp.divide(emb_2.T, jnp.clip(jnp.linalg.norm(emb_2, axis=1), a_min=eps)).T
+ return jnp.matmul(norm_emb_1, norm_emb_2.T)
+
+
+class FlaxStableDiffusionSafetyCheckerModule(nn.Module):
+ config: CLIPConfig
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.vision_model = FlaxCLIPVisionModule(self.config.vision_config)
+ self.visual_projection = nn.Dense(self.config.projection_dim, use_bias=False, dtype=self.dtype)
+
+ self.concept_embeds = self.param("concept_embeds", jax.nn.initializers.ones, (17, self.config.projection_dim))
+ self.special_care_embeds = self.param(
+ "special_care_embeds", jax.nn.initializers.ones, (3, self.config.projection_dim)
+ )
+
+ self.concept_embeds_weights = self.param("concept_embeds_weights", jax.nn.initializers.ones, (17,))
+ self.special_care_embeds_weights = self.param("special_care_embeds_weights", jax.nn.initializers.ones, (3,))
+
+ def __call__(self, clip_input):
+ pooled_output = self.vision_model(clip_input)[1]
+ image_embeds = self.visual_projection(pooled_output)
+
+ special_cos_dist = jax_cosine_distance(image_embeds, self.special_care_embeds)
+ cos_dist = jax_cosine_distance(image_embeds, self.concept_embeds)
+
+ # increase this value to create a stronger `nfsw` filter
+ # at the cost of increasing the possibility of filtering benign image inputs
+ adjustment = 0.0
+
+ special_scores = special_cos_dist - self.special_care_embeds_weights[None, :] + adjustment
+ special_scores = jnp.round(special_scores, 3)
+ is_special_care = jnp.any(special_scores > 0, axis=1, keepdims=True)
+ # Use a lower threshold if an image has any special care concept
+ special_adjustment = is_special_care * 0.01
+
+ concept_scores = cos_dist - self.concept_embeds_weights[None, :] + special_adjustment
+ concept_scores = jnp.round(concept_scores, 3)
+ has_nsfw_concepts = jnp.any(concept_scores > 0, axis=1)
+
+ return has_nsfw_concepts
+
+
+class FlaxStableDiffusionSafetyChecker(FlaxPreTrainedModel):
+ config_class = CLIPConfig
+ main_input_name = "clip_input"
+ module_class = FlaxStableDiffusionSafetyCheckerModule
+
+ def __init__(
+ self,
+ config: CLIPConfig,
+ input_shape: Optional[Tuple] = None,
+ seed: int = 0,
+ dtype: jnp.dtype = jnp.float32,
+ _do_init: bool = True,
+ **kwargs,
+ ):
+ if input_shape is None:
+ input_shape = (1, 224, 224, 3)
+ module = self.module_class(config=config, dtype=dtype, **kwargs)
+ super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
+
+ def init_weights(self, rng: jax.random.KeyArray, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
+ # init input tensor
+ clip_input = jax.random.normal(rng, input_shape)
+
+ params_rng, dropout_rng = jax.random.split(rng)
+ rngs = {"params": params_rng, "dropout": dropout_rng}
+
+ random_params = self.module.init(rngs, clip_input)["params"]
+
+ return random_params
+
+ def __call__(
+ self,
+ clip_input,
+ params: dict = None,
+ ):
+ clip_input = jnp.transpose(clip_input, (0, 2, 3, 1))
+
+ return self.module.apply(
+ {"params": params or self.params},
+ jnp.array(clip_input, dtype=jnp.float32),
+ rngs={},
+ )
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion/stable_unclip_image_normalizer.py b/diffusers/src/diffusers/pipelines/stable_diffusion/stable_unclip_image_normalizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..7362df7e80e72719133f1804600a618fe161f668
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion/stable_unclip_image_normalizer.py
@@ -0,0 +1,57 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Optional, Union
+
+import torch
+from torch import nn
+
+from ...configuration_utils import ConfigMixin, register_to_config
+from ...models.modeling_utils import ModelMixin
+
+
+class StableUnCLIPImageNormalizer(ModelMixin, ConfigMixin):
+ """
+ This class is used to hold the mean and standard deviation of the CLIP embedder used in stable unCLIP.
+
+ It is used to normalize the image embeddings before the noise is applied and un-normalize the noised image
+ embeddings.
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ embedding_dim: int = 768,
+ ):
+ super().__init__()
+
+ self.mean = nn.Parameter(torch.zeros(1, embedding_dim))
+ self.std = nn.Parameter(torch.ones(1, embedding_dim))
+
+ def to(
+ self,
+ torch_device: Optional[Union[str, torch.device]] = None,
+ torch_dtype: Optional[torch.dtype] = None,
+ ):
+ self.mean = nn.Parameter(self.mean.to(torch_device).to(torch_dtype))
+ self.std = nn.Parameter(self.std.to(torch_device).to(torch_dtype))
+ return self
+
+ def scale(self, embeds):
+ embeds = (embeds - self.mean) * 1.0 / self.std
+ return embeds
+
+ def unscale(self, embeds):
+ embeds = (embeds * self.std) + self.mean
+ return embeds
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__init__.py b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5aecfeac112e53b2fc49278c1acaa95a6c0c7257
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__init__.py
@@ -0,0 +1,71 @@
+from dataclasses import dataclass
+from enum import Enum
+from typing import List, Optional, Union
+
+import numpy as np
+import PIL
+from PIL import Image
+
+from ...utils import BaseOutput, is_torch_available, is_transformers_available
+
+
+@dataclass
+class SafetyConfig(object):
+ WEAK = {
+ "sld_warmup_steps": 15,
+ "sld_guidance_scale": 20,
+ "sld_threshold": 0.0,
+ "sld_momentum_scale": 0.0,
+ "sld_mom_beta": 0.0,
+ }
+ MEDIUM = {
+ "sld_warmup_steps": 10,
+ "sld_guidance_scale": 1000,
+ "sld_threshold": 0.01,
+ "sld_momentum_scale": 0.3,
+ "sld_mom_beta": 0.4,
+ }
+ STRONG = {
+ "sld_warmup_steps": 7,
+ "sld_guidance_scale": 2000,
+ "sld_threshold": 0.025,
+ "sld_momentum_scale": 0.5,
+ "sld_mom_beta": 0.7,
+ }
+ MAX = {
+ "sld_warmup_steps": 0,
+ "sld_guidance_scale": 5000,
+ "sld_threshold": 1.0,
+ "sld_momentum_scale": 0.5,
+ "sld_mom_beta": 0.7,
+ }
+
+
+@dataclass
+class StableDiffusionSafePipelineOutput(BaseOutput):
+ """
+ Output class for Safe Stable Diffusion pipelines.
+
+ Args:
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
+ num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
+ nsfw_content_detected (`List[bool]`)
+ List of flags denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, or `None` if safety checking could not be performed.
+ images (`List[PIL.Image.Image]` or `np.ndarray`)
+ List of denoised PIL images that were flagged by the safety checker any may contain "not-safe-for-work"
+ (nsfw) content, or `None` if no safety check was performed or no images were flagged.
+ applied_safety_concept (`str`)
+ The safety concept that was applied for safety guidance, or `None` if safety guidance was disabled
+ """
+
+ images: Union[List[PIL.Image.Image], np.ndarray]
+ nsfw_content_detected: Optional[List[bool]]
+ unsafe_images: Optional[Union[List[PIL.Image.Image], np.ndarray]]
+ applied_safety_concept: Optional[str]
+
+
+if is_transformers_available() and is_torch_available():
+ from .pipeline_stable_diffusion_safe import StableDiffusionPipelineSafe
+ from .safety_checker import SafeStableDiffusionSafetyChecker
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..29fc32641fe9d1e33e642577d6e8512ba73c7920
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..203ca038bce749d3c92e81f8fd7da29c13b0d530
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/pipeline_stable_diffusion_safe.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/pipeline_stable_diffusion_safe.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0152dfee3644f26328f8a80045b23792f9dc19d6
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/pipeline_stable_diffusion_safe.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/pipeline_stable_diffusion_safe.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/pipeline_stable_diffusion_safe.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..683320fe811c4addb0e6727d982838dbd6578fa6
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/pipeline_stable_diffusion_safe.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/safety_checker.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/safety_checker.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..13d088740209513f400bf286a56cbffe089b42d4
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/safety_checker.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/safety_checker.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/safety_checker.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..417993d23d5c3556490e28491902a83b5c6fe46e
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/__pycache__/safety_checker.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py
new file mode 100644
index 0000000000000000000000000000000000000000..850a0a4670e258378cc896475d7b02578025866e
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/pipeline_stable_diffusion_safe.py
@@ -0,0 +1,736 @@
+import inspect
+import warnings
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import torch
+from packaging import version
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
+
+from ...configuration_utils import FrozenDict
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import deprecate, is_accelerate_available, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline
+from . import StableDiffusionSafePipelineOutput
+from .safety_checker import SafeStableDiffusionSafetyChecker
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class StableDiffusionPipelineSafe(DiffusionPipeline):
+ r"""
+ Pipeline for text-to-image generation using Safe Latent Diffusion.
+
+ The implementation is based on the [`StableDiffusionPipeline`]
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ _optional_components = ["safety_checker", "feature_extractor"]
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet2DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ safety_checker: SafeStableDiffusionSafetyChecker,
+ feature_extractor: CLIPImageProcessor,
+ requires_safety_checker: bool = True,
+ ):
+ super().__init__()
+ safety_concept: Optional[str] = (
+ "an image showing hate, harassment, violence, suffering, humiliation, harm, suicide, sexual, nudity,"
+ " bodily fluids, blood, obscene gestures, illegal activity, drug use, theft, vandalism, weapons, child"
+ " abuse, brutality, cruelty"
+ )
+
+ if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
+ f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
+ "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
+ " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
+ " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
+ " file"
+ )
+ deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["steps_offset"] = 1
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
+ deprecation_message = (
+ f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
+ " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
+ " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
+ " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
+ " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
+ )
+ deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(scheduler.config)
+ new_config["clip_sample"] = False
+ scheduler._internal_dict = FrozenDict(new_config)
+
+ if safety_checker is None and requires_safety_checker:
+ logger.warning(
+ f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
+ " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
+ " results in services or applications open to the public. Both the diffusers team and Hugging Face"
+ " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
+ " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
+ " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
+ )
+
+ if safety_checker is not None and feature_extractor is None:
+ raise ValueError(
+ "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
+ " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
+ )
+
+ is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
+ version.parse(unet.config._diffusers_version).base_version
+ ) < version.parse("0.9.0.dev0")
+ is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
+ if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
+ deprecation_message = (
+ "The configuration file of the unet has set the default `sample_size` to smaller than"
+ " 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
+ " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
+ " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
+ " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
+ " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
+ " in the config might lead to incorrect results in future versions. If you have downloaded this"
+ " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
+ " the `unet/config.json` file"
+ )
+ deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
+ new_config = dict(unet.config)
+ new_config["sample_size"] = 64
+ unet._internal_dict = FrozenDict(new_config)
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ safety_checker=safety_checker,
+ feature_extractor=feature_extractor,
+ )
+ self._safety_text_concept = safety_concept
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+ self.register_to_config(requires_safety_checker=requires_safety_checker)
+
+ @property
+ def safety_concept(self):
+ r"""
+ Getter method for the safety concept used with SLD
+
+ Returns:
+ `str`: The text describing the safety concept
+ """
+ return self._safety_text_concept
+
+ @safety_concept.setter
+ def safety_concept(self, concept):
+ r"""
+ Setter method for the safety concept used with SLD
+
+ Args:
+ concept (`str`):
+ The text of the new safety concept
+ """
+ self._safety_text_concept = concept
+
+ def enable_sequential_cpu_offload(self):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device("cuda")
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae, self.safety_checker]:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ enable_safety_guidance,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ """
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="pt").input_ids
+
+ if not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # Encode the safety concept text
+ if enable_safety_guidance:
+ safety_concept_input = self.tokenizer(
+ [self._safety_text_concept],
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ safety_embeddings = self.text_encoder(safety_concept_input.input_ids.to(self.device))[0]
+
+ # duplicate safety embeddings for each generation per prompt, using mps friendly method
+ seq_len = safety_embeddings.shape[1]
+ safety_embeddings = safety_embeddings.repeat(batch_size, num_images_per_prompt, 1)
+ safety_embeddings = safety_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance + sld, we need to do three forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing three forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds, safety_embeddings])
+
+ else:
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def run_safety_checker(self, image, device, dtype, enable_safety_guidance):
+ if self.safety_checker is not None:
+ images = image.copy()
+ safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
+ image, has_nsfw_concept = self.safety_checker(
+ images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
+ )
+ flagged_images = np.zeros((2, *image.shape[1:]))
+ if any(has_nsfw_concept):
+ logger.warning(
+ "Potential NSFW content was detected in one or more images. A black image will be returned"
+ " instead."
+ f"{'You may look at this images in the `unsafe_images` variable of the output at your own discretion.' if enable_safety_guidance else 'Try again with a different prompt and/or seed.'}"
+ )
+ for idx, has_nsfw_concept in enumerate(has_nsfw_concept):
+ if has_nsfw_concept:
+ flagged_images[idx] = images[idx]
+ image[idx] = np.zeros(image[idx].shape) # black image
+ else:
+ has_nsfw_concept = None
+ flagged_images = None
+ return image, has_nsfw_concept, flagged_images
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def perform_safety_guidance(
+ self,
+ enable_safety_guidance,
+ safety_momentum,
+ noise_guidance,
+ noise_pred_out,
+ i,
+ sld_guidance_scale,
+ sld_warmup_steps,
+ sld_threshold,
+ sld_momentum_scale,
+ sld_mom_beta,
+ ):
+ # Perform SLD guidance
+ if enable_safety_guidance:
+ if safety_momentum is None:
+ safety_momentum = torch.zeros_like(noise_guidance)
+ noise_pred_text, noise_pred_uncond = noise_pred_out[0], noise_pred_out[1]
+ noise_pred_safety_concept = noise_pred_out[2]
+
+ # Equation 6
+ scale = torch.clamp(torch.abs((noise_pred_text - noise_pred_safety_concept)) * sld_guidance_scale, max=1.0)
+
+ # Equation 6
+ safety_concept_scale = torch.where(
+ (noise_pred_text - noise_pred_safety_concept) >= sld_threshold, torch.zeros_like(scale), scale
+ )
+
+ # Equation 4
+ noise_guidance_safety = torch.mul((noise_pred_safety_concept - noise_pred_uncond), safety_concept_scale)
+
+ # Equation 7
+ noise_guidance_safety = noise_guidance_safety + sld_momentum_scale * safety_momentum
+
+ # Equation 8
+ safety_momentum = sld_mom_beta * safety_momentum + (1 - sld_mom_beta) * noise_guidance_safety
+
+ if i >= sld_warmup_steps: # Warmup
+ # Equation 3
+ noise_guidance = noise_guidance - noise_guidance_safety
+ return noise_guidance, safety_momentum
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ sld_guidance_scale: Optional[float] = 1000,
+ sld_warmup_steps: Optional[int] = 10,
+ sld_threshold: Optional[float] = 0.01,
+ sld_momentum_scale: Optional[float] = 0.3,
+ sld_mom_beta: Optional[float] = 0.4,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ sld_guidance_scale (`float`, *optional*, defaults to 1000):
+ Safe latent guidance as defined in [Safe Latent Diffusion](https://arxiv.org/abs/2211.05105).
+ `sld_guidance_scale` is defined as sS of Eq. 6. If set to be less than 1, safety guidance will be
+ disabled.
+ sld_warmup_steps (`int`, *optional*, defaults to 10):
+ Number of warmup steps for safety guidance. SLD will only be applied for diffusion steps greater than
+ `sld_warmup_steps`. `sld_warmup_steps` is defined as `delta` of [Safe Latent
+ Diffusion](https://arxiv.org/abs/2211.05105).
+ sld_threshold (`float`, *optional*, defaults to 0.01):
+ Threshold that separates the hyperplane between appropriate and inappropriate images. `sld_threshold`
+ is defined as `lamda` of Eq. 5 in [Safe Latent Diffusion](https://arxiv.org/abs/2211.05105).
+ sld_momentum_scale (`float`, *optional*, defaults to 0.3):
+ Scale of the SLD momentum to be added to the safety guidance at each diffusion step. If set to 0.0
+ momentum will be disabled. Momentum is already built up during warmup, i.e. for diffusion steps smaller
+ than `sld_warmup_steps`. `sld_momentum_scale` is defined as `sm` of Eq. 7 in [Safe Latent
+ Diffusion](https://arxiv.org/abs/2211.05105).
+ sld_mom_beta (`float`, *optional*, defaults to 0.4):
+ Defines how safety guidance momentum builds up. `sld_mom_beta` indicates how much of the previous
+ momentum will be kept. Momentum is already built up during warmup, i.e. for diffusion steps smaller
+ than `sld_warmup_steps`. `sld_mom_beta` is defined as `beta m` of Eq. 8 in [Safe Latent
+ Diffusion](https://arxiv.org/abs/2211.05105).
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(prompt, height, width, callback_steps)
+
+ # 2. Define call parameters
+ batch_size = 1 if isinstance(prompt, str) else len(prompt)
+ device = self._execution_device
+
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ enable_safety_guidance = sld_guidance_scale > 1.0 and do_classifier_free_guidance
+ if not enable_safety_guidance:
+ warnings.warn("Safety checker disabled!")
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt, enable_safety_guidance
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs.
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ safety_momentum = None
+
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = (
+ torch.cat([latents] * (3 if enable_safety_guidance else 2))
+ if do_classifier_free_guidance
+ else latents
+ )
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_out = noise_pred.chunk((3 if enable_safety_guidance else 2))
+ noise_pred_uncond, noise_pred_text = noise_pred_out[0], noise_pred_out[1]
+
+ # default classifier free guidance
+ noise_guidance = noise_pred_text - noise_pred_uncond
+
+ # Perform SLD guidance
+ if enable_safety_guidance:
+ if safety_momentum is None:
+ safety_momentum = torch.zeros_like(noise_guidance)
+ noise_pred_safety_concept = noise_pred_out[2]
+
+ # Equation 6
+ scale = torch.clamp(
+ torch.abs((noise_pred_text - noise_pred_safety_concept)) * sld_guidance_scale, max=1.0
+ )
+
+ # Equation 6
+ safety_concept_scale = torch.where(
+ (noise_pred_text - noise_pred_safety_concept) >= sld_threshold,
+ torch.zeros_like(scale),
+ scale,
+ )
+
+ # Equation 4
+ noise_guidance_safety = torch.mul(
+ (noise_pred_safety_concept - noise_pred_uncond), safety_concept_scale
+ )
+
+ # Equation 7
+ noise_guidance_safety = noise_guidance_safety + sld_momentum_scale * safety_momentum
+
+ # Equation 8
+ safety_momentum = sld_mom_beta * safety_momentum + (1 - sld_mom_beta) * noise_guidance_safety
+
+ if i >= sld_warmup_steps: # Warmup
+ # Equation 3
+ noise_guidance = noise_guidance - noise_guidance_safety
+
+ noise_pred = noise_pred_uncond + guidance_scale * noise_guidance
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Run safety checker
+ image, has_nsfw_concept, flagged_images = self.run_safety_checker(
+ image, device, prompt_embeds.dtype, enable_safety_guidance
+ )
+
+ # 10. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+ if flagged_images is not None:
+ flagged_images = self.numpy_to_pil(flagged_images)
+
+ if not return_dict:
+ return (
+ image,
+ has_nsfw_concept,
+ self._safety_text_concept if enable_safety_guidance else None,
+ flagged_images,
+ )
+
+ return StableDiffusionSafePipelineOutput(
+ images=image,
+ nsfw_content_detected=has_nsfw_concept,
+ applied_safety_concept=self._safety_text_concept if enable_safety_guidance else None,
+ unsafe_images=flagged_images,
+ )
diff --git a/diffusers/src/diffusers/pipelines/stable_diffusion_safe/safety_checker.py b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/safety_checker.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b0c547496a0202dbfa1d8525a92565b3df62cbb
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stable_diffusion_safe/safety_checker.py
@@ -0,0 +1,109 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+import torch.nn as nn
+from transformers import CLIPConfig, CLIPVisionModel, PreTrainedModel
+
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+def cosine_distance(image_embeds, text_embeds):
+ normalized_image_embeds = nn.functional.normalize(image_embeds)
+ normalized_text_embeds = nn.functional.normalize(text_embeds)
+ return torch.mm(normalized_image_embeds, normalized_text_embeds.t())
+
+
+class SafeStableDiffusionSafetyChecker(PreTrainedModel):
+ config_class = CLIPConfig
+
+ _no_split_modules = ["CLIPEncoderLayer"]
+
+ def __init__(self, config: CLIPConfig):
+ super().__init__(config)
+
+ self.vision_model = CLIPVisionModel(config.vision_config)
+ self.visual_projection = nn.Linear(config.vision_config.hidden_size, config.projection_dim, bias=False)
+
+ self.concept_embeds = nn.Parameter(torch.ones(17, config.projection_dim), requires_grad=False)
+ self.special_care_embeds = nn.Parameter(torch.ones(3, config.projection_dim), requires_grad=False)
+
+ self.concept_embeds_weights = nn.Parameter(torch.ones(17), requires_grad=False)
+ self.special_care_embeds_weights = nn.Parameter(torch.ones(3), requires_grad=False)
+
+ @torch.no_grad()
+ def forward(self, clip_input, images):
+ pooled_output = self.vision_model(clip_input)[1] # pooled_output
+ image_embeds = self.visual_projection(pooled_output)
+
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds).cpu().float().numpy()
+ cos_dist = cosine_distance(image_embeds, self.concept_embeds).cpu().float().numpy()
+
+ result = []
+ batch_size = image_embeds.shape[0]
+ for i in range(batch_size):
+ result_img = {"special_scores": {}, "special_care": [], "concept_scores": {}, "bad_concepts": []}
+
+ # increase this value to create a stronger `nfsw` filter
+ # at the cost of increasing the possibility of filtering benign images
+ adjustment = 0.0
+
+ for concept_idx in range(len(special_cos_dist[0])):
+ concept_cos = special_cos_dist[i][concept_idx]
+ concept_threshold = self.special_care_embeds_weights[concept_idx].item()
+ result_img["special_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
+ if result_img["special_scores"][concept_idx] > 0:
+ result_img["special_care"].append({concept_idx, result_img["special_scores"][concept_idx]})
+ adjustment = 0.01
+
+ for concept_idx in range(len(cos_dist[0])):
+ concept_cos = cos_dist[i][concept_idx]
+ concept_threshold = self.concept_embeds_weights[concept_idx].item()
+ result_img["concept_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
+ if result_img["concept_scores"][concept_idx] > 0:
+ result_img["bad_concepts"].append(concept_idx)
+
+ result.append(result_img)
+
+ has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result]
+
+ return images, has_nsfw_concepts
+
+ @torch.no_grad()
+ def forward_onnx(self, clip_input: torch.FloatTensor, images: torch.FloatTensor):
+ pooled_output = self.vision_model(clip_input)[1] # pooled_output
+ image_embeds = self.visual_projection(pooled_output)
+
+ special_cos_dist = cosine_distance(image_embeds, self.special_care_embeds)
+ cos_dist = cosine_distance(image_embeds, self.concept_embeds)
+
+ # increase this value to create a stronger `nsfw` filter
+ # at the cost of increasing the possibility of filtering benign images
+ adjustment = 0.0
+
+ special_scores = special_cos_dist - self.special_care_embeds_weights + adjustment
+ # special_scores = special_scores.round(decimals=3)
+ special_care = torch.any(special_scores > 0, dim=1)
+ special_adjustment = special_care * 0.01
+ special_adjustment = special_adjustment.unsqueeze(1).expand(-1, cos_dist.shape[1])
+
+ concept_scores = (cos_dist - self.concept_embeds_weights) + special_adjustment
+ # concept_scores = concept_scores.round(decimals=3)
+ has_nsfw_concepts = torch.any(concept_scores > 0, dim=1)
+
+ return images, has_nsfw_concepts
diff --git a/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__init__.py b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a63c1d24afb2c4f36b0e284f0985a3ff508f4c7
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__init__.py
@@ -0,0 +1 @@
+from .pipeline_stochastic_karras_ve import KarrasVePipeline
diff --git a/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1d27be883dcd52b5736d4f2ddb3fd787a1c02a3e
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..55b9dc50c16e7a492c96d4e1cba7b9b489a0eb56
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/pipeline_stochastic_karras_ve.cpython-310.pyc b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/pipeline_stochastic_karras_ve.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..52c8c3eadbd27e5d57c269478b0fdf2ae3c7d649
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/pipeline_stochastic_karras_ve.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/pipeline_stochastic_karras_ve.cpython-39.pyc b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/pipeline_stochastic_karras_ve.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a61ae3c43df0a1b995825efe4cb398817544f648
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/__pycache__/pipeline_stochastic_karras_ve.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/stochastic_karras_ve/pipeline_stochastic_karras_ve.py b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/pipeline_stochastic_karras_ve.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e0ab15eb9758c42116cf67aab6d9d8a5a6dad7d
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/stochastic_karras_ve/pipeline_stochastic_karras_ve.py
@@ -0,0 +1,128 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Optional, Tuple, Union
+
+import torch
+
+from ...models import UNet2DModel
+from ...schedulers import KarrasVeScheduler
+from ...utils import randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class KarrasVePipeline(DiffusionPipeline):
+ r"""
+ Stochastic sampling from Karras et al. [1] tailored to the Variance-Expanding (VE) models [2]. Use Algorithm 2 and
+ the VE column of Table 1 from [1] for reference.
+
+ [1] Karras, Tero, et al. "Elucidating the Design Space of Diffusion-Based Generative Models."
+ https://arxiv.org/abs/2206.00364 [2] Song, Yang, et al. "Score-based generative modeling through stochastic
+ differential equations." https://arxiv.org/abs/2011.13456
+
+ Parameters:
+ unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
+ scheduler ([`KarrasVeScheduler`]):
+ Scheduler for the diffusion process to be used in combination with `unet` to denoise the encoded image.
+ """
+
+ # add type hints for linting
+ unet: UNet2DModel
+ scheduler: KarrasVeScheduler
+
+ def __init__(self, unet: UNet2DModel, scheduler: KarrasVeScheduler):
+ super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ num_inference_steps: int = 50,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ **kwargs,
+ ) -> Union[Tuple, ImagePipelineOutput]:
+ r"""
+ Args:
+ batch_size (`int`, *optional*, defaults to 1):
+ The number of images to generate.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if `return_dict` is
+ True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+
+ img_size = self.unet.config.sample_size
+ shape = (batch_size, 3, img_size, img_size)
+
+ model = self.unet
+
+ # sample x_0 ~ N(0, sigma_0^2 * I)
+ sample = randn_tensor(shape, generator=generator, device=self.device) * self.scheduler.init_noise_sigma
+
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ # here sigma_t == t_i from the paper
+ sigma = self.scheduler.schedule[t]
+ sigma_prev = self.scheduler.schedule[t - 1] if t > 0 else 0
+
+ # 1. Select temporarily increased noise level sigma_hat
+ # 2. Add new noise to move from sample_i to sample_hat
+ sample_hat, sigma_hat = self.scheduler.add_noise_to_input(sample, sigma, generator=generator)
+
+ # 3. Predict the noise residual given the noise magnitude `sigma_hat`
+ # The model inputs and output are adjusted by following eq. (213) in [1].
+ model_output = (sigma_hat / 2) * model((sample_hat + 1) / 2, sigma_hat / 2).sample
+
+ # 4. Evaluate dx/dt at sigma_hat
+ # 5. Take Euler step from sigma to sigma_prev
+ step_output = self.scheduler.step(model_output, sigma_hat, sigma_prev, sample_hat)
+
+ if sigma_prev != 0:
+ # 6. Apply 2nd order correction
+ # The model inputs and output are adjusted by following eq. (213) in [1].
+ model_output = (sigma_prev / 2) * model((step_output.prev_sample + 1) / 2, sigma_prev / 2).sample
+ step_output = self.scheduler.step_correct(
+ model_output,
+ sigma_hat,
+ sigma_prev,
+ sample_hat,
+ step_output.prev_sample,
+ step_output["derivative"],
+ )
+ sample = step_output.prev_sample
+
+ sample = (sample / 2 + 0.5).clamp(0, 1)
+ image = sample.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c2437857a23a0bbbba168cf9457ac8b72bd51e67
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py
@@ -0,0 +1,31 @@
+from dataclasses import dataclass
+from typing import List, Optional, Union
+
+import numpy as np
+import torch
+
+from ...utils import BaseOutput, OptionalDependencyNotAvailable, is_torch_available, is_transformers_available
+
+
+@dataclass
+class TextToVideoSDPipelineOutput(BaseOutput):
+ """
+ Output class for text to video pipelines.
+
+ Args:
+ frames (`List[np.ndarray]` or `torch.FloatTensor`)
+ List of denoised frames (essentially images) as NumPy arrays of shape `(height, width, num_channels)` or as
+ a `torch` tensor. NumPy array present the denoised images of the diffusion pipeline. The length of the list
+ denotes the video length i.e., the number of frames.
+ """
+
+ frames: Union[List[np.ndarray], torch.FloatTensor]
+
+
+try:
+ if not (is_transformers_available() and is_torch_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import * # noqa F403
+else:
+ from .pipeline_text_to_video_synth import TextToVideoSDPipeline # noqa: F401
diff --git a/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2eee91ed3adb5b9f3499474522ccb4895772b18d
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b6400100dda59fa1d75f506746add3efc00ee49b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/pipeline_text_to_video_synth.cpython-310.pyc b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/pipeline_text_to_video_synth.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..07b88f7d7ce3962b0cde45f4f2b10db4cda922dd
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/pipeline_text_to_video_synth.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/pipeline_text_to_video_synth.cpython-39.pyc b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/pipeline_text_to_video_synth.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1199407b54d8875c94fd4640362c0c2b3d487a36
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/__pycache__/pipeline_text_to_video_synth.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py
new file mode 100644
index 0000000000000000000000000000000000000000..1cbe78f0c964773ca64603b07bd5fda3d1e1ea19
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/text_to_video_synthesis/pipeline_text_to_video_synth.py
@@ -0,0 +1,677 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Any, Callable, Dict, List, Optional, Union
+
+import numpy as np
+import torch
+from transformers import CLIPTextModel, CLIPTokenizer
+
+from ...loaders import TextualInversionLoaderMixin
+from ...models import AutoencoderKL, UNet3DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import (
+ is_accelerate_available,
+ is_accelerate_version,
+ logging,
+ randn_tensor,
+ replace_example_docstring,
+)
+from ..pipeline_utils import DiffusionPipeline
+from . import TextToVideoSDPipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+EXAMPLE_DOC_STRING = """
+ Examples:
+ ```py
+ >>> import torch
+ >>> from diffusers import TextToVideoSDPipeline
+ >>> from diffusers.utils import export_to_video
+
+ >>> pipe = TextToVideoSDPipeline.from_pretrained(
+ ... "damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16"
+ ... )
+ >>> pipe.enable_model_cpu_offload()
+
+ >>> prompt = "Spiderman is surfing"
+ >>> video_frames = pipe(prompt).frames
+ >>> video_path = export_to_video(video_frames)
+ >>> video_path
+ ```
+"""
+
+
+def tensor2vid(video: torch.Tensor, mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) -> List[np.ndarray]:
+ # This code is copied from https://github.com/modelscope/modelscope/blob/1509fdb973e5871f37148a4b5e5964cafd43e64d/modelscope/pipelines/multi_modal/text_to_video_synthesis_pipeline.py#L78
+ # reshape to ncfhw
+ mean = torch.tensor(mean, device=video.device).reshape(1, -1, 1, 1, 1)
+ std = torch.tensor(std, device=video.device).reshape(1, -1, 1, 1, 1)
+ # unnormalize back to [0,1]
+ video = video.mul_(std).add_(mean)
+ video.clamp_(0, 1)
+ # prepare the final outputs
+ i, c, f, h, w = video.shape
+ images = video.permute(2, 3, 0, 4, 1).reshape(
+ f, h, i * w, c
+ ) # 1st (frames, h, batch_size, w, c) 2nd (frames, h, batch_size * w, c)
+ images = images.unbind(dim=0) # prepare a list of indvidual (consecutive frames)
+ images = [(image.cpu().numpy() * 255).astype("uint8") for image in images] # f h w c
+ return images
+
+
+class TextToVideoSDPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
+ r"""
+ Pipeline for text-to-video generation.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Same as Stable Diffusion 2.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet3DConditionModel`]): Conditional U-Net architecture to denoise the encoded video latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+
+ def __init__(
+ self,
+ vae: AutoencoderKL,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ unet: UNet3DConditionModel,
+ scheduler: KarrasDiffusionSchedulers,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ unet=unet,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
+ def enable_vae_slicing(self):
+ r"""
+ Enable sliced VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
+ steps. This is useful to save some memory and allow larger batch sizes.
+ """
+ self.vae.enable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_slicing
+ def disable_vae_slicing(self):
+ r"""
+ Disable sliced VAE decoding. If `enable_vae_slicing` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_slicing()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_tiling
+ def enable_vae_tiling(self):
+ r"""
+ Enable tiled VAE decoding.
+
+ When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in
+ several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
+ """
+ self.vae.enable_tiling()
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.disable_vae_tiling
+ def disable_vae_tiling(self):
+ r"""
+ Disable tiled VAE decoding. If `enable_vae_tiling` was previously invoked, this method will go back to
+ computing decoding in one step.
+ """
+ self.vae.disable_tiling()
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded
+ to GPU only when their specific submodule has its `forward` method called. Note that offloading happens on a
+ submodule basis. Memory savings are higher than with `enable_model_cpu_offload`, but performance is lower.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.14.0"):
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("`enable_sequential_cpu_offload` requires `accelerate v0.14.0` or higher")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
+ cpu_offload(cpu_offloaded_model, device)
+
+ def enable_model_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
+ to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
+ method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
+ `enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
+ """
+ if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ if self.device.type != "cpu":
+ self.to("cpu", silence_dtype_warnings=True)
+ torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ hook = None
+ for cpu_offloaded_model in [self.text_encoder, self.unet, self.vae]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.final_offload_hook = hook
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.unet, "_hf_hook"):
+ return self.device
+ for module in self.unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt=None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ ):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ """
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ if prompt_embeds is None:
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance and negative_prompt_embeds is None:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ # textual inversion: procecss multi-vector tokens if necessary
+ if isinstance(self, TextualInversionLoaderMixin):
+ uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = negative_prompt_embeds[0]
+
+ if do_classifier_free_guidance:
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+
+ negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+
+ batch_size, channels, num_frames, height, width = latents.shape
+ latents = latents.permute(0, 2, 1, 3, 4).reshape(batch_size * num_frames, channels, height, width)
+
+ image = self.vae.decode(latents).sample
+ video = (
+ image[None, :]
+ .reshape(
+ (
+ batch_size,
+ num_frames,
+ -1,
+ )
+ + image.shape[2:]
+ )
+ .permute(0, 2, 1, 3, 4)
+ )
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ video = video.float()
+ return video
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ def prepare_latents(
+ self, batch_size, num_channels_latents, num_frames, height, width, dtype, device, generator, latents=None
+ ):
+ shape = (
+ batch_size,
+ num_channels_latents,
+ num_frames,
+ height // self.vae_scale_factor,
+ width // self.vae_scale_factor,
+ )
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ @replace_example_docstring(EXAMPLE_DOC_STRING)
+ def __call__(
+ self,
+ prompt: Union[str, List[str]] = None,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_frames: int = 16,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 9.0,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ prompt_embeds: Optional[torch.FloatTensor] = None,
+ negative_prompt_embeds: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "np",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts to guide the video generation. If not defined, one has to pass `prompt_embeds`.
+ instead.
+ height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated video.
+ width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated video.
+ num_frames (`int`, *optional*, defaults to 16):
+ The number of video frames that are generated. Defaults to 16 frames which at 8 frames per seconds
+ amounts to 2 seconds of video.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality videos at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate videos that are closely linked to the text `prompt`,
+ usually at the expense of lower video quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the video generation. If not defined, one has to pass
+ `negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
+ less than `1`).
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for video
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`. Latents should be of shape
+ `(batch_size, num_channel, num_frames, height, width)`.
+ prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
+ provided, text embeddings will be generated from `prompt` input argument.
+ negative_prompt_embeds (`torch.FloatTensor`, *optional*):
+ Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
+ weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
+ argument.
+ output_type (`str`, *optional*, defaults to `"np"`):
+ The output format of the generate video. Choose between `torch.FloatTensor` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.TextToVideoSDPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Examples:
+
+ Returns:
+ [`~pipelines.stable_diffusion.TextToVideoSDPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.TextToVideoSDPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated frames.
+ """
+ # 0. Default height and width to unet
+ height = height or self.unet.config.sample_size * self.vae_scale_factor
+ width = width or self.unet.config.sample_size * self.vae_scale_factor
+
+ num_images_per_prompt = 1
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(
+ prompt, height, width, callback_steps, negative_prompt, prompt_embeds, negative_prompt_embeds
+ )
+
+ # 2. Define call parameters
+ if prompt is not None and isinstance(prompt, str):
+ batch_size = 1
+ elif prompt is not None and isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ batch_size = prompt_embeds.shape[0]
+
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ negative_prompt,
+ prompt_embeds=prompt_embeds,
+ negative_prompt_embeds=negative_prompt_embeds,
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ num_frames,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
+ with self.progress_bar(total=num_inference_steps) as progress_bar:
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.unet(
+ latent_model_input,
+ t,
+ encoder_hidden_states=prompt_embeds,
+ cross_attention_kwargs=cross_attention_kwargs,
+ ).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # reshape latents
+ bsz, channel, frames, width, height = latents.shape
+ latents = latents.permute(0, 2, 1, 3, 4).reshape(bsz * frames, channel, width, height)
+ noise_pred = noise_pred.permute(0, 2, 1, 3, 4).reshape(bsz * frames, channel, width, height)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # reshape latents back
+ latents = latents[None, :].reshape(bsz, frames, channel, width, height).permute(0, 2, 1, 3, 4)
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
+ progress_bar.update()
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ video_tensor = self.decode_latents(latents)
+
+ if output_type == "pt":
+ video = video_tensor
+ else:
+ video = tensor2vid(video_tensor)
+
+ # Offload last model to CPU
+ if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
+ self.final_offload_hook.offload()
+
+ if not return_dict:
+ return (video,)
+
+ return TextToVideoSDPipelineOutput(frames=video)
diff --git a/diffusers/src/diffusers/pipelines/unclip/__init__.py b/diffusers/src/diffusers/pipelines/unclip/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..075e66bb680aca294b36aa7ad0abb8d0f651cd92
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/unclip/__init__.py
@@ -0,0 +1,17 @@
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ is_torch_available,
+ is_transformers_available,
+ is_transformers_version,
+)
+
+
+try:
+ if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.25.0")):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import UnCLIPImageVariationPipeline, UnCLIPPipeline
+else:
+ from .pipeline_unclip import UnCLIPPipeline
+ from .pipeline_unclip_image_variation import UnCLIPImageVariationPipeline
+ from .text_proj import UnCLIPTextProjModel
diff --git a/diffusers/src/diffusers/pipelines/unclip/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/unclip/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9a3730ab6475b03ff89c949396a50183e5817d9b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/unclip/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/unclip/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/unclip/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..16b7008a9ffbaa0ea65d463896c4c730ea0865a9
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/unclip/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip.cpython-310.pyc b/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5da4bcb141a798f83d7fe3b0cf546db96bfc5889
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip.cpython-39.pyc b/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..22e0c2b351b5dfea00370339ebfbc186be563a4c
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip_image_variation.cpython-310.pyc b/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip_image_variation.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..44e1d14543abf19b8dfc818169b4cac4904d0deb
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip_image_variation.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip_image_variation.cpython-39.pyc b/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip_image_variation.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..07fc2302b6577290eb042abfd25446fd1aab2f1d
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/unclip/__pycache__/pipeline_unclip_image_variation.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/unclip/__pycache__/text_proj.cpython-310.pyc b/diffusers/src/diffusers/pipelines/unclip/__pycache__/text_proj.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..929e4a4313e60f0a45a2f196474dbde4a0ed62fd
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/unclip/__pycache__/text_proj.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/unclip/__pycache__/text_proj.cpython-39.pyc b/diffusers/src/diffusers/pipelines/unclip/__pycache__/text_proj.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d8fa2e08f3e931aba30ba5bc36ead80760a05a65
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/unclip/__pycache__/text_proj.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/unclip/pipeline_unclip.py b/diffusers/src/diffusers/pipelines/unclip/pipeline_unclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..3aac39b3a3b022724c67cfa5d387a08f03e5bbe7
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/unclip/pipeline_unclip.py
@@ -0,0 +1,534 @@
+# Copyright 2023 Kakao Brain and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import List, Optional, Tuple, Union
+
+import torch
+from torch.nn import functional as F
+from transformers import CLIPTextModelWithProjection, CLIPTokenizer
+from transformers.models.clip.modeling_clip import CLIPTextModelOutput
+
+from ...models import PriorTransformer, UNet2DConditionModel, UNet2DModel
+from ...pipelines import DiffusionPipeline
+from ...pipelines.pipeline_utils import ImagePipelineOutput
+from ...schedulers import UnCLIPScheduler
+from ...utils import is_accelerate_available, logging, randn_tensor
+from .text_proj import UnCLIPTextProjModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class UnCLIPPipeline(DiffusionPipeline):
+ """
+ Pipeline for text-to-image generation using unCLIP
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ text_encoder ([`CLIPTextModelWithProjection`]):
+ Frozen text-encoder.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ prior ([`PriorTransformer`]):
+ The canonincal unCLIP prior to approximate the image embedding from the text embedding.
+ text_proj ([`UnCLIPTextProjModel`]):
+ Utility class to prepare and combine the embeddings before they are passed to the decoder.
+ decoder ([`UNet2DConditionModel`]):
+ The decoder to invert the image embedding into an image.
+ super_res_first ([`UNet2DModel`]):
+ Super resolution unet. Used in all but the last step of the super resolution diffusion process.
+ super_res_last ([`UNet2DModel`]):
+ Super resolution unet. Used in the last step of the super resolution diffusion process.
+ prior_scheduler ([`UnCLIPScheduler`]):
+ Scheduler used in the prior denoising process. Just a modified DDPMScheduler.
+ decoder_scheduler ([`UnCLIPScheduler`]):
+ Scheduler used in the decoder denoising process. Just a modified DDPMScheduler.
+ super_res_scheduler ([`UnCLIPScheduler`]):
+ Scheduler used in the super resolution denoising process. Just a modified DDPMScheduler.
+
+ """
+
+ prior: PriorTransformer
+ decoder: UNet2DConditionModel
+ text_proj: UnCLIPTextProjModel
+ text_encoder: CLIPTextModelWithProjection
+ tokenizer: CLIPTokenizer
+ super_res_first: UNet2DModel
+ super_res_last: UNet2DModel
+
+ prior_scheduler: UnCLIPScheduler
+ decoder_scheduler: UnCLIPScheduler
+ super_res_scheduler: UnCLIPScheduler
+
+ def __init__(
+ self,
+ prior: PriorTransformer,
+ decoder: UNet2DConditionModel,
+ text_encoder: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ text_proj: UnCLIPTextProjModel,
+ super_res_first: UNet2DModel,
+ super_res_last: UNet2DModel,
+ prior_scheduler: UnCLIPScheduler,
+ decoder_scheduler: UnCLIPScheduler,
+ super_res_scheduler: UnCLIPScheduler,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ prior=prior,
+ decoder=decoder,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ text_proj=text_proj,
+ super_res_first=super_res_first,
+ super_res_last=super_res_last,
+ prior_scheduler=prior_scheduler,
+ decoder_scheduler=decoder_scheduler,
+ super_res_scheduler=super_res_scheduler,
+ )
+
+ def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ if latents.shape != shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
+ latents = latents.to(device)
+
+ latents = latents * scheduler.init_noise_sigma
+ return latents
+
+ def _encode_prompt(
+ self,
+ prompt,
+ device,
+ num_images_per_prompt,
+ do_classifier_free_guidance,
+ text_model_output: Optional[Union[CLIPTextModelOutput, Tuple]] = None,
+ text_attention_mask: Optional[torch.Tensor] = None,
+ ):
+ if text_model_output is None:
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ text_mask = text_inputs.attention_mask.bool().to(device)
+
+ untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
+
+ if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
+ text_input_ids, untruncated_ids
+ ):
+ removed_text = self.tokenizer.batch_decode(
+ untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
+ )
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+ text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
+
+ text_encoder_output = self.text_encoder(text_input_ids.to(device))
+
+ prompt_embeds = text_encoder_output.text_embeds
+ text_encoder_hidden_states = text_encoder_output.last_hidden_state
+
+ else:
+ batch_size = text_model_output[0].shape[0]
+ prompt_embeds, text_encoder_hidden_states = text_model_output[0], text_model_output[1]
+ text_mask = text_attention_mask
+
+ prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
+ text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
+ text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
+
+ if do_classifier_free_guidance:
+ uncond_tokens = [""] * batch_size
+
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ uncond_text_mask = uncond_input.attention_mask.bool().to(device)
+ negative_prompt_embeds_text_encoder_output = self.text_encoder(uncond_input.input_ids.to(device))
+
+ negative_prompt_embeds = negative_prompt_embeds_text_encoder_output.text_embeds
+ uncond_text_encoder_hidden_states = negative_prompt_embeds_text_encoder_output.last_hidden_state
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
+
+ seq_len = uncond_text_encoder_hidden_states.shape[1]
+ uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
+ uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
+ batch_size * num_images_per_prompt, seq_len, -1
+ )
+ uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
+
+ # done duplicates
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+ text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
+
+ text_mask = torch.cat([uncond_text_mask, text_mask])
+
+ return prompt_embeds, text_encoder_hidden_states, text_mask
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
+ models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
+ when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ # TODO: self.prior.post_process_latents is not covered by the offload hooks, so it fails if added to the list
+ models = [
+ self.decoder,
+ self.text_proj,
+ self.text_encoder,
+ self.super_res_first,
+ self.super_res_last,
+ ]
+ for cpu_offloaded_model in models:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if self.device != torch.device("meta") or not hasattr(self.decoder, "_hf_hook"):
+ return self.device
+ for module in self.decoder.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: int = 1,
+ prior_num_inference_steps: int = 25,
+ decoder_num_inference_steps: int = 25,
+ super_res_num_inference_steps: int = 7,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ prior_latents: Optional[torch.FloatTensor] = None,
+ decoder_latents: Optional[torch.FloatTensor] = None,
+ super_res_latents: Optional[torch.FloatTensor] = None,
+ text_model_output: Optional[Union[CLIPTextModelOutput, Tuple]] = None,
+ text_attention_mask: Optional[torch.Tensor] = None,
+ prior_guidance_scale: float = 4.0,
+ decoder_guidance_scale: float = 8.0,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ ):
+ """
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation. This can only be left undefined if
+ `text_model_output` and `text_attention_mask` is passed.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ prior_num_inference_steps (`int`, *optional*, defaults to 25):
+ The number of denoising steps for the prior. More denoising steps usually lead to a higher quality
+ image at the expense of slower inference.
+ decoder_num_inference_steps (`int`, *optional*, defaults to 25):
+ The number of denoising steps for the decoder. More denoising steps usually lead to a higher quality
+ image at the expense of slower inference.
+ super_res_num_inference_steps (`int`, *optional*, defaults to 7):
+ The number of denoising steps for super resolution. More denoising steps usually lead to a higher
+ quality image at the expense of slower inference.
+ generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ prior_latents (`torch.FloatTensor` of shape (batch size, embeddings dimension), *optional*):
+ Pre-generated noisy latents to be used as inputs for the prior.
+ decoder_latents (`torch.FloatTensor` of shape (batch size, channels, height, width), *optional*):
+ Pre-generated noisy latents to be used as inputs for the decoder.
+ super_res_latents (`torch.FloatTensor` of shape (batch size, channels, super res height, super res width), *optional*):
+ Pre-generated noisy latents to be used as inputs for the decoder.
+ prior_guidance_scale (`float`, *optional*, defaults to 4.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ decoder_guidance_scale (`float`, *optional*, defaults to 4.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ text_model_output (`CLIPTextModelOutput`, *optional*):
+ Pre-defined CLIPTextModel outputs that can be derived from the text encoder. Pre-defined text outputs
+ can be passed for tasks like text embedding interpolations. Make sure to also pass
+ `text_attention_mask` in this case. `prompt` can the be left to `None`.
+ text_attention_mask (`torch.Tensor`, *optional*):
+ Pre-defined CLIP text attention mask that can be derived from the tokenizer. Pre-defined text attention
+ masks are necessary when passing `text_model_output`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+ """
+ if prompt is not None:
+ if isinstance(prompt, str):
+ batch_size = 1
+ elif isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+ else:
+ batch_size = text_model_output[0].shape[0]
+
+ device = self._execution_device
+
+ batch_size = batch_size * num_images_per_prompt
+
+ do_classifier_free_guidance = prior_guidance_scale > 1.0 or decoder_guidance_scale > 1.0
+
+ prompt_embeds, text_encoder_hidden_states, text_mask = self._encode_prompt(
+ prompt, device, num_images_per_prompt, do_classifier_free_guidance, text_model_output, text_attention_mask
+ )
+
+ # prior
+
+ self.prior_scheduler.set_timesteps(prior_num_inference_steps, device=device)
+ prior_timesteps_tensor = self.prior_scheduler.timesteps
+
+ embedding_dim = self.prior.config.embedding_dim
+
+ prior_latents = self.prepare_latents(
+ (batch_size, embedding_dim),
+ prompt_embeds.dtype,
+ device,
+ generator,
+ prior_latents,
+ self.prior_scheduler,
+ )
+
+ for i, t in enumerate(self.progress_bar(prior_timesteps_tensor)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([prior_latents] * 2) if do_classifier_free_guidance else prior_latents
+
+ predicted_image_embedding = self.prior(
+ latent_model_input,
+ timestep=t,
+ proj_embedding=prompt_embeds,
+ encoder_hidden_states=text_encoder_hidden_states,
+ attention_mask=text_mask,
+ ).predicted_image_embedding
+
+ if do_classifier_free_guidance:
+ predicted_image_embedding_uncond, predicted_image_embedding_text = predicted_image_embedding.chunk(2)
+ predicted_image_embedding = predicted_image_embedding_uncond + prior_guidance_scale * (
+ predicted_image_embedding_text - predicted_image_embedding_uncond
+ )
+
+ if i + 1 == prior_timesteps_tensor.shape[0]:
+ prev_timestep = None
+ else:
+ prev_timestep = prior_timesteps_tensor[i + 1]
+
+ prior_latents = self.prior_scheduler.step(
+ predicted_image_embedding,
+ timestep=t,
+ sample=prior_latents,
+ generator=generator,
+ prev_timestep=prev_timestep,
+ ).prev_sample
+
+ prior_latents = self.prior.post_process_latents(prior_latents)
+
+ image_embeddings = prior_latents
+
+ # done prior
+
+ # decoder
+
+ text_encoder_hidden_states, additive_clip_time_embeddings = self.text_proj(
+ image_embeddings=image_embeddings,
+ prompt_embeds=prompt_embeds,
+ text_encoder_hidden_states=text_encoder_hidden_states,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ )
+
+ if device.type == "mps":
+ # HACK: MPS: There is a panic when padding bool tensors,
+ # so cast to int tensor for the pad and back to bool afterwards
+ text_mask = text_mask.type(torch.int)
+ decoder_text_mask = F.pad(text_mask, (self.text_proj.clip_extra_context_tokens, 0), value=1)
+ decoder_text_mask = decoder_text_mask.type(torch.bool)
+ else:
+ decoder_text_mask = F.pad(text_mask, (self.text_proj.clip_extra_context_tokens, 0), value=True)
+
+ self.decoder_scheduler.set_timesteps(decoder_num_inference_steps, device=device)
+ decoder_timesteps_tensor = self.decoder_scheduler.timesteps
+
+ num_channels_latents = self.decoder.in_channels
+ height = self.decoder.sample_size
+ width = self.decoder.sample_size
+
+ decoder_latents = self.prepare_latents(
+ (batch_size, num_channels_latents, height, width),
+ text_encoder_hidden_states.dtype,
+ device,
+ generator,
+ decoder_latents,
+ self.decoder_scheduler,
+ )
+
+ for i, t in enumerate(self.progress_bar(decoder_timesteps_tensor)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([decoder_latents] * 2) if do_classifier_free_guidance else decoder_latents
+
+ noise_pred = self.decoder(
+ sample=latent_model_input,
+ timestep=t,
+ encoder_hidden_states=text_encoder_hidden_states,
+ class_labels=additive_clip_time_embeddings,
+ attention_mask=decoder_text_mask,
+ ).sample
+
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred_uncond, _ = noise_pred_uncond.split(latent_model_input.shape[1], dim=1)
+ noise_pred_text, predicted_variance = noise_pred_text.split(latent_model_input.shape[1], dim=1)
+ noise_pred = noise_pred_uncond + decoder_guidance_scale * (noise_pred_text - noise_pred_uncond)
+ noise_pred = torch.cat([noise_pred, predicted_variance], dim=1)
+
+ if i + 1 == decoder_timesteps_tensor.shape[0]:
+ prev_timestep = None
+ else:
+ prev_timestep = decoder_timesteps_tensor[i + 1]
+
+ # compute the previous noisy sample x_t -> x_t-1
+ decoder_latents = self.decoder_scheduler.step(
+ noise_pred, t, decoder_latents, prev_timestep=prev_timestep, generator=generator
+ ).prev_sample
+
+ decoder_latents = decoder_latents.clamp(-1, 1)
+
+ image_small = decoder_latents
+
+ # done decoder
+
+ # super res
+
+ self.super_res_scheduler.set_timesteps(super_res_num_inference_steps, device=device)
+ super_res_timesteps_tensor = self.super_res_scheduler.timesteps
+
+ channels = self.super_res_first.in_channels // 2
+ height = self.super_res_first.sample_size
+ width = self.super_res_first.sample_size
+
+ super_res_latents = self.prepare_latents(
+ (batch_size, channels, height, width),
+ image_small.dtype,
+ device,
+ generator,
+ super_res_latents,
+ self.super_res_scheduler,
+ )
+
+ if device.type == "mps":
+ # MPS does not support many interpolations
+ image_upscaled = F.interpolate(image_small, size=[height, width])
+ else:
+ interpolate_antialias = {}
+ if "antialias" in inspect.signature(F.interpolate).parameters:
+ interpolate_antialias["antialias"] = True
+
+ image_upscaled = F.interpolate(
+ image_small, size=[height, width], mode="bicubic", align_corners=False, **interpolate_antialias
+ )
+
+ for i, t in enumerate(self.progress_bar(super_res_timesteps_tensor)):
+ # no classifier free guidance
+
+ if i == super_res_timesteps_tensor.shape[0] - 1:
+ unet = self.super_res_last
+ else:
+ unet = self.super_res_first
+
+ latent_model_input = torch.cat([super_res_latents, image_upscaled], dim=1)
+
+ noise_pred = unet(
+ sample=latent_model_input,
+ timestep=t,
+ ).sample
+
+ if i + 1 == super_res_timesteps_tensor.shape[0]:
+ prev_timestep = None
+ else:
+ prev_timestep = super_res_timesteps_tensor[i + 1]
+
+ # compute the previous noisy sample x_t -> x_t-1
+ super_res_latents = self.super_res_scheduler.step(
+ noise_pred, t, super_res_latents, prev_timestep=prev_timestep, generator=generator
+ ).prev_sample
+
+ image = super_res_latents
+ # done super res
+
+ # post processing
+
+ image = image * 0.5 + 0.5
+ image = image.clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/unclip/pipeline_unclip_image_variation.py b/diffusers/src/diffusers/pipelines/unclip/pipeline_unclip_image_variation.py
new file mode 100644
index 0000000000000000000000000000000000000000..56d522354d9a013cb319f4ef03654e9c42607735
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/unclip/pipeline_unclip_image_variation.py
@@ -0,0 +1,463 @@
+# Copyright 2023 Kakao Brain and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import List, Optional, Union
+
+import PIL
+import torch
+from torch.nn import functional as F
+from transformers import (
+ CLIPImageProcessor,
+ CLIPTextModelWithProjection,
+ CLIPTokenizer,
+ CLIPVisionModelWithProjection,
+)
+
+from ...models import UNet2DConditionModel, UNet2DModel
+from ...pipelines import DiffusionPipeline, ImagePipelineOutput
+from ...schedulers import UnCLIPScheduler
+from ...utils import is_accelerate_available, logging, randn_tensor
+from .text_proj import UnCLIPTextProjModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class UnCLIPImageVariationPipeline(DiffusionPipeline):
+ """
+ Pipeline to generate variations from an input image using unCLIP
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ text_encoder ([`CLIPTextModelWithProjection`]):
+ Frozen text-encoder.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `image_encoder`.
+ image_encoder ([`CLIPVisionModelWithProjection`]):
+ Frozen CLIP image-encoder. unCLIP Image Variation uses the vision portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPVisionModelWithProjection),
+ specifically the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ text_proj ([`UnCLIPTextProjModel`]):
+ Utility class to prepare and combine the embeddings before they are passed to the decoder.
+ decoder ([`UNet2DConditionModel`]):
+ The decoder to invert the image embedding into an image.
+ super_res_first ([`UNet2DModel`]):
+ Super resolution unet. Used in all but the last step of the super resolution diffusion process.
+ super_res_last ([`UNet2DModel`]):
+ Super resolution unet. Used in the last step of the super resolution diffusion process.
+ decoder_scheduler ([`UnCLIPScheduler`]):
+ Scheduler used in the decoder denoising process. Just a modified DDPMScheduler.
+ super_res_scheduler ([`UnCLIPScheduler`]):
+ Scheduler used in the super resolution denoising process. Just a modified DDPMScheduler.
+
+ """
+
+ decoder: UNet2DConditionModel
+ text_proj: UnCLIPTextProjModel
+ text_encoder: CLIPTextModelWithProjection
+ tokenizer: CLIPTokenizer
+ feature_extractor: CLIPImageProcessor
+ image_encoder: CLIPVisionModelWithProjection
+ super_res_first: UNet2DModel
+ super_res_last: UNet2DModel
+
+ decoder_scheduler: UnCLIPScheduler
+ super_res_scheduler: UnCLIPScheduler
+
+ def __init__(
+ self,
+ decoder: UNet2DConditionModel,
+ text_encoder: CLIPTextModelWithProjection,
+ tokenizer: CLIPTokenizer,
+ text_proj: UnCLIPTextProjModel,
+ feature_extractor: CLIPImageProcessor,
+ image_encoder: CLIPVisionModelWithProjection,
+ super_res_first: UNet2DModel,
+ super_res_last: UNet2DModel,
+ decoder_scheduler: UnCLIPScheduler,
+ super_res_scheduler: UnCLIPScheduler,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ decoder=decoder,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ text_proj=text_proj,
+ feature_extractor=feature_extractor,
+ image_encoder=image_encoder,
+ super_res_first=super_res_first,
+ super_res_last=super_res_last,
+ decoder_scheduler=decoder_scheduler,
+ super_res_scheduler=super_res_scheduler,
+ )
+
+ # Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.prepare_latents
+ def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ if latents.shape != shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
+ latents = latents.to(device)
+
+ latents = latents * scheduler.init_noise_sigma
+ return latents
+
+ def _encode_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance):
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ text_mask = text_inputs.attention_mask.bool().to(device)
+ text_encoder_output = self.text_encoder(text_input_ids.to(device))
+
+ prompt_embeds = text_encoder_output.text_embeds
+ text_encoder_hidden_states = text_encoder_output.last_hidden_state
+
+ prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
+ text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
+ text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
+
+ if do_classifier_free_guidance:
+ uncond_tokens = [""] * batch_size
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ uncond_text_mask = uncond_input.attention_mask.bool().to(device)
+ negative_prompt_embeds_text_encoder_output = self.text_encoder(uncond_input.input_ids.to(device))
+
+ negative_prompt_embeds = negative_prompt_embeds_text_encoder_output.text_embeds
+ uncond_text_encoder_hidden_states = negative_prompt_embeds_text_encoder_output.last_hidden_state
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
+
+ seq_len = uncond_text_encoder_hidden_states.shape[1]
+ uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
+ uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
+ batch_size * num_images_per_prompt, seq_len, -1
+ )
+ uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
+
+ # done duplicates
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+ text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
+
+ text_mask = torch.cat([uncond_text_mask, text_mask])
+
+ return prompt_embeds, text_encoder_hidden_states, text_mask
+
+ def _encode_image(self, image, device, num_images_per_prompt, image_embeddings: Optional[torch.Tensor] = None):
+ dtype = next(self.image_encoder.parameters()).dtype
+
+ if image_embeddings is None:
+ if not isinstance(image, torch.Tensor):
+ image = self.feature_extractor(images=image, return_tensors="pt").pixel_values
+
+ image = image.to(device=device, dtype=dtype)
+ image_embeddings = self.image_encoder(image).image_embeds
+
+ image_embeddings = image_embeddings.repeat_interleave(num_images_per_prompt, dim=0)
+
+ return image_embeddings
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
+ models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
+ when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ models = [
+ self.decoder,
+ self.text_proj,
+ self.text_encoder,
+ self.super_res_first,
+ self.super_res_last,
+ ]
+ for cpu_offloaded_model in models:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline._execution_device
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if self.device != torch.device("meta") or not hasattr(self.decoder, "_hf_hook"):
+ return self.device
+ for module in self.decoder.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ image: Optional[Union[PIL.Image.Image, List[PIL.Image.Image], torch.FloatTensor]] = None,
+ num_images_per_prompt: int = 1,
+ decoder_num_inference_steps: int = 25,
+ super_res_num_inference_steps: int = 7,
+ generator: Optional[torch.Generator] = None,
+ decoder_latents: Optional[torch.FloatTensor] = None,
+ super_res_latents: Optional[torch.FloatTensor] = None,
+ image_embeddings: Optional[torch.Tensor] = None,
+ decoder_guidance_scale: float = 8.0,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ ):
+ """
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ image (`PIL.Image.Image` or `List[PIL.Image.Image]` or `torch.FloatTensor`):
+ The image or images to guide the image generation. If you provide a tensor, it needs to comply with the
+ configuration of
+ [this](https://huggingface.co/fusing/karlo-image-variations-diffusers/blob/main/feature_extractor/preprocessor_config.json)
+ `CLIPImageProcessor`. Can be left to `None` only when `image_embeddings` are passed.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ decoder_num_inference_steps (`int`, *optional*, defaults to 25):
+ The number of denoising steps for the decoder. More denoising steps usually lead to a higher quality
+ image at the expense of slower inference.
+ super_res_num_inference_steps (`int`, *optional*, defaults to 7):
+ The number of denoising steps for super resolution. More denoising steps usually lead to a higher
+ quality image at the expense of slower inference.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ decoder_latents (`torch.FloatTensor` of shape (batch size, channels, height, width), *optional*):
+ Pre-generated noisy latents to be used as inputs for the decoder.
+ super_res_latents (`torch.FloatTensor` of shape (batch size, channels, super res height, super res width), *optional*):
+ Pre-generated noisy latents to be used as inputs for the decoder.
+ decoder_guidance_scale (`float`, *optional*, defaults to 4.0):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ image_embeddings (`torch.Tensor`, *optional*):
+ Pre-defined image embeddings that can be derived from the image encoder. Pre-defined image embeddings
+ can be passed for tasks like image interpolations. `image` can the be left to `None`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+ """
+ if image is not None:
+ if isinstance(image, PIL.Image.Image):
+ batch_size = 1
+ elif isinstance(image, list):
+ batch_size = len(image)
+ else:
+ batch_size = image.shape[0]
+ else:
+ batch_size = image_embeddings.shape[0]
+
+ prompt = [""] * batch_size
+
+ device = self._execution_device
+
+ batch_size = batch_size * num_images_per_prompt
+
+ do_classifier_free_guidance = decoder_guidance_scale > 1.0
+
+ prompt_embeds, text_encoder_hidden_states, text_mask = self._encode_prompt(
+ prompt, device, num_images_per_prompt, do_classifier_free_guidance
+ )
+
+ image_embeddings = self._encode_image(image, device, num_images_per_prompt, image_embeddings)
+
+ # decoder
+ text_encoder_hidden_states, additive_clip_time_embeddings = self.text_proj(
+ image_embeddings=image_embeddings,
+ prompt_embeds=prompt_embeds,
+ text_encoder_hidden_states=text_encoder_hidden_states,
+ do_classifier_free_guidance=do_classifier_free_guidance,
+ )
+
+ if device.type == "mps":
+ # HACK: MPS: There is a panic when padding bool tensors,
+ # so cast to int tensor for the pad and back to bool afterwards
+ text_mask = text_mask.type(torch.int)
+ decoder_text_mask = F.pad(text_mask, (self.text_proj.clip_extra_context_tokens, 0), value=1)
+ decoder_text_mask = decoder_text_mask.type(torch.bool)
+ else:
+ decoder_text_mask = F.pad(text_mask, (self.text_proj.clip_extra_context_tokens, 0), value=True)
+
+ self.decoder_scheduler.set_timesteps(decoder_num_inference_steps, device=device)
+ decoder_timesteps_tensor = self.decoder_scheduler.timesteps
+
+ num_channels_latents = self.decoder.in_channels
+ height = self.decoder.sample_size
+ width = self.decoder.sample_size
+
+ if decoder_latents is None:
+ decoder_latents = self.prepare_latents(
+ (batch_size, num_channels_latents, height, width),
+ text_encoder_hidden_states.dtype,
+ device,
+ generator,
+ decoder_latents,
+ self.decoder_scheduler,
+ )
+
+ for i, t in enumerate(self.progress_bar(decoder_timesteps_tensor)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([decoder_latents] * 2) if do_classifier_free_guidance else decoder_latents
+
+ noise_pred = self.decoder(
+ sample=latent_model_input,
+ timestep=t,
+ encoder_hidden_states=text_encoder_hidden_states,
+ class_labels=additive_clip_time_embeddings,
+ attention_mask=decoder_text_mask,
+ ).sample
+
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred_uncond, _ = noise_pred_uncond.split(latent_model_input.shape[1], dim=1)
+ noise_pred_text, predicted_variance = noise_pred_text.split(latent_model_input.shape[1], dim=1)
+ noise_pred = noise_pred_uncond + decoder_guidance_scale * (noise_pred_text - noise_pred_uncond)
+ noise_pred = torch.cat([noise_pred, predicted_variance], dim=1)
+
+ if i + 1 == decoder_timesteps_tensor.shape[0]:
+ prev_timestep = None
+ else:
+ prev_timestep = decoder_timesteps_tensor[i + 1]
+
+ # compute the previous noisy sample x_t -> x_t-1
+ decoder_latents = self.decoder_scheduler.step(
+ noise_pred, t, decoder_latents, prev_timestep=prev_timestep, generator=generator
+ ).prev_sample
+
+ decoder_latents = decoder_latents.clamp(-1, 1)
+
+ image_small = decoder_latents
+
+ # done decoder
+
+ # super res
+
+ self.super_res_scheduler.set_timesteps(super_res_num_inference_steps, device=device)
+ super_res_timesteps_tensor = self.super_res_scheduler.timesteps
+
+ channels = self.super_res_first.in_channels // 2
+ height = self.super_res_first.sample_size
+ width = self.super_res_first.sample_size
+
+ if super_res_latents is None:
+ super_res_latents = self.prepare_latents(
+ (batch_size, channels, height, width),
+ image_small.dtype,
+ device,
+ generator,
+ super_res_latents,
+ self.super_res_scheduler,
+ )
+
+ if device.type == "mps":
+ # MPS does not support many interpolations
+ image_upscaled = F.interpolate(image_small, size=[height, width])
+ else:
+ interpolate_antialias = {}
+ if "antialias" in inspect.signature(F.interpolate).parameters:
+ interpolate_antialias["antialias"] = True
+
+ image_upscaled = F.interpolate(
+ image_small, size=[height, width], mode="bicubic", align_corners=False, **interpolate_antialias
+ )
+
+ for i, t in enumerate(self.progress_bar(super_res_timesteps_tensor)):
+ # no classifier free guidance
+
+ if i == super_res_timesteps_tensor.shape[0] - 1:
+ unet = self.super_res_last
+ else:
+ unet = self.super_res_first
+
+ latent_model_input = torch.cat([super_res_latents, image_upscaled], dim=1)
+
+ noise_pred = unet(
+ sample=latent_model_input,
+ timestep=t,
+ ).sample
+
+ if i + 1 == super_res_timesteps_tensor.shape[0]:
+ prev_timestep = None
+ else:
+ prev_timestep = super_res_timesteps_tensor[i + 1]
+
+ # compute the previous noisy sample x_t -> x_t-1
+ super_res_latents = self.super_res_scheduler.step(
+ noise_pred, t, super_res_latents, prev_timestep=prev_timestep, generator=generator
+ ).prev_sample
+
+ image = super_res_latents
+
+ # done super res
+
+ # post processing
+
+ image = image * 0.5 + 0.5
+ image = image.clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/unclip/text_proj.py b/diffusers/src/diffusers/pipelines/unclip/text_proj.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a54c3319f2850084f523922b713cdd8f04a6750
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/unclip/text_proj.py
@@ -0,0 +1,86 @@
+# Copyright 2023 Kakao Brain and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+from torch import nn
+
+from ...configuration_utils import ConfigMixin, register_to_config
+from ...models import ModelMixin
+
+
+class UnCLIPTextProjModel(ModelMixin, ConfigMixin):
+ """
+ Utility class for CLIP embeddings. Used to combine the image and text embeddings into a format usable by the
+ decoder.
+
+ For more details, see the original paper: https://arxiv.org/abs/2204.06125 section 2.1
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ *,
+ clip_extra_context_tokens: int = 4,
+ clip_embeddings_dim: int = 768,
+ time_embed_dim: int,
+ cross_attention_dim,
+ ):
+ super().__init__()
+
+ self.learned_classifier_free_guidance_embeddings = nn.Parameter(torch.zeros(clip_embeddings_dim))
+
+ # parameters for additional clip time embeddings
+ self.embedding_proj = nn.Linear(clip_embeddings_dim, time_embed_dim)
+ self.clip_image_embeddings_project_to_time_embeddings = nn.Linear(clip_embeddings_dim, time_embed_dim)
+
+ # parameters for encoder hidden states
+ self.clip_extra_context_tokens = clip_extra_context_tokens
+ self.clip_extra_context_tokens_proj = nn.Linear(
+ clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim
+ )
+ self.encoder_hidden_states_proj = nn.Linear(clip_embeddings_dim, cross_attention_dim)
+ self.text_encoder_hidden_states_norm = nn.LayerNorm(cross_attention_dim)
+
+ def forward(self, *, image_embeddings, prompt_embeds, text_encoder_hidden_states, do_classifier_free_guidance):
+ if do_classifier_free_guidance:
+ # Add the classifier free guidance embeddings to the image embeddings
+ image_embeddings_batch_size = image_embeddings.shape[0]
+ classifier_free_guidance_embeddings = self.learned_classifier_free_guidance_embeddings.unsqueeze(0)
+ classifier_free_guidance_embeddings = classifier_free_guidance_embeddings.expand(
+ image_embeddings_batch_size, -1
+ )
+ image_embeddings = torch.cat([classifier_free_guidance_embeddings, image_embeddings], dim=0)
+
+ # The image embeddings batch size and the text embeddings batch size are equal
+ assert image_embeddings.shape[0] == prompt_embeds.shape[0]
+
+ batch_size = prompt_embeds.shape[0]
+
+ # "Specifically, we modify the architecture described in Nichol et al. (2021) by projecting and
+ # adding CLIP embeddings to the existing timestep embedding, ...
+ time_projected_prompt_embeds = self.embedding_proj(prompt_embeds)
+ time_projected_image_embeddings = self.clip_image_embeddings_project_to_time_embeddings(image_embeddings)
+ additive_clip_time_embeddings = time_projected_image_embeddings + time_projected_prompt_embeds
+
+ # ... and by projecting CLIP embeddings into four
+ # extra tokens of context that are concatenated to the sequence of outputs from the GLIDE text encoder"
+ clip_extra_context_tokens = self.clip_extra_context_tokens_proj(image_embeddings)
+ clip_extra_context_tokens = clip_extra_context_tokens.reshape(batch_size, -1, self.clip_extra_context_tokens)
+
+ text_encoder_hidden_states = self.encoder_hidden_states_proj(text_encoder_hidden_states)
+ text_encoder_hidden_states = self.text_encoder_hidden_states_norm(text_encoder_hidden_states)
+ text_encoder_hidden_states = text_encoder_hidden_states.permute(0, 2, 1)
+ text_encoder_hidden_states = torch.cat([clip_extra_context_tokens, text_encoder_hidden_states], dim=2)
+
+ return text_encoder_hidden_states, additive_clip_time_embeddings
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/versatile_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..abf9dcff59dbc922dcc7063a1e73560679a23696
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/versatile_diffusion/__init__.py
@@ -0,0 +1,24 @@
+from ...utils import (
+ OptionalDependencyNotAvailable,
+ is_torch_available,
+ is_transformers_available,
+ is_transformers_version,
+)
+
+
+try:
+ if not (is_transformers_available() and is_torch_available() and is_transformers_version(">=", "4.25.0")):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ...utils.dummy_torch_and_transformers_objects import (
+ VersatileDiffusionDualGuidedPipeline,
+ VersatileDiffusionImageVariationPipeline,
+ VersatileDiffusionPipeline,
+ VersatileDiffusionTextToImagePipeline,
+ )
+else:
+ from .modeling_text_unet import UNetFlatConditionModel
+ from .pipeline_versatile_diffusion import VersatileDiffusionPipeline
+ from .pipeline_versatile_diffusion_dual_guided import VersatileDiffusionDualGuidedPipeline
+ from .pipeline_versatile_diffusion_image_variation import VersatileDiffusionImageVariationPipeline
+ from .pipeline_versatile_diffusion_text_to_image import VersatileDiffusionTextToImagePipeline
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8fafedd8676b2c436fad5a9029eb0980e94dcc88
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..487f6b9439acaa2fb13ee7ab282014ef7a468b48
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/modeling_text_unet.cpython-310.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/modeling_text_unet.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b7b2cd22f0b6a45744fe4b069776ceaec1572004
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/modeling_text_unet.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/modeling_text_unet.cpython-39.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/modeling_text_unet.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9fb049b99c6f630f871000f66c970271fb5ab667
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/modeling_text_unet.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c1deb364ccc7a4849f1a527ec6b1ac7260058c5c
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9d578c0ea85dad25b07583c8e678c6dbca47b9f0
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_dual_guided.cpython-310.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_dual_guided.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e3ad69fadd012187725d16c70fda084df41483b5
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_dual_guided.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_dual_guided.cpython-39.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_dual_guided.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ced51a276b360487eb61a845890bd0d0058c093c
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_dual_guided.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_image_variation.cpython-310.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_image_variation.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5569f538a79ab0d823d9b7d4758d230e0399877c
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_image_variation.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_image_variation.cpython-39.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_image_variation.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1efb1772f70d5712b07d26f9c081582b591ffd52
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_image_variation.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_text_to_image.cpython-310.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_text_to_image.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6f0c68f5970ca5deb2fc287499801a8834ae5115
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_text_to_image.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_text_to_image.cpython-39.pyc b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_text_to_image.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b67346d8366dcfad3cb7373aca255b85938c5896
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/versatile_diffusion/__pycache__/pipeline_versatile_diffusion_text_to_image.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/modeling_text_unet.py b/diffusers/src/diffusers/pipelines/versatile_diffusion/modeling_text_unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ffceb61f8b1dc18e7878371b56d8425177abf43
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/versatile_diffusion/modeling_text_unet.py
@@ -0,0 +1,1554 @@
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+from ...configuration_utils import ConfigMixin, register_to_config
+from ...models import ModelMixin
+from ...models.attention import Attention
+from ...models.attention_processor import AttentionProcessor, AttnAddedKVProcessor, AttnProcessor
+from ...models.dual_transformer_2d import DualTransformer2DModel
+from ...models.embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
+from ...models.transformer_2d import Transformer2DModel, Transformer2DModelOutput
+from ...models.unet_2d_condition import UNet2DConditionOutput
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def get_down_block(
+ down_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ temb_channels,
+ add_downsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ downsample_padding=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+):
+ down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
+ if down_block_type == "DownBlockFlat":
+ return DownBlockFlat(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif down_block_type == "CrossAttnDownBlockFlat":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlockFlat")
+ return CrossAttnDownBlockFlat(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ add_downsample=add_downsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ downsample_padding=downsample_padding,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{down_block_type} is not supported.")
+
+
+def get_up_block(
+ up_block_type,
+ num_layers,
+ in_channels,
+ out_channels,
+ prev_output_channel,
+ temb_channels,
+ add_upsample,
+ resnet_eps,
+ resnet_act_fn,
+ attn_num_head_channels,
+ resnet_groups=None,
+ cross_attention_dim=None,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ resnet_time_scale_shift="default",
+):
+ up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
+ if up_block_type == "UpBlockFlat":
+ return UpBlockFlat(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif up_block_type == "CrossAttnUpBlockFlat":
+ if cross_attention_dim is None:
+ raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlockFlat")
+ return CrossAttnUpBlockFlat(
+ num_layers=num_layers,
+ in_channels=in_channels,
+ out_channels=out_channels,
+ prev_output_channel=prev_output_channel,
+ temb_channels=temb_channels,
+ add_upsample=add_upsample,
+ resnet_eps=resnet_eps,
+ resnet_act_fn=resnet_act_fn,
+ resnet_groups=resnet_groups,
+ cross_attention_dim=cross_attention_dim,
+ attn_num_head_channels=attn_num_head_channels,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ raise ValueError(f"{up_block_type} is not supported.")
+
+
+# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel with UNet2DConditionModel->UNetFlatConditionModel, nn.Conv2d->LinearMultiDim, Block2D->BlockFlat
+class UNetFlatConditionModel(ModelMixin, ConfigMixin):
+ r"""
+ UNetFlatConditionModel is a conditional 2D UNet model that takes in a noisy sample, conditional state, and a
+ timestep and returns sample shaped output.
+
+ This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
+ implements for all the models (such as downloading or saving, etc.)
+
+ Parameters:
+ sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
+ Height and width of input/output sample.
+ in_channels (`int`, *optional*, defaults to 4): The number of channels in the input sample.
+ out_channels (`int`, *optional*, defaults to 4): The number of channels in the output.
+ center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
+ flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
+ Whether to flip the sin to cos in the time embedding.
+ freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
+ down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlockFlat", "CrossAttnDownBlockFlat", "CrossAttnDownBlockFlat", "DownBlockFlat")`):
+ The tuple of downsample blocks to use.
+ mid_block_type (`str`, *optional*, defaults to `"UNetMidBlockFlatCrossAttn"`):
+ The mid block type. Choose from `UNetMidBlockFlatCrossAttn` or `UNetMidBlockFlatSimpleCrossAttn`, will skip
+ the mid block layer if `None`.
+ up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlockFlat", "CrossAttnUpBlockFlat", "CrossAttnUpBlockFlat", "CrossAttnUpBlockFlat",)`):
+ The tuple of upsample blocks to use.
+ only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
+ Whether to include self-attention in the basic transformer blocks, see
+ [`~models.attention.BasicTransformerBlock`].
+ block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
+ The tuple of output channels for each block.
+ layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
+ downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
+ mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
+ act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
+ norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
+ If `None`, it will skip the normalization and activation layers in post-processing
+ norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
+ cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
+ The dimension of the cross attention features.
+ attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
+ resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
+ for resnet blocks, see [`~models.resnet.ResnetBlockFlat`]. Choose from `default` or `scale_shift`.
+ class_embed_type (`str`, *optional*, defaults to None):
+ The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
+ `"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
+ num_class_embeds (`int`, *optional*, defaults to None):
+ Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
+ class conditioning with `class_embed_type` equal to `None`.
+ time_embedding_type (`str`, *optional*, default to `positional`):
+ The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
+ timestep_post_act (`str, *optional*, default to `None`):
+ The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
+ time_cond_proj_dim (`int`, *optional*, default to `None`):
+ The dimension of `cond_proj` layer in timestep embedding.
+ conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer.
+ conv_out_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_out` layer.
+ projection_class_embeddings_input_dim (`int`, *optional*): The dimension of the `class_labels` input when
+ using the "projection" `class_embed_type`. Required when using the "projection" `class_embed_type`.
+ class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
+ embeddings with the class embeddings.
+ """
+
+ _supports_gradient_checkpointing = True
+
+ @register_to_config
+ def __init__(
+ self,
+ sample_size: Optional[int] = None,
+ in_channels: int = 4,
+ out_channels: int = 4,
+ center_input_sample: bool = False,
+ flip_sin_to_cos: bool = True,
+ freq_shift: int = 0,
+ down_block_types: Tuple[str] = (
+ "CrossAttnDownBlockFlat",
+ "CrossAttnDownBlockFlat",
+ "CrossAttnDownBlockFlat",
+ "DownBlockFlat",
+ ),
+ mid_block_type: Optional[str] = "UNetMidBlockFlatCrossAttn",
+ up_block_types: Tuple[str] = (
+ "UpBlockFlat",
+ "CrossAttnUpBlockFlat",
+ "CrossAttnUpBlockFlat",
+ "CrossAttnUpBlockFlat",
+ ),
+ only_cross_attention: Union[bool, Tuple[bool]] = False,
+ block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
+ layers_per_block: int = 2,
+ downsample_padding: int = 1,
+ mid_block_scale_factor: float = 1,
+ act_fn: str = "silu",
+ norm_num_groups: Optional[int] = 32,
+ norm_eps: float = 1e-5,
+ cross_attention_dim: Union[int, Tuple[int]] = 1280,
+ attention_head_dim: Union[int, Tuple[int]] = 8,
+ dual_cross_attention: bool = False,
+ use_linear_projection: bool = False,
+ class_embed_type: Optional[str] = None,
+ num_class_embeds: Optional[int] = None,
+ upcast_attention: bool = False,
+ resnet_time_scale_shift: str = "default",
+ time_embedding_type: str = "positional",
+ timestep_post_act: Optional[str] = None,
+ time_cond_proj_dim: Optional[int] = None,
+ conv_in_kernel: int = 3,
+ conv_out_kernel: int = 3,
+ projection_class_embeddings_input_dim: Optional[int] = None,
+ class_embeddings_concat: bool = False,
+ ):
+ super().__init__()
+
+ self.sample_size = sample_size
+
+ # Check inputs
+ if len(down_block_types) != len(up_block_types):
+ raise ValueError(
+ "Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`:"
+ f" {down_block_types}. `up_block_types`: {up_block_types}."
+ )
+
+ if len(block_out_channels) != len(down_block_types):
+ raise ValueError(
+ "Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`:"
+ f" {block_out_channels}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
+ raise ValueError(
+ "Must provide the same number of `only_cross_attention` as `down_block_types`."
+ f" `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
+ )
+
+ if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
+ raise ValueError(
+ "Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`:"
+ f" {attention_head_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
+ raise ValueError(
+ "Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`:"
+ f" {cross_attention_dim}. `down_block_types`: {down_block_types}."
+ )
+
+ # input
+ conv_in_padding = (conv_in_kernel - 1) // 2
+ self.conv_in = LinearMultiDim(
+ in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
+ )
+
+ # time
+ if time_embedding_type == "fourier":
+ time_embed_dim = block_out_channels[0] * 2
+ if time_embed_dim % 2 != 0:
+ raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
+ self.time_proj = GaussianFourierProjection(
+ time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
+ )
+ timestep_input_dim = time_embed_dim
+ elif time_embedding_type == "positional":
+ time_embed_dim = block_out_channels[0] * 4
+
+ self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
+ timestep_input_dim = block_out_channels[0]
+ else:
+ raise ValueError(
+ f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
+ )
+
+ self.time_embedding = TimestepEmbedding(
+ timestep_input_dim,
+ time_embed_dim,
+ act_fn=act_fn,
+ post_act_fn=timestep_post_act,
+ cond_proj_dim=time_cond_proj_dim,
+ )
+
+ # class embedding
+ if class_embed_type is None and num_class_embeds is not None:
+ self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
+ elif class_embed_type == "timestep":
+ self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
+ elif class_embed_type == "identity":
+ self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
+ elif class_embed_type == "projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
+ # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
+ # 2. it projects from an arbitrary input dimension.
+ #
+ # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
+ # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
+ # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
+ self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
+ elif class_embed_type == "simple_projection":
+ if projection_class_embeddings_input_dim is None:
+ raise ValueError(
+ "`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
+ )
+ self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
+ else:
+ self.class_embedding = None
+
+ self.down_blocks = nn.ModuleList([])
+ self.up_blocks = nn.ModuleList([])
+
+ if isinstance(only_cross_attention, bool):
+ only_cross_attention = [only_cross_attention] * len(down_block_types)
+
+ if isinstance(attention_head_dim, int):
+ attention_head_dim = (attention_head_dim,) * len(down_block_types)
+
+ if isinstance(cross_attention_dim, int):
+ cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
+
+ if class_embeddings_concat:
+ # The time embeddings are concatenated with the class embeddings. The dimension of the
+ # time embeddings passed to the down, middle, and up blocks is twice the dimension of the
+ # regular time embeddings
+ blocks_time_embed_dim = time_embed_dim * 2
+ else:
+ blocks_time_embed_dim = time_embed_dim
+
+ # down
+ output_channel = block_out_channels[0]
+ for i, down_block_type in enumerate(down_block_types):
+ input_channel = output_channel
+ output_channel = block_out_channels[i]
+ is_final_block = i == len(block_out_channels) - 1
+
+ down_block = get_down_block(
+ down_block_type,
+ num_layers=layers_per_block,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_downsample=not is_final_block,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=cross_attention_dim[i],
+ attn_num_head_channels=attention_head_dim[i],
+ downsample_padding=downsample_padding,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.down_blocks.append(down_block)
+
+ # mid
+ if mid_block_type == "UNetMidBlockFlatCrossAttn":
+ self.mid_block = UNetMidBlockFlatCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ cross_attention_dim=cross_attention_dim[-1],
+ attn_num_head_channels=attention_head_dim[-1],
+ resnet_groups=norm_num_groups,
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ elif mid_block_type == "UNetMidBlockFlatSimpleCrossAttn":
+ self.mid_block = UNetMidBlockFlatSimpleCrossAttn(
+ in_channels=block_out_channels[-1],
+ temb_channels=blocks_time_embed_dim,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ output_scale_factor=mid_block_scale_factor,
+ cross_attention_dim=cross_attention_dim[-1],
+ attn_num_head_channels=attention_head_dim[-1],
+ resnet_groups=norm_num_groups,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ elif mid_block_type is None:
+ self.mid_block = None
+ else:
+ raise ValueError(f"unknown mid_block_type : {mid_block_type}")
+
+ # count how many layers upsample the images
+ self.num_upsamplers = 0
+
+ # up
+ reversed_block_out_channels = list(reversed(block_out_channels))
+ reversed_attention_head_dim = list(reversed(attention_head_dim))
+ reversed_cross_attention_dim = list(reversed(cross_attention_dim))
+ only_cross_attention = list(reversed(only_cross_attention))
+
+ output_channel = reversed_block_out_channels[0]
+ for i, up_block_type in enumerate(up_block_types):
+ is_final_block = i == len(block_out_channels) - 1
+
+ prev_output_channel = output_channel
+ output_channel = reversed_block_out_channels[i]
+ input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
+
+ # add upsample block for all BUT final layer
+ if not is_final_block:
+ add_upsample = True
+ self.num_upsamplers += 1
+ else:
+ add_upsample = False
+
+ up_block = get_up_block(
+ up_block_type,
+ num_layers=layers_per_block + 1,
+ in_channels=input_channel,
+ out_channels=output_channel,
+ prev_output_channel=prev_output_channel,
+ temb_channels=blocks_time_embed_dim,
+ add_upsample=add_upsample,
+ resnet_eps=norm_eps,
+ resnet_act_fn=act_fn,
+ resnet_groups=norm_num_groups,
+ cross_attention_dim=reversed_cross_attention_dim[i],
+ attn_num_head_channels=reversed_attention_head_dim[i],
+ dual_cross_attention=dual_cross_attention,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention[i],
+ upcast_attention=upcast_attention,
+ resnet_time_scale_shift=resnet_time_scale_shift,
+ )
+ self.up_blocks.append(up_block)
+ prev_output_channel = output_channel
+
+ # out
+ if norm_num_groups is not None:
+ self.conv_norm_out = nn.GroupNorm(
+ num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
+ )
+ self.conv_act = nn.SiLU()
+ else:
+ self.conv_norm_out = None
+ self.conv_act = None
+
+ conv_out_padding = (conv_out_kernel - 1) // 2
+ self.conv_out = LinearMultiDim(
+ block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
+ )
+
+ @property
+ def attn_processors(self) -> Dict[str, AttentionProcessor]:
+ r"""
+ Returns:
+ `dict` of attention processors: A dictionary containing all attention processors used in the model with
+ indexed by its weight name.
+ """
+ # set recursively
+ processors = {}
+
+ def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
+ if hasattr(module, "set_processor"):
+ processors[f"{name}.processor"] = module.processor
+
+ for sub_name, child in module.named_children():
+ fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
+
+ return processors
+
+ for name, module in self.named_children():
+ fn_recursive_add_processors(name, module, processors)
+
+ return processors
+
+ def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
+ r"""
+ Parameters:
+ `processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
+ The instantiated processor class or a dictionary of processor classes that will be set as the processor
+ of **all** `Attention` layers.
+ In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainable attention processors.:
+
+ """
+ count = len(self.attn_processors.keys())
+
+ if isinstance(processor, dict) and len(processor) != count:
+ raise ValueError(
+ f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
+ f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
+ )
+
+ def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
+ if hasattr(module, "set_processor"):
+ if not isinstance(processor, dict):
+ module.set_processor(processor)
+ else:
+ module.set_processor(processor.pop(f"{name}.processor"))
+
+ for sub_name, child in module.named_children():
+ fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
+
+ for name, module in self.named_children():
+ fn_recursive_attn_processor(name, module, processor)
+
+ def set_default_attn_processor(self):
+ """
+ Disables custom attention processors and sets the default attention implementation.
+ """
+ self.set_attn_processor(AttnProcessor())
+
+ def set_attention_slice(self, slice_size):
+ r"""
+ Enable sliced attention computation.
+
+ When this option is enabled, the attention module will split the input tensor in slices, to compute attention
+ in several steps. This is useful to save some memory in exchange for a small speed decrease.
+
+ Args:
+ slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
+ When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
+ `"max"`, maximum amount of memory will be saved by running only one slice at a time. If a number is
+ provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
+ must be a multiple of `slice_size`.
+ """
+ sliceable_head_dims = []
+
+ def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ sliceable_head_dims.append(module.sliceable_head_dim)
+
+ for child in module.children():
+ fn_recursive_retrieve_sliceable_dims(child)
+
+ # retrieve number of attention layers
+ for module in self.children():
+ fn_recursive_retrieve_sliceable_dims(module)
+
+ num_sliceable_layers = len(sliceable_head_dims)
+
+ if slice_size == "auto":
+ # half the attention head size is usually a good trade-off between
+ # speed and memory
+ slice_size = [dim // 2 for dim in sliceable_head_dims]
+ elif slice_size == "max":
+ # make smallest slice possible
+ slice_size = num_sliceable_layers * [1]
+
+ slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
+
+ if len(slice_size) != len(sliceable_head_dims):
+ raise ValueError(
+ f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
+ f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
+ )
+
+ for i in range(len(slice_size)):
+ size = slice_size[i]
+ dim = sliceable_head_dims[i]
+ if size is not None and size > dim:
+ raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
+
+ # Recursively walk through all the children.
+ # Any children which exposes the set_attention_slice method
+ # gets the message
+ def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
+ if hasattr(module, "set_attention_slice"):
+ module.set_attention_slice(slice_size.pop())
+
+ for child in module.children():
+ fn_recursive_set_attention_slice(child, slice_size)
+
+ reversed_slice_size = list(reversed(slice_size))
+ for module in self.children():
+ fn_recursive_set_attention_slice(module, reversed_slice_size)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (CrossAttnDownBlockFlat, DownBlockFlat, CrossAttnUpBlockFlat, UpBlockFlat)):
+ module.gradient_checkpointing = value
+
+ def forward(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[torch.Tensor, float, int],
+ encoder_hidden_states: torch.Tensor,
+ class_labels: Optional[torch.Tensor] = None,
+ timestep_cond: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
+ mid_block_additional_residual: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ return_dict: bool = True,
+ ) -> Union[UNet2DConditionOutput, Tuple]:
+ r"""
+ Args:
+ sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
+ timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
+ encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
+ encoder_attention_mask (`torch.Tensor`):
+ (batch, sequence_length) cross-attention mask (or bias), applied to encoder_hidden_states. If a
+ BoolTensor is provided, it will be turned into a bias, by adding a large negative value. False = hide
+ token. Other tensor types will be used as-is as bias values.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
+ cross_attention_kwargs (`dict`, *optional*):
+ A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
+ `self.processor` in
+ [diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
+
+ Returns:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
+ [`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ # By default samples have to be AT least a multiple of the overall upsampling factor.
+ # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
+ # However, the upsampling interpolation output size can be forced to fit any upsampling size
+ # on the fly if necessary.
+ default_overall_up_factor = 2**self.num_upsamplers
+
+ # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
+ forward_upsample_size = False
+ upsample_size = None
+
+ if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
+ logger.info("Forward upsample size to force interpolation output size.")
+ forward_upsample_size = True
+
+ # prepare attention_mask
+ if attention_mask is not None:
+ attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
+ attention_mask = attention_mask.unsqueeze(1)
+
+ # ensure encoder_attention_mask is a bias, and make it broadcastable over multi-head-attention channels
+ if encoder_attention_mask is not None:
+ # if it's a mask: turn it into a bias. otherwise: assume it's already a bias
+ if encoder_attention_mask.dtype is torch.bool:
+ encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
+ encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
+
+ # 0. center input if necessary
+ if self.config.center_input_sample:
+ sample = 2 * sample - 1.0
+
+ # 1. time
+ timesteps = timestep
+ if not torch.is_tensor(timesteps):
+ # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
+ # This would be a good case for the `match` statement (Python 3.10+)
+ is_mps = sample.device.type == "mps"
+ if isinstance(timestep, float):
+ dtype = torch.float32 if is_mps else torch.float64
+ else:
+ dtype = torch.int32 if is_mps else torch.int64
+ timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
+ elif len(timesteps.shape) == 0:
+ timesteps = timesteps[None].to(sample.device)
+
+ # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
+ timesteps = timesteps.expand(sample.shape[0])
+
+ t_emb = self.time_proj(timesteps)
+
+ # timesteps does not contain any weights and will always return f32 tensors
+ # but time_embedding might actually be running in fp16. so we need to cast here.
+ # there might be better ways to encapsulate this.
+ t_emb = t_emb.to(dtype=self.dtype)
+
+ emb = self.time_embedding(t_emb, timestep_cond)
+
+ if self.class_embedding is not None:
+ if class_labels is None:
+ raise ValueError("class_labels should be provided when num_class_embeds > 0")
+
+ if self.config.class_embed_type == "timestep":
+ class_labels = self.time_proj(class_labels)
+
+ class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
+
+ if self.config.class_embeddings_concat:
+ emb = torch.cat([emb, class_emb], dim=-1)
+ else:
+ emb = emb + class_emb
+
+ # 2. pre-process
+ sample = self.conv_in(sample)
+
+ # 3. down
+ down_block_res_samples = (sample,)
+ for downsample_block in self.down_blocks:
+ if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
+ sample, res_samples = downsample_block(
+ hidden_states=sample,
+ temb=emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ else:
+ sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
+
+ down_block_res_samples += res_samples
+
+ if down_block_additional_residuals is not None:
+ new_down_block_res_samples = ()
+
+ for down_block_res_sample, down_block_additional_residual in zip(
+ down_block_res_samples, down_block_additional_residuals
+ ):
+ down_block_res_sample = down_block_res_sample + down_block_additional_residual
+ new_down_block_res_samples += (down_block_res_sample,)
+
+ down_block_res_samples = new_down_block_res_samples
+
+ # 4. mid
+ if self.mid_block is not None:
+ sample = self.mid_block(
+ sample,
+ emb,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ cross_attention_kwargs=cross_attention_kwargs,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+
+ if mid_block_additional_residual is not None:
+ sample = sample + mid_block_additional_residual
+
+ # 5. up
+ for i, upsample_block in enumerate(self.up_blocks):
+ is_final_block = i == len(self.up_blocks) - 1
+
+ res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
+ down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
+
+ # if we have not reached the final block and need to forward the
+ # upsample size, we do it here
+ if not is_final_block and forward_upsample_size:
+ upsample_size = down_block_res_samples[-1].shape[2:]
+
+ if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
+ sample = upsample_block(
+ hidden_states=sample,
+ temb=emb,
+ res_hidden_states_tuple=res_samples,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ upsample_size=upsample_size,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ else:
+ sample = upsample_block(
+ hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
+ )
+
+ # 6. post-process
+ if self.conv_norm_out:
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+
+ if not return_dict:
+ return (sample,)
+
+ return UNet2DConditionOutput(sample=sample)
+
+
+class LinearMultiDim(nn.Linear):
+ def __init__(self, in_features, out_features=None, second_dim=4, *args, **kwargs):
+ in_features = [in_features, second_dim, 1] if isinstance(in_features, int) else list(in_features)
+ if out_features is None:
+ out_features = in_features
+ out_features = [out_features, second_dim, 1] if isinstance(out_features, int) else list(out_features)
+ self.in_features_multidim = in_features
+ self.out_features_multidim = out_features
+ super().__init__(np.array(in_features).prod(), np.array(out_features).prod())
+
+ def forward(self, input_tensor, *args, **kwargs):
+ shape = input_tensor.shape
+ n_dim = len(self.in_features_multidim)
+ input_tensor = input_tensor.reshape(*shape[0:-n_dim], self.in_features)
+ output_tensor = super().forward(input_tensor)
+ output_tensor = output_tensor.view(*shape[0:-n_dim], *self.out_features_multidim)
+ return output_tensor
+
+
+class ResnetBlockFlat(nn.Module):
+ def __init__(
+ self,
+ *,
+ in_channels,
+ out_channels=None,
+ dropout=0.0,
+ temb_channels=512,
+ groups=32,
+ groups_out=None,
+ pre_norm=True,
+ eps=1e-6,
+ time_embedding_norm="default",
+ use_in_shortcut=None,
+ second_dim=4,
+ **kwargs,
+ ):
+ super().__init__()
+ self.pre_norm = pre_norm
+ self.pre_norm = True
+
+ in_channels = [in_channels, second_dim, 1] if isinstance(in_channels, int) else list(in_channels)
+ self.in_channels_prod = np.array(in_channels).prod()
+ self.channels_multidim = in_channels
+
+ if out_channels is not None:
+ out_channels = [out_channels, second_dim, 1] if isinstance(out_channels, int) else list(out_channels)
+ out_channels_prod = np.array(out_channels).prod()
+ self.out_channels_multidim = out_channels
+ else:
+ out_channels_prod = self.in_channels_prod
+ self.out_channels_multidim = self.channels_multidim
+ self.time_embedding_norm = time_embedding_norm
+
+ if groups_out is None:
+ groups_out = groups
+
+ self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=self.in_channels_prod, eps=eps, affine=True)
+ self.conv1 = torch.nn.Conv2d(self.in_channels_prod, out_channels_prod, kernel_size=1, padding=0)
+
+ if temb_channels is not None:
+ self.time_emb_proj = torch.nn.Linear(temb_channels, out_channels_prod)
+ else:
+ self.time_emb_proj = None
+
+ self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels_prod, eps=eps, affine=True)
+ self.dropout = torch.nn.Dropout(dropout)
+ self.conv2 = torch.nn.Conv2d(out_channels_prod, out_channels_prod, kernel_size=1, padding=0)
+
+ self.nonlinearity = nn.SiLU()
+
+ self.use_in_shortcut = (
+ self.in_channels_prod != out_channels_prod if use_in_shortcut is None else use_in_shortcut
+ )
+
+ self.conv_shortcut = None
+ if self.use_in_shortcut:
+ self.conv_shortcut = torch.nn.Conv2d(
+ self.in_channels_prod, out_channels_prod, kernel_size=1, stride=1, padding=0
+ )
+
+ def forward(self, input_tensor, temb):
+ shape = input_tensor.shape
+ n_dim = len(self.channels_multidim)
+ input_tensor = input_tensor.reshape(*shape[0:-n_dim], self.in_channels_prod, 1, 1)
+ input_tensor = input_tensor.view(-1, self.in_channels_prod, 1, 1)
+
+ hidden_states = input_tensor
+
+ hidden_states = self.norm1(hidden_states)
+ hidden_states = self.nonlinearity(hidden_states)
+ hidden_states = self.conv1(hidden_states)
+
+ if temb is not None:
+ temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None]
+ hidden_states = hidden_states + temb
+
+ hidden_states = self.norm2(hidden_states)
+ hidden_states = self.nonlinearity(hidden_states)
+
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+
+ if self.conv_shortcut is not None:
+ input_tensor = self.conv_shortcut(input_tensor)
+
+ output_tensor = input_tensor + hidden_states
+
+ output_tensor = output_tensor.view(*shape[0:-n_dim], -1)
+ output_tensor = output_tensor.view(*shape[0:-n_dim], *self.out_channels_multidim)
+
+ return output_tensor
+
+
+# Copied from diffusers.models.unet_2d_blocks.DownBlock2D with DownBlock2D->DownBlockFlat, ResnetBlock2D->ResnetBlockFlat, Downsample2D->LinearMultiDim
+class DownBlockFlat(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_downsample=True,
+ downsample_padding=1,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlockFlat(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ LinearMultiDim(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, temb=None):
+ output_states = ()
+
+ for resnet in self.resnets:
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+# Copied from diffusers.models.unet_2d_blocks.CrossAttnDownBlock2D with CrossAttnDownBlock2D->CrossAttnDownBlockFlat, ResnetBlock2D->ResnetBlockFlat, Downsample2D->LinearMultiDim
+class CrossAttnDownBlockFlat(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ downsample_padding=1,
+ add_downsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+
+ for i in range(num_layers):
+ in_channels = in_channels if i == 0 else out_channels
+ resnets.append(
+ ResnetBlockFlat(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if not dual_cross_attention:
+ attentions.append(
+ Transformer2DModel(
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ else:
+ attentions.append(
+ DualTransformer2DModel(
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_downsample:
+ self.downsamplers = nn.ModuleList(
+ [
+ LinearMultiDim(
+ out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
+ )
+ ]
+ )
+ else:
+ self.downsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ temb: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ ):
+ output_states = ()
+
+ for resnet, attn in zip(self.resnets, self.attentions):
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ None, # timestep
+ None, # class_labels
+ cross_attention_kwargs,
+ attention_mask,
+ encoder_attention_mask,
+ )[0]
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ ).sample
+
+ output_states += (hidden_states,)
+
+ if self.downsamplers is not None:
+ for downsampler in self.downsamplers:
+ hidden_states = downsampler(hidden_states)
+
+ output_states += (hidden_states,)
+
+ return hidden_states, output_states
+
+
+# Copied from diffusers.models.unet_2d_blocks.UpBlock2D with UpBlock2D->UpBlockFlat, ResnetBlock2D->ResnetBlockFlat, Upsample2D->LinearMultiDim
+class UpBlockFlat(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ prev_output_channel: int,
+ out_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ ):
+ super().__init__()
+ resnets = []
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlockFlat(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([LinearMultiDim(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None):
+ for resnet in self.resnets:
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ else:
+ hidden_states = resnet(hidden_states, temb)
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+
+# Copied from diffusers.models.unet_2d_blocks.CrossAttnUpBlock2D with CrossAttnUpBlock2D->CrossAttnUpBlockFlat, ResnetBlock2D->ResnetBlockFlat, Upsample2D->LinearMultiDim
+class CrossAttnUpBlockFlat(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ prev_output_channel: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ cross_attention_dim=1280,
+ output_scale_factor=1.0,
+ add_upsample=True,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ only_cross_attention=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+ resnets = []
+ attentions = []
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+
+ for i in range(num_layers):
+ res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
+ resnet_in_channels = prev_output_channel if i == 0 else out_channels
+
+ resnets.append(
+ ResnetBlockFlat(
+ in_channels=resnet_in_channels + res_skip_channels,
+ out_channels=out_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+ if not dual_cross_attention:
+ attentions.append(
+ Transformer2DModel(
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ only_cross_attention=only_cross_attention,
+ upcast_attention=upcast_attention,
+ )
+ )
+ else:
+ attentions.append(
+ DualTransformer2DModel(
+ attn_num_head_channels,
+ out_channels // attn_num_head_channels,
+ in_channels=out_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ if add_upsample:
+ self.upsamplers = nn.ModuleList([LinearMultiDim(out_channels, use_conv=True, out_channels=out_channels)])
+ else:
+ self.upsamplers = None
+
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
+ temb: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ upsample_size: Optional[int] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ ):
+ for resnet, attn in zip(self.resnets, self.attentions):
+ # pop res hidden states
+ res_hidden_states = res_hidden_states_tuple[-1]
+ res_hidden_states_tuple = res_hidden_states_tuple[:-1]
+ hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
+
+ if self.training and self.gradient_checkpointing:
+
+ def create_custom_forward(module, return_dict=None):
+ def custom_forward(*inputs):
+ if return_dict is not None:
+ return module(*inputs, return_dict=return_dict)
+ else:
+ return module(*inputs)
+
+ return custom_forward
+
+ hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
+ hidden_states = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(attn, return_dict=False),
+ hidden_states,
+ encoder_hidden_states,
+ None, # timestep
+ None, # class_labels
+ cross_attention_kwargs,
+ attention_mask,
+ encoder_attention_mask,
+ )[0]
+ else:
+ hidden_states = resnet(hidden_states, temb)
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ ).sample
+
+ if self.upsamplers is not None:
+ for upsampler in self.upsamplers:
+ hidden_states = upsampler(hidden_states, upsample_size)
+
+ return hidden_states
+
+
+# Copied from diffusers.models.unet_2d_blocks.UNetMidBlock2DCrossAttn with UNetMidBlock2DCrossAttn->UNetMidBlockFlatCrossAttn, ResnetBlock2D->ResnetBlockFlat
+class UNetMidBlockFlatCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ dual_cross_attention=False,
+ use_linear_projection=False,
+ upcast_attention=False,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+ self.attn_num_head_channels = attn_num_head_channels
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlockFlat(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ if not dual_cross_attention:
+ attentions.append(
+ Transformer2DModel(
+ attn_num_head_channels,
+ in_channels // attn_num_head_channels,
+ in_channels=in_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ use_linear_projection=use_linear_projection,
+ upcast_attention=upcast_attention,
+ )
+ )
+ else:
+ attentions.append(
+ DualTransformer2DModel(
+ attn_num_head_channels,
+ in_channels // attn_num_head_channels,
+ in_channels=in_channels,
+ num_layers=1,
+ cross_attention_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ )
+ )
+ resnets.append(
+ ResnetBlockFlat(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ temb: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ cross_attention_kwargs: Optional[Dict[str, Any]] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ ) -> torch.FloatTensor:
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ output: Transformer2DModelOutput = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ cross_attention_kwargs=cross_attention_kwargs,
+ attention_mask=attention_mask,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ hidden_states = output.sample
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
+
+
+# Copied from diffusers.models.unet_2d_blocks.UNetMidBlock2DSimpleCrossAttn with UNetMidBlock2DSimpleCrossAttn->UNetMidBlockFlatSimpleCrossAttn, ResnetBlock2D->ResnetBlockFlat
+class UNetMidBlockFlatSimpleCrossAttn(nn.Module):
+ def __init__(
+ self,
+ in_channels: int,
+ temb_channels: int,
+ dropout: float = 0.0,
+ num_layers: int = 1,
+ resnet_eps: float = 1e-6,
+ resnet_time_scale_shift: str = "default",
+ resnet_act_fn: str = "swish",
+ resnet_groups: int = 32,
+ resnet_pre_norm: bool = True,
+ attn_num_head_channels=1,
+ output_scale_factor=1.0,
+ cross_attention_dim=1280,
+ ):
+ super().__init__()
+
+ self.has_cross_attention = True
+
+ self.attn_num_head_channels = attn_num_head_channels
+ resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
+
+ self.num_heads = in_channels // self.attn_num_head_channels
+
+ # there is always at least one resnet
+ resnets = [
+ ResnetBlockFlat(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ ]
+ attentions = []
+
+ for _ in range(num_layers):
+ attentions.append(
+ Attention(
+ query_dim=in_channels,
+ cross_attention_dim=in_channels,
+ heads=self.num_heads,
+ dim_head=attn_num_head_channels,
+ added_kv_proj_dim=cross_attention_dim,
+ norm_num_groups=resnet_groups,
+ bias=True,
+ upcast_softmax=True,
+ processor=AttnAddedKVProcessor(),
+ )
+ )
+ resnets.append(
+ ResnetBlockFlat(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ temb_channels=temb_channels,
+ eps=resnet_eps,
+ groups=resnet_groups,
+ dropout=dropout,
+ time_embedding_norm=resnet_time_scale_shift,
+ non_linearity=resnet_act_fn,
+ output_scale_factor=output_scale_factor,
+ pre_norm=resnet_pre_norm,
+ )
+ )
+
+ self.attentions = nn.ModuleList(attentions)
+ self.resnets = nn.ModuleList(resnets)
+
+ def forward(
+ self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None, cross_attention_kwargs=None
+ ):
+ cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
+ hidden_states = self.resnets[0](hidden_states, temb)
+ for attn, resnet in zip(self.attentions, self.resnets[1:]):
+ # attn
+ hidden_states = attn(
+ hidden_states,
+ encoder_hidden_states=encoder_hidden_states,
+ attention_mask=attention_mask,
+ **cross_attention_kwargs,
+ )
+
+ # resnet
+ hidden_states = resnet(hidden_states, temb)
+
+ return hidden_states
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion.py b/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d6b5e7863ebb9b53ba741138b0829eab509888c
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion.py
@@ -0,0 +1,434 @@
+import inspect
+from typing import Callable, List, Optional, Union
+
+import PIL.Image
+import torch
+from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModel
+
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import logging
+from ..pipeline_utils import DiffusionPipeline
+from .pipeline_versatile_diffusion_dual_guided import VersatileDiffusionDualGuidedPipeline
+from .pipeline_versatile_diffusion_image_variation import VersatileDiffusionImageVariationPipeline
+from .pipeline_versatile_diffusion_text_to_image import VersatileDiffusionTextToImagePipeline
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class VersatileDiffusionPipeline(DiffusionPipeline):
+ r"""
+ Pipeline for text-to-image generation using Stable Diffusion.
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vae ([`AutoencoderKL`]):
+ Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. Stable Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ safety_checker ([`StableDiffusionMegaSafetyChecker`]):
+ Classification module that estimates whether generated images could be considered offensive or harmful.
+ Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
+ feature_extractor ([`CLIPImageProcessor`]):
+ Model that extracts features from generated images to be used as inputs for the `safety_checker`.
+ """
+
+ tokenizer: CLIPTokenizer
+ image_feature_extractor: CLIPImageProcessor
+ text_encoder: CLIPTextModel
+ image_encoder: CLIPVisionModel
+ image_unet: UNet2DConditionModel
+ text_unet: UNet2DConditionModel
+ vae: AutoencoderKL
+ scheduler: KarrasDiffusionSchedulers
+
+ def __init__(
+ self,
+ tokenizer: CLIPTokenizer,
+ image_feature_extractor: CLIPImageProcessor,
+ text_encoder: CLIPTextModel,
+ image_encoder: CLIPVisionModel,
+ image_unet: UNet2DConditionModel,
+ text_unet: UNet2DConditionModel,
+ vae: AutoencoderKL,
+ scheduler: KarrasDiffusionSchedulers,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ tokenizer=tokenizer,
+ image_feature_extractor=image_feature_extractor,
+ text_encoder=text_encoder,
+ image_encoder=image_encoder,
+ image_unet=image_unet,
+ text_unet=text_unet,
+ vae=vae,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ @torch.no_grad()
+ def image_variation(
+ self,
+ image: Union[torch.FloatTensor, PIL.Image.Image],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ image (`PIL.Image.Image`, `List[PIL.Image.Image]` or `torch.Tensor`):
+ The image prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import VersatileDiffusionPipeline
+ >>> import torch
+ >>> import requests
+ >>> from io import BytesIO
+ >>> from PIL import Image
+
+ >>> # let's download an initial image
+ >>> url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
+
+ >>> response = requests.get(url)
+ >>> image = Image.open(BytesIO(response.content)).convert("RGB")
+
+ >>> pipe = VersatileDiffusionPipeline.from_pretrained(
+ ... "shi-labs/versatile-diffusion", torch_dtype=torch.float16
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> generator = torch.Generator(device="cuda").manual_seed(0)
+ >>> image = pipe.image_variation(image, generator=generator).images[0]
+ >>> image.save("./car_variation.png")
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ expected_components = inspect.signature(VersatileDiffusionImageVariationPipeline.__init__).parameters.keys()
+ components = {name: component for name, component in self.components.items() if name in expected_components}
+ return VersatileDiffusionImageVariationPipeline(**components)(
+ image=image,
+ height=height,
+ width=width,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ negative_prompt=negative_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ callback_steps=callback_steps,
+ )
+
+ @torch.no_grad()
+ def text_to_image(
+ self,
+ prompt: Union[str, List[str]],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import VersatileDiffusionPipeline
+ >>> import torch
+
+ >>> pipe = VersatileDiffusionPipeline.from_pretrained(
+ ... "shi-labs/versatile-diffusion", torch_dtype=torch.float16
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> generator = torch.Generator(device="cuda").manual_seed(0)
+ >>> image = pipe.text_to_image("an astronaut riding on a horse on mars", generator=generator).images[0]
+ >>> image.save("./astronaut.png")
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ expected_components = inspect.signature(VersatileDiffusionTextToImagePipeline.__init__).parameters.keys()
+ components = {name: component for name, component in self.components.items() if name in expected_components}
+ temp_pipeline = VersatileDiffusionTextToImagePipeline(**components)
+ output = temp_pipeline(
+ prompt=prompt,
+ height=height,
+ width=width,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ negative_prompt=negative_prompt,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ callback_steps=callback_steps,
+ )
+ # swap the attention blocks back to the original state
+ temp_pipeline._swap_unet_attention_blocks()
+
+ return output
+
+ @torch.no_grad()
+ def dual_guided(
+ self,
+ prompt: Union[PIL.Image.Image, List[PIL.Image.Image]],
+ image: Union[str, List[str]],
+ text_to_image_strength: float = 0.5,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import VersatileDiffusionPipeline
+ >>> import torch
+ >>> import requests
+ >>> from io import BytesIO
+ >>> from PIL import Image
+
+ >>> # let's download an initial image
+ >>> url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
+
+ >>> response = requests.get(url)
+ >>> image = Image.open(BytesIO(response.content)).convert("RGB")
+ >>> text = "a red car in the sun"
+
+ >>> pipe = VersatileDiffusionPipeline.from_pretrained(
+ ... "shi-labs/versatile-diffusion", torch_dtype=torch.float16
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> generator = torch.Generator(device="cuda").manual_seed(0)
+ >>> text_to_image_strength = 0.75
+
+ >>> image = pipe.dual_guided(
+ ... prompt=text, image=image, text_to_image_strength=text_to_image_strength, generator=generator
+ ... ).images[0]
+ >>> image.save("./car_variation.png")
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.ImagePipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.ImagePipelineOutput`] if `return_dict` is True, otherwise a `tuple. When
+ returning a tuple, the first element is a list with the generated images.
+ """
+
+ expected_components = inspect.signature(VersatileDiffusionDualGuidedPipeline.__init__).parameters.keys()
+ components = {name: component for name, component in self.components.items() if name in expected_components}
+ temp_pipeline = VersatileDiffusionDualGuidedPipeline(**components)
+ output = temp_pipeline(
+ prompt=prompt,
+ image=image,
+ text_to_image_strength=text_to_image_strength,
+ height=height,
+ width=width,
+ num_inference_steps=num_inference_steps,
+ guidance_scale=guidance_scale,
+ num_images_per_prompt=num_images_per_prompt,
+ eta=eta,
+ generator=generator,
+ latents=latents,
+ output_type=output_type,
+ return_dict=return_dict,
+ callback=callback,
+ callback_steps=callback_steps,
+ )
+ temp_pipeline._revert_dual_attention()
+
+ return output
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_dual_guided.py b/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_dual_guided.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f385ed6612cb353970ed60c7646680cbc4f5188
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_dual_guided.py
@@ -0,0 +1,585 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Tuple, Union
+
+import numpy as np
+import PIL
+import torch
+import torch.utils.checkpoint
+from transformers import (
+ CLIPImageProcessor,
+ CLIPTextModelWithProjection,
+ CLIPTokenizer,
+ CLIPVisionModelWithProjection,
+)
+
+from ...models import AutoencoderKL, DualTransformer2DModel, Transformer2DModel, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_available, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+from .modeling_text_unet import UNetFlatConditionModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class VersatileDiffusionDualGuidedPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ vqvae ([`VQModel`]):
+ Vector-quantized (VQ) Model to encode and decode images to and from latent representations.
+ bert ([`LDMBertModel`]):
+ Text-encoder model based on [BERT](https://huggingface.co/docs/transformers/model_doc/bert) architecture.
+ tokenizer (`transformers.BertTokenizer`):
+ Tokenizer of class
+ [BertTokenizer](https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+ tokenizer: CLIPTokenizer
+ image_feature_extractor: CLIPImageProcessor
+ text_encoder: CLIPTextModelWithProjection
+ image_encoder: CLIPVisionModelWithProjection
+ image_unet: UNet2DConditionModel
+ text_unet: UNetFlatConditionModel
+ vae: AutoencoderKL
+ scheduler: KarrasDiffusionSchedulers
+
+ _optional_components = ["text_unet"]
+
+ def __init__(
+ self,
+ tokenizer: CLIPTokenizer,
+ image_feature_extractor: CLIPImageProcessor,
+ text_encoder: CLIPTextModelWithProjection,
+ image_encoder: CLIPVisionModelWithProjection,
+ image_unet: UNet2DConditionModel,
+ text_unet: UNetFlatConditionModel,
+ vae: AutoencoderKL,
+ scheduler: KarrasDiffusionSchedulers,
+ ):
+ super().__init__()
+ self.register_modules(
+ tokenizer=tokenizer,
+ image_feature_extractor=image_feature_extractor,
+ text_encoder=text_encoder,
+ image_encoder=image_encoder,
+ image_unet=image_unet,
+ text_unet=text_unet,
+ vae=vae,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ if self.text_unet is not None and (
+ "dual_cross_attention" not in self.image_unet.config or not self.image_unet.config.dual_cross_attention
+ ):
+ # if loading from a universal checkpoint rather than a saved dual-guided pipeline
+ self._convert_to_dual_attention()
+
+ def remove_unused_weights(self):
+ self.register_modules(text_unet=None)
+
+ def _convert_to_dual_attention(self):
+ """
+ Replace image_unet's `Transformer2DModel` blocks with `DualTransformer2DModel` that contains transformer blocks
+ from both `image_unet` and `text_unet`
+ """
+ for name, module in self.image_unet.named_modules():
+ if isinstance(module, Transformer2DModel):
+ parent_name, index = name.rsplit(".", 1)
+ index = int(index)
+
+ image_transformer = self.image_unet.get_submodule(parent_name)[index]
+ text_transformer = self.text_unet.get_submodule(parent_name)[index]
+
+ config = image_transformer.config
+ dual_transformer = DualTransformer2DModel(
+ num_attention_heads=config.num_attention_heads,
+ attention_head_dim=config.attention_head_dim,
+ in_channels=config.in_channels,
+ num_layers=config.num_layers,
+ dropout=config.dropout,
+ norm_num_groups=config.norm_num_groups,
+ cross_attention_dim=config.cross_attention_dim,
+ attention_bias=config.attention_bias,
+ sample_size=config.sample_size,
+ num_vector_embeds=config.num_vector_embeds,
+ activation_fn=config.activation_fn,
+ num_embeds_ada_norm=config.num_embeds_ada_norm,
+ )
+ dual_transformer.transformers[0] = image_transformer
+ dual_transformer.transformers[1] = text_transformer
+
+ self.image_unet.get_submodule(parent_name)[index] = dual_transformer
+ self.image_unet.register_to_config(dual_cross_attention=True)
+
+ def _revert_dual_attention(self):
+ """
+ Revert the image_unet `DualTransformer2DModel` blocks back to `Transformer2DModel` with image_unet weights Call
+ this function if you reuse `image_unet` in another pipeline, e.g. `VersatileDiffusionPipeline`
+ """
+ for name, module in self.image_unet.named_modules():
+ if isinstance(module, DualTransformer2DModel):
+ parent_name, index = name.rsplit(".", 1)
+ index = int(index)
+ self.image_unet.get_submodule(parent_name)[index] = module.transformers[0]
+
+ self.image_unet.register_to_config(dual_cross_attention=False)
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.image_unet, self.text_unet, self.text_encoder, self.vae]:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device with unet->image_unet
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.image_unet, "_hf_hook"):
+ return self.device
+ for module in self.image_unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_text_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ """
+
+ def normalize_embeddings(encoder_output):
+ embeds = self.text_encoder.text_projection(encoder_output.last_hidden_state)
+ embeds_pooled = encoder_output.text_embeds
+ embeds = embeds / torch.norm(embeds_pooled.unsqueeze(1), dim=-1, keepdim=True)
+ return embeds
+
+ batch_size = len(prompt)
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="pt").input_ids
+
+ if not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = normalize_embeddings(prompt_embeds)
+
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens = [""] * batch_size
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = normalize_embeddings(negative_prompt_embeds)
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ def _encode_image_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ """
+
+ def normalize_embeddings(encoder_output):
+ embeds = self.image_encoder.vision_model.post_layernorm(encoder_output.last_hidden_state)
+ embeds = self.image_encoder.visual_projection(embeds)
+ embeds_pooled = embeds[:, 0:1]
+ embeds = embeds / torch.norm(embeds_pooled, dim=-1, keepdim=True)
+ return embeds
+
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ image_input = self.image_feature_extractor(images=prompt, return_tensors="pt")
+ pixel_values = image_input.pixel_values.to(device).to(self.image_encoder.dtype)
+ image_embeddings = self.image_encoder(pixel_values)
+ image_embeddings = normalize_embeddings(image_embeddings)
+
+ # duplicate image embeddings for each generation per prompt, using mps friendly method
+ bs_embed, seq_len, _ = image_embeddings.shape
+ image_embeddings = image_embeddings.repeat(1, num_images_per_prompt, 1)
+ image_embeddings = image_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_images = [np.zeros((512, 512, 3)) + 0.5] * batch_size
+ uncond_images = self.image_feature_extractor(images=uncond_images, return_tensors="pt")
+ pixel_values = uncond_images.pixel_values.to(device).to(self.image_encoder.dtype)
+ negative_prompt_embeds = self.image_encoder(pixel_values)
+ negative_prompt_embeds = normalize_embeddings(negative_prompt_embeds)
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and conditional embeddings into a single batch
+ # to avoid doing two forward passes
+ image_embeddings = torch.cat([negative_prompt_embeds, image_embeddings])
+
+ return image_embeddings
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ def check_inputs(self, prompt, image, height, width, callback_steps):
+ if not isinstance(prompt, str) and not isinstance(prompt, PIL.Image.Image) and not isinstance(prompt, list):
+ raise ValueError(f"`prompt` has to be of type `str` `PIL.Image` or `list` but is {type(prompt)}")
+ if not isinstance(image, str) and not isinstance(image, PIL.Image.Image) and not isinstance(image, list):
+ raise ValueError(f"`image` has to be of type `str` `PIL.Image` or `list` but is {type(image)}")
+
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ def set_transformer_params(self, mix_ratio: float = 0.5, condition_types: Tuple = ("text", "image")):
+ for name, module in self.image_unet.named_modules():
+ if isinstance(module, DualTransformer2DModel):
+ module.mix_ratio = mix_ratio
+
+ for i, type in enumerate(condition_types):
+ if type == "text":
+ module.condition_lengths[i] = self.text_encoder.config.max_position_embeddings
+ module.transformer_index_for_condition[i] = 1 # use the second (text) transformer
+ else:
+ module.condition_lengths[i] = 257
+ module.transformer_index_for_condition[i] = 0 # use the first (image) transformer
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[PIL.Image.Image, List[PIL.Image.Image]],
+ image: Union[str, List[str]],
+ text_to_image_strength: float = 0.5,
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import VersatileDiffusionDualGuidedPipeline
+ >>> import torch
+ >>> import requests
+ >>> from io import BytesIO
+ >>> from PIL import Image
+
+ >>> # let's download an initial image
+ >>> url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
+
+ >>> response = requests.get(url)
+ >>> image = Image.open(BytesIO(response.content)).convert("RGB")
+ >>> text = "a red car in the sun"
+
+ >>> pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained(
+ ... "shi-labs/versatile-diffusion", torch_dtype=torch.float16
+ ... )
+ >>> pipe.remove_unused_weights()
+ >>> pipe = pipe.to("cuda")
+
+ >>> generator = torch.Generator(device="cuda").manual_seed(0)
+ >>> text_to_image_strength = 0.75
+
+ >>> image = pipe(
+ ... prompt=text, image=image, text_to_image_strength=text_to_image_strength, generator=generator
+ ... ).images[0]
+ >>> image.save("./car_variation.png")
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.ImagePipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.ImagePipelineOutput`] if `return_dict` is True, otherwise a `tuple. When
+ returning a tuple, the first element is a list with the generated images.
+ """
+ # 0. Default height and width to unet
+ height = height or self.image_unet.config.sample_size * self.vae_scale_factor
+ width = width or self.image_unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(prompt, image, height, width, callback_steps)
+
+ # 2. Define call parameters
+ prompt = [prompt] if not isinstance(prompt, list) else prompt
+ image = [image] if not isinstance(image, list) else image
+ batch_size = len(prompt)
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompts
+ prompt_embeds = self._encode_text_prompt(prompt, device, num_images_per_prompt, do_classifier_free_guidance)
+ image_embeddings = self._encode_image_prompt(image, device, num_images_per_prompt, do_classifier_free_guidance)
+ dual_prompt_embeddings = torch.cat([prompt_embeds, image_embeddings], dim=1)
+ prompt_types = ("text", "image")
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.image_unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ dual_prompt_embeddings.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs.
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Combine the attention blocks of the image and text UNets
+ self.set_transformer_params(text_to_image_strength, prompt_types)
+
+ # 8. Denoising loop
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.image_unet(latent_model_input, t, encoder_hidden_states=dual_prompt_embeddings).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # 10. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_image_variation.py b/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_image_variation.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b47184d7773295a5701f8e80f89c64e721e8070
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_image_variation.py
@@ -0,0 +1,427 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+import PIL
+import torch
+import torch.utils.checkpoint
+from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection
+
+from ...models import AutoencoderKL, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_available, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class VersatileDiffusionImageVariationPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ vqvae ([`VQModel`]):
+ Vector-quantized (VQ) Model to encode and decode images to and from latent representations.
+ bert ([`LDMBertModel`]):
+ Text-encoder model based on [BERT](https://huggingface.co/docs/transformers/model_doc/bert) architecture.
+ tokenizer (`transformers.BertTokenizer`):
+ Tokenizer of class
+ [BertTokenizer](https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+ image_feature_extractor: CLIPImageProcessor
+ image_encoder: CLIPVisionModelWithProjection
+ image_unet: UNet2DConditionModel
+ vae: AutoencoderKL
+ scheduler: KarrasDiffusionSchedulers
+
+ def __init__(
+ self,
+ image_feature_extractor: CLIPImageProcessor,
+ image_encoder: CLIPVisionModelWithProjection,
+ image_unet: UNet2DConditionModel,
+ vae: AutoencoderKL,
+ scheduler: KarrasDiffusionSchedulers,
+ ):
+ super().__init__()
+ self.register_modules(
+ image_feature_extractor=image_feature_extractor,
+ image_encoder=image_encoder,
+ image_unet=image_unet,
+ vae=vae,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.image_unet, self.text_unet, self.text_encoder, self.vae]:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device with unet->image_unet
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.image_unet, "_hf_hook"):
+ return self.device
+ for module in self.image_unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ """
+
+ def normalize_embeddings(encoder_output):
+ embeds = self.image_encoder.vision_model.post_layernorm(encoder_output.last_hidden_state)
+ embeds = self.image_encoder.visual_projection(embeds)
+ embeds_pooled = embeds[:, 0:1]
+ embeds = embeds / torch.norm(embeds_pooled, dim=-1, keepdim=True)
+ return embeds
+
+ if isinstance(prompt, torch.Tensor) and len(prompt.shape) == 4:
+ prompt = list(prompt)
+
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ image_input = self.image_feature_extractor(images=prompt, return_tensors="pt")
+ pixel_values = image_input.pixel_values.to(device).to(self.image_encoder.dtype)
+ image_embeddings = self.image_encoder(pixel_values)
+ image_embeddings = normalize_embeddings(image_embeddings)
+
+ # duplicate image embeddings for each generation per prompt, using mps friendly method
+ bs_embed, seq_len, _ = image_embeddings.shape
+ image_embeddings = image_embeddings.repeat(1, num_images_per_prompt, 1)
+ image_embeddings = image_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_images: List[str]
+ if negative_prompt is None:
+ uncond_images = [np.zeros((512, 512, 3)) + 0.5] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, PIL.Image.Image):
+ uncond_images = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_images = negative_prompt
+
+ uncond_images = self.image_feature_extractor(images=uncond_images, return_tensors="pt")
+ pixel_values = uncond_images.pixel_values.to(device).to(self.image_encoder.dtype)
+ negative_prompt_embeds = self.image_encoder(pixel_values)
+ negative_prompt_embeds = normalize_embeddings(negative_prompt_embeds)
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and conditional embeddings into a single batch
+ # to avoid doing two forward passes
+ image_embeddings = torch.cat([negative_prompt_embeds, image_embeddings])
+
+ return image_embeddings
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_image_variation.StableDiffusionImageVariationPipeline.check_inputs
+ def check_inputs(self, image, height, width, callback_steps):
+ if (
+ not isinstance(image, torch.Tensor)
+ and not isinstance(image, PIL.Image.Image)
+ and not isinstance(image, list)
+ ):
+ raise ValueError(
+ "`image` has to be of type `torch.FloatTensor` or `PIL.Image.Image` or `List[PIL.Image.Image]` but is"
+ f" {type(image)}"
+ )
+
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ image: Union[PIL.Image.Image, List[PIL.Image.Image], torch.Tensor],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ image (`PIL.Image.Image`, `List[PIL.Image.Image]` or `torch.Tensor`):
+ The image prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import VersatileDiffusionImageVariationPipeline
+ >>> import torch
+ >>> import requests
+ >>> from io import BytesIO
+ >>> from PIL import Image
+
+ >>> # let's download an initial image
+ >>> url = "https://huggingface.co/datasets/diffusers/images/resolve/main/benz.jpg"
+
+ >>> response = requests.get(url)
+ >>> image = Image.open(BytesIO(response.content)).convert("RGB")
+
+ >>> pipe = VersatileDiffusionImageVariationPipeline.from_pretrained(
+ ... "shi-labs/versatile-diffusion", torch_dtype=torch.float16
+ ... )
+ >>> pipe = pipe.to("cuda")
+
+ >>> generator = torch.Generator(device="cuda").manual_seed(0)
+ >>> image = pipe(image, generator=generator).images[0]
+ >>> image.save("./car_variation.png")
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.image_unet.config.sample_size * self.vae_scale_factor
+ width = width or self.image_unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(image, height, width, callback_steps)
+
+ # 2. Define call parameters
+ batch_size = 1 if isinstance(image, PIL.Image.Image) else len(image)
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ image_embeddings = self._encode_prompt(
+ image, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.image_unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ image_embeddings.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs.
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.image_unet(latent_model_input, t, encoder_hidden_states=image_embeddings).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 8. Post-processing
+ image = self.decode_latents(latents)
+
+ # 9. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py b/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
new file mode 100644
index 0000000000000000000000000000000000000000..fdca625fd99d99ff31d0e0a65a30f52e4b002ce0
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
@@ -0,0 +1,501 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+from typing import Callable, List, Optional, Union
+
+import torch
+import torch.utils.checkpoint
+from transformers import CLIPImageProcessor, CLIPTextModelWithProjection, CLIPTokenizer
+
+from ...models import AutoencoderKL, Transformer2DModel, UNet2DConditionModel
+from ...schedulers import KarrasDiffusionSchedulers
+from ...utils import is_accelerate_available, logging, randn_tensor
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+from .modeling_text_unet import UNetFlatConditionModel
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class VersatileDiffusionTextToImagePipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ vqvae ([`VQModel`]):
+ Vector-quantized (VQ) Model to encode and decode images to and from latent representations.
+ bert ([`LDMBertModel`]):
+ Text-encoder model based on [BERT](https://huggingface.co/docs/transformers/model_doc/bert) architecture.
+ tokenizer (`transformers.BertTokenizer`):
+ Tokenizer of class
+ [BertTokenizer](https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertTokenizer).
+ unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
+ [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
+ """
+ tokenizer: CLIPTokenizer
+ image_feature_extractor: CLIPImageProcessor
+ text_encoder: CLIPTextModelWithProjection
+ image_unet: UNet2DConditionModel
+ text_unet: UNetFlatConditionModel
+ vae: AutoencoderKL
+ scheduler: KarrasDiffusionSchedulers
+
+ _optional_components = ["text_unet"]
+
+ def __init__(
+ self,
+ tokenizer: CLIPTokenizer,
+ text_encoder: CLIPTextModelWithProjection,
+ image_unet: UNet2DConditionModel,
+ text_unet: UNetFlatConditionModel,
+ vae: AutoencoderKL,
+ scheduler: KarrasDiffusionSchedulers,
+ ):
+ super().__init__()
+ self.register_modules(
+ tokenizer=tokenizer,
+ text_encoder=text_encoder,
+ image_unet=image_unet,
+ text_unet=text_unet,
+ vae=vae,
+ scheduler=scheduler,
+ )
+ self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
+
+ if self.text_unet is not None:
+ self._swap_unet_attention_blocks()
+
+ def _swap_unet_attention_blocks(self):
+ """
+ Swap the `Transformer2DModel` blocks between the image and text UNets
+ """
+ for name, module in self.image_unet.named_modules():
+ if isinstance(module, Transformer2DModel):
+ parent_name, index = name.rsplit(".", 1)
+ index = int(index)
+ self.image_unet.get_submodule(parent_name)[index], self.text_unet.get_submodule(parent_name)[index] = (
+ self.text_unet.get_submodule(parent_name)[index],
+ self.image_unet.get_submodule(parent_name)[index],
+ )
+
+ def remove_unused_weights(self):
+ self.register_modules(text_unet=None)
+
+ def enable_sequential_cpu_offload(self, gpu_id=0):
+ r"""
+ Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
+ text_encoder, vae and safety checker have their state dicts saved to CPU and then are moved to a
+ `torch.device('meta') and loaded to GPU only when their specific submodule has its `forward` method called.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload
+ else:
+ raise ImportError("Please install accelerate via `pip install accelerate`")
+
+ device = torch.device(f"cuda:{gpu_id}")
+
+ for cpu_offloaded_model in [self.image_unet, self.text_unet, self.text_encoder, self.vae]:
+ if cpu_offloaded_model is not None:
+ cpu_offload(cpu_offloaded_model, device)
+
+ @property
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device with unet->image_unet
+ def _execution_device(self):
+ r"""
+ Returns the device on which the pipeline's models will be executed. After calling
+ `pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
+ hooks.
+ """
+ if not hasattr(self.image_unet, "_hf_hook"):
+ return self.device
+ for module in self.image_unet.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+ return self.device
+
+ def _encode_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
+ r"""
+ Encodes the prompt into text encoder hidden states.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ prompt to be encoded
+ device: (`torch.device`):
+ torch device
+ num_images_per_prompt (`int`):
+ number of images that should be generated per prompt
+ do_classifier_free_guidance (`bool`):
+ whether to use classifier free guidance or not
+ negative_prompt (`str` or `List[str]`):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ """
+
+ def normalize_embeddings(encoder_output):
+ embeds = self.text_encoder.text_projection(encoder_output.last_hidden_state)
+ embeds_pooled = encoder_output.text_embeds
+ embeds = embeds / torch.norm(embeds_pooled.unsqueeze(1), dim=-1, keepdim=True)
+ return embeds
+
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+ untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="pt").input_ids
+
+ if not torch.equal(text_input_ids, untruncated_ids):
+ removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = text_inputs.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = self.text_encoder(
+ text_input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = normalize_embeddings(prompt_embeds)
+
+ # duplicate text embeddings for each generation per prompt, using mps friendly method
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
+
+ # get unconditional embeddings for classifier free guidance
+ if do_classifier_free_guidance:
+ uncond_tokens: List[str]
+ if negative_prompt is None:
+ uncond_tokens = [""] * batch_size
+ elif type(prompt) is not type(negative_prompt):
+ raise TypeError(
+ f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
+ f" {type(prompt)}."
+ )
+ elif isinstance(negative_prompt, str):
+ uncond_tokens = [negative_prompt]
+ elif batch_size != len(negative_prompt):
+ raise ValueError(
+ f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
+ f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
+ " the batch size of `prompt`."
+ )
+ else:
+ uncond_tokens = negative_prompt
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+
+ if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
+ attention_mask = uncond_input.attention_mask.to(device)
+ else:
+ attention_mask = None
+
+ negative_prompt_embeds = self.text_encoder(
+ uncond_input.input_ids.to(device),
+ attention_mask=attention_mask,
+ )
+ negative_prompt_embeds = normalize_embeddings(negative_prompt_embeds)
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
+ def decode_latents(self, latents):
+ latents = 1 / self.vae.config.scaling_factor * latents
+ image = self.vae.decode(latents).sample
+ image = (image / 2 + 0.5).clamp(0, 1)
+ # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
+ image = image.cpu().permute(0, 2, 3, 1).float().numpy()
+ return image
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
+ def prepare_extra_step_kwargs(self, generator, eta):
+ # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
+ # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
+ # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
+ # and should be between [0, 1]
+
+ accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ extra_step_kwargs = {}
+ if accepts_eta:
+ extra_step_kwargs["eta"] = eta
+
+ # check if the scheduler accepts generator
+ accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
+ if accepts_generator:
+ extra_step_kwargs["generator"] = generator
+ return extra_step_kwargs
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
+ def check_inputs(
+ self,
+ prompt,
+ height,
+ width,
+ callback_steps,
+ negative_prompt=None,
+ prompt_embeds=None,
+ negative_prompt_embeds=None,
+ ):
+ if height % 8 != 0 or width % 8 != 0:
+ raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ if prompt is not None and prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
+ " only forward one of the two."
+ )
+ elif prompt is None and prompt_embeds is None:
+ raise ValueError(
+ "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
+ )
+ elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ if negative_prompt is not None and negative_prompt_embeds is not None:
+ raise ValueError(
+ f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
+ f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
+ )
+
+ if prompt_embeds is not None and negative_prompt_embeds is not None:
+ if prompt_embeds.shape != negative_prompt_embeds.shape:
+ raise ValueError(
+ "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
+ f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
+ f" {negative_prompt_embeds.shape}."
+ )
+
+ # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
+ def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
+ shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
+ if isinstance(generator, list) and len(generator) != batch_size:
+ raise ValueError(
+ f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
+ f" size of {batch_size}. Make sure the batch size matches the length of the generators."
+ )
+
+ if latents is None:
+ latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
+ else:
+ latents = latents.to(device)
+
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * self.scheduler.init_noise_sigma
+ return latents
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ height: Optional[int] = None,
+ width: Optional[int] = None,
+ num_inference_steps: int = 50,
+ guidance_scale: float = 7.5,
+ negative_prompt: Optional[Union[str, List[str]]] = None,
+ num_images_per_prompt: Optional[int] = 1,
+ eta: float = 0.0,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ **kwargs,
+ ):
+ r"""
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ height (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The height in pixels of the generated image.
+ width (`int`, *optional*, defaults to self.image_unet.config.sample_size * self.vae_scale_factor):
+ The width in pixels of the generated image.
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ negative_prompt (`str` or `List[str]`, *optional*):
+ The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
+ if `guidance_scale` is less than `1`).
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ eta (`float`, *optional*, defaults to 0.0):
+ Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
+ [`schedulers.DDIMScheduler`], will be ignored for others.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor`, *optional*):
+ Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
+ generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
+ tensor will ge generated by sampling using the supplied random `generator`.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
+ plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Examples:
+
+ ```py
+ >>> from diffusers import VersatileDiffusionTextToImagePipeline
+ >>> import torch
+
+ >>> pipe = VersatileDiffusionTextToImagePipeline.from_pretrained(
+ ... "shi-labs/versatile-diffusion", torch_dtype=torch.float16
+ ... )
+ >>> pipe.remove_unused_weights()
+ >>> pipe = pipe.to("cuda")
+
+ >>> generator = torch.Generator(device="cuda").manual_seed(0)
+ >>> image = pipe("an astronaut riding on a horse on mars", generator=generator).images[0]
+ >>> image.save("./astronaut.png")
+ ```
+
+ Returns:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
+ [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
+ When returning a tuple, the first element is a list with the generated images, and the second element is a
+ list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
+ (nsfw) content, according to the `safety_checker`.
+ """
+ # 0. Default height and width to unet
+ height = height or self.image_unet.config.sample_size * self.vae_scale_factor
+ width = width or self.image_unet.config.sample_size * self.vae_scale_factor
+
+ # 1. Check inputs. Raise error if not correct
+ self.check_inputs(prompt, height, width, callback_steps)
+
+ # 2. Define call parameters
+ batch_size = 1 if isinstance(prompt, str) else len(prompt)
+ device = self._execution_device
+ # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
+ # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
+ # corresponds to doing no classifier free guidance.
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ # 3. Encode input prompt
+ prompt_embeds = self._encode_prompt(
+ prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ # 4. Prepare timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=device)
+ timesteps = self.scheduler.timesteps
+
+ # 5. Prepare latent variables
+ num_channels_latents = self.image_unet.in_channels
+ latents = self.prepare_latents(
+ batch_size * num_images_per_prompt,
+ num_channels_latents,
+ height,
+ width,
+ prompt_embeds.dtype,
+ device,
+ generator,
+ latents,
+ )
+
+ # 6. Prepare extra step kwargs.
+ extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
+
+ # 7. Denoising loop
+ for i, t in enumerate(self.progress_bar(timesteps)):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
+ latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
+
+ # predict the noise residual
+ noise_pred = self.image_unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
+
+ # perform guidance
+ if do_classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, latents)
+
+ # 9. Post-processing
+ image = self.decode_latents(latents)
+
+ # 10. Convert to PIL
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
diff --git a/diffusers/src/diffusers/pipelines/vq_diffusion/__init__.py b/diffusers/src/diffusers/pipelines/vq_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c9f14f000648347fe75a5bec0cb45d08c7d2ff9
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/vq_diffusion/__init__.py
@@ -0,0 +1,5 @@
+from ...utils import is_torch_available, is_transformers_available
+
+
+if is_transformers_available() and is_torch_available():
+ from .pipeline_vq_diffusion import LearnedClassifierFreeSamplingEmbeddings, VQDiffusionPipeline
diff --git a/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1678ee64387b3947b216b1779e41af46fdc3ab92
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d5ed79f26f4d640adfceb11dd7561749bf53fb0f
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/pipeline_vq_diffusion.cpython-310.pyc b/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/pipeline_vq_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..88ba3d9f2799d51539bd59eeb7810fb7a7e50f1b
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/pipeline_vq_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/pipeline_vq_diffusion.cpython-39.pyc b/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/pipeline_vq_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ad9bd4bc837c3f7ed2463ba0db63f143bc890dab
Binary files /dev/null and b/diffusers/src/diffusers/pipelines/vq_diffusion/__pycache__/pipeline_vq_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/pipelines/vq_diffusion/pipeline_vq_diffusion.py b/diffusers/src/diffusers/pipelines/vq_diffusion/pipeline_vq_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..9147afe127e4b24366249c4a6e058abae9501050
--- /dev/null
+++ b/diffusers/src/diffusers/pipelines/vq_diffusion/pipeline_vq_diffusion.py
@@ -0,0 +1,330 @@
+# Copyright 2023 Microsoft and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Callable, List, Optional, Tuple, Union
+
+import torch
+from transformers import CLIPTextModel, CLIPTokenizer
+
+from ...configuration_utils import ConfigMixin, register_to_config
+from ...models import ModelMixin, Transformer2DModel, VQModel
+from ...schedulers import VQDiffusionScheduler
+from ...utils import logging
+from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+class LearnedClassifierFreeSamplingEmbeddings(ModelMixin, ConfigMixin):
+ """
+ Utility class for storing learned text embeddings for classifier free sampling
+ """
+
+ @register_to_config
+ def __init__(self, learnable: bool, hidden_size: Optional[int] = None, length: Optional[int] = None):
+ super().__init__()
+
+ self.learnable = learnable
+
+ if self.learnable:
+ assert hidden_size is not None, "learnable=True requires `hidden_size` to be set"
+ assert length is not None, "learnable=True requires `length` to be set"
+
+ embeddings = torch.zeros(length, hidden_size)
+ else:
+ embeddings = None
+
+ self.embeddings = torch.nn.Parameter(embeddings)
+
+
+class VQDiffusionPipeline(DiffusionPipeline):
+ r"""
+ Pipeline for text-to-image generation using VQ Diffusion
+
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Args:
+ vqvae ([`VQModel`]):
+ Vector Quantized Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent
+ representations.
+ text_encoder ([`CLIPTextModel`]):
+ Frozen text-encoder. VQ Diffusion uses the text portion of
+ [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
+ the [clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32) variant.
+ tokenizer (`CLIPTokenizer`):
+ Tokenizer of class
+ [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
+ transformer ([`Transformer2DModel`]):
+ Conditional transformer to denoise the encoded image latents.
+ scheduler ([`VQDiffusionScheduler`]):
+ A scheduler to be used in combination with `transformer` to denoise the encoded image latents.
+ """
+
+ vqvae: VQModel
+ text_encoder: CLIPTextModel
+ tokenizer: CLIPTokenizer
+ transformer: Transformer2DModel
+ learned_classifier_free_sampling_embeddings: LearnedClassifierFreeSamplingEmbeddings
+ scheduler: VQDiffusionScheduler
+
+ def __init__(
+ self,
+ vqvae: VQModel,
+ text_encoder: CLIPTextModel,
+ tokenizer: CLIPTokenizer,
+ transformer: Transformer2DModel,
+ scheduler: VQDiffusionScheduler,
+ learned_classifier_free_sampling_embeddings: LearnedClassifierFreeSamplingEmbeddings,
+ ):
+ super().__init__()
+
+ self.register_modules(
+ vqvae=vqvae,
+ transformer=transformer,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ scheduler=scheduler,
+ learned_classifier_free_sampling_embeddings=learned_classifier_free_sampling_embeddings,
+ )
+
+ def _encode_prompt(self, prompt, num_images_per_prompt, do_classifier_free_guidance):
+ batch_size = len(prompt) if isinstance(prompt, list) else 1
+
+ # get prompt text embeddings
+ text_inputs = self.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=self.tokenizer.model_max_length,
+ return_tensors="pt",
+ )
+ text_input_ids = text_inputs.input_ids
+
+ if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
+ removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
+ logger.warning(
+ "The following part of your input was truncated because CLIP can only handle sequences up to"
+ f" {self.tokenizer.model_max_length} tokens: {removed_text}"
+ )
+ text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
+ prompt_embeds = self.text_encoder(text_input_ids.to(self.device))[0]
+
+ # NOTE: This additional step of normalizing the text embeddings is from VQ-Diffusion.
+ # While CLIP does normalize the pooled output of the text transformer when combining
+ # the image and text embeddings, CLIP does not directly normalize the last hidden state.
+ #
+ # CLIP normalizing the pooled output.
+ # https://github.com/huggingface/transformers/blob/d92e22d1f28324f513f3080e5c47c071a3916721/src/transformers/models/clip/modeling_clip.py#L1052-L1053
+ prompt_embeds = prompt_embeds / prompt_embeds.norm(dim=-1, keepdim=True)
+
+ # duplicate text embeddings for each generation per prompt
+ prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
+
+ if do_classifier_free_guidance:
+ if self.learned_classifier_free_sampling_embeddings.learnable:
+ negative_prompt_embeds = self.learned_classifier_free_sampling_embeddings.embeddings
+ negative_prompt_embeds = negative_prompt_embeds.unsqueeze(0).repeat(batch_size, 1, 1)
+ else:
+ uncond_tokens = [""] * batch_size
+
+ max_length = text_input_ids.shape[-1]
+ uncond_input = self.tokenizer(
+ uncond_tokens,
+ padding="max_length",
+ max_length=max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ negative_prompt_embeds = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
+ # See comment for normalizing text embeddings
+ negative_prompt_embeds = negative_prompt_embeds / negative_prompt_embeds.norm(dim=-1, keepdim=True)
+
+ # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
+ seq_len = negative_prompt_embeds.shape[1]
+ negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
+ negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # Here we concatenate the unconditional and text embeddings into a single batch
+ # to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+
+ return prompt_embeds
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ prompt: Union[str, List[str]],
+ num_inference_steps: int = 100,
+ guidance_scale: float = 5.0,
+ truncation_rate: float = 1.0,
+ num_images_per_prompt: int = 1,
+ generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
+ latents: Optional[torch.FloatTensor] = None,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
+ callback_steps: int = 1,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ """
+ Function invoked when calling the pipeline for generation.
+
+ Args:
+ prompt (`str` or `List[str]`):
+ The prompt or prompts to guide the image generation.
+ num_inference_steps (`int`, *optional*, defaults to 100):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ guidance_scale (`float`, *optional*, defaults to 7.5):
+ Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
+ `guidance_scale` is defined as `w` of equation 2. of [Imagen
+ Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
+ 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
+ usually at the expense of lower image quality.
+ truncation_rate (`float`, *optional*, defaults to 1.0 (equivalent to no truncation)):
+ Used to "truncate" the predicted classes for x_0 such that the cumulative probability for a pixel is at
+ most `truncation_rate`. The lowest probabilities that would increase the cumulative probability above
+ `truncation_rate` are set to zero.
+ num_images_per_prompt (`int`, *optional*, defaults to 1):
+ The number of images to generate per prompt.
+ generator (`torch.Generator`, *optional*):
+ One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
+ to make generation deterministic.
+ latents (`torch.FloatTensor` of shape (batch), *optional*):
+ Pre-generated noisy latents to be used as inputs for image generation. Must be valid embedding indices.
+ Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will
+ be generated of completely masked latent pixels.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generated image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+ callback (`Callable`, *optional*):
+ A function that will be called every `callback_steps` steps during inference. The function will be
+ called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
+ callback_steps (`int`, *optional*, defaults to 1):
+ The frequency at which the `callback` function will be called. If not specified, the callback will be
+ called at every step.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~ pipeline_utils.ImagePipelineOutput `] if `return_dict`
+ is True, otherwise a `tuple. When returning a tuple, the first element is a list with the generated images.
+ """
+ if isinstance(prompt, str):
+ batch_size = 1
+ elif isinstance(prompt, list):
+ batch_size = len(prompt)
+ else:
+ raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
+
+ batch_size = batch_size * num_images_per_prompt
+
+ do_classifier_free_guidance = guidance_scale > 1.0
+
+ prompt_embeds = self._encode_prompt(prompt, num_images_per_prompt, do_classifier_free_guidance)
+
+ if (callback_steps is None) or (
+ callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
+ ):
+ raise ValueError(
+ f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
+ f" {type(callback_steps)}."
+ )
+
+ # get the initial completely masked latents unless the user supplied it
+
+ latents_shape = (batch_size, self.transformer.num_latent_pixels)
+ if latents is None:
+ mask_class = self.transformer.num_vector_embeds - 1
+ latents = torch.full(latents_shape, mask_class).to(self.device)
+ else:
+ if latents.shape != latents_shape:
+ raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
+ if (latents < 0).any() or (latents >= self.transformer.num_vector_embeds).any():
+ raise ValueError(
+ "Unexpected latents value(s). All latents be valid embedding indices i.e. in the range 0,"
+ f" {self.transformer.num_vector_embeds - 1} (inclusive)."
+ )
+ latents = latents.to(self.device)
+
+ # set timesteps
+ self.scheduler.set_timesteps(num_inference_steps, device=self.device)
+
+ timesteps_tensor = self.scheduler.timesteps.to(self.device)
+
+ sample = latents
+
+ for i, t in enumerate(self.progress_bar(timesteps_tensor)):
+ # expand the sample if we are doing classifier free guidance
+ latent_model_input = torch.cat([sample] * 2) if do_classifier_free_guidance else sample
+
+ # predict the un-noised image
+ # model_output == `log_p_x_0`
+ model_output = self.transformer(latent_model_input, encoder_hidden_states=prompt_embeds, timestep=t).sample
+
+ if do_classifier_free_guidance:
+ model_output_uncond, model_output_text = model_output.chunk(2)
+ model_output = model_output_uncond + guidance_scale * (model_output_text - model_output_uncond)
+ model_output -= torch.logsumexp(model_output, dim=1, keepdim=True)
+
+ model_output = self.truncate(model_output, truncation_rate)
+
+ # remove `log(0)`'s (`-inf`s)
+ model_output = model_output.clamp(-70)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ sample = self.scheduler.step(model_output, timestep=t, sample=sample, generator=generator).prev_sample
+
+ # call the callback, if provided
+ if callback is not None and i % callback_steps == 0:
+ callback(i, t, sample)
+
+ embedding_channels = self.vqvae.config.vq_embed_dim
+ embeddings_shape = (batch_size, self.transformer.height, self.transformer.width, embedding_channels)
+ embeddings = self.vqvae.quantize.get_codebook_entry(sample, shape=embeddings_shape)
+ image = self.vqvae.decode(embeddings, force_not_quantize=True).sample
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,)
+
+ return ImagePipelineOutput(images=image)
+
+ def truncate(self, log_p_x_0: torch.FloatTensor, truncation_rate: float) -> torch.FloatTensor:
+ """
+ Truncates log_p_x_0 such that for each column vector, the total cumulative probability is `truncation_rate` The
+ lowest probabilities that would increase the cumulative probability above `truncation_rate` are set to zero.
+ """
+ sorted_log_p_x_0, indices = torch.sort(log_p_x_0, 1, descending=True)
+ sorted_p_x_0 = torch.exp(sorted_log_p_x_0)
+ keep_mask = sorted_p_x_0.cumsum(dim=1) < truncation_rate
+
+ # Ensure that at least the largest probability is not zeroed out
+ all_true = torch.full_like(keep_mask[:, 0:1, :], True)
+ keep_mask = torch.cat((all_true, keep_mask), dim=1)
+ keep_mask = keep_mask[:, :-1, :]
+
+ keep_mask = keep_mask.gather(1, indices.argsort(1))
+
+ rv = log_p_x_0.clone()
+
+ rv[~keep_mask] = -torch.inf # -inf = log(0)
+
+ return rv
diff --git a/diffusers/src/diffusers/schedulers/README.md b/diffusers/src/diffusers/schedulers/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..31ad27793e34783faabc222adf98691fb396a0d8
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/README.md
@@ -0,0 +1,3 @@
+# Schedulers
+
+For more information on the schedulers, please refer to the [docs](https://huggingface.co/docs/diffusers/api/schedulers/overview).
\ No newline at end of file
diff --git a/diffusers/src/diffusers/schedulers/__init__.py b/diffusers/src/diffusers/schedulers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e5d5bb40633f39008090ae56c15b94a8bc378d07
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/__init__.py
@@ -0,0 +1,74 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from ..utils import OptionalDependencyNotAvailable, is_flax_available, is_scipy_available, is_torch_available
+
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_pt_objects import * # noqa F403
+else:
+ from .scheduling_ddim import DDIMScheduler
+ from .scheduling_ddim_inverse import DDIMInverseScheduler
+ from .scheduling_ddpm import DDPMScheduler
+ from .scheduling_deis_multistep import DEISMultistepScheduler
+ from .scheduling_dpmsolver_multistep import DPMSolverMultistepScheduler
+ from .scheduling_dpmsolver_singlestep import DPMSolverSinglestepScheduler
+ from .scheduling_euler_ancestral_discrete import EulerAncestralDiscreteScheduler
+ from .scheduling_euler_discrete import EulerDiscreteScheduler
+ from .scheduling_heun_discrete import HeunDiscreteScheduler
+ from .scheduling_ipndm import IPNDMScheduler
+ from .scheduling_k_dpm_2_ancestral_discrete import KDPM2AncestralDiscreteScheduler
+ from .scheduling_k_dpm_2_discrete import KDPM2DiscreteScheduler
+ from .scheduling_karras_ve import KarrasVeScheduler
+ from .scheduling_pndm import PNDMScheduler
+ from .scheduling_repaint import RePaintScheduler
+ from .scheduling_sde_ve import ScoreSdeVeScheduler
+ from .scheduling_sde_vp import ScoreSdeVpScheduler
+ from .scheduling_unclip import UnCLIPScheduler
+ from .scheduling_unipc_multistep import UniPCMultistepScheduler
+ from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin
+ from .scheduling_vq_diffusion import VQDiffusionScheduler
+
+try:
+ if not is_flax_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_flax_objects import * # noqa F403
+else:
+ from .scheduling_ddim_flax import FlaxDDIMScheduler
+ from .scheduling_ddpm_flax import FlaxDDPMScheduler
+ from .scheduling_dpmsolver_multistep_flax import FlaxDPMSolverMultistepScheduler
+ from .scheduling_karras_ve_flax import FlaxKarrasVeScheduler
+ from .scheduling_lms_discrete_flax import FlaxLMSDiscreteScheduler
+ from .scheduling_pndm_flax import FlaxPNDMScheduler
+ from .scheduling_sde_ve_flax import FlaxScoreSdeVeScheduler
+ from .scheduling_utils_flax import (
+ FlaxKarrasDiffusionSchedulers,
+ FlaxSchedulerMixin,
+ FlaxSchedulerOutput,
+ broadcast_to_shape_from_left,
+ )
+
+
+try:
+ if not (is_torch_available() and is_scipy_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from ..utils.dummy_torch_and_scipy_objects import * # noqa F403
+else:
+ from .scheduling_lms_discrete import LMSDiscreteScheduler
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d8f2aad4182d68c4f4032d287c4e71ffb5364f5b
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..78a0fc197dcdb46a9a3fd9167f7636e46d897300
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5db98afb076df450c5bed8c77660b141ca3fe5e2
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c866e272705abee31347e6f437beca973151954f
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim_inverse.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim_inverse.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0458d49739a98afaf91425250e7d993bbd87847d
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim_inverse.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim_inverse.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim_inverse.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a94dd8b088efe73f5e92bf559476d6ce00c6a85c
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddim_inverse.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddpm.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddpm.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9171f13881e9cc88d813d13b330ec7e1be2f8f34
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddpm.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddpm.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddpm.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ab9cbf776eb5304fb8d66a8a24de65058a12ae09
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ddpm.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_deis_multistep.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_deis_multistep.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..df3cab02512c27fbca063a346236e0ad7d2817a2
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_deis_multistep.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_deis_multistep.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_deis_multistep.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5faf187977961d9fb360a651417415de4201fbeb
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_deis_multistep.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_multistep.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_multistep.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8953398306c0b1e34eb05ee3d7406f768da8562a
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_multistep.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_multistep.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_multistep.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6436967a66158f184b956fa4eee4f50b4519b200
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_multistep.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_singlestep.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_singlestep.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b0c3f7da64a287869e7aa620bc0eeca6793daf06
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_singlestep.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_singlestep.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_singlestep.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..abfd69dcf7ef818b909d898b2a92be6e34302e40
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_dpmsolver_singlestep.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_ancestral_discrete.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_ancestral_discrete.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fc51fbb186cb0ffcd07c9f54da0e7c848b432279
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_ancestral_discrete.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_ancestral_discrete.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_ancestral_discrete.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..88e0540535bfb44e8be46031dc3a5b3293623cce
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_ancestral_discrete.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_discrete.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_discrete.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..74d30e3ea63fce258029454f885d72e8e3d959d5
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_discrete.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_discrete.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_discrete.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1b073fbaaa01218df88c2318b3ee9c386deebf5c
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_euler_discrete.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_heun_discrete.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_heun_discrete.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6963ad75ec0d61b3360818cc94917b205656b895
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_heun_discrete.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_heun_discrete.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_heun_discrete.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..58631afd9af515f870d832941cf6f7fb2ba60877
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_heun_discrete.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ipndm.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ipndm.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2dc9ddbaf47458d7777ebec48c090a28a8ed86a6
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ipndm.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ipndm.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ipndm.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e75170f3c0e24cca0d981098f6f7c598b4b58c90
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_ipndm.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_ancestral_discrete.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_ancestral_discrete.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a24174e8afe153ff587beb6105a5d57a3f7f80f8
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_ancestral_discrete.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_ancestral_discrete.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_ancestral_discrete.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..dfbffdbb606146b9e9c544c3b5c44bbe4880ad56
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_ancestral_discrete.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_discrete.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_discrete.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..61ad3c4171552890efdfe3d597a2e82b8313a2c6
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_discrete.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_discrete.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_discrete.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..056964359a4d4748c6aa2c602a0dd434e5b0710a
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_k_dpm_2_discrete.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_karras_ve.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_karras_ve.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..354d8ab2d8adc6c1cdca752eb1452bb1ba9add87
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_karras_ve.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_karras_ve.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_karras_ve.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d9300c77dd07a44d9da39bf7d3943d4aeaa8cc74
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_karras_ve.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_lms_discrete.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_lms_discrete.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..757f7ccc4db55ee555ab1f62f913064161322dbc
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_lms_discrete.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_lms_discrete.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_lms_discrete.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..be147e554afc7ffb4c1884c6553215f159a34f1a
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_lms_discrete.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_pndm.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_pndm.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4151a938480bfb81c9ecb4179ec7a596ccd71813
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_pndm.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_pndm.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_pndm.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..76c26e6a94f63dd18f95cc40f5ee51cbe408b7d7
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_pndm.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_repaint.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_repaint.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5b9f5925e9d9dfd3880fa575d26573abe942b18f
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_repaint.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_repaint.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_repaint.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ba6bd9a3f11c773fc6fa0faa71483b7f675126b2
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_repaint.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_ve.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_ve.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8ebd38c2101ccc220d53d486ea4f7fa08e1cc78a
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_ve.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_ve.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_ve.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d07075790ff5de2e2aea2c5ddae26a1fdba6f02d
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_ve.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_vp.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_vp.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..919593e577d111fc68aad7a77f5ac4bec36e4f60
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_vp.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_vp.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_vp.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7071a3fd8991ace8a44e90ff52c10fee5de6b4cd
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_sde_vp.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unclip.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unclip.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b14342411446fc425a319da07d8ae9f2b53c9d3d
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unclip.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unclip.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unclip.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..243ac9b6a6d96fe7c4329848db4479adef4da5d4
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unclip.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unipc_multistep.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unipc_multistep.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e0132ed7c65f3c9606543d9261d8e41854e12120
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unipc_multistep.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unipc_multistep.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unipc_multistep.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..13c871722825ca7748ab86d54539f245ccb692ff
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_unipc_multistep.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_utils.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7845be794ee34665b3997256908398b3506b9b8e
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_utils.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cee26f65a99e32f6f8b70f1bb6b9cfee4eacd2be
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_vq_diffusion.cpython-310.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_vq_diffusion.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..36f64080a840aa787793387e0dbeed8eabf6d136
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_vq_diffusion.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/__pycache__/scheduling_vq_diffusion.cpython-39.pyc b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_vq_diffusion.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e02b8ee26f54dc28ce49f52302c14b44c8720f2c
Binary files /dev/null and b/diffusers/src/diffusers/schedulers/__pycache__/scheduling_vq_diffusion.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/schedulers/scheduling_ddim.py b/diffusers/src/diffusers/schedulers/scheduling_ddim.py
new file mode 100644
index 0000000000000000000000000000000000000000..29a79d391e55c3fbb947190911d89e0e9fb69e18
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_ddim.py
@@ -0,0 +1,405 @@
+# Copyright 2023 Stanford University Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
+# and https://github.com/hojonathanho/diffusion
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, randn_tensor
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin
+
+
+@dataclass
+# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->DDIM
+class DDIMSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999) -> torch.Tensor:
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class DDIMScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Denoising diffusion implicit models is a scheduler that extends the denoising procedure introduced in denoising
+ diffusion probabilistic models (DDPMs) with non-Markovian guidance.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2010.02502
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ clip_sample (`bool`, default `True`):
+ option to clip predicted sample for numerical stability.
