

initial commit
Browse files- README.md +1 -1
- __init__.py +1 -0
- app.py +374 -0
- data/__init__.py +1 -0
- data/collation.py +120 -0
- data/tokenizer.py +377 -0
- epoch-10.pt +3 -0
- images/vallex_framework.jpg +0 -0
- models/__init__.py +126 -0
- models/macros.py +11 -0
- models/vallex.py +825 -0
- modules/__init__.py +0 -0
- modules/activation.py +612 -0
- modules/embedding.py +97 -0
- modules/scaling.py +1401 -0
- modules/transformer.py +683 -0
- presets/alan.npz +3 -0
- presets/cafe.npz +3 -0
- presets/dingzhen_1.npz +3 -0
- presets/emotion_sleepiness.npz +3 -0
- presets/esta.npz +3 -0
- presets/prompt_1.npz +3 -0
- presets/seel_1.npz +3 -0
- presets/yaesakura_1.npz +3 -0
- requirements.txt +9 -0
- utils/__init__.py +9 -0
- utils/g2p/__init__.py +71 -0
- utils/g2p/bpe_69.json +141 -0
- utils/g2p/cleaners.py +34 -0
- utils/g2p/english.py +188 -0
- utils/g2p/japanese.py +154 -0
- utils/g2p/mandarin.py +326 -0
- utils/g2p/symbols.py +76 -0
README.md
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
---
|
| 2 |
title: VALL E X
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: green
|
| 5 |
colorTo: purple
|
| 6 |
sdk: gradio
|
|
|
|
| 1 |
---
|
| 2 |
title: VALL E X
|
| 3 |
+
emoji: 🎙
|
| 4 |
colorFrom: green
|
| 5 |
colorTo: purple
|
| 6 |
sdk: gradio
|
__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from . import data, models, modules, utils
|
app.py
ADDED
|
@@ -0,0 +1,374 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import pathlib
|
| 5 |
+
import time
|
| 6 |
+
import tempfile
|
| 7 |
+
from pathlib import Path
|
| 8 |
+
pathlib.PosixPath = pathlib.PosixPath
|
| 9 |
+
os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION"] = "python"
|
| 10 |
+
import torch
|
| 11 |
+
import torchaudio
|
| 12 |
+
import random
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
|
| 16 |
+
from data.tokenizer import (
|
| 17 |
+
AudioTokenizer,
|
| 18 |
+
tokenize_audio,
|
| 19 |
+
)
|
| 20 |
+
from data.collation import get_text_token_collater
|
| 21 |
+
from models.vallex import VALLE
|
| 22 |
+
from utils.g2p import PhonemeBpeTokenizer
|
| 23 |
+
|
| 24 |
+
import gradio as gr
|
| 25 |
+
import whisper
|
| 26 |
+
torch.set_num_threads(1)
|
| 27 |
+
torch.set_num_interop_threads(1)
|
| 28 |
+
torch._C._jit_set_profiling_executor(False)
|
| 29 |
+
torch._C._jit_set_profiling_mode(False)
|
| 30 |
+
torch._C._set_graph_executor_optimize(False)
|
| 31 |
+
# torch.manual_seed(42)
|
| 32 |
+
|
| 33 |
+
lang2token = {
|
| 34 |
+
'zh': "[ZH]",
|
| 35 |
+
'ja': "[JA]",
|
| 36 |
+
"en": "[EN]",
|
| 37 |
+
}
|
| 38 |
+
|
| 39 |
+
lang2code = {
|
| 40 |
+
'zh': 0,
|
| 41 |
+
'ja': 1,
|
| 42 |
+
"en": 2,
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
token2lang = {
|
| 46 |
+
'[ZH]': "zh",
|
| 47 |
+
'[JA]': "ja",
|
| 48 |
+
"[EN]": "en",
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
code2lang = {
|
| 52 |
+
0: 'zh',
|
| 53 |
+
1: 'ja',
|
| 54 |
+
2: "en",
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
langdropdown2token = {
|
| 60 |
+
'English': "[EN]",
|
| 61 |
+
'中文': "[ZH]",
|
| 62 |
+
'日本語': "[JA]",
|
| 63 |
+
'mix': "",
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
text_tokenizer = PhonemeBpeTokenizer(tokenizer_path="./utils/g2p/bpe_69.json")
|
| 67 |
+
text_collater = get_text_token_collater()
|
| 68 |
+
|
| 69 |
+
device = torch.device("cpu")
|
| 70 |
+
if torch.cuda.is_available():
|
| 71 |
+
device = torch.device("cuda", 0)
|
| 72 |
+
|
| 73 |
+
# VALL-E-X model
|
| 74 |
+
model = VALLE(
|
| 75 |
+
1024,
|
| 76 |
+
16,
|
| 77 |
+
12,
|
| 78 |
+
norm_first=True,
|
| 79 |
+
add_prenet=False,
|
| 80 |
+
prefix_mode=1,
|
| 81 |
+
share_embedding=True,
|
| 82 |
+
nar_scale_factor=1.0,
|
| 83 |
+
prepend_bos=True,
|
| 84 |
+
num_quantizers=8,
|
| 85 |
+
)
|
| 86 |
+
checkpoint = torch.load("./epoch-10.pt", map_location='cpu')
|
| 87 |
+
missing_keys, unexpected_keys = model.load_state_dict(
|
| 88 |
+
checkpoint["model"], strict=True
|
| 89 |
+
)
|
| 90 |
+
assert not missing_keys
|
| 91 |
+
model.to('cpu')
|
| 92 |
+
model.eval()
|
| 93 |
+
|
| 94 |
+
# Encodec model
|
| 95 |
+
audio_tokenizer = AudioTokenizer(device)
|
| 96 |
+
|
| 97 |
+
# ASR
|
| 98 |
+
whisper_model = whisper.load_model("medium").cpu()
|
| 99 |
+
|
| 100 |
+
def clear_prompts():
|
| 101 |
+
try:
|
| 102 |
+
path = tempfile.gettempdir()
|
| 103 |
+
for eachfile in os.listdir(path):
|
| 104 |
+
filename = os.path.join(path, eachfile)
|
| 105 |
+
if os.path.isfile(filename) and filename.endswith(".npz"):
|
| 106 |
+
lastmodifytime = os.stat(filename).st_mtime
|
| 107 |
+
endfiletime = time.time() - 60
|
| 108 |
+
if endfiletime > lastmodifytime:
|
| 109 |
+
os.remove(filename)
|
| 110 |
+
except:
|
| 111 |
+
return
|
| 112 |
+
|
| 113 |
+
def transcribe_one(model, audio_path):
|
| 114 |
+
# load audio and pad/trim it to fit 30 seconds
|
| 115 |
+
audio = whisper.load_audio(audio_path)
|
| 116 |
+
audio = whisper.pad_or_trim(audio)
|
| 117 |
+
|
| 118 |
+
# make log-Mel spectrogram and move to the same device as the model
|
| 119 |
+
mel = whisper.log_mel_spectrogram(audio).to(model.device)
|
| 120 |
+
|
| 121 |
+
# detect the spoken language
|
| 122 |
+
_, probs = model.detect_language(mel)
|
| 123 |
+
print(f"Detected language: {max(probs, key=probs.get)}")
|
| 124 |
+
lang = max(probs, key=probs.get)
|
| 125 |
+
# decode the audio
|
| 126 |
+
options = whisper.DecodingOptions(beam_size=5)
|
| 127 |
+
result = whisper.decode(model, mel, options)
|
| 128 |
+
|
| 129 |
+
# print the recognized text
|
| 130 |
+
print(result.text)
|
| 131 |
+
|
| 132 |
+
text_pr = result.text
|
| 133 |
+
if text_pr.strip(" ")[-1] not in "?!.,。,?!。、":
|
| 134 |
+
text_pr += "."
|
| 135 |
+
return lang, text_pr
|
| 136 |
+
|
| 137 |
+
def make_npz_prompt(name, uploaded_audio, recorded_audio):
|
| 138 |
+
global model, text_collater, text_tokenizer, audio_tokenizer
|
| 139 |
+
clear_prompts()
|
| 140 |
+
audio_prompt = uploaded_audio if uploaded_audio is not None else recorded_audio
|
| 141 |
+
sr, wav_pr = audio_prompt
|
| 142 |
+
wav_pr = torch.FloatTensor(wav_pr) / 32768
|
| 143 |
+
if wav_pr.size(-1) == 2:
|
| 144 |
+
wav_pr = wav_pr.mean(-1, keepdim=False)
|
| 145 |
+
text_pr, lang_pr = make_prompt(name, wav_pr, sr, save=False)
|
| 146 |
+
|
| 147 |
+
# tokenize audio
|
| 148 |
+
encoded_frames = tokenize_audio(audio_tokenizer, (wav_pr.unsqueeze(0), sr))
|
| 149 |
+
audio_tokens = encoded_frames[0][0].transpose(2, 1).cpu().numpy()
|
| 150 |
+
|
| 151 |
+
# tokenize text
|
| 152 |
+
text_tokens, enroll_x_lens = text_collater(
|
| 153 |
+
[
|
| 154 |
+
text_tokenizer.tokenize(text=f"{text_pr}".strip())
|
| 155 |
+
]
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
message = f"Detected language: {lang_pr}\n Detected text {text_pr}\n"
|
| 159 |
+
|
| 160 |
+
# save as npz file
|
| 161 |
+
np.savez(os.path.join(tempfile.gettempdir(), f"{name}.npz"),
|
| 162 |
+
audio_tokens=audio_tokens, text_tokens=text_tokens, lang_code=lang2code[lang_pr])
|
| 163 |
+
return message, os.path.join(tempfile.gettempdir(), f"{name}.npz")
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def make_prompt(name, wav, sr, save=True):
|
| 167 |
+
|
| 168 |
+
global whisper_model
|
| 169 |
+
whisper_model.to(device)
|
| 170 |
+
if not isinstance(wav, torch.FloatTensor):
|
| 171 |
+
wav = torch.tensor(wav)
|
| 172 |
+
if wav.abs().max() > 1:
|
| 173 |
+
wav /= wav.abs().max()
|
| 174 |
+
if wav.size(-1) == 2:
|
| 175 |
+
wav = wav.mean(-1, keepdim=False)
|
| 176 |
+
if wav.ndim == 1:
|
| 177 |
+
wav = wav.unsqueeze(0)
|
| 178 |
+
assert wav.ndim and wav.size(0) == 1
|
| 179 |
+
torchaudio.save(f"./prompts/{name}.wav", wav, sr)
|
| 180 |
+
lang, text = transcribe_one(whisper_model, f"./prompts/{name}.wav")
|
| 181 |
+
lang_token = lang2token[lang]
|
| 182 |
+
text = lang_token + text + lang_token
|
| 183 |
+
with open(f"./prompts/{name}.txt", 'w') as f:
|
| 184 |
+
f.write(text)
|
| 185 |
+
if not save:
|
| 186 |
+
os.remove(f"./prompts/{name}.wav")
|
| 187 |
+
os.remove(f"./prompts/{name}.txt")
|
| 188 |
+
|
| 189 |
+
whisper_model.cpu()
|
| 190 |
+
torch.cuda.empty_cache()
|
| 191 |
+
return text, lang
|
| 192 |
+
|
| 193 |
+
@torch.no_grad()
|
| 194 |
+
def infer_from_audio(text, language, accent, audio_prompt, record_audio_prompt):
|
| 195 |
+
global model, text_collater, text_tokenizer, audio_tokenizer
|
| 196 |
+
audio_prompt = audio_prompt if audio_prompt is not None else record_audio_prompt
|
| 197 |
+
sr, wav_pr = audio_prompt
|
| 198 |
+
wav_pr = torch.FloatTensor(wav_pr)/32768
|
| 199 |
+
if wav_pr.size(-1) == 2:
|
| 200 |
+
wav_pr = wav_pr.mean(-1, keepdim=False)
|
| 201 |
+
text_pr, lang_pr = make_prompt(str(random.randint(0, 10000000)), wav_pr, sr, save=False)
|
| 202 |
+
lang_token = langdropdown2token[language]
|
| 203 |
+
lang = token2lang[lang_token]
|
| 204 |
+
text = lang_token + text + lang_token
|
| 205 |
+
|
| 206 |
+
# onload model
|
| 207 |
+
model.to(device)
|
| 208 |
+
|
| 209 |
+
# tokenize audio
|
| 210 |
+
encoded_frames = tokenize_audio(audio_tokenizer, (wav_pr.unsqueeze(0), sr))
|
| 211 |
+
audio_prompts = encoded_frames[0][0].transpose(2, 1).to(device)
|
| 212 |
+
|
| 213 |
+
# tokenize text
|
| 214 |
+
logging.info(f"synthesize text: {text}")
|
| 215 |
+
text_tokens, text_tokens_lens = text_collater(
|
| 216 |
+
[
|
| 217 |
+
text_tokenizer.tokenize(text=f"{text_pr}{text}".strip())
|
| 218 |
+
]
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
enroll_x_lens = None
|
| 222 |
+
if text_pr:
|
| 223 |
+
_, enroll_x_lens = text_collater(
|
| 224 |
+
[
|
| 225 |
+
text_tokenizer.tokenize(text=f"{text_pr}".strip())
|
| 226 |
+
]
|
| 227 |
+
)
|
| 228 |
+
lang = lang if accent == "no-accent" else token2lang[langdropdown2token[accent]]
|
| 229 |
+
encoded_frames = model.inference(
|
| 230 |
+
text_tokens.to(device),
|
| 231 |
+
text_tokens_lens.to(device),
|
| 232 |
+
audio_prompts,
|
| 233 |
+
enroll_x_lens=enroll_x_lens,
|
| 234 |
+
top_k=-100,
|
| 235 |
+
temperature=1,
|
| 236 |
+
prompt_language=lang_pr,
|
| 237 |
+
text_language=lang,
|
| 238 |
+
)
|
| 239 |
+
samples = audio_tokenizer.decode(
|
| 240 |
+
[(encoded_frames.transpose(2, 1), None)]
|
| 241 |
+
)
|
| 242 |
+
|
| 243 |
+
# offload model
|
| 244 |
+
model.to('cpu')
|
| 245 |
+
torch.cuda.empty_cache()
|
| 246 |
+
|
| 247 |
+
message = f"text prompt: {text_pr}\nsythesized text: {text}"
|
| 248 |
+
return message, (24000, samples[0][0].cpu().numpy())
|
| 249 |
+
|
| 250 |
+
@torch.no_grad()
|
| 251 |
+
def infer_from_prompt(text, language, accent, prompt_file):
|
| 252 |
+
# onload model
|
| 253 |
+
model.to(device)
|
| 254 |
+
clear_prompts()
|
| 255 |
+
# text to synthesize
|
| 256 |
+
lang_token = langdropdown2token[language]
|
| 257 |
+
lang = token2lang[lang_token]
|
| 258 |
+
text = lang_token + text + lang_token
|
| 259 |
+
|
| 260 |
+
# load prompt
|
| 261 |
+
prompt_data = np.load(prompt_file.name)
|
| 262 |
+
audio_prompts = prompt_data['audio_tokens']
|
| 263 |
+
text_prompts = prompt_data['text_tokens']
|
| 264 |
+
lang_pr = prompt_data['lang_code']
|
| 265 |
+
lang_pr = code2lang[int(lang_pr)]
|
| 266 |
+
|
| 267 |
+
# numpy to tensor
|
| 268 |
+
audio_prompts = torch.tensor(audio_prompts).type(torch.int32).to(device)
|
| 269 |
+
text_prompts = torch.tensor(text_prompts).type(torch.int32)
|
| 270 |
+
|
| 271 |
+
enroll_x_lens = text_prompts.shape[-1]
|
| 272 |
+
logging.info(f"synthesize text: {text}")
|
| 273 |
+
text_tokens, text_tokens_lens = text_collater(
|
| 274 |
+
[
|
| 275 |
+
text_tokenizer.tokenize(text=f"_{text}".strip())
|
| 276 |
+
]
|
| 277 |
+
)
|
| 278 |
+
text_tokens = torch.cat([text_prompts, text_tokens], dim=-1)
|
| 279 |
+
text_tokens_lens += enroll_x_lens
|
| 280 |
+
# accent control
|
| 281 |
+
lang = lang if accent == "no-accent" else token2lang[langdropdown2token[accent]]
|
| 282 |
+
encoded_frames = model.inference(
|
| 283 |
+
text_tokens.to(device),
|
| 284 |
+
text_tokens_lens.to(device),
|
| 285 |
+
audio_prompts,
|
| 286 |
+
enroll_x_lens=enroll_x_lens,
|
| 287 |
+
top_k=-100,
|
| 288 |
+
temperature=1,
|
| 289 |
+
prompt_language=lang_pr,
|
| 290 |
+
text_language=lang,
|
| 291 |
+
)
|
| 292 |
+
samples = audio_tokenizer.decode(
|
| 293 |
+
[(encoded_frames.transpose(2, 1), None)]
|
| 294 |
+
)
|
| 295 |
+
|
| 296 |
+
# offload model
|
| 297 |
+
model.to('cpu')
|
| 298 |
+
torch.cuda.empty_cache()
|
| 299 |
+
|
| 300 |
+
message = f"sythesized text: {text}"
|
| 301 |
+
return message, (24000, samples[0][0].cpu().numpy())
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
def main():
|
| 305 |
+
app = gr.Blocks()
|
| 306 |
+
with app:
|
| 307 |
+
with gr.Tab("Infer from audio"):
|
| 308 |
+
with gr.Row():
|
| 309 |
+
with gr.Column():
|
| 310 |
+
|
| 311 |
+
textbox = gr.TextArea(label="Text",
|
| 312 |
+
placeholder="Type your sentence here",
|
| 313 |
+
value="Hello, it's nice to meet you.", elem_id=f"tts-input")
|
| 314 |
+
language_dropdown = gr.Dropdown(choices=['English', '中文', '日本語', 'mix'], value='English', label='language')
|
| 315 |
+
accent_dropdown = gr.Dropdown(choices=['no-accent', 'English', '中文', '日本語'], value='no-accent', label='accent')
|
| 316 |
+
upload_audio_prompt = gr.Audio(label='uploaded audio prompt', source='upload', interactive=True)
|
| 317 |
+
record_audio_prompt = gr.Audio(label='recorded audio prompt', source='microphone', interactive=True)
|
| 318 |
+
with gr.Column():
|
| 319 |
+
text_output = gr.Textbox(label="Message")
|
| 320 |
+
audio_output = gr.Audio(label="Output Audio", elem_id="tts-audio")
|
| 321 |
+
btn = gr.Button("Generate!")
|
| 322 |
+
btn.click(infer_from_audio,
|
| 323 |
+
inputs=[textbox, language_dropdown, accent_dropdown, upload_audio_prompt, record_audio_prompt],
|
| 324 |
+
outputs=[text_output, audio_output])
|
| 325 |
+
textbox_mp = gr.TextArea(label="Prompt name",
|
| 326 |
+
placeholder="Name your prompt here",
|
| 327 |
+
value="prompt_1", elem_id=f"prompt-name")
|
| 328 |
+
btn_mp = gr.Button("Make prompt!")
|
| 329 |
+
prompt_output = gr.File(interactive=False)
|
| 330 |
+
btn_mp.click(make_npz_prompt,
|
| 331 |
+
inputs=[textbox_mp, upload_audio_prompt, record_audio_prompt],
|
| 332 |
+
outputs=[text_output, prompt_output])
|
| 333 |
+
with gr.Tab("Make prompt"):
|
| 334 |
+
with gr.Row():
|
| 335 |
+
with gr.Column():
|
| 336 |
+
textbox2 = gr.TextArea(label="Prompt name",
|
| 337 |
+
placeholder="Name your prompt here",
|
| 338 |
+
value="prompt_1", elem_id=f"prompt-name")
|
| 339 |
+
upload_audio_prompt_2 = gr.Audio(label='uploaded audio prompt', source='upload', interactive=True)
|
| 340 |
+
record_audio_prompt_2 = gr.Audio(label='recorded audio prompt', source='microphone', interactive=True)
|
| 341 |
+
with gr.Column():
|
| 342 |
+
text_output_2 = gr.Textbox(label="Message")
|
| 343 |
+
prompt_output_2 = gr.File(interactive=False)
|
| 344 |
+
btn_2 = gr.Button("Make!")
|
| 345 |
+
btn_2.click(make_npz_prompt,
|
| 346 |
+
inputs=[textbox2, upload_audio_prompt_2, record_audio_prompt_2],
|
| 347 |
+
outputs=[text_output_2, prompt_output_2])
|
| 348 |
+
with gr.Tab("Infer from prompt"):
|
| 349 |
+
with gr.Row():
|
| 350 |
+
with gr.Column():
|
| 351 |
+
textbox_3 = gr.TextArea(label="Text",
|
| 352 |
+
placeholder="Type your sentence here",
|
| 353 |
+
value="Hello, it's nice to meet you.", elem_id=f"tts-input")
|
| 354 |
+
language_dropdown_3 = gr.Dropdown(choices=['English', '中文', '日本語', 'mix'], value='English',
|
| 355 |
+
label='language')
|
| 356 |
+
accent_dropdown_3 = gr.Dropdown(choices=['no-accent', 'English', '中文', '日本語'], value='no-accent',
|
| 357 |
+
label='accent')
|
| 358 |
+
prompt_file = gr.File(file_count='single', file_types=['.npz'], interactive=True)
|
| 359 |
+
with gr.Column():
|
| 360 |
+
text_output_3 = gr.Textbox(label="Message")
|
| 361 |
+
audio_output_3 = gr.Audio(label="Output Audio", elem_id="tts-audio")
|
| 362 |
+
btn_3 = gr.Button("Generate!")
|
| 363 |
+
btn_3.click(infer_from_prompt,
|
| 364 |
+
inputs=[textbox_3, language_dropdown_3, accent_dropdown_3, prompt_file],
|
| 365 |
+
outputs=[text_output_3, audio_output_3])
|
| 366 |
+
|
| 367 |
+
app.launch()
|
| 368 |
+
|
| 369 |
+
if __name__ == "__main__":
|
| 370 |
+
formatter = (
|
| 371 |
+
"%(asctime)s %(levelname)s [%(filename)s:%(lineno)d] %(message)s"
|
| 372 |
+
)
|
| 373 |
+
logging.basicConfig(format=formatter, level=logging.INFO)
|
| 374 |
+
main()
|
data/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .collation import *
|
data/collation.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
from typing import List, Tuple
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from utils import SymbolTable
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class TextTokenCollater:
|
| 11 |
+
"""Collate list of text tokens
|
| 12 |
+
|
| 13 |
+
Map sentences to integers. Sentences are padded to equal length.
|
| 14 |
+
Beginning and end-of-sequence symbols can be added.
|
| 15 |
+
|
| 16 |
+
Example:
|
| 17 |
+
>>> token_collater = TextTokenCollater(text_tokens)
|
| 18 |
+
>>> tokens_batch, tokens_lens = token_collater(text)
|
| 19 |
+
|
| 20 |
+
Returns:
|
| 21 |
+
tokens_batch: IntTensor of shape (B, L)
|
| 22 |
+
B: batch dimension, number of input sentences
|
| 23 |
+
L: length of the longest sentence
|
| 24 |
+
tokens_lens: IntTensor of shape (B,)
|
| 25 |
+
Length of each sentence after adding <eos> and <bos>
|
| 26 |
+
but before padding.
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
def __init__(
|
| 30 |
+
self,
|
| 31 |
+
text_tokens: List[str],
|
| 32 |
+
add_eos: bool = True,
|
| 33 |
+
add_bos: bool = True,
|
| 34 |
+
pad_symbol: str = "<pad>",
|
| 35 |
+
bos_symbol: str = "<bos>",
|
| 36 |
+
eos_symbol: str = "<eos>",
|
| 37 |
+
):
|
| 38 |
+
self.pad_symbol = pad_symbol
|
| 39 |
+
|
| 40 |
+
self.add_eos = add_eos
|
| 41 |
+
self.add_bos = add_bos
|
| 42 |
+
|
| 43 |
+
self.bos_symbol = bos_symbol
|
| 44 |
+
self.eos_symbol = eos_symbol
|
| 45 |
+
|
| 46 |
+
unique_tokens = (
|
| 47 |
+
[pad_symbol]
|
| 48 |
+
+ ([bos_symbol] if add_bos else [])
|
| 49 |
+
+ ([eos_symbol] if add_eos else [])
|
| 50 |
+
+ sorted(text_tokens)
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
self.token2idx = {token: idx for idx, token in enumerate(unique_tokens)}
|
| 54 |
+
self.idx2token = [token for token in unique_tokens]
|
| 55 |
+
|
| 56 |
+
def index(
|
| 57 |
+
self, tokens_list: List[str]
|
| 58 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 59 |
+
seqs, seq_lens = [], []
|
| 60 |
+
for tokens in tokens_list:
|
| 61 |
+
assert (
|
| 62 |
+
all([True if s in self.token2idx else False for s in tokens])
|
| 63 |
+
is True
|
| 64 |
+
)
|
| 65 |
+
seq = (
|
| 66 |
+
([self.bos_symbol] if self.add_bos else [])
|
| 67 |
+
+ list(tokens)
|
| 68 |
+
+ ([self.eos_symbol] if self.add_eos else [])
|
| 69 |
+
)
|
| 70 |
+
seqs.append(seq)
|
| 71 |
+
seq_lens.append(len(seq))
|
| 72 |
+
|
| 73 |
+
max_len = max(seq_lens)
|
| 74 |
+
for k, (seq, seq_len) in enumerate(zip(seqs, seq_lens)):
|
| 75 |
+
seq.extend([self.pad_symbol] * (max_len - seq_len))
|
| 76 |
+
|
| 77 |
+
tokens = torch.from_numpy(
|
| 78 |
+
np.array(
|
| 79 |
+
[[self.token2idx[token] for token in seq] for seq in seqs],
|
| 80 |
+
dtype=np.int64,
|
| 81 |
+
)
|
| 82 |
+
)
|
| 83 |
+
tokens_lens = torch.IntTensor(seq_lens)
|
| 84 |
+
|
| 85 |
+
return tokens, tokens_lens
|
| 86 |
+
|
| 87 |
+
def __call__(self, texts: List[str]) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 88 |
+
tokens_seqs = [[p for p in text] for text in texts]
|
| 89 |
+
max_len = len(max(tokens_seqs, key=len))
|
| 90 |
+
|
| 91 |
+
seqs = [
|
| 92 |
+
([self.bos_symbol] if self.add_bos else [])
|
| 93 |
+
+ list(seq)
|
| 94 |
+
+ ([self.eos_symbol] if self.add_eos else [])
|
| 95 |
+
+ [self.pad_symbol] * (max_len - len(seq))
|
| 96 |
+
for seq in tokens_seqs
|
| 97 |
+
]
|
| 98 |
+
|
| 99 |
+
tokens_batch = torch.from_numpy(
|
| 100 |
+
np.array(
|
| 101 |
+
[seq for seq in seqs],
|
| 102 |
+
dtype=np.int64,
|
| 103 |
+
)
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
tokens_lens = torch.IntTensor(
|
| 107 |
+
[
|
| 108 |
+
len(seq) + int(self.add_eos) + int(self.add_bos)
|
| 109 |
+
for seq in tokens_seqs
|
| 110 |
+
]
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
return tokens_batch, tokens_lens
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def get_text_token_collater() -> TextTokenCollater:
|
| 117 |
+
collater = TextTokenCollater(
|
| 118 |
+
['0'], add_bos=False, add_eos=False
|
| 119 |
+
)
|
| 120 |
+
return collater
|
data/tokenizer.py
ADDED
|
@@ -0,0 +1,377 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
# Copyright 2023 (authors: Feiteng Li)
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
import re
|
| 17 |
+
from dataclasses import asdict, dataclass
|
| 18 |
+
from typing import Any, Dict, List, Optional, Pattern, Union
|
| 19 |
+
|
| 20 |
+
import numpy as np
|
| 21 |
+
import torch
|
| 22 |
+
import torchaudio
|
| 23 |
+
from encodec import EncodecModel
|
| 24 |
+
from encodec.utils import convert_audio
|
| 25 |
+
from phonemizer.backend import EspeakBackend
|
| 26 |
+
from phonemizer.backend.espeak.language_switch import LanguageSwitch
|
| 27 |
+
from phonemizer.backend.espeak.words_mismatch import WordMismatch
|
| 28 |
+
from phonemizer.punctuation import Punctuation
|
| 29 |
+
from phonemizer.separator import Separator
|
| 30 |
+
from phonemizer.separator import Separator
|
| 31 |
+
|
| 32 |
+
try:
|
| 33 |
+
from pypinyin import Style, pinyin
|
| 34 |
+
from pypinyin.style._utils import get_finals, get_initials
|
| 35 |
+
except Exception:
|
| 36 |
+
pass
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class PypinyinBackend:
|
| 40 |
+
"""PypinyinBackend for Chinese. Most codes is referenced from espnet.
|
| 41 |
+
There are two types pinyin or initials_finals, one is
|
| 42 |
+
just like "ni1 hao3", the other is like "n i1 h ao3".
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
def __init__(
|
| 46 |
+
self,
|
| 47 |
+
backend="initials_finals",
|
| 48 |
+
punctuation_marks: Union[str, Pattern] = Punctuation.default_marks(),
|
| 49 |
+
) -> None:
|
| 50 |
+
self.backend = backend
|
| 51 |
+
self.punctuation_marks = punctuation_marks
|
| 52 |
+
|
| 53 |
+
def phonemize(
|
| 54 |
+
self, text: List[str], separator: Separator, strip=True, njobs=1
|
| 55 |
+
) -> List[str]:
|
| 56 |
+
assert isinstance(text, List)
|
| 57 |
+
phonemized = []
|
| 58 |
+
for _text in text:
|
| 59 |
+
_text = re.sub(" +", " ", _text.strip())
|
| 60 |
+
_text = _text.replace(" ", separator.word)
|
| 61 |
+
phones = []
|
| 62 |
+
if self.backend == "pypinyin":
|
| 63 |
+
for n, py in enumerate(
|
| 64 |
+
pinyin(
|
| 65 |
+
_text, style=Style.TONE3, neutral_tone_with_five=True
|
| 66 |
+
)
|
| 67 |
+
):
|
| 68 |
+
if all([c in self.punctuation_marks for c in py[0]]):
|
| 69 |
+
if len(phones):
|
| 70 |
+
assert phones[-1] == separator.syllable
|
| 71 |
+
phones.pop(-1)
|
| 72 |
+
|
| 73 |
+
phones.extend(list(py[0]))
|
| 74 |
+
else:
|
| 75 |
+
phones.extend([py[0], separator.syllable])
|
| 76 |
+
elif self.backend == "pypinyin_initials_finals":
|
| 77 |
+
for n, py in enumerate(
|
| 78 |
+
pinyin(
|
| 79 |
+
_text, style=Style.TONE3, neutral_tone_with_five=True
|
| 80 |
+
)
|
| 81 |
+
):
|
| 82 |
+
if all([c in self.punctuation_marks for c in py[0]]):
|
| 83 |
+
if len(phones):
|
| 84 |
+
assert phones[-1] == separator.syllable
|
| 85 |
+
phones.pop(-1)
|
| 86 |
+
phones.extend(list(py[0]))
|
| 87 |
+
else:
|
| 88 |
+
if py[0][-1].isalnum():
|
| 89 |
+
initial = get_initials(py[0], strict=False)
|
| 90 |
+
if py[0][-1].isdigit():
|
| 91 |
+
final = (
|
| 92 |
+
get_finals(py[0][:-1], strict=False)
|
| 93 |
+
+ py[0][-1]
|
| 94 |
+
)
|
| 95 |
+
else:
|
| 96 |
+
final = get_finals(py[0], strict=False)
|
| 97 |
+
phones.extend(
|
| 98 |
+
[
|
| 99 |
+
initial,
|
| 100 |
+
separator.phone,
|
| 101 |
+
final,
|
| 102 |
+
separator.syllable,
|
| 103 |
+
]
|
| 104 |
+
)
|
| 105 |
+
else:
|
| 106 |
+
assert ValueError
|
| 107 |
+
else:
|
| 108 |
+
raise NotImplementedError
|
| 109 |
+
phonemized.append(
|
| 110 |
+
"".join(phones).rstrip(f"{separator.word}{separator.syllable}")
|
| 111 |
+
)
|
| 112 |
+
return phonemized
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
class TextTokenizer:
|
| 116 |
+
"""Phonemize Text."""
|
| 117 |
+
|
| 118 |
+
def __init__(
|
| 119 |
+
self,
|
| 120 |
+
language="en-us",
|
| 121 |
+
backend="espeak",
|
| 122 |
+
separator=Separator(word="_", syllable="-", phone="|"),
|
| 123 |
+
preserve_punctuation=True,
|
| 124 |
+
punctuation_marks: Union[str, Pattern] = Punctuation.default_marks(),
|
| 125 |
+
with_stress: bool = False,
|
| 126 |
+
tie: Union[bool, str] = False,
|
| 127 |
+
language_switch: LanguageSwitch = "keep-flags",
|
| 128 |
+
words_mismatch: WordMismatch = "ignore",
|
| 129 |
+
) -> None:
|
| 130 |
+
if backend == "espeak":
|
| 131 |
+
phonemizer = EspeakBackend(
|
| 132 |
+
language,
|
| 133 |
+
punctuation_marks=punctuation_marks,
|
| 134 |
+
preserve_punctuation=preserve_punctuation,
|
| 135 |
+
with_stress=with_stress,
|
| 136 |
+
tie=tie,
|
| 137 |
+
language_switch=language_switch,
|
| 138 |
+
words_mismatch=words_mismatch,
|
| 139 |
+
)
|
| 140 |
+
elif backend in ["pypinyin", "pypinyin_initials_finals"]:
|
| 141 |
+
phonemizer = PypinyinBackend(
|
| 142 |
+
backend=backend,
|
| 143 |
+
punctuation_marks=punctuation_marks + separator.word,
|
| 144 |
+
)
|
| 145 |
+
else:
|
| 146 |
+
raise NotImplementedError(f"{backend}")
|
| 147 |
+
|
| 148 |
+
self.backend = phonemizer
|
| 149 |
+
self.separator = separator
|
| 150 |
+
|
| 151 |
+
def to_list(self, phonemized: str) -> List[str]:
|
| 152 |
+
fields = []
|
| 153 |
+
for word in phonemized.split(self.separator.word):
|
| 154 |
+
# "ɐ m|iː|n?" ɹ|ɪ|z|ɜː|v; h|ɪ|z.
|
| 155 |
+
pp = re.findall(r"\w+|[^\w\s]", word, re.UNICODE)
|
| 156 |
+
fields.extend(
|
| 157 |
+
[p for p in pp if p != self.separator.phone]
|
| 158 |
+
+ [self.separator.word]
|
| 159 |
+
)
|
| 160 |
+
assert len("".join(fields[:-1])) == len(phonemized) - phonemized.count(
|
| 161 |
+
self.separator.phone
|
| 162 |
+
)
|
| 163 |
+
return fields[:-1]
|
| 164 |
+
|
| 165 |
+
def __call__(self, text, strip=True) -> List[List[str]]:
|
| 166 |
+
if isinstance(text, str):
|
| 167 |
+
text = [text]
|
| 168 |
+
|
| 169 |
+
phonemized = self.backend.phonemize(
|
| 170 |
+
text, separator=self.separator, strip=strip, njobs=1
|
| 171 |
+
)
|
| 172 |
+
return [self.to_list(p) for p in phonemized]
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def tokenize_text(tokenizer: TextTokenizer, text: str) -> List[str]:
|
| 176 |
+
phonemes = tokenizer([text.strip()])
|
| 177 |
+
return phonemes[0] # k2symbols
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def remove_encodec_weight_norm(model):
|
| 181 |
+
from encodec.modules import SConv1d
|
| 182 |
+
from encodec.modules.seanet import SConvTranspose1d, SEANetResnetBlock
|
| 183 |
+
from torch.nn.utils import remove_weight_norm
|
| 184 |
+
|
| 185 |
+
encoder = model.encoder.model
|
| 186 |
+
for key in encoder._modules:
|
| 187 |
+
if isinstance(encoder._modules[key], SEANetResnetBlock):
|
| 188 |
+
remove_weight_norm(encoder._modules[key].shortcut.conv.conv)
|
| 189 |
+
block_modules = encoder._modules[key].block._modules
|
| 190 |
+
for skey in block_modules:
|
| 191 |
+
if isinstance(block_modules[skey], SConv1d):
|
| 192 |
+
remove_weight_norm(block_modules[skey].conv.conv)
|
| 193 |
+
elif isinstance(encoder._modules[key], SConv1d):
|
| 194 |
+
remove_weight_norm(encoder._modules[key].conv.conv)
|
| 195 |
+
|
| 196 |
+
decoder = model.decoder.model
|
| 197 |
+
for key in decoder._modules:
|
| 198 |
+
if isinstance(decoder._modules[key], SEANetResnetBlock):
|
| 199 |
+
remove_weight_norm(decoder._modules[key].shortcut.conv.conv)
|
| 200 |
+
block_modules = decoder._modules[key].block._modules
|
| 201 |
+
for skey in block_modules:
|
| 202 |
+
if isinstance(block_modules[skey], SConv1d):
|
| 203 |
+
remove_weight_norm(block_modules[skey].conv.conv)
|
| 204 |
+
elif isinstance(decoder._modules[key], SConvTranspose1d):
|
| 205 |
+
remove_weight_norm(decoder._modules[key].convtr.convtr)
|
| 206 |
+
elif isinstance(decoder._modules[key], SConv1d):
|
| 207 |
+
remove_weight_norm(decoder._modules[key].conv.conv)
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
class AudioTokenizer:
|
| 211 |
+
"""EnCodec audio."""
