Spaces:
Configuration error

Configuration error
Migrate to HF Space
Browse files- LICENSE +21 -0
- Pandas-profile-report-of-the-dataset.html +0 -0
- Pandas-profile-screenshot.png +0 -0
- README.md +29 -12
- _config.yml +1 -0
- app.py +146 -0
- feature-logs.txt +3 -0
- requirements.txt +4 -0
- sample-dataframe.png +0 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2020 howard-haowen
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
Pandas-profile-report-of-the-dataset.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Pandas-profile-screenshot.png
ADDED
|
README.md
CHANGED
|
@@ -1,12 +1,29 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[](https://mybinder.org/v2/gh/howard-haowen/Formosan-languages/HEAD)
|
| 2 |
+
|
| 3 |
+
# 台灣南島語-華語句庫資料集
|
| 4 |
+
(Dataset of Formosan-Mandarin sentence pairs)
|
| 5 |
+
|
| 6 |
+
[點我](https://share.streamlit.io/howard-haowen/formosan-languages/main/app.py)進入互動式查詢系統
|
| 7 |
+
|
| 8 |
+
## 資料概要
|
| 9 |
+
- 🎢 資料集合計約13萬筆台灣南島語-華語句對
|
| 10 |
+
- ⚠️ 此查詢系統僅供教學與研究之用,內容版權歸原始資料提供者所有
|
| 11 |
+
- 💻 隨機顯示10筆資料
|
| 12 |
+

|
| 13 |
+
|
| 14 |
+
## 資料來源
|
| 15 |
+
- 以下資料經由網路爬蟲取得。
|
| 16 |
+
+ 🥅 九階教材: [族語E樂園](http://web.klokah.tw)
|
| 17 |
+
+ 💬 生活會話: [族語E樂園](http://web.klokah.tw)
|
| 18 |
+
+ 🧗 句型: [族語E樂園](http://web.klokah.tw)
|
| 19 |
+
+ 🔭 文法: [臺灣南島語言叢書](https://alilin.apc.gov.tw/tw/)
|
| 20 |
+
- 詞典資料使用`PDFMiner` 將2019版的PDF檔轉成HTML,再用`BeautifulSoup`抓取句對,偶爾會出現族語跟華語對不上的情形。若發現錯誤,請[聯絡我📩](https://github.com/howard-haowen)。詞典中重複出現的句子已從資料集中刪除。
|
| 21 |
+
+ 📚 詞典: [原住民族語言線上詞典](https://e-dictionary.apc.gov.tw/Index.htm?fbclid=IwAR18XBJPj2xs7nhpPlIUZ-P3joQRGXx22rbVcUvp14ysQu6SdrWYvo7gWCc)
|
| 22 |
+
|
| 23 |
+
## 統計報告
|
| 24 |
+
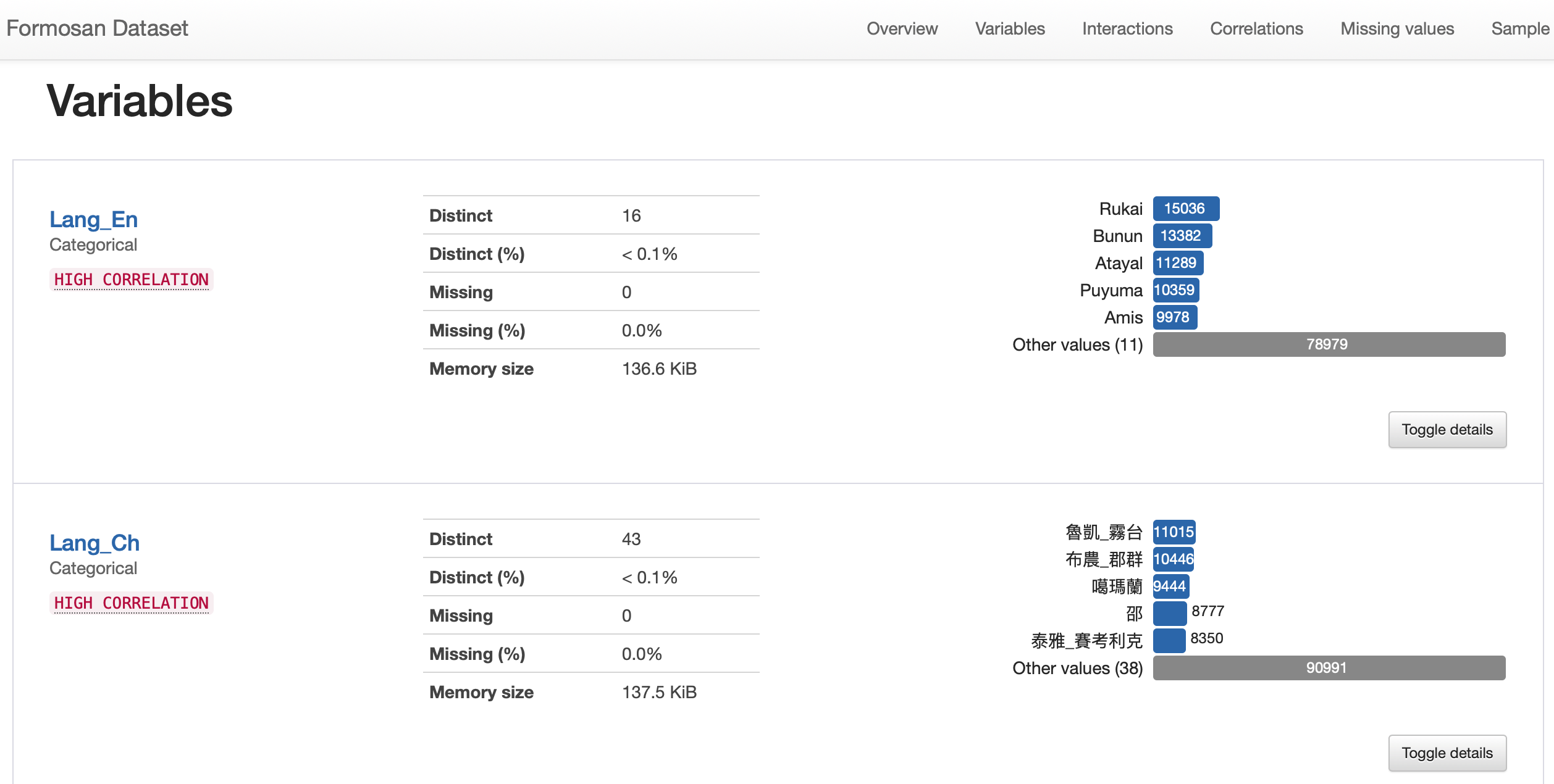
- 💻 點擊下面的預覽圖即可進入統計報告互動式查看頁面。報告中新增`word_counts`欄位,計算族語句子的字數。
|
| 25 |
+
|
| 26 |
+
[](https://howard-haowen.github.io/Formosan-languages/Pandas-profile-report-of-the-dataset.html)
|
| 27 |
+
|
| 28 |
+
***
|
| 29 |
+

|
_config.yml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