+ clip_sample_range (`float`, default `1.0`):
+ the maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
+ set_alpha_to_one (`bool`, default `True`):
+ each diffusion step uses the value of alphas product at that step and at the previous one. For the final
+ step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
+ otherwise it uses the value of alpha at step 0.
+ steps_offset (`int`, default `0`):
+ an offset added to the inference steps. You can use a combination of `offset=1` and
+ `set_alpha_to_one=False`, to make the last step use step 0 for the previous alpha product, as done in
+ stable diffusion.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ thresholding (`bool`, default `False`):
+ whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
+ Note that the thresholding method is unsuitable for latent-space diffusion models (such as
+ stable-diffusion).
+ dynamic_thresholding_ratio (`float`, default `0.995`):
+ the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
+ (https://arxiv.org/abs/2205.11487). Valid only when `thresholding=True`.
+ sample_max_value (`float`, default `1.0`):
+ the threshold value for dynamic thresholding. Valid only when `thresholding=True`.
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ clip_sample: bool = True,
+ set_alpha_to_one: bool = True,
+ steps_offset: int = 0,
+ prediction_type: str = "epsilon",
+ thresholding: bool = False,
+ dynamic_thresholding_ratio: float = 0.995,
+ clip_sample_range: float = 1.0,
+ sample_max_value: float = 1.0,
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ # At every step in ddim, we are looking into the previous alphas_cumprod
+ # For the final step, there is no previous alphas_cumprod because we are already at 0
+ # `set_alpha_to_one` decides whether we set this parameter simply to one or
+ # whether we use the final alpha of the "non-previous" one.
+ self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))
+
+ def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def _get_variance(self, timestep, prev_timestep):
+ alpha_prod_t = self.alphas_cumprod[timestep]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
+
+ return variance
+
+ # Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
+ def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ dynamic_max_val = (
+ sample.flatten(1)
+ .abs()
+ .quantile(self.config.dynamic_thresholding_ratio, dim=1)
+ .clamp_min(self.config.sample_max_value)
+ .view(-1, *([1] * (sample.ndim - 1)))
+ )
+ return sample.clamp(-dynamic_max_val, dynamic_max_val) / dynamic_max_val
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+
+ if num_inference_steps > self.config.num_train_timesteps:
+ raise ValueError(
+ f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
+ f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
+ f" maximal {self.config.num_train_timesteps} timesteps."
+ )
+
+ self.num_inference_steps = num_inference_steps
+ step_ratio = self.config.num_train_timesteps // self.num_inference_steps
+ # creates integer timesteps by multiplying by ratio
+ # casting to int to avoid issues when num_inference_step is power of 3
+ timesteps = (np.arange(0, num_inference_steps) * step_ratio).round()[::-1].copy().astype(np.int64)
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+ self.timesteps += self.config.steps_offset
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ eta: float = 0.0,
+ use_clipped_model_output: bool = False,
+ generator=None,
+ variance_noise: Optional[torch.FloatTensor] = None,
+ return_dict: bool = True,
+ ) -> Union[DDIMSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ eta (`float`): weight of noise for added noise in diffusion step.
+ use_clipped_model_output (`bool`): if `True`, compute "corrected" `model_output` from the clipped
+ predicted original sample. Necessary because predicted original sample is clipped to [-1, 1] when
+ `self.config.clip_sample` is `True`. If no clipping has happened, "corrected" `model_output` would
+ coincide with the one provided as input and `use_clipped_model_output` will have not effect.
+ generator: random number generator.
+ variance_noise (`torch.FloatTensor`): instead of generating noise for the variance using `generator`, we
+ can directly provide the noise for the variance itself. This is useful for methods such as
+ CycleDiffusion. (https://arxiv.org/abs/2210.05559)
+ return_dict (`bool`): option for returning tuple rather than DDIMSchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.DDIMSchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.DDIMSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # Ideally, read DDIM paper in-detail understanding
+
+ # Notation ( ->
+ # - pred_noise_t -> e_theta(x_t, t)
+ # - pred_original_sample -> f_theta(x_t, t) or x_0
+ # - std_dev_t -> sigma_t
+ # - eta -> η
+ # - pred_sample_direction -> "direction pointing to x_t"
+ # - pred_prev_sample -> "x_t-1"
+
+ # 1. get previous step value (=t-1)
+ prev_timestep = timestep - self.config.num_train_timesteps // self.num_inference_steps
+
+ # 2. compute alphas, betas
+ alpha_prod_t = self.alphas_cumprod[timestep]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
+
+ beta_prod_t = 1 - alpha_prod_t
+
+ # 3. compute predicted original sample from predicted noise also called
+ # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
+ pred_epsilon = model_output
+ elif self.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
+ elif self.config.prediction_type == "v_prediction":
+ pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
+ pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction`"
+ )
+
+ # 4. Clip or threshold "predicted x_0"
+ if self.config.clip_sample:
+ pred_original_sample = pred_original_sample.clamp(
+ -self.config.clip_sample_range, self.config.clip_sample_range
+ )
+
+ if self.config.thresholding:
+ pred_original_sample = self._threshold_sample(pred_original_sample)
+
+ # 5. compute variance: "sigma_t(η)" -> see formula (16)
+ # σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
+ variance = self._get_variance(timestep, prev_timestep)
+ std_dev_t = eta * variance ** (0.5)
+
+ if use_clipped_model_output:
+ # the pred_epsilon is always re-derived from the clipped x_0 in Glide
+ pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
+
+ # 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
+
+ # 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
+
+ if eta > 0:
+ if variance_noise is not None and generator is not None:
+ raise ValueError(
+ "Cannot pass both generator and variance_noise. Please make sure that either `generator` or"
+ " `variance_noise` stays `None`."
+ )
+
+ if variance_noise is None:
+ variance_noise = randn_tensor(
+ model_output.shape, generator=generator, device=model_output.device, dtype=model_output.dtype
+ )
+ variance = std_dev_t * variance_noise
+
+ prev_sample = prev_sample + variance
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return DDIMSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.IntTensor,
+ ) -> torch.FloatTensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as original_samples
+ self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
+ timesteps = timesteps.to(original_samples.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
+ return noisy_samples
+
+ def get_velocity(
+ self, sample: torch.FloatTensor, noise: torch.FloatTensor, timesteps: torch.IntTensor
+ ) -> torch.FloatTensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as sample
+ self.alphas_cumprod = self.alphas_cumprod.to(device=sample.device, dtype=sample.dtype)
+ timesteps = timesteps.to(sample.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(sample.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
+ return velocity
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py b/diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..db248c33077bf502e31cb2ab97141744b828b514
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py
@@ -0,0 +1,305 @@
+# Copyright 2023 Stanford University Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
+# and https://github.com/hojonathanho/diffusion
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import flax
+import jax.numpy as jnp
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils_flax import (
+ CommonSchedulerState,
+ FlaxKarrasDiffusionSchedulers,
+ FlaxSchedulerMixin,
+ FlaxSchedulerOutput,
+ add_noise_common,
+ get_velocity_common,
+)
+
+
+@flax.struct.dataclass
+class DDIMSchedulerState:
+ common: CommonSchedulerState
+ final_alpha_cumprod: jnp.ndarray
+
+ # setable values
+ init_noise_sigma: jnp.ndarray
+ timesteps: jnp.ndarray
+ num_inference_steps: Optional[int] = None
+
+ @classmethod
+ def create(
+ cls,
+ common: CommonSchedulerState,
+ final_alpha_cumprod: jnp.ndarray,
+ init_noise_sigma: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ):
+ return cls(
+ common=common,
+ final_alpha_cumprod=final_alpha_cumprod,
+ init_noise_sigma=init_noise_sigma,
+ timesteps=timesteps,
+ )
+
+
+@dataclass
+class FlaxDDIMSchedulerOutput(FlaxSchedulerOutput):
+ state: DDIMSchedulerState
+
+
+class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
+ """
+ Denoising diffusion implicit models is a scheduler that extends the denoising procedure introduced in denoising
+ diffusion probabilistic models (DDPMs) with non-Markovian guidance.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2010.02502
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`jnp.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ clip_sample (`bool`, default `True`):
+ option to clip predicted sample between -1 and 1 for numerical stability.
+ set_alpha_to_one (`bool`, default `True`):
+ each diffusion step uses the value of alphas product at that step and at the previous one. For the final
+ step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
+ otherwise it uses the value of alpha at step 0.
+ steps_offset (`int`, default `0`):
+ an offset added to the inference steps. You can use a combination of `offset=1` and
+ `set_alpha_to_one=False`, to make the last step use step 0 for the previous alpha product, as done in
+ stable diffusion.
+ prediction_type (`str`, default `epsilon`):
+ indicates whether the model predicts the noise (epsilon), or the samples. One of `epsilon`, `sample`.
+ `v-prediction` is not supported for this scheduler.
+ dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
+ the `dtype` used for params and computation.
+ """
+
+ _compatibles = [e.name for e in FlaxKarrasDiffusionSchedulers]
+
+ dtype: jnp.dtype
+
+ @property
+ def has_state(self):
+ return True
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[jnp.ndarray] = None,
+ set_alpha_to_one: bool = True,
+ steps_offset: int = 0,
+ prediction_type: str = "epsilon",
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ self.dtype = dtype
+
+ def create_state(self, common: Optional[CommonSchedulerState] = None) -> DDIMSchedulerState:
+ if common is None:
+ common = CommonSchedulerState.create(self)
+
+ # At every step in ddim, we are looking into the previous alphas_cumprod
+ # For the final step, there is no previous alphas_cumprod because we are already at 0
+ # `set_alpha_to_one` decides whether we set this parameter simply to one or
+ # whether we use the final alpha of the "non-previous" one.
+ final_alpha_cumprod = (
+ jnp.array(1.0, dtype=self.dtype) if self.config.set_alpha_to_one else common.alphas_cumprod[0]
+ )
+
+ # standard deviation of the initial noise distribution
+ init_noise_sigma = jnp.array(1.0, dtype=self.dtype)
+
+ timesteps = jnp.arange(0, self.config.num_train_timesteps).round()[::-1]
+
+ return DDIMSchedulerState.create(
+ common=common,
+ final_alpha_cumprod=final_alpha_cumprod,
+ init_noise_sigma=init_noise_sigma,
+ timesteps=timesteps,
+ )
+
+ def scale_model_input(
+ self, state: DDIMSchedulerState, sample: jnp.ndarray, timestep: Optional[int] = None
+ ) -> jnp.ndarray:
+ """
+ Args:
+ state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
+ sample (`jnp.ndarray`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `jnp.ndarray`: scaled input sample
+ """
+ return sample
+
+ def set_timesteps(
+ self, state: DDIMSchedulerState, num_inference_steps: int, shape: Tuple = ()
+ ) -> DDIMSchedulerState:
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ state (`DDIMSchedulerState`):
+ the `FlaxDDIMScheduler` state data class instance.
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+ step_ratio = self.config.num_train_timesteps // num_inference_steps
+ # creates integer timesteps by multiplying by ratio
+ # rounding to avoid issues when num_inference_step is power of 3
+ timesteps = (jnp.arange(0, num_inference_steps) * step_ratio).round()[::-1] + self.config.steps_offset
+
+ return state.replace(
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ )
+
+ def _get_variance(self, state: DDIMSchedulerState, timestep, prev_timestep):
+ alpha_prod_t = state.common.alphas_cumprod[timestep]
+ alpha_prod_t_prev = jnp.where(
+ prev_timestep >= 0, state.common.alphas_cumprod[prev_timestep], state.final_alpha_cumprod
+ )
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
+
+ return variance
+
+ def step(
+ self,
+ state: DDIMSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ eta: float = 0.0,
+ return_dict: bool = True,
+ ) -> Union[FlaxDDIMSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ state (`DDIMSchedulerState`): the `FlaxDDIMScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than FlaxDDIMSchedulerOutput class
+
+ Returns:
+ [`FlaxDDIMSchedulerOutput`] or `tuple`: [`FlaxDDIMSchedulerOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if state.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
+ # Ideally, read DDIM paper in-detail understanding
+
+ # Notation ( ->
+ # - pred_noise_t -> e_theta(x_t, t)
+ # - pred_original_sample -> f_theta(x_t, t) or x_0
+ # - std_dev_t -> sigma_t
+ # - eta -> η
+ # - pred_sample_direction -> "direction pointing to x_t"
+ # - pred_prev_sample -> "x_t-1"
+
+ # 1. get previous step value (=t-1)
+ prev_timestep = timestep - self.config.num_train_timesteps // state.num_inference_steps
+
+ alphas_cumprod = state.common.alphas_cumprod
+ final_alpha_cumprod = state.final_alpha_cumprod
+
+ # 2. compute alphas, betas
+ alpha_prod_t = alphas_cumprod[timestep]
+ alpha_prod_t_prev = jnp.where(prev_timestep >= 0, alphas_cumprod[prev_timestep], final_alpha_cumprod)
+
+ beta_prod_t = 1 - alpha_prod_t
+
+ # 3. compute predicted original sample from predicted noise also called
+ # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
+ pred_epsilon = model_output
+ elif self.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
+ elif self.config.prediction_type == "v_prediction":
+ pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
+ pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction`"
+ )
+
+ # 4. compute variance: "sigma_t(η)" -> see formula (16)
+ # σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
+ variance = self._get_variance(state, timestep, prev_timestep)
+ std_dev_t = eta * variance ** (0.5)
+
+ # 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
+
+ # 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
+
+ if not return_dict:
+ return (prev_sample, state)
+
+ return FlaxDDIMSchedulerOutput(prev_sample=prev_sample, state=state)
+
+ def add_noise(
+ self,
+ state: DDIMSchedulerState,
+ original_samples: jnp.ndarray,
+ noise: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ) -> jnp.ndarray:
+ return add_noise_common(state.common, original_samples, noise, timesteps)
+
+ def get_velocity(
+ self,
+ state: DDIMSchedulerState,
+ sample: jnp.ndarray,
+ noise: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ) -> jnp.ndarray:
+ return get_velocity_common(state.common, sample, noise, timesteps)
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_ddim_inverse.py b/diffusers/src/diffusers/schedulers/scheduling_ddim_inverse.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c9fc036a027c0d8220bc46d4ad9ca84cffee6a5
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_ddim_inverse.py
@@ -0,0 +1,268 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
+# and https://github.com/hojonathanho/diffusion
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from diffusers.configuration_utils import ConfigMixin, register_to_config
+from diffusers.schedulers.scheduling_utils import SchedulerMixin
+from diffusers.utils import BaseOutput, deprecate
+
+
+@dataclass
+# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->DDIM
+class DDIMSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999) -> torch.Tensor:
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class DDIMInverseScheduler(SchedulerMixin, ConfigMixin):
+ """
+ DDIMInverseScheduler is the reverse scheduler of [`DDIMScheduler`].
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2010.02502
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ clip_sample (`bool`, default `True`):
+ option to clip predicted sample for numerical stability.
+ clip_sample_range (`float`, default `1.0`):
+ the maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
+ set_alpha_to_zero (`bool`, default `True`):
+ each diffusion step uses the value of alphas product at that step and at the previous one. For the final
+ step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `0`,
+ otherwise it uses the value of alpha at step `num_train_timesteps - 1`.
+ steps_offset (`int`, default `0`):
+ an offset added to the inference steps. You can use a combination of `offset=1` and
+ `set_alpha_to_zero=False`, to make the last step use step `num_train_timesteps - 1` for the previous alpha
+ product.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ """
+
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ clip_sample: bool = True,
+ set_alpha_to_zero: bool = True,
+ steps_offset: int = 0,
+ prediction_type: str = "epsilon",
+ clip_sample_range: float = 1.0,
+ **kwargs,
+ ):
+ if kwargs.get("set_alpha_to_one", None) is not None:
+ deprecation_message = (
+ "The `set_alpha_to_one` argument is deprecated. Please use `set_alpha_to_zero` instead."
+ )
+ deprecate("set_alpha_to_one", "1.0.0", deprecation_message, standard_warn=False)
+ set_alpha_to_zero = kwargs["set_alpha_to_one"]
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ # At every step in inverted ddim, we are looking into the next alphas_cumprod
+ # For the final step, there is no next alphas_cumprod, and the index is out of bounds
+ # `set_alpha_to_zero` decides whether we set this parameter simply to zero
+ # in this case, self.step() just output the predicted noise
+ # or whether we use the final alpha of the "non-previous" one.
+ self.final_alpha_cumprod = torch.tensor(0.0) if set_alpha_to_zero else self.alphas_cumprod[-1]
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps).copy().astype(np.int64))
+
+ # Copied from diffusers.schedulers.scheduling_ddim.DDIMScheduler.scale_model_input
+ def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+
+ if num_inference_steps > self.config.num_train_timesteps:
+ raise ValueError(
+ f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
+ f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
+ f" maximal {self.config.num_train_timesteps} timesteps."
+ )
+
+ self.num_inference_steps = num_inference_steps
+ step_ratio = self.config.num_train_timesteps // self.num_inference_steps
+ # creates integer timesteps by multiplying by ratio
+ # casting to int to avoid issues when num_inference_step is power of 3
+ timesteps = (np.arange(0, num_inference_steps) * step_ratio).round().copy().astype(np.int64)
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+ self.timesteps += self.config.steps_offset
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ eta: float = 0.0,
+ use_clipped_model_output: bool = False,
+ variance_noise: Optional[torch.FloatTensor] = None,
+ return_dict: bool = True,
+ ) -> Union[DDIMSchedulerOutput, Tuple]:
+ # 1. get previous step value (=t+1)
+ prev_timestep = timestep + self.config.num_train_timesteps // self.num_inference_steps
+
+ # 2. compute alphas, betas
+ # change original implementation to exactly match noise levels for analogous forward process
+ alpha_prod_t = self.alphas_cumprod[timestep]
+ alpha_prod_t_prev = (
+ self.alphas_cumprod[prev_timestep]
+ if prev_timestep < self.config.num_train_timesteps
+ else self.final_alpha_cumprod
+ )
+
+ beta_prod_t = 1 - alpha_prod_t
+
+ # 3. compute predicted original sample from predicted noise also called
+ # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
+ pred_epsilon = model_output
+ elif self.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
+ elif self.config.prediction_type == "v_prediction":
+ pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
+ pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction`"
+ )
+
+ # 4. Clip or threshold "predicted x_0"
+ if self.config.clip_sample:
+ pred_original_sample = pred_original_sample.clamp(
+ -self.config.clip_sample_range, self.config.clip_sample_range
+ )
+
+ # 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ pred_sample_direction = (1 - alpha_prod_t_prev) ** (0.5) * pred_epsilon
+
+ # 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
+
+ if not return_dict:
+ return (prev_sample, pred_original_sample)
+ return DDIMSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_ddpm.py b/diffusers/src/diffusers/schedulers/scheduling_ddpm.py
new file mode 100644
index 0000000000000000000000000000000000000000..206294066cb32d84e958970a1dc3710747aa7d3b
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_ddpm.py
@@ -0,0 +1,395 @@
+# Copyright 2023 UC Berkeley Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/ermongroup/ddim
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, randn_tensor
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin
+
+
+@dataclass
+class DDPMSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class DDPMScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Denoising diffusion probabilistic models (DDPMs) explores the connections between denoising score matching and
+ Langevin dynamics sampling.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2006.11239
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ variance_type (`str`):
+ options to clip the variance used when adding noise to the denoised sample. Choose from `fixed_small`,
+ `fixed_small_log`, `fixed_large`, `fixed_large_log`, `learned` or `learned_range`.
+ clip_sample (`bool`, default `True`):
+ option to clip predicted sample for numerical stability.
+ clip_sample_range (`float`, default `1.0`):
+ the maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ thresholding (`bool`, default `False`):
+ whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
+ Note that the thresholding method is unsuitable for latent-space diffusion models (such as
+ stable-diffusion).
+ dynamic_thresholding_ratio (`float`, default `0.995`):
+ the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
+ (https://arxiv.org/abs/2205.11487). Valid only when `thresholding=True`.
+ sample_max_value (`float`, default `1.0`):
+ the threshold value for dynamic thresholding. Valid only when `thresholding=True`.
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ variance_type: str = "fixed_small",
+ clip_sample: bool = True,
+ prediction_type: str = "epsilon",
+ thresholding: bool = False,
+ dynamic_thresholding_ratio: float = 0.995,
+ clip_sample_range: float = 1.0,
+ sample_max_value: float = 1.0,
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ elif beta_schedule == "sigmoid":
+ # GeoDiff sigmoid schedule
+ betas = torch.linspace(-6, 6, num_train_timesteps)
+ self.betas = torch.sigmoid(betas) * (beta_end - beta_start) + beta_start
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+ self.one = torch.tensor(1.0)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy())
+
+ self.variance_type = variance_type
+
+ def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+
+ if num_inference_steps > self.config.num_train_timesteps:
+ raise ValueError(
+ f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
+ f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
+ f" maximal {self.config.num_train_timesteps} timesteps."
+ )
+
+ self.num_inference_steps = num_inference_steps
+
+ step_ratio = self.config.num_train_timesteps // self.num_inference_steps
+ timesteps = (np.arange(0, num_inference_steps) * step_ratio).round()[::-1].copy().astype(np.int64)
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+
+ def _get_variance(self, t, predicted_variance=None, variance_type=None):
+ num_inference_steps = self.num_inference_steps if self.num_inference_steps else self.config.num_train_timesteps
+ prev_t = t - self.config.num_train_timesteps // num_inference_steps
+ alpha_prod_t = self.alphas_cumprod[t]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
+ current_beta_t = 1 - alpha_prod_t / alpha_prod_t_prev
+
+ # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
+ # and sample from it to get previous sample
+ # x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
+ variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * current_beta_t
+
+ if variance_type is None:
+ variance_type = self.config.variance_type
+
+ # hacks - were probably added for training stability
+ if variance_type == "fixed_small":
+ variance = torch.clamp(variance, min=1e-20)
+ # for rl-diffuser https://arxiv.org/abs/2205.09991
+ elif variance_type == "fixed_small_log":
+ variance = torch.log(torch.clamp(variance, min=1e-20))
+ variance = torch.exp(0.5 * variance)
+ elif variance_type == "fixed_large":
+ variance = current_beta_t
+ elif variance_type == "fixed_large_log":
+ # Glide max_log
+ variance = torch.log(current_beta_t)
+ elif variance_type == "learned":
+ return predicted_variance
+ elif variance_type == "learned_range":
+ min_log = torch.log(variance)
+ max_log = torch.log(self.betas[t])
+ frac = (predicted_variance + 1) / 2
+ variance = frac * max_log + (1 - frac) * min_log
+
+ return variance
+
+ def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ dynamic_max_val = (
+ sample.flatten(1)
+ .abs()
+ .quantile(self.config.dynamic_thresholding_ratio, dim=1)
+ .clamp_min(self.config.sample_max_value)
+ .view(-1, *([1] * (sample.ndim - 1)))
+ )
+ return sample.clamp(-dynamic_max_val, dynamic_max_val) / dynamic_max_val
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ generator=None,
+ return_dict: bool = True,
+ ) -> Union[DDPMSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ generator: random number generator.
+ return_dict (`bool`): option for returning tuple rather than DDPMSchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.DDPMSchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.DDPMSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+
+ """
+ t = timestep
+ num_inference_steps = self.num_inference_steps if self.num_inference_steps else self.config.num_train_timesteps
+ prev_t = timestep - self.config.num_train_timesteps // num_inference_steps
+
+ if model_output.shape[1] == sample.shape[1] * 2 and self.variance_type in ["learned", "learned_range"]:
+ model_output, predicted_variance = torch.split(model_output, sample.shape[1], dim=1)
+ else:
+ predicted_variance = None
+
+ # 1. compute alphas, betas
+ alpha_prod_t = self.alphas_cumprod[t]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_t] if prev_t >= 0 else self.one
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+ current_alpha_t = alpha_prod_t / alpha_prod_t_prev
+ current_beta_t = 1 - current_alpha_t
+
+ # 2. compute predicted original sample from predicted noise also called
+ # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
+ elif self.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ elif self.config.prediction_type == "v_prediction":
+ pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample` or"
+ " `v_prediction` for the DDPMScheduler."
+ )
+
+ # 3. Clip or threshold "predicted x_0"
+ if self.config.clip_sample:
+ pred_original_sample = pred_original_sample.clamp(
+ -self.config.clip_sample_range, self.config.clip_sample_range
+ )
+
+ if self.config.thresholding:
+ pred_original_sample = self._threshold_sample(pred_original_sample)
+
+ # 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
+ # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * current_beta_t) / beta_prod_t
+ current_sample_coeff = current_alpha_t ** (0.5) * beta_prod_t_prev / beta_prod_t
+
+ # 5. Compute predicted previous sample µ_t
+ # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
+
+ # 6. Add noise
+ variance = 0
+ if t > 0:
+ device = model_output.device
+ variance_noise = randn_tensor(
+ model_output.shape, generator=generator, device=device, dtype=model_output.dtype
+ )
+ if self.variance_type == "fixed_small_log":
+ variance = self._get_variance(t, predicted_variance=predicted_variance) * variance_noise
+ elif self.variance_type == "learned_range":
+ variance = self._get_variance(t, predicted_variance=predicted_variance)
+ variance = torch.exp(0.5 * variance) * variance_noise
+ else:
+ variance = (self._get_variance(t, predicted_variance=predicted_variance) ** 0.5) * variance_noise
+
+ pred_prev_sample = pred_prev_sample + variance
+
+ if not return_dict:
+ return (pred_prev_sample,)
+
+ return DDPMSchedulerOutput(prev_sample=pred_prev_sample, pred_original_sample=pred_original_sample)
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.IntTensor,
+ ) -> torch.FloatTensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as original_samples
+ self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
+ timesteps = timesteps.to(original_samples.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
+ return noisy_samples
+
+ def get_velocity(
+ self, sample: torch.FloatTensor, noise: torch.FloatTensor, timesteps: torch.IntTensor
+ ) -> torch.FloatTensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as sample
+ self.alphas_cumprod = self.alphas_cumprod.to(device=sample.device, dtype=sample.dtype)
+ timesteps = timesteps.to(sample.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(sample.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
+ return velocity
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_ddpm_flax.py b/diffusers/src/diffusers/schedulers/scheduling_ddpm_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..529d2bd03a75403e298ec7a30808689a48cf5301
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_ddpm_flax.py
@@ -0,0 +1,299 @@
+# Copyright 2023 UC Berkeley Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/ermongroup/ddim
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import flax
+import jax
+import jax.numpy as jnp
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils_flax import (
+ CommonSchedulerState,
+ FlaxKarrasDiffusionSchedulers,
+ FlaxSchedulerMixin,
+ FlaxSchedulerOutput,
+ add_noise_common,
+ get_velocity_common,
+)
+
+
+@flax.struct.dataclass
+class DDPMSchedulerState:
+ common: CommonSchedulerState
+
+ # setable values
+ init_noise_sigma: jnp.ndarray
+ timesteps: jnp.ndarray
+ num_inference_steps: Optional[int] = None
+
+ @classmethod
+ def create(cls, common: CommonSchedulerState, init_noise_sigma: jnp.ndarray, timesteps: jnp.ndarray):
+ return cls(common=common, init_noise_sigma=init_noise_sigma, timesteps=timesteps)
+
+
+@dataclass
+class FlaxDDPMSchedulerOutput(FlaxSchedulerOutput):
+ state: DDPMSchedulerState
+
+
+class FlaxDDPMScheduler(FlaxSchedulerMixin, ConfigMixin):
+ """
+ Denoising diffusion probabilistic models (DDPMs) explores the connections between denoising score matching and
+ Langevin dynamics sampling.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2006.11239
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ variance_type (`str`):
+ options to clip the variance used when adding noise to the denoised sample. Choose from `fixed_small`,
+ `fixed_small_log`, `fixed_large`, `fixed_large_log`, `learned` or `learned_range`.
+ clip_sample (`bool`, default `True`):
+ option to clip predicted sample between -1 and 1 for numerical stability.
+ prediction_type (`str`, default `epsilon`):
+ indicates whether the model predicts the noise (epsilon), or the samples. One of `epsilon`, `sample`.
+ `v-prediction` is not supported for this scheduler.
+ dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
+ the `dtype` used for params and computation.
+ """
+
+ _compatibles = [e.name for e in FlaxKarrasDiffusionSchedulers]
+
+ dtype: jnp.dtype
+
+ @property
+ def has_state(self):
+ return True
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[jnp.ndarray] = None,
+ variance_type: str = "fixed_small",
+ clip_sample: bool = True,
+ prediction_type: str = "epsilon",
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ self.dtype = dtype
+
+ def create_state(self, common: Optional[CommonSchedulerState] = None) -> DDPMSchedulerState:
+ if common is None:
+ common = CommonSchedulerState.create(self)
+
+ # standard deviation of the initial noise distribution
+ init_noise_sigma = jnp.array(1.0, dtype=self.dtype)
+
+ timesteps = jnp.arange(0, self.config.num_train_timesteps).round()[::-1]
+
+ return DDPMSchedulerState.create(
+ common=common,
+ init_noise_sigma=init_noise_sigma,
+ timesteps=timesteps,
+ )
+
+ def scale_model_input(
+ self, state: DDPMSchedulerState, sample: jnp.ndarray, timestep: Optional[int] = None
+ ) -> jnp.ndarray:
+ """
+ Args:
+ state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
+ sample (`jnp.ndarray`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `jnp.ndarray`: scaled input sample
+ """
+ return sample
+
+ def set_timesteps(
+ self, state: DDPMSchedulerState, num_inference_steps: int, shape: Tuple = ()
+ ) -> DDPMSchedulerState:
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ state (`DDIMSchedulerState`):
+ the `FlaxDDPMScheduler` state data class instance.
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+
+ step_ratio = self.config.num_train_timesteps // num_inference_steps
+ # creates integer timesteps by multiplying by ratio
+ # rounding to avoid issues when num_inference_step is power of 3
+ timesteps = (jnp.arange(0, num_inference_steps) * step_ratio).round()[::-1]
+
+ return state.replace(
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ )
+
+ def _get_variance(self, state: DDPMSchedulerState, t, predicted_variance=None, variance_type=None):
+ alpha_prod_t = state.common.alphas_cumprod[t]
+ alpha_prod_t_prev = jnp.where(t > 0, state.common.alphas_cumprod[t - 1], jnp.array(1.0, dtype=self.dtype))
+
+ # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
+ # and sample from it to get previous sample
+ # x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
+ variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * state.common.betas[t]
+
+ if variance_type is None:
+ variance_type = self.config.variance_type
+
+ # hacks - were probably added for training stability
+ if variance_type == "fixed_small":
+ variance = jnp.clip(variance, a_min=1e-20)
+ # for rl-diffuser https://arxiv.org/abs/2205.09991
+ elif variance_type == "fixed_small_log":
+ variance = jnp.log(jnp.clip(variance, a_min=1e-20))
+ elif variance_type == "fixed_large":
+ variance = state.common.betas[t]
+ elif variance_type == "fixed_large_log":
+ # Glide max_log
+ variance = jnp.log(state.common.betas[t])
+ elif variance_type == "learned":
+ return predicted_variance
+ elif variance_type == "learned_range":
+ min_log = variance
+ max_log = state.common.betas[t]
+ frac = (predicted_variance + 1) / 2
+ variance = frac * max_log + (1 - frac) * min_log
+
+ return variance
+
+ def step(
+ self,
+ state: DDPMSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ key: Optional[jax.random.KeyArray] = None,
+ return_dict: bool = True,
+ ) -> Union[FlaxDDPMSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ state (`DDPMSchedulerState`): the `FlaxDDPMScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ key (`jax.random.KeyArray`): a PRNG key.
+ return_dict (`bool`): option for returning tuple rather than FlaxDDPMSchedulerOutput class
+
+ Returns:
+ [`FlaxDDPMSchedulerOutput`] or `tuple`: [`FlaxDDPMSchedulerOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ t = timestep
+
+ if key is None:
+ key = jax.random.PRNGKey(0)
+
+ if model_output.shape[1] == sample.shape[1] * 2 and self.config.variance_type in ["learned", "learned_range"]:
+ model_output, predicted_variance = jnp.split(model_output, sample.shape[1], axis=1)
+ else:
+ predicted_variance = None
+
+ # 1. compute alphas, betas
+ alpha_prod_t = state.common.alphas_cumprod[t]
+ alpha_prod_t_prev = jnp.where(t > 0, state.common.alphas_cumprod[t - 1], jnp.array(1.0, dtype=self.dtype))
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ # 2. compute predicted original sample from predicted noise also called
+ # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
+ elif self.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ elif self.config.prediction_type == "v_prediction":
+ pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample` "
+ " for the FlaxDDPMScheduler."
+ )
+
+ # 3. Clip "predicted x_0"
+ if self.config.clip_sample:
+ pred_original_sample = jnp.clip(pred_original_sample, -1, 1)
+
+ # 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
+ # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * state.common.betas[t]) / beta_prod_t
+ current_sample_coeff = state.common.alphas[t] ** (0.5) * beta_prod_t_prev / beta_prod_t
+
+ # 5. Compute predicted previous sample µ_t
+ # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
+
+ # 6. Add noise
+ def random_variance():
+ split_key = jax.random.split(key, num=1)
+ noise = jax.random.normal(split_key, shape=model_output.shape, dtype=self.dtype)
+ return (self._get_variance(state, t, predicted_variance=predicted_variance) ** 0.5) * noise
+
+ variance = jnp.where(t > 0, random_variance(), jnp.zeros(model_output.shape, dtype=self.dtype))
+
+ pred_prev_sample = pred_prev_sample + variance
+
+ if not return_dict:
+ return (pred_prev_sample, state)
+
+ return FlaxDDPMSchedulerOutput(prev_sample=pred_prev_sample, state=state)
+
+ def add_noise(
+ self,
+ state: DDPMSchedulerState,
+ original_samples: jnp.ndarray,
+ noise: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ) -> jnp.ndarray:
+ return add_noise_common(state.common, original_samples, noise, timesteps)
+
+ def get_velocity(
+ self,
+ state: DDPMSchedulerState,
+ sample: jnp.ndarray,
+ noise: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ) -> jnp.ndarray:
+ return get_velocity_common(state.common, sample, noise, timesteps)
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_deis_multistep.py b/diffusers/src/diffusers/schedulers/scheduling_deis_multistep.py
new file mode 100644
index 0000000000000000000000000000000000000000..39f8f17df5d30f80d13570177a08c181f92201f6
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_deis_multistep.py
@@ -0,0 +1,485 @@
+# Copyright 2023 FLAIR Lab and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: check https://arxiv.org/abs/2204.13902 and https://github.com/qsh-zh/deis for more info
+# The codebase is modified based on https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin, SchedulerOutput
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class DEISMultistepScheduler(SchedulerMixin, ConfigMixin):
+ """
+ DEIS (https://arxiv.org/abs/2204.13902) is a fast high order solver for diffusion ODEs. We slightly modify the
+ polynomial fitting formula in log-rho space instead of the original linear t space in DEIS paper. The modification
+ enjoys closed-form coefficients for exponential multistep update instead of replying on the numerical solver. More
+ variants of DEIS can be found in https://github.com/qsh-zh/deis.
+
+ Currently, we support the log-rho multistep DEIS. We recommend to use `solver_order=2 / 3` while `solver_order=1`
+ reduces to DDIM.
+
+ We also support the "dynamic thresholding" method in Imagen (https://arxiv.org/abs/2205.11487). For pixel-space
+ diffusion models, you can set `thresholding=True` to use the dynamic thresholding.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ solver_order (`int`, default `2`):
+ the order of DEIS; can be `1` or `2` or `3`. We recommend to use `solver_order=2` for guided sampling, and
+ `solver_order=3` for unconditional sampling.
+ prediction_type (`str`, default `epsilon`):
+ indicates whether the model predicts the noise (epsilon), or the data / `x0`. One of `epsilon`, `sample`,
+ or `v-prediction`.
+ thresholding (`bool`, default `False`):
+ whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
+ Note that the thresholding method is unsuitable for latent-space diffusion models (such as
+ stable-diffusion).
+ dynamic_thresholding_ratio (`float`, default `0.995`):
+ the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
+ (https://arxiv.org/abs/2205.11487).
+ sample_max_value (`float`, default `1.0`):
+ the threshold value for dynamic thresholding. Valid only when `thresholding=True`
+ algorithm_type (`str`, default `deis`):
+ the algorithm type for the solver. current we support multistep deis, we will add other variants of DEIS in
+ the future
+ lower_order_final (`bool`, default `True`):
+ whether to use lower-order solvers in the final steps. Only valid for < 15 inference steps. We empirically
+ find this trick can stabilize the sampling of DEIS for steps < 15, especially for steps <= 10.
+
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[np.ndarray] = None,
+ solver_order: int = 2,
+ prediction_type: str = "epsilon",
+ thresholding: bool = False,
+ dynamic_thresholding_ratio: float = 0.995,
+ sample_max_value: float = 1.0,
+ algorithm_type: str = "deis",
+ solver_type: str = "logrho",
+ lower_order_final: bool = True,
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+ # Currently we only support VP-type noise schedule
+ self.alpha_t = torch.sqrt(self.alphas_cumprod)
+ self.sigma_t = torch.sqrt(1 - self.alphas_cumprod)
+ self.lambda_t = torch.log(self.alpha_t) - torch.log(self.sigma_t)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # settings for DEIS
+ if algorithm_type not in ["deis"]:
+ if algorithm_type in ["dpmsolver", "dpmsolver++"]:
+ self.register_to_config(algorithm_type="deis")
+ else:
+ raise NotImplementedError(f"{algorithm_type} does is not implemented for {self.__class__}")
+
+ if solver_type not in ["logrho"]:
+ if solver_type in ["midpoint", "heun", "bh1", "bh2"]:
+ self.register_to_config(solver_type="logrho")
+ else:
+ raise NotImplementedError(f"solver type {solver_type} does is not implemented for {self.__class__}")
+
+ # setable values
+ self.num_inference_steps = None
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=np.float32)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps)
+ self.model_outputs = [None] * solver_order
+ self.lower_order_nums = 0
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+ timesteps = (
+ np.linspace(0, self.num_train_timesteps - 1, num_inference_steps + 1)
+ .round()[::-1][:-1]
+ .copy()
+ .astype(np.int64)
+ )
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+ self.model_outputs = [
+ None,
+ ] * self.config.solver_order
+ self.lower_order_nums = 0
+
+ # Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
+ def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ dynamic_max_val = (
+ sample.flatten(1)
+ .abs()
+ .quantile(self.config.dynamic_thresholding_ratio, dim=1)
+ .clamp_min(self.config.sample_max_value)
+ .view(-1, *([1] * (sample.ndim - 1)))
+ )
+ return sample.clamp(-dynamic_max_val, dynamic_max_val) / dynamic_max_val
+
+ def convert_model_output(
+ self, model_output: torch.FloatTensor, timestep: int, sample: torch.FloatTensor
+ ) -> torch.FloatTensor:
+ """
+ Convert the model output to the corresponding type that the algorithm DEIS needs.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the converted model output.
+ """
+ if self.config.prediction_type == "epsilon":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ x0_pred = (sample - sigma_t * model_output) / alpha_t
+ elif self.config.prediction_type == "sample":
+ x0_pred = model_output
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ x0_pred = alpha_t * sample - sigma_t * model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction` for the DEISMultistepScheduler."
+ )
+
+ if self.config.thresholding:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ orig_dtype = x0_pred.dtype
+ if orig_dtype not in [torch.float, torch.double]:
+ x0_pred = x0_pred.float()
+ x0_pred = self._threshold_sample(x0_pred).type(orig_dtype)
+
+ if self.config.algorithm_type == "deis":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ return (sample - alpha_t * x0_pred) / sigma_t
+ else:
+ raise NotImplementedError("only support log-rho multistep deis now")
+
+ def deis_first_order_update(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the first-order DEIS (equivalent to DDIM).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ lambda_t, lambda_s = self.lambda_t[prev_timestep], self.lambda_t[timestep]
+ alpha_t, alpha_s = self.alpha_t[prev_timestep], self.alpha_t[timestep]
+ sigma_t, _ = self.sigma_t[prev_timestep], self.sigma_t[timestep]
+ h = lambda_t - lambda_s
+ if self.config.algorithm_type == "deis":
+ x_t = (alpha_t / alpha_s) * sample - (sigma_t * (torch.exp(h) - 1.0)) * model_output
+ else:
+ raise NotImplementedError("only support log-rho multistep deis now")
+ return x_t
+
+ def multistep_deis_second_order_update(
+ self,
+ model_output_list: List[torch.FloatTensor],
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the second-order multistep DEIS.
+
+ Args:
+ model_output_list (`List[torch.FloatTensor]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ t, s0, s1 = prev_timestep, timestep_list[-1], timestep_list[-2]
+ m0, m1 = model_output_list[-1], model_output_list[-2]
+ alpha_t, alpha_s0, alpha_s1 = self.alpha_t[t], self.alpha_t[s0], self.alpha_t[s1]
+ sigma_t, sigma_s0, sigma_s1 = self.sigma_t[t], self.sigma_t[s0], self.sigma_t[s1]
+
+ rho_t, rho_s0, rho_s1 = sigma_t / alpha_t, sigma_s0 / alpha_s0, sigma_s1 / alpha_s1
+
+ if self.config.algorithm_type == "deis":
+
+ def ind_fn(t, b, c):
+ # Integrate[(log(t) - log(c)) / (log(b) - log(c)), {t}]
+ return t * (-np.log(c) + np.log(t) - 1) / (np.log(b) - np.log(c))
+
+ coef1 = ind_fn(rho_t, rho_s0, rho_s1) - ind_fn(rho_s0, rho_s0, rho_s1)
+ coef2 = ind_fn(rho_t, rho_s1, rho_s0) - ind_fn(rho_s0, rho_s1, rho_s0)
+
+ x_t = alpha_t * (sample / alpha_s0 + coef1 * m0 + coef2 * m1)
+ return x_t
+ else:
+ raise NotImplementedError("only support log-rho multistep deis now")
+
+ def multistep_deis_third_order_update(
+ self,
+ model_output_list: List[torch.FloatTensor],
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the third-order multistep DEIS.
+
+ Args:
+ model_output_list (`List[torch.FloatTensor]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ t, s0, s1, s2 = prev_timestep, timestep_list[-1], timestep_list[-2], timestep_list[-3]
+ m0, m1, m2 = model_output_list[-1], model_output_list[-2], model_output_list[-3]
+ alpha_t, alpha_s0, alpha_s1, alpha_s2 = self.alpha_t[t], self.alpha_t[s0], self.alpha_t[s1], self.alpha_t[s2]
+ sigma_t, sigma_s0, sigma_s1, simga_s2 = self.sigma_t[t], self.sigma_t[s0], self.sigma_t[s1], self.sigma_t[s2]
+ rho_t, rho_s0, rho_s1, rho_s2 = (
+ sigma_t / alpha_t,
+ sigma_s0 / alpha_s0,
+ sigma_s1 / alpha_s1,
+ simga_s2 / alpha_s2,
+ )
+
+ if self.config.algorithm_type == "deis":
+
+ def ind_fn(t, b, c, d):
+ # Integrate[(log(t) - log(c))(log(t) - log(d)) / (log(b) - log(c))(log(b) - log(d)), {t}]
+ numerator = t * (
+ np.log(c) * (np.log(d) - np.log(t) + 1)
+ - np.log(d) * np.log(t)
+ + np.log(d)
+ + np.log(t) ** 2
+ - 2 * np.log(t)
+ + 2
+ )
+ denominator = (np.log(b) - np.log(c)) * (np.log(b) - np.log(d))
+ return numerator / denominator
+
+ coef1 = ind_fn(rho_t, rho_s0, rho_s1, rho_s2) - ind_fn(rho_s0, rho_s0, rho_s1, rho_s2)
+ coef2 = ind_fn(rho_t, rho_s1, rho_s2, rho_s0) - ind_fn(rho_s0, rho_s1, rho_s2, rho_s0)
+ coef3 = ind_fn(rho_t, rho_s2, rho_s0, rho_s1) - ind_fn(rho_s0, rho_s2, rho_s0, rho_s1)
+
+ x_t = alpha_t * (sample / alpha_s0 + coef1 * m0 + coef2 * m1 + coef3 * m2)
+
+ return x_t
+ else:
+ raise NotImplementedError("only support log-rho multistep deis now")
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the multistep DEIS.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~scheduling_utils.SchedulerOutput`] or `tuple`: [`~scheduling_utils.SchedulerOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+ step_index = (self.timesteps == timestep).nonzero()
+ if len(step_index) == 0:
+ step_index = len(self.timesteps) - 1
+ else:
+ step_index = step_index.item()
+ prev_timestep = 0 if step_index == len(self.timesteps) - 1 else self.timesteps[step_index + 1]
+ lower_order_final = (
+ (step_index == len(self.timesteps) - 1) and self.config.lower_order_final and len(self.timesteps) < 15
+ )
+ lower_order_second = (
+ (step_index == len(self.timesteps) - 2) and self.config.lower_order_final and len(self.timesteps) < 15
+ )
+
+ model_output = self.convert_model_output(model_output, timestep, sample)
+ for i in range(self.config.solver_order - 1):
+ self.model_outputs[i] = self.model_outputs[i + 1]
+ self.model_outputs[-1] = model_output
+
+ if self.config.solver_order == 1 or self.lower_order_nums < 1 or lower_order_final:
+ prev_sample = self.deis_first_order_update(model_output, timestep, prev_timestep, sample)
+ elif self.config.solver_order == 2 or self.lower_order_nums < 2 or lower_order_second:
+ timestep_list = [self.timesteps[step_index - 1], timestep]
+ prev_sample = self.multistep_deis_second_order_update(
+ self.model_outputs, timestep_list, prev_timestep, sample
+ )
+ else:
+ timestep_list = [self.timesteps[step_index - 2], self.timesteps[step_index - 1], timestep]
+ prev_sample = self.multistep_deis_third_order_update(
+ self.model_outputs, timestep_list, prev_timestep, sample
+ )
+
+ if self.lower_order_nums < self.config.solver_order:
+ self.lower_order_nums += 1
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def scale_model_input(self, sample: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.IntTensor,
+ ) -> torch.FloatTensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as original_samples
+ self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
+ timesteps = timesteps.to(original_samples.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py b/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
new file mode 100644
index 0000000000000000000000000000000000000000..474d9b0d7339f656c46e106003390791c67ced3b
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
@@ -0,0 +1,534 @@
+# Copyright 2023 TSAIL Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/LuChengTHU/dpm-solver
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin, SchedulerOutput
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class DPMSolverMultistepScheduler(SchedulerMixin, ConfigMixin):
+ """
+ DPM-Solver (and the improved version DPM-Solver++) is a fast dedicated high-order solver for diffusion ODEs with
+ the convergence order guarantee. Empirically, sampling by DPM-Solver with only 20 steps can generate high-quality
+ samples, and it can generate quite good samples even in only 10 steps.
+
+ For more details, see the original paper: https://arxiv.org/abs/2206.00927 and https://arxiv.org/abs/2211.01095
+
+ Currently, we support the multistep DPM-Solver for both noise prediction models and data prediction models. We
+ recommend to use `solver_order=2` for guided sampling, and `solver_order=3` for unconditional sampling.
+
+ We also support the "dynamic thresholding" method in Imagen (https://arxiv.org/abs/2205.11487). For pixel-space
+ diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use the dynamic
+ thresholding. Note that the thresholding method is unsuitable for latent-space diffusion models (such as
+ stable-diffusion).
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ solver_order (`int`, default `2`):
+ the order of DPM-Solver; can be `1` or `2` or `3`. We recommend to use `solver_order=2` for guided
+ sampling, and `solver_order=3` for unconditional sampling.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ thresholding (`bool`, default `False`):
+ whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
+ For pixel-space diffusion models, you can set both `algorithm_type=dpmsolver++` and `thresholding=True` to
+ use the dynamic thresholding. Note that the thresholding method is unsuitable for latent-space diffusion
+ models (such as stable-diffusion).
+ dynamic_thresholding_ratio (`float`, default `0.995`):
+ the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
+ (https://arxiv.org/abs/2205.11487).
+ sample_max_value (`float`, default `1.0`):
+ the threshold value for dynamic thresholding. Valid only when `thresholding=True` and
+ `algorithm_type="dpmsolver++`.
+ algorithm_type (`str`, default `dpmsolver++`):
+ the algorithm type for the solver. Either `dpmsolver` or `dpmsolver++`. The `dpmsolver` type implements the
+ algorithms in https://arxiv.org/abs/2206.00927, and the `dpmsolver++` type implements the algorithms in
+ https://arxiv.org/abs/2211.01095. We recommend to use `dpmsolver++` with `solver_order=2` for guided
+ sampling (e.g. stable-diffusion).
+ solver_type (`str`, default `midpoint`):
+ the solver type for the second-order solver. Either `midpoint` or `heun`. The solver type slightly affects
+ the sample quality, especially for small number of steps. We empirically find that `midpoint` solvers are
+ slightly better, so we recommend to use the `midpoint` type.
+ lower_order_final (`bool`, default `True`):
+ whether to use lower-order solvers in the final steps. Only valid for < 15 inference steps. We empirically
+ find this trick can stabilize the sampling of DPM-Solver for steps < 15, especially for steps <= 10.
+
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ solver_order: int = 2,
+ prediction_type: str = "epsilon",
+ thresholding: bool = False,
+ dynamic_thresholding_ratio: float = 0.995,
+ sample_max_value: float = 1.0,
+ algorithm_type: str = "dpmsolver++",
+ solver_type: str = "midpoint",
+ lower_order_final: bool = True,
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+ # Currently we only support VP-type noise schedule
+ self.alpha_t = torch.sqrt(self.alphas_cumprod)
+ self.sigma_t = torch.sqrt(1 - self.alphas_cumprod)
+ self.lambda_t = torch.log(self.alpha_t) - torch.log(self.sigma_t)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # settings for DPM-Solver
+ if algorithm_type not in ["dpmsolver", "dpmsolver++"]:
+ if algorithm_type == "deis":
+ self.register_to_config(algorithm_type="dpmsolver++")
+ else:
+ raise NotImplementedError(f"{algorithm_type} does is not implemented for {self.__class__}")
+
+ if solver_type not in ["midpoint", "heun"]:
+ if solver_type in ["logrho", "bh1", "bh2"]:
+ self.register_to_config(solver_type="midpoint")
+ else:
+ raise NotImplementedError(f"{solver_type} does is not implemented for {self.__class__}")
+
+ # setable values
+ self.num_inference_steps = None
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=np.float32)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps)
+ self.model_outputs = [None] * solver_order
+ self.lower_order_nums = 0
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+ timesteps = (
+ np.linspace(0, self.num_train_timesteps - 1, num_inference_steps + 1)
+ .round()[::-1][:-1]
+ .copy()
+ .astype(np.int64)
+ )
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+ self.model_outputs = [
+ None,
+ ] * self.config.solver_order
+ self.lower_order_nums = 0
+
+ # Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
+ def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ dynamic_max_val = (
+ sample.flatten(1)
+ .abs()
+ .quantile(self.config.dynamic_thresholding_ratio, dim=1)
+ .clamp_min(self.config.sample_max_value)
+ .view(-1, *([1] * (sample.ndim - 1)))
+ )
+ return sample.clamp(-dynamic_max_val, dynamic_max_val) / dynamic_max_val
+
+ def convert_model_output(
+ self, model_output: torch.FloatTensor, timestep: int, sample: torch.FloatTensor
+ ) -> torch.FloatTensor:
+ """
+ Convert the model output to the corresponding type that the algorithm (DPM-Solver / DPM-Solver++) needs.
+
+ DPM-Solver is designed to discretize an integral of the noise prediction model, and DPM-Solver++ is designed to
+ discretize an integral of the data prediction model. So we need to first convert the model output to the
+ corresponding type to match the algorithm.
+
+ Note that the algorithm type and the model type is decoupled. That is to say, we can use either DPM-Solver or
+ DPM-Solver++ for both noise prediction model and data prediction model.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the converted model output.
+ """
+ # DPM-Solver++ needs to solve an integral of the data prediction model.
+ if self.config.algorithm_type == "dpmsolver++":
+ if self.config.prediction_type == "epsilon":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ x0_pred = (sample - sigma_t * model_output) / alpha_t
+ elif self.config.prediction_type == "sample":
+ x0_pred = model_output
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ x0_pred = alpha_t * sample - sigma_t * model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction` for the DPMSolverMultistepScheduler."
+ )
+
+ if self.config.thresholding:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ orig_dtype = x0_pred.dtype
+ if orig_dtype not in [torch.float, torch.double]:
+ x0_pred = x0_pred.float()
+ x0_pred = self._threshold_sample(x0_pred).type(orig_dtype)
+ return x0_pred
+ # DPM-Solver needs to solve an integral of the noise prediction model.
+ elif self.config.algorithm_type == "dpmsolver":
+ if self.config.prediction_type == "epsilon":
+ return model_output
+ elif self.config.prediction_type == "sample":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ epsilon = (sample - alpha_t * model_output) / sigma_t
+ return epsilon
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ epsilon = alpha_t * model_output + sigma_t * sample
+ return epsilon
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction` for the DPMSolverMultistepScheduler."
+ )
+
+ def dpm_solver_first_order_update(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the first-order DPM-Solver (equivalent to DDIM).
+
+ See https://arxiv.org/abs/2206.00927 for the detailed derivation.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ lambda_t, lambda_s = self.lambda_t[prev_timestep], self.lambda_t[timestep]
+ alpha_t, alpha_s = self.alpha_t[prev_timestep], self.alpha_t[timestep]
+ sigma_t, sigma_s = self.sigma_t[prev_timestep], self.sigma_t[timestep]
+ h = lambda_t - lambda_s
+ if self.config.algorithm_type == "dpmsolver++":
+ x_t = (sigma_t / sigma_s) * sample - (alpha_t * (torch.exp(-h) - 1.0)) * model_output
+ elif self.config.algorithm_type == "dpmsolver":
+ x_t = (alpha_t / alpha_s) * sample - (sigma_t * (torch.exp(h) - 1.0)) * model_output
+ return x_t
+
+ def multistep_dpm_solver_second_order_update(
+ self,
+ model_output_list: List[torch.FloatTensor],
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the second-order multistep DPM-Solver.
+
+ Args:
+ model_output_list (`List[torch.FloatTensor]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ t, s0, s1 = prev_timestep, timestep_list[-1], timestep_list[-2]
+ m0, m1 = model_output_list[-1], model_output_list[-2]
+ lambda_t, lambda_s0, lambda_s1 = self.lambda_t[t], self.lambda_t[s0], self.lambda_t[s1]
+ alpha_t, alpha_s0 = self.alpha_t[t], self.alpha_t[s0]
+ sigma_t, sigma_s0 = self.sigma_t[t], self.sigma_t[s0]
+ h, h_0 = lambda_t - lambda_s0, lambda_s0 - lambda_s1
+ r0 = h_0 / h
+ D0, D1 = m0, (1.0 / r0) * (m0 - m1)
+ if self.config.algorithm_type == "dpmsolver++":
+ # See https://arxiv.org/abs/2211.01095 for detailed derivations
+ if self.config.solver_type == "midpoint":
+ x_t = (
+ (sigma_t / sigma_s0) * sample
+ - (alpha_t * (torch.exp(-h) - 1.0)) * D0
+ - 0.5 * (alpha_t * (torch.exp(-h) - 1.0)) * D1
+ )
+ elif self.config.solver_type == "heun":
+ x_t = (
+ (sigma_t / sigma_s0) * sample
+ - (alpha_t * (torch.exp(-h) - 1.0)) * D0
+ + (alpha_t * ((torch.exp(-h) - 1.0) / h + 1.0)) * D1
+ )
+ elif self.config.algorithm_type == "dpmsolver":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ if self.config.solver_type == "midpoint":
+ x_t = (
+ (alpha_t / alpha_s0) * sample
+ - (sigma_t * (torch.exp(h) - 1.0)) * D0
+ - 0.5 * (sigma_t * (torch.exp(h) - 1.0)) * D1
+ )
+ elif self.config.solver_type == "heun":
+ x_t = (
+ (alpha_t / alpha_s0) * sample
+ - (sigma_t * (torch.exp(h) - 1.0)) * D0
+ - (sigma_t * ((torch.exp(h) - 1.0) / h - 1.0)) * D1
+ )
+ return x_t
+
+ def multistep_dpm_solver_third_order_update(
+ self,
+ model_output_list: List[torch.FloatTensor],
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the third-order multistep DPM-Solver.
+
+ Args:
+ model_output_list (`List[torch.FloatTensor]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ t, s0, s1, s2 = prev_timestep, timestep_list[-1], timestep_list[-2], timestep_list[-3]
+ m0, m1, m2 = model_output_list[-1], model_output_list[-2], model_output_list[-3]
+ lambda_t, lambda_s0, lambda_s1, lambda_s2 = (
+ self.lambda_t[t],
+ self.lambda_t[s0],
+ self.lambda_t[s1],
+ self.lambda_t[s2],
+ )
+ alpha_t, alpha_s0 = self.alpha_t[t], self.alpha_t[s0]
+ sigma_t, sigma_s0 = self.sigma_t[t], self.sigma_t[s0]
+ h, h_0, h_1 = lambda_t - lambda_s0, lambda_s0 - lambda_s1, lambda_s1 - lambda_s2
+ r0, r1 = h_0 / h, h_1 / h
+ D0 = m0
+ D1_0, D1_1 = (1.0 / r0) * (m0 - m1), (1.0 / r1) * (m1 - m2)
+ D1 = D1_0 + (r0 / (r0 + r1)) * (D1_0 - D1_1)
+ D2 = (1.0 / (r0 + r1)) * (D1_0 - D1_1)
+ if self.config.algorithm_type == "dpmsolver++":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ x_t = (
+ (sigma_t / sigma_s0) * sample
+ - (alpha_t * (torch.exp(-h) - 1.0)) * D0
+ + (alpha_t * ((torch.exp(-h) - 1.0) / h + 1.0)) * D1
+ - (alpha_t * ((torch.exp(-h) - 1.0 + h) / h**2 - 0.5)) * D2
+ )
+ elif self.config.algorithm_type == "dpmsolver":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ x_t = (
+ (alpha_t / alpha_s0) * sample
+ - (sigma_t * (torch.exp(h) - 1.0)) * D0
+ - (sigma_t * ((torch.exp(h) - 1.0) / h - 1.0)) * D1
+ - (sigma_t * ((torch.exp(h) - 1.0 - h) / h**2 - 0.5)) * D2
+ )
+ return x_t
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the multistep DPM-Solver.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~scheduling_utils.SchedulerOutput`] or `tuple`: [`~scheduling_utils.SchedulerOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+ step_index = (self.timesteps == timestep).nonzero()
+ if len(step_index) == 0:
+ step_index = len(self.timesteps) - 1
+ else:
+ step_index = step_index.item()
+ prev_timestep = 0 if step_index == len(self.timesteps) - 1 else self.timesteps[step_index + 1]
+ lower_order_final = (
+ (step_index == len(self.timesteps) - 1) and self.config.lower_order_final and len(self.timesteps) < 15
+ )
+ lower_order_second = (
+ (step_index == len(self.timesteps) - 2) and self.config.lower_order_final and len(self.timesteps) < 15
+ )
+
+ model_output = self.convert_model_output(model_output, timestep, sample)
+ for i in range(self.config.solver_order - 1):
+ self.model_outputs[i] = self.model_outputs[i + 1]
+ self.model_outputs[-1] = model_output
+
+ if self.config.solver_order == 1 or self.lower_order_nums < 1 or lower_order_final:
+ prev_sample = self.dpm_solver_first_order_update(model_output, timestep, prev_timestep, sample)
+ elif self.config.solver_order == 2 or self.lower_order_nums < 2 or lower_order_second:
+ timestep_list = [self.timesteps[step_index - 1], timestep]
+ prev_sample = self.multistep_dpm_solver_second_order_update(
+ self.model_outputs, timestep_list, prev_timestep, sample
+ )
+ else:
+ timestep_list = [self.timesteps[step_index - 2], self.timesteps[step_index - 1], timestep]
+ prev_sample = self.multistep_dpm_solver_third_order_update(
+ self.model_outputs, timestep_list, prev_timestep, sample
+ )
+
+ if self.lower_order_nums < self.config.solver_order:
+ self.lower_order_nums += 1
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def scale_model_input(self, sample: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.IntTensor,
+ ) -> torch.FloatTensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as original_samples
+ self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
+ timesteps = timesteps.to(original_samples.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_multistep_flax.py b/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_multistep_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b4ee67a7f5dbf8384eaedc0ede322284a413edd
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_multistep_flax.py
@@ -0,0 +1,622 @@
+# Copyright 2023 TSAIL Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/LuChengTHU/dpm-solver
+
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import flax
+import jax
+import jax.numpy as jnp
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils_flax import (
+ CommonSchedulerState,
+ FlaxKarrasDiffusionSchedulers,
+ FlaxSchedulerMixin,
+ FlaxSchedulerOutput,
+ add_noise_common,
+)
+
+
+@flax.struct.dataclass
+class DPMSolverMultistepSchedulerState:
+ common: CommonSchedulerState
+ alpha_t: jnp.ndarray
+ sigma_t: jnp.ndarray
+ lambda_t: jnp.ndarray
+
+ # setable values
+ init_noise_sigma: jnp.ndarray
+ timesteps: jnp.ndarray
+ num_inference_steps: Optional[int] = None
+
+ # running values
+ model_outputs: Optional[jnp.ndarray] = None
+ lower_order_nums: Optional[jnp.int32] = None
+ prev_timestep: Optional[jnp.int32] = None
+ cur_sample: Optional[jnp.ndarray] = None
+
+ @classmethod
+ def create(
+ cls,
+ common: CommonSchedulerState,
+ alpha_t: jnp.ndarray,
+ sigma_t: jnp.ndarray,
+ lambda_t: jnp.ndarray,
+ init_noise_sigma: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ):
+ return cls(
+ common=common,
+ alpha_t=alpha_t,
+ sigma_t=sigma_t,
+ lambda_t=lambda_t,
+ init_noise_sigma=init_noise_sigma,
+ timesteps=timesteps,
+ )
+
+
+@dataclass
+class FlaxDPMSolverMultistepSchedulerOutput(FlaxSchedulerOutput):
+ state: DPMSolverMultistepSchedulerState
+
+
+class FlaxDPMSolverMultistepScheduler(FlaxSchedulerMixin, ConfigMixin):
+ """
+ DPM-Solver (and the improved version DPM-Solver++) is a fast dedicated high-order solver for diffusion ODEs with
+ the convergence order guarantee. Empirically, sampling by DPM-Solver with only 20 steps can generate high-quality
+ samples, and it can generate quite good samples even in only 10 steps.
+
+ For more details, see the original paper: https://arxiv.org/abs/2206.00927 and https://arxiv.org/abs/2211.01095
+
+ Currently, we support the multistep DPM-Solver for both noise prediction models and data prediction models. We
+ recommend to use `solver_order=2` for guided sampling, and `solver_order=3` for unconditional sampling.
+
+ We also support the "dynamic thresholding" method in Imagen (https://arxiv.org/abs/2205.11487). For pixel-space
+ diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use the dynamic
+ thresholding. Note that the thresholding method is unsuitable for latent-space diffusion models (such as
+ stable-diffusion).
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2206.00927 and https://arxiv.org/abs/2211.01095
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ solver_order (`int`, default `2`):
+ the order of DPM-Solver; can be `1` or `2` or `3`. We recommend to use `solver_order=2` for guided
+ sampling, and `solver_order=3` for unconditional sampling.
+ prediction_type (`str`, default `epsilon`):
+ indicates whether the model predicts the noise (epsilon), or the data / `x0`. One of `epsilon`, `sample`,
+ or `v-prediction`.
+ thresholding (`bool`, default `False`):
+ whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
+ For pixel-space diffusion models, you can set both `algorithm_type=dpmsolver++` and `thresholding=True` to
+ use the dynamic thresholding. Note that the thresholding method is unsuitable for latent-space diffusion
+ models (such as stable-diffusion).
+ dynamic_thresholding_ratio (`float`, default `0.995`):
+ the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
+ (https://arxiv.org/abs/2205.11487).
+ sample_max_value (`float`, default `1.0`):
+ the threshold value for dynamic thresholding. Valid only when `thresholding=True` and
+ `algorithm_type="dpmsolver++`.
+ algorithm_type (`str`, default `dpmsolver++`):
+ the algorithm type for the solver. Either `dpmsolver` or `dpmsolver++`. The `dpmsolver` type implements the
+ algorithms in https://arxiv.org/abs/2206.00927, and the `dpmsolver++` type implements the algorithms in
+ https://arxiv.org/abs/2211.01095. We recommend to use `dpmsolver++` with `solver_order=2` for guided
+ sampling (e.g. stable-diffusion).
+ solver_type (`str`, default `midpoint`):
+ the solver type for the second-order solver. Either `midpoint` or `heun`. The solver type slightly affects
+ the sample quality, especially for small number of steps. We empirically find that `midpoint` solvers are
+ slightly better, so we recommend to use the `midpoint` type.
+ lower_order_final (`bool`, default `True`):
+ whether to use lower-order solvers in the final steps. Only valid for < 15 inference steps. We empirically
+ find this trick can stabilize the sampling of DPM-Solver for steps < 15, especially for steps <= 10.
+ dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
+ the `dtype` used for params and computation.
+ """
+
+ _compatibles = [e.name for e in FlaxKarrasDiffusionSchedulers]
+
+ dtype: jnp.dtype
+
+ @property
+ def has_state(self):
+ return True
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[jnp.ndarray] = None,
+ solver_order: int = 2,
+ prediction_type: str = "epsilon",
+ thresholding: bool = False,
+ dynamic_thresholding_ratio: float = 0.995,
+ sample_max_value: float = 1.0,
+ algorithm_type: str = "dpmsolver++",
+ solver_type: str = "midpoint",
+ lower_order_final: bool = True,
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ self.dtype = dtype
+
+ def create_state(self, common: Optional[CommonSchedulerState] = None) -> DPMSolverMultistepSchedulerState:
+ if common is None:
+ common = CommonSchedulerState.create(self)
+
+ # Currently we only support VP-type noise schedule
+ alpha_t = jnp.sqrt(common.alphas_cumprod)
+ sigma_t = jnp.sqrt(1 - common.alphas_cumprod)
+ lambda_t = jnp.log(alpha_t) - jnp.log(sigma_t)
+
+ # settings for DPM-Solver
+ if self.config.algorithm_type not in ["dpmsolver", "dpmsolver++"]:
+ raise NotImplementedError(f"{self.config.algorithm_type} does is not implemented for {self.__class__}")
+ if self.config.solver_type not in ["midpoint", "heun"]:
+ raise NotImplementedError(f"{self.config.solver_type} does is not implemented for {self.__class__}")
+
+ # standard deviation of the initial noise distribution
+ init_noise_sigma = jnp.array(1.0, dtype=self.dtype)
+
+ timesteps = jnp.arange(0, self.config.num_train_timesteps).round()[::-1]
+
+ return DPMSolverMultistepSchedulerState.create(
+ common=common,
+ alpha_t=alpha_t,
+ sigma_t=sigma_t,
+ lambda_t=lambda_t,
+ init_noise_sigma=init_noise_sigma,
+ timesteps=timesteps,
+ )
+
+ def set_timesteps(
+ self, state: DPMSolverMultistepSchedulerState, num_inference_steps: int, shape: Tuple
+ ) -> DPMSolverMultistepSchedulerState:
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ state (`DPMSolverMultistepSchedulerState`):
+ the `FlaxDPMSolverMultistepScheduler` state data class instance.
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ shape (`Tuple`):
+ the shape of the samples to be generated.
+ """
+
+ timesteps = (
+ jnp.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps + 1)
+ .round()[::-1][:-1]
+ .astype(jnp.int32)
+ )
+
+ # initial running values
+
+ model_outputs = jnp.zeros((self.config.solver_order,) + shape, dtype=self.dtype)
+ lower_order_nums = jnp.int32(0)
+ prev_timestep = jnp.int32(-1)
+ cur_sample = jnp.zeros(shape, dtype=self.dtype)
+
+ return state.replace(
+ num_inference_steps=num_inference_steps,
+ timesteps=timesteps,
+ model_outputs=model_outputs,
+ lower_order_nums=lower_order_nums,
+ prev_timestep=prev_timestep,
+ cur_sample=cur_sample,
+ )
+
+ def convert_model_output(
+ self,
+ state: DPMSolverMultistepSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ ) -> jnp.ndarray:
+ """
+ Convert the model output to the corresponding type that the algorithm (DPM-Solver / DPM-Solver++) needs.
+
+ DPM-Solver is designed to discretize an integral of the noise prediction model, and DPM-Solver++ is designed to
+ discretize an integral of the data prediction model. So we need to first convert the model output to the
+ corresponding type to match the algorithm.
+
+ Note that the algorithm type and the model type is decoupled. That is to say, we can use either DPM-Solver or
+ DPM-Solver++ for both noise prediction model and data prediction model.
+
+ Args:
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `jnp.ndarray`: the converted model output.
+ """
+ # DPM-Solver++ needs to solve an integral of the data prediction model.
+ if self.config.algorithm_type == "dpmsolver++":
+ if self.config.prediction_type == "epsilon":
+ alpha_t, sigma_t = state.alpha_t[timestep], state.sigma_t[timestep]
+ x0_pred = (sample - sigma_t * model_output) / alpha_t
+ elif self.config.prediction_type == "sample":
+ x0_pred = model_output
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = state.alpha_t[timestep], state.sigma_t[timestep]
+ x0_pred = alpha_t * sample - sigma_t * model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, "
+ " or `v_prediction` for the FlaxDPMSolverMultistepScheduler."
+ )
+
+ if self.config.thresholding:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ dynamic_max_val = jnp.percentile(
+ jnp.abs(x0_pred), self.config.dynamic_thresholding_ratio, axis=tuple(range(1, x0_pred.ndim))
+ )
+ dynamic_max_val = jnp.maximum(
+ dynamic_max_val, self.config.sample_max_value * jnp.ones_like(dynamic_max_val)
+ )
+ x0_pred = jnp.clip(x0_pred, -dynamic_max_val, dynamic_max_val) / dynamic_max_val
+ return x0_pred
+ # DPM-Solver needs to solve an integral of the noise prediction model.
+ elif self.config.algorithm_type == "dpmsolver":
+ if self.config.prediction_type == "epsilon":
+ return model_output
+ elif self.config.prediction_type == "sample":
+ alpha_t, sigma_t = state.alpha_t[timestep], state.sigma_t[timestep]
+ epsilon = (sample - alpha_t * model_output) / sigma_t
+ return epsilon
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = state.alpha_t[timestep], state.sigma_t[timestep]
+ epsilon = alpha_t * model_output + sigma_t * sample
+ return epsilon
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, "
+ " or `v_prediction` for the FlaxDPMSolverMultistepScheduler."
+ )
+
+ def dpm_solver_first_order_update(
+ self,
+ state: DPMSolverMultistepSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ prev_timestep: int,
+ sample: jnp.ndarray,
+ ) -> jnp.ndarray:
+ """
+ One step for the first-order DPM-Solver (equivalent to DDIM).
+
+ See https://arxiv.org/abs/2206.00927 for the detailed derivation.
+
+ Args:
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `jnp.ndarray`: the sample tensor at the previous timestep.
+ """
+ t, s0 = prev_timestep, timestep
+ m0 = model_output
+ lambda_t, lambda_s = state.lambda_t[t], state.lambda_t[s0]
+ alpha_t, alpha_s = state.alpha_t[t], state.alpha_t[s0]
+ sigma_t, sigma_s = state.sigma_t[t], state.sigma_t[s0]
+ h = lambda_t - lambda_s
+ if self.config.algorithm_type == "dpmsolver++":
+ x_t = (sigma_t / sigma_s) * sample - (alpha_t * (jnp.exp(-h) - 1.0)) * m0
+ elif self.config.algorithm_type == "dpmsolver":
+ x_t = (alpha_t / alpha_s) * sample - (sigma_t * (jnp.exp(h) - 1.0)) * m0
+ return x_t
+
+ def multistep_dpm_solver_second_order_update(
+ self,
+ state: DPMSolverMultistepSchedulerState,
+ model_output_list: jnp.ndarray,
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: jnp.ndarray,
+ ) -> jnp.ndarray:
+ """
+ One step for the second-order multistep DPM-Solver.
+
+ Args:
+ model_output_list (`List[jnp.ndarray]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `jnp.ndarray`: the sample tensor at the previous timestep.
+ """
+ t, s0, s1 = prev_timestep, timestep_list[-1], timestep_list[-2]
+ m0, m1 = model_output_list[-1], model_output_list[-2]
+ lambda_t, lambda_s0, lambda_s1 = state.lambda_t[t], state.lambda_t[s0], state.lambda_t[s1]
+ alpha_t, alpha_s0 = state.alpha_t[t], state.alpha_t[s0]
+ sigma_t, sigma_s0 = state.sigma_t[t], state.sigma_t[s0]
+ h, h_0 = lambda_t - lambda_s0, lambda_s0 - lambda_s1
+ r0 = h_0 / h
+ D0, D1 = m0, (1.0 / r0) * (m0 - m1)
+ if self.config.algorithm_type == "dpmsolver++":
+ # See https://arxiv.org/abs/2211.01095 for detailed derivations
+ if self.config.solver_type == "midpoint":
+ x_t = (
+ (sigma_t / sigma_s0) * sample
+ - (alpha_t * (jnp.exp(-h) - 1.0)) * D0
+ - 0.5 * (alpha_t * (jnp.exp(-h) - 1.0)) * D1
+ )
+ elif self.config.solver_type == "heun":
+ x_t = (
+ (sigma_t / sigma_s0) * sample
+ - (alpha_t * (jnp.exp(-h) - 1.0)) * D0
+ + (alpha_t * ((jnp.exp(-h) - 1.0) / h + 1.0)) * D1
+ )
+ elif self.config.algorithm_type == "dpmsolver":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ if self.config.solver_type == "midpoint":
+ x_t = (
+ (alpha_t / alpha_s0) * sample
+ - (sigma_t * (jnp.exp(h) - 1.0)) * D0
+ - 0.5 * (sigma_t * (jnp.exp(h) - 1.0)) * D1
+ )
+ elif self.config.solver_type == "heun":
+ x_t = (
+ (alpha_t / alpha_s0) * sample
+ - (sigma_t * (jnp.exp(h) - 1.0)) * D0
+ - (sigma_t * ((jnp.exp(h) - 1.0) / h - 1.0)) * D1
+ )
+ return x_t
+
+ def multistep_dpm_solver_third_order_update(
+ self,
+ state: DPMSolverMultistepSchedulerState,
+ model_output_list: jnp.ndarray,
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: jnp.ndarray,
+ ) -> jnp.ndarray:
+ """
+ One step for the third-order multistep DPM-Solver.
+
+ Args:
+ model_output_list (`List[jnp.ndarray]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `jnp.ndarray`: the sample tensor at the previous timestep.
+ """
+ t, s0, s1, s2 = prev_timestep, timestep_list[-1], timestep_list[-2], timestep_list[-3]
+ m0, m1, m2 = model_output_list[-1], model_output_list[-2], model_output_list[-3]
+ lambda_t, lambda_s0, lambda_s1, lambda_s2 = (
+ state.lambda_t[t],
+ state.lambda_t[s0],
+ state.lambda_t[s1],
+ state.lambda_t[s2],
+ )
+ alpha_t, alpha_s0 = state.alpha_t[t], state.alpha_t[s0]
+ sigma_t, sigma_s0 = state.sigma_t[t], state.sigma_t[s0]
+ h, h_0, h_1 = lambda_t - lambda_s0, lambda_s0 - lambda_s1, lambda_s1 - lambda_s2
+ r0, r1 = h_0 / h, h_1 / h
+ D0 = m0
+ D1_0, D1_1 = (1.0 / r0) * (m0 - m1), (1.0 / r1) * (m1 - m2)
+ D1 = D1_0 + (r0 / (r0 + r1)) * (D1_0 - D1_1)
+ D2 = (1.0 / (r0 + r1)) * (D1_0 - D1_1)
+ if self.config.algorithm_type == "dpmsolver++":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ x_t = (
+ (sigma_t / sigma_s0) * sample
+ - (alpha_t * (jnp.exp(-h) - 1.0)) * D0
+ + (alpha_t * ((jnp.exp(-h) - 1.0) / h + 1.0)) * D1
+ - (alpha_t * ((jnp.exp(-h) - 1.0 + h) / h**2 - 0.5)) * D2
+ )
+ elif self.config.algorithm_type == "dpmsolver":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ x_t = (
+ (alpha_t / alpha_s0) * sample
+ - (sigma_t * (jnp.exp(h) - 1.0)) * D0
+ - (sigma_t * ((jnp.exp(h) - 1.0) / h - 1.0)) * D1
+ - (sigma_t * ((jnp.exp(h) - 1.0 - h) / h**2 - 0.5)) * D2
+ )
+ return x_t
+
+ def step(
+ self,
+ state: DPMSolverMultistepSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ return_dict: bool = True,
+ ) -> Union[FlaxDPMSolverMultistepSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by DPM-Solver. Core function to propagate the diffusion process
+ from the learned model outputs (most often the predicted noise).
+
+ Args:
+ state (`DPMSolverMultistepSchedulerState`):
+ the `FlaxDPMSolverMultistepScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than FlaxDPMSolverMultistepSchedulerOutput class
+
+ Returns:
+ [`FlaxDPMSolverMultistepSchedulerOutput`] or `tuple`: [`FlaxDPMSolverMultistepSchedulerOutput`] if
+ `return_dict` is True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if state.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ (step_index,) = jnp.where(state.timesteps == timestep, size=1)
+ step_index = step_index[0]
+
+ prev_timestep = jax.lax.select(step_index == len(state.timesteps) - 1, 0, state.timesteps[step_index + 1])
+
+ model_output = self.convert_model_output(state, model_output, timestep, sample)
+
+ model_outputs_new = jnp.roll(state.model_outputs, -1, axis=0)
+ model_outputs_new = model_outputs_new.at[-1].set(model_output)
+ state = state.replace(
+ model_outputs=model_outputs_new,
+ prev_timestep=prev_timestep,
+ cur_sample=sample,
+ )
+
+ def step_1(state: DPMSolverMultistepSchedulerState) -> jnp.ndarray:
+ return self.dpm_solver_first_order_update(
+ state,
+ state.model_outputs[-1],
+ state.timesteps[step_index],
+ state.prev_timestep,
+ state.cur_sample,
+ )
+
+ def step_23(state: DPMSolverMultistepSchedulerState) -> jnp.ndarray:
+ def step_2(state: DPMSolverMultistepSchedulerState) -> jnp.ndarray:
+ timestep_list = jnp.array([state.timesteps[step_index - 1], state.timesteps[step_index]])
+ return self.multistep_dpm_solver_second_order_update(
+ state,
+ state.model_outputs,
+ timestep_list,
+ state.prev_timestep,
+ state.cur_sample,
+ )
+
+ def step_3(state: DPMSolverMultistepSchedulerState) -> jnp.ndarray:
+ timestep_list = jnp.array(
+ [
+ state.timesteps[step_index - 2],
+ state.timesteps[step_index - 1],
+ state.timesteps[step_index],
+ ]
+ )
+ return self.multistep_dpm_solver_third_order_update(
+ state,
+ state.model_outputs,
+ timestep_list,
+ state.prev_timestep,
+ state.cur_sample,
+ )
+
+ step_2_output = step_2(state)
+ step_3_output = step_3(state)
+
+ if self.config.solver_order == 2:
+ return step_2_output
+ elif self.config.lower_order_final and len(state.timesteps) < 15:
+ return jax.lax.select(
+ state.lower_order_nums < 2,
+ step_2_output,
+ jax.lax.select(
+ step_index == len(state.timesteps) - 2,
+ step_2_output,
+ step_3_output,
+ ),
+ )
+ else:
+ return jax.lax.select(
+ state.lower_order_nums < 2,
+ step_2_output,
+ step_3_output,
+ )
+
+ step_1_output = step_1(state)
+ step_23_output = step_23(state)
+
+ if self.config.solver_order == 1:
+ prev_sample = step_1_output
+
+ elif self.config.lower_order_final and len(state.timesteps) < 15:
+ prev_sample = jax.lax.select(
+ state.lower_order_nums < 1,
+ step_1_output,
+ jax.lax.select(
+ step_index == len(state.timesteps) - 1,
+ step_1_output,
+ step_23_output,
+ ),
+ )
+
+ else:
+ prev_sample = jax.lax.select(
+ state.lower_order_nums < 1,
+ step_1_output,
+ step_23_output,
+ )
+
+ state = state.replace(
+ lower_order_nums=jnp.minimum(state.lower_order_nums + 1, self.config.solver_order),
+ )
+
+ if not return_dict:
+ return (prev_sample, state)
+
+ return FlaxDPMSolverMultistepSchedulerOutput(prev_sample=prev_sample, state=state)
+
+ def scale_model_input(
+ self, state: DPMSolverMultistepSchedulerState, sample: jnp.ndarray, timestep: Optional[int] = None
+ ) -> jnp.ndarray:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ state (`DPMSolverMultistepSchedulerState`):
+ the `FlaxDPMSolverMultistepScheduler` state data class instance.
+ sample (`jnp.ndarray`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `jnp.ndarray`: scaled input sample
+ """
+ return sample
+
+ def add_noise(
+ self,
+ state: DPMSolverMultistepSchedulerState,
+ original_samples: jnp.ndarray,
+ noise: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ) -> jnp.ndarray:
+ return add_noise_common(state.common, original_samples, noise, timesteps)
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_singlestep.py b/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_singlestep.py
new file mode 100644
index 0000000000000000000000000000000000000000..a02171a2df91ed3d6aa55f4ee19405ea2a89146a
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_dpmsolver_singlestep.py
@@ -0,0 +1,609 @@
+# Copyright 2023 TSAIL Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/LuChengTHU/dpm-solver
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin, SchedulerOutput
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class DPMSolverSinglestepScheduler(SchedulerMixin, ConfigMixin):
+ """
+ DPM-Solver (and the improved version DPM-Solver++) is a fast dedicated high-order solver for diffusion ODEs with
+ the convergence order guarantee. Empirically, sampling by DPM-Solver with only 20 steps can generate high-quality
+ samples, and it can generate quite good samples even in only 10 steps.
+
+ For more details, see the original paper: https://arxiv.org/abs/2206.00927 and https://arxiv.org/abs/2211.01095
+
+ Currently, we support the singlestep DPM-Solver for both noise prediction models and data prediction models. We
+ recommend to use `solver_order=2` for guided sampling, and `solver_order=3` for unconditional sampling.
+
+ We also support the "dynamic thresholding" method in Imagen (https://arxiv.org/abs/2205.11487). For pixel-space
+ diffusion models, you can set both `algorithm_type="dpmsolver++"` and `thresholding=True` to use the dynamic
+ thresholding. Note that the thresholding method is unsuitable for latent-space diffusion models (such as
+ stable-diffusion).
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ solver_order (`int`, default `2`):
+ the order of DPM-Solver; can be `1` or `2` or `3`. We recommend to use `solver_order=2` for guided
+ sampling, and `solver_order=3` for unconditional sampling.
+ prediction_type (`str`, default `epsilon`):
+ indicates whether the model predicts the noise (epsilon), or the data / `x0`. One of `epsilon`, `sample`,
+ or `v-prediction`.
+ thresholding (`bool`, default `False`):
+ whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
+ For pixel-space diffusion models, you can set both `algorithm_type=dpmsolver++` and `thresholding=True` to
+ use the dynamic thresholding. Note that the thresholding method is unsuitable for latent-space diffusion
+ models (such as stable-diffusion).
+ dynamic_thresholding_ratio (`float`, default `0.995`):
+ the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
+ (https://arxiv.org/abs/2205.11487).
+ sample_max_value (`float`, default `1.0`):
+ the threshold value for dynamic thresholding. Valid only when `thresholding=True` and
+ `algorithm_type="dpmsolver++`.
+ algorithm_type (`str`, default `dpmsolver++`):
+ the algorithm type for the solver. Either `dpmsolver` or `dpmsolver++`. The `dpmsolver` type implements the
+ algorithms in https://arxiv.org/abs/2206.00927, and the `dpmsolver++` type implements the algorithms in
+ https://arxiv.org/abs/2211.01095. We recommend to use `dpmsolver++` with `solver_order=2` for guided
+ sampling (e.g. stable-diffusion).
+ solver_type (`str`, default `midpoint`):
+ the solver type for the second-order solver. Either `midpoint` or `heun`. The solver type slightly affects
+ the sample quality, especially for small number of steps. We empirically find that `midpoint` solvers are
+ slightly better, so we recommend to use the `midpoint` type.
+ lower_order_final (`bool`, default `True`):
+ whether to use lower-order solvers in the final steps. For singlestep schedulers, we recommend to enable
+ this to use up all the function evaluations.
+
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[np.ndarray] = None,
+ solver_order: int = 2,
+ prediction_type: str = "epsilon",
+ thresholding: bool = False,
+ dynamic_thresholding_ratio: float = 0.995,
+ sample_max_value: float = 1.0,
+ algorithm_type: str = "dpmsolver++",
+ solver_type: str = "midpoint",
+ lower_order_final: bool = True,
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+ # Currently we only support VP-type noise schedule
+ self.alpha_t = torch.sqrt(self.alphas_cumprod)
+ self.sigma_t = torch.sqrt(1 - self.alphas_cumprod)
+ self.lambda_t = torch.log(self.alpha_t) - torch.log(self.sigma_t)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # settings for DPM-Solver
+ if algorithm_type not in ["dpmsolver", "dpmsolver++"]:
+ if algorithm_type == "deis":
+ self.register_to_config(algorithm_type="dpmsolver++")
+ else:
+ raise NotImplementedError(f"{algorithm_type} does is not implemented for {self.__class__}")
+ if solver_type not in ["midpoint", "heun"]:
+ if solver_type in ["logrho", "bh1", "bh2"]:
+ self.register_to_config(solver_type="midpoint")
+ else:
+ raise NotImplementedError(f"{solver_type} does is not implemented for {self.__class__}")
+
+ # setable values
+ self.num_inference_steps = None
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=np.float32)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps)
+ self.model_outputs = [None] * solver_order
+ self.sample = None
+ self.order_list = self.get_order_list(num_train_timesteps)
+
+ def get_order_list(self, num_inference_steps: int) -> List[int]:
+ """
+ Computes the solver order at each time step.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+ steps = num_inference_steps
+ order = self.solver_order
+ if self.lower_order_final:
+ if order == 3:
+ if steps % 3 == 0:
+ orders = [1, 2, 3] * (steps // 3 - 1) + [1, 2] + [1]
+ elif steps % 3 == 1:
+ orders = [1, 2, 3] * (steps // 3) + [1]
+ else:
+ orders = [1, 2, 3] * (steps // 3) + [1, 2]
+ elif order == 2:
+ if steps % 2 == 0:
+ orders = [1, 2] * (steps // 2)
+ else:
+ orders = [1, 2] * (steps // 2) + [1]
+ elif order == 1:
+ orders = [1] * steps
+ else:
+ if order == 3:
+ orders = [1, 2, 3] * (steps // 3)
+ elif order == 2:
+ orders = [1, 2] * (steps // 2)
+ elif order == 1:
+ orders = [1] * steps
+ return orders
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+ timesteps = (
+ np.linspace(0, self.num_train_timesteps - 1, num_inference_steps + 1)
+ .round()[::-1][:-1]
+ .copy()
+ .astype(np.int64)
+ )
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+ self.model_outputs = [None] * self.config.solver_order
+ self.sample = None
+ self.orders = self.get_order_list(num_inference_steps)
+
+ # Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
+ def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ dynamic_max_val = (
+ sample.flatten(1)
+ .abs()
+ .quantile(self.config.dynamic_thresholding_ratio, dim=1)
+ .clamp_min(self.config.sample_max_value)
+ .view(-1, *([1] * (sample.ndim - 1)))
+ )
+ return sample.clamp(-dynamic_max_val, dynamic_max_val) / dynamic_max_val
+
+ def convert_model_output(
+ self, model_output: torch.FloatTensor, timestep: int, sample: torch.FloatTensor
+ ) -> torch.FloatTensor:
+ """
+ Convert the model output to the corresponding type that the algorithm (DPM-Solver / DPM-Solver++) needs.
+
+ DPM-Solver is designed to discretize an integral of the noise prediction model, and DPM-Solver++ is designed to
+ discretize an integral of the data prediction model. So we need to first convert the model output to the
+ corresponding type to match the algorithm.
+
+ Note that the algorithm type and the model type is decoupled. That is to say, we can use either DPM-Solver or
+ DPM-Solver++ for both noise prediction model and data prediction model.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the converted model output.
+ """
+ # DPM-Solver++ needs to solve an integral of the data prediction model.
+ if self.config.algorithm_type == "dpmsolver++":
+ if self.config.prediction_type == "epsilon":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ x0_pred = (sample - sigma_t * model_output) / alpha_t
+ elif self.config.prediction_type == "sample":
+ x0_pred = model_output
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ x0_pred = alpha_t * sample - sigma_t * model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction` for the DPMSolverSinglestepScheduler."
+ )
+
+ if self.config.thresholding:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ orig_dtype = x0_pred.dtype
+ if orig_dtype not in [torch.float, torch.double]:
+ x0_pred = x0_pred.float()
+ x0_pred = self._threshold_sample(x0_pred).type(orig_dtype)
+ return x0_pred
+ # DPM-Solver needs to solve an integral of the noise prediction model.
+ elif self.config.algorithm_type == "dpmsolver":
+ if self.config.prediction_type == "epsilon":
+ return model_output
+ elif self.config.prediction_type == "sample":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ epsilon = (sample - alpha_t * model_output) / sigma_t
+ return epsilon
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ epsilon = alpha_t * model_output + sigma_t * sample
+ return epsilon
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction` for the DPMSolverSinglestepScheduler."
+ )
+
+ def dpm_solver_first_order_update(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the first-order DPM-Solver (equivalent to DDIM).
+
+ See https://arxiv.org/abs/2206.00927 for the detailed derivation.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ lambda_t, lambda_s = self.lambda_t[prev_timestep], self.lambda_t[timestep]
+ alpha_t, alpha_s = self.alpha_t[prev_timestep], self.alpha_t[timestep]
+ sigma_t, sigma_s = self.sigma_t[prev_timestep], self.sigma_t[timestep]
+ h = lambda_t - lambda_s
+ if self.config.algorithm_type == "dpmsolver++":
+ x_t = (sigma_t / sigma_s) * sample - (alpha_t * (torch.exp(-h) - 1.0)) * model_output
+ elif self.config.algorithm_type == "dpmsolver":
+ x_t = (alpha_t / alpha_s) * sample - (sigma_t * (torch.exp(h) - 1.0)) * model_output
+ return x_t
+
+ def singlestep_dpm_solver_second_order_update(
+ self,
+ model_output_list: List[torch.FloatTensor],
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the second-order singlestep DPM-Solver.
+
+ It computes the solution at time `prev_timestep` from the time `timestep_list[-2]`.
+
+ Args:
+ model_output_list (`List[torch.FloatTensor]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ t, s0, s1 = prev_timestep, timestep_list[-1], timestep_list[-2]
+ m0, m1 = model_output_list[-1], model_output_list[-2]
+ lambda_t, lambda_s0, lambda_s1 = self.lambda_t[t], self.lambda_t[s0], self.lambda_t[s1]
+ alpha_t, alpha_s1 = self.alpha_t[t], self.alpha_t[s1]
+ sigma_t, sigma_s1 = self.sigma_t[t], self.sigma_t[s1]
+ h, h_0 = lambda_t - lambda_s1, lambda_s0 - lambda_s1
+ r0 = h_0 / h
+ D0, D1 = m1, (1.0 / r0) * (m0 - m1)
+ if self.config.algorithm_type == "dpmsolver++":
+ # See https://arxiv.org/abs/2211.01095 for detailed derivations
+ if self.config.solver_type == "midpoint":
+ x_t = (
+ (sigma_t / sigma_s1) * sample
+ - (alpha_t * (torch.exp(-h) - 1.0)) * D0
+ - 0.5 * (alpha_t * (torch.exp(-h) - 1.0)) * D1
+ )
+ elif self.config.solver_type == "heun":
+ x_t = (
+ (sigma_t / sigma_s1) * sample
+ - (alpha_t * (torch.exp(-h) - 1.0)) * D0
+ + (alpha_t * ((torch.exp(-h) - 1.0) / h + 1.0)) * D1
+ )
+ elif self.config.algorithm_type == "dpmsolver":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ if self.config.solver_type == "midpoint":
+ x_t = (
+ (alpha_t / alpha_s1) * sample
+ - (sigma_t * (torch.exp(h) - 1.0)) * D0
+ - 0.5 * (sigma_t * (torch.exp(h) - 1.0)) * D1
+ )
+ elif self.config.solver_type == "heun":
+ x_t = (
+ (alpha_t / alpha_s1) * sample
+ - (sigma_t * (torch.exp(h) - 1.0)) * D0
+ - (sigma_t * ((torch.exp(h) - 1.0) / h - 1.0)) * D1
+ )
+ return x_t
+
+ def singlestep_dpm_solver_third_order_update(
+ self,
+ model_output_list: List[torch.FloatTensor],
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ """
+ One step for the third-order singlestep DPM-Solver.
+
+ It computes the solution at time `prev_timestep` from the time `timestep_list[-3]`.
+
+ Args:
+ model_output_list (`List[torch.FloatTensor]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ t, s0, s1, s2 = prev_timestep, timestep_list[-1], timestep_list[-2], timestep_list[-3]
+ m0, m1, m2 = model_output_list[-1], model_output_list[-2], model_output_list[-3]
+ lambda_t, lambda_s0, lambda_s1, lambda_s2 = (
+ self.lambda_t[t],
+ self.lambda_t[s0],
+ self.lambda_t[s1],
+ self.lambda_t[s2],
+ )
+ alpha_t, alpha_s2 = self.alpha_t[t], self.alpha_t[s2]
+ sigma_t, sigma_s2 = self.sigma_t[t], self.sigma_t[s2]
+ h, h_0, h_1 = lambda_t - lambda_s2, lambda_s0 - lambda_s2, lambda_s1 - lambda_s2
+ r0, r1 = h_0 / h, h_1 / h
+ D0 = m2
+ D1_0, D1_1 = (1.0 / r1) * (m1 - m2), (1.0 / r0) * (m0 - m2)
+ D1 = (r0 * D1_0 - r1 * D1_1) / (r0 - r1)
+ D2 = 2.0 * (D1_1 - D1_0) / (r0 - r1)
+ if self.config.algorithm_type == "dpmsolver++":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ if self.config.solver_type == "midpoint":
+ x_t = (
+ (sigma_t / sigma_s2) * sample
+ - (alpha_t * (torch.exp(-h) - 1.0)) * D0
+ + (alpha_t * ((torch.exp(-h) - 1.0) / h + 1.0)) * D1_1
+ )
+ elif self.config.solver_type == "heun":
+ x_t = (
+ (sigma_t / sigma_s2) * sample
+ - (alpha_t * (torch.exp(-h) - 1.0)) * D0
+ + (alpha_t * ((torch.exp(-h) - 1.0) / h + 1.0)) * D1
+ - (alpha_t * ((torch.exp(-h) - 1.0 + h) / h**2 - 0.5)) * D2
+ )
+ elif self.config.algorithm_type == "dpmsolver":
+ # See https://arxiv.org/abs/2206.00927 for detailed derivations
+ if self.config.solver_type == "midpoint":
+ x_t = (
+ (alpha_t / alpha_s2) * sample
+ - (sigma_t * (torch.exp(h) - 1.0)) * D0
+ - (sigma_t * ((torch.exp(h) - 1.0) / h - 1.0)) * D1_1
+ )
+ elif self.config.solver_type == "heun":
+ x_t = (
+ (alpha_t / alpha_s2) * sample
+ - (sigma_t * (torch.exp(h) - 1.0)) * D0
+ - (sigma_t * ((torch.exp(h) - 1.0) / h - 1.0)) * D1
+ - (sigma_t * ((torch.exp(h) - 1.0 - h) / h**2 - 0.5)) * D2
+ )
+ return x_t
+
+ def singlestep_dpm_solver_update(
+ self,
+ model_output_list: List[torch.FloatTensor],
+ timestep_list: List[int],
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ order: int,
+ ) -> torch.FloatTensor:
+ """
+ One step for the singlestep DPM-Solver.
+
+ Args:
+ model_output_list (`List[torch.FloatTensor]`):
+ direct outputs from learned diffusion model at current and latter timesteps.
+ timestep (`int`): current and latter discrete timestep in the diffusion chain.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ order (`int`):
+ the solver order at this step.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ if order == 1:
+ return self.dpm_solver_first_order_update(model_output_list[-1], timestep_list[-1], prev_timestep, sample)
+ elif order == 2:
+ return self.singlestep_dpm_solver_second_order_update(
+ model_output_list, timestep_list, prev_timestep, sample
+ )
+ elif order == 3:
+ return self.singlestep_dpm_solver_third_order_update(
+ model_output_list, timestep_list, prev_timestep, sample
+ )
+ else:
+ raise ValueError(f"Order must be 1, 2, 3, got {order}")
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the singlestep DPM-Solver.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~scheduling_utils.SchedulerOutput`] or `tuple`: [`~scheduling_utils.SchedulerOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+ step_index = (self.timesteps == timestep).nonzero()
+ if len(step_index) == 0:
+ step_index = len(self.timesteps) - 1
+ else:
+ step_index = step_index.item()
+ prev_timestep = 0 if step_index == len(self.timesteps) - 1 else self.timesteps[step_index + 1]
+
+ model_output = self.convert_model_output(model_output, timestep, sample)
+ for i in range(self.config.solver_order - 1):
+ self.model_outputs[i] = self.model_outputs[i + 1]
+ self.model_outputs[-1] = model_output
+
+ order = self.order_list[step_index]
+ # For single-step solvers, we use the initial value at each time with order = 1.
+ if order == 1:
+ self.sample = sample
+
+ timestep_list = [self.timesteps[step_index - i] for i in range(order - 1, 0, -1)] + [timestep]
+ prev_sample = self.singlestep_dpm_solver_update(
+ self.model_outputs, timestep_list, prev_timestep, self.sample, order
+ )
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def scale_model_input(self, sample: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.IntTensor,
+ ) -> torch.FloatTensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as original_samples
+ self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
+ timesteps = timesteps.to(original_samples.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_euler_ancestral_discrete.py b/diffusers/src/diffusers/schedulers/scheduling_euler_ancestral_discrete.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b517bdec5703495afeee26a1c8ed4cb98561d7c
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_euler_ancestral_discrete.py
@@ -0,0 +1,309 @@
+# Copyright 2023 Katherine Crowson and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, logging, randn_tensor
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->EulerAncestralDiscrete
+class EulerAncestralDiscreteSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999) -> torch.Tensor:
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class EulerAncestralDiscreteScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Ancestral sampling with Euler method steps. Based on the original k-diffusion implementation by Katherine Crowson:
+ https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L72
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear` or `scaled_linear`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ prediction_type: str = "epsilon",
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+ sigmas = np.concatenate([sigmas[::-1], [0.0]]).astype(np.float32)
+ self.sigmas = torch.from_numpy(sigmas)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = self.sigmas.max()
+
+ # setable values
+ self.num_inference_steps = None
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=float)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps)
+ self.is_scale_input_called = False
+
+ def scale_model_input(
+ self, sample: torch.FloatTensor, timestep: Union[float, torch.FloatTensor]
+ ) -> torch.FloatTensor:
+ """
+ Scales the denoising model input by `(sigma**2 + 1) ** 0.5` to match the Euler algorithm.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`float` or `torch.FloatTensor`): the current timestep in the diffusion chain
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+ step_index = (self.timesteps == timestep).nonzero().item()
+ sigma = self.sigmas[step_index]
+ sample = sample / ((sigma**2 + 1) ** 0.5)
+ self.is_scale_input_called = True
+ return sample
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+
+ timesteps = np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=float)[::-1].copy()
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+ sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas)
+ sigmas = np.concatenate([sigmas, [0.0]]).astype(np.float32)
+ self.sigmas = torch.from_numpy(sigmas).to(device=device)
+ if str(device).startswith("mps"):
+ # mps does not support float64
+ self.timesteps = torch.from_numpy(timesteps).to(device, dtype=torch.float32)
+ else:
+ self.timesteps = torch.from_numpy(timesteps).to(device=device)
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: Union[float, torch.FloatTensor],
+ sample: torch.FloatTensor,
+ generator: Optional[torch.Generator] = None,
+ return_dict: bool = True,
+ ) -> Union[EulerAncestralDiscreteSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`float`): current timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ generator (`torch.Generator`, optional): Random number generator.
+ return_dict (`bool`): option for returning tuple rather than EulerAncestralDiscreteSchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.EulerAncestralDiscreteSchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.EulerAncestralDiscreteSchedulerOutput`] if `return_dict` is True, otherwise
+ a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+
+ if (
+ isinstance(timestep, int)
+ or isinstance(timestep, torch.IntTensor)
+ or isinstance(timestep, torch.LongTensor)
+ ):
+ raise ValueError(
+ (
+ "Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
+ " `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
+ " one of the `scheduler.timesteps` as a timestep."
+ ),
+ )
+
+ if not self.is_scale_input_called:
+ logger.warning(
+ "The `scale_model_input` function should be called before `step` to ensure correct denoising. "
+ "See `StableDiffusionPipeline` for a usage example."
+ )
+
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+
+ step_index = (self.timesteps == timestep).nonzero().item()
+ sigma = self.sigmas[step_index]
+
+ # 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = sample - sigma * model_output
+ elif self.config.prediction_type == "v_prediction":
+ # * c_out + input * c_skip
+ pred_original_sample = model_output * (-sigma / (sigma**2 + 1) ** 0.5) + (sample / (sigma**2 + 1))
+ elif self.config.prediction_type == "sample":
+ raise NotImplementedError("prediction_type not implemented yet: sample")
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
+ )
+
+ sigma_from = self.sigmas[step_index]
+ sigma_to = self.sigmas[step_index + 1]
+ sigma_up = (sigma_to**2 * (sigma_from**2 - sigma_to**2) / sigma_from**2) ** 0.5
+ sigma_down = (sigma_to**2 - sigma_up**2) ** 0.5
+
+ # 2. Convert to an ODE derivative
+ derivative = (sample - pred_original_sample) / sigma
+
+ dt = sigma_down - sigma
+
+ prev_sample = sample + derivative * dt
+
+ device = model_output.device
+ noise = randn_tensor(model_output.shape, dtype=model_output.dtype, device=device, generator=generator)
+
+ prev_sample = prev_sample + noise * sigma_up
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return EulerAncestralDiscreteSchedulerOutput(
+ prev_sample=prev_sample, pred_original_sample=pred_original_sample
+ )
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ # Make sure sigmas and timesteps have the same device and dtype as original_samples
+ self.sigmas = self.sigmas.to(device=original_samples.device, dtype=original_samples.dtype)
+ if original_samples.device.type == "mps" and torch.is_floating_point(timesteps):
+ # mps does not support float64
+ self.timesteps = self.timesteps.to(original_samples.device, dtype=torch.float32)
+ timesteps = timesteps.to(original_samples.device, dtype=torch.float32)
+ else:
+ self.timesteps = self.timesteps.to(original_samples.device)
+ timesteps = timesteps.to(original_samples.device)
+
+ schedule_timesteps = self.timesteps
+ step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps]
+
+ sigma = self.sigmas[step_indices].flatten()
+ while len(sigma.shape) < len(original_samples.shape):
+ sigma = sigma.unsqueeze(-1)
+
+ noisy_samples = original_samples + noise * sigma
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py b/diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6252904fd9ac250b555dfe00d08c2ce64e0936b
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py
@@ -0,0 +1,335 @@
+# Copyright 2023 Katherine Crowson and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, logging, randn_tensor
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+@dataclass
+# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->EulerDiscrete
+class EulerDiscreteSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class EulerDiscreteScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Euler scheduler (Algorithm 2) from Karras et al. (2022) https://arxiv.org/abs/2206.00364. . Based on the original
+ k-diffusion implementation by Katherine Crowson:
+ https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L51
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear` or `scaled_linear`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ prediction_type (`str`, default `"epsilon"`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ interpolation_type (`str`, default `"linear"`, optional):
+ interpolation type to compute intermediate sigmas for the scheduler denoising steps. Should be one of
+ [`"linear"`, `"log_linear"`].
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ prediction_type: str = "epsilon",
+ interpolation_type: str = "linear",
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+ sigmas = np.concatenate([sigmas[::-1], [0.0]]).astype(np.float32)
+ self.sigmas = torch.from_numpy(sigmas)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = self.sigmas.max()
+
+ # setable values
+ self.num_inference_steps = None
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=float)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps)
+ self.is_scale_input_called = False
+
+ def scale_model_input(
+ self, sample: torch.FloatTensor, timestep: Union[float, torch.FloatTensor]
+ ) -> torch.FloatTensor:
+ """
+ Scales the denoising model input by `(sigma**2 + 1) ** 0.5` to match the Euler algorithm.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`float` or `torch.FloatTensor`): the current timestep in the diffusion chain
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+ step_index = (self.timesteps == timestep).nonzero().item()
+ sigma = self.sigmas[step_index]
+
+ sample = sample / ((sigma**2 + 1) ** 0.5)
+
+ self.is_scale_input_called = True
+ return sample
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+
+ timesteps = np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=float)[::-1].copy()
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+
+ if self.config.interpolation_type == "linear":
+ sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas)
+ elif self.config.interpolation_type == "log_linear":
+ sigmas = torch.linspace(np.log(sigmas[-1]), np.log(sigmas[0]), num_inference_steps + 1).exp()
+ else:
+ raise ValueError(
+ f"{self.config.interpolation_type} is not implemented. Please specify interpolation_type to either"
+ " 'linear' or 'log_linear'"
+ )
+
+ sigmas = np.concatenate([sigmas, [0.0]]).astype(np.float32)
+ self.sigmas = torch.from_numpy(sigmas).to(device=device)
+ if str(device).startswith("mps"):
+ # mps does not support float64
+ self.timesteps = torch.from_numpy(timesteps).to(device, dtype=torch.float32)
+ else:
+ self.timesteps = torch.from_numpy(timesteps).to(device=device)
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: Union[float, torch.FloatTensor],
+ sample: torch.FloatTensor,
+ s_churn: float = 0.0,
+ s_tmin: float = 0.0,
+ s_tmax: float = float("inf"),
+ s_noise: float = 1.0,
+ generator: Optional[torch.Generator] = None,
+ return_dict: bool = True,
+ ) -> Union[EulerDiscreteSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`float`): current timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ s_churn (`float`)
+ s_tmin (`float`)
+ s_tmax (`float`)
+ s_noise (`float`)
+ generator (`torch.Generator`, optional): Random number generator.
+ return_dict (`bool`): option for returning tuple rather than EulerDiscreteSchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.EulerDiscreteSchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.EulerDiscreteSchedulerOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+
+ if (
+ isinstance(timestep, int)
+ or isinstance(timestep, torch.IntTensor)
+ or isinstance(timestep, torch.LongTensor)
+ ):
+ raise ValueError(
+ (
+ "Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
+ " `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
+ " one of the `scheduler.timesteps` as a timestep."
+ ),
+ )
+
+ if not self.is_scale_input_called:
+ logger.warning(
+ "The `scale_model_input` function should be called before `step` to ensure correct denoising. "
+ "See `StableDiffusionPipeline` for a usage example."
+ )
+
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+
+ step_index = (self.timesteps == timestep).nonzero().item()
+ sigma = self.sigmas[step_index]
+
+ gamma = min(s_churn / (len(self.sigmas) - 1), 2**0.5 - 1) if s_tmin <= sigma <= s_tmax else 0.0
+
+ noise = randn_tensor(
+ model_output.shape, dtype=model_output.dtype, device=model_output.device, generator=generator
+ )
+
+ eps = noise * s_noise
+ sigma_hat = sigma * (gamma + 1)
+
+ if gamma > 0:
+ sample = sample + eps * (sigma_hat**2 - sigma**2) ** 0.5
+
+ # 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
+ # NOTE: "original_sample" should not be an expected prediction_type but is left in for
+ # backwards compatibility
+ if self.config.prediction_type == "original_sample" or self.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ elif self.config.prediction_type == "epsilon":
+ pred_original_sample = sample - sigma_hat * model_output
+ elif self.config.prediction_type == "v_prediction":
+ # * c_out + input * c_skip
+ pred_original_sample = model_output * (-sigma / (sigma**2 + 1) ** 0.5) + (sample / (sigma**2 + 1))
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
+ )
+
+ # 2. Convert to an ODE derivative
+ derivative = (sample - pred_original_sample) / sigma_hat
+
+ dt = self.sigmas[step_index + 1] - sigma_hat
+
+ prev_sample = sample + derivative * dt
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return EulerDiscreteSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ # Make sure sigmas and timesteps have the same device and dtype as original_samples
+ self.sigmas = self.sigmas.to(device=original_samples.device, dtype=original_samples.dtype)
+ if original_samples.device.type == "mps" and torch.is_floating_point(timesteps):
+ # mps does not support float64
+ self.timesteps = self.timesteps.to(original_samples.device, dtype=torch.float32)
+ timesteps = timesteps.to(original_samples.device, dtype=torch.float32)
+ else:
+ self.timesteps = self.timesteps.to(original_samples.device)
+ timesteps = timesteps.to(original_samples.device)
+
+ schedule_timesteps = self.timesteps
+ step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps]
+
+ sigma = self.sigmas[step_indices].flatten()
+ while len(sigma.shape) < len(original_samples.shape):
+ sigma = sigma.unsqueeze(-1)
+
+ noisy_samples = original_samples + noise * sigma
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_heun_discrete.py b/diffusers/src/diffusers/schedulers/scheduling_heun_discrete.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7f1467fc53a7e27a7ffdb171a40791aa5b97134
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_heun_discrete.py
@@ -0,0 +1,299 @@
+# Copyright 2023 Katherine Crowson, The HuggingFace Team and hlky. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin, SchedulerOutput
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999) -> torch.Tensor:
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class HeunDiscreteScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Implements Algorithm 2 (Heun steps) from Karras et al. (2022). for discrete beta schedules. Based on the original
+ k-diffusion implementation by Katherine Crowson:
+ https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L90
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model. beta_start (`float`): the
+ starting `beta` value of inference. beta_end (`float`): the final `beta` value. beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear` or `scaled_linear`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ options to clip the variance used when adding noise to the denoised sample. Choose from `fixed_small`,
+ `fixed_small_log`, `fixed_large`, `fixed_large_log`, `learned` or `learned_range`.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 2
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.00085, # sensible defaults
+ beta_end: float = 0.012,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ prediction_type: str = "epsilon",
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ # set all values
+ self.set_timesteps(num_train_timesteps, None, num_train_timesteps)
+
+ def index_for_timestep(self, timestep):
+ indices = (self.timesteps == timestep).nonzero()
+ if self.state_in_first_order:
+ pos = -1
+ else:
+ pos = 0
+ return indices[pos].item()
+
+ def scale_model_input(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[float, torch.FloatTensor],
+ ) -> torch.FloatTensor:
+ """
+ Args:
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+ sample (`torch.FloatTensor`): input sample timestep (`int`, optional): current timestep
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ step_index = self.index_for_timestep(timestep)
+
+ sigma = self.sigmas[step_index]
+ sample = sample / ((sigma**2 + 1) ** 0.5)
+ return sample
+
+ def set_timesteps(
+ self,
+ num_inference_steps: int,
+ device: Union[str, torch.device] = None,
+ num_train_timesteps: Optional[int] = None,
+ ):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+
+ num_train_timesteps = num_train_timesteps or self.config.num_train_timesteps
+
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_inference_steps, dtype=float)[::-1].copy()
+
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+ sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas)
+ sigmas = np.concatenate([sigmas, [0.0]]).astype(np.float32)
+ sigmas = torch.from_numpy(sigmas).to(device=device)
+ self.sigmas = torch.cat([sigmas[:1], sigmas[1:-1].repeat_interleave(2), sigmas[-1:]])
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = self.sigmas.max()
+
+ timesteps = torch.from_numpy(timesteps)
+ timesteps = torch.cat([timesteps[:1], timesteps[1:].repeat_interleave(2)])
+
+ if str(device).startswith("mps"):
+ # mps does not support float64
+ self.timesteps = timesteps.to(device, dtype=torch.float32)
+ else:
+ self.timesteps = timesteps.to(device=device)
+
+ # empty dt and derivative
+ self.prev_derivative = None
+ self.dt = None
+
+ @property
+ def state_in_first_order(self):
+ return self.dt is None
+
+ def step(
+ self,
+ model_output: Union[torch.FloatTensor, np.ndarray],
+ timestep: Union[float, torch.FloatTensor],
+ sample: Union[torch.FloatTensor, np.ndarray],
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Args:
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+ model_output (`torch.FloatTensor` or `np.ndarray`): direct output from learned diffusion model. timestep
+ (`int`): current discrete timestep in the diffusion chain. sample (`torch.FloatTensor` or `np.ndarray`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+ Returns:
+ [`~schedulers.scheduling_utils.SchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.SchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ step_index = self.index_for_timestep(timestep)
+
+ if self.state_in_first_order:
+ sigma = self.sigmas[step_index]
+ sigma_next = self.sigmas[step_index + 1]
+ else:
+ # 2nd order / Heun's method
+ sigma = self.sigmas[step_index - 1]
+ sigma_next = self.sigmas[step_index]
+
+ # currently only gamma=0 is supported. This usually works best anyways.
+ # We can support gamma in the future but then need to scale the timestep before
+ # passing it to the model which requires a change in API
+ gamma = 0
+ sigma_hat = sigma * (gamma + 1) # Note: sigma_hat == sigma for now
+
+ # 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
+ if self.config.prediction_type == "epsilon":
+ sigma_input = sigma_hat if self.state_in_first_order else sigma_next
+ pred_original_sample = sample - sigma_input * model_output
+ elif self.config.prediction_type == "v_prediction":
+ sigma_input = sigma_hat if self.state_in_first_order else sigma_next
+ pred_original_sample = model_output * (-sigma_input / (sigma_input**2 + 1) ** 0.5) + (
+ sample / (sigma_input**2 + 1)
+ )
+ elif self.config.prediction_type == "sample":
+ raise NotImplementedError("prediction_type not implemented yet: sample")
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
+ )
+
+ if self.state_in_first_order:
+ # 2. Convert to an ODE derivative for 1st order
+ derivative = (sample - pred_original_sample) / sigma_hat
+ # 3. delta timestep
+ dt = sigma_next - sigma_hat
+
+ # store for 2nd order step
+ self.prev_derivative = derivative
+ self.dt = dt
+ self.sample = sample
+ else:
+ # 2. 2nd order / Heun's method
+ derivative = (sample - pred_original_sample) / sigma_next
+ derivative = (self.prev_derivative + derivative) / 2
+
+ # 3. take prev timestep & sample
+ dt = self.dt
+ sample = self.sample
+
+ # free dt and derivative
+ # Note, this puts the scheduler in "first order mode"
+ self.prev_derivative = None
+ self.dt = None
+ self.sample = None
+
+ prev_sample = sample + derivative * dt
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ # Make sure sigmas and timesteps have the same device and dtype as original_samples
+ self.sigmas = self.sigmas.to(device=original_samples.device, dtype=original_samples.dtype)
+ if original_samples.device.type == "mps" and torch.is_floating_point(timesteps):
+ # mps does not support float64
+ self.timesteps = self.timesteps.to(original_samples.device, dtype=torch.float32)
+ timesteps = timesteps.to(original_samples.device, dtype=torch.float32)
+ else:
+ self.timesteps = self.timesteps.to(original_samples.device)
+ timesteps = timesteps.to(original_samples.device)
+
+ step_indices = [self.index_for_timestep(t) for t in timesteps]
+
+ sigma = self.sigmas[step_indices].flatten()
+ while len(sigma.shape) < len(original_samples.shape):
+ sigma = sigma.unsqueeze(-1)
+
+ noisy_samples = original_samples + noise * sigma
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_ipndm.py b/diffusers/src/diffusers/schedulers/scheduling_ipndm.py
new file mode 100644
index 0000000000000000000000000000000000000000..80e521590782de6bc14e9b8c29642c7595fafc93
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_ipndm.py
@@ -0,0 +1,161 @@
+# Copyright 2023 Zhejiang University Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils import SchedulerMixin, SchedulerOutput
+
+
+class IPNDMScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Improved Pseudo numerical methods for diffusion models (iPNDM) ported from @crowsonkb's amazing k-diffusion
+ [library](https://github.com/crowsonkb/v-diffusion-pytorch/blob/987f8985e38208345c1959b0ea767a625831cc9b/diffusion/sampling.py#L296)
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2202.09778
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ """
+
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self, num_train_timesteps: int = 1000, trained_betas: Optional[Union[np.ndarray, List[float]]] = None
+ ):
+ # set `betas`, `alphas`, `timesteps`
+ self.set_timesteps(num_train_timesteps)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # For now we only support F-PNDM, i.e. the runge-kutta method
+ # For more information on the algorithm please take a look at the paper: https://arxiv.org/pdf/2202.09778.pdf
+ # mainly at formula (9), (12), (13) and the Algorithm 2.
+ self.pndm_order = 4
+
+ # running values
+ self.ets = []
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+ self.num_inference_steps = num_inference_steps
+ steps = torch.linspace(1, 0, num_inference_steps + 1)[:-1]
+ steps = torch.cat([steps, torch.tensor([0.0])])
+
+ if self.config.trained_betas is not None:
+ self.betas = torch.tensor(self.config.trained_betas, dtype=torch.float32)
+ else:
+ self.betas = torch.sin(steps * math.pi / 2) ** 2
+
+ self.alphas = (1.0 - self.betas**2) ** 0.5
+
+ timesteps = (torch.atan2(self.betas, self.alphas) / math.pi * 2)[:-1]
+ self.timesteps = timesteps.to(device)
+
+ self.ets = []
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the linear multi-step method. This has one forward pass with multiple
+ times to approximate the solution.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~scheduling_utils.SchedulerOutput`] or `tuple`: [`~scheduling_utils.SchedulerOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ timestep_index = (self.timesteps == timestep).nonzero().item()
+ prev_timestep_index = timestep_index + 1
+
+ ets = sample * self.betas[timestep_index] + model_output * self.alphas[timestep_index]
+ self.ets.append(ets)
+
+ if len(self.ets) == 1:
+ ets = self.ets[-1]
+ elif len(self.ets) == 2:
+ ets = (3 * self.ets[-1] - self.ets[-2]) / 2
+ elif len(self.ets) == 3:
+ ets = (23 * self.ets[-1] - 16 * self.ets[-2] + 5 * self.ets[-3]) / 12
+ else:
+ ets = (1 / 24) * (55 * self.ets[-1] - 59 * self.ets[-2] + 37 * self.ets[-3] - 9 * self.ets[-4])
+
+ prev_sample = self._get_prev_sample(sample, timestep_index, prev_timestep_index, ets)
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def scale_model_input(self, sample: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def _get_prev_sample(self, sample, timestep_index, prev_timestep_index, ets):
+ alpha = self.alphas[timestep_index]
+ sigma = self.betas[timestep_index]
+
+ next_alpha = self.alphas[prev_timestep_index]
+ next_sigma = self.betas[prev_timestep_index]
+
+ pred = (sample - sigma * ets) / max(alpha, 1e-8)
+ prev_sample = next_alpha * pred + ets * next_sigma
+
+ return prev_sample
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_k_dpm_2_ancestral_discrete.py b/diffusers/src/diffusers/schedulers/scheduling_k_dpm_2_ancestral_discrete.py
new file mode 100644
index 0000000000000000000000000000000000000000..c8b1f2c3bedf899d55a253b2c8a07709f6b476d8
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_k_dpm_2_ancestral_discrete.py
@@ -0,0 +1,352 @@
+# Copyright 2023 Katherine Crowson, The HuggingFace Team and hlky. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import randn_tensor
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin, SchedulerOutput
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999) -> torch.Tensor:
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class KDPM2AncestralDiscreteScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Scheduler created by @crowsonkb in [k_diffusion](https://github.com/crowsonkb/k-diffusion), see:
+ https://github.com/crowsonkb/k-diffusion/blob/5b3af030dd83e0297272d861c19477735d0317ec/k_diffusion/sampling.py#L188
+
+ Scheduler inspired by DPM-Solver-2 and Algorthim 2 from Karras et al. (2022).
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model. beta_start (`float`): the
+ starting `beta` value of inference. beta_end (`float`): the final `beta` value. beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear` or `scaled_linear`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ options to clip the variance used when adding noise to the denoised sample. Choose from `fixed_small`,
+ `fixed_small_log`, `fixed_large`, `fixed_large_log`, `learned` or `learned_range`.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 2
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.00085, # sensible defaults
+ beta_end: float = 0.012,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ prediction_type: str = "epsilon",
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ # set all values
+ self.set_timesteps(num_train_timesteps, None, num_train_timesteps)
+
+ def index_for_timestep(self, timestep):
+ indices = (self.timesteps == timestep).nonzero()
+ if self.state_in_first_order:
+ pos = -1
+ else:
+ pos = 0
+ return indices[pos].item()
+
+ def scale_model_input(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[float, torch.FloatTensor],
+ ) -> torch.FloatTensor:
+ """
+ Args:
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+ sample (`torch.FloatTensor`): input sample timestep (`int`, optional): current timestep
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ step_index = self.index_for_timestep(timestep)
+
+ if self.state_in_first_order:
+ sigma = self.sigmas[step_index]
+ else:
+ sigma = self.sigmas_interpol[step_index - 1]
+
+ sample = sample / ((sigma**2 + 1) ** 0.5)
+ return sample
+
+ def set_timesteps(
+ self,
+ num_inference_steps: int,
+ device: Union[str, torch.device] = None,
+ num_train_timesteps: Optional[int] = None,
+ ):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+
+ num_train_timesteps = num_train_timesteps or self.config.num_train_timesteps
+
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_inference_steps, dtype=float)[::-1].copy()
+
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+ self.log_sigmas = torch.from_numpy(np.log(sigmas)).to(device)
+
+ sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas)
+ sigmas = np.concatenate([sigmas, [0.0]]).astype(np.float32)
+ sigmas = torch.from_numpy(sigmas).to(device=device)
+
+ # compute up and down sigmas
+ sigmas_next = sigmas.roll(-1)
+ sigmas_next[-1] = 0.0
+ sigmas_up = (sigmas_next**2 * (sigmas**2 - sigmas_next**2) / sigmas**2) ** 0.5
+ sigmas_down = (sigmas_next**2 - sigmas_up**2) ** 0.5
+ sigmas_down[-1] = 0.0
+
+ # compute interpolated sigmas
+ sigmas_interpol = sigmas.log().lerp(sigmas_down.log(), 0.5).exp()
+ sigmas_interpol[-2:] = 0.0
+
+ # set sigmas
+ self.sigmas = torch.cat([sigmas[:1], sigmas[1:].repeat_interleave(2), sigmas[-1:]])
+ self.sigmas_interpol = torch.cat(
+ [sigmas_interpol[:1], sigmas_interpol[1:].repeat_interleave(2), sigmas_interpol[-1:]]
+ )
+ self.sigmas_up = torch.cat([sigmas_up[:1], sigmas_up[1:].repeat_interleave(2), sigmas_up[-1:]])
+ self.sigmas_down = torch.cat([sigmas_down[:1], sigmas_down[1:].repeat_interleave(2), sigmas_down[-1:]])
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = self.sigmas.max()
+
+ if str(device).startswith("mps"):
+ # mps does not support float64
+ timesteps = torch.from_numpy(timesteps).to(device, dtype=torch.float32)
+ else:
+ timesteps = torch.from_numpy(timesteps).to(device)
+
+ timesteps_interpol = self.sigma_to_t(sigmas_interpol).to(device)
+ interleaved_timesteps = torch.stack((timesteps_interpol[:-2, None], timesteps[1:, None]), dim=-1).flatten()
+
+ self.timesteps = torch.cat([timesteps[:1], interleaved_timesteps])
+
+ self.sample = None
+
+ def sigma_to_t(self, sigma):
+ # get log sigma
+ log_sigma = sigma.log()
+
+ # get distribution
+ dists = log_sigma - self.log_sigmas[:, None]
+
+ # get sigmas range
+ low_idx = dists.ge(0).cumsum(dim=0).argmax(dim=0).clamp(max=self.log_sigmas.shape[0] - 2)
+ high_idx = low_idx + 1
+
+ low = self.log_sigmas[low_idx]
+ high = self.log_sigmas[high_idx]
+
+ # interpolate sigmas
+ w = (low - log_sigma) / (low - high)
+ w = w.clamp(0, 1)
+
+ # transform interpolation to time range
+ t = (1 - w) * low_idx + w * high_idx
+ t = t.view(sigma.shape)
+ return t
+
+ @property
+ def state_in_first_order(self):
+ return self.sample is None
+
+ def step(
+ self,
+ model_output: Union[torch.FloatTensor, np.ndarray],
+ timestep: Union[float, torch.FloatTensor],
+ sample: Union[torch.FloatTensor, np.ndarray],
+ generator: Optional[torch.Generator] = None,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Args:
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+ model_output (`torch.FloatTensor` or `np.ndarray`): direct output from learned diffusion model. timestep
+ (`int`): current discrete timestep in the diffusion chain. sample (`torch.FloatTensor` or `np.ndarray`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+ Returns:
+ [`~schedulers.scheduling_utils.SchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.SchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ step_index = self.index_for_timestep(timestep)
+
+ if self.state_in_first_order:
+ sigma = self.sigmas[step_index]
+ sigma_interpol = self.sigmas_interpol[step_index]
+ sigma_up = self.sigmas_up[step_index]
+ sigma_down = self.sigmas_down[step_index - 1]
+ else:
+ # 2nd order / KPDM2's method
+ sigma = self.sigmas[step_index - 1]
+ sigma_interpol = self.sigmas_interpol[step_index - 1]
+ sigma_up = self.sigmas_up[step_index - 1]
+ sigma_down = self.sigmas_down[step_index - 1]
+
+ # currently only gamma=0 is supported. This usually works best anyways.
+ # We can support gamma in the future but then need to scale the timestep before
+ # passing it to the model which requires a change in API
+ gamma = 0
+ sigma_hat = sigma * (gamma + 1) # Note: sigma_hat == sigma for now
+
+ device = model_output.device
+ noise = randn_tensor(model_output.shape, dtype=model_output.dtype, device=device, generator=generator)
+
+ # 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
+ if self.config.prediction_type == "epsilon":
+ sigma_input = sigma_hat if self.state_in_first_order else sigma_interpol
+ pred_original_sample = sample - sigma_input * model_output
+ elif self.config.prediction_type == "v_prediction":
+ sigma_input = sigma_hat if self.state_in_first_order else sigma_interpol
+ pred_original_sample = model_output * (-sigma_input / (sigma_input**2 + 1) ** 0.5) + (
+ sample / (sigma_input**2 + 1)
+ )
+ elif self.config.prediction_type == "sample":
+ raise NotImplementedError("prediction_type not implemented yet: sample")
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
+ )
+
+ if self.state_in_first_order:
+ # 2. Convert to an ODE derivative for 1st order
+ derivative = (sample - pred_original_sample) / sigma_hat
+ # 3. delta timestep
+ dt = sigma_interpol - sigma_hat
+
+ # store for 2nd order step
+ self.sample = sample
+ self.dt = dt
+ prev_sample = sample + derivative * dt
+ else:
+ # DPM-Solver-2
+ # 2. Convert to an ODE derivative for 2nd order
+ derivative = (sample - pred_original_sample) / sigma_interpol
+ # 3. delta timestep
+ dt = sigma_down - sigma_hat
+
+ sample = self.sample
+ self.sample = None
+
+ prev_sample = sample + derivative * dt
+ prev_sample = prev_sample + noise * sigma_up
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ # Make sure sigmas and timesteps have the same device and dtype as original_samples
+ self.sigmas = self.sigmas.to(device=original_samples.device, dtype=original_samples.dtype)
+ if original_samples.device.type == "mps" and torch.is_floating_point(timesteps):
+ # mps does not support float64
+ self.timesteps = self.timesteps.to(original_samples.device, dtype=torch.float32)
+ timesteps = timesteps.to(original_samples.device, dtype=torch.float32)
+ else:
+ self.timesteps = self.timesteps.to(original_samples.device)
+ timesteps = timesteps.to(original_samples.device)
+
+ step_indices = [self.index_for_timestep(t) for t in timesteps]
+
+ sigma = self.sigmas[step_indices].flatten()
+ while len(sigma.shape) < len(original_samples.shape):
+ sigma = sigma.unsqueeze(-1)
+
+ noisy_samples = original_samples + noise * sigma
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_k_dpm_2_discrete.py b/diffusers/src/diffusers/schedulers/scheduling_k_dpm_2_discrete.py
new file mode 100644
index 0000000000000000000000000000000000000000..809da798f889ebe9d7788fd6c422918cd8e1b440
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_k_dpm_2_discrete.py
@@ -0,0 +1,333 @@
+# Copyright 2023 Katherine Crowson, The HuggingFace Team and hlky. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin, SchedulerOutput
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999) -> torch.Tensor:
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class KDPM2DiscreteScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Scheduler created by @crowsonkb in [k_diffusion](https://github.com/crowsonkb/k-diffusion), see:
+ https://github.com/crowsonkb/k-diffusion/blob/5b3af030dd83e0297272d861c19477735d0317ec/k_diffusion/sampling.py#L188
+
+ Scheduler inspired by DPM-Solver-2 and Algorthim 2 from Karras et al. (2022).
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model. beta_start (`float`): the
+ starting `beta` value of inference. beta_end (`float`): the final `beta` value. beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear` or `scaled_linear`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ options to clip the variance used when adding noise to the denoised sample. Choose from `fixed_small`,
+ `fixed_small_log`, `fixed_large`, `fixed_large_log`, `learned` or `learned_range`.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 2
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.00085, # sensible defaults
+ beta_end: float = 0.012,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ prediction_type: str = "epsilon",
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ # set all values
+ self.set_timesteps(num_train_timesteps, None, num_train_timesteps)
+
+ def index_for_timestep(self, timestep):
+ indices = (self.timesteps == timestep).nonzero()
+ if self.state_in_first_order:
+ pos = -1
+ else:
+ pos = 0
+ return indices[pos].item()
+
+ def scale_model_input(
+ self,
+ sample: torch.FloatTensor,
+ timestep: Union[float, torch.FloatTensor],
+ ) -> torch.FloatTensor:
+ """
+ Args:
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+ sample (`torch.FloatTensor`): input sample timestep (`int`, optional): current timestep
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ step_index = self.index_for_timestep(timestep)
+
+ if self.state_in_first_order:
+ sigma = self.sigmas[step_index]
+ else:
+ sigma = self.sigmas_interpol[step_index]
+
+ sample = sample / ((sigma**2 + 1) ** 0.5)
+ return sample
+
+ def set_timesteps(
+ self,
+ num_inference_steps: int,
+ device: Union[str, torch.device] = None,
+ num_train_timesteps: Optional[int] = None,
+ ):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+
+ num_train_timesteps = num_train_timesteps or self.config.num_train_timesteps
+
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_inference_steps, dtype=float)[::-1].copy()
+
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+ self.log_sigmas = torch.from_numpy(np.log(sigmas)).to(device)
+
+ sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas)
+ sigmas = np.concatenate([sigmas, [0.0]]).astype(np.float32)
+ sigmas = torch.from_numpy(sigmas).to(device=device)
+
+ # interpolate sigmas
+ sigmas_interpol = sigmas.log().lerp(sigmas.roll(1).log(), 0.5).exp()
+
+ self.sigmas = torch.cat([sigmas[:1], sigmas[1:].repeat_interleave(2), sigmas[-1:]])
+ self.sigmas_interpol = torch.cat(
+ [sigmas_interpol[:1], sigmas_interpol[1:].repeat_interleave(2), sigmas_interpol[-1:]]
+ )
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = self.sigmas.max()
+
+ if str(device).startswith("mps"):
+ # mps does not support float64
+ timesteps = torch.from_numpy(timesteps).to(device, dtype=torch.float32)
+ else:
+ timesteps = torch.from_numpy(timesteps).to(device)
+
+ # interpolate timesteps
+ timesteps_interpol = self.sigma_to_t(sigmas_interpol).to(device)
+ interleaved_timesteps = torch.stack((timesteps_interpol[1:-1, None], timesteps[1:, None]), dim=-1).flatten()
+
+ self.timesteps = torch.cat([timesteps[:1], interleaved_timesteps])
+
+ self.sample = None
+
+ def sigma_to_t(self, sigma):
+ # get log sigma
+ log_sigma = sigma.log()
+
+ # get distribution
+ dists = log_sigma - self.log_sigmas[:, None]
+
+ # get sigmas range
+ low_idx = dists.ge(0).cumsum(dim=0).argmax(dim=0).clamp(max=self.log_sigmas.shape[0] - 2)
+ high_idx = low_idx + 1
+
+ low = self.log_sigmas[low_idx]
+ high = self.log_sigmas[high_idx]
+
+ # interpolate sigmas
+ w = (low - log_sigma) / (low - high)
+ w = w.clamp(0, 1)
+
+ # transform interpolation to time range
+ t = (1 - w) * low_idx + w * high_idx
+ t = t.view(sigma.shape)
+ return t
+
+ @property
+ def state_in_first_order(self):
+ return self.sample is None
+
+ def step(
+ self,
+ model_output: Union[torch.FloatTensor, np.ndarray],
+ timestep: Union[float, torch.FloatTensor],
+ sample: Union[torch.FloatTensor, np.ndarray],
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Args:
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+ model_output (`torch.FloatTensor` or `np.ndarray`): direct output from learned diffusion model. timestep
+ (`int`): current discrete timestep in the diffusion chain. sample (`torch.FloatTensor` or `np.ndarray`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+ Returns:
+ [`~schedulers.scheduling_utils.SchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.SchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+ """
+ step_index = self.index_for_timestep(timestep)
+
+ if self.state_in_first_order:
+ sigma = self.sigmas[step_index]
+ sigma_interpol = self.sigmas_interpol[step_index + 1]
+ sigma_next = self.sigmas[step_index + 1]
+ else:
+ # 2nd order / KDPM2's method
+ sigma = self.sigmas[step_index - 1]
+ sigma_interpol = self.sigmas_interpol[step_index]
+ sigma_next = self.sigmas[step_index]
+
+ # currently only gamma=0 is supported. This usually works best anyways.
+ # We can support gamma in the future but then need to scale the timestep before
+ # passing it to the model which requires a change in API
+ gamma = 0
+ sigma_hat = sigma * (gamma + 1) # Note: sigma_hat == sigma for now
+
+ # 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
+ if self.config.prediction_type == "epsilon":
+ sigma_input = sigma_hat if self.state_in_first_order else sigma_interpol
+ pred_original_sample = sample - sigma_input * model_output
+ elif self.config.prediction_type == "v_prediction":
+ sigma_input = sigma_hat if self.state_in_first_order else sigma_interpol
+ pred_original_sample = model_output * (-sigma_input / (sigma_input**2 + 1) ** 0.5) + (
+ sample / (sigma_input**2 + 1)
+ )
+ elif self.config.prediction_type == "sample":
+ raise NotImplementedError("prediction_type not implemented yet: sample")
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
+ )
+
+ if self.state_in_first_order:
+ # 2. Convert to an ODE derivative for 1st order
+ derivative = (sample - pred_original_sample) / sigma_hat
+ # 3. delta timestep
+ dt = sigma_interpol - sigma_hat
+
+ # store for 2nd order step
+ self.sample = sample
+ else:
+ # DPM-Solver-2
+ # 2. Convert to an ODE derivative for 2nd order
+ derivative = (sample - pred_original_sample) / sigma_interpol
+
+ # 3. delta timestep
+ dt = sigma_next - sigma_hat
+
+ sample = self.sample
+ self.sample = None
+
+ prev_sample = sample + derivative * dt
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ # Make sure sigmas and timesteps have the same device and dtype as original_samples
+ self.sigmas = self.sigmas.to(device=original_samples.device, dtype=original_samples.dtype)
+ if original_samples.device.type == "mps" and torch.is_floating_point(timesteps):
+ # mps does not support float64
+ self.timesteps = self.timesteps.to(original_samples.device, dtype=torch.float32)
+ timesteps = timesteps.to(original_samples.device, dtype=torch.float32)
+ else:
+ self.timesteps = self.timesteps.to(original_samples.device)
+ timesteps = timesteps.to(original_samples.device)
+
+ step_indices = [self.index_for_timestep(t) for t in timesteps]
+
+ sigma = self.sigmas[step_indices].flatten()
+ while len(sigma.shape) < len(original_samples.shape):
+ sigma = sigma.unsqueeze(-1)
+
+ noisy_samples = original_samples + noise * sigma
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_karras_ve.py b/diffusers/src/diffusers/schedulers/scheduling_karras_ve.py
new file mode 100644
index 0000000000000000000000000000000000000000..87f6514a4e93e4a75bd6228ed852306b8c005c3d
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_karras_ve.py
@@ -0,0 +1,232 @@
+# Copyright 2023 NVIDIA and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, randn_tensor
+from .scheduling_utils import SchedulerMixin
+
+
+@dataclass
+class KarrasVeOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ derivative (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Derivative of predicted original image sample (x_0).
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ derivative: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+
+
+class KarrasVeScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Stochastic sampling from Karras et al. [1] tailored to the Variance-Expanding (VE) models [2]. Use Algorithm 2 and
+ the VE column of Table 1 from [1] for reference.
+
+ [1] Karras, Tero, et al. "Elucidating the Design Space of Diffusion-Based Generative Models."
+ https://arxiv.org/abs/2206.00364 [2] Song, Yang, et al. "Score-based generative modeling through stochastic
+ differential equations." https://arxiv.org/abs/2011.13456
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details on the parameters, see the original paper's Appendix E.: "Elucidating the Design Space of
+ Diffusion-Based Generative Models." https://arxiv.org/abs/2206.00364. The grid search values used to find the
+ optimal {s_noise, s_churn, s_min, s_max} for a specific model are described in Table 5 of the paper.
+
+ Args:
+ sigma_min (`float`): minimum noise magnitude
+ sigma_max (`float`): maximum noise magnitude
+ s_noise (`float`): the amount of additional noise to counteract loss of detail during sampling.
+ A reasonable range is [1.000, 1.011].
+ s_churn (`float`): the parameter controlling the overall amount of stochasticity.
+ A reasonable range is [0, 100].
+ s_min (`float`): the start value of the sigma range where we add noise (enable stochasticity).
+ A reasonable range is [0, 10].
+ s_max (`float`): the end value of the sigma range where we add noise.
+ A reasonable range is [0.2, 80].
+
+ """
+
+ order = 2
+
+ @register_to_config
+ def __init__(
+ self,
+ sigma_min: float = 0.02,
+ sigma_max: float = 100,
+ s_noise: float = 1.007,
+ s_churn: float = 80,
+ s_min: float = 0.05,
+ s_max: float = 50,
+ ):
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = sigma_max
+
+ # setable values
+ self.num_inference_steps: int = None
+ self.timesteps: np.IntTensor = None
+ self.schedule: torch.FloatTensor = None # sigma(t_i)
+
+ def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the continuous timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+
+ """
+ self.num_inference_steps = num_inference_steps
+ timesteps = np.arange(0, self.num_inference_steps)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+ schedule = [
+ (
+ self.config.sigma_max**2
+ * (self.config.sigma_min**2 / self.config.sigma_max**2) ** (i / (num_inference_steps - 1))
+ )
+ for i in self.timesteps
+ ]
+ self.schedule = torch.tensor(schedule, dtype=torch.float32, device=device)
+
+ def add_noise_to_input(
+ self, sample: torch.FloatTensor, sigma: float, generator: Optional[torch.Generator] = None
+ ) -> Tuple[torch.FloatTensor, float]:
+ """
+ Explicit Langevin-like "churn" step of adding noise to the sample according to a factor gamma_i ≥ 0 to reach a
+ higher noise level sigma_hat = sigma_i + gamma_i*sigma_i.
+
+ TODO Args:
+ """
+ if self.config.s_min <= sigma <= self.config.s_max:
+ gamma = min(self.config.s_churn / self.num_inference_steps, 2**0.5 - 1)
+ else:
+ gamma = 0
+
+ # sample eps ~ N(0, S_noise^2 * I)
+ eps = self.config.s_noise * randn_tensor(sample.shape, generator=generator).to(sample.device)
+ sigma_hat = sigma + gamma * sigma
+ sample_hat = sample + ((sigma_hat**2 - sigma**2) ** 0.5 * eps)
+
+ return sample_hat, sigma_hat
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ sigma_hat: float,
+ sigma_prev: float,
+ sample_hat: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[KarrasVeOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ sigma_hat (`float`): TODO
+ sigma_prev (`float`): TODO
+ sample_hat (`torch.FloatTensor`): TODO
+ return_dict (`bool`): option for returning tuple rather than KarrasVeOutput class
+
+ KarrasVeOutput: updated sample in the diffusion chain and derivative (TODO double check).
+ Returns:
+ [`~schedulers.scheduling_karras_ve.KarrasVeOutput`] or `tuple`:
+ [`~schedulers.scheduling_karras_ve.KarrasVeOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+
+ """
+
+ pred_original_sample = sample_hat + sigma_hat * model_output
+ derivative = (sample_hat - pred_original_sample) / sigma_hat
+ sample_prev = sample_hat + (sigma_prev - sigma_hat) * derivative
+
+ if not return_dict:
+ return (sample_prev, derivative)
+
+ return KarrasVeOutput(
+ prev_sample=sample_prev, derivative=derivative, pred_original_sample=pred_original_sample
+ )
+
+ def step_correct(
+ self,
+ model_output: torch.FloatTensor,
+ sigma_hat: float,
+ sigma_prev: float,
+ sample_hat: torch.FloatTensor,
+ sample_prev: torch.FloatTensor,
+ derivative: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[KarrasVeOutput, Tuple]:
+ """
+ Correct the predicted sample based on the output model_output of the network. TODO complete description
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ sigma_hat (`float`): TODO
+ sigma_prev (`float`): TODO
+ sample_hat (`torch.FloatTensor`): TODO
+ sample_prev (`torch.FloatTensor`): TODO
+ derivative (`torch.FloatTensor`): TODO
+ return_dict (`bool`): option for returning tuple rather than KarrasVeOutput class
+
+ Returns:
+ prev_sample (TODO): updated sample in the diffusion chain. derivative (TODO): TODO
+
+ """
+ pred_original_sample = sample_prev + sigma_prev * model_output
+ derivative_corr = (sample_prev - pred_original_sample) / sigma_prev
+ sample_prev = sample_hat + (sigma_prev - sigma_hat) * (0.5 * derivative + 0.5 * derivative_corr)
+
+ if not return_dict:
+ return (sample_prev, derivative)
+
+ return KarrasVeOutput(
+ prev_sample=sample_prev, derivative=derivative, pred_original_sample=pred_original_sample
+ )
+
+ def add_noise(self, original_samples, noise, timesteps):
+ raise NotImplementedError()
diff --git a/diffusers/src/diffusers/schedulers/scheduling_karras_ve_flax.py b/diffusers/src/diffusers/schedulers/scheduling_karras_ve_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..45c0dbddf7efd22df21cc9859e68d62b54aa8609
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_karras_ve_flax.py
@@ -0,0 +1,237 @@
+# Copyright 2023 NVIDIA and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import flax
+import jax.numpy as jnp
+from jax import random
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput
+from .scheduling_utils_flax import FlaxSchedulerMixin
+
+
+@flax.struct.dataclass
+class KarrasVeSchedulerState:
+ # setable values
+ num_inference_steps: Optional[int] = None
+ timesteps: Optional[jnp.ndarray] = None
+ schedule: Optional[jnp.ndarray] = None # sigma(t_i)
+
+ @classmethod
+ def create(cls):
+ return cls()
+
+
+@dataclass
+class FlaxKarrasVeOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ derivative (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)` for images):
+ Derivative of predicted original image sample (x_0).
+ state (`KarrasVeSchedulerState`): the `FlaxKarrasVeScheduler` state data class.
+ """
+
+ prev_sample: jnp.ndarray
+ derivative: jnp.ndarray
+ state: KarrasVeSchedulerState
+
+
+class FlaxKarrasVeScheduler(FlaxSchedulerMixin, ConfigMixin):
+ """
+ Stochastic sampling from Karras et al. [1] tailored to the Variance-Expanding (VE) models [2]. Use Algorithm 2 and
+ the VE column of Table 1 from [1] for reference.
+
+ [1] Karras, Tero, et al. "Elucidating the Design Space of Diffusion-Based Generative Models."
+ https://arxiv.org/abs/2206.00364 [2] Song, Yang, et al. "Score-based generative modeling through stochastic
+ differential equations." https://arxiv.org/abs/2011.13456
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details on the parameters, see the original paper's Appendix E.: "Elucidating the Design Space of
+ Diffusion-Based Generative Models." https://arxiv.org/abs/2206.00364. The grid search values used to find the
+ optimal {s_noise, s_churn, s_min, s_max} for a specific model are described in Table 5 of the paper.
+
+ Args:
+ sigma_min (`float`): minimum noise magnitude
+ sigma_max (`float`): maximum noise magnitude
+ s_noise (`float`): the amount of additional noise to counteract loss of detail during sampling.
+ A reasonable range is [1.000, 1.011].
+ s_churn (`float`): the parameter controlling the overall amount of stochasticity.
+ A reasonable range is [0, 100].
+ s_min (`float`): the start value of the sigma range where we add noise (enable stochasticity).
+ A reasonable range is [0, 10].
+ s_max (`float`): the end value of the sigma range where we add noise.
+ A reasonable range is [0.2, 80].
+ """
+
+ @property
+ def has_state(self):
+ return True
+
+ @register_to_config
+ def __init__(
+ self,
+ sigma_min: float = 0.02,
+ sigma_max: float = 100,
+ s_noise: float = 1.007,
+ s_churn: float = 80,
+ s_min: float = 0.05,
+ s_max: float = 50,
+ ):
+ pass
+
+ def create_state(self):
+ return KarrasVeSchedulerState.create()
+
+ def set_timesteps(
+ self, state: KarrasVeSchedulerState, num_inference_steps: int, shape: Tuple = ()
+ ) -> KarrasVeSchedulerState:
+ """
+ Sets the continuous timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ state (`KarrasVeSchedulerState`):
+ the `FlaxKarrasVeScheduler` state data class.
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+
+ """
+ timesteps = jnp.arange(0, num_inference_steps)[::-1].copy()
+ schedule = [
+ (
+ self.config.sigma_max**2
+ * (self.config.sigma_min**2 / self.config.sigma_max**2) ** (i / (num_inference_steps - 1))
+ )
+ for i in timesteps
+ ]
+
+ return state.replace(
+ num_inference_steps=num_inference_steps,
+ schedule=jnp.array(schedule, dtype=jnp.float32),
+ timesteps=timesteps,
+ )
+
+ def add_noise_to_input(
+ self,
+ state: KarrasVeSchedulerState,
+ sample: jnp.ndarray,
+ sigma: float,
+ key: random.KeyArray,
+ ) -> Tuple[jnp.ndarray, float]:
+ """
+ Explicit Langevin-like "churn" step of adding noise to the sample according to a factor gamma_i ≥ 0 to reach a
+ higher noise level sigma_hat = sigma_i + gamma_i*sigma_i.
+
+ TODO Args:
+ """
+ if self.config.s_min <= sigma <= self.config.s_max:
+ gamma = min(self.config.s_churn / state.num_inference_steps, 2**0.5 - 1)
+ else:
+ gamma = 0
+
+ # sample eps ~ N(0, S_noise^2 * I)
+ key = random.split(key, num=1)
+ eps = self.config.s_noise * random.normal(key=key, shape=sample.shape)
+ sigma_hat = sigma + gamma * sigma
+ sample_hat = sample + ((sigma_hat**2 - sigma**2) ** 0.5 * eps)
+
+ return sample_hat, sigma_hat
+
+ def step(
+ self,
+ state: KarrasVeSchedulerState,
+ model_output: jnp.ndarray,
+ sigma_hat: float,
+ sigma_prev: float,
+ sample_hat: jnp.ndarray,
+ return_dict: bool = True,
+ ) -> Union[FlaxKarrasVeOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ state (`KarrasVeSchedulerState`): the `FlaxKarrasVeScheduler` state data class.
+ model_output (`torch.FloatTensor` or `np.ndarray`): direct output from learned diffusion model.
+ sigma_hat (`float`): TODO
+ sigma_prev (`float`): TODO
+ sample_hat (`torch.FloatTensor` or `np.ndarray`): TODO
+ return_dict (`bool`): option for returning tuple rather than FlaxKarrasVeOutput class
+
+ Returns:
+ [`~schedulers.scheduling_karras_ve_flax.FlaxKarrasVeOutput`] or `tuple`: Updated sample in the diffusion
+ chain and derivative. [`~schedulers.scheduling_karras_ve_flax.FlaxKarrasVeOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+ """
+
+ pred_original_sample = sample_hat + sigma_hat * model_output
+ derivative = (sample_hat - pred_original_sample) / sigma_hat
+ sample_prev = sample_hat + (sigma_prev - sigma_hat) * derivative
+
+ if not return_dict:
+ return (sample_prev, derivative, state)
+
+ return FlaxKarrasVeOutput(prev_sample=sample_prev, derivative=derivative, state=state)
+
+ def step_correct(
+ self,
+ state: KarrasVeSchedulerState,
+ model_output: jnp.ndarray,
+ sigma_hat: float,
+ sigma_prev: float,
+ sample_hat: jnp.ndarray,
+ sample_prev: jnp.ndarray,
+ derivative: jnp.ndarray,
+ return_dict: bool = True,
+ ) -> Union[FlaxKarrasVeOutput, Tuple]:
+ """
+ Correct the predicted sample based on the output model_output of the network. TODO complete description
+
+ Args:
+ state (`KarrasVeSchedulerState`): the `FlaxKarrasVeScheduler` state data class.
+ model_output (`torch.FloatTensor` or `np.ndarray`): direct output from learned diffusion model.
+ sigma_hat (`float`): TODO
+ sigma_prev (`float`): TODO
+ sample_hat (`torch.FloatTensor` or `np.ndarray`): TODO
+ sample_prev (`torch.FloatTensor` or `np.ndarray`): TODO
+ derivative (`torch.FloatTensor` or `np.ndarray`): TODO
+ return_dict (`bool`): option for returning tuple rather than FlaxKarrasVeOutput class
+
+ Returns:
+ prev_sample (TODO): updated sample in the diffusion chain. derivative (TODO): TODO
+
+ """
+ pred_original_sample = sample_prev + sigma_prev * model_output
+ derivative_corr = (sample_prev - pred_original_sample) / sigma_prev
+ sample_prev = sample_hat + (sigma_prev - sigma_hat) * (0.5 * derivative + 0.5 * derivative_corr)
+
+ if not return_dict:
+ return (sample_prev, derivative, state)
+
+ return FlaxKarrasVeOutput(prev_sample=sample_prev, derivative=derivative, state=state)
+
+ def add_noise(self, state: KarrasVeSchedulerState, original_samples, noise, timesteps):
+ raise NotImplementedError()
diff --git a/diffusers/src/diffusers/schedulers/scheduling_lms_discrete.py b/diffusers/src/diffusers/schedulers/scheduling_lms_discrete.py
new file mode 100644
index 0000000000000000000000000000000000000000..0fe1f77f9b5c0c22c676dba122c085f63f0d84fa
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_lms_discrete.py
@@ -0,0 +1,313 @@
+# Copyright 2023 Katherine Crowson and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+import warnings
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from scipy import integrate
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin
+
+
+@dataclass
+# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->LMSDiscrete
+class LMSDiscreteSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class LMSDiscreteScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Linear Multistep Scheduler for discrete beta schedules. Based on the original k-diffusion implementation by
+ Katherine Crowson:
+ https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L181
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear` or `scaled_linear`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ prediction_type: str = "epsilon",
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+ sigmas = np.concatenate([sigmas[::-1], [0.0]]).astype(np.float32)
+ self.sigmas = torch.from_numpy(sigmas)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = self.sigmas.max()
+
+ # setable values
+ self.num_inference_steps = None
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=float)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps)
+ self.derivatives = []
+ self.is_scale_input_called = False
+
+ def scale_model_input(
+ self, sample: torch.FloatTensor, timestep: Union[float, torch.FloatTensor]
+ ) -> torch.FloatTensor:
+ """
+ Scales the denoising model input by `(sigma**2 + 1) ** 0.5` to match the K-LMS algorithm.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`float` or `torch.FloatTensor`): the current timestep in the diffusion chain
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+ step_index = (self.timesteps == timestep).nonzero().item()
+ sigma = self.sigmas[step_index]
+ sample = sample / ((sigma**2 + 1) ** 0.5)
+ self.is_scale_input_called = True
+ return sample
+
+ def get_lms_coefficient(self, order, t, current_order):
+ """
+ Compute a linear multistep coefficient.
+
+ Args:
+ order (TODO):
+ t (TODO):
+ current_order (TODO):
+ """
+
+ def lms_derivative(tau):
+ prod = 1.0
+ for k in range(order):
+ if current_order == k:
+ continue
+ prod *= (tau - self.sigmas[t - k]) / (self.sigmas[t - current_order] - self.sigmas[t - k])
+ return prod
+
+ integrated_coeff = integrate.quad(lms_derivative, self.sigmas[t], self.sigmas[t + 1], epsrel=1e-4)[0]
+
+ return integrated_coeff
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+
+ timesteps = np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=float)[::-1].copy()
+ sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
+ sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas)
+ sigmas = np.concatenate([sigmas, [0.0]]).astype(np.float32)
+
+ self.sigmas = torch.from_numpy(sigmas).to(device=device)
+ if str(device).startswith("mps"):
+ # mps does not support float64
+ self.timesteps = torch.from_numpy(timesteps).to(device, dtype=torch.float32)
+ else:
+ self.timesteps = torch.from_numpy(timesteps).to(device=device)
+
+ self.derivatives = []
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: Union[float, torch.FloatTensor],
+ sample: torch.FloatTensor,
+ order: int = 4,
+ return_dict: bool = True,
+ ) -> Union[LMSDiscreteSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`float`): current timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ order: coefficient for multi-step inference.
+ return_dict (`bool`): option for returning tuple rather than LMSDiscreteSchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.LMSDiscreteSchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.LMSDiscreteSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`.
+ When returning a tuple, the first element is the sample tensor.
+
+ """
+ if not self.is_scale_input_called:
+ warnings.warn(
+ "The `scale_model_input` function should be called before `step` to ensure correct denoising. "
+ "See `StableDiffusionPipeline` for a usage example."
+ )
+
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+ step_index = (self.timesteps == timestep).nonzero().item()
+ sigma = self.sigmas[step_index]
+
+ # 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = sample - sigma * model_output
+ elif self.config.prediction_type == "v_prediction":
+ # * c_out + input * c_skip
+ pred_original_sample = model_output * (-sigma / (sigma**2 + 1) ** 0.5) + (sample / (sigma**2 + 1))
+ elif self.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
+ )
+
+ # 2. Convert to an ODE derivative
+ derivative = (sample - pred_original_sample) / sigma
+ self.derivatives.append(derivative)
+ if len(self.derivatives) > order:
+ self.derivatives.pop(0)
+
+ # 3. Compute linear multistep coefficients
+ order = min(step_index + 1, order)
+ lms_coeffs = [self.get_lms_coefficient(order, step_index, curr_order) for curr_order in range(order)]
+
+ # 4. Compute previous sample based on the derivatives path
+ prev_sample = sample + sum(
+ coeff * derivative for coeff, derivative in zip(lms_coeffs, reversed(self.derivatives))
+ )
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return LMSDiscreteSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ # Make sure sigmas and timesteps have the same device and dtype as original_samples
+ sigmas = self.sigmas.to(device=original_samples.device, dtype=original_samples.dtype)
+ if original_samples.device.type == "mps" and torch.is_floating_point(timesteps):
+ # mps does not support float64
+ schedule_timesteps = self.timesteps.to(original_samples.device, dtype=torch.float32)
+ timesteps = timesteps.to(original_samples.device, dtype=torch.float32)
+ else:
+ schedule_timesteps = self.timesteps.to(original_samples.device)
+ timesteps = timesteps.to(original_samples.device)
+
+ step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps]
+
+ sigma = sigmas[step_indices].flatten()
+ while len(sigma.shape) < len(original_samples.shape):
+ sigma = sigma.unsqueeze(-1)
+
+ noisy_samples = original_samples + noise * sigma
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_lms_discrete_flax.py b/diffusers/src/diffusers/schedulers/scheduling_lms_discrete_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..f96e602afe121a09876b0ff7db1d3192e441e32a
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_lms_discrete_flax.py
@@ -0,0 +1,283 @@
+# Copyright 2023 Katherine Crowson and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import flax
+import jax.numpy as jnp
+from scipy import integrate
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils_flax import (
+ CommonSchedulerState,
+ FlaxKarrasDiffusionSchedulers,
+ FlaxSchedulerMixin,
+ FlaxSchedulerOutput,
+ broadcast_to_shape_from_left,
+)
+
+
+@flax.struct.dataclass
+class LMSDiscreteSchedulerState:
+ common: CommonSchedulerState
+
+ # setable values
+ init_noise_sigma: jnp.ndarray
+ timesteps: jnp.ndarray
+ sigmas: jnp.ndarray
+ num_inference_steps: Optional[int] = None
+
+ # running values
+ derivatives: Optional[jnp.ndarray] = None
+
+ @classmethod
+ def create(
+ cls, common: CommonSchedulerState, init_noise_sigma: jnp.ndarray, timesteps: jnp.ndarray, sigmas: jnp.ndarray
+ ):
+ return cls(common=common, init_noise_sigma=init_noise_sigma, timesteps=timesteps, sigmas=sigmas)
+
+
+@dataclass
+class FlaxLMSSchedulerOutput(FlaxSchedulerOutput):
+ state: LMSDiscreteSchedulerState
+
+
+class FlaxLMSDiscreteScheduler(FlaxSchedulerMixin, ConfigMixin):
+ """
+ Linear Multistep Scheduler for discrete beta schedules. Based on the original k-diffusion implementation by
+ Katherine Crowson:
+ https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L181
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear` or `scaled_linear`.
+ trained_betas (`jnp.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
+ the `dtype` used for params and computation.
+ """
+
+ _compatibles = [e.name for e in FlaxKarrasDiffusionSchedulers]
+
+ dtype: jnp.dtype
+
+ @property
+ def has_state(self):
+ return True
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[jnp.ndarray] = None,
+ prediction_type: str = "epsilon",
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ self.dtype = dtype
+
+ def create_state(self, common: Optional[CommonSchedulerState] = None) -> LMSDiscreteSchedulerState:
+ if common is None:
+ common = CommonSchedulerState.create(self)
+
+ timesteps = jnp.arange(0, self.config.num_train_timesteps).round()[::-1]
+ sigmas = ((1 - common.alphas_cumprod) / common.alphas_cumprod) ** 0.5
+
+ # standard deviation of the initial noise distribution
+ init_noise_sigma = sigmas.max()
+
+ return LMSDiscreteSchedulerState.create(
+ common=common,
+ init_noise_sigma=init_noise_sigma,
+ timesteps=timesteps,
+ sigmas=sigmas,
+ )
+
+ def scale_model_input(self, state: LMSDiscreteSchedulerState, sample: jnp.ndarray, timestep: int) -> jnp.ndarray:
+ """
+ Scales the denoising model input by `(sigma**2 + 1) ** 0.5` to match the K-LMS algorithm.
+
+ Args:
+ state (`LMSDiscreteSchedulerState`):
+ the `FlaxLMSDiscreteScheduler` state data class instance.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ timestep (`int`):
+ current discrete timestep in the diffusion chain.
+
+ Returns:
+ `jnp.ndarray`: scaled input sample
+ """
+ (step_index,) = jnp.where(state.timesteps == timestep, size=1)
+ step_index = step_index[0]
+
+ sigma = state.sigmas[step_index]
+ sample = sample / ((sigma**2 + 1) ** 0.5)
+ return sample
+
+ def get_lms_coefficient(self, state: LMSDiscreteSchedulerState, order, t, current_order):
+ """
+ Compute a linear multistep coefficient.
+
+ Args:
+ order (TODO):
+ t (TODO):
+ current_order (TODO):
+ """
+
+ def lms_derivative(tau):
+ prod = 1.0
+ for k in range(order):
+ if current_order == k:
+ continue
+ prod *= (tau - state.sigmas[t - k]) / (state.sigmas[t - current_order] - state.sigmas[t - k])
+ return prod
+
+ integrated_coeff = integrate.quad(lms_derivative, state.sigmas[t], state.sigmas[t + 1], epsrel=1e-4)[0]
+
+ return integrated_coeff
+
+ def set_timesteps(
+ self, state: LMSDiscreteSchedulerState, num_inference_steps: int, shape: Tuple = ()
+ ) -> LMSDiscreteSchedulerState:
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ state (`LMSDiscreteSchedulerState`):
+ the `FlaxLMSDiscreteScheduler` state data class instance.
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+
+ timesteps = jnp.linspace(self.config.num_train_timesteps - 1, 0, num_inference_steps, dtype=self.dtype)
+
+ low_idx = jnp.floor(timesteps).astype(jnp.int32)
+ high_idx = jnp.ceil(timesteps).astype(jnp.int32)
+
+ frac = jnp.mod(timesteps, 1.0)
+
+ sigmas = ((1 - state.common.alphas_cumprod) / state.common.alphas_cumprod) ** 0.5
+ sigmas = (1 - frac) * sigmas[low_idx] + frac * sigmas[high_idx]
+ sigmas = jnp.concatenate([sigmas, jnp.array([0.0], dtype=self.dtype)])
+
+ timesteps = timesteps.astype(jnp.int32)
+
+ # initial running values
+ derivatives = jnp.zeros((0,) + shape, dtype=self.dtype)
+
+ return state.replace(
+ timesteps=timesteps,
+ sigmas=sigmas,
+ num_inference_steps=num_inference_steps,
+ derivatives=derivatives,
+ )
+
+ def step(
+ self,
+ state: LMSDiscreteSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ order: int = 4,
+ return_dict: bool = True,
+ ) -> Union[FlaxLMSSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ state (`LMSDiscreteSchedulerState`): the `FlaxLMSDiscreteScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ order: coefficient for multi-step inference.