|
| 212 |
+
|
| 213 |
+
def __init__(
|
| 214 |
+
self,
|
| 215 |
+
device: Any = None,
|
| 216 |
+
) -> None:
|
| 217 |
+
# Instantiate a pretrained EnCodec model
|
| 218 |
+
model = EncodecModel.encodec_model_24khz()
|
| 219 |
+
model.set_target_bandwidth(6.0)
|
| 220 |
+
remove_encodec_weight_norm(model)
|
| 221 |
+
|
| 222 |
+
if not device:
|
| 223 |
+
device = torch.device("cpu")
|
| 224 |
+
if torch.cuda.is_available():
|
| 225 |
+
device = torch.device("cuda:0")
|
| 226 |
+
|
| 227 |
+
self._device = device
|
| 228 |
+
|
| 229 |
+
self.codec = model.to(device)
|
| 230 |
+
self.sample_rate = model.sample_rate
|
| 231 |
+
self.channels = model.channels
|
| 232 |
+
|
| 233 |
+
@property
|
| 234 |
+
def device(self):
|
| 235 |
+
return self._device
|
| 236 |
+
|
| 237 |
+
def encode(self, wav: torch.Tensor) -> torch.Tensor:
|
| 238 |
+
return self.codec.encode(wav.to(self.device))
|
| 239 |
+
|
| 240 |
+
def decode(self, frames: torch.Tensor) -> torch.Tensor:
|
| 241 |
+
return self.codec.decode(frames)
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def tokenize_audio(tokenizer: AudioTokenizer, audio):
|
| 245 |
+
# Load and pre-process the audio waveform
|
| 246 |
+
if isinstance(audio, str):
|
| 247 |
+
wav, sr = torchaudio.load(audio)
|
| 248 |
+
else:
|
| 249 |
+
wav, sr = audio
|
| 250 |
+
wav = convert_audio(wav, sr, tokenizer.sample_rate, tokenizer.channels)
|
| 251 |
+
wav = wav.unsqueeze(0)
|
| 252 |
+
|
| 253 |
+
# Extract discrete codes from EnCodec
|
| 254 |
+
with torch.no_grad():
|
| 255 |
+
encoded_frames = tokenizer.encode(wav)
|
| 256 |
+
return encoded_frames
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
# @dataclass
|
| 260 |
+
# class AudioTokenConfig:
|
| 261 |
+
# frame_shift: Seconds = 320.0 / 24000
|
| 262 |
+
# num_quantizers: int = 8
|
| 263 |
+
#
|
| 264 |
+
# def to_dict(self) -> Dict[str, Any]:
|
| 265 |
+
# return asdict(self)
|
| 266 |
+
#
|
| 267 |
+
# @staticmethod
|
| 268 |
+
# def from_dict(data: Dict[str, Any]) -> "AudioTokenConfig":
|
| 269 |
+
# return AudioTokenConfig(**data)
|
| 270 |
+
#
|
| 271 |
+
#
|
| 272 |
+
# class AudioTokenExtractor(FeatureExtractor):
|
| 273 |
+
# name = "encodec"
|
| 274 |
+
# config_type = AudioTokenConfig
|
| 275 |
+
#
|
| 276 |
+
# def __init__(self, config: Optional[Any] = None):
|
| 277 |
+
# super(AudioTokenExtractor, self).__init__(config)
|
| 278 |
+
# self.tokenizer = AudioTokenizer()
|
| 279 |
+
#
|
| 280 |
+
# def extract(
|
| 281 |
+
# self, samples: Union[np.ndarray, torch.Tensor], sampling_rate: int
|
| 282 |
+
# ) -> np.ndarray:
|
| 283 |
+
# if not isinstance(samples, torch.Tensor):
|
| 284 |
+
# samples = torch.from_numpy(samples)
|
| 285 |
+
# if sampling_rate != self.tokenizer.sample_rate:
|
| 286 |
+
# samples = convert_audio(
|
| 287 |
+
# samples,
|
| 288 |
+
# sampling_rate,
|
| 289 |
+
# self.tokenizer.sample_rate,
|
| 290 |
+
# self.tokenizer.channels,
|
| 291 |
+
# )
|
| 292 |
+
# if len(samples.shape) == 2:
|
| 293 |
+
# samples = samples.unsqueeze(0)
|
| 294 |
+
# else:
|
| 295 |
+
# raise ValueError()
|
| 296 |
+
#
|
| 297 |
+
# device = self.tokenizer.device
|
| 298 |
+
# encoded_frames = self.tokenizer.encode(samples.detach().to(device))
|
| 299 |
+
# codes = encoded_frames[0][0] # [B, n_q, T]
|
| 300 |
+
# if True:
|
| 301 |
+
# duration = round(samples.shape[-1] / sampling_rate, ndigits=12)
|
| 302 |
+
# expected_num_frames = compute_num_frames(
|
| 303 |
+
# duration=duration,
|
| 304 |
+
# frame_shift=self.frame_shift,
|
| 305 |
+
# sampling_rate=sampling_rate,
|
| 306 |
+
# )
|
| 307 |
+
# assert abs(codes.shape[-1] - expected_num_frames) <= 1
|
| 308 |
+
# codes = codes[..., :expected_num_frames]
|
| 309 |
+
# return codes.cpu().squeeze(0).permute(1, 0).numpy()
|
| 310 |
+
#
|
| 311 |
+
# @property
|
| 312 |
+
# def frame_shift(self) -> Seconds:
|
| 313 |
+
# return self.config.frame_shift
|
| 314 |
+
#
|
| 315 |
+
# def feature_dim(self, sampling_rate: int) -> int:
|
| 316 |
+
# return self.config.num_quantizers
|
| 317 |
+
#
|
| 318 |
+
# def pad_tensor_list(self, tensor_list, device, padding_value=0):
|
| 319 |
+
# # 计算每个张量的长度
|
| 320 |
+
# lengths = [tensor.shape[0] for tensor in tensor_list]
|
| 321 |
+
# # 使用pad_sequence函数进行填充
|
| 322 |
+
# tensor_list = [torch.Tensor(t).to(device) for t in tensor_list]
|
| 323 |
+
# padded_tensor = torch.nn.utils.rnn.pad_sequence(
|
| 324 |
+
# tensor_list, batch_first=True, padding_value=padding_value
|
| 325 |
+
# )
|
| 326 |
+
# return padded_tensor, lengths
|
| 327 |
+
#
|
| 328 |
+
# def extract_batch(self, samples, sampling_rate, lengths) -> np.ndarray:
|
| 329 |
+
# samples = [wav.squeeze() for wav in samples]
|
| 330 |
+
# device = self.tokenizer.device
|
| 331 |
+
# samples, lengths = self.pad_tensor_list(samples, device)
|
| 332 |
+
# samples = samples.unsqueeze(1)
|
| 333 |
+
#
|
| 334 |
+
# if not isinstance(samples, torch.Tensor):
|
| 335 |
+
# samples = torch.from_numpy(samples)
|
| 336 |
+
# if len(samples.shape) != 3:
|
| 337 |
+
# raise ValueError()
|
| 338 |
+
# if sampling_rate != self.tokenizer.sample_rate:
|
| 339 |
+
# samples = [
|
| 340 |
+
# convert_audio(
|
| 341 |
+
# wav,
|
| 342 |
+
# sampling_rate,
|
| 343 |
+
# self.tokenizer.sample_rate,
|
| 344 |
+
# self.tokenizer.channels,
|
| 345 |
+
# )
|
| 346 |
+
# for wav in samples
|
| 347 |
+
# ]
|
| 348 |
+
# # Extract discrete codes from EnCodec
|
| 349 |
+
# with torch.no_grad():
|
| 350 |
+
# encoded_frames = self.tokenizer.encode(samples.detach().to(device))
|
| 351 |
+
# encoded_frames = encoded_frames[0][0] # [B, n_q, T]
|
| 352 |
+
# batch_codes = []
|
| 353 |
+
# for b, length in enumerate(lengths):
|
| 354 |
+
# codes = encoded_frames[b]
|
| 355 |
+
# duration = round(length / sampling_rate, ndigits=12)
|
| 356 |
+
# expected_num_frames = compute_num_frames(
|
| 357 |
+
# duration=duration,
|
| 358 |
+
# frame_shift=self.frame_shift,
|
| 359 |
+
# sampling_rate=sampling_rate,
|
| 360 |
+
# )
|
| 361 |
+
# batch_codes.append(codes[..., :expected_num_frames])
|
| 362 |
+
# return [codes.cpu().permute(1, 0).numpy() for codes in batch_codes]
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
if __name__ == "__main__":
|
| 366 |
+
model = EncodecModel.encodec_model_24khz()
|
| 367 |
+
model.set_target_bandwidth(6.0)
|
| 368 |
+
|
| 369 |
+
samples = torch.from_numpy(np.random.random([4, 1, 1600])).type(
|
| 370 |
+
torch.float32
|
| 371 |
+
)
|
| 372 |
+
codes_raw = model.encode(samples)
|
| 373 |
+
|
| 374 |
+
remove_encodec_weight_norm(model)
|
| 375 |
+
codes_norm = model.encode(samples)
|
| 376 |
+
|
| 377 |
+
assert torch.allclose(codes_raw[0][0], codes_norm[0][0])
|
epoch-10.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c5fcd05ee0c9c84a16a7b44495c46262177e66d5d454c20ca5f1da9832dbd5ac
|
| 3 |
+
size 1482302113
|
images/vallex_framework.jpg
ADDED
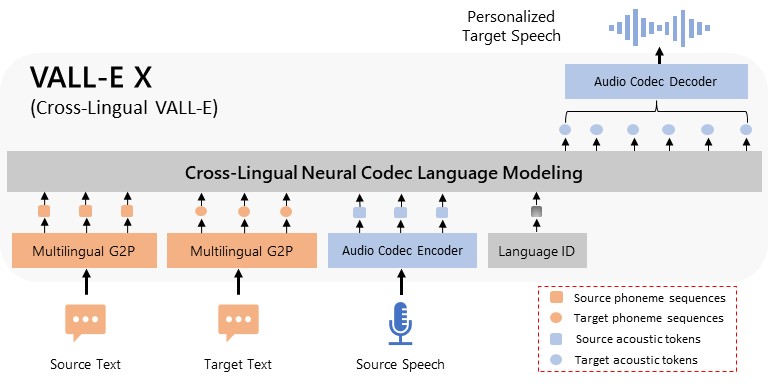
|
models/__init__.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
# from icefall.utils import AttributeDict, str2bool
|
| 5 |
+
|
| 6 |
+
from .macros import (
|
| 7 |
+
NUM_AUDIO_TOKENS,
|
| 8 |
+
NUM_MEL_BINS,
|
| 9 |
+
NUM_SPEAKER_CLASSES,
|
| 10 |
+
NUM_TEXT_TOKENS,
|
| 11 |
+
SPEAKER_EMBEDDING_DIM,
|
| 12 |
+
)
|
| 13 |
+
from .vallex import VALLE, VALLF
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def add_model_arguments(parser: argparse.ArgumentParser):
|
| 17 |
+
parser.add_argument(
|
| 18 |
+
"--model-name",
|
| 19 |
+
type=str,
|
| 20 |
+
default="VALL-E",
|
| 21 |
+
help="VALL-E, VALL-F, Transformer.",
|
| 22 |
+
)
|
| 23 |
+
parser.add_argument(
|
| 24 |
+
"--decoder-dim",
|
| 25 |
+
type=int,
|
| 26 |
+
default=1024,
|
| 27 |
+
help="Embedding dimension in the decoder model.",
|
| 28 |
+
)
|
| 29 |
+
parser.add_argument(
|
| 30 |
+
"--nhead",
|
| 31 |
+
type=int,
|
| 32 |
+
default=16,
|
| 33 |
+
help="Number of attention heads in the Decoder layers.",
|
| 34 |
+
)
|
| 35 |
+
parser.add_argument(
|
| 36 |
+
"--num-decoder-layers",
|
| 37 |
+
type=int,
|
| 38 |
+
default=12,
|
| 39 |
+
help="Number of Decoder layers.",
|
| 40 |
+
)
|
| 41 |
+
parser.add_argument(
|
| 42 |
+
"--scale-factor",
|
| 43 |
+
type=float,
|
| 44 |
+
default=1.0,
|
| 45 |
+
help="Model scale factor which will be assigned different meanings in different models.",
|
| 46 |
+
)
|
| 47 |
+
parser.add_argument(
|
| 48 |
+
"--norm-first",
|
| 49 |
+
type=bool,
|
| 50 |
+
default=True,
|
| 51 |
+
help="Pre or Post Normalization.",
|
| 52 |
+
)
|
| 53 |
+
parser.add_argument(
|
| 54 |
+
"--add-prenet",
|
| 55 |
+
type=bool,
|
| 56 |
+
default=False,
|
| 57 |
+
help="Whether add PreNet after Inputs.",
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
# VALL-E & F
|
| 61 |
+
parser.add_argument(
|
| 62 |
+
"--prefix-mode",
|
| 63 |
+
type=int,
|
| 64 |
+
default=1,
|
| 65 |
+
help="The mode for how to prefix VALL-E NAR Decoder, "
|
| 66 |
+
"0: no prefix, 1: 0 to random, 2: random to random, 4: chunk of pre or post utterance.",
|
| 67 |
+
)
|
| 68 |
+
parser.add_argument(
|
| 69 |
+
"--share-embedding",
|
| 70 |
+
type=bool,
|
| 71 |
+
default=True,
|
| 72 |
+
help="Share the parameters of the output projection layer with the parameters of the acoustic embedding.",
|
| 73 |
+
)
|
| 74 |
+
parser.add_argument(
|
| 75 |
+
"--prepend-bos",
|
| 76 |
+
type=bool,
|
| 77 |
+
default=False,
|
| 78 |
+
help="Whether prepend <BOS> to the acoustic tokens -> AR Decoder inputs.",
|
| 79 |
+
)
|
| 80 |
+
parser.add_argument(
|
| 81 |
+
"--num-quantizers",
|
| 82 |
+
type=int,
|
| 83 |
+
default=8,
|
| 84 |
+
help="Number of Audio/Semantic quantization layers.",
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
# Transformer
|
| 88 |
+
parser.add_argument(
|
| 89 |
+
"--scaling-xformers",
|
| 90 |
+
type=bool,
|
| 91 |
+
default=False,
|
| 92 |
+
help="Apply Reworked Conformer scaling on Transformers.",
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def get_model(params) -> nn.Module:
|
| 97 |
+
if params.model_name.lower() in ["vall-f", "vallf"]:
|
| 98 |
+
model = VALLF(
|
| 99 |
+
params.decoder_dim,
|
| 100 |
+
params.nhead,
|
| 101 |
+
params.num_decoder_layers,
|
| 102 |
+
norm_first=params.norm_first,
|
| 103 |
+
add_prenet=params.add_prenet,
|
| 104 |
+
prefix_mode=params.prefix_mode,
|
| 105 |
+
share_embedding=params.share_embedding,
|
| 106 |
+
nar_scale_factor=params.scale_factor,
|
| 107 |
+
prepend_bos=params.prepend_bos,
|
| 108 |
+
num_quantizers=params.num_quantizers,
|
| 109 |
+
)
|
| 110 |
+
elif params.model_name.lower() in ["vall-e", "valle"]:
|
| 111 |
+
model = VALLE(
|
| 112 |
+
params.decoder_dim,
|
| 113 |
+
params.nhead,
|
| 114 |
+
params.num_decoder_layers,
|
| 115 |
+
norm_first=params.norm_first,
|
| 116 |
+
add_prenet=params.add_prenet,
|
| 117 |
+
prefix_mode=params.prefix_mode,
|
| 118 |
+
share_embedding=params.share_embedding,
|
| 119 |
+
nar_scale_factor=params.scale_factor,
|
| 120 |
+
prepend_bos=params.prepend_bos,
|
| 121 |
+
num_quantizers=params.num_quantizers,
|
| 122 |
+
)
|
| 123 |
+
else:
|
| 124 |
+
raise ValueError("No such model")
|
| 125 |
+
|
| 126 |
+
return model
|
models/macros.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Text
|
| 2 |
+
NUM_TEXT_TOKENS = 2048
|
| 3 |
+
|
| 4 |
+
# Audio
|
| 5 |
+
NUM_AUDIO_TOKENS = 1024 # EnCodec RVQ bins
|
| 6 |
+
NUM_MEL_BINS = 100 # BigVGAN bigvgan_24khz_100band
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
# Speaker
|
| 10 |
+
NUM_SPEAKER_CLASSES = 4096
|
| 11 |
+
SPEAKER_EMBEDDING_DIM = 64
|
models/vallex.py
ADDED
|
@@ -0,0 +1,825 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 (authors: Feiteng Li)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import random
|
| 16 |
+
from typing import Dict, Iterator, List, Tuple, Union
|
| 17 |
+
|
| 18 |
+
import numpy as np
|
| 19 |
+
import torch
|
| 20 |
+
import torch.nn as nn
|
| 21 |
+
import torch.nn.functional as F
|
| 22 |
+
# from icefall.utils import make_pad_mask
|
| 23 |
+
# from torchmetrics.classification import MulticlassAccuracy
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
from modules.embedding import SinePositionalEmbedding, TokenEmbedding
|
| 27 |
+
from modules.transformer import (
|
| 28 |
+
AdaptiveLayerNorm,
|
| 29 |
+
LayerNorm,
|
| 30 |
+
TransformerDecoderLayer,
|
| 31 |
+
TransformerEncoder,
|
| 32 |
+
TransformerEncoderLayer,
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
from .macros import NUM_AUDIO_TOKENS, NUM_TEXT_TOKENS
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class Transpose(nn.Identity):
|
| 39 |
+
"""(N, T, D) -> (N, D, T)"""
|
| 40 |
+
|
| 41 |
+
def forward(self, input: torch.Tensor) -> torch.Tensor:
|
| 42 |
+
return input.transpose(1, 2)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
# NOTE: There are two ways to implement the model
|
| 46 |
+
# 1) [VALL-F] standard TransformerDecoder, use x as memory
|
| 47 |
+
# 2) [VALL-E] modified TransformerDecoder like GPT-x(e.g. causal TransformerEncoder),
|
| 48 |
+
# use x as the prefix of decoder inputs
|
| 49 |
+
class VALLF(nn.Module):
|
| 50 |
+
"""It implements https://arxiv.org/abs/2301.02111
|
| 51 |
+
"Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers"
|
| 52 |
+
"""
|
| 53 |
+
|
| 54 |
+
def __init__(
|
| 55 |
+
self,
|
| 56 |
+
d_model: int,
|
| 57 |
+
nhead: int,
|
| 58 |
+
num_layers: int,
|
| 59 |
+
norm_first: bool = True,
|
| 60 |
+
add_prenet: bool = False,
|
| 61 |
+
decoder_cls: Union[
|
| 62 |
+
nn.TransformerDecoder, nn.TransformerEncoder
|
| 63 |
+
] = nn.TransformerDecoder,
|
| 64 |
+
decoder_layer_cls: Union[
|
| 65 |
+
TransformerDecoderLayer, TransformerEncoderLayer
|
| 66 |
+
] = TransformerDecoderLayer,
|
| 67 |
+
prefix_mode: int = 0,
|
| 68 |
+
share_embedding: bool = True,
|
| 69 |
+
nar_scale_factor: float = 1.0,
|
| 70 |
+
prepend_bos: bool = True,
|
| 71 |
+
num_quantizers: int = 8,
|
| 72 |
+
):
|
| 73 |
+
"""
|
| 74 |
+
Args:
|
| 75 |
+
d_model:
|
| 76 |
+
The number of expected features in the input (required).
|
| 77 |
+
nhead:
|
| 78 |
+
The number of heads in the multiheadattention models (required).
|
| 79 |
+
num_layers:
|
| 80 |
+
The number of sub-decoder-layers in the decoder (required).
|
| 81 |
+
"""
|
| 82 |
+
super().__init__()
|
| 83 |
+
nar_d_model = int(d_model * nar_scale_factor)
|
| 84 |
+
|
| 85 |
+
self.ar_text_embedding = TokenEmbedding(d_model, NUM_TEXT_TOKENS) # W_x
|
| 86 |
+
self.nar_text_embedding = TokenEmbedding(nar_d_model, NUM_TEXT_TOKENS)
|
| 87 |
+
|
| 88 |
+
# ID NUM_AUDIO_TOKENS -> PAD
|
| 89 |
+
# ID NUM_AUDIO_TOKENS + 1 -> BOS
|
| 90 |
+
self.ar_audio_prepend_bos = prepend_bos
|
| 91 |
+
self.ar_audio_embedding = TokenEmbedding(
|
| 92 |
+
d_model, NUM_AUDIO_TOKENS + 1 + int(prepend_bos)
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
# PreNet
|
| 96 |
+
if add_prenet:
|
| 97 |
+
self.ar_text_prenet = nn.Sequential(
|
| 98 |
+
Transpose(),
|
| 99 |
+
nn.Conv1d(d_model, d_model, kernel_size=5, padding="same"),
|
| 100 |
+
nn.BatchNorm1d(d_model),
|
| 101 |
+
nn.ReLU(),
|
| 102 |
+
nn.Dropout(0.5),
|
| 103 |
+
nn.Conv1d(d_model, d_model, kernel_size=5, padding="same"),
|
| 104 |
+
nn.BatchNorm1d(d_model),
|
| 105 |
+
nn.ReLU(),
|
| 106 |
+
nn.Dropout(0.5),
|
| 107 |
+
nn.Conv1d(d_model, d_model, kernel_size=5, padding="same"),
|
| 108 |
+
nn.BatchNorm1d(d_model),
|
| 109 |
+
nn.ReLU(),
|
| 110 |
+
nn.Dropout(0.5),
|
| 111 |
+
Transpose(),
|
| 112 |
+
nn.Linear(d_model, d_model),
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
self.ar_audio_prenet = nn.Sequential(
|
| 116 |
+
nn.Linear(d_model, 256),
|
| 117 |
+
nn.ReLU(),
|
| 118 |
+
nn.Dropout(0.25),
|
| 119 |
+
nn.Linear(256, 256),
|
| 120 |
+
nn.ReLU(),
|
| 121 |
+
nn.Dropout(0.25),
|
| 122 |
+
nn.Linear(256, d_model),
|
| 123 |
+
)
|
| 124 |
+
else:
|
| 125 |
+
self.ar_text_prenet = nn.Identity()
|
| 126 |
+
self.ar_audio_prenet = nn.Identity()
|
| 127 |
+
|
| 128 |
+
self.ar_text_position = SinePositionalEmbedding(
|
| 129 |
+
d_model,
|
| 130 |
+
dropout=0.1,
|
| 131 |
+
scale=False,
|
| 132 |
+
alpha=True,
|
| 133 |
+
)
|
| 134 |
+
self.ar_audio_position = SinePositionalEmbedding(
|
| 135 |
+
d_model,
|
| 136 |
+
dropout=0.1,
|
| 137 |
+
scale=False,
|
| 138 |
+
alpha=True,
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
self.ar_decoder = decoder_cls(
|
| 142 |
+
decoder_layer_cls(
|
| 143 |
+
d_model,
|
| 144 |
+
nhead,
|
| 145 |
+
dim_feedforward=d_model * 4,
|
| 146 |
+
dropout=0.1,
|
| 147 |
+
batch_first=True,
|
| 148 |
+
norm_first=norm_first,
|
| 149 |
+
),
|
| 150 |
+
num_layers=num_layers,
|
| 151 |
+
norm=LayerNorm(d_model) if norm_first else None,
|
| 152 |
+
)
|
| 153 |
+
self.ar_predict_layer = nn.Linear(
|
| 154 |
+
d_model, NUM_AUDIO_TOKENS + 1, bias=False
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
self.rng = random.Random(0)
|
| 158 |
+
self.num_heads = nhead
|
| 159 |
+
self.prefix_mode = prefix_mode
|
| 160 |
+
self.num_quantizers = num_quantizers
|
| 161 |
+
|
| 162 |
+
assert num_quantizers >= 1
|
| 163 |
+
if num_quantizers > 1:
|
| 164 |
+
self.nar_audio_embeddings = nn.ModuleList(
|
| 165 |
+
[TokenEmbedding(nar_d_model, NUM_AUDIO_TOKENS + 1)]
|
| 166 |
+
+ [
|
| 167 |
+
TokenEmbedding(nar_d_model, NUM_AUDIO_TOKENS)
|
| 168 |
+
for i in range(num_quantizers - 1)
|
| 169 |
+
]
|
| 170 |
+
) # W_a
|
| 171 |
+
|
| 172 |
+
# PreNet
|
| 173 |
+
if add_prenet:
|
| 174 |
+
self.nar_text_prenet = nn.Sequential(
|
| 175 |
+
Transpose(),
|
| 176 |
+
nn.Conv1d(
|
| 177 |
+
nar_d_model, nar_d_model, kernel_size=5, padding="same"
|
| 178 |
+
),
|
| 179 |
+
nn.BatchNorm1d(nar_d_model),
|
| 180 |
+
nn.ReLU(),
|
| 181 |
+
nn.Dropout(0.5),
|
| 182 |
+
nn.Conv1d(
|
| 183 |
+
nar_d_model, nar_d_model, kernel_size=5, padding="same"
|
| 184 |
+
),
|
| 185 |
+
nn.BatchNorm1d(nar_d_model),
|
| 186 |
+
nn.ReLU(),
|
| 187 |
+
nn.Dropout(0.5),
|
| 188 |
+
nn.Conv1d(
|
| 189 |
+
nar_d_model, nar_d_model, kernel_size=5, padding="same"
|
| 190 |
+
),
|
| 191 |
+
nn.BatchNorm1d(nar_d_model),
|
| 192 |
+
nn.ReLU(),
|
| 193 |
+
nn.Dropout(0.5),
|
| 194 |
+
Transpose(),
|
| 195 |
+
nn.Linear(nar_d_model, nar_d_model),
|
| 196 |
+
)
|
| 197 |
+
self.nar_audio_prenet = nn.Sequential(
|
| 198 |
+
nn.Linear(nar_d_model, 256),
|
| 199 |
+
nn.ReLU(),
|
| 200 |
+
nn.Dropout(0.25),
|
| 201 |
+
nn.Linear(256, 256),
|
| 202 |
+
nn.ReLU(),
|
| 203 |
+
nn.Dropout(0.25),
|
| 204 |
+
nn.Linear(256, nar_d_model),
|
| 205 |
+
)
|
| 206 |
+
else:
|
| 207 |
+
self.nar_text_prenet = nn.Identity()
|
| 208 |
+
self.nar_audio_prenet = nn.Identity()
|
| 209 |
+
|
| 210 |
+
self.nar_text_position = SinePositionalEmbedding(
|
| 211 |
+
nar_d_model,
|
| 212 |
+
dropout=0.0,
|
| 213 |
+
scale=False,
|
| 214 |
+
alpha=False,
|
| 215 |
+
)
|
| 216 |
+
self.nar_audio_position = SinePositionalEmbedding(
|
| 217 |
+
nar_d_model,
|
| 218 |
+
dropout=0.1,
|
| 219 |
+
scale=False,
|
| 220 |
+
alpha=False,
|
| 221 |
+
)
|
| 222 |
+
|
| 223 |
+
self.nar_decoder = decoder_cls(
|
| 224 |
+
decoder_layer_cls(
|
| 225 |
+
nar_d_model,
|
| 226 |
+
int(nhead * nar_scale_factor),
|
| 227 |
+
dim_feedforward=nar_d_model * 4,
|
| 228 |
+
dropout=0.1,
|
| 229 |
+
batch_first=True,
|
| 230 |
+
norm_first=norm_first,
|
| 231 |
+
adaptive_layer_norm=True,
|
| 232 |
+
),
|
| 233 |
+
num_layers=int(num_layers * nar_scale_factor),
|
| 234 |
+
norm=AdaptiveLayerNorm(
|
| 235 |
+
nar_d_model, norm=nn.LayerNorm(nar_d_model)
|
| 236 |
+
)
|
| 237 |
+
if norm_first
|
| 238 |
+
else None,
|
| 239 |
+
)
|
| 240 |
+
self.nar_predict_layers = nn.ModuleList(
|
| 241 |
+
[
|
| 242 |
+
nn.Linear(nar_d_model, NUM_AUDIO_TOKENS, bias=False)
|
| 243 |
+
for i in range(num_quantizers - 1)
|
| 244 |
+
]
|
| 245 |
+
)
|
| 246 |
+
self.nar_stage_embeddings = nn.ModuleList(
|
| 247 |
+
[
|
| 248 |
+
TokenEmbedding(nar_d_model, 1)
|
| 249 |
+
for i in range(num_quantizers - 1)
|
| 250 |
+
]
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
if share_embedding:
|
| 254 |
+
# We share the parameters of the output projection layer with the parameters of the acoustic embedding Wa
|
| 255 |
+
# NOTE(Feiteng): In the experiment, this undermines accuracy
|
| 256 |
+
# self.ar_predict_layer.weight = self.ar_audio_embedding.weight
|
| 257 |
+
|
| 258 |
+
# We also share the parameters of the acoustic embedding layer and the output prediction layer,
|
| 259 |
+
# which means the weights of the j-th prediction layer are the same as the (j + 1)-th acoustic embedding layer.
|
| 260 |
+
for j in range(0, num_quantizers - 2):
|
| 261 |
+
self.nar_predict_layers[
|
| 262 |
+
j
|
| 263 |
+
].weight = self.nar_audio_embeddings[j + 2].weight
|
| 264 |
+
|
| 265 |
+
def stage_parameters(self, stage: int = 1) -> Iterator[nn.Parameter]:
|
| 266 |
+
assert stage > 0
|
| 267 |
+
if stage == 1:
|
| 268 |
+
for name, param in self.named_parameters():
|
| 269 |
+
if name.startswith("ar_"):
|
| 270 |
+
print(f" AR parameter: {name}")
|
| 271 |
+
yield param
|
| 272 |
+
|
| 273 |
+
if stage == 2:
|
| 274 |
+
for name, param in self.named_parameters():
|
| 275 |
+
if name.startswith("nar_"):
|
| 276 |
+
print(f"NAR parameter: {name}")
|
| 277 |
+
yield param
|
| 278 |
+
|
| 279 |
+
def stage_named_parameters(
|
| 280 |
+
self, stage: int = 1
|
| 281 |
+
) -> Iterator[Tuple[str, nn.Parameter]]:
|
| 282 |
+
assert stage > 0
|
| 283 |
+
if stage == 1:
|
| 284 |
+
for pair in self.named_parameters():
|
| 285 |
+
if pair[0].startswith("ar_"):
|
| 286 |
+
yield pair
|
| 287 |
+
|
| 288 |
+
if stage == 2:
|
| 289 |
+
for pair in self.named_parameters():
|
| 290 |
+
if pair[0].startswith("nar_"):
|
| 291 |
+
yield pair
|
| 292 |
+
|
| 293 |
+
def pad_y_eos(self, y, y_mask_int, eos_id):
|
| 294 |
+
targets = F.pad(y, (0, 1), value=0) + eos_id * F.pad(
|
| 295 |
+
y_mask_int, (0, 1), value=1
|
| 296 |
+
)
|
| 297 |
+
# inputs, targets
|
| 298 |
+
if self.ar_audio_prepend_bos:
|
| 299 |
+
return (
|
| 300 |
+
F.pad(targets[:, :-1], (1, 0), value=NUM_AUDIO_TOKENS + 1),
|
| 301 |
+
targets,
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
return targets[:, :-1], targets[:, 1:]
|
| 305 |
+
|
| 306 |
+
def _prepare_prompts(self, y, y_lens, codes, nar_stage, y_prompts_codes, prefix_mode):
|
| 307 |
+
# 5.1 For the NAR acoustic prompt tokens, we select a random segment waveform of 3 seconds
|
| 308 |
+
# from the same utterance.
|
| 309 |
+
# We implement this differently.
|
| 310 |
+
if prefix_mode == 0:
|
| 311 |
+
# no prefix
|
| 312 |
+
prefix_len = 0
|
| 313 |
+
y_emb = self.nar_audio_embeddings[0](y)
|
| 314 |
+
for j in range(1, nar_stage):
|
| 315 |
+
# Formula (4) (5)
|
| 316 |
+
y_emb = y_emb + self.nar_audio_embeddings[j](codes[..., j])
|
| 317 |
+
elif prefix_mode == 1:
|
| 318 |
+
# prefix at begining
|
| 319 |
+
int_low = (0.25 * y_lens.min()).type(torch.int64).item()
|
| 320 |
+
prefix_len = torch.randint(0, int_low * 2, size=()).item()
|
| 321 |
+
prefix_len = min(prefix_len, 225) # 24000/320 * 3s = 225 frames
|
| 322 |
+
|
| 323 |
+
y_prompts = self.nar_audio_embeddings[0](y[:, :prefix_len])
|
| 324 |
+
y_emb = self.nar_audio_embeddings[0](y[:, prefix_len:])
|
| 325 |
+
for j in range(1, self.num_quantizers):
|
| 326 |
+
y_prompts += self.nar_audio_embeddings[j](
|
| 327 |
+
codes[:, :prefix_len, j]
|
| 328 |
+
)
|
| 329 |
+
if j < nar_stage:
|
| 330 |
+
y_emb += self.nar_audio_embeddings[j](
|
| 331 |
+
codes[:, prefix_len:, j]
|
| 332 |
+
)
|
| 333 |
+
y_emb = torch.concat([y_prompts, y_emb], axis=1)
|
| 334 |
+
elif prefix_mode in [2, 4]:
|
| 335 |
+
if prefix_mode == 2:
|
| 336 |
+
# random prefix
|
| 337 |
+
prefix_len = min(225, int(0.25 * y_lens.min().item()))
|
| 338 |
+
|
| 339 |
+
y_prompts_codes = []
|
| 340 |
+
for b in range(codes.shape[0]):
|
| 341 |
+
start = self.rng.randint(0, y_lens[b].item() - prefix_len)
|
| 342 |
+
y_prompts_codes.append(
|
| 343 |
+
torch.clone(codes[b, start : start + prefix_len])
|
| 344 |
+
)
|
| 345 |
+
codes[
|
| 346 |
+
b, start : start + prefix_len, nar_stage
|
| 347 |
+
] = NUM_AUDIO_TOKENS
|
| 348 |
+
y_prompts_codes = torch.stack(y_prompts_codes, dim=0)
|
| 349 |
+
else:
|
| 350 |
+
prefix_len = y_prompts_codes.shape[1]
|
| 351 |
+
|
| 352 |
+
y_prompts = self.nar_audio_embeddings[0](y_prompts_codes[..., 0])
|
| 353 |
+
y_emb = self.nar_audio_embeddings[0](y)
|
| 354 |
+
for j in range(1, self.num_quantizers):
|
| 355 |
+
y_prompts += self.nar_audio_embeddings[j](
|
| 356 |
+
y_prompts_codes[..., j]
|
| 357 |
+
)
|
| 358 |
+
if j < nar_stage:
|
| 359 |
+
y_emb += self.nar_audio_embeddings[j](codes[..., j])
|
| 360 |
+
y_emb = torch.concat([y_prompts, y_emb], axis=1)
|
| 361 |
+
else:
|
| 362 |
+
raise ValueError
|
| 363 |
+
|
| 364 |
+
return y_emb, prefix_len
|
| 365 |
+
|
| 366 |
+
def forward(
|
| 367 |
+
self,
|
| 368 |
+
x: torch.Tensor,
|
| 369 |
+
x_lens: torch.Tensor,
|
| 370 |
+
y: Union[torch.Tensor],
|
| 371 |
+
y_lens: Union[torch.Tensor],
|
| 372 |
+
reduction: str = "sum",
|
| 373 |
+
train_stage: int = 0,
|
| 374 |
+
**kwargs,
|
| 375 |
+
) -> Tuple[torch.Tensor, Union[torch.Tensor, None]]:
|
| 376 |
+
raise NotImplementedError
|
| 377 |
+
|
| 378 |
+
def inference(
|
| 379 |
+
self,
|
| 380 |
+
x: torch.Tensor,
|
| 381 |
+
x_lens: torch.Tensor,
|
| 382 |
+
y: torch.Tensor,
|
| 383 |
+
enroll_x_lens: Union[torch.Tensor, None] = None,
|
| 384 |
+
top_k: int = -100,
|
| 385 |
+
temperature: float = 1.0,
|
| 386 |
+
) -> torch.Tensor:
|
| 387 |
+
raise NotImplementedError
|
| 388 |
+
|
| 389 |
+
def visualize(
|
| 390 |
+
self,
|
| 391 |
+
predicts: Tuple[torch.Tensor],
|
| 392 |
+
batch: Dict[str, Union[List, torch.Tensor]],
|
| 393 |
+
output_dir: str,
|
| 394 |
+
limit: int = 4,
|
| 395 |
+
) -> None:
|
| 396 |
+
raise NotImplementedError
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
class VALLE(VALLF):
|
| 400 |
+
"""It implements https://arxiv.org/abs/2301.02111
|
| 401 |
+
"Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers"
|
| 402 |
+
"""
|
| 403 |
+
|
| 404 |
+
def __init__(
|
| 405 |
+
self,
|
| 406 |
+
d_model: int,
|
| 407 |
+
nhead: int,
|
| 408 |
+
num_layers: int,
|
| 409 |
+
norm_first: bool = True,
|
| 410 |
+
add_prenet: bool = False,
|
| 411 |
+
prefix_mode: int = 0,
|
| 412 |
+
share_embedding: bool = True,
|
| 413 |
+
nar_scale_factor: float = 1.0,
|
| 414 |
+
**kwargs,
|
| 415 |
+
):
|
| 416 |
+
"""
|
| 417 |
+
Args:
|
| 418 |
+
d_model:
|
| 419 |
+
The number of expected features in the input (required).