theme: jekyll-theme-leap-day
|
app.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import streamlit as st
|
| 3 |
+
import streamlit.components.v1 as components
|
| 4 |
+
import re
|
| 5 |
+
from pandas_profiling import ProfileReport
|
| 6 |
+
|
| 7 |
+
def main():
|
| 8 |
+
st.title("台灣南島語-華語句庫資料集")
|
| 9 |
+
st.subheader("Dataset of Formosan-Mandarin sentence pairs")
|
| 10 |
+
st.markdown(
|
| 11 |
+
"""
|
| 12 |
+

|
| 13 |
+
|
| 14 |
+
### 資料概要
|
| 15 |
+
- 🎢 資料集合計約13萬筆台灣南島語-華語句對
|
| 16 |
+
- ⚠️ 此查詢系統僅供教學與研究之用,內容版權歸原始資料提供者所有
|
| 17 |
+
|
| 18 |
+
### 資料來源
|
| 19 |
+
- 以下資料經由網路爬蟲取得。
|
| 20 |
+
+ 🥅 九階教材: [族語E樂園](http://web.klokah.tw)
|
| 21 |
+
+ 💬 生活會話: [族語E樂園](http://web.klokah.tw)
|
| 22 |
+
+ 🧗 句型: [族語E樂園](http://web.klokah.tw)
|
| 23 |
+
+ 🔭 文法: [臺灣南島語言叢書](https://alilin.apc.gov.tw/tw/)
|
| 24 |
+
- 詞典資料使用`PDFMiner` 將2019版的PDF檔轉成HTML,再用`BeautifulSoup`抓取句對,偶爾會出現族語跟華語對不上的情形。若發現錯誤,請[聯絡我📩](https://github.com/howard-haowen)。詞典中重複出現的句子已從資料集中刪除。
|
| 25 |
+
+ 📚 詞典: [原住民族語言線上詞典](https://e-dictionary.apc.gov.tw/Index.htm?fbclid=IwAR18XBJPj2xs7nhpPlIUZ-P3joQRGXx22rbVcUvp14ysQu6SdrWYvo7gWCc)
|
| 26 |
+
|
| 27 |
+
### 查詢方法
|
| 28 |
+
- 🔭 過濾:使用左側欄功能選單可過濾資料來源(可多選)與語言,也可使用華語或族語進行關鍵詞查詢。
|
| 29 |
+
- 🔍 關鍵詞查詢支援[正則表達式](https://zh.wikipedia.org/zh-tw/正则表达式)。
|
| 30 |
+
- 🥳 族語範例:
|
| 31 |
+
+ 使用`cia *`查詢布農語,能找到包含`danumcia`、`luduncia`或`siulcia`等詞的句子。
|
| 32 |
+
+ 使用`[a-z]{15,}`查詢任何族語,能找到包含15個字母以上單詞的句子,方便過濾長詞。
|
| 33 |
+
- 🤩 華語範例:
|
| 34 |
+
+ 使用`^有一`查詢華語,能找到使用`有一天`、`有一塊`或`有一晚`等詞出現在句首的句子。
|
| 35 |
+
+ 使用`[0-9]{1,}`查詢華語,能找到包含羅馬數字的句子,如`我今年16歲了`。
|
| 36 |
+
- 📚 排序:點選標題列。例如點選`族語`欄位標題列內的任何地方,資料集便會根據族語重新排序。
|
| 37 |
+
- 💬 更多:文字長度超過欄寬時,將滑鼠滑到欄位上方即可顯示完整文字。
|
| 38 |
+
- 🥅 放大:點選表格右上角↘️進入全螢幕模式,再次點選↘️返回主頁。
|
| 39 |
+
|
| 40 |
+
"""
|
| 41 |
+
)
|
| 42 |
+
# fetch the raw data
|
| 43 |
+
df = get_data()
|
| 44 |
+
# pd.set_option('max_colwidth', 600)
|
| 45 |
+
|
| 46 |
+
# remap column names
|
| 47 |
+
zh_columns = {'Lang_En': 'Language','Lang_Ch': '語言_方言', 'Ab': '族語', 'Ch': '華語', 'From': '來源'}