+ return_dict (`bool`): option for returning tuple rather than FlaxLMSSchedulerOutput class
+
+ Returns:
+ [`FlaxLMSSchedulerOutput`] or `tuple`: [`FlaxLMSSchedulerOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if state.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ sigma = state.sigmas[timestep]
+
+ # 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = sample - sigma * model_output
+ elif self.config.prediction_type == "v_prediction":
+ # * c_out + input * c_skip
+ pred_original_sample = model_output * (-sigma / (sigma**2 + 1) ** 0.5) + (sample / (sigma**2 + 1))
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
+ )
+
+ # 2. Convert to an ODE derivative
+ derivative = (sample - pred_original_sample) / sigma
+ state = state.replace(derivatives=jnp.append(state.derivatives, derivative))
+ if len(state.derivatives) > order:
+ state = state.replace(derivatives=jnp.delete(state.derivatives, 0))
+
+ # 3. Compute linear multistep coefficients
+ order = min(timestep + 1, order)
+ lms_coeffs = [self.get_lms_coefficient(state, order, timestep, curr_order) for curr_order in range(order)]
+
+ # 4. Compute previous sample based on the derivatives path
+ prev_sample = sample + sum(
+ coeff * derivative for coeff, derivative in zip(lms_coeffs, reversed(state.derivatives))
+ )
+
+ if not return_dict:
+ return (prev_sample, state)
+
+ return FlaxLMSSchedulerOutput(prev_sample=prev_sample, state=state)
+
+ def add_noise(
+ self,
+ state: LMSDiscreteSchedulerState,
+ original_samples: jnp.ndarray,
+ noise: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ) -> jnp.ndarray:
+ sigma = state.sigmas[timesteps].flatten()
+ sigma = broadcast_to_shape_from_left(sigma, noise.shape)
+
+ noisy_samples = original_samples + noise * sigma
+
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_pndm.py b/diffusers/src/diffusers/schedulers/scheduling_pndm.py
new file mode 100644
index 0000000000000000000000000000000000000000..562cefb178933e40deccb82ebed66e891ee5ab87
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_pndm.py
@@ -0,0 +1,425 @@
+# Copyright 2023 Zhejiang University Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/ermongroup/ddim
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin, SchedulerOutput
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class PNDMScheduler(SchedulerMixin, ConfigMixin):
+ """
+ Pseudo numerical methods for diffusion models (PNDM) proposes using more advanced ODE integration techniques,
+ namely Runge-Kutta method and a linear multi-step method.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2202.09778
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ skip_prk_steps (`bool`):
+ allows the scheduler to skip the Runge-Kutta steps that are defined in the original paper as being required
+ before plms steps; defaults to `False`.
+ set_alpha_to_one (`bool`, default `False`):
+ each diffusion step uses the value of alphas product at that step and at the previous one. For the final
+ step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
+ otherwise it uses the value of alpha at step 0.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion process)
+ or `v_prediction` (see section 2.4 https://imagen.research.google/video/paper.pdf)
+ steps_offset (`int`, default `0`):
+ an offset added to the inference steps. You can use a combination of `offset=1` and
+ `set_alpha_to_one=False`, to make the last step use step 0 for the previous alpha product, as done in
+ stable diffusion.
+
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ skip_prk_steps: bool = False,
+ set_alpha_to_one: bool = False,
+ prediction_type: str = "epsilon",
+ steps_offset: int = 0,
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+
+ self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # For now we only support F-PNDM, i.e. the runge-kutta method
+ # For more information on the algorithm please take a look at the paper: https://arxiv.org/pdf/2202.09778.pdf
+ # mainly at formula (9), (12), (13) and the Algorithm 2.
+ self.pndm_order = 4
+
+ # running values
+ self.cur_model_output = 0
+ self.counter = 0
+ self.cur_sample = None
+ self.ets = []
+
+ # setable values
+ self.num_inference_steps = None
+ self._timesteps = np.arange(0, num_train_timesteps)[::-1].copy()
+ self.prk_timesteps = None
+ self.plms_timesteps = None
+ self.timesteps = None
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+
+ self.num_inference_steps = num_inference_steps
+ step_ratio = self.config.num_train_timesteps // self.num_inference_steps
+ # creates integer timesteps by multiplying by ratio
+ # casting to int to avoid issues when num_inference_step is power of 3
+ self._timesteps = (np.arange(0, num_inference_steps) * step_ratio).round()
+ self._timesteps += self.config.steps_offset
+
+ if self.config.skip_prk_steps:
+ # for some models like stable diffusion the prk steps can/should be skipped to
+ # produce better results. When using PNDM with `self.config.skip_prk_steps` the implementation
+ # is based on crowsonkb's PLMS sampler implementation: https://github.com/CompVis/latent-diffusion/pull/51
+ self.prk_timesteps = np.array([])
+ self.plms_timesteps = np.concatenate([self._timesteps[:-1], self._timesteps[-2:-1], self._timesteps[-1:]])[
+ ::-1
+ ].copy()
+ else:
+ prk_timesteps = np.array(self._timesteps[-self.pndm_order :]).repeat(2) + np.tile(
+ np.array([0, self.config.num_train_timesteps // num_inference_steps // 2]), self.pndm_order
+ )
+ self.prk_timesteps = (prk_timesteps[:-1].repeat(2)[1:-1])[::-1].copy()
+ self.plms_timesteps = self._timesteps[:-3][
+ ::-1
+ ].copy() # we copy to avoid having negative strides which are not supported by torch.from_numpy
+
+ timesteps = np.concatenate([self.prk_timesteps, self.plms_timesteps]).astype(np.int64)
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+
+ self.ets = []
+ self.counter = 0
+ self.cur_model_output = 0
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ This function calls `step_prk()` or `step_plms()` depending on the internal variable `counter`.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.SchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.SchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.counter < len(self.prk_timesteps) and not self.config.skip_prk_steps:
+ return self.step_prk(model_output=model_output, timestep=timestep, sample=sample, return_dict=return_dict)
+ else:
+ return self.step_plms(model_output=model_output, timestep=timestep, sample=sample, return_dict=return_dict)
+
+ def step_prk(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the Runge-Kutta method. RK takes 4 forward passes to approximate the
+ solution to the differential equation.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~scheduling_utils.SchedulerOutput`] or `tuple`: [`~scheduling_utils.SchedulerOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ diff_to_prev = 0 if self.counter % 2 else self.config.num_train_timesteps // self.num_inference_steps // 2
+ prev_timestep = timestep - diff_to_prev
+ timestep = self.prk_timesteps[self.counter // 4 * 4]
+
+ if self.counter % 4 == 0:
+ self.cur_model_output += 1 / 6 * model_output
+ self.ets.append(model_output)
+ self.cur_sample = sample
+ elif (self.counter - 1) % 4 == 0:
+ self.cur_model_output += 1 / 3 * model_output
+ elif (self.counter - 2) % 4 == 0:
+ self.cur_model_output += 1 / 3 * model_output
+ elif (self.counter - 3) % 4 == 0:
+ model_output = self.cur_model_output + 1 / 6 * model_output
+ self.cur_model_output = 0
+
+ # cur_sample should not be `None`
+ cur_sample = self.cur_sample if self.cur_sample is not None else sample
+
+ prev_sample = self._get_prev_sample(cur_sample, timestep, prev_timestep, model_output)
+ self.counter += 1
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def step_plms(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the linear multi-step method. This has one forward pass with multiple
+ times to approximate the solution.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~scheduling_utils.SchedulerOutput`] or `tuple`: [`~scheduling_utils.SchedulerOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ if not self.config.skip_prk_steps and len(self.ets) < 3:
+ raise ValueError(
+ f"{self.__class__} can only be run AFTER scheduler has been run "
+ "in 'prk' mode for at least 12 iterations "
+ "See: https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py "
+ "for more information."
+ )
+
+ prev_timestep = timestep - self.config.num_train_timesteps // self.num_inference_steps
+
+ if self.counter != 1:
+ self.ets = self.ets[-3:]
+ self.ets.append(model_output)
+ else:
+ prev_timestep = timestep
+ timestep = timestep + self.config.num_train_timesteps // self.num_inference_steps
+
+ if len(self.ets) == 1 and self.counter == 0:
+ model_output = model_output
+ self.cur_sample = sample
+ elif len(self.ets) == 1 and self.counter == 1:
+ model_output = (model_output + self.ets[-1]) / 2
+ sample = self.cur_sample
+ self.cur_sample = None
+ elif len(self.ets) == 2:
+ model_output = (3 * self.ets[-1] - self.ets[-2]) / 2
+ elif len(self.ets) == 3:
+ model_output = (23 * self.ets[-1] - 16 * self.ets[-2] + 5 * self.ets[-3]) / 12
+ else:
+ model_output = (1 / 24) * (55 * self.ets[-1] - 59 * self.ets[-2] + 37 * self.ets[-3] - 9 * self.ets[-4])
+
+ prev_sample = self._get_prev_sample(sample, timestep, prev_timestep, model_output)
+ self.counter += 1
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def scale_model_input(self, sample: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def _get_prev_sample(self, sample, timestep, prev_timestep, model_output):
+ # See formula (9) of PNDM paper https://arxiv.org/pdf/2202.09778.pdf
+ # this function computes x_(t−δ) using the formula of (9)
+ # Note that x_t needs to be added to both sides of the equation
+
+ # Notation ( ->
+ # alpha_prod_t -> α_t
+ # alpha_prod_t_prev -> α_(t−δ)
+ # beta_prod_t -> (1 - α_t)
+ # beta_prod_t_prev -> (1 - α_(t−δ))
+ # sample -> x_t
+ # model_output -> e_θ(x_t, t)
+ # prev_sample -> x_(t−δ)
+ alpha_prod_t = self.alphas_cumprod[timestep]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ if self.config.prediction_type == "v_prediction":
+ model_output = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
+ elif self.config.prediction_type != "epsilon":
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon` or `v_prediction`"
+ )
+
+ # corresponds to (α_(t−δ) - α_t) divided by
+ # denominator of x_t in formula (9) and plus 1
+ # Note: (α_(t−δ) - α_t) / (sqrt(α_t) * (sqrt(α_(t−δ)) + sqr(α_t))) =
+ # sqrt(α_(t−δ)) / sqrt(α_t))
+ sample_coeff = (alpha_prod_t_prev / alpha_prod_t) ** (0.5)
+
+ # corresponds to denominator of e_θ(x_t, t) in formula (9)
+ model_output_denom_coeff = alpha_prod_t * beta_prod_t_prev ** (0.5) + (
+ alpha_prod_t * beta_prod_t * alpha_prod_t_prev
+ ) ** (0.5)
+
+ # full formula (9)
+ prev_sample = (
+ sample_coeff * sample - (alpha_prod_t_prev - alpha_prod_t) * model_output / model_output_denom_coeff
+ )
+
+ return prev_sample
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.IntTensor,
+ ) -> torch.Tensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as original_samples
+ self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
+ timesteps = timesteps.to(original_samples.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_pndm_flax.py b/diffusers/src/diffusers/schedulers/scheduling_pndm_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..c654f2de8dd3e4f96403cce4b9db8f8b7b69861f
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_pndm_flax.py
@@ -0,0 +1,511 @@
+# Copyright 2023 Zhejiang University Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/ermongroup/ddim
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import flax
+import jax
+import jax.numpy as jnp
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils_flax import (
+ CommonSchedulerState,
+ FlaxKarrasDiffusionSchedulers,
+ FlaxSchedulerMixin,
+ FlaxSchedulerOutput,
+ add_noise_common,
+)
+
+
+@flax.struct.dataclass
+class PNDMSchedulerState:
+ common: CommonSchedulerState
+ final_alpha_cumprod: jnp.ndarray
+
+ # setable values
+ init_noise_sigma: jnp.ndarray
+ timesteps: jnp.ndarray
+ num_inference_steps: Optional[int] = None
+ prk_timesteps: Optional[jnp.ndarray] = None
+ plms_timesteps: Optional[jnp.ndarray] = None
+
+ # running values
+ cur_model_output: Optional[jnp.ndarray] = None
+ counter: Optional[jnp.int32] = None
+ cur_sample: Optional[jnp.ndarray] = None
+ ets: Optional[jnp.ndarray] = None
+
+ @classmethod
+ def create(
+ cls,
+ common: CommonSchedulerState,
+ final_alpha_cumprod: jnp.ndarray,
+ init_noise_sigma: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ):
+ return cls(
+ common=common,
+ final_alpha_cumprod=final_alpha_cumprod,
+ init_noise_sigma=init_noise_sigma,
+ timesteps=timesteps,
+ )
+
+
+@dataclass
+class FlaxPNDMSchedulerOutput(FlaxSchedulerOutput):
+ state: PNDMSchedulerState
+
+
+class FlaxPNDMScheduler(FlaxSchedulerMixin, ConfigMixin):
+ """
+ Pseudo numerical methods for diffusion models (PNDM) proposes using more advanced ODE integration techniques,
+ namely Runge-Kutta method and a linear multi-step method.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2202.09778
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`jnp.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ skip_prk_steps (`bool`):
+ allows the scheduler to skip the Runge-Kutta steps that are defined in the original paper as being required
+ before plms steps; defaults to `False`.
+ set_alpha_to_one (`bool`, default `False`):
+ each diffusion step uses the value of alphas product at that step and at the previous one. For the final
+ step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
+ otherwise it uses the value of alpha at step 0.
+ steps_offset (`int`, default `0`):
+ an offset added to the inference steps. You can use a combination of `offset=1` and
+ `set_alpha_to_one=False`, to make the last step use step 0 for the previous alpha product, as done in
+ stable diffusion.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
+ the `dtype` used for params and computation.
+ """
+
+ _compatibles = [e.name for e in FlaxKarrasDiffusionSchedulers]
+
+ dtype: jnp.dtype
+ pndm_order: int
+
+ @property
+ def has_state(self):
+ return True
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[jnp.ndarray] = None,
+ skip_prk_steps: bool = False,
+ set_alpha_to_one: bool = False,
+ steps_offset: int = 0,
+ prediction_type: str = "epsilon",
+ dtype: jnp.dtype = jnp.float32,
+ ):
+ self.dtype = dtype
+
+ # For now we only support F-PNDM, i.e. the runge-kutta method
+ # For more information on the algorithm please take a look at the paper: https://arxiv.org/pdf/2202.09778.pdf
+ # mainly at formula (9), (12), (13) and the Algorithm 2.
+ self.pndm_order = 4
+
+ def create_state(self, common: Optional[CommonSchedulerState] = None) -> PNDMSchedulerState:
+ if common is None:
+ common = CommonSchedulerState.create(self)
+
+ # At every step in ddim, we are looking into the previous alphas_cumprod
+ # For the final step, there is no previous alphas_cumprod because we are already at 0
+ # `set_alpha_to_one` decides whether we set this parameter simply to one or
+ # whether we use the final alpha of the "non-previous" one.
+ final_alpha_cumprod = (
+ jnp.array(1.0, dtype=self.dtype) if self.config.set_alpha_to_one else common.alphas_cumprod[0]
+ )
+
+ # standard deviation of the initial noise distribution
+ init_noise_sigma = jnp.array(1.0, dtype=self.dtype)
+
+ timesteps = jnp.arange(0, self.config.num_train_timesteps).round()[::-1]
+
+ return PNDMSchedulerState.create(
+ common=common,
+ final_alpha_cumprod=final_alpha_cumprod,
+ init_noise_sigma=init_noise_sigma,
+ timesteps=timesteps,
+ )
+
+ def set_timesteps(self, state: PNDMSchedulerState, num_inference_steps: int, shape: Tuple) -> PNDMSchedulerState:
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ state (`PNDMSchedulerState`):
+ the `FlaxPNDMScheduler` state data class instance.
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ shape (`Tuple`):
+ the shape of the samples to be generated.
+ """
+
+ step_ratio = self.config.num_train_timesteps // num_inference_steps
+ # creates integer timesteps by multiplying by ratio
+ # rounding to avoid issues when num_inference_step is power of 3
+ _timesteps = (jnp.arange(0, num_inference_steps) * step_ratio).round() + self.config.steps_offset
+
+ if self.config.skip_prk_steps:
+ # for some models like stable diffusion the prk steps can/should be skipped to
+ # produce better results. When using PNDM with `self.config.skip_prk_steps` the implementation
+ # is based on crowsonkb's PLMS sampler implementation: https://github.com/CompVis/latent-diffusion/pull/51
+
+ prk_timesteps = jnp.array([], dtype=jnp.int32)
+ plms_timesteps = jnp.concatenate([_timesteps[:-1], _timesteps[-2:-1], _timesteps[-1:]])[::-1]
+
+ else:
+ prk_timesteps = _timesteps[-self.pndm_order :].repeat(2) + jnp.tile(
+ jnp.array([0, self.config.num_train_timesteps // num_inference_steps // 2], dtype=jnp.int32),
+ self.pndm_order,
+ )
+
+ prk_timesteps = (prk_timesteps[:-1].repeat(2)[1:-1])[::-1]
+ plms_timesteps = _timesteps[:-3][::-1]
+
+ timesteps = jnp.concatenate([prk_timesteps, plms_timesteps])
+
+ # initial running values
+
+ cur_model_output = jnp.zeros(shape, dtype=self.dtype)
+ counter = jnp.int32(0)
+ cur_sample = jnp.zeros(shape, dtype=self.dtype)
+ ets = jnp.zeros((4,) + shape, dtype=self.dtype)
+
+ return state.replace(
+ timesteps=timesteps,
+ num_inference_steps=num_inference_steps,
+ prk_timesteps=prk_timesteps,
+ plms_timesteps=plms_timesteps,
+ cur_model_output=cur_model_output,
+ counter=counter,
+ cur_sample=cur_sample,
+ ets=ets,
+ )
+
+ def scale_model_input(
+ self, state: PNDMSchedulerState, sample: jnp.ndarray, timestep: Optional[int] = None
+ ) -> jnp.ndarray:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
+ sample (`jnp.ndarray`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `jnp.ndarray`: scaled input sample
+ """
+ return sample
+
+ def step(
+ self,
+ state: PNDMSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ return_dict: bool = True,
+ ) -> Union[FlaxPNDMSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ This function calls `step_prk()` or `step_plms()` depending on the internal variable `counter`.
+
+ Args:
+ state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than FlaxPNDMSchedulerOutput class
+
+ Returns:
+ [`FlaxPNDMSchedulerOutput`] or `tuple`: [`FlaxPNDMSchedulerOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+
+ if state.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ if self.config.skip_prk_steps:
+ prev_sample, state = self.step_plms(state, model_output, timestep, sample)
+ else:
+ prk_prev_sample, prk_state = self.step_prk(state, model_output, timestep, sample)
+ plms_prev_sample, plms_state = self.step_plms(state, model_output, timestep, sample)
+
+ cond = state.counter < len(state.prk_timesteps)
+
+ prev_sample = jax.lax.select(cond, prk_prev_sample, plms_prev_sample)
+
+ state = state.replace(
+ cur_model_output=jax.lax.select(cond, prk_state.cur_model_output, plms_state.cur_model_output),
+ ets=jax.lax.select(cond, prk_state.ets, plms_state.ets),
+ cur_sample=jax.lax.select(cond, prk_state.cur_sample, plms_state.cur_sample),
+ counter=jax.lax.select(cond, prk_state.counter, plms_state.counter),
+ )
+
+ if not return_dict:
+ return (prev_sample, state)
+
+ return FlaxPNDMSchedulerOutput(prev_sample=prev_sample, state=state)
+
+ def step_prk(
+ self,
+ state: PNDMSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ ) -> Union[FlaxPNDMSchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the Runge-Kutta method. RK takes 4 forward passes to approximate the
+ solution to the differential equation.
+
+ Args:
+ state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than FlaxPNDMSchedulerOutput class
+
+ Returns:
+ [`FlaxPNDMSchedulerOutput`] or `tuple`: [`FlaxPNDMSchedulerOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+
+ if state.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ diff_to_prev = jnp.where(
+ state.counter % 2, 0, self.config.num_train_timesteps // state.num_inference_steps // 2
+ )
+ prev_timestep = timestep - diff_to_prev
+ timestep = state.prk_timesteps[state.counter // 4 * 4]
+
+ model_output = jax.lax.select(
+ (state.counter % 4) != 3,
+ model_output, # remainder 0, 1, 2
+ state.cur_model_output + 1 / 6 * model_output, # remainder 3
+ )
+
+ state = state.replace(
+ cur_model_output=jax.lax.select_n(
+ state.counter % 4,
+ state.cur_model_output + 1 / 6 * model_output, # remainder 0
+ state.cur_model_output + 1 / 3 * model_output, # remainder 1
+ state.cur_model_output + 1 / 3 * model_output, # remainder 2
+ jnp.zeros_like(state.cur_model_output), # remainder 3
+ ),
+ ets=jax.lax.select(
+ (state.counter % 4) == 0,
+ state.ets.at[0:3].set(state.ets[1:4]).at[3].set(model_output), # remainder 0
+ state.ets, # remainder 1, 2, 3
+ ),
+ cur_sample=jax.lax.select(
+ (state.counter % 4) == 0,
+ sample, # remainder 0
+ state.cur_sample, # remainder 1, 2, 3
+ ),
+ )
+
+ cur_sample = state.cur_sample
+ prev_sample = self._get_prev_sample(state, cur_sample, timestep, prev_timestep, model_output)
+ state = state.replace(counter=state.counter + 1)
+
+ return (prev_sample, state)
+
+ def step_plms(
+ self,
+ state: PNDMSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ ) -> Union[FlaxPNDMSchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the linear multi-step method. This has one forward pass with multiple
+ times to approximate the solution.
+
+ Args:
+ state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than FlaxPNDMSchedulerOutput class
+
+ Returns:
+ [`FlaxPNDMSchedulerOutput`] or `tuple`: [`FlaxPNDMSchedulerOutput`] if `return_dict` is True, otherwise a
+ `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+
+ if state.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ # NOTE: There is no way to check in the jitted runtime if the prk mode was ran before
+
+ prev_timestep = timestep - self.config.num_train_timesteps // state.num_inference_steps
+ prev_timestep = jnp.where(prev_timestep > 0, prev_timestep, 0)
+
+ # Reference:
+ # if state.counter != 1:
+ # state.ets.append(model_output)
+ # else:
+ # prev_timestep = timestep
+ # timestep = timestep + self.config.num_train_timesteps // state.num_inference_steps
+
+ prev_timestep = jnp.where(state.counter == 1, timestep, prev_timestep)
+ timestep = jnp.where(
+ state.counter == 1, timestep + self.config.num_train_timesteps // state.num_inference_steps, timestep
+ )
+
+ # Reference:
+ # if len(state.ets) == 1 and state.counter == 0:
+ # model_output = model_output
+ # state.cur_sample = sample
+ # elif len(state.ets) == 1 and state.counter == 1:
+ # model_output = (model_output + state.ets[-1]) / 2
+ # sample = state.cur_sample
+ # state.cur_sample = None
+ # elif len(state.ets) == 2:
+ # model_output = (3 * state.ets[-1] - state.ets[-2]) / 2
+ # elif len(state.ets) == 3:
+ # model_output = (23 * state.ets[-1] - 16 * state.ets[-2] + 5 * state.ets[-3]) / 12
+ # else:
+ # model_output = (1 / 24) * (55 * state.ets[-1] - 59 * state.ets[-2] + 37 * state.ets[-3] - 9 * state.ets[-4])
+
+ state = state.replace(
+ ets=jax.lax.select(
+ state.counter != 1,
+ state.ets.at[0:3].set(state.ets[1:4]).at[3].set(model_output), # counter != 1
+ state.ets, # counter 1
+ ),
+ cur_sample=jax.lax.select(
+ state.counter != 1,
+ sample, # counter != 1
+ state.cur_sample, # counter 1
+ ),
+ )
+
+ state = state.replace(
+ cur_model_output=jax.lax.select_n(
+ jnp.clip(state.counter, 0, 4),
+ model_output, # counter 0
+ (model_output + state.ets[-1]) / 2, # counter 1
+ (3 * state.ets[-1] - state.ets[-2]) / 2, # counter 2
+ (23 * state.ets[-1] - 16 * state.ets[-2] + 5 * state.ets[-3]) / 12, # counter 3
+ (1 / 24)
+ * (55 * state.ets[-1] - 59 * state.ets[-2] + 37 * state.ets[-3] - 9 * state.ets[-4]), # counter >= 4
+ ),
+ )
+
+ sample = state.cur_sample
+ model_output = state.cur_model_output
+ prev_sample = self._get_prev_sample(state, sample, timestep, prev_timestep, model_output)
+ state = state.replace(counter=state.counter + 1)
+
+ return (prev_sample, state)
+
+ def _get_prev_sample(self, state: PNDMSchedulerState, sample, timestep, prev_timestep, model_output):
+ # See formula (9) of PNDM paper https://arxiv.org/pdf/2202.09778.pdf
+ # this function computes x_(t−δ) using the formula of (9)
+ # Note that x_t needs to be added to both sides of the equation
+
+ # Notation ( ->
+ # alpha_prod_t -> α_t
+ # alpha_prod_t_prev -> α_(t−δ)
+ # beta_prod_t -> (1 - α_t)
+ # beta_prod_t_prev -> (1 - α_(t−δ))
+ # sample -> x_t
+ # model_output -> e_θ(x_t, t)
+ # prev_sample -> x_(t−δ)
+ alpha_prod_t = state.common.alphas_cumprod[timestep]
+ alpha_prod_t_prev = jnp.where(
+ prev_timestep >= 0, state.common.alphas_cumprod[prev_timestep], state.final_alpha_cumprod
+ )
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ if self.config.prediction_type == "v_prediction":
+ model_output = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
+ elif self.config.prediction_type != "epsilon":
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon` or `v_prediction`"
+ )
+
+ # corresponds to (α_(t−δ) - α_t) divided by
+ # denominator of x_t in formula (9) and plus 1
+ # Note: (α_(t−δ) - α_t) / (sqrt(α_t) * (sqrt(α_(t−δ)) + sqr(α_t))) =
+ # sqrt(α_(t−δ)) / sqrt(α_t))
+ sample_coeff = (alpha_prod_t_prev / alpha_prod_t) ** (0.5)
+
+ # corresponds to denominator of e_θ(x_t, t) in formula (9)
+ model_output_denom_coeff = alpha_prod_t * beta_prod_t_prev ** (0.5) + (
+ alpha_prod_t * beta_prod_t * alpha_prod_t_prev
+ ) ** (0.5)
+
+ # full formula (9)
+ prev_sample = (
+ sample_coeff * sample - (alpha_prod_t_prev - alpha_prod_t) * model_output / model_output_denom_coeff
+ )
+
+ return prev_sample
+
+ def add_noise(
+ self,
+ state: PNDMSchedulerState,
+ original_samples: jnp.ndarray,
+ noise: jnp.ndarray,
+ timesteps: jnp.ndarray,
+ ) -> jnp.ndarray:
+ return add_noise_common(state.common, original_samples, noise, timesteps)
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_repaint.py b/diffusers/src/diffusers/schedulers/scheduling_repaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..96af210f06b10513ec72277315c9c1a84c3a5bef
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_repaint.py
@@ -0,0 +1,329 @@
+# Copyright 2023 ETH Zurich Computer Vision Lab and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, randn_tensor
+from .scheduling_utils import SchedulerMixin
+
+
+@dataclass
+class RePaintSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from
+ the current timestep. `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: torch.FloatTensor
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class RePaintScheduler(SchedulerMixin, ConfigMixin):
+ """
+ RePaint is a schedule for DDPM inpainting inside a given mask.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/pdf/2201.09865.pdf
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ eta (`float`):
+ The weight of noise for added noise in a diffusion step. Its value is between 0.0 and 1.0 -0.0 is DDIM and
+ 1.0 is DDPM scheduler respectively.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ variance_type (`str`):
+ options to clip the variance used when adding noise to the denoised sample. Choose from `fixed_small`,
+ `fixed_small_log`, `fixed_large`, `fixed_large_log`, `learned` or `learned_range`.
+ clip_sample (`bool`, default `True`):
+ option to clip predicted sample between -1 and 1 for numerical stability.
+
+ """
+
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ eta: float = 0.0,
+ trained_betas: Optional[np.ndarray] = None,
+ clip_sample: bool = True,
+ ):
+ if trained_betas is not None:
+ self.betas = torch.from_numpy(trained_betas)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ elif beta_schedule == "sigmoid":
+ # GeoDiff sigmoid schedule
+ betas = torch.linspace(-6, 6, num_train_timesteps)
+ self.betas = torch.sigmoid(betas) * (beta_end - beta_start) + beta_start
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+ self.one = torch.tensor(1.0)
+
+ self.final_alpha_cumprod = torch.tensor(1.0)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy())
+
+ self.eta = eta
+
+ def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def set_timesteps(
+ self,
+ num_inference_steps: int,
+ jump_length: int = 10,
+ jump_n_sample: int = 10,
+ device: Union[str, torch.device] = None,
+ ):
+ num_inference_steps = min(self.config.num_train_timesteps, num_inference_steps)
+ self.num_inference_steps = num_inference_steps
+
+ timesteps = []
+
+ jumps = {}
+ for j in range(0, num_inference_steps - jump_length, jump_length):
+ jumps[j] = jump_n_sample - 1
+
+ t = num_inference_steps
+ while t >= 1:
+ t = t - 1
+ timesteps.append(t)
+
+ if jumps.get(t, 0) > 0:
+ jumps[t] = jumps[t] - 1
+ for _ in range(jump_length):
+ t = t + 1
+ timesteps.append(t)
+
+ timesteps = np.array(timesteps) * (self.config.num_train_timesteps // self.num_inference_steps)
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+
+ def _get_variance(self, t):
+ prev_timestep = t - self.config.num_train_timesteps // self.num_inference_steps
+
+ alpha_prod_t = self.alphas_cumprod[t]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ # For t > 0, compute predicted variance βt (see formula (6) and (7) from
+ # https://arxiv.org/pdf/2006.11239.pdf) and sample from it to get
+ # previous sample x_{t-1} ~ N(pred_prev_sample, variance) == add
+ # variance to pred_sample
+ # Is equivalent to formula (16) in https://arxiv.org/pdf/2010.02502.pdf
+ # without eta.
+ # variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * self.betas[t]
+ variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
+
+ return variance
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ original_image: torch.FloatTensor,
+ mask: torch.FloatTensor,
+ generator: Optional[torch.Generator] = None,
+ return_dict: bool = True,
+ ) -> Union[RePaintSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned
+ diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ original_image (`torch.FloatTensor`):
+ the original image to inpaint on.
+ mask (`torch.FloatTensor`):
+ the mask where 0.0 values define which part of the original image to inpaint (change).
+ generator (`torch.Generator`, *optional*): random number generator.
+ return_dict (`bool`): option for returning tuple rather than
+ DDPMSchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.RePaintSchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.RePaintSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+
+ """
+ t = timestep
+ prev_timestep = timestep - self.config.num_train_timesteps // self.num_inference_steps
+
+ # 1. compute alphas, betas
+ alpha_prod_t = self.alphas_cumprod[t]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
+ beta_prod_t = 1 - alpha_prod_t
+
+ # 2. compute predicted original sample from predicted noise also called
+ # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ pred_original_sample = (sample - beta_prod_t**0.5 * model_output) / alpha_prod_t**0.5
+
+ # 3. Clip "predicted x_0"
+ if self.config.clip_sample:
+ pred_original_sample = torch.clamp(pred_original_sample, -1, 1)
+
+ # We choose to follow RePaint Algorithm 1 to get x_{t-1}, however we
+ # substitute formula (7) in the algorithm coming from DDPM paper
+ # (formula (4) Algorithm 2 - Sampling) with formula (12) from DDIM paper.
+ # DDIM schedule gives the same results as DDPM with eta = 1.0
+ # Noise is being reused in 7. and 8., but no impact on quality has
+ # been observed.
+
+ # 5. Add noise
+ device = model_output.device
+ noise = randn_tensor(model_output.shape, generator=generator, device=device, dtype=model_output.dtype)
+ std_dev_t = self.eta * self._get_variance(timestep) ** 0.5
+
+ variance = 0
+ if t > 0 and self.eta > 0:
+ variance = std_dev_t * noise
+
+ # 6. compute "direction pointing to x_t" of formula (12)
+ # from https://arxiv.org/pdf/2010.02502.pdf
+ pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** 0.5 * model_output
+
+ # 7. compute x_{t-1} of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
+ prev_unknown_part = alpha_prod_t_prev**0.5 * pred_original_sample + pred_sample_direction + variance
+
+ # 8. Algorithm 1 Line 5 https://arxiv.org/pdf/2201.09865.pdf
+ prev_known_part = (alpha_prod_t_prev**0.5) * original_image + ((1 - alpha_prod_t_prev) ** 0.5) * noise
+
+ # 9. Algorithm 1 Line 8 https://arxiv.org/pdf/2201.09865.pdf
+ pred_prev_sample = mask * prev_known_part + (1.0 - mask) * prev_unknown_part
+
+ if not return_dict:
+ return (
+ pred_prev_sample,
+ pred_original_sample,
+ )
+
+ return RePaintSchedulerOutput(prev_sample=pred_prev_sample, pred_original_sample=pred_original_sample)
+
+ def undo_step(self, sample, timestep, generator=None):
+ n = self.config.num_train_timesteps // self.num_inference_steps
+
+ for i in range(n):
+ beta = self.betas[timestep + i]
+ if sample.device.type == "mps":
+ # randn does not work reproducibly on mps
+ noise = randn_tensor(sample.shape, dtype=sample.dtype, generator=generator)
+ noise = noise.to(sample.device)
+ else:
+ noise = randn_tensor(sample.shape, generator=generator, device=sample.device, dtype=sample.dtype)
+
+ # 10. Algorithm 1 Line 10 https://arxiv.org/pdf/2201.09865.pdf
+ sample = (1 - beta) ** 0.5 * sample + beta**0.5 * noise
+
+ return sample
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.IntTensor,
+ ) -> torch.FloatTensor:
+ raise NotImplementedError("Use `DDPMScheduler.add_noise()` to train for sampling with RePaint.")
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_sde_ve.py b/diffusers/src/diffusers/schedulers/scheduling_sde_ve.py
new file mode 100644
index 0000000000000000000000000000000000000000..b92db0f048f091885faafa3b7969aea63f908e80
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_sde_ve.py
@@ -0,0 +1,284 @@
+# Copyright 2023 Google Brain and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/yang-song/score_sde_pytorch
+
+import math
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, randn_tensor
+from .scheduling_utils import SchedulerMixin, SchedulerOutput
+
+
+@dataclass
+class SdeVeOutput(BaseOutput):
+ """
+ Output class for the ScoreSdeVeScheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ prev_sample_mean (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Mean averaged `prev_sample`. Same as `prev_sample`, only mean-averaged over previous timesteps.
+ """
+
+ prev_sample: torch.FloatTensor
+ prev_sample_mean: torch.FloatTensor
+
+
+class ScoreSdeVeScheduler(SchedulerMixin, ConfigMixin):
+ """
+ The variance exploding stochastic differential equation (SDE) scheduler.
+
+ For more information, see the original paper: https://arxiv.org/abs/2011.13456
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ snr (`float`):
+ coefficient weighting the step from the model_output sample (from the network) to the random noise.
+ sigma_min (`float`):
+ initial noise scale for sigma sequence in sampling procedure. The minimum sigma should mirror the
+ distribution of the data.
+ sigma_max (`float`): maximum value used for the range of continuous timesteps passed into the model.
+ sampling_eps (`float`): the end value of sampling, where timesteps decrease progressively from 1 to
+ epsilon.
+ correct_steps (`int`): number of correction steps performed on a produced sample.
+ """
+
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 2000,
+ snr: float = 0.15,
+ sigma_min: float = 0.01,
+ sigma_max: float = 1348.0,
+ sampling_eps: float = 1e-5,
+ correct_steps: int = 1,
+ ):
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = sigma_max
+
+ # setable values
+ self.timesteps = None
+
+ self.set_sigmas(num_train_timesteps, sigma_min, sigma_max, sampling_eps)
+
+ def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def set_timesteps(
+ self, num_inference_steps: int, sampling_eps: float = None, device: Union[str, torch.device] = None
+ ):
+ """
+ Sets the continuous timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ sampling_eps (`float`, optional):
+ final timestep value (overrides value given at Scheduler instantiation).
+
+ """
+ sampling_eps = sampling_eps if sampling_eps is not None else self.config.sampling_eps
+
+ self.timesteps = torch.linspace(1, sampling_eps, num_inference_steps, device=device)
+
+ def set_sigmas(
+ self, num_inference_steps: int, sigma_min: float = None, sigma_max: float = None, sampling_eps: float = None
+ ):
+ """
+ Sets the noise scales used for the diffusion chain. Supporting function to be run before inference.
+
+ The sigmas control the weight of the `drift` and `diffusion` components of sample update.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ sigma_min (`float`, optional):
+ initial noise scale value (overrides value given at Scheduler instantiation).
+ sigma_max (`float`, optional):
+ final noise scale value (overrides value given at Scheduler instantiation).
+ sampling_eps (`float`, optional):
+ final timestep value (overrides value given at Scheduler instantiation).
+
+ """
+ sigma_min = sigma_min if sigma_min is not None else self.config.sigma_min
+ sigma_max = sigma_max if sigma_max is not None else self.config.sigma_max
+ sampling_eps = sampling_eps if sampling_eps is not None else self.config.sampling_eps
+ if self.timesteps is None:
+ self.set_timesteps(num_inference_steps, sampling_eps)
+
+ self.sigmas = sigma_min * (sigma_max / sigma_min) ** (self.timesteps / sampling_eps)
+ self.discrete_sigmas = torch.exp(torch.linspace(math.log(sigma_min), math.log(sigma_max), num_inference_steps))
+ self.sigmas = torch.tensor([sigma_min * (sigma_max / sigma_min) ** t for t in self.timesteps])
+
+ def get_adjacent_sigma(self, timesteps, t):
+ return torch.where(
+ timesteps == 0,
+ torch.zeros_like(t.to(timesteps.device)),
+ self.discrete_sigmas[timesteps - 1].to(timesteps.device),
+ )
+
+ def step_pred(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ generator: Optional[torch.Generator] = None,
+ return_dict: bool = True,
+ ) -> Union[SdeVeOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ generator: random number generator.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_sde_ve.SdeVeOutput`] or `tuple`: [`~schedulers.scheduling_sde_ve.SdeVeOutput`] if
+ `return_dict` is True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.timesteps is None:
+ raise ValueError(
+ "`self.timesteps` is not set, you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ timestep = timestep * torch.ones(
+ sample.shape[0], device=sample.device
+ ) # torch.repeat_interleave(timestep, sample.shape[0])
+ timesteps = (timestep * (len(self.timesteps) - 1)).long()
+
+ # mps requires indices to be in the same device, so we use cpu as is the default with cuda
+ timesteps = timesteps.to(self.discrete_sigmas.device)
+
+ sigma = self.discrete_sigmas[timesteps].to(sample.device)
+ adjacent_sigma = self.get_adjacent_sigma(timesteps, timestep).to(sample.device)
+ drift = torch.zeros_like(sample)
+ diffusion = (sigma**2 - adjacent_sigma**2) ** 0.5
+
+ # equation 6 in the paper: the model_output modeled by the network is grad_x log pt(x)
+ # also equation 47 shows the analog from SDE models to ancestral sampling methods
+ diffusion = diffusion.flatten()
+ while len(diffusion.shape) < len(sample.shape):
+ diffusion = diffusion.unsqueeze(-1)
+ drift = drift - diffusion**2 * model_output
+
+ # equation 6: sample noise for the diffusion term of
+ noise = randn_tensor(
+ sample.shape, layout=sample.layout, generator=generator, device=sample.device, dtype=sample.dtype
+ )
+ prev_sample_mean = sample - drift # subtract because `dt` is a small negative timestep
+ # TODO is the variable diffusion the correct scaling term for the noise?
+ prev_sample = prev_sample_mean + diffusion * noise # add impact of diffusion field g
+
+ if not return_dict:
+ return (prev_sample, prev_sample_mean)
+
+ return SdeVeOutput(prev_sample=prev_sample, prev_sample_mean=prev_sample_mean)
+
+ def step_correct(
+ self,
+ model_output: torch.FloatTensor,
+ sample: torch.FloatTensor,
+ generator: Optional[torch.Generator] = None,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Correct the predicted sample based on the output model_output of the network. This is often run repeatedly
+ after making the prediction for the previous timestep.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ generator: random number generator.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_sde_ve.SdeVeOutput`] or `tuple`: [`~schedulers.scheduling_sde_ve.SdeVeOutput`] if
+ `return_dict` is True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+ if self.timesteps is None:
+ raise ValueError(
+ "`self.timesteps` is not set, you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ # For small batch sizes, the paper "suggest replacing norm(z) with sqrt(d), where d is the dim. of z"
+ # sample noise for correction
+ noise = randn_tensor(sample.shape, layout=sample.layout, generator=generator).to(sample.device)
+
+ # compute step size from the model_output, the noise, and the snr
+ grad_norm = torch.norm(model_output.reshape(model_output.shape[0], -1), dim=-1).mean()
+ noise_norm = torch.norm(noise.reshape(noise.shape[0], -1), dim=-1).mean()
+ step_size = (self.config.snr * noise_norm / grad_norm) ** 2 * 2
+ step_size = step_size * torch.ones(sample.shape[0]).to(sample.device)
+ # self.repeat_scalar(step_size, sample.shape[0])
+
+ # compute corrected sample: model_output term and noise term
+ step_size = step_size.flatten()
+ while len(step_size.shape) < len(sample.shape):
+ step_size = step_size.unsqueeze(-1)
+ prev_sample_mean = sample + step_size * model_output
+ prev_sample = prev_sample_mean + ((step_size * 2) ** 0.5) * noise
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.FloatTensor,
+ ) -> torch.FloatTensor:
+ # Make sure sigmas and timesteps have the same device and dtype as original_samples
+ timesteps = timesteps.to(original_samples.device)
+ sigmas = self.discrete_sigmas.to(original_samples.device)[timesteps]
+ noise = torch.randn_like(original_samples) * sigmas[:, None, None, None]
+ noisy_samples = noise + original_samples
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_sde_ve_flax.py b/diffusers/src/diffusers/schedulers/scheduling_sde_ve_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6240559fc88fa45e4612dc3005ba66e10d3269d
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_sde_ve_flax.py
@@ -0,0 +1,279 @@
+# Copyright 2023 Google Brain and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/yang-song/score_sde_pytorch
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import flax
+import jax.numpy as jnp
+from jax import random
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils_flax import FlaxSchedulerMixin, FlaxSchedulerOutput, broadcast_to_shape_from_left
+
+
+@flax.struct.dataclass
+class ScoreSdeVeSchedulerState:
+ # setable values
+ timesteps: Optional[jnp.ndarray] = None
+ discrete_sigmas: Optional[jnp.ndarray] = None
+ sigmas: Optional[jnp.ndarray] = None
+
+ @classmethod
+ def create(cls):
+ return cls()
+
+
+@dataclass
+class FlaxSdeVeOutput(FlaxSchedulerOutput):
+ """
+ Output class for the ScoreSdeVeScheduler's step function output.
+
+ Args:
+ state (`ScoreSdeVeSchedulerState`):
+ prev_sample (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ prev_sample_mean (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)` for images):
+ Mean averaged `prev_sample`. Same as `prev_sample`, only mean-averaged over previous timesteps.
+ """
+
+ state: ScoreSdeVeSchedulerState
+ prev_sample: jnp.ndarray
+ prev_sample_mean: Optional[jnp.ndarray] = None
+
+
+class FlaxScoreSdeVeScheduler(FlaxSchedulerMixin, ConfigMixin):
+ """
+ The variance exploding stochastic differential equation (SDE) scheduler.
+
+ For more information, see the original paper: https://arxiv.org/abs/2011.13456
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ snr (`float`):
+ coefficient weighting the step from the model_output sample (from the network) to the random noise.
+ sigma_min (`float`):
+ initial noise scale for sigma sequence in sampling procedure. The minimum sigma should mirror the
+ distribution of the data.
+ sigma_max (`float`): maximum value used for the range of continuous timesteps passed into the model.
+ sampling_eps (`float`): the end value of sampling, where timesteps decrease progressively from 1 to
+ epsilon.
+ correct_steps (`int`): number of correction steps performed on a produced sample.
+ """
+
+ @property
+ def has_state(self):
+ return True
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 2000,
+ snr: float = 0.15,
+ sigma_min: float = 0.01,
+ sigma_max: float = 1348.0,
+ sampling_eps: float = 1e-5,
+ correct_steps: int = 1,
+ ):
+ pass
+
+ def create_state(self):
+ state = ScoreSdeVeSchedulerState.create()
+ return self.set_sigmas(
+ state,
+ self.config.num_train_timesteps,
+ self.config.sigma_min,
+ self.config.sigma_max,
+ self.config.sampling_eps,
+ )
+
+ def set_timesteps(
+ self, state: ScoreSdeVeSchedulerState, num_inference_steps: int, shape: Tuple = (), sampling_eps: float = None
+ ) -> ScoreSdeVeSchedulerState:
+ """
+ Sets the continuous timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ state (`ScoreSdeVeSchedulerState`): the `FlaxScoreSdeVeScheduler` state data class instance.
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ sampling_eps (`float`, optional):
+ final timestep value (overrides value given at Scheduler instantiation).
+
+ """
+ sampling_eps = sampling_eps if sampling_eps is not None else self.config.sampling_eps
+
+ timesteps = jnp.linspace(1, sampling_eps, num_inference_steps)
+ return state.replace(timesteps=timesteps)
+
+ def set_sigmas(
+ self,
+ state: ScoreSdeVeSchedulerState,
+ num_inference_steps: int,
+ sigma_min: float = None,
+ sigma_max: float = None,
+ sampling_eps: float = None,
+ ) -> ScoreSdeVeSchedulerState:
+ """
+ Sets the noise scales used for the diffusion chain. Supporting function to be run before inference.
+
+ The sigmas control the weight of the `drift` and `diffusion` components of sample update.
+
+ Args:
+ state (`ScoreSdeVeSchedulerState`): the `FlaxScoreSdeVeScheduler` state data class instance.
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ sigma_min (`float`, optional):
+ initial noise scale value (overrides value given at Scheduler instantiation).
+ sigma_max (`float`, optional):
+ final noise scale value (overrides value given at Scheduler instantiation).
+ sampling_eps (`float`, optional):
+ final timestep value (overrides value given at Scheduler instantiation).
+ """
+ sigma_min = sigma_min if sigma_min is not None else self.config.sigma_min
+ sigma_max = sigma_max if sigma_max is not None else self.config.sigma_max
+ sampling_eps = sampling_eps if sampling_eps is not None else self.config.sampling_eps
+ if state.timesteps is None:
+ state = self.set_timesteps(state, num_inference_steps, sampling_eps)
+
+ discrete_sigmas = jnp.exp(jnp.linspace(jnp.log(sigma_min), jnp.log(sigma_max), num_inference_steps))
+ sigmas = jnp.array([sigma_min * (sigma_max / sigma_min) ** t for t in state.timesteps])
+
+ return state.replace(discrete_sigmas=discrete_sigmas, sigmas=sigmas)
+
+ def get_adjacent_sigma(self, state, timesteps, t):
+ return jnp.where(timesteps == 0, jnp.zeros_like(t), state.discrete_sigmas[timesteps - 1])
+
+ def step_pred(
+ self,
+ state: ScoreSdeVeSchedulerState,
+ model_output: jnp.ndarray,
+ timestep: int,
+ sample: jnp.ndarray,
+ key: random.KeyArray,
+ return_dict: bool = True,
+ ) -> Union[FlaxSdeVeOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ state (`ScoreSdeVeSchedulerState`): the `FlaxScoreSdeVeScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ generator: random number generator.
+ return_dict (`bool`): option for returning tuple rather than FlaxSdeVeOutput class
+
+ Returns:
+ [`FlaxSdeVeOutput`] or `tuple`: [`FlaxSdeVeOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+
+ """
+ if state.timesteps is None:
+ raise ValueError(
+ "`state.timesteps` is not set, you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ timestep = timestep * jnp.ones(
+ sample.shape[0],
+ )
+ timesteps = (timestep * (len(state.timesteps) - 1)).long()
+
+ sigma = state.discrete_sigmas[timesteps]
+ adjacent_sigma = self.get_adjacent_sigma(state, timesteps, timestep)
+ drift = jnp.zeros_like(sample)
+ diffusion = (sigma**2 - adjacent_sigma**2) ** 0.5
+
+ # equation 6 in the paper: the model_output modeled by the network is grad_x log pt(x)
+ # also equation 47 shows the analog from SDE models to ancestral sampling methods
+ diffusion = diffusion.flatten()
+ diffusion = broadcast_to_shape_from_left(diffusion, sample.shape)
+ drift = drift - diffusion**2 * model_output
+
+ # equation 6: sample noise for the diffusion term of
+ key = random.split(key, num=1)
+ noise = random.normal(key=key, shape=sample.shape)
+ prev_sample_mean = sample - drift # subtract because `dt` is a small negative timestep
+ # TODO is the variable diffusion the correct scaling term for the noise?
+ prev_sample = prev_sample_mean + diffusion * noise # add impact of diffusion field g
+
+ if not return_dict:
+ return (prev_sample, prev_sample_mean, state)
+
+ return FlaxSdeVeOutput(prev_sample=prev_sample, prev_sample_mean=prev_sample_mean, state=state)
+
+ def step_correct(
+ self,
+ state: ScoreSdeVeSchedulerState,
+ model_output: jnp.ndarray,
+ sample: jnp.ndarray,
+ key: random.KeyArray,
+ return_dict: bool = True,
+ ) -> Union[FlaxSdeVeOutput, Tuple]:
+ """
+ Correct the predicted sample based on the output model_output of the network. This is often run repeatedly
+ after making the prediction for the previous timestep.
+
+ Args:
+ state (`ScoreSdeVeSchedulerState`): the `FlaxScoreSdeVeScheduler` state data class instance.
+ model_output (`jnp.ndarray`): direct output from learned diffusion model.
+ sample (`jnp.ndarray`):
+ current instance of sample being created by diffusion process.
+ generator: random number generator.
+ return_dict (`bool`): option for returning tuple rather than FlaxSdeVeOutput class
+
+ Returns:
+ [`FlaxSdeVeOutput`] or `tuple`: [`FlaxSdeVeOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+
+ """
+ if state.timesteps is None:
+ raise ValueError(
+ "`state.timesteps` is not set, you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ # For small batch sizes, the paper "suggest replacing norm(z) with sqrt(d), where d is the dim. of z"
+ # sample noise for correction
+ key = random.split(key, num=1)
+ noise = random.normal(key=key, shape=sample.shape)
+
+ # compute step size from the model_output, the noise, and the snr
+ grad_norm = jnp.linalg.norm(model_output)
+ noise_norm = jnp.linalg.norm(noise)
+ step_size = (self.config.snr * noise_norm / grad_norm) ** 2 * 2
+ step_size = step_size * jnp.ones(sample.shape[0])
+
+ # compute corrected sample: model_output term and noise term
+ step_size = step_size.flatten()
+ step_size = broadcast_to_shape_from_left(step_size, sample.shape)
+ prev_sample_mean = sample + step_size * model_output
+ prev_sample = prev_sample_mean + ((step_size * 2) ** 0.5) * noise
+
+ if not return_dict:
+ return (prev_sample, state)
+
+ return FlaxSdeVeOutput(prev_sample=prev_sample, state=state)
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_sde_vp.py b/diffusers/src/diffusers/schedulers/scheduling_sde_vp.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e2ead90edb57cd1eb1d270695e222d404064180
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_sde_vp.py
@@ -0,0 +1,90 @@
+# Copyright 2023 Google Brain and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: This file is strongly influenced by https://github.com/yang-song/score_sde_pytorch
+
+import math
+from typing import Union
+
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import randn_tensor
+from .scheduling_utils import SchedulerMixin
+
+
+class ScoreSdeVpScheduler(SchedulerMixin, ConfigMixin):
+ """
+ The variance preserving stochastic differential equation (SDE) scheduler.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more information, see the original paper: https://arxiv.org/abs/2011.13456
+
+ UNDER CONSTRUCTION
+
+ """
+
+ order = 1
+
+ @register_to_config
+ def __init__(self, num_train_timesteps=2000, beta_min=0.1, beta_max=20, sampling_eps=1e-3):
+ self.sigmas = None
+ self.discrete_sigmas = None
+ self.timesteps = None
+
+ def set_timesteps(self, num_inference_steps, device: Union[str, torch.device] = None):
+ self.timesteps = torch.linspace(1, self.config.sampling_eps, num_inference_steps, device=device)
+
+ def step_pred(self, score, x, t, generator=None):
+ if self.timesteps is None:
+ raise ValueError(
+ "`self.timesteps` is not set, you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ # TODO(Patrick) better comments + non-PyTorch
+ # postprocess model score
+ log_mean_coeff = (
+ -0.25 * t**2 * (self.config.beta_max - self.config.beta_min) - 0.5 * t * self.config.beta_min
+ )
+ std = torch.sqrt(1.0 - torch.exp(2.0 * log_mean_coeff))
+ std = std.flatten()
+ while len(std.shape) < len(score.shape):
+ std = std.unsqueeze(-1)
+ score = -score / std
+
+ # compute
+ dt = -1.0 / len(self.timesteps)
+
+ beta_t = self.config.beta_min + t * (self.config.beta_max - self.config.beta_min)
+ beta_t = beta_t.flatten()
+ while len(beta_t.shape) < len(x.shape):
+ beta_t = beta_t.unsqueeze(-1)
+ drift = -0.5 * beta_t * x
+
+ diffusion = torch.sqrt(beta_t)
+ drift = drift - diffusion**2 * score
+ x_mean = x + drift * dt
+
+ # add noise
+ noise = randn_tensor(x.shape, layout=x.layout, generator=generator, device=x.device, dtype=x.dtype)
+ x = x_mean + diffusion * math.sqrt(-dt) * noise
+
+ return x, x_mean
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_unclip.py b/diffusers/src/diffusers/schedulers/scheduling_unclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..6403ee3f15187cf6af97dc03ceb3ad3d0b538597
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_unclip.py
@@ -0,0 +1,306 @@
+# Copyright 2023 Kakao Brain and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput, randn_tensor
+from .scheduling_utils import SchedulerMixin
+
+
+@dataclass
+# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->UnCLIP
+class UnCLIPSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ """
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+
+
+# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class UnCLIPScheduler(SchedulerMixin, ConfigMixin):
+ """
+ This is a modified DDPM Scheduler specifically for the karlo unCLIP model.
+
+ This scheduler has some minor variations in how it calculates the learned range variance and dynamically
+ re-calculates betas based off the timesteps it is skipping.
+
+ The scheduler also uses a slightly different step ratio when computing timesteps to use for inference.
+
+ See [`~DDPMScheduler`] for more information on DDPM scheduling
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ variance_type (`str`):
+ options to clip the variance used when adding noise to the denoised sample. Choose from `fixed_small_log`
+ or `learned_range`.
+ clip_sample (`bool`, default `True`):
+ option to clip predicted sample between `-clip_sample_range` and `clip_sample_range` for numerical
+ stability.
+ clip_sample_range (`float`, default `1.0`):
+ The range to clip the sample between. See `clip_sample`.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion process)
+ or `sample` (directly predicting the noisy sample`)
+ """
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ variance_type: str = "fixed_small_log",
+ clip_sample: bool = True,
+ clip_sample_range: Optional[float] = 1.0,
+ prediction_type: str = "epsilon",
+ beta_schedule: str = "squaredcos_cap_v2",
+ ):
+ if beta_schedule != "squaredcos_cap_v2":
+ raise ValueError("UnCLIPScheduler only supports `beta_schedule`: 'squaredcos_cap_v2'")
+
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+ self.one = torch.tensor(1.0)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy())
+
+ self.variance_type = variance_type
+
+ def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+ timestep (`int`, optional): current timestep
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Note that this scheduler uses a slightly different step ratio than the other diffusers schedulers. The
+ different step ratio is to mimic the original karlo implementation and does not affect the quality or accuracy
+ of the results.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ """
+ self.num_inference_steps = num_inference_steps
+ step_ratio = (self.config.num_train_timesteps - 1) / (self.num_inference_steps - 1)
+ timesteps = (np.arange(0, num_inference_steps) * step_ratio).round()[::-1].copy().astype(np.int64)
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+
+ def _get_variance(self, t, prev_timestep=None, predicted_variance=None, variance_type=None):
+ if prev_timestep is None:
+ prev_timestep = t - 1
+
+ alpha_prod_t = self.alphas_cumprod[t]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.one
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ if prev_timestep == t - 1:
+ beta = self.betas[t]
+ else:
+ beta = 1 - alpha_prod_t / alpha_prod_t_prev
+
+ # For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
+ # and sample from it to get previous sample
+ # x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
+ variance = beta_prod_t_prev / beta_prod_t * beta
+
+ if variance_type is None:
+ variance_type = self.config.variance_type
+
+ # hacks - were probably added for training stability
+ if variance_type == "fixed_small_log":
+ variance = torch.log(torch.clamp(variance, min=1e-20))
+ variance = torch.exp(0.5 * variance)
+ elif variance_type == "learned_range":
+ # NOTE difference with DDPM scheduler
+ min_log = variance.log()
+ max_log = beta.log()
+
+ frac = (predicted_variance + 1) / 2
+ variance = frac * max_log + (1 - frac) * min_log
+
+ return variance
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ prev_timestep: Optional[int] = None,
+ generator=None,
+ return_dict: bool = True,
+ ) -> Union[UnCLIPSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
+ process from the learned model outputs (most often the predicted noise).
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ prev_timestep (`int`, *optional*): The previous timestep to predict the previous sample at.
+ Used to dynamically compute beta. If not given, `t-1` is used and the pre-computed beta is used.
+ generator: random number generator.
+ return_dict (`bool`): option for returning tuple rather than UnCLIPSchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.UnCLIPSchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.UnCLIPSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. When
+ returning a tuple, the first element is the sample tensor.
+
+ """
+ t = timestep
+
+ if model_output.shape[1] == sample.shape[1] * 2 and self.variance_type == "learned_range":
+ model_output, predicted_variance = torch.split(model_output, sample.shape[1], dim=1)
+ else:
+ predicted_variance = None
+
+ # 1. compute alphas, betas
+ if prev_timestep is None:
+ prev_timestep = t - 1
+
+ alpha_prod_t = self.alphas_cumprod[t]
+ alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.one
+ beta_prod_t = 1 - alpha_prod_t
+ beta_prod_t_prev = 1 - alpha_prod_t_prev
+
+ if prev_timestep == t - 1:
+ beta = self.betas[t]
+ alpha = self.alphas[t]
+ else:
+ beta = 1 - alpha_prod_t / alpha_prod_t_prev
+ alpha = 1 - beta
+
+ # 2. compute predicted original sample from predicted noise also called
+ # "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
+ if self.config.prediction_type == "epsilon":
+ pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
+ elif self.config.prediction_type == "sample":
+ pred_original_sample = model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon` or `sample`"
+ " for the UnCLIPScheduler."
+ )
+
+ # 3. Clip "predicted x_0"
+ if self.config.clip_sample:
+ pred_original_sample = torch.clamp(
+ pred_original_sample, -self.config.clip_sample_range, self.config.clip_sample_range
+ )
+
+ # 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
+ # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * beta) / beta_prod_t
+ current_sample_coeff = alpha ** (0.5) * beta_prod_t_prev / beta_prod_t
+
+ # 5. Compute predicted previous sample µ_t
+ # See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
+ pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
+
+ # 6. Add noise
+ variance = 0
+ if t > 0:
+ variance_noise = randn_tensor(
+ model_output.shape, dtype=model_output.dtype, generator=generator, device=model_output.device
+ )
+
+ variance = self._get_variance(
+ t,
+ predicted_variance=predicted_variance,
+ prev_timestep=prev_timestep,
+ )
+
+ if self.variance_type == "fixed_small_log":
+ variance = variance
+ elif self.variance_type == "learned_range":
+ variance = (0.5 * variance).exp()
+ else:
+ raise ValueError(
+ f"variance_type given as {self.variance_type} must be one of `fixed_small_log` or `learned_range`"
+ " for the UnCLIPScheduler."
+ )
+
+ variance = variance * variance_noise
+
+ pred_prev_sample = pred_prev_sample + variance
+
+ if not return_dict:
+ return (pred_prev_sample,)
+
+ return UnCLIPSchedulerOutput(prev_sample=pred_prev_sample, pred_original_sample=pred_original_sample)
diff --git a/diffusers/src/diffusers/schedulers/scheduling_unipc_multistep.py b/diffusers/src/diffusers/schedulers/scheduling_unipc_multistep.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4f38d0f5dadb2d67a1ce9ee329bf1494599396d
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_unipc_multistep.py
@@ -0,0 +1,611 @@
+# Copyright 2023 TSAIL Team and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# DISCLAIMER: check https://arxiv.org/abs/2302.04867 and https://github.com/wl-zhao/UniPC for more info
+# The codebase is modified based on https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_dpmsolver_multistep.py
+
+import math
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin, SchedulerOutput
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return torch.tensor(betas, dtype=torch.float32)
+
+
+class UniPCMultistepScheduler(SchedulerMixin, ConfigMixin):
+ """
+ UniPC is a training-free framework designed for the fast sampling of diffusion models, which consists of a
+ corrector (UniC) and a predictor (UniP) that share a unified analytical form and support arbitrary orders. UniPC is
+ by desinged model-agnostic, supporting pixel-space/latent-space DPMs on unconditional/conditional sampling. It can
+ also be applied to both noise prediction model and data prediction model. The corrector UniC can be also applied
+ after any off-the-shelf solvers to increase the order of accuracy.
+
+ For more details, see the original paper: https://arxiv.org/abs/2302.04867
+
+ Currently, we support the multistep UniPC for both noise prediction models and data prediction models. We recommend
+ to use `solver_order=2` for guided sampling, and `solver_order=3` for unconditional sampling.
+
+ We also support the "dynamic thresholding" method in Imagen (https://arxiv.org/abs/2205.11487). For pixel-space
+ diffusion models, you can set both `predict_x0=True` and `thresholding=True` to use the dynamic thresholding. Note
+ that the thresholding method is unsuitable for latent-space diffusion models (such as stable-diffusion).
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ Args:
+ num_train_timesteps (`int`): number of diffusion steps used to train the model.
+ beta_start (`float`): the starting `beta` value of inference.
+ beta_end (`float`): the final `beta` value.
+ beta_schedule (`str`):
+ the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
+ `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
+ trained_betas (`np.ndarray`, optional):
+ option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
+ solver_order (`int`, default `2`):
+ the order of UniPC, also the p in UniPC-p; can be any positive integer. Note that the effective order of
+ accuracy is `solver_order + 1` due to the UniC. We recommend to use `solver_order=2` for guided sampling,
+ and `solver_order=3` for unconditional sampling.
+ prediction_type (`str`, default `epsilon`, optional):
+ prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion
+ process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4
+ https://imagen.research.google/video/paper.pdf)
+ thresholding (`bool`, default `False`):
+ whether to use the "dynamic thresholding" method (introduced by Imagen, https://arxiv.org/abs/2205.11487).
+ For pixel-space diffusion models, you can set both `predict_x0=True` and `thresholding=True` to use the
+ dynamic thresholding. Note that the thresholding method is unsuitable for latent-space diffusion models
+ (such as stable-diffusion).
+ dynamic_thresholding_ratio (`float`, default `0.995`):
+ the ratio for the dynamic thresholding method. Default is `0.995`, the same as Imagen
+ (https://arxiv.org/abs/2205.11487).
+ sample_max_value (`float`, default `1.0`):
+ the threshold value for dynamic thresholding. Valid only when `thresholding=True` and `predict_x0=True`.
+ predict_x0 (`bool`, default `True`):
+ whether to use the updating algrithm on the predicted x0. See https://arxiv.org/abs/2211.01095 for details
+ solver_type (`str`, default `bh2`):
+ the solver type of UniPC. We recommend use `bh1` for unconditional sampling when steps < 10, and use `bh2`
+ otherwise.
+ lower_order_final (`bool`, default `True`):
+ whether to use lower-order solvers in the final steps. Only valid for < 15 inference steps. We empirically
+ find this trick can stabilize the sampling of DPM-Solver for steps < 15, especially for steps <= 10.
+ disable_corrector (`list`, default `[]`):
+ decide which step to disable the corrector. For large guidance scale, the misalignment between the
+ `epsilon_theta(x_t, c)`and `epsilon_theta(x_t^c, c)` might influence the convergence. This can be mitigated
+ by disable the corrector at the first few steps (e.g., disable_corrector=[0])
+ solver_p (`SchedulerMixin`, default `None`):
+ can be any other scheduler. If specified, the algorithm will become solver_p + UniC.
+ """
+
+ _compatibles = [e.name for e in KarrasDiffusionSchedulers]
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_train_timesteps: int = 1000,
+ beta_start: float = 0.0001,
+ beta_end: float = 0.02,
+ beta_schedule: str = "linear",
+ trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
+ solver_order: int = 2,
+ prediction_type: str = "epsilon",
+ thresholding: bool = False,
+ dynamic_thresholding_ratio: float = 0.995,
+ sample_max_value: float = 1.0,
+ predict_x0: bool = True,
+ solver_type: str = "bh2",
+ lower_order_final: bool = True,
+ disable_corrector: List[int] = [],
+ solver_p: SchedulerMixin = None,
+ ):
+ if trained_betas is not None:
+ self.betas = torch.tensor(trained_betas, dtype=torch.float32)
+ elif beta_schedule == "linear":
+ self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
+ elif beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ self.betas = (
+ torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
+ )
+ elif beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ self.betas = betas_for_alpha_bar(num_train_timesteps)
+ else:
+ raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
+
+ self.alphas = 1.0 - self.betas
+ self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
+ # Currently we only support VP-type noise schedule
+ self.alpha_t = torch.sqrt(self.alphas_cumprod)
+ self.sigma_t = torch.sqrt(1 - self.alphas_cumprod)
+ self.lambda_t = torch.log(self.alpha_t) - torch.log(self.sigma_t)
+
+ # standard deviation of the initial noise distribution
+ self.init_noise_sigma = 1.0
+
+ if solver_type not in ["bh1", "bh2"]:
+ if solver_type in ["midpoint", "heun", "logrho"]:
+ self.register_to_config(solver_type="bh1")
+ else:
+ raise NotImplementedError(f"{solver_type} does is not implemented for {self.__class__}")
+
+ self.predict_x0 = predict_x0
+ # setable values
+ self.num_inference_steps = None
+ timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=np.float32)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps)
+ self.model_outputs = [None] * solver_order
+ self.timestep_list = [None] * solver_order
+ self.lower_order_nums = 0
+ self.disable_corrector = disable_corrector
+ self.solver_p = solver_p
+ self.last_sample = None
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+ device (`str` or `torch.device`, optional):
+ the device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
+ """
+ self.num_inference_steps = num_inference_steps
+ timesteps = (
+ np.linspace(0, self.num_train_timesteps - 1, num_inference_steps + 1)
+ .round()[::-1][:-1]
+ .copy()
+ .astype(np.int64)
+ )
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+ self.model_outputs = [
+ None,
+ ] * self.config.solver_order
+ self.lower_order_nums = 0
+ self.last_sample = None
+ if self.solver_p:
+ self.solver_p.set_timesteps(num_inference_steps, device=device)
+
+ # Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
+ def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ dynamic_max_val = (
+ sample.flatten(1)
+ .abs()
+ .quantile(self.config.dynamic_thresholding_ratio, dim=1)
+ .clamp_min(self.config.sample_max_value)
+ .view(-1, *([1] * (sample.ndim - 1)))
+ )
+ return sample.clamp(-dynamic_max_val, dynamic_max_val) / dynamic_max_val
+
+ def convert_model_output(
+ self, model_output: torch.FloatTensor, timestep: int, sample: torch.FloatTensor
+ ) -> torch.FloatTensor:
+ r"""
+ Convert the model output to the corresponding type that the algorithm PC needs.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+
+ Returns:
+ `torch.FloatTensor`: the converted model output.
+ """
+ if self.predict_x0:
+ if self.config.prediction_type == "epsilon":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ x0_pred = (sample - sigma_t * model_output) / alpha_t
+ elif self.config.prediction_type == "sample":
+ x0_pred = model_output
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ x0_pred = alpha_t * sample - sigma_t * model_output
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction` for the UniPCMultistepScheduler."
+ )
+
+ if self.config.thresholding:
+ # Dynamic thresholding in https://arxiv.org/abs/2205.11487
+ orig_dtype = x0_pred.dtype
+ if orig_dtype not in [torch.float, torch.double]:
+ x0_pred = x0_pred.float()
+ x0_pred = self._threshold_sample(x0_pred).type(orig_dtype)
+ return x0_pred
+ else:
+ if self.config.prediction_type == "epsilon":
+ return model_output
+ elif self.config.prediction_type == "sample":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ epsilon = (sample - alpha_t * model_output) / sigma_t
+ return epsilon
+ elif self.config.prediction_type == "v_prediction":
+ alpha_t, sigma_t = self.alpha_t[timestep], self.sigma_t[timestep]
+ epsilon = alpha_t * model_output + sigma_t * sample
+ return epsilon
+ else:
+ raise ValueError(
+ f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
+ " `v_prediction` for the UniPCMultistepScheduler."
+ )
+
+ def multistep_uni_p_bh_update(
+ self,
+ model_output: torch.FloatTensor,
+ prev_timestep: int,
+ sample: torch.FloatTensor,
+ order: int,
+ ) -> torch.FloatTensor:
+ """
+ One step for the UniP (B(h) version). Alternatively, `self.solver_p` is used if is specified.
+
+ Args:
+ model_output (`torch.FloatTensor`):
+ direct outputs from learned diffusion model at the current timestep.
+ prev_timestep (`int`): previous discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ order (`int`): the order of UniP at this step, also the p in UniPC-p.
+
+ Returns:
+ `torch.FloatTensor`: the sample tensor at the previous timestep.
+ """
+ timestep_list = self.timestep_list
+ model_output_list = self.model_outputs
+
+ s0, t = self.timestep_list[-1], prev_timestep
+ m0 = model_output_list[-1]
+ x = sample
+
+ if self.solver_p:
+ x_t = self.solver_p.step(model_output, s0, x).prev_sample
+ return x_t
+
+ lambda_t, lambda_s0 = self.lambda_t[t], self.lambda_t[s0]
+ alpha_t, alpha_s0 = self.alpha_t[t], self.alpha_t[s0]
+ sigma_t, sigma_s0 = self.sigma_t[t], self.sigma_t[s0]
+
+ h = lambda_t - lambda_s0
+ device = sample.device
+
+ rks = []
+ D1s = []
+ for i in range(1, order):
+ si = timestep_list[-(i + 1)]
+ mi = model_output_list[-(i + 1)]
+ lambda_si = self.lambda_t[si]
+ rk = (lambda_si - lambda_s0) / h
+ rks.append(rk)
+ D1s.append((mi - m0) / rk)
+
+ rks.append(1.0)
+ rks = torch.tensor(rks, device=device)
+
+ R = []
+ b = []
+
+ hh = -h if self.predict_x0 else h
+ h_phi_1 = torch.expm1(hh) # h\phi_1(h) = e^h - 1
+ h_phi_k = h_phi_1 / hh - 1
+
+ factorial_i = 1
+
+ if self.config.solver_type == "bh1":
+ B_h = hh
+ elif self.config.solver_type == "bh2":
+ B_h = torch.expm1(hh)
+ else:
+ raise NotImplementedError()
+
+ for i in range(1, order + 1):
+ R.append(torch.pow(rks, i - 1))
+ b.append(h_phi_k * factorial_i / B_h)
+ factorial_i *= i + 1
+ h_phi_k = h_phi_k / hh - 1 / factorial_i
+
+ R = torch.stack(R)
+ b = torch.tensor(b, device=device)
+
+ if len(D1s) > 0:
+ D1s = torch.stack(D1s, dim=1) # (B, K)
+ # for order 2, we use a simplified version
+ if order == 2:
+ rhos_p = torch.tensor([0.5], dtype=x.dtype, device=device)
+ else:
+ rhos_p = torch.linalg.solve(R[:-1, :-1], b[:-1])
+ else:
+ D1s = None
+
+ if self.predict_x0:
+ x_t_ = sigma_t / sigma_s0 * x - alpha_t * h_phi_1 * m0
+ if D1s is not None:
+ pred_res = torch.einsum("k,bkchw->bchw", rhos_p, D1s)
+ else:
+ pred_res = 0
+ x_t = x_t_ - alpha_t * B_h * pred_res
+ else:
+ x_t_ = alpha_t / alpha_s0 * x - sigma_t * h_phi_1 * m0
+ if D1s is not None:
+ pred_res = torch.einsum("k,bkchw->bchw", rhos_p, D1s)
+ else:
+ pred_res = 0
+ x_t = x_t_ - sigma_t * B_h * pred_res
+
+ x_t = x_t.to(x.dtype)
+ return x_t
+
+ def multistep_uni_c_bh_update(
+ self,
+ this_model_output: torch.FloatTensor,
+ this_timestep: int,
+ last_sample: torch.FloatTensor,
+ this_sample: torch.FloatTensor,
+ order: int,
+ ) -> torch.FloatTensor:
+ """
+ One step for the UniC (B(h) version).
+
+ Args:
+ this_model_output (`torch.FloatTensor`): the model outputs at `x_t`
+ this_timestep (`int`): the current timestep `t`
+ last_sample (`torch.FloatTensor`): the generated sample before the last predictor: `x_{t-1}`
+ this_sample (`torch.FloatTensor`): the generated sample after the last predictor: `x_{t}`
+ order (`int`): the `p` of UniC-p at this step. Note that the effective order of accuracy
+ should be order + 1
+
+ Returns:
+ `torch.FloatTensor`: the corrected sample tensor at the current timestep.
+ """
+ timestep_list = self.timestep_list
+ model_output_list = self.model_outputs
+
+ s0, t = timestep_list[-1], this_timestep
+ m0 = model_output_list[-1]
+ x = last_sample
+ x_t = this_sample
+ model_t = this_model_output
+
+ lambda_t, lambda_s0 = self.lambda_t[t], self.lambda_t[s0]
+ alpha_t, alpha_s0 = self.alpha_t[t], self.alpha_t[s0]
+ sigma_t, sigma_s0 = self.sigma_t[t], self.sigma_t[s0]
+
+ h = lambda_t - lambda_s0
+ device = this_sample.device
+
+ rks = []
+ D1s = []
+ for i in range(1, order):
+ si = timestep_list[-(i + 1)]
+ mi = model_output_list[-(i + 1)]
+ lambda_si = self.lambda_t[si]
+ rk = (lambda_si - lambda_s0) / h
+ rks.append(rk)
+ D1s.append((mi - m0) / rk)
+
+ rks.append(1.0)
+ rks = torch.tensor(rks, device=device)
+
+ R = []
+ b = []
+
+ hh = -h if self.predict_x0 else h
+ h_phi_1 = torch.expm1(hh) # h\phi_1(h) = e^h - 1
+ h_phi_k = h_phi_1 / hh - 1
+
+ factorial_i = 1
+
+ if self.config.solver_type == "bh1":
+ B_h = hh
+ elif self.config.solver_type == "bh2":
+ B_h = torch.expm1(hh)
+ else:
+ raise NotImplementedError()
+
+ for i in range(1, order + 1):
+ R.append(torch.pow(rks, i - 1))
+ b.append(h_phi_k * factorial_i / B_h)
+ factorial_i *= i + 1
+ h_phi_k = h_phi_k / hh - 1 / factorial_i
+
+ R = torch.stack(R)
+ b = torch.tensor(b, device=device)
+
+ if len(D1s) > 0:
+ D1s = torch.stack(D1s, dim=1)
+ else:
+ D1s = None
+
+ # for order 1, we use a simplified version
+ if order == 1:
+ rhos_c = torch.tensor([0.5], dtype=x.dtype, device=device)
+ else:
+ rhos_c = torch.linalg.solve(R, b)
+
+ if self.predict_x0:
+ x_t_ = sigma_t / sigma_s0 * x - alpha_t * h_phi_1 * m0
+ if D1s is not None:
+ corr_res = torch.einsum("k,bkchw->bchw", rhos_c[:-1], D1s)
+ else:
+ corr_res = 0
+ D1_t = model_t - m0
+ x_t = x_t_ - alpha_t * B_h * (corr_res + rhos_c[-1] * D1_t)
+ else:
+ x_t_ = alpha_t / alpha_s0 * x - sigma_t * h_phi_1 * m0
+ if D1s is not None:
+ corr_res = torch.einsum("k,bkchw->bchw", rhos_c[:-1], D1s)
+ else:
+ corr_res = 0
+ D1_t = model_t - m0
+ x_t = x_t_ - sigma_t * B_h * (corr_res + rhos_c[-1] * D1_t)
+ x_t = x_t.to(x.dtype)
+ return x_t
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: int,
+ sample: torch.FloatTensor,
+ return_dict: bool = True,
+ ) -> Union[SchedulerOutput, Tuple]:
+ """
+ Step function propagating the sample with the multistep UniPC.
+
+ Args:
+ model_output (`torch.FloatTensor`): direct output from learned diffusion model.
+ timestep (`int`): current discrete timestep in the diffusion chain.
+ sample (`torch.FloatTensor`):
+ current instance of sample being created by diffusion process.
+ return_dict (`bool`): option for returning tuple rather than SchedulerOutput class
+
+ Returns:
+ [`~scheduling_utils.SchedulerOutput`] or `tuple`: [`~scheduling_utils.SchedulerOutput`] if `return_dict` is
+ True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
+
+ """
+
+ if self.num_inference_steps is None:
+ raise ValueError(
+ "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
+ )
+
+ if isinstance(timestep, torch.Tensor):
+ timestep = timestep.to(self.timesteps.device)
+ step_index = (self.timesteps == timestep).nonzero()
+ if len(step_index) == 0:
+ step_index = len(self.timesteps) - 1
+ else:
+ step_index = step_index.item()
+
+ use_corrector = (
+ step_index > 0 and step_index - 1 not in self.disable_corrector and self.last_sample is not None
+ )
+
+ model_output_convert = self.convert_model_output(model_output, timestep, sample)
+ if use_corrector:
+ sample = self.multistep_uni_c_bh_update(
+ this_model_output=model_output_convert,
+ this_timestep=timestep,
+ last_sample=self.last_sample,
+ this_sample=sample,
+ order=self.this_order,
+ )
+
+ # now prepare to run the predictor
+ prev_timestep = 0 if step_index == len(self.timesteps) - 1 else self.timesteps[step_index + 1]
+
+ for i in range(self.config.solver_order - 1):
+ self.model_outputs[i] = self.model_outputs[i + 1]
+ self.timestep_list[i] = self.timestep_list[i + 1]
+
+ self.model_outputs[-1] = model_output_convert
+ self.timestep_list[-1] = timestep
+
+ if self.config.lower_order_final:
+ this_order = min(self.config.solver_order, len(self.timesteps) - step_index)
+ else:
+ this_order = self.config.solver_order
+
+ self.this_order = min(this_order, self.lower_order_nums + 1) # warmup for multistep
+ assert self.this_order > 0
+
+ self.last_sample = sample
+ prev_sample = self.multistep_uni_p_bh_update(
+ model_output=model_output, # pass the original non-converted model output, in case solver-p is used
+ prev_timestep=prev_timestep,
+ sample=sample,
+ order=self.this_order,
+ )
+
+ if self.lower_order_nums < self.config.solver_order:
+ self.lower_order_nums += 1
+
+ if not return_dict:
+ return (prev_sample,)
+
+ return SchedulerOutput(prev_sample=prev_sample)
+
+ def scale_model_input(self, sample: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
+ """
+ Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
+ current timestep.
+
+ Args:
+ sample (`torch.FloatTensor`): input sample
+
+ Returns:
+ `torch.FloatTensor`: scaled input sample
+ """
+ return sample
+
+ def add_noise(
+ self,
+ original_samples: torch.FloatTensor,
+ noise: torch.FloatTensor,
+ timesteps: torch.IntTensor,
+ ) -> torch.FloatTensor:
+ # Make sure alphas_cumprod and timestep have same device and dtype as original_samples
+ self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
+ timesteps = timesteps.to(original_samples.device)
+
+ sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
+
+ sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
+
+ noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
+ return noisy_samples
+
+ def __len__(self):
+ return self.config.num_train_timesteps
diff --git a/diffusers/src/diffusers/schedulers/scheduling_utils.py b/diffusers/src/diffusers/schedulers/scheduling_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4121f75d850abc8fdbb7160cdbb3b5ba53e40d3
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_utils.py
@@ -0,0 +1,176 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import importlib
+import os
+from dataclasses import dataclass
+from enum import Enum
+from typing import Any, Dict, Optional, Union
+
+import torch
+
+from ..utils import BaseOutput
+
+
+SCHEDULER_CONFIG_NAME = "scheduler_config.json"
+
+
+# NOTE: We make this type an enum because it simplifies usage in docs and prevents
+# circular imports when used for `_compatibles` within the schedulers module.
+# When it's used as a type in pipelines, it really is a Union because the actual
+# scheduler instance is passed in.
+class KarrasDiffusionSchedulers(Enum):
+ DDIMScheduler = 1
+ DDPMScheduler = 2
+ PNDMScheduler = 3
+ LMSDiscreteScheduler = 4
+ EulerDiscreteScheduler = 5
+ HeunDiscreteScheduler = 6
+ EulerAncestralDiscreteScheduler = 7
+ DPMSolverMultistepScheduler = 8
+ DPMSolverSinglestepScheduler = 9
+ KDPM2DiscreteScheduler = 10
+ KDPM2AncestralDiscreteScheduler = 11
+ DEISMultistepScheduler = 12
+ UniPCMultistepScheduler = 13
+
+
+@dataclass
+class SchedulerOutput(BaseOutput):
+ """
+ Base class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ """
+
+ prev_sample: torch.FloatTensor
+
+
+class SchedulerMixin:
+ """
+ Mixin containing common functions for the schedulers.
+
+ Class attributes:
+ - **_compatibles** (`List[str]`) -- A list of classes that are compatible with the parent class, so that
+ `from_config` can be used from a class different than the one used to save the config (should be overridden
+ by parent class).
+ """
+
+ config_name = SCHEDULER_CONFIG_NAME
+ _compatibles = []
+ has_compatibles = True
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path: Dict[str, Any] = None,
+ subfolder: Optional[str] = None,
+ return_unused_kwargs=False,
+ **kwargs,
+ ):
+ r"""
+ Instantiate a Scheduler class from a pre-defined JSON configuration file inside a directory or Hub repo.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
+ Can be either:
+
+ - A string, the *model id* of a model repo on huggingface.co. Valid model ids should have an
+ organization name, like `google/ddpm-celebahq-256`.
+ - A path to a *directory* containing the schedluer configurations saved using
+ [`~SchedulerMixin.save_pretrained`], e.g., `./my_model_directory/`.
+ subfolder (`str`, *optional*):
+ In case the relevant files are located inside a subfolder of the model repo (either remote in
+ huggingface.co or downloaded locally), you can specify the folder name here.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ Whether kwargs that are not consumed by the Python class should be returned or not.
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `transformers-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models).
+
+
+
+
+
+ Activate the special ["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to
+ use this method in a firewalled environment.
+
+
+
+ """
+ config, kwargs, commit_hash = cls.load_config(
+ pretrained_model_name_or_path=pretrained_model_name_or_path,
+ subfolder=subfolder,
+ return_unused_kwargs=True,
+ return_commit_hash=True,
+ **kwargs,
+ )
+ return cls.from_config(config, return_unused_kwargs=return_unused_kwargs, **kwargs)
+
+ def save_pretrained(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
+ """
+ Save a scheduler configuration object to the directory `save_directory`, so that it can be re-loaded using the
+ [`~SchedulerMixin.from_pretrained`] class method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the configuration JSON file will be saved (will be created if it does not exist).
+ """
+ self.save_config(save_directory=save_directory, push_to_hub=push_to_hub, **kwargs)
+
+ @property
+ def compatibles(self):
+ """
+ Returns all schedulers that are compatible with this scheduler
+
+ Returns:
+ `List[SchedulerMixin]`: List of compatible schedulers
+ """
+ return self._get_compatibles()
+
+ @classmethod
+ def _get_compatibles(cls):
+ compatible_classes_str = list(set([cls.__name__] + cls._compatibles))
+ diffusers_library = importlib.import_module(__name__.split(".")[0])
+ compatible_classes = [
+ getattr(diffusers_library, c) for c in compatible_classes_str if hasattr(diffusers_library, c)
+ ]
+ return compatible_classes
diff --git a/diffusers/src/diffusers/schedulers/scheduling_utils_flax.py b/diffusers/src/diffusers/schedulers/scheduling_utils_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..19ce5b8360b9be5bb4b4ec46fbeac0715d6b5869
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_utils_flax.py
@@ -0,0 +1,284 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import importlib
+import math
+import os
+from dataclasses import dataclass
+from enum import Enum
+from typing import Any, Dict, Optional, Tuple, Union
+
+import flax
+import jax.numpy as jnp
+
+from ..utils import BaseOutput
+
+
+SCHEDULER_CONFIG_NAME = "scheduler_config.json"
+
+
+# NOTE: We make this type an enum because it simplifies usage in docs and prevents
+# circular imports when used for `_compatibles` within the schedulers module.
+# When it's used as a type in pipelines, it really is a Union because the actual
+# scheduler instance is passed in.
+class FlaxKarrasDiffusionSchedulers(Enum):
+ FlaxDDIMScheduler = 1
+ FlaxDDPMScheduler = 2
+ FlaxPNDMScheduler = 3
+ FlaxLMSDiscreteScheduler = 4
+ FlaxDPMSolverMultistepScheduler = 5
+
+
+@dataclass
+class FlaxSchedulerOutput(BaseOutput):
+ """
+ Base class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ """
+
+ prev_sample: jnp.ndarray
+
+
+class FlaxSchedulerMixin:
+ """
+ Mixin containing common functions for the schedulers.
+
+ Class attributes:
+ - **_compatibles** (`List[str]`) -- A list of classes that are compatible with the parent class, so that
+ `from_config` can be used from a class different than the one used to save the config (should be overridden
+ by parent class).
+ """
+
+ config_name = SCHEDULER_CONFIG_NAME
+ ignore_for_config = ["dtype"]
+ _compatibles = []
+ has_compatibles = True
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path: Dict[str, Any] = None,
+ subfolder: Optional[str] = None,
+ return_unused_kwargs=False,
+ **kwargs,
+ ):
+ r"""
+ Instantiate a Scheduler class from a pre-defined JSON-file.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
+ Can be either:
+
+ - A string, the *model id* of a model repo on huggingface.co. Valid model ids should have an
+ organization name, like `google/ddpm-celebahq-256`.
+ - A path to a *directory* containing model weights saved using [`~SchedulerMixin.save_pretrained`],
+ e.g., `./my_model_directory/`.
+ subfolder (`str`, *optional*):
+ In case the relevant files are located inside a subfolder of the model repo (either remote in
+ huggingface.co or downloaded locally), you can specify the folder name here.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ Whether kwargs that are not consumed by the Python class should be returned or not.
+
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received files. Will attempt to resume the download if such a
+ file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `transformers-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+
+
+
+ It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
+ models](https://huggingface.co/docs/hub/models-gated#gated-models).
+
+
+
+
+
+ Activate the special ["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to
+ use this method in a firewalled environment.
+
+
+
+ """
+ config, kwargs = cls.load_config(
+ pretrained_model_name_or_path=pretrained_model_name_or_path,
+ subfolder=subfolder,
+ return_unused_kwargs=True,
+ **kwargs,
+ )
+ scheduler, unused_kwargs = cls.from_config(config, return_unused_kwargs=True, **kwargs)
+
+ if hasattr(scheduler, "create_state") and getattr(scheduler, "has_state", False):
+ state = scheduler.create_state()
+
+ if return_unused_kwargs:
+ return scheduler, state, unused_kwargs
+
+ return scheduler, state
+
+ def save_pretrained(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
+ """
+ Save a scheduler configuration object to the directory `save_directory`, so that it can be re-loaded using the
+ [`~FlaxSchedulerMixin.from_pretrained`] class method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the configuration JSON file will be saved (will be created if it does not exist).
+ """
+ self.save_config(save_directory=save_directory, push_to_hub=push_to_hub, **kwargs)
+
+ @property
+ def compatibles(self):
+ """
+ Returns all schedulers that are compatible with this scheduler
+
+ Returns:
+ `List[SchedulerMixin]`: List of compatible schedulers
+ """
+ return self._get_compatibles()
+
+ @classmethod
+ def _get_compatibles(cls):
+ compatible_classes_str = list(set([cls.__name__] + cls._compatibles))
+ diffusers_library = importlib.import_module(__name__.split(".")[0])
+ compatible_classes = [
+ getattr(diffusers_library, c) for c in compatible_classes_str if hasattr(diffusers_library, c)
+ ]
+ return compatible_classes
+
+
+def broadcast_to_shape_from_left(x: jnp.ndarray, shape: Tuple[int]) -> jnp.ndarray:
+ assert len(shape) >= x.ndim
+ return jnp.broadcast_to(x.reshape(x.shape + (1,) * (len(shape) - x.ndim)), shape)
+
+
+def betas_for_alpha_bar(num_diffusion_timesteps: int, max_beta=0.999, dtype=jnp.float32) -> jnp.ndarray:
+ """
+ Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
+ (1-beta) over time from t = [0,1].
+
+ Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
+ to that part of the diffusion process.
+
+
+ Args:
+ num_diffusion_timesteps (`int`): the number of betas to produce.
+ max_beta (`float`): the maximum beta to use; use values lower than 1 to
+ prevent singularities.
+
+ Returns:
+ betas (`jnp.ndarray`): the betas used by the scheduler to step the model outputs
+ """
+
+ def alpha_bar(time_step):
+ return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
+
+ betas = []
+ for i in range(num_diffusion_timesteps):
+ t1 = i / num_diffusion_timesteps
+ t2 = (i + 1) / num_diffusion_timesteps
+ betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
+ return jnp.array(betas, dtype=dtype)
+
+
+@flax.struct.dataclass
+class CommonSchedulerState:
+ alphas: jnp.ndarray
+ betas: jnp.ndarray
+ alphas_cumprod: jnp.ndarray
+
+ @classmethod
+ def create(cls, scheduler):
+ config = scheduler.config
+
+ if config.trained_betas is not None:
+ betas = jnp.asarray(config.trained_betas, dtype=scheduler.dtype)
+ elif config.beta_schedule == "linear":
+ betas = jnp.linspace(config.beta_start, config.beta_end, config.num_train_timesteps, dtype=scheduler.dtype)
+ elif config.beta_schedule == "scaled_linear":
+ # this schedule is very specific to the latent diffusion model.
+ betas = (
+ jnp.linspace(
+ config.beta_start**0.5, config.beta_end**0.5, config.num_train_timesteps, dtype=scheduler.dtype
+ )
+ ** 2
+ )
+ elif config.beta_schedule == "squaredcos_cap_v2":
+ # Glide cosine schedule
+ betas = betas_for_alpha_bar(config.num_train_timesteps, dtype=scheduler.dtype)
+ else:
+ raise NotImplementedError(
+ f"beta_schedule {config.beta_schedule} is not implemented for scheduler {scheduler.__class__.__name__}"
+ )
+
+ alphas = 1.0 - betas
+
+ alphas_cumprod = jnp.cumprod(alphas, axis=0)
+
+ return cls(
+ alphas=alphas,
+ betas=betas,
+ alphas_cumprod=alphas_cumprod,
+ )
+
+
+def get_sqrt_alpha_prod(
+ state: CommonSchedulerState, original_samples: jnp.ndarray, noise: jnp.ndarray, timesteps: jnp.ndarray
+):
+ alphas_cumprod = state.alphas_cumprod
+
+ sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
+ sqrt_alpha_prod = sqrt_alpha_prod.flatten()
+ sqrt_alpha_prod = broadcast_to_shape_from_left(sqrt_alpha_prod, original_samples.shape)
+
+ sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
+ sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
+ sqrt_one_minus_alpha_prod = broadcast_to_shape_from_left(sqrt_one_minus_alpha_prod, original_samples.shape)
+
+ return sqrt_alpha_prod, sqrt_one_minus_alpha_prod
+
+
+def add_noise_common(
+ state: CommonSchedulerState, original_samples: jnp.ndarray, noise: jnp.ndarray, timesteps: jnp.ndarray
+):
+ sqrt_alpha_prod, sqrt_one_minus_alpha_prod = get_sqrt_alpha_prod(state, original_samples, noise, timesteps)
+ noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
+ return noisy_samples
+
+
+def get_velocity_common(state: CommonSchedulerState, sample: jnp.ndarray, noise: jnp.ndarray, timesteps: jnp.ndarray):
+ sqrt_alpha_prod, sqrt_one_minus_alpha_prod = get_sqrt_alpha_prod(state, sample, noise, timesteps)
+ velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
+ return velocity
diff --git a/diffusers/src/diffusers/schedulers/scheduling_vq_diffusion.py b/diffusers/src/diffusers/schedulers/scheduling_vq_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..b92722e4d462ca675bbf11230c1c39810de48b6e
--- /dev/null
+++ b/diffusers/src/diffusers/schedulers/scheduling_vq_diffusion.py
@@ -0,0 +1,496 @@
+# Copyright 2023 Microsoft and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from dataclasses import dataclass
+from typing import Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+from ..configuration_utils import ConfigMixin, register_to_config
+from ..utils import BaseOutput
+from .scheduling_utils import SchedulerMixin
+
+
+@dataclass
+class VQDiffusionSchedulerOutput(BaseOutput):
+ """
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.LongTensor` of shape `(batch size, num latent pixels)`):
+ Computed sample x_{t-1} of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ """
+
+ prev_sample: torch.LongTensor
+
+
+def index_to_log_onehot(x: torch.LongTensor, num_classes: int) -> torch.FloatTensor:
+ """
+ Convert batch of vector of class indices into batch of log onehot vectors
+
+ Args:
+ x (`torch.LongTensor` of shape `(batch size, vector length)`):
+ Batch of class indices
+
+ num_classes (`int`):
+ number of classes to be used for the onehot vectors
+
+ Returns:
+ `torch.FloatTensor` of shape `(batch size, num classes, vector length)`:
+ Log onehot vectors
+ """
+ x_onehot = F.one_hot(x, num_classes)
+ x_onehot = x_onehot.permute(0, 2, 1)
+ log_x = torch.log(x_onehot.float().clamp(min=1e-30))
+ return log_x
+
+
+def gumbel_noised(logits: torch.FloatTensor, generator: Optional[torch.Generator]) -> torch.FloatTensor:
+ """
+ Apply gumbel noise to `logits`
+ """
+ uniform = torch.rand(logits.shape, device=logits.device, generator=generator)
+ gumbel_noise = -torch.log(-torch.log(uniform + 1e-30) + 1e-30)
+ noised = gumbel_noise + logits
+ return noised
+
+
+def alpha_schedules(num_diffusion_timesteps: int, alpha_cum_start=0.99999, alpha_cum_end=0.000009):
+ """
+ Cumulative and non-cumulative alpha schedules.
+
+ See section 4.1.
+ """
+ att = (
+ np.arange(0, num_diffusion_timesteps) / (num_diffusion_timesteps - 1) * (alpha_cum_end - alpha_cum_start)
+ + alpha_cum_start
+ )
+ att = np.concatenate(([1], att))
+ at = att[1:] / att[:-1]
+ att = np.concatenate((att[1:], [1]))
+ return at, att
+
+
+def gamma_schedules(num_diffusion_timesteps: int, gamma_cum_start=0.000009, gamma_cum_end=0.99999):
+ """
+ Cumulative and non-cumulative gamma schedules.
+
+ See section 4.1.
+ """
+ ctt = (
+ np.arange(0, num_diffusion_timesteps) / (num_diffusion_timesteps - 1) * (gamma_cum_end - gamma_cum_start)
+ + gamma_cum_start
+ )
+ ctt = np.concatenate(([0], ctt))
+ one_minus_ctt = 1 - ctt
+ one_minus_ct = one_minus_ctt[1:] / one_minus_ctt[:-1]
+ ct = 1 - one_minus_ct
+ ctt = np.concatenate((ctt[1:], [0]))
+ return ct, ctt
+
+
+class VQDiffusionScheduler(SchedulerMixin, ConfigMixin):
+ """
+ The VQ-diffusion transformer outputs predicted probabilities of the initial unnoised image.
+
+ The VQ-diffusion scheduler converts the transformer's output into a sample for the unnoised image at the previous
+ diffusion timestep.
+
+ [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
+ function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
+ [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
+ [`~SchedulerMixin.from_pretrained`] functions.
+
+ For more details, see the original paper: https://arxiv.org/abs/2111.14822
+
+ Args:
+ num_vec_classes (`int`):
+ The number of classes of the vector embeddings of the latent pixels. Includes the class for the masked
+ latent pixel.
+
+ num_train_timesteps (`int`):
+ Number of diffusion steps used to train the model.
+
+ alpha_cum_start (`float`):
+ The starting cumulative alpha value.
+
+ alpha_cum_end (`float`):
+ The ending cumulative alpha value.
+
+ gamma_cum_start (`float`):
+ The starting cumulative gamma value.
+
+ gamma_cum_end (`float`):
+ The ending cumulative gamma value.
+ """
+
+ order = 1
+
+ @register_to_config
+ def __init__(
+ self,
+ num_vec_classes: int,
+ num_train_timesteps: int = 100,
+ alpha_cum_start: float = 0.99999,
+ alpha_cum_end: float = 0.000009,
+ gamma_cum_start: float = 0.000009,
+ gamma_cum_end: float = 0.99999,
+ ):
+ self.num_embed = num_vec_classes
+
+ # By convention, the index for the mask class is the last class index
+ self.mask_class = self.num_embed - 1
+
+ at, att = alpha_schedules(num_train_timesteps, alpha_cum_start=alpha_cum_start, alpha_cum_end=alpha_cum_end)
+ ct, ctt = gamma_schedules(num_train_timesteps, gamma_cum_start=gamma_cum_start, gamma_cum_end=gamma_cum_end)
+
+ num_non_mask_classes = self.num_embed - 1
+ bt = (1 - at - ct) / num_non_mask_classes
+ btt = (1 - att - ctt) / num_non_mask_classes
+
+ at = torch.tensor(at.astype("float64"))
+ bt = torch.tensor(bt.astype("float64"))
+ ct = torch.tensor(ct.astype("float64"))
+ log_at = torch.log(at)
+ log_bt = torch.log(bt)
+ log_ct = torch.log(ct)
+
+ att = torch.tensor(att.astype("float64"))
+ btt = torch.tensor(btt.astype("float64"))
+ ctt = torch.tensor(ctt.astype("float64"))
+ log_cumprod_at = torch.log(att)
+ log_cumprod_bt = torch.log(btt)
+ log_cumprod_ct = torch.log(ctt)
+
+ self.log_at = log_at.float()
+ self.log_bt = log_bt.float()
+ self.log_ct = log_ct.float()
+ self.log_cumprod_at = log_cumprod_at.float()
+ self.log_cumprod_bt = log_cumprod_bt.float()
+ self.log_cumprod_ct = log_cumprod_ct.float()
+
+ # setable values
+ self.num_inference_steps = None
+ self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy())
+
+ def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
+ """
+ Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
+
+ Args:
+ num_inference_steps (`int`):
+ the number of diffusion steps used when generating samples with a pre-trained model.
+
+ device (`str` or `torch.device`):
+ device to place the timesteps and the diffusion process parameters (alpha, beta, gamma) on.
+ """
+ self.num_inference_steps = num_inference_steps
+ timesteps = np.arange(0, self.num_inference_steps)[::-1].copy()
+ self.timesteps = torch.from_numpy(timesteps).to(device)
+
+ self.log_at = self.log_at.to(device)
+ self.log_bt = self.log_bt.to(device)
+ self.log_ct = self.log_ct.to(device)
+ self.log_cumprod_at = self.log_cumprod_at.to(device)
+ self.log_cumprod_bt = self.log_cumprod_bt.to(device)
+ self.log_cumprod_ct = self.log_cumprod_ct.to(device)
+
+ def step(
+ self,
+ model_output: torch.FloatTensor,
+ timestep: torch.long,
+ sample: torch.LongTensor,
+ generator: Optional[torch.Generator] = None,
+ return_dict: bool = True,
+ ) -> Union[VQDiffusionSchedulerOutput, Tuple]:
+ """
+ Predict the sample at the previous timestep via the reverse transition distribution i.e. Equation (11). See the
+ docstring for `self.q_posterior` for more in depth docs on how Equation (11) is computed.
+
+ Args:
+ log_p_x_0: (`torch.FloatTensor` of shape `(batch size, num classes - 1, num latent pixels)`):
+ The log probabilities for the predicted classes of the initial latent pixels. Does not include a
+ prediction for the masked class as the initial unnoised image cannot be masked.
+
+ t (`torch.long`):
+ The timestep that determines which transition matrices are used.
+
+ x_t: (`torch.LongTensor` of shape `(batch size, num latent pixels)`):
+ The classes of each latent pixel at time `t`
+
+ generator: (`torch.Generator` or None):
+ RNG for the noise applied to p(x_{t-1} | x_t) before it is sampled from.
+
+ return_dict (`bool`):
+ option for returning tuple rather than VQDiffusionSchedulerOutput class
+
+ Returns:
+ [`~schedulers.scheduling_utils.VQDiffusionSchedulerOutput`] or `tuple`:
+ [`~schedulers.scheduling_utils.VQDiffusionSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`.
+ When returning a tuple, the first element is the sample tensor.
+ """
+ if timestep == 0:
+ log_p_x_t_min_1 = model_output
+ else:
+ log_p_x_t_min_1 = self.q_posterior(model_output, sample, timestep)
+
+ log_p_x_t_min_1 = gumbel_noised(log_p_x_t_min_1, generator)
+
+ x_t_min_1 = log_p_x_t_min_1.argmax(dim=1)
+
+ if not return_dict:
+ return (x_t_min_1,)
+
+ return VQDiffusionSchedulerOutput(prev_sample=x_t_min_1)
+
+ def q_posterior(self, log_p_x_0, x_t, t):
+ """
+ Calculates the log probabilities for the predicted classes of the image at timestep `t-1`. I.e. Equation (11).
+
+ Instead of directly computing equation (11), we use Equation (5) to restate Equation (11) in terms of only
+ forward probabilities.
+
+ Equation (11) stated in terms of forward probabilities via Equation (5):
+
+ Where:
+ - the sum is over x_0 = {C_0 ... C_{k-1}} (classes for x_0)
+
+ p(x_{t-1} | x_t) = sum( q(x_t | x_{t-1}) * q(x_{t-1} | x_0) * p(x_0) / q(x_t | x_0) )
+
+ Args:
+ log_p_x_0: (`torch.FloatTensor` of shape `(batch size, num classes - 1, num latent pixels)`):
+ The log probabilities for the predicted classes of the initial latent pixels. Does not include a
+ prediction for the masked class as the initial unnoised image cannot be masked.
+
+ x_t: (`torch.LongTensor` of shape `(batch size, num latent pixels)`):
+ The classes of each latent pixel at time `t`
+
+ t (torch.Long):
+ The timestep that determines which transition matrix is used.
+
+ Returns:
+ `torch.FloatTensor` of shape `(batch size, num classes, num latent pixels)`:
+ The log probabilities for the predicted classes of the image at timestep `t-1`. I.e. Equation (11).
+ """
+ log_onehot_x_t = index_to_log_onehot(x_t, self.num_embed)
+
+ log_q_x_t_given_x_0 = self.log_Q_t_transitioning_to_known_class(
+ t=t, x_t=x_t, log_onehot_x_t=log_onehot_x_t, cumulative=True
+ )
+
+ log_q_t_given_x_t_min_1 = self.log_Q_t_transitioning_to_known_class(
+ t=t, x_t=x_t, log_onehot_x_t=log_onehot_x_t, cumulative=False
+ )
+
+ # p_0(x_0=C_0 | x_t) / q(x_t | x_0=C_0) ... p_n(x_0=C_0 | x_t) / q(x_t | x_0=C_0)
+ # . . .
+ # . . .
+ # . . .
+ # p_0(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1}) ... p_n(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1})
+ q = log_p_x_0 - log_q_x_t_given_x_0
+
+ # sum_0 = p_0(x_0=C_0 | x_t) / q(x_t | x_0=C_0) + ... + p_0(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1}), ... ,
+ # sum_n = p_n(x_0=C_0 | x_t) / q(x_t | x_0=C_0) + ... + p_n(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1})
+ q_log_sum_exp = torch.logsumexp(q, dim=1, keepdim=True)
+
+ # p_0(x_0=C_0 | x_t) / q(x_t | x_0=C_0) / sum_0 ... p_n(x_0=C_0 | x_t) / q(x_t | x_0=C_0) / sum_n
+ # . . .
+ # . . .
+ # . . .
+ # p_0(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1}) / sum_0 ... p_n(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1}) / sum_n
+ q = q - q_log_sum_exp
+
+ # (p_0(x_0=C_0 | x_t) / q(x_t | x_0=C_0) / sum_0) * a_cumulative_{t-1} + b_cumulative_{t-1} ... (p_n(x_0=C_0 | x_t) / q(x_t | x_0=C_0) / sum_n) * a_cumulative_{t-1} + b_cumulative_{t-1}
+ # . . .
+ # . . .
+ # . . .
+ # (p_0(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1}) / sum_0) * a_cumulative_{t-1} + b_cumulative_{t-1} ... (p_n(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1}) / sum_n) * a_cumulative_{t-1} + b_cumulative_{t-1}
+ # c_cumulative_{t-1} ... c_cumulative_{t-1}
+ q = self.apply_cumulative_transitions(q, t - 1)
+
+ # ((p_0(x_0=C_0 | x_t) / q(x_t | x_0=C_0) / sum_0) * a_cumulative_{t-1} + b_cumulative_{t-1}) * q(x_t | x_{t-1}=C_0) * sum_0 ... ((p_n(x_0=C_0 | x_t) / q(x_t | x_0=C_0) / sum_n) * a_cumulative_{t-1} + b_cumulative_{t-1}) * q(x_t | x_{t-1}=C_0) * sum_n
+ # . . .
+ # . . .
+ # . . .
+ # ((p_0(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1}) / sum_0) * a_cumulative_{t-1} + b_cumulative_{t-1}) * q(x_t | x_{t-1}=C_{k-1}) * sum_0 ... ((p_n(x_0=C_{k-1} | x_t) / q(x_t | x_0=C_{k-1}) / sum_n) * a_cumulative_{t-1} + b_cumulative_{t-1}) * q(x_t | x_{t-1}=C_{k-1}) * sum_n
+ # c_cumulative_{t-1} * q(x_t | x_{t-1}=C_k) * sum_0 ... c_cumulative_{t-1} * q(x_t | x_{t-1}=C_k) * sum_0
+ log_p_x_t_min_1 = q + log_q_t_given_x_t_min_1 + q_log_sum_exp
+
+ # For each column, there are two possible cases.
+ #
+ # Where:
+ # - sum(p_n(x_0))) is summing over all classes for x_0
+ # - C_i is the class transitioning from (not to be confused with c_t and c_cumulative_t being used for gamma's)
+ # - C_j is the class transitioning to
+ #
+ # 1. x_t is masked i.e. x_t = c_k
+ #
+ # Simplifying the expression, the column vector is:
+ # .
+ # .
+ # .
+ # (c_t / c_cumulative_t) * (a_cumulative_{t-1} * p_n(x_0 = C_i | x_t) + b_cumulative_{t-1} * sum(p_n(x_0)))
+ # .
+ # .
+ # .
+ # (c_cumulative_{t-1} / c_cumulative_t) * sum(p_n(x_0))
+ #
+ # From equation (11) stated in terms of forward probabilities, the last row is trivially verified.
+ #
+ # For the other rows, we can state the equation as ...
+ #
+ # (c_t / c_cumulative_t) * [b_cumulative_{t-1} * p(x_0=c_0) + ... + (a_cumulative_{t-1} + b_cumulative_{t-1}) * p(x_0=C_i) + ... + b_cumulative_{k-1} * p(x_0=c_{k-1})]
+ #
+ # This verifies the other rows.
+ #
+ # 2. x_t is not masked
+ #
+ # Simplifying the expression, there are two cases for the rows of the column vector, where C_j = C_i and where C_j != C_i:
+ # .
+ # .
+ # .
+ # C_j != C_i: b_t * ((b_cumulative_{t-1} / b_cumulative_t) * p_n(x_0 = c_0) + ... + ((a_cumulative_{t-1} + b_cumulative_{t-1}) / b_cumulative_t) * p_n(x_0 = C_i) + ... + (b_cumulative_{t-1} / (a_cumulative_t + b_cumulative_t)) * p_n(c_0=C_j) + ... + (b_cumulative_{t-1} / b_cumulative_t) * p_n(x_0 = c_{k-1}))
+ # .
+ # .
+ # .
+ # C_j = C_i: (a_t + b_t) * ((b_cumulative_{t-1} / b_cumulative_t) * p_n(x_0 = c_0) + ... + ((a_cumulative_{t-1} + b_cumulative_{t-1}) / (a_cumulative_t + b_cumulative_t)) * p_n(x_0 = C_i = C_j) + ... + (b_cumulative_{t-1} / b_cumulative_t) * p_n(x_0 = c_{k-1}))
+ # .
+ # .
+ # .
+ # 0
+ #
+ # The last row is trivially verified. The other rows can be verified by directly expanding equation (11) stated in terms of forward probabilities.
+ return log_p_x_t_min_1
+
+ def log_Q_t_transitioning_to_known_class(
+ self, *, t: torch.int, x_t: torch.LongTensor, log_onehot_x_t: torch.FloatTensor, cumulative: bool
+ ):
+ """
+ Returns the log probabilities of the rows from the (cumulative or non-cumulative) transition matrix for each
+ latent pixel in `x_t`.
+
+ See equation (7) for the complete non-cumulative transition matrix. The complete cumulative transition matrix
+ is the same structure except the parameters (alpha, beta, gamma) are the cumulative analogs.
+
+ Args:
+ t (torch.Long):
+ The timestep that determines which transition matrix is used.
+
+ x_t (`torch.LongTensor` of shape `(batch size, num latent pixels)`):
+ The classes of each latent pixel at time `t`.
+
+ log_onehot_x_t (`torch.FloatTensor` of shape `(batch size, num classes, num latent pixels)`):
+ The log one-hot vectors of `x_t`
+
+ cumulative (`bool`):
+ If cumulative is `False`, we use the single step transition matrix `t-1`->`t`. If cumulative is `True`,
+ we use the cumulative transition matrix `0`->`t`.
+
+ Returns:
+ `torch.FloatTensor` of shape `(batch size, num classes - 1, num latent pixels)`:
+ Each _column_ of the returned matrix is a _row_ of log probabilities of the complete probability
+ transition matrix.
+
+ When non cumulative, returns `self.num_classes - 1` rows because the initial latent pixel cannot be
+ masked.
+
+ Where:
+ - `q_n` is the probability distribution for the forward process of the `n`th latent pixel.
+ - C_0 is a class of a latent pixel embedding
+ - C_k is the class of the masked latent pixel
+
+ non-cumulative result (omitting logarithms):
+ ```
+ q_0(x_t | x_{t-1} = C_0) ... q_n(x_t | x_{t-1} = C_0)
+ . . .
+ . . .
+ . . .
+ q_0(x_t | x_{t-1} = C_k) ... q_n(x_t | x_{t-1} = C_k)
+ ```
+
+ cumulative result (omitting logarithms):
+ ```
+ q_0_cumulative(x_t | x_0 = C_0) ... q_n_cumulative(x_t | x_0 = C_0)
+ . . .
+ . . .
+ . . .
+ q_0_cumulative(x_t | x_0 = C_{k-1}) ... q_n_cumulative(x_t | x_0 = C_{k-1})
+ ```
+ """
+ if cumulative:
+ a = self.log_cumprod_at[t]
+ b = self.log_cumprod_bt[t]
+ c = self.log_cumprod_ct[t]
+ else:
+ a = self.log_at[t]
+ b = self.log_bt[t]
+ c = self.log_ct[t]
+
+ if not cumulative:
+ # The values in the onehot vector can also be used as the logprobs for transitioning
+ # from masked latent pixels. If we are not calculating the cumulative transitions,
+ # we need to save these vectors to be re-appended to the final matrix so the values
+ # aren't overwritten.
+ #
+ # `P(x_t!=mask|x_{t-1=mask}) = 0` and 0 will be the value of the last row of the onehot vector
+ # if x_t is not masked
+ #
+ # `P(x_t=mask|x_{t-1=mask}) = 1` and 1 will be the value of the last row of the onehot vector
+ # if x_t is masked
+ log_onehot_x_t_transitioning_from_masked = log_onehot_x_t[:, -1, :].unsqueeze(1)
+
+ # `index_to_log_onehot` will add onehot vectors for masked pixels,
+ # so the default one hot matrix has one too many rows. See the doc string
+ # for an explanation of the dimensionality of the returned matrix.
+ log_onehot_x_t = log_onehot_x_t[:, :-1, :]
+
+ # this is a cheeky trick to produce the transition probabilities using log one-hot vectors.
+ #
+ # Don't worry about what values this sets in the columns that mark transitions
+ # to masked latent pixels. They are overwrote later with the `mask_class_mask`.
+ #
+ # Looking at the below logspace formula in non-logspace, each value will evaluate to either
+ # `1 * a + b = a + b` where `log_Q_t` has the one hot value in the column
+ # or
+ # `0 * a + b = b` where `log_Q_t` has the 0 values in the column.
+ #
+ # See equation 7 for more details.
+ log_Q_t = (log_onehot_x_t + a).logaddexp(b)
+
+ # The whole column of each masked pixel is `c`
+ mask_class_mask = x_t == self.mask_class
+ mask_class_mask = mask_class_mask.unsqueeze(1).expand(-1, self.num_embed - 1, -1)
+ log_Q_t[mask_class_mask] = c
+
+ if not cumulative:
+ log_Q_t = torch.cat((log_Q_t, log_onehot_x_t_transitioning_from_masked), dim=1)
+
+ return log_Q_t
+
+ def apply_cumulative_transitions(self, q, t):
+ bsz = q.shape[0]
+ a = self.log_cumprod_at[t]
+ b = self.log_cumprod_bt[t]
+ c = self.log_cumprod_ct[t]
+
+ num_latent_pixels = q.shape[2]
+ c = c.expand(bsz, 1, num_latent_pixels)
+
+ q = (q + a).logaddexp(b)
+ q = torch.cat((q, c), dim=1)
+
+ return q
diff --git a/diffusers/src/diffusers/training_utils.py b/diffusers/src/diffusers/training_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..340b96e29ac5fb5ddf7e97f072932c63d5650cde
--- /dev/null
+++ b/diffusers/src/diffusers/training_utils.py
@@ -0,0 +1,322 @@
+import copy
+import os
+import random
+from typing import Any, Dict, Iterable, Optional, Union
+
+import numpy as np
+import torch
+
+from .utils import deprecate
+
+
+def enable_full_determinism(seed: int):
+ """
+ Helper function for reproducible behavior during distributed training. See
+ - https://pytorch.org/docs/stable/notes/randomness.html for pytorch
+ """
+ # set seed first
+ set_seed(seed)
+
+ # Enable PyTorch deterministic mode. This potentially requires either the environment
+ # variable 'CUDA_LAUNCH_BLOCKING' or 'CUBLAS_WORKSPACE_CONFIG' to be set,
+ # depending on the CUDA version, so we set them both here
+ os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
+ os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":16:8"
+ torch.use_deterministic_algorithms(True)
+
+ # Enable CUDNN deterministic mode
+ torch.backends.cudnn.deterministic = True
+ torch.backends.cudnn.benchmark = False
+
+
+def set_seed(seed: int):
+ """
+ Args:
+ Helper function for reproducible behavior to set the seed in `random`, `numpy`, `torch`.
+ seed (`int`): The seed to set.
+ """
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+ # ^^ safe to call this function even if cuda is not available
+
+
+# Adapted from torch-ema https://github.com/fadel/pytorch_ema/blob/master/torch_ema/ema.py#L14
+class EMAModel:
+ """
+ Exponential Moving Average of models weights
+ """
+
+ def __init__(
+ self,
+ parameters: Iterable[torch.nn.Parameter],
+ decay: float = 0.9999,
+ min_decay: float = 0.0,
+ update_after_step: int = 0,
+ use_ema_warmup: bool = False,
+ inv_gamma: Union[float, int] = 1.0,
+ power: Union[float, int] = 2 / 3,
+ model_cls: Optional[Any] = None,
+ model_config: Dict[str, Any] = None,
+ **kwargs,
+ ):
+ """
+ Args:
+ parameters (Iterable[torch.nn.Parameter]): The parameters to track.
+ decay (float): The decay factor for the exponential moving average.
+ min_decay (float): The minimum decay factor for the exponential moving average.
+ update_after_step (int): The number of steps to wait before starting to update the EMA weights.
+ use_ema_warmup (bool): Whether to use EMA warmup.
+ inv_gamma (float):
+ Inverse multiplicative factor of EMA warmup. Default: 1. Only used if `use_ema_warmup` is True.
+ power (float): Exponential factor of EMA warmup. Default: 2/3. Only used if `use_ema_warmup` is True.
+ device (Optional[Union[str, torch.device]]): The device to store the EMA weights on. If None, the EMA
+ weights will be stored on CPU.
+
+ @crowsonkb's notes on EMA Warmup:
+ If gamma=1 and power=1, implements a simple average. gamma=1, power=2/3 are good values for models you plan
+ to train for a million or more steps (reaches decay factor 0.999 at 31.6K steps, 0.9999 at 1M steps),
+ gamma=1, power=3/4 for models you plan to train for less (reaches decay factor 0.999 at 10K steps, 0.9999
+ at 215.4k steps).
+ """
+
+ if isinstance(parameters, torch.nn.Module):
+ deprecation_message = (
+ "Passing a `torch.nn.Module` to `ExponentialMovingAverage` is deprecated. "
+ "Please pass the parameters of the module instead."
+ )
+ deprecate(
+ "passing a `torch.nn.Module` to `ExponentialMovingAverage`",
+ "1.0.0",
+ deprecation_message,
+ standard_warn=False,
+ )
+ parameters = parameters.parameters()
+
+ # set use_ema_warmup to True if a torch.nn.Module is passed for backwards compatibility
+ use_ema_warmup = True
+
+ if kwargs.get("max_value", None) is not None:
+ deprecation_message = "The `max_value` argument is deprecated. Please use `decay` instead."
+ deprecate("max_value", "1.0.0", deprecation_message, standard_warn=False)
+ decay = kwargs["max_value"]
+
+ if kwargs.get("min_value", None) is not None:
+ deprecation_message = "The `min_value` argument is deprecated. Please use `min_decay` instead."
+ deprecate("min_value", "1.0.0", deprecation_message, standard_warn=False)
+ min_decay = kwargs["min_value"]
+
+ parameters = list(parameters)
+ self.shadow_params = [p.clone().detach() for p in parameters]
+
+ if kwargs.get("device", None) is not None:
+ deprecation_message = "The `device` argument is deprecated. Please use `to` instead."
+ deprecate("device", "1.0.0", deprecation_message, standard_warn=False)
+ self.to(device=kwargs["device"])
+
+ self.temp_stored_params = None
+
+ self.decay = decay
+ self.min_decay = min_decay
+ self.update_after_step = update_after_step
+ self.use_ema_warmup = use_ema_warmup
+ self.inv_gamma = inv_gamma
+ self.power = power
+ self.optimization_step = 0
+ self.cur_decay_value = None # set in `step()`
+
+ self.model_cls = model_cls
+ self.model_config = model_config
+
+ @classmethod
+ def from_pretrained(cls, path, model_cls) -> "EMAModel":
+ _, ema_kwargs = model_cls.load_config(path, return_unused_kwargs=True)
+ model = model_cls.from_pretrained(path)
+
+ ema_model = cls(model.parameters(), model_cls=model_cls, model_config=model.config)
+
+ ema_model.load_state_dict(ema_kwargs)
+ return ema_model
+
+ def save_pretrained(self, path):
+ if self.model_cls is None:
+ raise ValueError("`save_pretrained` can only be used if `model_cls` was defined at __init__.")
+
+ if self.model_config is None:
+ raise ValueError("`save_pretrained` can only be used if `model_config` was defined at __init__.")
+
+ model = self.model_cls.from_config(self.model_config)
+ state_dict = self.state_dict()
+ state_dict.pop("shadow_params", None)
+
+ model.register_to_config(**state_dict)
+ self.copy_to(model.parameters())
+ model.save_pretrained(path)
+
+ def get_decay(self, optimization_step: int) -> float:
+ """
+ Compute the decay factor for the exponential moving average.
+ """
+ step = max(0, optimization_step - self.update_after_step - 1)
+
+ if step <= 0:
+ return 0.0
+
+ if self.use_ema_warmup:
+ cur_decay_value = 1 - (1 + step / self.inv_gamma) ** -self.power
+ else:
+ cur_decay_value = (1 + step) / (10 + step)
+
+ cur_decay_value = min(cur_decay_value, self.decay)
+ # make sure decay is not smaller than min_decay
+ cur_decay_value = max(cur_decay_value, self.min_decay)
+ return cur_decay_value
+
+ @torch.no_grad()
+ def step(self, parameters: Iterable[torch.nn.Parameter]):
+ if isinstance(parameters, torch.nn.Module):
+ deprecation_message = (
+ "Passing a `torch.nn.Module` to `ExponentialMovingAverage.step` is deprecated. "
+ "Please pass the parameters of the module instead."
+ )
+ deprecate(
+ "passing a `torch.nn.Module` to `ExponentialMovingAverage.step`",
+ "1.0.0",
+ deprecation_message,
+ standard_warn=False,
+ )
+ parameters = parameters.parameters()
+
+ parameters = list(parameters)
+
+ self.optimization_step += 1
+
+ # Compute the decay factor for the exponential moving average.
+ decay = self.get_decay(self.optimization_step)
+ self.cur_decay_value = decay
+ one_minus_decay = 1 - decay
+
+ for s_param, param in zip(self.shadow_params, parameters):
+ if param.requires_grad:
+ s_param.sub_(one_minus_decay * (s_param - param))
+ else:
+ s_param.copy_(param)
+
+ def copy_to(self, parameters: Iterable[torch.nn.Parameter]) -> None:
+ """
+ Copy current averaged parameters into given collection of parameters.
+
+ Args:
+ parameters: Iterable of `torch.nn.Parameter`; the parameters to be
+ updated with the stored moving averages. If `None`, the parameters with which this
+ `ExponentialMovingAverage` was initialized will be used.
+ """
+ parameters = list(parameters)
+ for s_param, param in zip(self.shadow_params, parameters):
+ param.data.copy_(s_param.to(param.device).data)
+
+ def to(self, device=None, dtype=None) -> None:
+ r"""Move internal buffers of the ExponentialMovingAverage to `device`.
+
+ Args:
+ device: like `device` argument to `torch.Tensor.to`
+ """
+ # .to() on the tensors handles None correctly
+ self.shadow_params = [
+ p.to(device=device, dtype=dtype) if p.is_floating_point() else p.to(device=device)
+ for p in self.shadow_params
+ ]
+
+ def state_dict(self) -> dict:
+ r"""
+ Returns the state of the ExponentialMovingAverage as a dict. This method is used by accelerate during
+ checkpointing to save the ema state dict.
+ """
+ # Following PyTorch conventions, references to tensors are returned:
+ # "returns a reference to the state and not its copy!" -
+ # https://pytorch.org/tutorials/beginner/saving_loading_models.html#what-is-a-state-dict
+ return {
+ "decay": self.decay,
+ "min_decay": self.min_decay,
+ "optimization_step": self.optimization_step,
+ "update_after_step": self.update_after_step,
+ "use_ema_warmup": self.use_ema_warmup,
+ "inv_gamma": self.inv_gamma,
+ "power": self.power,
+ "shadow_params": self.shadow_params,
+ }
+
+ def store(self, parameters: Iterable[torch.nn.Parameter]) -> None:
+ r"""
+ Args:
+ Save the current parameters for restoring later.
+ parameters: Iterable of `torch.nn.Parameter`; the parameters to be
+ temporarily stored.
+ """
+ self.temp_stored_params = [param.detach().cpu().clone() for param in parameters]
+
+ def restore(self, parameters: Iterable[torch.nn.Parameter]) -> None:
+ r"""
+ Args:
+ Restore the parameters stored with the `store` method. Useful to validate the model with EMA parameters without:
+ affecting the original optimization process. Store the parameters before the `copy_to()` method. After
+ validation (or model saving), use this to restore the former parameters.
+ parameters: Iterable of `torch.nn.Parameter`; the parameters to be
+ updated with the stored parameters. If `None`, the parameters with which this
+ `ExponentialMovingAverage` was initialized will be used.
+ """
+ if self.temp_stored_params is None:
+ raise RuntimeError("This ExponentialMovingAverage has no `store()`ed weights " "to `restore()`")
+ for c_param, param in zip(self.temp_stored_params, parameters):
+ param.data.copy_(c_param.data)
+
+ # Better memory-wise.
+ self.temp_stored_params = None
+
+ def load_state_dict(self, state_dict: dict) -> None:
+ r"""
+ Args:
+ Loads the ExponentialMovingAverage state. This method is used by accelerate during checkpointing to save the
+ ema state dict.
+ state_dict (dict): EMA state. Should be an object returned
+ from a call to :meth:`state_dict`.
+ """
+ # deepcopy, to be consistent with module API
+ state_dict = copy.deepcopy(state_dict)
+
+ self.decay = state_dict.get("decay", self.decay)
+ if self.decay < 0.0 or self.decay > 1.0:
+ raise ValueError("Decay must be between 0 and 1")
+
+ self.min_decay = state_dict.get("min_decay", self.min_decay)
+ if not isinstance(self.min_decay, float):
+ raise ValueError("Invalid min_decay")
+
+ self.optimization_step = state_dict.get("optimization_step", self.optimization_step)
+ if not isinstance(self.optimization_step, int):
+ raise ValueError("Invalid optimization_step")
+
+ self.update_after_step = state_dict.get("update_after_step", self.update_after_step)
+ if not isinstance(self.update_after_step, int):
+ raise ValueError("Invalid update_after_step")
+
+ self.use_ema_warmup = state_dict.get("use_ema_warmup", self.use_ema_warmup)
+ if not isinstance(self.use_ema_warmup, bool):
+ raise ValueError("Invalid use_ema_warmup")
+
+ self.inv_gamma = state_dict.get("inv_gamma", self.inv_gamma)
+ if not isinstance(self.inv_gamma, (float, int)):
+ raise ValueError("Invalid inv_gamma")
+
+ self.power = state_dict.get("power", self.power)
+ if not isinstance(self.power, (float, int)):
+ raise ValueError("Invalid power")
+
+ shadow_params = state_dict.get("shadow_params", None)
+ if shadow_params is not None:
+ self.shadow_params = shadow_params
+ if not isinstance(self.shadow_params, list):
+ raise ValueError("shadow_params must be a list")
+ if not all(isinstance(p, torch.Tensor) for p in self.shadow_params):
+ raise ValueError("shadow_params must all be Tensors")
diff --git a/diffusers/src/diffusers/utils/.ipynb_checkpoints/__init__-checkpoint.py b/diffusers/src/diffusers/utils/.ipynb_checkpoints/__init__-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a1103ac1adfd346c200e2cccaa2f6f80b8c791b
--- /dev/null
+++ b/diffusers/src/diffusers/utils/.ipynb_checkpoints/__init__-checkpoint.py
@@ -0,0 +1,115 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+
+from packaging import version
+
+from .. import __version__
+from .accelerate_utils import apply_forward_hook
+from .constants import (
+ CONFIG_NAME,
+ DEPRECATED_REVISION_ARGS,
+ DIFFUSERS_CACHE,
+ DIFFUSERS_DYNAMIC_MODULE_NAME,
+ FLAX_WEIGHTS_NAME,
+ HF_MODULES_CACHE,
+ HUGGINGFACE_CO_RESOLVE_ENDPOINT,
+ ONNX_EXTERNAL_WEIGHTS_NAME,
+ ONNX_WEIGHTS_NAME,
+ SAFETENSORS_WEIGHTS_NAME,
+ WEIGHTS_NAME,
+)
+from .deprecation_utils import deprecate
+from .doc_utils import replace_example_docstring
+from .dynamic_modules_utils import get_class_from_dynamic_module
+from .hub_utils import (
+ HF_HUB_OFFLINE,
+ _add_variant,
+ _get_model_file,
+ extract_commit_hash,
+ http_user_agent,
+)
+from .import_utils import (
+ ENV_VARS_TRUE_AND_AUTO_VALUES,
+ ENV_VARS_TRUE_VALUES,
+ USE_JAX,
+ USE_TF,
+ USE_TORCH,
+ DummyObject,
+ OptionalDependencyNotAvailable,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_flax_available,
+ is_inflect_available,
+ is_k_diffusion_available,
+ is_k_diffusion_version,
+ is_librosa_available,
+ is_note_seq_available,
+ is_omegaconf_available,
+ is_onnx_available,
+ is_safetensors_available,
+ is_scipy_available,
+ is_tensorboard_available,
+ is_tf_available,
+ is_torch_available,
+ is_torch_version,
+ is_transformers_available,
+ is_transformers_version,
+ is_unidecode_available,
+ is_wandb_available,
+ is_xformers_available,
+ requires_backends,
+)
+from .logging import get_logger
+from .outputs import BaseOutput
+from .pil_utils import PIL_INTERPOLATION
+from .torch_utils import is_compiled_module, randn_tensor
+
+
+if is_torch_available():
+ from .testing_utils import (
+ floats_tensor,
+ load_hf_numpy,
+ load_image,
+ load_numpy,
+ nightly,
+ parse_flag_from_env,
+ print_tensor_test,
+ require_torch_2,
+ require_torch_gpu,
+ skip_mps,
+ slow,
+ torch_all_close,
+ torch_device,
+ )
+
+from .testing_utils import export_to_video
+
+
+logger = get_logger(__name__)
+
+
+def check_min_version(min_version):
+ if version.parse(__version__) < version.parse(min_version):
+ if "dev" in min_version:
+ error_message = (
+ "This example requires a source install from HuggingFace diffusers (see "
+ "`https://huggingface.co/docs/diffusers/installation#install-from-source`),"
+ )
+ else:
+ error_message = f"This example requires a minimum version of {min_version},"
+ error_message += f" but the version found is {__version__}.\n"
+ raise ImportError(error_message)
diff --git a/diffusers/src/diffusers/utils/.ipynb_checkpoints/dummy_torch_and_transformers_objects-checkpoint.py b/diffusers/src/diffusers/utils/.ipynb_checkpoints/dummy_torch_and_transformers_objects-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf85ff157f5797703ff9200a6e306a2ede80a707
--- /dev/null
+++ b/diffusers/src/diffusers/utils/.ipynb_checkpoints/dummy_torch_and_transformers_objects-checkpoint.py
@@ -0,0 +1,512 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class TextualInversionLoaderMixin(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class AltDiffusionImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class AltDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class AudioLDMPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class CycleDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class LDMTextToImagePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class PaintByExamplePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class SemanticStableDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionAttendAndExcitePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionControlNetPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionDepth2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionImageVariationPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionInpaintPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionInpaintPipelineLegacy(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionInstructPix2PixPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionLatentUpscalePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionModelEditingPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionPanoramaPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionPipelineSafe(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionPix2PixZeroPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionSAGPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionUpscalePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableUnCLIPImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableUnCLIPPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class TextToVideoSDPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class UnCLIPImageVariationPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class UnCLIPPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VersatileDiffusionDualGuidedPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VersatileDiffusionImageVariationPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VersatileDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VersatileDiffusionTextToImagePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VQDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
diff --git a/diffusers/src/diffusers/utils/__init__.py b/diffusers/src/diffusers/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a1103ac1adfd346c200e2cccaa2f6f80b8c791b
--- /dev/null
+++ b/diffusers/src/diffusers/utils/__init__.py
@@ -0,0 +1,115 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+
+from packaging import version
+
+from .. import __version__
+from .accelerate_utils import apply_forward_hook
+from .constants import (
+ CONFIG_NAME,
+ DEPRECATED_REVISION_ARGS,
+ DIFFUSERS_CACHE,
+ DIFFUSERS_DYNAMIC_MODULE_NAME,
+ FLAX_WEIGHTS_NAME,
+ HF_MODULES_CACHE,
+ HUGGINGFACE_CO_RESOLVE_ENDPOINT,
+ ONNX_EXTERNAL_WEIGHTS_NAME,
+ ONNX_WEIGHTS_NAME,
+ SAFETENSORS_WEIGHTS_NAME,
+ WEIGHTS_NAME,
+)
+from .deprecation_utils import deprecate
+from .doc_utils import replace_example_docstring
+from .dynamic_modules_utils import get_class_from_dynamic_module
+from .hub_utils import (
+ HF_HUB_OFFLINE,
+ _add_variant,
+ _get_model_file,
+ extract_commit_hash,
+ http_user_agent,
+)
+from .import_utils import (
+ ENV_VARS_TRUE_AND_AUTO_VALUES,
+ ENV_VARS_TRUE_VALUES,
+ USE_JAX,
+ USE_TF,
+ USE_TORCH,
+ DummyObject,
+ OptionalDependencyNotAvailable,
+ is_accelerate_available,
+ is_accelerate_version,
+ is_flax_available,
+ is_inflect_available,
+ is_k_diffusion_available,
+ is_k_diffusion_version,
+ is_librosa_available,
+ is_note_seq_available,
+ is_omegaconf_available,
+ is_onnx_available,
+ is_safetensors_available,
+ is_scipy_available,
+ is_tensorboard_available,
+ is_tf_available,
+ is_torch_available,
+ is_torch_version,
+ is_transformers_available,
+ is_transformers_version,
+ is_unidecode_available,
+ is_wandb_available,
+ is_xformers_available,
+ requires_backends,
+)
+from .logging import get_logger
+from .outputs import BaseOutput
+from .pil_utils import PIL_INTERPOLATION
+from .torch_utils import is_compiled_module, randn_tensor
+
+
+if is_torch_available():
+ from .testing_utils import (
+ floats_tensor,
+ load_hf_numpy,
+ load_image,
+ load_numpy,
+ nightly,
+ parse_flag_from_env,
+ print_tensor_test,
+ require_torch_2,
+ require_torch_gpu,
+ skip_mps,
+ slow,
+ torch_all_close,
+ torch_device,
+ )
+
+from .testing_utils import export_to_video
+
+
+logger = get_logger(__name__)
+
+
+def check_min_version(min_version):
+ if version.parse(__version__) < version.parse(min_version):
+ if "dev" in min_version:
+ error_message = (
+ "This example requires a source install from HuggingFace diffusers (see "
+ "`https://huggingface.co/docs/diffusers/installation#install-from-source`),"
+ )
+ else:
+ error_message = f"This example requires a minimum version of {min_version},"
+ error_message += f" but the version found is {__version__}.\n"
+ raise ImportError(error_message)
diff --git a/diffusers/src/diffusers/utils/__pycache__/__init__.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5d3480d75238e7f99534a833f28ab1dcd1b894f9
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/__init__.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/__init__.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4e80bf14798218dc9795805380c305bcf058d740
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/__init__.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/accelerate_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/accelerate_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4aa6264458f094907f7b2ee9015253948b5084d8
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/accelerate_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/accelerate_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/accelerate_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cf89313ce6414fc7f0b8906d2a8a355f339934b9
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/accelerate_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/constants.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/constants.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cb1fbc5849bc91344c1e6c078d5f09ab6261bc13
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/constants.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/constants.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/constants.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f8c124be971fa87499e517ed04c56d2713f94afa
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/constants.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/deprecation_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/deprecation_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..edc2e87e07c32a641264046b4c48746f27228ff6
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/deprecation_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/deprecation_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/deprecation_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..9476c07da5bdf71657a4df4d49ebdf0cf5d014aa
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/deprecation_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/doc_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/doc_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5b9d0cb44944127075690a18aeca3bd0359485d8
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/doc_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/doc_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/doc_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2a1ab9f880694dc3a86cbd980dc559e6a338efee
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/doc_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_flax_and_transformers_objects.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_flax_and_transformers_objects.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e0d89ca62cc1d5b92f8485eba5c47e7d7807d0f6
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_flax_and_transformers_objects.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_flax_and_transformers_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_flax_and_transformers_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a38a296e46c26466cd4357158738972e9b342769
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_flax_and_transformers_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_flax_objects.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_flax_objects.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4c5bc8ae7e9657d827108fef5e36a643d3497230
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_flax_objects.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_flax_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_flax_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..98d0358ebdfd20fd8b5a73342230d134b36107ec
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_flax_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_note_seq_objects.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_note_seq_objects.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3b0821e04ae54f98ce61932211e57582d4c2cfce
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_note_seq_objects.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_note_seq_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_note_seq_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1aba4b9df9b9f90dc873ce8053ad74f21002d469
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_note_seq_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_onnx_objects.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_onnx_objects.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e97244cb7a117c27f926c799af2149ed9ac62eb7
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_onnx_objects.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_onnx_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_onnx_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5baf6ff211f3df29b124a79c450152b6c5e2acb6
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_onnx_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_librosa_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_librosa_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f45295d66370b6428cd4d1ad746a417f1e88cc7f
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_librosa_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_k_diffusion_objects.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_k_diffusion_objects.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ff892e2c40c330141371fcff86e4d14615b0d73b
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_k_diffusion_objects.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_k_diffusion_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_k_diffusion_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c1c27768ec0076b8875e0e829554aacc4e40a98a
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_k_diffusion_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_onnx_objects.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_onnx_objects.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4b47c4c98400961184f5f09a89c5ee284d3db137
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_onnx_objects.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_onnx_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_onnx_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0b6171ecf59f23df8b6714a14cc11505a6ea2f55
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_and_onnx_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c17e1d953c55f9c8c4c9e319c0552fb1f9defc08
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_torch_and_transformers_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_transformers_and_torch_and_note_seq_objects.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_transformers_and_torch_and_note_seq_objects.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..883c716b3e28cfa06f31f7569d84dc3a99765de7
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_transformers_and_torch_and_note_seq_objects.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dummy_transformers_and_torch_and_note_seq_objects.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dummy_transformers_and_torch_and_note_seq_objects.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f17813df2b3728cb92a17d97144ecde4c8c2dfe1
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dummy_transformers_and_torch_and_note_seq_objects.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dynamic_modules_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/dynamic_modules_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2f8f30c6f28c24abdebfd3f15b39a5887c2edbd1
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dynamic_modules_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/dynamic_modules_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/dynamic_modules_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..59c31ac633597191a3e47f516bf2509aba58c9d4
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/dynamic_modules_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/hub_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/hub_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5a6d20089eeff87f76755bb9e3de47b3239f30b1
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/hub_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/hub_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/hub_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6812e55661957b02a212cd8f73139bc944fd796e
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/hub_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/import_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/import_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..ac4f43fa2a6be878bff0dc4d463da3e00393de61
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/import_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/import_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/import_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6e9ff664df7de18d8b99469fef28de3548be467f
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/import_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/logging.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/logging.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8a96e807c123b50f1d29e26ee1435a5f7664759d
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/logging.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/logging.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/logging.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7a164f80d1a054e9245cac6e12bb98eb793f2a22
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/logging.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/outputs.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/outputs.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e87e7f959c06219e8836562145791ca82d6767ba
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/outputs.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/outputs.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/outputs.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d1a1fd78702e0c48be14c91fee4cd6d5e4515681
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/outputs.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/pil_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/pil_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..42c734b7024f5375e3ba854be78a1e3c442d0d89
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/pil_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/pil_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/pil_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..69cf4d0271f079749b4930830256efafa1064547
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/pil_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/testing_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/testing_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8c2d472f323f54122a264e2ce6401ddec6f4af05
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/testing_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/testing_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/testing_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..59e36a405bf58f0d2dab7bc197ecfe30e62f628d
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/testing_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/torch_utils.cpython-310.pyc b/diffusers/src/diffusers/utils/__pycache__/torch_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..569e26fe9334b0f1c8b24b1465fb284c04bb48ad
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/torch_utils.cpython-310.pyc differ
diff --git a/diffusers/src/diffusers/utils/__pycache__/torch_utils.cpython-39.pyc b/diffusers/src/diffusers/utils/__pycache__/torch_utils.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..75d33cfd8b4f8b55659e92689be6bda00287a054
Binary files /dev/null and b/diffusers/src/diffusers/utils/__pycache__/torch_utils.cpython-39.pyc differ
diff --git a/diffusers/src/diffusers/utils/accelerate_utils.py b/diffusers/src/diffusers/utils/accelerate_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..10a83e1dd209cca198f4038d0d7e7228f9671859
--- /dev/null
+++ b/diffusers/src/diffusers/utils/accelerate_utils.py
@@ -0,0 +1,48 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Accelerate utilities: Utilities related to accelerate
+"""
+
+from packaging import version
+
+from .import_utils import is_accelerate_available
+
+
+if is_accelerate_available():
+ import accelerate
+
+
+def apply_forward_hook(method):
+ """
+ Decorator that applies a registered CpuOffload hook to an arbitrary function rather than `forward`. This is useful
+ for cases where a PyTorch module provides functions other than `forward` that should trigger a move to the
+ appropriate acceleration device. This is the case for `encode` and `decode` in [`AutoencoderKL`].
+
+ This decorator looks inside the internal `_hf_hook` property to find a registered offload hook.
+
+ :param method: The method to decorate. This method should be a method of a PyTorch module.
+ """
+ if not is_accelerate_available():
+ return method
+ accelerate_version = version.parse(accelerate.__version__).base_version
+ if version.parse(accelerate_version) < version.parse("0.17.0"):
+ return method
+
+ def wrapper(self, *args, **kwargs):
+ if hasattr(self, "_hf_hook") and hasattr(self._hf_hook, "pre_forward"):
+ self._hf_hook.pre_forward(self)
+ return method(self, *args, **kwargs)
+
+ return wrapper
diff --git a/diffusers/src/diffusers/utils/constants.py b/diffusers/src/diffusers/utils/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9e60a2a873b29a7d3adffbd7179be1670b3b417
--- /dev/null
+++ b/diffusers/src/diffusers/utils/constants.py
@@ -0,0 +1,32 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+
+from huggingface_hub.constants import HUGGINGFACE_HUB_CACHE, hf_cache_home
+
+
+default_cache_path = HUGGINGFACE_HUB_CACHE
+
+
+CONFIG_NAME = "config.json"
+WEIGHTS_NAME = "diffusion_pytorch_model.bin"
+FLAX_WEIGHTS_NAME = "diffusion_flax_model.msgpack"
+ONNX_WEIGHTS_NAME = "model.onnx"
+SAFETENSORS_WEIGHTS_NAME = "diffusion_pytorch_model.safetensors"
+ONNX_EXTERNAL_WEIGHTS_NAME = "weights.pb"
+HUGGINGFACE_CO_RESOLVE_ENDPOINT = "https://huggingface.co"
+DIFFUSERS_CACHE = default_cache_path
+DIFFUSERS_DYNAMIC_MODULE_NAME = "diffusers_modules"
+HF_MODULES_CACHE = os.getenv("HF_MODULES_CACHE", os.path.join(hf_cache_home, "modules"))
+DEPRECATED_REVISION_ARGS = ["fp16", "non-ema"]
diff --git a/diffusers/src/diffusers/utils/deprecation_utils.py b/diffusers/src/diffusers/utils/deprecation_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bdda664e102ea9913503b9e169fa97225d52c78
--- /dev/null
+++ b/diffusers/src/diffusers/utils/deprecation_utils.py
@@ -0,0 +1,49 @@
+import inspect
+import warnings
+from typing import Any, Dict, Optional, Union
+
+from packaging import version
+
+
+def deprecate(*args, take_from: Optional[Union[Dict, Any]] = None, standard_warn=True):
+ from .. import __version__
+
+ deprecated_kwargs = take_from
+ values = ()
+ if not isinstance(args[0], tuple):
+ args = (args,)
+
+ for attribute, version_name, message in args:
+ if version.parse(version.parse(__version__).base_version) >= version.parse(version_name):
+ raise ValueError(
+ f"The deprecation tuple {(attribute, version_name, message)} should be removed since diffusers'"
+ f" version {__version__} is >= {version_name}"
+ )
+
+ warning = None
+ if isinstance(deprecated_kwargs, dict) and attribute in deprecated_kwargs:
+ values += (deprecated_kwargs.pop(attribute),)
+ warning = f"The `{attribute}` argument is deprecated and will be removed in version {version_name}."
+ elif hasattr(deprecated_kwargs, attribute):
+ values += (getattr(deprecated_kwargs, attribute),)
+ warning = f"The `{attribute}` attribute is deprecated and will be removed in version {version_name}."
+ elif deprecated_kwargs is None:
+ warning = f"`{attribute}` is deprecated and will be removed in version {version_name}."
+
+ if warning is not None:
+ warning = warning + " " if standard_warn else ""
+ warnings.warn(warning + message, FutureWarning, stacklevel=2)
+
+ if isinstance(deprecated_kwargs, dict) and len(deprecated_kwargs) > 0:
+ call_frame = inspect.getouterframes(inspect.currentframe())[1]
+ filename = call_frame.filename
+ line_number = call_frame.lineno
+ function = call_frame.function
+ key, value = next(iter(deprecated_kwargs.items()))
+ raise TypeError(f"{function} in {filename} line {line_number-1} got an unexpected keyword argument `{key}`")
+
+ if len(values) == 0:
+ return
+ elif len(values) == 1:
+ return values[0]
+ return values
diff --git a/diffusers/src/diffusers/utils/doc_utils.py b/diffusers/src/diffusers/utils/doc_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f1f87743f99802931334bd51bf99985775116d59
--- /dev/null
+++ b/diffusers/src/diffusers/utils/doc_utils.py
@@ -0,0 +1,38 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Doc utilities: Utilities related to documentation
+"""
+import re
+
+
+def replace_example_docstring(example_docstring):
+ def docstring_decorator(fn):
+ func_doc = fn.__doc__
+ lines = func_doc.split("\n")
+ i = 0
+ while i < len(lines) and re.search(r"^\s*Examples?:\s*$", lines[i]) is None:
+ i += 1
+ if i < len(lines):
+ lines[i] = example_docstring
+ func_doc = "\n".join(lines)
+ else:
+ raise ValueError(
+ f"The function {fn} should have an empty 'Examples:' in its docstring as placeholder, "
+ f"current docstring is:\n{func_doc}"
+ )
+ fn.__doc__ = func_doc
+ return fn
+
+ return docstring_decorator
diff --git a/diffusers/src/diffusers/utils/dummy_flax_and_transformers_objects.py b/diffusers/src/diffusers/utils/dummy_flax_and_transformers_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..162bac1c4331149c4b5abde1eadd8013ab0cda99
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_flax_and_transformers_objects.py
@@ -0,0 +1,62 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class FlaxStableDiffusionControlNetPipeline(metaclass=DummyObject):
+ _backends = ["flax", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax", "transformers"])
+
+
+class FlaxStableDiffusionImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["flax", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax", "transformers"])
+
+
+class FlaxStableDiffusionInpaintPipeline(metaclass=DummyObject):
+ _backends = ["flax", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax", "transformers"])
+
+
+class FlaxStableDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["flax", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax", "transformers"])
diff --git a/diffusers/src/diffusers/utils/dummy_flax_objects.py b/diffusers/src/diffusers/utils/dummy_flax_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..2bb80d136f338d193c67773266355956afd1d98a
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_flax_objects.py
@@ -0,0 +1,197 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class FlaxControlNetModel(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxModelMixin(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxUNet2DConditionModel(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxAutoencoderKL(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxDDIMScheduler(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxDDPMScheduler(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxDPMSolverMultistepScheduler(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxKarrasVeScheduler(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxLMSDiscreteScheduler(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxPNDMScheduler(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxSchedulerMixin(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+
+class FlaxScoreSdeVeScheduler(metaclass=DummyObject):
+ _backends = ["flax"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["flax"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["flax"])
diff --git a/diffusers/src/diffusers/utils/dummy_note_seq_objects.py b/diffusers/src/diffusers/utils/dummy_note_seq_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..c02d0b015aedc37c01fb3b843bc79547aae5da68
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_note_seq_objects.py
@@ -0,0 +1,17 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class MidiProcessor(metaclass=DummyObject):
+ _backends = ["note_seq"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["note_seq"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["note_seq"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["note_seq"])
diff --git a/diffusers/src/diffusers/utils/dummy_onnx_objects.py b/diffusers/src/diffusers/utils/dummy_onnx_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..bde5f6ad0793e2d81bc638600b46ff81748d09ee
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_onnx_objects.py
@@ -0,0 +1,17 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class OnnxRuntimeModel(metaclass=DummyObject):
+ _backends = ["onnx"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["onnx"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["onnx"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["onnx"])
diff --git a/diffusers/src/diffusers/utils/dummy_pt_objects.py b/diffusers/src/diffusers/utils/dummy_pt_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..014e193aa32a95a444b20da0dbadb0b3ca599373
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_pt_objects.py
@@ -0,0 +1,705 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class AutoencoderKL(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class ControlNetModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class ModelMixin(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class PriorTransformer(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class T5FilmDecoder(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class Transformer2DModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class UNet1DModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class UNet2DConditionModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class UNet2DModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class UNet3DConditionModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class VQModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+def get_constant_schedule(*args, **kwargs):
+ requires_backends(get_constant_schedule, ["torch"])
+
+
+def get_constant_schedule_with_warmup(*args, **kwargs):
+ requires_backends(get_constant_schedule_with_warmup, ["torch"])
+
+
+def get_cosine_schedule_with_warmup(*args, **kwargs):
+ requires_backends(get_cosine_schedule_with_warmup, ["torch"])
+
+
+def get_cosine_with_hard_restarts_schedule_with_warmup(*args, **kwargs):
+ requires_backends(get_cosine_with_hard_restarts_schedule_with_warmup, ["torch"])
+
+
+def get_linear_schedule_with_warmup(*args, **kwargs):
+ requires_backends(get_linear_schedule_with_warmup, ["torch"])
+
+
+def get_polynomial_decay_schedule_with_warmup(*args, **kwargs):
+ requires_backends(get_polynomial_decay_schedule_with_warmup, ["torch"])
+
+
+def get_scheduler(*args, **kwargs):
+ requires_backends(get_scheduler, ["torch"])
+
+
+class AudioPipelineOutput(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DanceDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DDIMPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DDPMPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DiTPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class ImagePipelineOutput(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class KarrasVePipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class LDMPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class LDMSuperResolutionPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class PNDMPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class RePaintPipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class ScoreSdeVePipeline(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DDIMInverseScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DDIMScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DDPMScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DEISMultistepScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DPMSolverMultistepScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class DPMSolverSinglestepScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class EulerAncestralDiscreteScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class EulerDiscreteScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class HeunDiscreteScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class IPNDMScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class KarrasVeScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class KDPM2AncestralDiscreteScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class KDPM2DiscreteScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class PNDMScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class RePaintScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class SchedulerMixin(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class ScoreSdeVeScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class UnCLIPScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class UniPCMultistepScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class VQDiffusionScheduler(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+
+class EMAModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
diff --git a/diffusers/src/diffusers/utils/dummy_torch_and_librosa_objects.py b/diffusers/src/diffusers/utils/dummy_torch_and_librosa_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..2088bc4a744198284f22fe54e6f1055cf3568566
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_torch_and_librosa_objects.py
@@ -0,0 +1,32 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class AudioDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "librosa"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "librosa"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "librosa"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "librosa"])
+
+
+class Mel(metaclass=DummyObject):
+ _backends = ["torch", "librosa"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "librosa"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "librosa"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "librosa"])
diff --git a/diffusers/src/diffusers/utils/dummy_torch_and_scipy_objects.py b/diffusers/src/diffusers/utils/dummy_torch_and_scipy_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1ff25863822b04971d2c6dfdc17f5b28774cf05
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_torch_and_scipy_objects.py
@@ -0,0 +1,17 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class LMSDiscreteScheduler(metaclass=DummyObject):
+ _backends = ["torch", "scipy"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "scipy"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "scipy"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "scipy"])
diff --git a/diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_k_diffusion_objects.py b/diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_k_diffusion_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..56836f0b6d77b8daa25e956101694863e418339f
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_k_diffusion_objects.py
@@ -0,0 +1,17 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class StableDiffusionKDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers", "k_diffusion"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers", "k_diffusion"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "k_diffusion"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "k_diffusion"])
diff --git a/diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_onnx_objects.py b/diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_onnx_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7afad8226b87292100270e3e7daad6885be0e7f
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_torch_and_transformers_and_onnx_objects.py
@@ -0,0 +1,92 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class OnnxStableDiffusionImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers", "onnx"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+
+class OnnxStableDiffusionInpaintPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers", "onnx"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+
+class OnnxStableDiffusionInpaintPipelineLegacy(metaclass=DummyObject):
+ _backends = ["torch", "transformers", "onnx"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+
+class OnnxStableDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers", "onnx"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+
+class OnnxStableDiffusionUpscalePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers", "onnx"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+
+class StableDiffusionOnnxPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers", "onnx"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers", "onnx"])
diff --git a/diffusers/src/diffusers/utils/dummy_torch_and_transformers_objects.py b/diffusers/src/diffusers/utils/dummy_torch_and_transformers_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf85ff157f5797703ff9200a6e306a2ede80a707
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_torch_and_transformers_objects.py
@@ -0,0 +1,512 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class TextualInversionLoaderMixin(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class AltDiffusionImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class AltDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class AudioLDMPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class CycleDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class LDMTextToImagePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class PaintByExamplePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class SemanticStableDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionAttendAndExcitePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionControlNetPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionDepth2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionImageVariationPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionInpaintPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionInpaintPipelineLegacy(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionInstructPix2PixPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionLatentUpscalePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionModelEditingPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionPanoramaPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionPipelineSafe(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionPix2PixZeroPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionSAGPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableDiffusionUpscalePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableUnCLIPImg2ImgPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class StableUnCLIPPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class TextToVideoSDPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class UnCLIPImageVariationPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class UnCLIPPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VersatileDiffusionDualGuidedPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VersatileDiffusionImageVariationPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VersatileDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VersatileDiffusionTextToImagePipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+
+class VQDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["torch", "transformers"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch", "transformers"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch", "transformers"])
diff --git a/diffusers/src/diffusers/utils/dummy_transformers_and_torch_and_note_seq_objects.py b/diffusers/src/diffusers/utils/dummy_transformers_and_torch_and_note_seq_objects.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbde04e33f0abd86d12f3dee048a4f0585c9f19d
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dummy_transformers_and_torch_and_note_seq_objects.py
@@ -0,0 +1,17 @@
+# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+class SpectrogramDiffusionPipeline(metaclass=DummyObject):
+ _backends = ["transformers", "torch", "note_seq"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["transformers", "torch", "note_seq"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["transformers", "torch", "note_seq"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["transformers", "torch", "note_seq"])
diff --git a/diffusers/src/diffusers/utils/dynamic_modules_utils.py b/diffusers/src/diffusers/utils/dynamic_modules_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..1951c4fa2623b6b14b85c035395a738cdd733eea
--- /dev/null
+++ b/diffusers/src/diffusers/utils/dynamic_modules_utils.py
@@ -0,0 +1,456 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Utilities to dynamically load objects from the Hub."""
+
+import importlib
+import inspect
+import json
+import os
+import re
+import shutil
+import sys
+from distutils.version import StrictVersion
+from pathlib import Path
+from typing import Dict, Optional, Union
+from urllib import request
+
+from huggingface_hub import HfFolder, cached_download, hf_hub_download, model_info
+
+from .. import __version__
+from . import DIFFUSERS_DYNAMIC_MODULE_NAME, HF_MODULES_CACHE, logging
+
+
+COMMUNITY_PIPELINES_URL = (
+ "https://raw.githubusercontent.com/huggingface/diffusers/{revision}/examples/community/{pipeline}.py"
+)
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def get_diffusers_versions():
+ url = "https://pypi.org/pypi/diffusers/json"
+ releases = json.loads(request.urlopen(url).read())["releases"].keys()
+ return sorted(releases, key=StrictVersion)
+
+
+def init_hf_modules():
+ """
+ Creates the cache directory for modules with an init, and adds it to the Python path.
+ """
+ # This function has already been executed if HF_MODULES_CACHE already is in the Python path.
+ if HF_MODULES_CACHE in sys.path:
+ return
+
+ sys.path.append(HF_MODULES_CACHE)
+ os.makedirs(HF_MODULES_CACHE, exist_ok=True)
+ init_path = Path(HF_MODULES_CACHE) / "__init__.py"
+ if not init_path.exists():
+ init_path.touch()
+
+
+def create_dynamic_module(name: Union[str, os.PathLike]):
+ """
+ Creates a dynamic module in the cache directory for modules.
+ """
+ init_hf_modules()
+ dynamic_module_path = Path(HF_MODULES_CACHE) / name
+ # If the parent module does not exist yet, recursively create it.
+ if not dynamic_module_path.parent.exists():
+ create_dynamic_module(dynamic_module_path.parent)
+ os.makedirs(dynamic_module_path, exist_ok=True)
+ init_path = dynamic_module_path / "__init__.py"
+ if not init_path.exists():
+ init_path.touch()
+
+
+def get_relative_imports(module_file):
+ """
+ Get the list of modules that are relatively imported in a module file.
+
+ Args:
+ module_file (`str` or `os.PathLike`): The module file to inspect.
+ """
+ with open(module_file, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ # Imports of the form `import .xxx`
+ relative_imports = re.findall("^\s*import\s+\.(\S+)\s*$", content, flags=re.MULTILINE)
+ # Imports of the form `from .xxx import yyy`
+ relative_imports += re.findall("^\s*from\s+\.(\S+)\s+import", content, flags=re.MULTILINE)
+ # Unique-ify
+ return list(set(relative_imports))
+
+
+def get_relative_import_files(module_file):
+ """
+ Get the list of all files that are needed for a given module. Note that this function recurses through the relative
+ imports (if a imports b and b imports c, it will return module files for b and c).
+
+ Args:
+ module_file (`str` or `os.PathLike`): The module file to inspect.
+ """
+ no_change = False
+ files_to_check = [module_file]
+ all_relative_imports = []
+
+ # Let's recurse through all relative imports
+ while not no_change:
+ new_imports = []
+ for f in files_to_check:
+ new_imports.extend(get_relative_imports(f))
+
+ module_path = Path(module_file).parent
+ new_import_files = [str(module_path / m) for m in new_imports]
+ new_import_files = [f for f in new_import_files if f not in all_relative_imports]
+ files_to_check = [f"{f}.py" for f in new_import_files]
+
+ no_change = len(new_import_files) == 0
+ all_relative_imports.extend(files_to_check)
+
+ return all_relative_imports
+
+
+def check_imports(filename):
+ """
+ Check if the current Python environment contains all the libraries that are imported in a file.
+ """
+ with open(filename, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ # Imports of the form `import xxx`
+ imports = re.findall("^\s*import\s+(\S+)\s*$", content, flags=re.MULTILINE)
+ # Imports of the form `from xxx import yyy`
+ imports += re.findall("^\s*from\s+(\S+)\s+import", content, flags=re.MULTILINE)
+ # Only keep the top-level module
+ imports = [imp.split(".")[0] for imp in imports if not imp.startswith(".")]
+
+ # Unique-ify and test we got them all
+ imports = list(set(imports))
+ missing_packages = []
+ for imp in imports:
+ try:
+ importlib.import_module(imp)
+ except ImportError:
+ missing_packages.append(imp)
+
+ if len(missing_packages) > 0:
+ raise ImportError(
+ "This modeling file requires the following packages that were not found in your environment: "
+ f"{', '.join(missing_packages)}. Run `pip install {' '.join(missing_packages)}`"
+ )
+
+ return get_relative_imports(filename)
+
+
+def get_class_in_module(class_name, module_path):
+ """
+ Import a module on the cache directory for modules and extract a class from it.
+ """
+ module_path = module_path.replace(os.path.sep, ".")
+ module = importlib.import_module(module_path)
+
+ if class_name is None:
+ return find_pipeline_class(module)
+ return getattr(module, class_name)
+
+
+def find_pipeline_class(loaded_module):
+ """
+ Retrieve pipeline class that inherits from `DiffusionPipeline`. Note that there has to be exactly one class
+ inheriting from `DiffusionPipeline`.
+ """
+ from ..pipelines import DiffusionPipeline
+
+ cls_members = dict(inspect.getmembers(loaded_module, inspect.isclass))
+
+ pipeline_class = None
+ for cls_name, cls in cls_members.items():
+ if (
+ cls_name != DiffusionPipeline.__name__
+ and issubclass(cls, DiffusionPipeline)
+ and cls.__module__.split(".")[0] != "diffusers"
+ ):
+ if pipeline_class is not None:
+ raise ValueError(
+ f"Multiple classes that inherit from {DiffusionPipeline.__name__} have been found:"
+ f" {pipeline_class.__name__}, and {cls_name}. Please make sure to define only one in"
+ f" {loaded_module}."
+ )
+ pipeline_class = cls
+
+ return pipeline_class
+
+
+def get_cached_module_file(
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ module_file: str,
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ force_download: bool = False,
+ resume_download: bool = False,
+ proxies: Optional[Dict[str, str]] = None,
+ use_auth_token: Optional[Union[bool, str]] = None,
+ revision: Optional[str] = None,
+ local_files_only: bool = False,
+):
+ """
+ Prepares Downloads a module from a local folder or a distant repo and returns its path inside the cached
+ Transformers module.
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained model configuration hosted inside a model repo on
+ huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or namespaced
+ under a user or organization name, like `dbmdz/bert-base-german-cased`.
+ - a path to a *directory* containing a configuration file saved using the
+ [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+
+ module_file (`str`):
+ The name of the module file containing the class to look for.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
+ cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the configuration files and override the cached versions if they
+ exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received file. Attempts to resume the download if such a file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ use_auth_token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `transformers-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ local_files_only (`bool`, *optional*, defaults to `False`):
+ If `True`, will only try to load the tokenizer configuration from local files.
+
+
+
+ You may pass a token in `use_auth_token` if you are not logged in (`huggingface-cli long`) and want to use private
+ or [gated models](https://huggingface.co/docs/hub/models-gated#gated-models).
+
+
+
+ Returns:
+ `str`: The path to the module inside the cache.
+ """
+ # Download and cache module_file from the repo `pretrained_model_name_or_path` of grab it if it's a local file.
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+
+ module_file_or_url = os.path.join(pretrained_model_name_or_path, module_file)
+
+ if os.path.isfile(module_file_or_url):
+ resolved_module_file = module_file_or_url
+ submodule = "local"
+ elif pretrained_model_name_or_path.count("/") == 0:
+ available_versions = get_diffusers_versions()
+ # cut ".dev0"
+ latest_version = "v" + ".".join(__version__.split(".")[:3])
+
+ # retrieve github version that matches
+ if revision is None:
+ revision = latest_version if latest_version in available_versions else "main"
+ logger.info(f"Defaulting to latest_version: {revision}.")
+ elif revision in available_versions:
+ revision = f"v{revision}"
+ elif revision == "main":
+ revision = revision
+ else:
+ raise ValueError(
+ f"`custom_revision`: {revision} does not exist. Please make sure to choose one of"
+ f" {', '.join(available_versions + ['main'])}."
+ )
+
+ # community pipeline on GitHub
+ github_url = COMMUNITY_PIPELINES_URL.format(revision=revision, pipeline=pretrained_model_name_or_path)
+ try:
+ resolved_module_file = cached_download(
+ github_url,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=False,
+ )
+ submodule = "git"
+ module_file = pretrained_model_name_or_path + ".py"
+ except EnvironmentError:
+ logger.error(f"Could not locate the {module_file} inside {pretrained_model_name_or_path}.")
+ raise
+ else:
+ try:
+ # Load from URL or cache if already cached
+ resolved_module_file = hf_hub_download(
+ pretrained_model_name_or_path,
+ module_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ )
+ submodule = os.path.join("local", "--".join(pretrained_model_name_or_path.split("/")))
+ except EnvironmentError:
+ logger.error(f"Could not locate the {module_file} inside {pretrained_model_name_or_path}.")
+ raise
+
+ # Check we have all the requirements in our environment
+ modules_needed = check_imports(resolved_module_file)
+
+ # Now we move the module inside our cached dynamic modules.
+ full_submodule = DIFFUSERS_DYNAMIC_MODULE_NAME + os.path.sep + submodule
+ create_dynamic_module(full_submodule)
+ submodule_path = Path(HF_MODULES_CACHE) / full_submodule
+ if submodule == "local" or submodule == "git":
+ # We always copy local files (we could hash the file to see if there was a change, and give them the name of
+ # that hash, to only copy when there is a modification but it seems overkill for now).
+ # The only reason we do the copy is to avoid putting too many folders in sys.path.
+ shutil.copy(resolved_module_file, submodule_path / module_file)
+ for module_needed in modules_needed:
+ module_needed = f"{module_needed}.py"
+ shutil.copy(os.path.join(pretrained_model_name_or_path, module_needed), submodule_path / module_needed)
+ else:
+ # Get the commit hash
+ # TODO: we will get this info in the etag soon, so retrieve it from there and not here.