|
| 420 |
+
nhead:
|
| 421 |
+
The number of heads in the multiheadattention models (required).
|
| 422 |
+
num_layers:
|
| 423 |
+
The number of sub-decoder-layers in the decoder (required).
|
| 424 |
+
"""
|
| 425 |
+
super(VALLE, self).__init__(
|
| 426 |
+
d_model,
|
| 427 |
+
nhead,
|
| 428 |
+
num_layers,
|
| 429 |
+
norm_first=norm_first,
|
| 430 |
+
add_prenet=add_prenet,
|
| 431 |
+
decoder_cls=TransformerEncoder,
|
| 432 |
+
decoder_layer_cls=TransformerEncoderLayer,
|
| 433 |
+
prefix_mode=prefix_mode,
|
| 434 |
+
share_embedding=share_embedding,
|
| 435 |
+
nar_scale_factor=nar_scale_factor,
|
| 436 |
+
**kwargs,
|
| 437 |
+
)
|
| 438 |
+
self.language_ID = {
|
| 439 |
+
'en': 0,
|
| 440 |
+
'zh': 1,
|
| 441 |
+
'ja': 2,
|
| 442 |
+
}
|
| 443 |
+
self.ar_language_embedding = TokenEmbedding(d_model, len(self.language_ID))
|
| 444 |
+
self.nar_language_embedding = TokenEmbedding(d_model, len(self.language_ID))
|
| 445 |
+
|
| 446 |
+
def forward(
|
| 447 |
+
self,
|
| 448 |
+
x: torch.Tensor,
|
| 449 |
+
x_lens: torch.Tensor,
|
| 450 |
+
y: Union[torch.Tensor],
|
| 451 |
+
y_lens: Union[torch.Tensor],
|
| 452 |
+
reduction: str = "sum",
|
| 453 |
+
train_stage: int = 0,
|
| 454 |
+
**kwargs,
|
| 455 |
+
):
|
| 456 |
+
raise NotImplementedError
|
| 457 |
+
def inference(
|
| 458 |
+
self,
|
| 459 |
+
x: torch.Tensor,
|
| 460 |
+
x_lens: torch.Tensor,
|
| 461 |
+
y: torch.Tensor,
|
| 462 |
+
enroll_x_lens: torch.Tensor,
|
| 463 |
+
top_k: int = -100,
|
| 464 |
+
temperature: float = 1.0,
|
| 465 |
+
prompt_language: str = None,
|
| 466 |
+
text_language: str = None,
|
| 467 |
+
) -> torch.Tensor:
|
| 468 |
+
"""
|
| 469 |
+
Args:
|
| 470 |
+
x:
|
| 471 |
+
A 2-D tensor of shape (1, S).
|
| 472 |
+
x_lens:
|
| 473 |
+
A 1-D tensor of shape (1,). It contains the number of tokens in `x`
|
| 474 |
+
before padding.
|
| 475 |
+
y:
|
| 476 |
+
A 3-D tensor of shape (1, T, 8).
|
| 477 |
+
top_k: (`optional`) int
|
| 478 |
+
The number of highest probability tokens to keep for top-k-filtering. Default to -100.
|
| 479 |
+
temperature: (`optional`) float
|
| 480 |
+
The value used to module the next token probabilities. Must be strictly positive. Default to 1.0.
|
| 481 |
+
Returns:
|
| 482 |
+
Return the predicted audio code matrix.
|
| 483 |
+
"""
|
| 484 |
+
assert x.ndim == 2, x.shape
|
| 485 |
+
assert x_lens.ndim == 1, x_lens.shape
|
| 486 |
+
assert y.ndim == 3, y.shape
|
| 487 |
+
assert y.shape[0] == 1, y.shape
|
| 488 |
+
|
| 489 |
+
assert torch.all(x_lens > 0)
|
| 490 |
+
|
| 491 |
+
# NOTE: x has been padded in TextTokenCollater
|
| 492 |
+
text = x
|
| 493 |
+
x = self.ar_text_embedding(text)
|
| 494 |
+
# Add language embedding
|
| 495 |
+
prompt_language_id = torch.LongTensor(np.array([self.language_ID[prompt_language]])).to(x.device)
|
| 496 |
+
text_language_id = torch.LongTensor(np.array([self.language_ID[text_language]])).to(x.device)
|
| 497 |
+
x[:, :enroll_x_lens, :] += self.ar_language_embedding(prompt_language_id)
|
| 498 |
+
x[:, enroll_x_lens:, :] += self.ar_language_embedding(text_language_id)
|
| 499 |
+
x = self.ar_text_prenet(x)
|
| 500 |
+
x = self.ar_text_position(x)
|
| 501 |
+
|
| 502 |
+
text_len = x_lens.max()
|
| 503 |
+
prompts = y
|
| 504 |
+
prefix_len = y.shape[1]
|
| 505 |
+
|
| 506 |
+
# AR Decoder
|
| 507 |
+
# TODO: Managing decoder steps avoid repetitive computation
|
| 508 |
+
y = prompts[..., 0]
|
| 509 |
+
if self.ar_audio_prepend_bos:
|
| 510 |
+
y = F.pad(y, (1, 0), value=NUM_AUDIO_TOKENS + 1)
|
| 511 |
+
|
| 512 |
+
x_len = x_lens.max()
|
| 513 |
+
x_attn_mask = torch.zeros((x_len, x_len), dtype=torch.bool)
|
| 514 |
+
|
| 515 |
+
kv_cache = None
|
| 516 |
+
use_kv_caching = True
|
| 517 |
+
while True:
|
| 518 |
+
y_emb = self.ar_audio_embedding(y)
|
| 519 |
+
y_emb = self.ar_audio_prenet(y_emb)
|
| 520 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 521 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 522 |
+
|
| 523 |
+
y_len = y.shape[1]
|
| 524 |
+
x_attn_mask_pad = F.pad(
|
| 525 |
+
x_attn_mask,
|
| 526 |
+
(0, y_len),
|
| 527 |
+
value=True,
|
| 528 |
+
)
|
| 529 |
+
y_attn_mask = F.pad(
|
| 530 |
+
torch.triu(
|
| 531 |
+
torch.ones(y_len, y_len, dtype=torch.bool), diagonal=1
|
| 532 |
+
),
|
| 533 |
+
(x_len, 0),
|
| 534 |
+
value=False,
|
| 535 |
+
)
|
| 536 |
+
xy_attn_mask = torch.concat(
|
| 537 |
+
[x_attn_mask_pad, y_attn_mask], dim=0
|
| 538 |
+
).to(y.device)
|
| 539 |
+
|
| 540 |
+
|
| 541 |
+
if use_kv_caching and kv_cache is not None:
|
| 542 |
+
xy_pos = xy_pos[:, [-1]]
|
| 543 |
+
else:
|
| 544 |
+
pass
|
| 545 |
+
|
| 546 |
+
xy_dec, kv_cache = self.ar_decoder.infer(
|
| 547 |
+
xy_pos,
|
| 548 |
+
mask=xy_attn_mask,
|
| 549 |
+
past_kv=kv_cache,
|
| 550 |
+
use_cache=use_kv_caching,
|
| 551 |
+
)
|
| 552 |
+
# xy_dec, _ = self.ar_decoder(
|
| 553 |
+
# (xy_pos, None),
|
| 554 |
+
# mask=xy_attn_mask,
|
| 555 |
+
# )
|
| 556 |
+
|
| 557 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 558 |
+
samples = topk_sampling(
|
| 559 |
+
logits, top_k=top_k, top_p=1, temperature=temperature
|
| 560 |
+
)
|
| 561 |
+
|
| 562 |
+
if (
|
| 563 |
+
torch.argmax(logits, dim=-1)[0] == NUM_AUDIO_TOKENS
|
| 564 |
+
or samples[0, 0] == NUM_AUDIO_TOKENS
|
| 565 |
+
or (y.shape[1] - prompts.shape[1]) > x_lens.max() * 16
|
| 566 |
+
):
|
| 567 |
+
if prompts.shape[1] == y.shape[1]:
|
| 568 |
+
raise SyntaxError(
|
| 569 |
+
"well trained model shouldn't reach here."
|
| 570 |
+
)
|
| 571 |
+
|
| 572 |
+
print(f"VALL-E EOS [{prompts.shape[1]} -> {y.shape[1]}]")
|
| 573 |
+
break
|
| 574 |
+
|
| 575 |
+
y = torch.concat([y, samples], dim=1)
|
| 576 |
+
|
| 577 |
+
codes = [y[:, prefix_len + int(self.ar_audio_prepend_bos) :]]
|
| 578 |
+
if self.num_quantizers == 1:
|
| 579 |
+
return torch.stack(codes, dim=-1)
|
| 580 |
+
|
| 581 |
+
# Non-AR Decoders
|
| 582 |
+
y_emb = self.nar_audio_embeddings[0](
|
| 583 |
+
y[:, int(self.ar_audio_prepend_bos) :]
|
| 584 |
+
)
|
| 585 |
+
|
| 586 |
+
if self.prefix_mode in [2, 4]: # Exclude enrolled_phonemes
|
| 587 |
+
enrolled_len = enroll_x_lens.max().item()
|
| 588 |
+
# SOS + Synthesis Text + EOS
|
| 589 |
+
text = torch.concat(
|
| 590 |
+
[
|
| 591 |
+
text[:, :1],
|
| 592 |
+
text[:, enrolled_len - 1 :],
|
| 593 |
+
],
|
| 594 |
+
dim=1,
|
| 595 |
+
)
|
| 596 |
+
text_len = text_len - (enrolled_len - 2)
|
| 597 |
+
assert text.shape[0] == 1
|
| 598 |
+
|
| 599 |
+
x = self.nar_text_embedding(text)
|
| 600 |
+
# Add language embedding
|
| 601 |
+
prompt_language_id = torch.LongTensor(np.array([self.language_ID[prompt_language]])).to(x.device)
|
| 602 |
+
text_language_id = torch.LongTensor(np.array([self.language_ID[text_language]])).to(x.device)
|
| 603 |
+
x[:, :enroll_x_lens, :] += self.nar_language_embedding(prompt_language_id)
|
| 604 |
+
x[:, enroll_x_lens:, :] += self.nar_language_embedding(text_language_id)
|
| 605 |
+
x = self.nar_text_prenet(x)
|
| 606 |
+
x = self.nar_text_position(x)
|
| 607 |
+
|
| 608 |
+
if self.prefix_mode == 0:
|
| 609 |
+
for i, (predict_layer, embedding_layer) in enumerate(
|
| 610 |
+
zip(
|
| 611 |
+
self.nar_predict_layers,
|
| 612 |
+
self.nar_audio_embeddings[1:],
|
| 613 |
+
)
|
| 614 |
+
):
|
| 615 |
+
y_pos = self.nar_audio_prenet(y_emb)
|
| 616 |
+
y_pos = self.nar_audio_position(y_pos)
|
| 617 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 618 |
+
|
| 619 |
+
xy_dec, _ = self.nar_decoder(
|
| 620 |
+
(xy_pos, self.nar_stage_embeddings[i].weight)
|
| 621 |
+
)
|
| 622 |
+
logits = predict_layer(xy_dec[:, text_len + prefix_len :])
|
| 623 |
+
|
| 624 |
+
samples = torch.argmax(logits, dim=-1)
|
| 625 |
+
codes.append(samples)
|
| 626 |
+
|
| 627 |
+
if i < self.num_quantizers - 2:
|
| 628 |
+
y_emb[:, :prefix_len] += embedding_layer(
|
| 629 |
+
prompts[..., i + 1]
|
| 630 |
+
)
|
| 631 |
+
y_emb[:, prefix_len:] += embedding_layer(samples)
|
| 632 |
+
else:
|
| 633 |
+
for j in range(1, self.num_quantizers):
|
| 634 |
+
y_emb[:, :prefix_len] += self.nar_audio_embeddings[j](
|
| 635 |
+
prompts[..., j]
|
| 636 |
+
)
|
| 637 |
+
|
| 638 |
+
for i, (predict_layer, embedding_layer) in enumerate(
|
| 639 |
+
zip(
|
| 640 |
+
self.nar_predict_layers,
|
| 641 |
+
self.nar_audio_embeddings[1:],
|
| 642 |
+
)
|
| 643 |
+
):
|
| 644 |
+
y_pos = self.nar_audio_prenet(y_emb)
|
| 645 |
+
y_pos = self.nar_audio_position(y_pos)
|
| 646 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 647 |
+
|
| 648 |
+
xy_dec, _ = self.nar_decoder(
|
| 649 |
+
(xy_pos, self.nar_stage_embeddings[i].weight)
|
| 650 |
+
)
|
| 651 |
+
logits = predict_layer(xy_dec[:, text_len + prefix_len :])
|
| 652 |
+
|
| 653 |
+
samples = torch.argmax(logits, dim=-1)
|
| 654 |
+
codes.append(samples)
|
| 655 |
+
|
| 656 |
+
if i < self.num_quantizers - 2:
|
| 657 |
+
y_emb[:, prefix_len:] += embedding_layer(samples)
|
| 658 |
+
|
| 659 |
+
assert len(codes) == self.num_quantizers
|
| 660 |
+
return torch.stack(codes, dim=-1)
|
| 661 |
+
|
| 662 |
+
def continual(
|
| 663 |
+
self,
|
| 664 |
+
x: torch.Tensor,
|
| 665 |
+
x_lens: torch.Tensor,
|
| 666 |
+
y: torch.Tensor,
|
| 667 |
+
) -> torch.Tensor:
|
| 668 |
+
"""
|
| 669 |
+
Args:
|
| 670 |
+
x:
|
| 671 |
+
A 2-D tensor of shape (1, S).
|
| 672 |
+
x_lens:
|
| 673 |
+
A 1-D tensor of shape (1,). It contains the number of tokens in `x`
|
| 674 |
+
before padding.
|
| 675 |
+
y:
|
| 676 |
+
A 3-D tensor of shape (1, T, 8).
|
| 677 |
+
Returns:
|
| 678 |
+
Return the predicted audio code matrix.
|
| 679 |
+
"""
|
| 680 |
+
assert x.ndim == 2, x.shape
|
| 681 |
+
assert x_lens.ndim == 1, x_lens.shape
|
| 682 |
+
assert y.ndim == 3, y.shape
|
| 683 |
+
assert y.shape[0] == 1, y.shape
|
| 684 |
+
|
| 685 |
+
assert torch.all(x_lens > 0)
|
| 686 |
+
assert self.num_quantizers == 8
|
| 687 |
+
|
| 688 |
+
# NOTE: x has been padded in TextTokenCollater
|
| 689 |
+
text = x
|
| 690 |
+
x = self.ar_text_embedding(text)
|
| 691 |
+
x = self.ar_text_prenet(x)
|
| 692 |
+
x = self.ar_text_position(x)
|
| 693 |
+
|
| 694 |
+
text_len = x_lens.max()
|
| 695 |
+
|
| 696 |
+
prefix_len = min(int(y.shape[1] * 0.5), 3 * 75)
|
| 697 |
+
|
| 698 |
+
# AR Decoder
|
| 699 |
+
prompts = y[:, :prefix_len]
|
| 700 |
+
|
| 701 |
+
codes = [y[:, prefix_len:, 0]]
|
| 702 |
+
# Non-AR Decoders
|
| 703 |
+
x = self.nar_text_embedding(text)
|
| 704 |
+
x = self.nar_text_prenet(x)
|
| 705 |
+
x = self.nar_text_position(x)
|
| 706 |
+
|
| 707 |
+
y_emb = self.nar_audio_embeddings[0](y[..., 0])
|
| 708 |
+
|
| 709 |
+
if self.prefix_mode == 0:
|
| 710 |
+
for i, (predict_layer, embedding_layer) in enumerate(
|
| 711 |
+
zip(
|
| 712 |
+
self.nar_predict_layers,
|
| 713 |
+
self.nar_audio_embeddings[1:],
|
| 714 |
+
)
|
| 715 |
+
):
|
| 716 |
+
y_pos = self.nar_audio_position(y_emb)
|
| 717 |
+
y_pos = self.nar_audio_prenet(y_pos)
|
| 718 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 719 |
+
|
| 720 |
+
xy_dec, _ = self.nar_decoder(
|
| 721 |
+
(xy_pos, self.nar_stage_embeddings[i].weight)
|
| 722 |
+
)
|
| 723 |
+
logits = predict_layer(xy_dec[:, text_len + prefix_len :])
|
| 724 |
+
|
| 725 |
+
samples = torch.argmax(logits, dim=-1)
|
| 726 |
+
codes.append(samples)
|
| 727 |
+
|
| 728 |
+
if i < 6:
|
| 729 |
+
y_emb[:, :prefix_len] += embedding_layer(
|
| 730 |
+
prompts[..., i + 1]
|
| 731 |
+
)
|
| 732 |
+
y_emb[:, prefix_len:] += embedding_layer(samples)
|
| 733 |
+
else:
|
| 734 |
+
for j in range(1, 8):
|
| 735 |
+
y_emb[:, :prefix_len] += self.nar_audio_embeddings[j](
|
| 736 |
+
prompts[..., j]
|
| 737 |
+
)
|
| 738 |
+
|
| 739 |
+
for i, (predict_layer, embedding_layer) in enumerate(
|
| 740 |
+
zip(
|
| 741 |
+
self.nar_predict_layers,
|
| 742 |
+
self.nar_audio_embeddings[1:],
|
| 743 |
+
)
|
| 744 |
+
):
|
| 745 |
+
y_pos = self.nar_audio_prenet(y_emb)
|
| 746 |
+
y_pos = self.nar_audio_position(y_pos)
|
| 747 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 748 |
+
|
| 749 |
+
xy_dec, _ = self.nar_decoder(
|
| 750 |
+
(xy_pos, self.nar_stage_embeddings[i].weight)
|
| 751 |
+
)
|
| 752 |
+
logits = predict_layer(xy_dec[:, text_len + prefix_len :])
|
| 753 |
+
|
| 754 |
+
samples = torch.argmax(logits, dim=-1)
|
| 755 |
+
codes.append(samples)
|
| 756 |
+
|
| 757 |
+
if i < 6:
|
| 758 |
+
y_emb[:, prefix_len:] += embedding_layer(samples)
|
| 759 |
+
|
| 760 |
+
assert len(codes) == 8
|
| 761 |
+
return torch.stack(codes, dim=-1)
|
| 762 |
+
|
| 763 |
+
|
| 764 |
+
# https://github.com/microsoft/unilm/blob/master/xtune/src/transformers/modeling_utils.py
|
| 765 |
+
def top_k_top_p_filtering(
|
| 766 |
+
logits, top_k=0, top_p=1.0, filter_value=-float("Inf"), min_tokens_to_keep=1
|
| 767 |
+
):
|
| 768 |
+
"""Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
|
| 769 |
+
Args:
|
| 770 |
+
logits: logits distribution shape (batch size, vocabulary size)
|
| 771 |
+
if top_k > 0: keep only top k tokens with highest probability (top-k filtering).
|
| 772 |
+
if top_p < 1.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
|
| 773 |
+
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
|
| 774 |
+
Make sure we keep at least min_tokens_to_keep per batch example in the output
|
| 775 |
+
From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
|
| 776 |
+
"""
|
| 777 |
+
if top_k > 0:
|
| 778 |
+
top_k = min(
|
| 779 |
+
max(top_k, min_tokens_to_keep), logits.size(-1)
|
| 780 |
+
) # Safety check
|
| 781 |
+
# Remove all tokens with a probability less than the last token of the top-k
|
| 782 |
+
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
|
| 783 |
+
logits[indices_to_remove] = filter_value
|
| 784 |
+
|
| 785 |
+
if top_p < 1.0:
|
| 786 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
|
| 787 |
+
cumulative_probs = torch.cumsum(
|
| 788 |
+
F.softmax(sorted_logits, dim=-1), dim=-1
|
| 789 |
+
)
|
| 790 |
+
|
| 791 |
+
# Remove tokens with cumulative probability above the threshold (token with 0 are kept)
|
| 792 |
+
sorted_indices_to_remove = cumulative_probs > top_p
|
| 793 |
+
if min_tokens_to_keep > 1:
|
| 794 |
+
# Keep at least min_tokens_to_keep (set to min_tokens_to_keep-1 because we add the first one below)
|
| 795 |
+
sorted_indices_to_remove[..., :min_tokens_to_keep] = 0
|
| 796 |
+
# Shift the indices to the right to keep also the first token above the threshold
|
| 797 |
+
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[
|
| 798 |
+
..., :-1
|
| 799 |
+
].clone()
|
| 800 |
+
sorted_indices_to_remove[..., 0] = 0
|
| 801 |
+
|
| 802 |
+
# scatter sorted tensors to original indexing
|
| 803 |
+
indices_to_remove = sorted_indices_to_remove.scatter(
|
| 804 |
+
1, sorted_indices, sorted_indices_to_remove
|
| 805 |
+
)
|
| 806 |
+
logits[indices_to_remove] = filter_value
|
| 807 |
+
return logits
|
| 808 |
+
|
| 809 |
+
|
| 810 |
+
def topk_sampling(logits, top_k=10, top_p=1.0, temperature=1.0):
|
| 811 |
+
# temperature: (`optional`) float
|
| 812 |
+
# The value used to module the next token probabilities. Must be strictly positive. Default to 1.0.
|
| 813 |
+
# top_k: (`optional`) int
|
| 814 |
+
# The number of highest probability vocabulary tokens to keep for top-k-filtering. Between 1 and infinity. Default to 50.
|
| 815 |
+
# top_p: (`optional`) float
|
| 816 |
+
# The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling. Must be between 0 and 1. Default to 1.
|
| 817 |
+
|
| 818 |
+
# Temperature (higher temperature => more likely to sample low probability tokens)
|
| 819 |
+
if temperature != 1.0:
|
| 820 |
+
logits = logits / temperature
|
| 821 |
+
# Top-p/top-k filtering
|
| 822 |
+
logits = top_k_top_p_filtering(logits, top_k=top_k, top_p=top_p)
|
| 823 |
+
# Sample
|
| 824 |
+
token = torch.multinomial(F.softmax(logits, dim=-1), num_samples=1)
|
| 825 |
+
return token
|
modules/__init__.py
ADDED
|
File without changes
|
modules/activation.py
ADDED
|
@@ -0,0 +1,612 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, Tuple, List
|
| 2 |
+
import math
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import Tensor
|
| 6 |
+
from torch.nn import Linear, Module
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
from torch.nn.init import constant_, xavier_normal_, xavier_uniform_
|
| 9 |
+
from torch.nn.modules.linear import NonDynamicallyQuantizableLinear
|
| 10 |
+
from torch.nn.parameter import Parameter
|
| 11 |
+
|
| 12 |
+
def _in_projection_packed(
|
| 13 |
+
q: Tensor,
|
| 14 |
+
k: Tensor,
|
| 15 |
+
v: Tensor,
|
| 16 |
+
w: Tensor,
|
| 17 |
+
b: Optional[Tensor] = None,
|
| 18 |
+
) -> List[Tensor]:
|
| 19 |
+
r"""
|
| 20 |
+
Performs the in-projection step of the attention operation, using packed weights.
|
| 21 |
+
Output is a triple containing projection tensors for query, key and value.
|
| 22 |
+
|
| 23 |
+
Args:
|
| 24 |
+
q, k, v: query, key and value tensors to be projected. For self-attention,
|
| 25 |
+
these are typically the same tensor; for encoder-decoder attention,
|
| 26 |
+
k and v are typically the same tensor. (We take advantage of these
|
| 27 |
+
identities for performance if they are present.) Regardless, q, k and v
|
| 28 |
+
must share a common embedding dimension; otherwise their shapes may vary.
|
| 29 |
+
w: projection weights for q, k and v, packed into a single tensor. Weights
|
| 30 |
+
are packed along dimension 0, in q, k, v order.
|
| 31 |
+
b: optional projection biases for q, k and v, packed into a single tensor
|
| 32 |
+
in q, k, v order.
|
| 33 |
+
|
| 34 |
+
Shape:
|
| 35 |
+
Inputs:
|
| 36 |
+
- q: :math:`(..., E)` where E is the embedding dimension
|
| 37 |
+
- k: :math:`(..., E)` where E is the embedding dimension
|
| 38 |
+
- v: :math:`(..., E)` where E is the embedding dimension
|
| 39 |
+
- w: :math:`(E * 3, E)` where E is the embedding dimension
|
| 40 |
+
- b: :math:`E * 3` where E is the embedding dimension
|
| 41 |
+
|
| 42 |
+
Output:
|
| 43 |
+
- in output list :math:`[q', k', v']`, each output tensor will have the
|
| 44 |
+
same shape as the corresponding input tensor.
|
| 45 |
+
"""
|
| 46 |
+
E = q.size(-1)
|
| 47 |
+
if k is v:
|
| 48 |
+
if q is k:
|
| 49 |
+
# self-attention
|
| 50 |
+
return F.linear(q, w, b).chunk(3, dim=-1)
|
| 51 |
+
else:
|
| 52 |
+
# encoder-decoder attention
|
| 53 |
+
w_q, w_kv = w.split([E, E * 2])
|
| 54 |
+
if b is None:
|
| 55 |
+
b_q = b_kv = None
|
| 56 |
+
else:
|
| 57 |
+
b_q, b_kv = b.split([E, E * 2])
|
| 58 |
+
return (F.linear(q, w_q, b_q),) + F.linear(k, w_kv, b_kv).chunk(2, dim=-1)
|
| 59 |
+
else:
|
| 60 |
+
w_q, w_k, w_v = w.chunk(3)
|
| 61 |
+
if b is None:
|
| 62 |
+
b_q = b_k = b_v = None
|
| 63 |
+
else:
|
| 64 |
+
b_q, b_k, b_v = b.chunk(3)
|
| 65 |
+
return F.linear(q, w_q, b_q), F.linear(k, w_k, b_k), F.linear(v, w_v, b_v)
|
| 66 |
+
|
| 67 |
+
def _scaled_dot_product_attention(
|
| 68 |
+
q: Tensor,
|
| 69 |
+
k: Tensor,
|
| 70 |
+
v: Tensor,
|
| 71 |
+
attn_mask: Optional[Tensor] = None,
|
| 72 |
+
dropout_p: float = 0.0,
|
| 73 |
+
) -> Tuple[Tensor, Tensor]:
|
| 74 |
+
r"""
|
| 75 |
+
Computes scaled dot product attention on query, key and value tensors, using
|
| 76 |
+
an optional attention mask if passed, and applying dropout if a probability
|
| 77 |
+
greater than 0.0 is specified.
|
| 78 |
+
Returns a tensor pair containing attended values and attention weights.
|
| 79 |
+
|
| 80 |
+
Args:
|
| 81 |
+
q, k, v: query, key and value tensors. See Shape section for shape details.
|
| 82 |
+
attn_mask: optional tensor containing mask values to be added to calculated
|
| 83 |
+
attention. May be 2D or 3D; see Shape section for details.
|
| 84 |
+
dropout_p: dropout probability. If greater than 0.0, dropout is applied.
|
| 85 |
+
|
| 86 |
+
Shape:
|
| 87 |
+
- q: :math:`(B, Nt, E)` where B is batch size, Nt is the target sequence length,
|
| 88 |
+
and E is embedding dimension.
|
| 89 |
+
- key: :math:`(B, Ns, E)` where B is batch size, Ns is the source sequence length,
|
| 90 |
+
and E is embedding dimension.
|
| 91 |
+
- value: :math:`(B, Ns, E)` where B is batch size, Ns is the source sequence length,
|
| 92 |
+
and E is embedding dimension.
|
| 93 |
+
- attn_mask: either a 3D tensor of shape :math:`(B, Nt, Ns)` or a 2D tensor of
|
| 94 |
+
shape :math:`(Nt, Ns)`.
|
| 95 |
+
|
| 96 |
+
- Output: attention values have shape :math:`(B, Nt, E)`; attention weights
|
| 97 |
+
have shape :math:`(B, Nt, Ns)`
|
| 98 |
+
"""
|
| 99 |
+
B, Nt, E = q.shape
|
| 100 |
+
q = q / math.sqrt(E)
|
| 101 |
+
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
|
| 102 |
+
if attn_mask is not None:
|
| 103 |
+
attn = torch.baddbmm(attn_mask, q, k.transpose(-2, -1))
|
| 104 |
+
else:
|
| 105 |
+
attn = torch.bmm(q, k.transpose(-2, -1))
|
| 106 |
+
|
| 107 |
+
attn = F.softmax(attn, dim=-1)
|
| 108 |
+
if dropout_p > 0.0:
|
| 109 |
+
attn = F.dropout(attn, p=dropout_p)
|
| 110 |
+
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
|
| 111 |
+
output = torch.bmm(attn, v)
|
| 112 |
+
return output, attn
|
| 113 |
+
|
| 114 |
+
def multi_head_attention_forward(
|
| 115 |
+
x,
|
| 116 |
+
ipw,
|
| 117 |
+
ipb,
|
| 118 |
+
opw,
|
| 119 |
+
opb,
|
| 120 |
+
n_head,
|
| 121 |
+
attn_mask,
|
| 122 |
+
past_kv=None,
|
| 123 |
+
use_cache=False,
|
| 124 |
+
):
|
| 125 |
+
# x = x.transpose(1, 0)
|
| 126 |
+
# tgt_len, bsz, embed_dim = x.shape
|
| 127 |
+
# head_dim = embed_dim // n_head
|
| 128 |
+
# q, k, v = _in_projection_packed(x, x, x, ipw, ipb)
|
| 129 |
+
# q = q.contiguous().view(tgt_len, bsz * n_head, head_dim).transpose(0, 1)
|
| 130 |
+
# k = k.contiguous().view(k.shape[0], bsz * n_head, head_dim).transpose(0, 1)
|
| 131 |
+
# v = v.contiguous().view(v.shape[0], bsz * n_head, head_dim).transpose(0, 1)
|
| 132 |
+
|
| 133 |
+
# new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)
|
| 134 |
+
# new_attn_mask.masked_fill_(attn_mask, float("-inf"))
|
| 135 |
+
# attn_mask = new_attn_mask
|
| 136 |
+
#
|
| 137 |
+
# attn_output, attn_output_weights = _scaled_dot_product_attention(q, k, v, attn_mask, 0.0)
|
| 138 |
+
# attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len * bsz, embed_dim)
|
| 139 |
+
# attn_output = torch._C._nn.linear(attn_output, opw, opb)
|
| 140 |
+
# attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
|
| 141 |
+
|
| 142 |
+
B, T, C = x.size()
|
| 143 |
+
|
| 144 |
+
q, k, v = torch._C._nn.linear(x, ipw, ipb).chunk(3, dim=-1)
|
| 145 |
+
k = k.view(B, T, n_head, C // n_head).transpose(1, 2) # (B, nh, T, hs)
|
| 146 |
+
q = q.view(B, T, n_head, C // n_head).transpose(1, 2) # (B, nh, T, hs)
|
| 147 |
+
v = v.view(B, T, n_head, C // n_head).transpose(1, 2) # (B, nh, T, hs)
|
| 148 |
+
if past_kv is not None:
|
| 149 |
+
past_key = past_kv[0]
|
| 150 |
+
past_value = past_kv[1]
|
| 151 |
+
k = torch.cat((past_key, k), dim=-2)
|
| 152 |
+
v = torch.cat((past_value, v), dim=-2)
|
| 153 |
+
|
| 154 |
+
FULL_T = k.shape[-2]
|
| 155 |
+
|
| 156 |
+
if use_cache is True:
|
| 157 |
+
present = (k, v)
|
| 158 |
+
else:
|
| 159 |
+
present = None
|
| 160 |
+
|
| 161 |
+
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
|
| 162 |
+
att = att.masked_fill(attn_mask[FULL_T - T:FULL_T, :FULL_T], float('-inf'))
|
| 163 |
+
att = F.softmax(att, dim=-1)
|
| 164 |
+
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
|
| 165 |
+
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
|
| 166 |
+
y = torch._C._nn.linear(y, opw, opb)
|
| 167 |
+
return (y, present)
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class MultiheadAttention(Module):
|
| 171 |
+
r"""Allows the model to jointly attend to information
|
| 172 |
+
from different representation subspaces as described in the paper:
|
| 173 |
+
`Attention Is All You Need <https://arxiv.org/abs/1706.03762>`_.
|
| 174 |
+
|
| 175 |
+
Multi-Head Attention is defined as:
|
| 176 |
+
|
| 177 |
+
.. math::
|
| 178 |
+
\text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O
|
| 179 |
+
|
| 180 |
+
where :math:`head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)`.
|
| 181 |
+
|
| 182 |
+
``forward()`` will use a special optimized implementation if all of the following
|
| 183 |
+
conditions are met:
|
| 184 |
+
|
| 185 |
+
- self attention is being computed (i.e., ``query``, ``key``, and ``value`` are the same tensor. This
|
| 186 |
+
restriction will be loosened in the future.)
|
| 187 |
+
- Either autograd is disabled (using ``torch.inference_mode`` or ``torch.no_grad``) or no tensor argument ``requires_grad``
|
| 188 |
+
- training is disabled (using ``.eval()``)
|
| 189 |
+
- dropout is 0
|
| 190 |
+
- ``add_bias_kv`` is ``False``
|
| 191 |
+
- ``add_zero_attn`` is ``False``
|
| 192 |
+
- ``batch_first`` is ``True`` and the input is batched
|
| 193 |
+
- ``kdim`` and ``vdim`` are equal to ``embed_dim``
|
| 194 |
+
- at most one of ``key_padding_mask`` or ``attn_mask`` is passed
|
| 195 |
+
- if a `NestedTensor <https://pytorch.org/docs/stable/nested.html>`_ is passed, neither ``key_padding_mask``
|
| 196 |
+
nor ``attn_mask`` is passed
|
| 197 |
+
|
| 198 |
+
If the optimized implementation is in use, a
|
| 199 |
+
`NestedTensor <https://pytorch.org/docs/stable/nested.html>`_ can be passed for
|
| 200 |
+
``query``/``key``/``value`` to represent padding more efficiently than using a
|
| 201 |
+
padding mask. In this case, a `NestedTensor <https://pytorch.org/docs/stable/nested.html>`_
|
| 202 |
+
will be returned, and an additional speedup proportional to the fraction of the input
|
| 203 |
+
that is padding can be expected.
|
| 204 |
+
|
| 205 |
+
Args:
|
| 206 |
+
embed_dim: Total dimension of the model.
|
| 207 |
+
num_heads: Number of parallel attention heads. Note that ``embed_dim`` will be split
|
| 208 |
+
across ``num_heads`` (i.e. each head will have dimension ``embed_dim // num_heads``).
|
| 209 |
+
dropout: Dropout probability on ``attn_output_weights``. Default: ``0.0`` (no dropout).
|
| 210 |
+
bias: If specified, adds bias to input / output projection layers. Default: ``True``.
|
| 211 |
+
add_bias_kv: If specified, adds bias to the key and value sequences at dim=0. Default: ``False``.
|
| 212 |
+
add_zero_attn: If specified, adds a new batch of zeros to the key and value sequences at dim=1.
|
| 213 |
+
Default: ``False``.
|
| 214 |
+
kdim: Total number of features for keys. Default: ``None`` (uses ``kdim=embed_dim``).
|
| 215 |
+
vdim: Total number of features for values. Default: ``None`` (uses ``vdim=embed_dim``).
|
| 216 |
+
batch_first: If ``True``, then the input and output tensors are provided
|
| 217 |
+
as (batch, seq, feature). Default: ``False`` (seq, batch, feature).