|
| 48 |
+
df.rename(columns=zh_columns, inplace=True)
|
| 49 |
+
|
| 50 |
+
# set up filtering options
|
| 51 |
+
source_set = df['來源'].unique()
|
| 52 |
+
sources = st.sidebar.multiselect(
|
| 53 |
+
"請選擇資料來源",
|
| 54 |
+
options=source_set,
|
| 55 |
+
default='詞典',)
|
| 56 |
+
langs = st.sidebar.selectbox(
|
| 57 |
+
"請選擇語言",
|
| 58 |
+
options=['布農','阿美','撒奇萊雅','噶瑪蘭','魯凱','排灣','卑南',
|
| 59 |
+
'泰雅','賽德克','太魯閣','鄒','拉阿魯哇','卡那卡那富',
|
| 60 |
+
'邵','賽夏','達悟'],)
|
| 61 |
+
texts = st.sidebar.radio(
|
| 62 |
+
"請選擇關鍵詞查詢文字類別",
|
| 63 |
+
options=['華語','族語'],)
|
| 64 |
+
|
| 65 |
+
# filter by sources
|
| 66 |
+
s_filt = df['來源'].isin(sources)
|
| 67 |
+
|
| 68 |
+
# select a language
|
| 69 |
+
if langs == "噶瑪蘭":
|
| 70 |
+
l_filt = df['Language'] == "Kavalan"
|
| 71 |
+
elif langs == "阿美":
|
| 72 |
+
l_filt = df['Language'] == "Amis"
|
| 73 |
+
elif langs == "撒奇萊雅":
|
| 74 |
+
l_filt = df['Language'] == "Sakizaya"
|
| 75 |
+
elif langs == "魯凱":
|
| 76 |
+
l_filt = df['Language'] == "Rukai"
|
| 77 |
+
elif langs == "排灣":
|
| 78 |
+
l_filt = df['Language'] == "Paiwan"
|
| 79 |
+
elif langs == "卑南":
|
| 80 |
+
l_filt = df['Language'] == "Puyuma"
|
| 81 |
+
elif langs == "賽德克":
|
| 82 |
+
l_filt = df['Language'] == "Seediq"
|
| 83 |
+
elif langs == "邵":
|
| 84 |
+
l_filt = df['Language'] == "Thao"
|
| 85 |
+
elif langs == "拉阿魯哇":
|
| 86 |
+
l_filt = df['Language'] == "Saaroa"
|
| 87 |
+
elif langs == "達悟":
|
| 88 |
+
l_filt = df['Language'] == "Yami"
|
| 89 |
+
elif langs == "泰雅":
|
| 90 |
+
l_filt = df['Language'] == "Atayal"
|
| 91 |
+
elif langs == "太魯閣":
|
| 92 |
+
l_filt = df['Language'] == "Truku"
|
| 93 |
+
elif langs == "鄒":
|
| 94 |
+
l_filt = df['Language'] == "Tsou"
|
| 95 |
+
elif langs == "卡那卡那富":
|
| 96 |
+
l_filt = df['Language'] == "Kanakanavu"
|
| 97 |
+
elif langs == "賽夏":
|
| 98 |
+
l_filt = df['Language'] == "Saisiyat"
|
| 99 |
+
elif langs == "布農":
|
| 100 |
+
l_filt = df['Language'] == "Bunun"
|
| 101 |