+ if isinstance(use_auth_token, str):
+ token = use_auth_token
+ elif use_auth_token is True:
+ token = HfFolder.get_token()
+ else:
+ token = None
+
+ commit_hash = model_info(pretrained_model_name_or_path, revision=revision, token=token).sha
+
+ # The module file will end up being placed in a subfolder with the git hash of the repo. This way we get the
+ # benefit of versioning.
+ submodule_path = submodule_path / commit_hash
+ full_submodule = full_submodule + os.path.sep + commit_hash
+ create_dynamic_module(full_submodule)
+
+ if not (submodule_path / module_file).exists():
+ shutil.copy(resolved_module_file, submodule_path / module_file)
+ # Make sure we also have every file with relative
+ for module_needed in modules_needed:
+ if not (submodule_path / module_needed).exists():
+ get_cached_module_file(
+ pretrained_model_name_or_path,
+ f"{module_needed}.py",
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ local_files_only=local_files_only,
+ )
+ return os.path.join(full_submodule, module_file)
+
+
+def get_class_from_dynamic_module(
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ module_file: str,
+ class_name: Optional[str] = None,
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ force_download: bool = False,
+ resume_download: bool = False,
+ proxies: Optional[Dict[str, str]] = None,
+ use_auth_token: Optional[Union[bool, str]] = None,
+ revision: Optional[str] = None,
+ local_files_only: bool = False,
+ **kwargs,
+):
+ """
+ Extracts a class from a module file, present in the local folder or repository of a model.
+
+
+
+ Calling this function will execute the code in the module file found locally or downloaded from the Hub. It should
+ therefore only be called on trusted repos.
+
+
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained model configuration hosted inside a model repo on
+ huggingface.co. Valid model ids can be located at the root-level, like `bert-base-uncased`, or namespaced
+ under a user or organization name, like `dbmdz/bert-base-german-cased`.
+ - a path to a *directory* containing a configuration file saved using the
+ [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+
+ module_file (`str`):
+ The name of the module file containing the class to look for.
+ class_name (`str`):
+ The name of the class to import in the module.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
+ cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the configuration files and override the cached versions if they
+ exist.
+ resume_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to delete incompletely received file. Attempts to resume the download if such a file exists.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ use_auth_token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `transformers-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ local_files_only (`bool`, *optional*, defaults to `False`):
+ If `True`, will only try to load the tokenizer configuration from local files.
+
+
+
+ You may pass a token in `use_auth_token` if you are not logged in (`huggingface-cli long`) and want to use private
+ or [gated models](https://huggingface.co/docs/hub/models-gated#gated-models).
+
+
+
+ Returns:
+ `type`: The class, dynamically imported from the module.
+
+ Examples:
+
+ ```python
+ # Download module `modeling.py` from huggingface.co and cache then extract the class `MyBertModel` from this
+ # module.
+ cls = get_class_from_dynamic_module("sgugger/my-bert-model", "modeling.py", "MyBertModel")
+ ```"""
+ # And lastly we get the class inside our newly created module
+ final_module = get_cached_module_file(
+ pretrained_model_name_or_path,
+ module_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ use_auth_token=use_auth_token,
+ revision=revision,
+ local_files_only=local_files_only,
+ )
+ return get_class_in_module(class_name, final_module.replace(".py", ""))
diff --git a/diffusers/src/diffusers/utils/hub_utils.py b/diffusers/src/diffusers/utils/hub_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..511763ec668774d556f5a5bf622cb65082bba68d
--- /dev/null
+++ b/diffusers/src/diffusers/utils/hub_utils.py
@@ -0,0 +1,358 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+import re
+import sys
+import traceback
+import warnings
+from pathlib import Path
+from typing import Dict, Optional, Union
+from uuid import uuid4
+
+from huggingface_hub import HfFolder, ModelCard, ModelCardData, hf_hub_download, whoami
+from huggingface_hub.file_download import REGEX_COMMIT_HASH
+from huggingface_hub.utils import (
+ EntryNotFoundError,
+ RepositoryNotFoundError,
+ RevisionNotFoundError,
+ is_jinja_available,
+)
+from packaging import version
+from requests import HTTPError
+
+from .. import __version__
+from .constants import (
+ DEPRECATED_REVISION_ARGS,
+ DIFFUSERS_CACHE,
+ HUGGINGFACE_CO_RESOLVE_ENDPOINT,
+ SAFETENSORS_WEIGHTS_NAME,
+ WEIGHTS_NAME,
+)
+from .import_utils import (
+ ENV_VARS_TRUE_VALUES,
+ _flax_version,
+ _jax_version,
+ _onnxruntime_version,
+ _torch_version,
+ is_flax_available,
+ is_onnx_available,
+ is_torch_available,
+)
+from .logging import get_logger
+
+
+logger = get_logger(__name__)
+
+
+MODEL_CARD_TEMPLATE_PATH = Path(__file__).parent / "model_card_template.md"
+SESSION_ID = uuid4().hex
+HF_HUB_OFFLINE = os.getenv("HF_HUB_OFFLINE", "").upper() in ENV_VARS_TRUE_VALUES
+DISABLE_TELEMETRY = os.getenv("DISABLE_TELEMETRY", "").upper() in ENV_VARS_TRUE_VALUES
+HUGGINGFACE_CO_TELEMETRY = HUGGINGFACE_CO_RESOLVE_ENDPOINT + "/api/telemetry/"
+
+
+def http_user_agent(user_agent: Union[Dict, str, None] = None) -> str:
+ """
+ Formats a user-agent string with basic info about a request.
+ """
+ ua = f"diffusers/{__version__}; python/{sys.version.split()[0]}; session_id/{SESSION_ID}"
+ if DISABLE_TELEMETRY or HF_HUB_OFFLINE:
+ return ua + "; telemetry/off"
+ if is_torch_available():
+ ua += f"; torch/{_torch_version}"
+ if is_flax_available():
+ ua += f"; jax/{_jax_version}"
+ ua += f"; flax/{_flax_version}"
+ if is_onnx_available():
+ ua += f"; onnxruntime/{_onnxruntime_version}"
+ # CI will set this value to True
+ if os.environ.get("DIFFUSERS_IS_CI", "").upper() in ENV_VARS_TRUE_VALUES:
+ ua += "; is_ci/true"
+ if isinstance(user_agent, dict):
+ ua += "; " + "; ".join(f"{k}/{v}" for k, v in user_agent.items())
+ elif isinstance(user_agent, str):
+ ua += "; " + user_agent
+ return ua
+
+
+def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
+ if token is None:
+ token = HfFolder.get_token()
+ if organization is None:
+ username = whoami(token)["name"]
+ return f"{username}/{model_id}"
+ else:
+ return f"{organization}/{model_id}"
+
+
+def create_model_card(args, model_name):
+ if not is_jinja_available():
+ raise ValueError(
+ "Modelcard rendering is based on Jinja templates."
+ " Please make sure to have `jinja` installed before using `create_model_card`."
+ " To install it, please run `pip install Jinja2`."
+ )
+
+ if hasattr(args, "local_rank") and args.local_rank not in [-1, 0]:
+ return
+
+ hub_token = args.hub_token if hasattr(args, "hub_token") else None
+ repo_name = get_full_repo_name(model_name, token=hub_token)
+
+ model_card = ModelCard.from_template(
+ card_data=ModelCardData( # Card metadata object that will be converted to YAML block
+ language="en",
+ license="apache-2.0",
+ library_name="diffusers",
+ tags=[],
+ datasets=args.dataset_name,
+ metrics=[],
+ ),
+ template_path=MODEL_CARD_TEMPLATE_PATH,
+ model_name=model_name,
+ repo_name=repo_name,
+ dataset_name=args.dataset_name if hasattr(args, "dataset_name") else None,
+ learning_rate=args.learning_rate,
+ train_batch_size=args.train_batch_size,
+ eval_batch_size=args.eval_batch_size,
+ gradient_accumulation_steps=(
+ args.gradient_accumulation_steps if hasattr(args, "gradient_accumulation_steps") else None
+ ),
+ adam_beta1=args.adam_beta1 if hasattr(args, "adam_beta1") else None,
+ adam_beta2=args.adam_beta2 if hasattr(args, "adam_beta2") else None,
+ adam_weight_decay=args.adam_weight_decay if hasattr(args, "adam_weight_decay") else None,
+ adam_epsilon=args.adam_epsilon if hasattr(args, "adam_epsilon") else None,
+ lr_scheduler=args.lr_scheduler if hasattr(args, "lr_scheduler") else None,
+ lr_warmup_steps=args.lr_warmup_steps if hasattr(args, "lr_warmup_steps") else None,
+ ema_inv_gamma=args.ema_inv_gamma if hasattr(args, "ema_inv_gamma") else None,
+ ema_power=args.ema_power if hasattr(args, "ema_power") else None,
+ ema_max_decay=args.ema_max_decay if hasattr(args, "ema_max_decay") else None,
+ mixed_precision=args.mixed_precision,
+ )
+
+ card_path = os.path.join(args.output_dir, "README.md")
+ model_card.save(card_path)
+
+
+def extract_commit_hash(resolved_file: Optional[str], commit_hash: Optional[str] = None):
+ """
+ Extracts the commit hash from a resolved filename toward a cache file.
+ """
+ if resolved_file is None or commit_hash is not None:
+ return commit_hash
+ resolved_file = str(Path(resolved_file).as_posix())
+ search = re.search(r"snapshots/([^/]+)/", resolved_file)
+ if search is None:
+ return None
+ commit_hash = search.groups()[0]
+ return commit_hash if REGEX_COMMIT_HASH.match(commit_hash) else None
+
+
+# Old default cache path, potentially to be migrated.
+# This logic was more or less taken from `transformers`, with the following differences:
+# - Diffusers doesn't use custom environment variables to specify the cache path.
+# - There is no need to migrate the cache format, just move the files to the new location.
+hf_cache_home = os.path.expanduser(
+ os.getenv("HF_HOME", os.path.join(os.getenv("XDG_CACHE_HOME", "~/.cache"), "huggingface"))
+)
+old_diffusers_cache = os.path.join(hf_cache_home, "diffusers")
+
+
+def move_cache(old_cache_dir: Optional[str] = None, new_cache_dir: Optional[str] = None) -> None:
+ if new_cache_dir is None:
+ new_cache_dir = DIFFUSERS_CACHE
+ if old_cache_dir is None:
+ old_cache_dir = old_diffusers_cache
+
+ old_cache_dir = Path(old_cache_dir).expanduser()
+ new_cache_dir = Path(new_cache_dir).expanduser()
+ for old_blob_path in old_cache_dir.glob("**/blobs/*"):
+ if old_blob_path.is_file() and not old_blob_path.is_symlink():
+ new_blob_path = new_cache_dir / old_blob_path.relative_to(old_cache_dir)
+ new_blob_path.parent.mkdir(parents=True, exist_ok=True)
+ os.replace(old_blob_path, new_blob_path)
+ try:
+ os.symlink(new_blob_path, old_blob_path)
+ except OSError:
+ logger.warning(
+ "Could not create symlink between old cache and new cache. If you use an older version of diffusers again, files will be re-downloaded."
+ )
+ # At this point, old_cache_dir contains symlinks to the new cache (it can still be used).
+
+
+cache_version_file = os.path.join(DIFFUSERS_CACHE, "version_diffusers_cache.txt")
+if not os.path.isfile(cache_version_file):
+ cache_version = 0
+else:
+ with open(cache_version_file) as f:
+ cache_version = int(f.read())
+
+if cache_version < 1:
+ old_cache_is_not_empty = os.path.isdir(old_diffusers_cache) and len(os.listdir(old_diffusers_cache)) > 0
+ if old_cache_is_not_empty:
+ logger.warning(
+ "The cache for model files in Diffusers v0.14.0 has moved to a new location. Moving your "
+ "existing cached models. This is a one-time operation, you can interrupt it or run it "
+ "later by calling `diffusers.utils.hub_utils.move_cache()`."
+ )
+ try:
+ move_cache()
+ except Exception as e:
+ trace = "\n".join(traceback.format_tb(e.__traceback__))
+ logger.error(
+ f"There was a problem when trying to move your cache:\n\n{trace}\n{e.__class__.__name__}: {e}\n\nPlease "
+ "file an issue at https://github.com/huggingface/diffusers/issues/new/choose, copy paste this whole "
+ "message and we will do our best to help."
+ )
+
+if cache_version < 1:
+ try:
+ os.makedirs(DIFFUSERS_CACHE, exist_ok=True)
+ with open(cache_version_file, "w") as f:
+ f.write("1")
+ except Exception:
+ logger.warning(
+ f"There was a problem when trying to write in your cache folder ({DIFFUSERS_CACHE}). Please, ensure "
+ "the directory exists and can be written to."
+ )
+
+
+def _add_variant(weights_name: str, variant: Optional[str] = None) -> str:
+ if variant is not None:
+ splits = weights_name.split(".")
+ splits = splits[:-1] + [variant] + splits[-1:]
+ weights_name = ".".join(splits)
+
+ return weights_name
+
+
+def _get_model_file(
+ pretrained_model_name_or_path,
+ *,
+ weights_name,
+ subfolder,
+ cache_dir,
+ force_download,
+ proxies,
+ resume_download,
+ local_files_only,
+ use_auth_token,
+ user_agent,
+ revision,
+ commit_hash=None,
+):
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+ if os.path.isfile(pretrained_model_name_or_path):
+ return pretrained_model_name_or_path
+ elif os.path.isdir(pretrained_model_name_or_path):
+ if os.path.isfile(os.path.join(pretrained_model_name_or_path, weights_name)):
+ # Load from a PyTorch checkpoint
+ model_file = os.path.join(pretrained_model_name_or_path, weights_name)
+ return model_file
+ elif subfolder is not None and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, weights_name)
+ ):
+ model_file = os.path.join(pretrained_model_name_or_path, subfolder, weights_name)
+ return model_file
+ else:
+ raise EnvironmentError(
+ f"Error no file named {weights_name} found in directory {pretrained_model_name_or_path}."
+ )
+ else:
+ # 1. First check if deprecated way of loading from branches is used
+ if (
+ revision in DEPRECATED_REVISION_ARGS
+ and (weights_name == WEIGHTS_NAME or weights_name == SAFETENSORS_WEIGHTS_NAME)
+ and version.parse(version.parse(__version__).base_version) >= version.parse("0.17.0")
+ ):
+ try:
+ model_file = hf_hub_download(
+ pretrained_model_name_or_path,
+ filename=_add_variant(weights_name, revision),
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ subfolder=subfolder,
+ revision=revision or commit_hash,
+ )
+ warnings.warn(
+ f"Loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'` is deprecated. Loading instead from `revision='main'` with `variant={revision}`. Loading model variants via `revision='{revision}'` will be removed in diffusers v1. Please use `variant='{revision}'` instead.",
+ FutureWarning,
+ )
+ return model_file
+ except: # noqa: E722
+ warnings.warn(
+ f"You are loading the variant {revision} from {pretrained_model_name_or_path} via `revision='{revision}'`. This behavior is deprecated and will be removed in diffusers v1. One should use `variant='{revision}'` instead. However, it appears that {pretrained_model_name_or_path} currently does not have a {_add_variant(weights_name, revision)} file in the 'main' branch of {pretrained_model_name_or_path}. \n The Diffusers team and community would be very grateful if you could open an issue: https://github.com/huggingface/diffusers/issues/new with the title '{pretrained_model_name_or_path} is missing {_add_variant(weights_name, revision)}' so that the correct variant file can be added.",
+ FutureWarning,
+ )
+ try:
+ # 2. Load model file as usual
+ model_file = hf_hub_download(
+ pretrained_model_name_or_path,
+ filename=weights_name,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ use_auth_token=use_auth_token,
+ user_agent=user_agent,
+ subfolder=subfolder,
+ revision=revision or commit_hash,
+ )
+ return model_file
+
+ except RepositoryNotFoundError:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier "
+ "listed on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a "
+ "token having permission to this repo with `use_auth_token` or log in with `huggingface-cli "
+ "login`."
+ )
+ except RevisionNotFoundError:
+ raise EnvironmentError(
+ f"{revision} is not a valid git identifier (branch name, tag name or commit id) that exists for "
+ "this model name. Check the model page at "
+ f"'https://huggingface.co/{pretrained_model_name_or_path}' for available revisions."
+ )
+ except EntryNotFoundError:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named {weights_name}."
+ )
+ except HTTPError as err:
+ raise EnvironmentError(
+ f"There was a specific connection error when trying to load {pretrained_model_name_or_path}:\n{err}"
+ )
+ except ValueError:
+ raise EnvironmentError(
+ f"We couldn't connect to '{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this model, couldn't find it"
+ f" in the cached files and it looks like {pretrained_model_name_or_path} is not the path to a"
+ f" directory containing a file named {weights_name} or"
+ " \nCheckout your internet connection or see how to run the library in"
+ " offline mode at 'https://huggingface.co/docs/diffusers/installation#offline-mode'."
+ )
+ except EnvironmentError:
+ raise EnvironmentError(
+ f"Can't load the model for '{pretrained_model_name_or_path}'. If you were trying to load it from "
+ "'https://huggingface.co/models', make sure you don't have a local directory with the same name. "
+ f"Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a directory "
+ f"containing a file named {weights_name}"
+ )
diff --git a/diffusers/src/diffusers/utils/import_utils.py b/diffusers/src/diffusers/utils/import_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd7538b1b5e9ced4d0f3a724a78f2ff4f54a53fc
--- /dev/null
+++ b/diffusers/src/diffusers/utils/import_utils.py
@@ -0,0 +1,580 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Import utilities: Utilities related to imports and our lazy inits.
+"""
+import importlib.util
+import operator as op
+import os
+import sys
+from collections import OrderedDict
+from typing import Union
+
+from huggingface_hub.utils import is_jinja_available # noqa: F401
+from packaging import version
+from packaging.version import Version, parse
+
+from . import logging
+
+
+# The package importlib_metadata is in a different place, depending on the python version.
+if sys.version_info < (3, 8):
+ import importlib_metadata
+else:
+ import importlib.metadata as importlib_metadata
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+ENV_VARS_TRUE_VALUES = {"1", "ON", "YES", "TRUE"}
+ENV_VARS_TRUE_AND_AUTO_VALUES = ENV_VARS_TRUE_VALUES.union({"AUTO"})
+
+USE_TF = os.environ.get("USE_TF", "AUTO").upper()
+USE_TORCH = os.environ.get("USE_TORCH", "AUTO").upper()
+USE_JAX = os.environ.get("USE_FLAX", "AUTO").upper()
+USE_SAFETENSORS = os.environ.get("USE_SAFETENSORS", "AUTO").upper()
+
+STR_OPERATION_TO_FUNC = {">": op.gt, ">=": op.ge, "==": op.eq, "!=": op.ne, "<=": op.le, "<": op.lt}
+
+_torch_version = "N/A"
+if USE_TORCH in ENV_VARS_TRUE_AND_AUTO_VALUES and USE_TF not in ENV_VARS_TRUE_VALUES:
+ _torch_available = importlib.util.find_spec("torch") is not None
+ if _torch_available:
+ try:
+ _torch_version = importlib_metadata.version("torch")
+ logger.info(f"PyTorch version {_torch_version} available.")
+ except importlib_metadata.PackageNotFoundError:
+ _torch_available = False
+else:
+ logger.info("Disabling PyTorch because USE_TORCH is set")
+ _torch_available = False
+
+
+_tf_version = "N/A"
+if USE_TF in ENV_VARS_TRUE_AND_AUTO_VALUES and USE_TORCH not in ENV_VARS_TRUE_VALUES:
+ _tf_available = importlib.util.find_spec("tensorflow") is not None
+ if _tf_available:
+ candidates = (
+ "tensorflow",
+ "tensorflow-cpu",
+ "tensorflow-gpu",
+ "tf-nightly",
+ "tf-nightly-cpu",
+ "tf-nightly-gpu",
+ "intel-tensorflow",
+ "intel-tensorflow-avx512",
+ "tensorflow-rocm",
+ "tensorflow-macos",
+ "tensorflow-aarch64",
+ )
+ _tf_version = None
+ # For the metadata, we have to look for both tensorflow and tensorflow-cpu
+ for pkg in candidates:
+ try:
+ _tf_version = importlib_metadata.version(pkg)
+ break
+ except importlib_metadata.PackageNotFoundError:
+ pass
+ _tf_available = _tf_version is not None
+ if _tf_available:
+ if version.parse(_tf_version) < version.parse("2"):
+ logger.info(f"TensorFlow found but with version {_tf_version}. Diffusers requires version 2 minimum.")
+ _tf_available = False
+ else:
+ logger.info(f"TensorFlow version {_tf_version} available.")
+else:
+ logger.info("Disabling Tensorflow because USE_TORCH is set")
+ _tf_available = False
+
+_jax_version = "N/A"
+_flax_version = "N/A"
+if USE_JAX in ENV_VARS_TRUE_AND_AUTO_VALUES:
+ _flax_available = importlib.util.find_spec("jax") is not None and importlib.util.find_spec("flax") is not None
+ if _flax_available:
+ try:
+ _jax_version = importlib_metadata.version("jax")
+ _flax_version = importlib_metadata.version("flax")
+ logger.info(f"JAX version {_jax_version}, Flax version {_flax_version} available.")
+ except importlib_metadata.PackageNotFoundError:
+ _flax_available = False
+else:
+ _flax_available = False
+
+if USE_SAFETENSORS in ENV_VARS_TRUE_AND_AUTO_VALUES:
+ _safetensors_available = importlib.util.find_spec("safetensors") is not None
+ if _safetensors_available:
+ try:
+ _safetensors_version = importlib_metadata.version("safetensors")
+ logger.info(f"Safetensors version {_safetensors_version} available.")
+ except importlib_metadata.PackageNotFoundError:
+ _safetensors_available = False
+else:
+ logger.info("Disabling Safetensors because USE_TF is set")
+ _safetensors_available = False
+
+_transformers_available = importlib.util.find_spec("transformers") is not None
+try:
+ _transformers_version = importlib_metadata.version("transformers")
+ logger.debug(f"Successfully imported transformers version {_transformers_version}")
+except importlib_metadata.PackageNotFoundError:
+ _transformers_available = False
+
+
+_inflect_available = importlib.util.find_spec("inflect") is not None
+try:
+ _inflect_version = importlib_metadata.version("inflect")
+ logger.debug(f"Successfully imported inflect version {_inflect_version}")
+except importlib_metadata.PackageNotFoundError:
+ _inflect_available = False
+
+
+_unidecode_available = importlib.util.find_spec("unidecode") is not None
+try:
+ _unidecode_version = importlib_metadata.version("unidecode")
+ logger.debug(f"Successfully imported unidecode version {_unidecode_version}")
+except importlib_metadata.PackageNotFoundError:
+ _unidecode_available = False
+
+
+_onnxruntime_version = "N/A"
+_onnx_available = importlib.util.find_spec("onnxruntime") is not None
+if _onnx_available:
+ candidates = (
+ "onnxruntime",
+ "onnxruntime-gpu",
+ "ort_nightly_gpu",
+ "onnxruntime-directml",
+ "onnxruntime-openvino",
+ "ort_nightly_directml",
+ "onnxruntime-rocm",
+ "onnxruntime-training",
+ )
+ _onnxruntime_version = None
+ # For the metadata, we have to look for both onnxruntime and onnxruntime-gpu
+ for pkg in candidates:
+ try:
+ _onnxruntime_version = importlib_metadata.version(pkg)
+ break
+ except importlib_metadata.PackageNotFoundError:
+ pass
+ _onnx_available = _onnxruntime_version is not None
+ if _onnx_available:
+ logger.debug(f"Successfully imported onnxruntime version {_onnxruntime_version}")
+
+# (sayakpaul): importlib.util.find_spec("opencv-python") returns None even when it's installed.
+# _opencv_available = importlib.util.find_spec("opencv-python") is not None
+try:
+ candidates = (
+ "opencv-python",
+ "opencv-contrib-python",
+ "opencv-python-headless",
+ "opencv-contrib-python-headless",
+ )
+ _opencv_version = None
+ for pkg in candidates:
+ try:
+ _opencv_version = importlib_metadata.version(pkg)
+ break
+ except importlib_metadata.PackageNotFoundError:
+ pass
+ _opencv_available = _opencv_version is not None
+ if _opencv_available:
+ logger.debug(f"Successfully imported cv2 version {_opencv_version}")
+except importlib_metadata.PackageNotFoundError:
+ _opencv_available = False
+
+_scipy_available = importlib.util.find_spec("scipy") is not None
+try:
+ _scipy_version = importlib_metadata.version("scipy")
+ logger.debug(f"Successfully imported scipy version {_scipy_version}")
+except importlib_metadata.PackageNotFoundError:
+ _scipy_available = False
+
+_librosa_available = importlib.util.find_spec("librosa") is not None
+try:
+ _librosa_version = importlib_metadata.version("librosa")
+ logger.debug(f"Successfully imported librosa version {_librosa_version}")
+except importlib_metadata.PackageNotFoundError:
+ _librosa_available = False
+
+_accelerate_available = importlib.util.find_spec("accelerate") is not None
+try:
+ _accelerate_version = importlib_metadata.version("accelerate")
+ logger.debug(f"Successfully imported accelerate version {_accelerate_version}")
+except importlib_metadata.PackageNotFoundError:
+ _accelerate_available = False
+
+_xformers_available = importlib.util.find_spec("xformers") is not None
+try:
+ _xformers_version = importlib_metadata.version("xformers")
+ if _torch_available:
+ import torch
+
+ if version.Version(torch.__version__) < version.Version("1.12"):
+ raise ValueError("PyTorch should be >= 1.12")
+ logger.debug(f"Successfully imported xformers version {_xformers_version}")
+except importlib_metadata.PackageNotFoundError:
+ _xformers_available = False
+
+_k_diffusion_available = importlib.util.find_spec("k_diffusion") is not None
+try:
+ _k_diffusion_version = importlib_metadata.version("k_diffusion")
+ logger.debug(f"Successfully imported k-diffusion version {_k_diffusion_version}")
+except importlib_metadata.PackageNotFoundError:
+ _k_diffusion_available = False
+
+_note_seq_available = importlib.util.find_spec("note_seq") is not None
+try:
+ _note_seq_version = importlib_metadata.version("note_seq")
+ logger.debug(f"Successfully imported note-seq version {_note_seq_version}")
+except importlib_metadata.PackageNotFoundError:
+ _note_seq_available = False
+
+_wandb_available = importlib.util.find_spec("wandb") is not None
+try:
+ _wandb_version = importlib_metadata.version("wandb")
+ logger.debug(f"Successfully imported wandb version {_wandb_version }")
+except importlib_metadata.PackageNotFoundError:
+ _wandb_available = False
+
+_omegaconf_available = importlib.util.find_spec("omegaconf") is not None
+try:
+ _omegaconf_version = importlib_metadata.version("omegaconf")
+ logger.debug(f"Successfully imported omegaconf version {_omegaconf_version}")
+except importlib_metadata.PackageNotFoundError:
+ _omegaconf_available = False
+
+_tensorboard_available = importlib.util.find_spec("tensorboard")
+try:
+ _tensorboard_version = importlib_metadata.version("tensorboard")
+ logger.debug(f"Successfully imported tensorboard version {_tensorboard_version}")
+except importlib_metadata.PackageNotFoundError:
+ _tensorboard_available = False
+
+
+_compel_available = importlib.util.find_spec("compel")
+try:
+ _compel_version = importlib_metadata.version("compel")
+ logger.debug(f"Successfully imported compel version {_compel_version}")
+except importlib_metadata.PackageNotFoundError:
+ _compel_available = False
+
+
+def is_torch_available():
+ return _torch_available
+
+
+def is_safetensors_available():
+ return _safetensors_available
+
+
+def is_tf_available():
+ return _tf_available
+
+
+def is_flax_available():
+ return _flax_available
+
+
+def is_transformers_available():
+ return _transformers_available
+
+
+def is_inflect_available():
+ return _inflect_available
+
+
+def is_unidecode_available():
+ return _unidecode_available
+
+
+def is_onnx_available():
+ return _onnx_available
+
+
+def is_opencv_available():
+ return _opencv_available
+
+
+def is_scipy_available():
+ return _scipy_available
+
+
+def is_librosa_available():
+ return _librosa_available
+
+
+def is_xformers_available():
+ return _xformers_available
+
+
+def is_accelerate_available():
+ return _accelerate_available
+
+
+def is_k_diffusion_available():
+ return _k_diffusion_available
+
+
+def is_note_seq_available():
+ return _note_seq_available
+
+
+def is_wandb_available():
+ return _wandb_available
+
+
+def is_omegaconf_available():
+ return _omegaconf_available
+
+
+def is_tensorboard_available():
+ return _tensorboard_available
+
+
+def is_compel_available():
+ return _compel_available
+
+
+# docstyle-ignore
+FLAX_IMPORT_ERROR = """
+{0} requires the FLAX library but it was not found in your environment. Checkout the instructions on the
+installation page: https://github.com/google/flax and follow the ones that match your environment.
+"""
+
+# docstyle-ignore
+INFLECT_IMPORT_ERROR = """
+{0} requires the inflect library but it was not found in your environment. You can install it with pip: `pip install
+inflect`
+"""
+
+# docstyle-ignore
+PYTORCH_IMPORT_ERROR = """
+{0} requires the PyTorch library but it was not found in your environment. Checkout the instructions on the
+installation page: https://pytorch.org/get-started/locally/ and follow the ones that match your environment.
+"""
+
+# docstyle-ignore
+ONNX_IMPORT_ERROR = """
+{0} requires the onnxruntime library but it was not found in your environment. You can install it with pip: `pip
+install onnxruntime`
+"""
+
+# docstyle-ignore
+OPENCV_IMPORT_ERROR = """
+{0} requires the OpenCV library but it was not found in your environment. You can install it with pip: `pip
+install opencv-python`
+"""
+
+# docstyle-ignore
+SCIPY_IMPORT_ERROR = """
+{0} requires the scipy library but it was not found in your environment. You can install it with pip: `pip install
+scipy`
+"""
+
+# docstyle-ignore
+LIBROSA_IMPORT_ERROR = """
+{0} requires the librosa library but it was not found in your environment. Checkout the instructions on the
+installation page: https://librosa.org/doc/latest/install.html and follow the ones that match your environment.
+"""
+
+# docstyle-ignore
+TRANSFORMERS_IMPORT_ERROR = """
+{0} requires the transformers library but it was not found in your environment. You can install it with pip: `pip
+install transformers`
+"""
+
+# docstyle-ignore
+UNIDECODE_IMPORT_ERROR = """
+{0} requires the unidecode library but it was not found in your environment. You can install it with pip: `pip install
+Unidecode`
+"""
+
+# docstyle-ignore
+K_DIFFUSION_IMPORT_ERROR = """
+{0} requires the k-diffusion library but it was not found in your environment. You can install it with pip: `pip
+install k-diffusion`
+"""
+
+# docstyle-ignore
+NOTE_SEQ_IMPORT_ERROR = """
+{0} requires the note-seq library but it was not found in your environment. You can install it with pip: `pip
+install note-seq`
+"""
+
+# docstyle-ignore
+WANDB_IMPORT_ERROR = """
+{0} requires the wandb library but it was not found in your environment. You can install it with pip: `pip
+install wandb`
+"""
+
+# docstyle-ignore
+OMEGACONF_IMPORT_ERROR = """
+{0} requires the omegaconf library but it was not found in your environment. You can install it with pip: `pip
+install omegaconf`
+"""
+
+# docstyle-ignore
+TENSORBOARD_IMPORT_ERROR = """
+{0} requires the tensorboard library but it was not found in your environment. You can install it with pip: `pip
+install tensorboard`
+"""
+
+
+# docstyle-ignore
+COMPEL_IMPORT_ERROR = """
+{0} requires the compel library but it was not found in your environment. You can install it with pip: `pip install compel`
+"""
+
+BACKENDS_MAPPING = OrderedDict(
+ [
+ ("flax", (is_flax_available, FLAX_IMPORT_ERROR)),
+ ("inflect", (is_inflect_available, INFLECT_IMPORT_ERROR)),
+ ("onnx", (is_onnx_available, ONNX_IMPORT_ERROR)),
+ ("opencv", (is_opencv_available, OPENCV_IMPORT_ERROR)),
+ ("scipy", (is_scipy_available, SCIPY_IMPORT_ERROR)),
+ ("torch", (is_torch_available, PYTORCH_IMPORT_ERROR)),
+ ("transformers", (is_transformers_available, TRANSFORMERS_IMPORT_ERROR)),
+ ("unidecode", (is_unidecode_available, UNIDECODE_IMPORT_ERROR)),
+ ("librosa", (is_librosa_available, LIBROSA_IMPORT_ERROR)),
+ ("k_diffusion", (is_k_diffusion_available, K_DIFFUSION_IMPORT_ERROR)),
+ ("note_seq", (is_note_seq_available, NOTE_SEQ_IMPORT_ERROR)),
+ ("wandb", (is_wandb_available, WANDB_IMPORT_ERROR)),
+ ("omegaconf", (is_omegaconf_available, OMEGACONF_IMPORT_ERROR)),
+ ("tensorboard", (_tensorboard_available, TENSORBOARD_IMPORT_ERROR)),
+ ("compel", (_compel_available, COMPEL_IMPORT_ERROR)),
+ ]
+)
+
+
+def requires_backends(obj, backends):
+ if not isinstance(backends, (list, tuple)):
+ backends = [backends]
+
+ name = obj.__name__ if hasattr(obj, "__name__") else obj.__class__.__name__
+ checks = (BACKENDS_MAPPING[backend] for backend in backends)
+ failed = [msg.format(name) for available, msg in checks if not available()]
+ if failed:
+ raise ImportError("".join(failed))
+
+ if name in [
+ "VersatileDiffusionTextToImagePipeline",
+ "VersatileDiffusionPipeline",
+ "VersatileDiffusionDualGuidedPipeline",
+ "StableDiffusionImageVariationPipeline",
+ "UnCLIPPipeline",
+ ] and is_transformers_version("<", "4.25.0"):
+ raise ImportError(
+ f"You need to install `transformers>=4.25` in order to use {name}: \n```\n pip install"
+ " --upgrade transformers \n```"
+ )
+
+ if name in ["StableDiffusionDepth2ImgPipeline", "StableDiffusionPix2PixZeroPipeline"] and is_transformers_version(
+ "<", "4.26.0"
+ ):
+ raise ImportError(
+ f"You need to install `transformers>=4.26` in order to use {name}: \n```\n pip install"
+ " --upgrade transformers \n```"
+ )
+
+
+class DummyObject(type):
+ """
+ Metaclass for the dummy objects. Any class inheriting from it will return the ImportError generated by
+ `requires_backend` each time a user tries to access any method of that class.
+ """
+
+ def __getattr__(cls, key):
+ if key.startswith("_"):
+ return super().__getattr__(cls, key)
+ requires_backends(cls, cls._backends)
+
+
+# This function was copied from: https://github.com/huggingface/accelerate/blob/874c4967d94badd24f893064cc3bef45f57cadf7/src/accelerate/utils/versions.py#L319
+def compare_versions(library_or_version: Union[str, Version], operation: str, requirement_version: str):
+ """
+ Args:
+ Compares a library version to some requirement using a given operation.
+ library_or_version (`str` or `packaging.version.Version`):
+ A library name or a version to check.
+ operation (`str`):
+ A string representation of an operator, such as `">"` or `"<="`.
+ requirement_version (`str`):
+ The version to compare the library version against
+ """
+ if operation not in STR_OPERATION_TO_FUNC.keys():
+ raise ValueError(f"`operation` must be one of {list(STR_OPERATION_TO_FUNC.keys())}, received {operation}")
+ operation = STR_OPERATION_TO_FUNC[operation]
+ if isinstance(library_or_version, str):
+ library_or_version = parse(importlib_metadata.version(library_or_version))
+ return operation(library_or_version, parse(requirement_version))
+
+
+# This function was copied from: https://github.com/huggingface/accelerate/blob/874c4967d94badd24f893064cc3bef45f57cadf7/src/accelerate/utils/versions.py#L338
+def is_torch_version(operation: str, version: str):
+ """
+ Args:
+ Compares the current PyTorch version to a given reference with an operation.
+ operation (`str`):
+ A string representation of an operator, such as `">"` or `"<="`
+ version (`str`):
+ A string version of PyTorch
+ """
+ return compare_versions(parse(_torch_version), operation, version)
+
+
+def is_transformers_version(operation: str, version: str):
+ """
+ Args:
+ Compares the current Transformers version to a given reference with an operation.
+ operation (`str`):
+ A string representation of an operator, such as `">"` or `"<="`
+ version (`str`):
+ A version string
+ """
+ if not _transformers_available:
+ return False
+ return compare_versions(parse(_transformers_version), operation, version)
+
+
+def is_accelerate_version(operation: str, version: str):
+ """
+ Args:
+ Compares the current Accelerate version to a given reference with an operation.
+ operation (`str`):
+ A string representation of an operator, such as `">"` or `"<="`
+ version (`str`):
+ A version string
+ """
+ if not _accelerate_available:
+ return False
+ return compare_versions(parse(_accelerate_version), operation, version)
+
+
+def is_k_diffusion_version(operation: str, version: str):
+ """
+ Args:
+ Compares the current k-diffusion version to a given reference with an operation.
+ operation (`str`):
+ A string representation of an operator, such as `">"` or `"<="`
+ version (`str`):
+ A version string
+ """
+ if not _k_diffusion_available:
+ return False
+ return compare_versions(parse(_k_diffusion_version), operation, version)
+
+
+class OptionalDependencyNotAvailable(BaseException):
+ """An error indicating that an optional dependency of Diffusers was not found in the environment."""
diff --git a/diffusers/src/diffusers/utils/logging.py b/diffusers/src/diffusers/utils/logging.py
new file mode 100644
index 0000000000000000000000000000000000000000..3308d117e994d95d5dd7cb494d88512a61847fd6
--- /dev/null
+++ b/diffusers/src/diffusers/utils/logging.py
@@ -0,0 +1,342 @@
+# coding=utf-8
+# Copyright 2023 Optuna, Hugging Face
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Logging utilities."""
+
+import logging
+import os
+import sys
+import threading
+from logging import (
+ CRITICAL, # NOQA
+ DEBUG, # NOQA
+ ERROR, # NOQA
+ FATAL, # NOQA
+ INFO, # NOQA
+ NOTSET, # NOQA
+ WARN, # NOQA
+ WARNING, # NOQA
+)
+from typing import Optional
+
+from tqdm import auto as tqdm_lib
+
+
+_lock = threading.Lock()
+_default_handler: Optional[logging.Handler] = None
+
+log_levels = {
+ "debug": logging.DEBUG,
+ "info": logging.INFO,
+ "warning": logging.WARNING,
+ "error": logging.ERROR,
+ "critical": logging.CRITICAL,
+}
+
+_default_log_level = logging.WARNING
+
+_tqdm_active = True
+
+
+def _get_default_logging_level():
+ """
+ If DIFFUSERS_VERBOSITY env var is set to one of the valid choices return that as the new default level. If it is
+ not - fall back to `_default_log_level`
+ """
+ env_level_str = os.getenv("DIFFUSERS_VERBOSITY", None)
+ if env_level_str:
+ if env_level_str in log_levels:
+ return log_levels[env_level_str]
+ else:
+ logging.getLogger().warning(
+ f"Unknown option DIFFUSERS_VERBOSITY={env_level_str}, "
+ f"has to be one of: { ', '.join(log_levels.keys()) }"
+ )
+ return _default_log_level
+
+
+def _get_library_name() -> str:
+ return __name__.split(".")[0]
+
+
+def _get_library_root_logger() -> logging.Logger:
+ return logging.getLogger(_get_library_name())
+
+
+def _configure_library_root_logger() -> None:
+ global _default_handler
+
+ with _lock:
+ if _default_handler:
+ # This library has already configured the library root logger.
+ return
+ _default_handler = logging.StreamHandler() # Set sys.stderr as stream.
+ _default_handler.flush = sys.stderr.flush
+
+ # Apply our default configuration to the library root logger.
+ library_root_logger = _get_library_root_logger()
+ library_root_logger.addHandler(_default_handler)
+ library_root_logger.setLevel(_get_default_logging_level())
+ library_root_logger.propagate = False
+
+
+def _reset_library_root_logger() -> None:
+ global _default_handler
+
+ with _lock:
+ if not _default_handler:
+ return
+
+ library_root_logger = _get_library_root_logger()
+ library_root_logger.removeHandler(_default_handler)
+ library_root_logger.setLevel(logging.NOTSET)
+ _default_handler = None
+
+
+def get_log_levels_dict():
+ return log_levels
+
+
+def get_logger(name: Optional[str] = None) -> logging.Logger:
+ """
+ Return a logger with the specified name.
+
+ This function is not supposed to be directly accessed unless you are writing a custom diffusers module.
+ """
+
+ if name is None:
+ name = _get_library_name()
+
+ _configure_library_root_logger()
+ return logging.getLogger(name)
+
+
+def get_verbosity() -> int:
+ """
+ Return the current level for the 🤗 Diffusers' root logger as an int.
+
+ Returns:
+ `int`: The logging level.
+
+
+
+ 🤗 Diffusers has following logging levels:
+
+ - 50: `diffusers.logging.CRITICAL` or `diffusers.logging.FATAL`
+ - 40: `diffusers.logging.ERROR`
+ - 30: `diffusers.logging.WARNING` or `diffusers.logging.WARN`
+ - 20: `diffusers.logging.INFO`
+ - 10: `diffusers.logging.DEBUG`
+
+ """
+
+ _configure_library_root_logger()
+ return _get_library_root_logger().getEffectiveLevel()
+
+
+def set_verbosity(verbosity: int) -> None:
+ """
+ Set the verbosity level for the 🤗 Diffusers' root logger.
+
+ Args:
+ verbosity (`int`):
+ Logging level, e.g., one of:
+
+ - `diffusers.logging.CRITICAL` or `diffusers.logging.FATAL`
+ - `diffusers.logging.ERROR`
+ - `diffusers.logging.WARNING` or `diffusers.logging.WARN`
+ - `diffusers.logging.INFO`
+ - `diffusers.logging.DEBUG`
+ """
+
+ _configure_library_root_logger()
+ _get_library_root_logger().setLevel(verbosity)
+
+
+def set_verbosity_info():
+ """Set the verbosity to the `INFO` level."""
+ return set_verbosity(INFO)
+
+
+def set_verbosity_warning():
+ """Set the verbosity to the `WARNING` level."""
+ return set_verbosity(WARNING)
+
+
+def set_verbosity_debug():
+ """Set the verbosity to the `DEBUG` level."""
+ return set_verbosity(DEBUG)
+
+
+def set_verbosity_error():
+ """Set the verbosity to the `ERROR` level."""
+ return set_verbosity(ERROR)
+
+
+def disable_default_handler() -> None:
+ """Disable the default handler of the HuggingFace Diffusers' root logger."""
+
+ _configure_library_root_logger()
+
+ assert _default_handler is not None
+ _get_library_root_logger().removeHandler(_default_handler)
+
+
+def enable_default_handler() -> None:
+ """Enable the default handler of the HuggingFace Diffusers' root logger."""
+
+ _configure_library_root_logger()
+
+ assert _default_handler is not None
+ _get_library_root_logger().addHandler(_default_handler)
+
+
+def add_handler(handler: logging.Handler) -> None:
+ """adds a handler to the HuggingFace Diffusers' root logger."""
+
+ _configure_library_root_logger()
+
+ assert handler is not None
+ _get_library_root_logger().addHandler(handler)
+
+
+def remove_handler(handler: logging.Handler) -> None:
+ """removes given handler from the HuggingFace Diffusers' root logger."""
+
+ _configure_library_root_logger()
+
+ assert handler is not None and handler not in _get_library_root_logger().handlers
+ _get_library_root_logger().removeHandler(handler)
+
+
+def disable_propagation() -> None:
+ """
+ Disable propagation of the library log outputs. Note that log propagation is disabled by default.
+ """
+
+ _configure_library_root_logger()
+ _get_library_root_logger().propagate = False
+
+
+def enable_propagation() -> None:
+ """
+ Enable propagation of the library log outputs. Please disable the HuggingFace Diffusers' default handler to prevent
+ double logging if the root logger has been configured.
+ """
+
+ _configure_library_root_logger()
+ _get_library_root_logger().propagate = True
+
+
+def enable_explicit_format() -> None:
+ """
+ Enable explicit formatting for every HuggingFace Diffusers' logger. The explicit formatter is as follows:
+ ```
+ [LEVELNAME|FILENAME|LINE NUMBER] TIME >> MESSAGE
+ ```
+ All handlers currently bound to the root logger are affected by this method.
+ """
+ handlers = _get_library_root_logger().handlers
+
+ for handler in handlers:
+ formatter = logging.Formatter("[%(levelname)s|%(filename)s:%(lineno)s] %(asctime)s >> %(message)s")
+ handler.setFormatter(formatter)
+
+
+def reset_format() -> None:
+ """
+ Resets the formatting for HuggingFace Diffusers' loggers.
+
+ All handlers currently bound to the root logger are affected by this method.
+ """
+ handlers = _get_library_root_logger().handlers
+
+ for handler in handlers:
+ handler.setFormatter(None)
+
+
+def warning_advice(self, *args, **kwargs):
+ """
+ This method is identical to `logger.warning()`, but if env var DIFFUSERS_NO_ADVISORY_WARNINGS=1 is set, this
+ warning will not be printed
+ """
+ no_advisory_warnings = os.getenv("DIFFUSERS_NO_ADVISORY_WARNINGS", False)
+ if no_advisory_warnings:
+ return
+ self.warning(*args, **kwargs)
+
+
+logging.Logger.warning_advice = warning_advice
+
+
+class EmptyTqdm:
+ """Dummy tqdm which doesn't do anything."""
+
+ def __init__(self, *args, **kwargs): # pylint: disable=unused-argument
+ self._iterator = args[0] if args else None
+
+ def __iter__(self):
+ return iter(self._iterator)
+
+ def __getattr__(self, _):
+ """Return empty function."""
+
+ def empty_fn(*args, **kwargs): # pylint: disable=unused-argument
+ return
+
+ return empty_fn
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, type_, value, traceback):
+ return
+
+
+class _tqdm_cls:
+ def __call__(self, *args, **kwargs):
+ if _tqdm_active:
+ return tqdm_lib.tqdm(*args, **kwargs)
+ else:
+ return EmptyTqdm(*args, **kwargs)
+
+ def set_lock(self, *args, **kwargs):
+ self._lock = None
+ if _tqdm_active:
+ return tqdm_lib.tqdm.set_lock(*args, **kwargs)
+
+ def get_lock(self):
+ if _tqdm_active:
+ return tqdm_lib.tqdm.get_lock()
+
+
+tqdm = _tqdm_cls()
+
+
+def is_progress_bar_enabled() -> bool:
+ """Return a boolean indicating whether tqdm progress bars are enabled."""
+ global _tqdm_active
+ return bool(_tqdm_active)
+
+
+def enable_progress_bar():
+ """Enable tqdm progress bar."""
+ global _tqdm_active
+ _tqdm_active = True
+
+
+def disable_progress_bar():
+ """Disable tqdm progress bar."""
+ global _tqdm_active
+ _tqdm_active = False
diff --git a/diffusers/src/diffusers/utils/model_card_template.md b/diffusers/src/diffusers/utils/model_card_template.md
new file mode 100644
index 0000000000000000000000000000000000000000..f19c85b0fcf2f7b07e9c3f950a9657b3f2053f21
--- /dev/null
+++ b/diffusers/src/diffusers/utils/model_card_template.md
@@ -0,0 +1,50 @@
+---
+{{ card_data }}
+---
+
+
+
+# {{ model_name | default("Diffusion Model") }}
+
+## Model description
+
+This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
+on the `{{ dataset_name }}` dataset.
+
+## Intended uses & limitations
+
+#### How to use
+
+```python
+# TODO: add an example code snippet for running this diffusion pipeline
+```
+
+#### Limitations and bias
+
+[TODO: provide examples of latent issues and potential remediations]
+
+## Training data
+
+[TODO: describe the data used to train the model]
+
+### Training hyperparameters
+
+The following hyperparameters were used during training:
+- learning_rate: {{ learning_rate }}
+- train_batch_size: {{ train_batch_size }}
+- eval_batch_size: {{ eval_batch_size }}
+- gradient_accumulation_steps: {{ gradient_accumulation_steps }}
+- optimizer: AdamW with betas=({{ adam_beta1 }}, {{ adam_beta2 }}), weight_decay={{ adam_weight_decay }} and epsilon={{ adam_epsilon }}
+- lr_scheduler: {{ lr_scheduler }}
+- lr_warmup_steps: {{ lr_warmup_steps }}
+- ema_inv_gamma: {{ ema_inv_gamma }}
+- ema_inv_gamma: {{ ema_power }}
+- ema_inv_gamma: {{ ema_max_decay }}
+- mixed_precision: {{ mixed_precision }}
+
+### Training results
+
+📈 [TensorBoard logs](https://huggingface.co/{{ repo_name }}/tensorboard?#scalars)
+
+
diff --git a/diffusers/src/diffusers/utils/outputs.py b/diffusers/src/diffusers/utils/outputs.py
new file mode 100644
index 0000000000000000000000000000000000000000..b6e8a219e129ce66ce80f21b5da73dad900616b5
--- /dev/null
+++ b/diffusers/src/diffusers/utils/outputs.py
@@ -0,0 +1,108 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Generic utilities
+"""
+
+from collections import OrderedDict
+from dataclasses import fields
+from typing import Any, Tuple
+
+import numpy as np
+
+from .import_utils import is_torch_available
+
+
+def is_tensor(x):
+ """
+ Tests if `x` is a `torch.Tensor` or `np.ndarray`.
+ """
+ if is_torch_available():
+ import torch
+
+ if isinstance(x, torch.Tensor):
+ return True
+
+ return isinstance(x, np.ndarray)
+
+
+class BaseOutput(OrderedDict):
+ """
+ Base class for all model outputs as dataclass. Has a `__getitem__` that allows indexing by integer or slice (like a
+ tuple) or strings (like a dictionary) that will ignore the `None` attributes. Otherwise behaves like a regular
+ python dictionary.
+
+
+
+ You can't unpack a `BaseOutput` directly. Use the [`~utils.BaseOutput.to_tuple`] method to convert it to a tuple
+ before.
+
+
+ """
+
+ def __post_init__(self):
+ class_fields = fields(self)
+
+ # Safety and consistency checks
+ if not len(class_fields):
+ raise ValueError(f"{self.__class__.__name__} has no fields.")
+
+ first_field = getattr(self, class_fields[0].name)
+ other_fields_are_none = all(getattr(self, field.name) is None for field in class_fields[1:])
+
+ if other_fields_are_none and isinstance(first_field, dict):
+ for key, value in first_field.items():
+ self[key] = value
+ else:
+ for field in class_fields:
+ v = getattr(self, field.name)
+ if v is not None:
+ self[field.name] = v
+
+ def __delitem__(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
+
+ def setdefault(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
+
+ def pop(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
+
+ def update(self, *args, **kwargs):
+ raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
+
+ def __getitem__(self, k):
+ if isinstance(k, str):
+ inner_dict = dict(self.items())
+ return inner_dict[k]
+ else:
+ return self.to_tuple()[k]
+
+ def __setattr__(self, name, value):
+ if name in self.keys() and value is not None:
+ # Don't call self.__setitem__ to avoid recursion errors
+ super().__setitem__(name, value)
+ super().__setattr__(name, value)
+
+ def __setitem__(self, key, value):
+ # Will raise a KeyException if needed
+ super().__setitem__(key, value)
+ # Don't call self.__setattr__ to avoid recursion errors
+ super().__setattr__(key, value)
+
+ def to_tuple(self) -> Tuple[Any]:
+ """
+ Convert self to a tuple containing all the attributes/keys that are not `None`.
+ """
+ return tuple(self[k] for k in self.keys())
diff --git a/diffusers/src/diffusers/utils/pil_utils.py b/diffusers/src/diffusers/utils/pil_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..39d0a15a4e2fe39fecb01951b36c43368492f983
--- /dev/null
+++ b/diffusers/src/diffusers/utils/pil_utils.py
@@ -0,0 +1,21 @@
+import PIL.Image
+import PIL.ImageOps
+from packaging import version
+
+
+if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.Resampling.BILINEAR,
+ "bilinear": PIL.Image.Resampling.BILINEAR,
+ "bicubic": PIL.Image.Resampling.BICUBIC,
+ "lanczos": PIL.Image.Resampling.LANCZOS,
+ "nearest": PIL.Image.Resampling.NEAREST,
+ }
+else:
+ PIL_INTERPOLATION = {
+ "linear": PIL.Image.LINEAR,
+ "bilinear": PIL.Image.BILINEAR,
+ "bicubic": PIL.Image.BICUBIC,
+ "lanczos": PIL.Image.LANCZOS,
+ "nearest": PIL.Image.NEAREST,
+ }
diff --git a/diffusers/src/diffusers/utils/testing_utils.py b/diffusers/src/diffusers/utils/testing_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..afea0540b765d79fc9722edd383b1d336871351f
--- /dev/null
+++ b/diffusers/src/diffusers/utils/testing_utils.py
@@ -0,0 +1,498 @@
+import inspect
+import logging
+import os
+import random
+import re
+import tempfile
+import unittest
+import urllib.parse
+from distutils.util import strtobool
+from io import BytesIO, StringIO
+from pathlib import Path
+from typing import List, Optional, Union
+
+import numpy as np
+import PIL.Image
+import PIL.ImageOps
+import requests
+from packaging import version
+
+from .import_utils import (
+ BACKENDS_MAPPING,
+ is_compel_available,
+ is_flax_available,
+ is_note_seq_available,
+ is_onnx_available,
+ is_opencv_available,
+ is_torch_available,
+ is_torch_version,
+)
+from .logging import get_logger
+
+
+global_rng = random.Random()
+
+logger = get_logger(__name__)
+
+if is_torch_available():
+ import torch
+
+ if "DIFFUSERS_TEST_DEVICE" in os.environ:
+ torch_device = os.environ["DIFFUSERS_TEST_DEVICE"]
+
+ available_backends = ["cuda", "cpu", "mps"]
+ if torch_device not in available_backends:
+ raise ValueError(
+ f"unknown torch backend for diffusers tests: {torch_device}. Available backends are:"
+ f" {available_backends}"
+ )
+ logger.info(f"torch_device overrode to {torch_device}")
+ else:
+ torch_device = "cuda" if torch.cuda.is_available() else "cpu"
+ is_torch_higher_equal_than_1_12 = version.parse(
+ version.parse(torch.__version__).base_version
+ ) >= version.parse("1.12")
+
+ if is_torch_higher_equal_than_1_12:
+ # Some builds of torch 1.12 don't have the mps backend registered. See #892 for more details
+ mps_backend_registered = hasattr(torch.backends, "mps")
+ torch_device = "mps" if (mps_backend_registered and torch.backends.mps.is_available()) else torch_device
+
+
+def torch_all_close(a, b, *args, **kwargs):
+ if not is_torch_available():
+ raise ValueError("PyTorch needs to be installed to use this function.")
+ if not torch.allclose(a, b, *args, **kwargs):
+ assert False, f"Max diff is absolute {(a - b).abs().max()}. Diff tensor is {(a - b).abs()}."
+ return True
+
+
+def print_tensor_test(tensor, filename="test_corrections.txt", expected_tensor_name="expected_slice"):
+ test_name = os.environ.get("PYTEST_CURRENT_TEST")
+ if not torch.is_tensor(tensor):
+ tensor = torch.from_numpy(tensor)
+
+ tensor_str = str(tensor.detach().cpu().flatten().to(torch.float32)).replace("\n", "")
+ # format is usually:
+ # expected_slice = np.array([-0.5713, -0.3018, -0.9814, 0.04663, -0.879, 0.76, -1.734, 0.1044, 1.161])
+ output_str = tensor_str.replace("tensor", f"{expected_tensor_name} = np.array")
+ test_file, test_class, test_fn = test_name.split("::")
+ test_fn = test_fn.split()[0]
+ with open(filename, "a") as f:
+ print(";".join([test_file, test_class, test_fn, output_str]), file=f)
+
+
+def get_tests_dir(append_path=None):
+ """
+ Args:
+ append_path: optional path to append to the tests dir path
+ Return:
+ The full path to the `tests` dir, so that the tests can be invoked from anywhere. Optionally `append_path` is
+ joined after the `tests` dir the former is provided.
+ """
+ # this function caller's __file__
+ caller__file__ = inspect.stack()[1][1]
+ tests_dir = os.path.abspath(os.path.dirname(caller__file__))
+
+ while not tests_dir.endswith("tests"):
+ tests_dir = os.path.dirname(tests_dir)
+
+ if append_path:
+ return os.path.join(tests_dir, append_path)
+ else:
+ return tests_dir
+
+
+def parse_flag_from_env(key, default=False):
+ try:
+ value = os.environ[key]
+ except KeyError:
+ # KEY isn't set, default to `default`.
+ _value = default
+ else:
+ # KEY is set, convert it to True or False.
+ try:
+ _value = strtobool(value)
+ except ValueError:
+ # More values are supported, but let's keep the message simple.
+ raise ValueError(f"If set, {key} must be yes or no.")
+ return _value
+
+
+_run_slow_tests = parse_flag_from_env("RUN_SLOW", default=False)
+_run_nightly_tests = parse_flag_from_env("RUN_NIGHTLY", default=False)
+
+
+def floats_tensor(shape, scale=1.0, rng=None, name=None):
+ """Creates a random float32 tensor"""
+ if rng is None:
+ rng = global_rng
+
+ total_dims = 1
+ for dim in shape:
+ total_dims *= dim
+
+ values = []
+ for _ in range(total_dims):
+ values.append(rng.random() * scale)
+
+ return torch.tensor(data=values, dtype=torch.float).view(shape).contiguous()
+
+
+def slow(test_case):
+ """
+ Decorator marking a test as slow.
+
+ Slow tests are skipped by default. Set the RUN_SLOW environment variable to a truthy value to run them.
+
+ """
+ return unittest.skipUnless(_run_slow_tests, "test is slow")(test_case)
+
+
+def nightly(test_case):
+ """
+ Decorator marking a test that runs nightly in the diffusers CI.
+
+ Slow tests are skipped by default. Set the RUN_NIGHTLY environment variable to a truthy value to run them.
+
+ """
+ return unittest.skipUnless(_run_nightly_tests, "test is nightly")(test_case)
+
+
+def require_torch(test_case):
+ """
+ Decorator marking a test that requires PyTorch. These tests are skipped when PyTorch isn't installed.
+ """
+ return unittest.skipUnless(is_torch_available(), "test requires PyTorch")(test_case)
+
+
+def require_torch_2(test_case):
+ """
+ Decorator marking a test that requires PyTorch 2. These tests are skipped when it isn't installed.
+ """
+ return unittest.skipUnless(is_torch_available() and is_torch_version(">=", "2.0.0"), "test requires PyTorch 2")(
+ test_case
+ )
+
+
+def require_torch_gpu(test_case):
+ """Decorator marking a test that requires CUDA and PyTorch."""
+ return unittest.skipUnless(is_torch_available() and torch_device == "cuda", "test requires PyTorch+CUDA")(
+ test_case
+ )
+
+
+def skip_mps(test_case):
+ """Decorator marking a test to skip if torch_device is 'mps'"""
+ return unittest.skipUnless(torch_device != "mps", "test requires non 'mps' device")(test_case)
+
+
+def require_flax(test_case):
+ """
+ Decorator marking a test that requires JAX & Flax. These tests are skipped when one / both are not installed
+ """
+ return unittest.skipUnless(is_flax_available(), "test requires JAX & Flax")(test_case)
+
+
+def require_compel(test_case):
+ """
+ Decorator marking a test that requires compel: https://github.com/damian0815/compel. These tests are skipped when
+ the library is not installed.
+ """
+ return unittest.skipUnless(is_compel_available(), "test requires compel")(test_case)
+
+
+def require_onnxruntime(test_case):
+ """
+ Decorator marking a test that requires onnxruntime. These tests are skipped when onnxruntime isn't installed.
+ """
+ return unittest.skipUnless(is_onnx_available(), "test requires onnxruntime")(test_case)
+
+
+def require_note_seq(test_case):
+ """
+ Decorator marking a test that requires note_seq. These tests are skipped when note_seq isn't installed.
+ """
+ return unittest.skipUnless(is_note_seq_available(), "test requires note_seq")(test_case)
+
+
+def load_numpy(arry: Union[str, np.ndarray], local_path: Optional[str] = None) -> np.ndarray:
+ if isinstance(arry, str):
+ # local_path = "/home/patrick_huggingface_co/"
+ if local_path is not None:
+ # local_path can be passed to correct images of tests
+ return os.path.join(local_path, "/".join([arry.split("/")[-5], arry.split("/")[-2], arry.split("/")[-1]]))
+ elif arry.startswith("http://") or arry.startswith("https://"):
+ response = requests.get(arry)
+ response.raise_for_status()
+ arry = np.load(BytesIO(response.content))
+ elif os.path.isfile(arry):
+ arry = np.load(arry)
+ else:
+ raise ValueError(
+ f"Incorrect path or url, URLs must start with `http://` or `https://`, and {arry} is not a valid path"
+ )
+ elif isinstance(arry, np.ndarray):
+ pass
+ else:
+ raise ValueError(
+ "Incorrect format used for numpy ndarray. Should be an url linking to an image, a local path, or a"
+ " ndarray."
+ )
+
+ return arry
+
+
+def load_pt(url: str):
+ response = requests.get(url)
+ response.raise_for_status()
+ arry = torch.load(BytesIO(response.content))
+ return arry
+
+
+def load_image(image: Union[str, PIL.Image.Image]) -> PIL.Image.Image:
+ """
+ Args:
+ Loads `image` to a PIL Image.
+ image (`str` or `PIL.Image.Image`):
+ The image to convert to the PIL Image format.
+ Returns:
+ `PIL.Image.Image`: A PIL Image.
+ """
+ if isinstance(image, str):
+ if image.startswith("http://") or image.startswith("https://"):
+ image = PIL.Image.open(requests.get(image, stream=True).raw)
+ elif os.path.isfile(image):
+ image = PIL.Image.open(image)
+ else:
+ raise ValueError(
+ f"Incorrect path or url, URLs must start with `http://` or `https://`, and {image} is not a valid path"
+ )
+ elif isinstance(image, PIL.Image.Image):
+ image = image
+ else:
+ raise ValueError(
+ "Incorrect format used for image. Should be an url linking to an image, a local path, or a PIL image."
+ )
+ image = PIL.ImageOps.exif_transpose(image)
+ image = image.convert("RGB")
+ return image
+
+
+def export_to_video(video_frames: List[np.ndarray], output_video_path: str = None) -> str:
+ if is_opencv_available():
+ import cv2
+ else:
+ raise ImportError(BACKENDS_MAPPING["opencv"][1].format("export_to_video"))
+ if output_video_path is None:
+ output_video_path = tempfile.NamedTemporaryFile(suffix=".mp4").name
+
+ fourcc = cv2.VideoWriter_fourcc(*"mp4v")
+ h, w, c = video_frames[0].shape
+ video_writer = cv2.VideoWriter(output_video_path, fourcc, fps=8, frameSize=(w, h))
+ for i in range(len(video_frames)):
+ img = cv2.cvtColor(video_frames[i], cv2.COLOR_RGB2BGR)
+ video_writer.write(img)
+ return output_video_path
+
+
+def load_hf_numpy(path) -> np.ndarray:
+ if not path.startswith("http://") or path.startswith("https://"):
+ path = os.path.join(
+ "https://huggingface.co/datasets/fusing/diffusers-testing/resolve/main", urllib.parse.quote(path)
+ )
+
+ return load_numpy(path)
+
+
+# --- pytest conf functions --- #
+
+# to avoid multiple invocation from tests/conftest.py and examples/conftest.py - make sure it's called only once
+pytest_opt_registered = {}
+
+
+def pytest_addoption_shared(parser):
+ """
+ This function is to be called from `conftest.py` via `pytest_addoption` wrapper that has to be defined there.
+
+ It allows loading both `conftest.py` files at once without causing a failure due to adding the same `pytest`
+ option.
+
+ """
+ option = "--make-reports"
+ if option not in pytest_opt_registered:
+ parser.addoption(
+ option,
+ action="store",
+ default=False,
+ help="generate report files. The value of this option is used as a prefix to report names",
+ )
+ pytest_opt_registered[option] = 1
+
+
+def pytest_terminal_summary_main(tr, id):
+ """
+ Generate multiple reports at the end of test suite run - each report goes into a dedicated file in the current
+ directory. The report files are prefixed with the test suite name.
+
+ This function emulates --duration and -rA pytest arguments.
+
+ This function is to be called from `conftest.py` via `pytest_terminal_summary` wrapper that has to be defined
+ there.
+
+ Args:
+ - tr: `terminalreporter` passed from `conftest.py`
+ - id: unique id like `tests` or `examples` that will be incorporated into the final reports filenames - this is
+ needed as some jobs have multiple runs of pytest, so we can't have them overwrite each other.
+
+ NB: this functions taps into a private _pytest API and while unlikely, it could break should
+ pytest do internal changes - also it calls default internal methods of terminalreporter which
+ can be hijacked by various `pytest-` plugins and interfere.
+
+ """
+ from _pytest.config import create_terminal_writer
+
+ if not len(id):
+ id = "tests"
+
+ config = tr.config
+ orig_writer = config.get_terminal_writer()
+ orig_tbstyle = config.option.tbstyle
+ orig_reportchars = tr.reportchars
+
+ dir = "reports"
+ Path(dir).mkdir(parents=True, exist_ok=True)
+ report_files = {
+ k: f"{dir}/{id}_{k}.txt"
+ for k in [
+ "durations",
+ "errors",
+ "failures_long",
+ "failures_short",
+ "failures_line",
+ "passes",
+ "stats",
+ "summary_short",
+ "warnings",
+ ]
+ }
+
+ # custom durations report
+ # note: there is no need to call pytest --durations=XX to get this separate report
+ # adapted from https://github.com/pytest-dev/pytest/blob/897f151e/src/_pytest/runner.py#L66
+ dlist = []
+ for replist in tr.stats.values():
+ for rep in replist:
+ if hasattr(rep, "duration"):
+ dlist.append(rep)
+ if dlist:
+ dlist.sort(key=lambda x: x.duration, reverse=True)
+ with open(report_files["durations"], "w") as f:
+ durations_min = 0.05 # sec
+ f.write("slowest durations\n")
+ for i, rep in enumerate(dlist):
+ if rep.duration < durations_min:
+ f.write(f"{len(dlist)-i} durations < {durations_min} secs were omitted")
+ break
+ f.write(f"{rep.duration:02.2f}s {rep.when:<8} {rep.nodeid}\n")
+
+ def summary_failures_short(tr):
+ # expecting that the reports were --tb=long (default) so we chop them off here to the last frame
+ reports = tr.getreports("failed")
+ if not reports:
+ return
+ tr.write_sep("=", "FAILURES SHORT STACK")
+ for rep in reports:
+ msg = tr._getfailureheadline(rep)
+ tr.write_sep("_", msg, red=True, bold=True)
+ # chop off the optional leading extra frames, leaving only the last one
+ longrepr = re.sub(r".*_ _ _ (_ ){10,}_ _ ", "", rep.longreprtext, 0, re.M | re.S)
+ tr._tw.line(longrepr)
+ # note: not printing out any rep.sections to keep the report short
+
+ # use ready-made report funcs, we are just hijacking the filehandle to log to a dedicated file each
+ # adapted from https://github.com/pytest-dev/pytest/blob/897f151e/src/_pytest/terminal.py#L814
+ # note: some pytest plugins may interfere by hijacking the default `terminalreporter` (e.g.
+ # pytest-instafail does that)
+
+ # report failures with line/short/long styles
+ config.option.tbstyle = "auto" # full tb
+ with open(report_files["failures_long"], "w") as f:
+ tr._tw = create_terminal_writer(config, f)
+ tr.summary_failures()
+
+ # config.option.tbstyle = "short" # short tb
+ with open(report_files["failures_short"], "w") as f:
+ tr._tw = create_terminal_writer(config, f)
+ summary_failures_short(tr)
+
+ config.option.tbstyle = "line" # one line per error
+ with open(report_files["failures_line"], "w") as f:
+ tr._tw = create_terminal_writer(config, f)
+ tr.summary_failures()
+
+ with open(report_files["errors"], "w") as f:
+ tr._tw = create_terminal_writer(config, f)
+ tr.summary_errors()
+
+ with open(report_files["warnings"], "w") as f:
+ tr._tw = create_terminal_writer(config, f)
+ tr.summary_warnings() # normal warnings
+ tr.summary_warnings() # final warnings
+
+ tr.reportchars = "wPpsxXEf" # emulate -rA (used in summary_passes() and short_test_summary())
+ with open(report_files["passes"], "w") as f:
+ tr._tw = create_terminal_writer(config, f)
+ tr.summary_passes()
+
+ with open(report_files["summary_short"], "w") as f:
+ tr._tw = create_terminal_writer(config, f)
+ tr.short_test_summary()
+
+ with open(report_files["stats"], "w") as f:
+ tr._tw = create_terminal_writer(config, f)
+ tr.summary_stats()
+
+ # restore:
+ tr._tw = orig_writer
+ tr.reportchars = orig_reportchars
+ config.option.tbstyle = orig_tbstyle
+
+
+class CaptureLogger:
+ """
+ Args:
+ Context manager to capture `logging` streams
+ logger: 'logging` logger object
+ Returns:
+ The captured output is available via `self.out`
+ Example:
+ ```python
+ >>> from diffusers import logging
+ >>> from diffusers.testing_utils import CaptureLogger
+
+ >>> msg = "Testing 1, 2, 3"
+ >>> logging.set_verbosity_info()
+ >>> logger = logging.get_logger("diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.py")
+ >>> with CaptureLogger(logger) as cl:
+ ... logger.info(msg)
+ >>> assert cl.out, msg + "\n"
+ ```
+ """
+
+ def __init__(self, logger):
+ self.logger = logger
+ self.io = StringIO()
+ self.sh = logging.StreamHandler(self.io)
+ self.out = ""
+
+ def __enter__(self):
+ self.logger.addHandler(self.sh)
+ return self
+
+ def __exit__(self, *exc):
+ self.logger.removeHandler(self.sh)
+ self.out = self.io.getvalue()
+
+ def __repr__(self):
+ return f"captured: {self.out}\n"
diff --git a/diffusers/src/diffusers/utils/torch_utils.py b/diffusers/src/diffusers/utils/torch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9815cbceededd312bb75240508364fdd623524d
--- /dev/null
+++ b/diffusers/src/diffusers/utils/torch_utils.py
@@ -0,0 +1,77 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+PyTorch utilities: Utilities related to PyTorch
+"""
+from typing import List, Optional, Tuple, Union
+
+from . import logging
+from .import_utils import is_torch_available, is_torch_version
+
+
+if is_torch_available():
+ import torch
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+def randn_tensor(
+ shape: Union[Tuple, List],
+ generator: Optional[Union[List["torch.Generator"], "torch.Generator"]] = None,
+ device: Optional["torch.device"] = None,
+ dtype: Optional["torch.dtype"] = None,
+ layout: Optional["torch.layout"] = None,
+):
+ """This is a helper function that allows to create random tensors on the desired `device` with the desired `dtype`. When
+ passing a list of generators one can seed each batched size individually. If CPU generators are passed the tensor
+ will always be created on CPU.
+ """
+ # device on which tensor is created defaults to device
+ rand_device = device
+ batch_size = shape[0]
+
+ layout = layout or torch.strided
+ device = device or torch.device("cpu")
+
+ if generator is not None:
+ gen_device_type = generator.device.type if not isinstance(generator, list) else generator[0].device.type
+ if gen_device_type != device.type and gen_device_type == "cpu":
+ rand_device = "cpu"
+ if device != "mps":
+ logger.info(
+ f"The passed generator was created on 'cpu' even though a tensor on {device} was expected."
+ f" Tensors will be created on 'cpu' and then moved to {device}. Note that one can probably"
+ f" slighly speed up this function by passing a generator that was created on the {device} device."
+ )
+ elif gen_device_type != device.type and gen_device_type == "cuda":
+ raise ValueError(f"Cannot generate a {device} tensor from a generator of type {gen_device_type}.")
+
+ if isinstance(generator, list):
+ shape = (1,) + shape[1:]
+ latents = [
+ torch.randn(shape, generator=generator[i], device=rand_device, dtype=dtype, layout=layout)
+ for i in range(batch_size)
+ ]
+ latents = torch.cat(latents, dim=0).to(device)
+ else:
+ latents = torch.randn(shape, generator=generator, device=rand_device, dtype=dtype, layout=layout).to(device)
+
+ return latents
+
+
+def is_compiled_module(module):
+ """Check whether the module was compiled with torch.compile()"""
+ if is_torch_version("<", "2.0.0") or not hasattr(torch, "_dynamo"):
+ return False
+ return isinstance(module, torch._dynamo.eval_frame.OptimizedModule)
diff --git a/diffusers/tests/__init__.py b/diffusers/tests/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/conftest.py b/diffusers/tests/conftest.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a02a38163ab01b1c2d0d12d5578e06d91b77cc8
--- /dev/null
+++ b/diffusers/tests/conftest.py
@@ -0,0 +1,44 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# tests directory-specific settings - this file is run automatically
+# by pytest before any tests are run
+
+import sys
+import warnings
+from os.path import abspath, dirname, join
+
+
+# allow having multiple repository checkouts and not needing to remember to rerun
+# 'pip install -e .[dev]' when switching between checkouts and running tests.
+git_repo_path = abspath(join(dirname(dirname(__file__)), "src"))
+sys.path.insert(1, git_repo_path)
+
+# silence FutureWarning warnings in tests since often we can't act on them until
+# they become normal warnings - i.e. the tests still need to test the current functionality
+warnings.simplefilter(action="ignore", category=FutureWarning)
+
+
+def pytest_addoption(parser):
+ from diffusers.utils.testing_utils import pytest_addoption_shared
+
+ pytest_addoption_shared(parser)
+
+
+def pytest_terminal_summary(terminalreporter):
+ from diffusers.utils.testing_utils import pytest_terminal_summary_main
+
+ make_reports = terminalreporter.config.getoption("--make-reports")
+ if make_reports:
+ pytest_terminal_summary_main(terminalreporter, id=make_reports)
diff --git a/diffusers/tests/fixtures/custom_pipeline/pipeline.py b/diffusers/tests/fixtures/custom_pipeline/pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..9119ae30f42f58aab8a52f303c1879e4b3803468
--- /dev/null
+++ b/diffusers/tests/fixtures/custom_pipeline/pipeline.py
@@ -0,0 +1,101 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+# limitations under the License.
+
+
+from typing import Optional, Tuple, Union
+
+import torch
+
+from diffusers import DiffusionPipeline, ImagePipelineOutput
+
+
+class CustomLocalPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
+ [`DDPMScheduler`], or [`DDIMScheduler`].
+ """
+
+ def __init__(self, unet, scheduler):
+ super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ generator: Optional[torch.Generator] = None,
+ num_inference_steps: int = 50,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ **kwargs,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ r"""
+ Args:
+ batch_size (`int`, *optional*, defaults to 1):
+ The number of images to generate.
+ generator (`torch.Generator`, *optional*):
+ A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
+ deterministic.
+ eta (`float`, *optional*, defaults to 0.0):
+ The eta parameter which controls the scale of the variance (0 is DDIM and 1 is one type of DDPM).
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if
+ `return_dict` is True, otherwise a `tuple. When returning a tuple, the first element is a list with the
+ generated images.
+ """
+
+ # Sample gaussian noise to begin loop
+ image = torch.randn(
+ (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
+ generator=generator,
+ )
+ image = image.to(self.device)
+
+ # set step values
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ # 1. predict noise model_output
+ model_output = self.unet(image, t).sample
+
+ # 2. predict previous mean of image x_t-1 and add variance depending on eta
+ # eta corresponds to η in paper and should be between [0, 1]
+ # do x_t -> x_t-1
+ image = self.scheduler.step(model_output, t, image).prev_sample
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,), "This is a local test"
+
+ return ImagePipelineOutput(images=image), "This is a local test"
diff --git a/diffusers/tests/fixtures/custom_pipeline/what_ever.py b/diffusers/tests/fixtures/custom_pipeline/what_ever.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8af08d3980a6e9dbd5af240792edf013cef7313
--- /dev/null
+++ b/diffusers/tests/fixtures/custom_pipeline/what_ever.py
@@ -0,0 +1,101 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+# limitations under the License.
+
+
+from typing import Optional, Tuple, Union
+
+import torch
+
+from diffusers.pipeline_utils import DiffusionPipeline, ImagePipelineOutput
+
+
+class CustomLocalPipeline(DiffusionPipeline):
+ r"""
+ This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
+ library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
+
+ Parameters:
+ unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
+ scheduler ([`SchedulerMixin`]):
+ A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
+ [`DDPMScheduler`], or [`DDIMScheduler`].
+ """
+
+ def __init__(self, unet, scheduler):
+ super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler)
+
+ @torch.no_grad()
+ def __call__(
+ self,
+ batch_size: int = 1,
+ generator: Optional[torch.Generator] = None,
+ num_inference_steps: int = 50,
+ output_type: Optional[str] = "pil",
+ return_dict: bool = True,
+ **kwargs,
+ ) -> Union[ImagePipelineOutput, Tuple]:
+ r"""
+ Args:
+ batch_size (`int`, *optional*, defaults to 1):
+ The number of images to generate.
+ generator (`torch.Generator`, *optional*):
+ A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
+ deterministic.
+ eta (`float`, *optional*, defaults to 0.0):
+ The eta parameter which controls the scale of the variance (0 is DDIM and 1 is one type of DDPM).
+ num_inference_steps (`int`, *optional*, defaults to 50):
+ The number of denoising steps. More denoising steps usually lead to a higher quality image at the
+ expense of slower inference.
+ output_type (`str`, *optional*, defaults to `"pil"`):
+ The output format of the generate image. Choose between
+ [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
+ return_dict (`bool`, *optional*, defaults to `True`):
+ Whether or not to return a [`~pipeline_utils.ImagePipelineOutput`] instead of a plain tuple.
+
+ Returns:
+ [`~pipeline_utils.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if
+ `return_dict` is True, otherwise a `tuple. When returning a tuple, the first element is a list with the
+ generated images.
+ """
+
+ # Sample gaussian noise to begin loop
+ image = torch.randn(
+ (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
+ generator=generator,
+ )
+ image = image.to(self.device)
+
+ # set step values
+ self.scheduler.set_timesteps(num_inference_steps)
+
+ for t in self.progress_bar(self.scheduler.timesteps):
+ # 1. predict noise model_output
+ model_output = self.unet(image, t).sample
+
+ # 2. predict previous mean of image x_t-1 and add variance depending on eta
+ # eta corresponds to η in paper and should be between [0, 1]
+ # do x_t -> x_t-1
+ image = self.scheduler.step(model_output, t, image).prev_sample
+
+ image = (image / 2 + 0.5).clamp(0, 1)
+ image = image.cpu().permute(0, 2, 3, 1).numpy()
+ if output_type == "pil":
+ image = self.numpy_to_pil(image)
+
+ if not return_dict:
+ return (image,), "This is a local test"
+
+ return ImagePipelineOutput(images=image), "This is a local test"
diff --git a/diffusers/tests/fixtures/elise_format0.mid b/diffusers/tests/fixtures/elise_format0.mid
new file mode 100644
index 0000000000000000000000000000000000000000..33dbabe7ab1d4d28e43d9911255a510a8a672d77
Binary files /dev/null and b/diffusers/tests/fixtures/elise_format0.mid differ
diff --git a/diffusers/tests/models/__init__.py b/diffusers/tests/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/models/test_models_unet_1d.py b/diffusers/tests/models/test_models_unet_1d.py
new file mode 100644
index 0000000000000000000000000000000000000000..b814f5f88a302c7c0bdc869ab7674c5657eee775
--- /dev/null
+++ b/diffusers/tests/models/test_models_unet_1d.py
@@ -0,0 +1,284 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import torch
+
+from diffusers import UNet1DModel
+from diffusers.utils import floats_tensor, slow, torch_device
+
+from ..test_modeling_common import ModelTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class UNet1DModelTests(ModelTesterMixin, unittest.TestCase):
+ model_class = UNet1DModel
+
+ @property
+ def dummy_input(self):
+ batch_size = 4
+ num_features = 14
+ seq_len = 16
+
+ noise = floats_tensor((batch_size, num_features, seq_len)).to(torch_device)
+ time_step = torch.tensor([10] * batch_size).to(torch_device)
+
+ return {"sample": noise, "timestep": time_step}
+
+ @property
+ def input_shape(self):
+ return (4, 14, 16)
+
+ @property
+ def output_shape(self):
+ return (4, 14, 16)
+
+ def test_ema_training(self):
+ pass
+
+ def test_training(self):
+ pass
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_determinism(self):
+ super().test_determinism()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_outputs_equivalence(self):
+ super().test_outputs_equivalence()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_from_save_pretrained(self):
+ super().test_from_save_pretrained()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_from_save_pretrained_variant(self):
+ super().test_from_save_pretrained_variant()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_model_from_pretrained(self):
+ super().test_model_from_pretrained()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_output(self):
+ super().test_output()
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "block_out_channels": (32, 64, 128, 256),
+ "in_channels": 14,
+ "out_channels": 14,
+ "time_embedding_type": "positional",
+ "use_timestep_embedding": True,
+ "flip_sin_to_cos": False,
+ "freq_shift": 1.0,
+ "out_block_type": "OutConv1DBlock",
+ "mid_block_type": "MidResTemporalBlock1D",
+ "down_block_types": ("DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D"),
+ "up_block_types": ("UpResnetBlock1D", "UpResnetBlock1D", "UpResnetBlock1D"),
+ "act_fn": "mish",
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_from_pretrained_hub(self):
+ model, loading_info = UNet1DModel.from_pretrained(
+ "bglick13/hopper-medium-v2-value-function-hor32", output_loading_info=True, subfolder="unet"
+ )
+ self.assertIsNotNone(model)
+ self.assertEqual(len(loading_info["missing_keys"]), 0)
+
+ model.to(torch_device)
+ image = model(**self.dummy_input)
+
+ assert image is not None, "Make sure output is not None"
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_output_pretrained(self):
+ model = UNet1DModel.from_pretrained("bglick13/hopper-medium-v2-value-function-hor32", subfolder="unet")
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ num_features = model.in_channels
+ seq_len = 16
+ noise = torch.randn((1, seq_len, num_features)).permute(
+ 0, 2, 1
+ ) # match original, we can update values and remove
+ time_step = torch.full((num_features,), 0)
+
+ with torch.no_grad():
+ output = model(noise, time_step).sample.permute(0, 2, 1)
+
+ output_slice = output[0, -3:, -3:].flatten()
+ # fmt: off
+ expected_output_slice = torch.tensor([-2.137172, 1.1426016, 0.3688687, -0.766922, 0.7303146, 0.11038864, -0.4760633, 0.13270172, 0.02591348])
+ # fmt: on
+ self.assertTrue(torch.allclose(output_slice, expected_output_slice, rtol=1e-3))
+
+ def test_forward_with_norm_groups(self):
+ # Not implemented yet for this UNet
+ pass
+
+ @slow
+ def test_unet_1d_maestro(self):
+ model_id = "harmonai/maestro-150k"
+ model = UNet1DModel.from_pretrained(model_id, subfolder="unet")
+ model.to(torch_device)
+
+ sample_size = 65536
+ noise = torch.sin(torch.arange(sample_size)[None, None, :].repeat(1, 2, 1)).to(torch_device)
+ timestep = torch.tensor([1]).to(torch_device)
+
+ with torch.no_grad():
+ output = model(noise, timestep).sample
+
+ output_sum = output.abs().sum()
+ output_max = output.abs().max()
+
+ assert (output_sum - 224.0896).abs() < 4e-2
+ assert (output_max - 0.0607).abs() < 4e-4
+
+
+class UNetRLModelTests(ModelTesterMixin, unittest.TestCase):
+ model_class = UNet1DModel
+
+ @property
+ def dummy_input(self):
+ batch_size = 4
+ num_features = 14
+ seq_len = 16
+
+ noise = floats_tensor((batch_size, num_features, seq_len)).to(torch_device)
+ time_step = torch.tensor([10] * batch_size).to(torch_device)
+
+ return {"sample": noise, "timestep": time_step}
+
+ @property
+ def input_shape(self):
+ return (4, 14, 16)
+
+ @property
+ def output_shape(self):
+ return (4, 14, 1)
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_determinism(self):
+ super().test_determinism()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_outputs_equivalence(self):
+ super().test_outputs_equivalence()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_from_save_pretrained(self):
+ super().test_from_save_pretrained()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_from_save_pretrained_variant(self):
+ super().test_from_save_pretrained_variant()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_model_from_pretrained(self):
+ super().test_model_from_pretrained()
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_output(self):
+ # UNetRL is a value-function is different output shape
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = torch.Size((inputs_dict["sample"].shape[0], 1))
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_ema_training(self):
+ pass
+
+ def test_training(self):
+ pass
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "in_channels": 14,
+ "out_channels": 14,
+ "down_block_types": ["DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D", "DownResnetBlock1D"],
+ "up_block_types": [],
+ "out_block_type": "ValueFunction",
+ "mid_block_type": "ValueFunctionMidBlock1D",
+ "block_out_channels": [32, 64, 128, 256],
+ "layers_per_block": 1,
+ "downsample_each_block": True,
+ "use_timestep_embedding": True,
+ "freq_shift": 1.0,
+ "flip_sin_to_cos": False,
+ "time_embedding_type": "positional",
+ "act_fn": "mish",
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_from_pretrained_hub(self):
+ value_function, vf_loading_info = UNet1DModel.from_pretrained(
+ "bglick13/hopper-medium-v2-value-function-hor32", output_loading_info=True, subfolder="value_function"
+ )
+ self.assertIsNotNone(value_function)
+ self.assertEqual(len(vf_loading_info["missing_keys"]), 0)
+
+ value_function.to(torch_device)
+ image = value_function(**self.dummy_input)
+
+ assert image is not None, "Make sure output is not None"
+
+ @unittest.skipIf(torch_device == "mps", "mish op not supported in MPS")
+ def test_output_pretrained(self):
+ value_function, vf_loading_info = UNet1DModel.from_pretrained(
+ "bglick13/hopper-medium-v2-value-function-hor32", output_loading_info=True, subfolder="value_function"
+ )
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ num_features = value_function.in_channels
+ seq_len = 14
+ noise = torch.randn((1, seq_len, num_features)).permute(
+ 0, 2, 1
+ ) # match original, we can update values and remove
+ time_step = torch.full((num_features,), 0)
+
+ with torch.no_grad():
+ output = value_function(noise, time_step).sample
+
+ # fmt: off
+ expected_output_slice = torch.tensor([165.25] * seq_len)
+ # fmt: on
+ self.assertTrue(torch.allclose(output, expected_output_slice, rtol=1e-3))
+
+ def test_forward_with_norm_groups(self):
+ # Not implemented yet for this UNet
+ pass
diff --git a/diffusers/tests/models/test_models_unet_2d.py b/diffusers/tests/models/test_models_unet_2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..8f831fcf7cbfb298c5e4deb489cc0edae1f76a51
--- /dev/null
+++ b/diffusers/tests/models/test_models_unet_2d.py
@@ -0,0 +1,297 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import math
+import unittest
+
+import torch
+
+from diffusers import UNet2DModel
+from diffusers.utils import floats_tensor, logging, slow, torch_all_close, torch_device
+
+from ..test_modeling_common import ModelTesterMixin
+
+
+logger = logging.get_logger(__name__)
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class Unet2DModelTests(ModelTesterMixin, unittest.TestCase):
+ model_class = UNet2DModel
+
+ @property
+ def dummy_input(self):
+ batch_size = 4
+ num_channels = 3
+ sizes = (32, 32)
+
+ noise = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
+ time_step = torch.tensor([10]).to(torch_device)
+
+ return {"sample": noise, "timestep": time_step}
+
+ @property
+ def input_shape(self):
+ return (3, 32, 32)
+
+ @property
+ def output_shape(self):
+ return (3, 32, 32)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "block_out_channels": (32, 64),
+ "down_block_types": ("DownBlock2D", "AttnDownBlock2D"),
+ "up_block_types": ("AttnUpBlock2D", "UpBlock2D"),
+ "attention_head_dim": None,
+ "out_channels": 3,
+ "in_channels": 3,
+ "layers_per_block": 2,
+ "sample_size": 32,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+
+class UNetLDMModelTests(ModelTesterMixin, unittest.TestCase):
+ model_class = UNet2DModel
+
+ @property
+ def dummy_input(self):
+ batch_size = 4
+ num_channels = 4
+ sizes = (32, 32)
+
+ noise = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
+ time_step = torch.tensor([10]).to(torch_device)
+
+ return {"sample": noise, "timestep": time_step}
+
+ @property
+ def input_shape(self):
+ return (4, 32, 32)
+
+ @property
+ def output_shape(self):
+ return (4, 32, 32)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "sample_size": 32,
+ "in_channels": 4,
+ "out_channels": 4,
+ "layers_per_block": 2,
+ "block_out_channels": (32, 64),
+ "attention_head_dim": 32,
+ "down_block_types": ("DownBlock2D", "DownBlock2D"),
+ "up_block_types": ("UpBlock2D", "UpBlock2D"),
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_from_pretrained_hub(self):
+ model, loading_info = UNet2DModel.from_pretrained("fusing/unet-ldm-dummy-update", output_loading_info=True)
+
+ self.assertIsNotNone(model)
+ self.assertEqual(len(loading_info["missing_keys"]), 0)
+
+ model.to(torch_device)
+ image = model(**self.dummy_input).sample
+
+ assert image is not None, "Make sure output is not None"
+
+ @unittest.skipIf(torch_device != "cuda", "This test is supposed to run on GPU")
+ def test_from_pretrained_accelerate(self):
+ model, _ = UNet2DModel.from_pretrained("fusing/unet-ldm-dummy-update", output_loading_info=True)
+ model.to(torch_device)
+ image = model(**self.dummy_input).sample
+
+ assert image is not None, "Make sure output is not None"
+
+ @unittest.skipIf(torch_device != "cuda", "This test is supposed to run on GPU")
+ def test_from_pretrained_accelerate_wont_change_results(self):
+ # by defautl model loading will use accelerate as `low_cpu_mem_usage=True`
+ model_accelerate, _ = UNet2DModel.from_pretrained("fusing/unet-ldm-dummy-update", output_loading_info=True)
+ model_accelerate.to(torch_device)
+ model_accelerate.eval()
+
+ noise = torch.randn(
+ 1,
+ model_accelerate.config.in_channels,
+ model_accelerate.config.sample_size,
+ model_accelerate.config.sample_size,
+ generator=torch.manual_seed(0),
+ )
+ noise = noise.to(torch_device)
+ time_step = torch.tensor([10] * noise.shape[0]).to(torch_device)
+
+ arr_accelerate = model_accelerate(noise, time_step)["sample"]
+
+ # two models don't need to stay in the device at the same time
+ del model_accelerate
+ torch.cuda.empty_cache()
+ gc.collect()
+
+ model_normal_load, _ = UNet2DModel.from_pretrained(
+ "fusing/unet-ldm-dummy-update", output_loading_info=True, low_cpu_mem_usage=False
+ )
+ model_normal_load.to(torch_device)
+ model_normal_load.eval()
+ arr_normal_load = model_normal_load(noise, time_step)["sample"]
+
+ assert torch_all_close(arr_accelerate, arr_normal_load, rtol=1e-3)
+
+ def test_output_pretrained(self):
+ model = UNet2DModel.from_pretrained("fusing/unet-ldm-dummy-update")
+ model.eval()
+ model.to(torch_device)
+
+ noise = torch.randn(
+ 1,
+ model.config.in_channels,
+ model.config.sample_size,
+ model.config.sample_size,
+ generator=torch.manual_seed(0),
+ )
+ noise = noise.to(torch_device)
+ time_step = torch.tensor([10] * noise.shape[0]).to(torch_device)
+
+ with torch.no_grad():
+ output = model(noise, time_step).sample
+
+ output_slice = output[0, -1, -3:, -3:].flatten().cpu()
+ # fmt: off
+ expected_output_slice = torch.tensor([-13.3258, -20.1100, -15.9873, -17.6617, -23.0596, -17.9419, -13.3675, -16.1889, -12.3800])
+ # fmt: on
+
+ self.assertTrue(torch_all_close(output_slice, expected_output_slice, rtol=1e-3))
+
+
+class NCSNppModelTests(ModelTesterMixin, unittest.TestCase):
+ model_class = UNet2DModel
+
+ @property
+ def dummy_input(self, sizes=(32, 32)):
+ batch_size = 4
+ num_channels = 3
+
+ noise = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
+ time_step = torch.tensor(batch_size * [10]).to(dtype=torch.int32, device=torch_device)
+
+ return {"sample": noise, "timestep": time_step}
+
+ @property
+ def input_shape(self):
+ return (3, 32, 32)
+
+ @property
+ def output_shape(self):
+ return (3, 32, 32)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "block_out_channels": [32, 64, 64, 64],
+ "in_channels": 3,
+ "layers_per_block": 1,
+ "out_channels": 3,
+ "time_embedding_type": "fourier",
+ "norm_eps": 1e-6,
+ "mid_block_scale_factor": math.sqrt(2.0),
+ "norm_num_groups": None,
+ "down_block_types": [
+ "SkipDownBlock2D",
+ "AttnSkipDownBlock2D",
+ "SkipDownBlock2D",
+ "SkipDownBlock2D",
+ ],
+ "up_block_types": [
+ "SkipUpBlock2D",
+ "SkipUpBlock2D",
+ "AttnSkipUpBlock2D",
+ "SkipUpBlock2D",
+ ],
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ @slow
+ def test_from_pretrained_hub(self):
+ model, loading_info = UNet2DModel.from_pretrained("google/ncsnpp-celebahq-256", output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertEqual(len(loading_info["missing_keys"]), 0)
+
+ model.to(torch_device)
+ inputs = self.dummy_input
+ noise = floats_tensor((4, 3) + (256, 256)).to(torch_device)
+ inputs["sample"] = noise
+ image = model(**inputs)
+
+ assert image is not None, "Make sure output is not None"
+
+ @slow
+ def test_output_pretrained_ve_mid(self):
+ model = UNet2DModel.from_pretrained("google/ncsnpp-celebahq-256")
+ model.to(torch_device)
+
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ batch_size = 4
+ num_channels = 3
+ sizes = (256, 256)
+
+ noise = torch.ones((batch_size, num_channels) + sizes).to(torch_device)
+ time_step = torch.tensor(batch_size * [1e-4]).to(torch_device)
+
+ with torch.no_grad():
+ output = model(noise, time_step).sample
+
+ output_slice = output[0, -3:, -3:, -1].flatten().cpu()
+ # fmt: off
+ expected_output_slice = torch.tensor([-4836.2231, -6487.1387, -3816.7969, -7964.9253, -10966.2842, -20043.6016, 8137.0571, 2340.3499, 544.6114])
+ # fmt: on
+
+ self.assertTrue(torch_all_close(output_slice, expected_output_slice, rtol=1e-2))
+
+ def test_output_pretrained_ve_large(self):
+ model = UNet2DModel.from_pretrained("fusing/ncsnpp-ffhq-ve-dummy-update")
+ model.to(torch_device)
+
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ batch_size = 4
+ num_channels = 3
+ sizes = (32, 32)
+
+ noise = torch.ones((batch_size, num_channels) + sizes).to(torch_device)
+ time_step = torch.tensor(batch_size * [1e-4]).to(torch_device)
+
+ with torch.no_grad():
+ output = model(noise, time_step).sample
+
+ output_slice = output[0, -3:, -3:, -1].flatten().cpu()
+ # fmt: off
+ expected_output_slice = torch.tensor([-0.0325, -0.0900, -0.0869, -0.0332, -0.0725, -0.0270, -0.0101, 0.0227, 0.0256])
+ # fmt: on
+
+ self.assertTrue(torch_all_close(output_slice, expected_output_slice, rtol=1e-2))
+
+ def test_forward_with_norm_groups(self):
+ # not required for this model
+ pass
diff --git a/diffusers/tests/models/test_models_unet_2d_condition.py b/diffusers/tests/models/test_models_unet_2d_condition.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0cb9d3d8ebde3322c89dbec44f58f16985f6243
--- /dev/null
+++ b/diffusers/tests/models/test_models_unet_2d_condition.py
@@ -0,0 +1,944 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import os
+import tempfile
+import unittest
+
+import torch
+from parameterized import parameterized
+
+from diffusers import UNet2DConditionModel
+from diffusers.models.attention_processor import LoRAAttnProcessor
+from diffusers.utils import (
+ floats_tensor,
+ load_hf_numpy,
+ logging,
+ require_torch_gpu,
+ slow,
+ torch_all_close,
+ torch_device,
+)
+from diffusers.utils.import_utils import is_xformers_available
+
+from ..test_modeling_common import ModelTesterMixin
+
+
+logger = logging.get_logger(__name__)
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+def create_lora_layers(model):
+ lora_attn_procs = {}
+ for name in model.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else model.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = model.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(model.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = model.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+ lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
+
+ # add 1 to weights to mock trained weights
+ with torch.no_grad():
+ lora_attn_procs[name].to_q_lora.up.weight += 1
+ lora_attn_procs[name].to_k_lora.up.weight += 1
+ lora_attn_procs[name].to_v_lora.up.weight += 1
+ lora_attn_procs[name].to_out_lora.up.weight += 1
+
+ return lora_attn_procs
+
+
+class UNet2DConditionModelTests(ModelTesterMixin, unittest.TestCase):
+ model_class = UNet2DConditionModel
+
+ @property
+ def dummy_input(self):
+ batch_size = 4
+ num_channels = 4
+ sizes = (32, 32)
+
+ noise = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
+ time_step = torch.tensor([10]).to(torch_device)
+ encoder_hidden_states = floats_tensor((batch_size, 4, 32)).to(torch_device)
+
+ return {"sample": noise, "timestep": time_step, "encoder_hidden_states": encoder_hidden_states}
+
+ @property
+ def input_shape(self):
+ return (4, 32, 32)
+
+ @property
+ def output_shape(self):
+ return (4, 32, 32)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "block_out_channels": (32, 64),
+ "down_block_types": ("CrossAttnDownBlock2D", "DownBlock2D"),
+ "up_block_types": ("UpBlock2D", "CrossAttnUpBlock2D"),
+ "cross_attention_dim": 32,
+ "attention_head_dim": 8,
+ "out_channels": 4,
+ "in_channels": 4,
+ "layers_per_block": 2,
+ "sample_size": 32,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_enable_works(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+
+ model.enable_xformers_memory_efficient_attention()
+
+ assert (
+ model.mid_block.attentions[0].transformer_blocks[0].attn1.processor.__class__.__name__
+ == "XFormersAttnProcessor"
+ ), "xformers is not enabled"
+
+ @unittest.skipIf(torch_device == "mps", "Gradient checkpointing skipped on MPS")
+ def test_gradient_checkpointing(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ assert not model.is_gradient_checkpointing and model.training
+
+ out = model(**inputs_dict).sample
+ # run the backwards pass on the model. For backwards pass, for simplicity purpose,
+ # we won't calculate the loss and rather backprop on out.sum()
+ model.zero_grad()
+
+ labels = torch.randn_like(out)
+ loss = (out - labels).mean()
+ loss.backward()
+
+ # re-instantiate the model now enabling gradient checkpointing
+ model_2 = self.model_class(**init_dict)
+ # clone model
+ model_2.load_state_dict(model.state_dict())
+ model_2.to(torch_device)
+ model_2.enable_gradient_checkpointing()
+
+ assert model_2.is_gradient_checkpointing and model_2.training
+
+ out_2 = model_2(**inputs_dict).sample
+ # run the backwards pass on the model. For backwards pass, for simplicity purpose,
+ # we won't calculate the loss and rather backprop on out.sum()
+ model_2.zero_grad()
+ loss_2 = (out_2 - labels).mean()
+ loss_2.backward()
+
+ # compare the output and parameters gradients
+ self.assertTrue((loss - loss_2).abs() < 1e-5)
+ named_params = dict(model.named_parameters())
+ named_params_2 = dict(model_2.named_parameters())
+ for name, param in named_params.items():
+ self.assertTrue(torch_all_close(param.grad.data, named_params_2[name].grad.data, atol=5e-5))
+
+ def test_model_with_attention_head_dim_tuple(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_model_with_use_linear_projection(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["use_linear_projection"] = True
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_model_with_cross_attention_dim_tuple(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["cross_attention_dim"] = (32, 32)
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_model_with_simple_projection(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ batch_size, _, _, sample_size = inputs_dict["sample"].shape
+
+ init_dict["class_embed_type"] = "simple_projection"
+ init_dict["projection_class_embeddings_input_dim"] = sample_size
+
+ inputs_dict["class_labels"] = floats_tensor((batch_size, sample_size)).to(torch_device)
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_model_with_class_embeddings_concat(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ batch_size, _, _, sample_size = inputs_dict["sample"].shape
+
+ init_dict["class_embed_type"] = "simple_projection"
+ init_dict["projection_class_embeddings_input_dim"] = sample_size
+ init_dict["class_embeddings_concat"] = True
+
+ inputs_dict["class_labels"] = floats_tensor((batch_size, sample_size)).to(torch_device)
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_model_attention_slicing(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ model.set_attention_slice("auto")
+ with torch.no_grad():
+ output = model(**inputs_dict)
+ assert output is not None
+
+ model.set_attention_slice("max")
+ with torch.no_grad():
+ output = model(**inputs_dict)
+ assert output is not None
+
+ model.set_attention_slice(2)
+ with torch.no_grad():
+ output = model(**inputs_dict)
+ assert output is not None
+
+ def test_model_sliceable_head_dim(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ model = self.model_class(**init_dict)
+
+ def check_sliceable_dim_attr(module: torch.nn.Module):
+ if hasattr(module, "set_attention_slice"):
+ assert isinstance(module.sliceable_head_dim, int)
+
+ for child in module.children():
+ check_sliceable_dim_attr(child)
+
+ # retrieve number of attention layers
+ for module in model.children():
+ check_sliceable_dim_attr(module)
+
+ def test_special_attn_proc(self):
+ class AttnEasyProc(torch.nn.Module):
+ def __init__(self, num):
+ super().__init__()
+ self.weight = torch.nn.Parameter(torch.tensor(num))
+ self.is_run = False
+ self.number = 0
+ self.counter = 0
+
+ def __call__(self, attn, hidden_states, encoder_hidden_states=None, attention_mask=None, number=None):
+ batch_size, sequence_length, _ = hidden_states.shape
+ attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
+
+ query = attn.to_q(hidden_states)
+
+ encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
+ key = attn.to_k(encoder_hidden_states)
+ value = attn.to_v(encoder_hidden_states)
+
+ query = attn.head_to_batch_dim(query)
+ key = attn.head_to_batch_dim(key)
+ value = attn.head_to_batch_dim(value)
+
+ attention_probs = attn.get_attention_scores(query, key, attention_mask)
+ hidden_states = torch.bmm(attention_probs, value)
+ hidden_states = attn.batch_to_head_dim(hidden_states)
+
+ # linear proj
+ hidden_states = attn.to_out[0](hidden_states)
+ # dropout
+ hidden_states = attn.to_out[1](hidden_states)
+
+ hidden_states += self.weight
+
+ self.is_run = True
+ self.counter += 1
+ self.number = number
+
+ return hidden_states
+
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ processor = AttnEasyProc(5.0)
+
+ model.set_attn_processor(processor)
+ model(**inputs_dict, cross_attention_kwargs={"number": 123}).sample
+
+ assert processor.counter == 12
+ assert processor.is_run
+ assert processor.number == 123
+
+ def test_lora_processors(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ with torch.no_grad():
+ sample1 = model(**inputs_dict).sample
+
+ lora_attn_procs = {}
+ for name in model.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else model.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = model.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(model.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = model.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+
+ # add 1 to weights to mock trained weights
+ with torch.no_grad():
+ lora_attn_procs[name].to_q_lora.up.weight += 1
+ lora_attn_procs[name].to_k_lora.up.weight += 1
+ lora_attn_procs[name].to_v_lora.up.weight += 1
+ lora_attn_procs[name].to_out_lora.up.weight += 1
+
+ # make sure we can set a list of attention processors
+ model.set_attn_processor(lora_attn_procs)
+ model.to(torch_device)
+
+ # test that attn processors can be set to itself
+ model.set_attn_processor(model.attn_processors)
+
+ with torch.no_grad():
+ sample2 = model(**inputs_dict, cross_attention_kwargs={"scale": 0.0}).sample
+ sample3 = model(**inputs_dict, cross_attention_kwargs={"scale": 0.5}).sample
+ sample4 = model(**inputs_dict, cross_attention_kwargs={"scale": 0.5}).sample
+
+ assert (sample1 - sample2).abs().max() < 1e-4
+ assert (sample3 - sample4).abs().max() < 1e-4
+
+ # sample 2 and sample 3 should be different
+ assert (sample2 - sample3).abs().max() > 1e-4
+
+ def test_lora_save_load(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ torch.manual_seed(0)
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ with torch.no_grad():
+ old_sample = model(**inputs_dict).sample
+
+ lora_attn_procs = create_lora_layers(model)
+ model.set_attn_processor(lora_attn_procs)
+
+ with torch.no_grad():
+ sample = model(**inputs_dict, cross_attention_kwargs={"scale": 0.5}).sample
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_attn_procs(tmpdirname)
+ self.assertTrue(os.path.isfile(os.path.join(tmpdirname, "pytorch_lora_weights.bin")))
+ torch.manual_seed(0)
+ new_model = self.model_class(**init_dict)
+ new_model.to(torch_device)
+ new_model.load_attn_procs(tmpdirname)
+
+ with torch.no_grad():
+ new_sample = new_model(**inputs_dict, cross_attention_kwargs={"scale": 0.5}).sample
+
+ assert (sample - new_sample).abs().max() < 1e-4
+
+ # LoRA and no LoRA should NOT be the same
+ assert (sample - old_sample).abs().max() > 1e-4
+
+ def test_lora_save_load_safetensors(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ torch.manual_seed(0)
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ with torch.no_grad():
+ old_sample = model(**inputs_dict).sample
+
+ lora_attn_procs = {}
+ for name in model.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else model.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = model.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(model.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = model.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+ lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
+
+ # add 1 to weights to mock trained weights
+ with torch.no_grad():
+ lora_attn_procs[name].to_q_lora.up.weight += 1
+ lora_attn_procs[name].to_k_lora.up.weight += 1
+ lora_attn_procs[name].to_v_lora.up.weight += 1
+ lora_attn_procs[name].to_out_lora.up.weight += 1
+
+ model.set_attn_processor(lora_attn_procs)
+
+ with torch.no_grad():
+ sample = model(**inputs_dict, cross_attention_kwargs={"scale": 0.5}).sample
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_attn_procs(tmpdirname, safe_serialization=True)
+ self.assertTrue(os.path.isfile(os.path.join(tmpdirname, "pytorch_lora_weights.safetensors")))
+ torch.manual_seed(0)
+ new_model = self.model_class(**init_dict)
+ new_model.to(torch_device)
+ new_model.load_attn_procs(tmpdirname)
+
+ with torch.no_grad():
+ new_sample = new_model(**inputs_dict, cross_attention_kwargs={"scale": 0.5}).sample
+
+ assert (sample - new_sample).abs().max() < 1e-4
+
+ # LoRA and no LoRA should NOT be the same
+ assert (sample - old_sample).abs().max() > 1e-4
+
+ def test_lora_save_safetensors_load_torch(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ torch.manual_seed(0)
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ lora_attn_procs = {}
+ for name in model.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else model.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = model.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(model.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = model.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+ lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
+
+ model.set_attn_processor(lora_attn_procs)
+ # Saving as torch, properly reloads with directly filename
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_attn_procs(tmpdirname)
+ self.assertTrue(os.path.isfile(os.path.join(tmpdirname, "pytorch_lora_weights.bin")))
+ torch.manual_seed(0)
+ new_model = self.model_class(**init_dict)
+ new_model.to(torch_device)
+ new_model.load_attn_procs(tmpdirname, weight_name="pytorch_lora_weights.bin")
+
+ def test_lora_save_torch_force_load_safetensors_error(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ torch.manual_seed(0)
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ lora_attn_procs = {}
+ for name in model.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else model.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = model.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(model.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = model.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+ lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
+
+ model.set_attn_processor(lora_attn_procs)
+ # Saving as torch, properly reloads with directly filename
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_attn_procs(tmpdirname)
+ self.assertTrue(os.path.isfile(os.path.join(tmpdirname, "pytorch_lora_weights.bin")))
+ torch.manual_seed(0)
+ new_model = self.model_class(**init_dict)
+ new_model.to(torch_device)
+ with self.assertRaises(IOError) as e:
+ new_model.load_attn_procs(tmpdirname, use_safetensors=True)
+ self.assertIn("Error no file named pytorch_lora_weights.safetensors", str(e.exception))
+
+ def test_lora_on_off(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ torch.manual_seed(0)
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ with torch.no_grad():
+ old_sample = model(**inputs_dict).sample
+
+ lora_attn_procs = create_lora_layers(model)
+ model.set_attn_processor(lora_attn_procs)
+
+ with torch.no_grad():
+ sample = model(**inputs_dict, cross_attention_kwargs={"scale": 0.0}).sample
+
+ model.set_default_attn_processor()
+
+ with torch.no_grad():
+ new_sample = model(**inputs_dict).sample
+
+ assert (sample - new_sample).abs().max() < 1e-4
+ assert (sample - old_sample).abs().max() < 1e-4
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_lora_xformers_on_off(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = (8, 16)
+
+ torch.manual_seed(0)
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ lora_attn_procs = create_lora_layers(model)
+ model.set_attn_processor(lora_attn_procs)
+
+ # default
+ with torch.no_grad():
+ sample = model(**inputs_dict).sample
+
+ model.enable_xformers_memory_efficient_attention()
+ on_sample = model(**inputs_dict).sample
+
+ model.disable_xformers_memory_efficient_attention()
+ off_sample = model(**inputs_dict).sample
+
+ assert (sample - on_sample).abs().max() < 1e-4
+ assert (sample - off_sample).abs().max() < 1e-4
+
+
+@slow
+class UNet2DConditionModelIntegrationTests(unittest.TestCase):
+ def get_file_format(self, seed, shape):
+ return f"gaussian_noise_s={seed}_shape={'_'.join([str(s) for s in shape])}.npy"
+
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_latents(self, seed=0, shape=(4, 4, 64, 64), fp16=False):
+ dtype = torch.float16 if fp16 else torch.float32
+ image = torch.from_numpy(load_hf_numpy(self.get_file_format(seed, shape))).to(torch_device).to(dtype)
+ return image
+
+ def get_unet_model(self, fp16=False, model_id="CompVis/stable-diffusion-v1-4"):
+ revision = "fp16" if fp16 else None
+ torch_dtype = torch.float16 if fp16 else torch.float32
+
+ model = UNet2DConditionModel.from_pretrained(
+ model_id, subfolder="unet", torch_dtype=torch_dtype, revision=revision
+ )
+ model.to(torch_device).eval()
+
+ return model
+
+ def test_set_attention_slice_auto(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ unet = self.get_unet_model()
+ unet.set_attention_slice("auto")
+
+ latents = self.get_latents(33)
+ encoder_hidden_states = self.get_encoder_hidden_states(33)
+ timestep = 1
+
+ with torch.no_grad():
+ _ = unet(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+
+ assert mem_bytes < 5 * 10**9
+
+ def test_set_attention_slice_max(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ unet = self.get_unet_model()
+ unet.set_attention_slice("max")
+
+ latents = self.get_latents(33)
+ encoder_hidden_states = self.get_encoder_hidden_states(33)
+ timestep = 1
+
+ with torch.no_grad():
+ _ = unet(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+
+ assert mem_bytes < 5 * 10**9
+
+ def test_set_attention_slice_int(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ unet = self.get_unet_model()
+ unet.set_attention_slice(2)
+
+ latents = self.get_latents(33)
+ encoder_hidden_states = self.get_encoder_hidden_states(33)
+ timestep = 1
+
+ with torch.no_grad():
+ _ = unet(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+
+ assert mem_bytes < 5 * 10**9
+
+ def test_set_attention_slice_list(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ # there are 32 sliceable layers
+ slice_list = 16 * [2, 3]
+ unet = self.get_unet_model()
+ unet.set_attention_slice(slice_list)
+
+ latents = self.get_latents(33)
+ encoder_hidden_states = self.get_encoder_hidden_states(33)
+ timestep = 1
+
+ with torch.no_grad():
+ _ = unet(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+
+ assert mem_bytes < 5 * 10**9
+
+ def get_encoder_hidden_states(self, seed=0, shape=(4, 77, 768), fp16=False):
+ dtype = torch.float16 if fp16 else torch.float32
+ hidden_states = torch.from_numpy(load_hf_numpy(self.get_file_format(seed, shape))).to(torch_device).to(dtype)
+ return hidden_states
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [33, 4, [-0.4424, 0.1510, -0.1937, 0.2118, 0.3746, -0.3957, 0.0160, -0.0435]],
+ [47, 0.55, [-0.1508, 0.0379, -0.3075, 0.2540, 0.3633, -0.0821, 0.1719, -0.0207]],
+ [21, 0.89, [-0.6479, 0.6364, -0.3464, 0.8697, 0.4443, -0.6289, -0.0091, 0.1778]],
+ [9, 1000, [0.8888, -0.5659, 0.5834, -0.7469, 1.1912, -0.3923, 1.1241, -0.4424]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_compvis_sd_v1_4(self, seed, timestep, expected_slice):
+ model = self.get_unet_model(model_id="CompVis/stable-diffusion-v1-4")
+ latents = self.get_latents(seed)
+ encoder_hidden_states = self.get_encoder_hidden_states(seed)
+
+ timestep = torch.tensor([timestep], dtype=torch.long, device=torch_device)
+
+ with torch.no_grad():
+ sample = model(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ assert sample.shape == latents.shape
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=1e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [83, 4, [-0.2323, -0.1304, 0.0813, -0.3093, -0.0919, -0.1571, -0.1125, -0.5806]],
+ [17, 0.55, [-0.0831, -0.2443, 0.0901, -0.0919, 0.3396, 0.0103, -0.3743, 0.0701]],
+ [8, 0.89, [-0.4863, 0.0859, 0.0875, -0.1658, 0.9199, -0.0114, 0.4839, 0.4639]],
+ [3, 1000, [-0.5649, 0.2402, -0.5518, 0.1248, 1.1328, -0.2443, -0.0325, -1.0078]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_compvis_sd_v1_4_fp16(self, seed, timestep, expected_slice):
+ model = self.get_unet_model(model_id="CompVis/stable-diffusion-v1-4", fp16=True)
+ latents = self.get_latents(seed, fp16=True)
+ encoder_hidden_states = self.get_encoder_hidden_states(seed, fp16=True)
+
+ timestep = torch.tensor([timestep], dtype=torch.long, device=torch_device)
+
+ with torch.no_grad():
+ sample = model(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ assert sample.shape == latents.shape
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=5e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [33, 4, [-0.4430, 0.1570, -0.1867, 0.2376, 0.3205, -0.3681, 0.0525, -0.0722]],
+ [47, 0.55, [-0.1415, 0.0129, -0.3136, 0.2257, 0.3430, -0.0536, 0.2114, -0.0436]],
+ [21, 0.89, [-0.7091, 0.6664, -0.3643, 0.9032, 0.4499, -0.6541, 0.0139, 0.1750]],
+ [9, 1000, [0.8878, -0.5659, 0.5844, -0.7442, 1.1883, -0.3927, 1.1192, -0.4423]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_compvis_sd_v1_5(self, seed, timestep, expected_slice):
+ model = self.get_unet_model(model_id="runwayml/stable-diffusion-v1-5")
+ latents = self.get_latents(seed)
+ encoder_hidden_states = self.get_encoder_hidden_states(seed)
+
+ timestep = torch.tensor([timestep], dtype=torch.long, device=torch_device)
+
+ with torch.no_grad():
+ sample = model(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ assert sample.shape == latents.shape
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=1e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [83, 4, [-0.2695, -0.1669, 0.0073, -0.3181, -0.1187, -0.1676, -0.1395, -0.5972]],
+ [17, 0.55, [-0.1290, -0.2588, 0.0551, -0.0916, 0.3286, 0.0238, -0.3669, 0.0322]],
+ [8, 0.89, [-0.5283, 0.1198, 0.0870, -0.1141, 0.9189, -0.0150, 0.5474, 0.4319]],
+ [3, 1000, [-0.5601, 0.2411, -0.5435, 0.1268, 1.1338, -0.2427, -0.0280, -1.0020]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_compvis_sd_v1_5_fp16(self, seed, timestep, expected_slice):
+ model = self.get_unet_model(model_id="runwayml/stable-diffusion-v1-5", fp16=True)
+ latents = self.get_latents(seed, fp16=True)
+ encoder_hidden_states = self.get_encoder_hidden_states(seed, fp16=True)
+
+ timestep = torch.tensor([timestep], dtype=torch.long, device=torch_device)
+
+ with torch.no_grad():
+ sample = model(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ assert sample.shape == latents.shape
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=5e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [33, 4, [-0.7639, 0.0106, -0.1615, -0.3487, -0.0423, -0.7972, 0.0085, -0.4858]],
+ [47, 0.55, [-0.6564, 0.0795, -1.9026, -0.6258, 1.8235, 1.2056, 1.2169, 0.9073]],
+ [21, 0.89, [0.0327, 0.4399, -0.6358, 0.3417, 0.4120, -0.5621, -0.0397, -1.0430]],
+ [9, 1000, [0.1600, 0.7303, -1.0556, -0.3515, -0.7440, -1.2037, -1.8149, -1.8931]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_compvis_sd_inpaint(self, seed, timestep, expected_slice):
+ model = self.get_unet_model(model_id="runwayml/stable-diffusion-inpainting")
+ latents = self.get_latents(seed, shape=(4, 9, 64, 64))
+ encoder_hidden_states = self.get_encoder_hidden_states(seed)
+
+ timestep = torch.tensor([timestep], dtype=torch.long, device=torch_device)
+
+ with torch.no_grad():
+ sample = model(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ assert sample.shape == (4, 4, 64, 64)
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=1e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [83, 4, [-0.1047, -1.7227, 0.1067, 0.0164, -0.5698, -0.4172, -0.1388, 1.1387]],
+ [17, 0.55, [0.0975, -0.2856, -0.3508, -0.4600, 0.3376, 0.2930, -0.2747, -0.7026]],
+ [8, 0.89, [-0.0952, 0.0183, -0.5825, -0.1981, 0.1131, 0.4668, -0.0395, -0.3486]],
+ [3, 1000, [0.4790, 0.4949, -1.0732, -0.7158, 0.7959, -0.9478, 0.1105, -0.9741]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_compvis_sd_inpaint_fp16(self, seed, timestep, expected_slice):
+ model = self.get_unet_model(model_id="runwayml/stable-diffusion-inpainting", fp16=True)
+ latents = self.get_latents(seed, shape=(4, 9, 64, 64), fp16=True)
+ encoder_hidden_states = self.get_encoder_hidden_states(seed, fp16=True)
+
+ timestep = torch.tensor([timestep], dtype=torch.long, device=torch_device)
+
+ with torch.no_grad():
+ sample = model(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ assert sample.shape == (4, 4, 64, 64)
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=5e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [83, 4, [0.1514, 0.0807, 0.1624, 0.1016, -0.1896, 0.0263, 0.0677, 0.2310]],
+ [17, 0.55, [0.1164, -0.0216, 0.0170, 0.1589, -0.3120, 0.1005, -0.0581, -0.1458]],
+ [8, 0.89, [-0.1758, -0.0169, 0.1004, -0.1411, 0.1312, 0.1103, -0.1996, 0.2139]],
+ [3, 1000, [0.1214, 0.0352, -0.0731, -0.1562, -0.0994, -0.0906, -0.2340, -0.0539]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_stabilityai_sd_v2_fp16(self, seed, timestep, expected_slice):
+ model = self.get_unet_model(model_id="stabilityai/stable-diffusion-2", fp16=True)
+ latents = self.get_latents(seed, shape=(4, 4, 96, 96), fp16=True)
+ encoder_hidden_states = self.get_encoder_hidden_states(seed, shape=(4, 77, 1024), fp16=True)
+
+ timestep = torch.tensor([timestep], dtype=torch.long, device=torch_device)
+
+ with torch.no_grad():
+ sample = model(latents, timestep=timestep, encoder_hidden_states=encoder_hidden_states).sample
+
+ assert sample.shape == latents.shape
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=5e-3)
diff --git a/diffusers/tests/models/test_models_unet_2d_flax.py b/diffusers/tests/models/test_models_unet_2d_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..69a0704dca9dae32a7d612b82cbedc0454a0a1b5
--- /dev/null
+++ b/diffusers/tests/models/test_models_unet_2d_flax.py
@@ -0,0 +1,104 @@
+import gc
+import unittest
+
+from parameterized import parameterized
+
+from diffusers import FlaxUNet2DConditionModel
+from diffusers.utils import is_flax_available
+from diffusers.utils.testing_utils import load_hf_numpy, require_flax, slow
+
+
+if is_flax_available():
+ import jax
+ import jax.numpy as jnp
+
+
+@slow
+@require_flax
+class FlaxUNet2DConditionModelIntegrationTests(unittest.TestCase):
+ def get_file_format(self, seed, shape):
+ return f"gaussian_noise_s={seed}_shape={'_'.join([str(s) for s in shape])}.npy"
+
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+
+ def get_latents(self, seed=0, shape=(4, 4, 64, 64), fp16=False):
+ dtype = jnp.bfloat16 if fp16 else jnp.float32
+ image = jnp.array(load_hf_numpy(self.get_file_format(seed, shape)), dtype=dtype)
+ return image
+
+ def get_unet_model(self, fp16=False, model_id="CompVis/stable-diffusion-v1-4"):
+ dtype = jnp.bfloat16 if fp16 else jnp.float32
+ revision = "bf16" if fp16 else None
+
+ model, params = FlaxUNet2DConditionModel.from_pretrained(
+ model_id, subfolder="unet", dtype=dtype, revision=revision
+ )
+ return model, params
+
+ def get_encoder_hidden_states(self, seed=0, shape=(4, 77, 768), fp16=False):
+ dtype = jnp.bfloat16 if fp16 else jnp.float32
+ hidden_states = jnp.array(load_hf_numpy(self.get_file_format(seed, shape)), dtype=dtype)
+ return hidden_states
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [83, 4, [-0.2323, -0.1304, 0.0813, -0.3093, -0.0919, -0.1571, -0.1125, -0.5806]],
+ [17, 0.55, [-0.0831, -0.2443, 0.0901, -0.0919, 0.3396, 0.0103, -0.3743, 0.0701]],
+ [8, 0.89, [-0.4863, 0.0859, 0.0875, -0.1658, 0.9199, -0.0114, 0.4839, 0.4639]],
+ [3, 1000, [-0.5649, 0.2402, -0.5518, 0.1248, 1.1328, -0.2443, -0.0325, -1.0078]],
+ # fmt: on
+ ]
+ )
+ def test_compvis_sd_v1_4_flax_vs_torch_fp16(self, seed, timestep, expected_slice):
+ model, params = self.get_unet_model(model_id="CompVis/stable-diffusion-v1-4", fp16=True)
+ latents = self.get_latents(seed, fp16=True)
+ encoder_hidden_states = self.get_encoder_hidden_states(seed, fp16=True)
+
+ sample = model.apply(
+ {"params": params},
+ latents,
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=encoder_hidden_states,
+ ).sample
+
+ assert sample.shape == latents.shape
+
+ output_slice = jnp.asarray(jax.device_get((sample[-1, -2:, -2:, :2].flatten())), dtype=jnp.float32)
+ expected_output_slice = jnp.array(expected_slice, dtype=jnp.float32)
+
+ # Found torch (float16) and flax (bfloat16) outputs to be within this tolerance, in the same hardware
+ assert jnp.allclose(output_slice, expected_output_slice, atol=1e-2)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [83, 4, [0.1514, 0.0807, 0.1624, 0.1016, -0.1896, 0.0263, 0.0677, 0.2310]],
+ [17, 0.55, [0.1164, -0.0216, 0.0170, 0.1589, -0.3120, 0.1005, -0.0581, -0.1458]],
+ [8, 0.89, [-0.1758, -0.0169, 0.1004, -0.1411, 0.1312, 0.1103, -0.1996, 0.2139]],
+ [3, 1000, [0.1214, 0.0352, -0.0731, -0.1562, -0.0994, -0.0906, -0.2340, -0.0539]],
+ # fmt: on
+ ]
+ )
+ def test_stabilityai_sd_v2_flax_vs_torch_fp16(self, seed, timestep, expected_slice):
+ model, params = self.get_unet_model(model_id="stabilityai/stable-diffusion-2", fp16=True)
+ latents = self.get_latents(seed, shape=(4, 4, 96, 96), fp16=True)
+ encoder_hidden_states = self.get_encoder_hidden_states(seed, shape=(4, 77, 1024), fp16=True)
+
+ sample = model.apply(
+ {"params": params},
+ latents,
+ jnp.array(timestep, dtype=jnp.int32),
+ encoder_hidden_states=encoder_hidden_states,
+ ).sample
+
+ assert sample.shape == latents.shape
+
+ output_slice = jnp.asarray(jax.device_get((sample[-1, -2:, -2:, :2].flatten())), dtype=jnp.float32)
+ expected_output_slice = jnp.array(expected_slice, dtype=jnp.float32)
+
+ # Found torch (float16) and flax (bfloat16) outputs to be within this tolerance, on the same hardware
+ assert jnp.allclose(output_slice, expected_output_slice, atol=1e-2)
diff --git a/diffusers/tests/models/test_models_unet_3d_condition.py b/diffusers/tests/models/test_models_unet_3d_condition.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a0d74a3ea5ad6956e791029d4a3be2528ca4d28
--- /dev/null
+++ b/diffusers/tests/models/test_models_unet_3d_condition.py
@@ -0,0 +1,241 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers.models import ModelMixin, UNet3DConditionModel
+from diffusers.models.attention_processor import LoRAAttnProcessor
+from diffusers.utils import (
+ floats_tensor,
+ logging,
+ skip_mps,
+ torch_device,
+)
+from diffusers.utils.import_utils import is_xformers_available
+
+from ..test_modeling_common import ModelTesterMixin
+
+
+logger = logging.get_logger(__name__)
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+def create_lora_layers(model):
+ lora_attn_procs = {}
+ for name in model.attn_processors.keys():
+ cross_attention_dim = None if name.endswith("attn1.processor") else model.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = model.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(model.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = model.config.block_out_channels[block_id]
+
+ lora_attn_procs[name] = LoRAAttnProcessor(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+ lora_attn_procs[name] = lora_attn_procs[name].to(model.device)
+
+ # add 1 to weights to mock trained weights
+ with torch.no_grad():
+ lora_attn_procs[name].to_q_lora.up.weight += 1
+ lora_attn_procs[name].to_k_lora.up.weight += 1
+ lora_attn_procs[name].to_v_lora.up.weight += 1
+ lora_attn_procs[name].to_out_lora.up.weight += 1
+
+ return lora_attn_procs
+
+
+@skip_mps
+class UNet3DConditionModelTests(ModelTesterMixin, unittest.TestCase):
+ model_class = UNet3DConditionModel
+
+ @property
+ def dummy_input(self):
+ batch_size = 4
+ num_channels = 4
+ num_frames = 4
+ sizes = (32, 32)
+
+ noise = floats_tensor((batch_size, num_channels, num_frames) + sizes).to(torch_device)
+ time_step = torch.tensor([10]).to(torch_device)
+ encoder_hidden_states = floats_tensor((batch_size, 4, 32)).to(torch_device)
+
+ return {"sample": noise, "timestep": time_step, "encoder_hidden_states": encoder_hidden_states}
+
+ @property
+ def input_shape(self):
+ return (4, 4, 32, 32)
+
+ @property
+ def output_shape(self):
+ return (4, 4, 32, 32)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "block_out_channels": (32, 64),
+ "down_block_types": (
+ "CrossAttnDownBlock3D",
+ "DownBlock3D",
+ ),
+ "up_block_types": ("UpBlock3D", "CrossAttnUpBlock3D"),
+ "cross_attention_dim": 32,
+ "attention_head_dim": 8,
+ "out_channels": 4,
+ "in_channels": 4,
+ "layers_per_block": 1,
+ "sample_size": 32,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_enable_works(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+
+ model.enable_xformers_memory_efficient_attention()
+
+ assert (
+ model.mid_block.attentions[0].transformer_blocks[0].attn1.processor.__class__.__name__
+ == "XFormersAttnProcessor"
+ ), "xformers is not enabled"
+
+ # Overriding to set `norm_num_groups` needs to be different for this model.
+ def test_forward_with_norm_groups(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["norm_num_groups"] = 32
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ # Overriding since the UNet3D outputs a different structure.
+ def test_determinism(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ # Warmup pass when using mps (see #372)
+ if torch_device == "mps" and isinstance(model, ModelMixin):
+ model(**self.dummy_input)
+
+ first = model(**inputs_dict)
+ if isinstance(first, dict):
+ first = first.sample
+
+ second = model(**inputs_dict)
+ if isinstance(second, dict):
+ second = second.sample
+
+ out_1 = first.cpu().numpy()
+ out_2 = second.cpu().numpy()
+ out_1 = out_1[~np.isnan(out_1)]
+ out_2 = out_2[~np.isnan(out_2)]
+ max_diff = np.amax(np.abs(out_1 - out_2))
+ self.assertLessEqual(max_diff, 1e-5)
+
+ def test_model_attention_slicing(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = 8
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ model.set_attention_slice("auto")
+ with torch.no_grad():
+ output = model(**inputs_dict)
+ assert output is not None
+
+ model.set_attention_slice("max")
+ with torch.no_grad():
+ output = model(**inputs_dict)
+ assert output is not None
+
+ model.set_attention_slice(2)
+ with torch.no_grad():
+ output = model(**inputs_dict)
+ assert output is not None
+
+ # (`attn_processors`) needs to be implemented in this model for this test.
+ # def test_lora_processors(self):
+
+ # (`attn_processors`) needs to be implemented in this model for this test.
+ # def test_lora_save_load(self):
+
+ # (`attn_processors`) needs to be implemented for this test in the model.
+ # def test_lora_save_load_safetensors(self):
+
+ # (`attn_processors`) needs to be implemented for this test in the model.
+ # def test_lora_save_safetensors_load_torch(self):
+
+ # (`attn_processors`) needs to be implemented for this test.
+ # def test_lora_save_torch_force_load_safetensors_error(self):
+
+ # (`attn_processors`) needs to be added for this test.
+ # def test_lora_on_off(self):
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_lora_xformers_on_off(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["attention_head_dim"] = 4
+
+ torch.manual_seed(0)
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ lora_attn_procs = create_lora_layers(model)
+ model.set_attn_processor(lora_attn_procs)
+
+ # default
+ with torch.no_grad():
+ sample = model(**inputs_dict).sample
+
+ model.enable_xformers_memory_efficient_attention()
+ on_sample = model(**inputs_dict).sample
+
+ model.disable_xformers_memory_efficient_attention()
+ off_sample = model(**inputs_dict).sample
+
+ assert (sample - on_sample).abs().max() < 1e-4
+ assert (sample - off_sample).abs().max() < 1e-4
+
+
+# (todo: sayakpaul) implement SLOW tests.
diff --git a/diffusers/tests/models/test_models_vae.py b/diffusers/tests/models/test_models_vae.py
new file mode 100644
index 0000000000000000000000000000000000000000..abd4a078e6922f8454bd6b3b7f8a35b53a834d80
--- /dev/null
+++ b/diffusers/tests/models/test_models_vae.py
@@ -0,0 +1,345 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import torch
+from parameterized import parameterized
+
+from diffusers import AutoencoderKL
+from diffusers.utils import floats_tensor, load_hf_numpy, require_torch_gpu, slow, torch_all_close, torch_device
+
+from ..test_modeling_common import ModelTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class AutoencoderKLTests(ModelTesterMixin, unittest.TestCase):
+ model_class = AutoencoderKL
+
+ @property
+ def dummy_input(self):
+ batch_size = 4
+ num_channels = 3
+ sizes = (32, 32)
+
+ image = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
+
+ return {"sample": image}
+
+ @property
+ def input_shape(self):
+ return (3, 32, 32)
+
+ @property
+ def output_shape(self):
+ return (3, 32, 32)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "block_out_channels": [32, 64],
+ "in_channels": 3,
+ "out_channels": 3,
+ "down_block_types": ["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ "up_block_types": ["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ "latent_channels": 4,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_forward_signature(self):
+ pass
+
+ def test_training(self):
+ pass
+
+ @unittest.skipIf(torch_device == "mps", "Gradient checkpointing skipped on MPS")
+ def test_gradient_checkpointing(self):
+ # enable deterministic behavior for gradient checkpointing
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+
+ assert not model.is_gradient_checkpointing and model.training
+
+ out = model(**inputs_dict).sample
+ # run the backwards pass on the model. For backwards pass, for simplicity purpose,
+ # we won't calculate the loss and rather backprop on out.sum()
+ model.zero_grad()
+
+ labels = torch.randn_like(out)
+ loss = (out - labels).mean()
+ loss.backward()
+
+ # re-instantiate the model now enabling gradient checkpointing
+ model_2 = self.model_class(**init_dict)
+ # clone model
+ model_2.load_state_dict(model.state_dict())
+ model_2.to(torch_device)
+ model_2.enable_gradient_checkpointing()
+
+ assert model_2.is_gradient_checkpointing and model_2.training
+
+ out_2 = model_2(**inputs_dict).sample
+ # run the backwards pass on the model. For backwards pass, for simplicity purpose,
+ # we won't calculate the loss and rather backprop on out.sum()
+ model_2.zero_grad()
+ loss_2 = (out_2 - labels).mean()
+ loss_2.backward()
+
+ # compare the output and parameters gradients
+ self.assertTrue((loss - loss_2).abs() < 1e-5)
+ named_params = dict(model.named_parameters())
+ named_params_2 = dict(model_2.named_parameters())
+ for name, param in named_params.items():
+ self.assertTrue(torch_all_close(param.grad.data, named_params_2[name].grad.data, atol=5e-5))
+
+ def test_from_pretrained_hub(self):
+ model, loading_info = AutoencoderKL.from_pretrained("fusing/autoencoder-kl-dummy", output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertEqual(len(loading_info["missing_keys"]), 0)
+
+ model.to(torch_device)
+ image = model(**self.dummy_input)
+
+ assert image is not None, "Make sure output is not None"
+
+ def test_output_pretrained(self):
+ model = AutoencoderKL.from_pretrained("fusing/autoencoder-kl-dummy")
+ model = model.to(torch_device)
+ model.eval()
+
+ if torch_device == "mps":
+ generator = torch.manual_seed(0)
+ else:
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+
+ image = torch.randn(
+ 1,
+ model.config.in_channels,
+ model.config.sample_size,
+ model.config.sample_size,
+ generator=torch.manual_seed(0),
+ )
+ image = image.to(torch_device)
+ with torch.no_grad():
+ output = model(image, sample_posterior=True, generator=generator).sample
+
+ output_slice = output[0, -1, -3:, -3:].flatten().cpu()
+
+ # Since the VAE Gaussian prior's generator is seeded on the appropriate device,
+ # the expected output slices are not the same for CPU and GPU.
+ if torch_device == "mps":
+ expected_output_slice = torch.tensor(
+ [
+ -4.0078e-01,
+ -3.8323e-04,
+ -1.2681e-01,
+ -1.1462e-01,
+ 2.0095e-01,
+ 1.0893e-01,
+ -8.8247e-02,
+ -3.0361e-01,
+ -9.8644e-03,
+ ]
+ )
+ elif torch_device == "cpu":
+ expected_output_slice = torch.tensor(
+ [-0.1352, 0.0878, 0.0419, -0.0818, -0.1069, 0.0688, -0.1458, -0.4446, -0.0026]
+ )
+ else:
+ expected_output_slice = torch.tensor(
+ [-0.2421, 0.4642, 0.2507, -0.0438, 0.0682, 0.3160, -0.2018, -0.0727, 0.2485]
+ )
+
+ self.assertTrue(torch_all_close(output_slice, expected_output_slice, rtol=1e-2))
+
+
+@slow
+class AutoencoderKLIntegrationTests(unittest.TestCase):
+ def get_file_format(self, seed, shape):
+ return f"gaussian_noise_s={seed}_shape={'_'.join([str(s) for s in shape])}.npy"
+
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_sd_image(self, seed=0, shape=(4, 3, 512, 512), fp16=False):
+ dtype = torch.float16 if fp16 else torch.float32
+ image = torch.from_numpy(load_hf_numpy(self.get_file_format(seed, shape))).to(torch_device).to(dtype)
+ return image
+
+ def get_sd_vae_model(self, model_id="CompVis/stable-diffusion-v1-4", fp16=False):
+ revision = "fp16" if fp16 else None
+ torch_dtype = torch.float16 if fp16 else torch.float32
+
+ model = AutoencoderKL.from_pretrained(
+ model_id,
+ subfolder="vae",
+ torch_dtype=torch_dtype,
+ revision=revision,
+ )
+ model.to(torch_device).eval()
+
+ return model
+
+ def get_generator(self, seed=0):
+ if torch_device == "mps":
+ return torch.manual_seed(seed)
+ return torch.Generator(device=torch_device).manual_seed(seed)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [33, [-0.1603, 0.9878, -0.0495, -0.0790, -0.2709, 0.8375, -0.2060, -0.0824], [-0.2395, 0.0098, 0.0102, -0.0709, -0.2840, -0.0274, -0.0718, -0.1824]],
+ [47, [-0.2376, 0.1168, 0.1332, -0.4840, -0.2508, -0.0791, -0.0493, -0.4089], [0.0350, 0.0847, 0.0467, 0.0344, -0.0842, -0.0547, -0.0633, -0.1131]],
+ # fmt: on
+ ]
+ )
+ def test_stable_diffusion(self, seed, expected_slice, expected_slice_mps):
+ model = self.get_sd_vae_model()
+ image = self.get_sd_image(seed)
+ generator = self.get_generator(seed)
+
+ with torch.no_grad():
+ sample = model(image, generator=generator, sample_posterior=True).sample
+
+ assert sample.shape == image.shape
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice_mps if torch_device == "mps" else expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=1e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [33, [-0.0513, 0.0289, 1.3799, 0.2166, -0.2573, -0.0871, 0.5103, -0.0999]],
+ [47, [-0.4128, -0.1320, -0.3704, 0.1965, -0.4116, -0.2332, -0.3340, 0.2247]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_stable_diffusion_fp16(self, seed, expected_slice):
+ model = self.get_sd_vae_model(fp16=True)
+ image = self.get_sd_image(seed, fp16=True)
+ generator = self.get_generator(seed)
+
+ with torch.no_grad():
+ sample = model(image, generator=generator, sample_posterior=True).sample
+
+ assert sample.shape == image.shape
+
+ output_slice = sample[-1, -2:, :2, -2:].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=1e-2)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [33, [-0.1609, 0.9866, -0.0487, -0.0777, -0.2716, 0.8368, -0.2055, -0.0814], [-0.2395, 0.0098, 0.0102, -0.0709, -0.2840, -0.0274, -0.0718, -0.1824]],
+ [47, [-0.2377, 0.1147, 0.1333, -0.4841, -0.2506, -0.0805, -0.0491, -0.4085], [0.0350, 0.0847, 0.0467, 0.0344, -0.0842, -0.0547, -0.0633, -0.1131]],
+ # fmt: on
+ ]
+ )
+ def test_stable_diffusion_mode(self, seed, expected_slice, expected_slice_mps):
+ model = self.get_sd_vae_model()
+ image = self.get_sd_image(seed)
+
+ with torch.no_grad():
+ sample = model(image).sample
+
+ assert sample.shape == image.shape
+
+ output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice_mps if torch_device == "mps" else expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=1e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [13, [-0.2051, -0.1803, -0.2311, -0.2114, -0.3292, -0.3574, -0.2953, -0.3323]],
+ [37, [-0.2632, -0.2625, -0.2199, -0.2741, -0.4539, -0.4990, -0.3720, -0.4925]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_stable_diffusion_decode(self, seed, expected_slice):
+ model = self.get_sd_vae_model()
+ encoding = self.get_sd_image(seed, shape=(3, 4, 64, 64))
+
+ with torch.no_grad():
+ sample = model.decode(encoding).sample
+
+ assert list(sample.shape) == [3, 3, 512, 512]
+
+ output_slice = sample[-1, -2:, :2, -2:].flatten().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=1e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [27, [-0.0369, 0.0207, -0.0776, -0.0682, -0.1747, -0.1930, -0.1465, -0.2039]],
+ [16, [-0.1628, -0.2134, -0.2747, -0.2642, -0.3774, -0.4404, -0.3687, -0.4277]],
+ # fmt: on
+ ]
+ )
+ @require_torch_gpu
+ def test_stable_diffusion_decode_fp16(self, seed, expected_slice):
+ model = self.get_sd_vae_model(fp16=True)
+ encoding = self.get_sd_image(seed, shape=(3, 4, 64, 64), fp16=True)
+
+ with torch.no_grad():
+ sample = model.decode(encoding).sample
+
+ assert list(sample.shape) == [3, 3, 512, 512]
+
+ output_slice = sample[-1, -2:, :2, -2:].flatten().float().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ assert torch_all_close(output_slice, expected_output_slice, atol=5e-3)
+
+ @parameterized.expand(
+ [
+ # fmt: off
+ [33, [-0.3001, 0.0918, -2.6984, -3.9720, -3.2099, -5.0353, 1.7338, -0.2065, 3.4267]],
+ [47, [-1.5030, -4.3871, -6.0355, -9.1157, -1.6661, -2.7853, 2.1607, -5.0823, 2.5633]],
+ # fmt: on
+ ]
+ )
+ def test_stable_diffusion_encode_sample(self, seed, expected_slice):
+ model = self.get_sd_vae_model()
+ image = self.get_sd_image(seed)
+ generator = self.get_generator(seed)
+
+ with torch.no_grad():
+ dist = model.encode(image).latent_dist
+ sample = dist.sample(generator=generator)
+
+ assert list(sample.shape) == [image.shape[0], 4] + [i // 8 for i in image.shape[2:]]
+
+ output_slice = sample[0, -1, -3:, -3:].flatten().cpu()
+ expected_output_slice = torch.tensor(expected_slice)
+
+ tolerance = 1e-3 if torch_device != "mps" else 1e-2
+ assert torch_all_close(output_slice, expected_output_slice, atol=tolerance)
diff --git a/diffusers/tests/models/test_models_vae_flax.py b/diffusers/tests/models/test_models_vae_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fedb85eccfc73e9a0900f7bb947887da3ffe4e9
--- /dev/null
+++ b/diffusers/tests/models/test_models_vae_flax.py
@@ -0,0 +1,39 @@
+import unittest
+
+from diffusers import FlaxAutoencoderKL
+from diffusers.utils import is_flax_available
+from diffusers.utils.testing_utils import require_flax
+
+from ..test_modeling_common_flax import FlaxModelTesterMixin
+
+
+if is_flax_available():
+ import jax
+
+
+@require_flax
+class FlaxAutoencoderKLTests(FlaxModelTesterMixin, unittest.TestCase):
+ model_class = FlaxAutoencoderKL
+
+ @property
+ def dummy_input(self):
+ batch_size = 4
+ num_channels = 3
+ sizes = (32, 32)
+
+ prng_key = jax.random.PRNGKey(0)
+ image = jax.random.uniform(prng_key, ((batch_size, num_channels) + sizes))
+
+ return {"sample": image, "prng_key": prng_key}
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "block_out_channels": [32, 64],
+ "in_channels": 3,
+ "out_channels": 3,
+ "down_block_types": ["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ "up_block_types": ["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ "latent_channels": 4,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
diff --git a/diffusers/tests/models/test_models_vq.py b/diffusers/tests/models/test_models_vq.py
new file mode 100644
index 0000000000000000000000000000000000000000..66c33e07371e066bad3f0465ab923d67b79b4f52
--- /dev/null
+++ b/diffusers/tests/models/test_models_vq.py
@@ -0,0 +1,94 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import torch
+
+from diffusers import VQModel
+from diffusers.utils import floats_tensor, torch_device
+
+from ..test_modeling_common import ModelTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class VQModelTests(ModelTesterMixin, unittest.TestCase):
+ model_class = VQModel
+
+ @property
+ def dummy_input(self, sizes=(32, 32)):
+ batch_size = 4
+ num_channels = 3
+
+ image = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
+
+ return {"sample": image}
+
+ @property
+ def input_shape(self):
+ return (3, 32, 32)
+
+ @property
+ def output_shape(self):
+ return (3, 32, 32)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "block_out_channels": [32, 64],
+ "in_channels": 3,
+ "out_channels": 3,
+ "down_block_types": ["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ "up_block_types": ["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ "latent_channels": 3,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_forward_signature(self):
+ pass
+
+ def test_training(self):
+ pass
+
+ def test_from_pretrained_hub(self):
+ model, loading_info = VQModel.from_pretrained("fusing/vqgan-dummy", output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertEqual(len(loading_info["missing_keys"]), 0)
+
+ model.to(torch_device)
+ image = model(**self.dummy_input)
+
+ assert image is not None, "Make sure output is not None"
+
+ def test_output_pretrained(self):
+ model = VQModel.from_pretrained("fusing/vqgan-dummy")
+ model.to(torch_device).eval()
+
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ image = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
+ image = image.to(torch_device)
+ with torch.no_grad():
+ output = model(image).sample
+
+ output_slice = output[0, -1, -3:, -3:].flatten().cpu()
+ # fmt: off
+ expected_output_slice = torch.tensor([-0.0153, -0.4044, -0.1880, -0.5161, -0.2418, -0.4072, -0.1612, -0.0633, -0.0143])
+ # fmt: on
+ self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3))
diff --git a/diffusers/tests/pipeline_params.py b/diffusers/tests/pipeline_params.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0ac6c641c0bafef0f770409e9b75ec0aee013c1
--- /dev/null
+++ b/diffusers/tests/pipeline_params.py
@@ -0,0 +1,121 @@
+# These are canonical sets of parameters for different types of pipelines.
+# They are set on subclasses of `PipelineTesterMixin` as `params` and
+# `batch_params`.
+#
+# If a pipeline's set of arguments has minor changes from one of the common sets
+# of arguments, do not make modifications to the existing common sets of arguments.
+# I.e. a text to image pipeline with non-configurable height and width arguments
+# should set its attribute as `params = TEXT_TO_IMAGE_PARAMS - {'height', 'width'}`.