|
| 218 |
+
|
| 219 |
+
Examples::
|
| 220 |
+
|
| 221 |
+
>>> # xdoctest: +SKIP
|
| 222 |
+
>>> multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
|
| 223 |
+
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
|
| 224 |
+
|
| 225 |
+
"""
|
| 226 |
+
__constants__ = ["batch_first"]
|
| 227 |
+
bias_k: Optional[torch.Tensor]
|
| 228 |
+
bias_v: Optional[torch.Tensor]
|
| 229 |
+
|
| 230 |
+
def __init__(
|
| 231 |
+
self,
|
| 232 |
+
embed_dim,
|
| 233 |
+
num_heads,
|
| 234 |
+
dropout=0.0,
|
| 235 |
+
bias=True,
|
| 236 |
+
add_bias_kv=False,
|
| 237 |
+
add_zero_attn=False,
|
| 238 |
+
kdim=None,
|
| 239 |
+
vdim=None,
|
| 240 |
+
batch_first=False,
|
| 241 |
+
linear1_cls=Linear,
|
| 242 |
+
linear2_cls=Linear,
|
| 243 |
+
device=None,
|
| 244 |
+
dtype=None,
|
| 245 |
+
) -> None:
|
| 246 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 247 |
+
super(MultiheadAttention, self).__init__()
|
| 248 |
+
self.embed_dim = embed_dim
|
| 249 |
+
self.kdim = kdim if kdim is not None else embed_dim
|
| 250 |
+
self.vdim = vdim if vdim is not None else embed_dim
|
| 251 |
+
self._qkv_same_embed_dim = (
|
| 252 |
+
self.kdim == embed_dim and self.vdim == embed_dim
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
self.num_heads = num_heads
|
| 256 |
+
self.dropout = dropout
|
| 257 |
+
self.batch_first = batch_first
|
| 258 |
+
self.head_dim = embed_dim // num_heads
|
| 259 |
+
assert (
|
| 260 |
+
self.head_dim * num_heads == self.embed_dim
|
| 261 |
+
), "embed_dim must be divisible by num_heads"
|
| 262 |
+
|
| 263 |
+
if add_bias_kv:
|
| 264 |
+
self.bias_k = Parameter(
|
| 265 |
+
torch.empty((1, 1, embed_dim), **factory_kwargs)
|
| 266 |
+
)
|
| 267 |
+
self.bias_v = Parameter(
|
| 268 |
+
torch.empty((1, 1, embed_dim), **factory_kwargs)
|
| 269 |
+
)
|
| 270 |
+
else:
|
| 271 |
+
self.bias_k = self.bias_v = None
|
| 272 |
+
|
| 273 |
+
if linear1_cls == Linear:
|
| 274 |
+
if not self._qkv_same_embed_dim:
|
| 275 |
+
self.q_proj_weight = Parameter(
|
| 276 |
+
torch.empty((embed_dim, embed_dim), **factory_kwargs)
|
| 277 |
+
)
|
| 278 |
+
self.k_proj_weight = Parameter(
|
| 279 |
+
torch.empty((embed_dim, self.kdim), **factory_kwargs)
|
| 280 |
+
)
|
| 281 |
+
self.v_proj_weight = Parameter(
|
| 282 |
+
torch.empty((embed_dim, self.vdim), **factory_kwargs)
|
| 283 |
+
)
|
| 284 |
+
self.register_parameter("in_proj_weight", None)
|
| 285 |
+
else:
|
| 286 |
+
self.in_proj_weight = Parameter(
|
| 287 |
+
torch.empty((3 * embed_dim, embed_dim), **factory_kwargs)
|
| 288 |
+
)
|
| 289 |
+
self.register_parameter("q_proj_weight", None)
|
| 290 |
+
self.register_parameter("k_proj_weight", None)
|
| 291 |
+
self.register_parameter("v_proj_weight", None)
|
| 292 |
+
|
| 293 |
+
if bias:
|
| 294 |
+
self.in_proj_bias = Parameter(
|
| 295 |
+
torch.empty(3 * embed_dim, **factory_kwargs)
|
| 296 |
+
)
|
| 297 |
+
else:
|
| 298 |
+
self.register_parameter("in_proj_bias", None)
|
| 299 |
+
self.out_proj = NonDynamicallyQuantizableLinear(
|
| 300 |
+
embed_dim, embed_dim, bias=bias, **factory_kwargs
|
| 301 |
+
)
|
| 302 |
+
|
| 303 |
+
self._reset_parameters()
|
| 304 |
+
else:
|
| 305 |
+
if not self._qkv_same_embed_dim:
|
| 306 |
+
raise NotImplementedError
|
| 307 |
+
else:
|
| 308 |
+
self.in_proj_linear = linear1_cls(
|
| 309 |
+
embed_dim, 3 * embed_dim, bias=bias, **factory_kwargs
|
| 310 |
+
)
|
| 311 |
+
self.in_proj_weight = self.in_proj_linear.weight
|
| 312 |
+
|
| 313 |
+
self.register_parameter("q_proj_weight", None)
|
| 314 |
+
self.register_parameter("k_proj_weight", None)
|
| 315 |
+
self.register_parameter("v_proj_weight", None)
|
| 316 |
+
|
| 317 |
+
if bias:
|
| 318 |
+
self.in_proj_bias = self.in_proj_linear.bias
|
| 319 |
+
else:
|
| 320 |
+
self.register_parameter("in_proj_bias", None)
|
| 321 |
+
|
| 322 |
+
self.out_proj = linear2_cls(
|
| 323 |
+
embed_dim, embed_dim, bias=bias, **factory_kwargs
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
if self.bias_k is not None:
|
| 327 |
+
xavier_normal_(self.bias_k)
|
| 328 |
+
if self.bias_v is not None:
|
| 329 |
+
xavier_normal_(self.bias_v)
|
| 330 |
+
|
| 331 |
+
self.add_zero_attn = add_zero_attn
|
| 332 |
+
|
| 333 |
+
def _reset_parameters(self):
|
| 334 |
+
if self._qkv_same_embed_dim:
|
| 335 |
+
xavier_uniform_(self.in_proj_weight)
|
| 336 |
+
else:
|
| 337 |
+
xavier_uniform_(self.q_proj_weight)
|
| 338 |
+
xavier_uniform_(self.k_proj_weight)
|
| 339 |
+
xavier_uniform_(self.v_proj_weight)
|
| 340 |
+
|
| 341 |
+
if self.in_proj_bias is not None:
|
| 342 |
+
constant_(self.in_proj_bias, 0.0)
|
| 343 |
+
constant_(self.out_proj.bias, 0.0)
|
| 344 |
+
|
| 345 |
+
if self.bias_k is not None:
|
| 346 |
+
xavier_normal_(self.bias_k)
|
| 347 |
+
if self.bias_v is not None:
|
| 348 |
+
xavier_normal_(self.bias_v)
|
| 349 |
+
|
| 350 |
+
def __setstate__(self, state):
|
| 351 |
+
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
|
| 352 |
+
if "_qkv_same_embed_dim" not in state:
|
| 353 |
+
state["_qkv_same_embed_dim"] = True
|
| 354 |
+
|
| 355 |
+
super(MultiheadAttention, self).__setstate__(state)
|
| 356 |
+
|
| 357 |
+
def forward(
|
| 358 |
+
self,
|
| 359 |
+
query: Tensor,
|
| 360 |
+
key: Tensor,
|
| 361 |
+
value: Tensor,
|
| 362 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 363 |
+
need_weights: bool = True,
|
| 364 |
+
attn_mask: Optional[Tensor] = None,
|
| 365 |
+
average_attn_weights: bool = True,
|
| 366 |
+
) -> Tuple[Tensor, Optional[Tensor]]:
|
| 367 |
+
r"""
|
| 368 |
+
Args:
|
| 369 |
+
query: Query embeddings of shape :math:`(L, E_q)` for unbatched input, :math:`(L, N, E_q)` when ``batch_first=False``
|
| 370 |
+
or :math:`(N, L, E_q)` when ``batch_first=True``, where :math:`L` is the target sequence length,
|
| 371 |
+
:math:`N` is the batch size, and :math:`E_q` is the query embedding dimension ``embed_dim``.
|
| 372 |
+
Queries are compared against key-value pairs to produce the output.
|
| 373 |
+
See "Attention Is All You Need" for more details.
|
| 374 |
+
key: Key embeddings of shape :math:`(S, E_k)` for unbatched input, :math:`(S, N, E_k)` when ``batch_first=False``
|
| 375 |
+
or :math:`(N, S, E_k)` when ``batch_first=True``, where :math:`S` is the source sequence length,
|
| 376 |
+
:math:`N` is the batch size, and :math:`E_k` is the key embedding dimension ``kdim``.
|
| 377 |
+
See "Attention Is All You Need" for more details.
|
| 378 |
+
value: Value embeddings of shape :math:`(S, E_v)` for unbatched input, :math:`(S, N, E_v)` when
|
| 379 |
+
``batch_first=False`` or :math:`(N, S, E_v)` when ``batch_first=True``, where :math:`S` is the source
|
| 380 |
+
sequence length, :math:`N` is the batch size, and :math:`E_v` is the value embedding dimension ``vdim``.
|
| 381 |
+
See "Attention Is All You Need" for more details.
|
| 382 |
+
key_padding_mask: If specified, a mask of shape :math:`(N, S)` indicating which elements within ``key``
|
| 383 |
+
to ignore for the purpose of attention (i.e. treat as "padding"). For unbatched `query`, shape should be :math:`(S)`.
|
| 384 |
+
Binary and byte masks are supported.
|
| 385 |
+
For a binary mask, a ``True`` value indicates that the corresponding ``key`` value will be ignored for
|
| 386 |
+
the purpose of attention. For a float mask, it will be directly added to the corresponding ``key`` value.
|
| 387 |
+
need_weights: If specified, returns ``attn_output_weights`` in addition to ``attn_outputs``.
|
| 388 |
+
Default: ``True``.
|
| 389 |
+
attn_mask: If specified, a 2D or 3D mask preventing attention to certain positions. Must be of shape
|
| 390 |
+
:math:`(L, S)` or :math:`(N\cdot\text{num\_heads}, L, S)`, where :math:`N` is the batch size,
|
| 391 |
+
:math:`L` is the target sequence length, and :math:`S` is the source sequence length. A 2D mask will be
|
| 392 |
+
broadcasted across the batch while a 3D mask allows for a different mask for each entry in the batch.
|
| 393 |
+
Binary, byte, and float masks are supported. For a binary mask, a ``True`` value indicates that the
|
| 394 |
+
corresponding position is not allowed to attend. For a byte mask, a non-zero value indicates that the
|
| 395 |
+
corresponding position is not allowed to attend. For a float mask, the mask values will be added to
|
| 396 |
+
the attention weight.
|
| 397 |
+
average_attn_weights: If true, indicates that the returned ``attn_weights`` should be averaged across
|
| 398 |
+
heads. Otherwise, ``attn_weights`` are provided separately per head. Note that this flag only has an
|
| 399 |
+
effect when ``need_weights=True``. Default: ``True`` (i.e. average weights across heads)
|
| 400 |
+
|
| 401 |
+
Outputs:
|
| 402 |
+
- **attn_output** - Attention outputs of shape :math:`(L, E)` when input is unbatched,
|
| 403 |
+
:math:`(L, N, E)` when ``batch_first=False`` or :math:`(N, L, E)` when ``batch_first=True``,
|
| 404 |
+
where :math:`L` is the target sequence length, :math:`N` is the batch size, and :math:`E` is the
|
| 405 |
+
embedding dimension ``embed_dim``.
|
| 406 |
+
- **attn_output_weights** - Only returned when ``need_weights=True``. If ``average_attn_weights=True``,
|
| 407 |
+
returns attention weights averaged across heads of shape :math:`(L, S)` when input is unbatched or
|
| 408 |
+
:math:`(N, L, S)`, where :math:`N` is the batch size, :math:`L` is the target sequence length, and
|
| 409 |
+
:math:`S` is the source sequence length. If ``average_attn_weights=False``, returns attention weights per
|
| 410 |
+
head of shape :math:`(\text{num\_heads}, L, S)` when input is unbatched or :math:`(N, \text{num\_heads}, L, S)`.
|
| 411 |
+
|
| 412 |
+
.. note::
|
| 413 |
+
`batch_first` argument is ignored for unbatched inputs.
|
| 414 |
+
"""
|
| 415 |
+
is_batched = query.dim() == 3
|
| 416 |
+
if key_padding_mask is not None:
|
| 417 |
+
_kpm_dtype = key_padding_mask.dtype
|
| 418 |
+
if _kpm_dtype != torch.bool and not torch.is_floating_point(
|
| 419 |
+
key_padding_mask
|
| 420 |
+
):
|
| 421 |
+
raise AssertionError(
|
| 422 |
+
"only bool and floating types of key_padding_mask are supported"
|
| 423 |
+
)
|
| 424 |
+
why_not_fast_path = ""
|
| 425 |
+
if not is_batched:
|
| 426 |
+
why_not_fast_path = f"input not batched; expected query.dim() of 3 but got {query.dim()}"
|
| 427 |
+
elif query is not key or key is not value:
|
| 428 |
+
# When lifting this restriction, don't forget to either
|
| 429 |
+
# enforce that the dtypes all match or test cases where
|
| 430 |
+
# they don't!
|
| 431 |
+
why_not_fast_path = "non-self attention was used (query, key, and value are not the same Tensor)"
|
| 432 |
+
elif (
|
| 433 |
+
self.in_proj_bias is not None
|
| 434 |
+
and query.dtype != self.in_proj_bias.dtype
|
| 435 |
+
):
|
| 436 |
+
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_bias ({self.in_proj_bias.dtype}) don't match"
|
| 437 |
+
elif (
|
| 438 |
+
self.in_proj_weight is not None
|
| 439 |
+
and query.dtype != self.in_proj_weight.dtype
|
| 440 |
+
):
|
| 441 |
+
# this case will fail anyway, but at least they'll get a useful error message.
|
| 442 |
+
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_weight ({self.in_proj_weight.dtype}) don't match"
|
| 443 |
+
elif self.training:
|
| 444 |
+
why_not_fast_path = "training is enabled"
|
| 445 |
+
elif not self.batch_first:
|
| 446 |
+
why_not_fast_path = "batch_first was not True"
|
| 447 |
+
elif self.bias_k is not None:
|
| 448 |
+
why_not_fast_path = "self.bias_k was not None"
|
| 449 |
+
elif self.bias_v is not None:
|
| 450 |
+
why_not_fast_path = "self.bias_v was not None"
|
| 451 |
+
elif self.dropout:
|
| 452 |
+
why_not_fast_path = f"dropout was {self.dropout}, required zero"
|
| 453 |
+
elif self.add_zero_attn:
|
| 454 |
+
why_not_fast_path = "add_zero_attn was enabled"
|
| 455 |
+
elif not self._qkv_same_embed_dim:
|
| 456 |
+
why_not_fast_path = "_qkv_same_embed_dim was not True"
|
| 457 |
+
elif attn_mask is not None:
|
| 458 |
+
why_not_fast_path = "attn_mask was not None"
|
| 459 |
+
elif query.is_nested and key_padding_mask is not None:
|
| 460 |
+
why_not_fast_path = (
|
| 461 |
+
"key_padding_mask is not supported with NestedTensor input"
|
| 462 |
+
)
|
| 463 |
+
elif self.num_heads % 2 == 1:
|
| 464 |
+
why_not_fast_path = "num_heads is odd"
|
| 465 |
+
elif torch.is_autocast_enabled():
|
| 466 |
+
why_not_fast_path = "autocast is enabled"
|
| 467 |
+
|
| 468 |
+
if not why_not_fast_path:
|
| 469 |
+
tensor_args = (
|
| 470 |
+
query,
|
| 471 |
+
key,
|
| 472 |
+
value,
|
| 473 |
+
self.in_proj_weight,
|
| 474 |
+
self.in_proj_bias,
|
| 475 |
+
self.out_proj.weight,
|
| 476 |
+
self.out_proj.bias,
|
| 477 |
+
)
|
| 478 |
+
# We have to use list comprehensions below because TorchScript does not support
|
| 479 |
+
# generator expressions.
|
| 480 |
+
if torch.overrides.has_torch_function(tensor_args):
|
| 481 |
+
why_not_fast_path = "some Tensor argument has_torch_function"
|
| 482 |
+
elif not all(
|
| 483 |
+
[
|
| 484 |
+
(x is None or x.is_cuda or "cpu" in str(x.device))
|
| 485 |
+
for x in tensor_args
|
| 486 |
+
]
|
| 487 |
+
):
|
| 488 |
+
why_not_fast_path = (
|
| 489 |
+
"some Tensor argument is neither CUDA nor CPU"
|
| 490 |
+
)
|
| 491 |
+
elif torch.is_grad_enabled() and any(
|
| 492 |
+
[x is not None and x.requires_grad for x in tensor_args]
|
| 493 |
+
):
|
| 494 |
+
why_not_fast_path = (
|
| 495 |
+
"grad is enabled and at least one of query or the "
|
| 496 |
+
"input/output projection weights or biases requires_grad"
|
| 497 |
+
)
|
| 498 |
+
if not why_not_fast_path:
|
| 499 |
+
return torch._native_multi_head_attention(
|
| 500 |
+
query,
|
| 501 |
+
key,
|
| 502 |
+
value,
|
| 503 |
+
self.embed_dim,
|
| 504 |
+
self.num_heads,
|
| 505 |
+
self.in_proj_weight,
|
| 506 |
+
self.in_proj_bias,
|
| 507 |
+
self.out_proj.weight,
|
| 508 |
+
self.out_proj.bias,
|
| 509 |
+
key_padding_mask
|
| 510 |
+
if key_padding_mask is not None
|
| 511 |
+
else attn_mask,
|
| 512 |
+
need_weights,
|
| 513 |
+
average_attn_weights,
|
| 514 |
+
1
|
| 515 |
+
if key_padding_mask is not None
|
| 516 |
+
else 0
|
| 517 |
+
if attn_mask is not None
|
| 518 |
+
else None,
|
| 519 |
+
)
|
| 520 |
+
|
| 521 |
+
any_nested = query.is_nested or key.is_nested or value.is_nested
|
| 522 |
+
assert not any_nested, (
|
| 523 |
+
"MultiheadAttention does not support NestedTensor outside of its fast path. "
|
| 524 |
+
+ f"The fast path was not hit because {why_not_fast_path}"
|
| 525 |
+
)
|
| 526 |
+
|
| 527 |
+
if self.batch_first and is_batched:
|
| 528 |
+
# make sure that the transpose op does not affect the "is" property
|
| 529 |
+
if key is value:
|
| 530 |
+
if query is key:
|
| 531 |
+
query = key = value = query.transpose(1, 0)
|
| 532 |
+
else:
|
| 533 |
+
query, key = [x.transpose(1, 0) for x in (query, key)]
|
| 534 |
+
value = key
|
| 535 |
+
else:
|
| 536 |
+
query, key, value = [
|
| 537 |
+
x.transpose(1, 0) for x in (query, key, value)
|
| 538 |
+
]
|
| 539 |
+
|
| 540 |
+
if not self._qkv_same_embed_dim:
|
| 541 |
+
attn_output, attn_output_weights = F.multi_head_attention_forward(
|
| 542 |
+
query,
|
| 543 |
+
key,
|
| 544 |
+
value,
|
| 545 |
+
self.embed_dim,
|
| 546 |
+
self.num_heads,
|
| 547 |
+
self.in_proj_weight,
|
| 548 |
+
self.in_proj_bias,
|
| 549 |
+
self.bias_k,
|
| 550 |
+
self.bias_v,
|
| 551 |
+
self.add_zero_attn,
|
| 552 |
+
self.dropout,
|
| 553 |
+
self.out_proj.weight,
|
| 554 |
+
self.out_proj.bias,
|
| 555 |
+
training=self.training,
|
| 556 |
+
key_padding_mask=key_padding_mask,
|
| 557 |
+
need_weights=need_weights,
|
| 558 |
+
attn_mask=attn_mask,
|
| 559 |
+
use_separate_proj_weight=True,
|
| 560 |
+
q_proj_weight=self.q_proj_weight,
|
| 561 |
+
k_proj_weight=self.k_proj_weight,
|
| 562 |
+
v_proj_weight=self.v_proj_weight,
|
| 563 |
+
average_attn_weights=average_attn_weights,
|
| 564 |
+
)
|
| 565 |
+
else:
|
| 566 |
+
attn_output, attn_output_weights = F.multi_head_attention_forward(
|
| 567 |
+
query,
|
| 568 |
+
key,
|
| 569 |
+
value,
|
| 570 |
+
self.embed_dim,
|
| 571 |
+
self.num_heads,
|
| 572 |
+
self.in_proj_weight,
|
| 573 |
+
self.in_proj_bias,
|
| 574 |
+
self.bias_k,
|
| 575 |
+
self.bias_v,
|
| 576 |
+
self.add_zero_attn,
|
| 577 |
+
self.dropout,
|
| 578 |
+
self.out_proj.weight,
|
| 579 |
+
self.out_proj.bias,
|
| 580 |
+
training=self.training,
|
| 581 |
+
key_padding_mask=key_padding_mask,
|
| 582 |
+
need_weights=need_weights,
|
| 583 |
+
attn_mask=attn_mask,
|
| 584 |
+
average_attn_weights=average_attn_weights,
|
| 585 |
+
)
|
| 586 |
+
if self.batch_first and is_batched:
|
| 587 |
+
return attn_output.transpose(1, 0), attn_output_weights
|
| 588 |
+
else:
|
| 589 |
+
return attn_output, attn_output_weights
|
| 590 |
+
|
| 591 |
+
def infer(self,
|
| 592 |
+
x: Tensor,
|
| 593 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 594 |
+
need_weights: bool = True,
|
| 595 |
+
attn_mask: Optional[Tensor] = None,
|
| 596 |
+
average_attn_weights: bool = True,
|
| 597 |
+
past_kv = None,
|
| 598 |
+
use_cache = False
|
| 599 |
+
):
|
| 600 |
+
# x = x.transpose(1, 0)
|
| 601 |
+
y, kv = multi_head_attention_forward(
|
| 602 |
+
x=x,
|
| 603 |
+
ipw=self.in_proj_weight,
|
| 604 |
+
ipb=self.in_proj_bias,
|
| 605 |
+
opw=self.out_proj.weight,
|
| 606 |
+
opb=self.out_proj.bias,
|
| 607 |
+
n_head=self.num_heads,
|
| 608 |
+
attn_mask=attn_mask,
|
| 609 |
+
past_kv=past_kv,
|
| 610 |
+
use_cache=use_cache,
|
| 611 |
+
)
|
| 612 |
+
return (y, kv)
|
modules/embedding.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 (authors: Feiteng Li)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import math
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class TokenEmbedding(nn.Module):
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
dim_model: int,
|
| 25 |
+
vocab_size: int,
|
| 26 |
+
dropout: float = 0.0,
|
| 27 |
+
):
|
| 28 |
+
super().__init__()
|
| 29 |
+
|
| 30 |
+
self.vocab_size = vocab_size
|
| 31 |
+
self.dim_model = dim_model
|
| 32 |
+
|
| 33 |
+
self.dropout = torch.nn.Dropout(p=dropout)
|
| 34 |
+
self.word_embeddings = nn.Embedding(self.vocab_size, self.dim_model)
|
| 35 |
+
|
| 36 |
+
@property
|
| 37 |
+
def weight(self) -> torch.Tensor:
|
| 38 |
+
return self.word_embeddings.weight
|
| 39 |
+
|
| 40 |
+
def embedding(self, index: int) -> torch.Tensor:
|
| 41 |
+
return self.word_embeddings.weight[index : index + 1]
|
| 42 |
+
|
| 43 |
+
def forward(self, x: torch.Tensor):
|
| 44 |
+
X = self.word_embeddings(x)
|
| 45 |
+
X = self.dropout(X)
|
| 46 |
+
|
| 47 |
+
return X
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class SinePositionalEmbedding(nn.Module):
|
| 51 |
+
def __init__(
|
| 52 |
+
self,
|
| 53 |
+
dim_model: int,
|
| 54 |
+
dropout: float = 0.0,
|
| 55 |
+
scale: bool = False,
|
| 56 |
+
alpha: bool = False,
|
| 57 |
+
):
|
| 58 |
+
super().__init__()
|
| 59 |
+
self.dim_model = dim_model
|
| 60 |
+
self.x_scale = math.sqrt(dim_model) if scale else 1.0
|
| 61 |
+
self.alpha = nn.Parameter(torch.ones(1), requires_grad=alpha)
|
| 62 |
+
self.dropout = torch.nn.Dropout(p=dropout)
|
| 63 |
+
|
| 64 |
+
self.reverse = False
|
| 65 |
+
self.pe = None
|
| 66 |
+
self.extend_pe(torch.tensor(0.0).expand(1, 4000))
|
| 67 |
+
|
| 68 |
+
def extend_pe(self, x):
|
| 69 |
+
"""Reset the positional encodings."""
|
| 70 |
+
if self.pe is not None:
|
| 71 |
+
if self.pe.size(1) >= x.size(1):
|
| 72 |
+
if self.pe.dtype != x.dtype or self.pe.device != x.device:
|
| 73 |
+
self.pe = self.pe.to(dtype=x.dtype, device=x.device)
|
| 74 |
+
return
|
| 75 |
+
pe = torch.zeros(x.size(1), self.dim_model)
|
| 76 |
+
if self.reverse:
|
| 77 |
+
position = torch.arange(
|
| 78 |
+
x.size(1) - 1, -1, -1.0, dtype=torch.float32
|
| 79 |
+
).unsqueeze(1)
|
| 80 |
+
else:
|
| 81 |
+
position = torch.arange(
|
| 82 |
+
0, x.size(1), dtype=torch.float32
|
| 83 |
+
).unsqueeze(1)
|
| 84 |
+
div_term = torch.exp(
|
| 85 |
+
torch.arange(0, self.dim_model, 2, dtype=torch.float32)
|
| 86 |
+
* -(math.log(10000.0) / self.dim_model)
|
| 87 |
+
)
|
| 88 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 89 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 90 |
+
pe = pe.unsqueeze(0)
|
| 91 |
+
self.pe = pe.to(device=x.device, dtype=x.dtype).detach()
|
| 92 |
+
|
| 93 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 94 |
+
self.extend_pe(x)
|
| 95 |
+
output = x.unsqueeze(-1) if x.ndim == 2 else x
|
| 96 |
+
output = output * self.x_scale + self.alpha * self.pe[:, : x.size(1)]
|
| 97 |
+
return self.dropout(output)
|
modules/scaling.py
ADDED
|
@@ -0,0 +1,1401 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2022 Xiaomi Corp. (authors: Daniel Povey)
|
| 2 |
+
#
|
| 3 |
+
# See ../../../../LICENSE for clarification regarding multiple authors
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
import collections
|
| 19 |
+
import logging
|
| 20 |
+
import random
|
| 21 |
+
import math
|
| 22 |
+
from functools import reduce
|
| 23 |
+
from itertools import repeat
|
| 24 |
+
from typing import Optional, Tuple, Union
|
| 25 |
+
|
| 26 |
+
import torch
|
| 27 |
+
import torch.nn as nn
|
| 28 |
+
import torch.nn.functional as F
|
| 29 |
+
from torch import Tensor
|
| 30 |
+
from torch.nn import Embedding as ScaledEmbedding
|
| 31 |
+
|
| 32 |
+
from utils import Transpose
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class ActivationBalancerFunction(torch.autograd.Function):
|
| 36 |
+
@staticmethod
|
| 37 |
+
def forward(
|
| 38 |
+
ctx,
|
| 39 |
+
x: Tensor,
|
| 40 |
+
scale_factor: Tensor,
|
| 41 |
+
sign_factor: Optional[Tensor],
|
| 42 |
+
channel_dim: int,
|
| 43 |
+
) -> Tensor:
|
| 44 |
+
if channel_dim < 0:
|
| 45 |
+
channel_dim += x.ndim
|
| 46 |
+
ctx.channel_dim = channel_dim
|
| 47 |
+
xgt0 = x > 0
|
| 48 |
+
if sign_factor is None:
|
| 49 |
+
ctx.save_for_backward(xgt0, scale_factor)
|
| 50 |
+
else:
|
| 51 |
+
ctx.save_for_backward(xgt0, scale_factor, sign_factor)
|
| 52 |
+
return x
|
| 53 |
+
|
| 54 |
+
@staticmethod
|
| 55 |
+
def backward(ctx, x_grad: Tensor) -> Tuple[Tensor, None, None, None]:
|
| 56 |
+
if len(ctx.saved_tensors) == 3:
|
| 57 |
+
xgt0, scale_factor, sign_factor = ctx.saved_tensors
|
| 58 |
+
for _ in range(ctx.channel_dim, x_grad.ndim - 1):
|
| 59 |
+
scale_factor = scale_factor.unsqueeze(-1)
|
| 60 |
+
sign_factor = sign_factor.unsqueeze(-1)
|
| 61 |
+
factor = sign_factor + scale_factor * (xgt0.to(x_grad.dtype) - 0.5)
|
| 62 |
+
else:
|
| 63 |
+
xgt0, scale_factor = ctx.saved_tensors
|
| 64 |
+
for _ in range(ctx.channel_dim, x_grad.ndim - 1):
|
| 65 |
+
scale_factor = scale_factor.unsqueeze(-1)
|
| 66 |
+
factor = scale_factor * (xgt0.to(x_grad.dtype) - 0.5)
|
| 67 |
+
neg_delta_grad = x_grad.abs() * factor
|
| 68 |
+
return (
|
| 69 |
+
x_grad - neg_delta_grad,
|
| 70 |
+
None,
|
| 71 |
+
None,
|
| 72 |
+
None,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def _compute_scale_factor(
|
| 77 |
+
x: Tensor,
|
| 78 |
+
channel_dim: int,
|
| 79 |
+
min_abs: float,
|
| 80 |
+
max_abs: float,
|
| 81 |
+
gain_factor: float,
|
| 82 |
+
max_factor: float,
|
| 83 |
+
) -> Tensor:
|
| 84 |
+
if channel_dim < 0:
|
| 85 |
+
channel_dim += x.ndim
|
| 86 |
+
sum_dims = [d for d in range(x.ndim) if d != channel_dim]
|
| 87 |
+
x_abs_mean = torch.mean(x.abs(), dim=sum_dims).to(torch.float32)
|
| 88 |
+
|
| 89 |
+
if min_abs == 0.0:
|
| 90 |
+
below_threshold = 0.0
|
| 91 |
+
else:
|
| 92 |
+
# below_threshold is 0 if x_abs_mean > min_abs, can be at most max_factor if
|
| 93 |
+
# x_abs)_mean , min_abs.
|
| 94 |
+
below_threshold = (
|
| 95 |
+
(min_abs - x_abs_mean) * (gain_factor / min_abs)
|
| 96 |
+
).clamp(min=0, max=max_factor)
|
| 97 |
+
|
| 98 |
+
above_threshold = ((x_abs_mean - max_abs) * (gain_factor / max_abs)).clamp(
|
| 99 |
+
min=0, max=max_factor
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
return below_threshold - above_threshold
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def _compute_sign_factor(
|
| 106 |
+
x: Tensor,
|
| 107 |
+
channel_dim: int,
|
| 108 |
+
min_positive: float,
|
| 109 |
+
max_positive: float,
|
| 110 |
+
gain_factor: float,
|
| 111 |
+
max_factor: float,
|
| 112 |
+
) -> Tensor:
|
| 113 |
+
if channel_dim < 0:
|
| 114 |
+
channel_dim += x.ndim
|
| 115 |
+
sum_dims = [d for d in range(x.ndim) if d != channel_dim]
|
| 116 |
+
proportion_positive = torch.mean((x > 0).to(torch.float32), dim=sum_dims)
|
| 117 |
+
if min_positive == 0.0:
|
| 118 |
+
factor1 = 0.0
|
| 119 |
+
else:
|
| 120 |
+
# 0 if proportion_positive >= min_positive, else can be
|
| 121 |
+
# as large as max_factor.
|
| 122 |
+
factor1 = (
|
| 123 |
+
(min_positive - proportion_positive) * (gain_factor / min_positive)
|
| 124 |
+
).clamp_(min=0, max=max_factor)
|
| 125 |
+
|
| 126 |
+
if max_positive == 1.0:
|
| 127 |
+
factor2 = 0.0
|
| 128 |
+
else:
|
| 129 |
+
# 0 if self.proportion_positive <= max_positive, else can be
|
| 130 |
+
# as large as -max_factor.
|
| 131 |
+
factor2 = (
|
| 132 |
+
(proportion_positive - max_positive)
|
| 133 |
+
* (gain_factor / (1.0 - max_positive))
|
| 134 |
+
).clamp_(min=0, max=max_factor)
|
| 135 |
+
sign_factor = factor1 - factor2
|
| 136 |
+
# require min_positive != 0 or max_positive != 1:
|
| 137 |
+
assert not isinstance(sign_factor, float)
|
| 138 |
+
return sign_factor
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class ActivationScaleBalancerFunction(torch.autograd.Function):
|
| 142 |
+
"""
|
| 143 |
+
This object is used in class ActivationBalancer when the user specified
|
| 144 |
+
min_positive=0, max_positive=1, so there are no constraints on the signs
|
| 145 |
+
of the activations and only the absolute value has a constraint.
|
| 146 |
+
"""
|
| 147 |
+
|
| 148 |
+
@staticmethod
|
| 149 |
+
def forward(
|
| 150 |
+
ctx,
|
| 151 |
+
x: Tensor,
|
| 152 |
+
sign_factor: Tensor,
|
| 153 |
+
scale_factor: Tensor,
|
| 154 |
+
channel_dim: int,
|
| 155 |
+
) -> Tensor:
|
| 156 |
+
if channel_dim < 0:
|
| 157 |
+
channel_dim += x.ndim
|
| 158 |
+
ctx.channel_dim = channel_dim
|
| 159 |
+
xgt0 = x > 0
|
| 160 |
+
ctx.save_for_backward(xgt0, sign_factor, scale_factor)
|
| 161 |
+
return x
|
| 162 |
+
|
| 163 |
+
@staticmethod
|
| 164 |
+
def backward(ctx, x_grad: Tensor) -> Tuple[Tensor, None, None, None]:
|
| 165 |
+
xgt0, sign_factor, scale_factor = ctx.saved_tensors
|
| 166 |
+
for _ in range(ctx.channel_dim, x_grad.ndim - 1):
|
| 167 |
+
sign_factor = sign_factor.unsqueeze(-1)
|
| 168 |
+
scale_factor = scale_factor.unsqueeze(-1)
|
| 169 |
+
|
| 170 |
+
factor = sign_factor + scale_factor * (xgt0.to(x_grad.dtype) - 0.5)
|
| 171 |
+
neg_delta_grad = x_grad.abs() * factor
|
| 172 |
+
return (
|
| 173 |
+
x_grad - neg_delta_grad,
|
| 174 |
+
None,
|
| 175 |
+
None,
|
| 176 |
+
None,
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
class RandomClampFunction(torch.autograd.Function):
|
| 181 |
+
@staticmethod
|
| 182 |
+
def forward(
|
| 183 |
+
ctx,
|
| 184 |
+
x: Tensor,
|
| 185 |
+
min: Optional[float],
|
| 186 |
+
max: Optional[float],
|
| 187 |
+
prob: float,
|
| 188 |
+
reflect: float,
|
| 189 |
+
) -> Tensor:
|
| 190 |
+
x_clamped = torch.clamp(x, min=min, max=max)
|
| 191 |
+
mask = torch.rand_like(x) < prob
|
| 192 |
+
ans = torch.where(mask, x_clamped, x)
|
| 193 |
+
if x.requires_grad:
|
| 194 |
+
ctx.save_for_backward(ans == x)
|
| 195 |
+
ctx.reflect = reflect
|
| 196 |
+
if reflect != 0.0:
|
| 197 |
+
ans = ans * (1.0 + reflect) - (x * reflect)
|
| 198 |
+
return ans
|
| 199 |
+
|
| 200 |
+
@staticmethod
|
| 201 |
+
def backward(
|
| 202 |
+
ctx, ans_grad: Tensor
|
| 203 |
+
) -> Tuple[Tensor, None, None, None, None]:
|
| 204 |
+
(is_same,) = ctx.saved_tensors
|
| 205 |
+
x_grad = ans_grad * is_same.to(ans_grad.dtype)
|
| 206 |
+
reflect = ctx.reflect
|
| 207 |
+
if reflect != 0.0:
|
| 208 |
+
x_grad = x_grad * (1.0 + reflect) - (ans_grad * reflect)
|
| 209 |
+
return x_grad, None, None, None, None
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def random_clamp(
|
| 213 |
+
x: Tensor,
|
| 214 |
+
min: Optional[float] = None,
|
| 215 |
+
max: Optional[float] = None,
|
| 216 |
+
prob: float = 0.5,
|
| 217 |
+
reflect: float = 0.0,
|
| 218 |
+
):
|
| 219 |
+
return RandomClampFunction.apply(x, min, max, prob, reflect)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def random_cast_to_half(x: Tensor, min_abs: float = 5.0e-06) -> Tensor:
|
| 223 |
+
"""
|
| 224 |
+
A randomized way of casting a floating point value to half precision.
|
| 225 |
+
"""
|
| 226 |
+
if x.dtype == torch.float16:
|
| 227 |
+
return x
|
| 228 |
+
x_abs = x.abs()
|
| 229 |
+
is_too_small = x_abs < min_abs
|
| 230 |
+
# for elements where is_too_small is true, random_val will contain +-min_abs with
|
| 231 |
+
# probability (x.abs() / min_abs), and 0.0 otherwise. [so this preserves expectations,
|
| 232 |
+
# for those elements].
|
| 233 |
+
random_val = min_abs * x.sign() * (torch.rand_like(x) * min_abs < x_abs)
|
| 234 |
+
return torch.where(is_too_small, random_val, x).to(torch.float16)
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
class RandomGradFunction(torch.autograd.Function):
|
| 238 |
+
"""
|
| 239 |
+
Does nothing in forward pass; in backward pass, gets rid of very small grads using
|
| 240 |
+
randomized approach that preserves expectations (intended to reduce roundoff).