+
|
| 102 |
+
# create a text box for keyword search
|
| 103 |
+
text_box = st.sidebar.text_input('在下方輸入華語或族語,按下ENTER後便會自動更新查詢結果')
|
| 104 |
+
|
| 105 |
+
# search for keywords in Mandarin or Formosan
|
| 106 |
+
t_filt = df[texts].str.contains(text_box, flags=re.IGNORECASE)
|
| 107 |
+
|
| 108 |
+
# filter the data based on all criteria
|
| 109 |
+
filt_df = df[(s_filt)&(l_filt)&(t_filt)]
|
| 110 |
+
|
| 111 |
+
st.markdown(
|
| 112 |
+
"""
|
| 113 |
+
### 查詢結果
|
| 114 |
+
"""
|
| 115 |
+
)
|
| 116 |
+
# display the filtered data
|
| 117 |
+
st.dataframe(filt_df, 800, 400)
|
| 118 |
+
|
| 119 |
+
st.markdown(
|
| 120 |
+
"""
|
| 121 |
+
### 資料統計
|
| 122 |
+
"""
|
| 123 |
+
)
|
| 124 |
+
# display a data profile report
|
| 125 |
+
report = get_report()
|
| 126 |
+
components.html(report, width=800, height=800, scrolling=True)
|
| 127 |
+
|
| 128 |
+
# Cache the raw data and profile report to speed up subseuqent requests
|
| 129 |
+
@st.cache
|
| 130 |
+
def get_data():
|
| 131 |
+
df = pd.read_pickle('Formosan-Mandarin_sent_pairs_139023entries.pkl')
|
| 132 |
+
df = df.astype(str, errors='ignore')
|
| 133 |
+
df = df.applymap(lambda x: x[1:] if x.startswith(".") else x)
|
| 134 |
+
df = df.applymap(lambda x: x.strip())
|
| 135 |
+
filt = df.Ch.apply(len) < 5
|
| 136 |
+
df = df[~filt]
|
| 137 |
+
return df
|
| 138 |
+
|
| 139 |
+
@st.cache
|
| 140 |
+
def get_report():
|
| 141 |
+
df = get_data()
|
| 142 |
+
report = ProfileReport(df, title='Report', minimal=True).to_html()
|
| 143 |
+
return report
|
| 144 |
+
|
| 145 |
+
if __name__ == '__main__':
|
| 146 |
+
main()
|
feature-logs.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
2021-01-05 Added search by input querries, which support regex
|
| 2 |
+
2020-12-21 Added pandas-profiling
|
| 3 |
+
2020-12-17 Deployed Streamlit app
|
requirements.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit
|
| 2 |
+
pandas
|
| 3 |
+
pandas_profiling
|
| 4 |
+
jupyterlab-git
|
sample-dataframe.png
ADDED

|