+
+TEXT_TO_IMAGE_PARAMS = frozenset(
+ [
+ "prompt",
+ "height",
+ "width",
+ "guidance_scale",
+ "negative_prompt",
+ "prompt_embeds",
+ "negative_prompt_embeds",
+ "cross_attention_kwargs",
+ ]
+)
+
+TEXT_TO_IMAGE_BATCH_PARAMS = frozenset(["prompt", "negative_prompt"])
+
+IMAGE_VARIATION_PARAMS = frozenset(
+ [
+ "image",
+ "height",
+ "width",
+ "guidance_scale",
+ ]
+)
+
+IMAGE_VARIATION_BATCH_PARAMS = frozenset(["image"])
+
+TEXT_GUIDED_IMAGE_VARIATION_PARAMS = frozenset(
+ [
+ "prompt",
+ "image",
+ "height",
+ "width",
+ "guidance_scale",
+ "negative_prompt",
+ "prompt_embeds",
+ "negative_prompt_embeds",
+ ]
+)
+
+TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS = frozenset(["prompt", "image", "negative_prompt"])
+
+TEXT_GUIDED_IMAGE_INPAINTING_PARAMS = frozenset(
+ [
+ # Text guided image variation with an image mask
+ "prompt",
+ "image",
+ "mask_image",
+ "height",
+ "width",
+ "guidance_scale",
+ "negative_prompt",
+ "prompt_embeds",
+ "negative_prompt_embeds",
+ ]
+)
+
+TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS = frozenset(["prompt", "image", "mask_image", "negative_prompt"])
+
+IMAGE_INPAINTING_PARAMS = frozenset(
+ [
+ # image variation with an image mask
+ "image",
+ "mask_image",
+ "height",
+ "width",
+ "guidance_scale",
+ ]
+)
+
+IMAGE_INPAINTING_BATCH_PARAMS = frozenset(["image", "mask_image"])
+
+IMAGE_GUIDED_IMAGE_INPAINTING_PARAMS = frozenset(
+ [
+ "example_image",
+ "image",
+ "mask_image",
+ "height",
+ "width",
+ "guidance_scale",
+ ]
+)
+
+IMAGE_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS = frozenset(["example_image", "image", "mask_image"])
+
+CLASS_CONDITIONED_IMAGE_GENERATION_PARAMS = frozenset(["class_labels"])
+
+CLASS_CONDITIONED_IMAGE_GENERATION_BATCH_PARAMS = frozenset(["class_labels"])
+
+UNCONDITIONAL_IMAGE_GENERATION_PARAMS = frozenset(["batch_size"])
+
+UNCONDITIONAL_IMAGE_GENERATION_BATCH_PARAMS = frozenset([])
+
+UNCONDITIONAL_AUDIO_GENERATION_PARAMS = frozenset(["batch_size"])
+
+UNCONDITIONAL_AUDIO_GENERATION_BATCH_PARAMS = frozenset([])
+
+TEXT_TO_AUDIO_PARAMS = frozenset(
+ [
+ "prompt",
+ "audio_length_in_s",
+ "guidance_scale",
+ "negative_prompt",
+ "prompt_embeds",
+ "negative_prompt_embeds",
+ "cross_attention_kwargs",
+ ]
+)
+
+TEXT_TO_AUDIO_BATCH_PARAMS = frozenset(["prompt", "negative_prompt"])
+TOKENS_TO_AUDIO_GENERATION_PARAMS = frozenset(["input_tokens"])
+
+TOKENS_TO_AUDIO_GENERATION_BATCH_PARAMS = frozenset(["input_tokens"])
diff --git a/diffusers/tests/pipelines/__init__.py b/diffusers/tests/pipelines/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/altdiffusion/__init__.py b/diffusers/tests/pipelines/altdiffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/altdiffusion/test_alt_diffusion.py b/diffusers/tests/pipelines/altdiffusion/test_alt_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..faa56e18f74835a6f1fa2f63717fc9ba5c0a7e29
--- /dev/null
+++ b/diffusers/tests/pipelines/altdiffusion/test_alt_diffusion.py
@@ -0,0 +1,244 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, XLMRobertaTokenizer
+
+from diffusers import AltDiffusionPipeline, AutoencoderKL, DDIMScheduler, PNDMScheduler, UNet2DConditionModel
+from diffusers.pipelines.alt_diffusion.modeling_roberta_series import (
+ RobertaSeriesConfig,
+ RobertaSeriesModelWithTransformation,
+)
+from diffusers.utils import slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class AltDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = AltDiffusionPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+
+ # TODO: address the non-deterministic text encoder (fails for save-load tests)
+ # torch.manual_seed(0)
+ # text_encoder_config = RobertaSeriesConfig(
+ # hidden_size=32,
+ # project_dim=32,
+ # intermediate_size=37,
+ # layer_norm_eps=1e-05,
+ # num_attention_heads=4,
+ # num_hidden_layers=5,
+ # vocab_size=5002,
+ # )
+ # text_encoder = RobertaSeriesModelWithTransformation(text_encoder_config)
+
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ projection_dim=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=5002,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+
+ tokenizer = XLMRobertaTokenizer.from_pretrained("hf-internal-testing/tiny-xlm-roberta")
+ tokenizer.model_max_length = 77
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_alt_diffusion_ddim(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ torch.manual_seed(0)
+ text_encoder_config = RobertaSeriesConfig(
+ hidden_size=32,
+ project_dim=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ vocab_size=5002,
+ )
+ # TODO: remove after fixing the non-deterministic text encoder
+ text_encoder = RobertaSeriesModelWithTransformation(text_encoder_config)
+ components["text_encoder"] = text_encoder
+
+ alt_pipe = AltDiffusionPipeline(**components)
+ alt_pipe = alt_pipe.to(device)
+ alt_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ inputs["prompt"] = "A photo of an astronaut"
+ output = alt_pipe(**inputs)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array(
+ [0.5748162, 0.60447145, 0.48821217, 0.50100636, 0.5431185, 0.45763683, 0.49657696, 0.48132733, 0.47573093]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_alt_diffusion_pndm(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ components["scheduler"] = PNDMScheduler(skip_prk_steps=True)
+ torch.manual_seed(0)
+ text_encoder_config = RobertaSeriesConfig(
+ hidden_size=32,
+ project_dim=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ vocab_size=5002,
+ )
+ # TODO: remove after fixing the non-deterministic text encoder
+ text_encoder = RobertaSeriesModelWithTransformation(text_encoder_config)
+ components["text_encoder"] = text_encoder
+ alt_pipe = AltDiffusionPipeline(**components)
+ alt_pipe = alt_pipe.to(device)
+ alt_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = alt_pipe(**inputs)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array(
+ [0.51605093, 0.5707241, 0.47365507, 0.50578886, 0.5633877, 0.4642503, 0.5182081, 0.48763484, 0.49084237]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+
+@slow
+@require_torch_gpu
+class AltDiffusionPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_alt_diffusion(self):
+ # make sure here that pndm scheduler skips prk
+ alt_pipe = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion", safety_checker=None)
+ alt_pipe = alt_pipe.to(torch_device)
+ alt_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ output = alt_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=20, output_type="np")
+
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.1010, 0.0800, 0.0794, 0.0885, 0.0843, 0.0762, 0.0769, 0.0729, 0.0586])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_alt_diffusion_fast_ddim(self):
+ scheduler = DDIMScheduler.from_pretrained("BAAI/AltDiffusion", subfolder="scheduler")
+
+ alt_pipe = AltDiffusionPipeline.from_pretrained("BAAI/AltDiffusion", scheduler=scheduler, safety_checker=None)
+ alt_pipe = alt_pipe.to(torch_device)
+ alt_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+
+ output = alt_pipe([prompt], generator=generator, num_inference_steps=2, output_type="numpy")
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.4019, 0.4052, 0.3810, 0.4119, 0.3916, 0.3982, 0.4651, 0.4195, 0.5323])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/altdiffusion/test_alt_diffusion_img2img.py b/diffusers/tests/pipelines/altdiffusion/test_alt_diffusion_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..9396329434059db279d7b276af0301905fbc49cc
--- /dev/null
+++ b/diffusers/tests/pipelines/altdiffusion/test_alt_diffusion_img2img.py
@@ -0,0 +1,299 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from transformers import XLMRobertaTokenizer
+
+from diffusers import (
+ AltDiffusionImg2ImgPipeline,
+ AutoencoderKL,
+ PNDMScheduler,
+ UNet2DConditionModel,
+)
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.pipelines.alt_diffusion.modeling_roberta_series import (
+ RobertaSeriesConfig,
+ RobertaSeriesModelWithTransformation,
+)
+from diffusers.utils import floats_tensor, load_image, load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class AltDiffusionImg2ImgPipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @property
+ def dummy_image(self):
+ batch_size = 1
+ num_channels = 3
+ sizes = (32, 32)
+
+ image = floats_tensor((batch_size, num_channels) + sizes, rng=random.Random(0)).to(torch_device)
+ return image
+
+ @property
+ def dummy_cond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ return model
+
+ @property
+ def dummy_vae(self):
+ torch.manual_seed(0)
+ model = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ return model
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = RobertaSeriesConfig(
+ hidden_size=32,
+ project_dim=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=5006,
+ )
+ return RobertaSeriesModelWithTransformation(config)
+
+ @property
+ def dummy_extractor(self):
+ def extract(*args, **kwargs):
+ class Out:
+ def __init__(self):
+ self.pixel_values = torch.ones([0])
+
+ def to(self, device):
+ self.pixel_values.to(device)
+ return self
+
+ return Out()
+
+ return extract
+
+ def test_stable_diffusion_img2img_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = XLMRobertaTokenizer.from_pretrained("hf-internal-testing/tiny-xlm-roberta")
+ tokenizer.model_max_length = 77
+
+ init_image = self.dummy_image.to(device)
+
+ # make sure here that pndm scheduler skips prk
+ alt_pipe = AltDiffusionImg2ImgPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ alt_pipe.image_processor = VaeImageProcessor(vae_scale_factor=alt_pipe.vae_scale_factor, do_normalize=False)
+ alt_pipe = alt_pipe.to(device)
+ alt_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = alt_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ )
+
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = alt_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.4115, 0.3870, 0.4089, 0.4807, 0.4668, 0.4144, 0.4151, 0.4721, 0.4569])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 5e-3
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 5e-3
+
+ @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
+ def test_stable_diffusion_img2img_fp16(self):
+ """Test that stable diffusion img2img works with fp16"""
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = XLMRobertaTokenizer.from_pretrained("hf-internal-testing/tiny-xlm-roberta")
+ tokenizer.model_max_length = 77
+
+ init_image = self.dummy_image.to(torch_device)
+
+ # put models in fp16
+ unet = unet.half()
+ vae = vae.half()
+ bert = bert.half()
+
+ # make sure here that pndm scheduler skips prk
+ alt_pipe = AltDiffusionImg2ImgPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ alt_pipe.image_processor = VaeImageProcessor(vae_scale_factor=alt_pipe.vae_scale_factor, do_normalize=False)
+ alt_pipe = alt_pipe.to(torch_device)
+ alt_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ image = alt_pipe(
+ [prompt],
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ ).images
+
+ assert image.shape == (1, 32, 32, 3)
+
+ @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
+ def test_stable_diffusion_img2img_pipeline_multiple_of_8(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/img2img/sketch-mountains-input.jpg"
+ )
+ # resize to resolution that is divisible by 8 but not 16 or 32
+ init_image = init_image.resize((760, 504))
+
+ model_id = "BAAI/AltDiffusion"
+ pipe = AltDiffusionImg2ImgPipeline.from_pretrained(
+ model_id,
+ safety_checker=None,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ prompt = "A fantasy landscape, trending on artstation"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ strength=0.75,
+ guidance_scale=7.5,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images[0]
+
+ image_slice = image[255:258, 383:386, -1]
+
+ assert image.shape == (504, 760, 3)
+ expected_slice = np.array([0.9358, 0.9397, 0.9599, 0.9901, 1.0000, 1.0000, 0.9882, 1.0000, 1.0000])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+
+@slow
+@require_torch_gpu
+class AltDiffusionImg2ImgPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_stable_diffusion_img2img_pipeline_default(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/img2img/sketch-mountains-input.jpg"
+ )
+ init_image = init_image.resize((768, 512))
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/img2img/fantasy_landscape_alt.npy"
+ )
+
+ model_id = "BAAI/AltDiffusion"
+ pipe = AltDiffusionImg2ImgPipeline.from_pretrained(
+ model_id,
+ safety_checker=None,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ prompt = "A fantasy landscape, trending on artstation"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ strength=0.75,
+ guidance_scale=7.5,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images[0]
+
+ assert image.shape == (512, 768, 3)
+ # img2img is flaky across GPUs even in fp32, so using MAE here
+ assert np.abs(expected_image - image).max() < 1e-3
diff --git a/diffusers/tests/pipelines/audio_diffusion/__init__.py b/diffusers/tests/pipelines/audio_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/audio_diffusion/test_audio_diffusion.py b/diffusers/tests/pipelines/audio_diffusion/test_audio_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba389d9c936df1d096a54b02d332cfa8ac520901
--- /dev/null
+++ b/diffusers/tests/pipelines/audio_diffusion/test_audio_diffusion.py
@@ -0,0 +1,191 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import (
+ AudioDiffusionPipeline,
+ AutoencoderKL,
+ DDIMScheduler,
+ DDPMScheduler,
+ DiffusionPipeline,
+ Mel,
+ UNet2DConditionModel,
+ UNet2DModel,
+)
+from diffusers.utils import slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class PipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @property
+ def dummy_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ sample_size=(32, 64),
+ in_channels=1,
+ out_channels=1,
+ layers_per_block=2,
+ block_out_channels=(128, 128),
+ down_block_types=("AttnDownBlock2D", "DownBlock2D"),
+ up_block_types=("UpBlock2D", "AttnUpBlock2D"),
+ )
+ return model
+
+ @property
+ def dummy_unet_condition(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ sample_size=(64, 32),
+ in_channels=1,
+ out_channels=1,
+ layers_per_block=2,
+ block_out_channels=(128, 128),
+ down_block_types=("CrossAttnDownBlock2D", "DownBlock2D"),
+ up_block_types=("UpBlock2D", "CrossAttnUpBlock2D"),
+ cross_attention_dim=10,
+ )
+ return model
+
+ @property
+ def dummy_vqvae_and_unet(self):
+ torch.manual_seed(0)
+ vqvae = AutoencoderKL(
+ sample_size=(128, 64),
+ in_channels=1,
+ out_channels=1,
+ latent_channels=1,
+ layers_per_block=2,
+ block_out_channels=(128, 128),
+ down_block_types=("DownEncoderBlock2D", "DownEncoderBlock2D"),
+ up_block_types=("UpDecoderBlock2D", "UpDecoderBlock2D"),
+ )
+ unet = UNet2DModel(
+ sample_size=(64, 32),
+ in_channels=1,
+ out_channels=1,
+ layers_per_block=2,
+ block_out_channels=(128, 128),
+ down_block_types=("AttnDownBlock2D", "DownBlock2D"),
+ up_block_types=("UpBlock2D", "AttnUpBlock2D"),
+ )
+ return vqvae, unet
+
+ @slow
+ def test_audio_diffusion(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ mel = Mel()
+
+ scheduler = DDPMScheduler()
+ pipe = AudioDiffusionPipeline(vqvae=None, unet=self.dummy_unet, mel=mel, scheduler=scheduler)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device=device).manual_seed(42)
+ output = pipe(generator=generator, steps=4)
+ audio = output.audios[0]
+ image = output.images[0]
+
+ generator = torch.Generator(device=device).manual_seed(42)
+ output = pipe(generator=generator, steps=4, return_dict=False)
+ image_from_tuple = output[0][0]
+
+ assert audio.shape == (1, (self.dummy_unet.sample_size[1] - 1) * mel.hop_length)
+ assert image.height == self.dummy_unet.sample_size[0] and image.width == self.dummy_unet.sample_size[1]
+ image_slice = np.frombuffer(image.tobytes(), dtype="uint8")[:10]
+ image_from_tuple_slice = np.frombuffer(image_from_tuple.tobytes(), dtype="uint8")[:10]
+ expected_slice = np.array([69, 255, 255, 255, 0, 0, 77, 181, 12, 127])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() == 0
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() == 0
+
+ scheduler = DDIMScheduler()
+ dummy_vqvae_and_unet = self.dummy_vqvae_and_unet
+ pipe = AudioDiffusionPipeline(
+ vqvae=self.dummy_vqvae_and_unet[0], unet=dummy_vqvae_and_unet[1], mel=mel, scheduler=scheduler
+ )
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ np.random.seed(0)
+ raw_audio = np.random.uniform(-1, 1, ((dummy_vqvae_and_unet[0].sample_size[1] - 1) * mel.hop_length,))
+ generator = torch.Generator(device=device).manual_seed(42)
+ output = pipe(raw_audio=raw_audio, generator=generator, start_step=5, steps=10)
+ image = output.images[0]
+
+ assert (
+ image.height == self.dummy_vqvae_and_unet[0].sample_size[0]
+ and image.width == self.dummy_vqvae_and_unet[0].sample_size[1]
+ )
+ image_slice = np.frombuffer(image.tobytes(), dtype="uint8")[:10]
+ expected_slice = np.array([120, 117, 110, 109, 138, 167, 138, 148, 132, 121])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() == 0
+
+ dummy_unet_condition = self.dummy_unet_condition
+ pipe = AudioDiffusionPipeline(
+ vqvae=self.dummy_vqvae_and_unet[0], unet=dummy_unet_condition, mel=mel, scheduler=scheduler
+ )
+
+ np.random.seed(0)
+ encoding = torch.rand((1, 1, 10))
+ output = pipe(generator=generator, encoding=encoding)
+ image = output.images[0]
+ image_slice = np.frombuffer(image.tobytes(), dtype="uint8")[:10]
+ expected_slice = np.array([120, 139, 147, 123, 124, 96, 115, 121, 126, 144])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() == 0
+
+
+@slow
+@require_torch_gpu
+class PipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_audio_diffusion(self):
+ device = torch_device
+
+ pipe = DiffusionPipeline.from_pretrained("teticio/audio-diffusion-ddim-256")
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device=device).manual_seed(42)
+ output = pipe(generator=generator)
+ audio = output.audios[0]
+ image = output.images[0]
+
+ assert audio.shape == (1, (pipe.unet.sample_size[1] - 1) * pipe.mel.hop_length)
+ assert image.height == pipe.unet.sample_size[0] and image.width == pipe.unet.sample_size[1]
+ image_slice = np.frombuffer(image.tobytes(), dtype="uint8")[:10]
+ expected_slice = np.array([151, 167, 154, 144, 122, 134, 121, 105, 70, 26])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() == 0
diff --git a/diffusers/tests/pipelines/audioldm/__init__.py b/diffusers/tests/pipelines/audioldm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/audioldm/test_audioldm.py b/diffusers/tests/pipelines/audioldm/test_audioldm.py
new file mode 100644
index 0000000000000000000000000000000000000000..10de5440eb007ae4cfc57953ea943eeee3500340
--- /dev/null
+++ b/diffusers/tests/pipelines/audioldm/test_audioldm.py
@@ -0,0 +1,416 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+import torch.nn.functional as F
+from transformers import (
+ ClapTextConfig,
+ ClapTextModelWithProjection,
+ RobertaTokenizer,
+ SpeechT5HifiGan,
+ SpeechT5HifiGanConfig,
+)
+
+from diffusers import (
+ AudioLDMPipeline,
+ AutoencoderKL,
+ DDIMScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ UNet2DConditionModel,
+)
+from diffusers.utils import slow, torch_device
+
+from ...pipeline_params import TEXT_TO_AUDIO_BATCH_PARAMS, TEXT_TO_AUDIO_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+class AudioLDMPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = AudioLDMPipeline
+ params = TEXT_TO_AUDIO_PARAMS
+ batch_params = TEXT_TO_AUDIO_BATCH_PARAMS
+ required_optional_params = frozenset(
+ [
+ "num_inference_steps",
+ "num_waveforms_per_prompt",
+ "generator",
+ "latents",
+ "output_type",
+ "return_dict",
+ "callback",
+ "callback_steps",
+ ]
+ )
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=(32, 64),
+ class_embed_type="simple_projection",
+ projection_class_embeddings_input_dim=32,
+ class_embeddings_concat=True,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=1,
+ out_channels=1,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = ClapTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ projection_dim=32,
+ )
+ text_encoder = ClapTextModelWithProjection(text_encoder_config)
+ tokenizer = RobertaTokenizer.from_pretrained("hf-internal-testing/tiny-random-roberta", model_max_length=77)
+
+ vocoder_config = SpeechT5HifiGanConfig(
+ model_in_dim=8,
+ sampling_rate=16000,
+ upsample_initial_channel=16,
+ upsample_rates=[2, 2],
+ upsample_kernel_sizes=[4, 4],
+ resblock_kernel_sizes=[3, 7],
+ resblock_dilation_sizes=[[1, 3, 5], [1, 3, 5]],
+ normalize_before=False,
+ )
+
+ vocoder = SpeechT5HifiGan(vocoder_config)
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "vocoder": vocoder,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A hammer hitting a wooden surface",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ }
+ return inputs
+
+ def test_audioldm_ddim(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ audioldm_pipe = AudioLDMPipeline(**components)
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = audioldm_pipe(**inputs)
+ audio = output.audios[0]
+
+ assert audio.ndim == 1
+ assert len(audio) == 256
+
+ audio_slice = audio[:10]
+ expected_slice = np.array(
+ [-0.0050, 0.0050, -0.0060, 0.0033, -0.0026, 0.0033, -0.0027, 0.0033, -0.0028, 0.0033]
+ )
+
+ assert np.abs(audio_slice - expected_slice).max() < 1e-2
+
+ def test_audioldm_prompt_embeds(self):
+ components = self.get_dummy_components()
+ audioldm_pipe = AudioLDMPipeline(**components)
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ inputs["prompt"] = 3 * [inputs["prompt"]]
+
+ # forward
+ output = audioldm_pipe(**inputs)
+ audio_1 = output.audios[0]
+
+ inputs = self.get_dummy_inputs(torch_device)
+ prompt = 3 * [inputs.pop("prompt")]
+
+ text_inputs = audioldm_pipe.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=audioldm_pipe.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_inputs = text_inputs["input_ids"].to(torch_device)
+
+ prompt_embeds = audioldm_pipe.text_encoder(
+ text_inputs,
+ )
+ prompt_embeds = prompt_embeds.text_embeds
+ # additional L_2 normalization over each hidden-state
+ prompt_embeds = F.normalize(prompt_embeds, dim=-1)
+
+ inputs["prompt_embeds"] = prompt_embeds
+
+ # forward
+ output = audioldm_pipe(**inputs)
+ audio_2 = output.audios[0]
+
+ assert np.abs(audio_1 - audio_2).max() < 1e-2
+
+ def test_audioldm_negative_prompt_embeds(self):
+ components = self.get_dummy_components()
+ audioldm_pipe = AudioLDMPipeline(**components)
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ negative_prompt = 3 * ["this is a negative prompt"]
+ inputs["negative_prompt"] = negative_prompt
+ inputs["prompt"] = 3 * [inputs["prompt"]]
+
+ # forward
+ output = audioldm_pipe(**inputs)
+ audio_1 = output.audios[0]
+
+ inputs = self.get_dummy_inputs(torch_device)
+ prompt = 3 * [inputs.pop("prompt")]
+
+ embeds = []
+ for p in [prompt, negative_prompt]:
+ text_inputs = audioldm_pipe.tokenizer(
+ p,
+ padding="max_length",
+ max_length=audioldm_pipe.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_inputs = text_inputs["input_ids"].to(torch_device)
+
+ text_embeds = audioldm_pipe.text_encoder(
+ text_inputs,
+ )
+ text_embeds = text_embeds.text_embeds
+ # additional L_2 normalization over each hidden-state
+ text_embeds = F.normalize(text_embeds, dim=-1)
+
+ embeds.append(text_embeds)
+
+ inputs["prompt_embeds"], inputs["negative_prompt_embeds"] = embeds
+
+ # forward
+ output = audioldm_pipe(**inputs)
+ audio_2 = output.audios[0]
+
+ assert np.abs(audio_1 - audio_2).max() < 1e-2
+
+ def test_audioldm_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = PNDMScheduler(skip_prk_steps=True)
+ audioldm_pipe = AudioLDMPipeline(**components)
+ audioldm_pipe = audioldm_pipe.to(device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ negative_prompt = "egg cracking"
+ output = audioldm_pipe(**inputs, negative_prompt=negative_prompt)
+ audio = output.audios[0]
+
+ assert audio.ndim == 1
+ assert len(audio) == 256
+
+ audio_slice = audio[:10]
+ expected_slice = np.array(
+ [-0.0051, 0.0050, -0.0060, 0.0034, -0.0026, 0.0033, -0.0027, 0.0033, -0.0028, 0.0032]
+ )
+
+ assert np.abs(audio_slice - expected_slice).max() < 1e-2
+
+ def test_audioldm_num_waveforms_per_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = PNDMScheduler(skip_prk_steps=True)
+ audioldm_pipe = AudioLDMPipeline(**components)
+ audioldm_pipe = audioldm_pipe.to(device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A hammer hitting a wooden surface"
+
+ # test num_waveforms_per_prompt=1 (default)
+ audios = audioldm_pipe(prompt, num_inference_steps=2).audios
+
+ assert audios.shape == (1, 256)
+
+ # test num_waveforms_per_prompt=1 (default) for batch of prompts
+ batch_size = 2
+ audios = audioldm_pipe([prompt] * batch_size, num_inference_steps=2).audios
+
+ assert audios.shape == (batch_size, 256)
+
+ # test num_waveforms_per_prompt for single prompt
+ num_waveforms_per_prompt = 2
+ audios = audioldm_pipe(prompt, num_inference_steps=2, num_waveforms_per_prompt=num_waveforms_per_prompt).audios
+
+ assert audios.shape == (num_waveforms_per_prompt, 256)
+
+ # test num_waveforms_per_prompt for batch of prompts
+ batch_size = 2
+ audios = audioldm_pipe(
+ [prompt] * batch_size, num_inference_steps=2, num_waveforms_per_prompt=num_waveforms_per_prompt
+ ).audios
+
+ assert audios.shape == (batch_size * num_waveforms_per_prompt, 256)
+
+ def test_audioldm_audio_length_in_s(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ audioldm_pipe = AudioLDMPipeline(**components)
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+ vocoder_sampling_rate = audioldm_pipe.vocoder.config.sampling_rate
+
+ inputs = self.get_dummy_inputs(device)
+ output = audioldm_pipe(audio_length_in_s=0.016, **inputs)
+ audio = output.audios[0]
+
+ assert audio.ndim == 1
+ assert len(audio) / vocoder_sampling_rate == 0.016
+
+ output = audioldm_pipe(audio_length_in_s=0.032, **inputs)
+ audio = output.audios[0]
+
+ assert audio.ndim == 1
+ assert len(audio) / vocoder_sampling_rate == 0.032
+
+ def test_audioldm_vocoder_model_in_dim(self):
+ components = self.get_dummy_components()
+ audioldm_pipe = AudioLDMPipeline(**components)
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+
+ prompt = ["hey"]
+
+ output = audioldm_pipe(prompt, num_inference_steps=1)
+ audio_shape = output.audios.shape
+ assert audio_shape == (1, 256)
+
+ config = audioldm_pipe.vocoder.config
+ config.model_in_dim *= 2
+ audioldm_pipe.vocoder = SpeechT5HifiGan(config).to(torch_device)
+ output = audioldm_pipe(prompt, num_inference_steps=1)
+ audio_shape = output.audios.shape
+ # waveform shape is unchanged, we just have 2x the number of mel channels in the spectrogram
+ assert audio_shape == (1, 256)
+
+ def test_attention_slicing_forward_pass(self):
+ self._test_attention_slicing_forward_pass(test_mean_pixel_difference=False)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(test_mean_pixel_difference=False)
+
+
+@slow
+# @require_torch_gpu
+class AudioLDMPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ latents = np.random.RandomState(seed).standard_normal((1, 8, 128, 16))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "prompt": "A hammer hitting a wooden surface",
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 2.5,
+ }
+ return inputs
+
+ def test_audioldm(self):
+ audioldm_pipe = AudioLDMPipeline.from_pretrained("cvssp/audioldm")
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ inputs["num_inference_steps"] = 25
+ audio = audioldm_pipe(**inputs).audios[0]
+
+ assert audio.ndim == 1
+ assert len(audio) == 81920
+
+ audio_slice = audio[77230:77240]
+ expected_slice = np.array(
+ [-0.4884, -0.4607, 0.0023, 0.5007, 0.5896, 0.5151, 0.3813, -0.0208, -0.3687, -0.4315]
+ )
+ max_diff = np.abs(expected_slice - audio_slice).max()
+ assert max_diff < 1e-2
+
+ def test_audioldm_lms(self):
+ audioldm_pipe = AudioLDMPipeline.from_pretrained("cvssp/audioldm")
+ audioldm_pipe.scheduler = LMSDiscreteScheduler.from_config(audioldm_pipe.scheduler.config)
+ audioldm_pipe = audioldm_pipe.to(torch_device)
+ audioldm_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ audio = audioldm_pipe(**inputs).audios[0]
+
+ assert audio.ndim == 1
+ assert len(audio) == 81920
+
+ audio_slice = audio[27780:27790]
+ expected_slice = np.array([-0.2131, -0.0873, -0.0124, -0.0189, 0.0569, 0.1373, 0.1883, 0.2886, 0.3297, 0.2212])
+ max_diff = np.abs(expected_slice - audio_slice).max()
+ assert max_diff < 1e-2
diff --git a/diffusers/tests/pipelines/dance_diffusion/__init__.py b/diffusers/tests/pipelines/dance_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/dance_diffusion/test_dance_diffusion.py b/diffusers/tests/pipelines/dance_diffusion/test_dance_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbd4aa694b769a0903c505383d9634de8ebd4063
--- /dev/null
+++ b/diffusers/tests/pipelines/dance_diffusion/test_dance_diffusion.py
@@ -0,0 +1,160 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import DanceDiffusionPipeline, IPNDMScheduler, UNet1DModel
+from diffusers.utils import slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu, skip_mps
+
+from ...pipeline_params import UNCONDITIONAL_AUDIO_GENERATION_BATCH_PARAMS, UNCONDITIONAL_AUDIO_GENERATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class DanceDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = DanceDiffusionPipeline
+ params = UNCONDITIONAL_AUDIO_GENERATION_PARAMS
+ required_optional_params = PipelineTesterMixin.required_optional_params - {
+ "callback",
+ "latents",
+ "callback_steps",
+ "output_type",
+ "num_images_per_prompt",
+ }
+ batch_params = UNCONDITIONAL_AUDIO_GENERATION_BATCH_PARAMS
+ test_attention_slicing = False
+ test_cpu_offload = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet1DModel(
+ block_out_channels=(32, 32, 64),
+ extra_in_channels=16,
+ sample_size=512,
+ sample_rate=16_000,
+ in_channels=2,
+ out_channels=2,
+ flip_sin_to_cos=True,
+ use_timestep_embedding=False,
+ time_embedding_type="fourier",
+ mid_block_type="UNetMidBlock1D",
+ down_block_types=("DownBlock1DNoSkip", "DownBlock1D", "AttnDownBlock1D"),
+ up_block_types=("AttnUpBlock1D", "UpBlock1D", "UpBlock1DNoSkip"),
+ )
+ scheduler = IPNDMScheduler()
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "batch_size": 1,
+ "generator": generator,
+ "num_inference_steps": 4,
+ }
+ return inputs
+
+ def test_dance_diffusion(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ pipe = DanceDiffusionPipeline(**components)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = pipe(**inputs)
+ audio = output.audios
+
+ audio_slice = audio[0, -3:, -3:]
+
+ assert audio.shape == (1, 2, components["unet"].sample_size)
+ expected_slice = np.array([-0.7265, 1.0000, -0.8388, 0.1175, 0.9498, -1.0000])
+ assert np.abs(audio_slice.flatten() - expected_slice).max() < 1e-2
+
+ @skip_mps
+ def test_save_load_local(self):
+ return super().test_save_load_local()
+
+ @skip_mps
+ def test_dict_tuple_outputs_equivalent(self):
+ return super().test_dict_tuple_outputs_equivalent()
+
+ @skip_mps
+ def test_save_load_optional_components(self):
+ return super().test_save_load_optional_components()
+
+ @skip_mps
+ def test_attention_slicing_forward_pass(self):
+ return super().test_attention_slicing_forward_pass()
+
+
+@slow
+@require_torch_gpu
+class PipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_dance_diffusion(self):
+ device = torch_device
+
+ pipe = DanceDiffusionPipeline.from_pretrained("harmonai/maestro-150k")
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ output = pipe(generator=generator, num_inference_steps=100, audio_length_in_s=4.096)
+ audio = output.audios
+
+ audio_slice = audio[0, -3:, -3:]
+
+ assert audio.shape == (1, 2, pipe.unet.sample_size)
+ expected_slice = np.array([-0.0192, -0.0231, -0.0318, -0.0059, 0.0002, -0.0020])
+
+ assert np.abs(audio_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_dance_diffusion_fp16(self):
+ device = torch_device
+
+ pipe = DanceDiffusionPipeline.from_pretrained("harmonai/maestro-150k", torch_dtype=torch.float16)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ output = pipe(generator=generator, num_inference_steps=100, audio_length_in_s=4.096)
+ audio = output.audios
+
+ audio_slice = audio[0, -3:, -3:]
+
+ assert audio.shape == (1, 2, pipe.unet.sample_size)
+ expected_slice = np.array([-0.0367, -0.0488, -0.0771, -0.0525, -0.0444, -0.0341])
+
+ assert np.abs(audio_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/ddim/__init__.py b/diffusers/tests/pipelines/ddim/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/ddim/test_ddim.py b/diffusers/tests/pipelines/ddim/test_ddim.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d2c4e490d638861c4d06fb3c2ddff489a2773d3
--- /dev/null
+++ b/diffusers/tests/pipelines/ddim/test_ddim.py
@@ -0,0 +1,132 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import DDIMPipeline, DDIMScheduler, UNet2DModel
+from diffusers.utils.testing_utils import require_torch_gpu, slow, torch_device
+
+from ...pipeline_params import UNCONDITIONAL_IMAGE_GENERATION_BATCH_PARAMS, UNCONDITIONAL_IMAGE_GENERATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class DDIMPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = DDIMPipeline
+ params = UNCONDITIONAL_IMAGE_GENERATION_PARAMS
+ required_optional_params = PipelineTesterMixin.required_optional_params - {
+ "num_images_per_prompt",
+ "latents",
+ "callback",
+ "callback_steps",
+ }
+ batch_params = UNCONDITIONAL_IMAGE_GENERATION_BATCH_PARAMS
+ test_cpu_offload = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ scheduler = DDIMScheduler()
+ components = {"unet": unet, "scheduler": scheduler}
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "batch_size": 1,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_inference(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ self.assertEqual(image.shape, (1, 32, 32, 3))
+ expected_slice = np.array(
+ [1.000e00, 5.717e-01, 4.717e-01, 1.000e00, 0.000e00, 1.000e00, 3.000e-04, 0.000e00, 9.000e-04]
+ )
+ max_diff = np.abs(image_slice.flatten() - expected_slice).max()
+ self.assertLessEqual(max_diff, 1e-3)
+
+
+@slow
+@require_torch_gpu
+class DDIMPipelineIntegrationTests(unittest.TestCase):
+ def test_inference_cifar10(self):
+ model_id = "google/ddpm-cifar10-32"
+
+ unet = UNet2DModel.from_pretrained(model_id)
+ scheduler = DDIMScheduler()
+
+ ddim = DDIMPipeline(unet=unet, scheduler=scheduler)
+ ddim.to(torch_device)
+ ddim.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = ddim(generator=generator, eta=0.0, output_type="numpy").images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.1723, 0.1617, 0.1600, 0.1626, 0.1497, 0.1513, 0.1505, 0.1442, 0.1453])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_inference_ema_bedroom(self):
+ model_id = "google/ddpm-ema-bedroom-256"
+
+ unet = UNet2DModel.from_pretrained(model_id)
+ scheduler = DDIMScheduler.from_pretrained(model_id)
+
+ ddpm = DDIMPipeline(unet=unet, scheduler=scheduler)
+ ddpm.to(torch_device)
+ ddpm.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = ddpm(generator=generator, output_type="numpy").images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 256, 256, 3)
+ expected_slice = np.array([0.0060, 0.0201, 0.0344, 0.0024, 0.0018, 0.0002, 0.0022, 0.0000, 0.0069])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/ddpm/__init__.py b/diffusers/tests/pipelines/ddpm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/ddpm/test_ddpm.py b/diffusers/tests/pipelines/ddpm/test_ddpm.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e3e47cb74fbe07bb9ddf73c40b200bcea945237
--- /dev/null
+++ b/diffusers/tests/pipelines/ddpm/test_ddpm.py
@@ -0,0 +1,111 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import DDPMPipeline, DDPMScheduler, UNet2DModel
+from diffusers.utils.testing_utils import require_torch_gpu, slow, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class DDPMPipelineFastTests(unittest.TestCase):
+ @property
+ def dummy_uncond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ return model
+
+ def test_fast_inference(self):
+ device = "cpu"
+ unet = self.dummy_uncond_unet
+ scheduler = DDPMScheduler()
+
+ ddpm = DDPMPipeline(unet=unet, scheduler=scheduler)
+ ddpm.to(device)
+ ddpm.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image = ddpm(generator=generator, num_inference_steps=2, output_type="numpy").images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = ddpm(generator=generator, num_inference_steps=2, output_type="numpy", return_dict=False)[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array(
+ [9.956e-01, 5.785e-01, 4.675e-01, 9.930e-01, 0.0, 1.000, 1.199e-03, 2.648e-04, 5.101e-04]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_inference_predict_sample(self):
+ unet = self.dummy_uncond_unet
+ scheduler = DDPMScheduler(prediction_type="sample")
+
+ ddpm = DDPMPipeline(unet=unet, scheduler=scheduler)
+ ddpm.to(torch_device)
+ ddpm.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = ddpm(generator=generator, num_inference_steps=2, output_type="numpy").images
+
+ generator = torch.manual_seed(0)
+ image_eps = ddpm(generator=generator, num_inference_steps=2, output_type="numpy")[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_eps_slice = image_eps[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ tolerance = 1e-2 if torch_device != "mps" else 3e-2
+ assert np.abs(image_slice.flatten() - image_eps_slice.flatten()).max() < tolerance
+
+
+@slow
+@require_torch_gpu
+class DDPMPipelineIntegrationTests(unittest.TestCase):
+ def test_inference_cifar10(self):
+ model_id = "google/ddpm-cifar10-32"
+
+ unet = UNet2DModel.from_pretrained(model_id)
+ scheduler = DDPMScheduler.from_pretrained(model_id)
+
+ ddpm = DDPMPipeline(unet=unet, scheduler=scheduler)
+ ddpm.to(torch_device)
+ ddpm.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = ddpm(generator=generator, output_type="numpy").images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.4200, 0.3588, 0.1939, 0.3847, 0.3382, 0.2647, 0.4155, 0.3582, 0.3385])
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/dit/__init__.py b/diffusers/tests/pipelines/dit/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/dit/test_dit.py b/diffusers/tests/pipelines/dit/test_dit.py
new file mode 100644
index 0000000000000000000000000000000000000000..c514c3c7fa1d7b7a83307a04c37ca63dece289e5
--- /dev/null
+++ b/diffusers/tests/pipelines/dit/test_dit.py
@@ -0,0 +1,152 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import AutoencoderKL, DDIMScheduler, DiTPipeline, DPMSolverMultistepScheduler, Transformer2DModel
+from diffusers.utils import is_xformers_available, load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import (
+ CLASS_CONDITIONED_IMAGE_GENERATION_BATCH_PARAMS,
+ CLASS_CONDITIONED_IMAGE_GENERATION_PARAMS,
+)
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class DiTPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = DiTPipeline
+ params = CLASS_CONDITIONED_IMAGE_GENERATION_PARAMS
+ required_optional_params = PipelineTesterMixin.required_optional_params - {
+ "latents",
+ "num_images_per_prompt",
+ "callback",
+ "callback_steps",
+ }
+ batch_params = CLASS_CONDITIONED_IMAGE_GENERATION_BATCH_PARAMS
+ test_cpu_offload = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ transformer = Transformer2DModel(
+ sample_size=16,
+ num_layers=2,
+ patch_size=4,
+ attention_head_dim=8,
+ num_attention_heads=2,
+ in_channels=4,
+ out_channels=8,
+ attention_bias=True,
+ activation_fn="gelu-approximate",
+ num_embeds_ada_norm=1000,
+ norm_type="ada_norm_zero",
+ norm_elementwise_affine=False,
+ )
+ vae = AutoencoderKL()
+ scheduler = DDIMScheduler()
+ components = {"transformer": transformer.eval(), "vae": vae.eval(), "scheduler": scheduler}
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "class_labels": [1],
+ "generator": generator,
+ "num_inference_steps": 2,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_inference(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ self.assertEqual(image.shape, (1, 16, 16, 3))
+ expected_slice = np.array([0.4380, 0.4141, 0.5159, 0.0000, 0.4282, 0.6680, 0.5485, 0.2545, 0.6719])
+ max_diff = np.abs(image_slice.flatten() - expected_slice).max()
+ self.assertLessEqual(max_diff, 1e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(relax_max_difference=True, expected_max_diff=1e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=1e-3)
+
+
+@require_torch_gpu
+@slow
+class DiTPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_dit_256(self):
+ generator = torch.manual_seed(0)
+
+ pipe = DiTPipeline.from_pretrained("facebook/DiT-XL-2-256")
+ pipe.to("cuda")
+
+ words = ["vase", "umbrella", "white shark", "white wolf"]
+ ids = pipe.get_label_ids(words)
+
+ images = pipe(ids, generator=generator, num_inference_steps=40, output_type="np").images
+
+ for word, image in zip(words, images):
+ expected_image = load_numpy(
+ f"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/dit/{word}.npy"
+ )
+ assert np.abs((expected_image - image).max()) < 1e-2
+
+ def test_dit_512(self):
+ pipe = DiTPipeline.from_pretrained("facebook/DiT-XL-2-512")
+ pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+ pipe.to("cuda")
+
+ words = ["vase", "umbrella"]
+ ids = pipe.get_label_ids(words)
+
+ generator = torch.manual_seed(0)
+ images = pipe(ids, generator=generator, num_inference_steps=25, output_type="np").images
+
+ for word, image in zip(words, images):
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ f"/dit/{word}_512.npy"
+ )
+
+ assert np.abs((expected_image - image).max()) < 1e-1
diff --git a/diffusers/tests/pipelines/karras_ve/__init__.py b/diffusers/tests/pipelines/karras_ve/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/karras_ve/test_karras_ve.py b/diffusers/tests/pipelines/karras_ve/test_karras_ve.py
new file mode 100644
index 0000000000000000000000000000000000000000..391e61a2b9c90c58049270a192884bd358621c52
--- /dev/null
+++ b/diffusers/tests/pipelines/karras_ve/test_karras_ve.py
@@ -0,0 +1,86 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import KarrasVePipeline, KarrasVeScheduler, UNet2DModel
+from diffusers.utils.testing_utils import require_torch, slow, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class KarrasVePipelineFastTests(unittest.TestCase):
+ @property
+ def dummy_uncond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ return model
+
+ def test_inference(self):
+ unet = self.dummy_uncond_unet
+ scheduler = KarrasVeScheduler()
+
+ pipe = KarrasVePipeline(unet=unet, scheduler=scheduler)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = pipe(num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ generator = torch.manual_seed(0)
+ image_from_tuple = pipe(num_inference_steps=2, generator=generator, output_type="numpy", return_dict=False)[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+
+@slow
+@require_torch
+class KarrasVePipelineIntegrationTests(unittest.TestCase):
+ def test_inference(self):
+ model_id = "google/ncsnpp-celebahq-256"
+ model = UNet2DModel.from_pretrained(model_id)
+ scheduler = KarrasVeScheduler()
+
+ pipe = KarrasVePipeline(unet=model, scheduler=scheduler)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = pipe(num_inference_steps=20, generator=generator, output_type="numpy").images
+
+ image_slice = image[0, -3:, -3:, -1]
+ assert image.shape == (1, 256, 256, 3)
+ expected_slice = np.array([0.578, 0.5811, 0.5924, 0.5809, 0.587, 0.5886, 0.5861, 0.5802, 0.586])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/latent_diffusion/__init__.py b/diffusers/tests/pipelines/latent_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion.py b/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..3f2dbe5cec2a324d80fe7bcca1efffe9bcd3ab02
--- /dev/null
+++ b/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion.py
@@ -0,0 +1,202 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import AutoencoderKL, DDIMScheduler, LDMTextToImagePipeline, UNet2DConditionModel
+from diffusers.utils.testing_utils import load_numpy, nightly, require_torch_gpu, slow, torch_device
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class LDMTextToImagePipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = LDMTextToImagePipeline
+ params = TEXT_TO_IMAGE_PARAMS - {
+ "negative_prompt",
+ "negative_prompt_embeds",
+ "cross_attention_kwargs",
+ "prompt_embeds",
+ }
+ required_optional_params = PipelineTesterMixin.required_optional_params - {
+ "num_images_per_prompt",
+ "callback",
+ "callback_steps",
+ }
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+ test_cpu_offload = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=(32, 64),
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownEncoderBlock2D", "DownEncoderBlock2D"),
+ up_block_types=("UpDecoderBlock2D", "UpDecoderBlock2D"),
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vqvae": vae,
+ "bert": text_encoder,
+ "tokenizer": tokenizer,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_inference_text2img(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ pipe = LDMTextToImagePipeline(**components)
+ pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 16, 16, 3)
+ expected_slice = np.array([0.59450, 0.64078, 0.55509, 0.51229, 0.69640, 0.36960, 0.59296, 0.60801, 0.49332])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+
+@slow
+@require_torch_gpu
+class LDMTextToImagePipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, dtype=torch.float32, seed=0):
+ generator = torch.manual_seed(seed)
+ latents = np.random.RandomState(seed).standard_normal((1, 4, 32, 32))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_ldm_default_ddim(self):
+ pipe = LDMTextToImagePipeline.from_pretrained("CompVis/ldm-text2im-large-256").to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 256, 256, 3)
+ expected_slice = np.array([0.51825, 0.52850, 0.52543, 0.54258, 0.52304, 0.52569, 0.54363, 0.55276, 0.56878])
+ max_diff = np.abs(expected_slice - image_slice).max()
+ assert max_diff < 1e-3
+
+
+@nightly
+@require_torch_gpu
+class LDMTextToImagePipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, dtype=torch.float32, seed=0):
+ generator = torch.manual_seed(seed)
+ latents = np.random.RandomState(seed).standard_normal((1, 4, 32, 32))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 50,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_ldm_default_ddim(self):
+ pipe = LDMTextToImagePipeline.from_pretrained("CompVis/ldm-text2im-large-256").to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/ldm_text2img/ldm_large_256_ddim.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
diff --git a/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion_superresolution.py b/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion_superresolution.py
new file mode 100644
index 0000000000000000000000000000000000000000..f1aa2f08efbaac9d5d8ce55b2a01ebf9fc538bd1
--- /dev/null
+++ b/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion_superresolution.py
@@ -0,0 +1,131 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import random
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import DDIMScheduler, LDMSuperResolutionPipeline, UNet2DModel, VQModel
+from diffusers.utils import PIL_INTERPOLATION, floats_tensor, load_image, slow, torch_device
+from diffusers.utils.testing_utils import require_torch
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class LDMSuperResolutionPipelineFastTests(unittest.TestCase):
+ @property
+ def dummy_image(self):
+ batch_size = 1
+ num_channels = 3
+ sizes = (32, 32)
+
+ image = floats_tensor((batch_size, num_channels) + sizes, rng=random.Random(0)).to(torch_device)
+ return image
+
+ @property
+ def dummy_uncond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=6,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ return model
+
+ @property
+ def dummy_vq_model(self):
+ torch.manual_seed(0)
+ model = VQModel(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=3,
+ )
+ return model
+
+ def test_inference_superresolution(self):
+ device = "cpu"
+ unet = self.dummy_uncond_unet
+ scheduler = DDIMScheduler()
+ vqvae = self.dummy_vq_model
+
+ ldm = LDMSuperResolutionPipeline(unet=unet, vqvae=vqvae, scheduler=scheduler)
+ ldm.to(device)
+ ldm.set_progress_bar_config(disable=None)
+
+ init_image = self.dummy_image.to(device)
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image = ldm(image=init_image, generator=generator, num_inference_steps=2, output_type="numpy").images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.8678, 0.8245, 0.6381, 0.6830, 0.4385, 0.5599, 0.4641, 0.6201, 0.5150])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
+ def test_inference_superresolution_fp16(self):
+ unet = self.dummy_uncond_unet
+ scheduler = DDIMScheduler()
+ vqvae = self.dummy_vq_model
+
+ # put models in fp16
+ unet = unet.half()
+ vqvae = vqvae.half()
+
+ ldm = LDMSuperResolutionPipeline(unet=unet, vqvae=vqvae, scheduler=scheduler)
+ ldm.to(torch_device)
+ ldm.set_progress_bar_config(disable=None)
+
+ init_image = self.dummy_image.to(torch_device)
+
+ image = ldm(init_image, num_inference_steps=2, output_type="numpy").images
+
+ assert image.shape == (1, 64, 64, 3)
+
+
+@slow
+@require_torch
+class LDMSuperResolutionPipelineIntegrationTests(unittest.TestCase):
+ def test_inference_superresolution(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/vq_diffusion/teddy_bear_pool.png"
+ )
+ init_image = init_image.resize((64, 64), resample=PIL_INTERPOLATION["lanczos"])
+
+ ldm = LDMSuperResolutionPipeline.from_pretrained("duongna/ldm-super-resolution", device_map="auto")
+ ldm.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = ldm(image=init_image, generator=generator, num_inference_steps=20, output_type="numpy").images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 256, 256, 3)
+ expected_slice = np.array([0.7644, 0.7679, 0.7642, 0.7633, 0.7666, 0.7560, 0.7425, 0.7257, 0.6907])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion_uncond.py b/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion_uncond.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa7b33730d1815d2b1de20b48c6106407cc41770
--- /dev/null
+++ b/diffusers/tests/pipelines/latent_diffusion/test_latent_diffusion_uncond.py
@@ -0,0 +1,116 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel
+
+from diffusers import DDIMScheduler, LDMPipeline, UNet2DModel, VQModel
+from diffusers.utils.testing_utils import require_torch, slow, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class LDMPipelineFastTests(unittest.TestCase):
+ @property
+ def dummy_uncond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ return model
+
+ @property
+ def dummy_vq_model(self):
+ torch.manual_seed(0)
+ model = VQModel(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=3,
+ )
+ return model
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ return CLIPTextModel(config)
+
+ def test_inference_uncond(self):
+ unet = self.dummy_uncond_unet
+ scheduler = DDIMScheduler()
+ vae = self.dummy_vq_model
+
+ ldm = LDMPipeline(unet=unet, vqvae=vae, scheduler=scheduler)
+ ldm.to(torch_device)
+ ldm.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = ldm(generator=generator, num_inference_steps=2, output_type="numpy").images
+
+ generator = torch.manual_seed(0)
+ image_from_tuple = ldm(generator=generator, num_inference_steps=2, output_type="numpy", return_dict=False)[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.8512, 0.818, 0.6411, 0.6808, 0.4465, 0.5618, 0.46, 0.6231, 0.5172])
+ tolerance = 1e-2 if torch_device != "mps" else 3e-2
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < tolerance
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < tolerance
+
+
+@slow
+@require_torch
+class LDMPipelineIntegrationTests(unittest.TestCase):
+ def test_inference_uncond(self):
+ ldm = LDMPipeline.from_pretrained("CompVis/ldm-celebahq-256")
+ ldm.to(torch_device)
+ ldm.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = ldm(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 256, 256, 3)
+ expected_slice = np.array([0.4399, 0.44975, 0.46825, 0.474, 0.4359, 0.4581, 0.45095, 0.4341, 0.4447])
+ tolerance = 1e-2 if torch_device != "mps" else 3e-2
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < tolerance
diff --git a/diffusers/tests/pipelines/paint_by_example/__init__.py b/diffusers/tests/pipelines/paint_by_example/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/paint_by_example/test_paint_by_example.py b/diffusers/tests/pipelines/paint_by_example/test_paint_by_example.py
new file mode 100644
index 0000000000000000000000000000000000000000..81d1989200ac1ddbab305d5143ec98bcd654f46b
--- /dev/null
+++ b/diffusers/tests/pipelines/paint_by_example/test_paint_by_example.py
@@ -0,0 +1,210 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPVisionConfig
+
+from diffusers import AutoencoderKL, PaintByExamplePipeline, PNDMScheduler, UNet2DConditionModel
+from diffusers.pipelines.paint_by_example import PaintByExampleImageEncoder
+from diffusers.utils import floats_tensor, load_image, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import IMAGE_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS, IMAGE_GUIDED_IMAGE_INPAINTING_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class PaintByExamplePipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = PaintByExamplePipeline
+ params = IMAGE_GUIDED_IMAGE_INPAINTING_PARAMS
+ batch_params = IMAGE_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=9,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ config = CLIPVisionConfig(
+ hidden_size=32,
+ projection_dim=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ image_size=32,
+ patch_size=4,
+ )
+ image_encoder = PaintByExampleImageEncoder(config, proj_size=32)
+ feature_extractor = CLIPImageProcessor(crop_size=32, size=32)
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "image_encoder": image_encoder,
+ "safety_checker": None,
+ "feature_extractor": feature_extractor,
+ }
+ return components
+
+ def convert_to_pt(self, image):
+ image = np.array(image.convert("RGB"))
+ image = image[None].transpose(0, 3, 1, 2)
+ image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
+ return image
+
+ def get_dummy_inputs(self, device="cpu", seed=0):
+ # TODO: use tensor inputs instead of PIL, this is here just to leave the old expected_slices untouched
+ image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ init_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+ mask_image = Image.fromarray(np.uint8(image + 4)).convert("RGB").resize((64, 64))
+ example_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((32, 32))
+
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "example_image": example_image,
+ "image": init_image,
+ "mask_image": mask_image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_paint_by_example_inpaint(self):
+ components = self.get_dummy_components()
+
+ # make sure here that pndm scheduler skips prk
+ pipe = PaintByExamplePipeline(**components)
+ pipe = pipe.to("cpu")
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ output = pipe(**inputs)
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.4701, 0.5555, 0.3994, 0.5107, 0.5691, 0.4517, 0.5125, 0.4769, 0.4539])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_paint_by_example_image_tensor(self):
+ device = "cpu"
+ inputs = self.get_dummy_inputs()
+ inputs.pop("mask_image")
+ image = self.convert_to_pt(inputs.pop("image"))
+ mask_image = image.clamp(0, 1) / 2
+
+ # make sure here that pndm scheduler skips prk
+ pipe = PaintByExamplePipeline(**self.get_dummy_components())
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ output = pipe(image=image, mask_image=mask_image[:, 0], **inputs)
+ out_1 = output.images
+
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ mask_image = mask_image.cpu().permute(0, 2, 3, 1)[0]
+
+ image = Image.fromarray(np.uint8(image)).convert("RGB")
+ mask_image = Image.fromarray(np.uint8(mask_image)).convert("RGB")
+
+ output = pipe(**self.get_dummy_inputs())
+ out_2 = output.images
+
+ assert out_1.shape == (1, 64, 64, 3)
+ assert np.abs(out_1.flatten() - out_2.flatten()).max() < 5e-2
+
+
+@slow
+@require_torch_gpu
+class PaintByExamplePipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_paint_by_example(self):
+ # make sure here that pndm scheduler skips prk
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/paint_by_example/dog_in_bucket.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/paint_by_example/mask.png"
+ )
+ example_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/paint_by_example/panda.jpg"
+ )
+
+ pipe = PaintByExamplePipeline.from_pretrained("Fantasy-Studio/Paint-by-Example")
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(321)
+ output = pipe(
+ image=init_image,
+ mask_image=mask_image,
+ example_image=example_image,
+ generator=generator,
+ guidance_scale=5.0,
+ num_inference_steps=50,
+ output_type="np",
+ )
+
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.4834, 0.4811, 0.4874, 0.5122, 0.5081, 0.5144, 0.5291, 0.5290, 0.5374])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/pndm/__init__.py b/diffusers/tests/pipelines/pndm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/pndm/test_pndm.py b/diffusers/tests/pipelines/pndm/test_pndm.py
new file mode 100644
index 0000000000000000000000000000000000000000..bed5fea561dc670220c1864c614b68718e96a7ae
--- /dev/null
+++ b/diffusers/tests/pipelines/pndm/test_pndm.py
@@ -0,0 +1,87 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import PNDMPipeline, PNDMScheduler, UNet2DModel
+from diffusers.utils.testing_utils import require_torch, slow, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class PNDMPipelineFastTests(unittest.TestCase):
+ @property
+ def dummy_uncond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ return model
+
+ def test_inference(self):
+ unet = self.dummy_uncond_unet
+ scheduler = PNDMScheduler()
+
+ pndm = PNDMPipeline(unet=unet, scheduler=scheduler)
+ pndm.to(torch_device)
+ pndm.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = pndm(generator=generator, num_inference_steps=20, output_type="numpy").images
+
+ generator = torch.manual_seed(0)
+ image_from_tuple = pndm(generator=generator, num_inference_steps=20, output_type="numpy", return_dict=False)[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([1.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+
+@slow
+@require_torch
+class PNDMPipelineIntegrationTests(unittest.TestCase):
+ def test_inference_cifar10(self):
+ model_id = "google/ddpm-cifar10-32"
+
+ unet = UNet2DModel.from_pretrained(model_id)
+ scheduler = PNDMScheduler()
+
+ pndm = PNDMPipeline(unet=unet, scheduler=scheduler)
+ pndm.to(torch_device)
+ pndm.set_progress_bar_config(disable=None)
+ generator = torch.manual_seed(0)
+ image = pndm(generator=generator, output_type="numpy").images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.1564, 0.14645, 0.1406, 0.14715, 0.12425, 0.14045, 0.13115, 0.12175, 0.125])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/repaint/__init__.py b/diffusers/tests/pipelines/repaint/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/repaint/test_repaint.py b/diffusers/tests/pipelines/repaint/test_repaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..060e6c9161baab099bc11b3d843dd4b48f7e2fb6
--- /dev/null
+++ b/diffusers/tests/pipelines/repaint/test_repaint.py
@@ -0,0 +1,162 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import RePaintPipeline, RePaintScheduler, UNet2DModel
+from diffusers.utils.testing_utils import load_image, load_numpy, nightly, require_torch_gpu, skip_mps, torch_device
+
+from ...pipeline_params import IMAGE_INPAINTING_BATCH_PARAMS, IMAGE_INPAINTING_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class RepaintPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = RePaintPipeline
+ params = IMAGE_INPAINTING_PARAMS - {"width", "height", "guidance_scale"}
+ required_optional_params = PipelineTesterMixin.required_optional_params - {
+ "latents",
+ "num_images_per_prompt",
+ "callback",
+ "callback_steps",
+ }
+ batch_params = IMAGE_INPAINTING_BATCH_PARAMS
+ test_cpu_offload = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ torch.manual_seed(0)
+ unet = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ scheduler = RePaintScheduler()
+ components = {"unet": unet, "scheduler": scheduler}
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ image = np.random.RandomState(seed).standard_normal((1, 3, 32, 32))
+ image = torch.from_numpy(image).to(device=device, dtype=torch.float32)
+ mask = (image > 0).to(device=device, dtype=torch.float32)
+ inputs = {
+ "image": image,
+ "mask_image": mask,
+ "generator": generator,
+ "num_inference_steps": 5,
+ "eta": 0.0,
+ "jump_length": 2,
+ "jump_n_sample": 2,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_repaint(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = RePaintPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([1.0000, 0.5426, 0.5497, 0.2200, 1.0000, 1.0000, 0.5623, 1.0000, 0.6274])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ @skip_mps
+ def test_save_load_local(self):
+ return super().test_save_load_local()
+
+ # RePaint can hardly be made deterministic since the scheduler is currently always
+ # nondeterministic
+ @unittest.skip("non-deterministic pipeline")
+ def test_inference_batch_single_identical(self):
+ return super().test_inference_batch_single_identical()
+
+ @skip_mps
+ def test_dict_tuple_outputs_equivalent(self):
+ return super().test_dict_tuple_outputs_equivalent()
+
+ @skip_mps
+ def test_save_load_optional_components(self):
+ return super().test_save_load_optional_components()
+
+ @skip_mps
+ def test_attention_slicing_forward_pass(self):
+ return super().test_attention_slicing_forward_pass()
+
+
+@nightly
+@require_torch_gpu
+class RepaintPipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_celebahq(self):
+ original_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/"
+ "repaint/celeba_hq_256.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/mask_256.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/"
+ "repaint/celeba_hq_256_result.npy"
+ )
+
+ model_id = "google/ddpm-ema-celebahq-256"
+ unet = UNet2DModel.from_pretrained(model_id)
+ scheduler = RePaintScheduler.from_pretrained(model_id)
+
+ repaint = RePaintPipeline(unet=unet, scheduler=scheduler).to(torch_device)
+ repaint.set_progress_bar_config(disable=None)
+ repaint.enable_attention_slicing()
+
+ generator = torch.manual_seed(0)
+ output = repaint(
+ original_image,
+ mask_image,
+ num_inference_steps=250,
+ eta=0.0,
+ jump_length=10,
+ jump_n_sample=10,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images[0]
+
+ assert image.shape == (256, 256, 3)
+ assert np.abs(expected_image - image).mean() < 1e-2
diff --git a/diffusers/tests/pipelines/score_sde_ve/__init__.py b/diffusers/tests/pipelines/score_sde_ve/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/score_sde_ve/test_score_sde_ve.py b/diffusers/tests/pipelines/score_sde_ve/test_score_sde_ve.py
new file mode 100644
index 0000000000000000000000000000000000000000..036ecc3f6bf3c3a61780933c0a404ca91abe5dc4
--- /dev/null
+++ b/diffusers/tests/pipelines/score_sde_ve/test_score_sde_ve.py
@@ -0,0 +1,91 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import ScoreSdeVePipeline, ScoreSdeVeScheduler, UNet2DModel
+from diffusers.utils.testing_utils import require_torch, slow, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class ScoreSdeVeipelineFastTests(unittest.TestCase):
+ @property
+ def dummy_uncond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ return model
+
+ def test_inference(self):
+ unet = self.dummy_uncond_unet
+ scheduler = ScoreSdeVeScheduler()
+
+ sde_ve = ScoreSdeVePipeline(unet=unet, scheduler=scheduler)
+ sde_ve.to(torch_device)
+ sde_ve.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = sde_ve(num_inference_steps=2, output_type="numpy", generator=generator).images
+
+ generator = torch.manual_seed(0)
+ image_from_tuple = sde_ve(num_inference_steps=2, output_type="numpy", generator=generator, return_dict=False)[
+ 0
+ ]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+
+@slow
+@require_torch
+class ScoreSdeVePipelineIntegrationTests(unittest.TestCase):
+ def test_inference(self):
+ model_id = "google/ncsnpp-church-256"
+ model = UNet2DModel.from_pretrained(model_id)
+
+ scheduler = ScoreSdeVeScheduler.from_pretrained(model_id)
+
+ sde_ve = ScoreSdeVePipeline(unet=model, scheduler=scheduler)
+ sde_ve.to(torch_device)
+ sde_ve.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ image = sde_ve(num_inference_steps=10, output_type="numpy", generator=generator).images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 256, 256, 3)
+
+ expected_slice = np.array([0.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/semantic_stable_diffusion/__init__.py b/diffusers/tests/pipelines/semantic_stable_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/semantic_stable_diffusion/test_semantic_diffusion.py b/diffusers/tests/pipelines/semantic_stable_diffusion/test_semantic_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..b312c8184390c0eb7df751cbbbf1e1b5146fb428
--- /dev/null
+++ b/diffusers/tests/pipelines/semantic_stable_diffusion/test_semantic_diffusion.py
@@ -0,0 +1,601 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import AutoencoderKL, DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler, UNet2DConditionModel
+from diffusers.pipelines.semantic_stable_diffusion import SemanticStableDiffusionPipeline as StableDiffusionPipeline
+from diffusers.utils import floats_tensor, nightly, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class SafeDiffusionPipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @property
+ def dummy_image(self):
+ batch_size = 1
+ num_channels = 3
+ sizes = (32, 32)
+
+ image = floats_tensor((batch_size, num_channels) + sizes, rng=random.Random(0)).to(torch_device)
+ return image
+
+ @property
+ def dummy_cond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ return model
+
+ @property
+ def dummy_vae(self):
+ torch.manual_seed(0)
+ model = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ return model
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ return CLIPTextModel(config)
+
+ @property
+ def dummy_extractor(self):
+ def extract(*args, **kwargs):
+ class Out:
+ def __init__(self):
+ self.pixel_values = torch.ones([0])
+
+ def to(self, device):
+ self.pixel_values.to(device)
+ return self
+
+ return Out()
+
+ return extract
+
+ def test_semantic_diffusion_ddim(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5644, 0.6018, 0.4799, 0.5267, 0.5585, 0.4641, 0.516, 0.4964, 0.4792])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_semantic_diffusion_pndm(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
+
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5095, 0.5674, 0.4668, 0.5126, 0.5697, 0.4675, 0.5278, 0.4964, 0.4945])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_semantic_diffusion_no_safety_checker(self):
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-lms-pipe", safety_checker=None
+ )
+ assert isinstance(pipe, StableDiffusionPipeline)
+ assert isinstance(pipe.scheduler, LMSDiscreteScheduler)
+ assert pipe.safety_checker is None
+
+ image = pipe("example prompt", num_inference_steps=2).images[0]
+ assert image is not None
+
+ # check that there's no error when saving a pipeline with one of the models being None
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe = StableDiffusionPipeline.from_pretrained(tmpdirname)
+
+ # sanity check that the pipeline still works
+ assert pipe.safety_checker is None
+ image = pipe("example prompt", num_inference_steps=2).images[0]
+ assert image is not None
+
+ @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
+ def test_semantic_diffusion_fp16(self):
+ """Test that stable diffusion works with fp16"""
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # put models in fp16
+ unet = unet.half()
+ vae = vae.half()
+ bert = bert.half()
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ image = sd_pipe([prompt], num_inference_steps=2, output_type="np").images
+
+ assert image.shape == (1, 64, 64, 3)
+
+
+@nightly
+@require_torch_gpu
+class SemanticDiffusionPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_positive_guidance(self):
+ torch_device = "cuda"
+ pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "a photo of a cat"
+ edit = {
+ "editing_prompt": ["sunglasses"],
+ "reverse_editing_direction": [False],
+ "edit_warmup_steps": 10,
+ "edit_guidance_scale": 6,
+ "edit_threshold": 0.95,
+ "edit_momentum_scale": 0.5,
+ "edit_mom_beta": 0.6,
+ }
+
+ seed = 3
+ guidance_scale = 7
+
+ # no sega enabled
+ generator = torch.Generator(torch_device)
+ generator.manual_seed(seed)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [
+ 0.34673113,
+ 0.38492733,
+ 0.37597352,
+ 0.34086335,
+ 0.35650748,
+ 0.35579205,
+ 0.3384763,
+ 0.34340236,
+ 0.3573271,
+ ]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ # with sega enabled
+ # generator = torch.manual_seed(seed)
+ generator.manual_seed(seed)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ **edit,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [
+ 0.41887826,
+ 0.37728766,
+ 0.30138272,
+ 0.41416335,
+ 0.41664985,
+ 0.36283392,
+ 0.36191246,
+ 0.43364465,
+ 0.43001732,
+ ]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_negative_guidance(self):
+ torch_device = "cuda"
+ pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "an image of a crowded boulevard, realistic, 4k"
+ edit = {
+ "editing_prompt": "crowd, crowded, people",
+ "reverse_editing_direction": True,
+ "edit_warmup_steps": 10,
+ "edit_guidance_scale": 8.3,
+ "edit_threshold": 0.9,
+ "edit_momentum_scale": 0.5,
+ "edit_mom_beta": 0.6,
+ }
+
+ seed = 9
+ guidance_scale = 7
+
+ # no sega enabled
+ generator = torch.Generator(torch_device)
+ generator.manual_seed(seed)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [
+ 0.43497998,
+ 0.91814065,
+ 0.7540739,
+ 0.55580205,
+ 0.8467265,
+ 0.5389691,
+ 0.62574506,
+ 0.58897763,
+ 0.50926757,
+ ]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ # with sega enabled
+ # generator = torch.manual_seed(seed)
+ generator.manual_seed(seed)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ **edit,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [
+ 0.3089719,
+ 0.30500144,
+ 0.29016042,
+ 0.30630964,
+ 0.325687,
+ 0.29419225,
+ 0.2908091,
+ 0.28723598,
+ 0.27696294,
+ ]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_multi_cond_guidance(self):
+ torch_device = "cuda"
+ pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "a castle next to a river"
+ edit = {
+ "editing_prompt": ["boat on a river, boat", "monet, impression, sunrise"],
+ "reverse_editing_direction": False,
+ "edit_warmup_steps": [15, 18],
+ "edit_guidance_scale": 6,
+ "edit_threshold": [0.9, 0.8],
+ "edit_momentum_scale": 0.5,
+ "edit_mom_beta": 0.6,
+ }
+
+ seed = 48
+ guidance_scale = 7
+
+ # no sega enabled
+ generator = torch.Generator(torch_device)
+ generator.manual_seed(seed)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [
+ 0.75163555,
+ 0.76037145,
+ 0.61785,
+ 0.9189673,
+ 0.8627701,
+ 0.85189694,
+ 0.8512813,
+ 0.87012076,
+ 0.8312857,
+ ]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ # with sega enabled
+ # generator = torch.manual_seed(seed)
+ generator.manual_seed(seed)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ **edit,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [
+ 0.73553365,
+ 0.7537271,
+ 0.74341905,
+ 0.66480356,
+ 0.6472925,
+ 0.63039416,
+ 0.64812905,
+ 0.6749717,
+ 0.6517102,
+ ]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_guidance_fp16(self):
+ torch_device = "cuda"
+ pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "a photo of a cat"
+ edit = {
+ "editing_prompt": ["sunglasses"],
+ "reverse_editing_direction": [False],
+ "edit_warmup_steps": 10,
+ "edit_guidance_scale": 6,
+ "edit_threshold": 0.95,
+ "edit_momentum_scale": 0.5,
+ "edit_mom_beta": 0.6,
+ }
+
+ seed = 3
+ guidance_scale = 7
+
+ # no sega enabled
+ generator = torch.Generator(torch_device)
+ generator.manual_seed(seed)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [
+ 0.34887695,
+ 0.3876953,
+ 0.375,
+ 0.34423828,
+ 0.3581543,
+ 0.35717773,
+ 0.3383789,
+ 0.34570312,
+ 0.359375,
+ ]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ # with sega enabled
+ # generator = torch.manual_seed(seed)
+ generator.manual_seed(seed)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ **edit,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [
+ 0.42285156,
+ 0.36914062,
+ 0.29077148,
+ 0.42041016,
+ 0.41918945,
+ 0.35498047,
+ 0.3618164,
+ 0.4423828,
+ 0.43115234,
+ ]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/spectrogram_diffusion/__init__.py b/diffusers/tests/pipelines/spectrogram_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py b/diffusers/tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..594d7c598f7507d07973e9e2cd8f62a5f0a1b7fd
--- /dev/null
+++ b/diffusers/tests/pipelines/spectrogram_diffusion/test_spectrogram_diffusion.py
@@ -0,0 +1,235 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import DDPMScheduler, MidiProcessor, SpectrogramDiffusionPipeline
+from diffusers.pipelines.spectrogram_diffusion import SpectrogramContEncoder, SpectrogramNotesEncoder, T5FilmDecoder
+from diffusers.utils import require_torch_gpu, skip_mps, slow, torch_device
+from diffusers.utils.testing_utils import require_note_seq, require_onnxruntime
+
+from ...pipeline_params import TOKENS_TO_AUDIO_GENERATION_BATCH_PARAMS, TOKENS_TO_AUDIO_GENERATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+MIDI_FILE = "./tests/fixtures/elise_format0.mid"
+
+
+class SpectrogramDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = SpectrogramDiffusionPipeline
+ required_optional_params = PipelineTesterMixin.required_optional_params - {
+ "callback",
+ "latents",
+ "callback_steps",
+ "output_type",
+ "num_images_per_prompt",
+ }
+ test_attention_slicing = False
+ test_cpu_offload = False
+ batch_params = TOKENS_TO_AUDIO_GENERATION_PARAMS
+ params = TOKENS_TO_AUDIO_GENERATION_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ notes_encoder = SpectrogramNotesEncoder(
+ max_length=2048,
+ vocab_size=1536,
+ d_model=768,
+ dropout_rate=0.1,
+ num_layers=1,
+ num_heads=1,
+ d_kv=4,
+ d_ff=2048,
+ feed_forward_proj="gated-gelu",
+ )
+
+ continuous_encoder = SpectrogramContEncoder(
+ input_dims=128,
+ targets_context_length=256,
+ d_model=768,
+ dropout_rate=0.1,
+ num_layers=1,
+ num_heads=1,
+ d_kv=4,
+ d_ff=2048,
+ feed_forward_proj="gated-gelu",
+ )
+
+ decoder = T5FilmDecoder(
+ input_dims=128,
+ targets_length=256,
+ max_decoder_noise_time=20000.0,
+ d_model=768,
+ num_layers=1,
+ num_heads=1,
+ d_kv=4,
+ d_ff=2048,
+ dropout_rate=0.1,
+ )
+
+ scheduler = DDPMScheduler()
+
+ components = {
+ "notes_encoder": notes_encoder.eval(),
+ "continuous_encoder": continuous_encoder.eval(),
+ "decoder": decoder.eval(),
+ "scheduler": scheduler,
+ "melgan": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "input_tokens": [
+ [1134, 90, 1135, 1133, 1080, 112, 1132, 1080, 1133, 1079, 133, 1132, 1079, 1133, 1] + [0] * 2033
+ ],
+ "generator": generator,
+ "num_inference_steps": 4,
+ "output_type": "mel",
+ }
+ return inputs
+
+ def test_spectrogram_diffusion(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ pipe = SpectrogramDiffusionPipeline(**components)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = pipe(**inputs)
+ mel = output.audios
+
+ mel_slice = mel[0, -3:, -3:]
+
+ assert mel_slice.shape == (3, 3)
+ expected_slice = np.array(
+ [-11.512925, -4.788215, -0.46172905, -2.051715, -10.539147, -10.970963, -9.091634, 4.0, 4.0]
+ )
+ assert np.abs(mel_slice.flatten() - expected_slice).max() < 1e-2
+
+ @skip_mps
+ def test_save_load_local(self):
+ return super().test_save_load_local()
+
+ @skip_mps
+ def test_dict_tuple_outputs_equivalent(self):
+ return super().test_dict_tuple_outputs_equivalent()
+
+ @skip_mps
+ def test_save_load_optional_components(self):
+ return super().test_save_load_optional_components()
+
+ @skip_mps
+ def test_attention_slicing_forward_pass(self):
+ return super().test_attention_slicing_forward_pass()
+
+ def test_inference_batch_single_identical(self):
+ pass
+
+ def test_inference_batch_consistent(self):
+ pass
+
+ @skip_mps
+ def test_progress_bar(self):
+ return super().test_progress_bar()
+
+
+@slow
+@require_torch_gpu
+@require_onnxruntime
+@require_note_seq
+class PipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_callback(self):
+ # TODO - test that pipeline can decode tokens in a callback
+ # so that music can be played live
+ device = torch_device
+
+ pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
+ melgan = pipe.melgan
+ pipe.melgan = None
+
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ def callback(step, mel_output):
+ # decode mel to audio
+ audio = melgan(input_features=mel_output.astype(np.float32))[0]
+ assert len(audio[0]) == 81920 * (step + 1)
+ # simulate that audio is played
+ return audio
+
+ processor = MidiProcessor()
+ input_tokens = processor(MIDI_FILE)
+
+ input_tokens = input_tokens[:3]
+ generator = torch.manual_seed(0)
+ pipe(input_tokens, num_inference_steps=5, generator=generator, callback=callback, output_type="mel")
+
+ def test_spectrogram_fast(self):
+ device = torch_device
+
+ pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+ processor = MidiProcessor()
+
+ input_tokens = processor(MIDI_FILE)
+ # just run two denoising loops
+ input_tokens = input_tokens[:2]
+
+ generator = torch.manual_seed(0)
+ output = pipe(input_tokens, num_inference_steps=2, generator=generator)
+
+ audio = output.audios[0]
+
+ assert abs(np.abs(audio).sum() - 3612.841) < 1e-1
+
+ def test_spectrogram(self):
+ device = torch_device
+
+ pipe = SpectrogramDiffusionPipeline.from_pretrained("google/music-spectrogram-diffusion")
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ processor = MidiProcessor()
+
+ input_tokens = processor(MIDI_FILE)
+
+ # just run 4 denoising loops
+ input_tokens = input_tokens[:4]
+
+ generator = torch.manual_seed(0)
+ output = pipe(input_tokens, num_inference_steps=100, generator=generator)
+
+ audio = output.audios[0]
+ assert abs(np.abs(audio).sum() - 9389.1111) < 5e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion/__init__.py b/diffusers/tests/pipelines/stable_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_cycle_diffusion.py b/diffusers/tests/pipelines/stable_diffusion/test_cycle_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..5282cfd8dd2472ca8bf1bb785c6ee69268d4be52
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_cycle_diffusion.py
@@ -0,0 +1,268 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import AutoencoderKL, CycleDiffusionPipeline, DDIMScheduler, UNet2DConditionModel
+from diffusers.utils import floats_tensor, load_image, load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu, skip_mps
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS, TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class CycleDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = CycleDiffusionPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {
+ "negative_prompt",
+ "height",
+ "width",
+ "negative_prompt_embeds",
+ }
+ required_optional_params = PipelineTesterMixin.required_optional_params - {"latents"}
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS.union({"source_prompt"})
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ num_train_timesteps=1000,
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "An astronaut riding an elephant",
+ "source_prompt": "An astronaut riding a horse",
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "eta": 0.1,
+ "strength": 0.8,
+ "guidance_scale": 3,
+ "source_guidance_scale": 1,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_cycle(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ pipe = CycleDiffusionPipeline(**components)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = pipe(**inputs)
+ images = output.images
+
+ image_slice = images[0, -3:, -3:, -1]
+
+ assert images.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.4459, 0.4943, 0.4544, 0.6643, 0.5474, 0.4327, 0.5701, 0.5959, 0.5179])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
+ def test_stable_diffusion_cycle_fp16(self):
+ components = self.get_dummy_components()
+ for name, module in components.items():
+ if hasattr(module, "half"):
+ components[name] = module.half()
+ pipe = CycleDiffusionPipeline(**components)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)
+ images = output.images
+
+ image_slice = images[0, -3:, -3:, -1]
+
+ assert images.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.3506, 0.4543, 0.446, 0.4575, 0.5195, 0.4155, 0.5273, 0.518, 0.4116])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ @skip_mps
+ def test_save_load_local(self):
+ return super().test_save_load_local()
+
+ @unittest.skip("non-deterministic pipeline")
+ def test_inference_batch_single_identical(self):
+ return super().test_inference_batch_single_identical()
+
+ @skip_mps
+ def test_dict_tuple_outputs_equivalent(self):
+ return super().test_dict_tuple_outputs_equivalent()
+
+ @skip_mps
+ def test_save_load_optional_components(self):
+ return super().test_save_load_optional_components()
+
+ @skip_mps
+ def test_attention_slicing_forward_pass(self):
+ return super().test_attention_slicing_forward_pass()
+
+
+@slow
+@require_torch_gpu
+class CycleDiffusionPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_cycle_diffusion_pipeline_fp16(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/cycle-diffusion/black_colored_car.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/cycle-diffusion/blue_colored_car_fp16.npy"
+ )
+ init_image = init_image.resize((512, 512))
+
+ model_id = "CompVis/stable-diffusion-v1-4"
+ scheduler = DDIMScheduler.from_pretrained(model_id, subfolder="scheduler")
+ pipe = CycleDiffusionPipeline.from_pretrained(
+ model_id, scheduler=scheduler, safety_checker=None, torch_dtype=torch.float16, revision="fp16"
+ )
+
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ source_prompt = "A black colored car"
+ prompt = "A blue colored car"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ source_prompt=source_prompt,
+ image=init_image,
+ num_inference_steps=100,
+ eta=0.1,
+ strength=0.85,
+ guidance_scale=3,
+ source_guidance_scale=1,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images
+
+ # the values aren't exactly equal, but the images look the same visually
+ assert np.abs(image - expected_image).max() < 5e-1
+
+ def test_cycle_diffusion_pipeline(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/cycle-diffusion/black_colored_car.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/cycle-diffusion/blue_colored_car.npy"
+ )
+ init_image = init_image.resize((512, 512))
+
+ model_id = "CompVis/stable-diffusion-v1-4"
+ scheduler = DDIMScheduler.from_pretrained(model_id, subfolder="scheduler")
+ pipe = CycleDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, safety_checker=None)
+
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ source_prompt = "A black colored car"
+ prompt = "A blue colored car"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ source_prompt=source_prompt,
+ image=init_image,
+ num_inference_steps=100,
+ eta=0.1,
+ strength=0.85,
+ guidance_scale=3,
+ source_guidance_scale=1,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images
+
+ assert np.abs(image - expected_image).max() < 1e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion.py b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..74783faae421cb0a10a89fda4f19454f4cf834a8
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion.py
@@ -0,0 +1,306 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import tempfile
+import unittest
+
+import numpy as np
+
+from diffusers import (
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ LMSDiscreteScheduler,
+ OnnxStableDiffusionPipeline,
+ PNDMScheduler,
+)
+from diffusers.utils.testing_utils import is_onnx_available, nightly, require_onnxruntime, require_torch_gpu
+
+from ...test_pipelines_onnx_common import OnnxPipelineTesterMixin
+
+
+if is_onnx_available():
+ import onnxruntime as ort
+
+
+class OnnxStableDiffusionPipelineFastTests(OnnxPipelineTesterMixin, unittest.TestCase):
+ hub_checkpoint = "hf-internal-testing/tiny-random-OnnxStableDiffusionPipeline"
+
+ def get_dummy_inputs(self, seed=0):
+ generator = np.random.RandomState(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_pipeline_default_ddim(self):
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.65072, 0.58492, 0.48219, 0.55521, 0.53180, 0.55939, 0.50697, 0.39800, 0.46455])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_pipeline_pndm(self):
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config, skip_prk_steps=True)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.65863, 0.59425, 0.49326, 0.56313, 0.53875, 0.56627, 0.51065, 0.39777, 0.46330])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_pipeline_lms(self):
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.53755, 0.60786, 0.47402, 0.49488, 0.51869, 0.49819, 0.47985, 0.38957, 0.44279])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_pipeline_euler(self):
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.53755, 0.60786, 0.47402, 0.49488, 0.51869, 0.49819, 0.47985, 0.38957, 0.44279])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_pipeline_euler_ancestral(self):
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.53817, 0.60812, 0.47384, 0.49530, 0.51894, 0.49814, 0.47984, 0.38958, 0.44271])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_pipeline_dpm_multistep(self):
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.53895, 0.60808, 0.47933, 0.49608, 0.51886, 0.49950, 0.48053, 0.38957, 0.44200])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+
+@nightly
+@require_onnxruntime
+@require_torch_gpu
+class OnnxStableDiffusionPipelineIntegrationTests(unittest.TestCase):
+ @property
+ def gpu_provider(self):
+ return (
+ "CUDAExecutionProvider",
+ {
+ "gpu_mem_limit": "15000000000", # 15GB
+ "arena_extend_strategy": "kSameAsRequested",
+ },
+ )
+
+ @property
+ def gpu_options(self):
+ options = ort.SessionOptions()
+ options.enable_mem_pattern = False
+ return options
+
+ def test_inference_default_pndm(self):
+ # using the PNDM scheduler by default
+ sd_pipe = OnnxStableDiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ revision="onnx",
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ np.random.seed(0)
+ output = sd_pipe([prompt], guidance_scale=6.0, num_inference_steps=10, output_type="np")
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.0452, 0.0390, 0.0087, 0.0350, 0.0617, 0.0364, 0.0544, 0.0523, 0.0720])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_inference_ddim(self):
+ ddim_scheduler = DDIMScheduler.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", subfolder="scheduler", revision="onnx"
+ )
+ sd_pipe = OnnxStableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ revision="onnx",
+ scheduler=ddim_scheduler,
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "open neural network exchange"
+ generator = np.random.RandomState(0)
+ output = sd_pipe([prompt], guidance_scale=7.5, num_inference_steps=10, generator=generator, output_type="np")
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.2867, 0.1974, 0.1481, 0.7294, 0.7251, 0.6667, 0.4194, 0.5642, 0.6486])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_inference_k_lms(self):
+ lms_scheduler = LMSDiscreteScheduler.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", subfolder="scheduler", revision="onnx"
+ )
+ sd_pipe = OnnxStableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ revision="onnx",
+ scheduler=lms_scheduler,
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "open neural network exchange"
+ generator = np.random.RandomState(0)
+ output = sd_pipe([prompt], guidance_scale=7.5, num_inference_steps=10, generator=generator, output_type="np")
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.2306, 0.1959, 0.1593, 0.6549, 0.6394, 0.5408, 0.5065, 0.6010, 0.6161])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_intermediate_state(self):
+ number_of_steps = 0
+
+ def test_callback_fn(step: int, timestep: int, latents: np.ndarray) -> None:
+ test_callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 0:
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [-0.6772, -0.3835, -1.2456, 0.1905, -1.0974, 0.6967, -1.9353, 0.0178, 1.0167]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 1e-3
+ elif step == 5:
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [-0.3351, 0.2241, -0.1837, -0.2325, -0.6577, 0.3393, -0.0241, 0.5899, 1.3875]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 1e-3
+
+ test_callback_fn.has_been_called = False
+
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ revision="onnx",
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "Andromeda galaxy in a bottle"
+
+ generator = np.random.RandomState(0)
+ pipe(
+ prompt=prompt,
+ num_inference_steps=5,
+ guidance_scale=7.5,
+ generator=generator,
+ callback=test_callback_fn,
+ callback_steps=1,
+ )
+ assert test_callback_fn.has_been_called
+ assert number_of_steps == 6
+
+ def test_stable_diffusion_no_safety_checker(self):
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ revision="onnx",
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ assert isinstance(pipe, OnnxStableDiffusionPipeline)
+ assert pipe.safety_checker is None
+
+ image = pipe("example prompt", num_inference_steps=2).images[0]
+ assert image is not None
+
+ # check that there's no error when saving a pipeline with one of the models being None
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe = OnnxStableDiffusionPipeline.from_pretrained(tmpdirname)
+
+ # sanity check that the pipeline still works
+ assert pipe.safety_checker is None
+ image = pipe("example prompt", num_inference_steps=2).images[0]
+ assert image is not None
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_img2img.py b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1aa2f6dc0a1641f217f0b20ef93d2f82cf15140
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_img2img.py
@@ -0,0 +1,245 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import random
+import unittest
+
+import numpy as np
+
+from diffusers import (
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ LMSDiscreteScheduler,
+ OnnxStableDiffusionImg2ImgPipeline,
+ PNDMScheduler,
+)
+from diffusers.utils import floats_tensor
+from diffusers.utils.testing_utils import (
+ is_onnx_available,
+ load_image,
+ nightly,
+ require_onnxruntime,
+ require_torch_gpu,
+)
+
+from ...test_pipelines_onnx_common import OnnxPipelineTesterMixin
+
+
+if is_onnx_available():
+ import onnxruntime as ort
+
+
+class OnnxStableDiffusionImg2ImgPipelineFastTests(OnnxPipelineTesterMixin, unittest.TestCase):
+ hub_checkpoint = "hf-internal-testing/tiny-random-OnnxStableDiffusionPipeline"
+
+ def get_dummy_inputs(self, seed=0):
+ image = floats_tensor((1, 3, 128, 128), rng=random.Random(seed))
+ generator = np.random.RandomState(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "strength": 0.75,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_pipeline_default_ddim(self):
+ pipe = OnnxStableDiffusionImg2ImgPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.69643, 0.58484, 0.50314, 0.58760, 0.55368, 0.59643, 0.51529, 0.41217, 0.49087])
+ assert np.abs(image_slice - expected_slice).max() < 1e-1
+
+ def test_pipeline_pndm(self):
+ pipe = OnnxStableDiffusionImg2ImgPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config, skip_prk_steps=True)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.61737, 0.54642, 0.53183, 0.54465, 0.52742, 0.60525, 0.49969, 0.40655, 0.48154])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ def test_pipeline_lms(self):
+ pipe = OnnxStableDiffusionImg2ImgPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ # warmup pass to apply optimizations
+ _ = pipe(**self.get_dummy_inputs())
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.52761, 0.59977, 0.49033, 0.49619, 0.54282, 0.50311, 0.47600, 0.40918, 0.45203])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ def test_pipeline_euler(self):
+ pipe = OnnxStableDiffusionImg2ImgPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.52911, 0.60004, 0.49229, 0.49805, 0.54502, 0.50680, 0.47777, 0.41028, 0.45304])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ def test_pipeline_euler_ancestral(self):
+ pipe = OnnxStableDiffusionImg2ImgPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.52911, 0.60004, 0.49229, 0.49805, 0.54502, 0.50680, 0.47777, 0.41028, 0.45304])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ def test_pipeline_dpm_multistep(self):
+ pipe = OnnxStableDiffusionImg2ImgPipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 128, 128, 3)
+ expected_slice = np.array([0.65331, 0.58277, 0.48204, 0.56059, 0.53665, 0.56235, 0.50969, 0.40009, 0.46552])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+
+@nightly
+@require_onnxruntime
+@require_torch_gpu
+class OnnxStableDiffusionImg2ImgPipelineIntegrationTests(unittest.TestCase):
+ @property
+ def gpu_provider(self):
+ return (
+ "CUDAExecutionProvider",
+ {
+ "gpu_mem_limit": "15000000000", # 15GB
+ "arena_extend_strategy": "kSameAsRequested",
+ },
+ )
+
+ @property
+ def gpu_options(self):
+ options = ort.SessionOptions()
+ options.enable_mem_pattern = False
+ return options
+
+ def test_inference_default_pndm(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/img2img/sketch-mountains-input.jpg"
+ )
+ init_image = init_image.resize((768, 512))
+ # using the PNDM scheduler by default
+ pipe = OnnxStableDiffusionImg2ImgPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ revision="onnx",
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A fantasy landscape, trending on artstation"
+
+ generator = np.random.RandomState(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ strength=0.75,
+ guidance_scale=7.5,
+ num_inference_steps=10,
+ generator=generator,
+ output_type="np",
+ )
+ images = output.images
+ image_slice = images[0, 255:258, 383:386, -1]
+
+ assert images.shape == (1, 512, 768, 3)
+ expected_slice = np.array([0.4909, 0.5059, 0.5372, 0.4623, 0.4876, 0.5049, 0.4820, 0.4956, 0.5019])
+ # TODO: lower the tolerance after finding the cause of onnxruntime reproducibility issues
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 2e-2
+
+ def test_inference_k_lms(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/img2img/sketch-mountains-input.jpg"
+ )
+ init_image = init_image.resize((768, 512))
+ lms_scheduler = LMSDiscreteScheduler.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", subfolder="scheduler", revision="onnx"
+ )
+ pipe = OnnxStableDiffusionImg2ImgPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5",
+ revision="onnx",
+ scheduler=lms_scheduler,
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A fantasy landscape, trending on artstation"
+
+ generator = np.random.RandomState(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ strength=0.75,
+ guidance_scale=7.5,
+ num_inference_steps=20,
+ generator=generator,
+ output_type="np",
+ )
+ images = output.images
+ image_slice = images[0, 255:258, 383:386, -1]
+
+ assert images.shape == (1, 512, 768, 3)
+ expected_slice = np.array([0.8043, 0.926, 0.9581, 0.8119, 0.8954, 0.913, 0.7209, 0.7463, 0.7431])
+ # TODO: lower the tolerance after finding the cause of onnxruntime reproducibility issues
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 2e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_inpaint.py b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_inpaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..16287d64d154872f50b49b822daec79641f11f11
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_inpaint.py
@@ -0,0 +1,141 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+
+from diffusers import LMSDiscreteScheduler, OnnxStableDiffusionInpaintPipeline
+from diffusers.utils.testing_utils import (
+ is_onnx_available,
+ load_image,
+ nightly,
+ require_onnxruntime,
+ require_torch_gpu,
+)
+
+from ...test_pipelines_onnx_common import OnnxPipelineTesterMixin
+
+
+if is_onnx_available():
+ import onnxruntime as ort
+
+
+class OnnxStableDiffusionPipelineFastTests(OnnxPipelineTesterMixin, unittest.TestCase):
+ # FIXME: add fast tests
+ pass
+
+
+@nightly
+@require_onnxruntime
+@require_torch_gpu
+class OnnxStableDiffusionInpaintPipelineIntegrationTests(unittest.TestCase):
+ @property
+ def gpu_provider(self):
+ return (
+ "CUDAExecutionProvider",
+ {
+ "gpu_mem_limit": "15000000000", # 15GB
+ "arena_extend_strategy": "kSameAsRequested",
+ },
+ )
+
+ @property
+ def gpu_options(self):
+ options = ort.SessionOptions()
+ options.enable_mem_pattern = False
+ return options
+
+ def test_inference_default_pndm(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/in_paint/overture-creations-5sI6fQgYIuo.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/in_paint/overture-creations-5sI6fQgYIuo_mask.png"
+ )
+ pipe = OnnxStableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting",
+ revision="onnx",
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A red cat sitting on a park bench"
+
+ generator = np.random.RandomState(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ mask_image=mask_image,
+ guidance_scale=7.5,
+ num_inference_steps=10,
+ generator=generator,
+ output_type="np",
+ )
+ images = output.images
+ image_slice = images[0, 255:258, 255:258, -1]
+
+ assert images.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.2514, 0.3007, 0.3517, 0.1790, 0.2382, 0.3167, 0.1944, 0.2273, 0.2464])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_inference_k_lms(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/in_paint/overture-creations-5sI6fQgYIuo.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/in_paint/overture-creations-5sI6fQgYIuo_mask.png"
+ )
+ lms_scheduler = LMSDiscreteScheduler.from_pretrained(
+ "runwayml/stable-diffusion-inpainting", subfolder="scheduler", revision="onnx"
+ )
+ pipe = OnnxStableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting",
+ revision="onnx",
+ scheduler=lms_scheduler,
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A red cat sitting on a park bench"
+
+ generator = np.random.RandomState(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ mask_image=mask_image,
+ guidance_scale=7.5,
+ num_inference_steps=20,
+ generator=generator,
+ output_type="np",
+ )
+ images = output.images
+ image_slice = images[0, 255:258, 255:258, -1]
+
+ assert images.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.0086, 0.0077, 0.0083, 0.0093, 0.0107, 0.0139, 0.0094, 0.0097, 0.0125])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_inpaint_legacy.py b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_inpaint_legacy.py
new file mode 100644
index 0000000000000000000000000000000000000000..235aa32f7338579210520c675b3776b830cbe3da
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_inpaint_legacy.py
@@ -0,0 +1,97 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+
+from diffusers import OnnxStableDiffusionInpaintPipelineLegacy
+from diffusers.utils.testing_utils import (
+ is_onnx_available,
+ load_image,
+ load_numpy,
+ nightly,
+ require_onnxruntime,
+ require_torch_gpu,
+)
+
+
+if is_onnx_available():
+ import onnxruntime as ort
+
+
+@nightly
+@require_onnxruntime
+@require_torch_gpu
+class StableDiffusionOnnxInpaintLegacyPipelineIntegrationTests(unittest.TestCase):
+ @property
+ def gpu_provider(self):
+ return (
+ "CUDAExecutionProvider",
+ {
+ "gpu_mem_limit": "15000000000", # 15GB
+ "arena_extend_strategy": "kSameAsRequested",
+ },
+ )
+
+ @property
+ def gpu_options(self):
+ options = ort.SessionOptions()
+ options.enable_mem_pattern = False
+ return options
+
+ def test_inference(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/in_paint/overture-creations-5sI6fQgYIuo.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/in_paint/overture-creations-5sI6fQgYIuo_mask.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/in_paint/red_cat_sitting_on_a_park_bench_onnx.npy"
+ )
+
+ # using the PNDM scheduler by default
+ pipe = OnnxStableDiffusionInpaintPipelineLegacy.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ revision="onnx",
+ safety_checker=None,
+ feature_extractor=None,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A red cat sitting on a park bench"
+
+ generator = np.random.RandomState(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ mask_image=mask_image,
+ strength=0.75,
+ guidance_scale=7.5,
+ num_inference_steps=15,
+ generator=generator,
+ output_type="np",
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+ assert np.abs(expected_image - image).max() < 1e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_upscale.py b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..d1527a42a1e56b3de663c596a8457fab5006bfb2
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_onnx_stable_diffusion_upscale.py
@@ -0,0 +1,232 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import random
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import (
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ LMSDiscreteScheduler,
+ OnnxStableDiffusionUpscalePipeline,
+ PNDMScheduler,
+)
+from diffusers.utils import floats_tensor
+from diffusers.utils.testing_utils import (
+ is_onnx_available,
+ load_image,
+ nightly,
+ require_onnxruntime,
+ require_torch_gpu,
+)
+
+from ...test_pipelines_onnx_common import OnnxPipelineTesterMixin
+
+
+if is_onnx_available():
+ import onnxruntime as ort
+
+
+class OnnxStableDiffusionUpscalePipelineFastTests(OnnxPipelineTesterMixin, unittest.TestCase):
+ # TODO: is there an appropriate internal test set?
+ hub_checkpoint = "ssube/stable-diffusion-x4-upscaler-onnx"
+
+ def get_dummy_inputs(self, seed=0):
+ image = floats_tensor((1, 3, 128, 128), rng=random.Random(seed))
+ generator = torch.manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_pipeline_default_ddpm(self):
+ pipe = OnnxStableDiffusionUpscalePipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ # started as 128, should now be 512
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array(
+ [0.6974782, 0.68902093, 0.70135885, 0.7583618, 0.7804545, 0.7854912, 0.78667426, 0.78743863, 0.78070223]
+ )
+ assert np.abs(image_slice - expected_slice).max() < 1e-1
+
+ def test_pipeline_pndm(self):
+ pipe = OnnxStableDiffusionUpscalePipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config, skip_prk_steps=True)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array(
+ [0.6898892, 0.59240556, 0.52499527, 0.58866215, 0.52258235, 0.52572715, 0.62414473, 0.6174387, 0.6214964]
+ )
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ def test_pipeline_dpm_multistep(self):
+ pipe = OnnxStableDiffusionUpscalePipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array(
+ [0.7659278, 0.76437664, 0.75579107, 0.7691116, 0.77666986, 0.7727672, 0.7758664, 0.7812226, 0.76942515]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ def test_pipeline_euler(self):
+ pipe = OnnxStableDiffusionUpscalePipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array(
+ [0.6974782, 0.68902093, 0.70135885, 0.7583618, 0.7804545, 0.7854912, 0.78667426, 0.78743863, 0.78070223]
+ )
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ def test_pipeline_euler_ancestral(self):
+ pipe = OnnxStableDiffusionUpscalePipeline.from_pretrained(self.hub_checkpoint, provider="CPUExecutionProvider")
+ pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array(
+ [0.77424496, 0.773601, 0.7645288, 0.7769598, 0.7772739, 0.7738688, 0.78187233, 0.77879584, 0.767043]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+
+@nightly
+@require_onnxruntime
+@require_torch_gpu
+class OnnxStableDiffusionUpscalePipelineIntegrationTests(unittest.TestCase):
+ @property
+ def gpu_provider(self):
+ return (
+ "CUDAExecutionProvider",
+ {
+ "gpu_mem_limit": "15000000000", # 15GB
+ "arena_extend_strategy": "kSameAsRequested",
+ },
+ )
+
+ @property
+ def gpu_options(self):
+ options = ort.SessionOptions()
+ options.enable_mem_pattern = False
+ return options
+
+ def test_inference_default_ddpm(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/img2img/sketch-mountains-input.jpg"
+ )
+ init_image = init_image.resize((128, 128))
+ # using the PNDM scheduler by default
+ pipe = OnnxStableDiffusionUpscalePipeline.from_pretrained(
+ "ssube/stable-diffusion-x4-upscaler-onnx",
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A fantasy landscape, trending on artstation"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ guidance_scale=7.5,
+ num_inference_steps=10,
+ generator=generator,
+ output_type="np",
+ )
+ images = output.images
+ image_slice = images[0, 255:258, 383:386, -1]
+
+ assert images.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.4883, 0.4947, 0.4980, 0.4975, 0.4982, 0.4980, 0.5000, 0.5006, 0.4972])
+ # TODO: lower the tolerance after finding the cause of onnxruntime reproducibility issues
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 2e-2
+
+ def test_inference_k_lms(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/img2img/sketch-mountains-input.jpg"
+ )
+ init_image = init_image.resize((128, 128))
+ lms_scheduler = LMSDiscreteScheduler.from_pretrained(
+ "ssube/stable-diffusion-x4-upscaler-onnx", subfolder="scheduler"
+ )
+ pipe = OnnxStableDiffusionUpscalePipeline.from_pretrained(
+ "ssube/stable-diffusion-x4-upscaler-onnx",
+ scheduler=lms_scheduler,
+ provider=self.gpu_provider,
+ sess_options=self.gpu_options,
+ )
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A fantasy landscape, trending on artstation"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ guidance_scale=7.5,
+ num_inference_steps=20,
+ generator=generator,
+ output_type="np",
+ )
+ images = output.images
+ image_slice = images[0, 255:258, 383:386, -1]
+
+ assert images.shape == (1, 512, 512, 3)
+ expected_slice = np.array(
+ [0.50173753, 0.50223356, 0.502039, 0.50233036, 0.5023725, 0.5022601, 0.5018758, 0.50234085, 0.50241566]
+ )
+ # TODO: lower the tolerance after finding the cause of onnxruntime reproducibility issues
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 2e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..857122782d354cd5fcd5b69daf2f601be799c5d1
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion.py
@@ -0,0 +1,1025 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import gc
+import tempfile
+import time
+import unittest
+
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+ logging,
+)
+from diffusers.utils import load_numpy, nightly, slow, torch_device
+from diffusers.utils.testing_utils import CaptureLogger, require_torch_gpu
+
+from ...models.test_models_unet_2d_condition import create_lora_layers
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_ddim(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs)
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5643, 0.6017, 0.4799, 0.5267, 0.5584, 0.4641, 0.5159, 0.4963, 0.4791])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_lora(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ # forward 1
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ # set lora layers
+ lora_attn_procs = create_lora_layers(sd_pipe.unet)
+ sd_pipe.unet.set_attn_processor(lora_attn_procs)
+ sd_pipe = sd_pipe.to(torch_device)
+
+ # forward 2
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs, cross_attention_kwargs={"scale": 0.0})
+ image = output.images
+ image_slice_1 = image[0, -3:, -3:, -1]
+
+ # forward 3
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs, cross_attention_kwargs={"scale": 0.5})
+ image = output.images
+ image_slice_2 = image[0, -3:, -3:, -1]
+
+ assert np.abs(image_slice - image_slice_1).max() < 1e-2
+ assert np.abs(image_slice - image_slice_2).max() > 1e-2
+
+ def test_stable_diffusion_prompt_embeds(self):
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ inputs["prompt"] = 3 * [inputs["prompt"]]
+
+ # forward
+ output = sd_pipe(**inputs)
+ image_slice_1 = output.images[0, -3:, -3:, -1]
+
+ inputs = self.get_dummy_inputs(torch_device)
+ prompt = 3 * [inputs.pop("prompt")]
+
+ text_inputs = sd_pipe.tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=sd_pipe.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_inputs = text_inputs["input_ids"].to(torch_device)
+
+ prompt_embeds = sd_pipe.text_encoder(text_inputs)[0]
+
+ inputs["prompt_embeds"] = prompt_embeds
+
+ # forward
+ output = sd_pipe(**inputs)
+ image_slice_2 = output.images[0, -3:, -3:, -1]
+
+ assert np.abs(image_slice_1.flatten() - image_slice_2.flatten()).max() < 1e-4
+
+ def test_stable_diffusion_negative_prompt_embeds(self):
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ negative_prompt = 3 * ["this is a negative prompt"]
+ inputs["negative_prompt"] = negative_prompt
+ inputs["prompt"] = 3 * [inputs["prompt"]]
+
+ # forward
+ output = sd_pipe(**inputs)
+ image_slice_1 = output.images[0, -3:, -3:, -1]
+
+ inputs = self.get_dummy_inputs(torch_device)
+ prompt = 3 * [inputs.pop("prompt")]
+
+ embeds = []
+ for p in [prompt, negative_prompt]:
+ text_inputs = sd_pipe.tokenizer(
+ p,
+ padding="max_length",
+ max_length=sd_pipe.tokenizer.model_max_length,
+ truncation=True,
+ return_tensors="pt",
+ )
+ text_inputs = text_inputs["input_ids"].to(torch_device)
+
+ embeds.append(sd_pipe.text_encoder(text_inputs)[0])
+
+ inputs["prompt_embeds"], inputs["negative_prompt_embeds"] = embeds
+
+ # forward
+ output = sd_pipe(**inputs)
+ image_slice_2 = output.images[0, -3:, -3:, -1]
+
+ assert np.abs(image_slice_1.flatten() - image_slice_2.flatten()).max() < 1e-4
+
+ def test_stable_diffusion_ddim_factor_8(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs, height=136, width=136)
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 136, 136, 3)
+ expected_slice = np.array([0.5524, 0.5626, 0.6069, 0.4727, 0.386, 0.3995, 0.4613, 0.4328, 0.4269])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_pndm(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe.scheduler = PNDMScheduler(skip_prk_steps=True)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5094, 0.5674, 0.4667, 0.5125, 0.5696, 0.4674, 0.5277, 0.4964, 0.4945])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_no_safety_checker(self):
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-lms-pipe", safety_checker=None
+ )
+ assert isinstance(pipe, StableDiffusionPipeline)
+ assert isinstance(pipe.scheduler, LMSDiscreteScheduler)
+ assert pipe.safety_checker is None
+
+ image = pipe("example prompt", num_inference_steps=2).images[0]
+ assert image is not None
+
+ # check that there's no error when saving a pipeline with one of the models being None
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe = StableDiffusionPipeline.from_pretrained(tmpdirname)
+
+ # sanity check that the pipeline still works
+ assert pipe.safety_checker is None
+ image = pipe("example prompt", num_inference_steps=2).images[0]
+ assert image is not None
+
+ def test_stable_diffusion_k_lms(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array(
+ [
+ 0.47082293033599854,
+ 0.5371589064598083,
+ 0.4562119245529175,
+ 0.5220914483070374,
+ 0.5733777284622192,
+ 0.4795039892196655,
+ 0.5465868711471558,
+ 0.5074326395988464,
+ 0.5042197108268738,
+ ]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_k_euler_ancestral(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array(
+ [
+ 0.4707113206386566,
+ 0.5372191071510315,
+ 0.4563021957874298,
+ 0.5220003724098206,
+ 0.5734264850616455,
+ 0.4794946610927582,
+ 0.5463782548904419,
+ 0.5074145197868347,
+ 0.504422664642334,
+ ]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_k_euler(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe.scheduler = EulerDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array(
+ [
+ 0.47082313895225525,
+ 0.5371587872505188,
+ 0.4562119245529175,
+ 0.5220913887023926,
+ 0.5733776688575745,
+ 0.47950395941734314,
+ 0.546586811542511,
+ 0.5074326992034912,
+ 0.5042197108268738,
+ ]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_vae_slicing(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = LMSDiscreteScheduler.from_config(components["scheduler"].config)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ image_count = 4
+
+ inputs = self.get_dummy_inputs(device)
+ inputs["prompt"] = [inputs["prompt"]] * image_count
+ output_1 = sd_pipe(**inputs)
+
+ # make sure sliced vae decode yields the same result
+ sd_pipe.enable_vae_slicing()
+ inputs = self.get_dummy_inputs(device)
+ inputs["prompt"] = [inputs["prompt"]] * image_count
+ output_2 = sd_pipe(**inputs)
+
+ # there is a small discrepancy at image borders vs. full batch decode
+ assert np.abs(output_2.images.flatten() - output_1.images.flatten()).max() < 3e-3
+
+ def test_stable_diffusion_vae_tiling(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+
+ # make sure here that pndm scheduler skips prk
+ components["safety_checker"] = None
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+
+ # Test that tiled decode at 512x512 yields the same result as the non-tiled decode
+ generator = torch.Generator(device=device).manual_seed(0)
+ output_1 = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
+
+ # make sure tiled vae decode yields the same result
+ sd_pipe.enable_vae_tiling()
+ generator = torch.Generator(device=device).manual_seed(0)
+ output_2 = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
+
+ assert np.abs(output_2.images.flatten() - output_1.images.flatten()).max() < 5e-1
+
+ # test that tiled decode works with various shapes
+ shapes = [(1, 4, 73, 97), (1, 4, 97, 73), (1, 4, 49, 65), (1, 4, 65, 49)]
+ for shape in shapes:
+ zeros = torch.zeros(shape).to(device)
+ sd_pipe.vae.decode(zeros)
+
+ def test_stable_diffusion_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = PNDMScheduler(skip_prk_steps=True)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ negative_prompt = "french fries"
+ output = sd_pipe(**inputs, negative_prompt=negative_prompt)
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array(
+ [
+ 0.5108221173286438,
+ 0.5688379406929016,
+ 0.4685141146183014,
+ 0.5098261833190918,
+ 0.5657756328582764,
+ 0.4631010890007019,
+ 0.5226285457611084,
+ 0.49129390716552734,
+ 0.4899061322212219,
+ ]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_long_prompt(self):
+ components = self.get_dummy_components()
+ components["scheduler"] = LMSDiscreteScheduler.from_config(components["scheduler"].config)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ do_classifier_free_guidance = True
+ negative_prompt = None
+ num_images_per_prompt = 1
+ logger = logging.get_logger("diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion")
+
+ prompt = 25 * "@"
+ with CaptureLogger(logger) as cap_logger_3:
+ text_embeddings_3 = sd_pipe._encode_prompt(
+ prompt, torch_device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ prompt = 100 * "@"
+ with CaptureLogger(logger) as cap_logger:
+ text_embeddings = sd_pipe._encode_prompt(
+ prompt, torch_device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ negative_prompt = "Hello"
+ with CaptureLogger(logger) as cap_logger_2:
+ text_embeddings_2 = sd_pipe._encode_prompt(
+ prompt, torch_device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ assert text_embeddings_3.shape == text_embeddings_2.shape == text_embeddings.shape
+ assert text_embeddings.shape[1] == 77
+
+ assert cap_logger.out == cap_logger_2.out
+ # 100 - 77 + 1 (BOS token) + 1 (EOS token) = 25
+ assert cap_logger.out.count("@") == 25
+ assert cap_logger_3.out == ""
+
+ def test_stable_diffusion_height_width_opt(self):
+ components = self.get_dummy_components()
+ components["scheduler"] = LMSDiscreteScheduler.from_config(components["scheduler"].config)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "hey"
+
+ output = sd_pipe(prompt, num_inference_steps=1, output_type="np")
+ image_shape = output.images[0].shape[:2]
+ assert image_shape == (64, 64)
+
+ output = sd_pipe(prompt, num_inference_steps=1, height=96, width=96, output_type="np")
+ image_shape = output.images[0].shape[:2]
+ assert image_shape == (96, 96)
+
+ config = dict(sd_pipe.unet.config)
+ config["sample_size"] = 96
+ sd_pipe.unet = UNet2DConditionModel.from_config(config).to(torch_device)
+ output = sd_pipe(prompt, num_inference_steps=1, output_type="np")
+ image_shape = output.images[0].shape[:2]
+ assert image_shape == (192, 192)
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ latents = np.random.RandomState(seed).standard_normal((1, 4, 64, 64))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "prompt": "a photograph of an astronaut riding a horse",
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_1_1_pndm(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-1")
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.43625, 0.43554, 0.36670, 0.40660, 0.39703, 0.38658, 0.43936, 0.43557, 0.40592])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_1_4_pndm(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.57400, 0.47841, 0.31625, 0.63583, 0.58306, 0.55056, 0.50825, 0.56306, 0.55748])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_ddim(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None)
+ sd_pipe.scheduler = DDIMScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.38019, 0.28647, 0.27321, 0.40377, 0.38290, 0.35446, 0.39218, 0.38165, 0.42239])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_lms(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None)
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.10542, 0.09620, 0.07332, 0.09015, 0.09382, 0.07597, 0.08496, 0.07806, 0.06455])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_dpm(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None)
+ sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.03503, 0.03494, 0.01087, 0.03128, 0.02552, 0.00803, 0.00742, 0.00372, 0.00000])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_attention_slicing(self):
+ torch.cuda.reset_peak_memory_stats()
+ pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ # enable attention slicing
+ pipe.enable_attention_slicing()
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ image_sliced = pipe(**inputs).images
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+ # make sure that less than 3.75 GB is allocated
+ assert mem_bytes < 3.75 * 10**9
+
+ # disable slicing
+ pipe.disable_attention_slicing()
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ image = pipe(**inputs).images
+
+ # make sure that more than 3.75 GB is allocated
+ mem_bytes = torch.cuda.max_memory_allocated()
+ assert mem_bytes > 3.75 * 10**9
+ assert np.abs(image_sliced - image).max() < 1e-3
+
+ def test_stable_diffusion_vae_slicing(self):
+ torch.cuda.reset_peak_memory_stats()
+ pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ # enable vae slicing
+ pipe.enable_vae_slicing()
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ inputs["prompt"] = [inputs["prompt"]] * 4
+ inputs["latents"] = torch.cat([inputs["latents"]] * 4)
+ image_sliced = pipe(**inputs).images
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+ # make sure that less than 4 GB is allocated
+ assert mem_bytes < 4e9
+
+ # disable vae slicing
+ pipe.disable_vae_slicing()
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ inputs["prompt"] = [inputs["prompt"]] * 4
+ inputs["latents"] = torch.cat([inputs["latents"]] * 4)
+ image = pipe(**inputs).images
+
+ # make sure that more than 4 GB is allocated
+ mem_bytes = torch.cuda.max_memory_allocated()
+ assert mem_bytes > 4e9
+ # There is a small discrepancy at the image borders vs. a fully batched version.
+ assert np.abs(image_sliced - image).max() < 1e-2
+
+ def test_stable_diffusion_vae_tiling(self):
+ torch.cuda.reset_peak_memory_stats()
+ model_id = "CompVis/stable-diffusion-v1-4"
+ pipe = StableDiffusionPipeline.from_pretrained(model_id, revision="fp16", torch_dtype=torch.float16)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+ pipe.unet = pipe.unet.to(memory_format=torch.channels_last)
+ pipe.vae = pipe.vae.to(memory_format=torch.channels_last)
+
+ prompt = "a photograph of an astronaut riding a horse"
+
+ # enable vae tiling
+ pipe.enable_vae_tiling()
+ pipe.enable_model_cpu_offload()
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ output_chunked = pipe(
+ [prompt],
+ width=1024,
+ height=1024,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=2,
+ output_type="numpy",
+ )
+ image_chunked = output_chunked.images
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+
+ # disable vae tiling
+ pipe.disable_vae_tiling()
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ output = pipe(
+ [prompt],
+ width=1024,
+ height=1024,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=2,
+ output_type="numpy",
+ )
+ image = output.images
+
+ assert mem_bytes < 1e10
+ assert np.abs(image_chunked.flatten() - image.flatten()).max() < 1e-2
+
+ def test_stable_diffusion_fp16_vs_autocast(self):
+ # this test makes sure that the original model with autocast
+ # and the new model with fp16 yield the same result
+ pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ image_fp16 = pipe(**inputs).images
+
+ with torch.autocast(torch_device):
+ inputs = self.get_inputs(torch_device)
+ image_autocast = pipe(**inputs).images
+
+ # Make sure results are close enough
+ diff = np.abs(image_fp16.flatten() - image_autocast.flatten())
+ # They ARE different since ops are not run always at the same precision
+ # however, they should be extremely close.
+ assert diff.mean() < 2e-2
+
+ def test_stable_diffusion_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [-0.5693, -0.3018, -0.9746, 0.0518, -0.8770, 0.7559, -1.7402, 0.1022, 1.1582]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [-0.1958, -0.2993, -1.0166, -0.5005, -0.4810, 0.6162, -0.9492, 0.6621, 1.4492]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ callback_fn.has_been_called = False
+
+ pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == inputs["num_inference_steps"]
+
+ def test_stable_diffusion_low_cpu_mem_usage(self):
+ pipeline_id = "CompVis/stable-diffusion-v1-4"
+
+ start_time = time.time()
+ pipeline_low_cpu_mem_usage = StableDiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16)
+ pipeline_low_cpu_mem_usage.to(torch_device)
+ low_cpu_mem_usage_time = time.time() - start_time
+
+ start_time = time.time()
+ _ = StableDiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16, low_cpu_mem_usage=False)
+ normal_load_time = time.time() - start_time
+
+ assert 2 * low_cpu_mem_usage_time < normal_load_time
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.8 GB is allocated
+ assert mem_bytes < 2.8 * 10**9
+
+ def test_stable_diffusion_pipeline_with_model_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+
+ # Normal inference
+
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ torch_dtype=torch.float16,
+ )
+ pipe.unet.set_default_attn_processor()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ outputs = pipe(**inputs)
+ mem_bytes = torch.cuda.max_memory_allocated()
+
+ # With model offloading
+
+ # Reload but don't move to cuda
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ torch_dtype=torch.float16,
+ )
+ pipe.unet.set_default_attn_processor()
+
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+
+ outputs_offloaded = pipe(**inputs)
+ mem_bytes_offloaded = torch.cuda.max_memory_allocated()
+
+ assert np.abs(outputs.images - outputs_offloaded.images).max() < 1e-3
+ assert mem_bytes_offloaded < mem_bytes
+ assert mem_bytes_offloaded < 3.5 * 10**9
+ for module in pipe.text_encoder, pipe.unet, pipe.vae, pipe.safety_checker:
+ assert module.device == torch.device("cpu")
+
+ # With attention slicing
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe.enable_attention_slicing()
+ _ = pipe(**inputs)
+ mem_bytes_slicing = torch.cuda.max_memory_allocated()
+
+ assert mem_bytes_slicing < mem_bytes_offloaded
+ assert mem_bytes_slicing < 3 * 10**9
+
+ def test_stable_diffusion_textual_inversion(self):
+ pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+ pipe.load_textual_inversion("sd-concepts-library/low-poly-hd-logos-icons")
+
+ a111_file = hf_hub_download("hf-internal-testing/text_inv_embedding_a1111_format", "winter_style.pt")
+ a111_file_neg = hf_hub_download(
+ "hf-internal-testing/text_inv_embedding_a1111_format", "winter_style_negative.pt"
+ )
+ pipe.load_textual_inversion(a111_file)
+ pipe.load_textual_inversion(a111_file_neg)
+ pipe.to("cuda")
+
+ generator = torch.Generator(device="cpu").manual_seed(1)
+
+ prompt = "An logo of a turtle in strong Style-Winter with "
+ neg_prompt = "Style-Winter-neg"
+
+ image = pipe(prompt=prompt, negative_prompt=neg_prompt, generator=generator, output_type="np").images[0]
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/text_inv/winter_logo_style.npy"
+ )
+
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 5e-2
+
+
+@nightly
+@require_torch_gpu
+class StableDiffusionPipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ latents = np.random.RandomState(seed).standard_normal((1, 4, 64, 64))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "prompt": "a photograph of an astronaut riding a horse",
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 50,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_1_4_pndm(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4").to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_text2img/stable_diffusion_1_4_pndm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_1_5_pndm(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5").to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_text2img/stable_diffusion_1_5_pndm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_ddim(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4").to(torch_device)
+ sd_pipe.scheduler = DDIMScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_text2img/stable_diffusion_1_4_ddim.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_lms(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4").to(torch_device)
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_text2img/stable_diffusion_1_4_lms.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_euler(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4").to(torch_device)
+ sd_pipe.scheduler = EulerDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_text2img/stable_diffusion_1_4_euler.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_dpm(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4").to(torch_device)
+ sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ inputs["num_inference_steps"] = 25
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_text2img/stable_diffusion_1_4_dpm_multi.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..d556e6318f430d2761bb2ef02556b5bf0d1fcb88
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_controlnet.py
@@ -0,0 +1,594 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ ControlNetModel,
+ DDIMScheduler,
+ StableDiffusionControlNetPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_controlnet import MultiControlNetModel
+from diffusers.utils import load_image, load_numpy, randn_tensor, slow, torch_device
+from diffusers.utils.import_utils import is_xformers_available
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+class StableDiffusionControlNetPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+ image = randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ )
+
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": image,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+
+class StableDiffusionMultiControlNetPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionControlNetPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ torch.manual_seed(0)
+ controlnet1 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ controlnet2 = ControlNetModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ in_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ cross_attention_dim=32,
+ conditioning_embedding_out_channels=(16, 32),
+ )
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ controlnet = MultiControlNetModel([controlnet1, controlnet2])
+
+ components = {
+ "unet": unet,
+ "controlnet": controlnet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ controlnet_embedder_scale_factor = 2
+
+ images = [
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ randn_tensor(
+ (1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
+ generator=generator,
+ device=torch.device(device),
+ ),
+ ]
+
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "image": images,
+ }
+
+ return inputs
+
+ def test_attention_slicing_forward_pass(self):
+ return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(expected_max_diff=2e-3)
+
+ def test_save_pretrained_raise_not_implemented_exception(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ with tempfile.TemporaryDirectory() as tmpdir:
+ try:
+ # save_pretrained is not implemented for Multi-ControlNet
+ pipe.save_pretrained(tmpdir)
+ except NotImplementedError:
+ pass
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_float16(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_local(self):
+ ...
+
+ # override PipelineTesterMixin
+ @unittest.skip("save pretrained not implemented")
+ def test_save_load_optional_components(self):
+ ...
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionControlNetPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_canny(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "bird"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
+ )
+
+ output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (768, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-3
+
+ def test_depth(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-depth")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "Stormtrooper's lecture"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/stormtrooper_depth.png"
+ )
+
+ output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/stormtrooper_depth_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-3
+
+ def test_hed(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-hed")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "oil painting of handsome old man, masterpiece"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/man_hed.png"
+ )
+
+ output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (704, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/man_hed_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-3
+
+ def test_mlsd(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-mlsd")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "room"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/room_mlsd.png"
+ )
+
+ output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (704, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/room_mlsd_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-3
+
+ def test_normal(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-normal")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "cute toy"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/cute_toy_normal.png"
+ )
+
+ output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/cute_toy_normal_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-3
+
+ def test_openpose(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "Chef in the kitchen"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/pose.png"
+ )
+
+ output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (768, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/chef_pose_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-3
+
+ def test_scribble(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-scribble")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(5)
+ prompt = "bag"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bag_scribble.png"
+ )
+
+ output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (640, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bag_scribble_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-3
+
+ def test_seg(self):
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-seg")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(5)
+ prompt = "house"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/house_seg.png"
+ )
+
+ output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/house_seg_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-3
+
+ def test_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-seg")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
+ )
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+ pipe.enable_sequential_cpu_offload()
+
+ prompt = "house"
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/house_seg.png"
+ )
+
+ _ = pipe(
+ prompt,
+ image,
+ num_inference_steps=2,
+ output_type="np",
+ )
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 7 GB is allocated
+ assert mem_bytes < 4 * 10**9
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionMultiControlNetPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_pose_and_canny(self):
+ controlnet_canny = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
+ controlnet_pose = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose")
+
+ pipe = StableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=[controlnet_pose, controlnet_canny]
+ )
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ prompt = "bird and Chef"
+ image_canny = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
+ )
+ image_pose = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/pose.png"
+ )
+
+ output = pipe(prompt, [image_pose, image_canny], generator=generator, output_type="np", num_inference_steps=3)
+
+ image = output.images[0]
+
+ assert image.shape == (768, 512, 3)
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/pose_canny_out.npy"
+ )
+
+ assert np.abs(expected_image - image).max() < 5e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..268c013201775c8c78960960669ace207670fd51
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_flax_controlnet.py
@@ -0,0 +1,127 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+from diffusers import FlaxControlNetModel, FlaxStableDiffusionControlNetPipeline
+from diffusers.utils import is_flax_available, load_image, slow
+from diffusers.utils.testing_utils import require_flax
+
+
+if is_flax_available():
+ import jax
+ import jax.numpy as jnp
+ from flax.jax_utils import replicate
+ from flax.training.common_utils import shard
+
+
+@slow
+@require_flax
+class FlaxStableDiffusionControlNetPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+
+ def test_canny(self):
+ controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
+ "lllyasviel/sd-controlnet-canny", from_pt=True, dtype=jnp.bfloat16
+ )
+ pipe, params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, from_pt=True, dtype=jnp.bfloat16
+ )
+ params["controlnet"] = controlnet_params
+
+ prompts = "bird"
+ num_samples = jax.device_count()
+ prompt_ids = pipe.prepare_text_inputs([prompts] * num_samples)
+
+ canny_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
+ )
+ processed_image = pipe.prepare_image_inputs([canny_image] * num_samples)
+
+ rng = jax.random.PRNGKey(0)
+ rng = jax.random.split(rng, jax.device_count())
+
+ p_params = replicate(params)
+ prompt_ids = shard(prompt_ids)
+ processed_image = shard(processed_image)
+
+ images = pipe(
+ prompt_ids=prompt_ids,
+ image=processed_image,
+ params=p_params,
+ prng_seed=rng,
+ num_inference_steps=50,
+ jit=True,
+ ).images
+ assert images.shape == (jax.device_count(), 1, 768, 512, 3)
+
+ images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
+ image_slice = images[0, 253:256, 253:256, -1]
+
+ output_slice = jnp.asarray(jax.device_get(image_slice.flatten()))
+ expected_slice = jnp.array(
+ [0.167969, 0.116699, 0.081543, 0.154297, 0.132812, 0.108887, 0.169922, 0.169922, 0.205078]
+ )
+ print(f"output_slice: {output_slice}")
+ assert jnp.abs(output_slice - expected_slice).max() < 1e-2
+
+ def test_pose(self):
+ controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
+ "lllyasviel/sd-controlnet-openpose", from_pt=True, dtype=jnp.bfloat16
+ )
+ pipe, params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
+ "runwayml/stable-diffusion-v1-5", controlnet=controlnet, from_pt=True, dtype=jnp.bfloat16
+ )
+ params["controlnet"] = controlnet_params
+
+ prompts = "Chef in the kitchen"
+ num_samples = jax.device_count()
+ prompt_ids = pipe.prepare_text_inputs([prompts] * num_samples)
+
+ pose_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/pose.png"
+ )
+ processed_image = pipe.prepare_image_inputs([pose_image] * num_samples)
+
+ rng = jax.random.PRNGKey(0)
+ rng = jax.random.split(rng, jax.device_count())
+
+ p_params = replicate(params)
+ prompt_ids = shard(prompt_ids)
+ processed_image = shard(processed_image)
+
+ images = pipe(
+ prompt_ids=prompt_ids,
+ image=processed_image,
+ params=p_params,
+ prng_seed=rng,
+ num_inference_steps=50,
+ jit=True,
+ ).images
+ assert images.shape == (jax.device_count(), 1, 768, 512, 3)
+
+ images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
+ image_slice = images[0, 253:256, 253:256, -1]
+
+ output_slice = jnp.asarray(jax.device_get(image_slice.flatten()))
+ expected_slice = jnp.array(
+ [[0.271484, 0.261719, 0.275391, 0.277344, 0.279297, 0.291016, 0.294922, 0.302734, 0.302734]]
+ )
+ print(f"output_slice: {output_slice}")
+ assert jnp.abs(output_slice - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py
new file mode 100644
index 0000000000000000000000000000000000000000..01c2e22e48161b125e783273b55e395050646609
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_image_variation.py
@@ -0,0 +1,306 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPVisionConfig, CLIPVisionModelWithProjection
+
+from diffusers import (
+ AutoencoderKL,
+ DPMSolverMultistepScheduler,
+ PNDMScheduler,
+ StableDiffusionImageVariationPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import floats_tensor, load_image, load_numpy, nightly, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import IMAGE_VARIATION_BATCH_PARAMS, IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionImageVariationPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionImageVariationPipeline
+ params = IMAGE_VARIATION_PARAMS
+ batch_params = IMAGE_VARIATION_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ image_encoder_config = CLIPVisionConfig(
+ hidden_size=32,
+ projection_dim=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ image_size=32,
+ patch_size=4,
+ )
+ image_encoder = CLIPVisionModelWithProjection(image_encoder_config)
+ feature_extractor = CLIPImageProcessor(crop_size=32, size=32)
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "image_encoder": image_encoder,
+ "feature_extractor": feature_extractor,
+ "safety_checker": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed))
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ image = Image.fromarray(np.uint8(image)).convert("RGB").resize((32, 32))
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_img_variation_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionImageVariationPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5167, 0.5746, 0.4835, 0.4914, 0.5605, 0.4691, 0.5201, 0.4898, 0.4958])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_img_variation_multiple_images(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionImageVariationPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ inputs["image"] = 2 * [inputs["image"]]
+ output = sd_pipe(**inputs)
+
+ image = output.images
+
+ image_slice = image[-1, -3:, -3:, -1]
+
+ assert image.shape == (2, 64, 64, 3)
+ expected_slice = np.array([0.6568, 0.5470, 0.5684, 0.5444, 0.5945, 0.6221, 0.5508, 0.5531, 0.5263])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionImageVariationPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_imgvar/input_image_vermeer.png"
+ )
+ latents = np.random.RandomState(seed).standard_normal((1, 4, 64, 64))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "image": init_image,
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_img_variation_pipeline_default(self):
+ sd_pipe = StableDiffusionImageVariationPipeline.from_pretrained(
+ "lambdalabs/sd-image-variations-diffusers", safety_checker=None
+ )
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.84491, 0.90789, 0.75708, 0.78734, 0.83485, 0.70099, 0.66938, 0.68727, 0.61379])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_img_variation_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [-0.1621, 0.2837, -0.7979, -0.1221, -1.3057, 0.7681, -2.1191, 0.0464, 1.6309]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([0.6299, 1.7500, 1.1992, -2.1582, -1.8994, 0.7334, -0.7090, 1.0137, 1.5273])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ callback_fn.has_been_called = False
+
+ pipe = StableDiffusionImageVariationPipeline.from_pretrained(
+ "fusing/sd-image-variations-diffusers",
+ safety_checker=None,
+ torch_dtype=torch.float16,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == inputs["num_inference_steps"]
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ model_id = "fusing/sd-image-variations-diffusers"
+ pipe = StableDiffusionImageVariationPipeline.from_pretrained(
+ model_id, safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.6 GB is allocated
+ assert mem_bytes < 2.6 * 10**9
+
+
+@nightly
+@require_torch_gpu
+class StableDiffusionImageVariationPipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_imgvar/input_image_vermeer.png"
+ )
+ latents = np.random.RandomState(seed).standard_normal((1, 4, 64, 64))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "image": init_image,
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 50,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_img_variation_pndm(self):
+ sd_pipe = StableDiffusionImageVariationPipeline.from_pretrained("fusing/sd-image-variations-diffusers")
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_imgvar/lambdalabs_variations_pndm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_img_variation_dpm(self):
+ sd_pipe = StableDiffusionImageVariationPipeline.from_pretrained("fusing/sd-image-variations-diffusers")
+ sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ inputs["num_inference_steps"] = 25
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_imgvar/lambdalabs_variations_dpm_multi.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..e27f83fc04feb38edb85755dd9eaa48d528b95f8
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_img2img.py
@@ -0,0 +1,544 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionImg2ImgPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.image_processor import VaeImageProcessor
+from diffusers.utils import floats_tensor, load_image, load_numpy, nightly, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu, skip_mps
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS, TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionImg2ImgPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionImg2ImgPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"height", "width"}
+ required_optional_params = PipelineTesterMixin.required_optional_params - {"latents"}
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0, input_image_type="pt", output_type="np"):
+ image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ if input_image_type == "pt":
+ input_image = image
+ elif input_image_type == "np":
+ input_image = image.cpu().numpy().transpose(0, 2, 3, 1)
+ elif input_image_type == "pil":
+ input_image = image.cpu().numpy().transpose(0, 2, 3, 1)
+ input_image = VaeImageProcessor.numpy_to_pil(input_image)
+ else:
+ raise ValueError(f"unsupported input_image_type {input_image_type}.")
+
+ if output_type not in ["pt", "np", "pil"]:
+ raise ValueError(f"unsupported output_type {output_type}")
+
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "image": input_image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": output_type,
+ }
+ return inputs
+
+ def test_stable_diffusion_img2img_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionImg2ImgPipeline(**components)
+ sd_pipe.image_processor = VaeImageProcessor(vae_scale_factor=sd_pipe.vae_scale_factor, do_normalize=False)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.4492, 0.3865, 0.4222, 0.5854, 0.5139, 0.4379, 0.4193, 0.48, 0.4218])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_img2img_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionImg2ImgPipeline(**components)
+ sd_pipe.image_processor = VaeImageProcessor(vae_scale_factor=sd_pipe.vae_scale_factor, do_normalize=False)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ negative_prompt = "french fries"
+ output = sd_pipe(**inputs, negative_prompt=negative_prompt)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.4065, 0.3783, 0.4050, 0.5266, 0.4781, 0.4252, 0.4203, 0.4692, 0.4365])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_img2img_multiple_init_images(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionImg2ImgPipeline(**components)
+ sd_pipe.image_processor = VaeImageProcessor(vae_scale_factor=sd_pipe.vae_scale_factor, do_normalize=False)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ inputs["prompt"] = [inputs["prompt"]] * 2
+ inputs["image"] = inputs["image"].repeat(2, 1, 1, 1)
+ image = sd_pipe(**inputs).images
+ image_slice = image[-1, -3:, -3:, -1]
+
+ assert image.shape == (2, 32, 32, 3)
+ expected_slice = np.array([0.5144, 0.4447, 0.4735, 0.6676, 0.5526, 0.5454, 0.645, 0.5149, 0.4689])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_img2img_k_lms(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = LMSDiscreteScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear"
+ )
+ sd_pipe = StableDiffusionImg2ImgPipeline(**components)
+ sd_pipe.image_processor = VaeImageProcessor(vae_scale_factor=sd_pipe.vae_scale_factor, do_normalize=False)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.4367, 0.4986, 0.4372, 0.6706, 0.5665, 0.444, 0.5864, 0.6019, 0.5203])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ @skip_mps
+ def test_save_load_local(self):
+ return super().test_save_load_local()
+
+ @skip_mps
+ def test_dict_tuple_outputs_equivalent(self):
+ return super().test_dict_tuple_outputs_equivalent()
+
+ @skip_mps
+ def test_save_load_optional_components(self):
+ return super().test_save_load_optional_components()
+
+ @skip_mps
+ def test_attention_slicing_forward_pass(self):
+ return super().test_attention_slicing_forward_pass()
+
+ @skip_mps
+ def test_pt_np_pil_outputs_equivalent(self):
+ device = "cpu"
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionImg2ImgPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ output_pt = sd_pipe(**self.get_dummy_inputs(device, output_type="pt"))[0]
+ output_np = sd_pipe(**self.get_dummy_inputs(device, output_type="np"))[0]
+ output_pil = sd_pipe(**self.get_dummy_inputs(device, output_type="pil"))[0]
+
+ assert np.abs(output_pt.cpu().numpy().transpose(0, 2, 3, 1) - output_np).max() <= 1e-4
+ assert np.abs(np.array(output_pil[0]) - (output_np * 255).round()).max() <= 1e-4
+
+ @skip_mps
+ def test_image_types_consistent(self):
+ device = "cpu"
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionImg2ImgPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ output_pt = sd_pipe(**self.get_dummy_inputs(device, input_image_type="pt"))[0]
+ output_np = sd_pipe(**self.get_dummy_inputs(device, input_image_type="np"))[0]
+ output_pil = sd_pipe(**self.get_dummy_inputs(device, input_image_type="pil"))[0]
+
+ assert np.abs(output_pt - output_np).max() <= 1e-4
+ assert np.abs(output_pil - output_np).max() <= 1e-2
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionImg2ImgPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_img2img/sketch-mountains-input.png"
+ )
+ inputs = {
+ "prompt": "a fantasy landscape, concept art, high resolution",
+ "image": init_image,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "strength": 0.75,
+ "guidance_scale": 7.5,
+ "output_type": "np",
+ }
+ return inputs
+
+ def test_stable_diffusion_img2img_default(self):
+ pipe = StableDiffusionImg2ImgPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 768, 3)
+ expected_slice = np.array([0.4300, 0.4662, 0.4930, 0.3990, 0.4307, 0.4525, 0.3719, 0.4064, 0.3923])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-3
+
+ def test_stable_diffusion_img2img_k_lms(self):
+ pipe = StableDiffusionImg2ImgPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None)
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 768, 3)
+ expected_slice = np.array([0.0389, 0.0346, 0.0415, 0.0290, 0.0218, 0.0210, 0.0408, 0.0567, 0.0271])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-3
+
+ def test_stable_diffusion_img2img_ddim(self):
+ pipe = StableDiffusionImg2ImgPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None)
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 768, 3)
+ expected_slice = np.array([0.0593, 0.0607, 0.0851, 0.0582, 0.0636, 0.0721, 0.0751, 0.0981, 0.0781])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-3
+
+ def test_stable_diffusion_img2img_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 96)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([-0.4958, 0.5107, 1.1045, 2.7539, 4.6680, 3.8320, 1.5049, 1.8633, 2.6523])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 96)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([-0.4956, 0.5078, 1.0918, 2.7520, 4.6484, 3.8125, 1.5146, 1.8633, 2.6367])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ callback_fn.has_been_called = False
+
+ pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == 2
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.2 GB is allocated
+ assert mem_bytes < 2.2 * 10**9
+
+ def test_stable_diffusion_pipeline_with_model_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+
+ # Normal inference
+
+ pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ safety_checker=None,
+ torch_dtype=torch.float16,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe(**inputs)
+ mem_bytes = torch.cuda.max_memory_allocated()
+
+ # With model offloading
+
+ # Reload but don't move to cuda
+ pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ safety_checker=None,
+ torch_dtype=torch.float16,
+ )
+
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+ _ = pipe(**inputs)
+ mem_bytes_offloaded = torch.cuda.max_memory_allocated()
+
+ assert mem_bytes_offloaded < mem_bytes
+ for module in pipe.text_encoder, pipe.unet, pipe.vae:
+ assert module.device == torch.device("cpu")
+
+ def test_stable_diffusion_img2img_pipeline_multiple_of_8(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/img2img/sketch-mountains-input.jpg"
+ )
+ # resize to resolution that is divisible by 8 but not 16 or 32
+ init_image = init_image.resize((760, 504))
+
+ model_id = "CompVis/stable-diffusion-v1-4"
+ pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
+ model_id,
+ safety_checker=None,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ prompt = "A fantasy landscape, trending on artstation"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ strength=0.75,
+ guidance_scale=7.5,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images[0]
+
+ image_slice = image[255:258, 383:386, -1]
+
+ assert image.shape == (504, 760, 3)
+ expected_slice = np.array([0.9393, 0.9500, 0.9399, 0.9438, 0.9458, 0.9400, 0.9455, 0.9414, 0.9423])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 5e-3
+
+
+@nightly
+@require_torch_gpu
+class StableDiffusionImg2ImgPipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_img2img/sketch-mountains-input.png"
+ )
+ inputs = {
+ "prompt": "a fantasy landscape, concept art, high resolution",
+ "image": init_image,
+ "generator": generator,
+ "num_inference_steps": 50,
+ "strength": 0.75,
+ "guidance_scale": 7.5,
+ "output_type": "np",
+ }
+ return inputs
+
+ def test_img2img_pndm(self):
+ sd_pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_img2img/stable_diffusion_1_5_pndm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_img2img_ddim(self):
+ sd_pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe.scheduler = DDIMScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_img2img/stable_diffusion_1_5_ddim.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_img2img_lms(self):
+ sd_pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_img2img/stable_diffusion_1_5_lms.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_img2img_dpm(self):
+ sd_pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ inputs["num_inference_steps"] = 30
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_img2img/stable_diffusion_1_5_dpm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..3553679e0ef6db5a088f36f34558b10bf0d638d4
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint.py
@@ -0,0 +1,538 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DPMSolverMultistepScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionInpaintPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint import prepare_mask_and_masked_image
+from diffusers.utils import floats_tensor, load_image, load_numpy, nightly, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS, TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionInpaintPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionInpaintPipeline
+ params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
+ batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=9,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ # TODO: use tensor inputs instead of PIL, this is here just to leave the old expected_slices untouched
+ image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ init_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+ mask_image = Image.fromarray(np.uint8(image + 4)).convert("RGB").resize((64, 64))
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "image": init_image,
+ "mask_image": mask_image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_inpaint(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionInpaintPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.4723, 0.5731, 0.3939, 0.5441, 0.5922, 0.4392, 0.5059, 0.4651, 0.4474])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_inpaint_image_tensor(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionInpaintPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ output = sd_pipe(**inputs)
+ out_pil = output.images
+
+ inputs = self.get_dummy_inputs(device)
+ inputs["image"] = torch.tensor(np.array(inputs["image"]) / 127.5 - 1).permute(2, 0, 1).unsqueeze(0)
+ inputs["mask_image"] = torch.tensor(np.array(inputs["mask_image"]) / 255).permute(2, 0, 1)[:1].unsqueeze(0)
+ output = sd_pipe(**inputs)
+ out_tensor = output.images
+
+ assert out_pil.shape == (1, 64, 64, 3)
+ assert np.abs(out_pil.flatten() - out_tensor.flatten()).max() < 5e-2
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionInpaintPipelineSlowTests(unittest.TestCase):
+ def setUp(self):
+ super().setUp()
+
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_image.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_mask.png"
+ )
+ inputs = {
+ "prompt": "Face of a yellow cat, high resolution, sitting on a park bench",
+ "image": init_image,
+ "mask_image": mask_image,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_inpaint_ddim(self):
+ pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting", safety_checker=None
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.0427, 0.0460, 0.0483, 0.0460, 0.0584, 0.0521, 0.1549, 0.1695, 0.1794])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-4
+
+ def test_stable_diffusion_inpaint_fp16(self):
+ pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting", torch_dtype=torch.float16, safety_checker=None
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.1350, 0.1123, 0.1350, 0.1641, 0.1328, 0.1230, 0.1289, 0.1531, 0.1687])
+
+ assert np.abs(expected_slice - image_slice).max() < 5e-2
+
+ def test_stable_diffusion_inpaint_pndm(self):
+ pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting", safety_checker=None
+ )
+ pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.0425, 0.0273, 0.0344, 0.1694, 0.1727, 0.1812, 0.3256, 0.3311, 0.3272])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-4
+
+ def test_stable_diffusion_inpaint_k_lms(self):
+ pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting", safety_checker=None
+ )
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.9314, 0.7575, 0.9432, 0.8885, 0.9028, 0.7298, 0.9811, 0.9667, 0.7633])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-4
+
+ def test_stable_diffusion_inpaint_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ "runwayml/stable-diffusion-inpainting", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.2 GB is allocated
+ assert mem_bytes < 2.2 * 10**9
+
+
+@nightly
+@require_torch_gpu
+class StableDiffusionInpaintPipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_image.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_mask.png"
+ )
+ inputs = {
+ "prompt": "Face of a yellow cat, high resolution, sitting on a park bench",
+ "image": init_image,
+ "mask_image": mask_image,
+ "generator": generator,
+ "num_inference_steps": 50,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_inpaint_ddim(self):
+ sd_pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting")
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/stable_diffusion_inpaint_ddim.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_inpaint_pndm(self):
+ sd_pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting")
+ sd_pipe.scheduler = PNDMScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/stable_diffusion_inpaint_pndm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_inpaint_lms(self):
+ sd_pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting")
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/stable_diffusion_inpaint_lms.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_inpaint_dpm(self):
+ sd_pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting")
+ sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ inputs["num_inference_steps"] = 30
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/stable_diffusion_inpaint_dpm_multi.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+
+class StableDiffusionInpaintingPrepareMaskAndMaskedImageTests(unittest.TestCase):
+ def test_pil_inputs(self):
+ im = np.random.randint(0, 255, (32, 32, 3), dtype=np.uint8)
+ im = Image.fromarray(im)
+ mask = np.random.randint(0, 255, (32, 32), dtype=np.uint8) > 127.5
+ mask = Image.fromarray((mask * 255).astype(np.uint8))
+
+ t_mask, t_masked = prepare_mask_and_masked_image(im, mask)
+
+ self.assertTrue(isinstance(t_mask, torch.Tensor))
+ self.assertTrue(isinstance(t_masked, torch.Tensor))
+
+ self.assertEqual(t_mask.ndim, 4)
+ self.assertEqual(t_masked.ndim, 4)
+
+ self.assertEqual(t_mask.shape, (1, 1, 32, 32))
+ self.assertEqual(t_masked.shape, (1, 3, 32, 32))
+
+ self.assertTrue(t_mask.dtype == torch.float32)
+ self.assertTrue(t_masked.dtype == torch.float32)
+
+ self.assertTrue(t_mask.min() >= 0.0)
+ self.assertTrue(t_mask.max() <= 1.0)
+ self.assertTrue(t_masked.min() >= -1.0)
+ self.assertTrue(t_masked.min() <= 1.0)
+
+ self.assertTrue(t_mask.sum() > 0.0)
+
+ def test_np_inputs(self):
+ im_np = np.random.randint(0, 255, (32, 32, 3), dtype=np.uint8)
+ im_pil = Image.fromarray(im_np)
+ mask_np = np.random.randint(0, 255, (32, 32), dtype=np.uint8) > 127.5
+ mask_pil = Image.fromarray((mask_np * 255).astype(np.uint8))
+
+ t_mask_np, t_masked_np = prepare_mask_and_masked_image(im_np, mask_np)
+ t_mask_pil, t_masked_pil = prepare_mask_and_masked_image(im_pil, mask_pil)
+
+ self.assertTrue((t_mask_np == t_mask_pil).all())
+ self.assertTrue((t_masked_np == t_masked_pil).all())
+
+ def test_torch_3D_2D_inputs(self):
+ im_tensor = torch.randint(0, 255, (3, 32, 32), dtype=torch.uint8)
+ mask_tensor = torch.randint(0, 255, (32, 32), dtype=torch.uint8) > 127.5
+ im_np = im_tensor.numpy().transpose(1, 2, 0)
+ mask_np = mask_tensor.numpy()
+
+ t_mask_tensor, t_masked_tensor = prepare_mask_and_masked_image(im_tensor / 127.5 - 1, mask_tensor)
+ t_mask_np, t_masked_np = prepare_mask_and_masked_image(im_np, mask_np)
+
+ self.assertTrue((t_mask_tensor == t_mask_np).all())
+ self.assertTrue((t_masked_tensor == t_masked_np).all())
+
+ def test_torch_3D_3D_inputs(self):
+ im_tensor = torch.randint(0, 255, (3, 32, 32), dtype=torch.uint8)
+ mask_tensor = torch.randint(0, 255, (1, 32, 32), dtype=torch.uint8) > 127.5
+ im_np = im_tensor.numpy().transpose(1, 2, 0)
+ mask_np = mask_tensor.numpy()[0]
+
+ t_mask_tensor, t_masked_tensor = prepare_mask_and_masked_image(im_tensor / 127.5 - 1, mask_tensor)
+ t_mask_np, t_masked_np = prepare_mask_and_masked_image(im_np, mask_np)
+
+ self.assertTrue((t_mask_tensor == t_mask_np).all())
+ self.assertTrue((t_masked_tensor == t_masked_np).all())
+
+ def test_torch_4D_2D_inputs(self):
+ im_tensor = torch.randint(0, 255, (1, 3, 32, 32), dtype=torch.uint8)
+ mask_tensor = torch.randint(0, 255, (32, 32), dtype=torch.uint8) > 127.5
+ im_np = im_tensor.numpy()[0].transpose(1, 2, 0)
+ mask_np = mask_tensor.numpy()
+
+ t_mask_tensor, t_masked_tensor = prepare_mask_and_masked_image(im_tensor / 127.5 - 1, mask_tensor)
+ t_mask_np, t_masked_np = prepare_mask_and_masked_image(im_np, mask_np)
+
+ self.assertTrue((t_mask_tensor == t_mask_np).all())
+ self.assertTrue((t_masked_tensor == t_masked_np).all())
+
+ def test_torch_4D_3D_inputs(self):
+ im_tensor = torch.randint(0, 255, (1, 3, 32, 32), dtype=torch.uint8)
+ mask_tensor = torch.randint(0, 255, (1, 32, 32), dtype=torch.uint8) > 127.5
+ im_np = im_tensor.numpy()[0].transpose(1, 2, 0)
+ mask_np = mask_tensor.numpy()[0]
+
+ t_mask_tensor, t_masked_tensor = prepare_mask_and_masked_image(im_tensor / 127.5 - 1, mask_tensor)
+ t_mask_np, t_masked_np = prepare_mask_and_masked_image(im_np, mask_np)
+
+ self.assertTrue((t_mask_tensor == t_mask_np).all())
+ self.assertTrue((t_masked_tensor == t_masked_np).all())
+
+ def test_torch_4D_4D_inputs(self):
+ im_tensor = torch.randint(0, 255, (1, 3, 32, 32), dtype=torch.uint8)
+ mask_tensor = torch.randint(0, 255, (1, 1, 32, 32), dtype=torch.uint8) > 127.5
+ im_np = im_tensor.numpy()[0].transpose(1, 2, 0)
+ mask_np = mask_tensor.numpy()[0][0]
+
+ t_mask_tensor, t_masked_tensor = prepare_mask_and_masked_image(im_tensor / 127.5 - 1, mask_tensor)
+ t_mask_np, t_masked_np = prepare_mask_and_masked_image(im_np, mask_np)
+
+ self.assertTrue((t_mask_tensor == t_mask_np).all())
+ self.assertTrue((t_masked_tensor == t_masked_np).all())
+
+ def test_torch_batch_4D_3D(self):
+ im_tensor = torch.randint(0, 255, (2, 3, 32, 32), dtype=torch.uint8)
+ mask_tensor = torch.randint(0, 255, (2, 32, 32), dtype=torch.uint8) > 127.5
+
+ im_nps = [im.numpy().transpose(1, 2, 0) for im in im_tensor]
+ mask_nps = [mask.numpy() for mask in mask_tensor]
+
+ t_mask_tensor, t_masked_tensor = prepare_mask_and_masked_image(im_tensor / 127.5 - 1, mask_tensor)
+ nps = [prepare_mask_and_masked_image(i, m) for i, m in zip(im_nps, mask_nps)]
+ t_mask_np = torch.cat([n[0] for n in nps])
+ t_masked_np = torch.cat([n[1] for n in nps])
+
+ self.assertTrue((t_mask_tensor == t_mask_np).all())
+ self.assertTrue((t_masked_tensor == t_masked_np).all())
+
+ def test_torch_batch_4D_4D(self):
+ im_tensor = torch.randint(0, 255, (2, 3, 32, 32), dtype=torch.uint8)
+ mask_tensor = torch.randint(0, 255, (2, 1, 32, 32), dtype=torch.uint8) > 127.5
+
+ im_nps = [im.numpy().transpose(1, 2, 0) for im in im_tensor]
+ mask_nps = [mask.numpy()[0] for mask in mask_tensor]
+
+ t_mask_tensor, t_masked_tensor = prepare_mask_and_masked_image(im_tensor / 127.5 - 1, mask_tensor)
+ nps = [prepare_mask_and_masked_image(i, m) for i, m in zip(im_nps, mask_nps)]
+ t_mask_np = torch.cat([n[0] for n in nps])
+ t_masked_np = torch.cat([n[1] for n in nps])
+
+ self.assertTrue((t_mask_tensor == t_mask_np).all())
+ self.assertTrue((t_masked_tensor == t_masked_np).all())
+
+ def test_shape_mismatch(self):
+ # test height and width
+ with self.assertRaises(AssertionError):
+ prepare_mask_and_masked_image(torch.randn(3, 32, 32), torch.randn(64, 64))
+ # test batch dim
+ with self.assertRaises(AssertionError):
+ prepare_mask_and_masked_image(torch.randn(2, 3, 32, 32), torch.randn(4, 64, 64))
+ # test batch dim
+ with self.assertRaises(AssertionError):
+ prepare_mask_and_masked_image(torch.randn(2, 3, 32, 32), torch.randn(4, 1, 64, 64))
+
+ def test_type_mismatch(self):
+ # test tensors-only
+ with self.assertRaises(TypeError):
+ prepare_mask_and_masked_image(torch.rand(3, 32, 32), torch.rand(3, 32, 32).numpy())
+ # test tensors-only
+ with self.assertRaises(TypeError):
+ prepare_mask_and_masked_image(torch.rand(3, 32, 32).numpy(), torch.rand(3, 32, 32))
+
+ def test_channels_first(self):
+ # test channels first for 3D tensors
+ with self.assertRaises(AssertionError):
+ prepare_mask_and_masked_image(torch.rand(32, 32, 3), torch.rand(3, 32, 32))
+
+ def test_tensor_range(self):
+ # test im <= 1
+ with self.assertRaises(ValueError):
+ prepare_mask_and_masked_image(torch.ones(3, 32, 32) * 2, torch.rand(32, 32))
+ # test im >= -1
+ with self.assertRaises(ValueError):
+ prepare_mask_and_masked_image(torch.ones(3, 32, 32) * (-2), torch.rand(32, 32))
+ # test mask <= 1
+ with self.assertRaises(ValueError):
+ prepare_mask_and_masked_image(torch.rand(3, 32, 32), torch.ones(32, 32) * 2)
+ # test mask >= 0
+ with self.assertRaises(ValueError):
+ prepare_mask_and_masked_image(torch.rand(3, 32, 32), torch.ones(32, 32) * -1)
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint_legacy.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint_legacy.py
new file mode 100644
index 0000000000000000000000000000000000000000..15d94414ea2fa881a29d4876cb072da56492a0a0
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_inpaint_legacy.py
@@ -0,0 +1,538 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionInpaintPipelineLegacy,
+ UNet2DConditionModel,
+ UNet2DModel,
+ VQModel,
+)
+from diffusers.utils import floats_tensor, load_image, nightly, slow, torch_device
+from diffusers.utils.testing_utils import load_numpy, require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionInpaintLegacyPipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @property
+ def dummy_image(self):
+ batch_size = 1
+ num_channels = 3
+ sizes = (32, 32)
+
+ image = floats_tensor((batch_size, num_channels) + sizes, rng=random.Random(0)).to(torch_device)
+ return image
+
+ @property
+ def dummy_uncond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ return model
+
+ @property
+ def dummy_cond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ return model
+
+ @property
+ def dummy_cond_unet_inpaint(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=9,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ return model
+
+ @property
+ def dummy_vq_model(self):
+ torch.manual_seed(0)
+ model = VQModel(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=3,
+ )
+ return model
+
+ @property
+ def dummy_vae(self):
+ torch.manual_seed(0)
+ model = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ return model
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ return CLIPTextModel(config)
+
+ @property
+ def dummy_extractor(self):
+ def extract(*args, **kwargs):
+ class Out:
+ def __init__(self):
+ self.pixel_values = torch.ones([0])
+
+ def to(self, device):
+ self.pixel_values.to(device)
+ return self
+
+ return Out()
+
+ return extract
+
+ def test_stable_diffusion_inpaint_legacy(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ image = self.dummy_image.cpu().permute(0, 2, 3, 1)[0]
+ init_image = Image.fromarray(np.uint8(image)).convert("RGB")
+ mask_image = Image.fromarray(np.uint8(image + 4)).convert("RGB").resize((32, 32))
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionInpaintPipelineLegacy(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ mask_image=mask_image,
+ )
+
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ mask_image=mask_image,
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.4941, 0.5396, 0.4689, 0.6338, 0.5392, 0.4094, 0.5477, 0.5904, 0.5165])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_inpaint_legacy_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ image = self.dummy_image.cpu().permute(0, 2, 3, 1)[0]
+ init_image = Image.fromarray(np.uint8(image)).convert("RGB")
+ mask_image = Image.fromarray(np.uint8(image + 4)).convert("RGB").resize((32, 32))
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionInpaintPipelineLegacy(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ negative_prompt = "french fries"
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe(
+ prompt,
+ negative_prompt=negative_prompt,
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ mask_image=mask_image,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.4941, 0.5396, 0.4689, 0.6338, 0.5392, 0.4094, 0.5477, 0.5904, 0.5165])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_inpaint_legacy_num_images_per_prompt(self):
+ device = "cpu"
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ image = self.dummy_image.cpu().permute(0, 2, 3, 1)[0]
+ init_image = Image.fromarray(np.uint8(image)).convert("RGB")
+ mask_image = Image.fromarray(np.uint8(image + 4)).convert("RGB").resize((32, 32))
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionInpaintPipelineLegacy(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+
+ # test num_images_per_prompt=1 (default)
+ images = sd_pipe(
+ prompt,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ mask_image=mask_image,
+ ).images
+
+ assert images.shape == (1, 32, 32, 3)
+
+ # test num_images_per_prompt=1 (default) for batch of prompts
+ batch_size = 2
+ images = sd_pipe(
+ [prompt] * batch_size,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ mask_image=mask_image,
+ ).images
+
+ assert images.shape == (batch_size, 32, 32, 3)
+
+ # test num_images_per_prompt for single prompt
+ num_images_per_prompt = 2
+ images = sd_pipe(
+ prompt,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ mask_image=mask_image,
+ num_images_per_prompt=num_images_per_prompt,
+ ).images
+
+ assert images.shape == (num_images_per_prompt, 32, 32, 3)
+
+ # test num_images_per_prompt for batch of prompts
+ batch_size = 2
+ images = sd_pipe(
+ [prompt] * batch_size,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ mask_image=mask_image,
+ num_images_per_prompt=num_images_per_prompt,
+ ).images
+
+ assert images.shape == (batch_size * num_images_per_prompt, 32, 32, 3)
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionInpaintLegacyPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_image.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_mask.png"
+ )
+ inputs = {
+ "prompt": "A red cat sitting on a park bench",
+ "image": init_image,
+ "mask_image": mask_image,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "strength": 0.75,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_inpaint_legacy_pndm(self):
+ pipe = StableDiffusionInpaintPipelineLegacy.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.5665, 0.6117, 0.6430, 0.4057, 0.4594, 0.5658, 0.1596, 0.3106, 0.4305])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-4
+
+ def test_stable_diffusion_inpaint_legacy_k_lms(self):
+ pipe = StableDiffusionInpaintPipelineLegacy.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None
+ )
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.4534, 0.4467, 0.4329, 0.4329, 0.4339, 0.4220, 0.4244, 0.4332, 0.4426])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-4
+
+ def test_stable_diffusion_inpaint_legacy_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([0.5977, 1.5449, 1.0586, -0.3250, 0.7383, -0.0862, 0.4631, -0.2571, -1.1289])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 1e-3
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([0.5190, 1.1621, 0.6885, 0.2424, 0.3337, -0.1617, 0.6914, -0.1957, -0.5474])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 1e-3
+
+ callback_fn.has_been_called = False
+
+ pipe = StableDiffusionInpaintPipelineLegacy.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == 2
+
+
+@nightly
+@require_torch_gpu
+class StableDiffusionInpaintLegacyPipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_image.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint/input_bench_mask.png"
+ )
+ inputs = {
+ "prompt": "A red cat sitting on a park bench",
+ "image": init_image,
+ "mask_image": mask_image,
+ "generator": generator,
+ "num_inference_steps": 50,
+ "strength": 0.75,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_inpaint_pndm(self):
+ sd_pipe = StableDiffusionInpaintPipelineLegacy.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint_legacy/stable_diffusion_1_5_pndm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_inpaint_ddim(self):
+ sd_pipe = StableDiffusionInpaintPipelineLegacy.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe.scheduler = DDIMScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint_legacy/stable_diffusion_1_5_ddim.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_inpaint_lms(self):
+ sd_pipe = StableDiffusionInpaintPipelineLegacy.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint_legacy/stable_diffusion_1_5_lms.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_inpaint_dpm(self):
+ sd_pipe = StableDiffusionInpaintPipelineLegacy.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ inputs["num_inference_steps"] = 30
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_inpaint_legacy/stable_diffusion_1_5_dpm_multi.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_instruction_pix2pix.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_instruction_pix2pix.py
new file mode 100644
index 0000000000000000000000000000000000000000..25b0c6ea1432972a6303423ea8517420a6ab9499
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_instruction_pix2pix.py
@@ -0,0 +1,350 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ EulerAncestralDiscreteScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionInstructPix2PixPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import floats_tensor, load_image, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS, TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionInstructPix2PixPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionInstructPix2PixPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"height", "width", "cross_attention_kwargs"}
+ batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=8,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ image = Image.fromarray(np.uint8(image)).convert("RGB")
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "image_guidance_scale": 1,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_pix2pix_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionInstructPix2PixPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.7318, 0.3723, 0.4662, 0.623, 0.5770, 0.5014, 0.4281, 0.5550, 0.4813])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionInstructPix2PixPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ negative_prompt = "french fries"
+ output = sd_pipe(**inputs, negative_prompt=negative_prompt)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.7323, 0.3688, 0.4611, 0.6255, 0.5746, 0.5017, 0.433, 0.5553, 0.4827])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_multiple_init_images(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionInstructPix2PixPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ inputs["prompt"] = [inputs["prompt"]] * 2
+
+ image = np.array(inputs["image"]).astype(np.float32) / 255.0
+ image = torch.from_numpy(image).unsqueeze(0).to(device)
+ image = image.permute(0, 3, 1, 2)
+ inputs["image"] = image.repeat(2, 1, 1, 1)
+
+ image = sd_pipe(**inputs).images
+ image_slice = image[-1, -3:, -3:, -1]
+
+ assert image.shape == (2, 32, 32, 3)
+ expected_slice = np.array([0.606, 0.5712, 0.5099, 0.598, 0.5805, 0.7205, 0.6793, 0.554, 0.5607])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_euler(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = EulerAncestralDiscreteScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear"
+ )
+ sd_pipe = StableDiffusionInstructPix2PixPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ slice = [round(x, 4) for x in image_slice.flatten().tolist()]
+ print(",".join([str(x) for x in slice]))
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array([0.726, 0.3902, 0.4868, 0.585, 0.5672, 0.511, 0.3906, 0.551, 0.4846])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionInstructPix2PixPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, seed=0):
+ generator = torch.manual_seed(seed)
+ image = load_image(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_pix2pix/example.jpg"
+ )
+ inputs = {
+ "prompt": "turn him into a cyborg",
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "image_guidance_scale": 1.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_pix2pix_default(self):
+ pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ "timbrooks/instruct-pix2pix", safety_checker=None
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.5902, 0.6015, 0.6027, 0.5983, 0.6092, 0.6061, 0.5765, 0.5785, 0.5555])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_k_lms(self):
+ pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ "timbrooks/instruct-pix2pix", safety_checker=None
+ )
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.6578, 0.6817, 0.6972, 0.6761, 0.6856, 0.6916, 0.6428, 0.6516, 0.6301])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_ddim(self):
+ pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ "timbrooks/instruct-pix2pix", safety_checker=None
+ )
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.3828, 0.3834, 0.3818, 0.3792, 0.3865, 0.3752, 0.3792, 0.3847, 0.3753])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([-0.2463, -0.4644, -0.9756, 1.5176, 1.4414, 0.7866, 0.9897, 0.8521, 0.7983])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([-0.2644, -0.4626, -0.9653, 1.5176, 1.4551, 0.7686, 0.9805, 0.8452, 0.8115])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ callback_fn.has_been_called = False
+
+ pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ "timbrooks/instruct-pix2pix", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == 3
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ "timbrooks/instruct-pix2pix", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs()
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.2 GB is allocated
+ assert mem_bytes < 2.2 * 10**9
+
+ def test_stable_diffusion_pix2pix_pipeline_multiple_of_8(self):
+ inputs = self.get_inputs()
+ # resize to resolution that is divisible by 8 but not 16 or 32
+ inputs["image"] = inputs["image"].resize((504, 504))
+
+ model_id = "timbrooks/instruct-pix2pix"
+ pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained(
+ model_id,
+ safety_checker=None,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ output = pipe(**inputs)
+ image = output.images[0]
+
+ image_slice = image[255:258, 383:386, -1]
+
+ assert image.shape == (504, 504, 3)
+ expected_slice = np.array([0.2726, 0.2529, 0.2664, 0.2655, 0.2641, 0.2642, 0.2591, 0.2649, 0.2590])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 5e-3
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_k_diffusion.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_k_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..546b1d21252c6ef84d9d181839b7976d3d376082
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_k_diffusion.py
@@ -0,0 +1,106 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import StableDiffusionKDiffusionPipeline
+from diffusers.utils import slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_stable_diffusion_1(self):
+ sd_pipe = StableDiffusionKDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ sd_pipe.set_scheduler("sample_euler")
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=9.0, num_inference_steps=20, output_type="np")
+
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.0447, 0.0492, 0.0468, 0.0408, 0.0383, 0.0408, 0.0354, 0.0380, 0.0339])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_2(self):
+ sd_pipe = StableDiffusionKDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base")
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ sd_pipe.set_scheduler("sample_euler")
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=9.0, num_inference_steps=20, output_type="np")
+
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.1237, 0.1320, 0.1438, 0.1359, 0.1390, 0.1132, 0.1277, 0.1175, 0.1112])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 5e-1
+
+ def test_stable_diffusion_karras_sigmas(self):
+ sd_pipe = StableDiffusionKDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base")
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ sd_pipe.set_scheduler("sample_dpmpp_2m")
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ output = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=15,
+ output_type="np",
+ use_karras_sigmas=True,
+ )
+
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array(
+ [0.11381689, 0.12112921, 0.1389457, 0.12549606, 0.1244964, 0.10831517, 0.11562866, 0.10867816, 0.10499048]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_model_editing.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_model_editing.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d9b1e54ee6ebaddf8d6ca133ef322ed06853980
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_model_editing.py
@@ -0,0 +1,252 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ EulerAncestralDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionModelEditingPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu, skip_mps
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+@skip_mps
+class StableDiffusionModelEditingPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionModelEditingPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = DDIMScheduler()
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ generator = torch.manual_seed(seed)
+ inputs = {
+ "prompt": "A field of roses",
+ "generator": generator,
+ # Setting height and width to None to prevent OOMs on CPU.
+ "height": None,
+ "width": None,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_model_editing_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionModelEditingPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array(
+ [0.5217179, 0.50658035, 0.5003239, 0.41109088, 0.3595158, 0.46607107, 0.5323504, 0.5335255, 0.49187922]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_model_editing_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionModelEditingPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ negative_prompt = "french fries"
+ output = sd_pipe(**inputs, negative_prompt=negative_prompt)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array(
+ [0.546259, 0.5108156, 0.50897664, 0.41931948, 0.3748669, 0.4669299, 0.5427151, 0.54561913, 0.49353]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_model_editing_euler(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = EulerAncestralDiscreteScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear"
+ )
+ sd_pipe = StableDiffusionModelEditingPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array(
+ [0.47106352, 0.53579676, 0.45798016, 0.514294, 0.56856745, 0.4788605, 0.54380214, 0.5046455, 0.50404465]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_model_editing_pndm(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = PNDMScheduler()
+ sd_pipe = StableDiffusionModelEditingPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ # the pipeline does not expect pndm so test if it raises error.
+ with self.assertRaises(ValueError):
+ _ = sd_pipe(**inputs).images
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionModelEditingSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, seed=0):
+ generator = torch.manual_seed(seed)
+ inputs = {
+ "prompt": "A field of roses",
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_model_editing_default(self):
+ model_ckpt = "CompVis/stable-diffusion-v1-4"
+ pipe = StableDiffusionModelEditingPipeline.from_pretrained(model_ckpt, safety_checker=None)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+
+ expected_slice = np.array(
+ [0.6749496, 0.6386453, 0.51443267, 0.66094905, 0.61921215, 0.5491332, 0.5744417, 0.58075106, 0.5174658]
+ )
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-2
+
+ # make sure image changes after editing
+ pipe.edit_model("A pack of roses", "A pack of blue roses")
+
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(expected_slice - image_slice).max() > 1e-1
+
+ def test_stable_diffusion_model_editing_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ model_ckpt = "CompVis/stable-diffusion-v1-4"
+ scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
+ pipe = StableDiffusionModelEditingPipeline.from_pretrained(
+ model_ckpt, scheduler=scheduler, safety_checker=None
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs()
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 4.4 GB is allocated
+ assert mem_bytes < 4.4 * 10**9
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_panorama.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_panorama.py
new file mode 100644
index 0000000000000000000000000000000000000000..af26e19cca732ee3144bb38929949499d41f64b5
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_panorama.py
@@ -0,0 +1,342 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ EulerAncestralDiscreteScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionPanoramaPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu, skip_mps
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+@skip_mps
+class StableDiffusionPanoramaPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionPanoramaPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = DDIMScheduler()
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ generator = torch.manual_seed(seed)
+ inputs = {
+ "prompt": "a photo of the dolomites",
+ "generator": generator,
+ # Setting height and width to None to prevent OOMs on CPU.
+ "height": None,
+ "width": None,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_panorama_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPanoramaPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array([0.5101, 0.5006, 0.4962, 0.3995, 0.3501, 0.4632, 0.5339, 0.525, 0.4878])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_panorama_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPanoramaPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ negative_prompt = "french fries"
+ output = sd_pipe(**inputs, negative_prompt=negative_prompt)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array([0.5326, 0.5009, 0.5074, 0.4133, 0.371, 0.464, 0.5432, 0.5429, 0.4896])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_panorama_euler(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = EulerAncestralDiscreteScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear"
+ )
+ sd_pipe = StableDiffusionPanoramaPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array(
+ [0.48235387, 0.5423796, 0.46016198, 0.5377287, 0.5803722, 0.4876525, 0.5515428, 0.5045897, 0.50709957]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_panorama_pndm(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = PNDMScheduler()
+ sd_pipe = StableDiffusionPanoramaPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ # the pipeline does not expect pndm so test if it raises error.
+ with self.assertRaises(ValueError):
+ _ = sd_pipe(**inputs).images
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionPanoramaSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, seed=0):
+ generator = torch.manual_seed(seed)
+ inputs = {
+ "prompt": "a photo of the dolomites",
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_panorama_default(self):
+ model_ckpt = "stabilityai/stable-diffusion-2-base"
+ scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
+ pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, safety_checker=None)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 2048, 3)
+
+ expected_slice = np.array(
+ [
+ 0.36968392,
+ 0.27025372,
+ 0.32446766,
+ 0.28379387,
+ 0.36363274,
+ 0.30733347,
+ 0.27100027,
+ 0.27054125,
+ 0.25536096,
+ ]
+ )
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-2
+
+ def test_stable_diffusion_panorama_k_lms(self):
+ pipe = StableDiffusionPanoramaPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-base", safety_checker=None
+ )
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 2048, 3)
+
+ expected_slice = np.array(
+ [
+ [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ ]
+ ]
+ )
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-3
+
+ def test_stable_diffusion_panorama_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 256)
+ latents_slice = latents[0, -3:, -3:, -1]
+
+ expected_slice = np.array(
+ [
+ 0.18681869,
+ 0.33907816,
+ 0.5361276,
+ 0.14432865,
+ -0.02856611,
+ -0.73941123,
+ 0.23397987,
+ 0.47322682,
+ -0.37823164,
+ ]
+ )
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 256)
+ latents_slice = latents[0, -3:, -3:, -1]
+
+ expected_slice = np.array(
+ [
+ 0.18539645,
+ 0.33987248,
+ 0.5378559,
+ 0.14437142,
+ -0.02455261,
+ -0.7338317,
+ 0.23990755,
+ 0.47356272,
+ -0.3786505,
+ ]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ callback_fn.has_been_called = False
+
+ model_ckpt = "stabilityai/stable-diffusion-2-base"
+ scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
+ pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, safety_checker=None)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == 3
+
+ def test_stable_diffusion_panorama_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ model_ckpt = "stabilityai/stable-diffusion-2-base"
+ scheduler = DDIMScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
+ pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, safety_checker=None)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs()
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 5.2 GB is allocated
+ assert mem_bytes < 5.5 * 10**9
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_pix2pix_zero.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_pix2pix_zero.py
new file mode 100644
index 0000000000000000000000000000000000000000..46b93a0589ce1775e26921a6cc5dcdcf464c4b29
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_pix2pix_zero.py
@@ -0,0 +1,470 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMInverseScheduler,
+ DDIMScheduler,
+ DDPMScheduler,
+ EulerAncestralDiscreteScheduler,
+ LMSDiscreteScheduler,
+ StableDiffusionPix2PixZeroPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import load_image, load_pt, require_torch_gpu, skip_mps
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS, TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+@skip_mps
+class StableDiffusionPix2PixZeroPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionPix2PixZeroPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+
+ @classmethod
+ def setUpClass(cls):
+ cls.source_embeds = load_pt(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/pix2pix/src_emb_0.pt"
+ )
+
+ cls.target_embeds = load_pt(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/pix2pix/tgt_emb_0.pt"
+ )
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = DDIMScheduler()
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ "inverse_scheduler": None,
+ "caption_generator": None,
+ "caption_processor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ generator = torch.manual_seed(seed)
+
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "cross_attention_guidance_amount": 0.15,
+ "source_embeds": self.source_embeds,
+ "target_embeds": self.target_embeds,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_pix2pix_zero_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPix2PixZeroPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5184, 0.503, 0.4917, 0.4022, 0.3455, 0.464, 0.5324, 0.5323, 0.4894])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_zero_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPix2PixZeroPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ negative_prompt = "french fries"
+ output = sd_pipe(**inputs, negative_prompt=negative_prompt)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5464, 0.5072, 0.5012, 0.4124, 0.3624, 0.466, 0.5413, 0.5468, 0.4927])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_zero_euler(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = EulerAncestralDiscreteScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear"
+ )
+ sd_pipe = StableDiffusionPix2PixZeroPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5114, 0.5051, 0.5222, 0.5279, 0.5037, 0.5156, 0.4604, 0.4966, 0.504])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_pix2pix_zero_ddpm(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = DDPMScheduler()
+ sd_pipe = StableDiffusionPix2PixZeroPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5185, 0.5027, 0.492, 0.401, 0.3445, 0.464, 0.5321, 0.5327, 0.4892])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ # Non-determinism caused by the scheduler optimizing the latent inputs during inference
+ @unittest.skip("non-deterministic pipeline")
+ def test_inference_batch_single_identical(self):
+ return super().test_inference_batch_single_identical()
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionPix2PixZeroPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @classmethod
+ def setUpClass(cls):
+ cls.source_embeds = load_pt(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/pix2pix/cat.pt"
+ )
+
+ cls.target_embeds = load_pt(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/pix2pix/dog.pt"
+ )
+
+ def get_inputs(self, seed=0):
+ generator = torch.manual_seed(seed)
+
+ inputs = {
+ "prompt": "turn him into a cyborg",
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "cross_attention_guidance_amount": 0.15,
+ "source_embeds": self.source_embeds,
+ "target_embeds": self.target_embeds,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_pix2pix_zero_default(self):
+ pipe = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.5742, 0.5757, 0.5747, 0.5781, 0.5688, 0.5713, 0.5742, 0.5664, 0.5747])
+
+ assert np.abs(expected_slice - image_slice).max() < 5e-2
+
+ def test_stable_diffusion_pix2pix_zero_k_lms(self):
+ pipe = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.6367, 0.5459, 0.5146, 0.5479, 0.4905, 0.4753, 0.4961, 0.4629, 0.4624])
+
+ assert np.abs(expected_slice - image_slice).max() < 5e-2
+
+ def test_stable_diffusion_pix2pix_zero_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([0.1345, 0.268, 0.1539, 0.0726, 0.0959, 0.2261, -0.2673, 0.0277, -0.2062])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([0.1393, 0.2637, 0.1617, 0.0724, 0.0987, 0.2271, -0.2666, 0.0299, -0.2104])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ callback_fn.has_been_called = False
+
+ pipe = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == 3
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs()
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 8.2 GB is allocated
+ assert mem_bytes < 8.2 * 10**9
+
+
+@slow
+@require_torch_gpu
+class InversionPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @classmethod
+ def setUpClass(cls):
+ raw_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/pix2pix/cat_6.png"
+ )
+
+ raw_image = raw_image.convert("RGB").resize((512, 512))
+
+ cls.raw_image = raw_image
+
+ def test_stable_diffusion_pix2pix_inversion(self):
+ pipe = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.inverse_scheduler = DDIMInverseScheduler.from_config(pipe.scheduler.config)
+
+ caption = "a photography of a cat with flowers"
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ output = pipe.invert(caption, image=self.raw_image, generator=generator, num_inference_steps=10)
+ inv_latents = output[0]
+
+ image_slice = inv_latents[0, -3:, -3:, -1].flatten()
+
+ assert inv_latents.shape == (1, 4, 64, 64)
+ expected_slice = np.array([0.8447, -0.0730, 0.7588, -1.2070, -0.4678, 0.1511, -0.8555, 1.1816, -0.7666])
+
+ assert np.abs(expected_slice - image_slice.cpu().numpy()).max() < 5e-2
+
+ def test_stable_diffusion_2_pix2pix_inversion(self):
+ pipe = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.inverse_scheduler = DDIMInverseScheduler.from_config(pipe.scheduler.config)
+
+ caption = "a photography of a cat with flowers"
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ output = pipe.invert(caption, image=self.raw_image, generator=generator, num_inference_steps=10)
+ inv_latents = output[0]
+
+ image_slice = inv_latents[0, -3:, -3:, -1].flatten()
+
+ assert inv_latents.shape == (1, 4, 64, 64)
+ expected_slice = np.array([0.8970, -0.1611, 0.4766, -1.1162, -0.5923, 0.1050, -0.9678, 1.0537, -0.6050])
+
+ assert np.abs(expected_slice - image_slice.cpu().numpy()).max() < 5e-2
+
+ def test_stable_diffusion_pix2pix_full(self):
+ # numpy array of https://huggingface.co/datasets/hf-internal-testing/diffusers-images/blob/main/pix2pix/dog.png
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/pix2pix/dog.npy"
+ )
+
+ pipe = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.inverse_scheduler = DDIMInverseScheduler.from_config(pipe.scheduler.config)
+
+ caption = "a photography of a cat with flowers"
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ output = pipe.invert(caption, image=self.raw_image, generator=generator)
+ inv_latents = output[0]
+
+ source_prompts = 4 * ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
+ target_prompts = 4 * ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
+
+ source_embeds = pipe.get_embeds(source_prompts)
+ target_embeds = pipe.get_embeds(target_prompts)
+
+ image = pipe(
+ caption,
+ source_embeds=source_embeds,
+ target_embeds=target_embeds,
+ num_inference_steps=50,
+ cross_attention_guidance_amount=0.15,
+ generator=generator,
+ latents=inv_latents,
+ negative_prompt=caption,
+ output_type="np",
+ ).images
+
+ max_diff = np.abs(expected_image - image).mean()
+ assert max_diff < 0.05
+
+ def test_stable_diffusion_2_pix2pix_full(self):
+ # numpy array of https://huggingface.co/datasets/hf-internal-testing/diffusers-images/blob/main/pix2pix/dog_2.png
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/pix2pix/dog_2.npy"
+ )
+
+ pipe = StableDiffusionPix2PixZeroPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.inverse_scheduler = DDIMInverseScheduler.from_config(pipe.scheduler.config)
+
+ caption = "a photography of a cat with flowers"
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ output = pipe.invert(caption, image=self.raw_image, generator=generator)
+ inv_latents = output[0]
+
+ source_prompts = 4 * ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
+ target_prompts = 4 * ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
+
+ source_embeds = pipe.get_embeds(source_prompts)
+ target_embeds = pipe.get_embeds(target_prompts)
+
+ image = pipe(
+ caption,
+ source_embeds=source_embeds,
+ target_embeds=target_embeds,
+ num_inference_steps=125,
+ cross_attention_guidance_amount=0.015,
+ generator=generator,
+ latents=inv_latents,
+ negative_prompt=caption,
+ output_type="np",
+ ).images
+
+ mean_diff = np.abs(expected_image - image).mean()
+ assert mean_diff < 0.25
diff --git a/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_sag.py b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_sag.py
new file mode 100644
index 0000000000000000000000000000000000000000..abaefbcad0118cf494d10e6ba4c44638af9d285d
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion/test_stable_diffusion_sag.py
@@ -0,0 +1,184 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ StableDiffusionSAGPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionSAGPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionSAGPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+ test_cpu_offload = False
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": ".",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 1.0,
+ "sag_scale": 1.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_stable_diffusion_1(self):
+ sag_pipe = StableDiffusionSAGPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+ sag_pipe = sag_pipe.to(torch_device)
+ sag_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "."
+ generator = torch.manual_seed(0)
+ output = sag_pipe(
+ [prompt], generator=generator, guidance_scale=7.5, sag_scale=1.0, num_inference_steps=20, output_type="np"
+ )
+
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.1568, 0.1738, 0.1695, 0.1693, 0.1507, 0.1705, 0.1547, 0.1751, 0.1949])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 5e-2
+
+ def test_stable_diffusion_2(self):
+ sag_pipe = StableDiffusionSAGPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base")
+ sag_pipe = sag_pipe.to(torch_device)
+ sag_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "."