|
| 241 |
+
"""
|
| 242 |
+
|
| 243 |
+
@staticmethod
|
| 244 |
+
def forward(ctx, x: Tensor, min_abs: float) -> Tensor:
|
| 245 |
+
ctx.min_abs = min_abs
|
| 246 |
+
return x
|
| 247 |
+
|
| 248 |
+
@staticmethod
|
| 249 |
+
def backward(ctx, ans_grad: Tensor) -> Tuple[Tensor, None]:
|
| 250 |
+
if ans_grad.dtype == torch.float16:
|
| 251 |
+
return (
|
| 252 |
+
random_cast_to_half(
|
| 253 |
+
ans_grad.to(torch.float32), min_abs=ctx.min_abs
|
| 254 |
+
),
|
| 255 |
+
None,
|
| 256 |
+
)
|
| 257 |
+
else:
|
| 258 |
+
return ans_grad, None
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
class RandomGrad(torch.nn.Module):
|
| 262 |
+
"""
|
| 263 |
+
Gets rid of very small gradients using an expectation-preserving method, intended to increase
|
| 264 |
+
accuracy of training when using amp (automatic mixed precision)
|
| 265 |
+
"""
|
| 266 |
+
|
| 267 |
+
def __init__(self, min_abs: float = 5.0e-06):
|
| 268 |
+
super(RandomGrad, self).__init__()
|
| 269 |
+
self.min_abs = min_abs
|
| 270 |
+
|
| 271 |
+
def forward(self, x: Tensor):
|
| 272 |
+
if (
|
| 273 |
+
torch.jit.is_scripting()
|
| 274 |
+
or not self.training
|
| 275 |
+
or torch.jit.is_tracing()
|
| 276 |
+
):
|
| 277 |
+
return x
|
| 278 |
+
else:
|
| 279 |
+
return RandomGradFunction.apply(x, self.min_abs)
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
class SoftmaxFunction(torch.autograd.Function):
|
| 283 |
+
"""
|
| 284 |
+
Tries to handle half-precision derivatives in a randomized way that should
|
| 285 |
+
be more accurate for training than the default behavior.
|
| 286 |
+
"""
|
| 287 |
+
|
| 288 |
+
@staticmethod
|
| 289 |
+
def forward(ctx, x: Tensor, dim: int):
|
| 290 |
+
ans = x.softmax(dim=dim)
|
| 291 |
+
# if x dtype is float16, x.softmax() returns a float32 because
|
| 292 |
+
# (presumably) that op does not support float16, and autocast
|
| 293 |
+
# is enabled.
|
| 294 |
+
if torch.is_autocast_enabled():
|
| 295 |
+
ans = ans.to(torch.float16)
|
| 296 |
+
ctx.save_for_backward(ans)
|
| 297 |
+
ctx.x_dtype = x.dtype
|
| 298 |
+
ctx.dim = dim
|
| 299 |
+
return ans
|
| 300 |
+
|
| 301 |
+
@staticmethod
|
| 302 |
+
def backward(ctx, ans_grad: Tensor):
|
| 303 |
+
(ans,) = ctx.saved_tensors
|
| 304 |
+
with torch.cuda.amp.autocast(enabled=False):
|
| 305 |
+
ans_grad = ans_grad.to(torch.float32)
|
| 306 |
+
ans = ans.to(torch.float32)
|
| 307 |
+
x_grad = ans_grad * ans
|
| 308 |
+
x_grad = x_grad - ans * x_grad.sum(dim=ctx.dim, keepdim=True)
|
| 309 |
+
return x_grad, None
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
def softmax(x: Tensor, dim: int):
|
| 313 |
+
if torch.jit.is_scripting() or torch.jit.is_tracing():
|
| 314 |
+
return x.softmax(dim)
|
| 315 |
+
|
| 316 |
+
return SoftmaxFunction.apply(x, dim)
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class MaxEigLimiterFunction(torch.autograd.Function):
|
| 320 |
+
@staticmethod
|
| 321 |
+
def forward(
|
| 322 |
+
ctx,
|
| 323 |
+
x: Tensor,
|
| 324 |
+
coeffs: Tensor,
|
| 325 |
+
direction: Tensor,
|
| 326 |
+
channel_dim: int,
|
| 327 |
+
grad_scale: float,
|
| 328 |
+
) -> Tensor:
|
| 329 |
+
ctx.channel_dim = channel_dim
|
| 330 |
+
ctx.grad_scale = grad_scale
|
| 331 |
+
ctx.save_for_backward(x.detach(), coeffs.detach(), direction.detach())
|
| 332 |
+
return x
|
| 333 |
+
|
| 334 |
+
@staticmethod
|
| 335 |
+
def backward(ctx, x_grad, *args):
|
| 336 |
+
with torch.enable_grad():
|
| 337 |
+
(x_orig, coeffs, new_direction) = ctx.saved_tensors
|
| 338 |
+
x_orig.requires_grad = True
|
| 339 |
+
num_channels = x_orig.shape[ctx.channel_dim]
|
| 340 |
+
x = x_orig.transpose(ctx.channel_dim, -1).reshape(-1, num_channels)
|
| 341 |
+
new_direction.requires_grad = False
|
| 342 |
+
x = x - x.mean(dim=0)
|
| 343 |
+
x_var = (x ** 2).mean()
|
| 344 |
+
x_residual = x - coeffs * new_direction
|
| 345 |
+
x_residual_var = (x_residual ** 2).mean()
|
| 346 |
+
# `variance_proportion` is the proportion of the variance accounted for
|
| 347 |
+
# by the top eigen-direction. This is to be minimized.
|
| 348 |
+
variance_proportion = (x_var - x_residual_var) / (x_var + 1.0e-20)
|
| 349 |
+
variance_proportion.backward()
|
| 350 |
+
x_orig_grad = x_orig.grad
|
| 351 |
+
x_extra_grad = (
|
| 352 |
+
x_orig.grad
|
| 353 |
+
* ctx.grad_scale
|
| 354 |
+
* x_grad.norm()
|
| 355 |
+
/ (x_orig_grad.norm() + 1.0e-20)
|
| 356 |
+
)
|
| 357 |
+
return x_grad + x_extra_grad.detach(), None, None, None, None
|
| 358 |
+
|
| 359 |
+
|
| 360 |
+
class BasicNorm(torch.nn.Module):
|
| 361 |
+
"""
|
| 362 |
+
This is intended to be a simpler, and hopefully cheaper, replacement for
|
| 363 |
+
LayerNorm. The observation this is based on, is that Transformer-type
|
| 364 |
+
networks, especially with pre-norm, sometimes seem to set one of the
|
| 365 |
+
feature dimensions to a large constant value (e.g. 50), which "defeats"
|
| 366 |
+
the LayerNorm because the output magnitude is then not strongly dependent
|
| 367 |
+
on the other (useful) features. Presumably the weight and bias of the
|
| 368 |
+
LayerNorm are required to allow it to do this.
|
| 369 |
+
|
| 370 |
+
So the idea is to introduce this large constant value as an explicit
|
| 371 |
+
parameter, that takes the role of the "eps" in LayerNorm, so the network
|
| 372 |
+
doesn't have to do this trick. We make the "eps" learnable.
|
| 373 |
+
|
| 374 |
+
Args:
|
| 375 |
+
num_channels: the number of channels, e.g. 512.
|
| 376 |
+
channel_dim: the axis/dimension corresponding to the channel,
|
| 377 |
+
interprted as an offset from the input's ndim if negative.
|
| 378 |
+
shis is NOT the num_channels; it should typically be one of
|
| 379 |
+
{-2, -1, 0, 1, 2, 3}.
|
| 380 |
+
eps: the initial "epsilon" that we add as ballast in:
|
| 381 |
+
scale = ((input_vec**2).mean() + epsilon)**-0.5
|
| 382 |
+
Note: our epsilon is actually large, but we keep the name
|
| 383 |
+
to indicate the connection with conventional LayerNorm.
|
| 384 |
+
learn_eps: if true, we learn epsilon; if false, we keep it
|
| 385 |
+
at the initial value.
|
| 386 |
+
eps_min: float
|
| 387 |
+
eps_max: float
|
| 388 |
+
"""
|
| 389 |
+
|
| 390 |
+
def __init__(
|
| 391 |
+
self,
|
| 392 |
+
num_channels: int,
|
| 393 |
+
channel_dim: int = -1, # CAUTION: see documentation.
|
| 394 |
+
eps: float = 0.25,
|
| 395 |
+
learn_eps: bool = True,
|
| 396 |
+
eps_min: float = -3.0,
|
| 397 |
+
eps_max: float = 3.0,
|
| 398 |
+
) -> None:
|
| 399 |
+
super(BasicNorm, self).__init__()
|
| 400 |
+
self.num_channels = num_channels
|
| 401 |
+
self.channel_dim = channel_dim
|
| 402 |
+
if learn_eps:
|
| 403 |
+
self.eps = nn.Parameter(torch.tensor(eps).log().detach())
|
| 404 |
+
else:
|
| 405 |
+
self.register_buffer("eps", torch.tensor(eps).log().detach())
|
| 406 |
+
self.eps_min = eps_min
|
| 407 |
+
self.eps_max = eps_max
|
| 408 |
+
|
| 409 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 410 |
+
assert x.shape[self.channel_dim] == self.num_channels
|
| 411 |
+
eps = self.eps
|
| 412 |
+
if self.training and random.random() < 0.25:
|
| 413 |
+
# with probability 0.25, in training mode, clamp eps between the min
|
| 414 |
+
# and max; this will encourage it to learn parameters within the
|
| 415 |
+
# allowed range by making parameters that are outside the allowed
|
| 416 |
+
# range noisy.
|
| 417 |
+
|
| 418 |
+
# gradients to allow the parameter to get back into the allowed
|
| 419 |
+
# region if it happens to exit it.
|
| 420 |
+
eps = eps.clamp(min=self.eps_min, max=self.eps_max)
|
| 421 |
+
scales = (
|
| 422 |
+
torch.mean(x ** 2, dim=self.channel_dim, keepdim=True) + eps.exp()
|
| 423 |
+
) ** -0.5
|
| 424 |
+
return x * scales
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
def ScaledLinear(*args, initial_scale: float = 1.0, **kwargs) -> nn.Linear:
|
| 428 |
+
"""
|
| 429 |
+
Behaves like a constructor of a modified version of nn.Linear
|
| 430 |
+
that gives an easy way to set the default initial parameter scale.
|
| 431 |
+
|
| 432 |
+
Args:
|
| 433 |
+
Accepts the standard args and kwargs that nn.Linear accepts
|
| 434 |
+
e.g. in_features, out_features, bias=False.
|
| 435 |
+
|
| 436 |
+
initial_scale: you can override this if you want to increase
|
| 437 |
+
or decrease the initial magnitude of the module's output
|
| 438 |
+
(affects the initialization of weight_scale and bias_scale).
|
| 439 |
+
Another option, if you want to do something like this, is
|
| 440 |
+
to re-initialize the parameters.
|
| 441 |
+
"""
|
| 442 |
+
ans = nn.Linear(*args, **kwargs)
|
| 443 |
+
with torch.no_grad():
|
| 444 |
+
ans.weight[:] *= initial_scale
|
| 445 |
+
if ans.bias is not None:
|
| 446 |
+
torch.nn.init.uniform_(
|
| 447 |
+
ans.bias, -0.1 * initial_scale, 0.1 * initial_scale
|
| 448 |
+
)
|
| 449 |
+
return ans
|
| 450 |
+
|
| 451 |
+
|
| 452 |
+
def ScaledConv1d(
|
| 453 |
+
*args,
|
| 454 |
+
initial_scale: float = 1.0,
|
| 455 |
+
kernel_size: int = 3,
|
| 456 |
+
padding: str = "same",
|
| 457 |
+
**kwargs,
|
| 458 |
+
) -> nn.Conv1d:
|
| 459 |
+
"""
|
| 460 |
+
Behaves like a constructor of a modified version of nn.Conv1d
|
| 461 |
+
that gives an easy way to set the default initial parameter scale.
|
| 462 |
+
|
| 463 |
+
Args:
|
| 464 |
+
Accepts the standard args and kwargs that nn.Linear accepts
|
| 465 |
+
e.g. in_features, out_features, bias=False.
|
| 466 |
+
|
| 467 |
+
initial_scale: you can override this if you want to increase
|
| 468 |
+
or decrease the initial magnitude of the module's output
|
| 469 |
+
(affects the initialization of weight_scale and bias_scale).
|
| 470 |
+
Another option, if you want to do something like this, is
|
| 471 |
+
to re-initialize the parameters.
|
| 472 |
+
"""
|
| 473 |
+
ans = nn.Conv1d(*args, kernel_size=kernel_size, padding=padding, **kwargs)
|
| 474 |
+
with torch.no_grad():
|
| 475 |
+
ans.weight[:] *= initial_scale
|
| 476 |
+
if ans.bias is not None:
|
| 477 |
+
torch.nn.init.uniform_(
|
| 478 |
+
ans.bias, -0.1 * initial_scale, 0.1 * initial_scale
|
| 479 |
+
)
|
| 480 |
+
return ans
|
| 481 |
+
|
| 482 |
+
|
| 483 |
+
def TransposeScaledConv1d(
|
| 484 |
+
*args,
|
| 485 |
+
initial_scale: float = 1.0,
|
| 486 |
+
kernel_size: int = 3,
|
| 487 |
+
padding: str = "same",
|
| 488 |
+
**kwargs,
|
| 489 |
+
) -> nn.Sequential:
|
| 490 |
+
"""
|
| 491 |
+
Transpose -> ScaledConv1d
|
| 492 |
+
"""
|
| 493 |
+
return nn.Sequential(
|
| 494 |
+
Transpose(),
|
| 495 |
+
ScaledConv1d(
|
| 496 |
+
*args,
|
| 497 |
+
initial_scale=initial_scale,
|
| 498 |
+
kernel_size=kernel_size,
|
| 499 |
+
padding=padding,
|
| 500 |
+
**kwargs,
|
| 501 |
+
),
|
| 502 |
+
)
|
| 503 |
+
|
| 504 |
+
|
| 505 |
+
def ScaledConv1dTranspose(
|
| 506 |
+
*args,
|
| 507 |
+
initial_scale: float = 1.0,
|
| 508 |
+
kernel_size: int = 3,
|
| 509 |
+
padding: str = "same",
|
| 510 |
+
**kwargs,
|
| 511 |
+
) -> nn.Sequential:
|
| 512 |
+
"""
|
| 513 |
+
Transpose -> ScaledConv1d
|
| 514 |
+
"""
|
| 515 |
+
return nn.Sequential(
|
| 516 |
+
ScaledConv1d(
|
| 517 |
+
*args,
|
| 518 |
+
initial_scale=initial_scale,
|
| 519 |
+
kernel_size=kernel_size,
|
| 520 |
+
padding=padding,
|
| 521 |
+
**kwargs,
|
| 522 |
+
),
|
| 523 |
+
Transpose(),
|
| 524 |
+
)
|
| 525 |
+
|
| 526 |
+
|
| 527 |
+
def TransposeConv1d(
|
| 528 |
+
*args, kernel_size: int = 3, padding: str = "same", **kwargs
|
| 529 |
+
) -> nn.Sequential:
|
| 530 |
+
"""
|
| 531 |
+
Transpose -> Conv1d
|
| 532 |
+
"""
|
| 533 |
+
return nn.Sequential(
|
| 534 |
+
Transpose(),
|
| 535 |
+
nn.Conv1d(*args, kernel_size=kernel_size, padding=padding, **kwargs),
|
| 536 |
+
)
|
| 537 |
+
|
| 538 |
+
|
| 539 |
+
def Conv1dTranspose(
|
| 540 |
+
*args, kernel_size: int = 3, padding: str = "same", **kwargs
|
| 541 |
+
) -> nn.Sequential:
|
| 542 |
+
"""
|
| 543 |
+
ScaledConv1d -> Transpose
|
| 544 |
+
"""
|
| 545 |
+
return nn.Sequential(
|
| 546 |
+
nn.Conv1d(*args, kernel_size=kernel_size, padding=padding, **kwargs),
|
| 547 |
+
Transpose(),
|
| 548 |
+
)
|
| 549 |
+
|
| 550 |
+
|
| 551 |
+
class SRLinear(nn.Linear):
|
| 552 |
+
"""https://arxiv.org/abs/2303.06296
|
| 553 |
+
Stabilizing Transformer Training by Preventing Attention Entropy Collapse
|
| 554 |
+
"""
|
| 555 |
+
|
| 556 |
+
def __init__(self, in_features, out_features, bias=True, **kwargs):
|
| 557 |
+
super().__init__(in_features, out_features, bias=bias, **kwargs)
|
| 558 |
+
self.register_buffer(
|
| 559 |
+
"u", nn.functional.normalize(torch.randn(in_features), dim=0)
|
| 560 |
+
)
|
| 561 |
+
with torch.no_grad():
|
| 562 |
+
sigma = self.get_sigma()
|
| 563 |
+
self.register_buffer("spectral_norm", sigma)
|
| 564 |
+
self.sigma = nn.Parameter(torch.ones(1))
|
| 565 |
+
|
| 566 |
+
def get_sigma(self):
|
| 567 |
+
with torch.no_grad():
|
| 568 |
+
u = self.u
|
| 569 |
+
v = self.weight.mv(u)
|
| 570 |
+
v = nn.functional.normalize(v, dim=0)
|
| 571 |
+
u = self.weight.T.mv(v)
|
| 572 |
+
u = nn.functional.normalize(u, dim=0)
|
| 573 |
+
self.u.data.copy_(u)
|
| 574 |
+
return torch.einsum("c,cd,d->", v, self.weight, u)
|
| 575 |
+
|
| 576 |
+
def get_weight(self):
|
| 577 |
+
sigma = self.get_sigma()
|
| 578 |
+
if self.training:
|
| 579 |
+
self.spectral_norm.data.copy_(sigma)
|
| 580 |
+
weight = (self.sigma / sigma) * self.weight
|
| 581 |
+
return weight
|
| 582 |
+
|
| 583 |
+
def forward(self, x):
|
| 584 |
+
return nn.functional.linear(x, self.get_weight(), self.bias)
|
| 585 |
+
|
| 586 |
+
|
| 587 |
+
class SRConv1d(SRLinear):
|
| 588 |
+
def __init__(
|
| 589 |
+
self,
|
| 590 |
+
in_features,
|
| 591 |
+
out_features,
|
| 592 |
+
kernel_size,
|
| 593 |
+
stride: int = 1,
|
| 594 |
+
padding: str = "same",
|
| 595 |
+
bias: bool = True,
|
| 596 |
+
**kwargs,
|
| 597 |
+
):
|
| 598 |
+
in_features = in_features * kernel_size
|
| 599 |
+
super().__init__(in_features, out_features, bias=bias, **kwargs)
|
| 600 |
+
nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
|
| 601 |
+
self.kernel_size = kernel_size
|
| 602 |
+
self.stride = stride
|
| 603 |
+
self.padding = padding
|
| 604 |
+
|
| 605 |
+
def forward(self, x):
|
| 606 |
+
in_features = self.in_features // self.kernel_size
|
| 607 |
+
weight = self.get_weight().view(
|
| 608 |
+
self.out_features, in_features, self.kernel_size
|
| 609 |
+
)
|
| 610 |
+
return nn.functional.conv1d(
|
| 611 |
+
x, weight, bias=self.bias, stride=self.stride, padding=self.padding
|
| 612 |
+
)
|
| 613 |
+
|
| 614 |
+
|
| 615 |
+
def TransposeSRConv1d(
|
| 616 |
+
*args, kernel_size: int = 3, padding: str = "same", **kwargs
|
| 617 |
+
) -> nn.Sequential:
|
| 618 |
+
"""
|
| 619 |
+
Transpose -> SRConv1d
|
| 620 |
+
"""
|
| 621 |
+
return nn.Sequential(
|
| 622 |
+
Transpose(),
|
| 623 |
+
SRConv1d(*args, kernel_size=kernel_size, padding=padding, **kwargs),
|
| 624 |
+
)
|
| 625 |
+
|
| 626 |
+
|
| 627 |
+
def SRConv1dTranspose(
|
| 628 |
+
*args, kernel_size: int = 3, padding: str = "same", **kwargs
|
| 629 |
+
) -> nn.Sequential:
|
| 630 |
+
"""
|
| 631 |
+
SRConv1d -> Transpose
|
| 632 |
+
"""
|
| 633 |
+
return nn.Sequential(
|
| 634 |
+
SRConv1d(*args, kernel_size=kernel_size, padding=padding, **kwargs),
|
| 635 |
+
Transpose(),
|
| 636 |
+
)
|
| 637 |
+
|
| 638 |
+
|
| 639 |
+
class ActivationBalancer(torch.nn.Module):
|
| 640 |
+
"""
|
| 641 |
+
Modifies the backpropped derivatives of a function to try to encourage, for
|
| 642 |
+
each channel, that it is positive at least a proportion `threshold` of the
|
| 643 |
+
time. It does this by multiplying negative derivative values by up to
|
| 644 |
+
(1+max_factor), and positive derivative values by up to (1-max_factor),
|
| 645 |
+
interpolated from 1 at the threshold to those extremal values when none
|
| 646 |
+
of the inputs are positive.
|
| 647 |
+
|
| 648 |
+
Args:
|
| 649 |
+
num_channels: the number of channels
|
| 650 |
+
channel_dim: the dimension/axis corresponding to the channel, e.g.
|
| 651 |
+
-1, 0, 1, 2; will be interpreted as an offset from x.ndim if negative.
|
| 652 |
+
min_positive: the minimum, per channel, of the proportion of the time
|
| 653 |
+
that (x > 0), below which we start to modify the derivatives.
|
| 654 |
+
max_positive: the maximum, per channel, of the proportion of the time
|
| 655 |
+
that (x > 0), above which we start to modify the derivatives.
|
| 656 |
+
max_factor: the maximum factor by which we modify the derivatives for
|
| 657 |
+
either the sign constraint or the magnitude constraint;
|
| 658 |
+
e.g. with max_factor=0.02, the the derivatives would be multiplied by
|
| 659 |
+
values in the range [0.98..1.02].
|
| 660 |
+
sign_gain_factor: determines the 'gain' with which we increase the
|
| 661 |
+
change in gradient once the constraints on min_positive and max_positive
|
| 662 |
+
are violated.
|
| 663 |
+
scale_gain_factor: determines the 'gain' with which we increase the
|
| 664 |
+
change in gradient once the constraints on min_abs and max_abs
|
| 665 |
+
are violated.
|
| 666 |
+
min_abs: the minimum average-absolute-value difference from the mean
|
| 667 |
+
value per channel, which we allow, before we start to modify
|
| 668 |
+
the derivatives to prevent this.
|
| 669 |
+
max_abs: the maximum average-absolute-value difference from the mean
|
| 670 |
+
value per channel, which we allow, before we start to modify
|
| 671 |
+
the derivatives to prevent this.
|
| 672 |
+
min_prob: determines the minimum probability with which we modify the
|
| 673 |
+
gradients for the {min,max}_positive and {min,max}_abs constraints,
|
| 674 |
+
on each forward(). This is done randomly to prevent all layers
|
| 675 |
+
from doing it at the same time. Early in training we may use
|
| 676 |
+
higher probabilities than this; it will decay to this value.
|
| 677 |
+
"""
|
| 678 |
+
|
| 679 |
+
def __init__(
|
| 680 |
+
self,
|
| 681 |
+
num_channels: int,
|
| 682 |
+
channel_dim: int,
|
| 683 |
+
min_positive: float = 0.05,
|
| 684 |
+
max_positive: float = 0.95,
|
| 685 |
+
max_factor: float = 0.04,
|
| 686 |
+
sign_gain_factor: float = 0.01,
|
| 687 |
+
scale_gain_factor: float = 0.02,
|
| 688 |
+
min_abs: float = 0.2,
|
| 689 |
+
max_abs: float = 100.0,
|
| 690 |
+
min_prob: float = 0.1,
|
| 691 |
+
):
|
| 692 |
+
super(ActivationBalancer, self).__init__()
|
| 693 |
+
self.num_channels = num_channels
|
| 694 |
+
self.channel_dim = channel_dim
|
| 695 |
+
self.min_positive = min_positive
|
| 696 |
+
self.max_positive = max_positive
|
| 697 |
+
self.max_factor = max_factor
|
| 698 |
+
self.min_abs = min_abs
|
| 699 |
+
self.max_abs = max_abs
|
| 700 |
+
self.min_prob = min_prob
|
| 701 |
+
self.sign_gain_factor = sign_gain_factor
|
| 702 |
+
self.scale_gain_factor = scale_gain_factor
|
| 703 |
+
|
| 704 |
+
# count measures how many times the forward() function has been called.
|
| 705 |
+
# We occasionally sync this to a tensor called `count`, that exists to
|
| 706 |
+
# make sure it is synced to disk when we load and save the model.
|
| 707 |
+
self.cpu_count = 0
|
| 708 |
+
self.register_buffer("count", torch.tensor(0, dtype=torch.int64))
|
| 709 |
+
|
| 710 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 711 |
+
if (
|
| 712 |
+
torch.jit.is_scripting()
|
| 713 |
+
or not x.requires_grad
|
| 714 |
+
or torch.jit.is_tracing()
|
| 715 |
+
):
|
| 716 |
+
return _no_op(x)
|
| 717 |
+
|
| 718 |
+
count = self.cpu_count
|
| 719 |
+
self.cpu_count += 1
|
| 720 |
+
|
| 721 |
+
if random.random() < 0.01:
|
| 722 |
+
# Occasionally sync self.cpu_count with self.count.
|
| 723 |
+
# count affects the decay of 'prob'. don't do this on every iter,
|
| 724 |
+
# because syncing with the GPU is slow.
|
| 725 |
+
self.cpu_count = max(self.cpu_count, self.count.item())
|
| 726 |
+
self.count.fill_(self.cpu_count)
|
| 727 |
+
|
| 728 |
+
# the prob of doing some work exponentially decreases from 0.5 till it hits
|
| 729 |
+
# a floor at min_prob (==0.1, by default)
|
| 730 |
+
prob = max(self.min_prob, 0.5 ** (1 + (count / 4000.0)))
|
| 731 |
+
|
| 732 |
+
if random.random() < prob:
|
| 733 |
+
sign_gain_factor = 0.5
|
| 734 |
+
if self.min_positive != 0.0 or self.max_positive != 1.0:
|
| 735 |
+
sign_factor = _compute_sign_factor(
|
| 736 |
+
x,
|
| 737 |
+
self.channel_dim,
|
| 738 |
+
self.min_positive,
|
| 739 |
+
self.max_positive,
|
| 740 |
+
gain_factor=self.sign_gain_factor / prob,
|
| 741 |
+
max_factor=self.max_factor,
|
| 742 |
+
)
|
| 743 |
+
else:
|
| 744 |
+
sign_factor = None
|
| 745 |
+
|
| 746 |
+
scale_factor = _compute_scale_factor(
|
| 747 |
+
x.detach(),
|
| 748 |
+
self.channel_dim,
|
| 749 |
+
min_abs=self.min_abs,
|
| 750 |
+
max_abs=self.max_abs,
|
| 751 |
+
gain_factor=self.scale_gain_factor / prob,
|
| 752 |
+
max_factor=self.max_factor,
|
| 753 |
+
)
|
| 754 |
+
return ActivationBalancerFunction.apply(
|
| 755 |
+
x,
|
| 756 |
+
scale_factor,
|
| 757 |
+
sign_factor,
|
| 758 |
+
self.channel_dim,
|
| 759 |
+
)
|
| 760 |
+
else:
|
| 761 |
+
return _no_op(x)
|
| 762 |
+
|
| 763 |
+
|
| 764 |
+
def penalize_abs_values_gt(x: Tensor, limit: float, penalty: float) -> Tensor:
|
| 765 |
+
"""
|
| 766 |
+
Returns x unmodified, but in backprop will put a penalty for the excess of
|
| 767 |
+
the absolute values of elements of x over the limit "limit". E.g. if
|
| 768 |
+
limit == 10.0, then if x has any values over 10 it will get a penalty.
|
| 769 |
+
|
| 770 |
+
Caution: the value of this penalty will be affected by grad scaling used
|
| 771 |
+
in automatic mixed precision training. For this reasons we use this,
|
| 772 |
+
it shouldn't really matter, or may even be helpful; we just use this
|
| 773 |
+
to disallow really implausible values of scores to be given to softmax.
|
| 774 |
+
"""
|
| 775 |
+
x_sign = x.sign()
|
| 776 |
+
over_limit = (x.abs() - limit) > 0
|
| 777 |
+
# The following is a memory efficient way to penalize the absolute values of
|
| 778 |
+
# x that's over the limit. (The memory efficiency comes when you think
|
| 779 |
+
# about which items torch needs to cache for the autograd, and which ones it
|
| 780 |
+
# can throw away). The numerical value of aux_loss as computed here will
|
| 781 |
+
# actually be larger than it should be, by limit * over_limit.sum(), but it
|
| 782 |
+
# has the same derivative as the real aux_loss which is penalty * (x.abs() -
|
| 783 |
+
# limit).relu().
|
| 784 |
+
aux_loss = penalty * ((x_sign * over_limit).to(torch.int8) * x)
|
| 785 |
+
# note: we don't do sum() here on aux)_loss, but it's as if we had done
|
| 786 |
+
# sum() due to how with_loss() works.
|
| 787 |
+
x = with_loss(x, aux_loss)
|
| 788 |
+
# you must use x for something, or this will be ineffective.
|
| 789 |
+
return x
|
| 790 |
+
|
| 791 |
+
|
| 792 |
+
def _diag(x: Tensor): # like .diag(), but works for tensors with 3 dims.
|
| 793 |
+
if x.ndim == 2:
|
| 794 |
+
return x.diag()
|
| 795 |
+
else:
|
| 796 |
+
(batch, dim, dim) = x.shape
|
| 797 |
+
x = x.reshape(batch, dim * dim)
|
| 798 |
+
x = x[:, :: dim + 1]
|
| 799 |
+
assert x.shape == (batch, dim)
|
| 800 |
+
return x
|
| 801 |
+
|
| 802 |
+
|
| 803 |
+
def _whitening_metric(x: Tensor, num_groups: int):
|
| 804 |
+
"""
|
| 805 |
+
Computes the "whitening metric", a value which will be 1.0 if all the eigenvalues of
|
| 806 |
+
of the centered feature covariance are the same within each group's covariance matrix
|
| 807 |
+
and also between groups.
|
| 808 |
+
Args:
|
| 809 |
+
x: a Tensor of shape (*, num_channels)
|
| 810 |
+
num_groups: the number of groups of channels, a number >=1 that divides num_channels
|
| 811 |
+
Returns:
|
| 812 |
+
Returns a scalar Tensor that will be 1.0 if the data is "perfectly white" and
|
| 813 |
+
greater than 1.0 otherwise.
|
| 814 |
+
"""
|
| 815 |
+
assert x.dtype != torch.float16
|
| 816 |
+
x = x.reshape(-1, x.shape[-1])
|
| 817 |
+
(num_frames, num_channels) = x.shape
|
| 818 |
+
assert num_channels % num_groups == 0
|
| 819 |
+
channels_per_group = num_channels // num_groups
|
| 820 |
+
x = x.reshape(num_frames, num_groups, channels_per_group).transpose(0, 1)
|
| 821 |
+
# x now has shape (num_groups, num_frames, channels_per_group)
|
| 822 |
+
# subtract the mean so we use the centered, not uncentered, covariance.
|
| 823 |
+
# My experience has been that when we "mess with the gradients" like this,
|
| 824 |
+
# it's better not do anything that tries to move the mean around, because
|
| 825 |
+
# that can easily cause instability.
|
| 826 |
+
x = x - x.mean(dim=1, keepdim=True)
|
| 827 |
+
# x_covar: (num_groups, channels_per_group, channels_per_group)
|
| 828 |
+
x_covar = torch.matmul(x.transpose(1, 2), x)
|
| 829 |
+
x_covar_mean_diag = _diag(x_covar).mean()
|
| 830 |
+
# the following expression is what we'd get if we took the matrix product
|
| 831 |
+
# of each covariance and measured the mean of its trace, i.e.
|
| 832 |
+
# the same as _diag(torch.matmul(x_covar, x_covar)).mean().
|
| 833 |
+
x_covarsq_mean_diag = (x_covar ** 2).sum() / (
|
| 834 |
+
num_groups * channels_per_group
|
| 835 |
+
)
|
| 836 |
+
# this metric will be >= 1.0; the larger it is, the less 'white' the data was.
|
| 837 |
+
metric = x_covarsq_mean_diag / (x_covar_mean_diag ** 2 + 1.0e-20)
|
| 838 |
+
return metric
|
| 839 |
+
|
| 840 |
+
|
| 841 |
+
class WhiteningPenaltyFunction(torch.autograd.Function):
|
| 842 |
+
@staticmethod
|
| 843 |
+
def forward(
|
| 844 |
+
ctx,
|
| 845 |
+
x: Tensor,
|
| 846 |
+
num_groups: int,
|
| 847 |
+
whitening_limit: float,
|
| 848 |
+
grad_scale: float,
|
| 849 |
+
) -> Tensor:
|
| 850 |
+
ctx.save_for_backward(x)
|
| 851 |
+
ctx.num_groups = num_groups
|
| 852 |
+
ctx.whitening_limit = whitening_limit
|
| 853 |
+
ctx.grad_scale = grad_scale
|
| 854 |
+
return x
|
| 855 |
+
|
| 856 |
+
@staticmethod
|
| 857 |
+
def backward(ctx, x_grad: Tensor):
|
| 858 |
+
(x_orig,) = ctx.saved_tensors
|
| 859 |
+
with torch.enable_grad():
|
| 860 |
+
with torch.cuda.amp.autocast(enabled=False):
|
| 861 |
+
x_detached = x_orig.to(torch.float32).detach()
|
| 862 |
+
x_detached.requires_grad = True
|
| 863 |
+
|
| 864 |
+
metric = _whitening_metric(x_detached, ctx.num_groups)
|
| 865 |
+
|
| 866 |
+
if random.random() < 0.005 or __name__ == "__main__":
|
| 867 |
+
logging.info(
|
| 868 |
+
f"Whitening: num_groups={ctx.num_groups}, num_channels={x_orig.shape[-1]}, "
|
| 869 |
+
f"metric={metric.item():.2f} vs. limit={ctx.whitening_limit}"
|
| 870 |
+
)
|
| 871 |
+
|
| 872 |
+
(metric - ctx.whitening_limit).relu().backward()
|
| 873 |
+
penalty_grad = x_detached.grad
|
| 874 |
+
scale = ctx.grad_scale * (
|
| 875 |
+
x_grad.to(torch.float32).norm()
|
| 876 |
+
/ (penalty_grad.norm() + 1.0e-20)
|
| 877 |
+
)
|
| 878 |
+
penalty_grad = penalty_grad * scale
|
| 879 |
+
return x_grad + penalty_grad.to(x_grad.dtype), None, None, None
|
| 880 |
+
|
| 881 |
+
|
| 882 |
+
class Whiten(nn.Module):
|
| 883 |
+
def __init__(
|
| 884 |
+
self,
|
| 885 |
+
num_groups: int,
|
| 886 |
+
whitening_limit: float,
|
| 887 |
+
prob: Union[float, Tuple[float, float]],
|
| 888 |
+
grad_scale: float,
|
| 889 |
+
):
|
| 890 |
+
"""
|
| 891 |
+
Args:
|
| 892 |
+
num_groups: the number of groups to divide the channel dim into before
|
| 893 |
+
whitening. We will attempt to make the feature covariance
|
| 894 |
+
within each group, after mean subtraction, as "white" as possible,
|
| 895 |
+
while having the same trace across all groups.
|
| 896 |
+
whitening_limit: a value greater than 1.0, that dictates how much
|
| 897 |
+
freedom we have to violate the constraints. 1.0 would mean perfectly
|
| 898 |
+
white, with exactly the same trace across groups; larger values
|
| 899 |
+
give more freedom. E.g. 2.0.
|
| 900 |
+
prob: the probability with which we apply the gradient modification
|
| 901 |
+
(also affects the grad scale). May be supplied as a float,
|
| 902 |
+
or as a pair (min_prob, max_prob)
|
| 903 |
+
|
| 904 |
+
grad_scale: determines the scale on the gradient term from this object,
|
| 905 |
+
relative to the rest of the gradient on the attention weights.
|
| 906 |
+
E.g. 0.02 (you may want to use smaller values than this if prob is large)
|
| 907 |
+
"""
|
| 908 |
+
super(Whiten, self).__init__()
|
| 909 |
+
assert num_groups >= 1
|
| 910 |
+
assert whitening_limit >= 1
|
| 911 |
+
assert grad_scale >= 0
|
| 912 |
+
self.num_groups = num_groups
|
| 913 |
+
self.whitening_limit = whitening_limit
|
| 914 |
+
if isinstance(prob, float):
|
| 915 |
+
assert 0 < prob <= 1
|
| 916 |
+
self.prob = prob
|
| 917 |
+
else:
|
| 918 |
+
(self.min_prob, self.max_prob) = prob
|
| 919 |
+
assert 0 < self.min_prob < self.max_prob <= 1
|
| 920 |
+
self.prob = self.max_prob
|
| 921 |
+
|
| 922 |
+
self.grad_scale = grad_scale
|
| 923 |
+
|
| 924 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 925 |
+
"""
|
| 926 |
+
In the forward pass, this function just returns the input unmodified.
|
| 927 |
+
In the backward pass, it will modify the gradients to ensure that the
|
| 928 |
+
distribution in each group has close to (lambda times I) as the covariance
|
| 929 |
+
after mean subtraction, with the same lambda across groups.
|
| 930 |
+
For whitening_limit > 1, there will be more freedom to violate this
|
| 931 |
+
constraint.