+ generator = torch.manual_seed(0)
+ output = sag_pipe(
+ [prompt], generator=generator, guidance_scale=7.5, sag_scale=1.0, num_inference_steps=20, output_type="np"
+ )
+
+ image = output.images
+
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.3459, 0.2876, 0.2537, 0.3002, 0.2671, 0.2160, 0.3026, 0.2262, 0.2371])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 5e-2
+
+ def test_stable_diffusion_2_non_square(self):
+ sag_pipe = StableDiffusionSAGPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base")
+ sag_pipe = sag_pipe.to(torch_device)
+ sag_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "."
+ generator = torch.manual_seed(0)
+ output = sag_pipe(
+ [prompt],
+ width=768,
+ height=512,
+ generator=generator,
+ guidance_scale=7.5,
+ sag_scale=1.0,
+ num_inference_steps=20,
+ output_type="np",
+ )
+
+ image = output.images
+
+ assert image.shape == (1, 512, 768, 3)
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/__init__.py b/diffusers/tests/pipelines/stable_diffusion_2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa3c3d628e4f1ec74c6729db436e4f20c0e714c5
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion.py
@@ -0,0 +1,563 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+ logging,
+)
+from diffusers.utils import load_numpy, nightly, slow, torch_device
+from diffusers.utils.testing_utils import CaptureLogger, require_torch_gpu
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusion2PipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ # SD2-specific config below
+ attention_head_dim=(2, 4),
+ use_linear_projection=True,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ sample_size=128,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ # SD2-specific config below
+ hidden_act="gelu",
+ projection_dim=512,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_ddim(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5649, 0.6022, 0.4804, 0.5270, 0.5585, 0.4643, 0.5159, 0.4963, 0.4793])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_pndm(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = PNDMScheduler(skip_prk_steps=True)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5099, 0.5677, 0.4671, 0.5128, 0.5697, 0.4676, 0.5277, 0.4964, 0.4946])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_k_lms(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = LMSDiscreteScheduler.from_config(components["scheduler"].config)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.4717, 0.5376, 0.4568, 0.5225, 0.5734, 0.4797, 0.5467, 0.5074, 0.5043])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_k_euler_ancestral(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = EulerAncestralDiscreteScheduler.from_config(components["scheduler"].config)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.4715, 0.5376, 0.4569, 0.5224, 0.5734, 0.4797, 0.5465, 0.5074, 0.5046])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_k_euler(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ components["scheduler"] = EulerDiscreteScheduler.from_config(components["scheduler"].config)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.4717, 0.5376, 0.4568, 0.5225, 0.5734, 0.4797, 0.5467, 0.5074, 0.5043])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_long_prompt(self):
+ components = self.get_dummy_components()
+ components["scheduler"] = LMSDiscreteScheduler.from_config(components["scheduler"].config)
+ sd_pipe = StableDiffusionPipeline(**components)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ do_classifier_free_guidance = True
+ negative_prompt = None
+ num_images_per_prompt = 1
+ logger = logging.get_logger("diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion")
+
+ prompt = 25 * "@"
+ with CaptureLogger(logger) as cap_logger_3:
+ text_embeddings_3 = sd_pipe._encode_prompt(
+ prompt, torch_device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ prompt = 100 * "@"
+ with CaptureLogger(logger) as cap_logger:
+ text_embeddings = sd_pipe._encode_prompt(
+ prompt, torch_device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ negative_prompt = "Hello"
+ with CaptureLogger(logger) as cap_logger_2:
+ text_embeddings_2 = sd_pipe._encode_prompt(
+ prompt, torch_device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
+ )
+
+ assert text_embeddings_3.shape == text_embeddings_2.shape == text_embeddings.shape
+ assert text_embeddings.shape[1] == 77
+
+ assert cap_logger.out == cap_logger_2.out
+ # 100 - 77 + 1 (BOS token) + 1 (EOS token) = 25
+ assert cap_logger.out.count("@") == 25
+ assert cap_logger_3.out == ""
+
+
+@slow
+@require_torch_gpu
+class StableDiffusion2PipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ latents = np.random.RandomState(seed).standard_normal((1, 4, 64, 64))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "prompt": "a photograph of an astronaut riding a horse",
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_default_ddim(self):
+ pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-base")
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.49493, 0.47896, 0.40798, 0.54214, 0.53212, 0.48202, 0.47656, 0.46329, 0.48506])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_pndm(self):
+ pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-base")
+ pipe.scheduler = PNDMScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.49493, 0.47896, 0.40798, 0.54214, 0.53212, 0.48202, 0.47656, 0.46329, 0.48506])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_k_lms(self):
+ pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-base")
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1].flatten()
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.10440, 0.13115, 0.11100, 0.10141, 0.11440, 0.07215, 0.11332, 0.09693, 0.10006])
+ assert np.abs(image_slice - expected_slice).max() < 1e-4
+
+ def test_stable_diffusion_attention_slicing(self):
+ torch.cuda.reset_peak_memory_stats()
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-base", torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ # enable attention slicing
+ pipe.enable_attention_slicing()
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ image_sliced = pipe(**inputs).images
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+ # make sure that less than 3.3 GB is allocated
+ assert mem_bytes < 3.3 * 10**9
+
+ # disable slicing
+ pipe.disable_attention_slicing()
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ image = pipe(**inputs).images
+
+ # make sure that more than 3.3 GB is allocated
+ mem_bytes = torch.cuda.max_memory_allocated()
+ assert mem_bytes > 3.3 * 10**9
+ assert np.abs(image_sliced - image).max() < 1e-3
+
+ def test_stable_diffusion_text2img_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [-0.3862, -0.4507, -1.1729, 0.0686, -1.1045, 0.7124, -1.8301, 0.1903, 1.2773]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 64, 64)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [0.2720, -0.1863, -0.7383, -0.5029, -0.7534, 0.3970, -0.7646, 0.4468, 1.2686]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ callback_fn.has_been_called = False
+
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-base", torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == inputs["num_inference_steps"]
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-base", torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.8 GB is allocated
+ assert mem_bytes < 2.8 * 10**9
+
+ def test_stable_diffusion_pipeline_with_model_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+
+ # Normal inference
+
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-base",
+ torch_dtype=torch.float16,
+ )
+ pipe.unet.set_default_attn_processor()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ outputs = pipe(**inputs)
+ mem_bytes = torch.cuda.max_memory_allocated()
+
+ # With model offloading
+
+ # Reload but don't move to cuda
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-base",
+ torch_dtype=torch.float16,
+ )
+ pipe.unet.set_default_attn_processor()
+
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe.enable_model_cpu_offload()
+ pipe.set_progress_bar_config(disable=None)
+ inputs = self.get_inputs(torch_device, dtype=torch.float16)
+ outputs_offloaded = pipe(**inputs)
+ mem_bytes_offloaded = torch.cuda.max_memory_allocated()
+
+ assert np.abs(outputs.images - outputs_offloaded.images).max() < 1e-3
+ assert mem_bytes_offloaded < mem_bytes
+ assert mem_bytes_offloaded < 3 * 10**9
+ for module in pipe.text_encoder, pipe.unet, pipe.vae:
+ assert module.device == torch.device("cpu")
+
+ # With attention slicing
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe.enable_attention_slicing()
+ _ = pipe(**inputs)
+ mem_bytes_slicing = torch.cuda.max_memory_allocated()
+ assert mem_bytes_slicing < mem_bytes_offloaded
+
+
+@nightly
+@require_torch_gpu
+class StableDiffusion2PipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=generator_device).manual_seed(seed)
+ latents = np.random.RandomState(seed).standard_normal((1, 4, 64, 64))
+ latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
+ inputs = {
+ "prompt": "a photograph of an astronaut riding a horse",
+ "latents": latents,
+ "generator": generator,
+ "num_inference_steps": 50,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_2_0_default_ddim(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-base").to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_2_text2img/stable_diffusion_2_0_base_ddim.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_2_1_default_pndm(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base").to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_2_text2img/stable_diffusion_2_1_base_pndm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_ddim(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base").to(torch_device)
+ sd_pipe.scheduler = DDIMScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_2_text2img/stable_diffusion_2_1_base_ddim.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_lms(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base").to(torch_device)
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_2_text2img/stable_diffusion_2_1_base_lms.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_euler(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base").to(torch_device)
+ sd_pipe.scheduler = EulerDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_2_text2img/stable_diffusion_2_1_base_euler.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_stable_diffusion_dpm(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1-base").to(torch_device)
+ sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs(torch_device)
+ inputs["num_inference_steps"] = 25
+ image = sd_pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_2_text2img/stable_diffusion_2_1_base_dpm_multi.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_attend_and_excite.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_attend_and_excite.py
new file mode 100644
index 0000000000000000000000000000000000000000..780abf304a469ddefbe35d5f5132367fe3c8213d
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_attend_and_excite.py
@@ -0,0 +1,178 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ StableDiffusionAttendAndExcitePipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import load_numpy, skip_mps, slow
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+@skip_mps
+class StableDiffusionAttendAndExcitePipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionAttendAndExcitePipeline
+ test_attention_slicing = False
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS.union({"token_indices"})
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ # SD2-specific config below
+ attention_head_dim=(2, 4),
+ use_linear_projection=True,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ sample_size=128,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ # SD2-specific config below
+ hidden_act="gelu",
+ projection_dim=512,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = inputs = {
+ "prompt": "a cat and a frog",
+ "token_indices": [2, 5],
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ "max_iter_to_alter": 2,
+ "thresholds": {0: 0.7},
+ }
+ return inputs
+
+ def test_inference(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ self.assertEqual(image.shape, (1, 64, 64, 3))
+ expected_slice = np.array(
+ [0.5644937, 0.60543084, 0.48239064, 0.5206757, 0.55623394, 0.46045133, 0.5100435, 0.48919064, 0.4759359]
+ )
+ max_diff = np.abs(image_slice.flatten() - expected_slice).max()
+ self.assertLessEqual(max_diff, 1e-3)
+
+ def test_inference_batch_consistent(self):
+ # NOTE: Larger batch sizes cause this test to timeout, only test on smaller batches
+ self._test_inference_batch_consistent(batch_sizes=[2, 4])
+
+
+@require_torch_gpu
+@slow
+class StableDiffusionAttendAndExcitePipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_attend_and_excite_fp16(self):
+ generator = torch.manual_seed(51)
+
+ pipe = StableDiffusionAttendAndExcitePipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe.to("cuda")
+
+ prompt = "a painting of an elephant with glasses"
+ token_indices = [5, 7]
+
+ image = pipe(
+ prompt=prompt,
+ token_indices=token_indices,
+ guidance_scale=7.5,
+ generator=generator,
+ num_inference_steps=5,
+ max_iter_to_alter=5,
+ output_type="numpy",
+ ).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/attend-and-excite/elephant_glasses.npy"
+ )
+ assert np.abs((expected_image - image).max()) < 5e-1
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_depth.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_depth.py
new file mode 100644
index 0000000000000000000000000000000000000000..c2ad239f6888027a0e39c844c826f9482770b754
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_depth.py
@@ -0,0 +1,587 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import (
+ CLIPTextConfig,
+ CLIPTextModel,
+ CLIPTokenizer,
+ DPTConfig,
+ DPTFeatureExtractor,
+ DPTForDepthEstimation,
+)
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionDepth2ImgPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import (
+ floats_tensor,
+ is_accelerate_available,
+ is_accelerate_version,
+ load_image,
+ load_numpy,
+ nightly,
+ slow,
+ torch_device,
+)
+from diffusers.utils.testing_utils import require_torch_gpu, skip_mps
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS, TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+@skip_mps
+class StableDiffusionDepth2ImgPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionDepth2ImgPipeline
+ test_save_load_optional_components = False
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"height", "width"}
+ required_optional_params = PipelineTesterMixin.required_optional_params - {"latents"}
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=5,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ attention_head_dim=(2, 4),
+ use_linear_projection=True,
+ )
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ backbone_config = {
+ "global_padding": "same",
+ "layer_type": "bottleneck",
+ "depths": [3, 4, 9],
+ "out_features": ["stage1", "stage2", "stage3"],
+ "embedding_dynamic_padding": True,
+ "hidden_sizes": [96, 192, 384, 768],
+ "num_groups": 2,
+ }
+ depth_estimator_config = DPTConfig(
+ image_size=32,
+ patch_size=16,
+ num_channels=3,
+ hidden_size=32,
+ num_hidden_layers=4,
+ backbone_out_indices=(0, 1, 2, 3),
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ is_decoder=False,
+ initializer_range=0.02,
+ is_hybrid=True,
+ backbone_config=backbone_config,
+ backbone_featmap_shape=[1, 384, 24, 24],
+ )
+ depth_estimator = DPTForDepthEstimation(depth_estimator_config)
+ feature_extractor = DPTFeatureExtractor.from_pretrained(
+ "hf-internal-testing/tiny-random-DPTForDepthEstimation"
+ )
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "depth_estimator": depth_estimator,
+ "feature_extractor": feature_extractor,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed))
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ image = Image.fromarray(np.uint8(image)).convert("RGB").resize((32, 32))
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "image": image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_save_load_local(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir)
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir)
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(output - output_loaded).max()
+ self.assertLess(max_diff, 1e-4)
+
+ @unittest.skipIf(torch_device != "cuda", reason="float16 requires CUDA")
+ def test_save_load_float16(self):
+ components = self.get_dummy_components()
+ for name, module in components.items():
+ if hasattr(module, "half"):
+ components[name] = module.to(torch_device).half()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir)
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, torch_dtype=torch.float16)
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ for name, component in pipe_loaded.components.items():
+ if hasattr(component, "dtype"):
+ self.assertTrue(
+ component.dtype == torch.float16,
+ f"`{name}.dtype` switched from `float16` to {component.dtype} after loading.",
+ )
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(output - output_loaded).max()
+ self.assertLess(max_diff, 2e-2, "The output of the fp16 pipeline changed after saving and loading.")
+
+ @unittest.skipIf(torch_device != "cuda", reason="float16 requires CUDA")
+ def test_float16_inference(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ for name, module in components.items():
+ if hasattr(module, "half"):
+ components[name] = module.half()
+ pipe_fp16 = self.pipeline_class(**components)
+ pipe_fp16.to(torch_device)
+ pipe_fp16.set_progress_bar_config(disable=None)
+
+ output = pipe(**self.get_dummy_inputs(torch_device))[0]
+ output_fp16 = pipe_fp16(**self.get_dummy_inputs(torch_device))[0]
+
+ max_diff = np.abs(output - output_fp16).max()
+ self.assertLess(max_diff, 1.3e-2, "The outputs of the fp16 and fp32 pipelines are too different.")
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_accelerate_available() or is_accelerate_version("<", "0.14.0"),
+ reason="CPU offload is only available with CUDA and `accelerate v0.14.0` or higher",
+ )
+ def test_cpu_offload_forward_pass(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_without_offload = pipe(**inputs)[0]
+
+ pipe.enable_sequential_cpu_offload()
+ inputs = self.get_dummy_inputs(torch_device)
+ output_with_offload = pipe(**inputs)[0]
+
+ max_diff = np.abs(output_with_offload - output_without_offload).max()
+ self.assertLess(max_diff, 1e-4, "CPU offloading should not affect the inference results")
+
+ def test_dict_tuple_outputs_equivalent(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ output = pipe(**self.get_dummy_inputs(torch_device))[0]
+ output_tuple = pipe(**self.get_dummy_inputs(torch_device), return_dict=False)[0]
+
+ max_diff = np.abs(output - output_tuple).max()
+ self.assertLess(max_diff, 1e-4)
+
+ def test_progress_bar(self):
+ super().test_progress_bar()
+
+ def test_stable_diffusion_depth2img_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ pipe = StableDiffusionDepth2ImgPipeline(**components)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ if torch_device == "mps":
+ expected_slice = np.array([0.6071, 0.5035, 0.4378, 0.5776, 0.5753, 0.4316, 0.4513, 0.5263, 0.4546])
+ else:
+ expected_slice = np.array([0.6312, 0.4984, 0.4154, 0.4788, 0.5535, 0.4599, 0.4017, 0.5359, 0.4716])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_depth2img_negative_prompt(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ pipe = StableDiffusionDepth2ImgPipeline(**components)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ negative_prompt = "french fries"
+ output = pipe(**inputs, negative_prompt=negative_prompt)
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ if torch_device == "mps":
+ expected_slice = np.array([0.5825, 0.5135, 0.4095, 0.5452, 0.6059, 0.4211, 0.3994, 0.5177, 0.4335])
+ else:
+ expected_slice = np.array([0.6296, 0.5125, 0.3890, 0.4456, 0.5955, 0.4621, 0.3810, 0.5310, 0.4626])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_depth2img_multiple_init_images(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ pipe = StableDiffusionDepth2ImgPipeline(**components)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ inputs["prompt"] = [inputs["prompt"]] * 2
+ inputs["image"] = 2 * [inputs["image"]]
+ image = pipe(**inputs).images
+ image_slice = image[-1, -3:, -3:, -1]
+
+ assert image.shape == (2, 32, 32, 3)
+
+ if torch_device == "mps":
+ expected_slice = np.array([0.6501, 0.5150, 0.4939, 0.6688, 0.5437, 0.5758, 0.5115, 0.4406, 0.4551])
+ else:
+ expected_slice = np.array([0.6267, 0.5232, 0.6001, 0.6738, 0.5029, 0.6429, 0.5364, 0.4159, 0.4674])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ def test_stable_diffusion_depth2img_pil(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ pipe = StableDiffusionDepth2ImgPipeline(**components)
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ if torch_device == "mps":
+ expected_slice = np.array([0.53232, 0.47015, 0.40868, 0.45651, 0.4891, 0.4668, 0.4287, 0.48822, 0.47439])
+ else:
+ expected_slice = np.array([0.6312, 0.4984, 0.4154, 0.4788, 0.5535, 0.4599, 0.4017, 0.5359, 0.4716])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ @skip_mps
+ def test_attention_slicing_forward_pass(self):
+ return super().test_attention_slicing_forward_pass()
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionDepth2ImgPipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/depth2img/two_cats.png"
+ )
+ inputs = {
+ "prompt": "two tigers",
+ "image": init_image,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "strength": 0.75,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_depth2img_pipeline_default(self):
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-depth", safety_checker=None
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 480, 640, 3)
+ expected_slice = np.array([0.9057, 0.9365, 0.9258, 0.8937, 0.8555, 0.8541, 0.8260, 0.7747, 0.7421])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-4
+
+ def test_stable_diffusion_depth2img_pipeline_k_lms(self):
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-depth", safety_checker=None
+ )
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 480, 640, 3)
+ expected_slice = np.array([0.6363, 0.6274, 0.6309, 0.6370, 0.6226, 0.6286, 0.6213, 0.6453, 0.6306])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-4
+
+ def test_stable_diffusion_depth2img_pipeline_ddim(self):
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-depth", safety_checker=None
+ )
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images
+ image_slice = image[0, 253:256, 253:256, -1].flatten()
+
+ assert image.shape == (1, 480, 640, 3)
+ expected_slice = np.array([0.6424, 0.6524, 0.6249, 0.6041, 0.6634, 0.6420, 0.6522, 0.6555, 0.6436])
+
+ assert np.abs(expected_slice - image_slice).max() < 1e-4
+
+ def test_stable_diffusion_depth2img_intermediate_state(self):
+ number_of_steps = 0
+
+ def callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 1:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 60, 80)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [-0.7168, -1.5137, -0.1418, -2.9219, -2.7266, -2.4414, -2.1035, -3.0078, -1.7051]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 2:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 60, 80)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array(
+ [-0.7109, -1.5068, -0.1403, -2.9160, -2.7207, -2.4414, -2.1035, -3.0059, -1.7090]
+ )
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ callback_fn.has_been_called = False
+
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-depth", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ inputs = self.get_inputs(dtype=torch.float16)
+ pipe(**inputs, callback=callback_fn, callback_steps=1)
+ assert callback_fn.has_been_called
+ assert number_of_steps == 2
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-depth", safety_checker=None, torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ inputs = self.get_inputs(dtype=torch.float16)
+ _ = pipe(**inputs)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.9 GB is allocated
+ assert mem_bytes < 2.9 * 10**9
+
+
+@nightly
+@require_torch_gpu
+class StableDiffusionImg2ImgPipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def get_inputs(self, device="cpu", dtype=torch.float32, seed=0):
+ generator = torch.Generator(device=device).manual_seed(seed)
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/depth2img/two_cats.png"
+ )
+ inputs = {
+ "prompt": "two tigers",
+ "image": init_image,
+ "generator": generator,
+ "num_inference_steps": 3,
+ "strength": 0.75,
+ "guidance_scale": 7.5,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_depth2img_pndm(self):
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth")
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_depth2img/stable_diffusion_2_0_pndm.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_depth2img_ddim(self):
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth")
+ pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_depth2img/stable_diffusion_2_0_ddim.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_img2img_lms(self):
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth")
+ pipe.scheduler = LMSDiscreteScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs()
+ image = pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_depth2img/stable_diffusion_2_0_lms.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
+
+ def test_img2img_dpm(self):
+ pipe = StableDiffusionDepth2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-depth")
+ pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_inputs()
+ inputs["num_inference_steps"] = 30
+ image = pipe(**inputs).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
+ "/stable_diffusion_depth2img/stable_diffusion_2_0_dpm_multi.npy"
+ )
+ max_diff = np.abs(expected_image - image).max()
+ assert max_diff < 1e-3
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_flax.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..8db8ec7810068aab4517fe2066e3fab10a52f6f7
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_flax.py
@@ -0,0 +1,99 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+from diffusers import FlaxDPMSolverMultistepScheduler, FlaxStableDiffusionPipeline
+from diffusers.utils import is_flax_available, slow
+from diffusers.utils.testing_utils import require_flax
+
+
+if is_flax_available():
+ import jax
+ import jax.numpy as jnp
+ from flax.jax_utils import replicate
+ from flax.training.common_utils import shard
+
+
+@slow
+@require_flax
+class FlaxStableDiffusion2PipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+
+ def test_stable_diffusion_flax(self):
+ sd_pipe, params = FlaxStableDiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2",
+ revision="bf16",
+ dtype=jnp.bfloat16,
+ )
+
+ prompt = "A painting of a squirrel eating a burger"
+ num_samples = jax.device_count()
+ prompt = num_samples * [prompt]
+ prompt_ids = sd_pipe.prepare_inputs(prompt)
+
+ params = replicate(params)
+ prompt_ids = shard(prompt_ids)
+
+ prng_seed = jax.random.PRNGKey(0)
+ prng_seed = jax.random.split(prng_seed, jax.device_count())
+
+ images = sd_pipe(prompt_ids, params, prng_seed, num_inference_steps=25, jit=True)[0]
+ assert images.shape == (jax.device_count(), 1, 768, 768, 3)
+
+ images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
+ image_slice = images[0, 253:256, 253:256, -1]
+
+ output_slice = jnp.asarray(jax.device_get(image_slice.flatten()))
+ expected_slice = jnp.array([0.4238, 0.4414, 0.4395, 0.4453, 0.4629, 0.4590, 0.4531, 0.45508, 0.4512])
+ print(f"output_slice: {output_slice}")
+ assert jnp.abs(output_slice - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_dpm_flax(self):
+ model_id = "stabilityai/stable-diffusion-2"
+ scheduler, scheduler_params = FlaxDPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
+ sd_pipe, params = FlaxStableDiffusionPipeline.from_pretrained(
+ model_id,
+ scheduler=scheduler,
+ revision="bf16",
+ dtype=jnp.bfloat16,
+ )
+ params["scheduler"] = scheduler_params
+
+ prompt = "A painting of a squirrel eating a burger"
+ num_samples = jax.device_count()
+ prompt = num_samples * [prompt]
+ prompt_ids = sd_pipe.prepare_inputs(prompt)
+
+ params = replicate(params)
+ prompt_ids = shard(prompt_ids)
+
+ prng_seed = jax.random.PRNGKey(0)
+ prng_seed = jax.random.split(prng_seed, jax.device_count())
+
+ images = sd_pipe(prompt_ids, params, prng_seed, num_inference_steps=25, jit=True)[0]
+ assert images.shape == (jax.device_count(), 1, 768, 768, 3)
+
+ images = images.reshape((images.shape[0] * images.shape[1],) + images.shape[-3:])
+ image_slice = images[0, 253:256, 253:256, -1]
+
+ output_slice = jnp.asarray(jax.device_get(image_slice.flatten()))
+ expected_slice = jnp.array([0.4336, 0.42969, 0.4453, 0.4199, 0.4297, 0.4531, 0.4434, 0.4434, 0.4297])
+ print(f"output_slice: {output_slice}")
+ assert jnp.abs(output_slice - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_flax_inpaint.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_flax_inpaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..432619a79ddd32d288893e3021a14ab6893b370a
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_flax_inpaint.py
@@ -0,0 +1,82 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+from diffusers import FlaxStableDiffusionInpaintPipeline
+from diffusers.utils import is_flax_available, load_image, slow
+from diffusers.utils.testing_utils import require_flax
+
+
+if is_flax_available():
+ import jax
+ import jax.numpy as jnp
+ from flax.jax_utils import replicate
+ from flax.training.common_utils import shard
+
+
+@slow
+@require_flax
+class FlaxStableDiffusionInpaintPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+
+ def test_stable_diffusion_inpaint_pipeline(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/sd2-inpaint/init_image.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-inpaint/mask.png"
+ )
+
+ model_id = "xvjiarui/stable-diffusion-2-inpainting"
+ pipeline, params = FlaxStableDiffusionInpaintPipeline.from_pretrained(model_id, safety_checker=None)
+
+ prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+
+ prng_seed = jax.random.PRNGKey(0)
+ num_inference_steps = 50
+
+ num_samples = jax.device_count()
+ prompt = num_samples * [prompt]
+ init_image = num_samples * [init_image]
+ mask_image = num_samples * [mask_image]
+ prompt_ids, processed_masked_images, processed_masks = pipeline.prepare_inputs(prompt, init_image, mask_image)
+
+ # shard inputs and rng
+ params = replicate(params)
+ prng_seed = jax.random.split(prng_seed, jax.device_count())
+ prompt_ids = shard(prompt_ids)
+ processed_masked_images = shard(processed_masked_images)
+ processed_masks = shard(processed_masks)
+
+ output = pipeline(
+ prompt_ids, processed_masks, processed_masked_images, params, prng_seed, num_inference_steps, jit=True
+ )
+
+ images = output.images.reshape(num_samples, 512, 512, 3)
+
+ image_slice = images[0, 253:256, 253:256, -1]
+
+ output_slice = jnp.asarray(jax.device_get(image_slice.flatten()))
+ expected_slice = jnp.array(
+ [0.3611307, 0.37649736, 0.3757408, 0.38213953, 0.39295167, 0.3841631, 0.41554978, 0.4137475, 0.4217084]
+ )
+ print(f"output_slice: {output_slice}")
+ assert jnp.abs(output_slice - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_inpaint.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_inpaint.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee059314904fc31e748e99db6674c76190530ef7
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_inpaint.py
@@ -0,0 +1,255 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import AutoencoderKL, PNDMScheduler, StableDiffusionInpaintPipeline, UNet2DConditionModel
+from diffusers.utils import floats_tensor, load_image, load_numpy, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu, slow
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS, TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusion2InpaintPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionInpaintPipeline
+ params = TEXT_GUIDED_IMAGE_INPAINTING_PARAMS
+ batch_params = TEXT_GUIDED_IMAGE_INPAINTING_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=9,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ # SD2-specific config below
+ attention_head_dim=(2, 4),
+ use_linear_projection=True,
+ )
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ sample_size=128,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ # SD2-specific config below
+ hidden_act="gelu",
+ projection_dim=512,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "safety_checker": None,
+ "feature_extractor": None,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ # TODO: use tensor inputs instead of PIL, this is here just to leave the old expected_slices untouched
+ image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ image = image.cpu().permute(0, 2, 3, 1)[0]
+ init_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+ mask_image = Image.fromarray(np.uint8(image + 4)).convert("RGB").resize((64, 64))
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "image": init_image,
+ "mask_image": mask_image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_stable_diffusion_inpaint(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableDiffusionInpaintPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.4727, 0.5735, 0.3941, 0.5446, 0.5926, 0.4394, 0.5062, 0.4654, 0.4476])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionInpaintPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_stable_diffusion_inpaint_pipeline(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/sd2-inpaint/init_image.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-inpaint/mask.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-inpaint"
+ "/yellow_cat_sitting_on_a_park_bench.npy"
+ )
+
+ model_id = "stabilityai/stable-diffusion-2-inpainting"
+ pipe = StableDiffusionInpaintPipeline.from_pretrained(model_id, safety_checker=None)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ mask_image=mask_image,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+ assert np.abs(expected_image - image).max() < 1e-3
+
+ def test_stable_diffusion_inpaint_pipeline_fp16(self):
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/sd2-inpaint/init_image.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-inpaint/mask.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-inpaint"
+ "/yellow_cat_sitting_on_a_park_bench_fp16.npy"
+ )
+
+ model_id = "stabilityai/stable-diffusion-2-inpainting"
+ pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ model_id,
+ torch_dtype=torch.float16,
+ safety_checker=None,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=init_image,
+ mask_image=mask_image,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+ assert np.abs(expected_image - image).max() < 5e-1
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/sd2-inpaint/init_image.png"
+ )
+ mask_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-inpaint/mask.png"
+ )
+
+ model_id = "stabilityai/stable-diffusion-2-inpainting"
+ pndm = PNDMScheduler.from_pretrained(model_id, subfolder="scheduler")
+ pipe = StableDiffusionInpaintPipeline.from_pretrained(
+ model_id,
+ safety_checker=None,
+ scheduler=pndm,
+ torch_dtype=torch.float16,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
+
+ generator = torch.manual_seed(0)
+ _ = pipe(
+ prompt=prompt,
+ image=init_image,
+ mask_image=mask_image,
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ )
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.65 GB is allocated
+ assert mem_bytes < 2.65 * 10**9
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_latent_upscale.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_latent_upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..38f4b053714bb048f412883b10cb12bfbb010e93
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_latent_upscale.py
@@ -0,0 +1,229 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ EulerDiscreteScheduler,
+ StableDiffusionLatentUpscalePipeline,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import floats_tensor, load_image, load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS, TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionLatentUpscalePipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableDiffusionLatentUpscalePipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {
+ "height",
+ "width",
+ "cross_attention_kwargs",
+ "negative_prompt_embeds",
+ "prompt_embeds",
+ }
+ required_optional_params = PipelineTesterMixin.required_optional_params - {"num_images_per_prompt"}
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+ test_cpu_offload = True
+
+ @property
+ def dummy_image(self):
+ batch_size = 1
+ num_channels = 4
+ sizes = (16, 16)
+
+ image = floats_tensor((batch_size, num_channels) + sizes, rng=random.Random(0)).to(torch_device)
+ return image
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ act_fn="gelu",
+ attention_head_dim=8,
+ norm_num_groups=None,
+ block_out_channels=[32, 32, 64, 64],
+ time_cond_proj_dim=160,
+ conv_in_kernel=1,
+ conv_out_kernel=1,
+ cross_attention_dim=32,
+ down_block_types=(
+ "KDownBlock2D",
+ "KCrossAttnDownBlock2D",
+ "KCrossAttnDownBlock2D",
+ "KCrossAttnDownBlock2D",
+ ),
+ in_channels=8,
+ mid_block_type=None,
+ only_cross_attention=False,
+ out_channels=5,
+ resnet_time_scale_shift="scale_shift",
+ time_embedding_type="fourier",
+ timestep_post_act="gelu",
+ up_block_types=("KCrossAttnUpBlock2D", "KCrossAttnUpBlock2D", "KCrossAttnUpBlock2D", "KUpBlock2D"),
+ )
+ vae = AutoencoderKL(
+ block_out_channels=[32, 32, 64, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=[
+ "DownEncoderBlock2D",
+ "DownEncoderBlock2D",
+ "DownEncoderBlock2D",
+ "DownEncoderBlock2D",
+ ],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ scheduler = EulerDiscreteScheduler(prediction_type="sample")
+ text_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ hidden_act="quick_gelu",
+ projection_dim=512,
+ )
+ text_encoder = CLIPTextModel(text_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": model.eval(),
+ "vae": vae.eval(),
+ "scheduler": scheduler,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ }
+
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "image": self.dummy_image.cpu(),
+ "generator": generator,
+ "num_inference_steps": 2,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_inference(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ image = pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ self.assertEqual(image.shape, (1, 256, 256, 3))
+ expected_slice = np.array(
+ [0.47222412, 0.41921633, 0.44717434, 0.46874192, 0.42588258, 0.46150726, 0.4677534, 0.45583832, 0.48579055]
+ )
+ max_diff = np.abs(image_slice.flatten() - expected_slice).max()
+ self.assertLessEqual(max_diff, 1e-3)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical(relax_max_difference=False)
+
+
+@require_torch_gpu
+@slow
+class StableDiffusionLatentUpscalePipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_latent_upscaler_fp16(self):
+ generator = torch.manual_seed(33)
+
+ pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
+ pipe.to("cuda")
+
+ upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained(
+ "stabilityai/sd-x2-latent-upscaler", torch_dtype=torch.float16
+ )
+ upscaler.to("cuda")
+
+ prompt = "a photo of an astronaut high resolution, unreal engine, ultra realistic"
+
+ low_res_latents = pipe(prompt, generator=generator, output_type="latent").images
+
+ image = upscaler(
+ prompt=prompt,
+ image=low_res_latents,
+ num_inference_steps=20,
+ guidance_scale=0,
+ generator=generator,
+ output_type="np",
+ ).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/latent-upscaler/astronaut_1024.npy"
+ )
+ assert np.abs((expected_image - image).mean()) < 5e-2
+
+ def test_latent_upscaler_fp16_image(self):
+ generator = torch.manual_seed(33)
+
+ upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained(
+ "stabilityai/sd-x2-latent-upscaler", torch_dtype=torch.float16
+ )
+ upscaler.to("cuda")
+
+ prompt = "the temple of fire by Ross Tran and Gerardo Dottori, oil on canvas"
+
+ low_res_img = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/latent-upscaler/fire_temple_512.png"
+ )
+
+ image = upscaler(
+ prompt=prompt,
+ image=low_res_img,
+ num_inference_steps=20,
+ guidance_scale=0,
+ generator=generator,
+ output_type="np",
+ ).images[0]
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/latent-upscaler/fire_temple_1024.npy"
+ )
+ assert np.abs((expected_image - image).max()) < 5e-2
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_upscale.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_upscale.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8e7b858130bfd7ce9d8189d30a71cdd86e00b7e
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_upscale.py
@@ -0,0 +1,362 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from PIL import Image
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import AutoencoderKL, DDIMScheduler, DDPMScheduler, StableDiffusionUpscalePipeline, UNet2DConditionModel
+from diffusers.utils import floats_tensor, load_image, load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusionUpscalePipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @property
+ def dummy_image(self):
+ batch_size = 1
+ num_channels = 3
+ sizes = (32, 32)
+
+ image = floats_tensor((batch_size, num_channels) + sizes, rng=random.Random(0)).to(torch_device)
+ return image
+
+ @property
+ def dummy_cond_unet_upscale(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ block_out_channels=(32, 32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=7,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ # SD2-specific config below
+ attention_head_dim=8,
+ use_linear_projection=True,
+ only_cross_attention=(True, True, False),
+ num_class_embeds=100,
+ )
+ return model
+
+ @property
+ def dummy_vae(self):
+ torch.manual_seed(0)
+ model = AutoencoderKL(
+ block_out_channels=[32, 32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ return model
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ # SD2-specific config below
+ hidden_act="gelu",
+ projection_dim=512,
+ )
+ return CLIPTextModel(config)
+
+ def test_stable_diffusion_upscale(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet_upscale
+ low_res_scheduler = DDPMScheduler()
+ scheduler = DDIMScheduler(prediction_type="v_prediction")
+ vae = self.dummy_vae
+ text_encoder = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ image = self.dummy_image.cpu().permute(0, 2, 3, 1)[0]
+ low_res_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionUpscalePipeline(
+ unet=unet,
+ low_res_scheduler=low_res_scheduler,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ max_noise_level=350,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe(
+ [prompt],
+ image=low_res_image,
+ generator=generator,
+ guidance_scale=6.0,
+ noise_level=20,
+ num_inference_steps=2,
+ output_type="np",
+ )
+
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = sd_pipe(
+ [prompt],
+ image=low_res_image,
+ generator=generator,
+ guidance_scale=6.0,
+ noise_level=20,
+ num_inference_steps=2,
+ output_type="np",
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ expected_height_width = low_res_image.size[0] * 4
+ assert image.shape == (1, expected_height_width, expected_height_width, 3)
+ expected_slice = np.array([0.2562, 0.3606, 0.4204, 0.4469, 0.4822, 0.4647, 0.5315, 0.5748, 0.5606])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_upscale_batch(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet_upscale
+ low_res_scheduler = DDPMScheduler()
+ scheduler = DDIMScheduler(prediction_type="v_prediction")
+ vae = self.dummy_vae
+ text_encoder = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ image = self.dummy_image.cpu().permute(0, 2, 3, 1)[0]
+ low_res_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionUpscalePipeline(
+ unet=unet,
+ low_res_scheduler=low_res_scheduler,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ max_noise_level=350,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ output = sd_pipe(
+ 2 * [prompt],
+ image=2 * [low_res_image],
+ guidance_scale=6.0,
+ noise_level=20,
+ num_inference_steps=2,
+ output_type="np",
+ )
+ image = output.images
+ assert image.shape[0] == 2
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe(
+ [prompt],
+ image=low_res_image,
+ generator=generator,
+ num_images_per_prompt=2,
+ guidance_scale=6.0,
+ noise_level=20,
+ num_inference_steps=2,
+ output_type="np",
+ )
+ image = output.images
+ assert image.shape[0] == 2
+
+ @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
+ def test_stable_diffusion_upscale_fp16(self):
+ """Test that stable diffusion upscale works with fp16"""
+ unet = self.dummy_cond_unet_upscale
+ low_res_scheduler = DDPMScheduler()
+ scheduler = DDIMScheduler(prediction_type="v_prediction")
+ vae = self.dummy_vae
+ text_encoder = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ image = self.dummy_image.cpu().permute(0, 2, 3, 1)[0]
+ low_res_image = Image.fromarray(np.uint8(image)).convert("RGB").resize((64, 64))
+
+ # put models in fp16, except vae as it overflows in fp16
+ unet = unet.half()
+ text_encoder = text_encoder.half()
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionUpscalePipeline(
+ unet=unet,
+ low_res_scheduler=low_res_scheduler,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ max_noise_level=350,
+ )
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ image = sd_pipe(
+ [prompt],
+ image=low_res_image,
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ ).images
+
+ expected_height_width = low_res_image.size[0] * 4
+ assert image.shape == (1, expected_height_width, expected_height_width, 3)
+
+
+@slow
+@require_torch_gpu
+class StableDiffusionUpscalePipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_stable_diffusion_upscale_pipeline(self):
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/sd2-upscale/low_res_cat.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale"
+ "/upsampled_cat.npy"
+ )
+
+ model_id = "stabilityai/stable-diffusion-x4-upscaler"
+ pipe = StableDiffusionUpscalePipeline.from_pretrained(model_id)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ prompt = "a cat sitting on a park bench"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=image,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+ assert np.abs(expected_image - image).max() < 1e-3
+
+ def test_stable_diffusion_upscale_pipeline_fp16(self):
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/sd2-upscale/low_res_cat.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd2-upscale"
+ "/upsampled_cat_fp16.npy"
+ )
+
+ model_id = "stabilityai/stable-diffusion-x4-upscaler"
+ pipe = StableDiffusionUpscalePipeline.from_pretrained(
+ model_id,
+ torch_dtype=torch.float16,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ prompt = "a cat sitting on a park bench"
+
+ generator = torch.manual_seed(0)
+ output = pipe(
+ prompt=prompt,
+ image=image,
+ generator=generator,
+ output_type="np",
+ )
+ image = output.images[0]
+
+ assert image.shape == (512, 512, 3)
+ assert np.abs(expected_image - image).max() < 5e-1
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/sd2-upscale/low_res_cat.png"
+ )
+
+ model_id = "stabilityai/stable-diffusion-x4-upscaler"
+ pipe = StableDiffusionUpscalePipeline.from_pretrained(
+ model_id,
+ torch_dtype=torch.float16,
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing(1)
+ pipe.enable_sequential_cpu_offload()
+
+ prompt = "a cat sitting on a park bench"
+
+ generator = torch.manual_seed(0)
+ _ = pipe(
+ prompt=prompt,
+ image=image,
+ generator=generator,
+ num_inference_steps=5,
+ output_type="np",
+ )
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.9 GB is allocated
+ assert mem_bytes < 2.9 * 10**9
diff --git a/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_v_pred.py b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_v_pred.py
new file mode 100644
index 0000000000000000000000000000000000000000..8aab5845741c638d2d93a28f1a23616086adbddb
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_2/test_stable_diffusion_v_pred.py
@@ -0,0 +1,481 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import time
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerDiscreteScheduler,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.utils import load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class StableDiffusion2VPredictionPipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @property
+ def dummy_cond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ # SD2-specific config below
+ attention_head_dim=(2, 4),
+ use_linear_projection=True,
+ )
+ return model
+
+ @property
+ def dummy_vae(self):
+ torch.manual_seed(0)
+ model = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ sample_size=128,
+ )
+ return model
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ # SD2-specific config below
+ hidden_act="gelu",
+ projection_dim=64,
+ )
+ return CLIPTextModel(config)
+
+ def test_stable_diffusion_v_pred_ddim(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ prediction_type="v_prediction",
+ )
+
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=None,
+ requires_safety_checker=False,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.6424, 0.6109, 0.494, 0.5088, 0.4984, 0.4525, 0.5059, 0.5068, 0.4474])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_v_pred_k_euler(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = EulerDiscreteScheduler(
+ beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", prediction_type="v_prediction"
+ )
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=None,
+ requires_safety_checker=False,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
+
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.4616, 0.5184, 0.4887, 0.5111, 0.4839, 0.48, 0.5119, 0.5263, 0.4776])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
+ def test_stable_diffusion_v_pred_fp16(self):
+ """Test that stable diffusion v-prediction works with fp16"""
+ unet = self.dummy_cond_unet
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ prediction_type="v_prediction",
+ )
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # put models in fp16
+ unet = unet.half()
+ vae = vae.half()
+ bert = bert.half()
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=None,
+ requires_safety_checker=False,
+ )
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ image = sd_pipe([prompt], generator=generator, num_inference_steps=2, output_type="np").images
+
+ assert image.shape == (1, 64, 64, 3)
+
+
+@slow
+@require_torch_gpu
+class StableDiffusion2VPredictionPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_stable_diffusion_v_pred_default(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2")
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.enable_attention_slicing()
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=7.5, num_inference_steps=20, output_type="np")
+
+ image = output.images
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 768, 768, 3)
+ expected_slice = np.array([0.1868, 0.1922, 0.1527, 0.1921, 0.1908, 0.1624, 0.1779, 0.1652, 0.1734])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_v_pred_upcast_attention(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained(
+ "stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
+ )
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.enable_attention_slicing()
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=7.5, num_inference_steps=20, output_type="np")
+
+ image = output.images
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 768, 768, 3)
+ expected_slice = np.array([0.4209, 0.4087, 0.4097, 0.4209, 0.3860, 0.4329, 0.4280, 0.4324, 0.4187])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 5e-2
+
+ def test_stable_diffusion_v_pred_euler(self):
+ scheduler = EulerDiscreteScheduler.from_pretrained("stabilityai/stable-diffusion-2", subfolder="scheduler")
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", scheduler=scheduler)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.enable_attention_slicing()
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.manual_seed(0)
+
+ output = sd_pipe([prompt], generator=generator, num_inference_steps=5, output_type="numpy")
+ image = output.images
+
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 768, 768, 3)
+ expected_slice = np.array([0.1781, 0.1695, 0.1661, 0.1705, 0.1588, 0.1699, 0.2005, 0.1589, 0.1677])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_v_pred_dpm(self):
+ """
+ TODO: update this test after making DPM compatible with V-prediction!
+ """
+ scheduler = DPMSolverMultistepScheduler.from_pretrained(
+ "stabilityai/stable-diffusion-2", subfolder="scheduler"
+ )
+ sd_pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", scheduler=scheduler)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.enable_attention_slicing()
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "a photograph of an astronaut riding a horse"
+ generator = torch.manual_seed(0)
+ image = sd_pipe(
+ [prompt], generator=generator, guidance_scale=7.5, num_inference_steps=5, output_type="numpy"
+ ).images
+
+ image_slice = image[0, 253:256, 253:256, -1]
+ assert image.shape == (1, 768, 768, 3)
+ expected_slice = np.array([0.3303, 0.3184, 0.3291, 0.3300, 0.3256, 0.3113, 0.2965, 0.3134, 0.3192])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_attention_slicing_v_pred(self):
+ torch.cuda.reset_peak_memory_stats()
+ model_id = "stabilityai/stable-diffusion-2"
+ pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "a photograph of an astronaut riding a horse"
+
+ # make attention efficient
+ pipe.enable_attention_slicing()
+ generator = torch.manual_seed(0)
+ output_chunked = pipe(
+ [prompt], generator=generator, guidance_scale=7.5, num_inference_steps=10, output_type="numpy"
+ )
+ image_chunked = output_chunked.images
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+ # make sure that less than 5.5 GB is allocated
+ assert mem_bytes < 5.5 * 10**9
+
+ # disable slicing
+ pipe.disable_attention_slicing()
+ generator = torch.manual_seed(0)
+ output = pipe([prompt], generator=generator, guidance_scale=7.5, num_inference_steps=10, output_type="numpy")
+ image = output.images
+
+ # make sure that more than 5.5 GB is allocated
+ mem_bytes = torch.cuda.max_memory_allocated()
+ assert mem_bytes > 5.5 * 10**9
+ assert np.abs(image_chunked.flatten() - image.flatten()).max() < 1e-3
+
+ def test_stable_diffusion_text2img_pipeline_v_pred_default(self):
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/"
+ "sd2-text2img/astronaut_riding_a_horse_v_pred.npy"
+ )
+
+ pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2")
+ pipe.to(torch_device)
+ pipe.enable_attention_slicing()
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "astronaut riding a horse"
+
+ generator = torch.manual_seed(0)
+ output = pipe(prompt=prompt, guidance_scale=7.5, generator=generator, output_type="np")
+ image = output.images[0]
+
+ assert image.shape == (768, 768, 3)
+ assert np.abs(expected_image - image).max() < 7.5e-2
+
+ def test_stable_diffusion_text2img_pipeline_v_pred_fp16(self):
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/"
+ "sd2-text2img/astronaut_riding_a_horse_v_pred_fp16.npy"
+ )
+
+ pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", torch_dtype=torch.float16)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "astronaut riding a horse"
+
+ generator = torch.manual_seed(0)
+ output = pipe(prompt=prompt, guidance_scale=7.5, generator=generator, output_type="np")
+ image = output.images[0]
+
+ assert image.shape == (768, 768, 3)
+ assert np.abs(expected_image - image).max() < 7.5e-1
+
+ def test_stable_diffusion_text2img_intermediate_state_v_pred(self):
+ number_of_steps = 0
+
+ def test_callback_fn(step: int, timestep: int, latents: torch.FloatTensor) -> None:
+ test_callback_fn.has_been_called = True
+ nonlocal number_of_steps
+ number_of_steps += 1
+ if step == 0:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 96, 96)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([0.7749, 0.0325, 0.5088, 0.1619, 0.3372, 0.3667, -0.5186, 0.6860, 1.4326])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+ elif step == 19:
+ latents = latents.detach().cpu().numpy()
+ assert latents.shape == (1, 4, 96, 96)
+ latents_slice = latents[0, -3:, -3:, -1]
+ expected_slice = np.array([1.3887, 1.0273, 1.7266, 0.0726, 0.6611, 0.1598, -1.0547, 0.1522, 0.0227])
+
+ assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
+
+ test_callback_fn.has_been_called = False
+
+ pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+
+ prompt = "Andromeda galaxy in a bottle"
+
+ generator = torch.manual_seed(0)
+ pipe(
+ prompt=prompt,
+ num_inference_steps=20,
+ guidance_scale=7.5,
+ generator=generator,
+ callback=test_callback_fn,
+ callback_steps=1,
+ )
+ assert test_callback_fn.has_been_called
+ assert number_of_steps == 20
+
+ def test_stable_diffusion_low_cpu_mem_usage_v_pred(self):
+ pipeline_id = "stabilityai/stable-diffusion-2"
+
+ start_time = time.time()
+ pipeline_low_cpu_mem_usage = StableDiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16)
+ pipeline_low_cpu_mem_usage.to(torch_device)
+ low_cpu_mem_usage_time = time.time() - start_time
+
+ start_time = time.time()
+ _ = StableDiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16, low_cpu_mem_usage=False)
+ normal_load_time = time.time() - start_time
+
+ assert 2 * low_cpu_mem_usage_time < normal_load_time
+
+ def test_stable_diffusion_pipeline_with_sequential_cpu_offloading_v_pred(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipeline_id = "stabilityai/stable-diffusion-2"
+ prompt = "Andromeda galaxy in a bottle"
+
+ pipeline = StableDiffusionPipeline.from_pretrained(pipeline_id, torch_dtype=torch.float16)
+ pipeline = pipeline.to(torch_device)
+ pipeline.enable_attention_slicing(1)
+ pipeline.enable_sequential_cpu_offload()
+
+ generator = torch.manual_seed(0)
+ _ = pipeline(prompt, generator=generator, num_inference_steps=5)
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 2.8 GB is allocated
+ assert mem_bytes < 2.8 * 10**9
diff --git a/diffusers/tests/pipelines/stable_diffusion_safe/__init__.py b/diffusers/tests/pipelines/stable_diffusion_safe/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/stable_diffusion_safe/test_safe_diffusion.py b/diffusers/tests/pipelines/stable_diffusion_safe/test_safe_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f393a66d166ef80328af8fbb077013e09b1408d
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_diffusion_safe/test_safe_diffusion.py
@@ -0,0 +1,439 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import AutoencoderKL, DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler, UNet2DConditionModel
+from diffusers.pipelines.stable_diffusion_safe import StableDiffusionPipelineSafe as StableDiffusionPipeline
+from diffusers.utils import floats_tensor, nightly, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class SafeDiffusionPipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @property
+ def dummy_image(self):
+ batch_size = 1
+ num_channels = 3
+ sizes = (32, 32)
+
+ image = floats_tensor((batch_size, num_channels) + sizes, rng=random.Random(0)).to(torch_device)
+ return image
+
+ @property
+ def dummy_cond_unet(self):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ return model
+
+ @property
+ def dummy_vae(self):
+ torch.manual_seed(0)
+ model = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ return model
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ return CLIPTextModel(config)
+
+ @property
+ def dummy_extractor(self):
+ def extract(*args, **kwargs):
+ class Out:
+ def __init__(self):
+ self.pixel_values = torch.ones([0])
+
+ def to(self, device):
+ self.pixel_values.to(device)
+ return self
+
+ return Out()
+
+ return extract
+
+ def test_safe_diffusion_ddim(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5644, 0.6018, 0.4799, 0.5267, 0.5585, 0.4641, 0.516, 0.4964, 0.4792])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_pndm(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = sd_pipe([prompt], generator=generator, guidance_scale=6.0, num_inference_steps=2, output_type="np")
+
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=6.0,
+ num_inference_steps=2,
+ output_type="np",
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+ expected_slice = np.array([0.5095, 0.5674, 0.4668, 0.5126, 0.5697, 0.4675, 0.5278, 0.4964, 0.4945])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_stable_diffusion_no_safety_checker(self):
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-lms-pipe", safety_checker=None
+ )
+ assert isinstance(pipe, StableDiffusionPipeline)
+ assert isinstance(pipe.scheduler, LMSDiscreteScheduler)
+ assert pipe.safety_checker is None
+
+ image = pipe("example prompt", num_inference_steps=2).images[0]
+ assert image is not None
+
+ # check that there's no error when saving a pipeline with one of the models being None
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe = StableDiffusionPipeline.from_pretrained(tmpdirname)
+
+ # sanity check that the pipeline still works
+ assert pipe.safety_checker is None
+ image = pipe("example prompt", num_inference_steps=2).images[0]
+ assert image is not None
+
+ @unittest.skipIf(torch_device != "cuda", "This test requires a GPU")
+ def test_stable_diffusion_fp16(self):
+ """Test that stable diffusion works with fp16"""
+ unet = self.dummy_cond_unet
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ # put models in fp16
+ unet = unet.half()
+ vae = vae.half()
+ bert = bert.half()
+
+ # make sure here that pndm scheduler skips prk
+ sd_pipe = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger"
+ image = sd_pipe([prompt], num_inference_steps=2, output_type="np").images
+
+ assert image.shape == (1, 64, 64, 3)
+
+
+@nightly
+@require_torch_gpu
+class SafeDiffusionPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_harm_safe_stable_diffusion(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", safety_checker=None)
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = (
+ "portrait of girl with smokey eyes makeup in abandoned hotel, grange clothes, redshift, wide high angle"
+ " coloured polaroid photograph with flash, kodak film, hyper real, stunning moody cinematography, with"
+ " anamorphic lenses, by maripol, fallen angels by wong kar - wai, style of suspiria and neon demon and"
+ " children from bahnhof zoo, detailed "
+ )
+ seed = 4003660346
+ guidance_scale = 7
+
+ # without safety guidance (sld_guidance_scale = 0)
+ generator = torch.manual_seed(seed)
+ output = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ sld_guidance_scale=0,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [0.2278, 0.2231, 0.2249, 0.2333, 0.2303, 0.1885, 0.2273, 0.2144, 0.2176]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ # without safety guidance (strong configuration)
+ generator = torch.manual_seed(seed)
+ output = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ sld_guidance_scale=2000,
+ sld_warmup_steps=7,
+ sld_threshold=0.025,
+ sld_momentum_scale=0.5,
+ sld_mom_beta=0.7,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [0.2383, 0.2276, 0.236, 0.2192, 0.2186, 0.2053, 0.1971, 0.1901, 0.1719]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_nudity_safe_stable_diffusion(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", safety_checker=None)
+ sd_pipe.scheduler = LMSDiscreteScheduler.from_config(sd_pipe.scheduler.config)
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = "padme amidala taking a bath artwork, safe for work, no nudity"
+ seed = 2734971755
+ guidance_scale = 7
+
+ generator = torch.manual_seed(seed)
+ output = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ sld_guidance_scale=0,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [0.3502, 0.3622, 0.3396, 0.3642, 0.3478, 0.3318, 0.35, 0.3348, 0.3297]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ generator = torch.manual_seed(seed)
+ output = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ sld_guidance_scale=2000,
+ sld_warmup_steps=7,
+ sld_threshold=0.025,
+ sld_momentum_scale=0.5,
+ sld_mom_beta=0.7,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = [0.5531, 0.5206, 0.4895, 0.5156, 0.5182, 0.4751, 0.4802, 0.4803, 0.4443]
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_nudity_safetychecker_safe_stable_diffusion(self):
+ sd_pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
+ sd_pipe = sd_pipe.to(torch_device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ prompt = (
+ "the four horsewomen of the apocalypse, painting by tom of finland, gaston bussiere, craig mullins, j. c."
+ " leyendecker"
+ )
+ seed = 1044355234
+ guidance_scale = 12
+
+ generator = torch.manual_seed(seed)
+ output = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ sld_guidance_scale=0,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = np.array([0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
+
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-7
+
+ generator = torch.manual_seed(seed)
+ output = sd_pipe(
+ [prompt],
+ generator=generator,
+ guidance_scale=guidance_scale,
+ num_inference_steps=50,
+ output_type="np",
+ width=512,
+ height=512,
+ sld_guidance_scale=2000,
+ sld_warmup_steps=7,
+ sld_threshold=0.025,
+ sld_momentum_scale=0.5,
+ sld_mom_beta=0.7,
+ )
+
+ image = output.images
+ image_slice = image[0, -3:, -3:, -1]
+ expected_slice = np.array([0.5818, 0.6285, 0.6835, 0.6019, 0.625, 0.6754, 0.6096, 0.6334, 0.6561])
+ assert image.shape == (1, 512, 512, 3)
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/stable_unclip/__init__.py b/diffusers/tests/pipelines/stable_unclip/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/stable_unclip/test_stable_unclip.py b/diffusers/tests/pipelines/stable_unclip/test_stable_unclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..368ab21f24a91df7ff17ae8bf69a1acdfa949fab
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_unclip/test_stable_unclip.py
@@ -0,0 +1,229 @@
+import gc
+import unittest
+
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DDPMScheduler,
+ PriorTransformer,
+ StableUnCLIPPipeline,
+ UNet2DConditionModel,
+)
+from diffusers.pipelines.stable_diffusion.stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
+from diffusers.utils.testing_utils import load_numpy, require_torch_gpu, slow, torch_device
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin, assert_mean_pixel_difference
+
+
+class StableUnCLIPPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableUnCLIPPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+
+ # TODO(will) Expected attn_bias.stride(1) == 0 to be true, but got false
+ test_xformers_attention = False
+
+ def get_dummy_components(self):
+ embedder_hidden_size = 32
+ embedder_projection_dim = embedder_hidden_size
+
+ # prior components
+
+ torch.manual_seed(0)
+ prior_tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ torch.manual_seed(0)
+ prior_text_encoder = CLIPTextModelWithProjection(
+ CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=embedder_hidden_size,
+ projection_dim=embedder_projection_dim,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ )
+
+ torch.manual_seed(0)
+ prior = PriorTransformer(
+ num_attention_heads=2,
+ attention_head_dim=12,
+ embedding_dim=embedder_projection_dim,
+ num_layers=1,
+ )
+
+ torch.manual_seed(0)
+ prior_scheduler = DDPMScheduler(
+ variance_type="fixed_small_log",
+ prediction_type="sample",
+ num_train_timesteps=1000,
+ clip_sample=True,
+ clip_sample_range=5.0,
+ beta_schedule="squaredcos_cap_v2",
+ )
+
+ # regular denoising components
+
+ torch.manual_seed(0)
+ image_normalizer = StableUnCLIPImageNormalizer(embedding_dim=embedder_hidden_size)
+ image_noising_scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2")
+
+ torch.manual_seed(0)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ torch.manual_seed(0)
+ text_encoder = CLIPTextModel(
+ CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=embedder_hidden_size,
+ projection_dim=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ )
+
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("CrossAttnDownBlock2D", "DownBlock2D"),
+ up_block_types=("UpBlock2D", "CrossAttnUpBlock2D"),
+ block_out_channels=(32, 64),
+ attention_head_dim=(2, 4),
+ class_embed_type="projection",
+ # The class embeddings are the noise augmented image embeddings.
+ # I.e. the image embeddings concated with the noised embeddings of the same dimension
+ projection_class_embeddings_input_dim=embedder_projection_dim * 2,
+ cross_attention_dim=embedder_hidden_size,
+ layers_per_block=1,
+ upcast_attention=True,
+ use_linear_projection=True,
+ )
+
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_schedule="scaled_linear",
+ beta_start=0.00085,
+ beta_end=0.012,
+ prediction_type="v_prediction",
+ set_alpha_to_one=False,
+ steps_offset=1,
+ )
+
+ torch.manual_seed(0)
+ vae = AutoencoderKL()
+
+ components = {
+ # prior components
+ "prior_tokenizer": prior_tokenizer,
+ "prior_text_encoder": prior_text_encoder,
+ "prior": prior,
+ "prior_scheduler": prior_scheduler,
+ # image noising components
+ "image_normalizer": image_normalizer,
+ "image_noising_scheduler": image_noising_scheduler,
+ # regular denoising components
+ "tokenizer": tokenizer,
+ "text_encoder": text_encoder,
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ }
+
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "prior_num_inference_steps": 2,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ # Overriding PipelineTesterMixin::test_attention_slicing_forward_pass
+ # because UnCLIP GPU undeterminism requires a looser check.
+ def test_attention_slicing_forward_pass(self):
+ test_max_difference = torch_device == "cpu"
+
+ self._test_attention_slicing_forward_pass(test_max_difference=test_max_difference)
+
+ # Overriding PipelineTesterMixin::test_inference_batch_single_identical
+ # because UnCLIP undeterminism requires a looser check.
+ def test_inference_batch_single_identical(self):
+ test_max_difference = torch_device in ["cpu", "mps"]
+
+ self._test_inference_batch_single_identical(test_max_difference=test_max_difference)
+
+
+@slow
+@require_torch_gpu
+class StableUnCLIPPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_stable_unclip(self):
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/stable_unclip_2_1_l_anime_turtle_fp16.npy"
+ )
+
+ pipe = StableUnCLIPPipeline.from_pretrained("fusing/stable-unclip-2-1-l", torch_dtype=torch.float16)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ # stable unclip will oom when integration tests are run on a V100,
+ # so turn on memory savings
+ pipe.enable_attention_slicing()
+ pipe.enable_sequential_cpu_offload()
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ output = pipe("anime turle", generator=generator, output_type="np")
+
+ image = output.images[0]
+
+ assert image.shape == (768, 768, 3)
+
+ assert_mean_pixel_difference(image, expected_image)
+
+ def test_stable_unclip_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableUnCLIPPipeline.from_pretrained("fusing/stable-unclip-2-1-l", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+ pipe.enable_sequential_cpu_offload()
+
+ _ = pipe(
+ "anime turtle",
+ prior_num_inference_steps=2,
+ num_inference_steps=2,
+ output_type="np",
+ )
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 7 GB is allocated
+ assert mem_bytes < 7 * 10**9
diff --git a/diffusers/tests/pipelines/stable_unclip/test_stable_unclip_img2img.py b/diffusers/tests/pipelines/stable_unclip/test_stable_unclip_img2img.py
new file mode 100644
index 0000000000000000000000000000000000000000..f93fa3a59014498238591dbf158c09d319d5ad60
--- /dev/null
+++ b/diffusers/tests/pipelines/stable_unclip/test_stable_unclip_img2img.py
@@ -0,0 +1,282 @@
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from transformers import (
+ CLIPImageProcessor,
+ CLIPTextConfig,
+ CLIPTextModel,
+ CLIPTokenizer,
+ CLIPVisionConfig,
+ CLIPVisionModelWithProjection,
+)
+
+from diffusers import AutoencoderKL, DDIMScheduler, DDPMScheduler, StableUnCLIPImg2ImgPipeline, UNet2DConditionModel
+from diffusers.pipelines.pipeline_utils import DiffusionPipeline
+from diffusers.pipelines.stable_diffusion.stable_unclip_image_normalizer import StableUnCLIPImageNormalizer
+from diffusers.utils.import_utils import is_xformers_available
+from diffusers.utils.testing_utils import floats_tensor, load_image, load_numpy, require_torch_gpu, slow, torch_device
+
+from ...pipeline_params import TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS, TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import (
+ PipelineTesterMixin,
+ assert_mean_pixel_difference,
+)
+
+
+class StableUnCLIPImg2ImgPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = StableUnCLIPImg2ImgPipeline
+ params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS
+ batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
+
+ def get_dummy_components(self):
+ embedder_hidden_size = 32
+ embedder_projection_dim = embedder_hidden_size
+
+ # image encoding components
+
+ feature_extractor = CLIPImageProcessor(crop_size=32, size=32)
+
+ image_encoder = CLIPVisionModelWithProjection(
+ CLIPVisionConfig(
+ hidden_size=embedder_hidden_size,
+ projection_dim=embedder_projection_dim,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ image_size=32,
+ intermediate_size=37,
+ patch_size=1,
+ )
+ )
+
+ # regular denoising components
+
+ torch.manual_seed(0)
+ image_normalizer = StableUnCLIPImageNormalizer(embedding_dim=embedder_hidden_size)
+ image_noising_scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2")
+
+ torch.manual_seed(0)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ torch.manual_seed(0)
+ text_encoder = CLIPTextModel(
+ CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=embedder_hidden_size,
+ projection_dim=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ )
+
+ torch.manual_seed(0)
+ unet = UNet2DConditionModel(
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("CrossAttnDownBlock2D", "DownBlock2D"),
+ up_block_types=("UpBlock2D", "CrossAttnUpBlock2D"),
+ block_out_channels=(32, 64),
+ attention_head_dim=(2, 4),
+ class_embed_type="projection",
+ # The class embeddings are the noise augmented image embeddings.
+ # I.e. the image embeddings concated with the noised embeddings of the same dimension
+ projection_class_embeddings_input_dim=embedder_projection_dim * 2,
+ cross_attention_dim=embedder_hidden_size,
+ layers_per_block=1,
+ upcast_attention=True,
+ use_linear_projection=True,
+ )
+
+ torch.manual_seed(0)
+ scheduler = DDIMScheduler(
+ beta_schedule="scaled_linear",
+ beta_start=0.00085,
+ beta_end=0.012,
+ prediction_type="v_prediction",
+ set_alpha_to_one=False,
+ steps_offset=1,
+ )
+
+ torch.manual_seed(0)
+ vae = AutoencoderKL()
+
+ components = {
+ # image encoding components
+ "feature_extractor": feature_extractor,
+ "image_encoder": image_encoder,
+ # image noising components
+ "image_normalizer": image_normalizer,
+ "image_noising_scheduler": image_noising_scheduler,
+ # regular denoising components
+ "tokenizer": tokenizer,
+ "text_encoder": text_encoder,
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ }
+
+ return components
+
+ def get_dummy_inputs(self, device, seed=0, pil_image=True):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ input_image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+
+ if pil_image:
+ input_image = input_image * 0.5 + 0.5
+ input_image = input_image.clamp(0, 1)
+ input_image = input_image.cpu().permute(0, 2, 3, 1).float().numpy()
+ input_image = DiffusionPipeline.numpy_to_pil(input_image)[0]
+
+ return {
+ "prompt": "An anime racoon running a marathon",
+ "image": input_image,
+ "generator": generator,
+ "num_inference_steps": 2,
+ "output_type": "np",
+ }
+
+ def test_image_embeds_none(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = StableUnCLIPImg2ImgPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ inputs.update({"image_embeds": None})
+ image = sd_pipe(**inputs).images
+ image_slice = image[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 32, 32, 3)
+ expected_slice = np.array(
+ [0.34588397, 0.7747054, 0.5453714, 0.5227859, 0.57656777, 0.6532228, 0.5177634, 0.49932978, 0.56626225]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-3
+
+ # Overriding PipelineTesterMixin::test_attention_slicing_forward_pass
+ # because GPU undeterminism requires a looser check.
+ def test_attention_slicing_forward_pass(self):
+ test_max_difference = torch_device in ["cpu", "mps"]
+
+ self._test_attention_slicing_forward_pass(test_max_difference=test_max_difference)
+
+ # Overriding PipelineTesterMixin::test_inference_batch_single_identical
+ # because undeterminism requires a looser check.
+ def test_inference_batch_single_identical(self):
+ test_max_difference = torch_device in ["cpu", "mps"]
+
+ self._test_inference_batch_single_identical(test_max_difference=test_max_difference)
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass(test_max_difference=False)
+
+
+@slow
+@require_torch_gpu
+class StableUnCLIPImg2ImgPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_stable_unclip_l_img2img(self):
+ input_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/turtle.png"
+ )
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/stable_unclip_2_1_l_img2img_anime_turtle_fp16.npy"
+ )
+
+ pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "fusing/stable-unclip-2-1-l-img2img", torch_dtype=torch.float16
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ # stable unclip will oom when integration tests are run on a V100,
+ # so turn on memory savings
+ pipe.enable_attention_slicing()
+ pipe.enable_sequential_cpu_offload()
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ output = pipe(input_image, "anime turle", generator=generator, output_type="np")
+
+ image = output.images[0]
+
+ assert image.shape == (768, 768, 3)
+
+ assert_mean_pixel_difference(image, expected_image)
+
+ def test_stable_unclip_h_img2img(self):
+ input_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/turtle.png"
+ )
+
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/stable_unclip_2_1_h_img2img_anime_turtle_fp16.npy"
+ )
+
+ pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "fusing/stable-unclip-2-1-h-img2img", torch_dtype=torch.float16
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ # stable unclip will oom when integration tests are run on a V100,
+ # so turn on memory savings
+ pipe.enable_attention_slicing()
+ pipe.enable_sequential_cpu_offload()
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ output = pipe(input_image, "anime turle", generator=generator, output_type="np")
+
+ image = output.images[0]
+
+ assert image.shape == (768, 768, 3)
+
+ assert_mean_pixel_difference(image, expected_image)
+
+ def test_stable_unclip_img2img_pipeline_with_sequential_cpu_offloading(self):
+ input_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/stable_unclip/turtle.png"
+ )
+
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = StableUnCLIPImg2ImgPipeline.from_pretrained(
+ "fusing/stable-unclip-2-1-h-img2img", torch_dtype=torch.float16
+ )
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+ pipe.enable_sequential_cpu_offload()
+
+ _ = pipe(
+ input_image,
+ "anime turtle",
+ num_inference_steps=2,
+ output_type="np",
+ )
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 7 GB is allocated
+ assert mem_bytes < 7 * 10**9
diff --git a/diffusers/tests/pipelines/test_pipeline_utils.py b/diffusers/tests/pipelines/test_pipeline_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..51d987d8bb1151862f910822eb2c173ce4ff313c
--- /dev/null
+++ b/diffusers/tests/pipelines/test_pipeline_utils.py
@@ -0,0 +1,134 @@
+import unittest
+
+from diffusers.pipelines.pipeline_utils import is_safetensors_compatible
+
+
+class IsSafetensorsCompatibleTests(unittest.TestCase):
+ def test_all_is_compatible(self):
+ filenames = [
+ "safety_checker/pytorch_model.bin",
+ "safety_checker/model.safetensors",
+ "vae/diffusion_pytorch_model.bin",
+ "vae/diffusion_pytorch_model.safetensors",
+ "text_encoder/pytorch_model.bin",
+ "text_encoder/model.safetensors",
+ "unet/diffusion_pytorch_model.bin",
+ "unet/diffusion_pytorch_model.safetensors",
+ ]
+ self.assertTrue(is_safetensors_compatible(filenames))
+
+ def test_diffusers_model_is_compatible(self):
+ filenames = [
+ "unet/diffusion_pytorch_model.bin",
+ "unet/diffusion_pytorch_model.safetensors",
+ ]
+ self.assertTrue(is_safetensors_compatible(filenames))
+
+ def test_diffusers_model_is_not_compatible(self):
+ filenames = [
+ "safety_checker/pytorch_model.bin",
+ "safety_checker/model.safetensors",
+ "vae/diffusion_pytorch_model.bin",
+ "vae/diffusion_pytorch_model.safetensors",
+ "text_encoder/pytorch_model.bin",
+ "text_encoder/model.safetensors",
+ "unet/diffusion_pytorch_model.bin",
+ # Removed: 'unet/diffusion_pytorch_model.safetensors',
+ ]
+ self.assertFalse(is_safetensors_compatible(filenames))
+
+ def test_transformer_model_is_compatible(self):
+ filenames = [
+ "text_encoder/pytorch_model.bin",
+ "text_encoder/model.safetensors",
+ ]
+ self.assertTrue(is_safetensors_compatible(filenames))
+
+ def test_transformer_model_is_not_compatible(self):
+ filenames = [
+ "safety_checker/pytorch_model.bin",
+ "safety_checker/model.safetensors",
+ "vae/diffusion_pytorch_model.bin",
+ "vae/diffusion_pytorch_model.safetensors",
+ "text_encoder/pytorch_model.bin",
+ # Removed: 'text_encoder/model.safetensors',
+ "unet/diffusion_pytorch_model.bin",
+ "unet/diffusion_pytorch_model.safetensors",
+ ]
+ self.assertFalse(is_safetensors_compatible(filenames))
+
+ def test_all_is_compatible_variant(self):
+ filenames = [
+ "safety_checker/pytorch_model.fp16.bin",
+ "safety_checker/model.fp16.safetensors",
+ "vae/diffusion_pytorch_model.fp16.bin",
+ "vae/diffusion_pytorch_model.fp16.safetensors",
+ "text_encoder/pytorch_model.fp16.bin",
+ "text_encoder/model.fp16.safetensors",
+ "unet/diffusion_pytorch_model.fp16.bin",
+ "unet/diffusion_pytorch_model.fp16.safetensors",
+ ]
+ variant = "fp16"
+ self.assertTrue(is_safetensors_compatible(filenames, variant=variant))
+
+ def test_diffusers_model_is_compatible_variant(self):
+ filenames = [
+ "unet/diffusion_pytorch_model.fp16.bin",
+ "unet/diffusion_pytorch_model.fp16.safetensors",
+ ]
+ variant = "fp16"
+ self.assertTrue(is_safetensors_compatible(filenames, variant=variant))
+
+ def test_diffusers_model_is_compatible_variant_partial(self):
+ # pass variant but use the non-variant filenames
+ filenames = [
+ "unet/diffusion_pytorch_model.bin",
+ "unet/diffusion_pytorch_model.safetensors",
+ ]
+ variant = "fp16"
+ self.assertTrue(is_safetensors_compatible(filenames, variant=variant))
+
+ def test_diffusers_model_is_not_compatible_variant(self):
+ filenames = [
+ "safety_checker/pytorch_model.fp16.bin",
+ "safety_checker/model.fp16.safetensors",
+ "vae/diffusion_pytorch_model.fp16.bin",
+ "vae/diffusion_pytorch_model.fp16.safetensors",
+ "text_encoder/pytorch_model.fp16.bin",
+ "text_encoder/model.fp16.safetensors",
+ "unet/diffusion_pytorch_model.fp16.bin",
+ # Removed: 'unet/diffusion_pytorch_model.fp16.safetensors',
+ ]
+ variant = "fp16"
+ self.assertFalse(is_safetensors_compatible(filenames, variant=variant))
+
+ def test_transformer_model_is_compatible_variant(self):
+ filenames = [
+ "text_encoder/pytorch_model.fp16.bin",
+ "text_encoder/model.fp16.safetensors",
+ ]
+ variant = "fp16"
+ self.assertTrue(is_safetensors_compatible(filenames, variant=variant))
+
+ def test_transformer_model_is_compatible_variant_partial(self):
+ # pass variant but use the non-variant filenames
+ filenames = [
+ "text_encoder/pytorch_model.bin",
+ "text_encoder/model.safetensors",
+ ]
+ variant = "fp16"
+ self.assertTrue(is_safetensors_compatible(filenames, variant=variant))
+
+ def test_transformer_model_is_not_compatible_variant(self):
+ filenames = [
+ "safety_checker/pytorch_model.fp16.bin",
+ "safety_checker/model.fp16.safetensors",
+ "vae/diffusion_pytorch_model.fp16.bin",
+ "vae/diffusion_pytorch_model.fp16.safetensors",
+ "text_encoder/pytorch_model.fp16.bin",
+ # 'text_encoder/model.fp16.safetensors',
+ "unet/diffusion_pytorch_model.fp16.bin",
+ "unet/diffusion_pytorch_model.fp16.safetensors",
+ ]
+ variant = "fp16"
+ self.assertFalse(is_safetensors_compatible(filenames, variant=variant))
diff --git a/diffusers/tests/pipelines/text_to_video/__init__.py b/diffusers/tests/pipelines/text_to_video/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/text_to_video/test_text_to_video.py b/diffusers/tests/pipelines/text_to_video/test_text_to_video.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4331fda02ff6511a4b0d5cb7a49c1212129bbe2
--- /dev/null
+++ b/diffusers/tests/pipelines/text_to_video/test_text_to_video.py
@@ -0,0 +1,197 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMScheduler,
+ DPMSolverMultistepScheduler,
+ TextToVideoSDPipeline,
+ UNet3DConditionModel,
+)
+from diffusers.utils import load_numpy, skip_mps, slow
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+@skip_mps
+class TextToVideoSDPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = TextToVideoSDPipeline
+ params = TEXT_TO_IMAGE_PARAMS
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+ # No `output_type`.
+ required_optional_params = frozenset(
+ [
+ "num_inference_steps",
+ "generator",
+ "latents",
+ "return_dict",
+ "callback",
+ "callback_steps",
+ ]
+ )
+
+ def get_dummy_components(self):
+ torch.manual_seed(0)
+ unet = UNet3DConditionModel(
+ block_out_channels=(32, 64, 64, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("CrossAttnDownBlock3D", "CrossAttnDownBlock3D", "CrossAttnDownBlock3D", "DownBlock3D"),
+ up_block_types=("UpBlock3D", "CrossAttnUpBlock3D", "CrossAttnUpBlock3D", "CrossAttnUpBlock3D"),
+ cross_attention_dim=32,
+ attention_head_dim=4,
+ )
+ scheduler = DDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ clip_sample=False,
+ set_alpha_to_one=False,
+ )
+ torch.manual_seed(0)
+ vae = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ sample_size=128,
+ )
+ torch.manual_seed(0)
+ text_encoder_config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ hidden_act="gelu",
+ projection_dim=512,
+ )
+ text_encoder = CLIPTextModel(text_encoder_config)
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ components = {
+ "unet": unet,
+ "scheduler": scheduler,
+ "vae": vae,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ }
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "generator": generator,
+ "num_inference_steps": 2,
+ "guidance_scale": 6.0,
+ "output_type": "pt",
+ }
+ return inputs
+
+ def test_text_to_video_default_case(self):
+ device = "cpu" # ensure determinism for the device-dependent torch.Generator
+ components = self.get_dummy_components()
+ sd_pipe = TextToVideoSDPipeline(**components)
+ sd_pipe = sd_pipe.to(device)
+ sd_pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(device)
+ inputs["output_type"] = "np"
+ frames = sd_pipe(**inputs).frames
+ image_slice = frames[0][-3:, -3:, -1]
+
+ assert frames[0].shape == (64, 64, 3)
+ expected_slice = np.array([166, 184, 167, 118, 102, 123, 108, 93, 114])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_attention_slicing_forward_pass(self):
+ self._test_attention_slicing_forward_pass(test_mean_pixel_difference=False)
+
+ # (todo): sayakpaul
+ @unittest.skip(reason="Batching needs to be properly figured out first for this pipeline.")
+ def test_inference_batch_consistent(self):
+ pass
+
+ # (todo): sayakpaul
+ @unittest.skip(reason="Batching needs to be properly figured out first for this pipeline.")
+ def test_inference_batch_single_identical(self):
+ pass
+
+ @unittest.skip(reason="`num_images_per_prompt` argument is not supported for this pipeline.")
+ def test_num_images_per_prompt(self):
+ pass
+
+ def test_progress_bar(self):
+ return super().test_progress_bar()
+
+
+@slow
+@skip_mps
+class TextToVideoSDPipelineSlowTests(unittest.TestCase):
+ def test_full_model(self):
+ expected_video = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/text_to_video/video.npy"
+ )
+
+ pipe = TextToVideoSDPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b")
+ pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
+ pipe = pipe.to("cuda")
+
+ prompt = "Spiderman is surfing"
+ generator = torch.Generator(device="cpu").manual_seed(0)
+
+ video_frames = pipe(prompt, generator=generator, num_inference_steps=25, output_type="pt").frames
+ video = video_frames.cpu().numpy()
+
+ assert np.abs(expected_video - video).mean() < 5e-2
+
+ def test_two_step_model(self):
+ expected_video = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/text_to_video/video_2step.npy"
+ )
+
+ pipe = TextToVideoSDPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b")
+ pipe = pipe.to("cuda")
+
+ prompt = "Spiderman is surfing"
+ generator = torch.Generator(device="cpu").manual_seed(0)
+
+ video_frames = pipe(prompt, generator=generator, num_inference_steps=2, output_type="pt").frames
+ video = video_frames.cpu().numpy()
+
+ assert np.abs(expected_video - video).mean() < 5e-2
diff --git a/diffusers/tests/pipelines/unclip/__init__.py b/diffusers/tests/pipelines/unclip/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/unclip/test_unclip.py b/diffusers/tests/pipelines/unclip/test_unclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..c36fb02b190f271d57eca0c54a94a19acad0faf3
--- /dev/null
+++ b/diffusers/tests/pipelines/unclip/test_unclip.py
@@ -0,0 +1,498 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModelWithProjection, CLIPTokenizer
+
+from diffusers import PriorTransformer, UnCLIPPipeline, UnCLIPScheduler, UNet2DConditionModel, UNet2DModel
+from diffusers.pipelines.unclip.text_proj import UnCLIPTextProjModel
+from diffusers.utils import load_numpy, nightly, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu, skip_mps
+
+from ...pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin, assert_mean_pixel_difference
+
+
+class UnCLIPPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = UnCLIPPipeline
+ params = TEXT_TO_IMAGE_PARAMS - {
+ "negative_prompt",
+ "height",
+ "width",
+ "negative_prompt_embeds",
+ "guidance_scale",
+ "prompt_embeds",
+ "cross_attention_kwargs",
+ }
+ batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
+ required_optional_params = [
+ "generator",
+ "return_dict",
+ "prior_num_inference_steps",
+ "decoder_num_inference_steps",
+ "super_res_num_inference_steps",
+ ]
+ test_xformers_attention = False
+
+ @property
+ def text_embedder_hidden_size(self):
+ return 32
+
+ @property
+ def time_input_dim(self):
+ return 32
+
+ @property
+ def block_out_channels_0(self):
+ return self.time_input_dim
+
+ @property
+ def time_embed_dim(self):
+ return self.time_input_dim * 4
+
+ @property
+ def cross_attention_dim(self):
+ return 100
+
+ @property
+ def dummy_tokenizer(self):
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+ return tokenizer
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=self.text_embedder_hidden_size,
+ projection_dim=self.text_embedder_hidden_size,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ return CLIPTextModelWithProjection(config)
+
+ @property
+ def dummy_prior(self):
+ torch.manual_seed(0)
+
+ model_kwargs = {
+ "num_attention_heads": 2,
+ "attention_head_dim": 12,
+ "embedding_dim": self.text_embedder_hidden_size,
+ "num_layers": 1,
+ }
+
+ model = PriorTransformer(**model_kwargs)
+ return model
+
+ @property
+ def dummy_text_proj(self):
+ torch.manual_seed(0)
+
+ model_kwargs = {
+ "clip_embeddings_dim": self.text_embedder_hidden_size,
+ "time_embed_dim": self.time_embed_dim,
+ "cross_attention_dim": self.cross_attention_dim,
+ }
+
+ model = UnCLIPTextProjModel(**model_kwargs)
+ return model
+
+ @property
+ def dummy_decoder(self):
+ torch.manual_seed(0)
+
+ model_kwargs = {
+ "sample_size": 32,
+ # RGB in channels
+ "in_channels": 3,
+ # Out channels is double in channels because predicts mean and variance
+ "out_channels": 6,
+ "down_block_types": ("ResnetDownsampleBlock2D", "SimpleCrossAttnDownBlock2D"),
+ "up_block_types": ("SimpleCrossAttnUpBlock2D", "ResnetUpsampleBlock2D"),
+ "mid_block_type": "UNetMidBlock2DSimpleCrossAttn",
+ "block_out_channels": (self.block_out_channels_0, self.block_out_channels_0 * 2),
+ "layers_per_block": 1,
+ "cross_attention_dim": self.cross_attention_dim,
+ "attention_head_dim": 4,
+ "resnet_time_scale_shift": "scale_shift",
+ "class_embed_type": "identity",
+ }
+
+ model = UNet2DConditionModel(**model_kwargs)
+ return model
+
+ @property
+ def dummy_super_res_kwargs(self):
+ return {
+ "sample_size": 64,
+ "layers_per_block": 1,
+ "down_block_types": ("ResnetDownsampleBlock2D", "ResnetDownsampleBlock2D"),
+ "up_block_types": ("ResnetUpsampleBlock2D", "ResnetUpsampleBlock2D"),
+ "block_out_channels": (self.block_out_channels_0, self.block_out_channels_0 * 2),
+ "in_channels": 6,
+ "out_channels": 3,
+ }
+
+ @property
+ def dummy_super_res_first(self):
+ torch.manual_seed(0)
+
+ model = UNet2DModel(**self.dummy_super_res_kwargs)
+ return model
+
+ @property
+ def dummy_super_res_last(self):
+ # seeded differently to get different unet than `self.dummy_super_res_first`
+ torch.manual_seed(1)
+
+ model = UNet2DModel(**self.dummy_super_res_kwargs)
+ return model
+
+ def get_dummy_components(self):
+ prior = self.dummy_prior
+ decoder = self.dummy_decoder
+ text_proj = self.dummy_text_proj
+ text_encoder = self.dummy_text_encoder
+ tokenizer = self.dummy_tokenizer
+ super_res_first = self.dummy_super_res_first
+ super_res_last = self.dummy_super_res_last
+
+ prior_scheduler = UnCLIPScheduler(
+ variance_type="fixed_small_log",
+ prediction_type="sample",
+ num_train_timesteps=1000,
+ clip_sample_range=5.0,
+ )
+
+ decoder_scheduler = UnCLIPScheduler(
+ variance_type="learned_range",
+ prediction_type="epsilon",
+ num_train_timesteps=1000,
+ )
+
+ super_res_scheduler = UnCLIPScheduler(
+ variance_type="fixed_small_log",
+ prediction_type="epsilon",
+ num_train_timesteps=1000,
+ )
+
+ components = {
+ "prior": prior,
+ "decoder": decoder,
+ "text_proj": text_proj,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "super_res_first": super_res_first,
+ "super_res_last": super_res_last,
+ "prior_scheduler": prior_scheduler,
+ "decoder_scheduler": decoder_scheduler,
+ "super_res_scheduler": super_res_scheduler,
+ }
+
+ return components
+
+ def get_dummy_inputs(self, device, seed=0):
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+ inputs = {
+ "prompt": "horse",
+ "generator": generator,
+ "prior_num_inference_steps": 2,
+ "decoder_num_inference_steps": 2,
+ "super_res_num_inference_steps": 2,
+ "output_type": "numpy",
+ }
+ return inputs
+
+ def test_unclip(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(device)
+
+ pipe.set_progress_bar_config(disable=None)
+
+ output = pipe(**self.get_dummy_inputs(device))
+ image = output.images
+
+ image_from_tuple = pipe(
+ **self.get_dummy_inputs(device),
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array(
+ [
+ 0.9997,
+ 0.9988,
+ 0.0028,
+ 0.9997,
+ 0.9984,
+ 0.9965,
+ 0.0029,
+ 0.9986,
+ 0.0025,
+ ]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_unclip_passed_text_embed(self):
+ device = torch.device("cpu")
+
+ class DummyScheduler:
+ init_noise_sigma = 1
+
+ components = self.get_dummy_components()
+
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(device)
+
+ prior = components["prior"]
+ decoder = components["decoder"]
+ super_res_first = components["super_res_first"]
+ tokenizer = components["tokenizer"]
+ text_encoder = components["text_encoder"]
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ dtype = prior.dtype
+ batch_size = 1
+
+ shape = (batch_size, prior.config.embedding_dim)
+ prior_latents = pipe.prepare_latents(
+ shape, dtype=dtype, device=device, generator=generator, latents=None, scheduler=DummyScheduler()
+ )
+ shape = (batch_size, decoder.in_channels, decoder.sample_size, decoder.sample_size)
+ decoder_latents = pipe.prepare_latents(
+ shape, dtype=dtype, device=device, generator=generator, latents=None, scheduler=DummyScheduler()
+ )
+
+ shape = (
+ batch_size,
+ super_res_first.in_channels // 2,
+ super_res_first.sample_size,
+ super_res_first.sample_size,
+ )
+ super_res_latents = pipe.prepare_latents(
+ shape, dtype=dtype, device=device, generator=generator, latents=None, scheduler=DummyScheduler()
+ )
+
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "this is a prompt example"
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = pipe(
+ [prompt],
+ generator=generator,
+ prior_num_inference_steps=2,
+ decoder_num_inference_steps=2,
+ super_res_num_inference_steps=2,
+ prior_latents=prior_latents,
+ decoder_latents=decoder_latents,
+ super_res_latents=super_res_latents,
+ output_type="np",
+ )
+ image = output.images
+
+ text_inputs = tokenizer(
+ prompt,
+ padding="max_length",
+ max_length=tokenizer.model_max_length,
+ return_tensors="pt",
+ )
+ text_model_output = text_encoder(text_inputs.input_ids)
+ text_attention_mask = text_inputs.attention_mask
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_text = pipe(
+ generator=generator,
+ prior_num_inference_steps=2,
+ decoder_num_inference_steps=2,
+ super_res_num_inference_steps=2,
+ prior_latents=prior_latents,
+ decoder_latents=decoder_latents,
+ super_res_latents=super_res_latents,
+ text_model_output=text_model_output,
+ text_attention_mask=text_attention_mask,
+ output_type="np",
+ )[0]
+
+ # make sure passing text embeddings manually is identical
+ assert np.abs(image - image_from_text).max() < 1e-4
+
+ # Overriding PipelineTesterMixin::test_attention_slicing_forward_pass
+ # because UnCLIP GPU undeterminism requires a looser check.
+ @skip_mps
+ def test_attention_slicing_forward_pass(self):
+ test_max_difference = torch_device == "cpu"
+
+ self._test_attention_slicing_forward_pass(test_max_difference=test_max_difference)
+
+ # Overriding PipelineTesterMixin::test_inference_batch_single_identical
+ # because UnCLIP undeterminism requires a looser check.
+ @skip_mps
+ def test_inference_batch_single_identical(self):
+ test_max_difference = torch_device == "cpu"
+ relax_max_difference = True
+ additional_params_copy_to_batched_inputs = [
+ "prior_num_inference_steps",
+ "decoder_num_inference_steps",
+ "super_res_num_inference_steps",
+ ]
+
+ self._test_inference_batch_single_identical(
+ test_max_difference=test_max_difference,
+ relax_max_difference=relax_max_difference,
+ additional_params_copy_to_batched_inputs=additional_params_copy_to_batched_inputs,
+ )
+
+ def test_inference_batch_consistent(self):
+ additional_params_copy_to_batched_inputs = [
+ "prior_num_inference_steps",
+ "decoder_num_inference_steps",
+ "super_res_num_inference_steps",
+ ]
+
+ if torch_device == "mps":
+ # TODO: MPS errors with larger batch sizes
+ batch_sizes = [2, 3]
+ self._test_inference_batch_consistent(
+ batch_sizes=batch_sizes,
+ additional_params_copy_to_batched_inputs=additional_params_copy_to_batched_inputs,
+ )
+ else:
+ self._test_inference_batch_consistent(
+ additional_params_copy_to_batched_inputs=additional_params_copy_to_batched_inputs
+ )
+
+ @skip_mps
+ def test_dict_tuple_outputs_equivalent(self):
+ return super().test_dict_tuple_outputs_equivalent()
+
+ @skip_mps
+ def test_save_load_local(self):
+ return super().test_save_load_local()
+
+ @skip_mps
+ def test_save_load_optional_components(self):
+ return super().test_save_load_optional_components()
+
+
+@nightly
+class UnCLIPPipelineCPUIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_unclip_karlo_cpu_fp32(self):
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/unclip/karlo_v1_alpha_horse_cpu.npy"
+ )
+
+ pipeline = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha")
+ pipeline.set_progress_bar_config(disable=None)
+
+ generator = torch.manual_seed(0)
+ output = pipeline(
+ "horse",
+ num_images_per_prompt=1,
+ generator=generator,
+ output_type="np",
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (256, 256, 3)
+ assert np.abs(expected_image - image).max() < 1e-1
+
+
+@slow
+@require_torch_gpu
+class UnCLIPPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_unclip_karlo(self):
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/unclip/karlo_v1_alpha_horse_fp16.npy"
+ )
+
+ pipeline = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
+ pipeline = pipeline.to(torch_device)
+ pipeline.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ output = pipeline(
+ "horse",
+ generator=generator,
+ output_type="np",
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (256, 256, 3)
+
+ assert_mean_pixel_difference(image, expected_image)
+
+ def test_unclip_pipeline_with_sequential_cpu_offloading(self):
+ torch.cuda.empty_cache()
+ torch.cuda.reset_max_memory_allocated()
+ torch.cuda.reset_peak_memory_stats()
+
+ pipe = UnCLIPPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+ pipe.enable_attention_slicing()
+ pipe.enable_sequential_cpu_offload()
+
+ _ = pipe(
+ "horse",
+ num_images_per_prompt=1,
+ prior_num_inference_steps=2,
+ decoder_num_inference_steps=2,
+ super_res_num_inference_steps=2,
+ output_type="np",
+ )
+
+ mem_bytes = torch.cuda.max_memory_allocated()
+ # make sure that less than 7 GB is allocated
+ assert mem_bytes < 7 * 10**9
diff --git a/diffusers/tests/pipelines/unclip/test_unclip_image_variation.py b/diffusers/tests/pipelines/unclip/test_unclip_image_variation.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff32ac5f9aafb9140ec5b49dc79711d493b76788
--- /dev/null
+++ b/diffusers/tests/pipelines/unclip/test_unclip_image_variation.py
@@ -0,0 +1,508 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import random
+import unittest
+
+import numpy as np
+import torch
+from transformers import (
+ CLIPImageProcessor,
+ CLIPTextConfig,
+ CLIPTextModelWithProjection,
+ CLIPTokenizer,
+ CLIPVisionConfig,
+ CLIPVisionModelWithProjection,
+)
+
+from diffusers import (
+ DiffusionPipeline,
+ UnCLIPImageVariationPipeline,
+ UnCLIPScheduler,
+ UNet2DConditionModel,
+ UNet2DModel,
+)
+from diffusers.pipelines.unclip.text_proj import UnCLIPTextProjModel
+from diffusers.utils import floats_tensor, load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import load_image, require_torch_gpu, skip_mps
+
+from ...pipeline_params import IMAGE_VARIATION_BATCH_PARAMS, IMAGE_VARIATION_PARAMS
+from ...test_pipelines_common import PipelineTesterMixin, assert_mean_pixel_difference
+
+
+class UnCLIPImageVariationPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
+ pipeline_class = UnCLIPImageVariationPipeline
+ params = IMAGE_VARIATION_PARAMS - {"height", "width", "guidance_scale"}
+ batch_params = IMAGE_VARIATION_BATCH_PARAMS
+
+ required_optional_params = [
+ "generator",
+ "return_dict",
+ "decoder_num_inference_steps",
+ "super_res_num_inference_steps",
+ ]
+
+ @property
+ def text_embedder_hidden_size(self):
+ return 32
+
+ @property
+ def time_input_dim(self):
+ return 32
+
+ @property
+ def block_out_channels_0(self):
+ return self.time_input_dim
+
+ @property
+ def time_embed_dim(self):
+ return self.time_input_dim * 4
+
+ @property
+ def cross_attention_dim(self):
+ return 100
+
+ @property
+ def dummy_tokenizer(self):
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+ return tokenizer
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=self.text_embedder_hidden_size,
+ projection_dim=self.text_embedder_hidden_size,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ return CLIPTextModelWithProjection(config)
+
+ @property
+ def dummy_image_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPVisionConfig(
+ hidden_size=self.text_embedder_hidden_size,
+ projection_dim=self.text_embedder_hidden_size,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ image_size=32,
+ intermediate_size=37,
+ patch_size=1,
+ )
+ return CLIPVisionModelWithProjection(config)
+
+ @property
+ def dummy_text_proj(self):
+ torch.manual_seed(0)
+
+ model_kwargs = {
+ "clip_embeddings_dim": self.text_embedder_hidden_size,
+ "time_embed_dim": self.time_embed_dim,
+ "cross_attention_dim": self.cross_attention_dim,
+ }
+
+ model = UnCLIPTextProjModel(**model_kwargs)
+ return model
+
+ @property
+ def dummy_decoder(self):
+ torch.manual_seed(0)
+
+ model_kwargs = {
+ "sample_size": 32,
+ # RGB in channels
+ "in_channels": 3,
+ # Out channels is double in channels because predicts mean and variance
+ "out_channels": 6,
+ "down_block_types": ("ResnetDownsampleBlock2D", "SimpleCrossAttnDownBlock2D"),
+ "up_block_types": ("SimpleCrossAttnUpBlock2D", "ResnetUpsampleBlock2D"),
+ "mid_block_type": "UNetMidBlock2DSimpleCrossAttn",
+ "block_out_channels": (self.block_out_channels_0, self.block_out_channels_0 * 2),
+ "layers_per_block": 1,
+ "cross_attention_dim": self.cross_attention_dim,
+ "attention_head_dim": 4,
+ "resnet_time_scale_shift": "scale_shift",
+ "class_embed_type": "identity",
+ }
+
+ model = UNet2DConditionModel(**model_kwargs)
+ return model
+
+ @property
+ def dummy_super_res_kwargs(self):
+ return {
+ "sample_size": 64,
+ "layers_per_block": 1,
+ "down_block_types": ("ResnetDownsampleBlock2D", "ResnetDownsampleBlock2D"),
+ "up_block_types": ("ResnetUpsampleBlock2D", "ResnetUpsampleBlock2D"),
+ "block_out_channels": (self.block_out_channels_0, self.block_out_channels_0 * 2),
+ "in_channels": 6,
+ "out_channels": 3,
+ }
+
+ @property
+ def dummy_super_res_first(self):
+ torch.manual_seed(0)
+
+ model = UNet2DModel(**self.dummy_super_res_kwargs)
+ return model
+
+ @property
+ def dummy_super_res_last(self):
+ # seeded differently to get different unet than `self.dummy_super_res_first`
+ torch.manual_seed(1)
+
+ model = UNet2DModel(**self.dummy_super_res_kwargs)
+ return model
+
+ def get_dummy_components(self):
+ decoder = self.dummy_decoder
+ text_proj = self.dummy_text_proj
+ text_encoder = self.dummy_text_encoder
+ tokenizer = self.dummy_tokenizer
+ super_res_first = self.dummy_super_res_first
+ super_res_last = self.dummy_super_res_last
+
+ decoder_scheduler = UnCLIPScheduler(
+ variance_type="learned_range",
+ prediction_type="epsilon",
+ num_train_timesteps=1000,
+ )
+
+ super_res_scheduler = UnCLIPScheduler(
+ variance_type="fixed_small_log",
+ prediction_type="epsilon",
+ num_train_timesteps=1000,
+ )
+
+ feature_extractor = CLIPImageProcessor(crop_size=32, size=32)
+
+ image_encoder = self.dummy_image_encoder
+
+ return {
+ "decoder": decoder,
+ "text_encoder": text_encoder,
+ "tokenizer": tokenizer,
+ "text_proj": text_proj,
+ "feature_extractor": feature_extractor,
+ "image_encoder": image_encoder,
+ "super_res_first": super_res_first,
+ "super_res_last": super_res_last,
+ "decoder_scheduler": decoder_scheduler,
+ "super_res_scheduler": super_res_scheduler,
+ }
+
+ def get_dummy_inputs(self, device, seed=0, pil_image=True):
+ input_image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
+ if str(device).startswith("mps"):
+ generator = torch.manual_seed(seed)
+ else:
+ generator = torch.Generator(device=device).manual_seed(seed)
+
+ if pil_image:
+ input_image = input_image * 0.5 + 0.5
+ input_image = input_image.clamp(0, 1)
+ input_image = input_image.cpu().permute(0, 2, 3, 1).float().numpy()
+ input_image = DiffusionPipeline.numpy_to_pil(input_image)[0]
+
+ return {
+ "image": input_image,
+ "generator": generator,
+ "decoder_num_inference_steps": 2,
+ "super_res_num_inference_steps": 2,
+ "output_type": "np",
+ }
+
+ def test_unclip_image_variation_input_tensor(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(device)
+
+ pipe.set_progress_bar_config(disable=None)
+
+ pipeline_inputs = self.get_dummy_inputs(device, pil_image=False)
+
+ output = pipe(**pipeline_inputs)
+ image = output.images
+
+ tuple_pipeline_inputs = self.get_dummy_inputs(device, pil_image=False)
+
+ image_from_tuple = pipe(
+ **tuple_pipeline_inputs,
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array(
+ [
+ 0.9997,
+ 0.0002,
+ 0.9997,
+ 0.9997,
+ 0.9969,
+ 0.0023,
+ 0.9997,
+ 0.9969,
+ 0.9970,
+ ]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_unclip_image_variation_input_image(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(device)
+
+ pipe.set_progress_bar_config(disable=None)
+
+ pipeline_inputs = self.get_dummy_inputs(device, pil_image=True)
+
+ output = pipe(**pipeline_inputs)
+ image = output.images
+
+ tuple_pipeline_inputs = self.get_dummy_inputs(device, pil_image=True)
+
+ image_from_tuple = pipe(
+ **tuple_pipeline_inputs,
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 64, 64, 3)
+
+ expected_slice = np.array([0.9997, 0.0003, 0.9997, 0.9997, 0.9970, 0.0024, 0.9997, 0.9971, 0.9971])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_unclip_image_variation_input_list_images(self):
+ device = "cpu"
+
+ components = self.get_dummy_components()
+
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(device)
+
+ pipe.set_progress_bar_config(disable=None)
+
+ pipeline_inputs = self.get_dummy_inputs(device, pil_image=True)
+ pipeline_inputs["image"] = [
+ pipeline_inputs["image"],
+ pipeline_inputs["image"],
+ ]
+
+ output = pipe(**pipeline_inputs)
+ image = output.images
+
+ tuple_pipeline_inputs = self.get_dummy_inputs(device, pil_image=True)
+ tuple_pipeline_inputs["image"] = [
+ tuple_pipeline_inputs["image"],
+ tuple_pipeline_inputs["image"],
+ ]
+
+ image_from_tuple = pipe(
+ **tuple_pipeline_inputs,
+ return_dict=False,
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (2, 64, 64, 3)
+
+ expected_slice = np.array(
+ [
+ 0.9997,
+ 0.9989,
+ 0.0008,
+ 0.0021,
+ 0.9960,
+ 0.0018,
+ 0.0014,
+ 0.0002,
+ 0.9933,
+ ]
+ )
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_unclip_passed_image_embed(self):
+ device = torch.device("cpu")
+
+ class DummyScheduler:
+ init_noise_sigma = 1
+
+ components = self.get_dummy_components()
+
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(device)
+
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ dtype = pipe.decoder.dtype
+ batch_size = 1
+
+ shape = (batch_size, pipe.decoder.in_channels, pipe.decoder.sample_size, pipe.decoder.sample_size)
+ decoder_latents = pipe.prepare_latents(
+ shape, dtype=dtype, device=device, generator=generator, latents=None, scheduler=DummyScheduler()
+ )
+
+ shape = (
+ batch_size,
+ pipe.super_res_first.in_channels // 2,
+ pipe.super_res_first.sample_size,
+ pipe.super_res_first.sample_size,
+ )
+ super_res_latents = pipe.prepare_latents(
+ shape, dtype=dtype, device=device, generator=generator, latents=None, scheduler=DummyScheduler()
+ )
+
+ pipeline_inputs = self.get_dummy_inputs(device, pil_image=False)
+
+ img_out_1 = pipe(
+ **pipeline_inputs, decoder_latents=decoder_latents, super_res_latents=super_res_latents
+ ).images
+
+ pipeline_inputs = self.get_dummy_inputs(device, pil_image=False)
+ # Don't pass image, instead pass embedding
+ image = pipeline_inputs.pop("image")
+ image_embeddings = pipe.image_encoder(image).image_embeds
+
+ img_out_2 = pipe(
+ **pipeline_inputs,
+ decoder_latents=decoder_latents,
+ super_res_latents=super_res_latents,
+ image_embeddings=image_embeddings,
+ ).images
+
+ # make sure passing text embeddings manually is identical
+ assert np.abs(img_out_1 - img_out_2).max() < 1e-4
+
+ # Overriding PipelineTesterMixin::test_attention_slicing_forward_pass
+ # because UnCLIP GPU undeterminism requires a looser check.
+ @skip_mps
+ def test_attention_slicing_forward_pass(self):
+ test_max_difference = torch_device == "cpu"
+
+ self._test_attention_slicing_forward_pass(test_max_difference=test_max_difference)
+
+ # Overriding PipelineTesterMixin::test_inference_batch_single_identical
+ # because UnCLIP undeterminism requires a looser check.
+ @skip_mps
+ def test_inference_batch_single_identical(self):
+ test_max_difference = torch_device == "cpu"
+ relax_max_difference = True
+ additional_params_copy_to_batched_inputs = [
+ "decoder_num_inference_steps",
+ "super_res_num_inference_steps",
+ ]
+
+ self._test_inference_batch_single_identical(
+ test_max_difference=test_max_difference,
+ relax_max_difference=relax_max_difference,
+ additional_params_copy_to_batched_inputs=additional_params_copy_to_batched_inputs,
+ )
+
+ def test_inference_batch_consistent(self):
+ additional_params_copy_to_batched_inputs = [
+ "decoder_num_inference_steps",
+ "super_res_num_inference_steps",
+ ]
+
+ if torch_device == "mps":
+ # TODO: MPS errors with larger batch sizes
+ batch_sizes = [2, 3]
+ self._test_inference_batch_consistent(
+ batch_sizes=batch_sizes,
+ additional_params_copy_to_batched_inputs=additional_params_copy_to_batched_inputs,
+ )
+ else:
+ self._test_inference_batch_consistent(
+ additional_params_copy_to_batched_inputs=additional_params_copy_to_batched_inputs
+ )
+
+ @skip_mps
+ def test_dict_tuple_outputs_equivalent(self):
+ return super().test_dict_tuple_outputs_equivalent()
+
+ @skip_mps
+ def test_save_load_local(self):
+ return super().test_save_load_local()
+
+ @skip_mps
+ def test_save_load_optional_components(self):
+ return super().test_save_load_optional_components()
+
+
+@slow
+@require_torch_gpu
+class UnCLIPImageVariationPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_unclip_image_variation_karlo(self):
+ input_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/unclip/cat.png"
+ )
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/unclip/karlo_v1_alpha_cat_variation_fp16.npy"
+ )
+
+ pipeline = UnCLIPImageVariationPipeline.from_pretrained(
+ "kakaobrain/karlo-v1-alpha-image-variations", torch_dtype=torch.float16
+ )
+ pipeline = pipeline.to(torch_device)
+ pipeline.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device="cpu").manual_seed(0)
+ output = pipeline(
+ input_image,
+ generator=generator,
+ output_type="np",
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (256, 256, 3)
+
+ assert_mean_pixel_difference(image, expected_image)
diff --git a/diffusers/tests/pipelines/versatile_diffusion/__init__.py b/diffusers/tests/pipelines/versatile_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_dual_guided.py b/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_dual_guided.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e2b89982a6aad0fb2f2b7c8735b0e645665359f
--- /dev/null
+++ b/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_dual_guided.py
@@ -0,0 +1,107 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import VersatileDiffusionDualGuidedPipeline
+from diffusers.utils.testing_utils import load_image, nightly, require_torch_gpu, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+@nightly
+@require_torch_gpu
+class VersatileDiffusionDualGuidedPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_remove_unused_weights_save_load(self):
+ pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained("shi-labs/versatile-diffusion")
+ # remove text_unet
+ pipe.remove_unused_weights()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ second_prompt = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/versatile_diffusion/benz.jpg"
+ )
+
+ generator = torch.manual_seed(0)
+ image = pipe(
+ prompt="first prompt",
+ image=second_prompt,
+ text_to_image_strength=0.75,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=2,
+ output_type="numpy",
+ ).images
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained(tmpdirname)
+
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = generator.manual_seed(0)
+ new_image = pipe(
+ prompt="first prompt",
+ image=second_prompt,
+ text_to_image_strength=0.75,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=2,
+ output_type="numpy",
+ ).images
+
+ assert np.abs(image - new_image).sum() < 1e-5, "Models don't have the same forward pass"
+
+ def test_inference_dual_guided(self):
+ pipe = VersatileDiffusionDualGuidedPipeline.from_pretrained("shi-labs/versatile-diffusion")
+ pipe.remove_unused_weights()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ first_prompt = "cyberpunk 2077"
+ second_prompt = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/versatile_diffusion/benz.jpg"
+ )
+ generator = torch.manual_seed(0)
+ image = pipe(
+ prompt=first_prompt,
+ image=second_prompt,
+ text_to_image_strength=0.75,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=50,
+ output_type="numpy",
+ ).images
+
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.0787, 0.0849, 0.0826, 0.0812, 0.0807, 0.0795, 0.0818, 0.0798, 0.0779])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_image_variation.py b/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_image_variation.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4eabb9e3a0e18dd71a445bb8960b27d8699daac
--- /dev/null
+++ b/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_image_variation.py
@@ -0,0 +1,57 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import VersatileDiffusionImageVariationPipeline
+from diffusers.utils.testing_utils import load_image, require_torch_gpu, slow, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class VersatileDiffusionImageVariationPipelineFastTests(unittest.TestCase):
+ pass
+
+
+@slow
+@require_torch_gpu
+class VersatileDiffusionImageVariationPipelineIntegrationTests(unittest.TestCase):
+ def test_inference_image_variations(self):
+ pipe = VersatileDiffusionImageVariationPipeline.from_pretrained("shi-labs/versatile-diffusion")
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ image_prompt = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/versatile_diffusion/benz.jpg"
+ )
+ generator = torch.manual_seed(0)
+ image = pipe(
+ image=image_prompt,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=50,
+ output_type="numpy",
+ ).images
+
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.0441, 0.0469, 0.0507, 0.0575, 0.0632, 0.0650, 0.0865, 0.0909, 0.0945])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_mega.py b/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_mega.py
new file mode 100644
index 0000000000000000000000000000000000000000..b77c1baf41d5abe4adb17aebb600b80eedda6c39
--- /dev/null
+++ b/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_mega.py
@@ -0,0 +1,129 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import VersatileDiffusionPipeline
+from diffusers.utils.testing_utils import load_image, nightly, require_torch_gpu, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class VersatileDiffusionMegaPipelineFastTests(unittest.TestCase):
+ pass
+
+
+@nightly
+@require_torch_gpu
+class VersatileDiffusionMegaPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_from_save_pretrained(self):
+ pipe = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/versatile_diffusion/benz.jpg"
+ )
+
+ generator = torch.manual_seed(0)
+ image = pipe.dual_guided(
+ prompt="first prompt",
+ image=prompt_image,
+ text_to_image_strength=0.75,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=2,
+ output_type="numpy",
+ ).images
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe = VersatileDiffusionPipeline.from_pretrained(tmpdirname, torch_dtype=torch.float16)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = generator.manual_seed(0)
+ new_image = pipe.dual_guided(
+ prompt="first prompt",
+ image=prompt_image,
+ text_to_image_strength=0.75,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=2,
+ output_type="numpy",
+ ).images
+
+ assert np.abs(image - new_image).sum() < 1e-5, "Models don't have the same forward pass"
+
+ def test_inference_dual_guided_then_text_to_image(self):
+ pipe = VersatileDiffusionPipeline.from_pretrained("shi-labs/versatile-diffusion", torch_dtype=torch.float16)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "cyberpunk 2077"
+ init_image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/versatile_diffusion/benz.jpg"
+ )
+ generator = torch.manual_seed(0)
+ image = pipe.dual_guided(
+ prompt=prompt,
+ image=init_image,
+ text_to_image_strength=0.75,
+ generator=generator,
+ guidance_scale=7.5,
+ num_inference_steps=50,
+ output_type="numpy",
+ ).images
+
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.1448, 0.1619, 0.1741, 0.1086, 0.1147, 0.1128, 0.1199, 0.1165, 0.1001])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ prompt = "A painting of a squirrel eating a burger "
+ generator = torch.manual_seed(0)
+ image = pipe.text_to_image(
+ prompt=prompt, generator=generator, guidance_scale=7.5, num_inference_steps=50, output_type="numpy"
+ ).images
+
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.3367, 0.3169, 0.2656, 0.3870, 0.4790, 0.3796, 0.4009, 0.4878, 0.4778])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
+
+ image = pipe.image_variation(init_image, generator=generator, output_type="numpy").images
+
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.3076, 0.3123, 0.3284, 0.3782, 0.3770, 0.3894, 0.4297, 0.4331, 0.4456])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-1
diff --git a/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_text_to_image.py b/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_text_to_image.py
new file mode 100644
index 0000000000000000000000000000000000000000..194f660f7055308b41c47c14a35c41f3b2b1014b
--- /dev/null
+++ b/diffusers/tests/pipelines/versatile_diffusion/test_versatile_diffusion_text_to_image.py
@@ -0,0 +1,87 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import VersatileDiffusionTextToImagePipeline
+from diffusers.utils.testing_utils import nightly, require_torch_gpu, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class VersatileDiffusionTextToImagePipelineFastTests(unittest.TestCase):
+ pass
+
+
+@nightly
+@require_torch_gpu
+class VersatileDiffusionTextToImagePipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_remove_unused_weights_save_load(self):
+ pipe = VersatileDiffusionTextToImagePipeline.from_pretrained("shi-labs/versatile-diffusion")
+ # remove text_unet
+ pipe.remove_unused_weights()
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger "
+ generator = torch.manual_seed(0)
+ image = pipe(
+ prompt=prompt, generator=generator, guidance_scale=7.5, num_inference_steps=2, output_type="numpy"
+ ).images
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe = VersatileDiffusionTextToImagePipeline.from_pretrained(tmpdirname)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ generator = generator.manual_seed(0)
+ new_image = pipe(
+ prompt=prompt, generator=generator, guidance_scale=7.5, num_inference_steps=2, output_type="numpy"
+ ).images
+
+ assert np.abs(image - new_image).sum() < 1e-5, "Models don't have the same forward pass"
+
+ def test_inference_text2img(self):
+ pipe = VersatileDiffusionTextToImagePipeline.from_pretrained(
+ "shi-labs/versatile-diffusion", torch_dtype=torch.float16
+ )
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "A painting of a squirrel eating a burger "
+ generator = torch.manual_seed(0)
+ image = pipe(
+ prompt=prompt, generator=generator, guidance_scale=7.5, num_inference_steps=50, output_type="numpy"
+ ).images
+
+ image_slice = image[0, 253:256, 253:256, -1]
+
+ assert image.shape == (1, 512, 512, 3)
+ expected_slice = np.array([0.3367, 0.3169, 0.2656, 0.3870, 0.4790, 0.3796, 0.4009, 0.4878, 0.4778])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
diff --git a/diffusers/tests/pipelines/vq_diffusion/__init__.py b/diffusers/tests/pipelines/vq_diffusion/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/pipelines/vq_diffusion/test_vq_diffusion.py b/diffusers/tests/pipelines/vq_diffusion/test_vq_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..6769240db905abc75e2d04af89a1852911868751
--- /dev/null
+++ b/diffusers/tests/pipelines/vq_diffusion/test_vq_diffusion.py
@@ -0,0 +1,228 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import unittest
+
+import numpy as np
+import torch
+from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import Transformer2DModel, VQDiffusionPipeline, VQDiffusionScheduler, VQModel
+from diffusers.pipelines.vq_diffusion.pipeline_vq_diffusion import LearnedClassifierFreeSamplingEmbeddings
+from diffusers.utils import load_numpy, slow, torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class VQDiffusionPipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @property
+ def num_embed(self):
+ return 12
+
+ @property
+ def num_embeds_ada_norm(self):
+ return 12
+
+ @property
+ def text_embedder_hidden_size(self):
+ return 32
+
+ @property
+ def dummy_vqvae(self):
+ torch.manual_seed(0)
+ model = VQModel(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=3,
+ num_vq_embeddings=self.num_embed,
+ vq_embed_dim=3,
+ )
+ return model
+
+ @property
+ def dummy_tokenizer(self):
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+ return tokenizer
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=self.text_embedder_hidden_size,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ return CLIPTextModel(config)
+
+ @property
+ def dummy_transformer(self):
+ torch.manual_seed(0)
+
+ height = 12
+ width = 12
+
+ model_kwargs = {
+ "attention_bias": True,
+ "cross_attention_dim": 32,
+ "attention_head_dim": height * width,
+ "num_attention_heads": 1,
+ "num_vector_embeds": self.num_embed,
+ "num_embeds_ada_norm": self.num_embeds_ada_norm,
+ "norm_num_groups": 32,
+ "sample_size": width,
+ "activation_fn": "geglu-approximate",
+ }
+
+ model = Transformer2DModel(**model_kwargs)
+ return model
+
+ def test_vq_diffusion(self):
+ device = "cpu"
+
+ vqvae = self.dummy_vqvae
+ text_encoder = self.dummy_text_encoder
+ tokenizer = self.dummy_tokenizer
+ transformer = self.dummy_transformer
+ scheduler = VQDiffusionScheduler(self.num_embed)
+ learned_classifier_free_sampling_embeddings = LearnedClassifierFreeSamplingEmbeddings(learnable=False)
+
+ pipe = VQDiffusionPipeline(
+ vqvae=vqvae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ transformer=transformer,
+ scheduler=scheduler,
+ learned_classifier_free_sampling_embeddings=learned_classifier_free_sampling_embeddings,
+ )
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "teddy bear playing in the pool"
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = pipe([prompt], generator=generator, num_inference_steps=2, output_type="np")
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = pipe(
+ [prompt], generator=generator, output_type="np", return_dict=False, num_inference_steps=2
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 24, 24, 3)
+
+ expected_slice = np.array([0.6583, 0.6410, 0.5325, 0.5635, 0.5563, 0.4234, 0.6008, 0.5491, 0.4880])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+ def test_vq_diffusion_classifier_free_sampling(self):
+ device = "cpu"
+
+ vqvae = self.dummy_vqvae
+ text_encoder = self.dummy_text_encoder
+ tokenizer = self.dummy_tokenizer
+ transformer = self.dummy_transformer
+ scheduler = VQDiffusionScheduler(self.num_embed)
+ learned_classifier_free_sampling_embeddings = LearnedClassifierFreeSamplingEmbeddings(
+ learnable=True, hidden_size=self.text_embedder_hidden_size, length=tokenizer.model_max_length
+ )
+
+ pipe = VQDiffusionPipeline(
+ vqvae=vqvae,
+ text_encoder=text_encoder,
+ tokenizer=tokenizer,
+ transformer=transformer,
+ scheduler=scheduler,
+ learned_classifier_free_sampling_embeddings=learned_classifier_free_sampling_embeddings,
+ )
+ pipe = pipe.to(device)
+ pipe.set_progress_bar_config(disable=None)
+
+ prompt = "teddy bear playing in the pool"
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ output = pipe([prompt], generator=generator, num_inference_steps=2, output_type="np")
+ image = output.images
+
+ generator = torch.Generator(device=device).manual_seed(0)
+ image_from_tuple = pipe(
+ [prompt], generator=generator, output_type="np", return_dict=False, num_inference_steps=2
+ )[0]
+
+ image_slice = image[0, -3:, -3:, -1]
+ image_from_tuple_slice = image_from_tuple[0, -3:, -3:, -1]
+
+ assert image.shape == (1, 24, 24, 3)
+
+ expected_slice = np.array([0.6647, 0.6531, 0.5303, 0.5891, 0.5726, 0.4439, 0.6304, 0.5564, 0.4912])
+
+ assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
+ assert np.abs(image_from_tuple_slice.flatten() - expected_slice).max() < 1e-2
+
+
+@slow
+@require_torch_gpu
+class VQDiffusionPipelineIntegrationTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_vq_diffusion_classifier_free_sampling(self):
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ "/vq_diffusion/teddy_bear_pool_classifier_free_sampling.npy"
+ )
+
+ pipeline = VQDiffusionPipeline.from_pretrained("microsoft/vq-diffusion-ithq")
+ pipeline = pipeline.to(torch_device)
+ pipeline.set_progress_bar_config(disable=None)
+
+ # requires GPU generator for gumbel softmax
+ # don't use GPU generator in tests though
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ output = pipeline(
+ "teddy bear playing in the pool",
+ num_images_per_prompt=1,
+ generator=generator,
+ output_type="np",
+ )
+
+ image = output.images[0]
+
+ assert image.shape == (256, 256, 3)
+ assert np.abs(expected_image - image).max() < 1e-2
diff --git a/diffusers/tests/repo_utils/test_check_copies.py b/diffusers/tests/repo_utils/test_check_copies.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd0a22da2c3af2bed6f3029e84face108e3cbda3
--- /dev/null
+++ b/diffusers/tests/repo_utils/test_check_copies.py
@@ -0,0 +1,120 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import re
+import shutil
+import sys
+import tempfile
+import unittest
+
+import black
+
+
+git_repo_path = os.path.abspath(os.path.dirname(os.path.dirname(os.path.dirname(__file__))))
+sys.path.append(os.path.join(git_repo_path, "utils"))
+
+import check_copies # noqa: E402
+
+
+# This is the reference code that will be used in the tests.
+# If DDPMSchedulerOutput is changed in scheduling_ddpm.py, this code needs to be manually updated.
+REFERENCE_CODE = """ \"""
+ Output class for the scheduler's step function output.
+
+ Args:
+ prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the
+ denoising loop.
+ pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
+ The predicted denoised sample (x_{0}) based on the model output from the current timestep.
+ `pred_original_sample` can be used to preview progress or for guidance.
+ \"""
+
+ prev_sample: torch.FloatTensor
+ pred_original_sample: Optional[torch.FloatTensor] = None
+"""
+
+
+class CopyCheckTester(unittest.TestCase):
+ def setUp(self):
+ self.diffusers_dir = tempfile.mkdtemp()
+ os.makedirs(os.path.join(self.diffusers_dir, "schedulers/"))
+ check_copies.DIFFUSERS_PATH = self.diffusers_dir
+ shutil.copy(
+ os.path.join(git_repo_path, "src/diffusers/schedulers/scheduling_ddpm.py"),
+ os.path.join(self.diffusers_dir, "schedulers/scheduling_ddpm.py"),
+ )
+
+ def tearDown(self):
+ check_copies.DIFFUSERS_PATH = "src/diffusers"
+ shutil.rmtree(self.diffusers_dir)
+
+ def check_copy_consistency(self, comment, class_name, class_code, overwrite_result=None):
+ code = comment + f"\nclass {class_name}(nn.Module):\n" + class_code
+ if overwrite_result is not None:
+ expected = comment + f"\nclass {class_name}(nn.Module):\n" + overwrite_result
+ mode = black.Mode(target_versions={black.TargetVersion.PY35}, line_length=119)
+ code = black.format_str(code, mode=mode)
+ fname = os.path.join(self.diffusers_dir, "new_code.py")
+ with open(fname, "w", newline="\n") as f:
+ f.write(code)
+ if overwrite_result is None:
+ self.assertTrue(len(check_copies.is_copy_consistent(fname)) == 0)
+ else:
+ check_copies.is_copy_consistent(f.name, overwrite=True)
+ with open(fname, "r") as f:
+ self.assertTrue(f.read(), expected)
+
+ def test_find_code_in_diffusers(self):
+ code = check_copies.find_code_in_diffusers("schedulers.scheduling_ddpm.DDPMSchedulerOutput")
+ self.assertEqual(code, REFERENCE_CODE)
+
+ def test_is_copy_consistent(self):
+ # Base copy consistency
+ self.check_copy_consistency(
+ "# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput",
+ "DDPMSchedulerOutput",
+ REFERENCE_CODE + "\n",
+ )
+
+ # With no empty line at the end
+ self.check_copy_consistency(
+ "# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput",
+ "DDPMSchedulerOutput",
+ REFERENCE_CODE,
+ )
+
+ # Copy consistency with rename
+ self.check_copy_consistency(
+ "# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->Test",
+ "TestSchedulerOutput",
+ re.sub("DDPM", "Test", REFERENCE_CODE),
+ )
+
+ # Copy consistency with a really long name
+ long_class_name = "TestClassWithAReallyLongNameBecauseSomePeopleLikeThatForSomeReason"
+ self.check_copy_consistency(
+ f"# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->{long_class_name}",
+ f"{long_class_name}SchedulerOutput",
+ re.sub("Bert", long_class_name, REFERENCE_CODE),
+ )
+
+ # Copy consistency with overwrite
+ self.check_copy_consistency(
+ "# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->Test",
+ "TestSchedulerOutput",
+ REFERENCE_CODE,
+ overwrite_result=re.sub("DDPM", "Test", REFERENCE_CODE),
+ )
diff --git a/diffusers/tests/repo_utils/test_check_dummies.py b/diffusers/tests/repo_utils/test_check_dummies.py
new file mode 100644
index 0000000000000000000000000000000000000000..52a75d7b02e85f70cb347afb1429ca8beb942d21
--- /dev/null
+++ b/diffusers/tests/repo_utils/test_check_dummies.py
@@ -0,0 +1,122 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import sys
+import unittest
+
+
+git_repo_path = os.path.abspath(os.path.dirname(os.path.dirname(os.path.dirname(__file__))))
+sys.path.append(os.path.join(git_repo_path, "utils"))
+
+import check_dummies # noqa: E402
+from check_dummies import create_dummy_files, create_dummy_object, find_backend, read_init # noqa: E402
+
+
+# Align TRANSFORMERS_PATH in check_dummies with the current path
+check_dummies.PATH_TO_DIFFUSERS = os.path.join(git_repo_path, "src", "diffusers")
+
+
+class CheckDummiesTester(unittest.TestCase):
+ def test_find_backend(self):
+ simple_backend = find_backend(" if not is_torch_available():")
+ self.assertEqual(simple_backend, "torch")
+
+ # backend_with_underscore = find_backend(" if not is_tensorflow_text_available():")
+ # self.assertEqual(backend_with_underscore, "tensorflow_text")
+
+ double_backend = find_backend(" if not (is_torch_available() and is_transformers_available()):")
+ self.assertEqual(double_backend, "torch_and_transformers")
+
+ # double_backend_with_underscore = find_backend(
+ # " if not (is_sentencepiece_available() and is_tensorflow_text_available()):"
+ # )
+ # self.assertEqual(double_backend_with_underscore, "sentencepiece_and_tensorflow_text")
+
+ triple_backend = find_backend(
+ " if not (is_torch_available() and is_transformers_available() and is_onnx_available()):"
+ )
+ self.assertEqual(triple_backend, "torch_and_transformers_and_onnx")
+
+ def test_read_init(self):
+ objects = read_init()
+ # We don't assert on the exact list of keys to allow for smooth grow of backend-specific objects
+ self.assertIn("torch", objects)
+ self.assertIn("torch_and_transformers", objects)
+ self.assertIn("flax_and_transformers", objects)
+ self.assertIn("torch_and_transformers_and_onnx", objects)
+
+ # Likewise, we can't assert on the exact content of a key
+ self.assertIn("UNet2DModel", objects["torch"])
+ self.assertIn("FlaxUNet2DConditionModel", objects["flax"])
+ self.assertIn("StableDiffusionPipeline", objects["torch_and_transformers"])
+ self.assertIn("FlaxStableDiffusionPipeline", objects["flax_and_transformers"])
+ self.assertIn("LMSDiscreteScheduler", objects["torch_and_scipy"])
+ self.assertIn("OnnxStableDiffusionPipeline", objects["torch_and_transformers_and_onnx"])
+
+ def test_create_dummy_object(self):
+ dummy_constant = create_dummy_object("CONSTANT", "'torch'")
+ self.assertEqual(dummy_constant, "\nCONSTANT = None\n")
+
+ dummy_function = create_dummy_object("function", "'torch'")
+ self.assertEqual(
+ dummy_function, "\ndef function(*args, **kwargs):\n requires_backends(function, 'torch')\n"
+ )
+
+ expected_dummy_class = """
+class FakeClass(metaclass=DummyObject):
+ _backends = 'torch'
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, 'torch')
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, 'torch')
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, 'torch')
+"""
+ dummy_class = create_dummy_object("FakeClass", "'torch'")
+ self.assertEqual(dummy_class, expected_dummy_class)
+
+ def test_create_dummy_files(self):
+ expected_dummy_pytorch_file = """# This file is autogenerated by the command `make fix-copies`, do not edit.
+from ..utils import DummyObject, requires_backends
+
+
+CONSTANT = None
+
+
+def function(*args, **kwargs):
+ requires_backends(function, ["torch"])
+
+
+class FakeClass(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, ["torch"])
+"""
+ dummy_files = create_dummy_files({"torch": ["CONSTANT", "function", "FakeClass"]})
+ self.assertEqual(dummy_files["torch"], expected_dummy_pytorch_file)
diff --git a/diffusers/tests/schedulers/__init__.py b/diffusers/tests/schedulers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/diffusers/tests/schedulers/test_scheduler_ddim.py b/diffusers/tests/schedulers/test_scheduler_ddim.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9c85314d558af74b2ed325df5ed7722e1acd691
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_ddim.py
@@ -0,0 +1,140 @@
+import torch
+
+from diffusers import DDIMScheduler
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class DDIMSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (DDIMScheduler,)
+ forward_default_kwargs = (("eta", 0.0), ("num_inference_steps", 50))
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ "clip_sample": True,
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def full_loop(self, **config):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps, eta = 10, 0.0
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+
+ scheduler.set_timesteps(num_inference_steps)
+
+ for t in scheduler.timesteps:
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample, eta).prev_sample
+
+ return sample
+
+ def test_timesteps(self):
+ for timesteps in [100, 500, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_steps_offset(self):
+ for steps_offset in [0, 1]:
+ self.check_over_configs(steps_offset=steps_offset)
+
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(steps_offset=1)
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(5)
+ assert torch.equal(scheduler.timesteps, torch.LongTensor([801, 601, 401, 201, 1]))
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.0001, 0.001, 0.01, 0.1], [0.002, 0.02, 0.2, 2]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "squaredcos_cap_v2"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_clip_sample(self):
+ for clip_sample in [True, False]:
+ self.check_over_configs(clip_sample=clip_sample)
+
+ def test_thresholding(self):
+ self.check_over_configs(thresholding=False)
+ for threshold in [0.5, 1.0, 2.0]:
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(
+ thresholding=True,
+ prediction_type=prediction_type,
+ sample_max_value=threshold,
+ )
+
+ def test_time_indices(self):
+ for t in [1, 10, 49]:
+ self.check_over_forward(time_step=t)
+
+ def test_inference_steps(self):
+ for t, num_inference_steps in zip([1, 10, 50], [10, 50, 500]):
+ self.check_over_forward(time_step=t, num_inference_steps=num_inference_steps)
+
+ def test_eta(self):
+ for t, eta in zip([1, 10, 49], [0.0, 0.5, 1.0]):
+ self.check_over_forward(time_step=t, eta=eta)
+
+ def test_variance(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ assert torch.sum(torch.abs(scheduler._get_variance(0, 0) - 0.0)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(420, 400) - 0.14771)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(980, 960) - 0.32460)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(0, 0) - 0.0)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(487, 486) - 0.00979)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(999, 998) - 0.02)) < 1e-5
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 172.0067) < 1e-2
+ assert abs(result_mean.item() - 0.223967) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ sample = self.full_loop(prediction_type="v_prediction")
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 52.5302) < 1e-2
+ assert abs(result_mean.item() - 0.0684) < 1e-3
+
+ def test_full_loop_with_set_alpha_to_one(self):
+ # We specify different beta, so that the first alpha is 0.99
+ sample = self.full_loop(set_alpha_to_one=True, beta_start=0.01)
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 149.8295) < 1e-2
+ assert abs(result_mean.item() - 0.1951) < 1e-3
+
+ def test_full_loop_with_no_set_alpha_to_one(self):
+ # We specify different beta, so that the first alpha is 0.99
+ sample = self.full_loop(set_alpha_to_one=False, beta_start=0.01)
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 149.0784) < 1e-2
+ assert abs(result_mean.item() - 0.1941) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_ddpm.py b/diffusers/tests/schedulers/test_scheduler_ddpm.py
new file mode 100644
index 0000000000000000000000000000000000000000..b55a39ee2e79274691f5136b989cbaabb3f00932
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_ddpm.py
@@ -0,0 +1,131 @@
+import torch
+
+from diffusers import DDPMScheduler
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class DDPMSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (DDPMScheduler,)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ "variance_type": "fixed_small",
+ "clip_sample": True,
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [1, 5, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.0001, 0.001, 0.01, 0.1], [0.002, 0.02, 0.2, 2]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "squaredcos_cap_v2"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_variance_type(self):
+ for variance in ["fixed_small", "fixed_large", "other"]:
+ self.check_over_configs(variance_type=variance)
+
+ def test_clip_sample(self):
+ for clip_sample in [True, False]:
+ self.check_over_configs(clip_sample=clip_sample)
+
+ def test_thresholding(self):
+ self.check_over_configs(thresholding=False)
+ for threshold in [0.5, 1.0, 2.0]:
+ for prediction_type in ["epsilon", "sample", "v_prediction"]:
+ self.check_over_configs(
+ thresholding=True,
+ prediction_type=prediction_type,
+ sample_max_value=threshold,
+ )
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "sample", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_time_indices(self):
+ for t in [0, 500, 999]:
+ self.check_over_forward(time_step=t)
+
+ def test_variance(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ assert torch.sum(torch.abs(scheduler._get_variance(0) - 0.0)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(487) - 0.00979)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(999) - 0.02)) < 1e-5
+
+ def test_full_loop_no_noise(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_trained_timesteps = len(scheduler)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ generator = torch.manual_seed(0)
+
+ for t in reversed(range(num_trained_timesteps)):
+ # 1. predict noise residual
+ residual = model(sample, t)
+
+ # 2. predict previous mean of sample x_t-1
+ pred_prev_sample = scheduler.step(residual, t, sample, generator=generator).prev_sample
+
+ # if t > 0:
+ # noise = self.dummy_sample_deter
+ # variance = scheduler.get_variance(t) ** (0.5) * noise
+ #
+ # sample = pred_prev_sample + variance
+ sample = pred_prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 258.9606) < 1e-2
+ assert abs(result_mean.item() - 0.3372) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(prediction_type="v_prediction")
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_trained_timesteps = len(scheduler)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ generator = torch.manual_seed(0)
+
+ for t in reversed(range(num_trained_timesteps)):
+ # 1. predict noise residual
+ residual = model(sample, t)
+
+ # 2. predict previous mean of sample x_t-1
+ pred_prev_sample = scheduler.step(residual, t, sample, generator=generator).prev_sample
+
+ # if t > 0:
+ # noise = self.dummy_sample_deter
+ # variance = scheduler.get_variance(t) ** (0.5) * noise
+ #
+ # sample = pred_prev_sample + variance
+ sample = pred_prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 202.0296) < 1e-2
+ assert abs(result_mean.item() - 0.2631) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_deis.py b/diffusers/tests/schedulers/test_scheduler_deis.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b14601bc98240cca5ea75ae06343be20bc3ca79
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_deis.py
@@ -0,0 +1,237 @@
+import tempfile
+
+import torch
+
+from diffusers import (
+ DEISMultistepScheduler,
+ DPMSolverMultistepScheduler,
+ DPMSolverSinglestepScheduler,
+ UniPCMultistepScheduler,
+)
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class DEISMultistepSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (DEISMultistepScheduler,)
+ forward_default_kwargs = (("num_inference_steps", 25),)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ "solver_order": 2,
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ new_scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
+
+ output, new_output = sample, sample
+ for t in range(time_step, time_step + scheduler.config.solver_order + 1):
+ output = scheduler.step(residual, t, output, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, t, new_output, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ pass
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residuals (must be after setting timesteps)
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ # copy over dummy past residuals
+ new_scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residual (must be after setting timesteps)
+ new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
+
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def full_loop(self, scheduler=None, **config):
+ if scheduler is None:
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ return sample
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # copy over dummy past residuals (must be done after set_timesteps)
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ time_step_0 = scheduler.timesteps[5]
+ time_step_1 = scheduler.timesteps[6]
+
+ output_0 = scheduler.step(residual, time_step_0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step(residual, time_step_1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_switch(self):
+ # make sure that iterating over schedulers with same config names gives same results
+ # for defaults
+ scheduler = DEISMultistepScheduler(**self.get_scheduler_config())
+ sample = self.full_loop(scheduler=scheduler)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.23916) < 1e-3
+
+ scheduler = DPMSolverSinglestepScheduler.from_config(scheduler.config)
+ scheduler = DPMSolverMultistepScheduler.from_config(scheduler.config)
+ scheduler = UniPCMultistepScheduler.from_config(scheduler.config)
+ scheduler = DEISMultistepScheduler.from_config(scheduler.config)
+
+ sample = self.full_loop(scheduler=scheduler)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.23916) < 1e-3
+
+ def test_timesteps(self):
+ for timesteps in [25, 50, 100, 999, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_thresholding(self):
+ self.check_over_configs(thresholding=False)
+ for order in [1, 2, 3]:
+ for solver_type in ["logrho"]:
+ for threshold in [0.5, 1.0, 2.0]:
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(
+ thresholding=True,
+ prediction_type=prediction_type,
+ sample_max_value=threshold,
+ algorithm_type="deis",
+ solver_order=order,
+ solver_type=solver_type,
+ )
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_solver_order_and_type(self):
+ for algorithm_type in ["deis"]:
+ for solver_type in ["logrho"]:
+ for order in [1, 2, 3]:
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(
+ solver_order=order,
+ solver_type=solver_type,
+ prediction_type=prediction_type,
+ algorithm_type=algorithm_type,
+ )
+ sample = self.full_loop(
+ solver_order=order,
+ solver_type=solver_type,
+ prediction_type=prediction_type,
+ algorithm_type=algorithm_type,
+ )
+ assert not torch.isnan(sample).any(), "Samples have nan numbers"
+
+ def test_lower_order_final(self):
+ self.check_over_configs(lower_order_final=True)
+ self.check_over_configs(lower_order_final=False)
+
+ def test_inference_steps(self):
+ for num_inference_steps in [1, 2, 3, 5, 10, 50, 100, 999, 1000]:
+ self.check_over_forward(num_inference_steps=num_inference_steps, time_step=0)
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.23916) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ sample = self.full_loop(prediction_type="v_prediction")
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.091) < 1e-3
+
+ def test_fp16_support(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(thresholding=True, dynamic_thresholding_ratio=0)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter.half()
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ assert sample.dtype == torch.float16
diff --git a/diffusers/tests/schedulers/test_scheduler_dpm_multi.py b/diffusers/tests/schedulers/test_scheduler_dpm_multi.py
new file mode 100644
index 0000000000000000000000000000000000000000..295bbe882746793b09b196f054e392e22415d455
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_dpm_multi.py
@@ -0,0 +1,245 @@
+import tempfile
+
+import torch
+
+from diffusers import (
+ DEISMultistepScheduler,
+ DPMSolverMultistepScheduler,
+ DPMSolverSinglestepScheduler,
+ UniPCMultistepScheduler,
+)
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class DPMSolverMultistepSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (DPMSolverMultistepScheduler,)
+ forward_default_kwargs = (("num_inference_steps", 25),)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ "solver_order": 2,
+ "prediction_type": "epsilon",
+ "thresholding": False,
+ "sample_max_value": 1.0,
+ "algorithm_type": "dpmsolver++",
+ "solver_type": "midpoint",
+ "lower_order_final": False,
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ new_scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
+
+ output, new_output = sample, sample
+ for t in range(time_step, time_step + scheduler.config.solver_order + 1):
+ output = scheduler.step(residual, t, output, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, t, new_output, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ pass
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residuals (must be after setting timesteps)
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ # copy over dummy past residuals
+ new_scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residual (must be after setting timesteps)
+ new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
+
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def full_loop(self, scheduler=None, **config):
+ if scheduler is None:
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ return sample
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # copy over dummy past residuals (must be done after set_timesteps)
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ time_step_0 = scheduler.timesteps[5]
+ time_step_1 = scheduler.timesteps[6]
+
+ output_0 = scheduler.step(residual, time_step_0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step(residual, time_step_1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_timesteps(self):
+ for timesteps in [25, 50, 100, 999, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_thresholding(self):
+ self.check_over_configs(thresholding=False)
+ for order in [1, 2, 3]:
+ for solver_type in ["midpoint", "heun"]:
+ for threshold in [0.5, 1.0, 2.0]:
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(
+ thresholding=True,
+ prediction_type=prediction_type,
+ sample_max_value=threshold,
+ algorithm_type="dpmsolver++",
+ solver_order=order,
+ solver_type=solver_type,
+ )
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_solver_order_and_type(self):
+ for algorithm_type in ["dpmsolver", "dpmsolver++"]:
+ for solver_type in ["midpoint", "heun"]:
+ for order in [1, 2, 3]:
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(
+ solver_order=order,
+ solver_type=solver_type,
+ prediction_type=prediction_type,
+ algorithm_type=algorithm_type,
+ )
+ sample = self.full_loop(
+ solver_order=order,
+ solver_type=solver_type,
+ prediction_type=prediction_type,
+ algorithm_type=algorithm_type,
+ )
+ assert not torch.isnan(sample).any(), "Samples have nan numbers"
+
+ def test_lower_order_final(self):
+ self.check_over_configs(lower_order_final=True)
+ self.check_over_configs(lower_order_final=False)
+
+ def test_inference_steps(self):
+ for num_inference_steps in [1, 2, 3, 5, 10, 50, 100, 999, 1000]:
+ self.check_over_forward(num_inference_steps=num_inference_steps, time_step=0)
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.3301) < 1e-3
+
+ def test_full_loop_no_noise_thres(self):
+ sample = self.full_loop(thresholding=True, dynamic_thresholding_ratio=0.87, sample_max_value=0.5)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.6405) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ sample = self.full_loop(prediction_type="v_prediction")
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.2251) < 1e-3
+
+ def test_switch(self):
+ # make sure that iterating over schedulers with same config names gives same results
+ # for defaults
+ scheduler = DPMSolverMultistepScheduler(**self.get_scheduler_config())
+ sample = self.full_loop(scheduler=scheduler)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.3301) < 1e-3
+
+ scheduler = DPMSolverSinglestepScheduler.from_config(scheduler.config)
+ scheduler = UniPCMultistepScheduler.from_config(scheduler.config)
+ scheduler = DEISMultistepScheduler.from_config(scheduler.config)
+ scheduler = DPMSolverMultistepScheduler.from_config(scheduler.config)
+
+ sample = self.full_loop(scheduler=scheduler)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.3301) < 1e-3
+
+ def test_fp16_support(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(thresholding=True, dynamic_thresholding_ratio=0)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter.half()
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ assert sample.dtype == torch.float16
diff --git a/diffusers/tests/schedulers/test_scheduler_dpm_single.py b/diffusers/tests/schedulers/test_scheduler_dpm_single.py
new file mode 100644
index 0000000000000000000000000000000000000000..9dff04e7c99841f83d9cbbd34dde7ee4525541fe
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_dpm_single.py
@@ -0,0 +1,212 @@
+import tempfile
+
+import torch
+
+from diffusers import (
+ DEISMultistepScheduler,
+ DPMSolverMultistepScheduler,
+ DPMSolverSinglestepScheduler,
+ UniPCMultistepScheduler,
+)
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class DPMSolverSinglestepSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (DPMSolverSinglestepScheduler,)
+ forward_default_kwargs = (("num_inference_steps", 25),)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ "solver_order": 2,
+ "prediction_type": "epsilon",
+ "thresholding": False,
+ "sample_max_value": 1.0,
+ "algorithm_type": "dpmsolver++",
+ "solver_type": "midpoint",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ new_scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
+
+ output, new_output = sample, sample
+ for t in range(time_step, time_step + scheduler.config.solver_order + 1):
+ output = scheduler.step(residual, t, output, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, t, new_output, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ pass
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residuals (must be after setting timesteps)
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ # copy over dummy past residuals
+ new_scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residual (must be after setting timesteps)
+ new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
+
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def full_loop(self, scheduler=None, **config):
+ if scheduler is None:
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ return sample
+
+ def test_timesteps(self):
+ for timesteps in [25, 50, 100, 999, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_switch(self):
+ # make sure that iterating over schedulers with same config names gives same results
+ # for defaults
+ scheduler = DPMSolverSinglestepScheduler(**self.get_scheduler_config())
+ sample = self.full_loop(scheduler=scheduler)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.2791) < 1e-3
+
+ scheduler = DEISMultistepScheduler.from_config(scheduler.config)
+ scheduler = DPMSolverMultistepScheduler.from_config(scheduler.config)
+ scheduler = UniPCMultistepScheduler.from_config(scheduler.config)
+ scheduler = DPMSolverSinglestepScheduler.from_config(scheduler.config)
+
+ sample = self.full_loop(scheduler=scheduler)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.2791) < 1e-3
+
+ def test_thresholding(self):
+ self.check_over_configs(thresholding=False)
+ for order in [1, 2, 3]:
+ for solver_type in ["midpoint", "heun"]:
+ for threshold in [0.5, 1.0, 2.0]:
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(
+ thresholding=True,
+ prediction_type=prediction_type,
+ sample_max_value=threshold,
+ algorithm_type="dpmsolver++",
+ solver_order=order,
+ solver_type=solver_type,
+ )
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_solver_order_and_type(self):
+ for algorithm_type in ["dpmsolver", "dpmsolver++"]:
+ for solver_type in ["midpoint", "heun"]:
+ for order in [1, 2, 3]:
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(
+ solver_order=order,
+ solver_type=solver_type,
+ prediction_type=prediction_type,
+ algorithm_type=algorithm_type,
+ )
+ sample = self.full_loop(
+ solver_order=order,
+ solver_type=solver_type,
+ prediction_type=prediction_type,
+ algorithm_type=algorithm_type,
+ )
+ assert not torch.isnan(sample).any(), "Samples have nan numbers"
+
+ def test_lower_order_final(self):
+ self.check_over_configs(lower_order_final=True)
+ self.check_over_configs(lower_order_final=False)
+
+ def test_inference_steps(self):
+ for num_inference_steps in [1, 2, 3, 5, 10, 50, 100, 999, 1000]:
+ self.check_over_forward(num_inference_steps=num_inference_steps, time_step=0)
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.2791) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ sample = self.full_loop(prediction_type="v_prediction")
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.1453) < 1e-3
+
+ def test_fp16_support(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(thresholding=True, dynamic_thresholding_ratio=0)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter.half()
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ assert sample.dtype == torch.float16
diff --git a/diffusers/tests/schedulers/test_scheduler_euler.py b/diffusers/tests/schedulers/test_scheduler_euler.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d521b0075e18710b88ed3efe1f2652bb4718733
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_euler.py
@@ -0,0 +1,119 @@
+import torch
+
+from diffusers import EulerDiscreteScheduler
+from diffusers.utils import torch_device
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class EulerDiscreteSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (EulerDiscreteScheduler,)
+ num_inference_steps = 10
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1100,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [10, 50, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.00001, 0.0001, 0.001], [0.0002, 0.002, 0.02]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "scaled_linear"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_full_loop_no_noise(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ generator = torch.manual_seed(0)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 10.0807) < 1e-2
+ assert abs(result_mean.item() - 0.0131) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(prediction_type="v_prediction")
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ generator = torch.manual_seed(0)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 0.0002) < 1e-2
+ assert abs(result_mean.item() - 2.2676e-06) < 1e-3
+
+ def test_full_loop_device(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps, device=torch_device)
+
+ generator = torch.manual_seed(0)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for t in scheduler.timesteps:
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 10.0807) < 1e-2
+ assert abs(result_mean.item() - 0.0131) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_euler_ancestral.py b/diffusers/tests/schedulers/test_scheduler_euler_ancestral.py
new file mode 100644
index 0000000000000000000000000000000000000000..5fa36be6bc64e5fc6aac72e11e50e455089469cb
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_euler_ancestral.py
@@ -0,0 +1,118 @@
+import torch
+
+from diffusers import EulerAncestralDiscreteScheduler
+from diffusers.utils import torch_device
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class EulerAncestralDiscreteSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (EulerAncestralDiscreteScheduler,)
+ num_inference_steps = 10
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1100,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [10, 50, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.00001, 0.0001, 0.001], [0.0002, 0.002, 0.02]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "scaled_linear"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_full_loop_no_noise(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ generator = torch.manual_seed(0)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 152.3192) < 1e-2
+ assert abs(result_mean.item() - 0.1983) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(prediction_type="v_prediction")
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ generator = torch.manual_seed(0)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 108.4439) < 1e-2
+ assert abs(result_mean.item() - 0.1412) < 1e-3
+
+ def test_full_loop_device(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps, device=torch_device)
+ generator = torch.manual_seed(0)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for t in scheduler.timesteps:
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 152.3192) < 1e-2
+ assert abs(result_mean.item() - 0.1983) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_flax.py b/diffusers/tests/schedulers/test_scheduler_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..8f7ad59d285eb50a42ab5809ce60dd0bf26e026c
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_flax.py
@@ -0,0 +1,919 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import inspect
+import tempfile
+import unittest
+from typing import Dict, List, Tuple
+
+from diffusers import FlaxDDIMScheduler, FlaxDDPMScheduler, FlaxPNDMScheduler
+from diffusers.utils import is_flax_available
+from diffusers.utils.testing_utils import require_flax
+
+
+if is_flax_available():
+ import jax
+ import jax.numpy as jnp
+ from jax import random
+
+ jax_device = jax.default_backend()
+
+
+@require_flax
+class FlaxSchedulerCommonTest(unittest.TestCase):
+ scheduler_classes = ()
+ forward_default_kwargs = ()
+
+ @property
+ def dummy_sample(self):
+ batch_size = 4
+ num_channels = 3
+ height = 8
+ width = 8
+
+ key1, key2 = random.split(random.PRNGKey(0))
+ sample = random.uniform(key1, (batch_size, num_channels, height, width))
+
+ return sample, key2
+
+ @property
+ def dummy_sample_deter(self):
+ batch_size = 4
+ num_channels = 3
+ height = 8
+ width = 8
+
+ num_elems = batch_size * num_channels * height * width
+ sample = jnp.arange(num_elems)
+ sample = sample.reshape(num_channels, height, width, batch_size)
+ sample = sample / num_elems
+ return jnp.transpose(sample, (3, 0, 1, 2))
+
+ def get_scheduler_config(self):
+ raise NotImplementedError
+
+ def dummy_model(self):
+ def model(sample, t, *args):
+ return sample * t / (t + 1)
+
+ return model
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ sample, key = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler, new_state = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ new_state = new_scheduler.set_timesteps(new_state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output = scheduler.step(state, residual, time_step, sample, key, **kwargs).prev_sample
+ new_output = new_scheduler.step(new_state, residual, time_step, sample, key, **kwargs).prev_sample
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ kwargs.update(forward_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ sample, key = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler, new_state = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ new_state = new_scheduler.set_timesteps(new_state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output = scheduler.step(state, residual, time_step, sample, key, **kwargs).prev_sample
+ new_output = new_scheduler.step(new_state, residual, time_step, sample, key, **kwargs).prev_sample
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ sample, key = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler, new_state = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ new_state = new_scheduler.set_timesteps(new_state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output = scheduler.step(state, residual, 1, sample, key, **kwargs).prev_sample
+ new_output = new_scheduler.step(new_state, residual, 1, sample, key, **kwargs).prev_sample
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ sample, key = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output_0 = scheduler.step(state, residual, 0, sample, key, **kwargs).prev_sample
+ output_1 = scheduler.step(state, residual, 1, sample, key, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_scheduler_outputs_equivalence(self):
+ def set_nan_tensor_to_zero(t):
+ return t.at[t != t].set(0)
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object.values(), dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ jnp.allclose(set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {jnp.max(jnp.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {jnp.isnan(tuple_object).any()} and `inf`: {jnp.isinf(tuple_object)}. Dict has"
+ f" `nan`: {jnp.isnan(dict_object).any()} and `inf`: {jnp.isinf(dict_object)}."
+ ),
+ )
+
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ sample, key = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ outputs_dict = scheduler.step(state, residual, 0, sample, key, **kwargs)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ outputs_tuple = scheduler.step(state, residual, 0, sample, key, return_dict=False, **kwargs)
+
+ recursive_check(outputs_tuple[0], outputs_dict.prev_sample)
+
+ def test_deprecated_kwargs(self):
+ for scheduler_class in self.scheduler_classes:
+ has_kwarg_in_model_class = "kwargs" in inspect.signature(scheduler_class.__init__).parameters
+ has_deprecated_kwarg = len(scheduler_class._deprecated_kwargs) > 0
+
+ if has_kwarg_in_model_class and not has_deprecated_kwarg:
+ raise ValueError(
+ f"{scheduler_class} has `**kwargs` in its __init__ method but has not defined any deprecated"
+ " kwargs under the `_deprecated_kwargs` class attribute. Make sure to either remove `**kwargs` if"
+ " there are no deprecated arguments or add the deprecated argument with `_deprecated_kwargs ="
+ " []`"
+ )
+
+ if not has_kwarg_in_model_class and has_deprecated_kwarg:
+ raise ValueError(
+ f"{scheduler_class} doesn't have `**kwargs` in its __init__ method but has defined deprecated"
+ " kwargs under the `_deprecated_kwargs` class attribute. Make sure to either add the `**kwargs`"
+ f" argument to {self.model_class}.__init__ if there are deprecated arguments or remove the"
+ " deprecated argument from `_deprecated_kwargs = []`"
+ )
+
+
+@require_flax
+class FlaxDDPMSchedulerTest(FlaxSchedulerCommonTest):
+ scheduler_classes = (FlaxDDPMScheduler,)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ "variance_type": "fixed_small",
+ "clip_sample": True,
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [1, 5, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.0001, 0.001, 0.01, 0.1], [0.002, 0.02, 0.2, 2]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "squaredcos_cap_v2"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_variance_type(self):
+ for variance in ["fixed_small", "fixed_large", "other"]:
+ self.check_over_configs(variance_type=variance)
+
+ def test_clip_sample(self):
+ for clip_sample in [True, False]:
+ self.check_over_configs(clip_sample=clip_sample)
+
+ def test_time_indices(self):
+ for t in [0, 500, 999]:
+ self.check_over_forward(time_step=t)
+
+ def test_variance(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 0) - 0.0)) < 1e-5
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 487) - 0.00979)) < 1e-5
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 999) - 0.02)) < 1e-5
+
+ def test_full_loop_no_noise(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ num_trained_timesteps = len(scheduler)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ key1, key2 = random.split(random.PRNGKey(0))
+
+ for t in reversed(range(num_trained_timesteps)):
+ # 1. predict noise residual
+ residual = model(sample, t)
+
+ # 2. predict previous mean of sample x_t-1
+ output = scheduler.step(state, residual, t, sample, key1)
+ pred_prev_sample = output.prev_sample
+ state = output.state
+ key1, key2 = random.split(key2)
+
+ # if t > 0:
+ # noise = self.dummy_sample_deter
+ # variance = scheduler.get_variance(t) ** (0.5) * noise
+ #
+ # sample = pred_prev_sample + variance
+ sample = pred_prev_sample
+
+ result_sum = jnp.sum(jnp.abs(sample))
+ result_mean = jnp.mean(jnp.abs(sample))
+
+ if jax_device == "tpu":
+ assert abs(result_sum - 255.0714) < 1e-2
+ assert abs(result_mean - 0.332124) < 1e-3
+ else:
+ assert abs(result_sum - 255.1113) < 1e-2
+ assert abs(result_mean - 0.332176) < 1e-3
+
+
+@require_flax
+class FlaxDDIMSchedulerTest(FlaxSchedulerCommonTest):
+ scheduler_classes = (FlaxDDIMScheduler,)
+ forward_default_kwargs = (("num_inference_steps", 50),)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def full_loop(self, **config):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+ key1, key2 = random.split(random.PRNGKey(0))
+
+ num_inference_steps = 10
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+
+ state = scheduler.set_timesteps(state, num_inference_steps)
+
+ for t in state.timesteps:
+ residual = model(sample, t)
+ output = scheduler.step(state, residual, t, sample)
+ sample = output.prev_sample
+ state = output.state
+ key1, key2 = random.split(key2)
+
+ return sample
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler, new_state = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ new_state = new_scheduler.set_timesteps(new_state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output = scheduler.step(state, residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(new_state, residual, time_step, sample, **kwargs).prev_sample
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler, new_state = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ new_state = new_scheduler.set_timesteps(new_state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output = scheduler.step(state, residual, 1, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(new_state, residual, 1, sample, **kwargs).prev_sample
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ kwargs.update(forward_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler, new_state = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ new_state = new_scheduler.set_timesteps(new_state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output = scheduler.step(state, residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(new_state, residual, time_step, sample, **kwargs).prev_sample
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_scheduler_outputs_equivalence(self):
+ def set_nan_tensor_to_zero(t):
+ return t.at[t != t].set(0)
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object.values(), dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ jnp.allclose(set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {jnp.max(jnp.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {jnp.isnan(tuple_object).any()} and `inf`: {jnp.isinf(tuple_object)}. Dict has"
+ f" `nan`: {jnp.isnan(dict_object).any()} and `inf`: {jnp.isinf(dict_object)}."
+ ),
+ )
+
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ outputs_dict = scheduler.step(state, residual, 0, sample, **kwargs)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ outputs_tuple = scheduler.step(state, residual, 0, sample, return_dict=False, **kwargs)
+
+ recursive_check(outputs_tuple[0], outputs_dict.prev_sample)
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output_0 = scheduler.step(state, residual, 0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step(state, residual, 1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_timesteps(self):
+ for timesteps in [100, 500, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_steps_offset(self):
+ for steps_offset in [0, 1]:
+ self.check_over_configs(steps_offset=steps_offset)
+
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(steps_offset=1)
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+ state = scheduler.set_timesteps(state, 5)
+ assert jnp.equal(state.timesteps, jnp.array([801, 601, 401, 201, 1])).all()
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.0001, 0.001, 0.01, 0.1], [0.002, 0.02, 0.2, 2]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "squaredcos_cap_v2"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_time_indices(self):
+ for t in [1, 10, 49]:
+ self.check_over_forward(time_step=t)
+
+ def test_inference_steps(self):
+ for t, num_inference_steps in zip([1, 10, 50], [10, 50, 500]):
+ self.check_over_forward(time_step=t, num_inference_steps=num_inference_steps)
+
+ def test_variance(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 0, 0) - 0.0)) < 1e-5
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 420, 400) - 0.14771)) < 1e-5
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 980, 960) - 0.32460)) < 1e-5
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 0, 0) - 0.0)) < 1e-5
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 487, 486) - 0.00979)) < 1e-5
+ assert jnp.sum(jnp.abs(scheduler._get_variance(state, 999, 998) - 0.02)) < 1e-5
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+
+ result_sum = jnp.sum(jnp.abs(sample))
+ result_mean = jnp.mean(jnp.abs(sample))
+
+ assert abs(result_sum - 172.0067) < 1e-2
+ assert abs(result_mean - 0.223967) < 1e-3
+
+ def test_full_loop_with_set_alpha_to_one(self):
+ # We specify different beta, so that the first alpha is 0.99
+ sample = self.full_loop(set_alpha_to_one=True, beta_start=0.01)
+ result_sum = jnp.sum(jnp.abs(sample))
+ result_mean = jnp.mean(jnp.abs(sample))
+
+ if jax_device == "tpu":
+ assert abs(result_sum - 149.8409) < 1e-2
+ assert abs(result_mean - 0.1951) < 1e-3
+ else:
+ assert abs(result_sum - 149.8295) < 1e-2
+ assert abs(result_mean - 0.1951) < 1e-3
+
+ def test_full_loop_with_no_set_alpha_to_one(self):
+ # We specify different beta, so that the first alpha is 0.99
+ sample = self.full_loop(set_alpha_to_one=False, beta_start=0.01)
+ result_sum = jnp.sum(jnp.abs(sample))
+ result_mean = jnp.mean(jnp.abs(sample))
+
+ if jax_device == "tpu":
+ pass
+ # FIXME: both result_sum and result_mean are nan on TPU
+ # assert jnp.isnan(result_sum)
+ # assert jnp.isnan(result_mean)
+ else:
+ assert abs(result_sum - 149.0784) < 1e-2
+ assert abs(result_mean - 0.1941) < 1e-3
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "sample", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+
+@require_flax
+class FlaxPNDMSchedulerTest(FlaxSchedulerCommonTest):
+ scheduler_classes = (FlaxPNDMScheduler,)
+ forward_default_kwargs = (("num_inference_steps", 50),)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = jnp.array([residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05])
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+ state = scheduler.set_timesteps(state, num_inference_steps, shape=sample.shape)
+ # copy over dummy past residuals
+ state = state.replace(ets=dummy_past_residuals[:])
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler, new_state = scheduler_class.from_pretrained(tmpdirname)
+ new_state = new_scheduler.set_timesteps(new_state, num_inference_steps, shape=sample.shape)
+ # copy over dummy past residuals
+ new_state = new_state.replace(ets=dummy_past_residuals[:])
+
+ (prev_sample, state) = scheduler.step_prk(state, residual, time_step, sample, **kwargs)
+ (new_prev_sample, new_state) = new_scheduler.step_prk(new_state, residual, time_step, sample, **kwargs)
+
+ assert jnp.sum(jnp.abs(prev_sample - new_prev_sample)) < 1e-5, "Scheduler outputs are not identical"
+
+ output, _ = scheduler.step_plms(state, residual, time_step, sample, **kwargs)
+ new_output, _ = new_scheduler.step_plms(new_state, residual, time_step, sample, **kwargs)
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ pass
+
+ def test_scheduler_outputs_equivalence(self):
+ def set_nan_tensor_to_zero(t):
+ return t.at[t != t].set(0)
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object.values(), dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ jnp.allclose(set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {jnp.max(jnp.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {jnp.isnan(tuple_object).any()} and `inf`: {jnp.isinf(tuple_object)}. Dict has"
+ f" `nan`: {jnp.isnan(dict_object).any()} and `inf`: {jnp.isinf(dict_object)}."
+ ),
+ )
+
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps, shape=sample.shape)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ outputs_dict = scheduler.step(state, residual, 0, sample, **kwargs)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps, shape=sample.shape)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ outputs_tuple = scheduler.step(state, residual, 0, sample, return_dict=False, **kwargs)
+
+ recursive_check(outputs_tuple[0], outputs_dict.prev_sample)
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = jnp.array([residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05])
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+ state = scheduler.set_timesteps(state, num_inference_steps, shape=sample.shape)
+
+ # copy over dummy past residuals (must be after setting timesteps)
+ scheduler.ets = dummy_past_residuals[:]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler, new_state = scheduler_class.from_pretrained(tmpdirname)
+ # copy over dummy past residuals
+ new_state = new_scheduler.set_timesteps(new_state, num_inference_steps, shape=sample.shape)
+
+ # copy over dummy past residual (must be after setting timesteps)
+ new_state.replace(ets=dummy_past_residuals[:])
+
+ output, state = scheduler.step_prk(state, residual, time_step, sample, **kwargs)
+ new_output, new_state = new_scheduler.step_prk(new_state, residual, time_step, sample, **kwargs)
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ output, _ = scheduler.step_plms(state, residual, time_step, sample, **kwargs)
+ new_output, _ = new_scheduler.step_plms(new_state, residual, time_step, sample, **kwargs)
+
+ assert jnp.sum(jnp.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def full_loop(self, **config):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ state = scheduler.set_timesteps(state, num_inference_steps, shape=sample.shape)
+
+ for i, t in enumerate(state.prk_timesteps):
+ residual = model(sample, t)
+ sample, state = scheduler.step_prk(state, residual, t, sample)
+
+ for i, t in enumerate(state.plms_timesteps):
+ residual = model(sample, t)
+ sample, state = scheduler.step_plms(state, residual, t, sample)
+
+ return sample
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ state = scheduler.set_timesteps(state, num_inference_steps, shape=sample.shape)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # copy over dummy past residuals (must be done after set_timesteps)
+ dummy_past_residuals = jnp.array([residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05])
+ state = state.replace(ets=dummy_past_residuals[:])
+
+ output_0, state = scheduler.step_prk(state, residual, 0, sample, **kwargs)
+ output_1, state = scheduler.step_prk(state, residual, 1, sample, **kwargs)
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ output_0, state = scheduler.step_plms(state, residual, 0, sample, **kwargs)
+ output_1, state = scheduler.step_plms(state, residual, 1, sample, **kwargs)
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_timesteps(self):
+ for timesteps in [100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_steps_offset(self):
+ for steps_offset in [0, 1]:
+ self.check_over_configs(steps_offset=steps_offset)
+
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(steps_offset=1)
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+ state = scheduler.set_timesteps(state, 10, shape=())
+ assert jnp.equal(
+ state.timesteps,
+ jnp.array([901, 851, 851, 801, 801, 751, 751, 701, 701, 651, 651, 601, 601, 501, 401, 301, 201, 101, 1]),
+ ).all()
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.0001, 0.001], [0.002, 0.02]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "squaredcos_cap_v2"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_time_indices(self):
+ for t in [1, 5, 10]:
+ self.check_over_forward(time_step=t)
+
+ def test_inference_steps(self):
+ for t, num_inference_steps in zip([1, 5, 10], [10, 50, 100]):
+ self.check_over_forward(num_inference_steps=num_inference_steps)
+
+ def test_pow_of_3_inference_steps(self):
+ # earlier version of set_timesteps() caused an error indexing alpha's with inference steps as power of 3
+ num_inference_steps = 27
+
+ for scheduler_class in self.scheduler_classes:
+ sample, _ = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ state = scheduler.set_timesteps(state, num_inference_steps, shape=sample.shape)
+
+ # before power of 3 fix, would error on first step, so we only need to do two
+ for i, t in enumerate(state.prk_timesteps[:2]):
+ sample, state = scheduler.step_prk(state, residual, t, sample)
+
+ def test_inference_plms_no_past_residuals(self):
+ with self.assertRaises(ValueError):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ state = scheduler.create_state()
+
+ scheduler.step_plms(state, self.dummy_sample, 1, self.dummy_sample).prev_sample
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+ result_sum = jnp.sum(jnp.abs(sample))
+ result_mean = jnp.mean(jnp.abs(sample))
+
+ if jax_device == "tpu":
+ assert abs(result_sum - 198.1275) < 1e-2
+ assert abs(result_mean - 0.2580) < 1e-3
+ else:
+ assert abs(result_sum - 198.1318) < 1e-2
+ assert abs(result_mean - 0.2580) < 1e-3
+
+ def test_full_loop_with_set_alpha_to_one(self):
+ # We specify different beta, so that the first alpha is 0.99
+ sample = self.full_loop(set_alpha_to_one=True, beta_start=0.01)
+ result_sum = jnp.sum(jnp.abs(sample))
+ result_mean = jnp.mean(jnp.abs(sample))
+
+ if jax_device == "tpu":
+ assert abs(result_sum - 186.83226) < 1e-2
+ assert abs(result_mean - 0.24327) < 1e-3
+ else:
+ assert abs(result_sum - 186.9466) < 1e-2
+ assert abs(result_mean - 0.24342) < 1e-3
+
+ def test_full_loop_with_no_set_alpha_to_one(self):
+ # We specify different beta, so that the first alpha is 0.99
+ sample = self.full_loop(set_alpha_to_one=False, beta_start=0.01)
+ result_sum = jnp.sum(jnp.abs(sample))
+ result_mean = jnp.mean(jnp.abs(sample))
+
+ if jax_device == "tpu":
+ assert abs(result_sum - 186.83226) < 1e-2
+ assert abs(result_mean - 0.24327) < 1e-3
+ else:
+ assert abs(result_sum - 186.9482) < 1e-2
+ assert abs(result_mean - 0.2434) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_heun.py b/diffusers/tests/schedulers/test_scheduler_heun.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d38c8e2374c26e49c52f3430a3e595b35771436
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_heun.py
@@ -0,0 +1,131 @@
+import torch
+
+from diffusers import HeunDiscreteScheduler
+from diffusers.utils import torch_device
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class HeunDiscreteSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (HeunDiscreteScheduler,)
+ num_inference_steps = 10
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1100,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [10, 50, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.00001, 0.0001, 0.001], [0.0002, 0.002, 0.02]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "scaled_linear"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_full_loop_no_noise(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ if torch_device in ["cpu", "mps"]:
+ assert abs(result_sum.item() - 0.1233) < 1e-2
+ assert abs(result_mean.item() - 0.0002) < 1e-3
+ else:
+ # CUDA
+ assert abs(result_sum.item() - 0.1233) < 1e-2
+ assert abs(result_mean.item() - 0.0002) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(prediction_type="v_prediction")
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ if torch_device in ["cpu", "mps"]:
+ assert abs(result_sum.item() - 4.6934e-07) < 1e-2
+ assert abs(result_mean.item() - 6.1112e-10) < 1e-3
+ else:
+ # CUDA
+ assert abs(result_sum.item() - 4.693428650170972e-07) < 1e-2
+ assert abs(result_mean.item() - 0.0002) < 1e-3
+
+ def test_full_loop_device(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps, device=torch_device)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter.to(torch_device) * scheduler.init_noise_sigma
+
+ for t in scheduler.timesteps:
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ if str(torch_device).startswith("cpu"):
+ # The following sum varies between 148 and 156 on mps. Why?
+ assert abs(result_sum.item() - 0.1233) < 1e-2
+ assert abs(result_mean.item() - 0.0002) < 1e-3
+ elif str(torch_device).startswith("mps"):
+ # Larger tolerance on mps
+ assert abs(result_mean.item() - 0.0002) < 1e-2
+ else:
+ # CUDA
+ assert abs(result_sum.item() - 0.1233) < 1e-2
+ assert abs(result_mean.item() - 0.0002) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_ipndm.py b/diffusers/tests/schedulers/test_scheduler_ipndm.py
new file mode 100644
index 0000000000000000000000000000000000000000..549caed47fe8f100c2bc4164329210209595ba7f
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_ipndm.py
@@ -0,0 +1,161 @@
+import tempfile
+
+import torch
+
+from diffusers import IPNDMScheduler
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class IPNDMSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (IPNDMScheduler,)
+ forward_default_kwargs = (("num_inference_steps", 50),)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {"num_train_timesteps": 1000}
+ config.update(**kwargs)
+ return config
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ scheduler.ets = dummy_past_residuals[:]
+
+ if time_step is None:
+ time_step = scheduler.timesteps[len(scheduler.timesteps) // 2]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ new_scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ new_scheduler.ets = dummy_past_residuals[:]
+
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ pass
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residuals (must be after setting timesteps)
+ scheduler.ets = dummy_past_residuals[:]
+
+ if time_step is None:
+ time_step = scheduler.timesteps[len(scheduler.timesteps) // 2]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ # copy over dummy past residuals
+ new_scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residual (must be after setting timesteps)
+ new_scheduler.ets = dummy_past_residuals[:]
+
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def full_loop(self, **config):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ return sample
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # copy over dummy past residuals (must be done after set_timesteps)
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
+ scheduler.ets = dummy_past_residuals[:]
+
+ time_step_0 = scheduler.timesteps[5]
+ time_step_1 = scheduler.timesteps[6]
+
+ output_0 = scheduler.step(residual, time_step_0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step(residual, time_step_1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ output_0 = scheduler.step(residual, time_step_0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step(residual, time_step_1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_timesteps(self):
+ for timesteps in [100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps, time_step=None)
+
+ def test_inference_steps(self):
+ for t, num_inference_steps in zip([1, 5, 10], [10, 50, 100]):
+ self.check_over_forward(num_inference_steps=num_inference_steps, time_step=None)
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 2540529) < 10
diff --git a/diffusers/tests/schedulers/test_scheduler_kdpm2_ancestral.py b/diffusers/tests/schedulers/test_scheduler_kdpm2_ancestral.py
new file mode 100644
index 0000000000000000000000000000000000000000..45371121e66b8ffdcecb5cc86a91758e436b2955
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_kdpm2_ancestral.py
@@ -0,0 +1,123 @@
+import torch
+
+from diffusers import KDPM2AncestralDiscreteScheduler
+from diffusers.utils import torch_device
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class KDPM2AncestralDiscreteSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (KDPM2AncestralDiscreteScheduler,)
+ num_inference_steps = 10
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1100,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [10, 50, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.00001, 0.0001, 0.001], [0.0002, 0.002, 0.02]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "scaled_linear"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_full_loop_no_noise(self):
+ if torch_device == "mps":
+ return
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ generator = torch.manual_seed(0)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 13849.3877) < 1e-2
+ assert abs(result_mean.item() - 18.0331) < 5e-3
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_full_loop_with_v_prediction(self):
+ if torch_device == "mps":
+ return
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(prediction_type="v_prediction")
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ generator = torch.manual_seed(0)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 328.9970) < 1e-2
+ assert abs(result_mean.item() - 0.4284) < 1e-3
+
+ def test_full_loop_device(self):
+ if torch_device == "mps":
+ return
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps, device=torch_device)
+ generator = torch.manual_seed(0)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter.to(torch_device) * scheduler.init_noise_sigma
+
+ for t in scheduler.timesteps:
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample, generator=generator)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 13849.3818) < 1e-1
+ assert abs(result_mean.item() - 18.0331) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_kdpm2_discrete.py b/diffusers/tests/schedulers/test_scheduler_kdpm2_discrete.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f1bd1f8aeb78a9266a319fe1f097e7c4a5d0e2a
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_kdpm2_discrete.py
@@ -0,0 +1,132 @@
+import torch
+
+from diffusers import KDPM2DiscreteScheduler
+from diffusers.utils import torch_device
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class KDPM2DiscreteSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (KDPM2DiscreteScheduler,)
+ num_inference_steps = 10
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1100,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [10, 50, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.00001, 0.0001, 0.001], [0.0002, 0.002, 0.02]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "scaled_linear"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_full_loop_with_v_prediction(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(prediction_type="v_prediction")
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ if torch_device in ["cpu", "mps"]:
+ assert abs(result_sum.item() - 4.6934e-07) < 1e-2
+ assert abs(result_mean.item() - 6.1112e-10) < 1e-3
+ else:
+ # CUDA
+ assert abs(result_sum.item() - 4.693428650170972e-07) < 1e-2
+ assert abs(result_mean.item() - 0.0002) < 1e-3
+
+ def test_full_loop_no_noise(self):
+ if torch_device == "mps":
+ return
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ if torch_device in ["cpu", "mps"]:
+ assert abs(result_sum.item() - 20.4125) < 1e-2
+ assert abs(result_mean.item() - 0.0266) < 1e-3
+ else:
+ # CUDA
+ assert abs(result_sum.item() - 20.4125) < 1e-2
+ assert abs(result_mean.item() - 0.0266) < 1e-3
+
+ def test_full_loop_device(self):
+ if torch_device == "mps":
+ return
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps, device=torch_device)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter.to(torch_device) * scheduler.init_noise_sigma
+
+ for t in scheduler.timesteps:
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ if str(torch_device).startswith("cpu"):
+ # The following sum varies between 148 and 156 on mps. Why?
+ assert abs(result_sum.item() - 20.4125) < 1e-2
+ assert abs(result_mean.item() - 0.0266) < 1e-3
+ else:
+ # CUDA
+ assert abs(result_sum.item() - 20.4125) < 1e-2
+ assert abs(result_mean.item() - 0.0266) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_lms.py b/diffusers/tests/schedulers/test_scheduler_lms.py
new file mode 100644
index 0000000000000000000000000000000000000000..ca3574e9ee638546d313e5256feba804522da65b
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_lms.py
@@ -0,0 +1,115 @@
+import torch
+
+from diffusers import LMSDiscreteScheduler
+from diffusers.utils import torch_device
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class LMSDiscreteSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (LMSDiscreteScheduler,)
+ num_inference_steps = 10
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1100,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [10, 50, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.00001, 0.0001, 0.001], [0.0002, 0.002, 0.02]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "scaled_linear"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_time_indices(self):
+ for t in [0, 500, 800]:
+ self.check_over_forward(time_step=t)
+
+ def test_full_loop_no_noise(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 1006.388) < 1e-2
+ assert abs(result_mean.item() - 1.31) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(prediction_type="v_prediction")
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 0.0017) < 1e-2
+ assert abs(result_mean.item() - 2.2676e-06) < 1e-3
+
+ def test_full_loop_device(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(self.num_inference_steps, device=torch_device)
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter * scheduler.init_noise_sigma
+ sample = sample.to(torch_device)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sample = scheduler.scale_model_input(sample, t)
+
+ model_output = model(sample, t)
+
+ output = scheduler.step(model_output, t, sample)
+ sample = output.prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 1006.388) < 1e-2
+ assert abs(result_mean.item() - 1.31) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_pndm.py b/diffusers/tests/schedulers/test_scheduler_pndm.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1519f7c7e8e113aca61c8749c3a08f6f390309f
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_pndm.py
@@ -0,0 +1,242 @@
+import tempfile
+
+import torch
+
+from diffusers import PNDMScheduler
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class PNDMSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (PNDMScheduler,)
+ forward_default_kwargs = (("num_inference_steps", 50),)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ scheduler.ets = dummy_past_residuals[:]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ new_scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ new_scheduler.ets = dummy_past_residuals[:]
+
+ output = scheduler.step_prk(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step_prk(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ output = scheduler.step_plms(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step_plms(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ pass
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residuals (must be after setting timesteps)
+ scheduler.ets = dummy_past_residuals[:]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ # copy over dummy past residuals
+ new_scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residual (must be after setting timesteps)
+ new_scheduler.ets = dummy_past_residuals[:]
+
+ output = scheduler.step_prk(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step_prk(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ output = scheduler.step_plms(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step_plms(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def full_loop(self, **config):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.prk_timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step_prk(residual, t, sample).prev_sample
+
+ for i, t in enumerate(scheduler.plms_timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step_plms(residual, t, sample).prev_sample
+
+ return sample
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # copy over dummy past residuals (must be done after set_timesteps)
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.1, residual + 0.05]
+ scheduler.ets = dummy_past_residuals[:]
+
+ output_0 = scheduler.step_prk(residual, 0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step_prk(residual, 1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ output_0 = scheduler.step_plms(residual, 0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step_plms(residual, 1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_timesteps(self):
+ for timesteps in [100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_steps_offset(self):
+ for steps_offset in [0, 1]:
+ self.check_over_configs(steps_offset=steps_offset)
+
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(steps_offset=1)
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(10)
+ assert torch.equal(
+ scheduler.timesteps,
+ torch.LongTensor(
+ [901, 851, 851, 801, 801, 751, 751, 701, 701, 651, 651, 601, 601, 501, 401, 301, 201, 101, 1]
+ ),
+ )
+
+ def test_betas(self):
+ for beta_start, beta_end in zip([0.0001, 0.001], [0.002, 0.02]):
+ self.check_over_configs(beta_start=beta_start, beta_end=beta_end)
+
+ def test_schedules(self):
+ for schedule in ["linear", "squaredcos_cap_v2"]:
+ self.check_over_configs(beta_schedule=schedule)
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_time_indices(self):
+ for t in [1, 5, 10]:
+ self.check_over_forward(time_step=t)
+
+ def test_inference_steps(self):
+ for t, num_inference_steps in zip([1, 5, 10], [10, 50, 100]):
+ self.check_over_forward(num_inference_steps=num_inference_steps)
+
+ def test_pow_of_3_inference_steps(self):
+ # earlier version of set_timesteps() caused an error indexing alpha's with inference steps as power of 3
+ num_inference_steps = 27
+
+ for scheduler_class in self.scheduler_classes:
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(num_inference_steps)
+
+ # before power of 3 fix, would error on first step, so we only need to do two
+ for i, t in enumerate(scheduler.prk_timesteps[:2]):
+ sample = scheduler.step_prk(residual, t, sample).prev_sample
+
+ def test_inference_plms_no_past_residuals(self):
+ with self.assertRaises(ValueError):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.step_plms(self.dummy_sample, 1, self.dummy_sample).prev_sample
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 198.1318) < 1e-2
+ assert abs(result_mean.item() - 0.2580) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ sample = self.full_loop(prediction_type="v_prediction")
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 67.3986) < 1e-2
+ assert abs(result_mean.item() - 0.0878) < 1e-3
+
+ def test_full_loop_with_set_alpha_to_one(self):
+ # We specify different beta, so that the first alpha is 0.99
+ sample = self.full_loop(set_alpha_to_one=True, beta_start=0.01)
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 230.0399) < 1e-2
+ assert abs(result_mean.item() - 0.2995) < 1e-3
+
+ def test_full_loop_with_no_set_alpha_to_one(self):
+ # We specify different beta, so that the first alpha is 0.99
+ sample = self.full_loop(set_alpha_to_one=False, beta_start=0.01)
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 186.9482) < 1e-2
+ assert abs(result_mean.item() - 0.2434) < 1e-3
diff --git a/diffusers/tests/schedulers/test_scheduler_score_sde_ve.py b/diffusers/tests/schedulers/test_scheduler_score_sde_ve.py
new file mode 100644
index 0000000000000000000000000000000000000000..08c30f9b1e0c2ce1f7baab82f5076efabe465a69
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_score_sde_ve.py
@@ -0,0 +1,189 @@
+import tempfile
+import unittest
+
+import numpy as np
+import torch
+
+from diffusers import ScoreSdeVeScheduler
+
+
+class ScoreSdeVeSchedulerTest(unittest.TestCase):
+ # TODO adapt with class SchedulerCommonTest (scheduler needs Numpy Integration)
+ scheduler_classes = (ScoreSdeVeScheduler,)
+ forward_default_kwargs = ()
+
+ @property
+ def dummy_sample(self):
+ batch_size = 4
+ num_channels = 3
+ height = 8
+ width = 8
+
+ sample = torch.rand((batch_size, num_channels, height, width))
+
+ return sample
+
+ @property
+ def dummy_sample_deter(self):
+ batch_size = 4
+ num_channels = 3
+ height = 8
+ width = 8
+
+ num_elems = batch_size * num_channels * height * width
+ sample = torch.arange(num_elems)
+ sample = sample.reshape(num_channels, height, width, batch_size)
+ sample = sample / num_elems
+ sample = sample.permute(3, 0, 1, 2)
+
+ return sample
+
+ def dummy_model(self):
+ def model(sample, t, *args):
+ return sample * t / (t + 1)
+
+ return model
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 2000,
+ "snr": 0.15,
+ "sigma_min": 0.01,
+ "sigma_max": 1348,
+ "sampling_eps": 1e-5,
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+
+ for scheduler_class in self.scheduler_classes:
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+
+ output = scheduler.step_pred(
+ residual, time_step, sample, generator=torch.manual_seed(0), **kwargs
+ ).prev_sample
+ new_output = new_scheduler.step_pred(
+ residual, time_step, sample, generator=torch.manual_seed(0), **kwargs
+ ).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ output = scheduler.step_correct(residual, sample, generator=torch.manual_seed(0), **kwargs).prev_sample
+ new_output = new_scheduler.step_correct(
+ residual, sample, generator=torch.manual_seed(0), **kwargs
+ ).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler correction are not identical"
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ kwargs.update(forward_kwargs)
+
+ for scheduler_class in self.scheduler_classes:
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+
+ output = scheduler.step_pred(
+ residual, time_step, sample, generator=torch.manual_seed(0), **kwargs
+ ).prev_sample
+ new_output = new_scheduler.step_pred(
+ residual, time_step, sample, generator=torch.manual_seed(0), **kwargs
+ ).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ output = scheduler.step_correct(residual, sample, generator=torch.manual_seed(0), **kwargs).prev_sample
+ new_output = new_scheduler.step_correct(
+ residual, sample, generator=torch.manual_seed(0), **kwargs
+ ).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler correction are not identical"
+
+ def test_timesteps(self):
+ for timesteps in [10, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_sigmas(self):
+ for sigma_min, sigma_max in zip([0.0001, 0.001, 0.01], [1, 100, 1000]):
+ self.check_over_configs(sigma_min=sigma_min, sigma_max=sigma_max)
+
+ def test_time_indices(self):
+ for t in [0.1, 0.5, 0.75]:
+ self.check_over_forward(time_step=t)
+
+ def test_full_loop_no_noise(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 3
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+
+ scheduler.set_sigmas(num_inference_steps)
+ scheduler.set_timesteps(num_inference_steps)
+ generator = torch.manual_seed(0)
+
+ for i, t in enumerate(scheduler.timesteps):
+ sigma_t = scheduler.sigmas[i]
+
+ for _ in range(scheduler.config.correct_steps):
+ with torch.no_grad():
+ model_output = model(sample, sigma_t)
+ sample = scheduler.step_correct(model_output, sample, generator=generator, **kwargs).prev_sample
+
+ with torch.no_grad():
+ model_output = model(sample, sigma_t)
+
+ output = scheduler.step_pred(model_output, t, sample, generator=generator, **kwargs)
+ sample, _ = output.prev_sample, output.prev_sample_mean
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert np.isclose(result_sum.item(), 14372758528.0)
+ assert np.isclose(result_mean.item(), 18714530.0)
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output_0 = scheduler.step_pred(residual, 0, sample, generator=torch.manual_seed(0), **kwargs).prev_sample
+ output_1 = scheduler.step_pred(residual, 1, sample, generator=torch.manual_seed(0), **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
diff --git a/diffusers/tests/schedulers/test_scheduler_unclip.py b/diffusers/tests/schedulers/test_scheduler_unclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0ce1312e79f6762bc7573c3a90e58cb33a21bad
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_unclip.py
@@ -0,0 +1,137 @@
+import torch
+
+from diffusers import UnCLIPScheduler
+
+from .test_schedulers import SchedulerCommonTest
+
+
+# UnCLIPScheduler is a modified DDPMScheduler with a subset of the configuration.
+class UnCLIPSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (UnCLIPScheduler,)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "variance_type": "fixed_small_log",
+ "clip_sample": True,
+ "clip_sample_range": 1.0,
+ "prediction_type": "epsilon",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def test_timesteps(self):
+ for timesteps in [1, 5, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_variance_type(self):
+ for variance in ["fixed_small_log", "learned_range"]:
+ self.check_over_configs(variance_type=variance)
+
+ def test_clip_sample(self):
+ for clip_sample in [True, False]:
+ self.check_over_configs(clip_sample=clip_sample)
+
+ def test_clip_sample_range(self):
+ for clip_sample_range in [1, 5, 10, 20]:
+ self.check_over_configs(clip_sample_range=clip_sample_range)
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_time_indices(self):
+ for time_step in [0, 500, 999]:
+ for prev_timestep in [None, 5, 100, 250, 500, 750]:
+ if prev_timestep is not None and prev_timestep >= time_step:
+ continue
+
+ self.check_over_forward(time_step=time_step, prev_timestep=prev_timestep)
+
+ def test_variance_fixed_small_log(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(variance_type="fixed_small_log")
+ scheduler = scheduler_class(**scheduler_config)
+
+ assert torch.sum(torch.abs(scheduler._get_variance(0) - 1.0000e-10)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(487) - 0.0549625)) < 1e-5
+ assert torch.sum(torch.abs(scheduler._get_variance(999) - 0.9994987)) < 1e-5
+
+ def test_variance_learned_range(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(variance_type="learned_range")
+ scheduler = scheduler_class(**scheduler_config)
+
+ predicted_variance = 0.5
+
+ assert scheduler._get_variance(1, predicted_variance=predicted_variance) - -10.1712790 < 1e-5
+ assert scheduler._get_variance(487, predicted_variance=predicted_variance) - -5.7998052 < 1e-5
+ assert scheduler._get_variance(999, predicted_variance=predicted_variance) - -0.0010011 < 1e-5
+
+ def test_full_loop(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ timesteps = scheduler.timesteps
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ generator = torch.manual_seed(0)
+
+ for i, t in enumerate(timesteps):
+ # 1. predict noise residual
+ residual = model(sample, t)
+
+ # 2. predict previous mean of sample x_t-1
+ pred_prev_sample = scheduler.step(residual, t, sample, generator=generator).prev_sample
+
+ sample = pred_prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 252.2682495) < 1e-2
+ assert abs(result_mean.item() - 0.3284743) < 1e-3
+
+ def test_full_loop_skip_timesteps(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler.set_timesteps(25)
+
+ timesteps = scheduler.timesteps
+
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ generator = torch.manual_seed(0)
+
+ for i, t in enumerate(timesteps):
+ # 1. predict noise residual
+ residual = model(sample, t)
+
+ if i + 1 == timesteps.shape[0]:
+ prev_timestep = None
+ else:
+ prev_timestep = timesteps[i + 1]
+
+ # 2. predict previous mean of sample x_t-1
+ pred_prev_sample = scheduler.step(
+ residual, t, sample, prev_timestep=prev_timestep, generator=generator
+ ).prev_sample
+
+ sample = pred_prev_sample
+
+ result_sum = torch.sum(torch.abs(sample))
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_sum.item() - 258.2044983) < 1e-2
+ assert abs(result_mean.item() - 0.3362038) < 1e-3
+
+ def test_trained_betas(self):
+ pass
+
+ def test_add_noise_device(self):
+ pass
diff --git a/diffusers/tests/schedulers/test_scheduler_unipc.py b/diffusers/tests/schedulers/test_scheduler_unipc.py
new file mode 100644
index 0000000000000000000000000000000000000000..6154c8e2d625506f138c28da7a605e5739e6ffd3
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_unipc.py
@@ -0,0 +1,231 @@
+import tempfile
+
+import torch
+
+from diffusers import (
+ DEISMultistepScheduler,
+ DPMSolverMultistepScheduler,
+ DPMSolverSinglestepScheduler,
+ UniPCMultistepScheduler,
+)
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class UniPCMultistepSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (UniPCMultistepScheduler,)
+ forward_default_kwargs = (("num_inference_steps", 25),)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_train_timesteps": 1000,
+ "beta_start": 0.0001,
+ "beta_end": 0.02,
+ "beta_schedule": "linear",
+ "solver_order": 2,
+ "solver_type": "bh1",
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ new_scheduler.set_timesteps(num_inference_steps)
+ # copy over dummy past residuals
+ new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
+
+ output, new_output = sample, sample
+ for t in range(time_step, time_step + scheduler.config.solver_order + 1):
+ output = scheduler.step(residual, t, output, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, t, new_output, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residuals (must be after setting timesteps)
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+ # copy over dummy past residuals
+ new_scheduler.set_timesteps(num_inference_steps)
+
+ # copy over dummy past residual (must be after setting timesteps)
+ new_scheduler.model_outputs = dummy_past_residuals[: new_scheduler.config.solver_order]
+
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def full_loop(self, scheduler=None, **config):
+ if scheduler is None:
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ return sample
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # copy over dummy past residuals (must be done after set_timesteps)
+ dummy_past_residuals = [residual + 0.2, residual + 0.15, residual + 0.10]
+ scheduler.model_outputs = dummy_past_residuals[: scheduler.config.solver_order]
+
+ time_step_0 = scheduler.timesteps[5]
+ time_step_1 = scheduler.timesteps[6]
+
+ output_0 = scheduler.step(residual, time_step_0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step(residual, time_step_1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_switch(self):
+ # make sure that iterating over schedulers with same config names gives same results
+ # for defaults
+ scheduler = UniPCMultistepScheduler(**self.get_scheduler_config())
+ sample = self.full_loop(scheduler=scheduler)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.2521) < 1e-3
+
+ scheduler = DPMSolverSinglestepScheduler.from_config(scheduler.config)
+ scheduler = DEISMultistepScheduler.from_config(scheduler.config)
+ scheduler = DPMSolverMultistepScheduler.from_config(scheduler.config)
+ scheduler = UniPCMultistepScheduler.from_config(scheduler.config)
+
+ sample = self.full_loop(scheduler=scheduler)
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.2521) < 1e-3
+
+ def test_timesteps(self):
+ for timesteps in [25, 50, 100, 999, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_thresholding(self):
+ self.check_over_configs(thresholding=False)
+ for order in [1, 2, 3]:
+ for solver_type in ["bh1", "bh2"]:
+ for threshold in [0.5, 1.0, 2.0]:
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(
+ thresholding=True,
+ prediction_type=prediction_type,
+ sample_max_value=threshold,
+ solver_order=order,
+ solver_type=solver_type,
+ )
+
+ def test_prediction_type(self):
+ for prediction_type in ["epsilon", "v_prediction"]:
+ self.check_over_configs(prediction_type=prediction_type)
+
+ def test_solver_order_and_type(self):
+ for solver_type in ["bh1", "bh2"]:
+ for order in [1, 2, 3]:
+ for prediction_type in ["epsilon", "sample"]:
+ self.check_over_configs(
+ solver_order=order,
+ solver_type=solver_type,
+ prediction_type=prediction_type,
+ )
+ sample = self.full_loop(
+ solver_order=order,
+ solver_type=solver_type,
+ prediction_type=prediction_type,
+ )
+ assert not torch.isnan(sample).any(), "Samples have nan numbers"
+
+ def test_lower_order_final(self):
+ self.check_over_configs(lower_order_final=True)
+ self.check_over_configs(lower_order_final=False)
+
+ def test_inference_steps(self):
+ for num_inference_steps in [1, 2, 3, 5, 10, 50, 100, 999, 1000]:
+ self.check_over_forward(num_inference_steps=num_inference_steps, time_step=0)
+
+ def test_full_loop_no_noise(self):
+ sample = self.full_loop()
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.2521) < 1e-3
+
+ def test_full_loop_with_v_prediction(self):
+ sample = self.full_loop(prediction_type="v_prediction")
+ result_mean = torch.mean(torch.abs(sample))
+
+ assert abs(result_mean.item() - 0.1096) < 1e-3
+
+ def test_fp16_support(self):
+ scheduler_class = self.scheduler_classes[0]
+ scheduler_config = self.get_scheduler_config(thresholding=True, dynamic_thresholding_ratio=0)
+ scheduler = scheduler_class(**scheduler_config)
+
+ num_inference_steps = 10
+ model = self.dummy_model()
+ sample = self.dummy_sample_deter.half()
+ scheduler.set_timesteps(num_inference_steps)
+
+ for i, t in enumerate(scheduler.timesteps):
+ residual = model(sample, t)
+ sample = scheduler.step(residual, t, sample).prev_sample
+
+ assert sample.dtype == torch.float16
diff --git a/diffusers/tests/schedulers/test_scheduler_vq_diffusion.py b/diffusers/tests/schedulers/test_scheduler_vq_diffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..74437ad4548074a488917d3ea9b5eef4f0ac1532
--- /dev/null
+++ b/diffusers/tests/schedulers/test_scheduler_vq_diffusion.py
@@ -0,0 +1,56 @@
+import torch
+import torch.nn.functional as F
+
+from diffusers import VQDiffusionScheduler
+
+from .test_schedulers import SchedulerCommonTest
+
+
+class VQDiffusionSchedulerTest(SchedulerCommonTest):
+ scheduler_classes = (VQDiffusionScheduler,)
+
+ def get_scheduler_config(self, **kwargs):
+ config = {
+ "num_vec_classes": 4097,
+ "num_train_timesteps": 100,
+ }
+
+ config.update(**kwargs)
+ return config
+
+ def dummy_sample(self, num_vec_classes):
+ batch_size = 4
+ height = 8
+ width = 8
+
+ sample = torch.randint(0, num_vec_classes, (batch_size, height * width))
+
+ return sample
+
+ @property
+ def dummy_sample_deter(self):
+ assert False
+
+ def dummy_model(self, num_vec_classes):
+ def model(sample, t, *args):
+ batch_size, num_latent_pixels = sample.shape
+ logits = torch.rand((batch_size, num_vec_classes - 1, num_latent_pixels))
+ return_value = F.log_softmax(logits.double(), dim=1).float()
+ return return_value
+
+ return model
+
+ def test_timesteps(self):
+ for timesteps in [2, 5, 100, 1000]:
+ self.check_over_configs(num_train_timesteps=timesteps)
+
+ def test_num_vec_classes(self):
+ for num_vec_classes in [5, 100, 1000, 4000]:
+ self.check_over_configs(num_vec_classes=num_vec_classes)
+
+ def test_time_indices(self):
+ for t in [0, 50, 99]:
+ self.check_over_forward(time_step=t)
+
+ def test_add_noise_device(self):
+ pass
diff --git a/diffusers/tests/schedulers/test_schedulers.py b/diffusers/tests/schedulers/test_schedulers.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfbf5cbc798f52b2eceba8ba17747dc4d8ae8bc3
--- /dev/null
+++ b/diffusers/tests/schedulers/test_schedulers.py
@@ -0,0 +1,598 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import inspect
+import json
+import os
+import tempfile
+import unittest
+from typing import Dict, List, Tuple
+
+import numpy as np
+import torch
+
+import diffusers
+from diffusers import (
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ IPNDMScheduler,
+ LMSDiscreteScheduler,
+ VQDiffusionScheduler,
+ logging,
+)
+from diffusers.configuration_utils import ConfigMixin, register_to_config
+from diffusers.schedulers.scheduling_utils import SchedulerMixin
+from diffusers.utils import torch_device
+from diffusers.utils.testing_utils import CaptureLogger
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class SchedulerObject(SchedulerMixin, ConfigMixin):
+ config_name = "config.json"
+
+ @register_to_config
+ def __init__(
+ self,
+ a=2,
+ b=5,
+ c=(2, 5),
+ d="for diffusion",
+ e=[1, 3],
+ ):
+ pass
+
+
+class SchedulerObject2(SchedulerMixin, ConfigMixin):
+ config_name = "config.json"
+
+ @register_to_config
+ def __init__(
+ self,
+ a=2,
+ b=5,
+ c=(2, 5),
+ d="for diffusion",
+ f=[1, 3],
+ ):
+ pass
+
+
+class SchedulerObject3(SchedulerMixin, ConfigMixin):
+ config_name = "config.json"
+
+ @register_to_config
+ def __init__(
+ self,
+ a=2,
+ b=5,
+ c=(2, 5),
+ d="for diffusion",
+ e=[1, 3],
+ f=[1, 3],
+ ):
+ pass
+
+
+class SchedulerBaseTests(unittest.TestCase):
+ def test_save_load_from_different_config(self):
+ obj = SchedulerObject()
+
+ # mock add obj class to `diffusers`
+ setattr(diffusers, "SchedulerObject", SchedulerObject)
+ logger = logging.get_logger("diffusers.configuration_utils")
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ obj.save_config(tmpdirname)
+ with CaptureLogger(logger) as cap_logger_1:
+ config = SchedulerObject2.load_config(tmpdirname)
+ new_obj_1 = SchedulerObject2.from_config(config)
+
+ # now save a config parameter that is not expected
+ with open(os.path.join(tmpdirname, SchedulerObject.config_name), "r") as f:
+ data = json.load(f)
+ data["unexpected"] = True
+
+ with open(os.path.join(tmpdirname, SchedulerObject.config_name), "w") as f:
+ json.dump(data, f)
+
+ with CaptureLogger(logger) as cap_logger_2:
+ config = SchedulerObject.load_config(tmpdirname)
+ new_obj_2 = SchedulerObject.from_config(config)
+
+ with CaptureLogger(logger) as cap_logger_3:
+ config = SchedulerObject2.load_config(tmpdirname)
+ new_obj_3 = SchedulerObject2.from_config(config)
+
+ assert new_obj_1.__class__ == SchedulerObject2
+ assert new_obj_2.__class__ == SchedulerObject
+ assert new_obj_3.__class__ == SchedulerObject2
+
+ assert cap_logger_1.out == ""
+ assert (
+ cap_logger_2.out
+ == "The config attributes {'unexpected': True} were passed to SchedulerObject, but are not expected and"
+ " will"
+ " be ignored. Please verify your config.json configuration file.\n"
+ )
+ assert cap_logger_2.out.replace("SchedulerObject", "SchedulerObject2") == cap_logger_3.out
+
+ def test_save_load_compatible_schedulers(self):
+ SchedulerObject2._compatibles = ["SchedulerObject"]
+ SchedulerObject._compatibles = ["SchedulerObject2"]
+
+ obj = SchedulerObject()
+
+ # mock add obj class to `diffusers`
+ setattr(diffusers, "SchedulerObject", SchedulerObject)
+ setattr(diffusers, "SchedulerObject2", SchedulerObject2)
+ logger = logging.get_logger("diffusers.configuration_utils")
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ obj.save_config(tmpdirname)
+
+ # now save a config parameter that is expected by another class, but not origin class
+ with open(os.path.join(tmpdirname, SchedulerObject.config_name), "r") as f:
+ data = json.load(f)
+ data["f"] = [0, 0]
+ data["unexpected"] = True
+
+ with open(os.path.join(tmpdirname, SchedulerObject.config_name), "w") as f:
+ json.dump(data, f)
+
+ with CaptureLogger(logger) as cap_logger:
+ config = SchedulerObject.load_config(tmpdirname)
+ new_obj = SchedulerObject.from_config(config)
+
+ assert new_obj.__class__ == SchedulerObject
+
+ assert (
+ cap_logger.out
+ == "The config attributes {'unexpected': True} were passed to SchedulerObject, but are not expected and"
+ " will"
+ " be ignored. Please verify your config.json configuration file.\n"
+ )
+
+ def test_save_load_from_different_config_comp_schedulers(self):
+ SchedulerObject3._compatibles = ["SchedulerObject", "SchedulerObject2"]
+ SchedulerObject2._compatibles = ["SchedulerObject", "SchedulerObject3"]
+ SchedulerObject._compatibles = ["SchedulerObject2", "SchedulerObject3"]
+
+ obj = SchedulerObject()
+
+ # mock add obj class to `diffusers`
+ setattr(diffusers, "SchedulerObject", SchedulerObject)
+ setattr(diffusers, "SchedulerObject2", SchedulerObject2)
+ setattr(diffusers, "SchedulerObject3", SchedulerObject3)
+ logger = logging.get_logger("diffusers.configuration_utils")
+ logger.setLevel(diffusers.logging.INFO)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ obj.save_config(tmpdirname)
+
+ with CaptureLogger(logger) as cap_logger_1:
+ config = SchedulerObject.load_config(tmpdirname)
+ new_obj_1 = SchedulerObject.from_config(config)
+
+ with CaptureLogger(logger) as cap_logger_2:
+ config = SchedulerObject2.load_config(tmpdirname)
+ new_obj_2 = SchedulerObject2.from_config(config)
+
+ with CaptureLogger(logger) as cap_logger_3:
+ config = SchedulerObject3.load_config(tmpdirname)
+ new_obj_3 = SchedulerObject3.from_config(config)
+
+ assert new_obj_1.__class__ == SchedulerObject
+ assert new_obj_2.__class__ == SchedulerObject2
+ assert new_obj_3.__class__ == SchedulerObject3
+
+ assert cap_logger_1.out == ""
+ assert cap_logger_2.out == "{'f'} was not found in config. Values will be initialized to default values.\n"
+ assert cap_logger_3.out == "{'f'} was not found in config. Values will be initialized to default values.\n"
+
+
+class SchedulerCommonTest(unittest.TestCase):
+ scheduler_classes = ()
+ forward_default_kwargs = ()
+
+ @property
+ def dummy_sample(self):
+ batch_size = 4
+ num_channels = 3
+ height = 8
+ width = 8
+
+ sample = torch.rand((batch_size, num_channels, height, width))
+
+ return sample
+
+ @property
+ def dummy_sample_deter(self):
+ batch_size = 4
+ num_channels = 3
+ height = 8
+ width = 8
+
+ num_elems = batch_size * num_channels * height * width
+ sample = torch.arange(num_elems)
+ sample = sample.reshape(num_channels, height, width, batch_size)
+ sample = sample / num_elems
+ sample = sample.permute(3, 0, 1, 2)
+
+ return sample
+
+ def get_scheduler_config(self):
+ raise NotImplementedError
+
+ def dummy_model(self):
+ def model(sample, t, *args):
+ return sample * t / (t + 1)
+
+ return model
+
+ def check_over_configs(self, time_step=0, **config):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ # TODO(Suraj) - delete the following two lines once DDPM, DDIM, and PNDM have timesteps casted to float by default
+ if scheduler_class in (EulerAncestralDiscreteScheduler, EulerDiscreteScheduler, LMSDiscreteScheduler):
+ time_step = float(time_step)
+
+ scheduler_config = self.get_scheduler_config(**config)
+ scheduler = scheduler_class(**scheduler_config)
+
+ if scheduler_class == VQDiffusionScheduler:
+ num_vec_classes = scheduler_config["num_vec_classes"]
+ sample = self.dummy_sample(num_vec_classes)
+ model = self.dummy_model(num_vec_classes)
+ residual = model(sample, time_step)
+ else:
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ new_scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # Make sure `scale_model_input` is invoked to prevent a warning
+ if scheduler_class != VQDiffusionScheduler:
+ _ = scheduler.scale_model_input(sample, 0)
+ _ = new_scheduler.scale_model_input(sample, 0)
+
+ # Set the seed before step() as some schedulers are stochastic like EulerAncestralDiscreteScheduler, EulerDiscreteScheduler
+ if "generator" in set(inspect.signature(scheduler.step).parameters.keys()):
+ kwargs["generator"] = torch.manual_seed(0)
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ if "generator" in set(inspect.signature(scheduler.step).parameters.keys()):
+ kwargs["generator"] = torch.manual_seed(0)
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def check_over_forward(self, time_step=0, **forward_kwargs):
+ kwargs = dict(self.forward_default_kwargs)
+ kwargs.update(forward_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ if scheduler_class in (EulerAncestralDiscreteScheduler, EulerDiscreteScheduler, LMSDiscreteScheduler):
+ time_step = float(time_step)
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ if scheduler_class == VQDiffusionScheduler:
+ num_vec_classes = scheduler_config["num_vec_classes"]
+ sample = self.dummy_sample(num_vec_classes)
+ model = self.dummy_model(num_vec_classes)
+ residual = model(sample, time_step)
+ else:
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ new_scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ if "generator" in set(inspect.signature(scheduler.step).parameters.keys()):
+ kwargs["generator"] = torch.manual_seed(0)
+ output = scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ if "generator" in set(inspect.signature(scheduler.step).parameters.keys()):
+ kwargs["generator"] = torch.manual_seed(0)
+ new_output = new_scheduler.step(residual, time_step, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_from_save_pretrained(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ for scheduler_class in self.scheduler_classes:
+ timestep = 1
+ if scheduler_class in (EulerAncestralDiscreteScheduler, EulerDiscreteScheduler, LMSDiscreteScheduler):
+ timestep = float(timestep)
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ if scheduler_class == VQDiffusionScheduler:
+ num_vec_classes = scheduler_config["num_vec_classes"]
+ sample = self.dummy_sample(num_vec_classes)
+ model = self.dummy_model(num_vec_classes)
+ residual = model(sample, timestep)
+ else:
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_config(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ new_scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ if "generator" in set(inspect.signature(scheduler.step).parameters.keys()):
+ kwargs["generator"] = torch.manual_seed(0)
+ output = scheduler.step(residual, timestep, sample, **kwargs).prev_sample
+
+ if "generator" in set(inspect.signature(scheduler.step).parameters.keys()):
+ kwargs["generator"] = torch.manual_seed(0)
+ new_output = new_scheduler.step(residual, timestep, sample, **kwargs).prev_sample
+
+ assert torch.sum(torch.abs(output - new_output)) < 1e-5, "Scheduler outputs are not identical"
+
+ def test_compatibles(self):
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+
+ scheduler = scheduler_class(**scheduler_config)
+
+ assert all(c is not None for c in scheduler.compatibles)
+
+ for comp_scheduler_cls in scheduler.compatibles:
+ comp_scheduler = comp_scheduler_cls.from_config(scheduler.config)
+ assert comp_scheduler is not None
+
+ new_scheduler = scheduler_class.from_config(comp_scheduler.config)
+
+ new_scheduler_config = {k: v for k, v in new_scheduler.config.items() if k in scheduler.config}
+ scheduler_diff = {k: v for k, v in new_scheduler.config.items() if k not in scheduler.config}
+
+ # make sure that configs are essentially identical
+ assert new_scheduler_config == dict(scheduler.config)
+
+ # make sure that only differences are for configs that are not in init
+ init_keys = inspect.signature(scheduler_class.__init__).parameters.keys()
+ assert set(scheduler_diff.keys()).intersection(set(init_keys)) == set()
+
+ def test_from_pretrained(self):
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+
+ scheduler = scheduler_class(**scheduler_config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_pretrained(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+
+ assert scheduler.config == new_scheduler.config
+
+ def test_step_shape(self):
+ kwargs = dict(self.forward_default_kwargs)
+
+ num_inference_steps = kwargs.pop("num_inference_steps", None)
+
+ timestep_0 = 0
+ timestep_1 = 1
+
+ for scheduler_class in self.scheduler_classes:
+ if scheduler_class in (EulerAncestralDiscreteScheduler, EulerDiscreteScheduler, LMSDiscreteScheduler):
+ timestep_0 = float(timestep_0)
+ timestep_1 = float(timestep_1)
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ if scheduler_class == VQDiffusionScheduler:
+ num_vec_classes = scheduler_config["num_vec_classes"]
+ sample = self.dummy_sample(num_vec_classes)
+ model = self.dummy_model(num_vec_classes)
+ residual = model(sample, timestep_0)
+ else:
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ output_0 = scheduler.step(residual, timestep_0, sample, **kwargs).prev_sample
+ output_1 = scheduler.step(residual, timestep_1, sample, **kwargs).prev_sample
+
+ self.assertEqual(output_0.shape, sample.shape)
+ self.assertEqual(output_0.shape, output_1.shape)
+
+ def test_scheduler_outputs_equivalence(self):
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object.values(), dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
+ f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
+ ),
+ )
+
+ kwargs = dict(self.forward_default_kwargs)
+ num_inference_steps = kwargs.pop("num_inference_steps", 50)
+
+ timestep = 0
+ if len(self.scheduler_classes) > 0 and self.scheduler_classes[0] == IPNDMScheduler:
+ timestep = 1
+
+ for scheduler_class in self.scheduler_classes:
+ if scheduler_class in (EulerAncestralDiscreteScheduler, EulerDiscreteScheduler, LMSDiscreteScheduler):
+ timestep = float(timestep)
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ if scheduler_class == VQDiffusionScheduler:
+ num_vec_classes = scheduler_config["num_vec_classes"]
+ sample = self.dummy_sample(num_vec_classes)
+ model = self.dummy_model(num_vec_classes)
+ residual = model(sample, timestep)
+ else:
+ sample = self.dummy_sample
+ residual = 0.1 * sample
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # Set the seed before state as some schedulers are stochastic like EulerAncestralDiscreteScheduler, EulerDiscreteScheduler
+ if "generator" in set(inspect.signature(scheduler.step).parameters.keys()):
+ kwargs["generator"] = torch.manual_seed(0)
+ outputs_dict = scheduler.step(residual, timestep, sample, **kwargs)
+
+ if num_inference_steps is not None and hasattr(scheduler, "set_timesteps"):
+ scheduler.set_timesteps(num_inference_steps)
+ elif num_inference_steps is not None and not hasattr(scheduler, "set_timesteps"):
+ kwargs["num_inference_steps"] = num_inference_steps
+
+ # Set the seed before state as some schedulers are stochastic like EulerAncestralDiscreteScheduler, EulerDiscreteScheduler
+ if "generator" in set(inspect.signature(scheduler.step).parameters.keys()):
+ kwargs["generator"] = torch.manual_seed(0)
+ outputs_tuple = scheduler.step(residual, timestep, sample, return_dict=False, **kwargs)
+
+ recursive_check(outputs_tuple, outputs_dict)
+
+ def test_scheduler_public_api(self):
+ for scheduler_class in self.scheduler_classes:
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+
+ if scheduler_class != VQDiffusionScheduler:
+ self.assertTrue(
+ hasattr(scheduler, "init_noise_sigma"),
+ f"{scheduler_class} does not implement a required attribute `init_noise_sigma`",
+ )
+ self.assertTrue(
+ hasattr(scheduler, "scale_model_input"),
+ (
+ f"{scheduler_class} does not implement a required class method `scale_model_input(sample,"
+ " timestep)`"
+ ),
+ )
+ self.assertTrue(
+ hasattr(scheduler, "step"),
+ f"{scheduler_class} does not implement a required class method `step(...)`",
+ )
+
+ if scheduler_class != VQDiffusionScheduler:
+ sample = self.dummy_sample
+ scaled_sample = scheduler.scale_model_input(sample, 0.0)
+ self.assertEqual(sample.shape, scaled_sample.shape)
+
+ def test_add_noise_device(self):
+ for scheduler_class in self.scheduler_classes:
+ if scheduler_class == IPNDMScheduler:
+ continue
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config)
+ scheduler.set_timesteps(100)
+
+ sample = self.dummy_sample.to(torch_device)
+ scaled_sample = scheduler.scale_model_input(sample, 0.0)
+ self.assertEqual(sample.shape, scaled_sample.shape)
+
+ noise = torch.randn_like(scaled_sample).to(torch_device)
+ t = scheduler.timesteps[5][None]
+ noised = scheduler.add_noise(scaled_sample, noise, t)
+ self.assertEqual(noised.shape, scaled_sample.shape)
+
+ def test_deprecated_kwargs(self):
+ for scheduler_class in self.scheduler_classes:
+ has_kwarg_in_model_class = "kwargs" in inspect.signature(scheduler_class.__init__).parameters
+ has_deprecated_kwarg = len(scheduler_class._deprecated_kwargs) > 0
+
+ if has_kwarg_in_model_class and not has_deprecated_kwarg:
+ raise ValueError(
+ f"{scheduler_class} has `**kwargs` in its __init__ method but has not defined any deprecated"
+ " kwargs under the `_deprecated_kwargs` class attribute. Make sure to either remove `**kwargs` if"
+ " there are no deprecated arguments or add the deprecated argument with `_deprecated_kwargs ="
+ " []`"
+ )
+
+ if not has_kwarg_in_model_class and has_deprecated_kwarg:
+ raise ValueError(
+ f"{scheduler_class} doesn't have `**kwargs` in its __init__ method but has defined deprecated"
+ " kwargs under the `_deprecated_kwargs` class attribute. Make sure to either add the `**kwargs`"
+ f" argument to {self.model_class}.__init__ if there are deprecated arguments or remove the"
+ " deprecated argument from `_deprecated_kwargs = []`"
+ )
+
+ def test_trained_betas(self):
+ for scheduler_class in self.scheduler_classes:
+ if scheduler_class == VQDiffusionScheduler:
+ continue
+
+ scheduler_config = self.get_scheduler_config()
+ scheduler = scheduler_class(**scheduler_config, trained_betas=np.array([0.1, 0.3]))
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ scheduler.save_pretrained(tmpdirname)
+ new_scheduler = scheduler_class.from_pretrained(tmpdirname)
+
+ assert scheduler.betas.tolist() == new_scheduler.betas.tolist()
diff --git a/diffusers/tests/test_config.py b/diffusers/tests/test_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..95b0cdf9a597ef8ff26fab3ada4a2deeac156b8e
--- /dev/null
+++ b/diffusers/tests/test_config.py
@@ -0,0 +1,223 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import tempfile
+import unittest
+
+from diffusers import (
+ DDIMScheduler,
+ DDPMScheduler,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ PNDMScheduler,
+ logging,
+)
+from diffusers.configuration_utils import ConfigMixin, register_to_config
+from diffusers.utils.testing_utils import CaptureLogger
+
+
+class SampleObject(ConfigMixin):
+ config_name = "config.json"
+
+ @register_to_config
+ def __init__(
+ self,
+ a=2,
+ b=5,
+ c=(2, 5),
+ d="for diffusion",
+ e=[1, 3],
+ ):
+ pass
+
+
+class SampleObject2(ConfigMixin):
+ config_name = "config.json"
+
+ @register_to_config
+ def __init__(
+ self,
+ a=2,
+ b=5,
+ c=(2, 5),
+ d="for diffusion",
+ f=[1, 3],
+ ):
+ pass
+
+
+class SampleObject3(ConfigMixin):
+ config_name = "config.json"
+
+ @register_to_config
+ def __init__(
+ self,
+ a=2,
+ b=5,
+ c=(2, 5),
+ d="for diffusion",
+ e=[1, 3],
+ f=[1, 3],
+ ):
+ pass
+
+
+class ConfigTester(unittest.TestCase):
+ def test_load_not_from_mixin(self):
+ with self.assertRaises(ValueError):
+ ConfigMixin.load_config("dummy_path")
+
+ def test_register_to_config(self):
+ obj = SampleObject()
+ config = obj.config
+ assert config["a"] == 2
+ assert config["b"] == 5
+ assert config["c"] == (2, 5)
+ assert config["d"] == "for diffusion"
+ assert config["e"] == [1, 3]
+
+ # init ignore private arguments
+ obj = SampleObject(_name_or_path="lalala")
+ config = obj.config
+ assert config["a"] == 2
+ assert config["b"] == 5
+ assert config["c"] == (2, 5)
+ assert config["d"] == "for diffusion"
+ assert config["e"] == [1, 3]
+
+ # can override default
+ obj = SampleObject(c=6)
+ config = obj.config
+ assert config["a"] == 2
+ assert config["b"] == 5
+ assert config["c"] == 6
+ assert config["d"] == "for diffusion"
+ assert config["e"] == [1, 3]
+
+ # can use positional arguments.
+ obj = SampleObject(1, c=6)
+ config = obj.config
+ assert config["a"] == 1
+ assert config["b"] == 5
+ assert config["c"] == 6
+ assert config["d"] == "for diffusion"
+ assert config["e"] == [1, 3]
+
+ def test_save_load(self):
+ obj = SampleObject()
+ config = obj.config
+
+ assert config["a"] == 2
+ assert config["b"] == 5
+ assert config["c"] == (2, 5)
+ assert config["d"] == "for diffusion"
+ assert config["e"] == [1, 3]
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ obj.save_config(tmpdirname)
+ new_obj = SampleObject.from_config(SampleObject.load_config(tmpdirname))
+ new_config = new_obj.config
+
+ # unfreeze configs
+ config = dict(config)
+ new_config = dict(new_config)
+
+ assert config.pop("c") == (2, 5) # instantiated as tuple
+ assert new_config.pop("c") == [2, 5] # saved & loaded as list because of json
+ assert config == new_config
+
+ def test_load_ddim_from_pndm(self):
+ logger = logging.get_logger("diffusers.configuration_utils")
+
+ with CaptureLogger(logger) as cap_logger:
+ ddim = DDIMScheduler.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="scheduler"
+ )
+
+ assert ddim.__class__ == DDIMScheduler
+ # no warning should be thrown
+ assert cap_logger.out == ""
+
+ def test_load_euler_from_pndm(self):
+ logger = logging.get_logger("diffusers.configuration_utils")
+
+ with CaptureLogger(logger) as cap_logger:
+ euler = EulerDiscreteScheduler.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="scheduler"
+ )
+
+ assert euler.__class__ == EulerDiscreteScheduler
+ # no warning should be thrown
+ assert cap_logger.out == ""
+
+ def test_load_euler_ancestral_from_pndm(self):
+ logger = logging.get_logger("diffusers.configuration_utils")
+
+ with CaptureLogger(logger) as cap_logger:
+ euler = EulerAncestralDiscreteScheduler.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="scheduler"
+ )
+
+ assert euler.__class__ == EulerAncestralDiscreteScheduler
+ # no warning should be thrown
+ assert cap_logger.out == ""
+
+ def test_load_pndm(self):
+ logger = logging.get_logger("diffusers.configuration_utils")
+
+ with CaptureLogger(logger) as cap_logger:
+ pndm = PNDMScheduler.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="scheduler"
+ )
+
+ assert pndm.__class__ == PNDMScheduler
+ # no warning should be thrown
+ assert cap_logger.out == ""
+
+ def test_overwrite_config_on_load(self):
+ logger = logging.get_logger("diffusers.configuration_utils")
+
+ with CaptureLogger(logger) as cap_logger:
+ ddpm = DDPMScheduler.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch",
+ subfolder="scheduler",
+ prediction_type="sample",
+ beta_end=8,
+ )
+
+ with CaptureLogger(logger) as cap_logger_2:
+ ddpm_2 = DDPMScheduler.from_pretrained("google/ddpm-celebahq-256", beta_start=88)
+
+ assert ddpm.__class__ == DDPMScheduler
+ assert ddpm.config.prediction_type == "sample"
+ assert ddpm.config.beta_end == 8
+ assert ddpm_2.config.beta_start == 88
+
+ # no warning should be thrown
+ assert cap_logger.out == ""
+ assert cap_logger_2.out == ""
+
+ def test_load_dpmsolver(self):
+ logger = logging.get_logger("diffusers.configuration_utils")
+
+ with CaptureLogger(logger) as cap_logger:
+ dpm = DPMSolverMultistepScheduler.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="scheduler"
+ )
+
+ assert dpm.__class__ == DPMSolverMultistepScheduler
+ # no warning should be thrown
+ assert cap_logger.out == ""
diff --git a/diffusers/tests/test_ema.py b/diffusers/tests/test_ema.py
new file mode 100644
index 0000000000000000000000000000000000000000..812d83e2f2418817f4d7e0e1c81d1b1dedfa611d
--- /dev/null
+++ b/diffusers/tests/test_ema.py
@@ -0,0 +1,156 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import tempfile
+import unittest
+
+import torch
+
+from diffusers import UNet2DConditionModel
+from diffusers.training_utils import EMAModel
+from diffusers.utils.testing_utils import skip_mps, torch_device
+
+
+class EMAModelTests(unittest.TestCase):
+ model_id = "hf-internal-testing/tiny-stable-diffusion-pipe"
+ batch_size = 1
+ prompt_length = 77
+ text_encoder_hidden_dim = 32
+ num_in_channels = 4
+ latent_height = latent_width = 64
+ generator = torch.manual_seed(0)
+
+ def get_models(self, decay=0.9999):
+ unet = UNet2DConditionModel.from_pretrained(self.model_id, subfolder="unet")
+ unet = unet.to(torch_device)
+ ema_unet = EMAModel(unet.parameters(), decay=decay, model_cls=UNet2DConditionModel, model_config=unet.config)
+ return unet, ema_unet
+
+ def get_dummy_inputs(self):
+ noisy_latents = torch.randn(
+ self.batch_size, self.num_in_channels, self.latent_height, self.latent_width, generator=self.generator
+ ).to(torch_device)
+ timesteps = torch.randint(0, 1000, size=(self.batch_size,), generator=self.generator).to(torch_device)
+ encoder_hidden_states = torch.randn(
+ self.batch_size, self.prompt_length, self.text_encoder_hidden_dim, generator=self.generator
+ ).to(torch_device)
+ return noisy_latents, timesteps, encoder_hidden_states
+
+ def simulate_backprop(self, unet):
+ updated_state_dict = {}
+ for k, param in unet.state_dict().items():
+ updated_param = torch.randn_like(param) + (param * torch.randn_like(param))
+ updated_state_dict.update({k: updated_param})
+ unet.load_state_dict(updated_state_dict)
+ return unet
+
+ def test_optimization_steps_updated(self):
+ unet, ema_unet = self.get_models()
+ # Take the first (hypothetical) EMA step.
+ ema_unet.step(unet.parameters())
+ assert ema_unet.optimization_step == 1
+
+ # Take two more.
+ for _ in range(2):
+ ema_unet.step(unet.parameters())
+ assert ema_unet.optimization_step == 3
+
+ def test_shadow_params_not_updated(self):
+ unet, ema_unet = self.get_models()
+ # Since the `unet` is not being updated (i.e., backprop'd)
+ # there won't be any difference between the `params` of `unet`
+ # and `ema_unet` even if we call `ema_unet.step(unet.parameters())`.
+ ema_unet.step(unet.parameters())
+ orig_params = list(unet.parameters())
+ for s_param, param in zip(ema_unet.shadow_params, orig_params):
+ assert torch.allclose(s_param, param)
+
+ # The above holds true even if we call `ema.step()` multiple times since
+ # `unet` params are still not being updated.
+ for _ in range(4):
+ ema_unet.step(unet.parameters())
+ for s_param, param in zip(ema_unet.shadow_params, orig_params):
+ assert torch.allclose(s_param, param)
+
+ def test_shadow_params_updated(self):
+ unet, ema_unet = self.get_models()
+ # Here we simulate the parameter updates for `unet`. Since there might
+ # be some parameters which are initialized to zero we take extra care to
+ # initialize their values to something non-zero before the multiplication.
+ unet_pseudo_updated_step_one = self.simulate_backprop(unet)
+
+ # Take the EMA step.
+ ema_unet.step(unet_pseudo_updated_step_one.parameters())
+
+ # Now the EMA'd parameters won't be equal to the original model parameters.
+ orig_params = list(unet_pseudo_updated_step_one.parameters())
+ for s_param, param in zip(ema_unet.shadow_params, orig_params):
+ assert ~torch.allclose(s_param, param)
+
+ # Ensure this is the case when we take multiple EMA steps.
+ for _ in range(4):
+ ema_unet.step(unet.parameters())
+ for s_param, param in zip(ema_unet.shadow_params, orig_params):
+ assert ~torch.allclose(s_param, param)
+
+ def test_consecutive_shadow_params_updated(self):
+ # If we call EMA step after a backpropagation consecutively for two times,
+ # the shadow params from those two steps should be different.
+ unet, ema_unet = self.get_models()
+
+ # First backprop + EMA
+ unet_step_one = self.simulate_backprop(unet)
+ ema_unet.step(unet_step_one.parameters())
+ step_one_shadow_params = ema_unet.shadow_params
+
+ # Second backprop + EMA
+ unet_step_two = self.simulate_backprop(unet_step_one)
+ ema_unet.step(unet_step_two.parameters())
+ step_two_shadow_params = ema_unet.shadow_params
+
+ for step_one, step_two in zip(step_one_shadow_params, step_two_shadow_params):
+ assert ~torch.allclose(step_one, step_two)
+
+ def test_zero_decay(self):
+ # If there's no decay even if there are backprops, EMA steps
+ # won't take any effect i.e., the shadow params would remain the
+ # same.
+ unet, ema_unet = self.get_models(decay=0.0)
+ unet_step_one = self.simulate_backprop(unet)
+ ema_unet.step(unet_step_one.parameters())
+ step_one_shadow_params = ema_unet.shadow_params
+
+ unet_step_two = self.simulate_backprop(unet_step_one)
+ ema_unet.step(unet_step_two.parameters())
+ step_two_shadow_params = ema_unet.shadow_params
+
+ for step_one, step_two in zip(step_one_shadow_params, step_two_shadow_params):
+ assert torch.allclose(step_one, step_two)
+
+ @skip_mps
+ def test_serialization(self):
+ unet, ema_unet = self.get_models()
+ noisy_latents, timesteps, encoder_hidden_states = self.get_dummy_inputs()
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ ema_unet.save_pretrained(tmpdir)
+ loaded_unet = UNet2DConditionModel.from_pretrained(tmpdir, model_cls=UNet2DConditionModel)
+ loaded_unet = loaded_unet.to(unet.device)
+
+ # Since no EMA step has been performed the outputs should match.
+ output = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+ output_loaded = loaded_unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ assert torch.allclose(output, output_loaded, atol=1e-4)
diff --git a/diffusers/tests/test_hub_utils.py b/diffusers/tests/test_hub_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8b8ea3a2fd9b114ff184291e7ec73928ba885d7
--- /dev/null
+++ b/diffusers/tests/test_hub_utils.py
@@ -0,0 +1,51 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import unittest
+from pathlib import Path
+from tempfile import TemporaryDirectory
+from unittest.mock import Mock, patch
+
+import diffusers.utils.hub_utils
+
+
+class CreateModelCardTest(unittest.TestCase):
+ @patch("diffusers.utils.hub_utils.get_full_repo_name")
+ def test_create_model_card(self, repo_name_mock: Mock) -> None:
+ repo_name_mock.return_value = "full_repo_name"
+ with TemporaryDirectory() as tmpdir:
+ # Dummy args values
+ args = Mock()
+ args.output_dir = tmpdir
+ args.local_rank = 0
+ args.hub_token = "hub_token"
+ args.dataset_name = "dataset_name"
+ args.learning_rate = 0.01
+ args.train_batch_size = 100000
+ args.eval_batch_size = 10000
+ args.gradient_accumulation_steps = 0.01
+ args.adam_beta1 = 0.02
+ args.adam_beta2 = 0.03
+ args.adam_weight_decay = 0.0005
+ args.adam_epsilon = 0.000001
+ args.lr_scheduler = 1
+ args.lr_warmup_steps = 10
+ args.ema_inv_gamma = 0.001
+ args.ema_power = 0.1
+ args.ema_max_decay = 0.2
+ args.mixed_precision = True
+
+ # Model card mush be rendered and saved
+ diffusers.utils.hub_utils.create_model_card(args, model_name="model_name")
+ self.assertTrue((Path(tmpdir) / "README.md").is_file())
diff --git a/diffusers/tests/test_image_processor.py b/diffusers/tests/test_image_processor.py
new file mode 100644
index 0000000000000000000000000000000000000000..4f0e2c5aecfdaa63126e6d64fabf7cae4fba4b57
--- /dev/null
+++ b/diffusers/tests/test_image_processor.py
@@ -0,0 +1,149 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+import PIL
+import torch
+
+from diffusers.image_processor import VaeImageProcessor
+
+
+class ImageProcessorTest(unittest.TestCase):
+ @property
+ def dummy_sample(self):
+ batch_size = 1
+ num_channels = 3
+ height = 8
+ width = 8
+
+ sample = torch.rand((batch_size, num_channels, height, width))
+
+ return sample
+
+ def to_np(self, image):
+ if isinstance(image[0], PIL.Image.Image):
+ return np.stack([np.array(i) for i in image], axis=0)
+ elif isinstance(image, torch.Tensor):
+ return image.cpu().numpy().transpose(0, 2, 3, 1)
+ return image
+
+ def test_vae_image_processor_pt(self):
+ image_processor = VaeImageProcessor(do_resize=False, do_normalize=False)
+
+ input_pt = self.dummy_sample
+ input_np = self.to_np(input_pt)
+
+ for output_type in ["pt", "np", "pil"]:
+ out = image_processor.postprocess(
+ image_processor.preprocess(input_pt),
+ output_type=output_type,
+ )
+ out_np = self.to_np(out)
+ in_np = (input_np * 255).round() if output_type == "pil" else input_np
+ assert (
+ np.abs(in_np - out_np).max() < 1e-6
+ ), f"decoded output does not match input for output_type {output_type}"
+
+ def test_vae_image_processor_np(self):
+ image_processor = VaeImageProcessor(do_resize=False, do_normalize=False)
+ input_np = self.dummy_sample.cpu().numpy().transpose(0, 2, 3, 1)
+
+ for output_type in ["pt", "np", "pil"]:
+ out = image_processor.postprocess(image_processor.preprocess(input_np), output_type=output_type)
+
+ out_np = self.to_np(out)
+ in_np = (input_np * 255).round() if output_type == "pil" else input_np
+ assert (
+ np.abs(in_np - out_np).max() < 1e-6
+ ), f"decoded output does not match input for output_type {output_type}"
+
+ def test_vae_image_processor_pil(self):
+ image_processor = VaeImageProcessor(do_resize=False, do_normalize=False)
+
+ input_np = self.dummy_sample.cpu().numpy().transpose(0, 2, 3, 1)
+ input_pil = image_processor.numpy_to_pil(input_np)
+
+ for output_type in ["pt", "np", "pil"]:
+ out = image_processor.postprocess(image_processor.preprocess(input_pil), output_type=output_type)
+ for i, o in zip(input_pil, out):
+ in_np = np.array(i)
+ out_np = self.to_np(out) if output_type == "pil" else (self.to_np(out) * 255).round()
+ assert (
+ np.abs(in_np - out_np).max() < 1e-6
+ ), f"decoded output does not match input for output_type {output_type}"
+
+ def test_preprocess_input_3d(self):
+ image_processor = VaeImageProcessor(do_resize=False, do_normalize=False)
+
+ input_pt_4d = self.dummy_sample
+ input_pt_3d = input_pt_4d.squeeze(0)
+
+ out_pt_4d = image_processor.postprocess(
+ image_processor.preprocess(input_pt_4d),
+ output_type="np",
+ )
+ out_pt_3d = image_processor.postprocess(
+ image_processor.preprocess(input_pt_3d),
+ output_type="np",
+ )
+
+ input_np_4d = self.to_np(self.dummy_sample)
+ input_np_3d = input_np_4d.squeeze(0)
+
+ out_np_4d = image_processor.postprocess(
+ image_processor.preprocess(input_np_4d),
+ output_type="np",
+ )
+ out_np_3d = image_processor.postprocess(
+ image_processor.preprocess(input_np_3d),
+ output_type="np",
+ )
+
+ assert np.abs(out_pt_4d - out_pt_3d).max() < 1e-6
+ assert np.abs(out_np_4d - out_np_3d).max() < 1e-6
+
+ def test_preprocess_input_list(self):
+ image_processor = VaeImageProcessor(do_resize=False, do_normalize=False)
+
+ input_pt_4d = self.dummy_sample
+ input_pt_list = list(input_pt_4d)
+
+ out_pt_4d = image_processor.postprocess(
+ image_processor.preprocess(input_pt_4d),
+ output_type="np",
+ )
+
+ out_pt_list = image_processor.postprocess(
+ image_processor.preprocess(input_pt_list),
+ output_type="np",
+ )
+
+ input_np_4d = self.to_np(self.dummy_sample)
+ list(input_np_4d)
+
+ out_np_4d = image_processor.postprocess(
+ image_processor.preprocess(input_pt_4d),
+ output_type="np",
+ )
+
+ out_np_list = image_processor.postprocess(
+ image_processor.preprocess(input_pt_list),
+ output_type="np",
+ )
+
+ assert np.abs(out_pt_4d - out_pt_list).max() < 1e-6
+ assert np.abs(out_np_4d - out_np_list).max() < 1e-6
diff --git a/diffusers/tests/test_layers_utils.py b/diffusers/tests/test_layers_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0e2102b539eed99d2a3c0910c1c7d2d9def4c6f
--- /dev/null
+++ b/diffusers/tests/test_layers_utils.py
@@ -0,0 +1,586 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+import torch
+from torch import nn
+
+from diffusers.models.attention import GEGLU, AdaLayerNorm, ApproximateGELU, AttentionBlock
+from diffusers.models.embeddings import get_timestep_embedding
+from diffusers.models.resnet import Downsample2D, ResnetBlock2D, Upsample2D
+from diffusers.models.transformer_2d import Transformer2DModel
+from diffusers.utils import torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class EmbeddingsTests(unittest.TestCase):
+ def test_timestep_embeddings(self):
+ embedding_dim = 256
+ timesteps = torch.arange(16)
+
+ t1 = get_timestep_embedding(timesteps, embedding_dim)
+
+ # first vector should always be composed only of 0's and 1's
+ assert (t1[0, : embedding_dim // 2] - 0).abs().sum() < 1e-5
+ assert (t1[0, embedding_dim // 2 :] - 1).abs().sum() < 1e-5
+
+ # last element of each vector should be one
+ assert (t1[:, -1] - 1).abs().sum() < 1e-5
+
+ # For large embeddings (e.g. 128) the frequency of every vector is higher
+ # than the previous one which means that the gradients of later vectors are
+ # ALWAYS higher than the previous ones
+ grad_mean = np.abs(np.gradient(t1, axis=-1)).mean(axis=1)
+
+ prev_grad = 0.0
+ for grad in grad_mean:
+ assert grad > prev_grad
+ prev_grad = grad
+
+ def test_timestep_defaults(self):
+ embedding_dim = 16
+ timesteps = torch.arange(10)
+
+ t1 = get_timestep_embedding(timesteps, embedding_dim)
+ t2 = get_timestep_embedding(
+ timesteps, embedding_dim, flip_sin_to_cos=False, downscale_freq_shift=1, max_period=10_000
+ )
+
+ assert torch.allclose(t1.cpu(), t2.cpu(), 1e-3)
+
+ def test_timestep_flip_sin_cos(self):
+ embedding_dim = 16
+ timesteps = torch.arange(10)
+
+ t1 = get_timestep_embedding(timesteps, embedding_dim, flip_sin_to_cos=True)
+ t1 = torch.cat([t1[:, embedding_dim // 2 :], t1[:, : embedding_dim // 2]], dim=-1)
+
+ t2 = get_timestep_embedding(timesteps, embedding_dim, flip_sin_to_cos=False)
+
+ assert torch.allclose(t1.cpu(), t2.cpu(), 1e-3)
+
+ def test_timestep_downscale_freq_shift(self):
+ embedding_dim = 16
+ timesteps = torch.arange(10)
+
+ t1 = get_timestep_embedding(timesteps, embedding_dim, downscale_freq_shift=0)
+ t2 = get_timestep_embedding(timesteps, embedding_dim, downscale_freq_shift=1)
+
+ # get cosine half (vectors that are wrapped into cosine)
+ cosine_half = (t1 - t2)[:, embedding_dim // 2 :]
+
+ # cosine needs to be negative
+ assert (np.abs((cosine_half <= 0).numpy()) - 1).sum() < 1e-5
+
+ def test_sinoid_embeddings_hardcoded(self):
+ embedding_dim = 64
+ timesteps = torch.arange(128)
+
+ # standard unet, score_vde
+ t1 = get_timestep_embedding(timesteps, embedding_dim, downscale_freq_shift=1, flip_sin_to_cos=False)
+ # glide, ldm
+ t2 = get_timestep_embedding(timesteps, embedding_dim, downscale_freq_shift=0, flip_sin_to_cos=True)
+ # grad-tts
+ t3 = get_timestep_embedding(timesteps, embedding_dim, scale=1000)
+
+ assert torch.allclose(
+ t1[23:26, 47:50].flatten().cpu(),
+ torch.tensor([0.9646, 0.9804, 0.9892, 0.9615, 0.9787, 0.9882, 0.9582, 0.9769, 0.9872]),
+ 1e-3,
+ )
+ assert torch.allclose(
+ t2[23:26, 47:50].flatten().cpu(),
+ torch.tensor([0.3019, 0.2280, 0.1716, 0.3146, 0.2377, 0.1790, 0.3272, 0.2474, 0.1864]),
+ 1e-3,
+ )
+ assert torch.allclose(
+ t3[23:26, 47:50].flatten().cpu(),
+ torch.tensor([-0.9801, -0.9464, -0.9349, -0.3952, 0.8887, -0.9709, 0.5299, -0.2853, -0.9927]),
+ 1e-3,
+ )
+
+
+class Upsample2DBlockTests(unittest.TestCase):
+ def test_upsample_default(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 32, 32)
+ upsample = Upsample2D(channels=32, use_conv=False)
+ with torch.no_grad():
+ upsampled = upsample(sample)
+
+ assert upsampled.shape == (1, 32, 64, 64)
+ output_slice = upsampled[0, -1, -3:, -3:]
+ expected_slice = torch.tensor([-0.2173, -1.2079, -1.2079, 0.2952, 1.1254, 1.1254, 0.2952, 1.1254, 1.1254])
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_upsample_with_conv(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 32, 32)
+ upsample = Upsample2D(channels=32, use_conv=True)
+ with torch.no_grad():
+ upsampled = upsample(sample)
+
+ assert upsampled.shape == (1, 32, 64, 64)
+ output_slice = upsampled[0, -1, -3:, -3:]
+ expected_slice = torch.tensor([0.7145, 1.3773, 0.3492, 0.8448, 1.0839, -0.3341, 0.5956, 0.1250, -0.4841])
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_upsample_with_conv_out_dim(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 32, 32)
+ upsample = Upsample2D(channels=32, use_conv=True, out_channels=64)
+ with torch.no_grad():
+ upsampled = upsample(sample)
+
+ assert upsampled.shape == (1, 64, 64, 64)
+ output_slice = upsampled[0, -1, -3:, -3:]
+ expected_slice = torch.tensor([0.2703, 0.1656, -0.2538, -0.0553, -0.2984, 0.1044, 0.1155, 0.2579, 0.7755])
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_upsample_with_transpose(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 32, 32)
+ upsample = Upsample2D(channels=32, use_conv=False, use_conv_transpose=True)
+ with torch.no_grad():
+ upsampled = upsample(sample)
+
+ assert upsampled.shape == (1, 32, 64, 64)
+ output_slice = upsampled[0, -1, -3:, -3:]
+ expected_slice = torch.tensor([-0.3028, -0.1582, 0.0071, 0.0350, -0.4799, -0.1139, 0.1056, -0.1153, -0.1046])
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+
+class Downsample2DBlockTests(unittest.TestCase):
+ def test_downsample_default(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64)
+ downsample = Downsample2D(channels=32, use_conv=False)
+ with torch.no_grad():
+ downsampled = downsample(sample)
+
+ assert downsampled.shape == (1, 32, 32, 32)
+ output_slice = downsampled[0, -1, -3:, -3:]
+ expected_slice = torch.tensor([-0.0513, -0.3889, 0.0640, 0.0836, -0.5460, -0.0341, -0.0169, -0.6967, 0.1179])
+ max_diff = (output_slice.flatten() - expected_slice).abs().sum().item()
+ assert max_diff <= 1e-3
+ # assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-1)
+
+ def test_downsample_with_conv(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64)
+ downsample = Downsample2D(channels=32, use_conv=True)
+ with torch.no_grad():
+ downsampled = downsample(sample)
+
+ assert downsampled.shape == (1, 32, 32, 32)
+ output_slice = downsampled[0, -1, -3:, -3:]
+
+ expected_slice = torch.tensor(
+ [0.9267, 0.5878, 0.3337, 1.2321, -0.1191, -0.3984, -0.7532, -0.0715, -0.3913],
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_downsample_with_conv_pad1(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64)
+ downsample = Downsample2D(channels=32, use_conv=True, padding=1)
+ with torch.no_grad():
+ downsampled = downsample(sample)
+
+ assert downsampled.shape == (1, 32, 32, 32)
+ output_slice = downsampled[0, -1, -3:, -3:]
+ expected_slice = torch.tensor([0.9267, 0.5878, 0.3337, 1.2321, -0.1191, -0.3984, -0.7532, -0.0715, -0.3913])
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_downsample_with_conv_out_dim(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64)
+ downsample = Downsample2D(channels=32, use_conv=True, out_channels=16)
+ with torch.no_grad():
+ downsampled = downsample(sample)
+
+ assert downsampled.shape == (1, 16, 32, 32)
+ output_slice = downsampled[0, -1, -3:, -3:]
+ expected_slice = torch.tensor([-0.6586, 0.5985, 0.0721, 0.1256, -0.1492, 0.4436, -0.2544, 0.5021, 1.1522])
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+
+class ResnetBlock2DTests(unittest.TestCase):
+ def test_resnet_default(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ temb = torch.randn(1, 128).to(torch_device)
+ resnet_block = ResnetBlock2D(in_channels=32, temb_channels=128).to(torch_device)
+ with torch.no_grad():
+ output_tensor = resnet_block(sample, temb)
+
+ assert output_tensor.shape == (1, 32, 64, 64)
+ output_slice = output_tensor[0, -1, -3:, -3:]
+ expected_slice = torch.tensor(
+ [-1.9010, -0.2974, -0.8245, -1.3533, 0.8742, -0.9645, -2.0584, 1.3387, -0.4746], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_restnet_with_use_in_shortcut(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ temb = torch.randn(1, 128).to(torch_device)
+ resnet_block = ResnetBlock2D(in_channels=32, temb_channels=128, use_in_shortcut=True).to(torch_device)
+ with torch.no_grad():
+ output_tensor = resnet_block(sample, temb)
+
+ assert output_tensor.shape == (1, 32, 64, 64)
+ output_slice = output_tensor[0, -1, -3:, -3:]
+ expected_slice = torch.tensor(
+ [0.2226, -1.0791, -0.1629, 0.3659, -0.2889, -1.2376, 0.0582, 0.9206, 0.0044], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_resnet_up(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ temb = torch.randn(1, 128).to(torch_device)
+ resnet_block = ResnetBlock2D(in_channels=32, temb_channels=128, up=True).to(torch_device)
+ with torch.no_grad():
+ output_tensor = resnet_block(sample, temb)
+
+ assert output_tensor.shape == (1, 32, 128, 128)
+ output_slice = output_tensor[0, -1, -3:, -3:]
+ expected_slice = torch.tensor(
+ [1.2130, -0.8753, -0.9027, 1.5783, -0.5362, -0.5001, 1.0726, -0.7732, -0.4182], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_resnet_down(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ temb = torch.randn(1, 128).to(torch_device)
+ resnet_block = ResnetBlock2D(in_channels=32, temb_channels=128, down=True).to(torch_device)
+ with torch.no_grad():
+ output_tensor = resnet_block(sample, temb)
+
+ assert output_tensor.shape == (1, 32, 32, 32)
+ output_slice = output_tensor[0, -1, -3:, -3:]
+ expected_slice = torch.tensor(
+ [-0.3002, -0.7135, 0.1359, 0.0561, -0.7935, 0.0113, -0.1766, -0.6714, -0.0436], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_restnet_with_kernel_fir(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ temb = torch.randn(1, 128).to(torch_device)
+ resnet_block = ResnetBlock2D(in_channels=32, temb_channels=128, kernel="fir", down=True).to(torch_device)
+ with torch.no_grad():
+ output_tensor = resnet_block(sample, temb)
+
+ assert output_tensor.shape == (1, 32, 32, 32)
+ output_slice = output_tensor[0, -1, -3:, -3:]
+ expected_slice = torch.tensor(
+ [-0.0934, -0.5729, 0.0909, -0.2710, -0.5044, 0.0243, -0.0665, -0.5267, -0.3136], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_restnet_with_kernel_sde_vp(self):
+ torch.manual_seed(0)
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ temb = torch.randn(1, 128).to(torch_device)
+ resnet_block = ResnetBlock2D(in_channels=32, temb_channels=128, kernel="sde_vp", down=True).to(torch_device)
+ with torch.no_grad():
+ output_tensor = resnet_block(sample, temb)
+
+ assert output_tensor.shape == (1, 32, 32, 32)
+ output_slice = output_tensor[0, -1, -3:, -3:]
+ expected_slice = torch.tensor(
+ [-0.3002, -0.7135, 0.1359, 0.0561, -0.7935, 0.0113, -0.1766, -0.6714, -0.0436], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+
+class AttentionBlockTests(unittest.TestCase):
+ @unittest.skipIf(
+ torch_device == "mps", "Matmul crashes on MPS, see https://github.com/pytorch/pytorch/issues/84039"
+ )
+ def test_attention_block_default(self):
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ attentionBlock = AttentionBlock(
+ channels=32,
+ num_head_channels=1,
+ rescale_output_factor=1.0,
+ eps=1e-6,
+ norm_num_groups=32,
+ ).to(torch_device)
+ with torch.no_grad():
+ attention_scores = attentionBlock(sample)
+
+ assert attention_scores.shape == (1, 32, 64, 64)
+ output_slice = attention_scores[0, -1, -3:, -3:]
+
+ expected_slice = torch.tensor(
+ [-1.4975, -0.0038, -0.7847, -1.4567, 1.1220, -0.8962, -1.7394, 1.1319, -0.5427], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_attention_block_sd(self):
+ # This version uses SD params and is compatible with mps
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ sample = torch.randn(1, 512, 64, 64).to(torch_device)
+ attentionBlock = AttentionBlock(
+ channels=512,
+ rescale_output_factor=1.0,
+ eps=1e-6,
+ norm_num_groups=32,
+ ).to(torch_device)
+ with torch.no_grad():
+ attention_scores = attentionBlock(sample)
+
+ assert attention_scores.shape == (1, 512, 64, 64)
+ output_slice = attention_scores[0, -1, -3:, -3:]
+
+ expected_slice = torch.tensor(
+ [-0.6621, -0.0156, -3.2766, 0.8025, -0.8609, 0.2820, 0.0905, -1.1179, -3.2126], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+
+class Transformer2DModelTests(unittest.TestCase):
+ def test_spatial_transformer_default(self):
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ spatial_transformer_block = Transformer2DModel(
+ in_channels=32,
+ num_attention_heads=1,
+ attention_head_dim=32,
+ dropout=0.0,
+ cross_attention_dim=None,
+ ).to(torch_device)
+ with torch.no_grad():
+ attention_scores = spatial_transformer_block(sample).sample
+
+ assert attention_scores.shape == (1, 32, 64, 64)
+ output_slice = attention_scores[0, -1, -3:, -3:]
+
+ expected_slice = torch.tensor(
+ [-1.9455, -0.0066, -1.3933, -1.5878, 0.5325, -0.6486, -1.8648, 0.7515, -0.9689], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_spatial_transformer_cross_attention_dim(self):
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ sample = torch.randn(1, 64, 64, 64).to(torch_device)
+ spatial_transformer_block = Transformer2DModel(
+ in_channels=64,
+ num_attention_heads=2,
+ attention_head_dim=32,
+ dropout=0.0,
+ cross_attention_dim=64,
+ ).to(torch_device)
+ with torch.no_grad():
+ context = torch.randn(1, 4, 64).to(torch_device)
+ attention_scores = spatial_transformer_block(sample, context).sample
+
+ assert attention_scores.shape == (1, 64, 64, 64)
+ output_slice = attention_scores[0, -1, -3:, -3:]
+
+ expected_slice = torch.tensor(
+ [-0.2555, -0.8877, -2.4739, -2.2251, 1.2714, 0.0807, -0.4161, -1.6408, -0.0471], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_spatial_transformer_timestep(self):
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ num_embeds_ada_norm = 5
+
+ sample = torch.randn(1, 64, 64, 64).to(torch_device)
+ spatial_transformer_block = Transformer2DModel(
+ in_channels=64,
+ num_attention_heads=2,
+ attention_head_dim=32,
+ dropout=0.0,
+ cross_attention_dim=64,
+ num_embeds_ada_norm=num_embeds_ada_norm,
+ ).to(torch_device)
+ with torch.no_grad():
+ timestep_1 = torch.tensor(1, dtype=torch.long).to(torch_device)
+ timestep_2 = torch.tensor(2, dtype=torch.long).to(torch_device)
+ attention_scores_1 = spatial_transformer_block(sample, timestep=timestep_1).sample
+ attention_scores_2 = spatial_transformer_block(sample, timestep=timestep_2).sample
+
+ assert attention_scores_1.shape == (1, 64, 64, 64)
+ assert attention_scores_2.shape == (1, 64, 64, 64)
+
+ output_slice_1 = attention_scores_1[0, -1, -3:, -3:]
+ output_slice_2 = attention_scores_2[0, -1, -3:, -3:]
+
+ expected_slice_1 = torch.tensor(
+ [-0.1874, -0.9704, -1.4290, -1.3357, 1.5138, 0.3036, -0.0976, -1.1667, 0.1283], device=torch_device
+ )
+ expected_slice_2 = torch.tensor(
+ [-0.3493, -1.0924, -1.6161, -1.5016, 1.4245, 0.1367, -0.2526, -1.3109, -0.0547], device=torch_device
+ )
+
+ assert torch.allclose(output_slice_1.flatten(), expected_slice_1, atol=1e-3)
+ assert torch.allclose(output_slice_2.flatten(), expected_slice_2, atol=1e-3)
+
+ def test_spatial_transformer_dropout(self):
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ sample = torch.randn(1, 32, 64, 64).to(torch_device)
+ spatial_transformer_block = (
+ Transformer2DModel(
+ in_channels=32,
+ num_attention_heads=2,
+ attention_head_dim=16,
+ dropout=0.3,
+ cross_attention_dim=None,
+ )
+ .to(torch_device)
+ .eval()
+ )
+ with torch.no_grad():
+ attention_scores = spatial_transformer_block(sample).sample
+
+ assert attention_scores.shape == (1, 32, 64, 64)
+ output_slice = attention_scores[0, -1, -3:, -3:]
+
+ expected_slice = torch.tensor(
+ [-1.9380, -0.0083, -1.3771, -1.5819, 0.5209, -0.6441, -1.8545, 0.7563, -0.9615], device=torch_device
+ )
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ @unittest.skipIf(torch_device == "mps", "MPS does not support float64")
+ def test_spatial_transformer_discrete(self):
+ torch.manual_seed(0)
+ if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(0)
+
+ num_embed = 5
+
+ sample = torch.randint(0, num_embed, (1, 32)).to(torch_device)
+ spatial_transformer_block = (
+ Transformer2DModel(
+ num_attention_heads=1,
+ attention_head_dim=32,
+ num_vector_embeds=num_embed,
+ sample_size=16,
+ )
+ .to(torch_device)
+ .eval()
+ )
+
+ with torch.no_grad():
+ attention_scores = spatial_transformer_block(sample).sample
+
+ assert attention_scores.shape == (1, num_embed - 1, 32)
+
+ output_slice = attention_scores[0, -2:, -3:]
+
+ expected_slice = torch.tensor([-1.7648, -1.0241, -2.0985, -1.8035, -1.6404, -1.2098], device=torch_device)
+ assert torch.allclose(output_slice.flatten(), expected_slice, atol=1e-3)
+
+ def test_spatial_transformer_default_norm_layers(self):
+ spatial_transformer_block = Transformer2DModel(num_attention_heads=1, attention_head_dim=32, in_channels=32)
+
+ assert spatial_transformer_block.transformer_blocks[0].norm1.__class__ == nn.LayerNorm
+ assert spatial_transformer_block.transformer_blocks[0].norm3.__class__ == nn.LayerNorm
+
+ def test_spatial_transformer_ada_norm_layers(self):
+ spatial_transformer_block = Transformer2DModel(
+ num_attention_heads=1,
+ attention_head_dim=32,
+ in_channels=32,
+ num_embeds_ada_norm=5,
+ )
+
+ assert spatial_transformer_block.transformer_blocks[0].norm1.__class__ == AdaLayerNorm
+ assert spatial_transformer_block.transformer_blocks[0].norm3.__class__ == nn.LayerNorm
+
+ def test_spatial_transformer_default_ff_layers(self):
+ spatial_transformer_block = Transformer2DModel(
+ num_attention_heads=1,
+ attention_head_dim=32,
+ in_channels=32,
+ )
+
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[0].__class__ == GEGLU
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[1].__class__ == nn.Dropout
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[2].__class__ == nn.Linear
+
+ dim = 32
+ inner_dim = 128
+
+ # First dimension change
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[0].proj.in_features == dim
+ # NOTE: inner_dim * 2 because GEGLU
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[0].proj.out_features == inner_dim * 2
+
+ # Second dimension change
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[2].in_features == inner_dim
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[2].out_features == dim
+
+ def test_spatial_transformer_geglu_approx_ff_layers(self):
+ spatial_transformer_block = Transformer2DModel(
+ num_attention_heads=1,
+ attention_head_dim=32,
+ in_channels=32,
+ activation_fn="geglu-approximate",
+ )
+
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[0].__class__ == ApproximateGELU
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[1].__class__ == nn.Dropout
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[2].__class__ == nn.Linear
+
+ dim = 32
+ inner_dim = 128
+
+ # First dimension change
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[0].proj.in_features == dim
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[0].proj.out_features == inner_dim
+
+ # Second dimension change
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[2].in_features == inner_dim
+ assert spatial_transformer_block.transformer_blocks[0].ff.net[2].out_features == dim
+
+ def test_spatial_transformer_attention_bias(self):
+ spatial_transformer_block = Transformer2DModel(
+ num_attention_heads=1, attention_head_dim=32, in_channels=32, attention_bias=True
+ )
+
+ assert spatial_transformer_block.transformer_blocks[0].attn1.to_q.bias is not None
+ assert spatial_transformer_block.transformer_blocks[0].attn1.to_k.bias is not None
+ assert spatial_transformer_block.transformer_blocks[0].attn1.to_v.bias is not None
diff --git a/diffusers/tests/test_modeling_common.py b/diffusers/tests/test_modeling_common.py
new file mode 100644
index 0000000000000000000000000000000000000000..40aba3b24967683b2e64b53402d9f8bdc93be2a8
--- /dev/null
+++ b/diffusers/tests/test_modeling_common.py
@@ -0,0 +1,447 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+import tempfile
+import unittest
+import unittest.mock as mock
+from typing import Dict, List, Tuple
+
+import numpy as np
+import requests_mock
+import torch
+from requests.exceptions import HTTPError
+
+from diffusers.models import UNet2DConditionModel
+from diffusers.training_utils import EMAModel
+from diffusers.utils import torch_device
+from diffusers.utils.testing_utils import require_torch_gpu
+
+
+class ModelUtilsTest(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+
+ import diffusers
+
+ diffusers.utils.import_utils._safetensors_available = True
+
+ def test_accelerate_loading_error_message(self):
+ with self.assertRaises(ValueError) as error_context:
+ UNet2DConditionModel.from_pretrained("hf-internal-testing/stable-diffusion-broken", subfolder="unet")
+
+ # make sure that error message states what keys are missing
+ assert "conv_out.bias" in str(error_context.exception)
+
+ def test_cached_files_are_used_when_no_internet(self):
+ # A mock response for an HTTP head request to emulate server down
+ response_mock = mock.Mock()
+ response_mock.status_code = 500
+ response_mock.headers = {}
+ response_mock.raise_for_status.side_effect = HTTPError
+ response_mock.json.return_value = {}
+
+ # Download this model to make sure it's in the cache.
+ orig_model = UNet2DConditionModel.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="unet"
+ )
+
+ # Under the mock environment we get a 500 error when trying to reach the model.
+ with mock.patch("requests.request", return_value=response_mock):
+ # Download this model to make sure it's in the cache.
+ model = UNet2DConditionModel.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="unet", local_files_only=True
+ )
+
+ for p1, p2 in zip(orig_model.parameters(), model.parameters()):
+ if p1.data.ne(p2.data).sum() > 0:
+ assert False, "Parameters not the same!"
+
+ def test_one_request_upon_cached(self):
+ # TODO: For some reason this test fails on MPS where no HEAD call is made.
+ if torch_device == "mps":
+ return
+
+ import diffusers
+
+ diffusers.utils.import_utils._safetensors_available = False
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ with requests_mock.mock(real_http=True) as m:
+ UNet2DConditionModel.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="unet", cache_dir=tmpdirname
+ )
+
+ download_requests = [r.method for r in m.request_history]
+ assert download_requests.count("HEAD") == 2, "2 HEAD requests one for config, one for model"
+ assert download_requests.count("GET") == 2, "2 GET requests one for config, one for model"
+
+ with requests_mock.mock(real_http=True) as m:
+ UNet2DConditionModel.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", subfolder="unet", cache_dir=tmpdirname
+ )
+
+ cache_requests = [r.method for r in m.request_history]
+ assert (
+ "HEAD" == cache_requests[0] and len(cache_requests) == 1
+ ), "We should call only `model_info` to check for _commit hash and `send_telemetry`"
+
+ diffusers.utils.import_utils._safetensors_available = True
+
+ def test_weight_overwrite(self):
+ with tempfile.TemporaryDirectory() as tmpdirname, self.assertRaises(ValueError) as error_context:
+ UNet2DConditionModel.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch",
+ subfolder="unet",
+ cache_dir=tmpdirname,
+ in_channels=9,
+ )
+
+ # make sure that error message states what keys are missing
+ assert "Cannot load" in str(error_context.exception)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model = UNet2DConditionModel.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch",
+ subfolder="unet",
+ cache_dir=tmpdirname,
+ in_channels=9,
+ low_cpu_mem_usage=False,
+ ignore_mismatched_sizes=True,
+ )
+
+ assert model.config.in_channels == 9
+
+
+class ModelTesterMixin:
+ def test_from_save_pretrained(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ if hasattr(model, "set_default_attn_processor"):
+ model.set_default_attn_processor()
+ model.to(torch_device)
+ model.eval()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ new_model = self.model_class.from_pretrained(tmpdirname)
+ if hasattr(new_model, "set_default_attn_processor"):
+ new_model.set_default_attn_processor()
+ new_model.to(torch_device)
+
+ with torch.no_grad():
+ image = model(**inputs_dict)
+ if isinstance(image, dict):
+ image = image.sample
+
+ new_image = new_model(**inputs_dict)
+
+ if isinstance(new_image, dict):
+ new_image = new_image.sample
+
+ max_diff = (image - new_image).abs().sum().item()
+ self.assertLessEqual(max_diff, 5e-5, "Models give different forward passes")
+
+ def test_from_save_pretrained_variant(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ if hasattr(model, "set_default_attn_processor"):
+ model.set_default_attn_processor()
+ model.to(torch_device)
+ model.eval()
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname, variant="fp16")
+ new_model = self.model_class.from_pretrained(tmpdirname, variant="fp16")
+ if hasattr(new_model, "set_default_attn_processor"):
+ new_model.set_default_attn_processor()
+
+ # non-variant cannot be loaded
+ with self.assertRaises(OSError) as error_context:
+ self.model_class.from_pretrained(tmpdirname)
+
+ # make sure that error message states what keys are missing
+ assert "Error no file named diffusion_pytorch_model.bin found in directory" in str(error_context.exception)
+
+ new_model.to(torch_device)
+
+ with torch.no_grad():
+ image = model(**inputs_dict)
+ if isinstance(image, dict):
+ image = image.sample
+
+ new_image = new_model(**inputs_dict)
+
+ if isinstance(new_image, dict):
+ new_image = new_image.sample
+
+ max_diff = (image - new_image).abs().sum().item()
+ self.assertLessEqual(max_diff, 5e-5, "Models give different forward passes")
+
+ @require_torch_gpu
+ def test_from_save_pretrained_dynamo(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model = torch.compile(model)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ new_model = self.model_class.from_pretrained(tmpdirname)
+ new_model.to(torch_device)
+
+ assert new_model.__class__ == self.model_class
+
+ def test_from_save_pretrained_dtype(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ for dtype in [torch.float32, torch.float16, torch.bfloat16]:
+ if torch_device == "mps" and dtype == torch.bfloat16:
+ continue
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.to(dtype)
+ model.save_pretrained(tmpdirname)
+ new_model = self.model_class.from_pretrained(tmpdirname, low_cpu_mem_usage=True, torch_dtype=dtype)
+ assert new_model.dtype == dtype
+ new_model = self.model_class.from_pretrained(tmpdirname, low_cpu_mem_usage=False, torch_dtype=dtype)
+ assert new_model.dtype == dtype
+
+ def test_determinism(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ first = model(**inputs_dict)
+ if isinstance(first, dict):
+ first = first.sample
+
+ second = model(**inputs_dict)
+ if isinstance(second, dict):
+ second = second.sample
+
+ out_1 = first.cpu().numpy()
+ out_2 = second.cpu().numpy()
+ out_1 = out_1[~np.isnan(out_1)]
+ out_2 = out_2[~np.isnan(out_2)]
+ max_diff = np.amax(np.abs(out_1 - out_2))
+ self.assertLessEqual(max_diff, 1e-5)
+
+ def test_output(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_forward_with_norm_groups(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["norm_num_groups"] = 16
+ init_dict["block_out_channels"] = (16, 32)
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_forward_signature(self):
+ init_dict, _ = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["sample", "timestep"]
+ self.assertListEqual(arg_names[:2], expected_arg_names)
+
+ def test_model_from_pretrained(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ # test if the model can be loaded from the config
+ # and has all the expected shape
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ new_model = self.model_class.from_pretrained(tmpdirname)
+ new_model.to(torch_device)
+ new_model.eval()
+
+ # check if all parameters shape are the same
+ for param_name in model.state_dict().keys():
+ param_1 = model.state_dict()[param_name]
+ param_2 = new_model.state_dict()[param_name]
+ self.assertEqual(param_1.shape, param_2.shape)
+
+ with torch.no_grad():
+ output_1 = model(**inputs_dict)
+
+ if isinstance(output_1, dict):
+ output_1 = output_1.sample
+
+ output_2 = new_model(**inputs_dict)
+
+ if isinstance(output_2, dict):
+ output_2 = output_2.sample
+
+ self.assertEqual(output_1.shape, output_2.shape)
+
+ @unittest.skipIf(torch_device == "mps", "Training is not supported in mps")
+ def test_training(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.train()
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ noise = torch.randn((inputs_dict["sample"].shape[0],) + self.output_shape).to(torch_device)
+ loss = torch.nn.functional.mse_loss(output, noise)
+ loss.backward()
+
+ @unittest.skipIf(torch_device == "mps", "Training is not supported in mps")
+ def test_ema_training(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.train()
+ ema_model = EMAModel(model.parameters())
+
+ output = model(**inputs_dict)
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ noise = torch.randn((inputs_dict["sample"].shape[0],) + self.output_shape).to(torch_device)
+ loss = torch.nn.functional.mse_loss(output, noise)
+ loss.backward()
+ ema_model.step(model.parameters())
+
+ def test_outputs_equivalence(self):
+ def set_nan_tensor_to_zero(t):
+ # Temporary fallback until `aten::_index_put_impl_` is implemented in mps
+ # Track progress in https://github.com/pytorch/pytorch/issues/77764
+ device = t.device
+ if device.type == "mps":
+ t = t.to("cpu")
+ t[t != t] = 0
+ return t.to(device)
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (List, Tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, Dict):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object.values(), dict_object.values()):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
+ f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
+ ),
+ )
+
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs_dict = model(**inputs_dict)
+ outputs_tuple = model(**inputs_dict, return_dict=False)
+
+ recursive_check(outputs_tuple, outputs_dict)
+
+ @unittest.skipIf(torch_device == "mps", "Gradient checkpointing skipped on MPS")
+ def test_enable_disable_gradient_checkpointing(self):
+ if not self.model_class._supports_gradient_checkpointing:
+ return # Skip test if model does not support gradient checkpointing
+
+ init_dict, _ = self.prepare_init_args_and_inputs_for_common()
+
+ # at init model should have gradient checkpointing disabled
+ model = self.model_class(**init_dict)
+ self.assertFalse(model.is_gradient_checkpointing)
+
+ # check enable works
+ model.enable_gradient_checkpointing()
+ self.assertTrue(model.is_gradient_checkpointing)
+
+ # check disable works
+ model.disable_gradient_checkpointing()
+ self.assertFalse(model.is_gradient_checkpointing)
+
+ def test_deprecated_kwargs(self):
+ has_kwarg_in_model_class = "kwargs" in inspect.signature(self.model_class.__init__).parameters
+ has_deprecated_kwarg = len(self.model_class._deprecated_kwargs) > 0
+
+ if has_kwarg_in_model_class and not has_deprecated_kwarg:
+ raise ValueError(
+ f"{self.model_class} has `**kwargs` in its __init__ method but has not defined any deprecated kwargs"
+ " under the `_deprecated_kwargs` class attribute. Make sure to either remove `**kwargs` if there are"
+ " no deprecated arguments or add the deprecated argument with `_deprecated_kwargs ="
+ " []`"
+ )
+
+ if not has_kwarg_in_model_class and has_deprecated_kwarg:
+ raise ValueError(
+ f"{self.model_class} doesn't have `**kwargs` in its __init__ method but has defined deprecated kwargs"
+ " under the `_deprecated_kwargs` class attribute. Make sure to either add the `**kwargs` argument to"
+ f" {self.model_class}.__init__ if there are deprecated arguments or remove the deprecated argument"
+ " from `_deprecated_kwargs = []`"
+ )
diff --git a/diffusers/tests/test_modeling_common_flax.py b/diffusers/tests/test_modeling_common_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..8945aed7c93fb1e664c7b6d799f7e0a96525b1a2
--- /dev/null
+++ b/diffusers/tests/test_modeling_common_flax.py
@@ -0,0 +1,66 @@
+import inspect
+
+from diffusers.utils import is_flax_available
+from diffusers.utils.testing_utils import require_flax
+
+
+if is_flax_available():
+ import jax
+
+
+@require_flax
+class FlaxModelTesterMixin:
+ def test_output(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ model = self.model_class(**init_dict)
+ variables = model.init(inputs_dict["prng_key"], inputs_dict["sample"])
+ jax.lax.stop_gradient(variables)
+
+ output = model.apply(variables, inputs_dict["sample"])
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_forward_with_norm_groups(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+
+ init_dict["norm_num_groups"] = 16
+ init_dict["block_out_channels"] = (16, 32)
+
+ model = self.model_class(**init_dict)
+ variables = model.init(inputs_dict["prng_key"], inputs_dict["sample"])
+ jax.lax.stop_gradient(variables)
+
+ output = model.apply(variables, inputs_dict["sample"])
+
+ if isinstance(output, dict):
+ output = output.sample
+
+ self.assertIsNotNone(output)
+ expected_shape = inputs_dict["sample"].shape
+ self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
+
+ def test_deprecated_kwargs(self):
+ has_kwarg_in_model_class = "kwargs" in inspect.signature(self.model_class.__init__).parameters
+ has_deprecated_kwarg = len(self.model_class._deprecated_kwargs) > 0
+
+ if has_kwarg_in_model_class and not has_deprecated_kwarg:
+ raise ValueError(
+ f"{self.model_class} has `**kwargs` in its __init__ method but has not defined any deprecated kwargs"
+ " under the `_deprecated_kwargs` class attribute. Make sure to either remove `**kwargs` if there are"
+ " no deprecated arguments or add the deprecated argument with `_deprecated_kwargs ="
+ " []`"
+ )
+
+ if not has_kwarg_in_model_class and has_deprecated_kwarg:
+ raise ValueError(
+ f"{self.model_class} doesn't have `**kwargs` in its __init__ method but has defined deprecated kwargs"
+ " under the `_deprecated_kwargs` class attribute. Make sure to either add the `**kwargs` argument to"
+ f" {self.model_class}.__init__ if there are deprecated arguments or remove the deprecated argument"
+ " from `_deprecated_kwargs = []`"
+ )
diff --git a/diffusers/tests/test_outputs.py b/diffusers/tests/test_outputs.py
new file mode 100644
index 0000000000000000000000000000000000000000..50cbd1d54ee403f2b8e79c8ada629b6b97b1be66
--- /dev/null
+++ b/diffusers/tests/test_outputs.py
@@ -0,0 +1,60 @@
+import unittest
+from dataclasses import dataclass
+from typing import List, Union
+
+import numpy as np
+import PIL.Image
+
+from diffusers.utils.outputs import BaseOutput
+
+
+@dataclass
+class CustomOutput(BaseOutput):
+ images: Union[List[PIL.Image.Image], np.ndarray]
+
+
+class ConfigTester(unittest.TestCase):
+ def test_outputs_single_attribute(self):
+ outputs = CustomOutput(images=np.random.rand(1, 3, 4, 4))
+
+ # check every way of getting the attribute
+ assert isinstance(outputs.images, np.ndarray)
+ assert outputs.images.shape == (1, 3, 4, 4)
+ assert isinstance(outputs["images"], np.ndarray)
+ assert outputs["images"].shape == (1, 3, 4, 4)
+ assert isinstance(outputs[0], np.ndarray)
+ assert outputs[0].shape == (1, 3, 4, 4)
+
+ # test with a non-tensor attribute
+ outputs = CustomOutput(images=[PIL.Image.new("RGB", (4, 4))])
+
+ # check every way of getting the attribute
+ assert isinstance(outputs.images, list)
+ assert isinstance(outputs.images[0], PIL.Image.Image)
+ assert isinstance(outputs["images"], list)
+ assert isinstance(outputs["images"][0], PIL.Image.Image)
+ assert isinstance(outputs[0], list)
+ assert isinstance(outputs[0][0], PIL.Image.Image)
+
+ def test_outputs_dict_init(self):
+ # test output reinitialization with a `dict` for compatibility with `accelerate`
+ outputs = CustomOutput({"images": np.random.rand(1, 3, 4, 4)})
+
+ # check every way of getting the attribute
+ assert isinstance(outputs.images, np.ndarray)
+ assert outputs.images.shape == (1, 3, 4, 4)
+ assert isinstance(outputs["images"], np.ndarray)
+ assert outputs["images"].shape == (1, 3, 4, 4)
+ assert isinstance(outputs[0], np.ndarray)
+ assert outputs[0].shape == (1, 3, 4, 4)
+
+ # test with a non-tensor attribute
+ outputs = CustomOutput({"images": [PIL.Image.new("RGB", (4, 4))]})
+
+ # check every way of getting the attribute
+ assert isinstance(outputs.images, list)
+ assert isinstance(outputs.images[0], PIL.Image.Image)
+ assert isinstance(outputs["images"], list)
+ assert isinstance(outputs["images"][0], PIL.Image.Image)
+ assert isinstance(outputs[0], list)
+ assert isinstance(outputs[0][0], PIL.Image.Image)
diff --git a/diffusers/tests/test_pipelines.py b/diffusers/tests/test_pipelines.py
new file mode 100644
index 0000000000000000000000000000000000000000..0525eaca50daa74b6118e9669d36451d761a42e8
--- /dev/null
+++ b/diffusers/tests/test_pipelines.py
@@ -0,0 +1,1300 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import gc
+import json
+import os
+import random
+import shutil
+import sys
+import tempfile
+import unittest
+import unittest.mock as mock
+
+import numpy as np
+import PIL
+import requests_mock
+import safetensors.torch
+import torch
+from parameterized import parameterized
+from PIL import Image
+from requests.exceptions import HTTPError
+from transformers import CLIPImageProcessor, CLIPModel, CLIPTextConfig, CLIPTextModel, CLIPTokenizer
+
+from diffusers import (
+ AutoencoderKL,
+ DDIMPipeline,
+ DDIMScheduler,
+ DDPMPipeline,
+ DDPMScheduler,
+ DiffusionPipeline,
+ DPMSolverMultistepScheduler,
+ EulerAncestralDiscreteScheduler,
+ EulerDiscreteScheduler,
+ LMSDiscreteScheduler,
+ PNDMScheduler,
+ StableDiffusionImg2ImgPipeline,
+ StableDiffusionInpaintPipelineLegacy,
+ StableDiffusionPipeline,
+ UNet2DConditionModel,
+ UNet2DModel,
+ UniPCMultistepScheduler,
+ logging,
+)
+from diffusers.schedulers.scheduling_utils import SCHEDULER_CONFIG_NAME
+from diffusers.utils import (
+ CONFIG_NAME,
+ WEIGHTS_NAME,
+ floats_tensor,
+ is_flax_available,
+ nightly,
+ require_torch_2,
+ slow,
+ torch_device,
+)
+from diffusers.utils.testing_utils import CaptureLogger, get_tests_dir, load_numpy, require_compel, require_torch_gpu
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class DownloadTests(unittest.TestCase):
+ def test_one_request_upon_cached(self):
+ # TODO: For some reason this test fails on MPS where no HEAD call is made.
+ if torch_device == "mps":
+ return
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ with requests_mock.mock(real_http=True) as m:
+ DiffusionPipeline.download(
+ "hf-internal-testing/tiny-stable-diffusion-pipe", safety_checker=None, cache_dir=tmpdirname
+ )
+
+ download_requests = [r.method for r in m.request_history]
+ assert download_requests.count("HEAD") == 15, "15 calls to files"
+ assert download_requests.count("GET") == 17, "15 calls to files + model_info + model_index.json"
+ assert (
+ len(download_requests) == 32
+ ), "2 calls per file (15 files) + send_telemetry, model_info and model_index.json"
+
+ with requests_mock.mock(real_http=True) as m:
+ DiffusionPipeline.download(
+ "hf-internal-testing/tiny-stable-diffusion-pipe", safety_checker=None, cache_dir=tmpdirname
+ )
+
+ cache_requests = [r.method for r in m.request_history]
+ assert cache_requests.count("HEAD") == 1, "model_index.json is only HEAD"
+ assert cache_requests.count("GET") == 1, "model info is only GET"
+ assert (
+ len(cache_requests) == 2
+ ), "We should call only `model_info` to check for _commit hash and `send_telemetry`"
+
+ def test_download_only_pytorch(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ # pipeline has Flax weights
+ tmpdirname = DiffusionPipeline.download(
+ "hf-internal-testing/tiny-stable-diffusion-pipe", safety_checker=None, cache_dir=tmpdirname
+ )
+
+ all_root_files = [t[-1] for t in os.walk(os.path.join(tmpdirname))]
+ files = [item for sublist in all_root_files for item in sublist]
+
+ # None of the downloaded files should be a flax file even if we have some here:
+ # https://huggingface.co/hf-internal-testing/tiny-stable-diffusion-pipe/blob/main/unet/diffusion_flax_model.msgpack
+ assert not any(f.endswith(".msgpack") for f in files)
+ # We need to never convert this tiny model to safetensors for this test to pass
+ assert not any(f.endswith(".safetensors") for f in files)
+
+ def test_force_safetensors_error(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ # pipeline has Flax weights
+ with self.assertRaises(EnvironmentError):
+ tmpdirname = DiffusionPipeline.download(
+ "hf-internal-testing/tiny-stable-diffusion-pipe-no-safetensors",
+ safety_checker=None,
+ cache_dir=tmpdirname,
+ use_safetensors=True,
+ )
+
+ def test_returned_cached_folder(self):
+ prompt = "hello"
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", safety_checker=None
+ )
+ _, local_path = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", safety_checker=None, return_cached_folder=True
+ )
+ pipe_2 = StableDiffusionPipeline.from_pretrained(local_path)
+
+ pipe = pipe.to(torch_device)
+ pipe_2 = pipe_2.to(torch_device)
+
+ generator = torch.manual_seed(0)
+ out = pipe(prompt, num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ generator = torch.manual_seed(0)
+ out_2 = pipe_2(prompt, num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ assert np.max(np.abs(out - out_2)) < 1e-3
+
+ def test_download_safetensors(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ # pipeline has Flax weights
+ tmpdirname = DiffusionPipeline.download(
+ "hf-internal-testing/tiny-stable-diffusion-pipe-safetensors",
+ safety_checker=None,
+ cache_dir=tmpdirname,
+ )
+
+ all_root_files = [t[-1] for t in os.walk(os.path.join(tmpdirname))]
+ files = [item for sublist in all_root_files for item in sublist]
+
+ # None of the downloaded files should be a pytorch file even if we have some here:
+ # https://huggingface.co/hf-internal-testing/tiny-stable-diffusion-pipe/blob/main/unet/diffusion_flax_model.msgpack
+ assert not any(f.endswith(".bin") for f in files)
+
+ def test_download_no_safety_checker(self):
+ prompt = "hello"
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", safety_checker=None
+ )
+ pipe = pipe.to(torch_device)
+ generator = torch.manual_seed(0)
+ out = pipe(prompt, num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ pipe_2 = StableDiffusionPipeline.from_pretrained("hf-internal-testing/tiny-stable-diffusion-torch")
+ pipe_2 = pipe_2.to(torch_device)
+ generator = torch.manual_seed(0)
+ out_2 = pipe_2(prompt, num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ assert np.max(np.abs(out - out_2)) < 1e-3
+
+ def test_load_no_safety_checker_explicit_locally(self):
+ prompt = "hello"
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", safety_checker=None
+ )
+ pipe = pipe.to(torch_device)
+ generator = torch.manual_seed(0)
+ out = pipe(prompt, num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe_2 = StableDiffusionPipeline.from_pretrained(tmpdirname, safety_checker=None)
+ pipe_2 = pipe_2.to(torch_device)
+
+ generator = torch.manual_seed(0)
+
+ out_2 = pipe_2(prompt, num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ assert np.max(np.abs(out - out_2)) < 1e-3
+
+ def test_load_no_safety_checker_default_locally(self):
+ prompt = "hello"
+ pipe = StableDiffusionPipeline.from_pretrained("hf-internal-testing/tiny-stable-diffusion-torch")
+ pipe = pipe.to(torch_device)
+
+ generator = torch.manual_seed(0)
+ out = pipe(prompt, num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe.save_pretrained(tmpdirname)
+ pipe_2 = StableDiffusionPipeline.from_pretrained(tmpdirname)
+ pipe_2 = pipe_2.to(torch_device)
+
+ generator = torch.manual_seed(0)
+
+ out_2 = pipe_2(prompt, num_inference_steps=2, generator=generator, output_type="numpy").images
+
+ assert np.max(np.abs(out - out_2)) < 1e-3
+
+ def test_cached_files_are_used_when_no_internet(self):
+ # A mock response for an HTTP head request to emulate server down
+ response_mock = mock.Mock()
+ response_mock.status_code = 500
+ response_mock.headers = {}
+ response_mock.raise_for_status.side_effect = HTTPError
+ response_mock.json.return_value = {}
+
+ # Download this model to make sure it's in the cache.
+ orig_pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", safety_checker=None
+ )
+ orig_comps = {k: v for k, v in orig_pipe.components.items() if hasattr(v, "parameters")}
+
+ # Under the mock environment we get a 500 error when trying to reach the model.
+ with mock.patch("requests.request", return_value=response_mock):
+ # Download this model to make sure it's in the cache.
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", safety_checker=None, local_files_only=True
+ )
+ comps = {k: v for k, v in pipe.components.items() if hasattr(v, "parameters")}
+
+ for m1, m2 in zip(orig_comps.values(), comps.values()):
+ for p1, p2 in zip(m1.parameters(), m2.parameters()):
+ if p1.data.ne(p2.data).sum() > 0:
+ assert False, "Parameters not the same!"
+
+ def test_download_from_variant_folder(self):
+ for safe_avail in [False, True]:
+ import diffusers
+
+ diffusers.utils.import_utils._safetensors_available = safe_avail
+
+ other_format = ".bin" if safe_avail else ".safetensors"
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = StableDiffusionPipeline.download(
+ "hf-internal-testing/stable-diffusion-all-variants", cache_dir=tmpdirname
+ )
+ all_root_files = [t[-1] for t in os.walk(tmpdirname)]
+ files = [item for sublist in all_root_files for item in sublist]
+
+ # None of the downloaded files should be a variant file even if we have some here:
+ # https://huggingface.co/hf-internal-testing/stable-diffusion-all-variants/tree/main/unet
+ assert len(files) == 15, f"We should only download 15 files, not {len(files)}"
+ assert not any(f.endswith(other_format) for f in files)
+ # no variants
+ assert not any(len(f.split(".")) == 3 for f in files)
+
+ diffusers.utils.import_utils._safetensors_available = True
+
+ def test_download_variant_all(self):
+ for safe_avail in [False, True]:
+ import diffusers
+
+ diffusers.utils.import_utils._safetensors_available = safe_avail
+
+ other_format = ".bin" if safe_avail else ".safetensors"
+ this_format = ".safetensors" if safe_avail else ".bin"
+ variant = "fp16"
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = StableDiffusionPipeline.download(
+ "hf-internal-testing/stable-diffusion-all-variants", cache_dir=tmpdirname, variant=variant
+ )
+ all_root_files = [t[-1] for t in os.walk(tmpdirname)]
+ files = [item for sublist in all_root_files for item in sublist]
+
+ # None of the downloaded files should be a non-variant file even if we have some here:
+ # https://huggingface.co/hf-internal-testing/stable-diffusion-all-variants/tree/main/unet
+ assert len(files) == 15, f"We should only download 15 files, not {len(files)}"
+ # unet, vae, text_encoder, safety_checker
+ assert len([f for f in files if f.endswith(f"{variant}{this_format}")]) == 4
+ # all checkpoints should have variant ending
+ assert not any(f.endswith(this_format) and not f.endswith(f"{variant}{this_format}") for f in files)
+ assert not any(f.endswith(other_format) for f in files)
+
+ diffusers.utils.import_utils._safetensors_available = True
+
+ def test_download_variant_partly(self):
+ for safe_avail in [False, True]:
+ import diffusers
+
+ diffusers.utils.import_utils._safetensors_available = safe_avail
+
+ other_format = ".bin" if safe_avail else ".safetensors"
+ this_format = ".safetensors" if safe_avail else ".bin"
+ variant = "no_ema"
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = StableDiffusionPipeline.download(
+ "hf-internal-testing/stable-diffusion-all-variants", cache_dir=tmpdirname, variant=variant
+ )
+ all_root_files = [t[-1] for t in os.walk(tmpdirname)]
+ files = [item for sublist in all_root_files for item in sublist]
+
+ unet_files = os.listdir(os.path.join(tmpdirname, "unet"))
+
+ # Some of the downloaded files should be a non-variant file, check:
+ # https://huggingface.co/hf-internal-testing/stable-diffusion-all-variants/tree/main/unet
+ assert len(files) == 15, f"We should only download 15 files, not {len(files)}"
+ # only unet has "no_ema" variant
+ assert f"diffusion_pytorch_model.{variant}{this_format}" in unet_files
+ assert len([f for f in files if f.endswith(f"{variant}{this_format}")]) == 1
+ # vae, safety_checker and text_encoder should have no variant
+ assert sum(f.endswith(this_format) and not f.endswith(f"{variant}{this_format}") for f in files) == 3
+ assert not any(f.endswith(other_format) for f in files)
+
+ diffusers.utils.import_utils._safetensors_available = True
+
+ def test_download_broken_variant(self):
+ for safe_avail in [False, True]:
+ import diffusers
+
+ diffusers.utils.import_utils._safetensors_available = safe_avail
+ # text encoder is missing no variant and "no_ema" variant weights, so the following can't work
+ for variant in [None, "no_ema"]:
+ with self.assertRaises(OSError) as error_context:
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/stable-diffusion-broken-variants",
+ cache_dir=tmpdirname,
+ variant=variant,
+ )
+
+ assert "Error no file name" in str(error_context.exception)
+
+ # text encoder has fp16 variants so we can load it
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ tmpdirname = StableDiffusionPipeline.download(
+ "hf-internal-testing/stable-diffusion-broken-variants", cache_dir=tmpdirname, variant="fp16"
+ )
+
+ all_root_files = [t[-1] for t in os.walk(tmpdirname)]
+ files = [item for sublist in all_root_files for item in sublist]
+
+ # None of the downloaded files should be a non-variant file even if we have some here:
+ # https://huggingface.co/hf-internal-testing/stable-diffusion-broken-variants/tree/main/unet
+ assert len(files) == 15, f"We should only download 15 files, not {len(files)}"
+ # only unet has "no_ema" variant
+
+ diffusers.utils.import_utils._safetensors_available = True
+
+ def test_text_inversion_download(self):
+ pipe = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", safety_checker=None
+ )
+ pipe = pipe.to(torch_device)
+
+ num_tokens = len(pipe.tokenizer)
+
+ # single token load local
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ ten = {"<*>": torch.ones((32,))}
+ torch.save(ten, os.path.join(tmpdirname, "learned_embeds.bin"))
+
+ pipe.load_textual_inversion(tmpdirname)
+
+ token = pipe.tokenizer.convert_tokens_to_ids("<*>")
+ assert token == num_tokens, "Added token must be at spot `num_tokens`"
+ assert pipe.text_encoder.get_input_embeddings().weight[-1].sum().item() == 32
+ assert pipe._maybe_convert_prompt("<*>", pipe.tokenizer) == "<*>"
+
+ prompt = "hey <*>"
+ out = pipe(prompt, num_inference_steps=1, output_type="numpy").images
+ assert out.shape == (1, 128, 128, 3)
+
+ # single token load local with weight name
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ ten = {"<**>": 2 * torch.ones((1, 32))}
+ torch.save(ten, os.path.join(tmpdirname, "learned_embeds.bin"))
+
+ pipe.load_textual_inversion(tmpdirname, weight_name="learned_embeds.bin")
+
+ token = pipe.tokenizer.convert_tokens_to_ids("<**>")
+ assert token == num_tokens + 1, "Added token must be at spot `num_tokens`"
+ assert pipe.text_encoder.get_input_embeddings().weight[-1].sum().item() == 64
+ assert pipe._maybe_convert_prompt("<**>", pipe.tokenizer) == "<**>"
+
+ prompt = "hey <**>"
+ out = pipe(prompt, num_inference_steps=1, output_type="numpy").images
+ assert out.shape == (1, 128, 128, 3)
+
+ # multi token load
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ ten = {"<***>": torch.cat([3 * torch.ones((1, 32)), 4 * torch.ones((1, 32)), 5 * torch.ones((1, 32))])}
+ torch.save(ten, os.path.join(tmpdirname, "learned_embeds.bin"))
+
+ pipe.load_textual_inversion(tmpdirname)
+
+ token = pipe.tokenizer.convert_tokens_to_ids("<***>")
+ token_1 = pipe.tokenizer.convert_tokens_to_ids("<***>_1")
+ token_2 = pipe.tokenizer.convert_tokens_to_ids("<***>_2")
+
+ assert token == num_tokens + 2, "Added token must be at spot `num_tokens`"
+ assert token_1 == num_tokens + 3, "Added token must be at spot `num_tokens`"
+ assert token_2 == num_tokens + 4, "Added token must be at spot `num_tokens`"
+ assert pipe.text_encoder.get_input_embeddings().weight[-3].sum().item() == 96
+ assert pipe.text_encoder.get_input_embeddings().weight[-2].sum().item() == 128
+ assert pipe.text_encoder.get_input_embeddings().weight[-1].sum().item() == 160
+ assert pipe._maybe_convert_prompt("<***>", pipe.tokenizer) == "<***><***>_1<***>_2"
+
+ prompt = "hey <***>"
+ out = pipe(prompt, num_inference_steps=1, output_type="numpy").images
+ assert out.shape == (1, 128, 128, 3)
+
+ # multi token load a1111
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ ten = {
+ "string_to_param": {
+ "*": torch.cat([3 * torch.ones((1, 32)), 4 * torch.ones((1, 32)), 5 * torch.ones((1, 32))])
+ },
+ "name": "<****>",
+ }
+ torch.save(ten, os.path.join(tmpdirname, "a1111.bin"))
+
+ pipe.load_textual_inversion(tmpdirname, weight_name="a1111.bin")
+
+ token = pipe.tokenizer.convert_tokens_to_ids("<****>")
+ token_1 = pipe.tokenizer.convert_tokens_to_ids("<****>_1")
+ token_2 = pipe.tokenizer.convert_tokens_to_ids("<****>_2")
+
+ assert token == num_tokens + 5, "Added token must be at spot `num_tokens`"
+ assert token_1 == num_tokens + 6, "Added token must be at spot `num_tokens`"
+ assert token_2 == num_tokens + 7, "Added token must be at spot `num_tokens`"
+ assert pipe.text_encoder.get_input_embeddings().weight[-3].sum().item() == 96
+ assert pipe.text_encoder.get_input_embeddings().weight[-2].sum().item() == 128
+ assert pipe.text_encoder.get_input_embeddings().weight[-1].sum().item() == 160
+ assert pipe._maybe_convert_prompt("<****>", pipe.tokenizer) == "<****><****>_1<****>_2"
+
+ prompt = "hey <****>"
+ out = pipe(prompt, num_inference_steps=1, output_type="numpy").images
+ assert out.shape == (1, 128, 128, 3)
+
+
+class CustomPipelineTests(unittest.TestCase):
+ def test_load_custom_pipeline(self):
+ pipeline = DiffusionPipeline.from_pretrained(
+ "google/ddpm-cifar10-32", custom_pipeline="hf-internal-testing/diffusers-dummy-pipeline"
+ )
+ pipeline = pipeline.to(torch_device)
+ # NOTE that `"CustomPipeline"` is not a class that is defined in this library, but solely on the Hub
+ # under https://huggingface.co/hf-internal-testing/diffusers-dummy-pipeline/blob/main/pipeline.py#L24
+ assert pipeline.__class__.__name__ == "CustomPipeline"
+
+ def test_load_custom_github(self):
+ pipeline = DiffusionPipeline.from_pretrained(
+ "google/ddpm-cifar10-32", custom_pipeline="one_step_unet", custom_revision="main"
+ )
+
+ # make sure that on "main" pipeline gives only ones because of: https://github.com/huggingface/diffusers/pull/1690
+ with torch.no_grad():
+ output = pipeline()
+
+ assert output.numel() == output.sum()
+
+ # hack since Python doesn't like overwriting modules: https://stackoverflow.com/questions/3105801/unload-a-module-in-python
+ # Could in the future work with hashes instead.
+ del sys.modules["diffusers_modules.git.one_step_unet"]
+
+ pipeline = DiffusionPipeline.from_pretrained(
+ "google/ddpm-cifar10-32", custom_pipeline="one_step_unet", custom_revision="0.10.2"
+ )
+ with torch.no_grad():
+ output = pipeline()
+
+ assert output.numel() != output.sum()
+
+ assert pipeline.__class__.__name__ == "UnetSchedulerOneForwardPipeline"
+
+ def test_run_custom_pipeline(self):
+ pipeline = DiffusionPipeline.from_pretrained(
+ "google/ddpm-cifar10-32", custom_pipeline="hf-internal-testing/diffusers-dummy-pipeline"
+ )
+ pipeline = pipeline.to(torch_device)
+ images, output_str = pipeline(num_inference_steps=2, output_type="np")
+
+ assert images[0].shape == (1, 32, 32, 3)
+
+ # compare output to https://huggingface.co/hf-internal-testing/diffusers-dummy-pipeline/blob/main/pipeline.py#L102
+ assert output_str == "This is a test"
+
+ def test_local_custom_pipeline_repo(self):
+ local_custom_pipeline_path = get_tests_dir("fixtures/custom_pipeline")
+ pipeline = DiffusionPipeline.from_pretrained(
+ "google/ddpm-cifar10-32", custom_pipeline=local_custom_pipeline_path
+ )
+ pipeline = pipeline.to(torch_device)
+ images, output_str = pipeline(num_inference_steps=2, output_type="np")
+
+ assert pipeline.__class__.__name__ == "CustomLocalPipeline"
+ assert images[0].shape == (1, 32, 32, 3)
+ # compare to https://github.com/huggingface/diffusers/blob/main/tests/fixtures/custom_pipeline/pipeline.py#L102
+ assert output_str == "This is a local test"
+
+ def test_local_custom_pipeline_file(self):
+ local_custom_pipeline_path = get_tests_dir("fixtures/custom_pipeline")
+ local_custom_pipeline_path = os.path.join(local_custom_pipeline_path, "what_ever.py")
+ pipeline = DiffusionPipeline.from_pretrained(
+ "google/ddpm-cifar10-32", custom_pipeline=local_custom_pipeline_path
+ )
+ pipeline = pipeline.to(torch_device)
+ images, output_str = pipeline(num_inference_steps=2, output_type="np")
+
+ assert pipeline.__class__.__name__ == "CustomLocalPipeline"
+ assert images[0].shape == (1, 32, 32, 3)
+ # compare to https://github.com/huggingface/diffusers/blob/main/tests/fixtures/custom_pipeline/pipeline.py#L102
+ assert output_str == "This is a local test"
+
+ @slow
+ @require_torch_gpu
+ def test_download_from_git(self):
+ clip_model_id = "laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
+
+ feature_extractor = CLIPImageProcessor.from_pretrained(clip_model_id)
+ clip_model = CLIPModel.from_pretrained(clip_model_id, torch_dtype=torch.float16)
+
+ pipeline = DiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ custom_pipeline="clip_guided_stable_diffusion",
+ clip_model=clip_model,
+ feature_extractor=feature_extractor,
+ torch_dtype=torch.float16,
+ )
+ pipeline.enable_attention_slicing()
+ pipeline = pipeline.to(torch_device)
+
+ # NOTE that `"CLIPGuidedStableDiffusion"` is not a class that is defined in the pypi package of th e library, but solely on the community examples folder of GitHub under:
+ # https://github.com/huggingface/diffusers/blob/main/examples/community/clip_guided_stable_diffusion.py
+ assert pipeline.__class__.__name__ == "CLIPGuidedStableDiffusion"
+
+ image = pipeline("a prompt", num_inference_steps=2, output_type="np").images[0]
+ assert image.shape == (512, 512, 3)
+
+
+class PipelineFastTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ import diffusers
+
+ diffusers.utils.import_utils._safetensors_available = True
+
+ def dummy_image(self):
+ batch_size = 1
+ num_channels = 3
+ sizes = (32, 32)
+
+ image = floats_tensor((batch_size, num_channels) + sizes, rng=random.Random(0)).to(torch_device)
+ return image
+
+ def dummy_uncond_unet(self, sample_size=32):
+ torch.manual_seed(0)
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=sample_size,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ return model
+
+ def dummy_cond_unet(self, sample_size=32):
+ torch.manual_seed(0)
+ model = UNet2DConditionModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=sample_size,
+ in_channels=4,
+ out_channels=4,
+ down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
+ up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
+ cross_attention_dim=32,
+ )
+ return model
+
+ @property
+ def dummy_vae(self):
+ torch.manual_seed(0)
+ model = AutoencoderKL(
+ block_out_channels=[32, 64],
+ in_channels=3,
+ out_channels=3,
+ down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
+ up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
+ latent_channels=4,
+ )
+ return model
+
+ @property
+ def dummy_text_encoder(self):
+ torch.manual_seed(0)
+ config = CLIPTextConfig(
+ bos_token_id=0,
+ eos_token_id=2,
+ hidden_size=32,
+ intermediate_size=37,
+ layer_norm_eps=1e-05,
+ num_attention_heads=4,
+ num_hidden_layers=5,
+ pad_token_id=1,
+ vocab_size=1000,
+ )
+ return CLIPTextModel(config)
+
+ @property
+ def dummy_extractor(self):
+ def extract(*args, **kwargs):
+ class Out:
+ def __init__(self):
+ self.pixel_values = torch.ones([0])
+
+ def to(self, device):
+ self.pixel_values.to(device)
+ return self
+
+ return Out()
+
+ return extract
+
+ @parameterized.expand(
+ [
+ [DDIMScheduler, DDIMPipeline, 32],
+ [DDPMScheduler, DDPMPipeline, 32],
+ [DDIMScheduler, DDIMPipeline, (32, 64)],
+ [DDPMScheduler, DDPMPipeline, (64, 32)],
+ ]
+ )
+ def test_uncond_unet_components(self, scheduler_fn=DDPMScheduler, pipeline_fn=DDPMPipeline, sample_size=32):
+ unet = self.dummy_uncond_unet(sample_size)
+ scheduler = scheduler_fn()
+ pipeline = pipeline_fn(unet, scheduler).to(torch_device)
+
+ generator = torch.manual_seed(0)
+ out_image = pipeline(
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ ).images
+ sample_size = (sample_size, sample_size) if isinstance(sample_size, int) else sample_size
+ assert out_image.shape == (1, *sample_size, 3)
+
+ def test_stable_diffusion_components(self):
+ """Test that components property works correctly"""
+ unet = self.dummy_cond_unet()
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ image = self.dummy_image().cpu().permute(0, 2, 3, 1)[0]
+ init_image = Image.fromarray(np.uint8(image)).convert("RGB")
+ mask_image = Image.fromarray(np.uint8(image + 4)).convert("RGB").resize((32, 32))
+
+ # make sure here that pndm scheduler skips prk
+ inpaint = StableDiffusionInpaintPipelineLegacy(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ ).to(torch_device)
+ img2img = StableDiffusionImg2ImgPipeline(**inpaint.components).to(torch_device)
+ text2img = StableDiffusionPipeline(**inpaint.components).to(torch_device)
+
+ prompt = "A painting of a squirrel eating a burger"
+
+ generator = torch.manual_seed(0)
+ image_inpaint = inpaint(
+ [prompt],
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ mask_image=mask_image,
+ ).images
+ image_img2img = img2img(
+ [prompt],
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ image=init_image,
+ ).images
+ image_text2img = text2img(
+ [prompt],
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ ).images
+
+ assert image_inpaint.shape == (1, 32, 32, 3)
+ assert image_img2img.shape == (1, 32, 32, 3)
+ assert image_text2img.shape == (1, 64, 64, 3)
+
+ @require_torch_gpu
+ def test_pipe_false_offload_warn(self):
+ unet = self.dummy_cond_unet()
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ sd = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+
+ sd.enable_model_cpu_offload()
+
+ logger = logging.get_logger("diffusers.pipelines.pipeline_utils")
+ with CaptureLogger(logger) as cap_logger:
+ sd.to("cuda")
+
+ assert "It is strongly recommended against doing so" in str(cap_logger)
+
+ sd = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+
+ def test_set_scheduler(self):
+ unet = self.dummy_cond_unet()
+ scheduler = PNDMScheduler(skip_prk_steps=True)
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ sd = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=scheduler,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+
+ sd.scheduler = DDIMScheduler.from_config(sd.scheduler.config)
+ assert isinstance(sd.scheduler, DDIMScheduler)
+ sd.scheduler = DDPMScheduler.from_config(sd.scheduler.config)
+ assert isinstance(sd.scheduler, DDPMScheduler)
+ sd.scheduler = PNDMScheduler.from_config(sd.scheduler.config)
+ assert isinstance(sd.scheduler, PNDMScheduler)
+ sd.scheduler = LMSDiscreteScheduler.from_config(sd.scheduler.config)
+ assert isinstance(sd.scheduler, LMSDiscreteScheduler)
+ sd.scheduler = EulerDiscreteScheduler.from_config(sd.scheduler.config)
+ assert isinstance(sd.scheduler, EulerDiscreteScheduler)
+ sd.scheduler = EulerAncestralDiscreteScheduler.from_config(sd.scheduler.config)
+ assert isinstance(sd.scheduler, EulerAncestralDiscreteScheduler)
+ sd.scheduler = DPMSolverMultistepScheduler.from_config(sd.scheduler.config)
+ assert isinstance(sd.scheduler, DPMSolverMultistepScheduler)
+
+ def test_set_scheduler_consistency(self):
+ unet = self.dummy_cond_unet()
+ pndm = PNDMScheduler.from_config("hf-internal-testing/tiny-stable-diffusion-torch", subfolder="scheduler")
+ ddim = DDIMScheduler.from_config("hf-internal-testing/tiny-stable-diffusion-torch", subfolder="scheduler")
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ sd = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=pndm,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+
+ pndm_config = sd.scheduler.config
+ sd.scheduler = DDPMScheduler.from_config(pndm_config)
+ sd.scheduler = PNDMScheduler.from_config(sd.scheduler.config)
+ pndm_config_2 = sd.scheduler.config
+ pndm_config_2 = {k: v for k, v in pndm_config_2.items() if k in pndm_config}
+
+ assert dict(pndm_config) == dict(pndm_config_2)
+
+ sd = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=ddim,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=None,
+ feature_extractor=self.dummy_extractor,
+ )
+
+ ddim_config = sd.scheduler.config
+ sd.scheduler = LMSDiscreteScheduler.from_config(ddim_config)
+ sd.scheduler = DDIMScheduler.from_config(sd.scheduler.config)
+ ddim_config_2 = sd.scheduler.config
+ ddim_config_2 = {k: v for k, v in ddim_config_2.items() if k in ddim_config}
+
+ assert dict(ddim_config) == dict(ddim_config_2)
+
+ def test_save_safe_serialization(self):
+ pipeline = StableDiffusionPipeline.from_pretrained("hf-internal-testing/tiny-stable-diffusion-torch")
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipeline.save_pretrained(tmpdirname, safe_serialization=True)
+
+ # Validate that the VAE safetensor exists and are of the correct format
+ vae_path = os.path.join(tmpdirname, "vae", "diffusion_pytorch_model.safetensors")
+ assert os.path.exists(vae_path), f"Could not find {vae_path}"
+ _ = safetensors.torch.load_file(vae_path)
+
+ # Validate that the UNet safetensor exists and are of the correct format
+ unet_path = os.path.join(tmpdirname, "unet", "diffusion_pytorch_model.safetensors")
+ assert os.path.exists(unet_path), f"Could not find {unet_path}"
+ _ = safetensors.torch.load_file(unet_path)
+
+ # Validate that the text encoder safetensor exists and are of the correct format
+ text_encoder_path = os.path.join(tmpdirname, "text_encoder", "model.safetensors")
+ assert os.path.exists(text_encoder_path), f"Could not find {text_encoder_path}"
+ _ = safetensors.torch.load_file(text_encoder_path)
+
+ pipeline = StableDiffusionPipeline.from_pretrained(tmpdirname)
+ assert pipeline.unet is not None
+ assert pipeline.vae is not None
+ assert pipeline.text_encoder is not None
+ assert pipeline.scheduler is not None
+ assert pipeline.feature_extractor is not None
+
+ def test_no_pytorch_download_when_doing_safetensors(self):
+ # by default we don't download
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ _ = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/diffusers-stable-diffusion-tiny-all", cache_dir=tmpdirname
+ )
+
+ path = os.path.join(
+ tmpdirname,
+ "models--hf-internal-testing--diffusers-stable-diffusion-tiny-all",
+ "snapshots",
+ "07838d72e12f9bcec1375b0482b80c1d399be843",
+ "unet",
+ )
+ # safetensors exists
+ assert os.path.exists(os.path.join(path, "diffusion_pytorch_model.safetensors"))
+ # pytorch does not
+ assert not os.path.exists(os.path.join(path, "diffusion_pytorch_model.bin"))
+
+ def test_no_safetensors_download_when_doing_pytorch(self):
+ # mock diffusers safetensors not available
+ import diffusers
+
+ diffusers.utils.import_utils._safetensors_available = False
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ _ = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/diffusers-stable-diffusion-tiny-all", cache_dir=tmpdirname
+ )
+
+ path = os.path.join(
+ tmpdirname,
+ "models--hf-internal-testing--diffusers-stable-diffusion-tiny-all",
+ "snapshots",
+ "07838d72e12f9bcec1375b0482b80c1d399be843",
+ "unet",
+ )
+ # safetensors does not exists
+ assert not os.path.exists(os.path.join(path, "diffusion_pytorch_model.safetensors"))
+ # pytorch does
+ assert os.path.exists(os.path.join(path, "diffusion_pytorch_model.bin"))
+
+ diffusers.utils.import_utils._safetensors_available = True
+
+ def test_optional_components(self):
+ unet = self.dummy_cond_unet()
+ pndm = PNDMScheduler.from_config("hf-internal-testing/tiny-stable-diffusion-torch", subfolder="scheduler")
+ vae = self.dummy_vae
+ bert = self.dummy_text_encoder
+ tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
+
+ orig_sd = StableDiffusionPipeline(
+ unet=unet,
+ scheduler=pndm,
+ vae=vae,
+ text_encoder=bert,
+ tokenizer=tokenizer,
+ safety_checker=unet,
+ feature_extractor=self.dummy_extractor,
+ )
+ sd = orig_sd
+
+ assert sd.config.requires_safety_checker is True
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ sd.save_pretrained(tmpdirname)
+
+ # Test that passing None works
+ sd = StableDiffusionPipeline.from_pretrained(
+ tmpdirname, feature_extractor=None, safety_checker=None, requires_safety_checker=False
+ )
+
+ assert sd.config.requires_safety_checker is False
+ assert sd.config.safety_checker == (None, None)
+ assert sd.config.feature_extractor == (None, None)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ sd.save_pretrained(tmpdirname)
+
+ # Test that loading previous None works
+ sd = StableDiffusionPipeline.from_pretrained(tmpdirname)
+
+ assert sd.config.requires_safety_checker is False
+ assert sd.config.safety_checker == (None, None)
+ assert sd.config.feature_extractor == (None, None)
+
+ orig_sd.save_pretrained(tmpdirname)
+
+ # Test that loading without any directory works
+ shutil.rmtree(os.path.join(tmpdirname, "safety_checker"))
+ with open(os.path.join(tmpdirname, sd.config_name)) as f:
+ config = json.load(f)
+ config["safety_checker"] = [None, None]
+ with open(os.path.join(tmpdirname, sd.config_name), "w") as f:
+ json.dump(config, f)
+
+ sd = StableDiffusionPipeline.from_pretrained(tmpdirname, requires_safety_checker=False)
+ sd.save_pretrained(tmpdirname)
+ sd = StableDiffusionPipeline.from_pretrained(tmpdirname)
+
+ assert sd.config.requires_safety_checker is False
+ assert sd.config.safety_checker == (None, None)
+ assert sd.config.feature_extractor == (None, None)
+
+ # Test that loading from deleted model index works
+ with open(os.path.join(tmpdirname, sd.config_name)) as f:
+ config = json.load(f)
+ del config["safety_checker"]
+ del config["feature_extractor"]
+ with open(os.path.join(tmpdirname, sd.config_name), "w") as f:
+ json.dump(config, f)
+
+ sd = StableDiffusionPipeline.from_pretrained(tmpdirname)
+
+ assert sd.config.requires_safety_checker is False
+ assert sd.config.safety_checker == (None, None)
+ assert sd.config.feature_extractor == (None, None)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ sd.save_pretrained(tmpdirname)
+
+ # Test that partially loading works
+ sd = StableDiffusionPipeline.from_pretrained(tmpdirname, feature_extractor=self.dummy_extractor)
+
+ assert sd.config.requires_safety_checker is False
+ assert sd.config.safety_checker == (None, None)
+ assert sd.config.feature_extractor != (None, None)
+
+ # Test that partially loading works
+ sd = StableDiffusionPipeline.from_pretrained(
+ tmpdirname,
+ feature_extractor=self.dummy_extractor,
+ safety_checker=unet,
+ requires_safety_checker=[True, True],
+ )
+
+ assert sd.config.requires_safety_checker == [True, True]
+ assert sd.config.safety_checker != (None, None)
+ assert sd.config.feature_extractor != (None, None)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ sd.save_pretrained(tmpdirname)
+ sd = StableDiffusionPipeline.from_pretrained(tmpdirname, feature_extractor=self.dummy_extractor)
+
+ assert sd.config.requires_safety_checker == [True, True]
+ assert sd.config.safety_checker != (None, None)
+ assert sd.config.feature_extractor != (None, None)
+
+
+@slow
+@require_torch_gpu
+class PipelineSlowTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_smart_download(self):
+ model_id = "hf-internal-testing/unet-pipeline-dummy"
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ _ = DiffusionPipeline.from_pretrained(model_id, cache_dir=tmpdirname, force_download=True)
+ local_repo_name = "--".join(["models"] + model_id.split("/"))
+ snapshot_dir = os.path.join(tmpdirname, local_repo_name, "snapshots")
+ snapshot_dir = os.path.join(snapshot_dir, os.listdir(snapshot_dir)[0])
+
+ # inspect all downloaded files to make sure that everything is included
+ assert os.path.isfile(os.path.join(snapshot_dir, DiffusionPipeline.config_name))
+ assert os.path.isfile(os.path.join(snapshot_dir, CONFIG_NAME))
+ assert os.path.isfile(os.path.join(snapshot_dir, SCHEDULER_CONFIG_NAME))
+ assert os.path.isfile(os.path.join(snapshot_dir, WEIGHTS_NAME))
+ assert os.path.isfile(os.path.join(snapshot_dir, "scheduler", SCHEDULER_CONFIG_NAME))
+ assert os.path.isfile(os.path.join(snapshot_dir, "unet", WEIGHTS_NAME))
+ assert os.path.isfile(os.path.join(snapshot_dir, "unet", WEIGHTS_NAME))
+ # let's make sure the super large numpy file:
+ # https://huggingface.co/hf-internal-testing/unet-pipeline-dummy/blob/main/big_array.npy
+ # is not downloaded, but all the expected ones
+ assert not os.path.isfile(os.path.join(snapshot_dir, "big_array.npy"))
+
+ def test_warning_unused_kwargs(self):
+ model_id = "hf-internal-testing/unet-pipeline-dummy"
+ logger = logging.get_logger("diffusers.pipelines")
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ with CaptureLogger(logger) as cap_logger:
+ DiffusionPipeline.from_pretrained(
+ model_id,
+ not_used=True,
+ cache_dir=tmpdirname,
+ force_download=True,
+ )
+
+ assert (
+ cap_logger.out.strip().split("\n")[-1]
+ == "Keyword arguments {'not_used': True} are not expected by DDPMPipeline and will be ignored."
+ )
+
+ def test_from_save_pretrained(self):
+ # 1. Load models
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ scheduler = DDPMScheduler(num_train_timesteps=10)
+
+ ddpm = DDPMPipeline(model, scheduler)
+ ddpm.to(torch_device)
+ ddpm.set_progress_bar_config(disable=None)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ ddpm.save_pretrained(tmpdirname)
+ new_ddpm = DDPMPipeline.from_pretrained(tmpdirname)
+ new_ddpm.to(torch_device)
+
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ image = ddpm(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ new_image = new_ddpm(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ assert np.abs(image - new_image).sum() < 1e-5, "Models don't give the same forward pass"
+
+ @require_torch_2
+ def test_from_save_pretrained_dynamo(self):
+ # 1. Load models
+ model = UNet2DModel(
+ block_out_channels=(32, 64),
+ layers_per_block=2,
+ sample_size=32,
+ in_channels=3,
+ out_channels=3,
+ down_block_types=("DownBlock2D", "AttnDownBlock2D"),
+ up_block_types=("AttnUpBlock2D", "UpBlock2D"),
+ )
+ model = torch.compile(model)
+ scheduler = DDPMScheduler(num_train_timesteps=10)
+
+ ddpm = DDPMPipeline(model, scheduler)
+ ddpm.to(torch_device)
+ ddpm.set_progress_bar_config(disable=None)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ ddpm.save_pretrained(tmpdirname)
+ new_ddpm = DDPMPipeline.from_pretrained(tmpdirname)
+ new_ddpm.to(torch_device)
+
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ image = ddpm(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ new_image = new_ddpm(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ assert np.abs(image - new_image).sum() < 1e-5, "Models don't give the same forward pass"
+
+ def test_from_pretrained_hub(self):
+ model_path = "google/ddpm-cifar10-32"
+
+ scheduler = DDPMScheduler(num_train_timesteps=10)
+
+ ddpm = DDPMPipeline.from_pretrained(model_path, scheduler=scheduler)
+ ddpm = ddpm.to(torch_device)
+ ddpm.set_progress_bar_config(disable=None)
+
+ ddpm_from_hub = DiffusionPipeline.from_pretrained(model_path, scheduler=scheduler)
+ ddpm_from_hub = ddpm_from_hub.to(torch_device)
+ ddpm_from_hub.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ image = ddpm(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ new_image = ddpm_from_hub(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ assert np.abs(image - new_image).sum() < 1e-5, "Models don't give the same forward pass"
+
+ def test_from_pretrained_hub_pass_model(self):
+ model_path = "google/ddpm-cifar10-32"
+
+ scheduler = DDPMScheduler(num_train_timesteps=10)
+
+ # pass unet into DiffusionPipeline
+ unet = UNet2DModel.from_pretrained(model_path)
+ ddpm_from_hub_custom_model = DiffusionPipeline.from_pretrained(model_path, unet=unet, scheduler=scheduler)
+ ddpm_from_hub_custom_model = ddpm_from_hub_custom_model.to(torch_device)
+ ddpm_from_hub_custom_model.set_progress_bar_config(disable=None)
+
+ ddpm_from_hub = DiffusionPipeline.from_pretrained(model_path, scheduler=scheduler)
+ ddpm_from_hub = ddpm_from_hub.to(torch_device)
+ ddpm_from_hub_custom_model.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ image = ddpm_from_hub_custom_model(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ generator = torch.Generator(device=torch_device).manual_seed(0)
+ new_image = ddpm_from_hub(generator=generator, num_inference_steps=5, output_type="numpy").images
+
+ assert np.abs(image - new_image).sum() < 1e-5, "Models don't give the same forward pass"
+
+ def test_output_format(self):
+ model_path = "google/ddpm-cifar10-32"
+
+ scheduler = DDIMScheduler.from_pretrained(model_path)
+ pipe = DDIMPipeline.from_pretrained(model_path, scheduler=scheduler)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ images = pipe(output_type="numpy").images
+ assert images.shape == (1, 32, 32, 3)
+ assert isinstance(images, np.ndarray)
+
+ images = pipe(output_type="pil", num_inference_steps=4).images
+ assert isinstance(images, list)
+ assert len(images) == 1
+ assert isinstance(images[0], PIL.Image.Image)
+
+ # use PIL by default
+ images = pipe(num_inference_steps=4).images
+ assert isinstance(images, list)
+ assert isinstance(images[0], PIL.Image.Image)
+
+ def test_from_flax_from_pt(self):
+ pipe_pt = StableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-torch", safety_checker=None
+ )
+ pipe_pt.to(torch_device)
+
+ if not is_flax_available():
+ raise ImportError("Make sure flax is installed.")
+
+ from diffusers import FlaxStableDiffusionPipeline
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe_pt.save_pretrained(tmpdirname)
+
+ pipe_flax, params = FlaxStableDiffusionPipeline.from_pretrained(
+ tmpdirname, safety_checker=None, from_pt=True
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ pipe_flax.save_pretrained(tmpdirname, params=params)
+ pipe_pt_2 = StableDiffusionPipeline.from_pretrained(tmpdirname, safety_checker=None, from_flax=True)
+ pipe_pt_2.to(torch_device)
+
+ prompt = "Hello"
+
+ generator = torch.manual_seed(0)
+ image_0 = pipe_pt(
+ [prompt],
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ ).images[0]
+
+ generator = torch.manual_seed(0)
+ image_1 = pipe_pt_2(
+ [prompt],
+ generator=generator,
+ num_inference_steps=2,
+ output_type="np",
+ ).images[0]
+
+ assert np.abs(image_0 - image_1).sum() < 1e-5, "Models don't give the same forward pass"
+
+ @require_compel
+ def test_weighted_prompts_compel(self):
+ from compel import Compel
+
+ pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
+ pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
+ pipe.enable_model_cpu_offload()
+ pipe.enable_attention_slicing()
+
+ compel = Compel(tokenizer=pipe.tokenizer, text_encoder=pipe.text_encoder)
+
+ prompt = "a red cat playing with a ball{}"
+
+ prompts = [prompt.format(s) for s in ["", "++", "--"]]
+
+ prompt_embeds = compel(prompts)
+
+ generator = [torch.Generator(device="cpu").manual_seed(33) for _ in range(prompt_embeds.shape[0])]
+
+ images = pipe(
+ prompt_embeds=prompt_embeds, generator=generator, num_inference_steps=20, output_type="numpy"
+ ).images
+
+ for i, image in enumerate(images):
+ expected_image = load_numpy(
+ "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
+ f"/compel/forest_{i}.npy"
+ )
+
+ assert np.abs(image - expected_image).max() < 1e-2
+
+
+@nightly
+@require_torch_gpu
+class PipelineNightlyTests(unittest.TestCase):
+ def tearDown(self):
+ # clean up the VRAM after each test
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_ddpm_ddim_equality_batched(self):
+ seed = 0
+ model_id = "google/ddpm-cifar10-32"
+
+ unet = UNet2DModel.from_pretrained(model_id)
+ ddpm_scheduler = DDPMScheduler()
+ ddim_scheduler = DDIMScheduler()
+
+ ddpm = DDPMPipeline(unet=unet, scheduler=ddpm_scheduler)
+ ddpm.to(torch_device)
+ ddpm.set_progress_bar_config(disable=None)
+
+ ddim = DDIMPipeline(unet=unet, scheduler=ddim_scheduler)
+ ddim.to(torch_device)
+ ddim.set_progress_bar_config(disable=None)
+
+ generator = torch.Generator(device=torch_device).manual_seed(seed)
+ ddpm_images = ddpm(batch_size=2, generator=generator, output_type="numpy").images
+
+ generator = torch.Generator(device=torch_device).manual_seed(seed)
+ ddim_images = ddim(
+ batch_size=2,
+ generator=generator,
+ num_inference_steps=1000,
+ eta=1.0,
+ output_type="numpy",
+ use_clipped_model_output=True, # Need this to make DDIM match DDPM
+ ).images
+
+ # the values aren't exactly equal, but the images look the same visually
+ assert np.abs(ddpm_images - ddim_images).max() < 1e-1
diff --git a/diffusers/tests/test_pipelines_common.py b/diffusers/tests/test_pipelines_common.py
new file mode 100644
index 0000000000000000000000000000000000000000..13fbe924c799a6b427d1ed55b4d8f6cb4dd824fb
--- /dev/null
+++ b/diffusers/tests/test_pipelines_common.py
@@ -0,0 +1,590 @@
+import contextlib
+import gc
+import inspect
+import io
+import re
+import tempfile
+import unittest
+from typing import Callable, Union
+
+import numpy as np
+import torch
+
+import diffusers
+from diffusers import DiffusionPipeline
+from diffusers.utils import logging
+from diffusers.utils.import_utils import is_accelerate_available, is_accelerate_version, is_xformers_available
+from diffusers.utils.testing_utils import require_torch, torch_device
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+def to_np(tensor):
+ if isinstance(tensor, torch.Tensor):
+ tensor = tensor.detach().cpu().numpy()
+
+ return tensor
+
+
+@require_torch
+class PipelineTesterMixin:
+ """
+ This mixin is designed to be used with unittest.TestCase classes.
+ It provides a set of common tests for each PyTorch pipeline, e.g. saving and loading the pipeline,
+ equivalence of dict and tuple outputs, etc.
+ """
+
+ # Canonical parameters that are passed to `__call__` regardless
+ # of the type of pipeline. They are always optional and have common
+ # sense default values.
+ required_optional_params = frozenset(
+ [
+ "num_inference_steps",
+ "num_images_per_prompt",
+ "generator",
+ "latents",
+ "output_type",
+ "return_dict",
+ "callback",
+ "callback_steps",
+ ]
+ )
+
+ # set these parameters to False in the child class if the pipeline does not support the corresponding functionality
+ test_attention_slicing = True
+ test_cpu_offload = True
+ test_xformers_attention = True
+
+ def get_generator(self, seed):
+ device = torch_device if torch_device != "mps" else "cpu"
+ generator = torch.Generator(device).manual_seed(seed)
+ return generator
+
+ @property
+ def pipeline_class(self) -> Union[Callable, DiffusionPipeline]:
+ raise NotImplementedError(
+ "You need to set the attribute `pipeline_class = ClassNameOfPipeline` in the child test class. "
+ "See existing pipeline tests for reference."
+ )
+
+ def get_dummy_components(self):
+ raise NotImplementedError(
+ "You need to implement `get_dummy_components(self)` in the child test class. "
+ "See existing pipeline tests for reference."
+ )
+
+ def get_dummy_inputs(self, device, seed=0):
+ raise NotImplementedError(
+ "You need to implement `get_dummy_inputs(self, device, seed)` in the child test class. "
+ "See existing pipeline tests for reference."
+ )
+
+ @property
+ def params(self) -> frozenset:
+ raise NotImplementedError(
+ "You need to set the attribute `params` in the child test class. "
+ "`params` are checked for if all values are present in `__call__`'s signature."
+ " You can set `params` using one of the common set of parameters defined in`pipeline_params.py`"
+ " e.g., `TEXT_TO_IMAGE_PARAMS` defines the common parameters used in text to "
+ "image pipelines, including prompts and prompt embedding overrides."
+ "If your pipeline's set of arguments has minor changes from one of the common sets of arguments, "
+ "do not make modifications to the existing common sets of arguments. I.e. a text to image pipeline "
+ "with non-configurable height and width arguments should set the attribute as "
+ "`params = TEXT_TO_IMAGE_PARAMS - {'height', 'width'}`. "
+ "See existing pipeline tests for reference."
+ )
+
+ @property
+ def batch_params(self) -> frozenset:
+ raise NotImplementedError(
+ "You need to set the attribute `batch_params` in the child test class. "
+ "`batch_params` are the parameters required to be batched when passed to the pipeline's "
+ "`__call__` method. `pipeline_params.py` provides some common sets of parameters such as "
+ "`TEXT_TO_IMAGE_BATCH_PARAMS`, `IMAGE_VARIATION_BATCH_PARAMS`, etc... If your pipeline's "
+ "set of batch arguments has minor changes from one of the common sets of batch arguments, "
+ "do not make modifications to the existing common sets of batch arguments. I.e. a text to "
+ "image pipeline `negative_prompt` is not batched should set the attribute as "
+ "`batch_params = TEXT_TO_IMAGE_BATCH_PARAMS - {'negative_prompt'}`. "
+ "See existing pipeline tests for reference."
+ )
+
+ def tearDown(self):
+ # clean up the VRAM after each test in case of CUDA runtime errors
+ super().tearDown()
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ def test_save_load_local(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir)
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir)
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(max_diff, 1e-4)
+
+ def test_pipeline_call_signature(self):
+ self.assertTrue(
+ hasattr(self.pipeline_class, "__call__"), f"{self.pipeline_class} should have a `__call__` method"
+ )
+
+ parameters = inspect.signature(self.pipeline_class.__call__).parameters
+
+ optional_parameters = set()
+
+ for k, v in parameters.items():
+ if v.default != inspect._empty:
+ optional_parameters.add(k)
+
+ parameters = set(parameters.keys())
+ parameters.remove("self")
+ parameters.discard("kwargs") # kwargs can be added if arguments of pipeline call function are deprecated
+
+ remaining_required_parameters = set()
+
+ for param in self.params:
+ if param not in parameters:
+ remaining_required_parameters.add(param)
+
+ self.assertTrue(
+ len(remaining_required_parameters) == 0,
+ f"Required parameters not present: {remaining_required_parameters}",
+ )
+
+ remaining_required_optional_parameters = set()
+
+ for param in self.required_optional_params:
+ if param not in optional_parameters:
+ remaining_required_optional_parameters.add(param)
+
+ self.assertTrue(
+ len(remaining_required_optional_parameters) == 0,
+ f"Required optional parameters not present: {remaining_required_optional_parameters}",
+ )
+
+ def test_inference_batch_consistent(self):
+ self._test_inference_batch_consistent()
+
+ def _test_inference_batch_consistent(
+ self, batch_sizes=[2, 4, 13], additional_params_copy_to_batched_inputs=["num_inference_steps"]
+ ):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+
+ logger = logging.get_logger(pipe.__module__)
+ logger.setLevel(level=diffusers.logging.FATAL)
+
+ # batchify inputs
+ for batch_size in batch_sizes:
+ batched_inputs = {}
+ for name, value in inputs.items():
+ if name in self.batch_params:
+ # prompt is string
+ if name == "prompt":
+ len_prompt = len(value)
+ # make unequal batch sizes
+ batched_inputs[name] = [value[: len_prompt // i] for i in range(1, batch_size + 1)]
+
+ # make last batch super long
+ batched_inputs[name][-1] = 2000 * "very long"
+ # or else we have images
+ else:
+ batched_inputs[name] = batch_size * [value]
+ elif name == "batch_size":
+ batched_inputs[name] = batch_size
+ else:
+ batched_inputs[name] = value
+
+ for arg in additional_params_copy_to_batched_inputs:
+ batched_inputs[arg] = inputs[arg]
+
+ batched_inputs["output_type"] = None
+
+ if self.pipeline_class.__name__ == "DanceDiffusionPipeline":
+ batched_inputs.pop("output_type")
+
+ output = pipe(**batched_inputs)
+
+ assert len(output[0]) == batch_size
+
+ batched_inputs["output_type"] = "np"
+
+ if self.pipeline_class.__name__ == "DanceDiffusionPipeline":
+ batched_inputs.pop("output_type")
+
+ output = pipe(**batched_inputs)[0]
+
+ assert output.shape[0] == batch_size
+
+ logger.setLevel(level=diffusers.logging.WARNING)
+
+ def test_inference_batch_single_identical(self):
+ self._test_inference_batch_single_identical()
+
+ def _test_inference_batch_single_identical(
+ self,
+ test_max_difference=None,
+ test_mean_pixel_difference=None,
+ relax_max_difference=False,
+ expected_max_diff=1e-4,
+ additional_params_copy_to_batched_inputs=["num_inference_steps"],
+ ):
+ if test_max_difference is None:
+ # TODO(Pedro) - not sure why, but not at all reproducible at the moment it seems
+ # make sure that batched and non-batched is identical
+ test_max_difference = torch_device != "mps"
+
+ if test_mean_pixel_difference is None:
+ # TODO same as above
+ test_mean_pixel_difference = torch_device != "mps"
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+
+ logger = logging.get_logger(pipe.__module__)
+ logger.setLevel(level=diffusers.logging.FATAL)
+
+ # batchify inputs
+ batched_inputs = {}
+ batch_size = 3
+ for name, value in inputs.items():
+ if name in self.batch_params:
+ # prompt is string
+ if name == "prompt":
+ len_prompt = len(value)
+ # make unequal batch sizes
+ batched_inputs[name] = [value[: len_prompt // i] for i in range(1, batch_size + 1)]
+
+ # make last batch super long
+ batched_inputs[name][-1] = 2000 * "very long"
+ # or else we have images
+ else:
+ batched_inputs[name] = batch_size * [value]
+ elif name == "batch_size":
+ batched_inputs[name] = batch_size
+ elif name == "generator":
+ batched_inputs[name] = [self.get_generator(i) for i in range(batch_size)]
+ else:
+ batched_inputs[name] = value
+
+ for arg in additional_params_copy_to_batched_inputs:
+ batched_inputs[arg] = inputs[arg]
+
+ if self.pipeline_class.__name__ != "DanceDiffusionPipeline":
+ batched_inputs["output_type"] = "np"
+
+ output_batch = pipe(**batched_inputs)
+ assert output_batch[0].shape[0] == batch_size
+
+ inputs["generator"] = self.get_generator(0)
+
+ output = pipe(**inputs)
+
+ logger.setLevel(level=diffusers.logging.WARNING)
+ if test_max_difference:
+ if relax_max_difference:
+ # Taking the median of the largest differences
+ # is resilient to outliers
+ diff = np.abs(output_batch[0][0] - output[0][0])
+ diff = diff.flatten()
+ diff.sort()
+ max_diff = np.median(diff[-5:])
+ else:
+ max_diff = np.abs(output_batch[0][0] - output[0][0]).max()
+ assert max_diff < expected_max_diff
+
+ if test_mean_pixel_difference:
+ assert_mean_pixel_difference(output_batch[0][0], output[0][0])
+
+ def test_dict_tuple_outputs_equivalent(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ output = pipe(**self.get_dummy_inputs(torch_device))[0]
+ output_tuple = pipe(**self.get_dummy_inputs(torch_device), return_dict=False)[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_tuple)).max()
+ self.assertLess(max_diff, 1e-4)
+
+ def test_components_function(self):
+ init_components = self.get_dummy_components()
+ pipe = self.pipeline_class(**init_components)
+
+ self.assertTrue(hasattr(pipe, "components"))
+ self.assertTrue(set(pipe.components.keys()) == set(init_components.keys()))
+
+ @unittest.skipIf(torch_device != "cuda", reason="float16 requires CUDA")
+ def test_float16_inference(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ pipe_fp16 = self.pipeline_class(**components)
+ pipe_fp16.to(torch_device, torch.float16)
+ pipe_fp16.set_progress_bar_config(disable=None)
+
+ output = pipe(**self.get_dummy_inputs(torch_device))[0]
+ output_fp16 = pipe_fp16(**self.get_dummy_inputs(torch_device))[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_fp16)).max()
+ self.assertLess(max_diff, 1e-2, "The outputs of the fp16 and fp32 pipelines are too different.")