|
| 932 |
+
|
| 933 |
+
Args:
|
| 934 |
+
x: the input of shape (*, num_channels)
|
| 935 |
+
|
| 936 |
+
Returns:
|
| 937 |
+
x, unmodified. You should make sure
|
| 938 |
+
you use the returned value, or the graph will be freed
|
| 939 |
+
and nothing will happen in backprop.
|
| 940 |
+
"""
|
| 941 |
+
if (
|
| 942 |
+
not x.requires_grad
|
| 943 |
+
or random.random() > self.prob
|
| 944 |
+
or self.grad_scale == 0
|
| 945 |
+
):
|
| 946 |
+
return _no_op(x)
|
| 947 |
+
else:
|
| 948 |
+
if hasattr(self, "min_prob") and random.random() < 0.25:
|
| 949 |
+
# occasionally switch between min_prob and max_prob, based on whether
|
| 950 |
+
# we are above or below the threshold.
|
| 951 |
+
if (
|
| 952 |
+
_whitening_metric(x.to(torch.float32), self.num_groups)
|
| 953 |
+
> self.whitening_limit
|
| 954 |
+
):
|
| 955 |
+
# there would be a change to the grad.
|
| 956 |
+
self.prob = self.max_prob
|
| 957 |
+
else:
|
| 958 |
+
self.prob = self.min_prob
|
| 959 |
+
|
| 960 |
+
return WhiteningPenaltyFunction.apply(
|
| 961 |
+
x, self.num_groups, self.whitening_limit, self.grad_scale
|
| 962 |
+
)
|
| 963 |
+
|
| 964 |
+
|
| 965 |
+
class WithLoss(torch.autograd.Function):
|
| 966 |
+
@staticmethod
|
| 967 |
+
def forward(ctx, x: Tensor, y: Tensor):
|
| 968 |
+
ctx.y_shape = y.shape
|
| 969 |
+
return x
|
| 970 |
+
|
| 971 |
+
@staticmethod
|
| 972 |
+
def backward(ctx, ans_grad: Tensor):
|
| 973 |
+
return ans_grad, torch.ones(
|
| 974 |
+
ctx.y_shape, dtype=ans_grad.dtype, device=ans_grad.device
|
| 975 |
+
)
|
| 976 |
+
|
| 977 |
+
|
| 978 |
+
def with_loss(x, y):
|
| 979 |
+
if torch.jit.is_scripting() or torch.jit.is_tracing():
|
| 980 |
+
return x
|
| 981 |
+
# returns x but adds y.sum() to the loss function.
|
| 982 |
+
return WithLoss.apply(x, y)
|
| 983 |
+
|
| 984 |
+
|
| 985 |
+
def _no_op(x: Tensor) -> Tensor:
|
| 986 |
+
if torch.jit.is_scripting() or torch.jit.is_tracing():
|
| 987 |
+
return x
|
| 988 |
+
else:
|
| 989 |
+
# a no-op function that will have a node in the autograd graph,
|
| 990 |
+
# to avoid certain bugs relating to backward hooks
|
| 991 |
+
return x.chunk(1, dim=-1)[0]
|
| 992 |
+
|
| 993 |
+
|
| 994 |
+
class Identity(torch.nn.Module):
|
| 995 |
+
def __init__(self):
|
| 996 |
+
super(Identity, self).__init__()
|
| 997 |
+
|
| 998 |
+
def forward(self, x):
|
| 999 |
+
return _no_op(x)
|
| 1000 |
+
|
| 1001 |
+
|
| 1002 |
+
class MaxEig(torch.nn.Module):
|
| 1003 |
+
"""
|
| 1004 |
+
Modifies the backpropped derivatives of a function to try to discourage
|
| 1005 |
+
that any given direction in activation space accounts for more than
|
| 1006 |
+
a specified proportion of the covariance (e.g. 0.2).
|
| 1007 |
+
|
| 1008 |
+
|
| 1009 |
+
Args:
|
| 1010 |
+
num_channels: the number of channels
|
| 1011 |
+
channel_dim: the dimension/axis corresponding to the channel, e.g.
|
| 1012 |
+
-1, 0, 1, 2; will be interpreted as an offset from x.ndim if negative.
|
| 1013 |
+
max_var_per_eig: the maximum proportion of the variance of the
|
| 1014 |
+
features/channels, after mean subtraction, that can come from
|
| 1015 |
+
any given eigenvalue.
|
| 1016 |
+
min_prob: the minimum probability with which we apply this during any invocation
|
| 1017 |
+
of forward(), assuming last time we applied the constraint it was
|
| 1018 |
+
not active; supplied for speed.
|
| 1019 |
+
scale: determines the scale with which we modify the gradients, relative
|
| 1020 |
+
to the existing / unmodified gradients
|
| 1021 |
+
"""
|
| 1022 |
+
|
| 1023 |
+
def __init__(
|
| 1024 |
+
self,
|
| 1025 |
+
num_channels: int,
|
| 1026 |
+
channel_dim: int,
|
| 1027 |
+
max_var_per_eig: float = 0.2,
|
| 1028 |
+
min_prob: float = 0.01,
|
| 1029 |
+
scale: float = 0.01,
|
| 1030 |
+
):
|
| 1031 |
+
super(MaxEig, self).__init__()
|
| 1032 |
+
self.num_channels = num_channels
|
| 1033 |
+
self.channel_dim = channel_dim
|
| 1034 |
+
self.scale = scale
|
| 1035 |
+
assert max_var_per_eig == 0.0 or max_var_per_eig > 1.0 / num_channels
|
| 1036 |
+
self.max_var_per_eig = max_var_per_eig
|
| 1037 |
+
|
| 1038 |
+
# we figure out the dominant direction using the power method: starting with
|
| 1039 |
+
# a random vector, keep multiplying by the covariance and renormalizing.
|
| 1040 |
+
with torch.no_grad():
|
| 1041 |
+
# arbitrary.. would use randn() but want to leave the rest of the model's
|
| 1042 |
+
# random parameters unchanged for comparison
|
| 1043 |
+
direction = torch.arange(num_channels).to(torch.float)
|
| 1044 |
+
direction = direction / direction.norm()
|
| 1045 |
+
self.register_buffer("max_eig_direction", direction)
|
| 1046 |
+
|
| 1047 |
+
self.min_prob = min_prob
|
| 1048 |
+
# cur_prob is the current probability we'll use to apply the ActivationBalancer.
|
| 1049 |
+
# We'll regress this towards prob, each tiem we try to apply it and it is not
|
| 1050 |
+
# active.
|
| 1051 |
+
self.cur_prob = 1.0
|
| 1052 |
+
|
| 1053 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 1054 |
+
if (
|
| 1055 |
+
torch.jit.is_scripting()
|
| 1056 |
+
or self.max_var_per_eig <= 0
|
| 1057 |
+
or random.random() > self.cur_prob
|
| 1058 |
+
or torch.jit.is_tracing()
|
| 1059 |
+
):
|
| 1060 |
+
return _no_op(x)
|
| 1061 |
+
|
| 1062 |
+
with torch.cuda.amp.autocast(enabled=False):
|
| 1063 |
+
eps = 1.0e-20
|
| 1064 |
+
orig_x = x
|
| 1065 |
+
x = x.to(torch.float32)
|
| 1066 |
+
with torch.no_grad():
|
| 1067 |
+
x = x.transpose(self.channel_dim, -1).reshape(
|
| 1068 |
+
-1, self.num_channels
|
| 1069 |
+
)
|
| 1070 |
+
x = x - x.mean(dim=0)
|
| 1071 |
+
new_direction, coeffs = self._find_direction_coeffs(
|
| 1072 |
+
x, self.max_eig_direction
|
| 1073 |
+
)
|
| 1074 |
+
x_var = (x ** 2).mean()
|
| 1075 |
+
x_residual = x - coeffs * new_direction
|
| 1076 |
+
x_residual_var = (x_residual ** 2).mean()
|
| 1077 |
+
|
| 1078 |
+
# `variance_proportion` is the proportion of the variance accounted for
|
| 1079 |
+
# by the top eigen-direction.
|
| 1080 |
+
variance_proportion = (x_var - x_residual_var) / (
|
| 1081 |
+
x_var + 1.0e-20
|
| 1082 |
+
)
|
| 1083 |
+
|
| 1084 |
+
# ensure new direction is nonzero even if x == 0, by including `direction`.
|
| 1085 |
+
self._set_direction(
|
| 1086 |
+
0.1 * self.max_eig_direction + new_direction
|
| 1087 |
+
)
|
| 1088 |
+
|
| 1089 |
+
if random.random() < 0.01 or __name__ == "__main__":
|
| 1090 |
+
logging.info(
|
| 1091 |
+
f"variance_proportion = {variance_proportion.item()}, shape={tuple(orig_x.shape)}, cur_prob={self.cur_prob}"
|
| 1092 |
+
)
|
| 1093 |
+
|
| 1094 |
+
if variance_proportion >= self.max_var_per_eig:
|
| 1095 |
+
# The constraint is active. Note, we should quite rarely
|
| 1096 |
+
# reach here, only near the beginning of training if we are
|
| 1097 |
+
# starting to diverge, should this constraint be active.
|
| 1098 |
+
cur_prob = self.cur_prob
|
| 1099 |
+
self.cur_prob = (
|
| 1100 |
+
1.0 # next time, do the update with probability 1.0.
|
| 1101 |
+
)
|
| 1102 |
+
return MaxEigLimiterFunction.apply(
|
| 1103 |
+
orig_x, coeffs, new_direction, self.channel_dim, self.scale
|
| 1104 |
+
)
|
| 1105 |
+
else:
|
| 1106 |
+
# let self.cur_prob exponentially approach self.min_prob, as
|
| 1107 |
+
# long as the constraint is inactive.
|
| 1108 |
+
self.cur_prob = 0.75 * self.cur_prob + 0.25 * self.min_prob
|
| 1109 |
+
return orig_x
|
| 1110 |
+
|
| 1111 |
+
def _set_direction(self, direction: Tensor):
|
| 1112 |
+
"""
|
| 1113 |
+
Sets self.max_eig_direction to a normalized version of `direction`
|
| 1114 |
+
"""
|
| 1115 |
+
direction = direction.detach()
|
| 1116 |
+
direction = direction / direction.norm()
|
| 1117 |
+
direction_sum = direction.sum().item()
|
| 1118 |
+
if direction_sum - direction_sum == 0: # no inf/nan
|
| 1119 |
+
self.max_eig_direction[:] = direction
|
| 1120 |
+
else:
|
| 1121 |
+
logging.info(
|
| 1122 |
+
f"Warning: sum of direction in MaxEig is {direction_sum}, "
|
| 1123 |
+
"num_channels={self.num_channels}, channel_dim={self.channel_dim}"
|
| 1124 |
+
)
|
| 1125 |
+
|
| 1126 |
+
def _find_direction_coeffs(
|
| 1127 |
+
self, x: Tensor, prev_direction: Tensor
|
| 1128 |
+
) -> Tuple[Tensor, Tensor, Tensor]:
|
| 1129 |
+
"""
|
| 1130 |
+
Figure out (an approximation to) the proportion of the variance of a set of
|
| 1131 |
+
feature vectors that can be attributed to the top eigen-direction.
|
| 1132 |
+
Args:
|
| 1133 |
+
x: a Tensor of shape (num_frames, num_channels), with num_frames > 1.
|
| 1134 |
+
prev_direction: a Tensor of shape (num_channels,), that is our previous estimate
|
| 1135 |
+
of the top eigen-direction, or a random direction if this is the first
|
| 1136 |
+
iteration. Does not have to be normalized, but should be nonzero.
|
| 1137 |
+
|
| 1138 |
+
Returns: (cur_direction, coeffs), where:
|
| 1139 |
+
cur_direction: a Tensor of shape (num_channels,) that is the current
|
| 1140 |
+
estimate of the top eigen-direction.
|
| 1141 |
+
coeffs: a Tensor of shape (num_frames, 1) that minimizes, or
|
| 1142 |
+
approximately minimizes, (x - coeffs * cur_direction).norm()
|
| 1143 |
+
"""
|
| 1144 |
+
(num_frames, num_channels) = x.shape
|
| 1145 |
+
assert num_channels > 1 and num_frames > 1
|
| 1146 |
+
assert prev_direction.shape == (num_channels,)
|
| 1147 |
+
# `coeffs` are the coefficients of `prev_direction` in x.
|
| 1148 |
+
# actually represent the coeffs up to a constant positive factor.
|
| 1149 |
+
coeffs = (x * prev_direction).sum(dim=1, keepdim=True) + 1.0e-10
|
| 1150 |
+
cur_direction = (x * coeffs).sum(dim=0) / (
|
| 1151 |
+
(coeffs ** 2).sum() + 1.0e-20
|
| 1152 |
+
)
|
| 1153 |
+
return cur_direction, coeffs
|
| 1154 |
+
|
| 1155 |
+
|
| 1156 |
+
class DoubleSwishFunction(torch.autograd.Function):
|
| 1157 |
+
"""
|
| 1158 |
+
double_swish(x) = x * torch.sigmoid(x-1)
|
| 1159 |
+
This is a definition, originally motivated by its close numerical
|
| 1160 |
+
similarity to swish(swish(x)), where swish(x) = x * sigmoid(x).
|
| 1161 |
+
|
| 1162 |
+
Memory-efficient derivative computation:
|
| 1163 |
+
double_swish(x) = x * s, where s(x) = torch.sigmoid(x-1)
|
| 1164 |
+
double_swish'(x) = d/dx double_swish(x) = x * s'(x) + x' * s(x) = x * s'(x) + s(x).
|
| 1165 |
+
Now, s'(x) = s(x) * (1-s(x)).
|
| 1166 |
+
double_swish'(x) = x * s'(x) + s(x).
|
| 1167 |
+
= x * s(x) * (1-s(x)) + s(x).
|
| 1168 |
+
= double_swish(x) * (1-s(x)) + s(x)
|
| 1169 |
+
... so we just need to remember s(x) but not x itself.
|
| 1170 |
+
"""
|
| 1171 |
+
|
| 1172 |
+
@staticmethod
|
| 1173 |
+
def forward(ctx, x: Tensor) -> Tensor:
|
| 1174 |
+
requires_grad = x.requires_grad
|
| 1175 |
+
x_dtype = x.dtype
|
| 1176 |
+
if x.dtype == torch.float16:
|
| 1177 |
+
x = x.to(torch.float32)
|
| 1178 |
+
|
| 1179 |
+
s = torch.sigmoid(x - 1.0)
|
| 1180 |
+
y = x * s
|
| 1181 |
+
|
| 1182 |
+
if requires_grad:
|
| 1183 |
+
deriv = y * (1 - s) + s
|
| 1184 |
+
# notes on derivative of x * sigmoid(x - 1):
|
| 1185 |
+
# https://www.wolframalpha.com/input?i=d%2Fdx+%28x+*+sigmoid%28x-1%29%29
|
| 1186 |
+
# min \simeq -0.043638. Take floor as -0.043637 so it's a lower bund
|
| 1187 |
+
# max \simeq 1.1990. Take ceil to be 1.2 so it's an upper bound.
|
| 1188 |
+
# the combination of "+ torch.rand_like(deriv)" and casting to torch.uint8 (which
|
| 1189 |
+
# floors), should be expectation-preserving.
|
| 1190 |
+
floor = -0.043637
|
| 1191 |
+
ceil = 1.2
|
| 1192 |
+
d_scaled = (deriv - floor) * (
|
| 1193 |
+
255.0 / (ceil - floor)
|
| 1194 |
+
) + torch.rand_like(deriv)
|
| 1195 |
+
if __name__ == "__main__":
|
| 1196 |
+
# for self-testing only.
|
| 1197 |
+
assert d_scaled.min() >= 0.0
|
| 1198 |
+
assert d_scaled.max() < 256.0
|
| 1199 |
+
d_int = d_scaled.to(torch.uint8)
|
| 1200 |
+
ctx.save_for_backward(d_int)
|
| 1201 |
+
if x.dtype == torch.float16 or torch.is_autocast_enabled():
|
| 1202 |
+
y = y.to(torch.float16)
|
| 1203 |
+
return y
|
| 1204 |
+
|
| 1205 |
+
@staticmethod
|
| 1206 |
+
def backward(ctx, y_grad: Tensor) -> Tensor:
|
| 1207 |
+
(d,) = ctx.saved_tensors
|
| 1208 |
+
# the same constants as used in forward pass.
|
| 1209 |
+
floor = -0.043637
|
| 1210 |
+
ceil = 1.2
|
| 1211 |
+
d = d * ((ceil - floor) / 255.0) + floor
|
| 1212 |
+
return y_grad * d
|
| 1213 |
+
|
| 1214 |
+
|
| 1215 |
+
class DoubleSwish(torch.nn.Module):
|
| 1216 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 1217 |
+
"""Return double-swish activation function which is an approximation to Swish(Swish(x)),
|
| 1218 |
+
that we approximate closely with x * sigmoid(x-1).
|
| 1219 |
+
"""
|
| 1220 |
+
if torch.jit.is_scripting() or torch.jit.is_tracing():
|
| 1221 |
+
return x * torch.sigmoid(x - 1.0)
|
| 1222 |
+
return DoubleSwishFunction.apply(x)
|
| 1223 |
+
|
| 1224 |
+
|
| 1225 |
+
def BalancedDoubleSwish(
|
| 1226 |
+
d_model, channel_dim=-1, max_abs=10.0, min_prob=0.25
|
| 1227 |
+
) -> nn.Sequential:
|
| 1228 |
+
"""
|
| 1229 |
+
ActivationBalancer -> DoubleSwish
|
| 1230 |
+
"""
|
| 1231 |
+
balancer = ActivationBalancer(
|
| 1232 |
+
d_model, channel_dim=channel_dim, max_abs=max_abs, min_prob=min_prob
|
| 1233 |
+
)
|
| 1234 |
+
return nn.Sequential(
|
| 1235 |
+
balancer,
|
| 1236 |
+
DoubleSwish(),
|
| 1237 |
+
)
|
| 1238 |
+
|
| 1239 |
+
|
| 1240 |
+
def _test_max_eig():
|
| 1241 |
+
for proportion in [0.1, 0.5, 10.0]:
|
| 1242 |
+
logging.info(f"proportion = {proportion}")
|
| 1243 |
+
x = torch.randn(100, 128)
|
| 1244 |
+
direction = torch.randn(128)
|
| 1245 |
+
coeffs = torch.randn(100, 1)
|
| 1246 |
+
x += proportion * direction * coeffs
|
| 1247 |
+
|
| 1248 |
+
x.requires_grad = True
|
| 1249 |
+
|
| 1250 |
+
num_channels = 128
|
| 1251 |
+
m = MaxEig(
|
| 1252 |
+
num_channels, 1, 0.5, scale=0.1 # channel_dim # max_var_per_eig
|
| 1253 |
+
) # grad_scale
|
| 1254 |
+
|
| 1255 |
+
for _ in range(4):
|
| 1256 |
+
y = m(x)
|
| 1257 |
+
|
| 1258 |
+
y_grad = torch.randn_like(x)
|
| 1259 |
+
y.backward(gradient=y_grad)
|
| 1260 |
+
|
| 1261 |
+
if proportion < 0.2:
|
| 1262 |
+
assert torch.allclose(x.grad, y_grad, atol=1.0e-02)
|
| 1263 |
+
elif proportion > 1.0:
|
| 1264 |
+
assert not torch.allclose(x.grad, y_grad)
|
| 1265 |
+
|
| 1266 |
+
|
| 1267 |
+
def _test_whiten():
|
| 1268 |
+
for proportion in [0.1, 0.5, 10.0]:
|
| 1269 |
+
logging.info(f"_test_whiten(): proportion = {proportion}")
|
| 1270 |
+
x = torch.randn(100, 128)
|
| 1271 |
+
direction = torch.randn(128)
|
| 1272 |
+
coeffs = torch.randn(100, 1)
|
| 1273 |
+
x += proportion * direction * coeffs
|
| 1274 |
+
|
| 1275 |
+
x.requires_grad = True
|
| 1276 |
+
|
| 1277 |
+
num_channels = 128
|
| 1278 |
+
m = Whiten(
|
| 1279 |
+
1, 5.0, prob=1.0, grad_scale=0.1 # num_groups # whitening_limit,
|
| 1280 |
+
) # grad_scale
|
| 1281 |
+
|
| 1282 |
+
for _ in range(4):
|
| 1283 |
+
y = m(x)
|
| 1284 |
+
|
| 1285 |
+
y_grad = torch.randn_like(x)
|
| 1286 |
+
y.backward(gradient=y_grad)
|
| 1287 |
+
|
| 1288 |
+
if proportion < 0.2:
|
| 1289 |
+
assert torch.allclose(x.grad, y_grad)
|
| 1290 |
+
elif proportion > 1.0:
|
| 1291 |
+
assert not torch.allclose(x.grad, y_grad)
|
| 1292 |
+
|
| 1293 |
+
|
| 1294 |
+
def _test_activation_balancer_sign():
|
| 1295 |
+
probs = torch.arange(0, 1, 0.01)
|
| 1296 |
+
N = 1000
|
| 1297 |
+
x = 1.0 * (
|
| 1298 |
+
(2.0 * (torch.rand(probs.numel(), N) < probs.unsqueeze(-1))) - 1.0
|
| 1299 |
+
)
|
| 1300 |
+
x = x.detach()
|
| 1301 |
+
x.requires_grad = True
|
| 1302 |
+
m = ActivationBalancer(
|
| 1303 |
+
probs.numel(),
|
| 1304 |
+
channel_dim=0,
|
| 1305 |
+
min_positive=0.05,
|
| 1306 |
+
max_positive=0.95,
|
| 1307 |
+
max_factor=0.2,
|
| 1308 |
+
min_abs=0.0,
|
| 1309 |
+
)
|
| 1310 |
+
|
| 1311 |
+
y_grad = torch.sign(torch.randn(probs.numel(), N))
|
| 1312 |
+
|
| 1313 |
+
y = m(x)
|
| 1314 |
+
y.backward(gradient=y_grad)
|
| 1315 |
+
print("_test_activation_balancer_sign: x = ", x)
|
| 1316 |
+
print("_test_activation_balancer_sign: y grad = ", y_grad)
|
| 1317 |
+
print("_test_activation_balancer_sign: x grad = ", x.grad)
|
| 1318 |
+
|
| 1319 |
+
|
| 1320 |
+
def _test_activation_balancer_magnitude():
|
| 1321 |
+
magnitudes = torch.arange(0, 1, 0.01)
|
| 1322 |
+
N = 1000
|
| 1323 |
+
x = torch.sign(torch.randn(magnitudes.numel(), N)) * magnitudes.unsqueeze(
|
| 1324 |
+
-1
|
| 1325 |
+
)
|
| 1326 |
+
x = x.detach()
|
| 1327 |
+
x.requires_grad = True
|
| 1328 |
+
m = ActivationBalancer(
|
| 1329 |
+
magnitudes.numel(),
|
| 1330 |
+
channel_dim=0,
|
| 1331 |
+
min_positive=0.0,
|
| 1332 |
+
max_positive=1.0,
|
| 1333 |
+
max_factor=0.2,
|
| 1334 |
+
min_abs=0.2,
|
| 1335 |
+
max_abs=0.8,
|
| 1336 |
+
min_prob=1.0,
|
| 1337 |
+
)
|
| 1338 |
+
|
| 1339 |
+
y_grad = torch.sign(torch.randn(magnitudes.numel(), N))
|
| 1340 |
+
|
| 1341 |
+
y = m(x)
|
| 1342 |
+
y.backward(gradient=y_grad)
|
| 1343 |
+
print("_test_activation_balancer_magnitude: x = ", x)
|
| 1344 |
+
print("_test_activation_balancer_magnitude: y grad = ", y_grad)
|
| 1345 |
+
print("_test_activation_balancer_magnitude: x grad = ", x.grad)
|
| 1346 |
+
|
| 1347 |
+
|
| 1348 |
+
def _test_basic_norm():
|
| 1349 |
+
num_channels = 128
|
| 1350 |
+
m = BasicNorm(num_channels=num_channels, channel_dim=1)
|
| 1351 |
+
|
| 1352 |
+
x = torch.randn(500, num_channels)
|
| 1353 |
+
|
| 1354 |
+
y = m(x)
|
| 1355 |
+
|
| 1356 |
+
assert y.shape == x.shape
|
| 1357 |
+
x_rms = (x ** 2).mean().sqrt()
|
| 1358 |
+
y_rms = (y ** 2).mean().sqrt()
|
| 1359 |
+
print("x rms = ", x_rms)
|
| 1360 |
+
print("y rms = ", y_rms)
|
| 1361 |
+
assert y_rms < x_rms
|
| 1362 |
+
assert y_rms > 0.5 * x_rms
|
| 1363 |
+
|
| 1364 |
+
|
| 1365 |
+
def _test_double_swish_deriv():
|
| 1366 |
+
x = torch.randn(10, 12, dtype=torch.double) * 3.0
|
| 1367 |
+
x.requires_grad = True
|
| 1368 |
+
m = DoubleSwish()
|
| 1369 |
+
|
| 1370 |
+
tol = (1.2 - (-0.043637)) / 255.0
|
| 1371 |
+
torch.autograd.gradcheck(m, x, atol=tol)
|
| 1372 |
+
|
| 1373 |
+
# for self-test.
|
| 1374 |
+
x = torch.randn(1000, 1000, dtype=torch.double) * 3.0
|
| 1375 |
+
x.requires_grad = True
|
| 1376 |
+
y = m(x)
|
| 1377 |
+
|
| 1378 |
+
|
| 1379 |
+
def _test_softmax():
|
| 1380 |
+
a = torch.randn(2, 10, dtype=torch.float64)
|
| 1381 |
+
b = a.clone()
|
| 1382 |
+
a.requires_grad = True
|
| 1383 |
+
b.requires_grad = True
|
| 1384 |
+
a.softmax(dim=1)[:, 0].sum().backward()
|
| 1385 |
+
print("a grad = ", a.grad)
|
| 1386 |
+
softmax(b, dim=1)[:, 0].sum().backward()
|
| 1387 |
+
print("b grad = ", b.grad)
|
| 1388 |
+
assert torch.allclose(a.grad, b.grad)
|
| 1389 |
+
|
| 1390 |
+
|
| 1391 |
+
if __name__ == "__main__":
|
| 1392 |
+
logging.getLogger().setLevel(logging.INFO)
|
| 1393 |
+
torch.set_num_threads(1)
|
| 1394 |
+
torch.set_num_interop_threads(1)
|
| 1395 |
+
_test_softmax()
|
| 1396 |
+
_test_whiten()
|
| 1397 |
+
_test_max_eig()
|
| 1398 |
+
_test_activation_balancer_sign()
|
| 1399 |
+
_test_activation_balancer_magnitude()
|
| 1400 |
+
_test_basic_norm()
|
| 1401 |
+
_test_double_swish_deriv()
|
modules/transformer.py
ADDED
|
@@ -0,0 +1,683 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import numbers
|
| 3 |
+
from functools import partial
|
| 4 |
+
from typing import Any, Callable, List, Optional, Tuple, Union
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torch import Tensor, nn
|
| 8 |
+
from torch.nn import functional as F
|
| 9 |
+
|
| 10 |
+
from .activation import MultiheadAttention
|
| 11 |
+
from .scaling import ActivationBalancer, BalancedDoubleSwish
|
| 12 |
+
from .scaling import BasicNorm as _BasicNorm
|
| 13 |
+
|
| 14 |
+
_shape_t = Union[int, List[int], torch.Size]
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class LayerNorm(nn.Module):
|
| 18 |
+
__constants__ = ["normalized_shape", "eps", "elementwise_affine"]
|
| 19 |
+
normalized_shape: Tuple[int, ...]
|
| 20 |
+
eps: float
|
| 21 |
+
elementwise_affine: bool
|
| 22 |
+
|
| 23 |
+
def __init__(
|
| 24 |
+
self,
|
| 25 |
+
normalized_shape: _shape_t,
|
| 26 |
+
eps: float = 1e-5,
|
| 27 |
+
elementwise_affine: bool = True,
|
| 28 |
+
device=None,
|
| 29 |
+
dtype=None,
|
| 30 |
+
) -> None:
|
| 31 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 32 |
+
super(LayerNorm, self).__init__()
|
| 33 |
+
if isinstance(normalized_shape, numbers.Integral):
|
| 34 |
+
# mypy error: incompatible types in assignment
|
| 35 |
+
normalized_shape = (normalized_shape,) # type: ignore[assignment]
|
| 36 |
+
self.normalized_shape = tuple(normalized_shape) # type: ignore[arg-type]
|
| 37 |
+
self.eps = eps
|
| 38 |
+
self.elementwise_affine = elementwise_affine
|
| 39 |
+
if self.elementwise_affine:
|
| 40 |
+
self.weight = nn.Parameter(
|
| 41 |
+
torch.empty(self.normalized_shape, **factory_kwargs)
|
| 42 |
+
)
|
| 43 |
+
self.bias = nn.Parameter(
|
| 44 |
+
torch.empty(self.normalized_shape, **factory_kwargs)
|
| 45 |
+
)
|
| 46 |
+
else:
|
| 47 |
+
self.register_parameter("weight", None)
|
| 48 |
+
self.register_parameter("bias", None)
|
| 49 |
+
|
| 50 |
+
self.reset_parameters()
|
| 51 |
+
|
| 52 |
+
def reset_parameters(self) -> None:
|
| 53 |
+
if self.elementwise_affine:
|
| 54 |
+
nn.init.ones_(self.weight)
|
| 55 |
+
nn.init.zeros_(self.bias)
|
| 56 |
+
|
| 57 |
+
def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
|
| 58 |
+
if isinstance(input, tuple):
|
| 59 |
+
input, embedding = input
|
| 60 |
+
return (
|
| 61 |
+
F.layer_norm(
|
| 62 |
+
input,
|
| 63 |
+
self.normalized_shape,
|
| 64 |
+
self.weight,
|
| 65 |
+
self.bias,
|
| 66 |
+
self.eps,
|
| 67 |
+
),
|
| 68 |
+
embedding,
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
assert embedding is None
|
| 72 |
+
return F.layer_norm(
|
| 73 |
+
input, self.normalized_shape, self.weight, self.bias, self.eps
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
def extra_repr(self) -> str:
|
| 77 |
+
return (
|
| 78 |
+
"{normalized_shape}, eps={eps}, "
|
| 79 |
+
"elementwise_affine={elementwise_affine}".format(**self.__dict__)
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class AdaptiveLayerNorm(nn.Module):
|
| 84 |
+
r"""Adaptive Layer Normalization"""
|
| 85 |
+
|
| 86 |
+
def __init__(self, d_model, norm) -> None:
|
| 87 |
+
super(AdaptiveLayerNorm, self).__init__()
|
| 88 |
+
self.project_layer = nn.Linear(d_model, 2 * d_model)
|
| 89 |
+
self.norm = norm
|
| 90 |
+
self.d_model = d_model
|
| 91 |
+
self.eps = self.norm.eps
|
| 92 |
+
|
| 93 |
+
def forward(self, input: Tensor, embedding: Tensor = None) -> Tensor:
|
| 94 |
+
if isinstance(input, tuple):
|
| 95 |
+
input, embedding = input
|
| 96 |
+
weight, bias = torch.split(
|
| 97 |
+
self.project_layer(embedding),
|
| 98 |
+
split_size_or_sections=self.d_model,
|
| 99 |
+
dim=-1,
|
| 100 |
+
)
|
| 101 |
+
return (weight * self.norm(input) + bias, embedding)
|
| 102 |
+
|
| 103 |
+
weight, bias = torch.split(
|
| 104 |
+
self.project_layer(embedding),
|
| 105 |
+
split_size_or_sections=self.d_model,
|
| 106 |
+
dim=-1,
|
| 107 |
+
)
|
| 108 |
+
return weight * self.norm(input) + bias
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class BasicNorm(_BasicNorm):
|
| 112 |
+
def __init__(
|
| 113 |
+
self,
|
| 114 |
+
d_model: int,
|
| 115 |
+
eps: float = 1e-5,
|
| 116 |
+
device=None,
|
| 117 |
+
dtype=None,
|
| 118 |
+
):
|
| 119 |
+
super(BasicNorm, self).__init__(d_model, eps=eps)
|
| 120 |
+
|
| 121 |
+
def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
|
| 122 |
+
if isinstance(input, tuple):
|
| 123 |
+
input, embedding = input
|
| 124 |
+
return (
|
| 125 |
+
super(BasicNorm, self).forward(input),
|
| 126 |
+
embedding,
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
assert embedding is None
|
| 130 |
+
return super(BasicNorm, self).forward(input)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class BalancedBasicNorm(nn.Module):
|
| 134 |
+
def __init__(
|
| 135 |
+
self,
|
| 136 |
+
d_model: int,
|
| 137 |
+
eps: float = 1e-5,
|
| 138 |
+
device=None,
|
| 139 |
+
dtype=None,
|
| 140 |
+
):
|
| 141 |
+
super(BalancedBasicNorm, self).__init__()
|
| 142 |
+
self.balancer = ActivationBalancer(
|
| 143 |
+
d_model,
|
| 144 |
+
channel_dim=-1,
|
| 145 |
+
min_positive=0.45,
|
| 146 |
+
max_positive=0.55,
|
| 147 |
+
max_abs=6.0,
|
| 148 |
+
)
|
| 149 |
+
self.norm = BasicNorm(d_model, eps, device=device, dtype=dtype)
|
| 150 |
+
|
| 151 |
+
def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
|
| 152 |
+
if isinstance(input, tuple):
|
| 153 |
+
input, embedding = input
|
| 154 |
+
return self.norm((self.balancer(input), embedding))
|
| 155 |
+
|
| 156 |
+
assert embedding is None
|
| 157 |
+
return self.norm(self.balancer(input))
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
class IdentityNorm(nn.Module):
|
| 161 |
+
def __init__(
|
| 162 |
+
self,
|
| 163 |
+
d_model: int,
|
| 164 |
+
eps: float = 1e-5,
|
| 165 |
+
device=None,
|
| 166 |
+
dtype=None,
|
| 167 |
+
) -> None:
|
| 168 |
+
super(IdentityNorm, self).__init__()
|
| 169 |
+
|
| 170 |
+
def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
|
| 171 |
+
if isinstance(input, tuple):
|
| 172 |
+
return input
|
| 173 |
+
|
| 174 |
+
assert embedding is None
|
| 175 |
+
return input
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
class TransformerEncoderLayer(nn.Module):
|
| 179 |
+
__constants__ = ["batch_first", "norm_first"]
|
| 180 |
+
|
| 181 |
+
def __init__(
|
| 182 |
+
self,
|
| 183 |
+
d_model: int,
|
| 184 |
+
nhead: int,
|
| 185 |
+
dim_feedforward: int = 2048,
|
| 186 |
+
dropout: float = 0.1,
|
| 187 |
+
activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
|
| 188 |
+
batch_first: bool = False,
|
| 189 |
+
norm_first: bool = False,
|
| 190 |
+
device=None,
|
| 191 |
+
dtype=None,
|
| 192 |
+
linear1_self_attention_cls: nn.Module = nn.Linear,
|
| 193 |
+
linear2_self_attention_cls: nn.Module = nn.Linear,
|
| 194 |
+
linear1_feedforward_cls: nn.Module = nn.Linear,
|
| 195 |
+
linear2_feedforward_cls: nn.Module = nn.Linear,
|
| 196 |
+
layer_norm_cls: nn.Module = LayerNorm,
|
| 197 |
+
layer_norm_eps: float = 1e-5,
|
| 198 |
+
adaptive_layer_norm=False,
|
| 199 |
+
) -> None:
|
| 200 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 201 |
+
super(TransformerEncoderLayer, self).__init__()
|
| 202 |
+
self.self_attn = MultiheadAttention(
|
| 203 |
+
d_model,
|
| 204 |
+
nhead,
|
| 205 |
+
dropout=dropout,
|
| 206 |
+
batch_first=batch_first,
|
| 207 |
+
linear1_cls=linear1_self_attention_cls,
|
| 208 |
+
linear2_cls=linear2_self_attention_cls,
|
| 209 |
+
**factory_kwargs,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
# Implementation of Feedforward model
|
| 213 |
+
self.linear1 = linear1_feedforward_cls(
|
| 214 |
+
d_model, dim_feedforward, **factory_kwargs
|
| 215 |
+
)
|
| 216 |
+
self.dropout = nn.Dropout(dropout)
|
| 217 |
+
self.linear2 = linear2_feedforward_cls(
|
| 218 |
+
dim_feedforward, d_model, **factory_kwargs
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
self.norm_first = norm_first
|
| 222 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 223 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 224 |
+
|
| 225 |
+
# Legacy string support for activation function.
|
| 226 |
+
if isinstance(activation, str):
|
| 227 |
+
activation = _get_activation_fn(activation)
|
| 228 |
+
elif isinstance(activation, partial):
|
| 229 |
+
activation = activation(d_model)
|
| 230 |
+
elif activation == BalancedDoubleSwish:
|
| 231 |
+
activation = BalancedDoubleSwish(d_model)
|
| 232 |
+
|
| 233 |
+
# # We can't test self.activation in forward() in TorchScript,
|
| 234 |
+
# # so stash some information about it instead.
|
| 235 |
+
# if activation is F.relu or isinstance(activation, torch.nn.ReLU):
|
| 236 |
+
# self.activation_relu_or_gelu = 1
|
| 237 |
+
# elif activation is F.gelu or isinstance(activation, torch.nn.GELU):
|
| 238 |
+
# self.activation_relu_or_gelu = 2
|
| 239 |
+
# else:
|
| 240 |
+
# self.activation_relu_or_gelu = 0
|
| 241 |
+
self.activation = activation
|
| 242 |
+
|
| 243 |
+
norm1 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
|
| 244 |
+
if layer_norm_cls == IdentityNorm:
|
| 245 |
+
norm2 = BalancedBasicNorm(
|
| 246 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 247 |
+
)
|
| 248 |
+
else:
|
| 249 |
+
norm2 = layer_norm_cls(
|
| 250 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
if adaptive_layer_norm:
|
| 254 |
+
self.norm1 = AdaptiveLayerNorm(d_model, norm1)
|
| 255 |
+
self.norm2 = AdaptiveLayerNorm(d_model, norm2)
|
| 256 |
+
else:
|
| 257 |
+
self.norm1 = norm1
|
| 258 |
+
self.norm2 = norm2
|
| 259 |
+
|
| 260 |
+
def __setstate__(self, state):
|
| 261 |
+
super(TransformerEncoderLayer, self).__setstate__(state)
|
| 262 |
+
if not hasattr(self, "activation"):
|
| 263 |
+
self.activation = F.relu
|
| 264 |
+
|
| 265 |
+
def forward(
|
| 266 |
+
self,
|
| 267 |
+
src: Tensor,
|
| 268 |
+
src_mask: Optional[Tensor] = None,
|
| 269 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 270 |
+
) -> Tensor:
|
| 271 |
+
r"""Pass the input through the encoder layer.
|
| 272 |
+
|
| 273 |
+
Args:
|
| 274 |
+
src: the sequence to the encoder layer (required).
|
| 275 |
+
src_mask: the mask for the src sequence (optional).
|
| 276 |
+
src_key_padding_mask: the mask for the src keys per batch (optional).
|
| 277 |
+
|
| 278 |
+
Shape:
|
| 279 |
+
see the docs in Transformer class.
|
| 280 |
+
"""
|
| 281 |
+
x, stage_embedding = src, None
|
| 282 |
+
is_src_tuple = False
|
| 283 |
+
if isinstance(src, tuple):
|
| 284 |
+
x, stage_embedding = src
|
| 285 |
+
is_src_tuple = True
|
| 286 |
+
|
| 287 |
+
if src_key_padding_mask is not None:
|
| 288 |
+
_skpm_dtype = src_key_padding_mask.dtype
|
| 289 |
+
if _skpm_dtype != torch.bool and not torch.is_floating_point(
|
| 290 |
+
src_key_padding_mask
|
| 291 |
+
):
|
| 292 |
+
raise AssertionError(
|
| 293 |
+
"only bool and floating types of key_padding_mask are supported"
|
| 294 |
+
)
|
| 295 |
+
|
| 296 |
+
if self.norm_first:
|
| 297 |
+
x = x + self._sa_block(
|
| 298 |
+
self.norm1(x, stage_embedding),
|
| 299 |
+
src_mask,
|
| 300 |
+
src_key_padding_mask,
|
| 301 |
+
)
|
| 302 |
+
x = x + self._ff_block(self.norm2(x, stage_embedding))
|
| 303 |
+
else:
|
| 304 |
+
x = self.norm1(
|
| 305 |
+
x + self._sa_block(x, src_mask, src_key_padding_mask),
|
| 306 |
+
stage_embedding,
|
| 307 |
+
)
|
| 308 |
+
x = self.norm2(x + self._ff_block(x), stage_embedding)
|
| 309 |
+
|
| 310 |
+
if is_src_tuple:
|
| 311 |
+
return (x, stage_embedding)
|
| 312 |
+
return x
|
| 313 |
+
|
| 314 |
+
def infer(
|
| 315 |
+
self,
|
| 316 |
+
src: Tensor,
|
| 317 |
+
src_mask: Optional[Tensor] = None,
|
| 318 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 319 |
+
past_kv: Optional[Tensor] = None,
|
| 320 |
+
use_cache: bool = False,
|
| 321 |
+
):
|
| 322 |
+
x, stage_embedding = src, None
|
| 323 |
+
is_src_tuple = False
|
| 324 |
+
if isinstance(src, tuple):
|
| 325 |
+
x, stage_embedding = src
|
| 326 |
+
is_src_tuple = True
|
| 327 |
+
|
| 328 |
+
if src_key_padding_mask is not None:
|
| 329 |
+
_skpm_dtype = src_key_padding_mask.dtype
|
| 330 |
+
if _skpm_dtype != torch.bool and not torch.is_floating_point(
|
| 331 |
+
src_key_padding_mask
|
| 332 |
+
):
|
| 333 |
+
raise AssertionError(
|
| 334 |
+
"only bool and floating types of key_padding_mask are supported"
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
if self.norm_first:
|
| 338 |
+
x_attn_out, kv = self.self_attn.infer(
|
| 339 |
+
self.norm1(x, stage_embedding),
|
| 340 |
+
attn_mask=src_mask,
|
| 341 |
+
key_padding_mask=src_key_padding_mask,
|
| 342 |
+
need_weights=False,
|
| 343 |
+
past_kv=past_kv,
|
| 344 |
+
use_cache=use_cache,
|
| 345 |
+
)
|
| 346 |
+
x = x + x_attn_out
|
| 347 |
+
x = x + self._ff_block(self.norm2(x, stage_embedding))
|
| 348 |
+
|
| 349 |
+
if is_src_tuple:
|
| 350 |
+
return (x, stage_embedding)
|
| 351 |
+
return (x, kv)
|
| 352 |
+
|
| 353 |
+
# self-attention block
|
| 354 |
+
def _sa_block(
|
| 355 |
+
self,
|
| 356 |
+
x: Tensor,
|
| 357 |
+
attn_mask: Optional[Tensor],
|
| 358 |
+
key_padding_mask: Optional[Tensor],
|
| 359 |
+
) -> Tensor:
|
| 360 |
+
x = self.self_attn(
|
| 361 |
+
x,
|
| 362 |
+
x,
|
| 363 |
+
x,
|
| 364 |
+
attn_mask=attn_mask,
|
| 365 |
+
key_padding_mask=key_padding_mask,
|
| 366 |
+
need_weights=False,
|
| 367 |
+
)[0]
|
| 368 |
+
return self.dropout1(x)
|
| 369 |
+
|
| 370 |
+
# feed forward block
|
| 371 |
+
def _ff_block(self, x: Tensor) -> Tensor:
|
| 372 |
+
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
|
| 373 |
+
return self.dropout2(x)
|
| 374 |
+
|
| 375 |
+
|
| 376 |
+
class TransformerEncoder(nn.Module):
|
| 377 |
+
r"""TransformerEncoder is a stack of N encoder layers. Users can build the
|
| 378 |
+
BERT(https://arxiv.org/abs/1810.04805) model with corresponding parameters.
|
| 379 |
+
|
| 380 |
+
Args:
|
| 381 |
+
encoder_layer: an instance of the TransformerEncoderLayer() class (required).
|
| 382 |
+
num_layers: the number of sub-encoder-layers in the encoder (required).
|
| 383 |
+
norm: the layer normalization component (optional).
|
| 384 |
+
enable_nested_tensor: if True, input will automatically convert to nested tensor
|
| 385 |
+
(and convert back on output). This will improve the overall performance of
|
| 386 |
+
TransformerEncoder when padding rate is high. Default: ``True`` (enabled).
|
| 387 |
+
|
| 388 |
+
Examples::
|
| 389 |
+
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
|
| 390 |
+
>>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
|
| 391 |
+
>>> src = torch.rand(10, 32, 512)
|
| 392 |
+
>>> out = transformer_encoder(src)
|
| 393 |
+
"""
|
| 394 |
+
__constants__ = ["norm"]
|
| 395 |
+
|
| 396 |
+
def __init__(self, encoder_layer, num_layers, norm=None):
|
| 397 |
+
super(TransformerEncoder, self).__init__()
|
| 398 |
+
self.layers = _get_clones(encoder_layer, num_layers)
|
| 399 |
+
self.num_layers = num_layers
|
| 400 |
+
self.norm = norm
|
| 401 |
+
|
| 402 |
+
def forward(
|
| 403 |
+
self,
|
| 404 |
+
src: Tensor,
|
| 405 |
+
mask: Optional[Tensor] = None,
|
| 406 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 407 |
+
return_layer_states: bool = False,
|
| 408 |
+
) -> Tensor:
|
| 409 |
+
r"""Pass the input through the encoder layers in turn.
|
| 410 |
+
|
| 411 |
+
Args:
|
| 412 |
+
src: the sequence to the encoder (required).
|
| 413 |
+
mask: the mask for the src sequence (optional).
|
| 414 |
+
src_key_padding_mask: the mask for the src keys per batch (optional).
|
| 415 |
+
return_layer_states: return layers' state (optional).
|
| 416 |
+
|
| 417 |
+
Shape:
|
| 418 |
+
see the docs in Transformer class.
|
| 419 |
+
"""
|
| 420 |
+
if return_layer_states:
|
| 421 |
+
layer_states = [] # layers' output
|
| 422 |
+
output = src
|
| 423 |
+
for mod in self.layers:
|
| 424 |
+
output = mod(
|
| 425 |
+
output,
|
| 426 |
+
src_mask=mask,
|
| 427 |
+
src_key_padding_mask=src_key_padding_mask,
|
| 428 |
+
)
|
| 429 |
+
layer_states.append(output[0])
|
| 430 |
+
|
| 431 |
+
if self.norm is not None:
|
| 432 |
+
output = self.norm(output)
|
| 433 |
+
|
| 434 |
+
return layer_states, output
|
| 435 |
+
|
| 436 |
+
output = src
|
| 437 |
+
for mod in self.layers:
|
| 438 |
+
output = mod(
|
| 439 |
+
output, src_mask=mask, src_key_padding_mask=src_key_padding_mask
|
| 440 |
+
)
|
| 441 |
+
|
| 442 |
+
if self.norm is not None:
|
| 443 |
+
output = self.norm(output)
|
| 444 |
+
|
| 445 |
+
return output
|
| 446 |
+
|
| 447 |
+
def infer(
|
| 448 |
+
self,
|
| 449 |
+
src: Tensor,
|
| 450 |
+
mask: Optional[Tensor] = None,
|
| 451 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 452 |
+
return_layer_states: bool = False,
|
| 453 |
+
past_kv: Optional[Tensor] = None,
|
| 454 |
+
use_cache: bool = False,
|
| 455 |
+
):
|
| 456 |
+
if past_kv is None:
|
| 457 |
+
past_length = 0
|
| 458 |
+
past_kv = tuple([None] * self.num_layers)
|
| 459 |
+
else:
|
| 460 |
+
past_length = past_kv[0][0].size(-2)
|
| 461 |
+
new_kv = () if use_cache else None
|
| 462 |
+
output = src
|
| 463 |
+
for mod, past_layer_kv in zip(self.layers, past_kv):
|
| 464 |
+
output, kv = mod.infer(
|
| 465 |
+
output, src_mask=mask, src_key_padding_mask=src_key_padding_mask, past_kv=past_layer_kv, use_cache=use_cache
|
| 466 |
+
)
|
| 467 |
+
if use_cache:
|
| 468 |
+
new_kv = new_kv + (kv,)
|
| 469 |
+
|
| 470 |
+
if self.norm is not None:
|
| 471 |
+
output = self.norm(output)
|
| 472 |
+
|
| 473 |
+
return output, new_kv
|
| 474 |
+
|
| 475 |
+
|
| 476 |
+
class TransformerDecoderLayer(nn.Module):
|
| 477 |
+
__constants__ = ["batch_first", "norm_first"]
|
| 478 |
+
|
| 479 |
+
def __init__(
|
| 480 |
+
self,
|
| 481 |
+
d_model: int,
|
| 482 |
+
nhead: int,
|
| 483 |
+
dim_feedforward: int = 2048,
|
| 484 |
+
dropout: float = 0.1,
|
| 485 |
+
activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
|
| 486 |
+
linear1_self_attention_cls: nn.Module = nn.Linear,
|
| 487 |
+
linear2_self_attention_cls: nn.Module = nn.Linear,
|
| 488 |
+
linear1_feedforward_cls: nn.Module = nn.Linear,
|
| 489 |
+
linear2_feedforward_cls: nn.Module = nn.Linear,
|
| 490 |
+
batch_first: bool = False,
|
| 491 |
+
norm_first: bool = False,
|
| 492 |
+
device=None,
|
| 493 |
+
dtype=None,
|
| 494 |
+
layer_norm_cls: nn.Module = LayerNorm,
|
| 495 |
+
layer_norm_eps: float = 1e-5,
|
| 496 |
+
adaptive_layer_norm=False,
|
| 497 |
+
) -> None:
|
| 498 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 499 |
+
super(TransformerDecoderLayer, self).__init__()
|
| 500 |
+
self.self_attn = MultiheadAttention(
|
| 501 |
+
d_model,
|
| 502 |
+
nhead,
|
| 503 |
+
dropout=dropout,
|
| 504 |
+
batch_first=batch_first,
|
| 505 |
+
linear1_cls=linear1_self_attention_cls,
|
| 506 |
+
linear2_cls=linear2_self_attention_cls,
|
| 507 |
+
**factory_kwargs,
|
| 508 |
+
)
|
| 509 |
+
self.multihead_attn = MultiheadAttention(
|
| 510 |
+
d_model,
|
| 511 |
+
nhead,
|
| 512 |
+
dropout=dropout,
|
| 513 |
+
batch_first=batch_first,
|
| 514 |
+
linear1_cls=linear1_self_attention_cls,
|
| 515 |
+
linear2_cls=linear2_self_attention_cls,
|
| 516 |
+
**factory_kwargs,
|
| 517 |
+
)
|
| 518 |
+
# Implementation of Feedforward model
|
| 519 |
+
self.linear1 = linear1_feedforward_cls(
|
| 520 |
+
d_model, dim_feedforward, **factory_kwargs
|
| 521 |
+
)
|
| 522 |
+
self.dropout = nn.Dropout(dropout)
|
| 523 |
+
self.linear2 = linear2_feedforward_cls(
|
| 524 |
+
dim_feedforward, d_model, **factory_kwargs
|
| 525 |
+
)
|
| 526 |
+
|
| 527 |
+
self.norm_first = norm_first
|
| 528 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 529 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 530 |
+
self.dropout3 = nn.Dropout(dropout)
|
| 531 |
+
|
| 532 |
+
# Legacy string support for activation function.
|
| 533 |
+
if isinstance(activation, str):
|
| 534 |
+
self.activation = _get_activation_fn(activation)
|
| 535 |
+
elif isinstance(activation, partial):
|
| 536 |
+
self.activation = activation(d_model)
|
| 537 |
+
elif activation == BalancedDoubleSwish:
|
| 538 |
+
self.activation = BalancedDoubleSwish(d_model)
|
| 539 |
+
else:
|
| 540 |
+
self.activation = activation
|
| 541 |
+
|
| 542 |
+
if adaptive_layer_norm:
|
| 543 |
+
norm1 = layer_norm_cls(
|
| 544 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 545 |
+
)
|
| 546 |
+
norm2 = layer_norm_cls(
|
| 547 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 548 |
+
)
|
| 549 |
+
norm3 = layer_norm_cls(
|
| 550 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 551 |
+
)
|
| 552 |
+
|
| 553 |
+
self.norm1 = AdaptiveLayerNorm(d_model, norm1)
|
| 554 |
+
self.norm2 = AdaptiveLayerNorm(d_model, norm2)
|
| 555 |
+
self.norm3 = AdaptiveLayerNorm(d_model, norm3)
|
| 556 |
+
else:
|
| 557 |
+
self.norm1 = layer_norm_cls(
|
| 558 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 559 |
+
)
|
| 560 |
+
self.norm2 = layer_norm_cls(
|
| 561 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 562 |
+
)
|
| 563 |
+
if layer_norm_cls == IdentityNorm:
|
| 564 |
+
self.norm3 = BalancedBasicNorm(
|
| 565 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 566 |
+
)
|
| 567 |
+
else:
|
| 568 |
+
self.norm3 = layer_norm_cls(
|
| 569 |
+
d_model, eps=layer_norm_eps, **factory_kwargs
|
| 570 |
+
)
|
| 571 |
+
|
| 572 |
+
def forward(
|
| 573 |
+
self,
|
| 574 |
+
tgt: Tensor,
|
| 575 |
+
memory: Tensor,
|
| 576 |
+
tgt_mask: Optional[Tensor] = None,
|
| 577 |
+
memory_mask: Optional[Tensor] = None,
|
| 578 |
+
tgt_key_padding_mask: Optional[Tensor] = None,
|
| 579 |
+
memory_key_padding_mask: Optional[Tensor] = None,
|
| 580 |
+
) -> Tensor:
|
| 581 |
+
r"""Pass the inputs (and mask) through the decoder layer.
|
| 582 |
+
|
| 583 |
+
Args:
|
| 584 |
+
tgt: the sequence to the decoder layer (required).
|
| 585 |
+
memory: the sequence from the last layer of the encoder (required).
|
| 586 |
+
tgt_mask: the mask for the tgt sequence (optional).
|
| 587 |
+
memory_mask: the mask for the memory sequence (optional).
|
| 588 |
+
tgt_key_padding_mask: the mask for the tgt keys per batch (optional).
|
| 589 |
+
memory_key_padding_mask: the mask for the memory keys per batch (optional).
|
| 590 |
+
|
| 591 |
+
Shape:
|
| 592 |
+
see the docs in Transformer class.
|
| 593 |
+
"""
|
| 594 |
+
tgt_is_tuple = False
|
| 595 |
+
if isinstance(tgt, tuple):
|
| 596 |
+
x, stage_embedding = tgt
|
| 597 |
+
tgt_is_tuple = True
|
| 598 |
+
else:
|
| 599 |
+
x, stage_embedding = tgt, None
|
| 600 |
+
|
| 601 |
+
if self.norm_first:
|
| 602 |
+
x = x + self._sa_block(
|
| 603 |
+
self.norm1(x, stage_embedding), tgt_mask, tgt_key_padding_mask
|
| 604 |
+
)
|
| 605 |
+
x = x + self._mha_block(
|
| 606 |
+
self.norm2(x, stage_embedding),
|
| 607 |
+
memory,
|
| 608 |
+
memory_mask,
|
| 609 |
+
memory_key_padding_mask,
|
| 610 |
+
)
|
| 611 |
+
x = x + self._ff_block(self.norm3(x, stage_embedding))
|
| 612 |
+
else:
|
| 613 |
+
x = self.norm1(
|
| 614 |
+
x + self._sa_block(x, tgt_mask, tgt_key_padding_mask),
|
| 615 |
+
stage_embedding,
|
| 616 |
+
)
|
| 617 |
+
x = self.norm2(
|
| 618 |
+
x
|
| 619 |
+
+ self._mha_block(
|
| 620 |
+
x, memory, memory_mask, memory_key_padding_mask
|
| 621 |
+
),
|
| 622 |
+
stage_embedding,
|
| 623 |
+
)
|
| 624 |
+
x = self.norm3(x + self._ff_block(x), stage_embedding)
|
| 625 |
+
|
| 626 |
+
if tgt_is_tuple:
|
| 627 |
+
return (x, stage_embedding)
|
| 628 |
+
return x
|
| 629 |
+
|
| 630 |
+
# self-attention block
|
| 631 |
+
def _sa_block(
|
| 632 |
+
self,
|
| 633 |
+
x: Tensor,
|
| 634 |
+
attn_mask: Optional[Tensor],
|
| 635 |
+
key_padding_mask: Optional[Tensor],
|
| 636 |
+
) -> Tensor:
|
| 637 |
+
x = self.self_attn(
|
| 638 |
+
x,
|
| 639 |
+
x,
|
| 640 |
+
x,
|
| 641 |
+
attn_mask=attn_mask,
|
| 642 |
+
key_padding_mask=key_padding_mask,
|
| 643 |
+
need_weights=False,
|
| 644 |
+
)[0]
|
| 645 |
+
return self.dropout1(x)
|
| 646 |
+
|
| 647 |
+
# multihead attention block
|
| 648 |
+
def _mha_block(
|
| 649 |
+
self,
|
| 650 |
+
x: Tensor,
|
| 651 |
+
mem: Tensor,
|
| 652 |
+
attn_mask: Optional[Tensor],
|
| 653 |
+
key_padding_mask: Optional[Tensor],
|
| 654 |
+
) -> Tensor:
|
| 655 |
+
x = self.multihead_attn(
|
| 656 |
+
x,
|
| 657 |
+
mem,
|
| 658 |
+
mem,
|
| 659 |
+
attn_mask=attn_mask,
|
| 660 |
+
key_padding_mask=key_padding_mask,
|
| 661 |
+
need_weights=False,
|
| 662 |
+
)[0]
|
| 663 |
+
return self.dropout2(x)
|
| 664 |
+
|
| 665 |
+
# feed forward block
|
| 666 |
+
def _ff_block(self, x: Tensor) -> Tensor:
|
| 667 |
+
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
|
| 668 |
+
return self.dropout3(x)
|
| 669 |
+
|
| 670 |
+
|
| 671 |
+
def _get_clones(module, N):
|
| 672 |
+
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
|
| 673 |
+
|
| 674 |
+
|
| 675 |
+
def _get_activation_fn(activation: str) -> Callable[[Tensor], Tensor]:
|
| 676 |
+
if activation == "relu":
|
| 677 |
+
return F.relu
|
| 678 |
+
elif activation == "gelu":
|
| 679 |
+
return F.gelu
|
| 680 |
+
|
| 681 |
+
raise RuntimeError(
|
| 682 |
+
"activation should be relu/gelu, not {}".format(activation)
|
| 683 |
+
)
|
presets/alan.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:28838c3f0b2f9f315b34e9b940f30641306f0cadc5c527857cd1cc408547ed1c
|
| 3 |
+
size 50002
|
presets/cafe.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d78d96f5829da8f69c327ff25958da5b451305fdc9c308f7e67f13cf8d640fea
|
| 3 |
+
size 22442
|
presets/dingzhen_1.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4d19167c65eefef5e42dfaa1919ff5149ca0a93cb052396a47d1f42f9865f5f8
|
| 3 |
+
size 18154
|
presets/emotion_sleepiness.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0f866a278a10c7b6b494fb62589a9d8fef778ccf272df3b0d5510f45b243b5c
|
| 3 |
+
size 33218
|
presets/esta.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4f944e135d901a00e74e7affe6757334e9a2679c10ad7ae4bcb5b33569d77eba
|
| 3 |
+
size 40250
|
presets/prompt_1.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2bd0e41e72e657bdf9c6ceaea0294807faea2db623a0e33b39e1a8eebcf4d21c
|
| 3 |
+
size 87338
|
presets/seel_1.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:44ad2e900df3625f9753e949dc5a7d8479c4091e24cb18cbf46e34e29498d952
|
| 3 |
+
size 13554
|
presets/yaesakura_1.npz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b388a18d286b4ba13d45bae373a716c0010dc40ae9c940d53b5a04cbc64e95ff
|
| 3 |
+
size 12442
|
requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
torch
|
| 3 |
+
torchaudio
|
| 4 |
+
encodec
|
| 5 |
+
pyopenjtalk
|
| 6 |
+
pypinyin
|
| 7 |
+
inflect
|
| 8 |
+
cn2an
|
| 9 |
+
eng_to_ipa
|
utils/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class Transpose(nn.Identity):
|
| 6 |
+
"""(N, T, D) -> (N, D, T)"""
|
| 7 |
+
|
| 8 |
+
def forward(self, input: torch.Tensor) -> torch.Tensor:
|
| 9 |
+
return input.transpose(1, 2)
|
utils/g2p/__init__.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" from https://github.com/keithito/tacotron """
|
| 2 |
+
import utils.g2p.cleaners
|
| 3 |
+
from utils.g2p.symbols import symbols
|
| 4 |
+
from tokenizers import Tokenizer
|
| 5 |
+
|
| 6 |
+
# Mappings from symbol to numeric ID and vice versa:
|
| 7 |
+
_symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 8 |
+
_id_to_symbol = {i: s for i, s in enumerate(symbols)}
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class PhonemeBpeTokenizer:
|
| 12 |
+
def __init__(self, tokenizer_path = "./utils/g2p/bpe_1024.json"):
|
| 13 |
+
self.tokenizer = Tokenizer.from_file(tokenizer_path)
|
| 14 |
+
|
| 15 |
+
def tokenize(self, text):
|
| 16 |
+
# 1. convert text to phoneme
|
| 17 |
+
phonemes = _clean_text(text, ['cje_cleaners'])
|
| 18 |
+
# 2. replace blank space " " with "_"
|
| 19 |
+
phonemes = phonemes.replace(" ", "_")
|
| 20 |
+
# 3. tokenize phonemes
|
| 21 |
+
phoneme_tokens = self.tokenizer.encode(phonemes).ids
|
| 22 |
+
if not len(phoneme_tokens):
|
| 23 |
+
phoneme_tokens = self.tokenizer.encode(text).ids
|
| 24 |
+
return phoneme_tokens
|
| 25 |
+
|
| 26 |
+
def text_to_sequence(text, cleaner_names):
|
| 27 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 28 |
+
Args:
|
| 29 |
+
text: string to convert to a sequence
|
| 30 |
+
cleaner_names: names of the cleaner functions to run the text through
|
| 31 |
+
Returns:
|
| 32 |
+
List of integers corresponding to the symbols in the text
|
| 33 |
+
'''
|
| 34 |
+
sequence = []
|
| 35 |
+
symbol_to_id = {s: i for i, s in enumerate(symbols)}
|
| 36 |
+
clean_text = _clean_text(text, cleaner_names)
|
| 37 |
+
for symbol in clean_text:
|
| 38 |
+
if symbol not in symbol_to_id.keys():
|
| 39 |
+
continue
|
| 40 |
+
symbol_id = symbol_to_id[symbol]
|
| 41 |
+
sequence += [symbol_id]
|
| 42 |
+
return sequence
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def cleaned_text_to_sequence(cleaned_text):
|
| 46 |
+
'''Converts a string of text to a sequence of IDs corresponding to the symbols in the text.
|
| 47 |
+
Args:
|
| 48 |
+
text: string to convert to a sequence
|
| 49 |
+
Returns:
|
| 50 |
+
List of integers corresponding to the symbols in the text
|
| 51 |
+
'''
|
| 52 |
+
sequence = [_symbol_to_id[symbol] for symbol in cleaned_text if symbol in _symbol_to_id.keys()]
|
| 53 |
+
return sequence
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def sequence_to_text(sequence):
|
| 57 |
+
'''Converts a sequence of IDs back to a string'''
|
| 58 |
+
result = ''
|
| 59 |
+
for symbol_id in sequence:
|
| 60 |
+
s = _id_to_symbol[symbol_id]
|
| 61 |
+
result += s
|
| 62 |
+
return result
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def _clean_text(text, cleaner_names):
|
| 66 |
+
for name in cleaner_names:
|
| 67 |
+
cleaner = getattr(cleaners, name)
|
| 68 |
+
if not cleaner:
|
| 69 |
+
raise Exception('Unknown cleaner: %s' % name)
|
| 70 |
+
text = cleaner(text)
|
| 71 |
+
return text
|
utils/g2p/bpe_69.json
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"version": "1.0",
|
| 3 |
+
"truncation": null,
|
| 4 |
+
"padding": null,
|
| 5 |
+
"added_tokens": [
|
| 6 |
+
{
|
| 7 |
+
"id": 0,
|
| 8 |
+
"content": "[UNK]",
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"lstrip": false,
|
| 11 |
+
"rstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"special": true
|
| 14 |
+
},
|
| 15 |
+
{
|
| 16 |
+
"id": 1,
|
| 17 |
+
"content": "[CLS]",
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"normalized": false,
|
| 22 |
+
"special": true
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"id": 2,
|
| 26 |
+
"content": "[SEP]",
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"lstrip": false,
|
| 29 |
+
"rstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"special": true
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"id": 3,
|
| 35 |
+
"content": "[PAD]",
|
| 36 |
+
"single_word": false,
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"rstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"special": true
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
"id": 4,
|
| 44 |
+
"content": "[MASK]",
|
| 45 |
+
"single_word": false,
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"special": true
|
| 50 |
+
}
|
| 51 |
+
],
|
| 52 |
+
"normalizer": null,
|
| 53 |
+
"pre_tokenizer": {
|
| 54 |
+
"type": "Whitespace"
|
| 55 |
+
},
|
| 56 |
+
"post_processor": null,
|
| 57 |
+
"decoder": null,
|
| 58 |
+
"model": {
|
| 59 |
+
"type": "BPE",
|
| 60 |
+
"dropout": null,
|
| 61 |
+
"unk_token": "[UNK]",
|
| 62 |
+
"continuing_subword_prefix": null,
|
| 63 |
+
"end_of_word_suffix": null,
|
| 64 |
+
"fuse_unk": false,
|
| 65 |
+
"byte_fallback": false,
|
| 66 |
+
"vocab": {
|
| 67 |
+
"[UNK]": 0,
|
| 68 |
+
"[CLS]": 1,
|
| 69 |
+
"[SEP]": 2,
|
| 70 |
+
"[PAD]": 3,
|
| 71 |
+
"[MASK]": 4,
|
| 72 |
+
"!": 5,
|
| 73 |
+
"#": 6,
|
| 74 |
+
"*": 7,
|
| 75 |
+
",": 8,
|
| 76 |
+
"-": 9,
|
| 77 |
+
".": 10,
|
| 78 |
+
"=": 11,
|
| 79 |
+
"?": 12,
|
| 80 |
+
"N": 13,
|
| 81 |
+
"Q": 14,
|
| 82 |
+
"^": 15,
|
| 83 |
+
"_": 16,
|
| 84 |
+
"`": 17,
|
| 85 |
+
"a": 18,
|
| 86 |
+
"b": 19,
|
| 87 |
+
"d": 20,
|
| 88 |
+
"e": 21,
|
| 89 |
+
"f": 22,
|
| 90 |
+
"g": 23,
|
| 91 |
+
"h": 24,
|
| 92 |
+
"i": 25,
|
| 93 |
+
"j": 26,
|
| 94 |
+
"k": 27,
|
| 95 |
+
"l": 28,
|
| 96 |
+
"m": 29,
|
| 97 |
+
"n": 30,
|
| 98 |
+
"o": 31,
|
| 99 |
+
"p": 32,
|
| 100 |
+
"s": 33,
|
| 101 |
+
"t": 34,
|
| 102 |
+
"u": 35,
|
| 103 |
+
"v": 36,
|
| 104 |
+
"w": 37,
|
| 105 |
+
"x": 38,
|
| 106 |
+
"y": 39,
|
| 107 |
+
"z": 40,
|
| 108 |
+
"~": 41,
|
| 109 |
+
"æ": 42,
|
| 110 |
+
"ç": 43,
|
| 111 |
+
"ð": 44,
|
| 112 |
+
"ŋ": 45,
|
| 113 |
+
"ɑ": 46,
|
| 114 |
+
"ɔ": 47,
|
| 115 |
+
"ə": 48,
|
| 116 |
+
"ɛ": 49,
|
| 117 |
+
"ɥ": 50,
|
| 118 |
+
"ɪ": 51,
|
| 119 |
+
"ɫ": 52,
|
| 120 |
+
"ɯ": 53,
|
| 121 |
+
"ɸ": 54,
|
| 122 |
+
"ɹ": 55,
|
| 123 |
+
"ɾ": 56,
|
| 124 |
+
"ʃ": 57,
|
| 125 |
+
"ʊ": 58,
|
| 126 |
+
"ʑ": 59,
|
| 127 |
+
"ʒ": 60,
|
| 128 |
+
"ʰ": 61,
|
| 129 |
+
"ˈ": 62,
|
| 130 |
+
"ˌ": 63,
|
| 131 |
+
"θ": 64,
|
| 132 |
+
"…": 65,
|
| 133 |
+
"⁼": 66,
|
| 134 |
+
"↑": 67,
|
| 135 |
+
"→": 68,
|
| 136 |
+
"↓": 69
|
| 137 |
+
},
|
| 138 |
+
"merges": [
|
| 139 |
+
]
|
| 140 |
+
}
|
| 141 |
+
}
|
utils/g2p/cleaners.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from utils.g2p.japanese import japanese_to_romaji_with_accent, japanese_to_ipa, japanese_to_ipa2, japanese_to_ipa3
|
| 3 |
+
from utils.g2p.mandarin import number_to_chinese, chinese_to_bopomofo, latin_to_bopomofo, chinese_to_romaji, chinese_to_lazy_ipa, chinese_to_ipa, chinese_to_ipa2
|
| 4 |
+
from utils.g2p.english import english_to_lazy_ipa, english_to_ipa2, english_to_lazy_ipa2
|
| 5 |
+
|
| 6 |
+
def japanese_cleaners(text):
|
| 7 |
+
text = japanese_to_romaji_with_accent(text)
|
| 8 |
+
text = re.sub(r'([A-Za-z])$', r'\1.', text)
|
| 9 |
+
return text
|
| 10 |
+
|
| 11 |
+
def japanese_cleaners2(text):
|
| 12 |
+
return japanese_cleaners(text).replace('ts', 'ʦ').replace('...', '…')
|
| 13 |
+
|
| 14 |
+
def chinese_cleaners(text):
|
| 15 |
+
'''Pipeline for Chinese text'''
|
| 16 |
+
text = number_to_chinese(text)
|
| 17 |
+
text = chinese_to_bopomofo(text)
|
| 18 |
+
text = latin_to_bopomofo(text)
|
| 19 |
+
text = re.sub(r'([ˉˊˇˋ˙])$', r'\1。', text)
|
| 20 |
+
return text
|
| 21 |
+
|
| 22 |
+
def cje_cleaners(text):
|
| 23 |
+
if text.find('[ZH]') != -1:
|
| 24 |
+
text = re.sub(r'\[ZH\](.*?)\[ZH\]',
|
| 25 |
+
lambda x: chinese_to_ipa(x.group(1))+' ', text)
|
| 26 |
+
if text.find('[JA]') != -1:
|
| 27 |
+
text = re.sub(r'\[JA\](.*?)\[JA\]',
|
| 28 |
+
lambda x: japanese_to_ipa2(x.group(1))+' ', text)
|
| 29 |
+
if text.find('[EN]') != -1:
|
| 30 |
+
text = re.sub(r'\[EN\](.*?)\[EN\]',
|
| 31 |
+
lambda x: english_to_ipa2(x.group(1))+' ', text)
|
| 32 |
+
text = re.sub(r'\s+$', '', text)
|
| 33 |
+
text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
|
| 34 |
+
return text
|
utils/g2p/english.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" from https://github.com/keithito/tacotron """
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
Cleaners are transformations that run over the input text at both training and eval time.
|
| 5 |
+
|
| 6 |
+
Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
|
| 7 |
+
hyperparameter. Some cleaners are English-specific. You'll typically want to use:
|
| 8 |
+
1. "english_cleaners" for English text
|
| 9 |
+
2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
|
| 10 |
+
the Unidecode library (https://pypi.python.org/pypi/Unidecode)
|
| 11 |
+
3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
|
| 12 |
+
the symbols in symbols.py to match your data).
|
| 13 |
+
'''
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
# Regular expression matching whitespace:
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
import re
|
| 20 |
+
from unidecode import unidecode
|
| 21 |
+
import inflect
|
| 22 |
+
_inflect = inflect.engine()
|
| 23 |
+
_comma_number_re = re.compile(r'([0-9][0-9\,]+[0-9])')
|
| 24 |
+
_decimal_number_re = re.compile(r'([0-9]+\.[0-9]+)')
|
| 25 |
+
_pounds_re = re.compile(r'£([0-9\,]*[0-9]+)')
|
| 26 |
+
_dollars_re = re.compile(r'\$([0-9\.\,]*[0-9]+)')
|
| 27 |
+
_ordinal_re = re.compile(r'[0-9]+(st|nd|rd|th)')
|
| 28 |
+
_number_re = re.compile(r'[0-9]+')
|
| 29 |
+
|
| 30 |
+
# List of (regular expression, replacement) pairs for abbreviations:
|
| 31 |
+
_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 32 |
+
('mrs', 'misess'),
|
| 33 |
+
('mr', 'mister'),
|
| 34 |
+
('dr', 'doctor'),
|
| 35 |
+
('st', 'saint'),
|
| 36 |
+
('co', 'company'),
|
| 37 |
+
('jr', 'junior'),
|
| 38 |
+
('maj', 'major'),
|
| 39 |
+
('gen', 'general'),
|
| 40 |
+
('drs', 'doctors'),
|
| 41 |
+
('rev', 'reverend'),
|
| 42 |
+
('lt', 'lieutenant'),
|
| 43 |
+
('hon', 'honorable'),
|
| 44 |
+
('sgt', 'sergeant'),
|
| 45 |
+
('capt', 'captain'),
|
| 46 |
+
('esq', 'esquire'),
|
| 47 |
+
('ltd', 'limited'),
|
| 48 |
+
('col', 'colonel'),
|
| 49 |
+
('ft', 'fort'),
|
| 50 |
+
]]
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# List of (ipa, lazy ipa) pairs:
|
| 54 |
+
_lazy_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 55 |
+
('r', 'ɹ'),
|
| 56 |
+
('æ', 'e'),
|
| 57 |
+
('ɑ', 'a'),
|
| 58 |
+
('ɔ', 'o'),
|
| 59 |
+
('ð', 'z'),
|
| 60 |
+
('θ', 's'),
|
| 61 |
+
('ɛ', 'e'),
|
| 62 |
+
('ɪ', 'i'),
|
| 63 |
+
('ʊ', 'u'),
|
| 64 |
+
('ʒ', 'ʥ'),
|
| 65 |
+
('ʤ', 'ʥ'),
|
| 66 |
+
('ˈ', '↓'),
|
| 67 |
+
]]
|
| 68 |
+
|
| 69 |
+
# List of (ipa, lazy ipa2) pairs:
|
| 70 |
+
_lazy_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 71 |
+
('r', 'ɹ'),
|
| 72 |
+
('ð', 'z'),
|
| 73 |
+
('θ', 's'),
|
| 74 |
+
('ʒ', 'ʑ'),
|
| 75 |
+
('ʤ', 'dʑ'),
|
| 76 |
+
('ˈ', '↓'),
|
| 77 |
+
]]
|
| 78 |
+
|
| 79 |
+
# List of (ipa, ipa2) pairs
|
| 80 |
+
_ipa_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 81 |
+
('r', 'ɹ'),
|
| 82 |
+
('ʤ', 'dʒ'),
|
| 83 |
+
('ʧ', 'tʃ')
|
| 84 |
+
]]
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def expand_abbreviations(text):
|
| 88 |
+
for regex, replacement in _abbreviations:
|
| 89 |
+
text = re.sub(regex, replacement, text)
|
| 90 |
+
return text
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def collapse_whitespace(text):
|
| 94 |
+
return re.sub(r'\s+', ' ', text)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def _remove_commas(m):
|
| 98 |
+
return m.group(1).replace(',', '')
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def _expand_decimal_point(m):
|
| 102 |
+
return m.group(1).replace('.', ' point ')
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def _expand_dollars(m):
|
| 106 |
+
match = m.group(1)
|
| 107 |
+
parts = match.split('.')