+
+ @unittest.skipIf(torch_device != "cuda", reason="float16 requires CUDA")
+ def test_save_load_float16(self):
+ components = self.get_dummy_components()
+ for name, module in components.items():
+ if hasattr(module, "half"):
+ components[name] = module.to(torch_device).half()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir)
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir, torch_dtype=torch.float16)
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ for name, component in pipe_loaded.components.items():
+ if hasattr(component, "dtype"):
+ self.assertTrue(
+ component.dtype == torch.float16,
+ f"`{name}.dtype` switched from `float16` to {component.dtype} after loading.",
+ )
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(max_diff, 1e-2, "The output of the fp16 pipeline changed after saving and loading.")
+
+ def test_save_load_optional_components(self):
+ if not hasattr(self.pipeline_class, "_optional_components"):
+ return
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ # set all optional components to None
+ for optional_component in pipe._optional_components:
+ setattr(pipe, optional_component, None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output = pipe(**inputs)[0]
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ pipe.save_pretrained(tmpdir)
+ pipe_loaded = self.pipeline_class.from_pretrained(tmpdir)
+ pipe_loaded.to(torch_device)
+ pipe_loaded.set_progress_bar_config(disable=None)
+
+ for optional_component in pipe._optional_components:
+ self.assertTrue(
+ getattr(pipe_loaded, optional_component) is None,
+ f"`{optional_component}` did not stay set to None after loading.",
+ )
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_loaded = pipe_loaded(**inputs)[0]
+
+ max_diff = np.abs(to_np(output) - to_np(output_loaded)).max()
+ self.assertLess(max_diff, 1e-4)
+
+ @unittest.skipIf(torch_device != "cuda", reason="CUDA and CPU are required to switch devices")
+ def test_to_device(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.set_progress_bar_config(disable=None)
+
+ pipe.to("cpu")
+ model_devices = [component.device.type for component in components.values() if hasattr(component, "device")]
+ self.assertTrue(all(device == "cpu" for device in model_devices))
+
+ output_cpu = pipe(**self.get_dummy_inputs("cpu"))[0]
+ self.assertTrue(np.isnan(output_cpu).sum() == 0)
+
+ pipe.to("cuda")
+ model_devices = [component.device.type for component in components.values() if hasattr(component, "device")]
+ self.assertTrue(all(device == "cuda" for device in model_devices))
+
+ output_cuda = pipe(**self.get_dummy_inputs("cuda"))[0]
+ self.assertTrue(np.isnan(to_np(output_cuda)).sum() == 0)
+
+ def test_to_dtype(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.set_progress_bar_config(disable=None)
+
+ model_dtypes = [component.dtype for component in components.values() if hasattr(component, "dtype")]
+ self.assertTrue(all(dtype == torch.float32 for dtype in model_dtypes))
+
+ pipe.to(torch_dtype=torch.float16)
+ model_dtypes = [component.dtype for component in components.values() if hasattr(component, "dtype")]
+ self.assertTrue(all(dtype == torch.float16 for dtype in model_dtypes))
+
+ def test_attention_slicing_forward_pass(self):
+ self._test_attention_slicing_forward_pass()
+
+ def _test_attention_slicing_forward_pass(
+ self, test_max_difference=True, test_mean_pixel_difference=True, expected_max_diff=1e-3
+ ):
+ if not self.test_attention_slicing:
+ return
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_without_slicing = pipe(**inputs)[0]
+
+ pipe.enable_attention_slicing(slice_size=1)
+ inputs = self.get_dummy_inputs(torch_device)
+ output_with_slicing = pipe(**inputs)[0]
+
+ if test_max_difference:
+ max_diff = np.abs(to_np(output_with_slicing) - to_np(output_without_slicing)).max()
+ self.assertLess(max_diff, expected_max_diff, "Attention slicing should not affect the inference results")
+
+ if test_mean_pixel_difference:
+ assert_mean_pixel_difference(output_with_slicing[0], output_without_slicing[0])
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_accelerate_available() or is_accelerate_version("<", "0.14.0"),
+ reason="CPU offload is only available with CUDA and `accelerate v0.14.0` or higher",
+ )
+ def test_cpu_offload_forward_pass(self):
+ if not self.test_cpu_offload:
+ return
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_without_offload = pipe(**inputs)[0]
+
+ pipe.enable_sequential_cpu_offload()
+ inputs = self.get_dummy_inputs(torch_device)
+ output_with_offload = pipe(**inputs)[0]
+
+ max_diff = np.abs(to_np(output_with_offload) - to_np(output_without_offload)).max()
+ self.assertLess(max_diff, 1e-4, "CPU offloading should not affect the inference results")
+
+ @unittest.skipIf(
+ torch_device != "cuda" or not is_xformers_available(),
+ reason="XFormers attention is only available with CUDA and `xformers` installed",
+ )
+ def test_xformers_attention_forwardGenerator_pass(self):
+ self._test_xformers_attention_forwardGenerator_pass()
+
+ def _test_xformers_attention_forwardGenerator_pass(self, test_max_difference=True, expected_max_diff=1e-4):
+ if not self.test_xformers_attention:
+ return
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ output_without_offload = pipe(**inputs)[0]
+
+ pipe.enable_xformers_memory_efficient_attention()
+ inputs = self.get_dummy_inputs(torch_device)
+ output_with_offload = pipe(**inputs)[0]
+
+ if test_max_difference:
+ max_diff = np.abs(output_with_offload - output_without_offload).max()
+ self.assertLess(max_diff, expected_max_diff, "XFormers attention should not affect the inference results")
+
+ assert_mean_pixel_difference(output_with_offload[0], output_without_offload[0])
+
+ def test_progress_bar(self):
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe.to(torch_device)
+
+ inputs = self.get_dummy_inputs(torch_device)
+ with io.StringIO() as stderr, contextlib.redirect_stderr(stderr):
+ _ = pipe(**inputs)
+ stderr = stderr.getvalue()
+ # we can't calculate the number of progress steps beforehand e.g. for strength-dependent img2img,
+ # so we just match "5" in "#####| 1/5 [00:01<00:00]"
+ max_steps = re.search("/(.*?) ", stderr).group(1)
+ self.assertTrue(max_steps is not None and len(max_steps) > 0)
+ self.assertTrue(
+ f"{max_steps}/{max_steps}" in stderr, "Progress bar should be enabled and stopped at the max step"
+ )
+
+ pipe.set_progress_bar_config(disable=True)
+ with io.StringIO() as stderr, contextlib.redirect_stderr(stderr):
+ _ = pipe(**inputs)
+ self.assertTrue(stderr.getvalue() == "", "Progress bar should be disabled")
+
+ def test_num_images_per_prompt(self):
+ sig = inspect.signature(self.pipeline_class.__call__)
+
+ if "num_images_per_prompt" not in sig.parameters:
+ return
+
+ components = self.get_dummy_components()
+ pipe = self.pipeline_class(**components)
+ pipe = pipe.to(torch_device)
+ pipe.set_progress_bar_config(disable=None)
+
+ batch_sizes = [1, 2]
+ num_images_per_prompts = [1, 2]
+
+ for batch_size in batch_sizes:
+ for num_images_per_prompt in num_images_per_prompts:
+ inputs = self.get_dummy_inputs(torch_device)
+
+ for key in inputs.keys():
+ if key in self.batch_params:
+ inputs[key] = batch_size * [inputs[key]]
+
+ images = pipe(**inputs, num_images_per_prompt=num_images_per_prompt).images
+
+ assert images.shape[0] == batch_size * num_images_per_prompt
+
+
+# Some models (e.g. unCLIP) are extremely likely to significantly deviate depending on which hardware is used.
+# This helper function is used to check that the image doesn't deviate on average more than 10 pixels from a
+# reference image.
+def assert_mean_pixel_difference(image, expected_image):
+ image = np.asarray(DiffusionPipeline.numpy_to_pil(image)[0], dtype=np.float32)
+ expected_image = np.asarray(DiffusionPipeline.numpy_to_pil(expected_image)[0], dtype=np.float32)
+ avg_diff = np.abs(image - expected_image).mean()
+ assert avg_diff < 10, f"Error image deviates {avg_diff} pixels on average"
diff --git a/diffusers/tests/test_pipelines_flax.py b/diffusers/tests/test_pipelines_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..a461930f3a83ecfc8134d50ce5978d329d79f5c9
--- /dev/null
+++ b/diffusers/tests/test_pipelines_flax.py
@@ -0,0 +1,226 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import tempfile
+import unittest
+
+import numpy as np
+
+from diffusers.utils import is_flax_available
+from diffusers.utils.testing_utils import require_flax, slow
+
+
+if is_flax_available():
+ import jax
+ import jax.numpy as jnp
+ from flax.jax_utils import replicate
+ from flax.training.common_utils import shard
+ from jax import pmap
+
+ from diffusers import FlaxDDIMScheduler, FlaxDiffusionPipeline, FlaxStableDiffusionPipeline
+
+
+@require_flax
+class DownloadTests(unittest.TestCase):
+ def test_download_only_pytorch(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ # pipeline has Flax weights
+ _ = FlaxDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-pipe", safety_checker=None, cache_dir=tmpdirname
+ )
+
+ all_root_files = [t[-1] for t in os.walk(os.path.join(tmpdirname, os.listdir(tmpdirname)[0], "snapshots"))]
+ files = [item for sublist in all_root_files for item in sublist]
+
+ # None of the downloaded files should be a PyTorch file even if we have some here:
+ # https://huggingface.co/hf-internal-testing/tiny-stable-diffusion-pipe/blob/main/unet/diffusion_pytorch_model.bin
+ assert not any(f.endswith(".bin") for f in files)
+
+
+@slow
+@require_flax
+class FlaxPipelineTests(unittest.TestCase):
+ def test_dummy_all_tpus(self):
+ pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
+ "hf-internal-testing/tiny-stable-diffusion-pipe", safety_checker=None
+ )
+
+ prompt = (
+ "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of"
+ " field, close up, split lighting, cinematic"
+ )
+
+ prng_seed = jax.random.PRNGKey(0)
+ num_inference_steps = 4
+
+ num_samples = jax.device_count()
+ prompt = num_samples * [prompt]
+ prompt_ids = pipeline.prepare_inputs(prompt)
+
+ p_sample = pmap(pipeline.__call__, static_broadcasted_argnums=(3,))
+
+ # shard inputs and rng
+ params = replicate(params)
+ prng_seed = jax.random.split(prng_seed, num_samples)
+ prompt_ids = shard(prompt_ids)
+
+ images = p_sample(prompt_ids, params, prng_seed, num_inference_steps).images
+
+ assert images.shape == (num_samples, 1, 64, 64, 3)
+ if jax.device_count() == 8:
+ assert np.abs(np.abs(images[0, 0, :2, :2, -2:], dtype=np.float32).sum() - 3.1111548) < 1e-3
+ assert np.abs(np.abs(images, dtype=np.float32).sum() - 199746.95) < 5e-1
+
+ images_pil = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
+
+ assert len(images_pil) == num_samples
+
+ def test_stable_diffusion_v1_4(self):
+ pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", revision="flax", safety_checker=None
+ )
+
+ prompt = (
+ "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of"
+ " field, close up, split lighting, cinematic"
+ )
+
+ prng_seed = jax.random.PRNGKey(0)
+ num_inference_steps = 50
+
+ num_samples = jax.device_count()
+ prompt = num_samples * [prompt]
+ prompt_ids = pipeline.prepare_inputs(prompt)
+
+ p_sample = pmap(pipeline.__call__, static_broadcasted_argnums=(3,))
+
+ # shard inputs and rng
+ params = replicate(params)
+ prng_seed = jax.random.split(prng_seed, num_samples)
+ prompt_ids = shard(prompt_ids)
+
+ images = p_sample(prompt_ids, params, prng_seed, num_inference_steps).images
+
+ assert images.shape == (num_samples, 1, 512, 512, 3)
+ if jax.device_count() == 8:
+ assert np.abs((np.abs(images[0, 0, :2, :2, -2:], dtype=np.float32).sum() - 0.05652401)) < 1e-3
+ assert np.abs((np.abs(images, dtype=np.float32).sum() - 2383808.2)) < 5e-1
+
+ def test_stable_diffusion_v1_4_bfloat_16(self):
+ pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", revision="bf16", dtype=jnp.bfloat16, safety_checker=None
+ )
+
+ prompt = (
+ "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of"
+ " field, close up, split lighting, cinematic"
+ )
+
+ prng_seed = jax.random.PRNGKey(0)
+ num_inference_steps = 50
+
+ num_samples = jax.device_count()
+ prompt = num_samples * [prompt]
+ prompt_ids = pipeline.prepare_inputs(prompt)
+
+ p_sample = pmap(pipeline.__call__, static_broadcasted_argnums=(3,))
+
+ # shard inputs and rng
+ params = replicate(params)
+ prng_seed = jax.random.split(prng_seed, num_samples)
+ prompt_ids = shard(prompt_ids)
+
+ images = p_sample(prompt_ids, params, prng_seed, num_inference_steps).images
+
+ assert images.shape == (num_samples, 1, 512, 512, 3)
+ if jax.device_count() == 8:
+ assert np.abs((np.abs(images[0, 0, :2, :2, -2:], dtype=np.float32).sum() - 0.06652832)) < 1e-3
+ assert np.abs((np.abs(images, dtype=np.float32).sum() - 2384849.8)) < 5e-1
+
+ def test_stable_diffusion_v1_4_bfloat_16_with_safety(self):
+ pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4", revision="bf16", dtype=jnp.bfloat16
+ )
+
+ prompt = (
+ "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of"
+ " field, close up, split lighting, cinematic"
+ )
+
+ prng_seed = jax.random.PRNGKey(0)
+ num_inference_steps = 50
+
+ num_samples = jax.device_count()
+ prompt = num_samples * [prompt]
+ prompt_ids = pipeline.prepare_inputs(prompt)
+
+ # shard inputs and rng
+ params = replicate(params)
+ prng_seed = jax.random.split(prng_seed, num_samples)
+ prompt_ids = shard(prompt_ids)
+
+ images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
+
+ assert images.shape == (num_samples, 1, 512, 512, 3)
+ if jax.device_count() == 8:
+ assert np.abs((np.abs(images[0, 0, :2, :2, -2:], dtype=np.float32).sum() - 0.06652832)) < 1e-3
+ assert np.abs((np.abs(images, dtype=np.float32).sum() - 2384849.8)) < 5e-1
+
+ def test_stable_diffusion_v1_4_bfloat_16_ddim(self):
+ scheduler = FlaxDDIMScheduler(
+ beta_start=0.00085,
+ beta_end=0.012,
+ beta_schedule="scaled_linear",
+ set_alpha_to_one=False,
+ steps_offset=1,
+ )
+
+ pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
+ "CompVis/stable-diffusion-v1-4",
+ revision="bf16",
+ dtype=jnp.bfloat16,
+ scheduler=scheduler,
+ safety_checker=None,
+ )
+ scheduler_state = scheduler.create_state()
+
+ params["scheduler"] = scheduler_state
+
+ prompt = (
+ "A cinematic film still of Morgan Freeman starring as Jimi Hendrix, portrait, 40mm lens, shallow depth of"
+ " field, close up, split lighting, cinematic"
+ )
+
+ prng_seed = jax.random.PRNGKey(0)
+ num_inference_steps = 50
+
+ num_samples = jax.device_count()
+ prompt = num_samples * [prompt]
+ prompt_ids = pipeline.prepare_inputs(prompt)
+
+ p_sample = pmap(pipeline.__call__, static_broadcasted_argnums=(3,))
+
+ # shard inputs and rng
+ params = replicate(params)
+ prng_seed = jax.random.split(prng_seed, num_samples)
+ prompt_ids = shard(prompt_ids)
+
+ images = p_sample(prompt_ids, params, prng_seed, num_inference_steps).images
+
+ assert images.shape == (num_samples, 1, 512, 512, 3)
+ if jax.device_count() == 8:
+ assert np.abs((np.abs(images[0, 0, :2, :2, -2:], dtype=np.float32).sum() - 0.045043945)) < 1e-3
+ assert np.abs((np.abs(images, dtype=np.float32).sum() - 2347693.5)) < 5e-1
diff --git a/diffusers/tests/test_pipelines_onnx_common.py b/diffusers/tests/test_pipelines_onnx_common.py
new file mode 100644
index 0000000000000000000000000000000000000000..575ecd0075318e8ec62ab7cd76bff5b0b1ca82ad
--- /dev/null
+++ b/diffusers/tests/test_pipelines_onnx_common.py
@@ -0,0 +1,12 @@
+from diffusers.utils.testing_utils import require_onnxruntime
+
+
+@require_onnxruntime
+class OnnxPipelineTesterMixin:
+ """
+ This mixin is designed to be used with unittest.TestCase classes.
+ It provides a set of common tests for each ONNXRuntime pipeline, e.g. saving and loading the pipeline,
+ equivalence of dict and tuple outputs, etc.
+ """
+
+ pass
diff --git a/diffusers/tests/test_training.py b/diffusers/tests/test_training.py
new file mode 100644
index 0000000000000000000000000000000000000000..d540f997622148082874272ff7cebffea4d4450d
--- /dev/null
+++ b/diffusers/tests/test_training.py
@@ -0,0 +1,86 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import torch
+
+from diffusers import DDIMScheduler, DDPMScheduler, UNet2DModel
+from diffusers.training_utils import set_seed
+from diffusers.utils.testing_utils import slow
+
+
+torch.backends.cuda.matmul.allow_tf32 = False
+
+
+class TrainingTests(unittest.TestCase):
+ def get_model_optimizer(self, resolution=32):
+ set_seed(0)
+ model = UNet2DModel(sample_size=resolution, in_channels=3, out_channels=3)
+ optimizer = torch.optim.SGD(model.parameters(), lr=0.0001)
+ return model, optimizer
+
+ @slow
+ def test_training_step_equality(self):
+ device = "cpu" # ensure full determinism without setting the CUBLAS_WORKSPACE_CONFIG env variable
+ ddpm_scheduler = DDPMScheduler(
+ num_train_timesteps=1000,
+ beta_start=0.0001,
+ beta_end=0.02,
+ beta_schedule="linear",
+ clip_sample=True,
+ )
+ ddim_scheduler = DDIMScheduler(
+ num_train_timesteps=1000,
+ beta_start=0.0001,
+ beta_end=0.02,
+ beta_schedule="linear",
+ clip_sample=True,
+ )
+
+ assert ddpm_scheduler.config.num_train_timesteps == ddim_scheduler.config.num_train_timesteps
+
+ # shared batches for DDPM and DDIM
+ set_seed(0)
+ clean_images = [torch.randn((4, 3, 32, 32)).clip(-1, 1).to(device) for _ in range(4)]
+ noise = [torch.randn((4, 3, 32, 32)).to(device) for _ in range(4)]
+ timesteps = [torch.randint(0, 1000, (4,)).long().to(device) for _ in range(4)]
+
+ # train with a DDPM scheduler
+ model, optimizer = self.get_model_optimizer(resolution=32)
+ model.train().to(device)
+ for i in range(4):
+ optimizer.zero_grad()
+ ddpm_noisy_images = ddpm_scheduler.add_noise(clean_images[i], noise[i], timesteps[i])
+ ddpm_noise_pred = model(ddpm_noisy_images, timesteps[i]).sample
+ loss = torch.nn.functional.mse_loss(ddpm_noise_pred, noise[i])
+ loss.backward()
+ optimizer.step()
+ del model, optimizer
+
+ # recreate the model and optimizer, and retry with DDIM
+ model, optimizer = self.get_model_optimizer(resolution=32)
+ model.train().to(device)
+ for i in range(4):
+ optimizer.zero_grad()
+ ddim_noisy_images = ddim_scheduler.add_noise(clean_images[i], noise[i], timesteps[i])
+ ddim_noise_pred = model(ddim_noisy_images, timesteps[i]).sample
+ loss = torch.nn.functional.mse_loss(ddim_noise_pred, noise[i])
+ loss.backward()
+ optimizer.step()
+ del model, optimizer
+
+ self.assertTrue(torch.allclose(ddpm_noisy_images, ddim_noisy_images, atol=1e-5))
+ self.assertTrue(torch.allclose(ddpm_noise_pred, ddim_noise_pred, atol=1e-5))
diff --git a/diffusers/tests/test_unet_2d_blocks.py b/diffusers/tests/test_unet_2d_blocks.py
new file mode 100644
index 0000000000000000000000000000000000000000..e560240422ace376e8ccca989da9144ee8e8d98d
--- /dev/null
+++ b/diffusers/tests/test_unet_2d_blocks.py
@@ -0,0 +1,337 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import unittest
+
+from diffusers.models.unet_2d_blocks import * # noqa F403
+from diffusers.utils import torch_device
+
+from .test_unet_blocks_common import UNetBlockTesterMixin
+
+
+class DownBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = DownBlock2D # noqa F405
+ block_type = "down"
+
+ def test_output(self):
+ expected_slice = [-0.0232, -0.9869, 0.8054, -0.0637, -0.1688, -1.4264, 0.4470, -1.3394, 0.0904]
+ super().test_output(expected_slice)
+
+
+class ResnetDownsampleBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = ResnetDownsampleBlock2D # noqa F405
+ block_type = "down"
+
+ def test_output(self):
+ expected_slice = [0.0710, 0.2410, -0.7320, -1.0757, -1.1343, 0.3540, -0.0133, -0.2576, 0.0948]
+ super().test_output(expected_slice)
+
+
+class AttnDownBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = AttnDownBlock2D # noqa F405
+ block_type = "down"
+
+ def test_output(self):
+ expected_slice = [0.0636, 0.8964, -0.6234, -1.0131, 0.0844, 0.4935, 0.3437, 0.0911, -0.2957]
+ super().test_output(expected_slice)
+
+
+class CrossAttnDownBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = CrossAttnDownBlock2D # noqa F405
+ block_type = "down"
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict, inputs_dict = super().prepare_init_args_and_inputs_for_common()
+ init_dict["cross_attention_dim"] = 32
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [0.2440, -0.6953, -0.2140, -0.3874, 0.1966, 1.2077, 0.0441, -0.7718, 0.2800]
+ super().test_output(expected_slice)
+
+
+class SimpleCrossAttnDownBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = SimpleCrossAttnDownBlock2D # noqa F405
+ block_type = "down"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_encoder_hidden_states=True)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict, inputs_dict = super().prepare_init_args_and_inputs_for_common()
+ init_dict["cross_attention_dim"] = 32
+ return init_dict, inputs_dict
+
+ @unittest.skipIf(torch_device == "mps", "MPS result is not consistent")
+ def test_output(self):
+ expected_slice = [0.7921, -0.0992, -0.1962, -0.7695, -0.4242, 0.7804, 0.4737, 0.2765, 0.3338]
+ super().test_output(expected_slice)
+
+
+class SkipDownBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = SkipDownBlock2D # noqa F405
+ block_type = "down"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_skip_sample=True)
+
+ def test_output(self):
+ expected_slice = [-0.0845, -0.2087, -0.2465, 0.0971, 0.1900, -0.0484, 0.2664, 0.4179, 0.5069]
+ super().test_output(expected_slice)
+
+
+class AttnSkipDownBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = AttnSkipDownBlock2D # noqa F405
+ block_type = "down"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_skip_sample=True)
+
+ def test_output(self):
+ expected_slice = [0.5539, 0.1609, 0.4924, 0.0537, -0.1995, 0.4050, 0.0979, -0.2721, -0.0642]
+ super().test_output(expected_slice)
+
+
+class DownEncoderBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = DownEncoderBlock2D # noqa F405
+ block_type = "down"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_temb=False)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "in_channels": 32,
+ "out_channels": 32,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [1.1102, 0.5302, 0.4872, -0.0023, -0.8042, 0.0483, -0.3489, -0.5632, 0.7626]
+ super().test_output(expected_slice)
+
+
+class AttnDownEncoderBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = AttnDownEncoderBlock2D # noqa F405
+ block_type = "down"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_temb=False)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "in_channels": 32,
+ "out_channels": 32,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [0.8966, -0.1486, 0.8568, 0.8141, -0.9046, -0.1342, -0.0972, -0.7417, 0.1538]
+ super().test_output(expected_slice)
+
+
+class UNetMidBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = UNetMidBlock2D # noqa F405
+ block_type = "mid"
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "in_channels": 32,
+ "temb_channels": 128,
+ }
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [-0.1062, 1.7248, 0.3494, 1.4569, -0.0910, -1.2421, -0.9984, 0.6736, 1.0028]
+ super().test_output(expected_slice)
+
+
+class UNetMidBlock2DCrossAttnTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = UNetMidBlock2DCrossAttn # noqa F405
+ block_type = "mid"
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict, inputs_dict = super().prepare_init_args_and_inputs_for_common()
+ init_dict["cross_attention_dim"] = 32
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [0.1879, 2.2653, 0.5987, 1.1568, -0.8454, -1.6109, -0.8919, 0.8306, 1.6758]
+ super().test_output(expected_slice)
+
+
+class UNetMidBlock2DSimpleCrossAttnTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = UNetMidBlock2DSimpleCrossAttn # noqa F405
+ block_type = "mid"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_encoder_hidden_states=True)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict, inputs_dict = super().prepare_init_args_and_inputs_for_common()
+ init_dict["cross_attention_dim"] = 32
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [0.7143, 1.9974, 0.5448, 1.3977, 0.1282, -1.1237, -1.4238, 0.5530, 0.8880]
+ super().test_output(expected_slice)
+
+
+class UpBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = UpBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_res_hidden_states_tuple=True)
+
+ def test_output(self):
+ expected_slice = [-0.2041, -0.4165, -0.3022, 0.0041, -0.6628, -0.7053, 0.1928, -0.0325, 0.0523]
+ super().test_output(expected_slice)
+
+
+class ResnetUpsampleBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = ResnetUpsampleBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_res_hidden_states_tuple=True)
+
+ def test_output(self):
+ expected_slice = [0.2287, 0.3549, -0.1346, 0.4797, -0.1715, -0.9649, 0.7305, -0.5864, -0.6244]
+ super().test_output(expected_slice)
+
+
+class CrossAttnUpBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = CrossAttnUpBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_res_hidden_states_tuple=True)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict, inputs_dict = super().prepare_init_args_and_inputs_for_common()
+ init_dict["cross_attention_dim"] = 32
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [-0.2796, -0.4364, -0.1067, -0.2693, 0.1894, 0.3869, -0.3470, 0.4584, 0.5091]
+ super().test_output(expected_slice)
+
+
+class SimpleCrossAttnUpBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = SimpleCrossAttnUpBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_res_hidden_states_tuple=True, include_encoder_hidden_states=True)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict, inputs_dict = super().prepare_init_args_and_inputs_for_common()
+ init_dict["cross_attention_dim"] = 32
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [0.2645, 0.1480, 0.0909, 0.8044, -0.9758, -0.9083, 0.0994, -1.1453, -0.7402]
+ super().test_output(expected_slice)
+
+
+class AttnUpBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = AttnUpBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_res_hidden_states_tuple=True)
+
+ @unittest.skipIf(torch_device == "mps", "MPS result is not consistent")
+ def test_output(self):
+ expected_slice = [0.0979, 0.1326, 0.0021, 0.0659, 0.2249, 0.0059, 0.1132, 0.5952, 0.1033]
+ super().test_output(expected_slice)
+
+
+class SkipUpBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = SkipUpBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_res_hidden_states_tuple=True)
+
+ def test_output(self):
+ expected_slice = [-0.0893, -0.1234, -0.1506, -0.0332, 0.0123, -0.0211, 0.0566, 0.0143, 0.0362]
+ super().test_output(expected_slice)
+
+
+class AttnSkipUpBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = AttnSkipUpBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_res_hidden_states_tuple=True)
+
+ def test_output(self):
+ expected_slice = [0.0361, 0.0617, 0.2787, -0.0350, 0.0342, 0.3421, -0.0843, 0.0913, 0.3015]
+ super().test_output(expected_slice)
+
+
+class UpDecoderBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = UpDecoderBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_temb=False)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {"in_channels": 32, "out_channels": 32}
+
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [0.4404, 0.1998, -0.9886, -0.3320, -0.3128, -0.7034, -0.6955, -0.2338, -0.3137]
+ super().test_output(expected_slice)
+
+
+class AttnUpDecoderBlock2DTests(UNetBlockTesterMixin, unittest.TestCase):
+ block_class = AttnUpDecoderBlock2D # noqa F405
+ block_type = "up"
+
+ @property
+ def dummy_input(self):
+ return super().get_dummy_input(include_temb=False)
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {"in_channels": 32, "out_channels": 32}
+
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_output(self):
+ expected_slice = [0.6738, 0.4491, 0.1055, 1.0710, 0.7316, 0.3339, 0.3352, 0.1023, 0.3568]
+ super().test_output(expected_slice)
diff --git a/diffusers/tests/test_unet_blocks_common.py b/diffusers/tests/test_unet_blocks_common.py
new file mode 100644
index 0000000000000000000000000000000000000000..17b7f65d6da31c43f062eaa6bed7284ce85e471f
--- /dev/null
+++ b/diffusers/tests/test_unet_blocks_common.py
@@ -0,0 +1,121 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import unittest
+from typing import Tuple
+
+import torch
+
+from diffusers.utils import floats_tensor, randn_tensor, torch_all_close, torch_device
+from diffusers.utils.testing_utils import require_torch
+
+
+@require_torch
+class UNetBlockTesterMixin:
+ @property
+ def dummy_input(self):
+ return self.get_dummy_input()
+
+ @property
+ def output_shape(self):
+ if self.block_type == "down":
+ return (4, 32, 16, 16)
+ elif self.block_type == "mid":
+ return (4, 32, 32, 32)
+ elif self.block_type == "up":
+ return (4, 32, 64, 64)
+
+ raise ValueError(f"'{self.block_type}' is not a supported block_type. Set it to 'up', 'mid', or 'down'.")
+
+ def get_dummy_input(
+ self,
+ include_temb=True,
+ include_res_hidden_states_tuple=False,
+ include_encoder_hidden_states=False,
+ include_skip_sample=False,
+ ):
+ batch_size = 4
+ num_channels = 32
+ sizes = (32, 32)
+
+ generator = torch.manual_seed(0)
+ device = torch.device(torch_device)
+ shape = (batch_size, num_channels) + sizes
+ hidden_states = randn_tensor(shape, generator=generator, device=device)
+ dummy_input = {"hidden_states": hidden_states}
+
+ if include_temb:
+ temb_channels = 128
+ dummy_input["temb"] = randn_tensor((batch_size, temb_channels), generator=generator, device=device)
+
+ if include_res_hidden_states_tuple:
+ generator_1 = torch.manual_seed(1)
+ dummy_input["res_hidden_states_tuple"] = (randn_tensor(shape, generator=generator_1, device=device),)
+
+ if include_encoder_hidden_states:
+ dummy_input["encoder_hidden_states"] = floats_tensor((batch_size, 32, 32)).to(torch_device)
+
+ if include_skip_sample:
+ dummy_input["skip_sample"] = randn_tensor(((batch_size, 3) + sizes), generator=generator, device=device)
+
+ return dummy_input
+
+ def prepare_init_args_and_inputs_for_common(self):
+ init_dict = {
+ "in_channels": 32,
+ "out_channels": 32,
+ "temb_channels": 128,
+ }
+ if self.block_type == "up":
+ init_dict["prev_output_channel"] = 32
+
+ if self.block_type == "mid":
+ init_dict.pop("out_channels")
+
+ inputs_dict = self.dummy_input
+ return init_dict, inputs_dict
+
+ def test_output(self, expected_slice):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ unet_block = self.block_class(**init_dict)
+ unet_block.to(torch_device)
+ unet_block.eval()
+
+ with torch.no_grad():
+ output = unet_block(**inputs_dict)
+
+ if isinstance(output, Tuple):
+ output = output[0]
+
+ self.assertEqual(output.shape, self.output_shape)
+
+ output_slice = output[0, -1, -3:, -3:]
+ expected_slice = torch.tensor(expected_slice).to(torch_device)
+ assert torch_all_close(output_slice.flatten(), expected_slice, atol=5e-3)
+
+ @unittest.skipIf(torch_device == "mps", "Training is not supported in mps")
+ def test_training(self):
+ init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
+ model = self.block_class(**init_dict)
+ model.to(torch_device)
+ model.train()
+ output = model(**inputs_dict)
+
+ if isinstance(output, Tuple):
+ output = output[0]
+
+ device = torch.device(torch_device)
+ noise = randn_tensor(output.shape, device=device)
+ loss = torch.nn.functional.mse_loss(output, noise)
+ loss.backward()
diff --git a/diffusers/tests/test_utils.py b/diffusers/tests/test_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..4fc4e1a06638ae14848424db24f212ae24afbf34
--- /dev/null
+++ b/diffusers/tests/test_utils.py
@@ -0,0 +1,170 @@
+# coding=utf-8
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from diffusers import __version__
+from diffusers.utils import deprecate
+
+
+class DeprecateTester(unittest.TestCase):
+ higher_version = ".".join([str(int(__version__.split(".")[0]) + 1)] + __version__.split(".")[1:])
+ lower_version = "0.0.1"
+
+ def test_deprecate_function_arg(self):
+ kwargs = {"deprecated_arg": 4}
+
+ with self.assertWarns(FutureWarning) as warning:
+ output = deprecate("deprecated_arg", self.higher_version, "message", take_from=kwargs)
+
+ assert output == 4
+ assert (
+ str(warning.warning)
+ == f"The `deprecated_arg` argument is deprecated and will be removed in version {self.higher_version}."
+ " message"
+ )
+
+ def test_deprecate_function_arg_tuple(self):
+ kwargs = {"deprecated_arg": 4}
+
+ with self.assertWarns(FutureWarning) as warning:
+ output = deprecate(("deprecated_arg", self.higher_version, "message"), take_from=kwargs)
+
+ assert output == 4
+ assert (
+ str(warning.warning)
+ == f"The `deprecated_arg` argument is deprecated and will be removed in version {self.higher_version}."
+ " message"
+ )
+
+ def test_deprecate_function_args(self):
+ kwargs = {"deprecated_arg_1": 4, "deprecated_arg_2": 8}
+ with self.assertWarns(FutureWarning) as warning:
+ output_1, output_2 = deprecate(
+ ("deprecated_arg_1", self.higher_version, "Hey"),
+ ("deprecated_arg_2", self.higher_version, "Hey"),
+ take_from=kwargs,
+ )
+ assert output_1 == 4
+ assert output_2 == 8
+ assert (
+ str(warning.warnings[0].message)
+ == "The `deprecated_arg_1` argument is deprecated and will be removed in version"
+ f" {self.higher_version}. Hey"
+ )
+ assert (
+ str(warning.warnings[1].message)
+ == "The `deprecated_arg_2` argument is deprecated and will be removed in version"
+ f" {self.higher_version}. Hey"
+ )
+
+ def test_deprecate_function_incorrect_arg(self):
+ kwargs = {"deprecated_arg": 4}
+
+ with self.assertRaises(TypeError) as error:
+ deprecate(("wrong_arg", self.higher_version, "message"), take_from=kwargs)
+
+ assert "test_deprecate_function_incorrect_arg in" in str(error.exception)
+ assert "line" in str(error.exception)
+ assert "got an unexpected keyword argument `deprecated_arg`" in str(error.exception)
+
+ def test_deprecate_arg_no_kwarg(self):
+ with self.assertWarns(FutureWarning) as warning:
+ deprecate(("deprecated_arg", self.higher_version, "message"))
+
+ assert (
+ str(warning.warning)
+ == f"`deprecated_arg` is deprecated and will be removed in version {self.higher_version}. message"
+ )
+
+ def test_deprecate_args_no_kwarg(self):
+ with self.assertWarns(FutureWarning) as warning:
+ deprecate(
+ ("deprecated_arg_1", self.higher_version, "Hey"),
+ ("deprecated_arg_2", self.higher_version, "Hey"),
+ )
+ assert (
+ str(warning.warnings[0].message)
+ == f"`deprecated_arg_1` is deprecated and will be removed in version {self.higher_version}. Hey"
+ )
+ assert (
+ str(warning.warnings[1].message)
+ == f"`deprecated_arg_2` is deprecated and will be removed in version {self.higher_version}. Hey"
+ )
+
+ def test_deprecate_class_obj(self):
+ class Args:
+ arg = 5
+
+ with self.assertWarns(FutureWarning) as warning:
+ arg = deprecate(("arg", self.higher_version, "message"), take_from=Args())
+
+ assert arg == 5
+ assert (
+ str(warning.warning)
+ == f"The `arg` attribute is deprecated and will be removed in version {self.higher_version}. message"
+ )
+
+ def test_deprecate_class_objs(self):
+ class Args:
+ arg = 5
+ foo = 7
+
+ with self.assertWarns(FutureWarning) as warning:
+ arg_1, arg_2 = deprecate(
+ ("arg", self.higher_version, "message"),
+ ("foo", self.higher_version, "message"),
+ ("does not exist", self.higher_version, "message"),
+ take_from=Args(),
+ )
+
+ assert arg_1 == 5
+ assert arg_2 == 7
+ assert (
+ str(warning.warning)
+ == f"The `arg` attribute is deprecated and will be removed in version {self.higher_version}. message"
+ )
+ assert (
+ str(warning.warnings[0].message)
+ == f"The `arg` attribute is deprecated and will be removed in version {self.higher_version}. message"
+ )
+ assert (
+ str(warning.warnings[1].message)
+ == f"The `foo` attribute is deprecated and will be removed in version {self.higher_version}. message"
+ )
+
+ def test_deprecate_incorrect_version(self):
+ kwargs = {"deprecated_arg": 4}
+
+ with self.assertRaises(ValueError) as error:
+ deprecate(("wrong_arg", self.lower_version, "message"), take_from=kwargs)
+
+ assert (
+ str(error.exception)
+ == "The deprecation tuple ('wrong_arg', '0.0.1', 'message') should be removed since diffusers' version"
+ f" {__version__} is >= {self.lower_version}"
+ )
+
+ def test_deprecate_incorrect_no_standard_warn(self):
+ with self.assertWarns(FutureWarning) as warning:
+ deprecate(("deprecated_arg", self.higher_version, "This message is better!!!"), standard_warn=False)
+
+ assert str(warning.warning) == "This message is better!!!"
+
+ def test_deprecate_stacklevel(self):
+ with self.assertWarns(FutureWarning) as warning:
+ deprecate(("deprecated_arg", self.higher_version, "This message is better!!!"), standard_warn=False)
+ assert str(warning.warning) == "This message is better!!!"
+ assert "diffusers/tests/test_utils.py" in warning.filename
diff --git a/diffusers/utils/check_config_docstrings.py b/diffusers/utils/check_config_docstrings.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a80ed1c69ddbb57be7249eaa10263585ac23c82
--- /dev/null
+++ b/diffusers/utils/check_config_docstrings.py
@@ -0,0 +1,84 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import importlib
+import inspect
+import os
+import re
+
+
+# All paths are set with the intent you should run this script from the root of the repo with the command
+# python utils/check_config_docstrings.py
+PATH_TO_TRANSFORMERS = "src/transformers"
+
+
+# This is to make sure the transformers module imported is the one in the repo.
+spec = importlib.util.spec_from_file_location(
+ "transformers",
+ os.path.join(PATH_TO_TRANSFORMERS, "__init__.py"),
+ submodule_search_locations=[PATH_TO_TRANSFORMERS],
+)
+transformers = spec.loader.load_module()
+
+CONFIG_MAPPING = transformers.models.auto.configuration_auto.CONFIG_MAPPING
+
+# Regex pattern used to find the checkpoint mentioned in the docstring of `config_class`.
+# For example, `[bert-base-uncased](https://huggingface.co/bert-base-uncased)`
+_re_checkpoint = re.compile("\[(.+?)\]\((https://huggingface\.co/.+?)\)")
+
+
+CONFIG_CLASSES_TO_IGNORE_FOR_DOCSTRING_CHECKPOINT_CHECK = {
+ "CLIPConfigMixin",
+ "DecisionTransformerConfigMixin",
+ "EncoderDecoderConfigMixin",
+ "RagConfigMixin",
+ "SpeechEncoderDecoderConfigMixin",
+ "VisionEncoderDecoderConfigMixin",
+ "VisionTextDualEncoderConfigMixin",
+}
+
+
+def check_config_docstrings_have_checkpoints():
+ configs_without_checkpoint = []
+
+ for config_class in list(CONFIG_MAPPING.values()):
+ checkpoint_found = False
+
+ # source code of `config_class`
+ config_source = inspect.getsource(config_class)
+ checkpoints = _re_checkpoint.findall(config_source)
+
+ for checkpoint in checkpoints:
+ # Each `checkpoint` is a tuple of a checkpoint name and a checkpoint link.
+ # For example, `('bert-base-uncased', 'https://huggingface.co/bert-base-uncased')`
+ ckpt_name, ckpt_link = checkpoint
+
+ # verify the checkpoint name corresponds to the checkpoint link
+ ckpt_link_from_name = f"https://huggingface.co/{ckpt_name}"
+ if ckpt_link == ckpt_link_from_name:
+ checkpoint_found = True
+ break
+
+ name = config_class.__name__
+ if not checkpoint_found and name not in CONFIG_CLASSES_TO_IGNORE_FOR_DOCSTRING_CHECKPOINT_CHECK:
+ configs_without_checkpoint.append(name)
+
+ if len(configs_without_checkpoint) > 0:
+ message = "\n".join(sorted(configs_without_checkpoint))
+ raise ValueError(f"The following configurations don't contain any valid checkpoint:\n{message}")
+
+
+if __name__ == "__main__":
+ check_config_docstrings_have_checkpoints()
diff --git a/diffusers/utils/check_copies.py b/diffusers/utils/check_copies.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ba573bb920eeb6787487f043db3c2896b656b92
--- /dev/null
+++ b/diffusers/utils/check_copies.py
@@ -0,0 +1,213 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import glob
+import importlib.util
+import os
+import re
+
+import black
+from doc_builder.style_doc import style_docstrings_in_code
+
+
+# All paths are set with the intent you should run this script from the root of the repo with the command
+# python utils/check_copies.py
+DIFFUSERS_PATH = "src/diffusers"
+REPO_PATH = "."
+
+
+# This is to make sure the diffusers module imported is the one in the repo.
+spec = importlib.util.spec_from_file_location(
+ "diffusers",
+ os.path.join(DIFFUSERS_PATH, "__init__.py"),
+ submodule_search_locations=[DIFFUSERS_PATH],
+)
+diffusers_module = spec.loader.load_module()
+
+
+def _should_continue(line, indent):
+ return line.startswith(indent) or len(line) <= 1 or re.search(r"^\s*\)(\s*->.*:|:)\s*$", line) is not None
+
+
+def find_code_in_diffusers(object_name):
+ """Find and return the code source code of `object_name`."""
+ parts = object_name.split(".")
+ i = 0
+
+ # First let's find the module where our object lives.
+ module = parts[i]
+ while i < len(parts) and not os.path.isfile(os.path.join(DIFFUSERS_PATH, f"{module}.py")):
+ i += 1
+ if i < len(parts):
+ module = os.path.join(module, parts[i])
+ if i >= len(parts):
+ raise ValueError(f"`object_name` should begin with the name of a module of diffusers but got {object_name}.")
+
+ with open(os.path.join(DIFFUSERS_PATH, f"{module}.py"), "r", encoding="utf-8", newline="\n") as f:
+ lines = f.readlines()
+
+ # Now let's find the class / func in the code!
+ indent = ""
+ line_index = 0
+ for name in parts[i + 1 :]:
+ while (
+ line_index < len(lines) and re.search(rf"^{indent}(class|def)\s+{name}(\(|\:)", lines[line_index]) is None
+ ):
+ line_index += 1
+ indent += " "
+ line_index += 1
+
+ if line_index >= len(lines):
+ raise ValueError(f" {object_name} does not match any function or class in {module}.")
+
+ # We found the beginning of the class / func, now let's find the end (when the indent diminishes).
+ start_index = line_index
+ while line_index < len(lines) and _should_continue(lines[line_index], indent):
+ line_index += 1
+ # Clean up empty lines at the end (if any).
+ while len(lines[line_index - 1]) <= 1:
+ line_index -= 1
+
+ code_lines = lines[start_index:line_index]
+ return "".join(code_lines)
+
+
+_re_copy_warning = re.compile(r"^(\s*)#\s*Copied from\s+diffusers\.(\S+\.\S+)\s*($|\S.*$)")
+_re_replace_pattern = re.compile(r"^\s*(\S+)->(\S+)(\s+.*|$)")
+_re_fill_pattern = re.compile(r"]*>")
+
+
+def get_indent(code):
+ lines = code.split("\n")
+ idx = 0
+ while idx < len(lines) and len(lines[idx]) == 0:
+ idx += 1
+ if idx < len(lines):
+ return re.search(r"^(\s*)\S", lines[idx]).groups()[0]
+ return ""
+
+
+def blackify(code):
+ """
+ Applies the black part of our `make style` command to `code`.
+ """
+ has_indent = len(get_indent(code)) > 0
+ if has_indent:
+ code = f"class Bla:\n{code}"
+ mode = black.Mode(target_versions={black.TargetVersion.PY37}, line_length=119, preview=True)
+ result = black.format_str(code, mode=mode)
+ result, _ = style_docstrings_in_code(result)
+ return result[len("class Bla:\n") :] if has_indent else result
+
+
+def is_copy_consistent(filename, overwrite=False):
+ """
+ Check if the code commented as a copy in `filename` matches the original.
+ Return the differences or overwrites the content depending on `overwrite`.
+ """
+ with open(filename, "r", encoding="utf-8", newline="\n") as f:
+ lines = f.readlines()
+ diffs = []
+ line_index = 0
+ # Not a for loop cause `lines` is going to change (if `overwrite=True`).
+ while line_index < len(lines):
+ search = _re_copy_warning.search(lines[line_index])
+ if search is None:
+ line_index += 1
+ continue
+
+ # There is some copied code here, let's retrieve the original.
+ indent, object_name, replace_pattern = search.groups()
+ theoretical_code = find_code_in_diffusers(object_name)
+ theoretical_indent = get_indent(theoretical_code)
+
+ start_index = line_index + 1 if indent == theoretical_indent else line_index + 2
+ indent = theoretical_indent
+ line_index = start_index
+
+ # Loop to check the observed code, stop when indentation diminishes or if we see a End copy comment.
+ should_continue = True
+ while line_index < len(lines) and should_continue:
+ line_index += 1
+ if line_index >= len(lines):
+ break
+ line = lines[line_index]
+ should_continue = _should_continue(line, indent) and re.search(f"^{indent}# End copy", line) is None
+ # Clean up empty lines at the end (if any).
+ while len(lines[line_index - 1]) <= 1:
+ line_index -= 1
+
+ observed_code_lines = lines[start_index:line_index]
+ observed_code = "".join(observed_code_lines)
+
+ # Remove any nested `Copied from` comments to avoid circular copies
+ theoretical_code = [line for line in theoretical_code.split("\n") if _re_copy_warning.search(line) is None]
+ theoretical_code = "\n".join(theoretical_code)
+
+ # Before comparing, use the `replace_pattern` on the original code.
+ if len(replace_pattern) > 0:
+ patterns = replace_pattern.replace("with", "").split(",")
+ patterns = [_re_replace_pattern.search(p) for p in patterns]
+ for pattern in patterns:
+ if pattern is None:
+ continue
+ obj1, obj2, option = pattern.groups()
+ theoretical_code = re.sub(obj1, obj2, theoretical_code)
+ if option.strip() == "all-casing":
+ theoretical_code = re.sub(obj1.lower(), obj2.lower(), theoretical_code)
+ theoretical_code = re.sub(obj1.upper(), obj2.upper(), theoretical_code)
+
+ # Blackify after replacement. To be able to do that, we need the header (class or function definition)
+ # from the previous line
+ theoretical_code = blackify(lines[start_index - 1] + theoretical_code)
+ theoretical_code = theoretical_code[len(lines[start_index - 1]) :]
+
+ # Test for a diff and act accordingly.
+ if observed_code != theoretical_code:
+ diffs.append([object_name, start_index])
+ if overwrite:
+ lines = lines[:start_index] + [theoretical_code] + lines[line_index:]
+ line_index = start_index + 1
+
+ if overwrite and len(diffs) > 0:
+ # Warn the user a file has been modified.
+ print(f"Detected changes, rewriting {filename}.")
+ with open(filename, "w", encoding="utf-8", newline="\n") as f:
+ f.writelines(lines)
+ return diffs
+
+
+def check_copies(overwrite: bool = False):
+ all_files = glob.glob(os.path.join(DIFFUSERS_PATH, "**/*.py"), recursive=True)
+ diffs = []
+ for filename in all_files:
+ new_diffs = is_copy_consistent(filename, overwrite)
+ diffs += [f"- {filename}: copy does not match {d[0]} at line {d[1]}" for d in new_diffs]
+ if not overwrite and len(diffs) > 0:
+ diff = "\n".join(diffs)
+ raise Exception(
+ "Found the following copy inconsistencies:\n"
+ + diff
+ + "\nRun `make fix-copies` or `python utils/check_copies.py --fix_and_overwrite` to fix them."
+ )
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
+ args = parser.parse_args()
+
+ check_copies(args.fix_and_overwrite)
diff --git a/diffusers/utils/check_doc_toc.py b/diffusers/utils/check_doc_toc.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff9285c63f16865d0b7a7e6672ee93552b15f77a
--- /dev/null
+++ b/diffusers/utils/check_doc_toc.py
@@ -0,0 +1,158 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+from collections import defaultdict
+
+import yaml
+
+
+PATH_TO_TOC = "docs/source/en/_toctree.yml"
+
+
+def clean_doc_toc(doc_list):
+ """
+ Cleans the table of content of the model documentation by removing duplicates and sorting models alphabetically.
+ """
+ counts = defaultdict(int)
+ overview_doc = []
+ new_doc_list = []
+ for doc in doc_list:
+ if "local" in doc:
+ counts[doc["local"]] += 1
+
+ if doc["title"].lower() == "overview":
+ overview_doc.append({"local": doc["local"], "title": doc["title"]})
+ else:
+ new_doc_list.append(doc)
+
+ doc_list = new_doc_list
+ duplicates = [key for key, value in counts.items() if value > 1]
+
+ new_doc = []
+ for duplicate_key in duplicates:
+ titles = list({doc["title"] for doc in doc_list if doc["local"] == duplicate_key})
+ if len(titles) > 1:
+ raise ValueError(
+ f"{duplicate_key} is present several times in the documentation table of content at "
+ "`docs/source/en/_toctree.yml` with different *Title* values. Choose one of those and remove the "
+ "others."
+ )
+ # Only add this once
+ new_doc.append({"local": duplicate_key, "title": titles[0]})
+
+ # Add none duplicate-keys
+ new_doc.extend([doc for doc in doc_list if "local" not in counts or counts[doc["local"]] == 1])
+ new_doc = sorted(new_doc, key=lambda s: s["title"].lower())
+
+ # "overview" gets special treatment and is always first
+ if len(overview_doc) > 1:
+ raise ValueError("{doc_list} has two 'overview' docs which is not allowed.")
+
+ overview_doc.extend(new_doc)
+
+ # Sort
+ return overview_doc
+
+
+def check_scheduler_doc(overwrite=False):
+ with open(PATH_TO_TOC, encoding="utf-8") as f:
+ content = yaml.safe_load(f.read())
+
+ # Get to the API doc
+ api_idx = 0
+ while content[api_idx]["title"] != "API":
+ api_idx += 1
+ api_doc = content[api_idx]["sections"]
+
+ # Then to the model doc
+ scheduler_idx = 0
+ while api_doc[scheduler_idx]["title"] != "Schedulers":
+ scheduler_idx += 1
+
+ scheduler_doc = api_doc[scheduler_idx]["sections"]
+ new_scheduler_doc = clean_doc_toc(scheduler_doc)
+
+ diff = False
+ if new_scheduler_doc != scheduler_doc:
+ diff = True
+ if overwrite:
+ api_doc[scheduler_idx]["sections"] = new_scheduler_doc
+
+ if diff:
+ if overwrite:
+ content[api_idx]["sections"] = api_doc
+ with open(PATH_TO_TOC, "w", encoding="utf-8") as f:
+ f.write(yaml.dump(content, allow_unicode=True))
+ else:
+ raise ValueError(
+ "The model doc part of the table of content is not properly sorted, run `make style` to fix this."
+ )
+
+
+def check_pipeline_doc(overwrite=False):
+ with open(PATH_TO_TOC, encoding="utf-8") as f:
+ content = yaml.safe_load(f.read())
+
+ # Get to the API doc
+ api_idx = 0
+ while content[api_idx]["title"] != "API":
+ api_idx += 1
+ api_doc = content[api_idx]["sections"]
+
+ # Then to the model doc
+ pipeline_idx = 0
+ while api_doc[pipeline_idx]["title"] != "Pipelines":
+ pipeline_idx += 1
+
+ diff = False
+ pipeline_docs = api_doc[pipeline_idx]["sections"]
+ new_pipeline_docs = []
+
+ # sort sub pipeline docs
+ for pipeline_doc in pipeline_docs:
+ if "section" in pipeline_doc:
+ sub_pipeline_doc = pipeline_doc["section"]
+ new_sub_pipeline_doc = clean_doc_toc(sub_pipeline_doc)
+ if overwrite:
+ pipeline_doc["section"] = new_sub_pipeline_doc
+ new_pipeline_docs.append(pipeline_doc)
+
+ # sort overall pipeline doc
+ new_pipeline_docs = clean_doc_toc(new_pipeline_docs)
+
+ if new_pipeline_docs != pipeline_docs:
+ diff = True
+ if overwrite:
+ api_doc[pipeline_idx]["sections"] = new_pipeline_docs
+
+ if diff:
+ if overwrite:
+ content[api_idx]["sections"] = api_doc
+ with open(PATH_TO_TOC, "w", encoding="utf-8") as f:
+ f.write(yaml.dump(content, allow_unicode=True))
+ else:
+ raise ValueError(
+ "The model doc part of the table of content is not properly sorted, run `make style` to fix this."
+ )
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
+ args = parser.parse_args()
+
+ check_scheduler_doc(args.fix_and_overwrite)
+ check_pipeline_doc(args.fix_and_overwrite)
diff --git a/diffusers/utils/check_dummies.py b/diffusers/utils/check_dummies.py
new file mode 100644
index 0000000000000000000000000000000000000000..16b7c8c117dc453f0956d6318d217c3395af7792
--- /dev/null
+++ b/diffusers/utils/check_dummies.py
@@ -0,0 +1,172 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import os
+import re
+
+
+# All paths are set with the intent you should run this script from the root of the repo with the command
+# python utils/check_dummies.py
+PATH_TO_DIFFUSERS = "src/diffusers"
+
+# Matches is_xxx_available()
+_re_backend = re.compile(r"is\_([a-z_]*)_available\(\)")
+# Matches from xxx import bla
+_re_single_line_import = re.compile(r"\s+from\s+\S*\s+import\s+([^\(\s].*)\n")
+
+
+DUMMY_CONSTANT = """
+{0} = None
+"""
+
+DUMMY_CLASS = """
+class {0}(metaclass=DummyObject):
+ _backends = {1}
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, {1})
+
+ @classmethod
+ def from_config(cls, *args, **kwargs):
+ requires_backends(cls, {1})
+
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ requires_backends(cls, {1})
+"""
+
+
+DUMMY_FUNCTION = """
+def {0}(*args, **kwargs):
+ requires_backends({0}, {1})
+"""
+
+
+def find_backend(line):
+ """Find one (or multiple) backend in a code line of the init."""
+ backends = _re_backend.findall(line)
+ if len(backends) == 0:
+ return None
+
+ return "_and_".join(backends)
+
+
+def read_init():
+ """Read the init and extracts PyTorch, TensorFlow, SentencePiece and Tokenizers objects."""
+ with open(os.path.join(PATH_TO_DIFFUSERS, "__init__.py"), "r", encoding="utf-8", newline="\n") as f:
+ lines = f.readlines()
+
+ # Get to the point we do the actual imports for type checking
+ line_index = 0
+ backend_specific_objects = {}
+ # Go through the end of the file
+ while line_index < len(lines):
+ # If the line contains is_backend_available, we grab all objects associated with the `else` block
+ backend = find_backend(lines[line_index])
+ if backend is not None:
+ while not lines[line_index].startswith("else:"):
+ line_index += 1
+ line_index += 1
+ objects = []
+ # Until we unindent, add backend objects to the list
+ while line_index < len(lines) and len(lines[line_index]) > 1:
+ line = lines[line_index]
+ single_line_import_search = _re_single_line_import.search(line)
+ if single_line_import_search is not None:
+ objects.extend(single_line_import_search.groups()[0].split(", "))
+ elif line.startswith(" " * 8):
+ objects.append(line[8:-2])
+ line_index += 1
+
+ if len(objects) > 0:
+ backend_specific_objects[backend] = objects
+ else:
+ line_index += 1
+
+ return backend_specific_objects
+
+
+def create_dummy_object(name, backend_name):
+ """Create the code for the dummy object corresponding to `name`."""
+ if name.isupper():
+ return DUMMY_CONSTANT.format(name)
+ elif name.islower():
+ return DUMMY_FUNCTION.format(name, backend_name)
+ else:
+ return DUMMY_CLASS.format(name, backend_name)
+
+
+def create_dummy_files(backend_specific_objects=None):
+ """Create the content of the dummy files."""
+ if backend_specific_objects is None:
+ backend_specific_objects = read_init()
+ # For special correspondence backend to module name as used in the function requires_modulename
+ dummy_files = {}
+
+ for backend, objects in backend_specific_objects.items():
+ backend_name = "[" + ", ".join(f'"{b}"' for b in backend.split("_and_")) + "]"
+ dummy_file = "# This file is autogenerated by the command `make fix-copies`, do not edit.\n"
+ dummy_file += "from ..utils import DummyObject, requires_backends\n\n"
+ dummy_file += "\n".join([create_dummy_object(o, backend_name) for o in objects])
+ dummy_files[backend] = dummy_file
+
+ return dummy_files
+
+
+def check_dummies(overwrite=False):
+ """Check if the dummy files are up to date and maybe `overwrite` with the right content."""
+ dummy_files = create_dummy_files()
+ # For special correspondence backend to shortcut as used in utils/dummy_xxx_objects.py
+ short_names = {"torch": "pt"}
+
+ # Locate actual dummy modules and read their content.
+ path = os.path.join(PATH_TO_DIFFUSERS, "utils")
+ dummy_file_paths = {
+ backend: os.path.join(path, f"dummy_{short_names.get(backend, backend)}_objects.py")
+ for backend in dummy_files.keys()
+ }
+
+ actual_dummies = {}
+ for backend, file_path in dummy_file_paths.items():
+ if os.path.isfile(file_path):
+ with open(file_path, "r", encoding="utf-8", newline="\n") as f:
+ actual_dummies[backend] = f.read()
+ else:
+ actual_dummies[backend] = ""
+
+ for backend in dummy_files.keys():
+ if dummy_files[backend] != actual_dummies[backend]:
+ if overwrite:
+ print(
+ f"Updating diffusers.utils.dummy_{short_names.get(backend, backend)}_objects.py as the main "
+ "__init__ has new objects."
+ )
+ with open(dummy_file_paths[backend], "w", encoding="utf-8", newline="\n") as f:
+ f.write(dummy_files[backend])
+ else:
+ raise ValueError(
+ "The main __init__ has objects that are not present in "
+ f"diffusers.utils.dummy_{short_names.get(backend, backend)}_objects.py. Run `make fix-copies` "
+ "to fix this."
+ )
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
+ args = parser.parse_args()
+
+ check_dummies(args.fix_and_overwrite)
diff --git a/diffusers/utils/check_inits.py b/diffusers/utils/check_inits.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b1cdb6fcefd9475bc6bb94a79200913c3601f95
--- /dev/null
+++ b/diffusers/utils/check_inits.py
@@ -0,0 +1,299 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import collections
+import importlib.util
+import os
+import re
+from pathlib import Path
+
+
+PATH_TO_TRANSFORMERS = "src/transformers"
+
+
+# Matches is_xxx_available()
+_re_backend = re.compile(r"is\_([a-z_]*)_available()")
+# Catches a one-line _import_struct = {xxx}
+_re_one_line_import_struct = re.compile(r"^_import_structure\s+=\s+\{([^\}]+)\}")
+# Catches a line with a key-values pattern: "bla": ["foo", "bar"]
+_re_import_struct_key_value = re.compile(r'\s+"\S*":\s+\[([^\]]*)\]')
+# Catches a line if not is_foo_available
+_re_test_backend = re.compile(r"^\s*if\s+not\s+is\_[a-z_]*\_available\(\)")
+# Catches a line _import_struct["bla"].append("foo")
+_re_import_struct_add_one = re.compile(r'^\s*_import_structure\["\S*"\]\.append\("(\S*)"\)')
+# Catches a line _import_struct["bla"].extend(["foo", "bar"]) or _import_struct["bla"] = ["foo", "bar"]
+_re_import_struct_add_many = re.compile(r"^\s*_import_structure\[\S*\](?:\.extend\(|\s*=\s+)\[([^\]]*)\]")
+# Catches a line with an object between quotes and a comma: "MyModel",
+_re_quote_object = re.compile('^\s+"([^"]+)",')
+# Catches a line with objects between brackets only: ["foo", "bar"],
+_re_between_brackets = re.compile("^\s+\[([^\]]+)\]")
+# Catches a line with from foo import bar, bla, boo
+_re_import = re.compile(r"\s+from\s+\S*\s+import\s+([^\(\s].*)\n")
+# Catches a line with try:
+_re_try = re.compile(r"^\s*try:")
+# Catches a line with else:
+_re_else = re.compile(r"^\s*else:")
+
+
+def find_backend(line):
+ """Find one (or multiple) backend in a code line of the init."""
+ if _re_test_backend.search(line) is None:
+ return None
+ backends = [b[0] for b in _re_backend.findall(line)]
+ backends.sort()
+ return "_and_".join(backends)
+
+
+def parse_init(init_file):
+ """
+ Read an init_file and parse (per backend) the _import_structure objects defined and the TYPE_CHECKING objects
+ defined
+ """
+ with open(init_file, "r", encoding="utf-8", newline="\n") as f:
+ lines = f.readlines()
+
+ line_index = 0
+ while line_index < len(lines) and not lines[line_index].startswith("_import_structure = {"):
+ line_index += 1
+
+ # If this is a traditional init, just return.
+ if line_index >= len(lines):
+ return None
+
+ # First grab the objects without a specific backend in _import_structure
+ objects = []
+ while not lines[line_index].startswith("if TYPE_CHECKING") and find_backend(lines[line_index]) is None:
+ line = lines[line_index]
+ # If we have everything on a single line, let's deal with it.
+ if _re_one_line_import_struct.search(line):
+ content = _re_one_line_import_struct.search(line).groups()[0]
+ imports = re.findall("\[([^\]]+)\]", content)
+ for imp in imports:
+ objects.extend([obj[1:-1] for obj in imp.split(", ")])
+ line_index += 1
+ continue
+ single_line_import_search = _re_import_struct_key_value.search(line)
+ if single_line_import_search is not None:
+ imports = [obj[1:-1] for obj in single_line_import_search.groups()[0].split(", ") if len(obj) > 0]
+ objects.extend(imports)
+ elif line.startswith(" " * 8 + '"'):
+ objects.append(line[9:-3])
+ line_index += 1
+
+ import_dict_objects = {"none": objects}
+ # Let's continue with backend-specific objects in _import_structure
+ while not lines[line_index].startswith("if TYPE_CHECKING"):
+ # If the line is an if not is_backend_available, we grab all objects associated.
+ backend = find_backend(lines[line_index])
+ # Check if the backend declaration is inside a try block:
+ if _re_try.search(lines[line_index - 1]) is None:
+ backend = None
+
+ if backend is not None:
+ line_index += 1
+
+ # Scroll until we hit the else block of try-except-else
+ while _re_else.search(lines[line_index]) is None:
+ line_index += 1
+
+ line_index += 1
+
+ objects = []
+ # Until we unindent, add backend objects to the list
+ while len(lines[line_index]) <= 1 or lines[line_index].startswith(" " * 4):
+ line = lines[line_index]
+ if _re_import_struct_add_one.search(line) is not None:
+ objects.append(_re_import_struct_add_one.search(line).groups()[0])
+ elif _re_import_struct_add_many.search(line) is not None:
+ imports = _re_import_struct_add_many.search(line).groups()[0].split(", ")
+ imports = [obj[1:-1] for obj in imports if len(obj) > 0]
+ objects.extend(imports)
+ elif _re_between_brackets.search(line) is not None:
+ imports = _re_between_brackets.search(line).groups()[0].split(", ")
+ imports = [obj[1:-1] for obj in imports if len(obj) > 0]
+ objects.extend(imports)
+ elif _re_quote_object.search(line) is not None:
+ objects.append(_re_quote_object.search(line).groups()[0])
+ elif line.startswith(" " * 8 + '"'):
+ objects.append(line[9:-3])
+ elif line.startswith(" " * 12 + '"'):
+ objects.append(line[13:-3])
+ line_index += 1
+
+ import_dict_objects[backend] = objects
+ else:
+ line_index += 1
+
+ # At this stage we are in the TYPE_CHECKING part, first grab the objects without a specific backend
+ objects = []
+ while (
+ line_index < len(lines)
+ and find_backend(lines[line_index]) is None
+ and not lines[line_index].startswith("else")
+ ):
+ line = lines[line_index]
+ single_line_import_search = _re_import.search(line)
+ if single_line_import_search is not None:
+ objects.extend(single_line_import_search.groups()[0].split(", "))
+ elif line.startswith(" " * 8):
+ objects.append(line[8:-2])
+ line_index += 1
+
+ type_hint_objects = {"none": objects}
+ # Let's continue with backend-specific objects
+ while line_index < len(lines):
+ # If the line is an if is_backend_available, we grab all objects associated.
+ backend = find_backend(lines[line_index])
+ # Check if the backend declaration is inside a try block:
+ if _re_try.search(lines[line_index - 1]) is None:
+ backend = None
+
+ if backend is not None:
+ line_index += 1
+
+ # Scroll until we hit the else block of try-except-else
+ while _re_else.search(lines[line_index]) is None:
+ line_index += 1
+
+ line_index += 1
+
+ objects = []
+ # Until we unindent, add backend objects to the list
+ while len(lines[line_index]) <= 1 or lines[line_index].startswith(" " * 8):
+ line = lines[line_index]
+ single_line_import_search = _re_import.search(line)
+ if single_line_import_search is not None:
+ objects.extend(single_line_import_search.groups()[0].split(", "))
+ elif line.startswith(" " * 12):
+ objects.append(line[12:-2])
+ line_index += 1
+
+ type_hint_objects[backend] = objects
+ else:
+ line_index += 1
+
+ return import_dict_objects, type_hint_objects
+
+
+def analyze_results(import_dict_objects, type_hint_objects):
+ """
+ Analyze the differences between _import_structure objects and TYPE_CHECKING objects found in an init.
+ """
+
+ def find_duplicates(seq):
+ return [k for k, v in collections.Counter(seq).items() if v > 1]
+
+ if list(import_dict_objects.keys()) != list(type_hint_objects.keys()):
+ return ["Both sides of the init do not have the same backends!"]
+
+ errors = []
+ for key in import_dict_objects.keys():
+ duplicate_imports = find_duplicates(import_dict_objects[key])
+ if duplicate_imports:
+ errors.append(f"Duplicate _import_structure definitions for: {duplicate_imports}")
+ duplicate_type_hints = find_duplicates(type_hint_objects[key])
+ if duplicate_type_hints:
+ errors.append(f"Duplicate TYPE_CHECKING objects for: {duplicate_type_hints}")
+
+ if sorted(set(import_dict_objects[key])) != sorted(set(type_hint_objects[key])):
+ name = "base imports" if key == "none" else f"{key} backend"
+ errors.append(f"Differences for {name}:")
+ for a in type_hint_objects[key]:
+ if a not in import_dict_objects[key]:
+ errors.append(f" {a} in TYPE_HINT but not in _import_structure.")
+ for a in import_dict_objects[key]:
+ if a not in type_hint_objects[key]:
+ errors.append(f" {a} in _import_structure but not in TYPE_HINT.")
+ return errors
+
+
+def check_all_inits():
+ """
+ Check all inits in the transformers repo and raise an error if at least one does not define the same objects in
+ both halves.
+ """
+ failures = []
+ for root, _, files in os.walk(PATH_TO_TRANSFORMERS):
+ if "__init__.py" in files:
+ fname = os.path.join(root, "__init__.py")
+ objects = parse_init(fname)
+ if objects is not None:
+ errors = analyze_results(*objects)
+ if len(errors) > 0:
+ errors[0] = f"Problem in {fname}, both halves do not define the same objects.\n{errors[0]}"
+ failures.append("\n".join(errors))
+ if len(failures) > 0:
+ raise ValueError("\n\n".join(failures))
+
+
+def get_transformers_submodules():
+ """
+ Returns the list of Transformers submodules.
+ """
+ submodules = []
+ for path, directories, files in os.walk(PATH_TO_TRANSFORMERS):
+ for folder in directories:
+ # Ignore private modules
+ if folder.startswith("_"):
+ directories.remove(folder)
+ continue
+ # Ignore leftovers from branches (empty folders apart from pycache)
+ if len(list((Path(path) / folder).glob("*.py"))) == 0:
+ continue
+ short_path = str((Path(path) / folder).relative_to(PATH_TO_TRANSFORMERS))
+ submodule = short_path.replace(os.path.sep, ".")
+ submodules.append(submodule)
+ for fname in files:
+ if fname == "__init__.py":
+ continue
+ short_path = str((Path(path) / fname).relative_to(PATH_TO_TRANSFORMERS))
+ submodule = short_path.replace(".py", "").replace(os.path.sep, ".")
+ if len(submodule.split(".")) == 1:
+ submodules.append(submodule)
+ return submodules
+
+
+IGNORE_SUBMODULES = [
+ "convert_pytorch_checkpoint_to_tf2",
+ "modeling_flax_pytorch_utils",
+]
+
+
+def check_submodules():
+ # This is to make sure the transformers module imported is the one in the repo.
+ spec = importlib.util.spec_from_file_location(
+ "transformers",
+ os.path.join(PATH_TO_TRANSFORMERS, "__init__.py"),
+ submodule_search_locations=[PATH_TO_TRANSFORMERS],
+ )
+ transformers = spec.loader.load_module()
+
+ module_not_registered = [
+ module
+ for module in get_transformers_submodules()
+ if module not in IGNORE_SUBMODULES and module not in transformers._import_structure.keys()
+ ]
+ if len(module_not_registered) > 0:
+ list_of_modules = "\n".join(f"- {module}" for module in module_not_registered)
+ raise ValueError(
+ "The following submodules are not properly registered in the main init of Transformers:\n"
+ f"{list_of_modules}\n"
+ "Make sure they appear somewhere in the keys of `_import_structure` with an empty list as value."
+ )
+
+
+if __name__ == "__main__":
+ check_all_inits()
+ check_submodules()
diff --git a/diffusers/utils/check_repo.py b/diffusers/utils/check_repo.py
new file mode 100644
index 0000000000000000000000000000000000000000..cfd2964f9dcc80051cbb995eaafe4ea1aaed06af
--- /dev/null
+++ b/diffusers/utils/check_repo.py
@@ -0,0 +1,761 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import importlib
+import inspect
+import os
+import re
+import warnings
+from collections import OrderedDict
+from difflib import get_close_matches
+from pathlib import Path
+
+from diffusers.models.auto import get_values
+from diffusers.utils import ENV_VARS_TRUE_VALUES, is_flax_available, is_tf_available, is_torch_available
+
+
+# All paths are set with the intent you should run this script from the root of the repo with the command
+# python utils/check_repo.py
+PATH_TO_DIFFUSERS = "src/diffusers"
+PATH_TO_TESTS = "tests"
+PATH_TO_DOC = "docs/source/en"
+
+# Update this list with models that are supposed to be private.
+PRIVATE_MODELS = [
+ "DPRSpanPredictor",
+ "RealmBertModel",
+ "T5Stack",
+ "TFDPRSpanPredictor",
+]
+
+# Update this list for models that are not tested with a comment explaining the reason it should not be.
+# Being in this list is an exception and should **not** be the rule.
+IGNORE_NON_TESTED = PRIVATE_MODELS.copy() + [
+ # models to ignore for not tested
+ "OPTDecoder", # Building part of bigger (tested) model.
+ "DecisionTransformerGPT2Model", # Building part of bigger (tested) model.
+ "SegformerDecodeHead", # Building part of bigger (tested) model.
+ "PLBartEncoder", # Building part of bigger (tested) model.
+ "PLBartDecoder", # Building part of bigger (tested) model.
+ "PLBartDecoderWrapper", # Building part of bigger (tested) model.
+ "BigBirdPegasusEncoder", # Building part of bigger (tested) model.
+ "BigBirdPegasusDecoder", # Building part of bigger (tested) model.
+ "BigBirdPegasusDecoderWrapper", # Building part of bigger (tested) model.
+ "DetrEncoder", # Building part of bigger (tested) model.
+ "DetrDecoder", # Building part of bigger (tested) model.
+ "DetrDecoderWrapper", # Building part of bigger (tested) model.
+ "M2M100Encoder", # Building part of bigger (tested) model.
+ "M2M100Decoder", # Building part of bigger (tested) model.
+ "Speech2TextEncoder", # Building part of bigger (tested) model.
+ "Speech2TextDecoder", # Building part of bigger (tested) model.
+ "LEDEncoder", # Building part of bigger (tested) model.
+ "LEDDecoder", # Building part of bigger (tested) model.
+ "BartDecoderWrapper", # Building part of bigger (tested) model.
+ "BartEncoder", # Building part of bigger (tested) model.
+ "BertLMHeadModel", # Needs to be setup as decoder.
+ "BlenderbotSmallEncoder", # Building part of bigger (tested) model.
+ "BlenderbotSmallDecoderWrapper", # Building part of bigger (tested) model.
+ "BlenderbotEncoder", # Building part of bigger (tested) model.
+ "BlenderbotDecoderWrapper", # Building part of bigger (tested) model.
+ "MBartEncoder", # Building part of bigger (tested) model.
+ "MBartDecoderWrapper", # Building part of bigger (tested) model.
+ "MegatronBertLMHeadModel", # Building part of bigger (tested) model.
+ "MegatronBertEncoder", # Building part of bigger (tested) model.
+ "MegatronBertDecoder", # Building part of bigger (tested) model.
+ "MegatronBertDecoderWrapper", # Building part of bigger (tested) model.
+ "PegasusEncoder", # Building part of bigger (tested) model.
+ "PegasusDecoderWrapper", # Building part of bigger (tested) model.
+ "DPREncoder", # Building part of bigger (tested) model.
+ "ProphetNetDecoderWrapper", # Building part of bigger (tested) model.
+ "RealmBertModel", # Building part of bigger (tested) model.
+ "RealmReader", # Not regular model.
+ "RealmScorer", # Not regular model.
+ "RealmForOpenQA", # Not regular model.
+ "ReformerForMaskedLM", # Needs to be setup as decoder.
+ "Speech2Text2DecoderWrapper", # Building part of bigger (tested) model.
+ "TFDPREncoder", # Building part of bigger (tested) model.
+ "TFElectraMainLayer", # Building part of bigger (tested) model (should it be a TFModelMixin ?)
+ "TFRobertaForMultipleChoice", # TODO: fix
+ "TrOCRDecoderWrapper", # Building part of bigger (tested) model.
+ "SeparableConv1D", # Building part of bigger (tested) model.
+ "FlaxBartForCausalLM", # Building part of bigger (tested) model.
+ "FlaxBertForCausalLM", # Building part of bigger (tested) model. Tested implicitly through FlaxRobertaForCausalLM.
+ "OPTDecoderWrapper",
+]
+
+# Update this list with test files that don't have a tester with a `all_model_classes` variable and which don't
+# trigger the common tests.
+TEST_FILES_WITH_NO_COMMON_TESTS = [
+ "models/decision_transformer/test_modeling_decision_transformer.py",
+ "models/camembert/test_modeling_camembert.py",
+ "models/mt5/test_modeling_flax_mt5.py",
+ "models/mbart/test_modeling_mbart.py",
+ "models/mt5/test_modeling_mt5.py",
+ "models/pegasus/test_modeling_pegasus.py",
+ "models/camembert/test_modeling_tf_camembert.py",
+ "models/mt5/test_modeling_tf_mt5.py",
+ "models/xlm_roberta/test_modeling_tf_xlm_roberta.py",
+ "models/xlm_roberta/test_modeling_flax_xlm_roberta.py",
+ "models/xlm_prophetnet/test_modeling_xlm_prophetnet.py",
+ "models/xlm_roberta/test_modeling_xlm_roberta.py",
+ "models/vision_text_dual_encoder/test_modeling_vision_text_dual_encoder.py",
+ "models/vision_text_dual_encoder/test_modeling_flax_vision_text_dual_encoder.py",
+ "models/decision_transformer/test_modeling_decision_transformer.py",
+]
+
+# Update this list for models that are not in any of the auto MODEL_XXX_MAPPING. Being in this list is an exception and
+# should **not** be the rule.
+IGNORE_NON_AUTO_CONFIGURED = PRIVATE_MODELS.copy() + [
+ # models to ignore for model xxx mapping
+ "DPTForDepthEstimation",
+ "DecisionTransformerGPT2Model",
+ "GLPNForDepthEstimation",
+ "ViltForQuestionAnswering",
+ "ViltForImagesAndTextClassification",
+ "ViltForImageAndTextRetrieval",
+ "ViltForMaskedLM",
+ "XGLMEncoder",
+ "XGLMDecoder",
+ "XGLMDecoderWrapper",
+ "PerceiverForMultimodalAutoencoding",
+ "PerceiverForOpticalFlow",
+ "SegformerDecodeHead",
+ "FlaxBeitForMaskedImageModeling",
+ "PLBartEncoder",
+ "PLBartDecoder",
+ "PLBartDecoderWrapper",
+ "BeitForMaskedImageModeling",
+ "CLIPTextModel",
+ "CLIPVisionModel",
+ "TFCLIPTextModel",
+ "TFCLIPVisionModel",
+ "FlaxCLIPTextModel",
+ "FlaxCLIPVisionModel",
+ "FlaxWav2Vec2ForCTC",
+ "DetrForSegmentation",
+ "DPRReader",
+ "FlaubertForQuestionAnswering",
+ "FlavaImageCodebook",
+ "FlavaTextModel",
+ "FlavaImageModel",
+ "FlavaMultimodalModel",
+ "GPT2DoubleHeadsModel",
+ "LukeForMaskedLM",
+ "LukeForEntityClassification",
+ "LukeForEntityPairClassification",
+ "LukeForEntitySpanClassification",
+ "OpenAIGPTDoubleHeadsModel",
+ "RagModel",
+ "RagSequenceForGeneration",
+ "RagTokenForGeneration",
+ "RealmEmbedder",
+ "RealmForOpenQA",
+ "RealmScorer",
+ "RealmReader",
+ "TFDPRReader",
+ "TFGPT2DoubleHeadsModel",
+ "TFOpenAIGPTDoubleHeadsModel",
+ "TFRagModel",
+ "TFRagSequenceForGeneration",
+ "TFRagTokenForGeneration",
+ "Wav2Vec2ForCTC",
+ "HubertForCTC",
+ "SEWForCTC",
+ "SEWDForCTC",
+ "XLMForQuestionAnswering",
+ "XLNetForQuestionAnswering",
+ "SeparableConv1D",
+ "VisualBertForRegionToPhraseAlignment",
+ "VisualBertForVisualReasoning",
+ "VisualBertForQuestionAnswering",
+ "VisualBertForMultipleChoice",
+ "TFWav2Vec2ForCTC",
+ "TFHubertForCTC",
+ "MaskFormerForInstanceSegmentation",
+]
+
+# Update this list for models that have multiple model types for the same
+# model doc
+MODEL_TYPE_TO_DOC_MAPPING = OrderedDict(
+ [
+ ("data2vec-text", "data2vec"),
+ ("data2vec-audio", "data2vec"),
+ ("data2vec-vision", "data2vec"),
+ ]
+)
+
+
+# This is to make sure the transformers module imported is the one in the repo.
+spec = importlib.util.spec_from_file_location(
+ "diffusers",
+ os.path.join(PATH_TO_DIFFUSERS, "__init__.py"),
+ submodule_search_locations=[PATH_TO_DIFFUSERS],
+)
+diffusers = spec.loader.load_module()
+
+
+def check_model_list():
+ """Check the model list inside the transformers library."""
+ # Get the models from the directory structure of `src/diffusers/models/`
+ models_dir = os.path.join(PATH_TO_DIFFUSERS, "models")
+ _models = []
+ for model in os.listdir(models_dir):
+ model_dir = os.path.join(models_dir, model)
+ if os.path.isdir(model_dir) and "__init__.py" in os.listdir(model_dir):
+ _models.append(model)
+
+ # Get the models from the directory structure of `src/transformers/models/`
+ models = [model for model in dir(diffusers.models) if not model.startswith("__")]
+
+ missing_models = sorted(set(_models).difference(models))
+ if missing_models:
+ raise Exception(
+ f"The following models should be included in {models_dir}/__init__.py: {','.join(missing_models)}."
+ )
+
+
+# If some modeling modules should be ignored for all checks, they should be added in the nested list
+# _ignore_modules of this function.
+def get_model_modules():
+ """Get the model modules inside the transformers library."""
+ _ignore_modules = [
+ "modeling_auto",
+ "modeling_encoder_decoder",
+ "modeling_marian",
+ "modeling_mmbt",
+ "modeling_outputs",
+ "modeling_retribert",
+ "modeling_utils",
+ "modeling_flax_auto",
+ "modeling_flax_encoder_decoder",
+ "modeling_flax_utils",
+ "modeling_speech_encoder_decoder",
+ "modeling_flax_speech_encoder_decoder",
+ "modeling_flax_vision_encoder_decoder",
+ "modeling_transfo_xl_utilities",
+ "modeling_tf_auto",
+ "modeling_tf_encoder_decoder",
+ "modeling_tf_outputs",
+ "modeling_tf_pytorch_utils",
+ "modeling_tf_utils",
+ "modeling_tf_transfo_xl_utilities",
+ "modeling_tf_vision_encoder_decoder",
+ "modeling_vision_encoder_decoder",
+ ]
+ modules = []
+ for model in dir(diffusers.models):
+ # There are some magic dunder attributes in the dir, we ignore them
+ if not model.startswith("__"):
+ model_module = getattr(diffusers.models, model)
+ for submodule in dir(model_module):
+ if submodule.startswith("modeling") and submodule not in _ignore_modules:
+ modeling_module = getattr(model_module, submodule)
+ if inspect.ismodule(modeling_module):
+ modules.append(modeling_module)
+ return modules
+
+
+def get_models(module, include_pretrained=False):
+ """Get the objects in module that are models."""
+ models = []
+ model_classes = (diffusers.ModelMixin, diffusers.TFModelMixin, diffusers.FlaxModelMixin)
+ for attr_name in dir(module):
+ if not include_pretrained and ("Pretrained" in attr_name or "PreTrained" in attr_name):
+ continue
+ attr = getattr(module, attr_name)
+ if isinstance(attr, type) and issubclass(attr, model_classes) and attr.__module__ == module.__name__:
+ models.append((attr_name, attr))
+ return models
+
+
+def is_a_private_model(model):
+ """Returns True if the model should not be in the main init."""
+ if model in PRIVATE_MODELS:
+ return True
+
+ # Wrapper, Encoder and Decoder are all privates
+ if model.endswith("Wrapper"):
+ return True
+ if model.endswith("Encoder"):
+ return True
+ if model.endswith("Decoder"):
+ return True
+ return False
+
+
+def check_models_are_in_init():
+ """Checks all models defined in the library are in the main init."""
+ models_not_in_init = []
+ dir_transformers = dir(diffusers)
+ for module in get_model_modules():
+ models_not_in_init += [
+ model[0] for model in get_models(module, include_pretrained=True) if model[0] not in dir_transformers
+ ]
+
+ # Remove private models
+ models_not_in_init = [model for model in models_not_in_init if not is_a_private_model(model)]
+ if len(models_not_in_init) > 0:
+ raise Exception(f"The following models should be in the main init: {','.join(models_not_in_init)}.")
+
+
+# If some test_modeling files should be ignored when checking models are all tested, they should be added in the
+# nested list _ignore_files of this function.
+def get_model_test_files():
+ """Get the model test files.
+
+ The returned files should NOT contain the `tests` (i.e. `PATH_TO_TESTS` defined in this script). They will be
+ considered as paths relative to `tests`. A caller has to use `os.path.join(PATH_TO_TESTS, ...)` to access the files.
+ """
+
+ _ignore_files = [
+ "test_modeling_common",
+ "test_modeling_encoder_decoder",
+ "test_modeling_flax_encoder_decoder",
+ "test_modeling_flax_speech_encoder_decoder",
+ "test_modeling_marian",
+ "test_modeling_tf_common",
+ "test_modeling_tf_encoder_decoder",
+ ]
+ test_files = []
+ # Check both `PATH_TO_TESTS` and `PATH_TO_TESTS/models`
+ model_test_root = os.path.join(PATH_TO_TESTS, "models")
+ model_test_dirs = []
+ for x in os.listdir(model_test_root):
+ x = os.path.join(model_test_root, x)
+ if os.path.isdir(x):
+ model_test_dirs.append(x)
+
+ for target_dir in [PATH_TO_TESTS] + model_test_dirs:
+ for file_or_dir in os.listdir(target_dir):
+ path = os.path.join(target_dir, file_or_dir)
+ if os.path.isfile(path):
+ filename = os.path.split(path)[-1]
+ if "test_modeling" in filename and os.path.splitext(filename)[0] not in _ignore_files:
+ file = os.path.join(*path.split(os.sep)[1:])
+ test_files.append(file)
+
+ return test_files
+
+
+# This is a bit hacky but I didn't find a way to import the test_file as a module and read inside the tester class
+# for the all_model_classes variable.
+def find_tested_models(test_file):
+ """Parse the content of test_file to detect what's in all_model_classes"""
+ # This is a bit hacky but I didn't find a way to import the test_file as a module and read inside the class
+ with open(os.path.join(PATH_TO_TESTS, test_file), "r", encoding="utf-8", newline="\n") as f:
+ content = f.read()
+ all_models = re.findall(r"all_model_classes\s+=\s+\(\s*\(([^\)]*)\)", content)
+ # Check with one less parenthesis as well
+ all_models += re.findall(r"all_model_classes\s+=\s+\(([^\)]*)\)", content)
+ if len(all_models) > 0:
+ model_tested = []
+ for entry in all_models:
+ for line in entry.split(","):
+ name = line.strip()
+ if len(name) > 0:
+ model_tested.append(name)
+ return model_tested
+
+
+def check_models_are_tested(module, test_file):
+ """Check models defined in module are tested in test_file."""
+ # XxxModelMixin are not tested
+ defined_models = get_models(module)
+ tested_models = find_tested_models(test_file)
+ if tested_models is None:
+ if test_file.replace(os.path.sep, "/") in TEST_FILES_WITH_NO_COMMON_TESTS:
+ return
+ return [
+ f"{test_file} should define `all_model_classes` to apply common tests to the models it tests. "
+ + "If this intentional, add the test filename to `TEST_FILES_WITH_NO_COMMON_TESTS` in the file "
+ + "`utils/check_repo.py`."
+ ]
+ failures = []
+ for model_name, _ in defined_models:
+ if model_name not in tested_models and model_name not in IGNORE_NON_TESTED:
+ failures.append(
+ f"{model_name} is defined in {module.__name__} but is not tested in "
+ + f"{os.path.join(PATH_TO_TESTS, test_file)}. Add it to the all_model_classes in that file."
+ + "If common tests should not applied to that model, add its name to `IGNORE_NON_TESTED`"
+ + "in the file `utils/check_repo.py`."
+ )
+ return failures
+
+
+def check_all_models_are_tested():
+ """Check all models are properly tested."""
+ modules = get_model_modules()
+ test_files = get_model_test_files()
+ failures = []
+ for module in modules:
+ test_file = [file for file in test_files if f"test_{module.__name__.split('.')[-1]}.py" in file]
+ if len(test_file) == 0:
+ failures.append(f"{module.__name__} does not have its corresponding test file {test_file}.")
+ elif len(test_file) > 1:
+ failures.append(f"{module.__name__} has several test files: {test_file}.")
+ else:
+ test_file = test_file[0]
+ new_failures = check_models_are_tested(module, test_file)
+ if new_failures is not None:
+ failures += new_failures
+ if len(failures) > 0:
+ raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
+
+
+def get_all_auto_configured_models():
+ """Return the list of all models in at least one auto class."""
+ result = set() # To avoid duplicates we concatenate all model classes in a set.
+ if is_torch_available():
+ for attr_name in dir(diffusers.models.auto.modeling_auto):
+ if attr_name.startswith("MODEL_") and attr_name.endswith("MAPPING_NAMES"):
+ result = result | set(get_values(getattr(diffusers.models.auto.modeling_auto, attr_name)))
+ if is_tf_available():
+ for attr_name in dir(diffusers.models.auto.modeling_tf_auto):
+ if attr_name.startswith("TF_MODEL_") and attr_name.endswith("MAPPING_NAMES"):
+ result = result | set(get_values(getattr(diffusers.models.auto.modeling_tf_auto, attr_name)))
+ if is_flax_available():
+ for attr_name in dir(diffusers.models.auto.modeling_flax_auto):
+ if attr_name.startswith("FLAX_MODEL_") and attr_name.endswith("MAPPING_NAMES"):
+ result = result | set(get_values(getattr(diffusers.models.auto.modeling_flax_auto, attr_name)))
+ return list(result)
+
+
+def ignore_unautoclassed(model_name):
+ """Rules to determine if `name` should be in an auto class."""
+ # Special white list
+ if model_name in IGNORE_NON_AUTO_CONFIGURED:
+ return True
+ # Encoder and Decoder should be ignored
+ if "Encoder" in model_name or "Decoder" in model_name:
+ return True
+ return False
+
+
+def check_models_are_auto_configured(module, all_auto_models):
+ """Check models defined in module are each in an auto class."""
+ defined_models = get_models(module)
+ failures = []
+ for model_name, _ in defined_models:
+ if model_name not in all_auto_models and not ignore_unautoclassed(model_name):
+ failures.append(
+ f"{model_name} is defined in {module.__name__} but is not present in any of the auto mapping. "
+ "If that is intended behavior, add its name to `IGNORE_NON_AUTO_CONFIGURED` in the file "
+ "`utils/check_repo.py`."
+ )
+ return failures
+
+
+def check_all_models_are_auto_configured():
+ """Check all models are each in an auto class."""
+ missing_backends = []
+ if not is_torch_available():
+ missing_backends.append("PyTorch")
+ if not is_tf_available():
+ missing_backends.append("TensorFlow")
+ if not is_flax_available():
+ missing_backends.append("Flax")
+ if len(missing_backends) > 0:
+ missing = ", ".join(missing_backends)
+ if os.getenv("TRANSFORMERS_IS_CI", "").upper() in ENV_VARS_TRUE_VALUES:
+ raise Exception(
+ "Full quality checks require all backends to be installed (with `pip install -e .[dev]` in the "
+ f"Transformers repo, the following are missing: {missing}."
+ )
+ else:
+ warnings.warn(
+ "Full quality checks require all backends to be installed (with `pip install -e .[dev]` in the "
+ f"Transformers repo, the following are missing: {missing}. While it's probably fine as long as you "
+ "didn't make any change in one of those backends modeling files, you should probably execute the "
+ "command above to be on the safe side."
+ )
+ modules = get_model_modules()
+ all_auto_models = get_all_auto_configured_models()
+ failures = []
+ for module in modules:
+ new_failures = check_models_are_auto_configured(module, all_auto_models)
+ if new_failures is not None:
+ failures += new_failures
+ if len(failures) > 0:
+ raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
+
+
+_re_decorator = re.compile(r"^\s*@(\S+)\s+$")
+
+
+def check_decorator_order(filename):
+ """Check that in the test file `filename` the slow decorator is always last."""
+ with open(filename, "r", encoding="utf-8", newline="\n") as f:
+ lines = f.readlines()
+ decorator_before = None
+ errors = []
+ for i, line in enumerate(lines):
+ search = _re_decorator.search(line)
+ if search is not None:
+ decorator_name = search.groups()[0]
+ if decorator_before is not None and decorator_name.startswith("parameterized"):
+ errors.append(i)
+ decorator_before = decorator_name
+ elif decorator_before is not None:
+ decorator_before = None
+ return errors
+
+
+def check_all_decorator_order():
+ """Check that in all test files, the slow decorator is always last."""
+ errors = []
+ for fname in os.listdir(PATH_TO_TESTS):
+ if fname.endswith(".py"):
+ filename = os.path.join(PATH_TO_TESTS, fname)
+ new_errors = check_decorator_order(filename)
+ errors += [f"- {filename}, line {i}" for i in new_errors]
+ if len(errors) > 0:
+ msg = "\n".join(errors)
+ raise ValueError(
+ "The parameterized decorator (and its variants) should always be first, but this is not the case in the"
+ f" following files:\n{msg}"
+ )
+
+
+def find_all_documented_objects():
+ """Parse the content of all doc files to detect which classes and functions it documents"""
+ documented_obj = []
+ for doc_file in Path(PATH_TO_DOC).glob("**/*.rst"):
+ with open(doc_file, "r", encoding="utf-8", newline="\n") as f:
+ content = f.read()
+ raw_doc_objs = re.findall(r"(?:autoclass|autofunction):: transformers.(\S+)\s+", content)
+ documented_obj += [obj.split(".")[-1] for obj in raw_doc_objs]
+ for doc_file in Path(PATH_TO_DOC).glob("**/*.mdx"):
+ with open(doc_file, "r", encoding="utf-8", newline="\n") as f:
+ content = f.read()
+ raw_doc_objs = re.findall("\[\[autodoc\]\]\s+(\S+)\s+", content)
+ documented_obj += [obj.split(".")[-1] for obj in raw_doc_objs]
+ return documented_obj
+
+
+# One good reason for not being documented is to be deprecated. Put in this list deprecated objects.
+DEPRECATED_OBJECTS = [
+ "AutoModelWithLMHead",
+ "BartPretrainedModel",
+ "DataCollator",
+ "DataCollatorForSOP",
+ "GlueDataset",
+ "GlueDataTrainingArguments",
+ "LineByLineTextDataset",
+ "LineByLineWithRefDataset",
+ "LineByLineWithSOPTextDataset",
+ "PretrainedBartModel",
+ "PretrainedFSMTModel",
+ "SingleSentenceClassificationProcessor",
+ "SquadDataTrainingArguments",
+ "SquadDataset",
+ "SquadExample",
+ "SquadFeatures",
+ "SquadV1Processor",
+ "SquadV2Processor",
+ "TFAutoModelWithLMHead",
+ "TFBartPretrainedModel",
+ "TextDataset",
+ "TextDatasetForNextSentencePrediction",
+ "Wav2Vec2ForMaskedLM",
+ "Wav2Vec2Tokenizer",
+ "glue_compute_metrics",
+ "glue_convert_examples_to_features",
+ "glue_output_modes",
+ "glue_processors",
+ "glue_tasks_num_labels",
+ "squad_convert_examples_to_features",
+ "xnli_compute_metrics",
+ "xnli_output_modes",
+ "xnli_processors",
+ "xnli_tasks_num_labels",
+ "TFTrainer",
+ "TFTrainingArguments",
+]
+
+# Exceptionally, some objects should not be documented after all rules passed.
+# ONLY PUT SOMETHING IN THIS LIST AS A LAST RESORT!
+UNDOCUMENTED_OBJECTS = [
+ "AddedToken", # This is a tokenizers class.
+ "BasicTokenizer", # Internal, should never have been in the main init.
+ "CharacterTokenizer", # Internal, should never have been in the main init.
+ "DPRPretrainedReader", # Like an Encoder.
+ "DummyObject", # Just picked by mistake sometimes.
+ "MecabTokenizer", # Internal, should never have been in the main init.
+ "ModelCard", # Internal type.
+ "SqueezeBertModule", # Internal building block (should have been called SqueezeBertLayer)
+ "TFDPRPretrainedReader", # Like an Encoder.
+ "TransfoXLCorpus", # Internal type.
+ "WordpieceTokenizer", # Internal, should never have been in the main init.
+ "absl", # External module
+ "add_end_docstrings", # Internal, should never have been in the main init.
+ "add_start_docstrings", # Internal, should never have been in the main init.
+ "cached_path", # Internal used for downloading models.
+ "convert_tf_weight_name_to_pt_weight_name", # Internal used to convert model weights
+ "logger", # Internal logger
+ "logging", # External module
+ "requires_backends", # Internal function
+]
+
+# This list should be empty. Objects in it should get their own doc page.
+SHOULD_HAVE_THEIR_OWN_PAGE = [
+ # Benchmarks
+ "PyTorchBenchmark",
+ "PyTorchBenchmarkArguments",
+ "TensorFlowBenchmark",
+ "TensorFlowBenchmarkArguments",
+]
+
+
+def ignore_undocumented(name):
+ """Rules to determine if `name` should be undocumented."""
+ # NOT DOCUMENTED ON PURPOSE.
+ # Constants uppercase are not documented.
+ if name.isupper():
+ return True
+ # ModelMixins / Encoders / Decoders / Layers / Embeddings / Attention are not documented.
+ if (
+ name.endswith("ModelMixin")
+ or name.endswith("Decoder")
+ or name.endswith("Encoder")
+ or name.endswith("Layer")
+ or name.endswith("Embeddings")
+ or name.endswith("Attention")
+ ):
+ return True
+ # Submodules are not documented.
+ if os.path.isdir(os.path.join(PATH_TO_DIFFUSERS, name)) or os.path.isfile(
+ os.path.join(PATH_TO_DIFFUSERS, f"{name}.py")
+ ):
+ return True
+ # All load functions are not documented.
+ if name.startswith("load_tf") or name.startswith("load_pytorch"):
+ return True
+ # is_xxx_available functions are not documented.
+ if name.startswith("is_") and name.endswith("_available"):
+ return True
+ # Deprecated objects are not documented.
+ if name in DEPRECATED_OBJECTS or name in UNDOCUMENTED_OBJECTS:
+ return True
+ # MMBT model does not really work.
+ if name.startswith("MMBT"):
+ return True
+ if name in SHOULD_HAVE_THEIR_OWN_PAGE:
+ return True
+ return False
+
+
+def check_all_objects_are_documented():
+ """Check all models are properly documented."""
+ documented_objs = find_all_documented_objects()
+ modules = diffusers._modules
+ objects = [c for c in dir(diffusers) if c not in modules and not c.startswith("_")]
+ undocumented_objs = [c for c in objects if c not in documented_objs and not ignore_undocumented(c)]
+ if len(undocumented_objs) > 0:
+ raise Exception(
+ "The following objects are in the public init so should be documented:\n - "
+ + "\n - ".join(undocumented_objs)
+ )
+ check_docstrings_are_in_md()
+ check_model_type_doc_match()
+
+
+def check_model_type_doc_match():
+ """Check all doc pages have a corresponding model type."""
+ model_doc_folder = Path(PATH_TO_DOC) / "model_doc"
+ model_docs = [m.stem for m in model_doc_folder.glob("*.mdx")]
+
+ model_types = list(diffusers.models.auto.configuration_auto.MODEL_NAMES_MAPPING.keys())
+ model_types = [MODEL_TYPE_TO_DOC_MAPPING[m] if m in MODEL_TYPE_TO_DOC_MAPPING else m for m in model_types]
+
+ errors = []
+ for m in model_docs:
+ if m not in model_types and m != "auto":
+ close_matches = get_close_matches(m, model_types)
+ error_message = f"{m} is not a proper model identifier."
+ if len(close_matches) > 0:
+ close_matches = "/".join(close_matches)
+ error_message += f" Did you mean {close_matches}?"
+ errors.append(error_message)
+
+ if len(errors) > 0:
+ raise ValueError(
+ "Some model doc pages do not match any existing model type:\n"
+ + "\n".join(errors)
+ + "\nYou can add any missing model type to the `MODEL_NAMES_MAPPING` constant in "
+ "models/auto/configuration_auto.py."
+ )
+
+
+# Re pattern to catch :obj:`xx`, :class:`xx`, :func:`xx` or :meth:`xx`.
+_re_rst_special_words = re.compile(r":(?:obj|func|class|meth):`([^`]+)`")
+# Re pattern to catch things between double backquotes.
+_re_double_backquotes = re.compile(r"(^|[^`])``([^`]+)``([^`]|$)")
+# Re pattern to catch example introduction.
+_re_rst_example = re.compile(r"^\s*Example.*::\s*$", flags=re.MULTILINE)
+
+
+def is_rst_docstring(docstring):
+ """
+ Returns `True` if `docstring` is written in rst.
+ """
+ if _re_rst_special_words.search(docstring) is not None:
+ return True
+ if _re_double_backquotes.search(docstring) is not None:
+ return True
+ if _re_rst_example.search(docstring) is not None:
+ return True
+ return False
+
+
+def check_docstrings_are_in_md():
+ """Check all docstrings are in md"""
+ files_with_rst = []
+ for file in Path(PATH_TO_DIFFUSERS).glob("**/*.py"):
+ with open(file, "r") as f:
+ code = f.read()
+ docstrings = code.split('"""')
+
+ for idx, docstring in enumerate(docstrings):
+ if idx % 2 == 0 or not is_rst_docstring(docstring):
+ continue
+ files_with_rst.append(file)
+ break
+
+ if len(files_with_rst) > 0:
+ raise ValueError(
+ "The following files have docstrings written in rst:\n"
+ + "\n".join([f"- {f}" for f in files_with_rst])
+ + "\nTo fix this run `doc-builder convert path_to_py_file` after installing `doc-builder`\n"
+ "(`pip install git+https://github.com/huggingface/doc-builder`)"
+ )
+
+
+def check_repo_quality():
+ """Check all models are properly tested and documented."""
+ print("Checking all models are included.")
+ check_model_list()
+ print("Checking all models are public.")
+ check_models_are_in_init()
+ print("Checking all models are properly tested.")
+ check_all_decorator_order()
+ check_all_models_are_tested()
+ print("Checking all objects are properly documented.")
+ check_all_objects_are_documented()
+ print("Checking all models are in at least one auto class.")
+ check_all_models_are_auto_configured()
+
+
+if __name__ == "__main__":
+ check_repo_quality()
diff --git a/diffusers/utils/check_table.py b/diffusers/utils/check_table.py
new file mode 100644
index 0000000000000000000000000000000000000000..8bd6d9eae9ce7994f6c5f6171c08ebf2928fa3be
--- /dev/null
+++ b/diffusers/utils/check_table.py
@@ -0,0 +1,185 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import collections
+import importlib.util
+import os
+import re
+
+
+# All paths are set with the intent you should run this script from the root of the repo with the command
+# python utils/check_table.py
+TRANSFORMERS_PATH = "src/diffusers"
+PATH_TO_DOCS = "docs/source/en"
+REPO_PATH = "."
+
+
+def _find_text_in_file(filename, start_prompt, end_prompt):
+ """
+ Find the text in `filename` between a line beginning with `start_prompt` and before `end_prompt`, removing empty
+ lines.
+ """
+ with open(filename, "r", encoding="utf-8", newline="\n") as f:
+ lines = f.readlines()
+ # Find the start prompt.
+ start_index = 0
+ while not lines[start_index].startswith(start_prompt):
+ start_index += 1
+ start_index += 1
+
+ end_index = start_index
+ while not lines[end_index].startswith(end_prompt):
+ end_index += 1
+ end_index -= 1
+
+ while len(lines[start_index]) <= 1:
+ start_index += 1
+ while len(lines[end_index]) <= 1:
+ end_index -= 1
+ end_index += 1
+ return "".join(lines[start_index:end_index]), start_index, end_index, lines
+
+
+# Add here suffixes that are used to identify models, separated by |
+ALLOWED_MODEL_SUFFIXES = "Model|Encoder|Decoder|ForConditionalGeneration"
+# Regexes that match TF/Flax/PT model names.
+_re_tf_models = re.compile(r"TF(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
+_re_flax_models = re.compile(r"Flax(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
+# Will match any TF or Flax model too so need to be in an else branch afterthe two previous regexes.
+_re_pt_models = re.compile(r"(.*)(?:Model|Encoder|Decoder|ForConditionalGeneration)")
+
+
+# This is to make sure the diffusers module imported is the one in the repo.
+spec = importlib.util.spec_from_file_location(
+ "diffusers",
+ os.path.join(TRANSFORMERS_PATH, "__init__.py"),
+ submodule_search_locations=[TRANSFORMERS_PATH],
+)
+diffusers_module = spec.loader.load_module()
+
+
+# Thanks to https://stackoverflow.com/questions/29916065/how-to-do-camelcase-split-in-python
+def camel_case_split(identifier):
+ "Split a camelcased `identifier` into words."
+ matches = re.finditer(".+?(?:(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])|$)", identifier)
+ return [m.group(0) for m in matches]
+
+
+def _center_text(text, width):
+ text_length = 2 if text == "✅" or text == "❌" else len(text)
+ left_indent = (width - text_length) // 2
+ right_indent = width - text_length - left_indent
+ return " " * left_indent + text + " " * right_indent
+
+
+def get_model_table_from_auto_modules():
+ """Generates an up-to-date model table from the content of the auto modules."""
+ # Dictionary model names to config.
+ config_mapping_names = diffusers_module.models.auto.configuration_auto.CONFIG_MAPPING_NAMES
+ model_name_to_config = {
+ name: config_mapping_names[code]
+ for code, name in diffusers_module.MODEL_NAMES_MAPPING.items()
+ if code in config_mapping_names
+ }
+ model_name_to_prefix = {name: config.replace("ConfigMixin", "") for name, config in model_name_to_config.items()}
+
+ # Dictionaries flagging if each model prefix has a slow/fast tokenizer, backend in PT/TF/Flax.
+ slow_tokenizers = collections.defaultdict(bool)
+ fast_tokenizers = collections.defaultdict(bool)
+ pt_models = collections.defaultdict(bool)
+ tf_models = collections.defaultdict(bool)
+ flax_models = collections.defaultdict(bool)
+
+ # Let's lookup through all diffusers object (once).
+ for attr_name in dir(diffusers_module):
+ lookup_dict = None
+ if attr_name.endswith("Tokenizer"):
+ lookup_dict = slow_tokenizers
+ attr_name = attr_name[:-9]
+ elif attr_name.endswith("TokenizerFast"):
+ lookup_dict = fast_tokenizers
+ attr_name = attr_name[:-13]
+ elif _re_tf_models.match(attr_name) is not None:
+ lookup_dict = tf_models
+ attr_name = _re_tf_models.match(attr_name).groups()[0]
+ elif _re_flax_models.match(attr_name) is not None:
+ lookup_dict = flax_models
+ attr_name = _re_flax_models.match(attr_name).groups()[0]
+ elif _re_pt_models.match(attr_name) is not None:
+ lookup_dict = pt_models
+ attr_name = _re_pt_models.match(attr_name).groups()[0]
+
+ if lookup_dict is not None:
+ while len(attr_name) > 0:
+ if attr_name in model_name_to_prefix.values():
+ lookup_dict[attr_name] = True
+ break
+ # Try again after removing the last word in the name
+ attr_name = "".join(camel_case_split(attr_name)[:-1])
+
+ # Let's build that table!
+ model_names = list(model_name_to_config.keys())
+ model_names.sort(key=str.lower)
+ columns = ["Model", "Tokenizer slow", "Tokenizer fast", "PyTorch support", "TensorFlow support", "Flax Support"]
+ # We'll need widths to properly display everything in the center (+2 is to leave one extra space on each side).
+ widths = [len(c) + 2 for c in columns]
+ widths[0] = max([len(name) for name in model_names]) + 2
+
+ # Build the table per se
+ table = "|" + "|".join([_center_text(c, w) for c, w in zip(columns, widths)]) + "|\n"
+ # Use ":-----:" format to center-aligned table cell texts
+ table += "|" + "|".join([":" + "-" * (w - 2) + ":" for w in widths]) + "|\n"
+
+ check = {True: "✅", False: "❌"}
+ for name in model_names:
+ prefix = model_name_to_prefix[name]
+ line = [
+ name,
+ check[slow_tokenizers[prefix]],
+ check[fast_tokenizers[prefix]],
+ check[pt_models[prefix]],
+ check[tf_models[prefix]],
+ check[flax_models[prefix]],
+ ]
+ table += "|" + "|".join([_center_text(l, w) for l, w in zip(line, widths)]) + "|\n"
+ return table
+
+
+def check_model_table(overwrite=False):
+ """Check the model table in the index.rst is consistent with the state of the lib and maybe `overwrite`."""
+ current_table, start_index, end_index, lines = _find_text_in_file(
+ filename=os.path.join(PATH_TO_DOCS, "index.mdx"),
+ start_prompt="",
+ )
+ new_table = get_model_table_from_auto_modules()
+
+ if current_table != new_table:
+ if overwrite:
+ with open(os.path.join(PATH_TO_DOCS, "index.mdx"), "w", encoding="utf-8", newline="\n") as f:
+ f.writelines(lines[:start_index] + [new_table] + lines[end_index:])
+ else:
+ raise ValueError(
+ "The model table in the `index.mdx` has not been updated. Run `make fix-copies` to fix this."
+ )
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
+ args = parser.parse_args()
+
+ check_model_table(args.fix_and_overwrite)
diff --git a/diffusers/utils/custom_init_isort.py b/diffusers/utils/custom_init_isort.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8ef799c5e6c83f864bc0db06f874324342802c5
--- /dev/null
+++ b/diffusers/utils/custom_init_isort.py
@@ -0,0 +1,252 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import os
+import re
+
+
+PATH_TO_TRANSFORMERS = "src/diffusers"
+
+# Pattern that looks at the indentation in a line.
+_re_indent = re.compile(r"^(\s*)\S")
+# Pattern that matches `"key":" and puts `key` in group 0.
+_re_direct_key = re.compile(r'^\s*"([^"]+)":')
+# Pattern that matches `_import_structure["key"]` and puts `key` in group 0.
+_re_indirect_key = re.compile(r'^\s*_import_structure\["([^"]+)"\]')
+# Pattern that matches `"key",` and puts `key` in group 0.
+_re_strip_line = re.compile(r'^\s*"([^"]+)",\s*$')
+# Pattern that matches any `[stuff]` and puts `stuff` in group 0.
+_re_bracket_content = re.compile(r"\[([^\]]+)\]")
+
+
+def get_indent(line):
+ """Returns the indent in `line`."""
+ search = _re_indent.search(line)
+ return "" if search is None else search.groups()[0]
+
+
+def split_code_in_indented_blocks(code, indent_level="", start_prompt=None, end_prompt=None):
+ """
+ Split `code` into its indented blocks, starting at `indent_level`. If provided, begins splitting after
+ `start_prompt` and stops at `end_prompt` (but returns what's before `start_prompt` as a first block and what's
+ after `end_prompt` as a last block, so `code` is always the same as joining the result of this function).
+ """
+ # Let's split the code into lines and move to start_index.
+ index = 0
+ lines = code.split("\n")
+ if start_prompt is not None:
+ while not lines[index].startswith(start_prompt):
+ index += 1
+ blocks = ["\n".join(lines[:index])]
+ else:
+ blocks = []
+
+ # We split into blocks until we get to the `end_prompt` (or the end of the block).
+ current_block = [lines[index]]
+ index += 1
+ while index < len(lines) and (end_prompt is None or not lines[index].startswith(end_prompt)):
+ if len(lines[index]) > 0 and get_indent(lines[index]) == indent_level:
+ if len(current_block) > 0 and get_indent(current_block[-1]).startswith(indent_level + " "):
+ current_block.append(lines[index])
+ blocks.append("\n".join(current_block))
+ if index < len(lines) - 1:
+ current_block = [lines[index + 1]]
+ index += 1
+ else:
+ current_block = []
+ else:
+ blocks.append("\n".join(current_block))
+ current_block = [lines[index]]
+ else:
+ current_block.append(lines[index])
+ index += 1
+
+ # Adds current block if it's nonempty.
+ if len(current_block) > 0:
+ blocks.append("\n".join(current_block))
+
+ # Add final block after end_prompt if provided.
+ if end_prompt is not None and index < len(lines):
+ blocks.append("\n".join(lines[index:]))
+
+ return blocks
+
+
+def ignore_underscore(key):
+ "Wraps a `key` (that maps an object to string) to lower case and remove underscores."
+
+ def _inner(x):
+ return key(x).lower().replace("_", "")
+
+ return _inner
+
+
+def sort_objects(objects, key=None):
+ "Sort a list of `objects` following the rules of isort. `key` optionally maps an object to a str."
+
+ # If no key is provided, we use a noop.
+ def noop(x):
+ return x
+
+ if key is None:
+ key = noop
+ # Constants are all uppercase, they go first.
+ constants = [obj for obj in objects if key(obj).isupper()]
+ # Classes are not all uppercase but start with a capital, they go second.
+ classes = [obj for obj in objects if key(obj)[0].isupper() and not key(obj).isupper()]
+ # Functions begin with a lowercase, they go last.
+ functions = [obj for obj in objects if not key(obj)[0].isupper()]
+
+ key1 = ignore_underscore(key)
+ return sorted(constants, key=key1) + sorted(classes, key=key1) + sorted(functions, key=key1)
+
+
+def sort_objects_in_import(import_statement):
+ """
+ Return the same `import_statement` but with objects properly sorted.
+ """
+
+ # This inner function sort imports between [ ].
+ def _replace(match):
+ imports = match.groups()[0]
+ if "," not in imports:
+ return f"[{imports}]"
+ keys = [part.strip().replace('"', "") for part in imports.split(",")]
+ # We will have a final empty element if the line finished with a comma.
+ if len(keys[-1]) == 0:
+ keys = keys[:-1]
+ return "[" + ", ".join([f'"{k}"' for k in sort_objects(keys)]) + "]"
+
+ lines = import_statement.split("\n")
+ if len(lines) > 3:
+ # Here we have to sort internal imports that are on several lines (one per name):
+ # key: [
+ # "object1",
+ # "object2",
+ # ...
+ # ]
+
+ # We may have to ignore one or two lines on each side.
+ idx = 2 if lines[1].strip() == "[" else 1
+ keys_to_sort = [(i, _re_strip_line.search(line).groups()[0]) for i, line in enumerate(lines[idx:-idx])]
+ sorted_indices = sort_objects(keys_to_sort, key=lambda x: x[1])
+ sorted_lines = [lines[x[0] + idx] for x in sorted_indices]
+ return "\n".join(lines[:idx] + sorted_lines + lines[-idx:])
+ elif len(lines) == 3:
+ # Here we have to sort internal imports that are on one separate line:
+ # key: [
+ # "object1", "object2", ...
+ # ]
+ if _re_bracket_content.search(lines[1]) is not None:
+ lines[1] = _re_bracket_content.sub(_replace, lines[1])
+ else:
+ keys = [part.strip().replace('"', "") for part in lines[1].split(",")]
+ # We will have a final empty element if the line finished with a comma.
+ if len(keys[-1]) == 0:
+ keys = keys[:-1]
+ lines[1] = get_indent(lines[1]) + ", ".join([f'"{k}"' for k in sort_objects(keys)])
+ return "\n".join(lines)
+ else:
+ # Finally we have to deal with imports fitting on one line
+ import_statement = _re_bracket_content.sub(_replace, import_statement)
+ return import_statement
+
+
+def sort_imports(file, check_only=True):
+ """
+ Sort `_import_structure` imports in `file`, `check_only` determines if we only check or overwrite.
+ """
+ with open(file, "r") as f:
+ code = f.read()
+
+ if "_import_structure" not in code:
+ return
+
+ # Blocks of indent level 0
+ main_blocks = split_code_in_indented_blocks(
+ code, start_prompt="_import_structure = {", end_prompt="if TYPE_CHECKING:"
+ )
+
+ # We ignore block 0 (everything until start_prompt) and the last block (everything after end_prompt).
+ for block_idx in range(1, len(main_blocks) - 1):
+ # Check if the block contains some `_import_structure`s thingy to sort.
+ block = main_blocks[block_idx]
+ block_lines = block.split("\n")
+
+ # Get to the start of the imports.
+ line_idx = 0
+ while line_idx < len(block_lines) and "_import_structure" not in block_lines[line_idx]:
+ # Skip dummy import blocks
+ if "import dummy" in block_lines[line_idx]:
+ line_idx = len(block_lines)
+ else:
+ line_idx += 1
+ if line_idx >= len(block_lines):
+ continue
+
+ # Ignore beginning and last line: they don't contain anything.
+ internal_block_code = "\n".join(block_lines[line_idx:-1])
+ indent = get_indent(block_lines[1])
+ # Slit the internal block into blocks of indent level 1.
+ internal_blocks = split_code_in_indented_blocks(internal_block_code, indent_level=indent)
+ # We have two categories of import key: list or _import_structure[key].append/extend
+ pattern = _re_direct_key if "_import_structure" in block_lines[0] else _re_indirect_key
+ # Grab the keys, but there is a trap: some lines are empty or just comments.
+ keys = [(pattern.search(b).groups()[0] if pattern.search(b) is not None else None) for b in internal_blocks]
+ # We only sort the lines with a key.
+ keys_to_sort = [(i, key) for i, key in enumerate(keys) if key is not None]
+ sorted_indices = [x[0] for x in sorted(keys_to_sort, key=lambda x: x[1])]
+
+ # We reorder the blocks by leaving empty lines/comments as they were and reorder the rest.
+ count = 0
+ reordered_blocks = []
+ for i in range(len(internal_blocks)):
+ if keys[i] is None:
+ reordered_blocks.append(internal_blocks[i])
+ else:
+ block = sort_objects_in_import(internal_blocks[sorted_indices[count]])
+ reordered_blocks.append(block)
+ count += 1
+
+ # And we put our main block back together with its first and last line.
+ main_blocks[block_idx] = "\n".join(block_lines[:line_idx] + reordered_blocks + [block_lines[-1]])
+
+ if code != "\n".join(main_blocks):
+ if check_only:
+ return True
+ else:
+ print(f"Overwriting {file}.")
+ with open(file, "w") as f:
+ f.write("\n".join(main_blocks))
+
+
+def sort_imports_in_all_inits(check_only=True):
+ failures = []
+ for root, _, files in os.walk(PATH_TO_TRANSFORMERS):
+ if "__init__.py" in files:
+ result = sort_imports(os.path.join(root, "__init__.py"), check_only=check_only)
+ if result:
+ failures = [os.path.join(root, "__init__.py")]
+ if len(failures) > 0:
+ raise ValueError(f"Would overwrite {len(failures)} files, run `make style`.")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--check_only", action="store_true", help="Whether to only check or fix style.")
+ args = parser.parse_args()
+
+ sort_imports_in_all_inits(check_only=args.check_only)
diff --git a/diffusers/utils/get_modified_files.py b/diffusers/utils/get_modified_files.py
new file mode 100644
index 0000000000000000000000000000000000000000..650c61ccb21eff8407147563b103733b472546cd
--- /dev/null
+++ b/diffusers/utils/get_modified_files.py
@@ -0,0 +1,34 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# this script reports modified .py files under the desired list of top-level sub-dirs passed as a list of arguments, e.g.:
+# python ./utils/get_modified_files.py utils src tests examples
+#
+# it uses git to find the forking point and which files were modified - i.e. files not under git won't be considered
+# since the output of this script is fed into Makefile commands it doesn't print a newline after the results
+
+import re
+import subprocess
+import sys
+
+
+fork_point_sha = subprocess.check_output("git merge-base main HEAD".split()).decode("utf-8")
+modified_files = subprocess.check_output(f"git diff --name-only {fork_point_sha}".split()).decode("utf-8").split()
+
+joined_dirs = "|".join(sys.argv[1:])
+regex = re.compile(rf"^({joined_dirs}).*?\.py$")
+
+relevant_modified_files = [x for x in modified_files if regex.match(x)]
+print(" ".join(relevant_modified_files), end="")
diff --git a/diffusers/utils/overwrite_expected_slice.py b/diffusers/utils/overwrite_expected_slice.py
new file mode 100644
index 0000000000000000000000000000000000000000..7aa66727150a120241e9e1020acc1d395dc2e5f2
--- /dev/null
+++ b/diffusers/utils/overwrite_expected_slice.py
@@ -0,0 +1,90 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+from collections import defaultdict
+
+
+def overwrite_file(file, class_name, test_name, correct_line, done_test):
+ _id = f"{file}_{class_name}_{test_name}"
+ done_test[_id] += 1
+
+ with open(file, "r") as f:
+ lines = f.readlines()
+
+ class_regex = f"class {class_name}("
+ test_regex = f"{4 * ' '}def {test_name}("
+ line_begin_regex = f"{8 * ' '}{correct_line.split()[0]}"
+ another_line_begin_regex = f"{16 * ' '}{correct_line.split()[0]}"
+ in_class = False
+ in_func = False
+ in_line = False
+ insert_line = False
+ count = 0
+ spaces = 0
+
+ new_lines = []
+ for line in lines:
+ if line.startswith(class_regex):
+ in_class = True
+ elif in_class and line.startswith(test_regex):
+ in_func = True
+ elif in_class and in_func and (line.startswith(line_begin_regex) or line.startswith(another_line_begin_regex)):
+ spaces = len(line.split(correct_line.split()[0])[0])
+ count += 1
+
+ if count == done_test[_id]:
+ in_line = True
+
+ if in_class and in_func and in_line:
+ if ")" not in line:
+ continue
+ else:
+ insert_line = True
+
+ if in_class and in_func and in_line and insert_line:
+ new_lines.append(f"{spaces * ' '}{correct_line}")
+ in_class = in_func = in_line = insert_line = False
+ else:
+ new_lines.append(line)
+
+ with open(file, "w") as f:
+ for line in new_lines:
+ f.write(line)
+
+
+def main(correct, fail=None):
+ if fail is not None:
+ with open(fail, "r") as f:
+ test_failures = {l.strip() for l in f.readlines()}
+ else:
+ test_failures = None
+
+ with open(correct, "r") as f:
+ correct_lines = f.readlines()
+
+ done_tests = defaultdict(int)
+ for line in correct_lines:
+ file, class_name, test_name, correct_line = line.split(";")
+ if test_failures is None or "::".join([file, class_name, test_name]) in test_failures:
+ overwrite_file(file, class_name, test_name, correct_line, done_tests)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--correct_filename", help="filename of tests with expected result")
+ parser.add_argument("--fail_filename", help="filename of test failures", type=str, default=None)
+ args = parser.parse_args()
+
+ main(args.correct_filename, args.fail_filename)
diff --git a/diffusers/utils/print_env.py b/diffusers/utils/print_env.py
new file mode 100644
index 0000000000000000000000000000000000000000..88cb674bf31ace69122b925c0b31eddf812fcdb4
--- /dev/null
+++ b/diffusers/utils/print_env.py
@@ -0,0 +1,48 @@
+#!/usr/bin/env python3
+
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# this script dumps information about the environment
+
+import os
+import platform
+import sys
+
+
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
+
+print("Python version:", sys.version)
+
+print("OS platform:", platform.platform())
+print("OS architecture:", platform.machine())
+
+try:
+ import torch
+
+ print("Torch version:", torch.__version__)
+ print("Cuda available:", torch.cuda.is_available())
+ print("Cuda version:", torch.version.cuda)
+ print("CuDNN version:", torch.backends.cudnn.version())
+ print("Number of GPUs available:", torch.cuda.device_count())
+except ImportError:
+ print("Torch version:", None)
+
+try:
+ import transformers
+
+ print("transformers version:", transformers.__version__)
+except ImportError:
+ print("transformers version:", None)
diff --git a/diffusers/utils/release.py b/diffusers/utils/release.py
new file mode 100644
index 0000000000000000000000000000000000000000..758fb70caaca409947c9dba2fe13fb2546060b32
--- /dev/null
+++ b/diffusers/utils/release.py
@@ -0,0 +1,162 @@
+# coding=utf-8
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import os
+import re
+
+import packaging.version
+
+
+PATH_TO_EXAMPLES = "examples/"
+REPLACE_PATTERNS = {
+ "examples": (re.compile(r'^check_min_version\("[^"]+"\)\s*$', re.MULTILINE), 'check_min_version("VERSION")\n'),
+ "init": (re.compile(r'^__version__\s+=\s+"([^"]+)"\s*$', re.MULTILINE), '__version__ = "VERSION"\n'),
+ "setup": (re.compile(r'^(\s*)version\s*=\s*"[^"]+",', re.MULTILINE), r'\1version="VERSION",'),
+ "doc": (re.compile(r'^(\s*)release\s*=\s*"[^"]+"$', re.MULTILINE), 'release = "VERSION"\n'),
+}
+REPLACE_FILES = {
+ "init": "src/diffusers/__init__.py",
+ "setup": "setup.py",
+}
+README_FILE = "README.md"
+
+
+def update_version_in_file(fname, version, pattern):
+ """Update the version in one file using a specific pattern."""
+ with open(fname, "r", encoding="utf-8", newline="\n") as f:
+ code = f.read()
+ re_pattern, replace = REPLACE_PATTERNS[pattern]
+ replace = replace.replace("VERSION", version)
+ code = re_pattern.sub(replace, code)
+ with open(fname, "w", encoding="utf-8", newline="\n") as f:
+ f.write(code)
+
+
+def update_version_in_examples(version):
+ """Update the version in all examples files."""
+ for folder, directories, fnames in os.walk(PATH_TO_EXAMPLES):
+ # Removing some of the folders with non-actively maintained examples from the walk
+ if "research_projects" in directories:
+ directories.remove("research_projects")
+ if "legacy" in directories:
+ directories.remove("legacy")
+ for fname in fnames:
+ if fname.endswith(".py"):
+ update_version_in_file(os.path.join(folder, fname), version, pattern="examples")
+
+
+def global_version_update(version, patch=False):
+ """Update the version in all needed files."""
+ for pattern, fname in REPLACE_FILES.items():
+ update_version_in_file(fname, version, pattern)
+ if not patch:
+ update_version_in_examples(version)
+
+
+def clean_main_ref_in_model_list():
+ """Replace the links from main doc tp stable doc in the model list of the README."""
+ # If the introduction or the conclusion of the list change, the prompts may need to be updated.
+ _start_prompt = "🤗 Transformers currently provides the following architectures"
+ _end_prompt = "1. Want to contribute a new model?"
+ with open(README_FILE, "r", encoding="utf-8", newline="\n") as f:
+ lines = f.readlines()
+
+ # Find the start of the list.
+ start_index = 0
+ while not lines[start_index].startswith(_start_prompt):
+ start_index += 1
+ start_index += 1
+
+ index = start_index
+ # Update the lines in the model list.
+ while not lines[index].startswith(_end_prompt):
+ if lines[index].startswith("1."):
+ lines[index] = lines[index].replace(
+ "https://huggingface.co/docs/diffusers/main/model_doc",
+ "https://huggingface.co/docs/diffusers/model_doc",
+ )
+ index += 1
+
+ with open(README_FILE, "w", encoding="utf-8", newline="\n") as f:
+ f.writelines(lines)
+
+
+def get_version():
+ """Reads the current version in the __init__."""
+ with open(REPLACE_FILES["init"], "r") as f:
+ code = f.read()
+ default_version = REPLACE_PATTERNS["init"][0].search(code).groups()[0]
+ return packaging.version.parse(default_version)
+
+
+def pre_release_work(patch=False):
+ """Do all the necessary pre-release steps."""
+ # First let's get the default version: base version if we are in dev, bump minor otherwise.
+ default_version = get_version()
+ if patch and default_version.is_devrelease:
+ raise ValueError("Can't create a patch version from the dev branch, checkout a released version!")
+ if default_version.is_devrelease:
+ default_version = default_version.base_version
+ elif patch:
+ default_version = f"{default_version.major}.{default_version.minor}.{default_version.micro + 1}"
+ else:
+ default_version = f"{default_version.major}.{default_version.minor + 1}.0"
+
+ # Now let's ask nicely if that's the right one.
+ version = input(f"Which version are you releasing? [{default_version}]")
+ if len(version) == 0:
+ version = default_version
+
+ print(f"Updating version to {version}.")
+ global_version_update(version, patch=patch)
+
+
+# if not patch:
+# print("Cleaning main README, don't forget to run `make fix-copies`.")
+# clean_main_ref_in_model_list()
+
+
+def post_release_work():
+ """Do all the necesarry post-release steps."""
+ # First let's get the current version
+ current_version = get_version()
+ dev_version = f"{current_version.major}.{current_version.minor + 1}.0.dev0"
+ current_version = current_version.base_version
+
+ # Check with the user we got that right.
+ version = input(f"Which version are we developing now? [{dev_version}]")
+ if len(version) == 0:
+ version = dev_version
+
+ print(f"Updating version to {version}.")
+ global_version_update(version)
+
+
+# print("Cleaning main README, don't forget to run `make fix-copies`.")
+# clean_main_ref_in_model_list()
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--post_release", action="store_true", help="Whether this is pre or post release.")
+ parser.add_argument("--patch", action="store_true", help="Whether or not this is a patch release.")
+ args = parser.parse_args()
+ if not args.post_release:
+ pre_release_work(patch=args.patch)
+ elif args.patch:
+ print("Nothing to do after a patch :-)")
+ else:
+ post_release_work()
diff --git a/diffusers/utils/stale.py b/diffusers/utils/stale.py
new file mode 100644
index 0000000000000000000000000000000000000000..12932f31c243f44566fb65daf80b0b3637cc8a95
--- /dev/null
+++ b/diffusers/utils/stale.py
@@ -0,0 +1,77 @@
+# Copyright 2023 The HuggingFace Team, the AllenNLP library authors. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Script to close stale issue. Taken in part from the AllenNLP repository.
+https://github.com/allenai/allennlp.
+"""
+import os
+from datetime import datetime as dt
+
+from github import Github
+
+
+LABELS_TO_EXEMPT = [
+ "good first issue",
+ "good second issue",
+ "good difficult issue",
+ "enhancement",
+ "new pipeline/model",
+ "new scheduler",
+ "wip",
+]
+
+
+def main():
+ g = Github(os.environ["GITHUB_TOKEN"])
+ repo = g.get_repo("huggingface/diffusers")
+ open_issues = repo.get_issues(state="open")
+
+ for issue in open_issues:
+ comments = sorted(issue.get_comments(), key=lambda i: i.created_at, reverse=True)
+ last_comment = comments[0] if len(comments) > 0 else None
+ if (
+ last_comment is not None
+ and last_comment.user.login == "github-actions[bot]"
+ and (dt.utcnow() - issue.updated_at).days > 7
+ and (dt.utcnow() - issue.created_at).days >= 30
+ and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
+ ):
+ # Closes the issue after 7 days of inactivity since the Stalebot notification.
+ issue.edit(state="closed")
+ elif (
+ "stale" in issue.get_labels()
+ and last_comment is not None
+ and last_comment.user.login != "github-actions[bot]"
+ ):
+ # Opens the issue if someone other than Stalebot commented.
+ issue.edit(state="open")
+ issue.remove_from_labels("stale")
+ elif (
+ (dt.utcnow() - issue.updated_at).days > 23
+ and (dt.utcnow() - issue.created_at).days >= 30
+ and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
+ ):
+ # Post a Stalebot notification after 23 days of inactivity.
+ issue.create_comment(
+ "This issue has been automatically marked as stale because it has not had "
+ "recent activity. If you think this still needs to be addressed "
+ "please comment on this thread.\n\nPlease note that issues that do not follow the "
+ "[contributing guidelines](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md) "
+ "are likely to be ignored."
+ )
+ issue.add_to_labels("stale")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/models.py b/models.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ffdacfe885a977546d48c18eccee5b51f314d25
--- /dev/null
+++ b/models.py
@@ -0,0 +1,304 @@
+import yaml
+import random
+import inspect
+import numpy as np
+from tqdm import tqdm
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from einops import repeat
+from tools.torch_tools import wav_to_fbank
+
+from audioldm.audio.stft import TacotronSTFT
+from audioldm.variational_autoencoder import AutoencoderKL
+from audioldm.utils import default_audioldm_config, get_metadata
+
+from transformers import CLIPTokenizer, AutoTokenizer
+from transformers import CLIPTextModel, T5EncoderModel, AutoModel
+
+import sys
+sys.path.insert(0, "diffusers/src")
+
+import diffusers
+from diffusers.utils import randn_tensor
+from diffusers import DDPMScheduler, UNet2DConditionModel
+from diffusers import AutoencoderKL as DiffuserAutoencoderKL
+
+
+def build_pretrained_models(name):
+ checkpoint = torch.load(get_metadata()[name]["path"], map_location="cpu")
+ scale_factor = checkpoint["state_dict"]["scale_factor"].item()
+
+ vae_state_dict = {k[18:]: v for k, v in checkpoint["state_dict"].items() if "first_stage_model." in k}
+
+ config = default_audioldm_config(name)
+ vae_config = config["model"]["params"]["first_stage_config"]["params"]
+ vae_config["scale_factor"] = scale_factor
+
+ vae = AutoencoderKL(**vae_config)
+ vae.load_state_dict(vae_state_dict)
+
+ fn_STFT = TacotronSTFT(
+ config["preprocessing"]["stft"]["filter_length"],
+ config["preprocessing"]["stft"]["hop_length"],
+ config["preprocessing"]["stft"]["win_length"],
+ config["preprocessing"]["mel"]["n_mel_channels"],
+ config["preprocessing"]["audio"]["sampling_rate"],
+ config["preprocessing"]["mel"]["mel_fmin"],
+ config["preprocessing"]["mel"]["mel_fmax"],
+ )
+
+ vae.eval()
+ fn_STFT.eval()
+ return vae, fn_STFT
+
+
+class AudioDiffusion(nn.Module):
+ def __init__(
+ self,
+ text_encoder_name,
+ scheduler_name,
+ unet_model_name=None,
+ unet_model_config_path=None,
+ snr_gamma=None,
+ freeze_text_encoder=True,
+ uncondition=False,
+
+ ):
+ super().__init__()
+
+ assert unet_model_name is not None or unet_model_config_path is not None, "Either UNet pretrain model name or a config file path is required"
+
+ self.text_encoder_name = text_encoder_name
+ self.scheduler_name = scheduler_name
+ self.unet_model_name = unet_model_name
+ self.unet_model_config_path = unet_model_config_path
+ self.snr_gamma = snr_gamma
+ self.freeze_text_encoder = freeze_text_encoder
+ self.uncondition = uncondition
+
+ # https://huggingface.co/docs/diffusers/v0.14.0/en/api/schedulers/overview
+ self.noise_scheduler = DDPMScheduler.from_pretrained(self.scheduler_name, subfolder="scheduler")
+ self.inference_scheduler = DDPMScheduler.from_pretrained(self.scheduler_name, subfolder="scheduler")
+
+ if unet_model_config_path:
+ unet_config = UNet2DConditionModel.load_config(unet_model_config_path)
+ self.unet = UNet2DConditionModel.from_config(unet_config, subfolder="unet")
+ self.set_from = "random"
+ print("UNet initialized randomly.")
+ else:
+ self.unet = UNet2DConditionModel.from_pretrained(unet_model_name, subfolder="unet")
+ self.set_from = "pre-trained"
+ self.group_in = nn.Sequential(nn.Linear(8, 512), nn.Linear(512, 4))
+ self.group_out = nn.Sequential(nn.Linear(4, 512), nn.Linear(512, 8))
+ print("UNet initialized from stable diffusion checkpoint.")
+
+ if "stable-diffusion" in self.text_encoder_name:
+ self.tokenizer = CLIPTokenizer.from_pretrained(self.text_encoder_name, subfolder="tokenizer")
+ self.text_encoder = CLIPTextModel.from_pretrained(self.text_encoder_name, subfolder="text_encoder")
+ elif "t5" in self.text_encoder_name:
+ self.tokenizer = AutoTokenizer.from_pretrained(self.text_encoder_name)
+ self.text_encoder = T5EncoderModel.from_pretrained(self.text_encoder_name)
+ else:
+ self.tokenizer = AutoTokenizer.from_pretrained(self.text_encoder_name)
+ self.text_encoder = AutoModel.from_pretrained(self.text_encoder_name)
+
+ def compute_snr(self, timesteps):
+ """
+ Computes SNR as per https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L847-L849
+ """
+ alphas_cumprod = self.noise_scheduler.alphas_cumprod
+ sqrt_alphas_cumprod = alphas_cumprod**0.5
+ sqrt_one_minus_alphas_cumprod = (1.0 - alphas_cumprod) ** 0.5
+
+ # Expand the tensors.
+ # Adapted from https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L1026
+ sqrt_alphas_cumprod = sqrt_alphas_cumprod.to(device=timesteps.device)[timesteps].float()
+ while len(sqrt_alphas_cumprod.shape) < len(timesteps.shape):
+ sqrt_alphas_cumprod = sqrt_alphas_cumprod[..., None]
+ alpha = sqrt_alphas_cumprod.expand(timesteps.shape)
+
+ sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod.to(device=timesteps.device)[timesteps].float()
+ while len(sqrt_one_minus_alphas_cumprod.shape) < len(timesteps.shape):
+ sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod[..., None]
+ sigma = sqrt_one_minus_alphas_cumprod.expand(timesteps.shape)
+
+ # Compute SNR.
+ snr = (alpha / sigma) ** 2
+ return snr
+
+ def encode_text(self, prompt):
+ device = self.text_encoder.device
+ batch = self.tokenizer(
+ prompt, max_length=self.tokenizer.model_max_length, padding=True, truncation=True, return_tensors="pt"
+ )
+ input_ids, attention_mask = batch.input_ids.to(device), batch.attention_mask.to(device)
+
+ if self.freeze_text_encoder:
+ with torch.no_grad():
+ encoder_hidden_states = self.text_encoder(
+ input_ids=input_ids, attention_mask=attention_mask
+ )[0]
+ else:
+ encoder_hidden_states = self.text_encoder(
+ input_ids=input_ids, attention_mask=attention_mask
+ )[0]
+
+ boolean_encoder_mask = (attention_mask == 1).to(device)
+ return encoder_hidden_states, boolean_encoder_mask
+
+ def forward(self, latents, prompt):
+ device = self.text_encoder.device
+ num_train_timesteps = self.noise_scheduler.num_train_timesteps
+ self.noise_scheduler.set_timesteps(num_train_timesteps, device=device)
+
+ encoder_hidden_states, boolean_encoder_mask = self.encode_text(prompt)
+
+ if self.uncondition:
+ mask_indices = [k for k in range(len(prompt)) if random.random() < 0.1]
+ if len(mask_indices) > 0:
+ encoder_hidden_states[mask_indices] = 0
+
+ bsz = latents.shape[0]
+ # Sample a random timestep for each instance
+ timesteps = torch.randint(0, self.noise_scheduler.num_train_timesteps, (bsz,), device=device)
+ timesteps = timesteps.long()
+
+ noise = torch.randn_like(latents)
+ noisy_latents = self.noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the target for loss depending on the prediction type
+ if self.noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif self.noise_scheduler.config.prediction_type == "v_prediction":
+ target = self.noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {self.noise_scheduler.config.prediction_type}")
+
+ if self.set_from == "random":
+ model_pred = self.unet(
+ noisy_latents, timesteps, encoder_hidden_states,
+ encoder_attention_mask=boolean_encoder_mask
+ ).sample
+
+ elif self.set_from == "pre-trained":
+ compressed_latents = self.group_in(noisy_latents.permute(0, 2, 3, 1).contiguous()).permute(0, 3, 1, 2).contiguous()
+ model_pred = self.unet(
+ compressed_latents, timesteps, encoder_hidden_states,
+ encoder_attention_mask=boolean_encoder_mask
+ ).sample
+ model_pred = self.group_out(model_pred.permute(0, 2, 3, 1).contiguous()).permute(0, 3, 1, 2).contiguous()
+
+ if self.snr_gamma is None:
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+ else:
+ # Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
+ # Adaptef from huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py
+ snr = self.compute_snr(timesteps)
+ mse_loss_weights = (
+ torch.stack([snr, self.snr_gamma * torch.ones_like(timesteps)], dim=1).min(dim=1)[0] / snr
+ )
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
+ loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
+ loss = loss.mean()
+
+ return loss
+
+ @torch.no_grad()
+ def inference(self, prompt, inference_scheduler, num_steps=20, guidance_scale=3, num_samples_per_prompt=1,
+ disable_progress=True):
+ device = self.text_encoder.device
+ classifier_free_guidance = guidance_scale > 1.0
+ batch_size = len(prompt) * num_samples_per_prompt
+
+ if classifier_free_guidance:
+ prompt_embeds, boolean_prompt_mask = self.encode_text_classifier_free(prompt, num_samples_per_prompt)
+ else:
+ prompt_embeds, boolean_prompt_mask = self.encode_text(prompt)
+ prompt_embeds = prompt_embeds.repeat_interleave(num_samples_per_prompt, 0)
+ boolean_prompt_mask = boolean_prompt_mask.repeat_interleave(num_samples_per_prompt, 0)
+
+ inference_scheduler.set_timesteps(num_steps, device=device)
+ timesteps = inference_scheduler.timesteps
+
+ num_channels_latents = self.unet.in_channels
+ latents = self.prepare_latents(batch_size, inference_scheduler, num_channels_latents, prompt_embeds.dtype, device)
+
+ num_warmup_steps = len(timesteps) - num_steps * inference_scheduler.order
+ progress_bar = tqdm(range(num_steps), disable=disable_progress)
+
+ for i, t in enumerate(timesteps):
+ # expand the latents if we are doing classifier free guidance
+ latent_model_input = torch.cat([latents] * 2) if classifier_free_guidance else latents
+ latent_model_input = inference_scheduler.scale_model_input(latent_model_input, t)
+
+ noise_pred = self.unet(
+ latent_model_input, t, encoder_hidden_states=prompt_embeds,
+ encoder_attention_mask=boolean_prompt_mask
+ ).sample
+
+ # perform guidance
+ if classifier_free_guidance:
+ noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
+ noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
+
+ # compute the previous noisy sample x_t -> x_t-1
+ latents = inference_scheduler.step(noise_pred, t, latents).prev_sample
+
+ # call the callback, if provided
+ if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % inference_scheduler.order == 0):
+ progress_bar.update(1)
+
+ if self.set_from == "pre-trained":
+ latents = self.group_out(latents.permute(0, 2, 3, 1).contiguous()).permute(0, 3, 1, 2).contiguous()
+ return latents
+
+ def prepare_latents(self, batch_size, inference_scheduler, num_channels_latents, dtype, device):
+ shape = (batch_size, num_channels_latents, 256, 16)
+ latents = randn_tensor(shape, generator=None, device=device, dtype=dtype)
+ # scale the initial noise by the standard deviation required by the scheduler
+ latents = latents * inference_scheduler.init_noise_sigma
+ return latents
+
+ def encode_text_classifier_free(self, prompt, num_samples_per_prompt):
+ device = self.text_encoder.device
+ batch = self.tokenizer(
+ prompt, max_length=self.tokenizer.model_max_length, padding=True, truncation=True, return_tensors="pt"
+ )
+ input_ids, attention_mask = batch.input_ids.to(device), batch.attention_mask.to(device)
+
+ with torch.no_grad():
+ prompt_embeds = self.text_encoder(
+ input_ids=input_ids, attention_mask=attention_mask
+ )[0]
+
+ prompt_embeds = prompt_embeds.repeat_interleave(num_samples_per_prompt, 0)
+ attention_mask = attention_mask.repeat_interleave(num_samples_per_prompt, 0)
+
+ # get unconditional embeddings for classifier free guidance
+ uncond_tokens = [""] * len(prompt)
+
+ max_length = prompt_embeds.shape[1]
+ uncond_batch = self.tokenizer(
+ uncond_tokens, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt",
+ )
+ uncond_input_ids = uncond_batch.input_ids.to(device)
+ uncond_attention_mask = uncond_batch.attention_mask.to(device)
+
+ with torch.no_grad():
+ negative_prompt_embeds = self.text_encoder(
+ input_ids=uncond_input_ids, attention_mask=uncond_attention_mask
+ )[0]
+
+ negative_prompt_embeds = negative_prompt_embeds.repeat_interleave(num_samples_per_prompt, 0)
+ uncond_attention_mask = uncond_attention_mask.repeat_interleave(num_samples_per_prompt, 0)
+
+ # For classifier free guidance, we need to do two forward passes.
+ # We concatenate the unconditional and text embeddings into a single batch to avoid doing two forward passes
+ prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
+ prompt_mask = torch.cat([uncond_attention_mask, attention_mask])
+ boolean_prompt_mask = (prompt_mask == 1).to(device)
+
+ return prompt_embeds, boolean_prompt_mask
\ No newline at end of file
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..da6a5a1ba503717a34bc0eb3481783f0a24f6a52
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,33 @@
+torch==2.0.1
+spaces==0.26.0
+torchaudio==2.0.2
+torchvision==0.15.2
+transformers==4.31.0
+accelerate==0.21.0
+datasets==2.1.0
+einops==0.6.1
+h5py==3.8.0
+huggingface_hub==0.19.4
+importlib_metadata==6.3.0
+librosa==0.9.2
+matplotlib==3.5.2
+numpy==1.23.0
+omegaconf==2.3.0
+packaging==23.1
+pandas==1.4.1
+progressbar33==2.4
+protobuf==3.20.*
+resampy==0.4.2
+safetensors==0.3.2
+sentencepiece==0.1.99
+scikit_image==0.19.3
+scikit_learn==1.2.2
+scipy==1.8.0
+soundfile==0.12.1
+ssr_eval==0.0.6
+torchlibrosa==0.1.0
+tqdm==4.63.1
+wandb==0.12.14
+ipython==8.12.0
+gradio==4.3.0
+wavio==0.0.7
\ No newline at end of file
diff --git a/setup.py b/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc9737bdcc3f4a80b96e5e212744e55fe2dcdd02
--- /dev/null
+++ b/setup.py
@@ -0,0 +1,7 @@
+import os
+requirement_path = "requirements.txt"
+install_requires = []
+if os.path.isfile(requirement_path):
+ with open(requirement_path) as f:
+ install_requires = f.read().splitlines()
+setup(name="mypackage", install_requires=install_requires, [...])
\ No newline at end of file
diff --git a/tools/.ipynb_checkpoints/mix-checkpoint.py b/tools/.ipynb_checkpoints/mix-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..5311d659098ab2a64486828fc531a3e6dcb49759
--- /dev/null
+++ b/tools/.ipynb_checkpoints/mix-checkpoint.py
@@ -0,0 +1,51 @@
+import numpy as np
+
+
+def a_weight(fs, n_fft, min_db=-80.0):
+ freq = np.linspace(0, fs // 2, n_fft // 2 + 1)
+ freq_sq = np.power(freq, 2)
+ freq_sq[0] = 1.0
+ weight = 2.0 + 20.0 * (2 * np.log10(12194) + 2 * np.log10(freq_sq)
+ - np.log10(freq_sq + 12194 ** 2)
+ - np.log10(freq_sq + 20.6 ** 2)
+ - 0.5 * np.log10(freq_sq + 107.7 ** 2)
+ - 0.5 * np.log10(freq_sq + 737.9 ** 2))
+ weight = np.maximum(weight, min_db)
+
+ return weight
+
+
+def compute_gain(sound, fs, min_db=-80.0, mode="A_weighting"):
+ if fs == 16000:
+ n_fft = 2048
+ elif fs == 44100:
+ n_fft = 4096
+ else:
+ raise Exception("Invalid fs {}".format(fs))
+ stride = n_fft // 2
+
+ gain = []
+ for i in range(0, len(sound) - n_fft + 1, stride):
+ if mode == "RMSE":
+ g = np.mean(sound[i: i + n_fft] ** 2)
+ elif mode == "A_weighting":
+ spec = np.fft.rfft(np.hanning(n_fft + 1)[:-1] * sound[i: i + n_fft])
+ power_spec = np.abs(spec) ** 2
+ a_weighted_spec = power_spec * np.power(10, a_weight(fs, n_fft) / 10)
+ g = np.sum(a_weighted_spec)
+ else:
+ raise Exception("Invalid mode {}".format(mode))
+ gain.append(g)
+
+ gain = np.array(gain)
+ gain = np.maximum(gain, np.power(10, min_db / 10))
+ gain_db = 10 * np.log10(gain)
+ return gain_db
+
+
+def mix(sound1, sound2, r, fs):
+ gain1 = np.max(compute_gain(sound1, fs)) # Decibel
+ gain2 = np.max(compute_gain(sound2, fs))
+ t = 1.0 / (1 + np.power(10, (gain1 - gain2) / 20.) * (1 - r) / r)
+ sound = ((sound1 * t + sound2 * (1 - t)) / np.sqrt(t ** 2 + (1 - t) ** 2))
+ return sound
\ No newline at end of file
diff --git a/tools/.ipynb_checkpoints/torch_tools-checkpoint.py b/tools/.ipynb_checkpoints/torch_tools-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..d83d3137460aaf04ef1b335efb42ddb37d24b3ea
--- /dev/null
+++ b/tools/.ipynb_checkpoints/torch_tools-checkpoint.py
@@ -0,0 +1,133 @@
+import torch
+import torchaudio
+import random
+import itertools
+import numpy as np
+from tools.mix import mix
+
+
+def normalize_wav(waveform):
+ waveform = waveform - torch.mean(waveform)
+ waveform = waveform / (torch.max(torch.abs(waveform)) + 1e-8)
+ return waveform * 0.5
+
+
+def pad_wav(waveform, segment_length):
+ waveform_length = len(waveform)
+
+ if segment_length is None or waveform_length == segment_length:
+ return waveform
+ elif waveform_length > segment_length:
+ return waveform[:segment_length]
+ else:
+ pad_wav = torch.zeros(segment_length - waveform_length).to(waveform.device)
+ waveform = torch.cat([waveform, pad_wav])
+ return waveform
+
+
+def _pad_spec(fbank, target_length=1024):
+ batch, n_frames, channels = fbank.shape
+ p = target_length - n_frames
+ if p > 0:
+ pad = torch.zeros(batch, p, channels).to(fbank.device)
+ fbank = torch.cat([fbank, pad], 1)
+ elif p < 0:
+ fbank = fbank[:, :target_length, :]
+
+ if channels % 2 != 0:
+ fbank = fbank[:, :, :-1]
+
+ return fbank
+
+
+def read_wav_file(filename, segment_length):
+ waveform, sr = torchaudio.load(filename) # Faster!!!
+ try:
+ waveform = torchaudio.functional.resample(waveform, orig_freq=sr, new_freq=16000)[0]
+ except:
+ print ("0 length wav encountered. Setting to random:", filename)
+ waveform = torch.rand(160000)
+
+ try:
+ waveform = normalize_wav(waveform)
+ except:
+ print ("Exception normalizing:", filename)
+ waveform = torch.ones(160000)
+ waveform = pad_wav(waveform, segment_length).unsqueeze(0)
+ waveform = waveform / torch.max(torch.abs(waveform))
+ waveform = 0.5 * waveform
+ return waveform
+
+
+def get_mel_from_wav(audio, _stft):
+ audio = torch.nan_to_num(torch.clip(audio, -1, 1))
+ audio = torch.autograd.Variable(audio, requires_grad=False)
+ melspec, log_magnitudes_stft, energy = _stft.mel_spectrogram(audio)
+ return melspec, log_magnitudes_stft, energy
+
+
+def wav_to_fbank(paths, target_length=1024, fn_STFT=None):
+ assert fn_STFT is not None
+
+ waveform = torch.cat([read_wav_file(path, target_length * 160) for path in paths], 0) # hop size is 160
+
+ fbank, log_magnitudes_stft, energy = get_mel_from_wav(waveform, fn_STFT)
+ fbank = fbank.transpose(1, 2)
+ log_magnitudes_stft = log_magnitudes_stft.transpose(1, 2)
+
+ fbank, log_magnitudes_stft = _pad_spec(fbank, target_length), _pad_spec(
+ log_magnitudes_stft, target_length
+ )
+
+ return fbank, log_magnitudes_stft, waveform
+
+
+def uncapitalize(s):
+ if s:
+ return s[:1].lower() + s[1:]
+ else:
+ return ""
+
+
+def mix_wavs_and_captions(path1, path2, caption1, caption2, target_length=1024):
+ sound1 = read_wav_file(path1, target_length * 160)[0].numpy()
+ sound2 = read_wav_file(path2, target_length * 160)[0].numpy()
+ mixed_sound = mix(sound1, sound2, 0.5, 16000).reshape(1, -1)
+ mixed_caption = "{} and {}".format(caption1, uncapitalize(caption2))
+ return mixed_sound, mixed_caption
+
+
+def augment(paths, texts, num_items=4, target_length=1024):
+ mixed_sounds, mixed_captions = [], []
+ combinations = list(itertools.combinations(list(range(len(texts))), 2))
+ random.shuffle(combinations)
+ if len(combinations) < num_items:
+ selected_combinations = combinations
+ else:
+ selected_combinations = combinations[:num_items]
+
+ for (i, j) in selected_combinations:
+ new_sound, new_caption = mix_wavs_and_captions(paths[i], paths[j], texts[i], texts[j], target_length)
+ mixed_sounds.append(new_sound)
+ mixed_captions.append(new_caption)
+
+ waveform = torch.tensor(np.concatenate(mixed_sounds, 0))
+ waveform = waveform / torch.max(torch.abs(waveform))
+ waveform = 0.5 * waveform
+
+ return waveform, mixed_captions
+
+
+def augment_wav_to_fbank(paths, texts, num_items=4, target_length=1024, fn_STFT=None):
+ assert fn_STFT is not None
+
+ waveform, captions = augment(paths, texts)
+ fbank, log_magnitudes_stft, energy = get_mel_from_wav(waveform, fn_STFT)
+ fbank = fbank.transpose(1, 2)
+ log_magnitudes_stft = log_magnitudes_stft.transpose(1, 2)
+
+ fbank, log_magnitudes_stft = _pad_spec(fbank, target_length), _pad_spec(
+ log_magnitudes_stft, target_length
+ )
+
+ return fbank, log_magnitudes_stft, waveform, captions
\ No newline at end of file
diff --git a/tools/__init__.py b/tools/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/tools/__pycache__/__init__.cpython-310.pyc b/tools/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fd0d27cf13002fdbee2e7b3846a416d1892cddb4
Binary files /dev/null and b/tools/__pycache__/__init__.cpython-310.pyc differ
diff --git a/tools/__pycache__/__init__.cpython-39.pyc b/tools/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..561587f0c04bf1252ca1bafd64202d6c4f16dc4c
Binary files /dev/null and b/tools/__pycache__/__init__.cpython-39.pyc differ
diff --git a/tools/__pycache__/mix.cpython-310.pyc b/tools/__pycache__/mix.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0593806772e9ccb1d5316b96bb2594b6a104f9d8
Binary files /dev/null and b/tools/__pycache__/mix.cpython-310.pyc differ
diff --git a/tools/__pycache__/mix.cpython-39.pyc b/tools/__pycache__/mix.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..41ffc9487eec38d22b7f3640a209d4a97c12aca4
Binary files /dev/null and b/tools/__pycache__/mix.cpython-39.pyc differ
diff --git a/tools/__pycache__/torch_tools.cpython-310.pyc b/tools/__pycache__/torch_tools.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..2db92955f41b3ebfe789c486da45a4b8ccabaa38
Binary files /dev/null and b/tools/__pycache__/torch_tools.cpython-310.pyc differ
diff --git a/tools/__pycache__/torch_tools.cpython-39.pyc b/tools/__pycache__/torch_tools.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8056cd3e5331af8e98495dd4a98f02279e11541e
Binary files /dev/null and b/tools/__pycache__/torch_tools.cpython-39.pyc differ
diff --git a/tools/mix.py b/tools/mix.py
new file mode 100644
index 0000000000000000000000000000000000000000..5311d659098ab2a64486828fc531a3e6dcb49759
--- /dev/null
+++ b/tools/mix.py
@@ -0,0 +1,51 @@
+import numpy as np
+
+
+def a_weight(fs, n_fft, min_db=-80.0):
+ freq = np.linspace(0, fs // 2, n_fft // 2 + 1)
+ freq_sq = np.power(freq, 2)
+ freq_sq[0] = 1.0
+ weight = 2.0 + 20.0 * (2 * np.log10(12194) + 2 * np.log10(freq_sq)
+ - np.log10(freq_sq + 12194 ** 2)
+ - np.log10(freq_sq + 20.6 ** 2)
+ - 0.5 * np.log10(freq_sq + 107.7 ** 2)
+ - 0.5 * np.log10(freq_sq + 737.9 ** 2))
+ weight = np.maximum(weight, min_db)
+
+ return weight
+
+
+def compute_gain(sound, fs, min_db=-80.0, mode="A_weighting"):
+ if fs == 16000:
+ n_fft = 2048
+ elif fs == 44100:
+ n_fft = 4096
+ else:
+ raise Exception("Invalid fs {}".format(fs))
+ stride = n_fft // 2
+
+ gain = []
+ for i in range(0, len(sound) - n_fft + 1, stride):
+ if mode == "RMSE":
+ g = np.mean(sound[i: i + n_fft] ** 2)
+ elif mode == "A_weighting":
+ spec = np.fft.rfft(np.hanning(n_fft + 1)[:-1] * sound[i: i + n_fft])
+ power_spec = np.abs(spec) ** 2
+ a_weighted_spec = power_spec * np.power(10, a_weight(fs, n_fft) / 10)
+ g = np.sum(a_weighted_spec)
+ else:
+ raise Exception("Invalid mode {}".format(mode))
+ gain.append(g)
+
+ gain = np.array(gain)
+ gain = np.maximum(gain, np.power(10, min_db / 10))
+ gain_db = 10 * np.log10(gain)
+ return gain_db
+
+
+def mix(sound1, sound2, r, fs):
+ gain1 = np.max(compute_gain(sound1, fs)) # Decibel
+ gain2 = np.max(compute_gain(sound2, fs))
+ t = 1.0 / (1 + np.power(10, (gain1 - gain2) / 20.) * (1 - r) / r)
+ sound = ((sound1 * t + sound2 * (1 - t)) / np.sqrt(t ** 2 + (1 - t) ** 2))
+ return sound
\ No newline at end of file
diff --git a/tools/torch_tools.py b/tools/torch_tools.py
new file mode 100644
index 0000000000000000000000000000000000000000..d83d3137460aaf04ef1b335efb42ddb37d24b3ea
--- /dev/null
+++ b/tools/torch_tools.py
@@ -0,0 +1,133 @@
+import torch
+import torchaudio
+import random
+import itertools
+import numpy as np
+from tools.mix import mix
+
+
+def normalize_wav(waveform):
+ waveform = waveform - torch.mean(waveform)
+ waveform = waveform / (torch.max(torch.abs(waveform)) + 1e-8)
+ return waveform * 0.5
+
+
+def pad_wav(waveform, segment_length):
+ waveform_length = len(waveform)
+
+ if segment_length is None or waveform_length == segment_length:
+ return waveform
+ elif waveform_length > segment_length:
+ return waveform[:segment_length]
+ else:
+ pad_wav = torch.zeros(segment_length - waveform_length).to(waveform.device)
+ waveform = torch.cat([waveform, pad_wav])
+ return waveform
+
+
+def _pad_spec(fbank, target_length=1024):
+ batch, n_frames, channels = fbank.shape
+ p = target_length - n_frames
+ if p > 0:
+ pad = torch.zeros(batch, p, channels).to(fbank.device)
+ fbank = torch.cat([fbank, pad], 1)
+ elif p < 0:
+ fbank = fbank[:, :target_length, :]
+
+ if channels % 2 != 0:
+ fbank = fbank[:, :, :-1]
+
+ return fbank
+
+
+def read_wav_file(filename, segment_length):
+ waveform, sr = torchaudio.load(filename) # Faster!!!
+ try:
+ waveform = torchaudio.functional.resample(waveform, orig_freq=sr, new_freq=16000)[0]
+ except:
+ print ("0 length wav encountered. Setting to random:", filename)
+ waveform = torch.rand(160000)
+
+ try:
+ waveform = normalize_wav(waveform)
+ except:
+ print ("Exception normalizing:", filename)
+ waveform = torch.ones(160000)
+ waveform = pad_wav(waveform, segment_length).unsqueeze(0)
+ waveform = waveform / torch.max(torch.abs(waveform))
+ waveform = 0.5 * waveform
+ return waveform
+
+
+def get_mel_from_wav(audio, _stft):
+ audio = torch.nan_to_num(torch.clip(audio, -1, 1))
+ audio = torch.autograd.Variable(audio, requires_grad=False)
+ melspec, log_magnitudes_stft, energy = _stft.mel_spectrogram(audio)
+ return melspec, log_magnitudes_stft, energy
+
+
+def wav_to_fbank(paths, target_length=1024, fn_STFT=None):
+ assert fn_STFT is not None
+
+ waveform = torch.cat([read_wav_file(path, target_length * 160) for path in paths], 0) # hop size is 160
+
+ fbank, log_magnitudes_stft, energy = get_mel_from_wav(waveform, fn_STFT)
+ fbank = fbank.transpose(1, 2)
+ log_magnitudes_stft = log_magnitudes_stft.transpose(1, 2)
+
+ fbank, log_magnitudes_stft = _pad_spec(fbank, target_length), _pad_spec(
+ log_magnitudes_stft, target_length
+ )
+
+ return fbank, log_magnitudes_stft, waveform
+
+
+def uncapitalize(s):
+ if s:
+ return s[:1].lower() + s[1:]
+ else:
+ return ""
+
+
+def mix_wavs_and_captions(path1, path2, caption1, caption2, target_length=1024):
+ sound1 = read_wav_file(path1, target_length * 160)[0].numpy()
+ sound2 = read_wav_file(path2, target_length * 160)[0].numpy()
+ mixed_sound = mix(sound1, sound2, 0.5, 16000).reshape(1, -1)
+ mixed_caption = "{} and {}".format(caption1, uncapitalize(caption2))
+ return mixed_sound, mixed_caption
+
+
+def augment(paths, texts, num_items=4, target_length=1024):
+ mixed_sounds, mixed_captions = [], []
+ combinations = list(itertools.combinations(list(range(len(texts))), 2))
+ random.shuffle(combinations)
+ if len(combinations) < num_items:
+ selected_combinations = combinations
+ else:
+ selected_combinations = combinations[:num_items]
+
+ for (i, j) in selected_combinations:
+ new_sound, new_caption = mix_wavs_and_captions(paths[i], paths[j], texts[i], texts[j], target_length)
+ mixed_sounds.append(new_sound)
+ mixed_captions.append(new_caption)
+
+ waveform = torch.tensor(np.concatenate(mixed_sounds, 0))
+ waveform = waveform / torch.max(torch.abs(waveform))
+ waveform = 0.5 * waveform
+
+ return waveform, mixed_captions
+
+
+def augment_wav_to_fbank(paths, texts, num_items=4, target_length=1024, fn_STFT=None):
+ assert fn_STFT is not None
+
+ waveform, captions = augment(paths, texts)
+ fbank, log_magnitudes_stft, energy = get_mel_from_wav(waveform, fn_STFT)
+ fbank = fbank.transpose(1, 2)
+ log_magnitudes_stft = log_magnitudes_stft.transpose(1, 2)
+
+ fbank, log_magnitudes_stft = _pad_spec(fbank, target_length), _pad_spec(
+ log_magnitudes_stft, target_length
+ )
+
+ return fbank, log_magnitudes_stft, waveform, captions
\ No newline at end of file