|
| 108 |
+
if len(parts) > 2:
|
| 109 |
+
return match + ' dollars' # Unexpected format
|
| 110 |
+
dollars = int(parts[0]) if parts[0] else 0
|
| 111 |
+
cents = int(parts[1]) if len(parts) > 1 and parts[1] else 0
|
| 112 |
+
if dollars and cents:
|
| 113 |
+
dollar_unit = 'dollar' if dollars == 1 else 'dollars'
|
| 114 |
+
cent_unit = 'cent' if cents == 1 else 'cents'
|
| 115 |
+
return '%s %s, %s %s' % (dollars, dollar_unit, cents, cent_unit)
|
| 116 |
+
elif dollars:
|
| 117 |
+
dollar_unit = 'dollar' if dollars == 1 else 'dollars'
|
| 118 |
+
return '%s %s' % (dollars, dollar_unit)
|
| 119 |
+
elif cents:
|
| 120 |
+
cent_unit = 'cent' if cents == 1 else 'cents'
|
| 121 |
+
return '%s %s' % (cents, cent_unit)
|
| 122 |
+
else:
|
| 123 |
+
return 'zero dollars'
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def _expand_ordinal(m):
|
| 127 |
+
return _inflect.number_to_words(m.group(0))
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def _expand_number(m):
|
| 131 |
+
num = int(m.group(0))
|
| 132 |
+
if num > 1000 and num < 3000:
|
| 133 |
+
if num == 2000:
|
| 134 |
+
return 'two thousand'
|
| 135 |
+
elif num > 2000 and num < 2010:
|
| 136 |
+
return 'two thousand ' + _inflect.number_to_words(num % 100)
|
| 137 |
+
elif num % 100 == 0:
|
| 138 |
+
return _inflect.number_to_words(num // 100) + ' hundred'
|
| 139 |
+
else:
|
| 140 |
+
return _inflect.number_to_words(num, andword='', zero='oh', group=2).replace(', ', ' ')
|
| 141 |
+
else:
|
| 142 |
+
return _inflect.number_to_words(num, andword='')
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def normalize_numbers(text):
|
| 146 |
+
text = re.sub(_comma_number_re, _remove_commas, text)
|
| 147 |
+
text = re.sub(_pounds_re, r'\1 pounds', text)
|
| 148 |
+
text = re.sub(_dollars_re, _expand_dollars, text)
|
| 149 |
+
text = re.sub(_decimal_number_re, _expand_decimal_point, text)
|
| 150 |
+
text = re.sub(_ordinal_re, _expand_ordinal, text)
|
| 151 |
+
text = re.sub(_number_re, _expand_number, text)
|
| 152 |
+
return text
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def mark_dark_l(text):
|
| 156 |
+
return re.sub(r'l([^aeiouæɑɔəɛɪʊ ]*(?: |$))', lambda x: 'ɫ'+x.group(1), text)
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def english_to_ipa(text):
|
| 160 |
+
import eng_to_ipa as ipa
|
| 161 |
+
text = unidecode(text).lower()
|
| 162 |
+
text = expand_abbreviations(text)
|
| 163 |
+
text = normalize_numbers(text)
|
| 164 |
+
phonemes = ipa.convert(text)
|
| 165 |
+
phonemes = collapse_whitespace(phonemes)
|
| 166 |
+
return phonemes
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def english_to_lazy_ipa(text):
|
| 170 |
+
text = english_to_ipa(text)
|
| 171 |
+
for regex, replacement in _lazy_ipa:
|
| 172 |
+
text = re.sub(regex, replacement, text)
|
| 173 |
+
return text
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def english_to_ipa2(text):
|
| 177 |
+
text = english_to_ipa(text)
|
| 178 |
+
text = mark_dark_l(text)
|
| 179 |
+
for regex, replacement in _ipa_to_ipa2:
|
| 180 |
+
text = re.sub(regex, replacement, text)
|
| 181 |
+
return text.replace('...', '…')
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def english_to_lazy_ipa2(text):
|
| 185 |
+
text = english_to_ipa(text)
|
| 186 |
+
for regex, replacement in _lazy_ipa2:
|
| 187 |
+
text = re.sub(regex, replacement, text)
|
| 188 |
+
return text
|
utils/g2p/japanese.py
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
from unidecode import unidecode
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
# Regular expression matching Japanese without punctuation marks:
|
| 7 |
+
_japanese_characters = re.compile(
|
| 8 |
+
r'[A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
|
| 9 |
+
|
| 10 |
+
# Regular expression matching non-Japanese characters or punctuation marks:
|
| 11 |
+
_japanese_marks = re.compile(
|
| 12 |
+
r'[^A-Za-z\d\u3005\u3040-\u30ff\u4e00-\u9fff\uff11-\uff19\uff21-\uff3a\uff41-\uff5a\uff66-\uff9d]')
|
| 13 |
+
|
| 14 |
+
# List of (symbol, Japanese) pairs for marks:
|
| 15 |
+
_symbols_to_japanese = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 16 |
+
('%', 'パーセント')
|
| 17 |
+
]]
|
| 18 |
+
|
| 19 |
+
# List of (romaji, ipa) pairs for marks:
|
| 20 |
+
_romaji_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 21 |
+
('ts', 'ʦ'),
|
| 22 |
+
('u', 'ɯ'),
|
| 23 |
+
('j', 'ʥ'),
|
| 24 |
+
('y', 'j'),
|
| 25 |
+
('ni', 'n^i'),
|
| 26 |
+
('nj', 'n^'),
|
| 27 |
+
('hi', 'çi'),
|
| 28 |
+
('hj', 'ç'),
|
| 29 |
+
('f', 'ɸ'),
|
| 30 |
+
('I', 'i*'),
|
| 31 |
+
('U', 'ɯ*'),
|
| 32 |
+
('r', 'ɾ')
|
| 33 |
+
]]
|
| 34 |
+
|
| 35 |
+
# List of (romaji, ipa2) pairs for marks:
|
| 36 |
+
_romaji_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 37 |
+
('u', 'ɯ'),
|
| 38 |
+
('ʧ', 'tʃ'),
|
| 39 |
+
('j', 'dʑ'),
|
| 40 |
+
('y', 'j'),
|
| 41 |
+
('ni', 'n^i'),
|
| 42 |
+
('nj', 'n^'),
|
| 43 |
+
('hi', 'çi'),
|
| 44 |
+
('hj', 'ç'),
|
| 45 |
+
('f', 'ɸ'),
|
| 46 |
+
('I', 'i*'),
|
| 47 |
+
('U', 'ɯ*'),
|
| 48 |
+
('r', 'ɾ')
|
| 49 |
+
]]
|
| 50 |
+
|
| 51 |
+
# List of (consonant, sokuon) pairs:
|
| 52 |
+
_real_sokuon = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 53 |
+
(r'Q([↑↓]*[kg])', r'k#\1'),
|
| 54 |
+
(r'Q([↑↓]*[tdjʧ])', r't#\1'),
|
| 55 |
+
(r'Q([↑↓]*[sʃ])', r's\1'),
|
| 56 |
+
(r'Q([↑↓]*[pb])', r'p#\1')
|
| 57 |
+
]]
|
| 58 |
+
|
| 59 |
+
# List of (consonant, hatsuon) pairs:
|
| 60 |
+
_real_hatsuon = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 61 |
+
(r'N([↑↓]*[pbm])', r'm\1'),
|
| 62 |
+
(r'N([↑↓]*[ʧʥj])', r'n^\1'),
|
| 63 |
+
(r'N([↑↓]*[tdn])', r'n\1'),
|
| 64 |
+
(r'N([↑↓]*[kg])', r'ŋ\1')
|
| 65 |
+
]]
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def symbols_to_japanese(text):
|
| 69 |
+
for regex, replacement in _symbols_to_japanese:
|
| 70 |
+
text = re.sub(regex, replacement, text)
|
| 71 |
+
return text
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def japanese_to_romaji_with_accent(text):
|
| 75 |
+
'''Reference https://r9y9.github.io/ttslearn/latest/notebooks/ch10_Recipe-Tacotron.html'''
|
| 76 |
+
import pyopenjtalk
|
| 77 |
+
text = symbols_to_japanese(text)
|
| 78 |
+
sentences = re.split(_japanese_marks, text)
|
| 79 |
+
marks = re.findall(_japanese_marks, text)
|
| 80 |
+
text = ''
|
| 81 |
+
for i, sentence in enumerate(sentences):
|
| 82 |
+
if re.match(_japanese_characters, sentence):
|
| 83 |
+
if text != '':
|
| 84 |
+
text += ' '
|
| 85 |
+
labels = pyopenjtalk.extract_fullcontext(sentence)
|
| 86 |
+
for n, label in enumerate(labels):
|
| 87 |
+
phoneme = re.search(r'\-([^\+]*)\+', label).group(1)
|
| 88 |
+
if phoneme not in ['sil', 'pau']:
|
| 89 |
+
text += phoneme.replace('ch', 'ʧ').replace('sh',
|
| 90 |
+
'ʃ').replace('cl', 'Q')
|
| 91 |
+
else:
|
| 92 |
+
continue
|
| 93 |
+
# n_moras = int(re.search(r'/F:(\d+)_', label).group(1))
|
| 94 |
+
a1 = int(re.search(r"/A:(\-?[0-9]+)\+", label).group(1))
|
| 95 |
+
a2 = int(re.search(r"\+(\d+)\+", label).group(1))
|
| 96 |
+
a3 = int(re.search(r"\+(\d+)/", label).group(1))
|
| 97 |
+
if re.search(r'\-([^\+]*)\+', labels[n + 1]).group(1) in ['sil', 'pau']:
|
| 98 |
+
a2_next = -1
|
| 99 |
+
else:
|
| 100 |
+
a2_next = int(
|
| 101 |
+
re.search(r"\+(\d+)\+", labels[n + 1]).group(1))
|
| 102 |
+
# Accent phrase boundary
|
| 103 |
+
if a3 == 1 and a2_next == 1:
|
| 104 |
+
text += ' '
|
| 105 |
+
# Falling
|
| 106 |
+
elif a1 == 0 and a2_next == a2 + 1:
|
| 107 |
+
text += '↓'
|
| 108 |
+
# Rising
|
| 109 |
+
elif a2 == 1 and a2_next == 2:
|
| 110 |
+
text += '↑'
|
| 111 |
+
if i < len(marks):
|
| 112 |
+
text += unidecode(marks[i]).replace(' ', '')
|
| 113 |
+
return text
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def get_real_sokuon(text):
|
| 117 |
+
for regex, replacement in _real_sokuon:
|
| 118 |
+
text = re.sub(regex, replacement, text)
|
| 119 |
+
return text
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def get_real_hatsuon(text):
|
| 123 |
+
for regex, replacement in _real_hatsuon:
|
| 124 |
+
text = re.sub(regex, replacement, text)
|
| 125 |
+
return text
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def japanese_to_ipa(text):
|
| 129 |
+
text = japanese_to_romaji_with_accent(text).replace('...', '…')
|
| 130 |
+
text = re.sub(
|
| 131 |
+
r'([aiueo])\1+', lambda x: x.group(0)[0]+'ː'*(len(x.group(0))-1), text)
|
| 132 |
+
text = get_real_sokuon(text)
|
| 133 |
+
text = get_real_hatsuon(text)
|
| 134 |
+
for regex, replacement in _romaji_to_ipa:
|
| 135 |
+
text = re.sub(regex, replacement, text)
|
| 136 |
+
return text
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def japanese_to_ipa2(text):
|
| 140 |
+
text = japanese_to_romaji_with_accent(text).replace('...', '…')
|
| 141 |
+
text = get_real_sokuon(text)
|
| 142 |
+
text = get_real_hatsuon(text)
|
| 143 |
+
for regex, replacement in _romaji_to_ipa2:
|
| 144 |
+
text = re.sub(regex, replacement, text)
|
| 145 |
+
return text
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def japanese_to_ipa3(text):
|
| 149 |
+
text = japanese_to_ipa2(text).replace('n^', 'ȵ').replace(
|
| 150 |
+
'ʃ', 'ɕ').replace('*', '\u0325').replace('#', '\u031a')
|
| 151 |
+
text = re.sub(
|
| 152 |
+
r'([aiɯeo])\1+', lambda x: x.group(0)[0]+'ː'*(len(x.group(0))-1), text)
|
| 153 |
+
text = re.sub(r'((?:^|\s)(?:ts|tɕ|[kpt]))', r'\1ʰ', text)
|
| 154 |
+
return text
|
utils/g2p/mandarin.py
ADDED
|
@@ -0,0 +1,326 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import sys
|
| 3 |
+
import re
|
| 4 |
+
import jieba
|
| 5 |
+
import cn2an
|
| 6 |
+
import logging
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
# List of (Latin alphabet, bopomofo) pairs:
|
| 10 |
+
_latin_to_bopomofo = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 11 |
+
('a', 'ㄟˉ'),
|
| 12 |
+
('b', 'ㄅㄧˋ'),
|
| 13 |
+
('c', 'ㄙㄧˉ'),
|
| 14 |
+
('d', 'ㄉㄧˋ'),
|
| 15 |
+
('e', 'ㄧˋ'),
|
| 16 |
+
('f', 'ㄝˊㄈㄨˋ'),
|
| 17 |
+
('g', 'ㄐㄧˋ'),
|
| 18 |
+
('h', 'ㄝˇㄑㄩˋ'),
|
| 19 |
+
('i', 'ㄞˋ'),
|
| 20 |
+
('j', 'ㄐㄟˋ'),
|
| 21 |
+
('k', 'ㄎㄟˋ'),
|
| 22 |
+
('l', 'ㄝˊㄛˋ'),
|
| 23 |
+
('m', 'ㄝˊㄇㄨˋ'),
|
| 24 |
+
('n', 'ㄣˉ'),
|
| 25 |
+
('o', 'ㄡˉ'),
|
| 26 |
+
('p', 'ㄆㄧˉ'),
|
| 27 |
+
('q', 'ㄎㄧㄡˉ'),
|
| 28 |
+
('r', 'ㄚˋ'),
|
| 29 |
+
('s', 'ㄝˊㄙˋ'),
|
| 30 |
+
('t', 'ㄊㄧˋ'),
|
| 31 |
+
('u', 'ㄧㄡˉ'),
|
| 32 |
+
('v', 'ㄨㄧˉ'),
|
| 33 |
+
('w', 'ㄉㄚˋㄅㄨˋㄌㄧㄡˋ'),
|
| 34 |
+
('x', 'ㄝˉㄎㄨˋㄙˋ'),
|
| 35 |
+
('y', 'ㄨㄞˋ'),
|
| 36 |
+
('z', 'ㄗㄟˋ')
|
| 37 |
+
]]
|
| 38 |
+
|
| 39 |
+
# List of (bopomofo, romaji) pairs:
|
| 40 |
+
_bopomofo_to_romaji = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 41 |
+
('ㄅㄛ', 'p⁼wo'),
|
| 42 |
+
('ㄆㄛ', 'pʰwo'),
|
| 43 |
+
('ㄇㄛ', 'mwo'),
|
| 44 |
+
('ㄈㄛ', 'fwo'),
|
| 45 |
+
('ㄅ', 'p⁼'),
|
| 46 |
+
('ㄆ', 'pʰ'),
|
| 47 |
+
('ㄇ', 'm'),
|
| 48 |
+
('ㄈ', 'f'),
|
| 49 |
+
('ㄉ', 't⁼'),
|
| 50 |
+
('ㄊ', 'tʰ'),
|
| 51 |
+
('ㄋ', 'n'),
|
| 52 |
+
('ㄌ', 'l'),
|
| 53 |
+
('ㄍ', 'k⁼'),
|
| 54 |
+
('ㄎ', 'kʰ'),
|
| 55 |
+
('ㄏ', 'h'),
|
| 56 |
+
('ㄐ', 'ʧ⁼'),
|
| 57 |
+
('ㄑ', 'ʧʰ'),
|
| 58 |
+
('ㄒ', 'ʃ'),
|
| 59 |
+
('ㄓ', 'ʦ`⁼'),
|
| 60 |
+
('ㄔ', 'ʦ`ʰ'),
|
| 61 |
+
('ㄕ', 's`'),
|
| 62 |
+
('ㄖ', 'ɹ`'),
|
| 63 |
+
('ㄗ', 'ʦ⁼'),
|
| 64 |
+
('ㄘ', 'ʦʰ'),
|
| 65 |
+
('ㄙ', 's'),
|
| 66 |
+
('ㄚ', 'a'),
|
| 67 |
+
('ㄛ', 'o'),
|
| 68 |
+
('ㄜ', 'ə'),
|
| 69 |
+
('ㄝ', 'e'),
|
| 70 |
+
('ㄞ', 'ai'),
|
| 71 |
+
('ㄟ', 'ei'),
|
| 72 |
+
('ㄠ', 'au'),
|
| 73 |
+
('ㄡ', 'ou'),
|
| 74 |
+
('ㄧㄢ', 'yeNN'),
|
| 75 |
+
('ㄢ', 'aNN'),
|
| 76 |
+
('ㄧㄣ', 'iNN'),
|
| 77 |
+
('ㄣ', 'əNN'),
|
| 78 |
+
('ㄤ', 'aNg'),
|
| 79 |
+
('ㄧㄥ', 'iNg'),
|
| 80 |
+
('ㄨㄥ', 'uNg'),
|
| 81 |
+
('ㄩㄥ', 'yuNg'),
|
| 82 |
+
('ㄥ', 'əNg'),
|
| 83 |
+
('ㄦ', 'əɻ'),
|
| 84 |
+
('ㄧ', 'i'),
|
| 85 |
+
('ㄨ', 'u'),
|
| 86 |
+
('ㄩ', 'ɥ'),
|
| 87 |
+
('ˉ', '→'),
|
| 88 |
+
('ˊ', '↑'),
|
| 89 |
+
('ˇ', '↓↑'),
|
| 90 |
+
('ˋ', '↓'),
|
| 91 |
+
('˙', ''),
|
| 92 |
+
(',', ','),
|
| 93 |
+
('。', '.'),
|
| 94 |
+
('!', '!'),
|
| 95 |
+
('?', '?'),
|
| 96 |
+
('—', '-')
|
| 97 |
+
]]
|
| 98 |
+
|
| 99 |
+
# List of (romaji, ipa) pairs:
|
| 100 |
+
_romaji_to_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
|
| 101 |
+
('ʃy', 'ʃ'),
|
| 102 |
+
('ʧʰy', 'ʧʰ'),
|
| 103 |
+
('ʧ⁼y', 'ʧ⁼'),
|
| 104 |
+
('NN', 'n'),
|
| 105 |
+
('Ng', 'ŋ'),
|
| 106 |
+
('y', 'j'),
|
| 107 |
+
('h', 'x')
|
| 108 |
+
]]
|
| 109 |
+
|
| 110 |
+
# List of (bopomofo, ipa) pairs:
|
| 111 |
+
_bopomofo_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 112 |
+
('ㄅㄛ', 'p⁼wo'),
|
| 113 |
+
('ㄆㄛ', 'pʰwo'),
|
| 114 |
+
('ㄇㄛ', 'mwo'),
|
| 115 |
+
('ㄈㄛ', 'fwo'),
|
| 116 |
+
('ㄅ', 'p⁼'),
|
| 117 |
+
('ㄆ', 'pʰ'),
|
| 118 |
+
('ㄇ', 'm'),
|
| 119 |
+
('ㄈ', 'f'),
|
| 120 |
+
('ㄉ', 't⁼'),
|
| 121 |
+
('ㄊ', 'tʰ'),
|
| 122 |
+
('ㄋ', 'n'),
|
| 123 |
+
('ㄌ', 'l'),
|
| 124 |
+
('ㄍ', 'k⁼'),
|
| 125 |
+
('ㄎ', 'kʰ'),
|
| 126 |
+
('ㄏ', 'x'),
|
| 127 |
+
('ㄐ', 'tʃ⁼'),
|
| 128 |
+
('ㄑ', 'tʃʰ'),
|
| 129 |
+
('ㄒ', 'ʃ'),
|
| 130 |
+
('ㄓ', 'ts`⁼'),
|
| 131 |
+
('ㄔ', 'ts`ʰ'),
|
| 132 |
+
('ㄕ', 's`'),
|
| 133 |
+
('ㄖ', 'ɹ`'),
|
| 134 |
+
('ㄗ', 'ts⁼'),
|
| 135 |
+
('ㄘ', 'tsʰ'),
|
| 136 |
+
('ㄙ', 's'),
|
| 137 |
+
('ㄚ', 'a'),
|
| 138 |
+
('ㄛ', 'o'),
|
| 139 |
+
('ㄜ', 'ə'),
|
| 140 |
+
('ㄝ', 'ɛ'),
|
| 141 |
+
('ㄞ', 'aɪ'),
|
| 142 |
+
('ㄟ', 'eɪ'),
|
| 143 |
+
('ㄠ', 'ɑʊ'),
|
| 144 |
+
('ㄡ', 'oʊ'),
|
| 145 |
+
('ㄧㄢ', 'jɛn'),
|
| 146 |
+
('ㄩㄢ', 'ɥæn'),
|
| 147 |
+
('ㄢ', 'an'),
|
| 148 |
+
('ㄧㄣ', 'in'),
|
| 149 |
+
('ㄩㄣ', 'ɥn'),
|
| 150 |
+
('ㄣ', 'ən'),
|
| 151 |
+
('ㄤ', 'ɑŋ'),
|
| 152 |
+
('ㄧㄥ', 'iŋ'),
|
| 153 |
+
('ㄨㄥ', 'ʊŋ'),
|
| 154 |
+
('ㄩㄥ', 'jʊŋ'),
|
| 155 |
+
('ㄥ', 'əŋ'),
|
| 156 |
+
('ㄦ', 'əɻ'),
|
| 157 |
+
('ㄧ', 'i'),
|
| 158 |
+
('ㄨ', 'u'),
|
| 159 |
+
('ㄩ', 'ɥ'),
|
| 160 |
+
('ˉ', '→'),
|
| 161 |
+
('ˊ', '↑'),
|
| 162 |
+
('ˇ', '↓↑'),
|
| 163 |
+
('ˋ', '↓'),
|
| 164 |
+
('˙', ''),
|
| 165 |
+
(',', ','),
|
| 166 |
+
('。', '.'),
|
| 167 |
+
('!', '!'),
|
| 168 |
+
('?', '?'),
|
| 169 |
+
('—', '-')
|
| 170 |
+
]]
|
| 171 |
+
|
| 172 |
+
# List of (bopomofo, ipa2) pairs:
|
| 173 |
+
_bopomofo_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
|
| 174 |
+
('ㄅㄛ', 'pwo'),
|
| 175 |
+
('ㄆㄛ', 'pʰwo'),
|
| 176 |
+
('ㄇㄛ', 'mwo'),
|
| 177 |
+
('ㄈㄛ', 'fwo'),
|
| 178 |
+
('ㄅ', 'p'),
|
| 179 |
+
('ㄆ', 'pʰ'),
|
| 180 |
+
('ㄇ', 'm'),
|
| 181 |
+
('ㄈ', 'f'),
|
| 182 |
+
('ㄉ', 't'),
|
| 183 |
+
('ㄊ', 'tʰ'),
|
| 184 |
+
('ㄋ', 'n'),
|
| 185 |
+
('ㄌ', 'l'),
|
| 186 |
+
('ㄍ', 'k'),
|
| 187 |
+
('ㄎ', 'kʰ'),
|
| 188 |
+
('ㄏ', 'h'),
|
| 189 |
+
('ㄐ', 'tɕ'),
|
| 190 |
+
('ㄑ', 'tɕʰ'),
|
| 191 |
+
('ㄒ', 'ɕ'),
|
| 192 |
+
('ㄓ', 'tʂ'),
|
| 193 |
+
('ㄔ', 'tʂʰ'),
|
| 194 |
+
('ㄕ', 'ʂ'),
|
| 195 |
+
('ㄖ', 'ɻ'),
|
| 196 |
+
('ㄗ', 'ts'),
|
| 197 |
+
('ㄘ', 'tsʰ'),
|
| 198 |
+
('ㄙ', 's'),
|
| 199 |
+
('ㄚ', 'a'),
|
| 200 |
+
('ㄛ', 'o'),
|
| 201 |
+
('ㄜ', 'ɤ'),
|
| 202 |
+
('ㄝ', 'ɛ'),
|
| 203 |
+
('ㄞ', 'aɪ'),
|
| 204 |
+
('ㄟ', 'eɪ'),
|
| 205 |
+
('ㄠ', 'ɑʊ'),
|
| 206 |
+
('ㄡ', 'oʊ'),
|
| 207 |
+
('ㄧㄢ', 'jɛn'),
|
| 208 |
+
('ㄩㄢ', 'yæn'),
|
| 209 |
+
('ㄢ', 'an'),
|
| 210 |
+
('ㄧㄣ', 'in'),
|
| 211 |
+
('ㄩㄣ', 'yn'),
|
| 212 |
+
('ㄣ', 'ən'),
|
| 213 |
+
('ㄤ', 'ɑŋ'),
|
| 214 |
+
('ㄧㄥ', 'iŋ'),
|
| 215 |
+
('ㄨㄥ', 'ʊŋ'),
|
| 216 |
+
('ㄩㄥ', 'jʊŋ'),
|
| 217 |
+
('ㄥ', 'ɤŋ'),
|
| 218 |
+
('ㄦ', 'əɻ'),
|
| 219 |
+
('ㄧ', 'i'),
|
| 220 |
+
('ㄨ', 'u'),
|
| 221 |
+
('ㄩ', 'y'),
|
| 222 |
+
('ˉ', '˥'),
|
| 223 |
+
('ˊ', '˧˥'),
|
| 224 |
+
('ˇ', '˨˩˦'),
|
| 225 |
+
('ˋ', '˥˩'),
|
| 226 |
+
('˙', ''),
|
| 227 |
+
(',', ','),
|
| 228 |
+
('。', '.'),
|
| 229 |
+
('!', '!'),
|
| 230 |
+
('?', '?'),
|
| 231 |
+
('—', '-')
|
| 232 |
+
]]
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def number_to_chinese(text):
|
| 236 |
+
numbers = re.findall(r'\d+(?:\.?\d+)?', text)
|
| 237 |
+
for number in numbers:
|
| 238 |
+
text = text.replace(number, cn2an.an2cn(number), 1)
|
| 239 |
+
return text
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def chinese_to_bopomofo(text):
|
| 243 |
+
from pypinyin import lazy_pinyin, BOPOMOFO
|
| 244 |
+
text = text.replace('、', ',').replace(';', ',').replace(':', ',')
|
| 245 |
+
words = jieba.lcut(text, cut_all=False)
|
| 246 |
+
text = ''
|
| 247 |
+
for word in words:
|
| 248 |
+
bopomofos = lazy_pinyin(word, BOPOMOFO)
|
| 249 |
+
if not re.search('[\u4e00-\u9fff]', word):
|
| 250 |
+
text += word
|
| 251 |
+
continue
|
| 252 |
+
for i in range(len(bopomofos)):
|
| 253 |
+
bopomofos[i] = re.sub(r'([\u3105-\u3129])$', r'\1ˉ', bopomofos[i])
|
| 254 |
+
if text != '':
|
| 255 |
+
text += ' '
|
| 256 |
+
text += ''.join(bopomofos)
|
| 257 |
+
return text
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def latin_to_bopomofo(text):
|
| 261 |
+
for regex, replacement in _latin_to_bopomofo:
|
| 262 |
+
text = re.sub(regex, replacement, text)
|
| 263 |
+
return text
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def bopomofo_to_romaji(text):
|
| 267 |
+
for regex, replacement in _bopomofo_to_romaji:
|
| 268 |
+
text = re.sub(regex, replacement, text)
|
| 269 |
+
return text
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def bopomofo_to_ipa(text):
|
| 273 |
+
for regex, replacement in _bopomofo_to_ipa:
|
| 274 |
+
text = re.sub(regex, replacement, text)
|
| 275 |
+
return text
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
def bopomofo_to_ipa2(text):
|
| 279 |
+
for regex, replacement in _bopomofo_to_ipa2:
|
| 280 |
+
text = re.sub(regex, replacement, text)
|
| 281 |
+
return text
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
def chinese_to_romaji(text):
|
| 285 |
+
text = number_to_chinese(text)
|
| 286 |
+
text = chinese_to_bopomofo(text)
|
| 287 |
+
text = latin_to_bopomofo(text)
|
| 288 |
+
text = bopomofo_to_romaji(text)
|
| 289 |
+
text = re.sub('i([aoe])', r'y\1', text)
|
| 290 |
+
text = re.sub('u([aoəe])', r'w\1', text)
|
| 291 |
+
text = re.sub('([ʦsɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
|
| 292 |
+
r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
|
| 293 |
+
text = re.sub('([ʦs][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
|
| 294 |
+
return text
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
def chinese_to_lazy_ipa(text):
|
| 298 |
+
text = chinese_to_romaji(text)
|
| 299 |
+
for regex, replacement in _romaji_to_ipa:
|
| 300 |
+
text = re.sub(regex, replacement, text)
|
| 301 |
+
return text
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
def chinese_to_ipa(text):
|
| 305 |
+
text = number_to_chinese(text)
|
| 306 |
+
text = chinese_to_bopomofo(text)
|
| 307 |
+
text = latin_to_bopomofo(text)
|
| 308 |
+
text = bopomofo_to_ipa(text)
|
| 309 |
+
text = re.sub('i([aoe])', r'j\1', text)
|
| 310 |
+
text = re.sub('u([aoəe])', r'w\1', text)
|
| 311 |
+
text = re.sub('([sɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
|
| 312 |
+
r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
|
| 313 |
+
text = re.sub('([s][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
|
| 314 |
+
return text
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
def chinese_to_ipa2(text):
|
| 318 |
+
text = number_to_chinese(text)
|
| 319 |
+
text = chinese_to_bopomofo(text)
|
| 320 |
+
text = latin_to_bopomofo(text)
|
| 321 |
+
text = bopomofo_to_ipa2(text)
|
| 322 |
+
text = re.sub(r'i([aoe])', r'j\1', text)
|
| 323 |
+
text = re.sub(r'u([aoəe])', r'w\1', text)
|
| 324 |
+
text = re.sub(r'([ʂɹ]ʰ?)([˩˨˧˦˥ ]+|$)', r'\1ʅ\2', text)
|
| 325 |
+
text = re.sub(r'(sʰ?)([˩˨˧˦˥ ]+|$)', r'\1ɿ\2', text)
|
| 326 |
+
return text
|
utils/g2p/symbols.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Defines the set of symbols used in text input to the model.
|
| 3 |
+
'''
|
| 4 |
+
|
| 5 |
+
# japanese_cleaners
|
| 6 |
+
# _pad = '_'
|
| 7 |
+
# _punctuation = ',.!?-'
|
| 8 |
+
# _letters = 'AEINOQUabdefghijkmnoprstuvwyzʃʧ↓↑ '
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
'''# japanese_cleaners2
|
| 12 |
+
_pad = '_'
|
| 13 |
+
_punctuation = ',.!?-~…'
|
| 14 |
+
_letters = 'AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ '
|
| 15 |
+
'''
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
'''# korean_cleaners
|
| 19 |
+
_pad = '_'
|
| 20 |
+
_punctuation = ',.!?…~'
|
| 21 |
+
_letters = 'ㄱㄴㄷㄹㅁㅂㅅㅇㅈㅊㅋㅌㅍㅎㄲㄸㅃㅆㅉㅏㅓㅗㅜㅡㅣㅐㅔ '
|
| 22 |
+
'''
|
| 23 |
+
|
| 24 |
+
'''# chinese_cleaners
|
| 25 |
+
_pad = '_'
|
| 26 |
+
_punctuation = ',。!?—…'
|
| 27 |
+
_letters = 'ㄅㄆㄇㄈㄉㄊㄋㄌㄍㄎㄏㄐㄑㄒㄓㄔㄕㄖㄗㄘㄙㄚㄛㄜㄝㄞㄟㄠㄡㄢㄣㄤㄥㄦㄧㄨㄩˉˊˇˋ˙ '
|
| 28 |
+
'''
|
| 29 |
+
|
| 30 |
+
# # zh_ja_mixture_cleaners
|
| 31 |
+
# _pad = '_'
|
| 32 |
+
# _punctuation = ',.!?-~…'
|
| 33 |
+
# _letters = 'AEINOQUabdefghijklmnoprstuvwyzʃʧʦɯɹəɥ⁼ʰ`→↓↑ '
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
'''# sanskrit_cleaners
|
| 37 |
+
_pad = '_'
|
| 38 |
+
_punctuation = '।'
|
| 39 |
+
_letters = 'ँंःअआइईउऊऋएऐओऔकखगघङचछजझञटठडढणतथदधनपफबभमयरलळवशषसहऽािीुूृॄेैोौ्ॠॢ '
|
| 40 |
+
'''
|
| 41 |
+
|
| 42 |
+
'''# cjks_cleaners
|
| 43 |
+
_pad = '_'
|
| 44 |
+
_punctuation = ',.!?-~…'
|
| 45 |
+
_letters = 'NQabdefghijklmnopstuvwxyzʃʧʥʦɯɹəɥçɸɾβŋɦː⁼ʰ`^#*=→↓↑ '
|
| 46 |
+
'''
|
| 47 |
+
|
| 48 |
+
'''# thai_cleaners
|
| 49 |
+
_pad = '_'
|
| 50 |
+
_punctuation = '.!? '
|
| 51 |
+
_letters = 'กขฃคฆงจฉชซฌญฎฏฐฑฒณดตถทธนบปผฝพฟภมยรฤลวศษสหฬอฮฯะัาำิีึืุูเแโใไๅๆ็่้๊๋์'
|
| 52 |
+
'''
|
| 53 |
+
|
| 54 |
+
# # cjke_cleaners2
|
| 55 |
+
_pad = '_'
|
| 56 |
+
_punctuation = ',.!?-~…'
|
| 57 |
+
_letters = 'NQabdefghijklmnopstuvwxyzɑæʃʑçɯɪɔɛɹðəɫɥɸʊɾʒθβŋɦ⁼ʰ`^#*=ˈˌ→↓↑ '
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
'''# shanghainese_cleaners
|
| 61 |
+
_pad = '_'
|
| 62 |
+
_punctuation = ',.!?…'
|
| 63 |
+
_letters = 'abdfghiklmnopstuvyzøŋȵɑɔɕəɤɦɪɿʑʔʰ̩̃ᴀᴇ15678 '
|
| 64 |
+
'''
|
| 65 |
+
|
| 66 |
+
'''# chinese_dialect_cleaners
|
| 67 |
+
_pad = '_'
|
| 68 |
+
_punctuation = ',.!?~…─'
|
| 69 |
+
_letters = '#Nabdefghijklmnoprstuvwxyzæçøŋœȵɐɑɒɓɔɕɗɘəɚɛɜɣɤɦɪɭɯɵɷɸɻɾɿʂʅʊʋʌʏʑʔʦʮʰʷˀː˥˦˧˨˩̥̩̃̚ᴀᴇ↑↓∅ⱼ '
|
| 70 |
+
'''
|
| 71 |
+
|
| 72 |
+
# Export all symbols:
|
| 73 |
+
symbols = [_pad] + list(_punctuation) + list(_letters)
|
| 74 |
+
|
| 75 |
+
# Special symbol ids
|
| 76 |
+
SPACE_ID = symbols.index(" ")
|